On asymptotic extrapolation |
|
| January 27, 2009 |
|
 . This work has
partially been supported by the ANR Gecko project.
. This work has
partially been supported by the ANR Gecko project.
Consider a power series In this paper, we will present a general scheme for the design of such “asymptotic extrapolation algorithms”. Roughly speaking, using discrete differentiation and techniques from automatic asymptotics, we strip off the terms of the asymptotic expansion one by one. The knowledge of more terms of the asymptotic expansion will then allow us to approximate the coefficients in the expansion with high accuracy.
|
Consider an infinite sequence 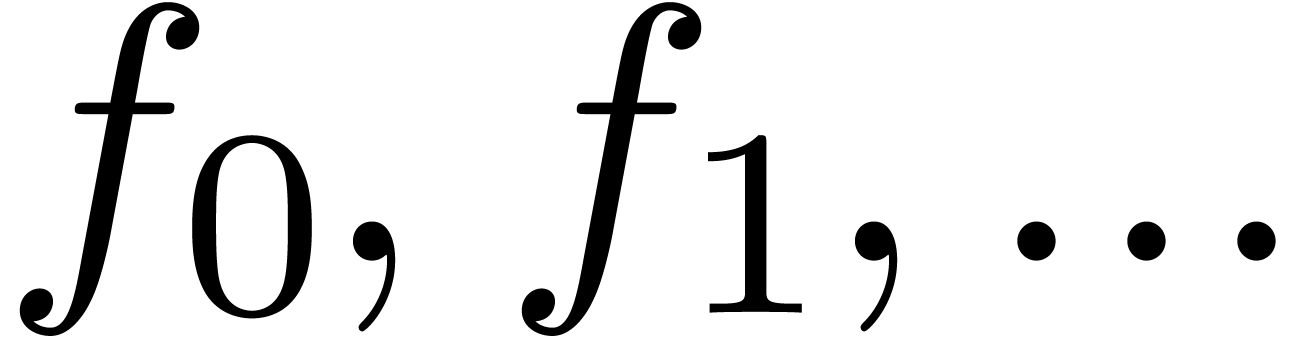 of real numbers.
If are the coefficients of a formal power series
of real numbers.
If are the coefficients of a formal power series
 , then it is well-known [Pól37, Wil04, FS96] that a
lot of information about the behaviour of
, then it is well-known [Pól37, Wil04, FS96] that a
lot of information about the behaviour of 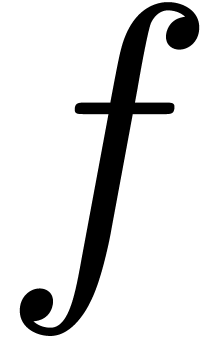 near
its dominant singularity can be obtained from the asymptotic behaviour
of the sequence . However, if
is the solution to some complicated equation,
then it can be hard to compute the asymptotic behaviour using formal
methods. On the other hand, the coefficients of
such a solution can often be computed
numerically up to a high order [vdH02a]. This raises the
question of how to guess the asymptotic behaviour of , based on this numerical evidence.
near
its dominant singularity can be obtained from the asymptotic behaviour
of the sequence . However, if
is the solution to some complicated equation,
then it can be hard to compute the asymptotic behaviour using formal
methods. On the other hand, the coefficients of
such a solution can often be computed
numerically up to a high order [vdH02a]. This raises the
question of how to guess the asymptotic behaviour of , based on this numerical evidence.
Assume for instance that we have fixed a class 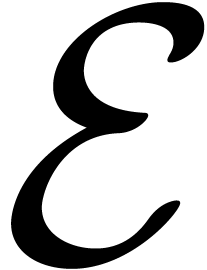 of “admissible asymptotic extrapolations”, such as all
expressions of the form
of “admissible asymptotic extrapolations”, such as all
expressions of the form
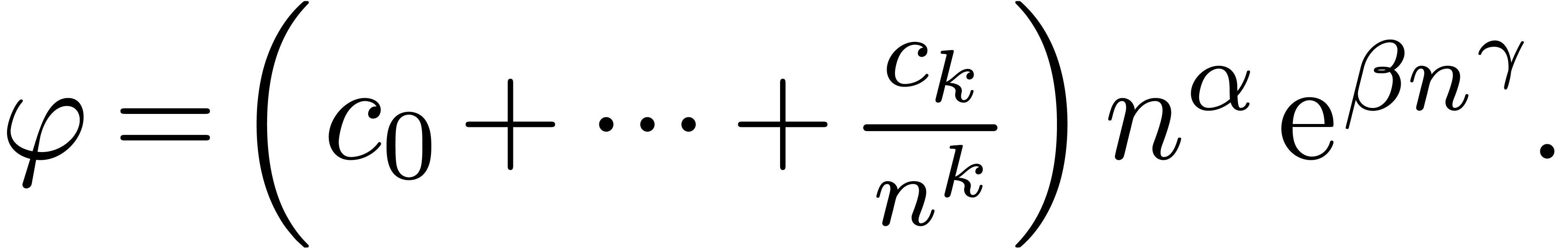 |
(1) |
Given the first coefficients  of , the problem of asymptotic
extrapolation is to find a “simple” expression
of , the problem of asymptotic
extrapolation is to find a “simple” expression  , which approximates
, which approximates  well in the sense that the relative error
well in the sense that the relative error
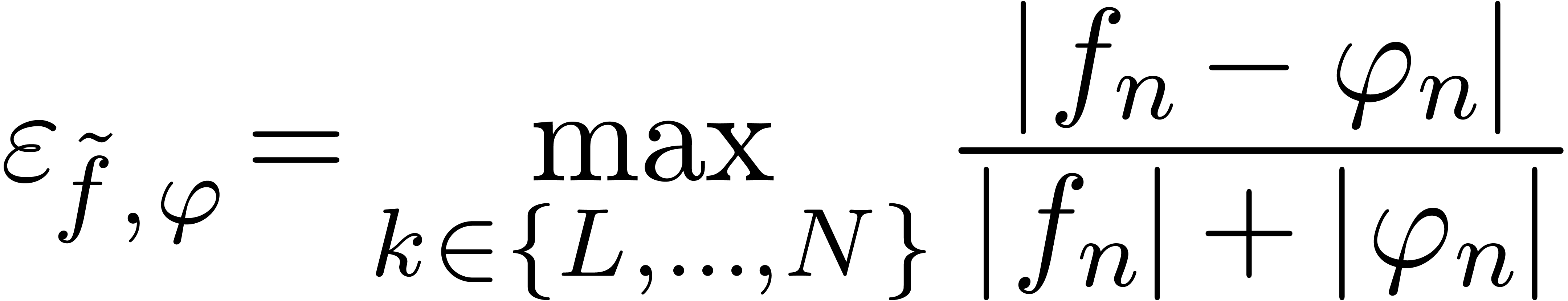 |
(2) |
is small. Here  is a suitably chosen number, such
as
is a suitably chosen number, such
as  . In general, we are just
interested in a good extrapolation formula, and not necessarily in the
best one in the class . It is
also important that the extrapolation continues to provide good
approximations for
. In general, we are just
interested in a good extrapolation formula, and not necessarily in the
best one in the class . It is
also important that the extrapolation continues to provide good
approximations for  , even
though we have no direct means of verification.
, even
though we have no direct means of verification.
A good measure for the complexity of an expression
is its number  of continuous parameters.
For instance, taking
of continuous parameters.
For instance, taking  as in the formula (1),
the continuous parameters are
as in the formula (1),
the continuous parameters are  ,
,
 ,
,  and
and
 , whence
, whence  . Another possible measure is the size
. Another possible measure is the size
 of as an expression. For
our sample expression from (1),
this yields
of as an expression. For
our sample expression from (1),
this yields 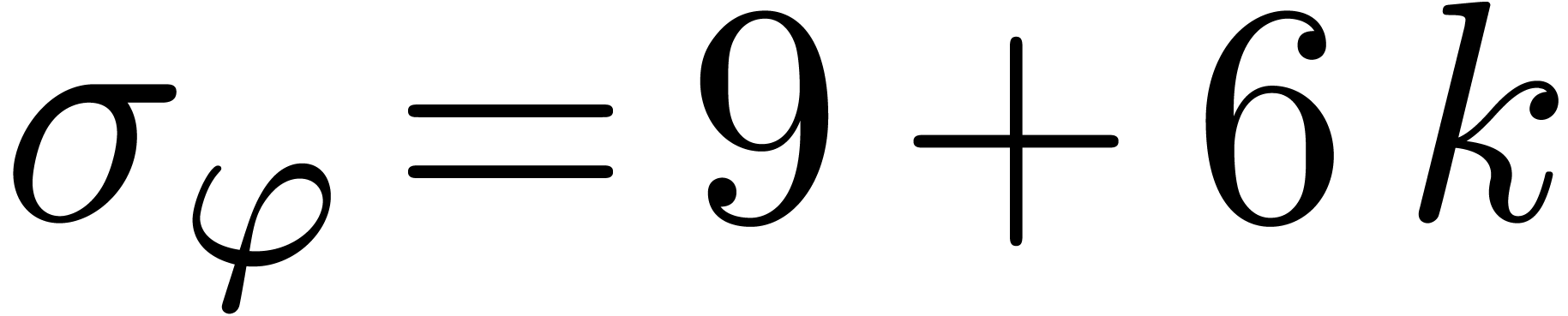 , when counting
, when counting
 for each of the operations
for each of the operations  ,
,  ,
,
 , ^,
, ^,  , as well as for
, as well as for 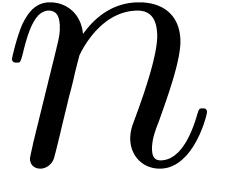 and each of the constants. Since the expression size depends on the way operations are encoded, the
measure should generally be preferred. Notice
also that one usually has
and each of the constants. Since the expression size depends on the way operations are encoded, the
measure should generally be preferred. Notice
also that one usually has 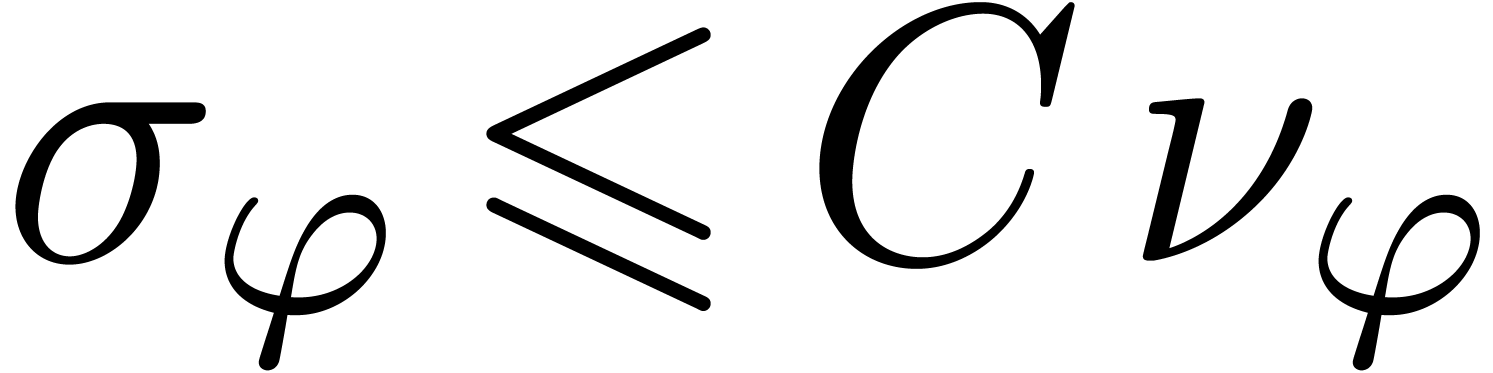 for a fixed constant
for a fixed constant
 .
.
In fact, the systematic integration of “guessing tools” into
symbolic computation packages would be a useful thing. Indeed, current
systems can be quite good at all kinds of formal manipulations. However,
in the daily practice of scientific discovery, it would be helpful if
these systems could also detect hidden properties, which may not be
directly apparent or expected, and whose validity generally depends on
heuristics. Some well-known guessing tools in this direction are the
LLL-algorithm [LLL82] and algorithms for the computation of
Padé-Hermite forms [BL94, Der94], with
an implementation in the
In the area of numerical analysis, several algorithms have been
developed for accelerating the convergence of sequences, with
applications to asymptotic extrapolation. One of the best available
tools is the E-algorithm [Wen01, BZ91], which
can be used when consists of linear expressions
of the form
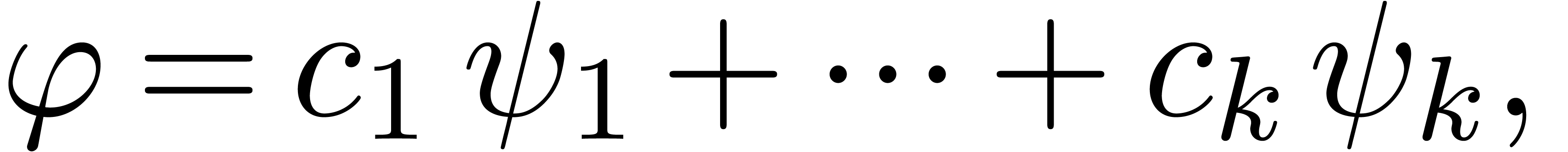 |
(3) |
with continuous parameters  ,
and where
,
and where  are general functions, possibly
subject to some growth conditions at infinity. Here we use the standard
notations
are general functions, possibly
subject to some growth conditions at infinity. Here we use the standard
notations 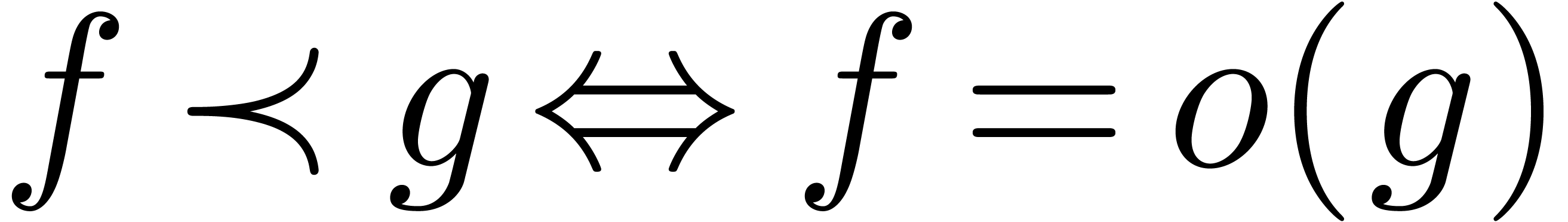 ,
, 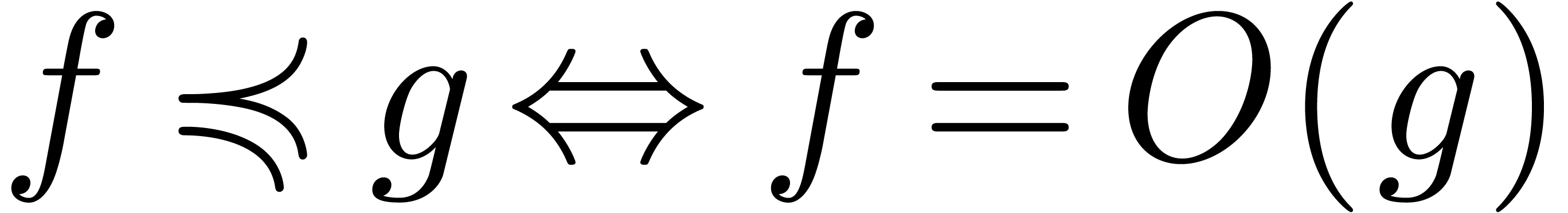 and
and 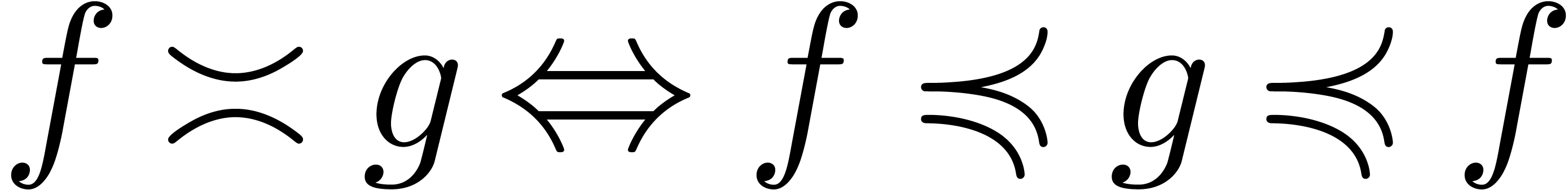 . Notice that the
E-algorithm can sometimes be used indirectly: if
. Notice that the
E-algorithm can sometimes be used indirectly: if 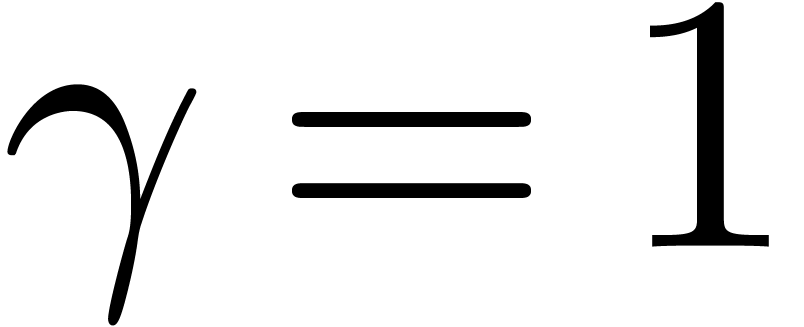 in (1), then
in (1), then
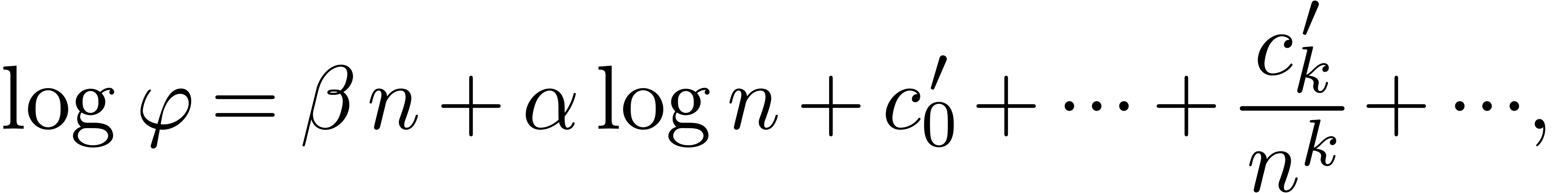
with 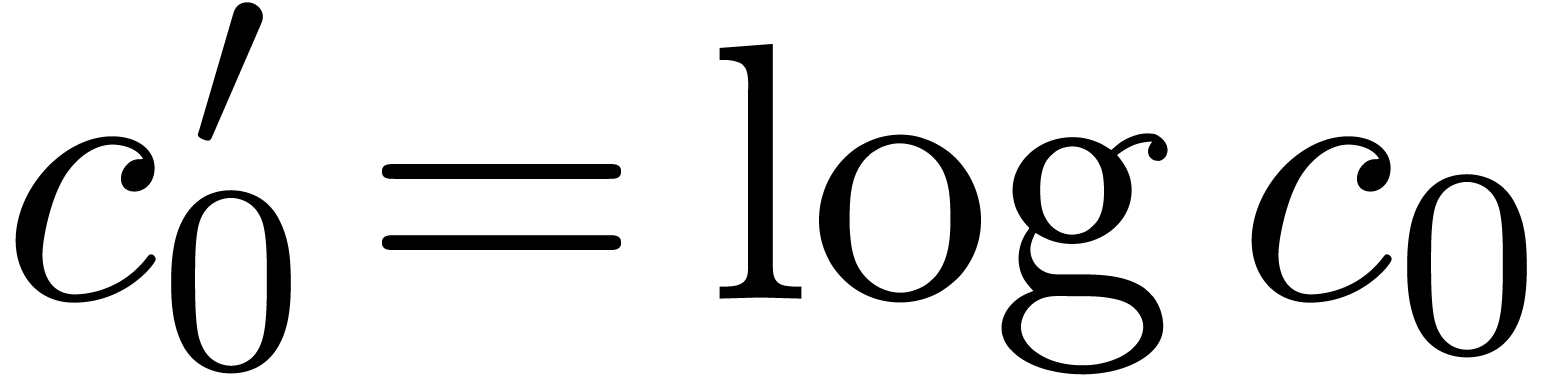 ,
, 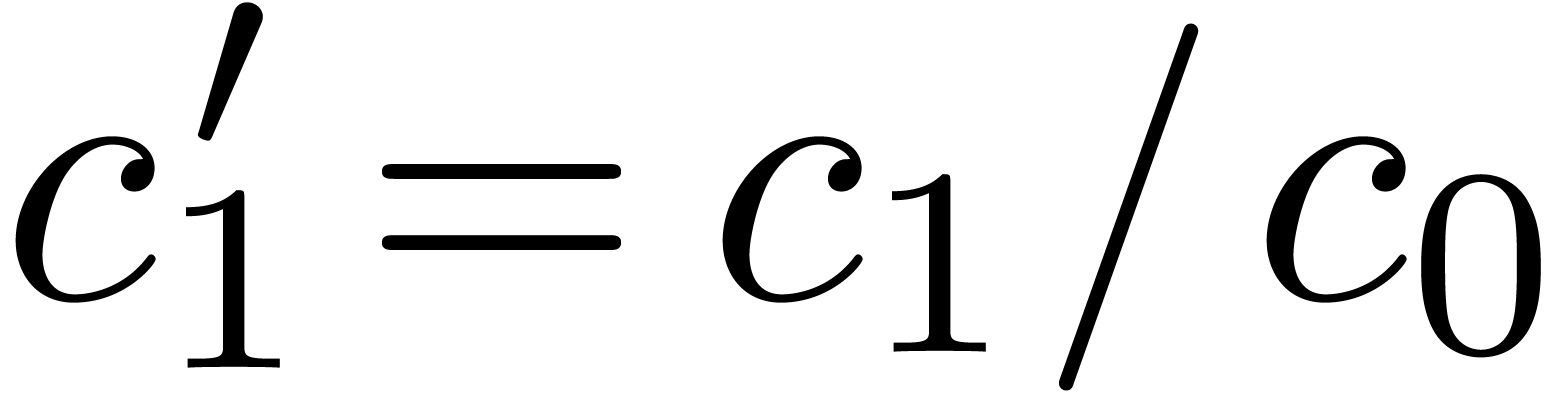 , etc., is asymptotically of the
required form (3).
, etc., is asymptotically of the
required form (3).
We are aware of little work beyond the identification of parameters which occur linearly in a known expression. A so called “Gevreytiseur” is under development [CDFT01] for recognizing expansions of Gevrey type and with an asymptotic behaviour
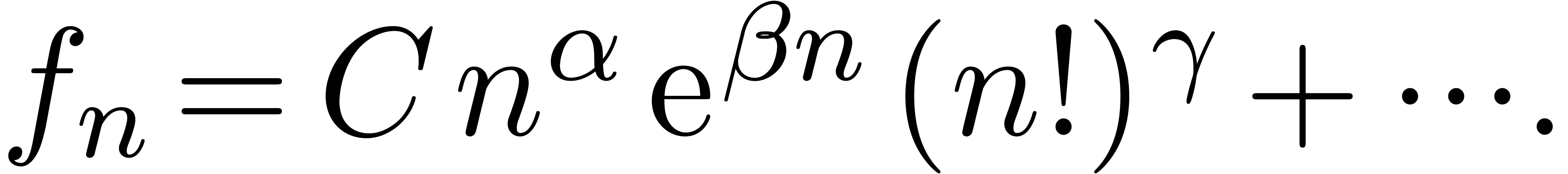 |
(4) |
One of the referees also made us aware of work [JG99, CGJ+05] on extrapolations of the form
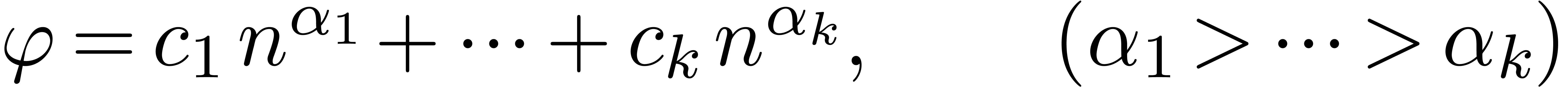
where, in addition to the coefficients ,
some of the exponents 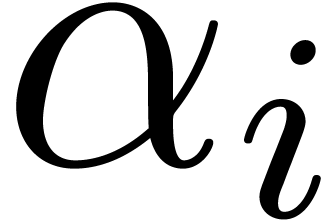 may be unknown (even
though guesses often exist, in which case one only has to determine
whether the corresponding coefficient
may be unknown (even
though guesses often exist, in which case one only has to determine
whether the corresponding coefficient 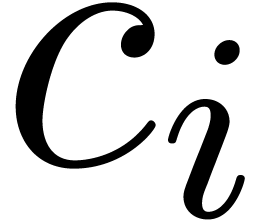 vanishes).
vanishes).
In this paper, we will be concerned with the case when
is the set of exp-log expressions. An exp-log expression is
constructed from the rational numbers, real parameters and using field operations, exponentiation and logarithm. It
was already pointed out by Hardy that the asymptotic behaviour of many
functions occurring in analysis, combinatorics and number theory can be
expressed in asymptotic scales formed by exp-log functions [Har10,
Har11, Sha90, Sal91, RSSvdH96].
More generally, the field of transseries (which can be seen as the
“exp-log completion” of the field of germs of exp-log
functions at infinity) enjoys remarkable closure properties [vdH06c,
Éca92].
The main problem with naive approaches for asymptotic extrapolation is
that, even when we have a good algorithm for the determination of the
dominant term  of the expansion of
of the expansion of 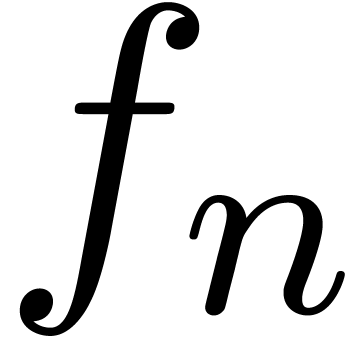 , it makes little sense to recurse the
algorithm for the difference
, it makes little sense to recurse the
algorithm for the difference 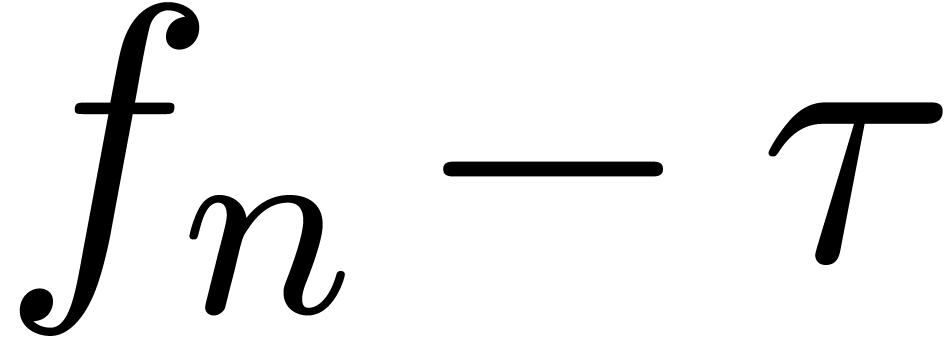 .
Indeed, a small error in the determination of , , and for an expansion of type
(4) will result in a difference
which is either asymptotic to or . Even if we computed
.
Indeed, a small error in the determination of , , and for an expansion of type
(4) will result in a difference
which is either asymptotic to or . Even if we computed  with great accuracy, this will be of little help with current
extrapolation techniques. Without further knowledge about the remainder
with great accuracy, this will be of little help with current
extrapolation techniques. Without further knowledge about the remainder
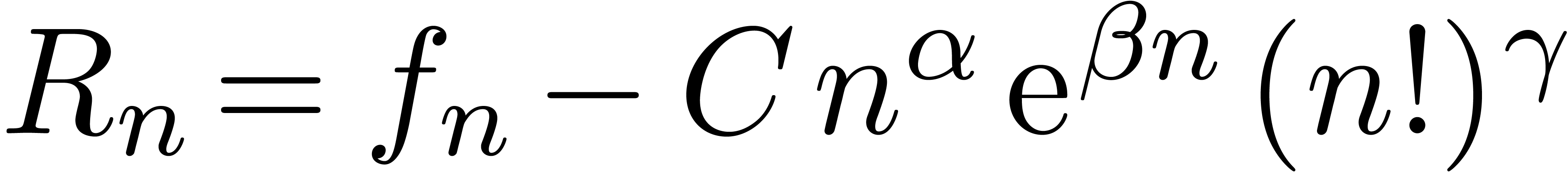 , it is also hard to obtain
approximations for , , ,
with relative errors less than
, it is also hard to obtain
approximations for , , ,
with relative errors less than  , no matter which classical or clever numerical
algorithm is used.
, no matter which classical or clever numerical
algorithm is used.
Instead of directly searching the dominant term
of the asymptotic expansion of
and subtracting it from
,
a better idea
1. A variant of the idea is to kill  leading subdominant terms (e.g. Aitken's method),
after which the limit of the sequence can be read off
immediately with high accuracy.
leading subdominant terms (e.g. Aitken's method),
after which the limit of the sequence can be read off
immediately with high accuracy.
 which kills the dominant term, and recursively apply asymptotic
extrapolation to the transformed sequence
which kills the dominant term, and recursively apply asymptotic
extrapolation to the transformed sequence
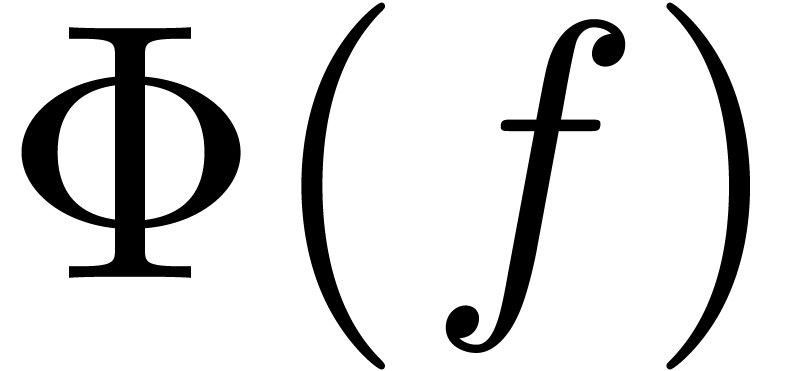 .
For instance, if
.
For instance, if
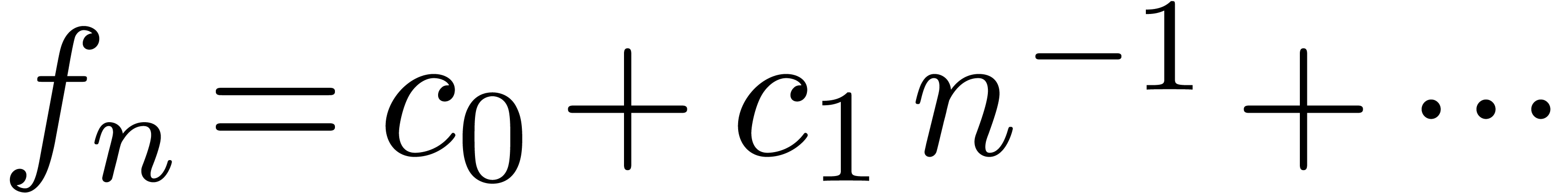 ,
then we may take
,
then we may take
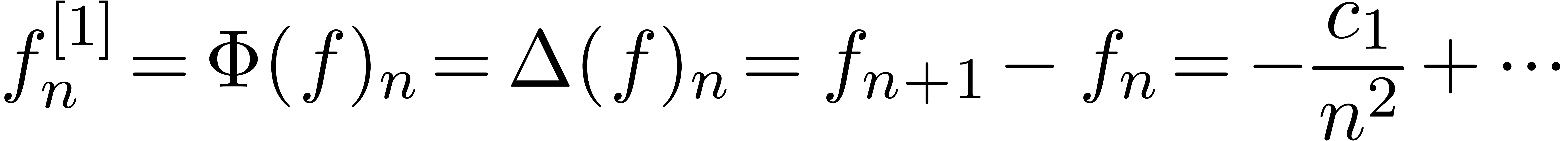
as our first transformation and 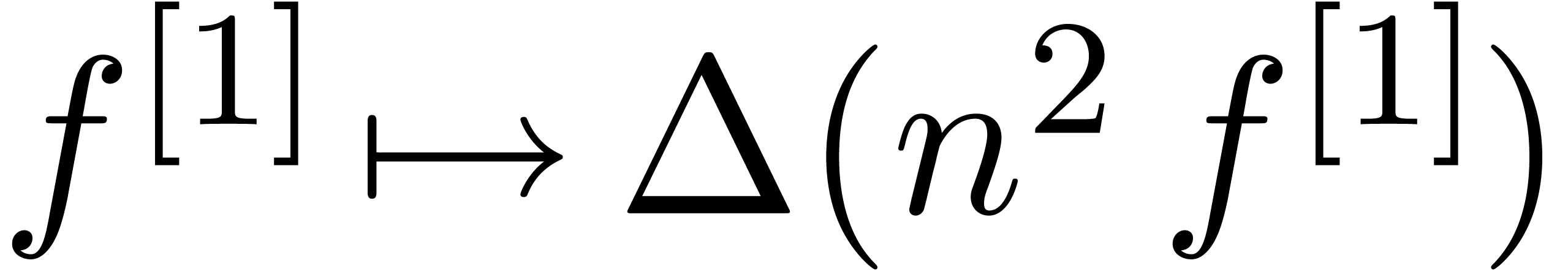 for the second
transformation. Similarly, if
for the second
transformation. Similarly, if 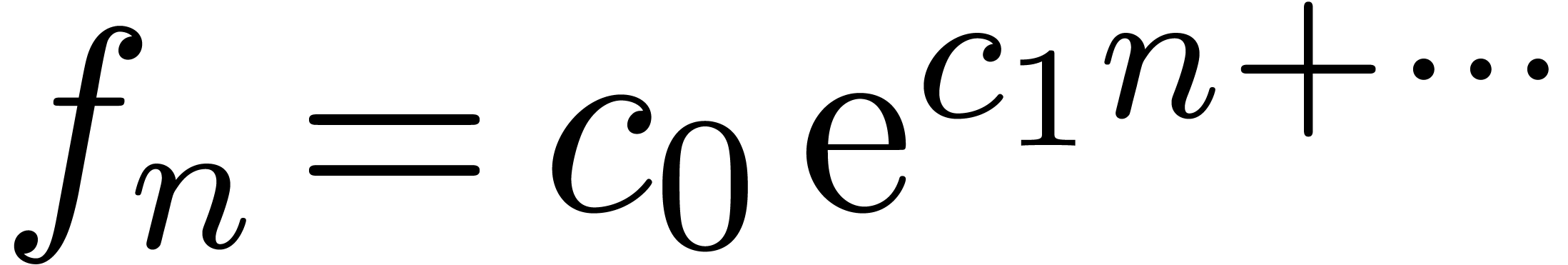 ,
then we may take
,
then we may take
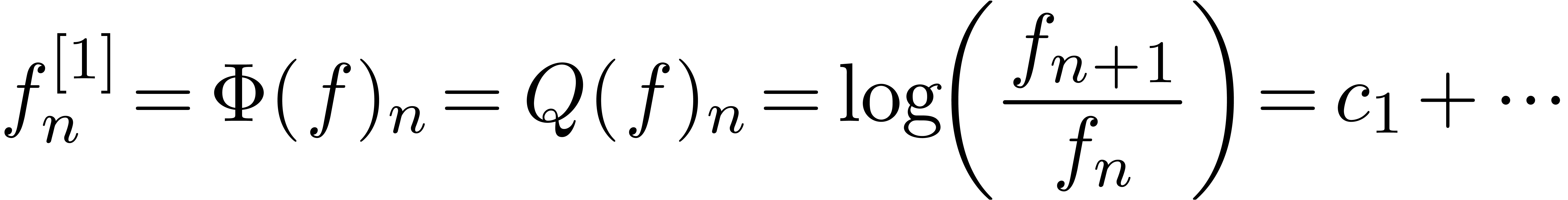
and proceed with the transformation  .
After a finite number of transformations
.
After a finite number of transformations

