The efficient multiplication of polynomials over the finite field
|
|
The efficient multiplication of polynomials over the finite field
|
Modern algorithms for fast polynomial multiplication are generally based
on evaluation-interpolation strategies and more particularly on
the discrete Fourier transform (DFT). Taking coefficients in the
finite field  with two elements, the problem of
multiplying in
with two elements, the problem of
multiplying in 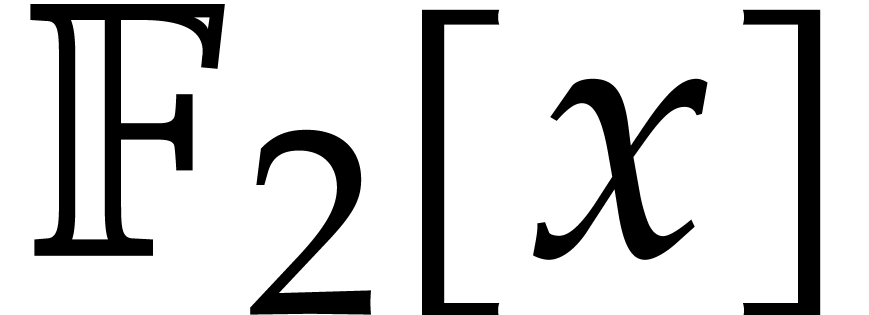 is also known as carryless
integer multiplication (assuming binary notation). The aim of this
paper is to present a practically efficient solution for large degrees.
is also known as carryless
integer multiplication (assuming binary notation). The aim of this
paper is to present a practically efficient solution for large degrees.
One major obstruction to evaluation-interpolation strategies over small finite fields is the potential lack of evaluation points. The customary remedy is to work in suitable extension fields. Remains the question of how to reduce the incurred overhead as much as possible.
More specifically, it was shown in [7] that multiplication
in can be done efficiently by reducing it to
polynomial multiplication over the Babylonian field 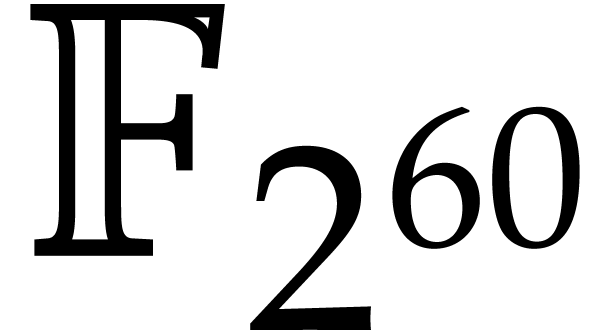 . Part of this reduction relied on
Kronecker segmentation, which involves an overhead of a factor two. In
this paper, we present a variant of a new algorithm from [11]
that removes this overhead almost entirely. We also report on our
. Part of this reduction relied on
Kronecker segmentation, which involves an overhead of a factor two. In
this paper, we present a variant of a new algorithm from [11]
that removes this overhead almost entirely. We also report on our
For a long time, the best known algorithm for carryless integer
multiplication was Schönhage's triadic variant [16] of
Schönhage–Strassen's algorithm [17] for integer
multiplication: it achieves a complexity 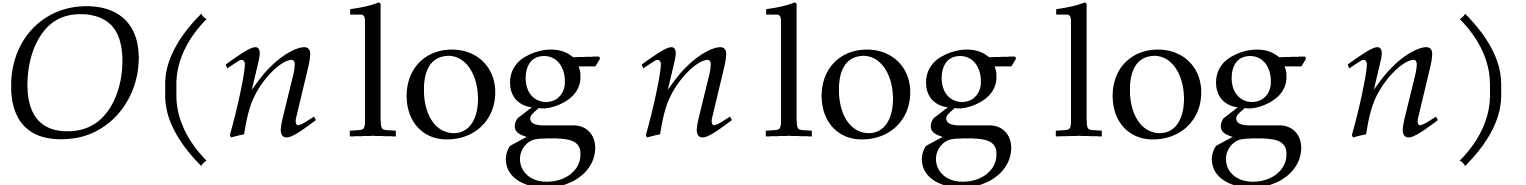 for the
multiplication of two polynomials of degree
for the
multiplication of two polynomials of degree  . Recently [8], Harvey, van der Hoeven
and Lecerf proved the sharper bound
. Recently [8], Harvey, van der Hoeven
and Lecerf proved the sharper bound 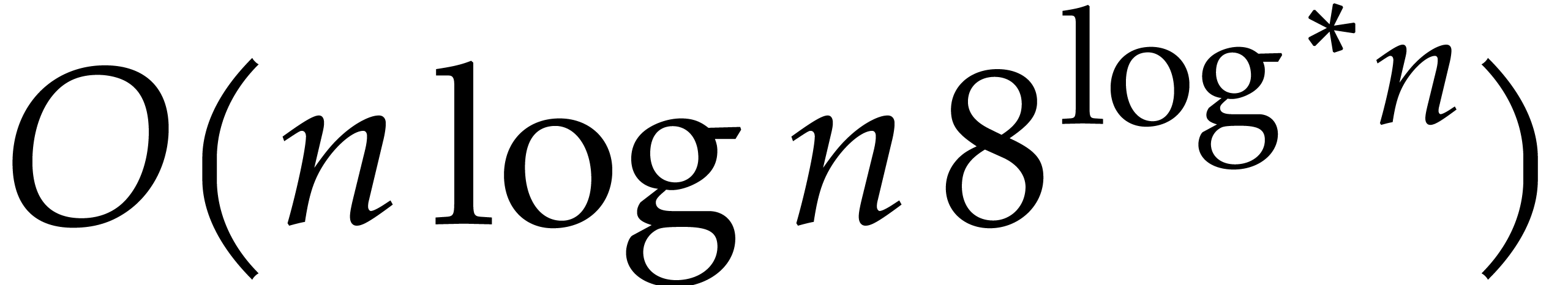 ,
but also showed that several of the new ideas could be used for faster
practical implementations [7].
,
but also showed that several of the new ideas could be used for faster
practical implementations [7].
More specifically, they showed how to reduce multiplication in to DFTs over ,
which can be computed efficiently due to the existence of many small
prime divisors of 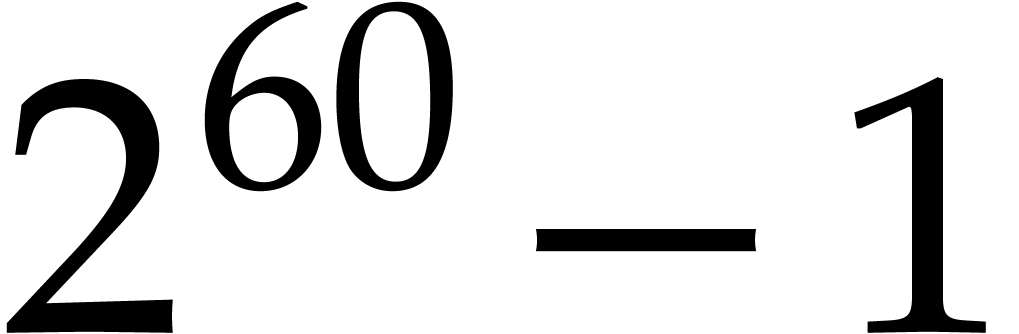 . Their
reduction relies on Kronecker segmentation: given two input
polynomials
. Their
reduction relies on Kronecker segmentation: given two input
polynomials 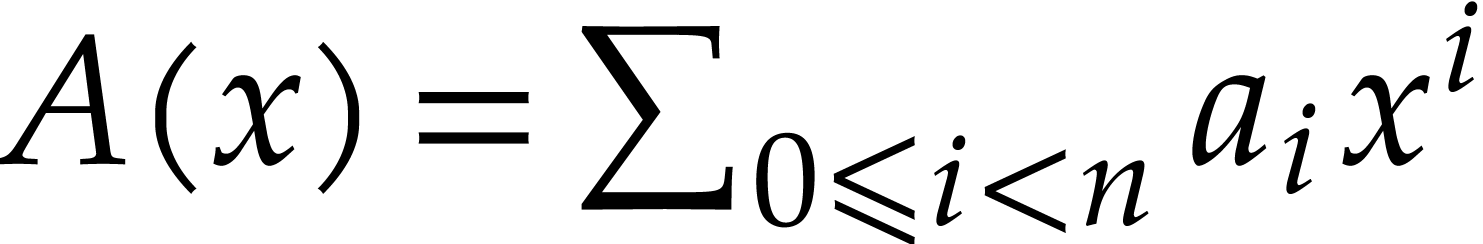 and
and 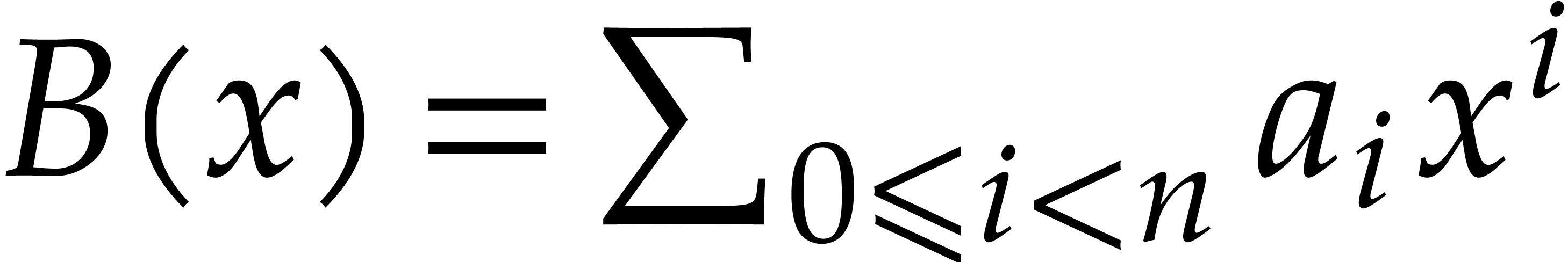 in , one cuts them into chunks of 30
bits and forms
in , one cuts them into chunks of 30
bits and forms 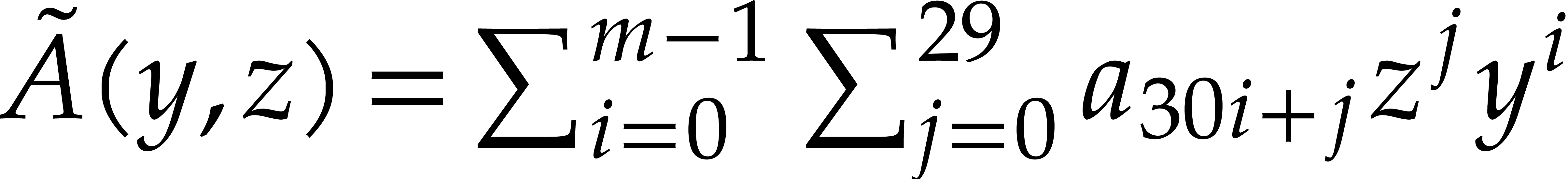 and
and 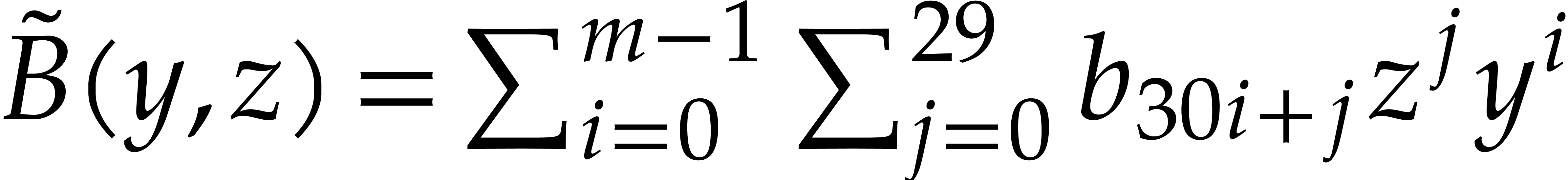 ,
where
,
where 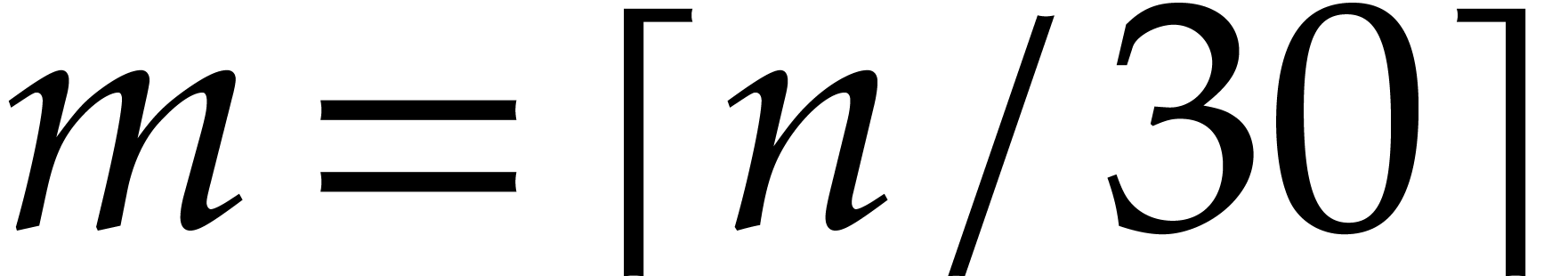 (the least integer
(the least integer 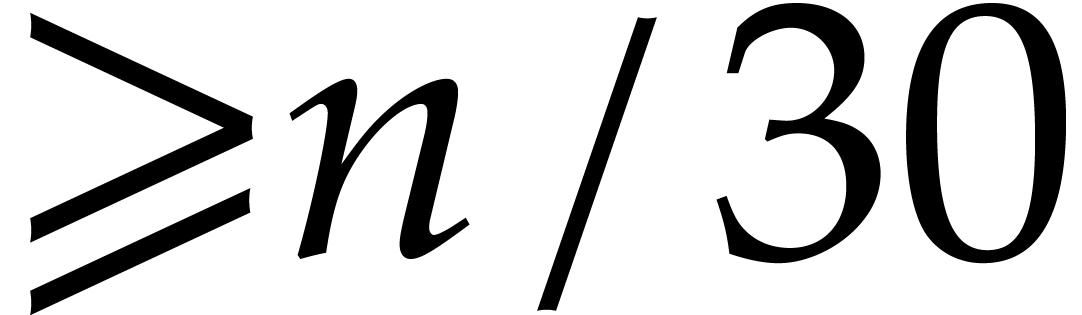 ). Hence
). Hence 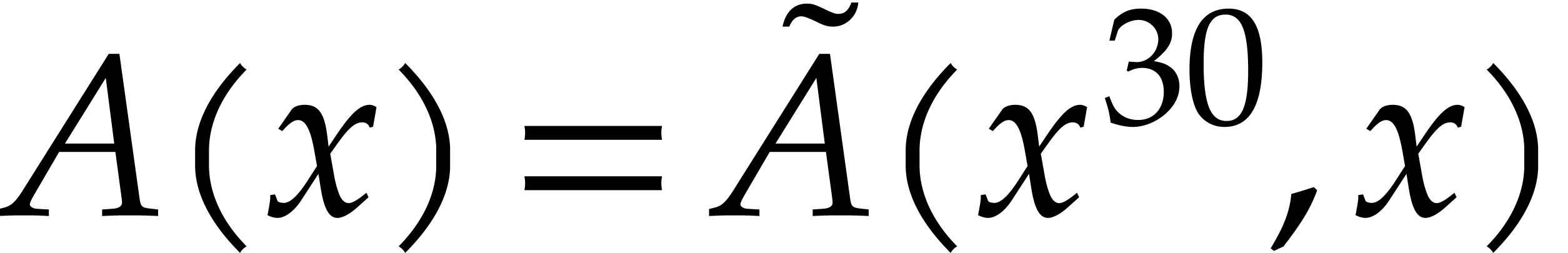 ,
,
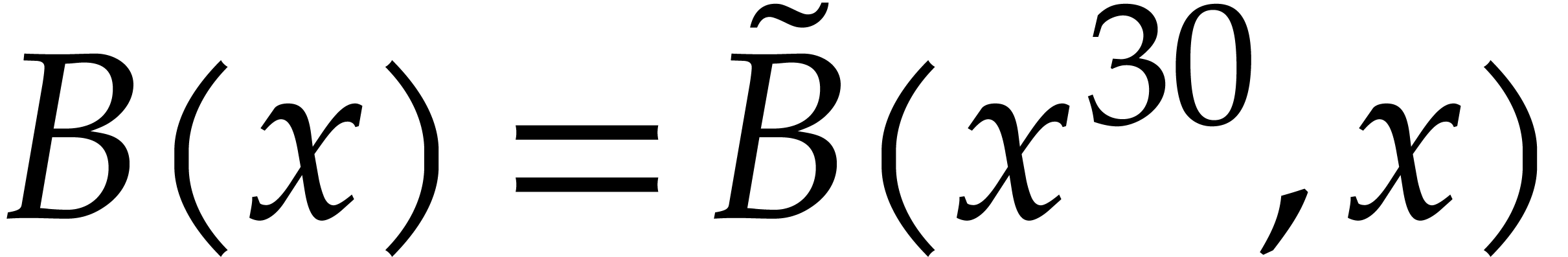 , and the product
, and the product  satisfies
satisfies 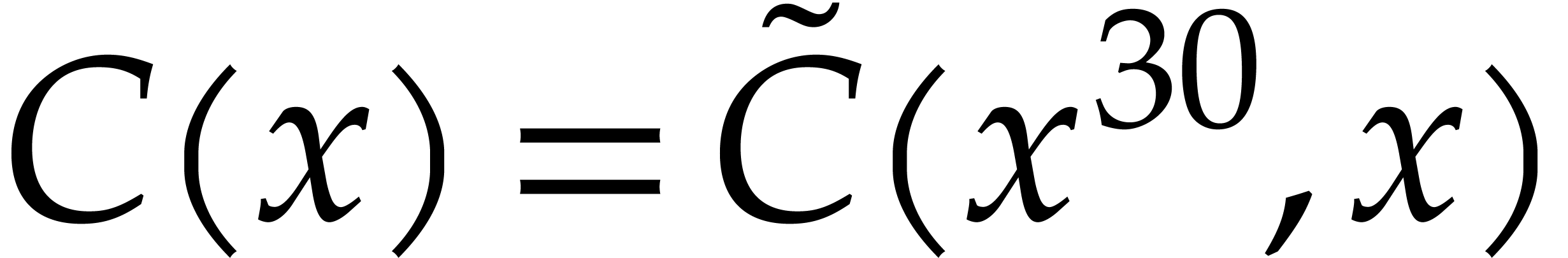 ,
where
,
where 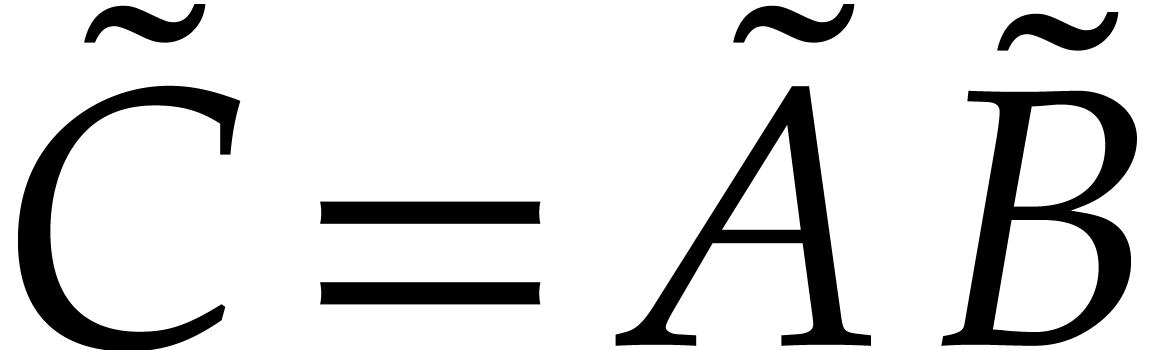 . Now
. Now  and
and  are multiplied in
are multiplied in 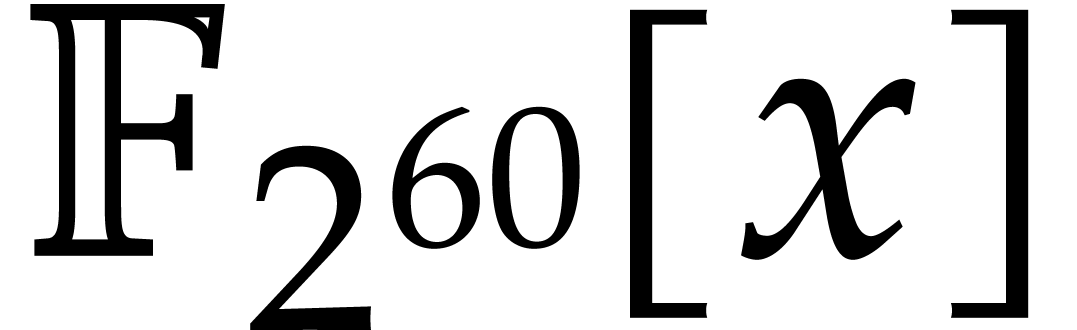 by
reinterpreting
by
reinterpreting  as the generator of . The recovery of
as the generator of . The recovery of  is
possible since its degree in is bounded by
is
possible since its degree in is bounded by 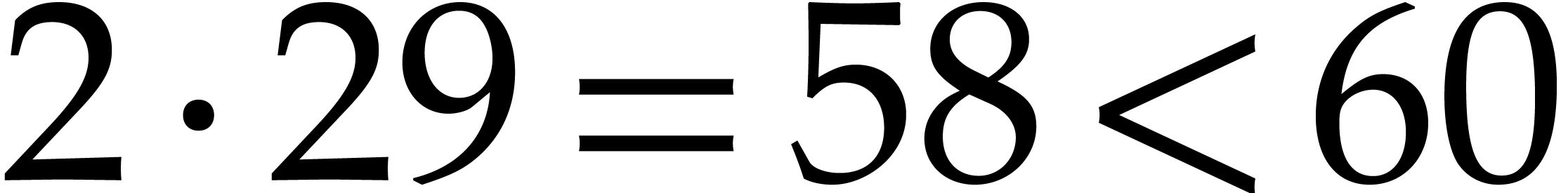 . However, in terms of input size,
half of
. However, in terms of input size,
half of 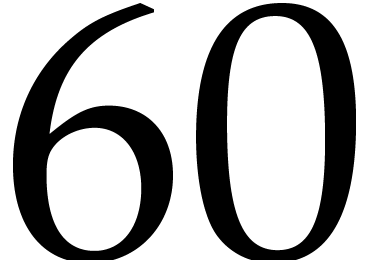 coefficients of
coefficients of  and
and 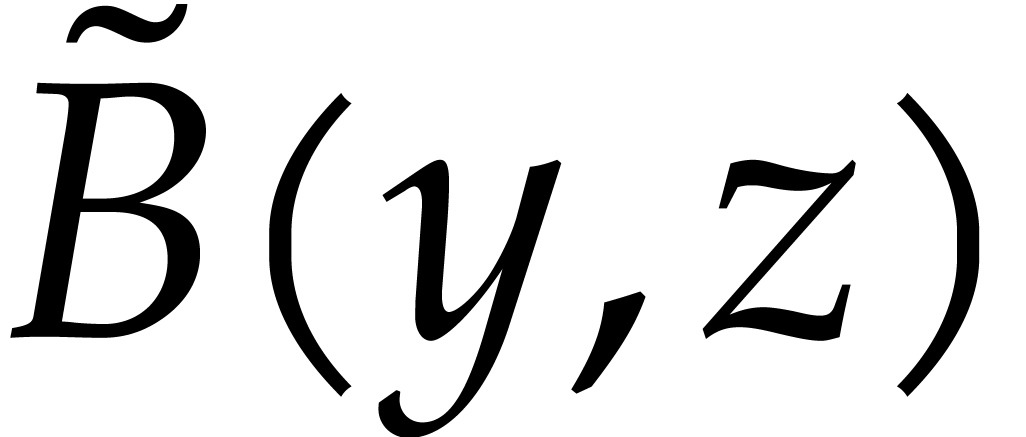 in are “left
blank”, when reinterpreted inside .
Consequently, this reduction method based on Kronecker segmentation
involves a constant overhead of roughly
in are “left
blank”, when reinterpreted inside .
Consequently, this reduction method based on Kronecker segmentation
involves a constant overhead of roughly 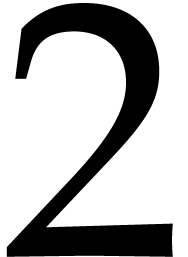 .
In fact, when considering algorithms with asymptotically softly linear
costs, comparing relative input sizes gives a rough approximation of the
relative costs.
.
In fact, when considering algorithms with asymptotically softly linear
costs, comparing relative input sizes gives a rough approximation of the
relative costs.
