Newton's method and FFT trading |
|
| March 13, 2010 |
|
 . This work has
been supported by the ANR
. This work has
been supported by the ANR
Let
|
Let 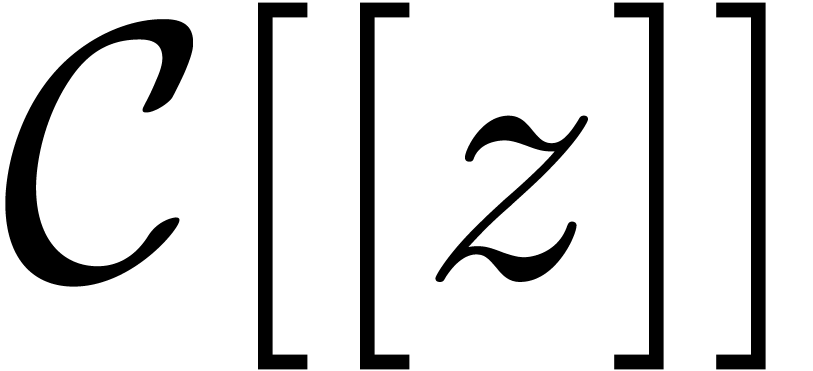 be the ring of power series over an
effective ring
be the ring of power series over an
effective ring 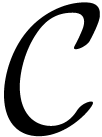 . It will be
convenient to assume that
. It will be
convenient to assume that  .
In fact, it will suffice that all natural numbers up to the desired
series expansion order can be inverted in .
In this paper, we are concerned with the efficient resolution of
implicit equations over .
Such an equation may be presented in fixed-point form as
.
In fact, it will suffice that all natural numbers up to the desired
series expansion order can be inverted in .
In this paper, we are concerned with the efficient resolution of
implicit equations over .
Such an equation may be presented in fixed-point form as
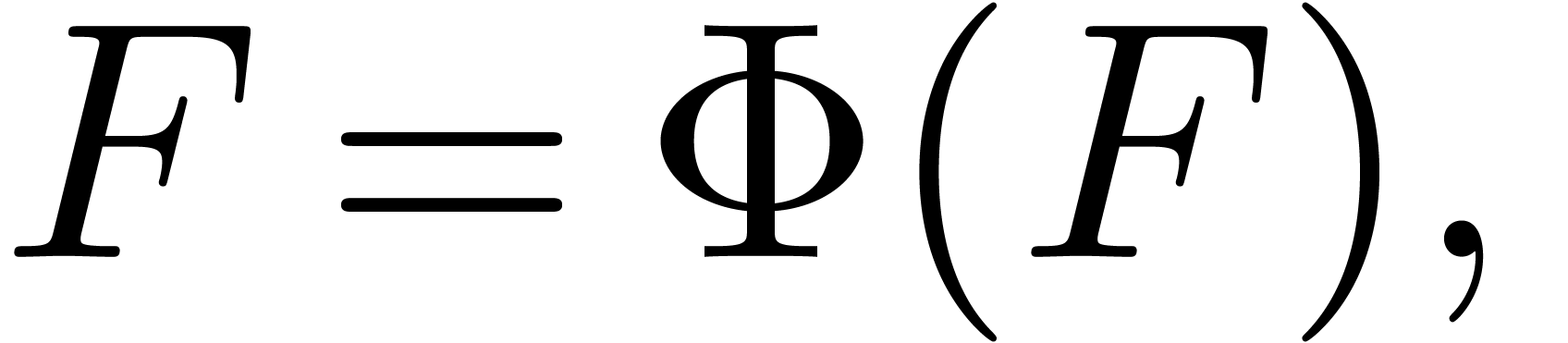 |
(1) |
where  is an indeterminate vector in
is an indeterminate vector in 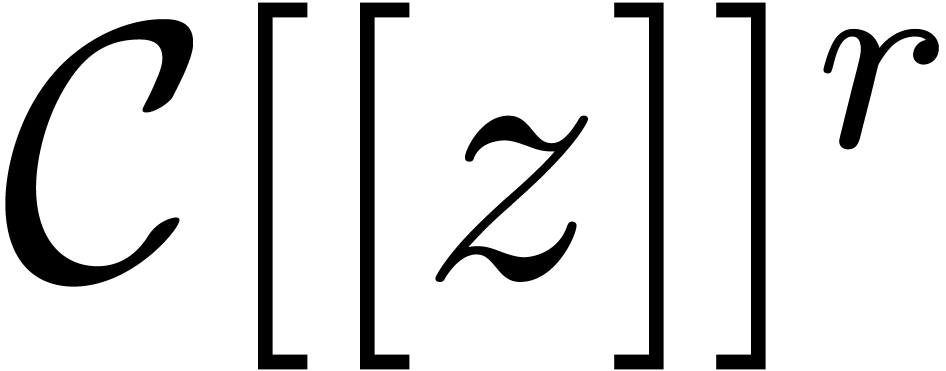 with
with 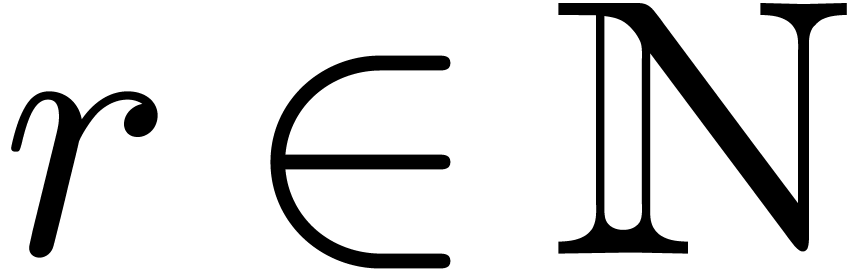 . The
operator
. The
operator  is constructed using classical
operations like addition, multiplication, integration or postcomposition
with a series
is constructed using classical
operations like addition, multiplication, integration or postcomposition
with a series 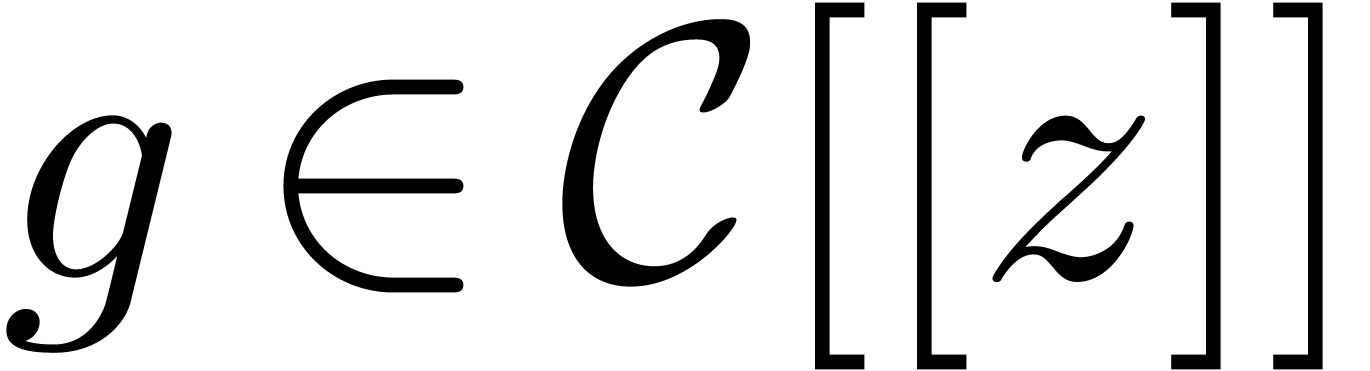 with
with  .
In addition, we require that the coefficient
.
In addition, we require that the coefficient 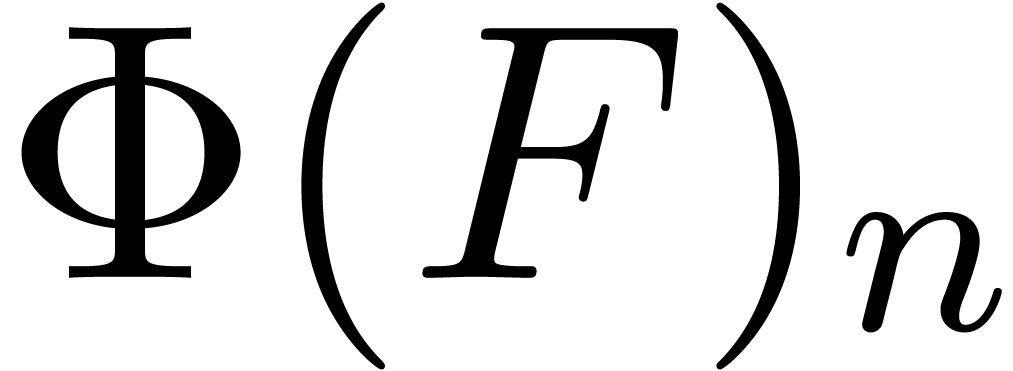 of
of
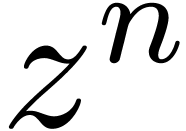 in
in  depends only on
coefficients
depends only on
coefficients 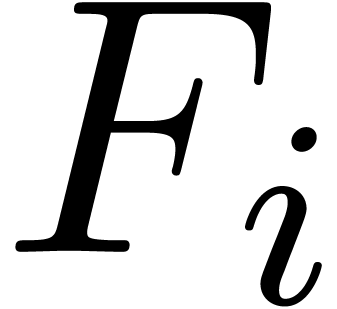 with
with 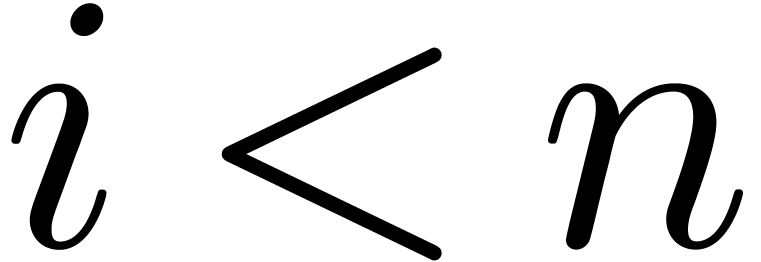 ,
which allows for the recursive determination of all coefficients.
,
which allows for the recursive determination of all coefficients.
In particular, linear and algebraic differential equations may be put into the form (1). Indeed, given a linear differential system
where  is an
is an  matrix with
coefficients in , we may take
matrix with
coefficients in , we may take
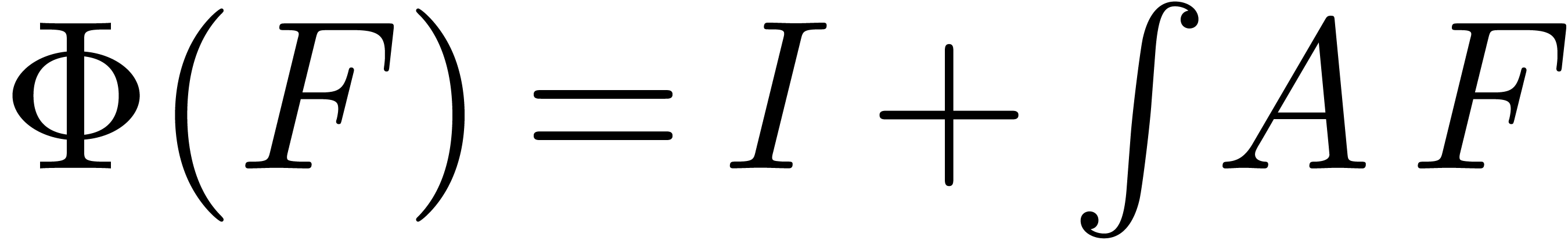 . Similarly, if
. Similarly, if  is a tuple of
is a tuple of  polynomials in
polynomials in 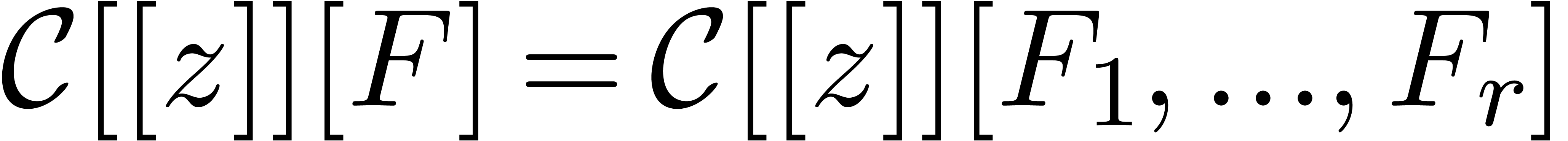 , then the initial value problem
, then the initial value problem
may be put in the form (1) by taking 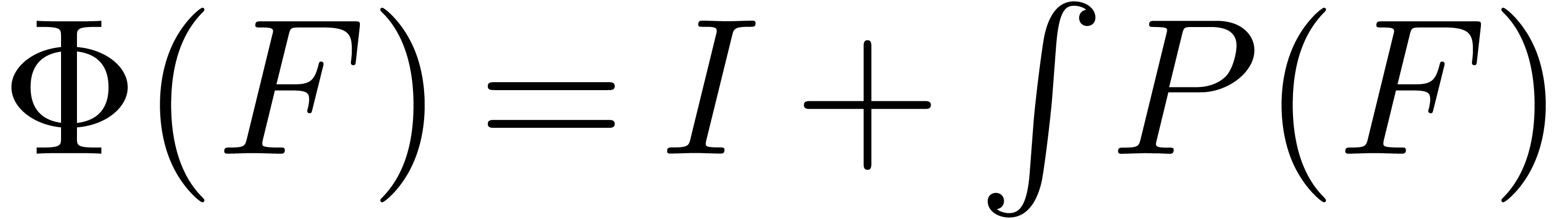 .
.
For our complexity results, and unless stated otherwise, we will always
assume that polynomials are multiplied using evaluation-interpolation.
If contains all 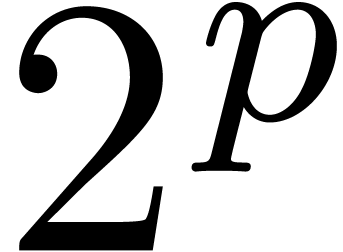 -th
roots of unity with
-th
roots of unity with 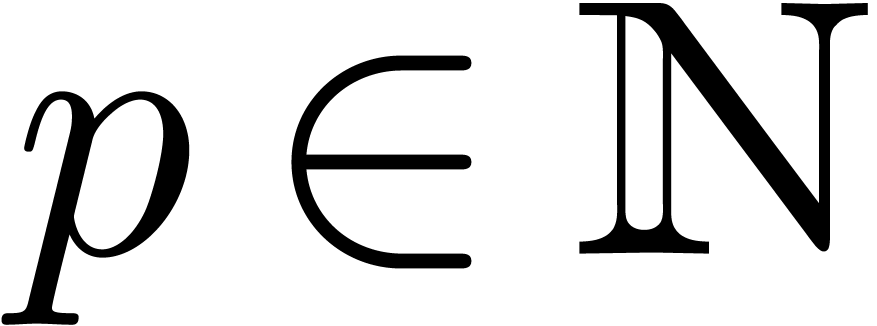 , then it
is classical that two polynomials of degrees
, then it
is classical that two polynomials of degrees 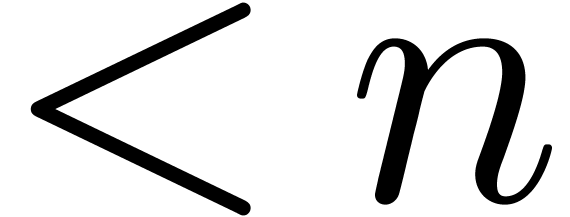 can
be multiplied using
can
be multiplied using 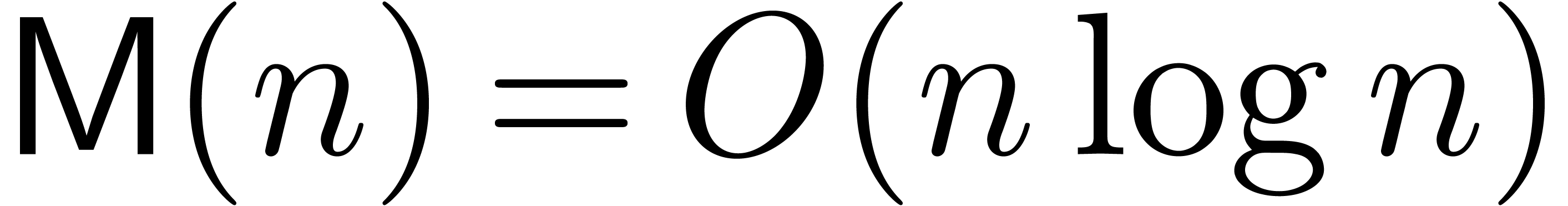 operations over , using the fast Fourier transform [CT65].
In general, such roots of unity can be added artificially [SS71,
CK91, vdH02a] and the complexity becomes
operations over , using the fast Fourier transform [CT65].
In general, such roots of unity can be added artificially [SS71,
CK91, vdH02a] and the complexity becomes 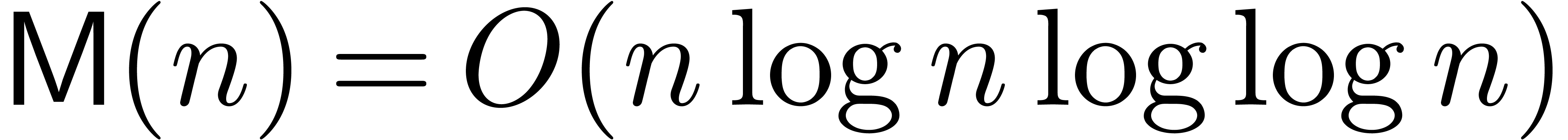 . We will respectively refer to
these two cases as the standard and the synthetic FFT
models. More details about evaluation-interpolation will be provided in
section 2.
. We will respectively refer to
these two cases as the standard and the synthetic FFT
models. More details about evaluation-interpolation will be provided in
section 2.
Let 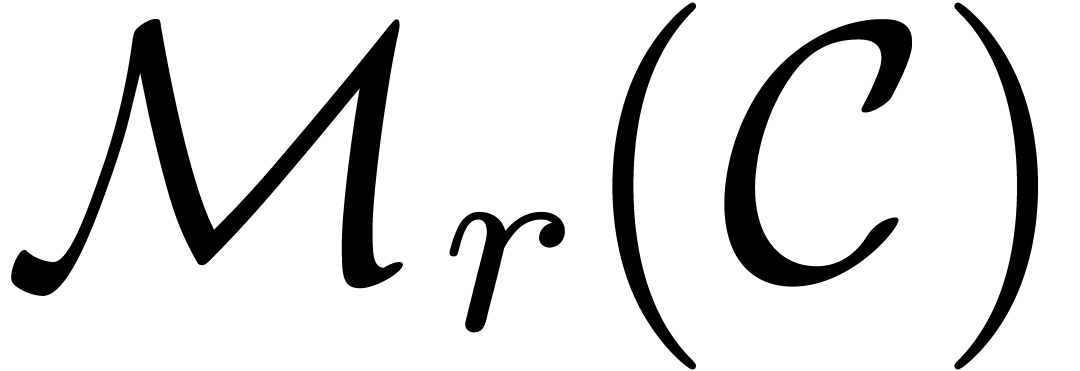 be the set of
matrices over . It is
classical that two matrices in can be multiplied
in time
be the set of
matrices over . It is
classical that two matrices in can be multiplied
in time 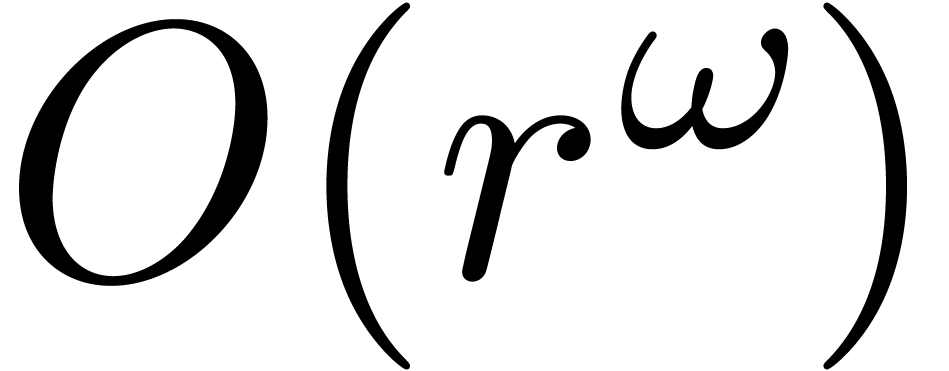 with
with 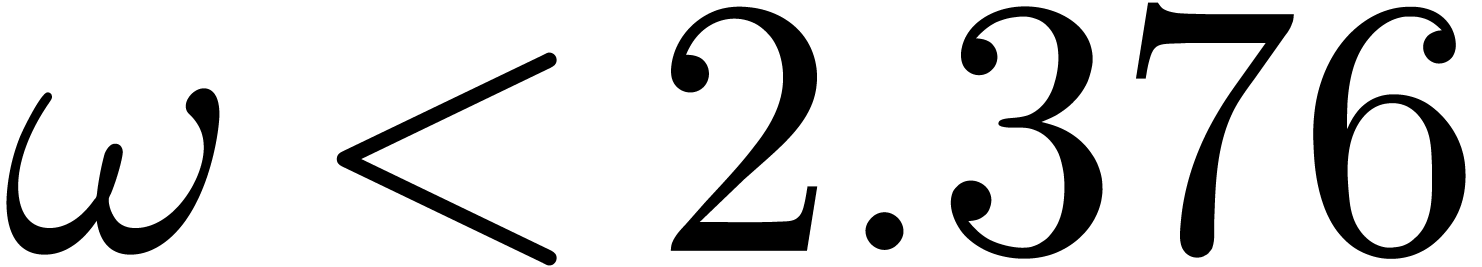 [Str69,
Pan84, CW87]. We will denote by
[Str69,
Pan84, CW87]. We will denote by 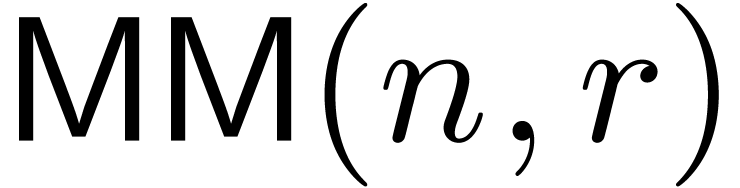 the cost of multiplying two polynomials of degrees with coefficients in .
When using evaluation-interpolation in the standard FFT model, one has
the cost of multiplying two polynomials of degrees with coefficients in .
When using evaluation-interpolation in the standard FFT model, one has
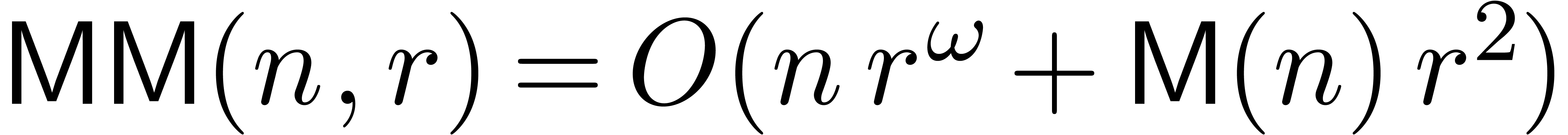 and
and 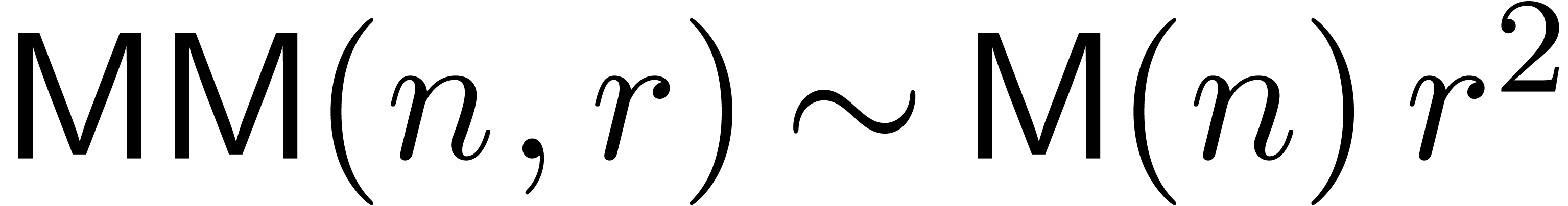 if
if 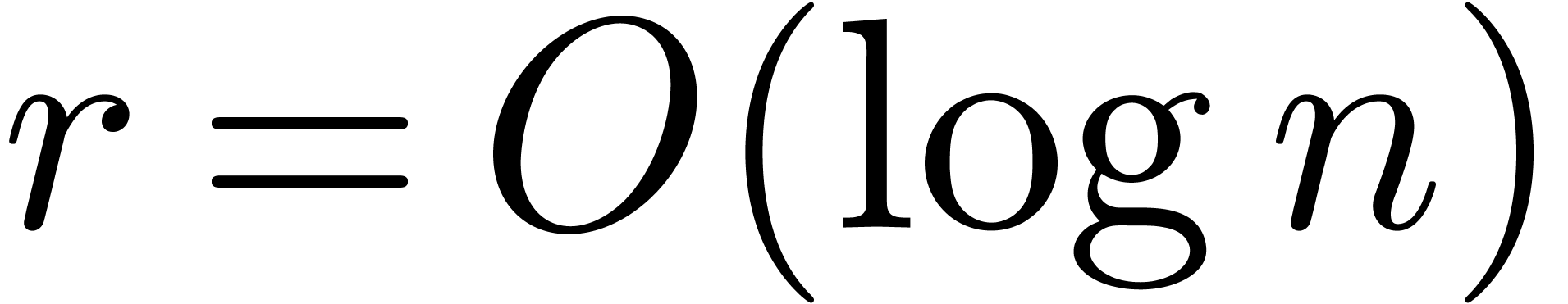 .
.
In [BK78], it was shown that Newton's method may be applied
in the power series context for the computation of the first  coefficients of the solution to
(2) or (3) in time
coefficients of the solution to
(2) or (3) in time 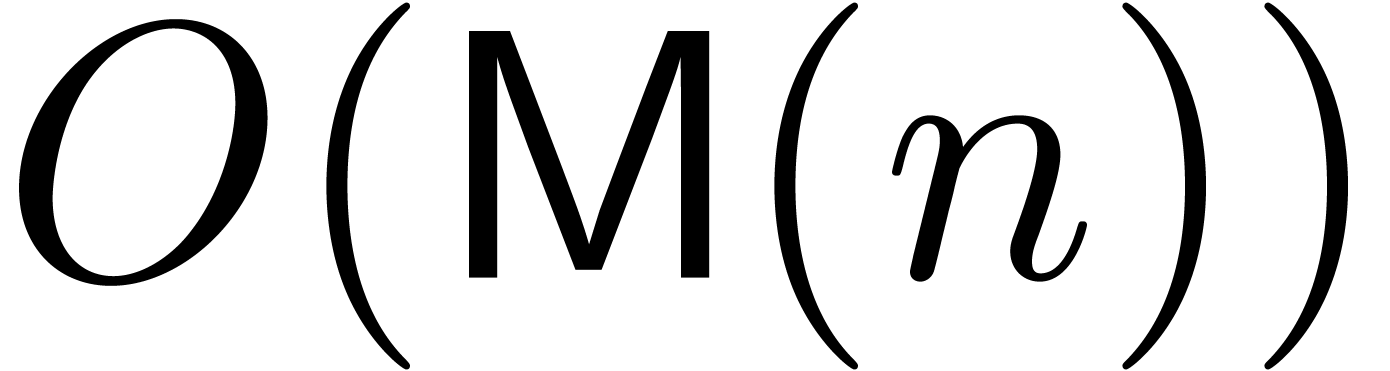 . However, this complexity does not take into
account the dependence on the order ,
which was shown to be exponential in [vdH02a]. Recently [BCO+07], this dependence in has been
reduced to a quadratic factor. In particular, the first
coefficients of the solution to (3)
can be computed in time
. However, this complexity does not take into
account the dependence on the order ,
which was shown to be exponential in [vdH02a]. Recently [BCO+07], this dependence in has been
reduced to a quadratic factor. In particular, the first
coefficients of the solution to (3)
can be computed in time 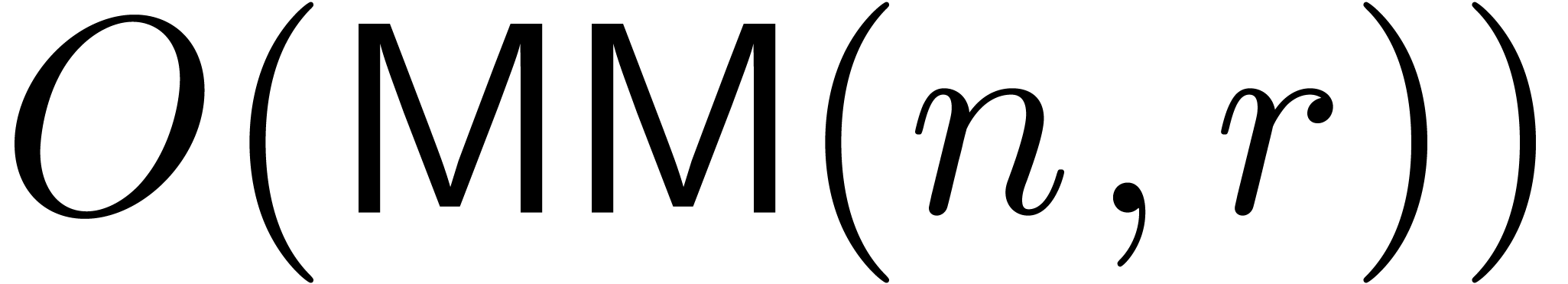 . In
fact, the resolution of (2) in the case when and
. In
fact, the resolution of (2) in the case when and 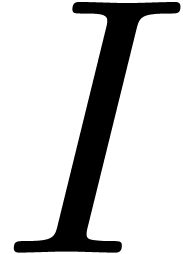 are replaced by matrices in
are replaced by matrices in
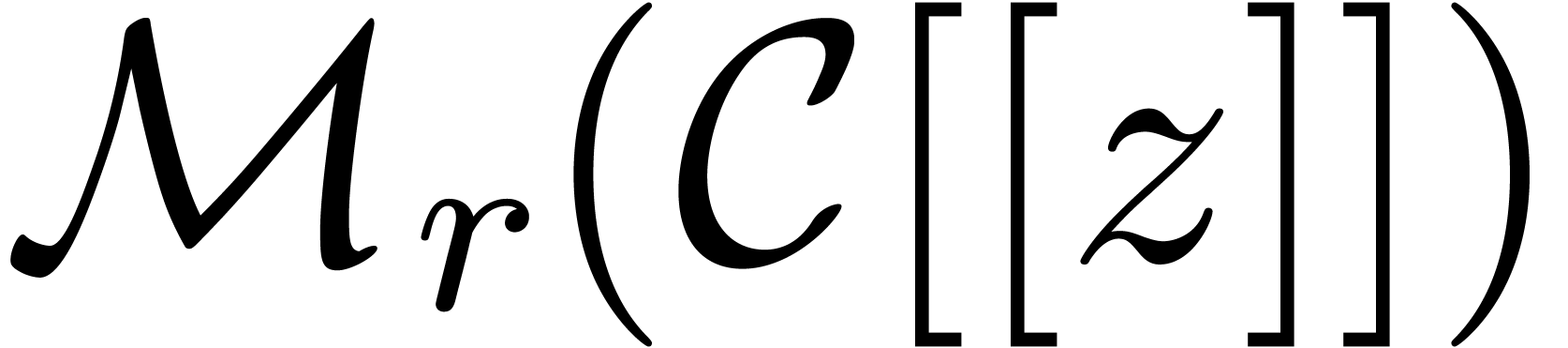 resp. can
also be done in time . Taking
resp. can
also be done in time . Taking
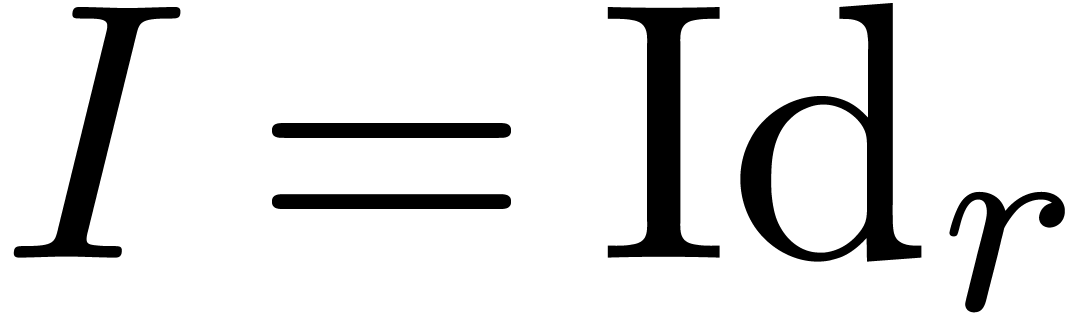 , this corresponds to the
computation of a fundamental system of solutions.
, this corresponds to the
computation of a fundamental system of solutions.
However, the new complexity is not optimal in the case when the matrix
is sparse. This occurs in particular when a
linear differential equation
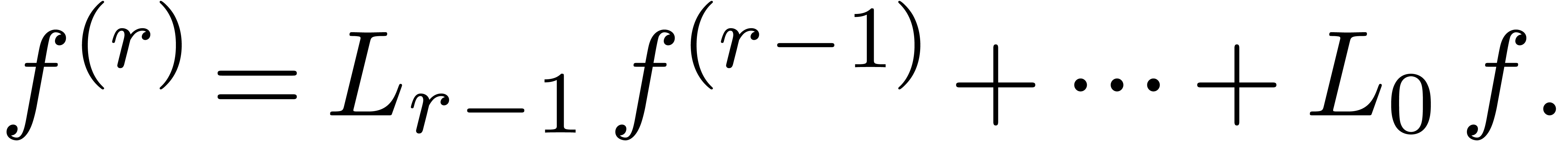 |
(4) |
is rewritten in matrix form. In this case, the method from [BCO+07]
for the asymptotically efficient resolution of the vector version of (4) as a function of gives rise to an
overhead of 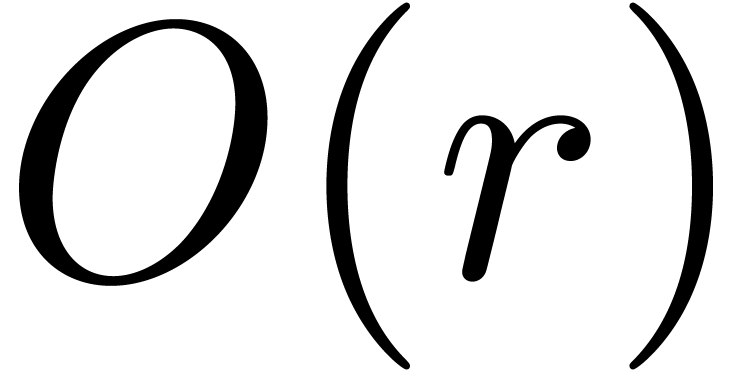 , due to the fact
that we need to compute a full basis of solutions in order to apply the
Newton iteration.
, due to the fact
that we need to compute a full basis of solutions in order to apply the
Newton iteration.
In [vdH97, vdH02a], the alternative approach
of relaxed evaluation was presented in order to solve equations of the
form (1). More precisely, let 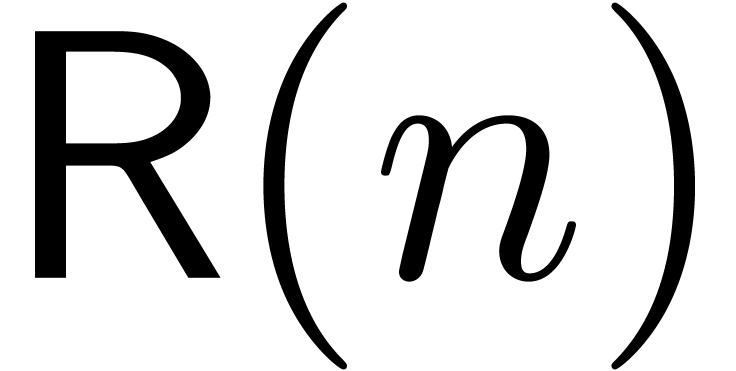 be
the cost to gradually compute terms of
the product
be
the cost to gradually compute terms of
the product 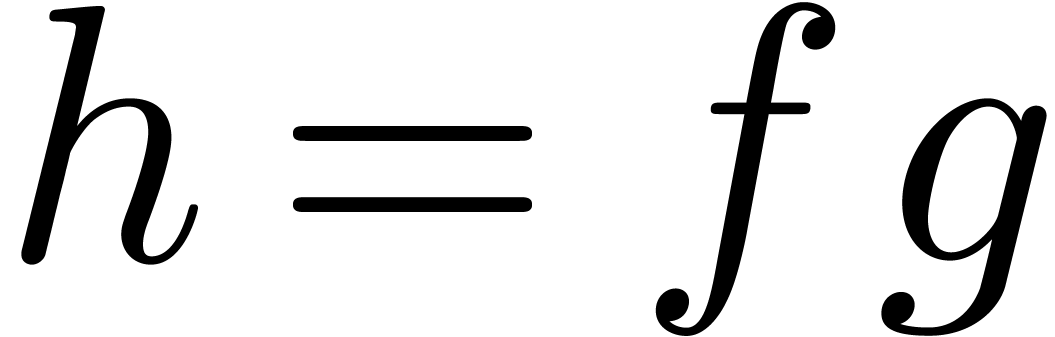 of two series
of two series 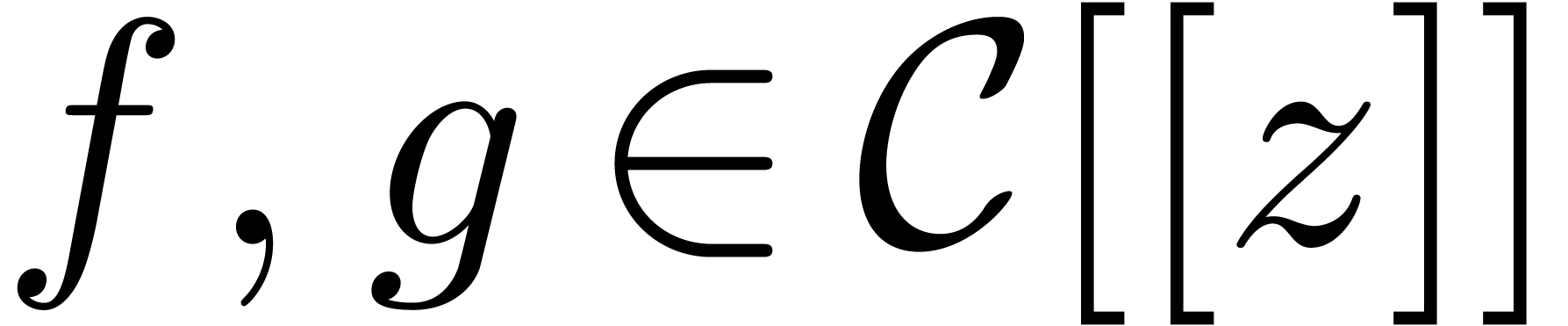 . This means that the terms of
. This means that the terms of 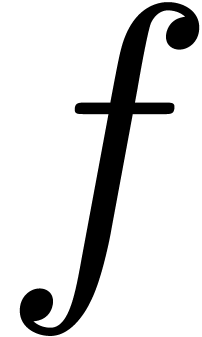 and
and  are given one by one, and that we require
are given one by one, and that we require
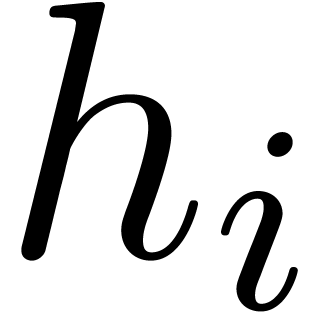 to be returned as soon as
to be returned as soon as  and
and  are known (
are known ( ).
In [vdH97, vdH02a], we proved that
).
In [vdH97, vdH02a], we proved that  . In the standard FFT model, this
bound was further reduced in [vdH07a] to
. In the standard FFT model, this
bound was further reduced in [vdH07a] to 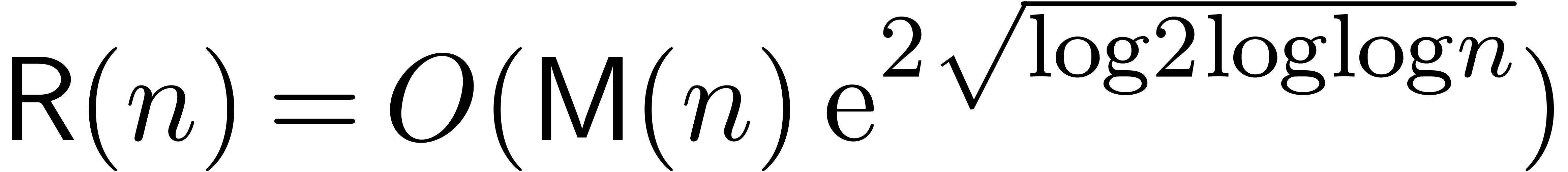 . We also notice that the additional
. We also notice that the additional 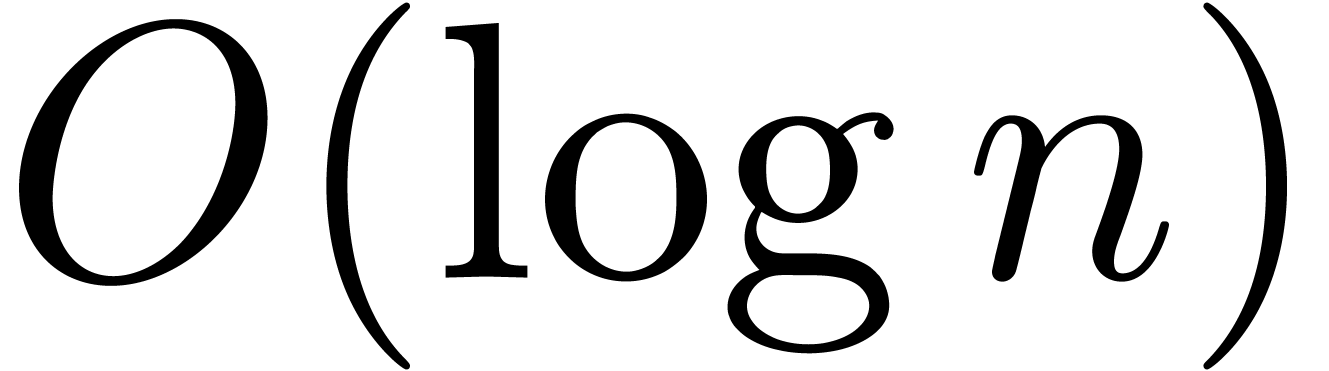 or
or 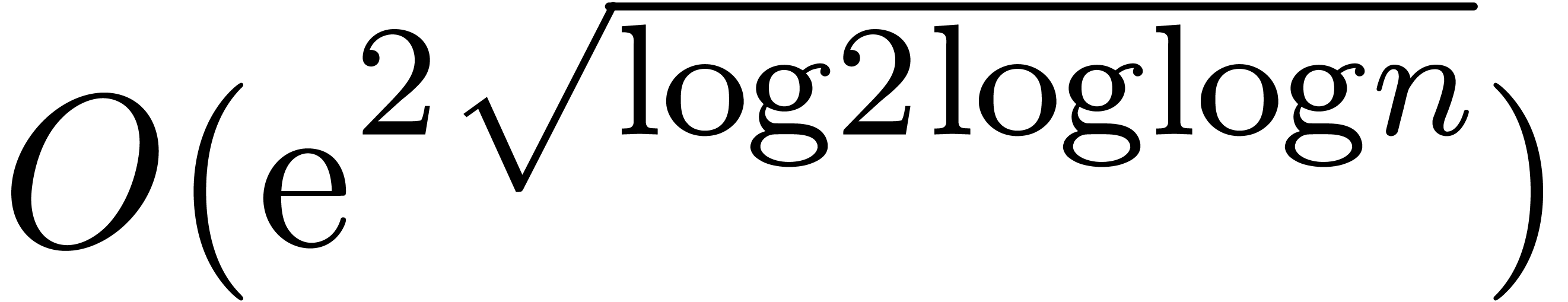 overhead only occurs in FFT
models: when using Karatsuba or Toom-Cook multiplication [KO63,
Too63, Coo66], one has
overhead only occurs in FFT
models: when using Karatsuba or Toom-Cook multiplication [KO63,
Too63, Coo66], one has  . One particularly nice feature of relaxed
evaluation is that the mere relaxed evaluation of
provides us with the solution to (1). Therefore, the
complexity of the resolution of systems like (2) or (3) only depends on the sparse size of
as an expression, without any additional overhead in .
. One particularly nice feature of relaxed
evaluation is that the mere relaxed evaluation of
provides us with the solution to (1). Therefore, the
complexity of the resolution of systems like (2) or (3) only depends on the sparse size of
as an expression, without any additional overhead in .
Let 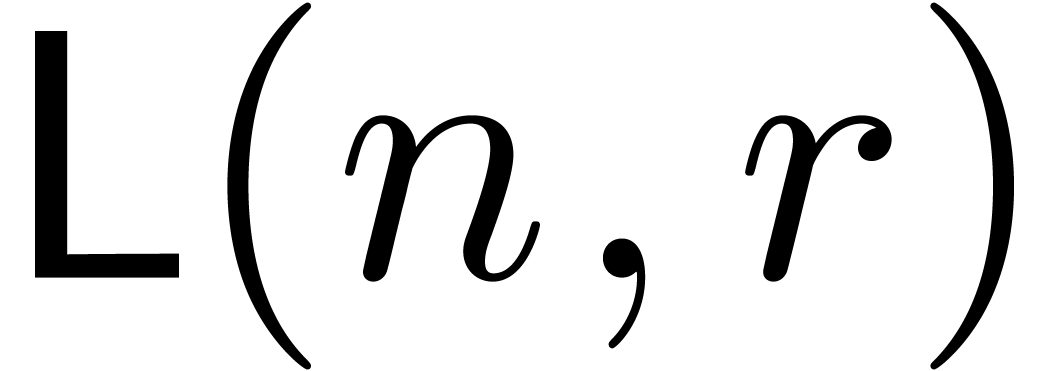 denote the complexity of computing the first
coefficients of the solution to (4).
By what precedes, we have both
denote the complexity of computing the first
coefficients of the solution to (4).
By what precedes, we have both 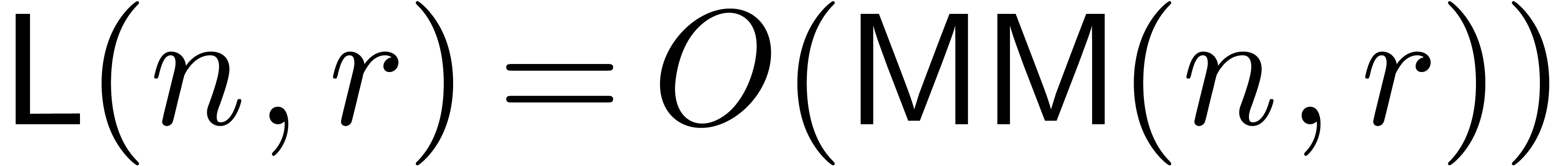 and
and 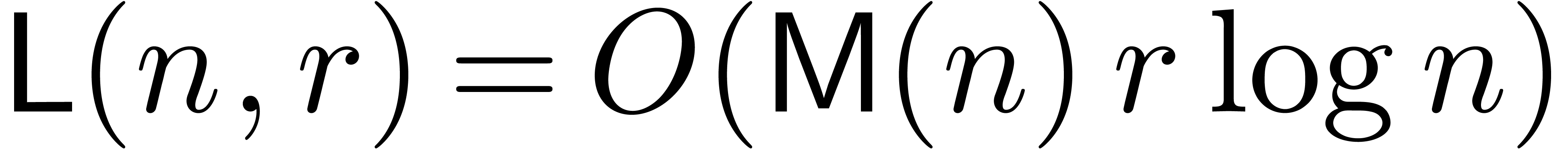 . A natural question is whether we may further
reduce this bound to
. A natural question is whether we may further
reduce this bound to 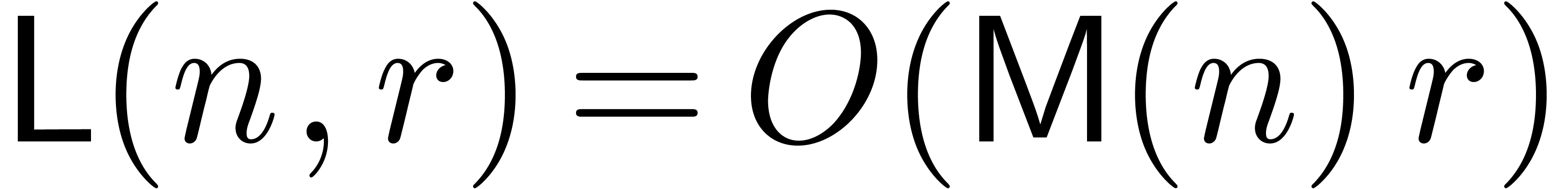 or even
or even  . This would be optimal in the sense that the
cost of resolution would be the same as the cost of the verification
that the result is correct. A similar problem may be stated for the
resolution of systems (2) or (3).
. This would be optimal in the sense that the
cost of resolution would be the same as the cost of the verification
that the result is correct. A similar problem may be stated for the
resolution of systems (2) or (3).
In this paper, we present several results in this direction. The idea is
as follows. Given 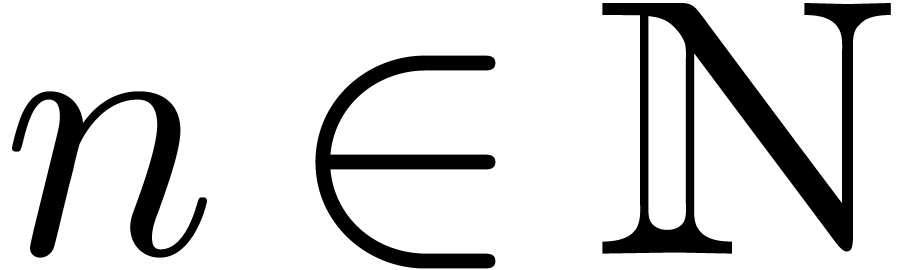 , we first
choose a suitable
, we first
choose a suitable 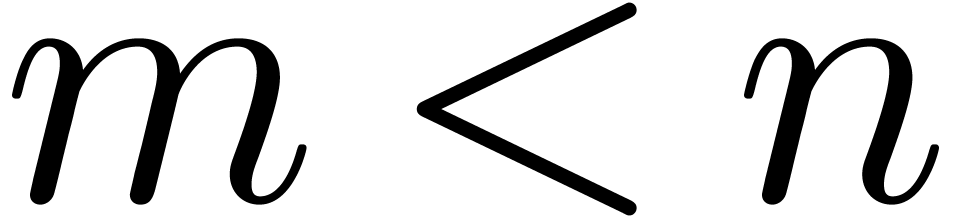 , typically
of the order
, typically
of the order 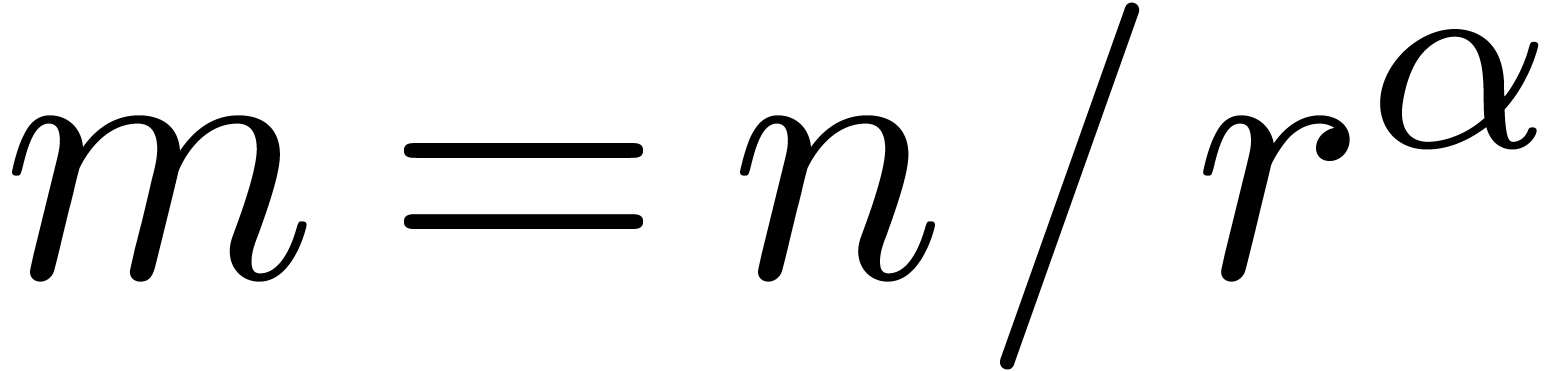 . Then we use
Newton iterations for determining successive blocks of
. Then we use
Newton iterations for determining successive blocks of  coefficients of in terms of the previous
coefficients of and
coefficients of in terms of the previous
coefficients of and  . The product is computed
using a lazy or relaxed method, but on FFT-ed blocks of coefficients.
Roughly speaking, we apply Newton's method up to an order , where the overhead of
the method is not yet perceptible. The remaining Newton steps are then
traded against an asymptotically less efficient lazy or relaxed method
without the overhead, but which is actually more
efficient when working on FFT-ed blocks of coefficients.
. The product is computed
using a lazy or relaxed method, but on FFT-ed blocks of coefficients.
Roughly speaking, we apply Newton's method up to an order , where the overhead of
the method is not yet perceptible. The remaining Newton steps are then
traded against an asymptotically less efficient lazy or relaxed method
without the overhead, but which is actually more
efficient when working on FFT-ed blocks of coefficients.
In fact, FFT trading is already useful in the more elementary case of
power series division. In order to enhance the readability of the paper,
we will therefore introduce the technique on this example in section 3. In the FFT model, this leads to an order
division algorithm of time complexity 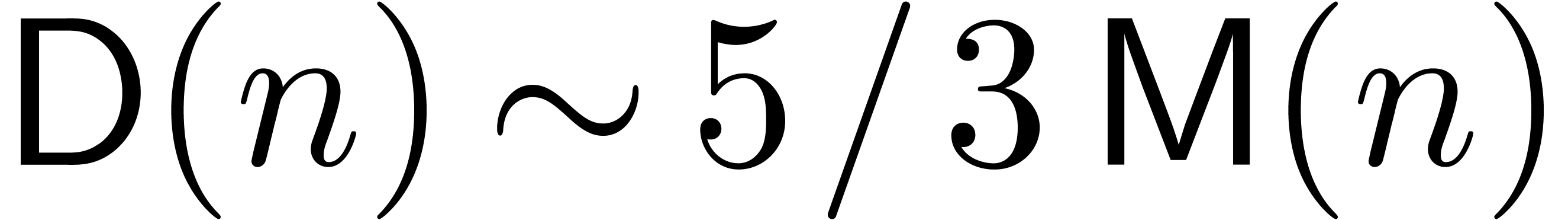 ,
which improves on the best previously known bound
,
which improves on the best previously known bound 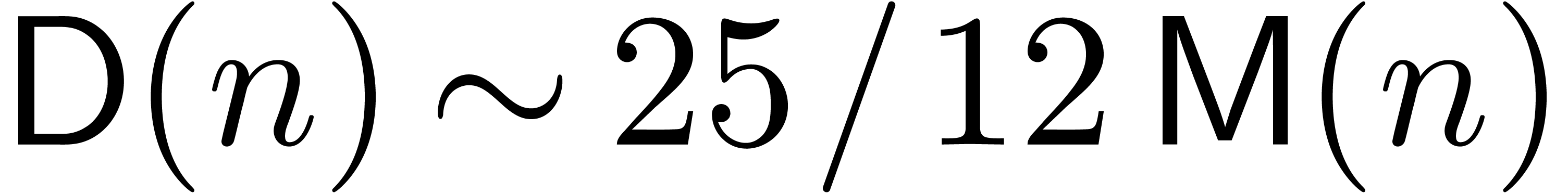 [HZ04]. Notice that
[HZ04]. Notice that 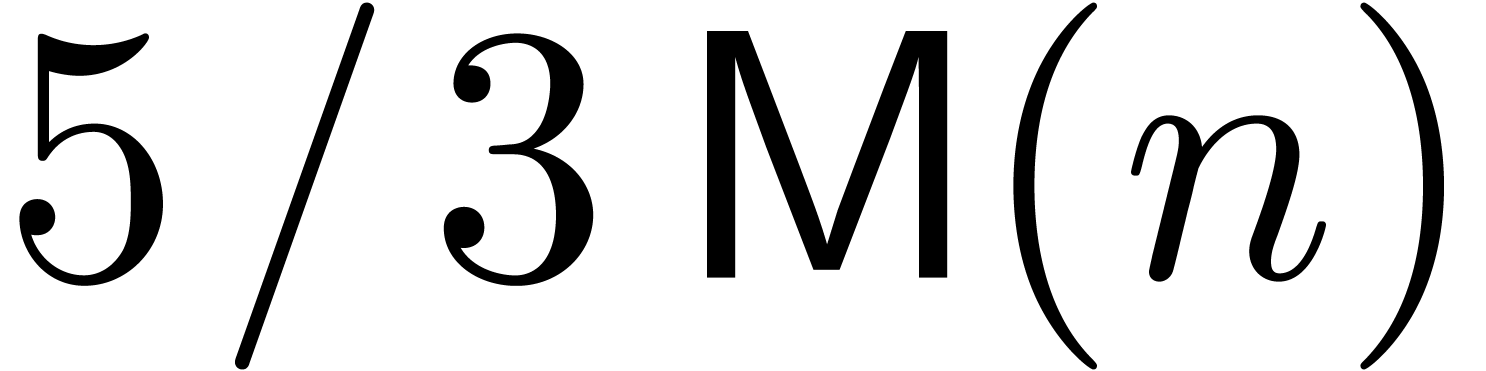 should be read
should be read
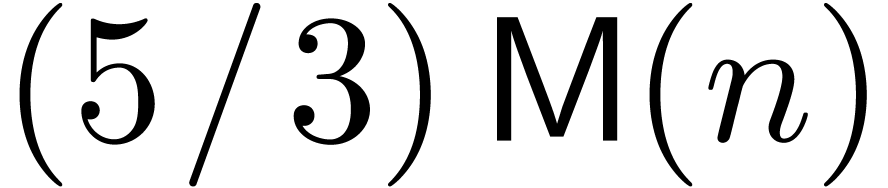 and likewise for other fractions of this kind.
Division with remainder of a polynomial of degree
and likewise for other fractions of this kind.
Division with remainder of a polynomial of degree 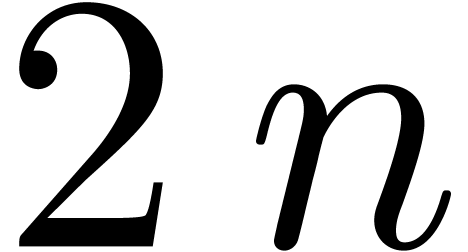 by a polynomial of degree can be done in time
by a polynomial of degree can be done in time
 ; the best previously known
bound was
; the best previously known
bound was 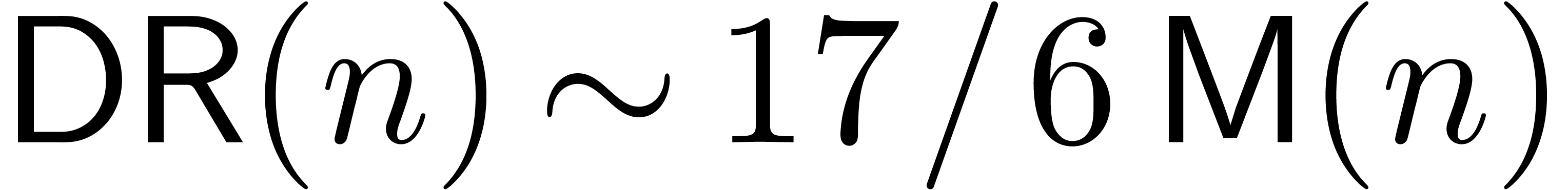 (private communication by Paul
Zimmermann).
(private communication by Paul
Zimmermann).
In sections 4 and 5, we treat the cases of
linear and algebraic differential equations. The main results are
summarized in Tables 3 and 4 and analyzed in
detail in section 7. In particular, the exponential of a
power series can now be computed at order in
time 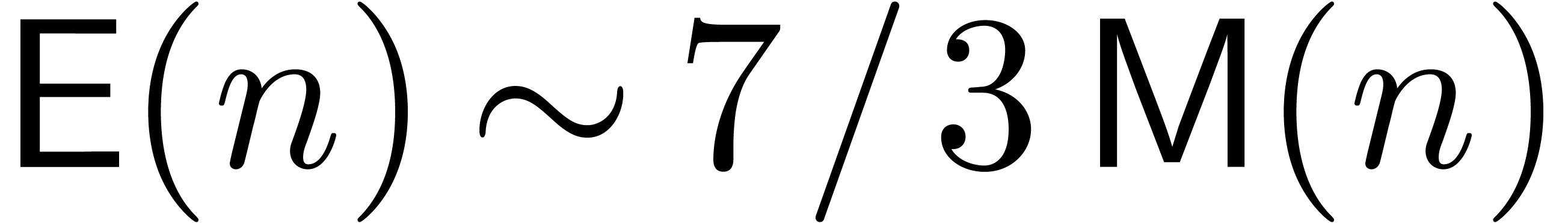 instead of
instead of 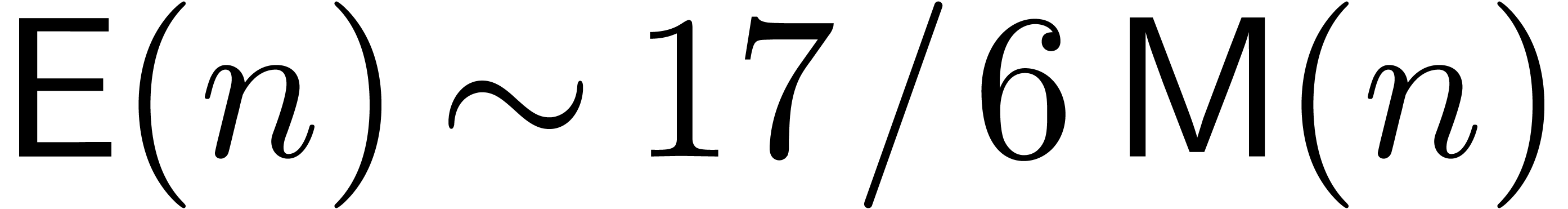 [Ber00].
[Ber00].
In two recent papers [Har09a, Har09b] David
Harvey has further improved the technique of FFT trading. In the
standard FFT model, the FFT coincides up to a constant factor with the
inverse of its transpose. This has been exploited in [Har09a]
to get better bounds 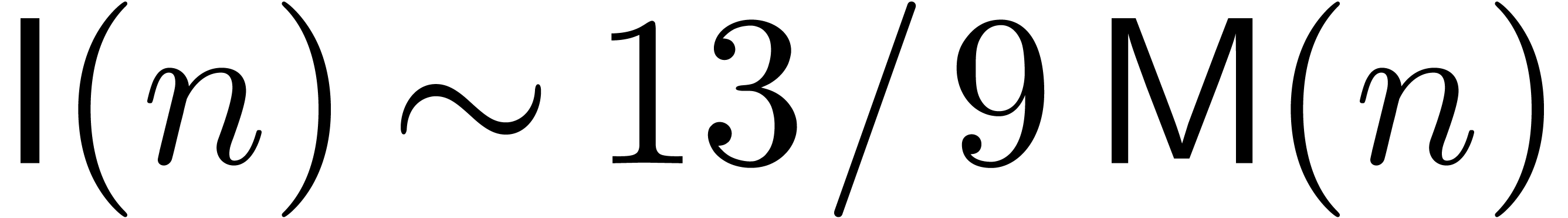 and
and  for power series inversion and square roots. In [Har09b],
the complexity for exponentiation has been further improved to
for power series inversion and square roots. In [Har09b],
the complexity for exponentiation has been further improved to 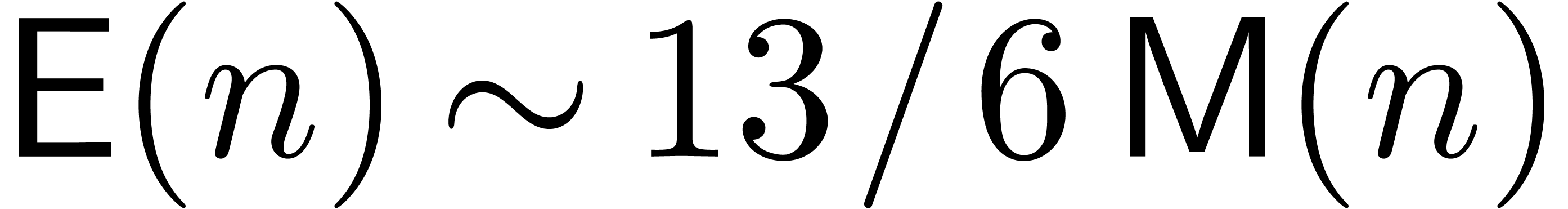 . In table 1, we have
summarized the new results for elementary operations on power series.