the resulting sequence 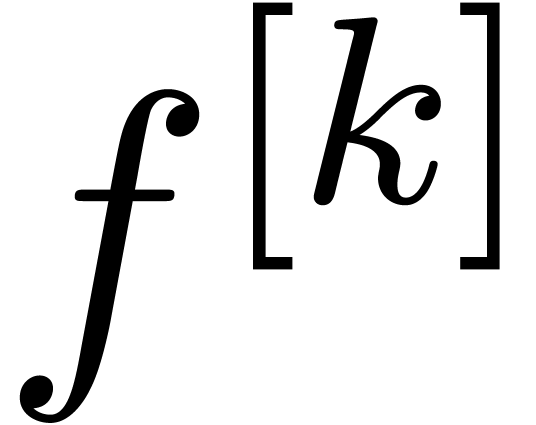 looses its accuracy, and
we brutally extrapolate it by zero
looses its accuracy, and
we brutally extrapolate it by zero
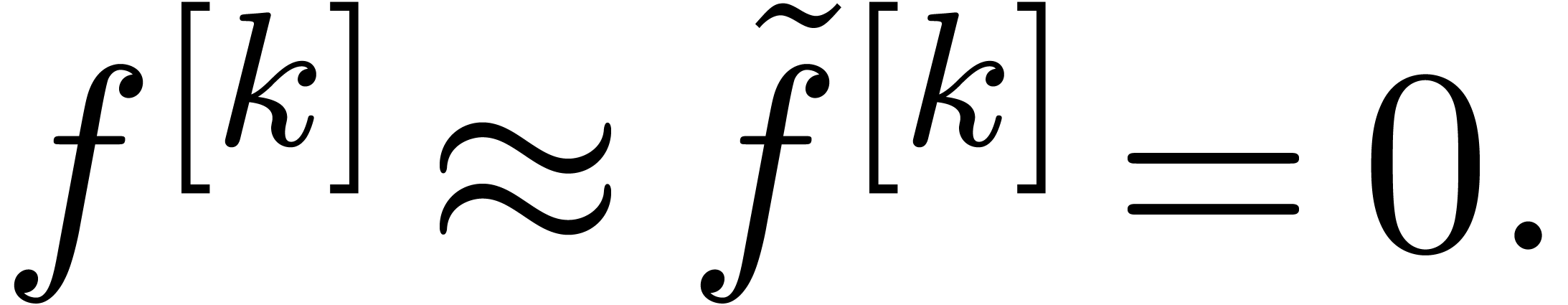
Following the transformations in the opposite way, we next solve the equations
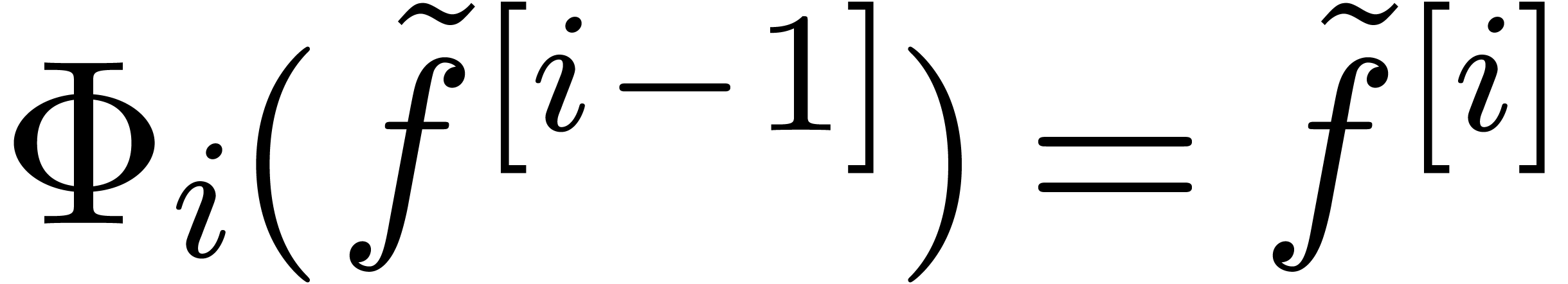 |
(5) |
for 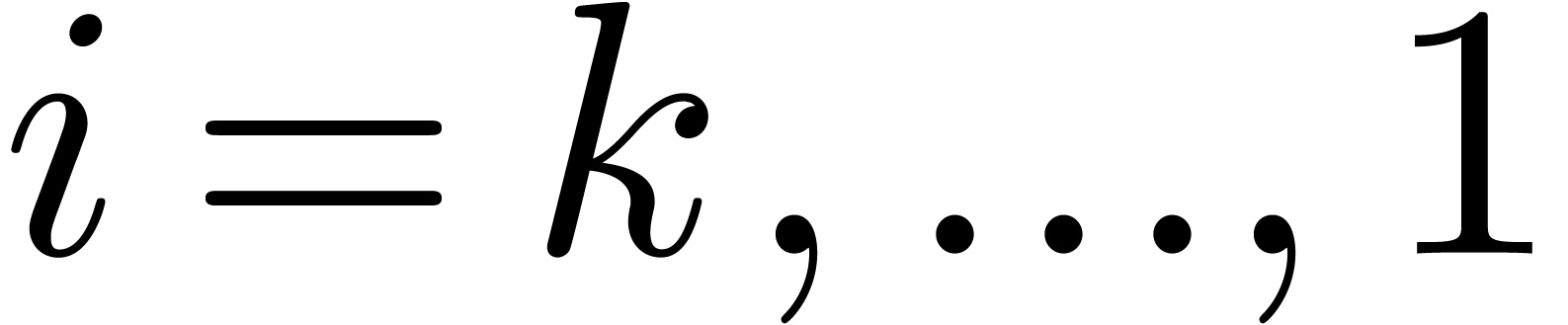 . The resolution of (5) involves the numeric determination of the continuous
parameter (or parameters
. The resolution of (5) involves the numeric determination of the continuous
parameter (or parameters  , in general) which was killed by
, in general) which was killed by 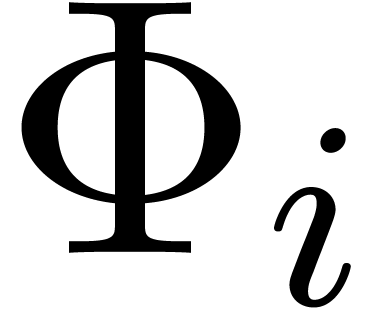 . For decreasing the
accuracy of the so-computed parameters and
extrapolations
. For decreasing the
accuracy of the so-computed parameters and
extrapolations  tends to increase. The end-result
tends to increase. The end-result
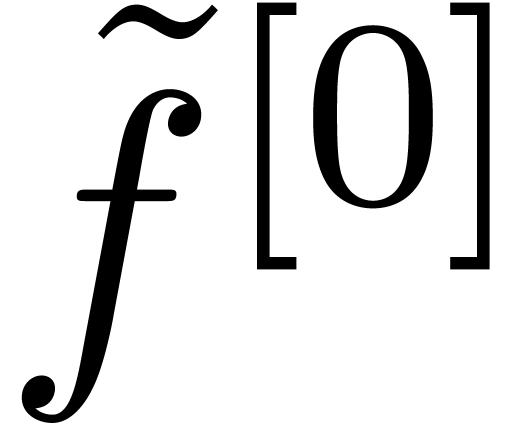 is the desired extrapolation of .
is the desired extrapolation of .
The above scheme is actually a “meta-algorithm” in the sense
that we have not yet specified the precise transformations which are
applied. In section 2, we will discuss in more detail some
of the “atomic” transformations which can be used. Each
atomic transformation comes with a numeric criterion whether it makes
sense to apply it. For instance, the finite difference operator should be used on sequences which are not far from
being constant. In section 3, we next describe our main
asymptotic extrapolation scheme, based on the prior choice of a finite
number of atomic transformations.
A priori, our scheme either returns the extrapolation in a
numeric form or as a sequence of inverses of atomic transformations.
However, such extrapolations are not necessarily readable from a human
point of view. In [vdH08], it is shown how to solve the
equations (5) in the field of formal transseries. Finite
truncations of these transseries then yield exp-log extrapolations for
, as will be detailed in
section 4. Once the shape of a good exp-log extrapolation
is known, the continuous parameters may be refined a posteriori
using iterative improvements.
The new extrapolation scheme has been implemented (but not yet
documented) in the
Combining both ad hoc and classical techniques, such as the E-algorithm, experts will be able to obtain most of the asymptotic extrapolations considered in this paper by hand. Indeed, the right transformations to be applied at each stage are usually clear on practical examples. Nevertheless, we believe that a more systematic and automatic approach is a welcome contribution. Despite several difficulties which remain to be settled, our current scheme manages to correctly extrapolate sequences with various forms of asymptotic behaviour. Our scheme also raises some intriguing problems about appropriate sets of atomic transformations and the approximation of sequences with regular behaviour at infinity by linear combinations of other sequences of the same kind.
Remark
As explained in the introduction, our main approach for finding an
asymptotic extrapolation for is through the
application of a finite number of atomic transformations  on the sequence .
Each time that we expect to satisfy a specific
kind of asymptotic behaviour, we apply the corresponding atomic
transformation. For instance, if we expect to
tend to a constant, which corresponds to an asymptotic behaviour of the
form
on the sequence .
Each time that we expect to satisfy a specific
kind of asymptotic behaviour, we apply the corresponding atomic
transformation. For instance, if we expect to
tend to a constant, which corresponds to an asymptotic behaviour of the
form 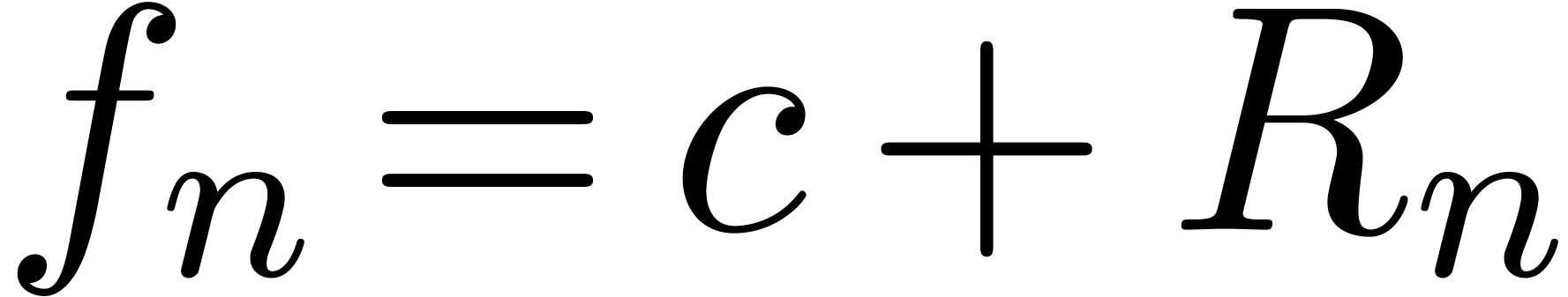 with
with 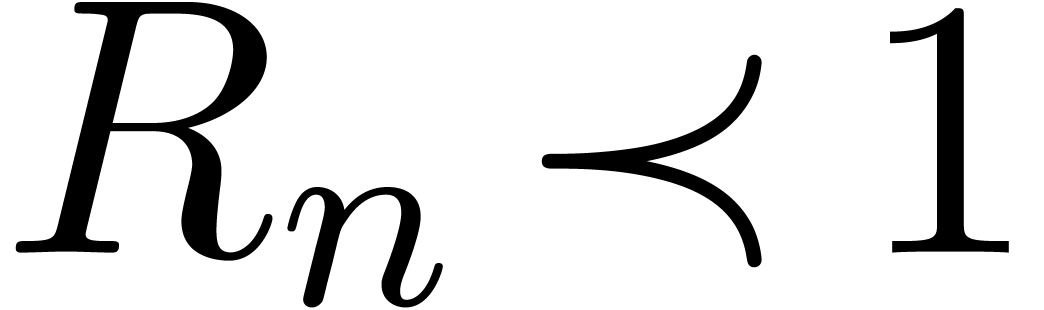 ,
then we may apply the finite difference operator .
,
then we may apply the finite difference operator .
More generally, we are thus confronted to the following subproblem: given a suspected asymptotic behaviour
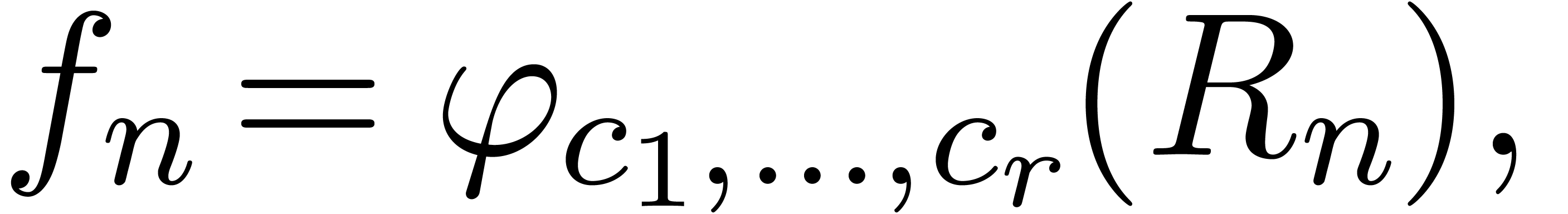 |
(6) |
where  are continuous parameters and
are continuous parameters and 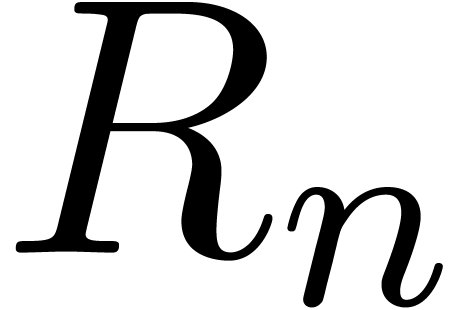 is a remainder sequence, we should
is a remainder sequence, we should
Find a numeric criterion for deciding whether
potentially admits an asymptotic behaviour of the form (6),
or very likely does not have such a behaviour.
Find a sequence transformation 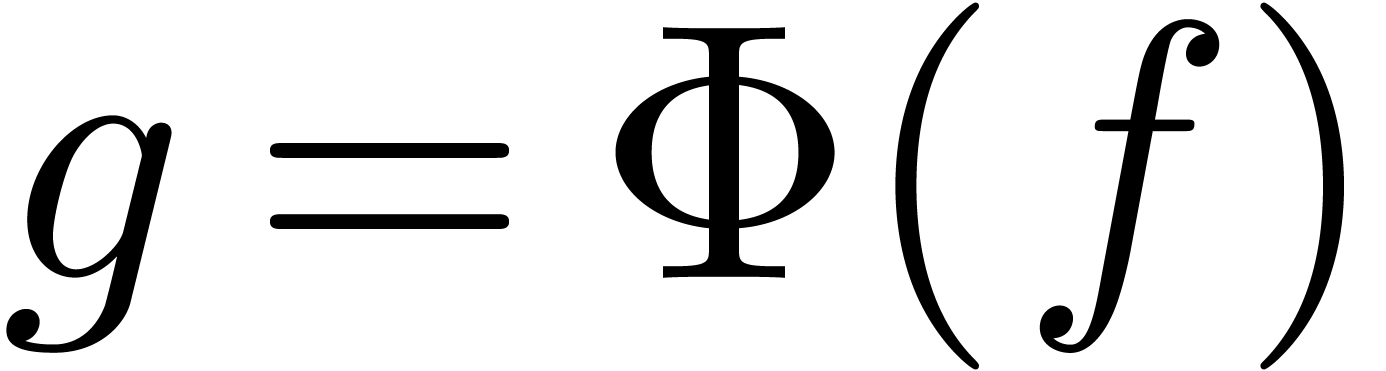 ,
such that
,
such that  only depends on , but not on the continuous parameters
.
only depends on , but not on the continuous parameters
.
Find a way to numerically solve the equation 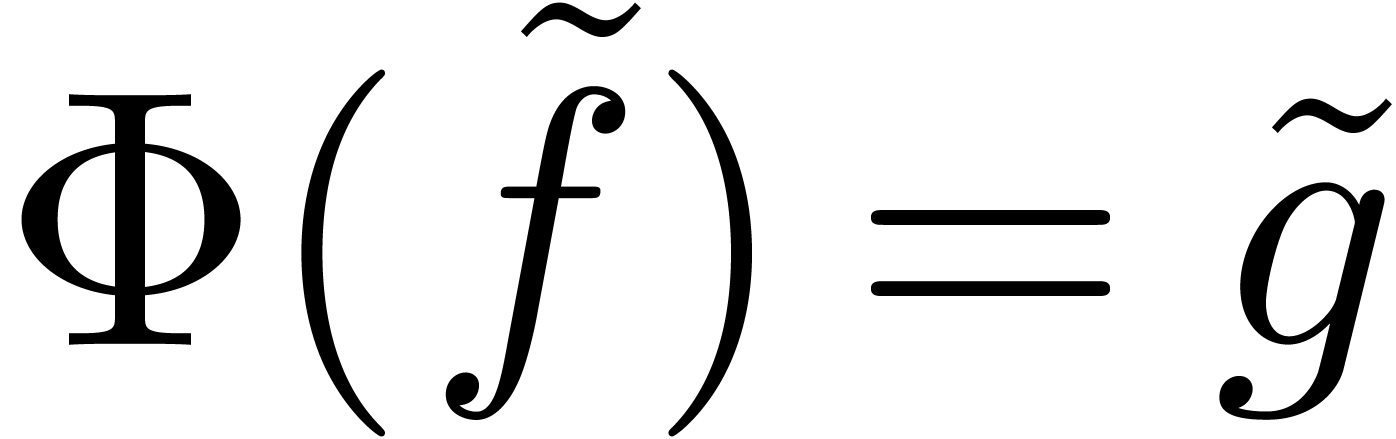 , when a numerical extrapolation
, when a numerical extrapolation  for is known.
for is known.
In this section, we will solve this subproblem for several basic types
of asymptotic behaviour (6). In the next section, we will
show how to combine the corresponding atomic transformations into a full
asymptotic extrapolation scheme. If a sequence
satisfies the numeric criterion associated to the atomic transformation
, then we say that is acceptable for .
tends to a finite limit  , we have
, we have
 |
(7) |
A simple numerical criterion for this situation is
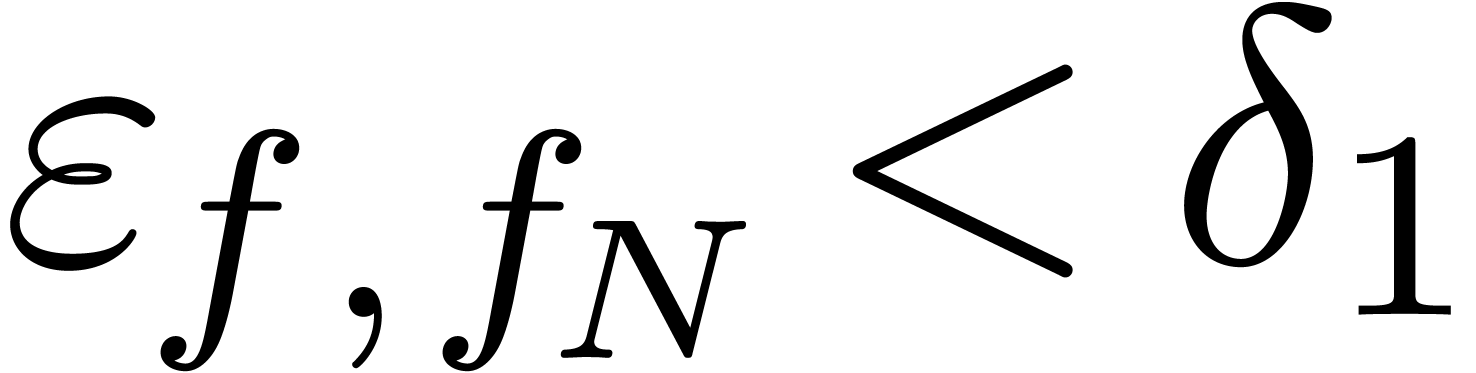 |
(8) |
for a suitable threshold 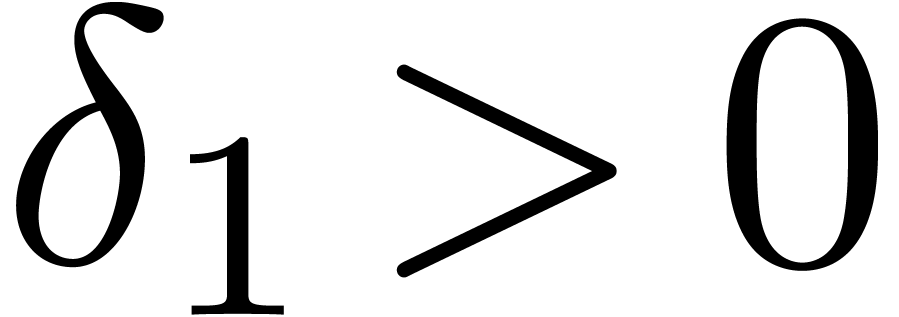 .
The continuous parameter is killed by the finite
difference operator :
.
The continuous parameter is killed by the finite
difference operator :
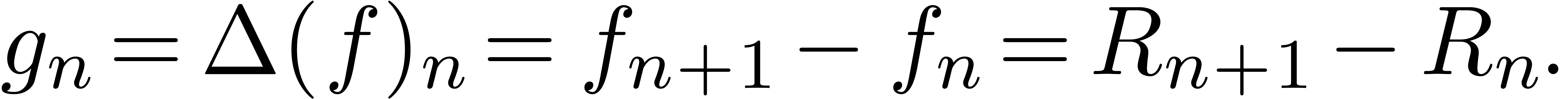
Given an asymptotic extrapolation for , we may extrapolate by
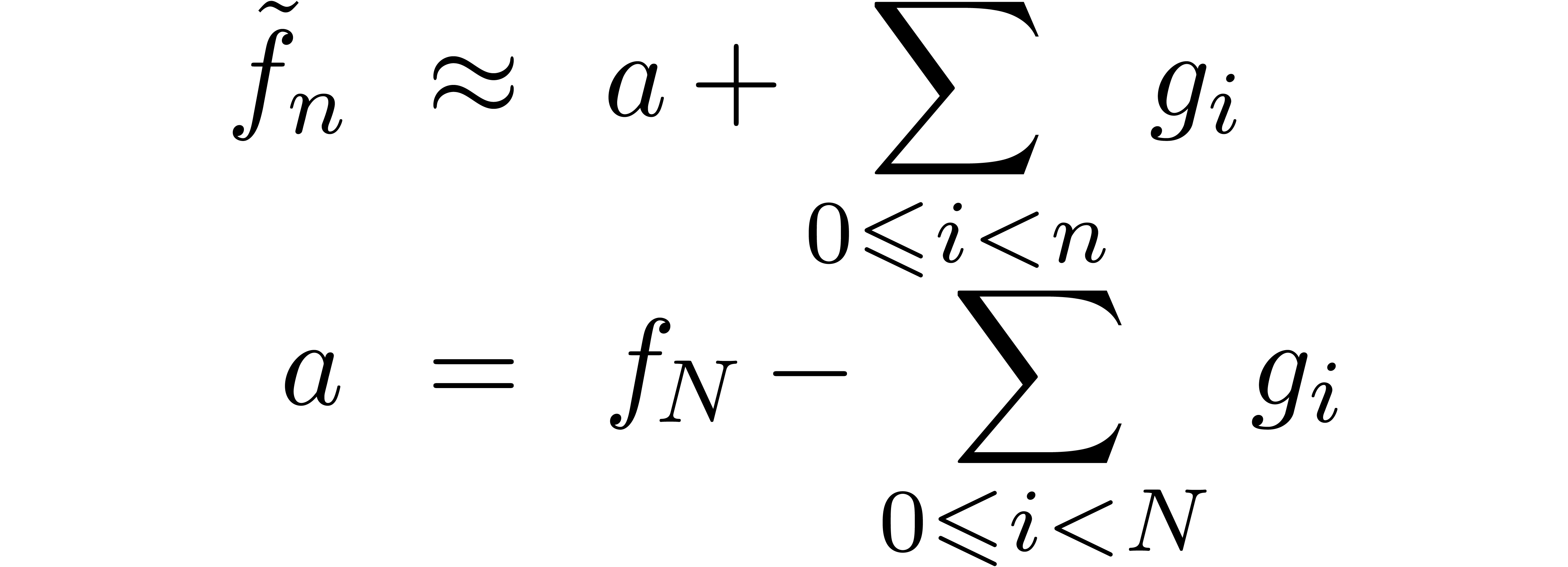
In compact form, we thus have 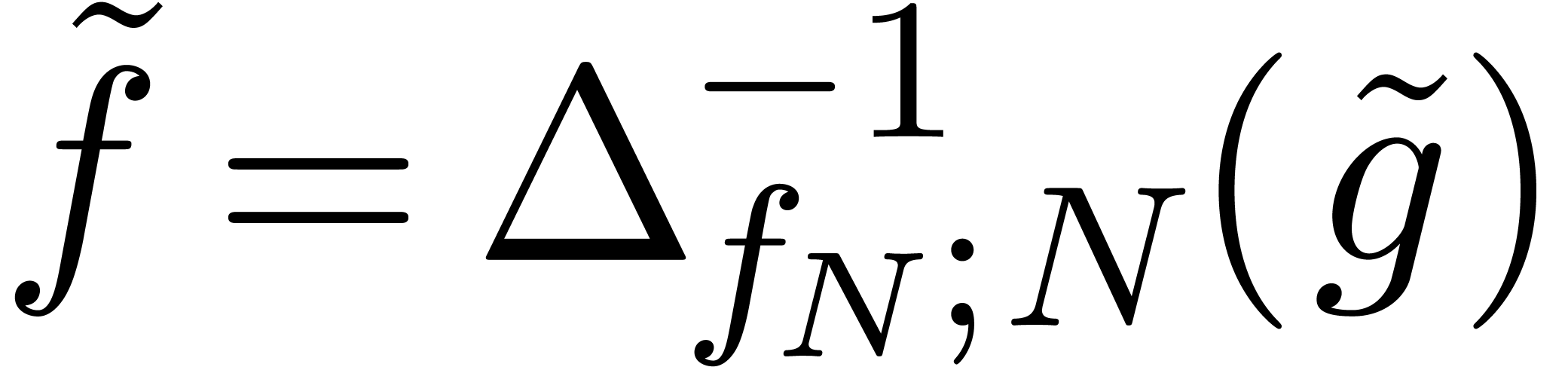 ,
where
,
where 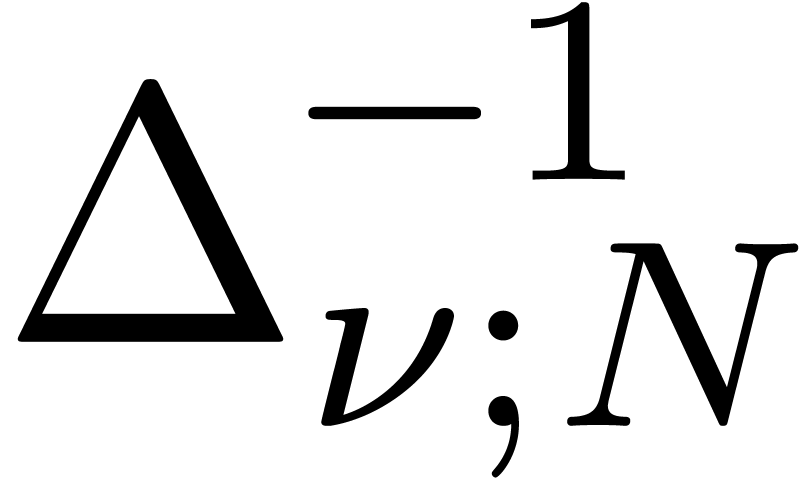 is the inverse of
for which the
is the inverse of
for which the  -th coefficient
is given by
-th coefficient
is given by  .
.
to be of the form
 |
(9) |
where 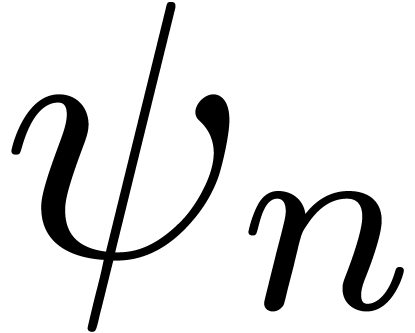 is a simple explicit function, such as
is a simple explicit function, such as
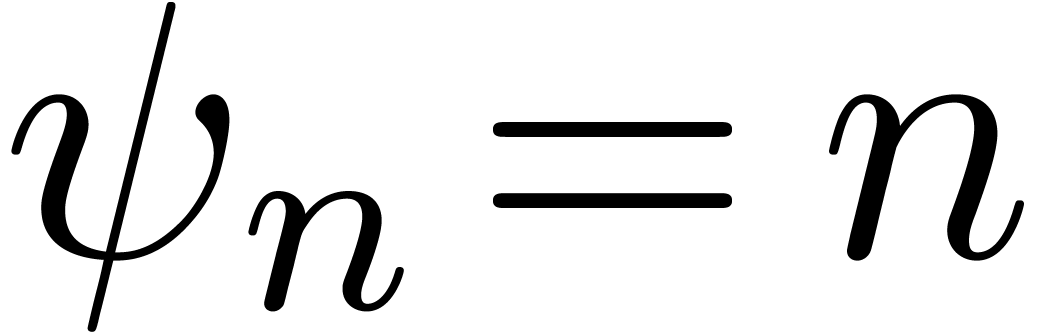 ,
, 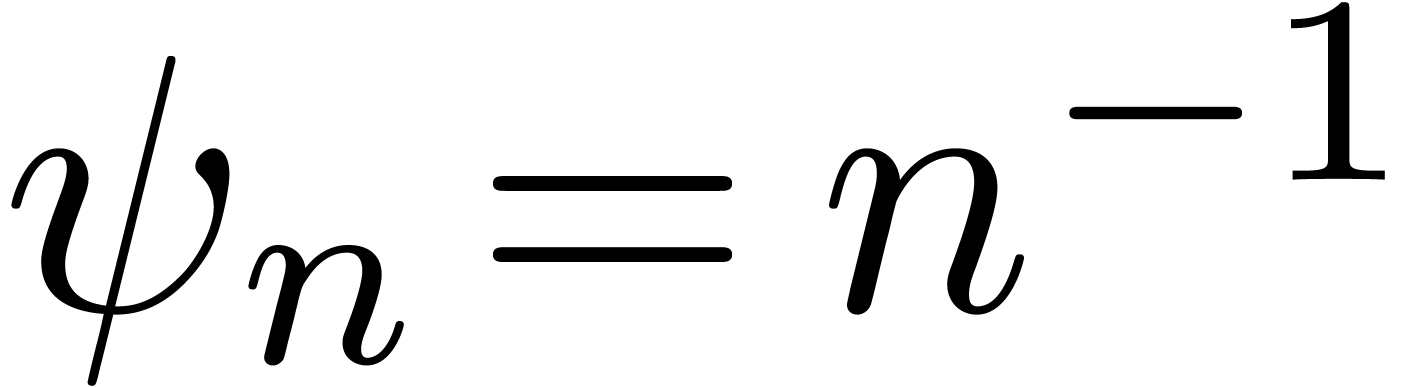 or
or
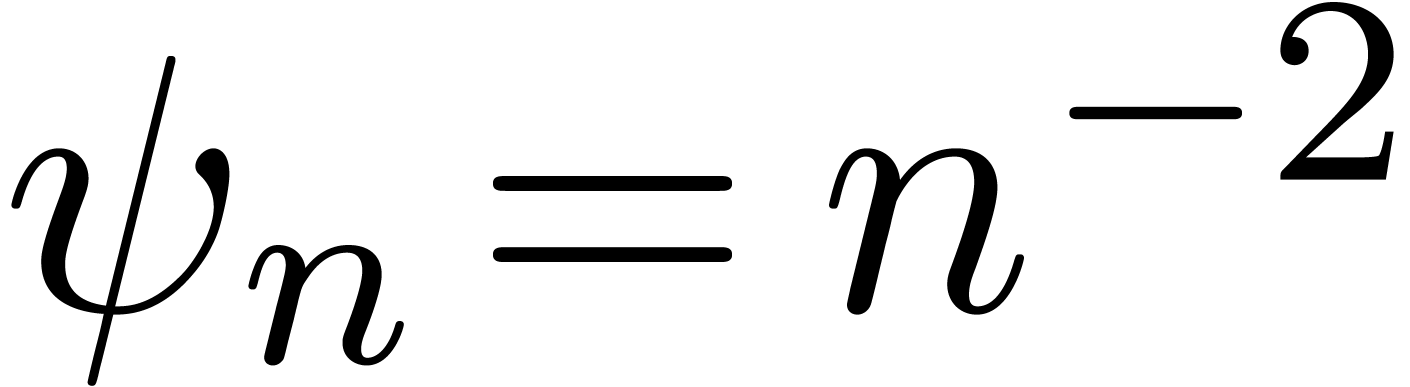 . A simple numeric criterion
for this situation is
. A simple numeric criterion
for this situation is
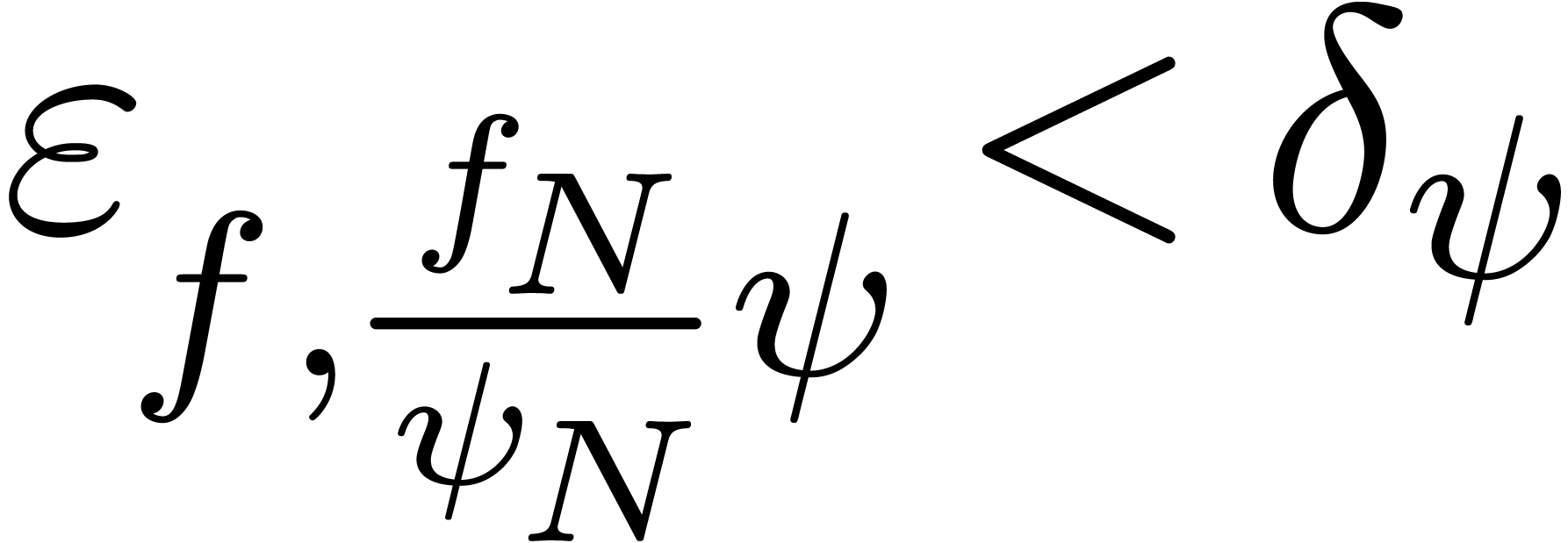 |
(10) |
for a suitable threshold 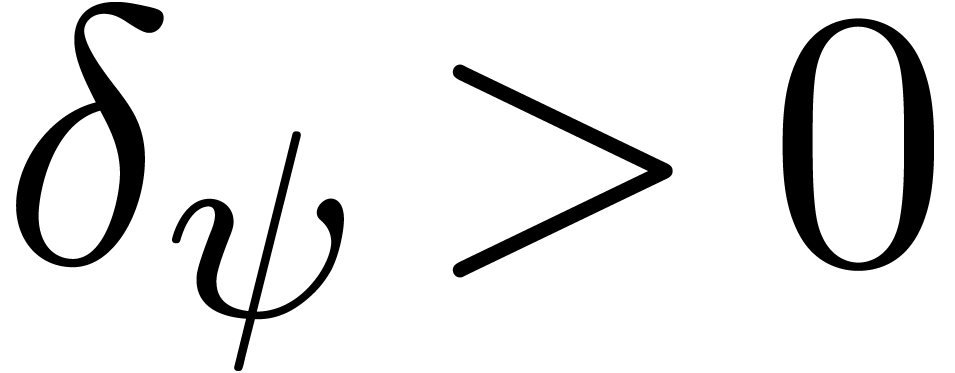 . We
usually take
. We
usually take 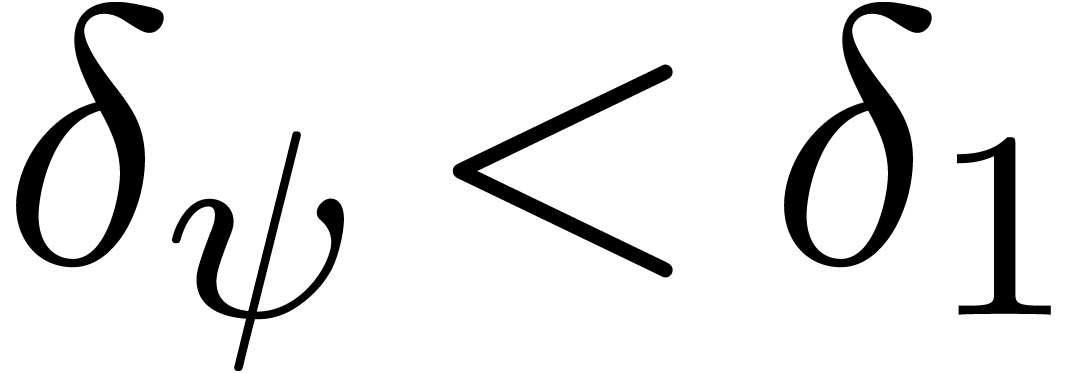 . More
generally,
. More
generally, 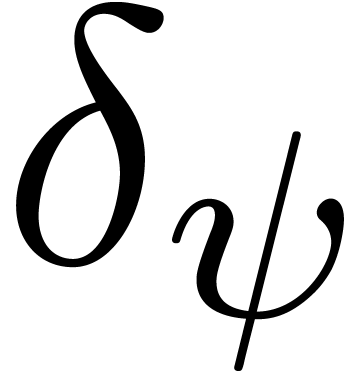 is taken smaller for more complicated
functions. For instance, one might take
is taken smaller for more complicated
functions. For instance, one might take 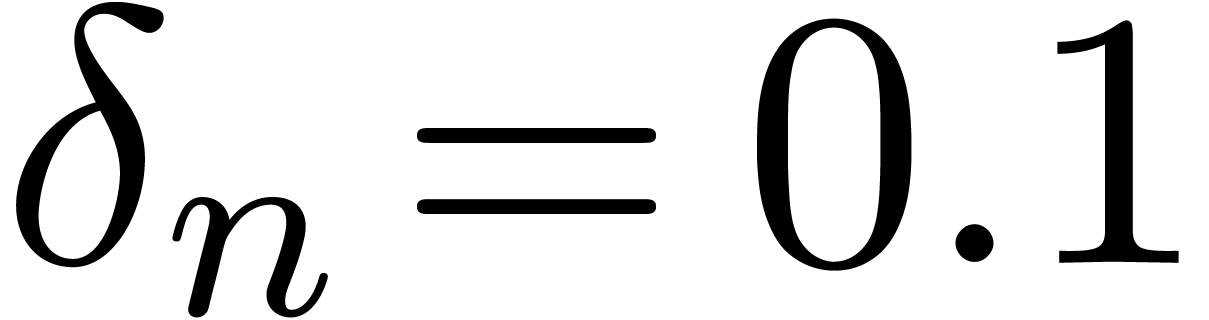 ,
but
,
but 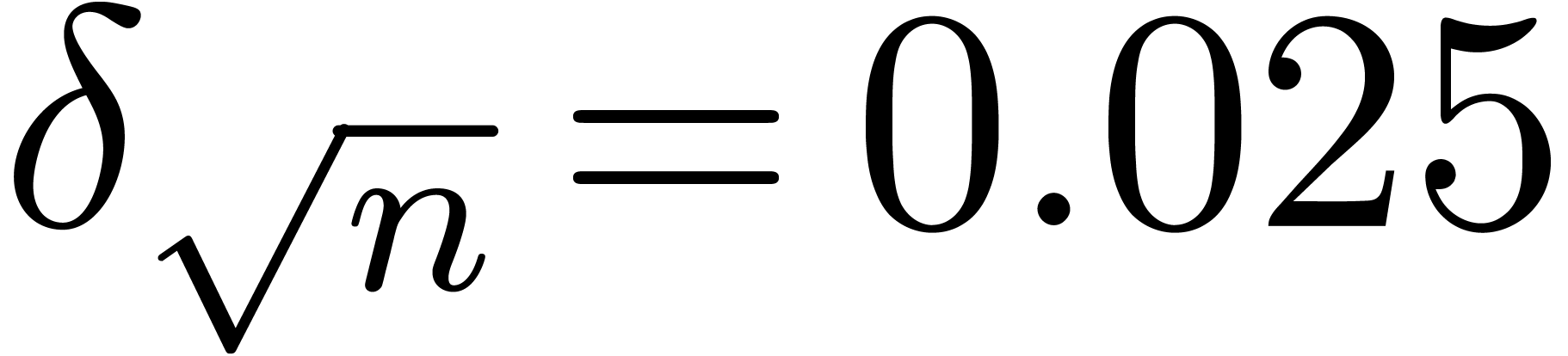 . Whenever is of the form (9), it is natural to apply
the scaling operator
. Whenever is of the form (9), it is natural to apply
the scaling operator 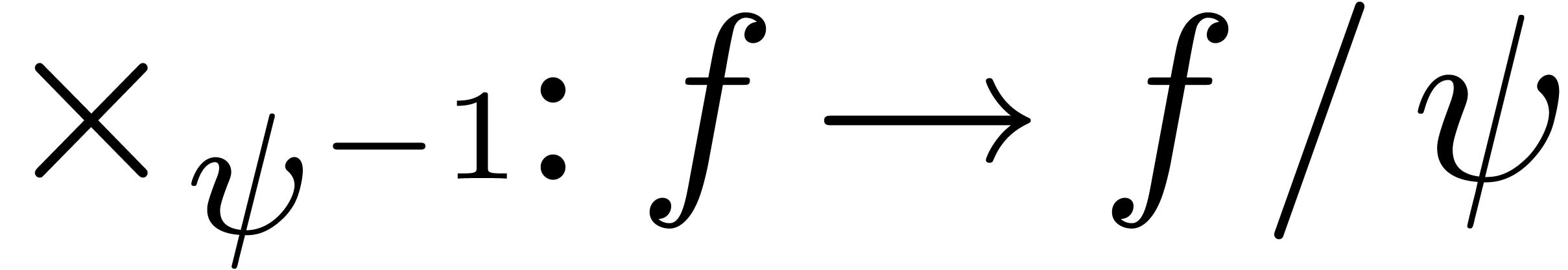 to . Given an extrapolation
to . Given an extrapolation  for
for
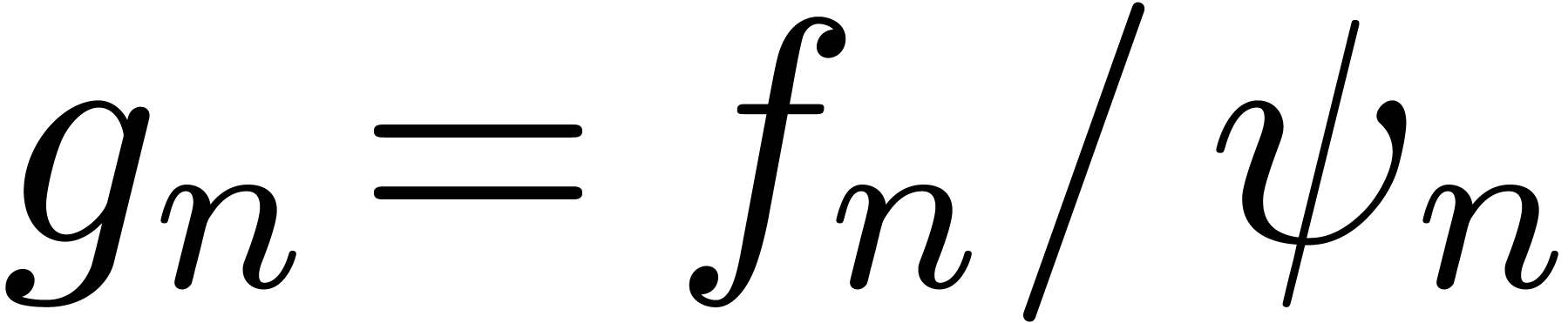 , we simply scale back
, we simply scale back 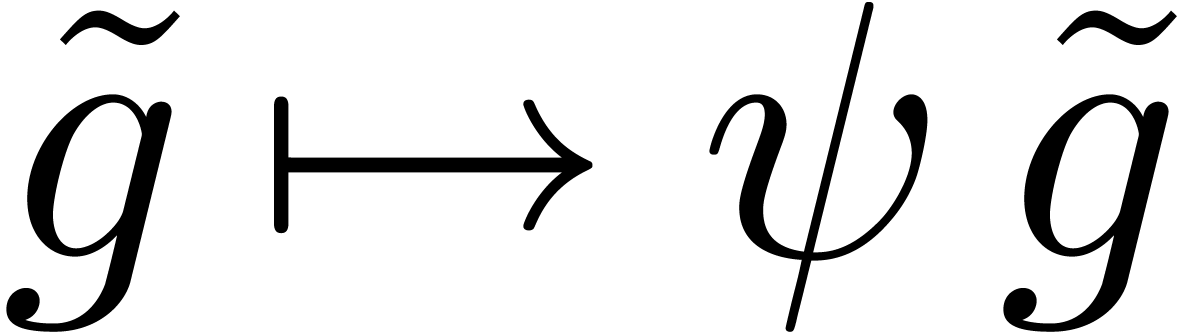 in order to obtain the extrapolation for .
in order to obtain the extrapolation for .
has a regular asymptotic
behaviour, which does not fall into any special case, then we may
write