Recently van der Hoeven and Larrieu [11] have proposed a
new way to reduce multiplication of polynomials in 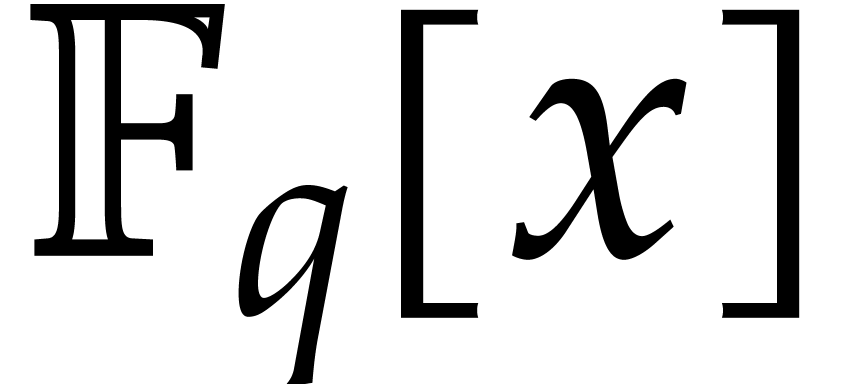 to the computation of DFTs over an extension
to the computation of DFTs over an extension 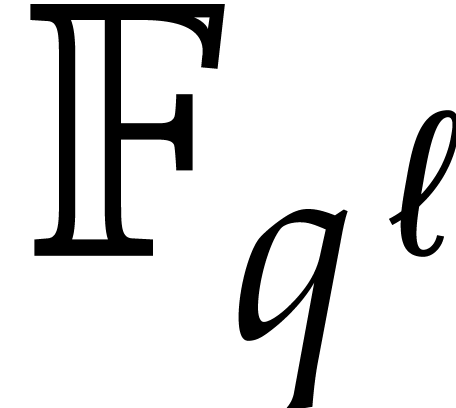 . Roughly speaking, they have shown that the DFT of
a polynomial in
. Roughly speaking, they have shown that the DFT of
a polynomial in 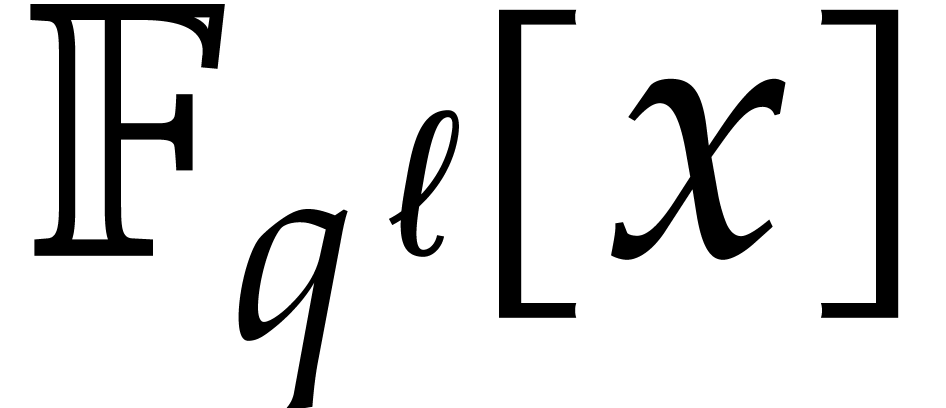 could be computed almost
could be computed almost 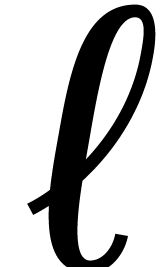 times faster if its coefficients happen to lie in the
subfield
times faster if its coefficients happen to lie in the
subfield 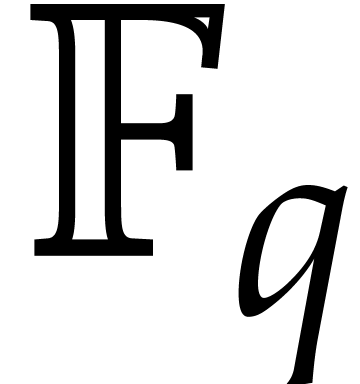 . Using their
algorithm, called the Frobenius FFT, it is theoretically
possible to avoid the overhead of Kronecker segmentation, and thereby to
gain a factor of two with respect to [7]. However,
application of the Frobenius FFT as described in [11]
involves computations in all intermediate fields
. Using their
algorithm, called the Frobenius FFT, it is theoretically
possible to avoid the overhead of Kronecker segmentation, and thereby to
gain a factor of two with respect to [7]. However,
application of the Frobenius FFT as described in [11]
involves computations in all intermediate fields 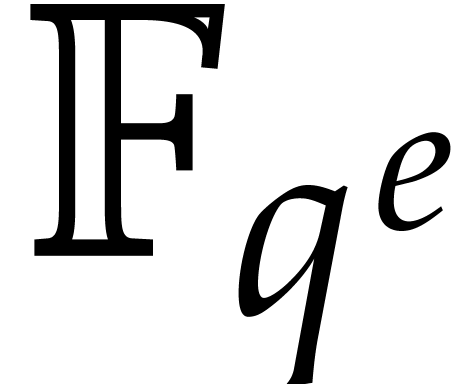 between and .
This makes the theoretical speed-up of two harder to achieve and
practical implementations more cumbersome.
between and .
This makes the theoretical speed-up of two harder to achieve and
practical implementations more cumbersome.
Besides Schönhage–Strassen type algorithms, let us mention
that other strategies such as the additive Fourier transform
have been developed for 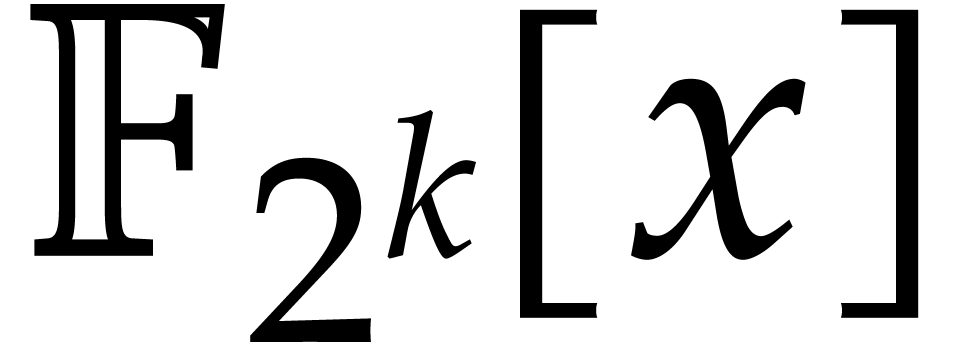 [4, 15]. A competitive implementation based on the latter
transform has been achieved very recently by Chen et al. [2]—notice
that their preprint [2] does not take into account our new
implementation. For more historical details on the complexity of
polynomial multiplication we refer the reader to the introductions of
[7, 8] and to the book by von zur Gathen and
Gerhard [5].
[4, 15]. A competitive implementation based on the latter
transform has been achieved very recently by Chen et al. [2]—notice
that their preprint [2] does not take into account our new
implementation. For more historical details on the complexity of
polynomial multiplication we refer the reader to the introductions of
[7, 8] and to the book by von zur Gathen and
Gerhard [5].
This paper contains two main results. In section 3, we
describe a variant of the Frobenius DFT for the special extension of
over .
Using a single rewriting step, this new algorithm reduces the
computation of a Frobenius DFT to the computation of an ordinary DFT
over , thereby avoiding
computations in any intermediate fields 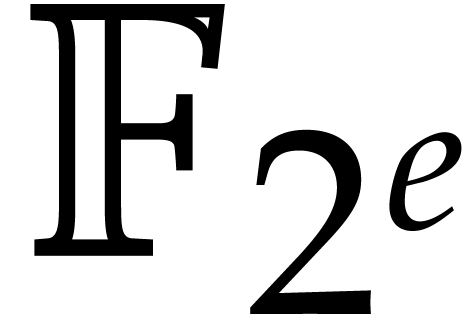 with
with
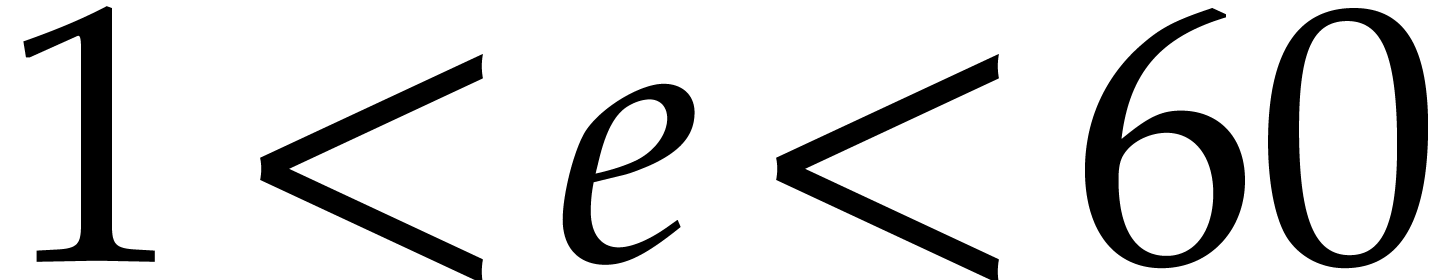 and
and 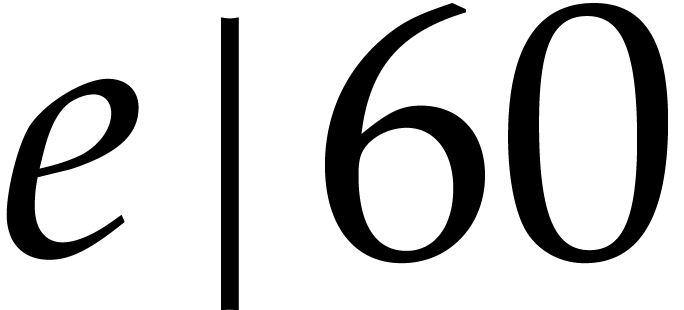 .
.
Our second main result is a practical implementation of the new
algorithm and our ability to indeed gain a factor that approaches two
with respect to our previous work. We underline that in both cases, DFTs
over represent the bulk of the computation, but
the lengths of the DFTs are halved for the new algorithm. In particular,
the observed acceleration is due to our new algorithm and not the result
of ad hoc code tuning or hardware specific optimizations.
In section 4, we present some of the low level
implementation details concerning the new rewriting step. Our timings
are presented in section 5. Our implementation outperforms
the reference library .
We also outperform the recent implementation by Chen et al. [2].
Finally, the evaluation-interpolation strategy used by our algorithm is
particularly well suited for multiplying matrices of polynomials over
, as reported in section 5.
Let 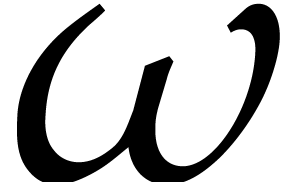 be a primitive root of unity of order in . The
discrete Fourier transform (DFT) of an -tuple
be a primitive root of unity of order in . The
discrete Fourier transform (DFT) of an -tuple 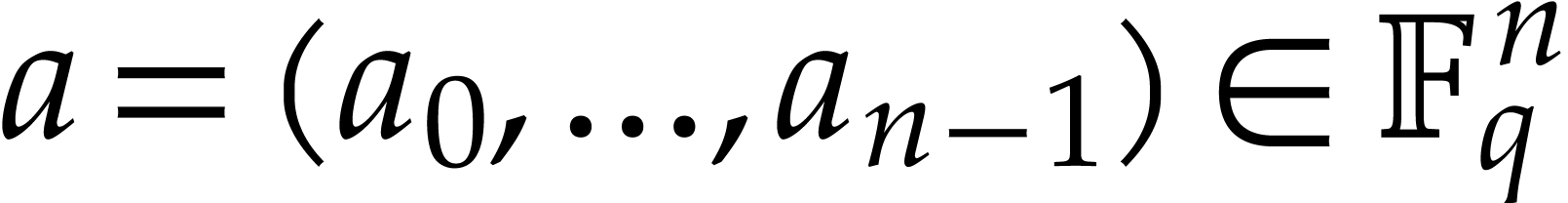 with respect to is
with respect to is 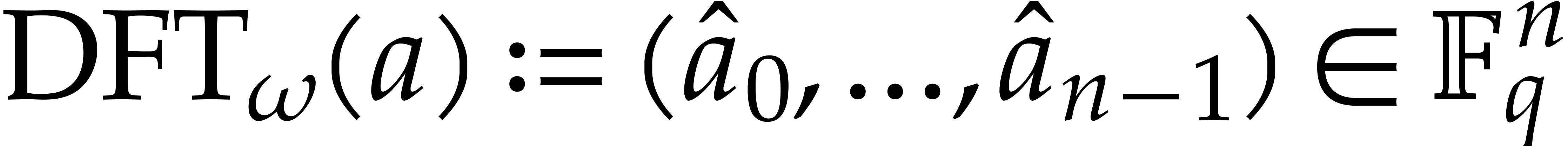 , where
, where
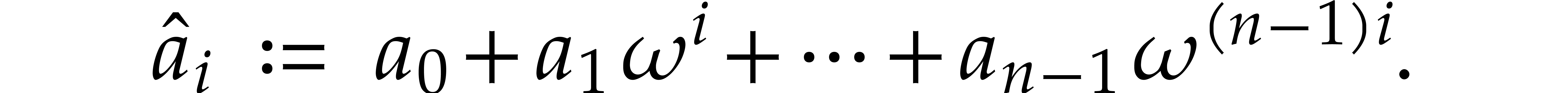
Hence 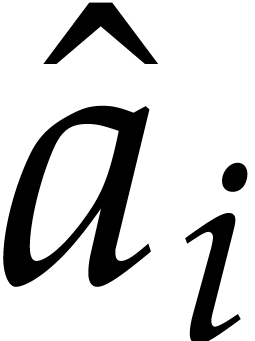 is the evaluation of the polynomial
is the evaluation of the polynomial 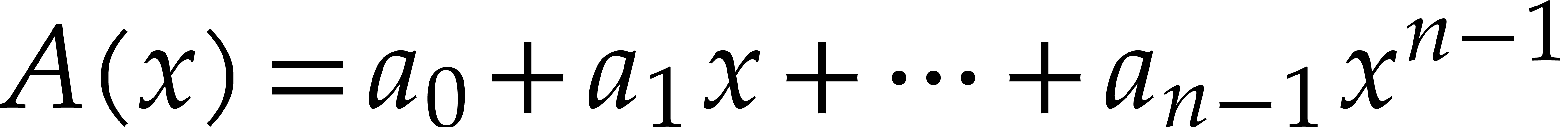 at
at 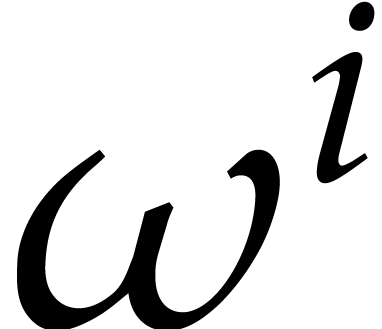 . For
simplicity we often identify
. For
simplicity we often identify  with
with  and we simply write
and we simply write 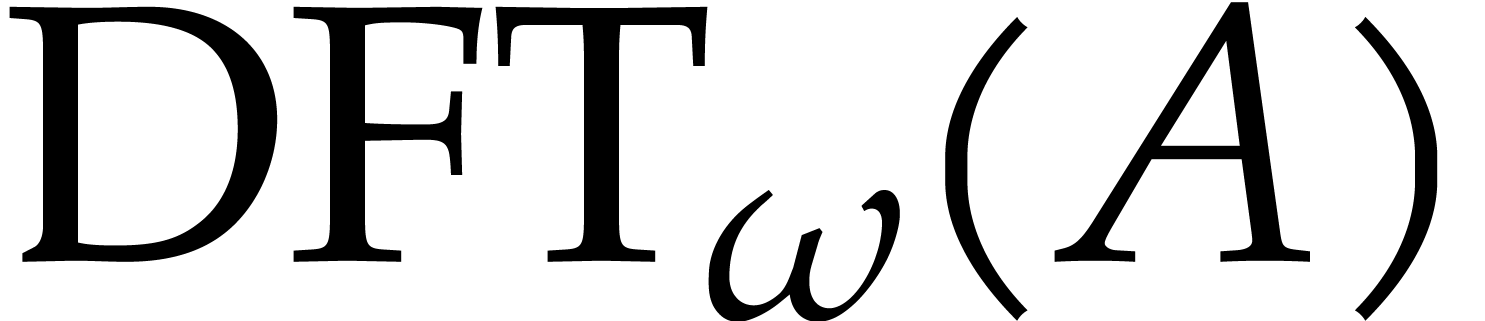 .
The inverse transform is related to the direct transform via
.
The inverse transform is related to the direct transform via 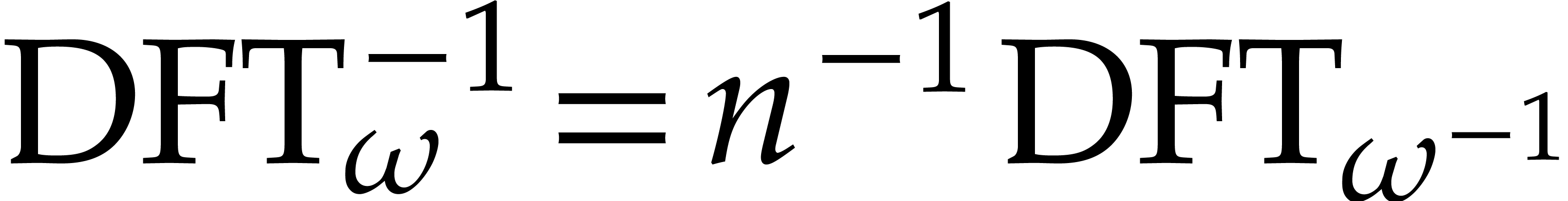 , which follows from the well known
formula
, which follows from the well known
formula
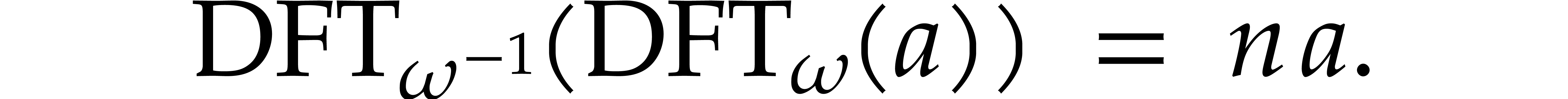
If properly factors as 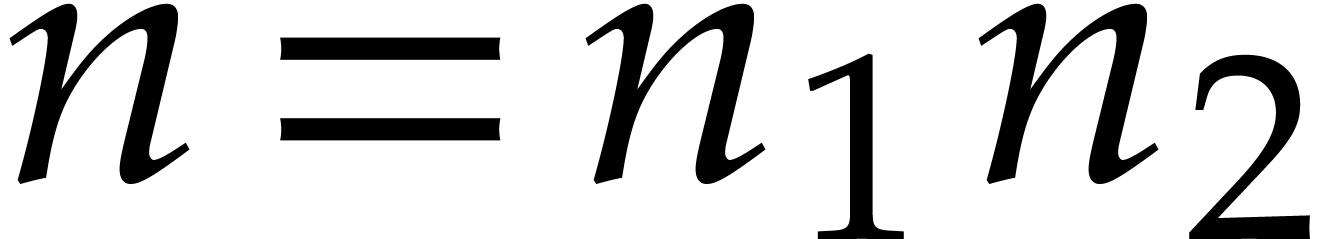 , then
, then 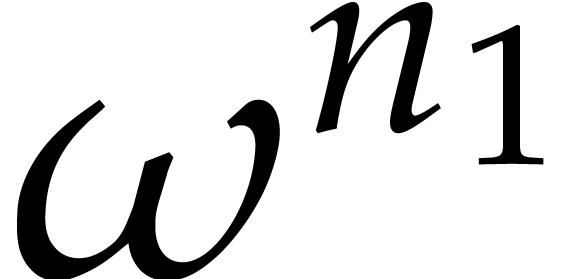 is an
is an 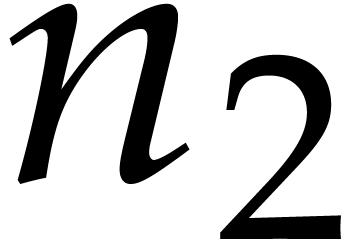 -th primitive root of unity and
-th primitive root of unity and 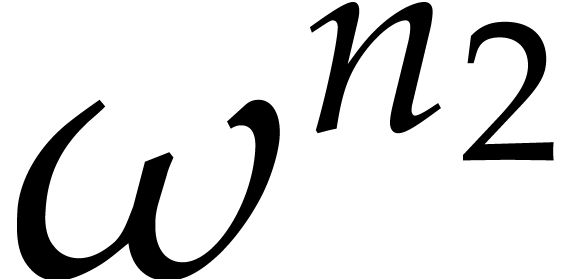 is an
is an 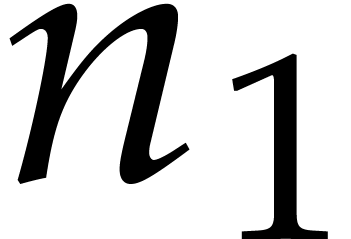 -th
primitive root of unity. Moreover, for any
-th
primitive root of unity. Moreover, for any  and
and
 , we have
, we have
If 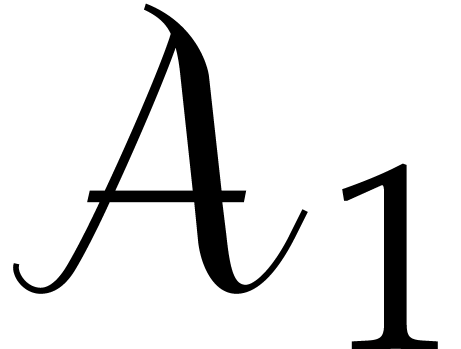 and
and 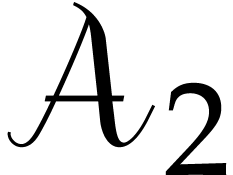 are algorithms
for computing DFTs of length and , we may use
as follows. For each
are algorithms
for computing DFTs of length and , we may use
as follows. For each  , the
sum inside the brackets corresponds to the
, the
sum inside the brackets corresponds to the 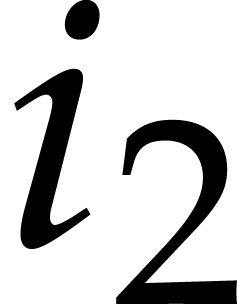 -th
coefficient of a DFT of the -tuple
-th
coefficient of a DFT of the -tuple
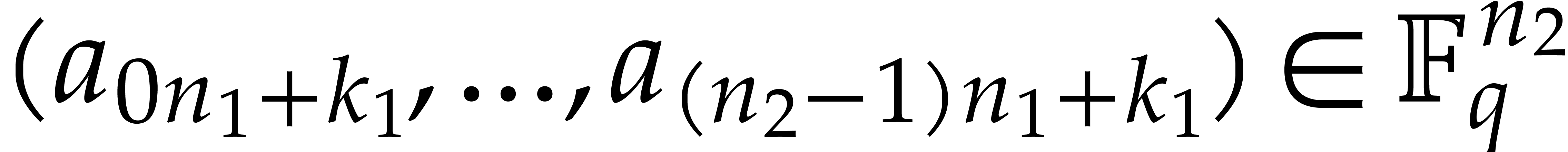 with respect to .
Evaluating these inner DFTs requires
calls to . Next, we multiply
by the twiddle factors
with respect to .
Evaluating these inner DFTs requires
calls to . Next, we multiply
by the twiddle factors 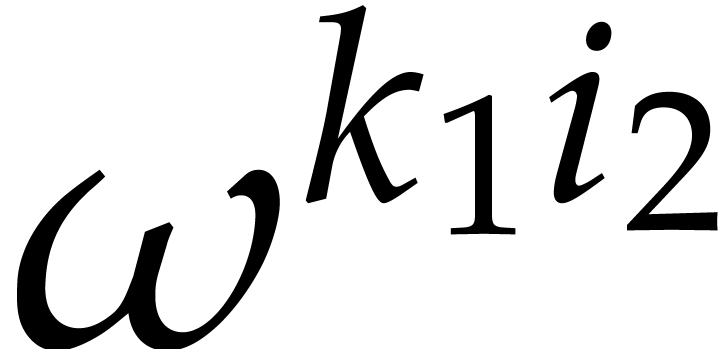 ,
at a cost of operations in . Finally, for each , the outer sum corresponds to the
,
at a cost of operations in . Finally, for each , the outer sum corresponds to the  -th coefficient of a DFT of an -tuple in
-th coefficient of a DFT of an -tuple in 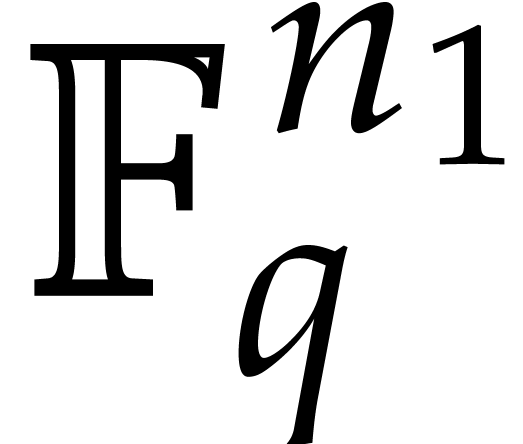 with respect
to . These outer DFTs
require calls to .
Iterating this decomposition for further factorizations of and yields the seminal
Cooley–Tukey algorithm [3].
with respect
to . These outer DFTs
require calls to .