. In table 1, we have
summarized the new results for elementary operations on power series.
It is well known that FFT multiplication allows for tricks of the above kind, in the case when a given argument is used in several multiplications. In the case of FFT trading, we artificially replace an asymptotically fast method by a slower method on FFT-ed blocks, so as to use this property. We refer to [Ber00] (see also remark 14 below) for a variant and further applications of this technique (called FFT caching by the author). The central idea behind [vdH07a] is also similar. In section 6, we outline yet another application to the truncated multiplication of dense polynomials.
The efficient resolution of differential equations in power series admits several interesting applications, which are discussed in more detail in [vdH02a]. In particular, certified integration of dynamical systems at high precision is a topic which currently interests us [Moo66, Loh88, MB96, Loh01, MB04, vdH07b].
Remark
|
||||||||||||||||||||||||
Table 1. Table with the best
asymptotic time complexities of several operations on power
series with respect to the cost |
Let be a ring in which 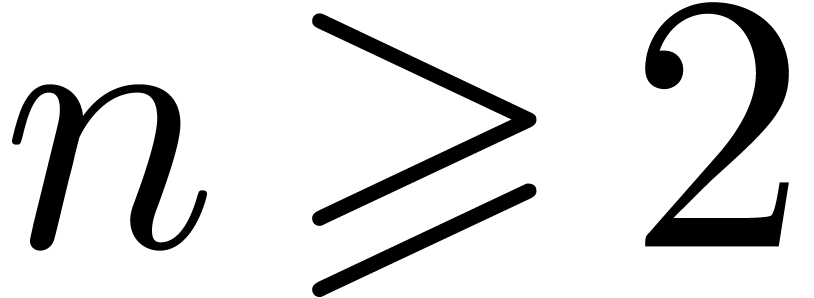 is not a zero-divisor and assume that contains a
primitive -th root
is not a zero-divisor and assume that contains a
primitive -th root  of unity. Given a polynomial
of unity. Given a polynomial 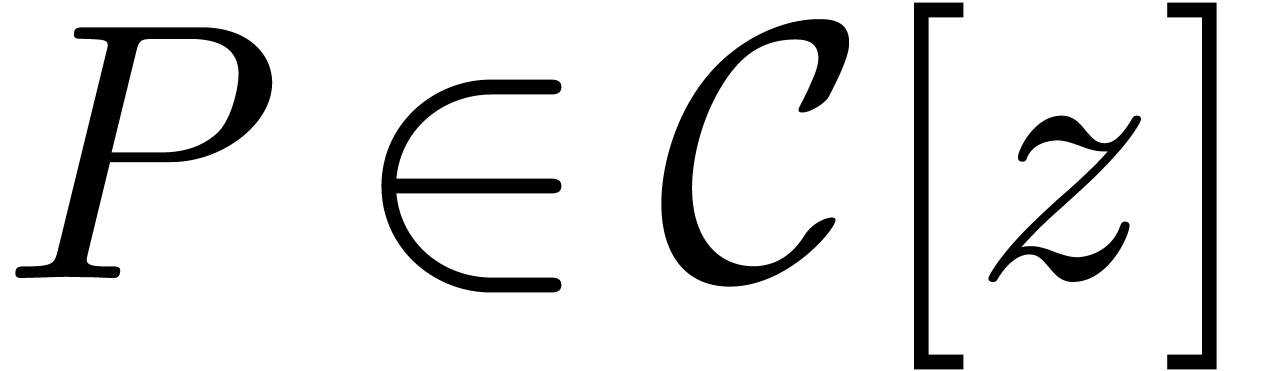 of
degree , and identifying with its vector
of
degree , and identifying with its vector  of
coefficients, its discrete Fourier transform
of
coefficients, its discrete Fourier transform 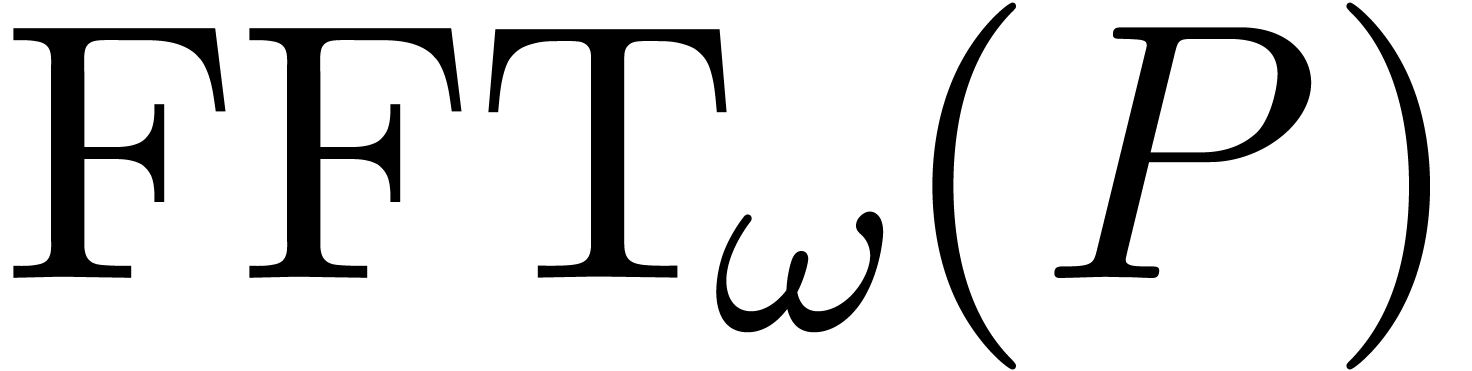 is
defined by
is
defined by
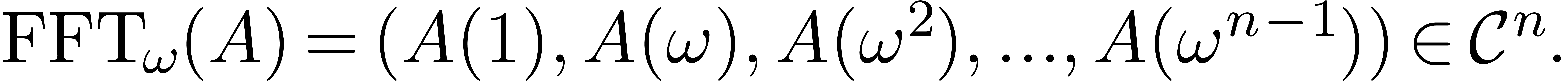
If is a power of two, then the fast Fourier
transform [CT65] allows us to perform the transformation
 and its inverse
and its inverse
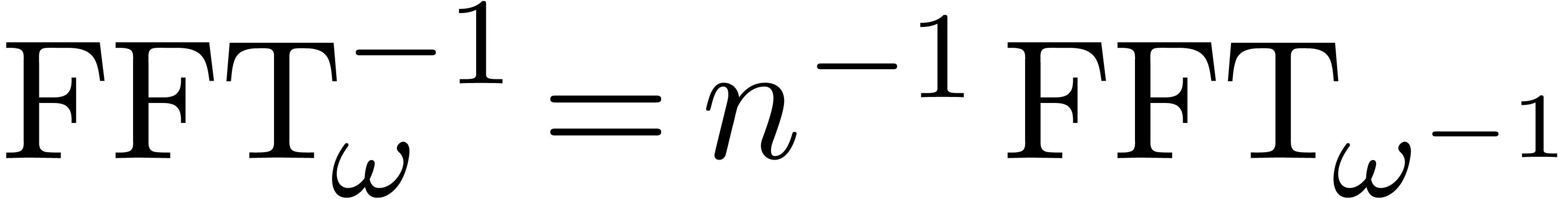
using 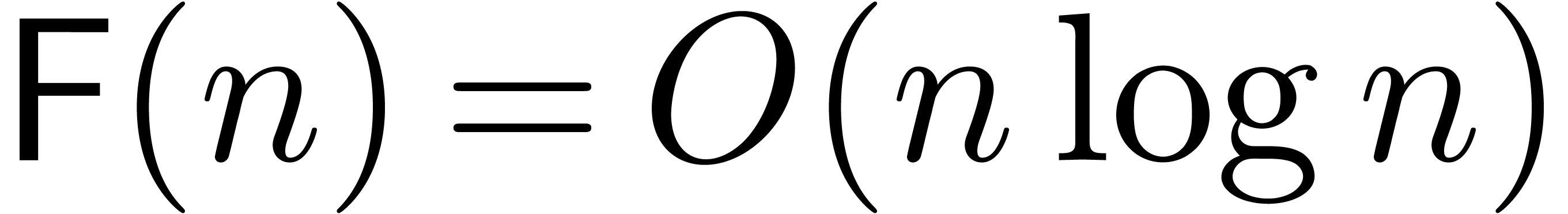 operations in . If
operations in . If 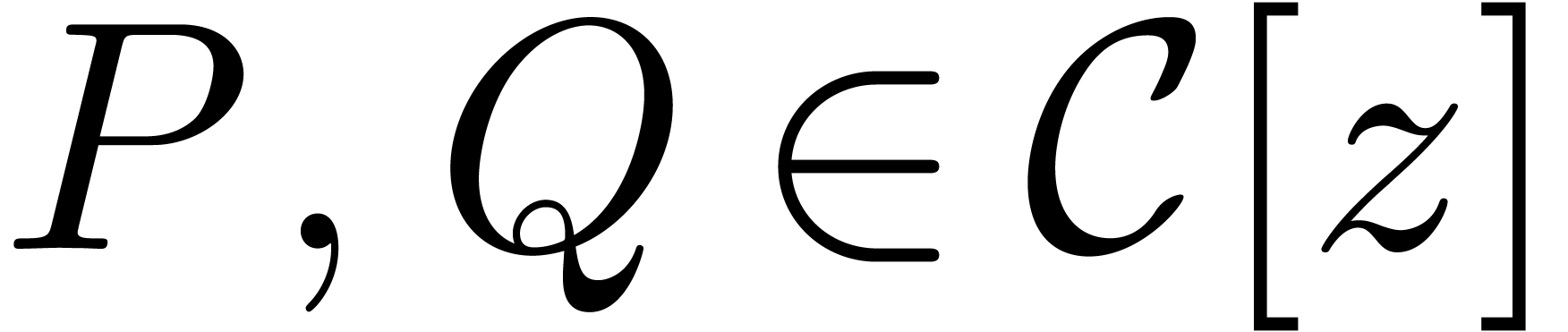 are two polynomials
with
are two polynomials
with 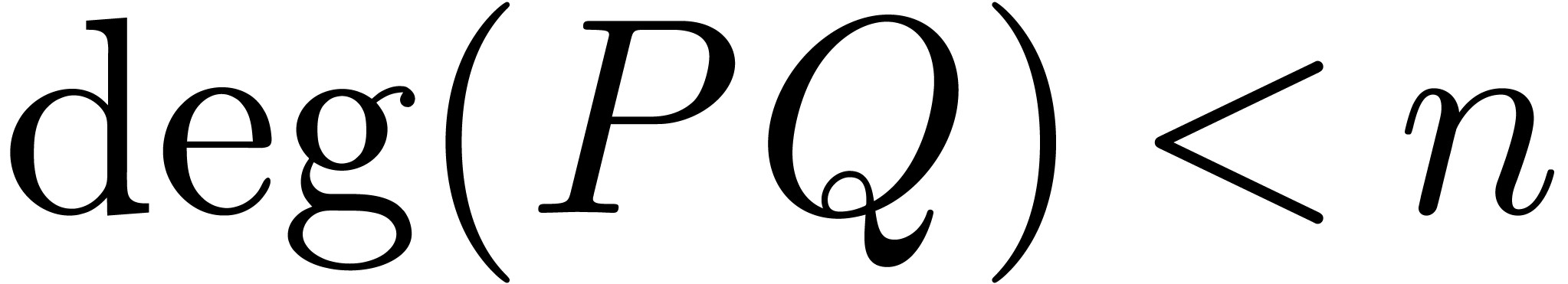 , then we clearly have
, then we clearly have
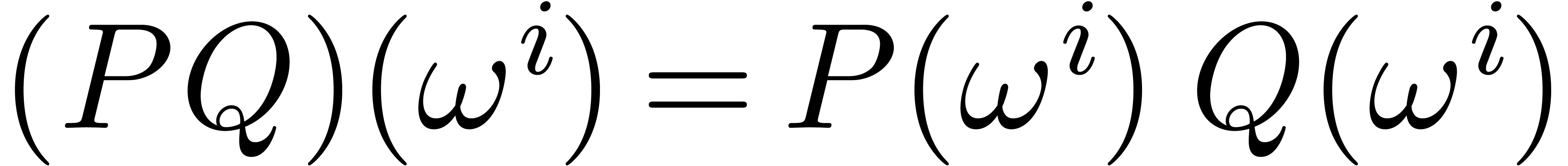 for all
for all  ,
whence
,
whence  . Consequently, we may
compute
. Consequently, we may
compute 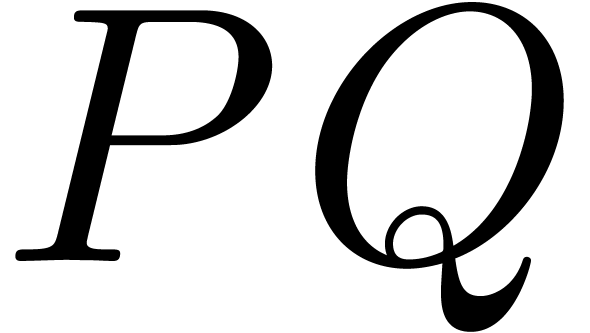 using
using
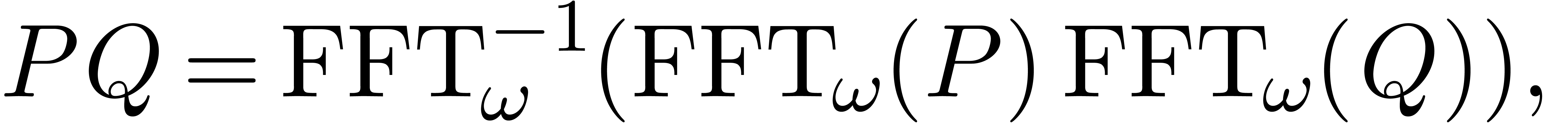
where 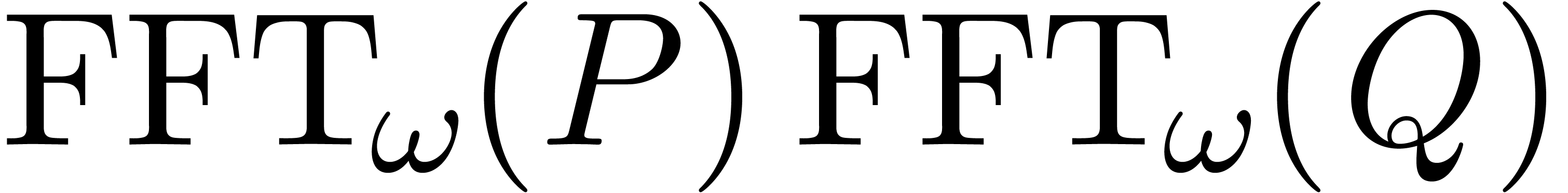 stands for the componentwise product of
the vectors and
stands for the componentwise product of
the vectors and 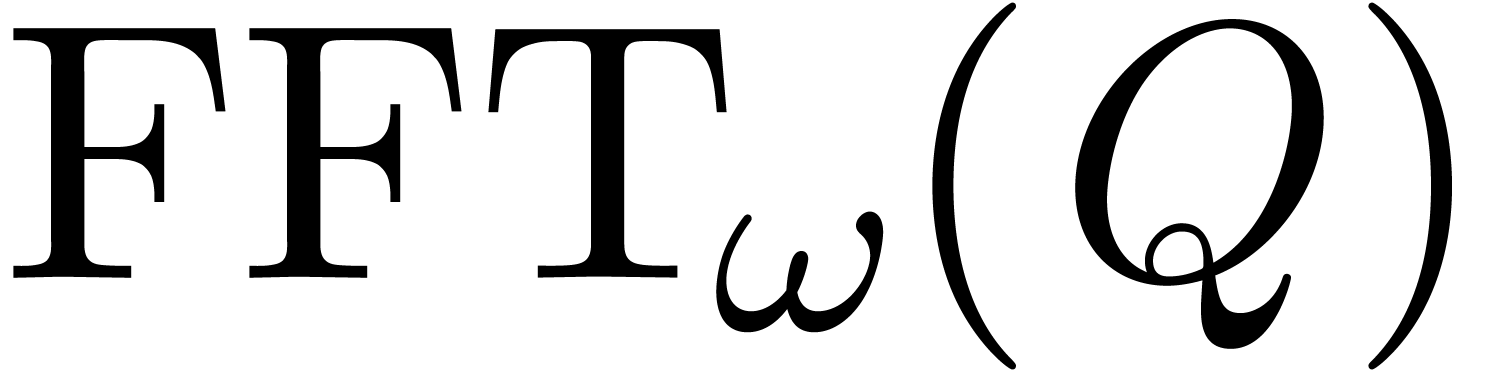 .
If is a power of two, this takes
.
If is a power of two, this takes 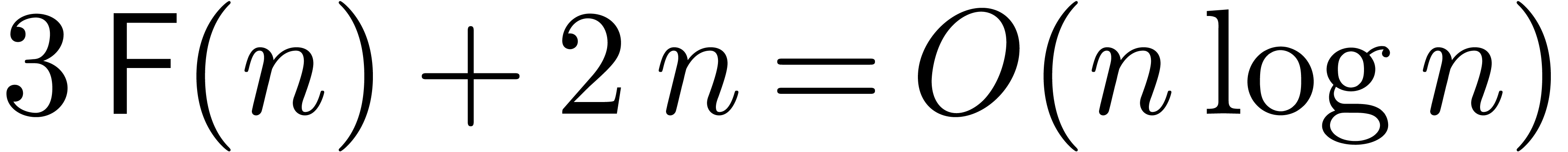 operations in .
operations in .
More generally, let 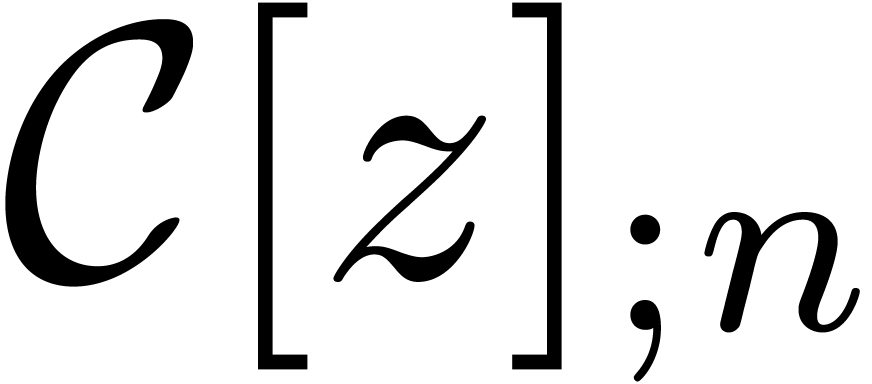 denote the set of
polynomials of degree . Then
an evaluation-interpolation scheme at degree
and
denote the set of
polynomials of degree . Then
an evaluation-interpolation scheme at degree
and 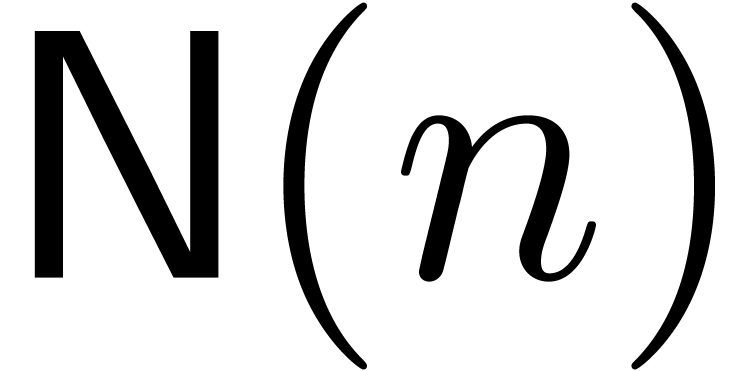 points consists of two computable -linear mappings
points consists of two computable -linear mappings
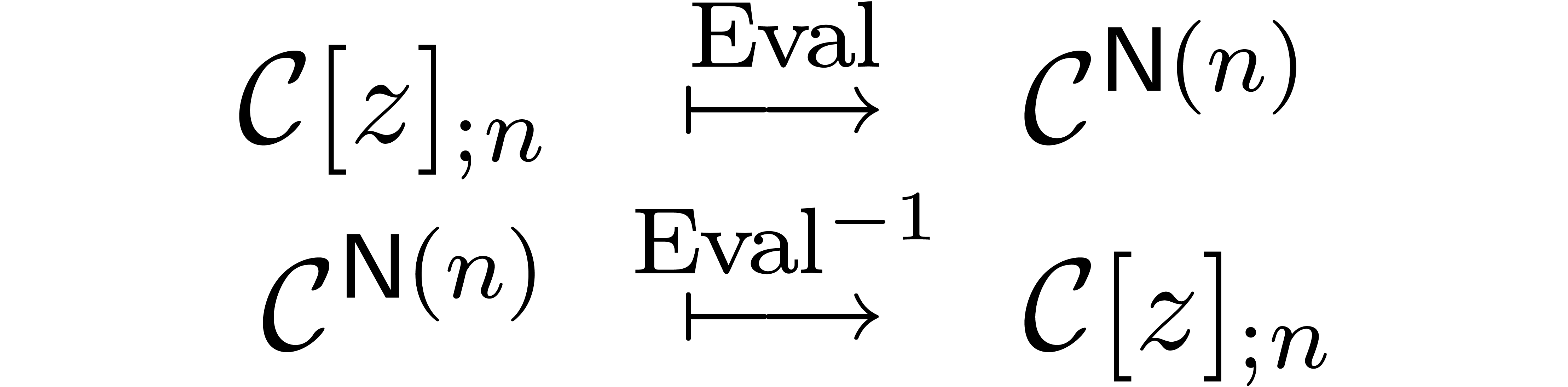
with the property that

for all with .
We will denote by 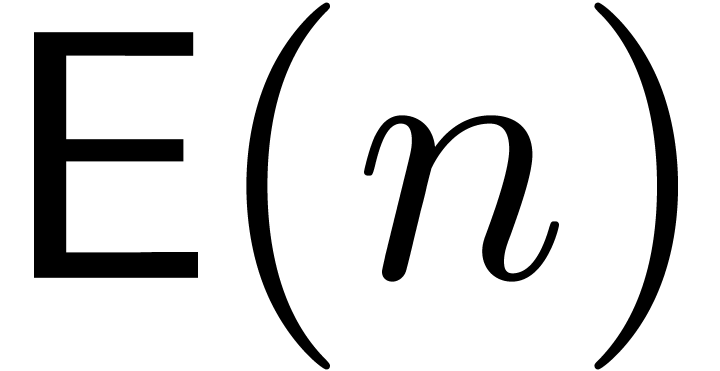 the maximum of the time
complexities of
the maximum of the time
complexities of 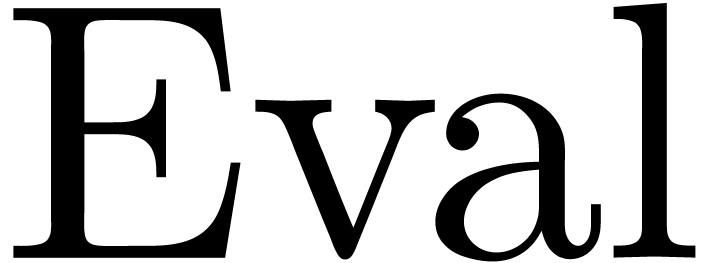 and
and 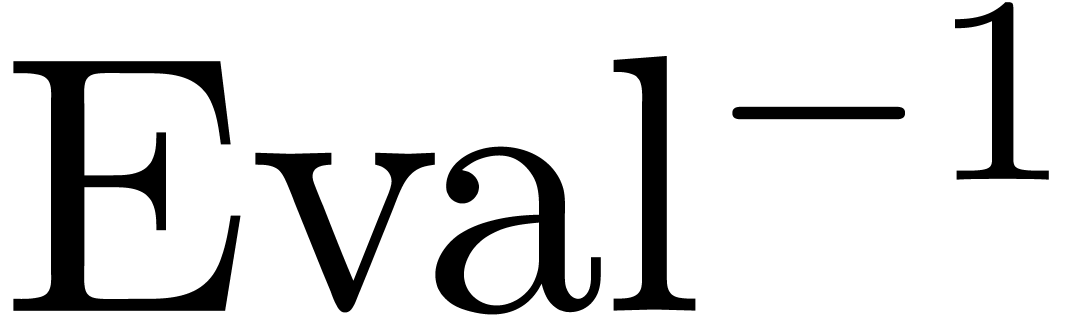 . Given with , we may then compute
in time
. Given with , we may then compute
in time  .
.
An evaluation-interpolation model is a recipe which associates
an evaluation-interpolation scheme to any degree . Most fast multiplication schemes in the literature
are actually based on evaluation-interpolation models. In the sequel, we
will therefore assume that the cost 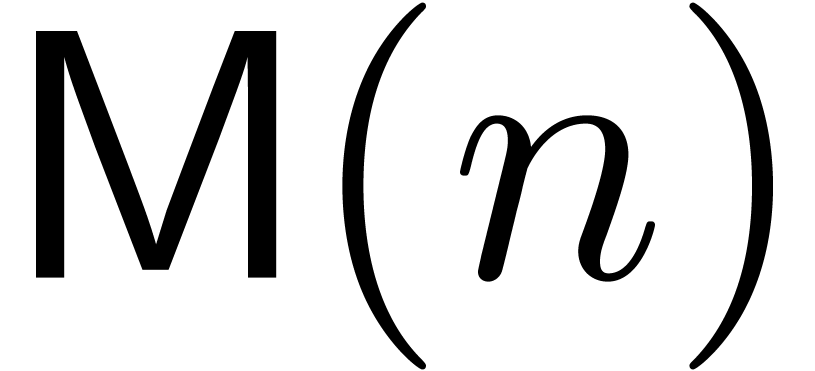 of
multiplying two polynomials of degrees is given
by
of
multiplying two polynomials of degrees is given
by
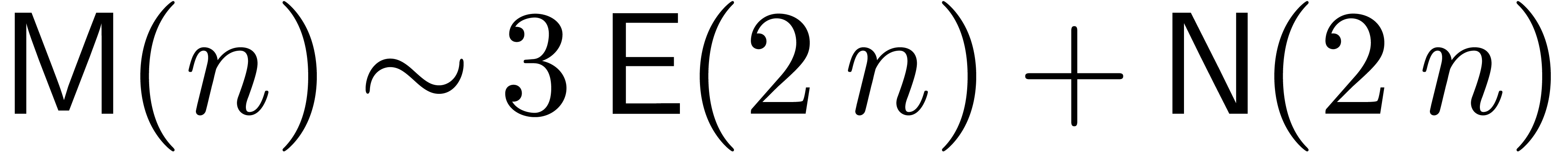 |
(5) |
for a suitable evaluation-interpolation model. Similarly, if scalar matrices can be multiplied in time 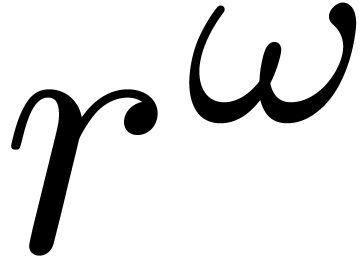 , then we will assume that the cost of multiplying two matrices whose
entries are polynomials of degrees is given by
, then we will assume that the cost of multiplying two matrices whose
entries are polynomials of degrees is given by
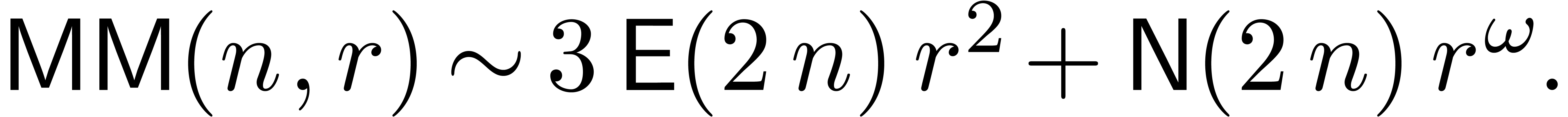 |
(6) |
Notice also that a matrix-vector product takes a time
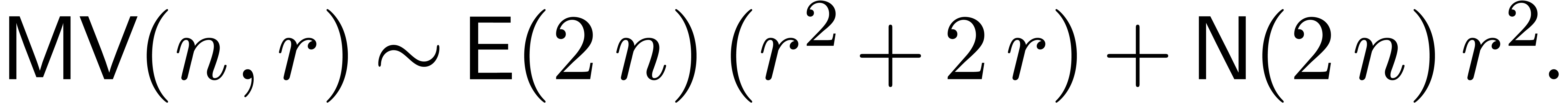 |
(7) |
Let again be a ring in which 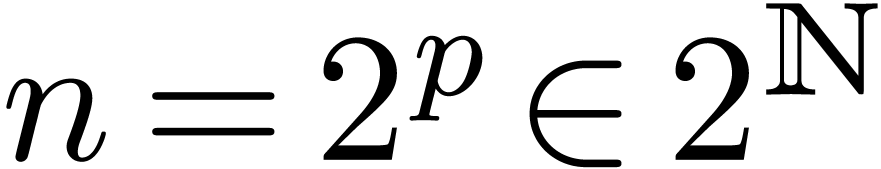 is not a zero-divisor and assume that contains a
primitive -th root of unity.
Then we have seen that the FFT provides us with an
evaluation-interpolation scheme at degree ,
with
is not a zero-divisor and assume that contains a
primitive -th root of unity.
Then we have seen that the FFT provides us with an
evaluation-interpolation scheme at degree ,
with
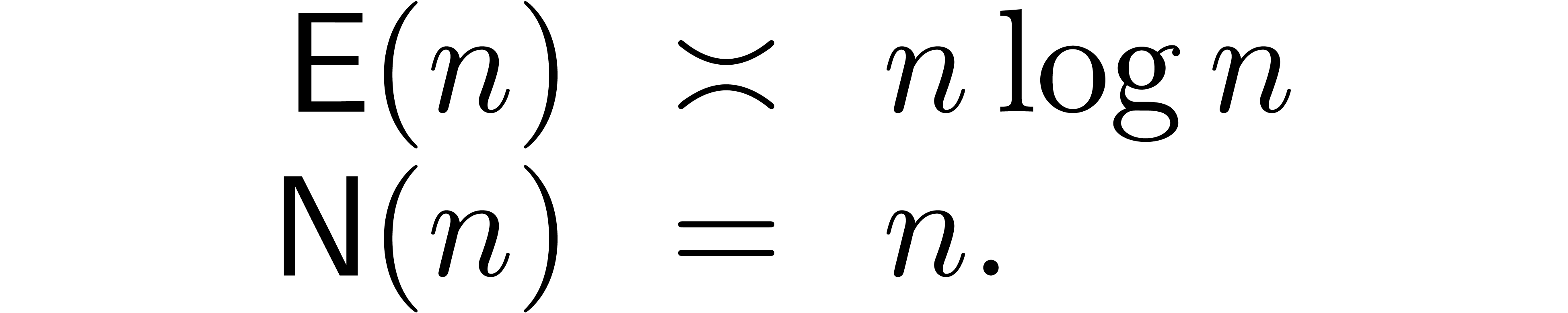
In fact, if 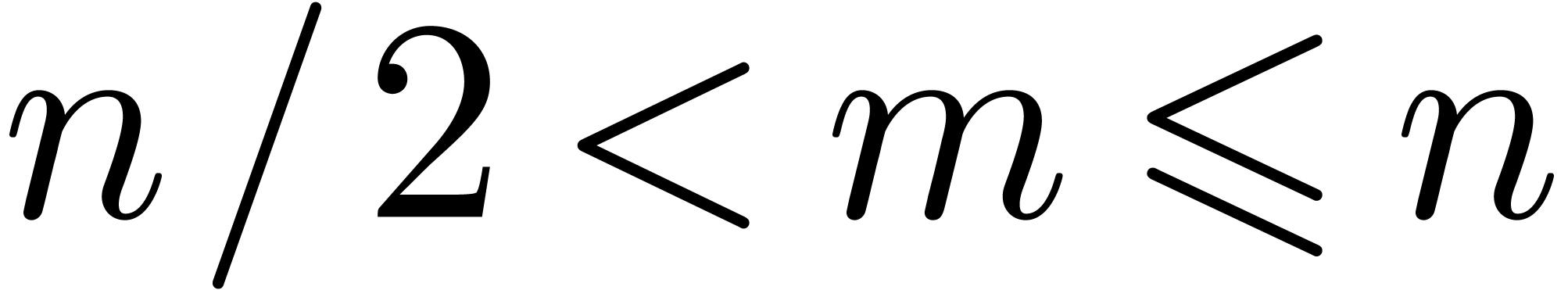 , then the
truncated Fourier transform [vdH04, vdH05]
still provides us with an evaluation-interpolation scheme with
, then the
truncated Fourier transform [vdH04, vdH05]
still provides us with an evaluation-interpolation scheme with 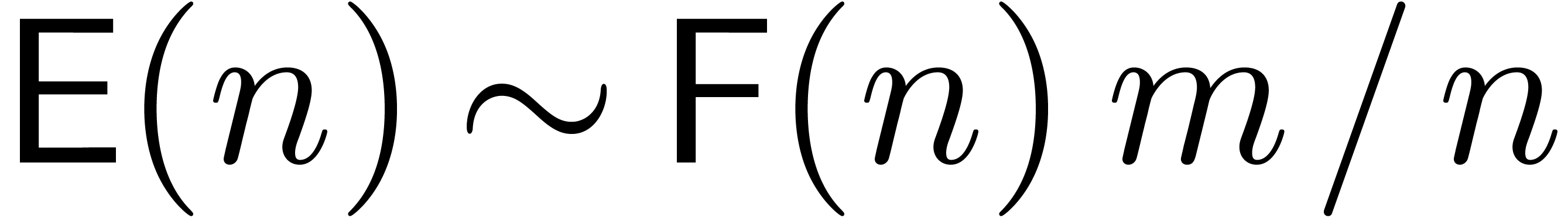 and
and 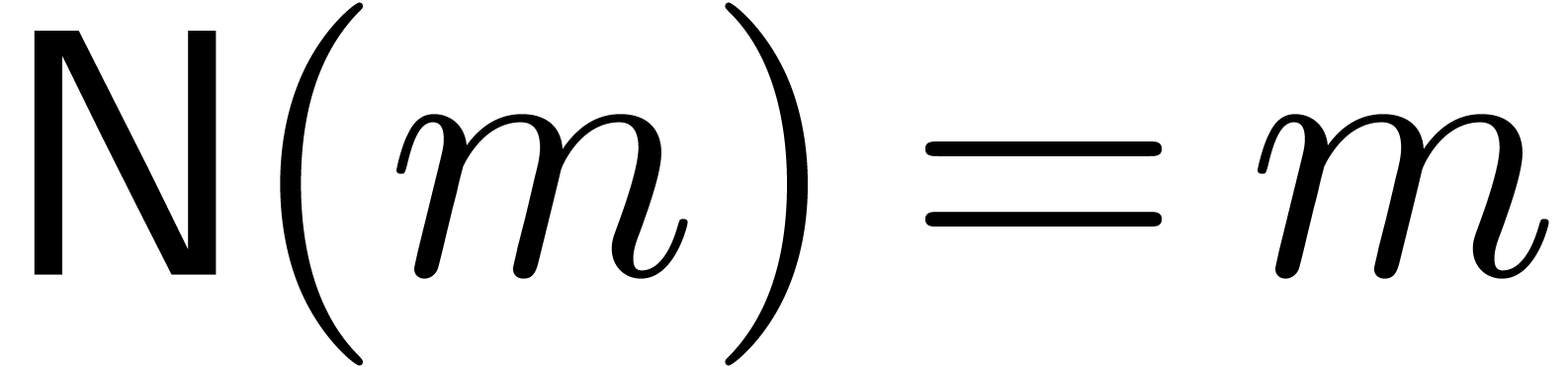 . We will
call this evaluation-interpolation model the standard FFT
model.
. We will
call this evaluation-interpolation model the standard FFT
model.
If does not contain a primitive -th root of unity, then we may artificially
adjoin a suitable root of unity to as follows
[SS71, CK91]. We first decompose 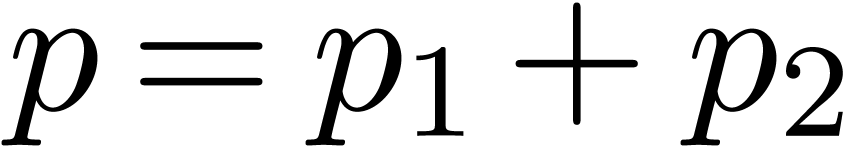 ,
, 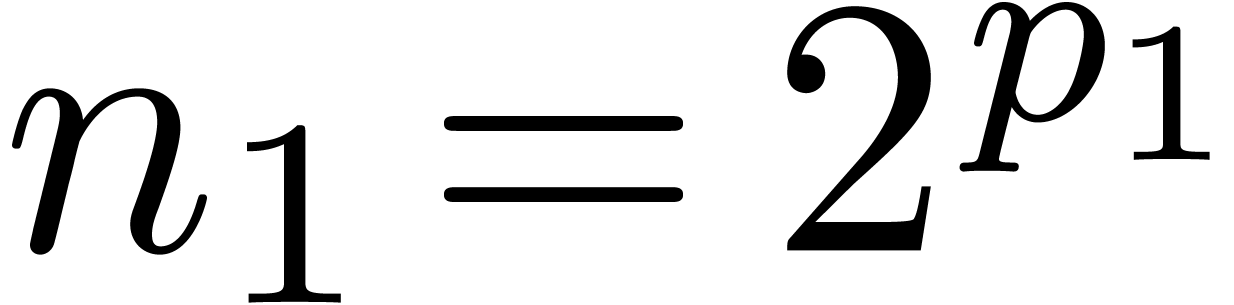 ,
,
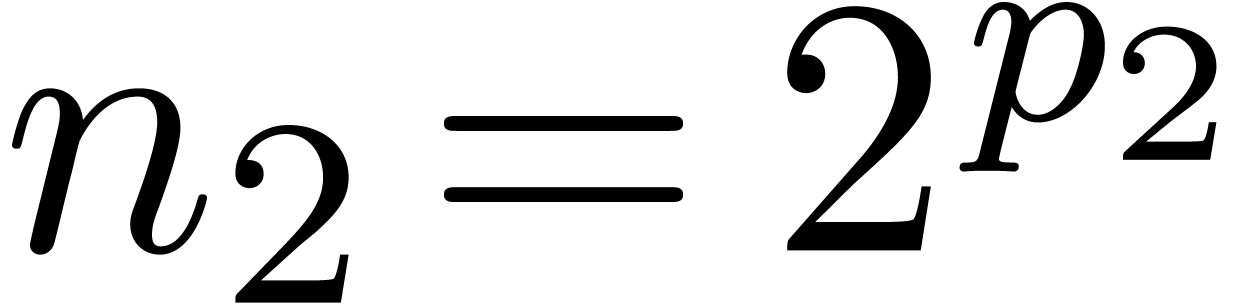 , with
, with 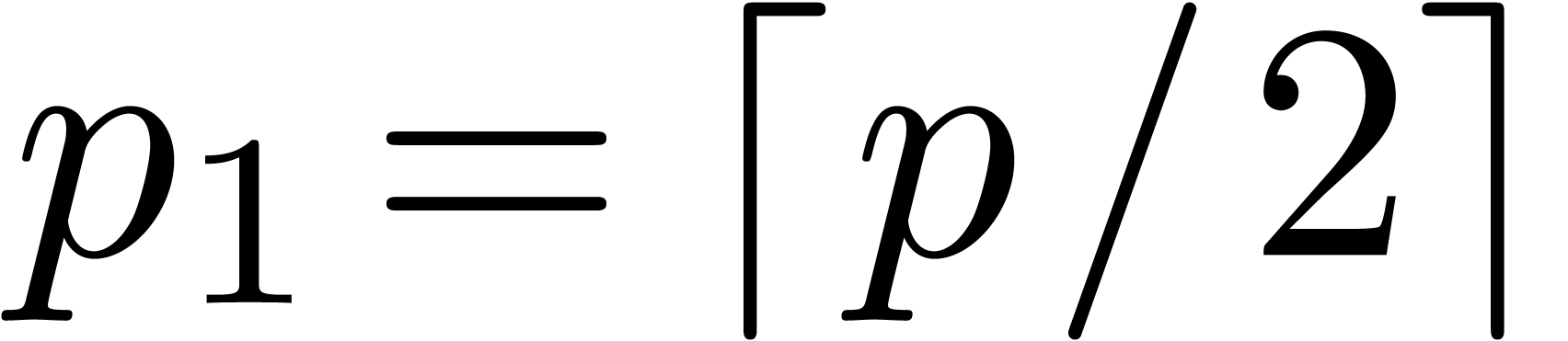 and
and 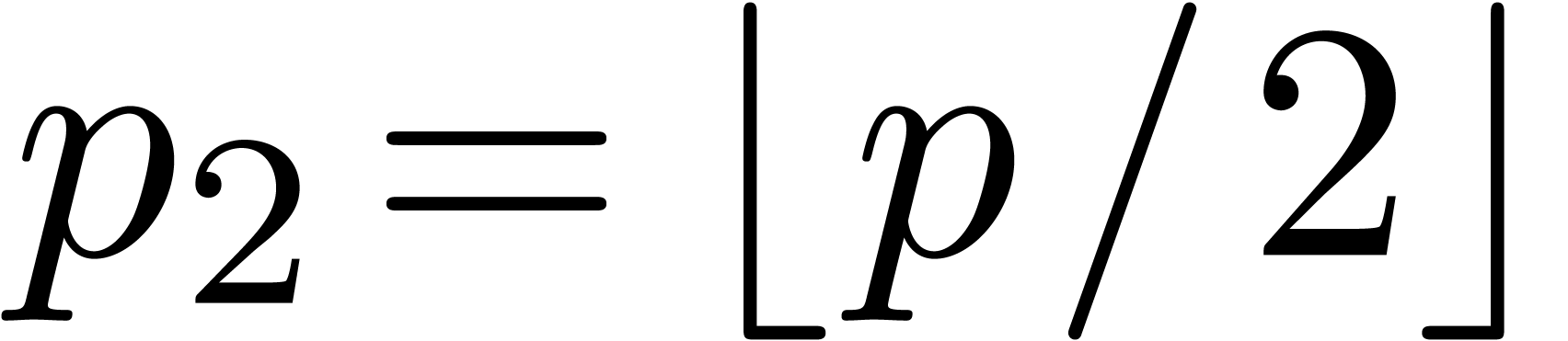 . Any polynomial in corresponds to a unique polynomial in
. Any polynomial in corresponds to a unique polynomial in  . We will consider the problem of multiplying
in the latter ring. Consider the following sequence:
. We will consider the problem of multiplying
in the latter ring. Consider the following sequence:
The first map is a natural identification when setting 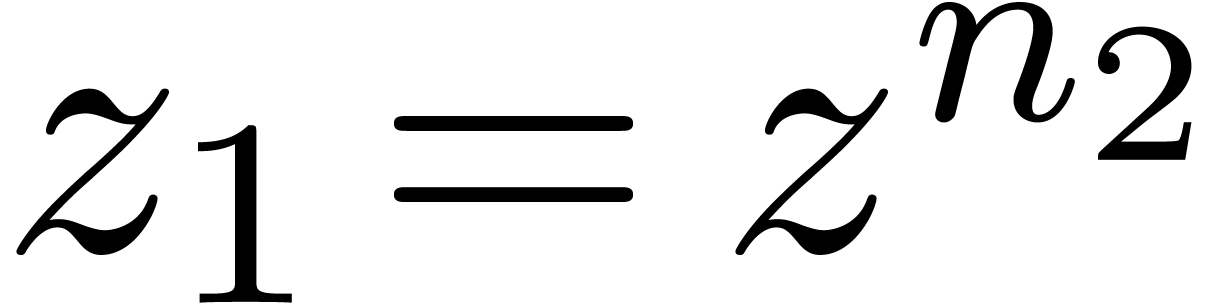 . The injection
. The injection  corresponds to writing elements of
corresponds to writing elements of 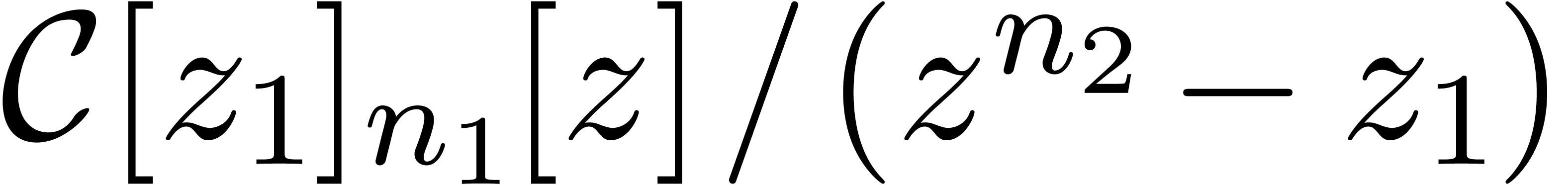 as
polynomials in
as
polynomials in 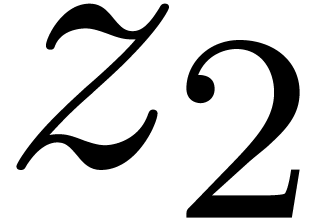 of degrees
of degrees 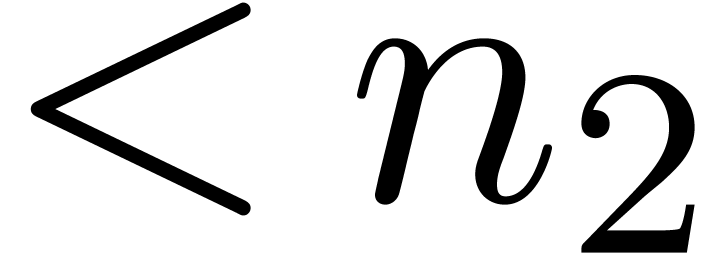 , and padding with zeros. Since
, and padding with zeros. Since 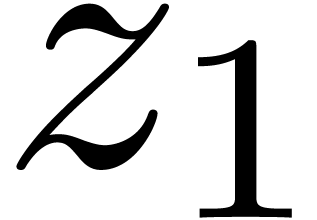 is a primitive
is a primitive 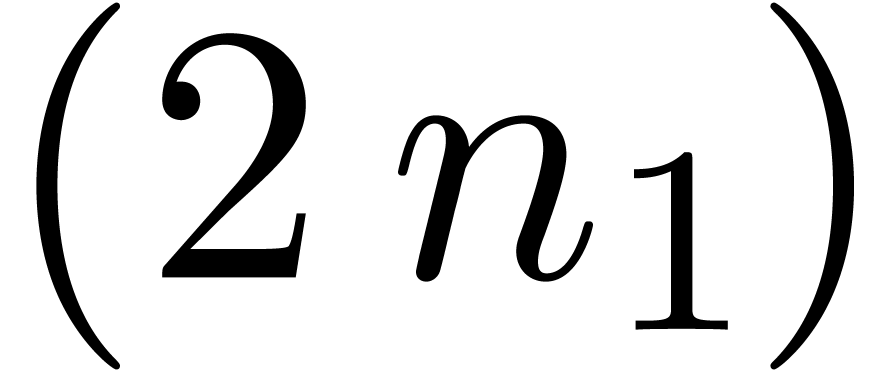 -th root of
unity and
-th root of
unity and 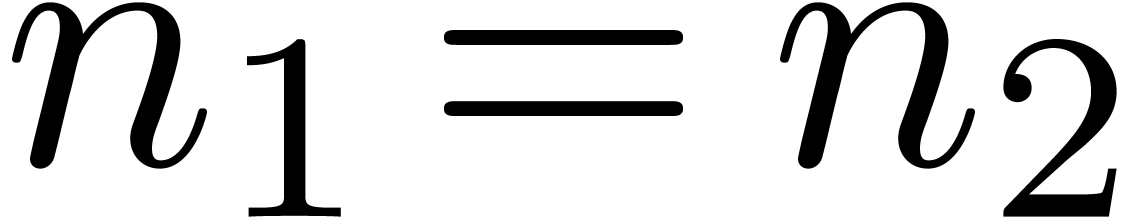 or
or  ,
we may finally perform an FFT in with respect to
or
,
we may finally perform an FFT in with respect to
or 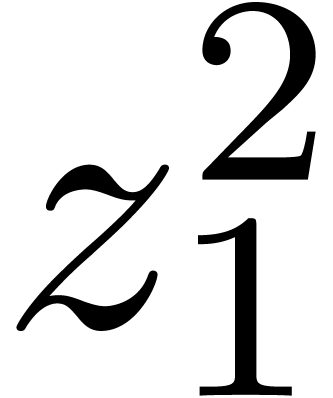 .
Each of the arrows can be reversed; in the case of , we take
.
Each of the arrows can be reversed; in the case of , we take
In particular, we have 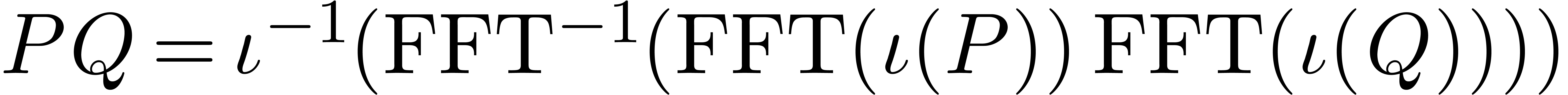 for all
for all  . Repeating the construction on
. Repeating the construction on 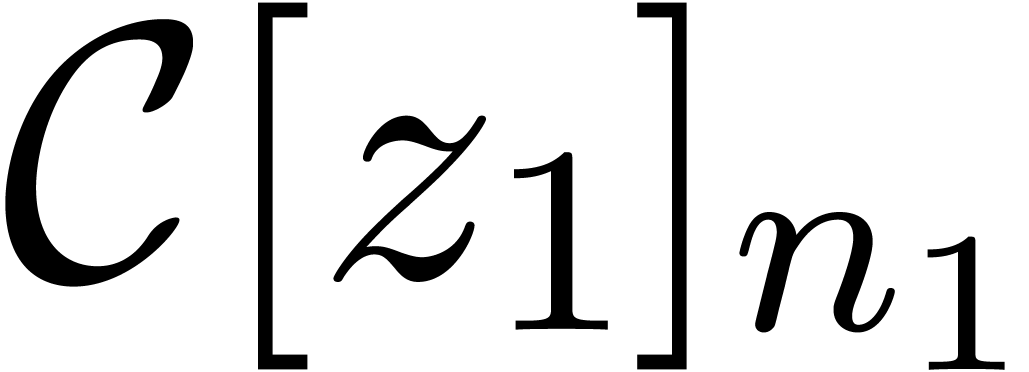 , we end up with an evaluation-interpolation
model with
, we end up with an evaluation-interpolation
model with
We will call this model the synthetic FFT model. Using similar
ideas to those in [CK91], the model adapts to the case when
 is a zero-divisor.
is a zero-divisor.
If is infinite, then we may also use multipoint
evaluation and interpolation in order to construct an
evaluation-interpolation scheme at any degree. Using arbitrary points,
we obtain [MB72, Str73, BM74]
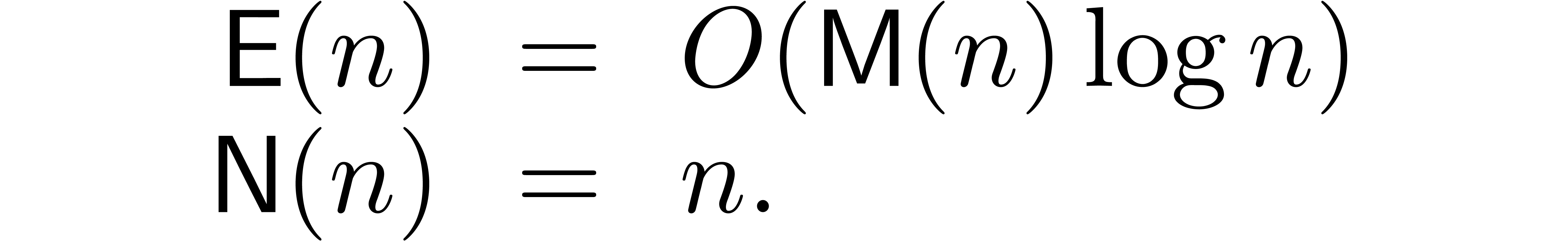
If it is possible to take points in a geometric progression, then one even has [BS05]
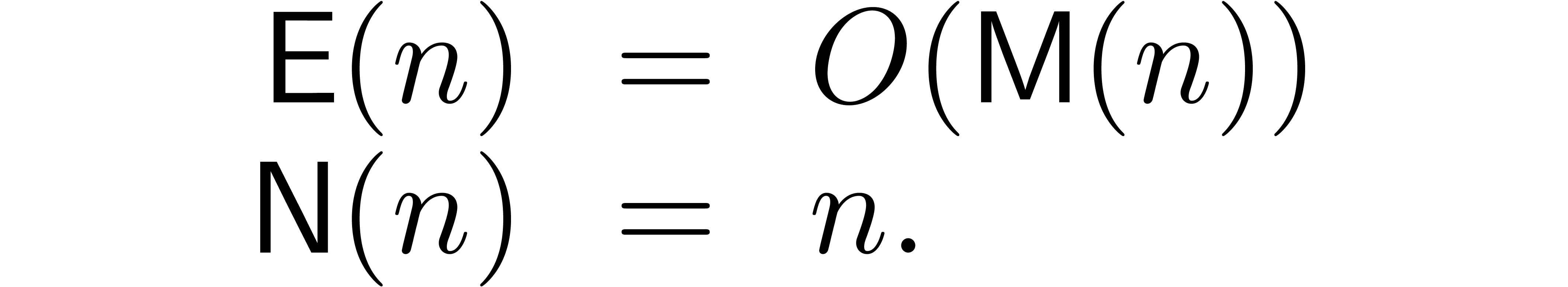
Of course, these evaluation-interpolation models are already based on
fast multiplication, whence they are not suitable for designing the fast
multiplication (5). On the other hand, for large values of
, they may perform better
than the synthetic FFT model on matrix and matrix-vector products (6) and (7).
For small values of , it is
sometimes interesting to use simpler, but asymptotically slower
evaluation-interpolation models. For instance, we may iterate the
construction
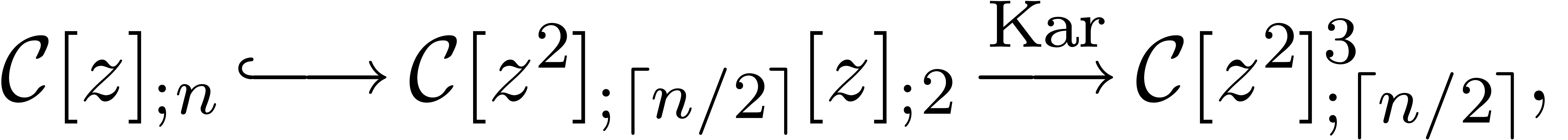
where
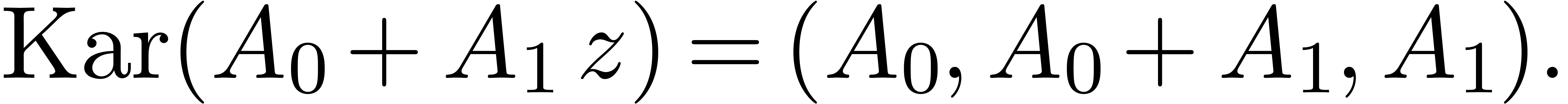
This yields an evaluation-interpolation model with
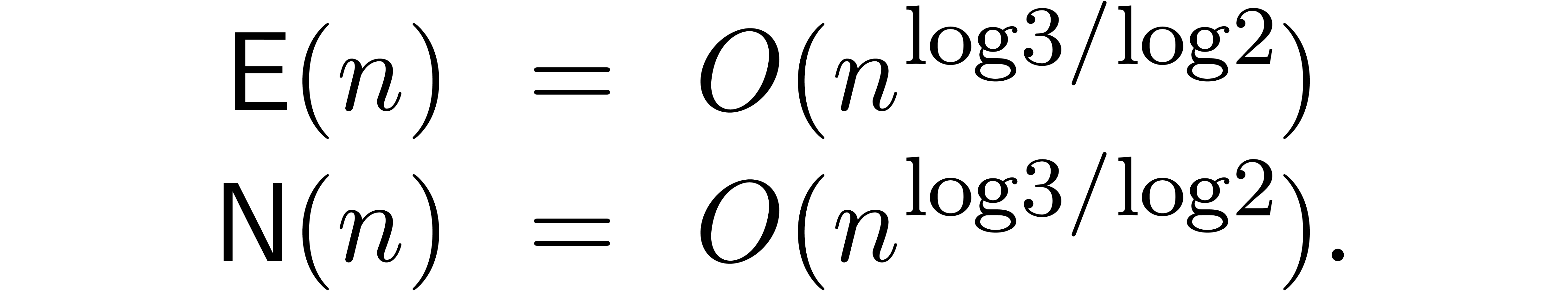
This “Karatsuba model” corresponds to even-odd Karatsuba multiplication. In a similar way, one may construct Toom-Cook models.
A lot of the complexity results for polynomials also hold for integers,
by considering them as the evaluations of polynomials in 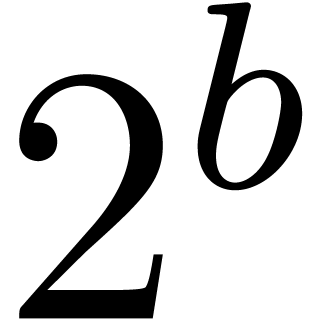 for a suitable word length
for a suitable word length 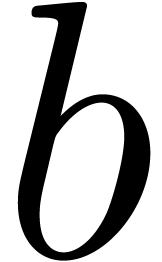 .
For integer matrix multiplications, several evaluation-interpolation
models are of interest. First of all, one may use approximate floating
point arithmetic of bit length
.
For integer matrix multiplications, several evaluation-interpolation
models are of interest. First of all, one may use approximate floating
point arithmetic of bit length 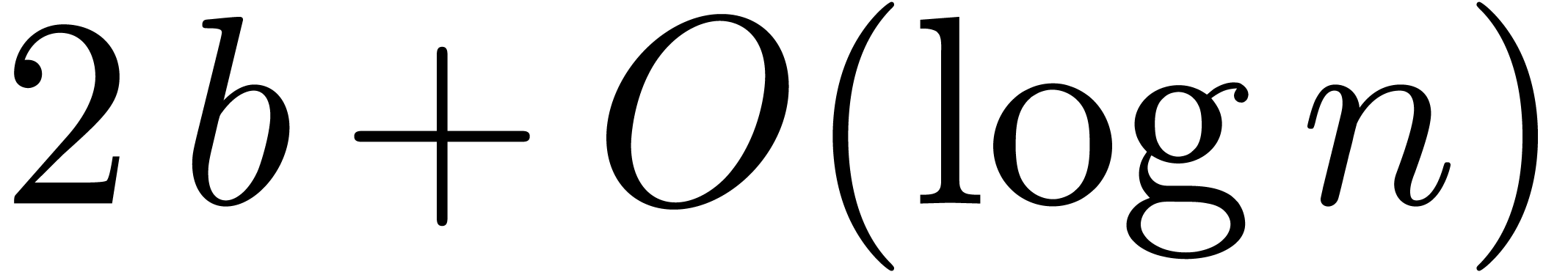 .
Secondly, one may fit the -bit
coefficients in
.
Secondly, one may fit the -bit
coefficients in 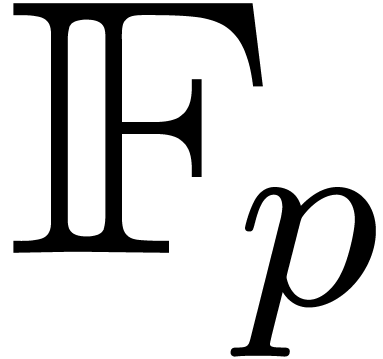 where
has many
where
has many 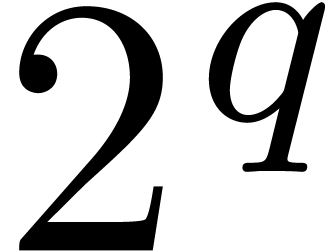 -th roots of unity
(e.g.
-th roots of unity
(e.g.  ). These
two models are counterparts of the standard FFT model. One may also use
the Schönhage-Strassen model (which is the counterpart of the
synthetic FFT model). For large matrix sizes, one may finally use
Chinese remaindering, which is the natural counterpart of multipoint
evaluation.
). These
two models are counterparts of the standard FFT model. One may also use
the Schönhage-Strassen model (which is the counterpart of the
synthetic FFT model). For large matrix sizes, one may finally use
Chinese remaindering, which is the natural counterpart of multipoint
evaluation.
In practice, operations in do not have a
constant cost. Nevertheless, when computing with truncations of a power
series 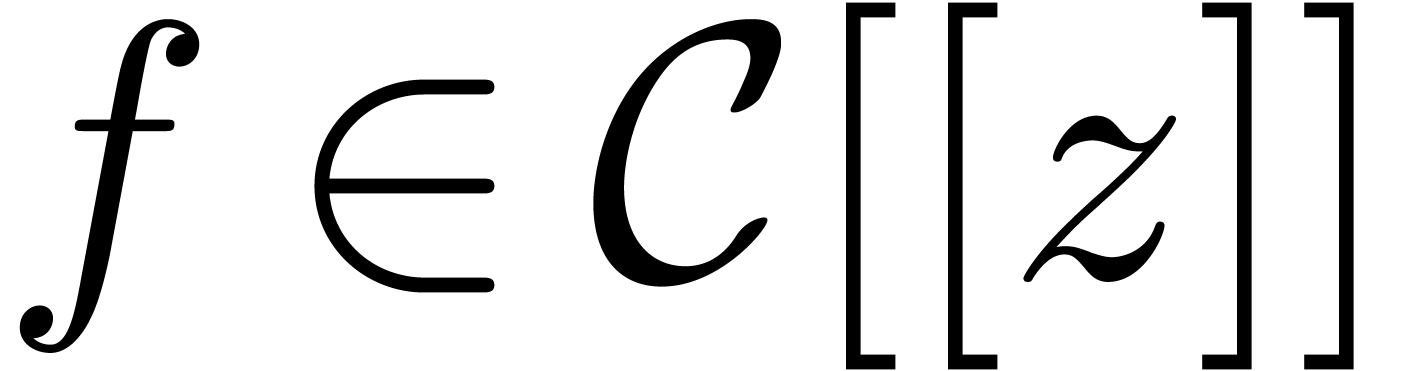 , it is usually the
case that the bit size of
, it is usually the
case that the bit size of 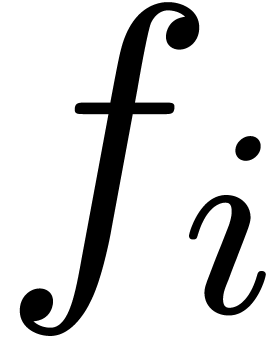 is proportional to
(or a power of ).
Consequently, the worst cost of an operation in
is usually bounded by a constant times the average cost of the same
operation over the complete computation.
is proportional to
(or a power of ).
Consequently, the worst cost of an operation in
is usually bounded by a constant times the average cost of the same
operation over the complete computation.
Let be the product of two power series . In order to efficiently compute
only a part 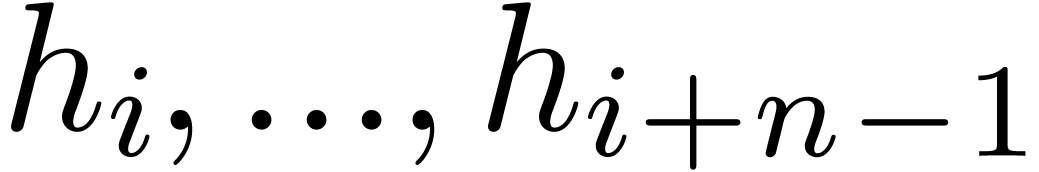 of
of  ,
a useful tool is the so called “middle product” [HQZ04].
Let
,
a useful tool is the so called “middle product” [HQZ04].