The only necessary condition for this to work is that the sign of ultimately does not change. The corresponding numeric
criterion can simply taken to be
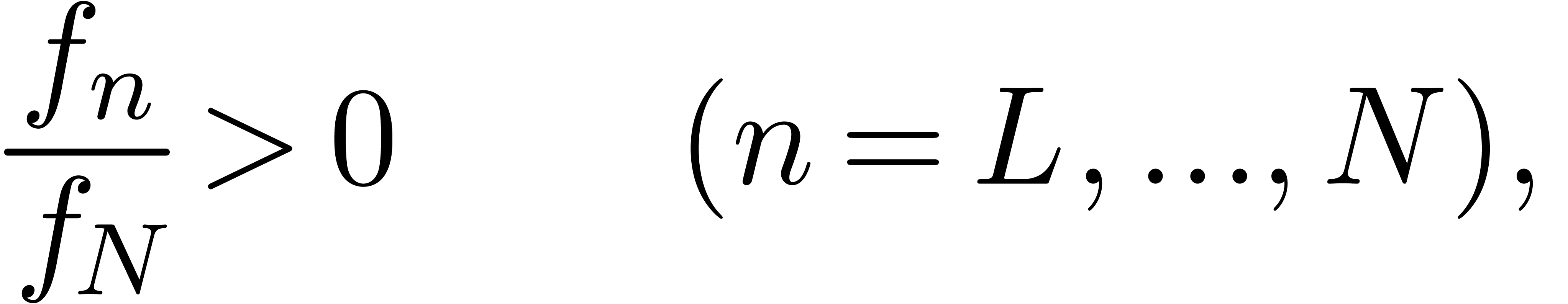
with the optional exclusion of the other cases (8) and (10). If the criterion is satisfied, then we may apply the
transformation 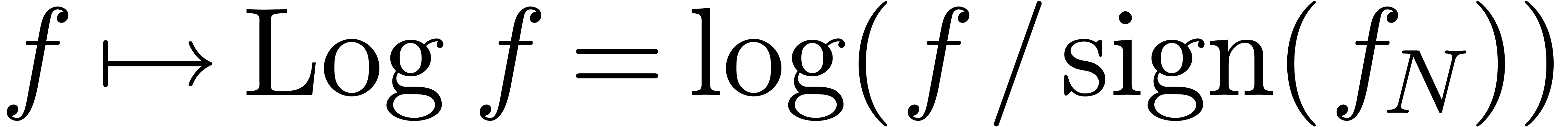 , whose
inverse is given by
, whose
inverse is given by 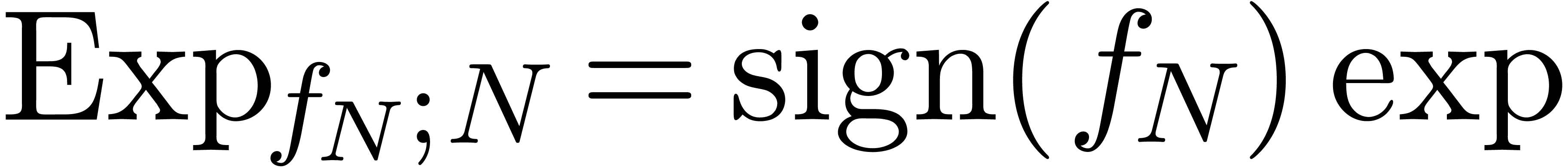 . As a
variant, we may consider an asymptotic behaviour of the form
. As a
variant, we may consider an asymptotic behaviour of the form
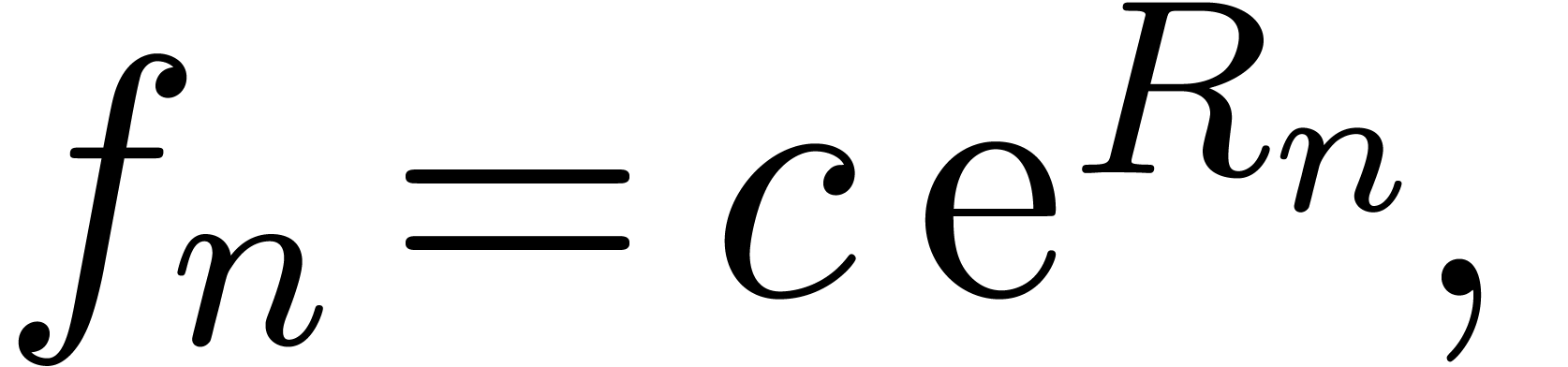
and use the atomic transformation 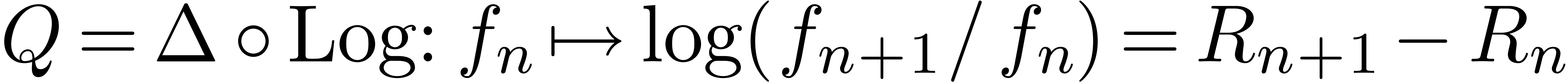 .
.
 |
(11) |
then we may successively apply the operators
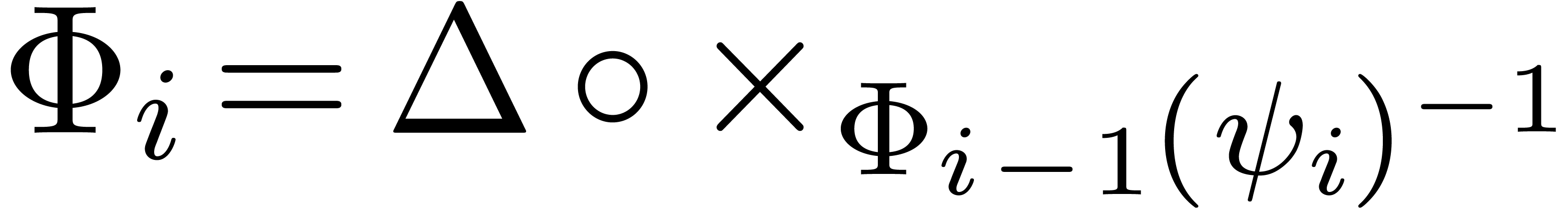
for 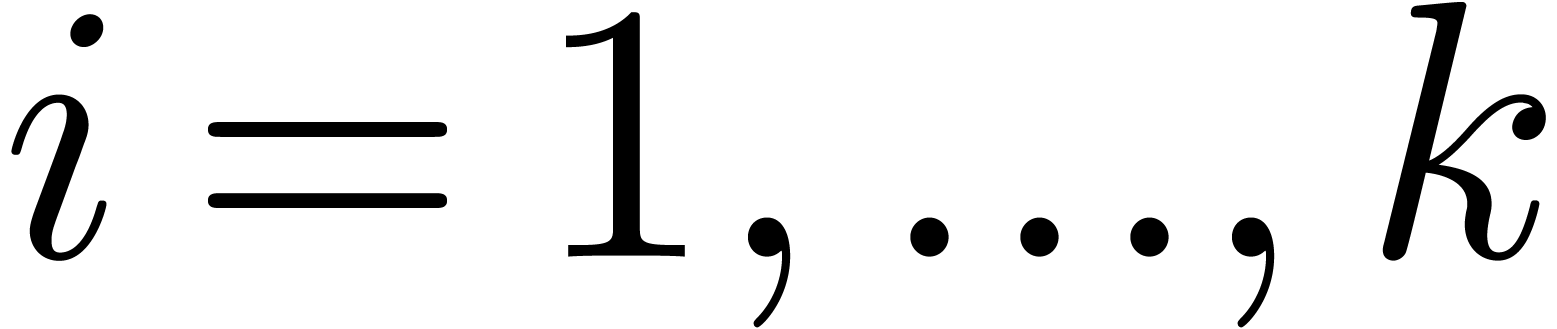 , and where
, and where 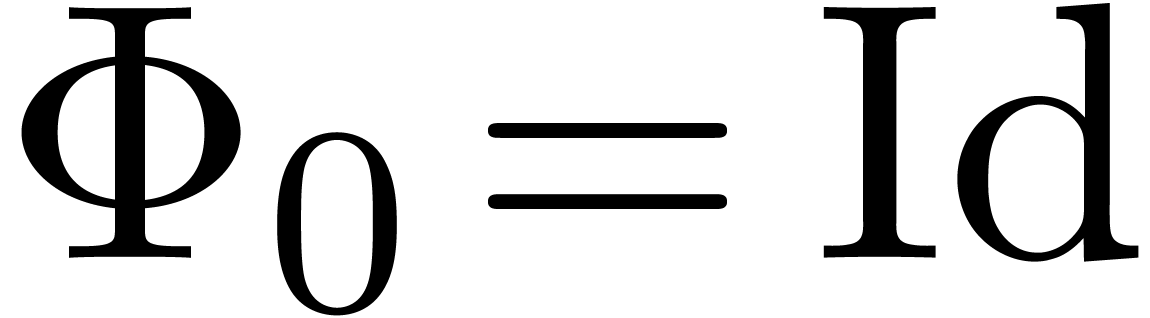 . This is equivalent to the E-algorithm and
related to the “all-in-one” transformation given by
. This is equivalent to the E-algorithm and
related to the “all-in-one” transformation given by
Of course,  is acceptable for
if and only if and
is acceptable for
if and only if and  are
acceptable for resp. . Another example is given by asymptotic
behaviour of the type
are
acceptable for resp. . Another example is given by asymptotic
behaviour of the type
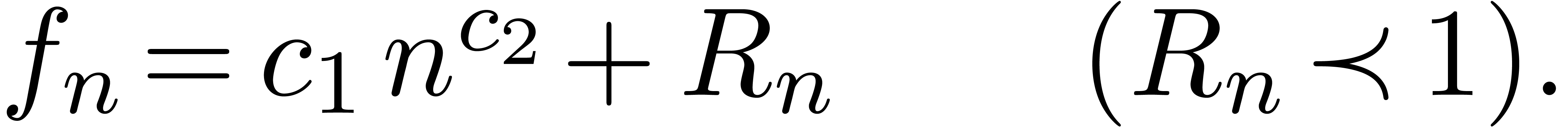 |
(12) |
In that case, we may apply the transformation  . More generally, the logarithmic/exponential
transformations can be rather violent, so it is often useful to restrict
their acceptability.
. More generally, the logarithmic/exponential
transformations can be rather violent, so it is often useful to restrict
their acceptability.
, such that
the dominant asymptotic behaviour of depends
on . The main trouble comes
from the fact that we need a transformation of the form 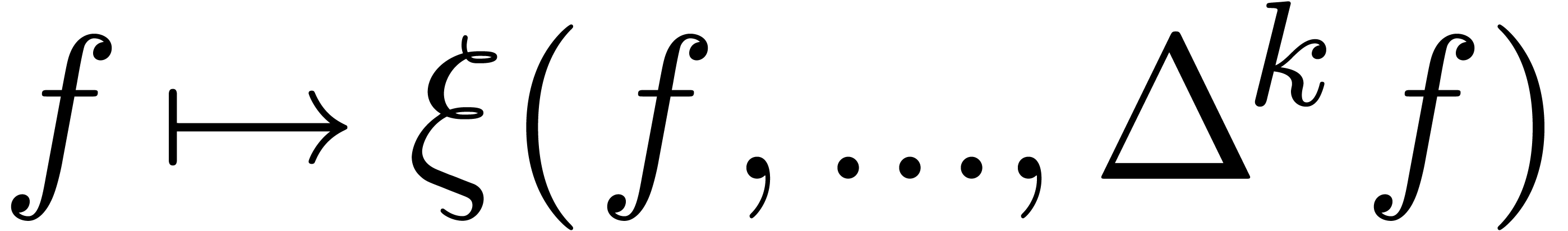 .
.
Indeed, consider the modified problem, when is
an infinitely differentiable function on 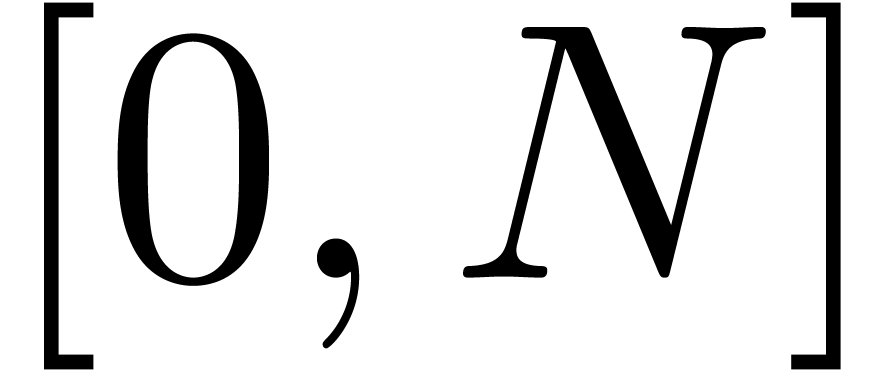 rather
than a sequence. For simplicity, we will also assume that
rather
than a sequence. For simplicity, we will also assume that 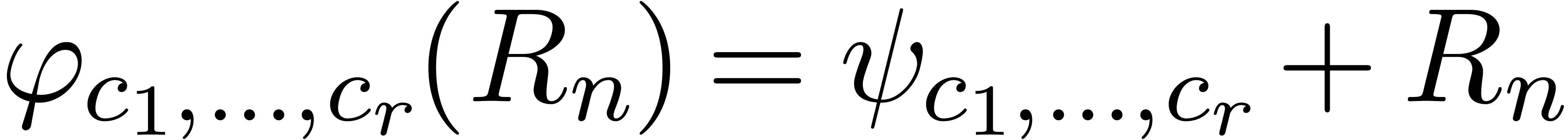 , where
, where 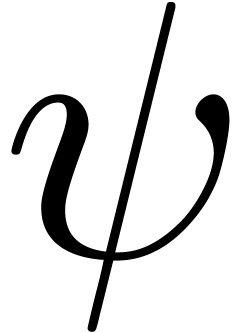 is an exp-log
function in and .
Since the set of algebraically differential functions forms a field
which is closed under composition, satisfies an
algebraic differential equation
is an exp-log
function in and .
Since the set of algebraically differential functions forms a field
which is closed under composition, satisfies an
algebraic differential equation 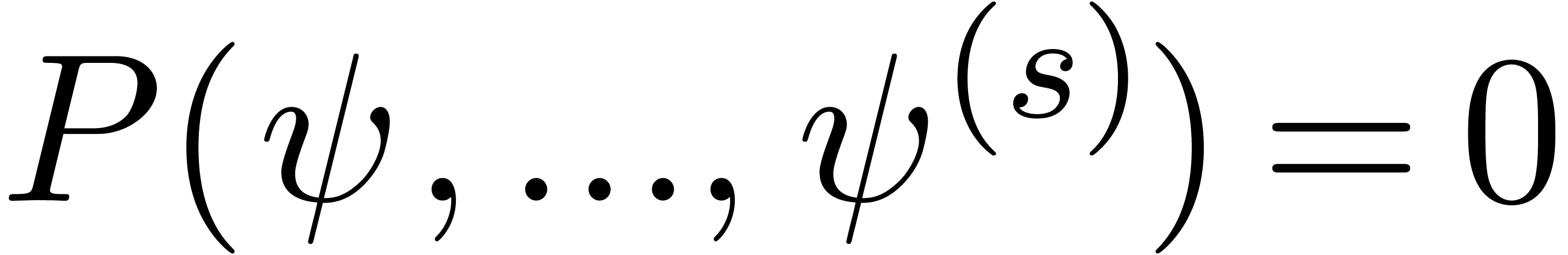 in and we simply take
in and we simply take 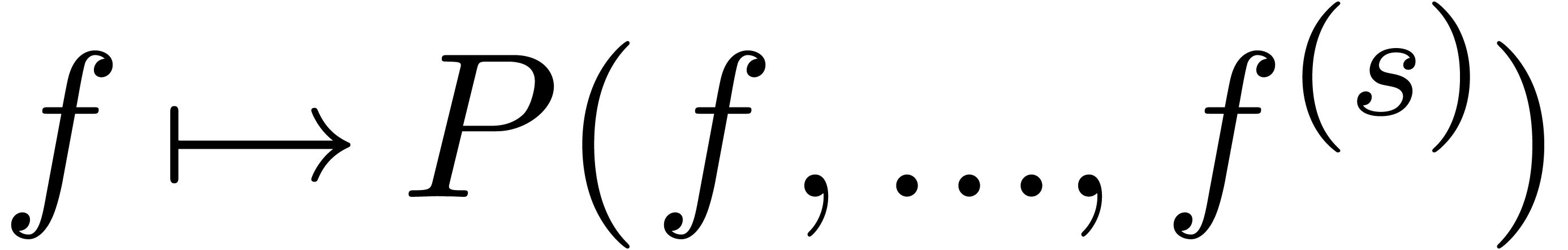 for our atomic
transformation. If is sufficiently small, then
the intermediate value theorem for transseries [vdH06c,
Chapter 9] ensures the existence of a transseries solution to
for our atomic
transformation. If is sufficiently small, then
the intermediate value theorem for transseries [vdH06c,
Chapter 9] ensures the existence of a transseries solution to  , which can actually be given an
analytic meaning [vdH06b].
, which can actually be given an
analytic meaning [vdH06b].
Unfortunately, the field of functions which satisfy an algebraic
difference equation is not closed under composition. In particular, let
us consider the sequence 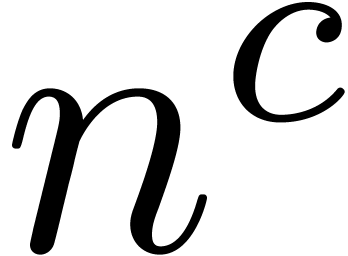 ,
where is a formal parameter. We claim that this
sequence does not satisfy an algebraic difference equation. Indeed,
assume the contrary and let
,
where is a formal parameter. We claim that this
sequence does not satisfy an algebraic difference equation. Indeed,
assume the contrary and let
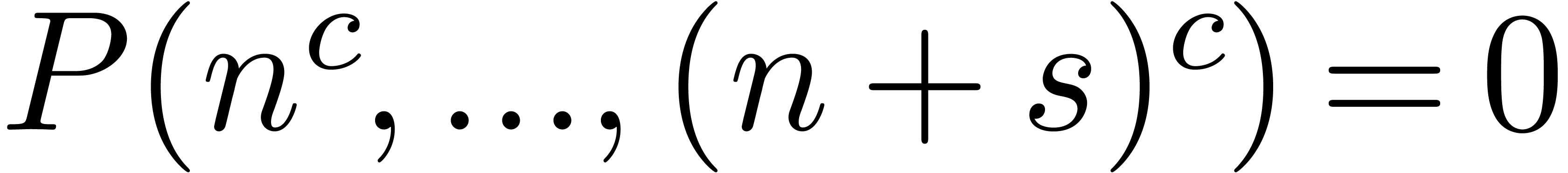
be a relation of minimal order and minimal degree. Considering as a complex number, turning around the singularity at
 results in a new relation
results in a new relation
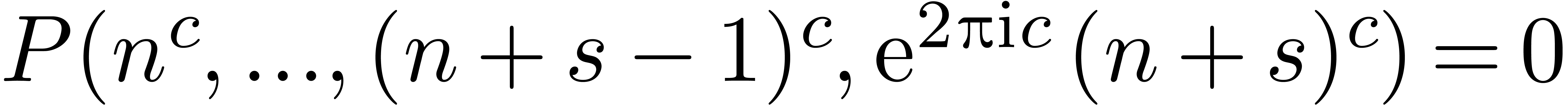
Combining this relation with the previous one, we obtain a relation of
smaller degree or order. In particular, this shows that for an
asymptotic behaviour of the form (12), there exists no
algebraic atomic transformation which will
completely eliminate  and make
apparent in the dominant behaviour of .
and make
apparent in the dominant behaviour of .
Throughout this section we assume that we have fixed a finite set  of atomic transformations. One possible choice for
is
of atomic transformations. One possible choice for
is 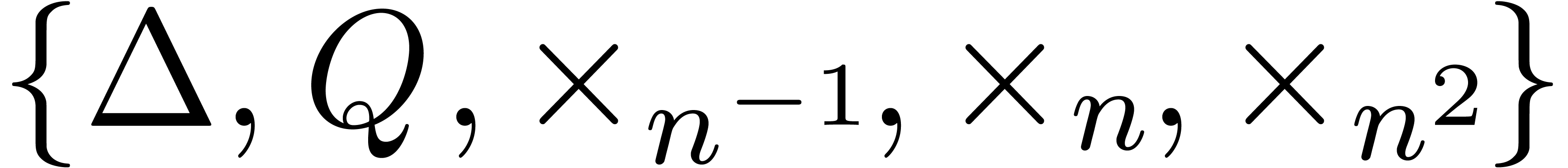 ,
but other selections will be discussed below. Each transformation
,
but other selections will be discussed below. Each transformation  comes with a criterion for acceptability.
Furthermore, given an asymptotic extrapolation
for , we assume that we may
compute the inverse operator
comes with a criterion for acceptability.
Furthermore, given an asymptotic extrapolation
for , we assume that we may
compute the inverse operator 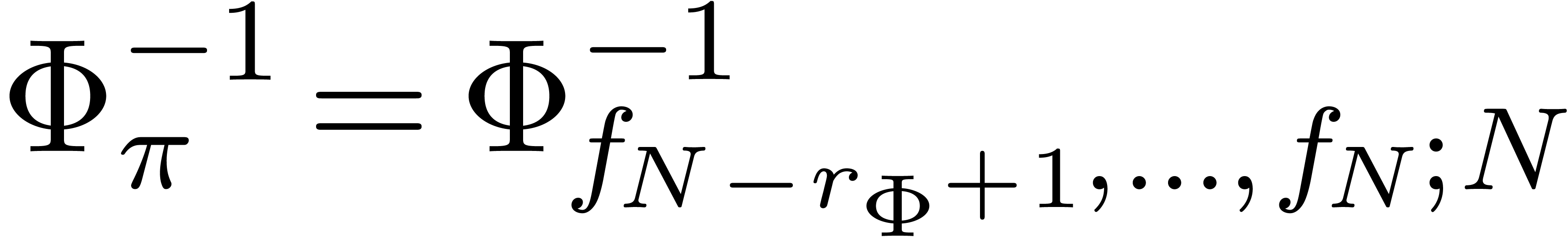 of , for which
of , for which 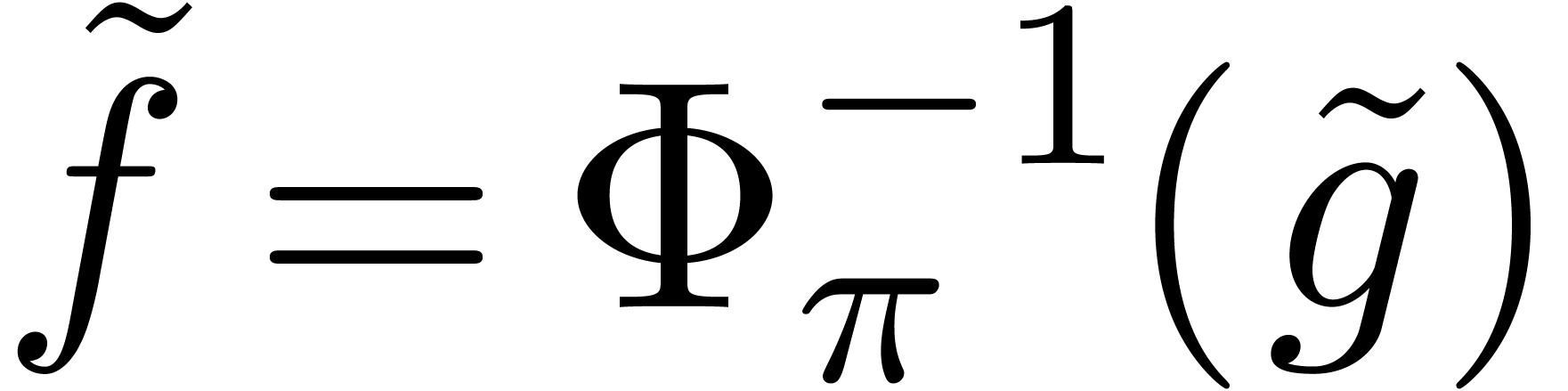 coincides
with on the last
coincides
with on the last  known
coefficients
known
coefficients 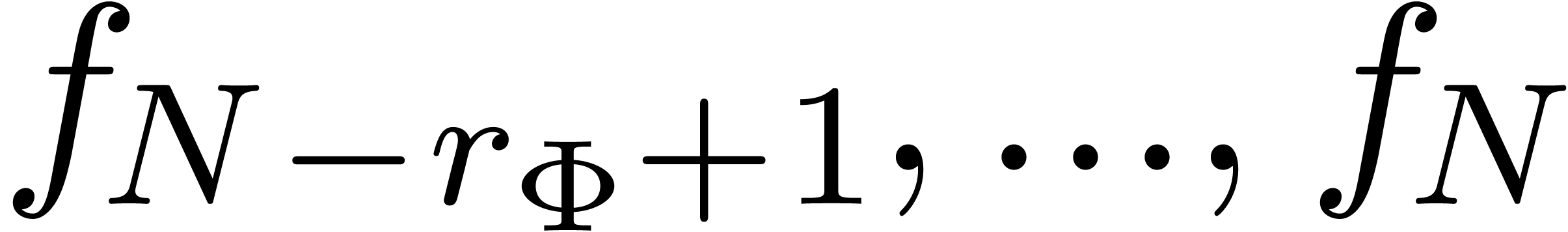 .
.
Given an input series and an
“extrapolation order” 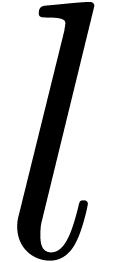 ,
the asymptotic extrapolation scheme simply attempts to apply all
composite transformations
,
the asymptotic extrapolation scheme simply attempts to apply all
composite transformations  on , where
on , where 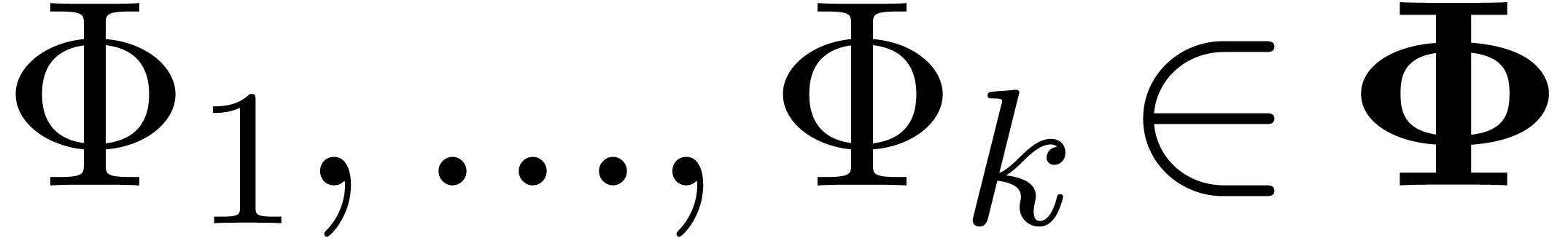 and
and 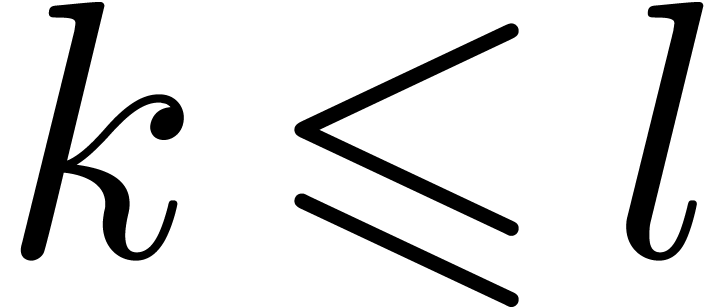 . The scheme returns a set of
possible extrapolations. Each asymptotic extrapolation is returned in
the form of a recipe
. The scheme returns a set of
possible extrapolations. Each asymptotic extrapolation is returned in
the form of a recipe 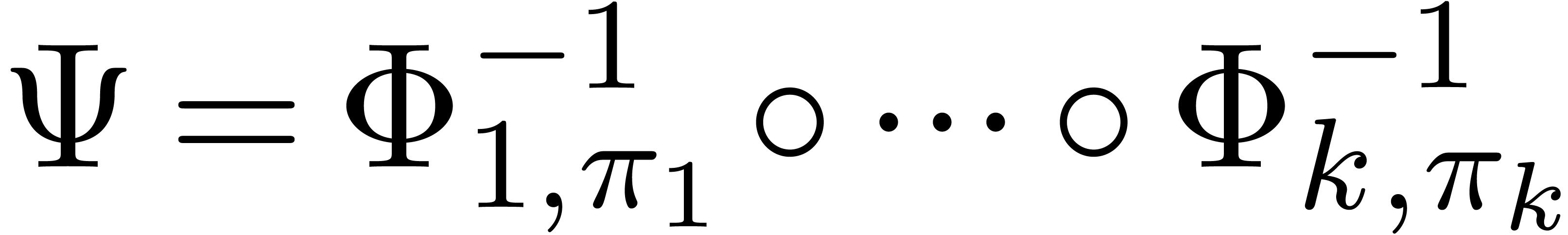 ,
for suitable parameters
,
for suitable parameters  .
When applying this recipe to the zero sequence, we obtain a numeric
extrapolation
.
When applying this recipe to the zero sequence, we obtain a numeric
extrapolation 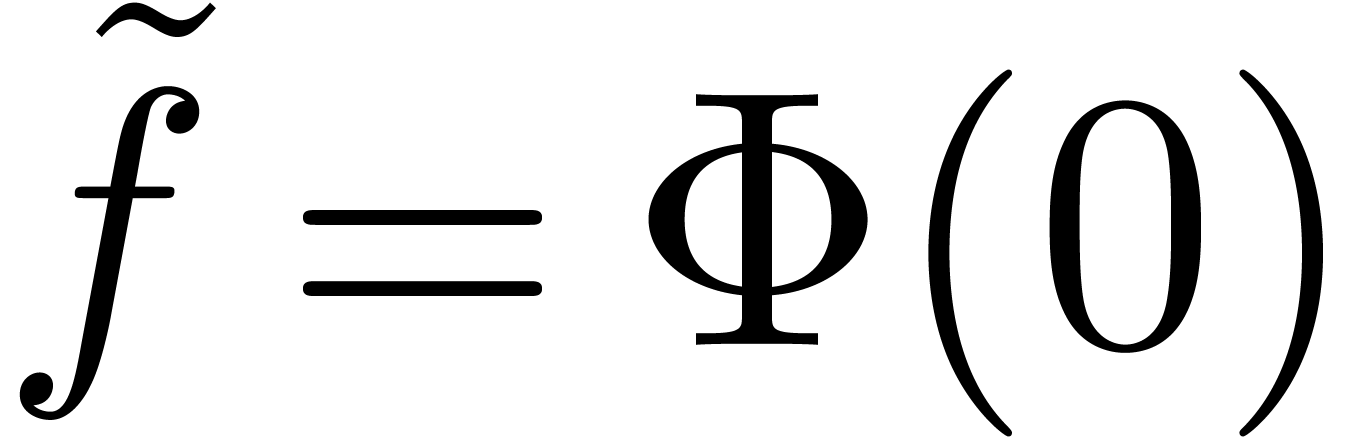 of .
In particular, the resulting extrapolations can optionally be sorted on
the relative error
of .
In particular, the resulting extrapolations can optionally be sorted on
the relative error 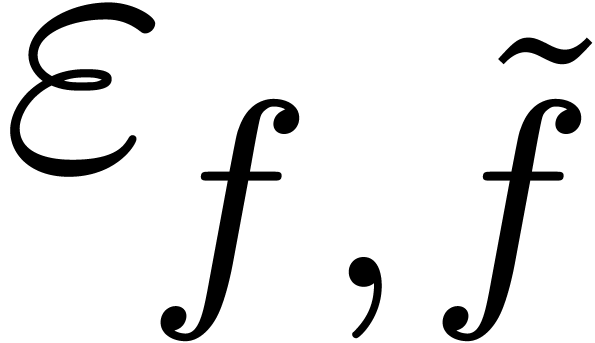 , after
which we may keep only the best or
, after
which we may keep only the best or  best results.
The inverse of a recipe will be called a
reductor.
best results.
The inverse of a recipe will be called a
reductor.
Algorithm extrapolate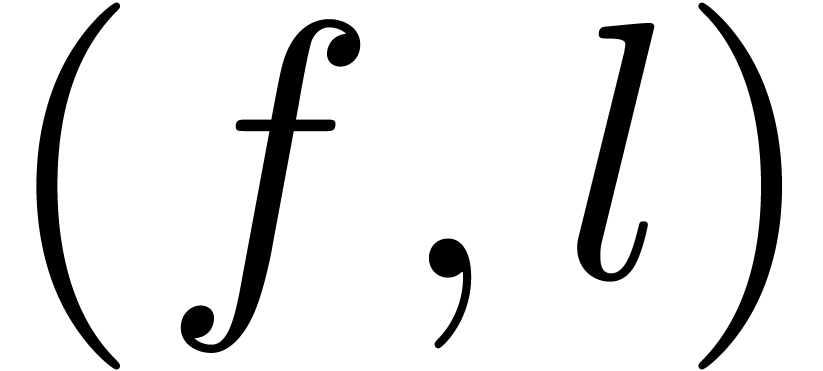
Input: a finite sequence and
the extrapolation order 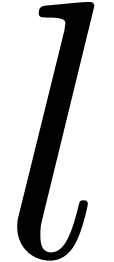
Output: a set of extrapolations of the form 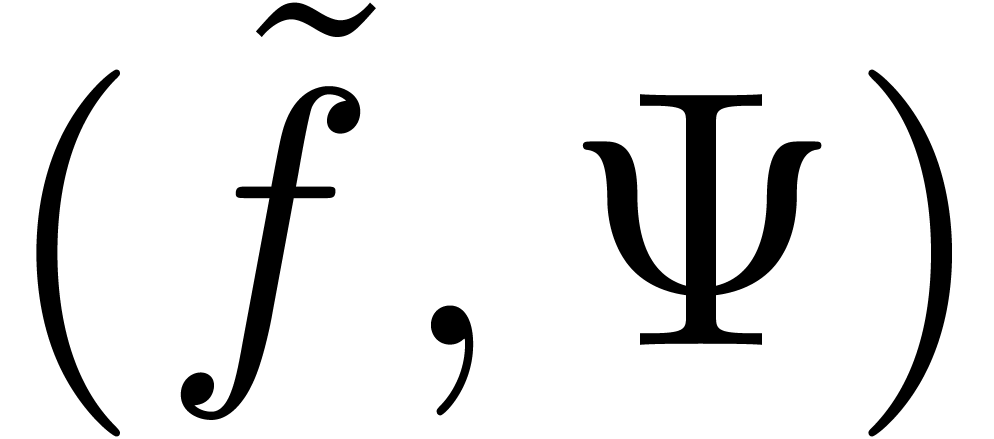 for
for 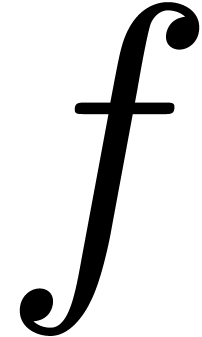
Let 
For each  such that
such that  is
acceptable for and
is
acceptable for and 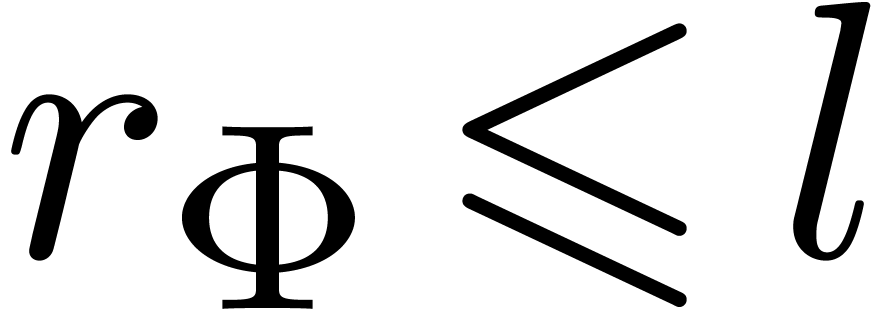 do
do

