Let
polynomial reduction; Gröbner basis; complexity; algorithm
|
|
Let
polynomial reduction; Gröbner basis; complexity; algorithm
|
Gröbner bases, also known as standard bases, are a powerful tool for solving systems of polynomial equations, or to compute modulo polynomial ideals. The research area dedicated to their computation is very active, and there is an abundant literature on efficient algorithms for this task. See for example [5, 6, 8] and references therein. Although this problem requires exponential space in the worst case [21], it is in fact tractable for many practical instances. For example, computer algebra systems often implement Faugère's F5 algorithm [6] that is very efficient if the system has sufficient regularity. In this case, a polynomial complexity bound (counting the number of field operations in terms of the expected output size) was established in [1].
The F5 algorithm and all other currently known fast algorithms for
Gröbner basis computations rely on linear algebra, and it may seem
surprising that fast FFT-based polynomial arithmetic is not used in this
area. This can be seen as an illustration of how difficult it is to
compute standard bases, but there is another explanation:
traditionnally, Gröbner basis algorithms consider a large number of
variables and the degree of the generating polynomials is kept small;
but fast polynomial arithmetic works best in the opposite regime (a
fixed number of variables and large degrees). Even in this setting, it
is not clear how to use FFT techniques for Gröbner basis
computation. As a first step, one may consider related problems, such as
the reduction of multivariate polynomials. It was shown in [16]
that reduction can be done in quasi-linear time with respect to the size
of the equation  . However,
this equation is in general much larger than the intrinsic complexity of
the problem, given by the size of
. However,
this equation is in general much larger than the intrinsic complexity of
the problem, given by the size of 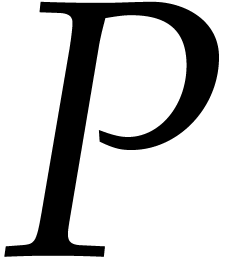 and the degree
and the degree
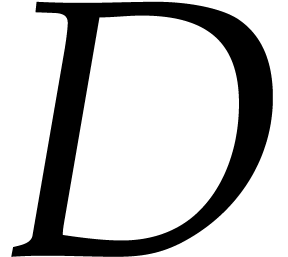 of the ideal (which is linked to the size of the
generating polynomials). Recent work in the bivariate setting [17]
gave an asymptotically optimal reduction algorithm for a particular
class of Gröbner bases. This algorithm relies on a terse
representation of
of the ideal (which is linked to the size of the
generating polynomials). Recent work in the bivariate setting [17]
gave an asymptotically optimal reduction algorithm for a particular
class of Gröbner bases. This algorithm relies on a terse
representation of 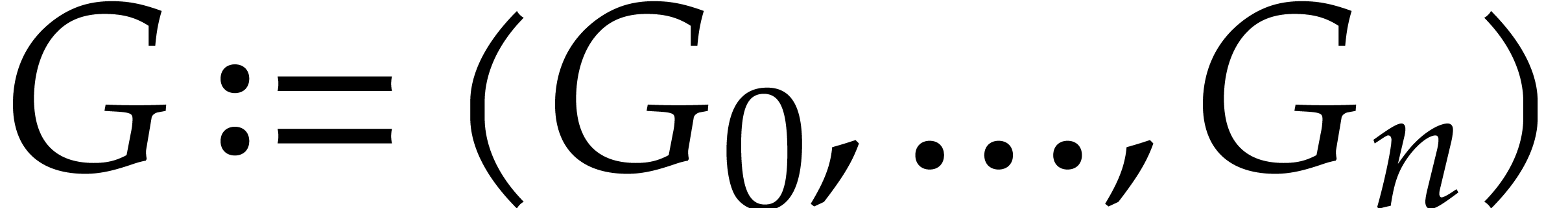 in
in 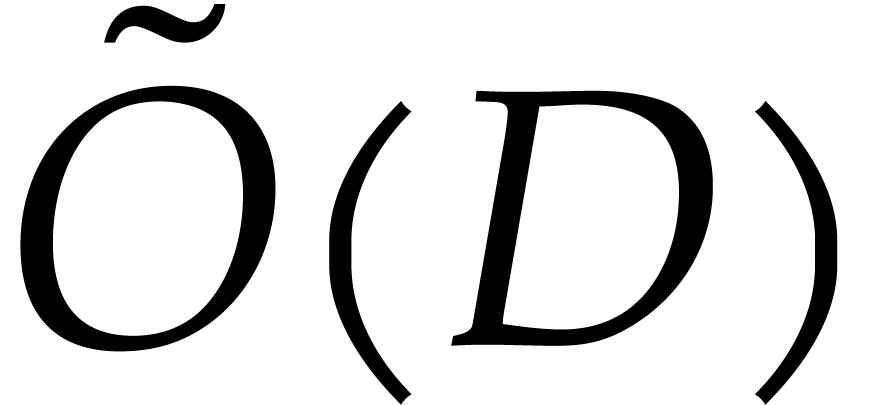 space, where
space, where  stands for the “soft
Oh” notation (that hides poly-logarithmic factors) [11].
Assuming that this representation has been precomputed, the extended
reduction can be performed in time
stands for the “soft
Oh” notation (that hides poly-logarithmic factors) [11].
Assuming that this representation has been precomputed, the extended
reduction can be performed in time 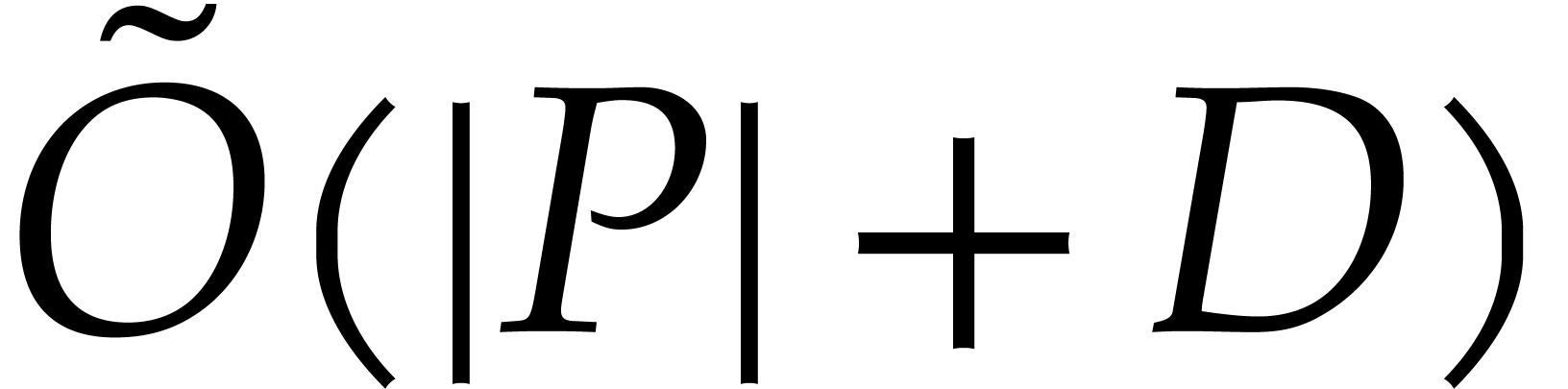 ,
instead of the previous
,
instead of the previous 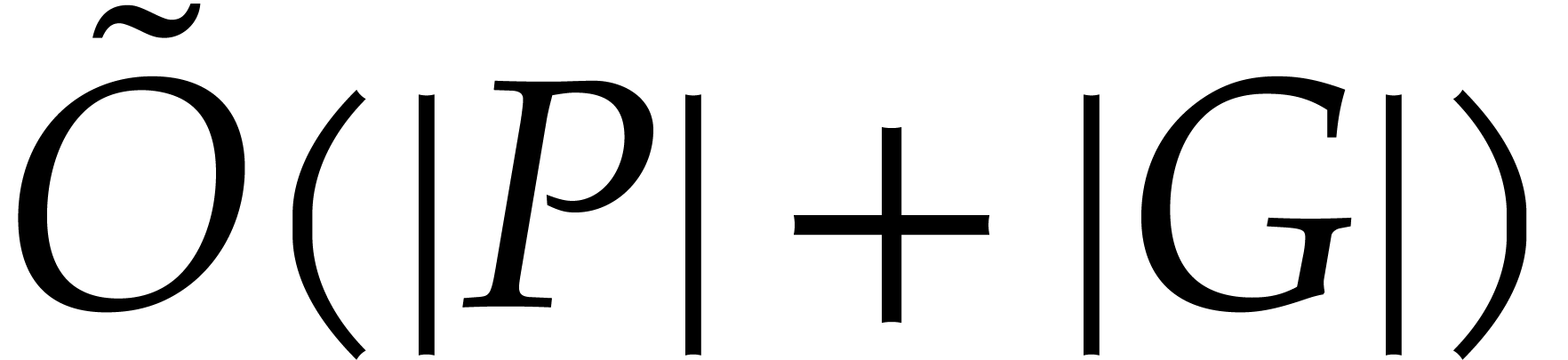 where
where  .
.
Instead of making regularity assumptions on the Gröbner basis
itself, one may focus on the generating polynomials. If the ideal is
defined by generic polynomials given in total degree, then the
Gröbner basis presents a particular structure, as studied for
example in [10, 22]. This situation is often
used as a benchmark for polynomial system solving: see the PoSSo problem
[7]. In this paper, we restrict ourselves to the bivariate
case, as studied for example in [20]. In what follows,  are generic polynomials of degree
are generic polynomials of degree 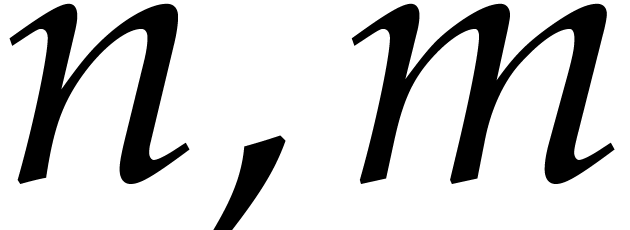 respectively. We denote by
respectively. We denote by 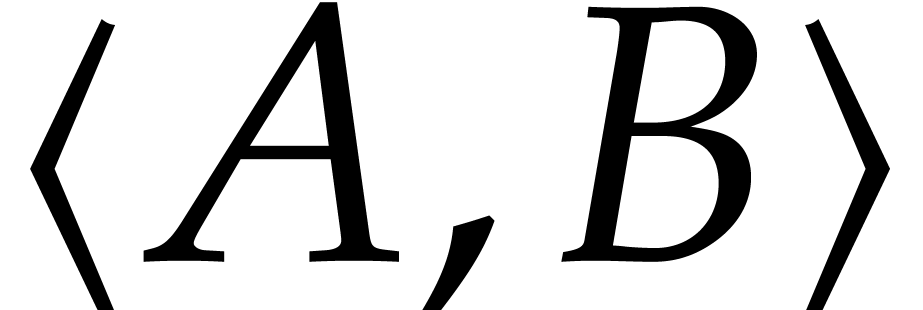 the ideal they
generate, and we consider its Gröbner basis with respect to the
graded lexicographic order. The computation of such a basis is
classical, but the hypotheses from [17] are not satisfied.
However, we show in this paper that a similar terse representation does
exist in this case. Therefore, reduction in quasi-linear time remains
possible, and it even turns out that the suitable representation can be
computed in time from the input
the ideal they
generate, and we consider its Gröbner basis with respect to the
graded lexicographic order. The computation of such a basis is
classical, but the hypotheses from [17] are not satisfied.
However, we show in this paper that a similar terse representation does
exist in this case. Therefore, reduction in quasi-linear time remains
possible, and it even turns out that the suitable representation can be
computed in time from the input 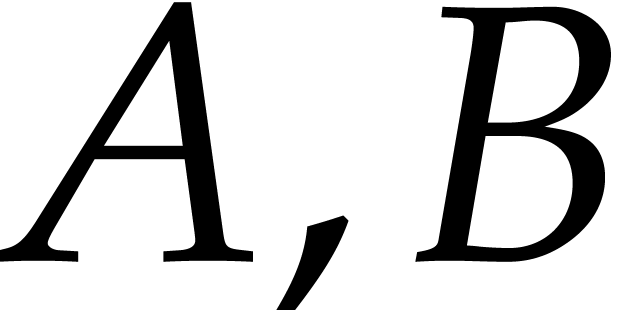 . Combining these two algorithms, we obtain an
ideal membership test
. Combining these two algorithms, we obtain an
ideal membership test 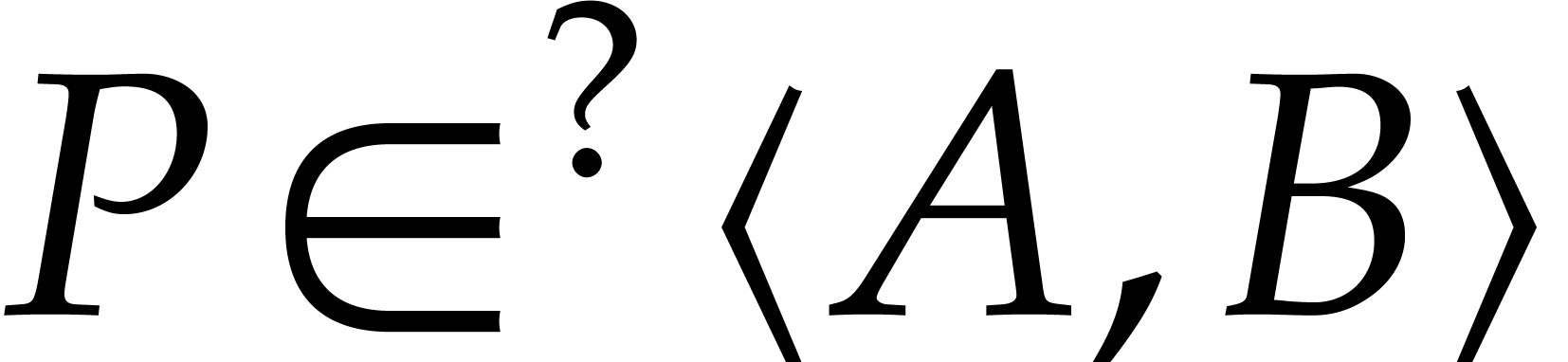 in quasi-linear time , without any precomputation.
Similarly, there is a quasi-linear multiplication algorithm for
in quasi-linear time , without any precomputation.
Similarly, there is a quasi-linear multiplication algorithm for 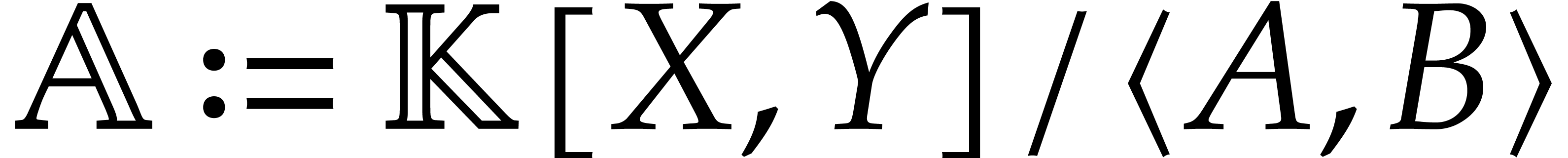 (again without precomputation). Finally, we show that
the reduced Gröbner basis can be computed in quasi-linear time with
respect to the output size.
(again without precomputation). Finally, we show that
the reduced Gröbner basis can be computed in quasi-linear time with
respect to the output size.
Notations and terminology. We assume that the
reader is familiar with the theory of Gröbner basis and refer to
[11, 2] for basic expositions. We denote the
set of monomials in 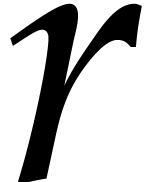 variables by
variables by 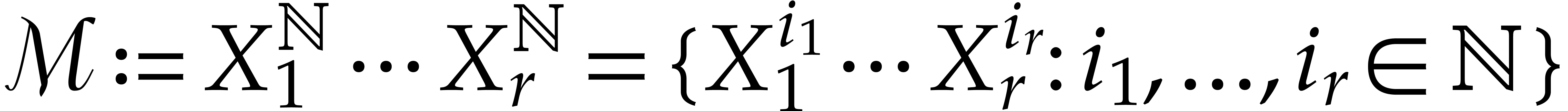 . A monomial ordering
. A monomial ordering  on
on 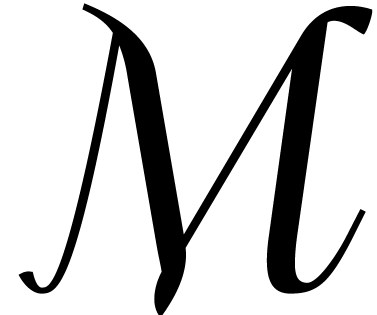 is a total ordering that
is compatible with multiplication. Given a polynomial in variables
is a total ordering that
is compatible with multiplication. Given a polynomial in variables 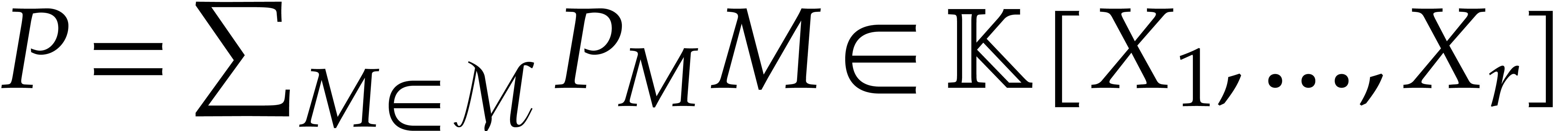 , its
support
, its
support  is the set of monomials
is the set of monomials  with
with 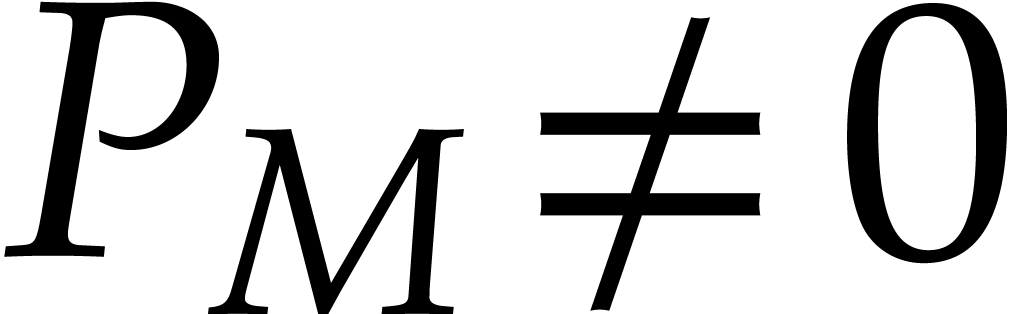 . If
. If
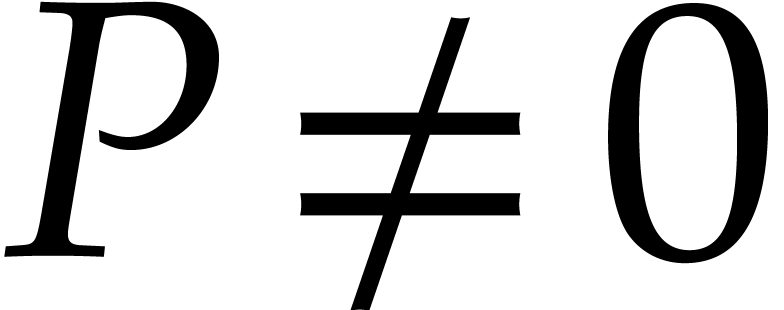 , then
admits a maximal element for that is called its
leading monomial and that we denote by
, then
admits a maximal element for that is called its
leading monomial and that we denote by 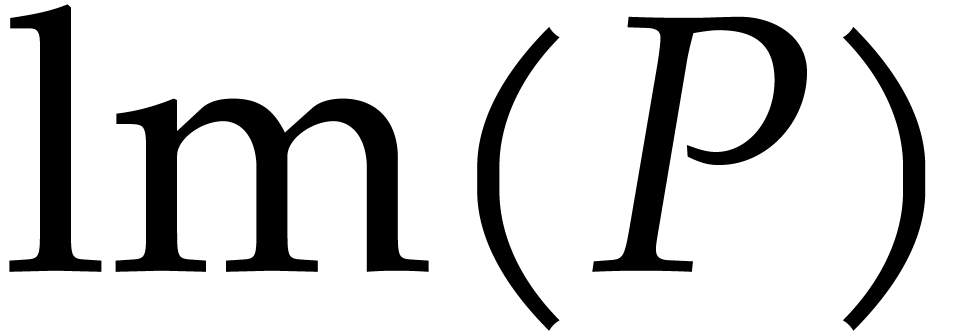 . If
. If  ,
then we say that
,
then we say that 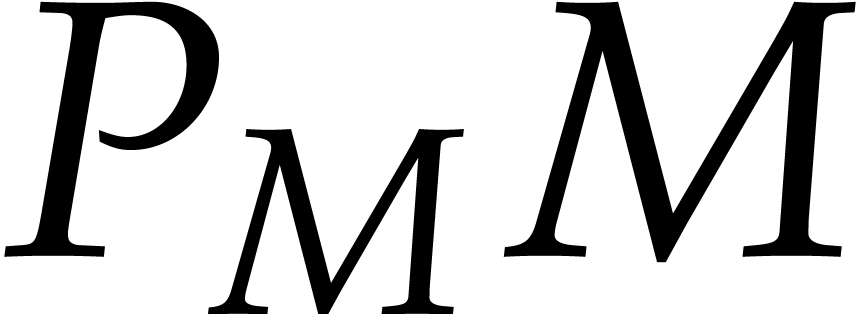 is a term in
is a term in 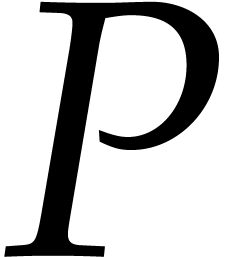 . Given a tuple
. Given a tuple 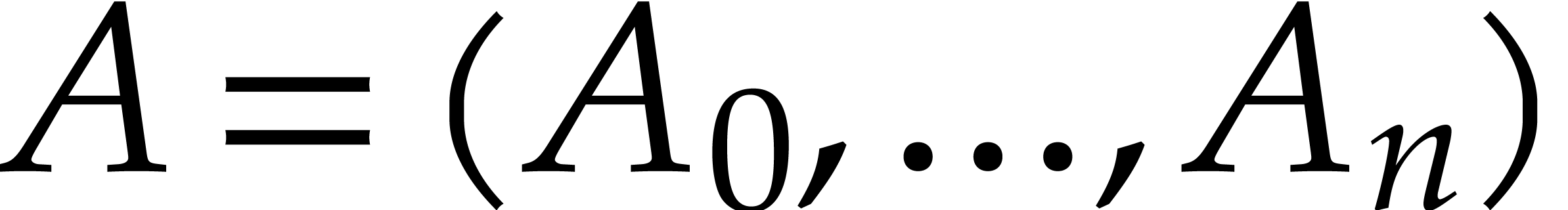 of polynomials in
of polynomials in 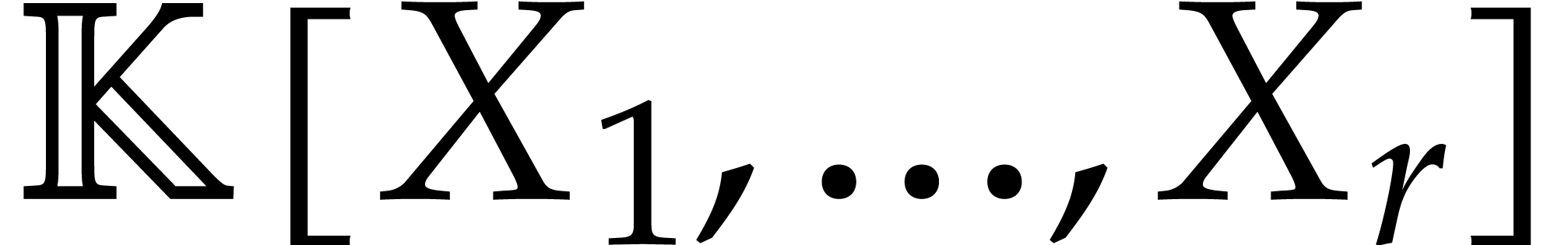 , we say
that is reduced with respect to
, we say
that is reduced with respect to  if contains no monomial that
is a multiple of the leading monomial of one of the
if contains no monomial that
is a multiple of the leading monomial of one of the 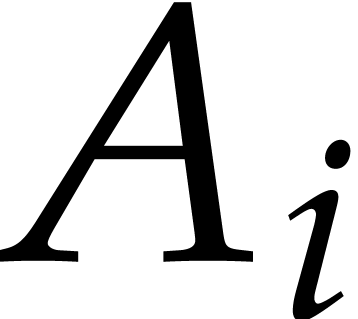 .
.
Unless stated otherwise, we will always work in the bivariate setting
when  , and use
, and use 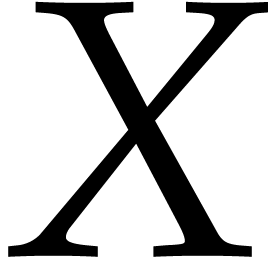 and
and 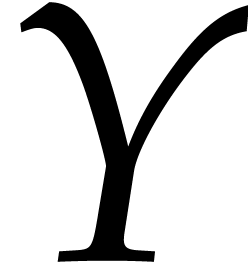 as our main indeterminates
instead of
as our main indeterminates
instead of 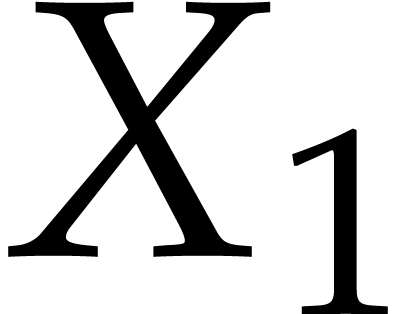 and
and 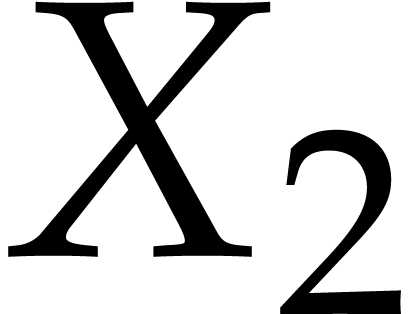 .
In particular,
.
In particular, 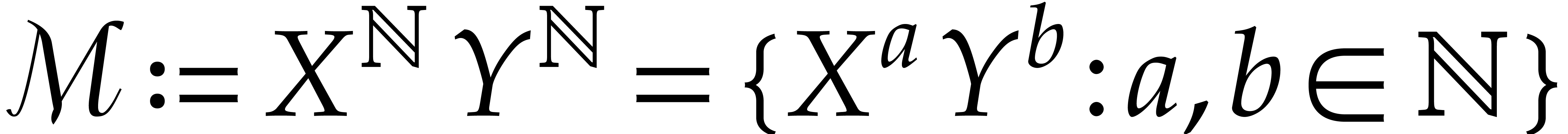 . Moreover, we
only consider the usual degree lexicographic order with
. Moreover, we
only consider the usual degree lexicographic order with  , that is
, that is
Acknowledgements. We thank Vincent Neiger for his remark that simplified Algorithm 6.
We consider an ideal 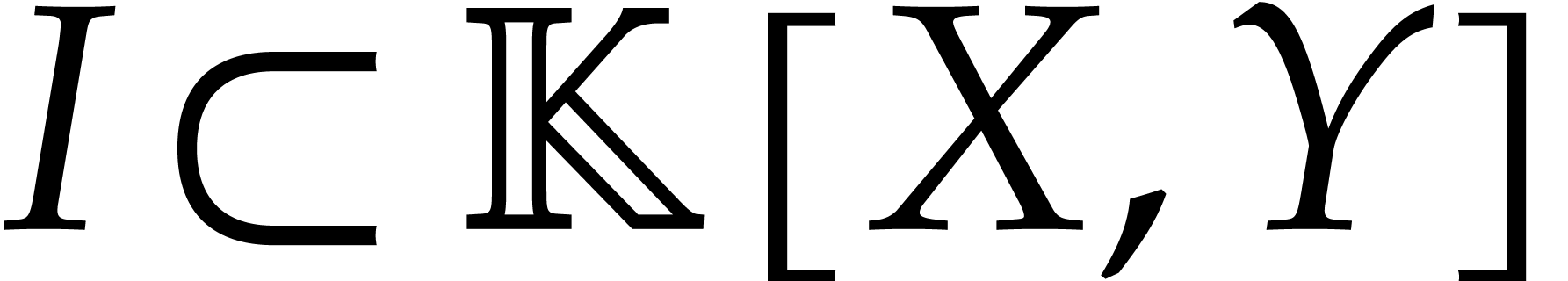 generated by two generic
polynomials of total degree
and we assume
generated by two generic
polynomials of total degree
and we assume  . Here the
adjective “generic” should be understood as “no
accidental cancellation occurs during the computation”. This is
typically the case if are chosen at random:
assuming
. Here the
adjective “generic” should be understood as “no
accidental cancellation occurs during the computation”. This is
typically the case if are chosen at random:
assuming  has sufficiently many elements, the
probability of an accidental cancellation is small. In this generic
bivariate setting, it is well known that the reduced Gröbner basis
has sufficiently many elements, the
probability of an accidental cancellation is small. In this generic
bivariate setting, it is well known that the reduced Gröbner basis
 of
of  with respect to
with respect to  can essentially be computed as follows:
can essentially be computed as follows:
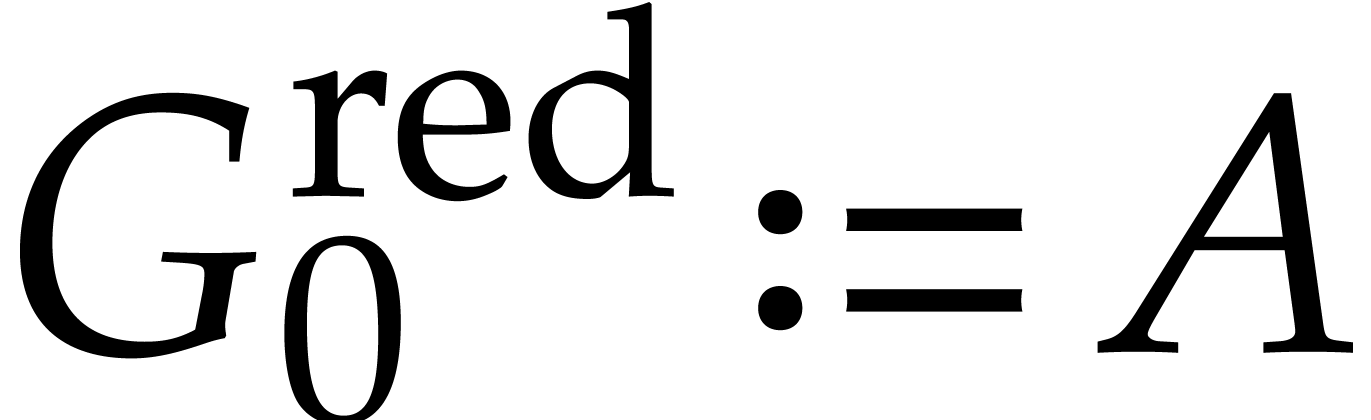 ,
, 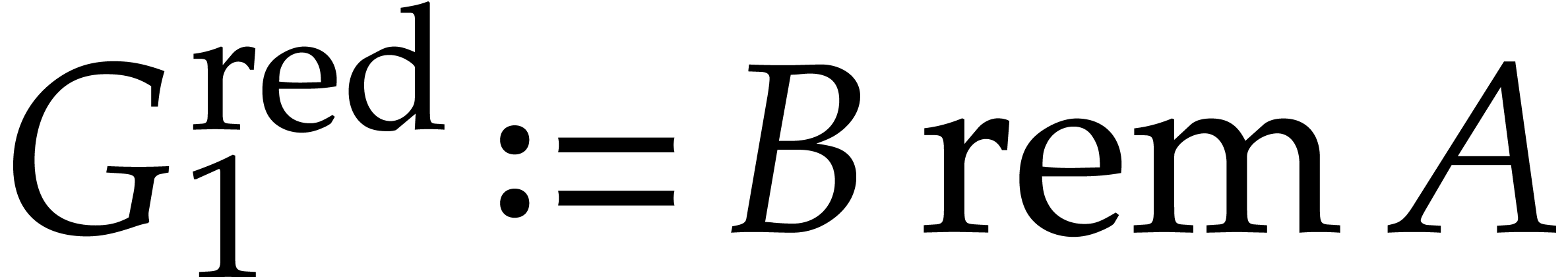 .