Let 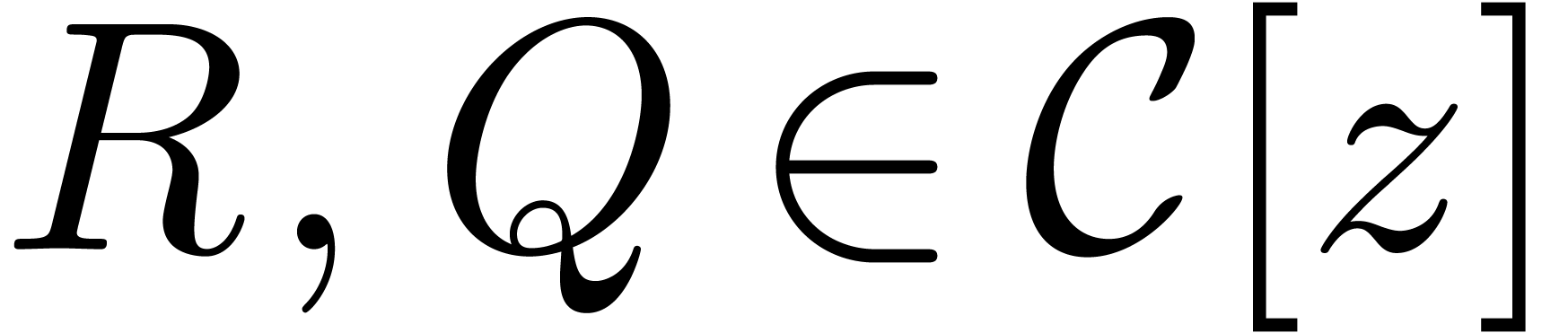 be two polynomials with
be two polynomials with 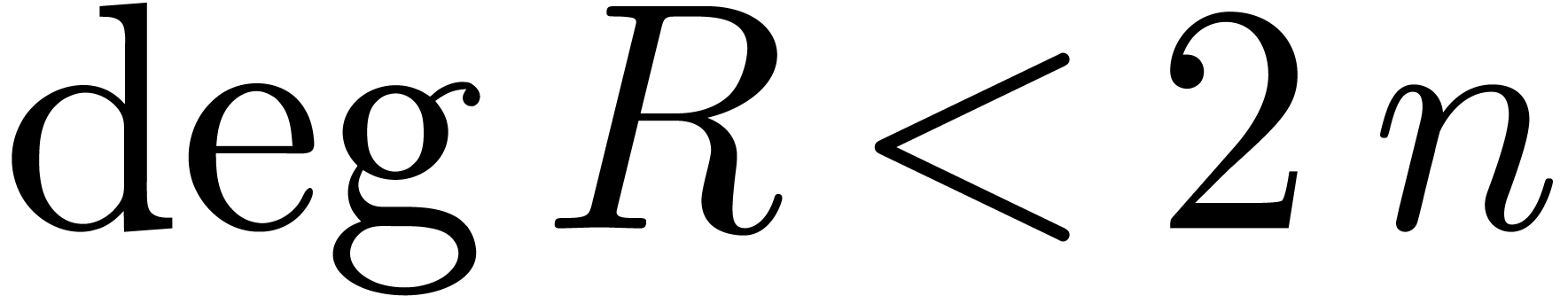 and
and  . Then we define their
middle product
. Then we define their
middle product 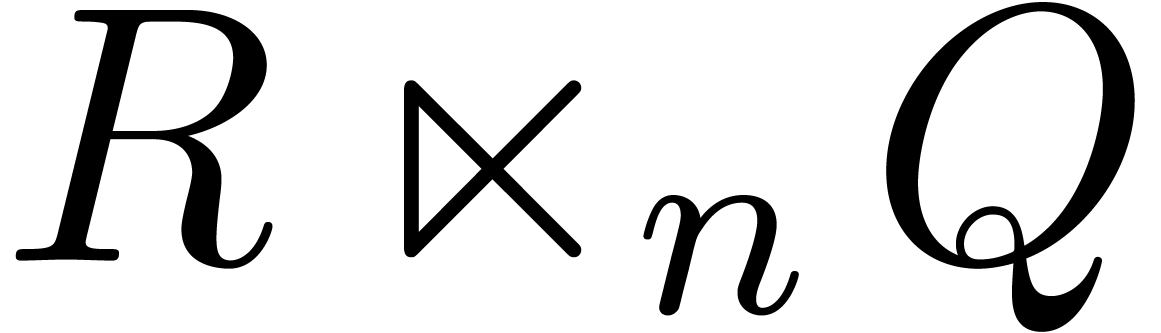 (or simply
(or simply  if is clear from the context) by
if is clear from the context) by
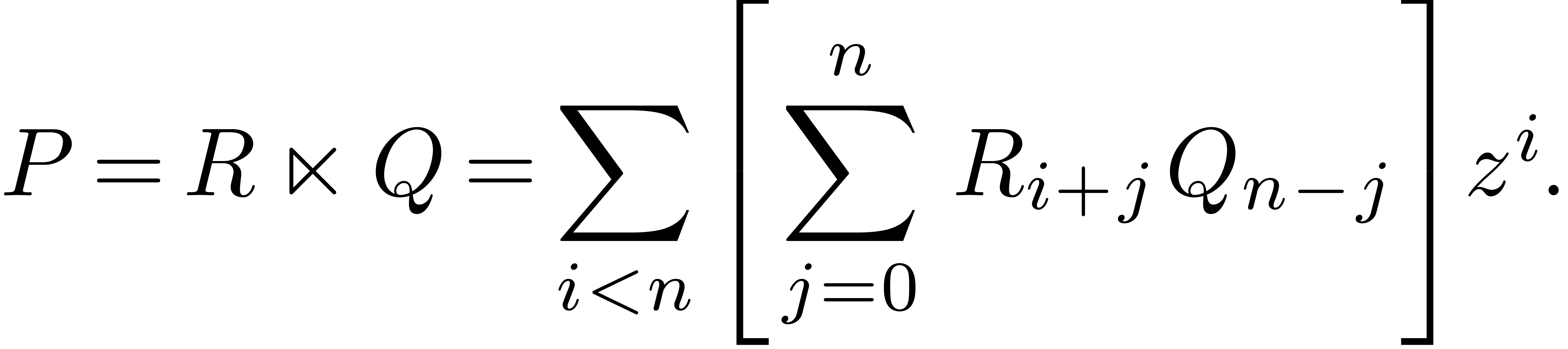
Notice that this definition generalizes to the case when  and are arbitrary rings with a
multiplication
and are arbitrary rings with a
multiplication  , and
, and  ,
, 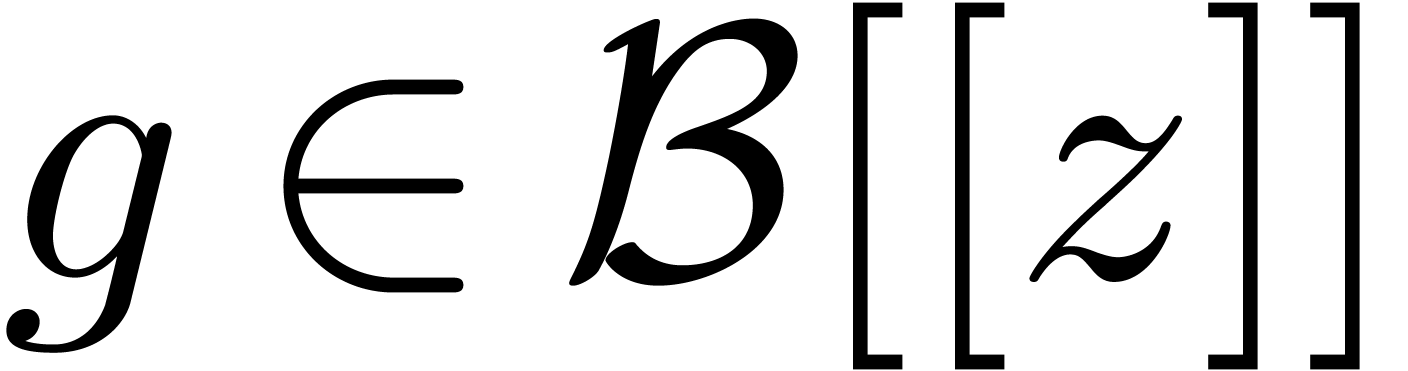 .
In matrix form, we have
.
In matrix form, we have
This formula is almost the transposed form of a usual product. More
precisely, if 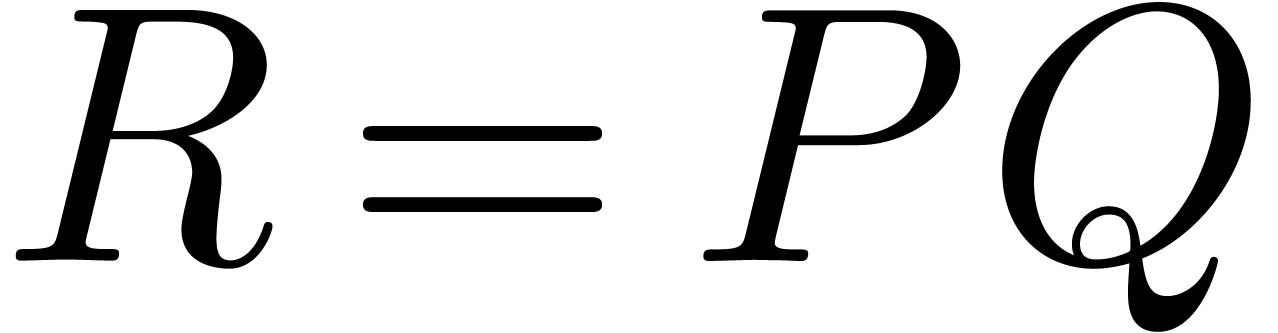 with
with 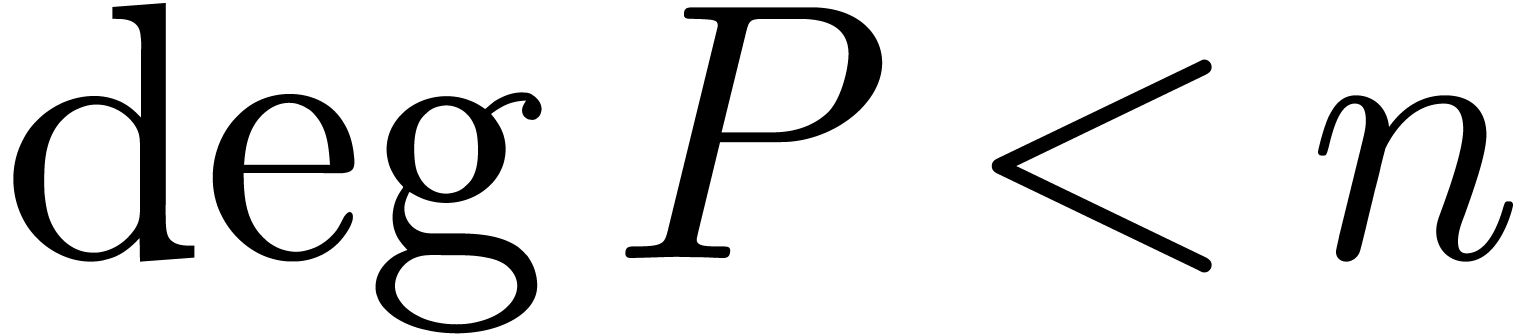 and
, then we have
and
, then we have
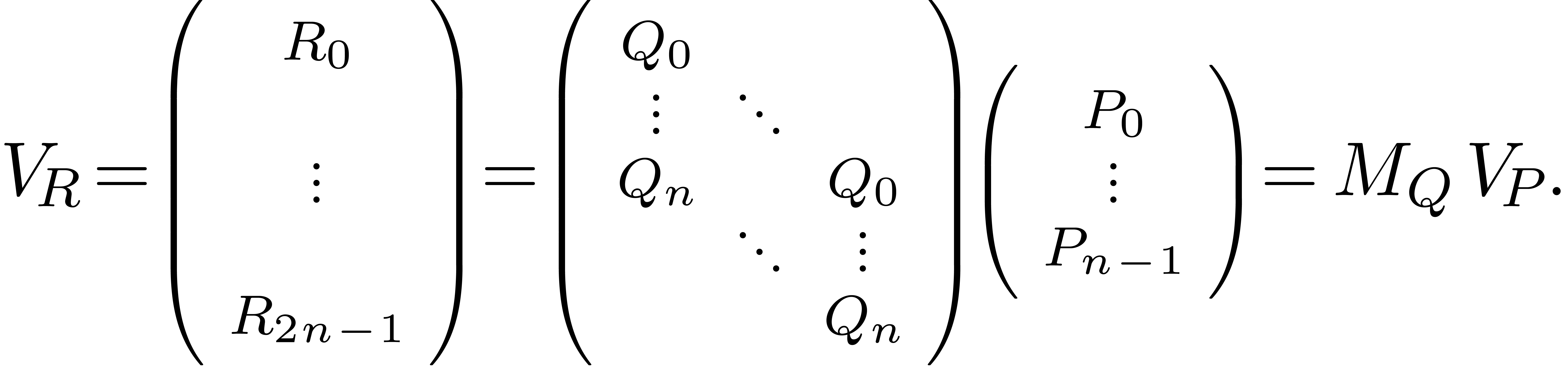
In other words, 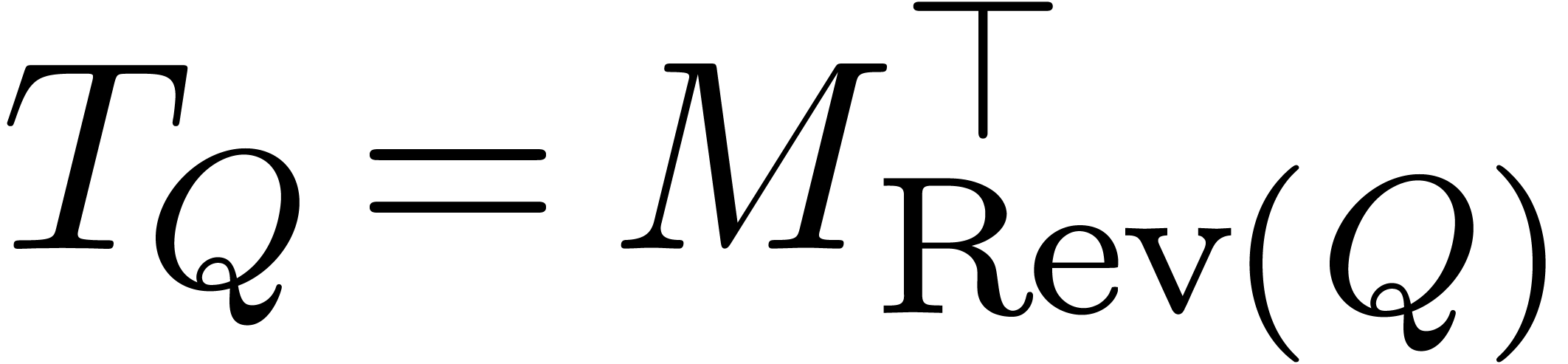 , where
, where  denotes the transpose of a matrix
denotes the transpose of a matrix  and
and 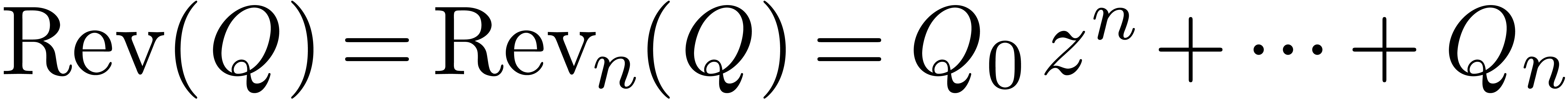 .
.
For a fixed evaluation-interpolation scheme, the product  is computed efficiently using evaluation and
interpolation. More precisely, the operator at
degree
is computed efficiently using evaluation and
interpolation. More precisely, the operator at
degree  , restricted to
polynomials of degree corresponds to an
, restricted to
polynomials of degree corresponds to an 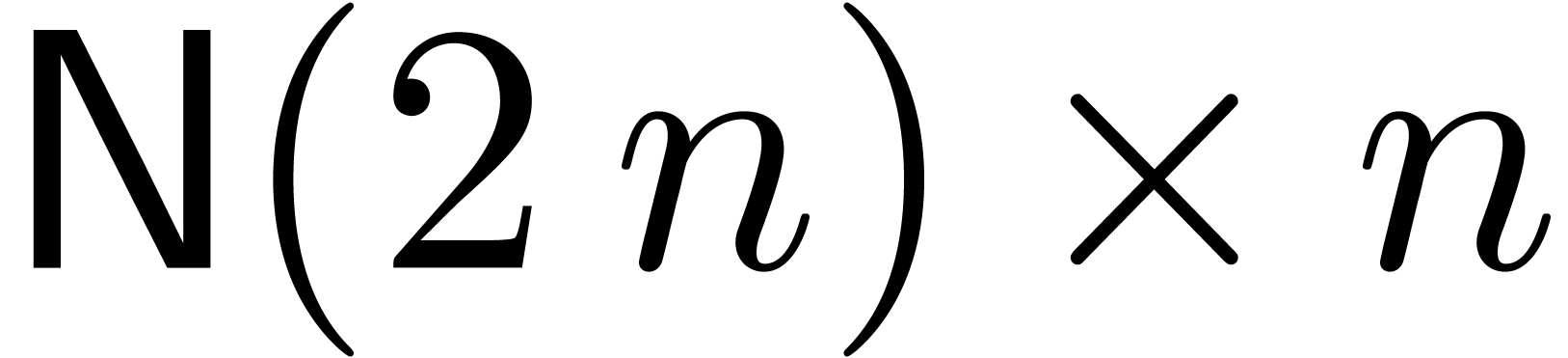 matrix
matrix  :
:
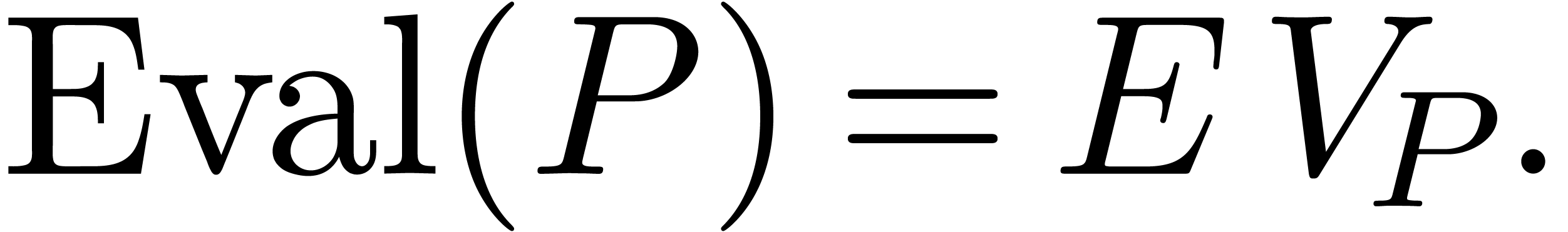
Let  be the diagonal matrix with entries
be the diagonal matrix with entries 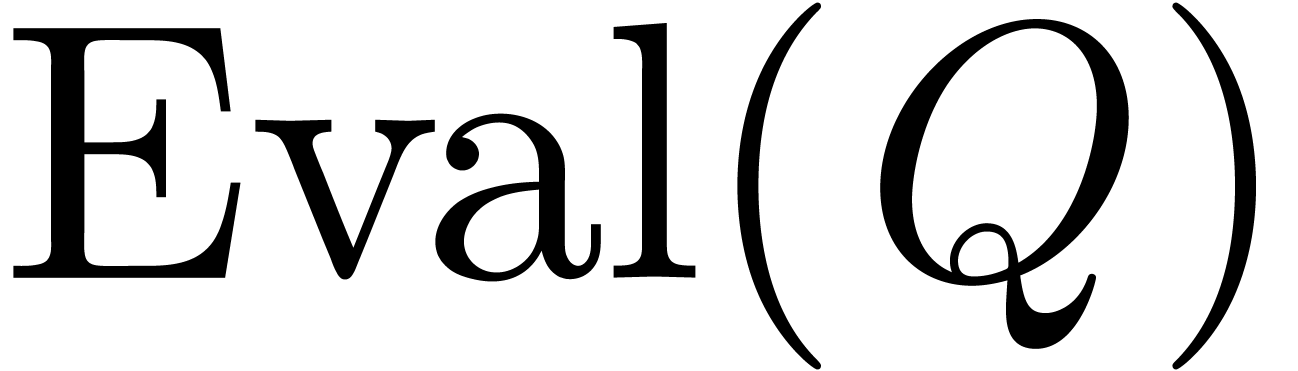 . Then
. Then
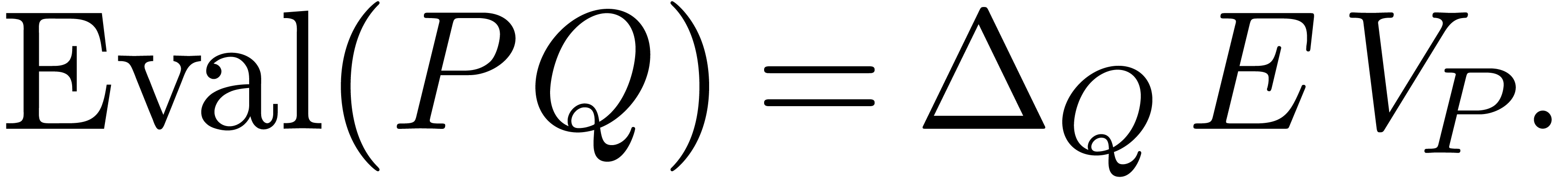
Finally, the operator at degree  corresponds to a
corresponds to a  matrix
matrix  :
:

Since this equality holds for all ,
it follows that
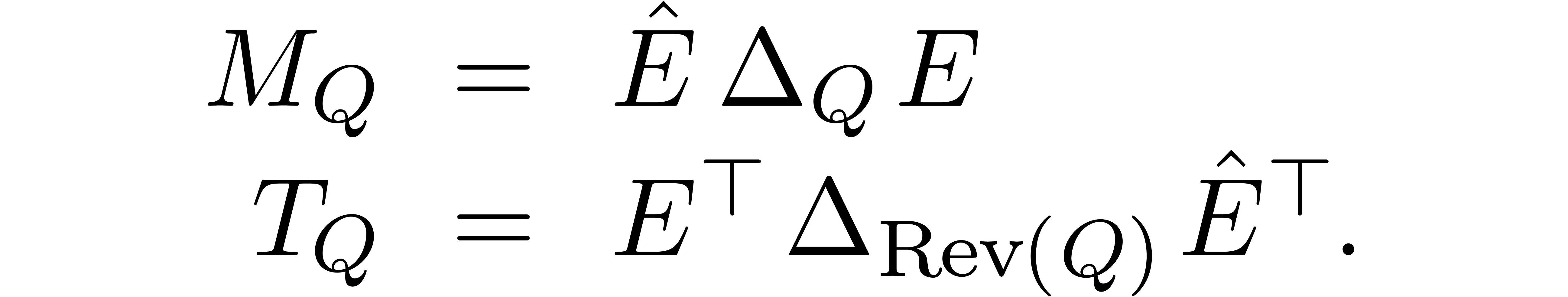
Assuming that the algorithms and for evaluation and interpolation only use -linear operations, the actions of  and
and  on vectors can be computed by
the transpositions
on vectors can be computed by
the transpositions  and
and 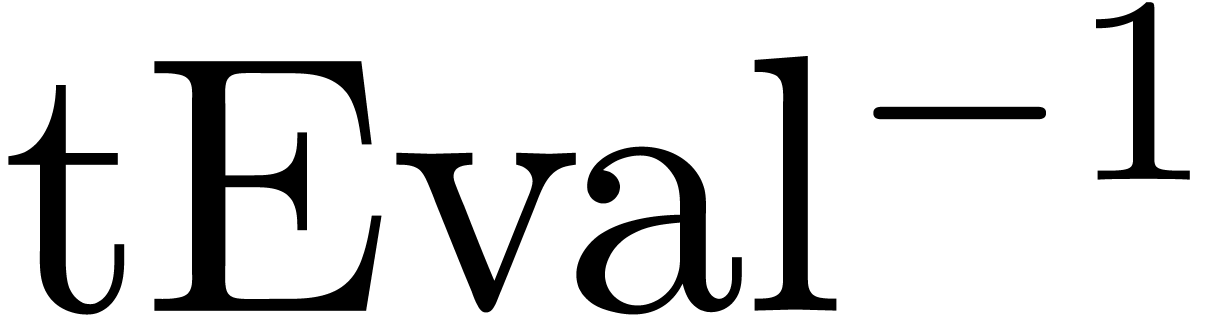 of these algorithms in time
of these algorithms in time  [Bor56,
Ber]. We may thus compute the middle product using
[Bor56,
Ber]. We may thus compute the middle product using
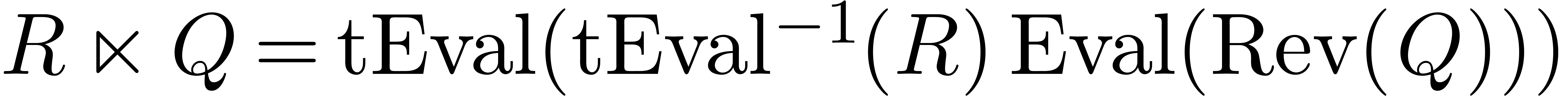 |
(8) |
in time  . In the standard FFT
model, the matrix is actually symmetric and is the upper half part of a symmetric matrix. Hence,
(8) becomes
. In the standard FFT
model, the matrix is actually symmetric and is the upper half part of a symmetric matrix. Hence,
(8) becomes
One may also use the alternative formula [Har09a]
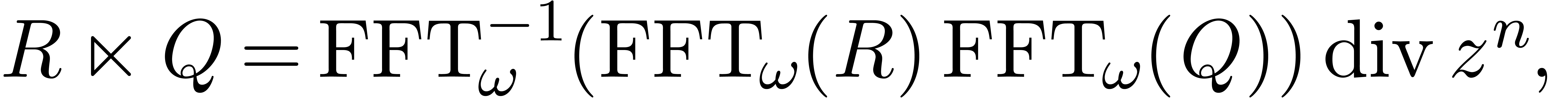
which is based on the fact that standard FFT multiplication of  and
and  really computes the exact
product of
really computes the exact
product of  modulo
modulo 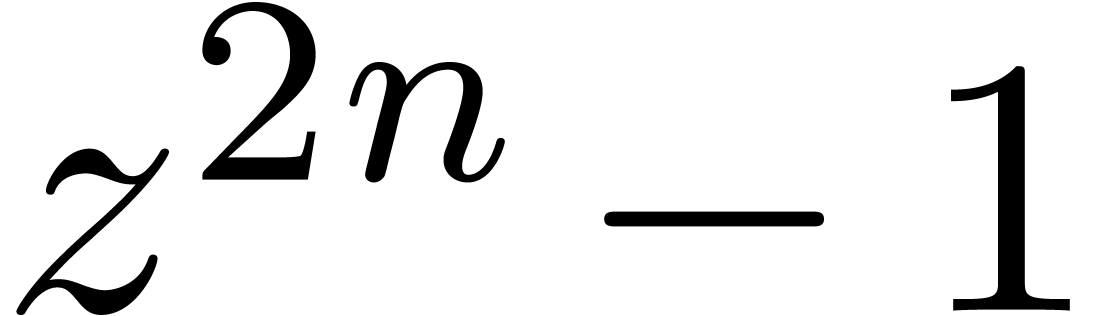 .
Writing
.
Writing 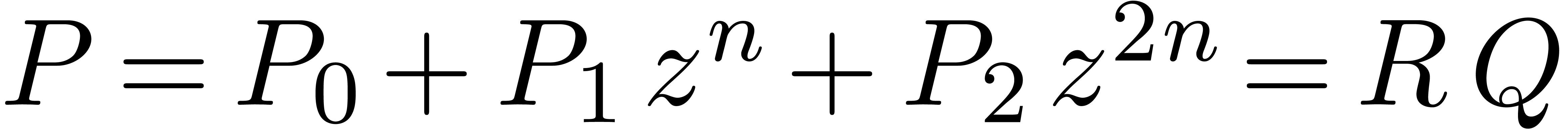 with
with 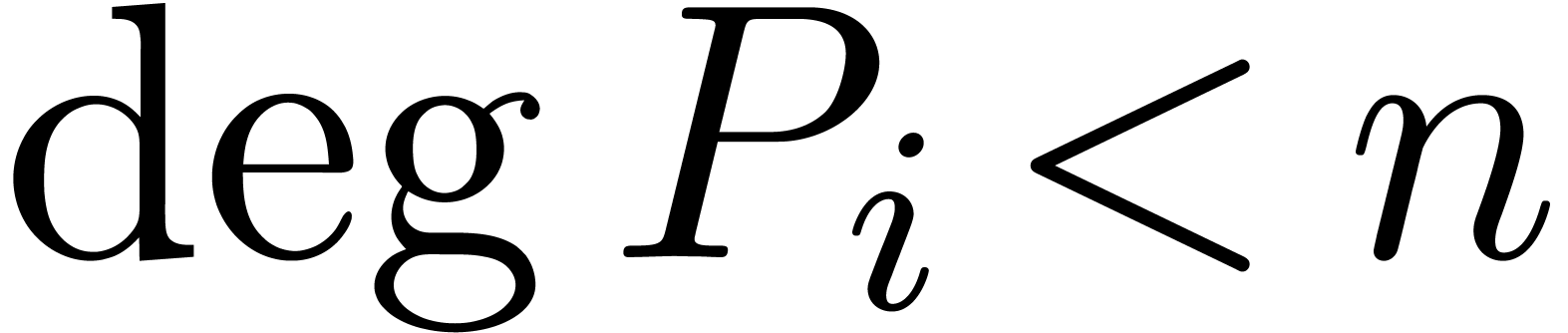 ,
we then notice that
,
we then notice that 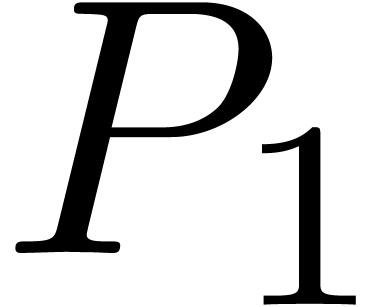 coincides with the middle
product, whereas
coincides with the middle
product, whereas 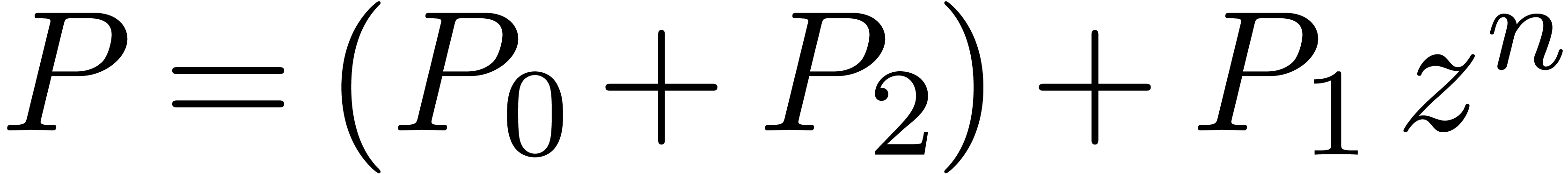 modulo .
modulo .
Given a power series (and similarly for vectors
or matrices of power series, or power series of vectors or matrices) and
integers 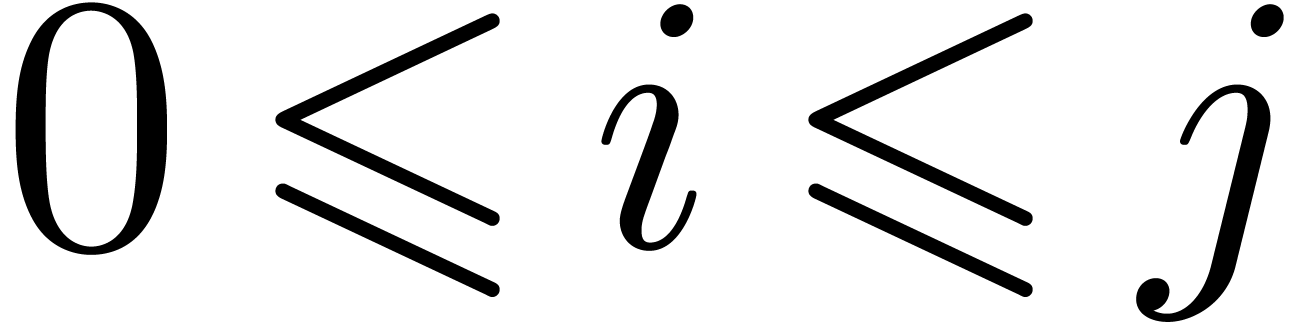 , we will use the
notations:
, we will use the
notations:

By convention, 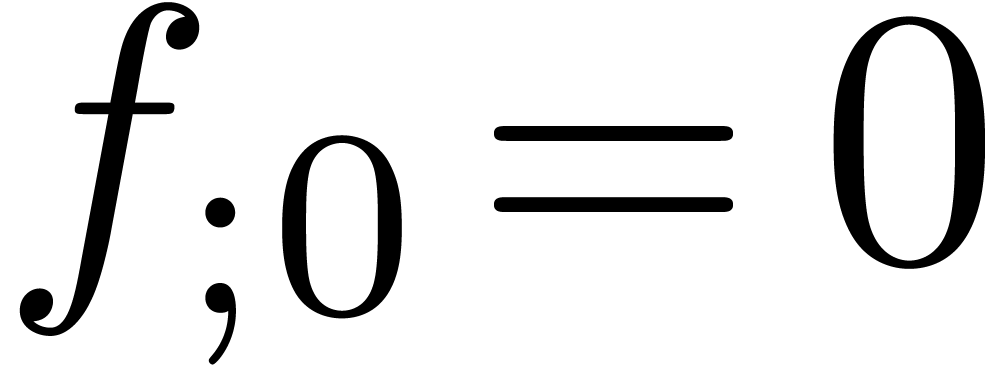 and
and 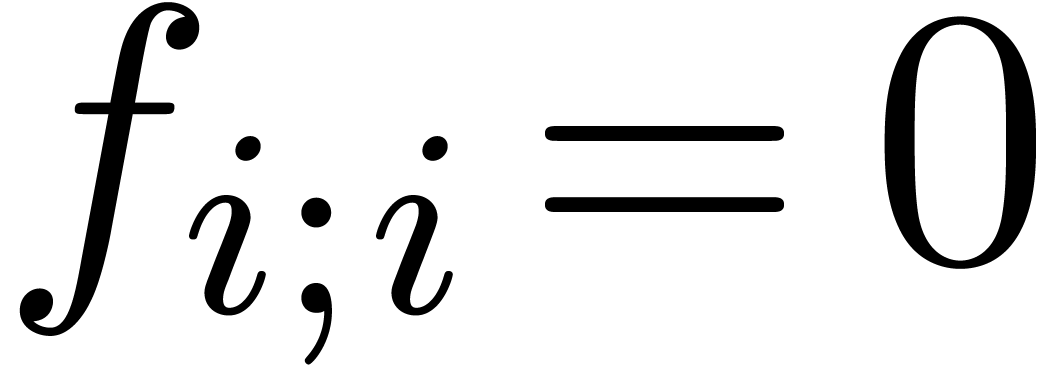 for
all .
for
all .
Let 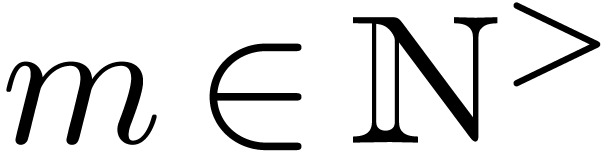 be fixed. Any series
be fixed. Any series 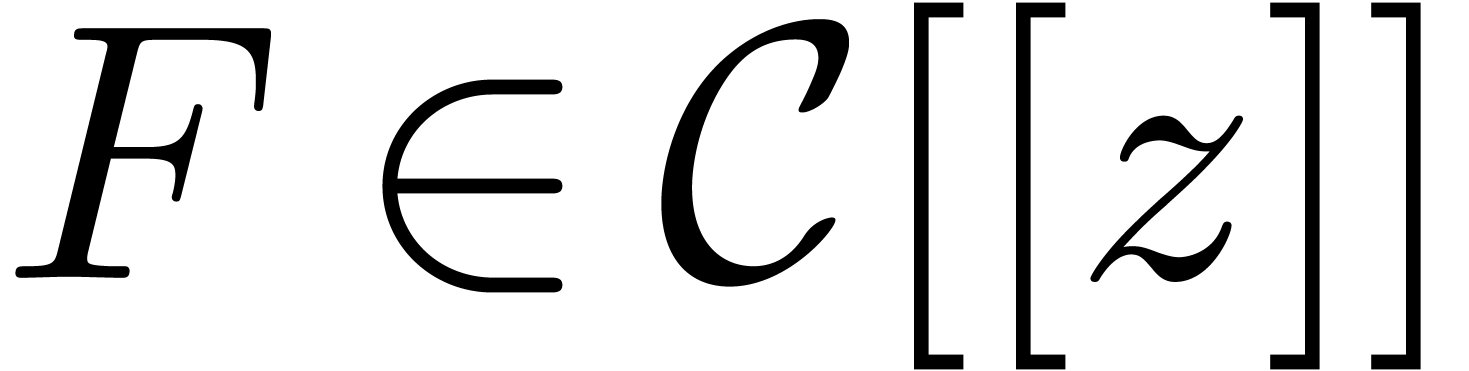 in
in  may be rewritten blockwise as a power series
may be rewritten blockwise as a power series
 in
in 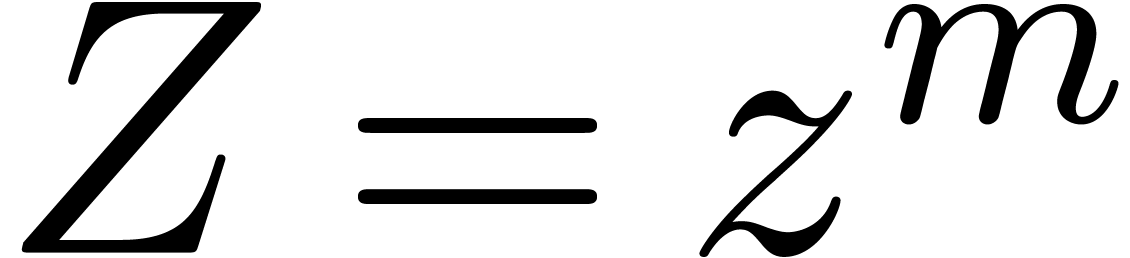 with coefficients
with coefficients
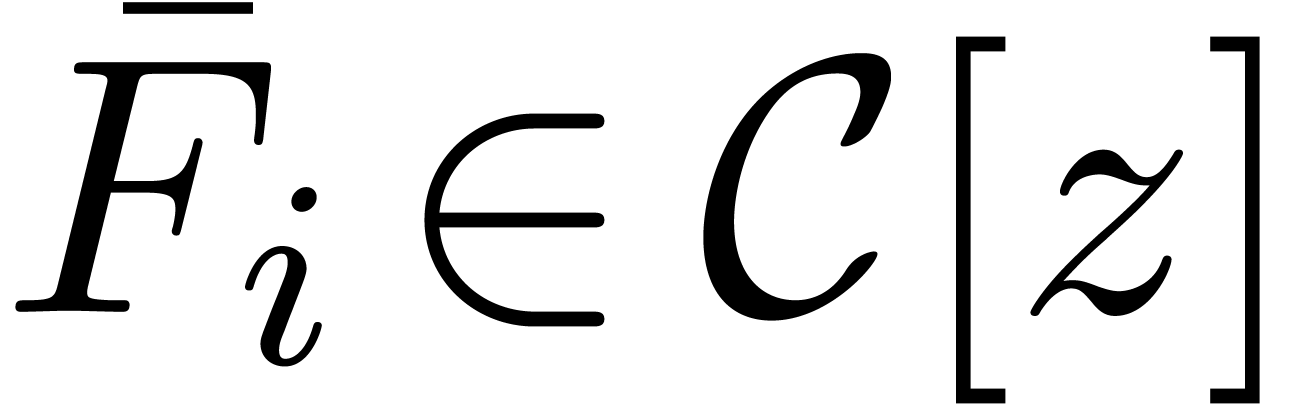 ,
, 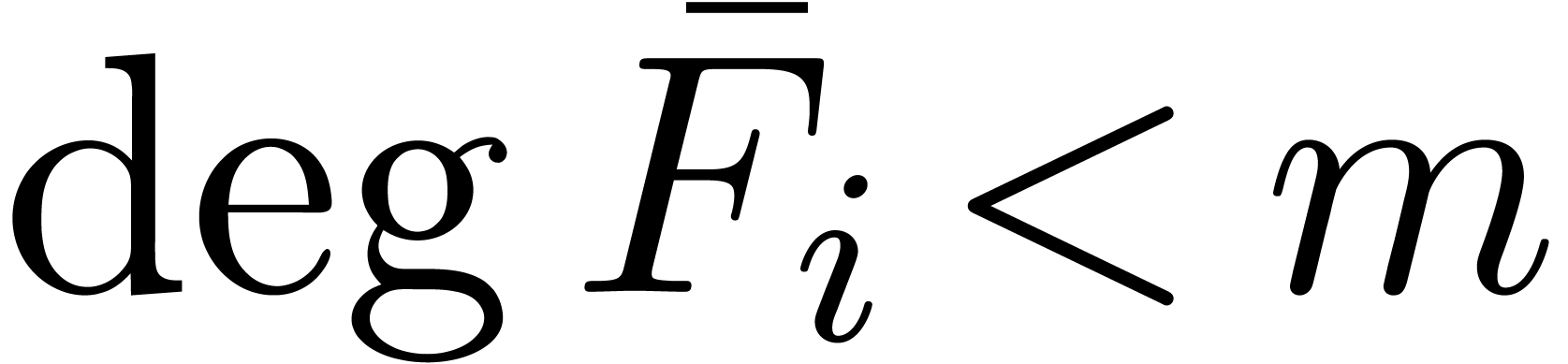 :
:
Let us now consider the computation of a product 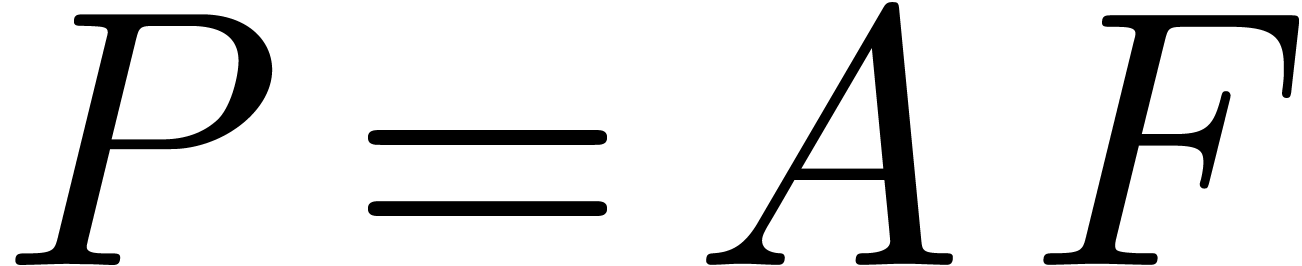 , where
, where  .
The coefficients of the blockwise product
.
The coefficients of the blockwise product 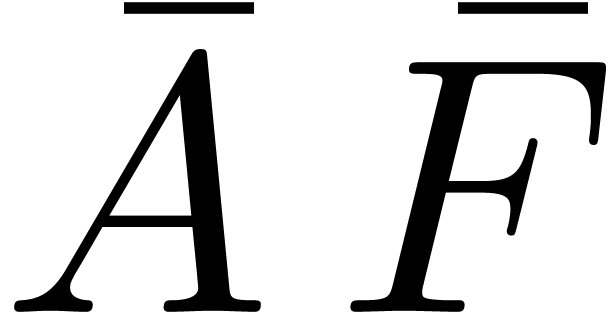 are
polynomials of degrees
are
polynomials of degrees  instead of
instead of  . In order to recover the coefficients of
. In order to recover the coefficients of 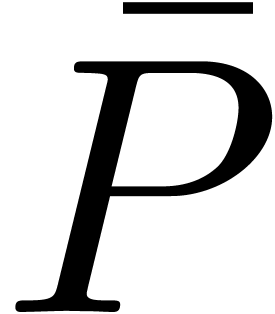 , we define the “contraction
operator”
, we define the “contraction
operator”  : given a
series
: given a
series 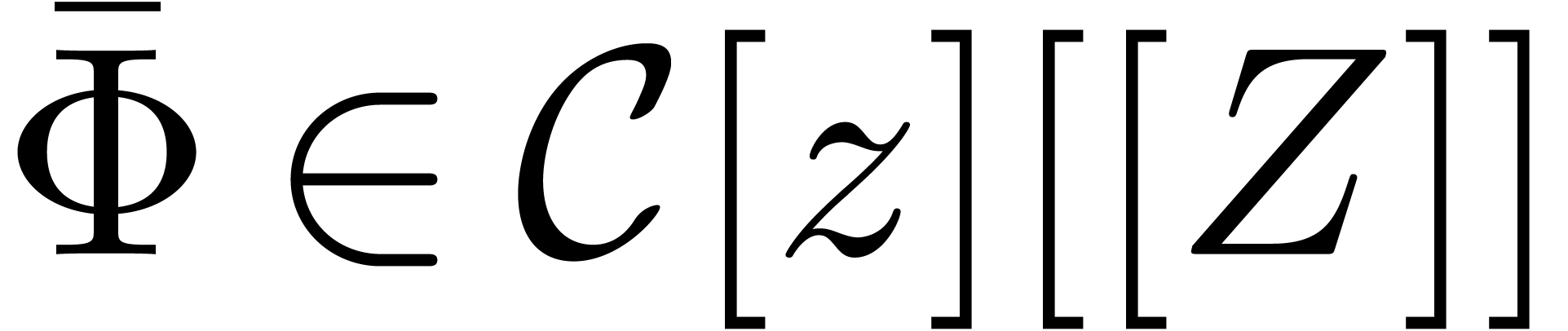 , whose coefficients
are polynomials of degrees
, whose coefficients
are polynomials of degrees  ,
we let
,
we let
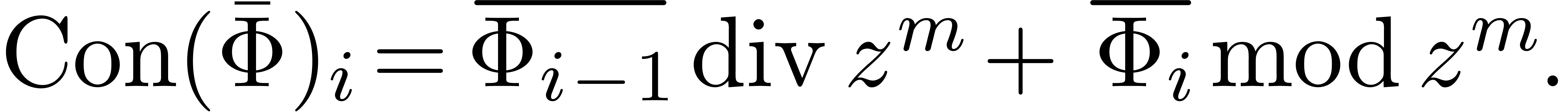
Then we have
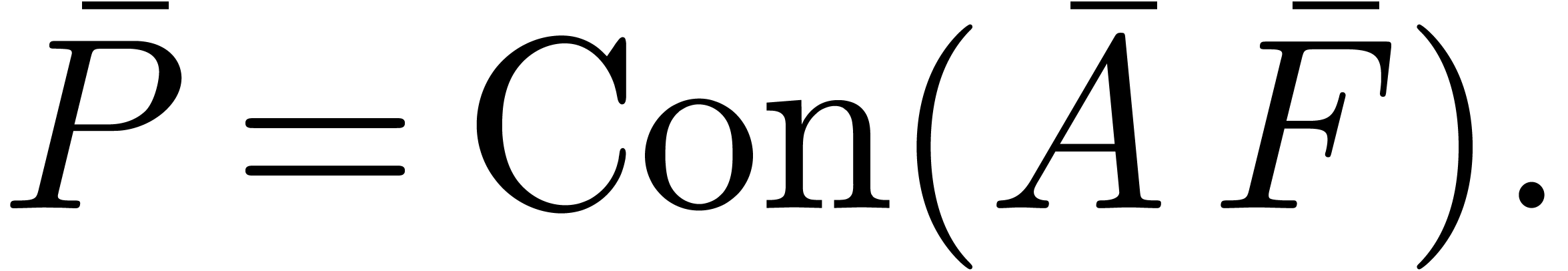 |
(10) |
Alternatively, we may first “extend” the series  using
using
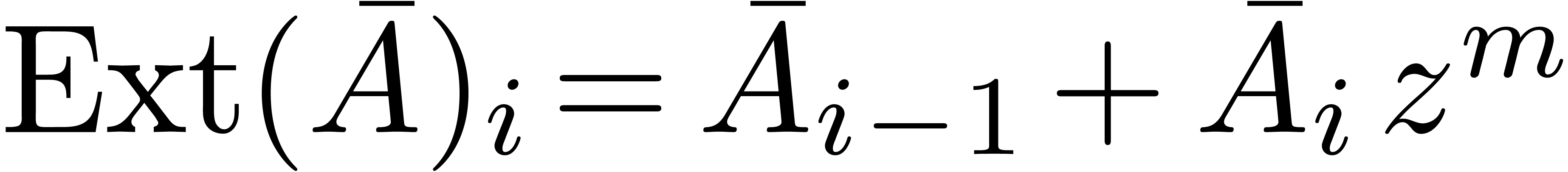
and then compute using middle products:
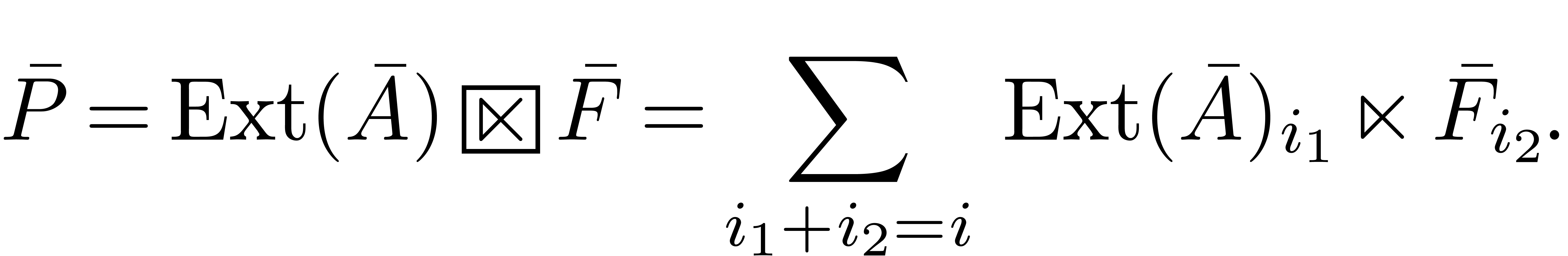 |
(11) |
These formulas are illustrated in Figure 1. From now on, and for reasons which are detailed in remark 2, we will use formula (11) for all product computations.
Assume now that we have fixed an evaluation-interpolation model for
polynomials of degrees . Then
we may replace the polynomial representations of the blockwise
coefficients 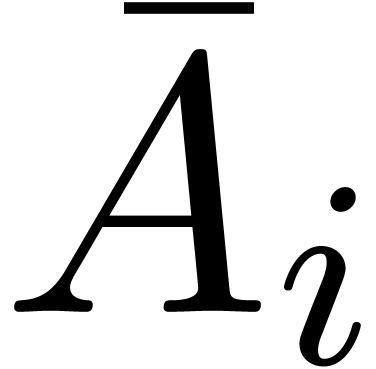 and
and 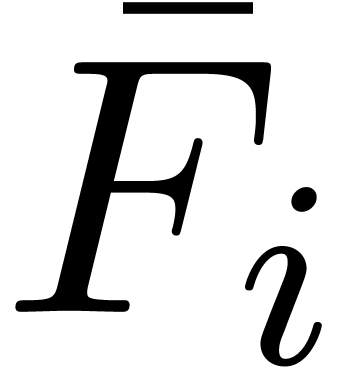 by
their transforms
by
their transforms
compute convolution products in the transformed model
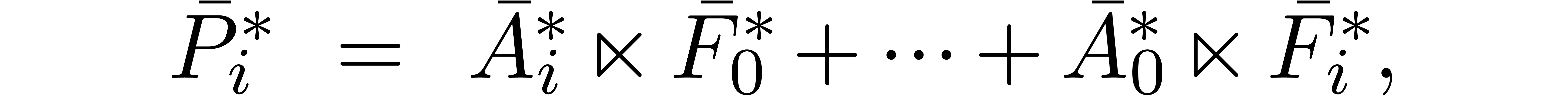
and apply (8) in order to recover the coefficients
In particular, assuming  and
and  known, we may compute
known, we may compute  using
using  scalar multiplications and
scalar multiplications and  using an additional
time
using an additional
time  .
.
Remark will be computed one by one as a
function of the previous diagonal sums 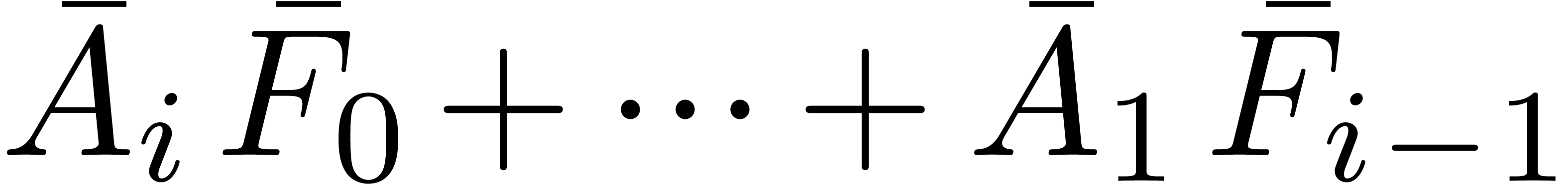 .
In particular, when using (10), the computation of the high
part
.
In particular, when using (10), the computation of the high
part 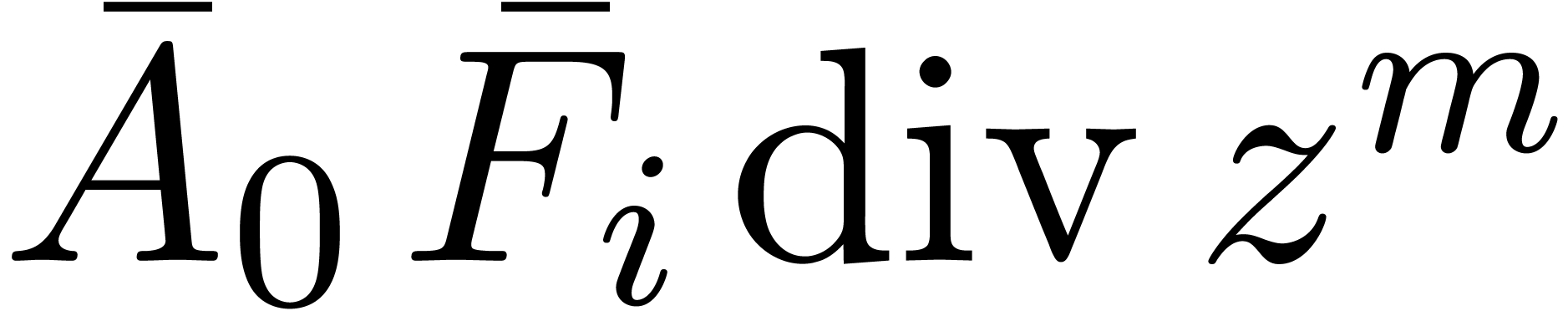 of
of 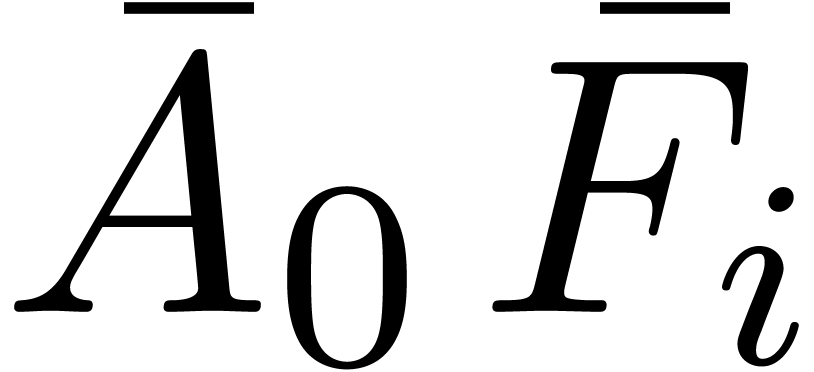 will need to be
done separately at the next iteration. When using middle products, this
computation is naturally integrated into the product
will need to be
done separately at the next iteration. When using middle products, this
computation is naturally integrated into the product 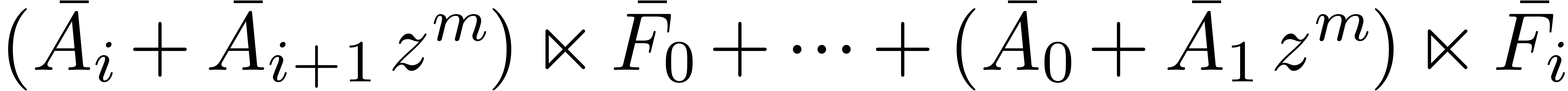 .
.
  |
Let  be two power series such that
be two power series such that 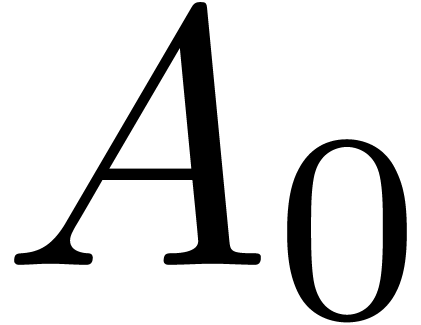 is invertible. Assume that we want to compute the first
is invertible. Assume that we want to compute the first
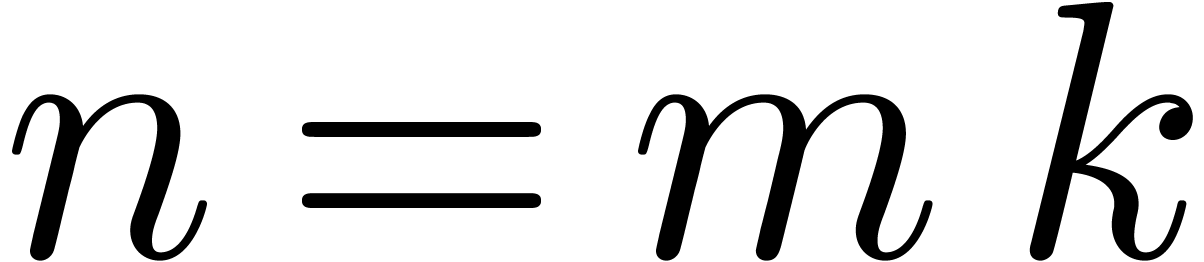 coefficients of
coefficients of 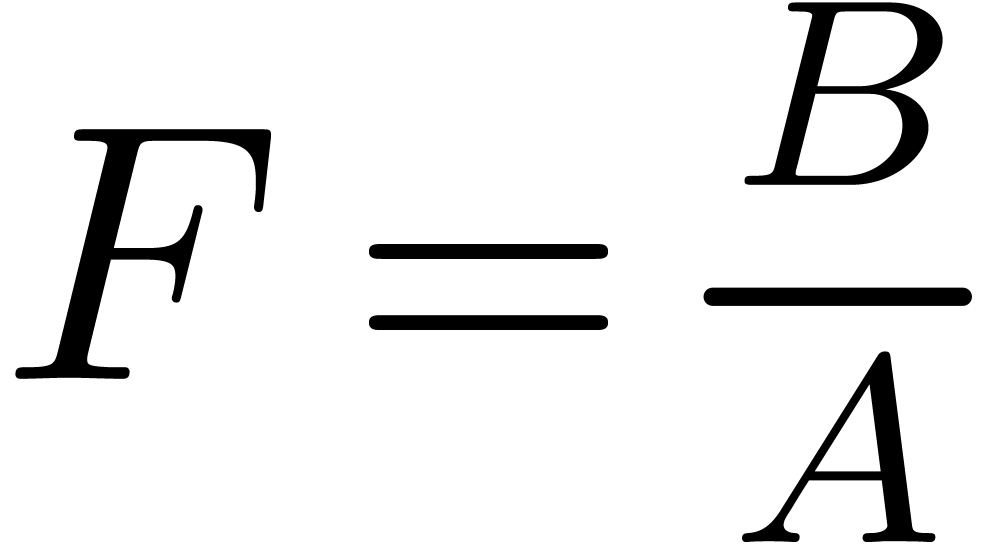 .
Denoting
.