For each  do
do
Compute parameters  with
with 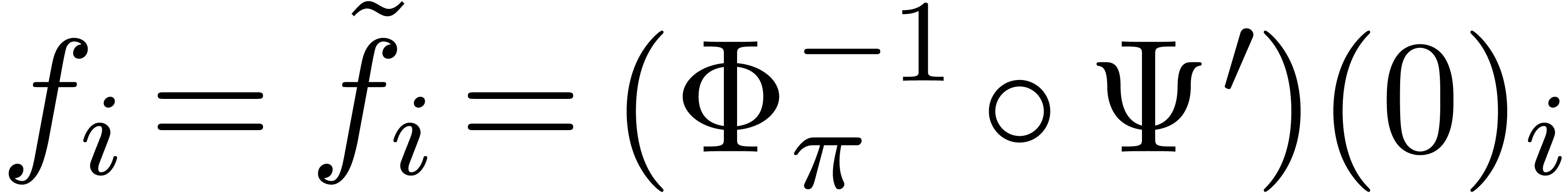 for
for 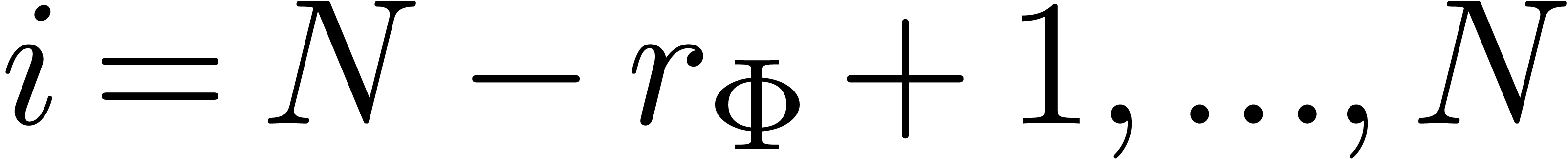
Set 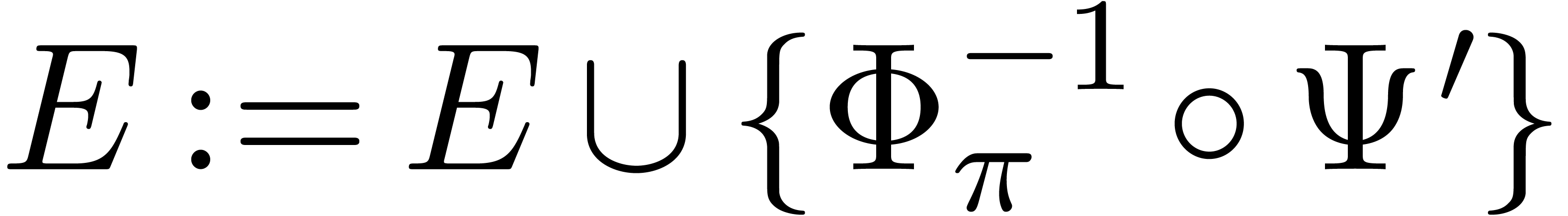
Return 
Remark 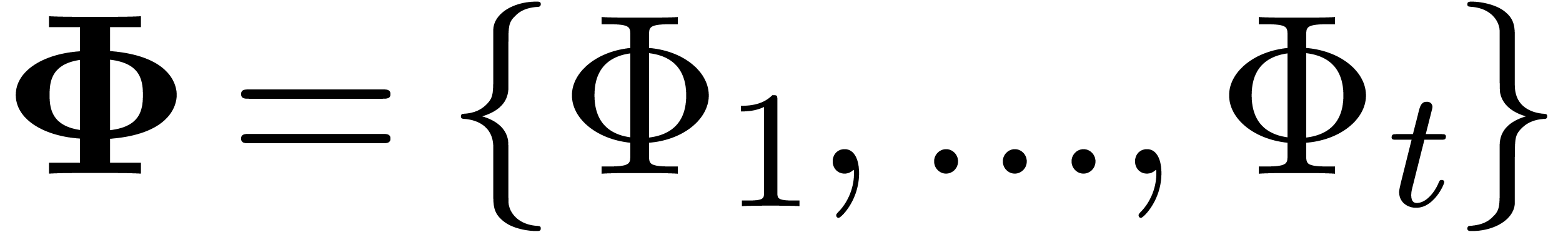 is often designed in such a way that no more
than one transformation is acceptable at a time.
For instance, the criterion for acceptability by
might include the condition that
is often designed in such a way that no more
than one transformation is acceptable at a time.
For instance, the criterion for acceptability by
might include the condition that  is not
acceptable for any
is not
acceptable for any  . Indeed,
it is important to keep the number of accepted transformations small at
each stage, in order to prevent combinatorial explosion. For some
additional considerations, we refer to section 6.3.
. Indeed,
it is important to keep the number of accepted transformations small at
each stage, in order to prevent combinatorial explosion. For some
additional considerations, we refer to section 6.3.
Remark
are intervals instead of floating point numbers, and the deterioration
of the relative precision will be more explicit during the application
of the successive transformations. As to the actual extrapolation, one
should replace  by the smallest interval which
contains
by the smallest interval which
contains  at the last step, and similarly for the
determination of the other continuous parameters. Again, this has the
advantage of giving a more precise idea on the accuracy of the
continuous parameters. We refer to section 3 of our earlier preprint [vdH06a] for a worked example using interval arithmetic.
at the last step, and similarly for the
determination of the other continuous parameters. Again, this has the
advantage of giving a more precise idea on the accuracy of the
continuous parameters. We refer to section 3 of our earlier preprint [vdH06a] for a worked example using interval arithmetic.
Clearly, the choice of and the corresponding
criteria is primordial for the success of our extrapolation scheme under
various circumstances. Reduced sets of
transformations and strict criteria are recommended in the case when the
user already has some idea about possible shapes for the asymptotic
expansion. Larger sets and looser criteria may
allow the detection of more complex asymptotic behaviours, at the risk
of finding incorrect extrapolations. Let us discuss a few other possible
choices for in more detail.
admits an asymptotic
expansion in the form of a power series
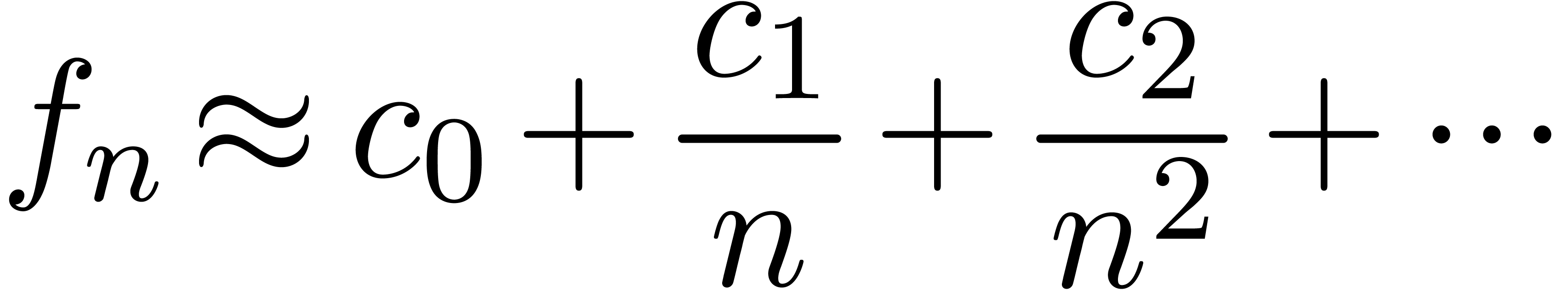 |
(13) |
Applying the transformation 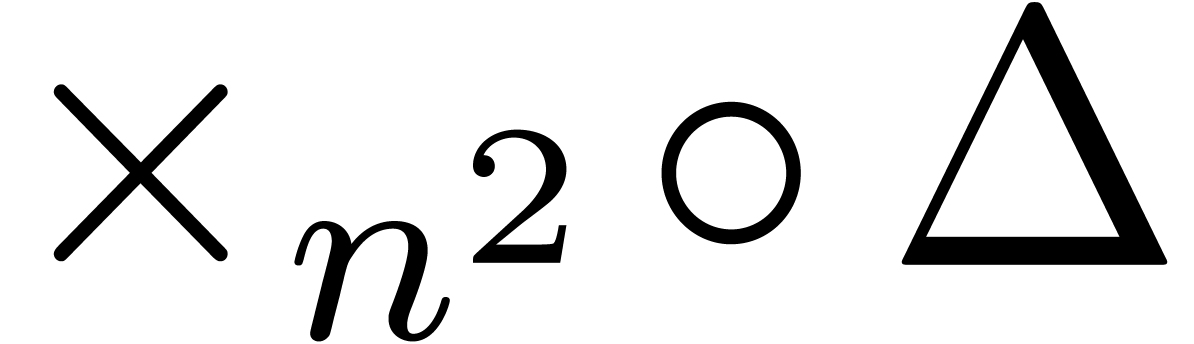 on this expansion,
we obtain
on this expansion,
we obtain
which has a similar shape. Assuming that none of the coefficients vanishes, the set 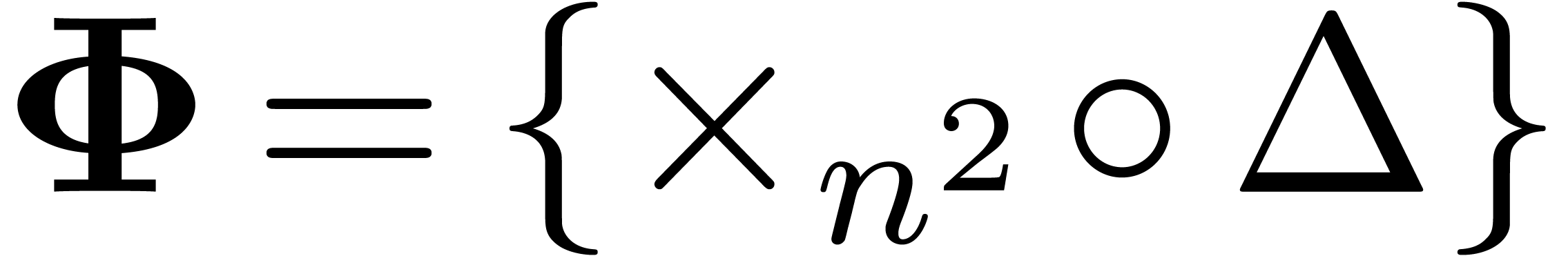 or
or  therefore suffices for the extrapolation of . In the case when some of the
coefficients vanish, we should rather take
therefore suffices for the extrapolation of . In the case when some of the
coefficients vanish, we should rather take 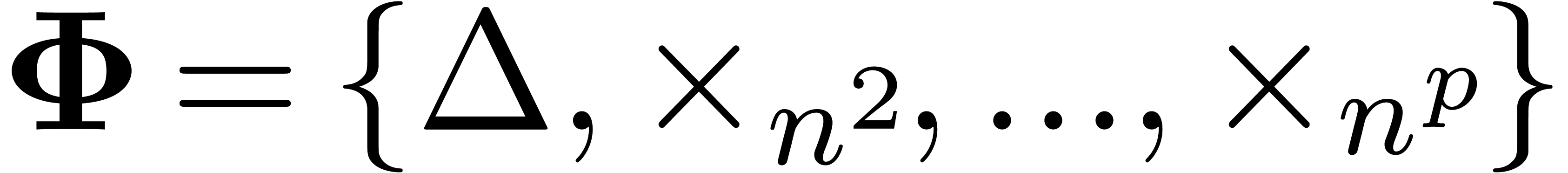 .
.
has an asymptotic expansion
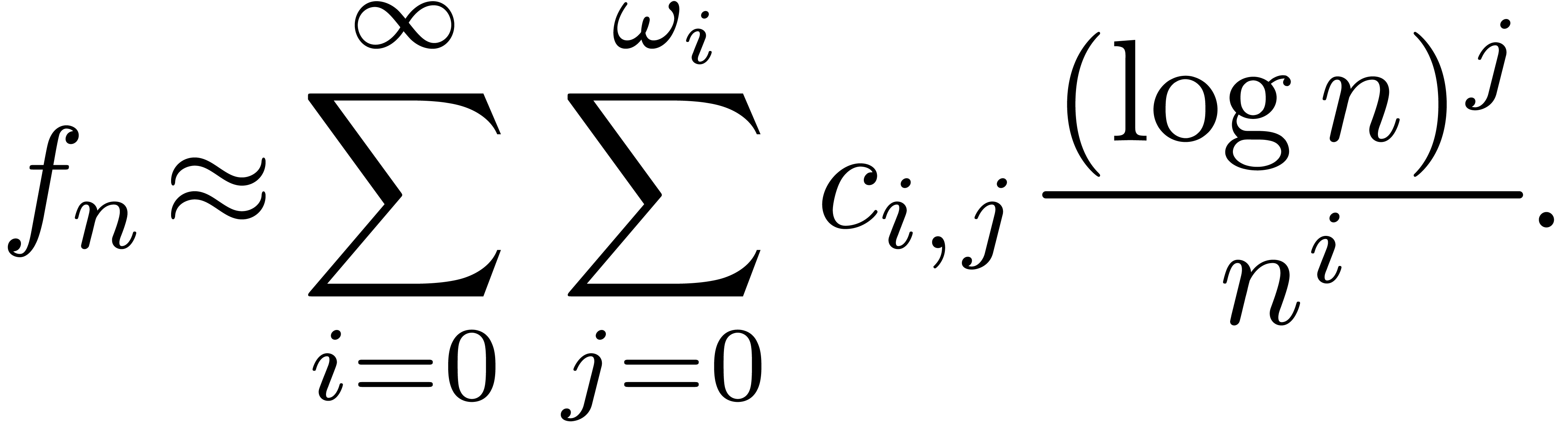
If 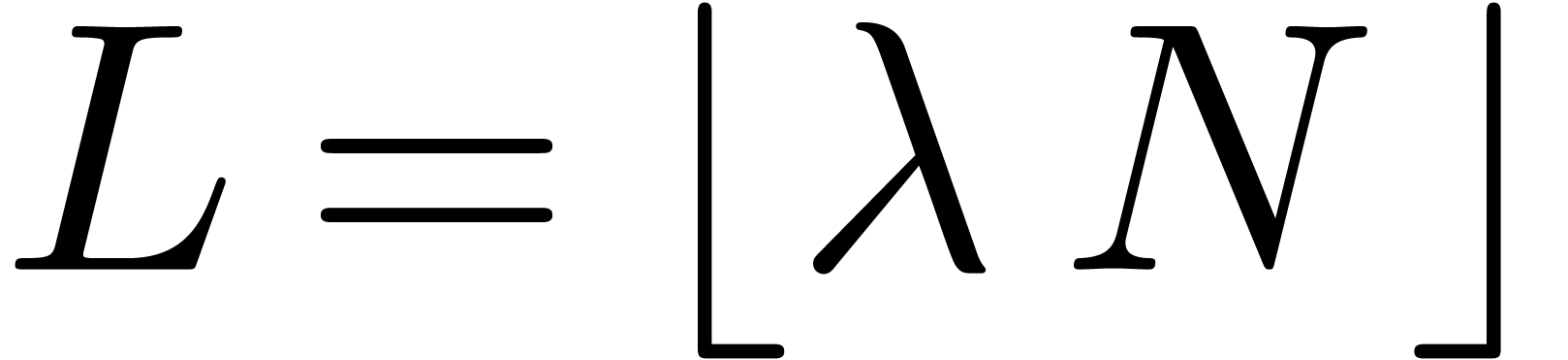 for a fixed constant
for a fixed constant  , then the relative error
, then the relative error 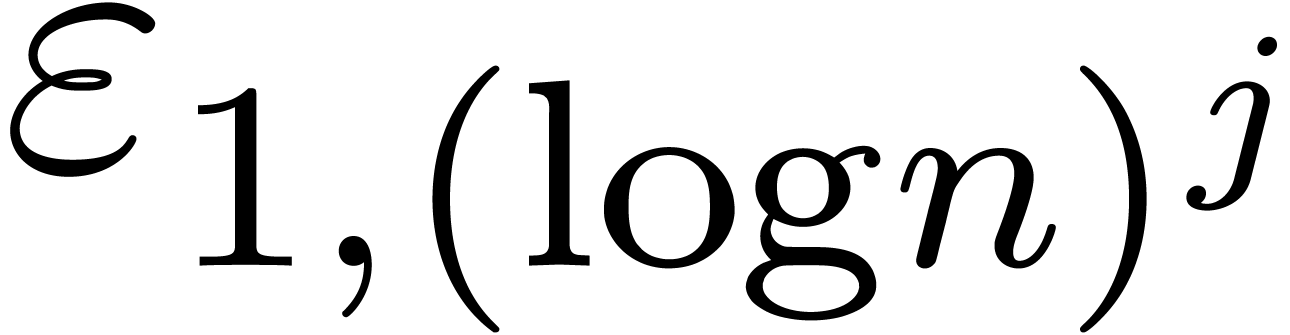 tends to zero for
tends to zero for 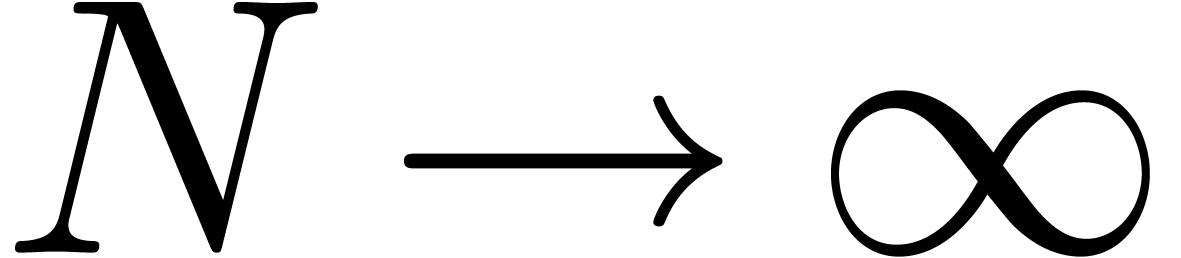 and fixed
and fixed  . In particular, if
. In particular, if  , then the asymptotic extrapolation scheme will
attempt to apply on any sequence with
, then the asymptotic extrapolation scheme will
attempt to apply on any sequence with 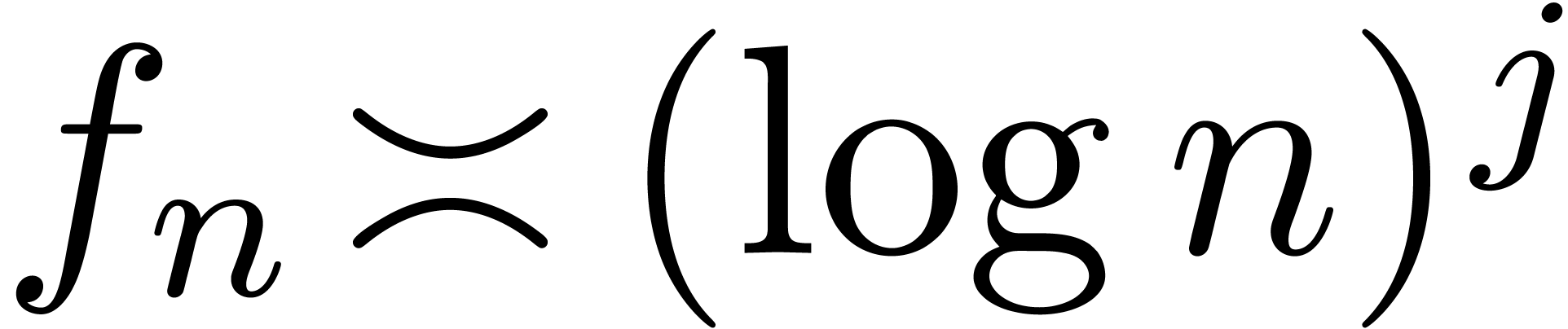 . Since
. Since
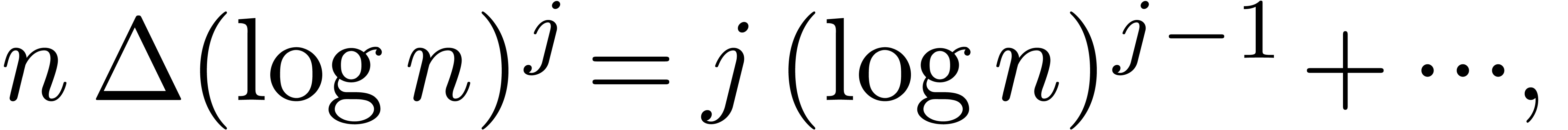
it follows that the set 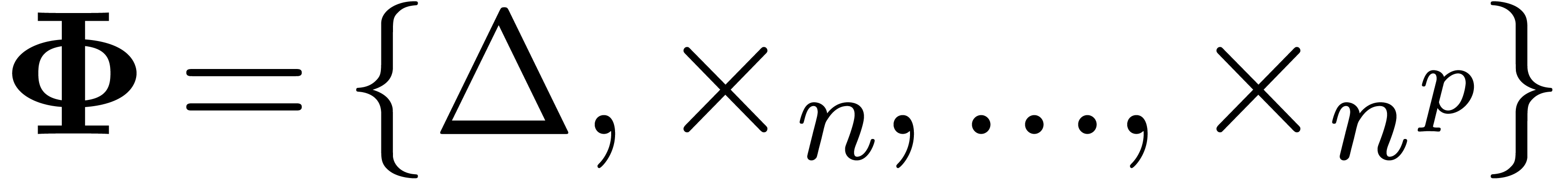 usually suffices for the
asymptotic extrapolation of (assuming that is sufficiently large).
usually suffices for the
asymptotic extrapolation of (assuming that is sufficiently large).
allows us to detect asymptotic behaviours of the form
(12). More generally, assume that
admits a generalized power series expansion with unknown (real)
exponents
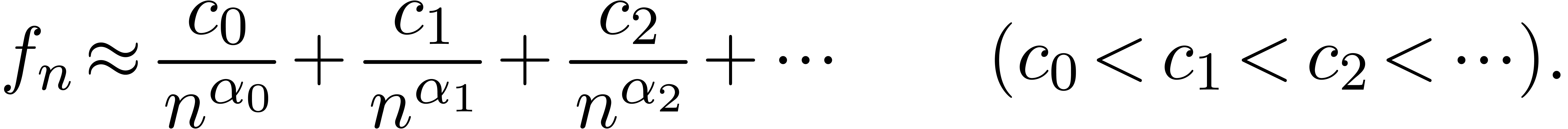
Then the set 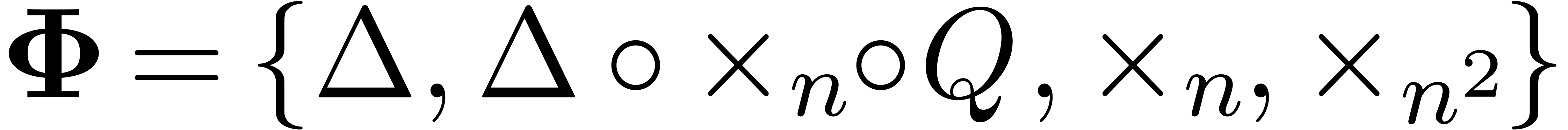 will suffice for the asymptotic
extrapolation of .
will suffice for the asymptotic
extrapolation of .
is the product of a complicated “transmonomial” and a
simple power series expansion, as in (1). In that case,
we may slightly modify our extrapolation scheme in order to allow for
a larger set 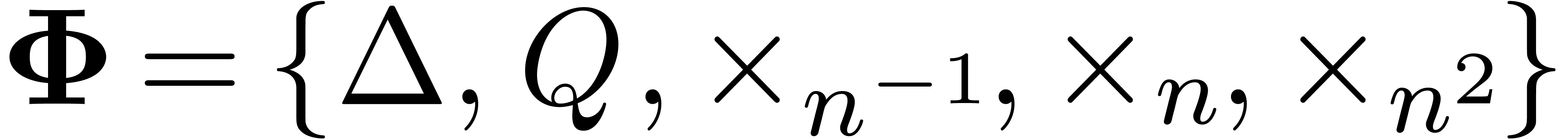 for the first few steps and a
reduced set for later steps.
for the first few steps and a
reduced set for later steps.
Asymptotic extrapolations of ,
as computed in the previous section, are given either numerically, or
using a recipe in terms of the inverses of the operators in . For instance, in the case of a power series
expansion (13), the computed recipe is typically of the
form
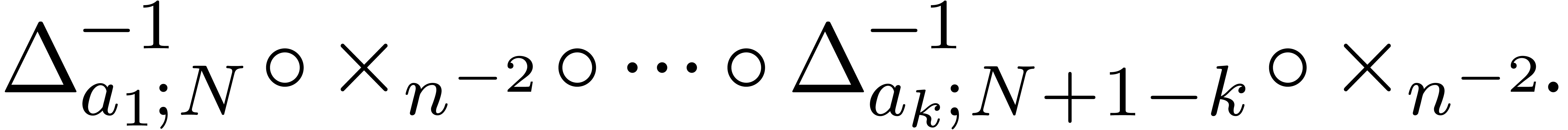 |
(14) |
Unfortunately, the corresponding values of  can
not directly be read off from this recipe. In this section, we will
discuss techniques for obtaining asymptotic extrapolations in a symbolic
and more human readable form.
can
not directly be read off from this recipe. In this section, we will
discuss techniques for obtaining asymptotic extrapolations in a symbolic
and more human readable form.
Remark
Remark
A convenient and quite general setting for the computation with
asymptotic expansions is to restrict our attention to exp-log functions
or transseries. An exp-log function is constructed from the
constants and an infinitely large indeterminate
using the field operations, exponentiation and logarithm. Several
algorithms exist for the computation with exp-log functions at infinity
[Sha89, Sal91, RSSvdH96, Sha96,
Gru96, vdH97]. A transseries is
formed in a similar way, except that, under certain support conditions,
we allow additions to be replaced by infinite summations. An example of
a transseries is
The field of formal transseries at infinity is stable under many operations, such as differentiation, integration, composition and functional inversion. However, transseries are formal objects and often divergent. Techniques for the computation with transseries can be found in [Éca92, RSSvdH96, vdH97, vdH06c, vdH08].
The aim of this paper is not to go into details about the computational
aspects of transseries. A heuristic approach, which is particularly well
adapted to the present context, is described in [vdH08].
From the computational point of view, we recall that a transseries is approximated by an infinite sum
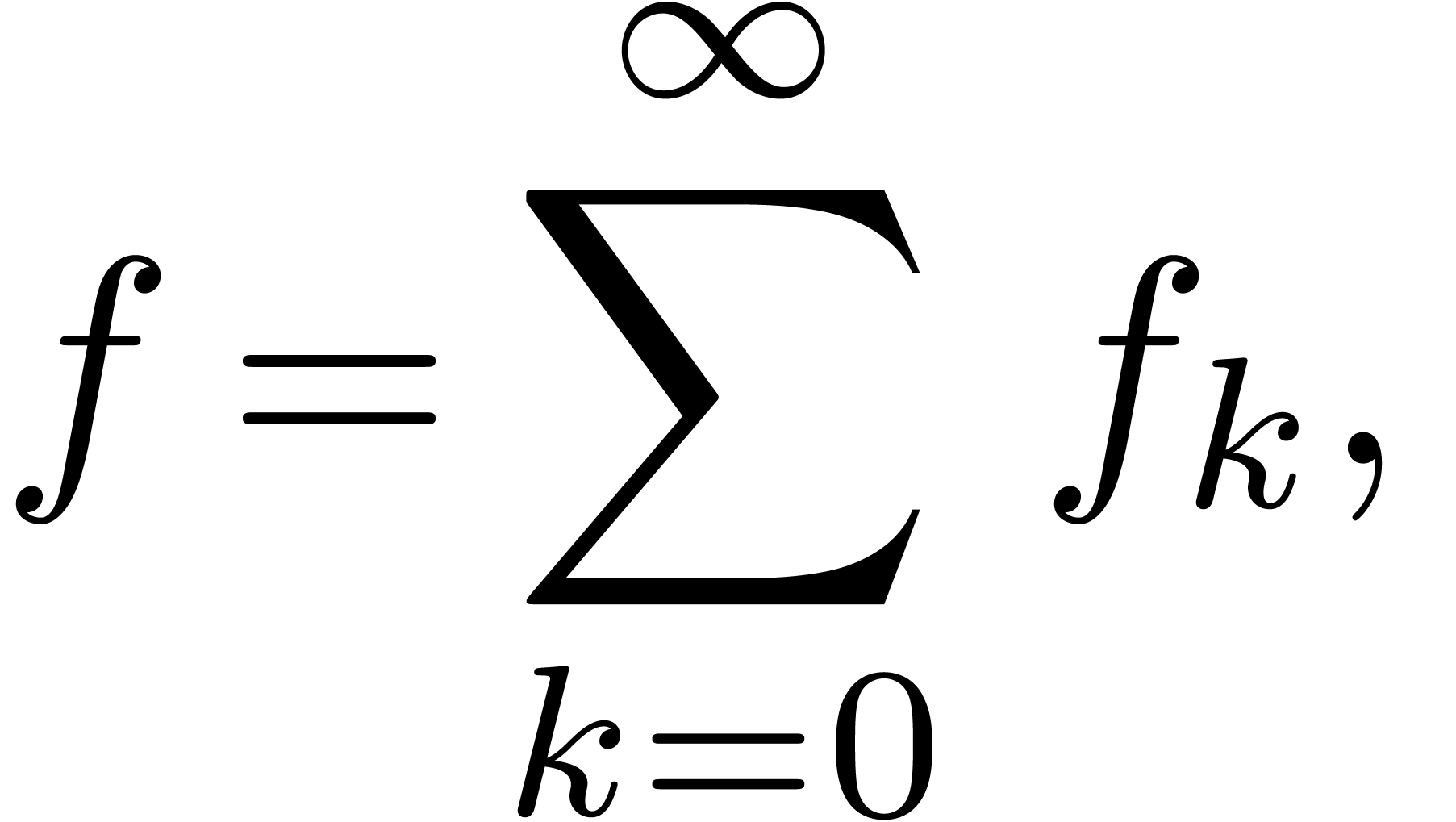 |
(15) |
where each 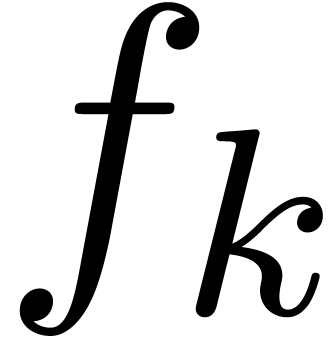 is a finite linear
combination of transmonomials. Each transmonomial is either an iterated
logarithm or the exponential of another transseries. Furthermore, it is
described in [vdH08] how to perform common operations on
transseries, such as differentiation, integration, composition, as well
as discrete summation
is a finite linear
combination of transmonomials. Each transmonomial is either an iterated
logarithm or the exponential of another transseries. Furthermore, it is
described in [vdH08] how to perform common operations on
transseries, such as differentiation, integration, composition, as well
as discrete summation  .
Finally, we notice that the technique of summation up to the least term
[Poi93] can be used recursively for the approximate numeric
evaluation of (15), even if is
divergent. Whenever extrapolates
.
Finally, we notice that the technique of summation up to the least term
[Poi93] can be used recursively for the approximate numeric
evaluation of (15), even if is
divergent. Whenever extrapolates 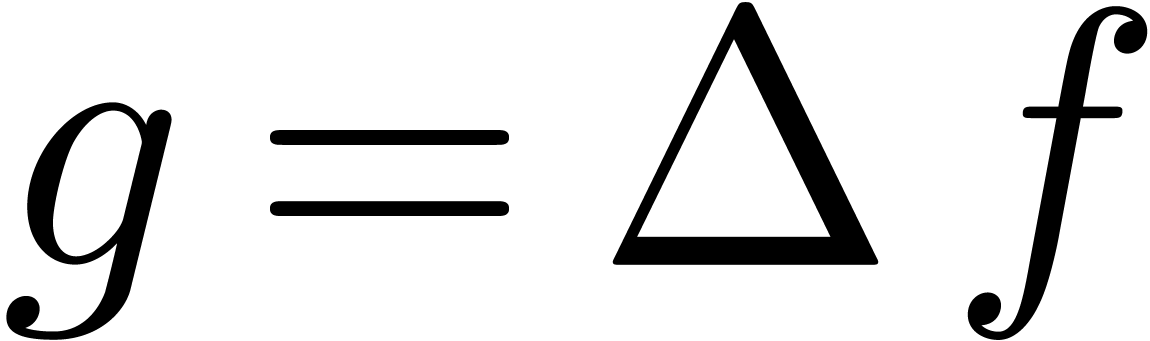 , this allows us in particular to compute
, this allows us in particular to compute 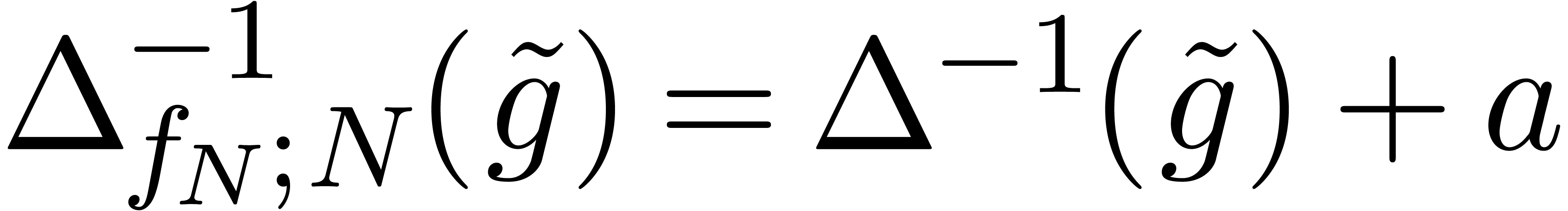 , with
, with  .
.
Returning to our asymptotic extrapolation scheme, it follows that the
inverses of the atomic transformations from section 2 can
systematically be applied to transseries instead of numeric sequences.
In other words, given the recipe of an
asymptotic extrapolation, we simply compute  as a
transseries. If we want an exp-log extrapolation, then we truncate
as a
transseries. If we want an exp-log extrapolation, then we truncate  for the order
for the order  which yields
the best numeric extrapolation. Of course, the truncations are done
recursively, for all transseries whose exponentials occur as
transmonomials in the expansions of
which yields
the best numeric extrapolation. Of course, the truncations are done
recursively, for all transseries whose exponentials occur as
transmonomials in the expansions of  .
.
Several techniques can be used to enhance the quality of the returned
exp-log extrapolations. Indeed, due to truncation and the process of
summation up to the least term, the accuracies of the numeric parameters
in the exp-log extrapolation may be deteriorated with respect to those
in the original recipe. Let 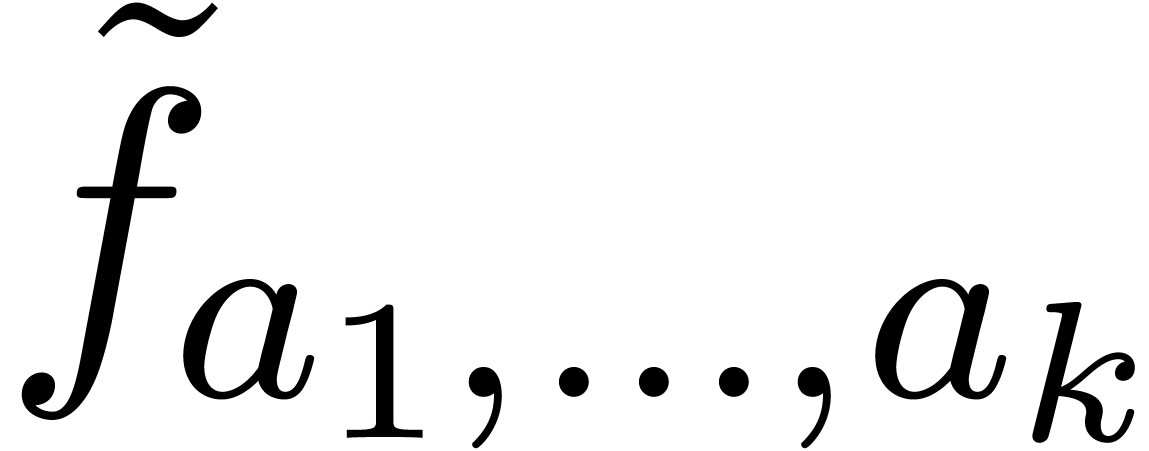 be an exp-log
extrapolation depending on parameters
be an exp-log
extrapolation depending on parameters  .
One way to enhance the quality of our extrapolation is by iterative
improvement. For instance, we may use Newton's method for searching the
zeros of the function
.
One way to enhance the quality of our extrapolation is by iterative
improvement. For instance, we may use Newton's method for searching the
zeros of the function
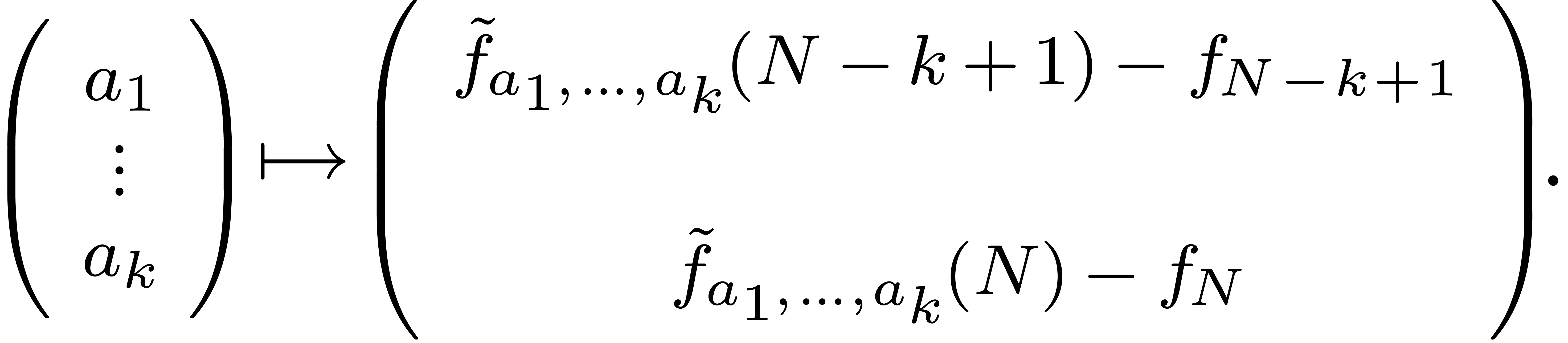
Alternatively, we may perform a least square fit on the range  . Another approach to a
posteriori enhancement is to search closed form expressions for the
parameters
. Another approach to a
posteriori enhancement is to search closed form expressions for the
parameters  , such as
integers, rational numbers or simple linear combinations of known
constants
, such as
integers, rational numbers or simple linear combinations of known
constants  ,
,  , etc. Such closed form expressions can be
guessed by continuous fraction expansion or using the LLL-algorithm [LLL82]. In cases of success, it may be worthy to adjust the
set of atomic transformations and rerun the extrapolation scheme. For
instance, if we find an extrapolation such as
, etc. Such closed form expressions can be
guessed by continuous fraction expansion or using the LLL-algorithm [LLL82]. In cases of success, it may be worthy to adjust the
set of atomic transformations and rerun the extrapolation scheme. For
instance, if we find an extrapolation such as
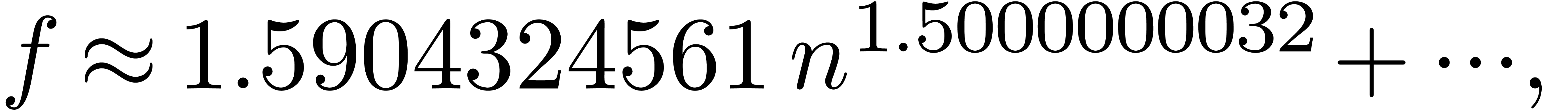
then we may add 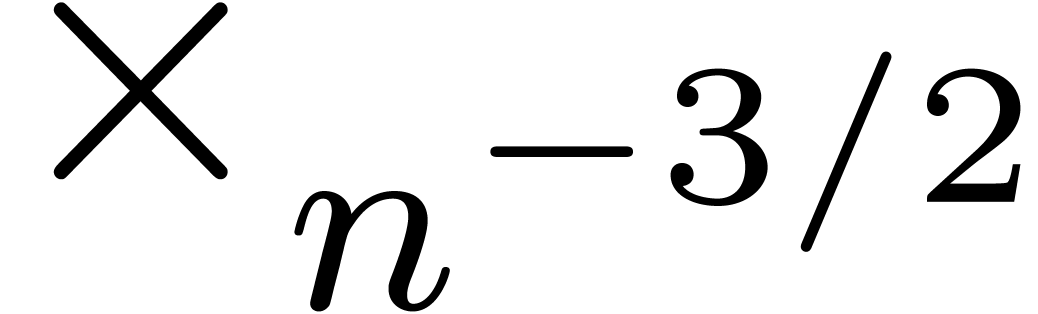 as an atomic transformation.
This spares the determination of one continuous parameter, which
increases the accuracy of the successive transformed sequences.
as an atomic transformation.
This spares the determination of one continuous parameter, which
increases the accuracy of the successive transformed sequences.
In this section, we will present the results of running our scheme on a
series of explicit examples, as well as an example from [CGJ+05]
suggested by one of the referees. We have tried several sets of atomic
transformations , using
various criteria and thresholds. In what follows, we systematically take
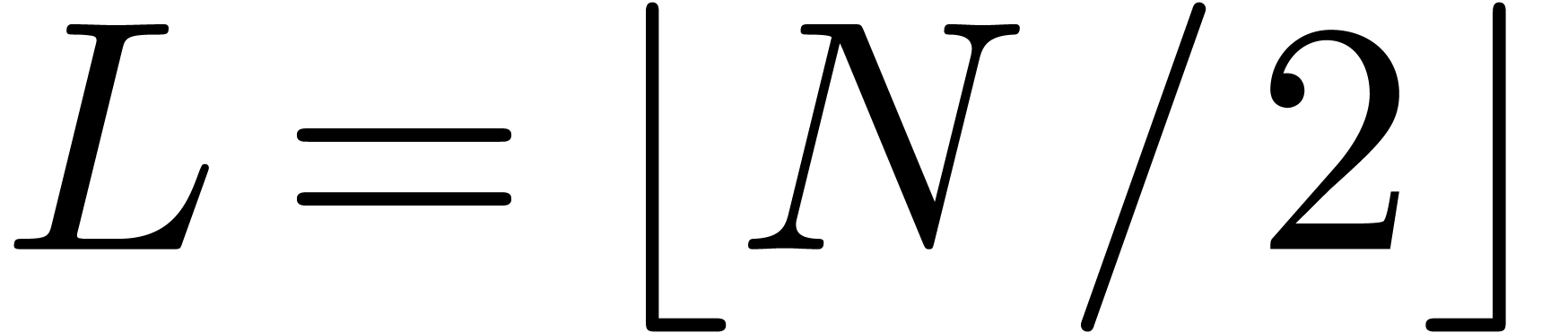 , and the precise algorithm
works as follows:
, and the precise algorithm
works as follows:
If 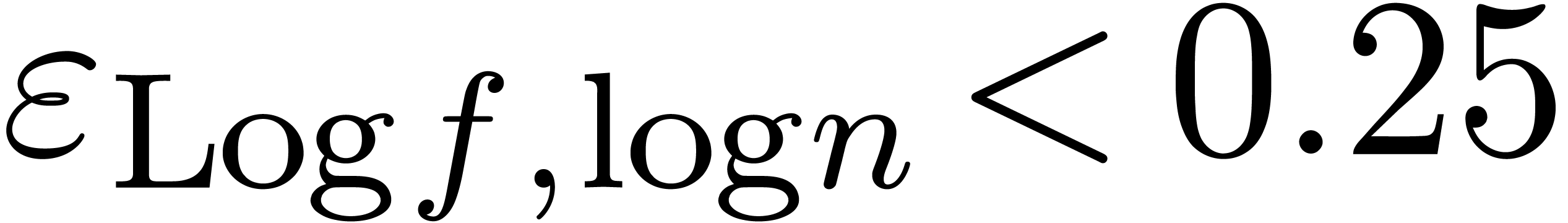 ,
, 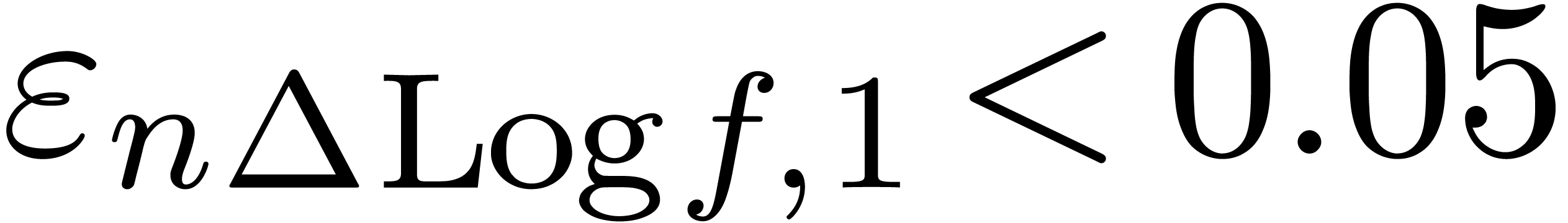 and
and  (where norms are taken on ), we apply the transformation
(where norms are taken on ), we apply the transformation 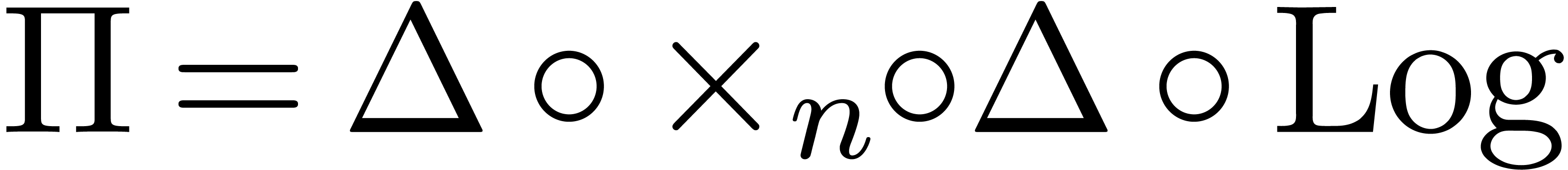 in order to detect expansions of the form
in order to detect expansions of the form 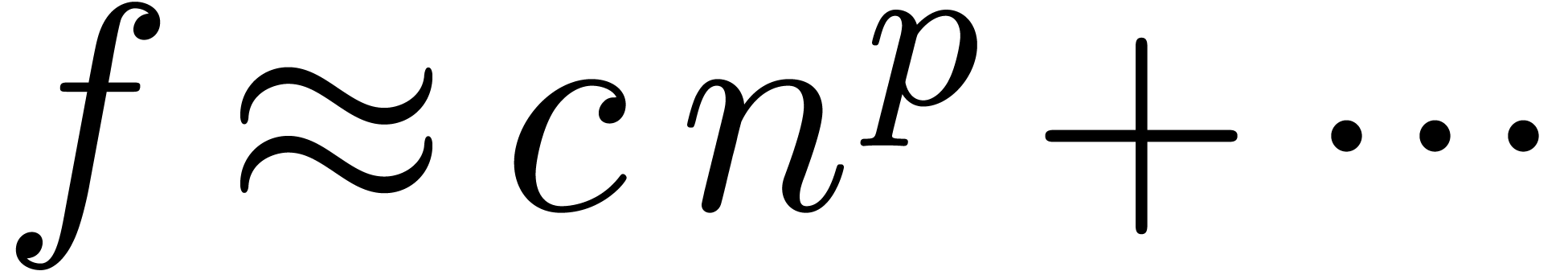 . Moreover, if the last coefficient
. Moreover, if the last coefficient 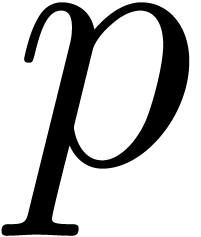 of the sequence
of the sequence  is close
to an integer
is close
to an integer 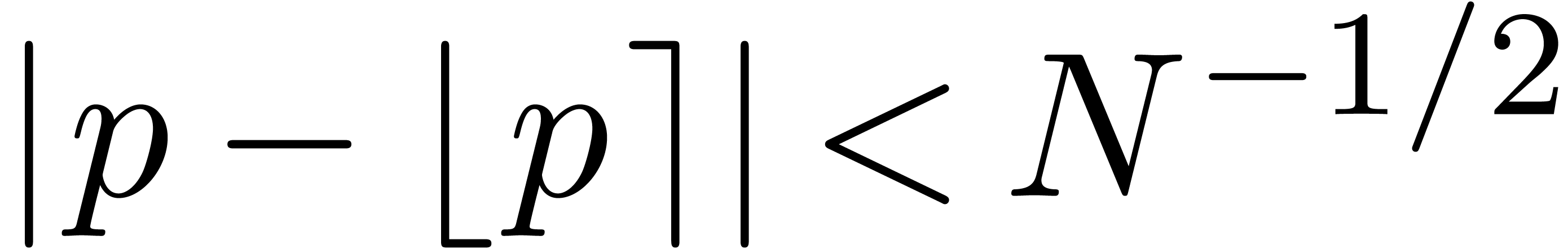 , then we
rather apply
, then we
rather apply 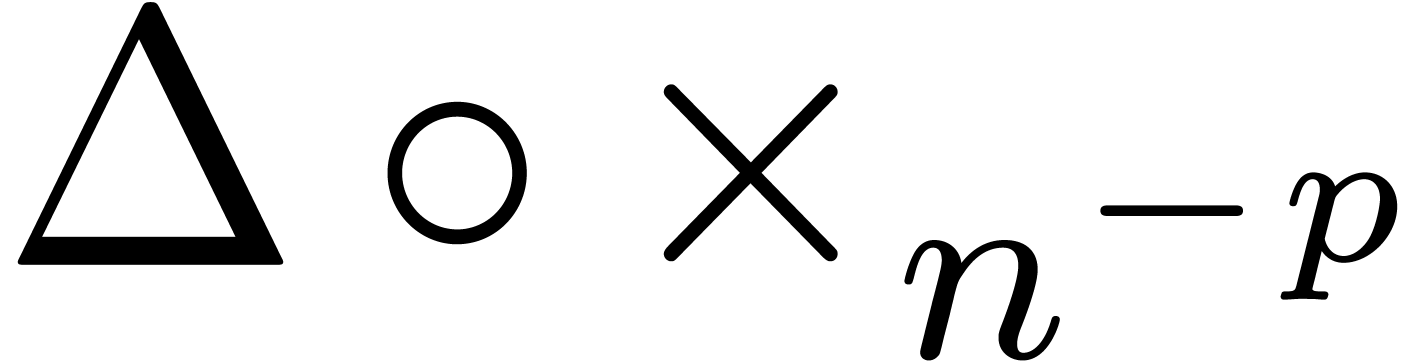
If step 1 does not succeed and 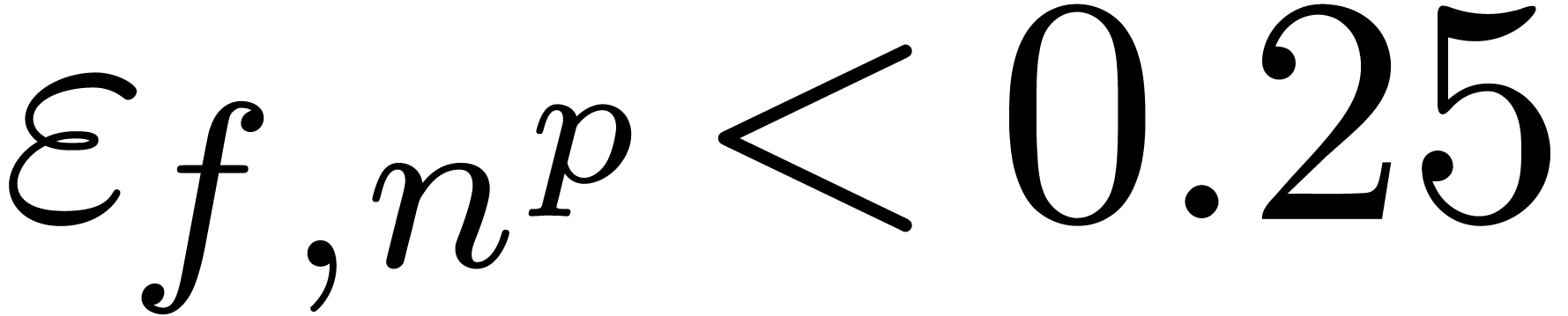 for some
for some
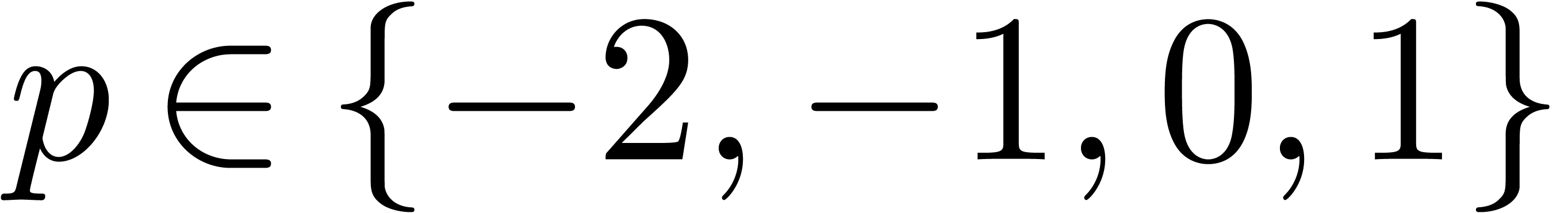 , then we apply the
transformation
, then we apply the
transformation  .
.
If steps 1 and 2 do not succeed and does not
change sign on , then we
apply  .
.
In other words, we first check whether has an
expansion of the form , with
a high degree of certainty. If not, then we still try for 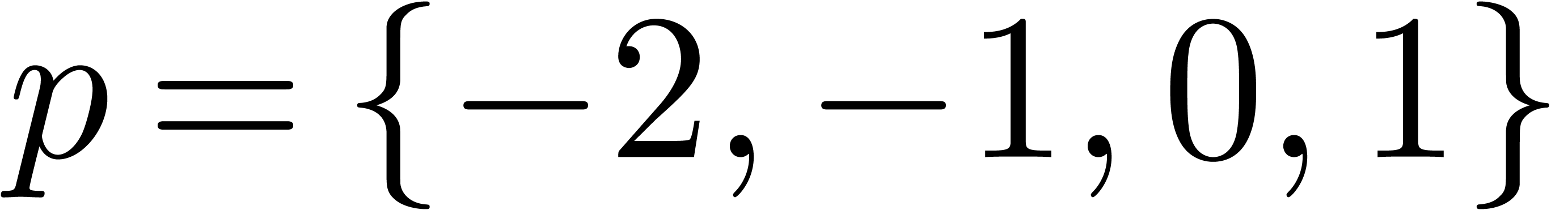 with a bit less certainty. In cases of panic, we fall back
on the transformation
with a bit less certainty. In cases of panic, we fall back
on the transformation  .
.
We want to emphasize that the above choices are preliminary. We are
still investigating better choices for  and the
thresholds, and more particular transformations for the detection of
common expansion patterns.
and the
thresholds, and more particular transformations for the detection of
common expansion patterns.
For our first series of examples, we took 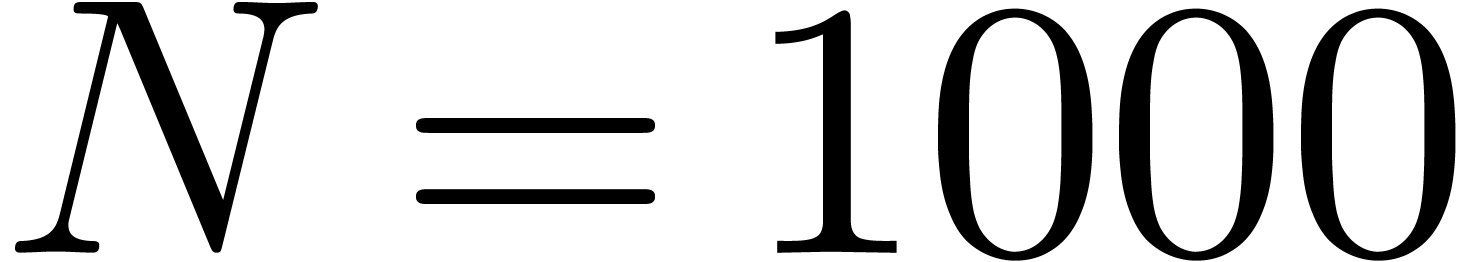 and
considered several explicit sequences. The results have been summarized
in table 1 below. For all examples we used a precision of
512 bits, except for
and
considered several explicit sequences. The results have been summarized
in table 1 below. For all examples we used a precision of
512 bits, except for 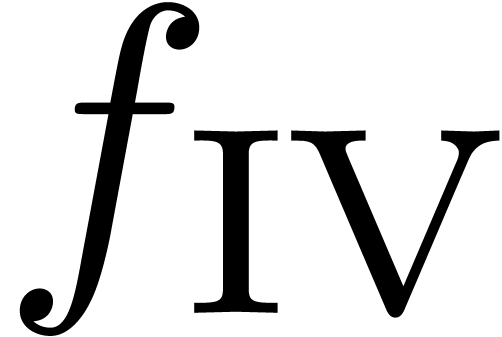 , in
which case we used
, in
which case we used 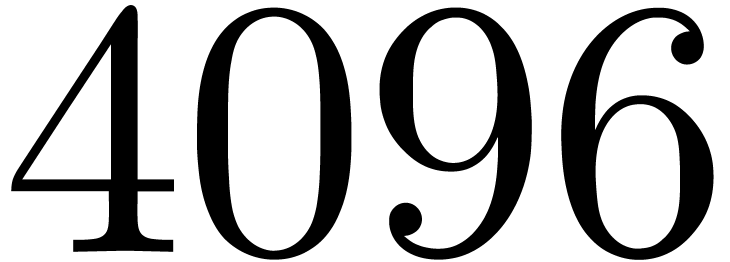 bits.
bits.
The first sequence 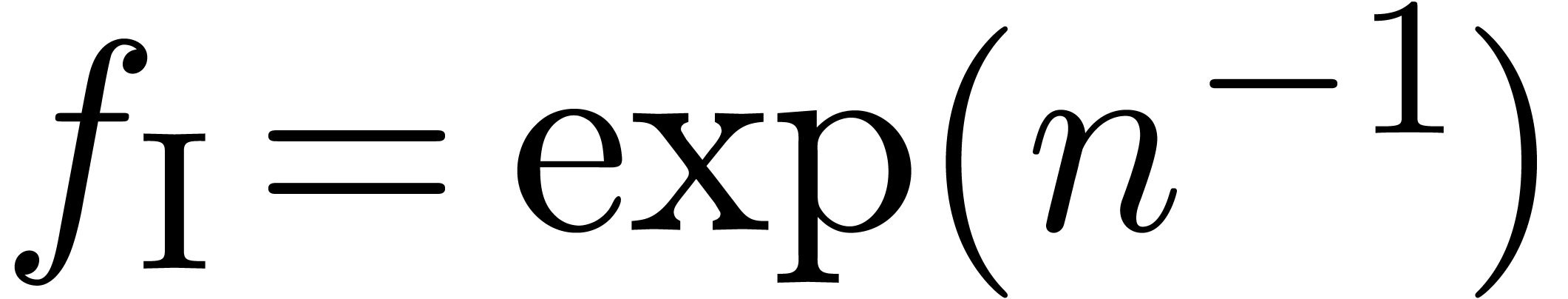 is an ordinary power series
in
is an ordinary power series
in 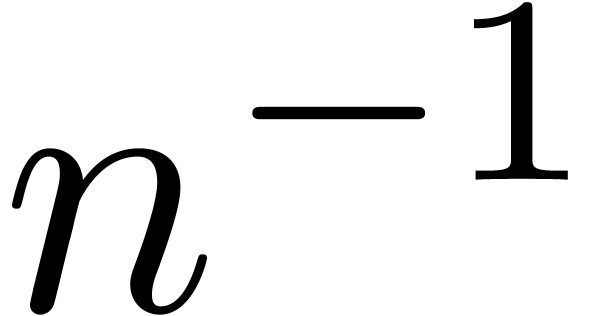 , which is well recognized
(3 decimal digits per iteration, as expected). Notice the remarkable
presence of a
, which is well recognized
(3 decimal digits per iteration, as expected). Notice the remarkable
presence of a  -transformation.
The second sequence
-transformation.
The second sequence 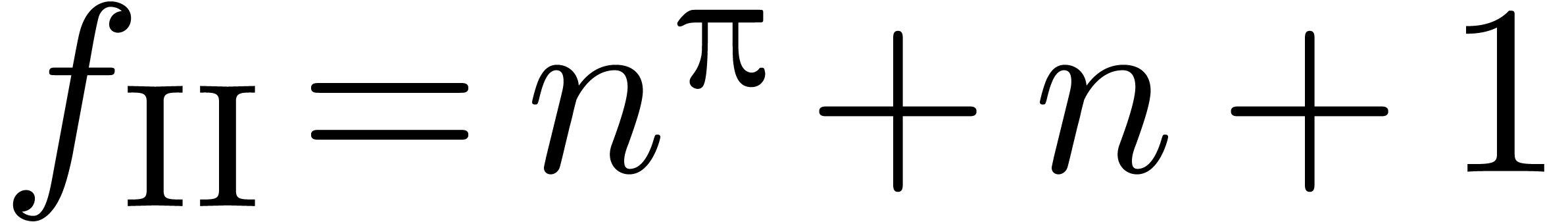 demonstrates the ability to
detect expansions in with arbitrary exponents.
The third sequence
demonstrates the ability to
detect expansions in with arbitrary exponents.
The third sequence 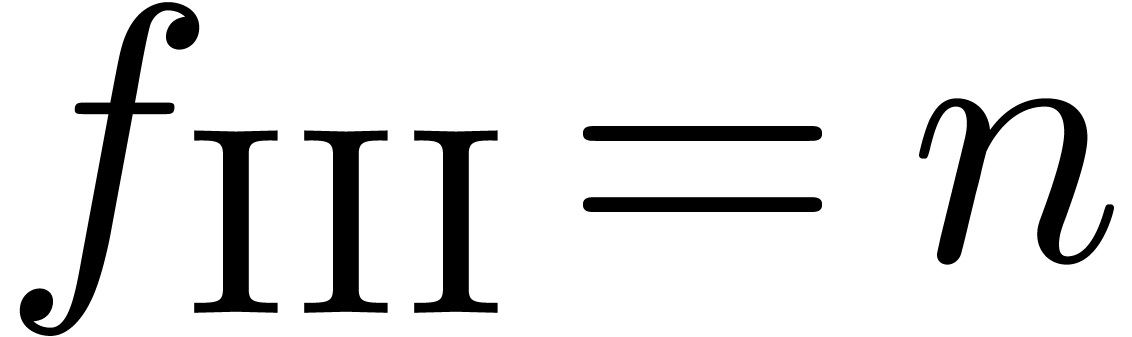 ! reduces
to an ordinary power series expansion after the transformation
! reduces
to an ordinary power series expansion after the transformation  and is therefore well recognized. The fourth sequence
and is therefore well recognized. The fourth sequence 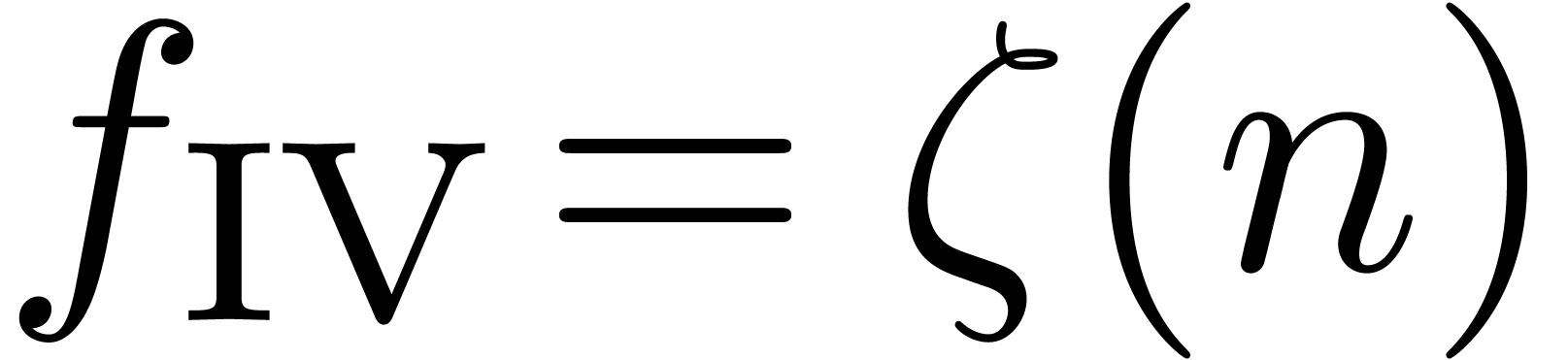 shows that we are also able to detect expansions in
shows that we are also able to detect expansions in
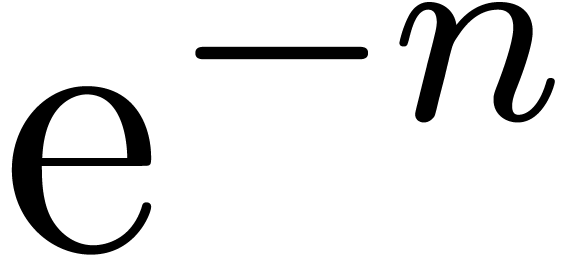 with arbitrary exponents. The next two sequences
with arbitrary exponents. The next two sequences
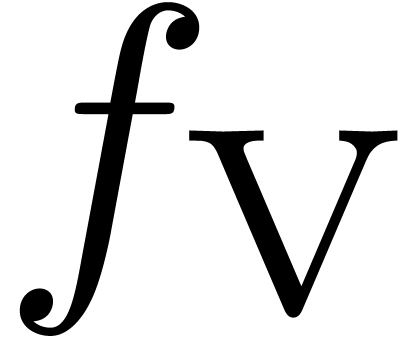 and
and  essentially concern
the detection of expansions of the form
essentially concern
the detection of expansions of the form 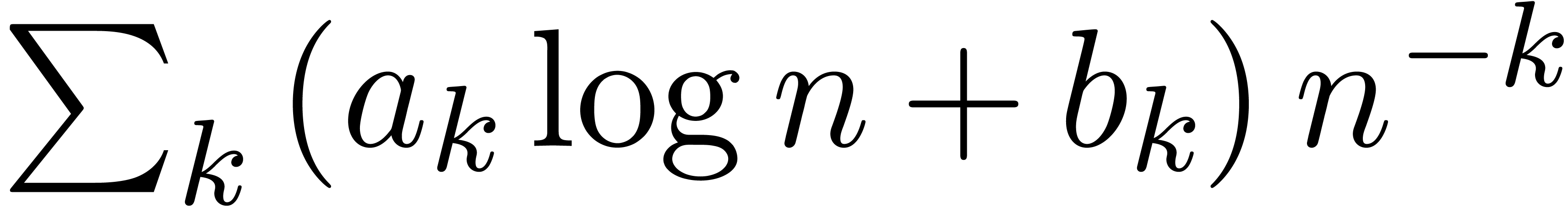 .
This works well for a few iterations, but the presence of
.
This works well for a few iterations, but the presence of 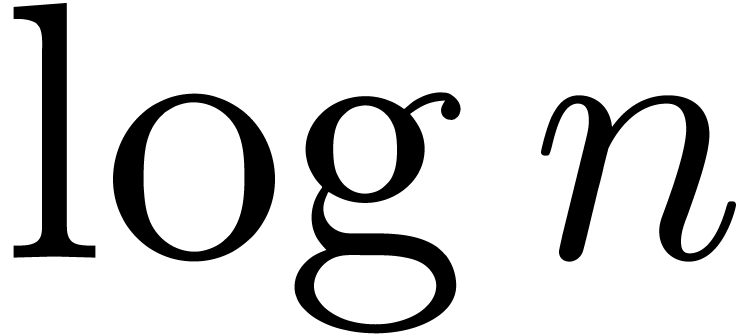 tends to slow down the convergence and becomes problematic
at higher orders. Finally, we considered an expansion in
tends to slow down the convergence and becomes problematic
at higher orders. Finally, we considered an expansion in 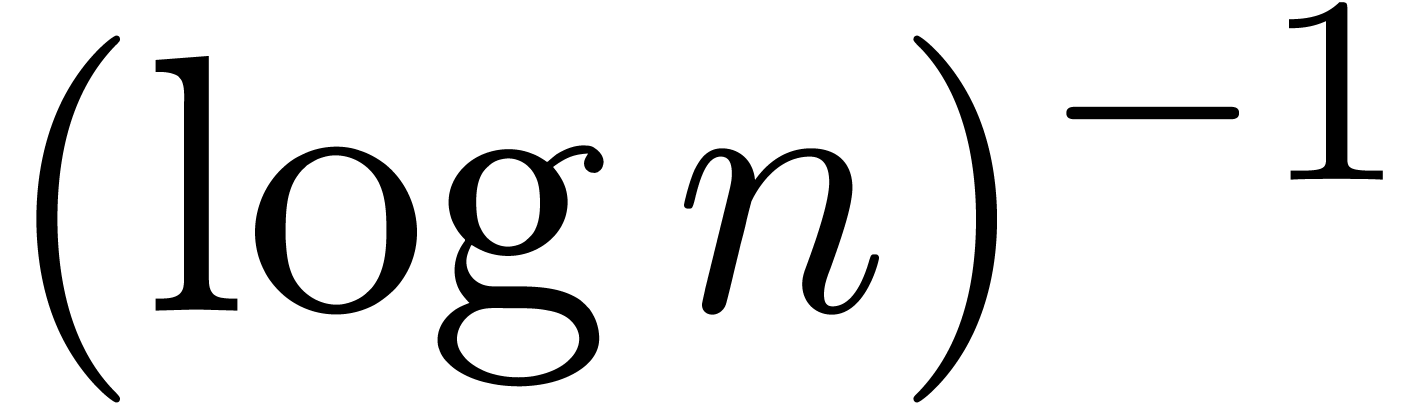 , which should be hopeless for our algorithm
due to the slow increase of .
, which should be hopeless for our algorithm
due to the slow increase of .
|
||||||||||||||||||||||||||||||||
Having obtained the recipes for each of the sequences, we next applied the post-treatment of section 4 in order to find asymptotic expansions in the more readable exp-log form. The results are shown below:

