Let
|
|
Let
|
Given a ring 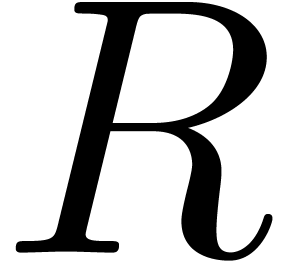 , a basic
problem in complexity theory is to find an upper bound for the cost of
multiplying two polynomials in
, a basic
problem in complexity theory is to find an upper bound for the cost of
multiplying two polynomials in 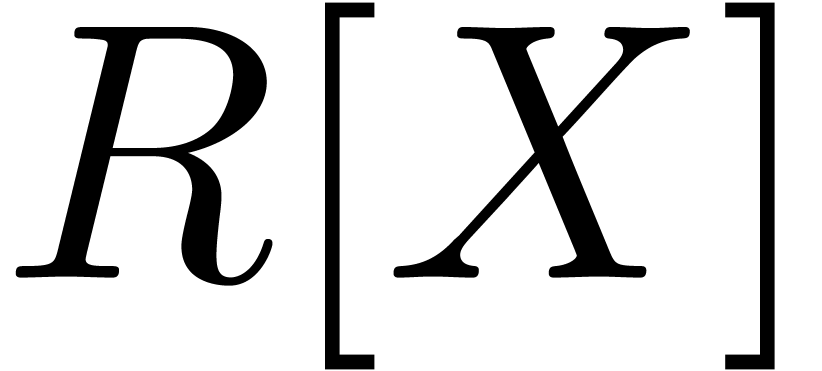 of degree less
than
of degree less
than  . Several complexity
models may be considered. In algebraic complexity models, such
as the straight-line program model [9, Chapter 4], we count
the number of ring operations in ,
denoted
. Several complexity
models may be considered. In algebraic complexity models, such
as the straight-line program model [9, Chapter 4], we count
the number of ring operations in ,
denoted 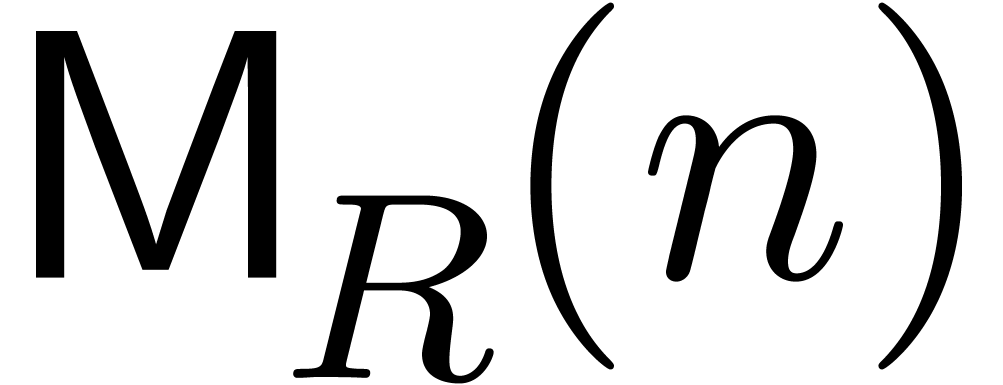 . In this model, the
best currently known bound
. In this model, the
best currently known bound 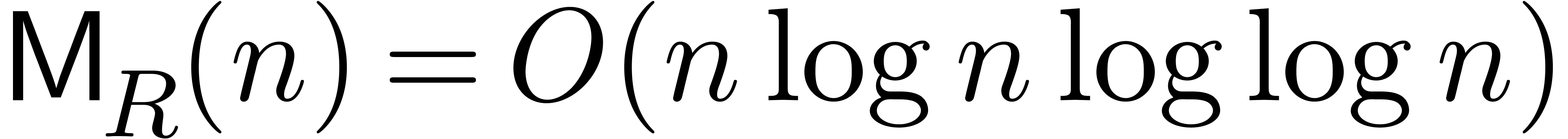 was obtained by
Cantor and Kaltofen [10]. More precisely, their algorithm
performs
was obtained by
Cantor and Kaltofen [10]. More precisely, their algorithm
performs 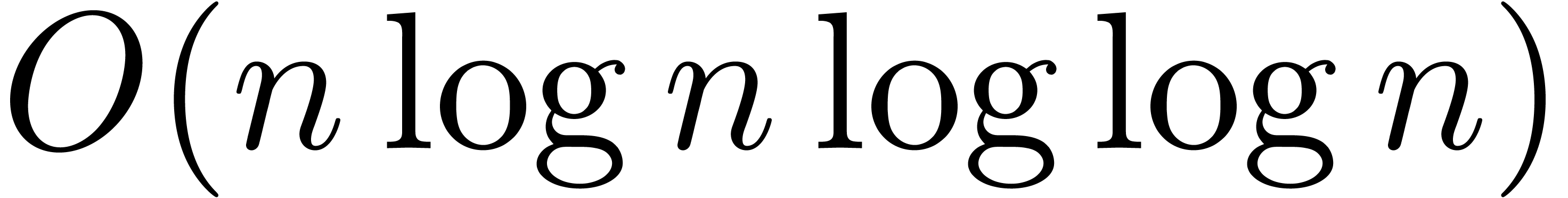 additions and subtractions and
additions and subtractions and 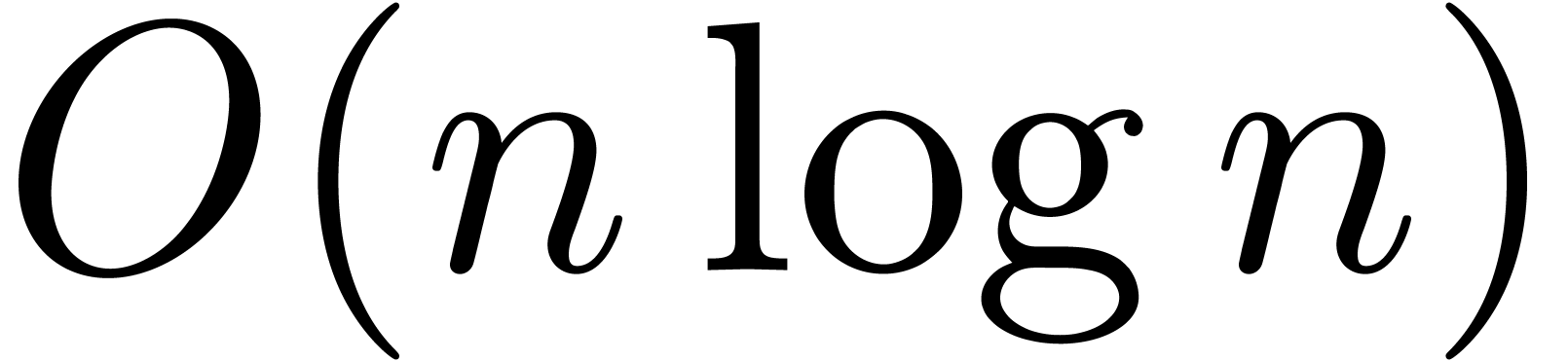 multiplications in .
Their bound may be viewed as an algebraic analogue of the
Schönhage–Strassen result for integer multiplication [32] and generalises previous work by Schönhage [31].
These algorithms all rely on suitable incarnations of the fast Fourier
transform (FFT) [12]. For details we refer the reader to
[17, Chapter 8].
multiplications in .
Their bound may be viewed as an algebraic analogue of the
Schönhage–Strassen result for integer multiplication [32] and generalises previous work by Schönhage [31].
These algorithms all rely on suitable incarnations of the fast Fourier
transform (FFT) [12]. For details we refer the reader to
[17, Chapter 8].
In this paper we are mainly interested in the case that
is the finite field 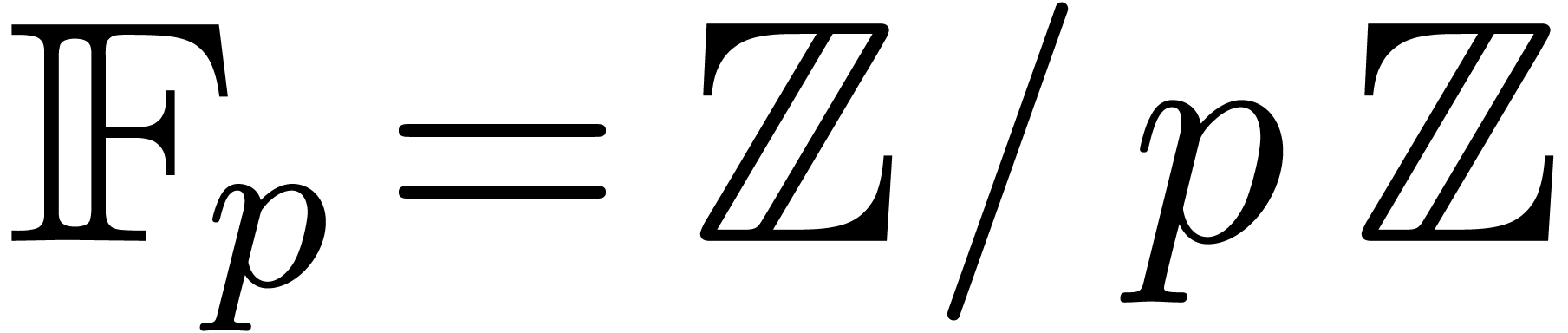 for some prime
for some prime  . The standard bit complexity model
based on deterministic multitape Turing machines [26] is
more realistic in this setting, as it takes into account the dependence
on . We write
. The standard bit complexity model
based on deterministic multitape Turing machines [26] is
more realistic in this setting, as it takes into account the dependence
on . We write  for the bit complexity of multiplying two polynomials in
for the bit complexity of multiplying two polynomials in
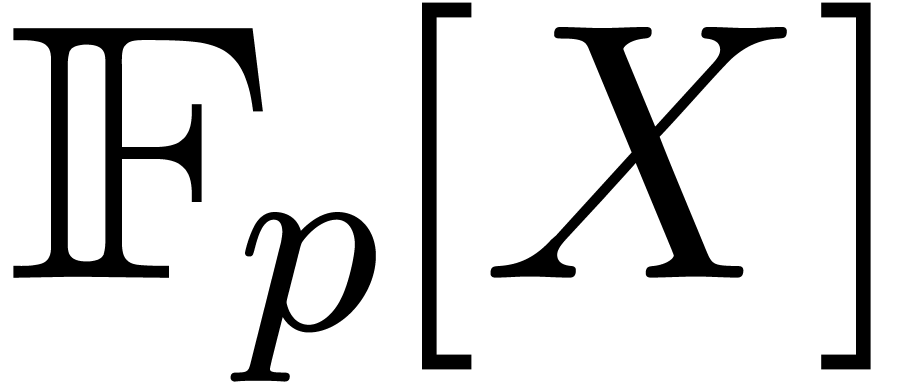 of degree less than . Two basic approaches are known for obtaining good
asymptotic bounds for .
of degree less than . Two basic approaches are known for obtaining good
asymptotic bounds for .
If is not too large compared to , then one may use Kronecker
substitution, which converts the problem to integer multiplication
by packing the coefficients into large integers. Let 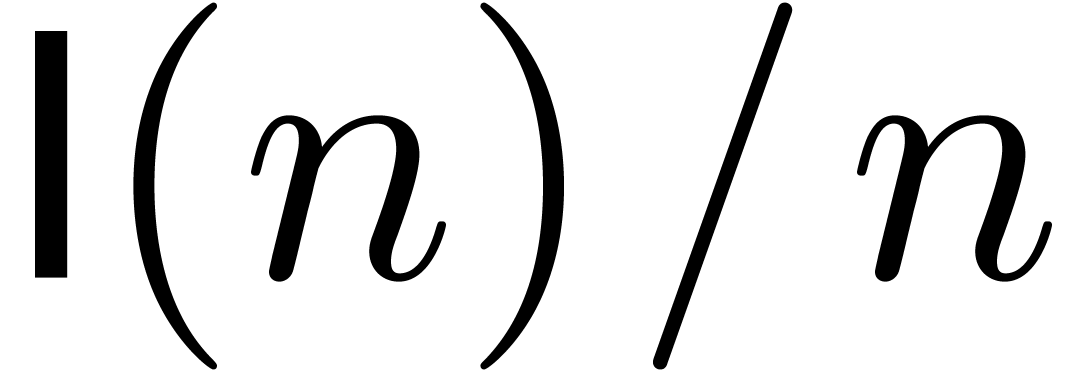 denote the bit complexity of -bit
integer multiplication. Throughout the paper, we make the customary
assumption that
denote the bit complexity of -bit
integer multiplication. Throughout the paper, we make the customary
assumption that 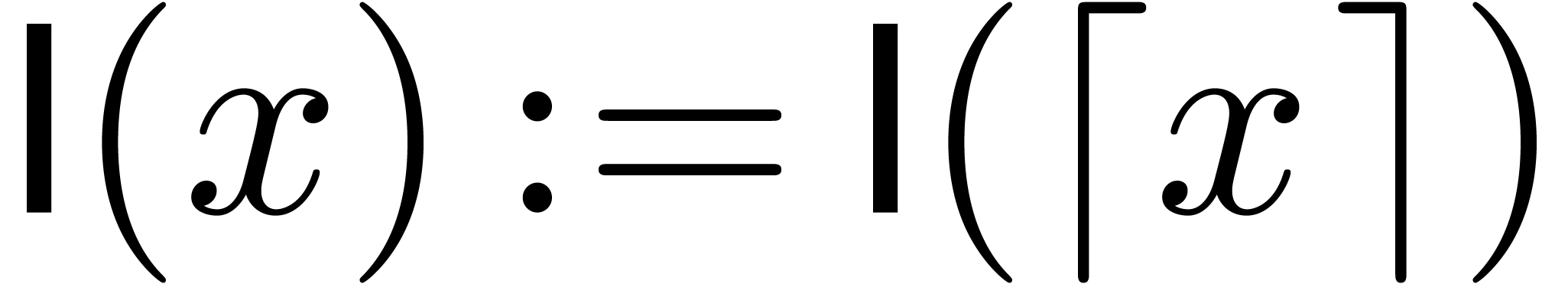 is increasing, and for
convenience we define
is increasing, and for
convenience we define 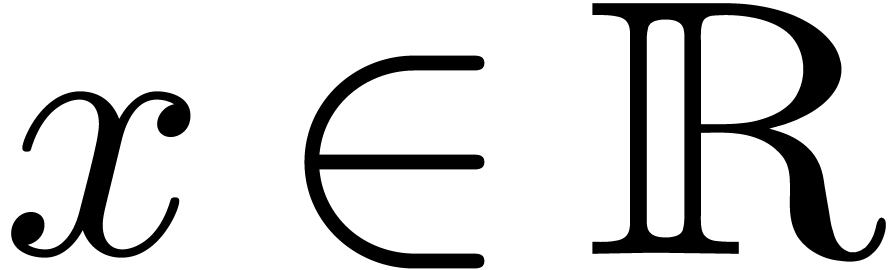 for
for 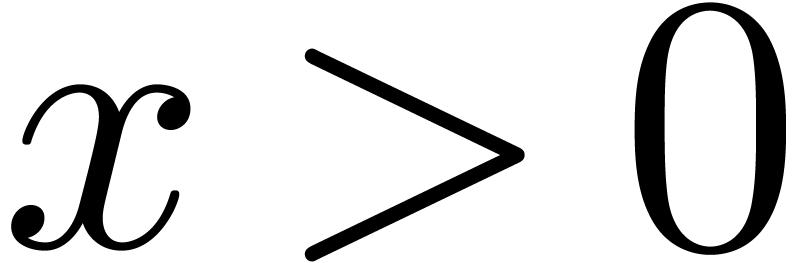 ,
, 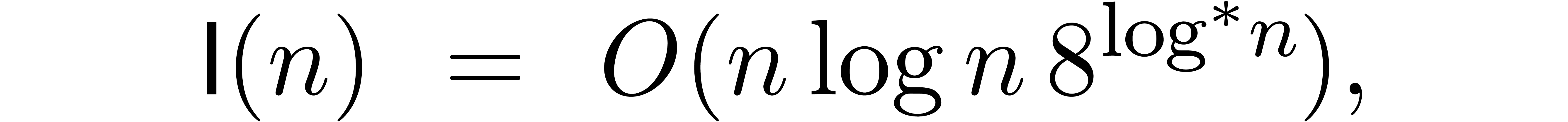 .
According to our recent sharpening [18] of Fürer's
bound [15], we may take
.
According to our recent sharpening [18] of Fürer's
bound [15], we may take
where  denotes the iterated logarithm for , i.e.,
denotes the iterated logarithm for , i.e.,
If 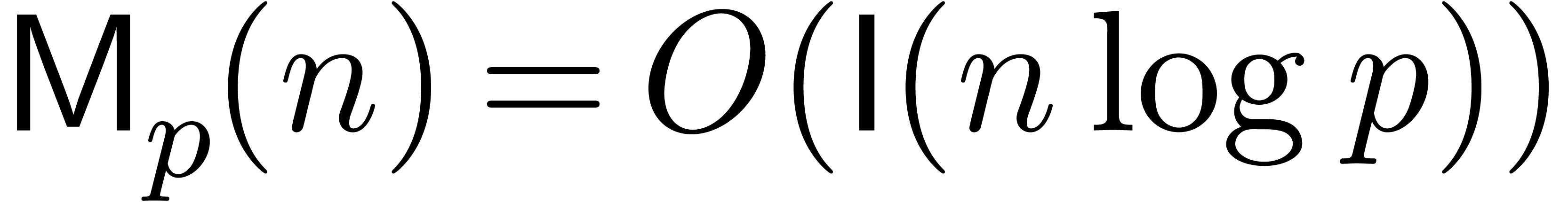 , then Kronecker
substitution yields
, then Kronecker
substitution yields  (see section 2.6),
so we have
(see section 2.6),
so we have
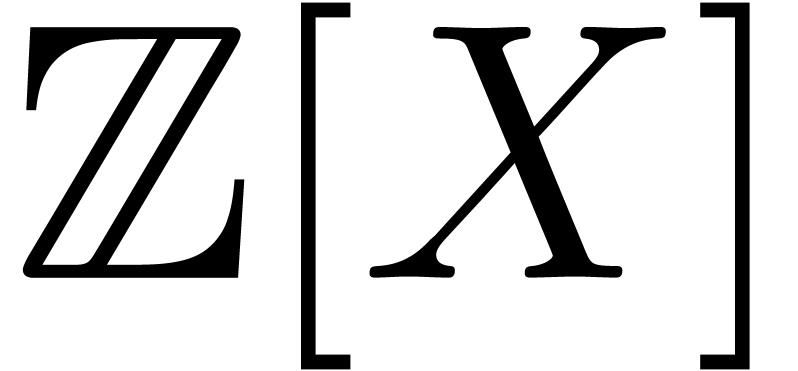
However, Kronecker substitution leads to inferior bounds when is large compared to ,
due to coefficient growth in the lifted product in  . In this situation the best existing method is
the algebraic Schönhage–Strassen algorithm (i.e., the
Cantor–Kaltofen algorithm). In the Turing model this yields the
bound
. In this situation the best existing method is
the algebraic Schönhage–Strassen algorithm (i.e., the
Cantor–Kaltofen algorithm). In the Turing model this yields the
bound
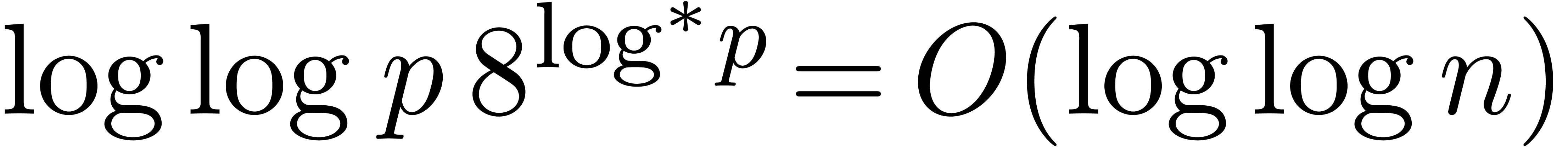
The first term dominates for large enough ,
say for 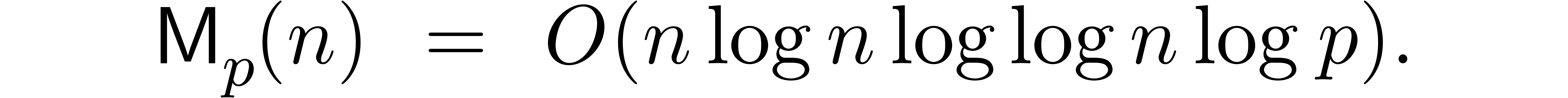 , and we get simply
, and we get simply
Since Fürer's breakthrough result, there has been a gap between
what is known for integer multiplication and for multiplication in . Namely, it has remained an open
question whether the factor 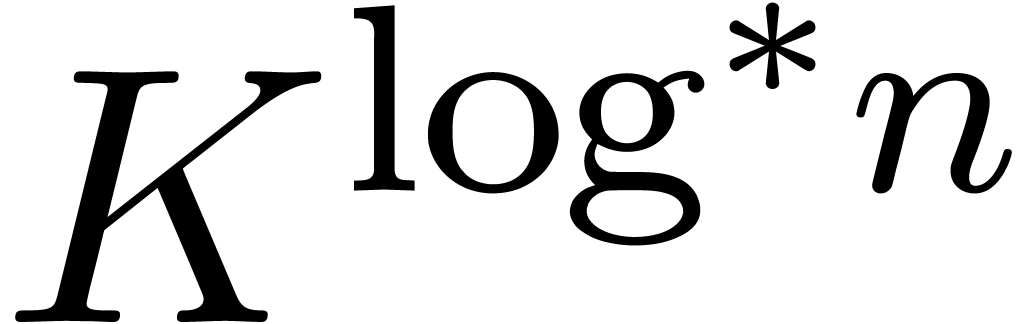 appearing in
appearing in 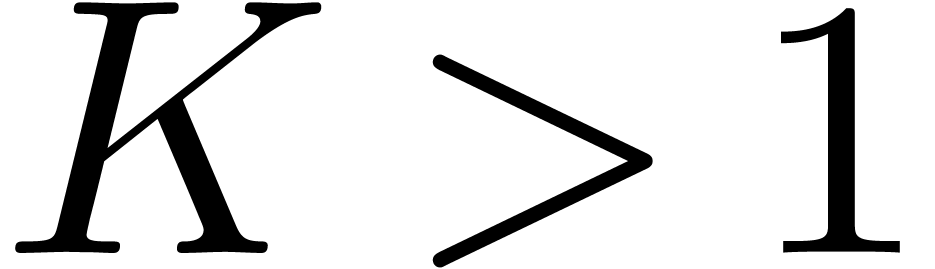 for some
for some  . It seems that
Fürer's construction does not work in .
. It seems that
Fürer's construction does not work in .
The main result of this paper is a new algorithm that completely closes the gap mentioned above.
The bound follows immediately via Kronecker substitution if . The bulk of the paper concerns the reverse
case where is large compared to . For example, if 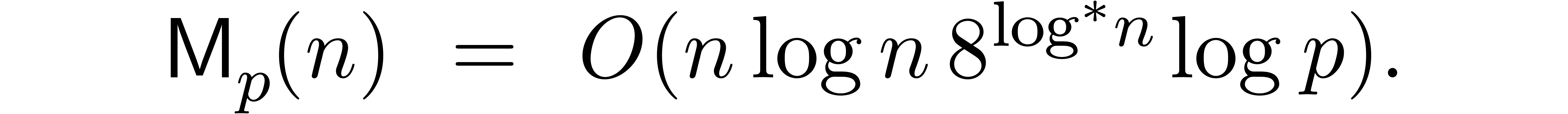 ,
the bound becomes simply
,
the bound becomes simply
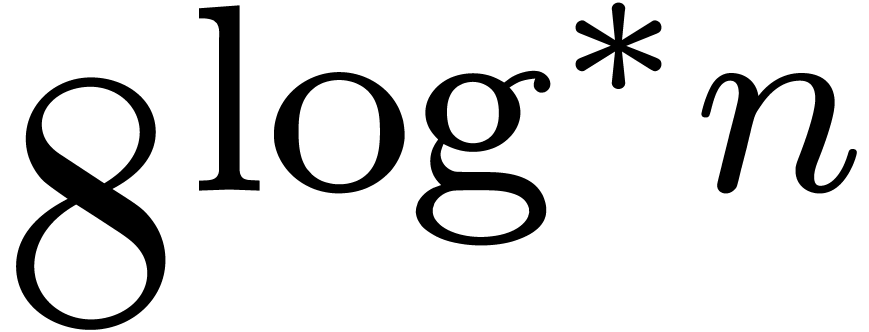
As promised, this replaces the factor in 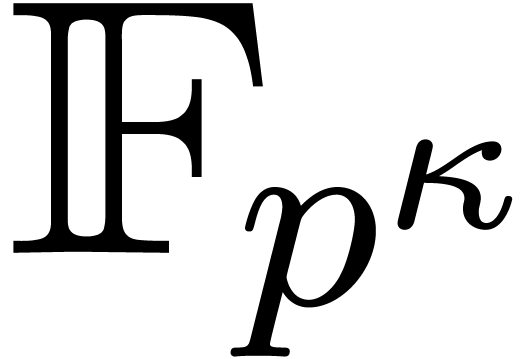 .
.
The basic idea of the new algorithm is as follows. We first construct a
special extension 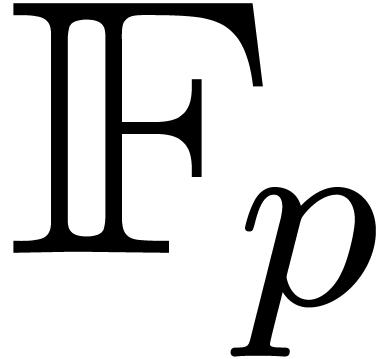 of
of  , where
, where  is exponentially
smaller than , and for which
is exponentially
smaller than , and for which
 has many small divisors. These divisors are
themselves exponentially smaller than ,
yet they are so numerous that their product is comparable to . We now convert the given
multiplication problem in to multiplication in
has many small divisors. These divisors are
themselves exponentially smaller than ,
yet they are so numerous that their product is comparable to . We now convert the given
multiplication problem in to multiplication in
 , by cutting up the
polynomials into small pieces, and we then multiply in
by using FFTs over . Applying
the Cooley–Tukey method to the small divisors of , we decompose the FFTs into transforms of
exponentially shorter lengths (not necessarily powers of two). We use
Bluestein's method to convert each short transform to a convolution over
, and then use Kronecker
substitution (from bivariate to univariate polynomials) to convert this
to multiplication in . These
latter multiplications are then handled recursively. We continue the
recursion until is comparable to , at which point we switch to using Kronecker
substitution (from polynomials to integers).
, by cutting up the
polynomials into small pieces, and we then multiply in
by using FFTs over . Applying
the Cooley–Tukey method to the small divisors of , we decompose the FFTs into transforms of
exponentially shorter lengths (not necessarily powers of two). We use
Bluestein's method to convert each short transform to a convolution over
, and then use Kronecker
substitution (from bivariate to univariate polynomials) to convert this
to multiplication in . These
latter multiplications are then handled recursively. We continue the
recursion until is comparable to , at which point we switch to using Kronecker
substitution (from polynomials to integers).
In many respects this approach is very similar to the algorithm for integer multiplication introduced in [18], but there are various additional technical issues to address. We recommend [18] as a gentle introduction to the main ideas.
We also prove the following conditional result.
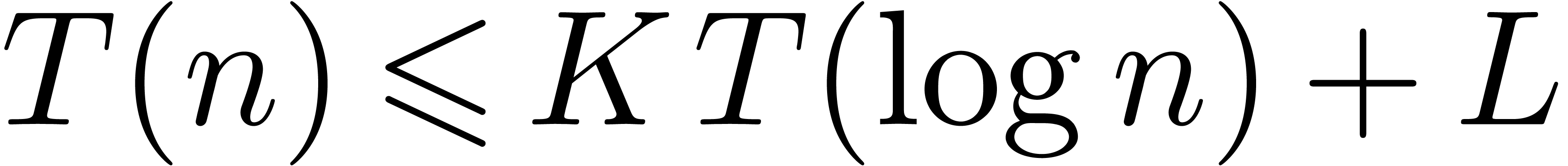
holds uniformly for all 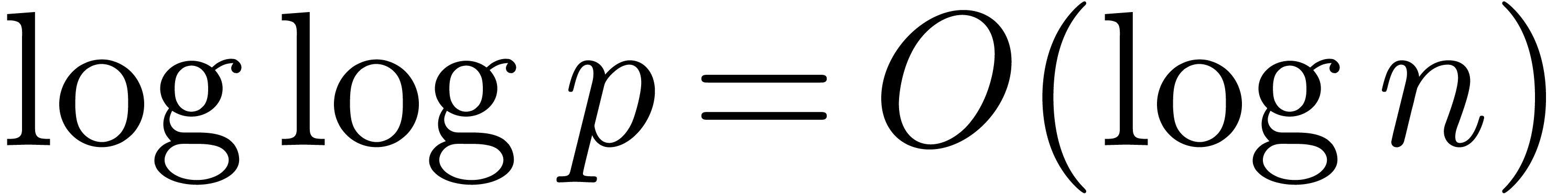 and all primes
and all primes
 .
.
Of these conjectures, Conjecture 8.3 seems to be in reach for specialists in analytic number theory; Conjecture 8.5 is at least as hard as Artin's conjecture on primitive roots, but may be tractable under the generalised Riemann hypothesis (GRH); and Conjecture 8.1 is almost as strong as the Lenstra–Pomerance–Wagstaff conjecture on the distribution of Mersenne primes, and seems to be inaccessible at present.
The paper is structured as follows. In section 2, we start with a survey of relevant basic techniques: discrete Fourier transforms (DFTs) and FFTs, Bluestein's chirp transform, and Kronecker substitution. Most of this material is repeated from [18, Section 2] for the convenience of the reader; however, sections 2.5 and 2.6 differ substantially.
In section 3, we recall basic complexity results for
arithmetic in finite fields. In particular, we consider the construction
of irreducible polynomials in ,
algorithms for finding roots of unity in ,
and the cost of arithmetic in and .
In section 4, we show how to construct special extensions
of whose multiplicative group has a large
subgroup of highly smooth order, i.e., is divisible by many small
integers. The main tool is [2, Theorem 3].
Section 5 gives complexity bounds for functions that
satisfy recurrence inequalities involving postcompositions with
“logarithmically slow” functions. The prototype of such an
inequality is  , where
, where  and
and 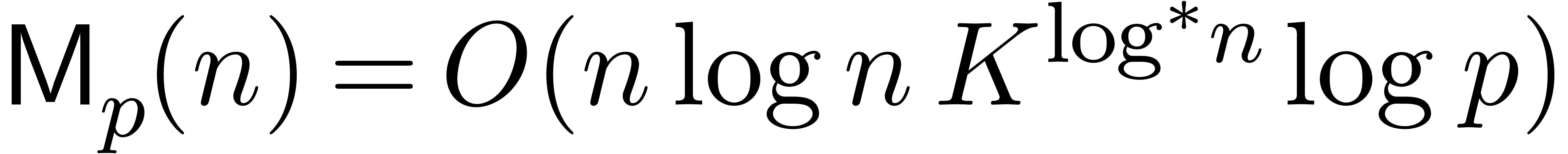 are constants. The
definitions and theorems are duplicated from [18, Section
5]; for the proofs, see [18].
are constants. The
definitions and theorems are duplicated from [18, Section
5]; for the proofs, see [18].
To minimise the constant in the bound  (for large relative to ), we need one more tool: in
section 6, we present a polynomial analogue of the
Crandall–Fagin convolution algorithm [13]. This
allows us to convert a cyclic convolution over
of length , where is arbitrary, into a cyclic convolution over of somewhat smaller length
(for large relative to ), we need one more tool: in
section 6, we present a polynomial analogue of the
Crandall–Fagin convolution algorithm [13]. This
allows us to convert a cyclic convolution over
of length , where is arbitrary, into a cyclic convolution over of somewhat smaller length  ,
where is prescribed and where
,
where is prescribed and where 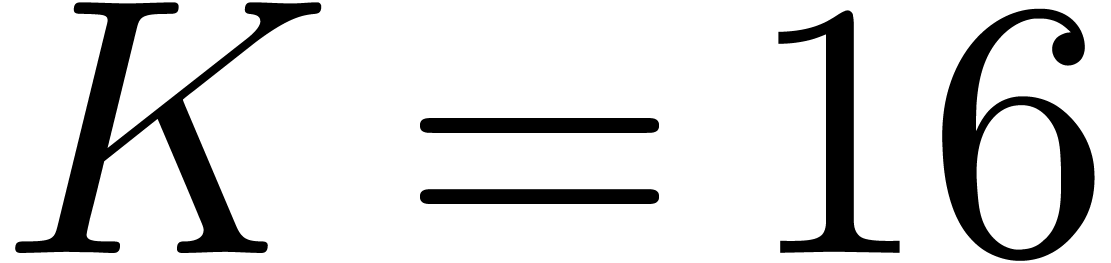 . (We can still obtain
. (We can still obtain 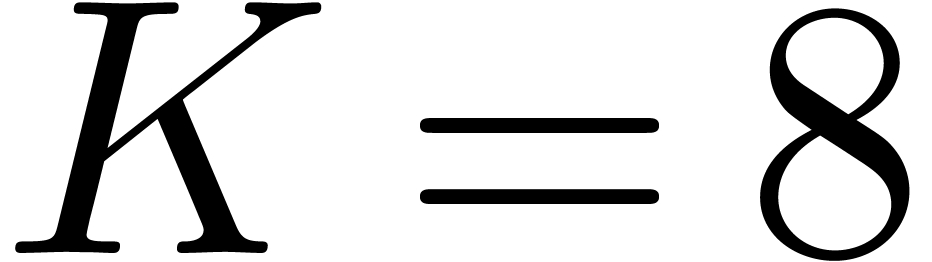 without using this Crandall–Fagin analogue, but we do not know how
to reach
without using this Crandall–Fagin analogue, but we do not know how
to reach 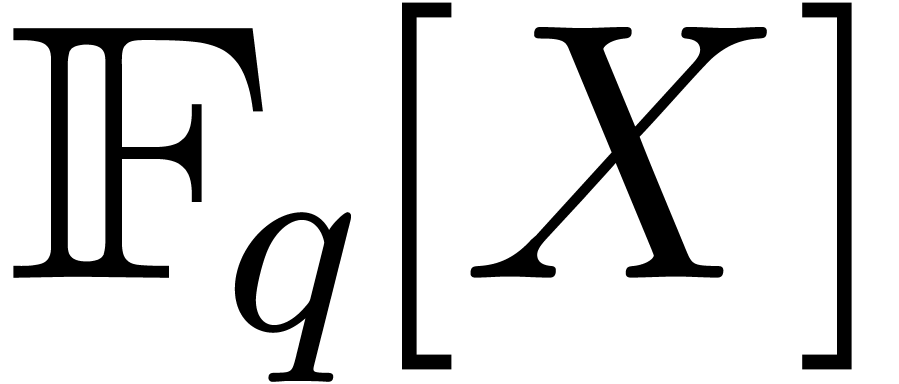 without it.)
without it.)
Section 7 is devoted to the proof of Theorem 1.1. Section 8 gives the proof of Theorem 1.2, and discusses the three number-theoretic hypotheses of that theorem.
The last section offers some final notes and suggested directions for
generalisation. We first quickly dispense with the bit complexity of
multiplication in  for prime powers
for prime powers 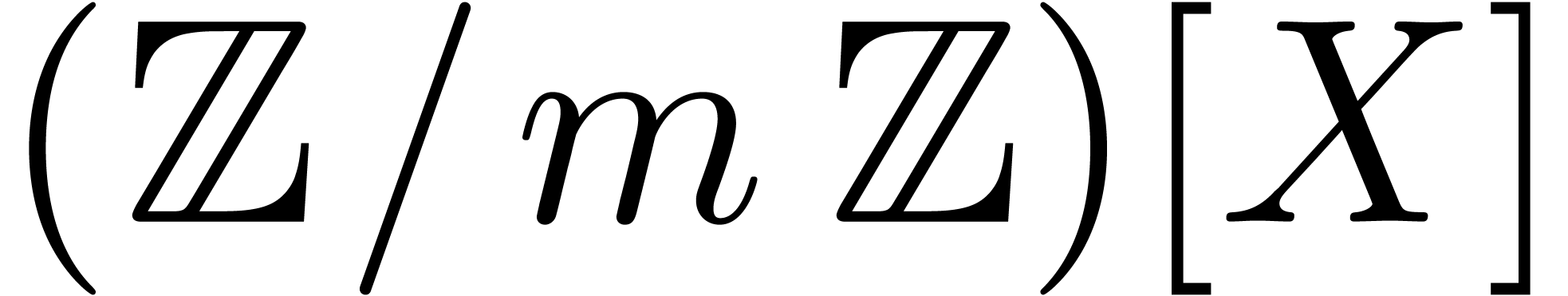 , and in
, and in 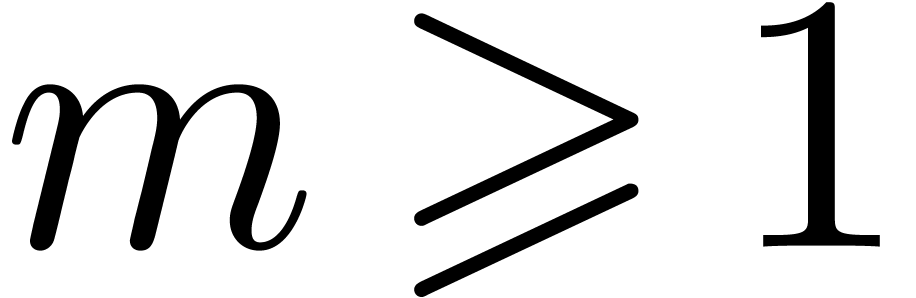 for arbitrary
integers
for arbitrary
integers 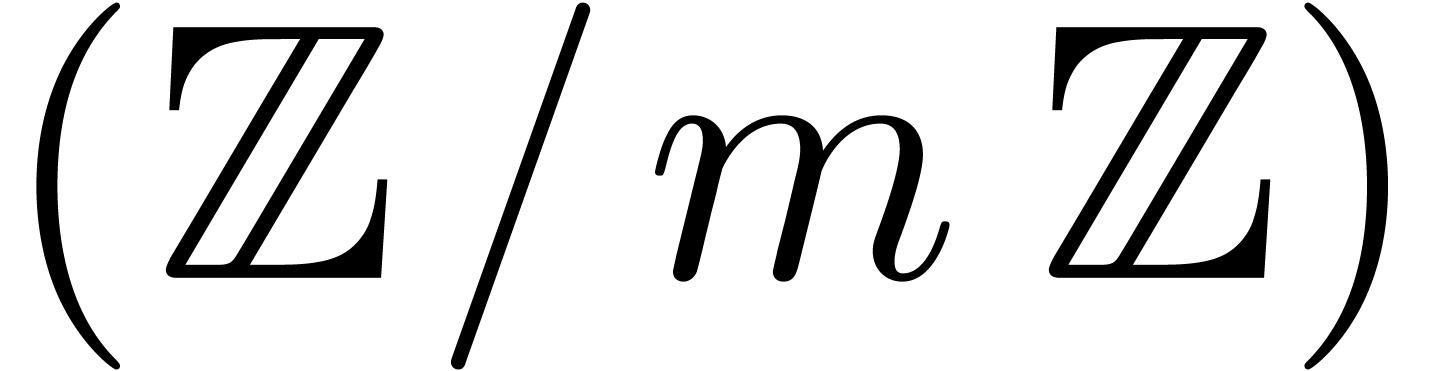 . We then sketch
some algebraic complexity bounds for polynomial multiplication over
-algebras and
. We then sketch
some algebraic complexity bounds for polynomial multiplication over
-algebras and 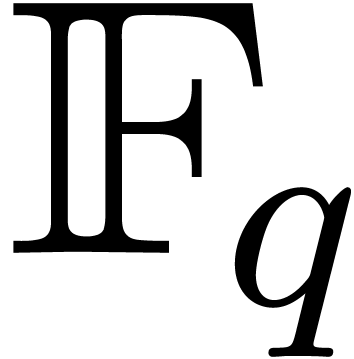 -algebras, especially in the straight-line
program model. Our techniques also give rise to new strategies for
polynomial evaluation-interpolation over
-algebras, especially in the straight-line
program model. Our techniques also give rise to new strategies for
polynomial evaluation-interpolation over  .
This may for instance be applied to the efficient multiplication of
polynomial matrices over .
Although we have not implemented any of our algorithms yet, we conclude
by a few remarks on their expected efficiency in practice.
.
This may for instance be applied to the efficient multiplication of
polynomial matrices over .
Although we have not implemented any of our algorithms yet, we conclude
by a few remarks on their expected efficiency in practice.
Notations. We use Hardy's notations 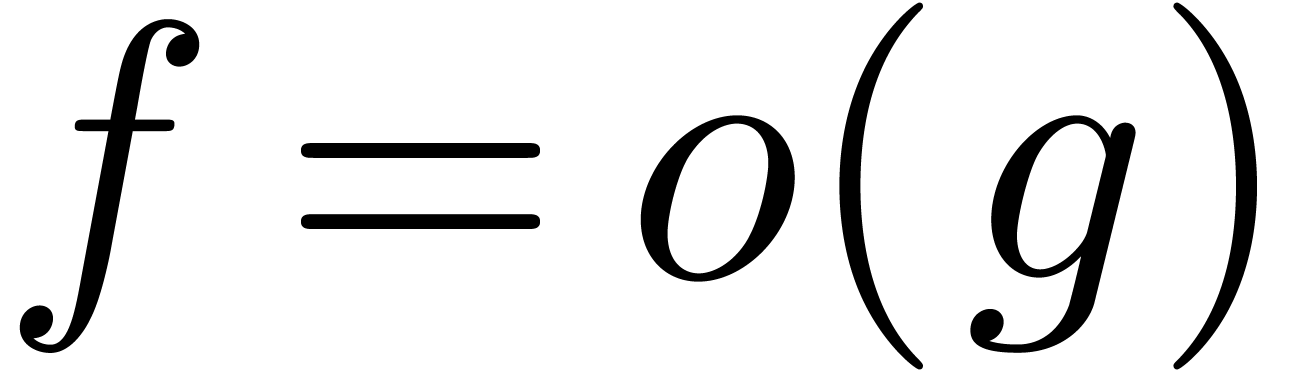 for
for  , and
, and 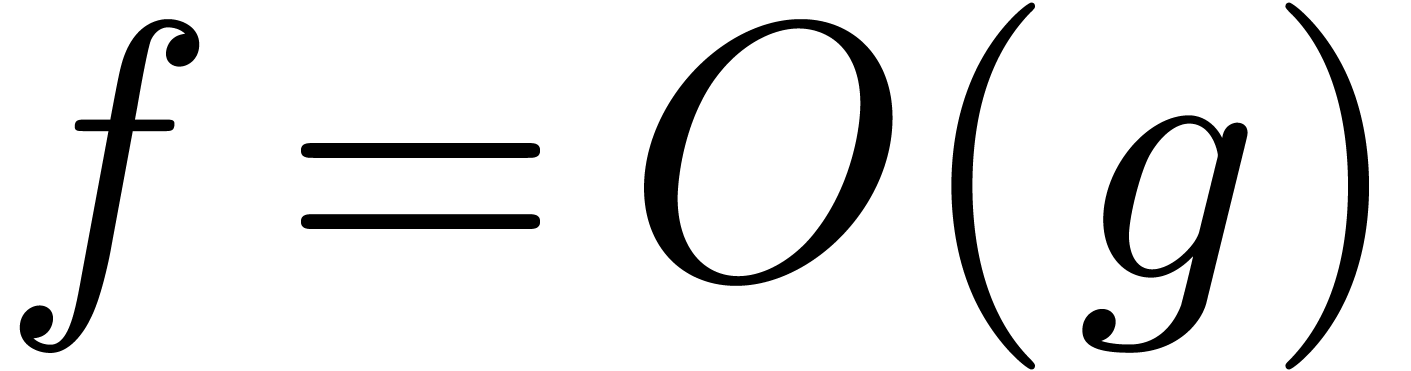 for
for  and
and 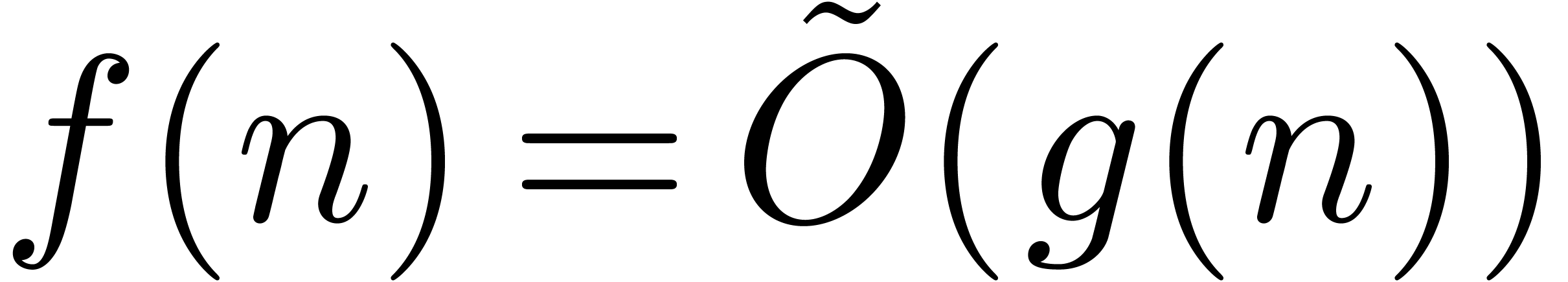 . The “soft-Oh” notation
. The “soft-Oh” notation 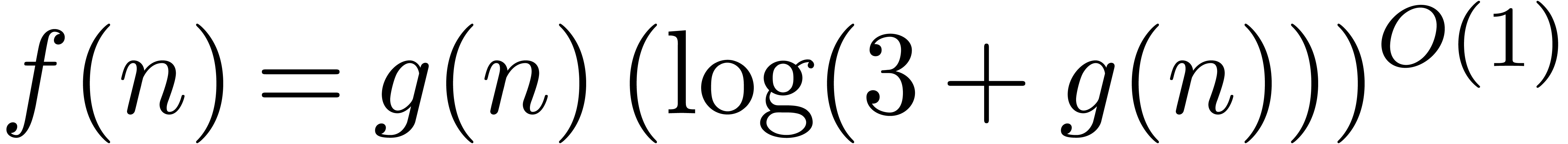 means that
means that  (see [17,
Chapter 25, Section 7] for details). The symbol
(see [17,
Chapter 25, Section 7] for details). The symbol  denotes the set of non-negative real numbers, and
denotes the set of non-negative real numbers, and 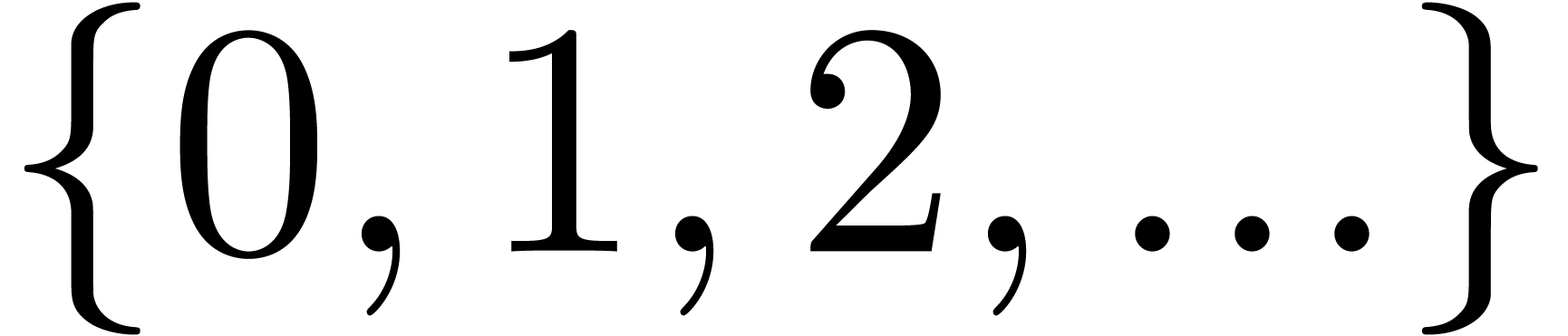 denotes
denotes  . For a ring
. For a ring  and
and  , we
write
, we
write 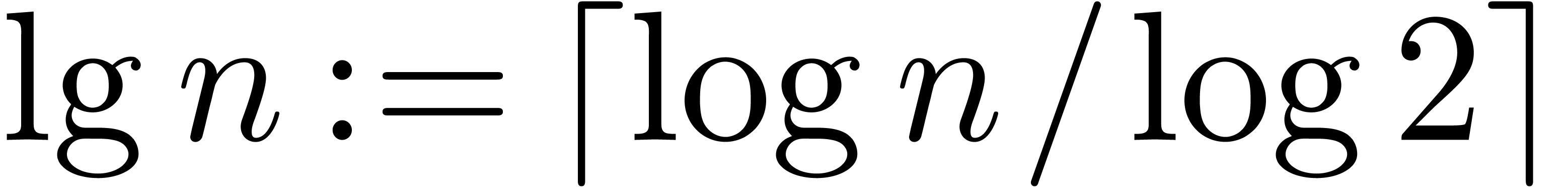 .
.
We will write  . In
expressions like
. In
expressions like 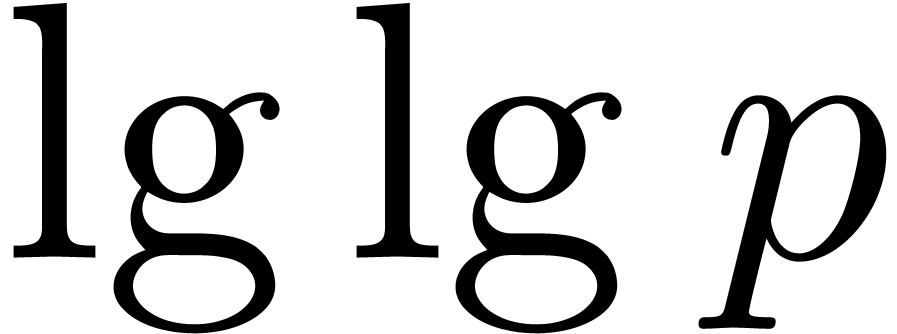 or
or 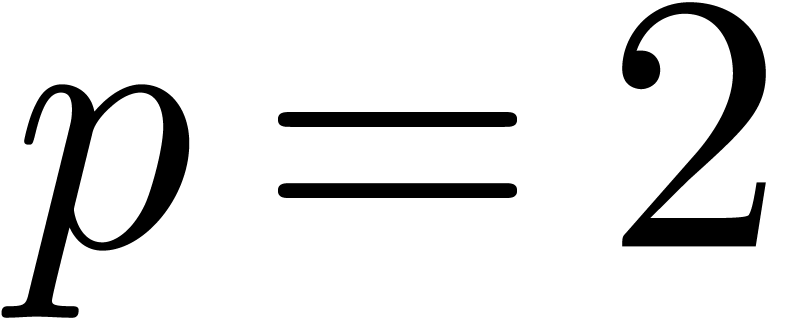 , we tacitly assume that the function is adjusted so
as to take positive values for small primes such as
, we tacitly assume that the function is adjusted so
as to take positive values for small primes such as  .
.
Acknowledgments. We would like to thank Karim Belabas for directing us to the paper [2], and Igor Shparlinski for answering some analytic number theory questions.
This section recalls basic facts on Fourier transforms and related techniques used in subsequent sections. For more details and historical references we refer the reader to standard books on the subject such as [3, 9, 17, 30].
In the Turing model, we have available a fixed number of linear tapes.
An 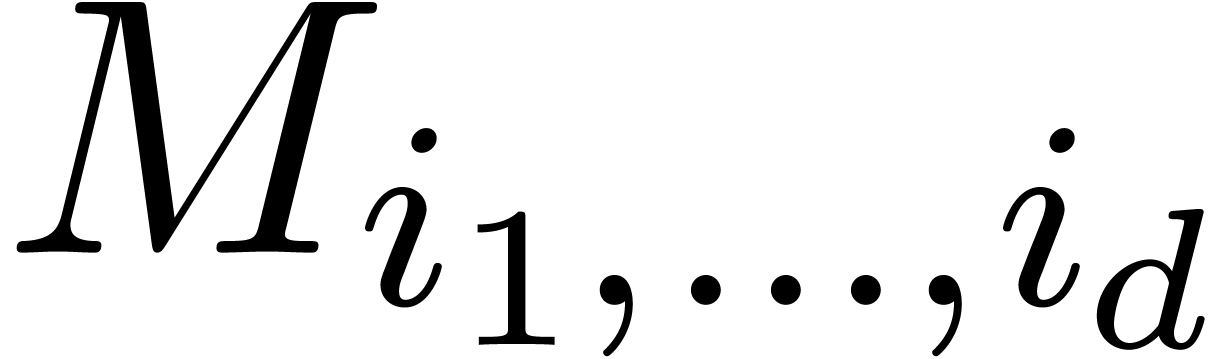 array
array 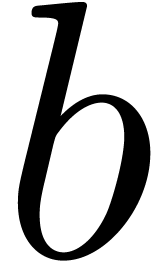 of
of 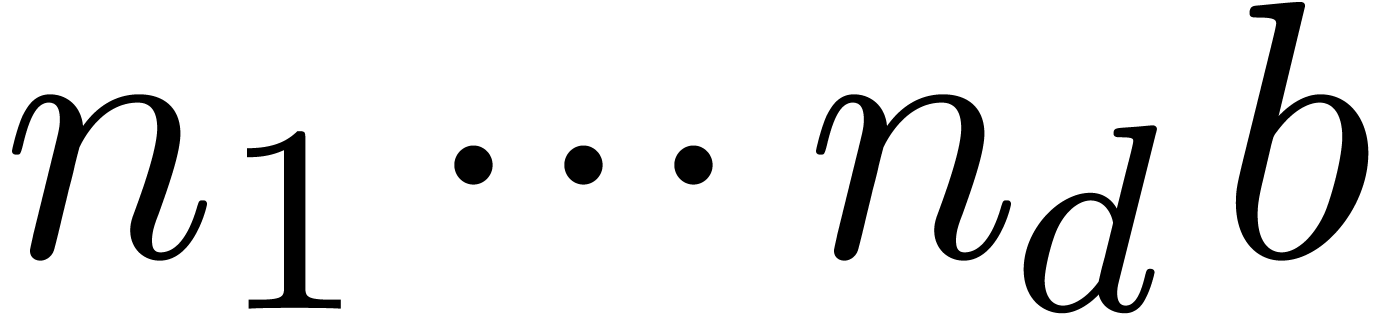 -bit elements is stored as a linear array of
-bit elements is stored as a linear array of
 bits. We generally assume that the elements are
ordered lexicographically by
bits. We generally assume that the elements are
ordered lexicographically by  ,
though this is just an implementation detail.
,
though this is just an implementation detail.
What is significant from a complexity point of view is that occasionally
we must switch representations, to access an array (say 2-dimensional)
by “rows” or by “columns”. In the Turing model,
we may transpose an 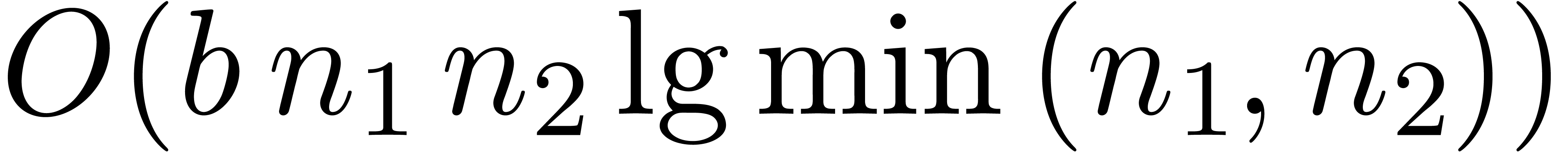 matrix of -bit elements in time
matrix of -bit elements in time  , using the algorithm of [7, Appendix].
Briefly, the idea is to split the matrix into two halves along the
“short” dimension, and transpose each half recursively.
, using the algorithm of [7, Appendix].
Briefly, the idea is to split the matrix into two halves along the
“short” dimension, and transpose each half recursively.
We will also require more complex rearrangements of data, for which we
resort to sorting. Suppose that  is a totally
ordered set, whose elements are represented by bit strings of length
, and suppose that we can
compare elements of in time
is a totally
ordered set, whose elements are represented by bit strings of length
, and suppose that we can
compare elements of in time  . Then an array of
elements of may be sorted in time
. Then an array of
elements of may be sorted in time  using merge sort [22], which can be
implemented efficiently on a Turing machine.
using merge sort [22], which can be
implemented efficiently on a Turing machine.
Let be a commutative ring with identity and let
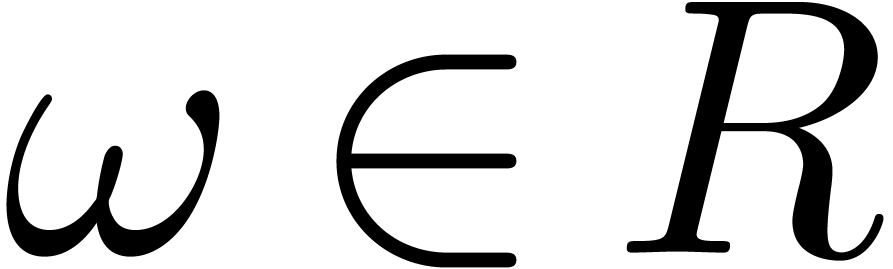 . An element
. An element 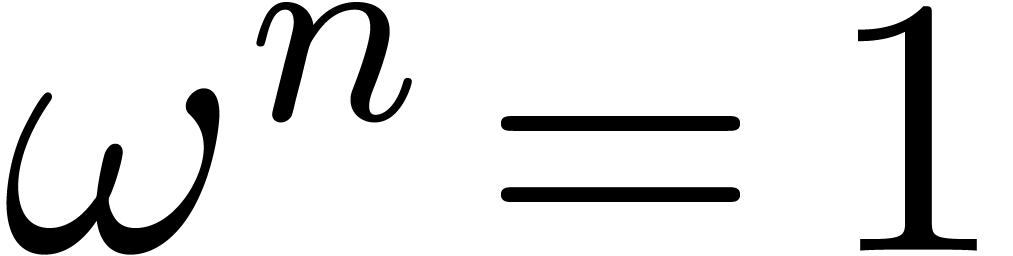 is said to be a principal -th
root of unity if
is said to be a principal -th
root of unity if 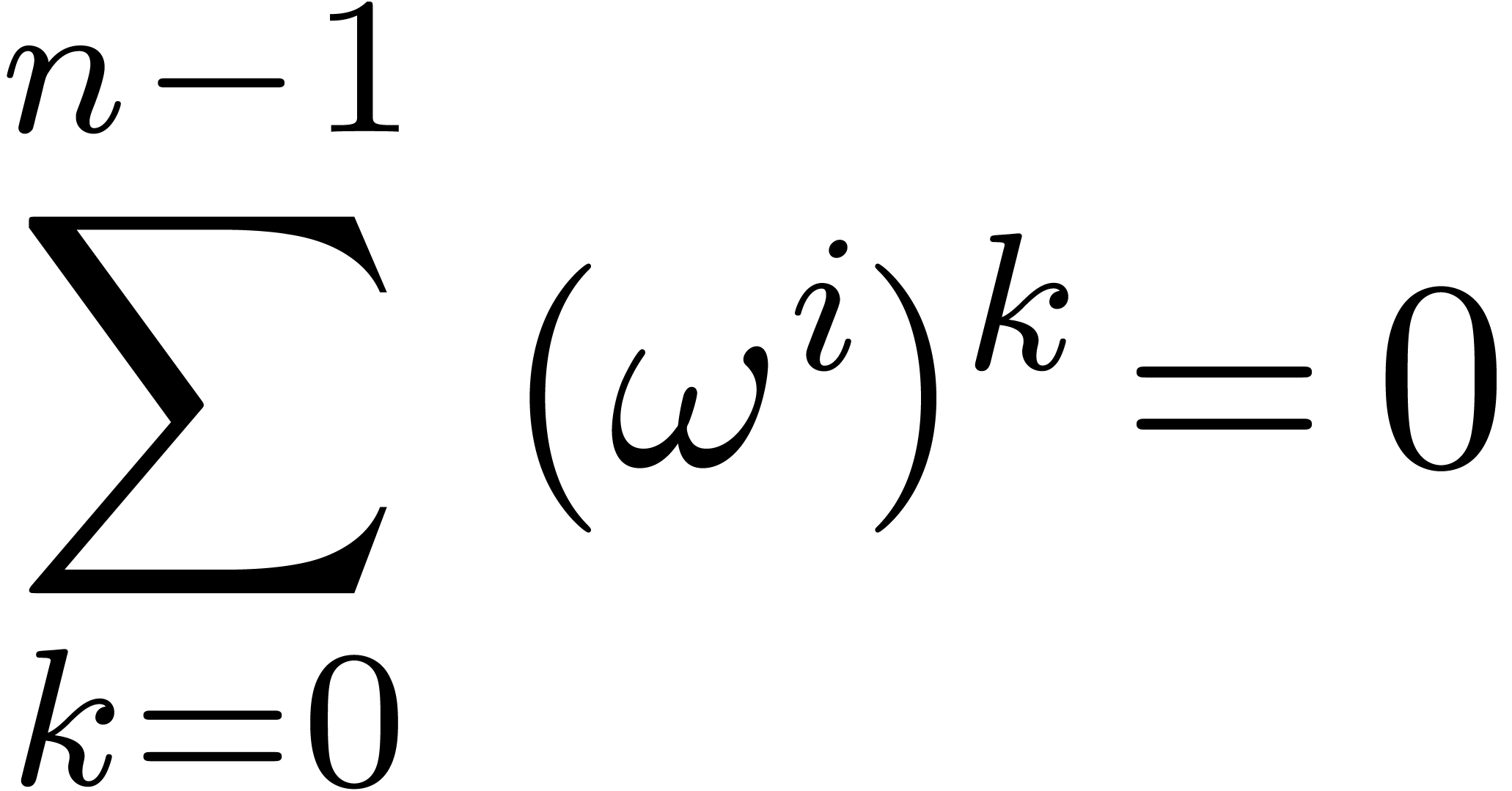 and
and
 |
(2.1) |
for all 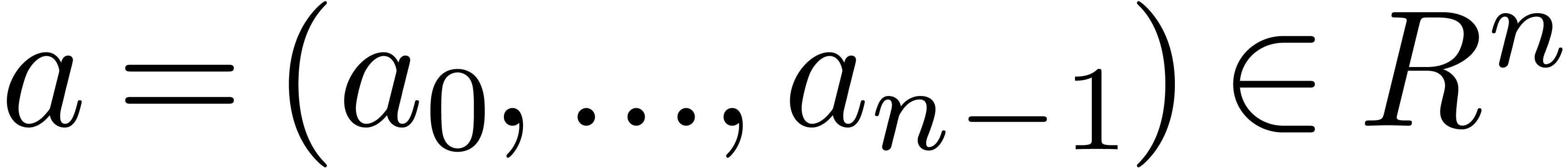 . In this case, we
define the discrete Fourier transform (or DFT) of an -tuple
. In this case, we
define the discrete Fourier transform (or DFT) of an -tuple  with
respect to
with
respect to 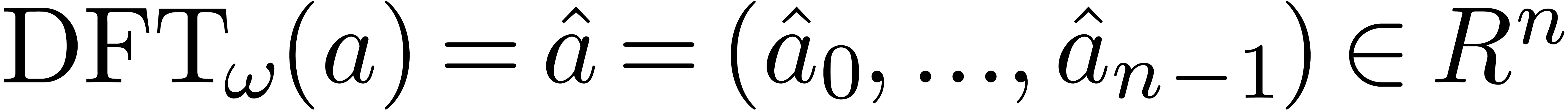 to be
to be 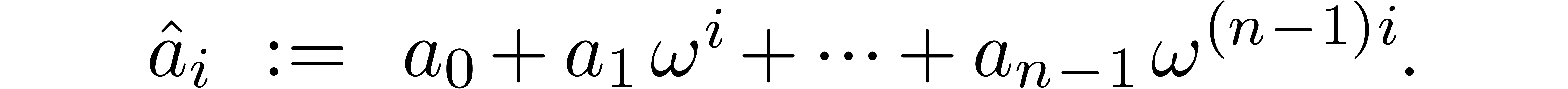 where
where
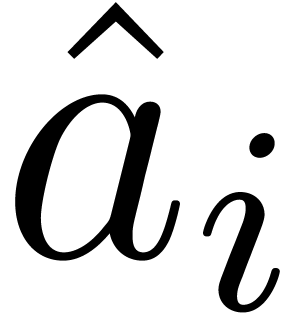
That is, 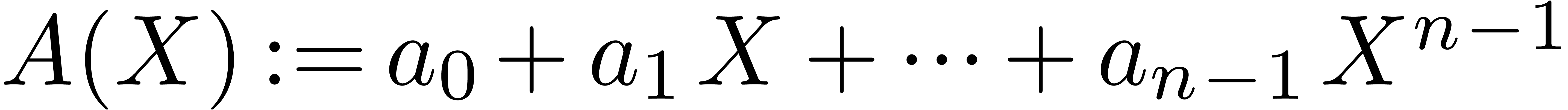 is the evaluation of the polynomial
is the evaluation of the polynomial
 at
at 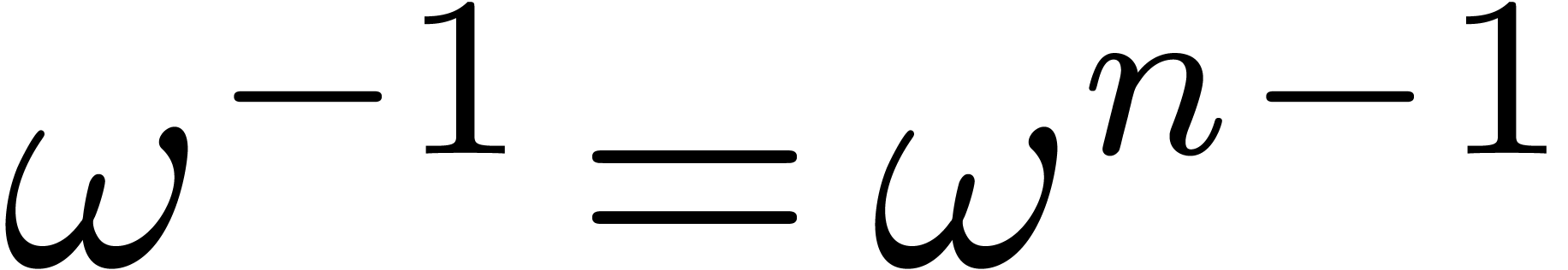 .
.
If is a principal -th
root of unity, then so is its inverse 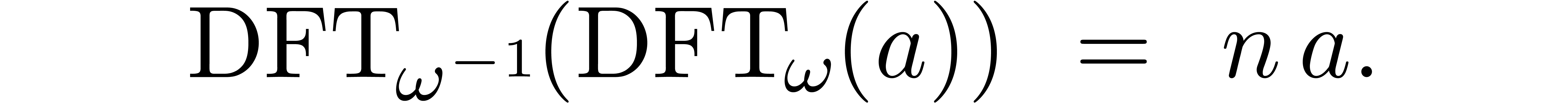 ,
and we have
,
and we have
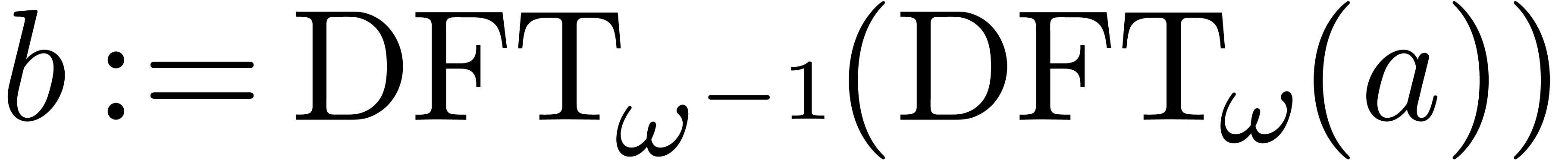
Indeed, writing  , the
relation (2.1) implies that
, the
relation (2.1) implies that
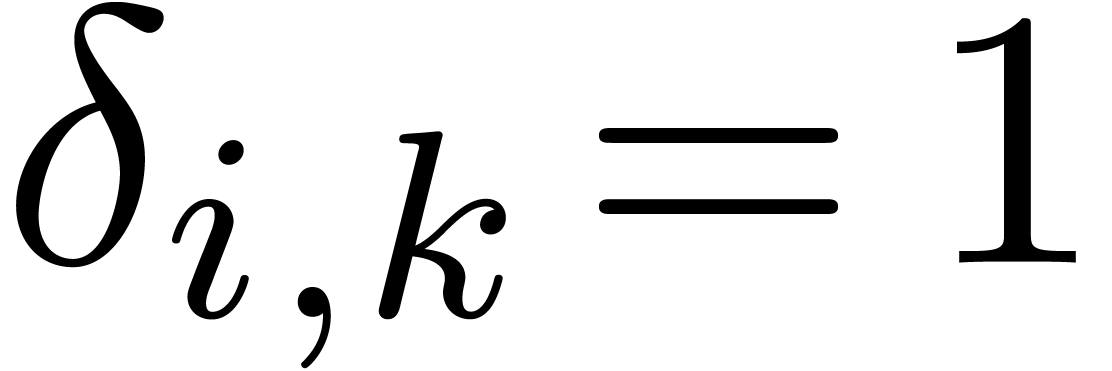
where 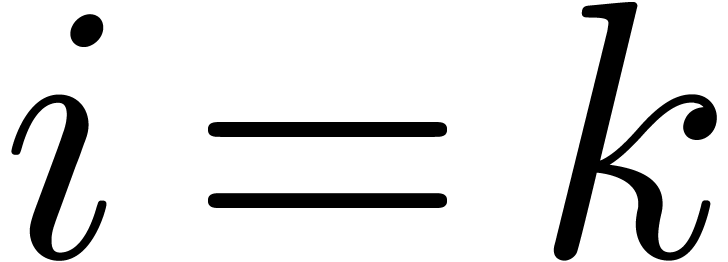 if
if 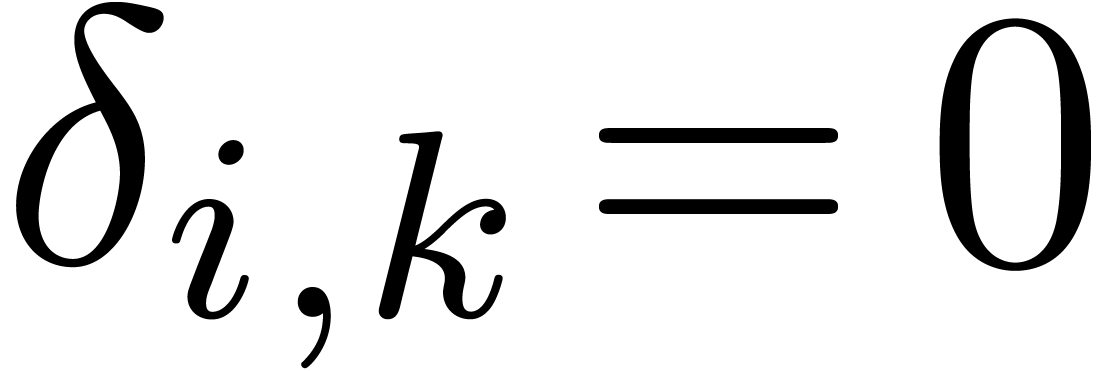 and
and 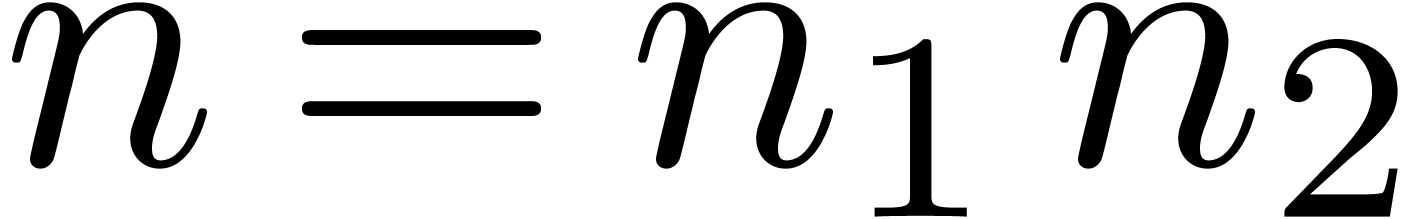 otherwise.
otherwise.
Remark  .
In this setting, the concept of principal root of unity coincides with
the more familiar primitive root of unity.
.
In this setting, the concept of principal root of unity coincides with
the more familiar primitive root of unity.
Let be a principal -th
root of unity and let 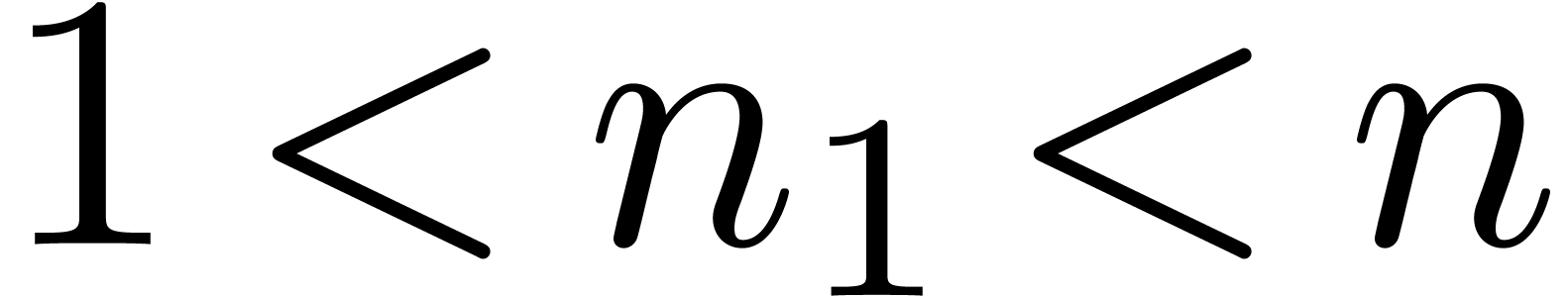 where
where 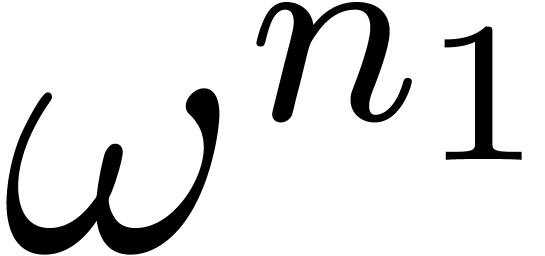 . Then
. Then  is a principal
is a principal
 -th root of unity and
-th root of unity and  is a principal
is a principal  -th
root of unity. Moreover, for any
-th
root of unity. Moreover, for any  and
and  , we have
, we have
If 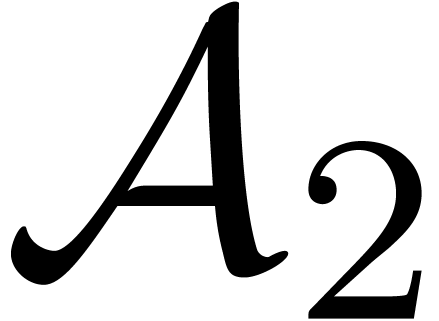 and
and  are algorithms
for computing DFTs of length and , we may use
are algorithms
for computing DFTs of length and , we may use  for computing DFTs of
length as follows.
for computing DFTs of
length as follows.
For each 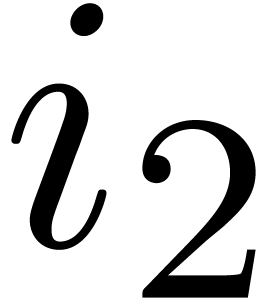 , the sum inside the
brackets corresponds to the
, the sum inside the
brackets corresponds to the 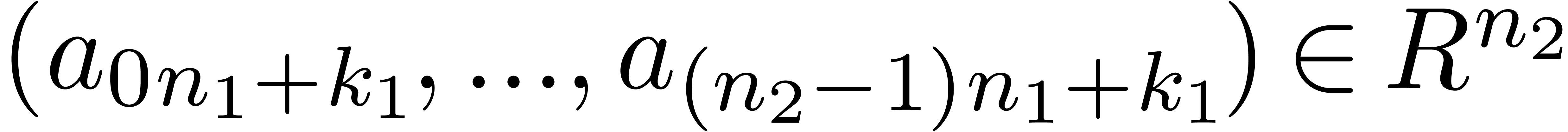 -th
coefficient of a DFT of the -tuple
-th
coefficient of a DFT of the -tuple
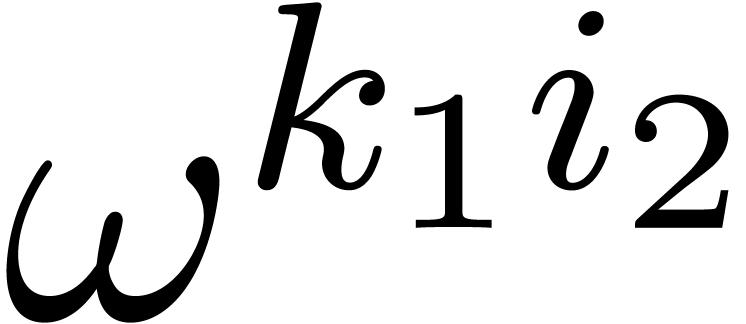 with respect to .
Evaluating these inner DFTs requires
calls to . Next, we multiply
by the twiddle factors
with respect to .
Evaluating these inner DFTs requires
calls to . Next, we multiply
by the twiddle factors 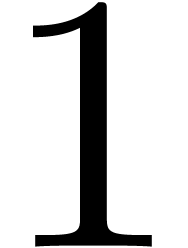 ,
at a cost of operations in . (Actually, fewer than
multiplications are required, as some of the twiddle factors are equal
to
,
at a cost of operations in . (Actually, fewer than
multiplications are required, as some of the twiddle factors are equal
to  . This optimisation, while
important in practice, has no asymptotic effect on the algorithms
discussed in this paper.) Finally, for each , the outer sum corresponds to the
. This optimisation, while
important in practice, has no asymptotic effect on the algorithms
discussed in this paper.) Finally, for each , the outer sum corresponds to the  -th coefficient of a DFT of an -tuple in
-th coefficient of a DFT of an -tuple in  with respect
to . These outer DFTs
require calls to .
with respect
to . These outer DFTs
require calls to .
Denoting by 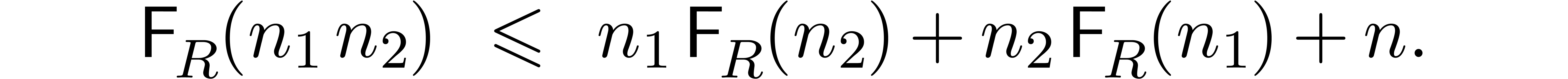 the number of ring operations needed
to compute a DFT of length ,
and assuming that we have available a precomputed table of twiddle
factors, we obtain
the number of ring operations needed
to compute a DFT of length ,
and assuming that we have available a precomputed table of twiddle
factors, we obtain
For a factorisation 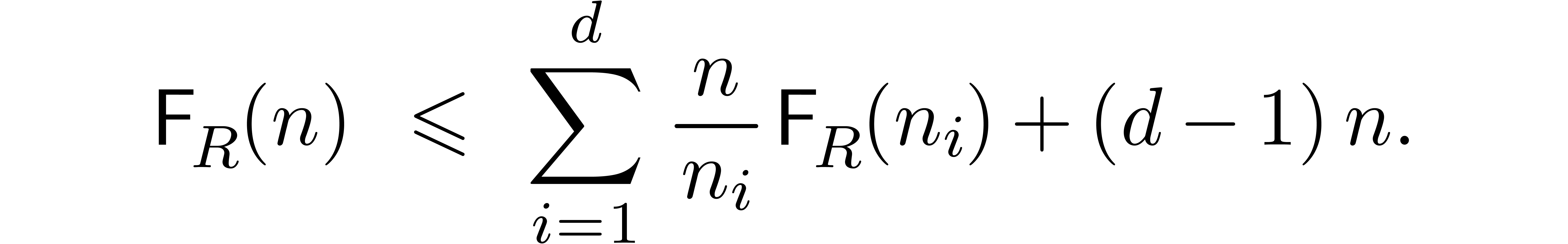 , this
yields recursively
, this
yields recursively
The corresponding algorithm is denoted  .
The
.
The  operation is neither commutative nor
associative; the above expression will always be taken to mean
operation is neither commutative nor
associative; the above expression will always be taken to mean 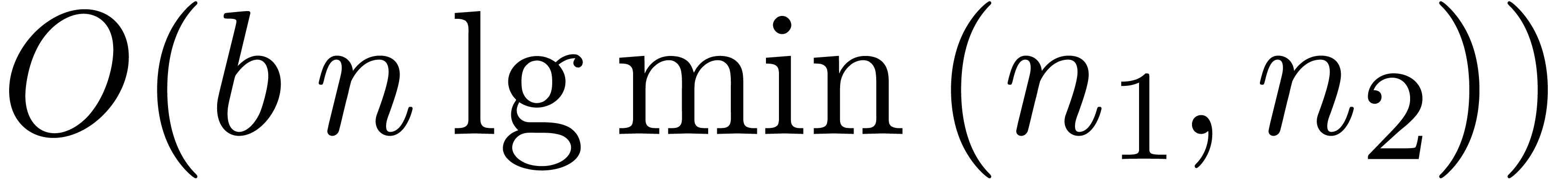 .
.
The above discussion requires several modifications in the Turing model.
Assume that elements of are represented by bits.
First, for , we must add a
rearrangement cost of  to efficiently access the
rows and columns for the recursive subtransforms (see section 2.1).
For the general case
to efficiently access the
rows and columns for the recursive subtransforms (see section 2.1).
For the general case 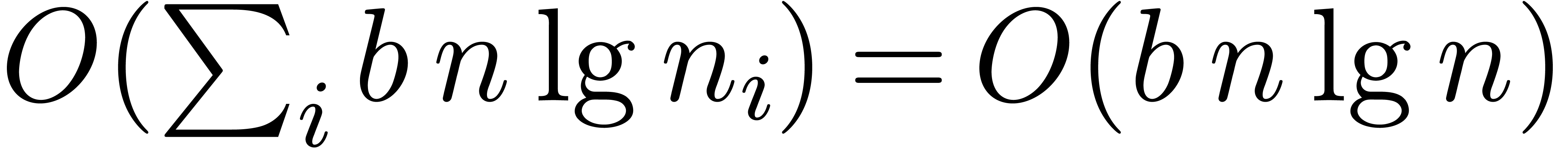 , the
total rearrangement cost is bounded by
, the
total rearrangement cost is bounded by  .
.
Second, we will sometimes use non-algebraic algorithms to compute
the subtransforms, so it may not make sense to express their cost in
terms of  . The relation
. The relation
where  is the (Turing) cost of a transform of
length over ,
and where
is the (Turing) cost of a transform of
length over ,
and where 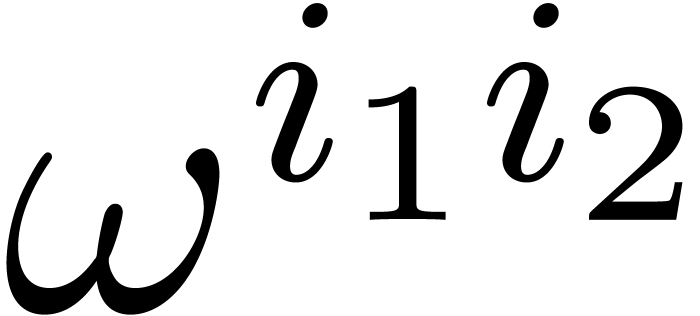 is the cost of a single multiplication
in .
is the cost of a single multiplication
in .