Denoting 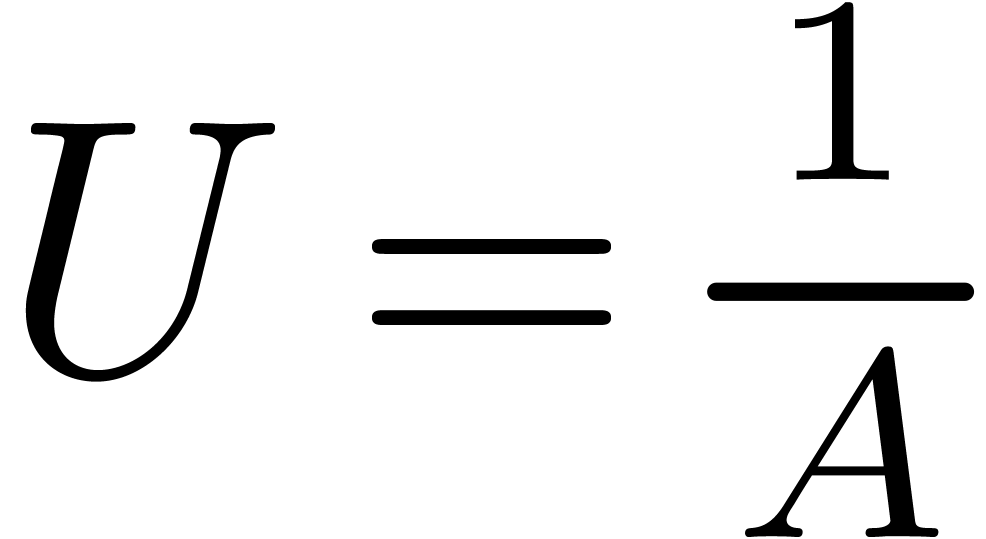 , we first compute
, we first compute
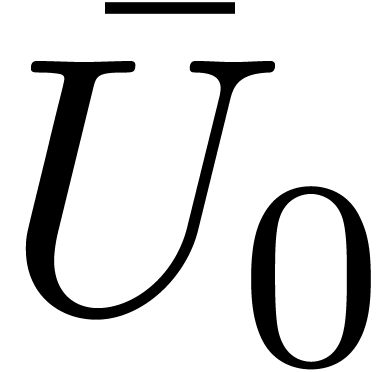 using a classical Newton iteration [BK78,
Sch00]. Given
using a classical Newton iteration [BK78,
Sch00]. Given 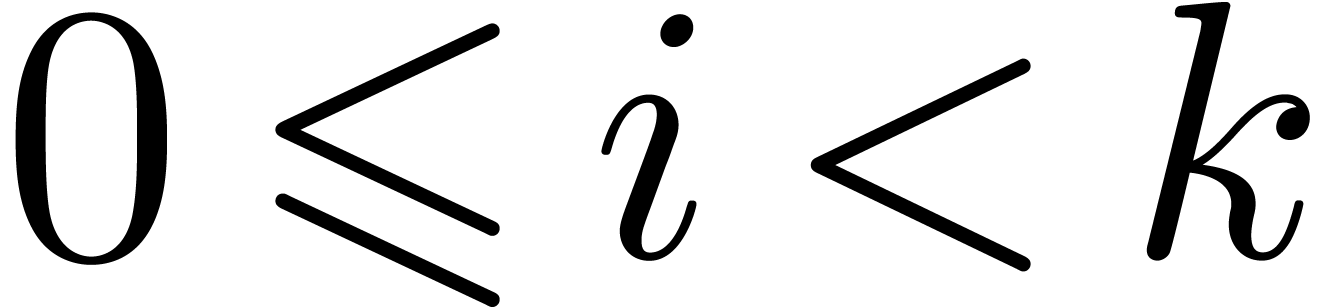 ,
assume that
,
assume that 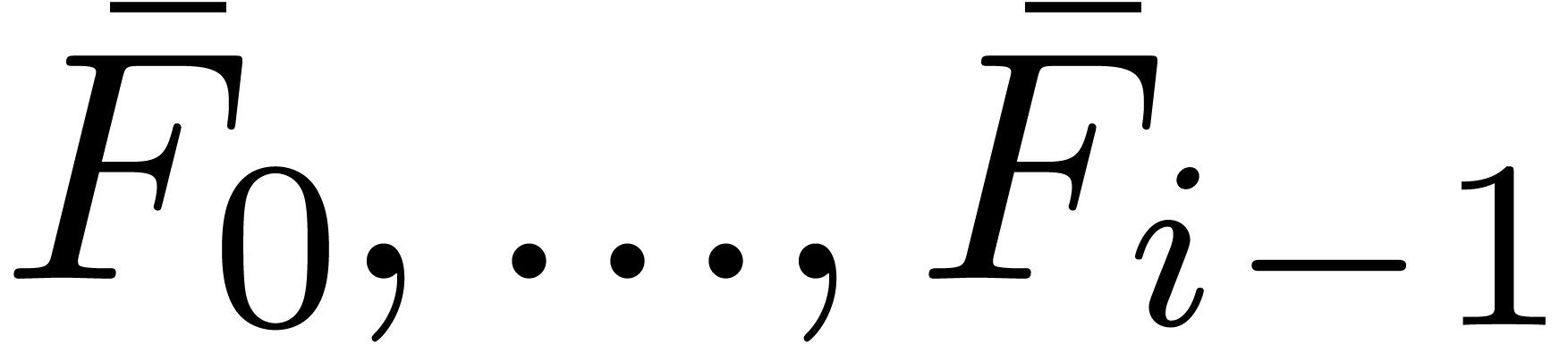 have been computed, and let
have been computed, and let
Setting 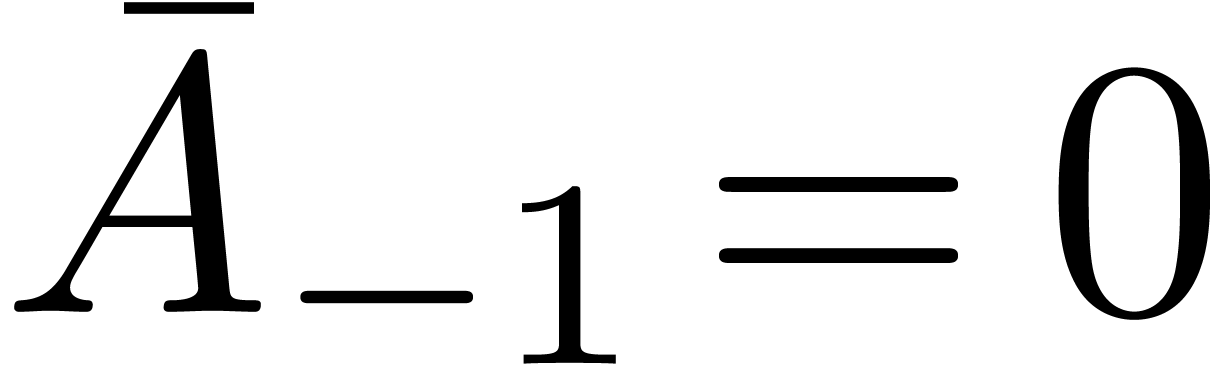 , we then must have
, we then must have
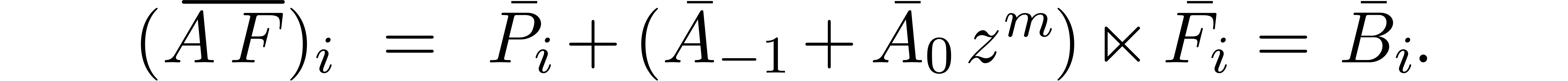
It thus suffices to take
Carrying out this iterative method in an evaluation-interpolation model
for polynomials of degrees yields the following
algorithm:
Algorithm divide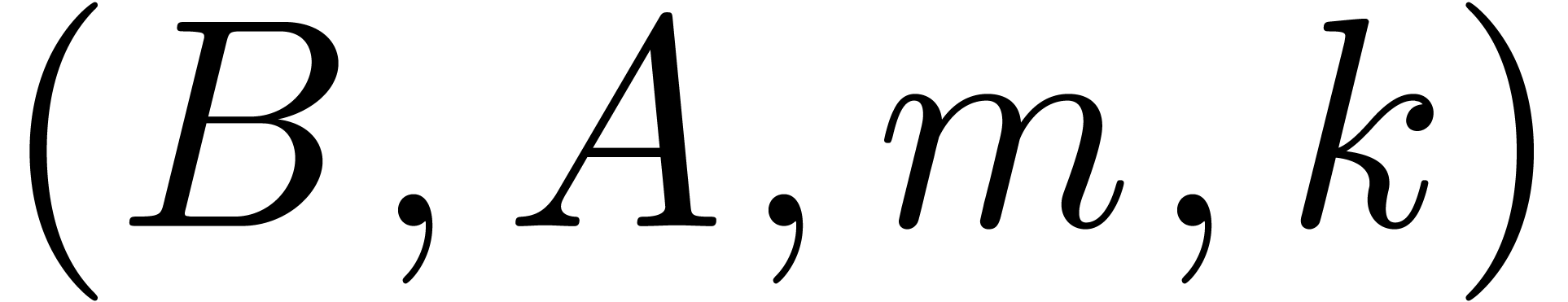
at order 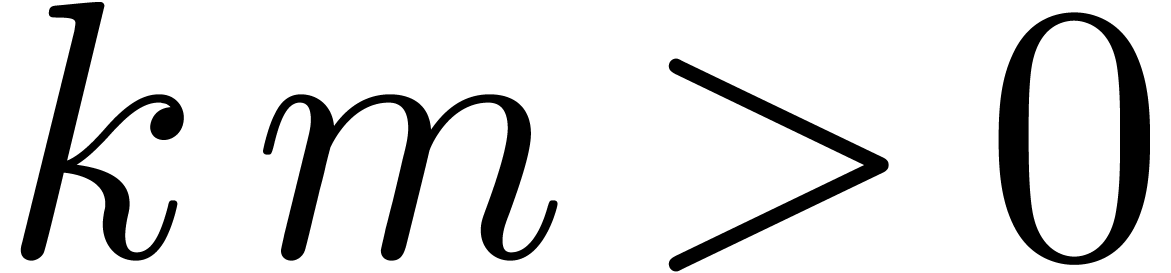 ,
such that is invertible.
,
such that is invertible.
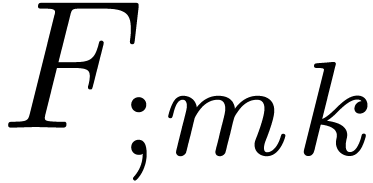 , where .
, where .
Compute and 
For  do
do
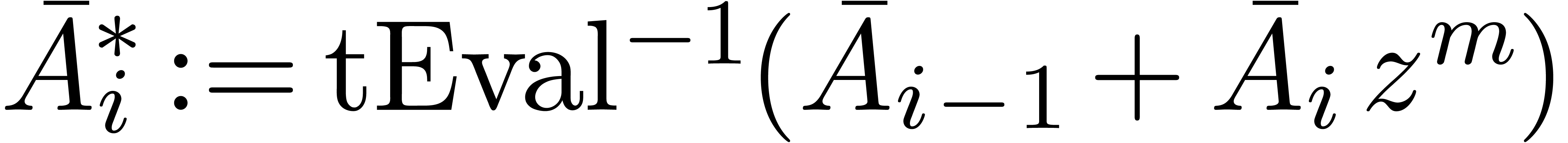
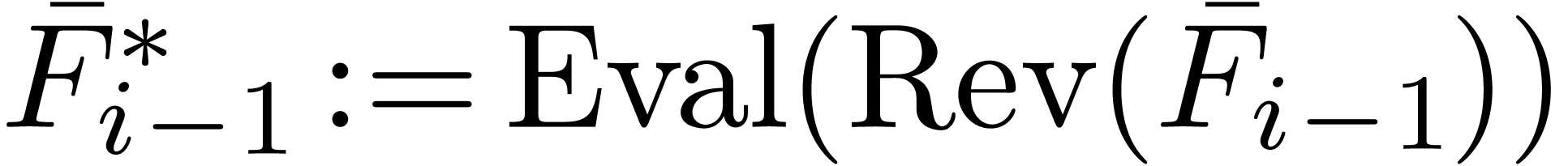
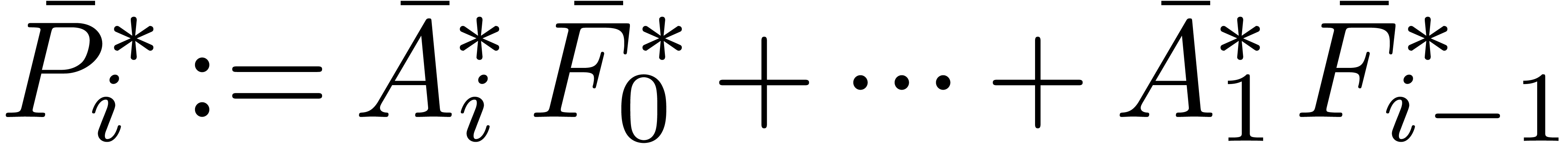

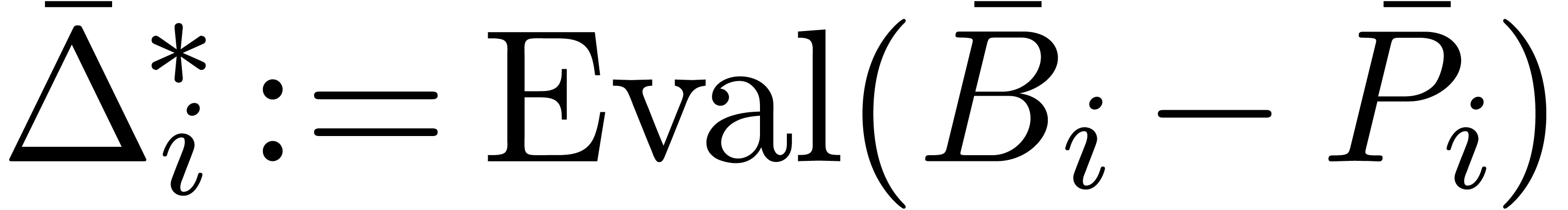
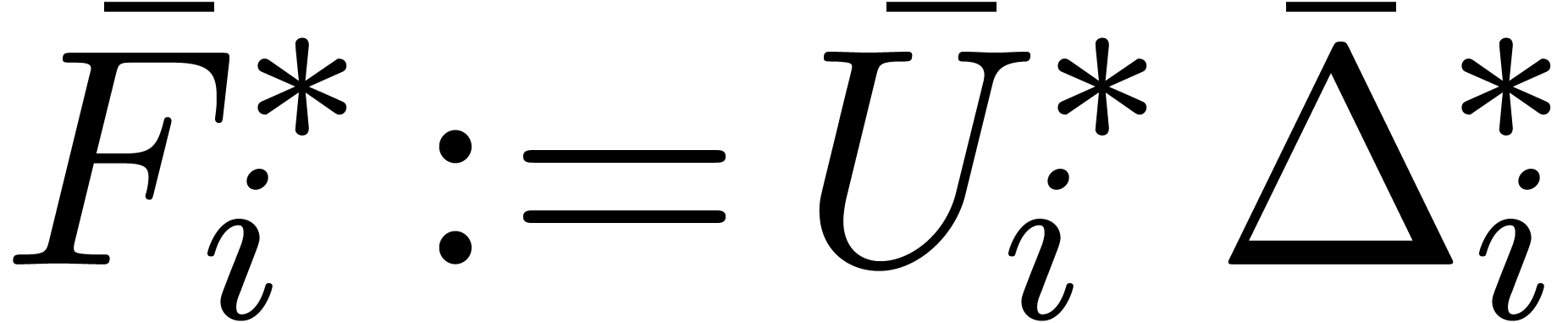
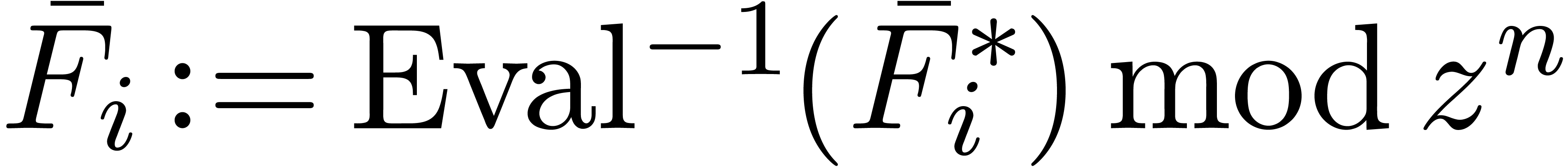
Return 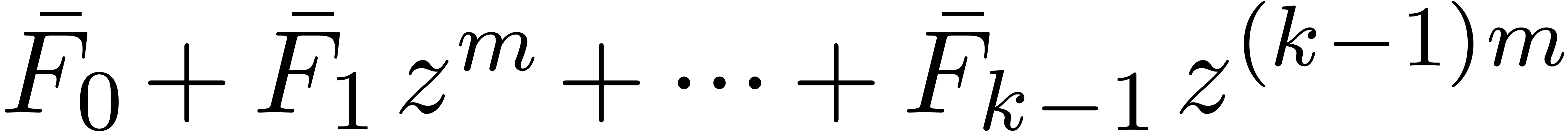
Remark 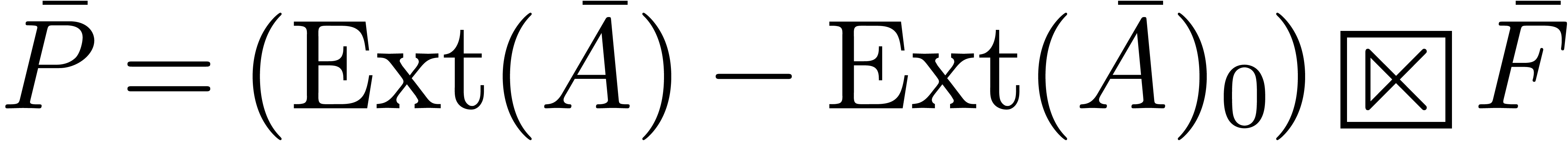 are
computed in a naive manner using
are
computed in a naive manner using
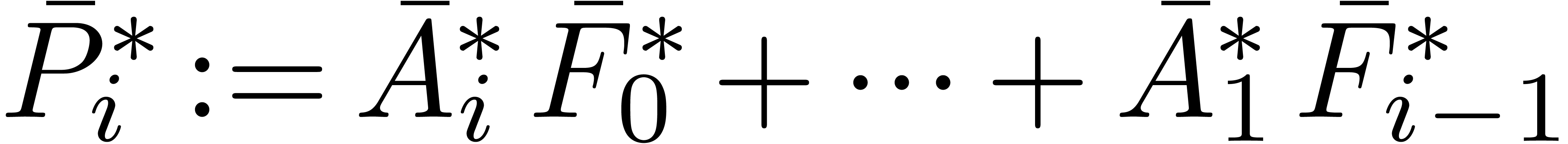
Alternatively, we may rewrite (15) as an implicit equation
in the transformed model and use a relaxed algorithm for its resolution
[vdH02a, vdH07a]. For this purpose, we first
extend the operators  ,
,  , etc. blockwise to
series
, etc. blockwise to
series  in
in  using
using
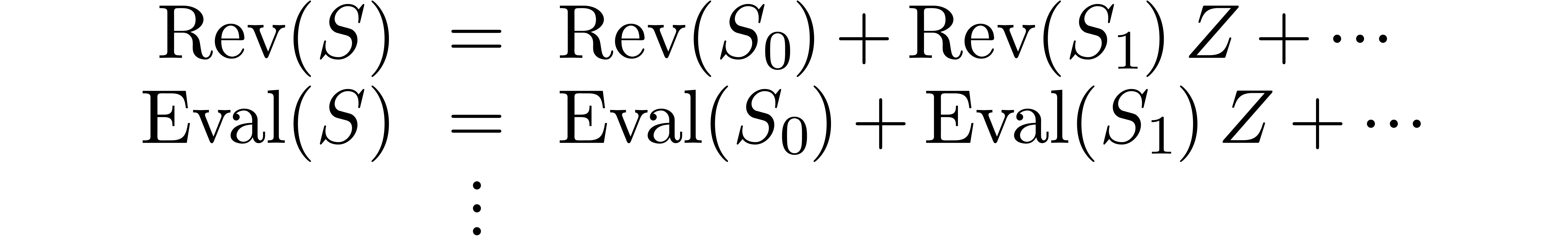
Then the equation (15) may be rewritten as
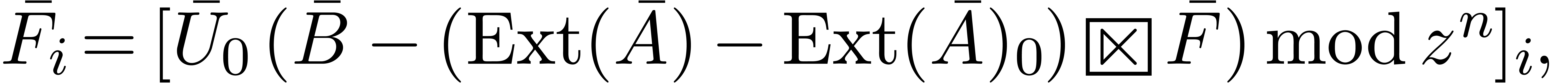
which leads to the blockwise implicit equation
In the transformed model, this equation becomes
and we solve it using a relaxed multiplication algorithm.
From now on, it will be convenient to restrict our attention to
evaluation-interpolation models for which 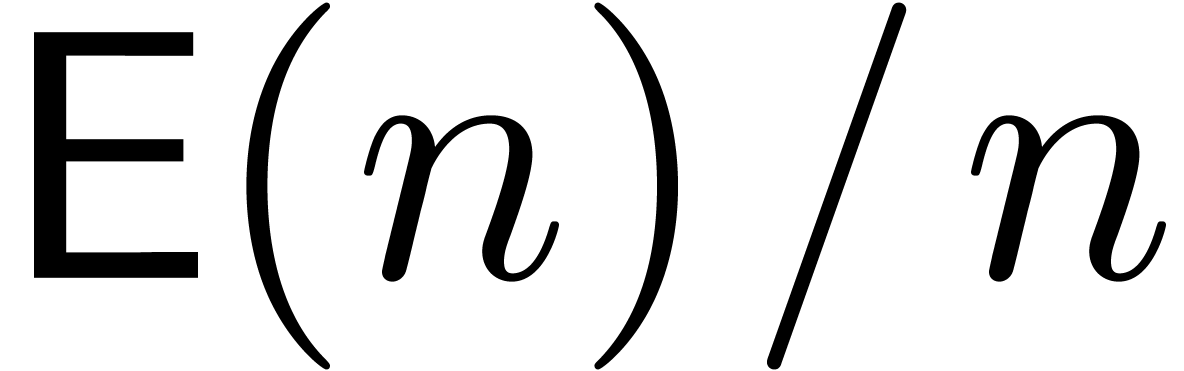 and
and
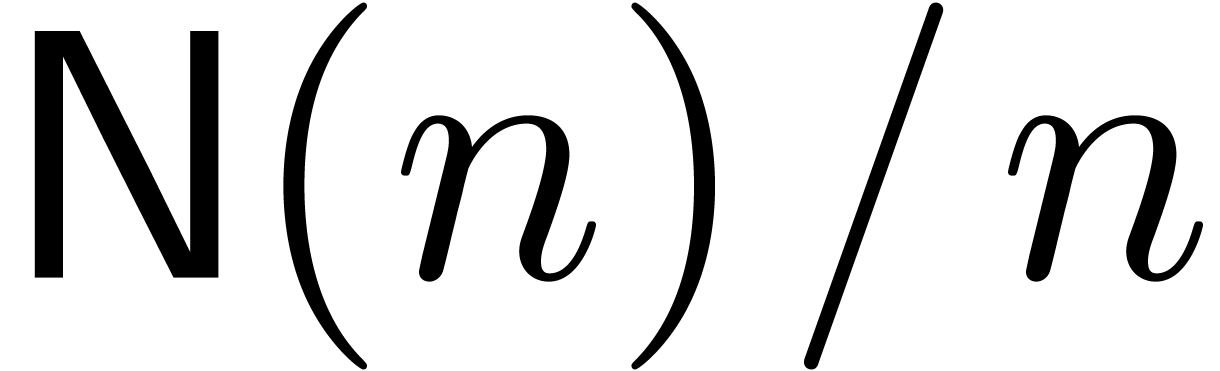 are increasing functions in
and
are increasing functions in
and 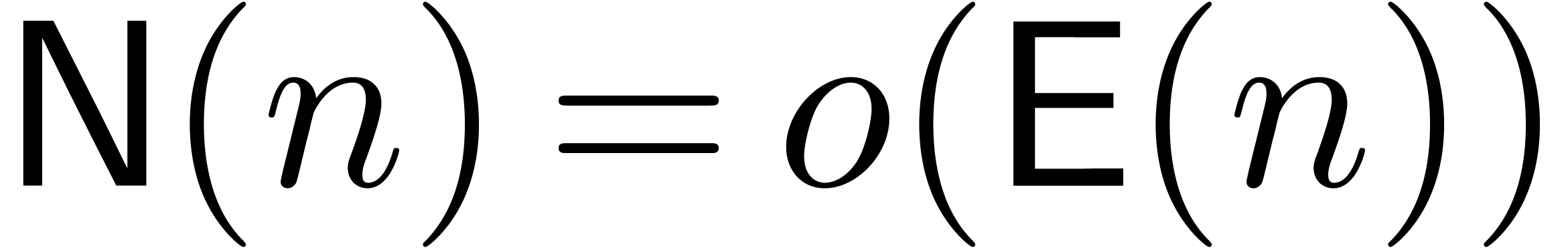 . Given two functions
and in , we will write
. Given two functions
and in , we will write 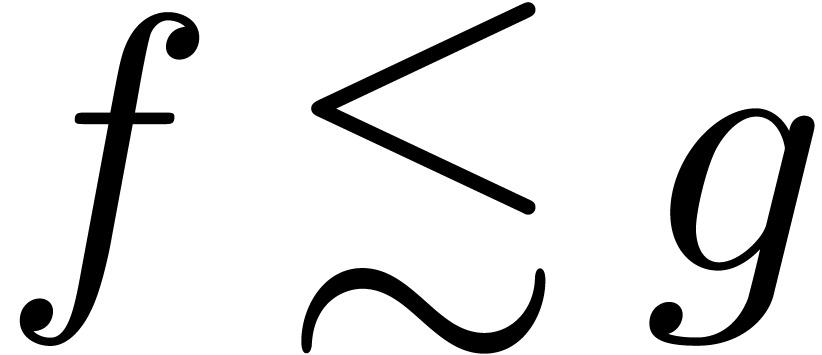 if for
any
if for
any  we have
we have 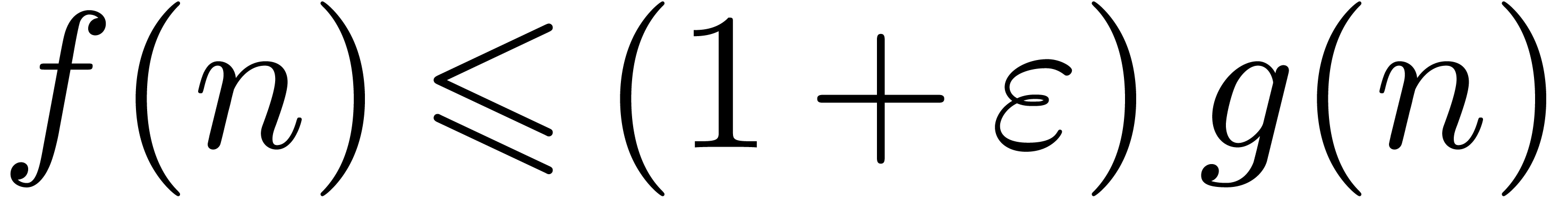 for all
sufficiently large .
for all
sufficiently large .
Proof. Let us analyze the complexity of 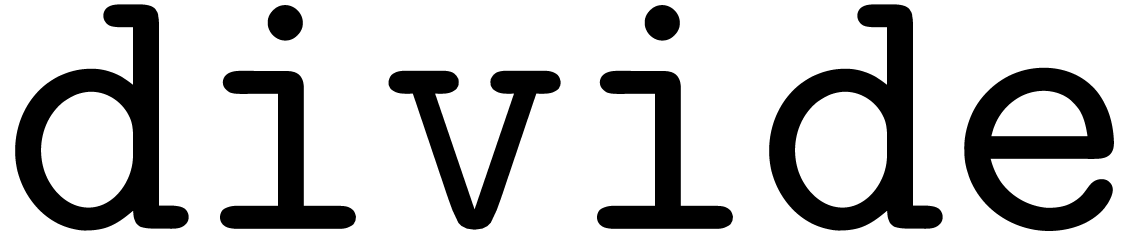 . The precomputation of can be done in time
. The precomputation of can be done in time  when using a
fast algorithm [HQZ04] based on Newton's method. The main
loop accounts for
when using a
fast algorithm [HQZ04] based on Newton's method. The main
loop accounts for
Five evaluation-interpolations of cost 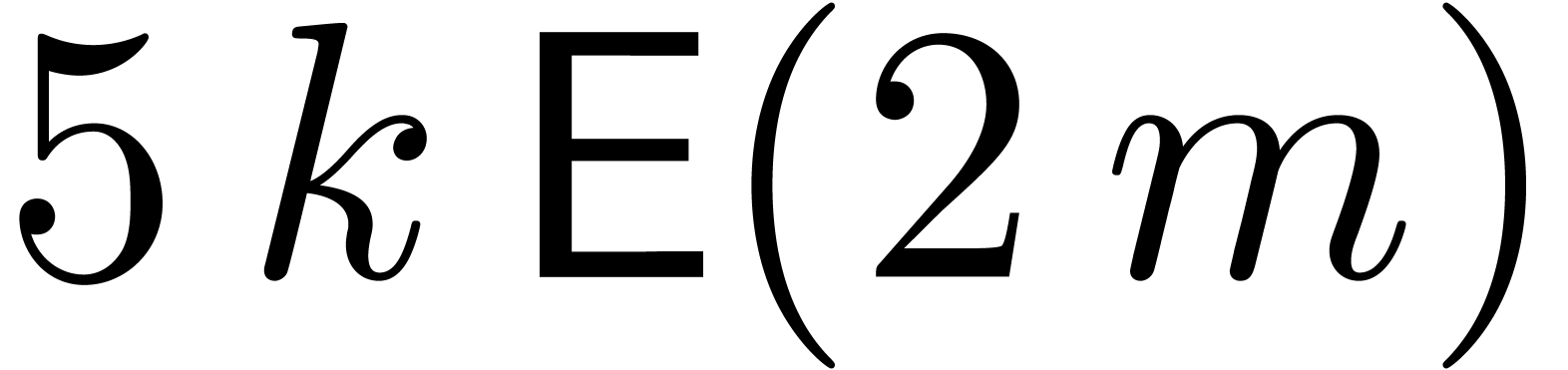 .
.
One naive order 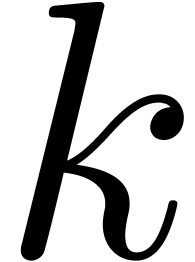 product in the transformed
model of cost
product in the transformed
model of cost 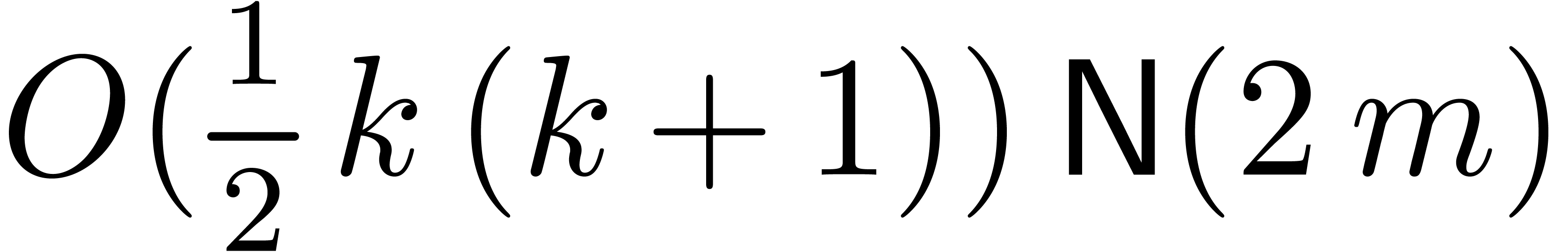 . In view
of Remark 3, the naive product may be replaced by a
relaxed product, which leads to a cost
. In view
of Remark 3, the naive product may be replaced by a
relaxed product, which leads to a cost  .
.
scalar multiplications in the transformed
model of cost 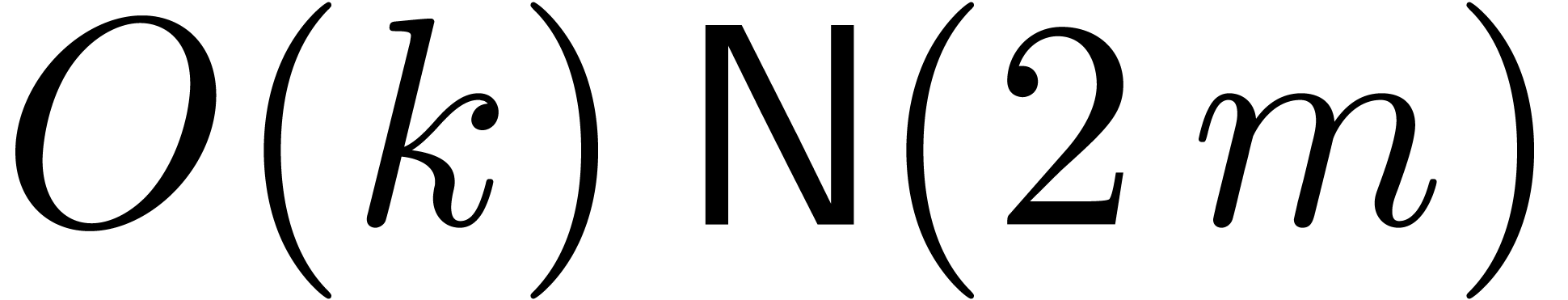 .
.
Adding up these costs, the complete division takes a time
Choosing 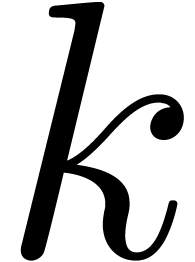 such that
such that 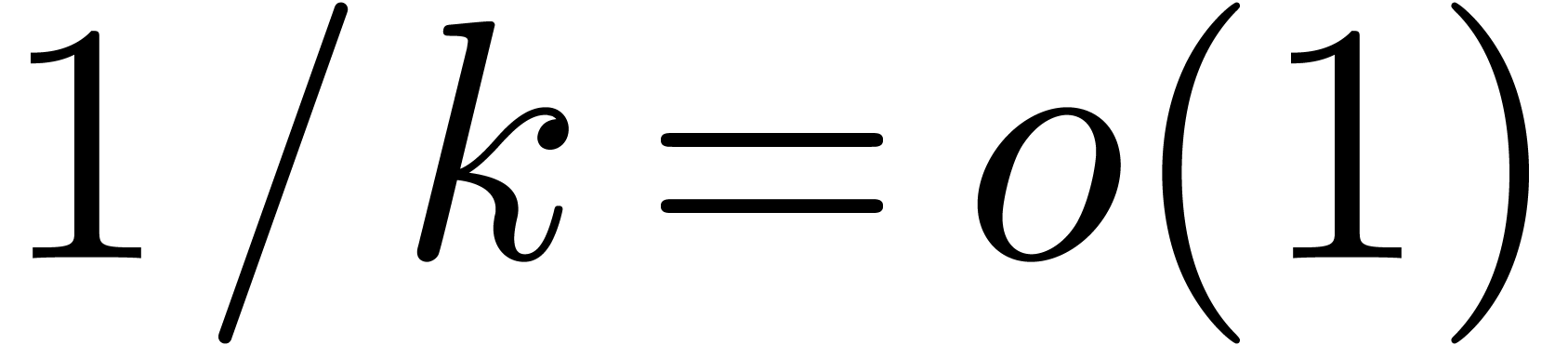 and
and
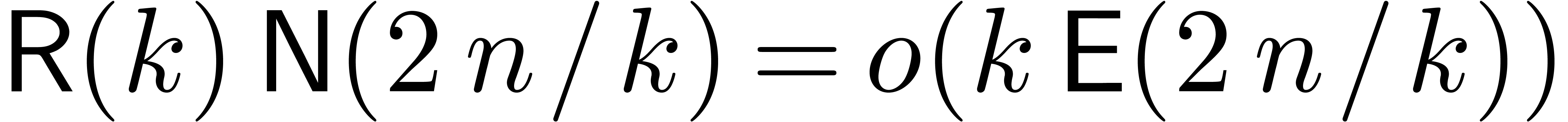 , the theorem follows. The
choice
, the theorem follows. The
choice 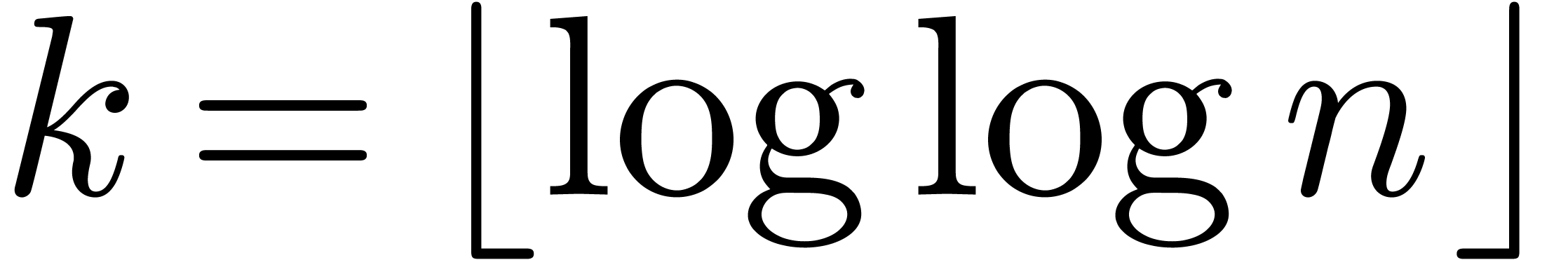 works both in the standard and the
synthetic FFT model.
works both in the standard and the
synthetic FFT model.
Remark should be chosen not too large, so as to
keep  reasonably small. According to (16),
we need
reasonably small. According to (16),
we need  in order to beat the best previously
known division algorithm [HZ04], which happens for
in order to beat the best previously
known division algorithm [HZ04], which happens for 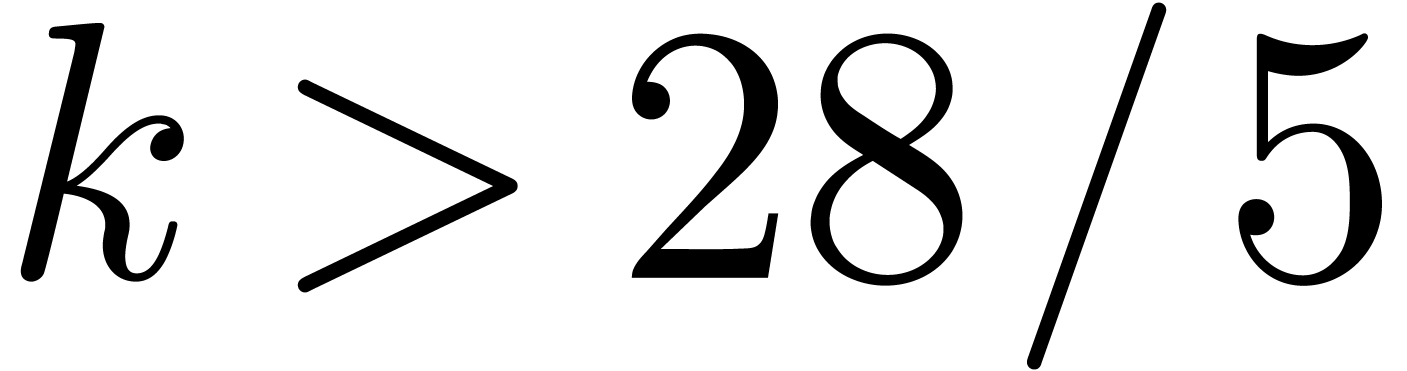 .
.
Remark , the fact that we perform
more multiplications in the transformed model is compensated by the fact
that the FFTs are computed for smaller sizes. Let us compare in detail a
truncated FFT multiplication at order 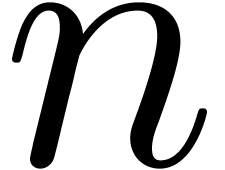 and a
blockwise multiplication as in section 3.1 at order
and a
blockwise multiplication as in section 3.1 at order 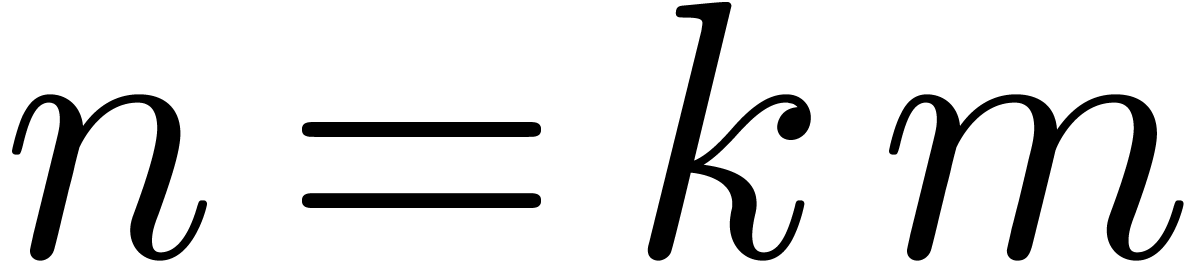 .
.
For simplicity, we will assume the standard FFT model and naive inner
multiplication. The 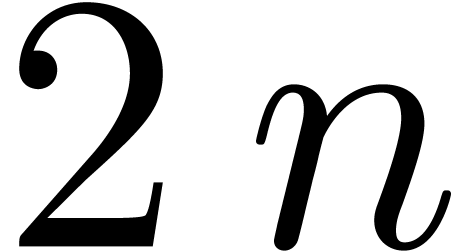 inner multiplications in the
classical FFT multiplication are replaced by
inner multiplications in the
classical FFT multiplication are replaced by 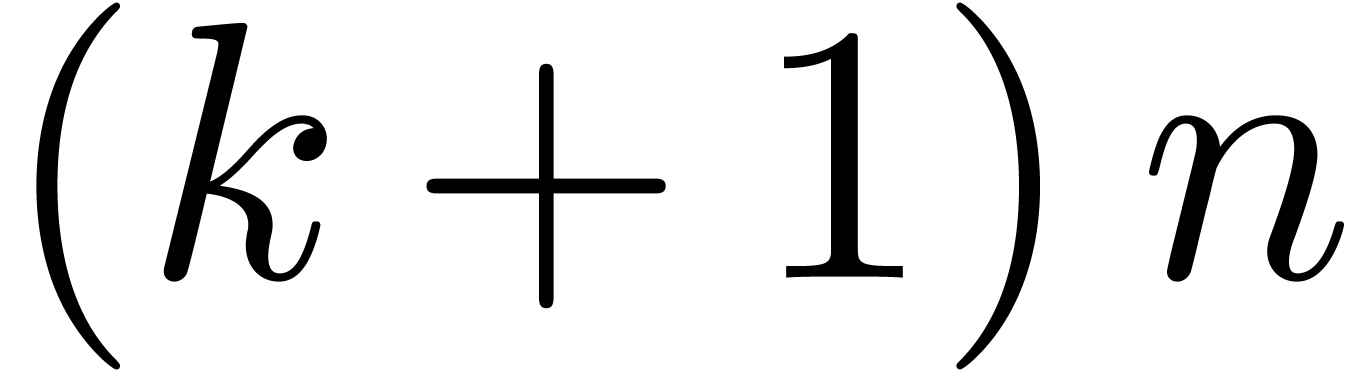 inner multiplications in the blockwise model, accounting for
inner multiplications in the blockwise model, accounting for 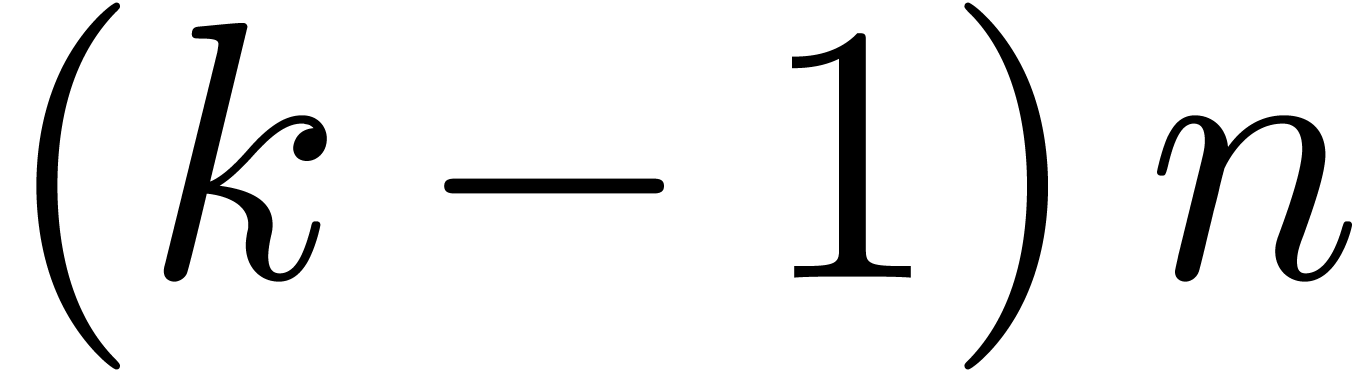 extra multiplications. Every FFT at size
is replaced by FFTs of size
extra multiplications. Every FFT at size
is replaced by FFTs of size 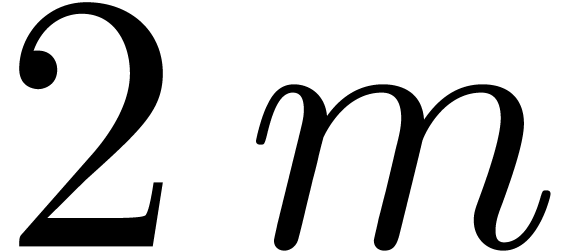 , thereby saving approximately
, thereby saving approximately 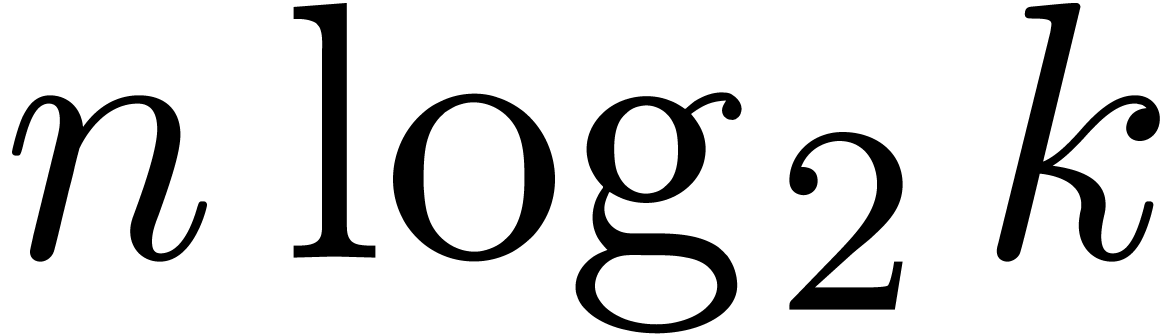 multiplications. For
multiplications. For 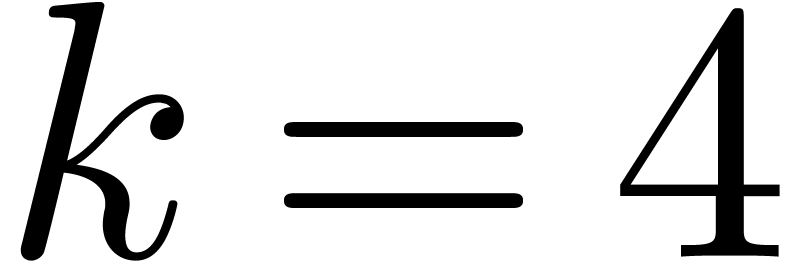 , the
blockwise algorithm therefore saves
, the
blockwise algorithm therefore saves 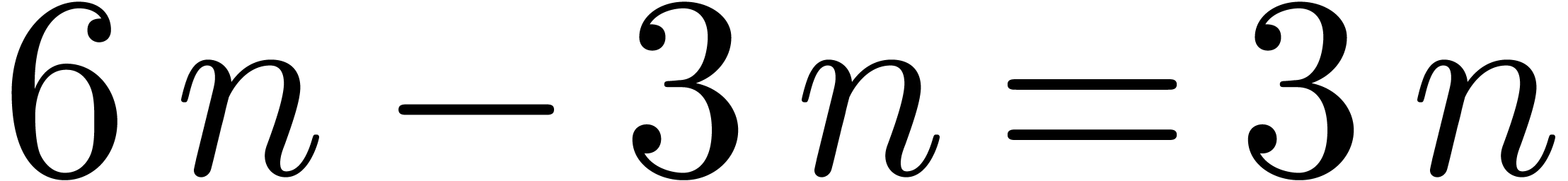 multiplications. For
multiplications. For 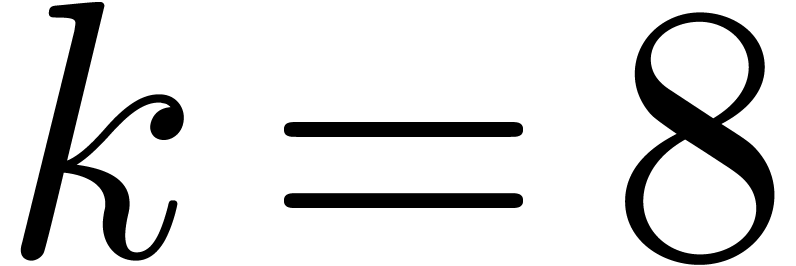 , we
save
, we
save 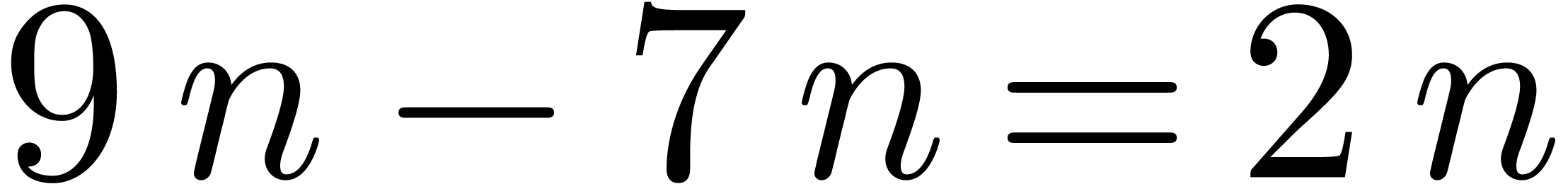 multiplications. For
multiplications. For 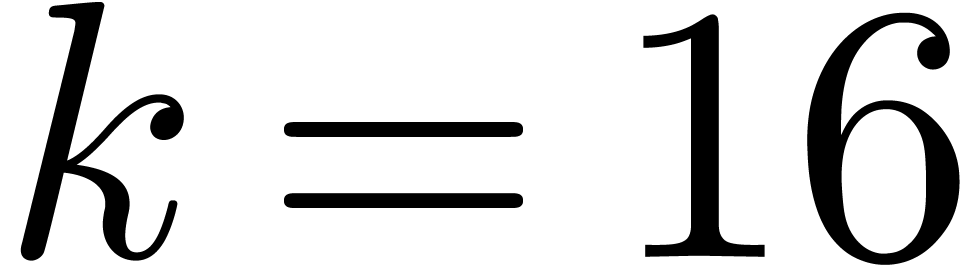 , we perform
, we perform 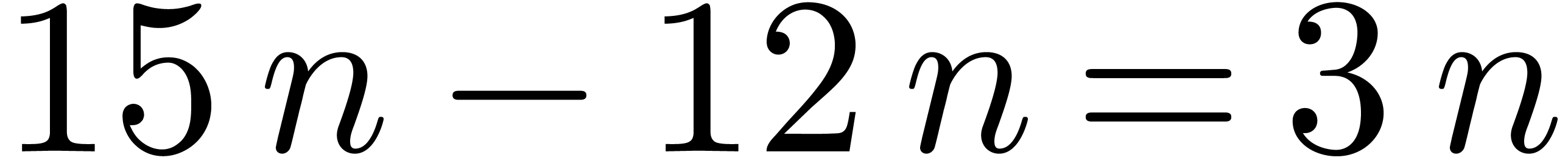 more
multiplications.
more
multiplications.
Using relaxed Karatsuba multiplication, we only need 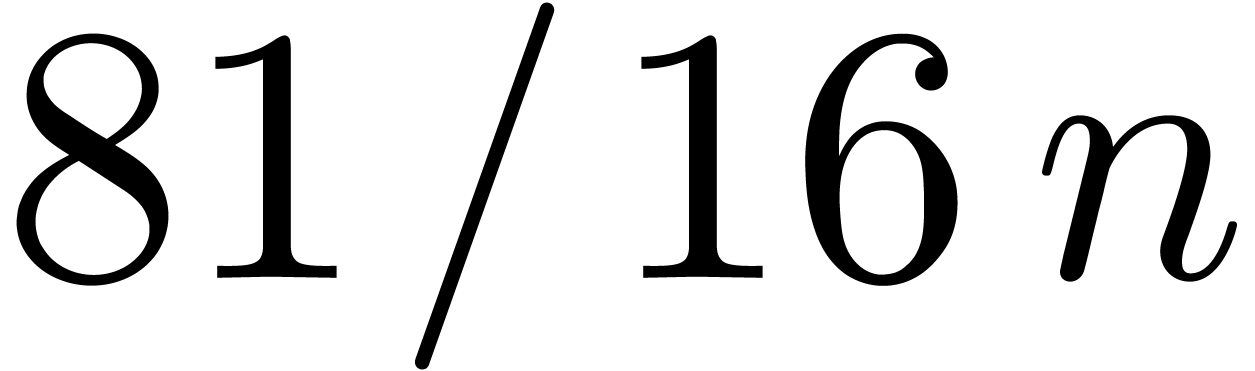 inner multiplications in the blockwise model for , so we save
inner multiplications in the blockwise model for , so we save 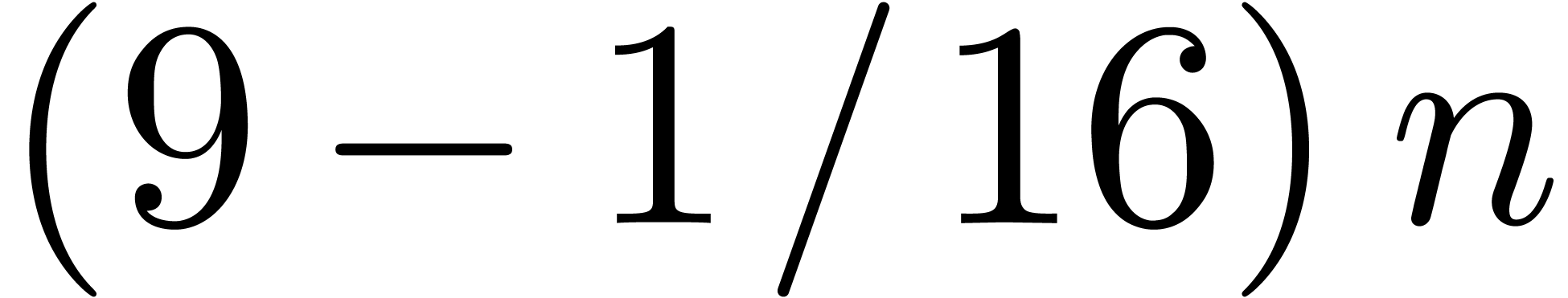 multiplications. We also notice that the division algorithm requires
five FFTs instead of three for multiplication. For
and naive inner multiplication, this means that we actually
“save”
multiplications. We also notice that the division algorithm requires
five FFTs instead of three for multiplication. For
and naive inner multiplication, this means that we actually
“save” 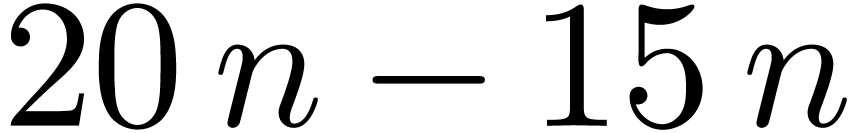 multiplications. In any case,
the analysis shows that blockwise algorithms should perform well for
moderate values of , at least
for the standard FFT model.
multiplications. In any case,
the analysis shows that blockwise algorithms should perform well for
moderate values of , at least
for the standard FFT model.
Remark  , the coefficients
, the coefficients
can be computed using  additional transforms of
cost
additional transforms of
cost 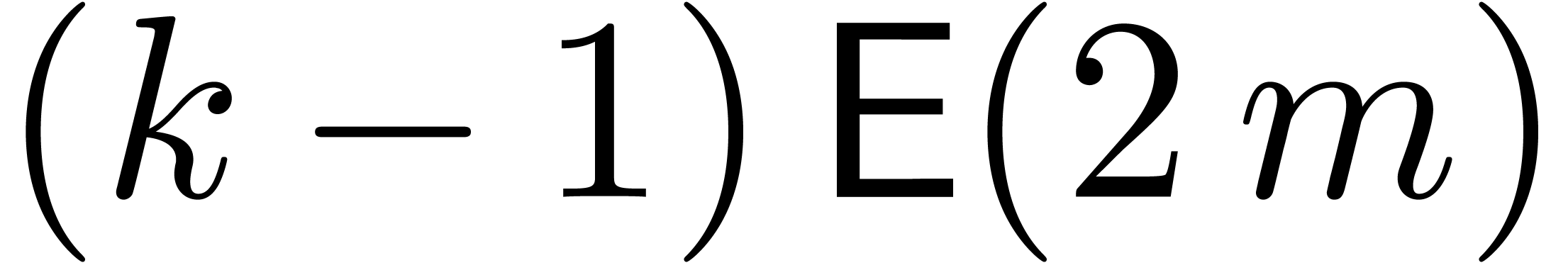 and
and  additional
inner multiplications. This implies that the quotient and the remainder
of a division of a polynomial
additional
inner multiplications. This implies that the quotient and the remainder
of a division of a polynomial  of degree
of degree  by a polynomial
by a polynomial  of degree
of degree
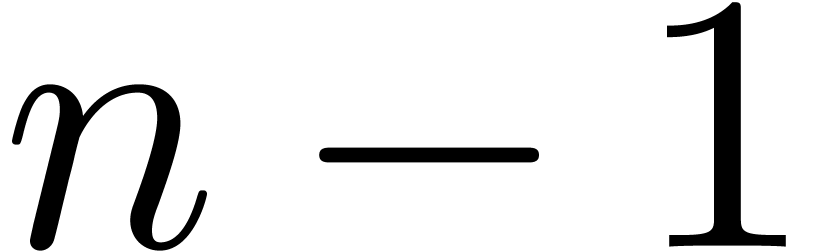 can be computed in time
can be computed in time 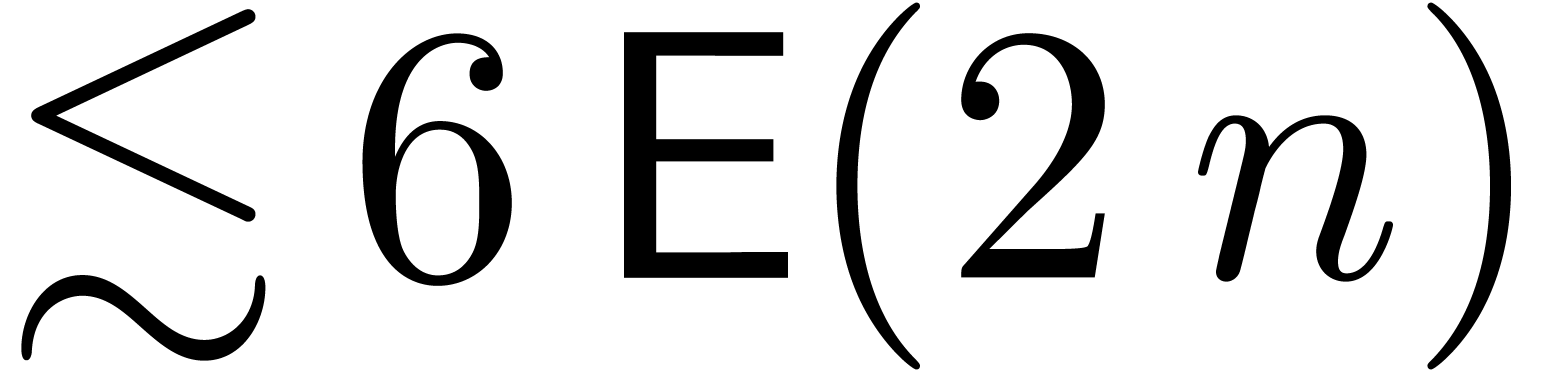 . Indeed, it suffices to take
. Indeed, it suffices to take 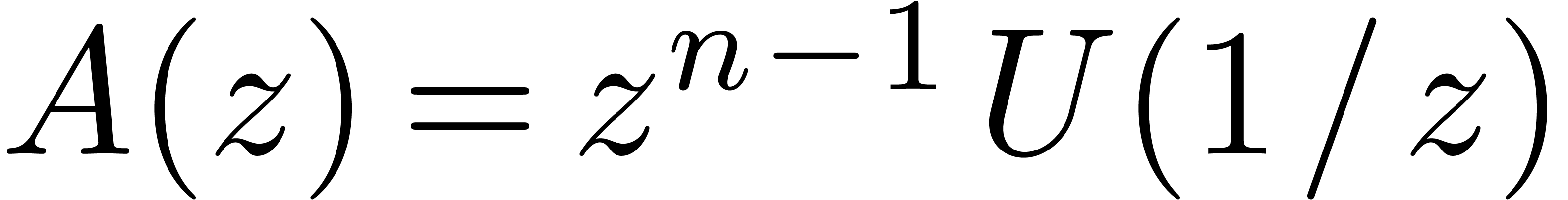 ,
, 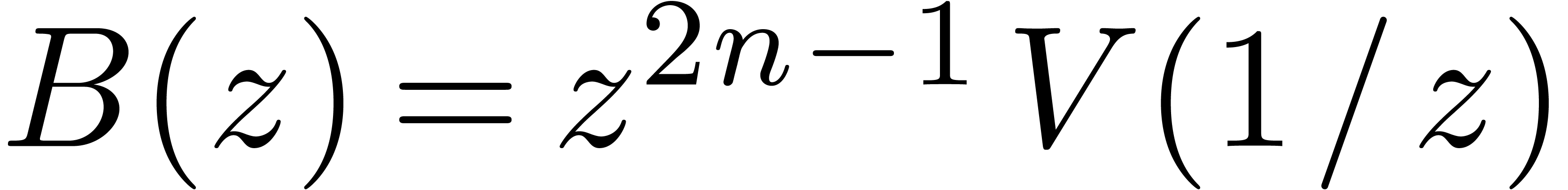 , and
apply the above argument.
, and
apply the above argument.
Remark with a large -th
root of unity) than for the synthetic model (Schönhage-Strassen
multiplication).
In order to simplify our exposition, it is convenient to write all
differential equations in terms of the operator 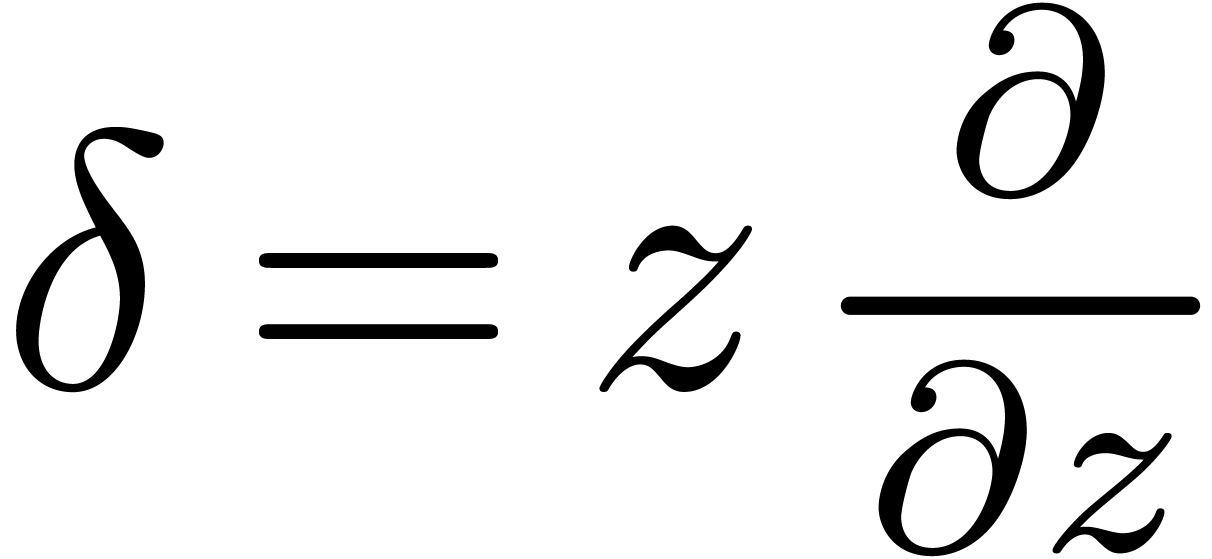 . The inverse
. The inverse 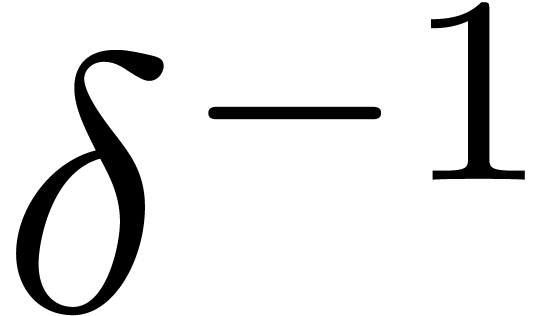 of
of  is defined by
is defined by
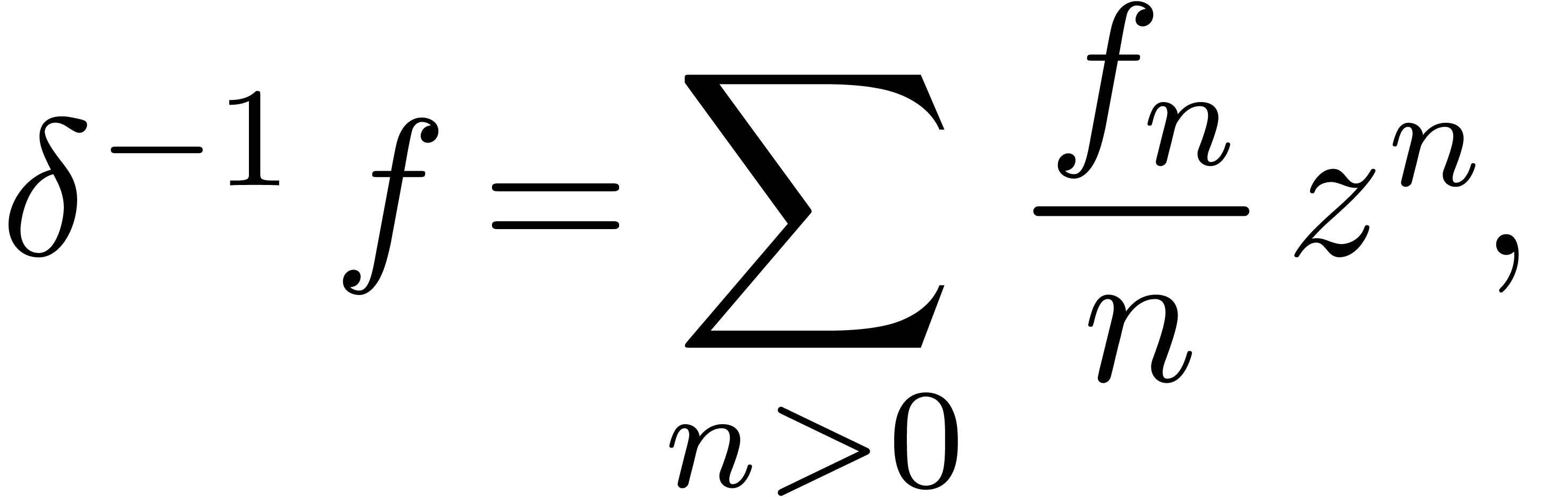
for all with 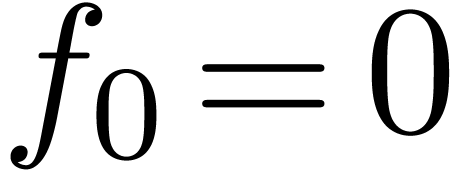 .
.