.
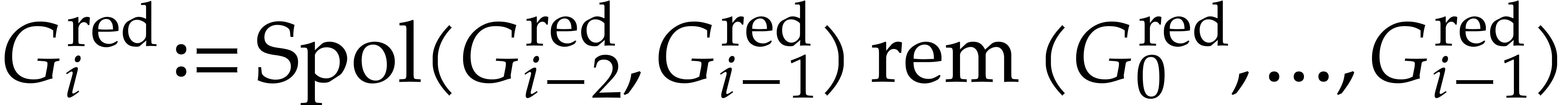 for all
for all 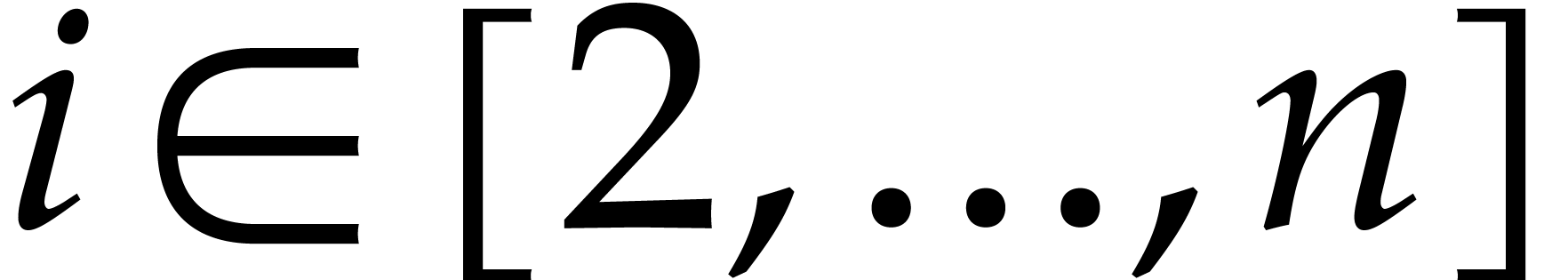 .
.
Remark ,
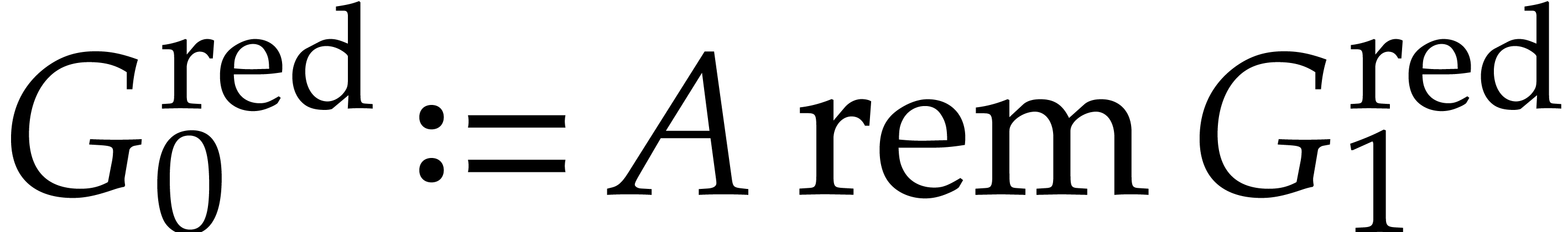 to ensure that no term in
to ensure that no term in 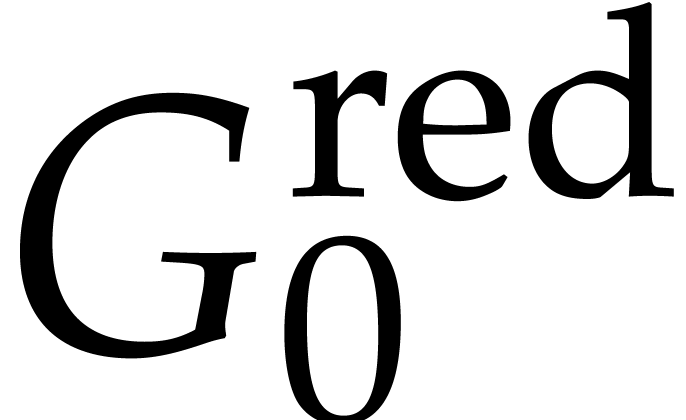 is divisible by the leading term of
is divisible by the leading term of 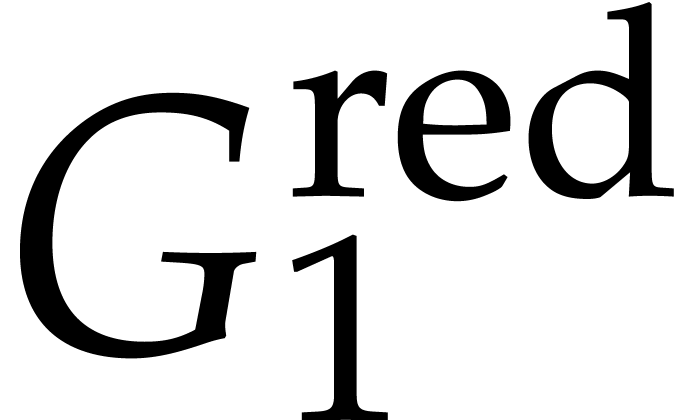 (which may
happen if
(which may
happen if  ). Moreover,
elements of the reduced basis must be monic; this means a division by
the leading coefficient is missing in the given formulas.
). Moreover,
elements of the reduced basis must be monic; this means a division by
the leading coefficient is missing in the given formulas.
We will show next how to construct another (non-reduced) Gröbner
basis 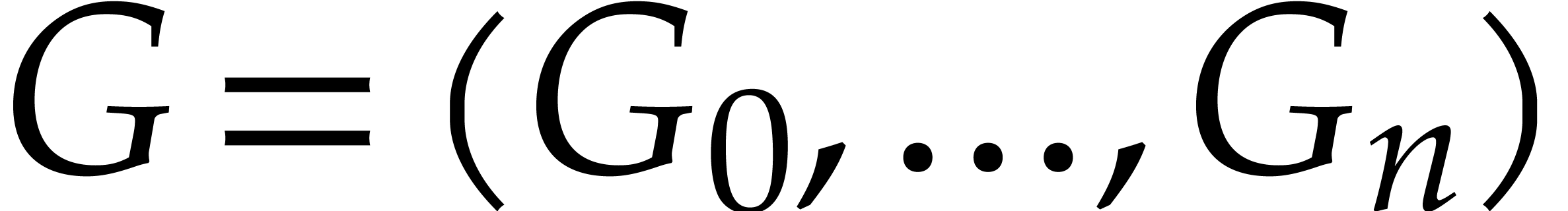 with even simpler recurrence relations.
Based on these recurrence relations, we will design a variant of the
algorithm from [17] that computes the reduction modulo
with even simpler recurrence relations.
Based on these recurrence relations, we will design a variant of the
algorithm from [17] that computes the reduction modulo  in quasi-linear time.
in quasi-linear time.
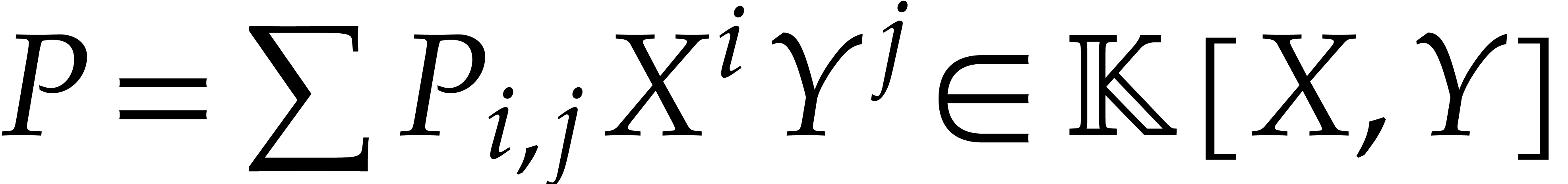 of total degree
of total degree
 , we define its dominant
diagonal
, we define its dominant
diagonal 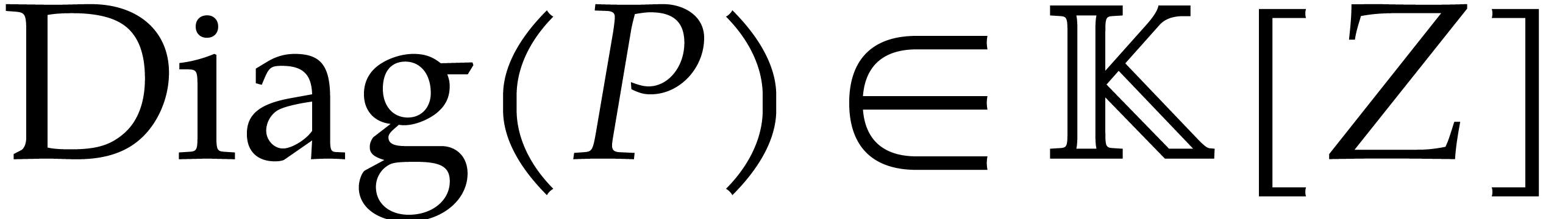 by
by 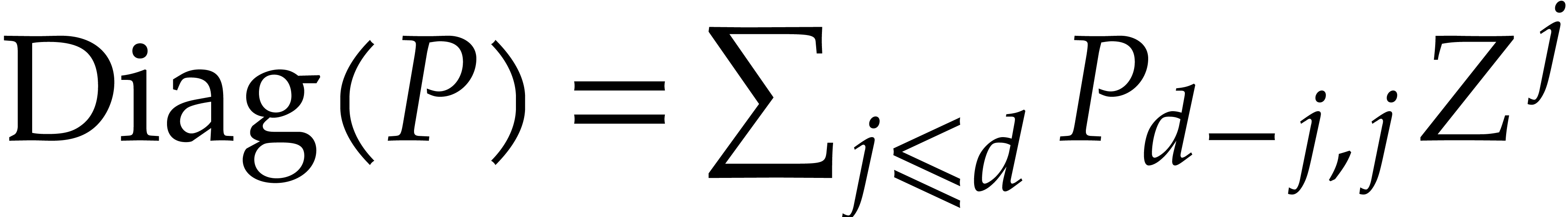 .
.
We have the trivial properties that 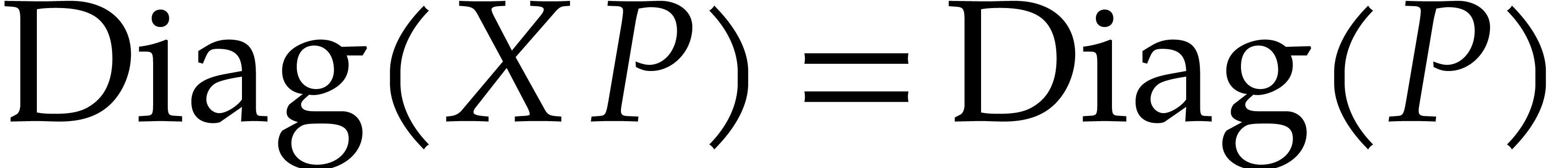 and
and 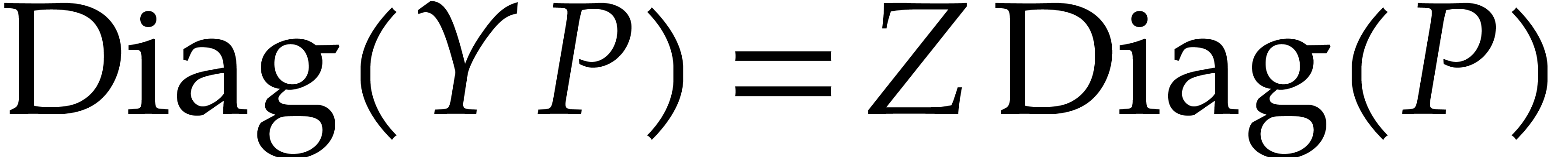 . For generic
. For generic  and
and  , the diagonals
, the diagonals 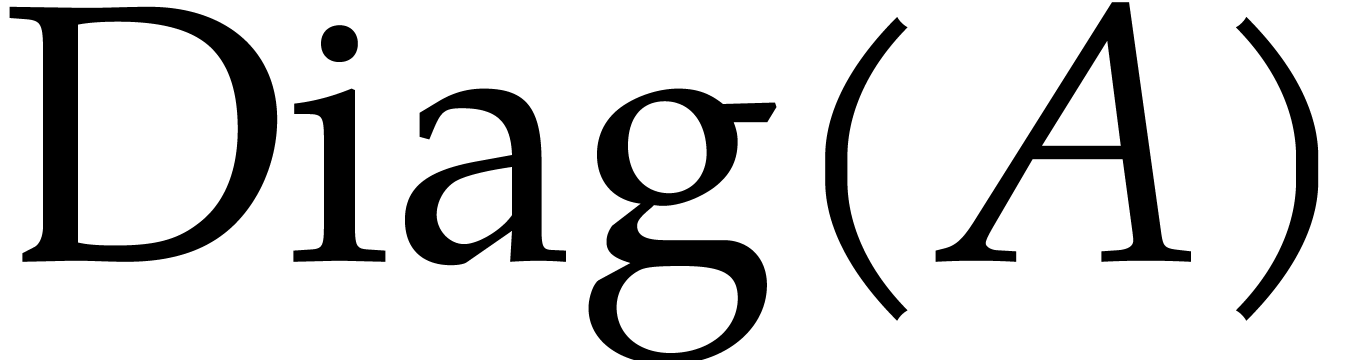 and
and 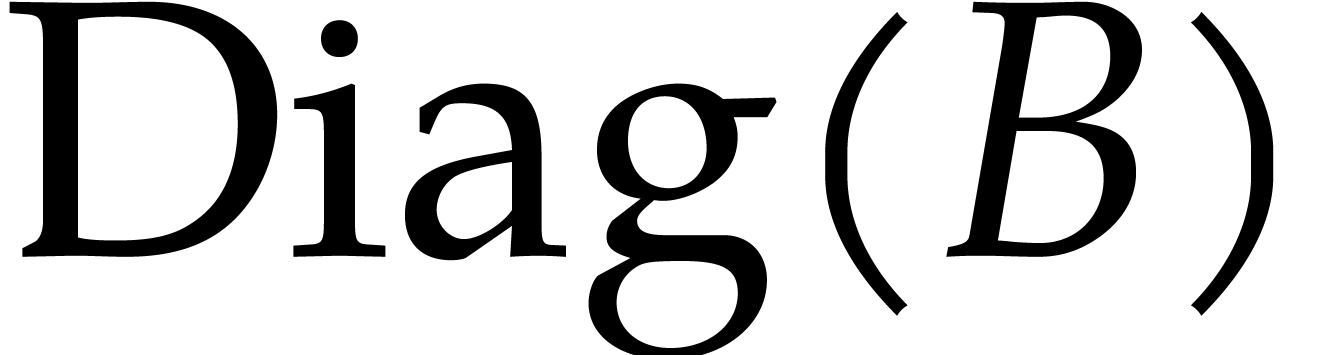 are also generic. Then the
remainders during the Euclidean algorithm follow a normal sequence (that
is the degrees decrease by exactly 1 at each step).
are also generic. Then the
remainders during the Euclidean algorithm follow a normal sequence (that
is the degrees decrease by exactly 1 at each step).
Remark 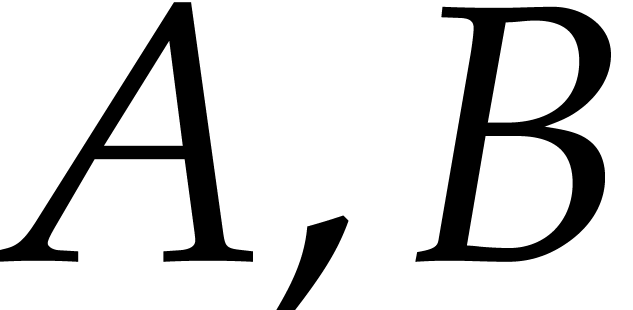 are generic”, we actually make two
assumptions. The first one is that the remainders follow a normal
sequence as we just mentioned. The second one is simply that the
coefficient of
are generic”, we actually make two
assumptions. The first one is that the remainders follow a normal
sequence as we just mentioned. The second one is simply that the
coefficient of 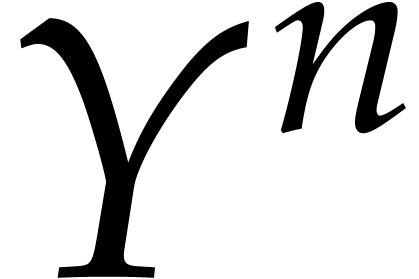 in is
nonzero, so that is the leading monomial of
.
in is
nonzero, so that is the leading monomial of
.
Let us consider the sequence  defined as:
defined as:
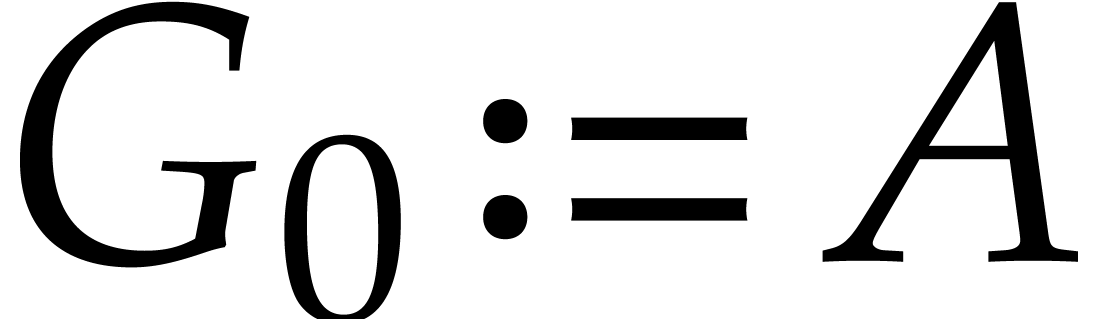 ,
, 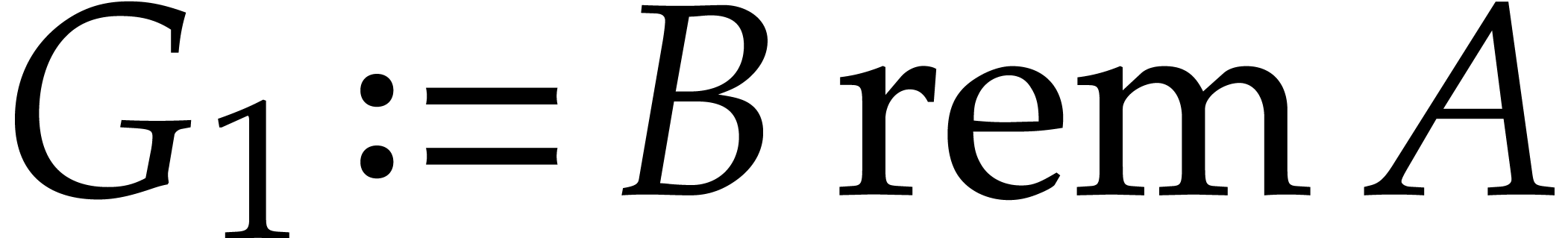 ,
,
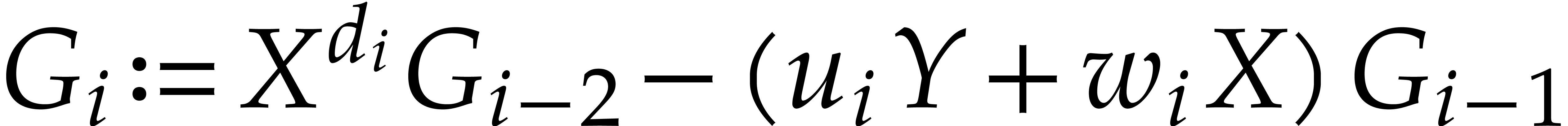 for all where (with
the notation
for all where (with
the notation  )
)
Let us first notice that the term 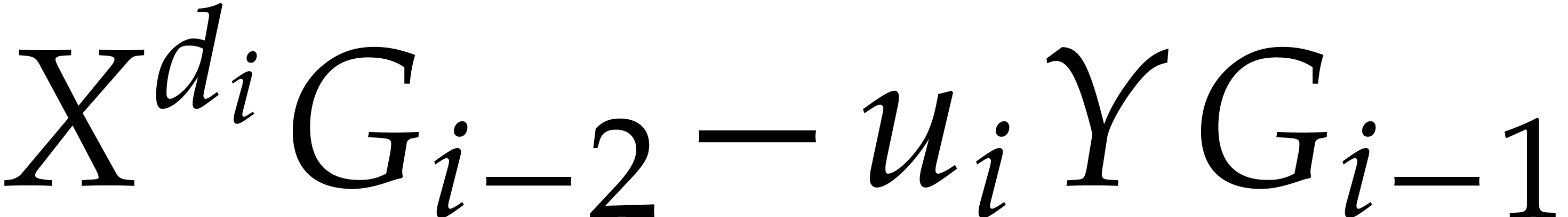 corresponds to
the S-polynomial of
corresponds to
the S-polynomial of 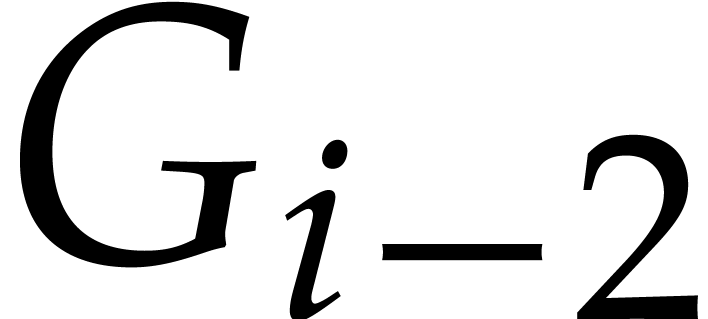 and
and 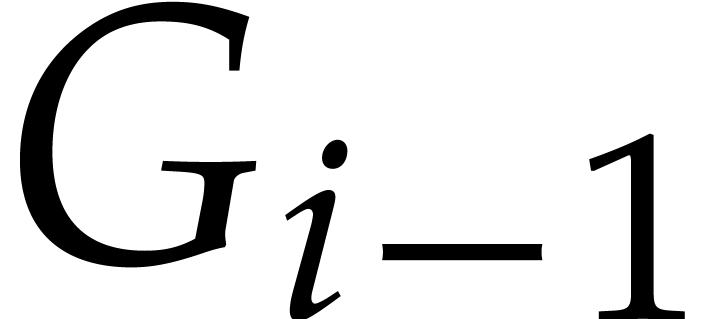 , as in the classical Buchberger algorithm [3].
We observe next that
, as in the classical Buchberger algorithm [3].
We observe next that 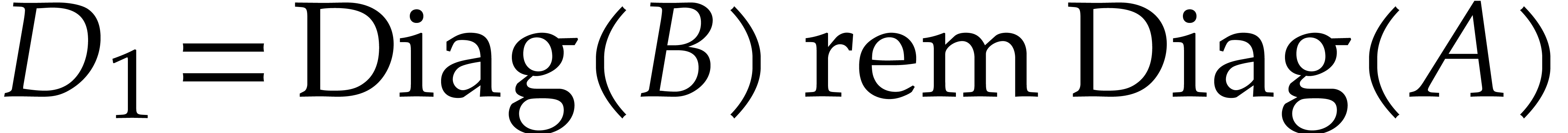 , and
for
, and
for 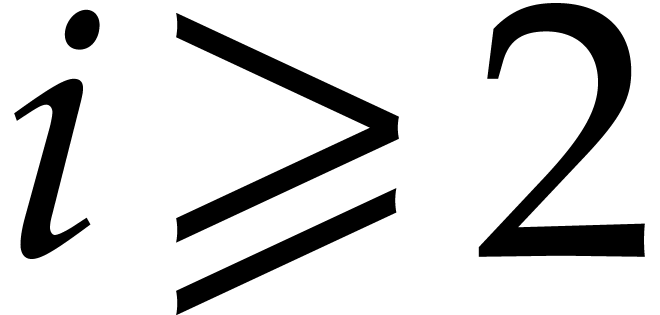 ,
, 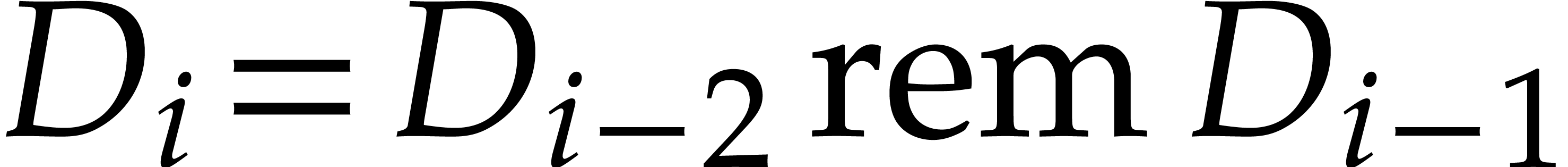 , so that the diagonals are the successive
remainders in the Euclidean algorithm (hence the quotients of degree 1).
From these two facts, we deduce that the
, so that the diagonals are the successive
remainders in the Euclidean algorithm (hence the quotients of degree 1).
From these two facts, we deduce that the 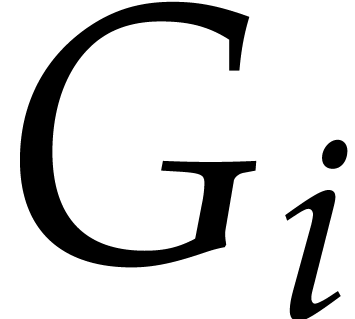 have
the same leading monomials as the
have
the same leading monomials as the 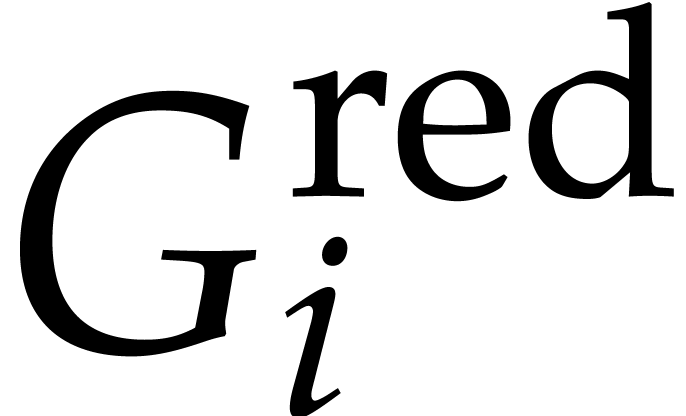 ,
so is a Gröbner basis of
with respect to . Of course,
any
,
so is a Gröbner basis of
with respect to . Of course,
any 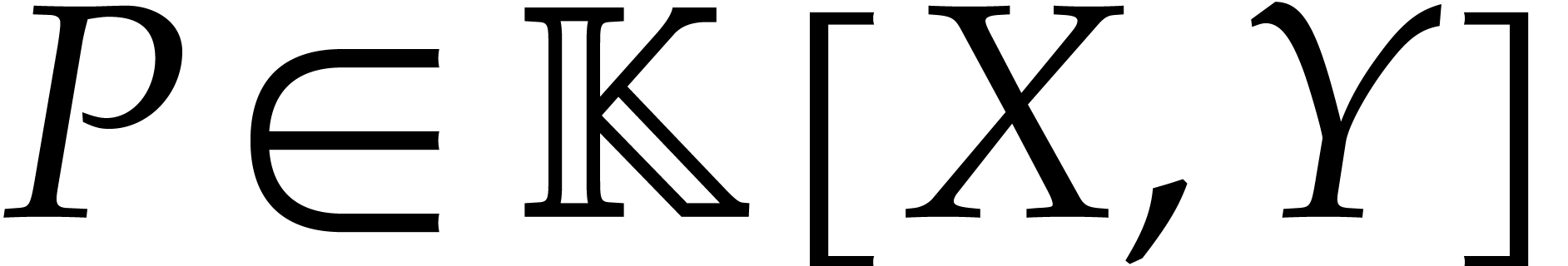 has the same normal form with respect to
and
has the same normal form with respect to
and  .
.