Finally, we point out that requires access to a
table of twiddle factors 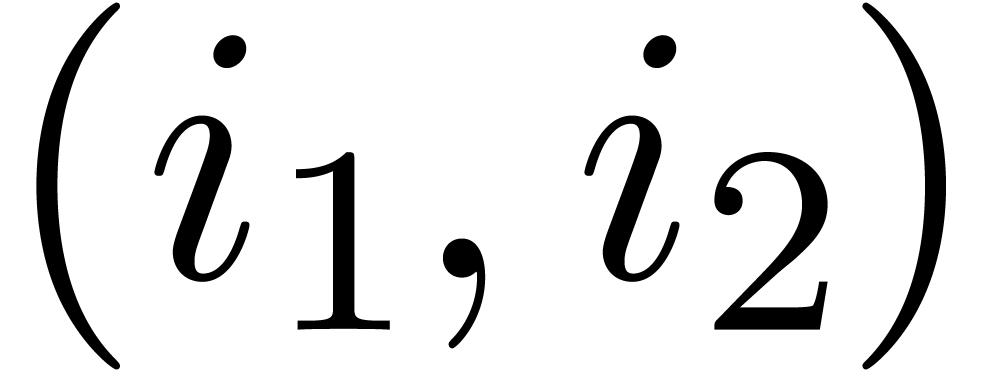 ,
ordered lexicographically by
,
ordered lexicographically by 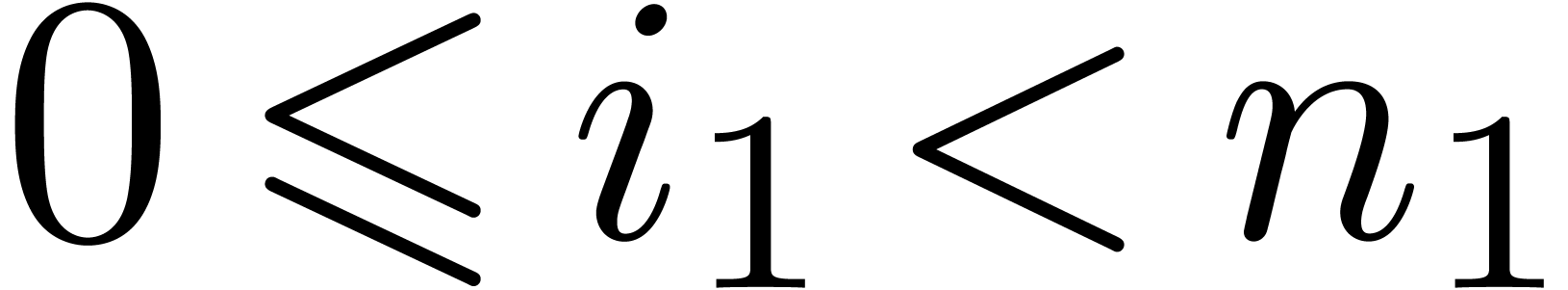 ,
for
,
for 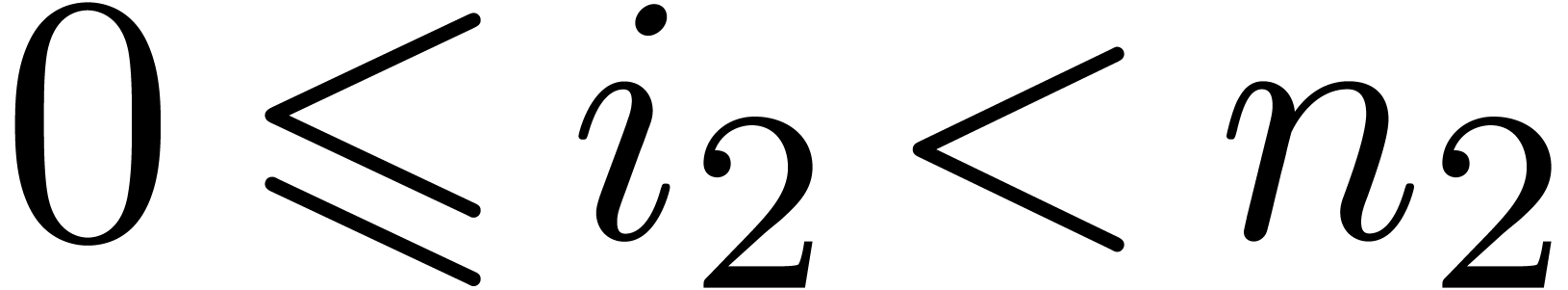 ,
,  . Assuming that we are given as input a precomputed
table of the form
. Assuming that we are given as input a precomputed
table of the form 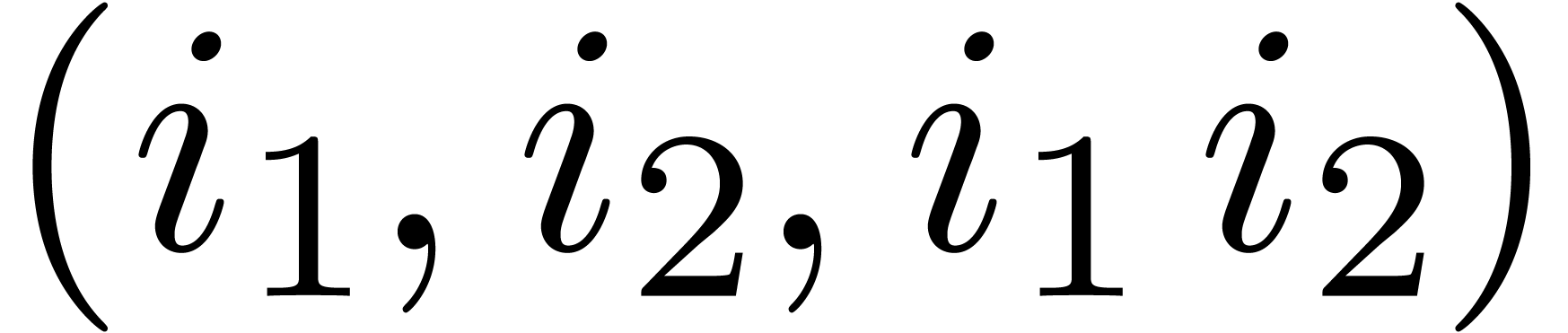 , we must
show how to extract the required twiddle factor table in the correct
order. We first construct a list of triples
, we must
show how to extract the required twiddle factor table in the correct
order. We first construct a list of triples  , ordered by ,
in time
, ordered by ,
in time 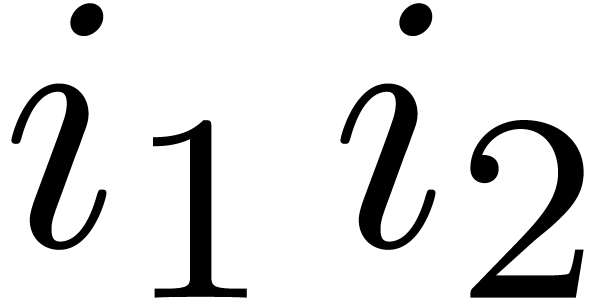 ; then sort by
; then sort by  in time
in time 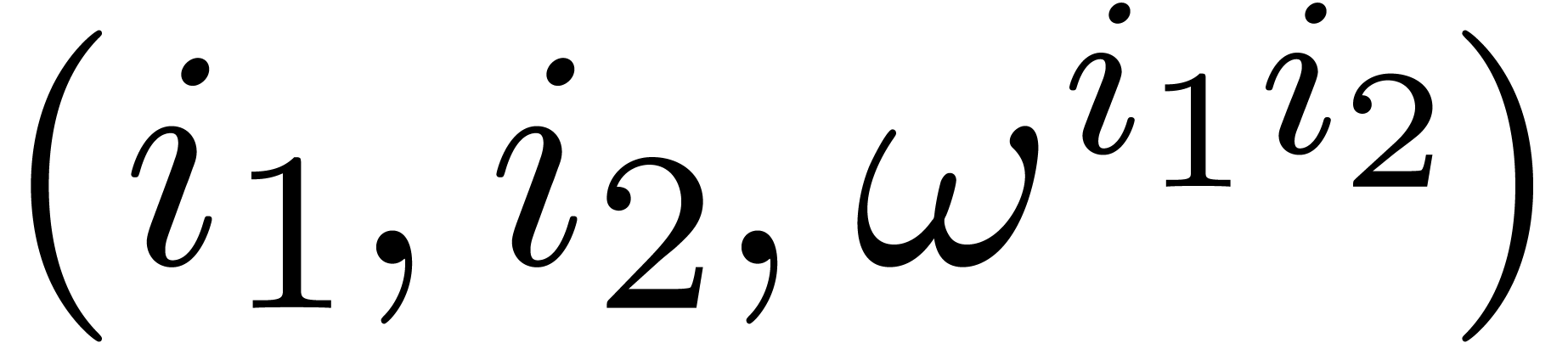 (see section 2.1);
then merge with the given root table to obtain a table
(see section 2.1);
then merge with the given root table to obtain a table 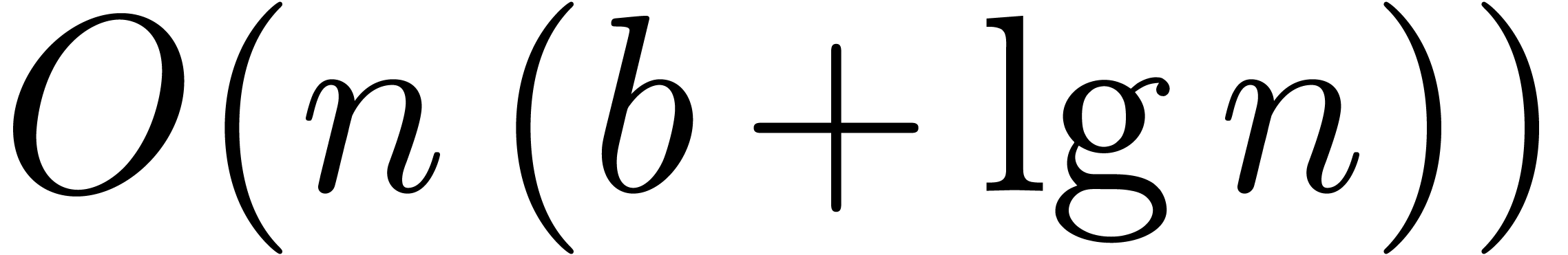 , ordered by ,
in time
, ordered by ,
in time 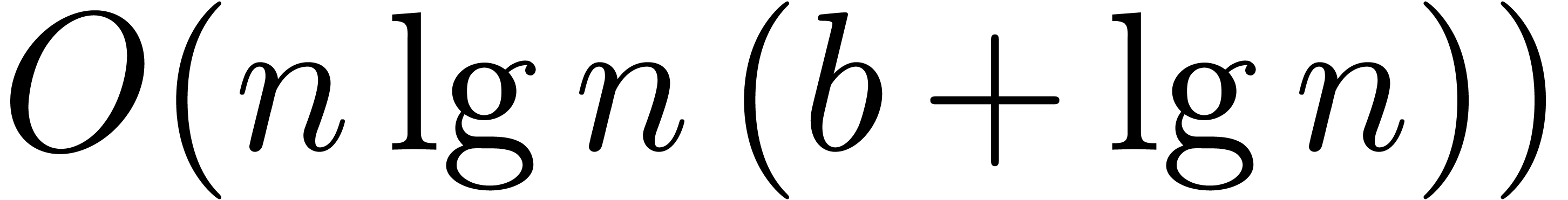 ; and finally sort by
in time
; and finally sort by
in time  .
The total cost of the extraction is thus .
.
The total cost of the extraction is thus .
The corresponding cost for is determined as
follows. Assuming that the table is given as
input, we first extract the subtables of ( )-th
roots of unity for
)-th
roots of unity for  in time
in time 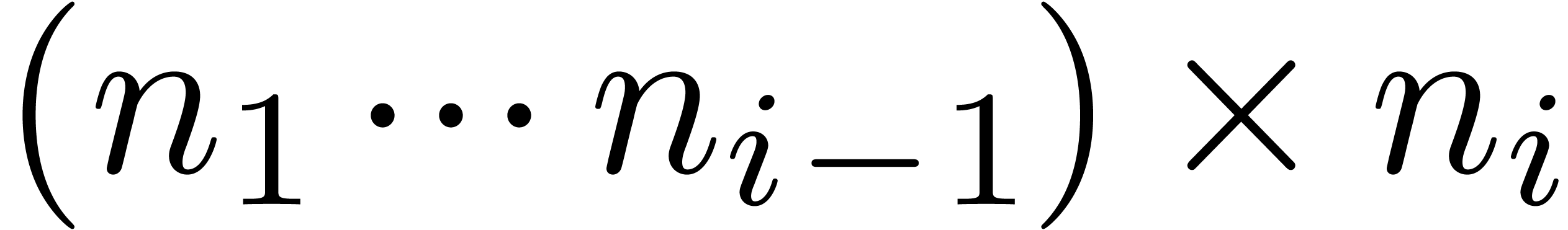 . Extracting the twiddle factor table for the
decomposition
. Extracting the twiddle factor table for the
decomposition 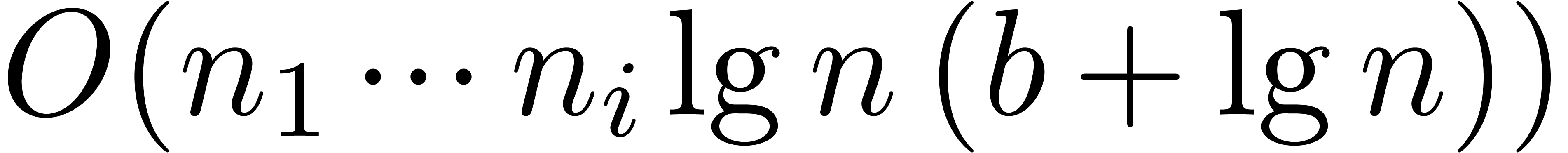 then costs
then costs 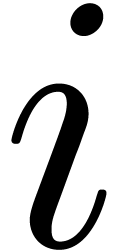 ; the total over all
; the total over all 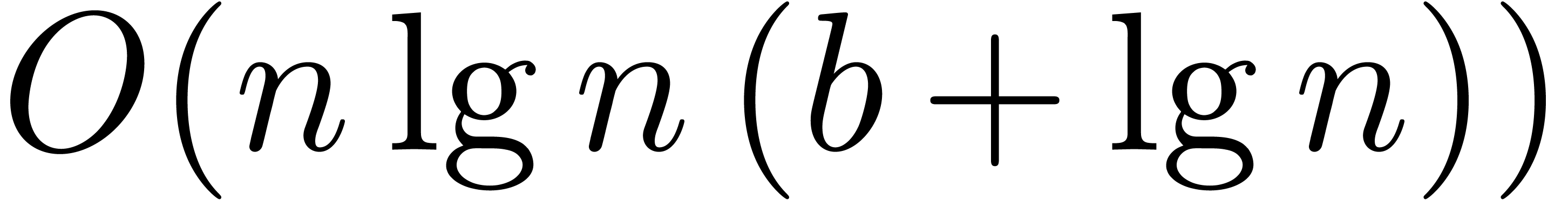 is
again
is
again  .
.
Remark  , as
in [18, Section 3], this requires a slight increase in the
working precision. Similar comments apply to the root tables used in
Bluestein's algorithm in section 2.5.
, as
in [18, Section 3], this requires a slight increase in the
working precision. Similar comments apply to the root tables used in
Bluestein's algorithm in section 2.5.
Let be a principal -th
root of unity in and assume that is invertible in .
Consider two polynomials  and
and  in . Let
in . Let 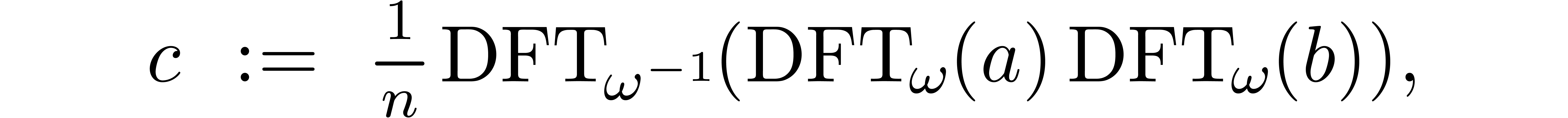 be the polynomial defined by
be the polynomial defined by
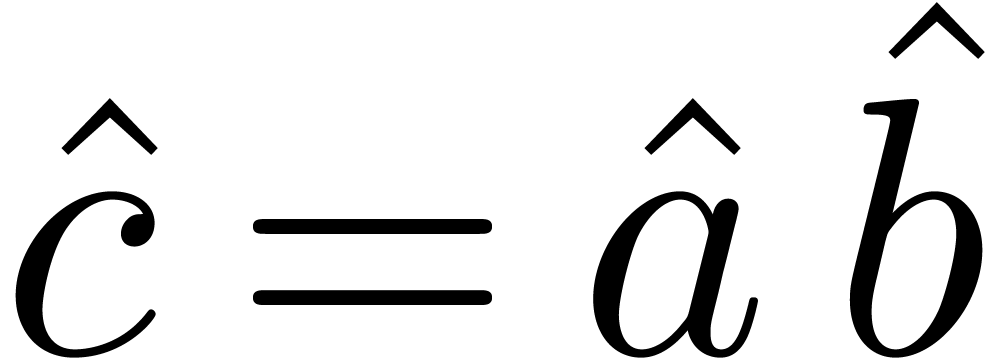
where the product of the DFTs is taken pointwise. By construction, we
have 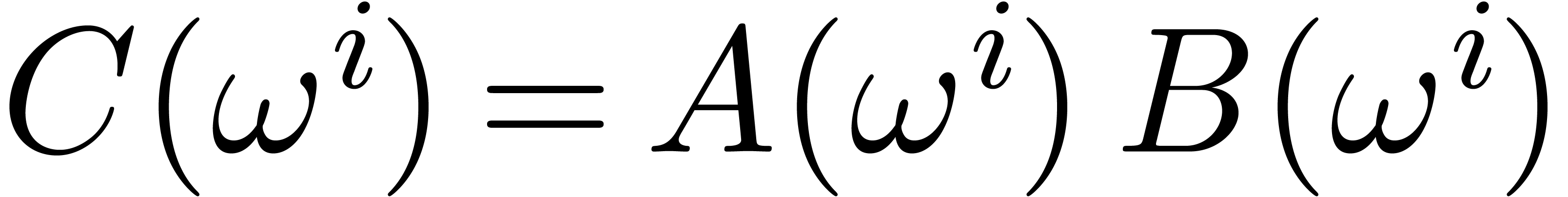 , which means that
, which means that  for all
for all  .
The product
.
The product  of
of  and
and 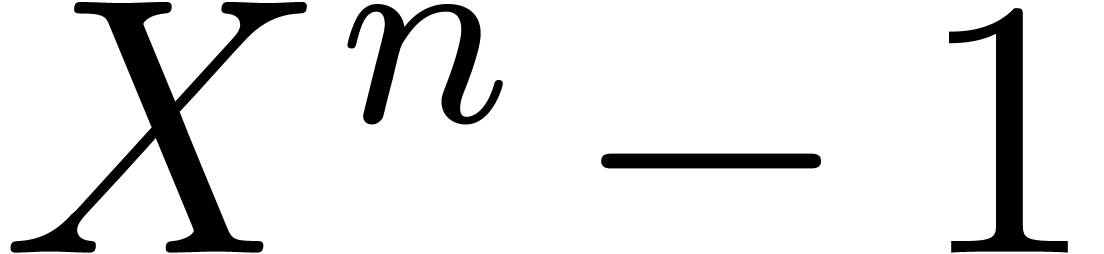 modulo
modulo 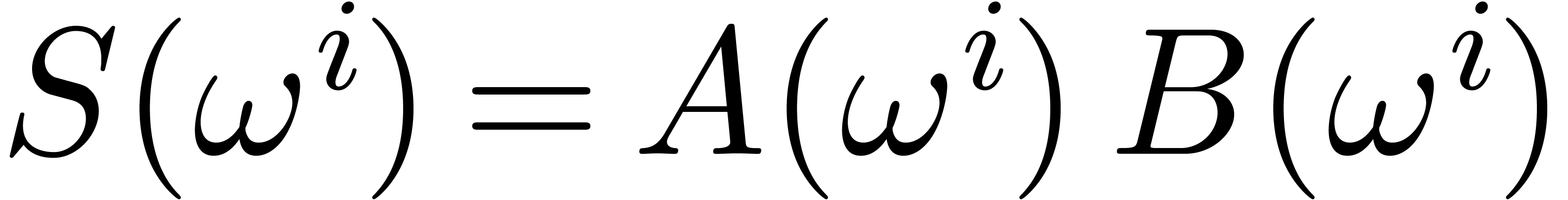 also satisfies
also satisfies 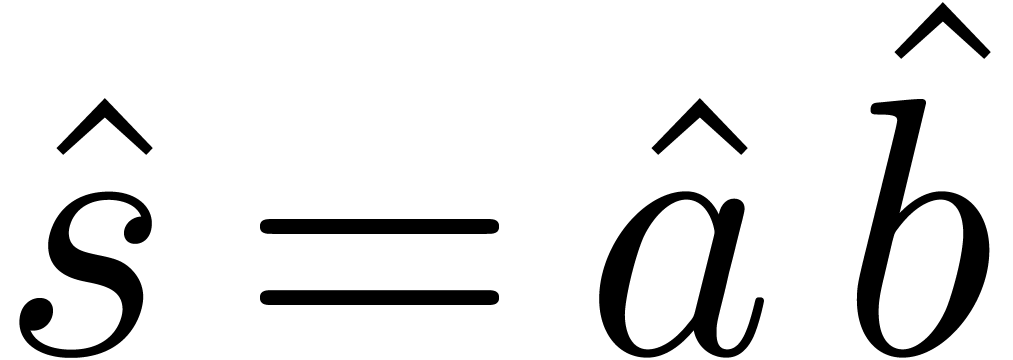 for all .
Consequently,
for all .
Consequently, 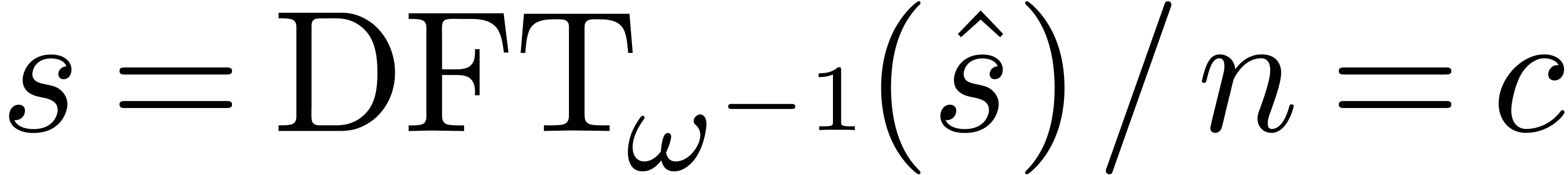 ,
, 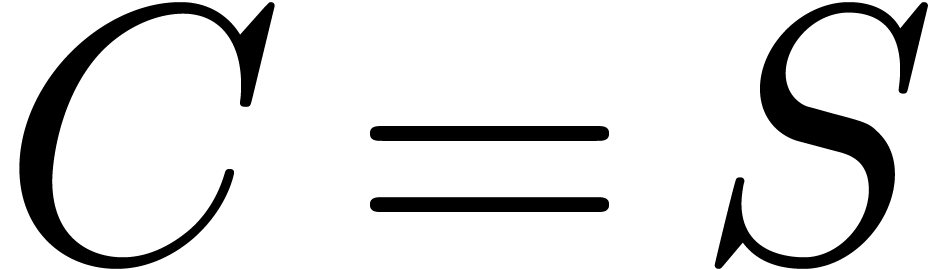 , whence
, whence 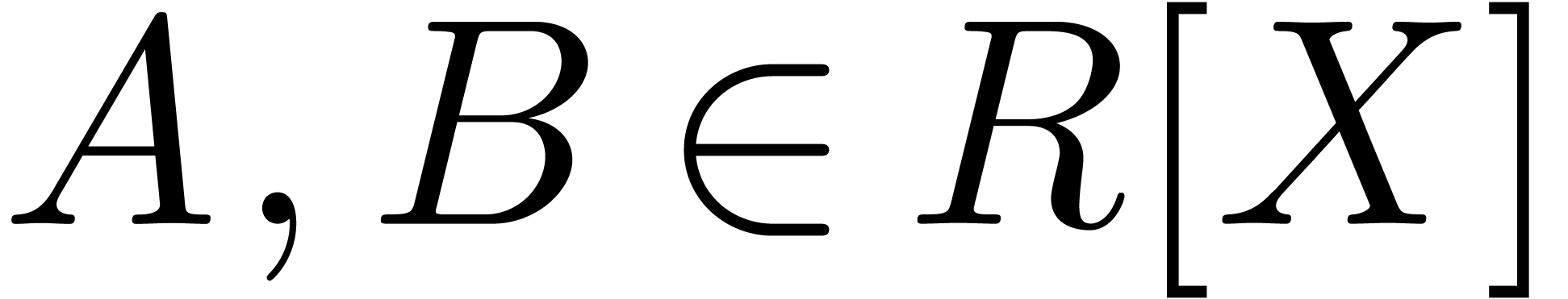 .
.
For polynomials  with
with  and
and
 , we thus obtain an algorithm
for the computation of
, we thus obtain an algorithm
for the computation of 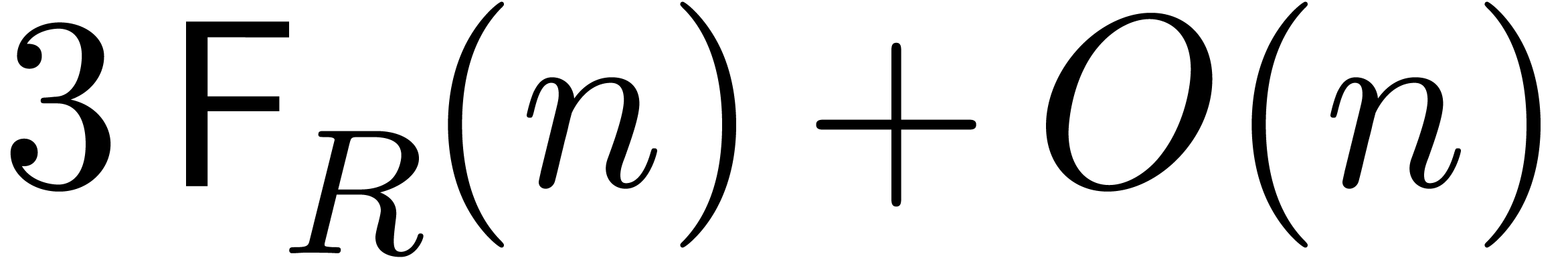 modulo
using at most
modulo
using at most 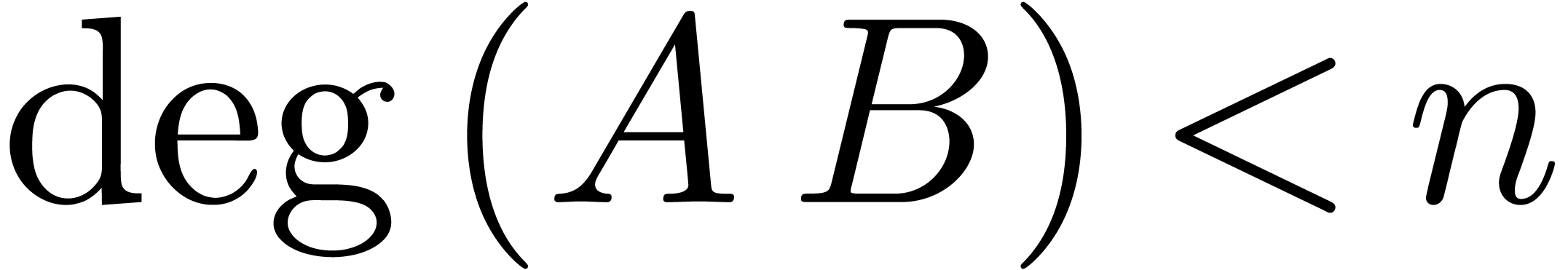 operations in . Modular products of this type are also called
cyclic convolutions. If
operations in . Modular products of this type are also called
cyclic convolutions. If 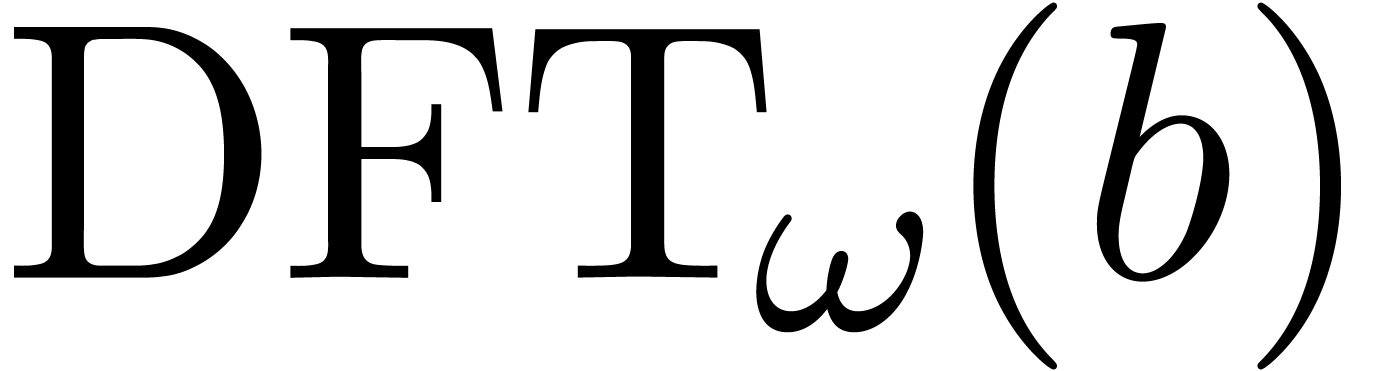 ,
then we may recover the product from its
reduction modulo . This
multiplication method is called FFT multiplication.
,
then we may recover the product from its
reduction modulo . This
multiplication method is called FFT multiplication.
If one of the arguments (say )
is fixed and we want to compute many products
(or cyclic convolutions) for different ,
then we may precompute 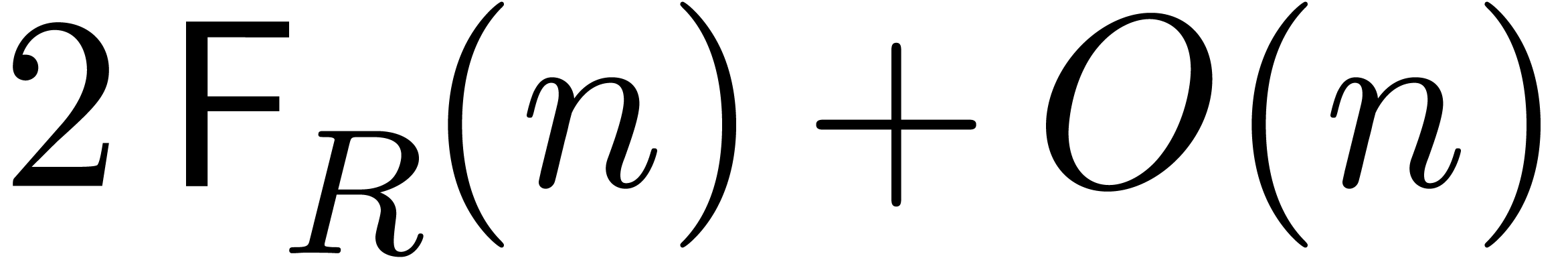 ,
after which each new product can be computed
using only
,
after which each new product can be computed
using only 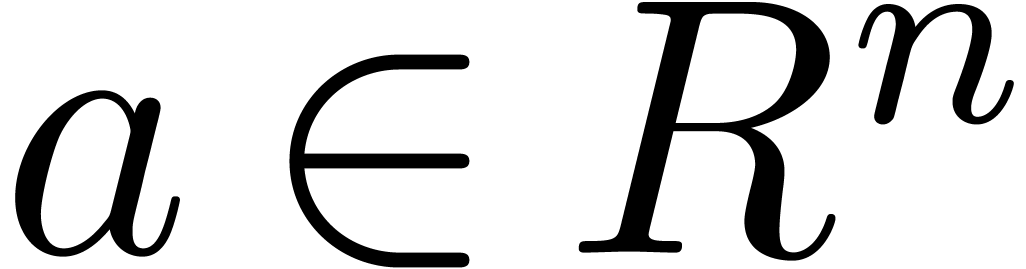 operations in .
operations in .
We have shown above how to multiply polynomials using DFTs. Inversely, it is possible to reduce the computation of DFTs — of arbitrary length, not necessarily a power of two — to polynomial multiplication [5], as follows.
Let be a principal -th
root of unity and consider an -tuple
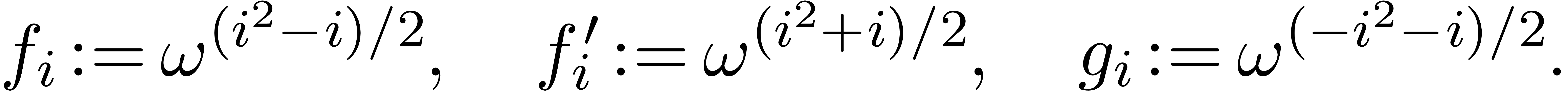 . First consider the case
that is odd. Let
. First consider the case
that is odd. Let
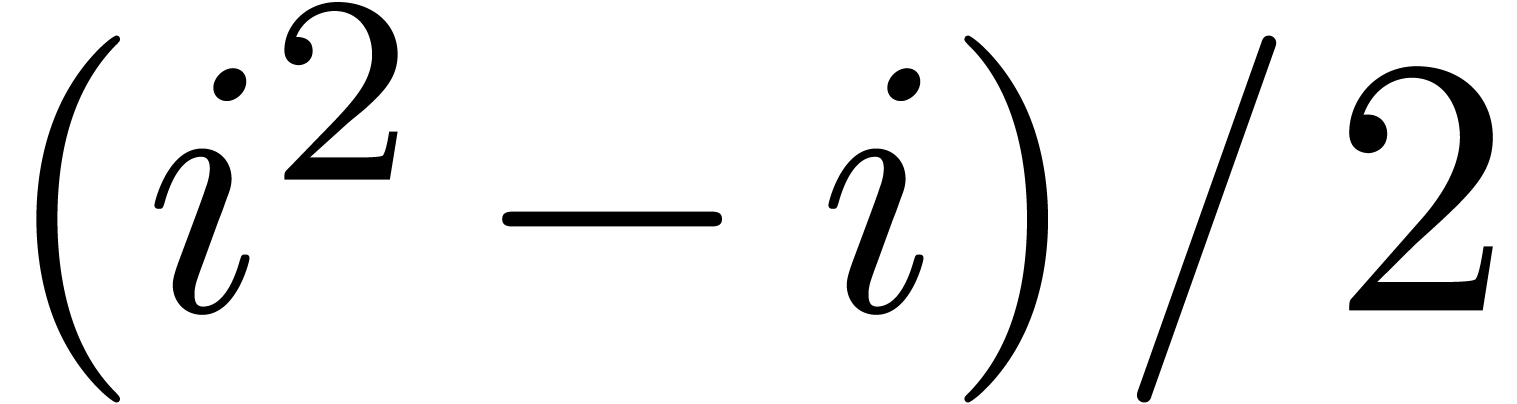
Note that 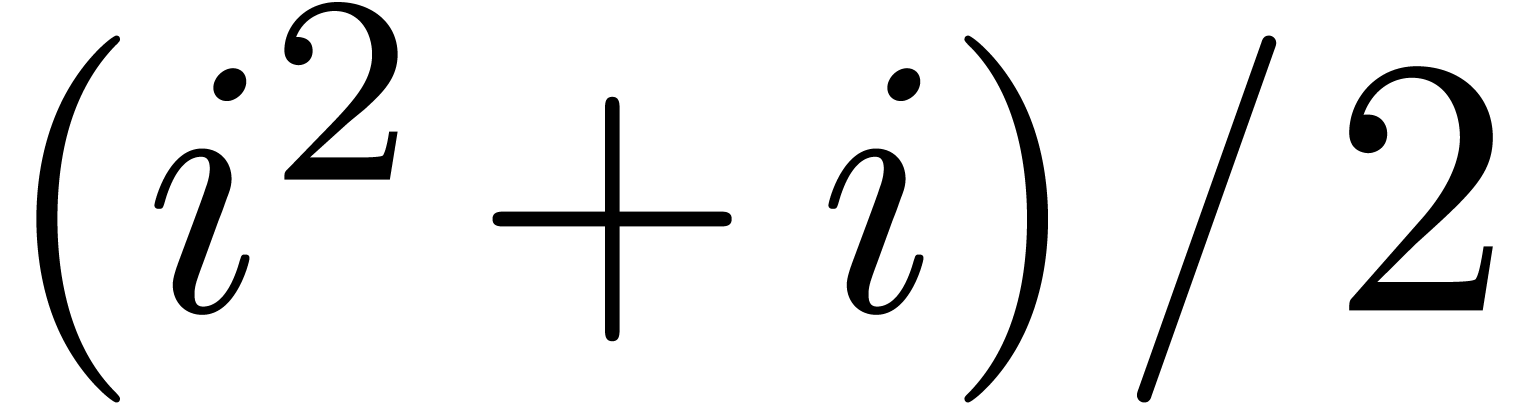 and
and  are
integers, and that
are
integers, and that
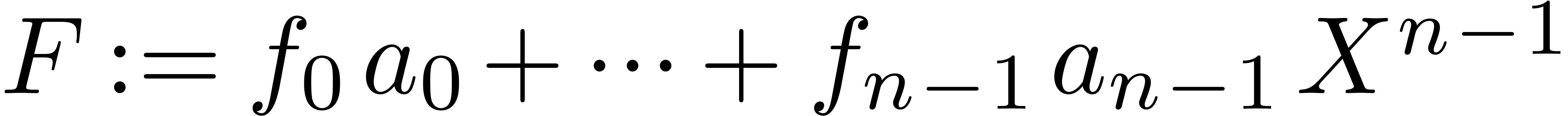
Let 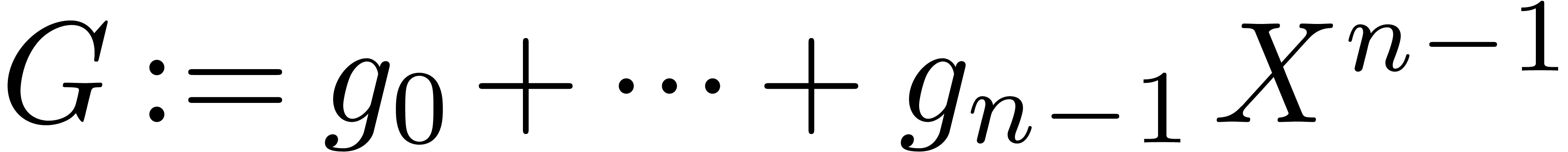 ,
, 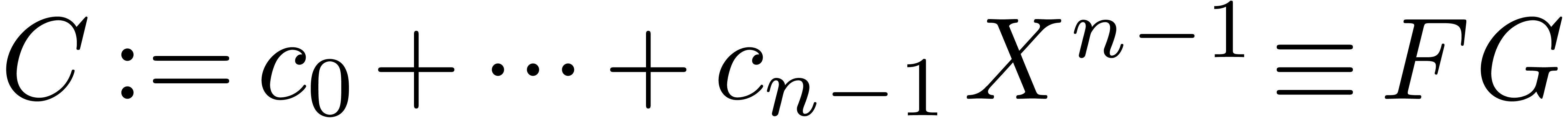 and
and  modulo .
Then
modulo .
Then
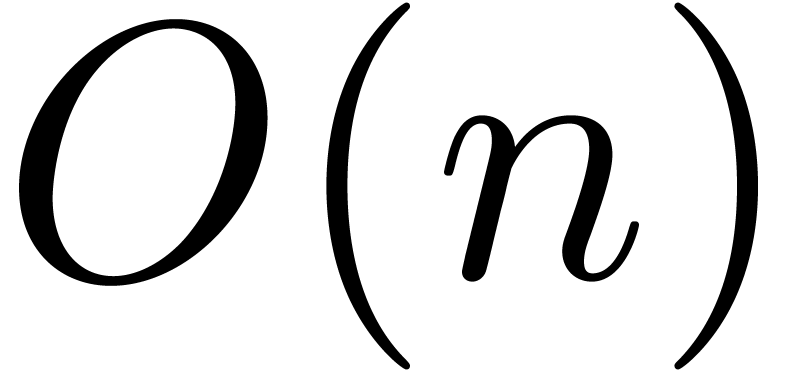
In other words, the computation of a DFT of odd length
reduces to a cyclic convolution product of the same length , together with  additional operations in .
Notice that the polynomial
additional operations in .
Notice that the polynomial  is fixed and
independent of
is fixed and
independent of  in this product.
in this product.
Now suppose that is even. In this case we
require that 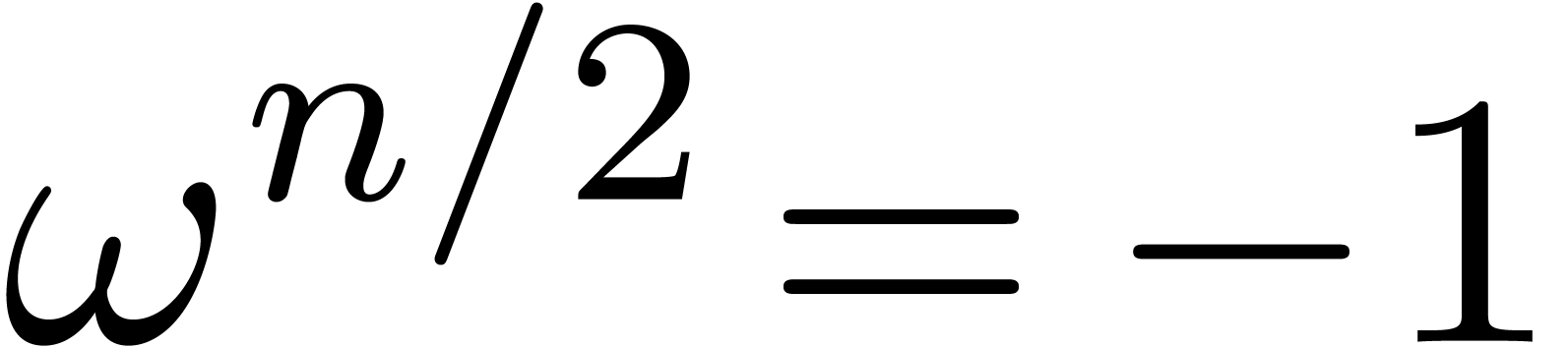 be invertible in , and that
be invertible in , and that 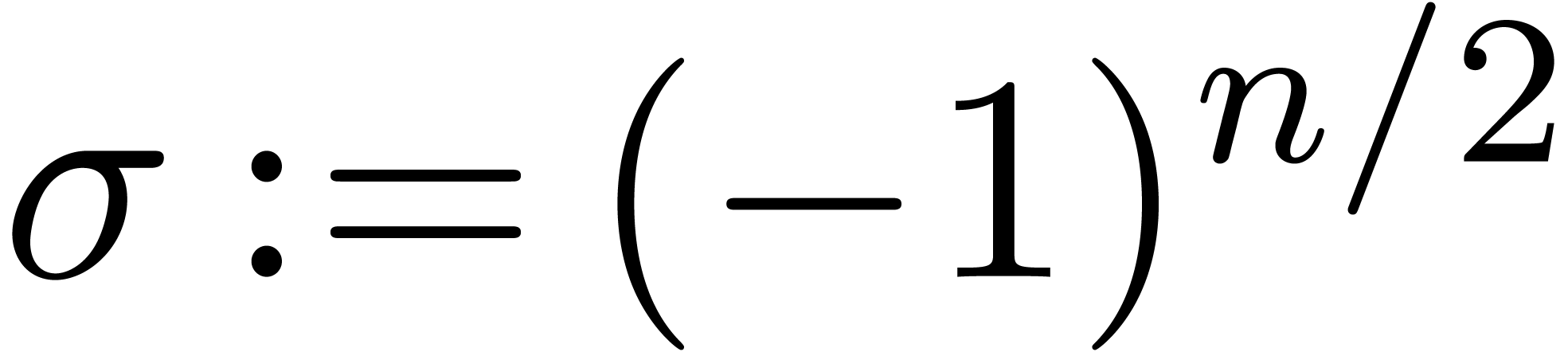 .
Let
.
Let 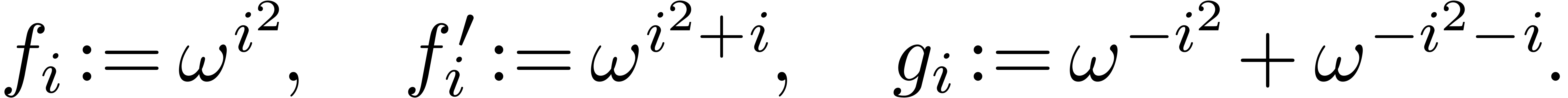 , and put
, and put
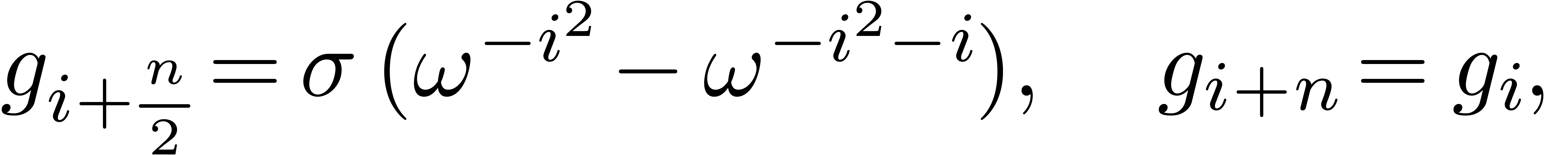
Then
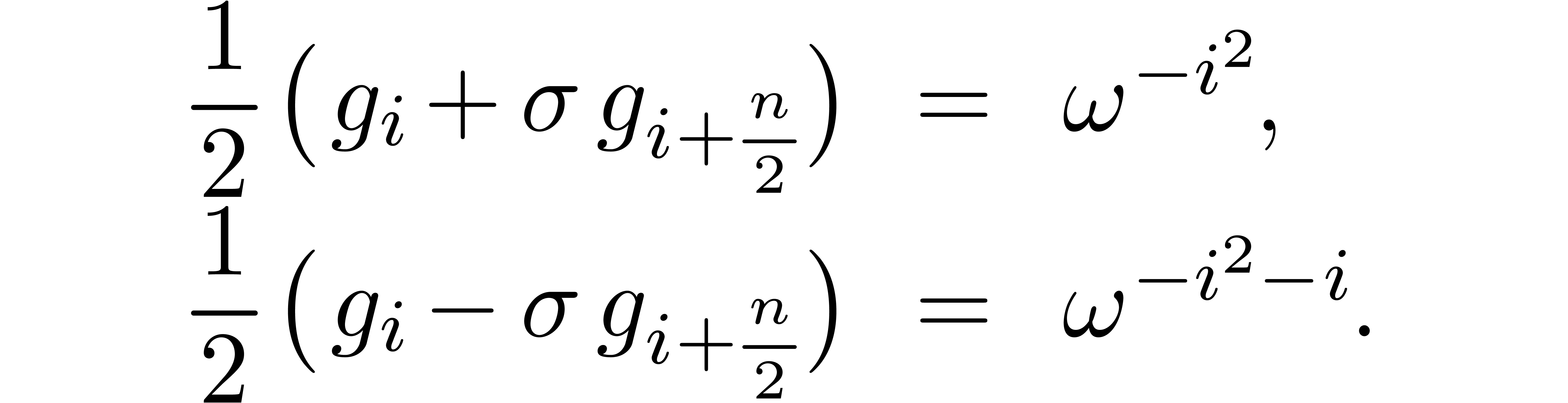
and

As above, let , and modulo . Then for  we have
we have
and similarly
Again, the DFT reduces to a convolution of length , together with additional
operations in .
The only complication in the Turing model is the cost of extracting the
 ,
,  and
and
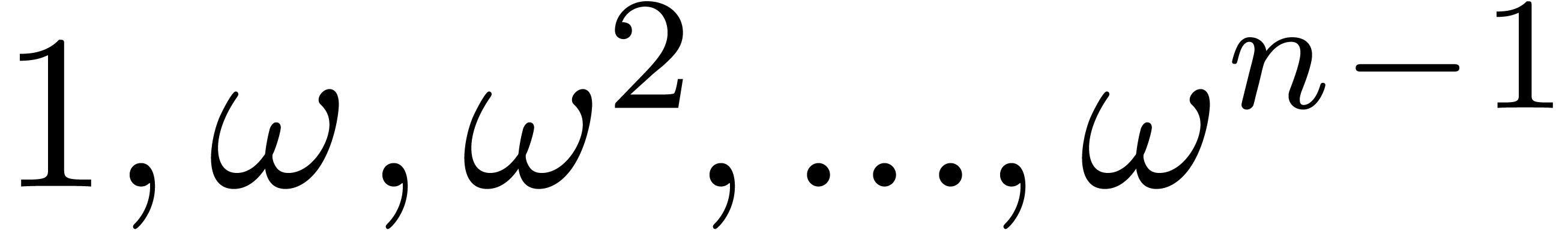 in the correct order. For example, consider the
in the case that is odd.
Given as input a precomputed table
in the correct order. For example, consider the
in the case that is odd.
Given as input a precomputed table 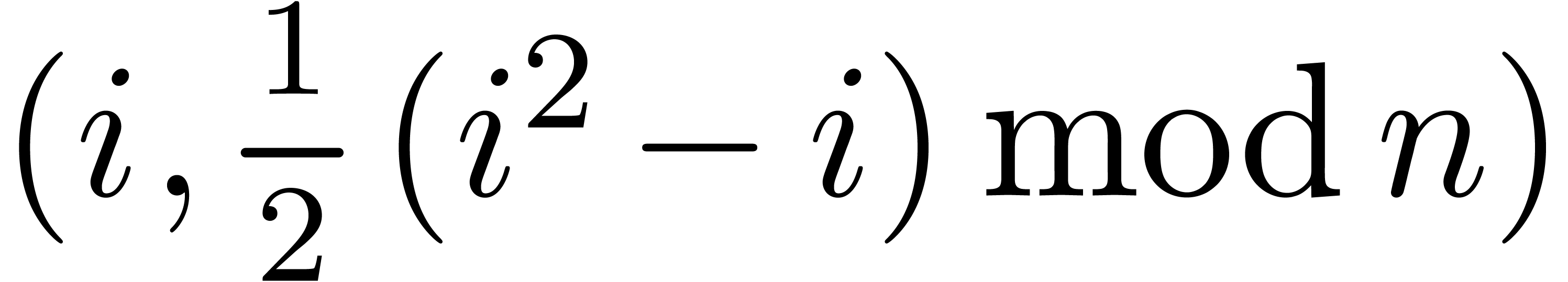 ,
we may extract the in time
by applying the strategy from section 2.3 to the pairs
,
we may extract the in time
by applying the strategy from section 2.3 to the pairs 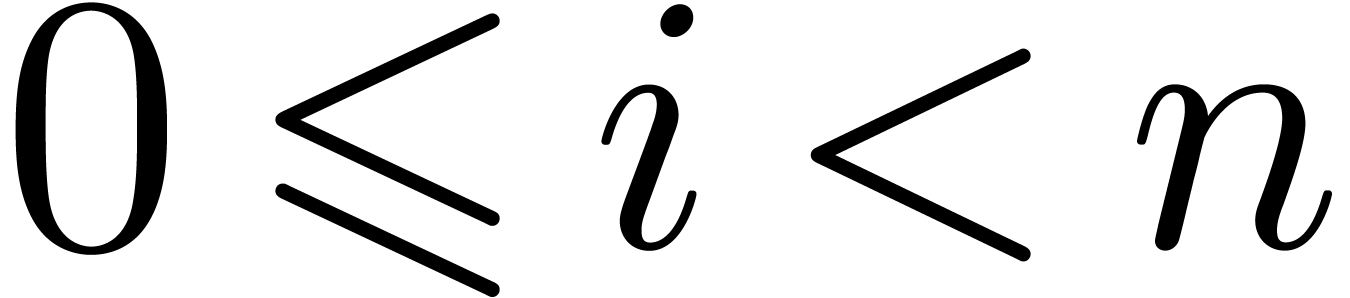 for
for 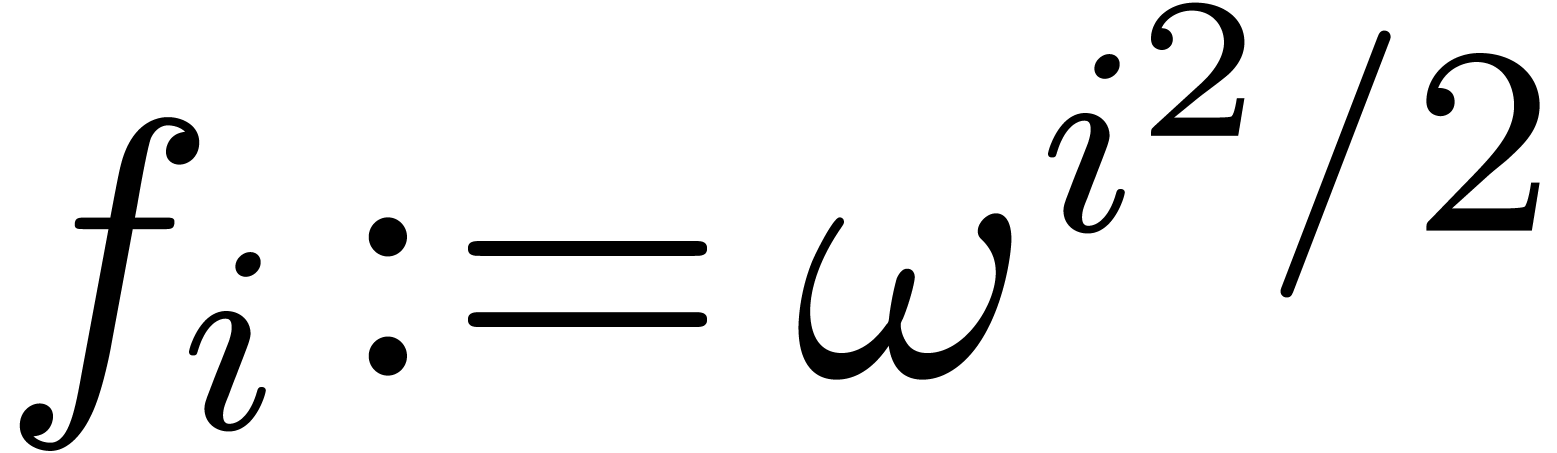 . The
other sequences are handled similarly. For the
in the case that is even, we also need to
perform additions in ; assuming that additions in
have cost , this is already
covered by the above bound.
. The
other sequences are handled similarly. For the
in the case that is even, we also need to
perform additions in ; assuming that additions in
have cost , this is already
covered by the above bound.
Remark 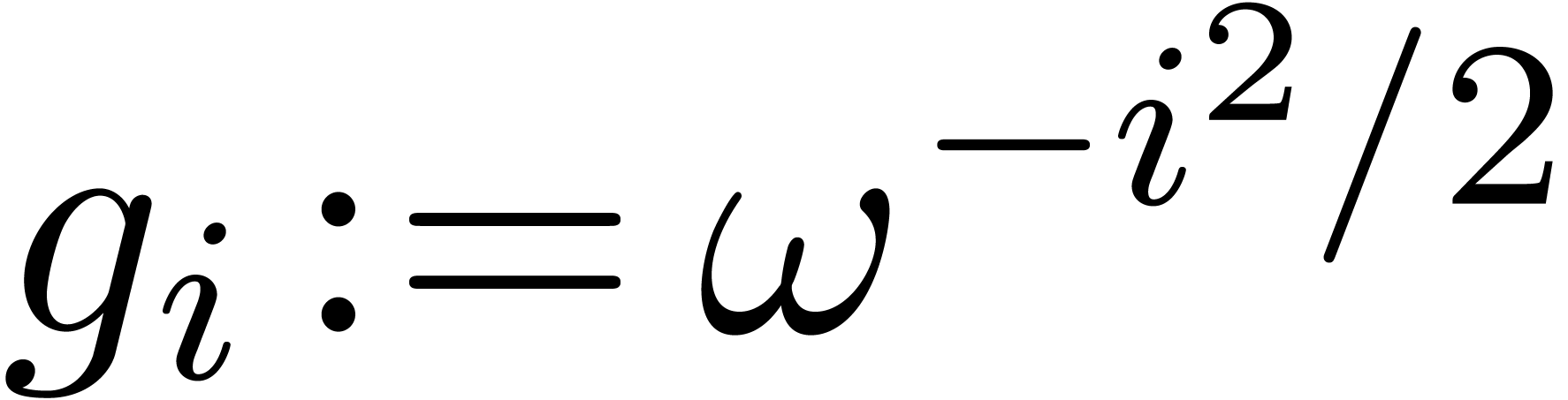 ,
,
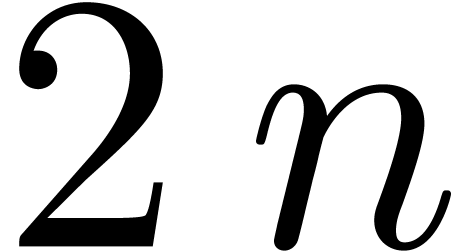 . This has two drawbacks in
our setting. First, it requires the presence of
. This has two drawbacks in
our setting. First, it requires the presence of  -th roots of unity, which may not exist in . Second, if
is odd, it leads to negacyclic convolutions, rather than cyclic
convolutions. The variants used here avoid both of these problems.
-th roots of unity, which may not exist in . Second, if
is odd, it leads to negacyclic convolutions, rather than cyclic
convolutions. The variants used here avoid both of these problems.
Remark
Multiplication in may be reduced to
multiplication in 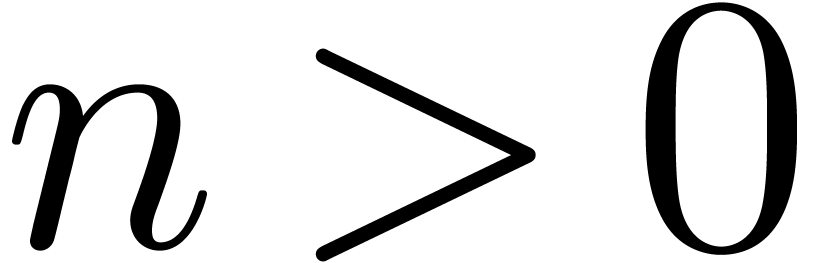 using the classical technique
of Kronecker substitution [17, Corollary 8.27].
More precisely, let
using the classical technique
of Kronecker substitution [17, Corollary 8.27].
More precisely, let 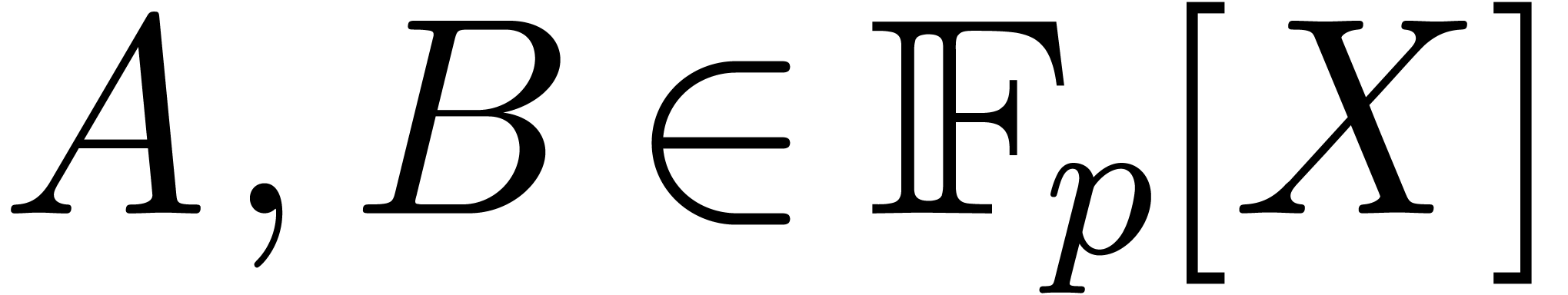 and suppose that we are
given two polynomials
and suppose that we are
given two polynomials 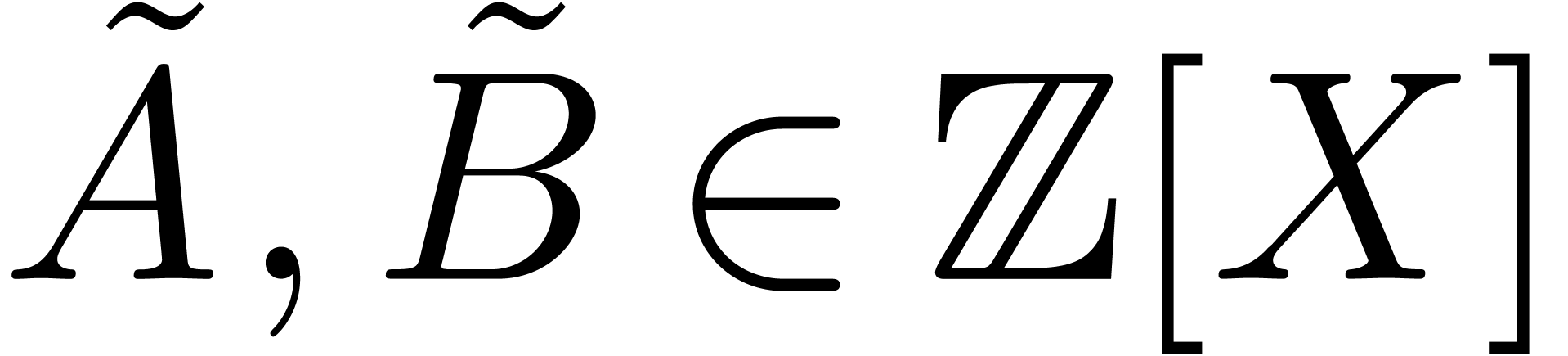 of degree less than . Let
of degree less than . Let  be
lifts of these polynomials, with coefficients
be
lifts of these polynomials, with coefficients  and
and  satisfying
satisfying 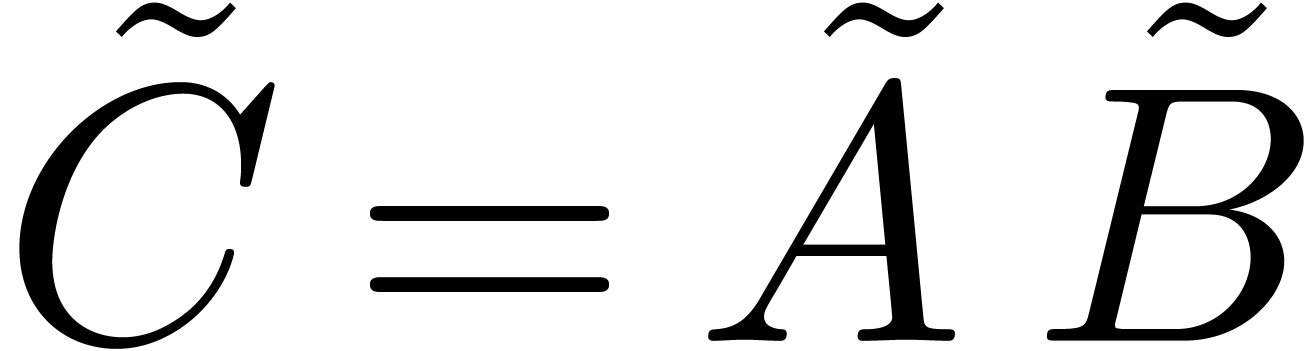 .
Then for the product
.
Then for the product 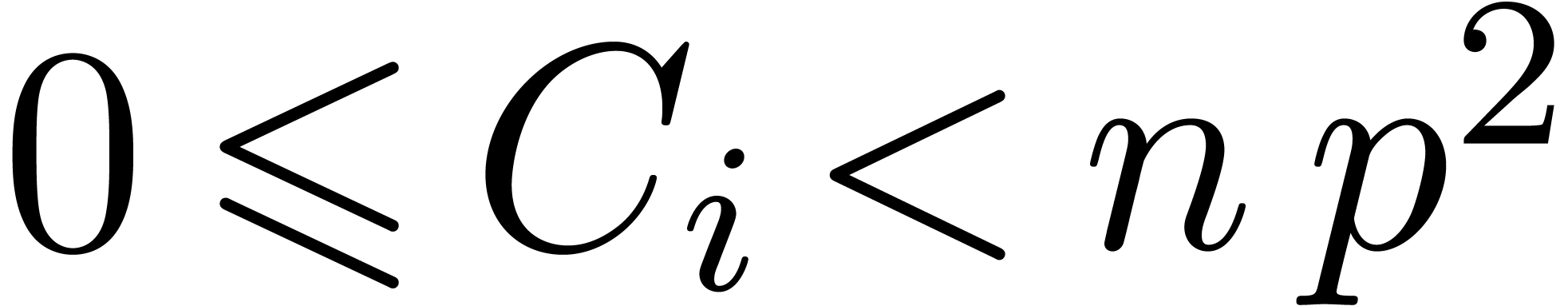 we have
we have  , and the coefficients of
, and the coefficients of 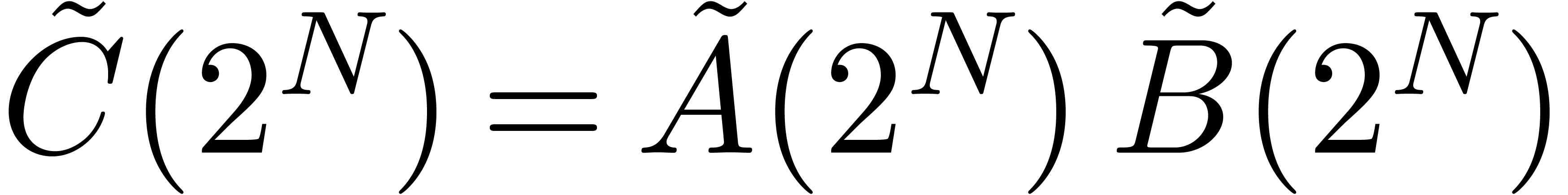 may be read off the integer product
may be read off the integer product 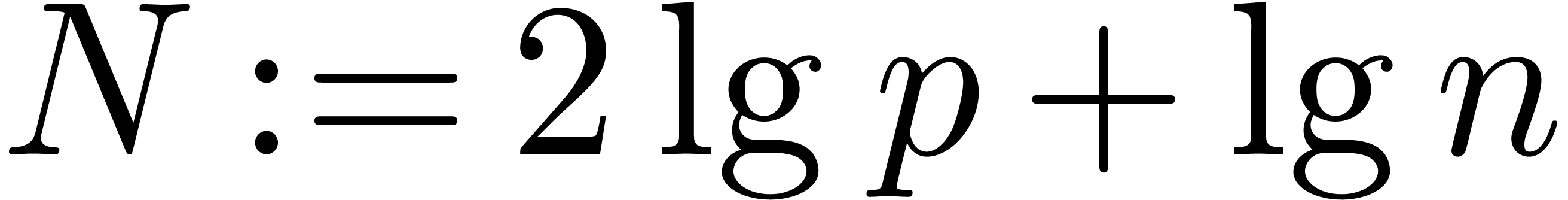 where
where 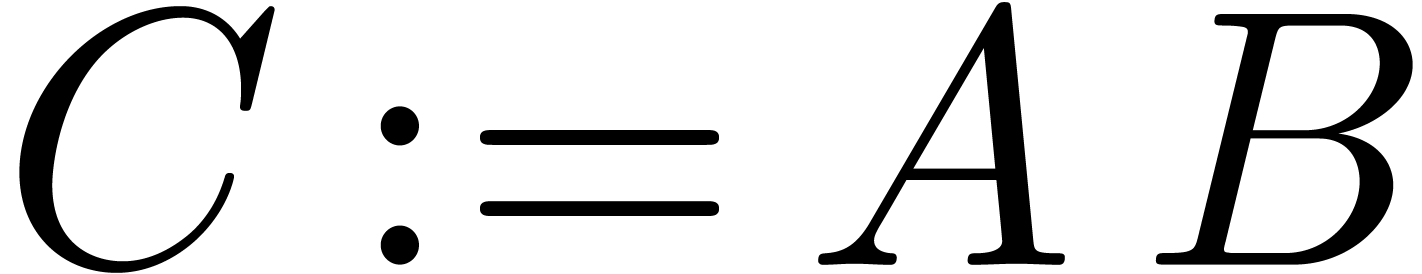 . We deduce the coefficients of
. We deduce the coefficients of
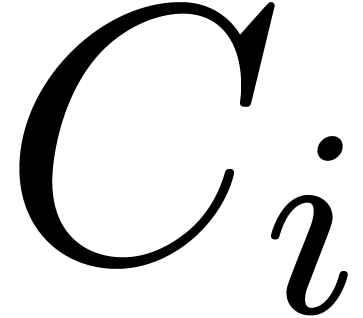 by dividing each
by dividing each 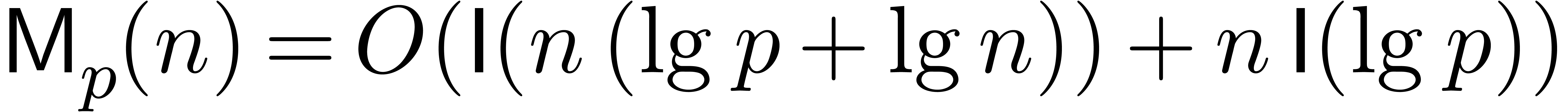 by
. This shows that
by
. This shows that 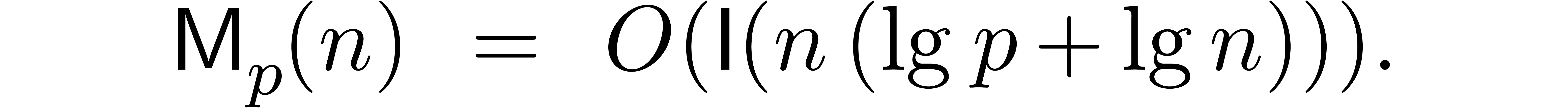 . Using the assumption that is increasing, we obtain
. Using the assumption that is increasing, we obtain
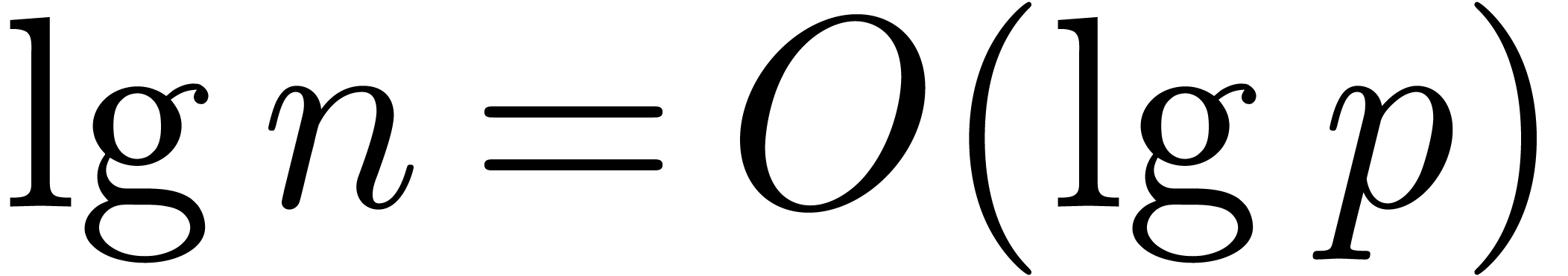
If we also assume that  ,
i.e., that the degree is not too large, then this becomes simply
,
i.e., that the degree is not too large, then this becomes simply
A second type of Kronecker substitution reduces bivariate polynomial
multiplication to the univariate case. Indeed, let
and 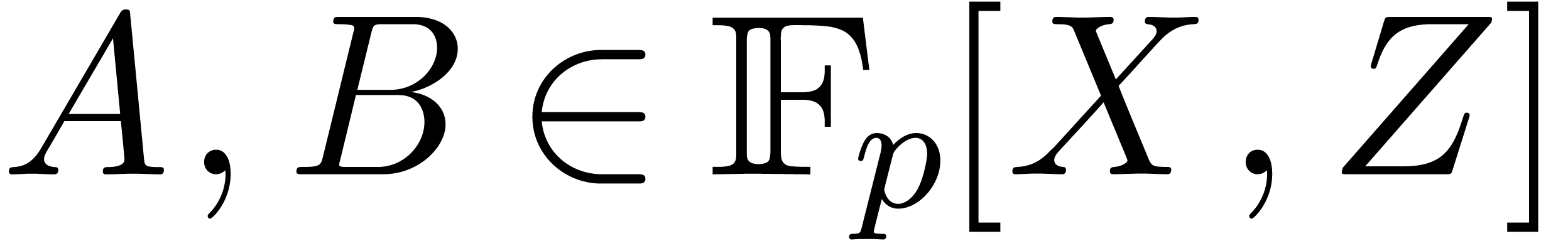 , and suppose that
, and suppose that 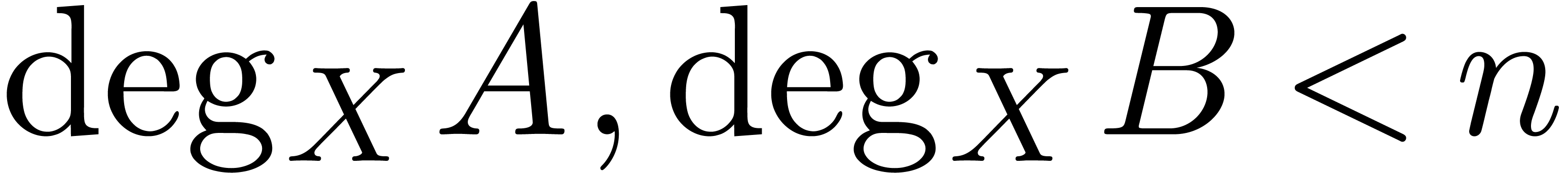 , where
, where 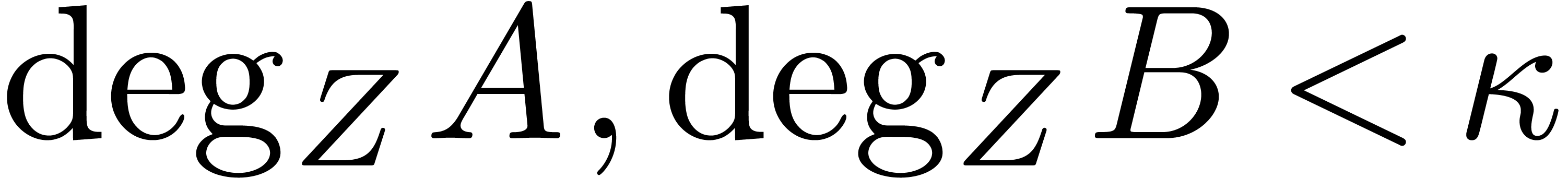 and
and
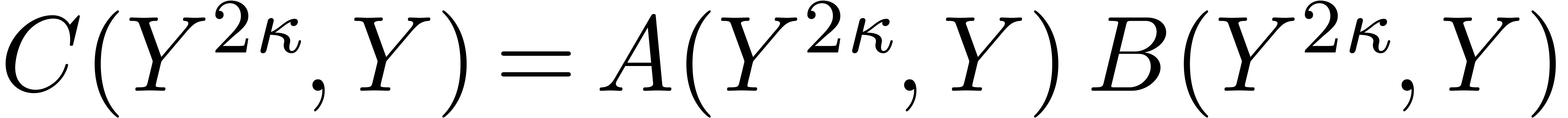 . We may then recover from the univariate product
. We may then recover from the univariate product  in
in 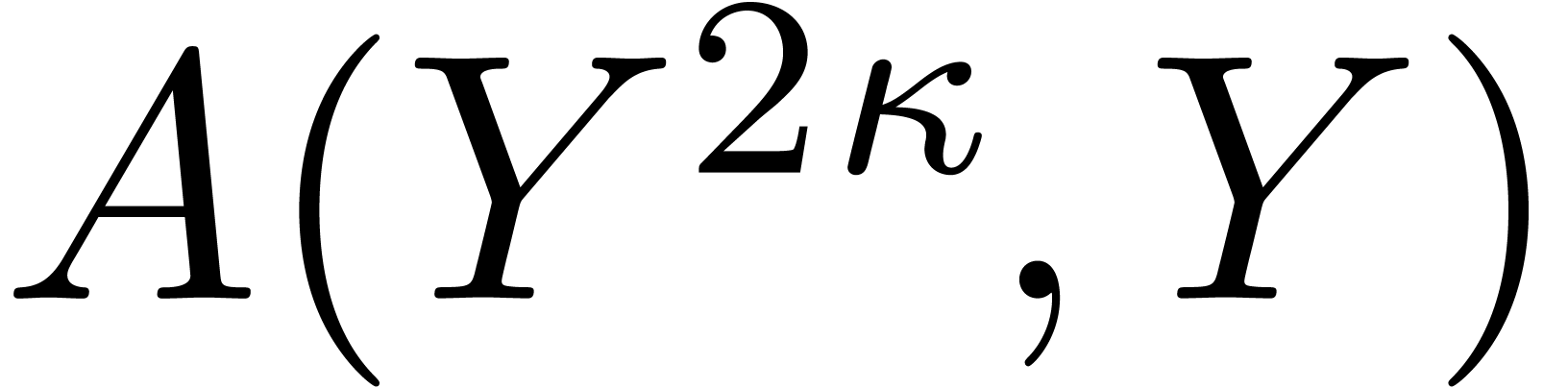 . Note that
. Note that 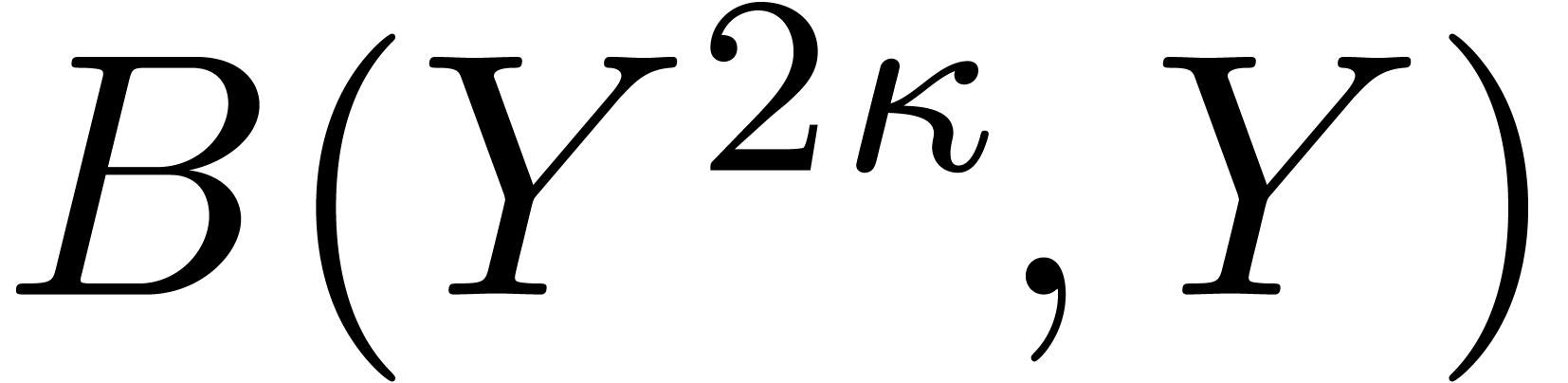 and
and  have degree less than
have degree less than  , so the cost of the bivariate
product is
, so the cost of the bivariate
product is  .
.
The same method works for computing cyclic convolutions: to multiply
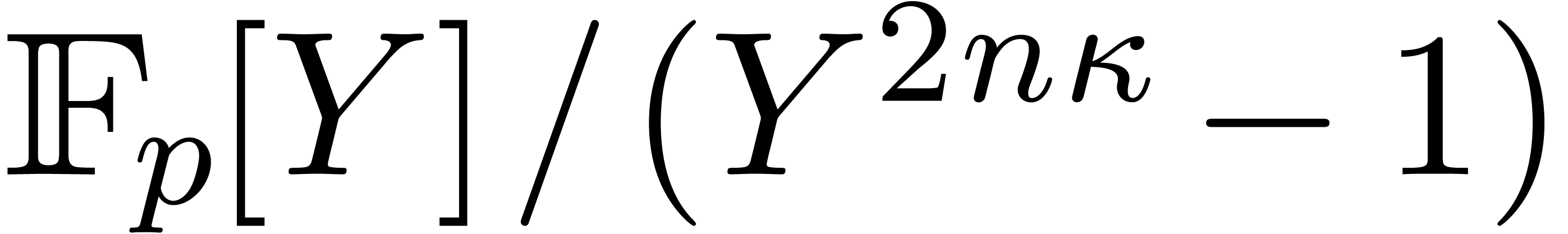 , the same substitution leads
to a product in
, the same substitution leads
to a product in 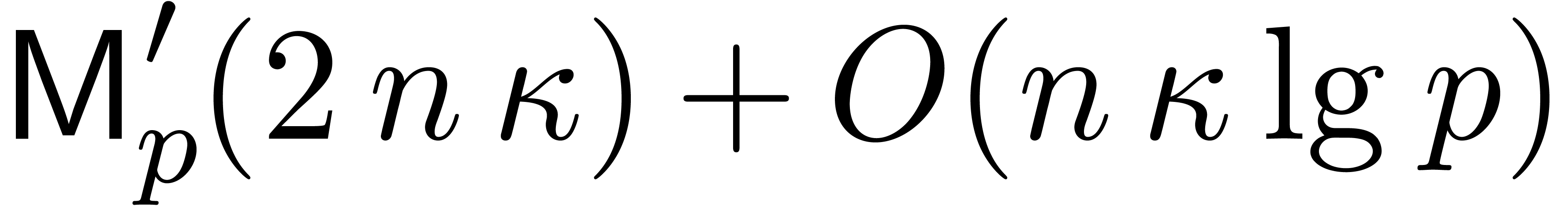 . The cost is
thus
. The cost is
thus 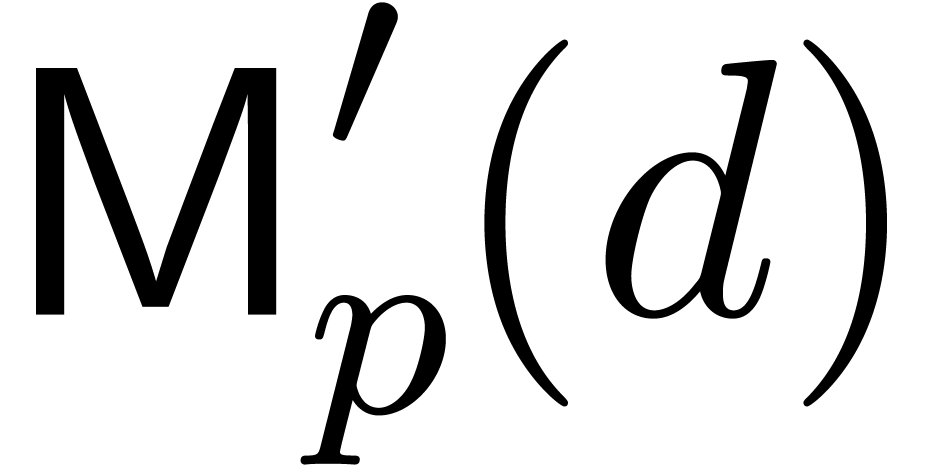 , where
, where 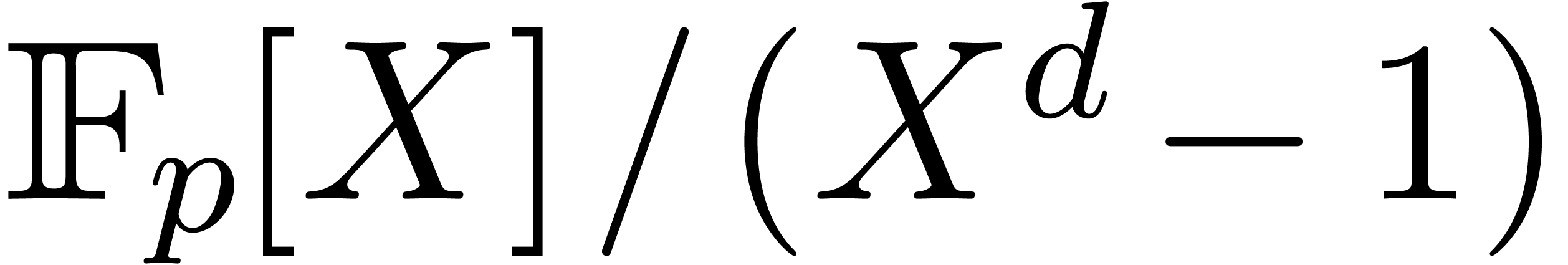 denotes the cost of a multiplication in
denotes the cost of a multiplication in 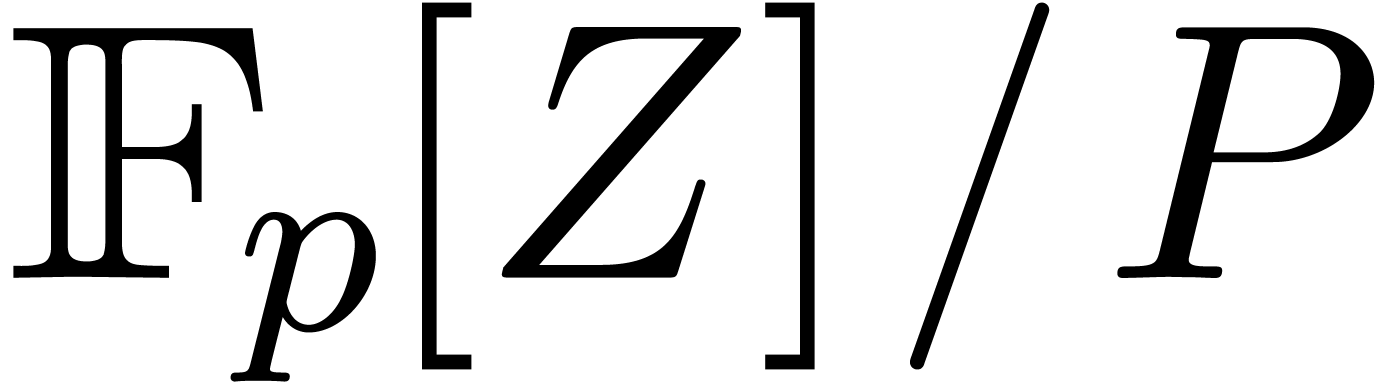 .
.
Let be a prime and let . In this section we review basic results concerning
arithmetic in and .
We assume throughout that is represented as  for some irreducible monic polynomial
for some irreducible monic polynomial  of degree .
Thus an element of is represented uniquely by
its residue modulo
of degree .
Thus an element of is represented uniquely by
its residue modulo  , i.e., by
a polynomial
, i.e., by
a polynomial  of degree less than .
of degree less than .
be a prime and let  . We may compute a monic irreducible
polynomial of degree
. We may compute a monic irreducible
polynomial of degree  in time
in time  .
.
Proof. See [33, Theorem 3.2].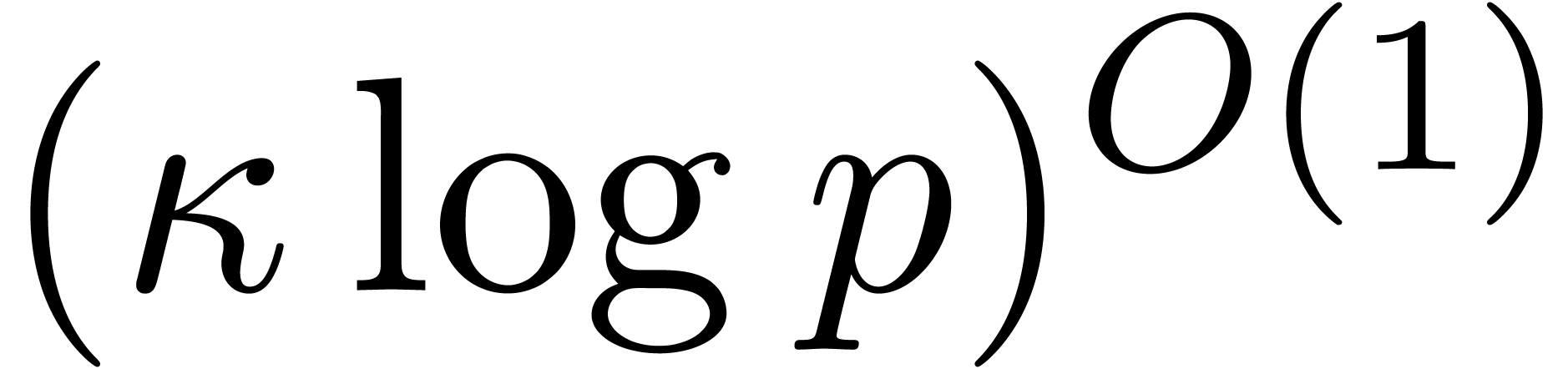
The above complexity bound is very pessimistic in practice. Better
complexity bounds are known if we allow randomised algorithms, or
unproved hypotheses. For instance, assuming GRH, the bound reduces to
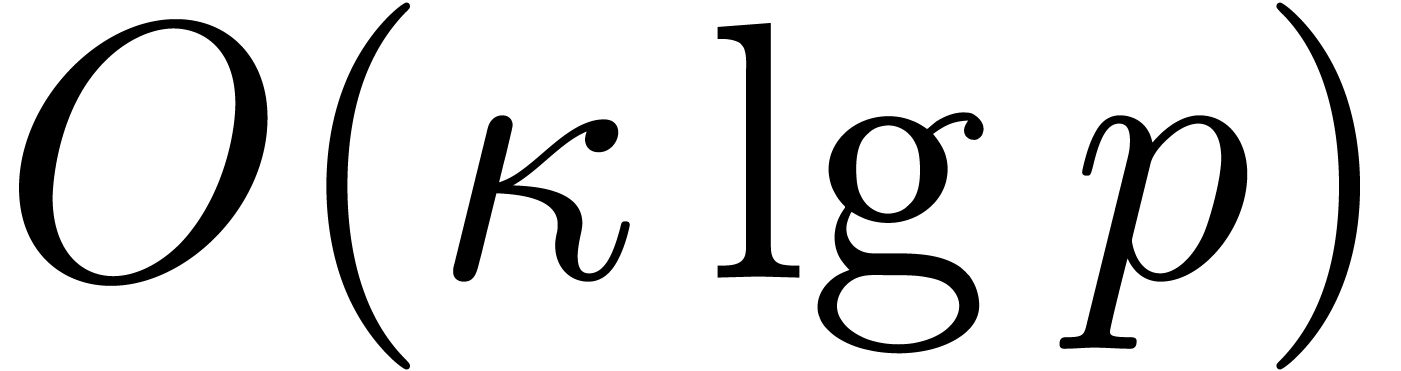 [1].
[1].
We now consider the cost of arithmetic in ,
assuming that is given. Addition and subtraction
in have cost 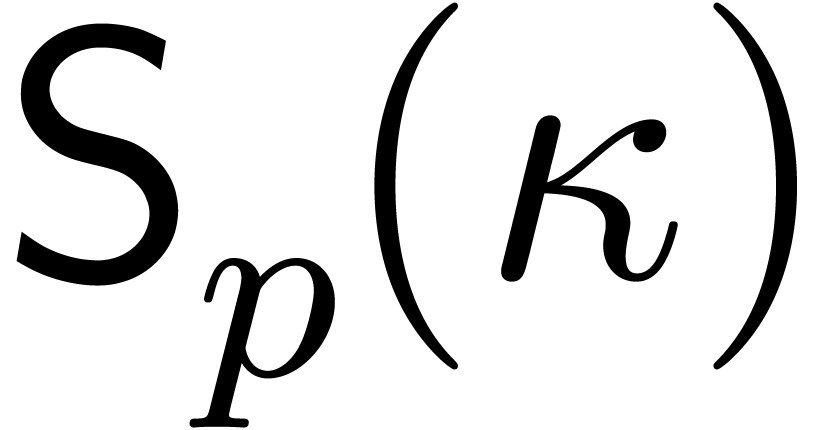 .
For multiplication we will always use the Schönhage–Strassen
algorithm. Denote by
.