Given a matrix 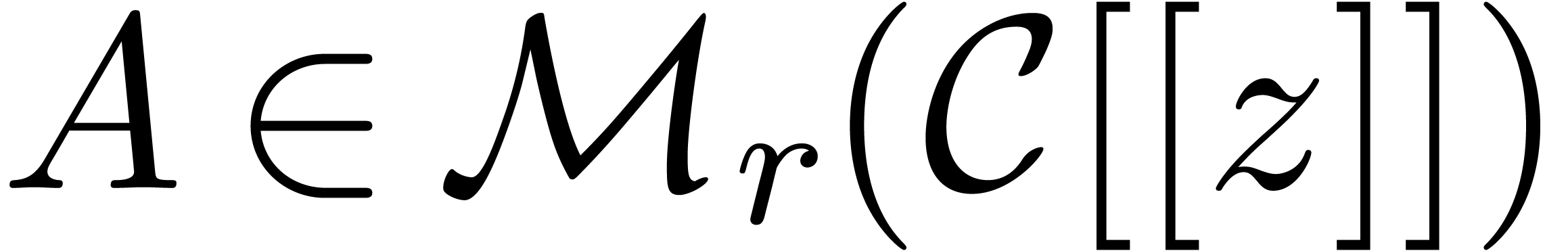 with
with 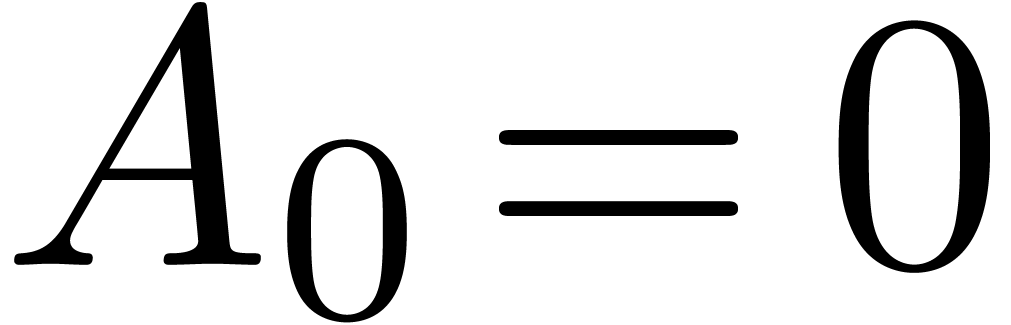 , the equation
, the equation
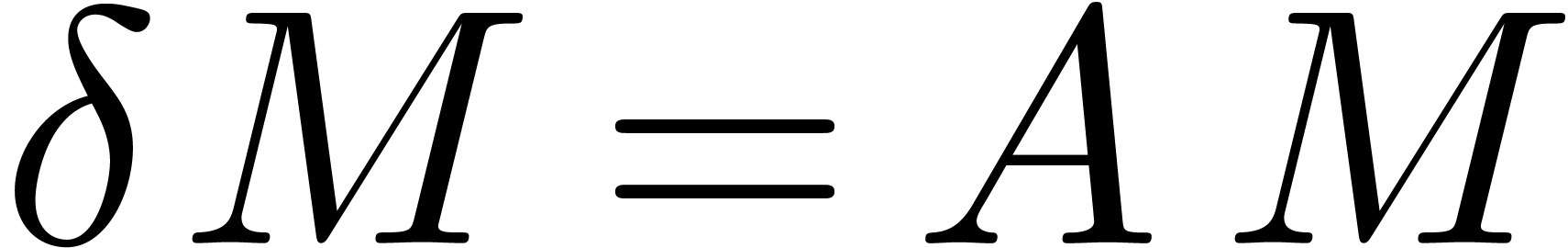 |
(17) |
admits a unique solution 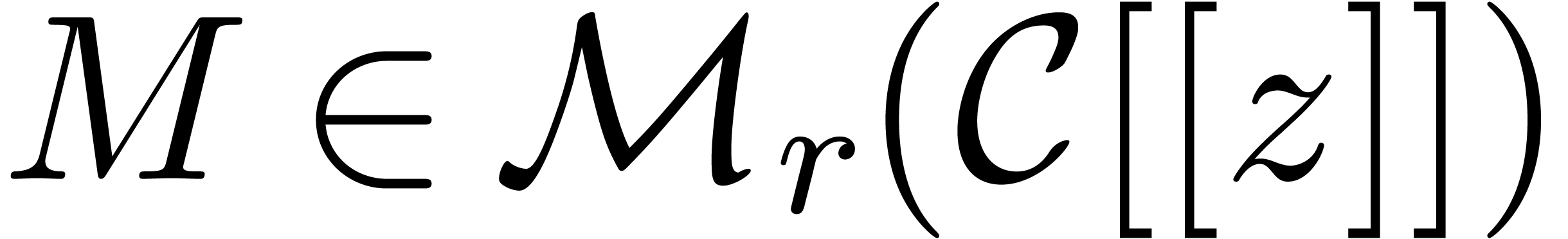 with
with 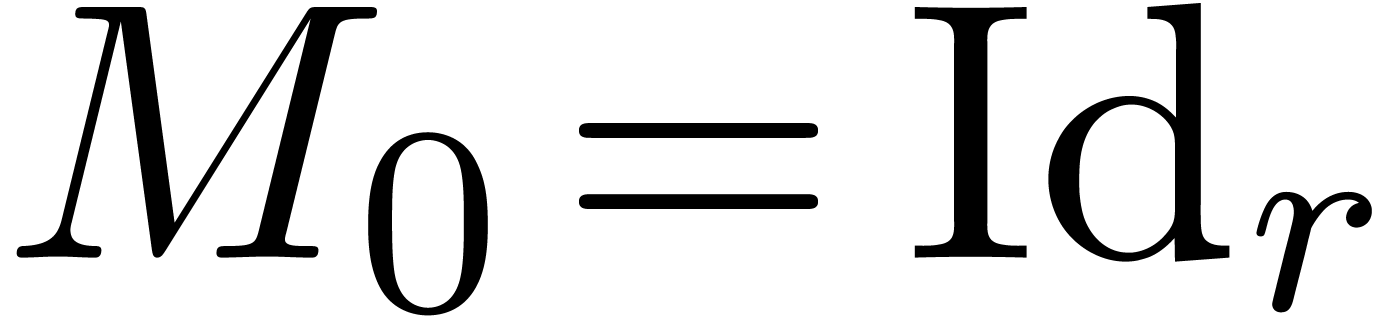 . The main idea of [BCO+07] is to
provide a Newton iteration for the computation of . More precisely, assume that
. The main idea of [BCO+07] is to
provide a Newton iteration for the computation of . More precisely, assume that 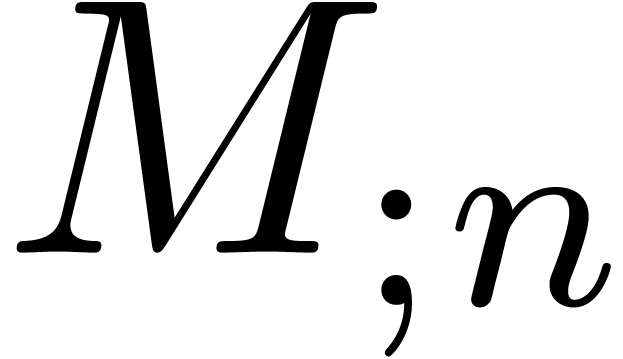 and
and 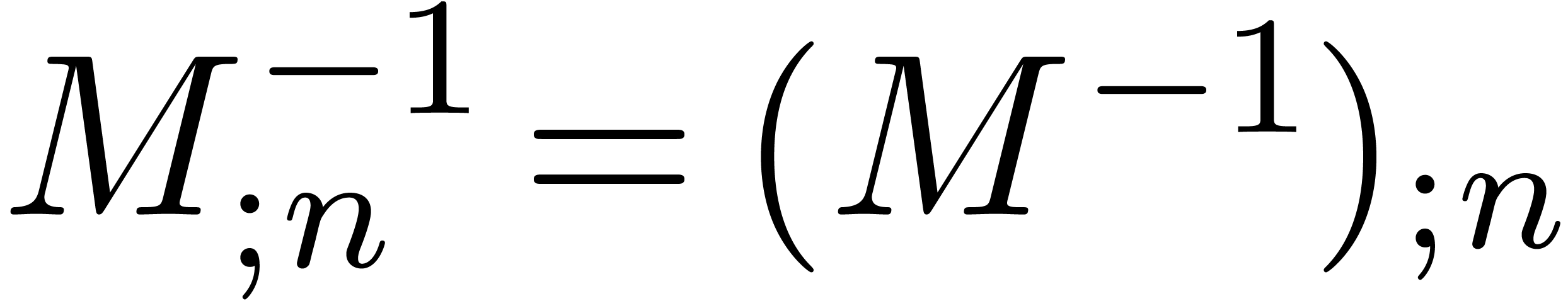 are known. Then we have
are known. Then we have
 |
(18) |
Indeed, setting
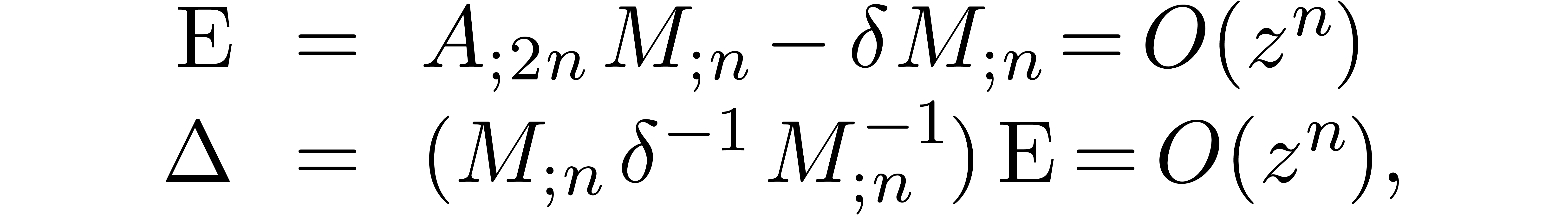
we have
so that 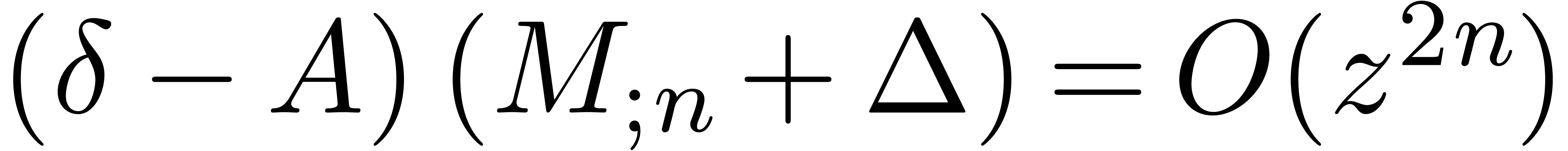 and
and 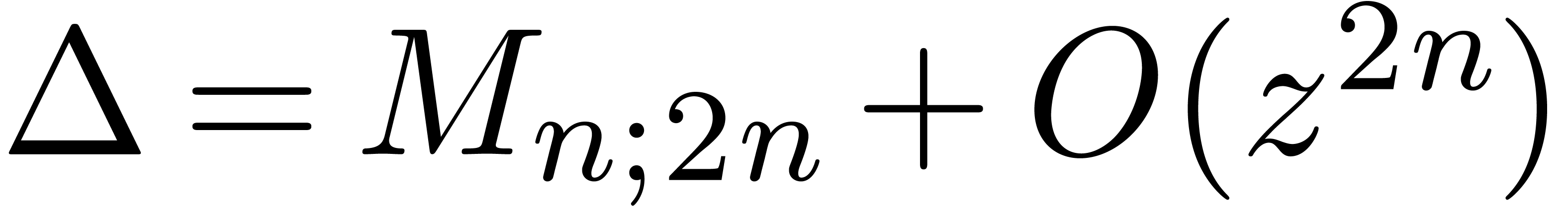 .
Computing and
.
Computing and 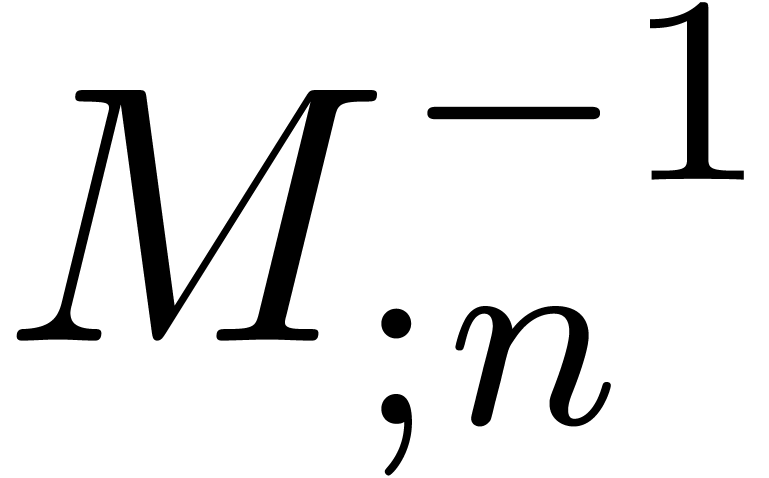 together
using (18) and the usual Newton iteration [Sch33,
MC79]
together
using (18) and the usual Newton iteration [Sch33,
MC79]
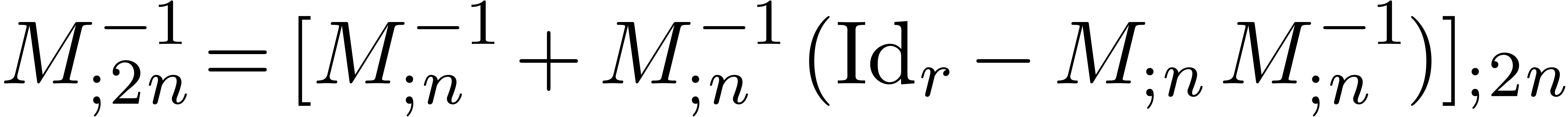 |
(19) |
for inverses yields an algorithm of time complexity . The quantities 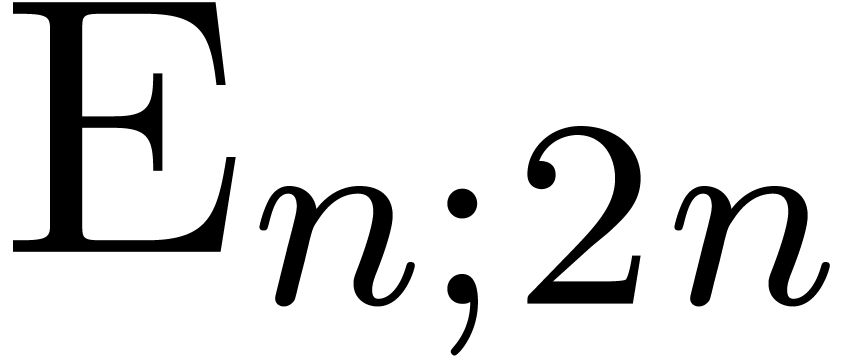 and
and
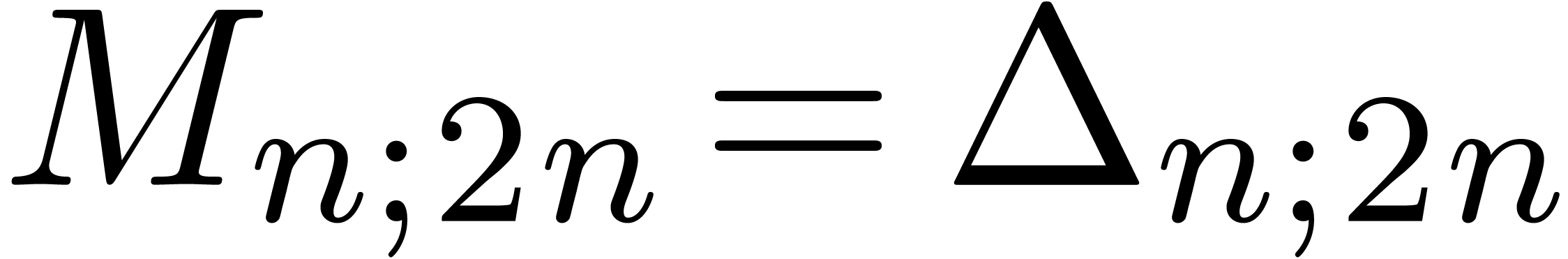 may be computed efficiently using the middle
product algorithm.
may be computed efficiently using the middle
product algorithm.
Instead of doubling the precision at each step, we may also increment
the number of known terms with a fixed number of terms . More precisely, given 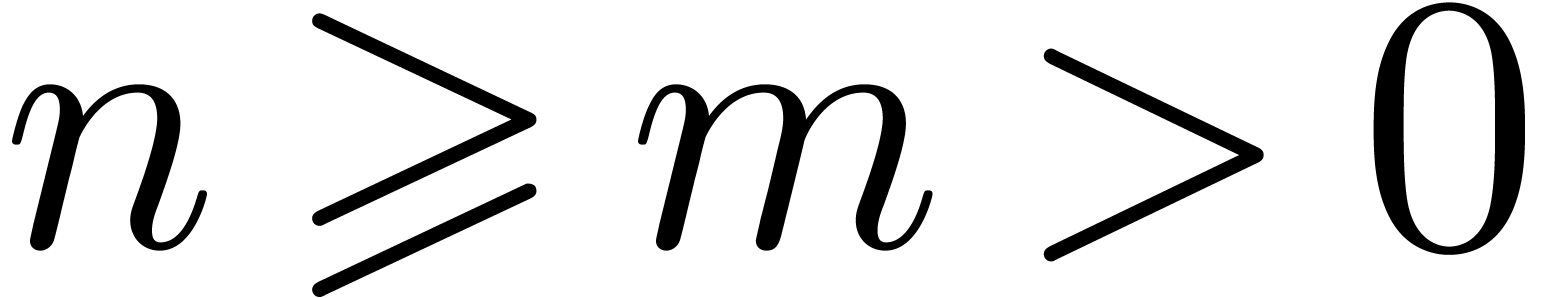 , we have
, we have
 |
(20) |
This relation is proved in a similar way as (18). The same
recurrence may also be applied for computing blocks of coefficients of
the unique solution 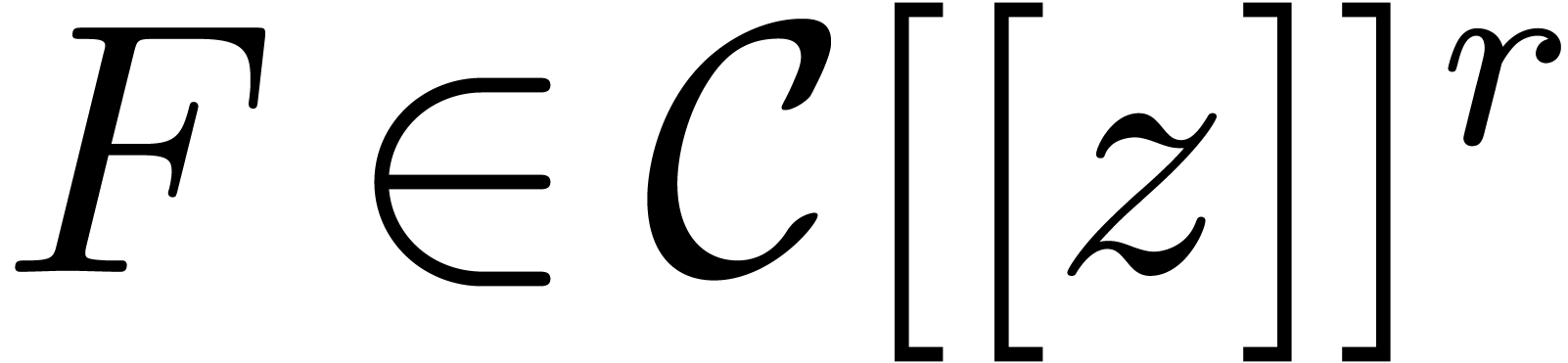 to the vector linear
differential equation
to the vector linear
differential equation
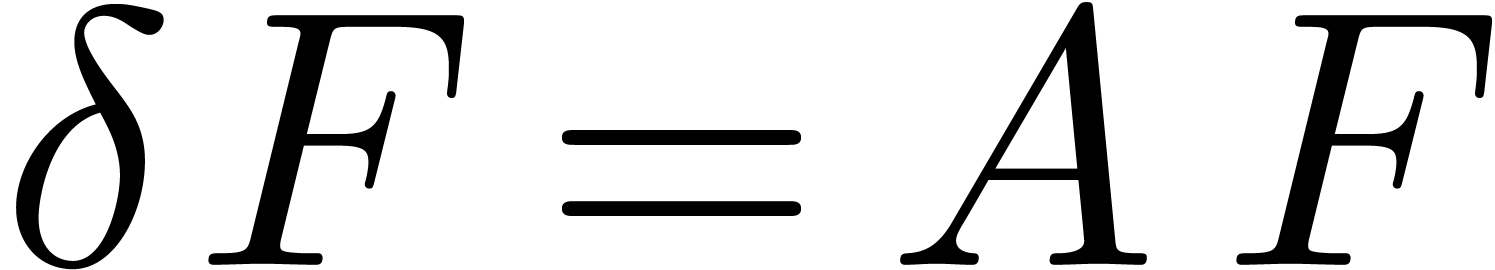 |
(21) |
with initial condition 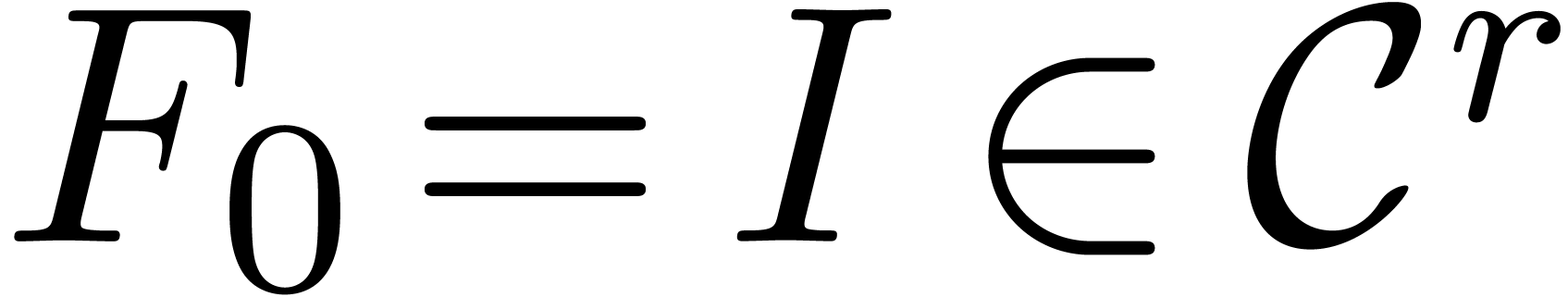 :
:
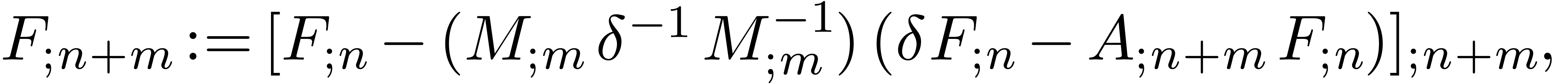
or
 |
(22) |
Both the right-hand sides of the equations (20) and (22) may be computed efficiently using the middle product algorithm.
The block notations and
from section 3.1 naturally generalize to series of matrices
and series of vectors. The derivation operates
in a blockwise fashion:

We define the blockwise operator  ,
with
,
with
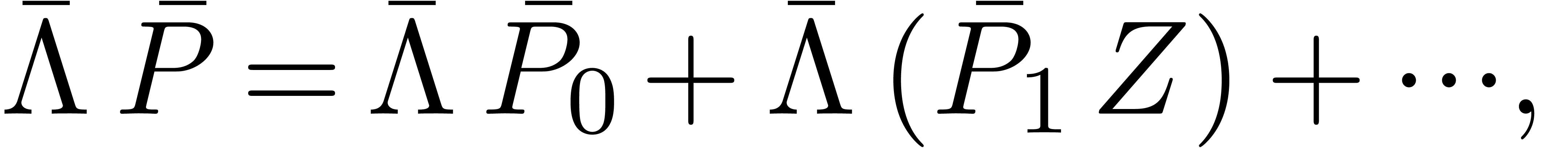
by
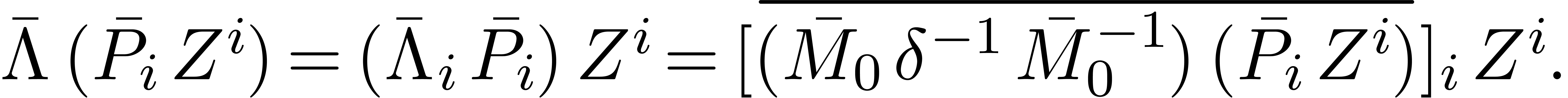
In practice, we may compute 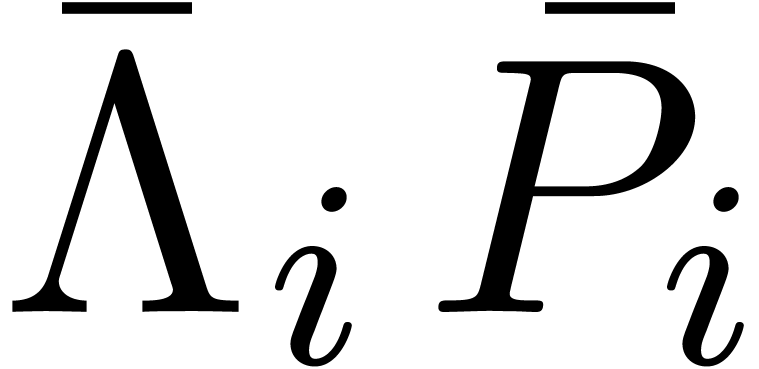 by
by
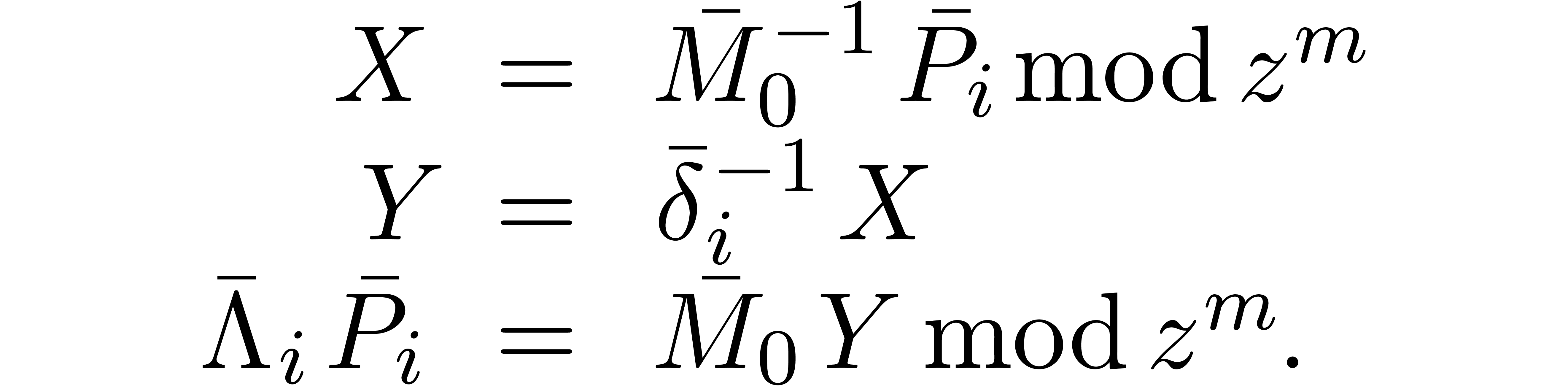
Now (22) yields a formula for the blockwise resolution of (17):
Assume that we have fixed an evaluation-interpolation scheme at degree
. Replacing the blockwise
coefficients and by
their transforms (12-13) and applying (23), we may compute by
evaluation-interpolation:
Of course, 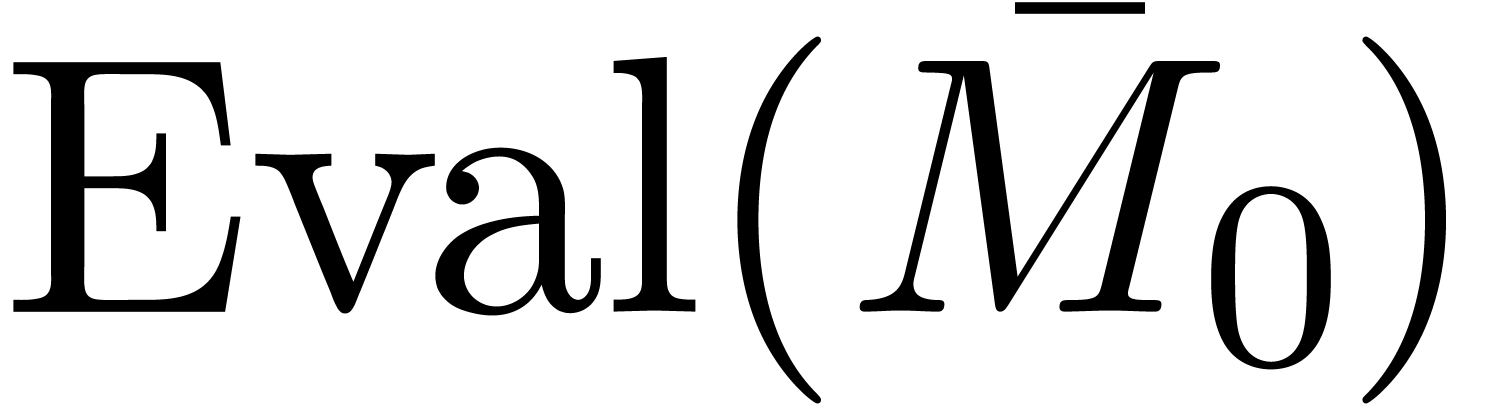 and
and 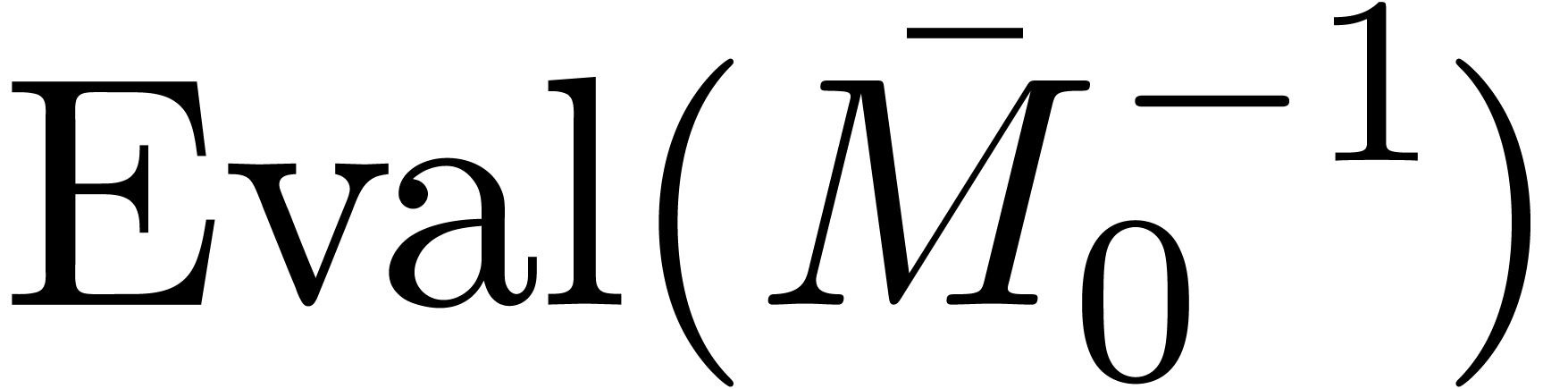 only need
to be computed once. This leads to the following algorithm for the
computation of
only need
to be computed once. This leads to the following algorithm for the
computation of 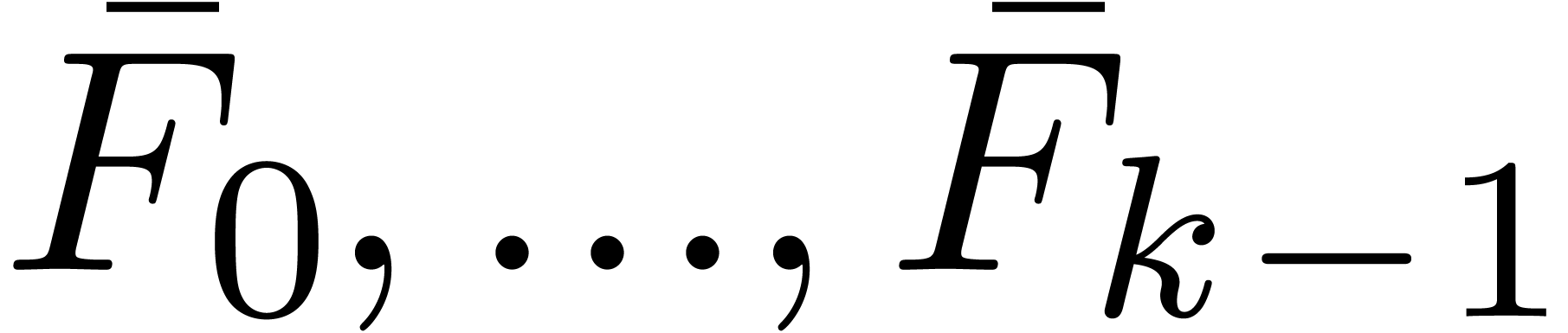 :
:
Algorithm lin_solve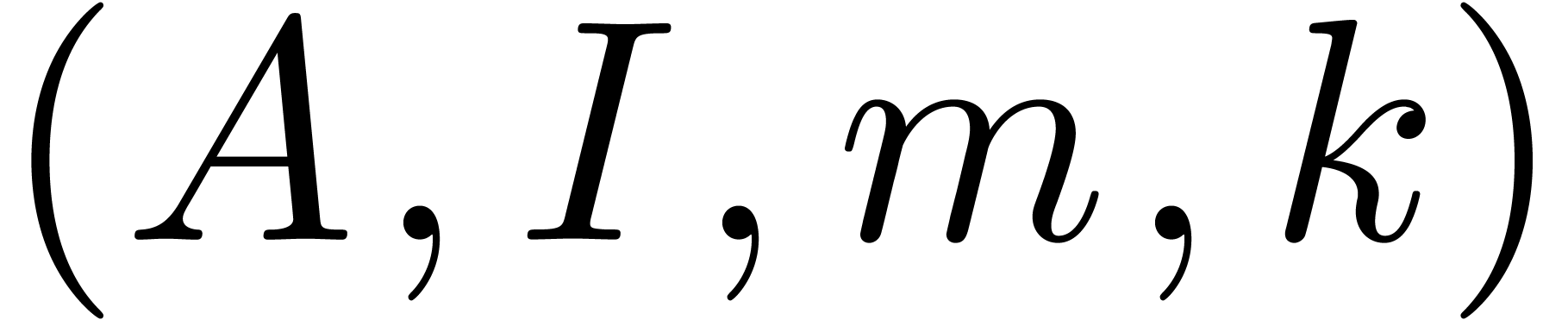
 and
and
Compute 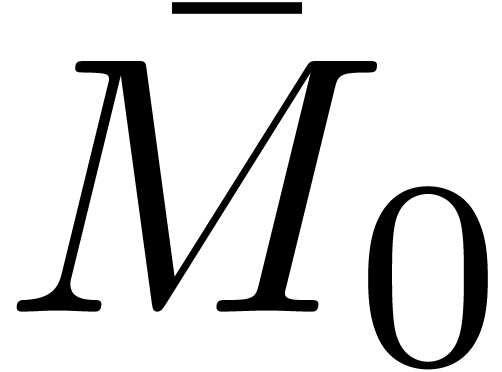 ,
, 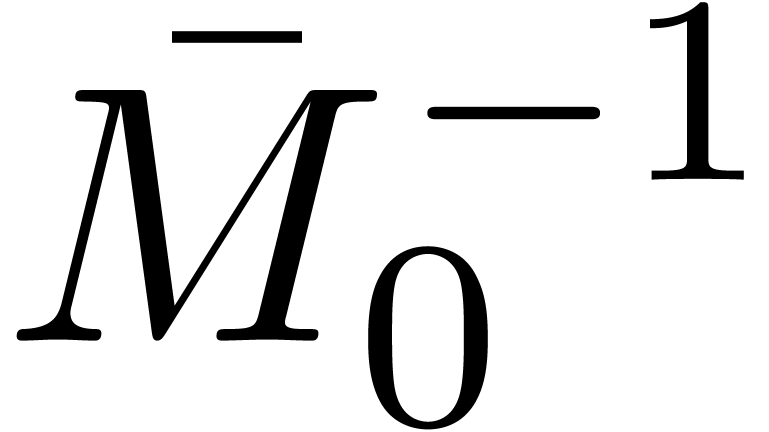 and
and 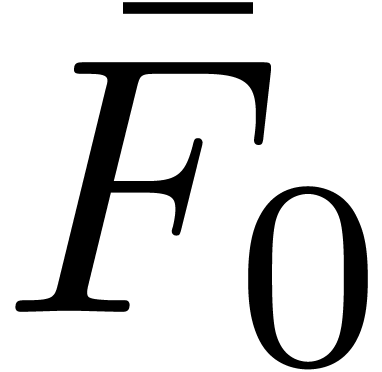 as in section 4.1
as in section 4.1
For  do
do
Return
Remark  are computed in a
naive manner. In a similar way as in Remark 3, we may use a
relaxed algorithm instead. More precisely, the equation (23)
may be rewritten as
are computed in a
naive manner. In a similar way as in Remark 3, we may use a
relaxed algorithm instead. More precisely, the equation (23)
may be rewritten as
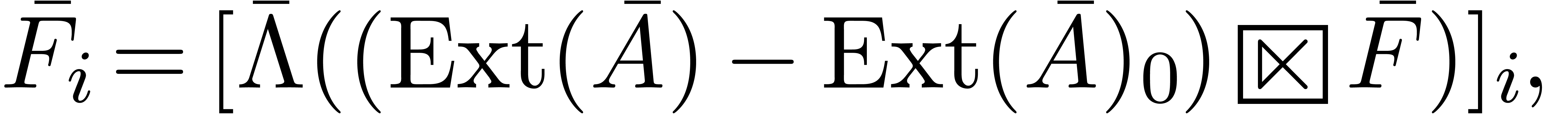
which leads to the blockwise implicit equation
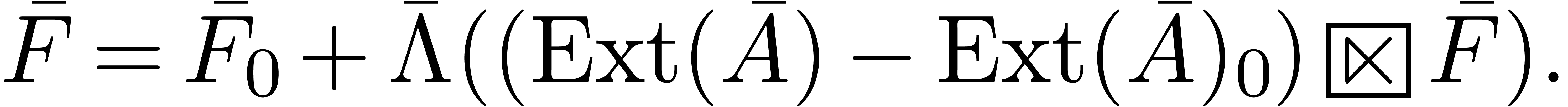
In the transformed model, this equation becomes
We understand that  is computed blockwise in the
transformed model.
is computed blockwise in the
transformed model.
Assuming that has  non-zero entries, we denote by
non-zero entries, we denote by 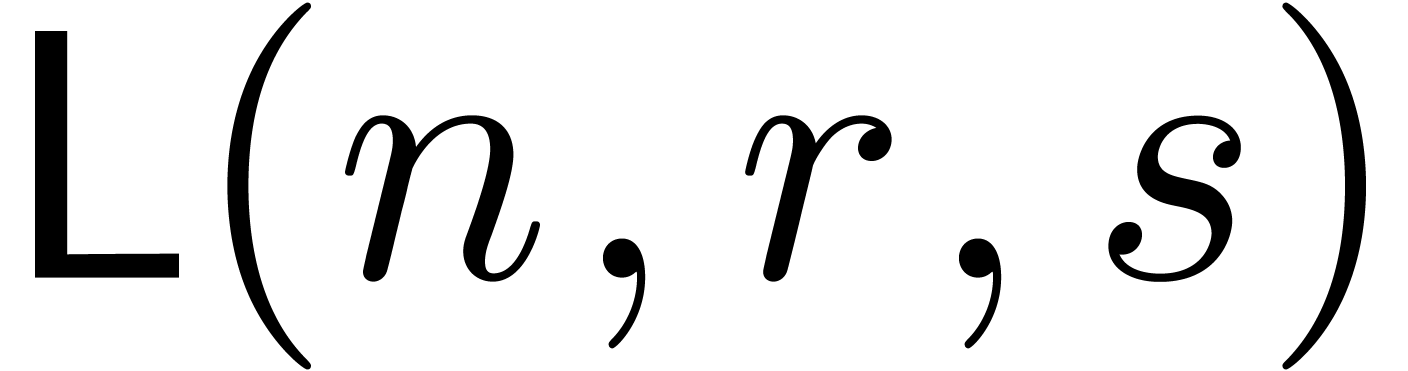 the time
complexity in order to compute the truncated solution
the time
complexity in order to compute the truncated solution 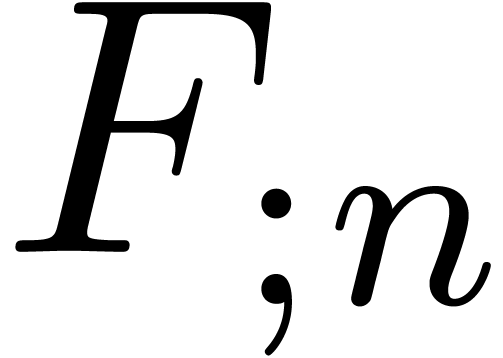 to .
to .
 has
has  non-zero
entries. Assume that
non-zero
entries. Assume that 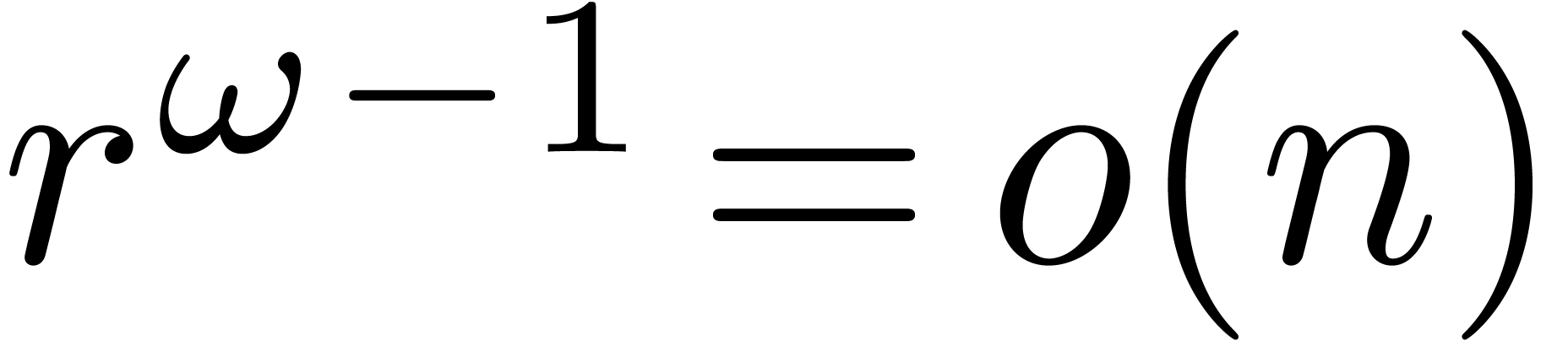 and
and 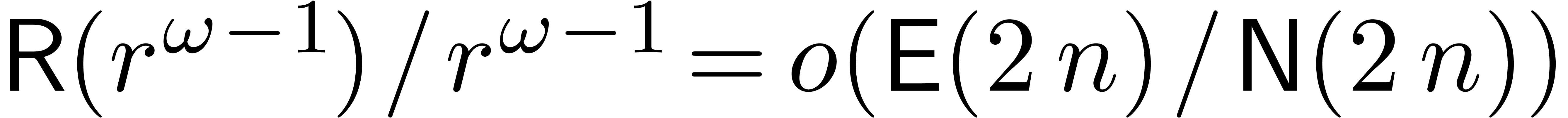 . Then there exists an algorithm which
computes the truncated solution to in
time
. Then there exists an algorithm which
computes the truncated solution to in
time
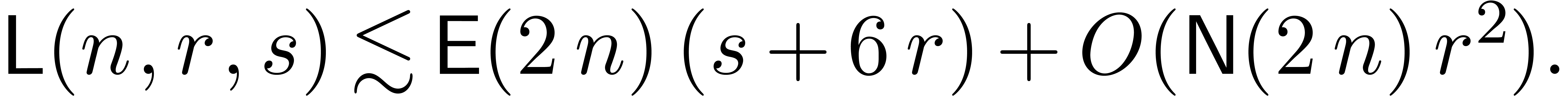 |
(24) |
Proof. In our algorithm, let 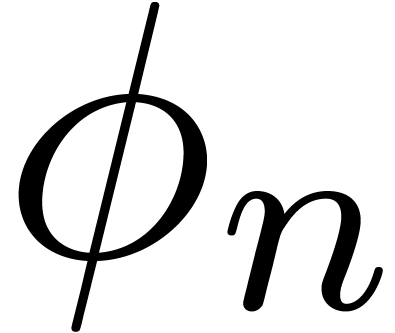 be a function which increases towards infinity, such that
be a function which increases towards infinity, such that 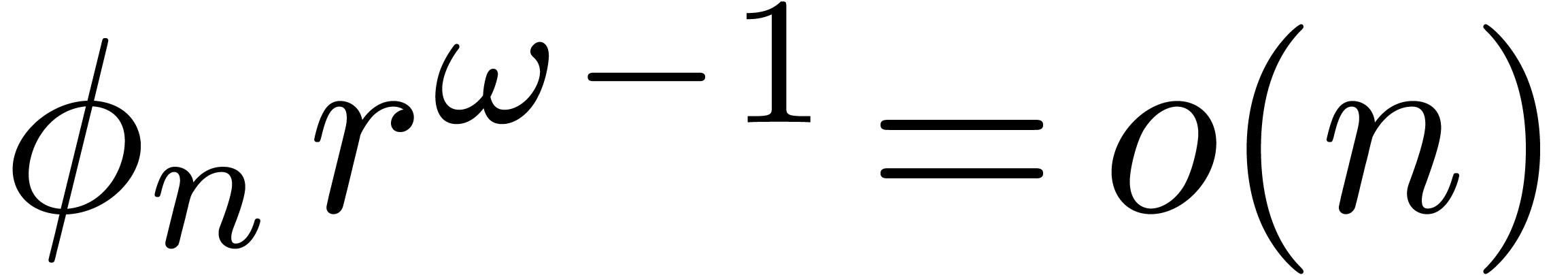 and
and 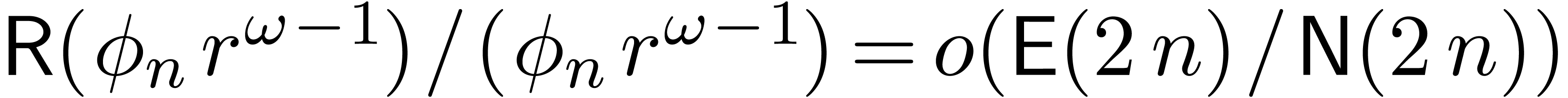 . We take
. We take
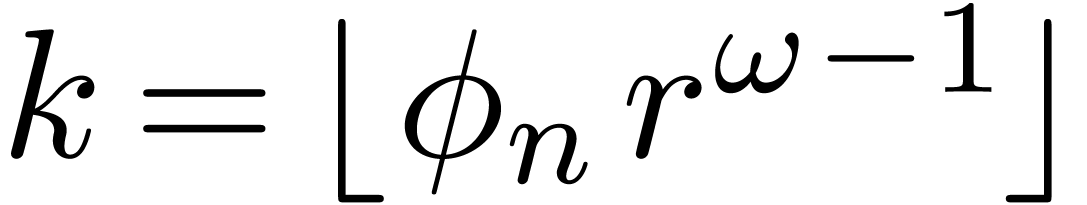 and
and 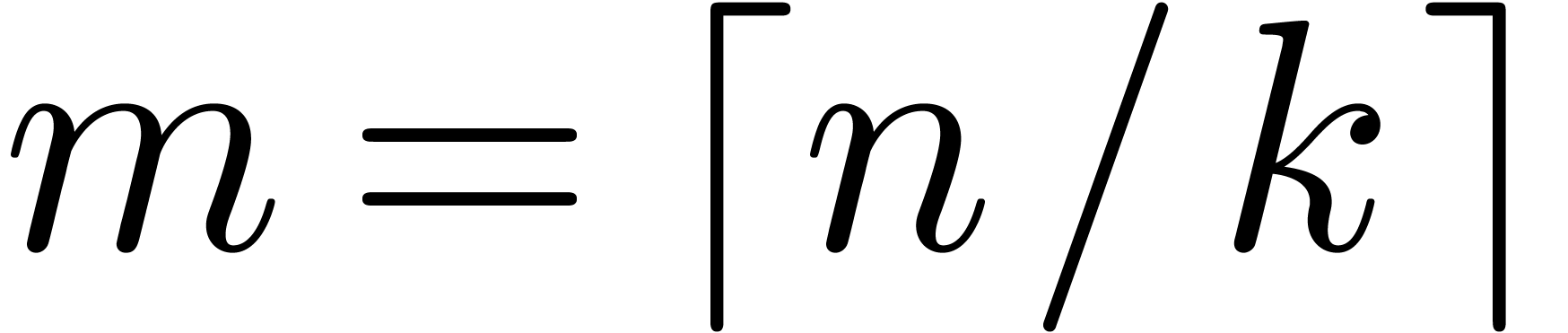 ,
so that
,
so that 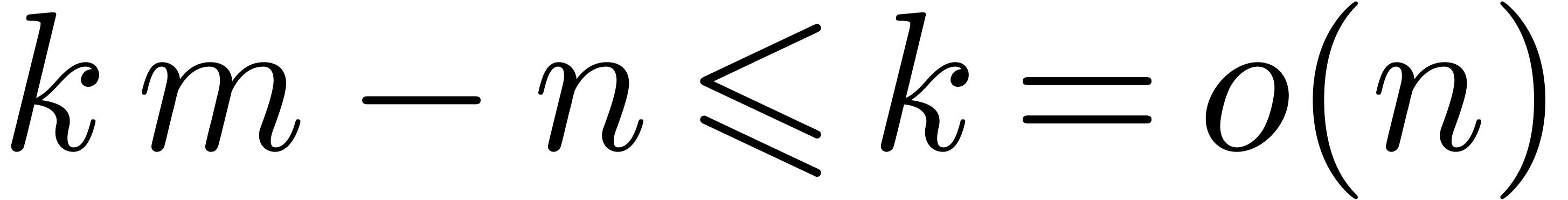 . Let us carefully
examine the cost of our algorithm for these choices of
and :
. Let us carefully
examine the cost of our algorithm for these choices of
and :
By the choice of , the
precomputation of , and  requires a time
requires a time
Similarly, the precomputation of and 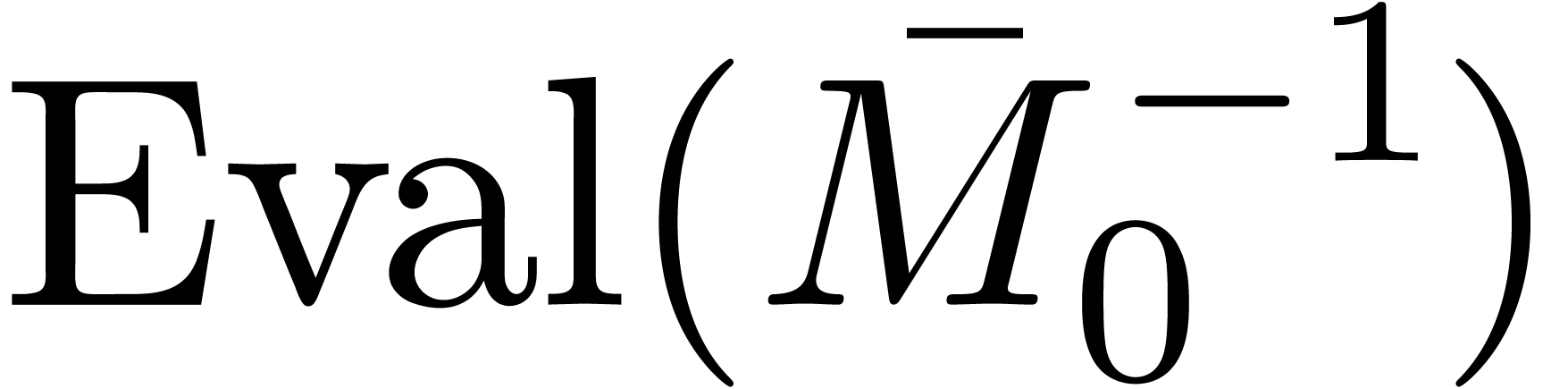 can be done in time
can be done in time
The computation of the transforms 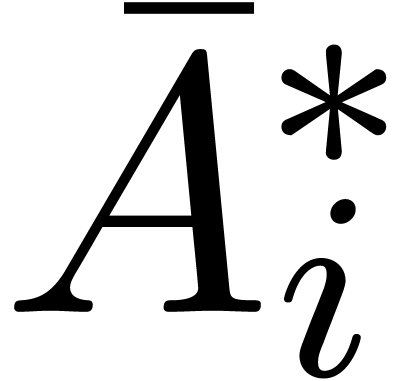 ,
,
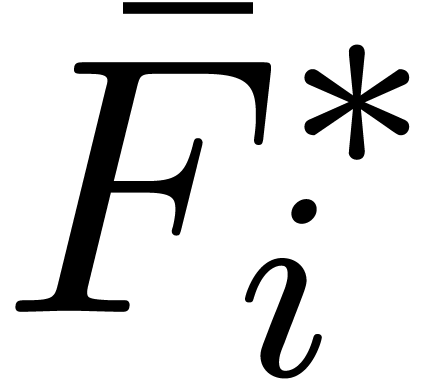 and the inverse transforms
can be done in time
and the inverse transforms
can be done in time
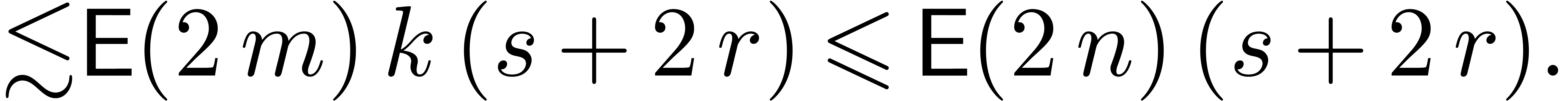
The computation of  products
products 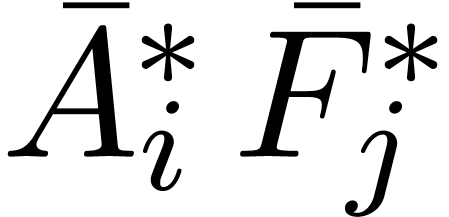 in the transformed model requires a time
in the transformed model requires a time
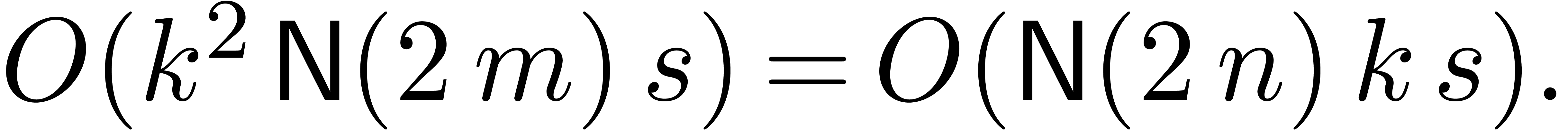
Using a relaxed multiplication algorithm, this cost further reduces to
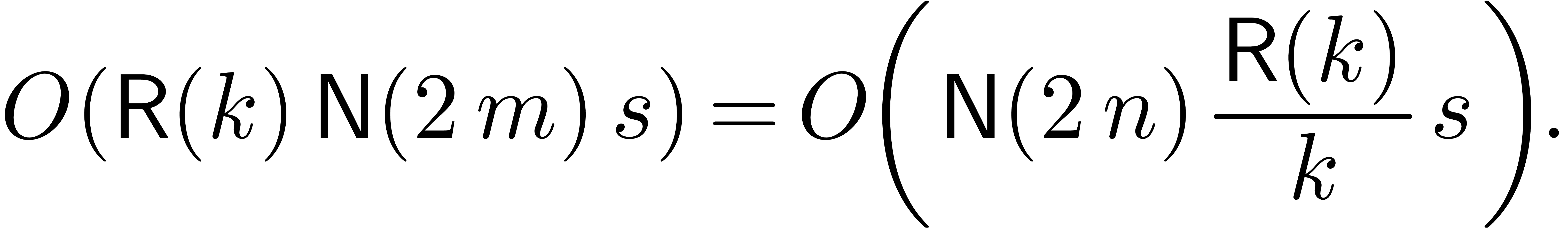
The computation of 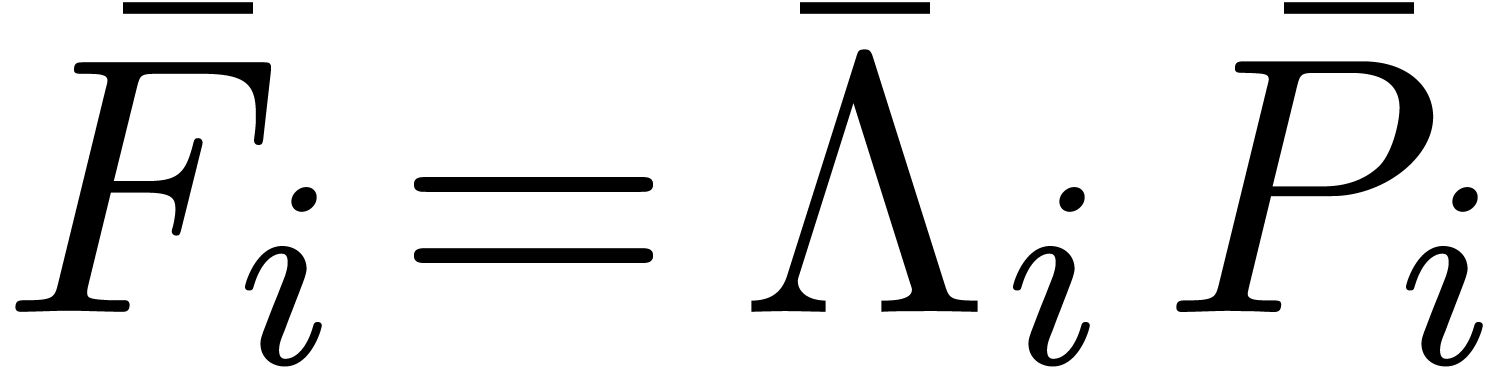 involves
involves 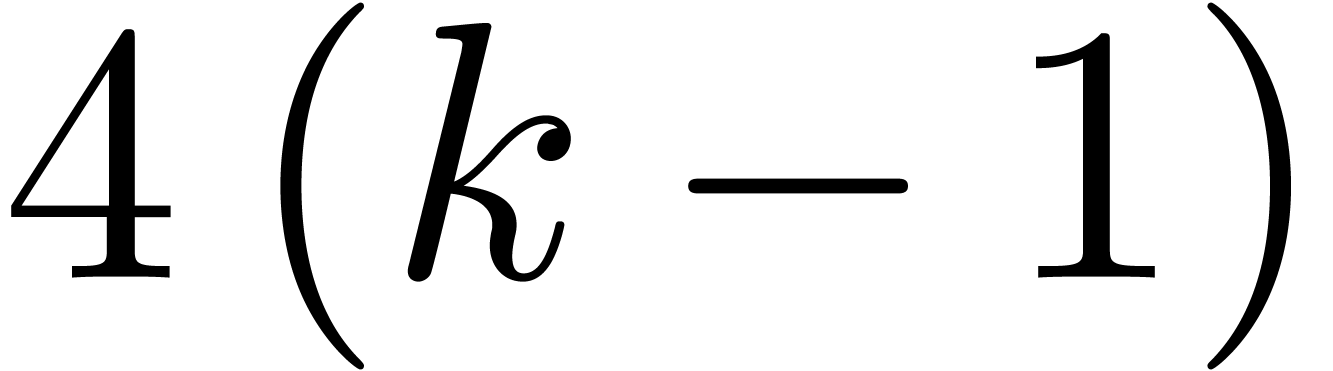 vectorial evaluations-interpolations, of cost
vectorial evaluations-interpolations, of cost
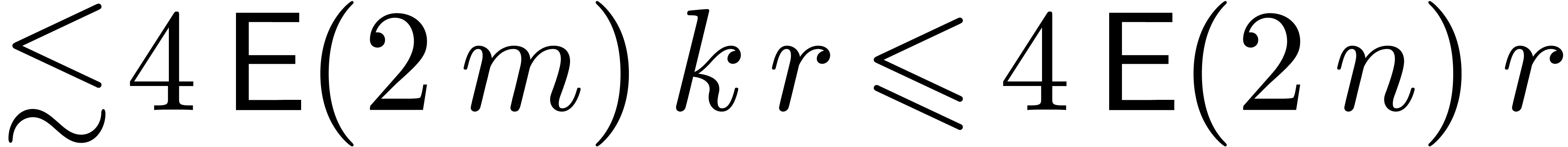
and 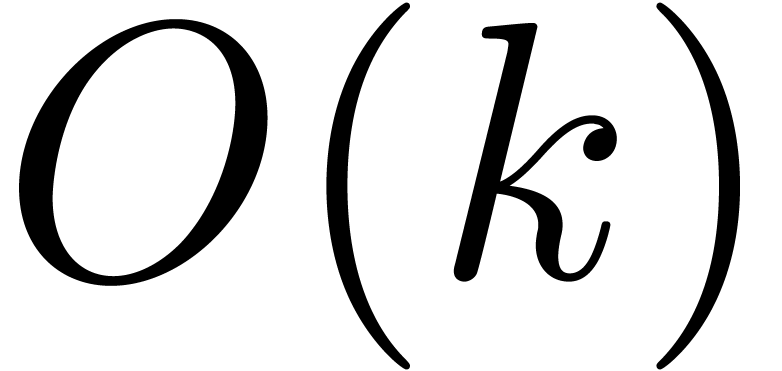 matrix-vector multiplications in the
transformed model, of cost
matrix-vector multiplications in the
transformed model, of cost
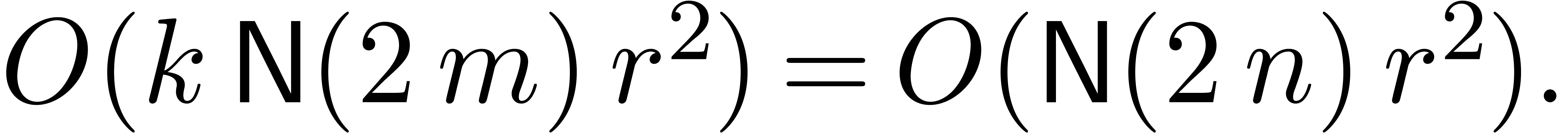
Adding up the different contributions, we obtain the bound
By construction, 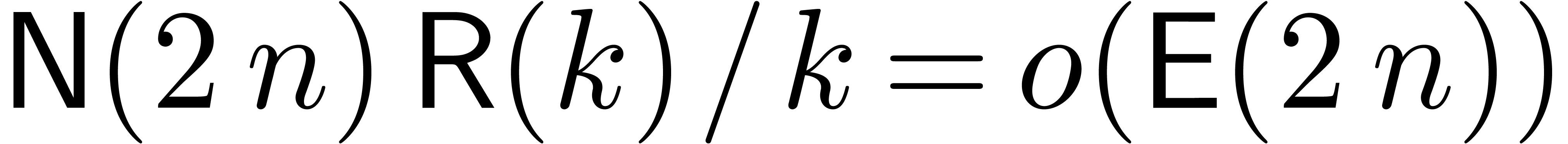 , and the
result follows.
, and the
result follows.