With this construction, it is easy to deduce higher order recurrence
relations 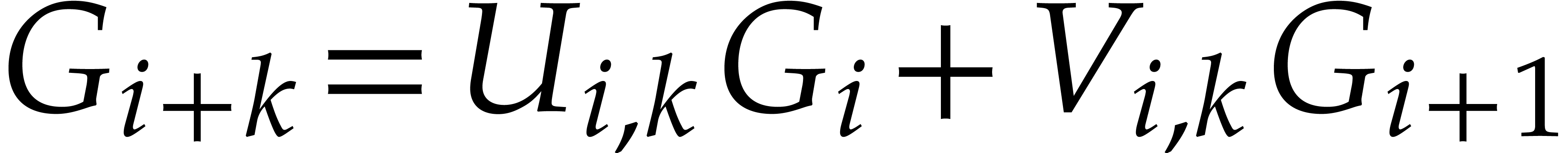 for each
for each 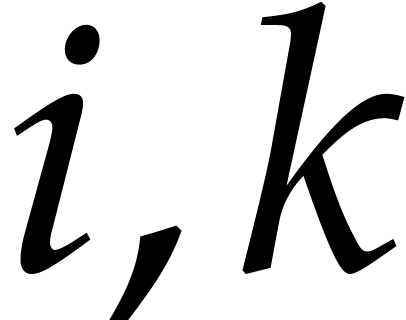 (with
(with
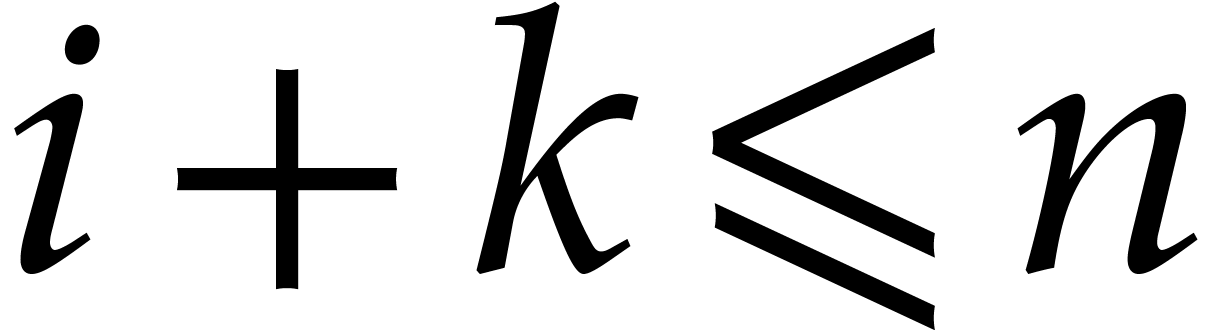 ). As we will see in section
4, the polynomials
). As we will see in section
4, the polynomials 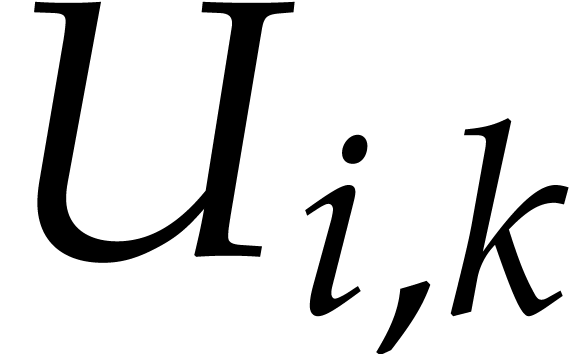 and
and 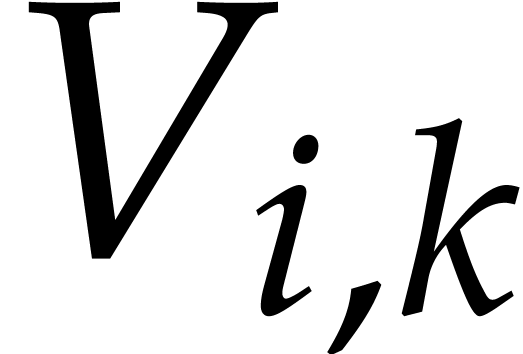 have a size that can be controlled as a function of . More precisely, they are
homogeneous polynomials of degree roughly
have a size that can be controlled as a function of . More precisely, they are
homogeneous polynomials of degree roughly 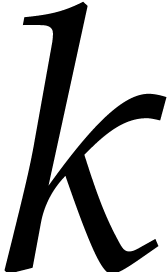 .
.
In this section, we quickly review some basic complexities for
fundamental operations on polynomials over a field . Notice that results presented in this section
are not specific to the bivariate case. Running times will always be
measured in terms of the required number of field operations in .
We denote by 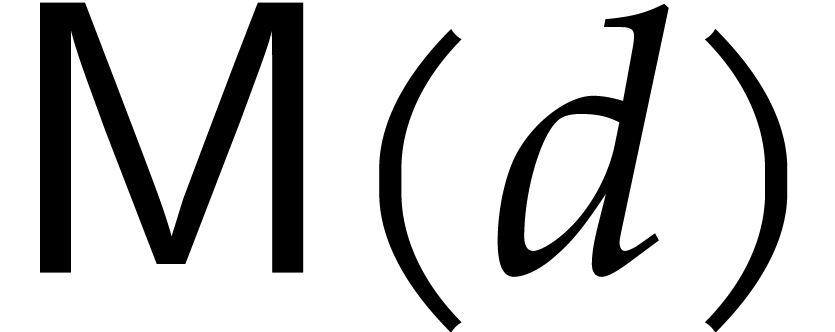 the cost of multiplying two dense
univariate polynomials of degree
the cost of multiplying two dense
univariate polynomials of degree  in
in 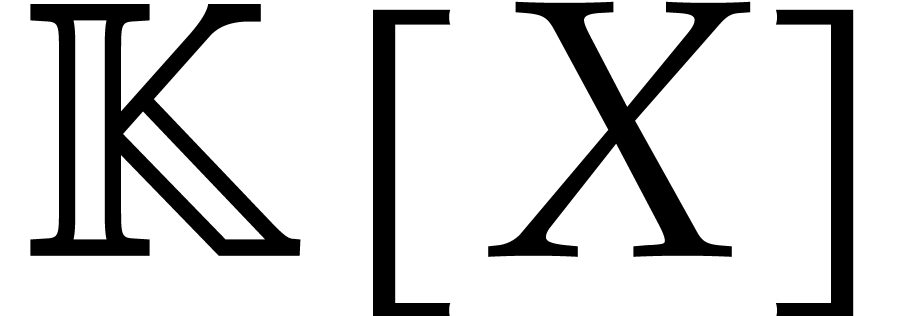 . Over general fields, one may take [24,
23, 4]
. Over general fields, one may take [24,
23, 4]
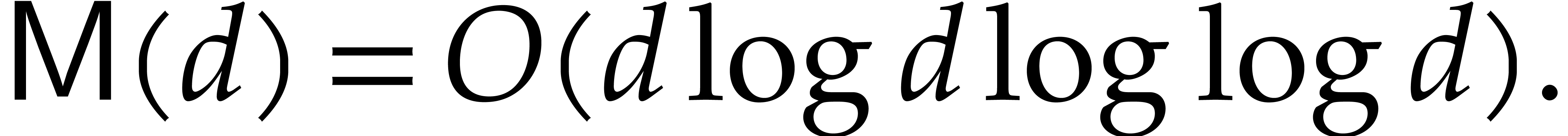
In the case of fields of positive characteristic, one may even take
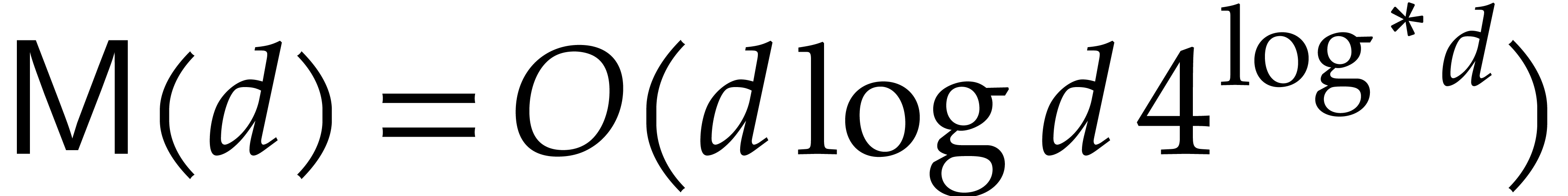 , where
, where  denotes the iterated logarithm [13, 14]. We
make the customary assumptions that
denotes the iterated logarithm [13, 14]. We
make the customary assumptions that 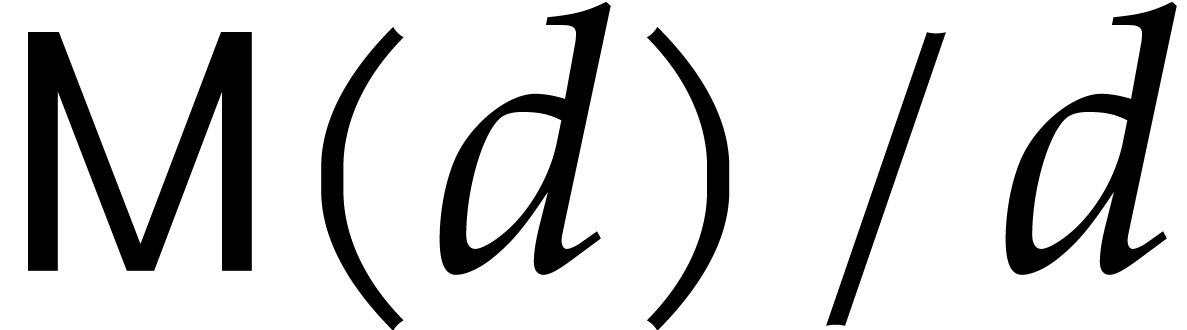 is
increasing and that
is
increasing and that 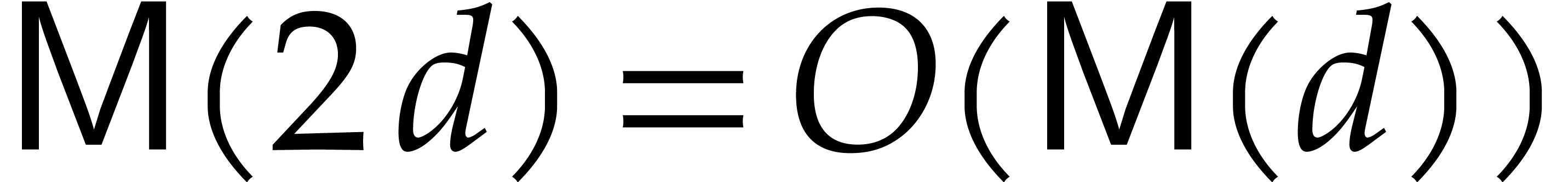 , with
the usual implications, such as
, with
the usual implications, such as 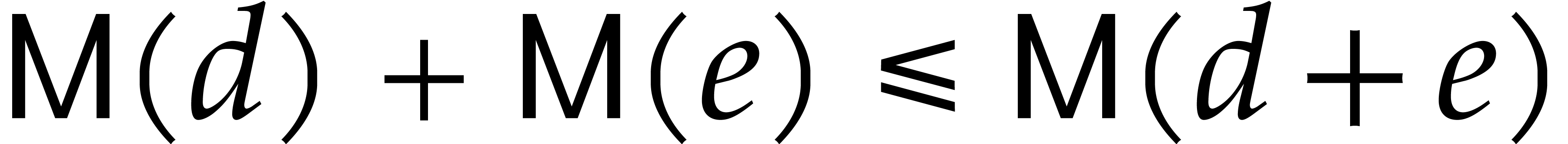 .
.
For multivariate polynomials, the cost of multiplication depends on the
geometry of the support. The classical example involves dense
“block” polynomials in of degree
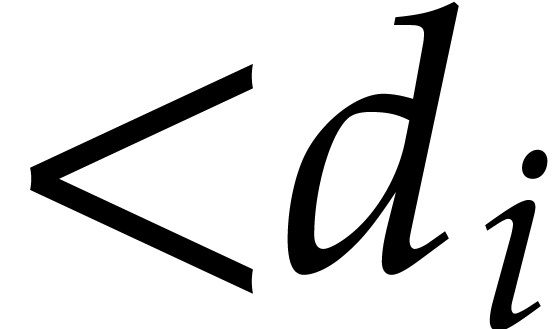 in each variable
in each variable 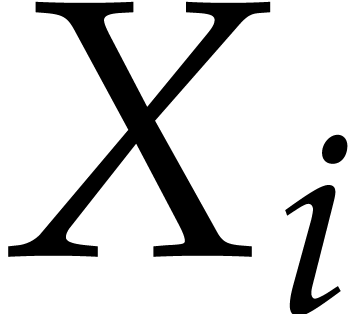 .
This case can be reduced to multiplication of univariate polynomials of
degree
.
This case can be reduced to multiplication of univariate polynomials of
degree 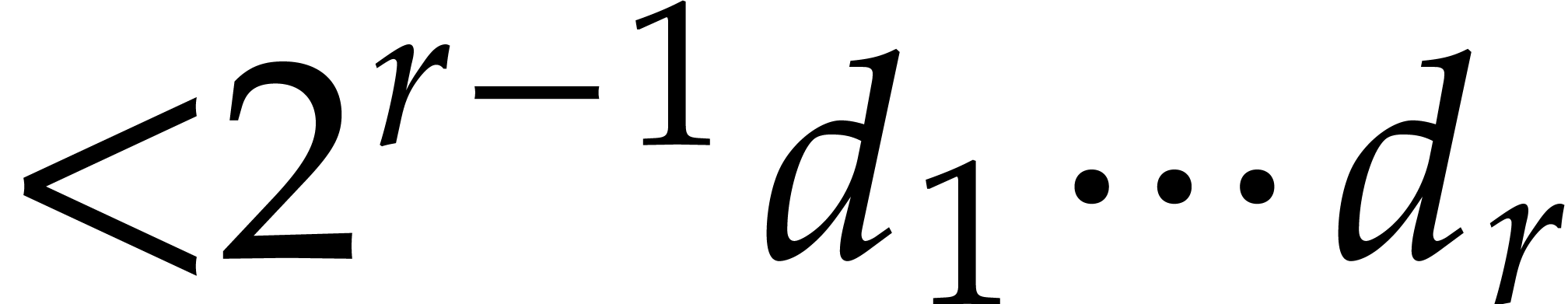 using the well known technique of
Kronecker substitution [11]. More generally, for
polynomials such that the support of the product is included in an
initial segment with elements, it is possible to
compute the product in time
using the well known technique of
Kronecker substitution [11]. More generally, for
polynomials such that the support of the product is included in an
initial segment with elements, it is possible to
compute the product in time 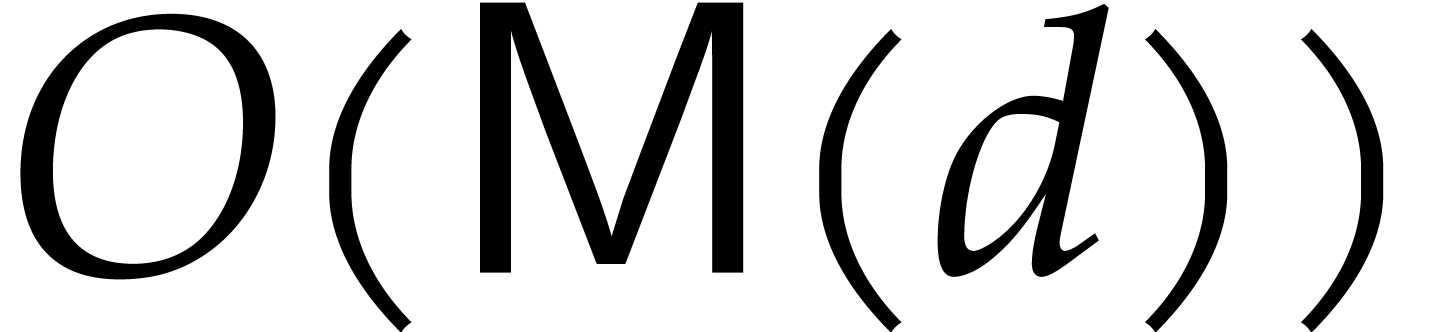 [18].
Here an initial segment of
[18].
Here an initial segment of 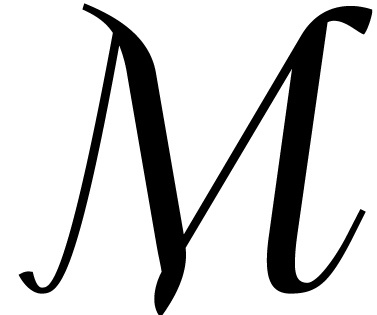 is a (finite) subset
is a (finite) subset
 such that for any monomial
such that for any monomial  , all its divisors are again in .
, all its divisors are again in .
For the purpose of this paper, we need to consider dense polynomials
in 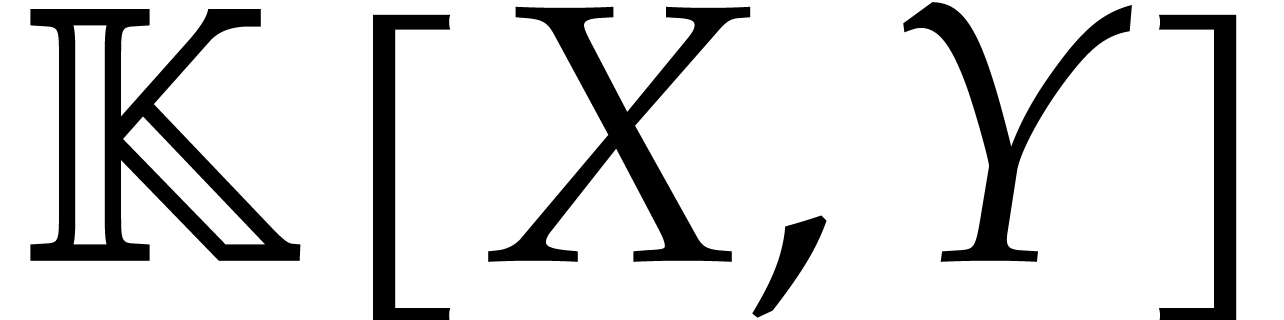 whose supports are
contained in sets of the form
whose supports are
contained in sets of the form 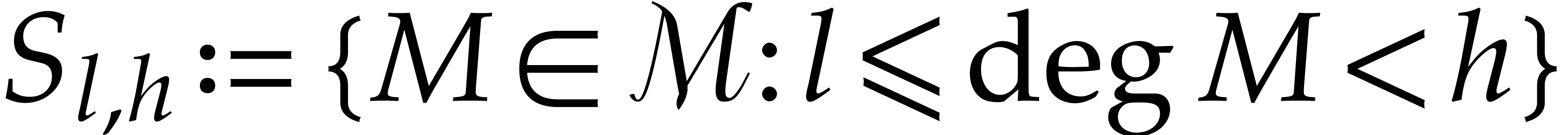 .
Modulo the change of variables
.
Modulo the change of variables 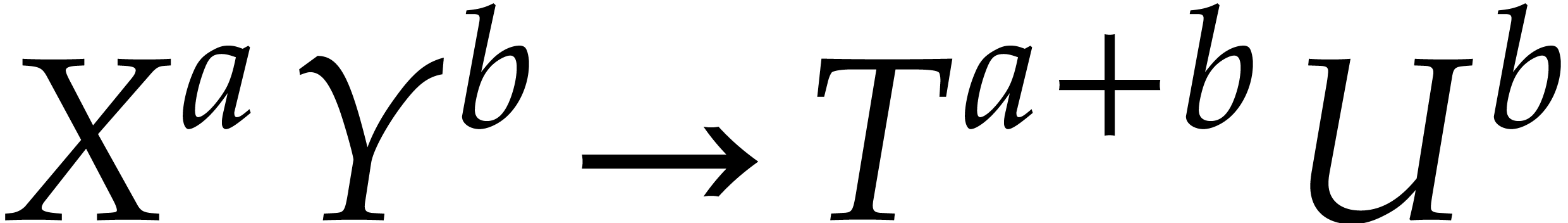 ,
such a polynomial can be rewritten as
,
such a polynomial can be rewritten as 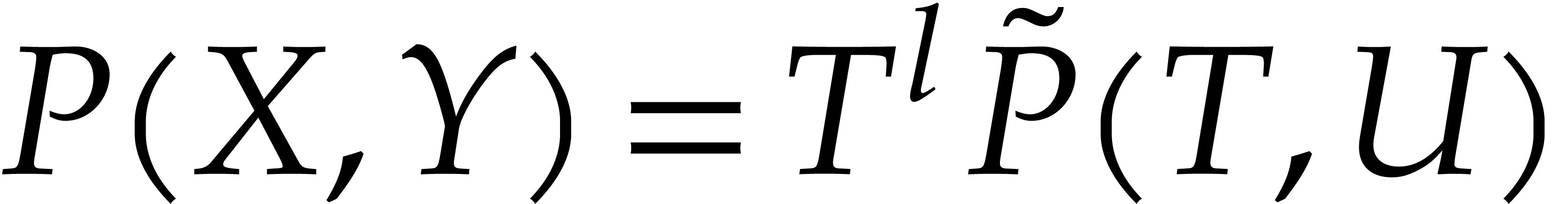 ,
where the support of
,
where the support of 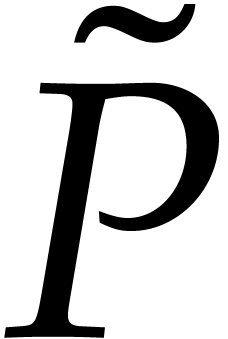 is an initial segment with
the same size as
is an initial segment with
the same size as 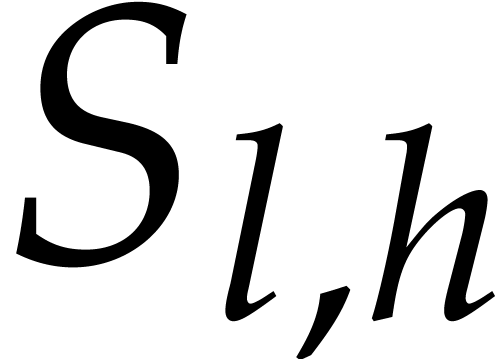 . For a
product of two polynomials of this type with a support of size , this means that the product can
again be computed in time .
. For a
product of two polynomials of this type with a support of size , this means that the product can
again be computed in time .
For the above polynomial multiplication algorithms, we assume that the
input polynomials are entirely given from the outset. In specific
settings, the input polynomials may be only partially known at some
point, and it can be interesting to anticipate the computation of the
partial output. This is particularly true when working with (truncated)
formal power series  instead of polynomials,
where it is common that the coefficients are given as a stream.
instead of polynomials,
where it is common that the coefficients are given as a stream.
In this so-called “relaxed (or online) computation model”,
the coefficient 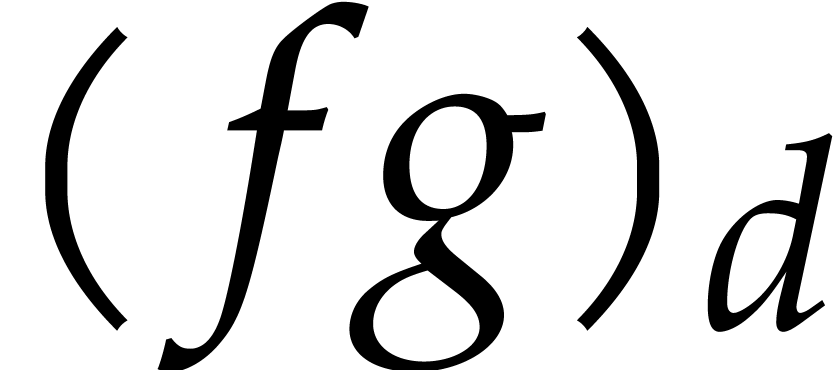 of a product of two series
of a product of two series 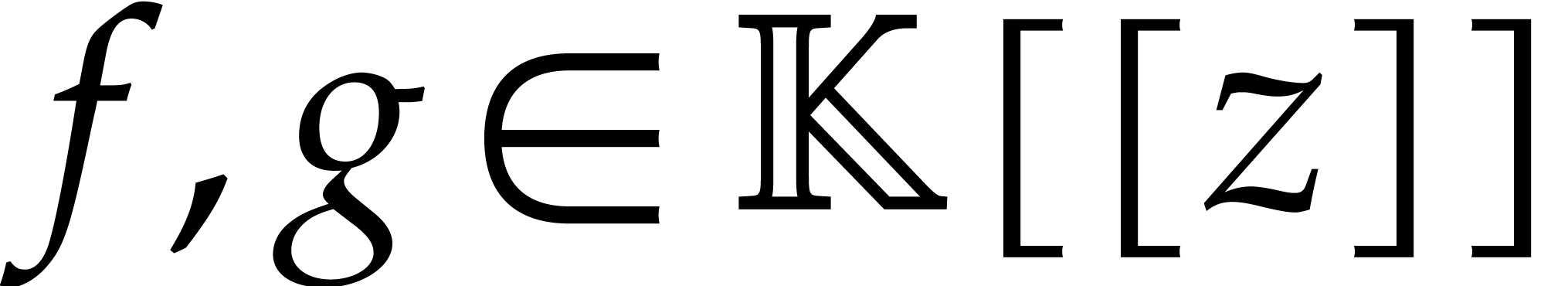 must be output as soon as
must be output as soon as  and
and
 are known. This model has the advantage that
subsequent coefficients
are known. This model has the advantage that
subsequent coefficients 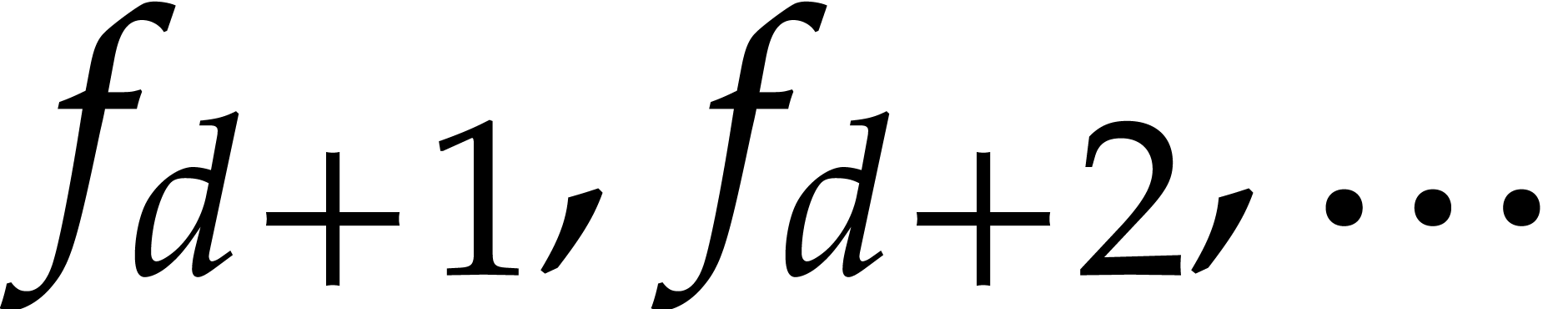 and
and 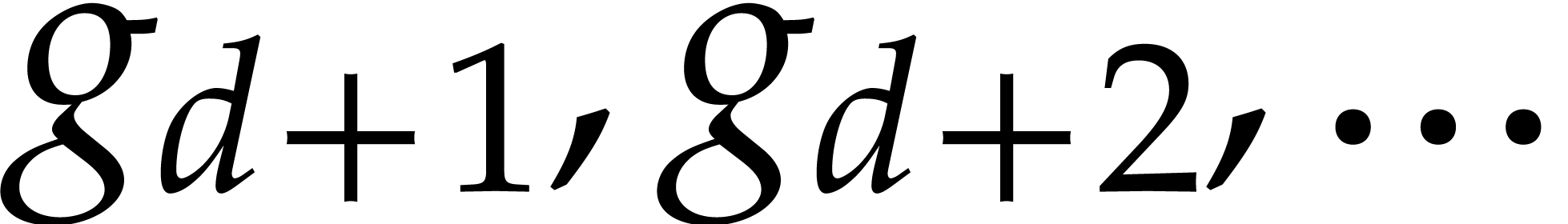 are allowed to depend on the result .
This often allows us to solve equations involving power series
are allowed to depend on the result .