The obtained expansions are remarkably accurate in the cases of 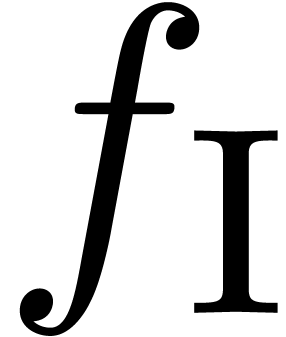 ,
, 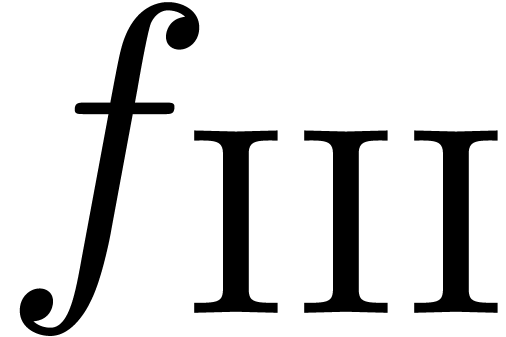 and . We were particularly happy to
recover Stirling's formula in a completely automatic numeric-symbolic
manner. The expansions for
and . We were particularly happy to
recover Stirling's formula in a completely automatic numeric-symbolic
manner. The expansions for 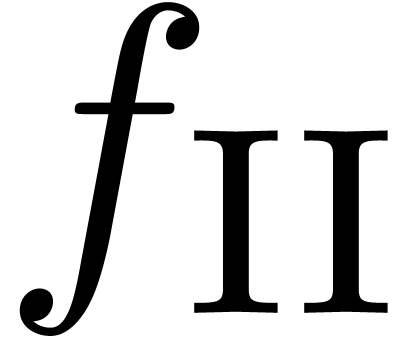 ,
and are also close to
the correct ones, when neglecting terms with small coefficients. The
last expansion is more problematic; errors typically occur when a
numerically small expression on is incorrectly
assumed to be infinitesimal. Such mistakes may lead to the computation
of absurdly complicated transseries expansions, which occasionally fail
to terminate. For instance, we only obtained exp-log expansions for
extrapolations at order
,
and are also close to
the correct ones, when neglecting terms with small coefficients. The
last expansion is more problematic; errors typically occur when a
numerically small expression on is incorrectly
assumed to be infinitesimal. Such mistakes may lead to the computation
of absurdly complicated transseries expansions, which occasionally fail
to terminate. For instance, we only obtained exp-log expansions for
extrapolations at order  in the last two
examples.
in the last two
examples.
Let us now consider the sequence ,
where is the number of self-avoiding walks of
size on a triangular lattice [CGJ+05].
The terms with 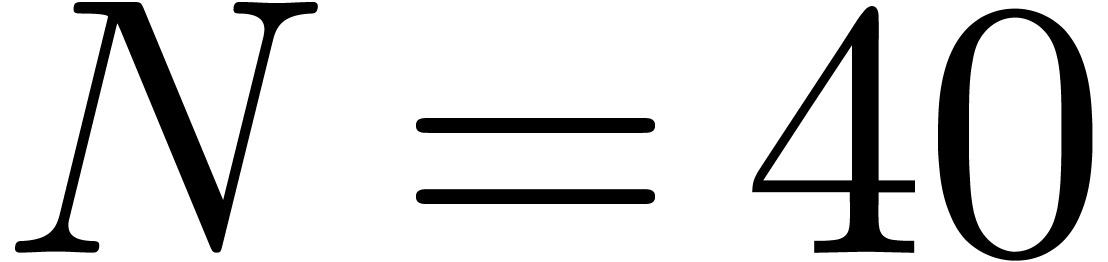 are as
follows:
are as
follows:

It is theoretically known that
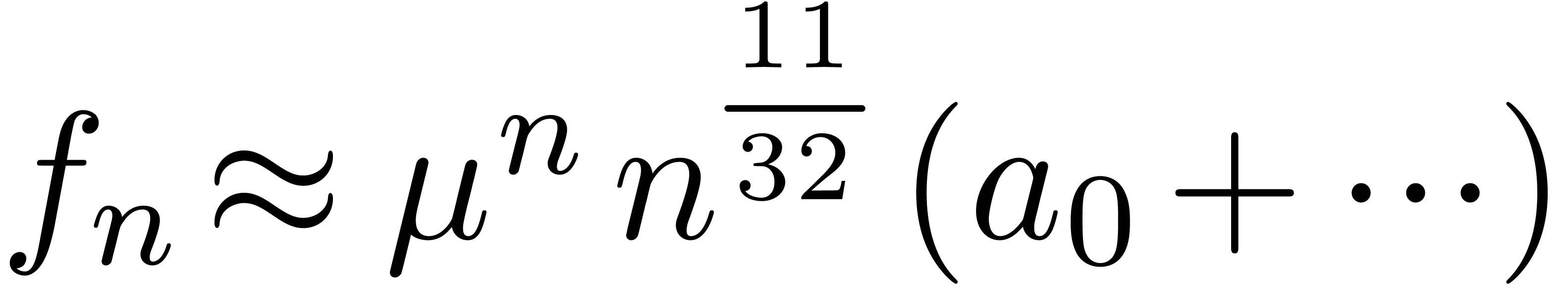 |
(16) |
and the authors of [CGJ+05] actually expect an expansion of the type
 |
(17) |
In view of (16), we have applied our asymptotic
extrapolation algorithm on ,
by forcing the transformation 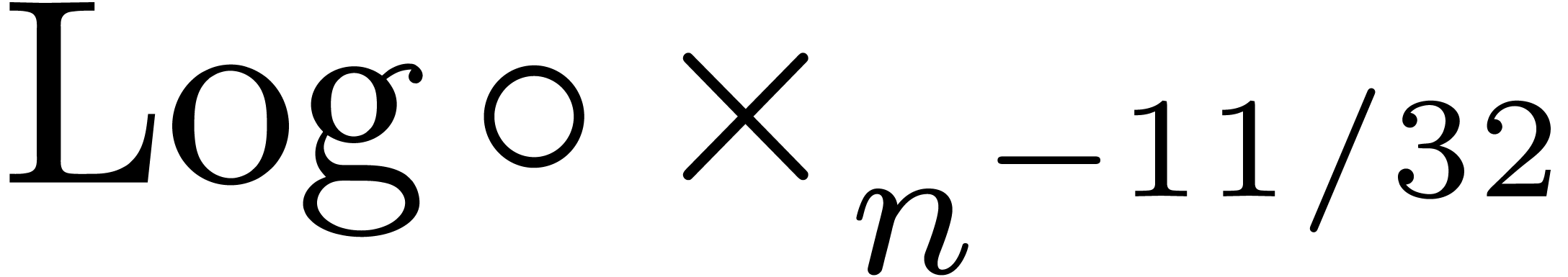 at the start. This
yields the expansion
at the start. This
yields the expansion

which is quite close to the expected expansion. The corresponding reductor is given by