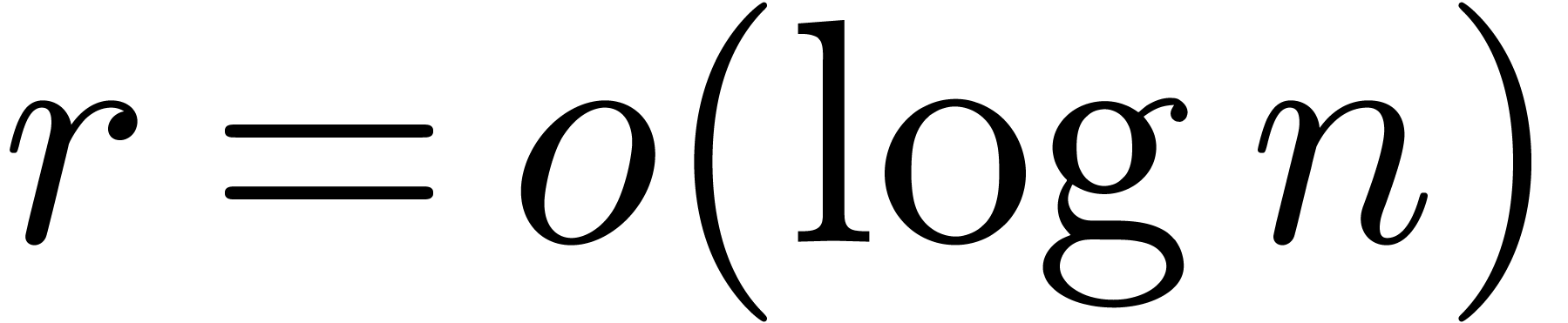 , we have
, we have
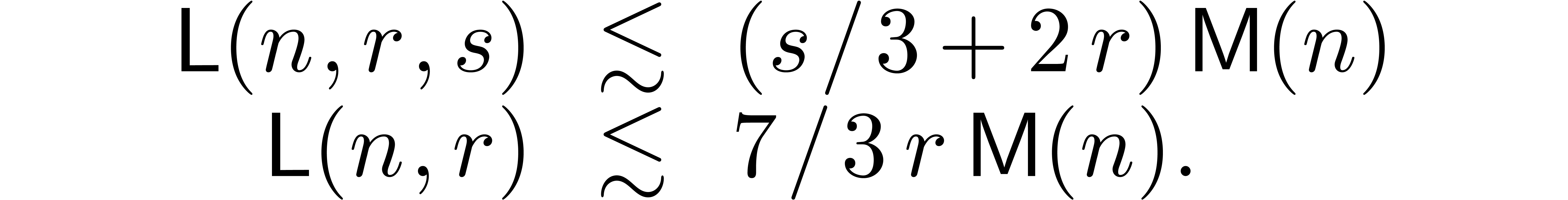
The same bounds are obtained in the synthetic FFT model if 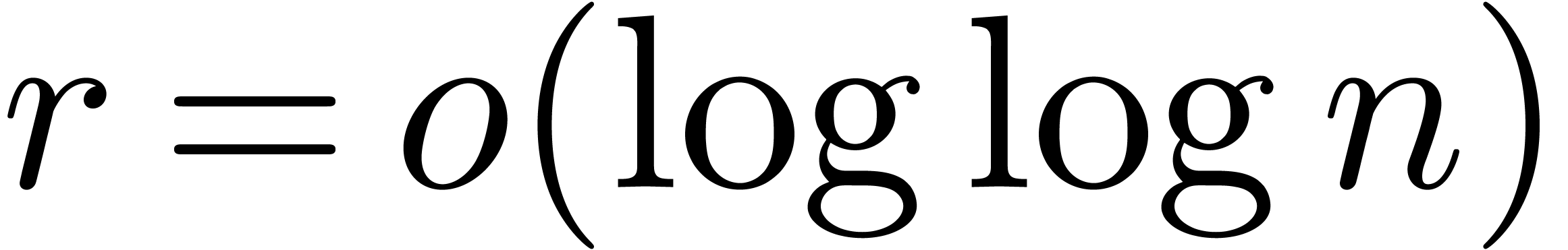 .
.
Remark. Of course, 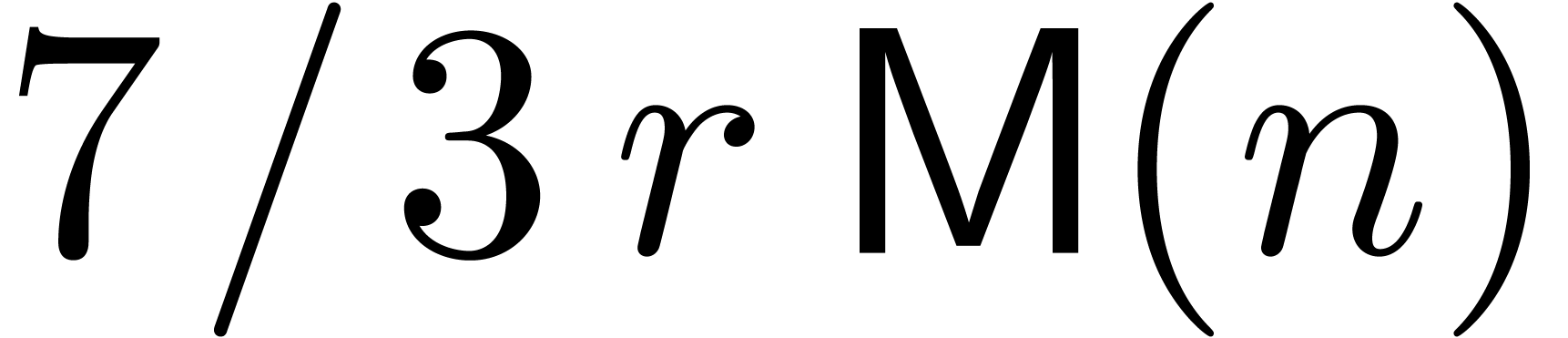 should be read
should be read 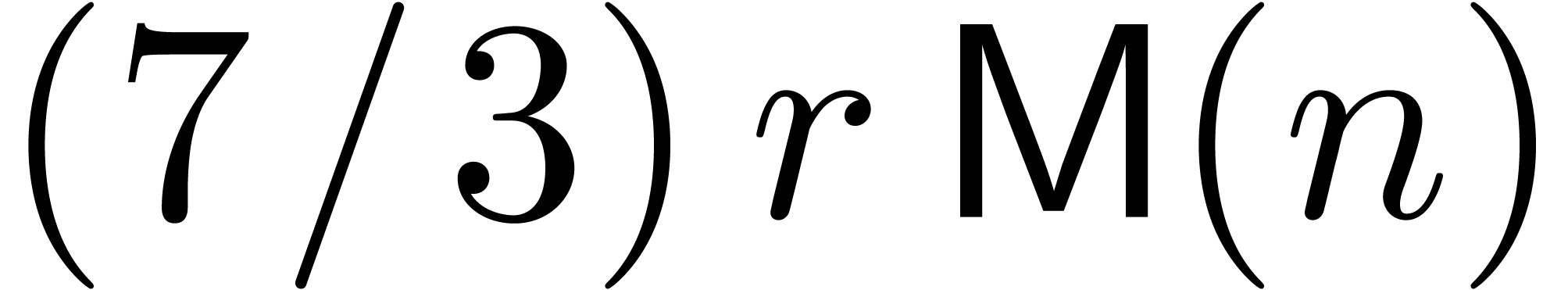 and likewise below.
and likewise below.
Proof. In the standard FFT model, we have 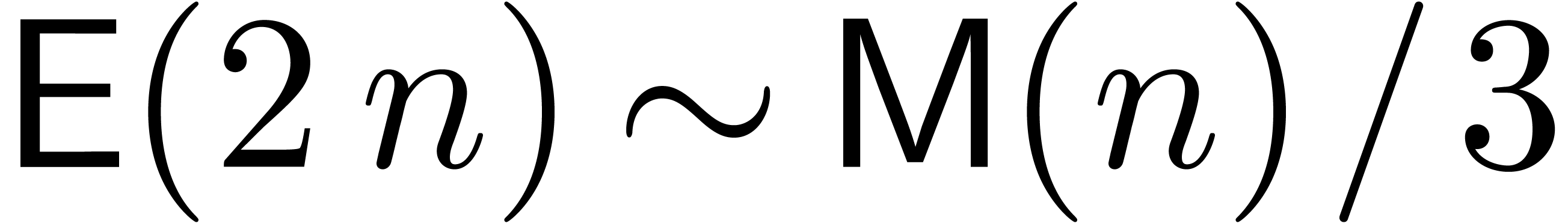 ,
, 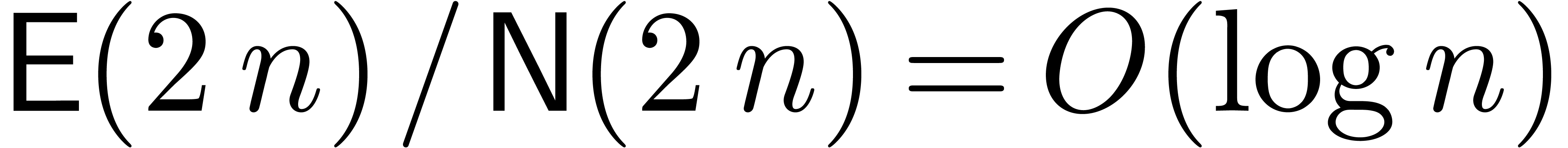 and
and
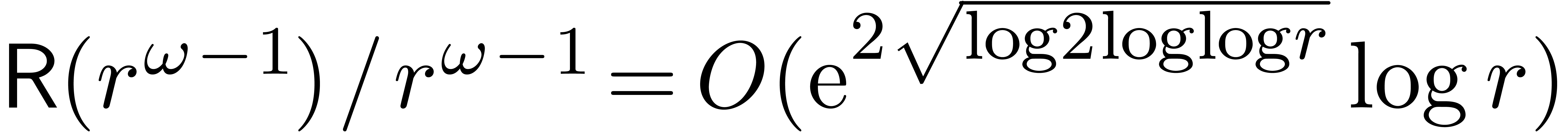 . If , we may therefore apply the theorem and the second
term in (24) becomes negligible with respect to the first
one.
. If , we may therefore apply the theorem and the second
term in (24) becomes negligible with respect to the first
one.
In the synthetic FFT model, we have ,
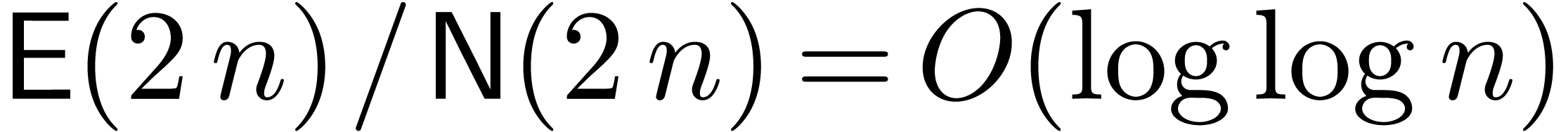 and
and 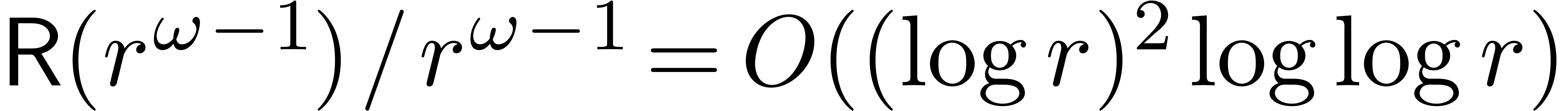 .
If , we may again apply the
theorem and the second term in (24) becomes
negligible.
.
If , we may again apply the
theorem and the second term in (24) becomes
negligible.
Remark just sufficiently large such
that the precomputation has a small cost with respect to the remainder
of the computation. This is already the case for
close to 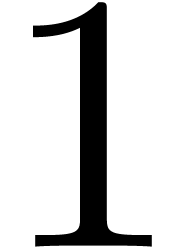 .
.
Remark 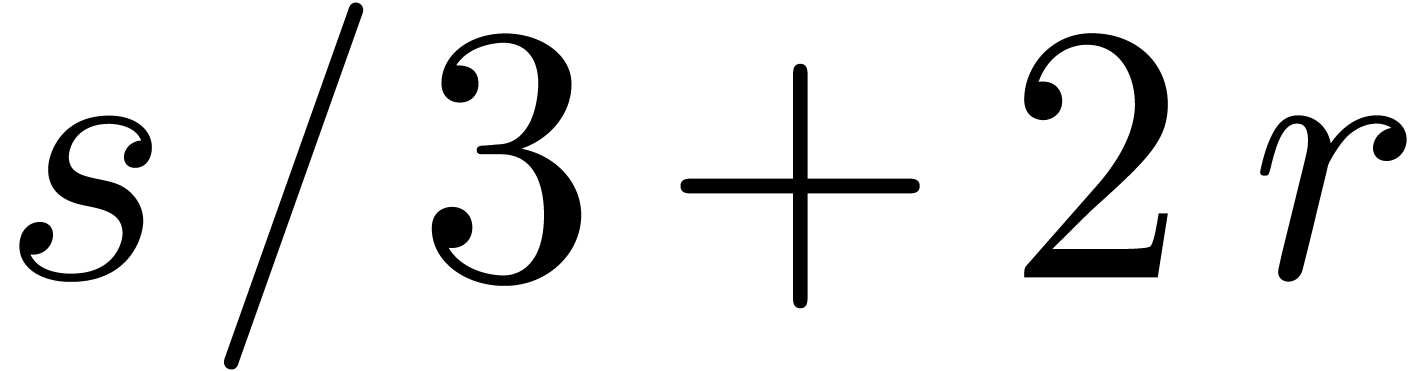 in Corollary 11. As explained in Remark 2, using a more straightforward multiplication algorithm seems
to require one additional transform. This leads to the factor
in Corollary 11. As explained in Remark 2, using a more straightforward multiplication algorithm seems
to require one additional transform. This leads to the factor 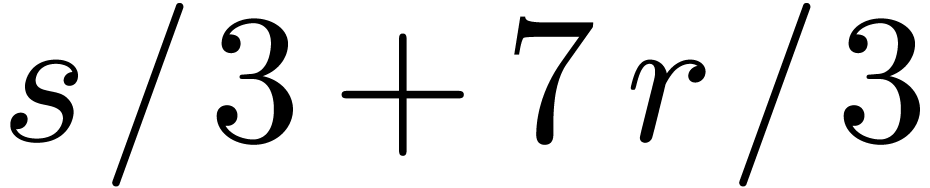 .
.
Remark 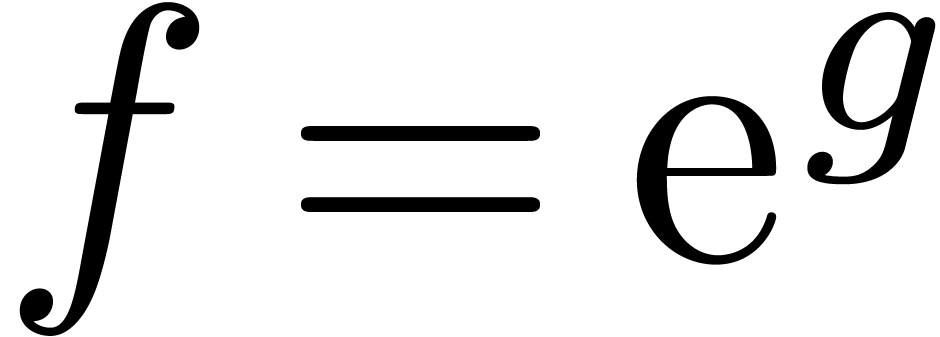 of a power series
of a power series  .
We obtain an algorithm of time complexity
.
We obtain an algorithm of time complexity 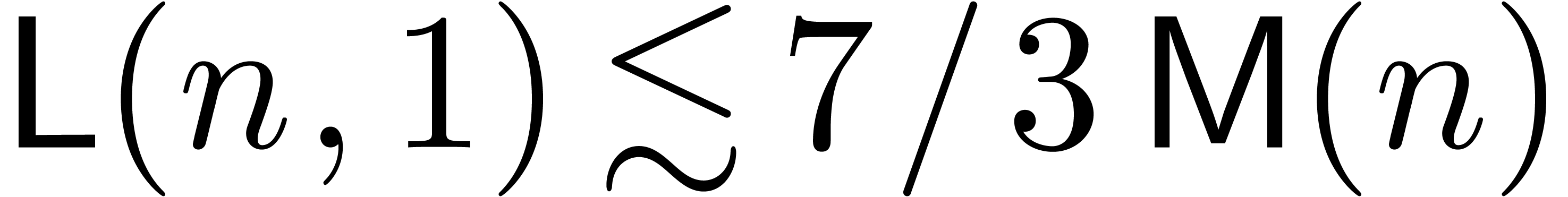 ,
which yields an improvement over [Ber00, HZ04].
Notice that FFT trading is a variant of Newton caching in [Ber00],
but not exactly the same: in our case, we use an “order ” Newton iteration, whereas
Bernstein uses classical Newton iterations on block-decomposed series.
,
which yields an improvement over [Ber00, HZ04].
Notice that FFT trading is a variant of Newton caching in [Ber00],
but not exactly the same: in our case, we use an “order ” Newton iteration, whereas
Bernstein uses classical Newton iterations on block-decomposed series.
Remark 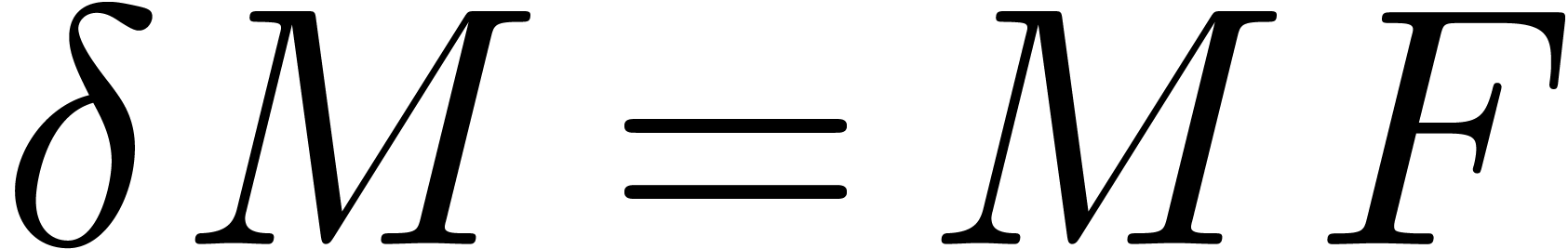 with . The unique solution
with . The unique solution
 corresponds to a fundamental system of solutions
to (21). A similar complexity analysis to the one in the
proof of Theorem 10 yields the bound
corresponds to a fundamental system of solutions
to (21). A similar complexity analysis to the one in the
proof of Theorem 10 yields the bound
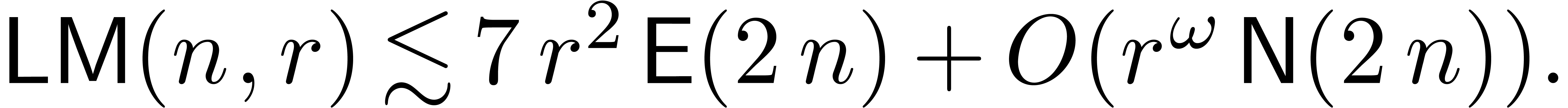
Under the additional hypotheses of the corollary, we thus get
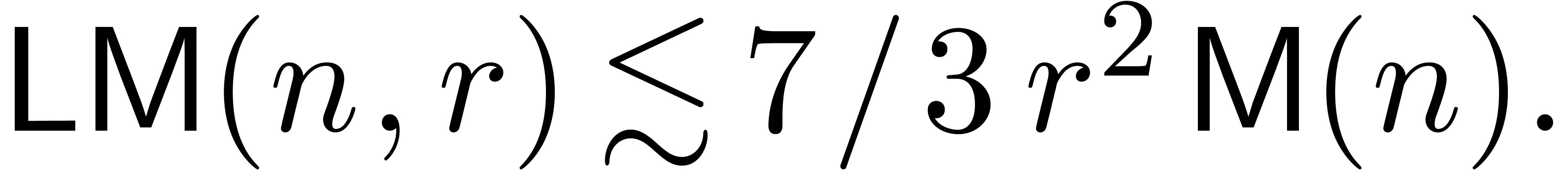
Remark
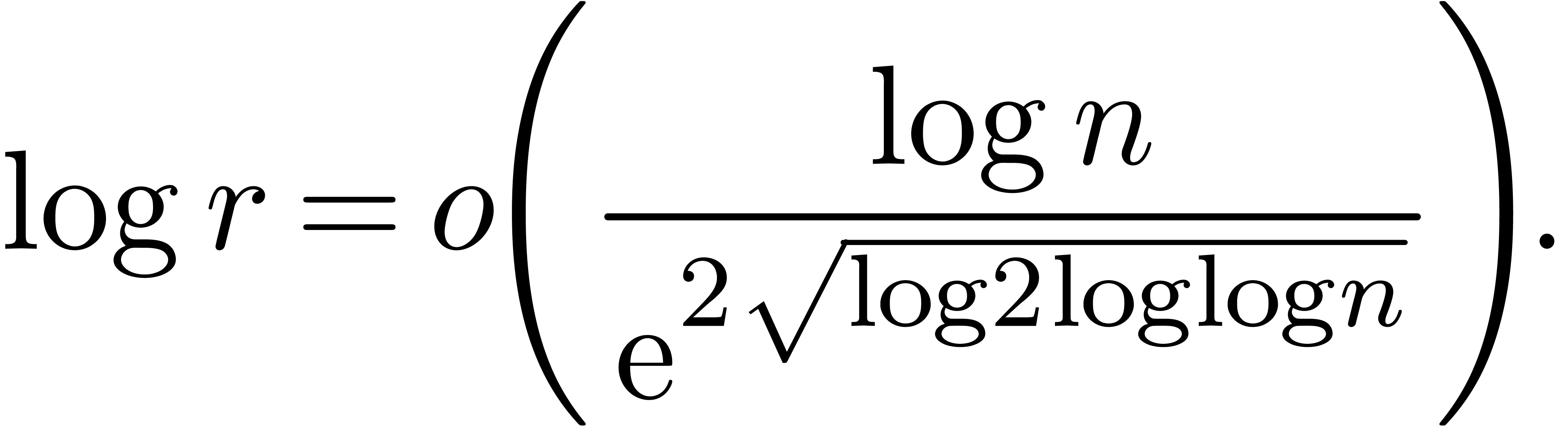 |
(25) |
If 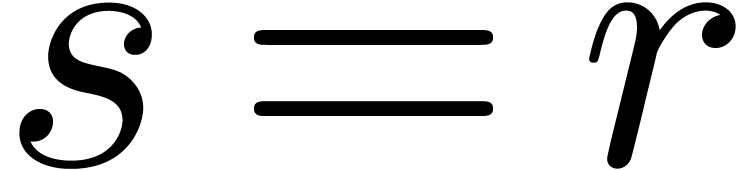 , then we obtain
, then we obtain

This complexity should be compared to the bound provided by a relaxed approach
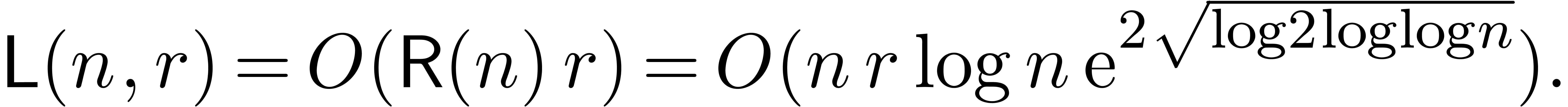
If , our new approach gains a
factor . On the other hand,
the relaxed approach becomes more efficient for moderate orders 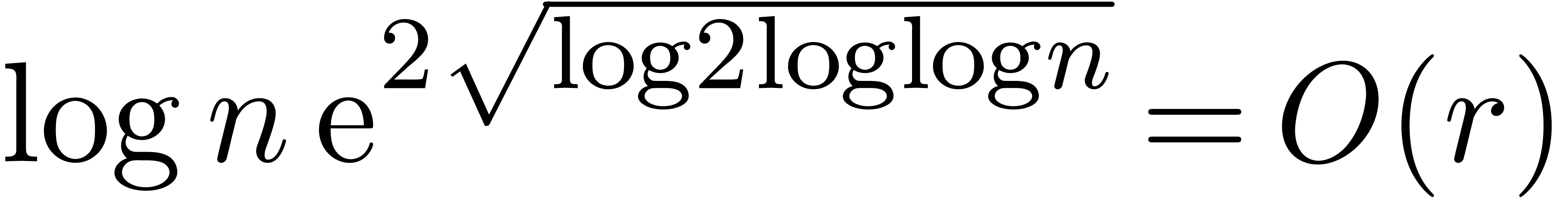 .
.
In the case when 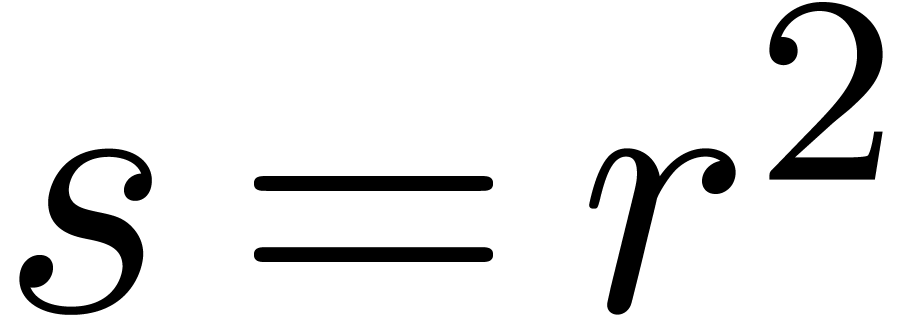 , the
theorem yields
, the
theorem yields
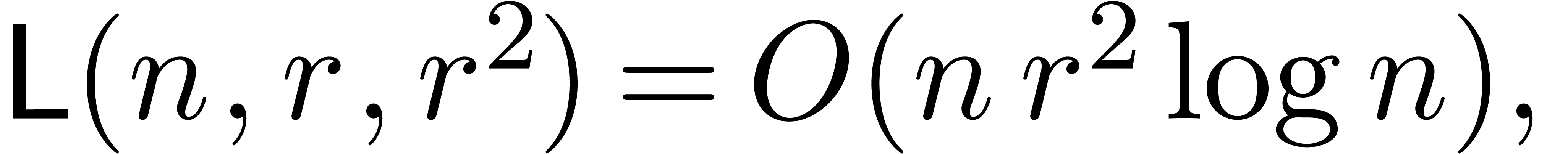
whereas the relaxed approach yields the bound
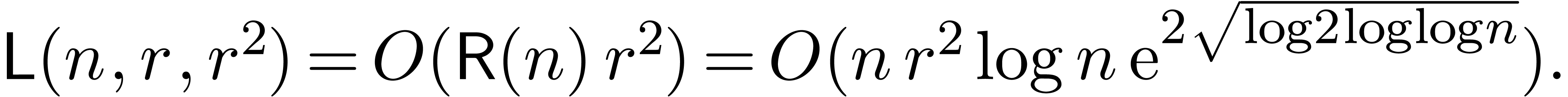
We thus gain a factor under the sole assumption
(25).
Remark  does not admit many -th roots of unity, we have the choice between the
synthetic FFT model and multipoint evaluation-interpolation. In the
synthetic FFT model, the almost optimal bounds from Corollary 11
are reached under the rather harsh assumption . This makes the method interesting only for
particularly low orders
does not admit many -th roots of unity, we have the choice between the
synthetic FFT model and multipoint evaluation-interpolation. In the
synthetic FFT model, the almost optimal bounds from Corollary 11
are reached under the rather harsh assumption . This makes the method interesting only for
particularly low orders 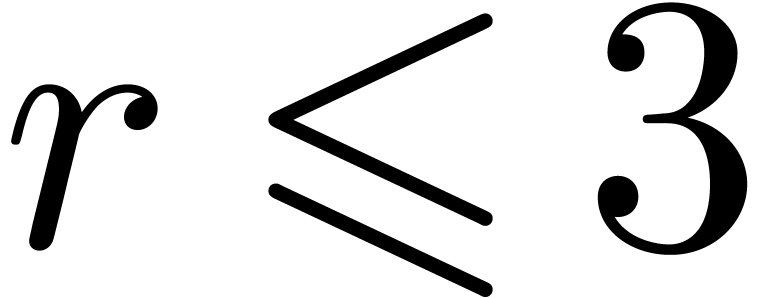 (maybe
(maybe 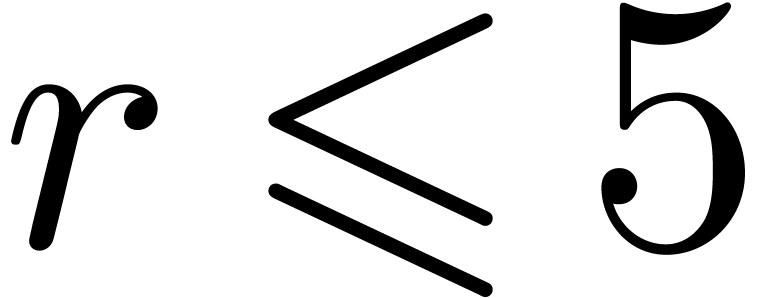 for really huge values of ).
for really huge values of ).
If admits an infinity of points in geometric
progression, then we may also use multipoint evaluation-interpolation
with 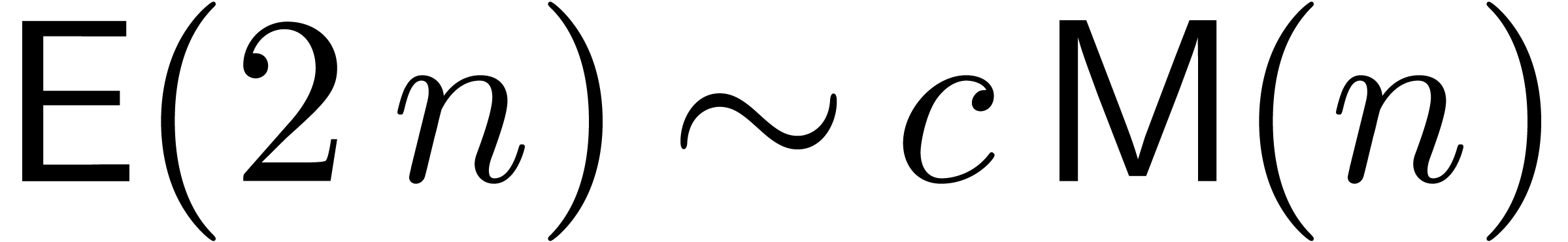 and
and 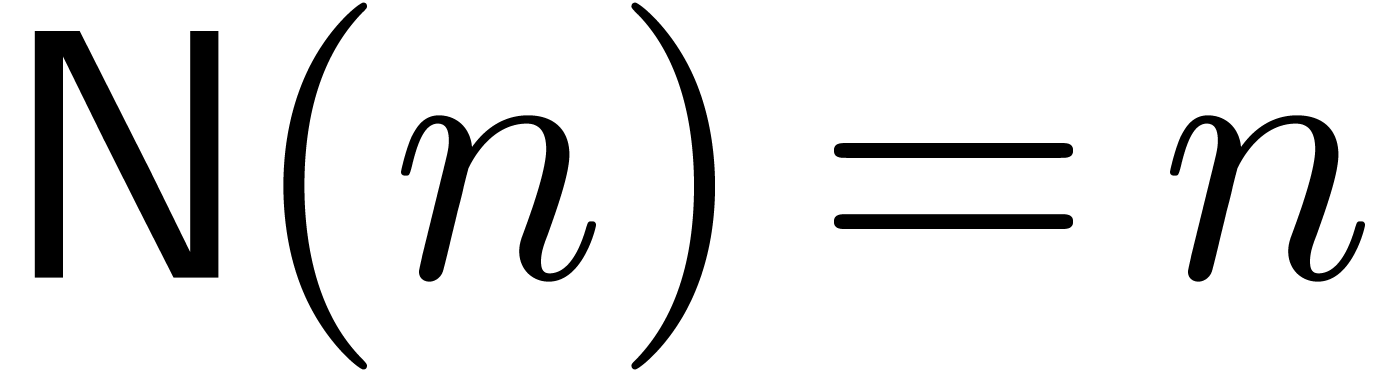 for some
constant
for some
constant  . In a similar way
as in Corollary 11, one obtains the bound
. In a similar way
as in Corollary 11, one obtains the bound
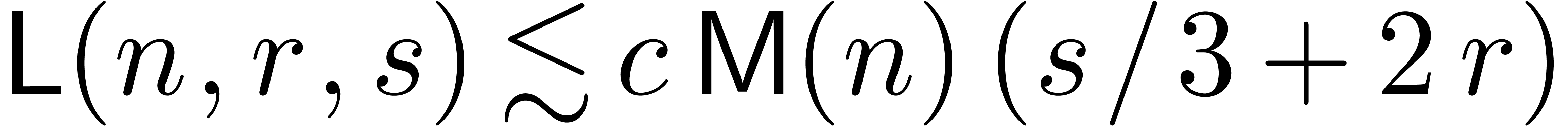
under the assumption 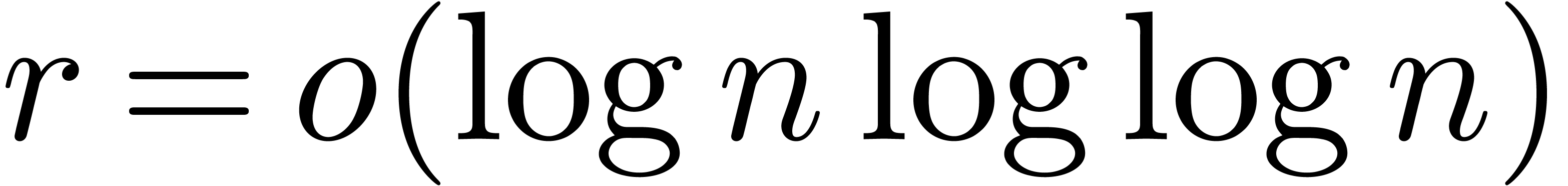 , since
, since
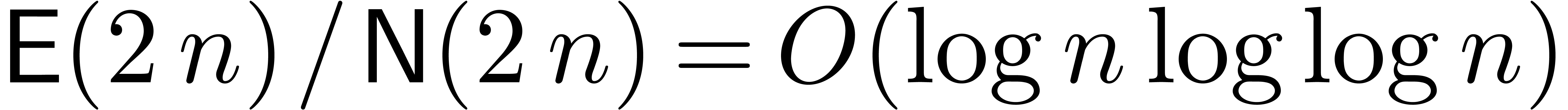 . If , then the assumption may even be replaced by
. If , then the assumption may even be replaced by 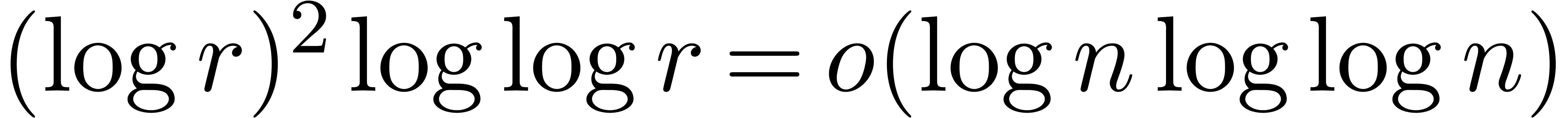 . Recall that
. Recall that  in this context. Therefore, we potentially gain a factor compared to the relaxed approach.
in this context. Therefore, we potentially gain a factor compared to the relaxed approach.
Remark  in any model with
in any model with 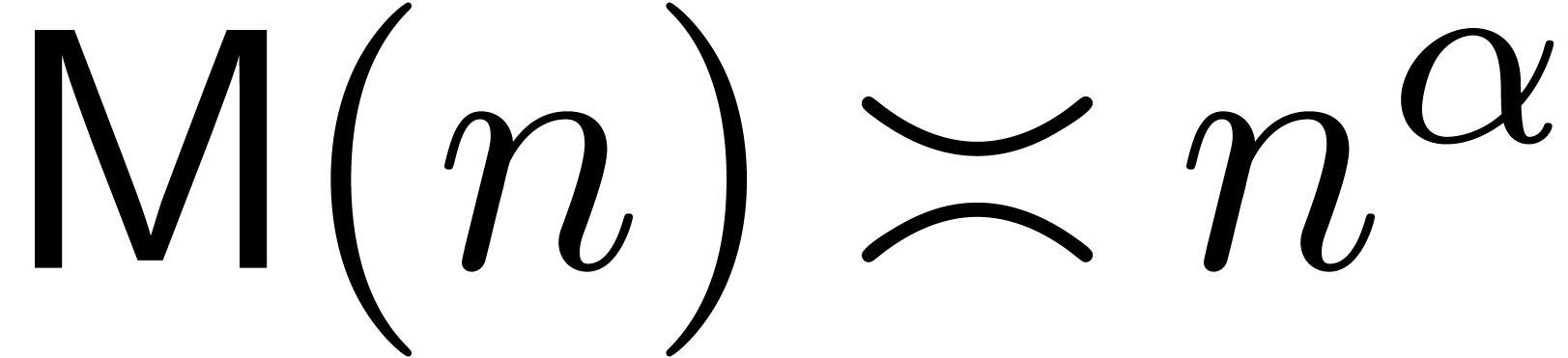 for
for  . The Karatsuba model is
even essentially relaxed, in the sense that
. The Karatsuba model is
even essentially relaxed, in the sense that 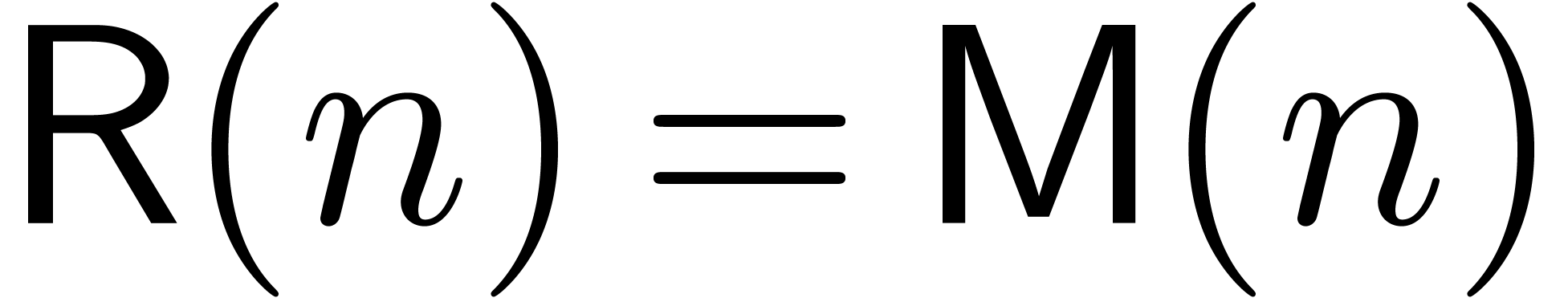 . Therefore, the use of Newton's method at best
allows for the gain of a constant factor. Moreover, FFT trading also
does not help, since
. Therefore, the use of Newton's method at best
allows for the gain of a constant factor. Moreover, FFT trading also
does not help, since  in such models, so the
second term in (24) can never be neglected with respect to
the first term.
in such models, so the
second term in (24) can never be neglected with respect to
the first term.
Remark 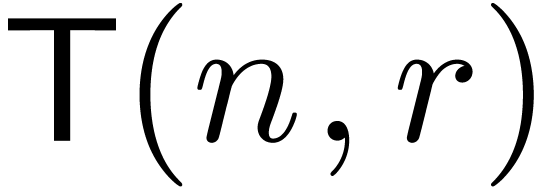 denote the
complexity of computing both and
denote the
complexity of computing both and 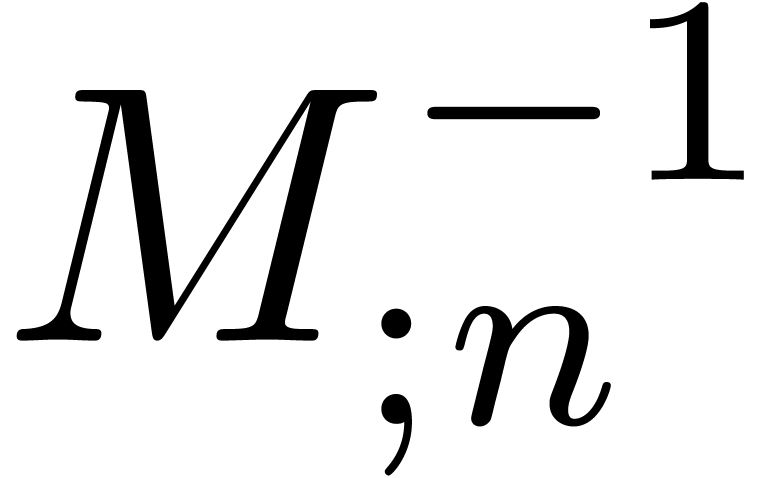 . One has
. One has
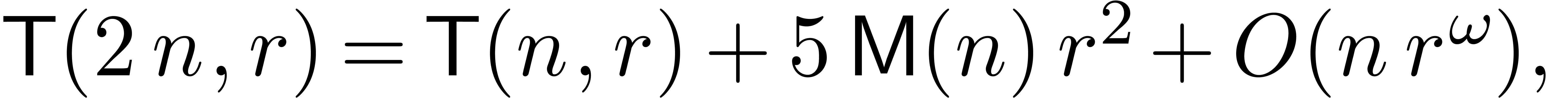
since the product  and the formulas (18)
and (19) give rise to
and the formulas (18)
and (19) give rise to  matrix
multiplications. This yields
matrix
multiplications. This yields
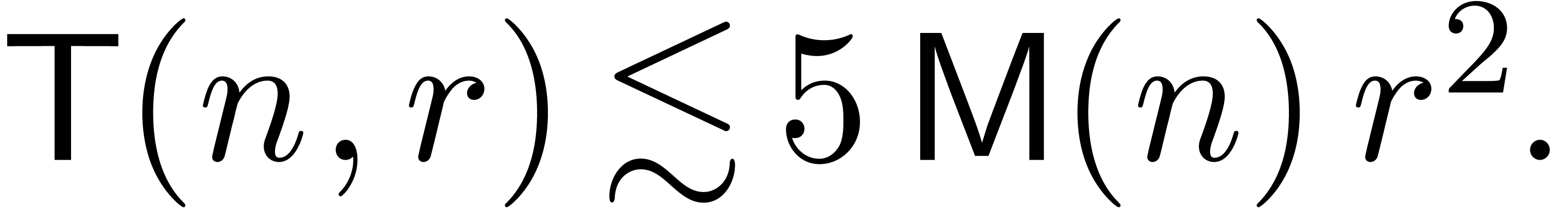
Notice that we may subtract the cost 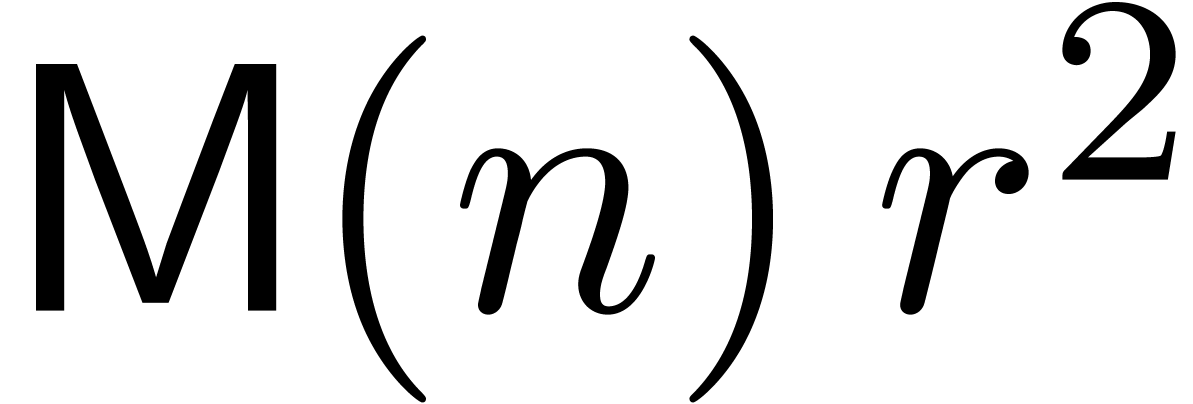 if the
final
if the
final 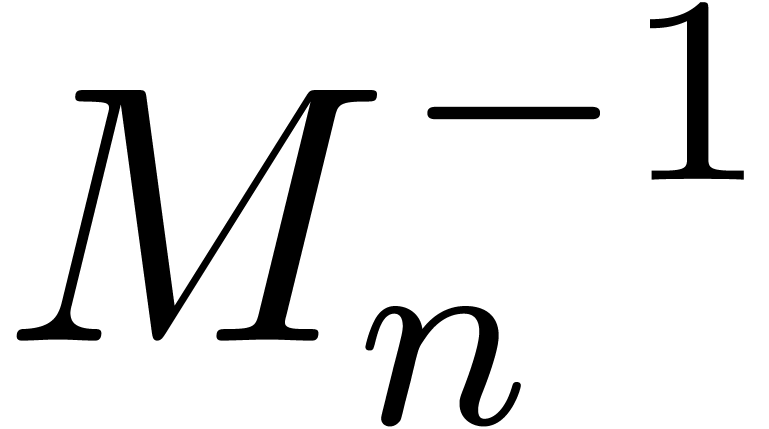 is not needed. It follows that
is not needed. It follows that
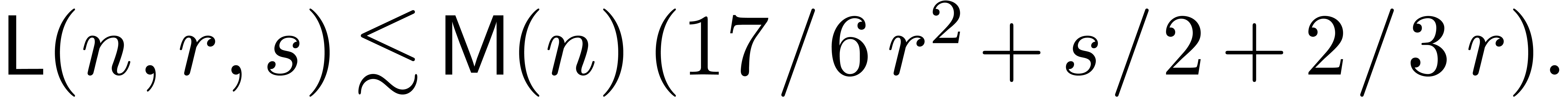
Using a trick from [Sch00], one may even prove that
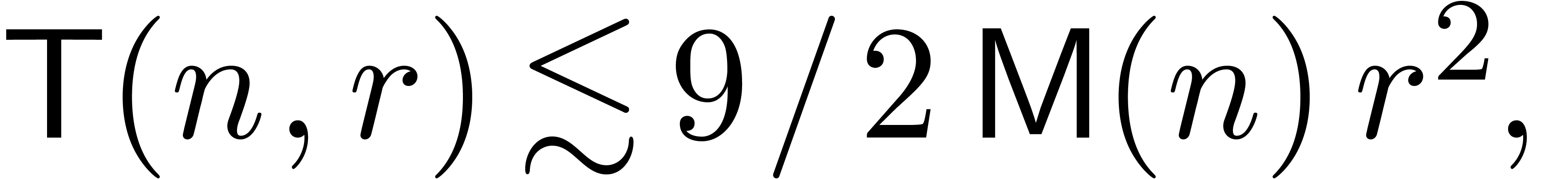
which yields
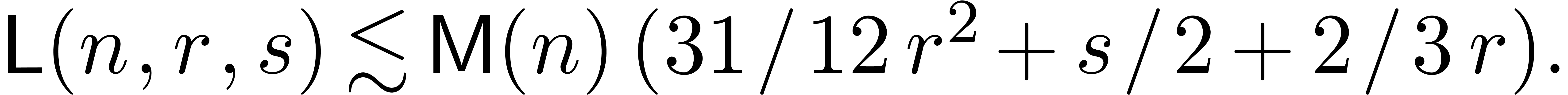
Assuming that one is able to solve the linearized version of an implicit equation (1), it is classical that Newton's method can again be used to solve the equation itself [BK78, vdH02a, BCO+07]. Before we show how to do this for algebraic systems of differential equations, let us first give a few definitions for polynomial expressions.
Given a vector of series variables, we will
represent polynomials in 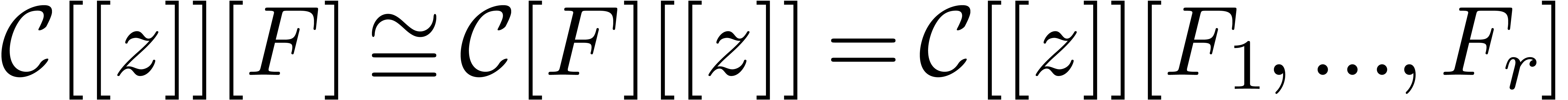 by dags (directed
acyclic graphs), whose leaves are either series in
or variables , and whose
inner nodes are additions, subtractions or multiplications. An example
of such a dag is shown in Figure 2. We will denote by
by dags (directed
acyclic graphs), whose leaves are either series in
or variables , and whose
inner nodes are additions, subtractions or multiplications. An example
of such a dag is shown in Figure 2. We will denote by 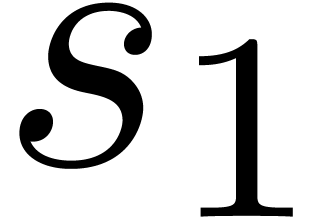 and
and 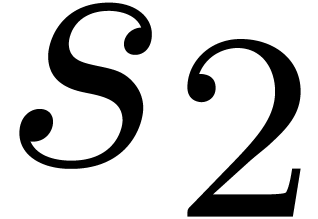 the number of nodes which
occur as an operand resp. result of a multiplication. We
call
the number of nodes which
occur as an operand resp. result of a multiplication. We
call  the multiplicative size of the dag
and the total number
the multiplicative size of the dag
and the total number 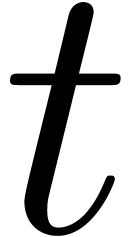 of nodes the total
size of the dag. Using evaluation-interpolation, one may compute
of nodes the total
size of the dag. Using evaluation-interpolation, one may compute
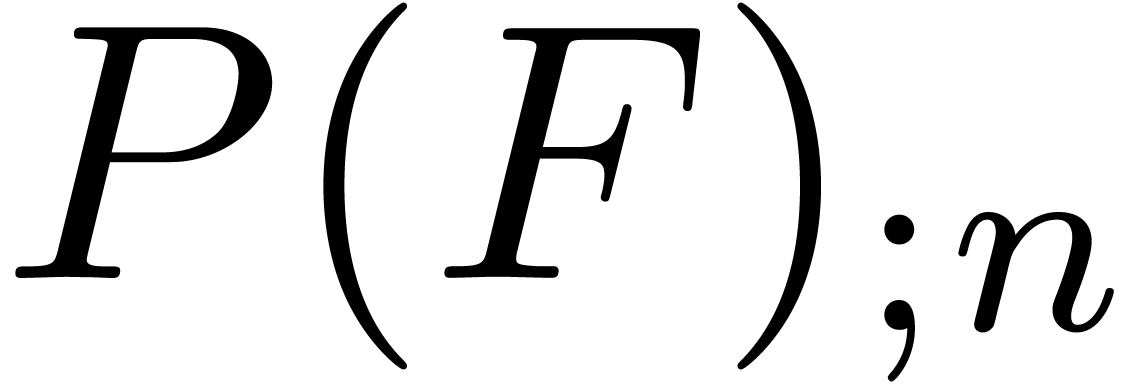 in terms of in time
in terms of in time
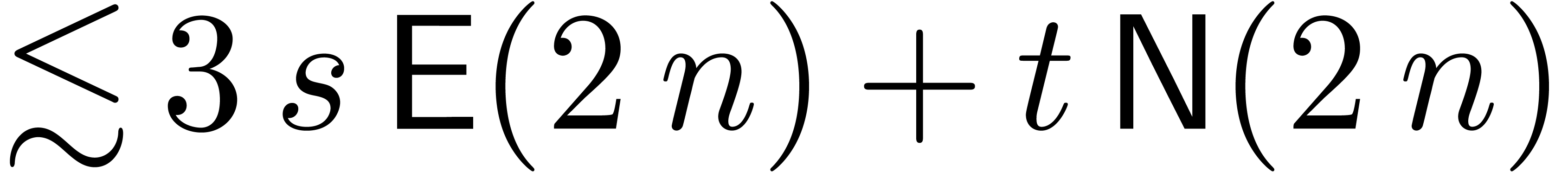 .
.
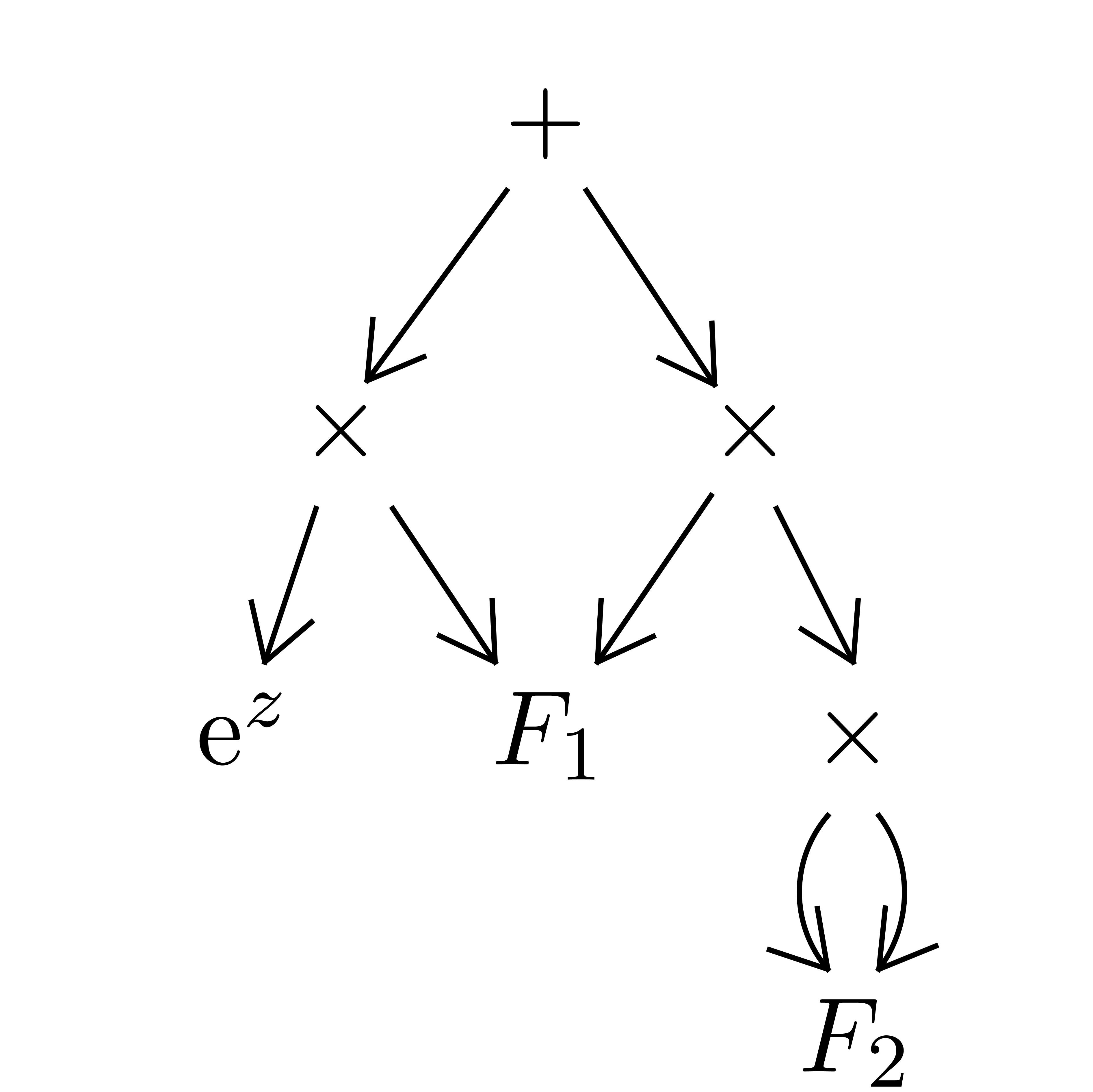 |
Now assume that we are given an -dimensional
system
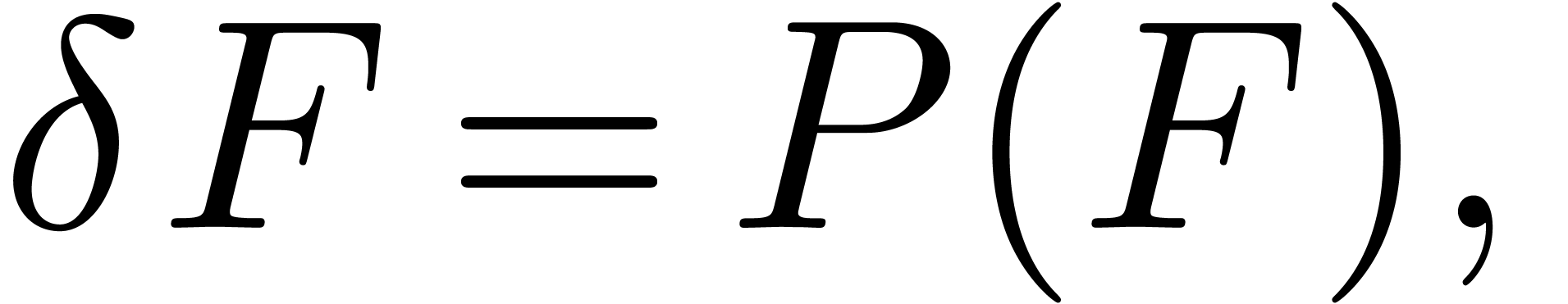 |
(26) |
with initial condition , and
where 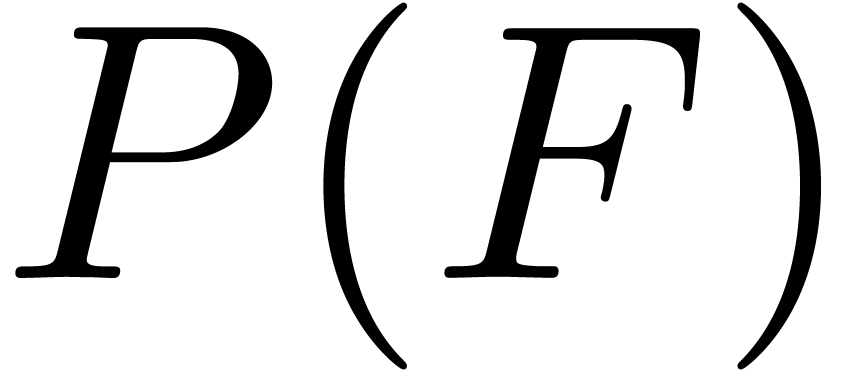 is a tuple of
polynomials in
is a tuple of
polynomials in  . Given the
unique solution to this initial value problem,
consider the Jacobian matrix
. Given the
unique solution to this initial value problem,
consider the Jacobian matrix
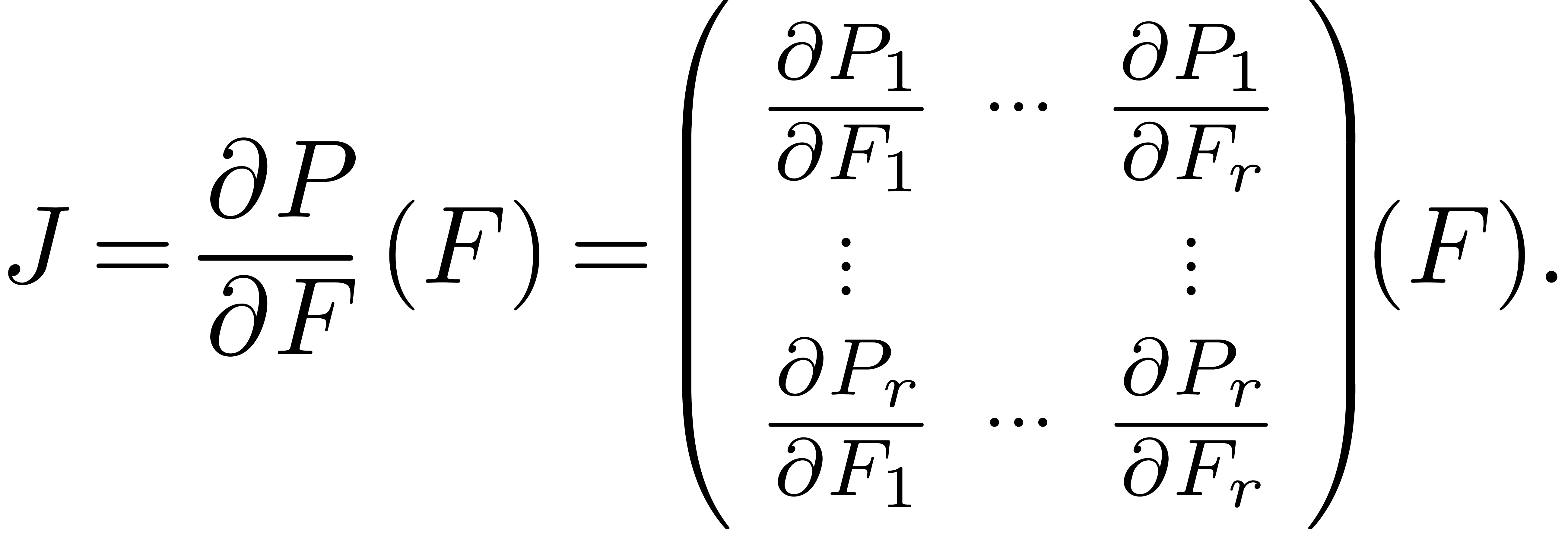
Assuming that 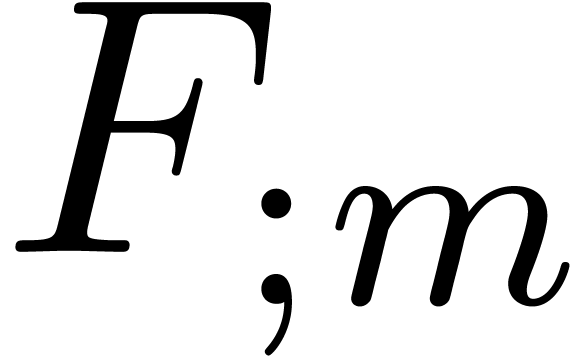 is known, we may compute
is known, we may compute 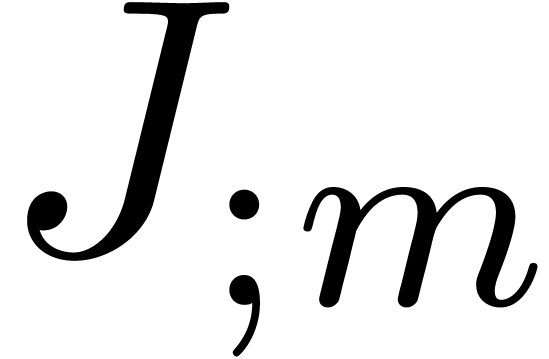 in time
in time 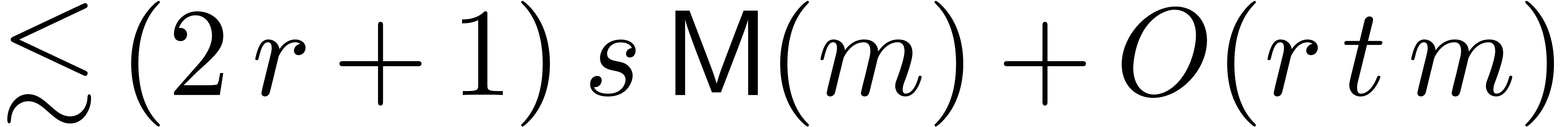 using the standard
differentiation rules. For
using the standard
differentiation rules. For  ,
we have
,
we have
so that
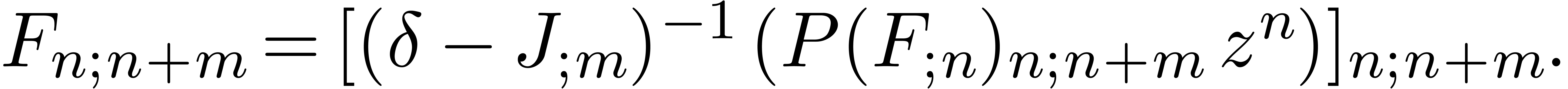 |
(27) |
Let us again adopt the notation (9). We will compute and 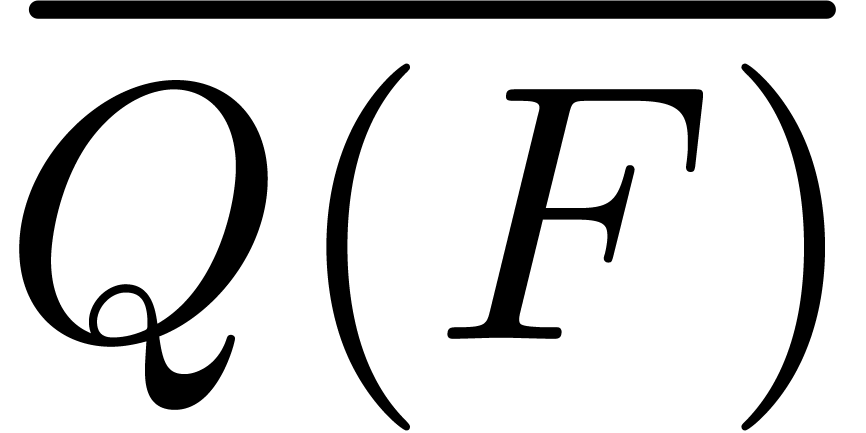 for any subexpression
for any subexpression
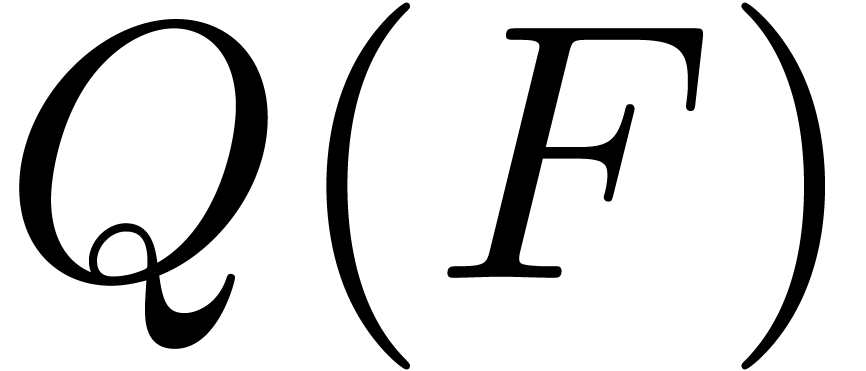 of in a relaxed manner.