For multiplication we will always use the Schönhage–Strassen
algorithm. Denote by 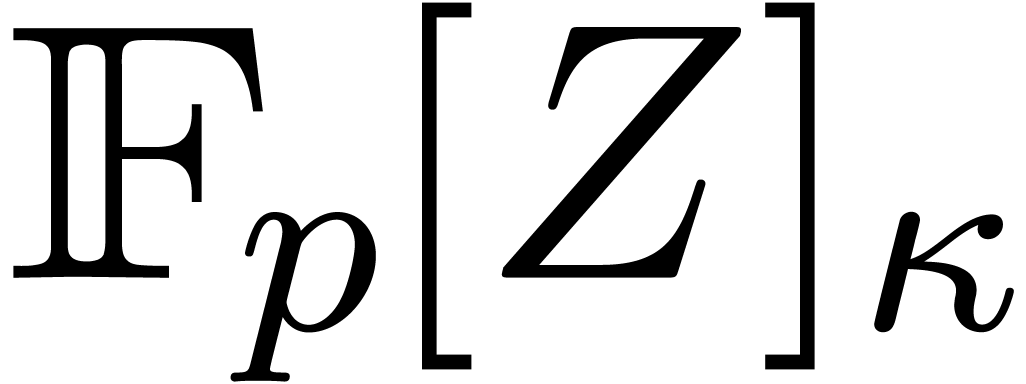 the cost of multiplying
polynomials in
the cost of multiplying
polynomials in  by this method, i.e., using the
polynomial variant [31] for the polynomials themselves,
followed by the integer version [32] to handle the
coefficient multiplications. Then we have
by this method, i.e., using the
polynomial variant [31] for the polynomials themselves,
followed by the integer version [32] to handle the
coefficient multiplications. Then we have
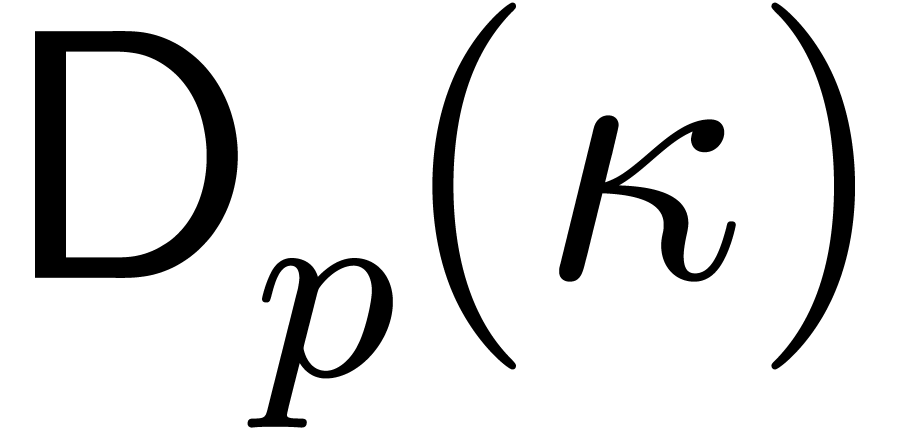
Of course, we could use the new multiplication algorithm recursively for
these products, but it turns out that Schönhage–Strassen is
fast enough, and leads to a simpler complexity analysis in section 7. Let 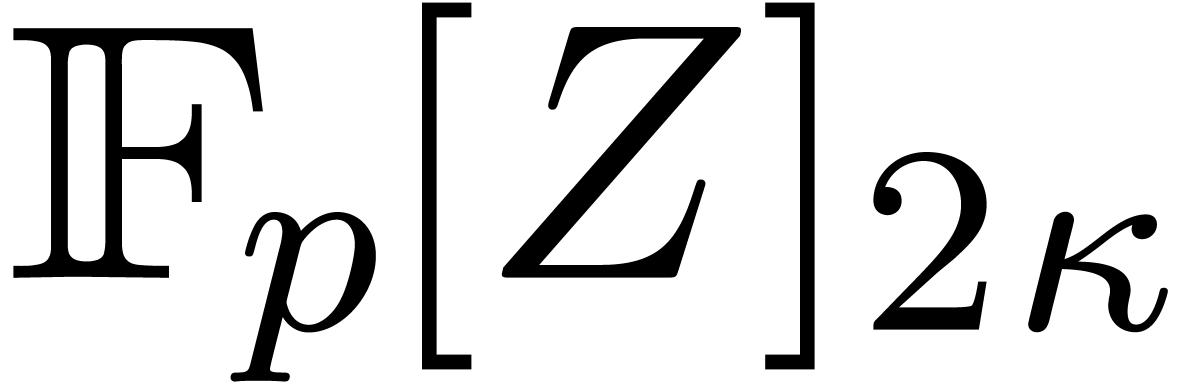 denote the cost of dividing a
polynomial in
denote the cost of dividing a
polynomial in 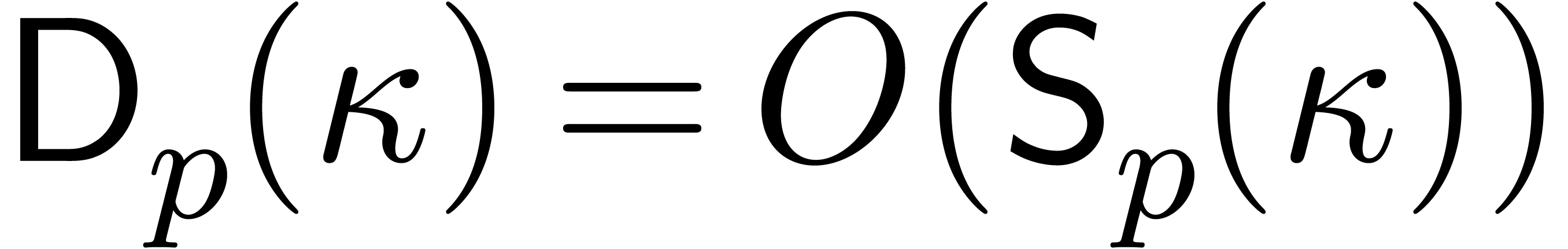 by ,
returning the quotient and remainder. Using Newton's method [17,
Chapter 9] we have
by ,
returning the quotient and remainder. Using Newton's method [17,
Chapter 9] we have 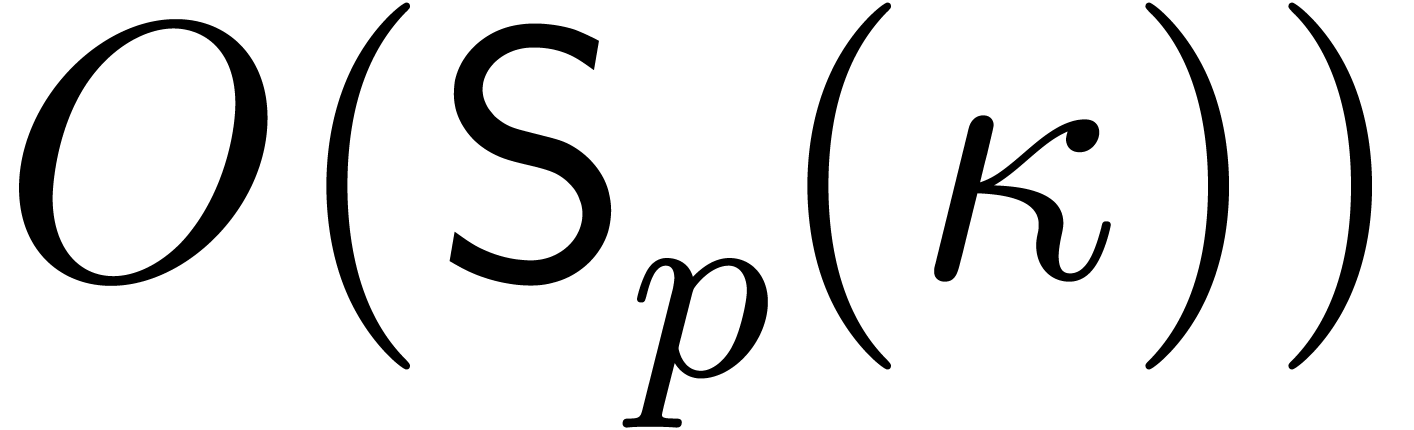 . Thus
elements of may be multiplied in time
. Thus
elements of may be multiplied in time 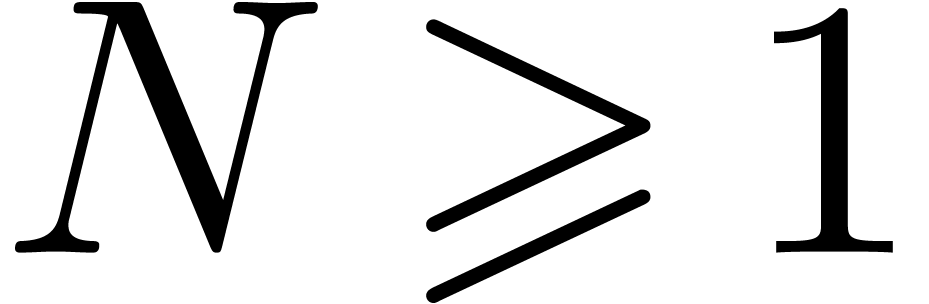 .
.
Let  be a divisor of . To compute a DFT over of
length , we must first have
access to a primitive -th
root of unity in . In general
it is very difficult to find a primitive root of , as it requires knowledge of the factorisation of
. However, to find a
primitive -th root, Lemma 3.3 below shows that it is enough to know the factorisation of
. The construction relies on
the following existence result.
be a divisor of . To compute a DFT over of
length , we must first have
access to a primitive -th
root of unity in . In general
it is very difficult to find a primitive root of , as it requires knowledge of the factorisation of
. However, to find a
primitive -th root, Lemma 3.3 below shows that it is enough to know the factorisation of
. The construction relies on
the following existence result.
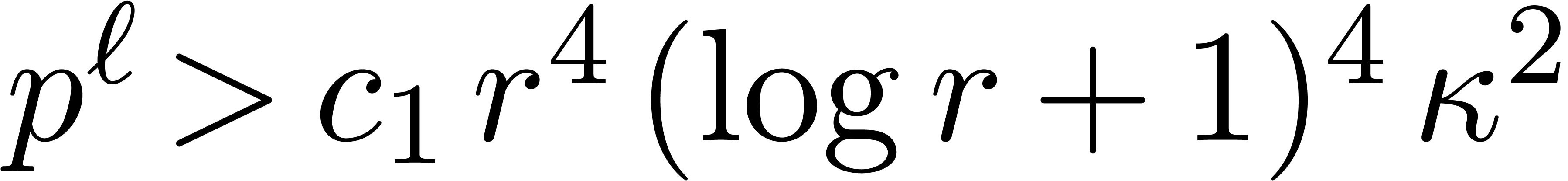 be a positive integer such that
be a positive integer such that
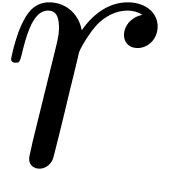 , where
, where  is the number of distinct prime divisors of , and where
is the number of distinct prime divisors of , and where  is a certain
absolute constant. Then there exists a monic irreducible polynomial
is a certain
absolute constant. Then there exists a monic irreducible polynomial
 of degree such that
of degree such that
 modulo
modulo 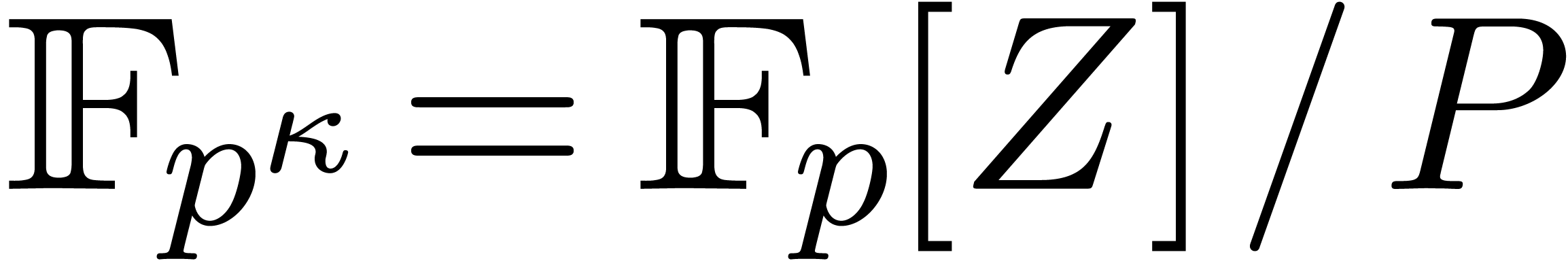 is a primitive
root of unity for
is a primitive
root of unity for  .
.
Proof. This is [34, Theorem
1.1].
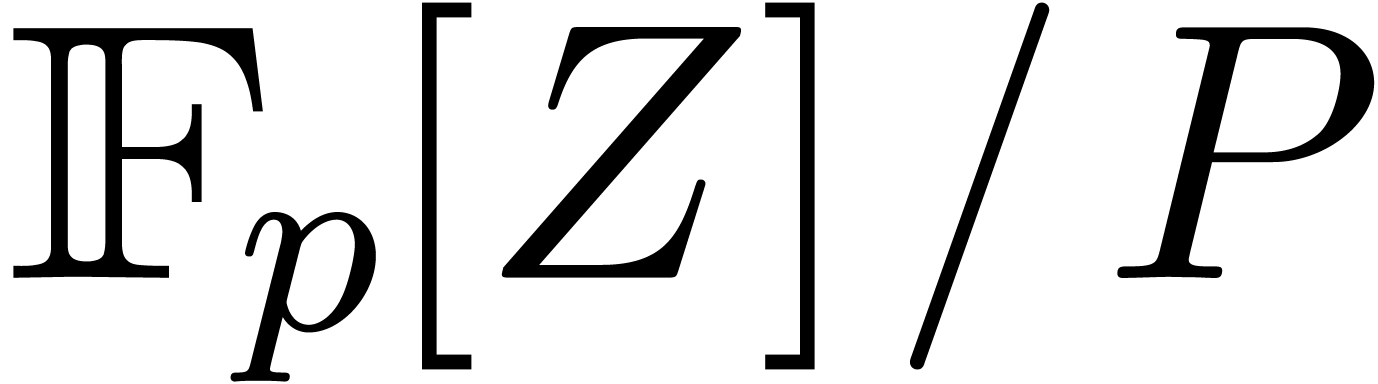 divides
and that the factorisation of is given. Then
we may compute a primitive -th
root of unity in
divides
and that the factorisation of is given. Then
we may compute a primitive -th
root of unity in 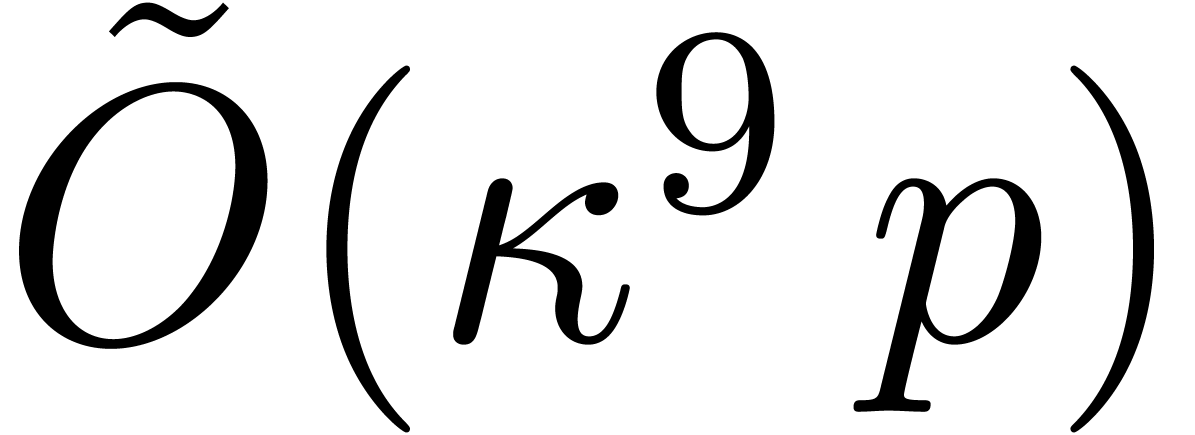 in time
in time 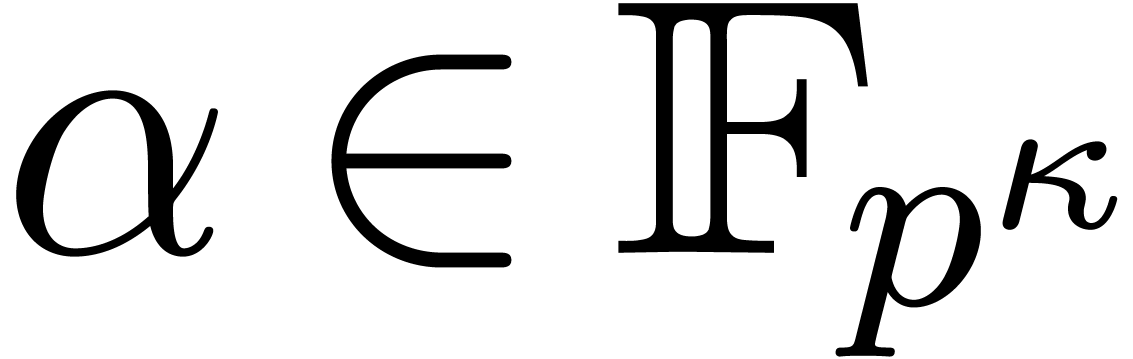 .
.
Proof. Testing whether a given 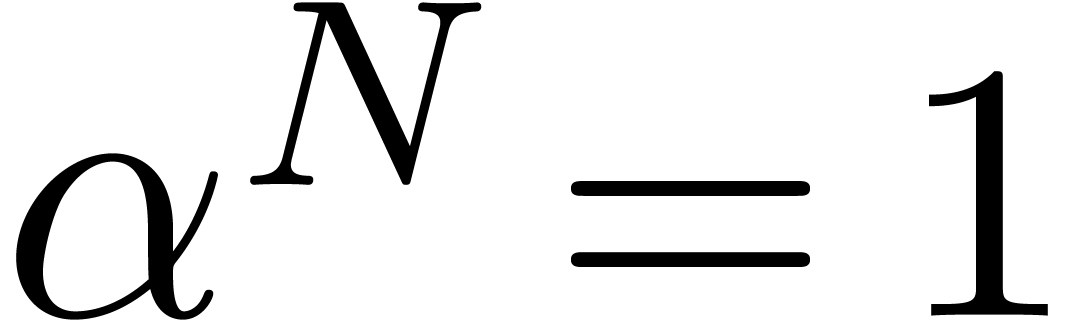 is a primitive -th root of
unity reduces to checking that
is a primitive -th root of
unity reduces to checking that 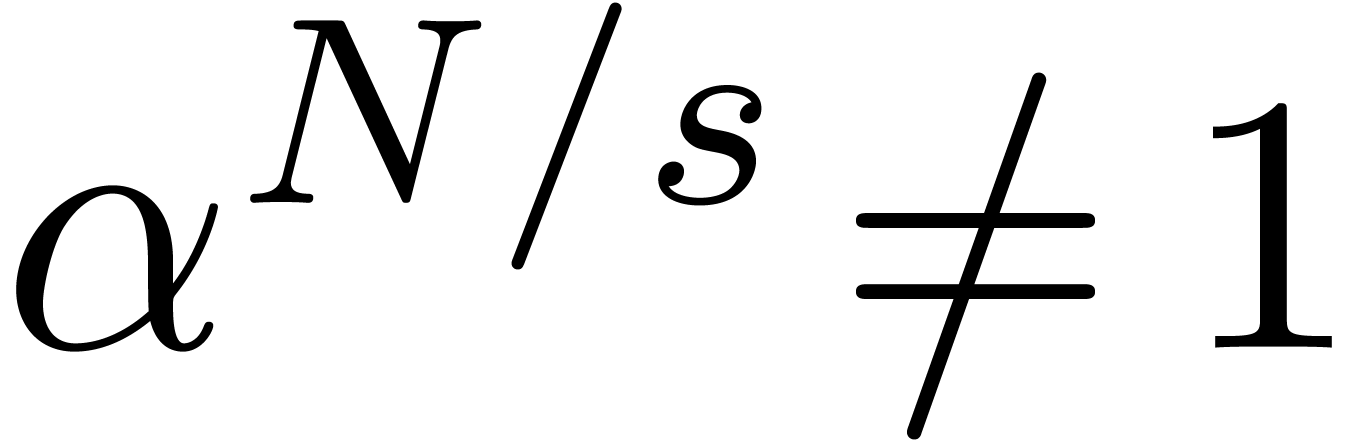 and
and  for every prime divisor
for every prime divisor 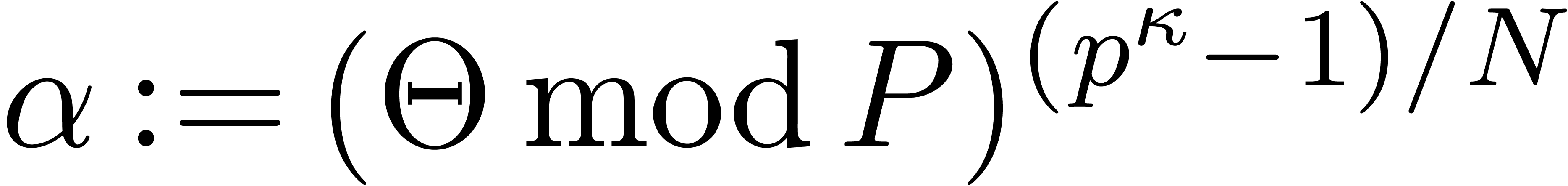 of . According to Lemma 3.2,
it suffices to apply this test to
of . According to Lemma 3.2,
it suffices to apply this test to  for
for  running over all monic polynomials of degree
running over all monic polynomials of degree 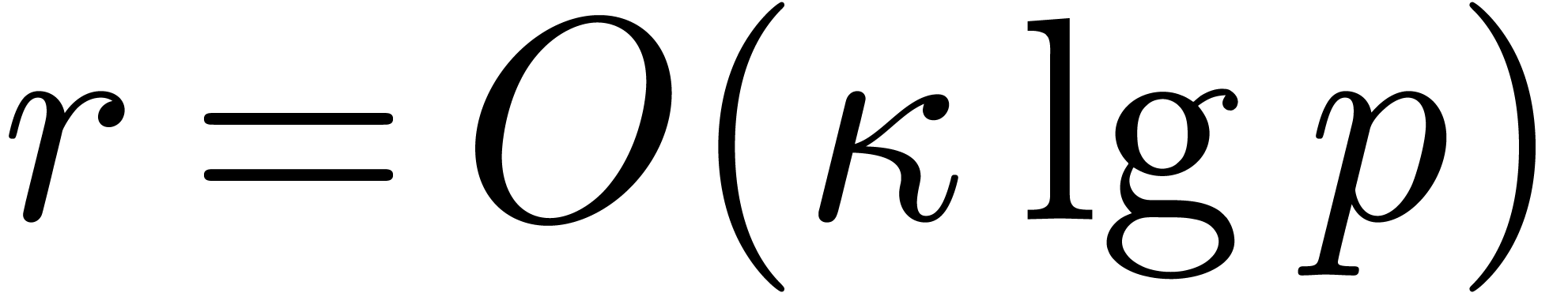 , where
, where 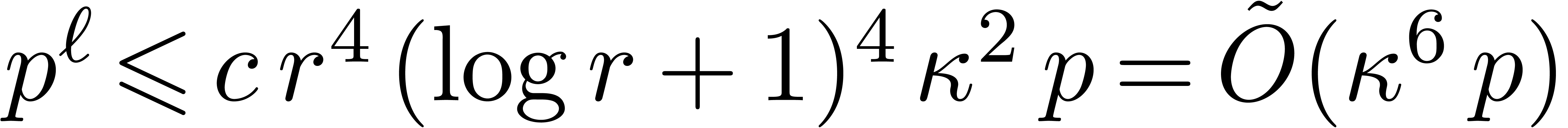 is as in the
lemma. The number of candidates is at most
is as in the
lemma. The number of candidates is at most 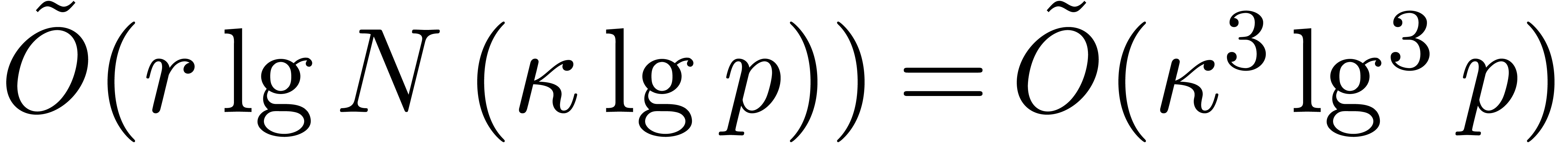 ,
and each candidate can be tested in time
,
and each candidate can be tested in time 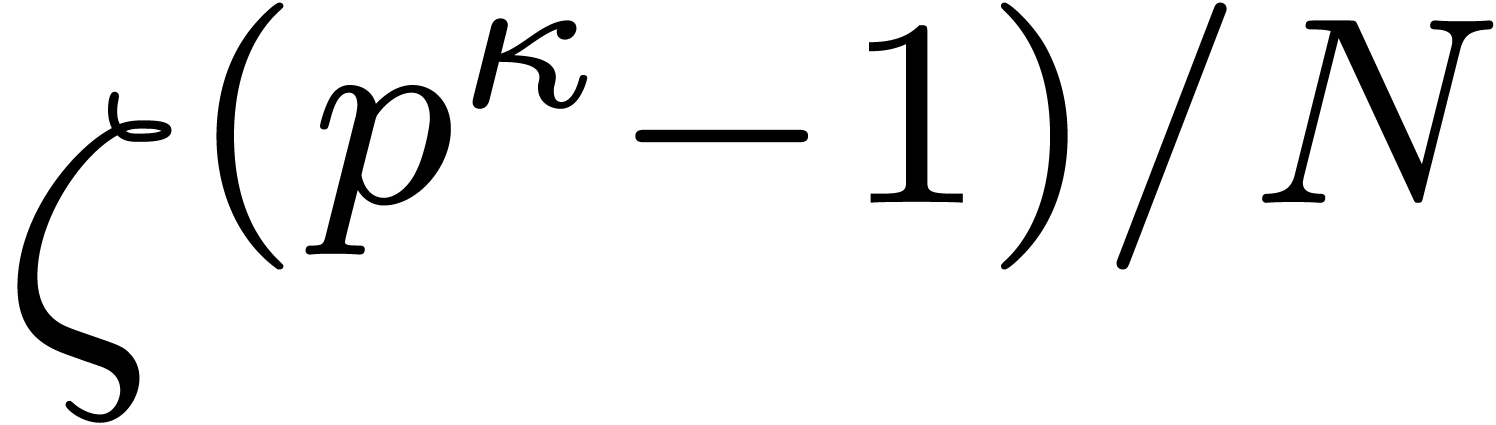 using
binary exponentiation.
using
binary exponentiation.
Of course, we can do much better if randomised algorithms are allowed,
since  is reasonably likely to be a primitive
-th root for randomly
selected
is reasonably likely to be a primitive
-th root for randomly
selected 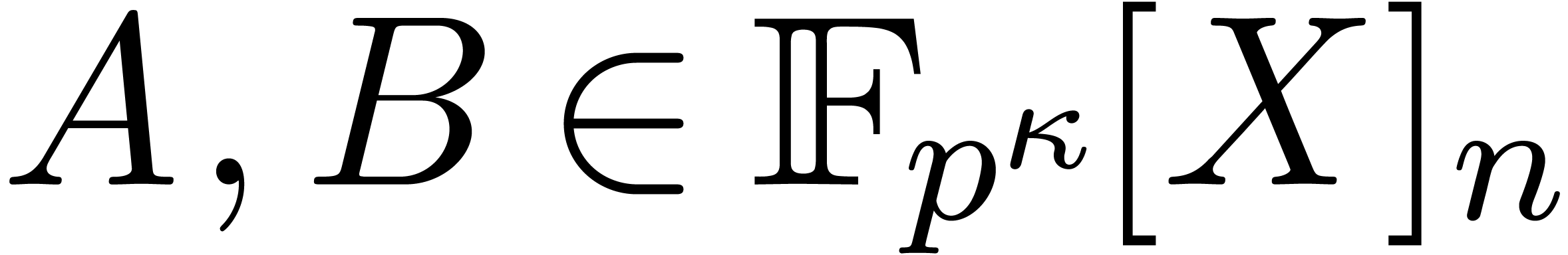 .
.
Finally, we consider polynomial multiplication over . Let ,
and let 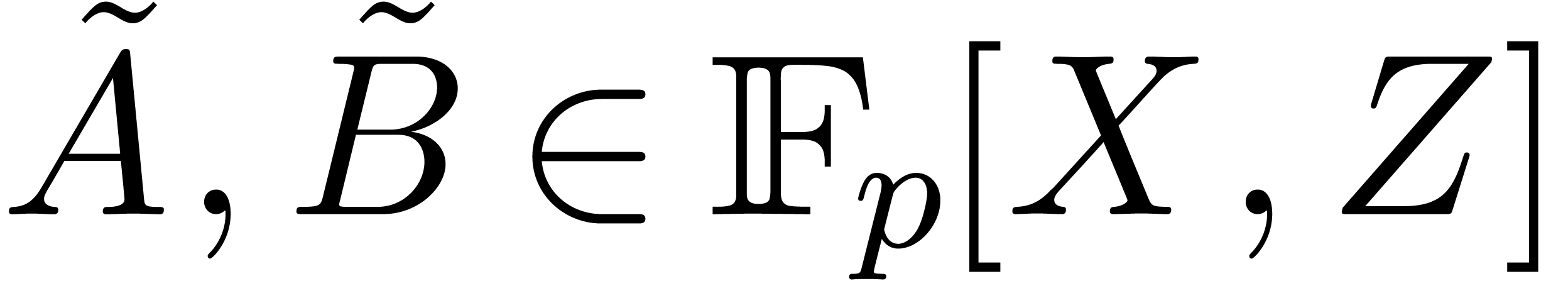 . Let
. Let  be their natural lifts, i.e., of degree less than with respect to
be their natural lifts, i.e., of degree less than with respect to 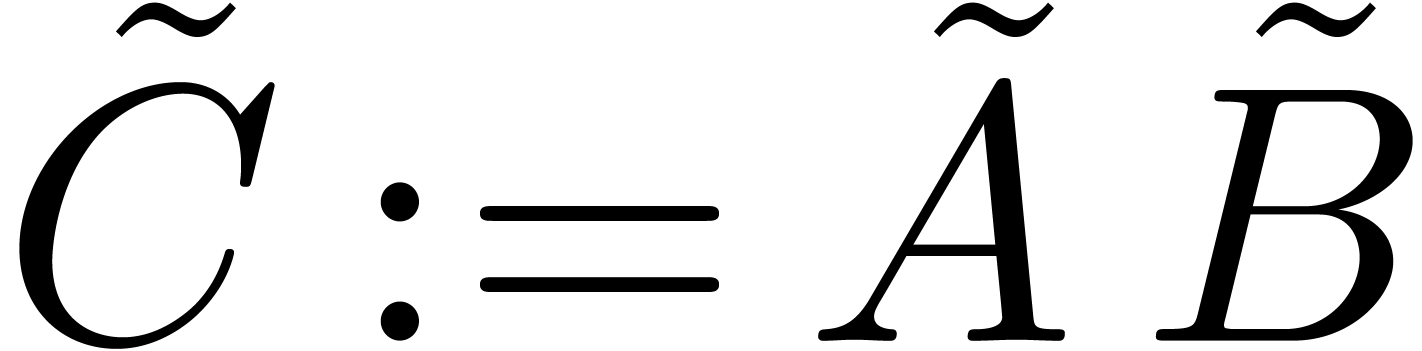 .
The bivariate product
.
The bivariate product 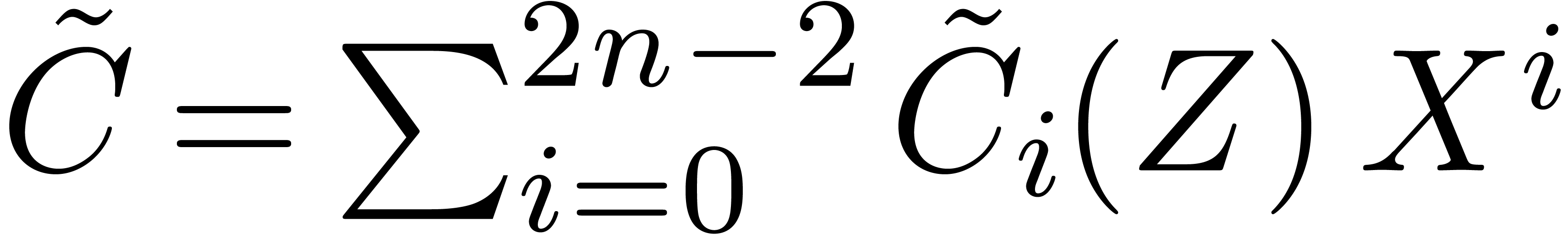 may be computed using
Kronecker substitution (section 2.6) in time . Writing
may be computed using
Kronecker substitution (section 2.6) in time . Writing  ,
to recover we must divide each
,
to recover we must divide each 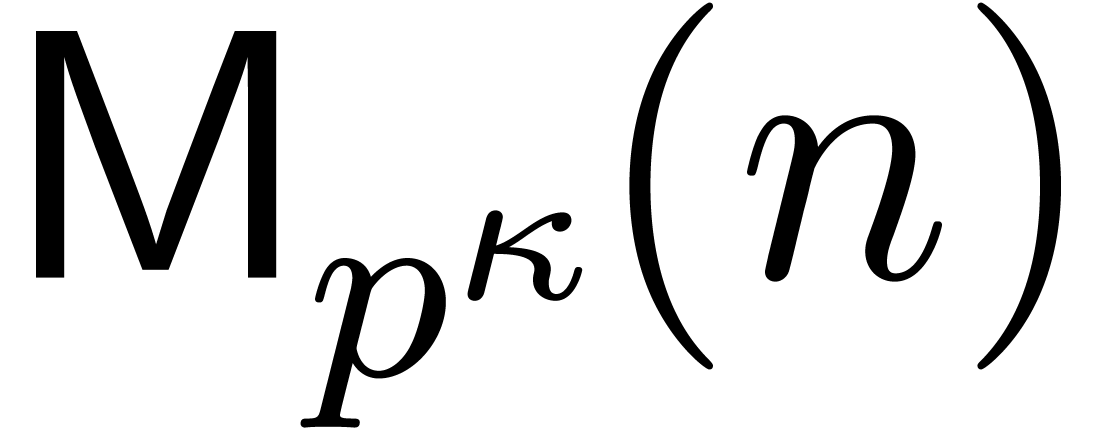 by . Denoting by
by . Denoting by 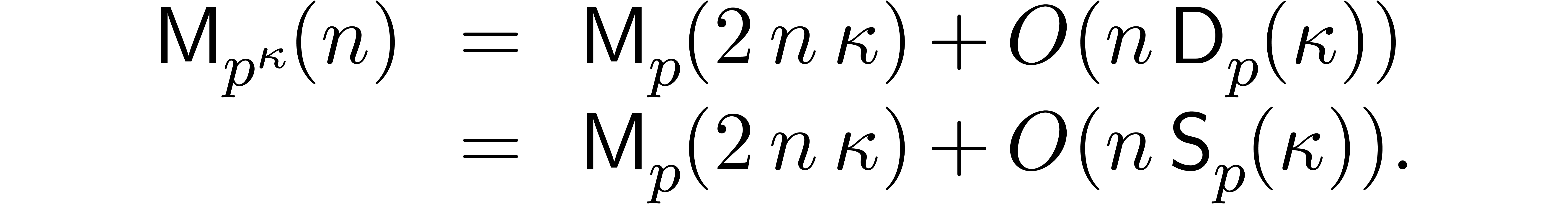 the complexity of the original multiplication problem, we
obtain
the complexity of the original multiplication problem, we
obtain
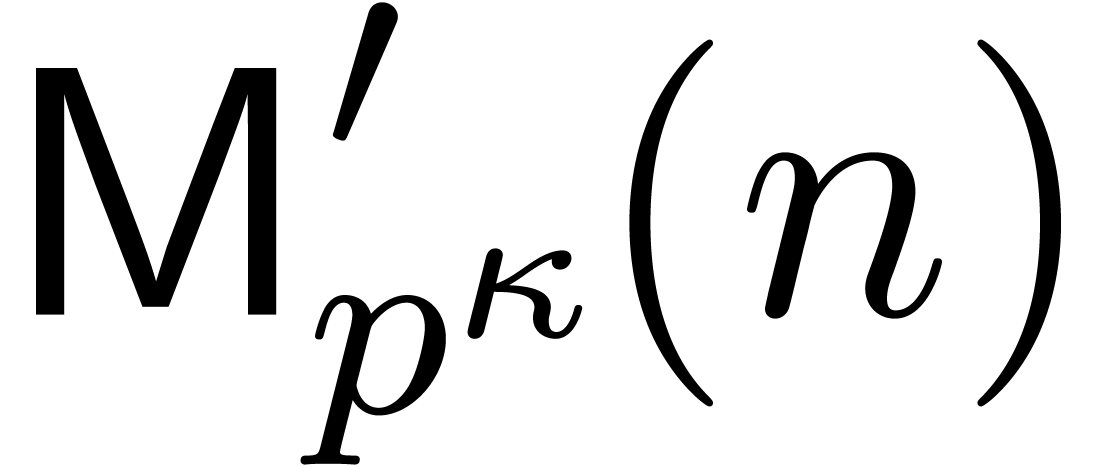
As in section 2.6, the same method may be used for cyclic
convolutions. If 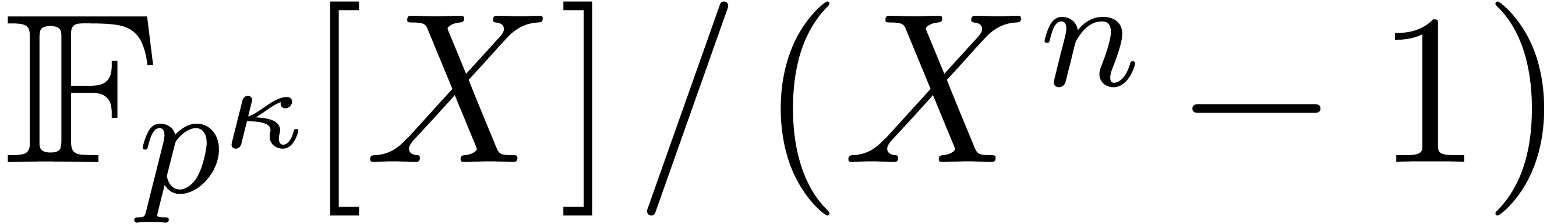 denotes the cost of
multiplication in
denotes the cost of
multiplication in 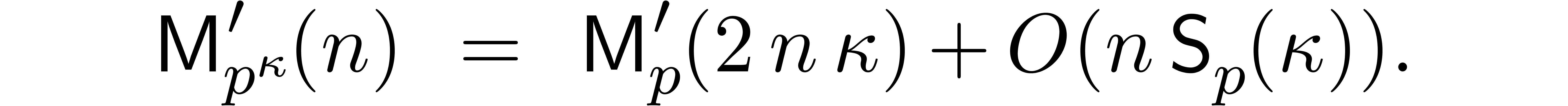 , then we
get
, then we
get
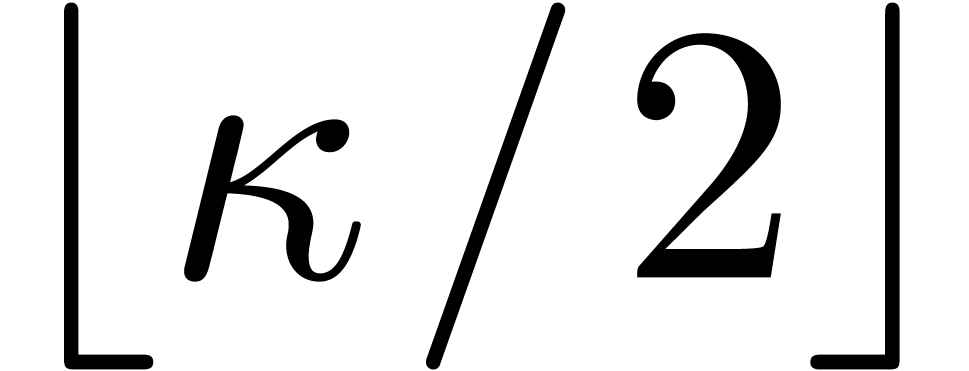
Remark
to multiplication in by splitting the inputs
into chunks of size 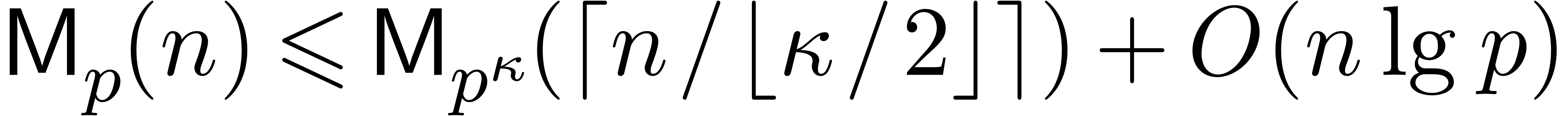 . This
leads to the bound
. This
leads to the bound 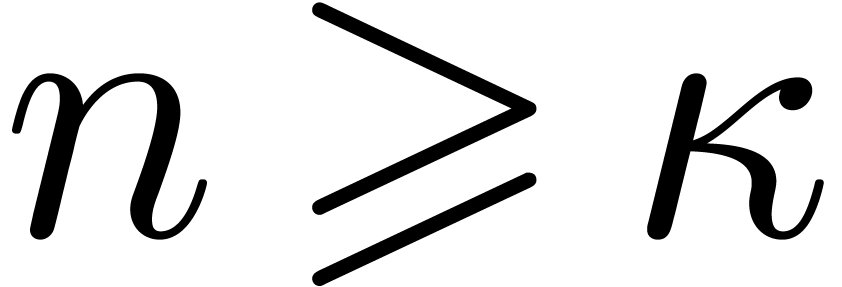 for
for 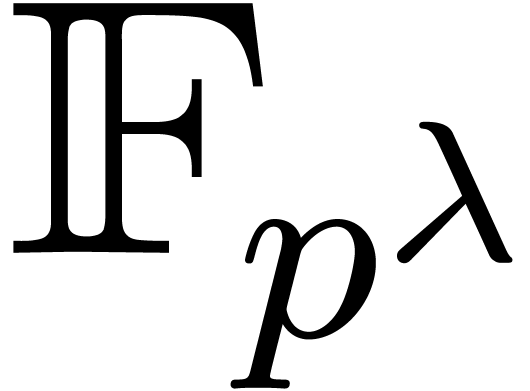 . A variant of this procedure is developed in detail
in section 6.
. A variant of this procedure is developed in detail
in section 6.
The aim of this section is to prove the following theorem, which allows
us to construct “small” extensions 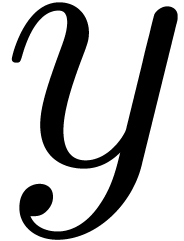 of containing “many” roots of unity
of “low” order. Recall that a positive integer is said to be
of containing “many” roots of unity
of “low” order. Recall that a positive integer is said to be
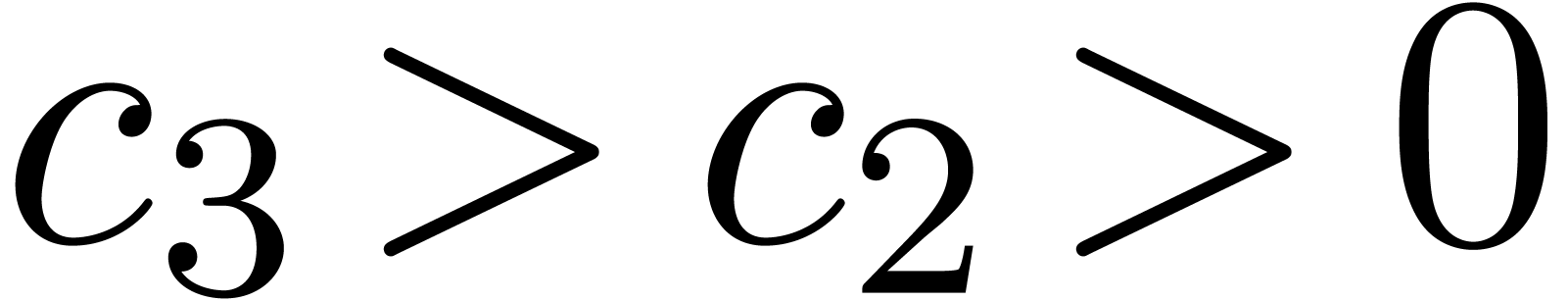 -smooth if all of its
prime divisors are less than or equal to .
-smooth if all of its
prime divisors are less than or equal to .
 and
and  with the following properties. Let be a prime and let
with the following properties. Let be a prime and let 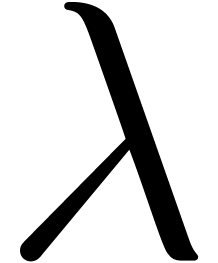 .
Then there exists an integer
.
Then there exists an integer 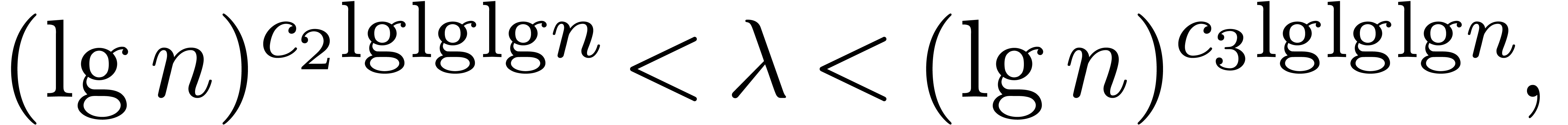 in the
interval
in the
interval

and a  -smooth integer
-smooth integer
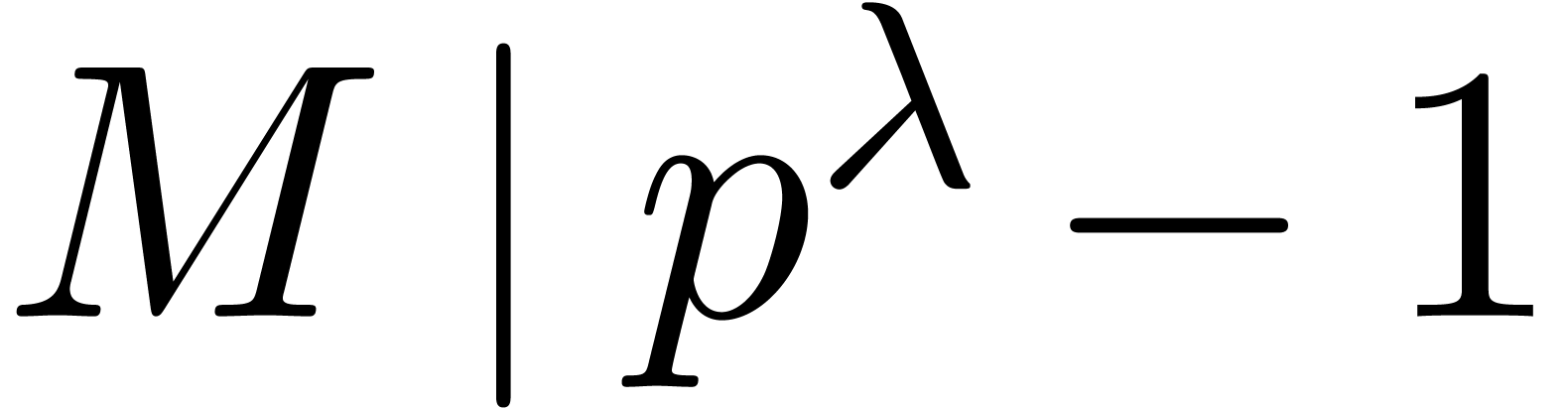 , such that
, such that 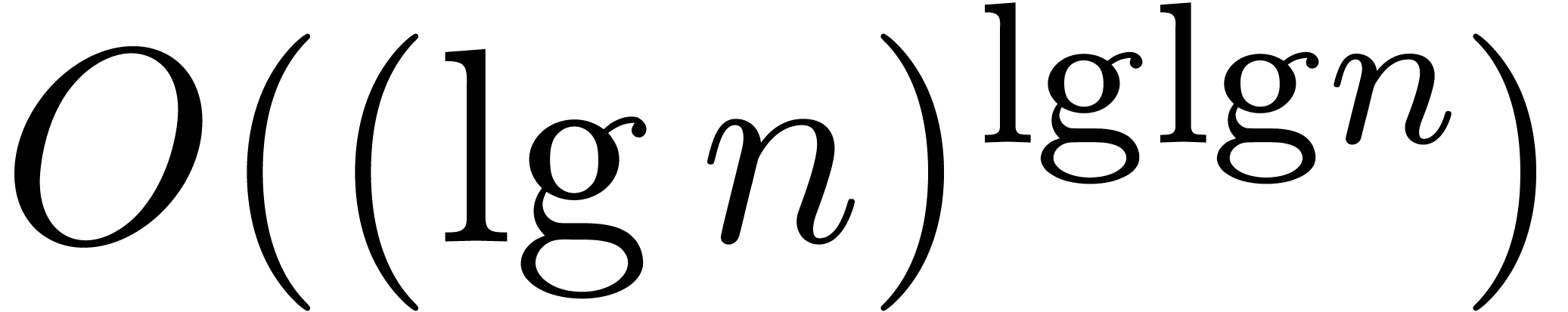 . Moreover, given and
, we may compute and the prime factorisation of M in time
. Moreover, given and
, we may compute and the prime factorisation of M in time 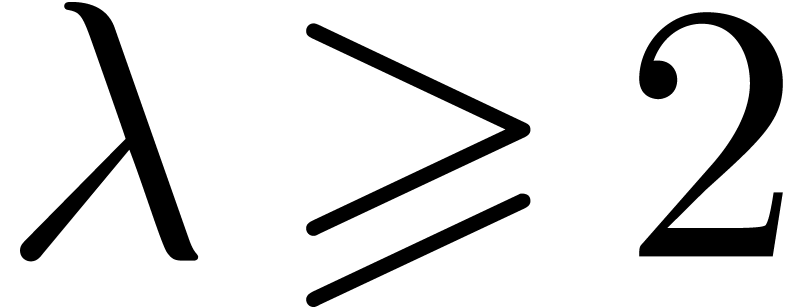 .
.
The proof depends on a series of preparatory lemmas. For 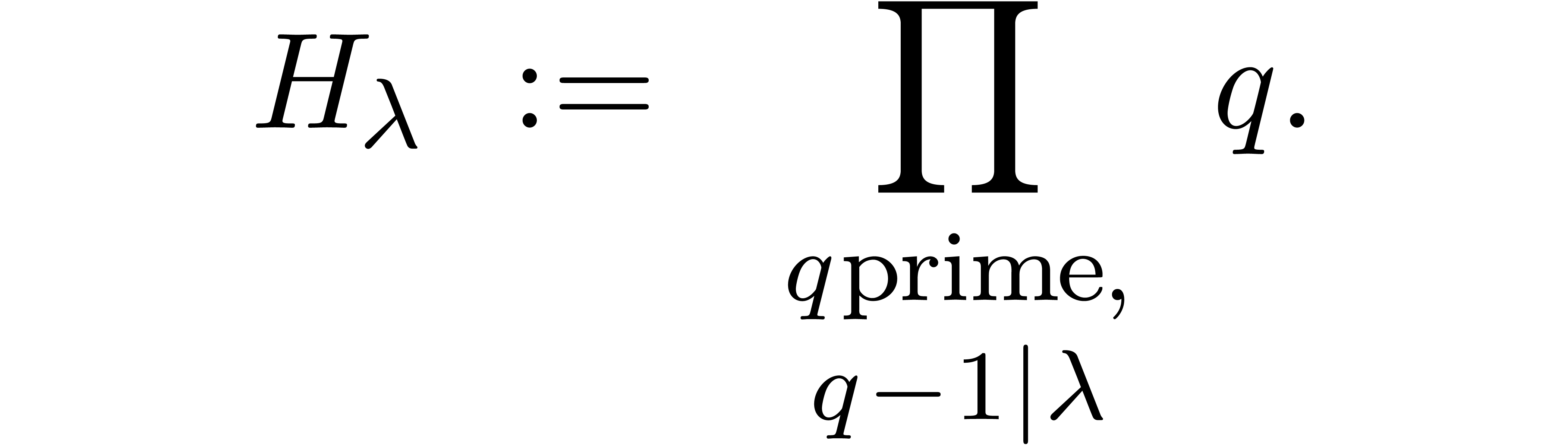 , define
, define

For example,  and
and  .
Note that
.
Note that  is always squarefree and
is always squarefree and  -smooth. We are interested in finding
-smooth. We are interested in finding  for which is unusually large; that
is, for which has many divisors
for which is unusually large; that
is, for which has many divisors  such that
such that 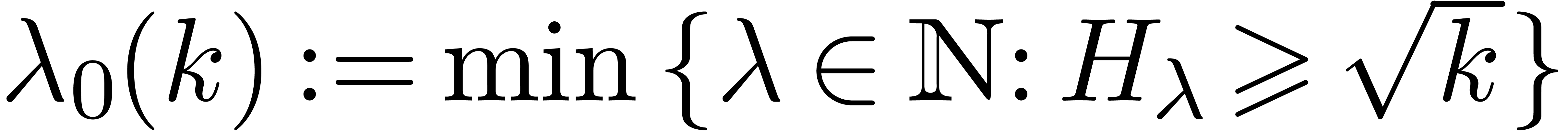 happens to be prime. Most of the heavy
lifting is done by the following remarkable result.
happens to be prime. Most of the heavy
lifting is done by the following remarkable result.
Proof. This is part of [2, Theorem
3]. (The threshold 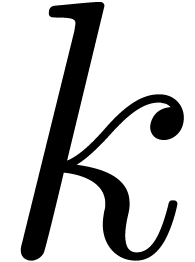 could of course be replaced
by any fixed power of
could of course be replaced
by any fixed power of 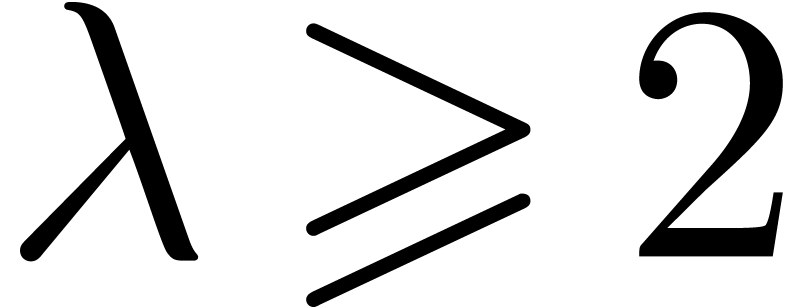 . It is
stated this way in [2] because that paper is concerned with
primality testing.)
. It is
stated this way in [2] because that paper is concerned with
primality testing.)
The link between and is
as follows.
Proof. We take 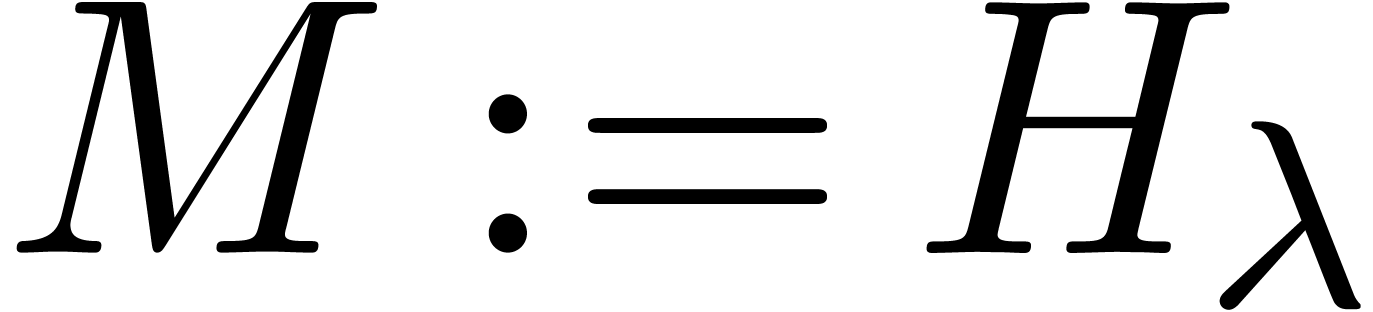 if divides ,
and otherwise
if divides ,
and otherwise 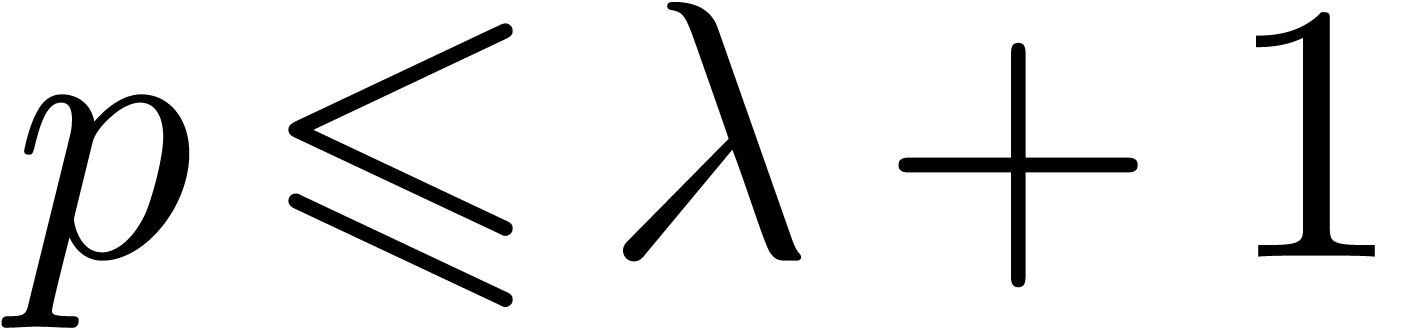 . In the former
case we must have
. In the former
case we must have 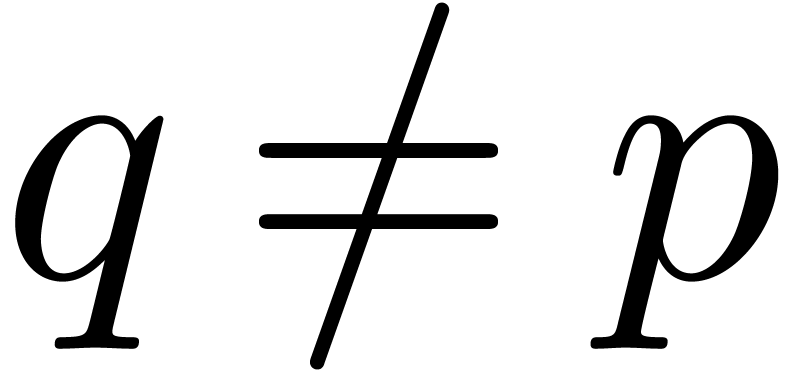 , so in
both cases
, so in
both cases 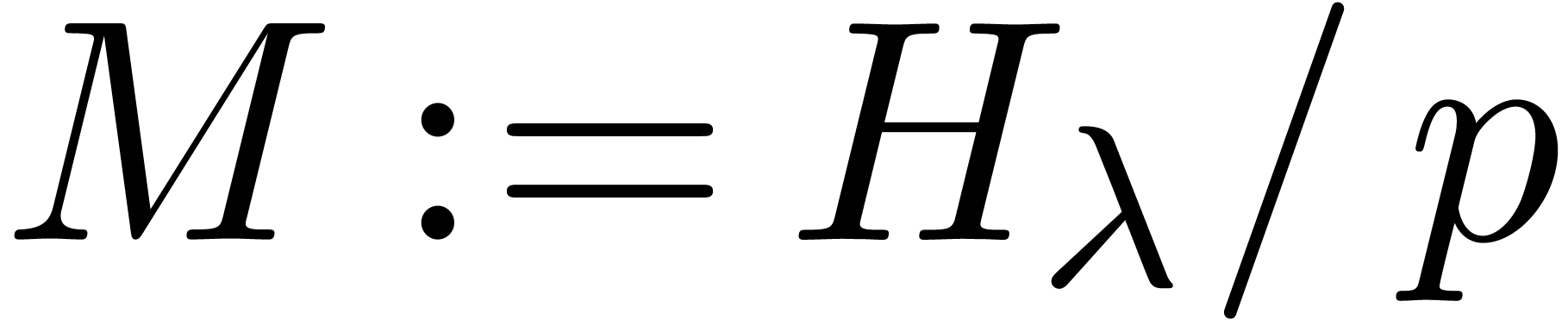 . To see that
, consider any prime divisor
. To see that
, consider any prime divisor
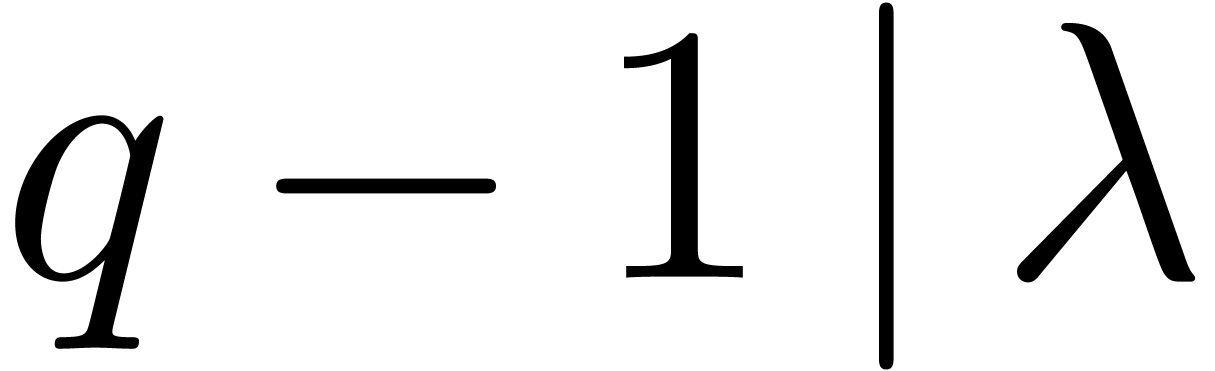 of .
Then
of .
Then 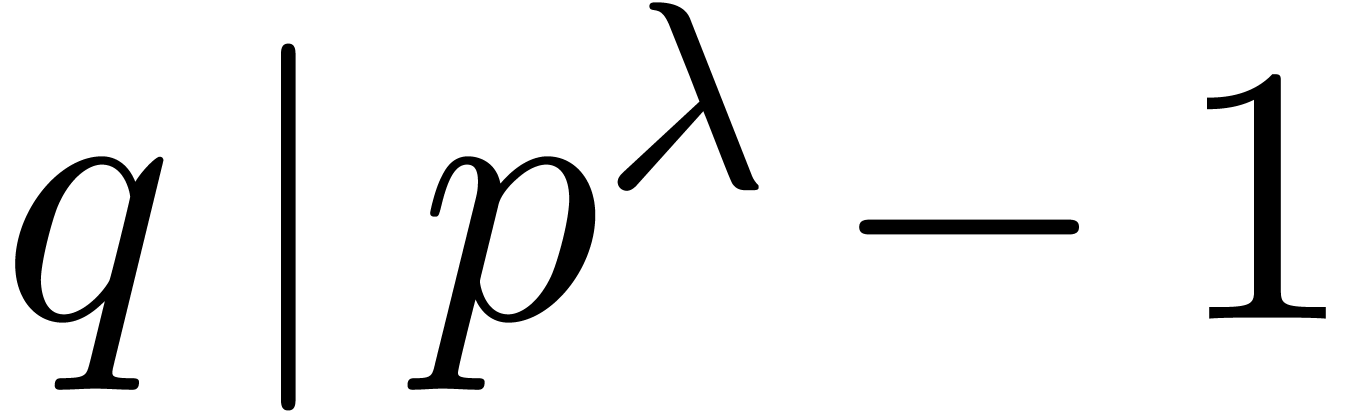 , so
, so  by Fermat's little theorem.
by Fermat's little theorem.
Remark 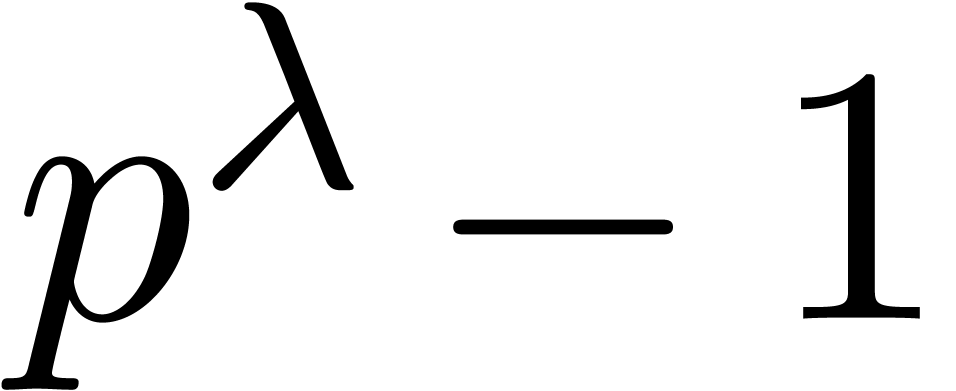 constructed in Lemma 4.3 only takes
into account the structure of ,
and ignores
constructed in Lemma 4.3 only takes
into account the structure of ,
and ignores  itself. In practice, will often have small factors other than those in , possibly including repeated
factors (which are never detected by ).
For example,
itself. In practice, will often have small factors other than those in , possibly including repeated
factors (which are never detected by ).
For example,  , but
, but  . In an implementation, one should
always incorporate these highly valuable “accidental”
factors into . We will ignore
them in our theoretical discussion.
. In an implementation, one should
always incorporate these highly valuable “accidental”
factors into . We will ignore
them in our theoretical discussion.
Next we give a simple sieving algorithm that tabulates approximations of
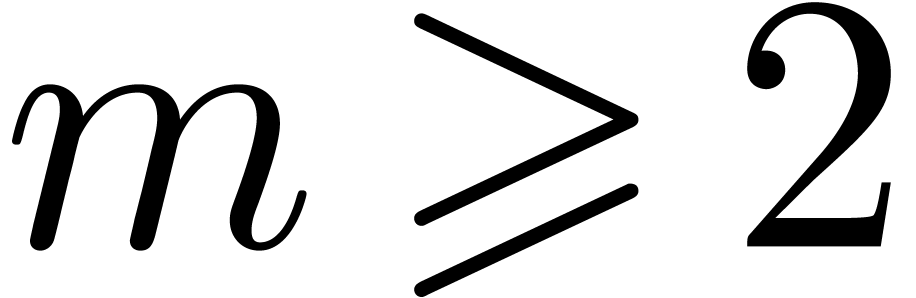 for all up to a
prescribed bound.
for all up to a
prescribed bound.
Proof. Initialise a table of 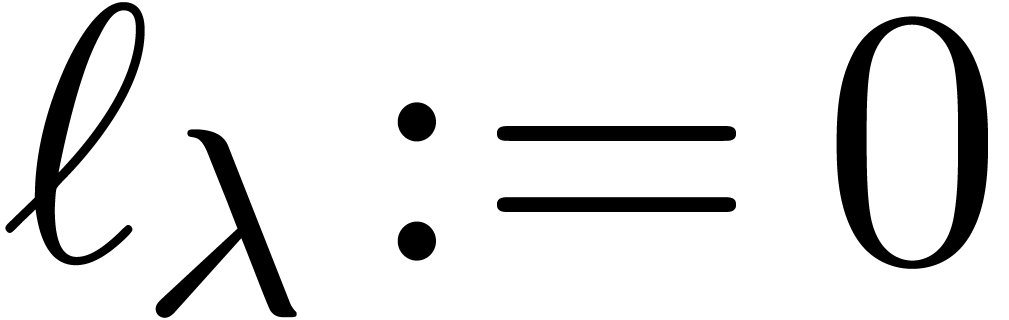 with
with 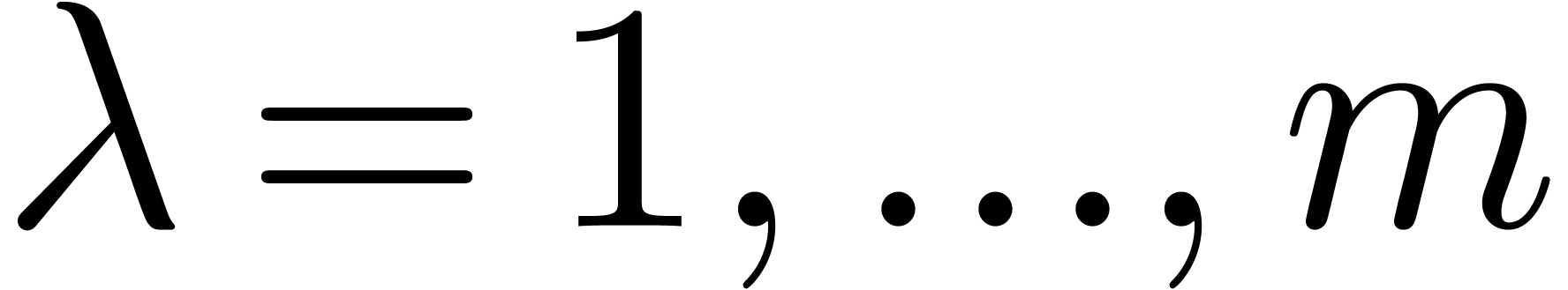 for
for 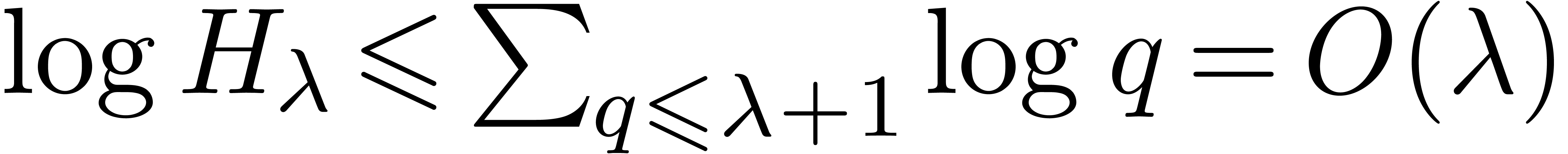 .
Since
.
Since 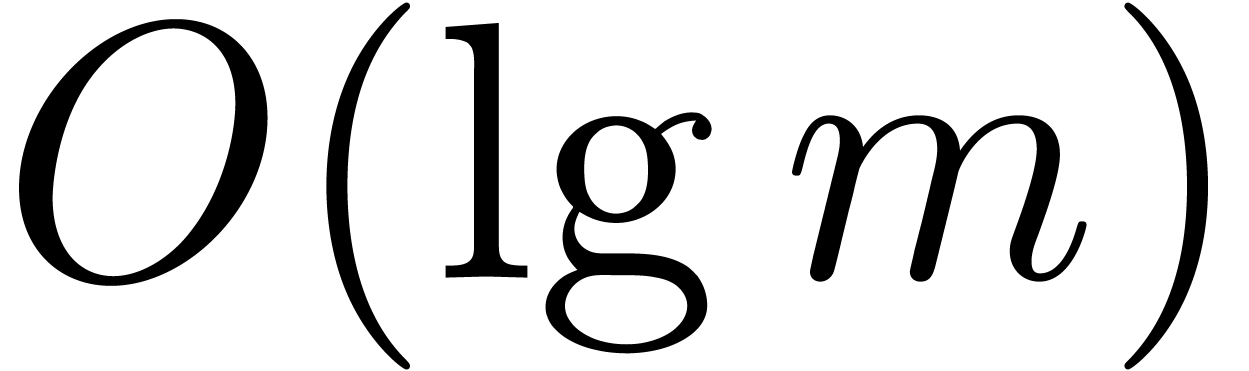 , it suffices to set
aside
, it suffices to set
aside 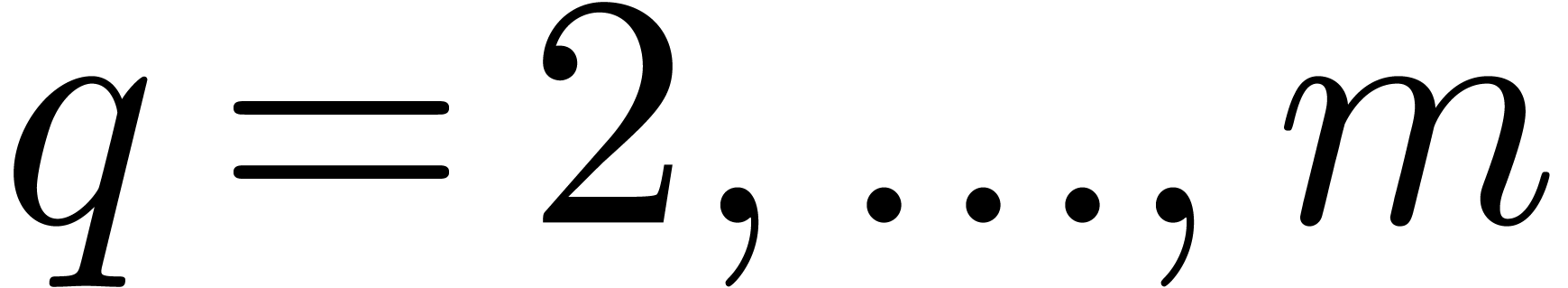 bits for each .
bits for each .
For each integer  , perform
the following steps. First test whether
, perform
the following steps. First test whether 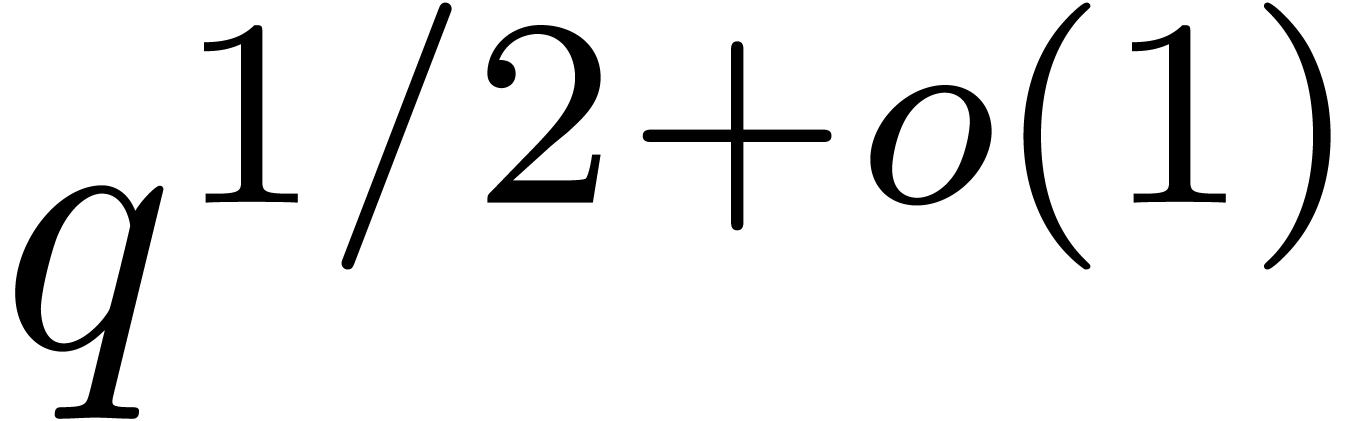 is
prime, discarding it if not. Using trial division, the cost is
is
prime, discarding it if not. Using trial division, the cost is 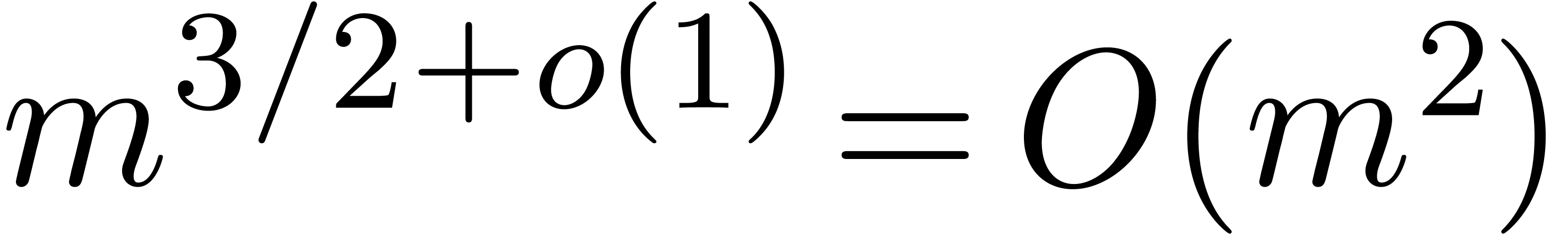 , so
, so  overall. Now assume that is found to be prime.
Using a fast algorithm for computing logarithms [8],
compute an integer
overall. Now assume that is found to be prime.
Using a fast algorithm for computing logarithms [8],
compute an integer  such that
such that  , where
, where  ,
in time
,
in time  . Scan through the
table, replacing by
. Scan through the
table, replacing by  for
those divisible by
for
those divisible by 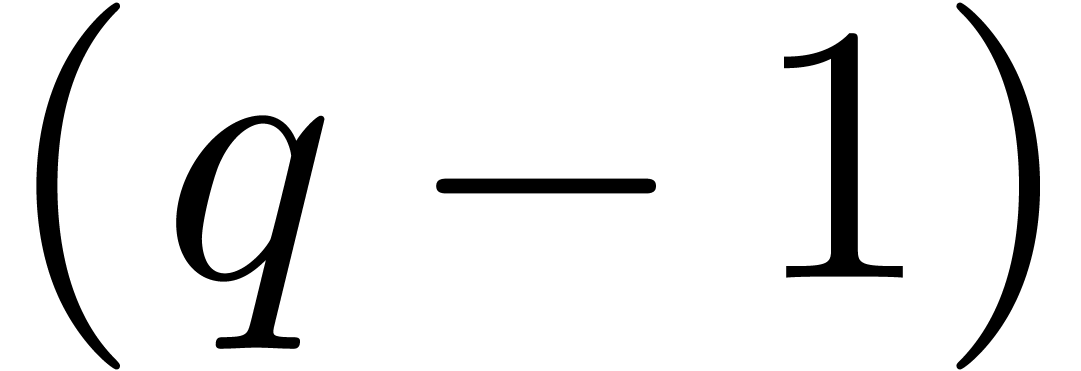 ,
i.e., every
,
i.e., every 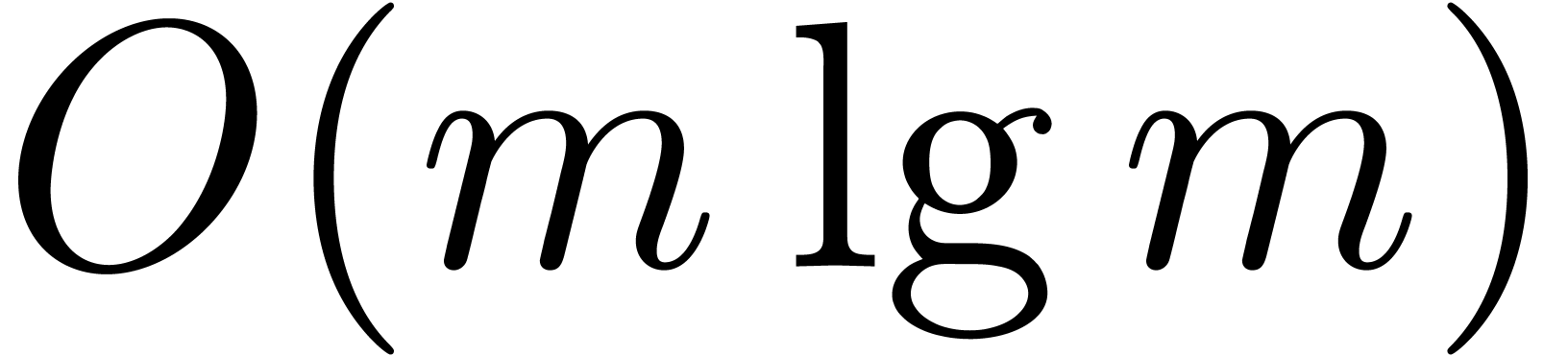 -th entry, in
time
-th entry, in
time 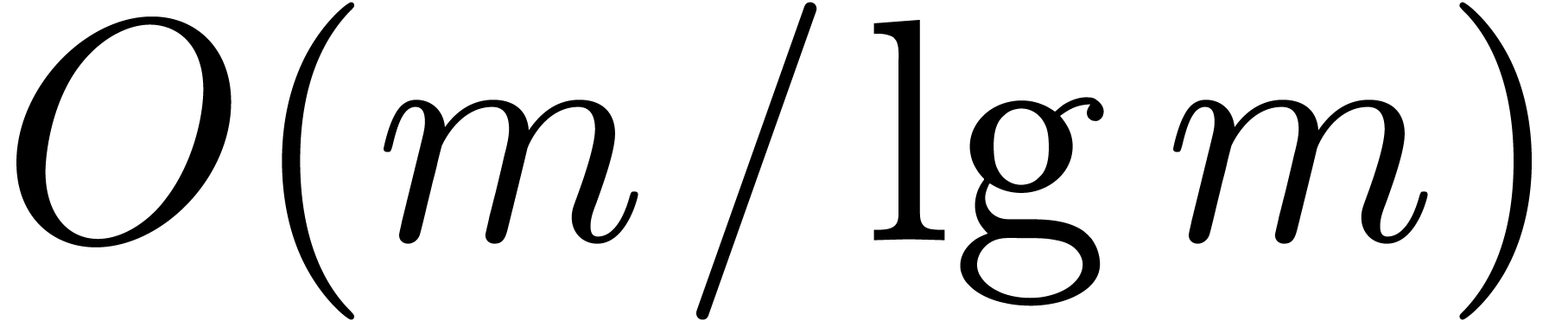 . The total cost for
each prime is ,
and there are
. The total cost for
each prime is ,
and there are 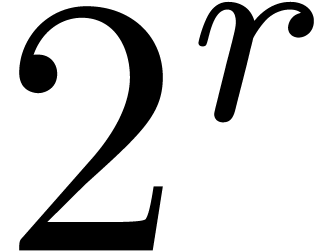 primes, so the overall cost is
primes, so the overall cost is
 . At the end, we divide each
by
. At the end, we divide each
by 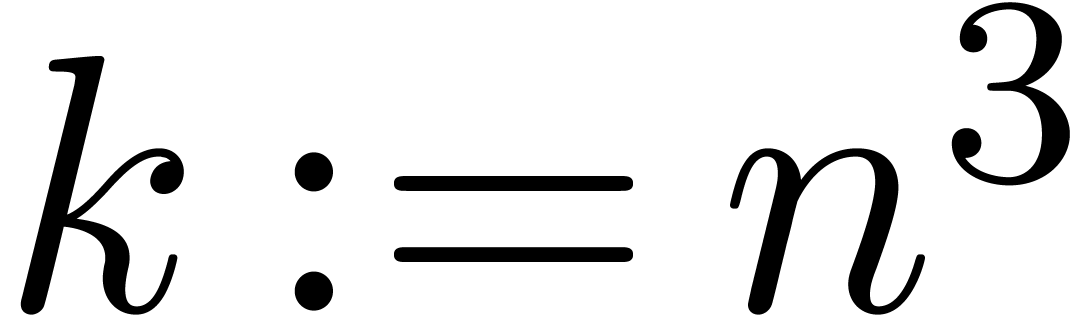 ,
yielding the required approximations satisfying
,
yielding the required approximations satisfying
Proof of Theorem 4.1. We are given
and as input. Applying
Lemma 4.2 with 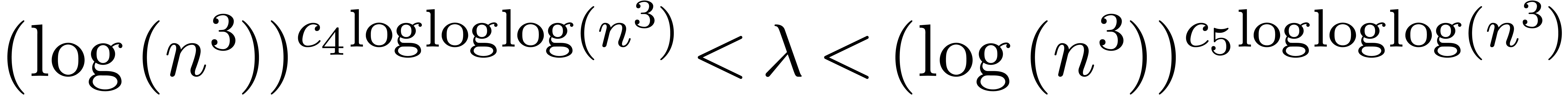 ,
we find that for large enough there exists some
with
,
we find that for large enough there exists some
with
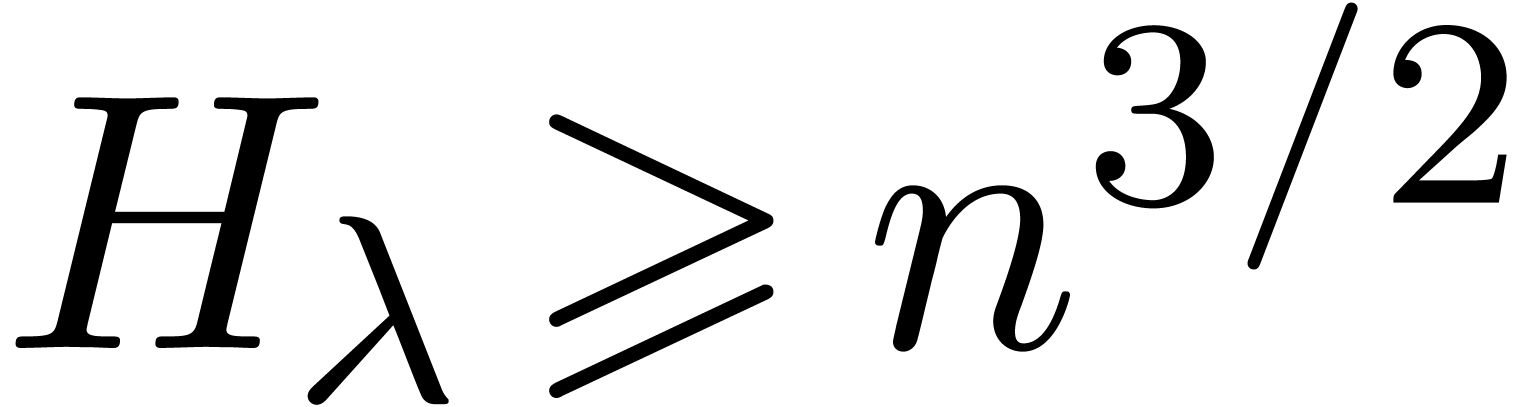
and such that  . Choose any
positive
. Choose any
positive  and any
and any  .
Since
.
Since
we have
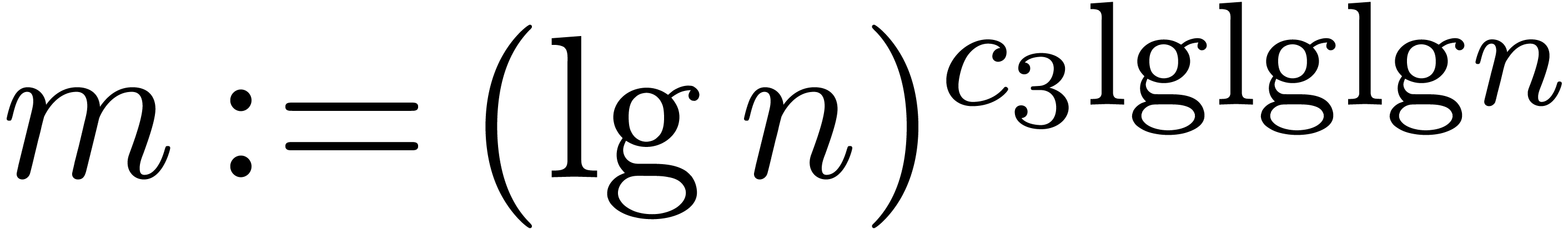
for large . Using Lemma 4.5, we may find one such in time
, where 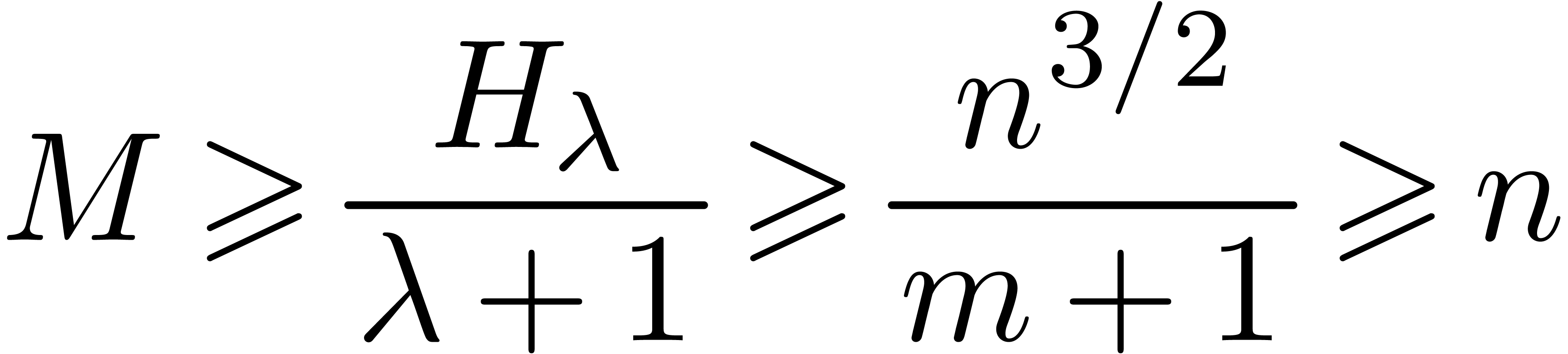 .
.