As explained in [CGJ+05], the detection of the exponent
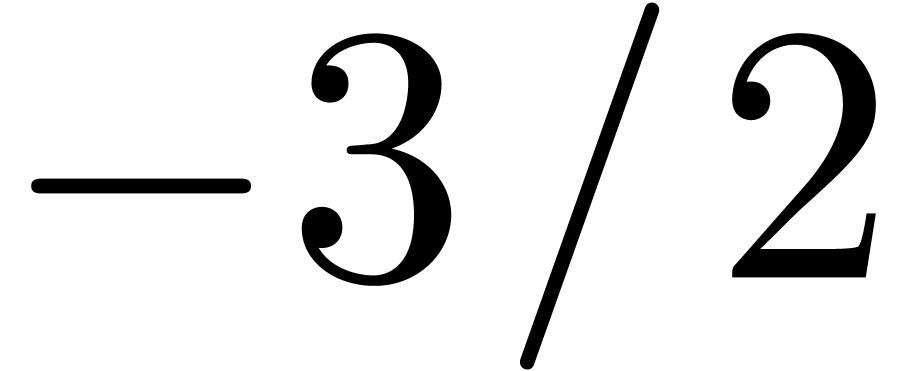 for
for 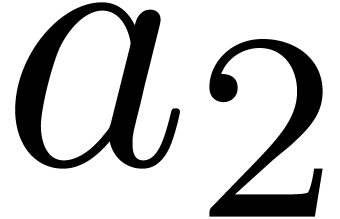 is somewhat critical
due to the possible appearance of an additional term
is somewhat critical
due to the possible appearance of an additional term 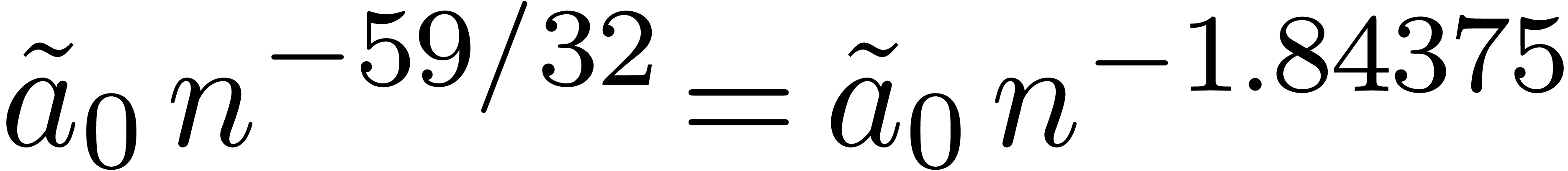 . The authors argue that it is difficult to
confirm or refute the presence of such a term, based on numerical
evidence up to order only. We agree with this
analysis. Nevertheless, it is striking that the exponent returned by our
algorithm is not far from the mean value
. The authors argue that it is difficult to
confirm or refute the presence of such a term, based on numerical
evidence up to order only. We agree with this
analysis. Nevertheless, it is striking that the exponent returned by our
algorithm is not far from the mean value  of
of 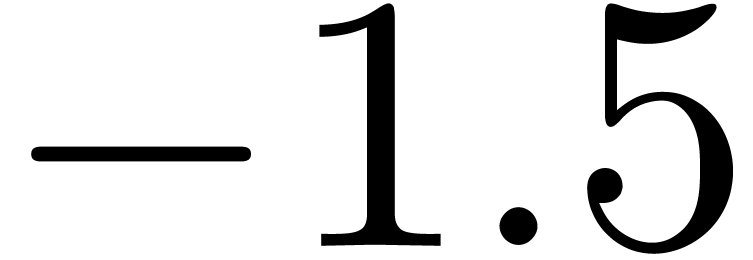 and
and  .
Also, the algorithm failed to detect a clean
.
Also, the algorithm failed to detect a clean  -transformation, which might indicate the presence
of two terms with close exponents.
-transformation, which might indicate the presence
of two terms with close exponents.
There is still significant room for improving our choice of in section 5, and the corresponding criteria
for acceptability. Failures to detect the expected form of asymptotic
expansion can be due to the following main reasons:
Even for , the set of transforms does not allow for the detection of
the correct asymptotic expansion.
At a certain step of the extrapolation process, the wrong atomic transformation is applied.
A recipe is found for the asymptotic extrapolation, but the corresponding exp-log extrapolation is incorrect or too hard to compute.
In this section, we will discuss the different types of failure in more detail and examine what can be done about them.
Of course, the class of asymptotic expansions which can be guessed by
our extrapolation scheme is closely related to the choice of . Asymptotic behaviour for which no
adequate atomic transformation is available will therefore not be
detected. For instance, none of the transformations discussed so far can
be used for the detection of oscillatory sequences such as 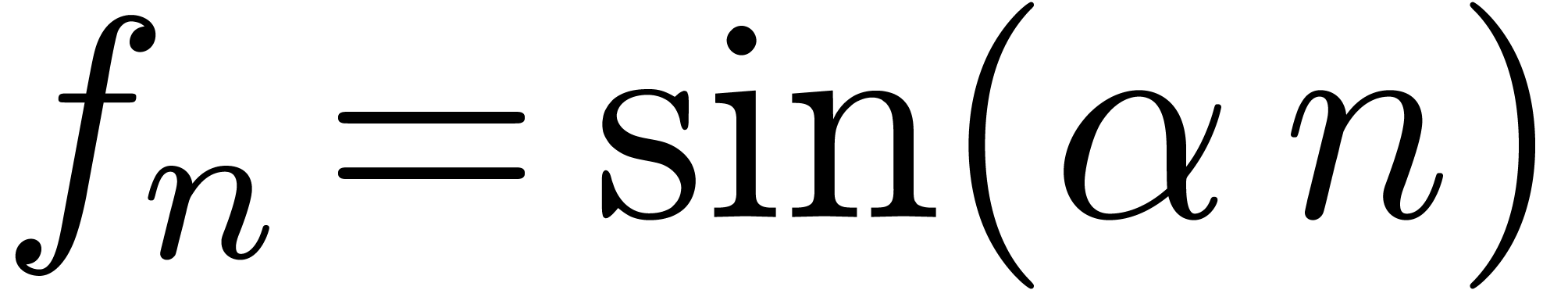 .
.
A more subtle sequence which cannot be detected using
is 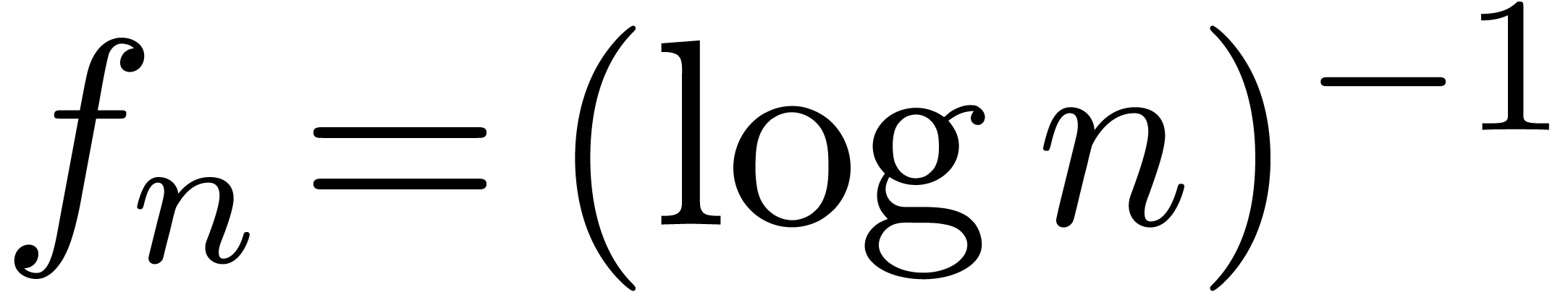 . In order to detect , we might add the transformation
. In order to detect , we might add the transformation
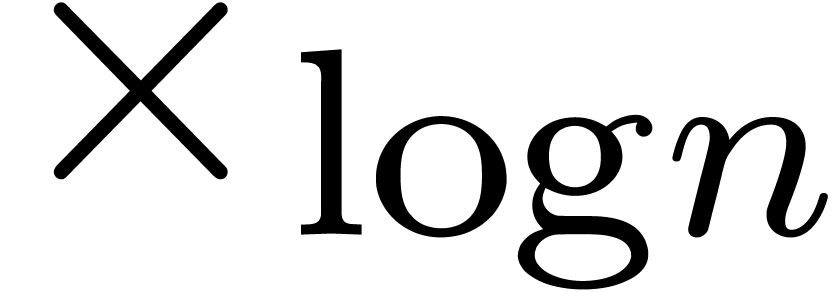 . However, the corresponding
criterion should be designed with care: as noticed in section 3,
sequences of the form
. However, the corresponding
criterion should be designed with care: as noticed in section 3,
sequences of the form 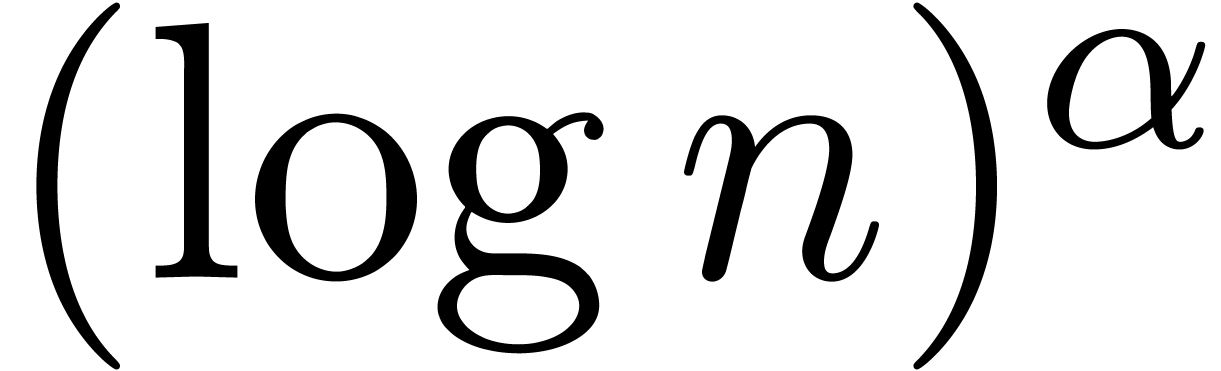 are easily mistaken for
constant sequences, when taking
are easily mistaken for
constant sequences, when taking  for a fixed
for a fixed
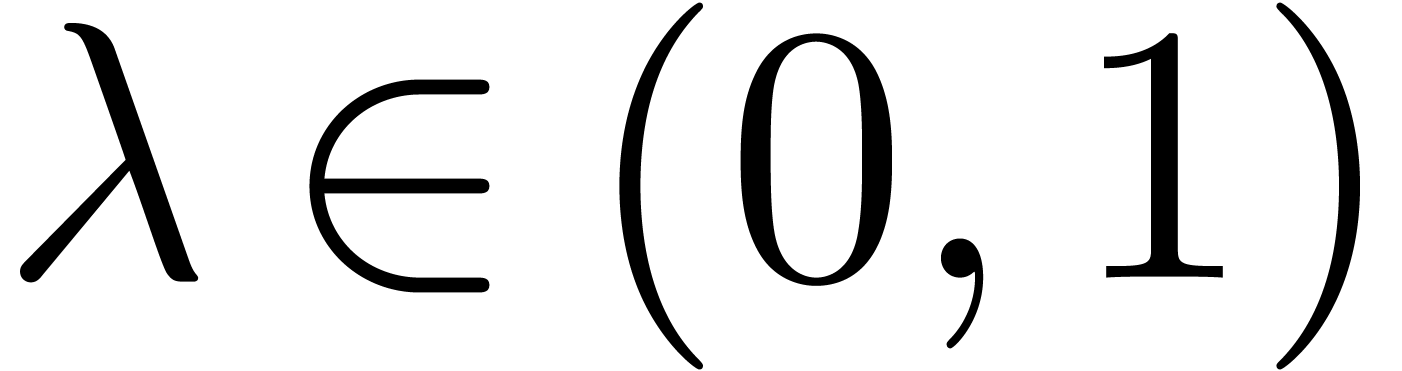 . A more robust criterion
might require
. A more robust criterion
might require 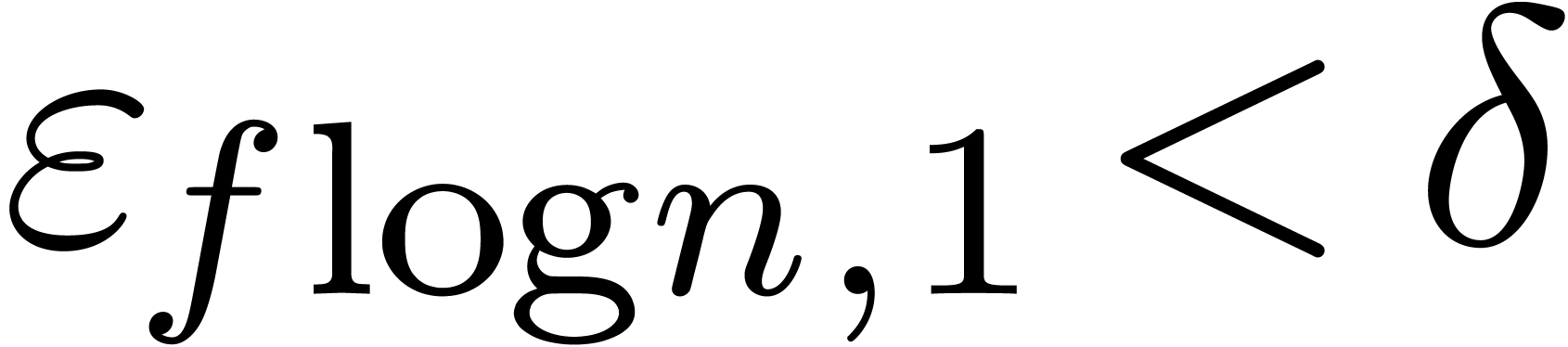 ,
, 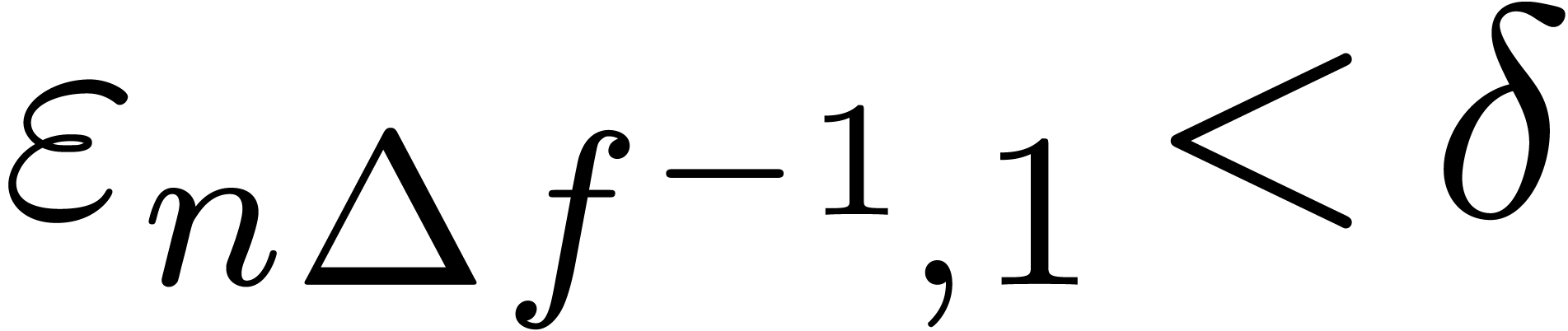 as well as
as well as 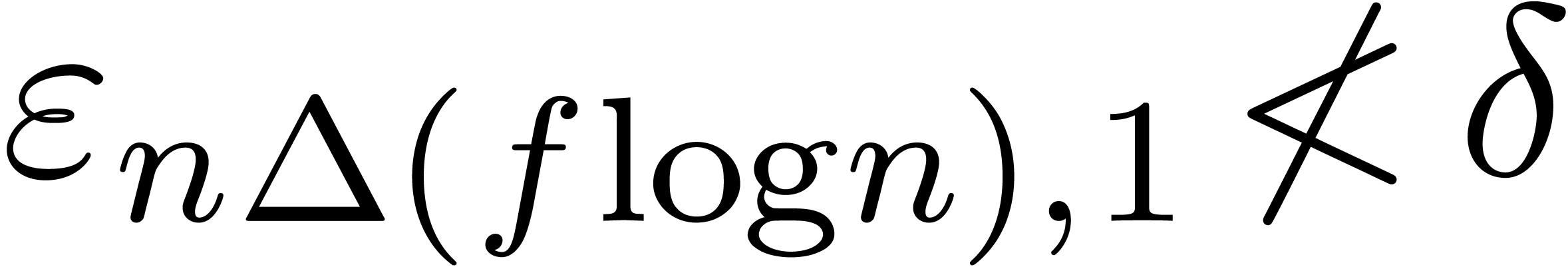 for a suitable
threshold
for a suitable
threshold  .
.
Another more intricate difficulty occurs when the various transformations introduce an infinite number of parasite terms. For instance, consider the expansion
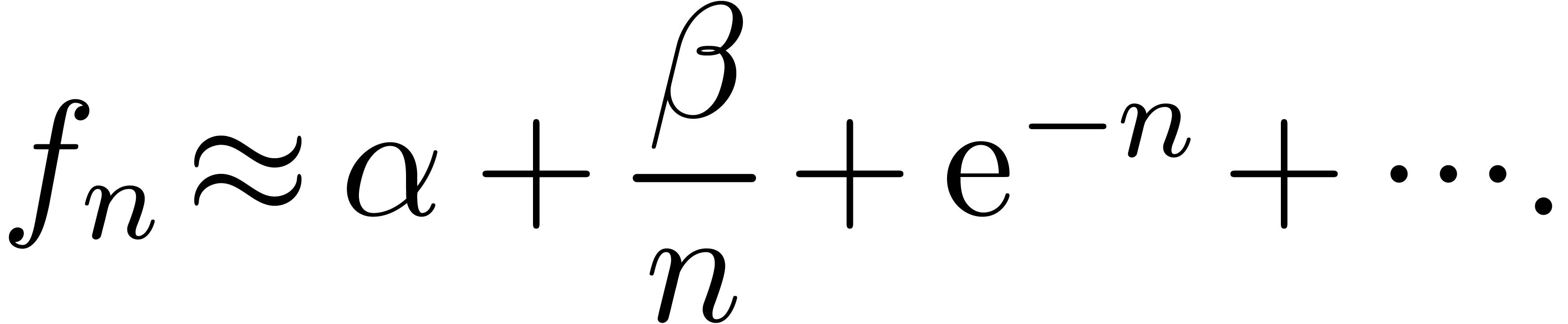 |
(18) |
When applying one -transformation,
we obtain
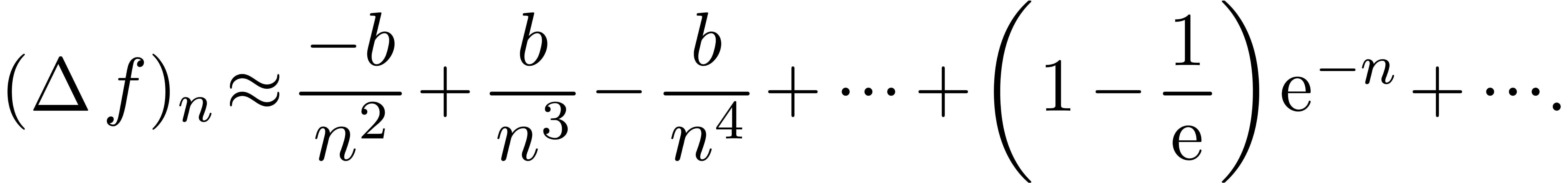 |
(19) |
The extrapolation of (19) therefore leads to an infinite
number of  -transformations,
in order to clear the infinity of terms which were introduced by the
first -transformation. In
particular, the presence of the will not be
detected. The phenomenon aggravates when parasite logarithmic terms are
introduced. For instance, if we start the extrapolation of
-transformations,
in order to clear the infinity of terms which were introduced by the
first -transformation. In
particular, the presence of the will not be
detected. The phenomenon aggravates when parasite logarithmic terms are
introduced. For instance, if we start the extrapolation of
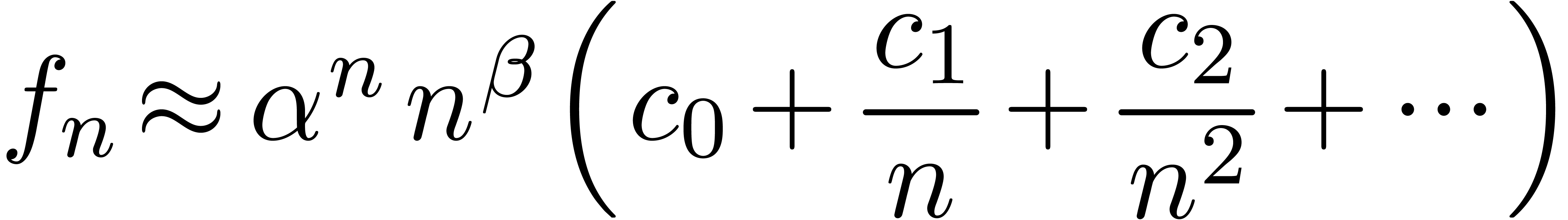
with the transformation 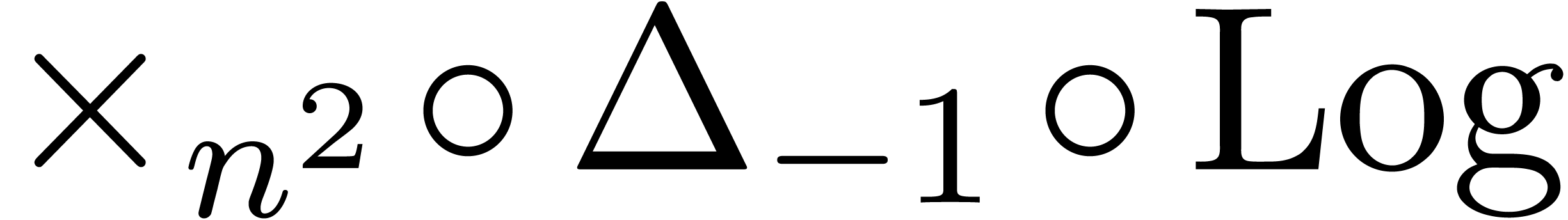 instead of , then we are lead to the extrapolation of an
expansion of the form
instead of , then we are lead to the extrapolation of an
expansion of the form
We have seen in the previous section (examples
and ) that such expansions
are much harder to detect than ordinary power series expansions. This is
why we often prefer the -transformation
over 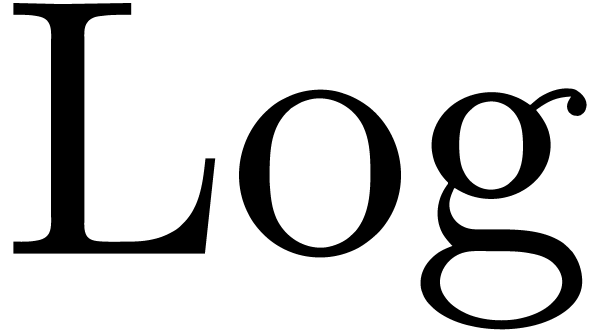 .
.
The real reason behind the above difficulty is that “nice”
expansions in exp-log form, such as (18), do not coincide
with “nice” expansions constructed using the inverses of
operators in . For instance,
the expansion
is “nice” in the second sense, since
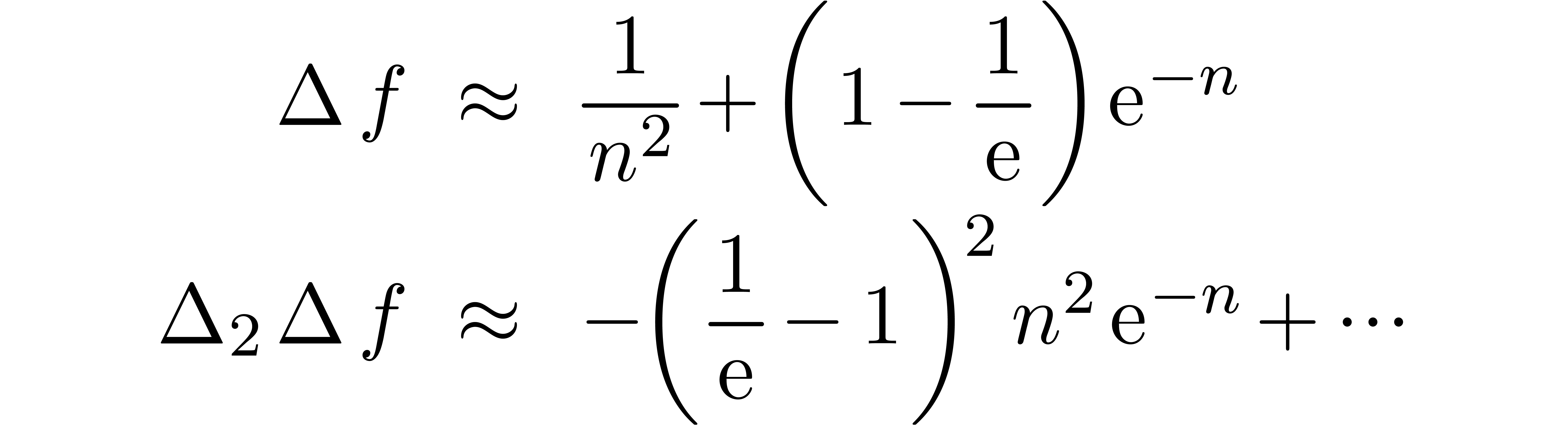
In order to detect “nice” exp-log expansions, we have to
adapt the set so as to kill several continuous
parameters at a time. In the case of linear combinations (11),
this can be done using the transformations of the E-algorithm, modulo
prior determination of the functions 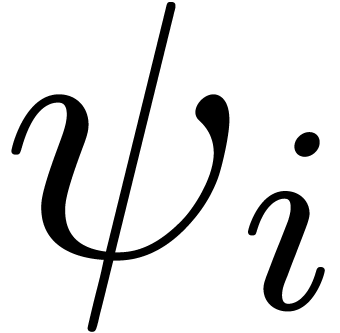 .
In general, the required transformations cease to be simple; see the
discussion at the end of section 2. One idea might be to
use the relation
.
In general, the required transformations cease to be simple; see the
discussion at the end of section 2. One idea might be to
use the relation
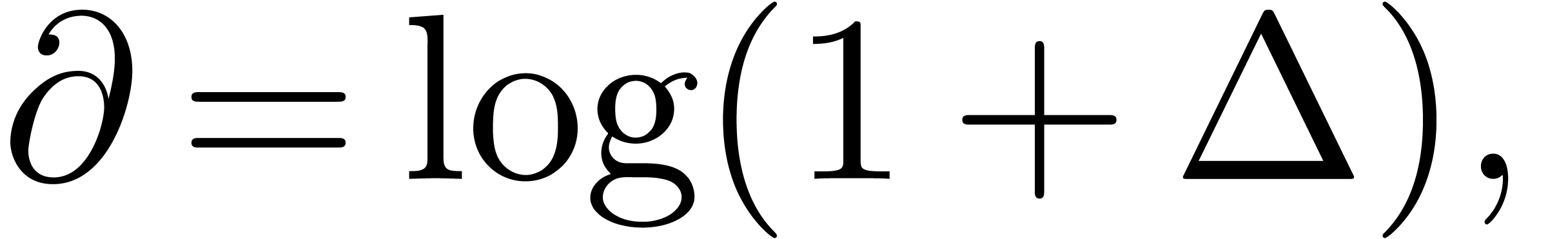
in combination with summation up to the least term, in order to replace the finite difference operator by a genuine derivation.
One particular strength of our asymptotic extrapolation scheme is that it is strongly guided by the asymptotic behaviour of the original sequence and its successive transformations. If the asymptotic expansion of the sequence is given by a transseries, then this property is preserved during the extrapolation process. Theoretically, it is therefore possible to always select the right transformation at each stage.
In practice however, the asymptotic regime is not necessarily reached.
Furthermore, numerical tests on the dominant asymptotic behaviour of a
sequence have to be designed with care. If bad luck or bad design result
in the selection of the wrong transformation at a certain stage, then
the obtained extrapolation will be incorrect from the asymptotic view.
Nevertheless, its numeric relative error on the range
may still be very small, which can make it hard to detect that something
went wrong.
Let us first consider the situation in which the asymptotic regime is not necessarily reached. This is typically the case for expansions such as
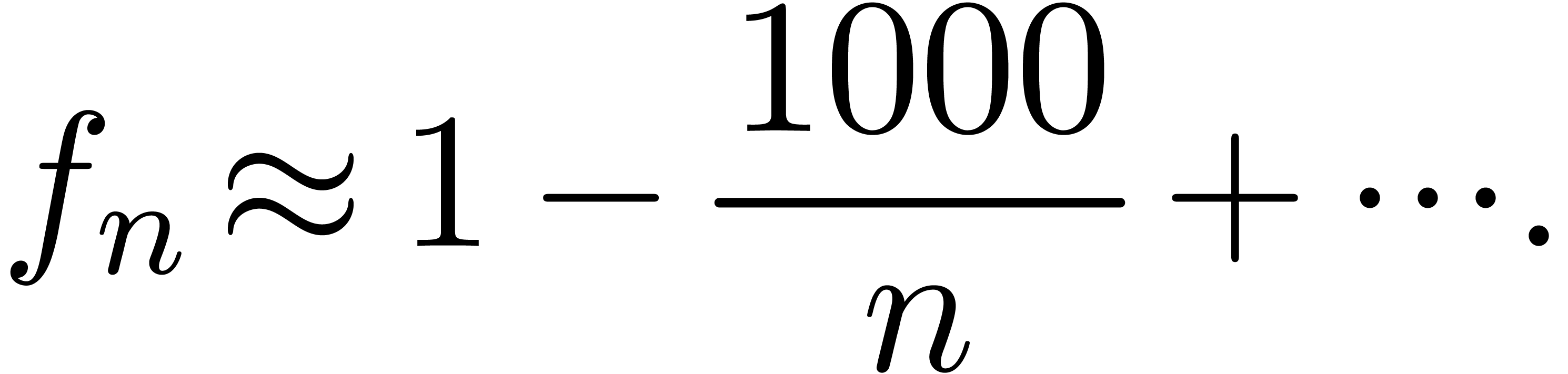 |
(20) |
For 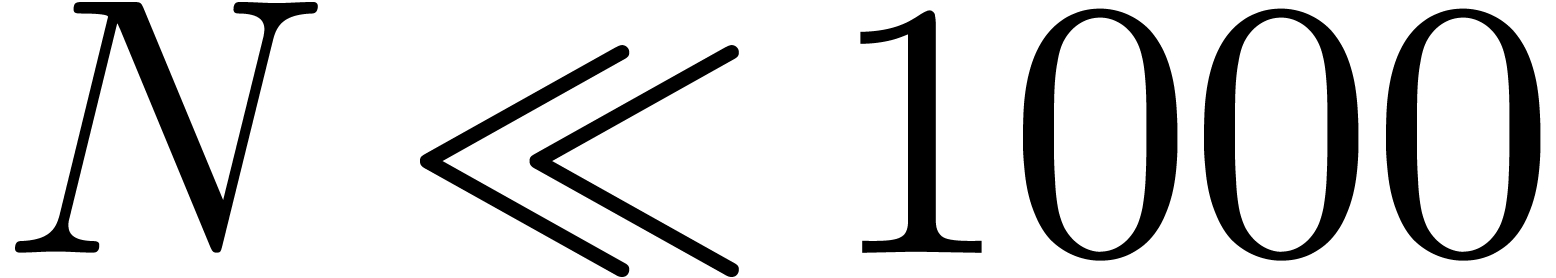 , our scheme will
incorrectly assume that
, our scheme will
incorrectly assume that 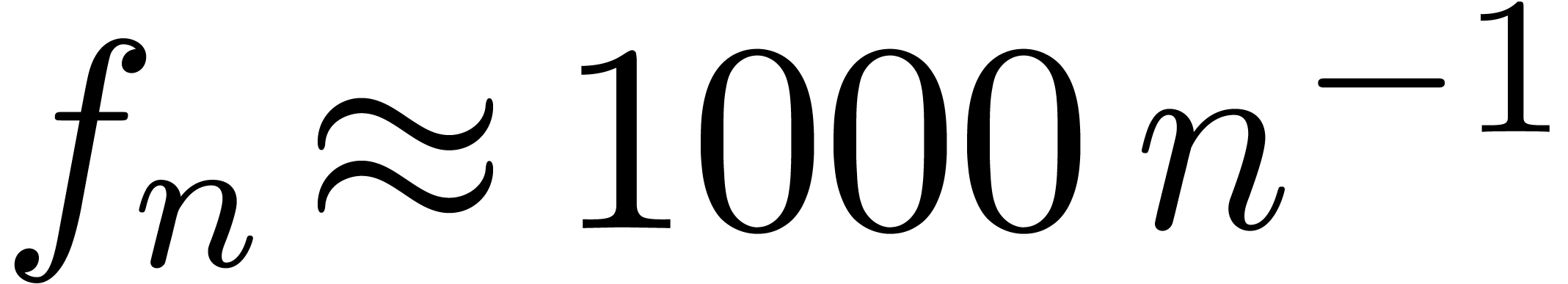 . The
sequence from section 5 leads to a
similar situation:
. The
sequence from section 5 leads to a
similar situation:
This explains our problems to detect the right expansion, even for large
values of such as 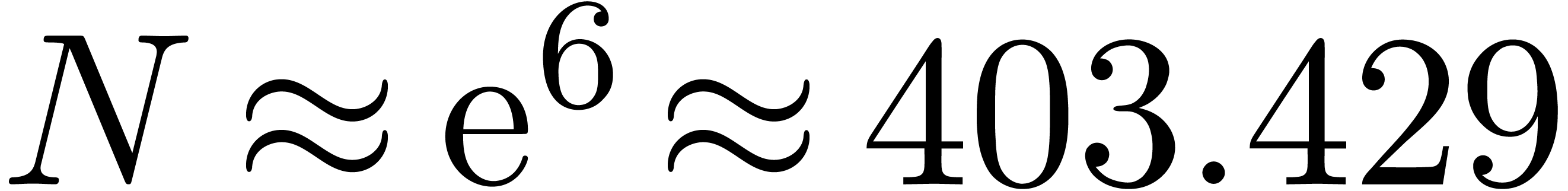 or
or
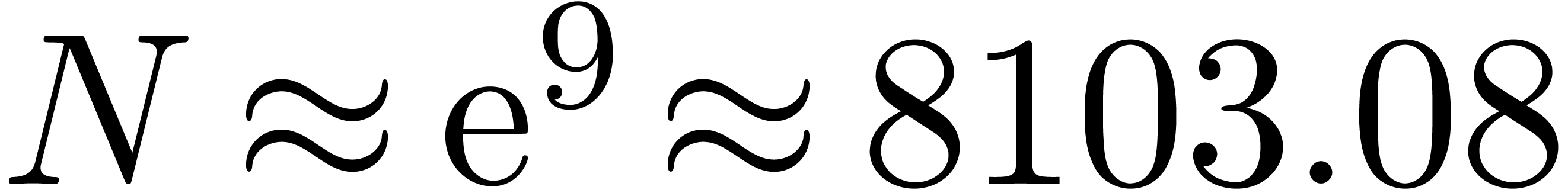 .
.
The best remedy is to add an atomic transformation which detects the two
leading terms together. For instance, we may use the transformation  in (20) and
in (20) and  in
(21) and (22). Of course, in order to gain
something, we also need to adjust the acceptability criteria. For
instance, in the cases of (21) and (22), we
may simply require that
in
(21) and (22). Of course, in order to gain
something, we also need to adjust the acceptability criteria. For
instance, in the cases of (21) and (22), we
may simply require that 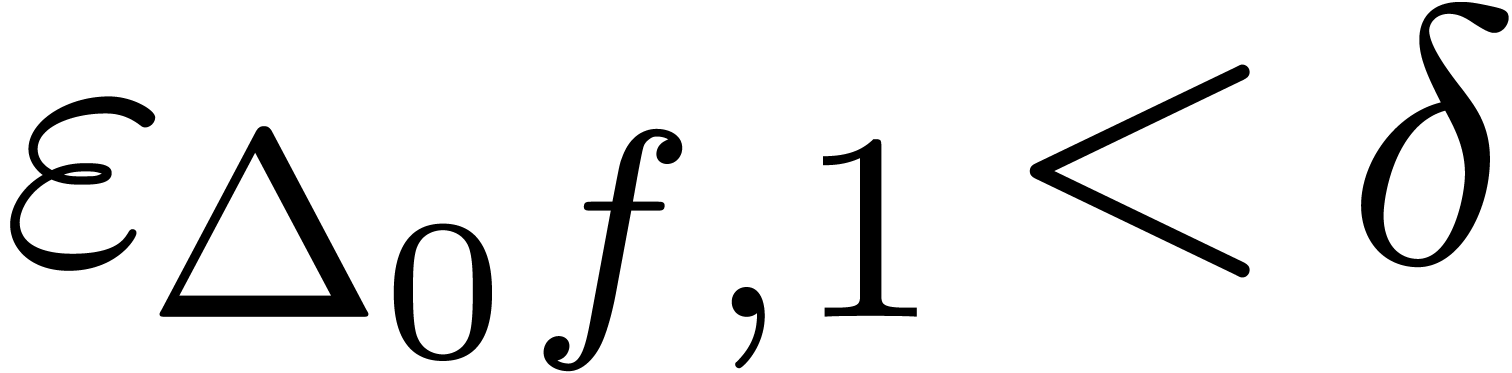 for a suitable threshold
, instead of the combined
requirements
for a suitable threshold
, instead of the combined
requirements 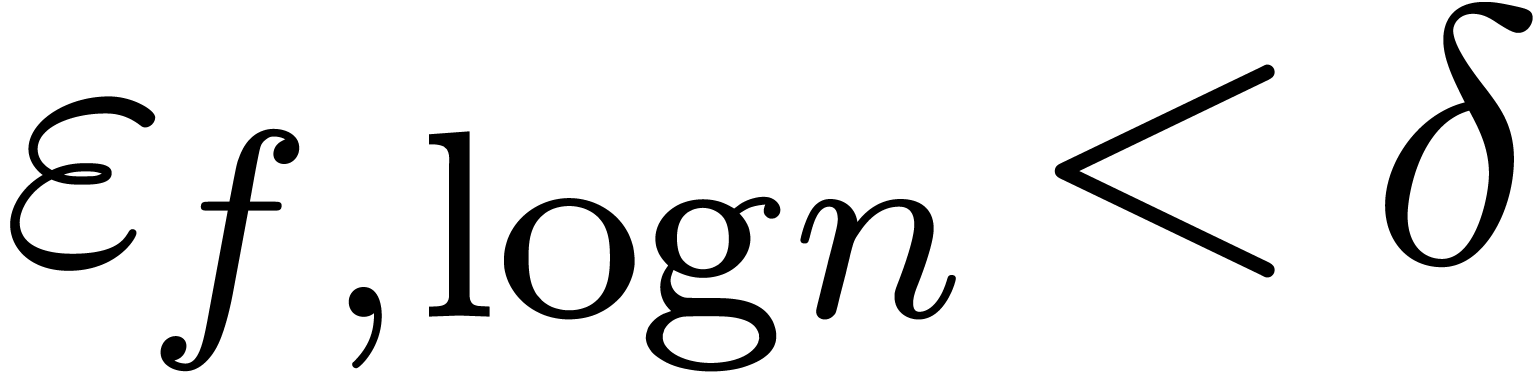 (or
(or 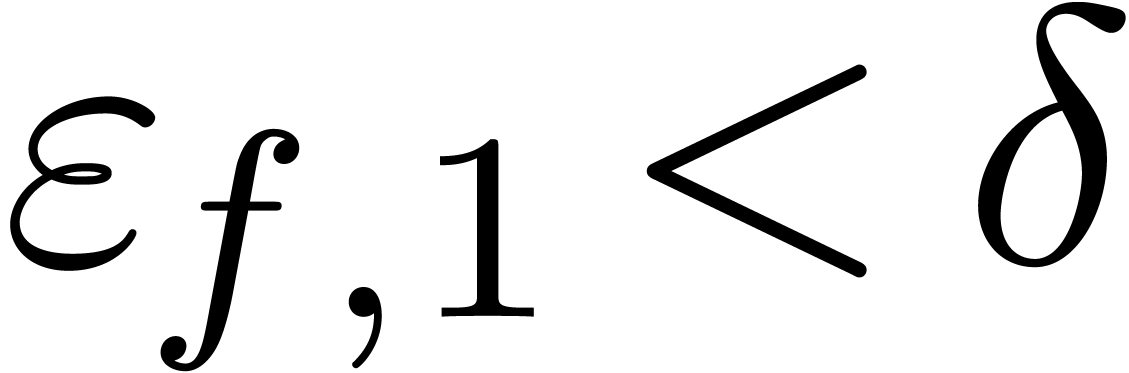 )
and . Of course, a drawback
of our remedy is that there are many possibilities for the subdominant
term(s) to be killed. Consequently, we will only be able to correct
cancellations on or near the range in a few
special cases which occur frequently in practice. For the time being, it
seems that polynomials in or
)
and . Of course, a drawback
of our remedy is that there are many possibilities for the subdominant
term(s) to be killed. Consequently, we will only be able to correct
cancellations on or near the range in a few
special cases which occur frequently in practice. For the time being, it
seems that polynomials in or 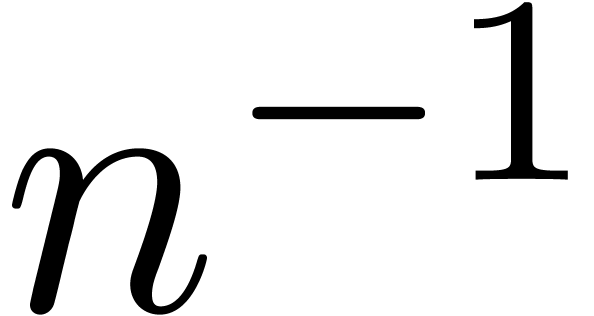 deserve special treatment, but more experimentation is needed in order
to complete this list.
deserve special treatment, but more experimentation is needed in order
to complete this list.
Another major problem is the determination of a suitable value for and good thresholds for tests
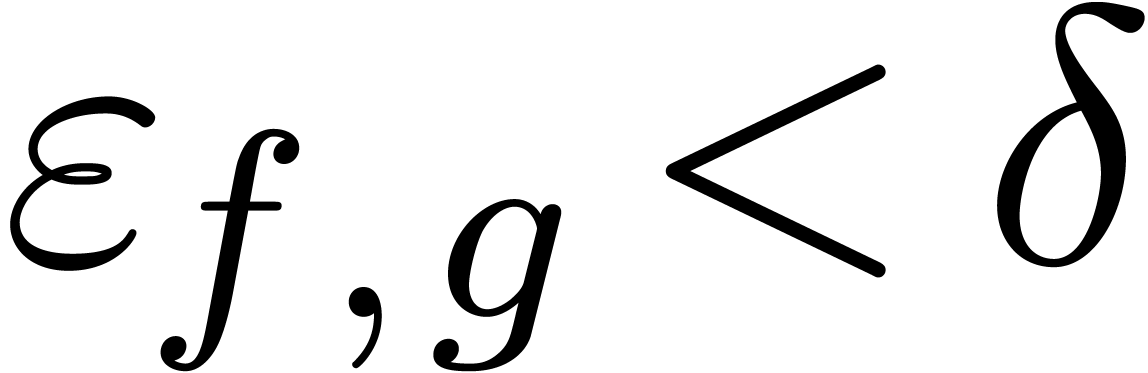 on the relative error. Let us first examine some
frequent mistakes, due to inadequate thresholds. As we have seen before,
our scheme frequently assumes sequences of the form
on the relative error. Let us first examine some
frequent mistakes, due to inadequate thresholds. As we have seen before,
our scheme frequently assumes sequences of the form 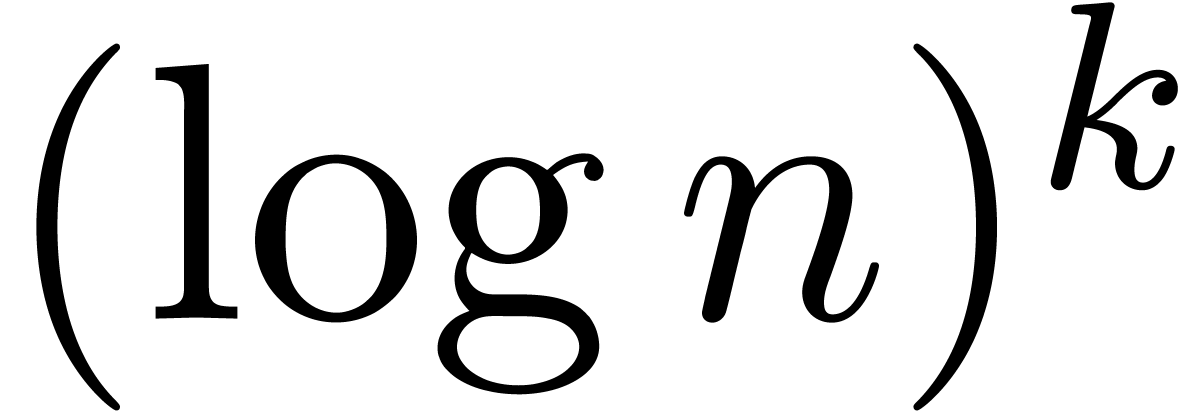 to be constant on the range .
Fortunately, this is a rather harmless mistake, because we usually want
to apply both for and
to be constant on the range .
Fortunately, this is a rather harmless mistake, because we usually want
to apply both for and
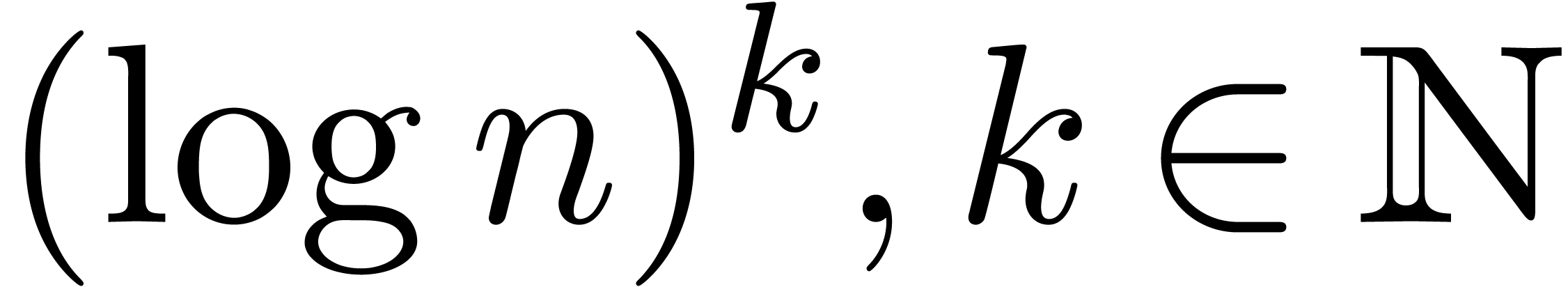 . A more annoying mistake is
to consider
. A more annoying mistake is
to consider 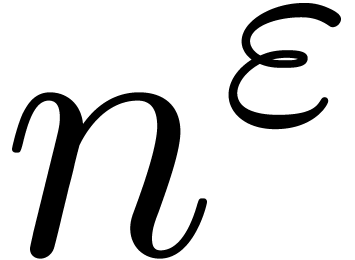 as a constant for small
as a constant for small 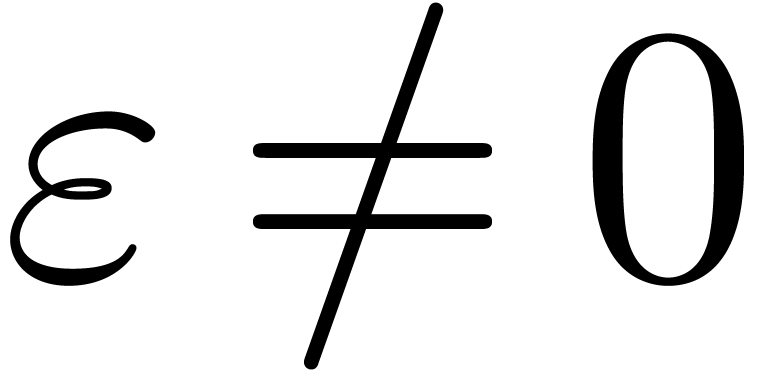 . This typically happens when
is too large. Conversely, if is too small, then
we may fail to recognize that
. This typically happens when
is too large. Conversely, if is too small, then
we may fail to recognize that 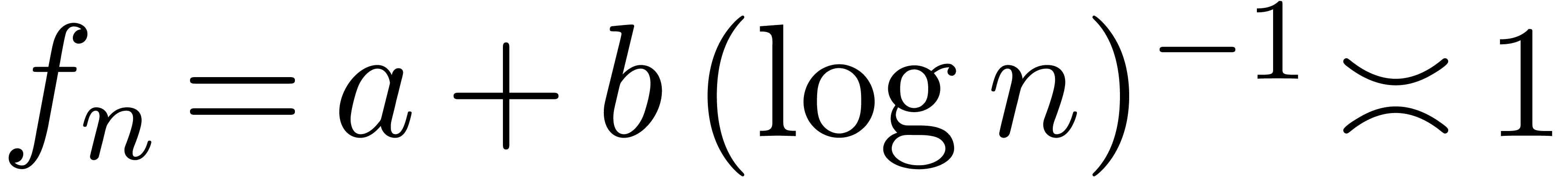 .
.
An interesting experiment for quantifying the risk of mistakes is to
examine how well basic functions, such as 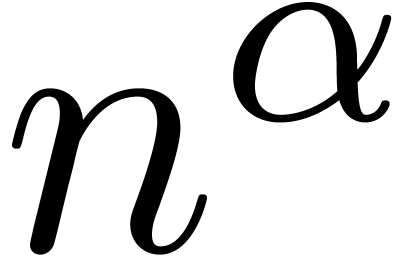 ,
,
,
, 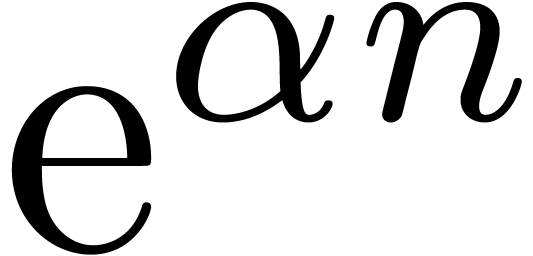 , are approximated by other basic functions on the
range
, are approximated by other basic functions on the
range  . More precisely, given
sequences and
. More precisely, given
sequences and  ,
we solve the system
,
we solve the system
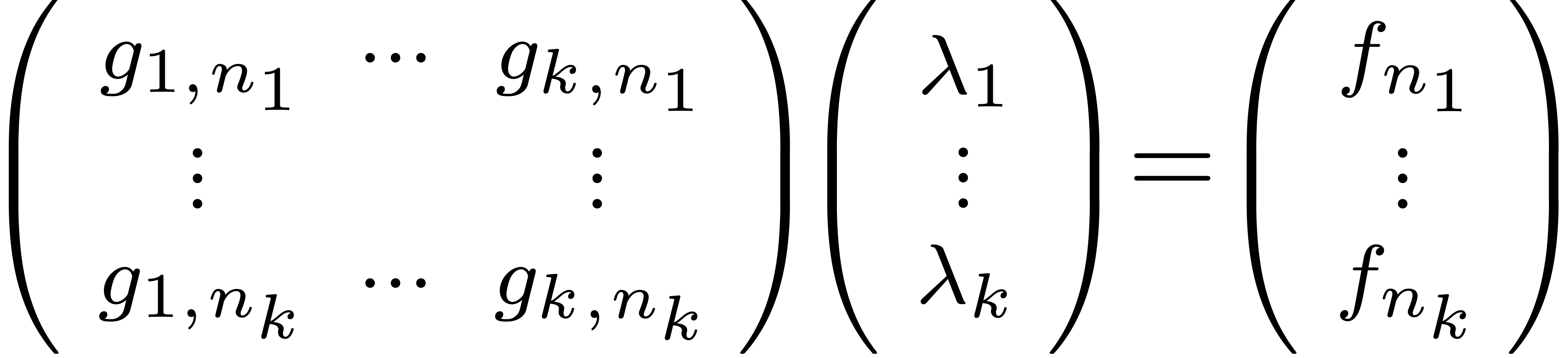
for  and consider the relative error
and consider the relative error
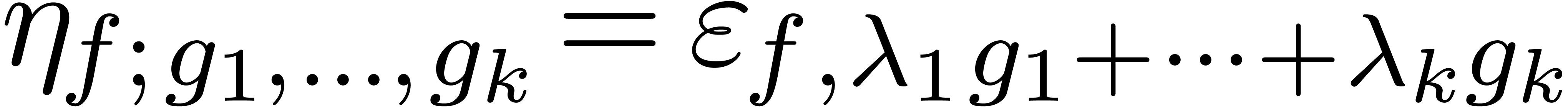
of the obtained approximation of by  . Some results are shown in table 2,
where we took the
. Some results are shown in table 2,
where we took the  equally spaced. The table
shows a significant risk of confusions for and
the quasi-absence of confusions for
equally spaced. The table
shows a significant risk of confusions for and
the quasi-absence of confusions for  .
Unfortunately, when taking too small, we often
fail to be in the asymptotic regime and we will either need to increase
the thresholds or improve the detection of
several terms in the expansion at once. We may also start check the
criteria several times for increasing values of : transformations which are accepted for smaller
values of can be applied with a greater degree
of confidence.
.
Unfortunately, when taking too small, we often
fail to be in the asymptotic regime and we will either need to increase
the thresholds or improve the detection of
several terms in the expansion at once. We may also start check the
criteria several times for increasing values of : transformations which are accepted for smaller
values of can be applied with a greater degree
of confidence.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
A final point about the design of a good set of
atomic transformations is whether we allow several transformations to be
acceptable for the same sequence (as in our general scheme), or rather
insist on immediately finding the right transformation at each step. For
instance, in section 6.1, we argued that -transformations are usually preferable over
-transformations. However, in
section 5.2, starting with 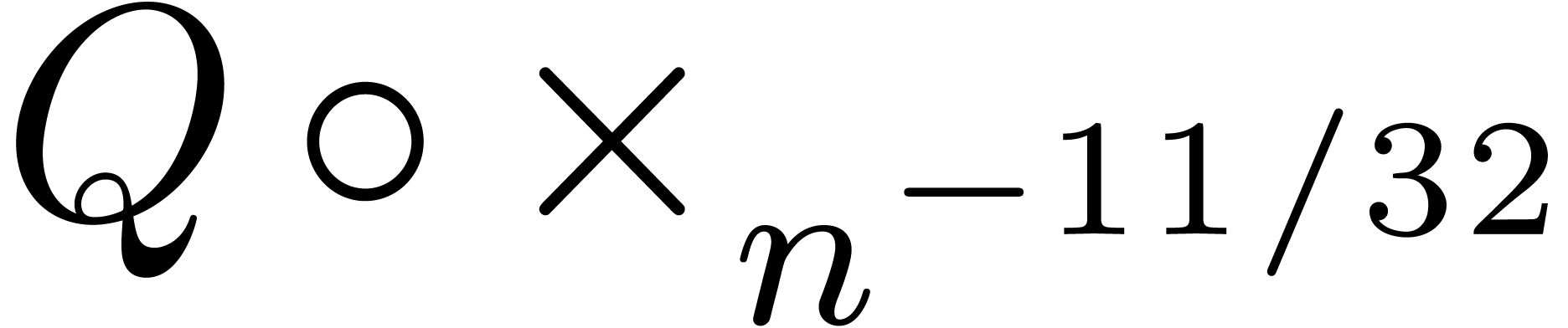 instead
of
instead
of 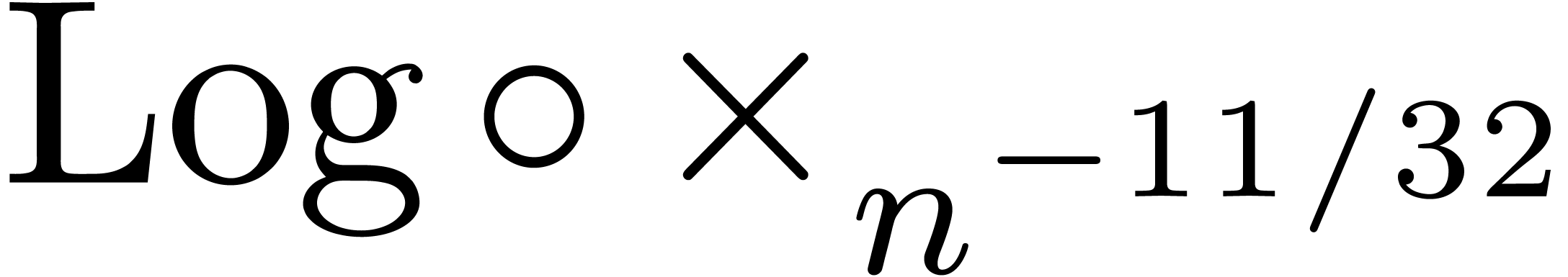 leads to an extrapolation of inferior
quality. More generally, it is not rare that a better extrapolation is
found using a slightly different transformation. This might be due to
subtle cancellations in the asymptotic expansion which occur only for
one of the transformations.
leads to an extrapolation of inferior
quality. More generally, it is not rare that a better extrapolation is
found using a slightly different transformation. This might be due to
subtle cancellations in the asymptotic expansion which occur only for
one of the transformations.
However, a systematic search for magic transformations is quite time-consuming, so we strongly recommend to restrict such searches to the first few iterations. Moreover, one should avoid using the increased flexibility for loosening the acceptability criteria: a better relative error for a numeric extrapolation is no guarantee for a better asymptotic quality. For instance, in the case of an expansion
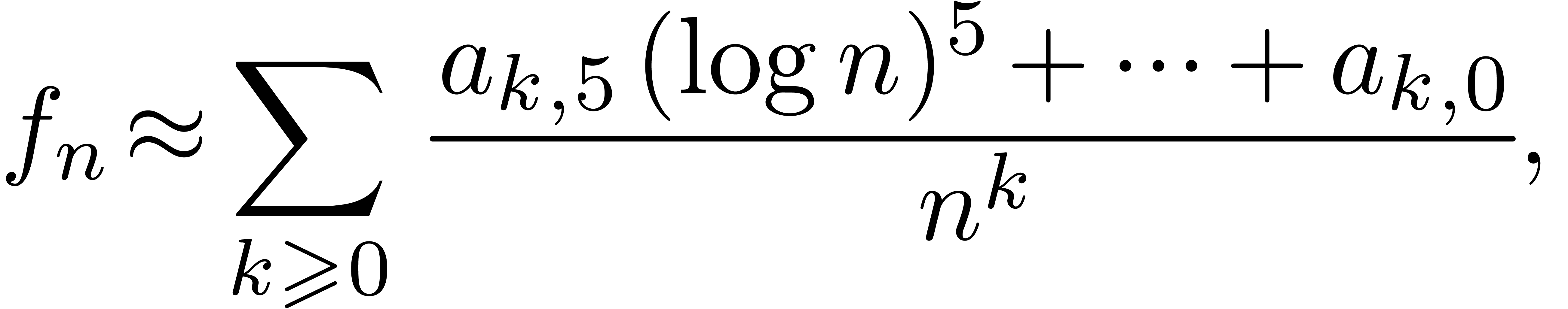
with and 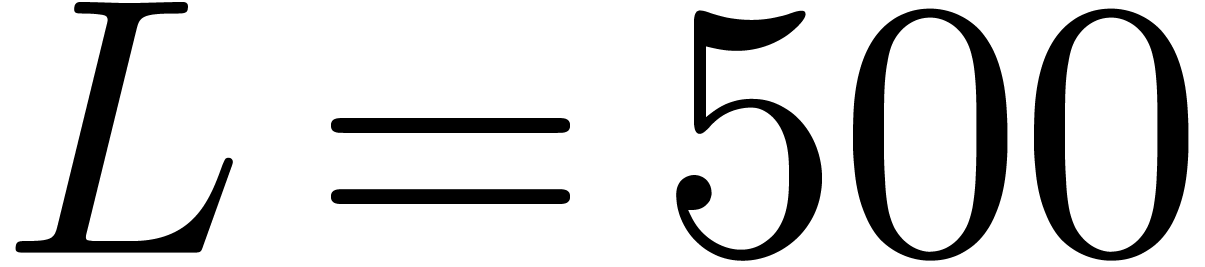 ,
we can only hope to gain
,
we can only hope to gain  decimal digits modulo
an increase of the extrapolation order by
decimal digits modulo
an increase of the extrapolation order by  .
A simple interpolation
.
A simple interpolation
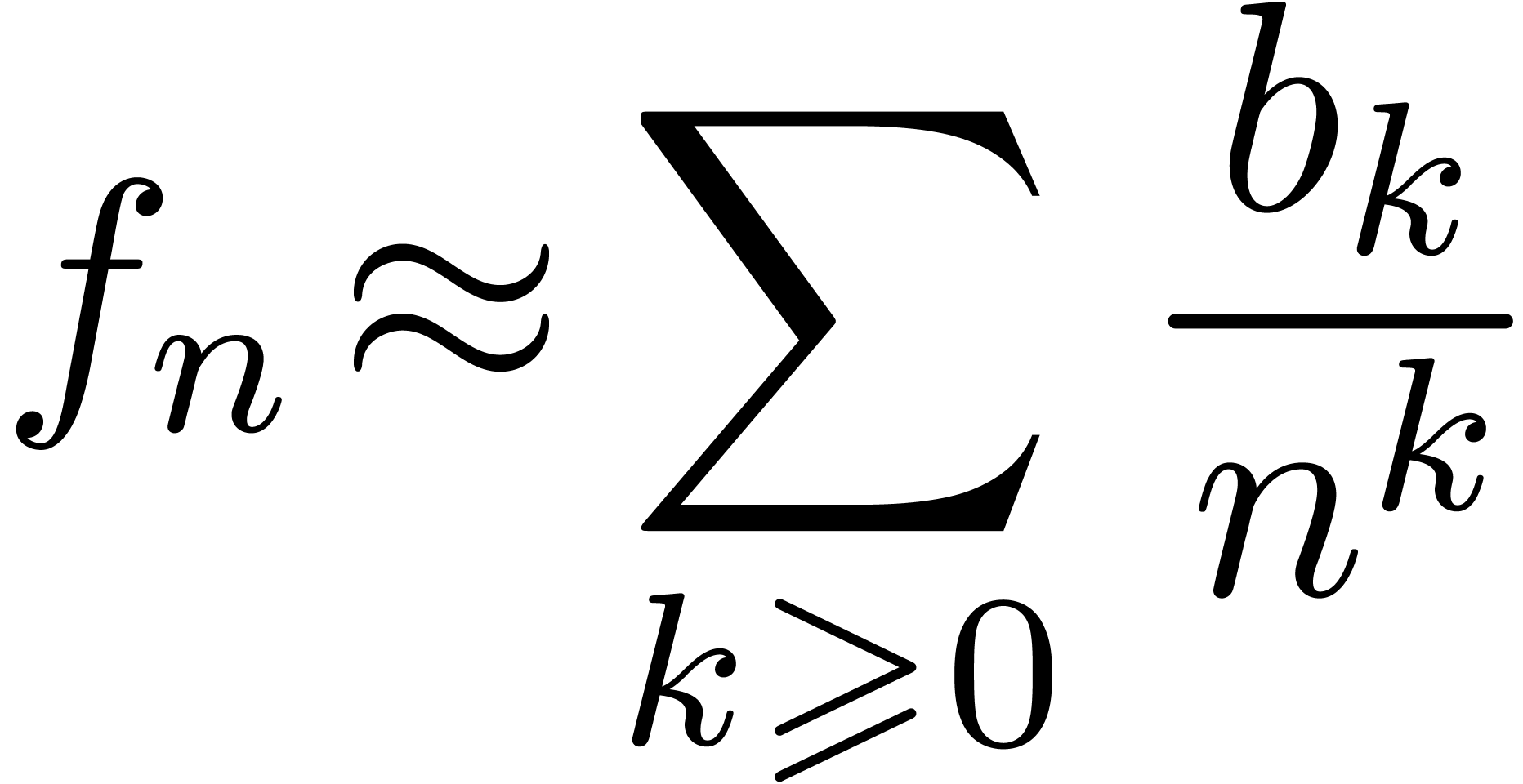
on the range will often yield better results at
the same order. Nevertheless, we may expect 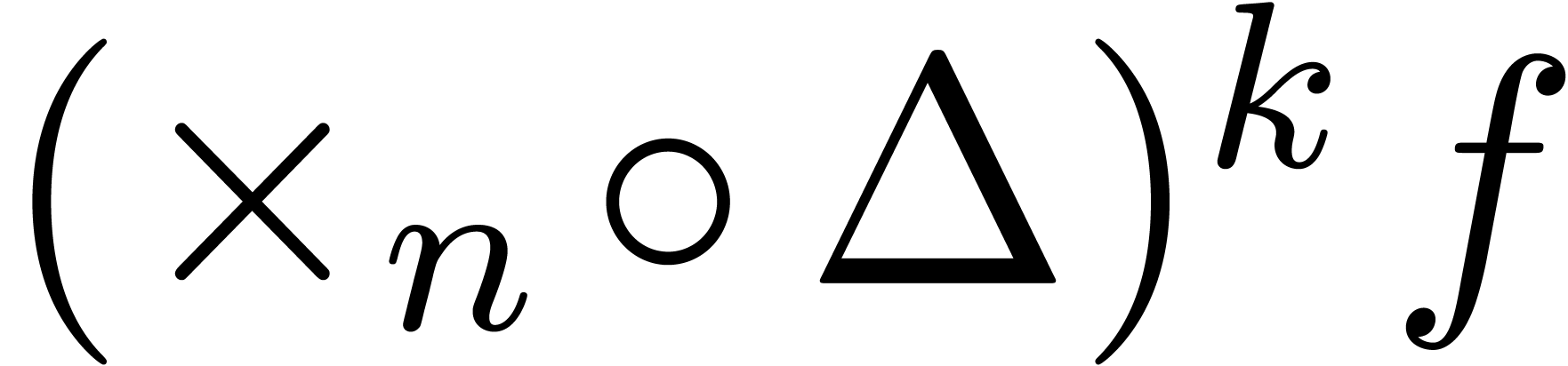 to
be exceptionally small whenever
to
be exceptionally small whenever  ,
which should never be the case for transformations of the form
,
which should never be the case for transformations of the form 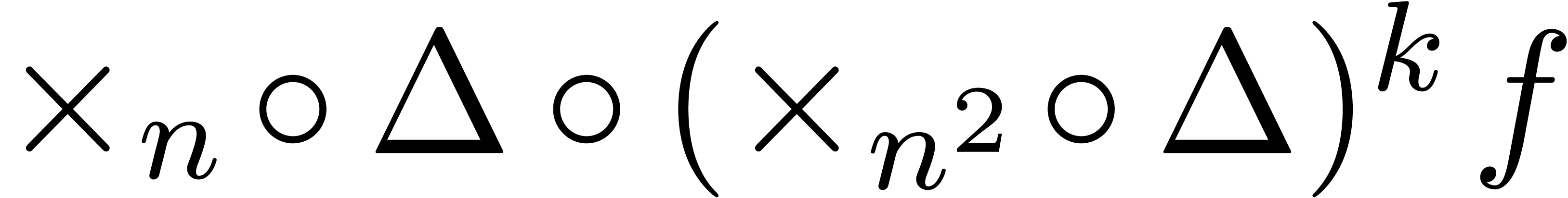 . Be guided by the asymptotics at
appropriate moments!
. Be guided by the asymptotics at
appropriate moments!
Whenever the asymptotic extrapolation scheme returns an incorrect
answer, the computed exp-log extrapolations quickly tend to become
absurd. Typically, we retrieve expansions of the type 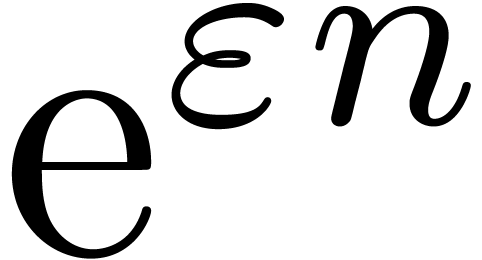 or instead of
or instead of 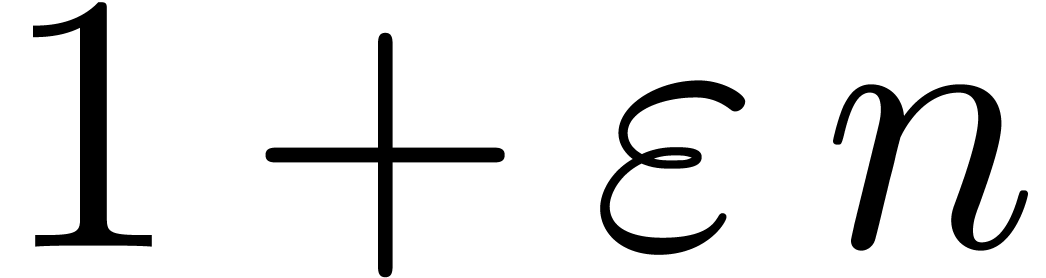 or
or 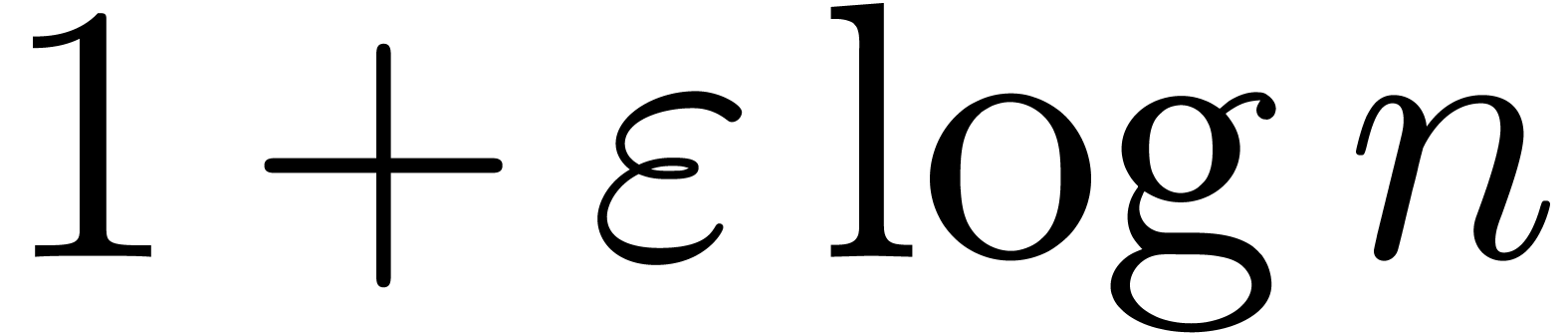 , where
, where  is
a small non-zero numeric parameter, which really should vanish from a
theoretic point of view. In section 5.1, we have seen an
example
is
a small non-zero numeric parameter, which really should vanish from a
theoretic point of view. In section 5.1, we have seen an
example 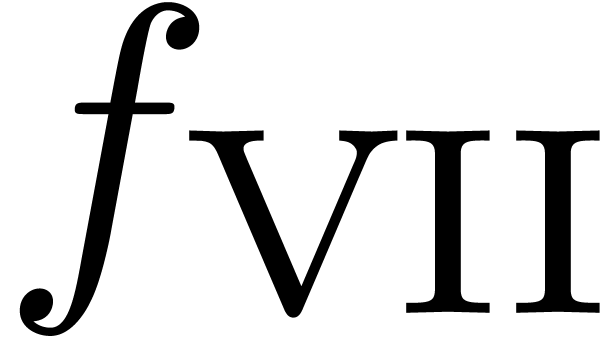 of this phenomenon. Actually, the
computation of exp-log extrapolations frequently does not terminate at
all. We probably should abort computations when the transseries
extrapolations involve too many asymptotic scales.
of this phenomenon. Actually, the
computation of exp-log extrapolations frequently does not terminate at
all. We probably should abort computations when the transseries
extrapolations involve too many asymptotic scales.
The above phenomenon is interesting in itself, because it might enable
us to improve the detection of incorrect expansions: when incorporating
the computation of the exp-log extrapolations into the main scheme, we
may check a posteriori that the asymptotic assumptions made on
the sequence are still satisfied by the resulting extrapolation. In this
way, we might get rid of all extrapolations which are good from a
numeric point of view on the range ,
but incorrect for large .
However, we have not investigated in detail yet whether our algorithms
for the computation with transseries may themselves be a source of
errors, especially in the case when we use summation up to the least
term.
Our extrapolation scheme may be generalized along several lines. First
of all, the restriction to real-valued sequences is not really
essential. Most of the ideas generalize in a straightforward way to
complex sequences. Only the transformation 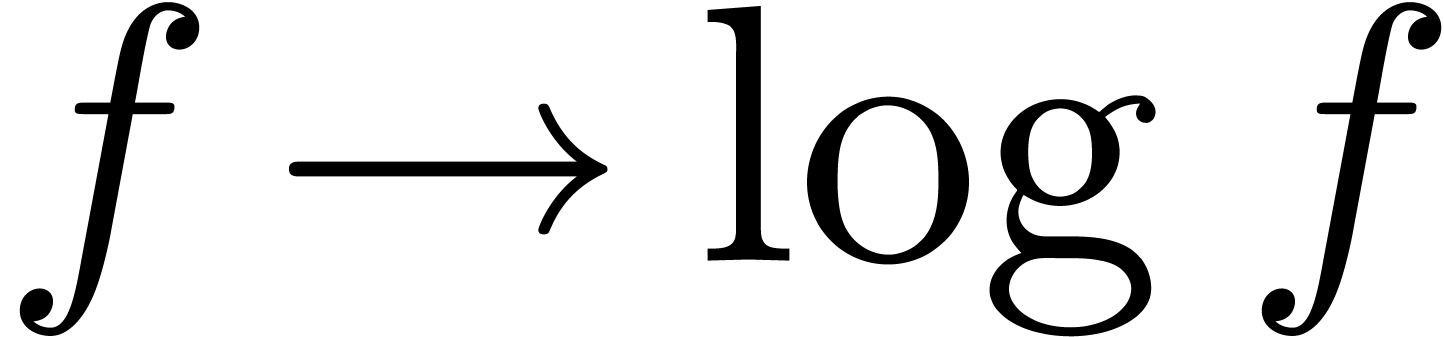 requires a bit more care. In order to compute
requires a bit more care. In order to compute 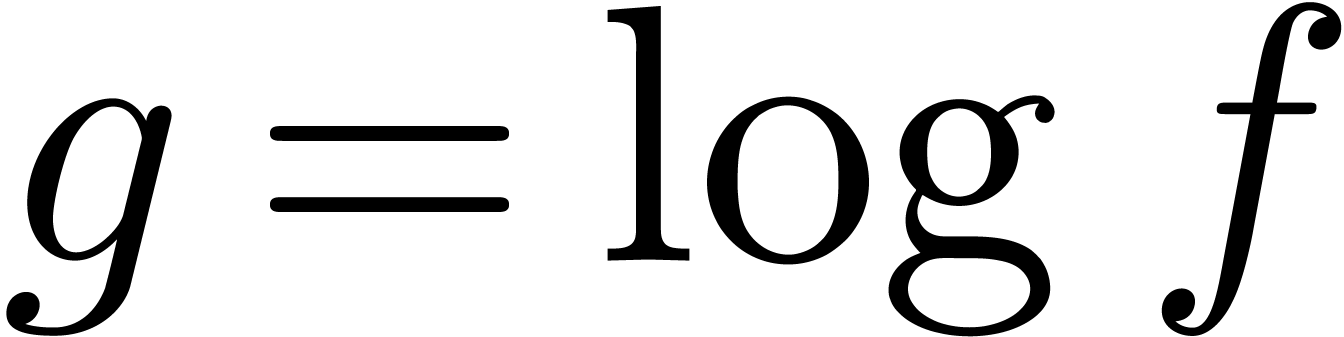 , we first compute
, we first compute 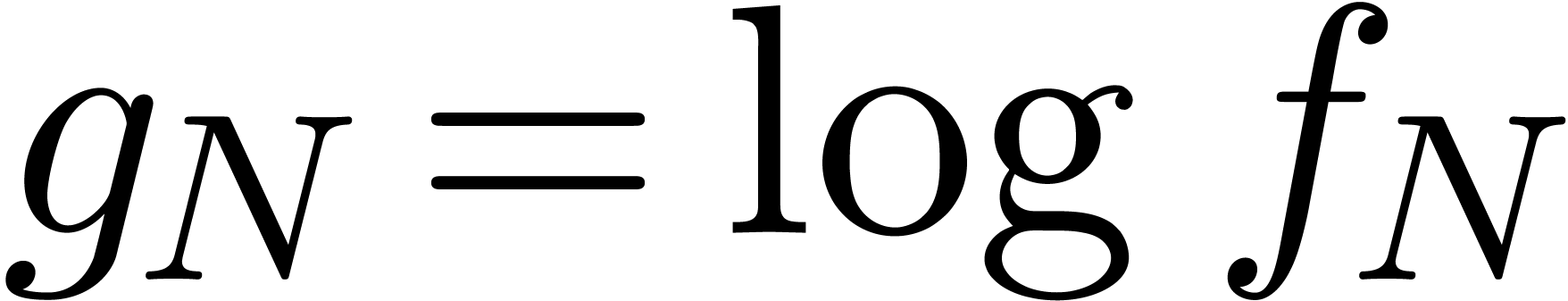 using the
principal determination of the logarithm. We next compute the other
terms using
using the
principal determination of the logarithm. We next compute the other
terms using
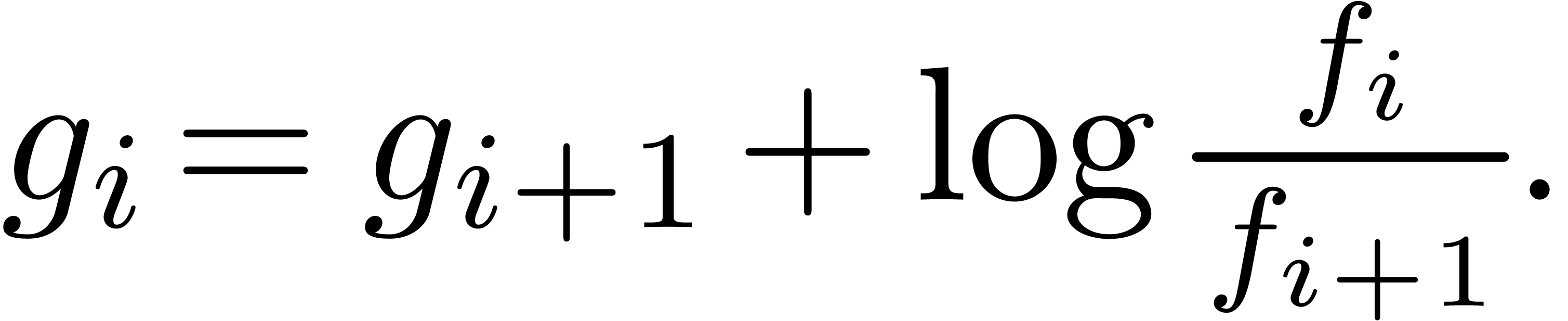
For more information about complex transseries, we refer to [vdH01]. Notice that the present scheme will only work well for complex transseries expansions which do not essentially involve oscillation. The expansion
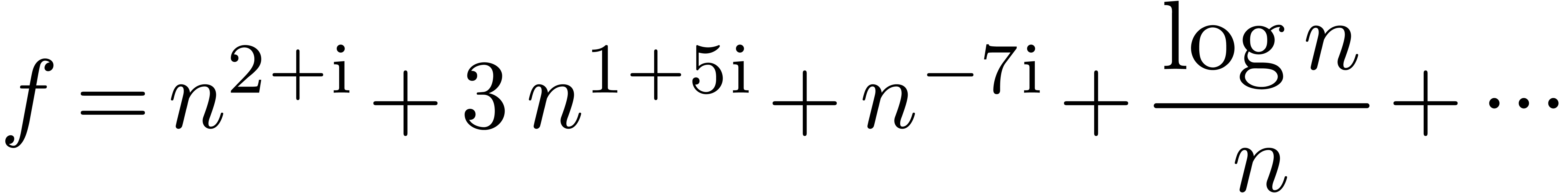
will typically fall in our setting, but our scheme will fail to
recognize a sequence as simple as 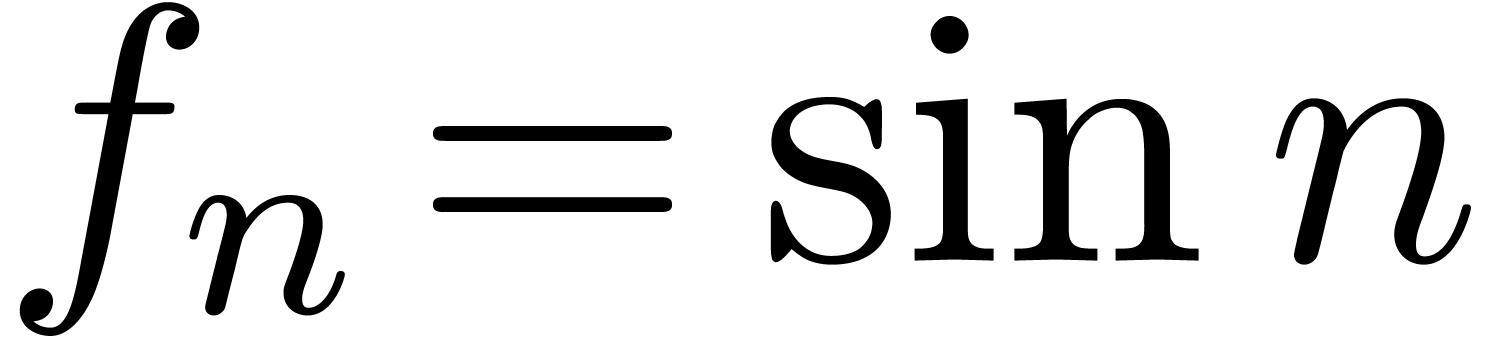 .
One approach for removing this drawback is discussed in [PF07].
.
One approach for removing this drawback is discussed in [PF07].
Another direction for generalization is to consider multivariate power
series. For instance, assume that the coefficients 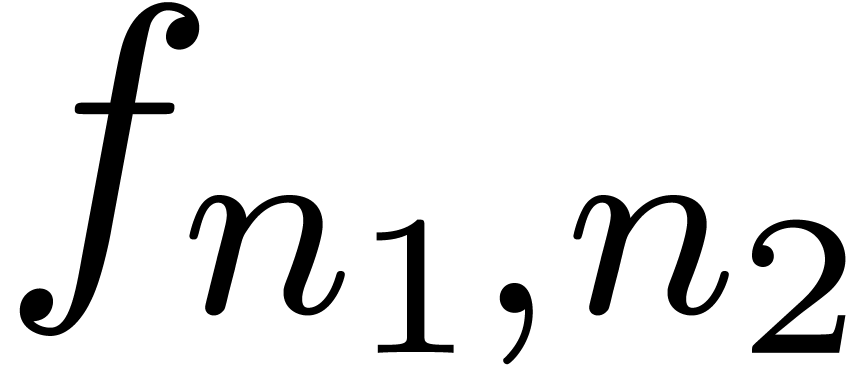 of a bivariate power series are known up to
of a bivariate power series are known up to 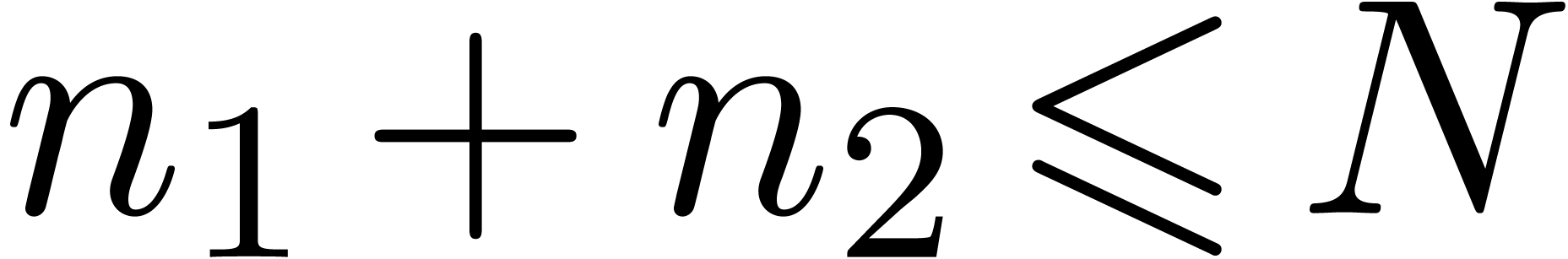 . Then one may pick
. Then one may pick 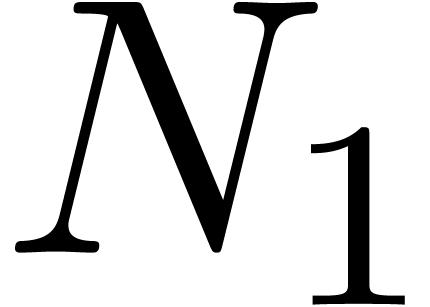 and
and 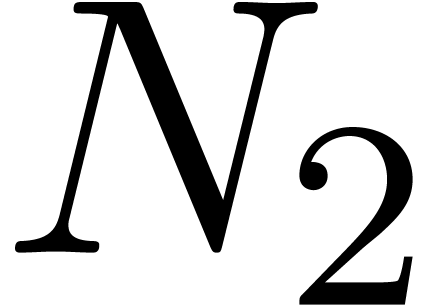 with
with 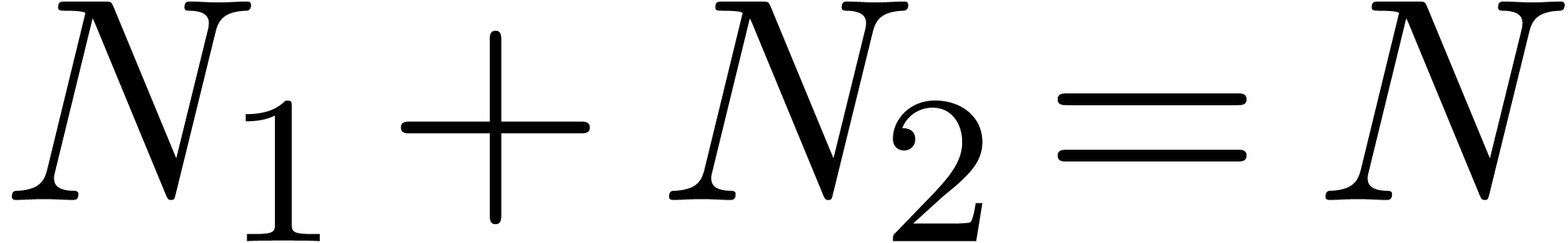 and apply the scheme to
the sequences
and apply the scheme to
the sequences 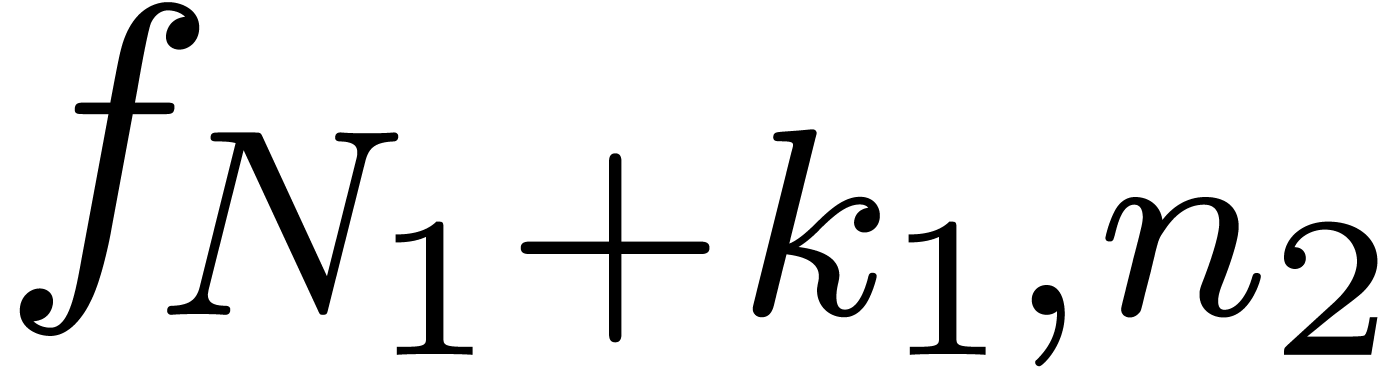 in
in 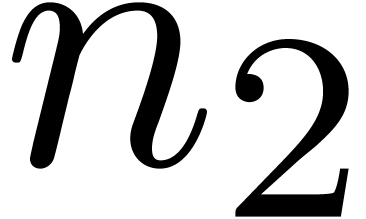 for
different small values of
for
different small values of  .
One may next try to interpolate the resulting expansions as a function
of
.
One may next try to interpolate the resulting expansions as a function
of 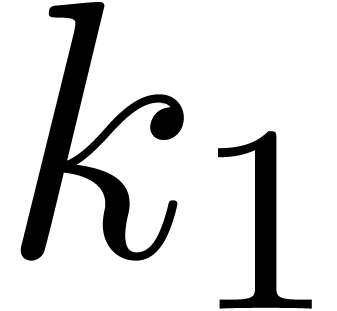 . Alternatively, one might
investigate a generalization of the scheme where discrete
differentiation is applied in an alternate fashion with respect to
. Alternatively, one might
investigate a generalization of the scheme where discrete
differentiation is applied in an alternate fashion with respect to 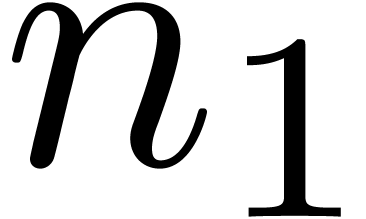 and . Of
course, in the multivariate case, it is expected that there are several
asymptotic regions, according to the choice of
and . Of
course, in the multivariate case, it is expected that there are several
asymptotic regions, according to the choice of 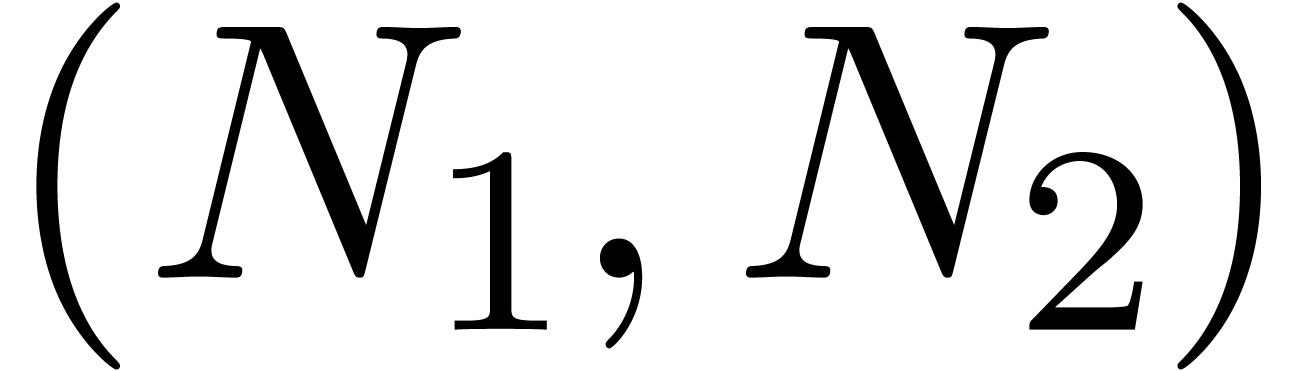 .
.
In fact, the dependency of the asymptotic expansion on the choice of
does not only occur in the multivariate case:
for the extrapolation recipes presented so far, it would be of interest
to study the dependency of the obtained expansion as a function of . For instance, consider the
sequence
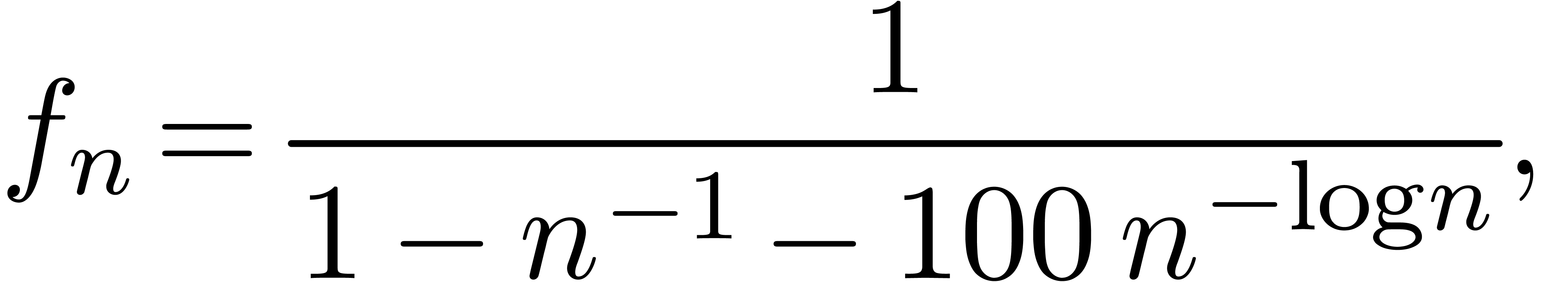
which admits a transfinite asymptotic expansion
Depending on the value of some of the a
priori invisible terms 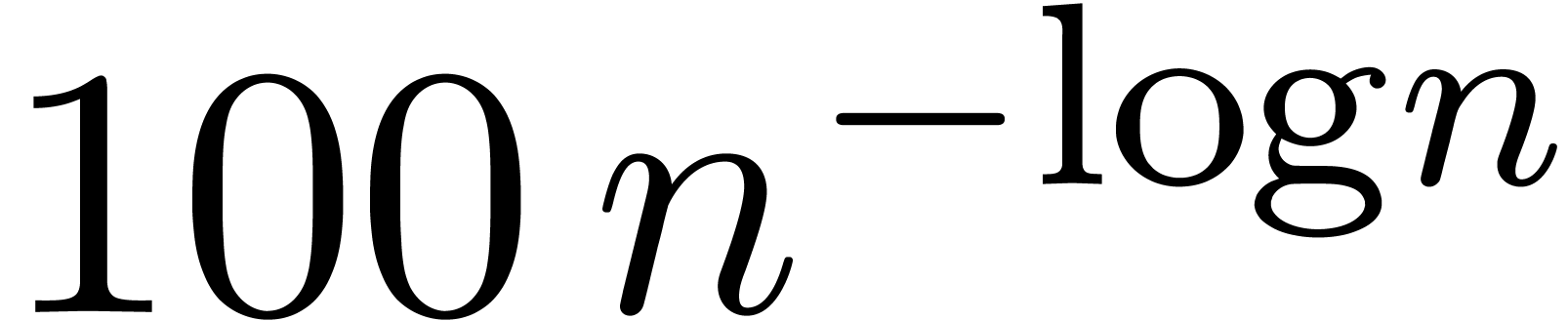 ,
etc. may suddenly become dominant from a numerical point of
view. This phenomenon is best illustrated by reordering the terms in the
expansion as a function of their magnitude, for different values of
:
,
etc. may suddenly become dominant from a numerical point of
view. This phenomenon is best illustrated by reordering the terms in the
expansion as a function of their magnitude, for different values of
:

It may therefore be interesting to apply the asymptotic extrapolation
scheme for different values of and try to
reconstruct the complete transfinite expansion by combining the
different results. Here we notice that the detection of a term like 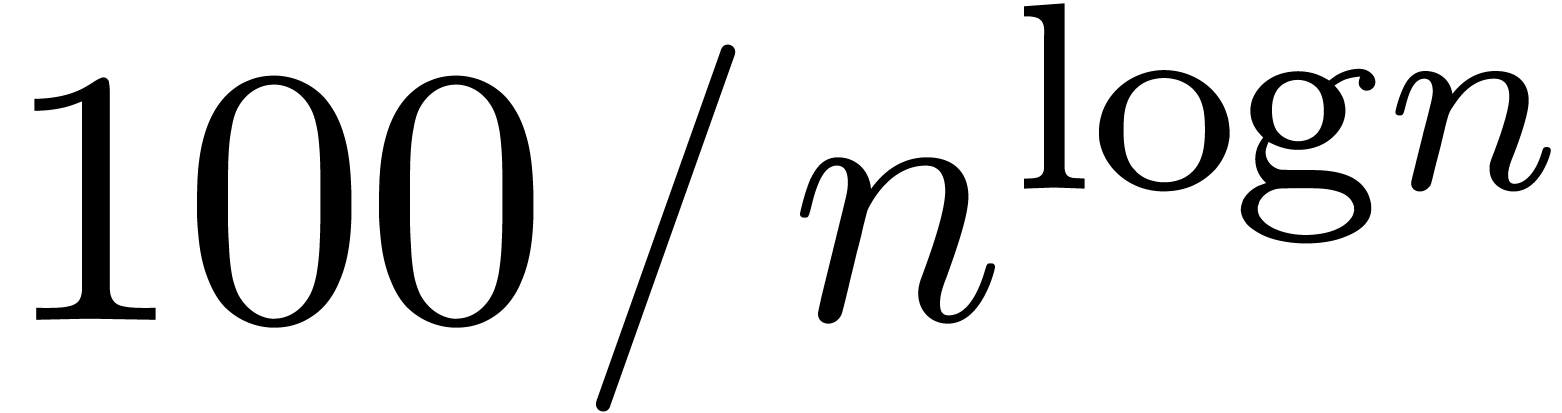 in the expansion for
in the expansion for 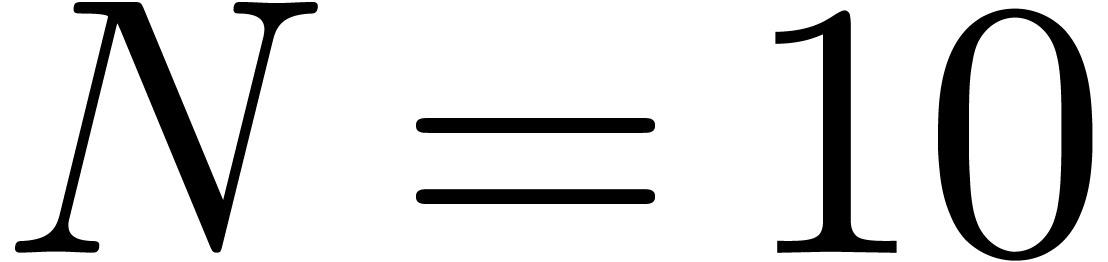 may help
for the detection of the term
may help
for the detection of the term 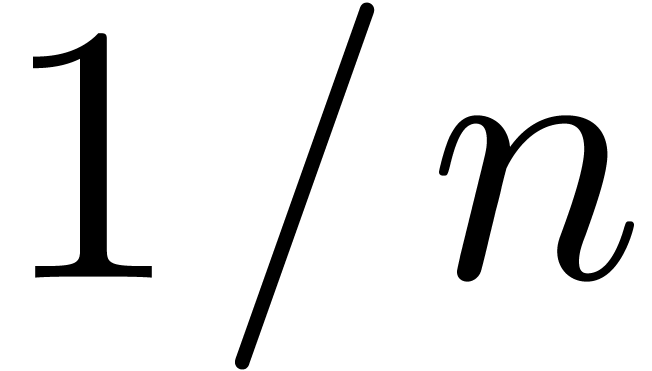 in the second
expansion for
in the second
expansion for 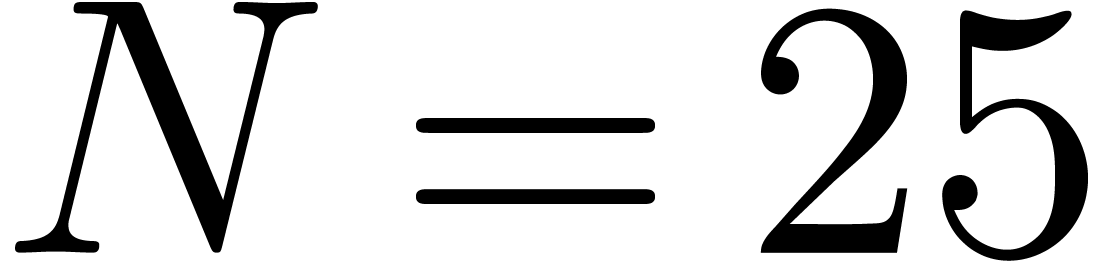 , since we may
subtract it from the expansion (and vice versa).
, since we may
subtract it from the expansion (and vice versa).
G. Alefeld and J. Herzberger. Introduction to interval analysis. Academic Press, New York, 1983.
B. Beckermann and G. Labahn. A uniform approach for the fast computation of matrix-type Padé approximants. SIAM J. Matrix Analysis and Applications, pages 804–823, 1994.
C. Brezinski and R. Zaglia. Extrapolation Methods. Theory and Practice. North-Holland, Amsterdam, 1991.
M. Canalis-Durand, F. Michel F., and M. Teisseyre. Algorithms for formal reduction of vector field singularities. Journal of Dynamical and Control Systems, 7(1):101–125, January 2001.
S. Caracciolo, A. J. Guttmann, I. Jensen, A. Pelissetto, A. N. Rogers, and A. D. Sokal. Correction-to-scaling exponents for two-dimensional self-avoiding walks. J. Stat. Phys., 120:1037–1100, 2005.
H. Derksen. An algorithm to compute generalized padé-hermite forms. Technical Report Rep. 9403, Catholic University Nijmegen, January 1994.
J. Écalle. Introduction aux fonctions analysables et preuve constructive de la conjecture de Dulac. Hermann, collection: Actualités mathématiques, 1992.
P. Flajolet and R. Sedgewick. An introduction to the analysis of algorithms. Addison Wesley, Reading, Massachusetts, 1996.
M. Grimmer, K. Petras, and N. Revol. Multiple precision interval packages: Comparing different approaches. Technical Report RR 2003-32, LIP, École Normale Supérieure de Lyon, 2003.
D. Gruntz. On computing limits in a symbolic manipulation system. PhD thesis, E.T.H. Zürich, Switzerland, 1996.
G.H. Hardy. Orders of infinity. Cambridge Univ. Press, 1910.
G.H. Hardy. Properties of logarithmico-exponential functions. Proceedings of the London Mathematical Society, 10(2):54–90, 1911.
I. Jensen and A. J. Guttmann. Self-avoiding polygons on the square lattice. J. Phys., 32:4867–4876, 1999.
A.K. Lenstra, H.W. Lenstra, and L. Lovász. Factoring polynomials with rational coefficients. Math. Ann., 261:515–534, 1982.
R.E. Moore. Interval analysis. Prentice Hall, Englewood Cliffs, N.J., 1966.
W. Pauls. Complex singularities of ideal incompressibles flows. PhD thesis, University Nice-Sophia Antipolis, 2007.
W. Pauls and U. Frisch. A Borel transform method for locating singularities of Taylor and Fourier series. J. Stat. Phys, 127:1095–1119, 2007.
W. Pauls, T. Matsumoto, U. Frisch, and J. Bec. Nature of complex singularities for the 2D Euler equation. Technical report, 2006.
H. Poincaré. Les méthodes nouvelles de la mécanique céleste, volume Tôme II. Gauthier-Villars, Paris, 1893.
G. Pólya. Kombinatorische Anzahlbestimmungen für Gruppen, Graphen und chemische Verbindungen. Acta Mathematica, 68:145–254, 1937.
D. Richardson, B. Salvy, J. Shackell, and J. van der Hoeven. Expansions of exp-log functions. In Y.N. Lakhsman, editor, Proc. ISSAC '96, pages 309–313, Zürich, Switzerland, July 1996.
B. Salvy. Asymptotique automatique et fonctions génératrices. PhD thesis, École Polytechnique, France, 1991.
J. Shackell. A differential-equations approach to functional equivalence. In Proc. ISSAC '89, pages 7–10, Portland, Oregon, A.C.M., New York, 1989. ACM Press.
J. Shackell. Growth estimates for exp-log functions. Journal of Symbolic Computation, 10:611–632, 1990.
J. Shackell. Limits of Liouvillian functions. Proc. of the London Math. Soc., 72:124–156, 1996. Appeared in 1991 as a technical report at the Univ. of Kent, Canterbury.
B. Salvy and P. Zimmermann. Gfun: a Maple package for the manipulation of generating and holonomic functions in one variable. ACM Trans. on Math. Software, 20(2):163–177, 1994.
J. van der Hoeven. Automatic asymptotics. PhD thesis, École polytechnique, Palaiseau, France, 1997.
J. van der Hoeven. Complex transseries solutions to algebraic differential equations. Technical Report 2001-34, Univ. d'Orsay, 2001.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven et al. Mathemagix, 2002. http://www.mathemagix.org.
J. van der Hoeven. Algorithms for asymptotic interpolation. Technical Report 2006-12, Univ. Paris-Sud, 2006.
J. van der Hoeven. Transserial Hardy fields. Technical Report 2006-37, Univ. Paris-Sud, 2006. Accepted for publication.
J. van der Hoeven. Transseries and real differential algebra, volume 1888 of Lecture Notes in Mathematics. Springer-Verlag, 2006.
J. van der Hoeven. Meta-expansion of transseries. Technical Report 2008-03, Université Paris-Sud, Orsay, France, 2008. Short version presented at ROGICS 2008, Mahdia, Tunesia.
E. J. Weniger. Nonlinear sequence transformations: Computational tools for the acceleration of convergence and the summation of divergent series. Technical Report math.CA/0107080, Arxiv, 2001.
H.S. Wilf. Generatingfunctionology. Academic Press, 2nd edition, 2004. http://www.math.upenn.edu/~wilf/DownldGF.html.
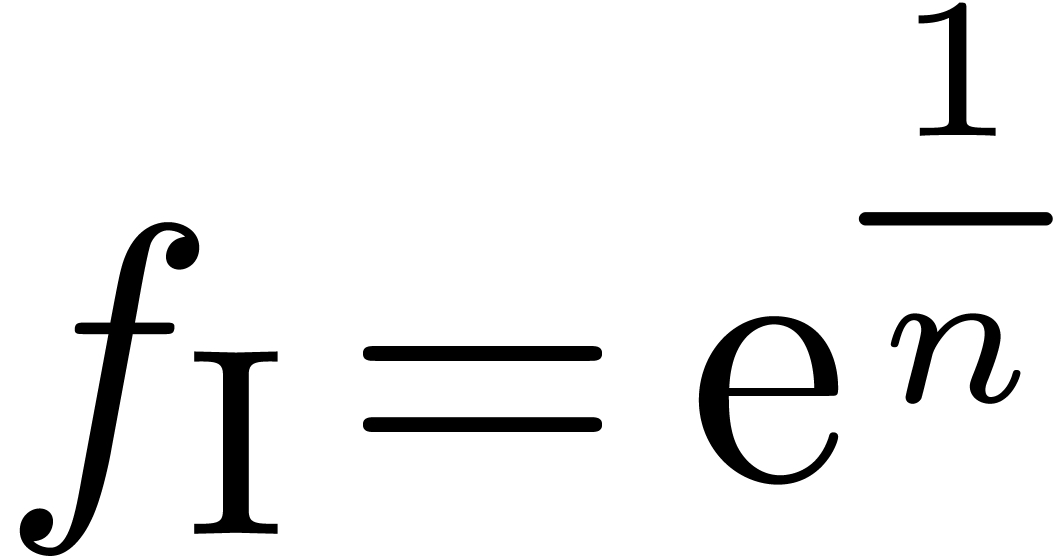
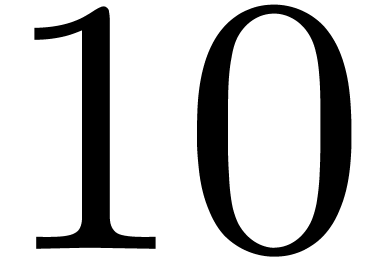
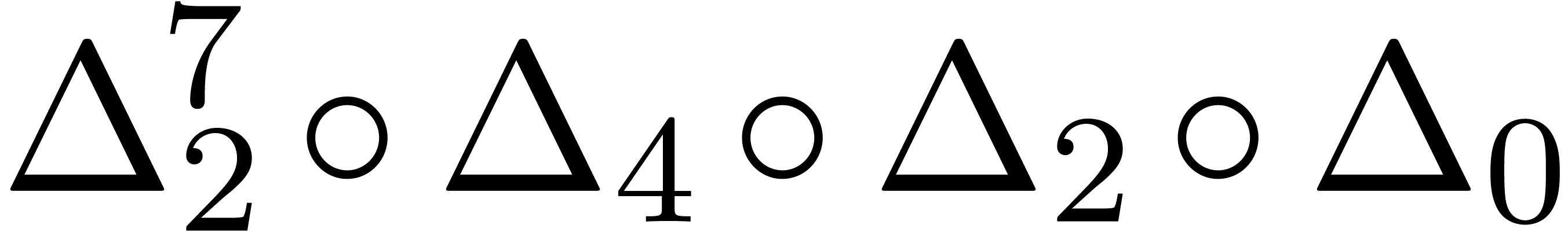
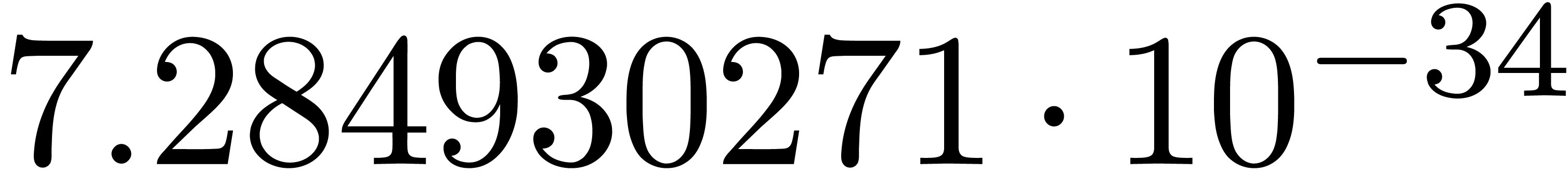

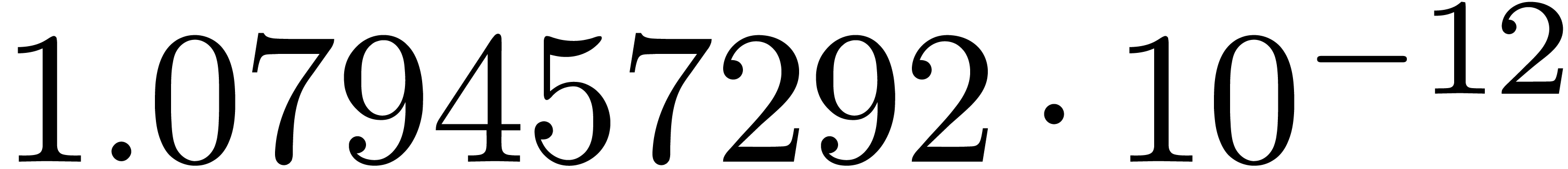
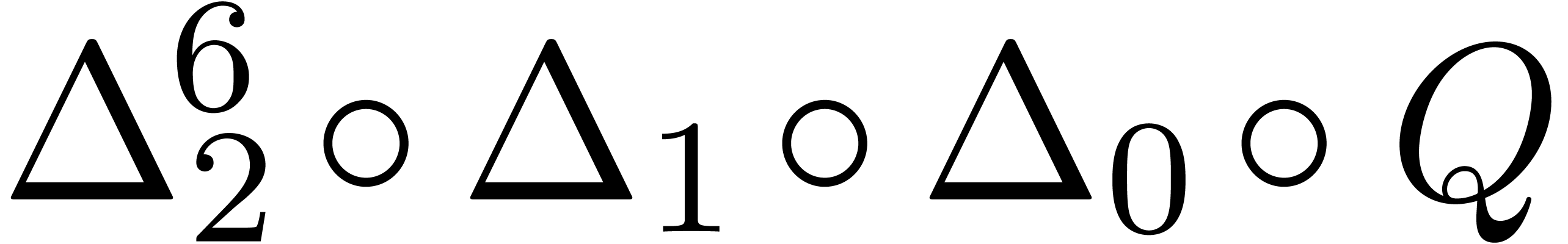
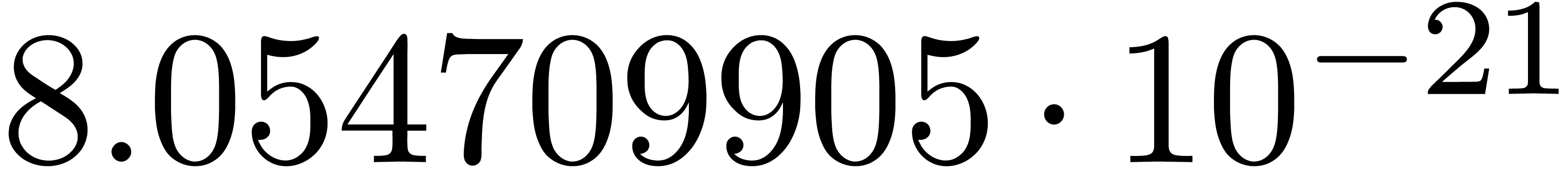
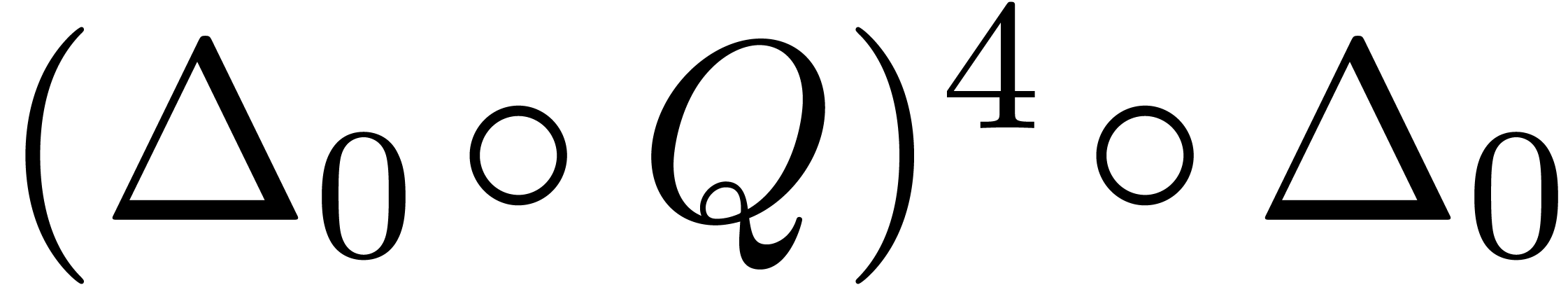
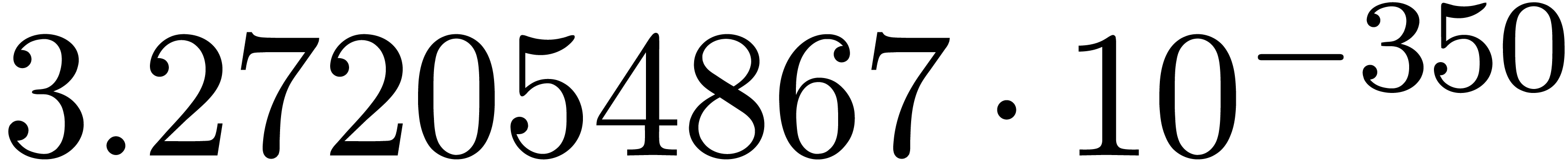
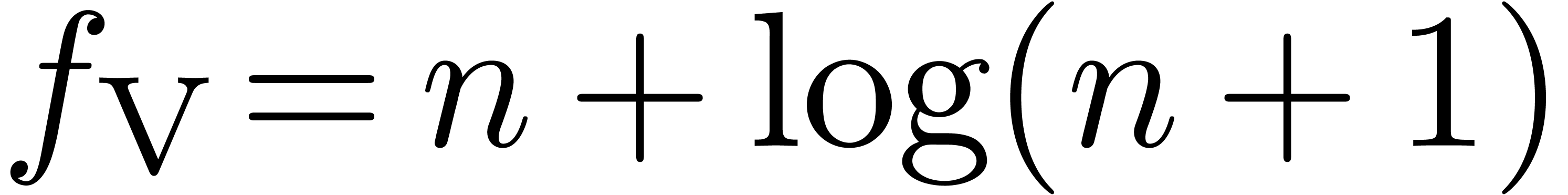

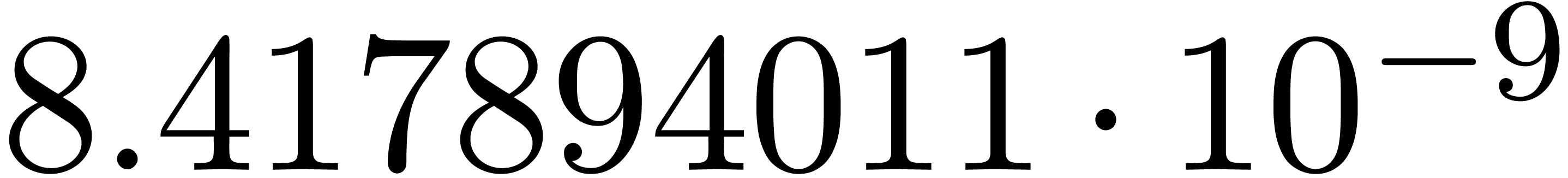
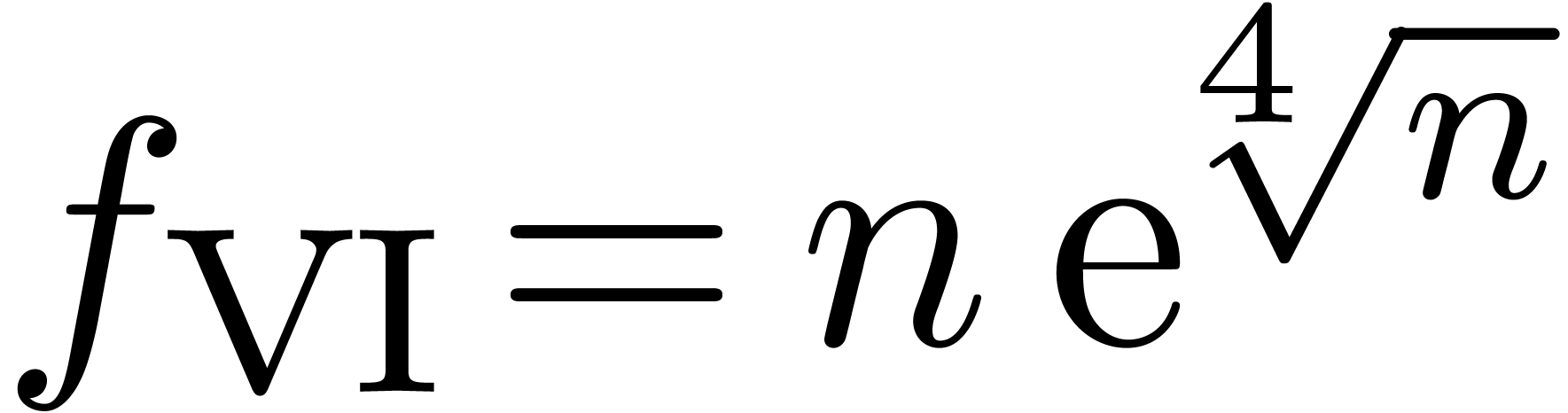
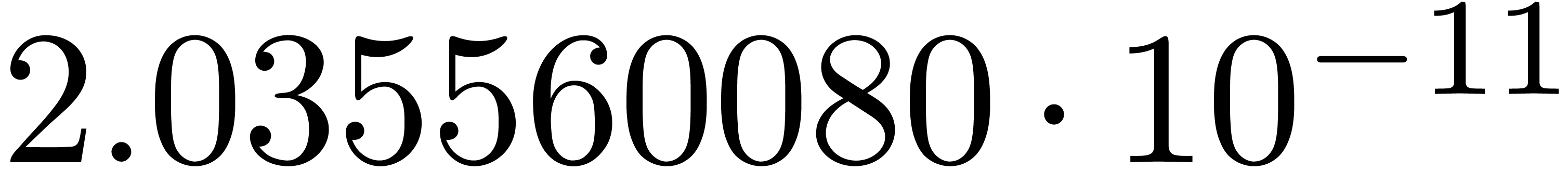
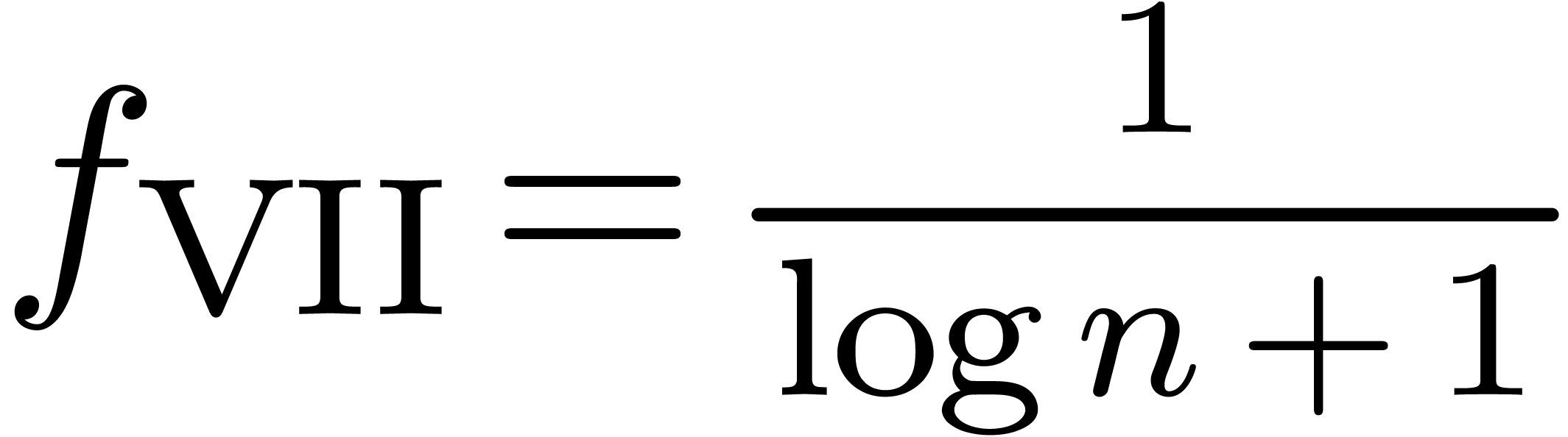
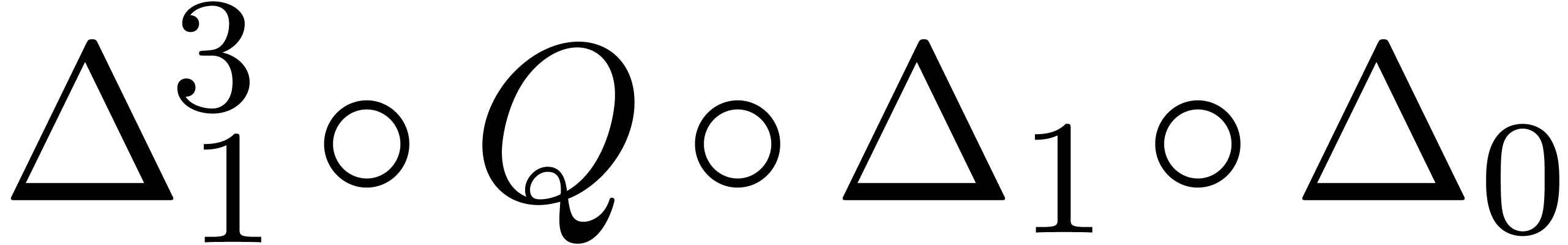
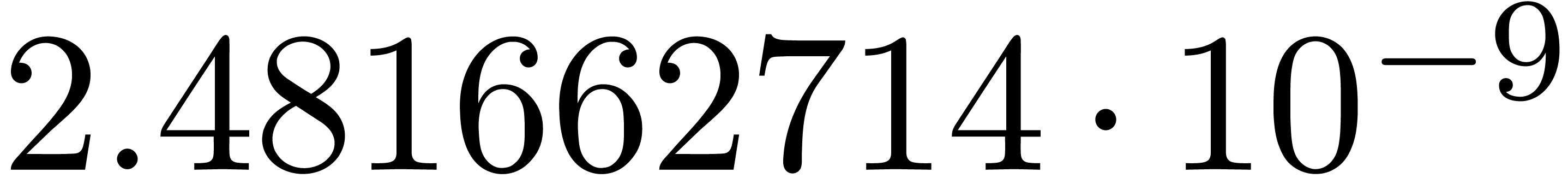
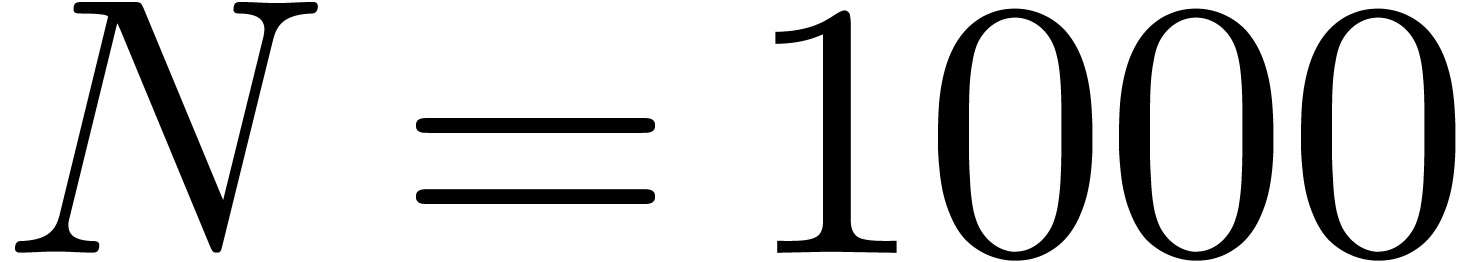 and order
and order 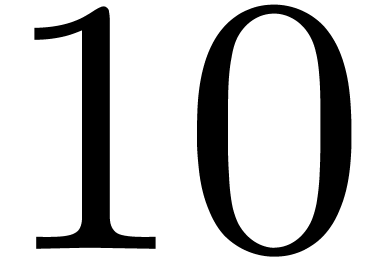 .
.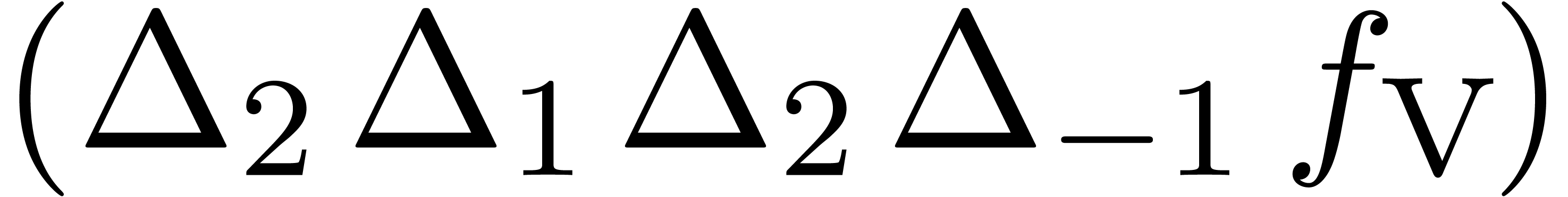