This often allows us to solve equations involving power series 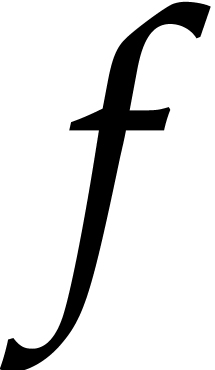 by rewriting them into recursive equations of the
form
by rewriting them into recursive equations of the
form  , with the property that
the coefficient
, with the property that
the coefficient 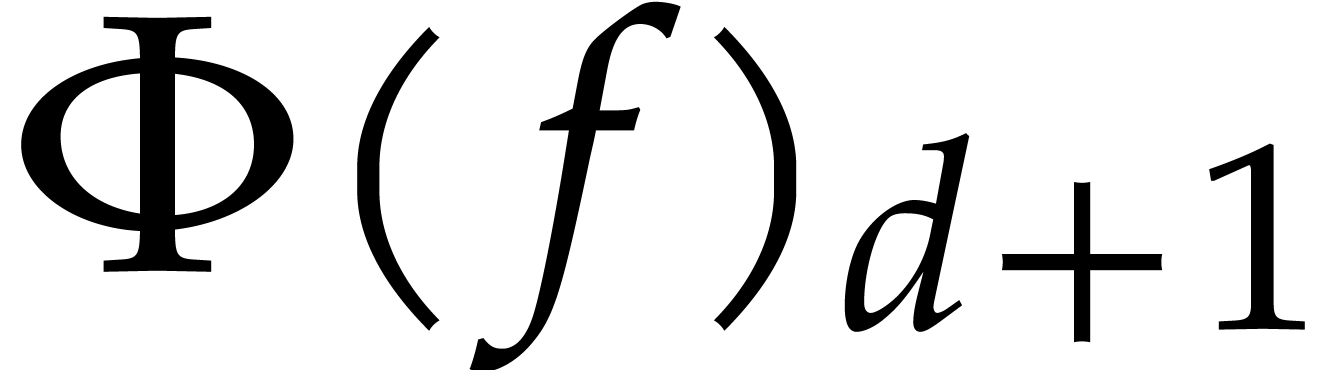 only depends on earlier
coefficients for all . For instance, in order to invert a power series of
the form
only depends on earlier
coefficients for all . For instance, in order to invert a power series of
the form 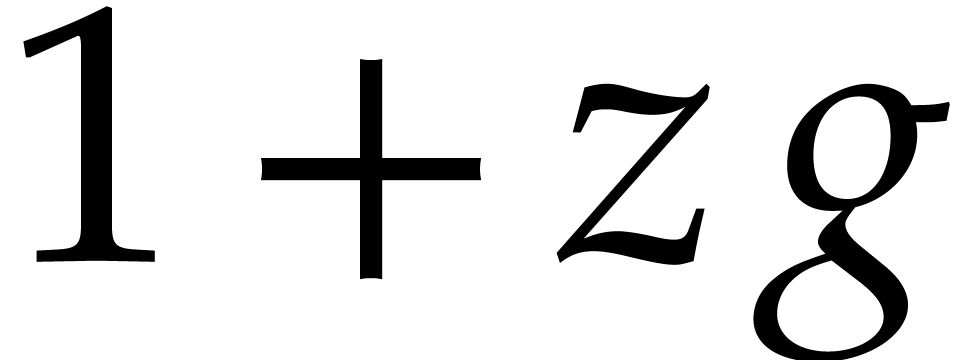 with
with 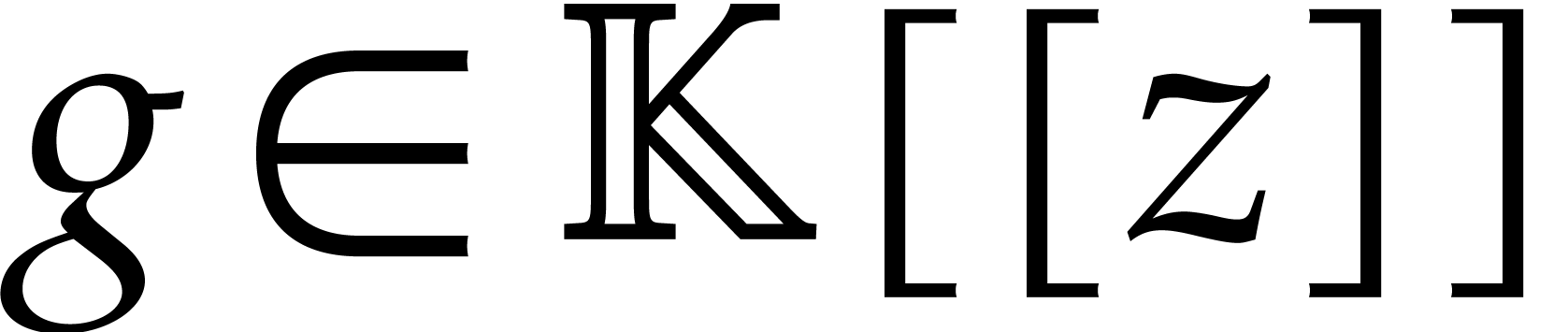 ,
we may take
,
we may take 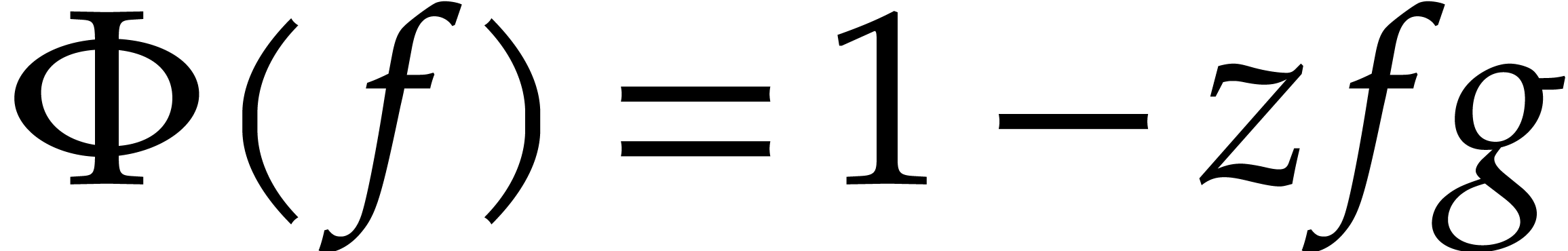 . Similarly, if
has characteristic zero, then the exponential of
a power series with
. Similarly, if
has characteristic zero, then the exponential of
a power series with 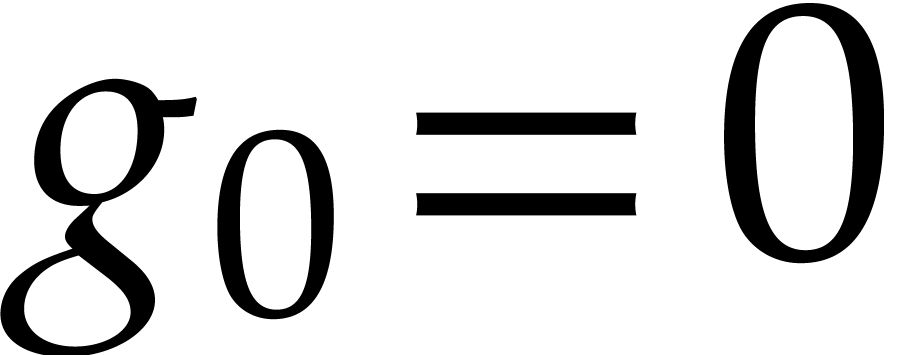 can
be computed by taking
can
be computed by taking 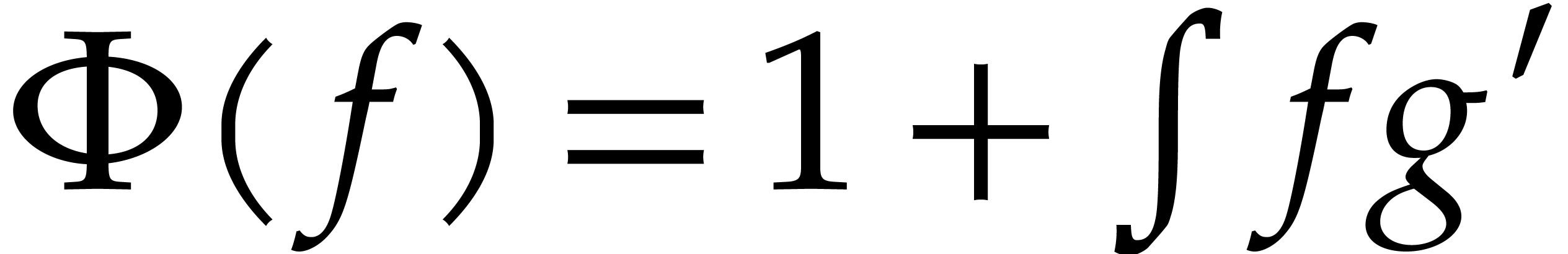 .
.
From a complexity point of view, let 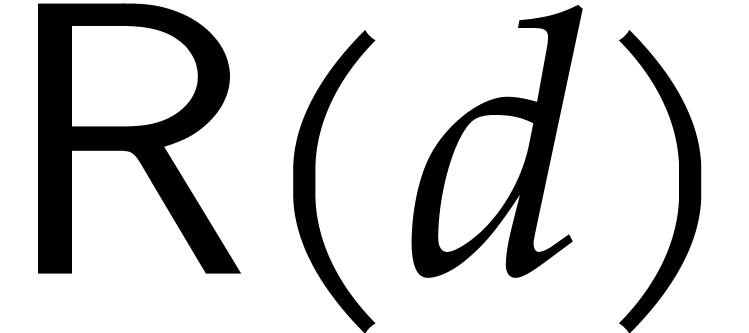 denote the
cost of the relaxed multiplication of two polynomials of degree
denote the
cost of the relaxed multiplication of two polynomials of degree 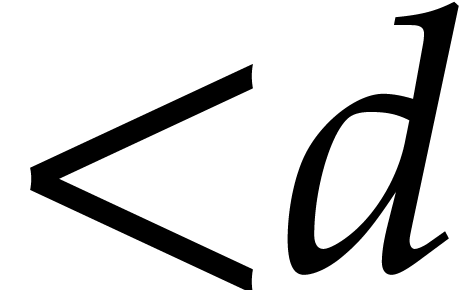 . The relaxed model prevents us
from directly using fast “zealous” multiplication algorithms
from the previous section that are typically based on
FFT-multiplication. Fortunately, it was shown in [15, 9] that
. The relaxed model prevents us
from directly using fast “zealous” multiplication algorithms
from the previous section that are typically based on
FFT-multiplication. Fortunately, it was shown in [15, 9] that
 |
(1) |
This relaxed multiplication algorithm admits the advantage that it may use any zealous multiplication as a black box. Through the direct use of FFT-based techniques, the following bound has also been established in [19]:
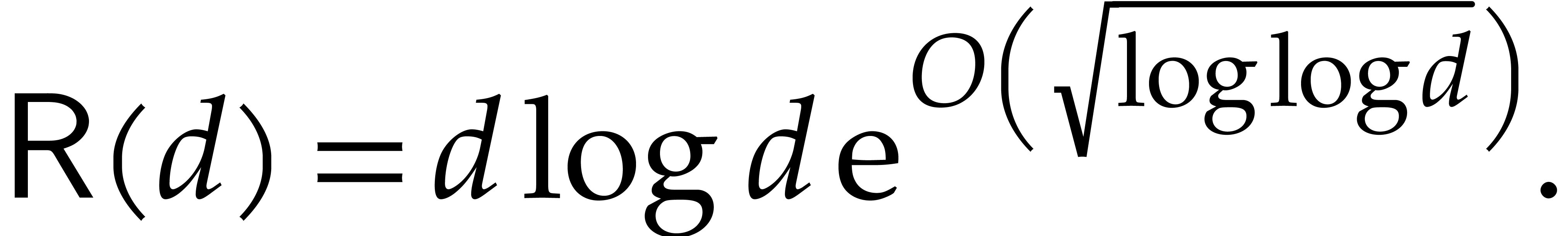
In the sequel, we will only use a suitable multivariate generalization of the algorithm from [15, 9], so we will always assume that
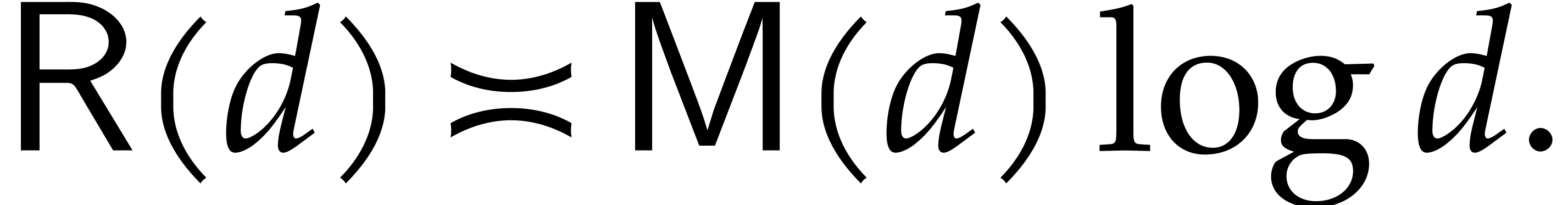
In particular, we have 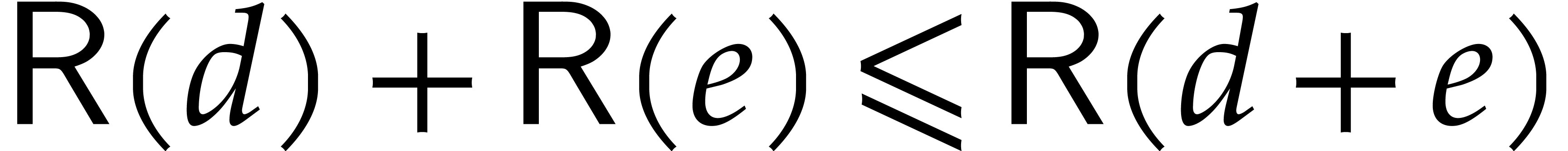 .
.
Let us now consider a Gröbner basis of an ideal in , or, more generally, an auto-reduced tuple
of polynomials in .
Then for any 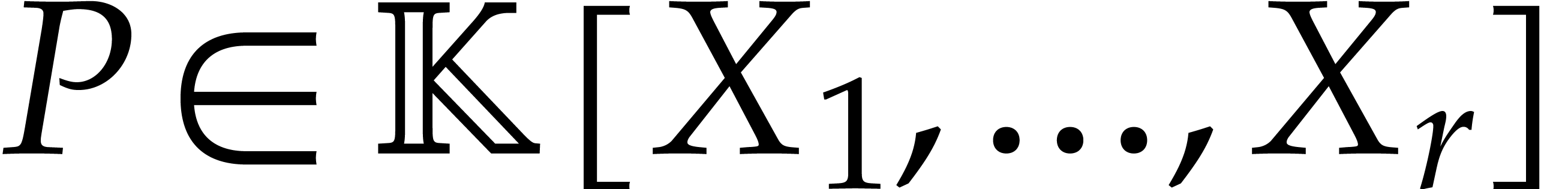 , we may compute
a relation
, we may compute
a relation

such that  is reduced with respect to . We call
is reduced with respect to . We call 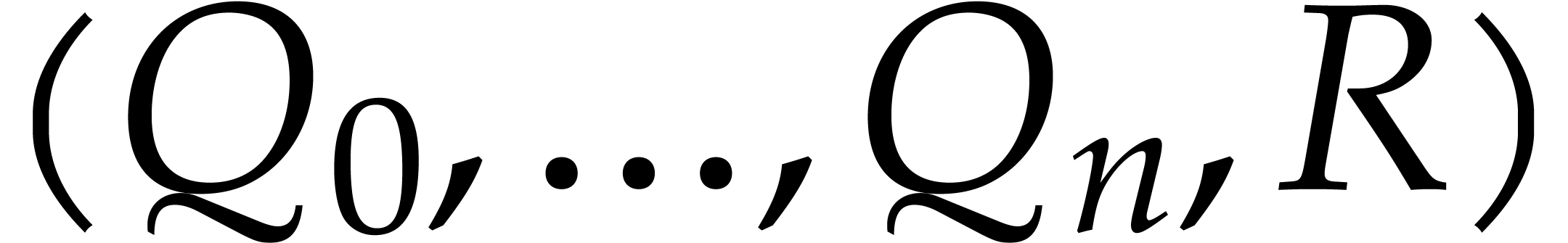 an extended reduction of with respect
to .
an extended reduction of with respect
to .
The computation of such an extended reduction is a good example of a
problem that can be solved efficiently using relaxed multiplication and
recursive equations. For a multivariate polynomial
 with dense support of any of the types discussed in section
3.1
, let
with dense support of any of the types discussed in section
3.1
, let
 denote a bound for the size of its support. With
as in (
1
), it has been shown
denote a bound for the size of its support. With
as in (
1
), it has been shown
1. The results from [16] actually apply for more general types of supports, but this will not be needed in this paper.
 and the
remainder
can be computed in time
and the
remainder
can be computed in time
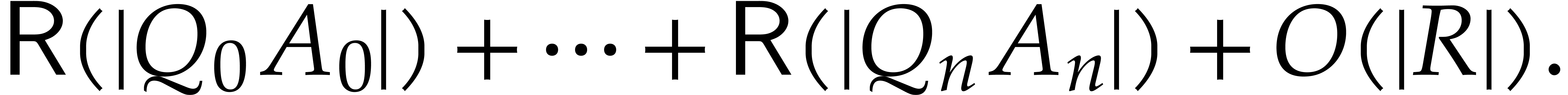 |
(2) |
This implies in particular that the extended reduction can be computed
in quasi-linear time in the size of the equation  . However, as pointed out in the introduction, this
equation is in general much larger than the input polynomial .
. However, as pointed out in the introduction, this
equation is in general much larger than the input polynomial .
Extended reductions are far from being unique
(only is unique, and only if
is a Gröbner basis). The algorithm from [16] for the
computation of an extended reduction relies on a selection
strategy that uniquely determines the quotients. More precisely,
for every monomial  , we
define the set
, we
define the set 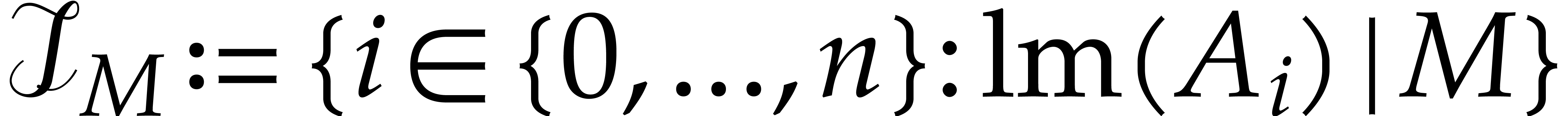 ; then we need
a rule to chose a particular index
; then we need
a rule to chose a particular index 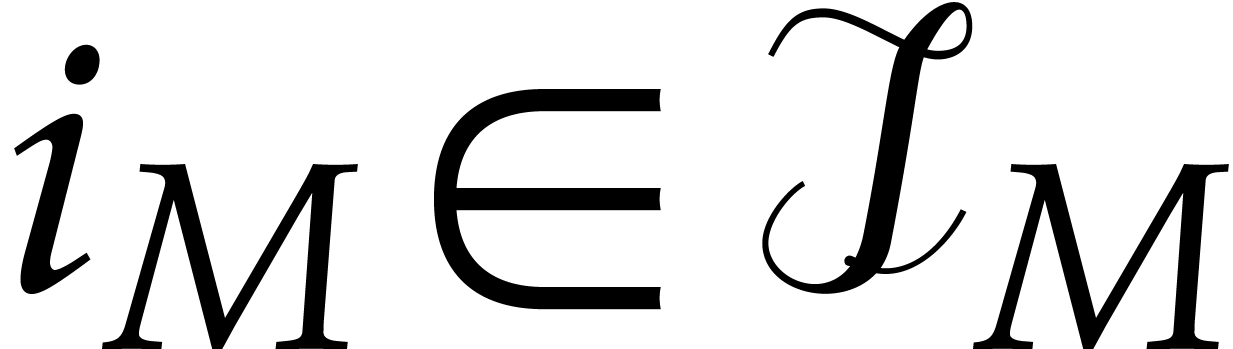 (assuming
(assuming
 is non-empty). The initial formulation [16]
used the simplest such strategy by taking
is non-empty). The initial formulation [16]
used the simplest such strategy by taking  ,
but the complexity bound (2) holds for any selection
strategy. Now the total size of all quotients
may be much larger than the size of for a
general selection strategy. One of the key ingredients of the fast
reduction algorithm in this paper is the careful design of a
“dichotomic selection strategy” that enables us to control
the degrees of the quotients.
,
but the complexity bound (2) holds for any selection
strategy. Now the total size of all quotients
may be much larger than the size of for a
general selection strategy. One of the key ingredients of the fast
reduction algorithm in this paper is the careful design of a
“dichotomic selection strategy” that enables us to control
the degrees of the quotients.
Remark
The ideal has a degree 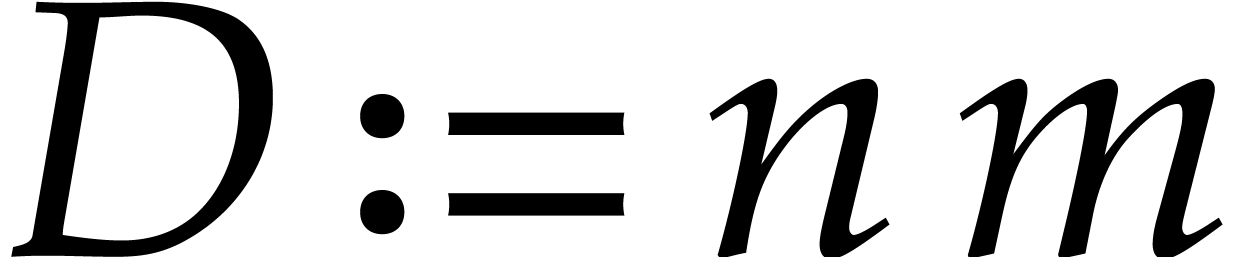 , and the reduced Gröbner basis
, and the reduced Gröbner basis 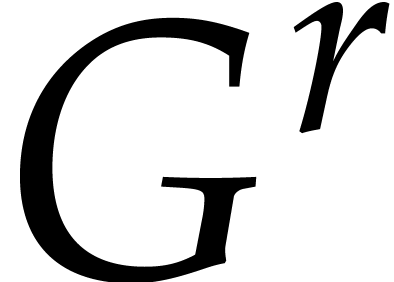 takes space
takes space 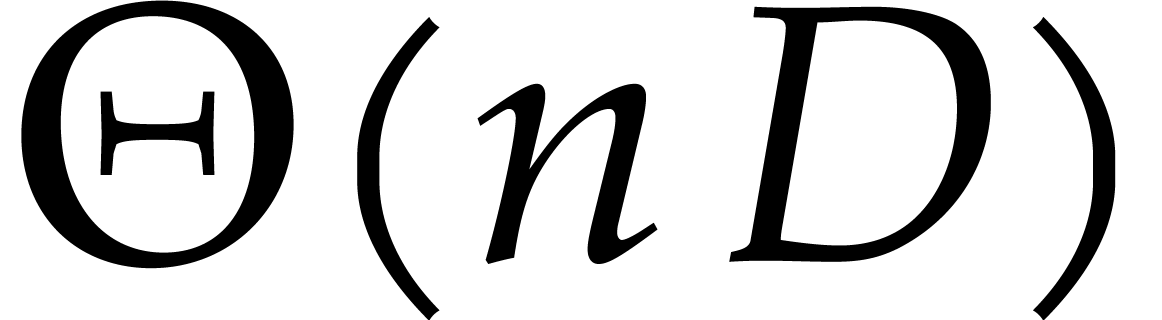 .
This overhead compared to can be reduced: it was
shown in [17] that special bases called vanilla
Gröbner bases admit a terse representation in space that allow for efficient reduction. Obtaining such a terse
representation can be expensive, even if the Gröbner basis is
known, but this can be seen as a precomputation. However, for the graded
lexicographic order, neither nor are vanilla, so the results from [17] do not
apply. Nevertheless, we show in this section that
does admit a concise representation which is analogous to the
concept of terse representation. This representation is compatible with
a new reduction algorithm detailed in section 5, and it
turns out that it can even be computed in time
from the input .
.
This overhead compared to can be reduced: it was
shown in [17] that special bases called vanilla
Gröbner bases admit a terse representation in space that allow for efficient reduction. Obtaining such a terse
representation can be expensive, even if the Gröbner basis is
known, but this can be seen as a precomputation. However, for the graded
lexicographic order, neither nor are vanilla, so the results from [17] do not
apply. Nevertheless, we show in this section that
does admit a concise representation which is analogous to the
concept of terse representation. This representation is compatible with
a new reduction algorithm detailed in section 5, and it
turns out that it can even be computed in time
from the input .
As detailled in section 2, the basis
is constructed such that there are recurrence relations of the form for each 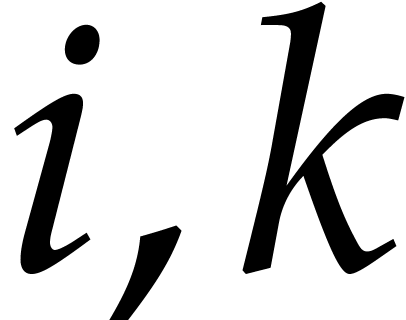 (with ). Equivalently, it is more convenient to write
this in matrix notation
(with ). Equivalently, it is more convenient to write
this in matrix notation
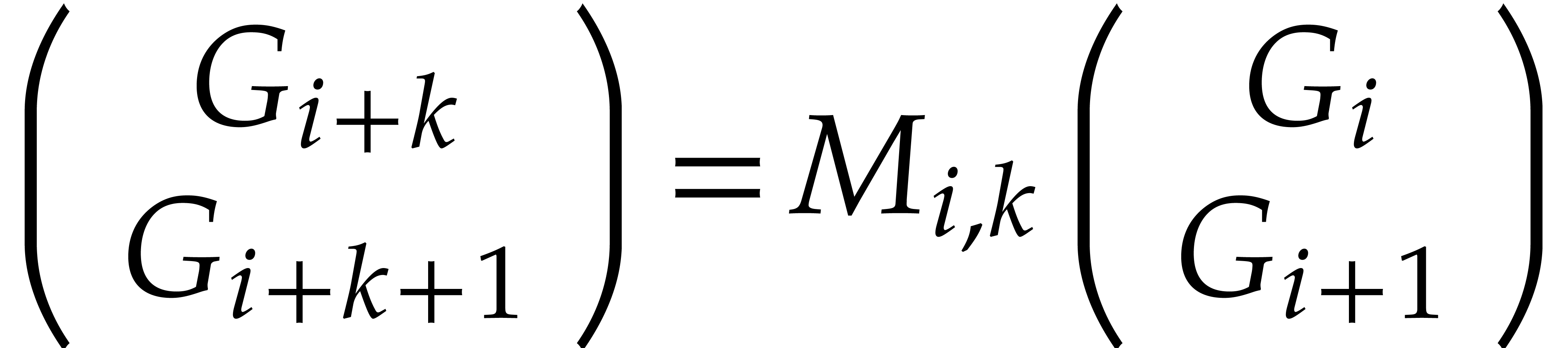 |
(3) |
(where we set 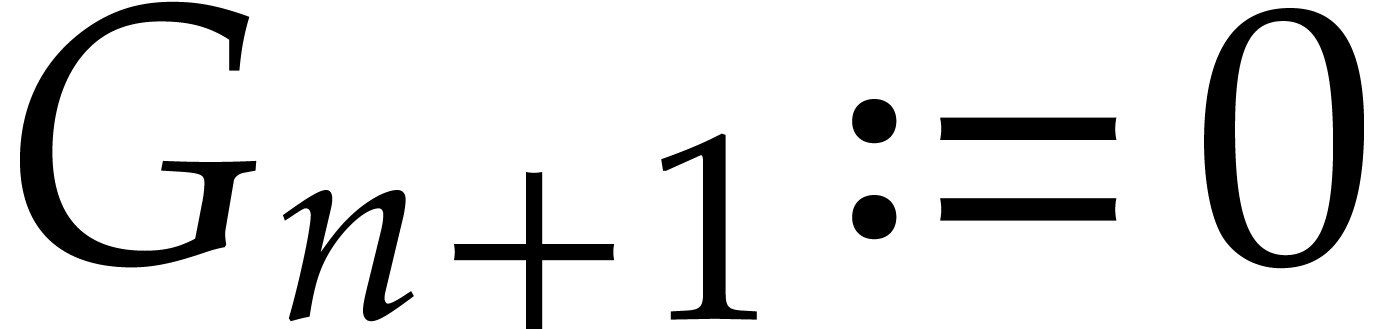 to avoid case distinction). This
matrix notation has the advantage that the
to avoid case distinction). This
matrix notation has the advantage that the 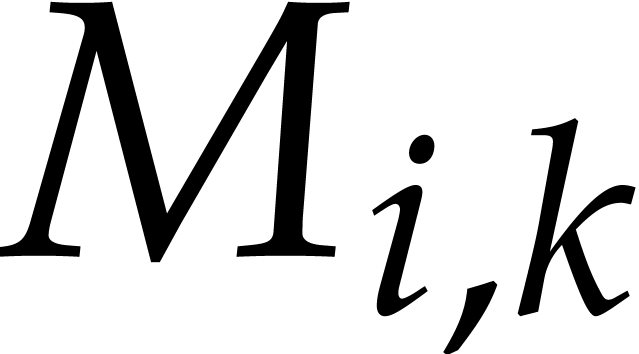 can
be computed from one another using
can
be computed from one another using 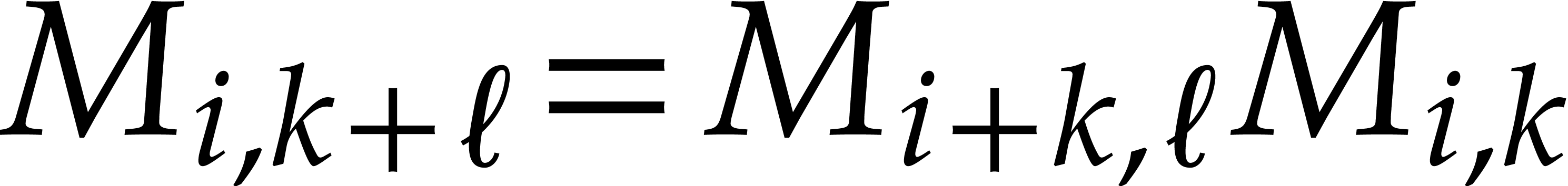 .
Moreover, the size of the coefficients of the
can be controlled as a function of .
.
Moreover, the size of the coefficients of the
can be controlled as a function of .