Each series will actually be broken up into its
head
of in a relaxed manner.
Each series will actually be broken up into its
head 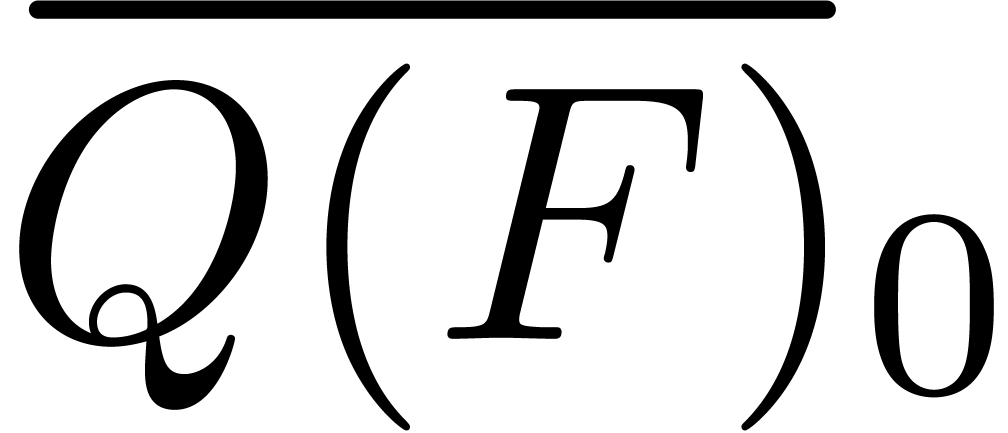 and its tail
and its tail 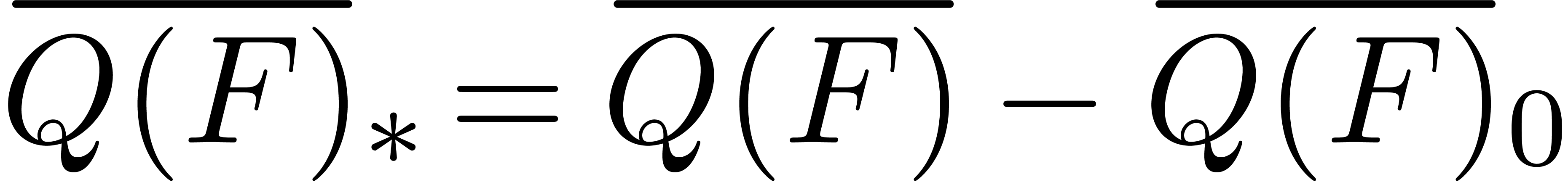 ,
so that sums and products are really computed using
,
so that sums and products are really computed using
Assume that 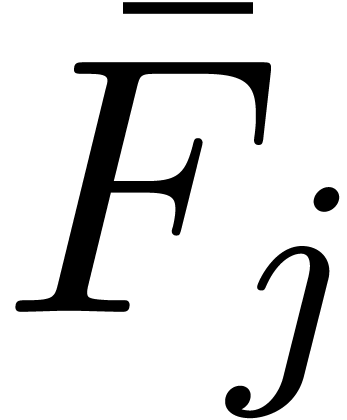 and
and 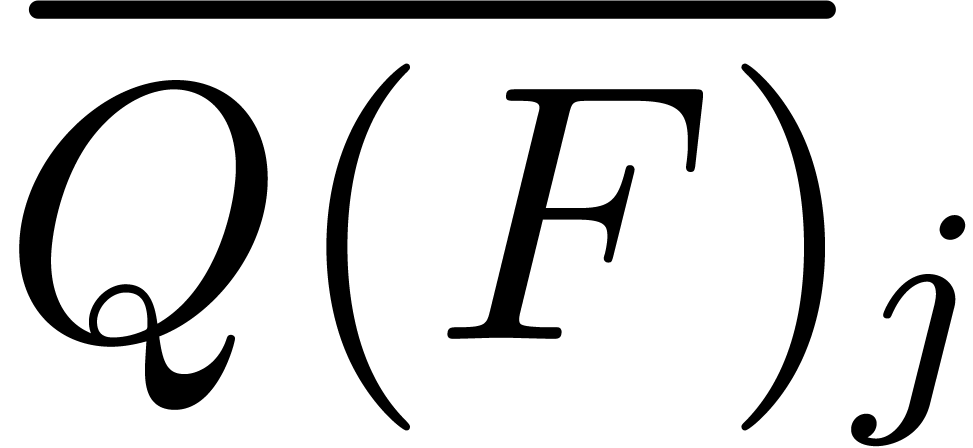 have
been evaluated for all
have
been evaluated for all 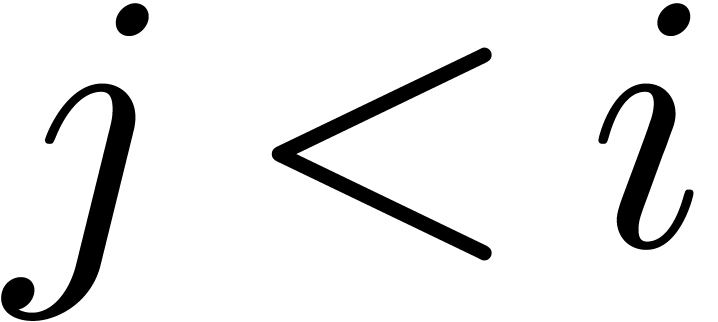 and notice that
and notice that
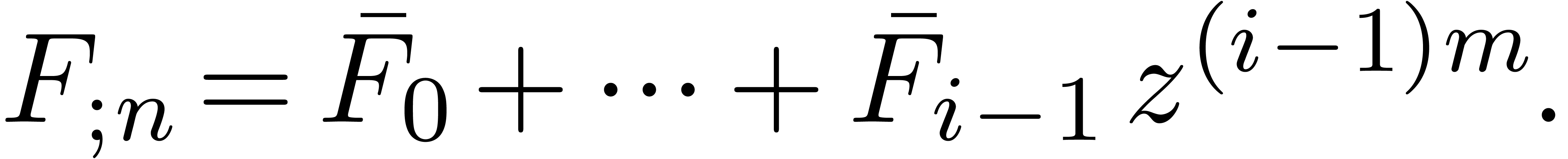
The advantage of our modified way to compute the
is that it also allows us to efficiently evaluate 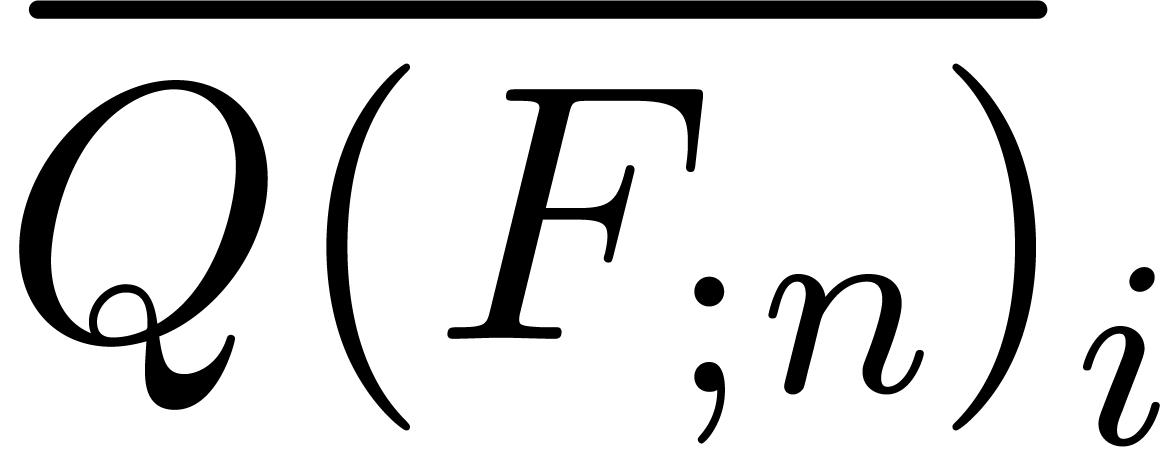 . Indeed, since
. Indeed, since 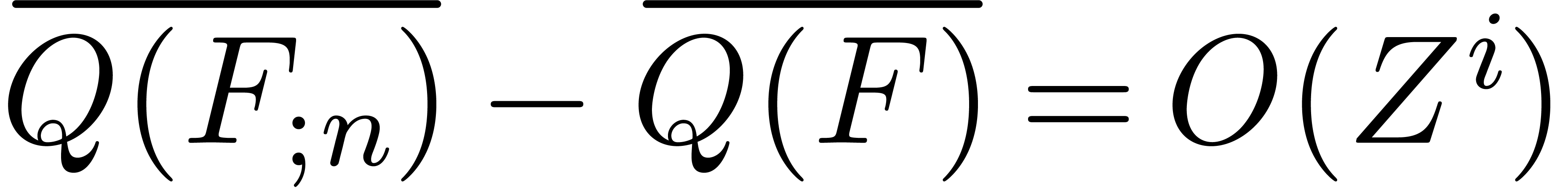 ,
we have
,
we have
We may finally compute using
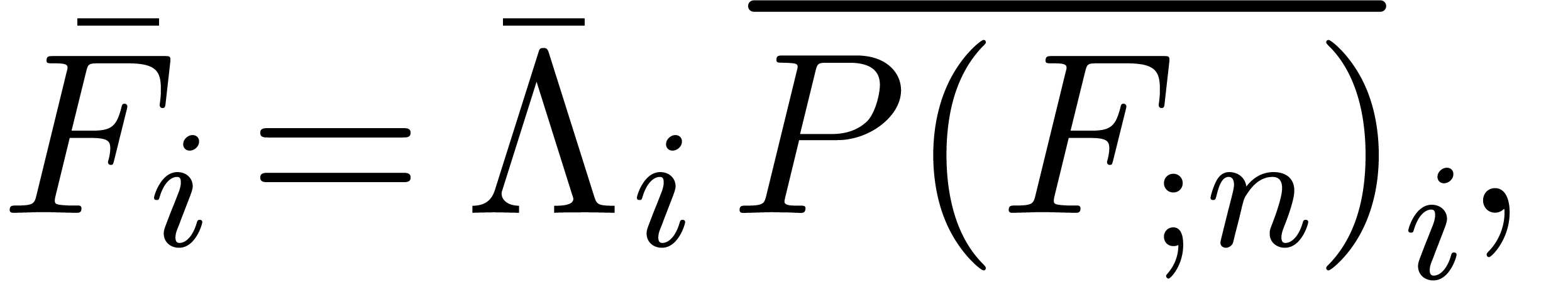 |
(28) |
where is the blockwise operator which acts on
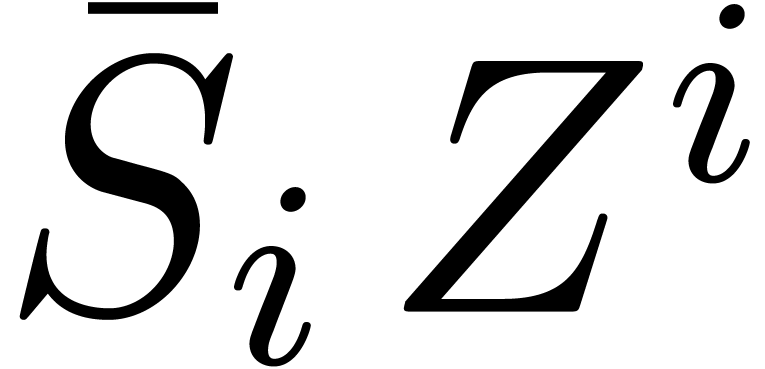 by
by
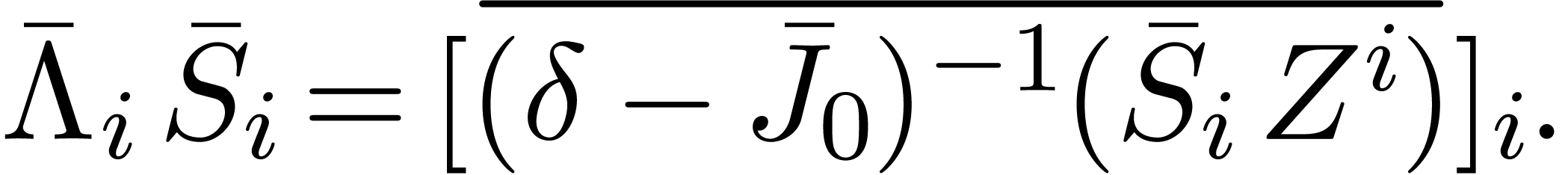
Let us now analyze the time complexity 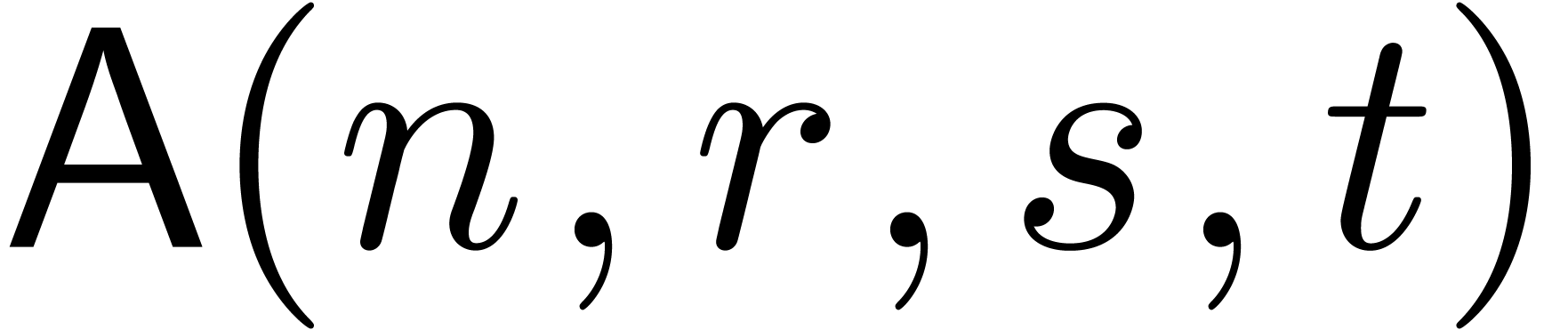 of the
computation of .
of the
computation of .
 -dimensional
system
-dimensional
system  is a polynomial, given by a dag of multiplicative size and total size
is a polynomial, given by a dag of multiplicative size and total size 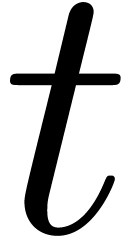 .
Assume that and .
Then there exists an algorithm which computes
in time
.
Assume that and .
Then there exists an algorithm which computes
in time
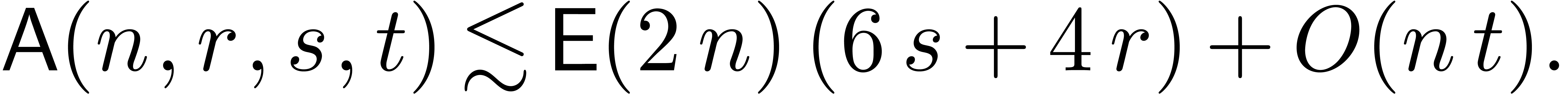
Proof. In order to perform all multiplications
in the transformed model, we have to compute both  and
and  for each argument
for each argument 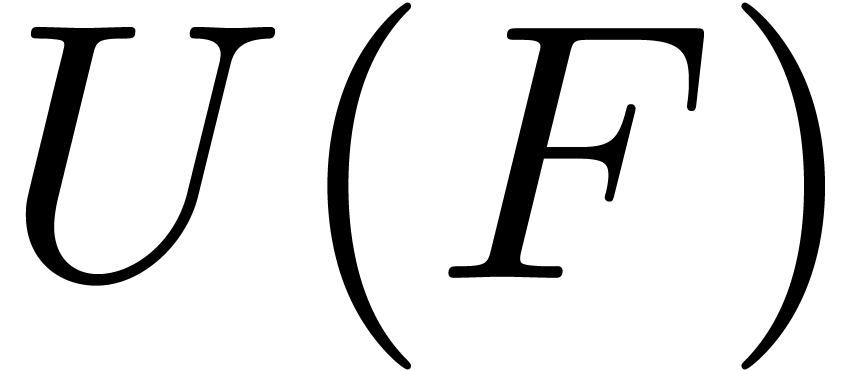 of
a multiplicative subexpression of and
of
a multiplicative subexpression of and  and
and  for each multiplicative
subexpression of .
This amounts to a total of
for each multiplicative
subexpression of .
This amounts to a total of 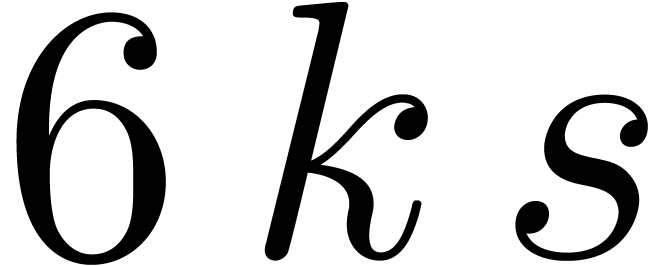 evaluations-interpolations of size ,
of cost
evaluations-interpolations of size ,
of cost  . The computations of
the using (28) induce an additional
cost
. The computations of
the using (28) induce an additional
cost 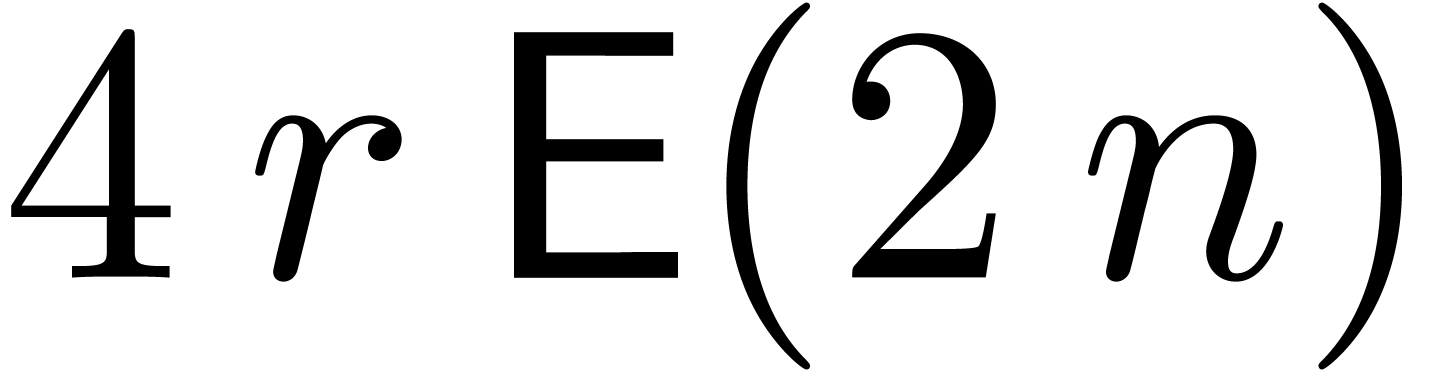 . The relaxed
multiplications in the transformed model correspond to a cost
. The relaxed
multiplications in the transformed model correspond to a cost 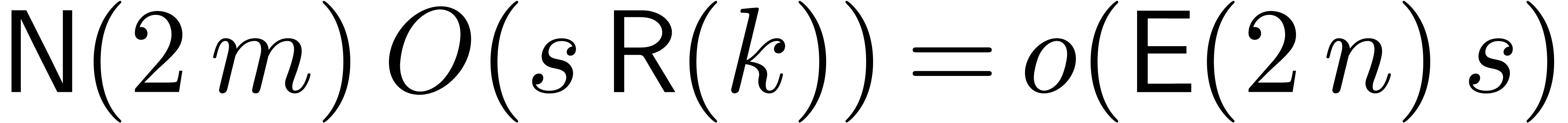 . The additions are done in the
untransformed model, in time
. The additions are done in the
untransformed model, in time 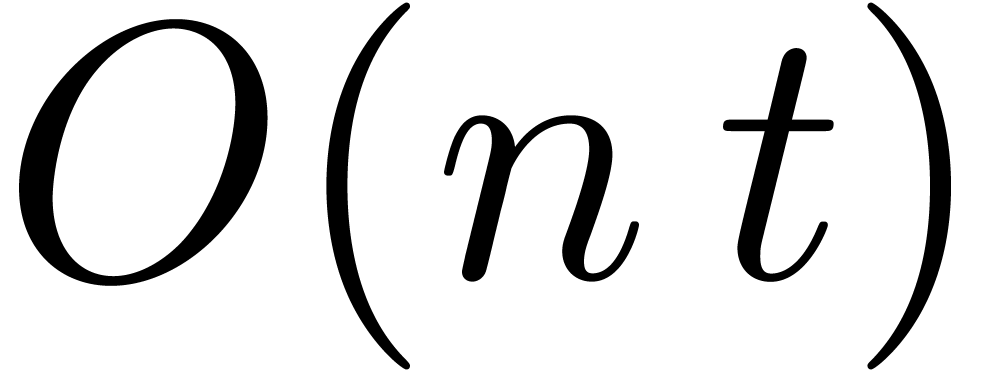 .
The precomputation of
.
The precomputation of 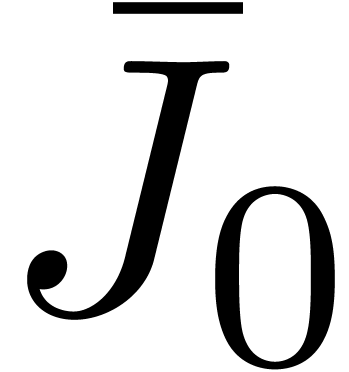 ,
, 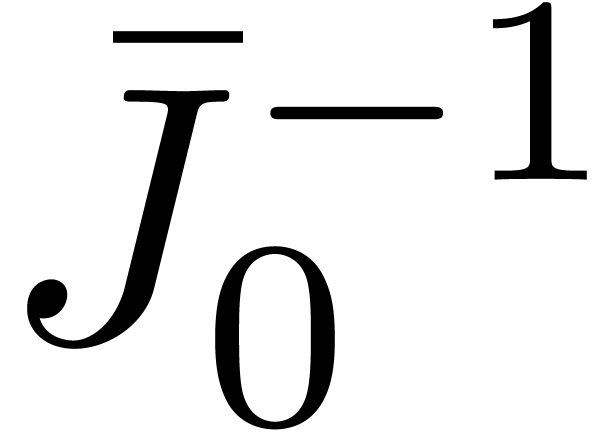 and its transforms have a negligible cost
and its transforms have a negligible cost  .
.
, we have
The same bound holds in the synthetic FFT model, assuming that
.
Remark only depend
linearly on  , it is possible
to adapt a similar technique as in the previous section and perform
these multiplications using the middle product. This allows for a
reduction of the factor
, it is possible
to adapt a similar technique as in the previous section and perform
these multiplications using the middle product. This allows for a
reduction of the factor 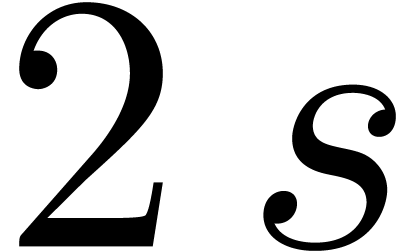 to something between
and .
to something between
and .
Remark
However, the factor 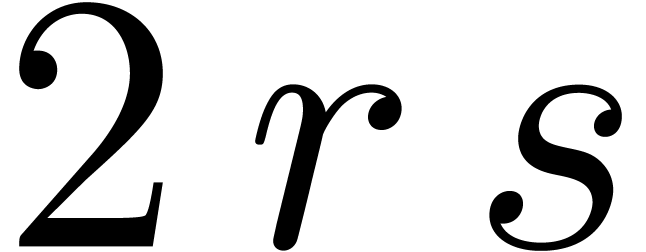 is quite pessimistic. For
instance, if the expressions
is quite pessimistic. For
instance, if the expressions  do not share any
common subexpressions, then we may use automatic differentiation [BS83] for the computation of
do not share any
common subexpressions, then we may use automatic differentiation [BS83] for the computation of 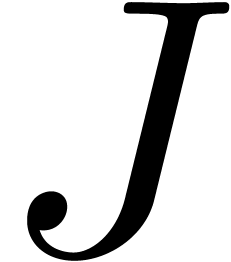 .
The multiplicative size
.
The multiplicative size 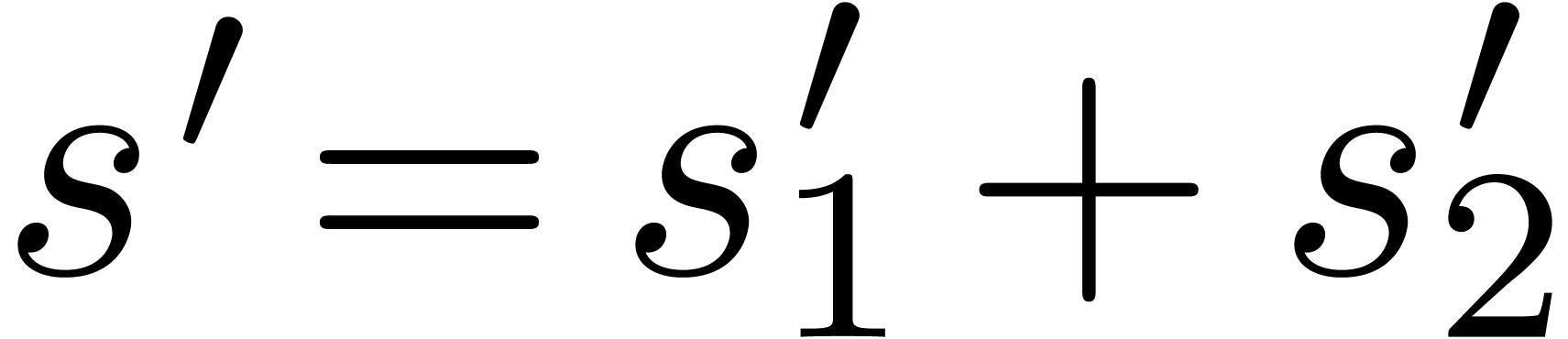 for this circuit is
given by
for this circuit is
given by 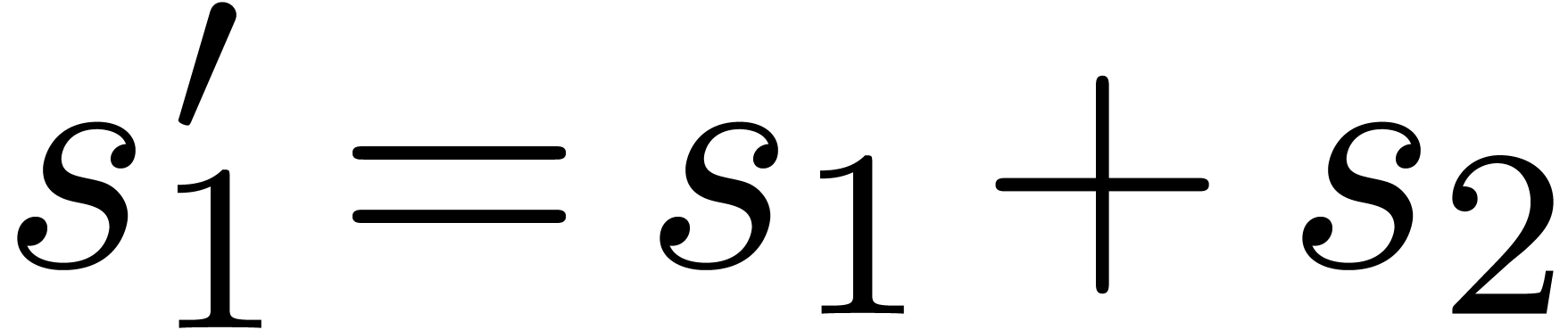 and
and 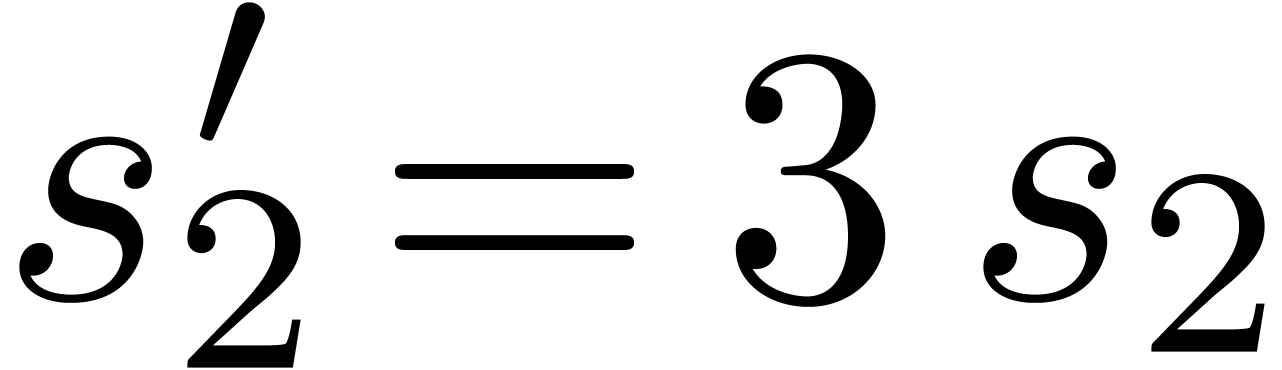 ,
whence
,
whence 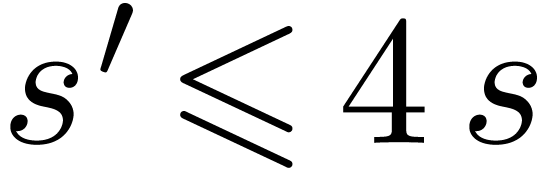 and
and
Assume the standard FFT model. It is well-known that discrete
FFTs are most efficient on blocks of size with
. In particular, without
taking particular care, one may lose a factor
when computing the product of two polynomials
and of degrees with
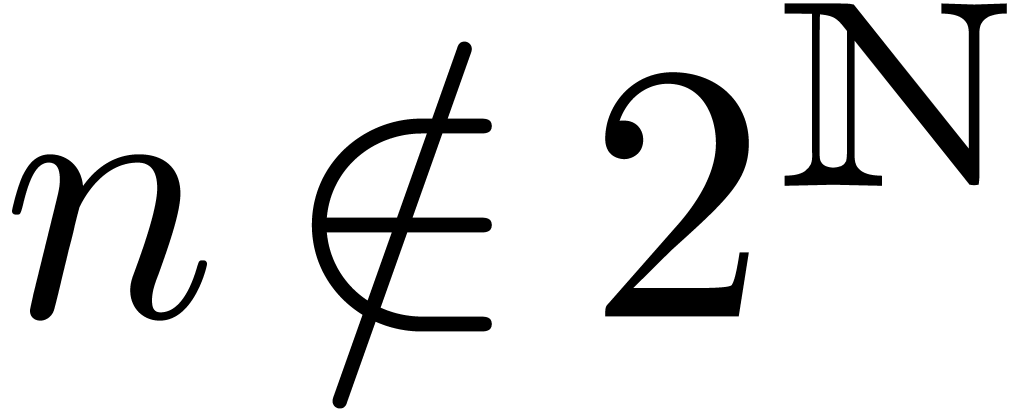 . One strategy to remove this
problem is to use the TFT (truncated Fourier transform) as detailed in
[vdH04, vdH05]. Another way to smooth the
complexity is to cut and
in smaller blocks, and trade superfluous and asymptotically expensive
FFTs against asymptotically less expensive multiplications in the FFT
model.
. One strategy to remove this
problem is to use the TFT (truncated Fourier transform) as detailed in
[vdH04, vdH05]. Another way to smooth the
complexity is to cut and
in smaller blocks, and trade superfluous and asymptotically expensive
FFTs against asymptotically less expensive multiplications in the FFT
model.
More precisely, we cut and
into 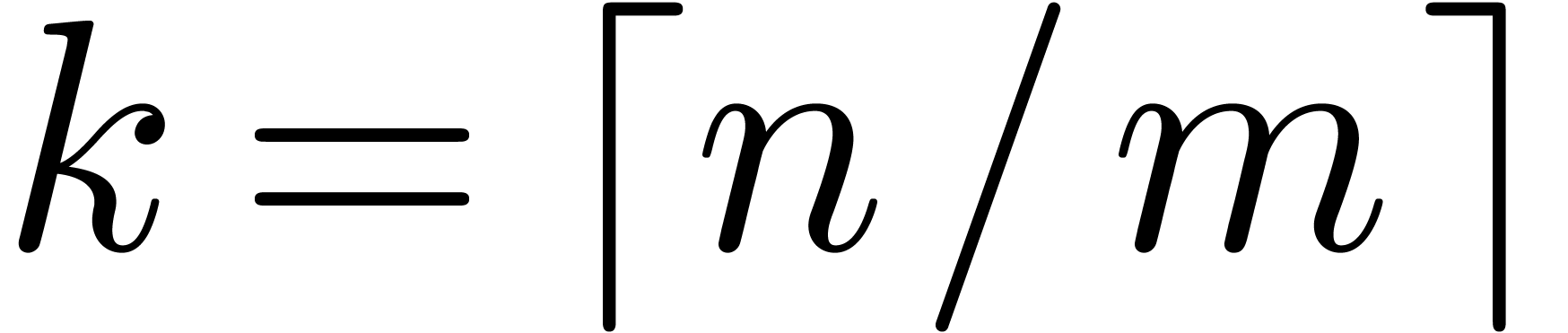 parts of size
parts of size 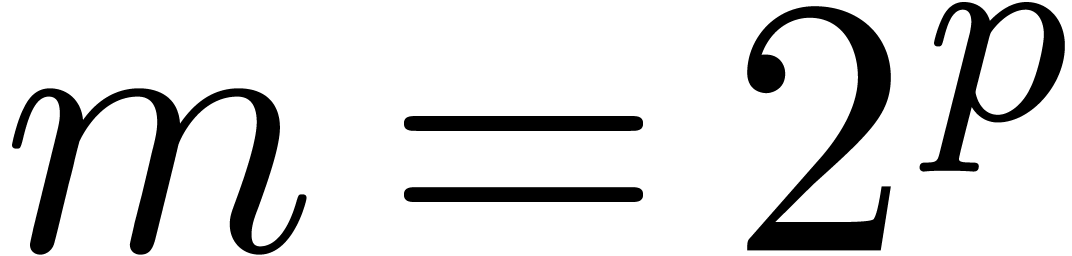 ,
where
,
where 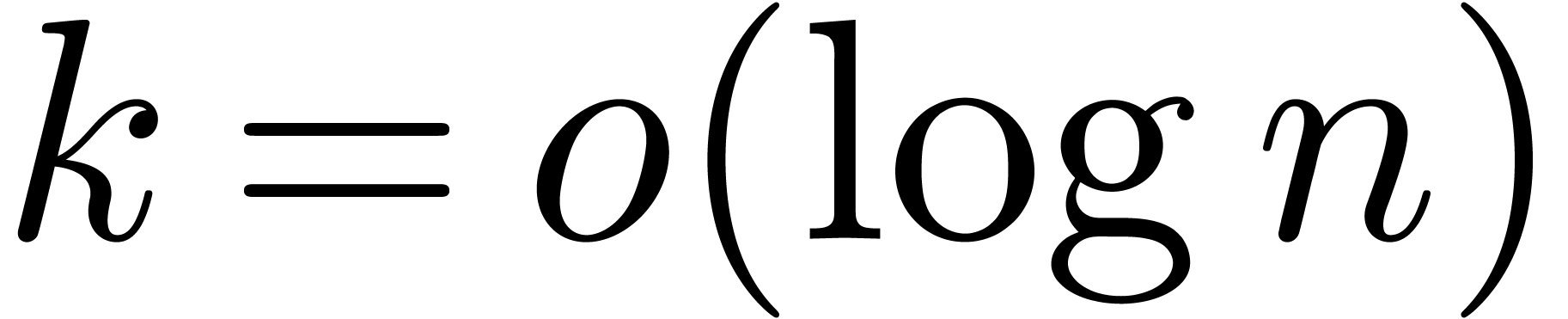 grows slowly to infinity with . With the notation (9), and using
FFTs at size
grows slowly to infinity with . With the notation (9), and using
FFTs at size 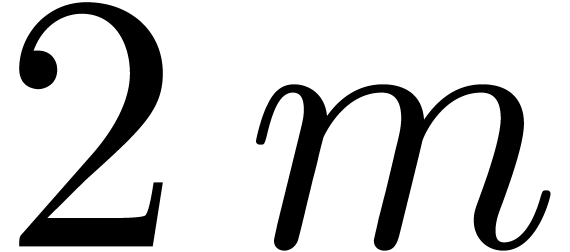 for evaluation-interpolation, we
compute as follows:
for evaluation-interpolation, we
compute as follows:
We first transform  and
and  for
for 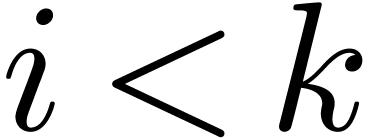 .
.
We compute the naive product  of the
polynomials and
of the
polynomials and  in
in
 .
.
We compute  for
for 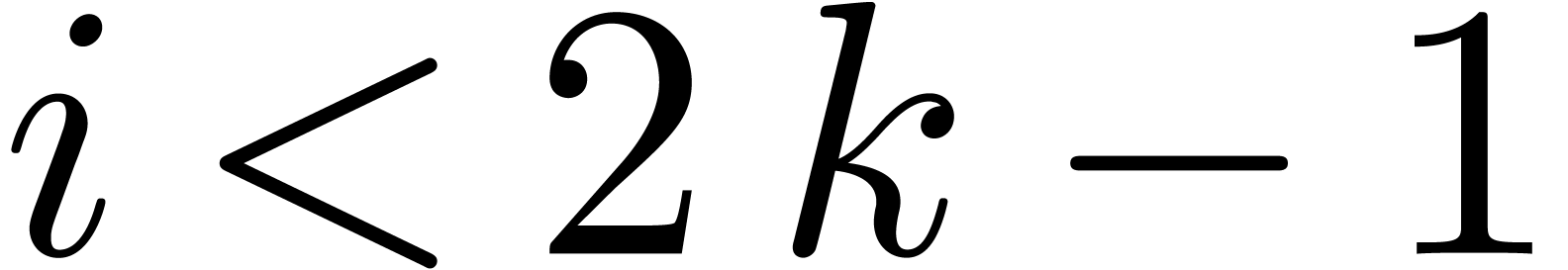 and
return
and
return 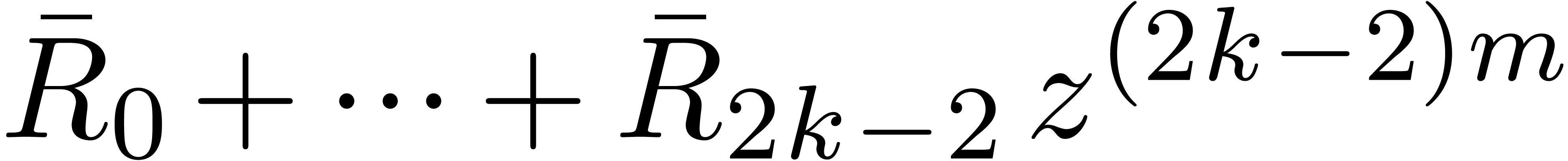 .
.
Let  be the constant such that
be the constant such that 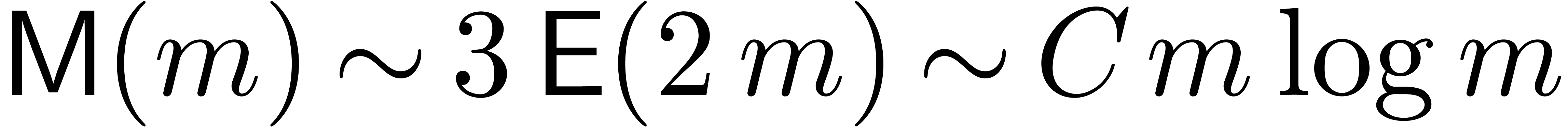 for
for  . Then the above
algorithm requires
. Then the above
algorithm requires
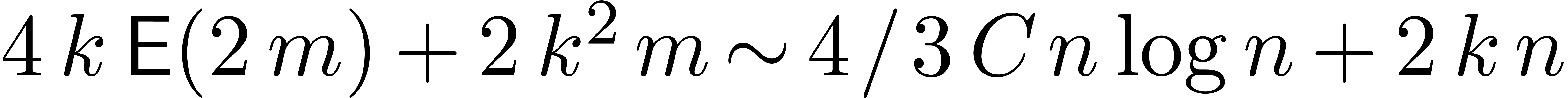
operations in . If we only
need the truncated product 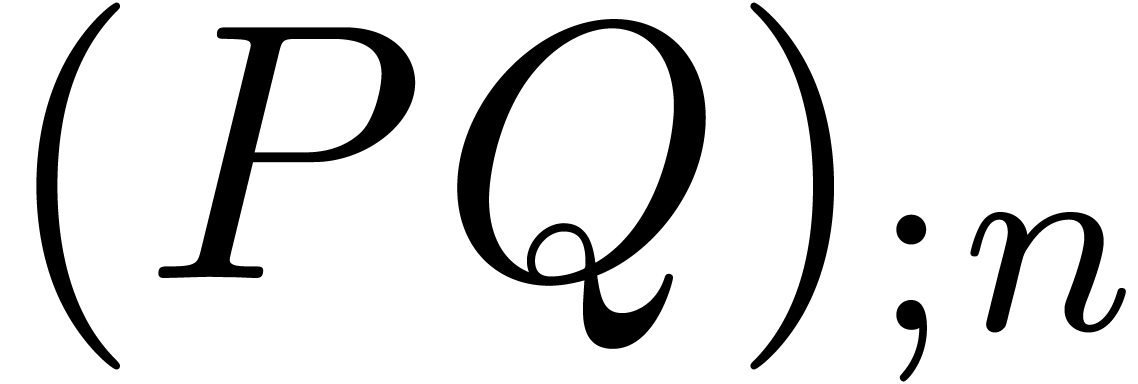 ,
then we may save inverse transforms and half of
the inner multiplications, so the complexity reduces to
,
then we may save inverse transforms and half of
the inner multiplications, so the complexity reduces to
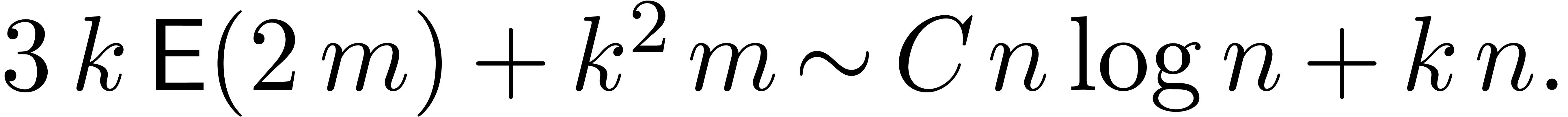
Both complexities depend smoothly on and admit
no major jumps at powers of two.
In this particular case, it turns out that the TFT transform is always better, because both the full and the truncated product can be computed using only
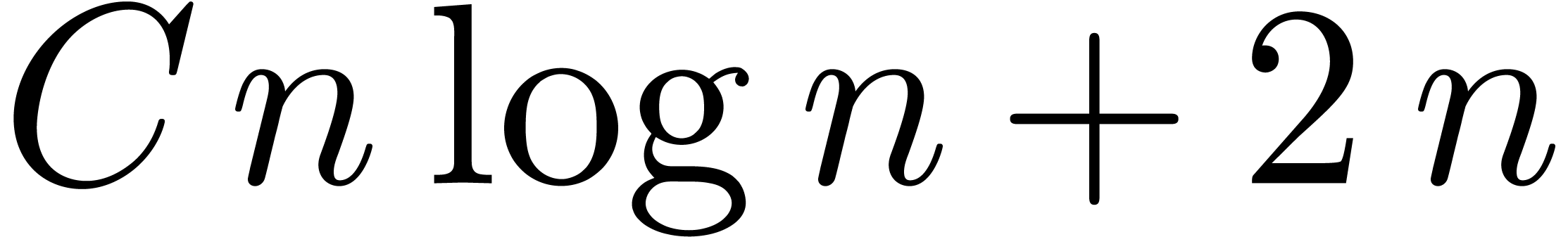
operations in . However, in
the multivariate setting, the TFT also has its pitfalls. More precisely,
consider two multivariate polynomials 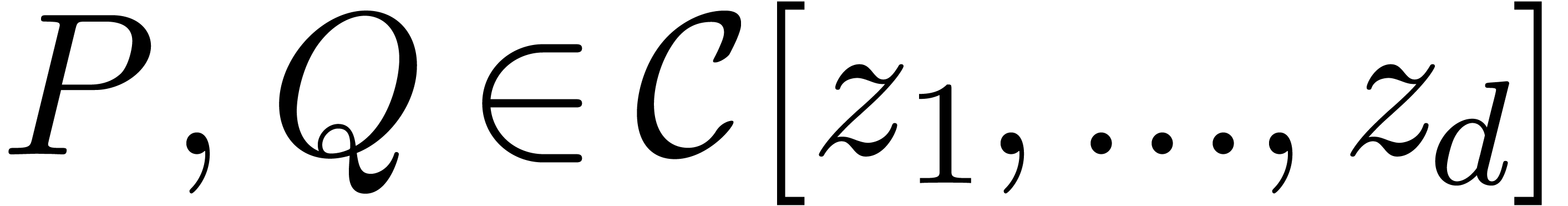 whose
supports have a “dense flavour”. Typically, we may assume
the supports to be convex subsets of
whose
supports have a “dense flavour”. Typically, we may assume
the supports to be convex subsets of 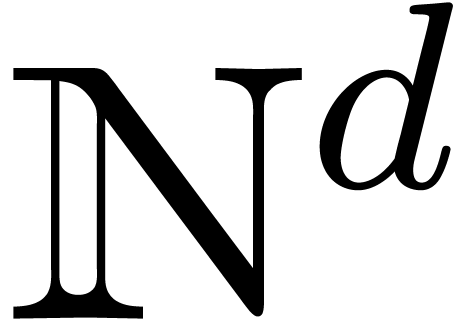 .
In addition one may consider truncated products, where we are only
interested in certain monomials of the product. In order to apply the
TFT, one typically has to require in addition that the supports of and are initial segments of
. Even then, the overhead for
certain types of supports may increase if
.
In addition one may consider truncated products, where we are only
interested in certain monomials of the product. In order to apply the
TFT, one typically has to require in addition that the supports of and are initial segments of
. Even then, the overhead for
certain types of supports may increase if 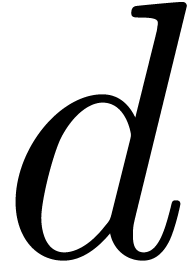 gets
large.
gets
large.
One particularly interesting case for complexity studies is the
computation of the truncated product of two dense polynomials and with total degree . This is typically encountered in the
integration of dynamical systems using Taylor models. Although the TFT
is a powerful tool for small dimensions 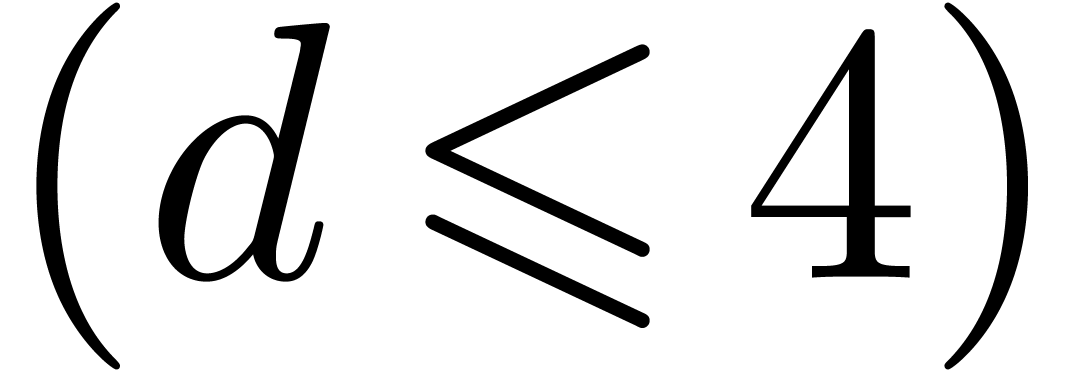 ,
FFT trading might be an interesting complement for moderate dimensions
,
FFT trading might be an interesting complement for moderate dimensions
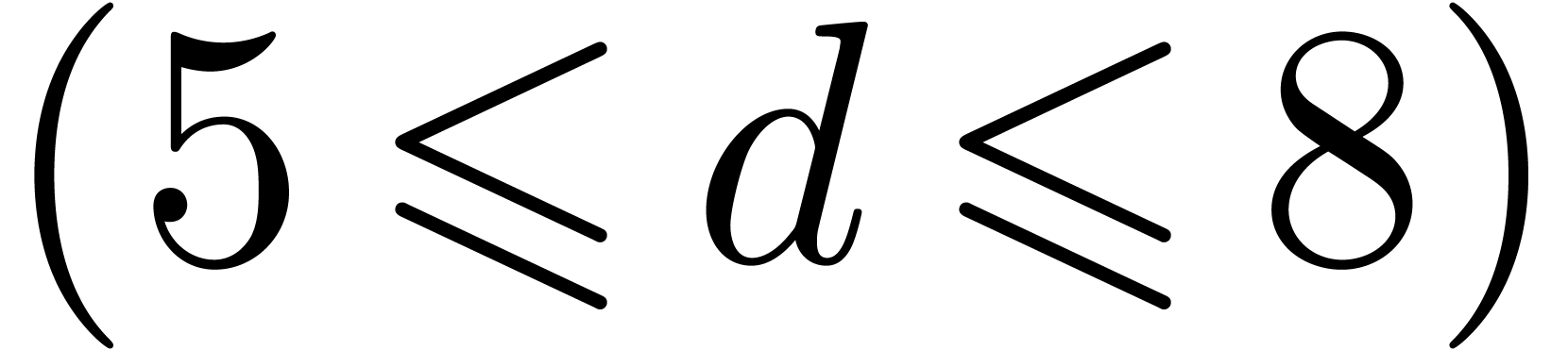 . For even larger dimensions,
one may use [LS03] or [vdH02a, Section 6.3.5].
The idea is again to cut in blocks
. For even larger dimensions,
one may use [LS03] or [vdH02a, Section 6.3.5].
The idea is again to cut in blocks
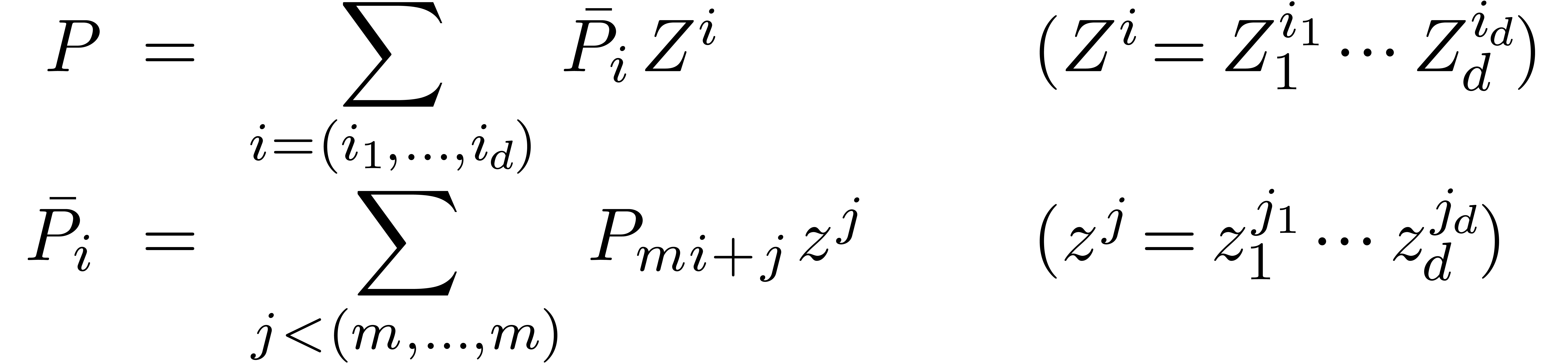
where is small (and
preferably a power of two). Each block is then transformed using an FFT
(or a suitable TFT, since the supports of the blocks are still initial
segments when restricted to the block). We next compute the truncated
product of the transformed polynomials 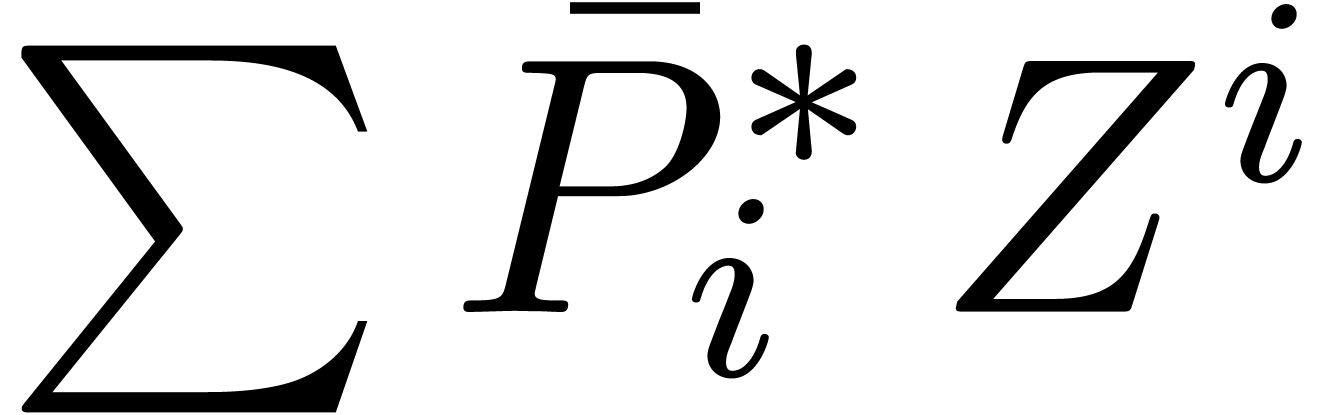 and
and 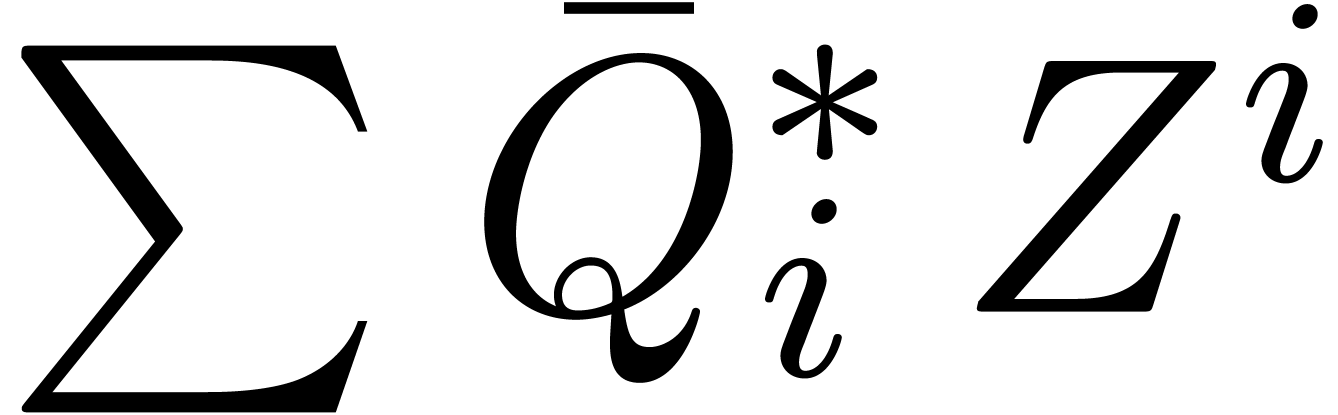 in a naive way and transform back.
in a naive way and transform back.
Let us analyze the complexity of this algorithm. The number 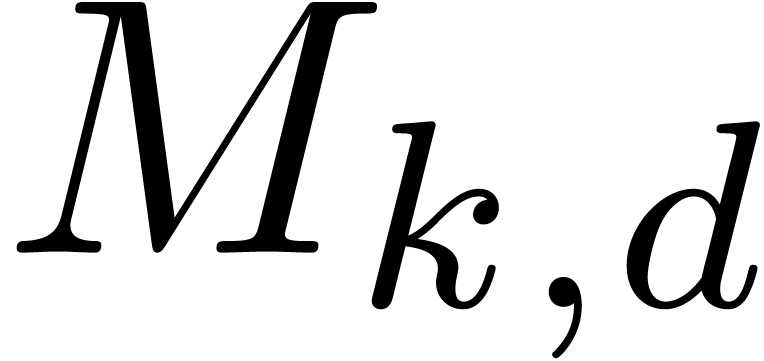 of monomials of total degree is
given by
of monomials of total degree is
given by
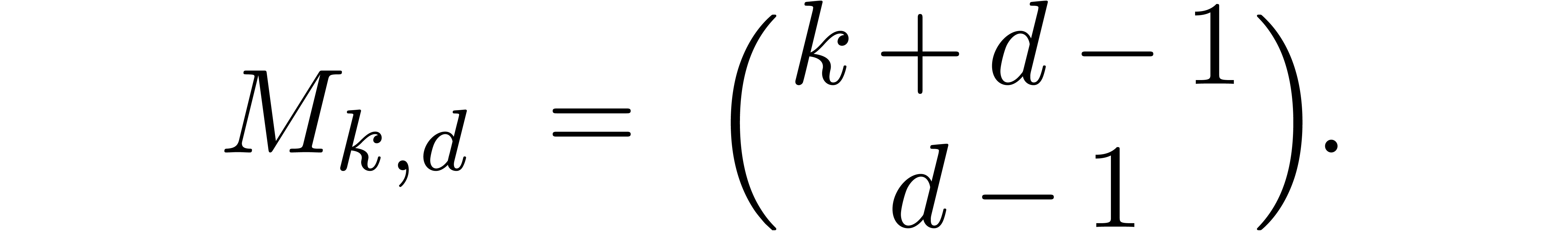
In particular, 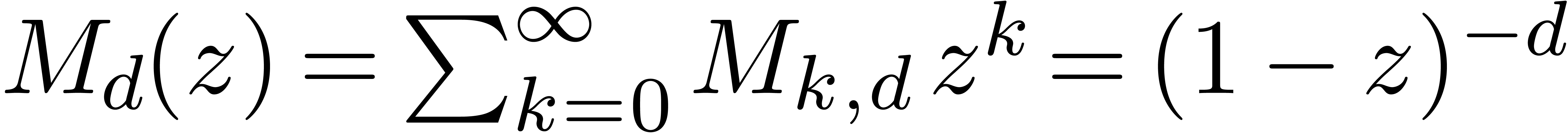 and
and 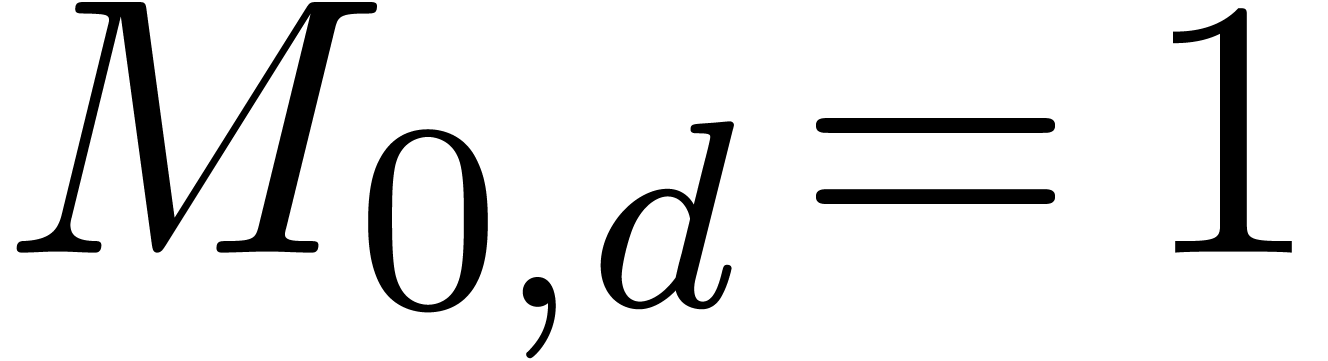 .
In order to compute the monomials in
.
In order to compute the monomials in  of total
degree , we need
of total
degree , we need
since 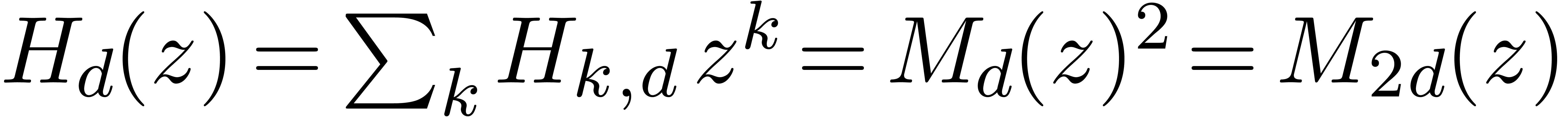 . In total, we thus
need
. In total, we thus
need
multiplications of TFT-ed blocks, since 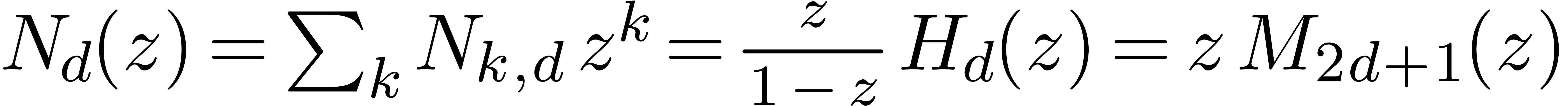 .
For large , we have
.