Let be as in Lemma 4.3. Then divides ,
and
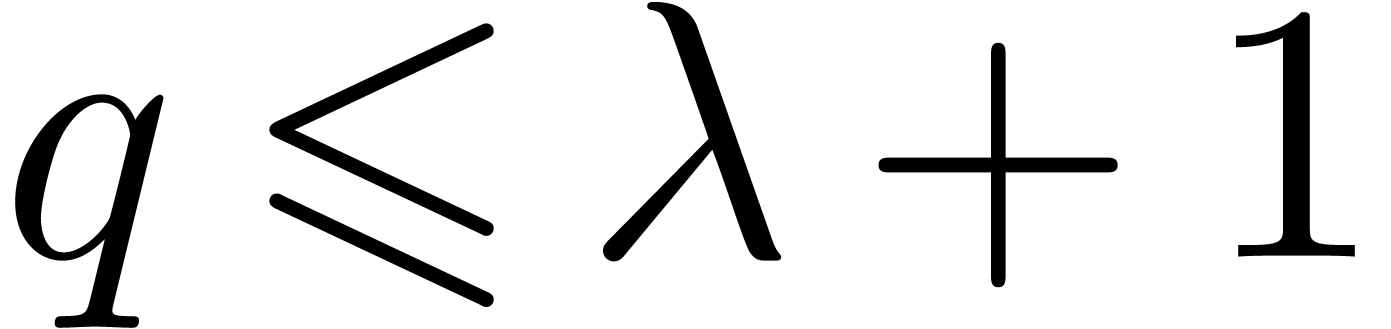
for large . We may compute
the prime factorisation of by simply enumerating
the primes 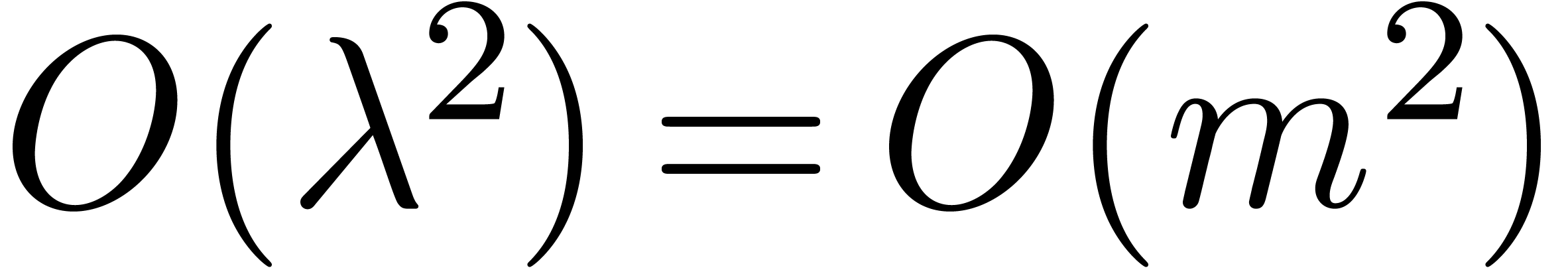 , , and checking whether
divides for each .
This can be done in time
, , and checking whether
divides for each .
This can be done in time  .
.
The main multiplication algorithm depends on a reduction of a
“long” DFT to many “short” DFTs. It is essential
to have some control over the long and short transform lengths. The
following result packages together the prime divisors of the
abovementioned  , to obtain a
long transform length near a given target , and short transform lengths
, to obtain a
long transform length near a given target , and short transform lengths  near a given target
near a given target  .
.
, , ,
be as in Theorem 4.1. Let  and
and 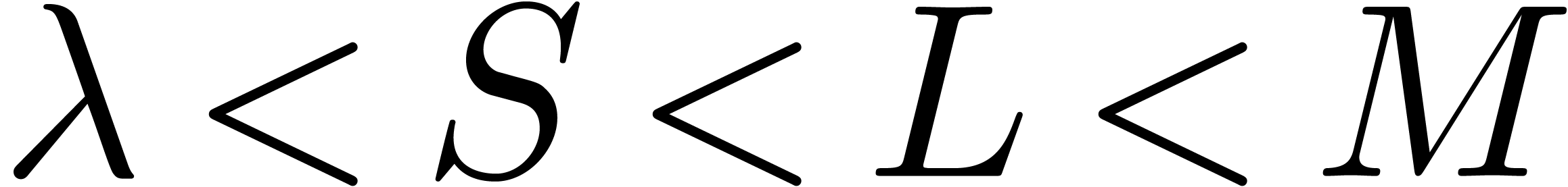 be positive integers
such that
be positive integers
such that  . Then there
exist -smooth integers
. Then there
exist -smooth integers  with the following properties:
with the following properties:
Given , , ,
and the prime factorisation of ,
we may compute such (and their factorisations)
in time  .
.
Proof. Let  be the prime
decomposition of . Taking
be the prime
decomposition of . Taking
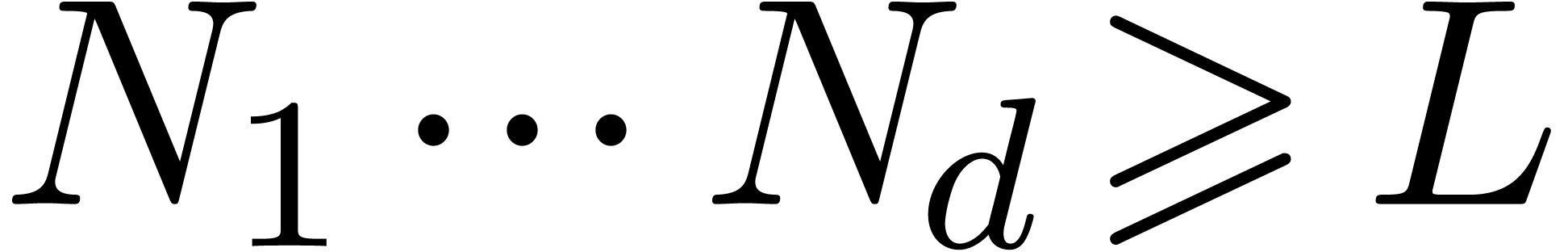 minimal with
minimal with 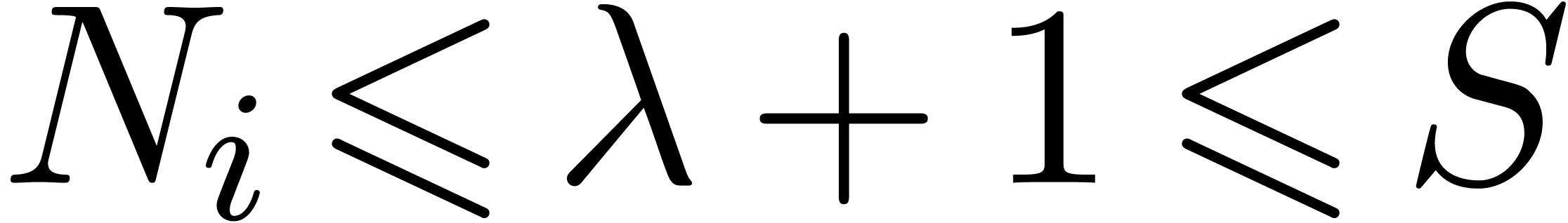 ,
we ensure that (a) and (b) are satisfied. At
this stage we have
,
we ensure that (a) and (b) are satisfied. At
this stage we have 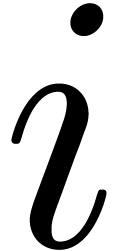 for all
for all  . As long as the tuple
. As long as the tuple 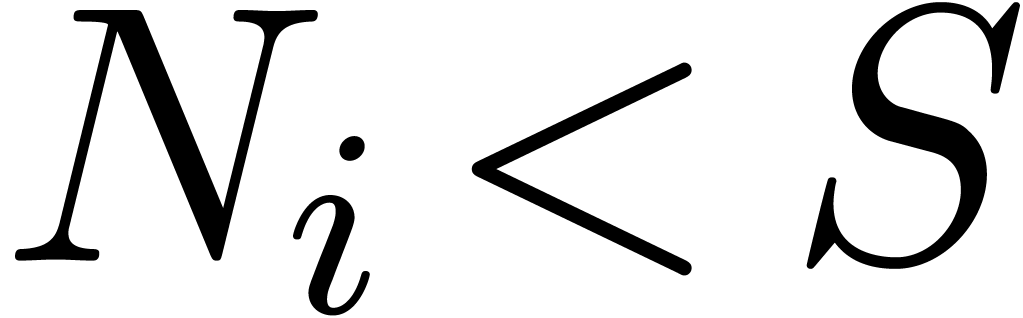 contains an entry with
contains an entry with 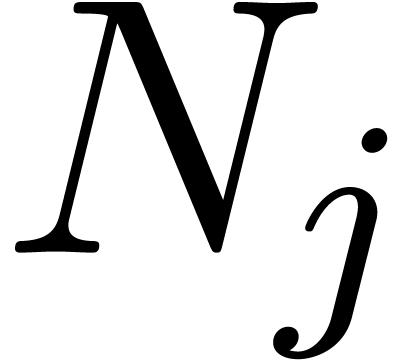 , we pick the two smallest entries
and
, we pick the two smallest entries
and 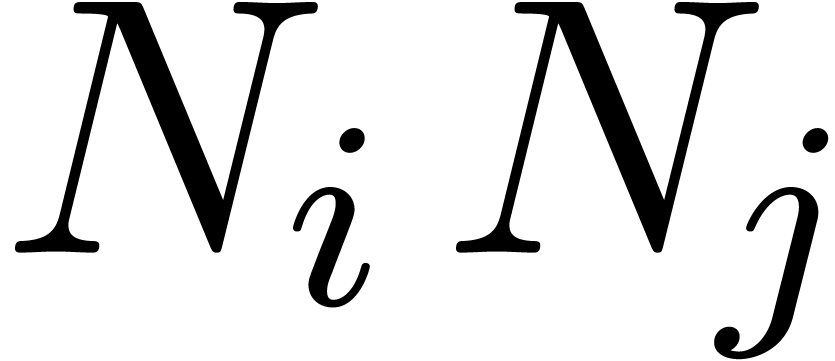 and replace them by a single entry
and replace them by a single entry 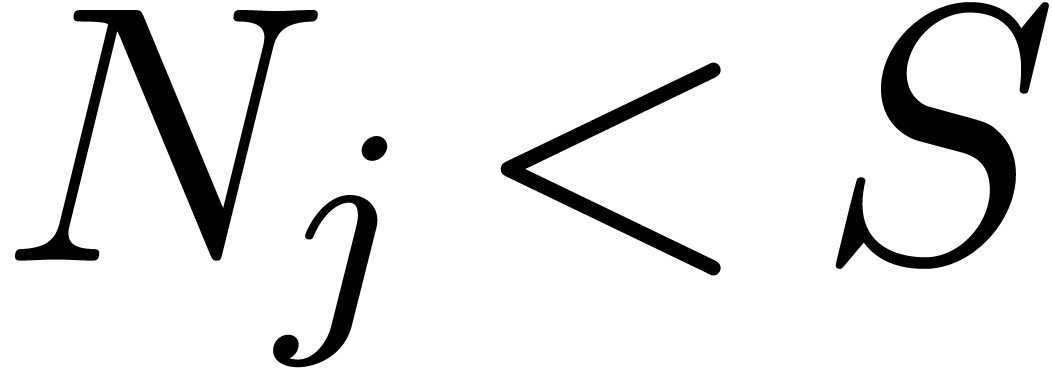 . Clearly, this does not alter the
product of all entries, so (a) and
(b) continue to hold. Furthermore, as long as there exist
two entries and with
and
. Clearly, this does not alter the
product of all entries, so (a) and
(b) continue to hold. Furthermore, as long as there exist
two entries and with
and 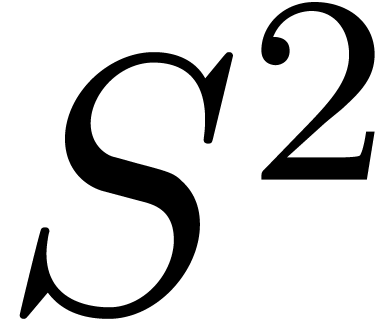 ,
new entries will always be smaller than
,
new entries will always be smaller than 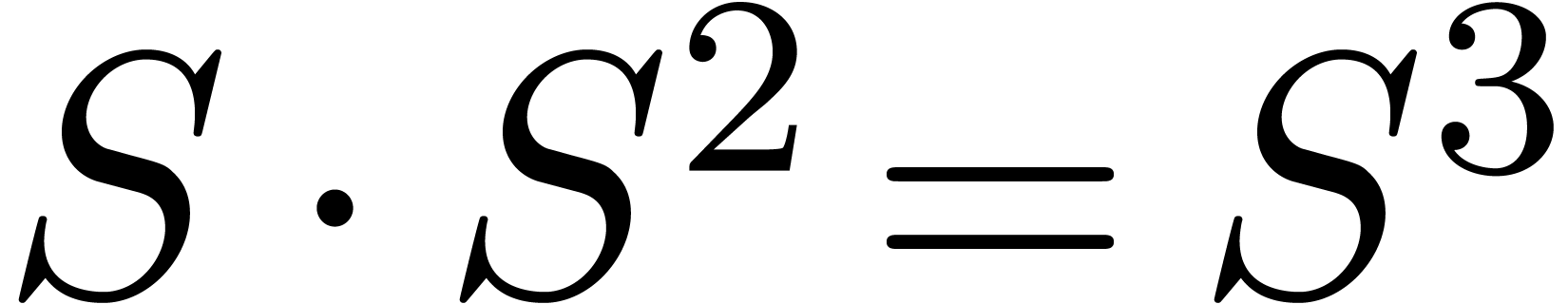 . Only at the very last step of the
loop, the second smallest entry might be larger
than . In that case, the
product of the entry with
with is still bounded by
. Only at the very last step of the
loop, the second smallest entry might be larger
than . In that case, the
product of the entry with
with is still bounded by  . This shows that condition (c) is
satisfied at the end of the loop.
. This shows that condition (c) is
satisfied at the end of the loop.
Determining requires at most 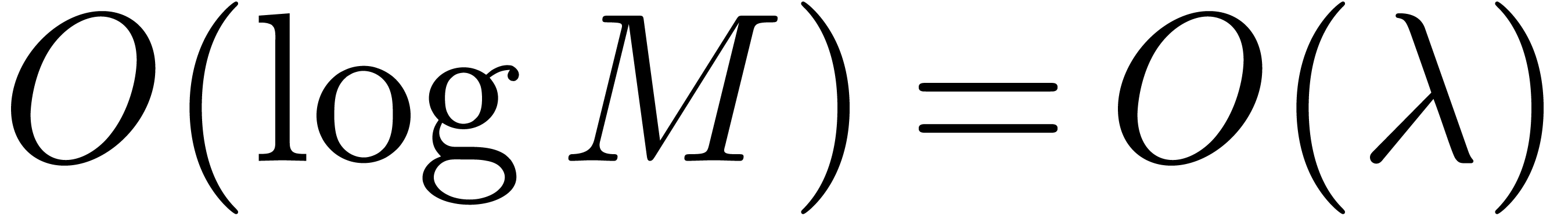 multiplications of integers less than .
There are at most iterations of the replacement
loop. Each iteration must scan through at most
integers of bit size
multiplications of integers less than .
There are at most iterations of the replacement
loop. Each iteration must scan through at most
integers of bit size 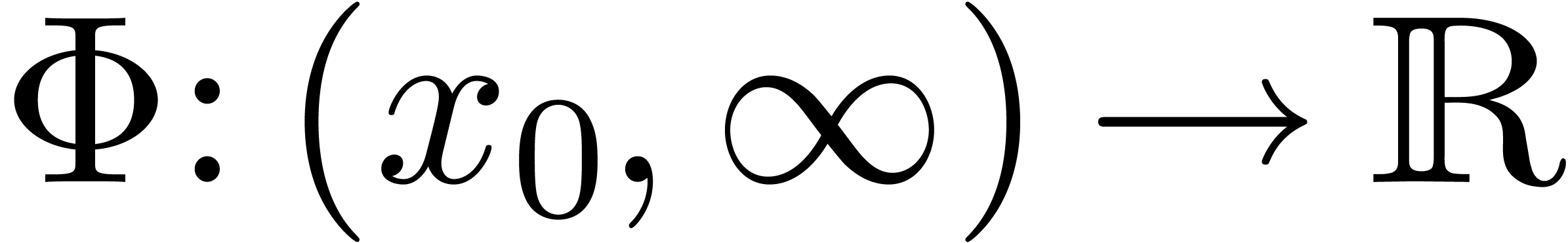 and perform one
multiplication on such integers.
and perform one
multiplication on such integers.
Let  be a smooth increasing function, for some
be a smooth increasing function, for some
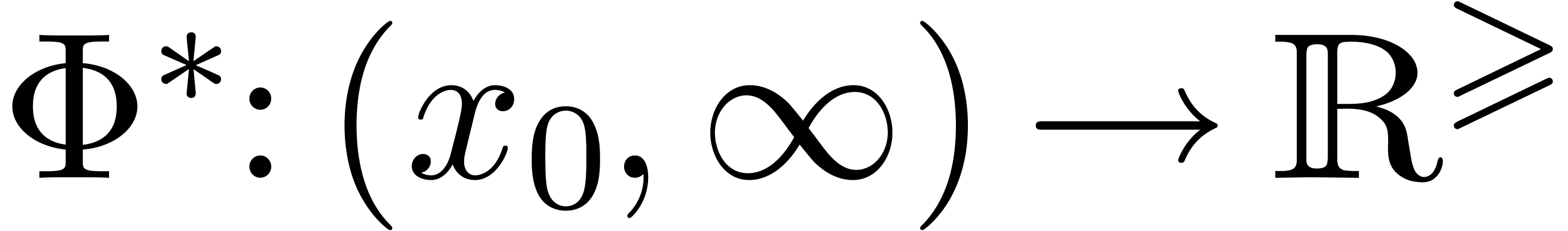 . We say that
. We say that  is an iterator of
is an iterator of  if
if  is increasing and if
is increasing and if
for all sufficiently large 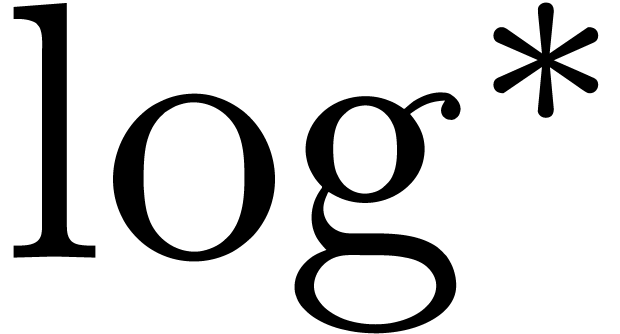 .
.
For instance, the standard iterated logarithm  defined in (1.2) is an iterator of
defined in (1.2) is an iterator of  . An analogous iterator may be defined for any
smooth increasing function for which there
exists some
. An analogous iterator may be defined for any
smooth increasing function for which there
exists some 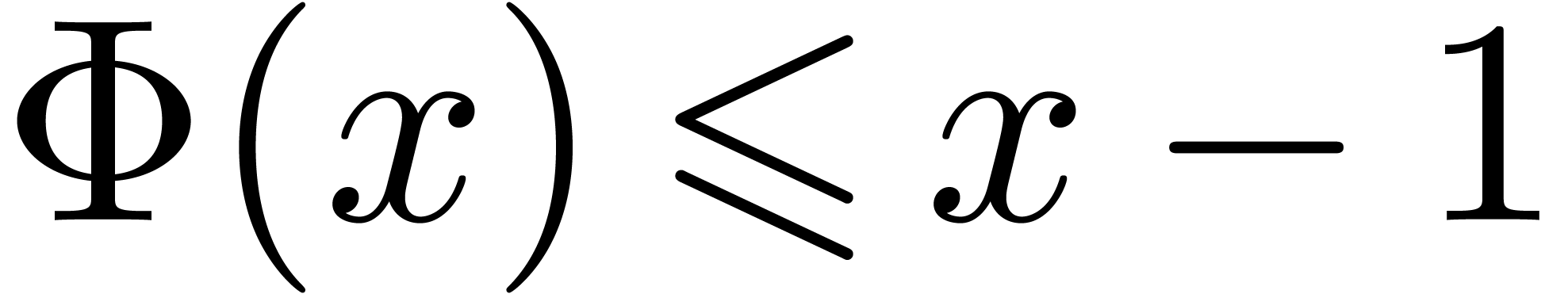 such that
such that 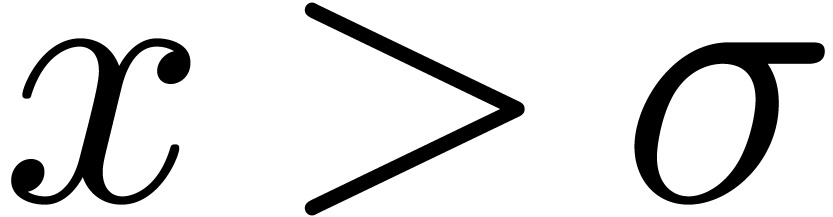 for all
for all 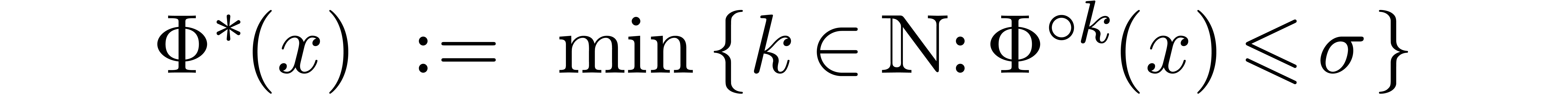 . Indeed, in that
case,
. Indeed, in that
case,
is well-defined and satisfies (5.1) for all . It will sometimes be convenient to increase
 so that is satisfied on
the whole domain of .
so that is satisfied on
the whole domain of .
We say that is logarithmically slow if
there exists an 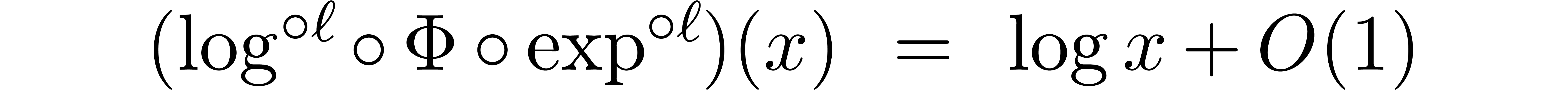 such that
such that
for  . For example, the
functions
. For example, the
functions  ,
, 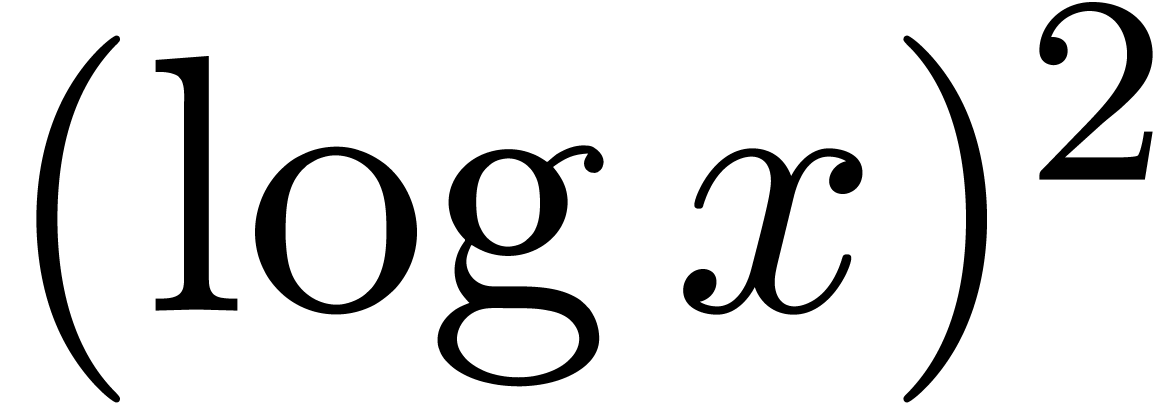 ,
, 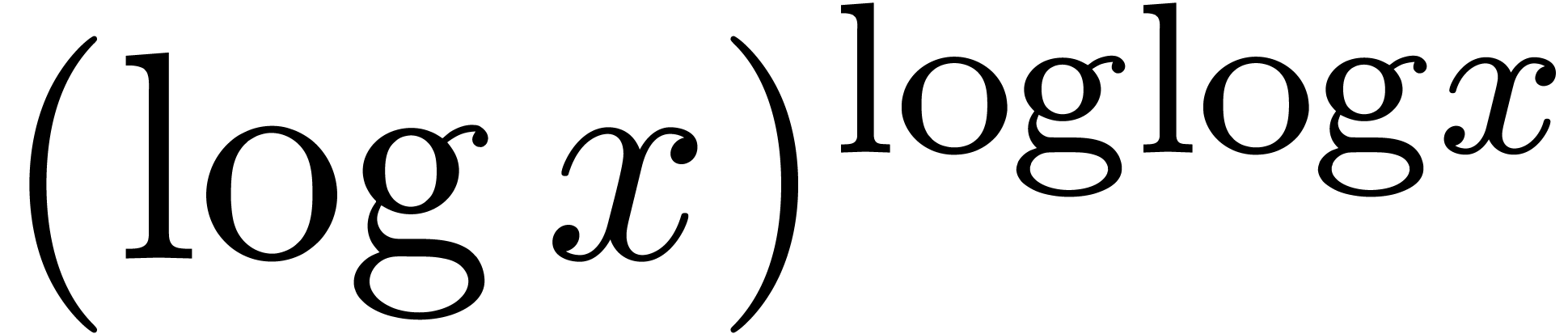 and
and  are logarithmically slow, with
are logarithmically slow, with  respectively.
respectively.
be a logarithmically slow
function. Then there exists such that for all 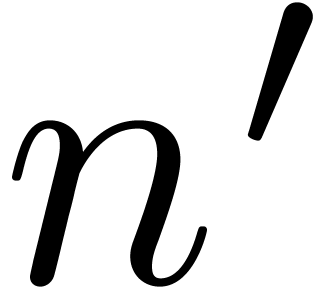 .
Consequently all logarithmically slow functions admit iterators.
.
Consequently all logarithmically slow functions admit iterators.
In this paper, the main role played by logarithmically slow functions is
to measure size reduction in multiplication algorithms. In other
words, multiplication of objects of size will be
reduced to multiplication of objects of size  , where
, where 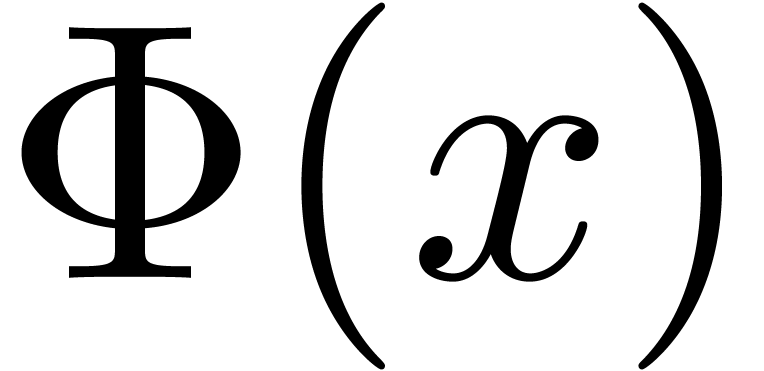 for some
logarithmically slow function
for some
logarithmically slow function  .
The following result asserts that, from the point of view of iterators,
such functions are more or less interchangeable with
.
The following result asserts that, from the point of view of iterators,
such functions are more or less interchangeable with  .
.
The next result is our main tool for converting recurrence inequalities into actual asymptotic bounds for solutions.
 ,
,
 and
and 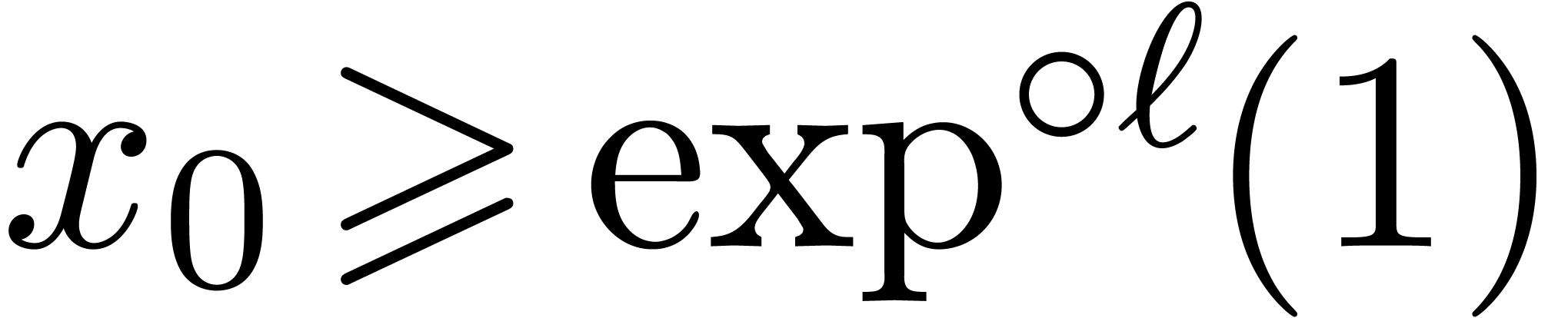 .
Let
.
Let 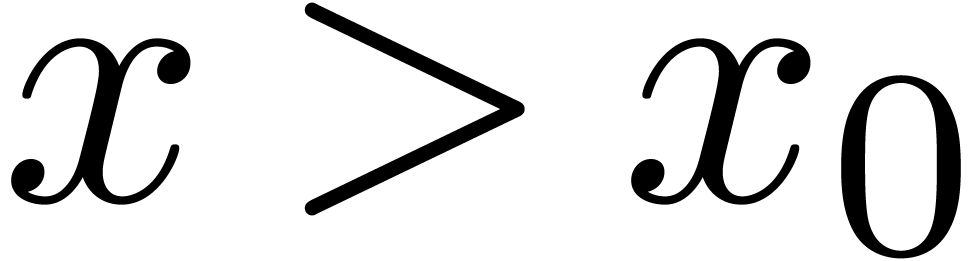 , and let be a logarithmically slow function such that for all
, and let be a logarithmically slow function such that for all  .
Then there exists a positive constant
.
Then there exists a positive constant  (depending on ,
(depending on , 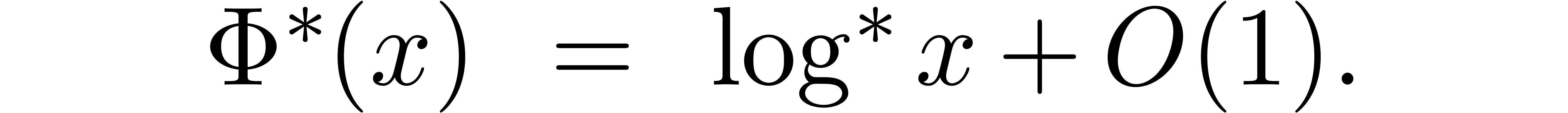 ,
,  ,
,
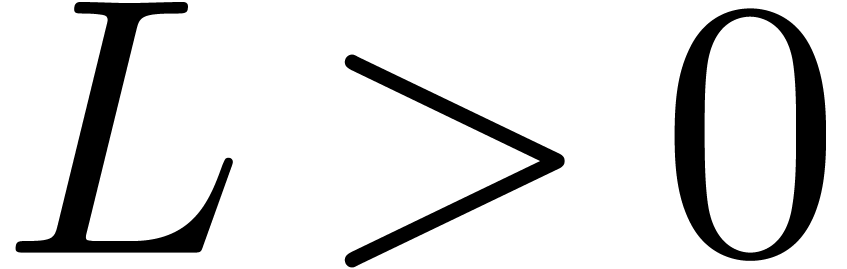 and )
with the following property.
and )
with the following property.
Let and 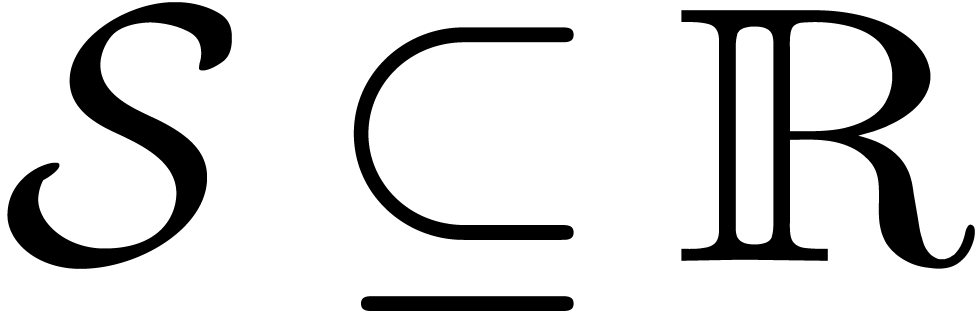 .
Let
.
Let 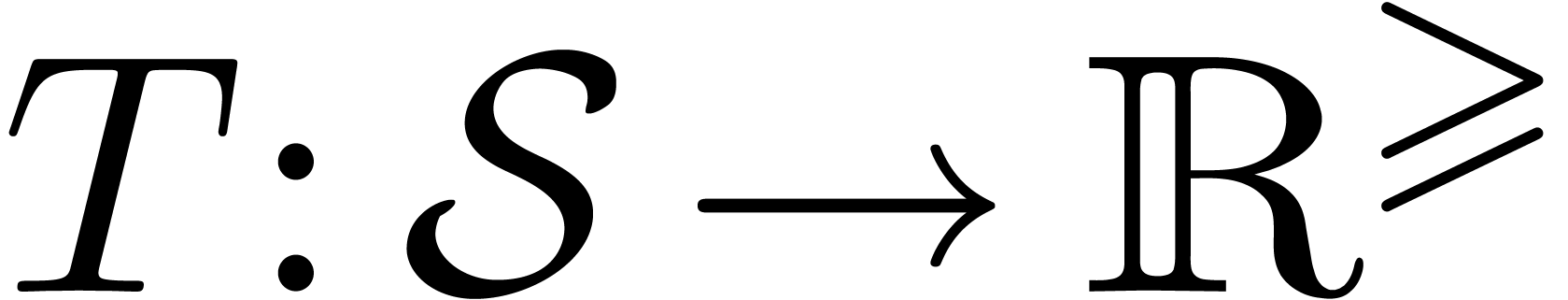 , and let
, and let 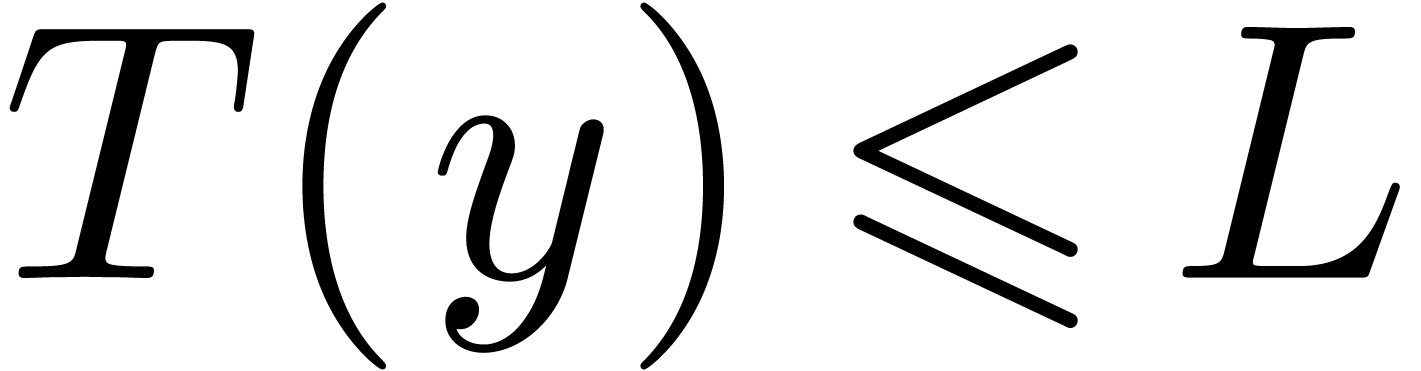 be any function satisfying the following recurrence.
First,
be any function satisfying the following recurrence.
First,  for all
for all  ,
,
 . Second, for all ,
. Second, for all ,  ,
there exist
,
there exist 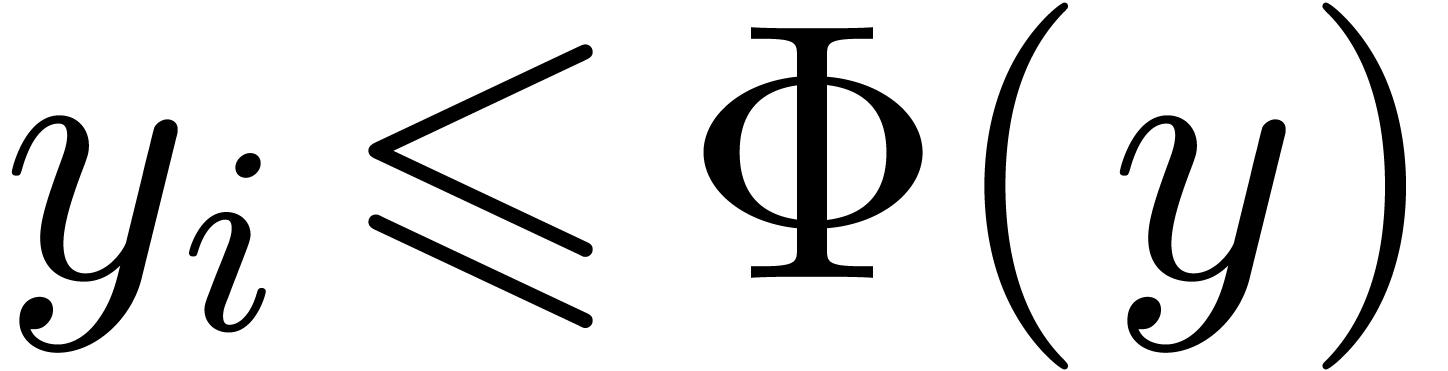 with
with 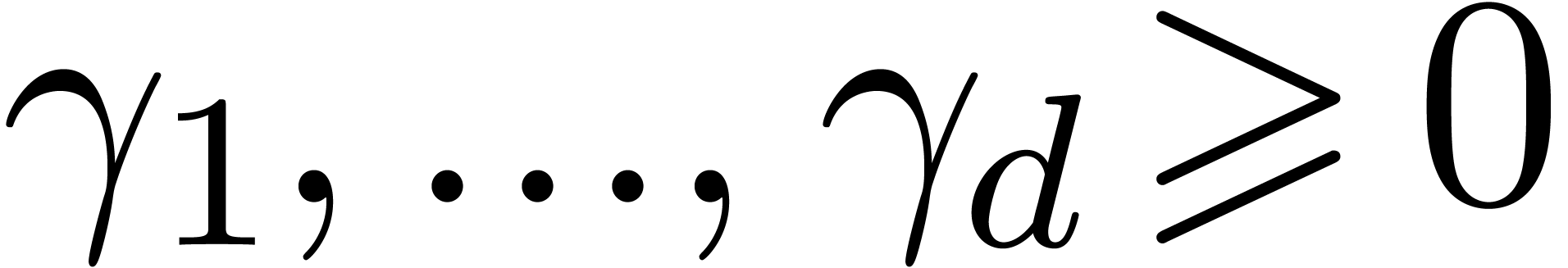 ,
and weights
,
and weights 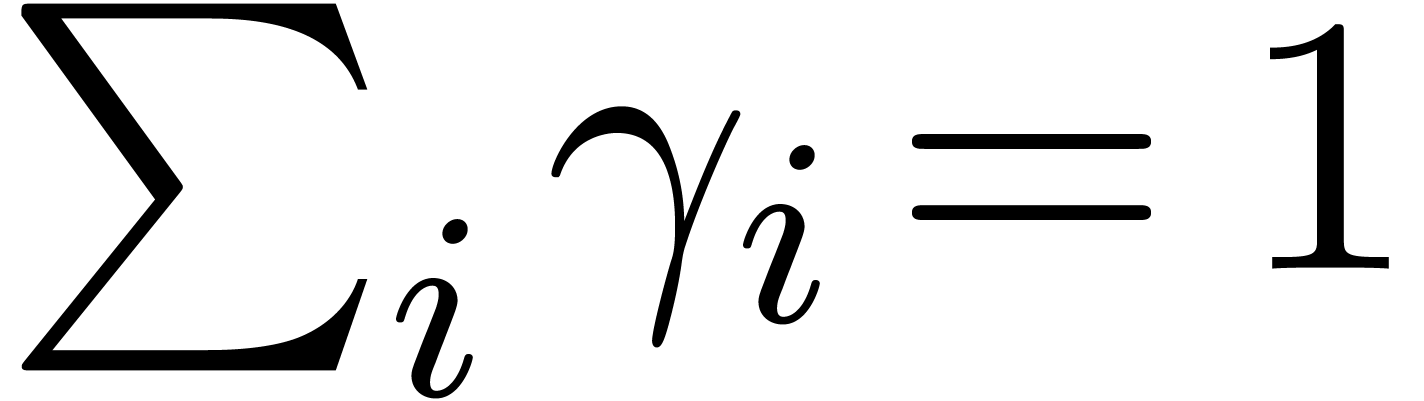 with
with  ,
such that
,
such that
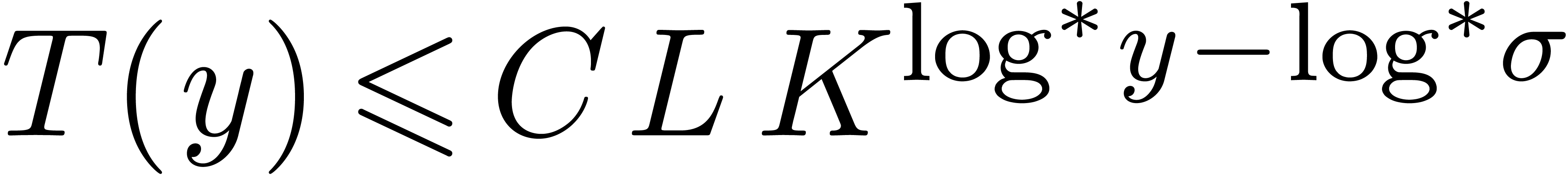
Then we have  for all , .
for all , .
Consider the problem of computing the product of two -bit integers modulo  . The naive approach is to compute their ordinary
. The naive approach is to compute their ordinary
 -bit product and then reduce
modulo
-bit product and then reduce
modulo 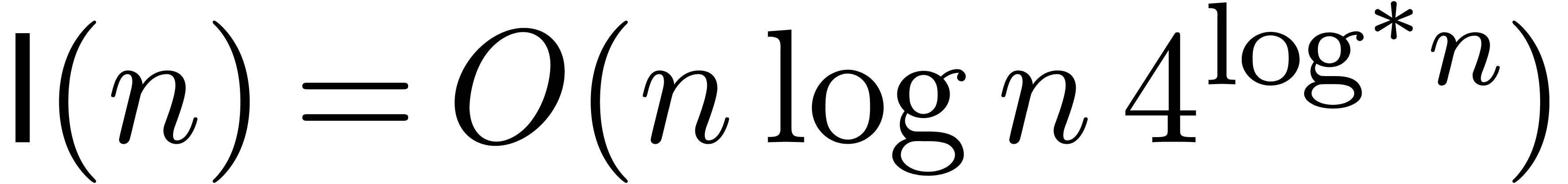 . The reduction cost
is negligible because of the special form of . If is divisible by a high
power of two, one can save a factor of two by using the fact that FFTs
naturally compute cyclic convolutions.
. The reduction cost
is negligible because of the special form of . If is divisible by a high
power of two, one can save a factor of two by using the fact that FFTs
naturally compute cyclic convolutions.
An ingenious algorithm of Crandall and Fagin [13] allows
for the gain of this precious factor of two for arbitrary . Their algorithm is routinely used in the extreme case
where is prime, in the large-scale GIMPS search
for Mersenne primes (see http://www.mersenne.org/).
A variant of the Crandall–Fagin algorithm was a key ingredient of
our algorithm for integer multiplication that conjecturally achieves the
bound 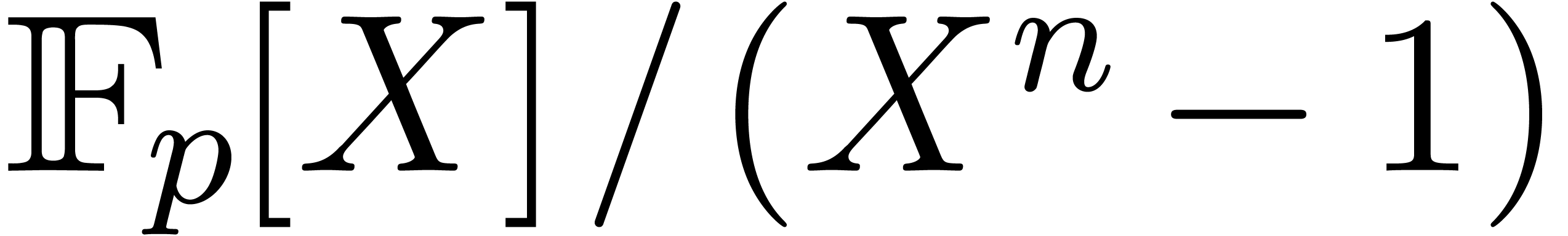 [18, Section 9]. In this
section we present yet another variant, for computing products in
[18, Section 9]. In this
section we present yet another variant, for computing products in 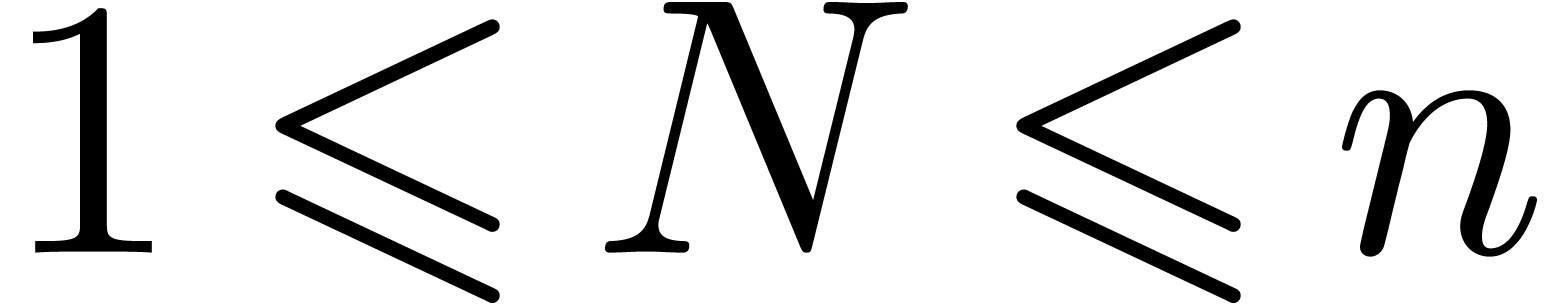 .
.
Let ,
and be positive integers with 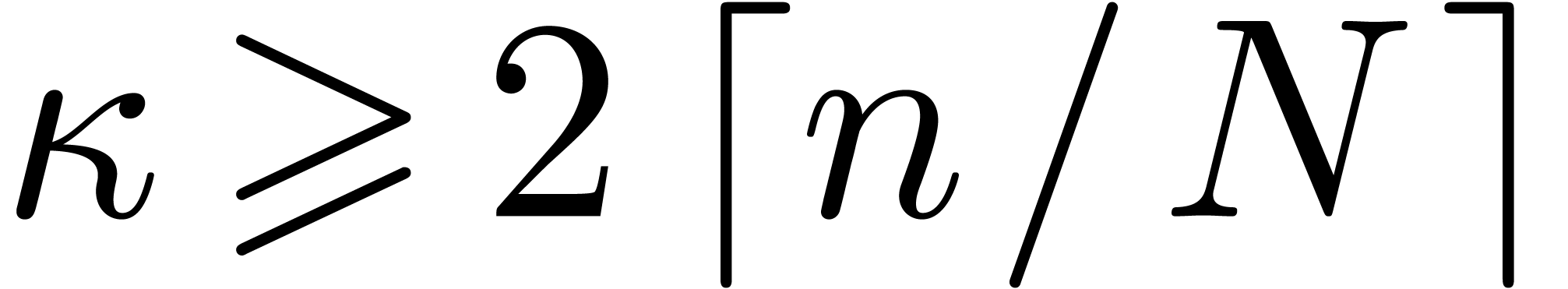 and
and 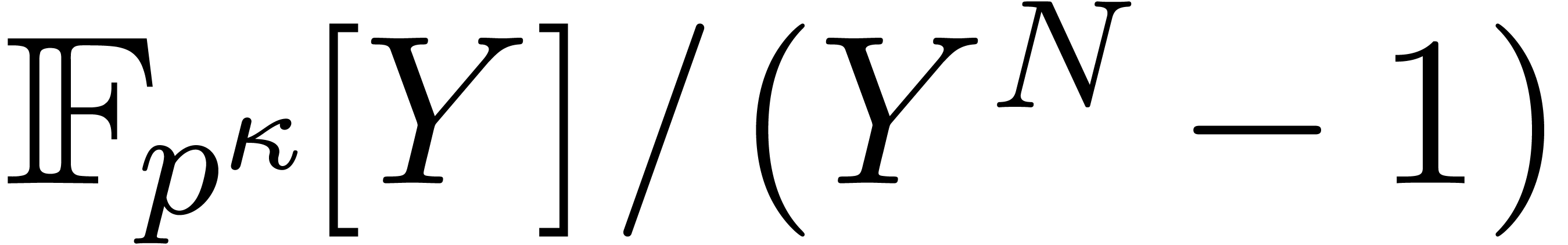 . Our aim is to reduce
multiplication in to multiplication in
. Our aim is to reduce
multiplication in to multiplication in 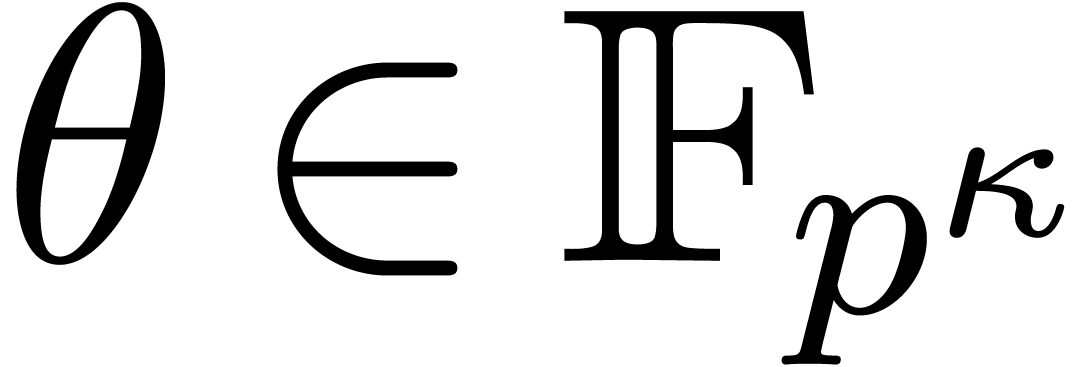 . In the applications in subsequent
sections, will be a divisor of
with many small factors, so that we can multiply efficiently in using FFTs over .
. In the applications in subsequent
sections, will be a divisor of
with many small factors, so that we can multiply efficiently in using FFTs over .
Suppose that is represented as , for some irreducible
of degree . The reduction
relies on the existence of an element 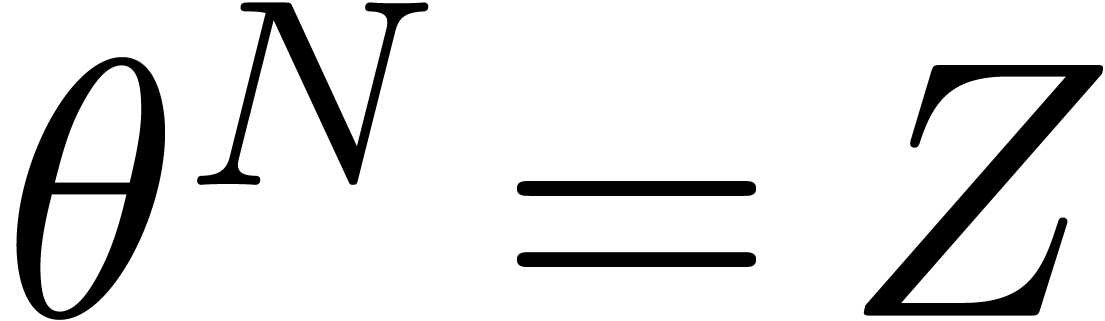 such that
such that
 . (This is the analogue of
the real -th root of appearing in the usual Crandall–Fagin
algorithm, which was originally formulated over
. (This is the analogue of
the real -th root of appearing in the usual Crandall–Fagin
algorithm, which was originally formulated over  .) It is easy to see that such
.) It is easy to see that such  may not always exist; for example, there is no cube root of in
may not always exist; for example, there is no cube root of in 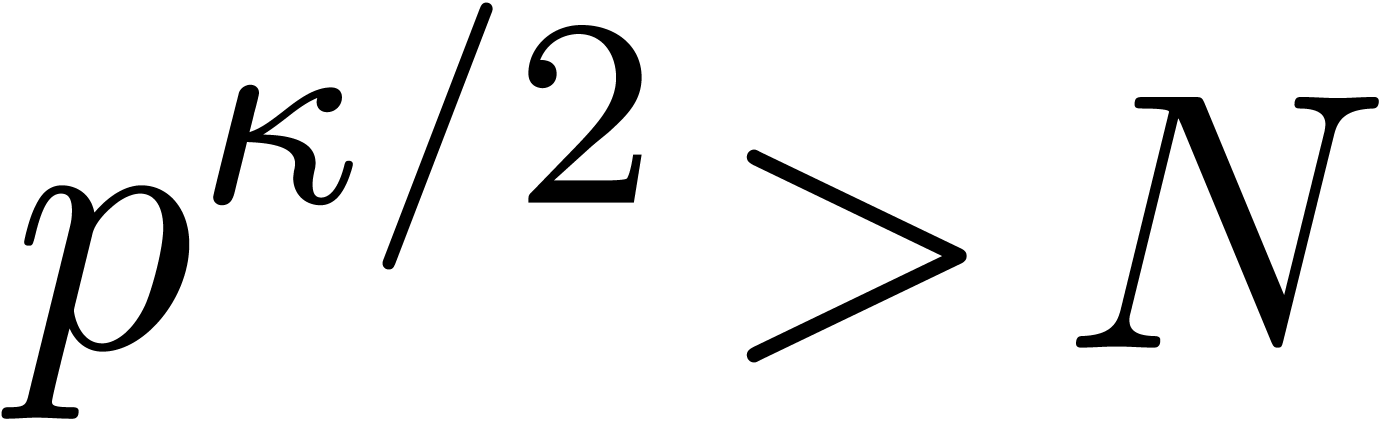 .
Nevertheless, the next result shows that if is
large enough, then we can always find some modulus
for which a suitable exists.
.
Nevertheless, the next result shows that if is
large enough, then we can always find some modulus
for which a suitable exists.
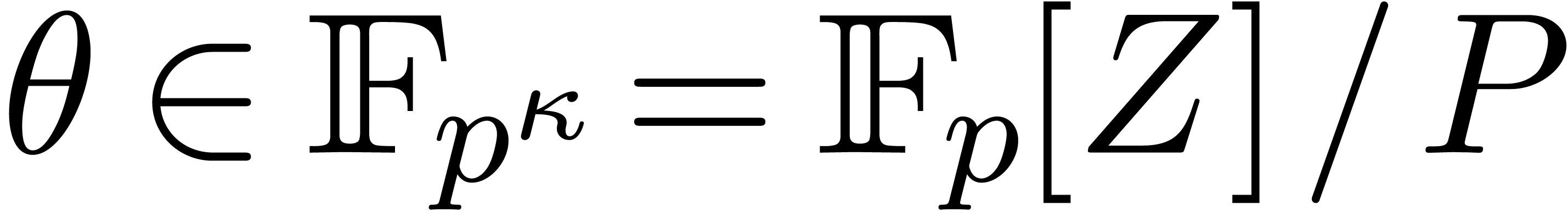 .
Then we may compute an irreducible polynomial
of degree , and an element
.
Then we may compute an irreducible polynomial
of degree , and an element
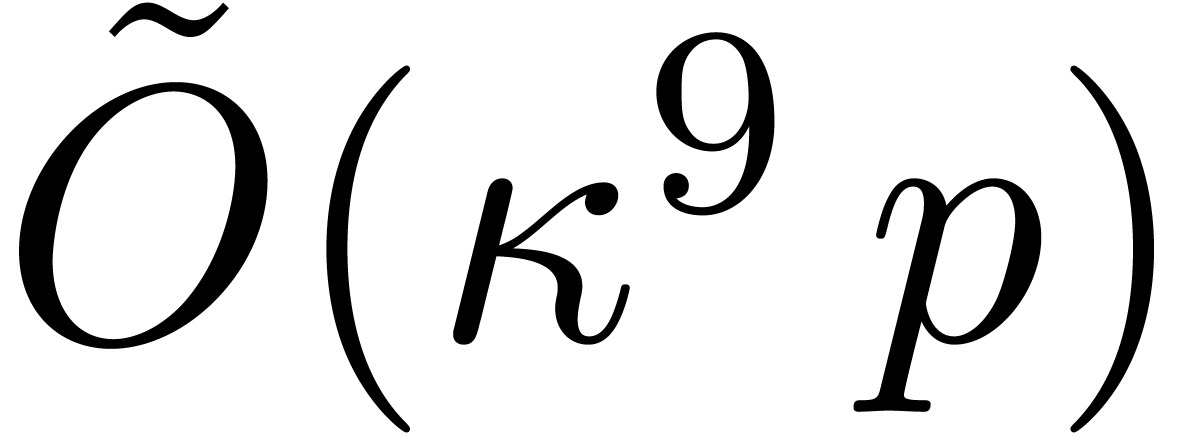 such that ,
in time
such that ,
in time  .
.
Proof. We first observe that if 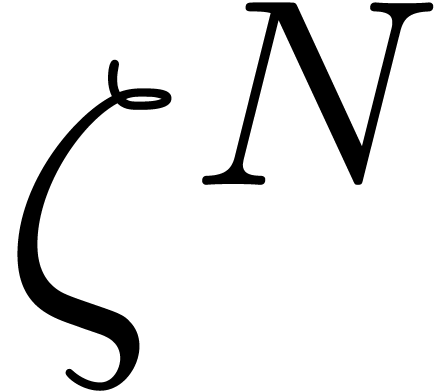 is a primitive root, then
is a primitive root, then 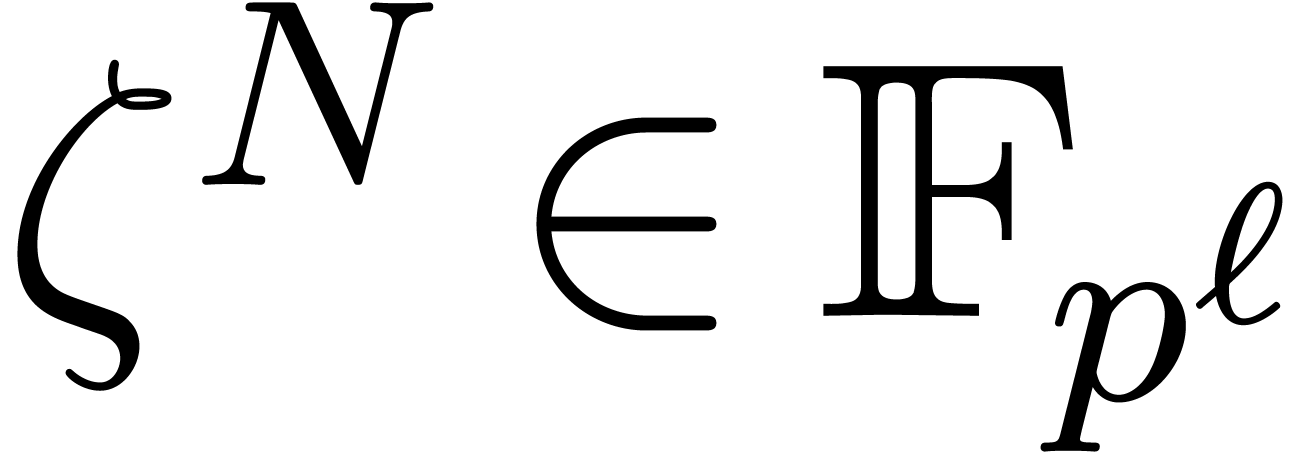 cannot lie in a proper
subfield of . (This property
is independent of .) Indeed,
if
cannot lie in a proper
subfield of . (This property
is independent of .) Indeed,
if 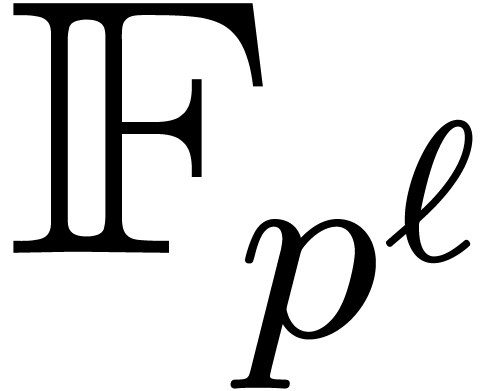 for some proper divisor
of , then every -th power in lies in
for some proper divisor
of , then every -th power in lies in
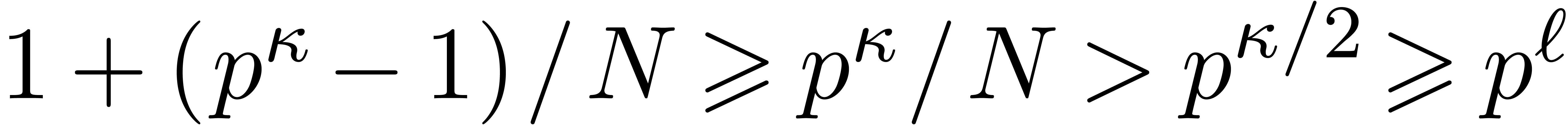 . This contradicts the fact
that the number of -th powers
in is at least
. This contradicts the fact
that the number of -th powers
in is at least  .
.
Now we give an algorithm for computing and 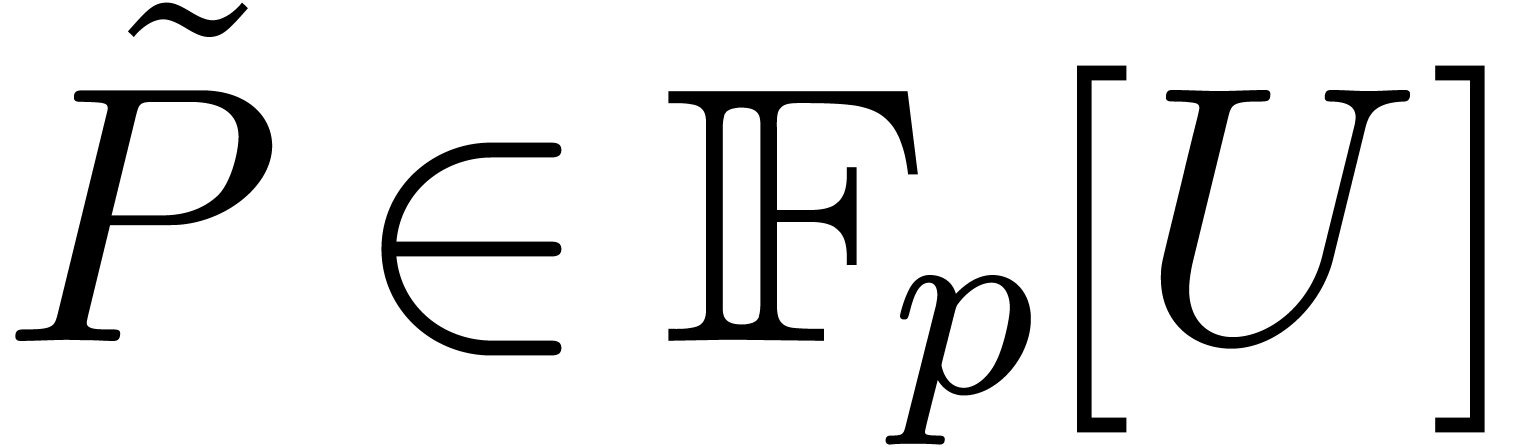 . We start by using Lemma 3.1
to compute an irreducible
. We start by using Lemma 3.1
to compute an irreducible 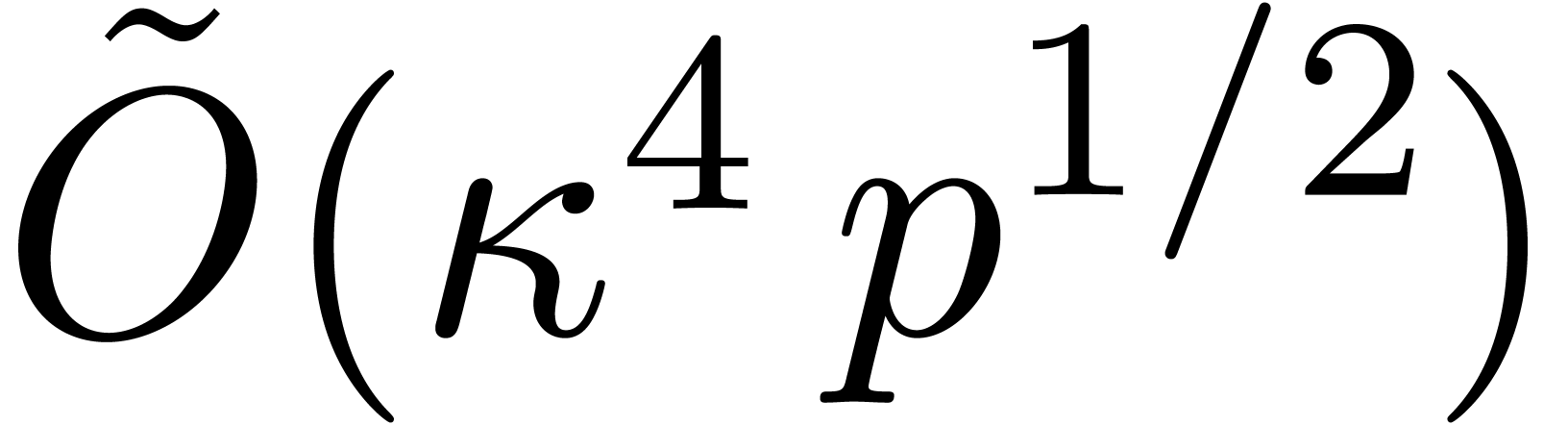 of degree in time
of degree in time 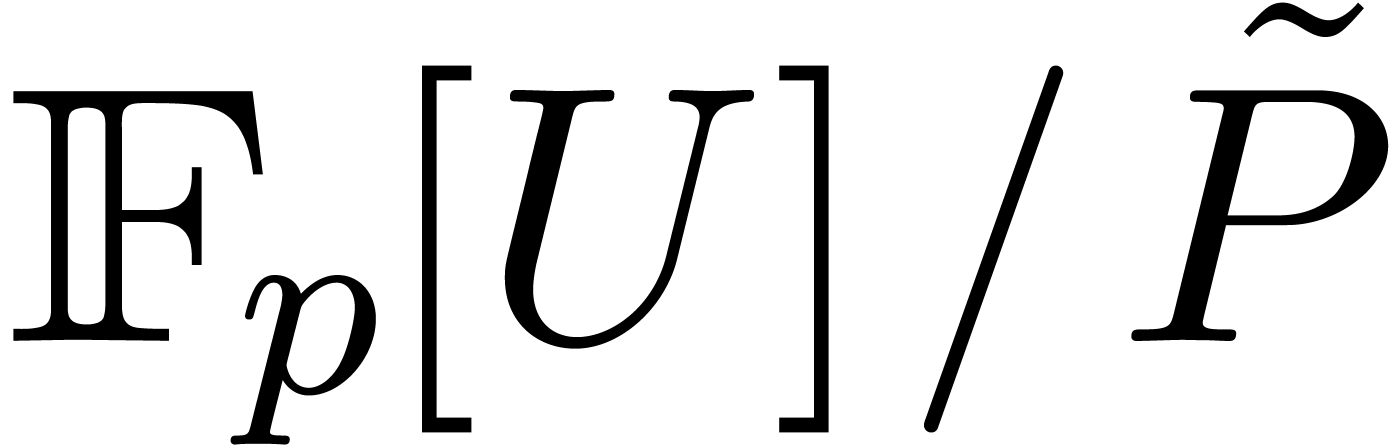 , and
we temporarily represent as
, and
we temporarily represent as 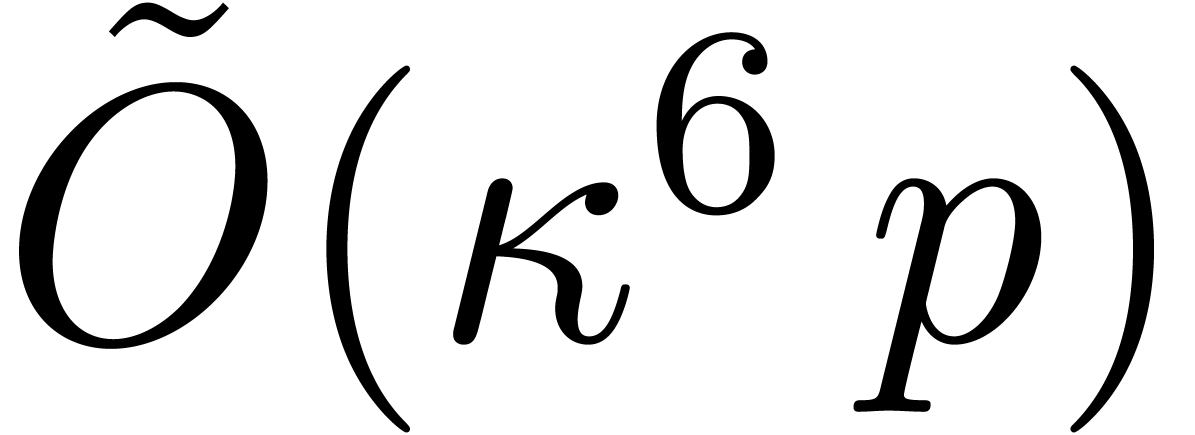 .
.
Using Lemma 3.2, we may construct a list of  candidates for primitive roots of
(see the proof of Lemma 3.3). For each candidate
candidates for primitive roots of
(see the proof of Lemma 3.3). For each candidate 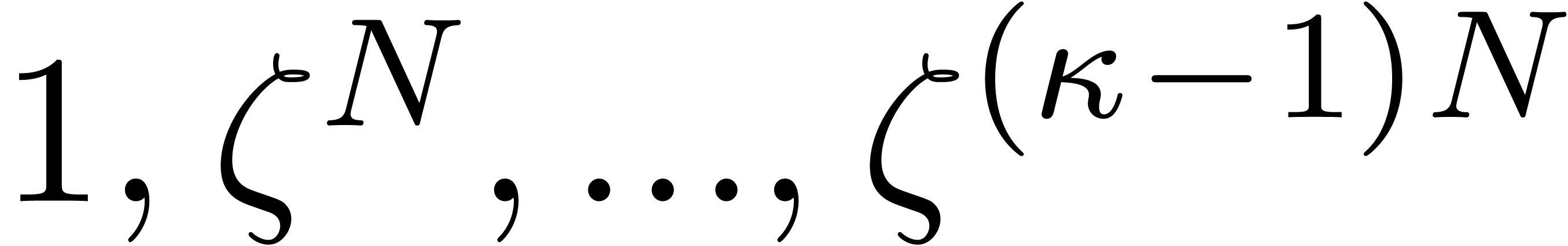 , we compute
and its powers
, we compute
and its powers 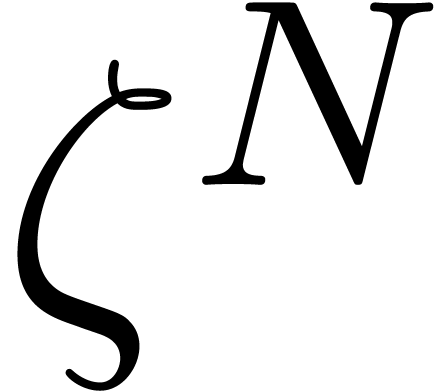 . If these are
linearly dependent over then
belongs to a proper subfield (and so, as shown above,
is not actually a primitive root). Thus we must eventually encounter
some for which they are linearly independent. We
take to be the minimal polynomial of this
. If these are
linearly dependent over then
belongs to a proper subfield (and so, as shown above,
is not actually a primitive root). Thus we must eventually encounter
some for which they are linearly independent. We
take to be the minimal polynomial of this  , which may be computed by finding
a linear relation among
, which may be computed by finding
a linear relation among 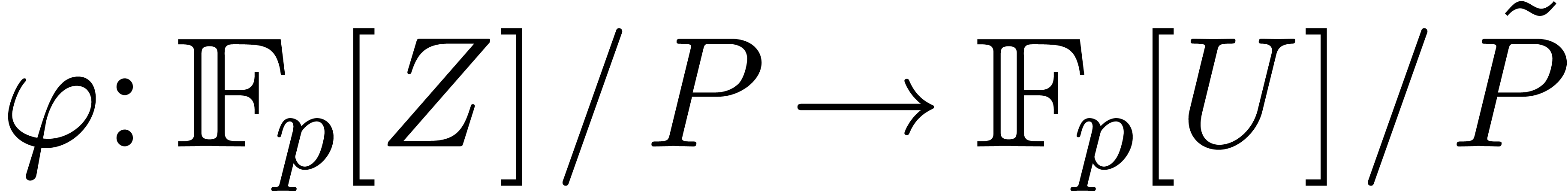 . Let
. Let
 be the isomorphism that sends
be the isomorphism that sends  to . The matrix of
to . The matrix of  with respect to the standard bases
with respect to the standard bases 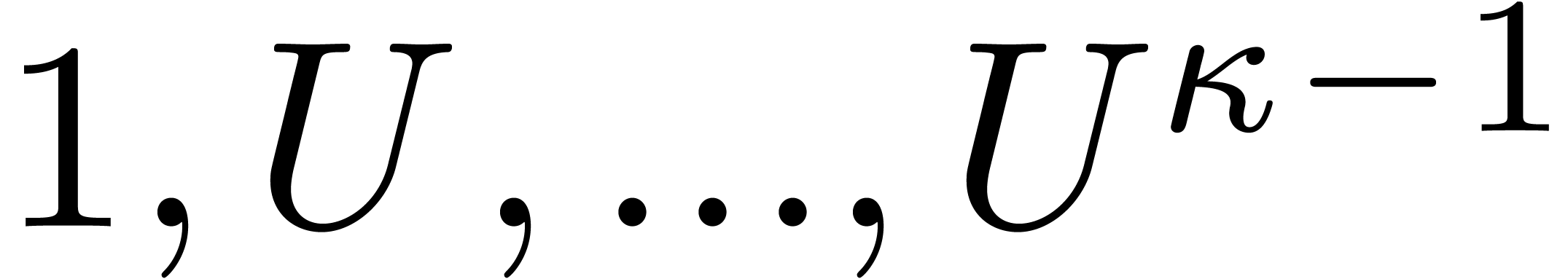 and
and 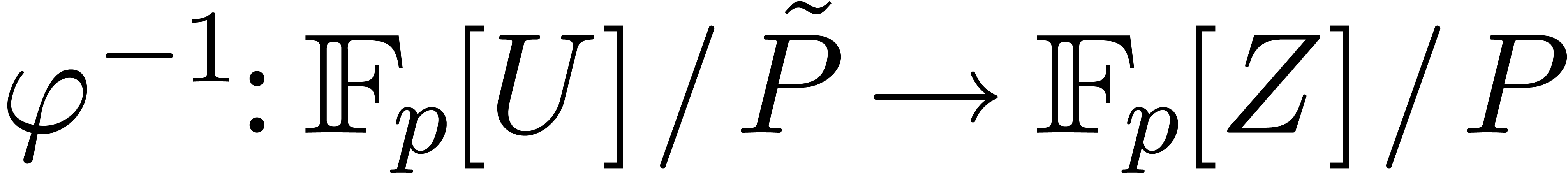 is given by the coefficients of . The inverse of this matrix yields the matrix
of
is given by the coefficients of . The inverse of this matrix yields the matrix
of 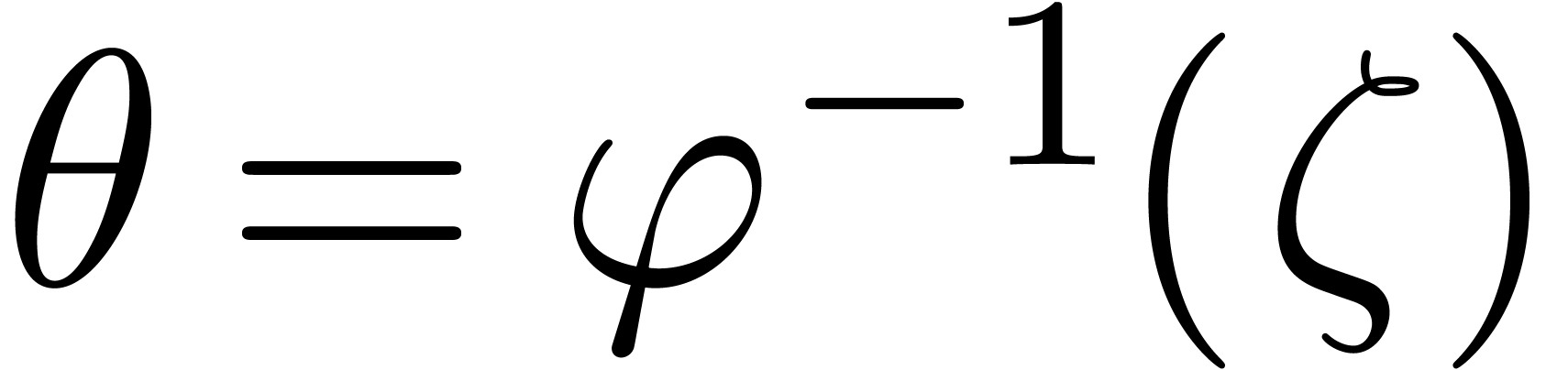 . We then set
. We then set 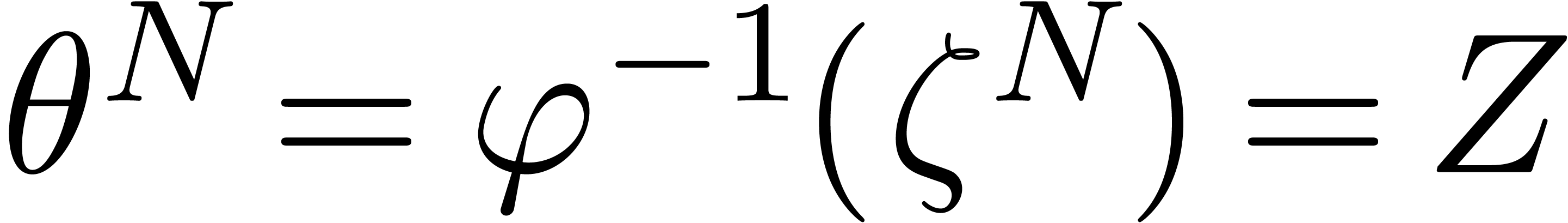 , so that
, so that  .
.
For each candidate , the cost
of computing the necessary powers of is 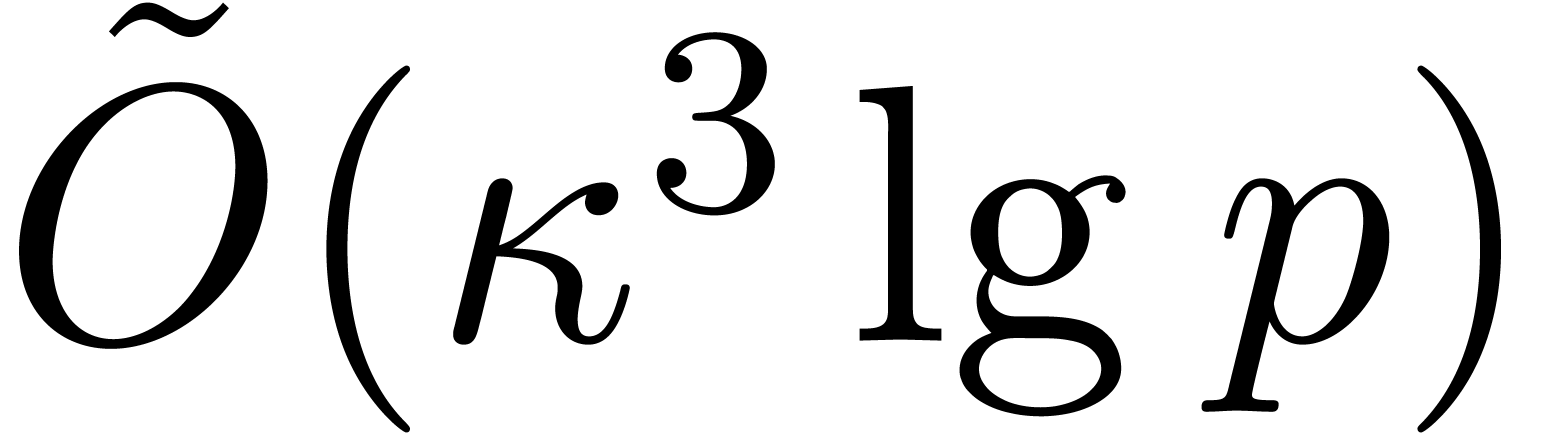 , and the various linear algebra
steps require time
, and the various linear algebra
steps require time 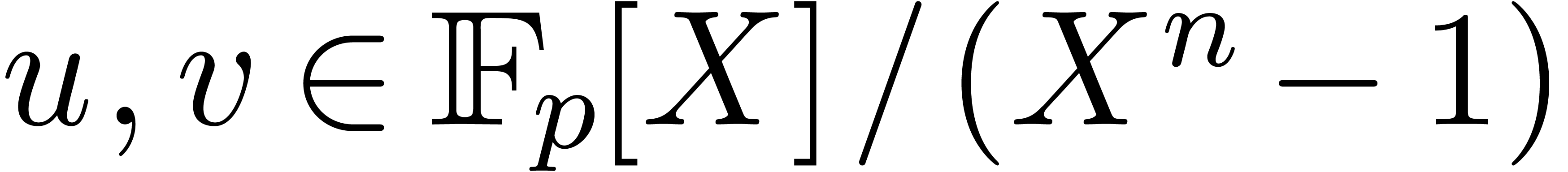 using classical matrix
arithmetic.
using classical matrix
arithmetic.
In the remainder of this section, we fix some
and as in Proposition 6.1, and
assume that is represented as . Suppose that we wish to compute the product
of  . The presentation here
closely follows that of [18, Section 9.2]. We decompose
. The presentation here
closely follows that of [18, Section 9.2]. We decompose
 and
and 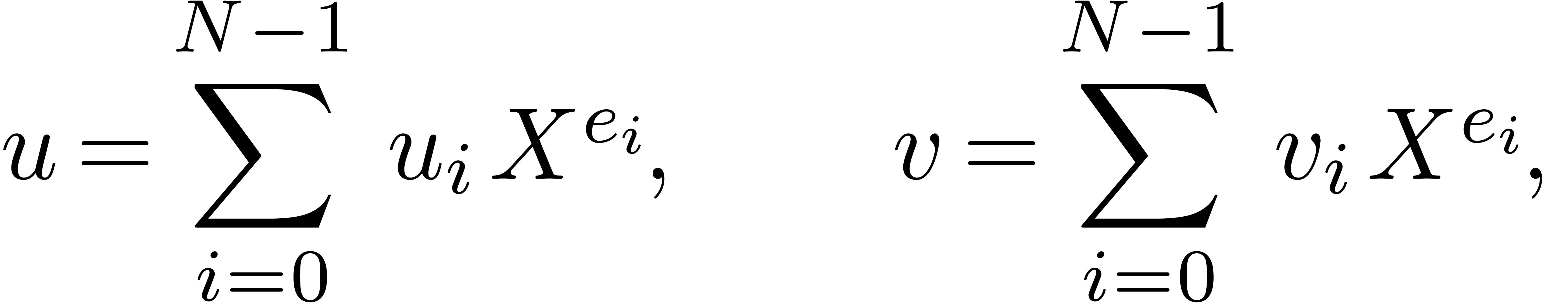 as
as
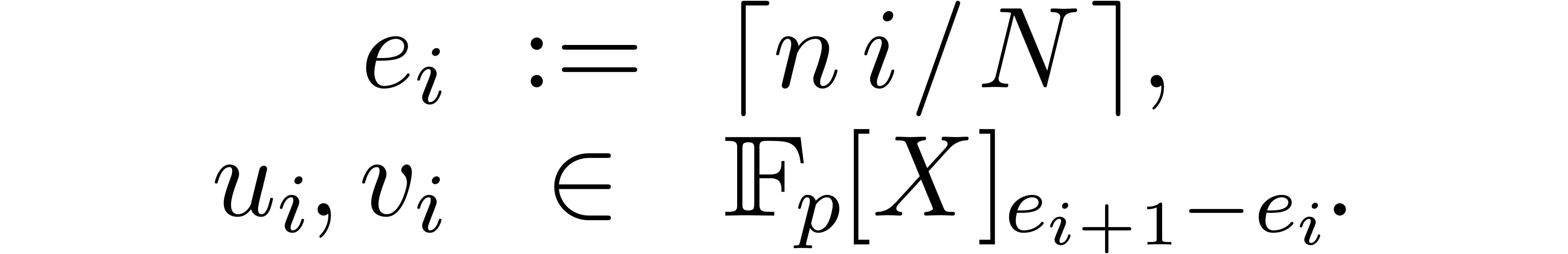 |
(6.1) |
where
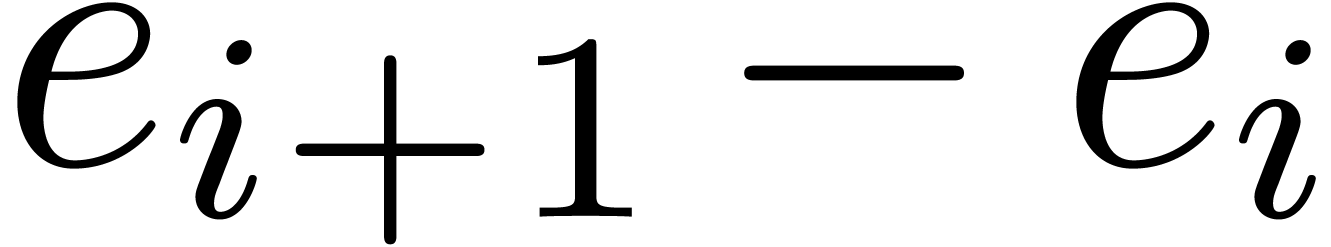
Notice that 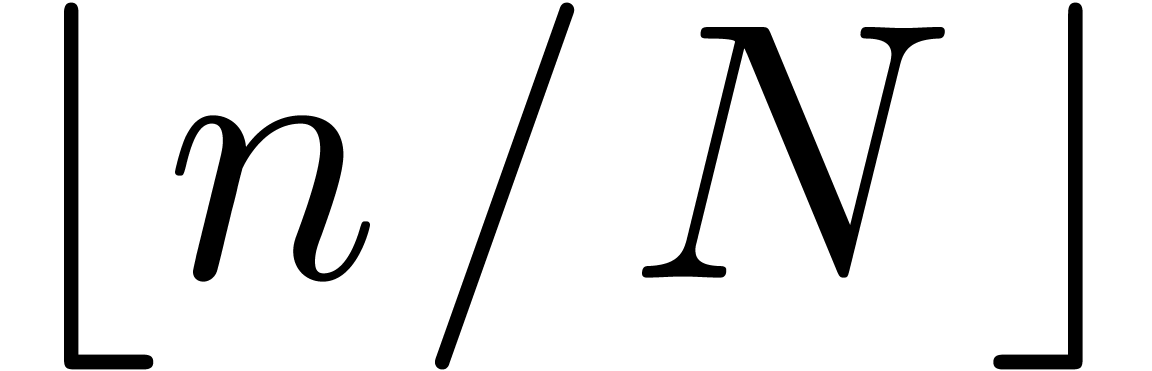 takes only two possible values:
takes only two possible values: 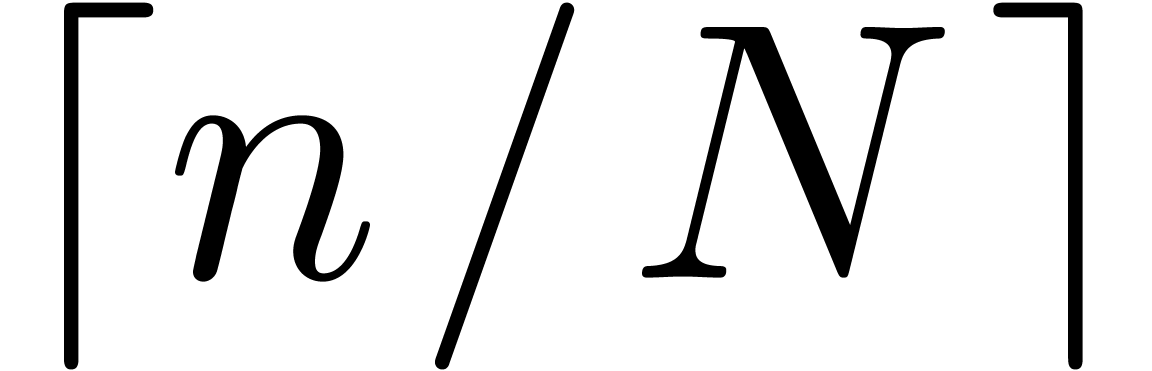 or
or 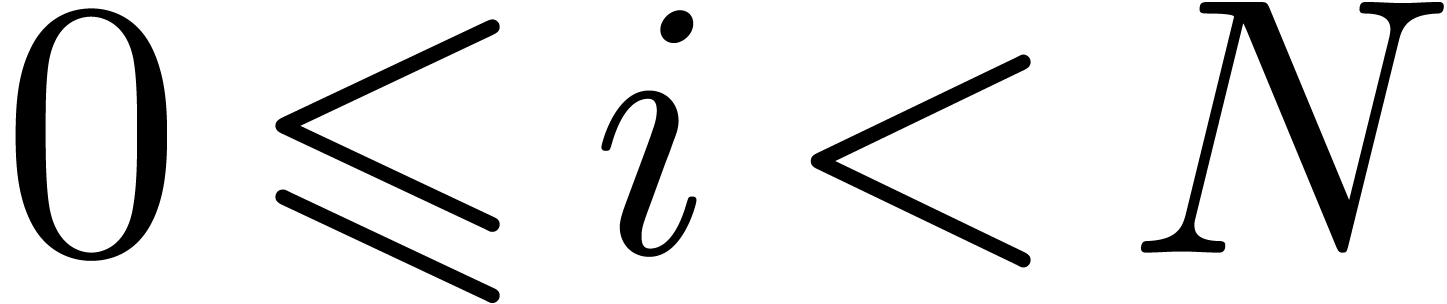 .