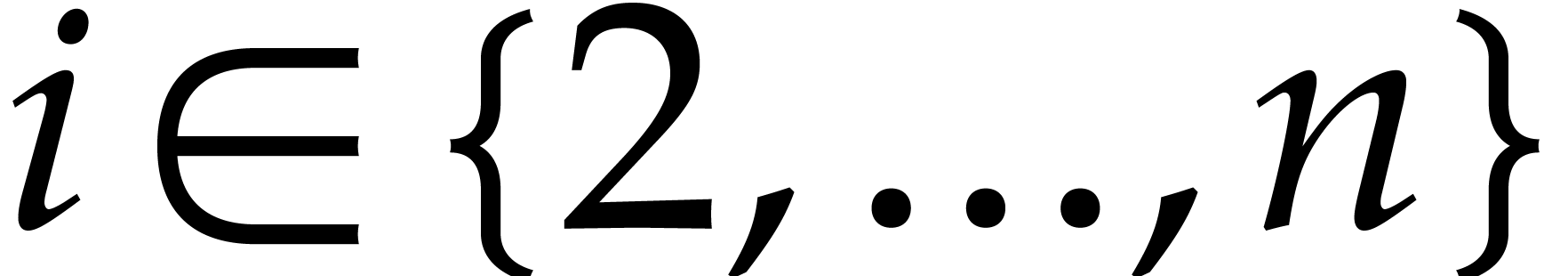 , let
, let 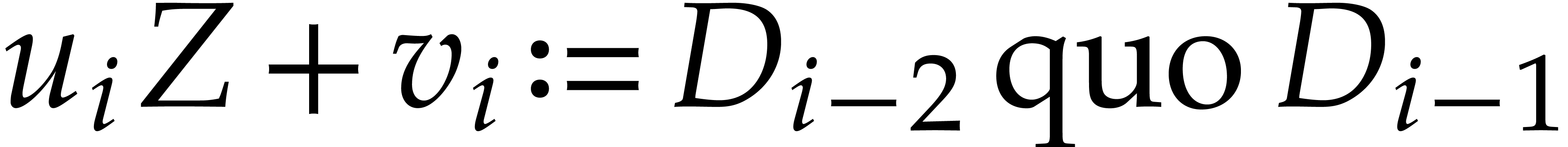 be the successive quotients in the euclidean
algorithm for the dominant diagonals
be the successive quotients in the euclidean
algorithm for the dominant diagonals  and
and  (as in section 2). For each
(as in section 2). For each  with
with 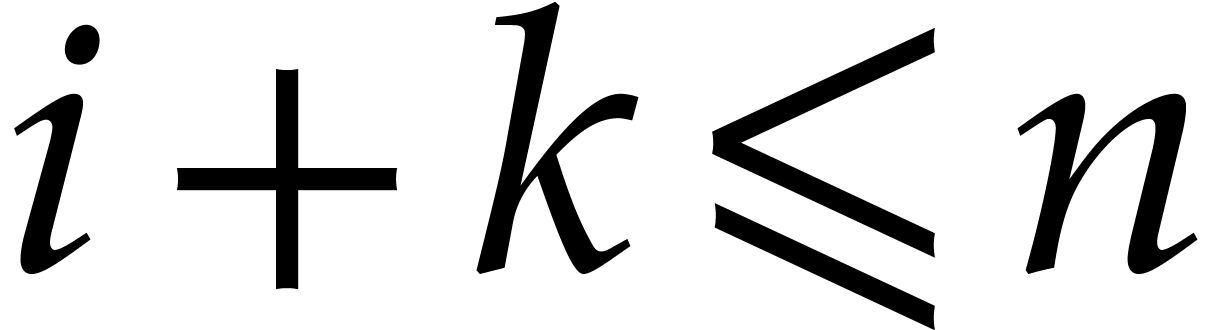 , define
the matrix by
, define
the matrix by
be as
in Definition 5. For all 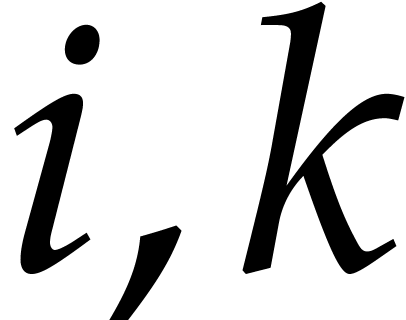 with
, we then have
with
, we then have
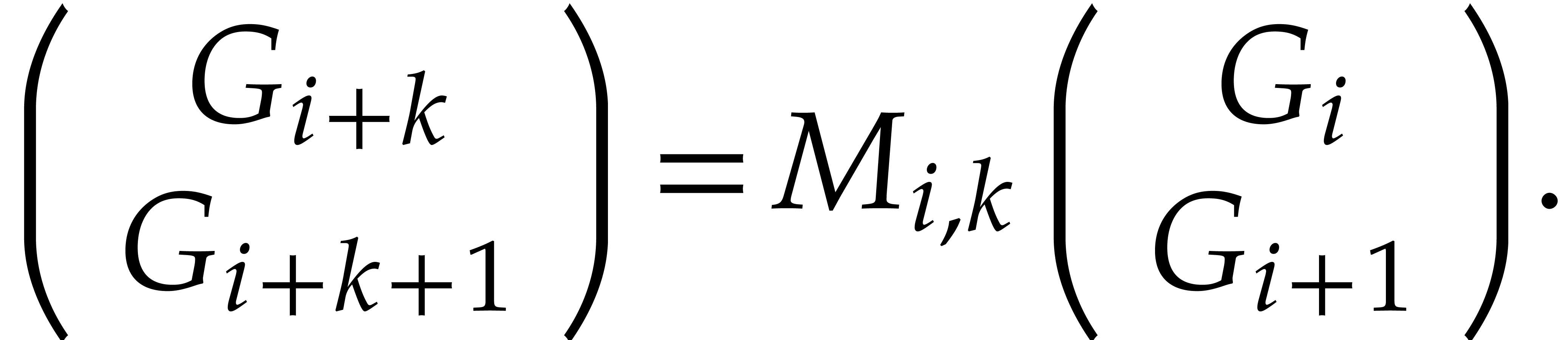
Also, for all 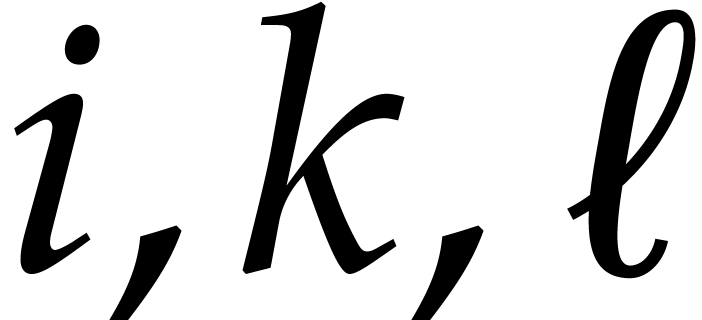 with
with
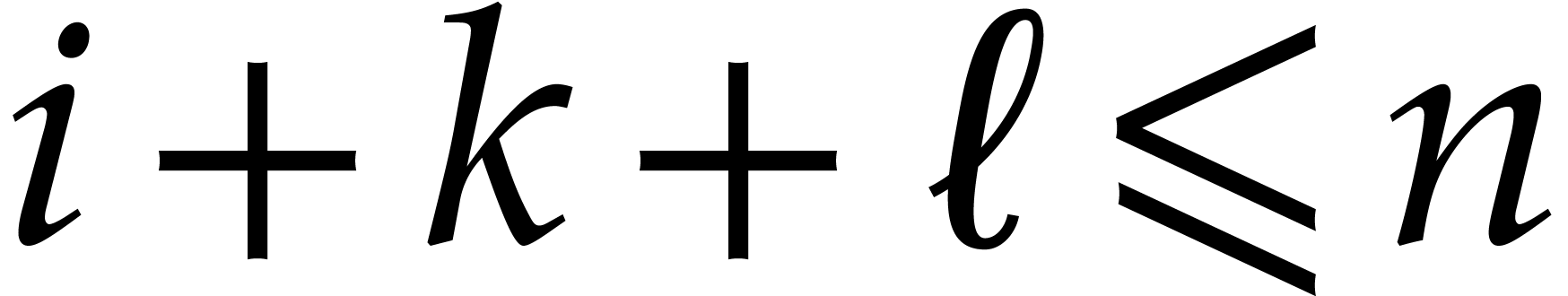 .
.
Now consider the polynomials 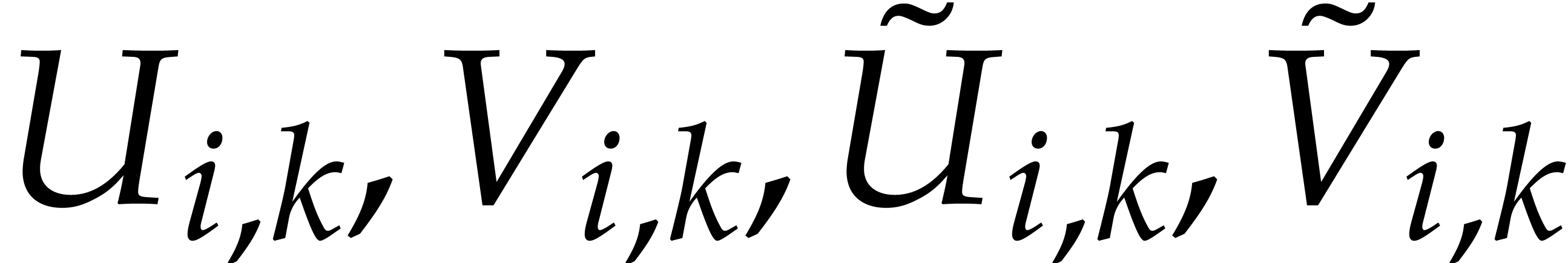 such that
such that
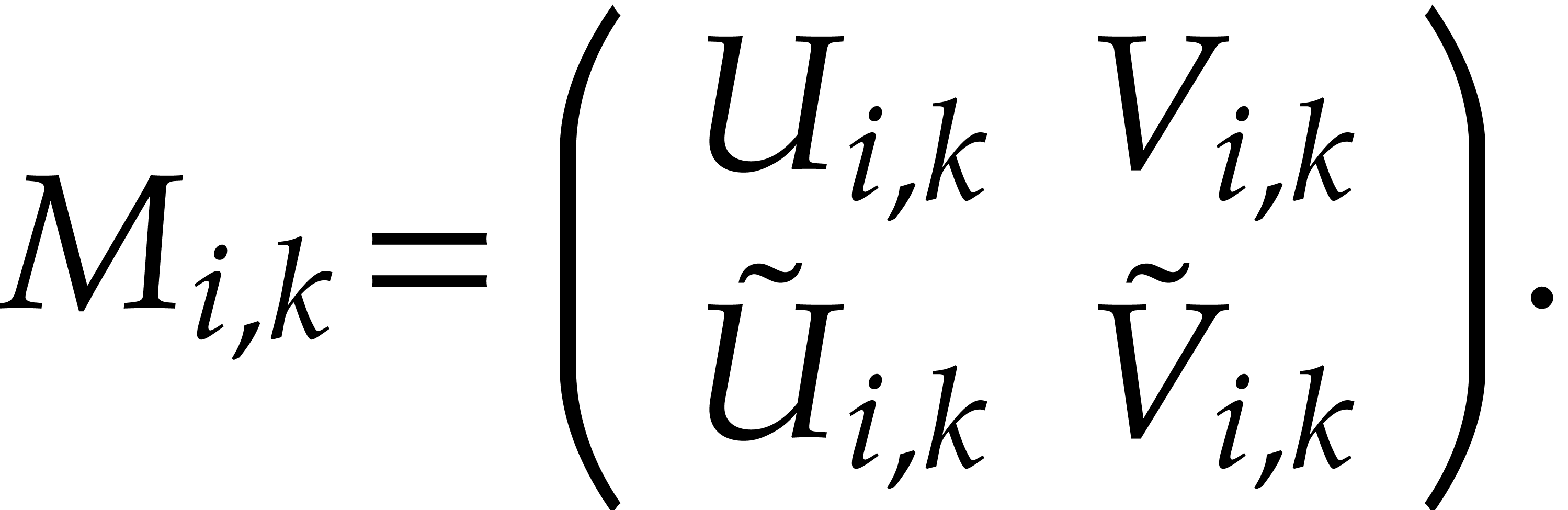
With the convention that the zero polynomial is homogeneous of any degree, we have
For all  , is homogeneous of degree
, is homogeneous of degree  and
and 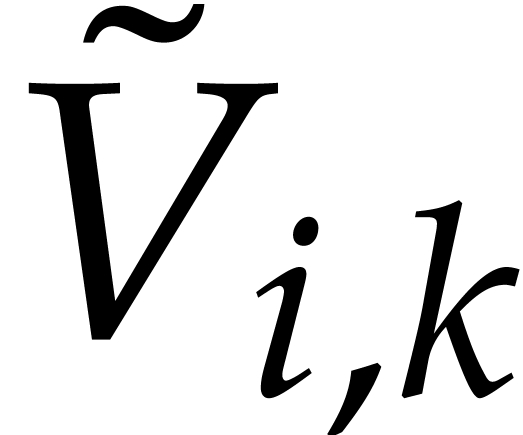 is homogeneous of degree .
is homogeneous of degree .
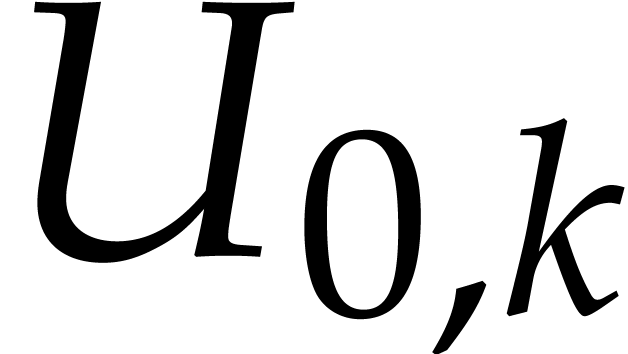 is homogeneous of degree
is homogeneous of degree  and
and 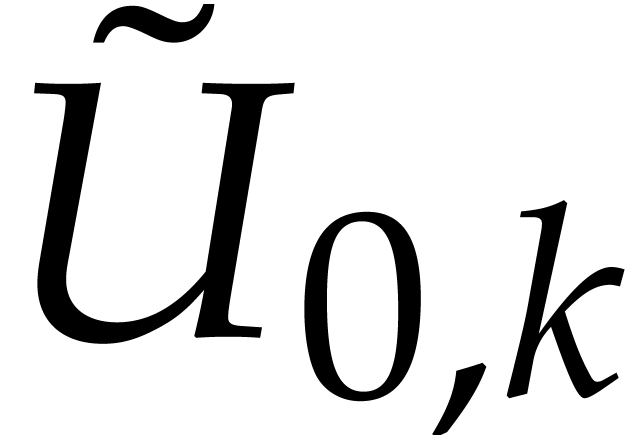 is homogeneous of
degree
is homogeneous of
degree  .
.
For all  , is homogeneous of degree
and
, is homogeneous of degree
and 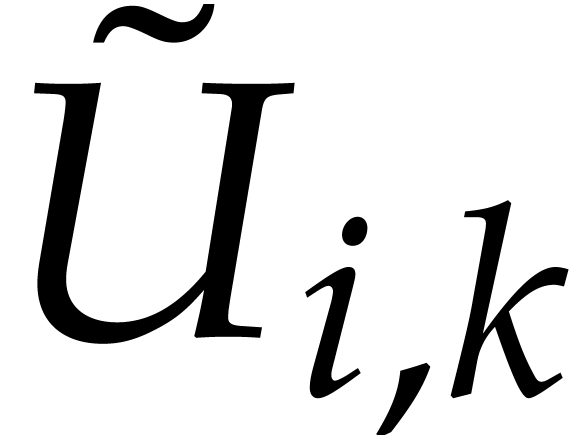 is homogeneous of degree
is homogeneous of degree  .
.
Proof. This is an immediate induction on  using
using 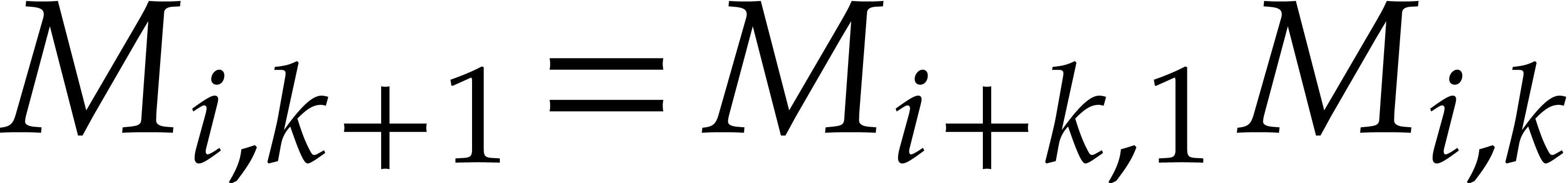 .
.
As in [17], we use a dichotomic selection strategy to
control the degrees of the quotients in the extended reduction, together
with rewriting rules to evaluate the combination  . Then it is sufficient to know enough head terms of
each to compute the reduction. Finally, we
observe that if and
. Then it is sufficient to know enough head terms of
each to compute the reduction. Finally, we
observe that if and  are
known with sufficient precision, then
are
known with sufficient precision, then 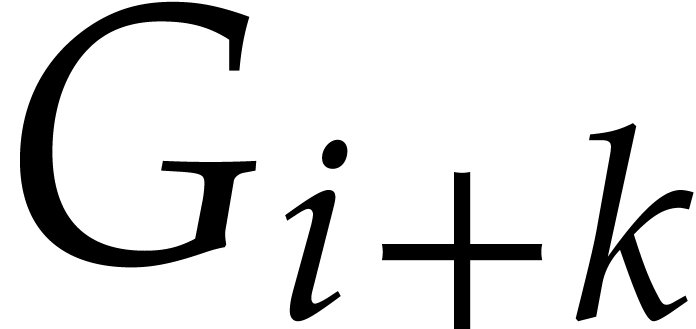 and
and 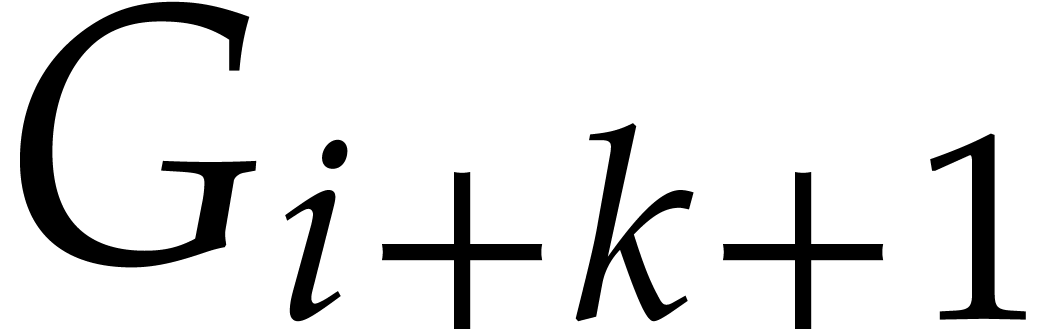 can be computed with the same precision using the
relation (3) above. More formally, we define the precision
as follows:
can be computed with the same precision using the
relation (3) above. More formally, we define the precision
as follows:
,
we define its upper truncation with precision 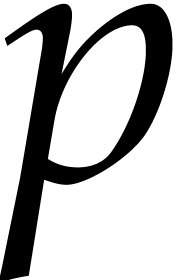 as the polynomial
as the polynomial  such that
such that
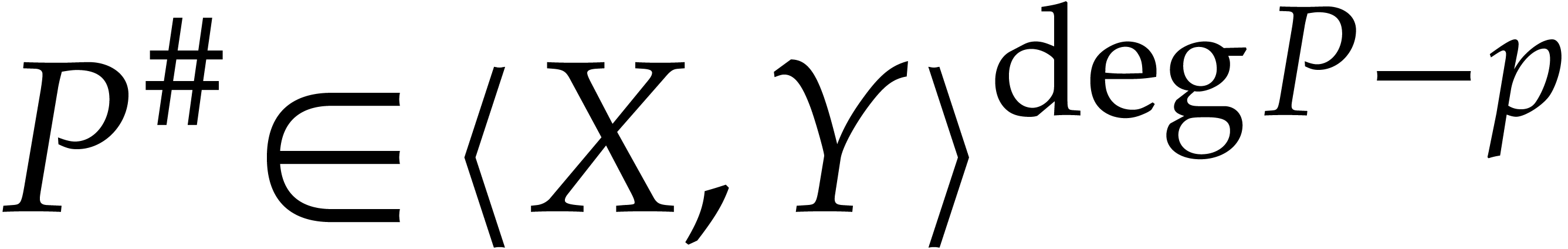 ;
;
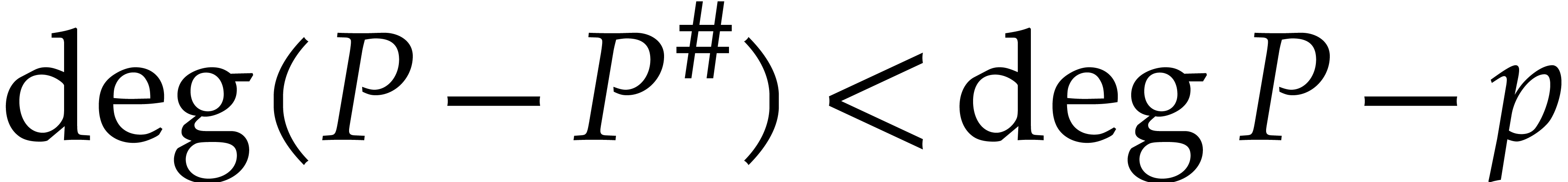 .
.
In other words, and 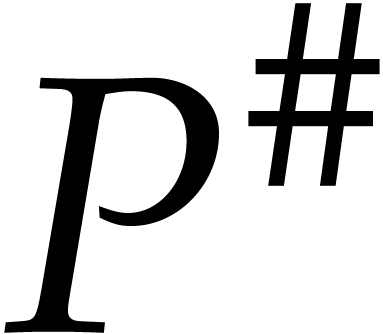 have the same terms of degree at least
have the same terms of degree at least 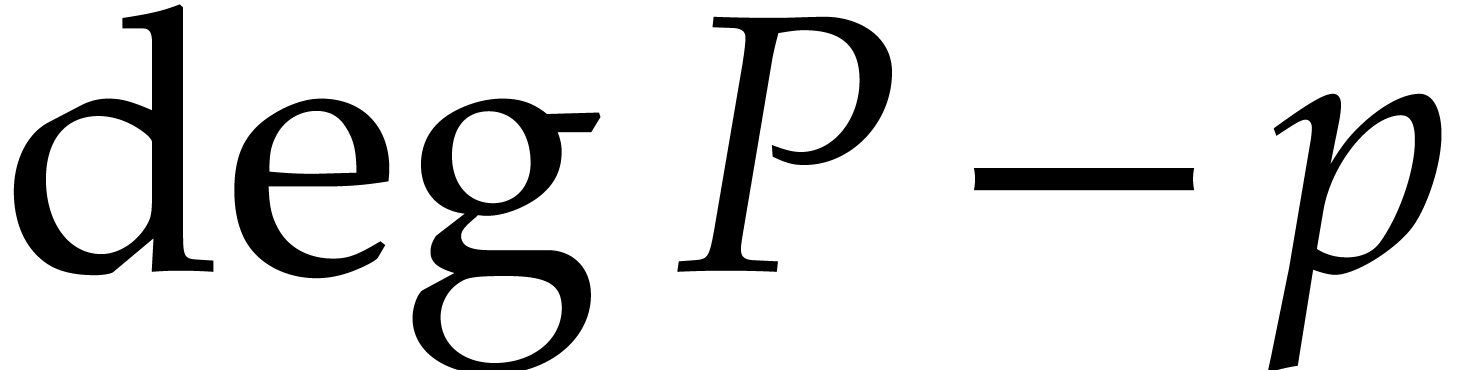 ,
but all terms of of degree less than are zero.
,
but all terms of of degree less than are zero.
With the dichotomic selection strategy that we plan to use, we have 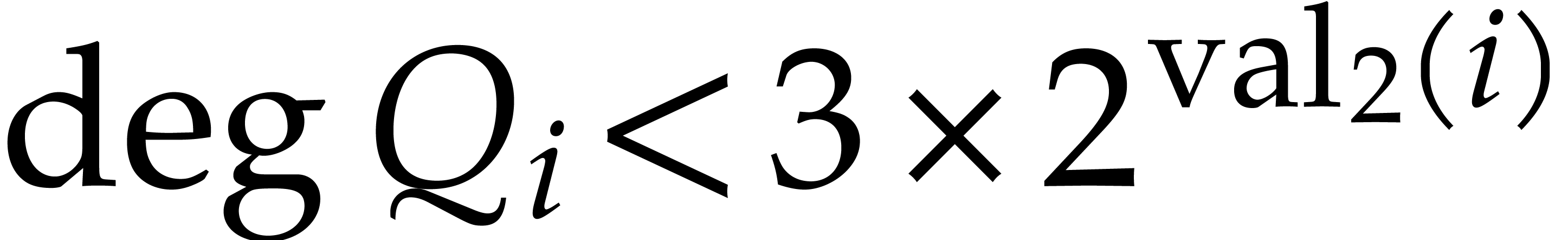 for
for 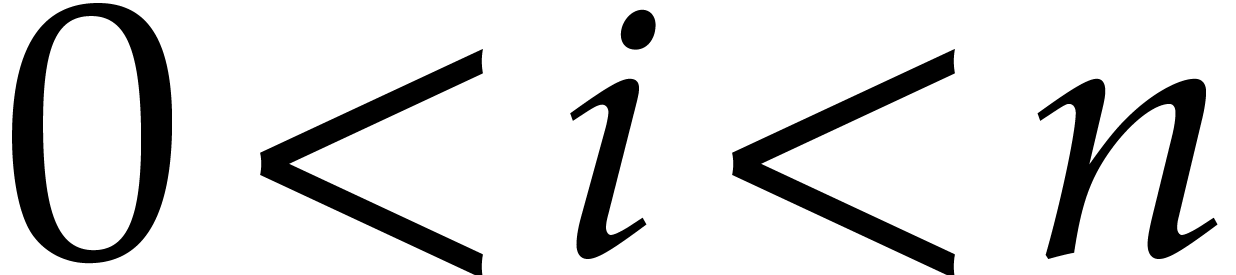 , so
it is a priori sufficient to compute
with this precision. However, the rewriting rules between the involve two consecutive elements, so that
, so
it is a priori sufficient to compute
with this precision. However, the rewriting rules between the involve two consecutive elements, so that 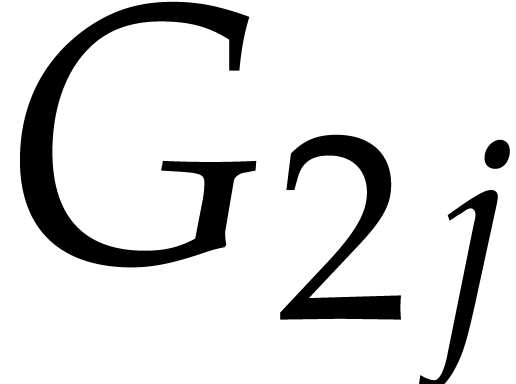 and
and 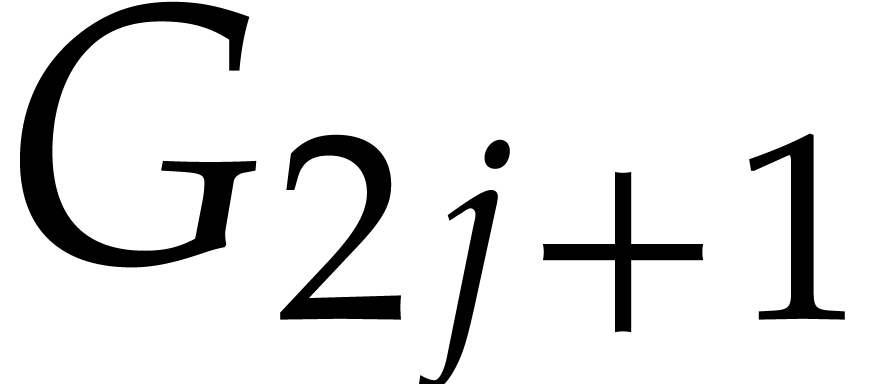 need to be known with the same precision.
need to be known with the same precision.
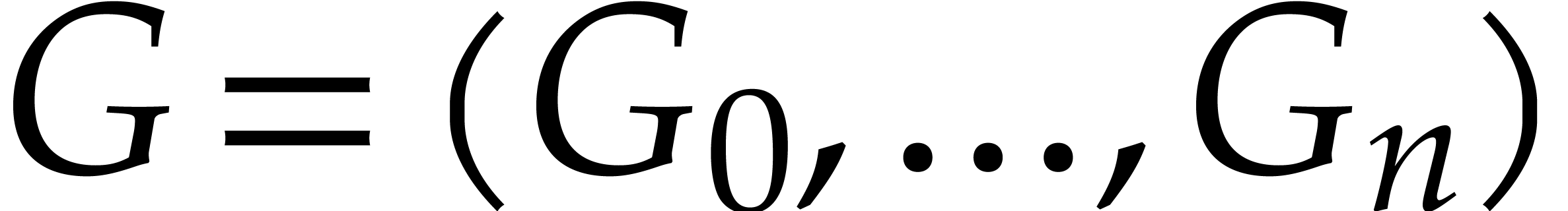 consists of the following data:
consists of the following data:
The sequence of truncated elements 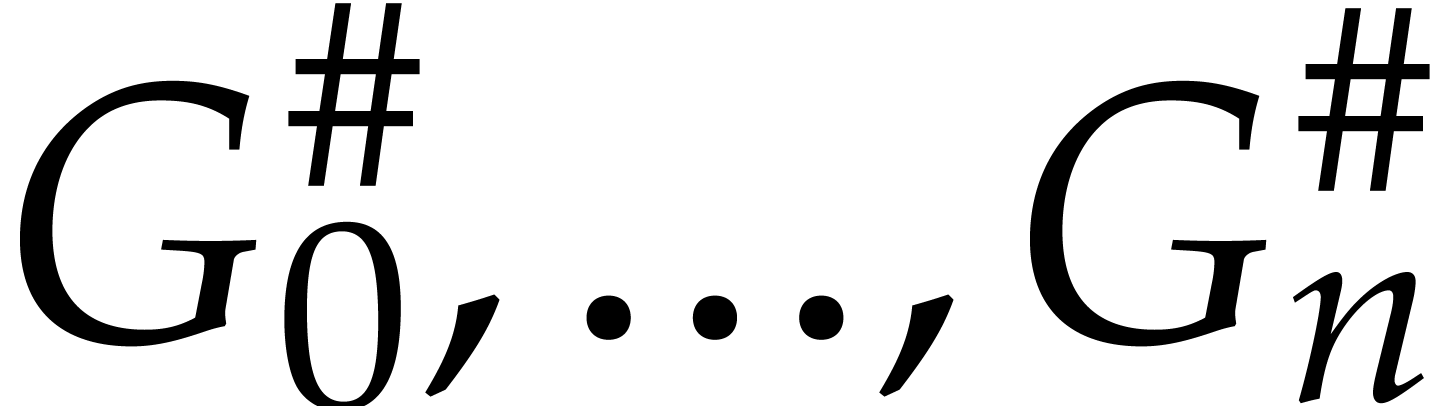 ,
where
,
where
for  ,
,  ;
;
for all other ,
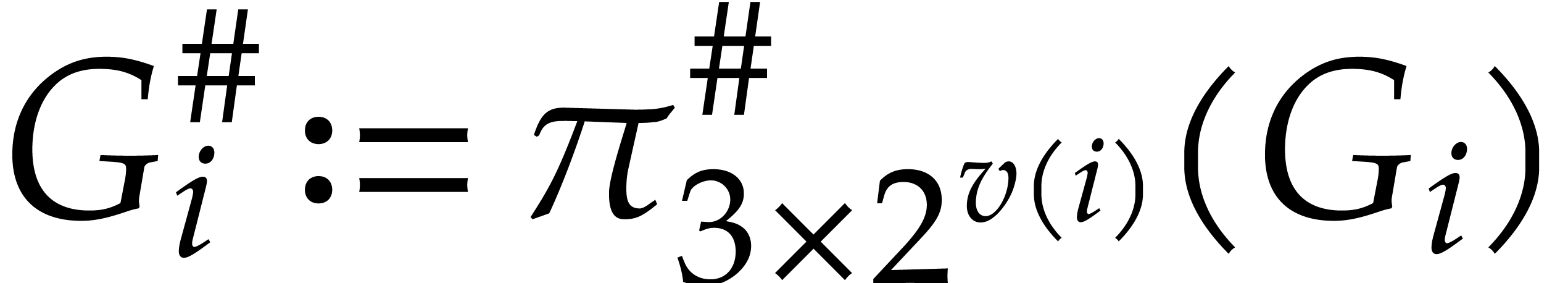 , with the
notation
, with the
notation 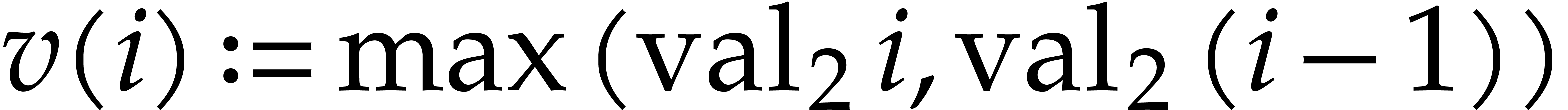 ;
;
The collection of rewriting matrices  for
each
for
each  where the notation
is defined as follows: with the matrices
as in Definition 5, we set
where the notation
is defined as follows: with the matrices
as in Definition 5, we set
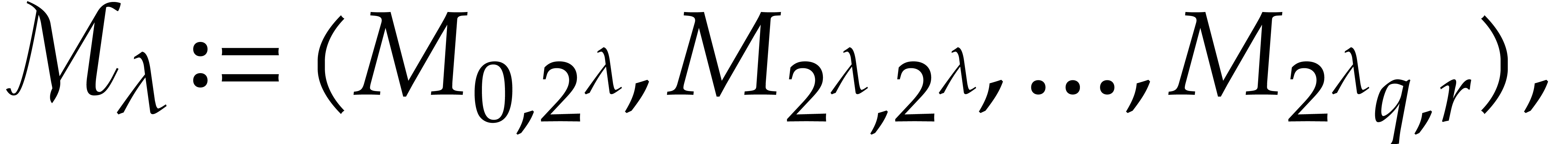
with 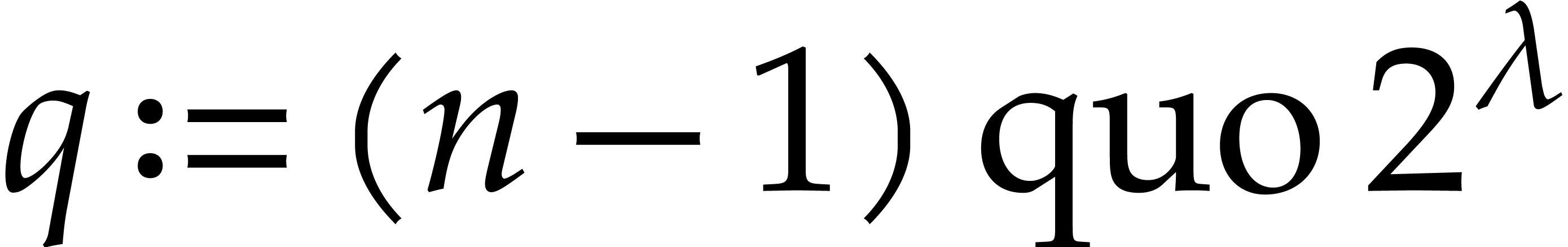 and
and 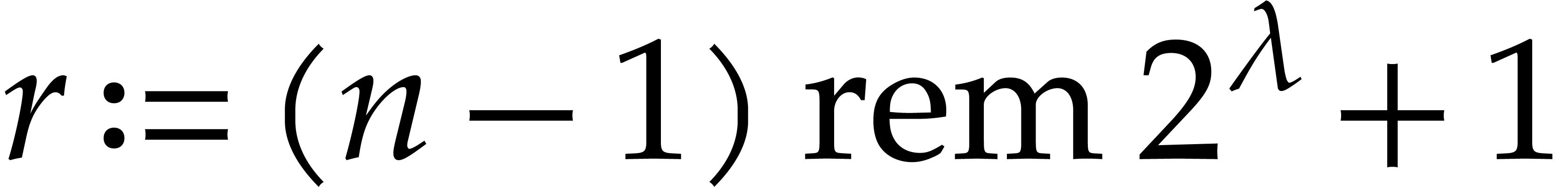 .