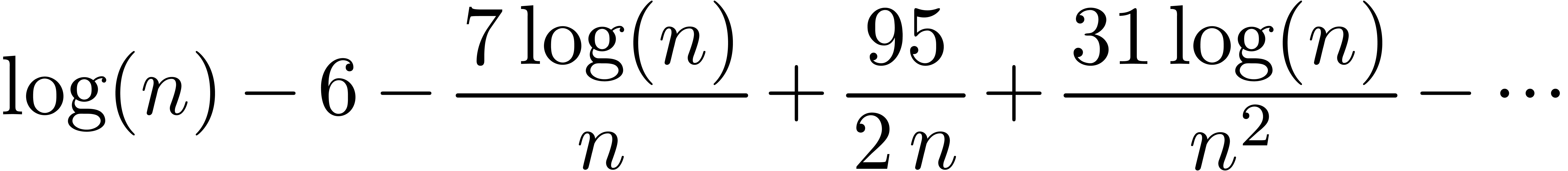

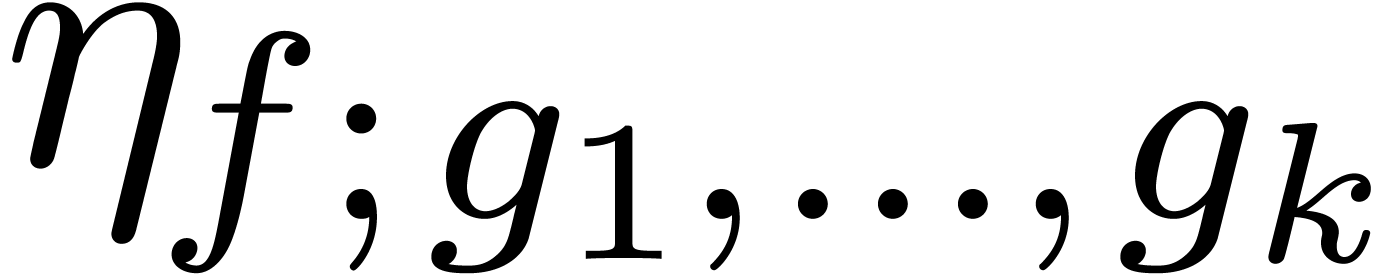 for
for 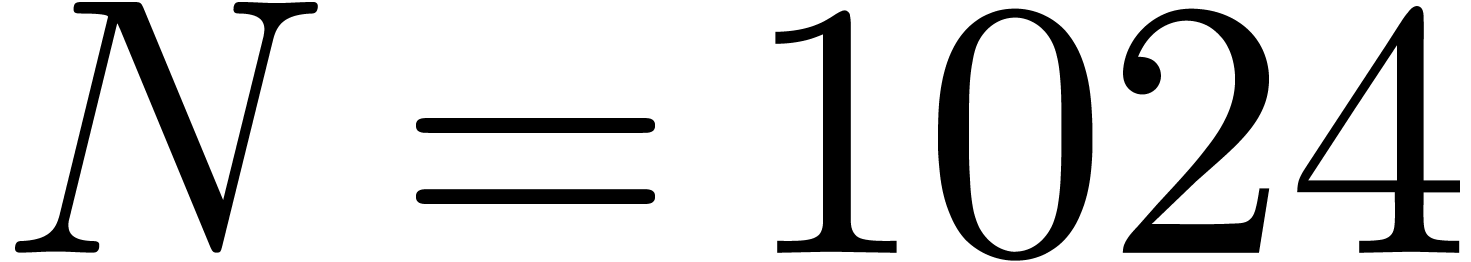 and
and 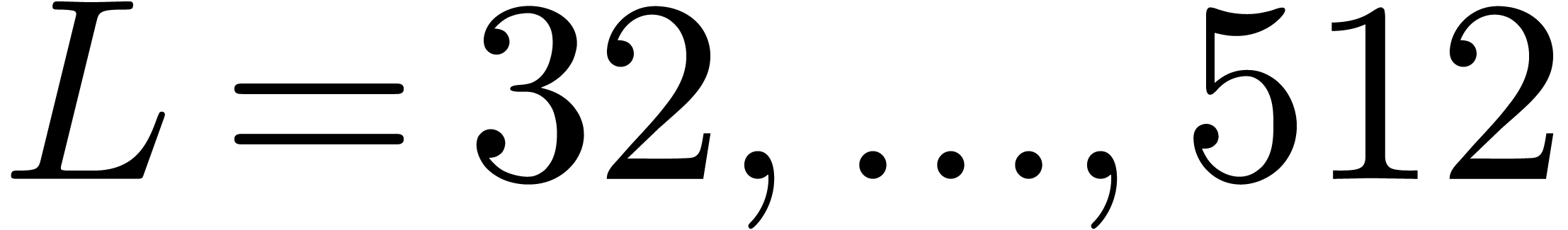
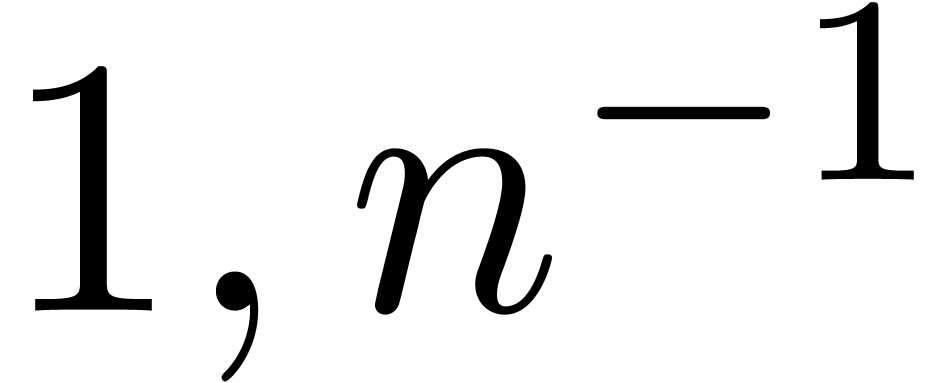




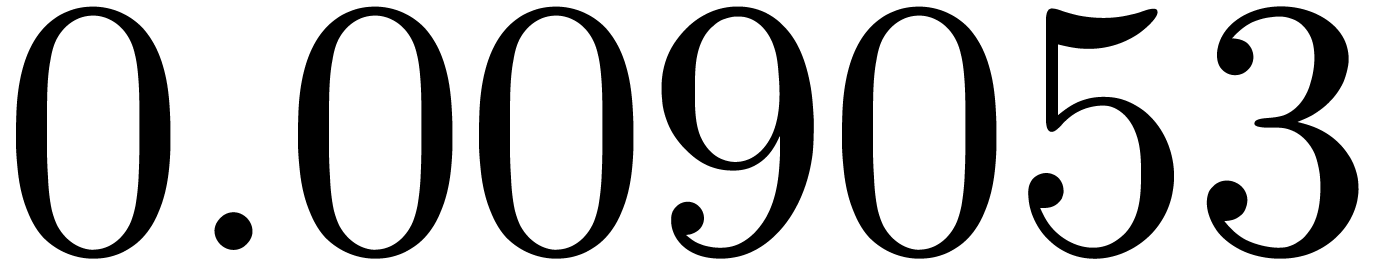
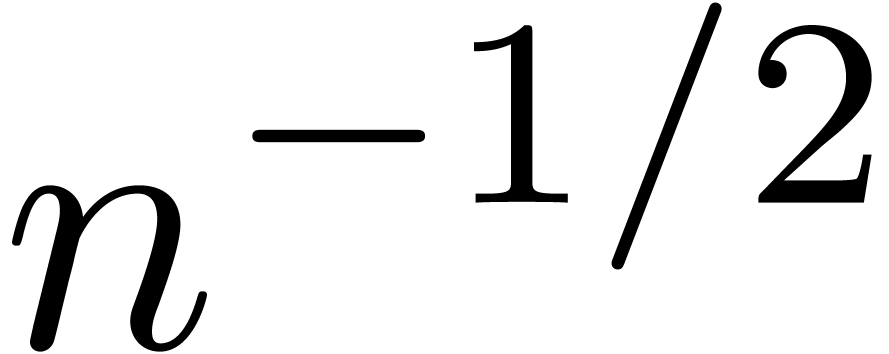
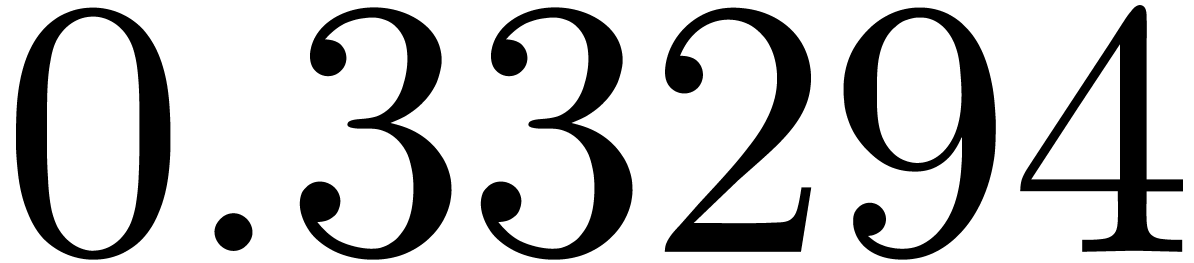
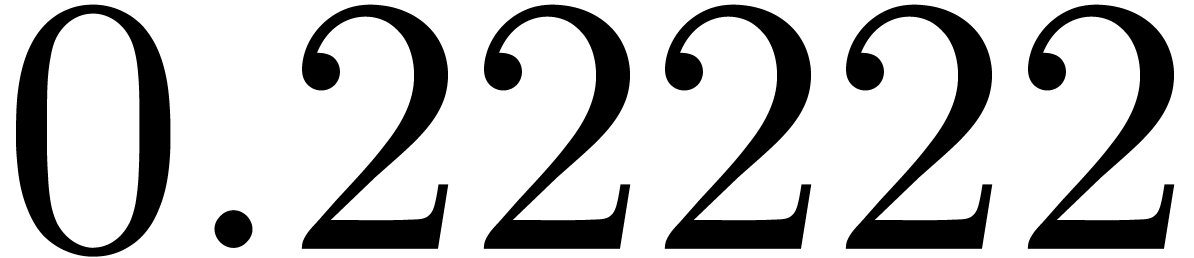
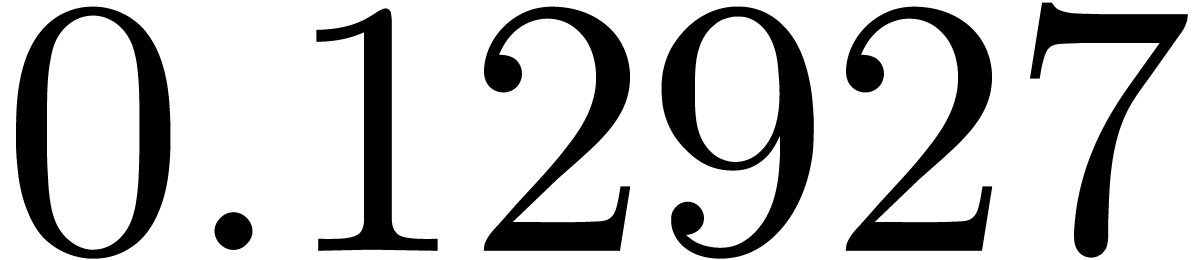
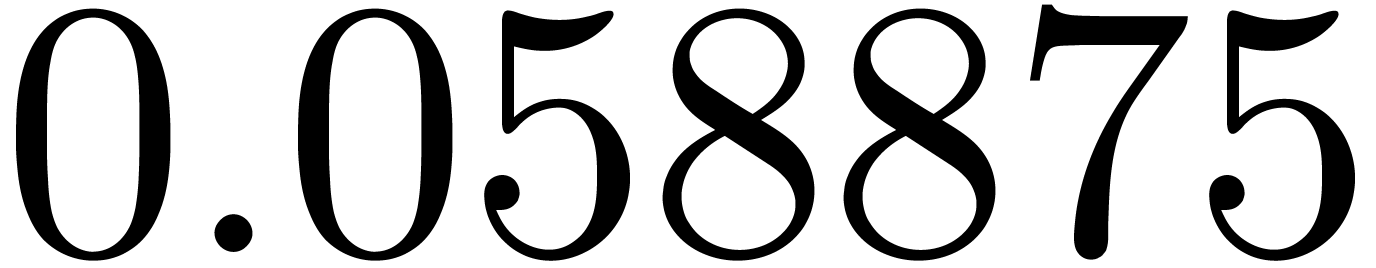
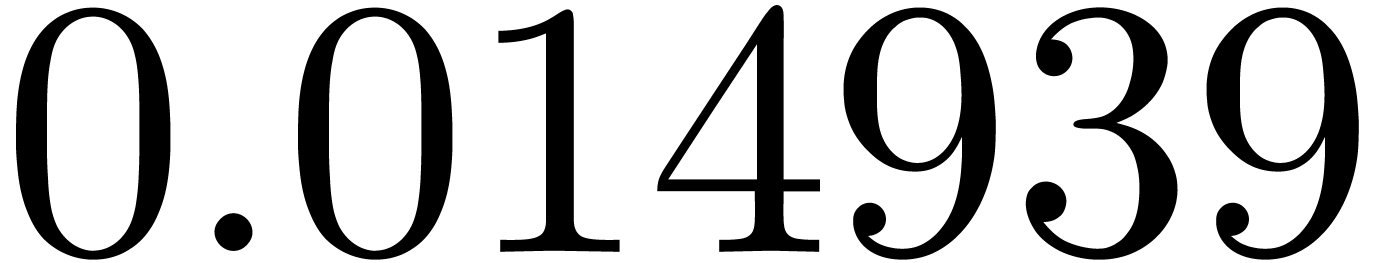
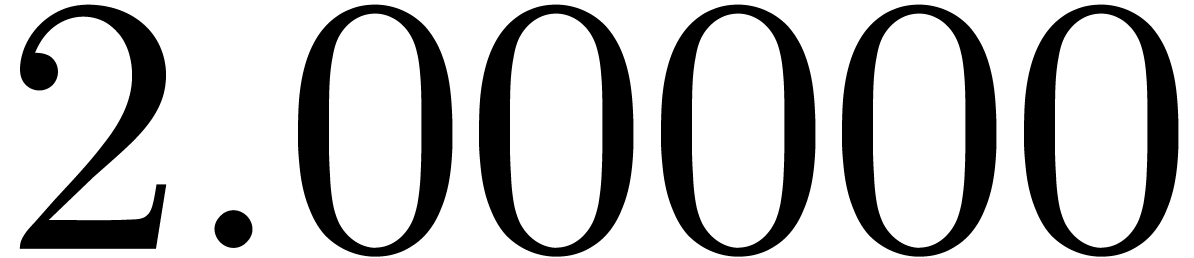
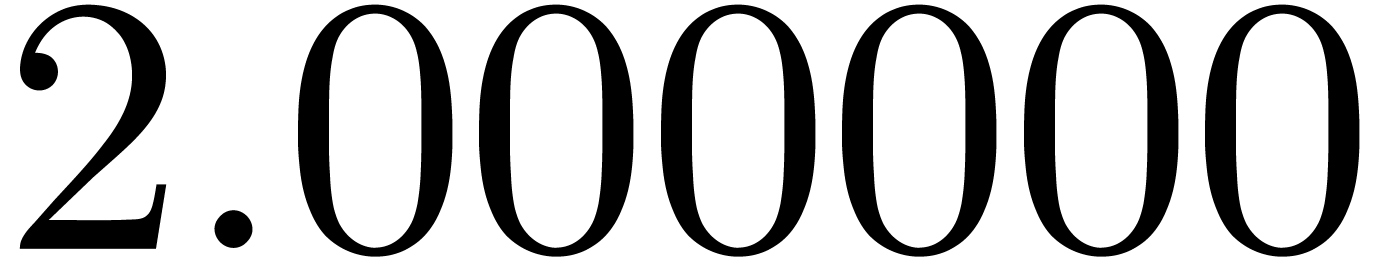
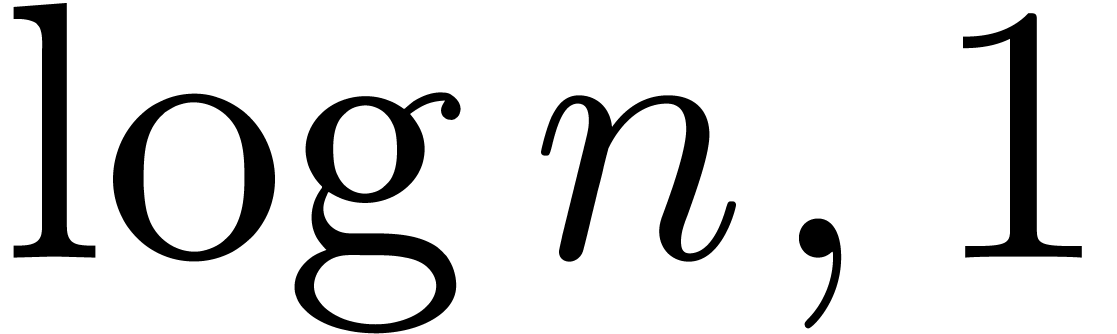

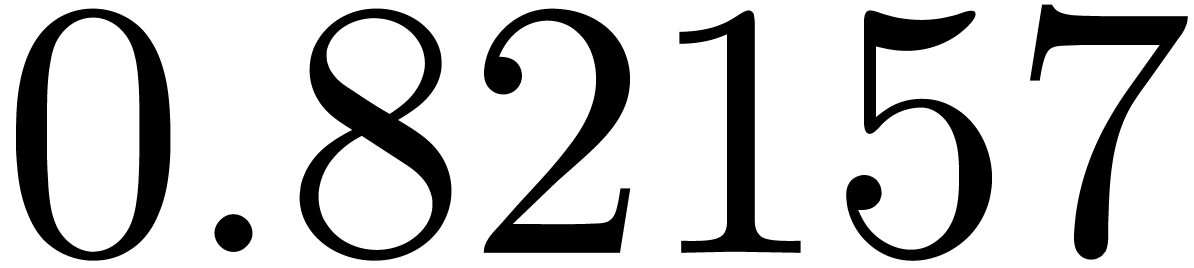
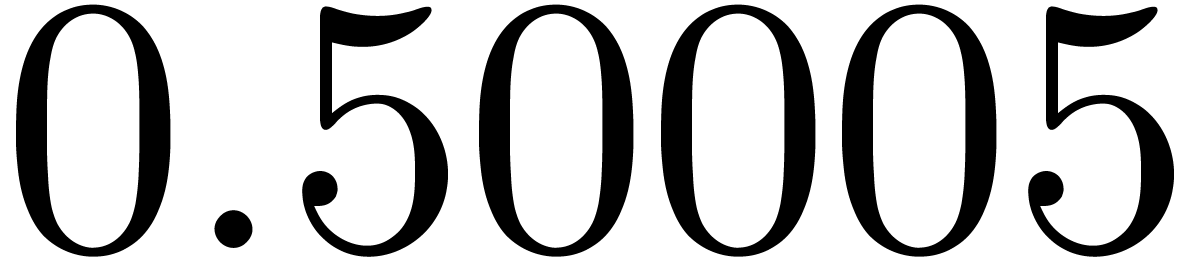

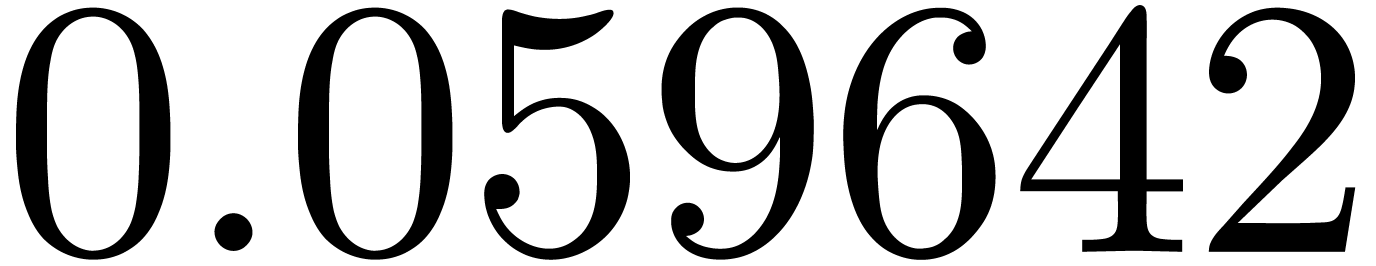
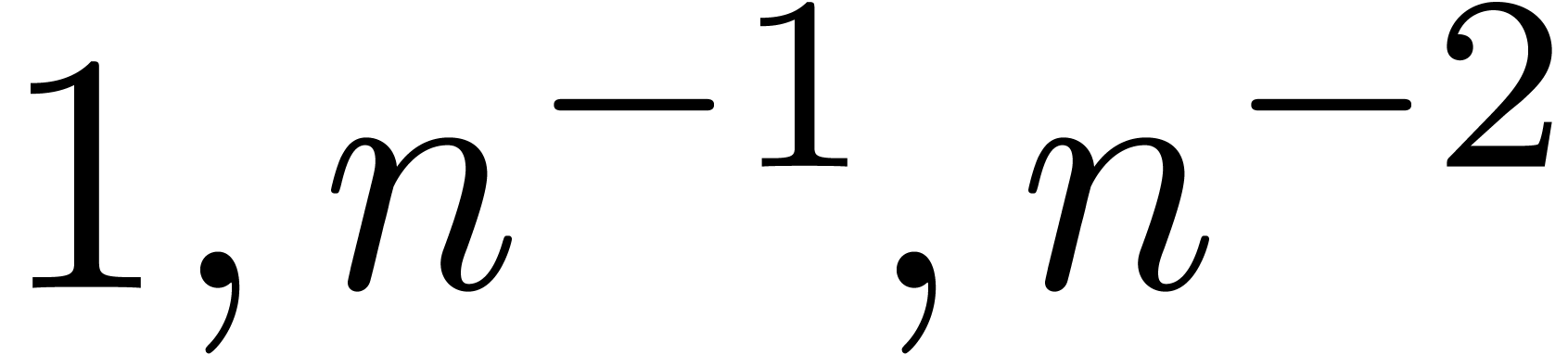
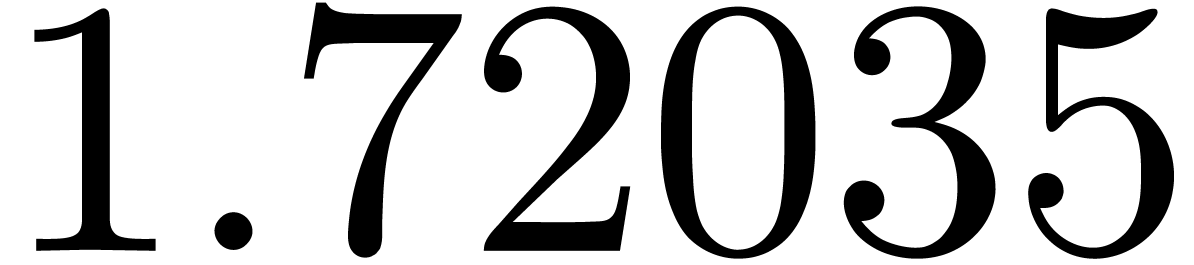


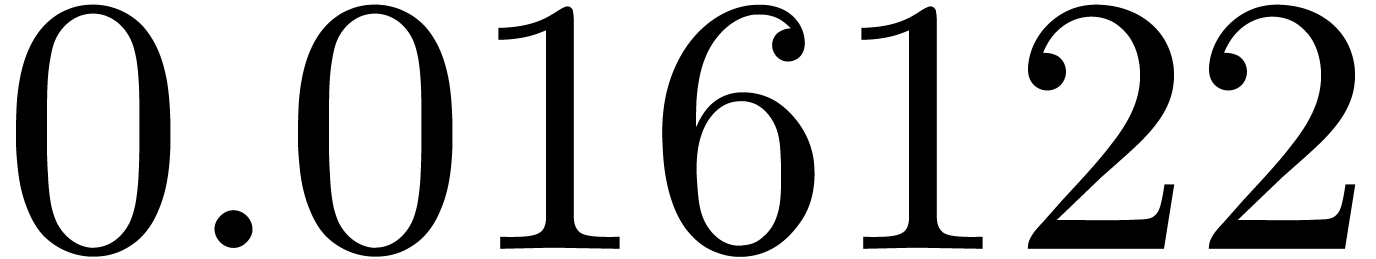
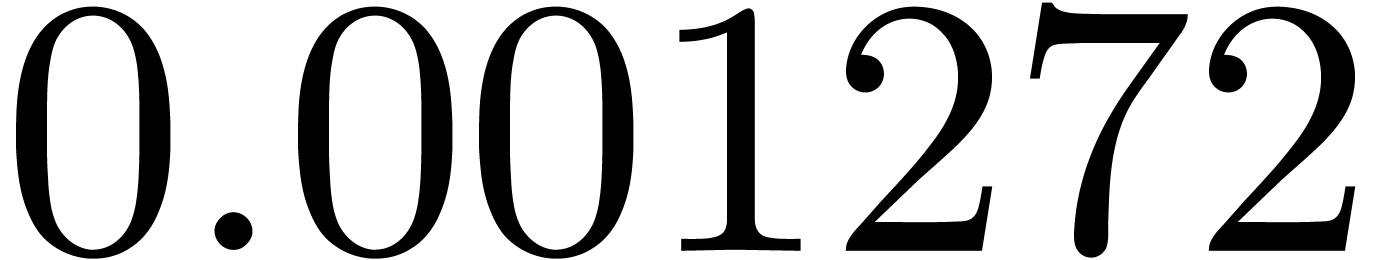
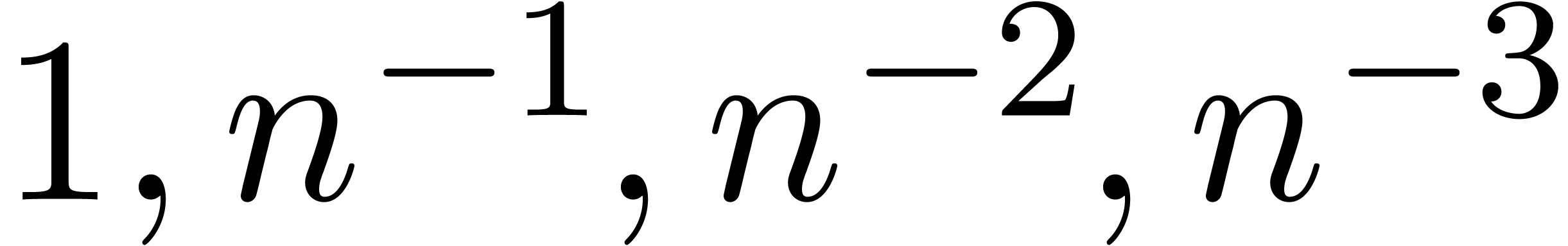

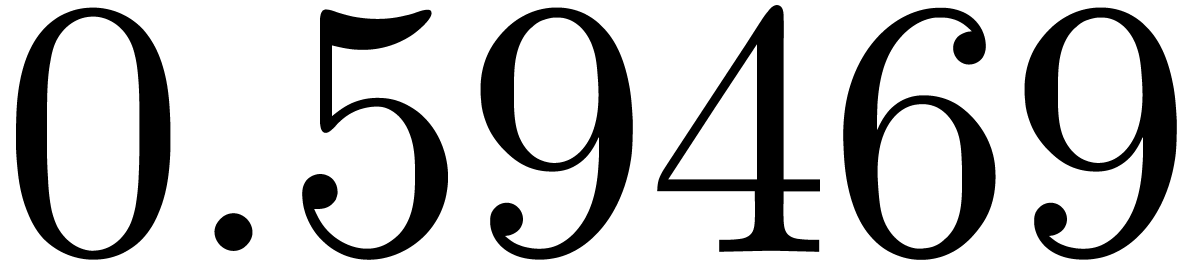
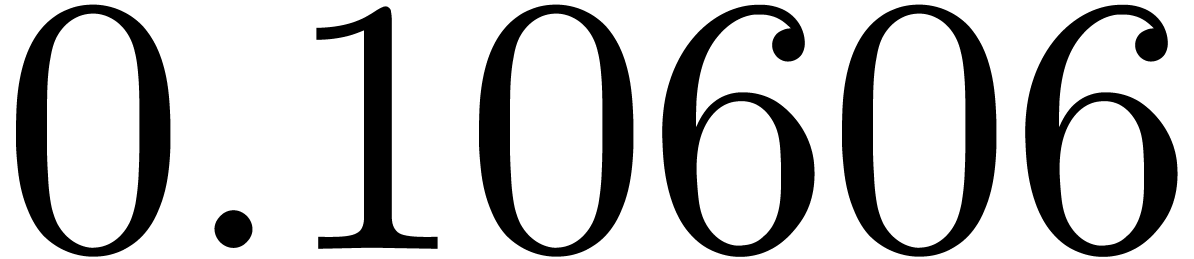
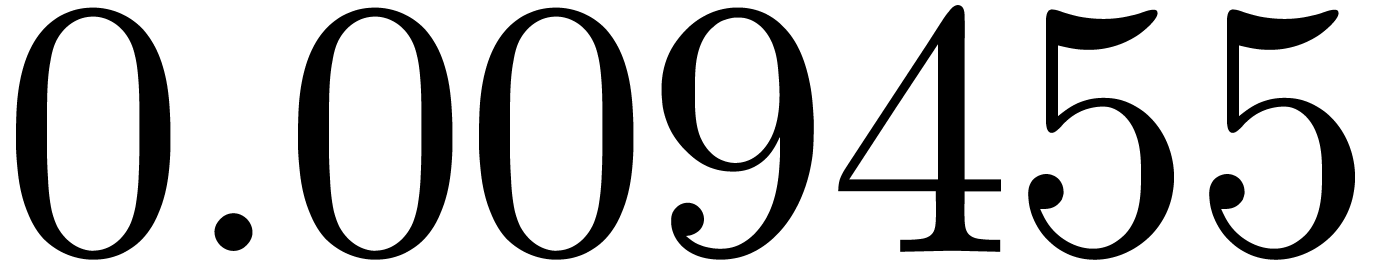
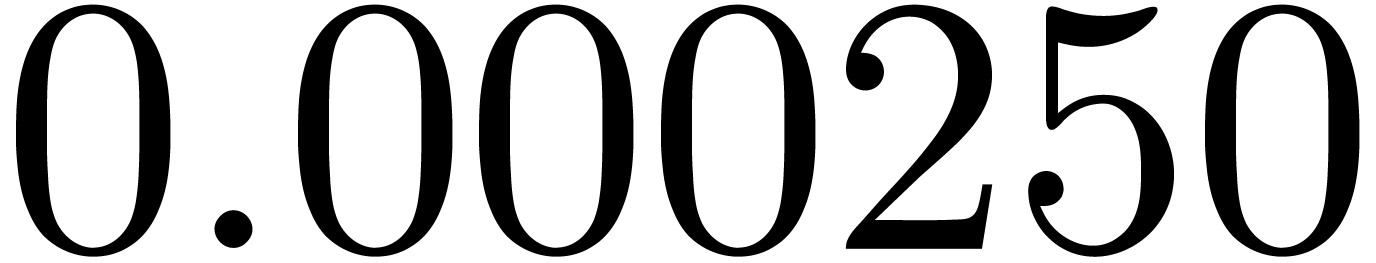
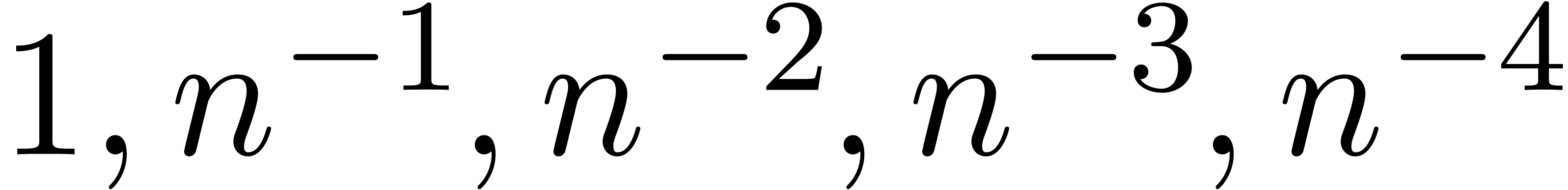
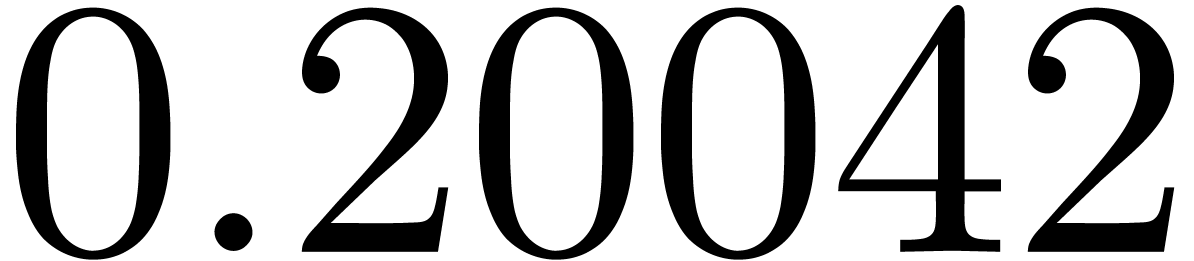
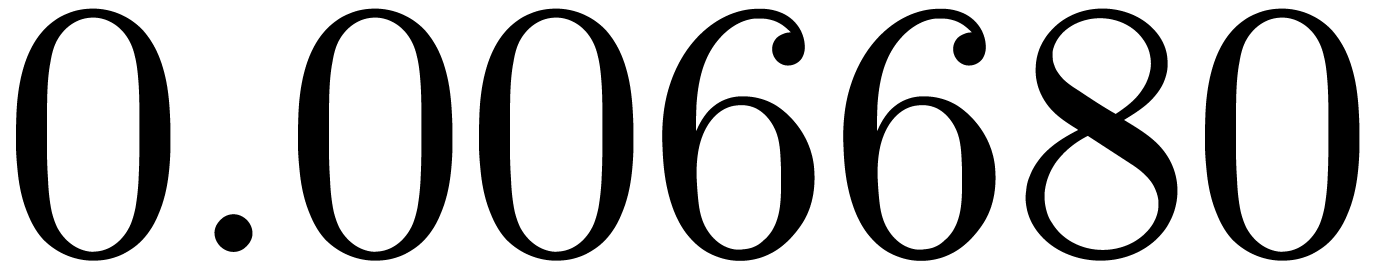
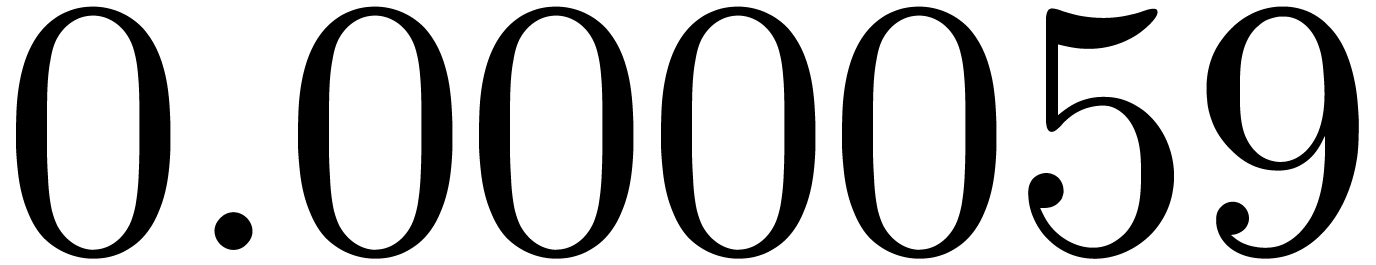


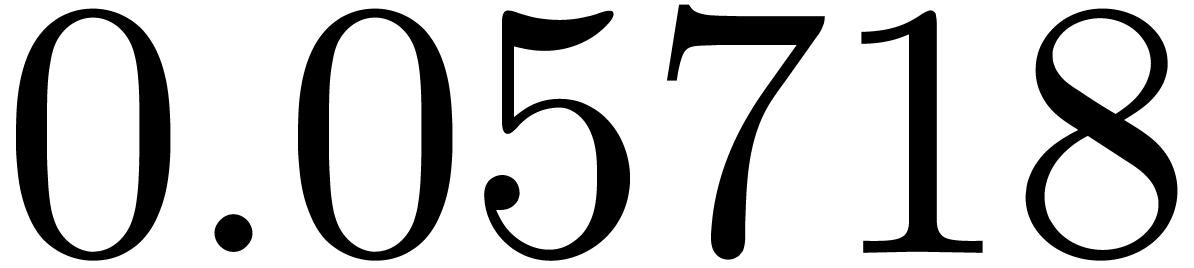
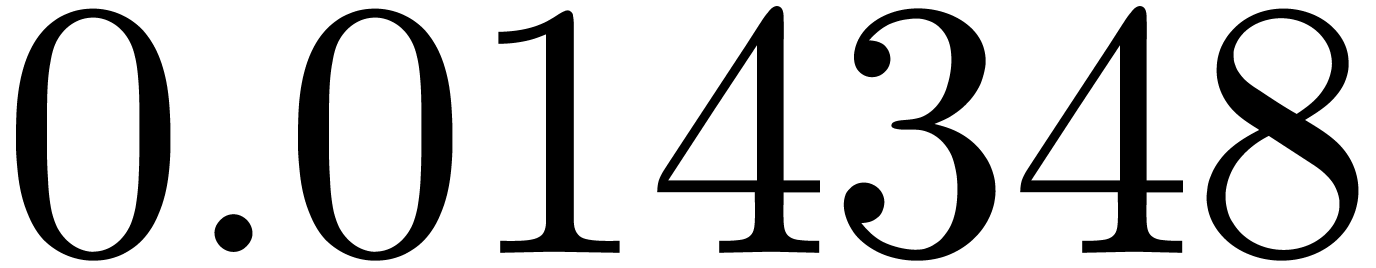
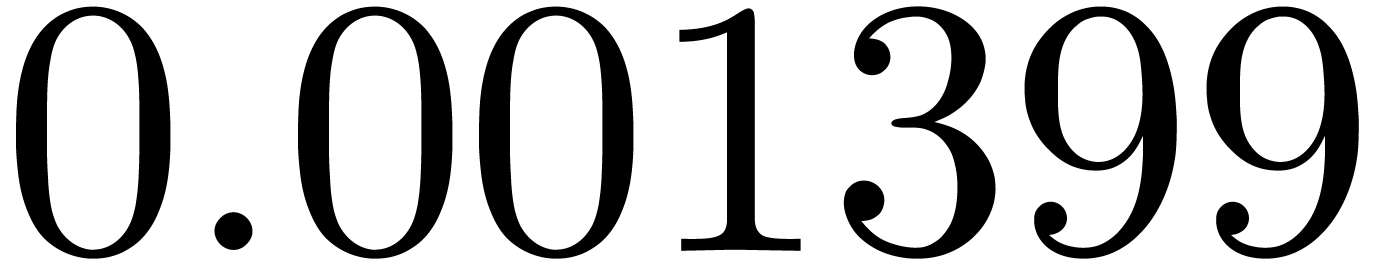
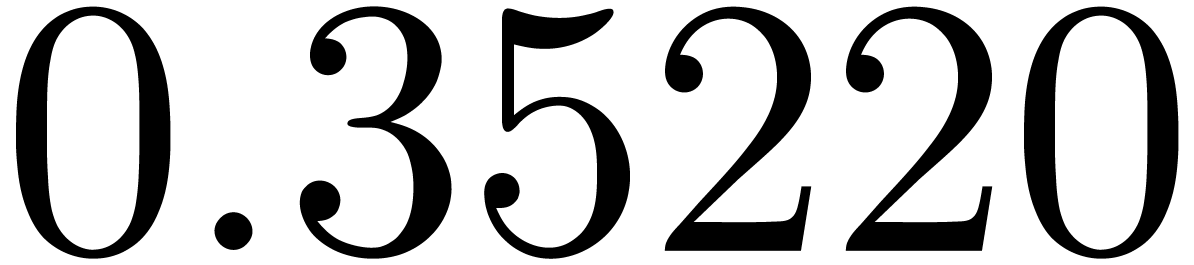

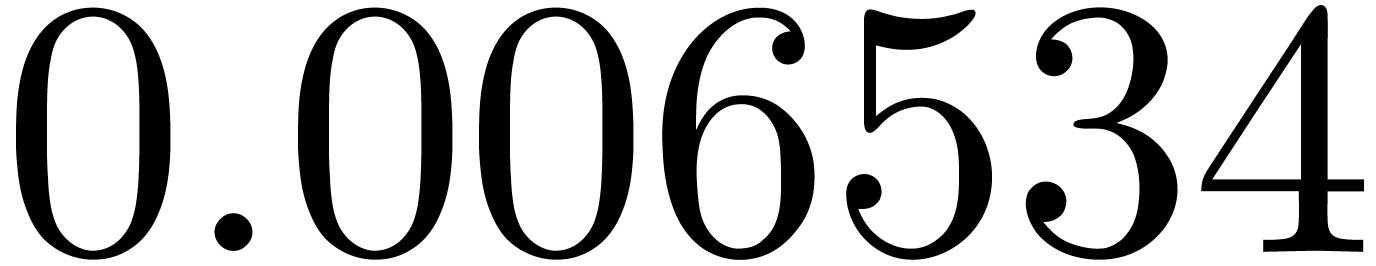
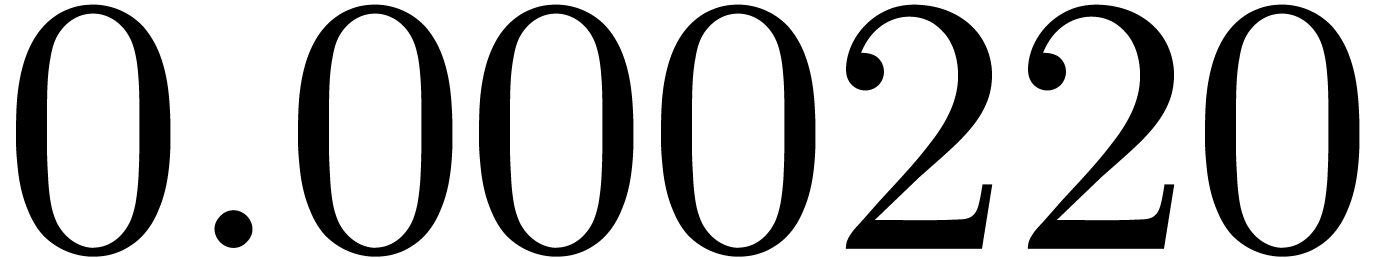
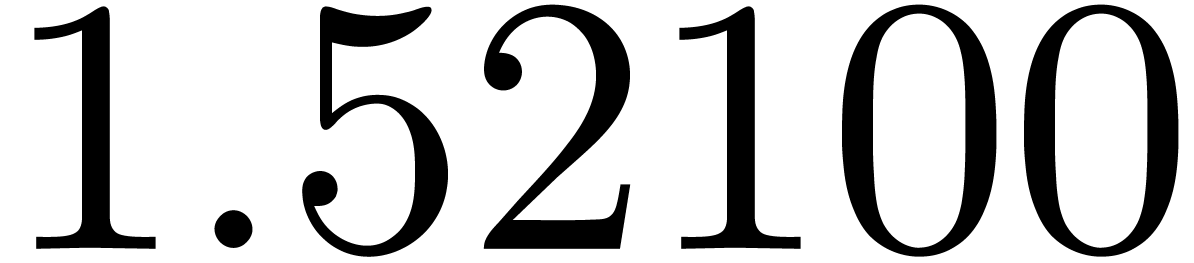


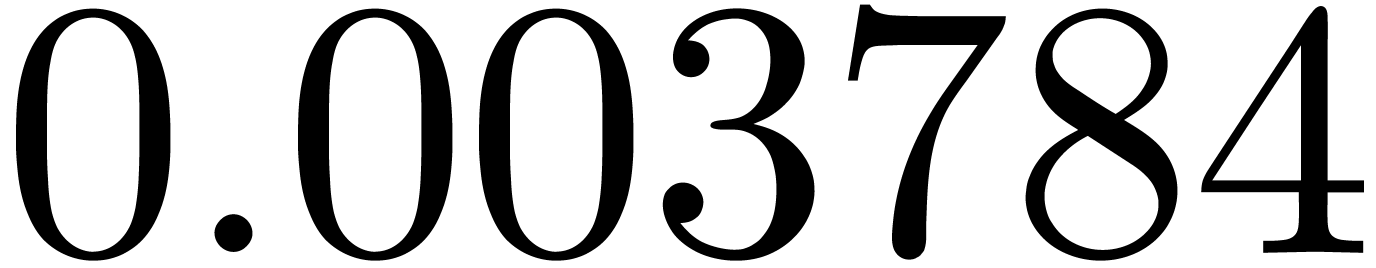
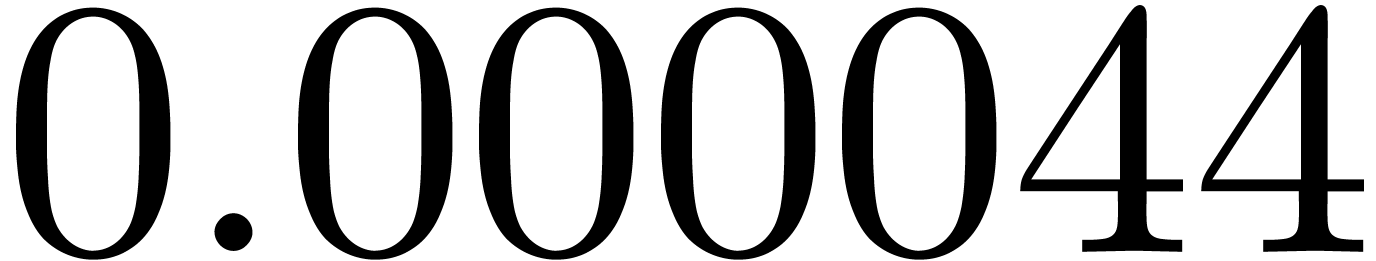
 of other given sequences
of other given sequences  on the range
on the range  ,
, .
.