.
For 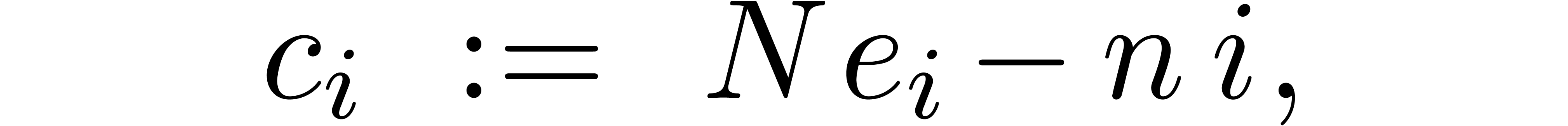 , let
, let
so that  . For any
. For any  , define
, define 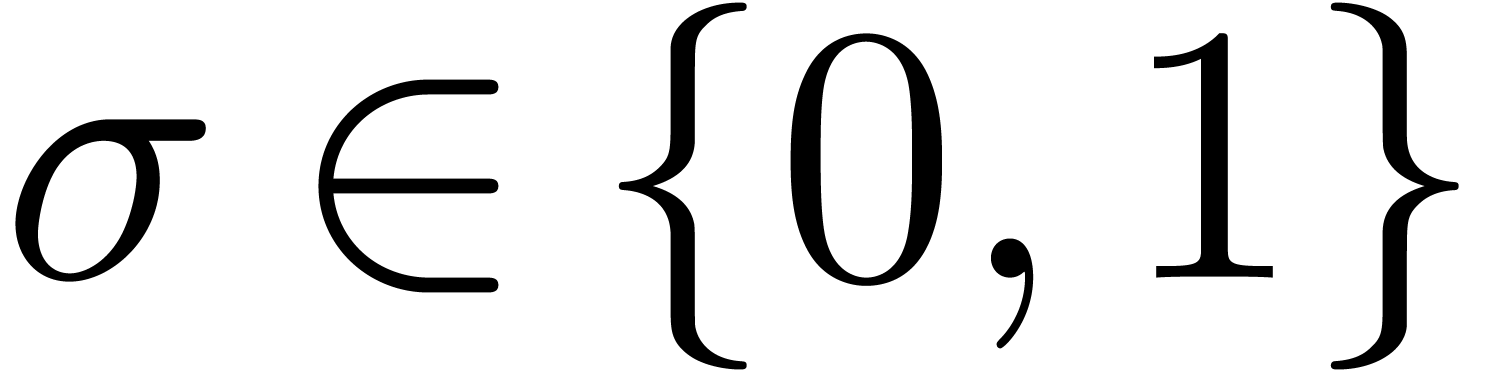 as
follows. Choose
as
follows. Choose 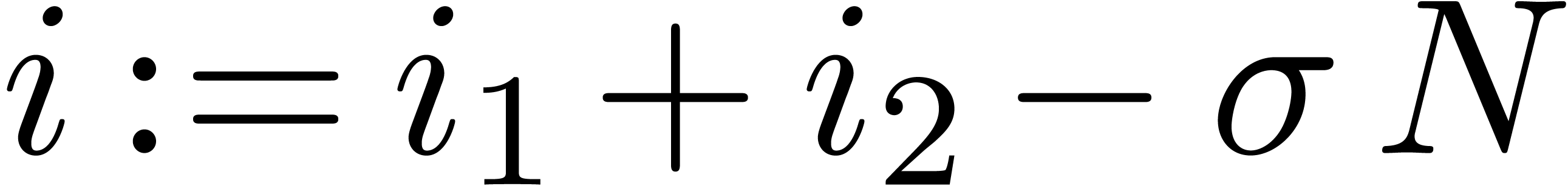 so that
so that 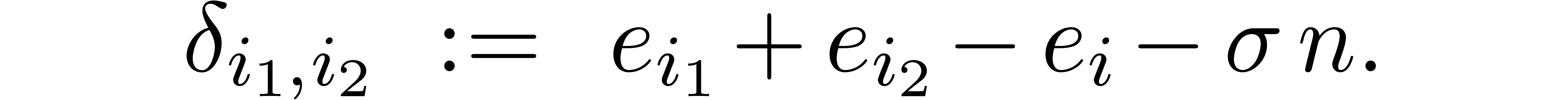 lies in the interval , and
put
lies in the interval , and
put
From (6.2), we have
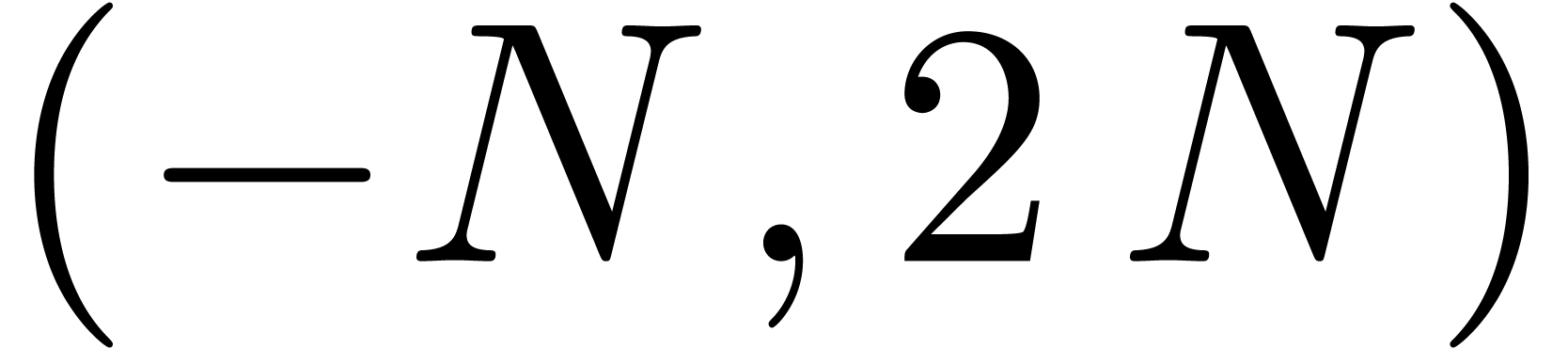
Since the left hand side lies in the interval 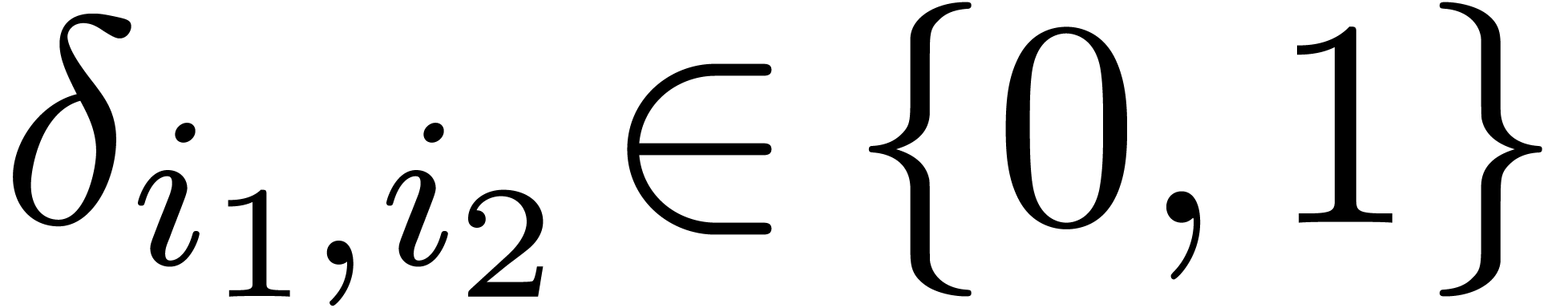 , this shows that
, this shows that 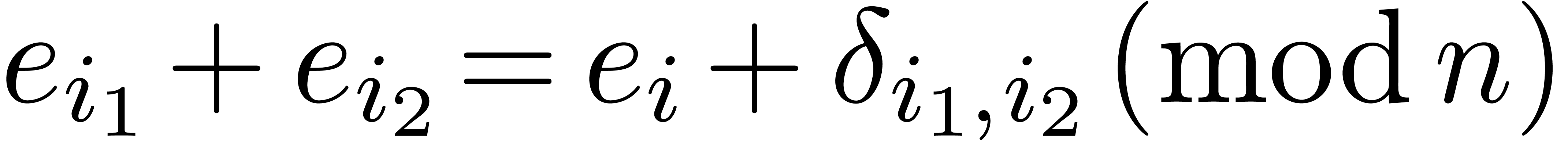 .
Now, since
.
Now, since  , we have
, we have
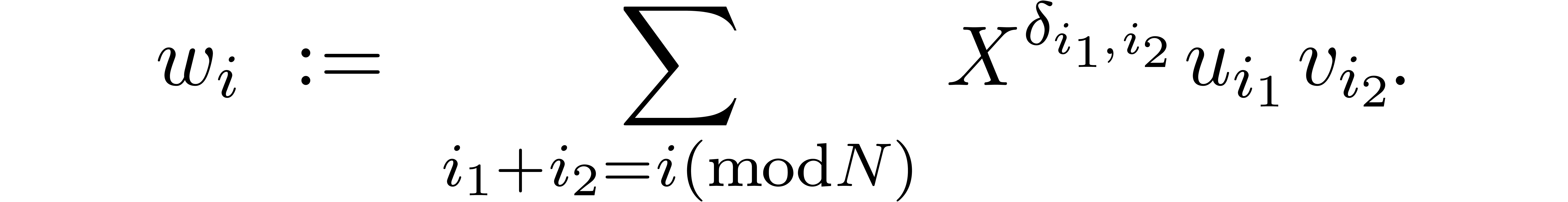
where
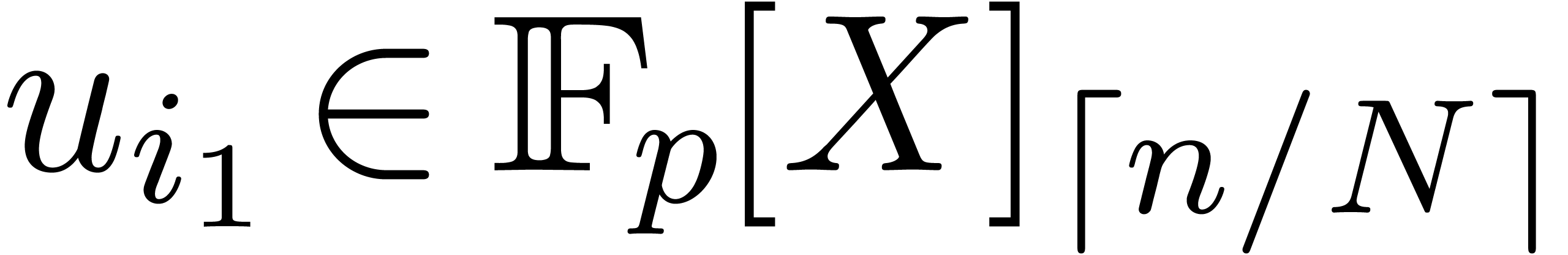
Since 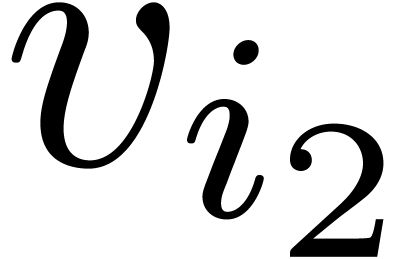 and similarly for
and similarly for 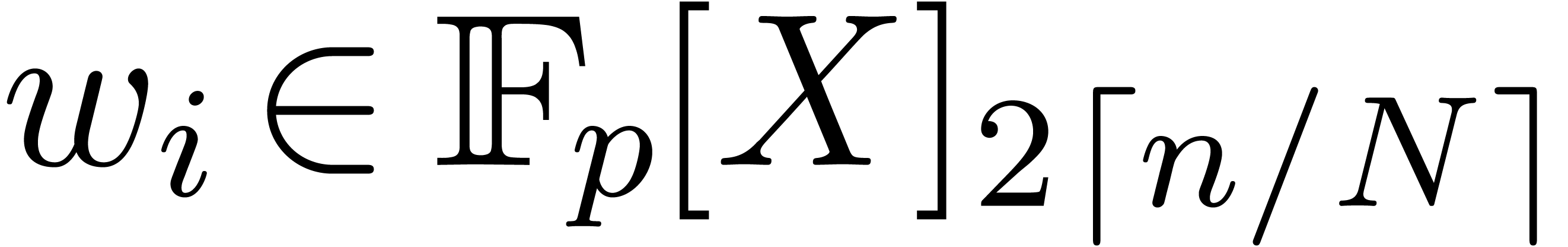 , we have
, we have  .
Note that we may recover
.
Note that we may recover 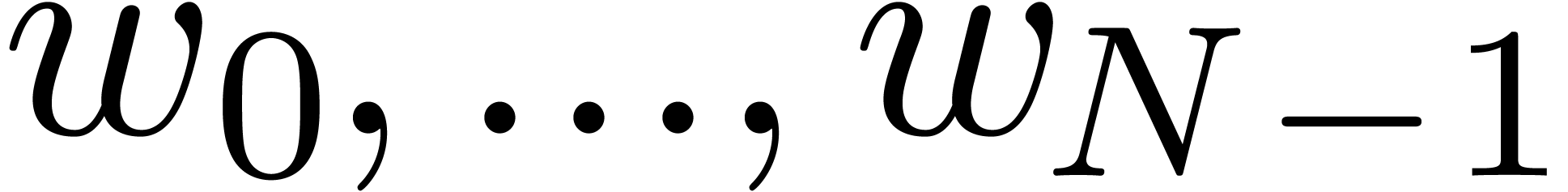 from
from 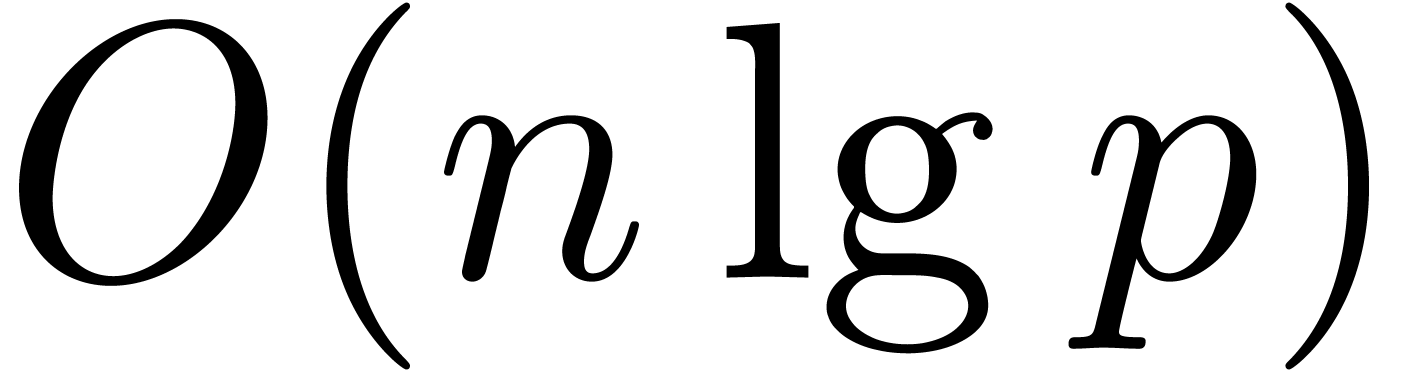 in time
in time 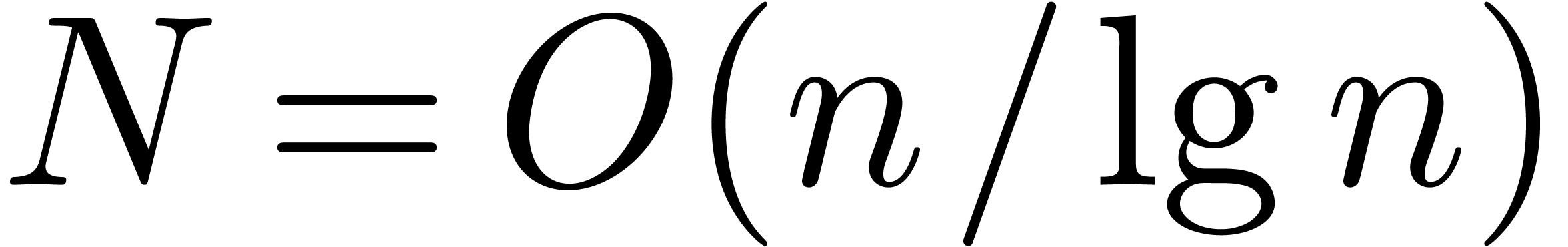 , by a standard
overlap-add procedure (provided that
, by a standard
overlap-add procedure (provided that 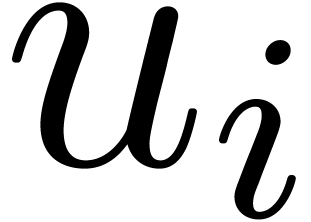 ).
).
Now, regarding 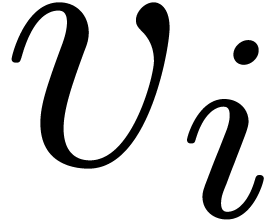 and
and 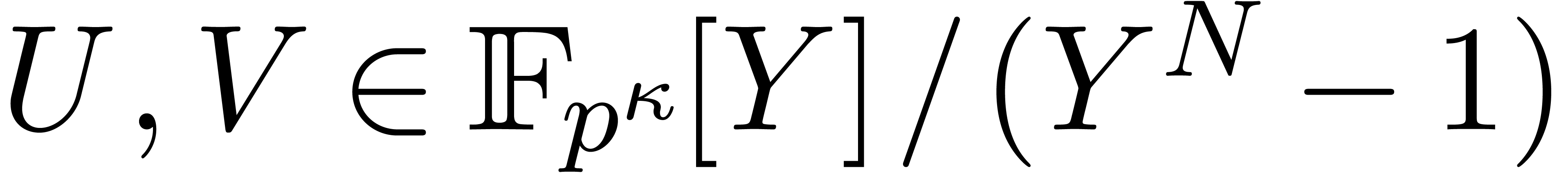 as
elements of by sending
to , define polynomials
as
elements of by sending
to , define polynomials 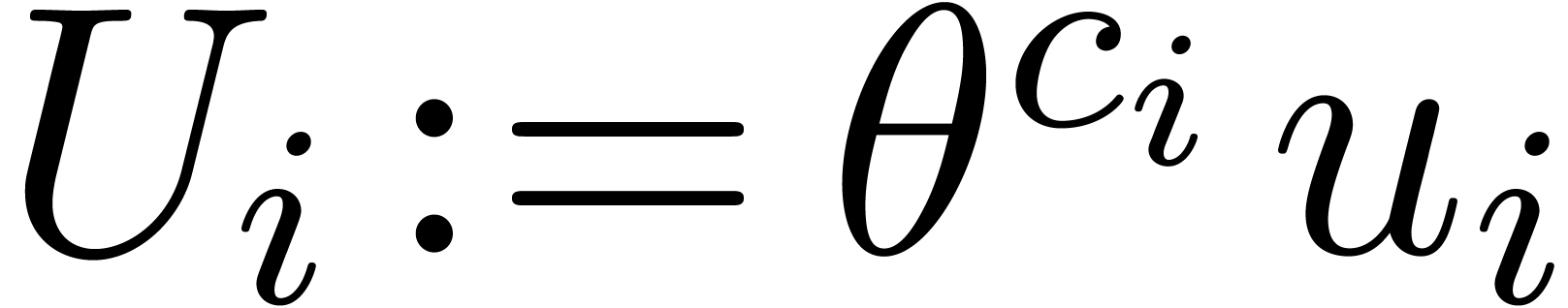 by
by 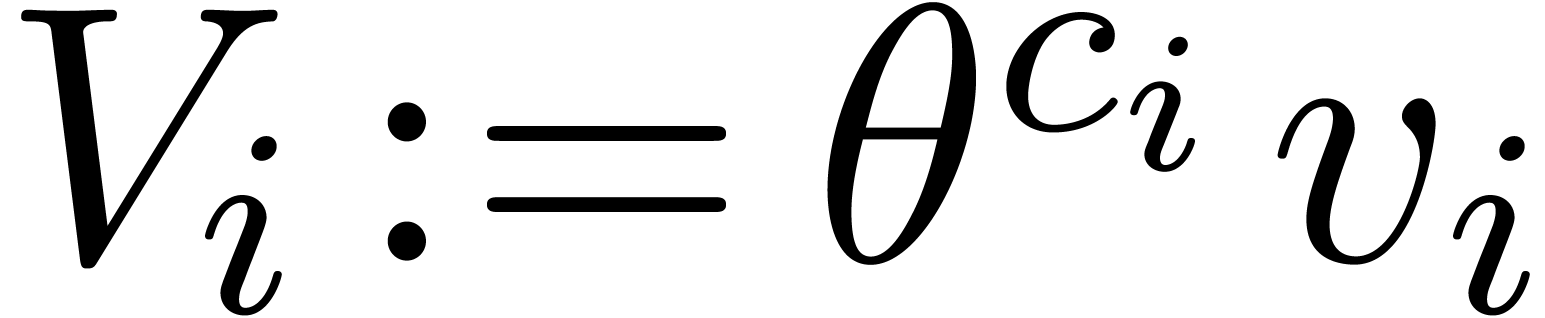 and
and 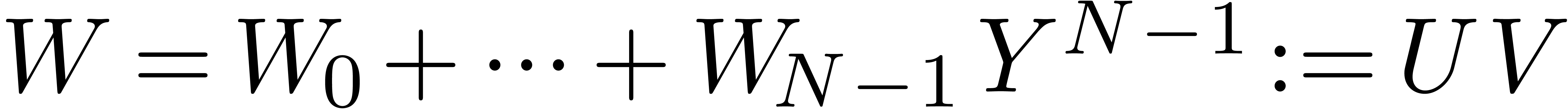 for , and let
for , and let  be their (cyclic) product. Then
be their (cyclic) product. Then
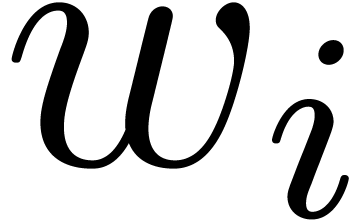
coincides with the reinterpretation of  as an
element of . Moreover, we may
recover unambiguously from
as an
element of . Moreover, we may
recover unambiguously from  , as and . Altogether, this shows how to reduce
multiplication in
, as and . Altogether, this shows how to reduce
multiplication in 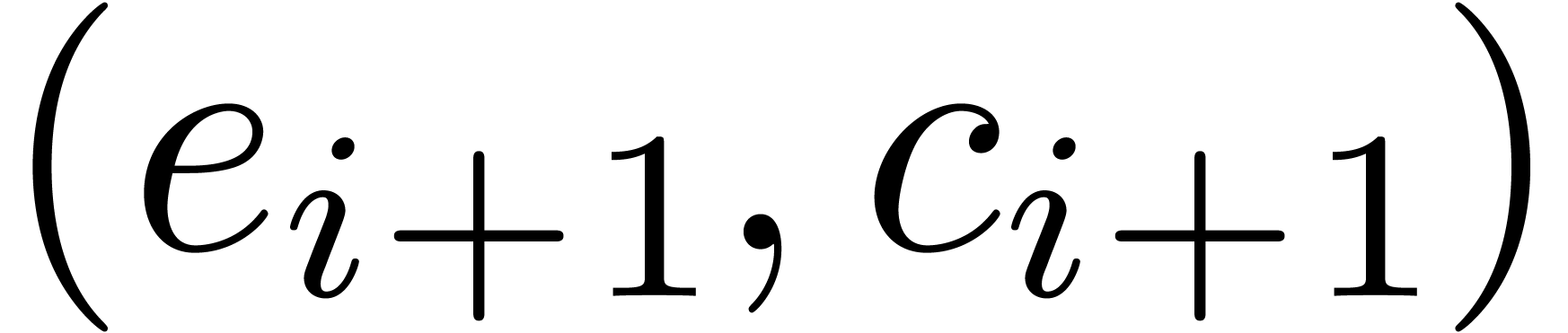 to multiplication in .
to multiplication in .
Remark 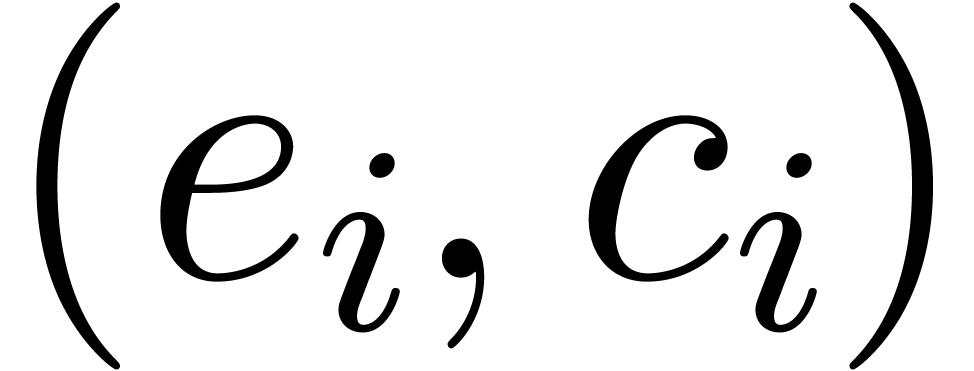 can be computed from
can be computed from 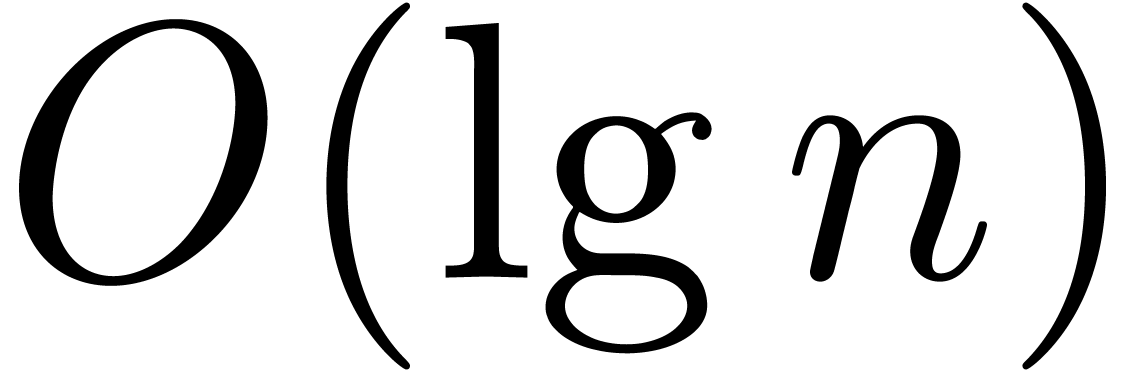 in
in 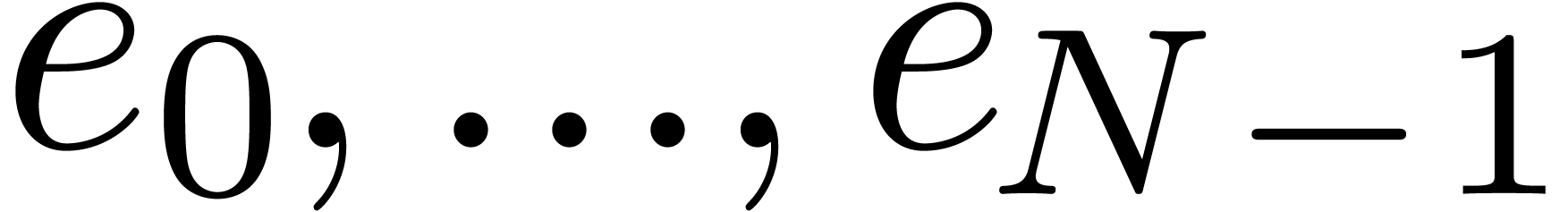 bit operations, so we may compute the sequences
bit operations, so we may compute the sequences  and
and 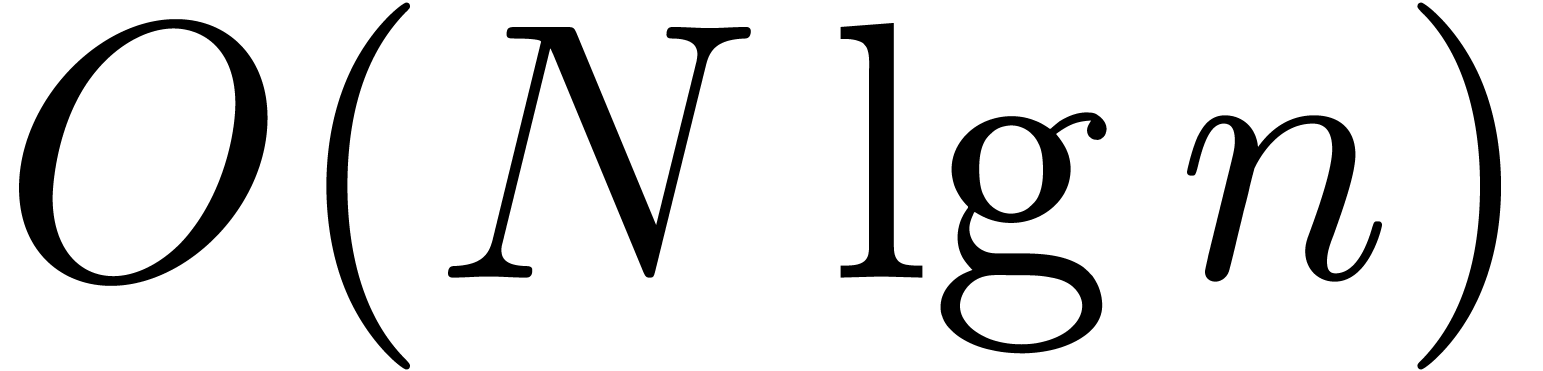 in time
in time 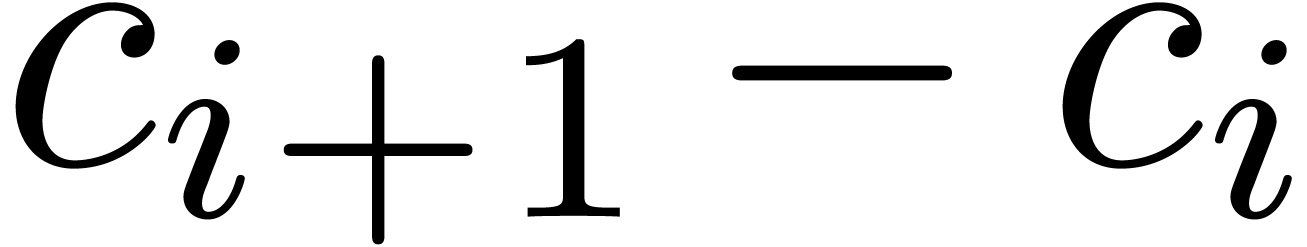 . Moreover, since
. Moreover, since 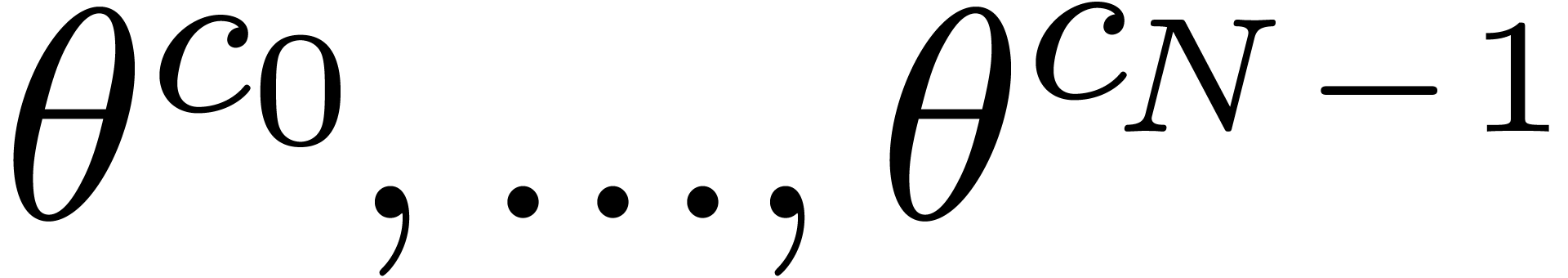 takes
on only two possible values, we may compute the sequence
takes
on only two possible values, we may compute the sequence 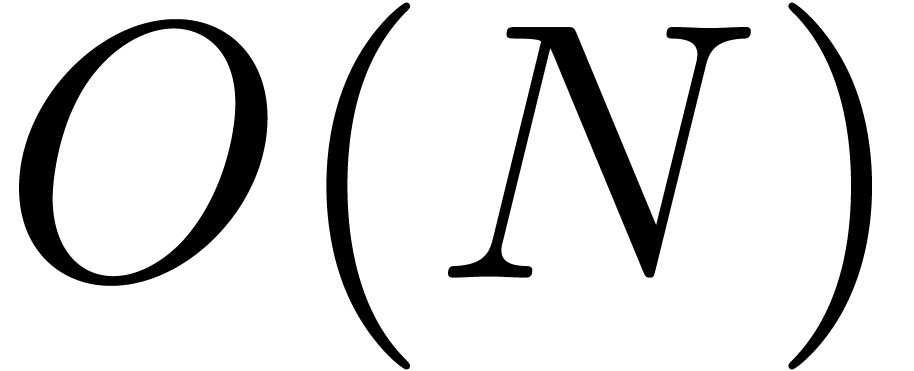 using
using  multiplications in .
multiplications in .
Consider the problem of computing  products
products 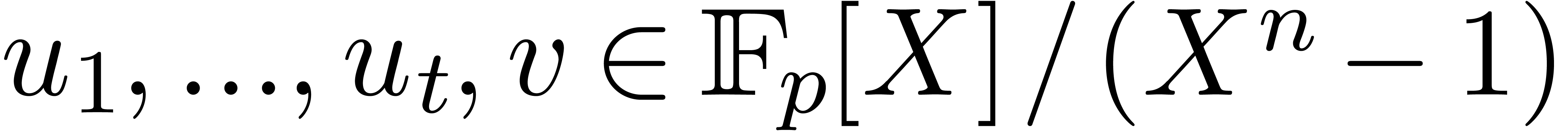 with
with 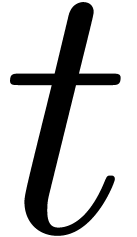 ,
i.e.,
,
i.e., 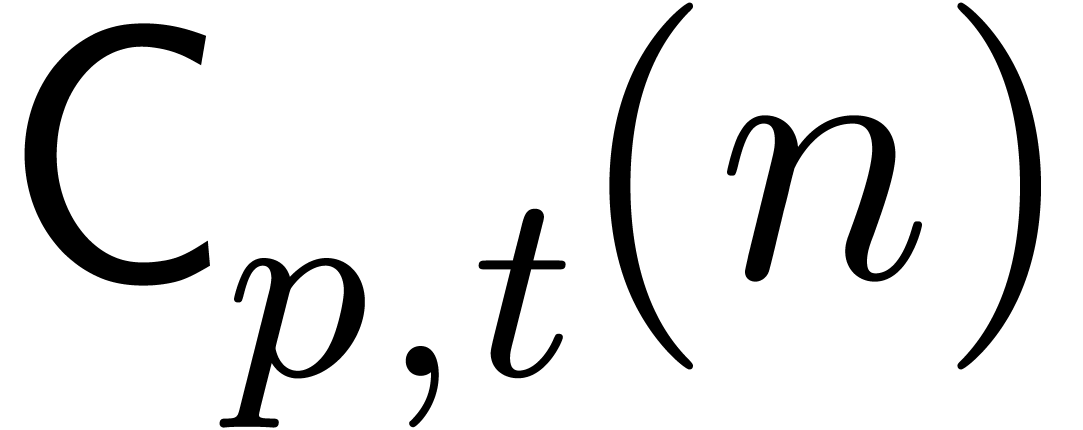 products with one fixed operand. Denote
the cost of this operation by
products with one fixed operand. Denote
the cost of this operation by  .
Our algorithm for this problem will perform
.
Our algorithm for this problem will perform 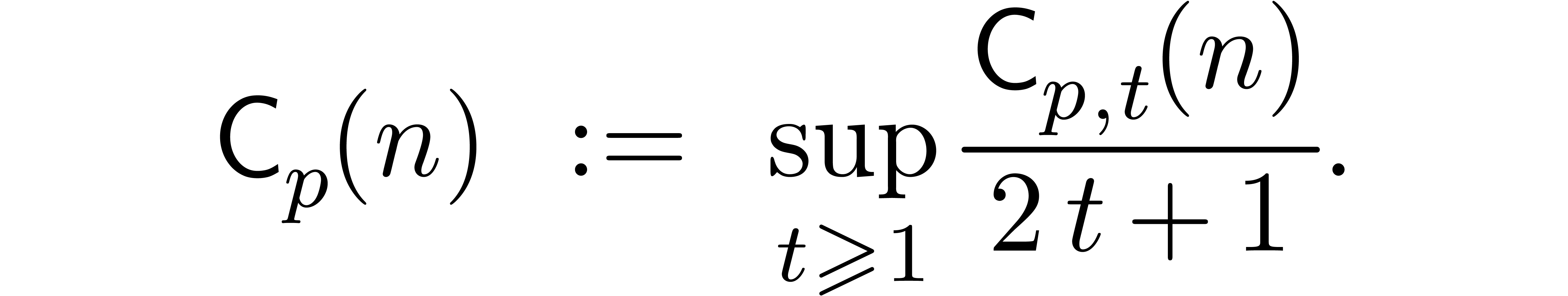 forward DFTs and inverse DFTs, so it is
convenient to introduce the normalisation
forward DFTs and inverse DFTs, so it is
convenient to introduce the normalisation
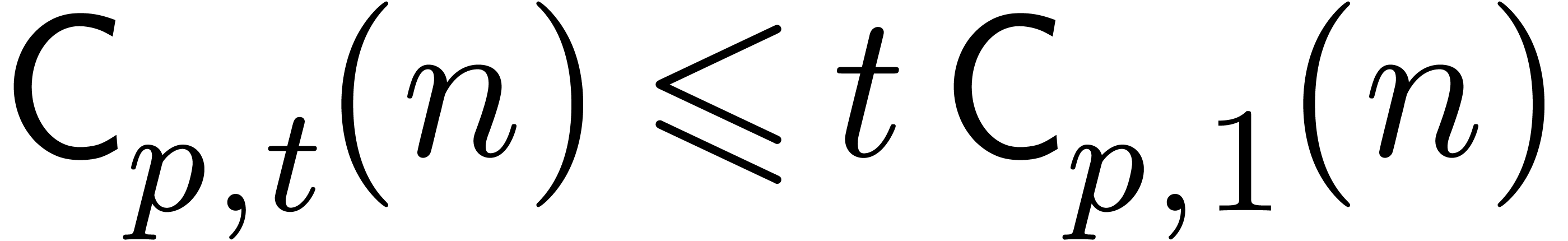
This is well-defined since clearly 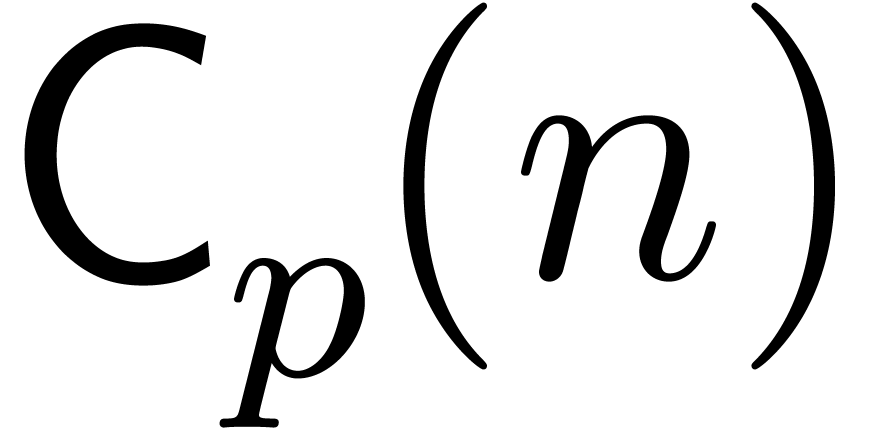 .
Roughly speaking,
.
Roughly speaking,  may be thought of as the
notional cost of a single DFT.
may be thought of as the
notional cost of a single DFT.
The problem of multiplying two polynomials in of
degree less than  may be reduced to the above
problem by using zero-padding, i.e., taking
may be reduced to the above
problem by using zero-padding, i.e., taking 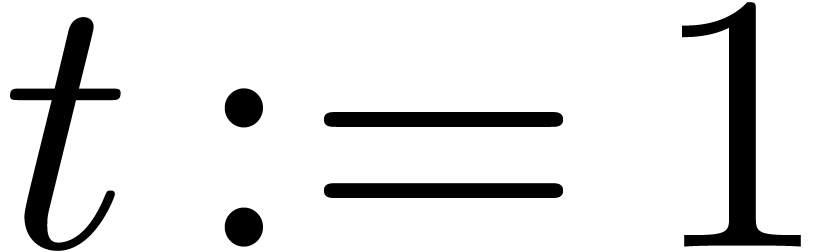 and
and
 . Since
. Since 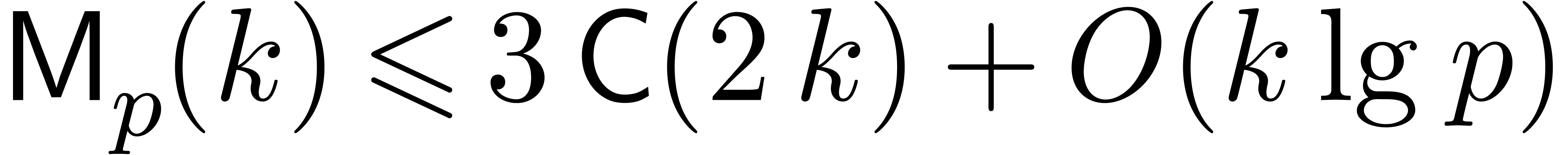 , we obtain
, we obtain  .
Thus it suffices to obtain a good bound for .
.
Thus it suffices to obtain a good bound for .
The next theorem gives the core of the new algorithm for the case that
is large relative to .
 and a logarithmically slow
function with the following property. For all
integers
and a logarithmically slow
function with the following property. For all
integers 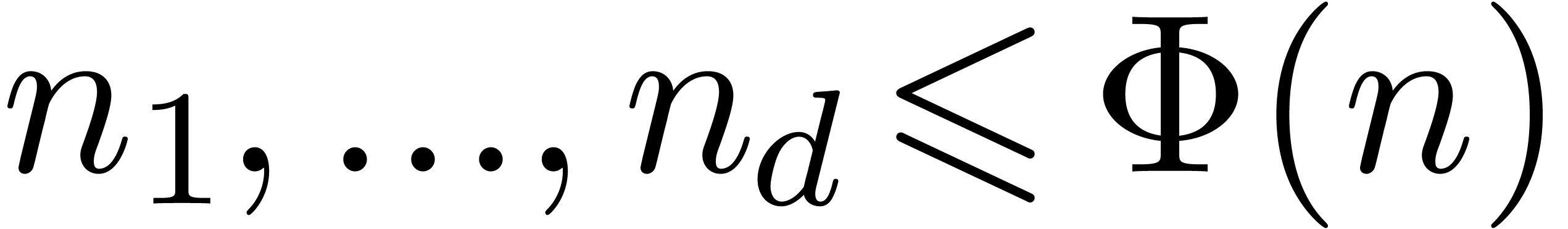 , there exist
integers
, there exist
integers  , and weights with ,
such that
, and weights with ,
such that
uniformly for 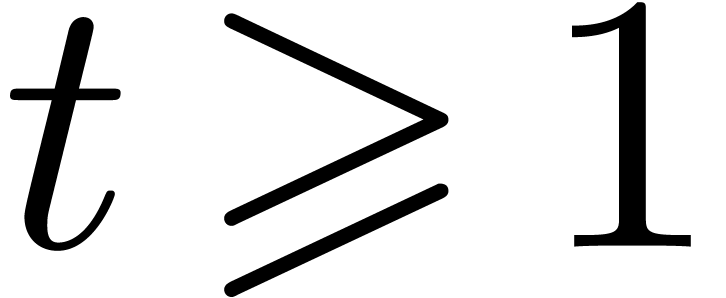 .
.
Proof. We wish to compute 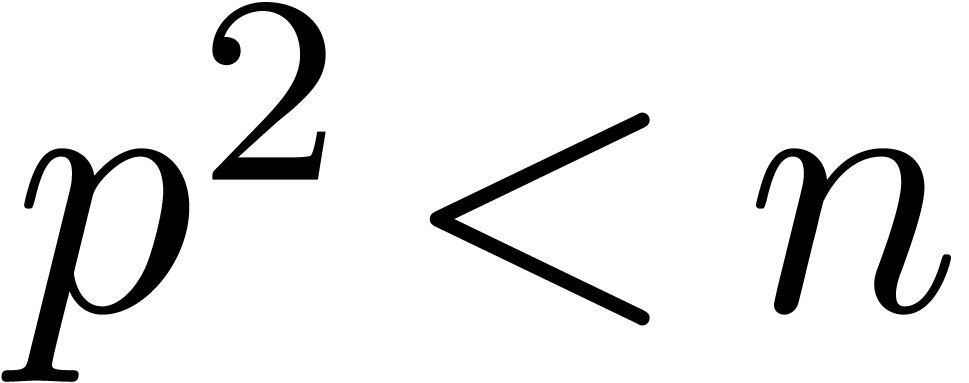 products with ,
for some sufficiently large .
We assume throughout that
products with ,
for some sufficiently large .
We assume throughout that 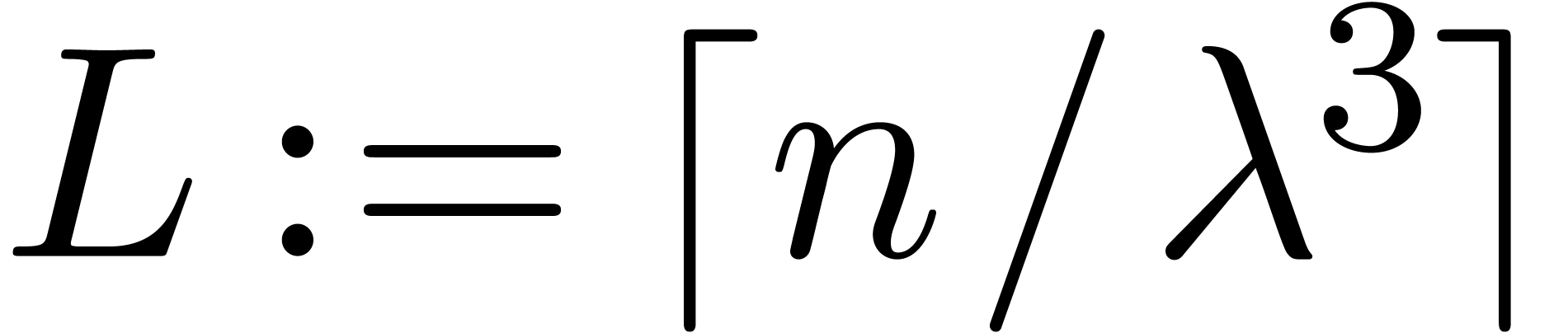 .
.
Choose parameters. Using Theorem 4.1, we
obtain integers and with
and so that , , and is -smooth. We choose long and short target
transform lengths 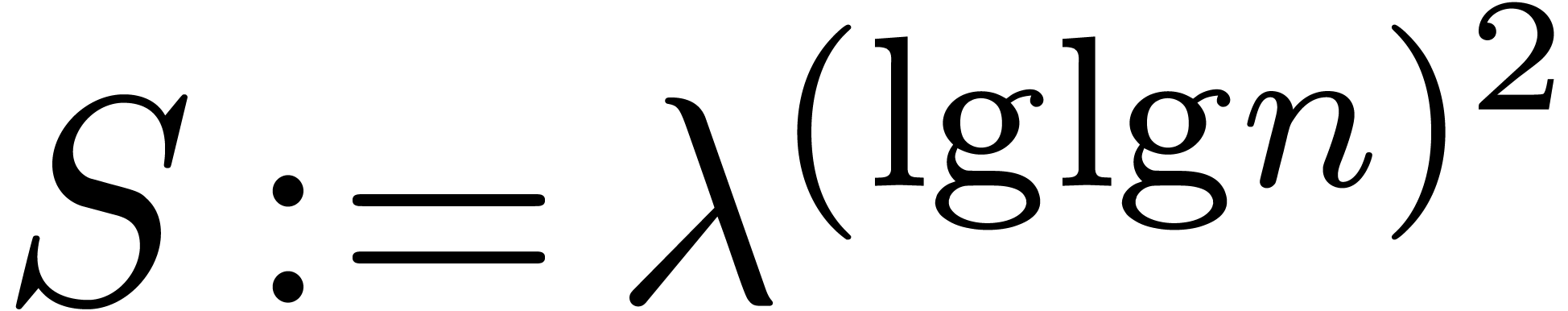 and
and 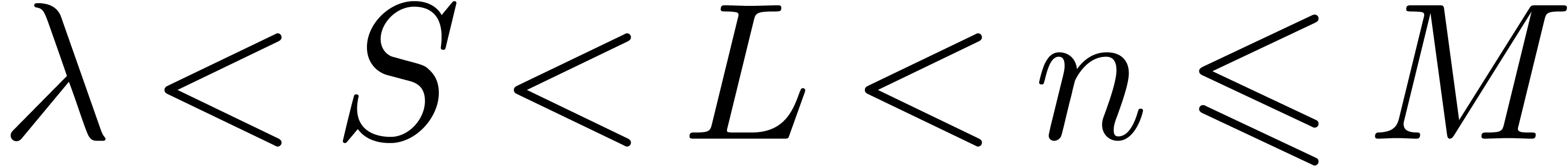 . For large enough we then
have
. For large enough we then
have 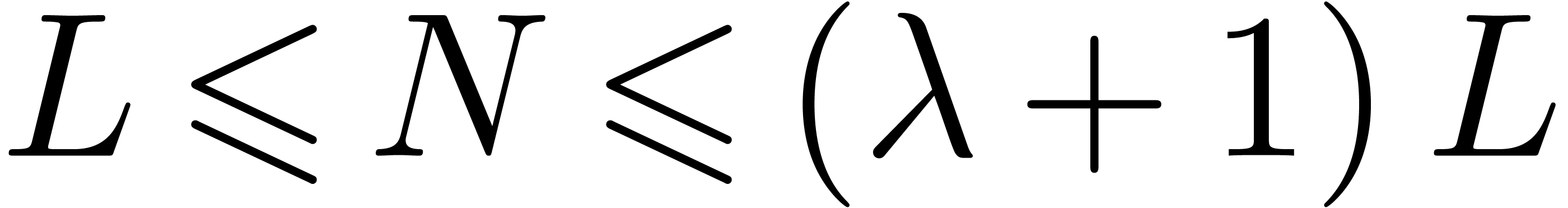 , so we may apply
Theorem 4.6. This yields -smooth
integers , with known
factorisations, such that
, so we may apply
Theorem 4.6. This yields -smooth
integers , with known
factorisations, such that 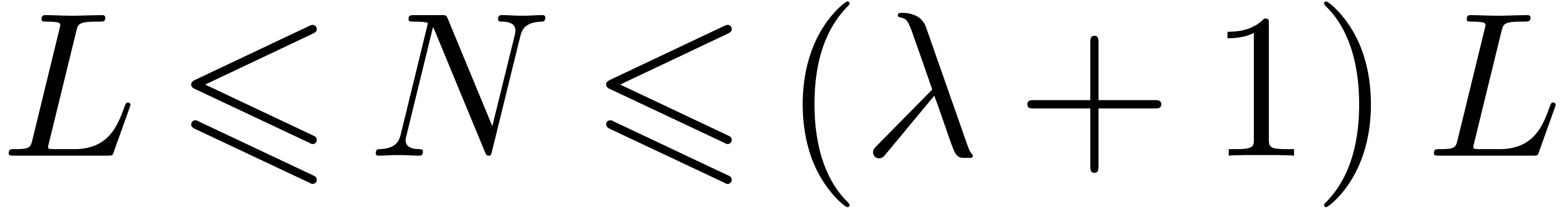 divides and lies in the range
divides and lies in the range 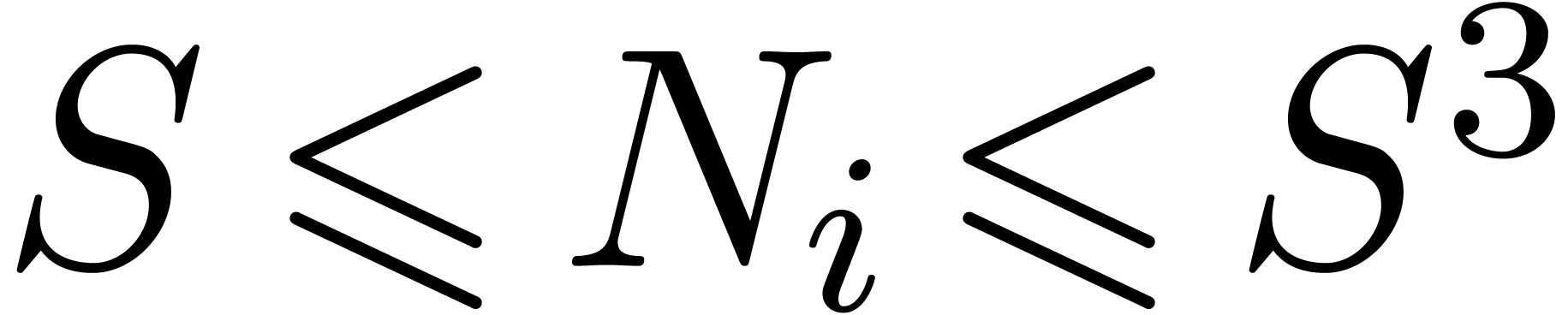 ,
and such that
,
and such that 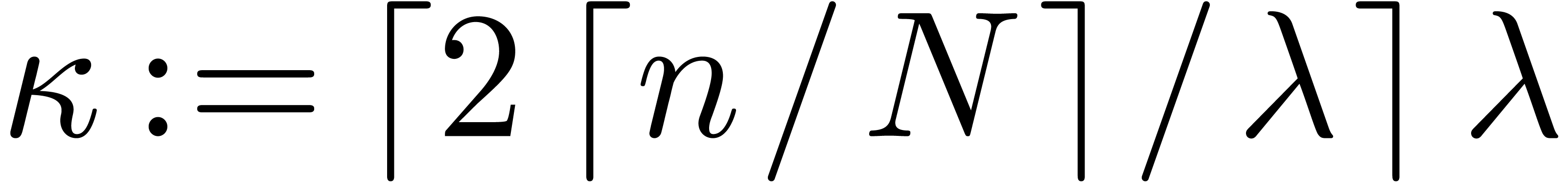 for all . Finally we set
for all . Finally we set 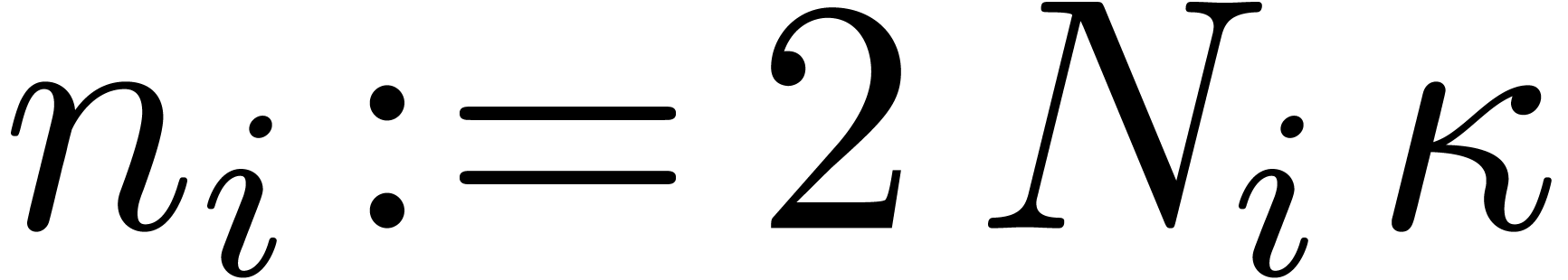 ,
so that also divides , and we put
,
so that also divides , and we put 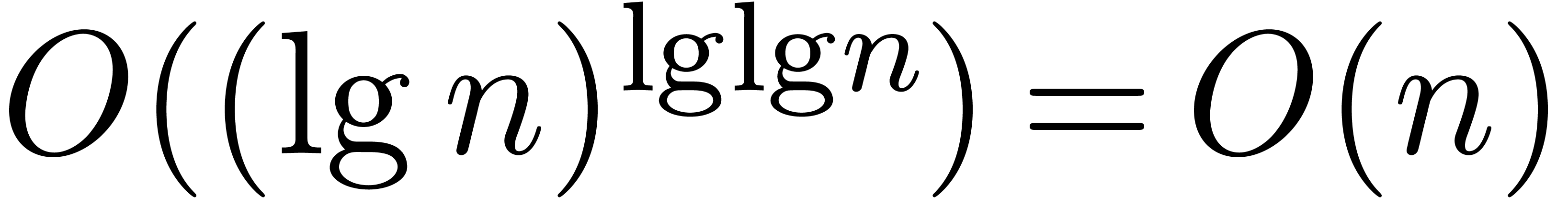 .
All of these parameters may be computed in time
.
All of these parameters may be computed in time 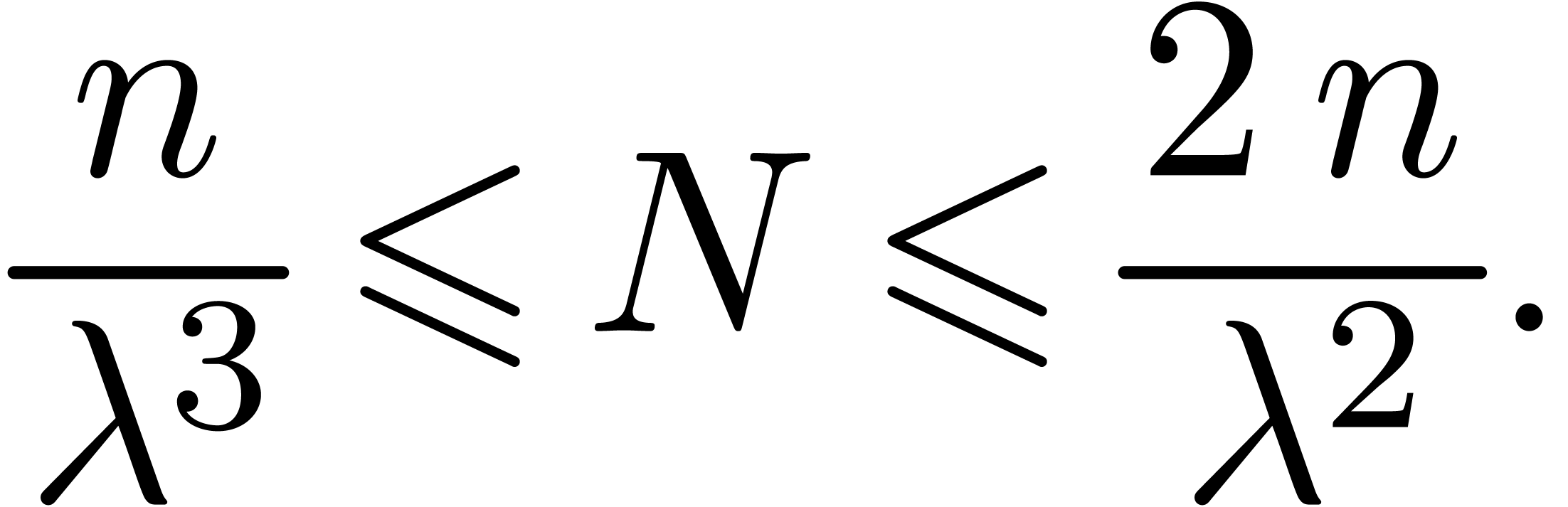 .
.
For large , we observe that
the following estimates hold. First, we have
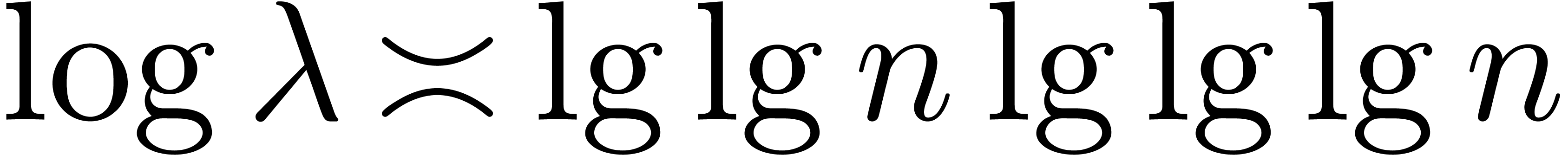
Since 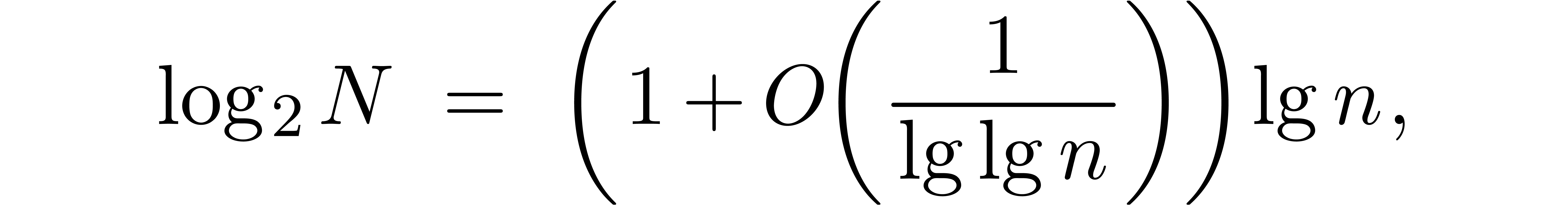 , it follows that
, it follows that
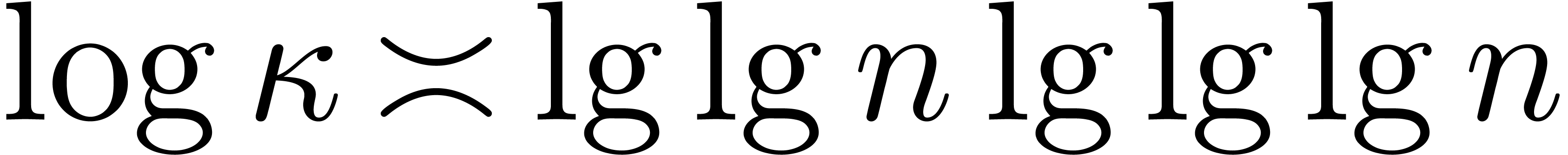
and also that 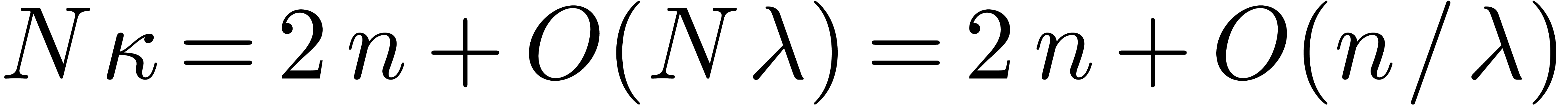 . We have
. We have 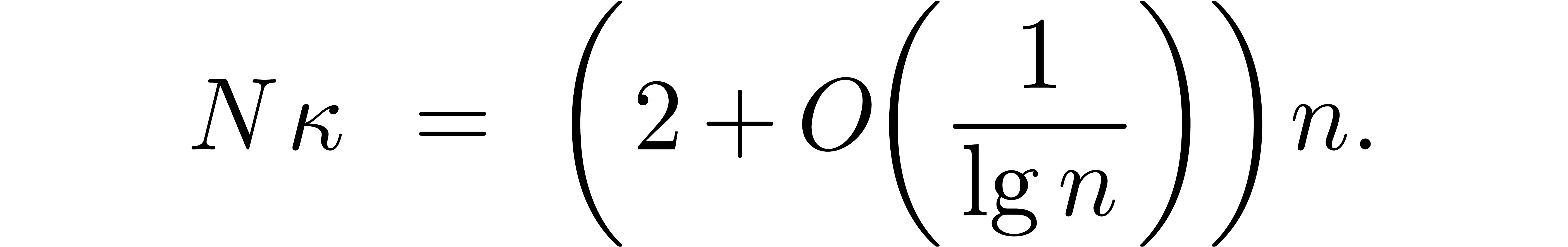 , so
, so
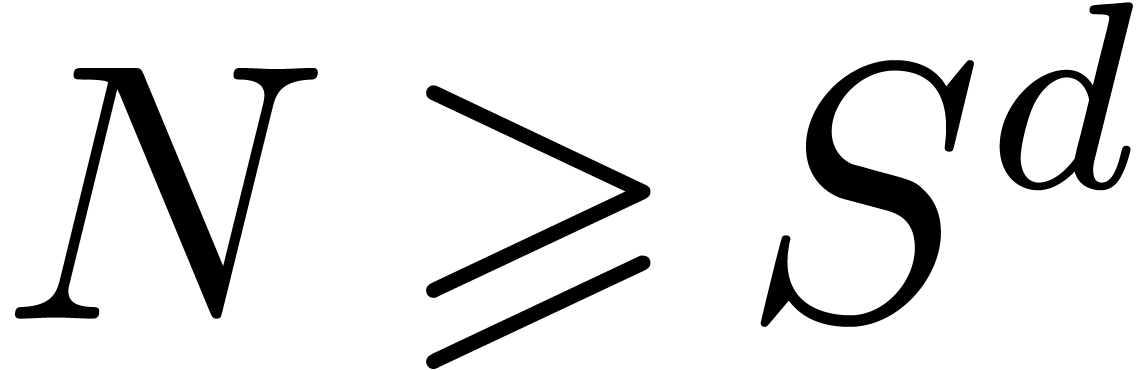
To estimate , note that 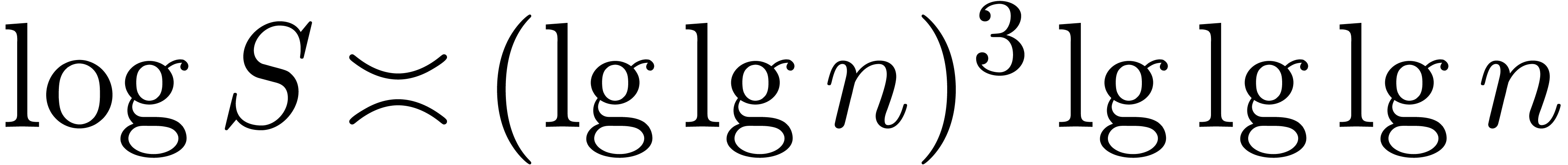 and
and 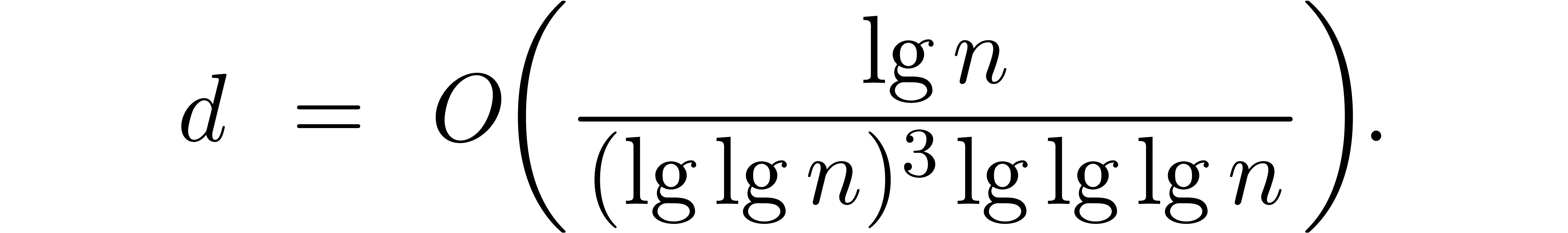 , so
, so
Since 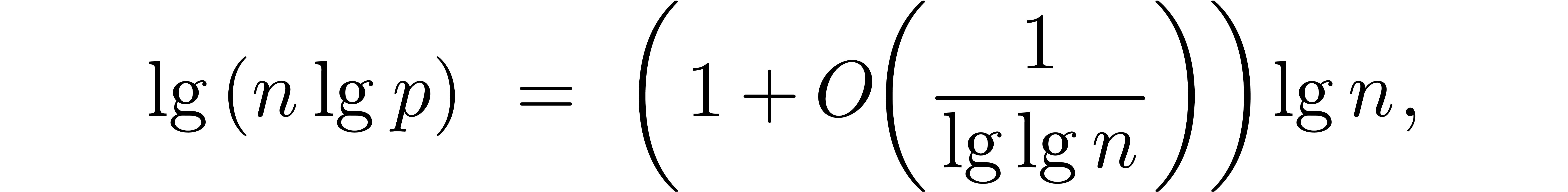 we have
we have
and as 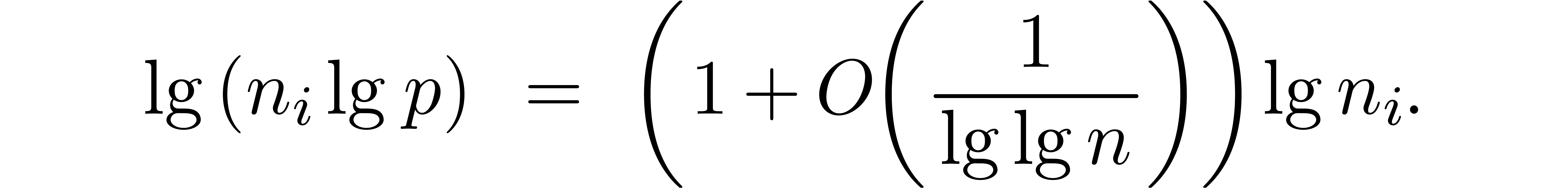 , we similarly obtain
, we similarly obtain
Crandall–Fagin reduction. Let us check that the
hypotheses of section 6.1 are satisfied, to enable the
reduction to multiplication in .
We certainly have 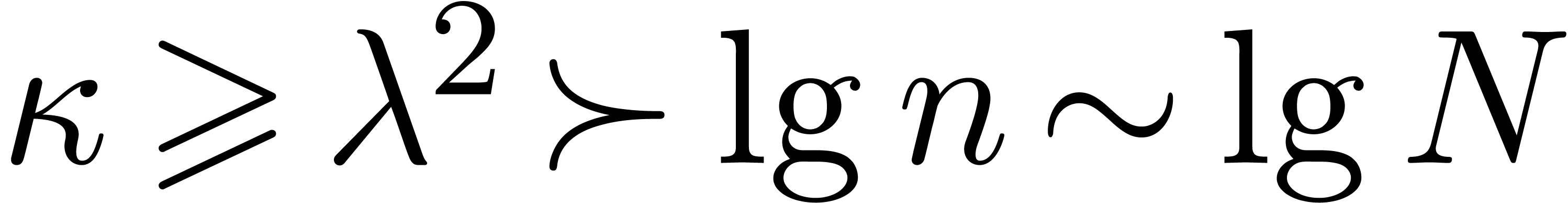 and . For Proposition 6.1, observe that
and . For Proposition 6.1, observe that
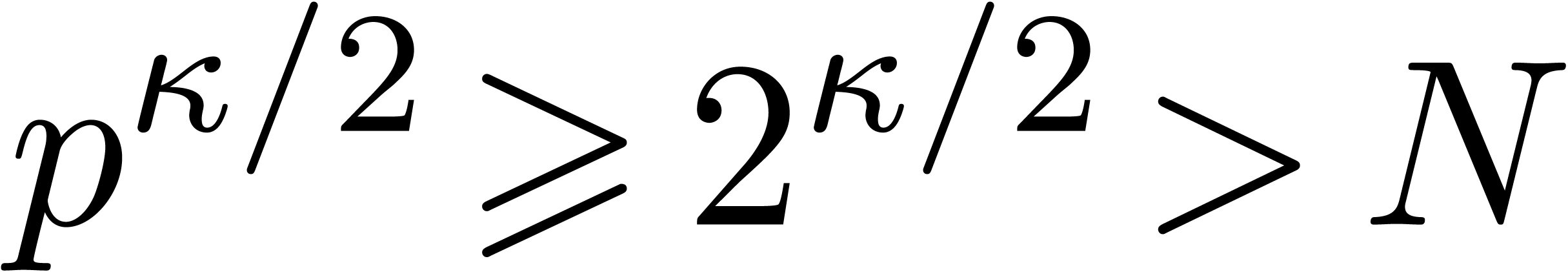 , so
, so 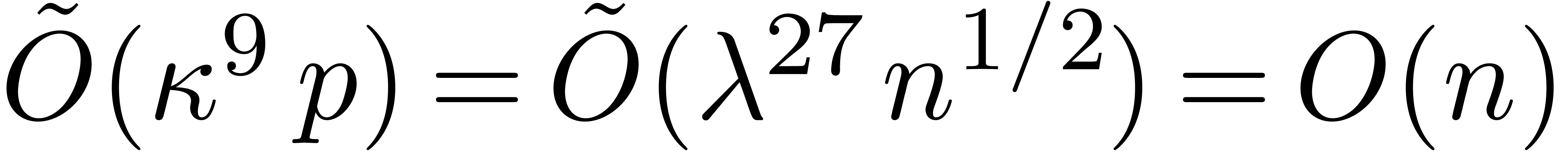 for large . Thus we obtain an
irreducible of degree , and an element such that
, in time
for large . Thus we obtain an
irreducible of degree , and an element such that
, in time 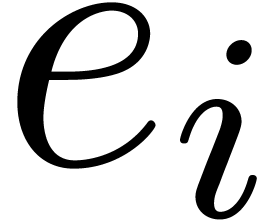 . Each multiplication in
has cost (see section 3).
. Each multiplication in
has cost (see section 3).
Computing the sequences 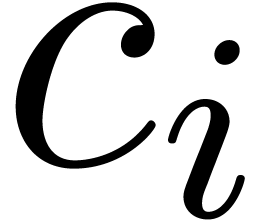 and
and 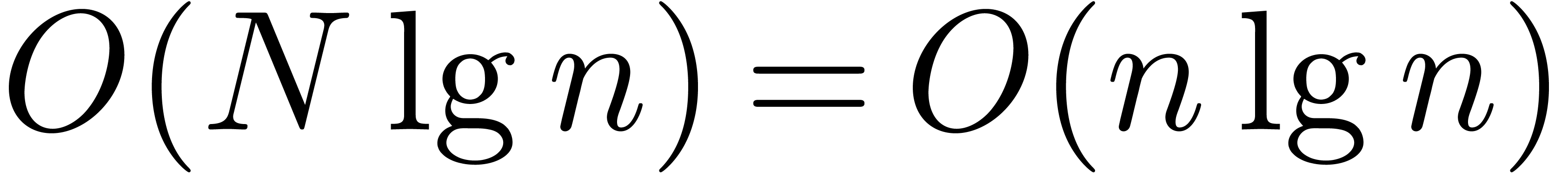 costs
costs 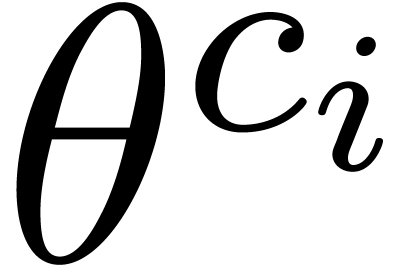 , and computing the
sequence
, and computing the
sequence 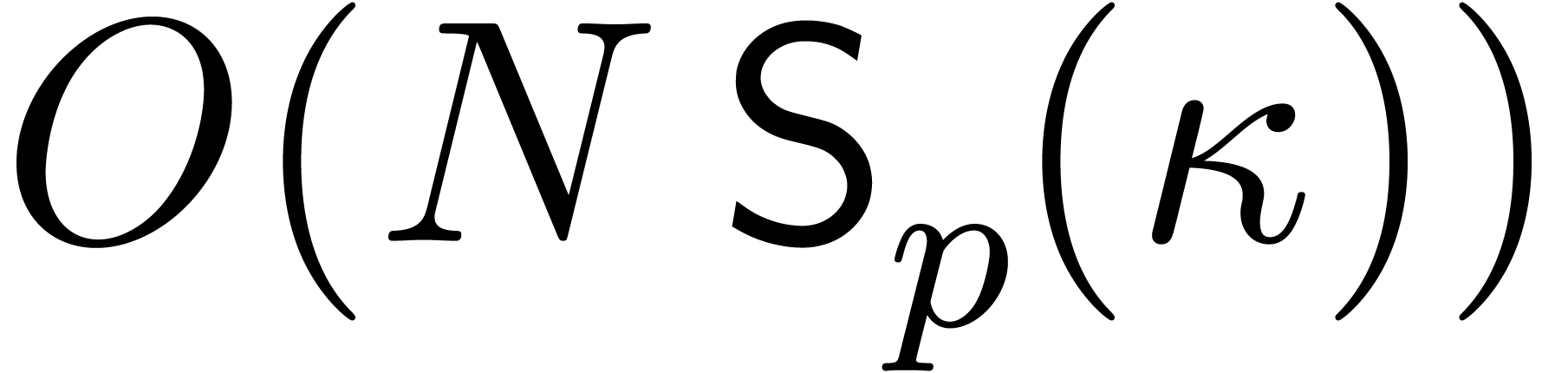 costs
costs 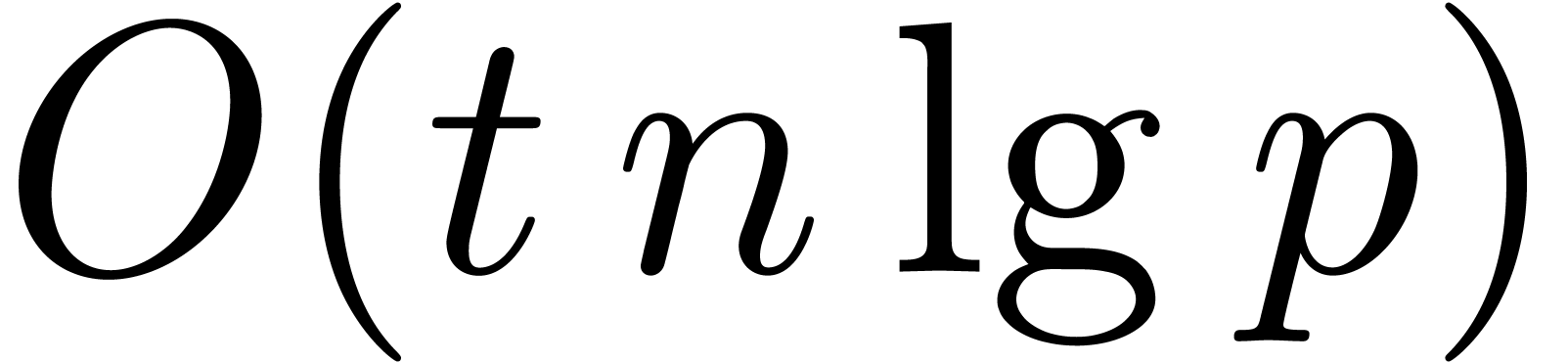 .
The initial splitting and final overlap-add phases require time
.
The initial splitting and final overlap-add phases require time  , and the multiplications by and
, and the multiplications by and 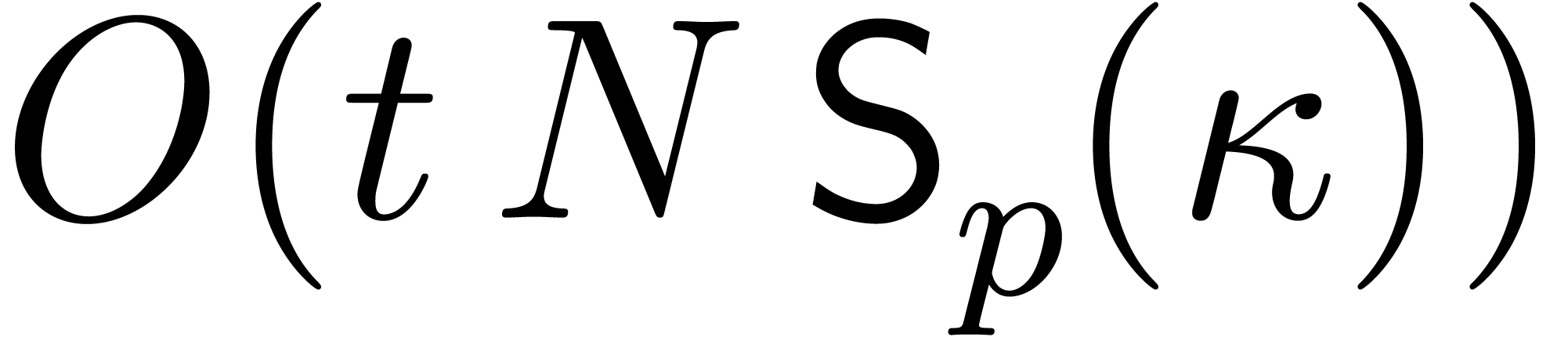 cost
cost 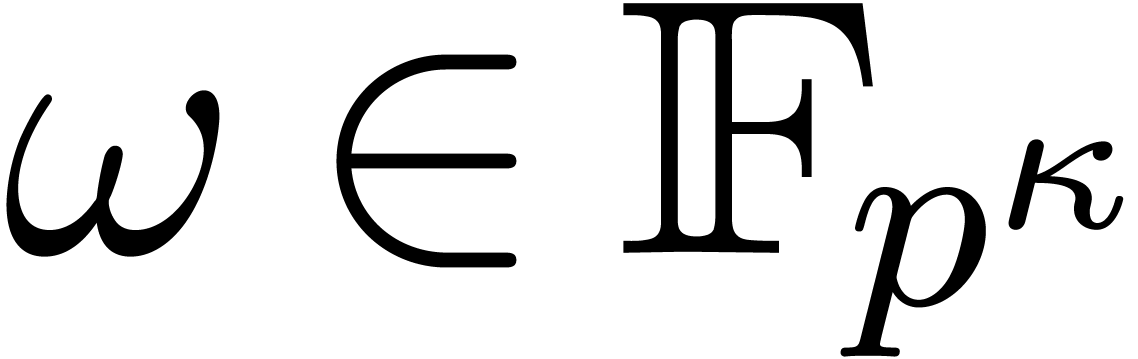 .
.
Long transforms. The factorisation of
is known, and divides , so by Lemma 3.3 we may compute a
primitive -th root of unity
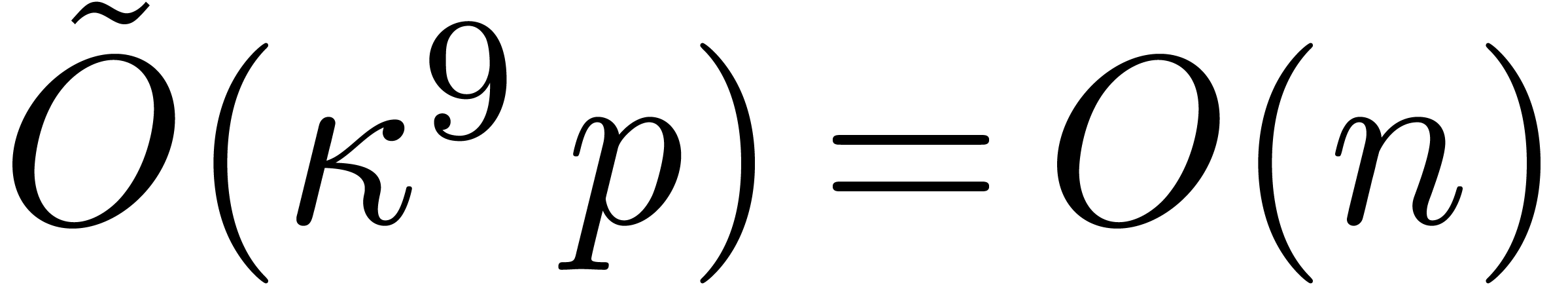 in time
in time  .
.
We will multiply in by using DFTs with respect
to 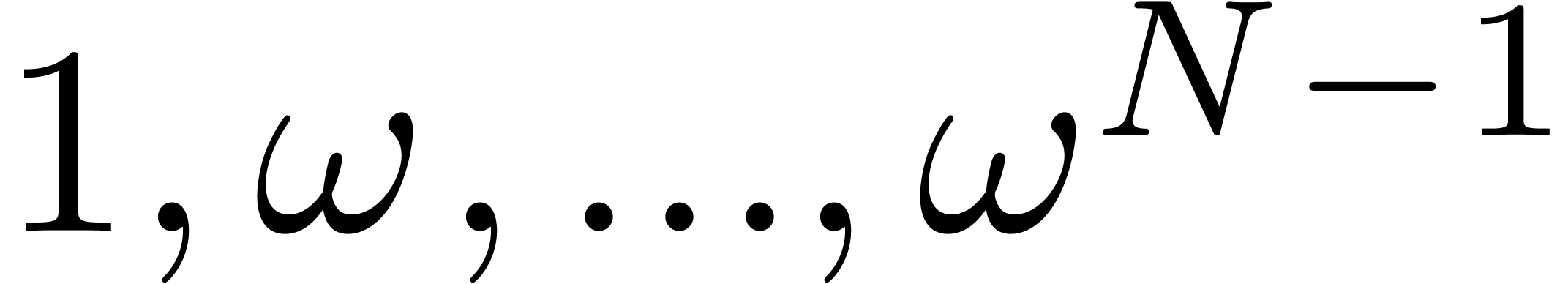 . The table of roots
. The table of roots 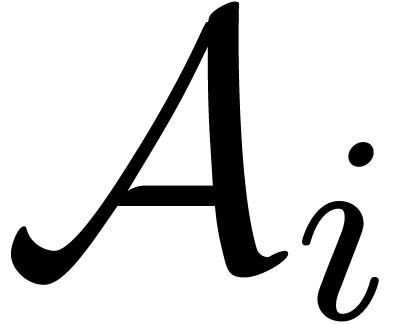 may be computed in time .
In a moment, we will describe an algorithm
may be computed in time .