Iterating this decomposition for further factorizations of and yields the seminal
Cooley–Tukey algorithm [3].
Let be a polynomial in
and let be a primitive root of unity in some
extension of .
We write 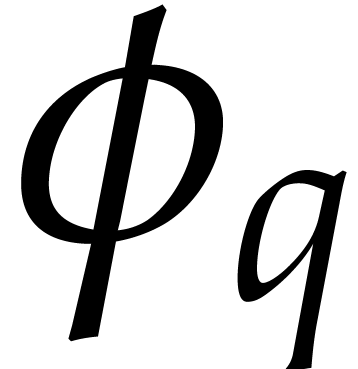 for the Frobenius map
for the Frobenius map  in and notice that
in and notice that
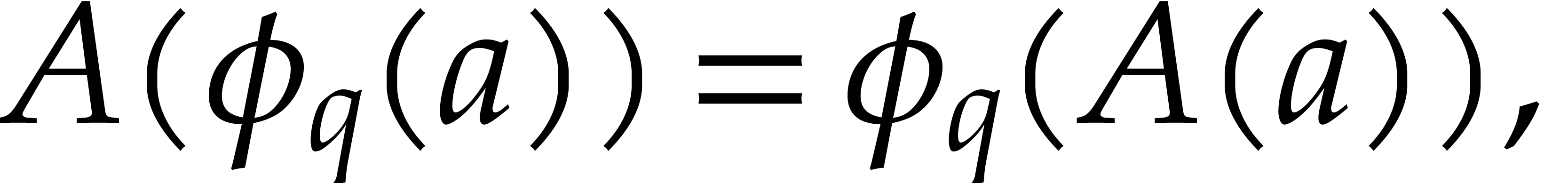 |
(2) |
for any 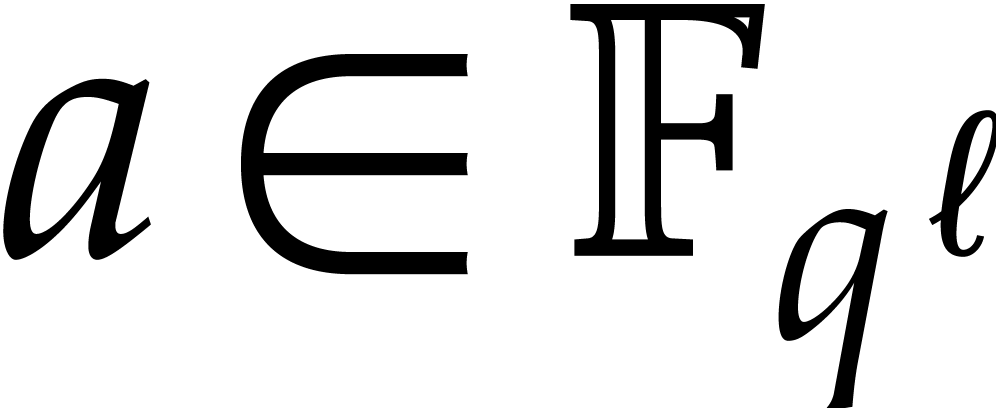 . This formula
implies many nontrivial relations for the DFT of : if
. This formula
implies many nontrivial relations for the DFT of : if 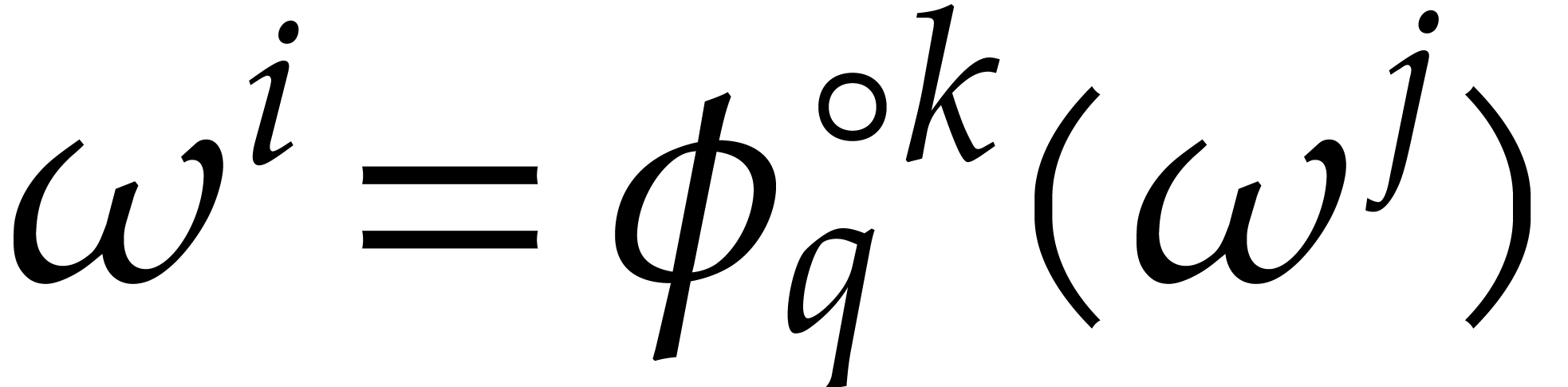 ,
then we have
,
then we have 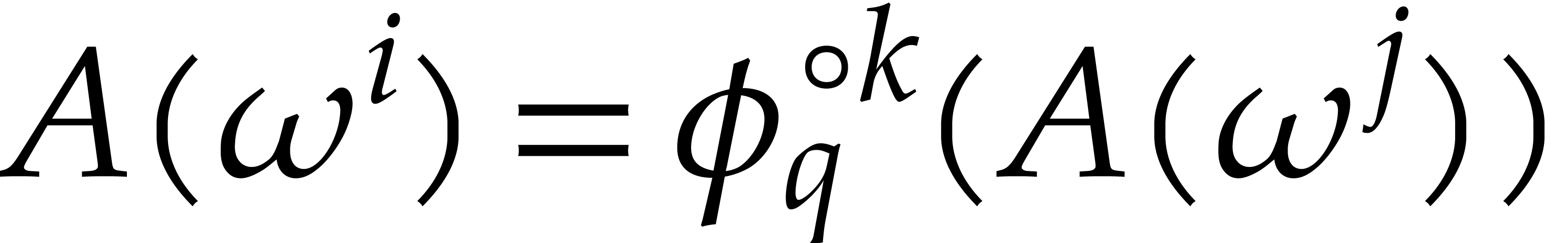 . In other
words, some values of the DFT of can be deduced
from others, and the advantage of the Frobenius transform introduced in
[11] is to restrict the bulk of the evaluations to a
minimum number of points.
. In other
words, some values of the DFT of can be deduced
from others, and the advantage of the Frobenius transform introduced in
[11] is to restrict the bulk of the evaluations to a
minimum number of points.
Let denote the order of the root , and consider the set 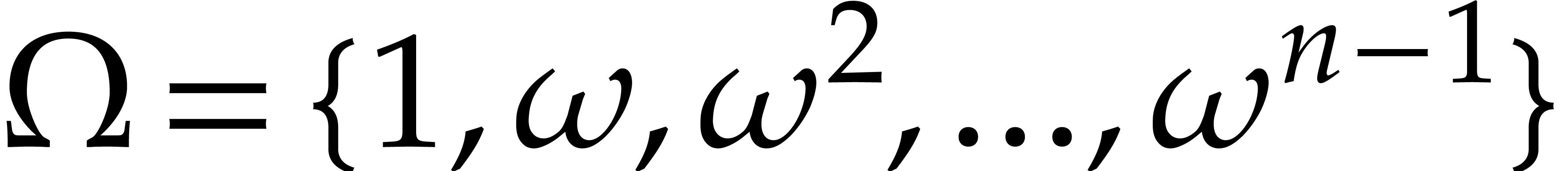 . This set is clearly globally stable under , so the group
. This set is clearly globally stable under , so the group 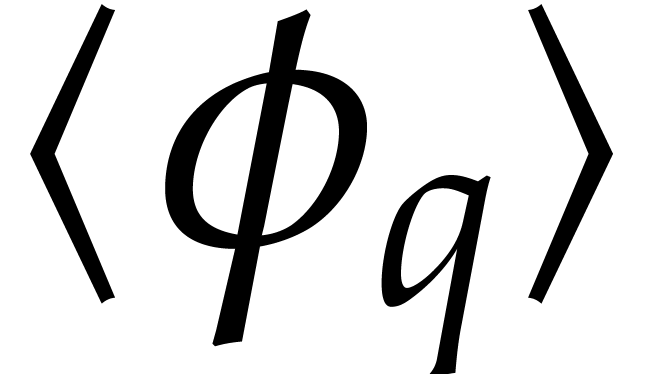 generated by acts naturally on it. This action
partitions
generated by acts naturally on it. This action
partitions  into disjoint orbits. Assume that we
have a section
into disjoint orbits. Assume that we
have a section 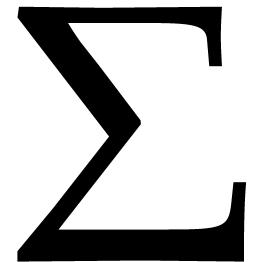 of that
contains exactly one element in each orbit. Then formula (2)
allows us to recover from the evaluations of
at each of the points in . The vector
of that
contains exactly one element in each orbit. Then formula (2)
allows us to recover from the evaluations of
at each of the points in . The vector 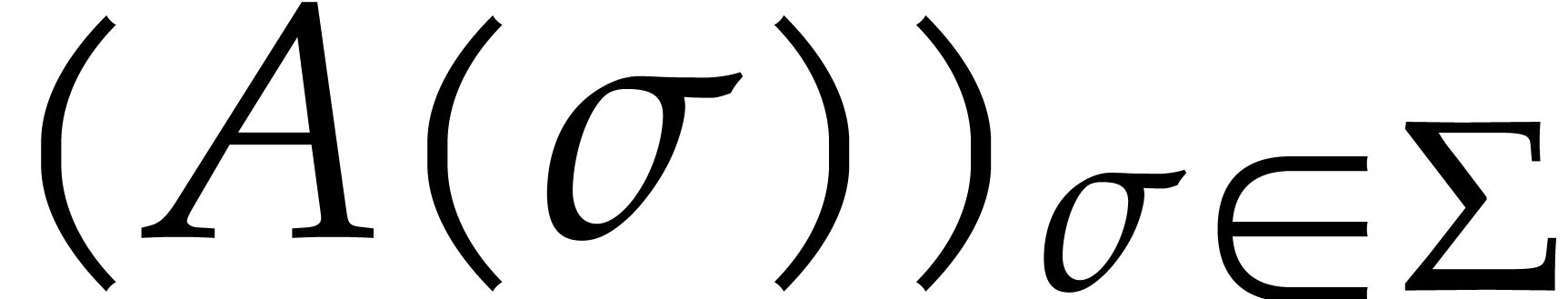 is called the
Frobenius DFT of .
is called the
Frobenius DFT of .
to
To efficiently reduce a multiplication in into
DFTs over , we use an order
that divides and such
that  for some integer
for some integer 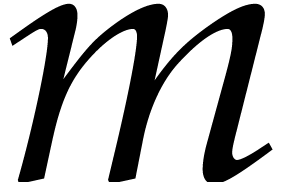 . We perform the decomposition
. We perform the decomposition 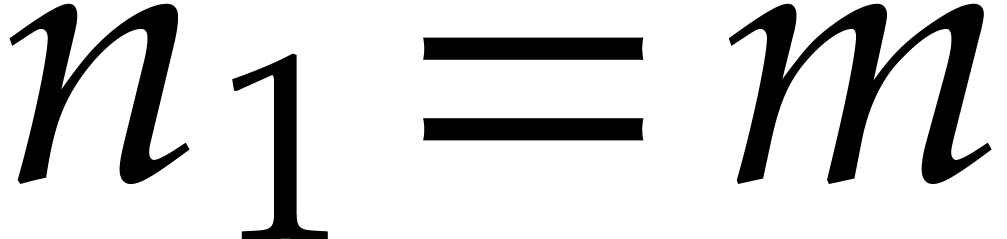 and
and 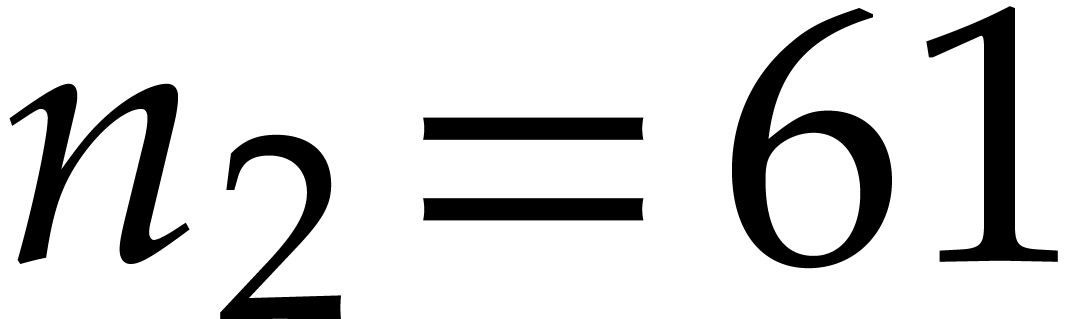 . Let be a primitive
-th root of unity in . The discrete Fourier transform of
. Let be a primitive
-th root of unity in . The discrete Fourier transform of
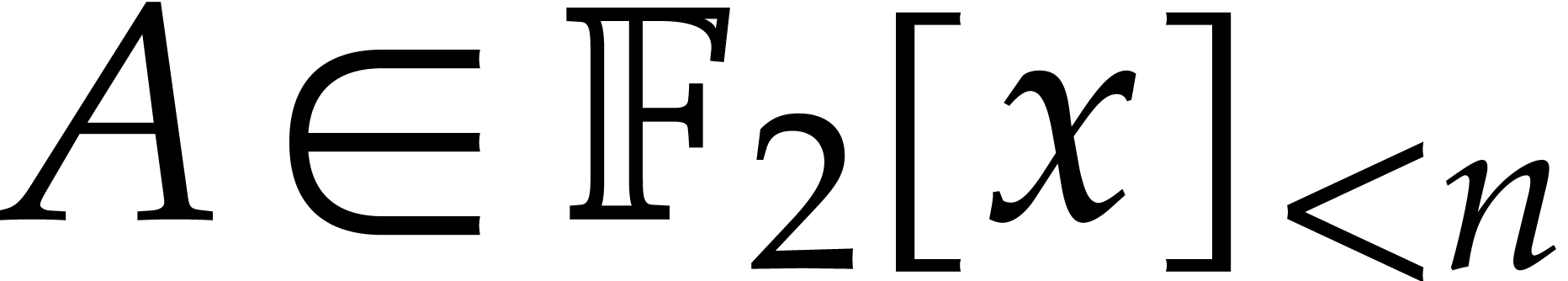 , given by
, given by 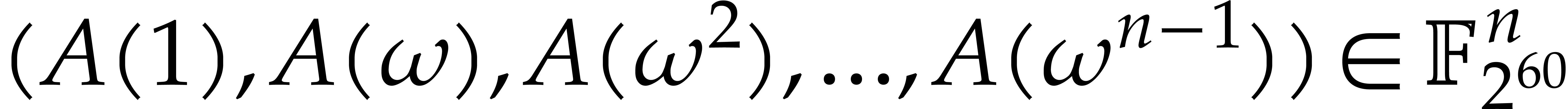 , can be reorganized into
, can be reorganized into 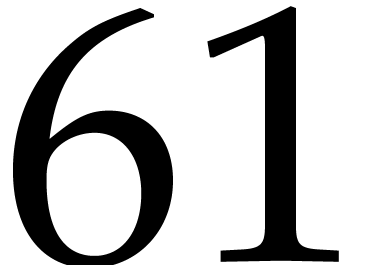 slices as follows
slices as follows
The variant of the Frobenius DFT of that we
introduce in the present paper corresponds to computing only the second
slice:
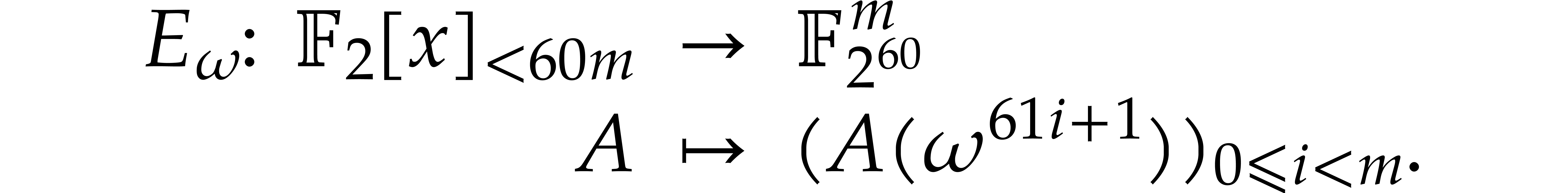
Let us show that this transform is actually a bijection. The following
lemma shows that the slices 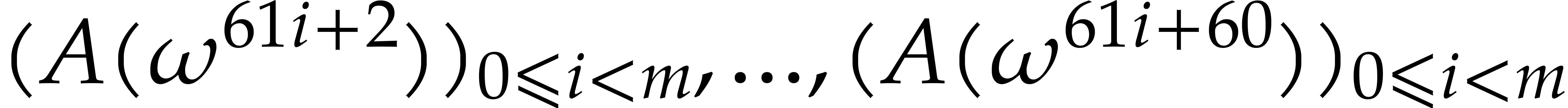 can be deduced from
the second slice
can be deduced from
the second slice 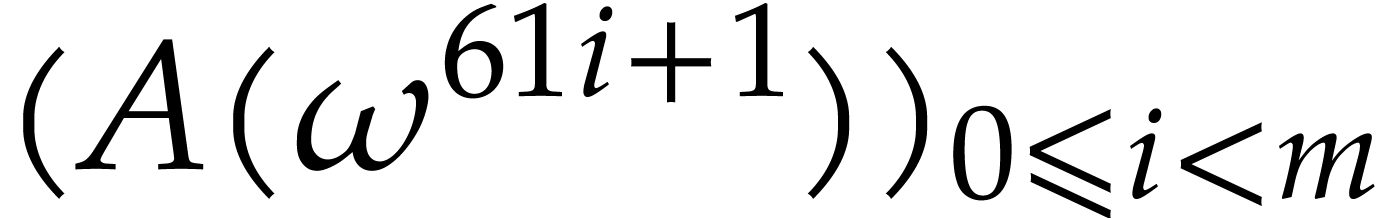 using the action of the
Frobenius map
using the action of the
Frobenius map 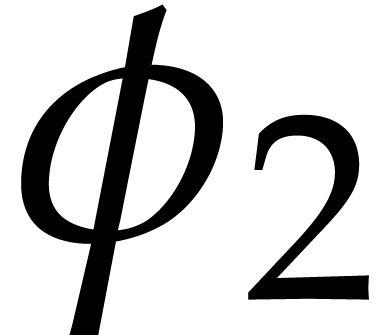 .
.
Proof. Let 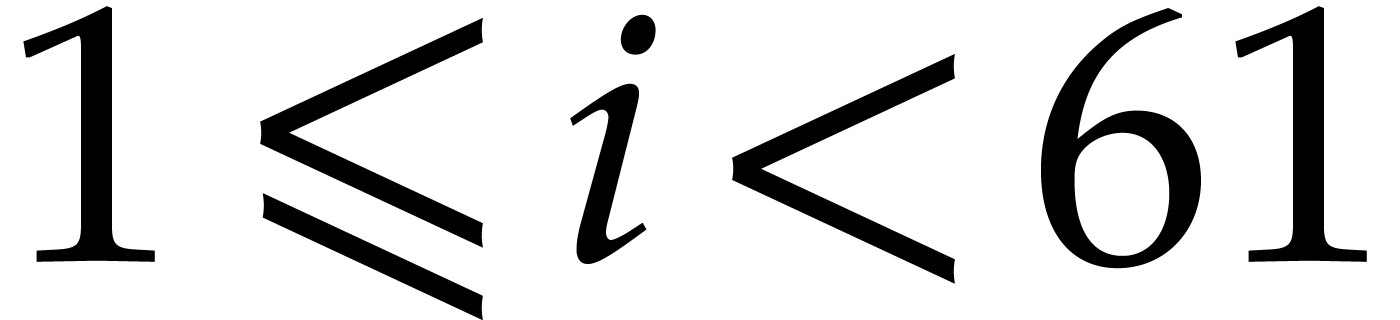 and
and 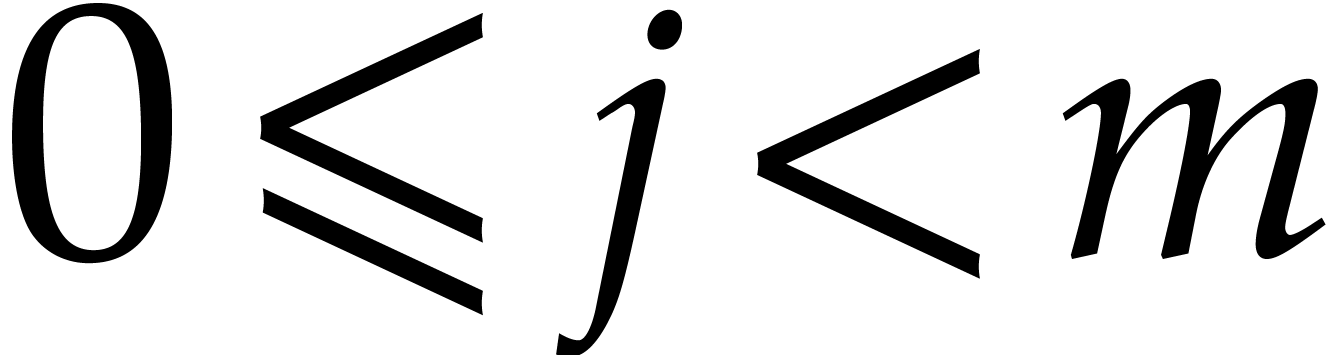 , we have
, we have 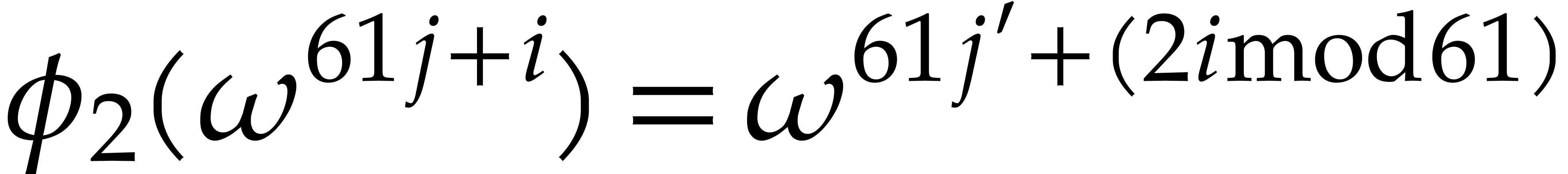 for some integer
for some integer 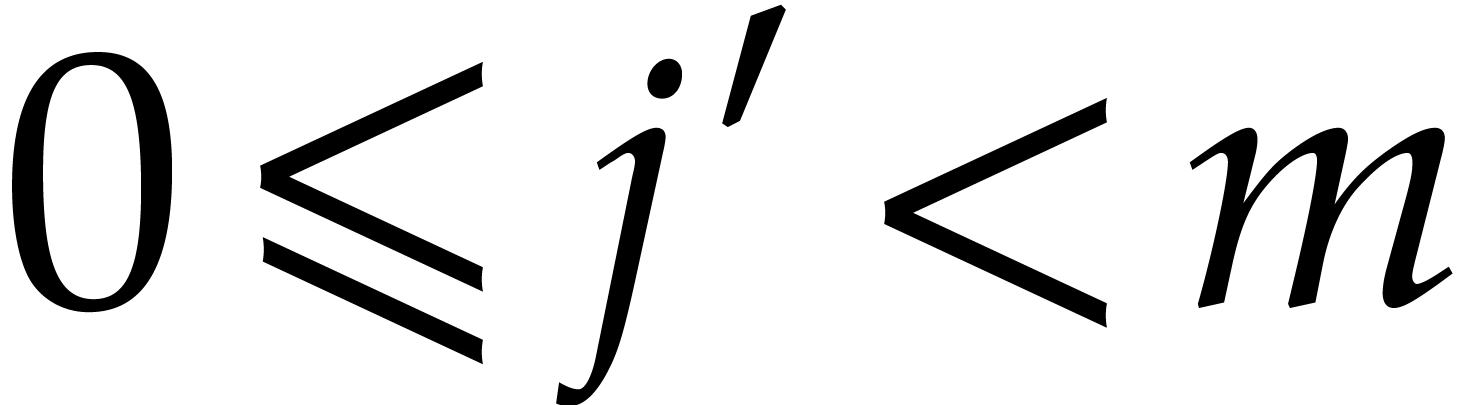 , so the
action of
, so the
action of  onto
onto  is well
defined. Notice that
is well
defined. Notice that  is primitive for the
multiplicative group
is primitive for the
multiplicative group  . This
implies that for any there exists
. This
implies that for any there exists 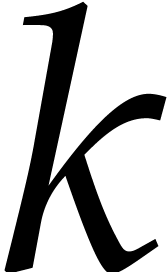 such that
such that  .