.
As expected, the concise representation requires quasi-linear space with respect to the degree of the ideal.
Proof. It is easy to see that
has degree at most 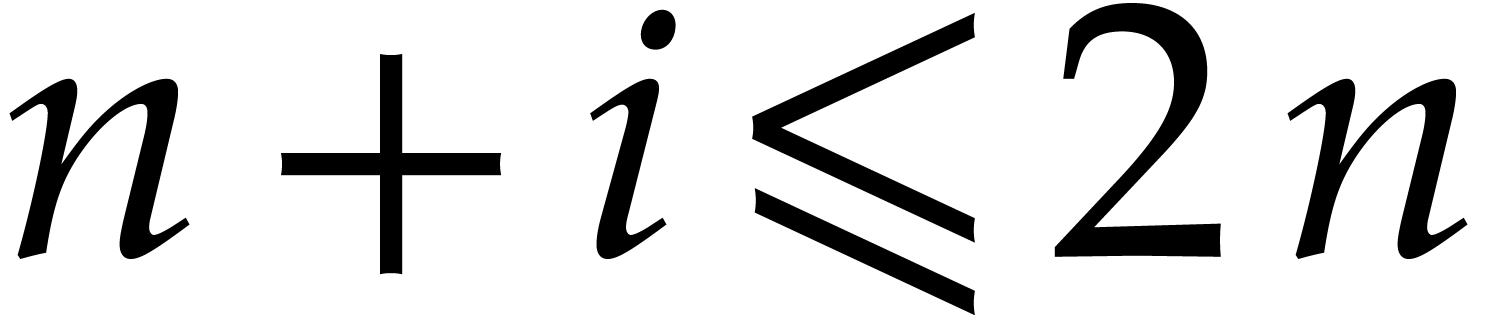 in the variable , and at most
in the variable , and at most 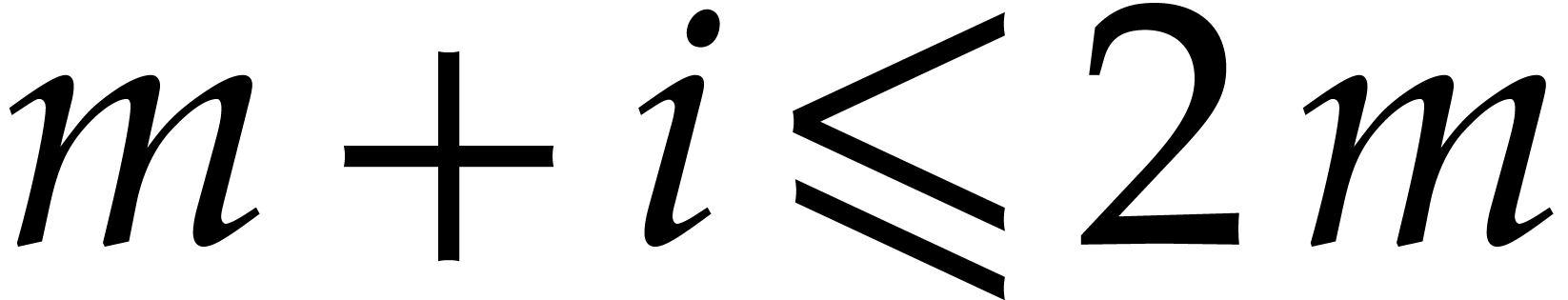 in the
variable and in total degree. Then for , each non-truncated element
in the
variable and in total degree. Then for , each non-truncated element 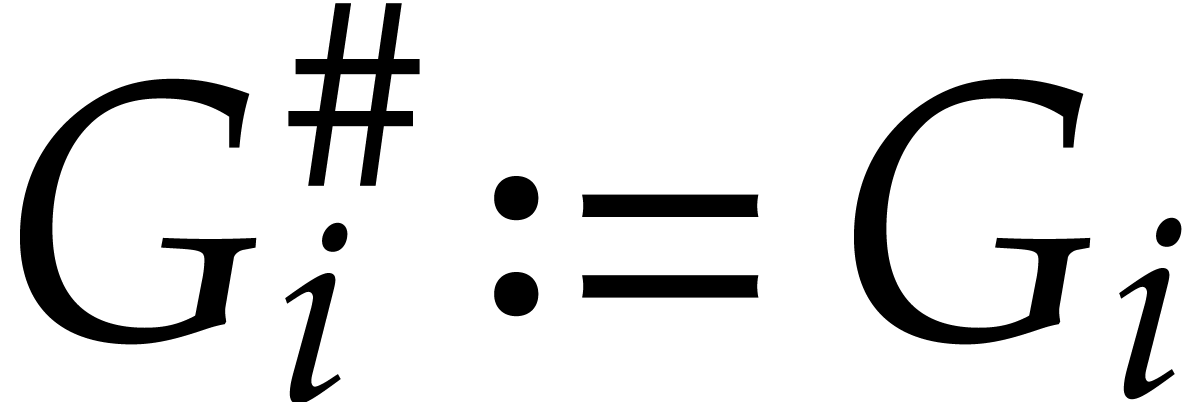 takes
takes 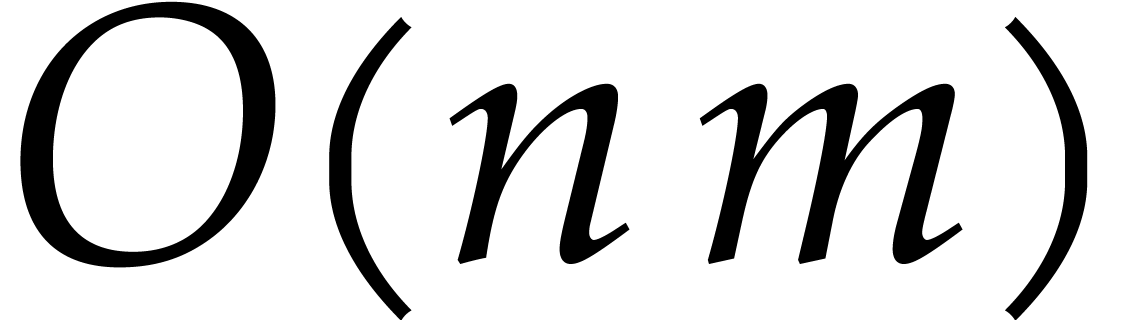 space. Similarly, for
space. Similarly, for
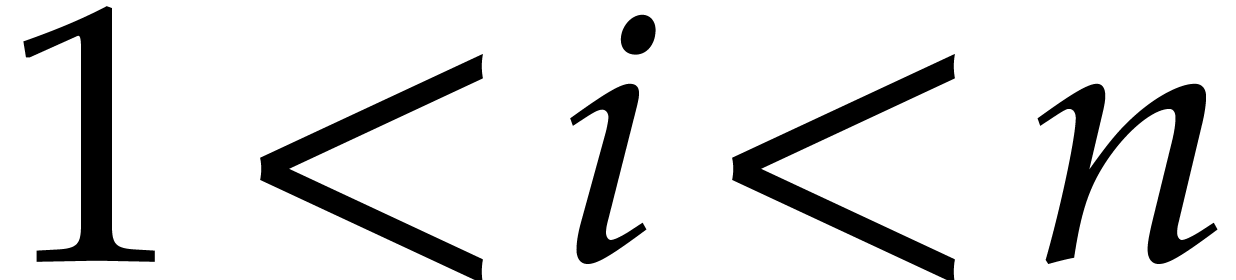 , each truncated element
, each truncated element  requires
requires 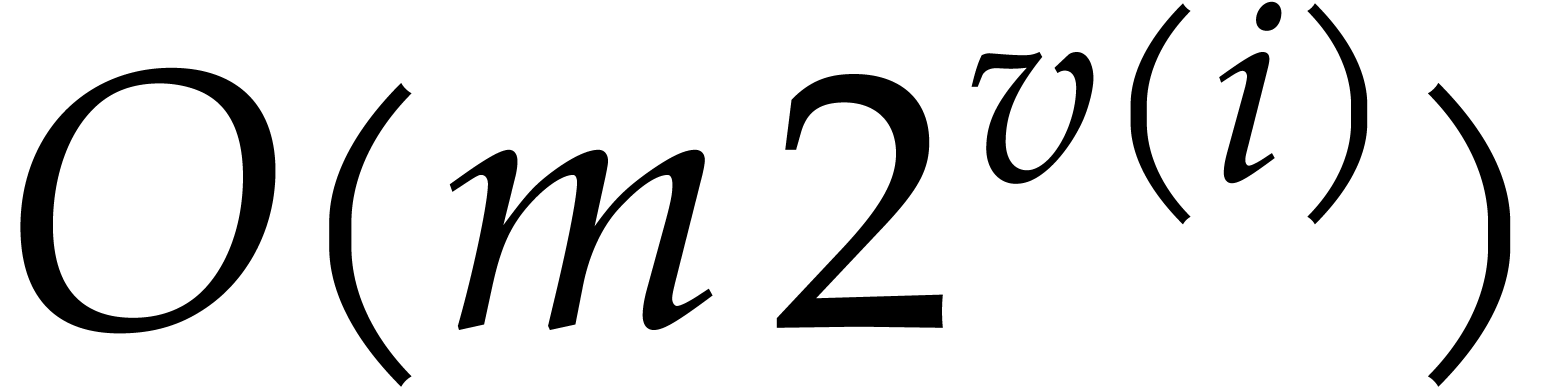 space. For each
space. For each
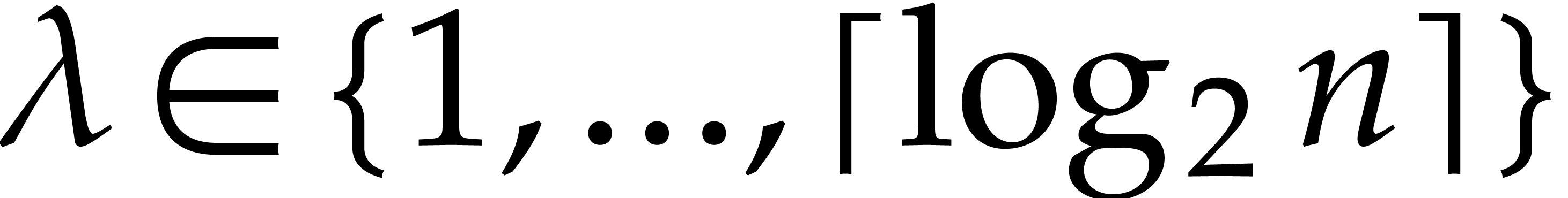 , there are roughly
, there are roughly 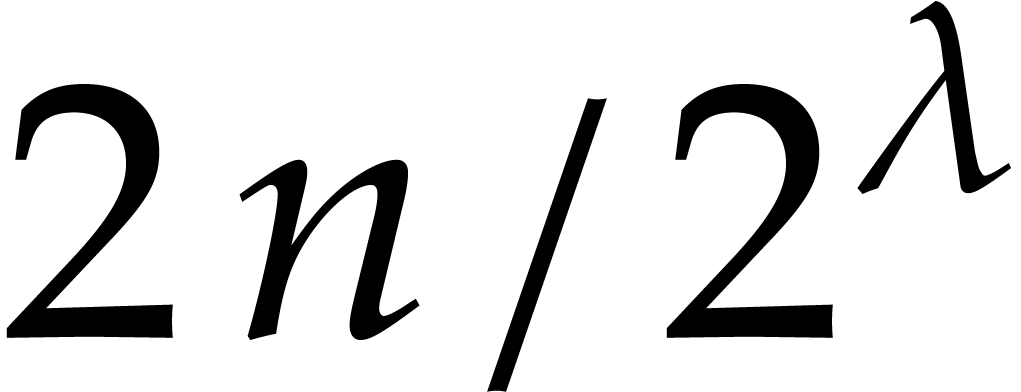 indices
indices  such that
such that 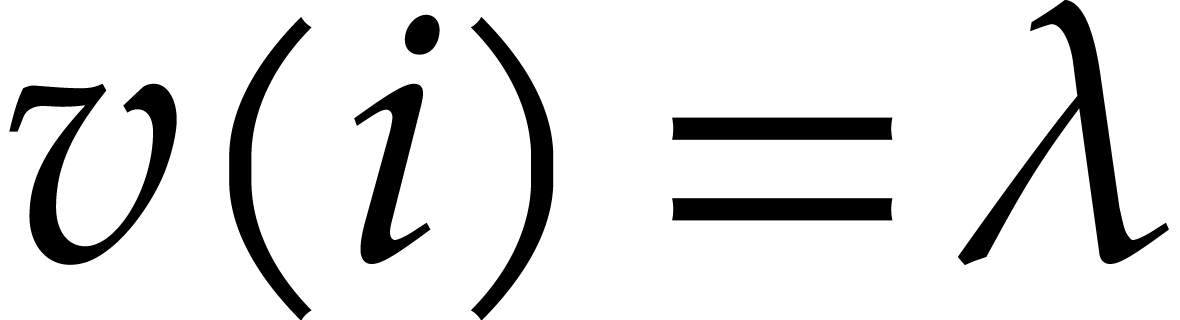 , so all elements together require
, so all elements together require 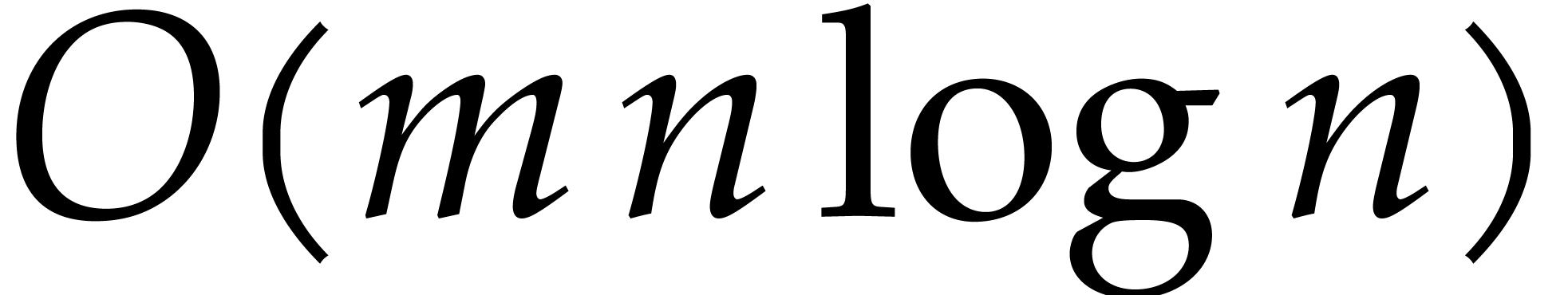 space.
space.
There are 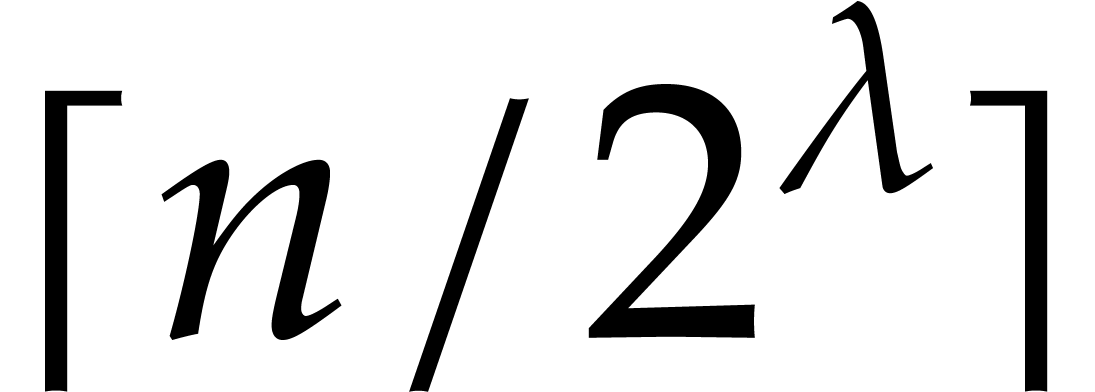 elements in , each consisting of four homogeneous polynomials of
degree roughly
elements in , each consisting of four homogeneous polynomials of
degree roughly 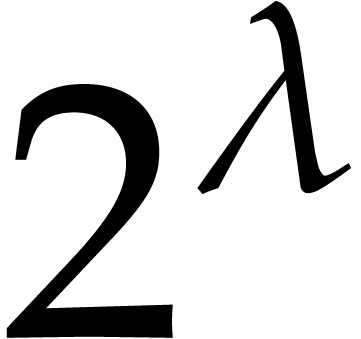 (by Proposition 6),
except for
(by Proposition 6),
except for 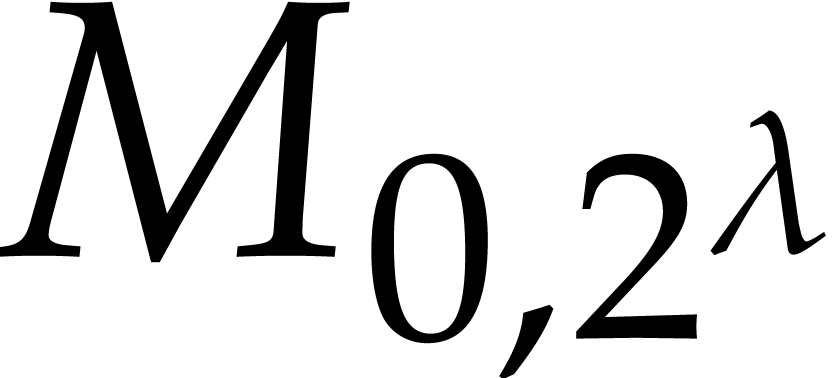 that has two polynomial entries of
degree roughly and two entries of degree roughly
that has two polynomial entries of
degree roughly and two entries of degree roughly
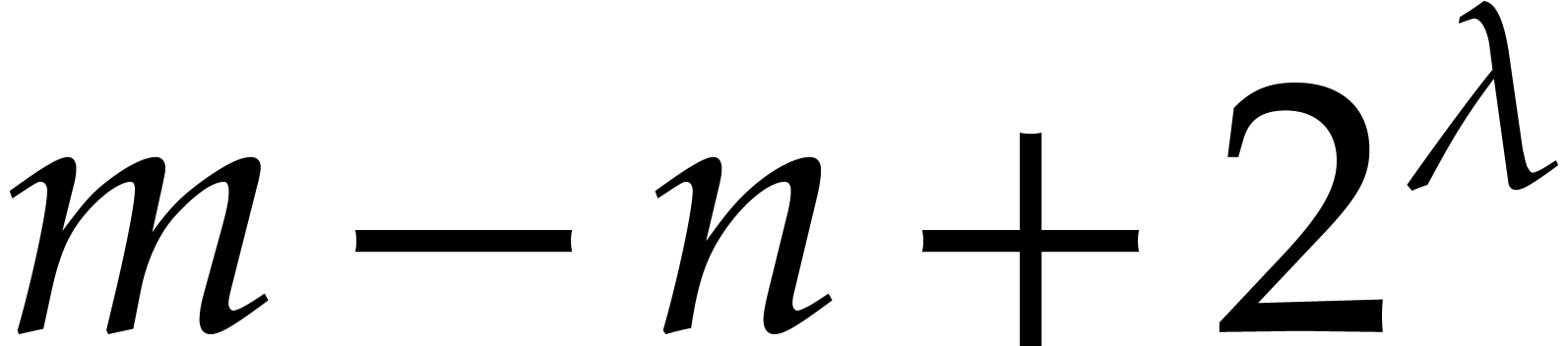 . Hence
requires
. Hence
requires  space and the collection of all takes
space and the collection of all takes  space.
space.
The definition of the concise representation as above is constructive,
but the order of the computation must be carefully chosen to achieve the
expected quasi-linear complexity. First, by exploiting the recurrence
relations , it is easy to
compute 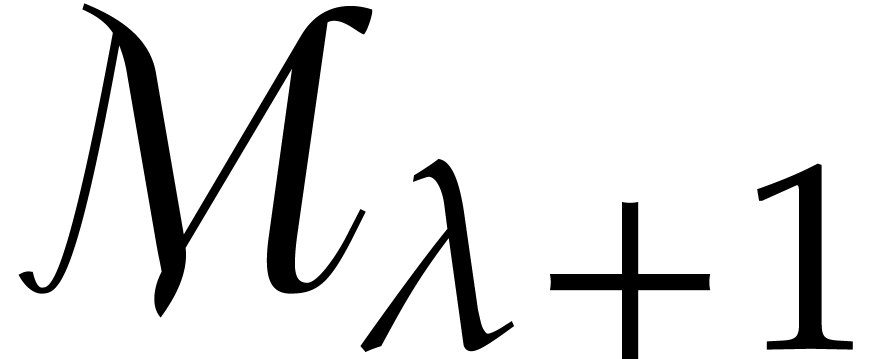 from using the
following auxilliary function:
from using the
following auxilliary function:
Algorithm
Input: as in Definition 8.
Output: as in Definition 8.
Set 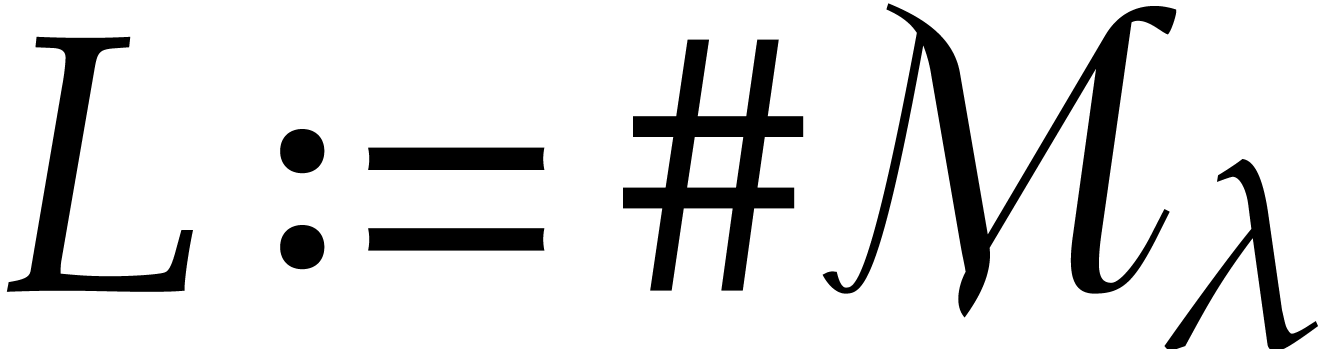 .
.
For each 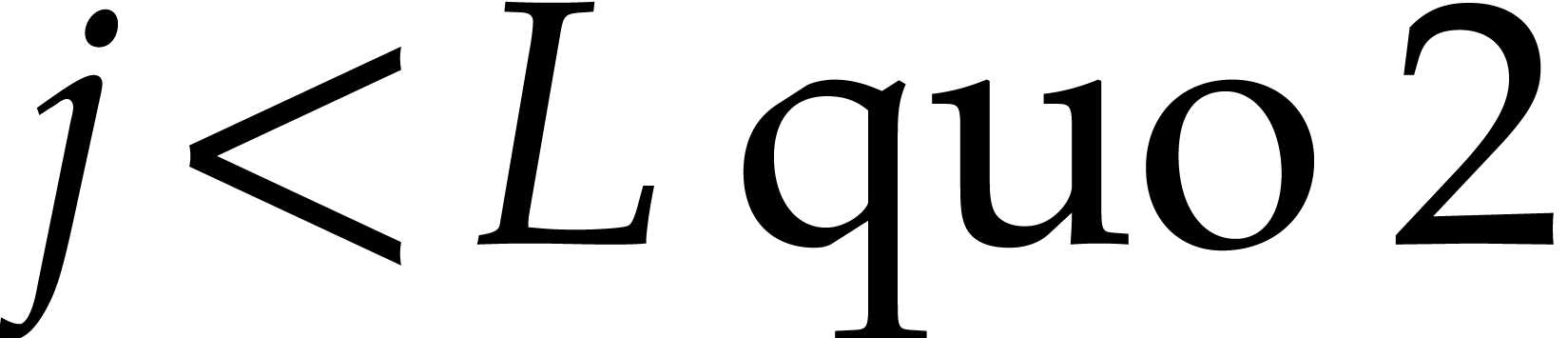 :
:
Set 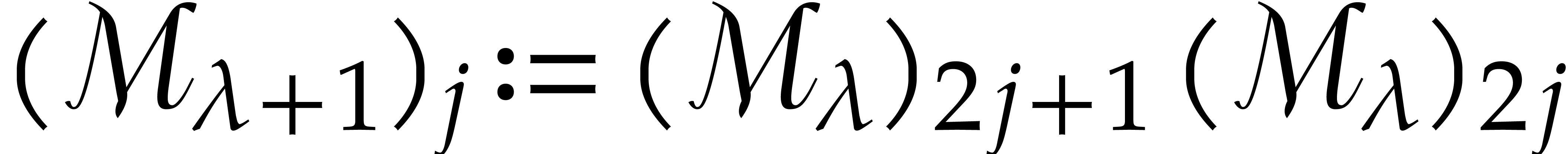 .
.
If  :
:
Set 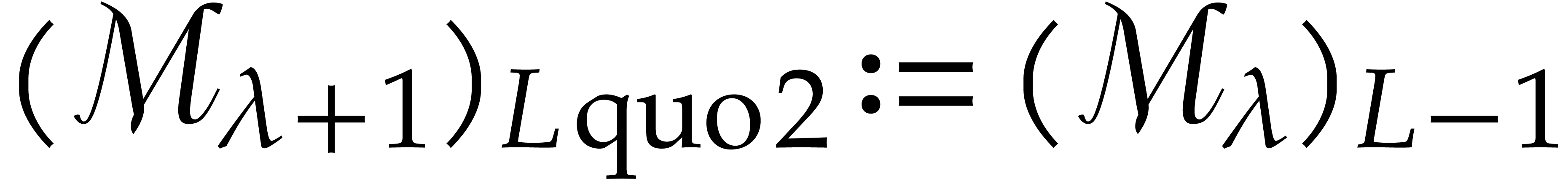 .
.
Return .
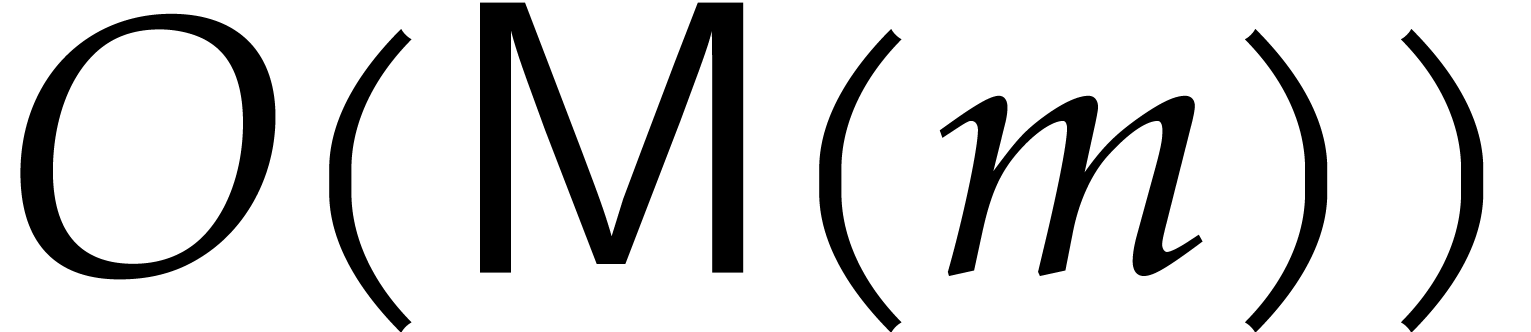 .
.
Proof. Recall that for
all with .