In a moment, we will describe an algorithm 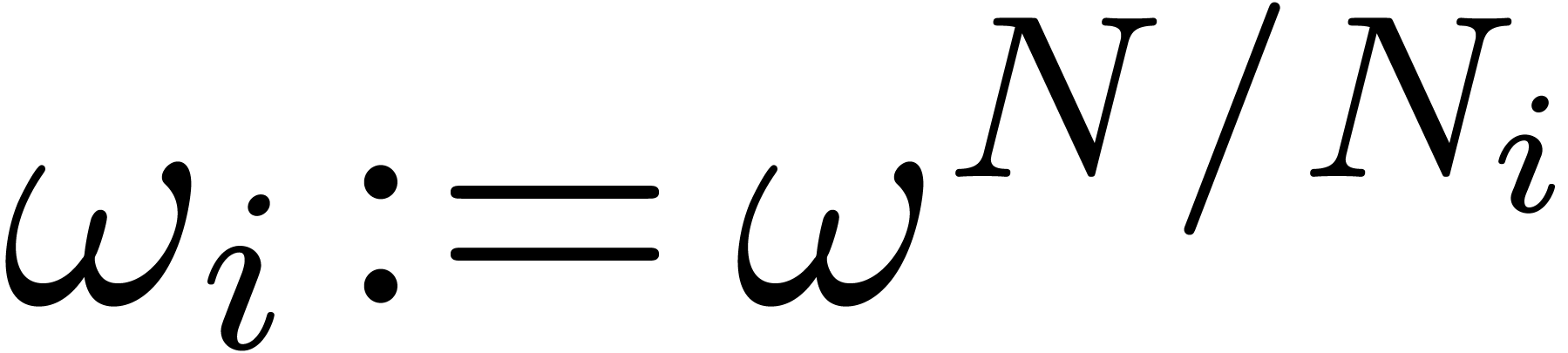 for
computing a “short” DFT of length
with respect to
for
computing a “short” DFT of length
with respect to  ; we then use
the algorithm
; we then use
the algorithm  for the main transform of length
(see section 2.3). The
corresponding twiddle factor tables may be extracted in time
for the main transform of length
(see section 2.3). The
corresponding twiddle factor tables may be extracted in time  .
.
Let  denote the complexity of
denote the complexity of  , and for
, and for 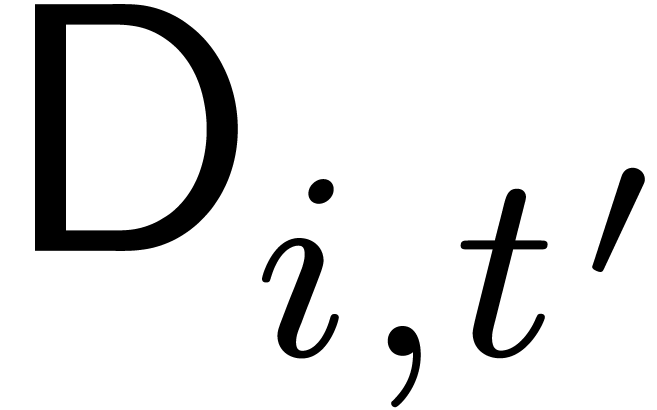 let
let  denote the cost of performing
denote the cost of performing  independent DFTs of length using . Then by
independent DFTs of length using . Then by
The last term is simply 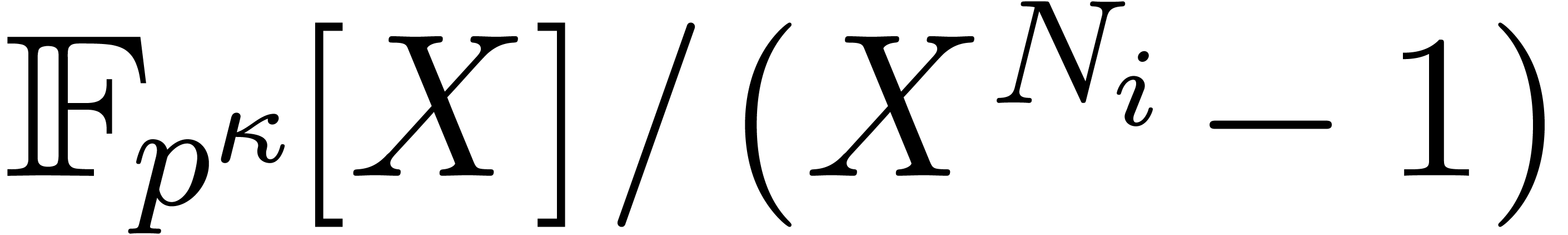 .
.
Bluestein conversion. We now begin constructing , assuming that
independent transforms are sought. We first use Bluestein's algorithm
(section 2.5) to convert each DFT of length to a multiplication in  .
We must check that
.
We must check that 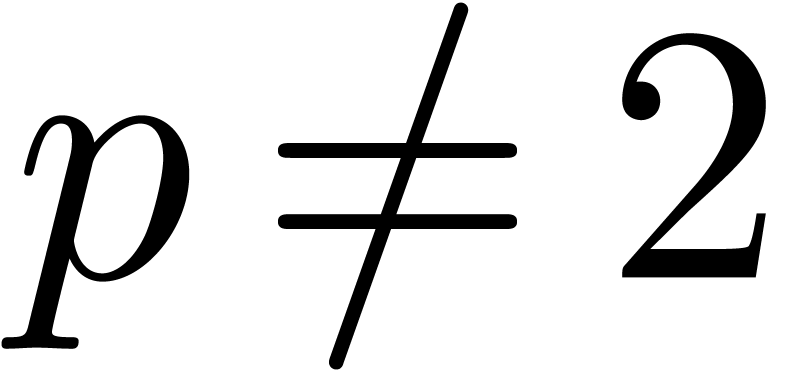 is invertible in if is even; indeed, if is even, then so is ,
so
is invertible in if is even; indeed, if is even, then so is ,
so 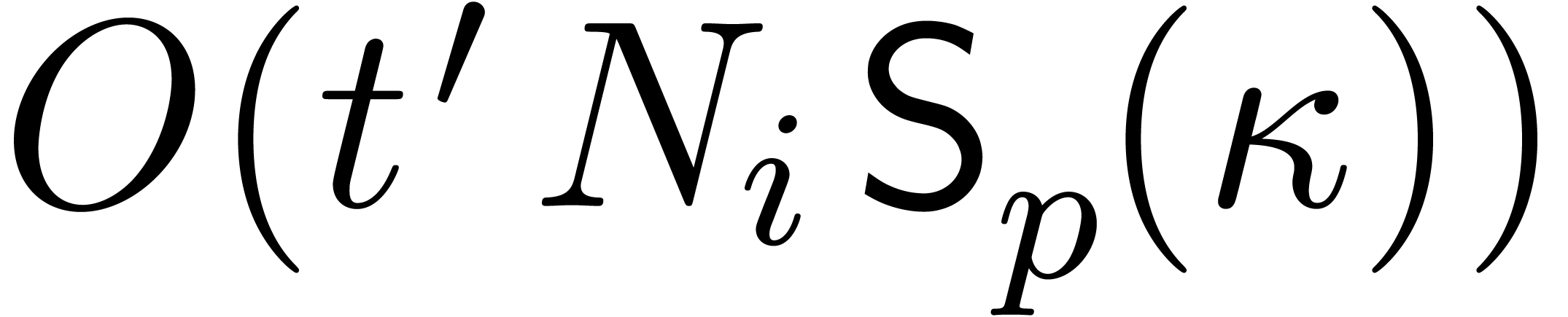 . The Bluestein conversion
contributes
. The Bluestein conversion
contributes 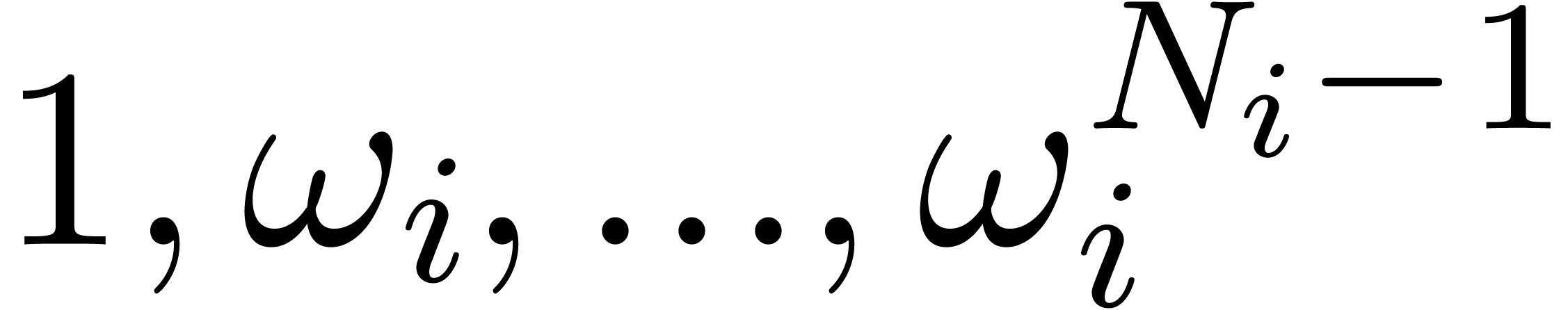 to the cost of .
to the cost of .
We must also compute a suitable table of roots, once at the top level.
We first extract the table 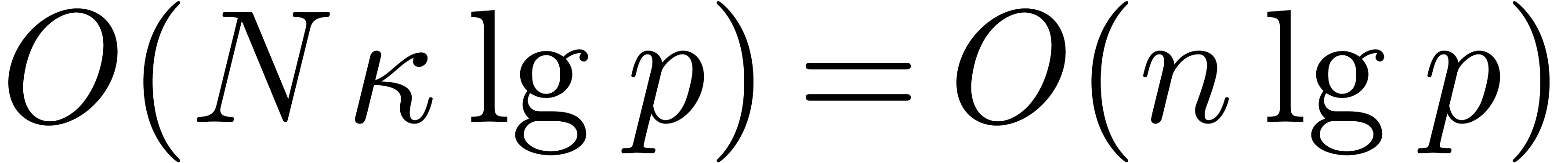 from the top level
table in time
from the top level
table in time  , and then sort
them into the correct order (and perform any necessary additions) in
time
, and then sort
them into the correct order (and perform any necessary additions) in
time 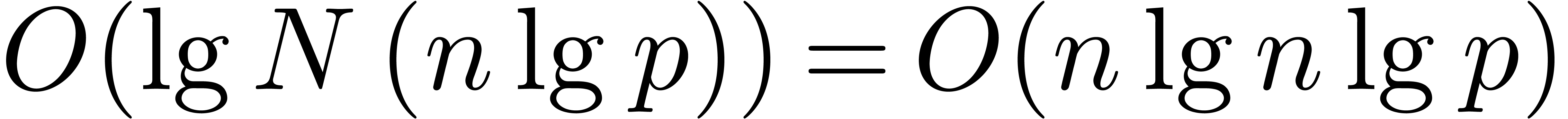 . Over all the cost is
. Over all the cost is 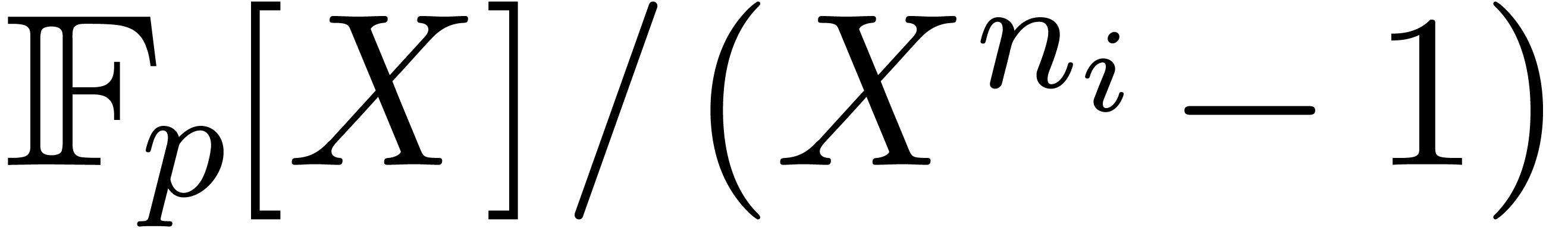 .
.
Kronecker substitution. We finally convert each
multiplication in to a multiplication in 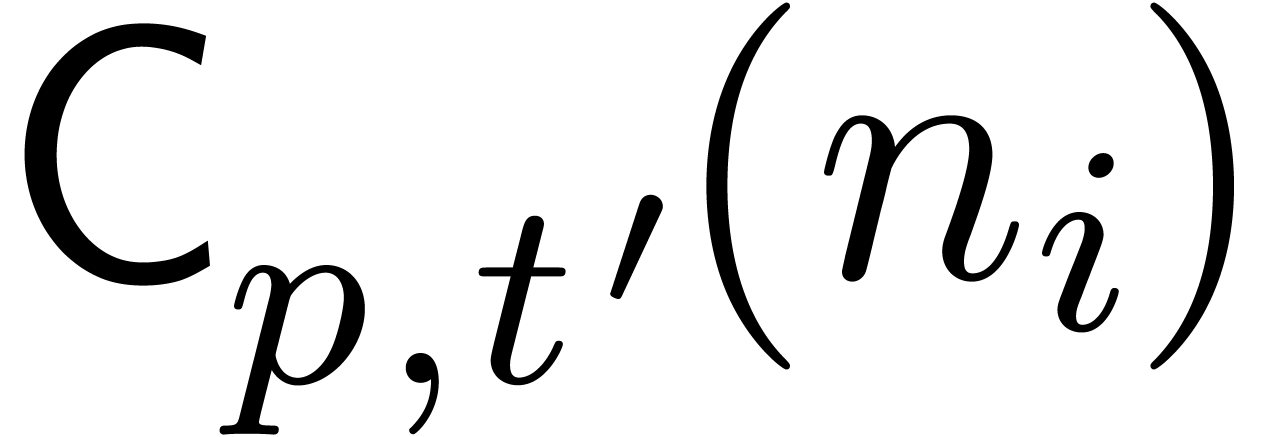 using Kronecker substitution (see section 2.6).
The latter multiplications have cost
using Kronecker substitution (see section 2.6).
The latter multiplications have cost 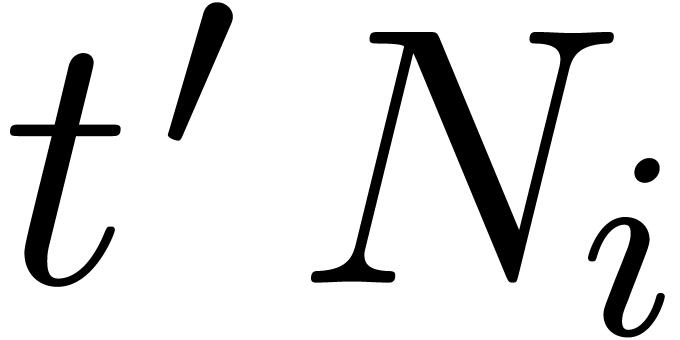 ,
since one argument is fixed. After the multiplications, we must also
perform
,
since one argument is fixed. After the multiplications, we must also
perform 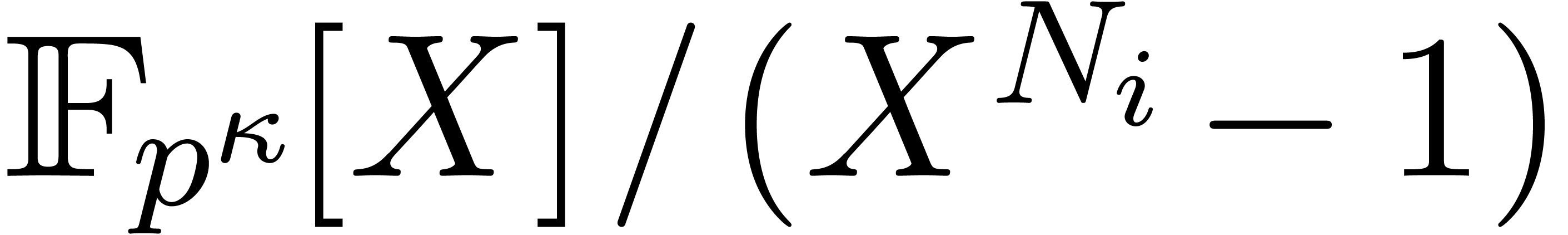 divisions by to
recover the results in
divisions by to
recover the results in 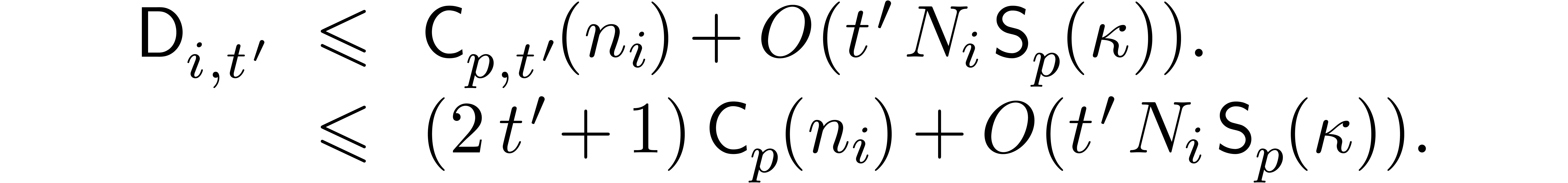 , at
cost . Consolidating the
estimates for the Bluestein conversion and Kronecker substitution, we
have
, at
cost . Consolidating the
estimates for the Bluestein conversion and Kronecker substitution, we
have
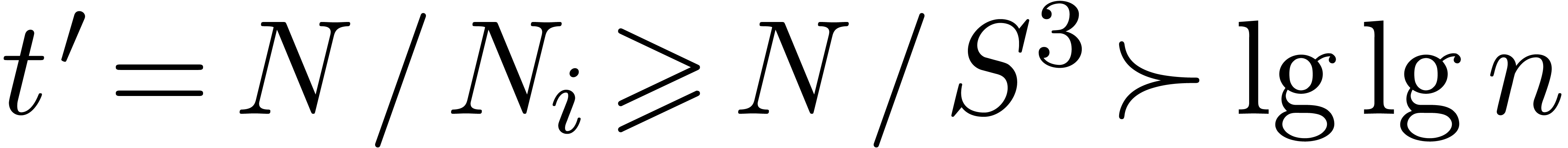
For  , this becomes
, this becomes
Conclusion. Summing over yields
Since
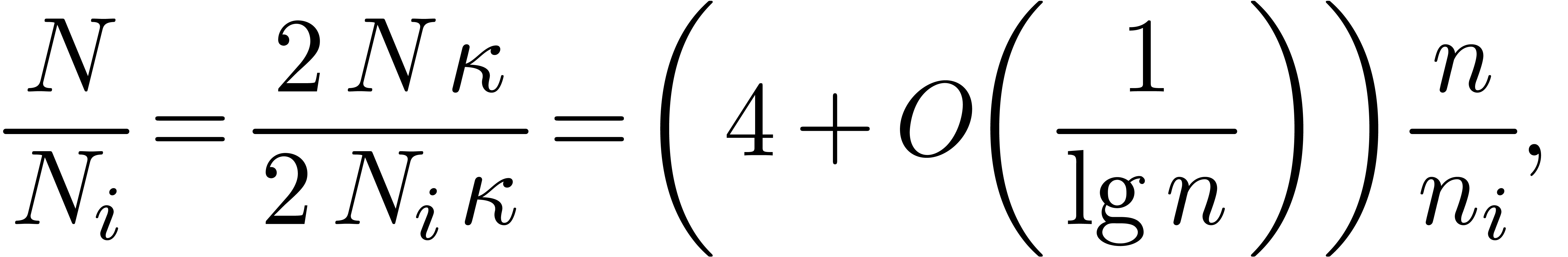
and
this becomes
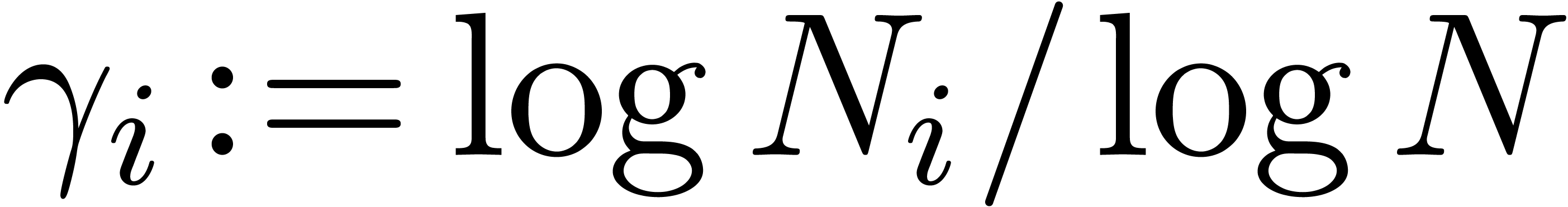
Let  , so that . Since
, so that . Since
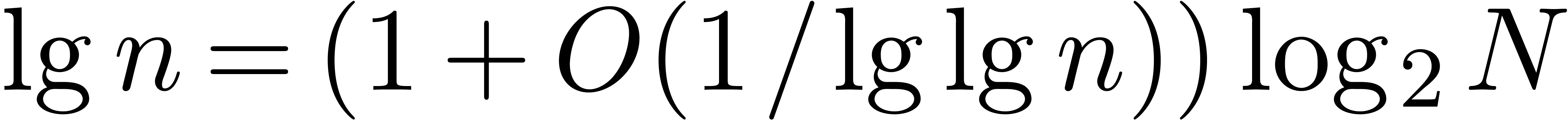
and  , we get
, we get
To compute the desired 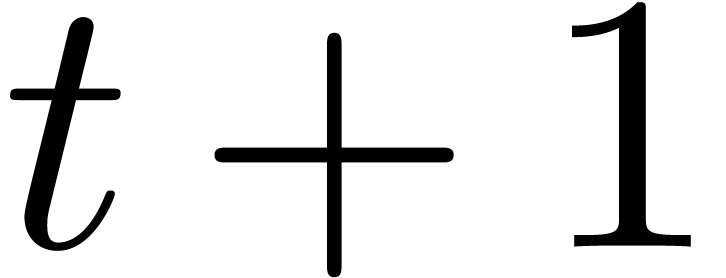 products, we must execute
products, we must execute
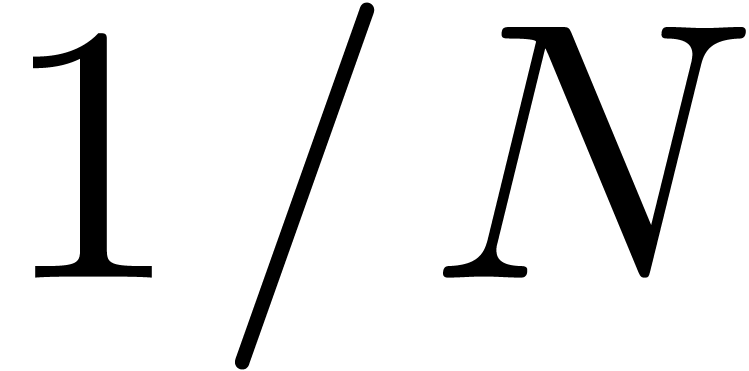 forward transforms, and
inverse transforms. Each product also requires
pointwise multiplications in and multiplications by
forward transforms, and
inverse transforms. Each product also requires
pointwise multiplications in and multiplications by 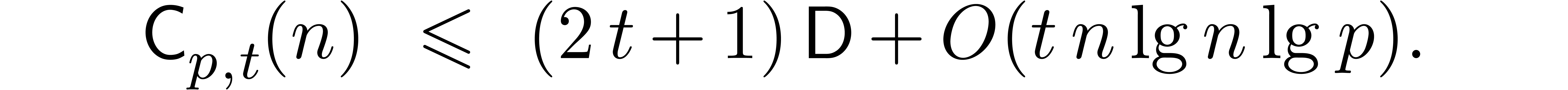 .
These have cost , which is
absorbed by the term. Thus we obtain
.
These have cost , which is
absorbed by the term. Thus we obtain
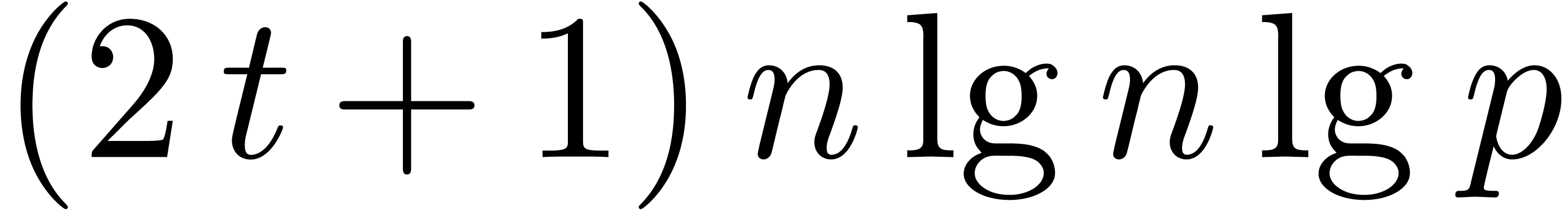
Dividing by  , taking suprema
over , and using
, taking suprema
over , and using
Finally, since
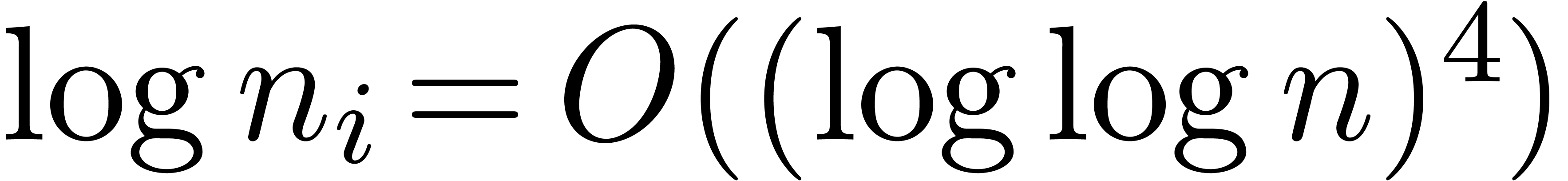
we have 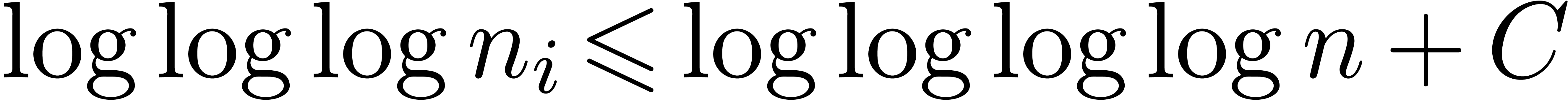 and hence
and hence 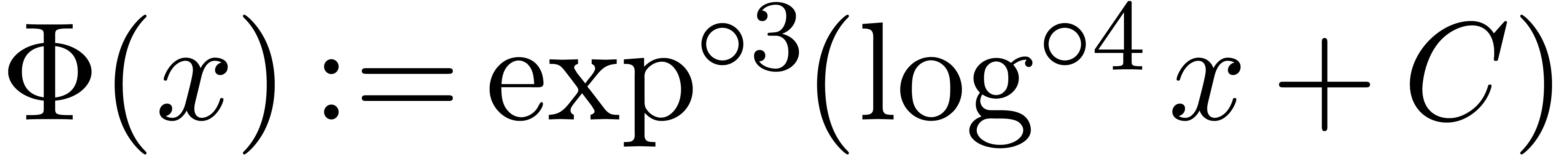 for
some constant and all large . We may then take
for
some constant and all large . We may then take  .
.
Now we may prove the main theorem announced in the introduction.
Proof of Theorem 1.1. For define
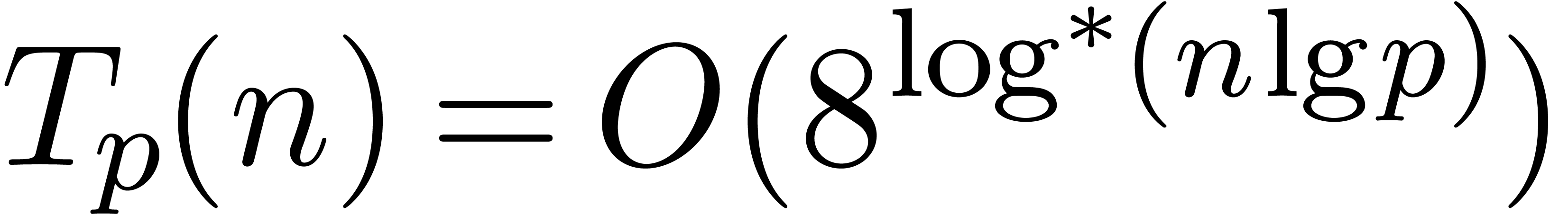
It suffices to prove that 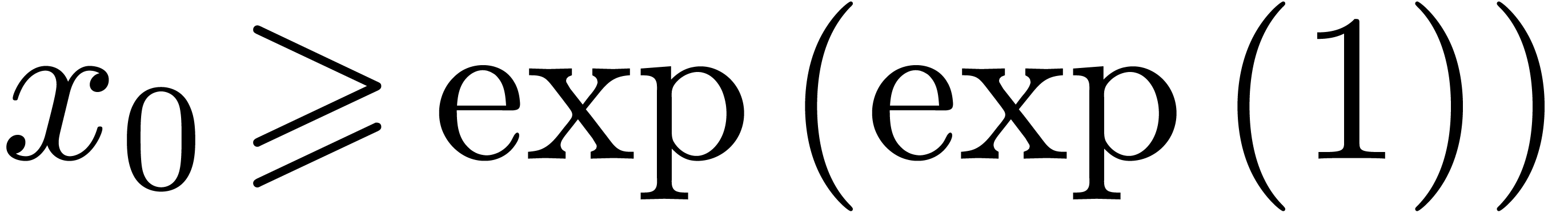 ,
uniformly in and .
,
uniformly in and .
Let and be as in Theorem
7.1. Increasing if necessary, we
may assume that for , and that 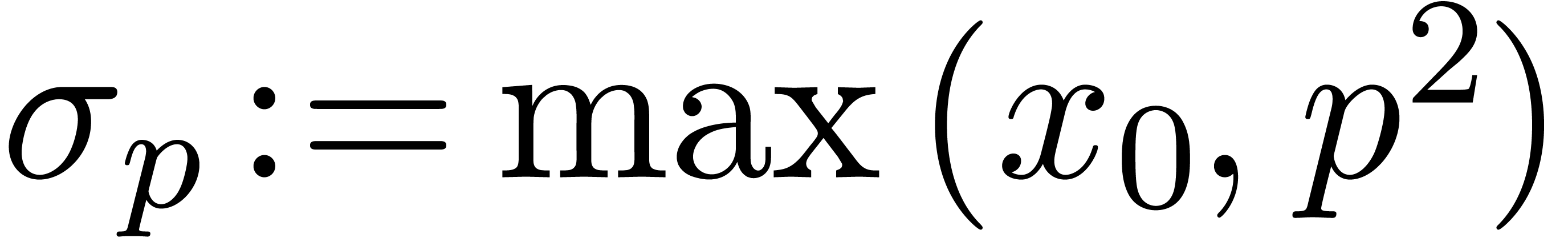 .
.
Let 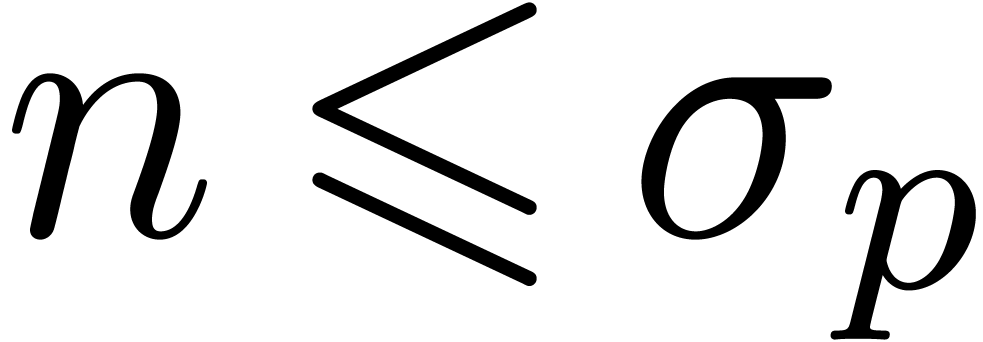 for each .
We will consider the regions
for each .
We will consider the regions 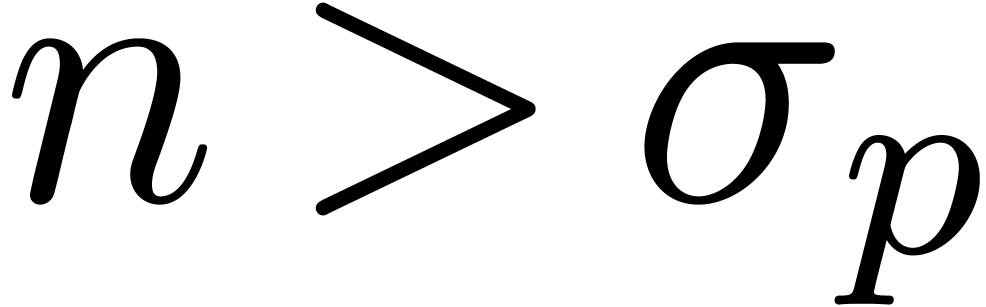 and
and 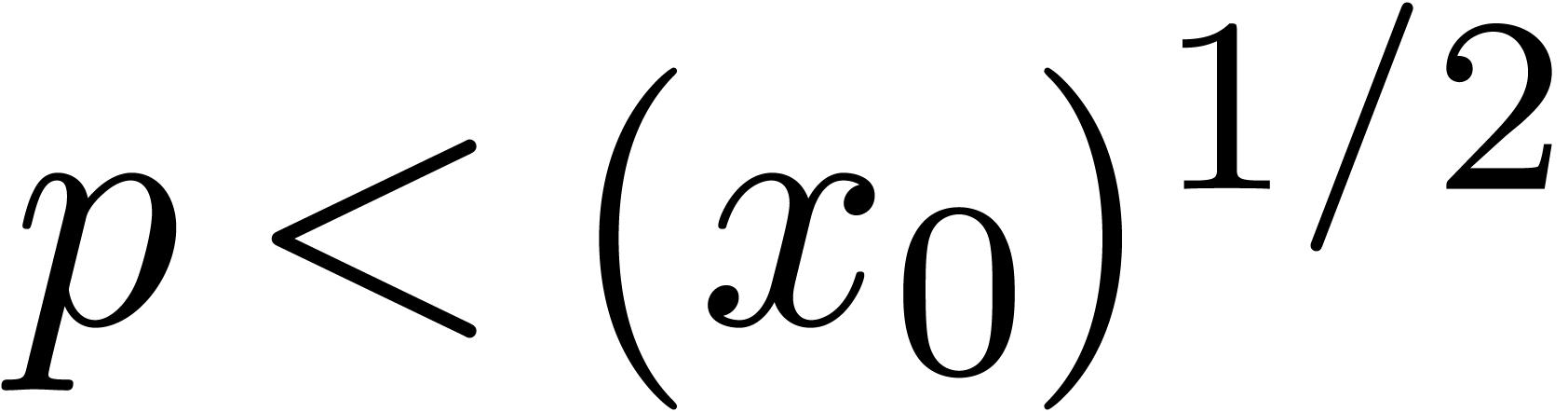 separately. First consider the case . There are only finitely many primes
separately. First consider the case . There are only finitely many primes 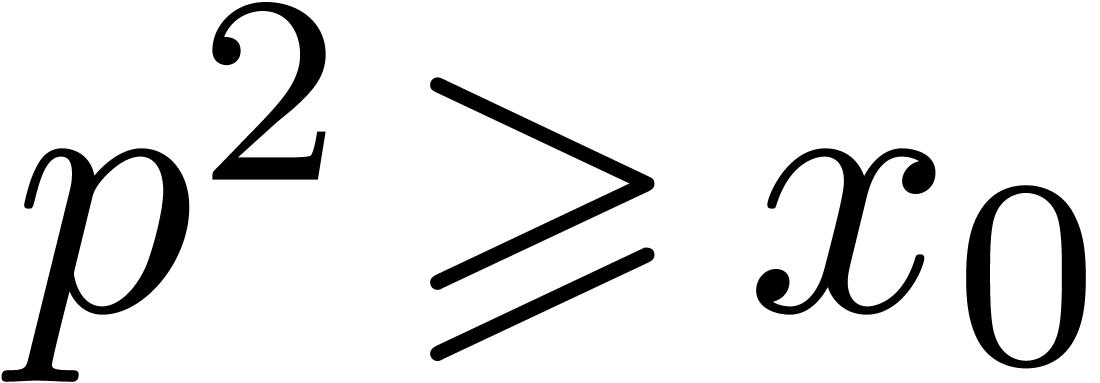 , so we may assume that
, so we may assume that 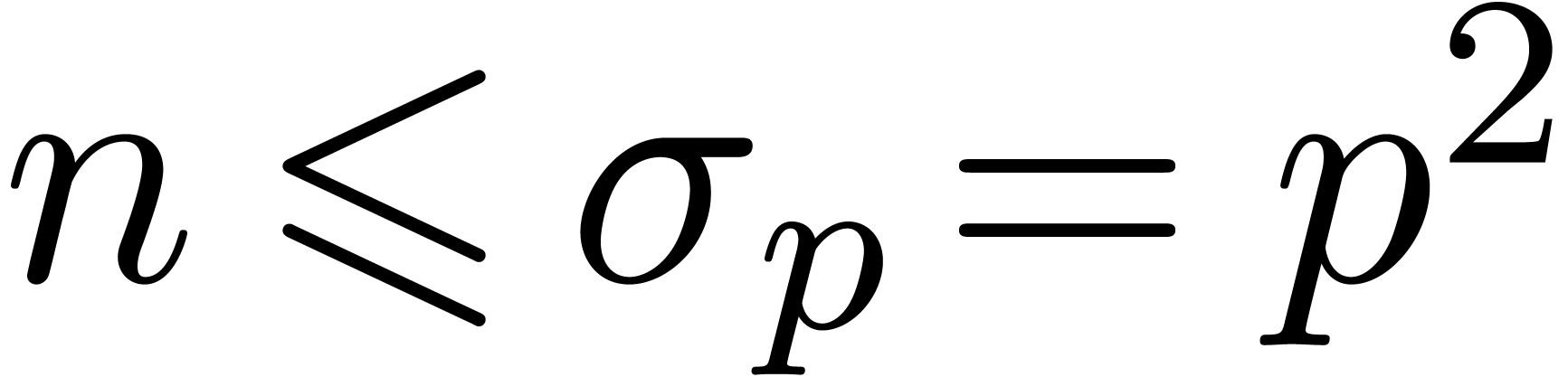 and that
and that  . In this region we
use Kronecker substitution: by
. In this region we
use Kronecker substitution: by
and since
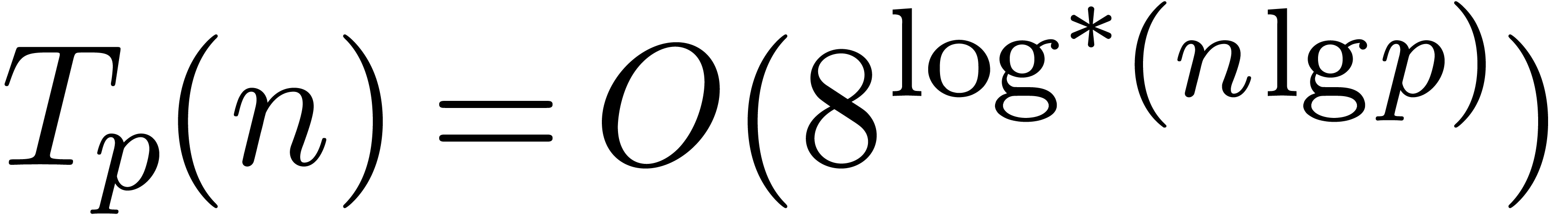
we get 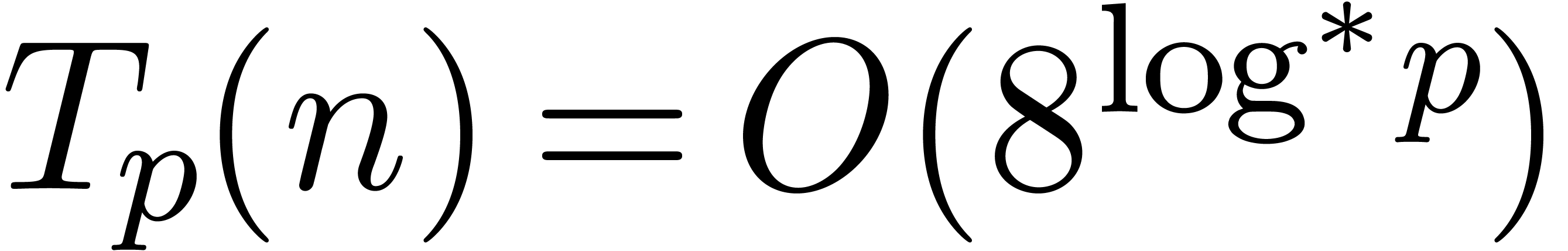 uniformly for . In fact, this even shows that
uniformly for . In fact, this even shows that 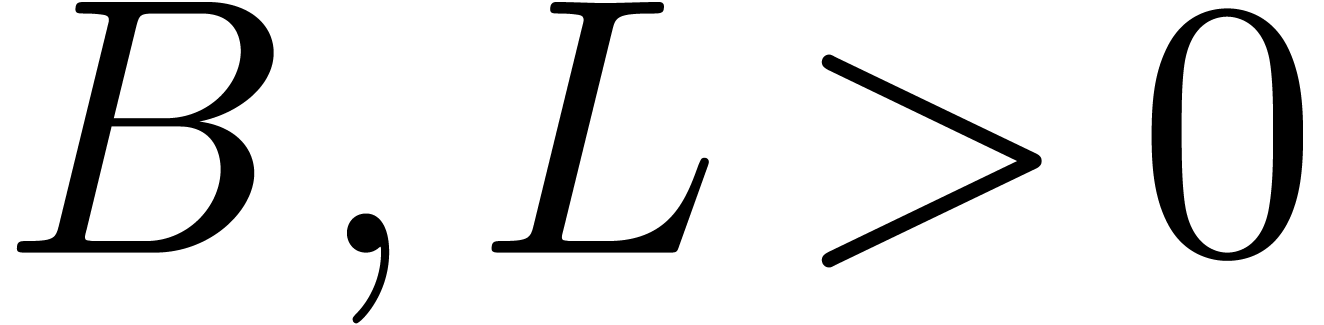 uniformly for .
uniformly for .
Now consider the case . Here
we invoke Theorem 7.1 to obtain absolute constants  such that for every ,
there exist and
such that for every ,
there exist and  such
that
such
that
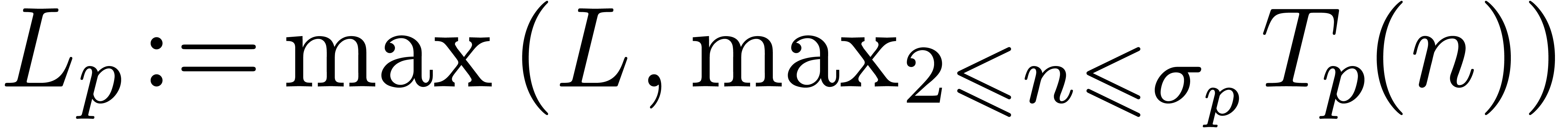
Set 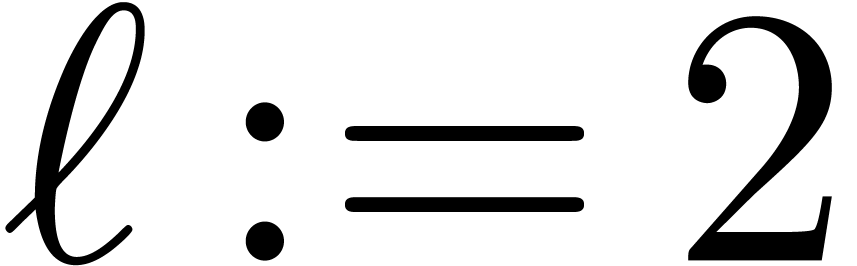 . Applying Proposition 5.3 with
. Applying Proposition 5.3 with 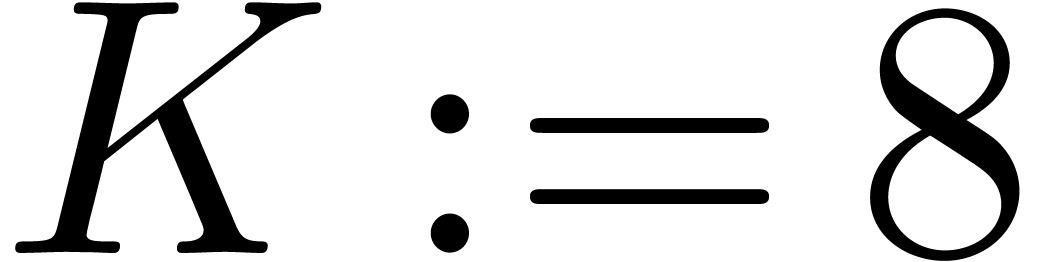 ,
, 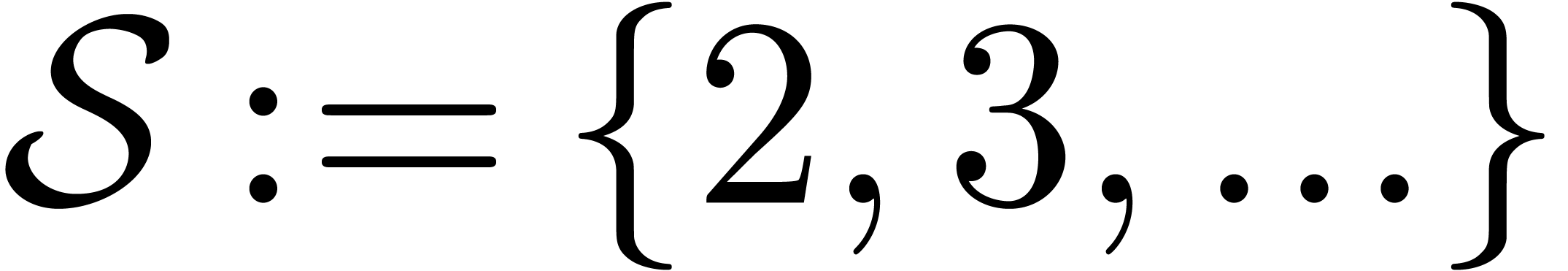 ,
, 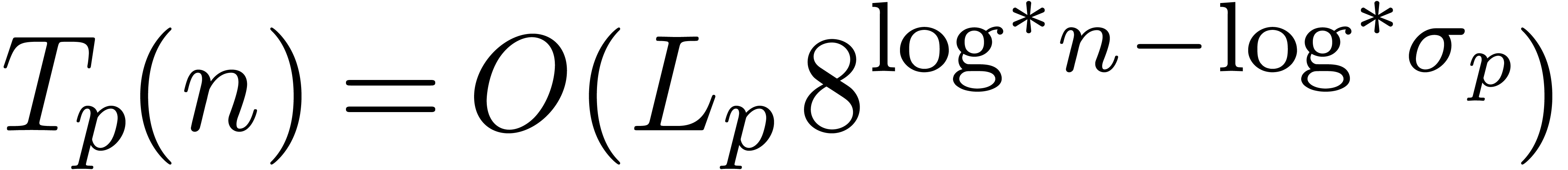 ,
we find that
,
we find that 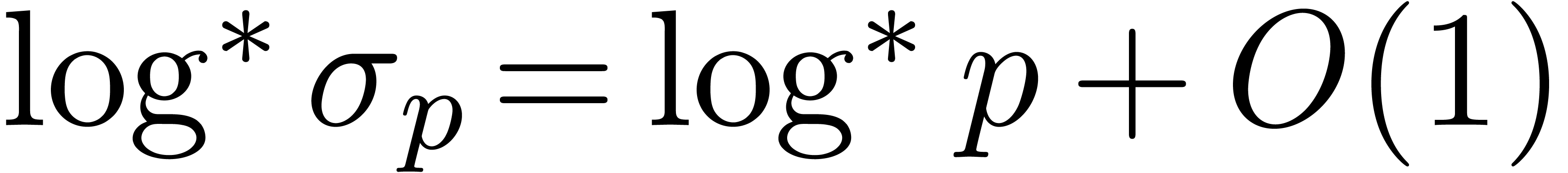 uniformly for . Since
uniformly for . Since 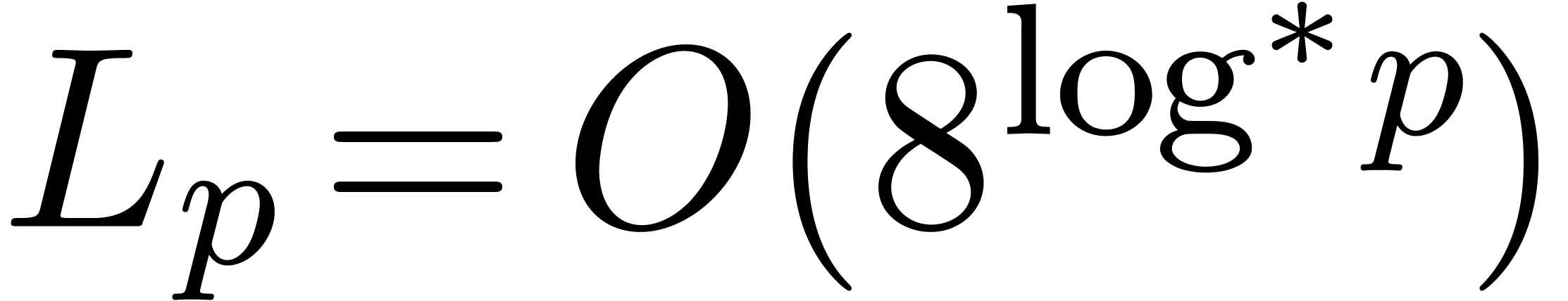 and
and 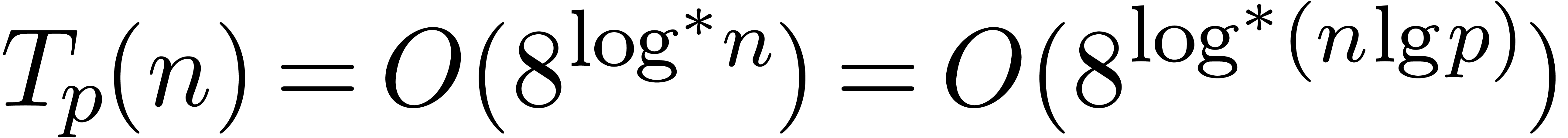 , we conclude that
, we conclude that 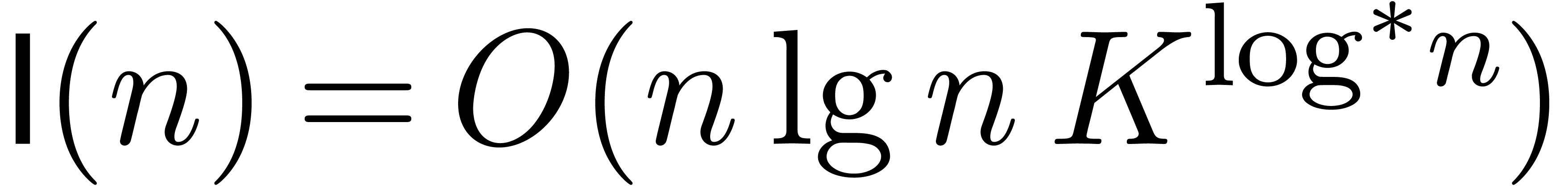 uniformly for .
uniformly for .
Recall that in [18] we established the bound 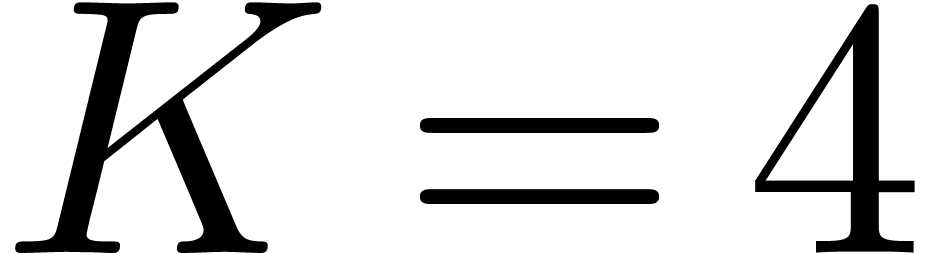 with for the complexity of integer
multiplication. We also proved that this can be improved to
with for the complexity of integer
multiplication. We also proved that this can be improved to 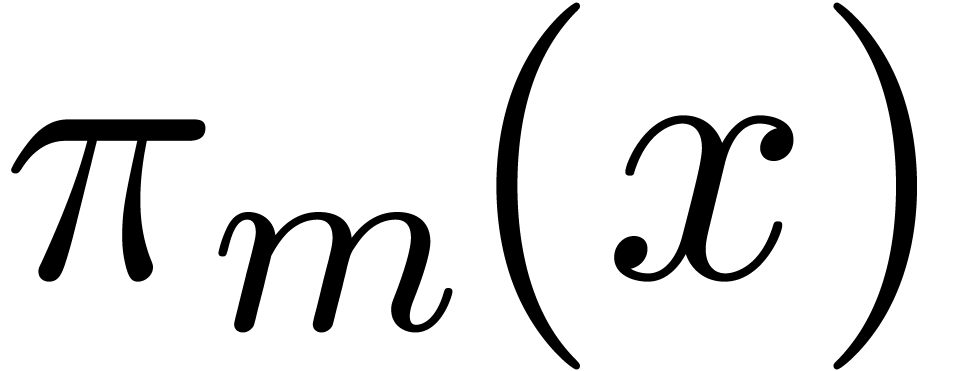 , assuming the following slight weakening of
the Lenstra–Pomerance–Wagstaff conjecture on the
distribution of Mersenne primes [28, 35] (see
[18, Section 9] for further discussion).
, assuming the following slight weakening of
the Lenstra–Pomerance–Wagstaff conjecture on the
distribution of Mersenne primes [28, 35] (see
[18, Section 9] for further discussion).
 be the number of
Mersenne primes less than
be the number of
Mersenne primes less than  .
Then there exist constants
.
Then there exist constants 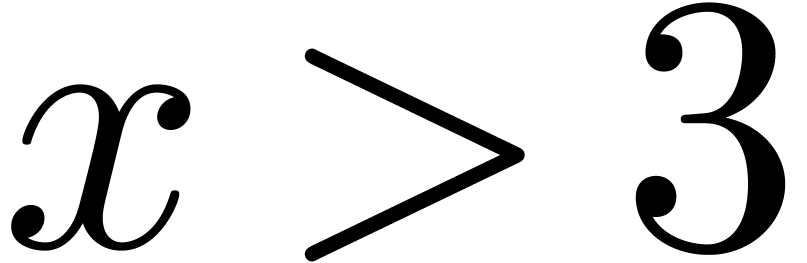 such that for all
such that for all
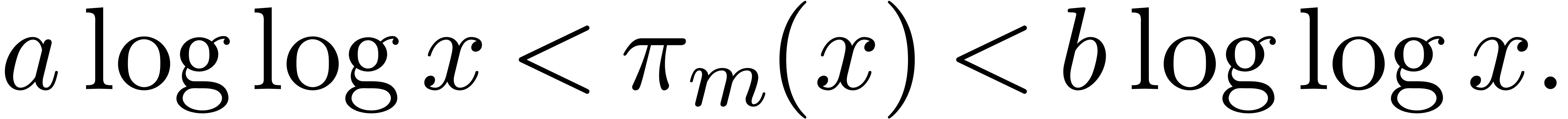 ,
,
The source of the (conjectural) speedup is as follows. The algorithm of [18, Section 6] computes DFTs
over , and so we encounter
the “short product obstruction”. Namely, to compute the
product of two real numbers with significant
bits using FFT algorithms, we are forced to compute a full product of
two -bit integers, and then
truncate the result to bits. To achieve , we replaced the coefficient ring
by the finite field 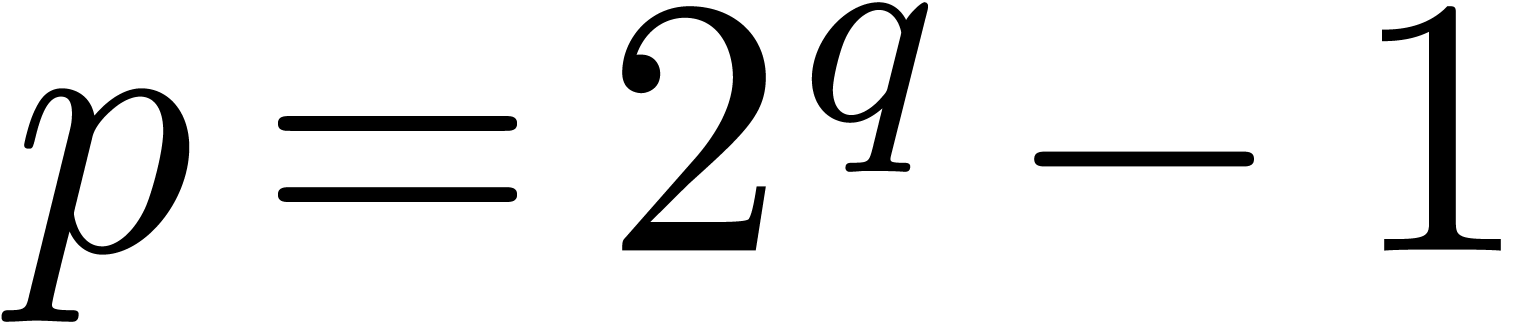 , where
, where 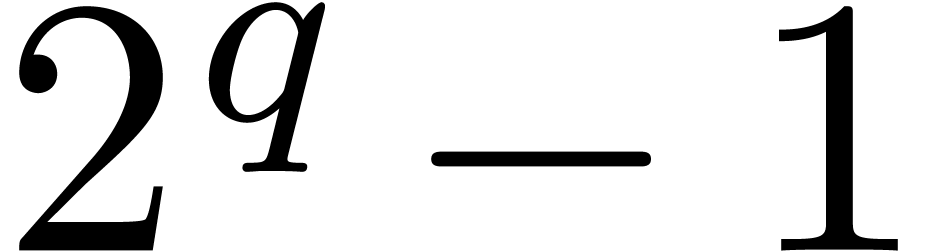 is a Mersenne prime.
Multiplication modulo
is a Mersenne prime.
Multiplication modulo 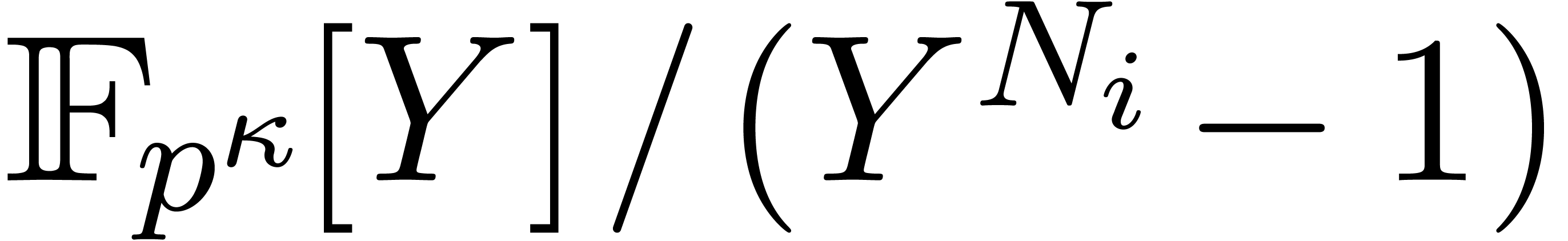 is a “cyclic
product” rather than a short product, and this saves a factor of
two at each recursion level.
is a “cyclic
product” rather than a short product, and this saves a factor of
two at each recursion level.
The aim of this section is to outline a credible strategy for achieving
the same improvement, from to , in the context of multiplication in , at least under certain plausible
number-theoretic hypotheses.
Consider the problem of multiplying polynomials in
of degree less than . In the
Kronecker substitution region, i.e., for ,
we can of course achieve if we assume Conjecture
8.1.
Now consider the region where is much larger
than . In the algorithm of
section 7, we reduced the multiplication problem to
computing products in 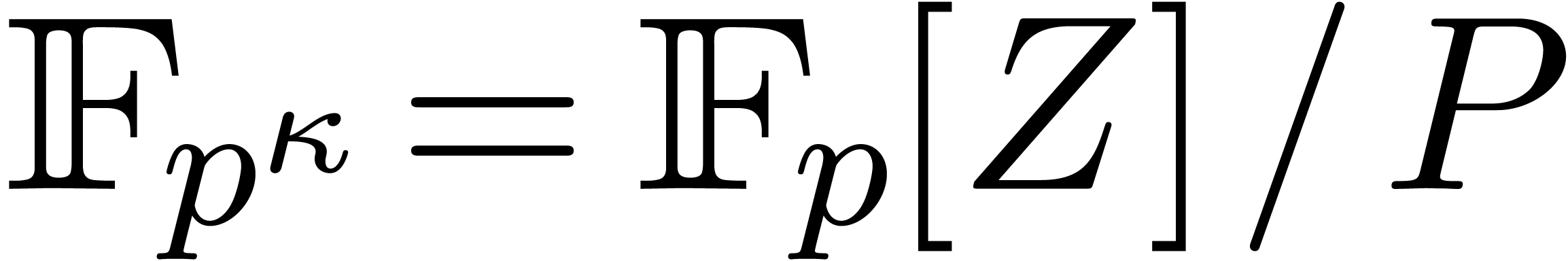 , where
, where
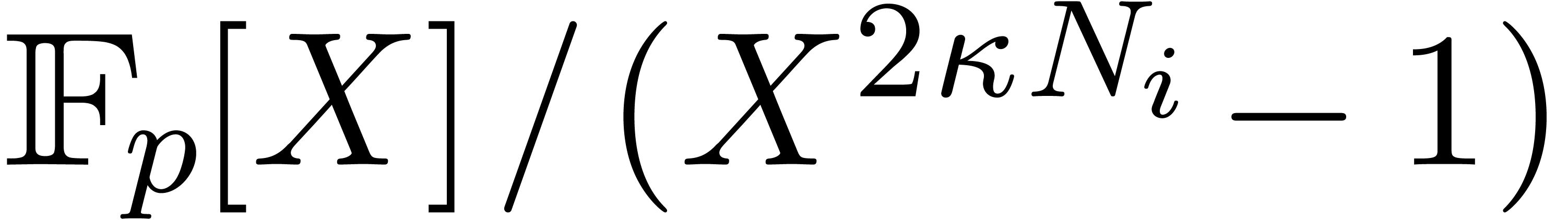 for some monic irreducible
of degree , and where is a “short” transform length. These
multiplications were in turn converted to multiplications in
for some monic irreducible
of degree , and where is a “short” transform length. These
multiplications were in turn converted to multiplications in 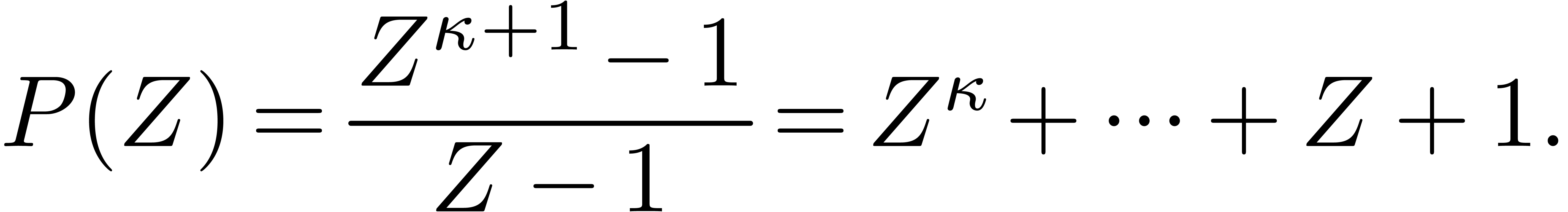 via Kronecker substitution. It is exactly this factor of
two in zero-padding that we wish to avoid.
via Kronecker substitution. It is exactly this factor of
two in zero-padding that we wish to avoid.
Taking our cue from the integer case, we observe that if the modulus
is of a particularly special form, then this
factor of two can be eliminated. Indeed, suppose that
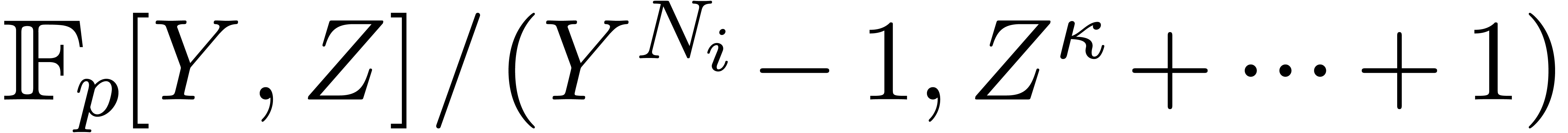
Then is isomorphic to 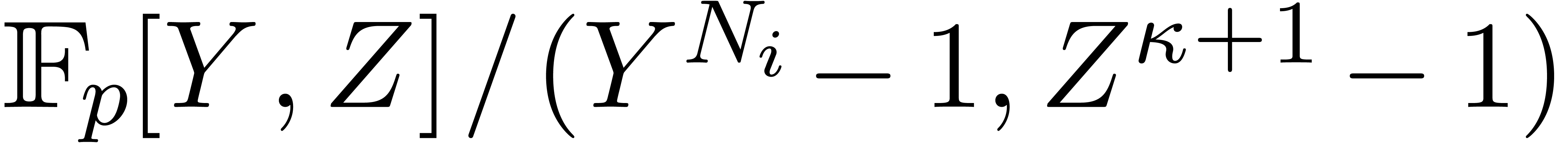 , which is a quotient of
, which is a quotient of 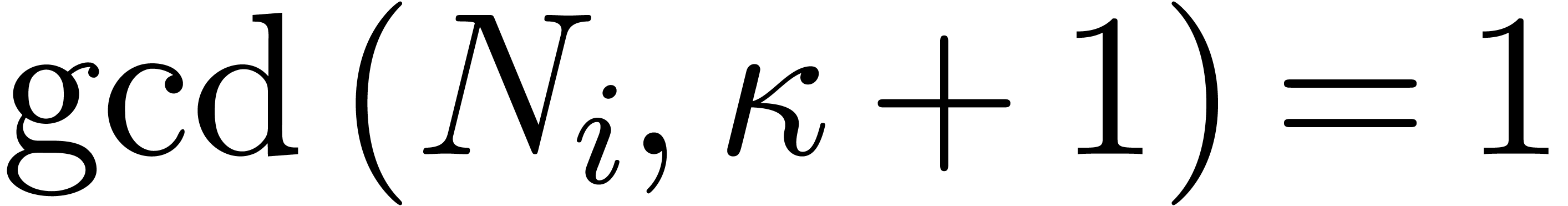 . Assuming further that
. Assuming further that 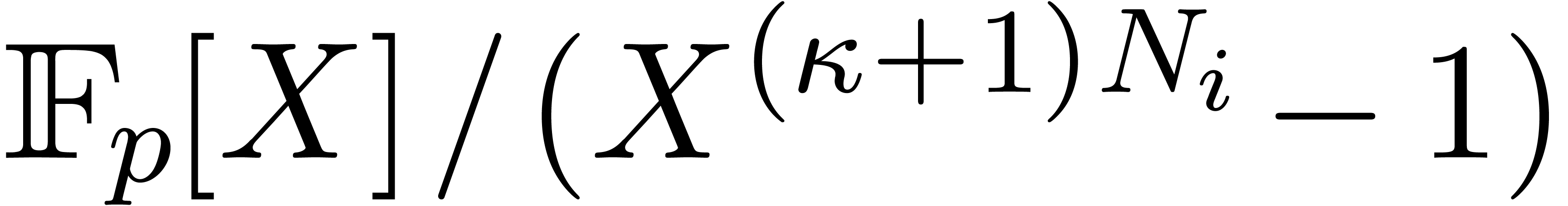 , the latter ring is isomorphic to
, the latter ring is isomorphic to 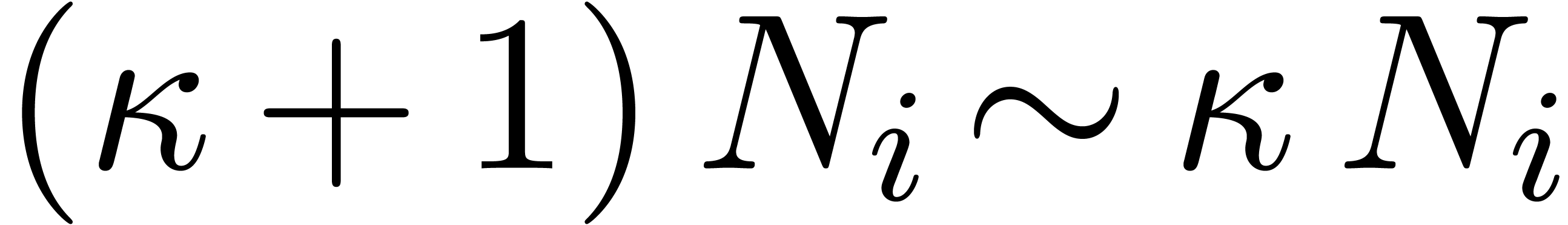 . In other words, we can reduce a cyclic
convolution over of length
to a cyclic convolution over of length
. In other words, we can reduce a cyclic
convolution over of length
to a cyclic convolution over of length 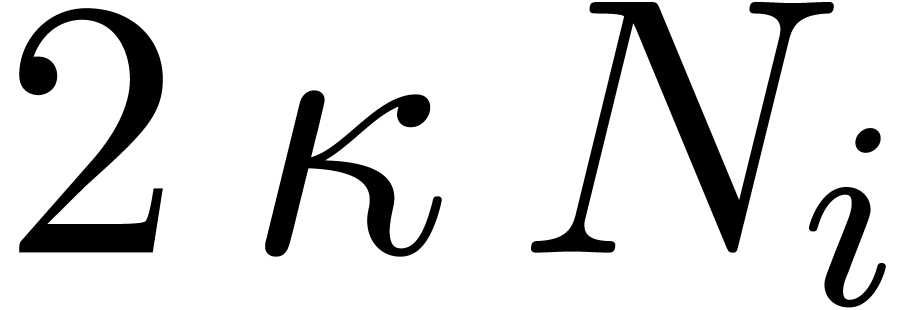 , rather than length
, rather than length  . This saves a factor of two at this recursion
level; if we can manage something similar at every recursion level, we
reduce from
. This saves a factor of two at this recursion
level; if we can manage something similar at every recursion level, we
reduce from  to
to 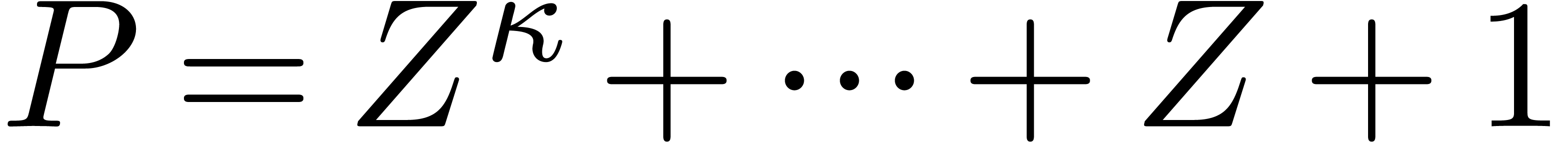 .
.
The essential question is therefore how to choose
so that 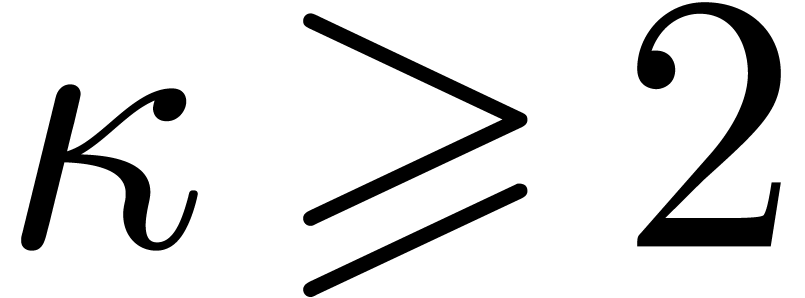 is irreducible over . The following lemma gives a simple
number-theoretic characterisation of such .
is irreducible over . The following lemma gives a simple
number-theoretic characterisation of such .
 . The
polynomial is irreducible over if and only if
. The
polynomial is irreducible over if and only if 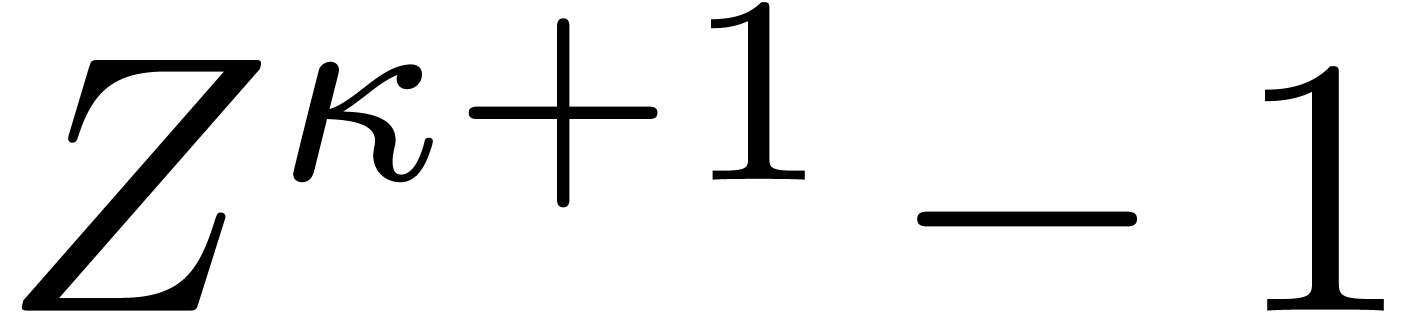 is prime and is a primitive root modulo .
is prime and is a primitive root modulo .
Proof. If is a
nontrivial factor of , then
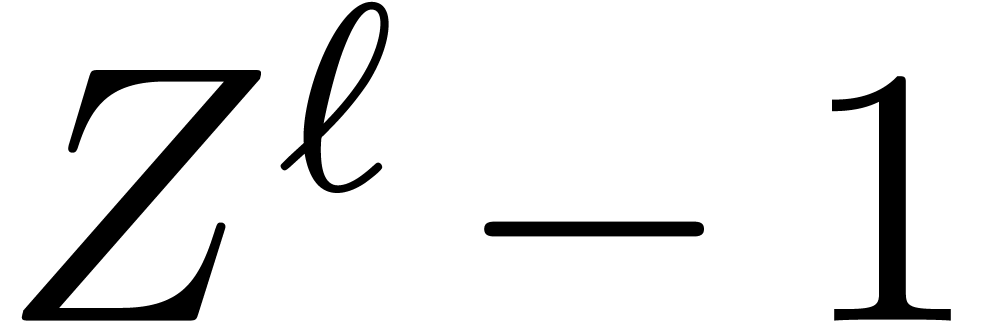 is divisible by
is divisible by  ,
so has the nontrivial factor
,
so has the nontrivial factor 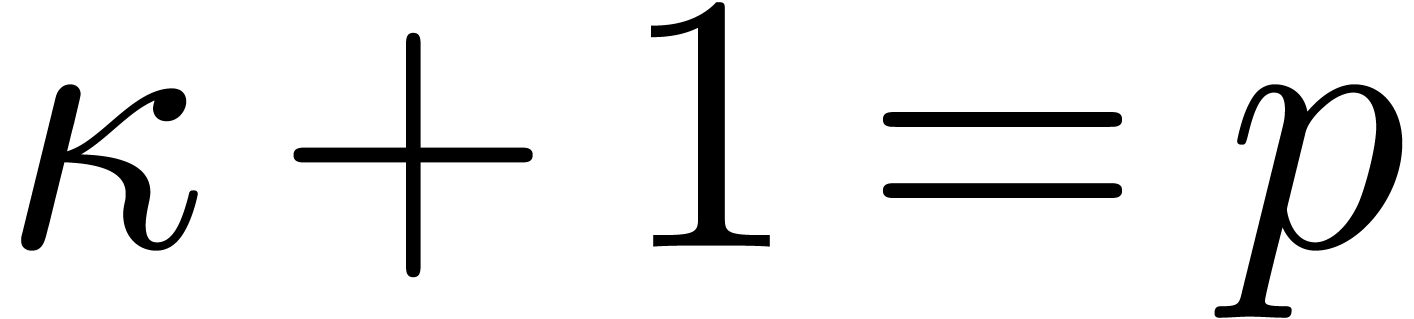 . On the other hand, suppose that is prime. If
. On the other hand, suppose that is prime. If 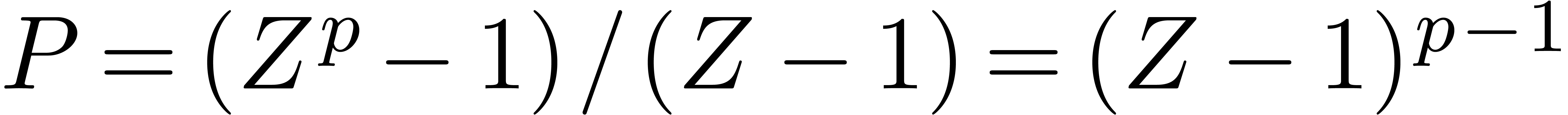 ,
then
,
then  is not irreducible; otherwise, the number
of irreducible factors of over
is exactly
is not irreducible; otherwise, the number
of irreducible factors of over
is exactly  , where
, where 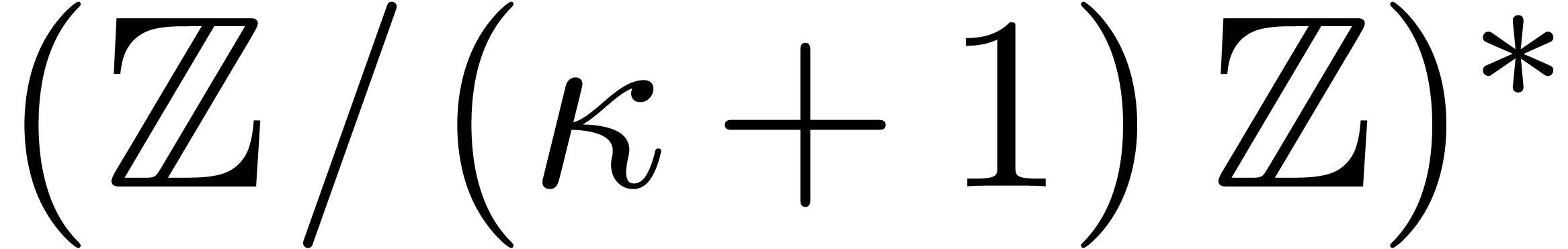 is the order of in
is the order of in 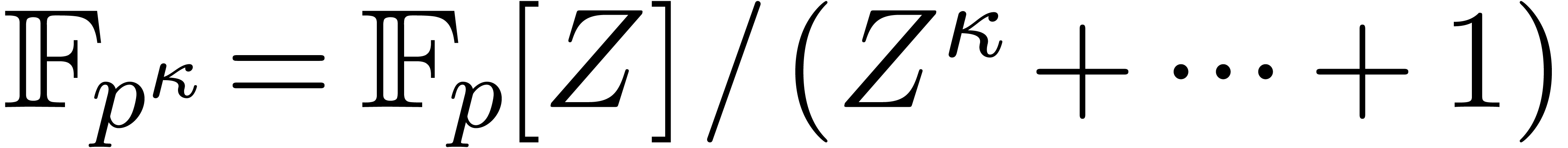 [36, Theorem 2.13 and Proposition 2.14] (this
last statement is sometimes called the “cyclotomic reciprocity
law”).
[36, Theorem 2.13 and Proposition 2.14] (this
last statement is sometimes called the “cyclotomic reciprocity
law”).
A first attempt to reach might run as follows.
First choose as in the proof of Theorem 7.1,
so that has many roots of unity of smooth order.
Then use the same multiplication algorithm as before, but now working
over 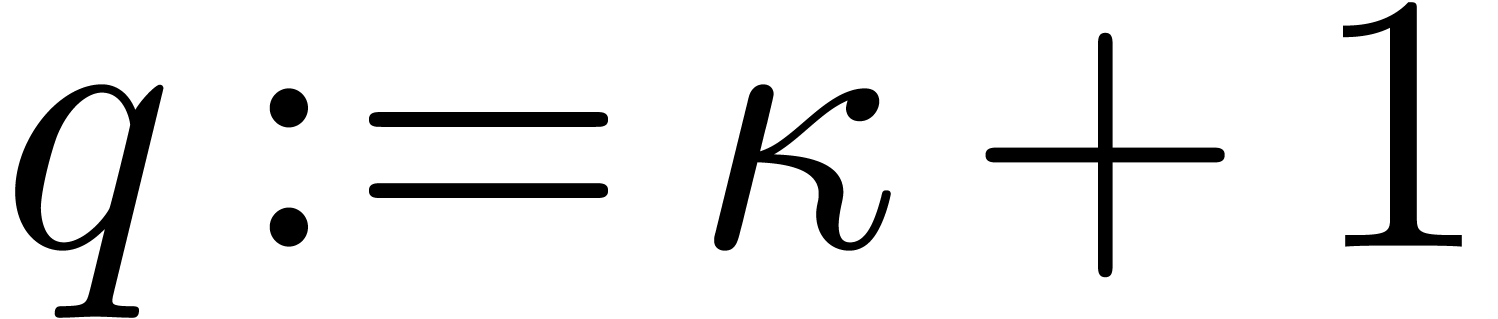 , where
is the smallest positive multiple of such that
, where
is the smallest positive multiple of such that
 is prime and such that
is a primitive root modulo .
is prime and such that
is a primitive root modulo .
Unfortunately this plan does not quite work, for reasons that we now explain.
First, if  , there may be a
trivial obstruction to the existence of suitable . For example, if
, there may be a
trivial obstruction to the existence of suitable . For example, if  and
and 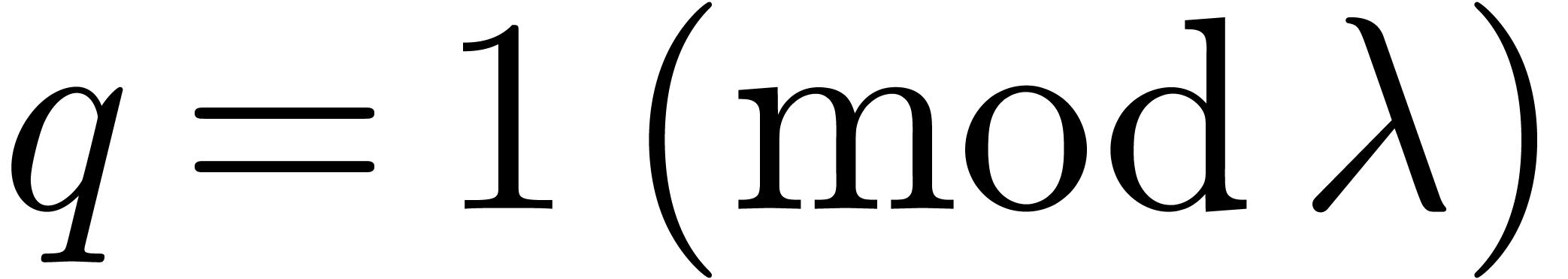 , then for any
, then for any 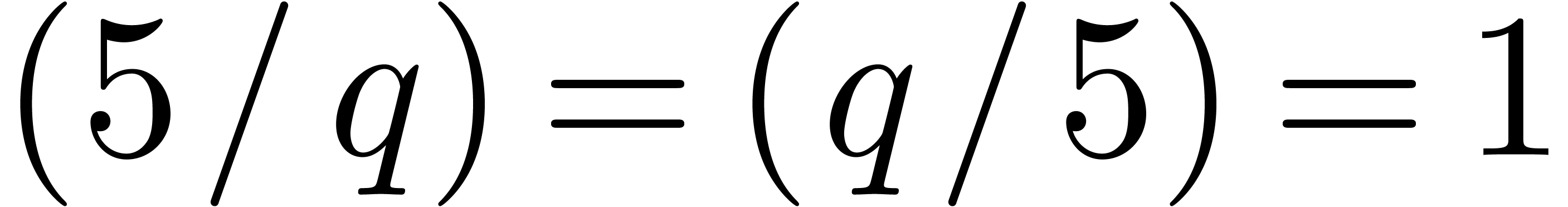 we have
we have  by quadratic reciprocity, so
by quadratic reciprocity, so  cannot be a primitive root modulo . The only way to avoid this seems to be to insist
that not be divisible by
in the first place. Therefore we propose the following strengthening of
Lemma 4.2.
cannot be a primitive root modulo . The only way to avoid this seems to be to insist
that not be divisible by
in the first place. Therefore we propose the following strengthening of
Lemma 4.2.
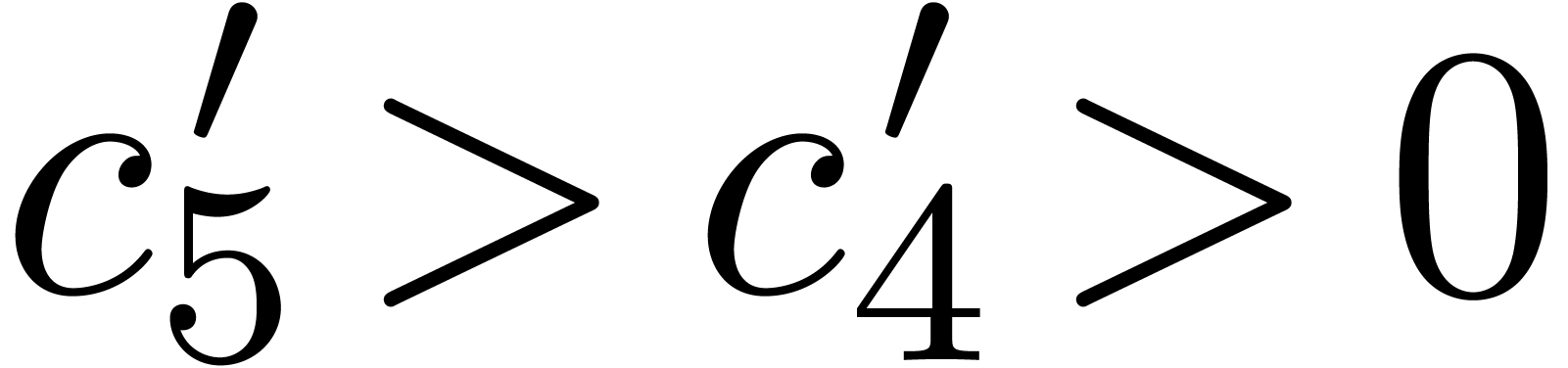
There exist computable absolute constants 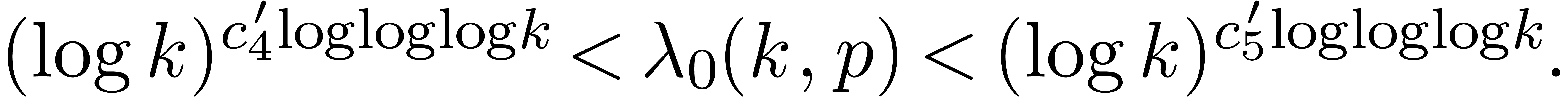 such that for any integer
such that for any integer 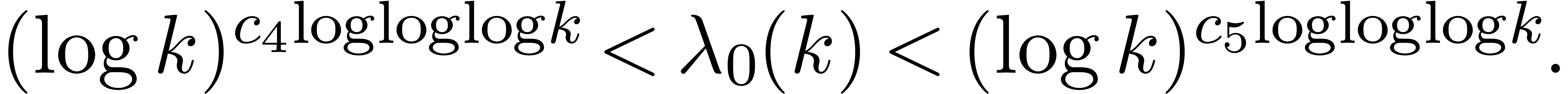 and any prime we have
and any prime we have
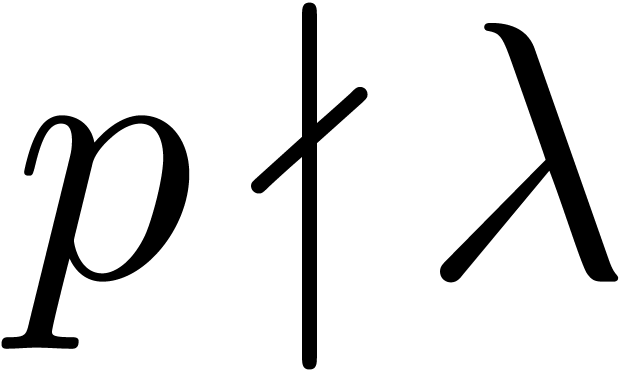
It seems likely that this conjecture should be accessible to specialists
in analytic number theory. Experimentally, the “missing”
factor does not seem to have much effect on the
propensity of to have many divisors such that is prime. We could not
find a quick way to prove the conjecture directly from Lemma 4.2.