Consequently we have
.
Consequently we have 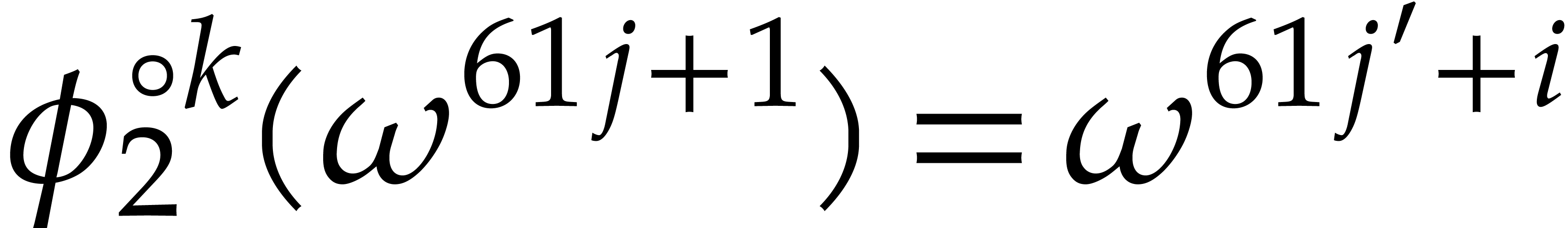 for some , whence
for some , whence 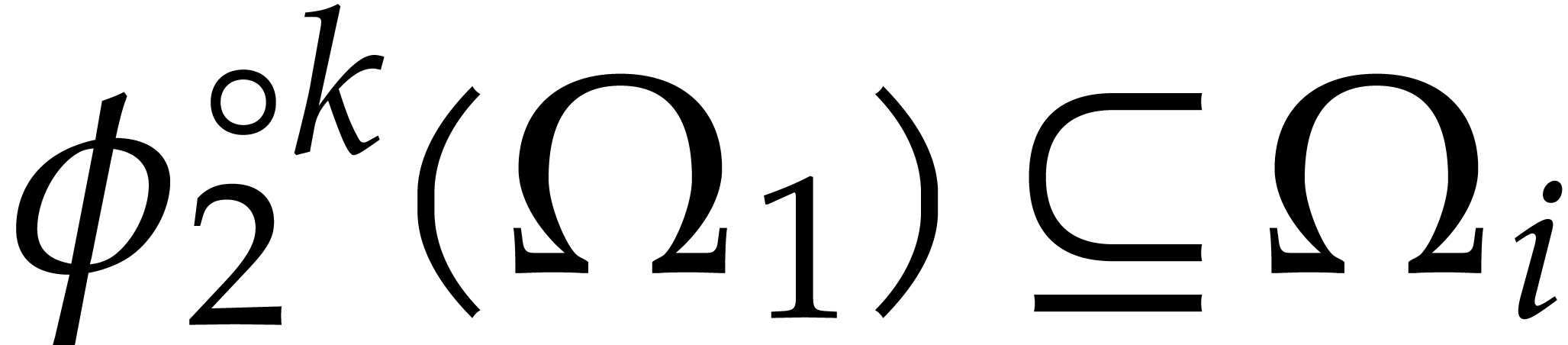 .
Since is injective the latter inclusion is an
equality.
.
Since is injective the latter inclusion is an
equality.
If we were needed the complete ,
then we would still have to compute the first slice 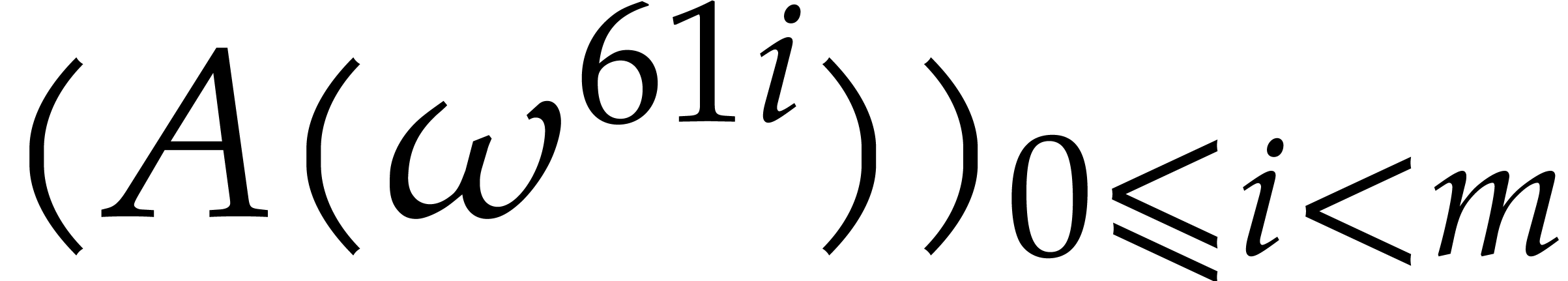 . The second main new idea with respect to [11] is to discard this first slice and to restrict ourselves
to input polynomials of degrees
. The second main new idea with respect to [11] is to discard this first slice and to restrict ourselves
to input polynomials of degrees 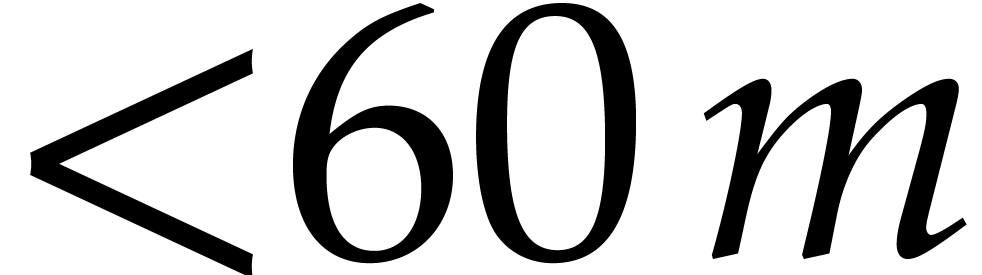 . In this way,
. In this way, 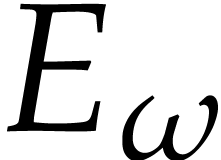 can be
inverted, as proved in the following proposition.
can be
inverted, as proved in the following proposition.
Proof. The dimensions of the source and
destination spaces of over
being the same, it suffices to prove that is
injective. Let 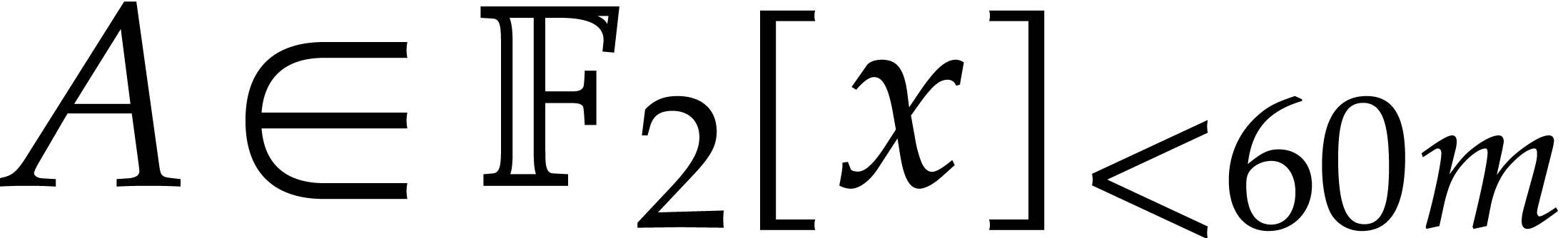 be such that
be such that 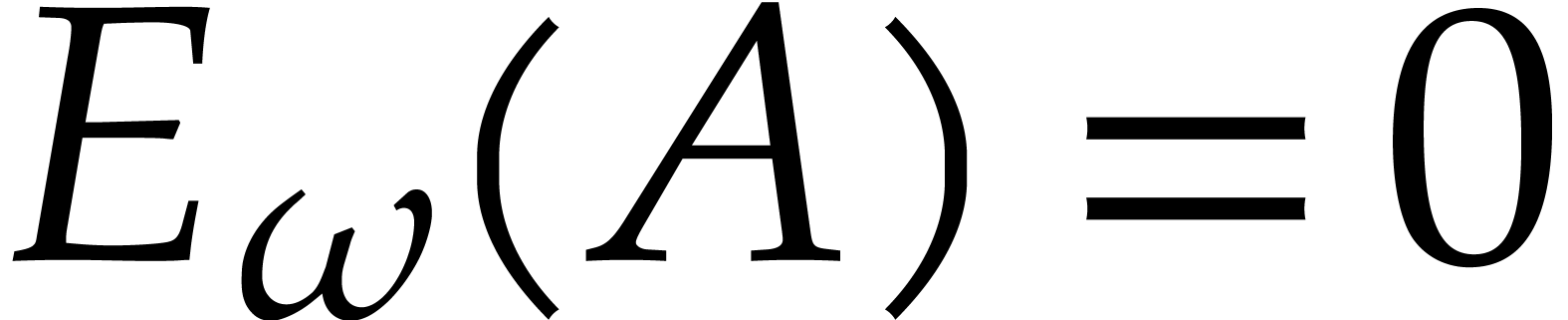 . By construction,
. By construction,  vanishes at
vanishes at  distinct values, namely
distinct values, namely 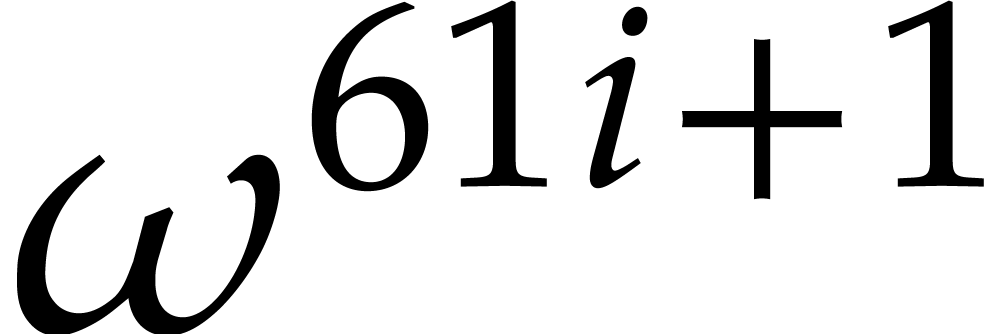 for
for 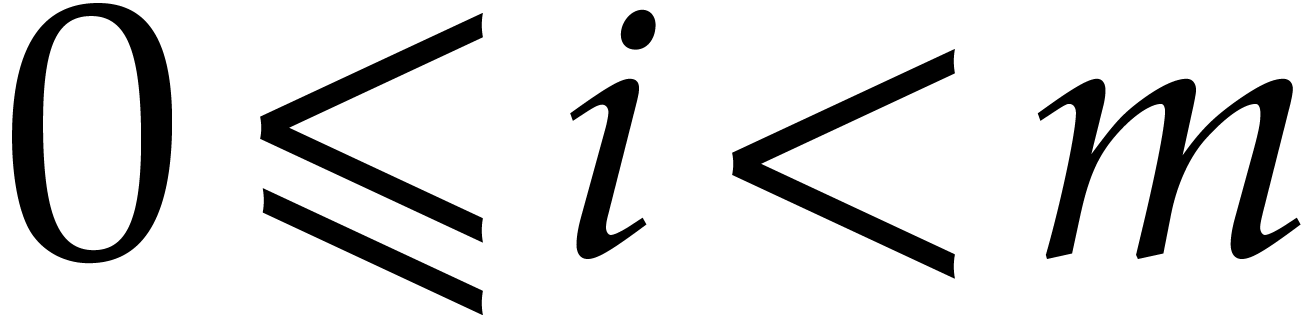 . Under the
action of it also vanishes at
. Under the
action of it also vanishes at 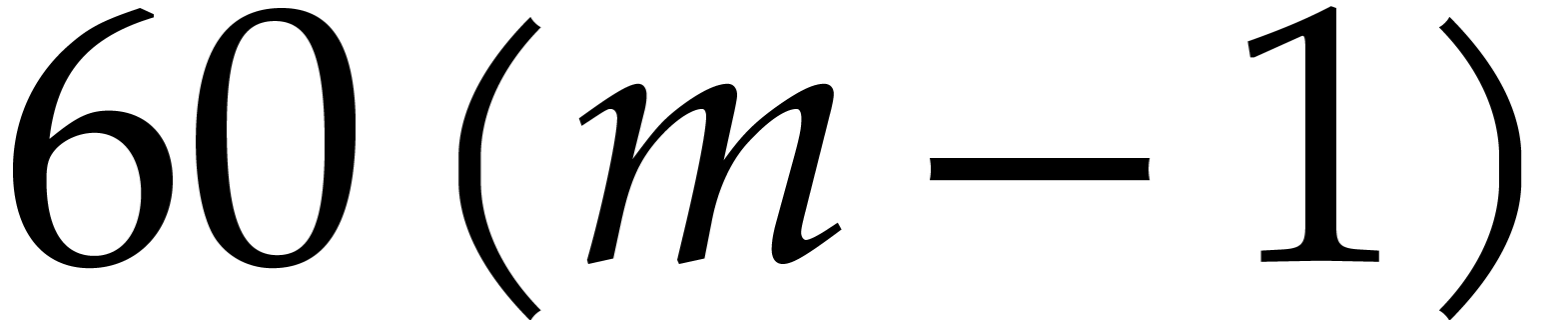 other values by Lemma 1, whence
other values by Lemma 1, whence 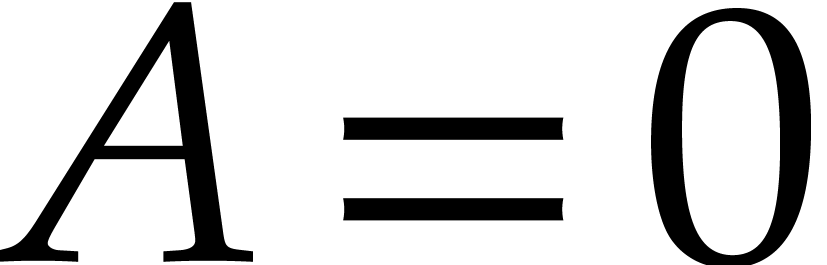 .
.
Remark being bijective is due to the
fact that is primitive in the multiplicative
group . Among the prime
divisors of , the factors 3,
5, 11 and 13 also have this property, but taking
allows us to divide the size of the evaluation-interpolation scheme by
60, which is optimal.
We decompose the computation of into two
routines. The first routine is written  and
called the Frobenius encoding:
and
called the Frobenius encoding:
Below, we will choose  in such a way that is essentially a simple reorganization of the
coefficients of .
in such a way that is essentially a simple reorganization of the
coefficients of .
We observe that the coefficients of 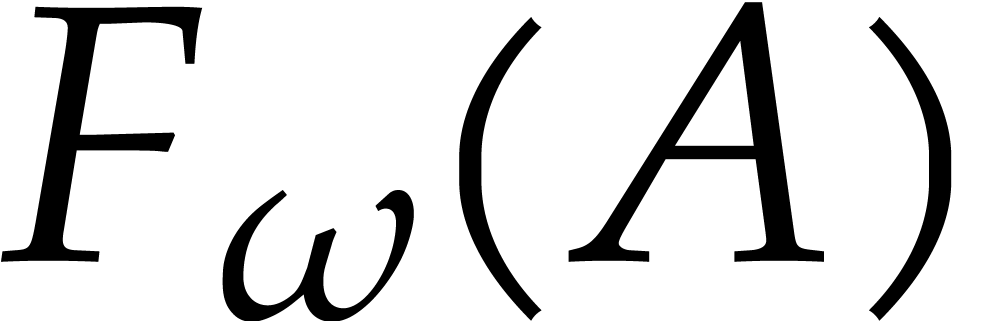 are part of
the values of the inner DFTs of in the
Cooley–Tukey formula and .
The second task is the computation of the corresponding outer DFT of
order :
are part of
the values of the inner DFTs of in the
Cooley–Tukey formula and .
The second task is the computation of the corresponding outer DFT of
order :
Proof. This formula follows from
Summarizing, we have reduced the computation of a DFT of size 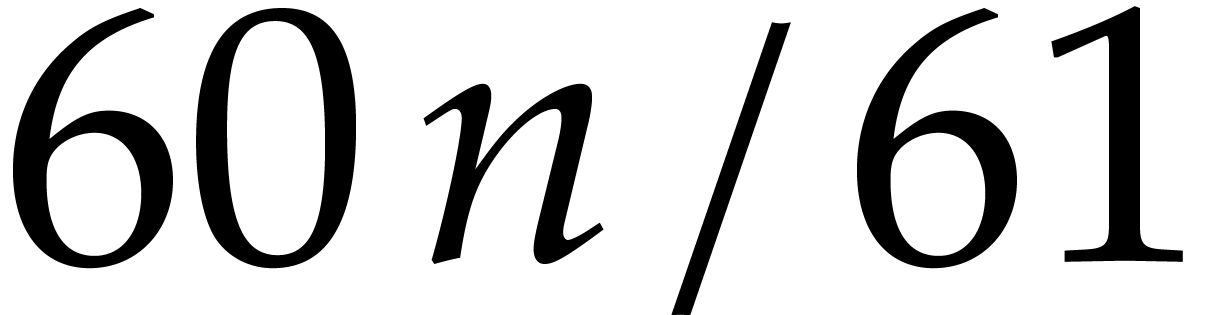 over to a DFT of size
over to a DFT of size 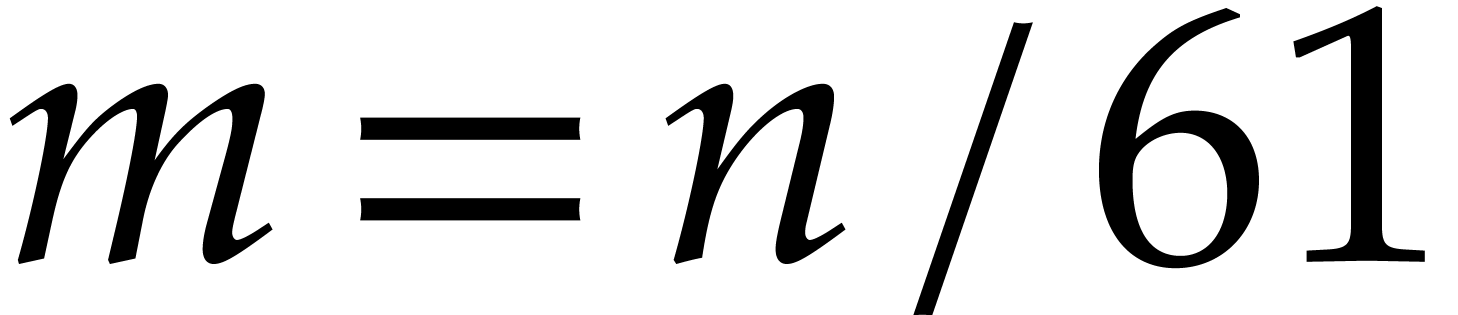 over . This
reduction preserves data size.
over . This
reduction preserves data size.
The computation of involves the evaluation of
polynomials in 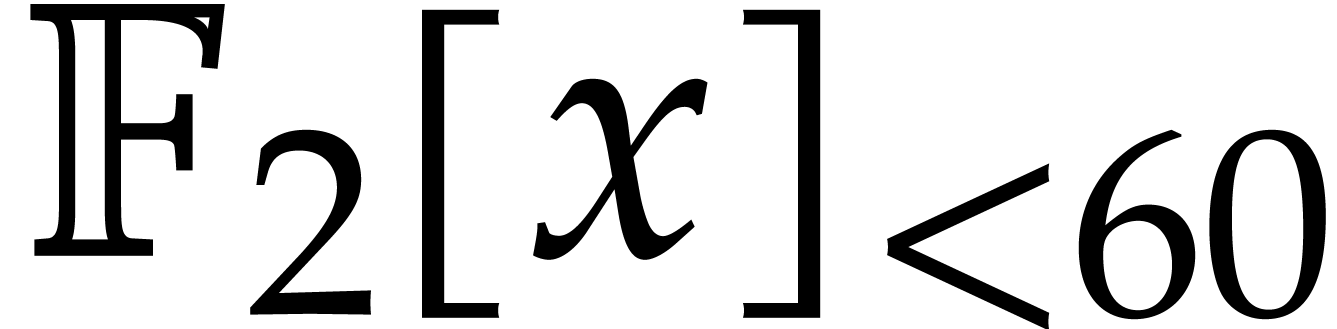 at
at 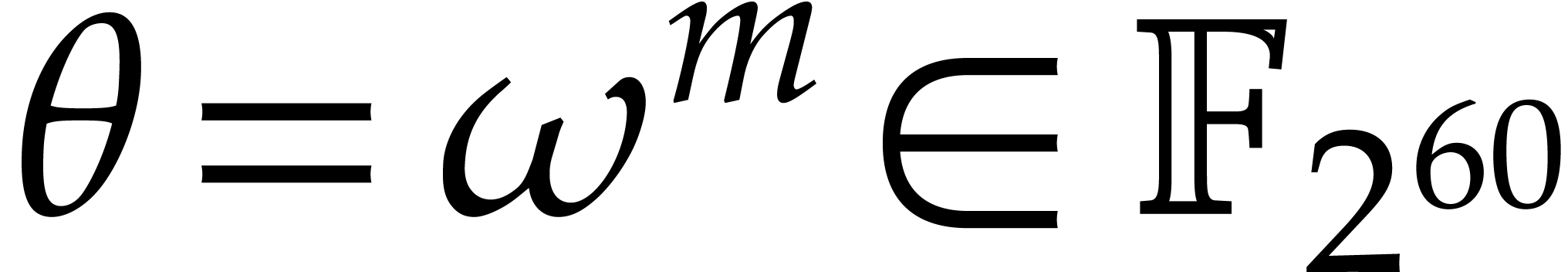 . In order to perform these
evaluations fast, we fix the representation of
. In order to perform these
evaluations fast, we fix the representation of 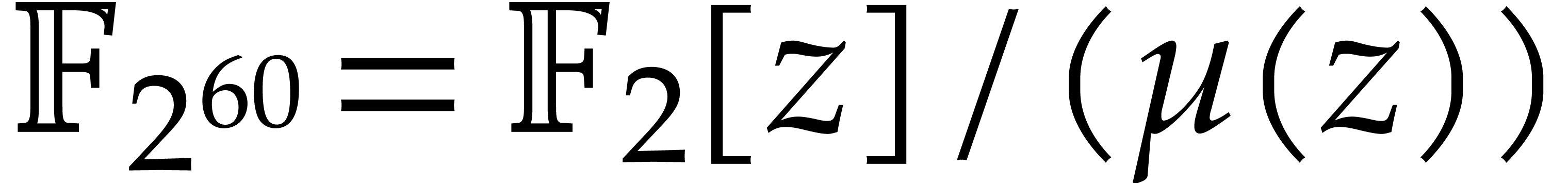 and the primitive root
and the primitive root  of unity of maximal order
to be given by
of unity of maximal order
to be given by
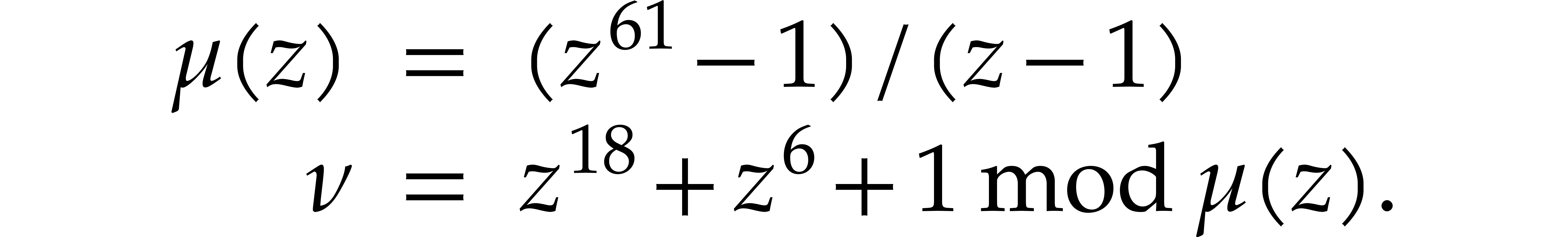
Setting 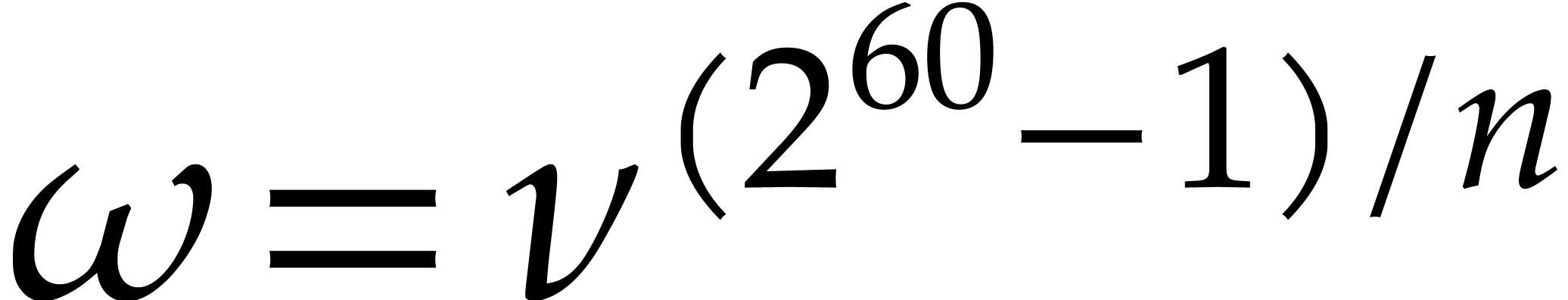 and
and 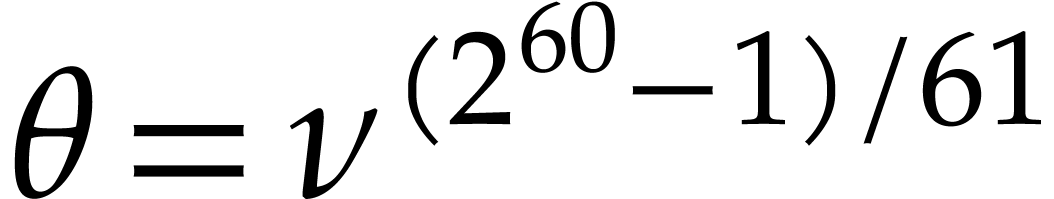 ,
it can be checked that
,
it can be checked that 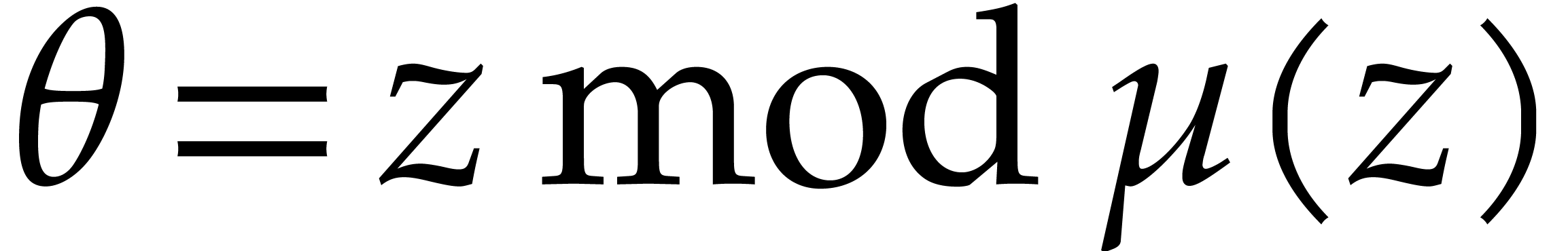 .