In particular, taking  shows that
shows that 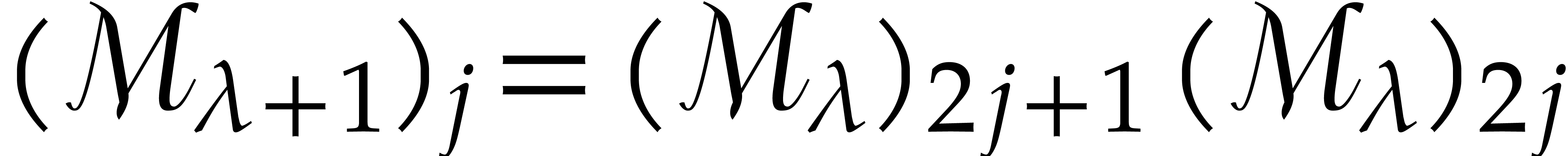 if
if  . Concerning
the last element of (that is,
. Concerning
the last element of (that is, 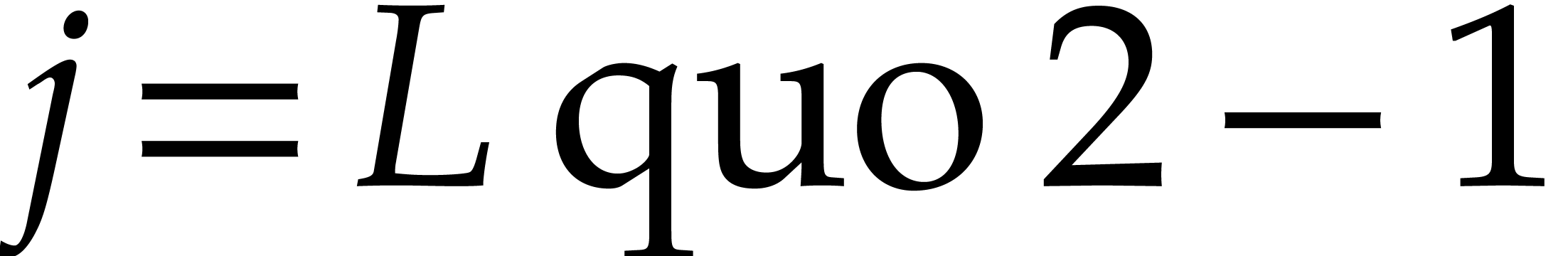 if
if  is even,
is even, 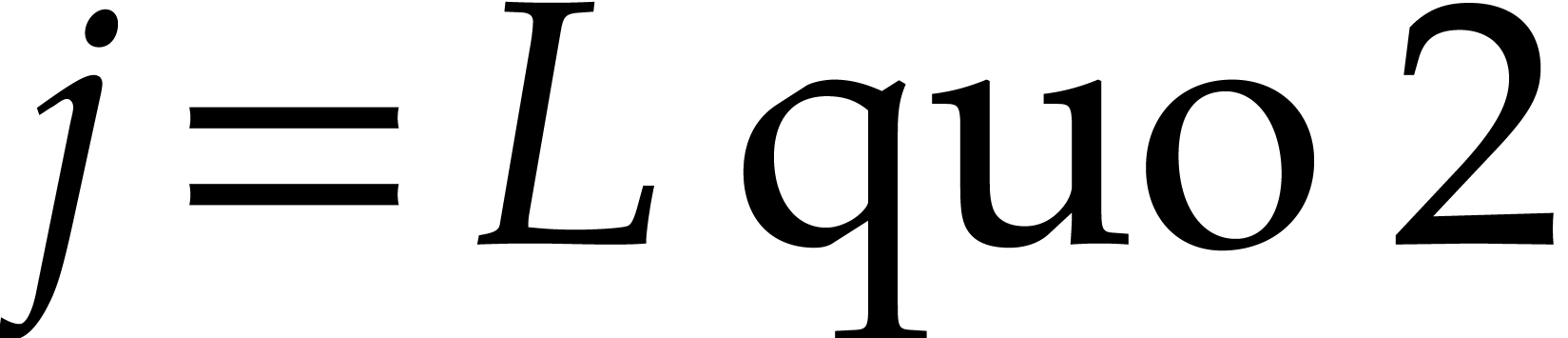 otherwise),
define
otherwise),
define

If  , then
, then 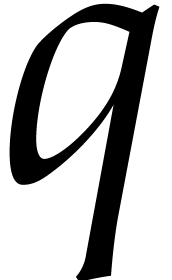 is odd, that is
is odd, that is 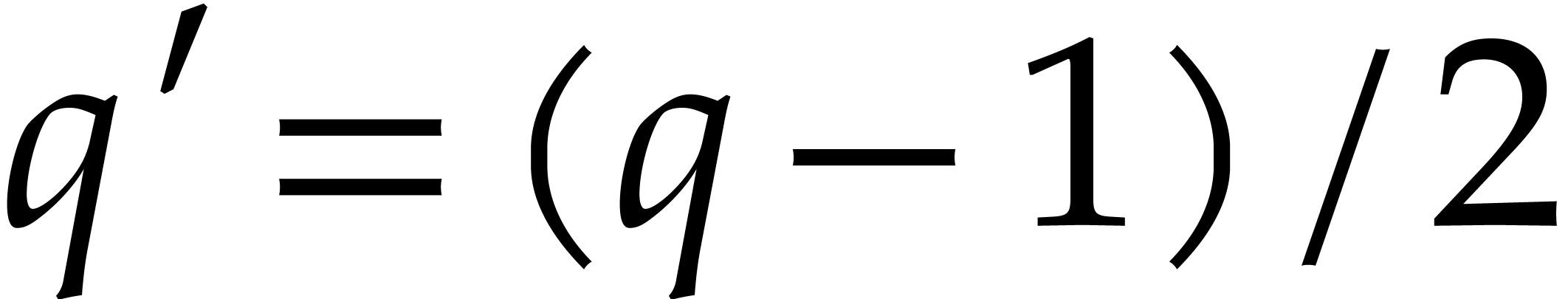 and
and 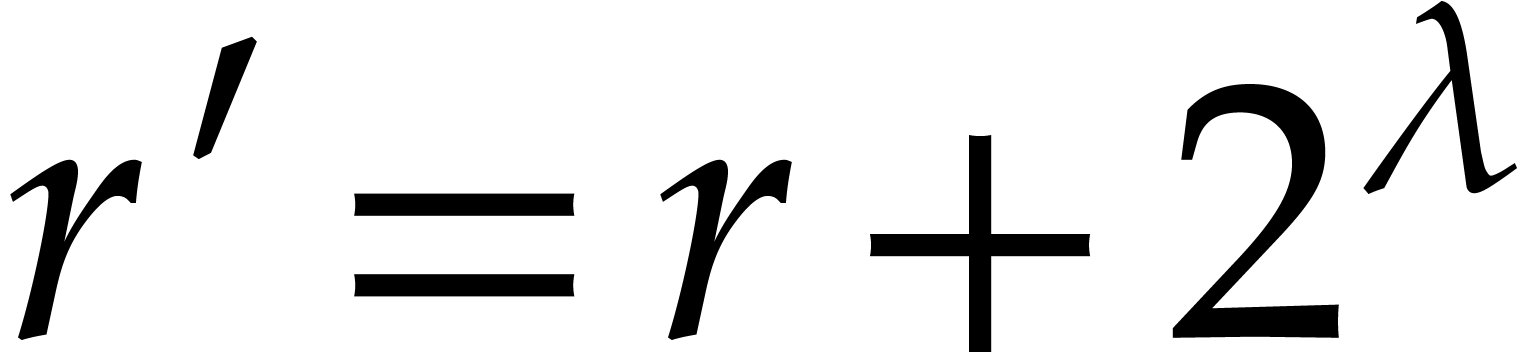 , so that
, so that 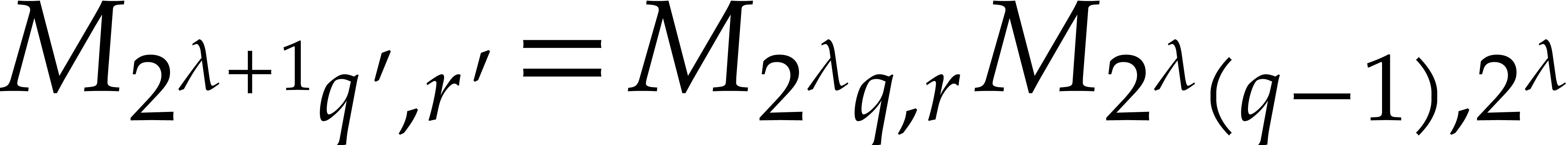 is indeed the
product of the last two elements of .
Conversely if , then
is indeed the
product of the last two elements of .
Conversely if , then 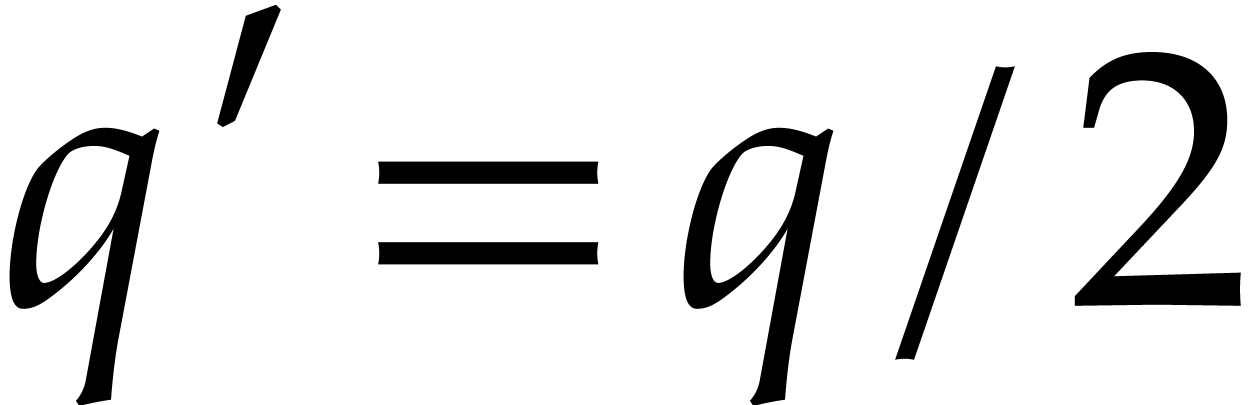 and
and 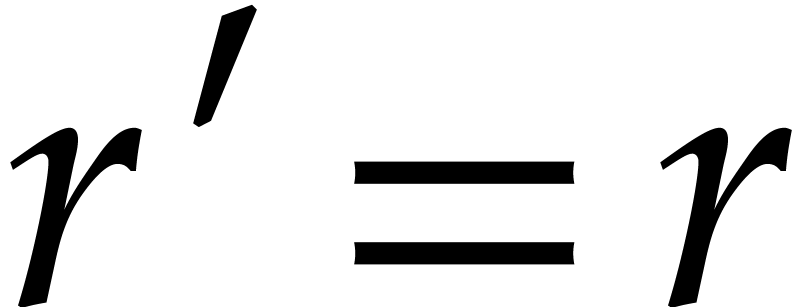 so that
and have the same last element.
so that
and have the same last element.
The complexity bound is obtained with the same argument as for
Proposition 9.
The algorithm to compute the concise representation can be decomposed in
three steps. First a euclidean algorithm gives recurrence relations of
order 1. A second elementary step is to deduce higher order relations by
the above algorithm. Finally, one has to compute the truncated basis
elements . Starting with
those of highest precision avoids computing unnecessary terms, so that
quasi-linear complexity can be achieved.
Algorithm
Output:  , the
concise representation of a Gröbner basis of
, the
concise representation of a Gröbner basis of 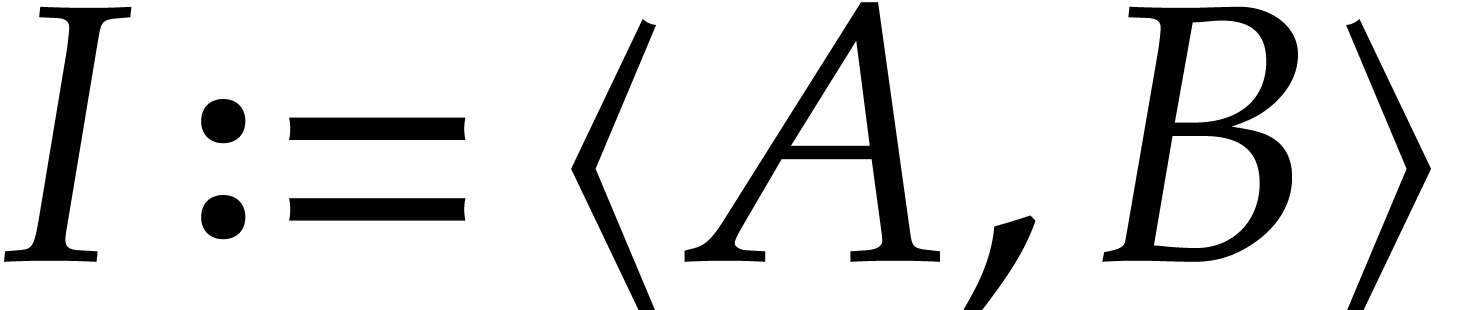 with respect to .
with respect to .
Set 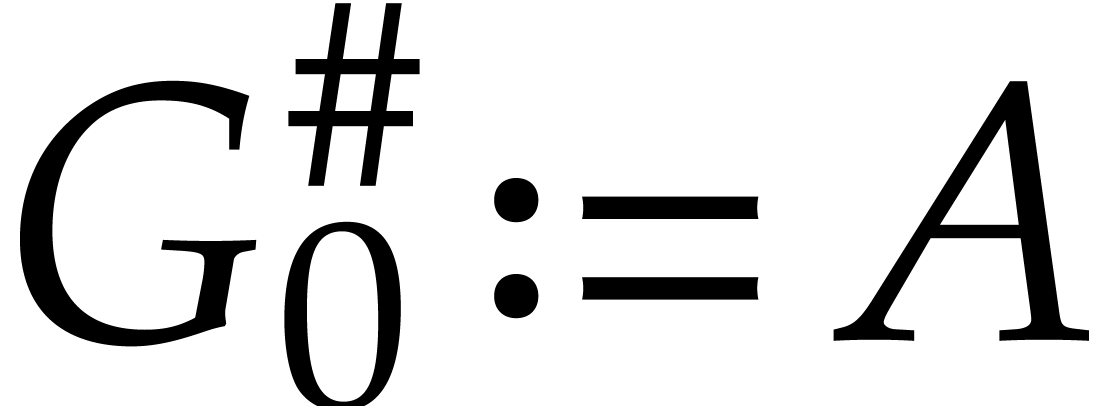 and
and 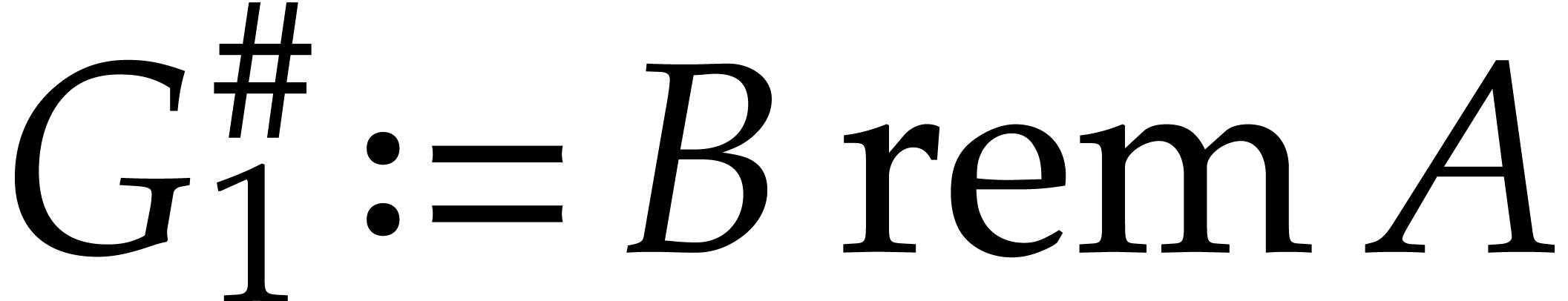 .
.
Set  and
and  .
.
For each :
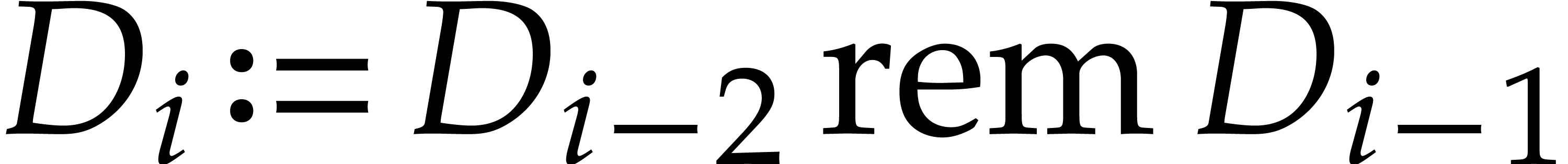 and .
and .
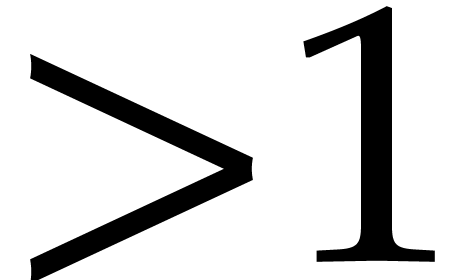
If 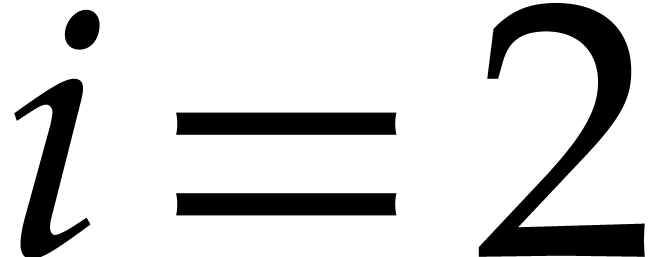 , then set
, then set 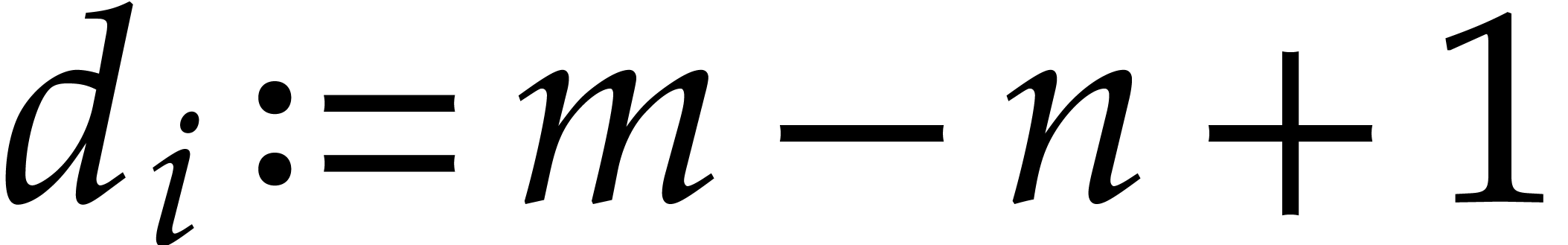 , otherwise set
, otherwise set 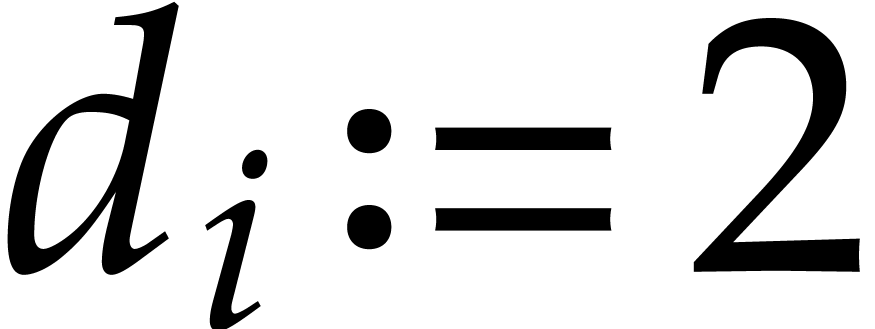 .
.
Set 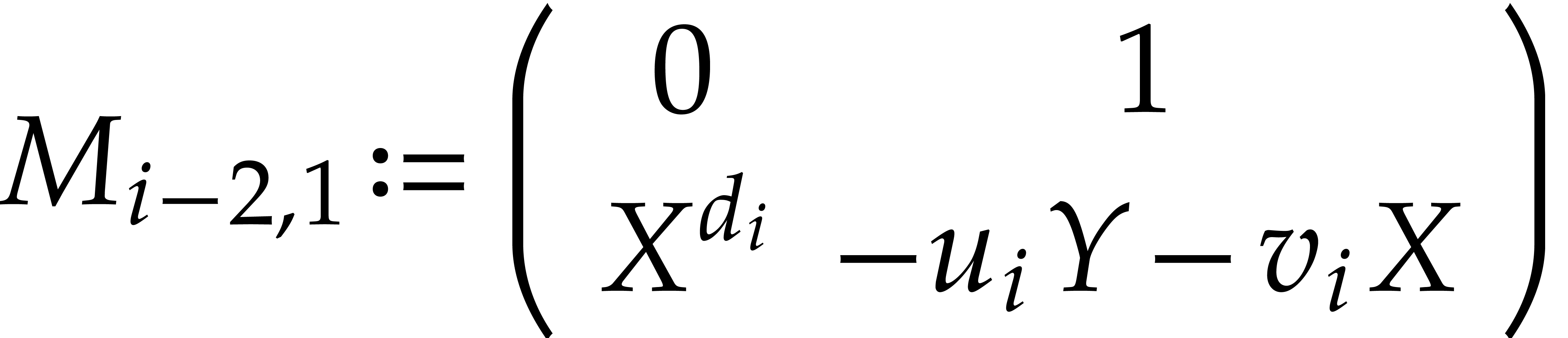 .
.
Set 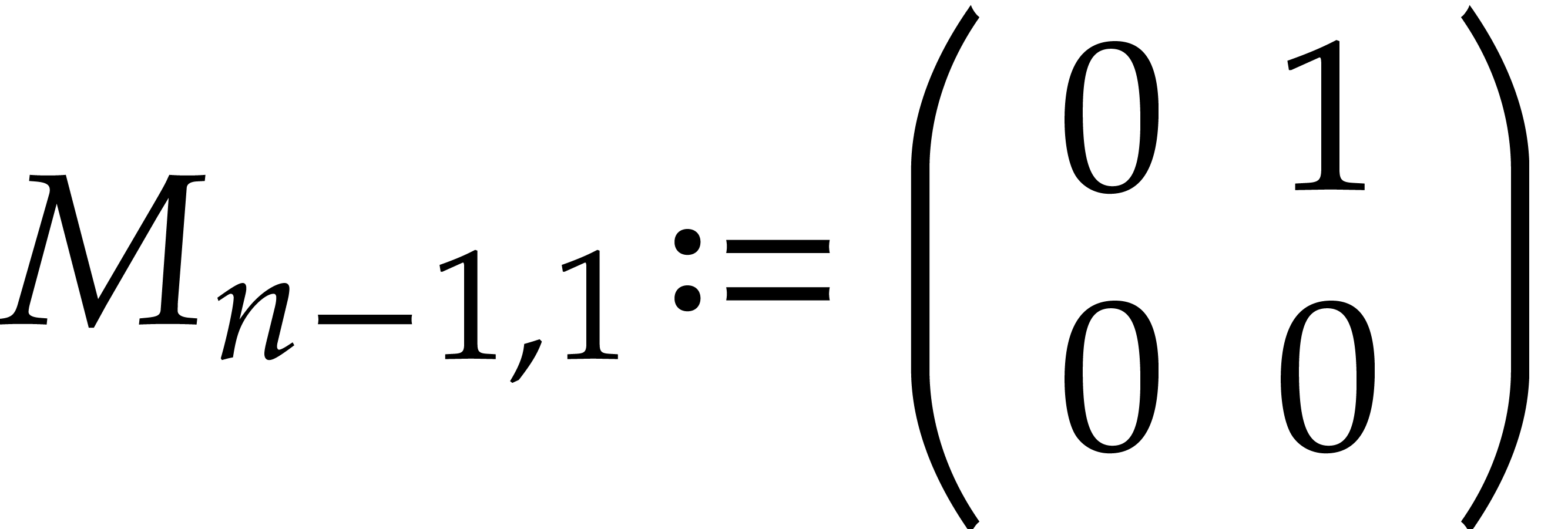 and
and 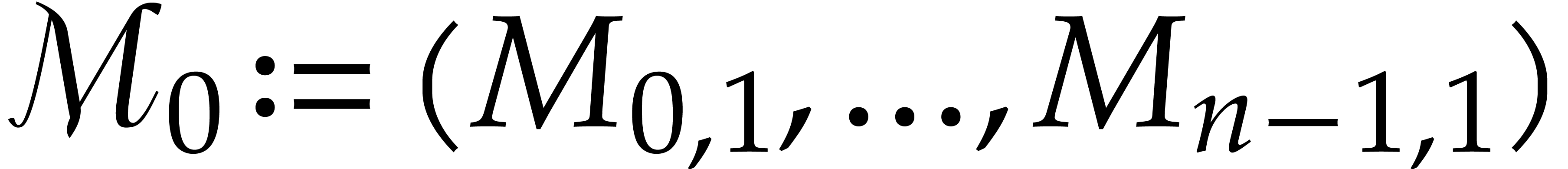 .
.
For each 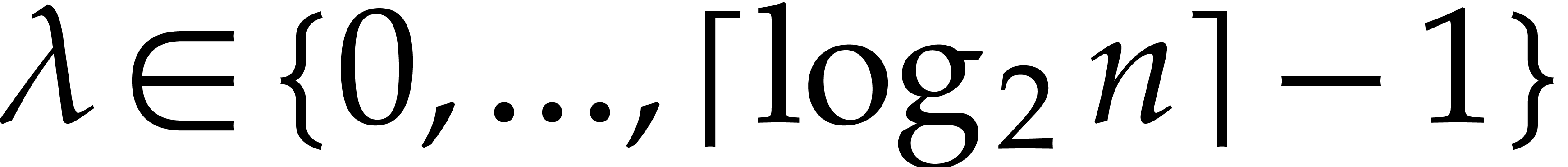 :
:
Compute from using
Algorithm 1.
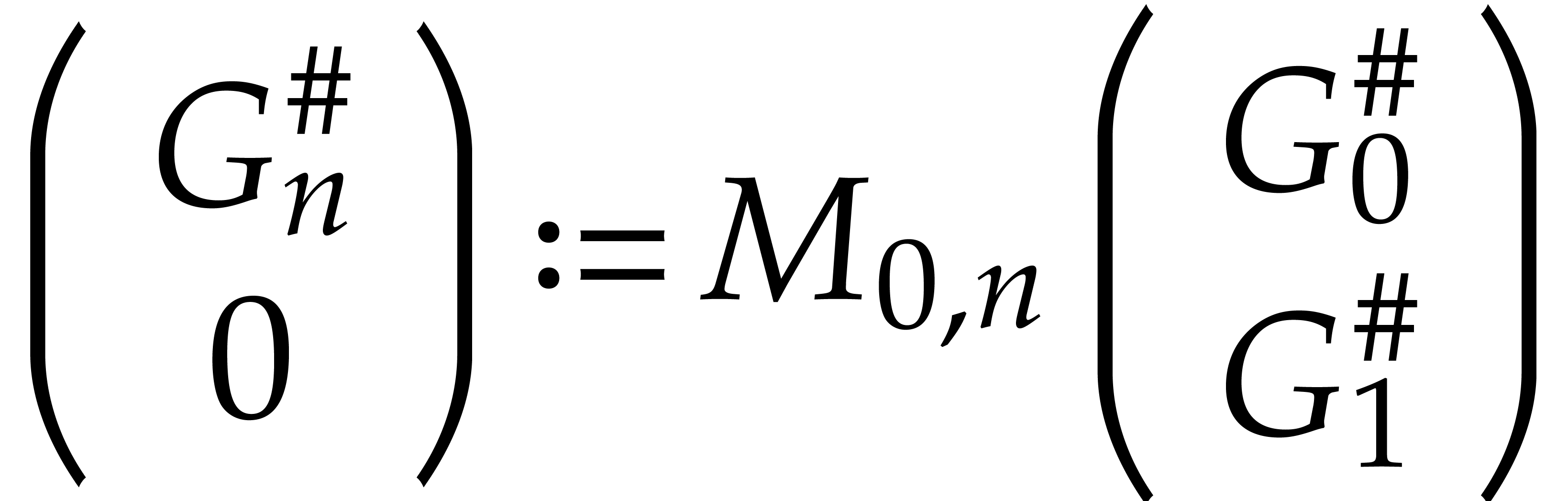 .
.
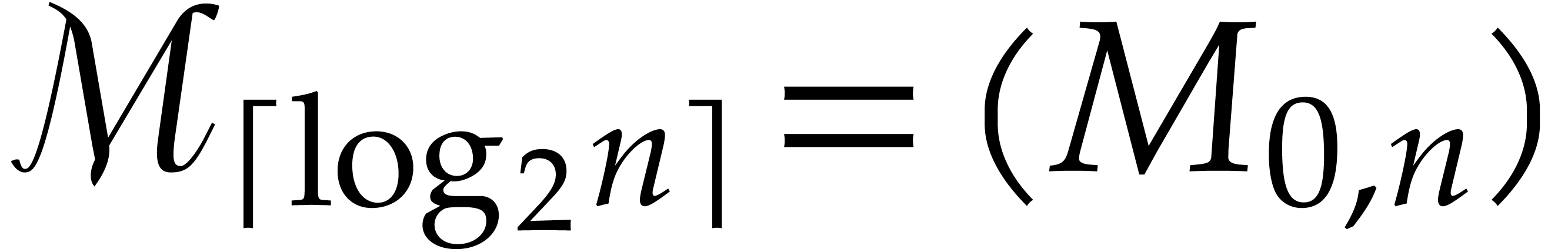
For each 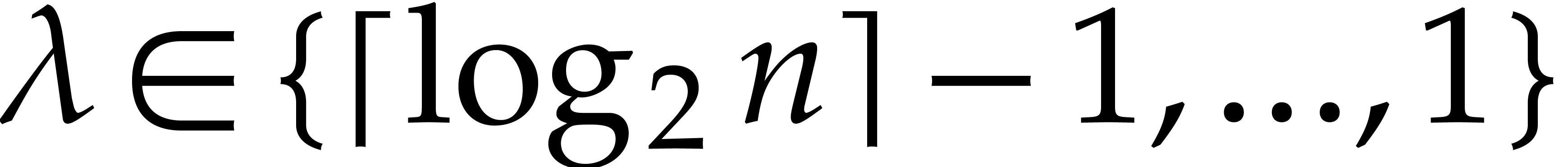 :
:
 with
with  ,
set
,
set
Return  and
and 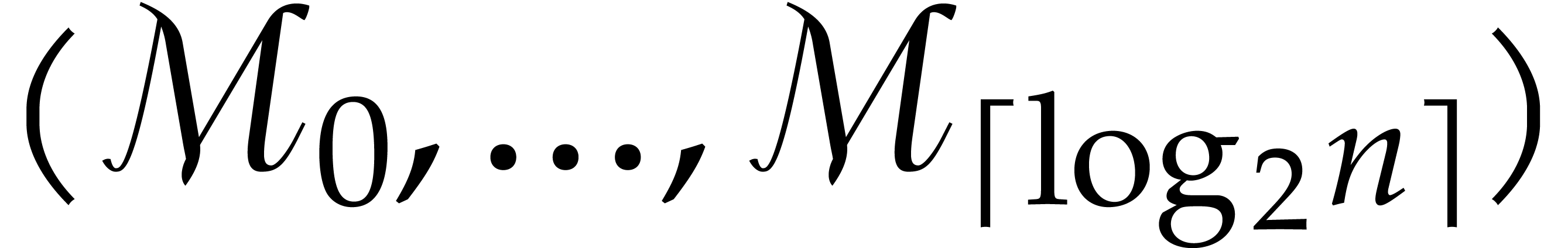 .