The second problem is more serious. A special case of Artin's
conjecture on primitive roots (see [25] for a survey)
asserts that for any prime ,
there are infinitely many primes for which is a primitive root modulo . Unfortunately, there is not even a single prime
for which Artin's conjecture is known to hold!
Therefore, in general we cannot prove existence of a suitable .
However, we do have the following result of Lenstra, which states that
the only obstruction to the existence of is the
trivial one noted above, provided we are willing to accept GRH.
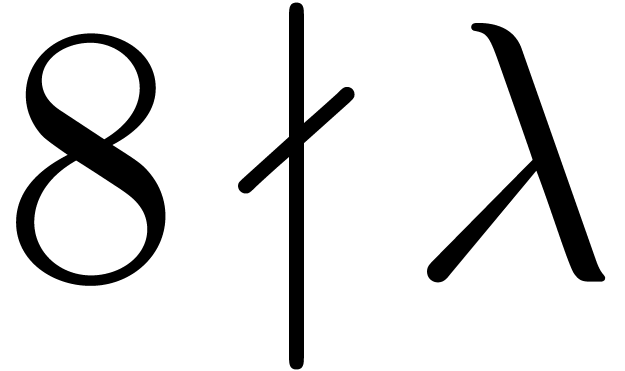 if is odd, or that
if is odd, or that 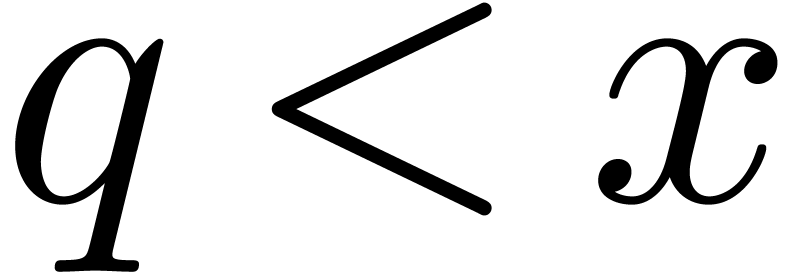 if . Then there exist infinitely many primes
such that is a
primitive root modulo .
if . Then there exist infinitely many primes
such that is a
primitive root modulo .
Proof. This is a special case of [23,
Theorem 8.3]. (For a description of exactly which number fields are
supposed to satisfy GRH for this result to hold, see [23,
Theorem 3.1].)
The third problem is that existence of is not
enough; we also need a bound on its size, as a function of and . The
literature provides little guidance on this question. Under the
hypotheses of Lemma 8.4 (including GRH), it is known that
the number of primes 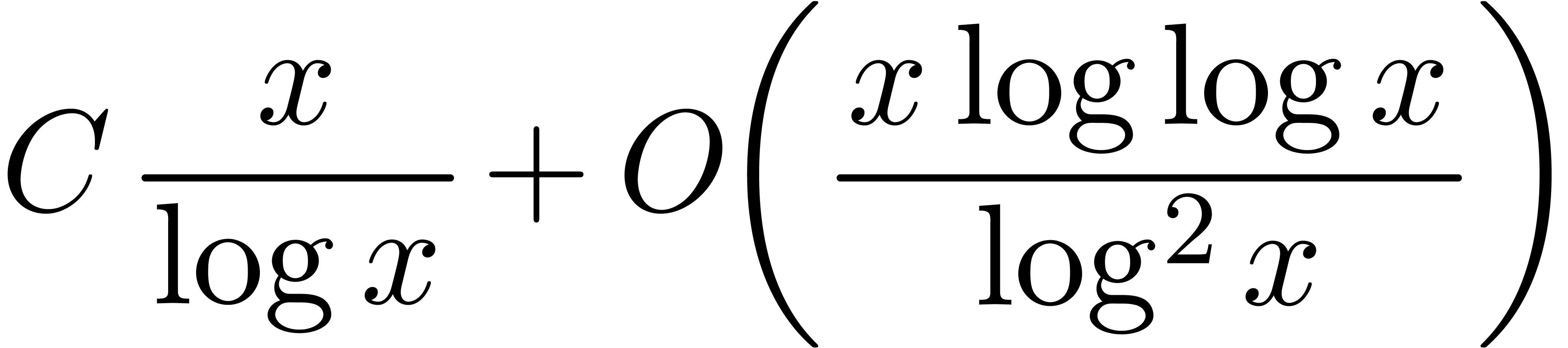 such that
and for which is a primitive root modulo grows as
such that
and for which is a primitive root modulo grows as
 |
(8.1) |
for some positive  (see for example [24,
Theorem 2]). Both and the implied big-
(see for example [24,
Theorem 2]). Both and the implied big-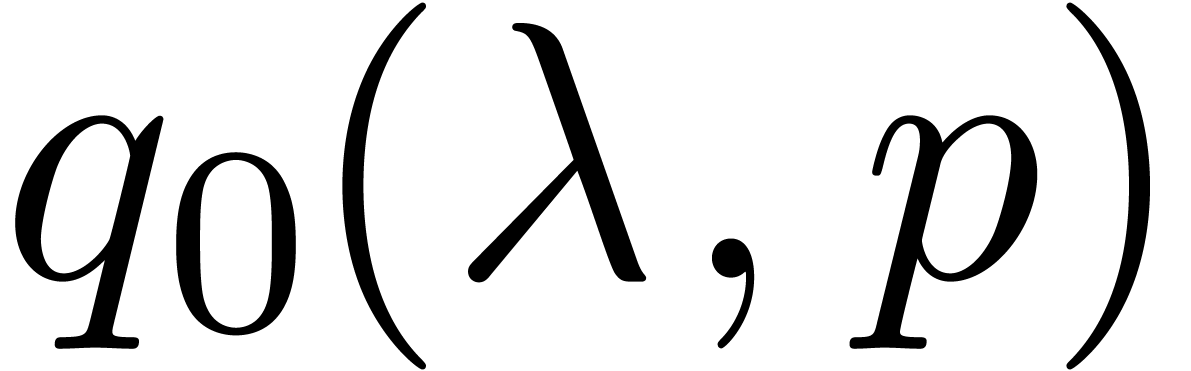 constant depend on and . While the value of is reasonably well understood, we could not find in the
literature a similarly precise description of the implied constant, so
we have been unable to derive a bound for .
constant depend on and . While the value of is reasonably well understood, we could not find in the
literature a similarly precise description of the implied constant, so
we have been unable to derive a bound for .
In the interests of getting our conjectural algorithm off the ground, we
make the following guess. Define  to be the
smallest prime such that
and such that is a primitive root modulo (assuming that such exists).
to be the
smallest prime such that
and such that is a primitive root modulo (assuming that such exists).
 and a logarithmically slow function
and a logarithmically slow function  with the
following property. Suppose that if is odd, or that if , and suppose that
with the
following property. Suppose that if is odd, or that if , and suppose that 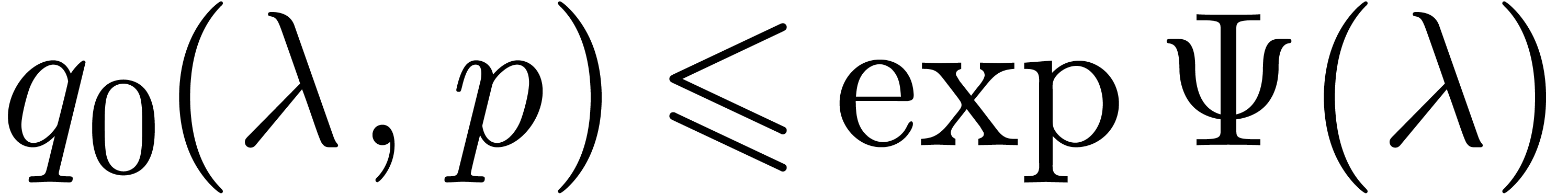 . Then
. Then 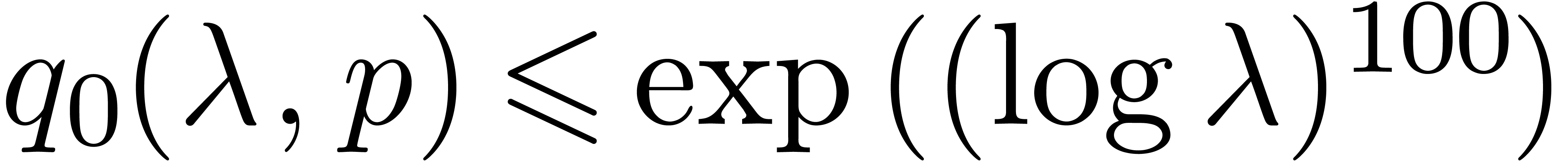 .
.
We have deliberately given an absurdly weak formulation of this
conjecture, so as to provide the largest possible target for analytic
number theorists. For example, it would be enough to prove that 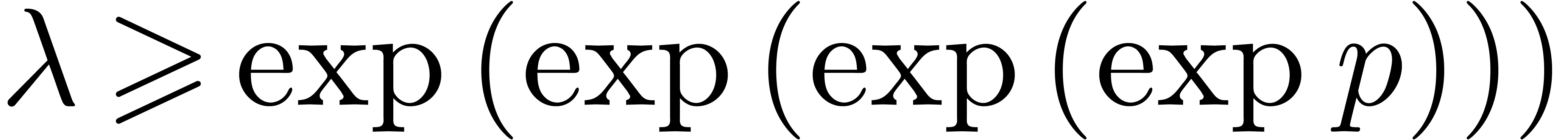 for all
for all 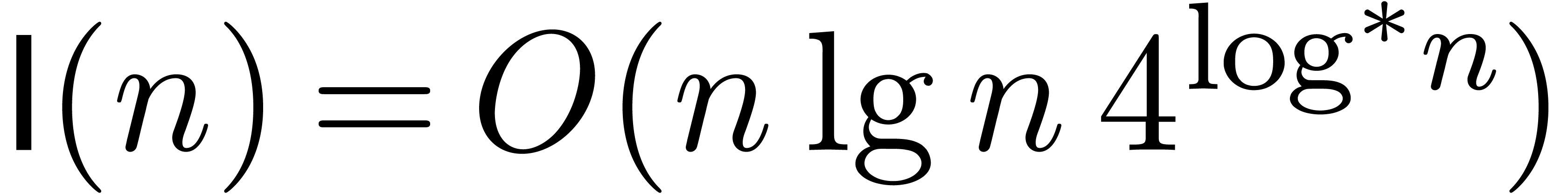 .
We suspect that the conjecture is accessible under GRH; presumably a
proof would require analysing the implied constant in
.
We suspect that the conjecture is accessible under GRH; presumably a
proof would require analysing the implied constant in
Remark to be large compared to is that it is easy to construct, using the Chinese
remainder theorem, a prime which fails to be a
primitive root modulo for all primes up to a prescribed bound.
Proof of Theorem 1.2. The proof is similar to that of Theorem 1.1. We will only give a sketch, highlighting the main differences.
In the region , we use
Kronecker substitution together with [18, Theorem 2], which
states that 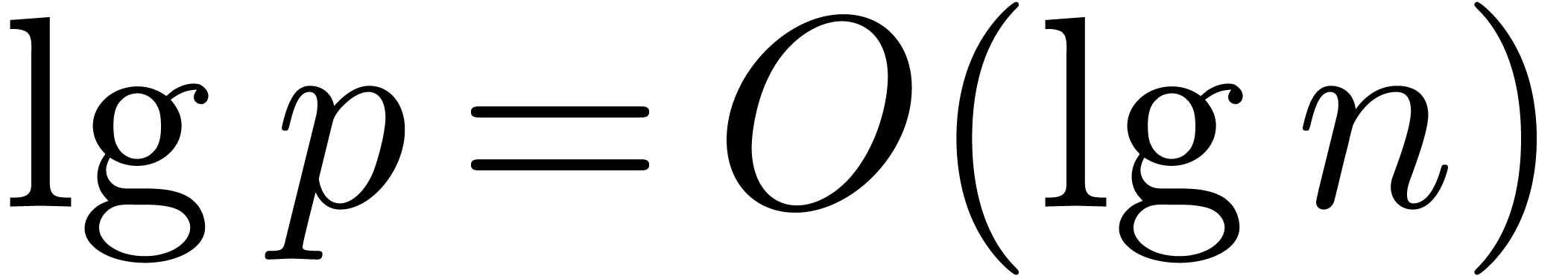 under Conjecture 8.1.
under Conjecture 8.1.
Now assume that 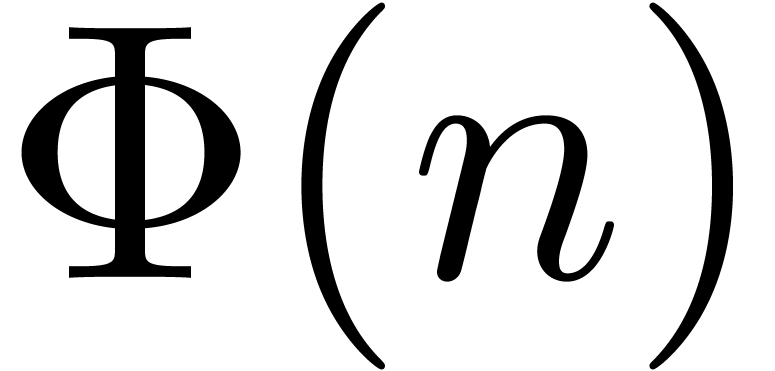 . We will
pursue a strategy similar to Theorem 7.1, recursing from
down to an exponentially smaller
. We will
pursue a strategy similar to Theorem 7.1, recursing from
down to an exponentially smaller 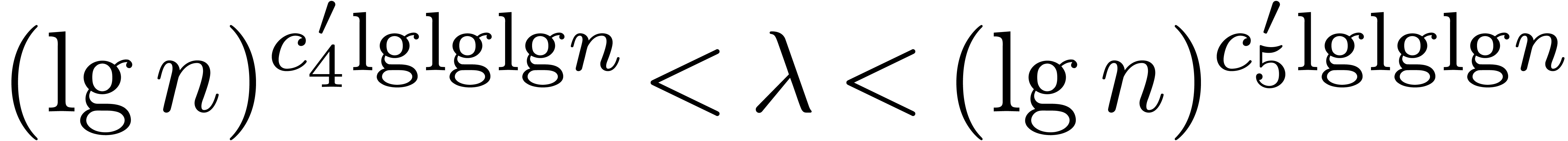 . Assume that we wish to compute products in with one fixed
operand.
. Assume that we wish to compute products in with one fixed
operand.
Using an appropriate modification of Theorem 4.1, in which
the use of Lemma 4.2 is replaced by Conjecture 8.3,
we find integers and
such that  ,
(or if ),
, , and is -smooth.
,
(or if ),
, , and is -smooth.
Now we wish to apply Conjecture 8.5 to construct suitable
. However, that conjecture
requires that . If we have
instead 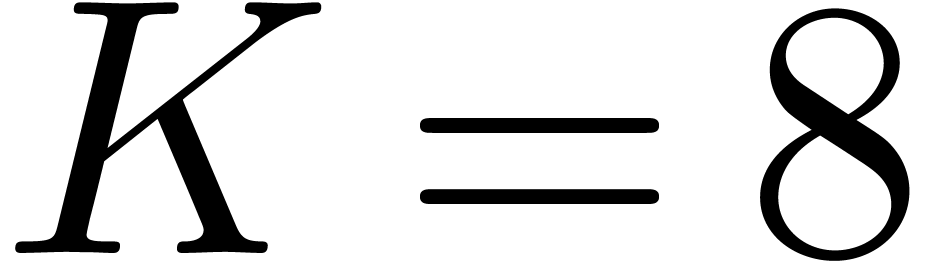 , we simply use the
algorithm of Theorem 7.1. This yields the expansion factor
, we simply use the
algorithm of Theorem 7.1. This yields the expansion factor
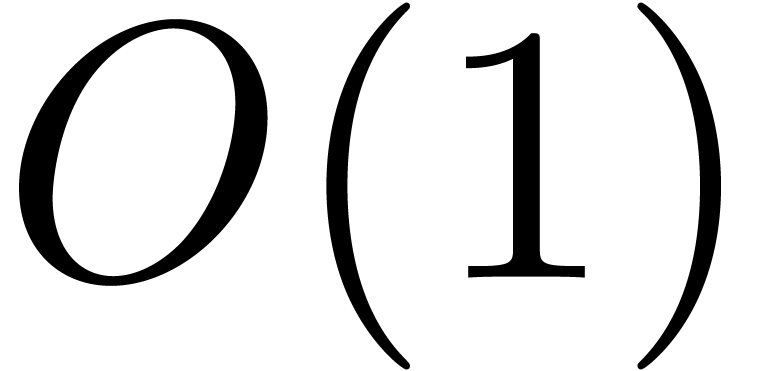 , but only for
, but only for  recursion levels (depending on
recursion levels (depending on 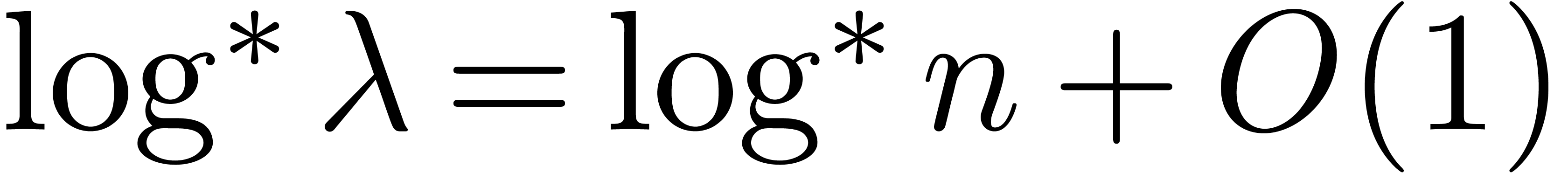 ), since
), since 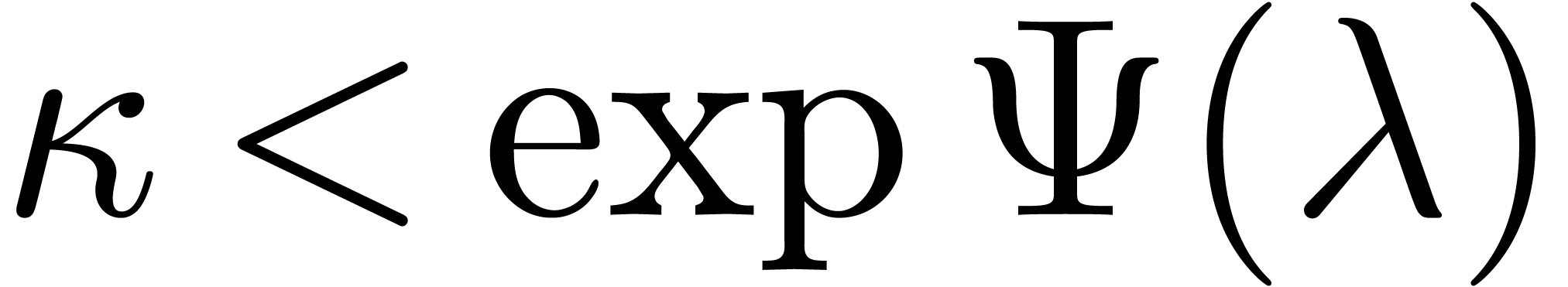 .
So it is permissible to assume that ,
losing only a constant factor in the main complexity bound for the last
few recursion levels.
.
So it is permissible to assume that ,
losing only a constant factor in the main complexity bound for the last
few recursion levels.
Applying Conjecture 8.5 and Lemma 8.2, we
obtain a positive multiple of , such that is prime,
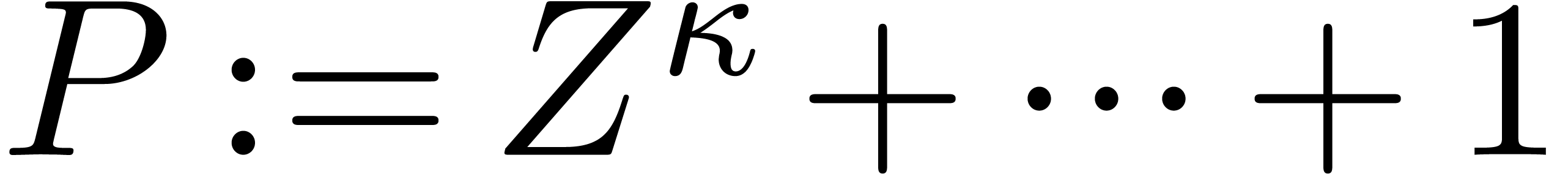 , and
, and 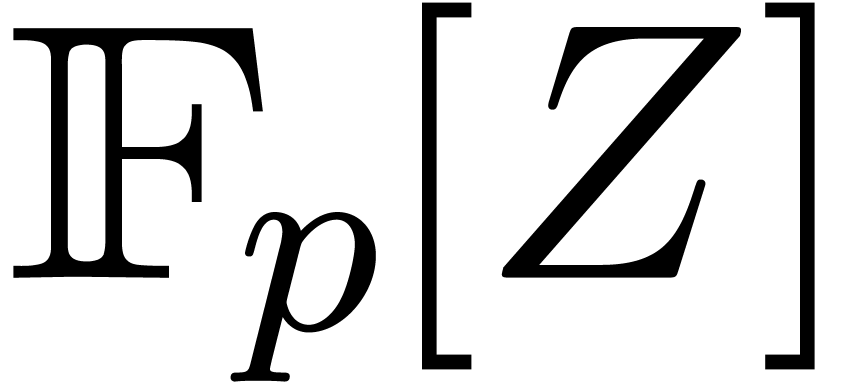 is irreducible in
is irreducible in 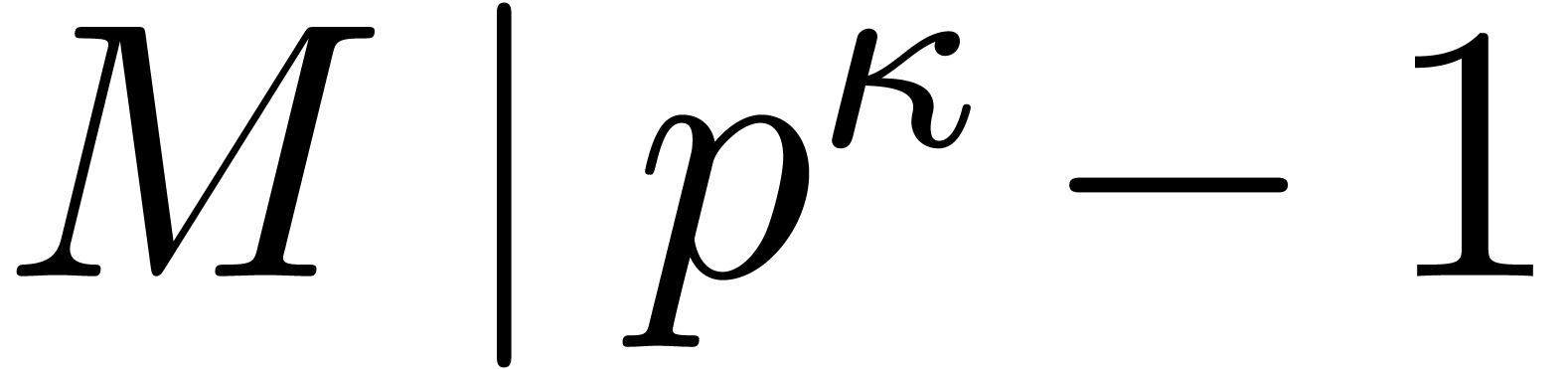 . We will
take as our model for ; note that
. We will
take as our model for ; note that 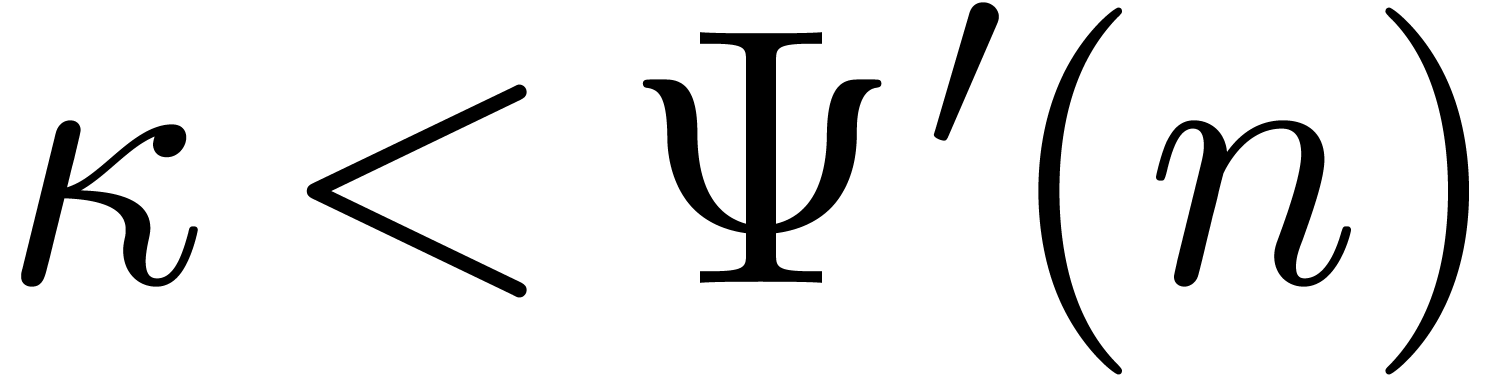 .
.
Notice that 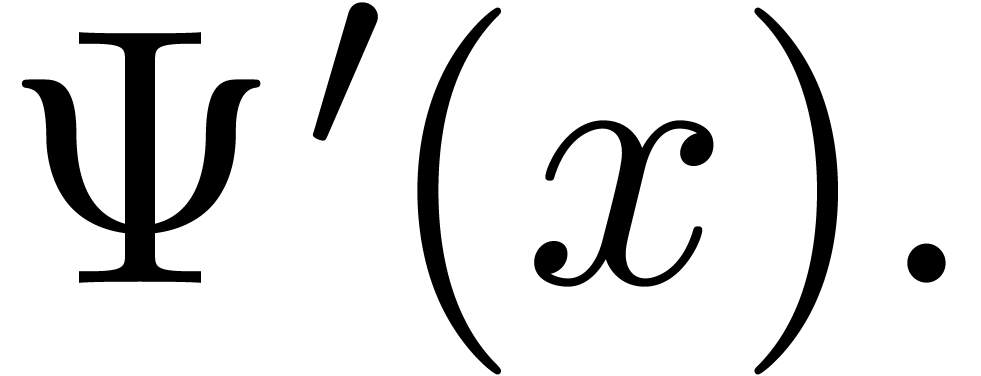 for some logarithmically slow
function
for some logarithmically slow
function  Indeed, there exists
and
Indeed, there exists
and 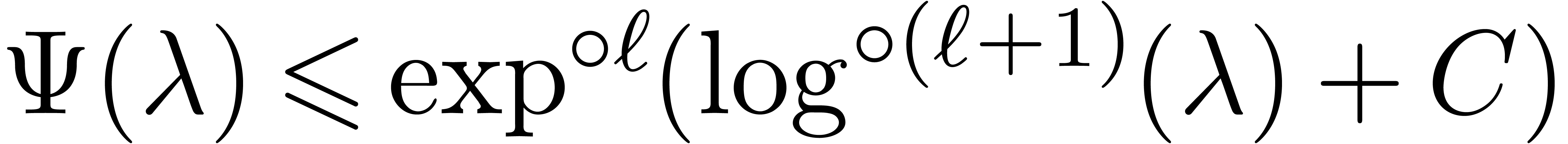 such that
such that 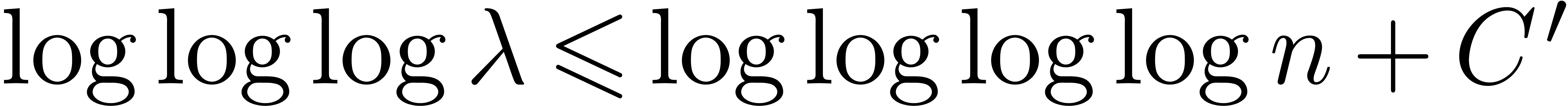 and
and 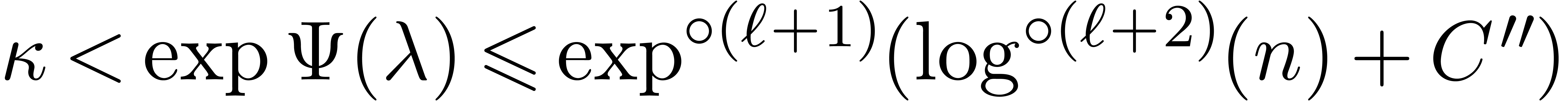 for large .
Increasing if necessary, we get
for large .
Increasing if necessary, we get 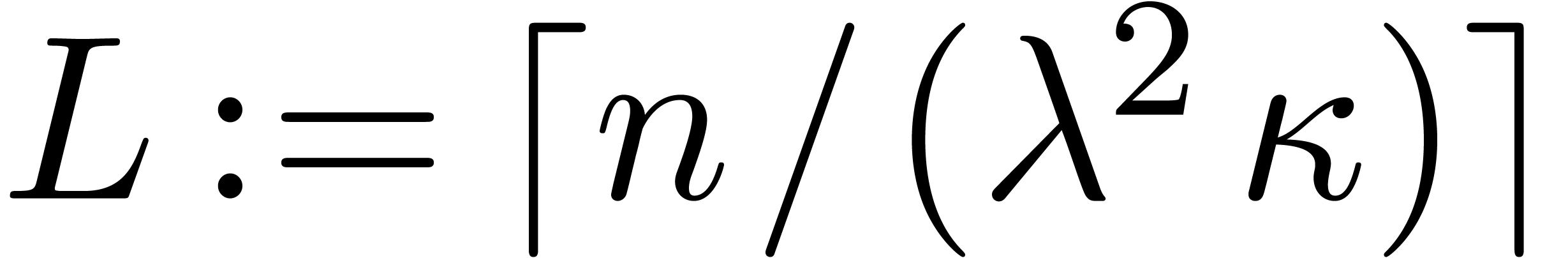 , the latter being a logarithmically slow
function of .
, the latter being a logarithmically slow
function of .
In the proof of Theorem 7.1, we selected the transform
length first, and then chose
to fine-tune the total bit size. Here we have less control over , so we must use a different
strategy. Choose target long and short transform lengths 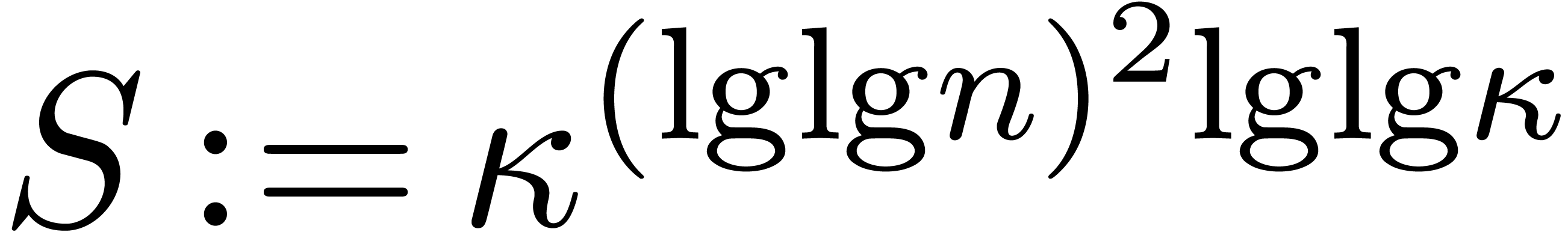 and
and 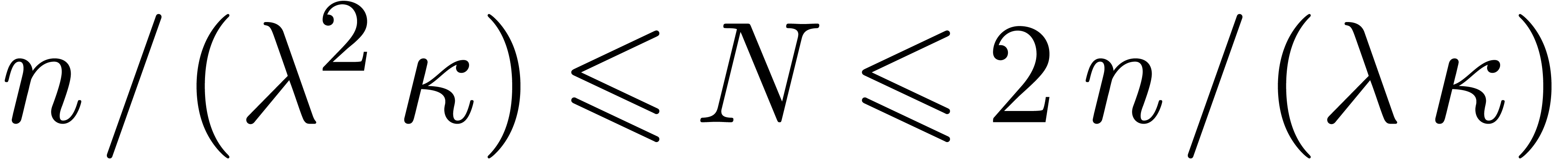 . Applying
Theorem 4.6, we obtain -smooth
integers such that
divides and for each
, and such that
. Applying
Theorem 4.6, we obtain -smooth
integers such that
divides and for each
, and such that 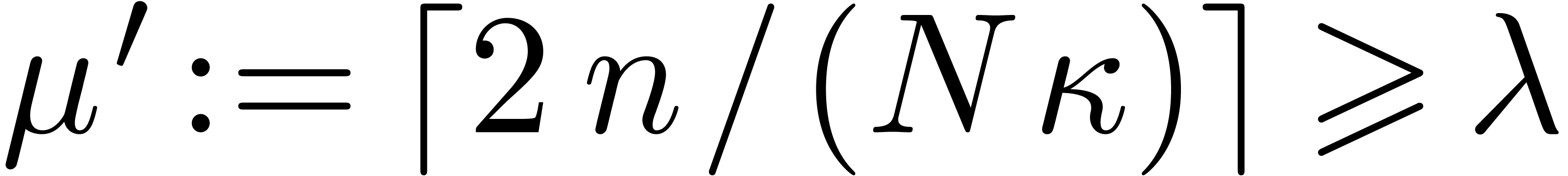 for large . Let
for large . Let
 , and let
, and let 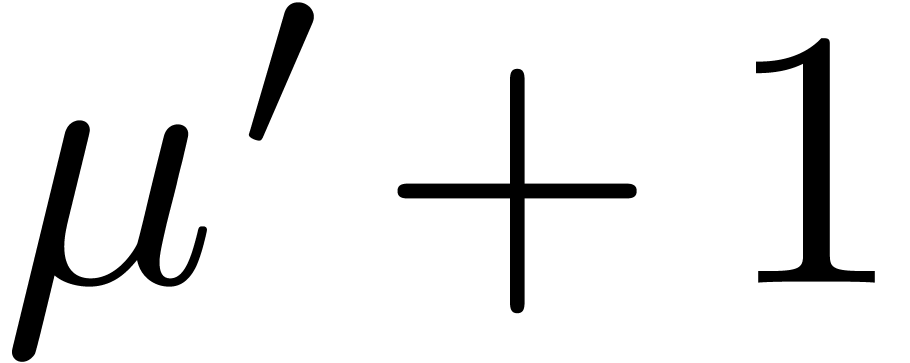 be the smallest prime greater than
be the smallest prime greater than  and different
to . By [4] we
have
and different
to . By [4] we
have 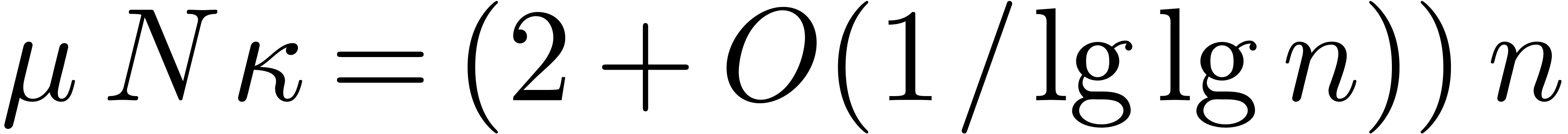 , so
, so 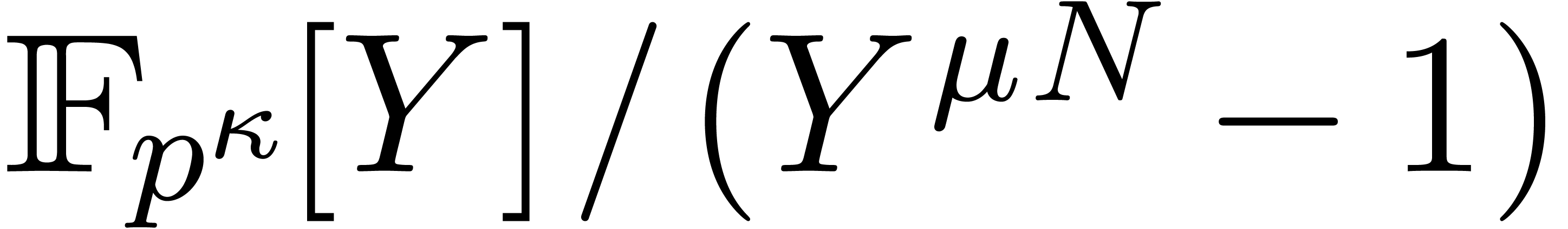 .
.
We now apply the Crandall–Fagin algorithm to reduce multiplication
in to multiplication in 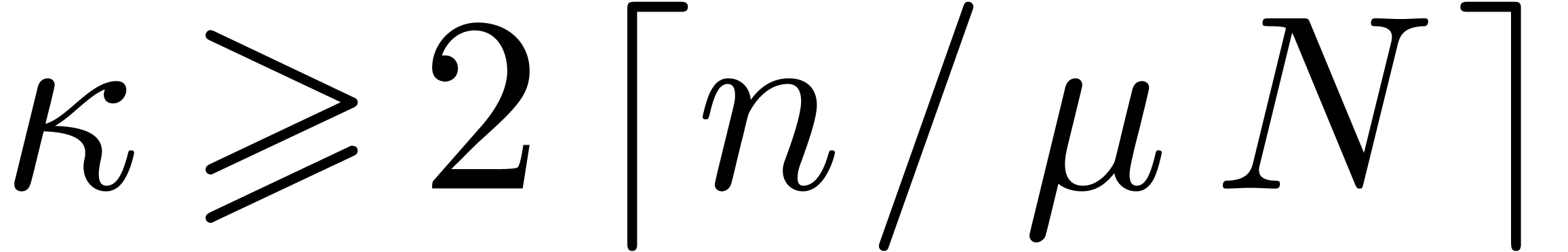 . The prerequisite
. The prerequisite 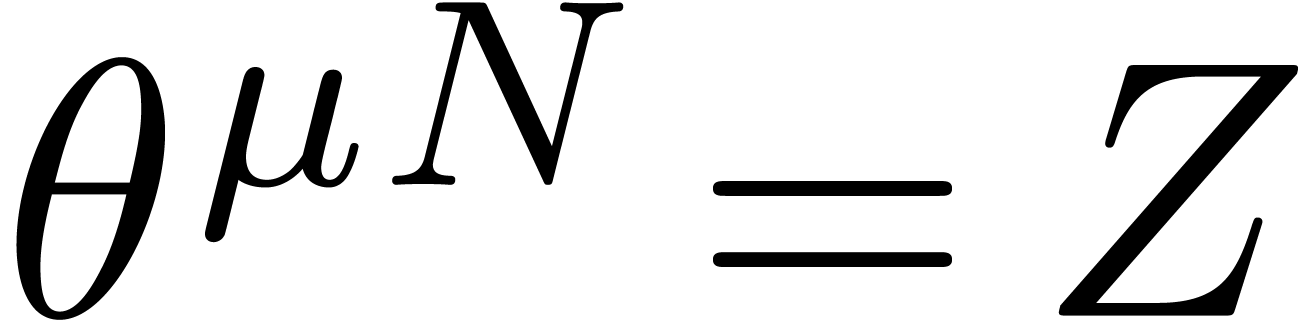 is
satisfied (since is even). Instead of using
Proposition 6.1 to construct
satisfying
is
satisfied (since is even). Instead of using
Proposition 6.1 to construct
satisfying 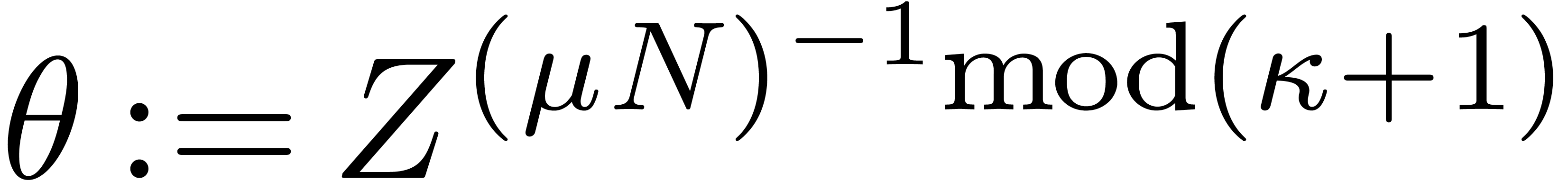 , we may simply
take
, we may simply
take 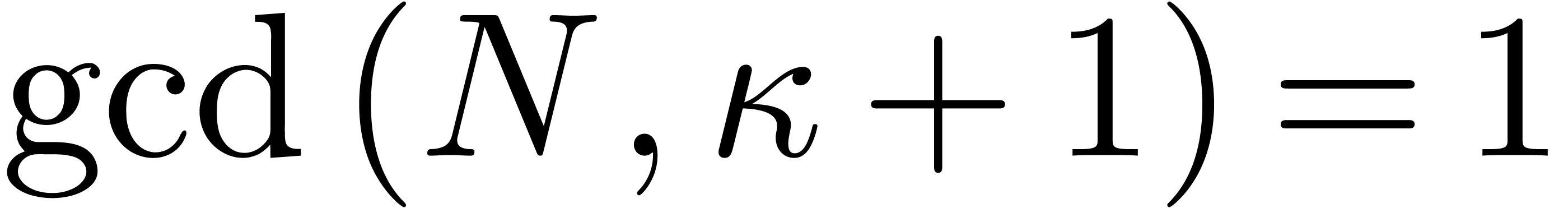 . The required modular
inverse exists, as and
are distinct primes, and
. The required modular
inverse exists, as and
are distinct primes, and 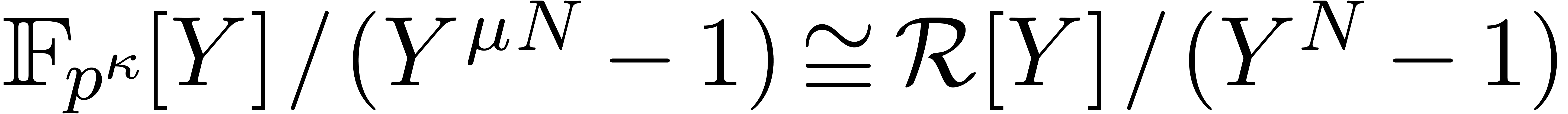 since
is -smooth.
since
is -smooth.
We now take advantage of the isomorphism 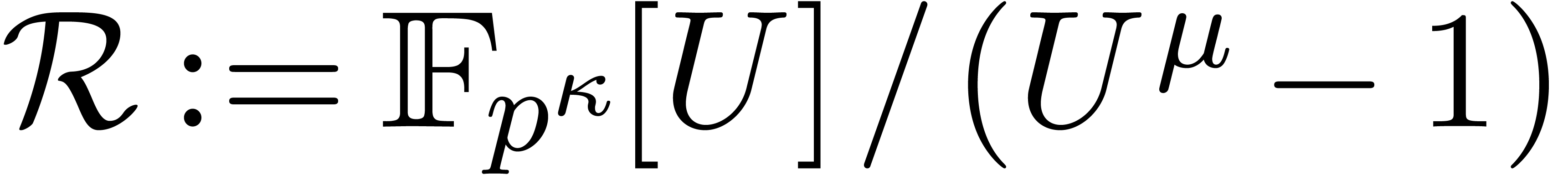 ,
where
,
where  . We multiply in
. We multiply in  by using DFTs over
by using DFTs over 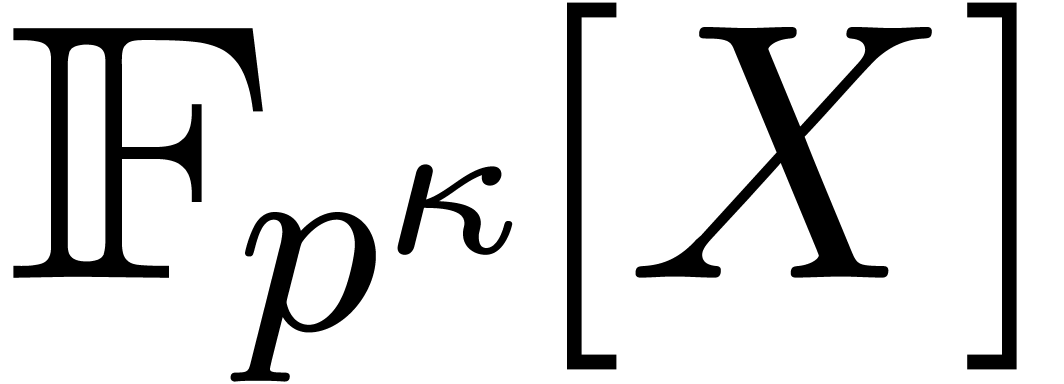 :
one DFT of length over
reduces to DFTs of length
over . The latter are handled
by decomposing into short transforms of length , which are in turn converted to multiplications in
via Bluestein's algorithm. Finally –- and
this is where all the hard work pays off –- each such
multiplication reduces to a multiplication in , since .
The multiplications in itself are handled using
the algebraic Schönhage–Strassen algorithm.
:
one DFT of length over
reduces to DFTs of length
over . The latter are handled
by decomposing into short transforms of length , which are in turn converted to multiplications in
via Bluestein's algorithm. Finally –- and
this is where all the hard work pays off –- each such
multiplication reduces to a multiplication in , since .
The multiplications in itself are handled using
the algebraic Schönhage–Strassen algorithm.
We omit the rest of the complexity argument, which is essentially the
same as that of Theorem 7.1 and Theorem 1.1.
We mention only that was chosen sufficiently
large that the multiplications in and in make a negligible contribution overall.
In this section we outline some directions along which the results in this paper can be extended. We also provide some hints concerning the practical usefulness of the new ideas. Our treatment is more sketchy and we plan to provide more details in a forthcoming paper.
Recall that denotes the cost of multiplying
polynomials in  of degree less than , where we assume that some model for has been fixed in advance.
of degree less than , where we assume that some model for has been fixed in advance.
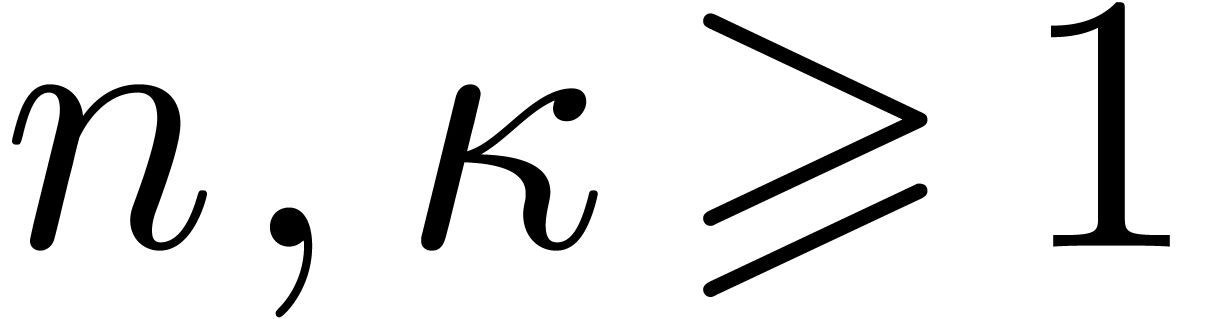
uniformly for all  and all primes . Assuming Conjectures 8.1,
8.3 and 8.5, we may replace
by
and all primes . Assuming Conjectures 8.1,
8.3 and 8.5, we may replace
by 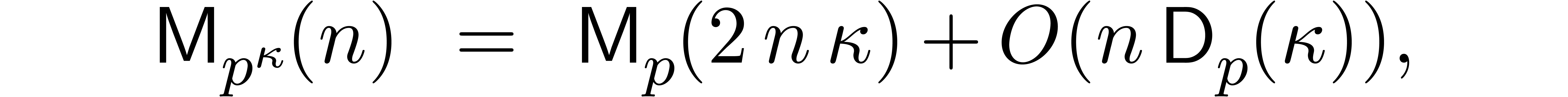 .
.
Indeed, we saw in section 3 that
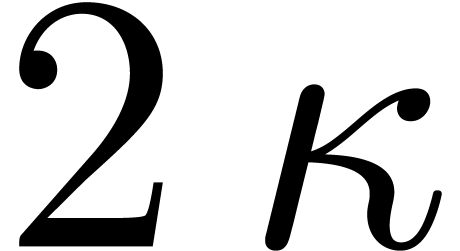
where denotes the cost of dividing a polynomial
of degree less than 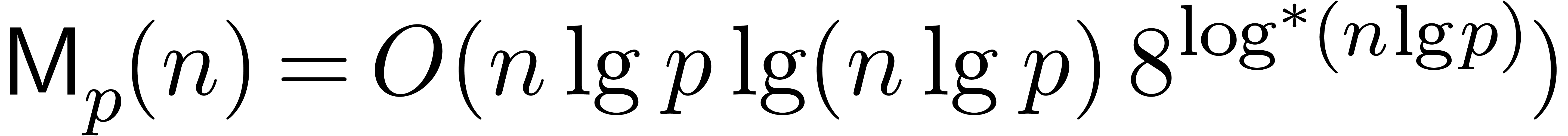 by . Having established the bound
by . Having established the bound 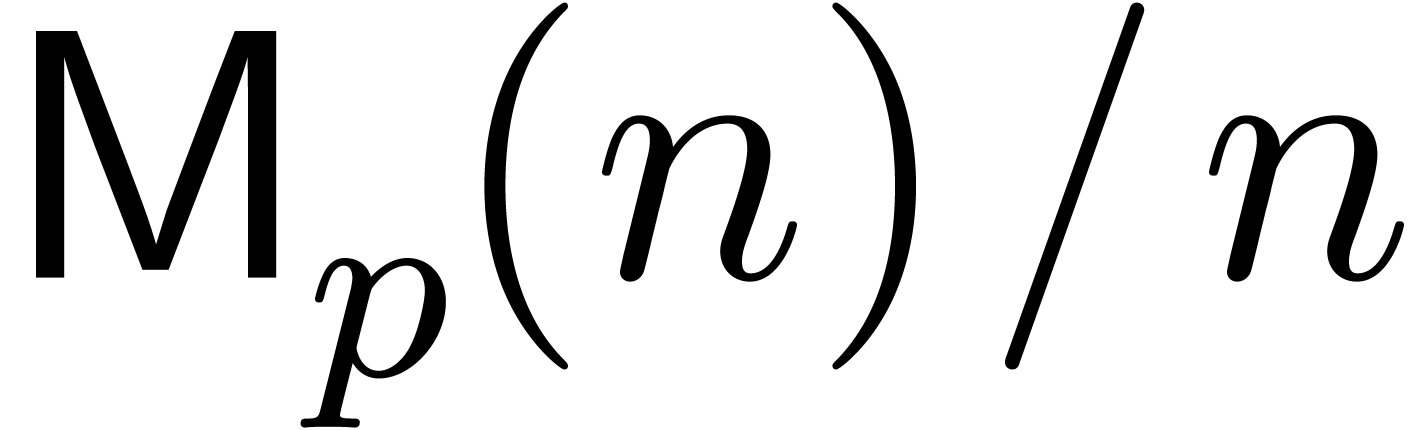 , it is now permissible to assume that
, it is now permissible to assume that 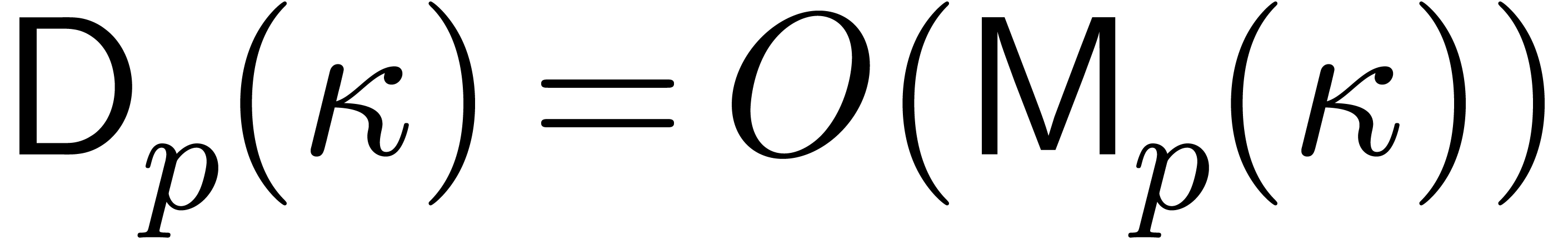 is increasing, so the usual argument for Newton
iteration shows that
is increasing, so the usual argument for Newton
iteration shows that 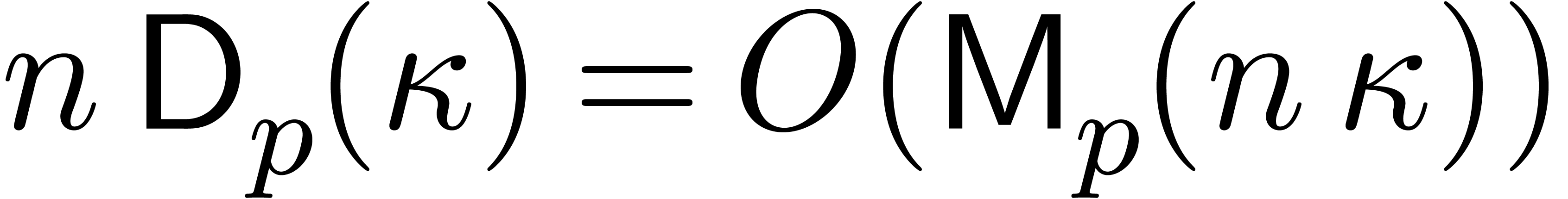 . Using
again that is increasing, we obtain
. Using
again that is increasing, we obtain 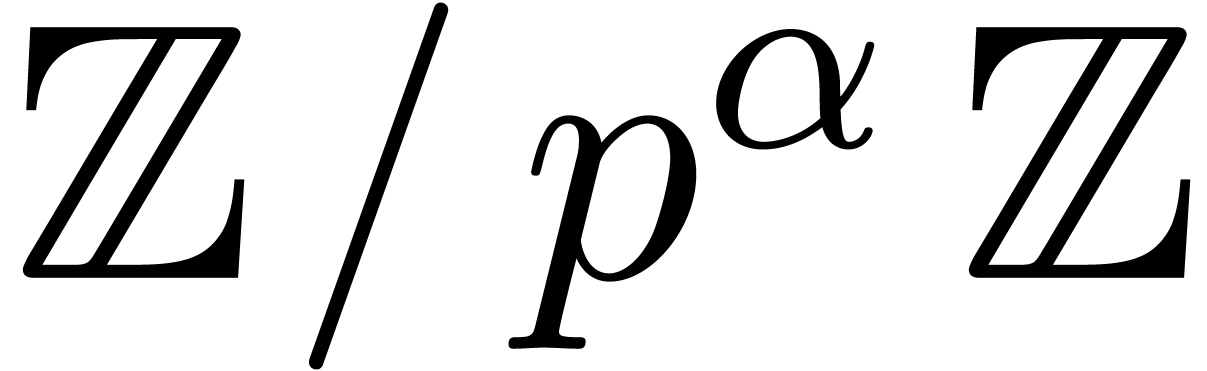 .
.
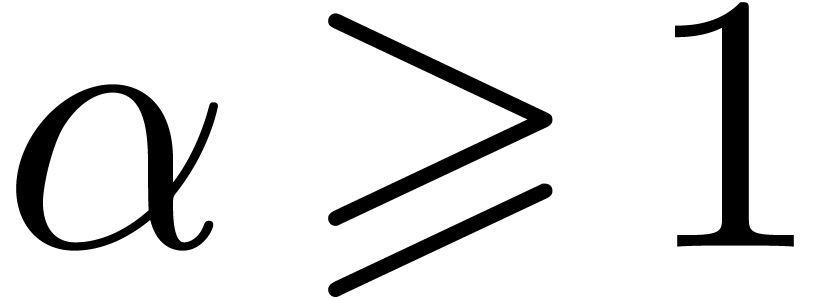
For any prime and any integer 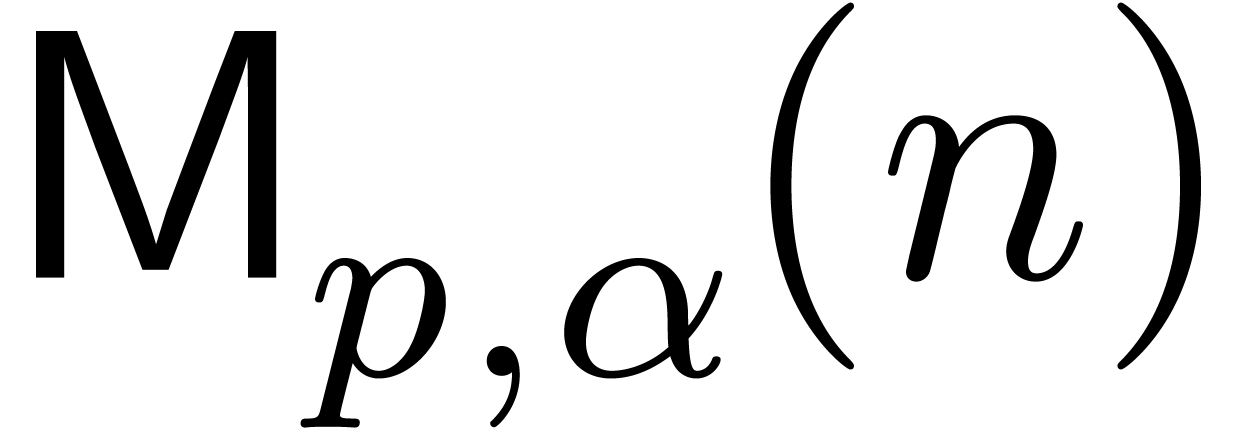 , denote by
, denote by 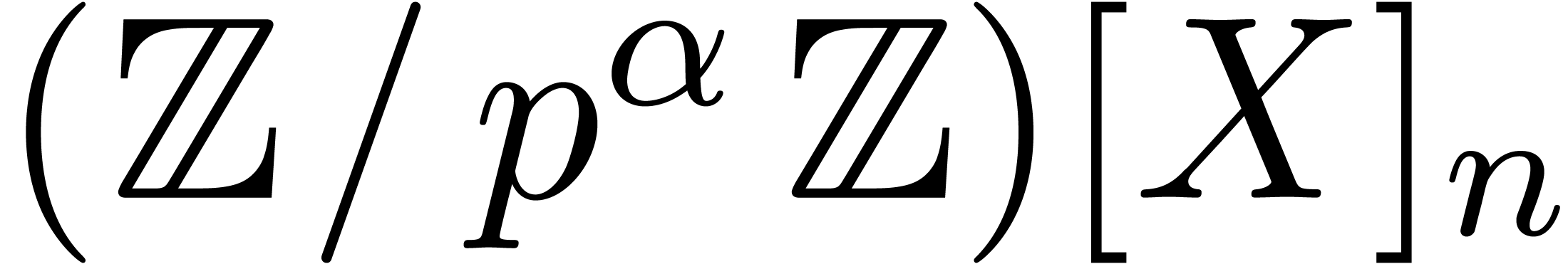 the bit
complexity of multiplying polynomials in
the bit
complexity of multiplying polynomials in  .
.
uniformly for all 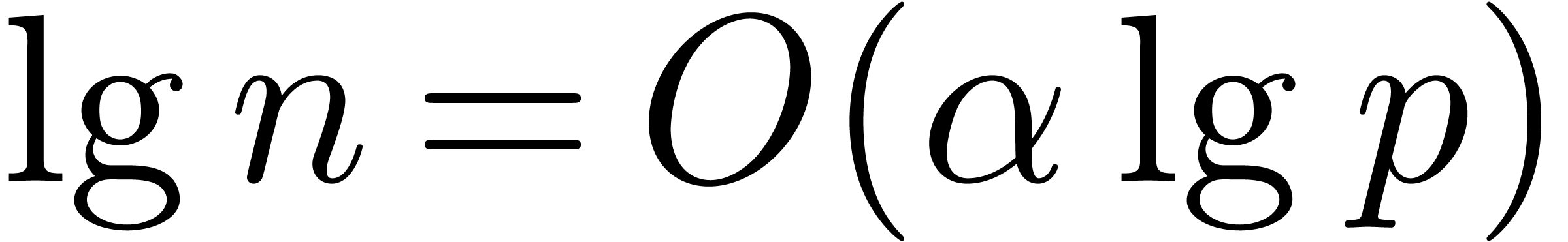 and all primes . Assuming Conjectures 8.1,
8.3 and 8.5, we may replace
by .
and all primes . Assuming Conjectures 8.1,
8.3 and 8.5, we may replace
by .
For 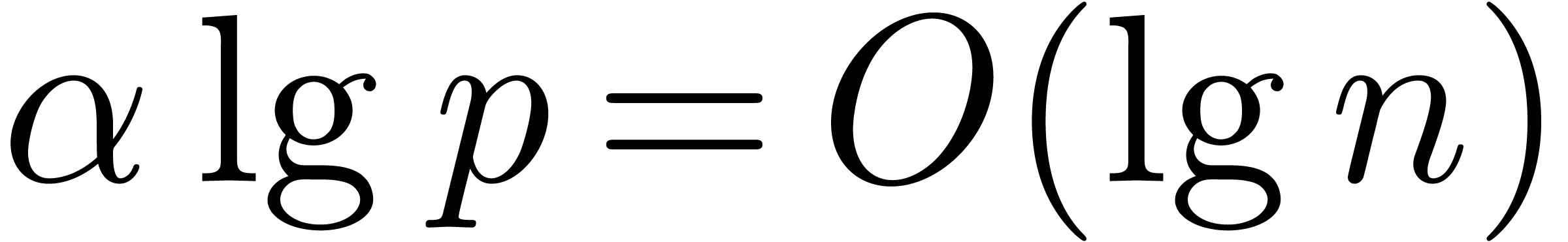 we may simply use Kronecker substitution.
For
we may simply use Kronecker substitution.
For 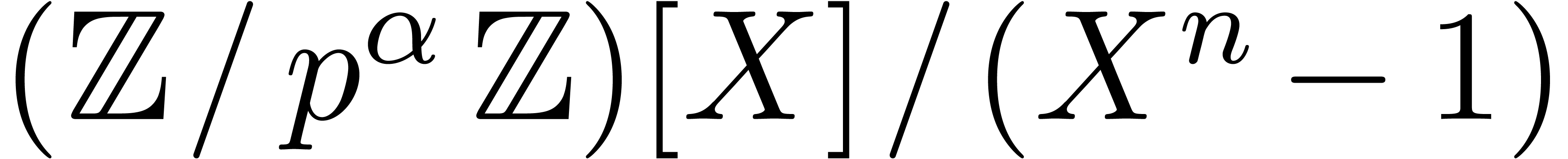 we must modify the algorithm of section 7. Recall that in that algorithm we reduced multiplication in
to multiplication ,
where is a transform length dividing . Our task is to define a ring
, analogous to , so that multiplication in
we must modify the algorithm of section 7. Recall that in that algorithm we reduced multiplication in
to multiplication ,
where is a transform length dividing . Our task is to define a ring
, analogous to , so that multiplication in 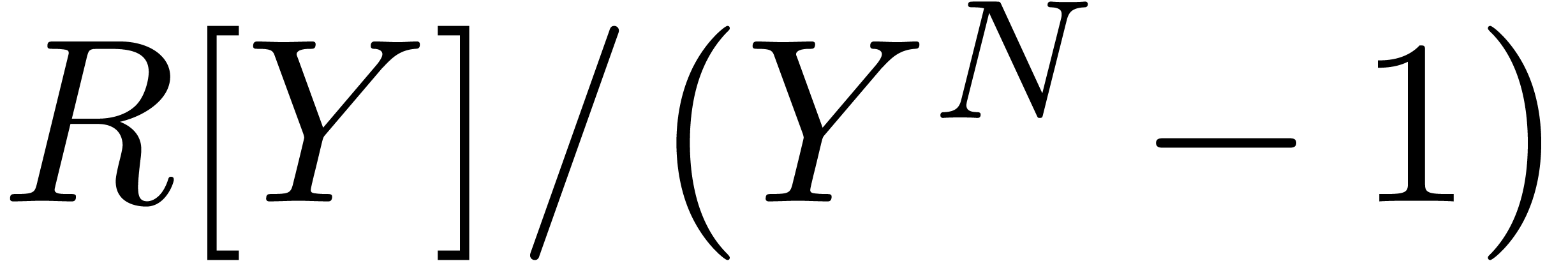 can be reduced to multiplication in
can be reduced to multiplication in  .
.
Let 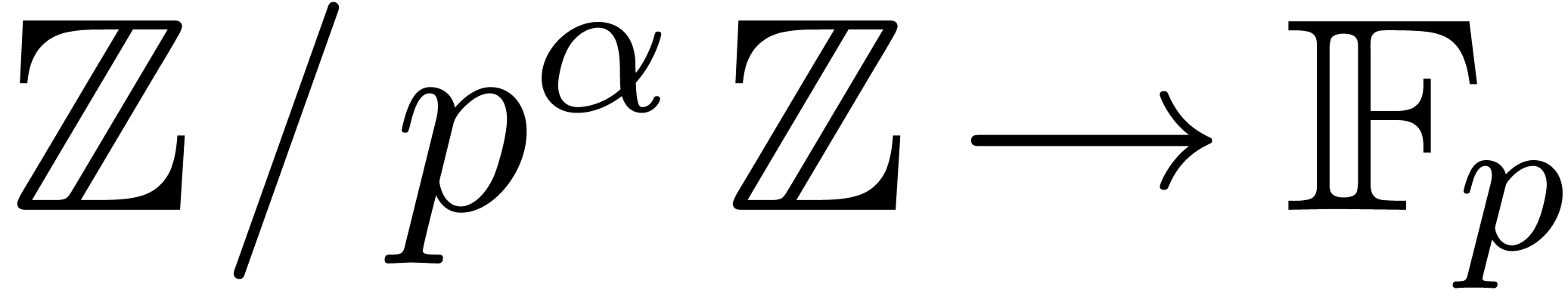 be the natural projection
be the natural projection  , and write also for
the corresponding map
, and write also for
the corresponding map  . Let
be any monic irreducible polynomial of degree
, and let
. Let
be any monic irreducible polynomial of degree
, and let  be an arbitrary lift via ,
also monic of degree . Then
be an arbitrary lift via ,
also monic of degree . Then
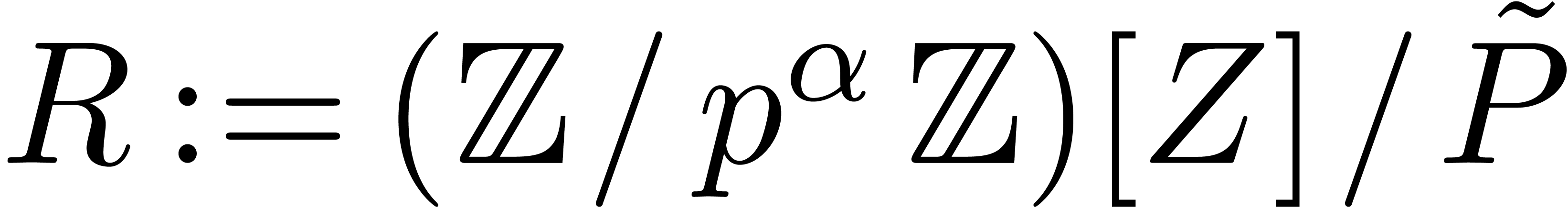 is irreducible, and we will take
is irreducible, and we will take 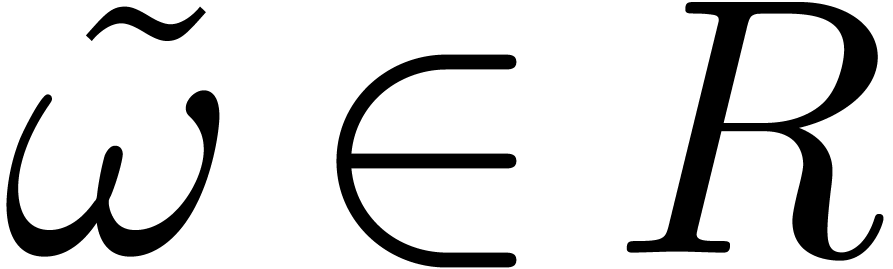 .
.
Any primitive -th root of
unity has a unique lift to a principal -th root of unity  . (This can be seen, for example, by observing
that
. (This can be seen, for example, by observing
that  must be the image in
of a Teichmüller lift of in the -adic field whose residue field is
.) Given , we may compute
efficiently using fast Newton lifting [11, Section 12.3].
must be the image in
of a Teichmüller lift of in the -adic field whose residue field is
.) Given , we may compute
efficiently using fast Newton lifting [11, Section 12.3].
Moreover, if we choose and
as in Proposition 6.1, so that , then fast Newton lifting can also be used to
obtain 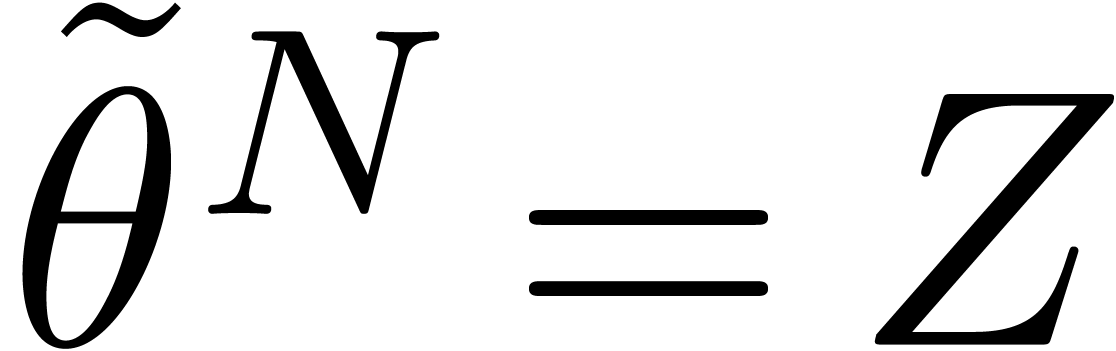 such that
such that 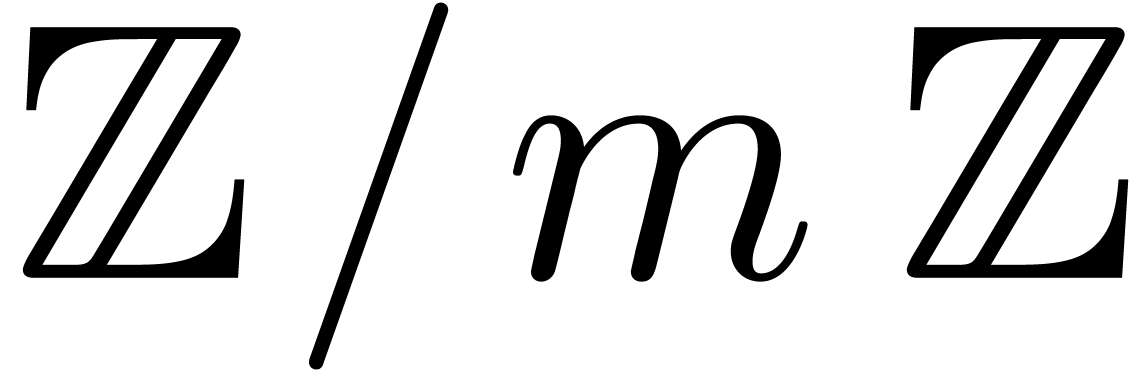 in
.
in
.
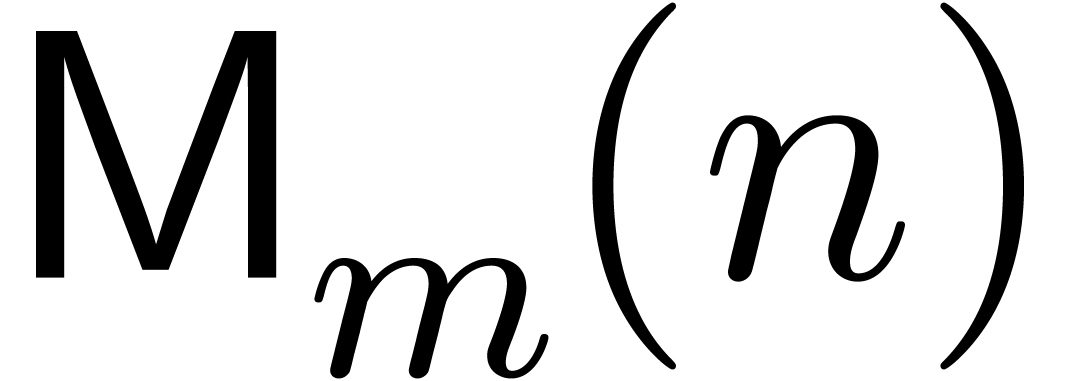
For any , denote by  the bit complexity of multiplying polynomials in
the bit complexity of multiplying polynomials in  .
.
We use the isomorphism 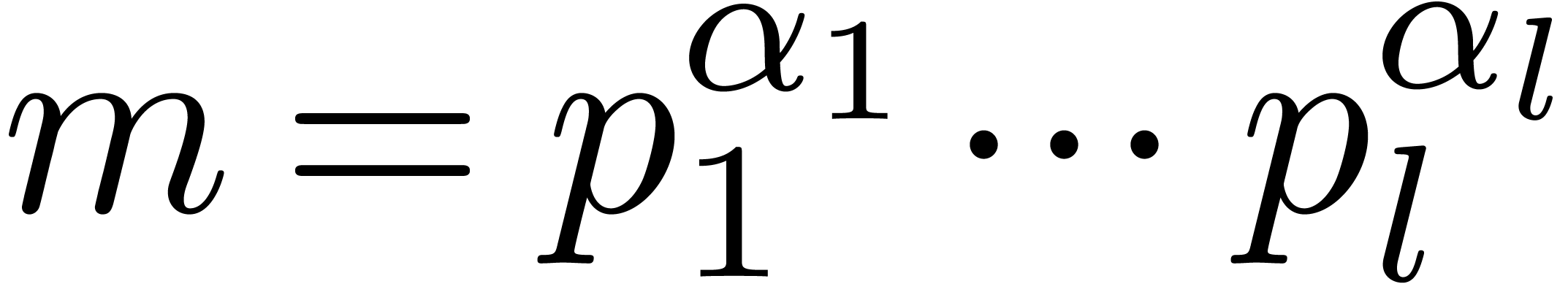 ,
where
,
where 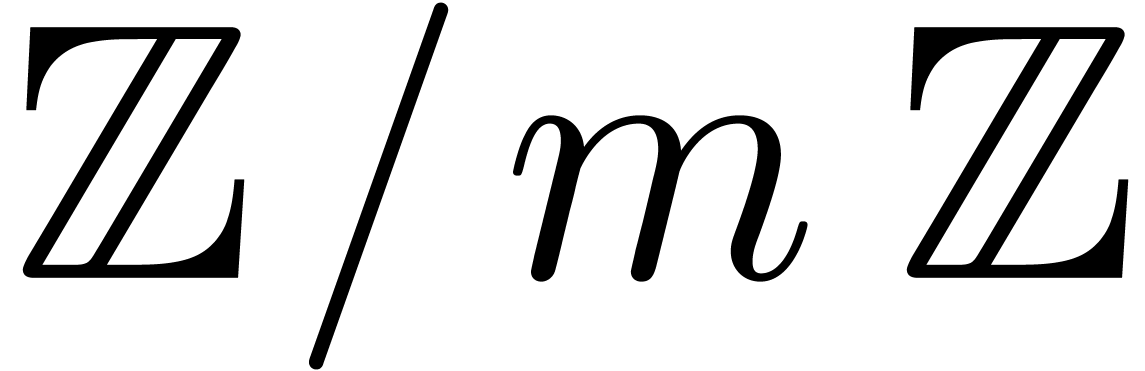 is the prime decomposition of . The cost of converting between the
is the prime decomposition of . The cost of converting between the 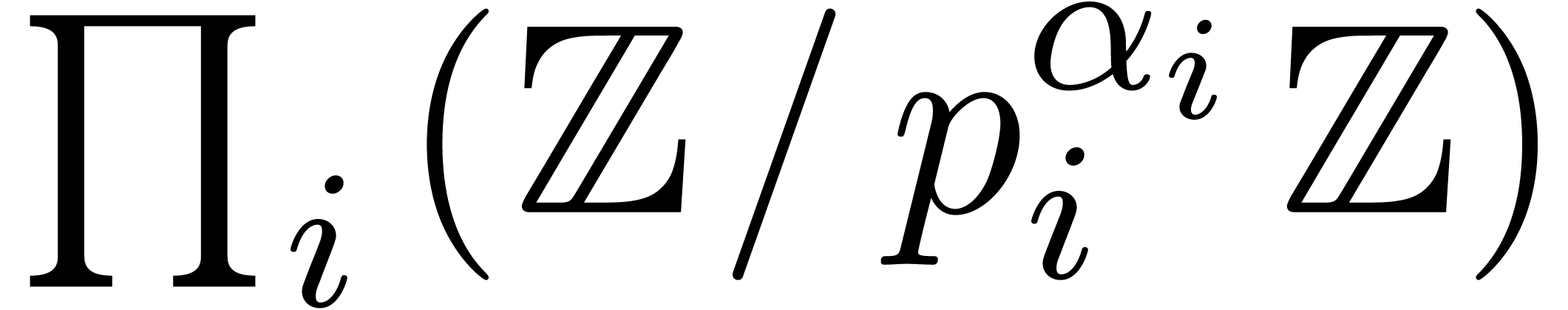 and
and 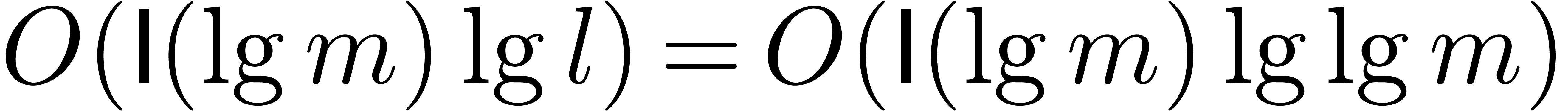 representations is
representations is  [17, Section 10.3]. By Theorem ?
we get
[17, Section 10.3]. By Theorem ?
we get
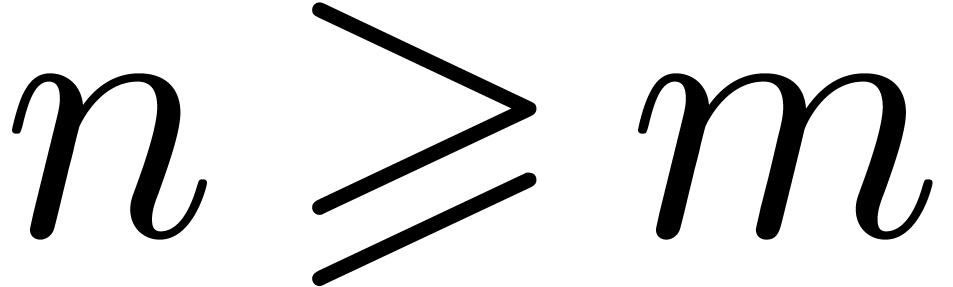
The first term dominates if 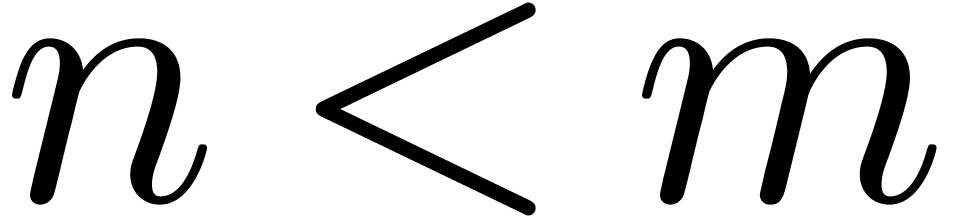 .
If
.
If  we may simply use Kronecker substitution.
we may simply use Kronecker substitution.
Until now we have considered only complexity bounds in the Turing model.
The new techniques also lead to improved bounds in algebraic complexity
models. In what follows, 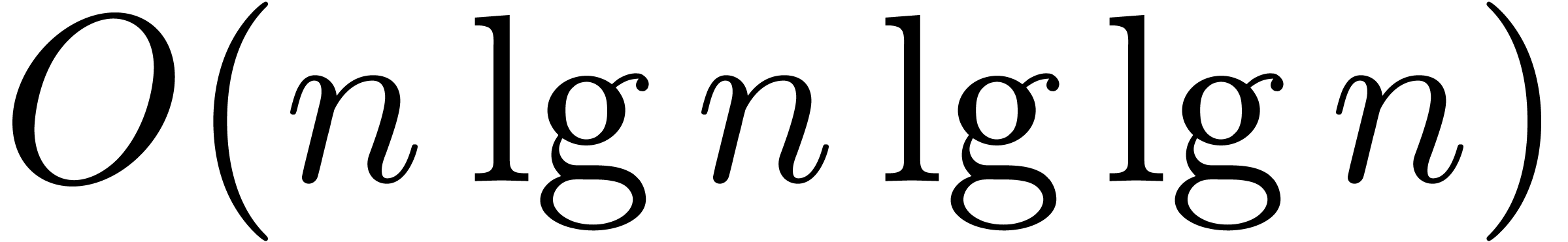 is always a commutative
ring with identity.
is always a commutative
ring with identity.
For the simplest case, first assume that is an
-algebra for some prime . In the straight-line program
model [9, Chapter 4], we count the number of additions and
subtractions in , the number
of scalar multiplications (multiplications by elements of ), and the number of nonscalar multiplications
(multiplications in ). As
pointed out in the introduction, the best known bound for the total
complexity was previously  ,
which was achieved by the Cantor–Kaltofen algorithm.
,
which was achieved by the Cantor–Kaltofen algorithm.
be an -algebra. We may multiply two polynomials in 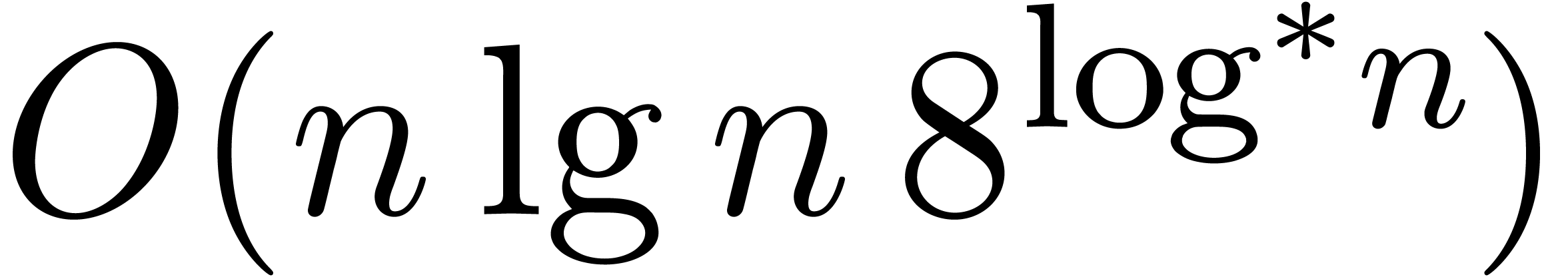 of degree less than using
of degree less than using
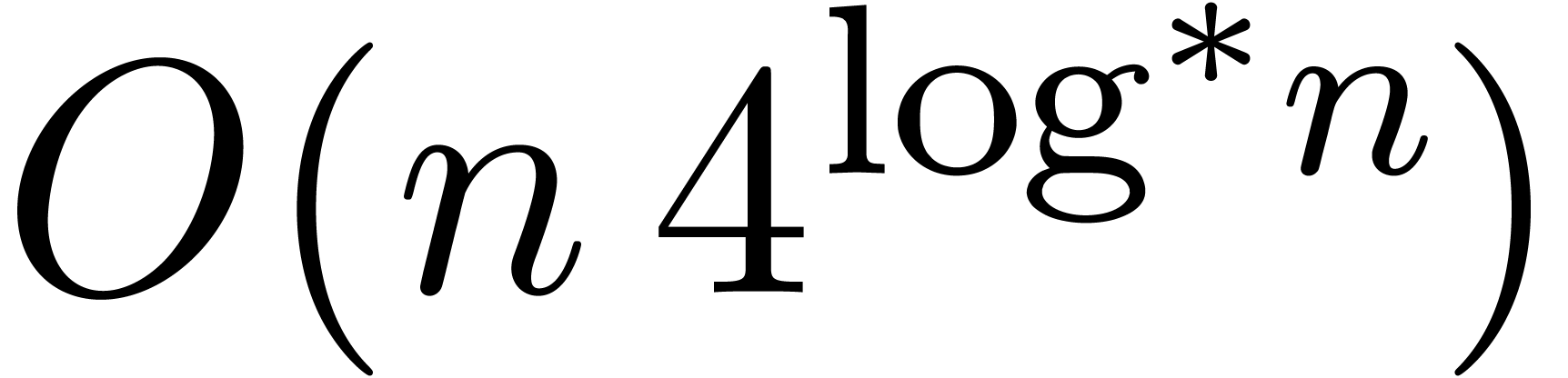 additions, subtractions, and scalar
multiplications, and
additions, subtractions, and scalar
multiplications, and  nonscalar
multiplications. These bounds are uniform over all primes and all -algebras
.
nonscalar
multiplications. These bounds are uniform over all primes and all -algebras
.