Evaluation of a polynomial in at can now be done efficiently.
.
Evaluation of a polynomial in at can now be done efficiently.
Algorithm
Output: .
Assumption:  divides .
divides .
For  , build
, build 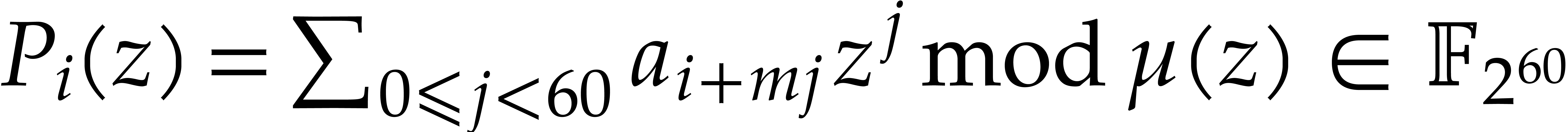 .
.
Return 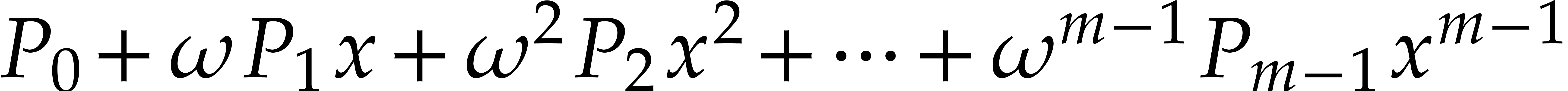 .
.
Proof. This deduces immediately from the
definition of in formula (3), using
the fact that in our representation.
Algorithm
Output: 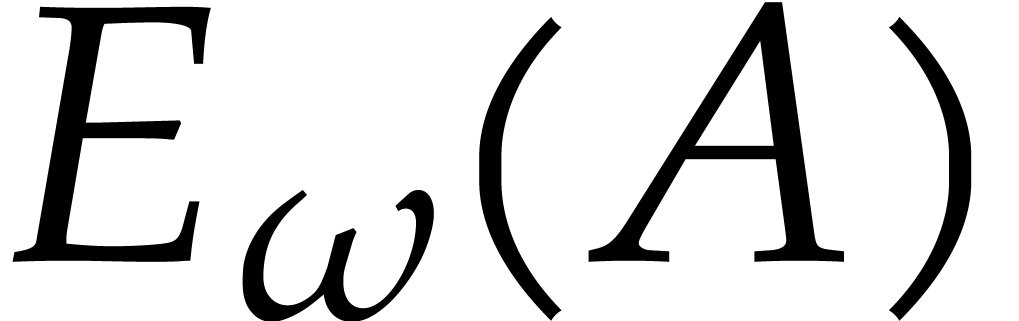 .
.
Assumption: divides .
Compute the Frobenius encoding  of by Algorithm 1.
of by Algorithm 1.
Compute the DFT of with respect to 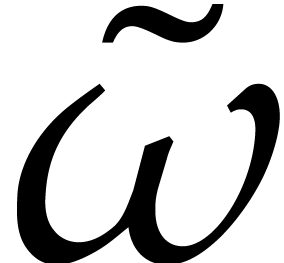 .
.
Proof. The correctness simply follows from
Propositions 4 and 5.
By combining Propositions 2 and 4, the map
is invertible and its inverse may be computed by
the following algorithm.
Algorithm
Output: 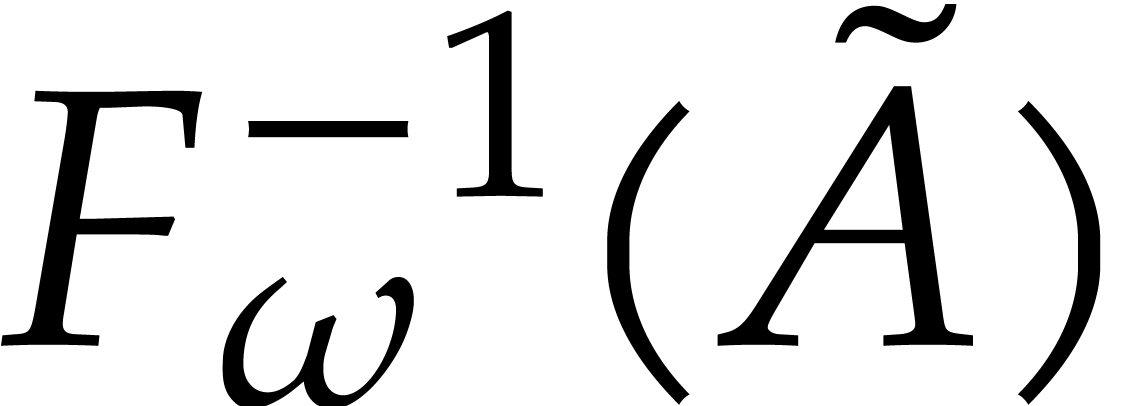 .
.
Assumption: divides .
For , build the
preimage 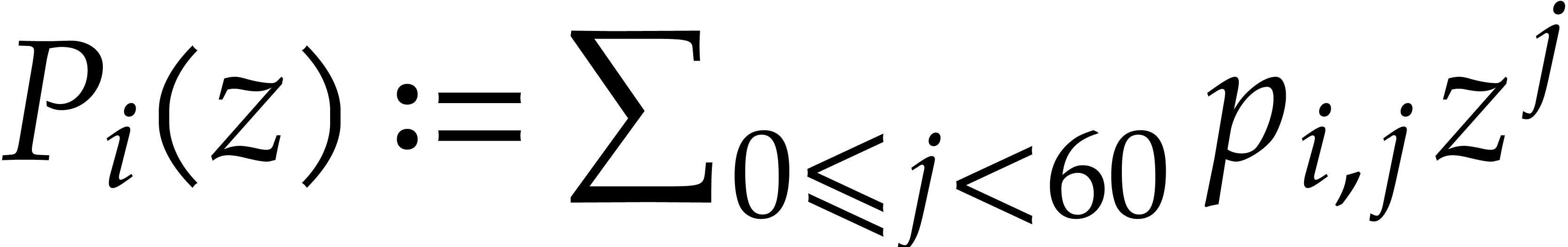 of
of 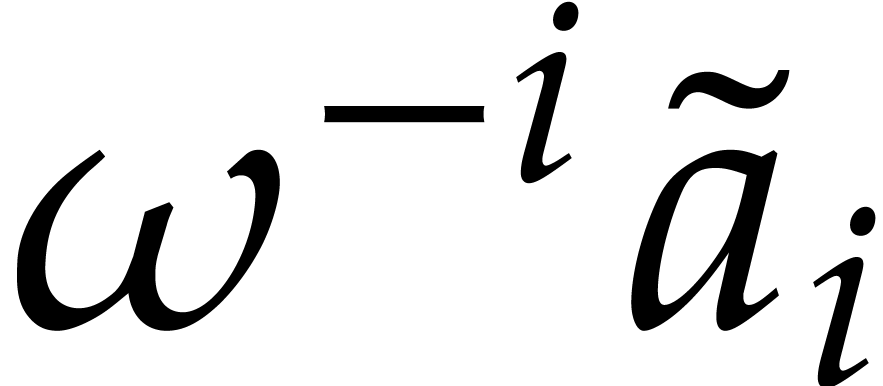 .
.
Return 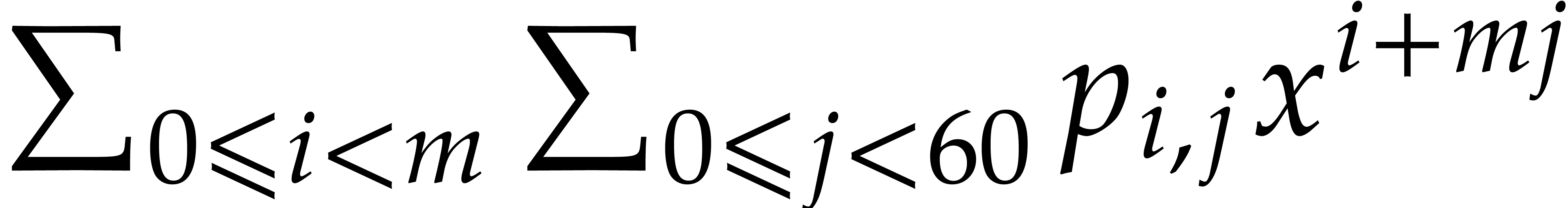 .
.
Proof. This is a straightforward inversion of
Algorithm 1.
Algorithm
Output: 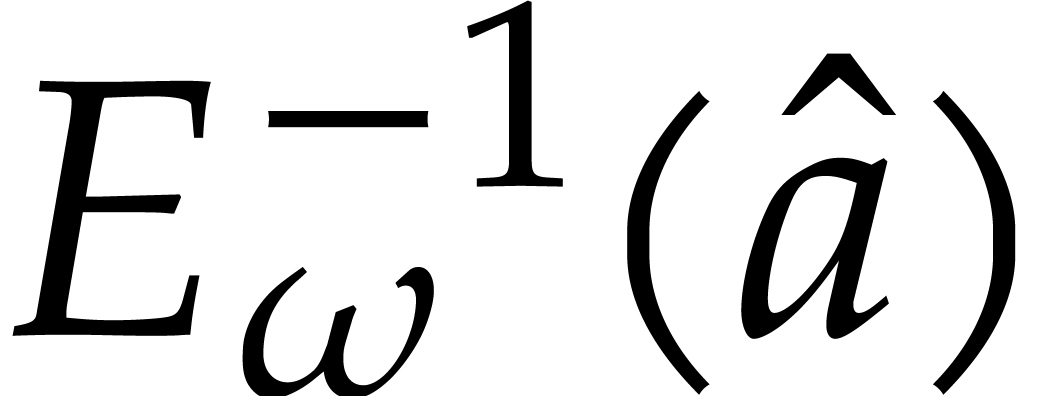 .
.
Assumption: divides .
Compute the inverse DFT 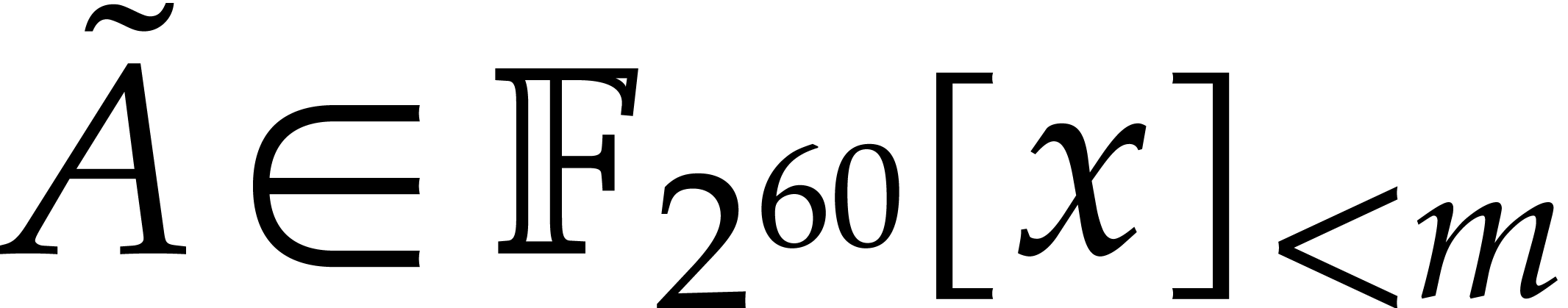 of
of  with respect to .
with respect to .
Compute the Frobenius decoding of by Algorithm 3 and return .
Proof. The correctness simply follows from
Propositions 4 and 7.
Using the standard technique of multiplication by
evaluation-interpolation, we may now compute products in as follows:
Algorithm
Output: 
Proof. The correctness simply follows from
Propositions 6 and 8 and using the fact that
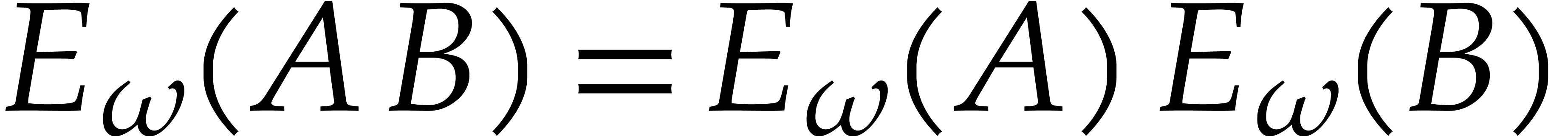 , since
, since 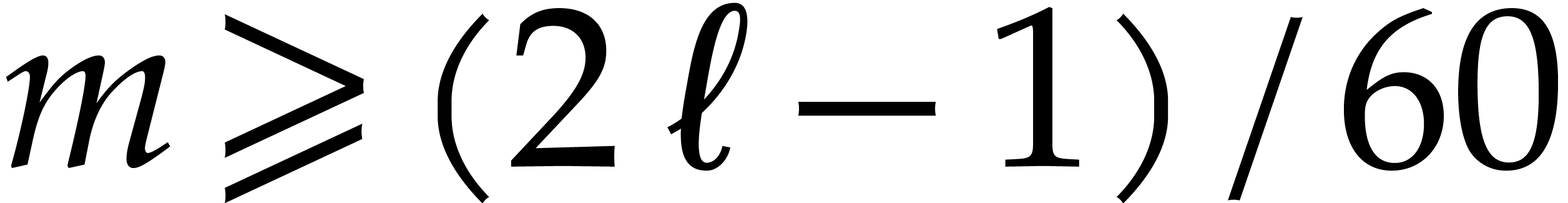 .
.
For step 1, the actual determination of
has been discussed in [7, section 3]. In fact it is often
better not to pick the smallest possible value for
but a slightly larger one that is also very smooth. Since admits many small prime divisors, such smooth values of
usually indeed exist.
We follow
Our implementations are done for an AVX2-enabled processor and an
operating system compliant to System V Application Binary Interface. The
 elements of type uint64_t. Recall that the platform
disposes of
elements of type uint64_t. Recall that the platform
disposes of 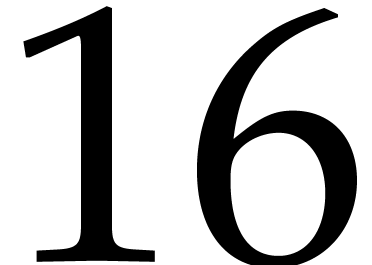 AVX registers which must be
allocated accurately in order to minimize read and write accesses to the
memory.
AVX registers which must be
allocated accurately in order to minimize read and write accesses to the
memory.
Our new polynomial product is implemented in the
Polynomials over are supposed to be given in
packed representation, which means that coefficients are stored
as a vector of contiguous bits in memory. For the implementation
considered in this paper, a polynomial of degree  is stored into
is stored into 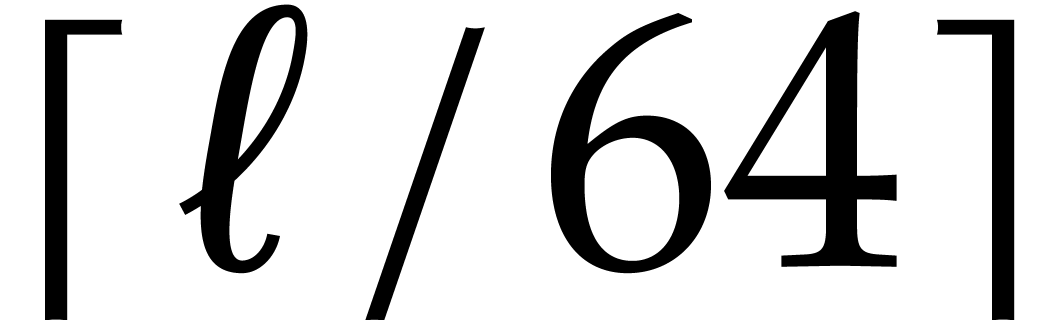 quad words, starting with the
low-degree coefficients: the constant term is the least significant bit
of the first word. The last word is suitably padded with zeros.
quad words, starting with the
low-degree coefficients: the constant term is the least significant bit
of the first word. The last word is suitably padded with zeros.
Reading or writing one coefficient or a range of coefficients of a
polynomial in packed representation must be done carefully to avoid
invalid memory access. Let be such a polynomial
of type uint64_t*. Reading the coefficient 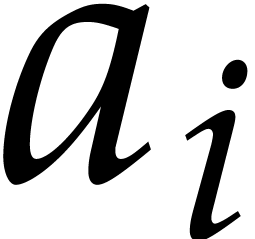 of degree
of degree  in
is obtained as ([i
>> 6] >> (i & 63)) & 1. However, reading or
writing a single coefficient should be avoided as much as possible for
efficiency, so we prefer handling ranges of 256 bits. In the sequel the
function of prototype
in
is obtained as ([i
>> 6] >> (i & 63)) & 1. However, reading or
writing a single coefficient should be avoided as much as possible for
efficiency, so we prefer handling ranges of 256 bits. In the sequel the
function of prototype
void load (avx_uint64_t&  , const uint64_t* ,
, const uint64_t* ,
const uint64_t&  ,
const uint64_t&
,
const uint64_t&  , const
uint64_t&
, const
uint64_t&  );
);
returns the 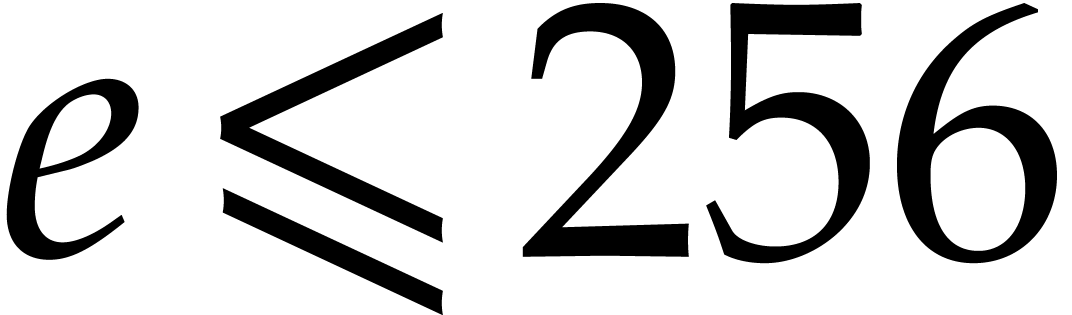 bits of
starting from into
bits of
starting from into  .
Bits beyond position are considered to be zero.
.
Bits beyond position are considered to be zero.
For arithmetic operations in we refer the reader
to [7, section 3.1]. In the sequel we only appeal to the
function
uint64_t f2_60_mul (const uint64_t&
 , const uint64_t&
, const uint64_t& 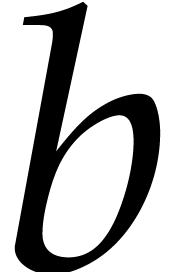 );
);
that multiplies the two elements and 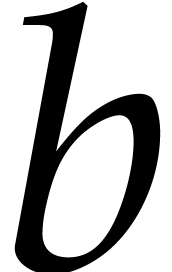 of in packed representation.
of in packed representation.
We also use a packed column-major representation for matrices over . For instance, an  bit matrix
bit matrix 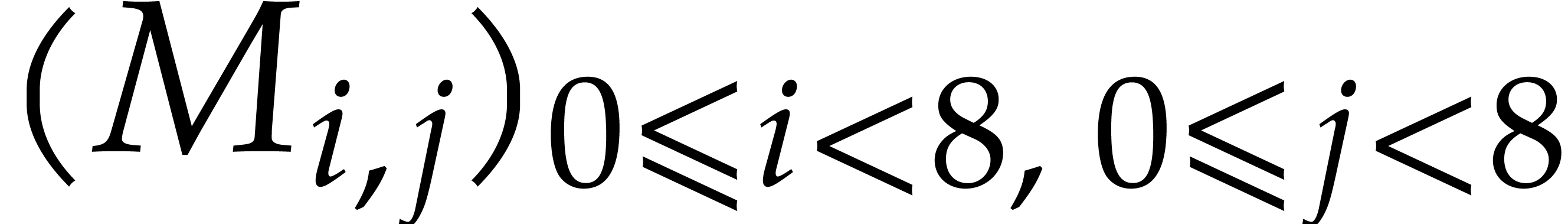 is encoded as a quad word whose
is encoded as a quad word whose 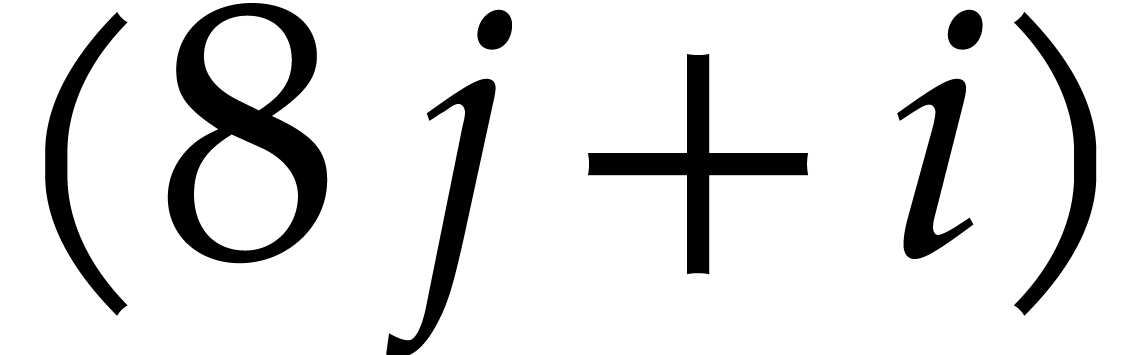 -th bit is
-th bit is 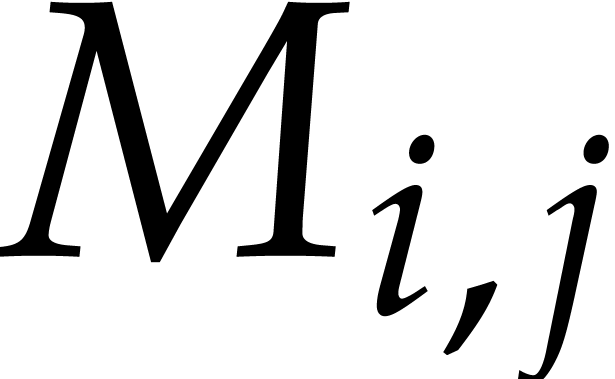 . Similarly, a
. Similarly, a 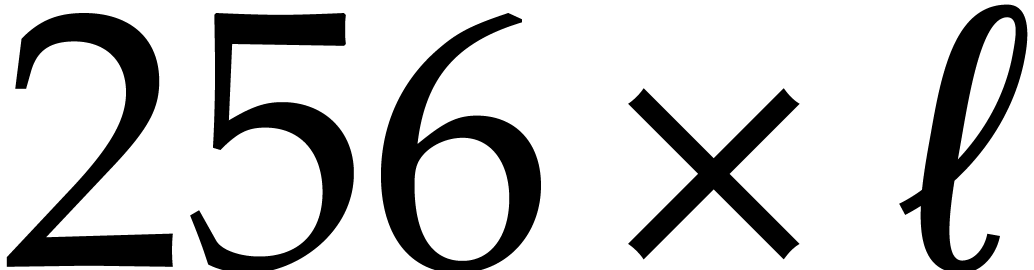 matrix
matrix 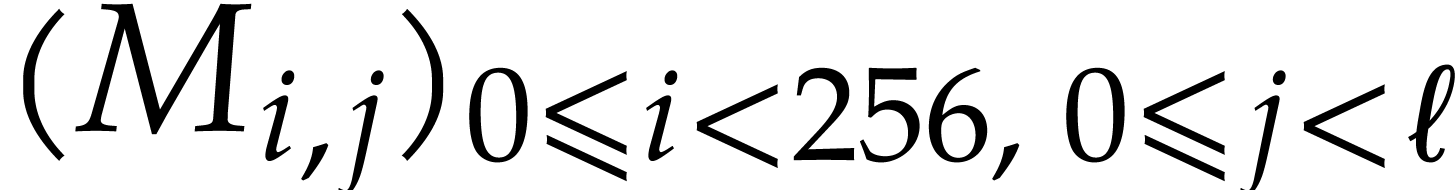 may be seen as a vector
may be seen as a vector  of
type avx_uint64_t*, so
corresponds to the -th bit of
[
of
type avx_uint64_t*, so
corresponds to the -th bit of
[ ].