For large , we have
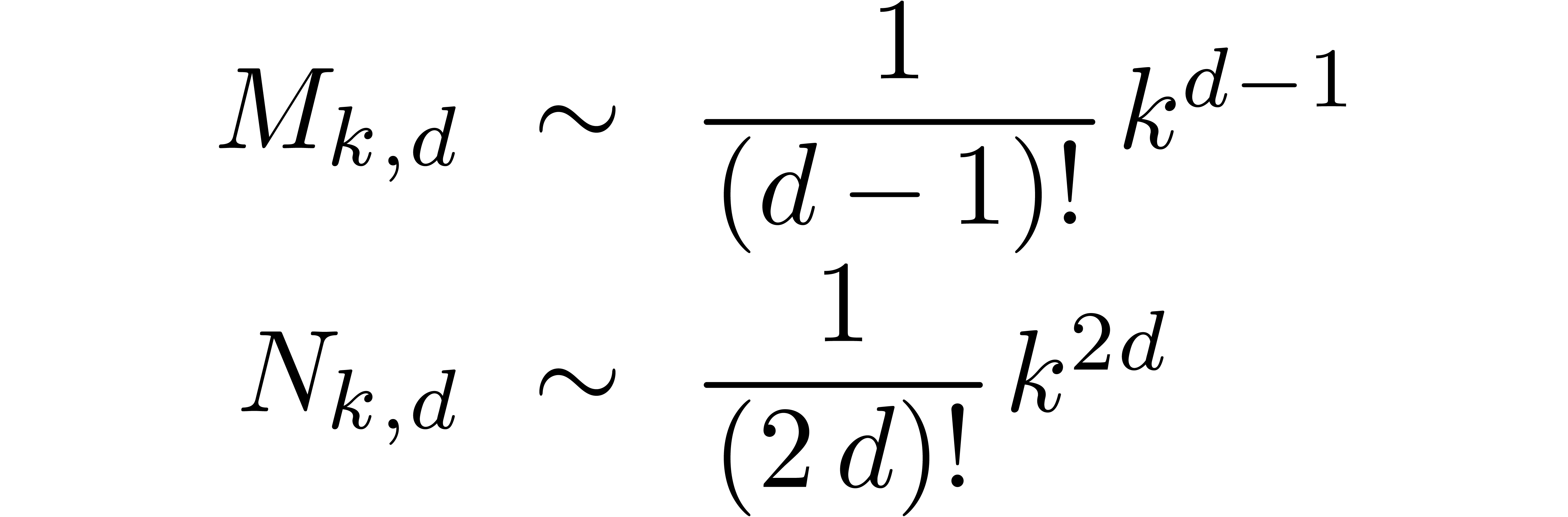
We may therefore hope for some gain with respect to plain FFT multiplication whenever
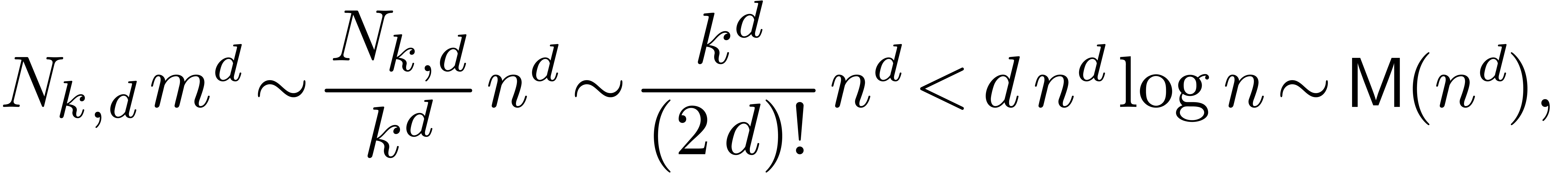
i.e. if
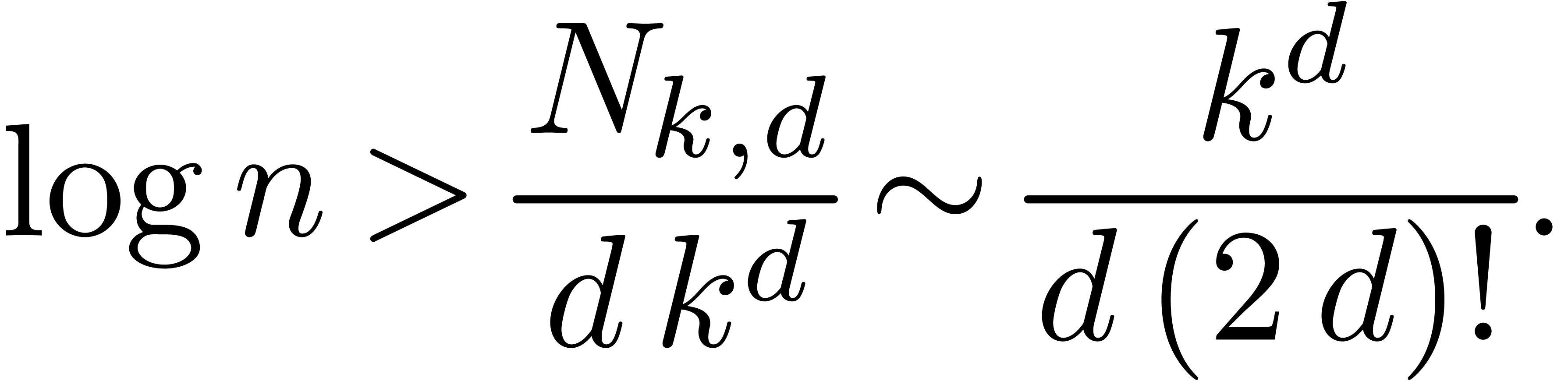
In Table 2, we have shown the values of 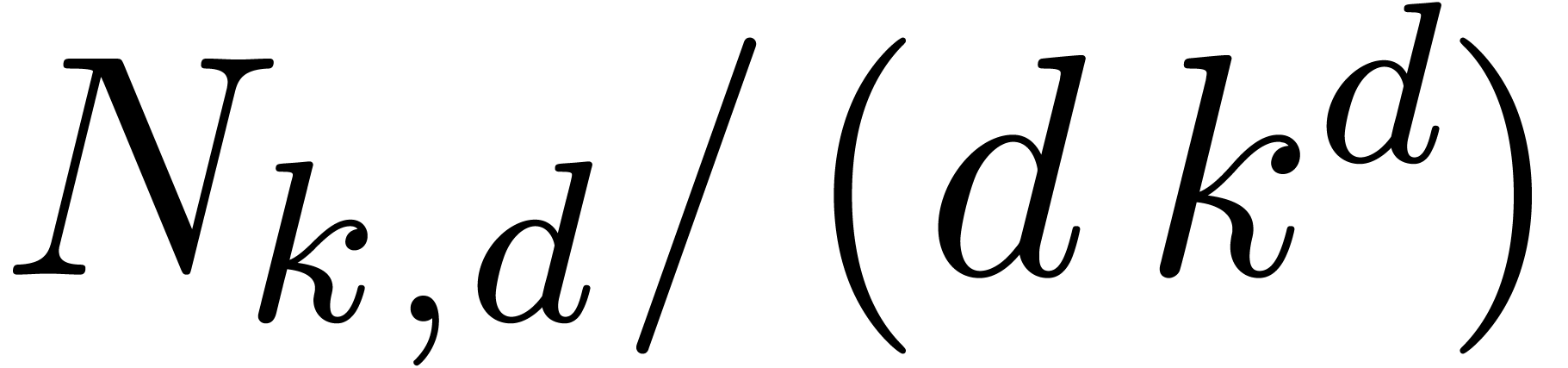 for small values of and . It is clear from the table that FFT trading can be
used quite systematically in order to improve the performance. For
larger dimensions, the gain becomes particularly important. This should
not come as a surprise, because naive multiplication is more efficient
than FFT multiplication for
for small values of and . It is clear from the table that FFT trading can be
used quite systematically in order to improve the performance. For
larger dimensions, the gain becomes particularly important. This should
not come as a surprise, because naive multiplication is more efficient
than FFT multiplication for 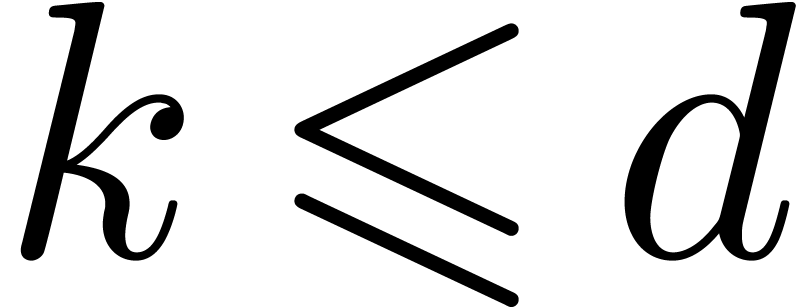 .
.
The main advantage of the above method over other techniques, such as
the TFT, is that the shape of the support is preserved during the
reduction  (as well as for the “destination
support”). However, the TFT also allows for some additional tricks
[vdH05, Section 9] and it is not yet clear to us which
approach is best in practice. Of course, the above technique becomes
even more useful in the case of more general truncated multiplications
for dense supports with shapes which do not allow for TFT
multiplication.
(as well as for the “destination
support”). However, the TFT also allows for some additional tricks
[vdH05, Section 9] and it is not yet clear to us which
approach is best in practice. Of course, the above technique becomes
even more useful in the case of more general truncated multiplications
for dense supports with shapes which do not allow for TFT
multiplication.
For small values of , we
notice that the even/odd version of Karatsuba multiplication presents
the same advantage of geometry preservation (see [HZ02] for
the one-dimensional case). In fact, fast multiplication using FFT
trading is quite analogous to this method, which generalizes for
Toom-Cook multiplication. In the context of numerical computations, the
property of geometry preservation is reflected by increased numerical
stability.
To finish, we would like to draw the attention of the reader to another
advantage of FFT trading: for really huge values of , it leads to a reduction in memory usage.
Indeed, when computing the coefficients of a product sequentially 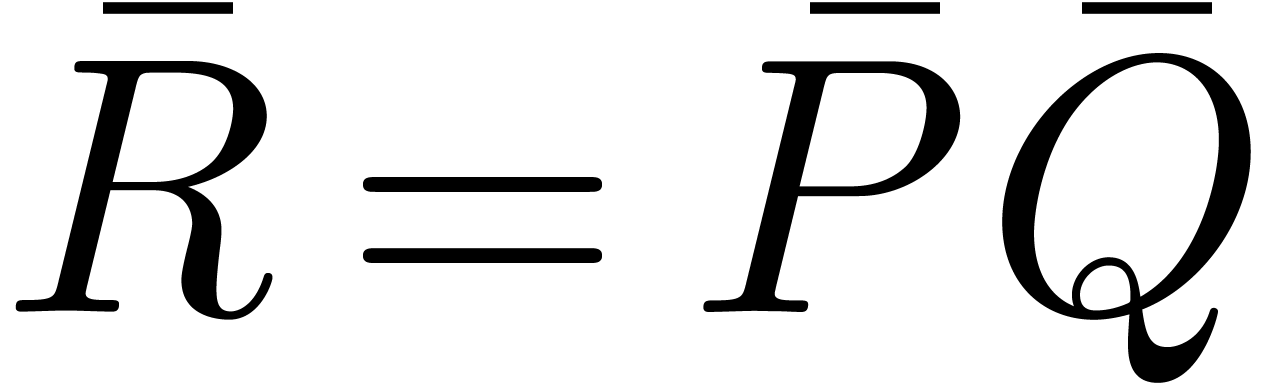 , we only need to store the
transform
, we only need to store the
transform 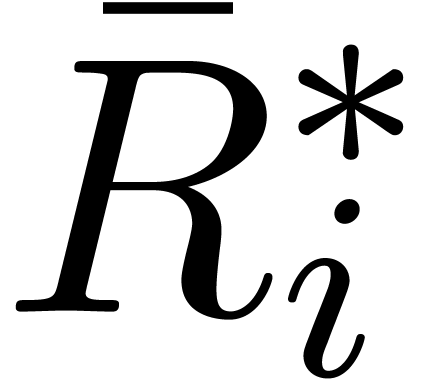 of one coefficient in the result at a
time.
of one coefficient in the result at a
time.
We have summarized the main results of this paper in Tables 3
and 4. We recall that in the
standard FFT model and otherwise. Consequently,
the new approach allows at best for a gain in
the standard FFT model and in the synthetic FFT
model. In practice, the factor behaves very much
like a constant, so the new algorithms become interesting only for quite
large values of . As pointed
out in remark 18, FFT trading loses its interest in
asymptotically slower evaluation-interpolation models, such as the
Karatsuba model. We plan to come back to practical complexity issues as
soon as implementations of all algorithms are available in the
|
||||||||||
One interesting remaining problem is to reduce the cost of computing a
fundamental system of solutions to (4). This would be
possible if one can speed up the joint computation of the FFTs of 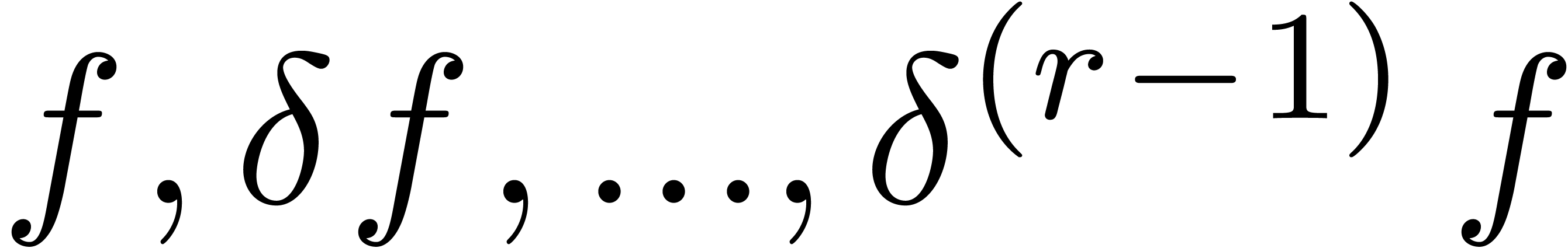 .
.
Another interesting question is to what extent Newton's method can be generalized. Clearly, it is not hard to consider more general equations of the kind
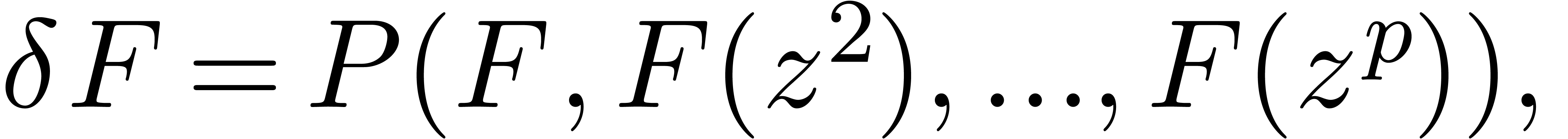
since the series  merely act as perturbations.
However, it seems harder (but maybe not impossible) to deal with
equations of the type
merely act as perturbations.
However, it seems harder (but maybe not impossible) to deal with
equations of the type
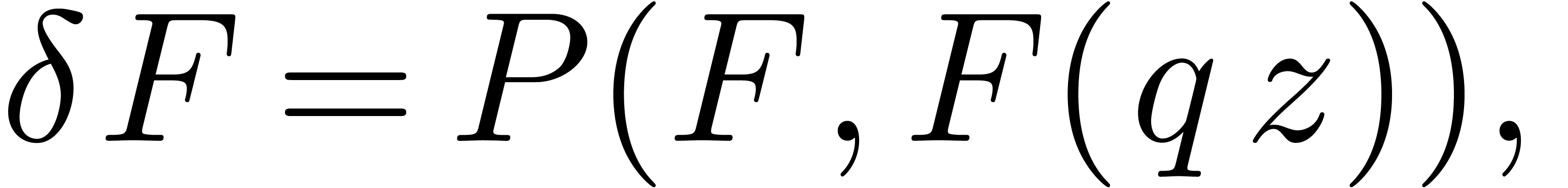
since it is not clear a priori how to generalize the concept of a fundamental system of solutions and its use in the Newton iteration.
In the case of partial differential equations with initial conditions on
a hyperplane, the fundamental system of solutions generally has infinite
dimension, so essentially new ideas would be needed here. Nevertheless,
the strategy of relaxed evaluation applies in all these cases, with the
usual overhead in general and
overhead in the standard FFT model.
A. Bostan, F. Chyzak, F. Ollivier, B. Salvy, É. Schost, and A. Sedoglavic. Fast computation of power series solutions of systems of differential equations. In Proceedings of the 18th ACM-SIAM Symposium on Discrete Algorithms, New Orleans, Louisiana, U.S.A., January 2007.
D. Bernstein. The transposition principle. http://cr.yp.to/transposition.html.
D. Bernstein. Removing redundancy in high precision Newton iteration. Available from http://cr.yp.to/fastnewton.html, 2000.
R.P. Brent and H.T. Kung. Fast algorithms for manipulating formal power series. Journal of the ACM, 25:581–595, 1978.
A. Borodin and R.T. Moenck. Fast modular transforms. Journal of Computer and System Sciences, 8:366–386, 1974.
J. L. Bordewijk. Inter-reciprocity applied to electrical networks. Applied Scientific Research B: Electrophysics, Acoustics, Optics, Mathematical Methods, 6:1–74, 1956.
Walter Baur and Volker Strassen. The complexity of partial derivatives. Theor. Comput. Sci., 22:317–330, 1983.
A. Bostan and É. Schost. Polynomial evaluation and interpolation on special sets of points. Journal of Complexity, 21(4):420–446, August 2005. Festschrift for the 70th Birthday of Arnold Schönhage.
D.G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28:693–701, 1991.
S.A. Cook. On the minimum computation time of functions. PhD thesis, Harvard University, 1966.
J.W. Cooley and J.W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
D. Coppersmith and S. Winograd. Matrix multiplication
via arithmetic progressions. In Proc. of the  Annual Symposium on Theory of Computing, pages 1–6,
New York City, may 25–27 1987.
Annual Symposium on Theory of Computing, pages 1–6,
New York City, may 25–27 1987.
David Harvey. Faster algorithms for the square root and reciprocal of power series, 2009. http://arxiv.org/abs/0910.1926.
David Harvey. Faster exponentials of power series, 2009. http://arxiv.org/abs/0911.3110.
Guillaume Hanrot, Michel Quercia, and Paul Zimmermann. The middle product algorithm I. Speeding up the division and square root of power series. AAECC, 14(6):415–438, 2004.
Guillaume Hanrot and Paul Zimmermann. A long note on Mulders' short product. Research Report 4654, INRIA, December 2002. Available from http://www.loria.fr/ hanrot/Papers/mulders.ps.
G. Hanrot and P. Zimmermann. Newton iteration revisited. http://www.loria.fr/ zimmerma/papers/fastnewton.ps.gz, 2004.
A. Karatsuba and J. Ofman. Multiplication of multidigit numbers on automata. Soviet Physics Doklady, 7:595–596, 1963.
R. Lohner. Einschließung der Lösung gewöhnlicher Anfangs- und Randwertaufgaben und Anwendugen. PhD thesis, Universität Karlsruhe, 1988.
R. Lohner. On the ubiquity of the wrapping effect in the computation of error bounds. In U. Kulisch, R. Lohner, and A. Facius, editors, Perspectives on enclosure methods, pages 201–217, Wien, New York, 2001. Springer.
G. Lecerf and É. Schost. Fast multivariate power series multiplication in characteristic zero. SADIO Electronic Journal on Informatics and Operations Research, 5(1):1–10, September 2003.
R.T. Moenck and A. Borodin. Fast modular transforms via division. In Thirteenth annual IEEE symposium on switching and automata theory, pages 90–96, Univ. Maryland, College Park, Md., 1972.
K. Makino and M. Berz. Remainder differential algebras and their applications. In M. Berz, C. Bischof, G. Corliss, and A. Griewank, editors, Computational differentiation: techniques, applications and tools, pages 63–74, SIAM, Philadelphia, 1996.
K. Makino and M. Berz. Suppression of the wrapping effect by Taylor model-based validated integrators. Technical Report MSU Report MSUHEP 40910, Michigan State University, 2004.
R.T. Moenck and J.H. Carter. Approximate algorithms to derive exact solutions to systems of linear equations. In Symbolic and algebraic computation (EUROSAM '79, Marseille), volume 72 of LNCS, pages 65–73, Berlin, 1979. Springer.
R.E. Moore. Interval Analysis. Prentice Hall, Englewood Cliffs, N.J., 1966.
V. Pan. How to multiply matrices faster, volume 179 of Lect. Notes in Math. Springer, 1984.
G. Schulz. Iterative Berechnung der reziproken Matrix. Z. Angew. Math. Mech., 13:57–59, 1933.
A. Schönhage. Variations on computing reciprocals of power series. Inform. Process. Lett., 74:41–46, 2000.
A. Schönhage and V. Strassen. Schnelle Multiplikation grosser Zahlen. Computing, 7:281–292, 1971.
V. Strassen. Gaussian elimination is not optimal. Numer. Math., 13:352–356, 1969.
V. Strassen. Die Berechnungskomplexität von elementarsymmetrischen Funktionen und von Interpolationskoeffizienten. Numer. Math., 20:238–251, 1973.
A.L. Toom. The complexity of a scheme of functional elements realizing the multiplication of integers. Soviet Mathematics, 4(2):714–716, 1963.
J. van der Hoeven. Lazy multiplication of formal power series. In W. W. Küchlin, editor, Proc. ISSAC '97, pages 17–20, Maui, Hawaii, July 1997.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven et al. Mathemagix, 2002. http://www.mathemagix.org.
J. van der Hoeven. The truncated Fourier transform and applications. In J. Gutierrez, editor, Proc. ISSAC 2004, pages 290–296, Univ. of Cantabria, Santander, Spain, July 4–7 2004.
J. van der Hoeven. Notes on the Truncated Fourier Transform. Technical Report 2005-5, Université Paris-Sud, Orsay, France, 2005.
J. van der Hoeven. Newton's method and FFT trading. Technical Report 2006-17, Univ. Paris-Sud, 2006. http://www.texmacs.org/joris/fnewton/fnewton-abs.html.
J. van der Hoeven. New algorithms for relaxed multiplication. JSC, 42(8):792–802, 2007.
J. van der Hoeven. On effective analytic continuation. MCS, 1(1):111–175, 2007.
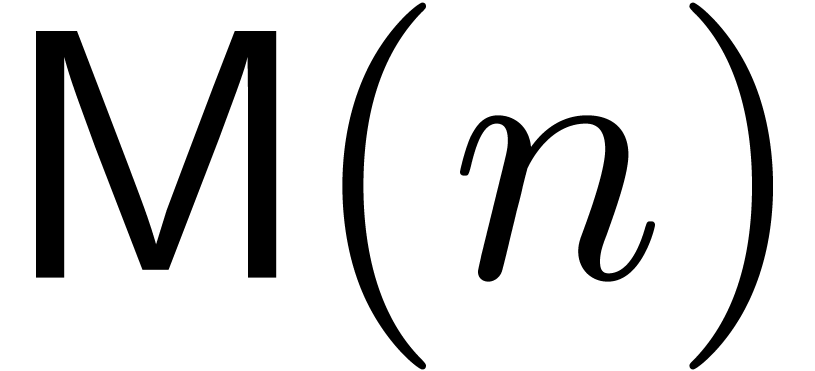 denotes the complexity for multiplying two
polynomials of degree
denotes the complexity for multiplying two
polynomials of degree 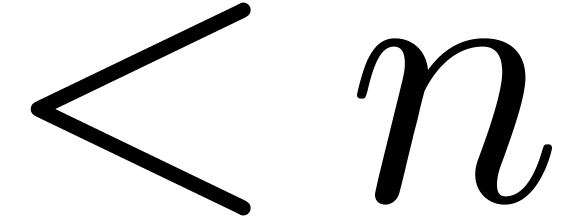 over
over 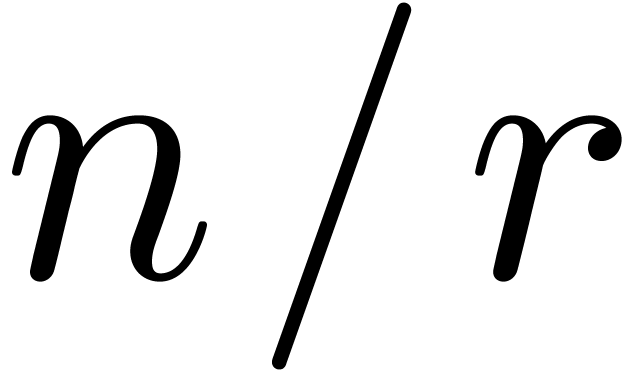 ,
,

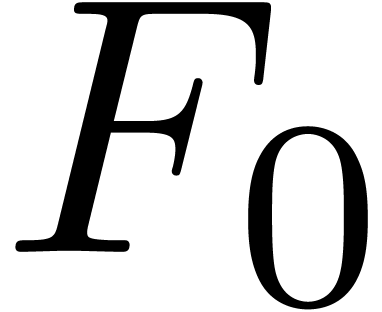
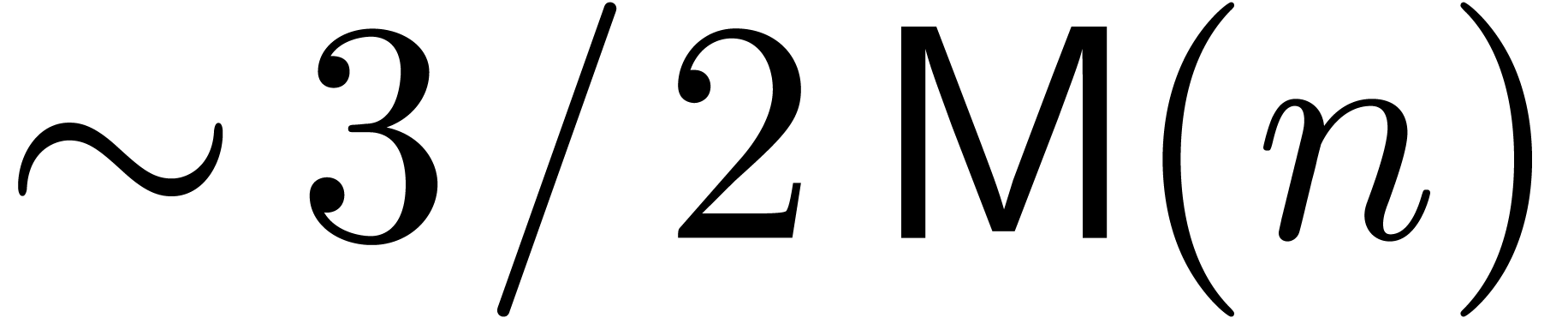
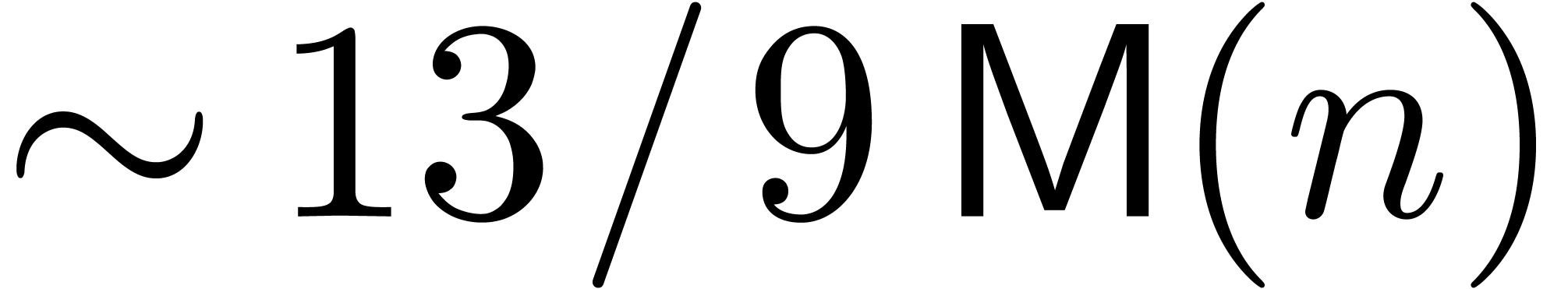
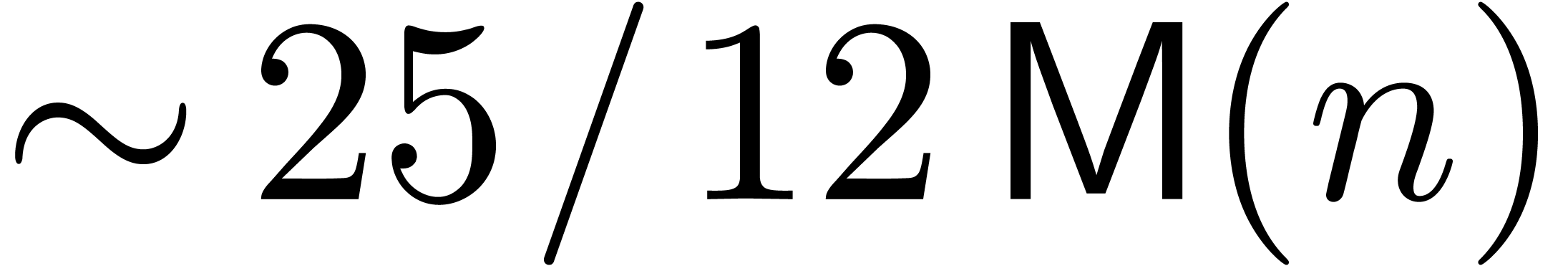
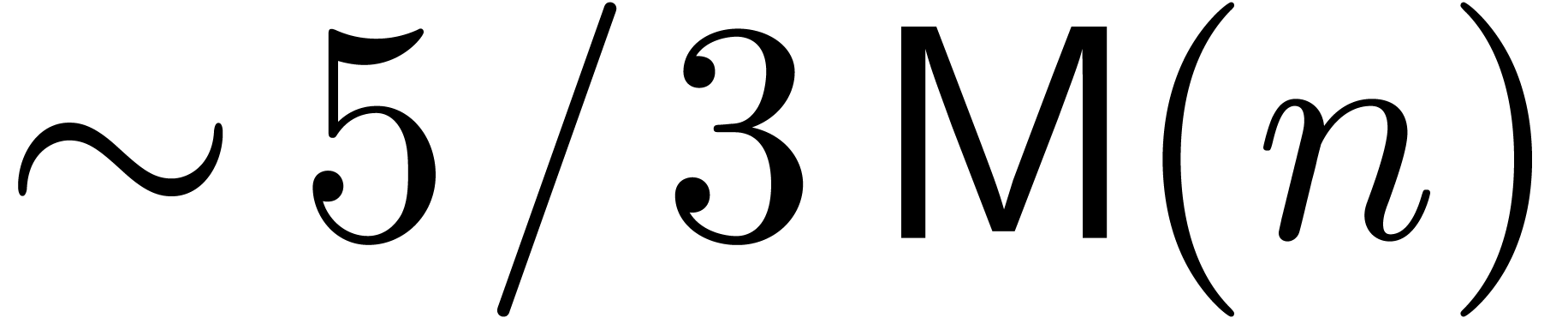
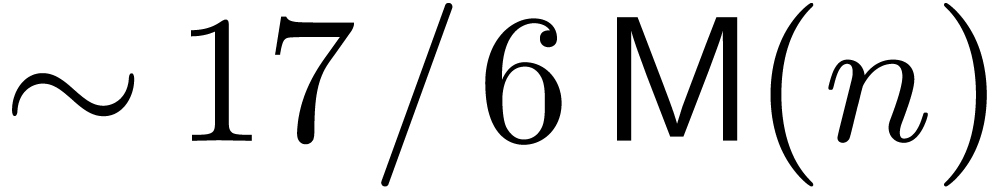

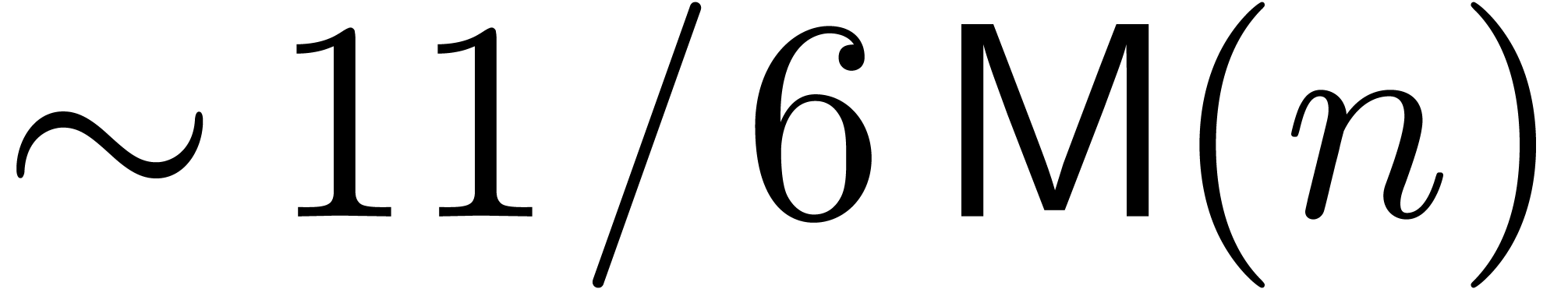
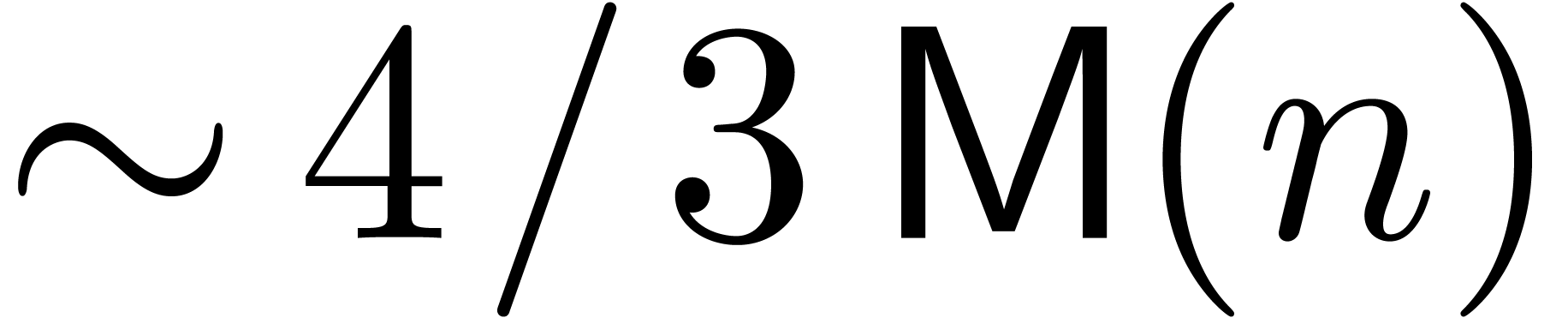
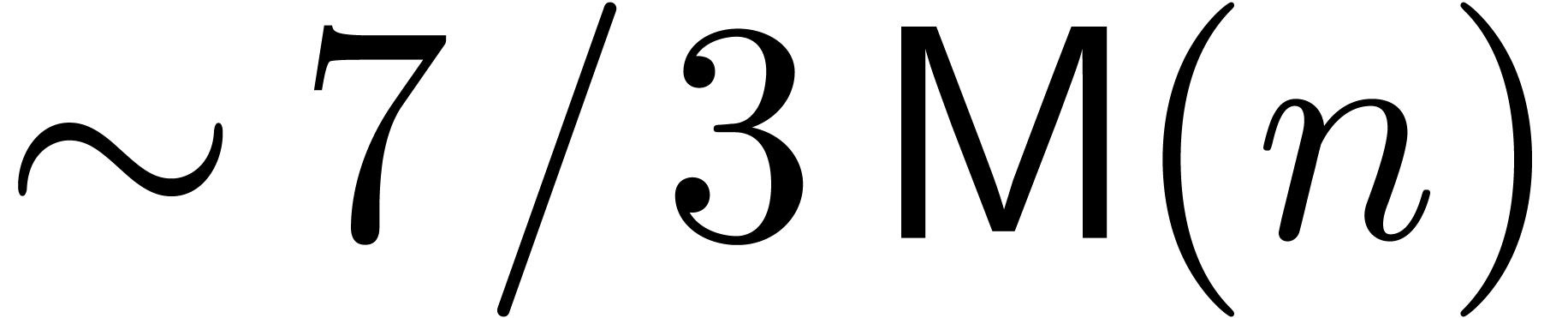
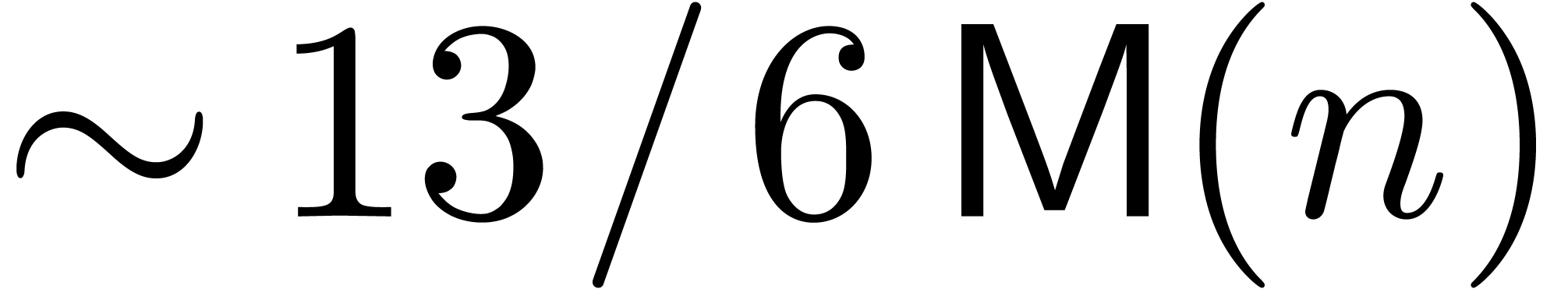

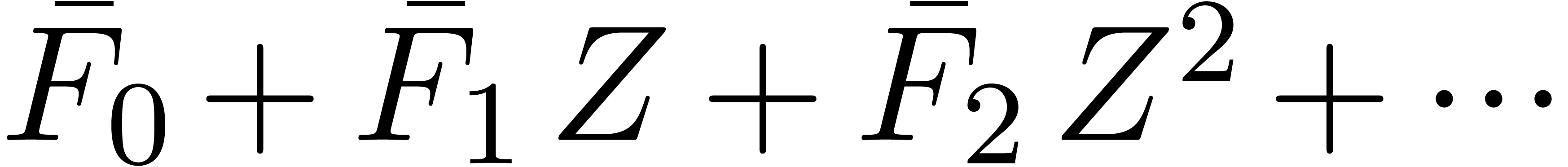
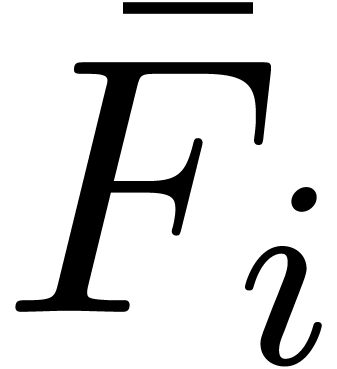
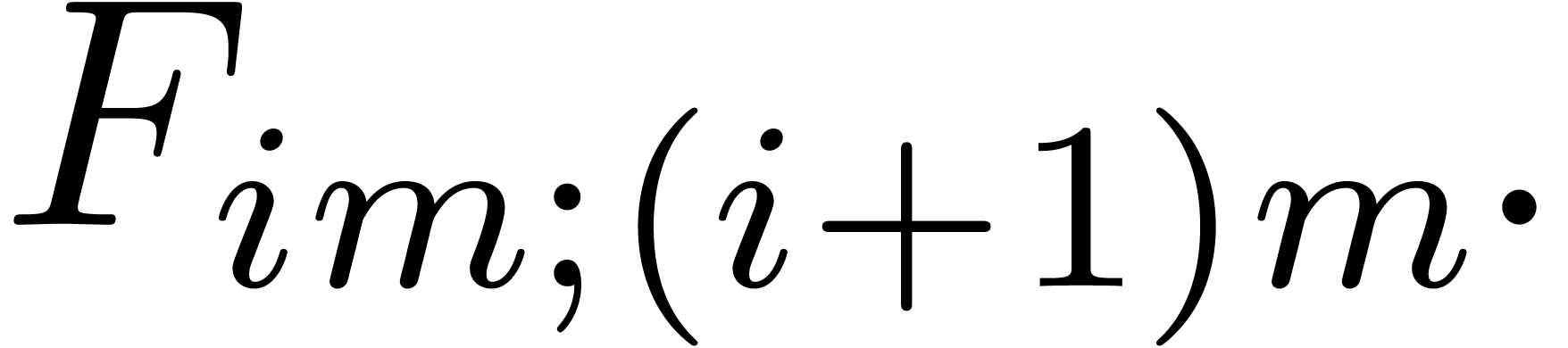
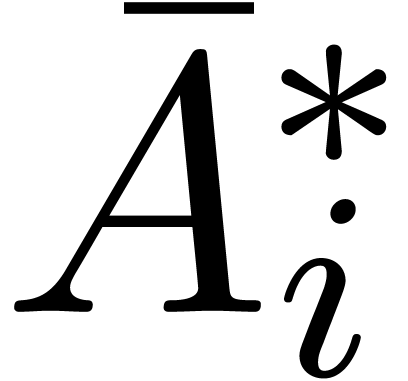
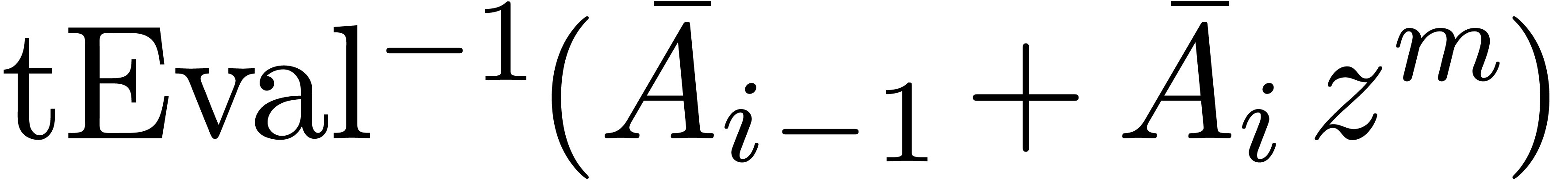
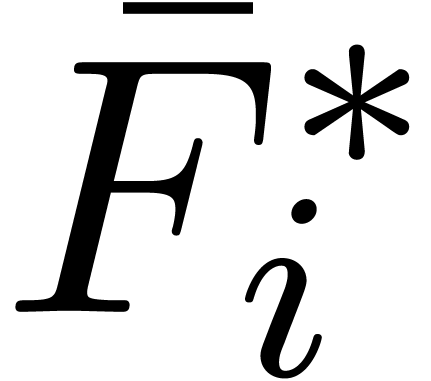


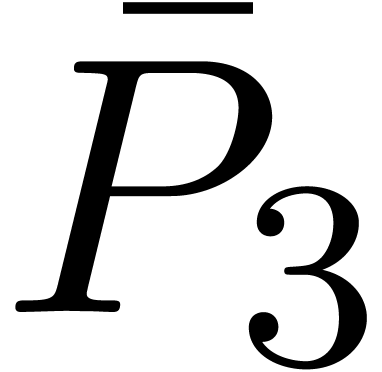 ,
,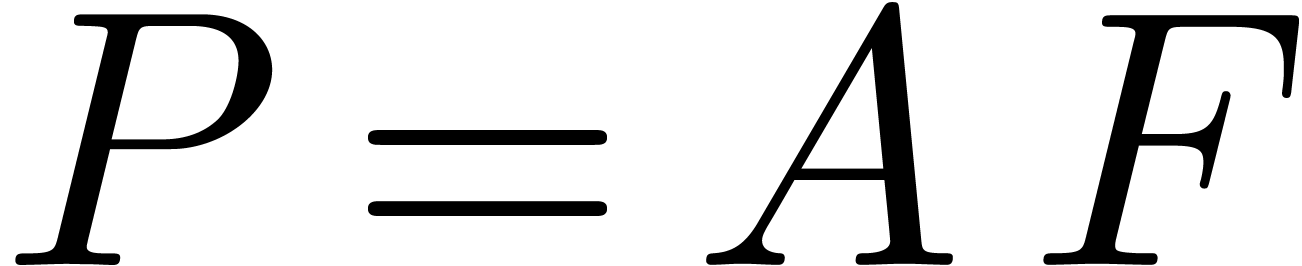 .
.
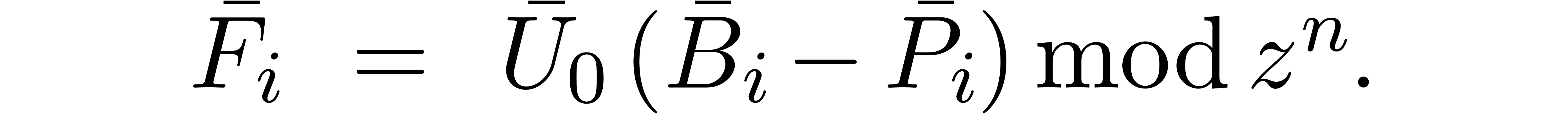
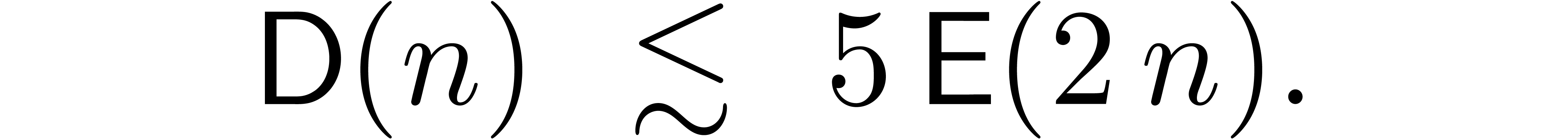
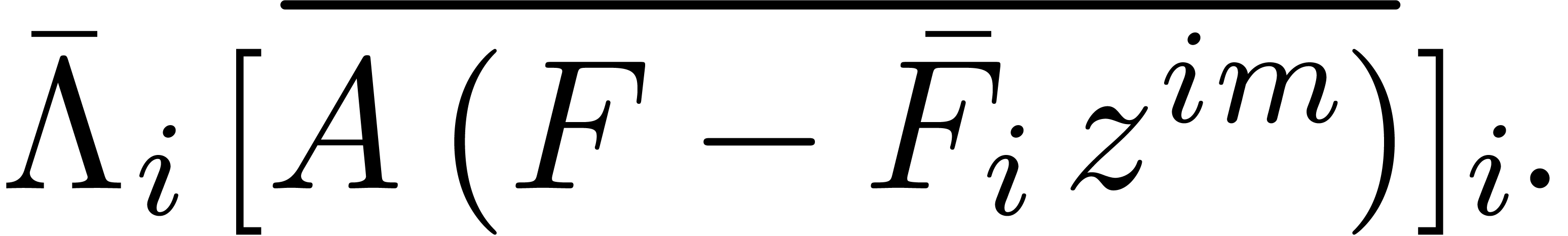
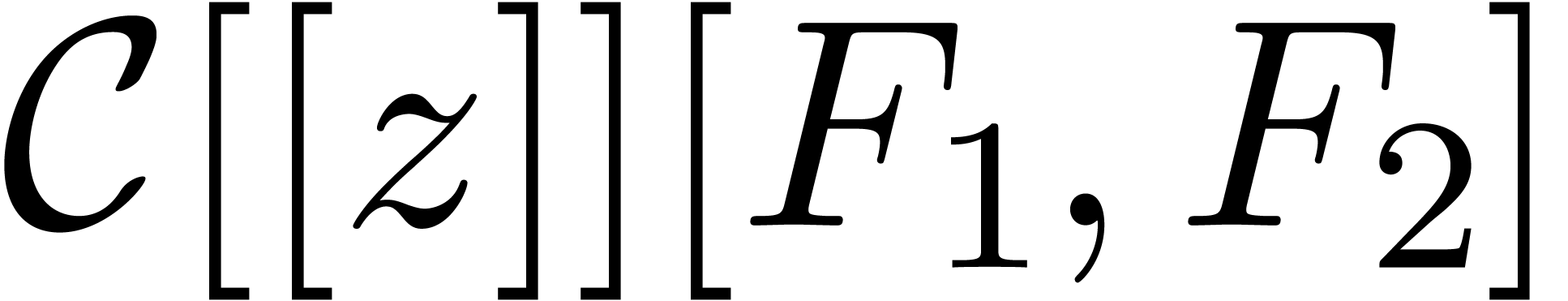 ,
,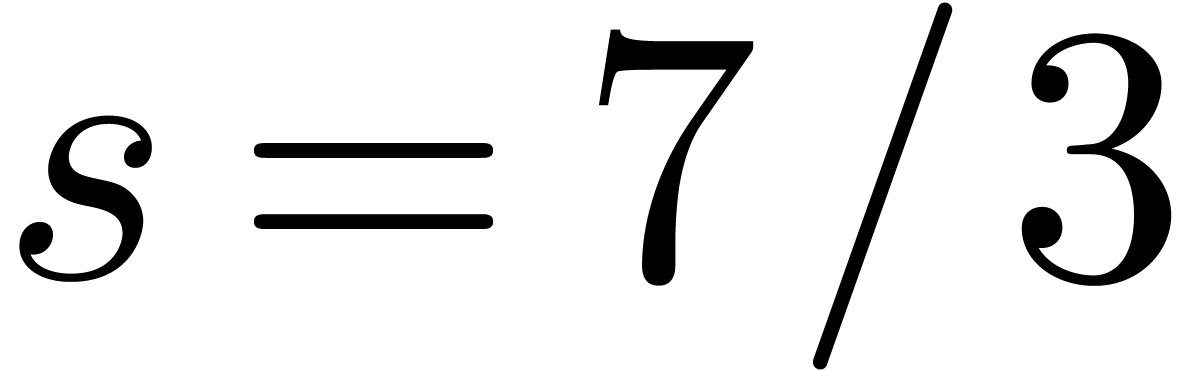 (since
(since 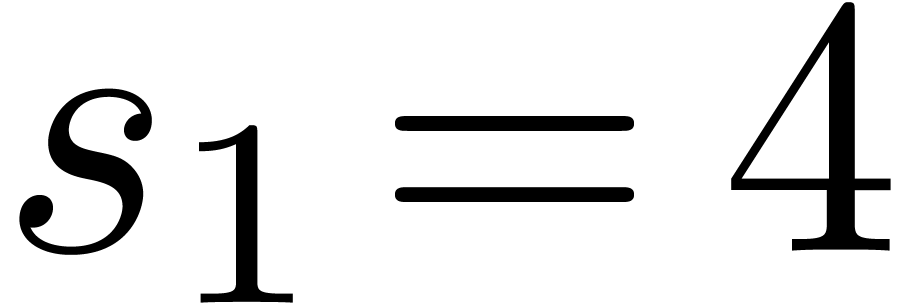 and
and 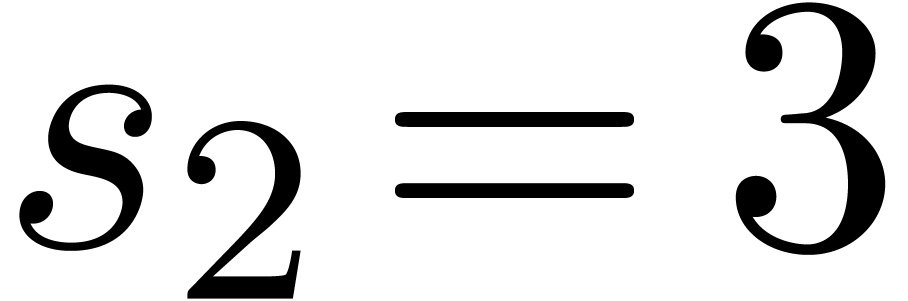 )
) .
.
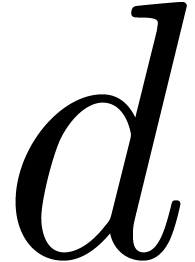 and
and 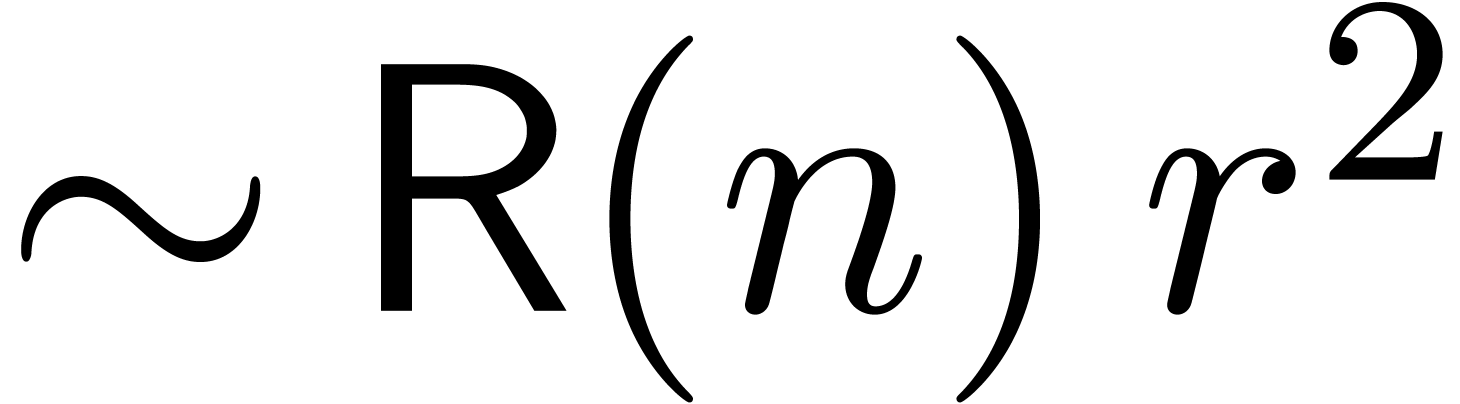
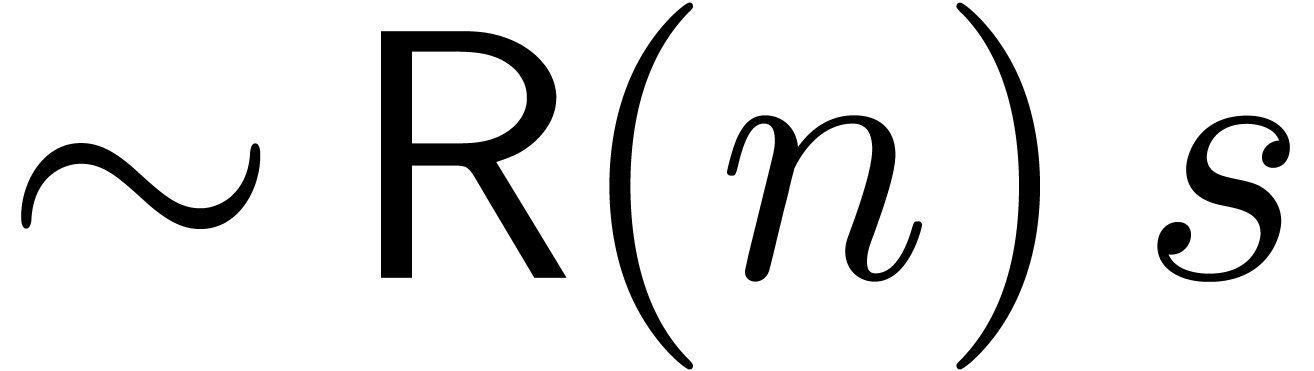
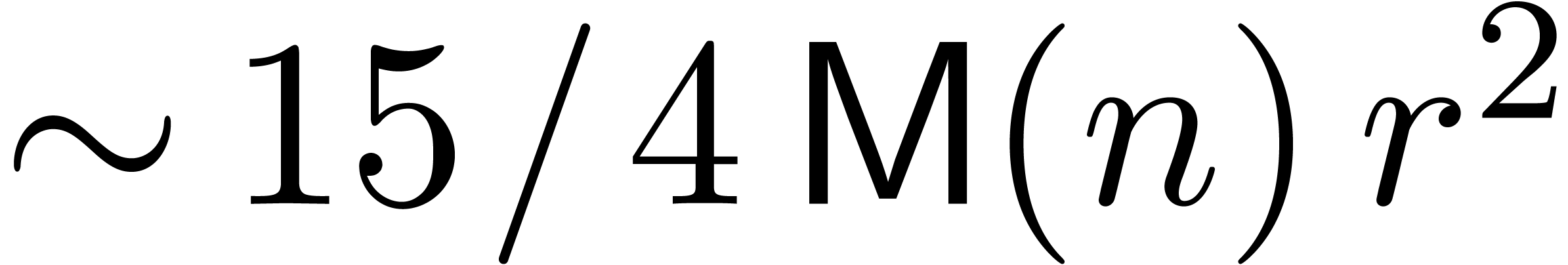
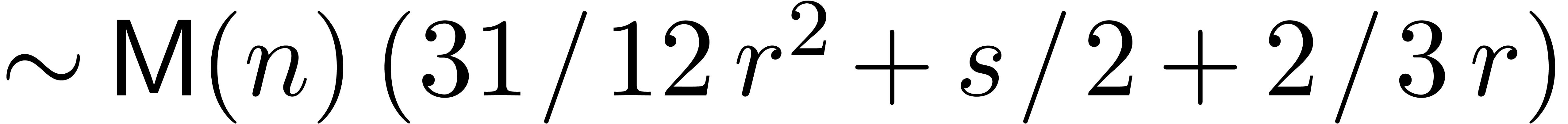
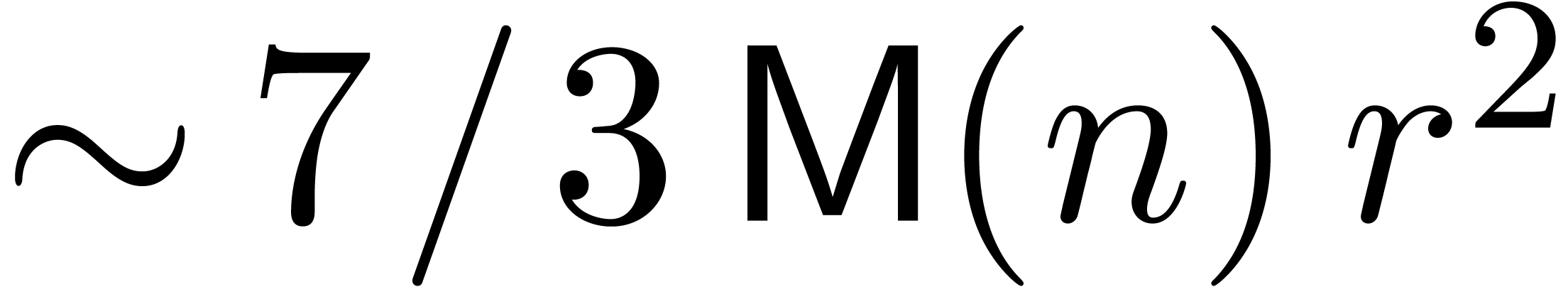
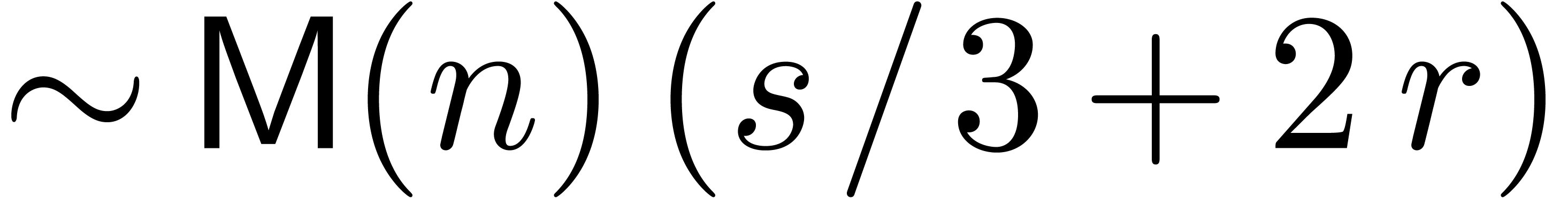
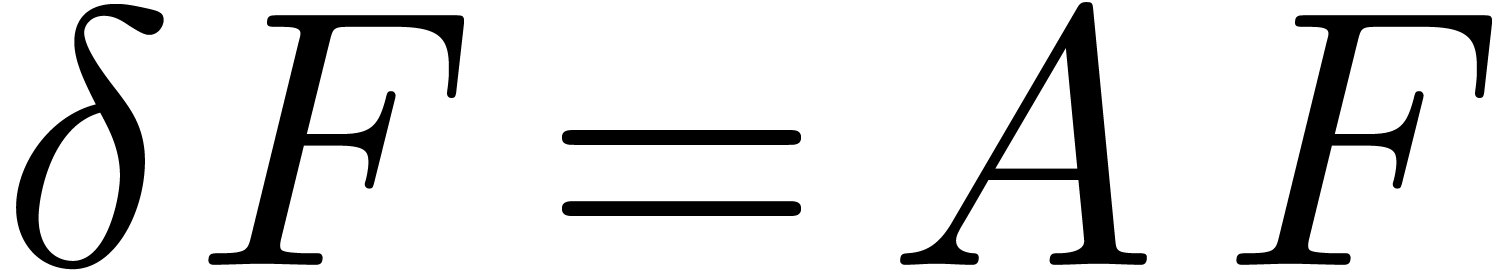 of linear differential equations
up to
of linear differential equations
up to 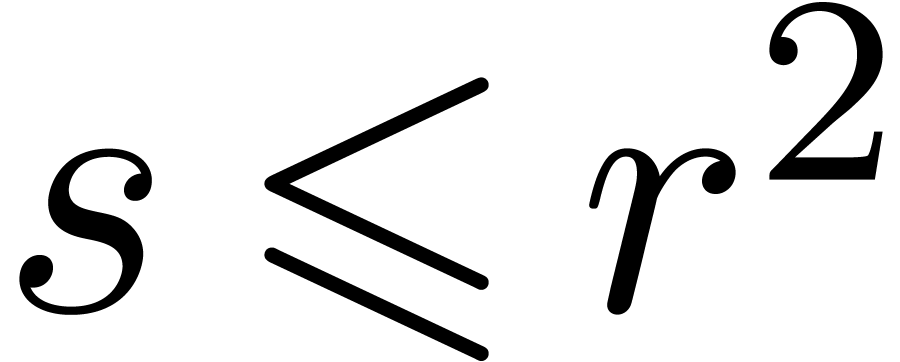 ).
).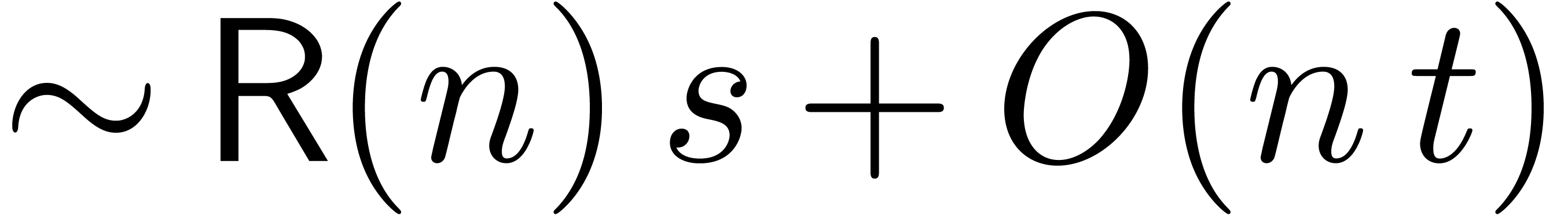
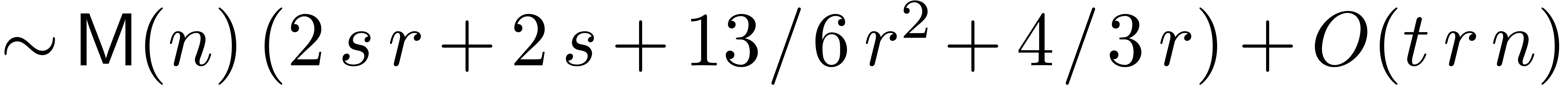
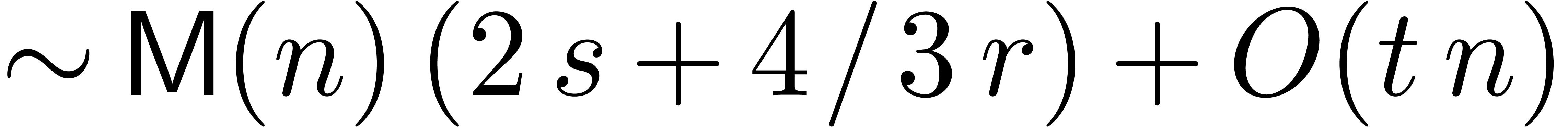
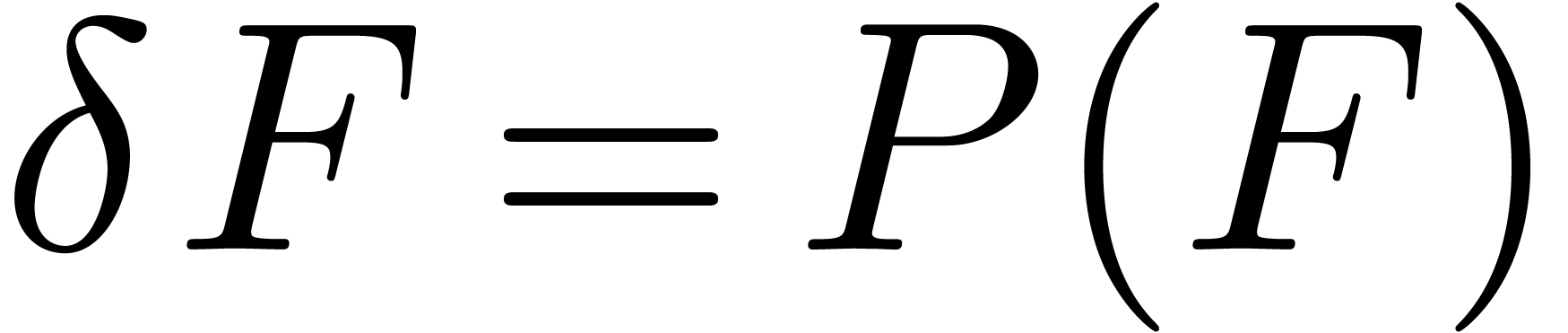 up to
up to 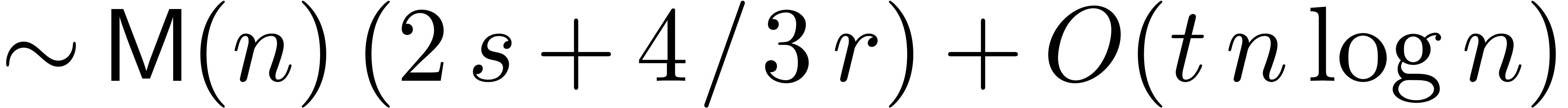 ,
,