The idea of the proof is to use the same algorithm as in section 7, but instead of switching to Kronecker substitution when we
reach 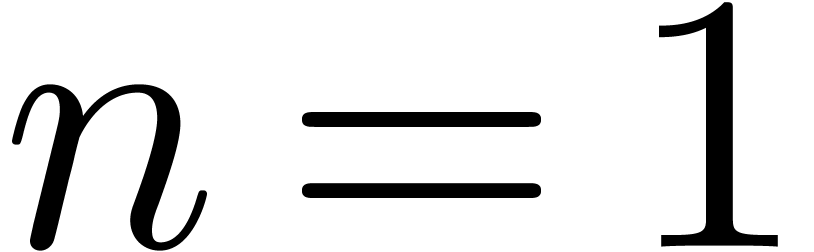 , we simply recurse all
the way down to
, we simply recurse all
the way down to 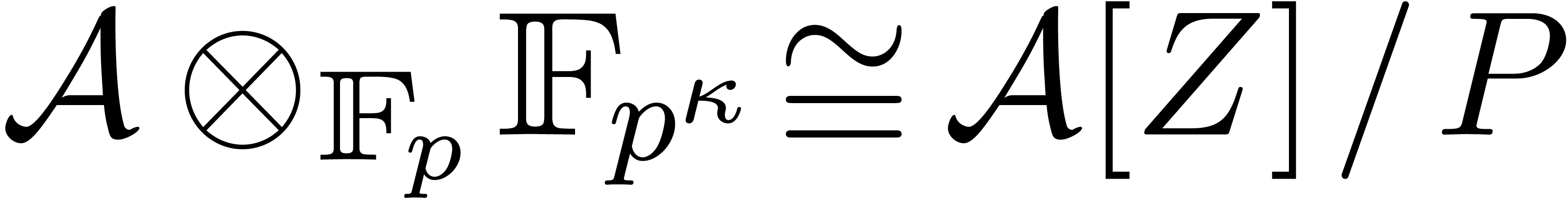 . The role of
the extension is played by
. The role of
the extension is played by 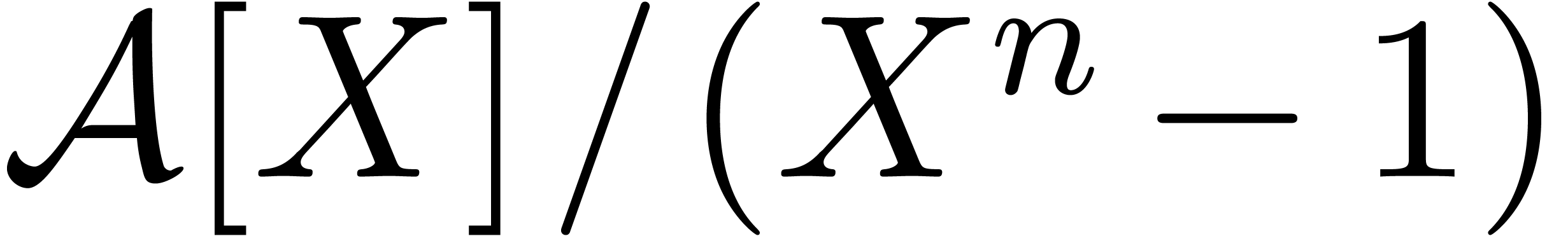 , where is monic and
irreducible of degree (here we have used the
fact that may be viewed as a subring of , since
contains an identity element and hence a copy of ). Thus we reduce multiplication in
, where is monic and
irreducible of degree (here we have used the
fact that may be viewed as a subring of , since
contains an identity element and hence a copy of ). Thus we reduce multiplication in 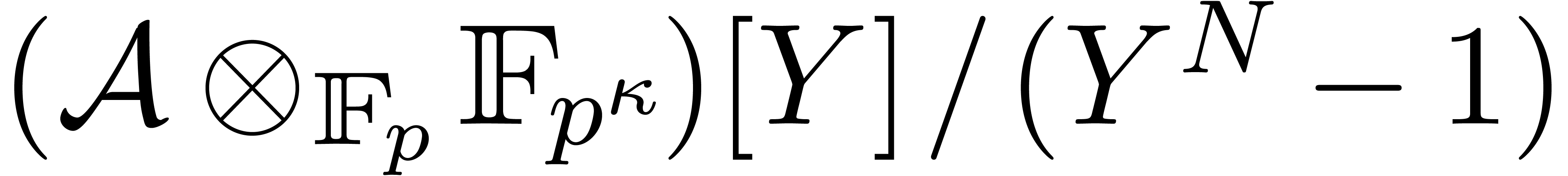 to multiplication in
to multiplication in 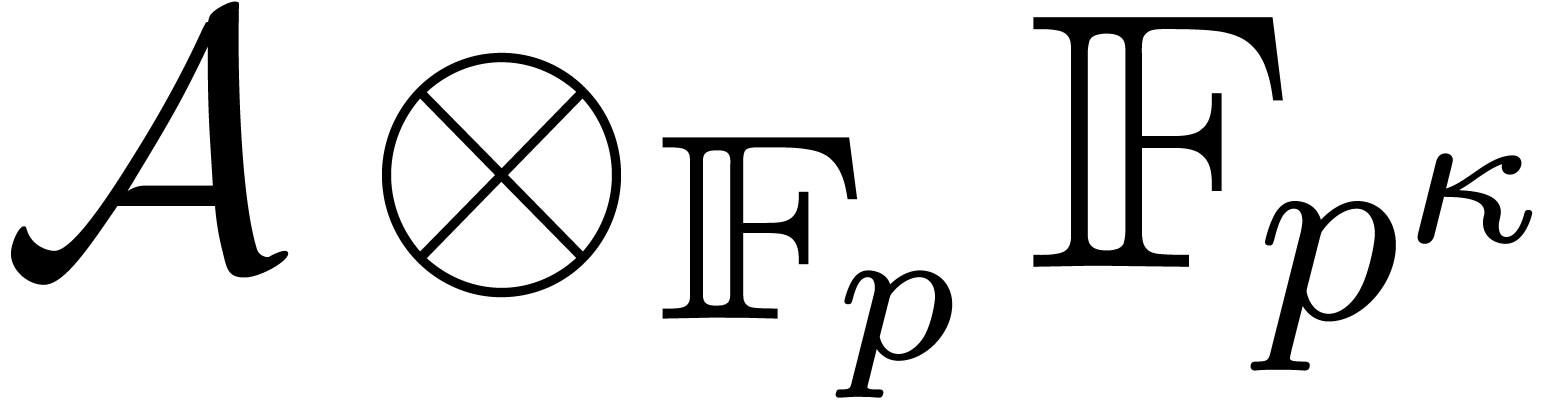 . The
latter multiplication may be handled by DFTs over
. The
latter multiplication may be handled by DFTs over 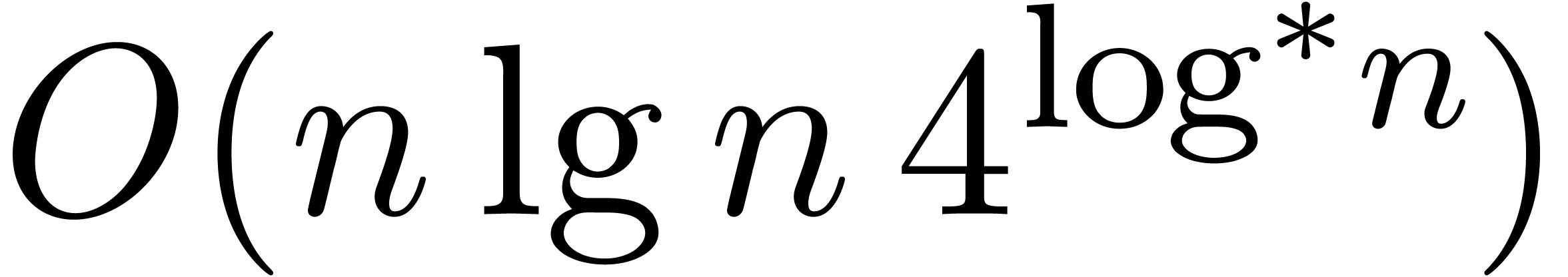 , since any primitive -th
root of unity in corresponds naturally to a
principal -th root of unity
in .
, since any primitive -th
root of unity in corresponds naturally to a
principal -th root of unity
in .
The bound covers the cost of the DFTs, which are
accomplished entirely using additions, subtractions and scalar
multiplications. Nonscalar multiplications are needed only for the
pointwise multiplication step. To explain the
bound, we observe that at each recursion level the total “data
size” grows by a factor of four: one factor of two arises from the
Crandall–Fagin splitting, and another factor of two from the
Kronecker substitution.
Note that in the straight-line program model, we give a different
algorithm for each . Thus all
precomputed objects, such as the defining polynomial
and the required roots of unity, are obtained free of cost (they are
built directly into the structure of the algorithm). The uniformity in
follows from the fact that the bounds for and in Theorem 4.1
are independent of , although
of course the algorithm will be different for each . For each fixed ,
we may use the same straight-line program for all -algebras .
Assuming Conjectures 8.3 and 8.5, the bounds
may be improved to respectively 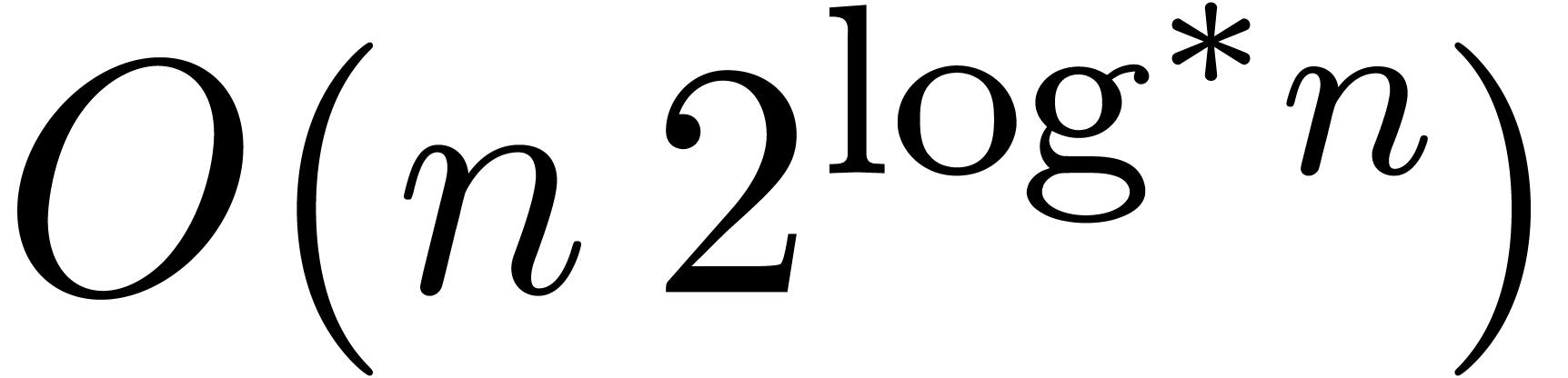 and
and 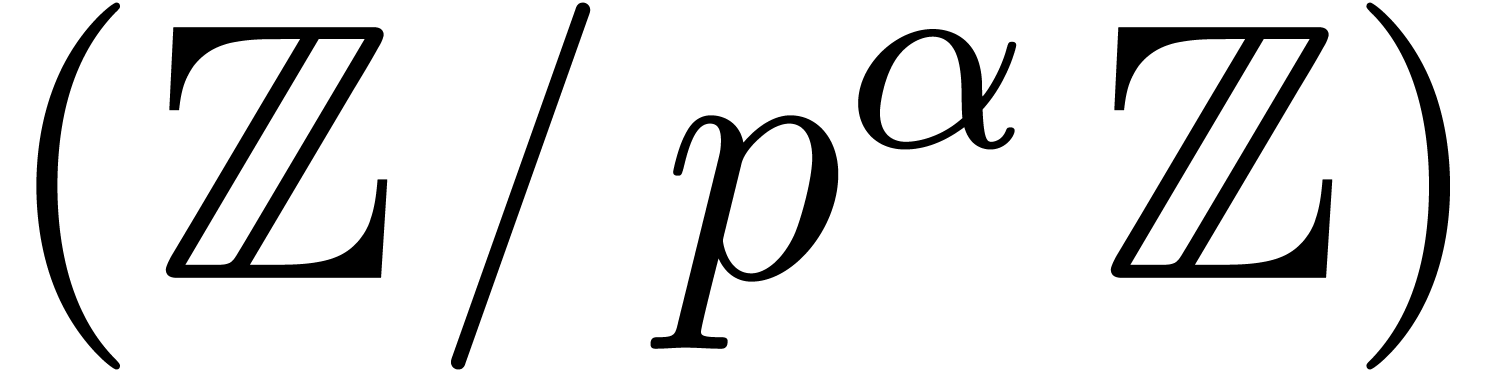 . However, in this case we lose uniformity in
, due to the issue raised in
Remark 8.6.
. However, in this case we lose uniformity in
, due to the issue raised in
Remark 8.6.
Theorem 9.4 can be generalised to 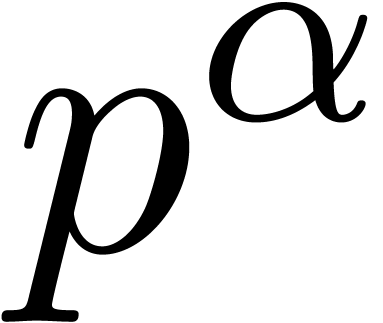 -algebras, along the same lines as section 9.2.
It is also possible to handle -algebras
for any integer , i.e., rings
of finite characteristic, but we cannot proceed exactly as in section 9.3, because the straight-line model has no provision for a
“reduction modulo
-algebras, along the same lines as section 9.2.
It is also possible to handle -algebras
for any integer , i.e., rings
of finite characteristic, but we cannot proceed exactly as in section 9.3, because the straight-line model has no provision for a
“reduction modulo 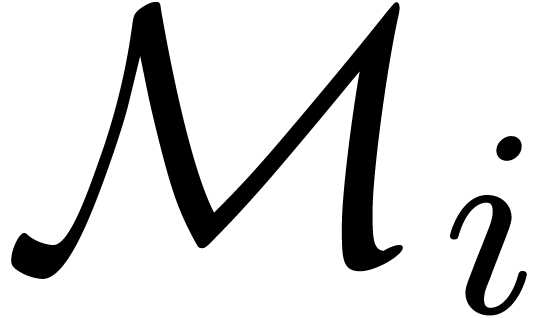 ”
operation. Instead, we use a device introduced in [10].
Suppose that and that is
now a -algebra. For each we may construct a straight-line program
”
operation. Instead, we use a device introduced in [10].
Suppose that and that is
now a -algebra. For each we may construct a straight-line program 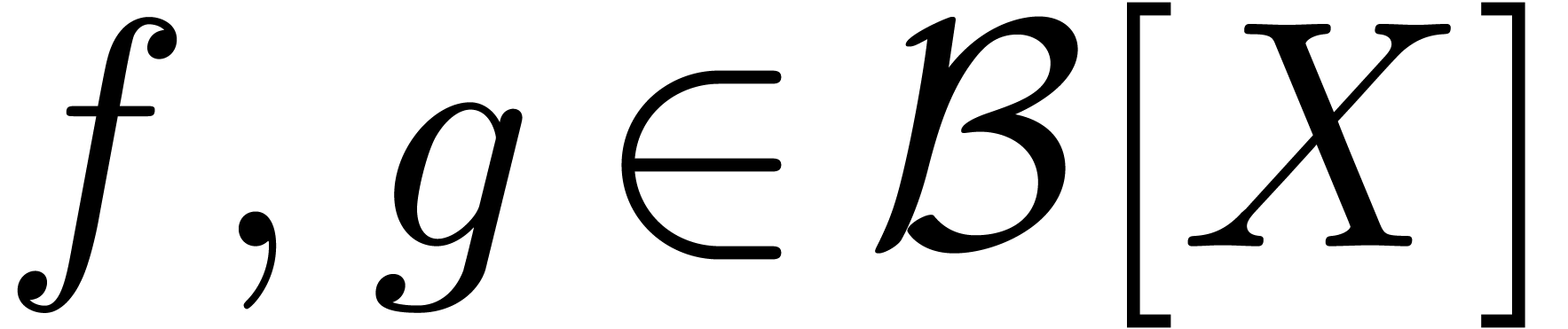 that takes as input polynomials
that takes as input polynomials  of
degree less than , where
of
degree less than , where 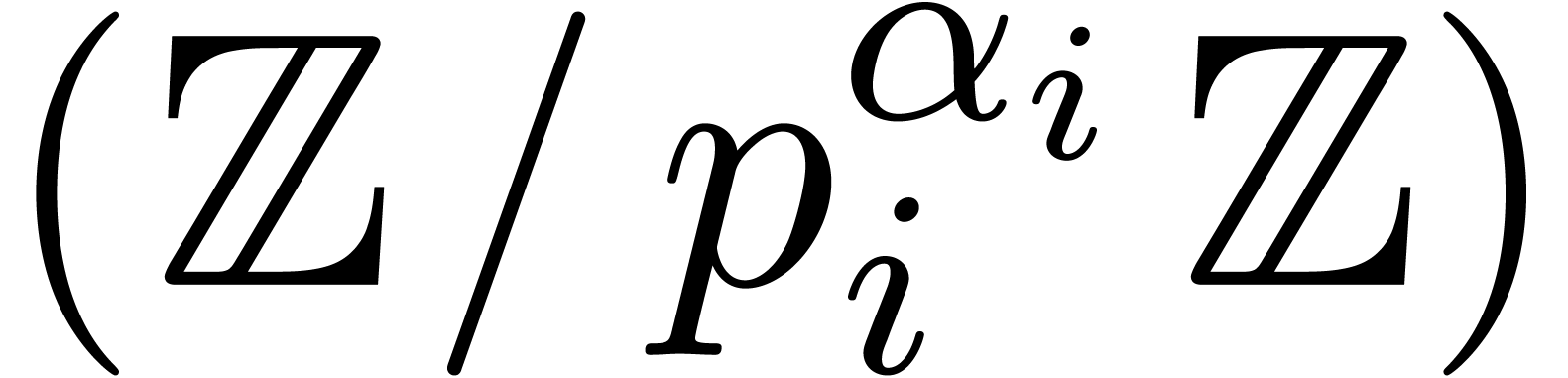 is any
is any  -algebra,
and computes
-algebra,
and computes 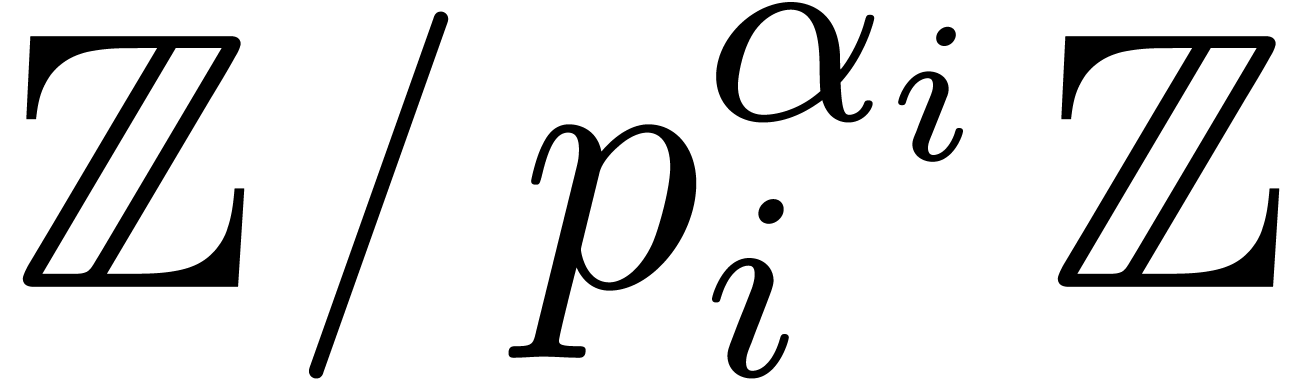 . By replacing
every constant in
. By replacing
every constant in 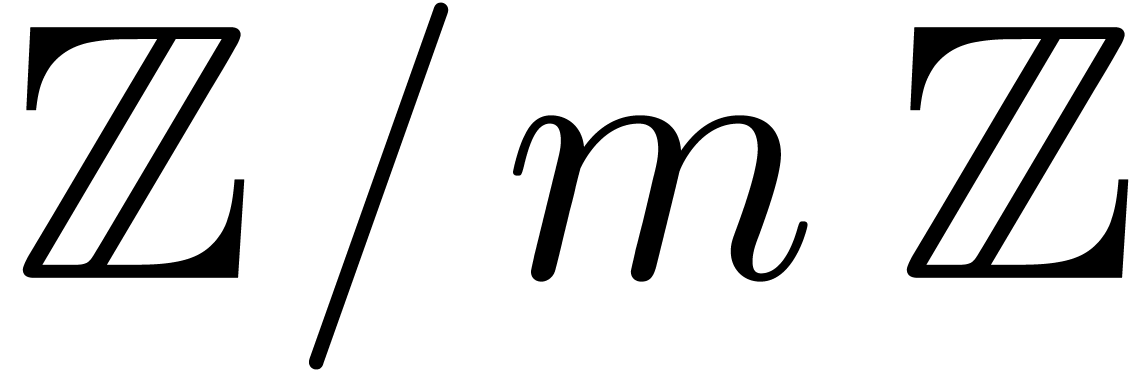 by a compatible constant in
by a compatible constant in
 , we obtain a straight-line
program
, we obtain a straight-line
program 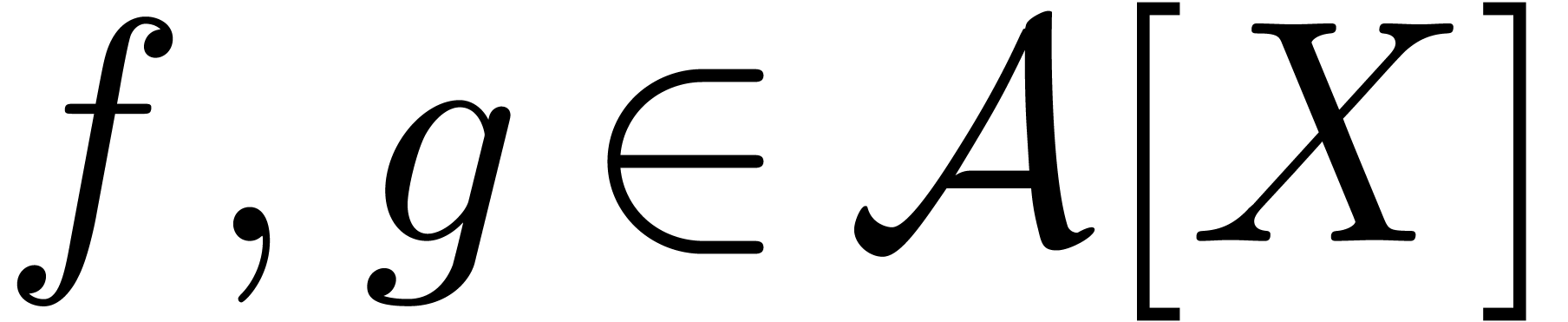 that takes as input
that takes as input 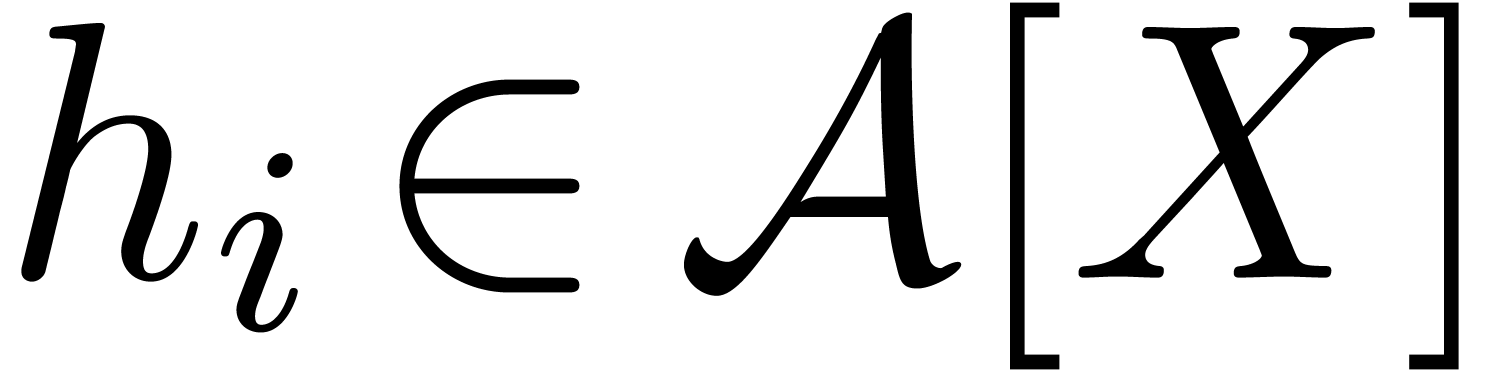 of degree less than , and
computes
of degree less than , and
computes 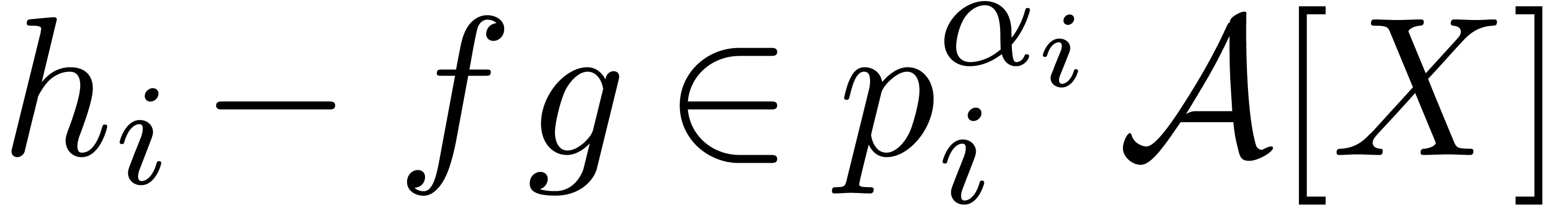 such that
such that 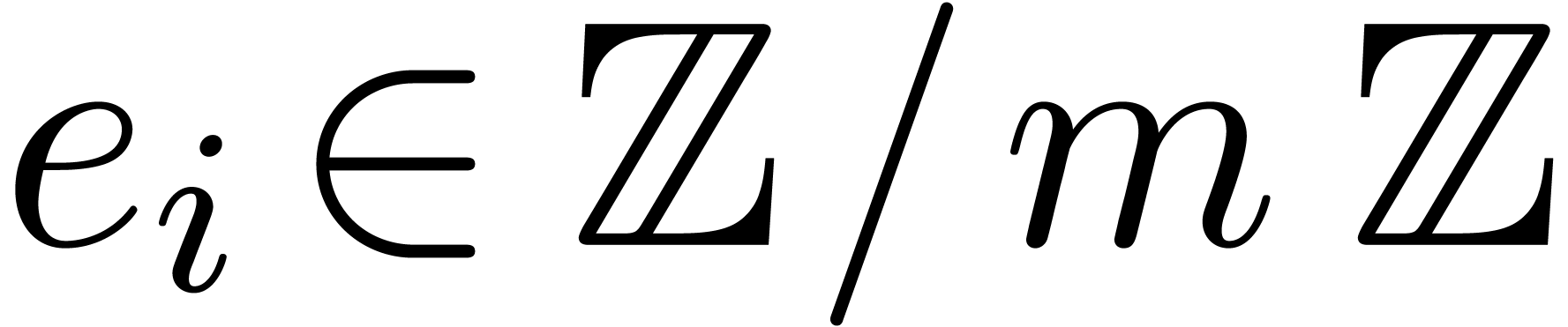 .
By the Chinese remainder theorem we may choose
.
By the Chinese remainder theorem we may choose 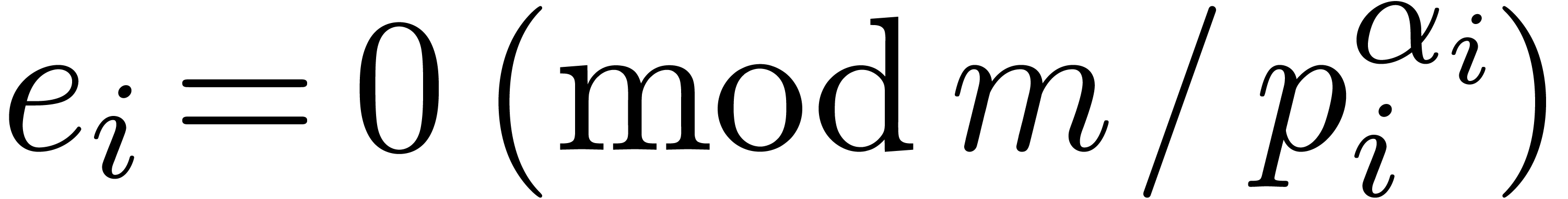 such that
such that  and
and 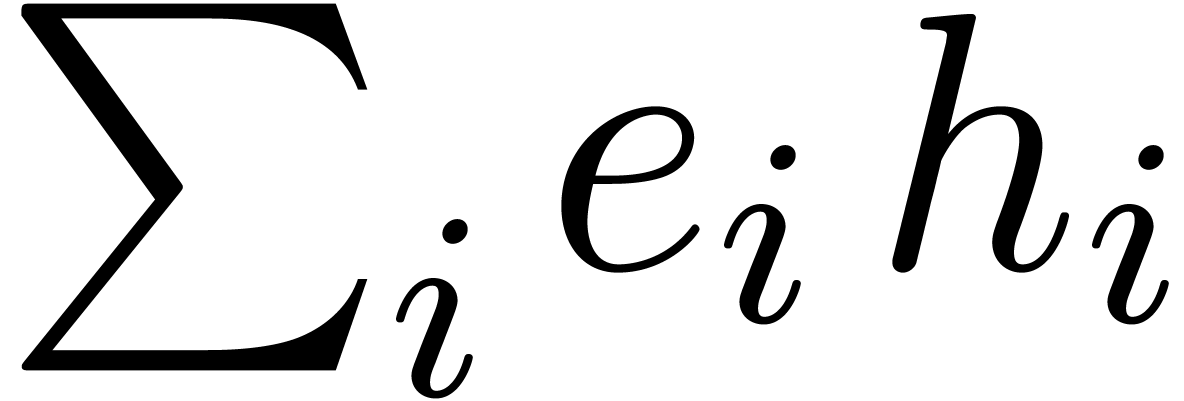 for each
. The linear combination
for each
. The linear combination 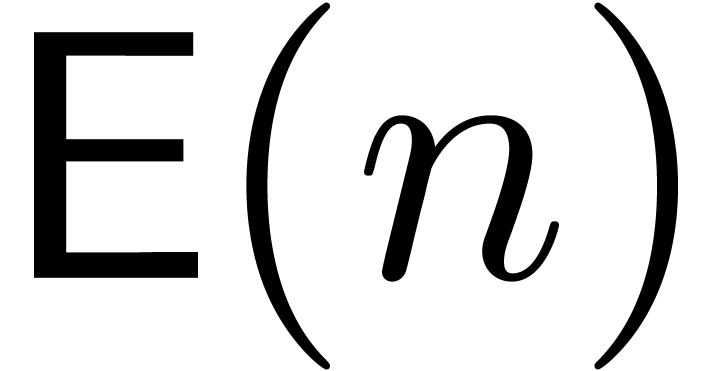 is then equal to in . We conclude that we may multiply
polynomials in using
additions, subtractions and scalar multiplications (by elements of ), and
nonscalar multiplications (i.e., multiplications in ). These bounds are not uniform in , but for each they are
uniform over all -algebras.
is then equal to in . We conclude that we may multiply
polynomials in using
additions, subtractions and scalar multiplications (by elements of ), and
nonscalar multiplications (i.e., multiplications in ). These bounds are not uniform in , but for each they are
uniform over all -algebras.
If we wish to take into account the cost of precomputations, and give a
single algorithm that works uniformly for all
and , we may use a more
refined complexity model such as the BSS model [6]. In this
model, a machine over is, roughly
speaking, a Turing machine in which the tape cells hold elements of
. Actually, we need a
multi-tape version of the model described in [6]. The
machine can perform arithmetic operations on elements of in unit time, but can also manipulate data such as index
variables in the same way as a Turing machine, and must deal with data
layout in the same way as a Turing machine. In this model we obtain
similar bounds to Theorem 9.4, but without uniformity in
. Alternatively, we could
obtain bounds uniform in if we added extra terms
to account for the precomputations.
Another point of view in Theorem 9.4 is that we have
described a new evaluation-interpolation strategy for polynomials
over an -algebra . We refer the reader to [21,
Sections 2.1–2.4] for classical examples of
evaluation-interpolation schemes, and [16] for algorithms
specific to finite fields. Such schemes are characterised by two
quantities: the evaluation/interpolation complexity 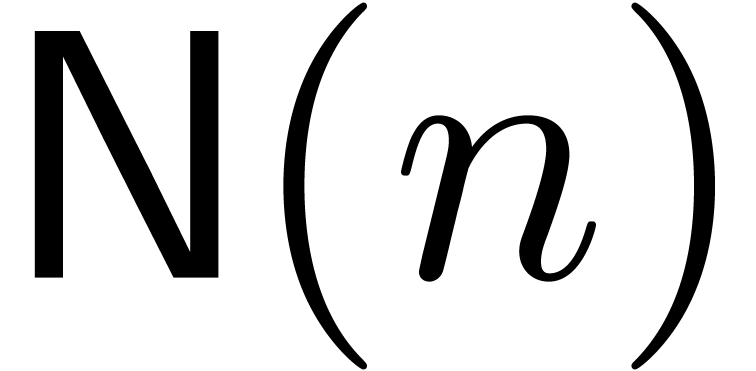 and the number
and the number 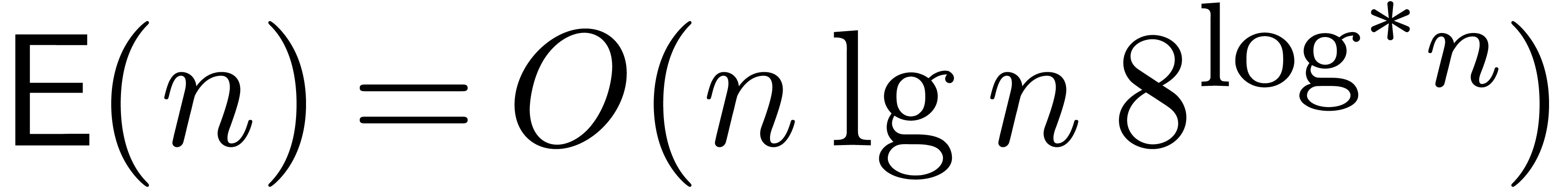 of evaluation points. The new
algorithms yield the bounds
of evaluation points. The new
algorithms yield the bounds 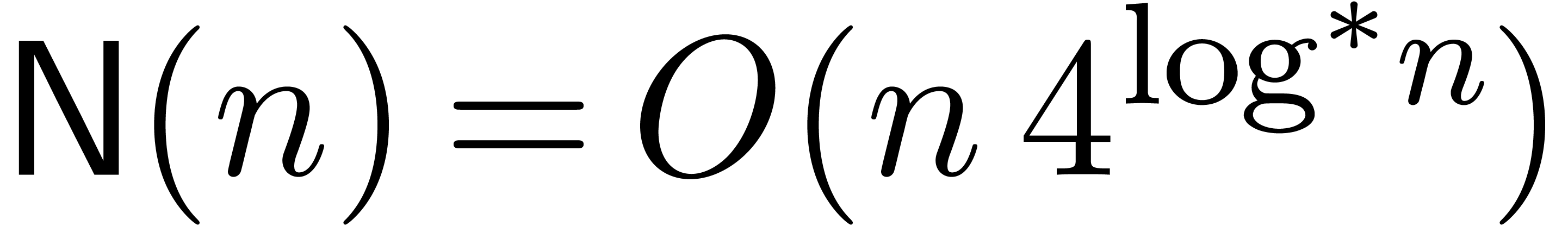 and
and  , and these can be used to prove complexity
bounds for problems more general than polynomial multiplication. For
example, we can multiply
, and these can be used to prove complexity
bounds for problems more general than polynomial multiplication. For
example, we can multiply  matrices with entries
in
matrices with entries
in 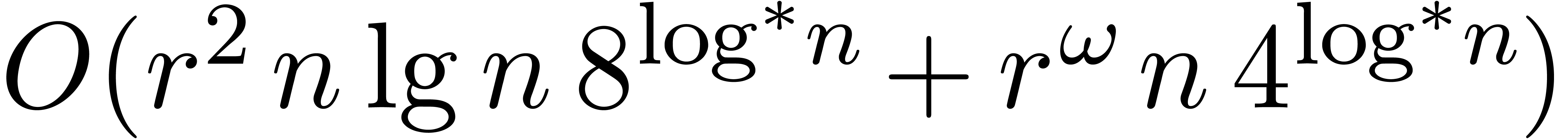 using
using  ring
operations, where is an exponent of matrix
multiplication. One of the main advantages of our algorithms is that
is almost linear, contrary to synthetic FFT
methods [10, 31] derived from
Schönhage–Strassen multiplication [32], which
achieve only
ring
operations, where is an exponent of matrix
multiplication. One of the main advantages of our algorithms is that
is almost linear, contrary to synthetic FFT
methods [10, 31] derived from
Schönhage–Strassen multiplication [32], which
achieve only  .
.
In the setting of bilinear complexity [9, Chapter 14], the
new algorithms do not improve asymptotically on the best known bounds.
For example, it is known [27] that for any
there exist 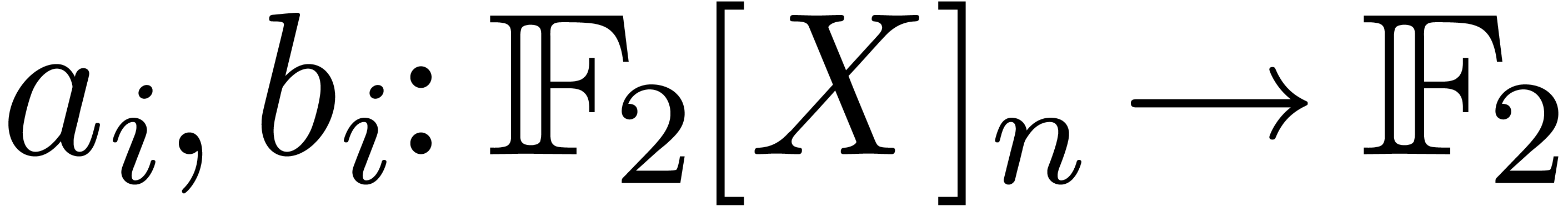 -linear maps
-linear maps 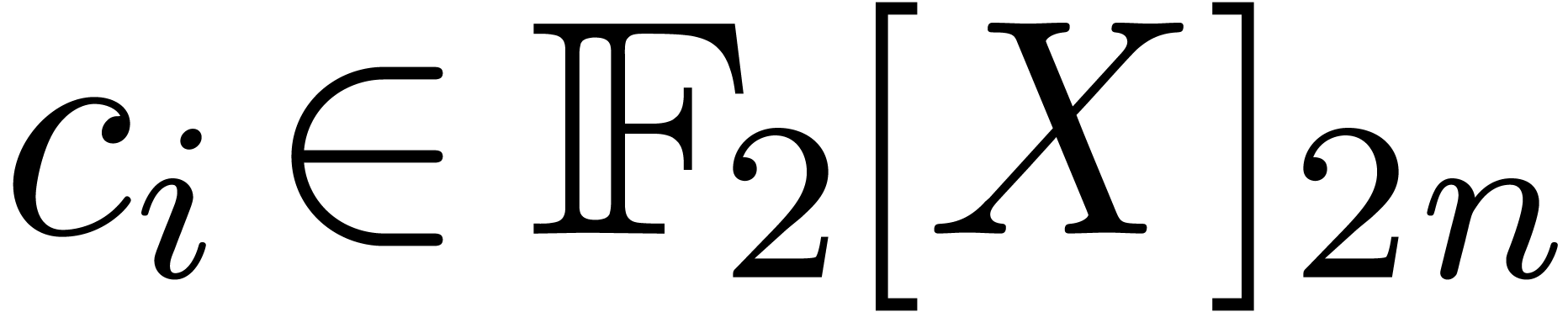 and polynomials
and polynomials  for
for 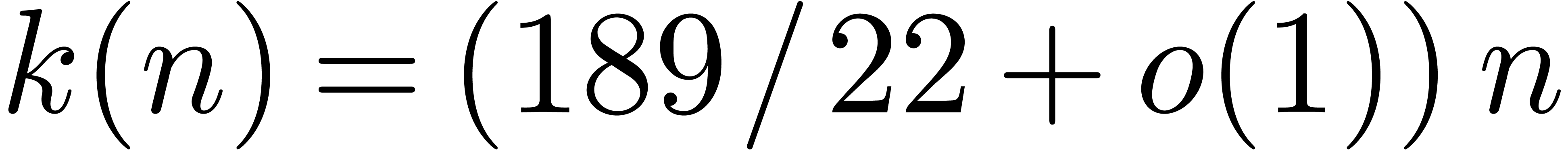 , with
, with 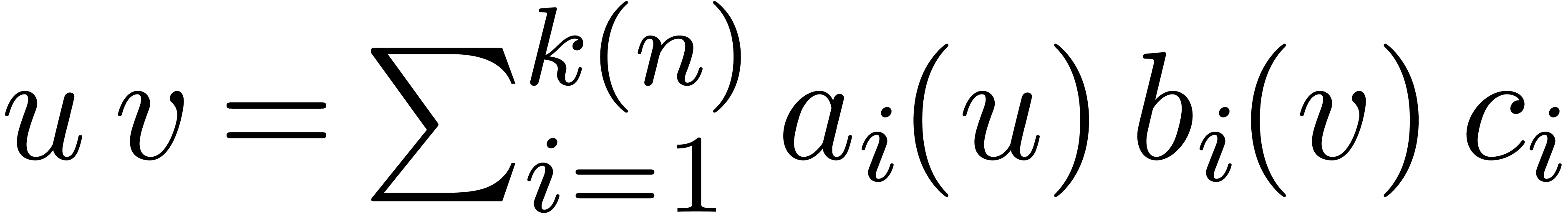 , such that
, such that 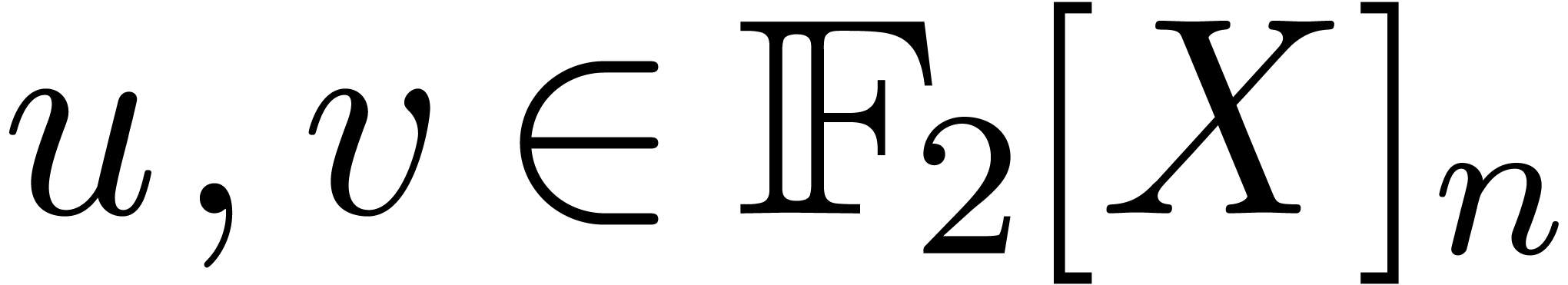 for all
for all 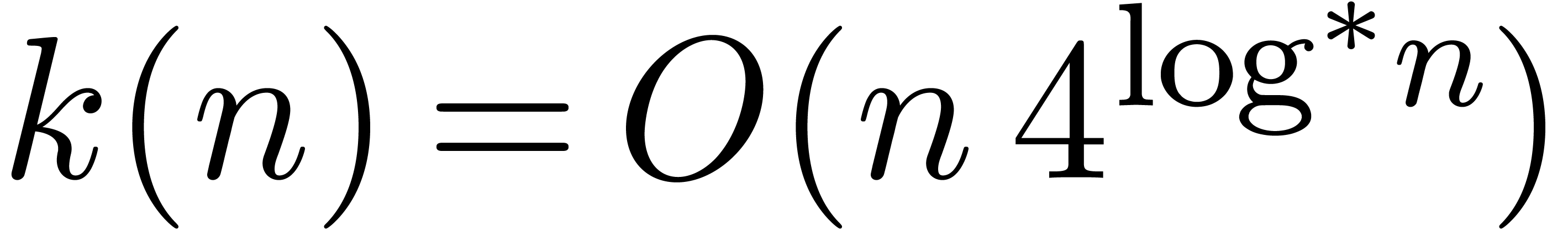 . The new method yields the
asymptotically inferior bound
. The new method yields the
asymptotically inferior bound 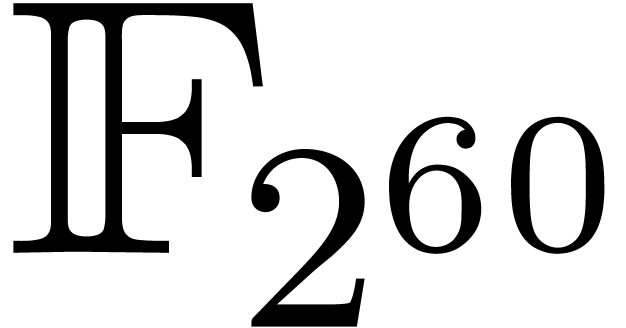 .
Nevertheless, these bounds are asymptotic and do not take into account
that our new algorithm would rather work over (say)
.
Nevertheless, these bounds are asymptotic and do not take into account
that our new algorithm would rather work over (say) 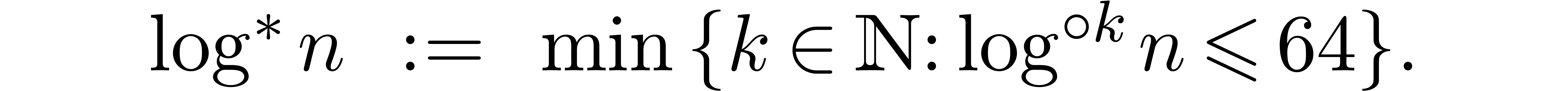 instead of . In practice, the
new method might therefore outperform the bilinear algorithms from [27].
instead of . In practice, the
new method might therefore outperform the bilinear algorithms from [27].
The new complexity bounds have a quite theoretic flavour: in practice,
slowly growing functions such as and really behave as constants. Furthermore, for concrete
applications, it would be more relevant to redefine
as
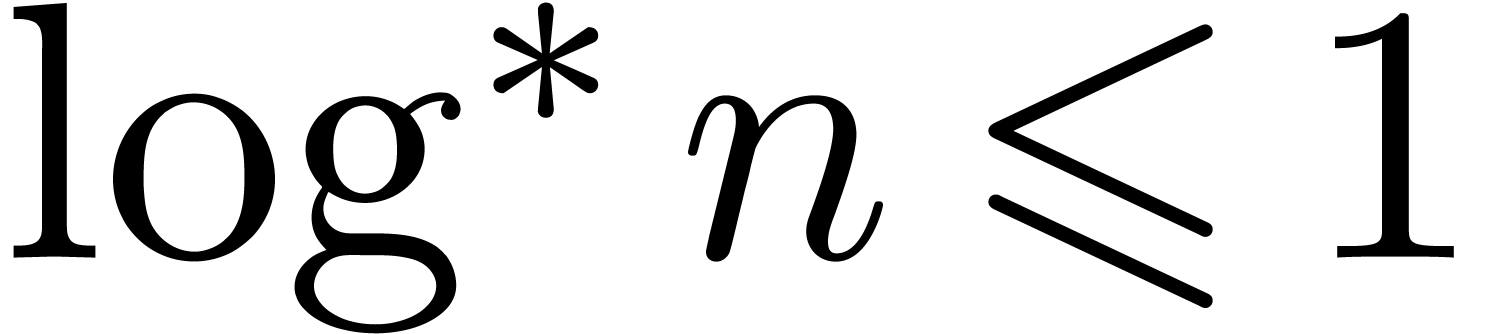
With this definition, we observe that  for all
feasible values of in the foreseeable future.
Nevertheless, we think that variants of the ideas in this paper could
still be useful in practice.
for all
feasible values of in the foreseeable future.
Nevertheless, we think that variants of the ideas in this paper could
still be useful in practice.
Let us briefly sketch how an efficient multiplication algorithm over
could be implemented. Various modern processors
offer a special instruction for the multiplication of two polynomials in
 . The practical translation
of the results from section 4 is to work over the field
. The practical translation
of the results from section 4 is to work over the field
 where
where  .
This has two advantages. First, if we represent elements of by their residues modulo
.
This has two advantages. First, if we represent elements of by their residues modulo  ,
i.e., using a redundant representation, then each multiplication in requires a single hardware multiply instruction,
followed by simple shift and XOR instructions. Second, there exist
primitive roots of unity of high smooth order
,
i.e., using a redundant representation, then each multiplication in requires a single hardware multiply instruction,
followed by simple shift and XOR instructions. Second, there exist
primitive roots of unity of high smooth order 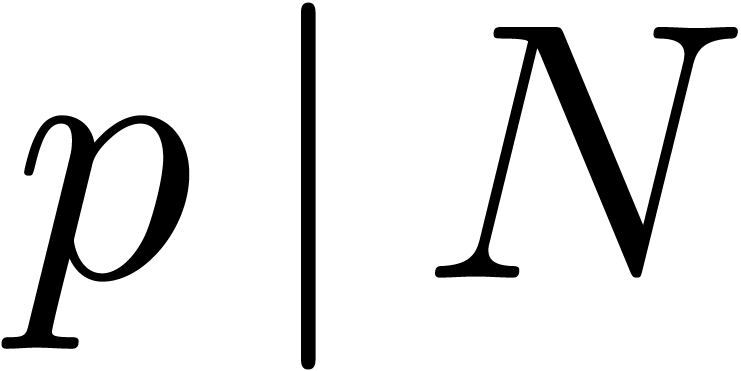 .
.
Transforms of small prime lengths 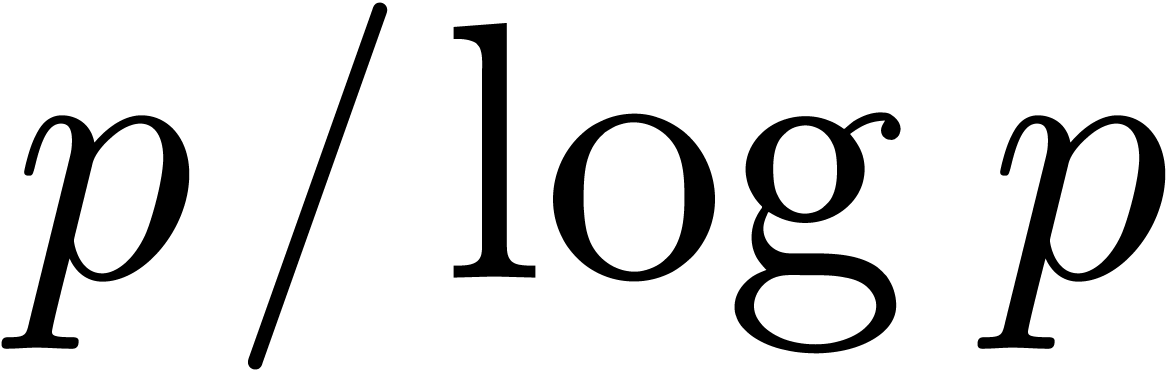 over can be implemented using specialised codelets, similar to
those implemented in FFTW3 [14]. Roughly speaking, the
constant factor of a radix- DFT is
over can be implemented using specialised codelets, similar to
those implemented in FFTW3 [14]. Roughly speaking, the
constant factor of a radix- DFT is  . In our case,
. In our case, 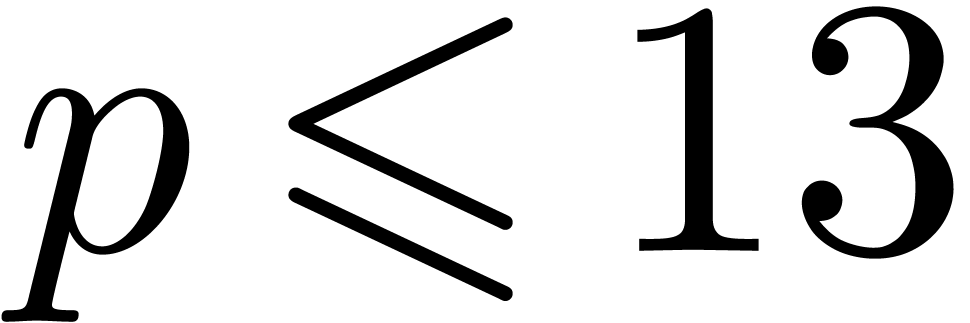 ,
so specialised codelets should remain reasonably efficient for
,
so specialised codelets should remain reasonably efficient for  . Consequently, through the mere
use of such small radices, we obtain efficient algorithms for computing
DFTs of lengths dividing
. Consequently, through the mere
use of such small radices, we obtain efficient algorithms for computing
DFTs of lengths dividing  . To
handle larger primes, we may use any algorithm for converting DFTs to
convolutions. Rather than use Bluestein's algorithm as in the
theoretical portion of the paper, it is more economical in this case to
use Rader's algorithm, which reduces a DFT of length
to a cyclic convolution of length
. To
handle larger primes, we may use any algorithm for converting DFTs to
convolutions. Rather than use Bluestein's algorithm as in the
theoretical portion of the paper, it is more economical in this case to
use Rader's algorithm, which reduces a DFT of length
to a cyclic convolution of length 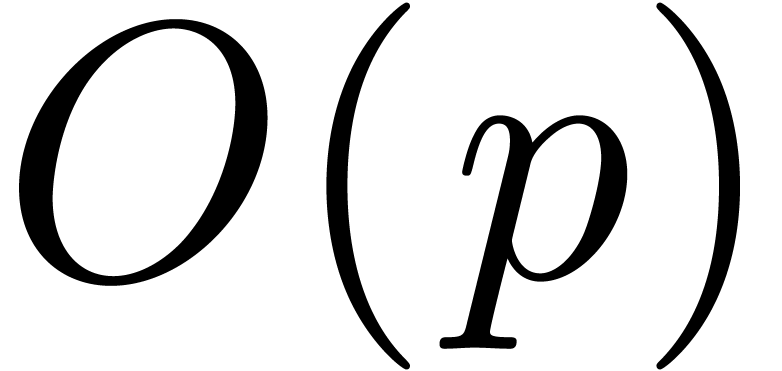 ,
together with
,
together with  additions in
(see also Remark 2.4).
additions in
(see also Remark 2.4).
More precisely, consider the remaining transform lengths  ,
,  ,
,
 ,
,  ,
,  and
and  . We have
. We have  ,
,
 ,
,  ,
,  ,
, 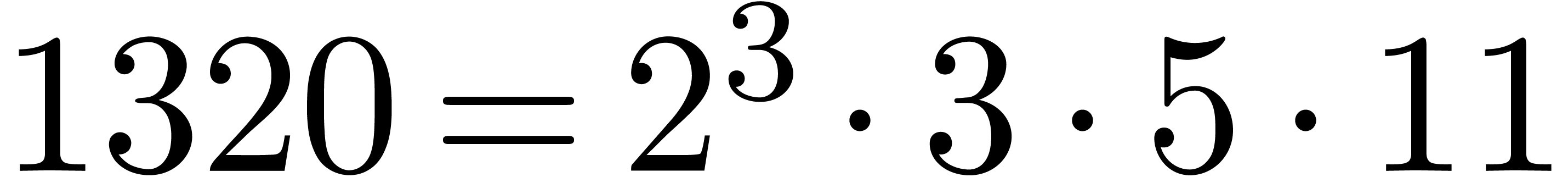 and
and  , so
in each case, the DFT reduces to a two-dimensional convolution of size
, so
in each case, the DFT reduces to a two-dimensional convolution of size
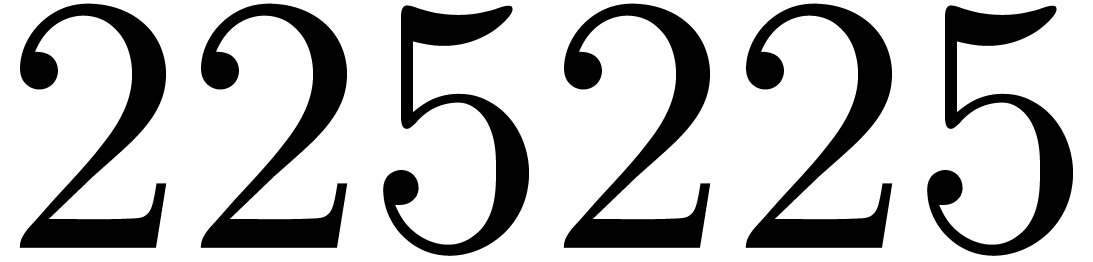 , where
is a divisor of
, where
is a divisor of  and
and  . Such a convolution in turn reduces to
. Such a convolution in turn reduces to 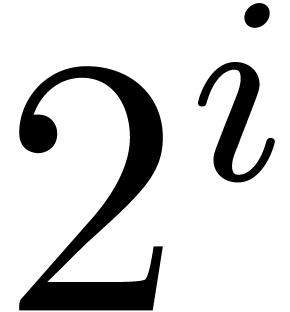 DFTs of length together with convolutions of length
DFTs of length together with convolutions of length  .
The latter cannot be handled using DFTs over , since there are no roots of unity of order , or , but in any case they are all very
short convolutions and could be performed directly, or by using
Karatsuba's algorithm.
.
The latter cannot be handled using DFTs over , since there are no roots of unity of order , or , but in any case they are all very
short convolutions and could be performed directly, or by using
Karatsuba's algorithm.
Transforms of other lengths dividing may be
reduced to these cases via the Cooley–Tukey algorithm. Finally, to
handle arbitrary input lengths efficiently, we may use a mixed-radix
generalisation of the truncated Fourier transform [19, 20].
We also reemphasise the fact that DFTs of this kind can be used as an
evaluation-interpolation technique. This approach is for instance
attractive for the multiplication of polynomial matrices over .
We have not yet implemented any of these algorithms. We expect that much fine-tuning will be necessary to make them most effective in practice. We intend to report on this issue in a future work.
L. M. Adleman and H. W. Lenstra Jr. Finding irreducible polynomials over finite fields. In Proceedings of the eighteenth annual ACM symposium on Theory of computing, STOC '86, pages 350–355. ACM Press, 1986.
L. M. Adleman, C. Pomerance, and R. S. Rumely. On distinguishing prime numbers from composite numbers. Annals of Math., 117:173–206, 1983.
A. V. Aho, J. E. Hopcroft, and J. D. Ullman. The design and analysis of computer algorithms. Addison-Wesley, 1974.
R. C. Baker, G. Harman, and J. Pintz. The difference between consecutive primes. II. Proc. London Math. Soc. (3), 83(3):532–562, 2001.
L. I. Bluestein. A linear filtering approach to the computation of discrete Fourier transform. IEEE Transactions on Audio and Electroacoustics, 18(4):451–455, 1970.
L. Blum, F. Cucker, M. Shub, and S. Smale. Complexity and real computation. Springer-Verlag, 1998.
A. Bostan, P. Gaudry, and É. Schost. Linear recurrences with polynomial coefficients and application to integer factorization and Cartier-Manin operator. SIAM J. Comput., 36:1777–1806, 2007.
R. P. Brent. Fast multiple-precision evaluation of elementary functions. J. Assoc. Comput. Mach., 23(2):242–251, 1976.
P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic complexity theory. Springer-Verlag, 1997.
D. G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Infor., 28:693–701, 1991.
H. Cohen, G. Frey, R. Avanzi, Ch. Doche, T. Lange, K. Nguyen, and F. Vercauteren, editors. Handbook of elliptic and hyperelliptic curve cryptography. Discrete Mathematics and its Applications. Chapman & Hall/CRC, Boca Raton, FL, 2006.
J. W. Cooley and J. W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
R. Crandall and B. Fagin. Discrete weighted transforms and large-integer arithmetic. Math. Comp., 62(205):305–324, 1994.
M. Frigo and S. G. Johnson. The design and implementation of FFTW3. Proc. IEEE, 93(2):216–231, 2005.
M. Fürer. Faster integer multiplication. In Proceedings of the Thirty-Ninth ACM Symposium on Theory of Computing, STOC 2007, pages 57–66, New York, NY, USA, 2007. ACM Press.
S. Gao and T. Mateer. Additive fast Fourier transforms over finite fields. IEEE Trans. Inform. Theory, 56(12):6265–6272, 2010.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, 2nd edition, 2002.
D. Harvey, J. van der Hoeven, and G. Lecerf. Even faster integer multiplication. Technical report, HAL, 2014. http://hal.archives-ouvertes.fr.
J. van der Hoeven. The truncated Fourier transform and applications. In J. Gutierrez, editor, Proc. ISSAC 2004, pages 290–296, Univ. of Cantabria, Santander, Spain, July 4–7 2004.
J. van der Hoeven. Notes on the Truncated Fourier Transform. Technical Report 2005-5, Université Paris-Sud, Orsay, France, 2005.
J. van der Hoeven. Newton's method and FFT trading. J. Symbolic Comput., 45(8):857–878, 2010.
D. E. Knuth. The art of computer programming, volume 3: Sorting and Searching. Addison-Wesley, Reading, MA, 1998.
H. W. Lenstra, Jr. On Artin's conjecture and Euclid's algorithm in global fields. Invent. Math., 42:201–224, 1977.
P. Moree. On primes in arithmetic progression having a prescribed primitive root. J. Number Theory, 78(1):85–98, 1999.
P. Moree. Artin's primitive root conjecture—a survey. Integers, 12(6):1305–1416, 2012.
C. H. Papadimitriou. Computational Complexity. Addison-Wesley, 1994.
J. Pieltant and H. Randriam. New uniform and asymptotic upper bounds on the tensor rank of multiplication in extensions of finite fields. Math. Comp., 2014. To appear.
C. Pomerance. Recent developments in primality testing. Math. Intelligencer, 3(3):97–105, 1980/81.
C. M. Rader. Discrete Fourier transforms when the number of data samples is prime. Proc. IEEE, 56(6):1107–1108, June 1968.
K. R. Rao, D. N. Kim, and J. J. Hwang. Fast Fourier Transform - Algorithms and Applications. Signals and Communication Technology. Springer-Verlag, 2010.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Infor., 7:395–398, 1977.
A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.
V. Shoup. New algorithms for finding irreducible polynomials over finite fields. Math. Comp., 189:435–447, 1990.
V. Shoup. Searching for primitive roots in finite fields. Math. Comp., 58:369–380, 1992.
S. Wagstaff. Divisors of Mersenne numbers. Math. Comp., 40(161):385–397, 1983.
L. C. Washington. Introduction to cyclotomic fields, volume 83 of Graduate Texts in Mathematics. Springer-Verlag, New York, second edition, 1997.
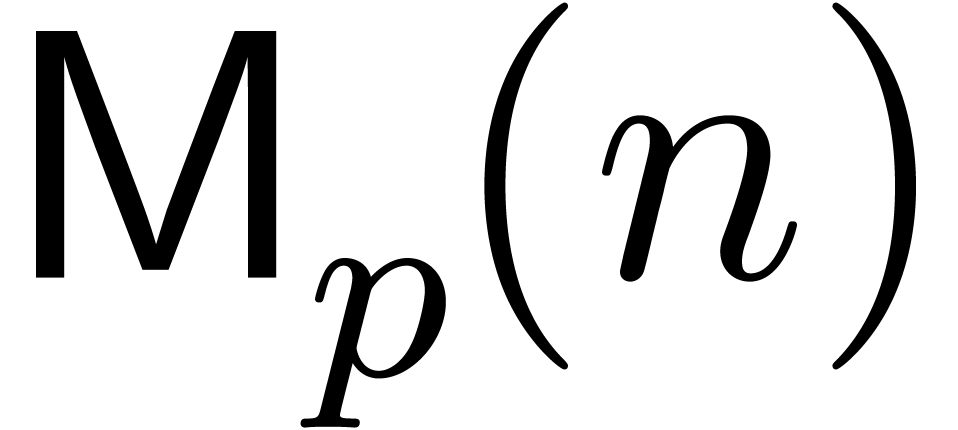 denote the bit complexity of multiplying two polynomials in
denote the bit complexity of multiplying two polynomials in 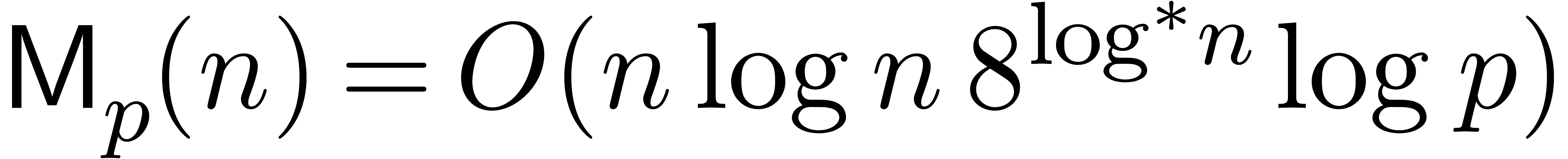 ,
,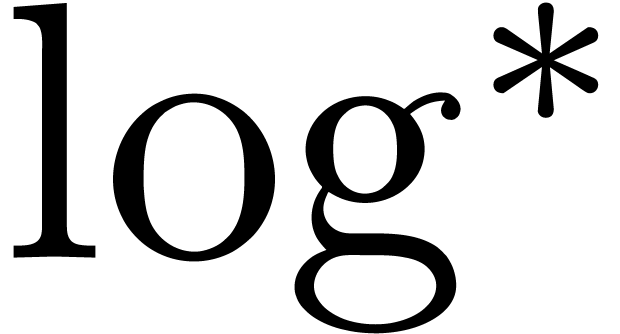 is the iterated logarithm. This is the first known
Fürer-type complexity bound for
is the iterated logarithm. This is the first known
Fürer-type complexity bound for 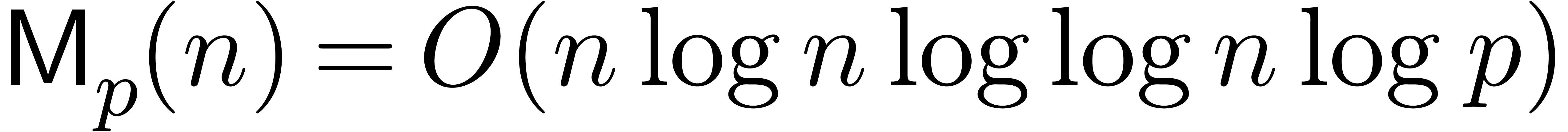 .
.
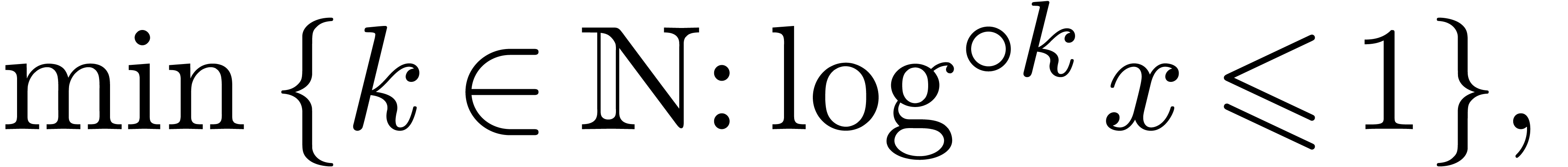
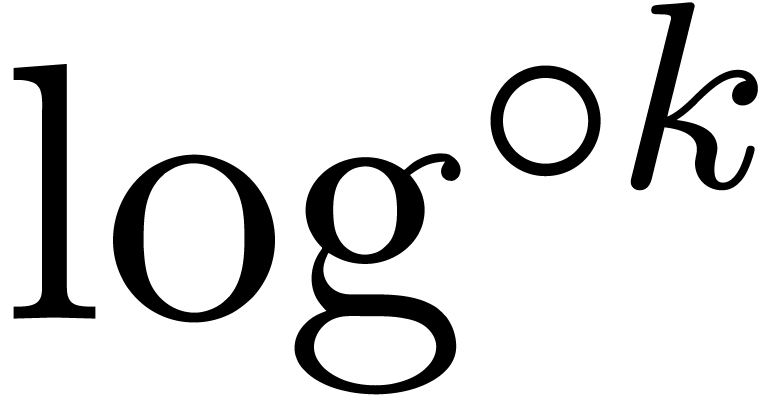
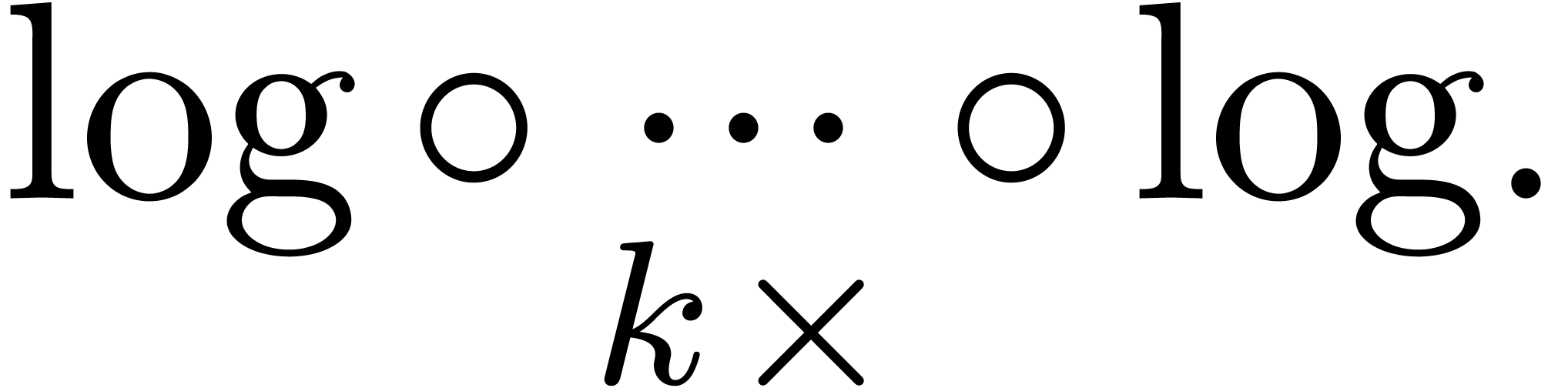
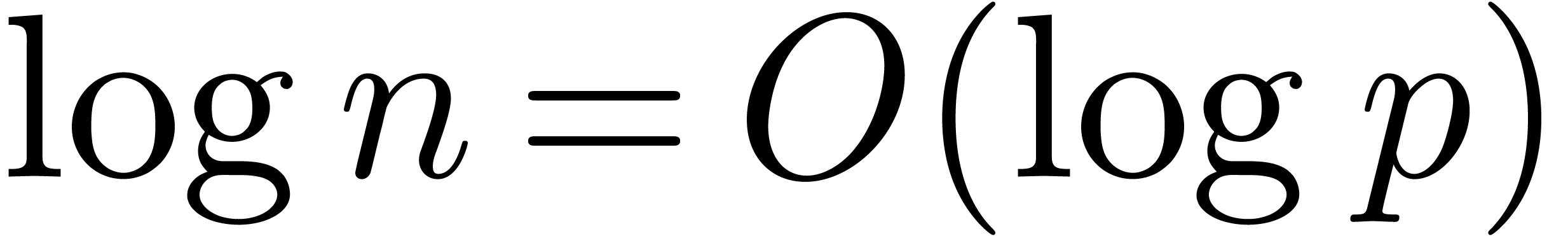
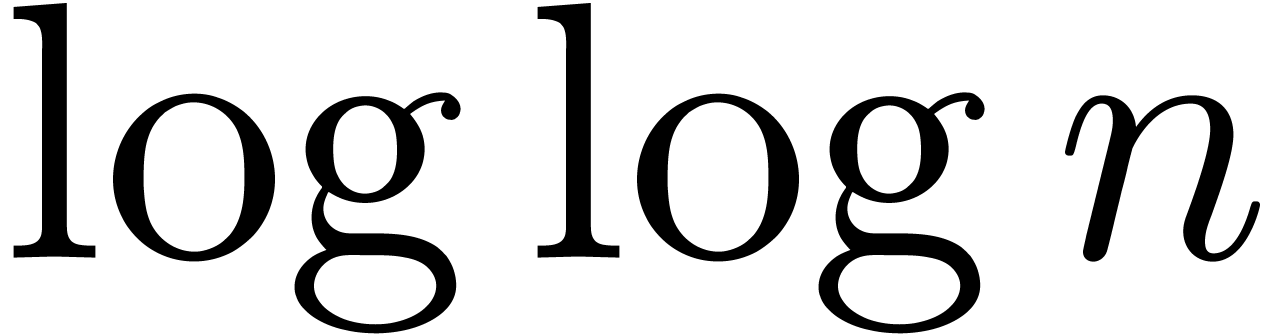
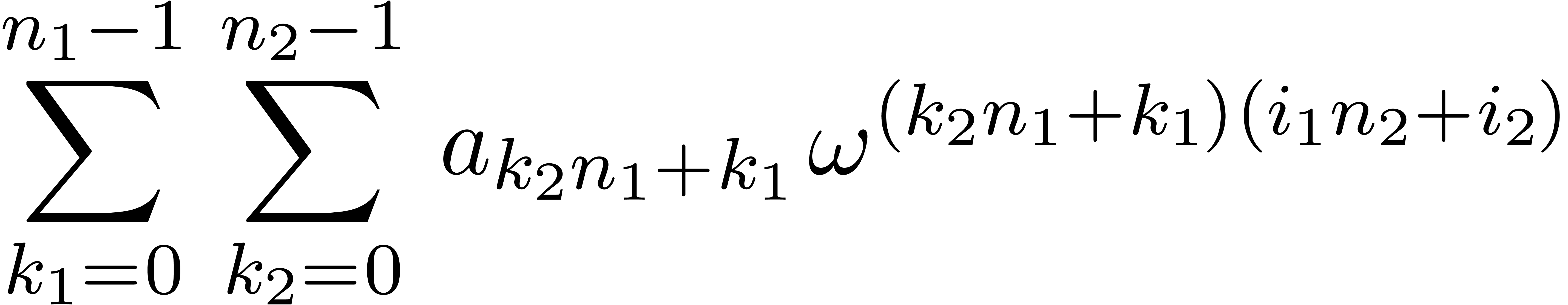

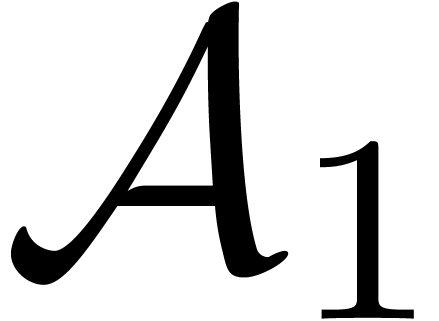

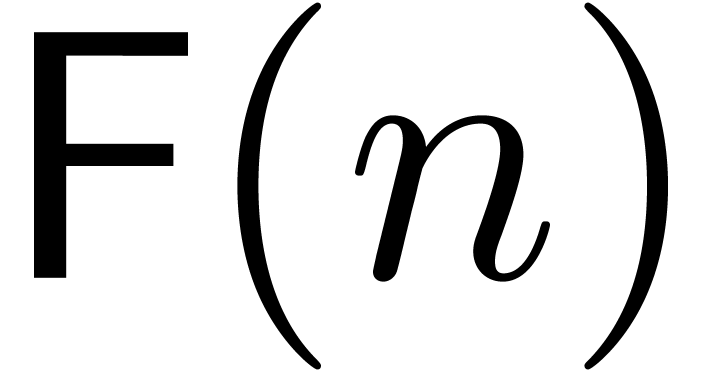
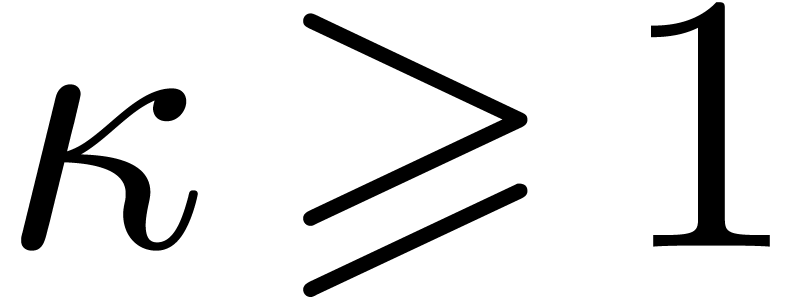
 .
. such that
for any integer
such that
for any integer 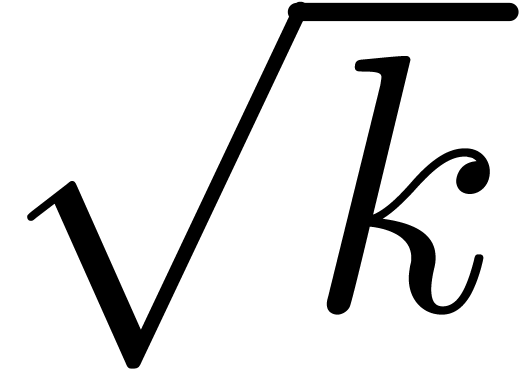
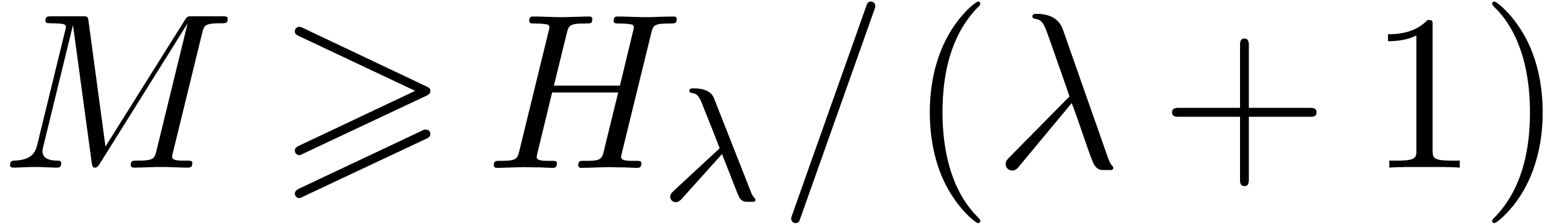 .
.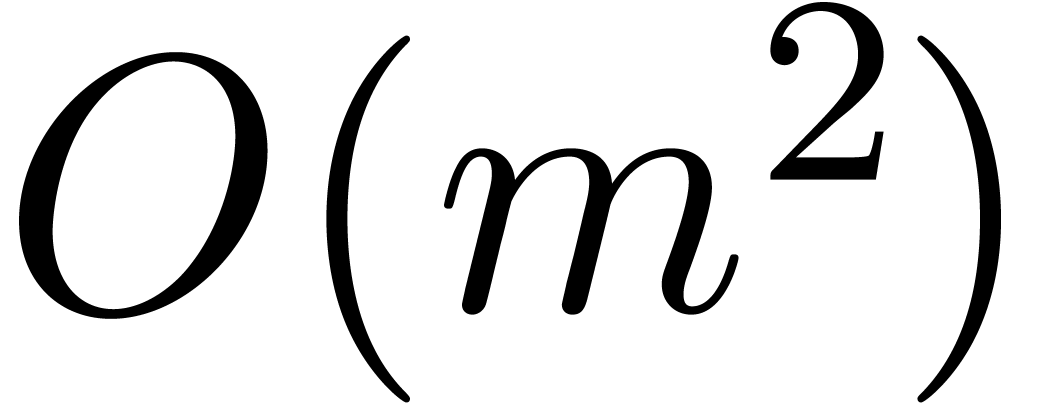 .
.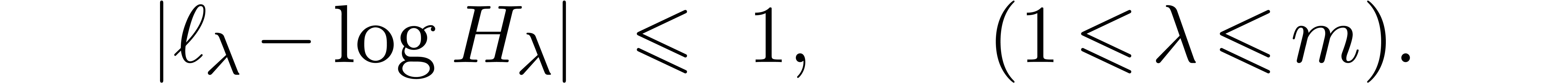 with
with
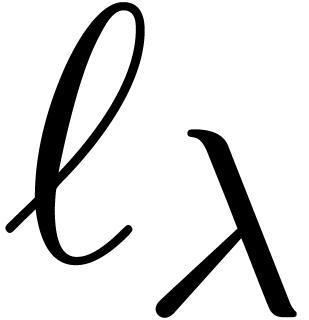
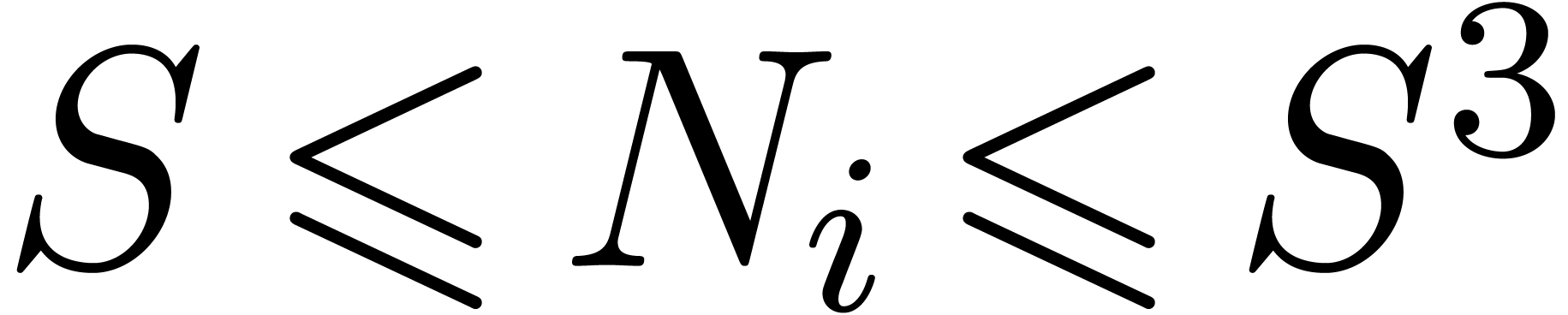 .
.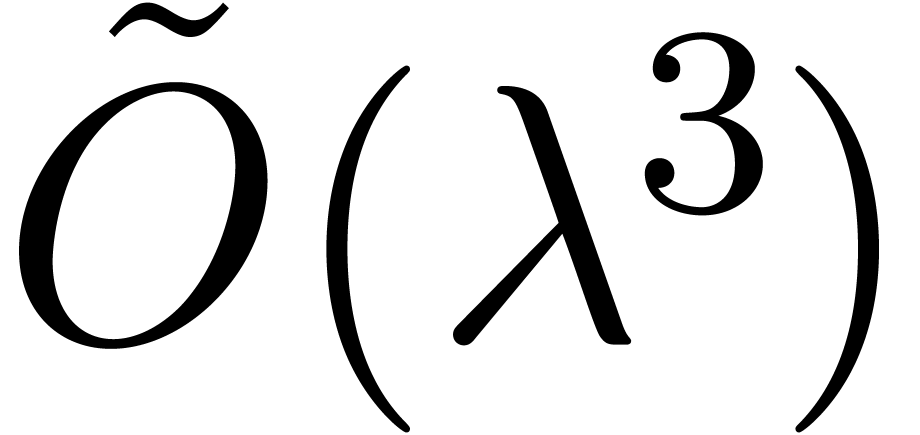 for all
for all 

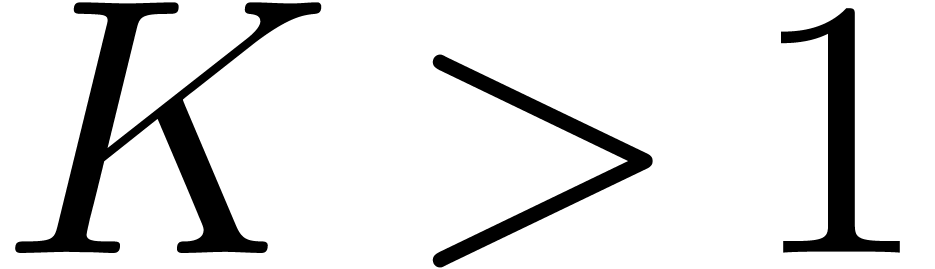
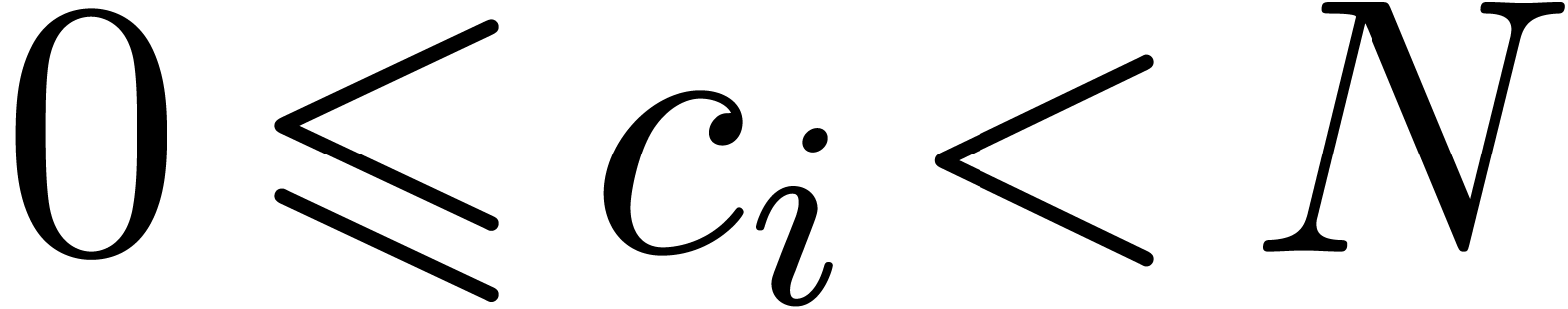
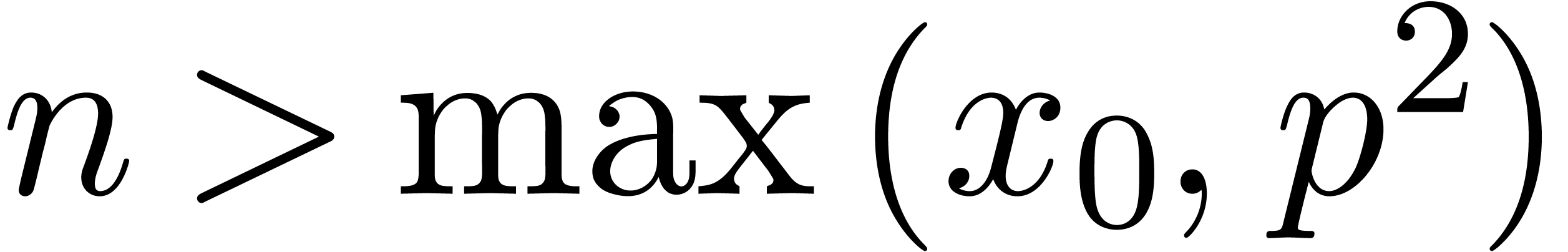
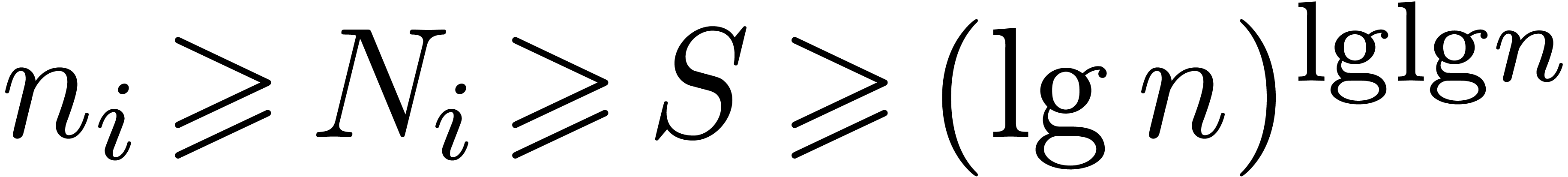
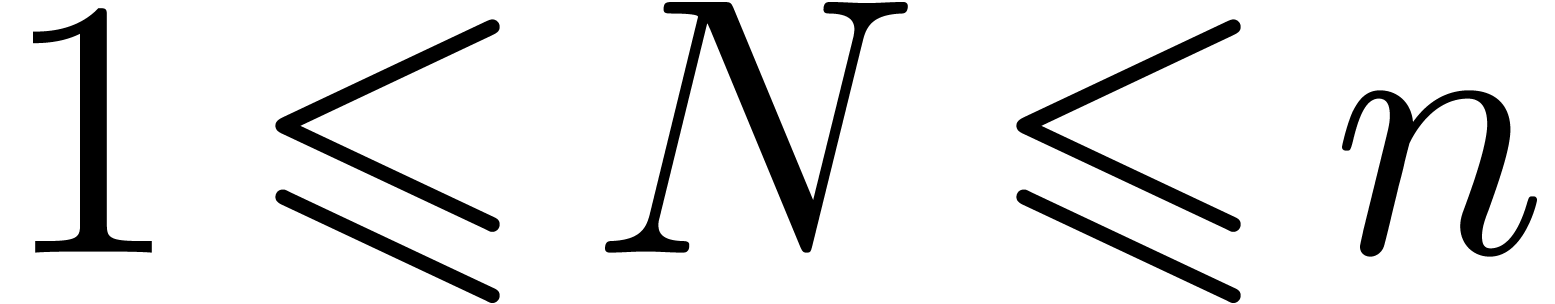
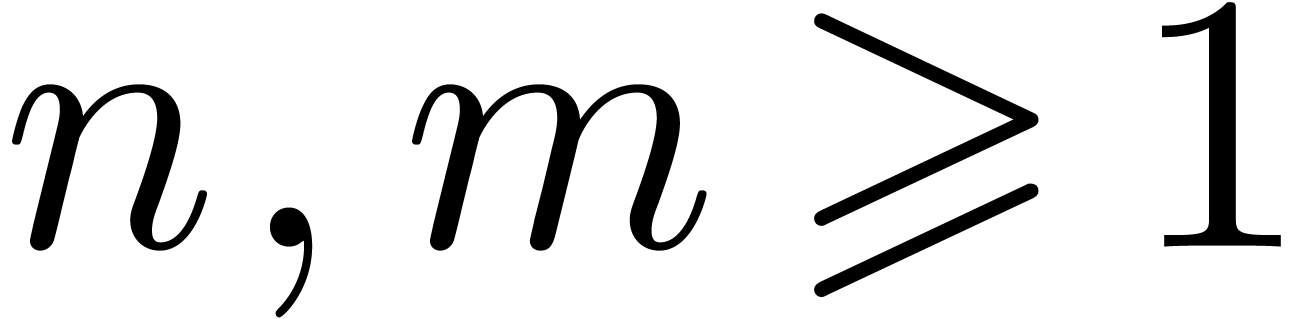
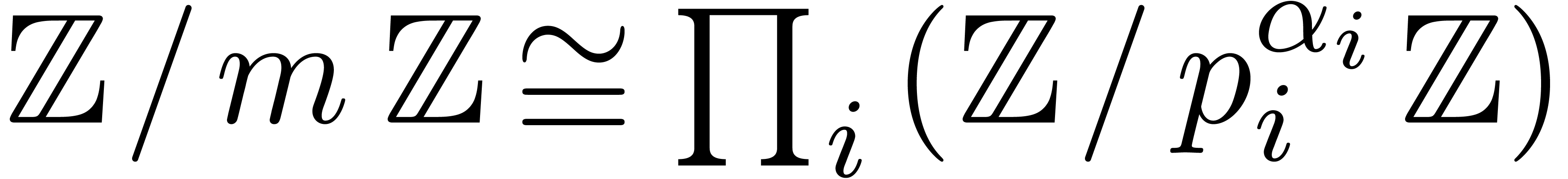 .
.