].
The Frobenius encoding essentially boils down to matrix transpositions.
Our main building block is  bit matrix
transposition. We decompose this transposition in a suitable way with
regards to data locality, register allocation and vectorization.
bit matrix
transposition. We decompose this transposition in a suitable way with
regards to data locality, register allocation and vectorization.
For the computation of general transpositions, we repeatedly make use of
the well-known divide and conquer strategy: to transpose an  matrix
matrix  , where
and are even, we
decompose
, where
and are even, we
decompose 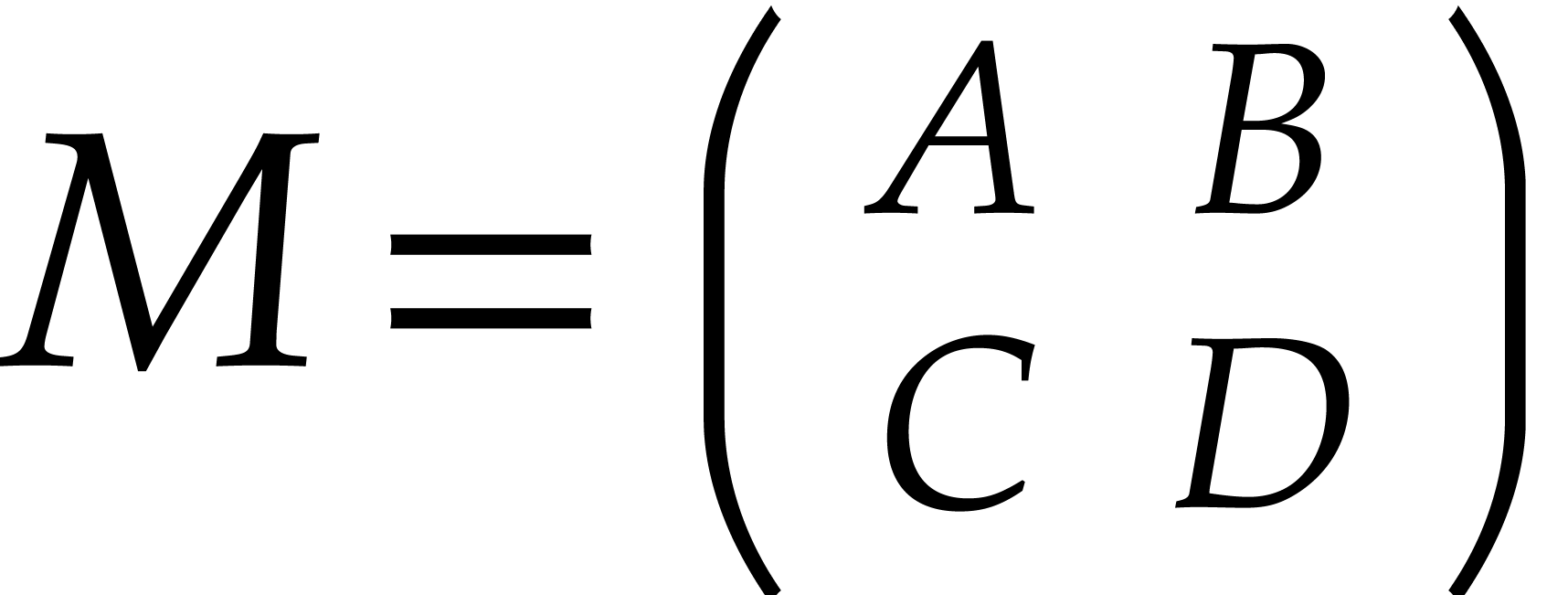 , where
, where 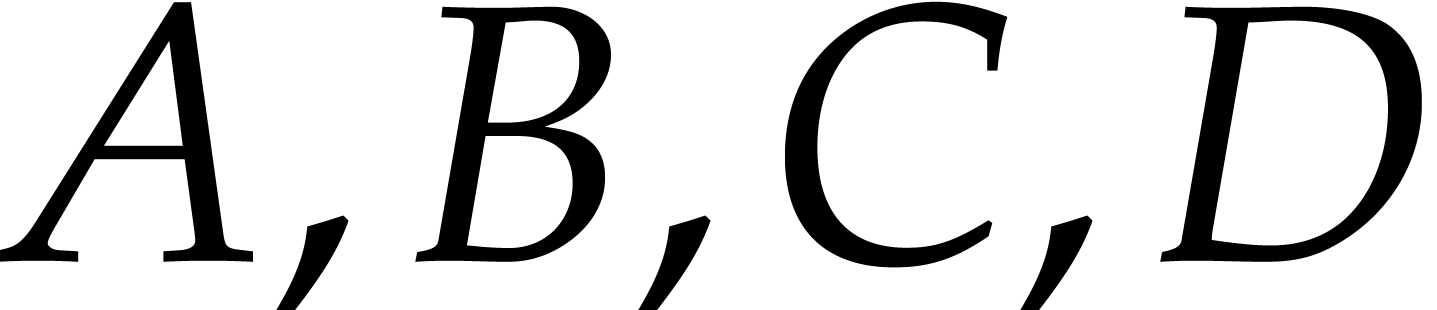 are
are  matrices; we swap the
anti-diagonal blocks
matrices; we swap the
anti-diagonal blocks 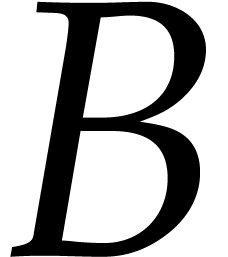 and
and  and recursively transpose each block .
and recursively transpose each block .
bit matrices
The basic task we begin with is the transposition of a packed bit matrix. The solution used here is borrowed from [18, Chapter 7, section 3].
Function
Output: The transpose  of
of  in packed representation.
in packed representation.
uint64_t
packed_matrix_bit_8x8_transpose (const
uint64_t& ) {
uint64_t 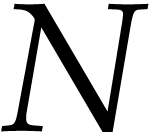 = ;
= ;
static const uint64_t mask_4 = 0x00000000f0f0f0f0;
static const uint64_t mask_2 = 0x0000cccc0000cccc;
static const uint64_t mask_1 = 0x00aa00aa00aa00aa;
uint64_t ;
= ((
>> 28) ^ )
& mask_4; =
^ ;
=
<< 28; = ^ ;
= ((
>> 14) ^ )
& mask_2; =
^ ;
=
<< 14; = ^ ;
= ((
>> 7) ^ ) &
mask_1; = ^
;
=
<< 7; = ^ ;
return ;
}
In steps 6 and 7, the anti-diagonal  blocks are
swapped. In steps 8 and 9, the matrix is seen as
four matrices whose anti-diagonal
blocks are
swapped. In steps 8 and 9, the matrix is seen as
four matrices whose anti-diagonal  blocks are swapped. In steps 10 and 11, the matrix is seen as sixteen matrices
whose anti-diagonal elements are swapped. All in all, 18 instructions, 3
constants and one auxiliary variable are needed to transpose a packed
bit matrix in this way.
blocks are swapped. In steps 10 and 11, the matrix is seen as sixteen matrices
whose anti-diagonal elements are swapped. All in all, 18 instructions, 3
constants and one auxiliary variable are needed to transpose a packed
bit matrix in this way.
One advantage of the above algorithm is that it admits a straightforward AVX vectorization that we will denote by
avx_uint64_t
avx_packed_matrix_bit_8x8_transpose
(const avx_uint64_t& );
This routine transposes four bit matrices 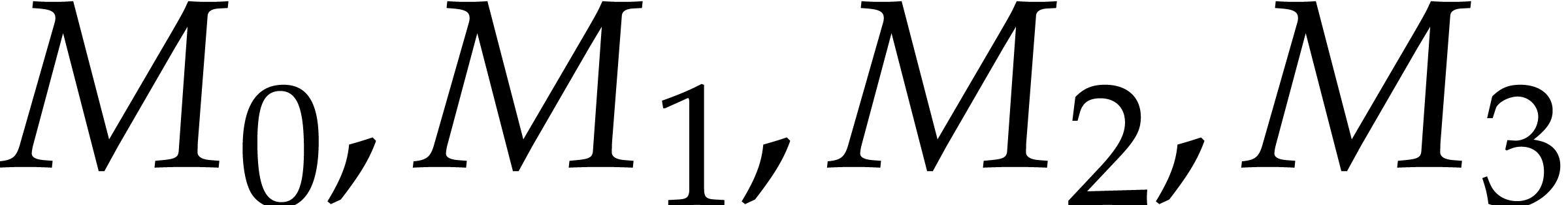 that are packed successively into an AVX register of
type avx_uint64_t. We emphasize that this task is
not the same as transposing a
that are packed successively into an AVX register of
type avx_uint64_t. We emphasize that this task is
not the same as transposing a 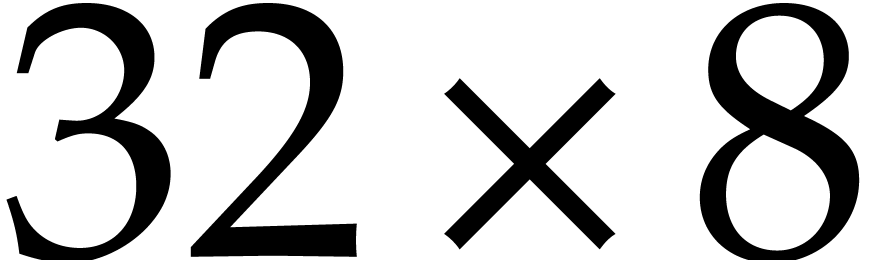 or
or 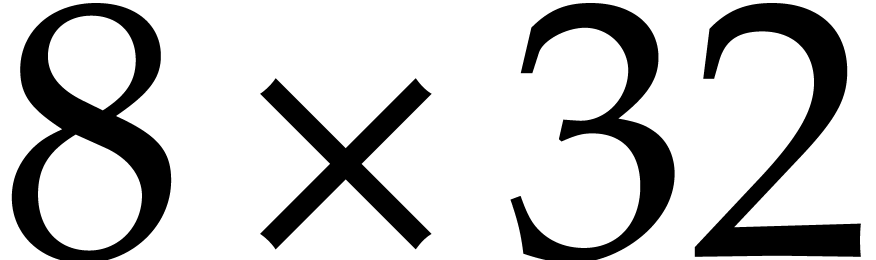 bit matrices.
bit matrices.
Remark  bit matrices:
bit matrices:
uint64_t mask = 0x0101010101010101;
uint64_t  =
0;
=
0;
for (unsigned = 0;
< 8; ++)
|= _pext_u64 (, mask << )
<< (8 * );
The loop can be unrolled while precompting the shift amounts and masks, which leads to a faster sequential implementation. Unfortunately this approach cannot be vectorized with the AVX2 technology. Other sequential solutions even exist, based on lookup tables or integer arithmetic, but their vectorization is again problematic. Practical efficiencies are reported in section 5.
byte matrices simultaneously
Our next task is to design a transposition algorithm of four packed byte matrices simultaneously. More precisely, it
performs the following operation on a packed
byte matrix:
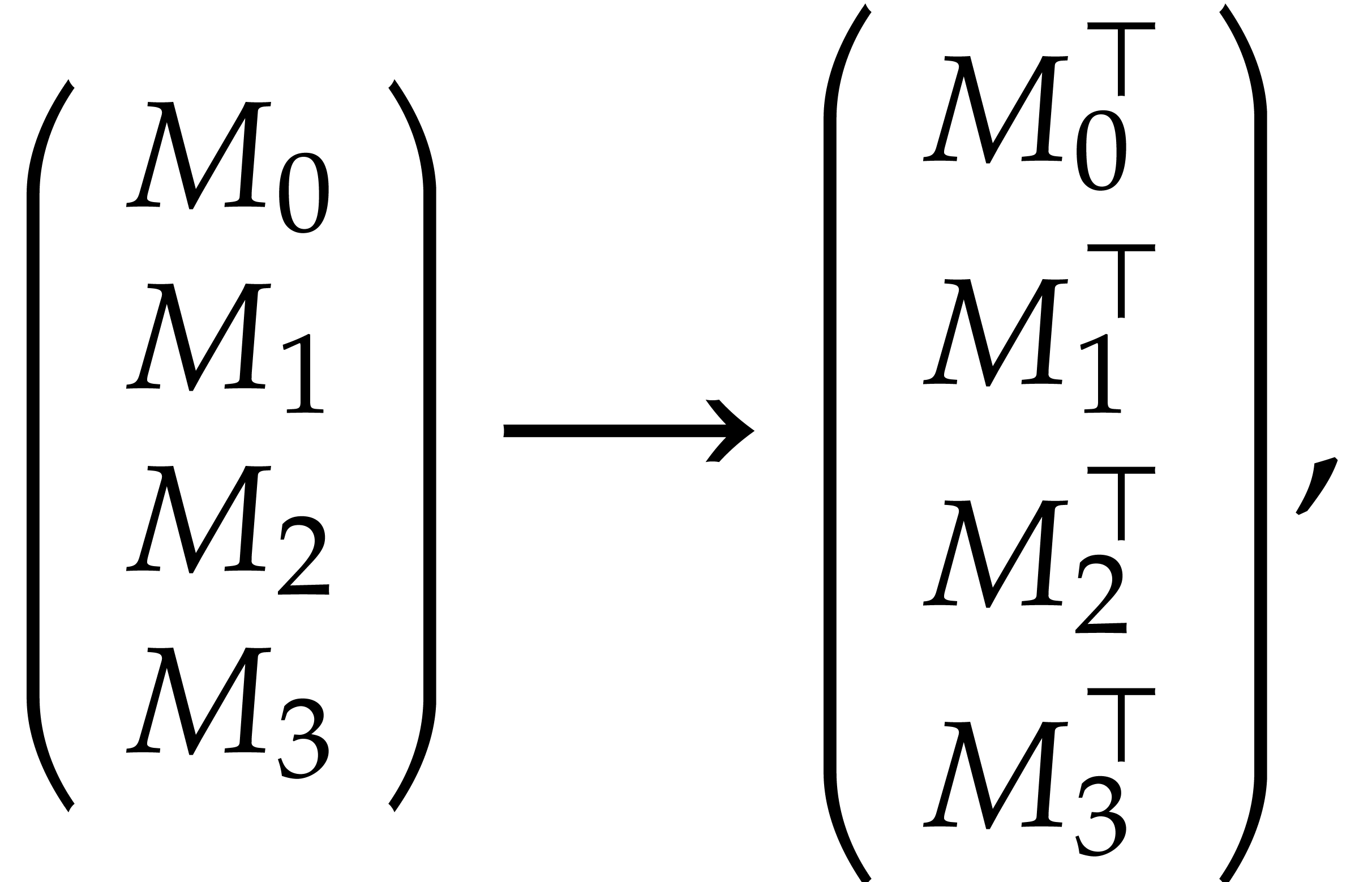
where the  are blocks.
This operation has the following prototype in the sequel:
are blocks.
This operation has the following prototype in the sequel:
void avx_packed_matrix_byte_8x8_transpose
(avx_uint64_t* dest, const avx_uint64_t* src);
This function works as follows. First the input src is
loaded into eight AVX registers  .
Each
.
Each  is seen as a vector of four uint64_t:
for
is seen as a vector of four uint64_t:
for 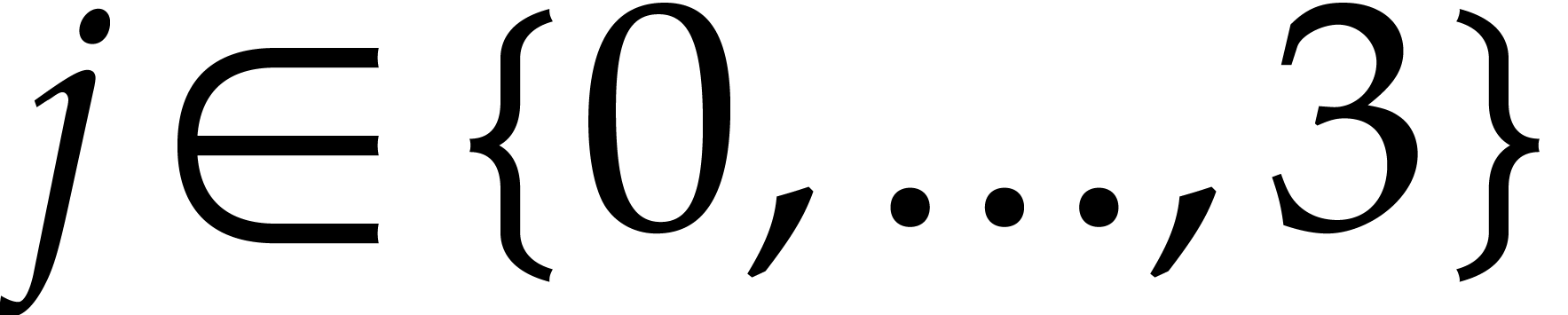 ,
,  thus represent the byte matrix
thus represent the byte matrix 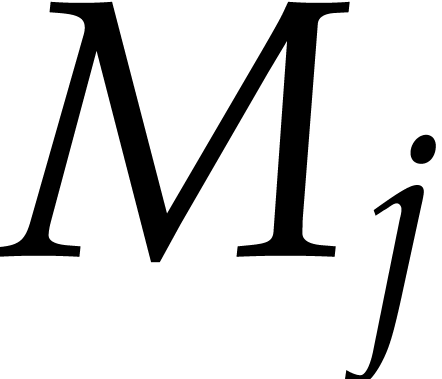 . Then we transpose these four matrices
simultaneously in-register by means of AVX shift and blend operations
over 32, 16 and 8 bits entries in the spirit of the aforementioned
divide and conquer strategy.
. Then we transpose these four matrices
simultaneously in-register by means of AVX shift and blend operations
over 32, 16 and 8 bits entries in the spirit of the aforementioned
divide and conquer strategy.
bit
matrices
Having the above subroutines at our disposal, we can now present our
algorithm to transpose a packed bit matrix. The
input bit matrix of type 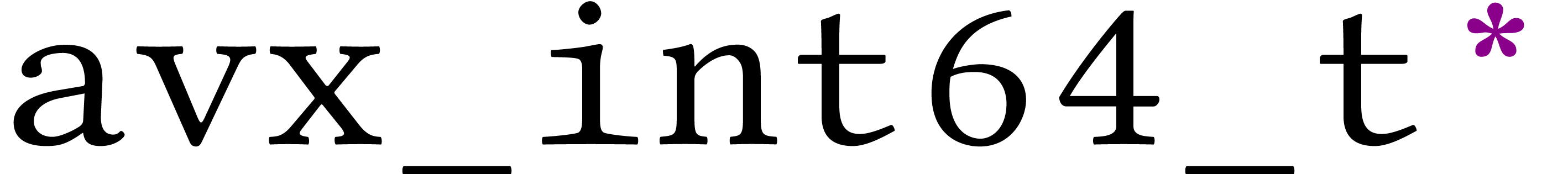 is written
is written  . The transposed output matrix is written
. The transposed output matrix is written 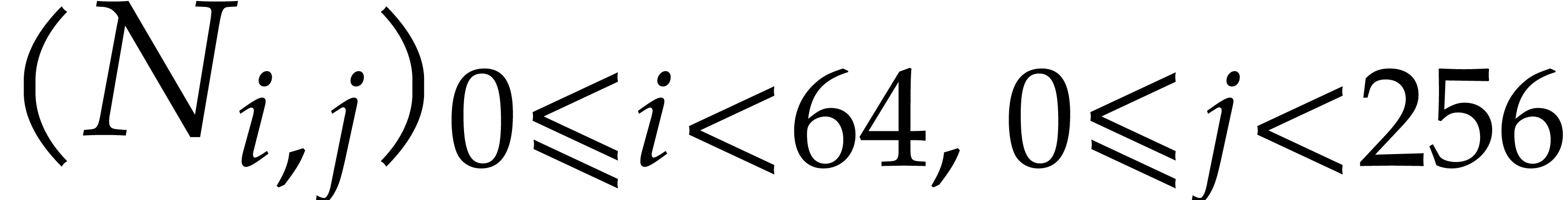 and has type uint64_t*. We first
compute the auxiliary byte matrix
and has type uint64_t*. We first
compute the auxiliary byte matrix  as follows:
as follows:
static avx_uint64_t  [64];
[64];
for (int i= 0; i < 8; i++) {
avx_packed_matrix_byte_8x8_transpose ( + 8*i, + 8*i);
for (int k= 0; k < 8; k++)
T[8*i+k]= avx_packed_matrix_bit_8x8_transpose(T[8*i+k]); }
If we write 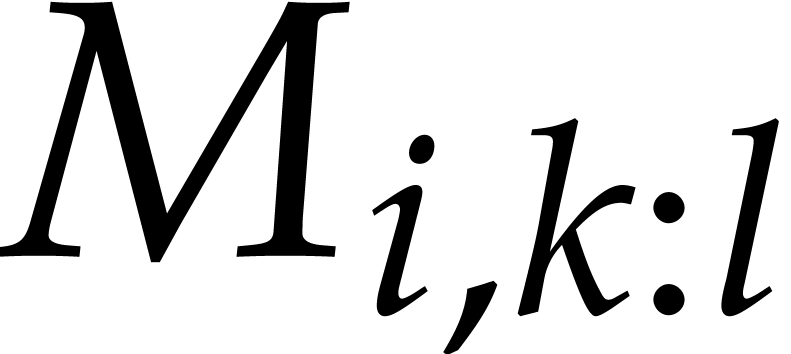 for the byte representing the packed
bit vector
for the byte representing the packed
bit vector  , then contains the following
, then contains the following  byte
matrix:
byte
matrix:

First, for all 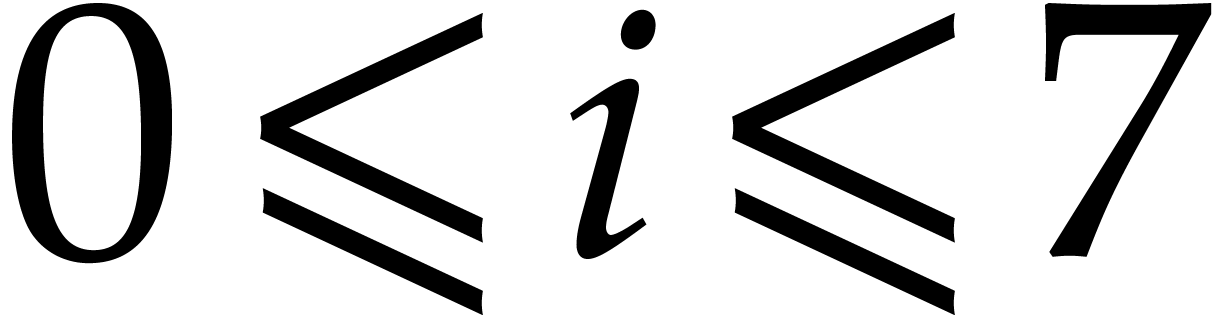 , we load
column
, we load
column  into the AVX register . We interpret these registers as forming a
byte matrix that we transpose in-registers. This
transposition is again performed in the spirit of the aforementioned
divide and conquer strategy and makes use of various specific AVX2
instructions. We obtain
into the AVX register . We interpret these registers as forming a
byte matrix that we transpose in-registers. This
transposition is again performed in the spirit of the aforementioned
divide and conquer strategy and makes use of various specific AVX2
instructions. We obtain
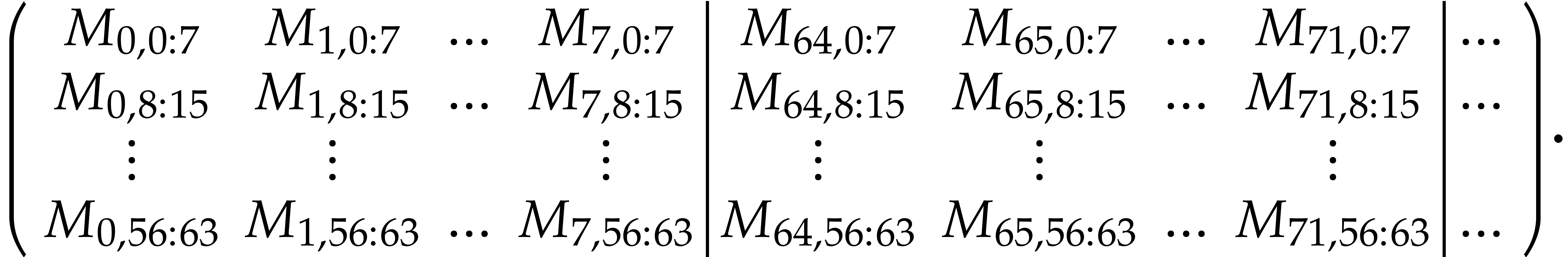
More precisely, for 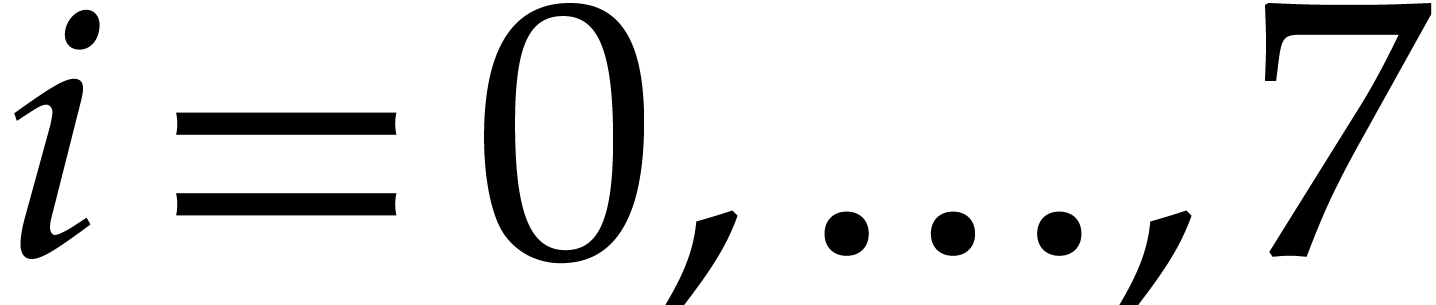 , the
group of four consecutive columns from
, the
group of four consecutive columns from  until
until
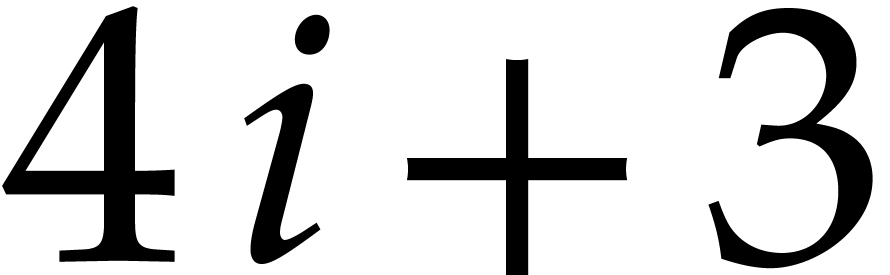 is in the register .
We save the registers at the addresses
is in the register .
We save the registers at the addresses 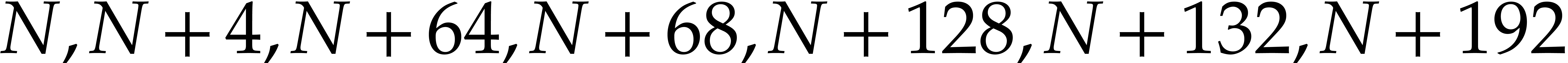 and
and 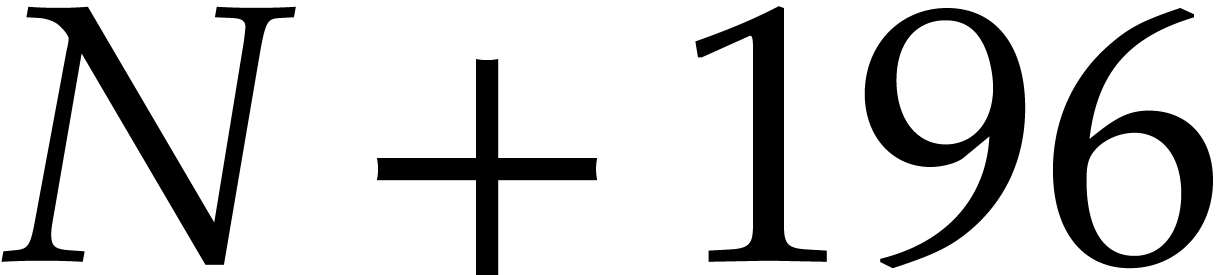 .
.
For each 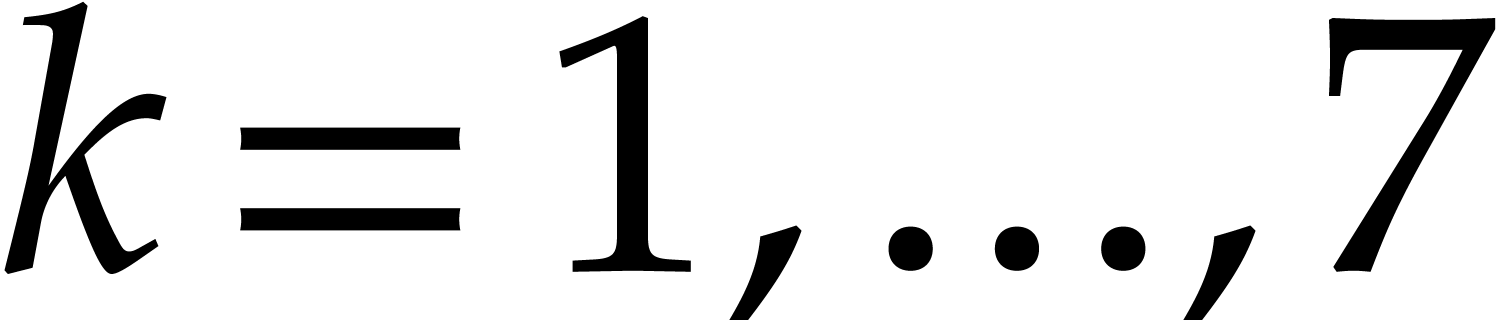 , we build a similar
byte matrix from the columns
, we build a similar
byte matrix from the columns  of , and transpose this
matrix using the same algorithm. This time the result is saved at the
addresses
of , and transpose this
matrix using the same algorithm. This time the result is saved at the
addresses  and
and 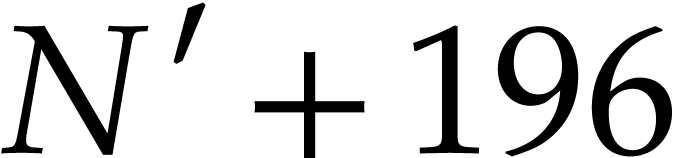 ,
where
,
where 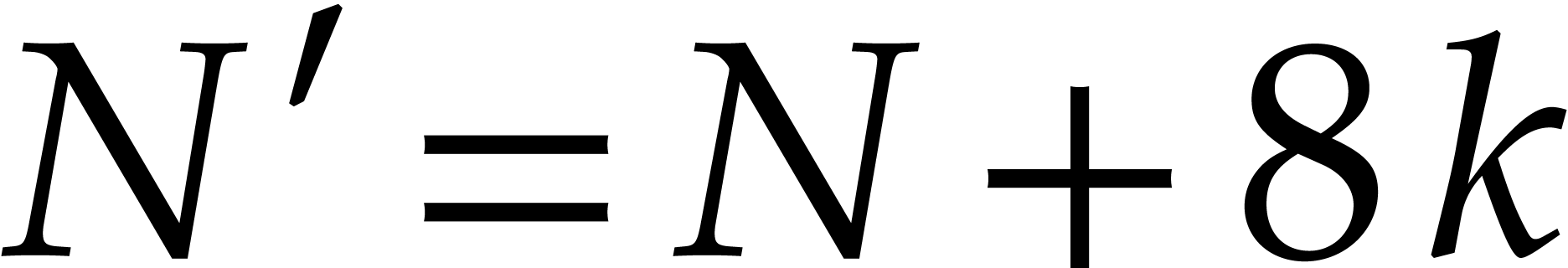 . This yields an
efficient routine for transposing into , whose prototype is given by
. This yields an
efficient routine for transposing into , whose prototype is given by
void packed_matrix_bit_256x64_transpose
(uint64_t* ,
(const avx_uint64_t*) );
If the input polynomial has degree less than
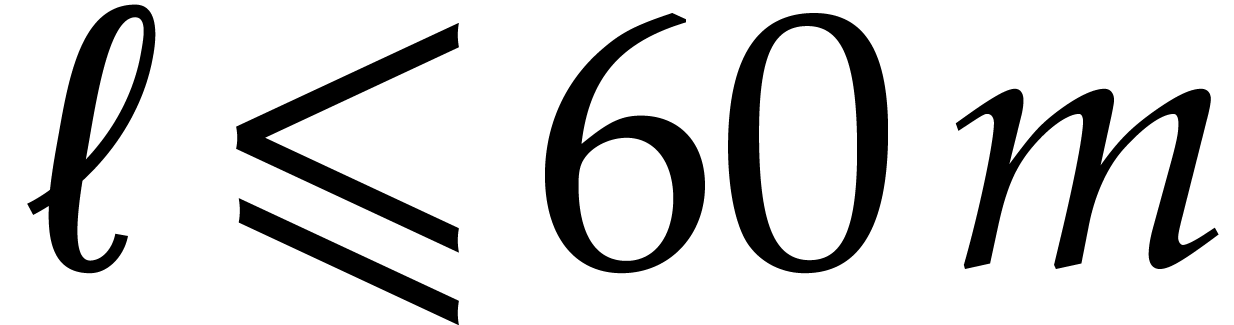 and is in packed representation, then it can
also be seen as a
and is in packed representation, then it can
also be seen as a  matrix in packed
representation (except a padding with zeros could be necessary to adjust
the size).
matrix in packed
representation (except a padding with zeros could be necessary to adjust
the size).
In this setting, the polynomials 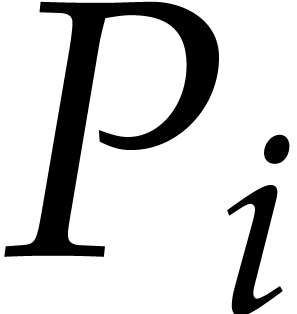 of Algorithm 1 are simply read as the rows of the matrix. Therefore, to
compute the Frobenius encoding ,
we only need to transpose this matrix, then add 4 rows of zeros for
alignment (because we store one element of per
quad word) and multiply by twiddle factors. This leads to the following
implementation:
of Algorithm 1 are simply read as the rows of the matrix. Therefore, to
compute the Frobenius encoding ,
we only need to transpose this matrix, then add 4 rows of zeros for
alignment (because we store one element of per
quad word) and multiply by twiddle factors. This leads to the following
implementation:
Function
Output: stored from pointer
to allocated quad
words.
Assumptions: divides and 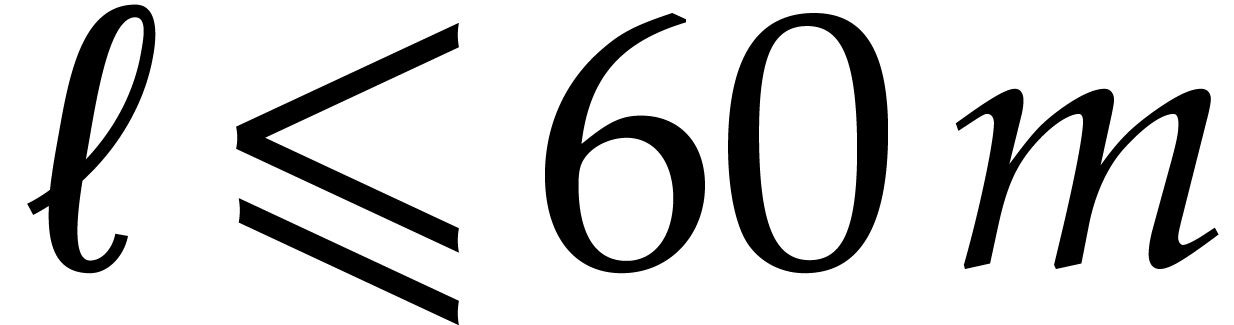 .
.
void encode (uint64_t* , const uint64_t& ,
const uint64_t* ,
const uint64_t& )
{
uint64_t  = 1, = 0,
= 1, = 0, 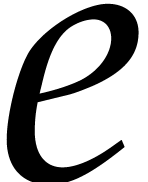 = 0;
= 0;
avx_uint64_t [64];
uint64_t 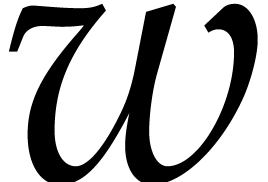 [256];
[256];
while ( < ) {
= min (
- , 256);
for (int = 0; < 64; ++)
load ([], , ,
+ * , );
packed_matrix_bit_256x64_transpose (, );
for (int = 0; < e; ++)
{
[ + ]
= f2_60_mul ([], );
= f2_60_mul (, ); }
+= ; }
Remark. To optimize read accesses, it is better
to run loop 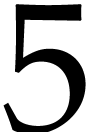 for
for 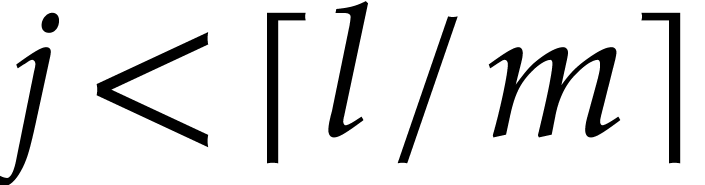 and to
initialize the remaining
and to
initialize the remaining  [
[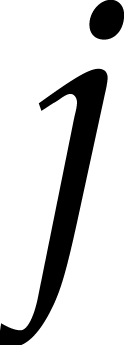 ] to zero. Indeed, for a
product of degree , we
typically multiply two polynomials of degree
] to zero. Indeed, for a
product of degree , we
typically multiply two polynomials of degree 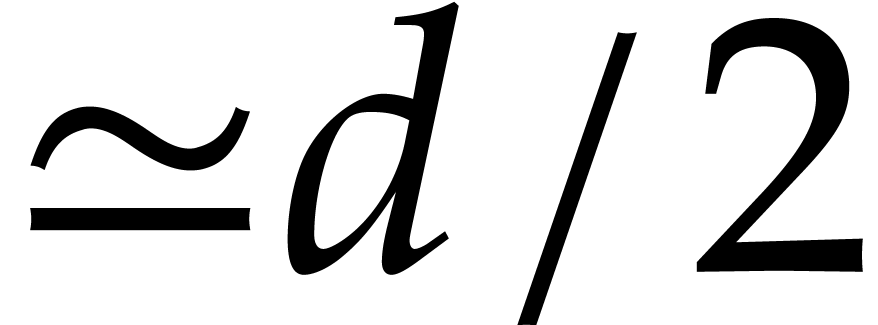 , which means
, which means  when computing
the direct transform.
when computing
the direct transform.
The Frobenius decoding consists in inverting the encoding. The implementation issues are the same, so we refer to our source code for further details.
The platform considered in this paper is equipped with an  GHz and 32 GB of
GHz and 32 GB of  MHz DDR4 memory.
This CPU features AVX2, BMI2 and CLMUL technologies (family number
MHz DDR4 memory.
This CPU features AVX2, BMI2 and CLMUL technologies (family number  and model number 94). The platform runs the
and model number 94). The platform runs the
We use version 1.2 of the 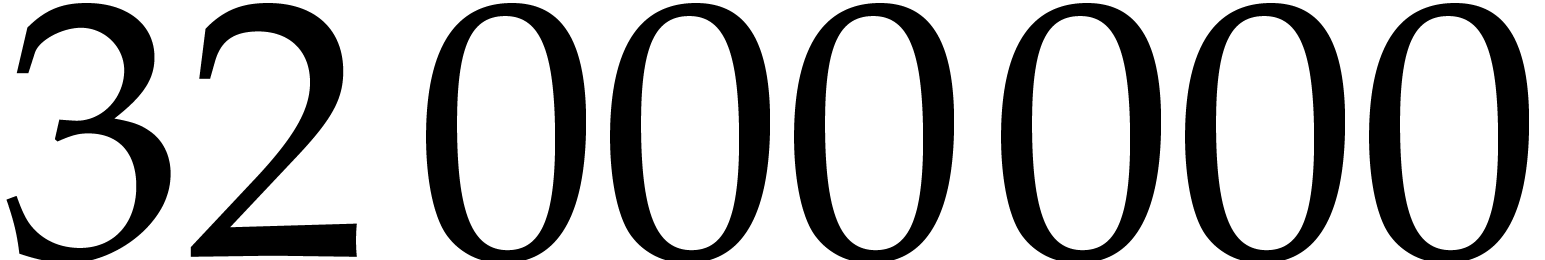 input quad words. We also compare to the implementation of
the additive Fourier transform by Chen et al. [2], using
the GIT version of 2017, September, 1.
input quad words. We also compare to the implementation of
the additive Fourier transform by Chen et al. [2], using
the GIT version of 2017, September, 1.
Concerning the cost of the Frobenius encoding and decoding, Function 1 takes about 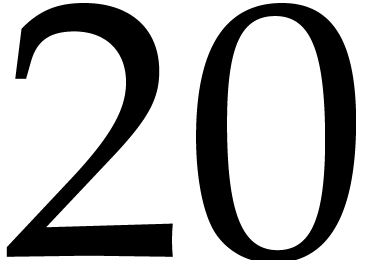 CPU cycles when compiled
with the sole -O3 option. With the additional options
-mtune=native -mavx2 -mbmi2, the BMI2 version of Remark
10 takes about 16 CPU cycles. The vectorized version of
Function 1 transposes four packed
bit matrices simultaneously in about 20 cycles, which makes an average
of
CPU cycles when compiled
with the sole -O3 option. With the additional options
-mtune=native -mavx2 -mbmi2, the BMI2 version of Remark
10 takes about 16 CPU cycles. The vectorized version of
Function 1 transposes four packed
bit matrices simultaneously in about 20 cycles, which makes an average
of 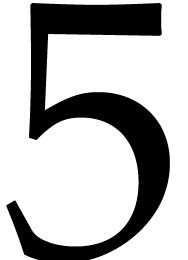 cycles per matrix.
cycles per matrix.
It it interesting to examine the performance of the sole transpositions
made during the Frobenius encoding and decoding (that is discarding
products by twiddle factors in ).
From sizes of a few kilobytes this average cost per quad word is about 8
cycles with the AVX2 technology, and it is about 23 cycles without.
Unfortunately the vectorization speed-up is not as close to 4 as we
would have liked.
Since the encoding and decoding costs are linear, their relative
contribution to the total computation time of polynomial products
decreases for large sizes. For two input polynomials in
of 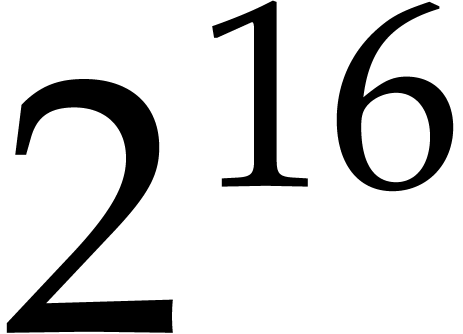 quad words, the contribution is about
quad words, the contribution is about 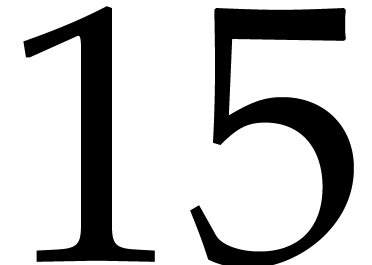 %; for
%; for 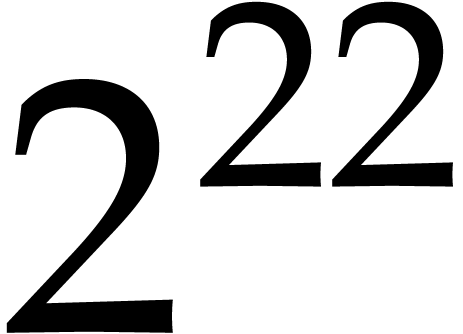 quad
words, it is about
quad
words, it is about 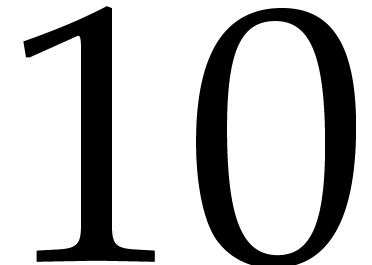 %.
%.
In Figure 1 we report timings in milliseconds for
multiplying two polynomials in 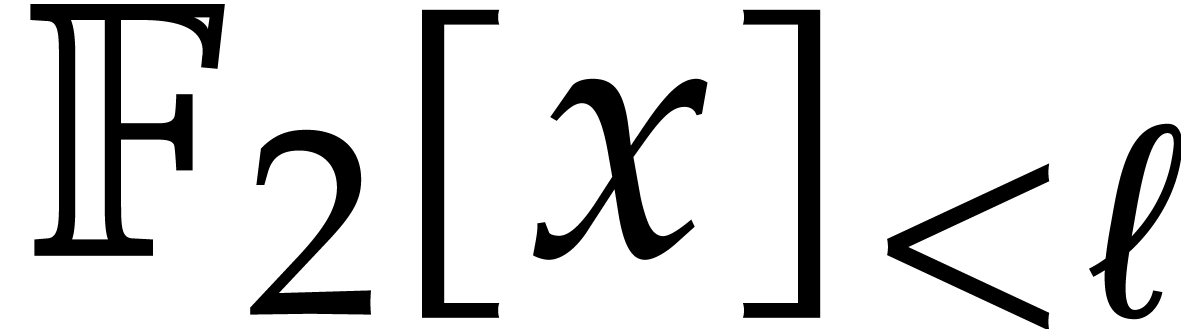 ,
hence each of input size quad
words—indicated in abscissa and obtained from justinline/bench/polynomial_f2_bench.mmx.
Notice that our implementation in [7] was faster than
version 1.1 of predicted by the asymptotic complexity analysis.
Let us mention that our new implementation becomes faster than is larger than
,
hence each of input size quad
words—indicated in abscissa and obtained from justinline/bench/polynomial_f2_bench.mmx.
Notice that our implementation in [7] was faster than
version 1.1 of predicted by the asymptotic complexity analysis.
Let us mention that our new implementation becomes faster than is larger than  .
.
As in [7], one major advantage of DFTs over the Babylonian
field is the compactness of the evaluated
FFT-representation of polynomials. This makes linear algebra over particularly efficient: instead of multiplying  matrices over naively by
means of
matrices over naively by
means of 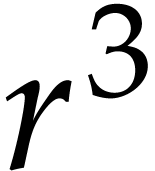 polynomial products of degree
polynomial products of degree 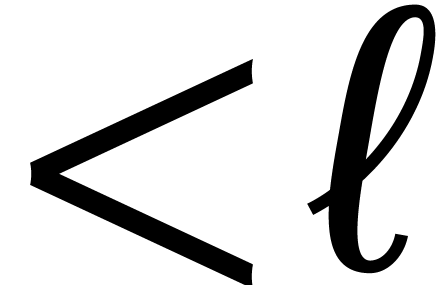 , we use the standard
evaluation-interpolation approach. In our context, this comes down to:
(a) computing the
, we use the standard
evaluation-interpolation approach. In our context, this comes down to:
(a) computing the 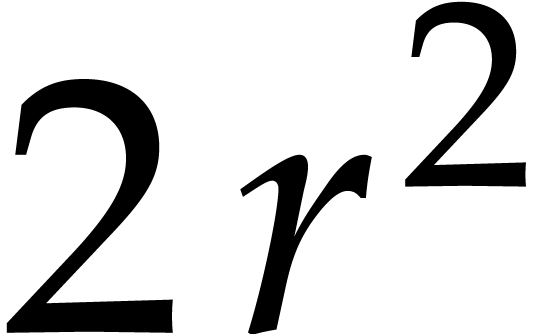 Frobenius encodings, (b) the
direct DFTs of all entries of the two matrices
to be multiplied, (c) performing the
Frobenius encodings, (b) the
direct DFTs of all entries of the two matrices
to be multiplied, (c) performing the 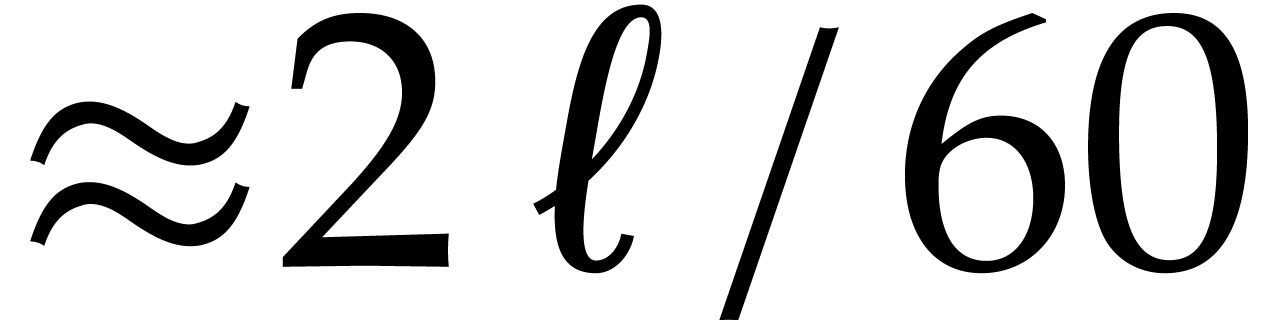 products of
matrices over ,
(d) computing the
products of
matrices over ,
(d) computing the 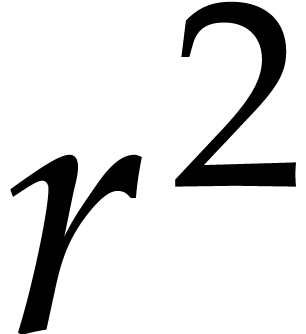 inverse DFTs and Frobenius
decodings of the so-computed matrix products.
inverse DFTs and Frobenius
decodings of the so-computed matrix products.
Timings for matrices over
are obatined from
justinline/bench/matrix_polynomial_f2_bench.mmx
and are reported in Table
1
. The row “this paper” confirms the practical gain of this
fast approach within our implementation. For comparison, the row “
polynomial multiplications using
The present paper describes a major new approach for the efficient
computation of large carryless products. It confirms the excellent
arithmetic properties of the Babylonian field
for practical purposes, when compared to the fastest previously
available strategies.
Improvements are still possible for our implementation of DFTs over
. First, taking advantage of
the more recent AVX-512 technologies is an important challenge. This is
difficult due to the current lack of 256 or 512 bit SIMD counterparts
for the vpclmulqdq assembly instruction (carryless
multiplication of two quad words). However, larger vector instruction
would be beneficial for matrix transposition, and even more taking into
account that there are twice as many 512 bit registers as 256 bit
registers; so we can expect a significant speed-up for the Frobenius
encoding/decoding stages. The second expected improvement concerns the
use of truncated Fourier transforms [9, 14] in
order to smoothen the graph from Figure 1. Finally we
expect that our new ideas around the Frobenius transform might be
applicable to other small finite fields.
R. P. Brent, P. Gaudry, E. Thomé, and P.
Zimmermann. Faster multiplication in GF . In A. van der Poorten and A. Stein,
editors, Algorithmic Number Theory, volume 5011 of
Lect. Notes Comput. Sci., pages 153–166. Springer
Berlin Heidelberg, 2008.
. In A. van der Poorten and A. Stein,
editors, Algorithmic Number Theory, volume 5011 of
Lect. Notes Comput. Sci., pages 153–166. Springer
Berlin Heidelberg, 2008.
Ming-Shing Chen, Chen-Mou Cheng, Po-Chun Kuo, Wen-Ding Li, and Bo-Yin Yang. Faster multiplication for long binary polynomials. https://arxiv.org/abs/1708.09746, 2017.
J. W. Cooley and J. W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
S. Gao and T. Mateer. Additive fast Fourier transforms over finite fields. IEEE Trans. Inform. Theory, 56(12):6265–6272, 2010.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, 3rd edition, 2013.
GCC, the GNU Compiler Collection. Software available at http://gcc.gnu.org, from 1987.
D. Harvey, J. van der Hoeven, and G. Lecerf. Fast
polynomial multiplication over 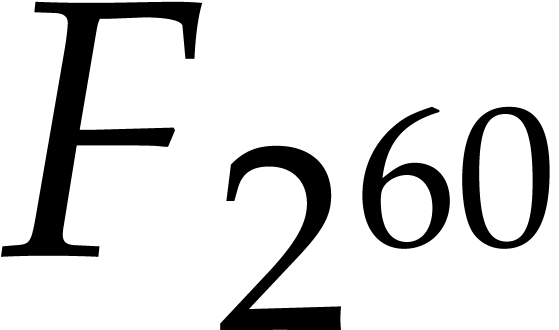 .
In M. Rosenkranz, editor, Proceedings of the ACM on
International Symposium on Symbolic and Algebraic
Computation, ISSAC '16, pages 255–262. ACM, 2016.
.
In M. Rosenkranz, editor, Proceedings of the ACM on
International Symposium on Symbolic and Algebraic
Computation, ISSAC '16, pages 255–262. ACM, 2016.
D. Harvey, J. van der Hoeven, and G. Lecerf. Faster polynomial multiplication over finite fields. J. ACM, 63(6), 2017. Article 52.
J. van der Hoeven. The truncated Fourier transform and applications. In J. Schicho, editor, Proceedings of the 2004 International Symposium on Symbolic and Algebraic Computation, ISSAC '04, pages 290–296. ACM, 2004.
J. van der Hoeven. Newton's method and FFT trading. J. Symbolic Comput., 45(8):857–878, 2010.
J. van der Hoeven and R. Larrieu. The Frobenius FFT. In M. Burr, editor, Proceedings of the 2017 ACM on International Symposium on Symbolic and Algebraic Computation, ISSAC '17, pages 437–444. ACM, 2017.
J. van der Hoeven and G. Lecerf. Interfacing Mathemagix with C++. In M. Monagan, G. Cooperman, and M. Giesbrecht, editors, Proceedings of the 2013 ACM on International Symposium on Symbolic and Algebraic Computation, ISSAC '13, pages 363–370. ACM, 2013.
J. van der Hoeven and G. Lecerf. Mathemagix User Guide. https://hal.archives-ouvertes.fr/hal-00785549, 2013.
R. Larrieu. The truncated Fourier transform for mixed radices. In M. Burr, editor, Proceedings of the 2017 ACM on International Symposium on Symbolic and Algebraic Computation, ISSAC '17, pages 261–268. ACM, 2017.
Sian-Jheng Lin, Wei-Ho Chung, and S. Yunghsiang Han. Novel polynomial basis and its application to Reed-Solomon erasure codes. In 2014 IEEE 55th Annual Symposium on Foundations of Computer Science (FOCS), pages 316–325. IEEE, 2014.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Infor., 7:395–398, 1977.
A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.
H. S. Warren. Hacker's Delight. Addison-Wesley, 2nd edition, 2012.
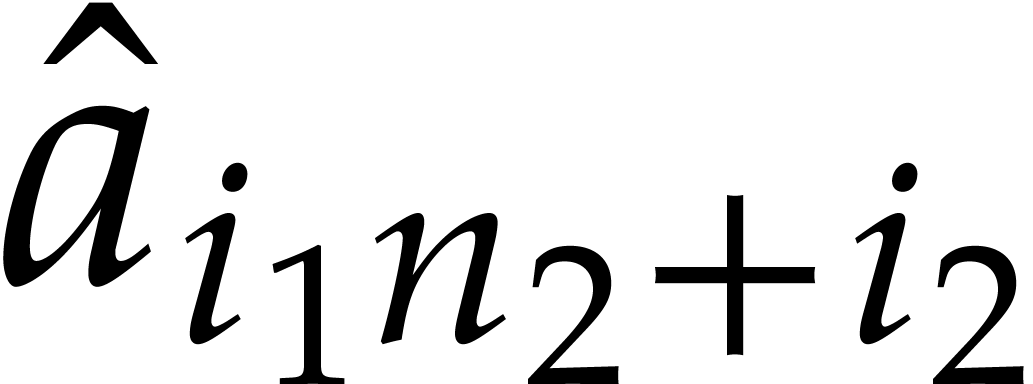

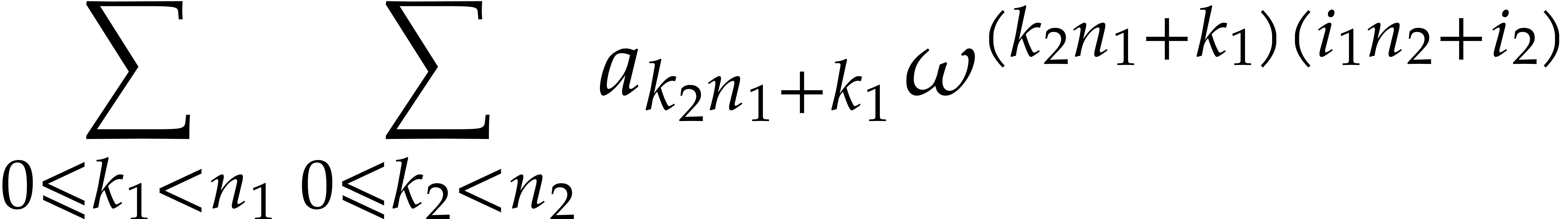
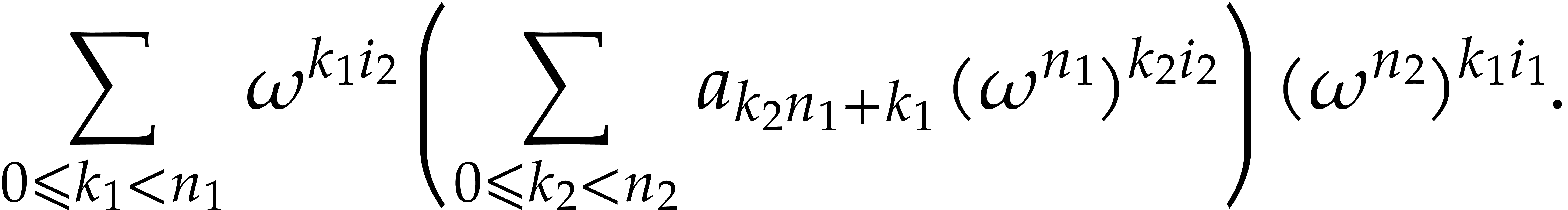
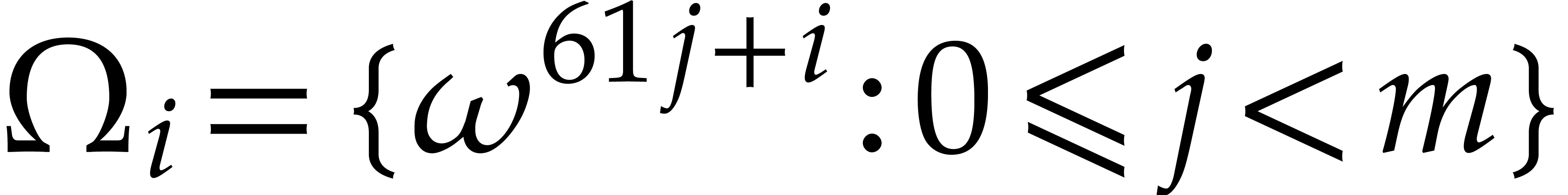 for
for 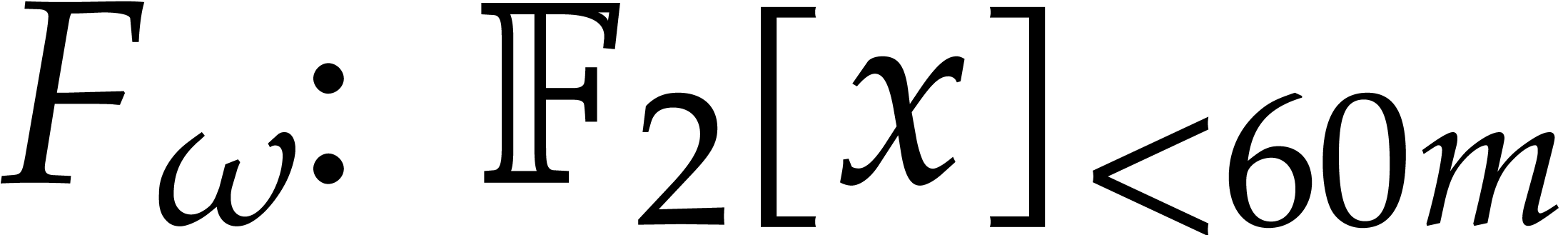
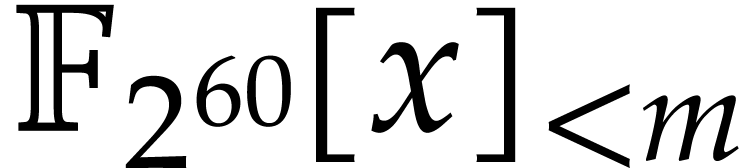
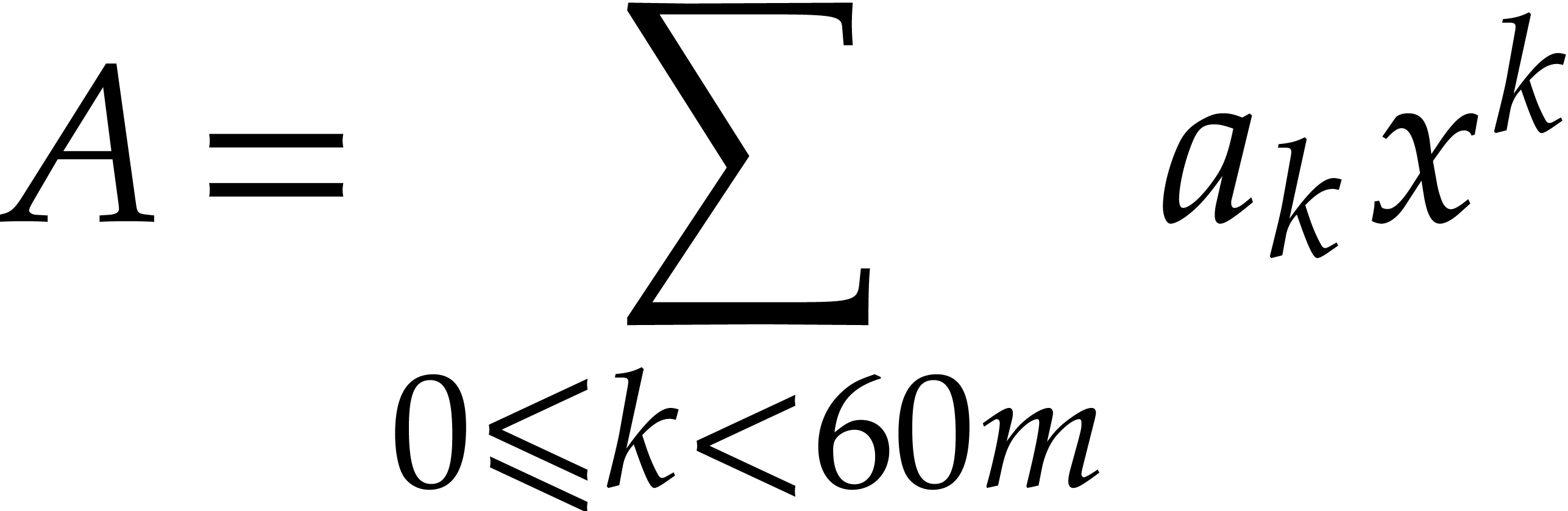
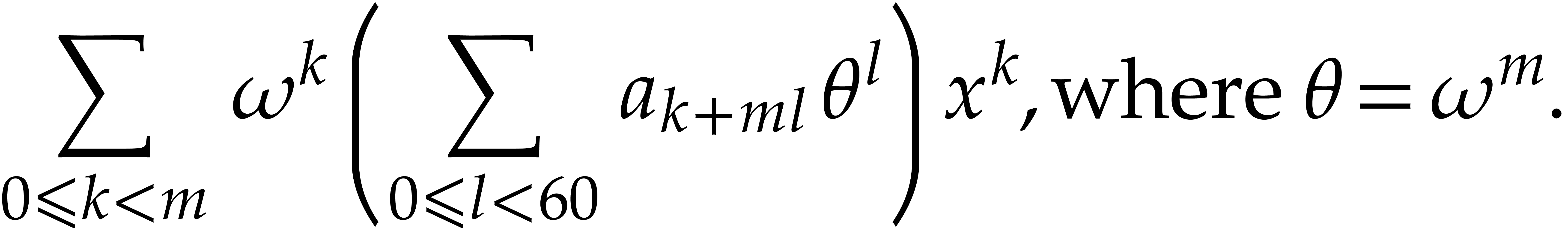
 .
.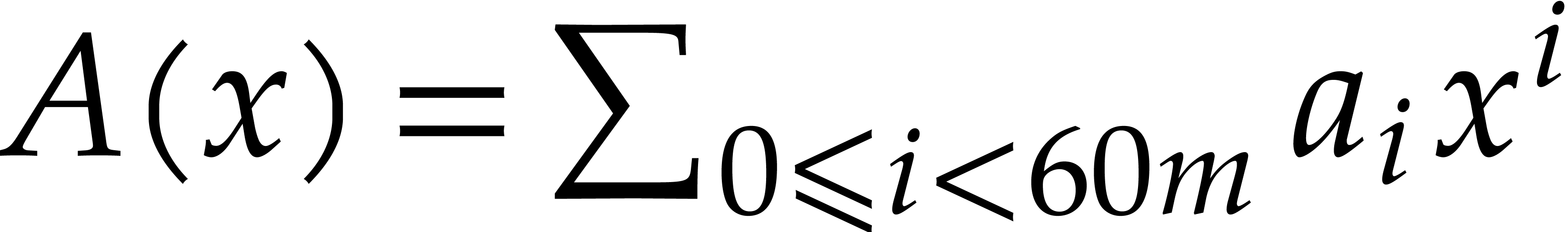 .
.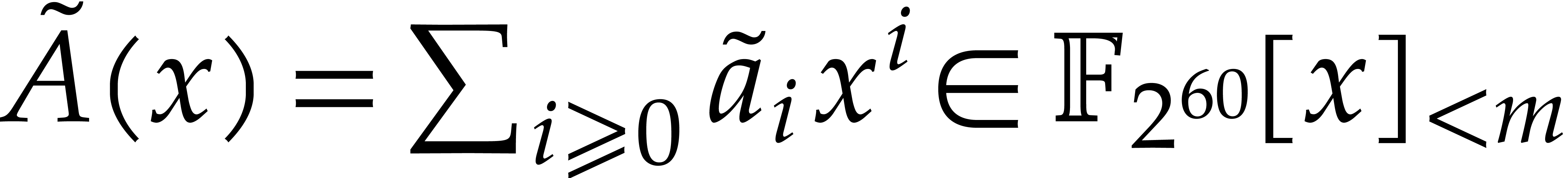 .
.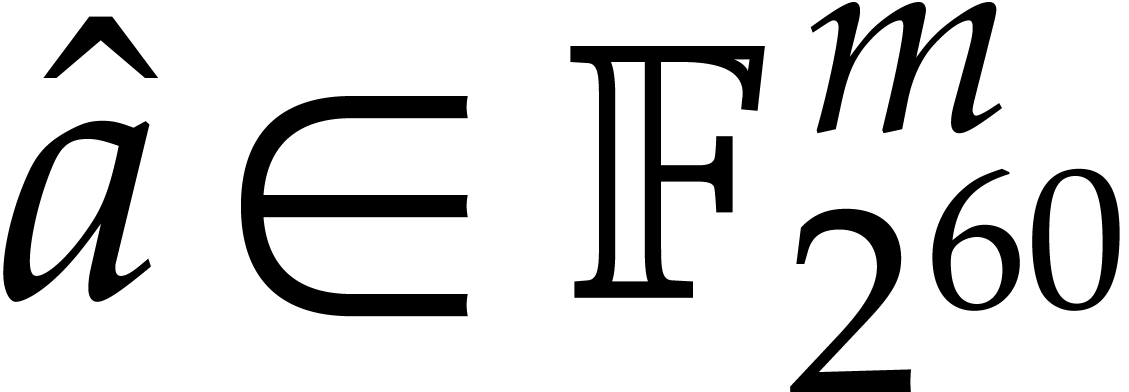 .
. .
.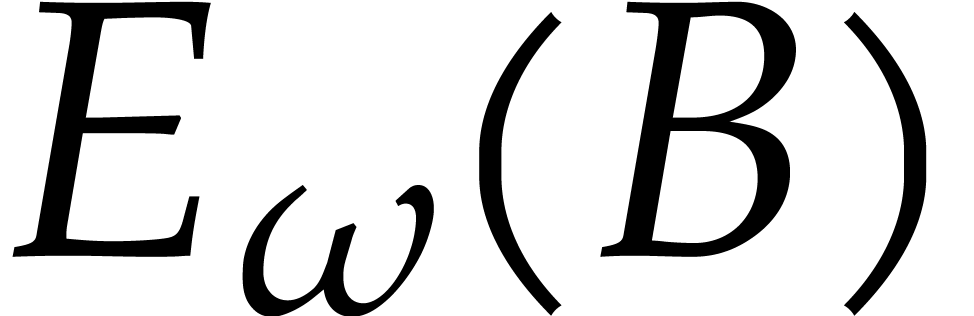 by
Algorithm
by
Algorithm 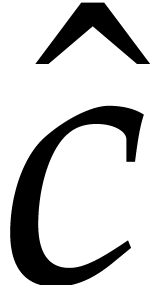 as the entry-wise product of
as the entry-wise product of
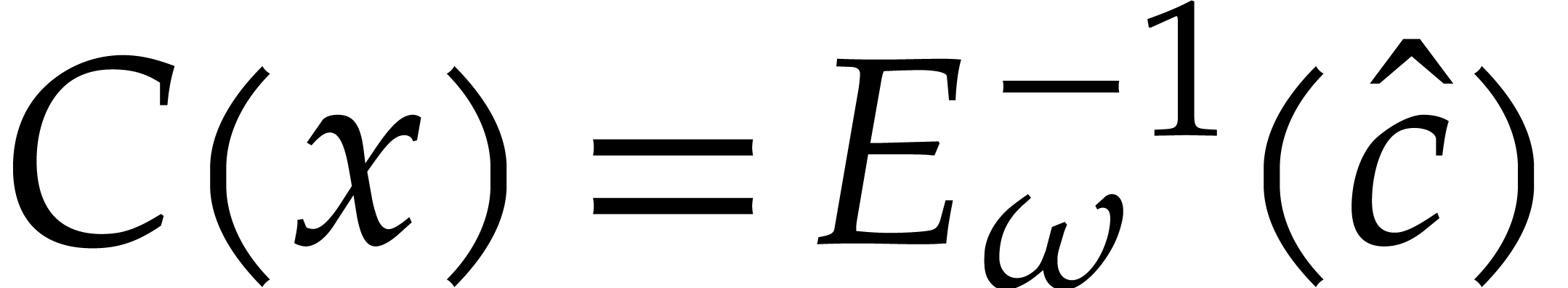 by Algorithm
by Algorithm 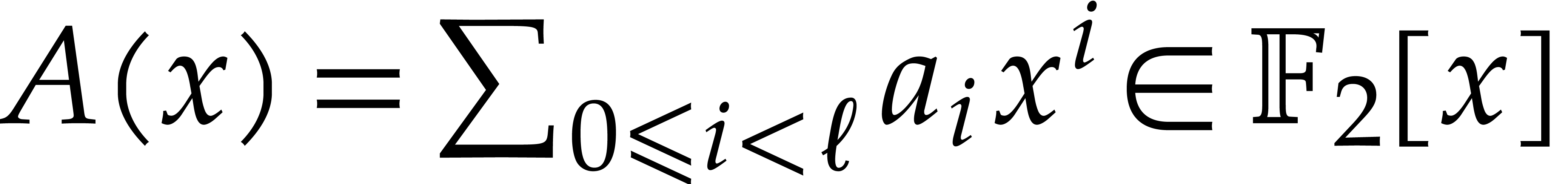 .
.
 quad words, timings in milliseconds.
quad words, timings in milliseconds.
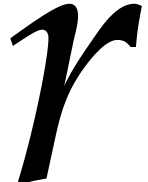
 matrices over
matrices over 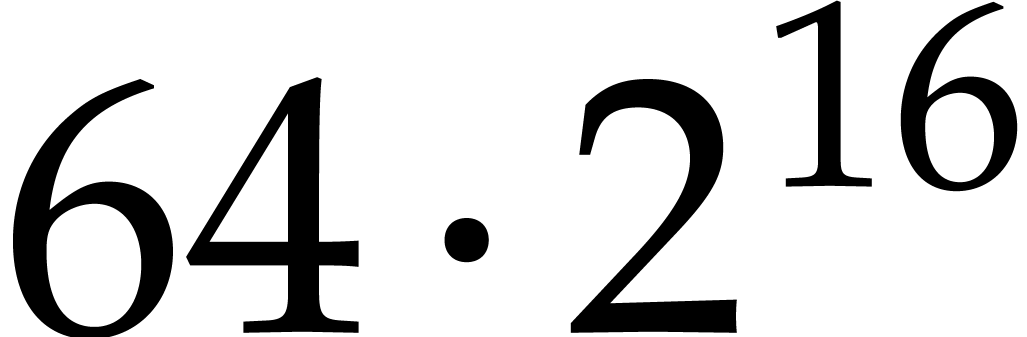 ,
,