.
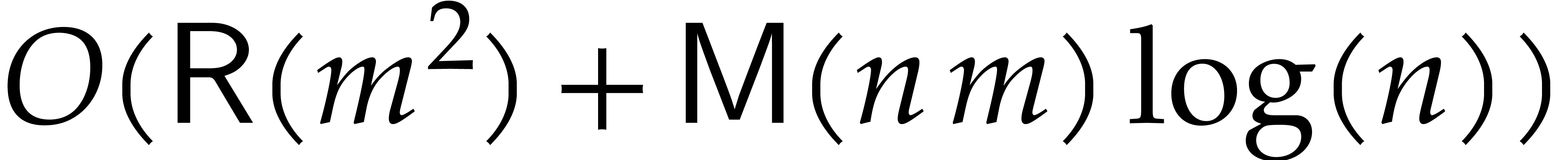
Proof. The reduction can
be done in a relaxed way at a cost of 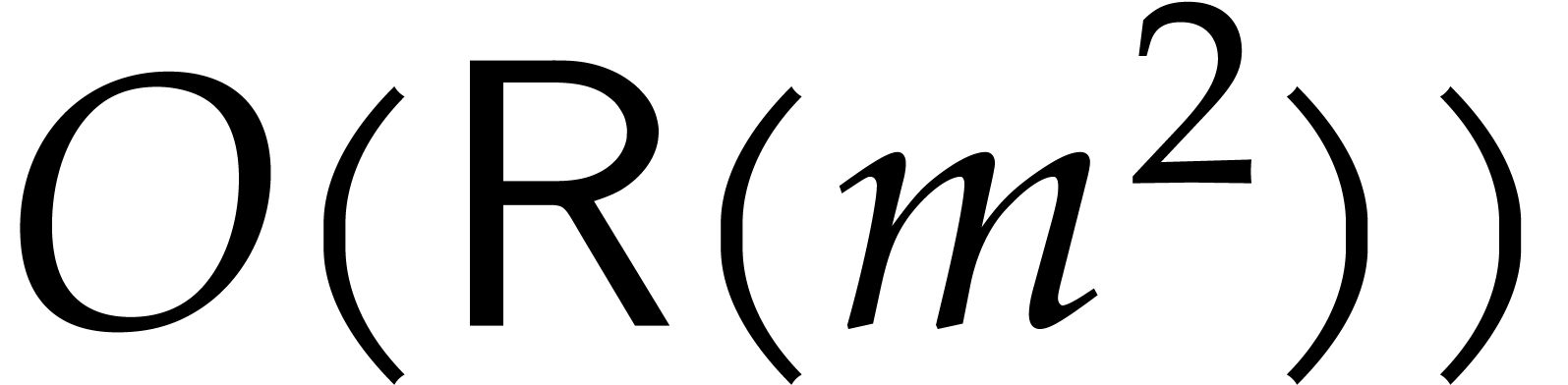 .
The first loop is clearly correct and each step requires
.
The first loop is clearly correct and each step requires 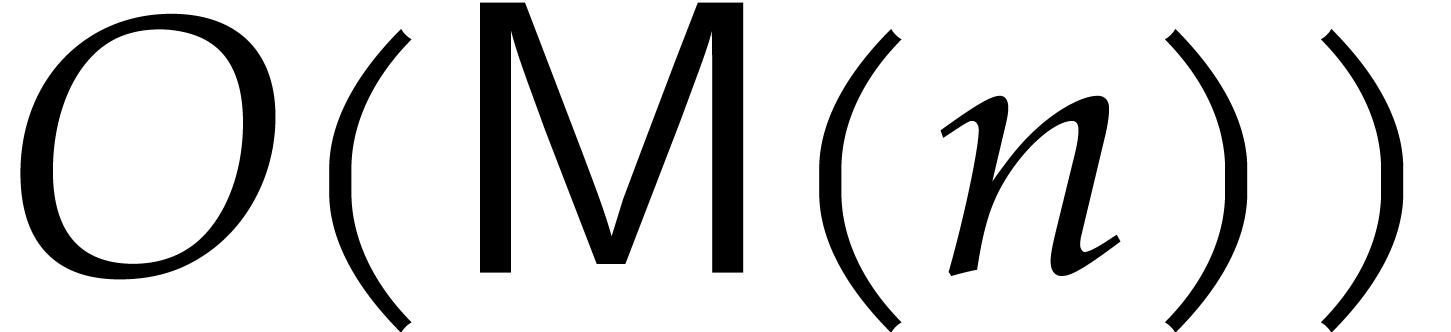 operations. Alternatively, all the successive quotients
can be computed with a fast Euclidean algorithm (see for example [11]) at a cost of
operations. Alternatively, all the successive quotients
can be computed with a fast Euclidean algorithm (see for example [11]) at a cost of 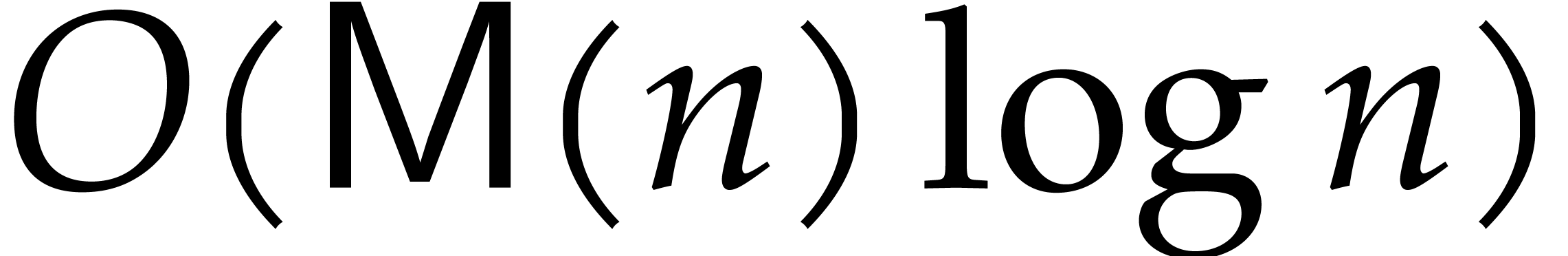 operations.
operations.
In the last loop on  , since
the precision decreases at each step and since there is no accidental
cancellation, the invariant
, since
the precision decreases at each step and since there is no accidental
cancellation, the invariant
holds. Indeed, regarding upper truncations, it is clear that 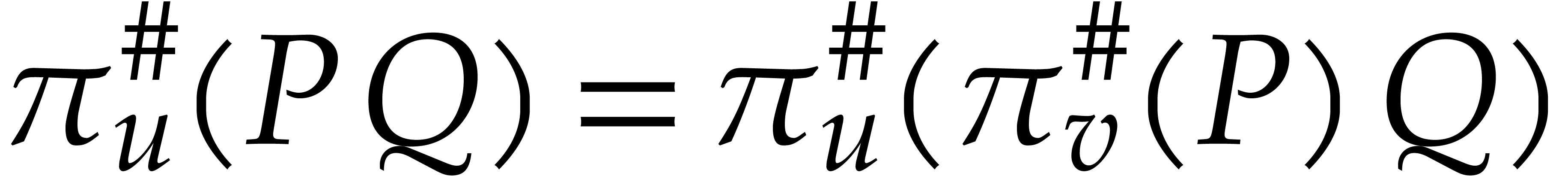 as soon as
as soon as 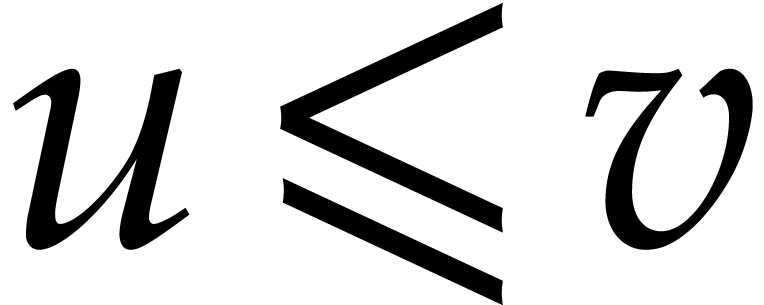 .
Then we have (handle the case
.
Then we have (handle the case 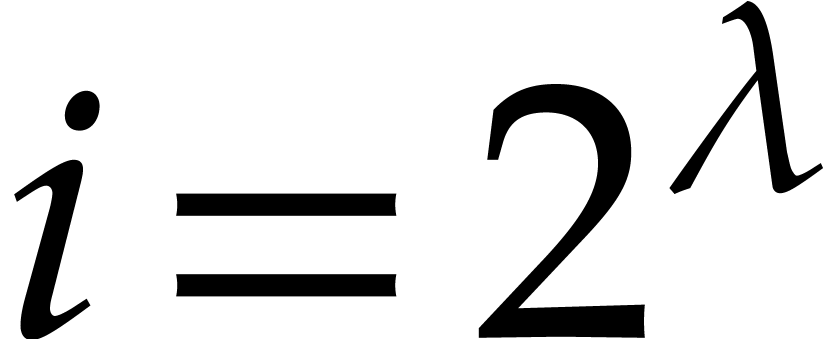 separately)
separately)
which proves the correctness. Let us now evaluate the complexity of this
loop. For each index such that , we have to estimate the support of 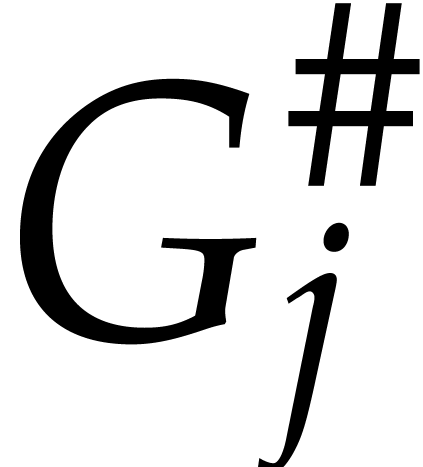 and
and 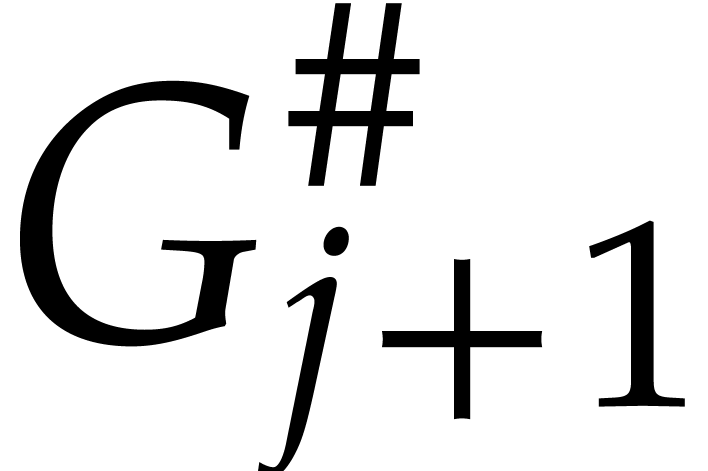 (where
(where 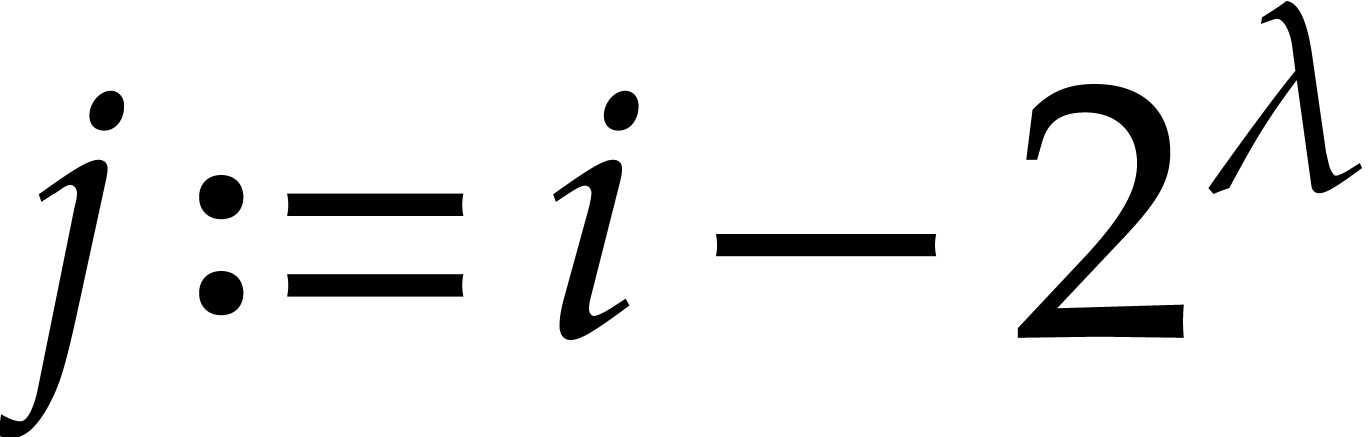 ). For ,
). For ,
 and
and 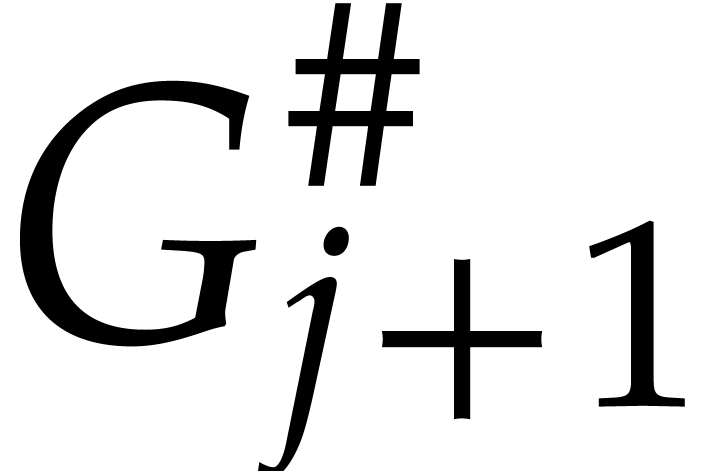 are completely
known, with a support of size
are completely
known, with a support of size 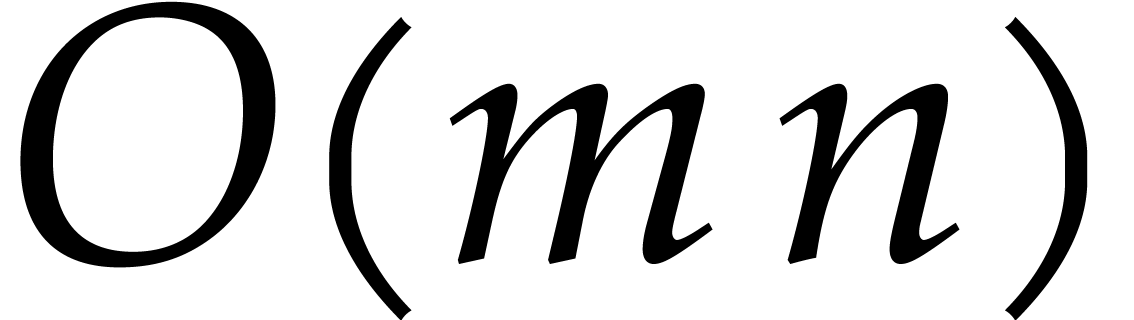 .
In all other cases and
are upper truncations, with a support of size
.
In all other cases and
are upper truncations, with a support of size 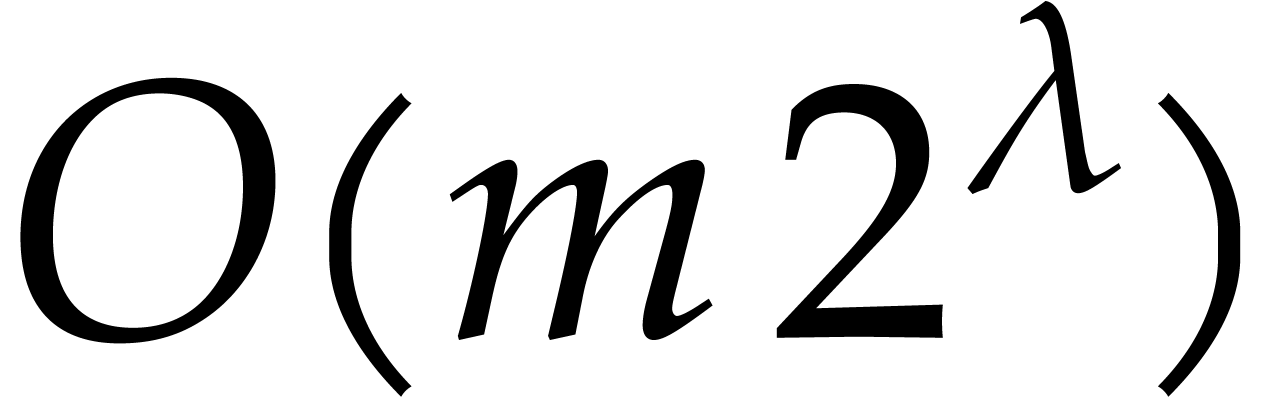 . Consequently, each iteration of the loop requires
. Consequently, each iteration of the loop requires
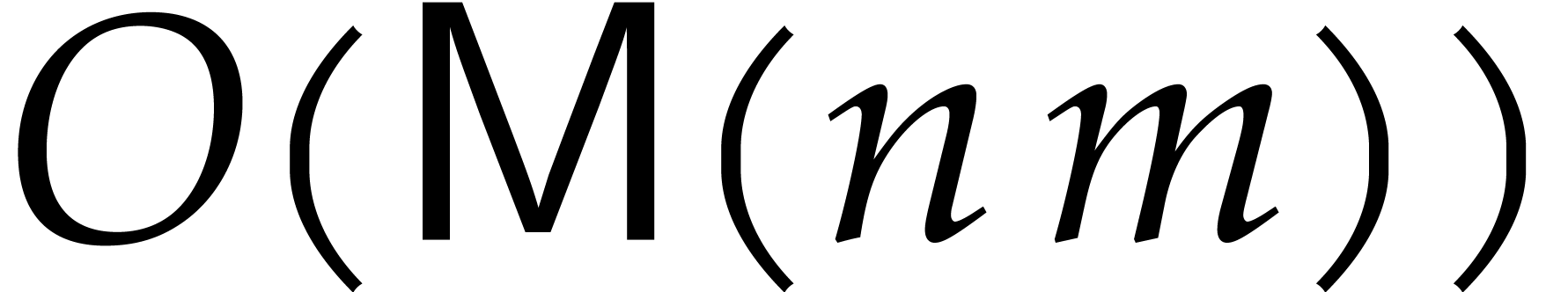 operations.
operations.
In this section, we present a variant of the algorithm from [17]
that performs the reduction in quasi-linear time using the concise
representation of . The
general idea is the same: reduce modulo the truncated basis to compute
the quotients faster, and to compute the remainder, use the recurrence
relations to maintain sufficient precision. However, crucial differences
with the setting of vanilla Gröbner bases from [17]
make the new reduction algorithm more cumbersome.
To understand the difficulties we have to overcome in this section, let
us recall how reduction algorithms work. Say that
is to be reduced modulo ;
then the most common way is to successively reduce the terms of in decreasing order with respect to the relevant
monomial ordering. This is in particular how the relaxed algorithm from
section 3.3 works (see [16] for the details).
If we decompose the set of all monomials into slices of constant degree,
we see that the different slices are handled one after the other
(starting with those of highest degrees).
In the setting of vanilla Gröbner bases from [17],
these slices are roughly parallel to the Gröbner stairs. This
implies that the quotients with respect to the truncated basis 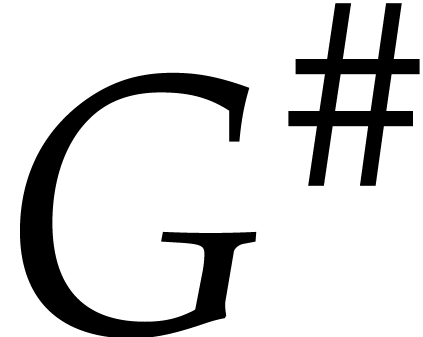 are also valid with respect to the full basis (under the assumption that the degrees of the quotients
are controlled, and that each
are also valid with respect to the full basis (under the assumption that the degrees of the quotients
are controlled, and that each  is known with the
appropriate precision). Then the reduction algorithm decomposes in two
phases:
is known with the
appropriate precision). Then the reduction algorithm decomposes in two
phases:
Compute the quotients by reducing modulo
. Here the speedup comes
from the fact that the equation

is much smaller (in terms of the number of coefficients) than the equation
 |
(4) |
Rewrite equation (4) to compute the remainder . First, find new quotients
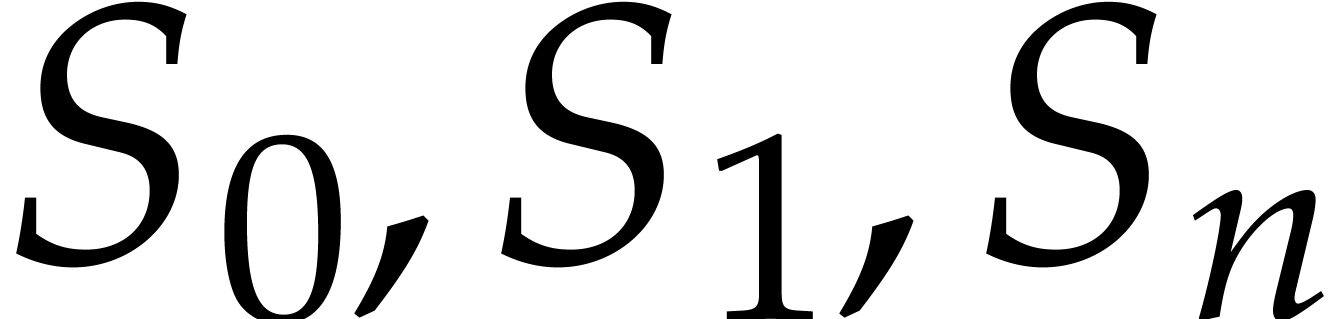 such that
such that
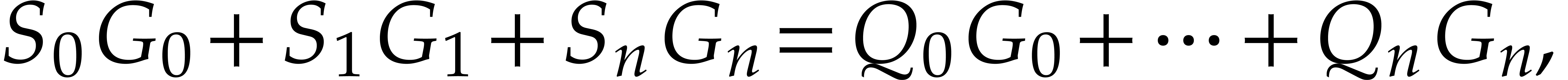
then compute as
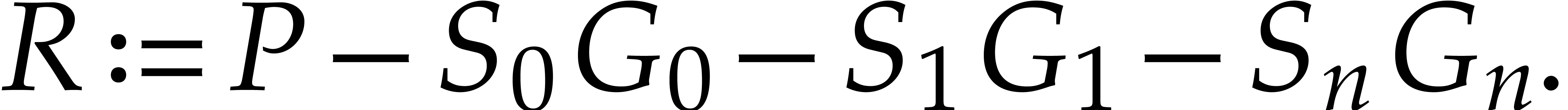 |
(5) |
As we said earlier, Gröbner bases in the setting of this paper are
not vanilla. In particular, the slices of constant degree are
not parallel to the Gröbner stairs: the former have a slope of
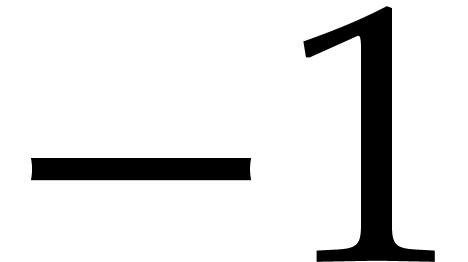 , while the latter have a
slope of
, while the latter have a
slope of 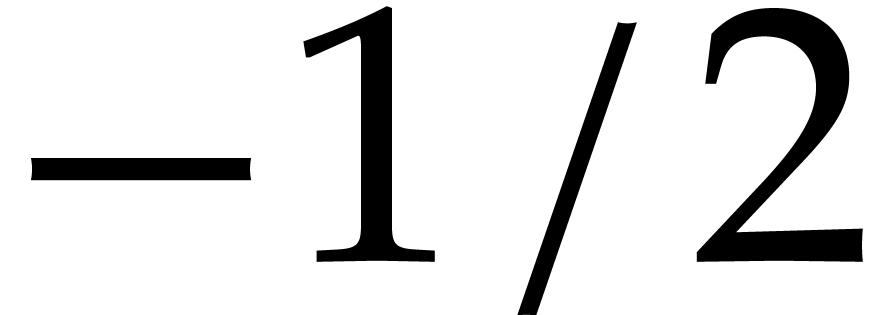 . For this reason,
even with the bound on the degree of the
. For this reason,
even with the bound on the degree of the  ,
there are terms of
,
there are terms of  that are not in normal form
with respect to . This
implies that the quotients with respect to are
not valid with respect to .
To maintain sufficient precision to compute the remainder, the two
phases must be merged, and equation (4) is rewritten
“on the fly” during the reduction algorithm. More precisely,
as soon as the quotient
that are not in normal form
with respect to . This
implies that the quotients with respect to are
not valid with respect to .
To maintain sufficient precision to compute the remainder, the two
phases must be merged, and equation (4) is rewritten
“on the fly” during the reduction algorithm. More precisely,
as soon as the quotient  is known, the product
is known, the product
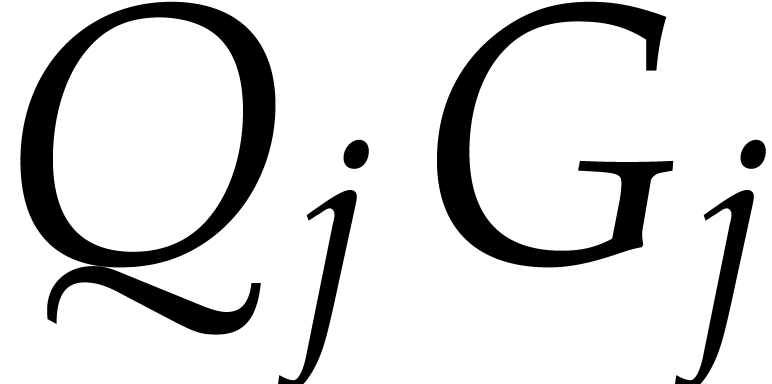 is replaced by some
is replaced by some 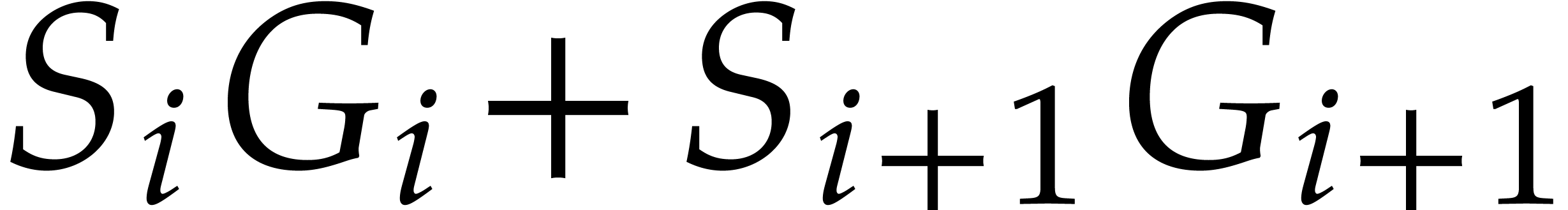 , where
, where  are known with
precision larger than
are known with
precision larger than  .
.
To control the degrees of the quotients, we use a dichotomic selection
strategy as presented in Figure 1. The idea is to reduce
each monomial preferably against one end of the Gröbner basis ( or
or  ), or
the where has the
highest valuation. To describe the reduction algorithm, it is convenient
to introduce the function
), or
the where has the
highest valuation. To describe the reduction algorithm, it is convenient
to introduce the function  (depending on the
leading terms of the )
defined as follows:
(depending on the
leading terms of the )
defined as follows:
Notice that this definition is non-ambiguous: there is only one index
with  maximal such that
maximal such that
 . Indeed, if
. Indeed, if  have the same valuation
have the same valuation  ,
then there is some with
,
then there is some with 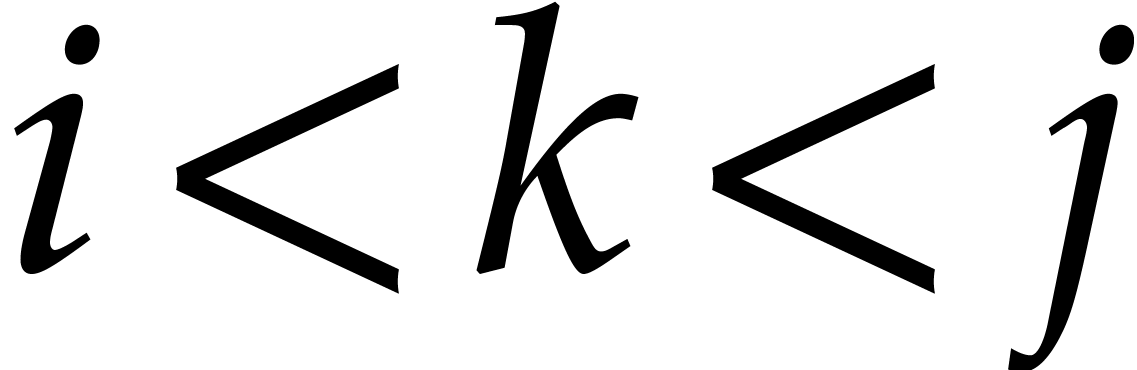 and
and  . Moreover, if
. Moreover, if  and
and 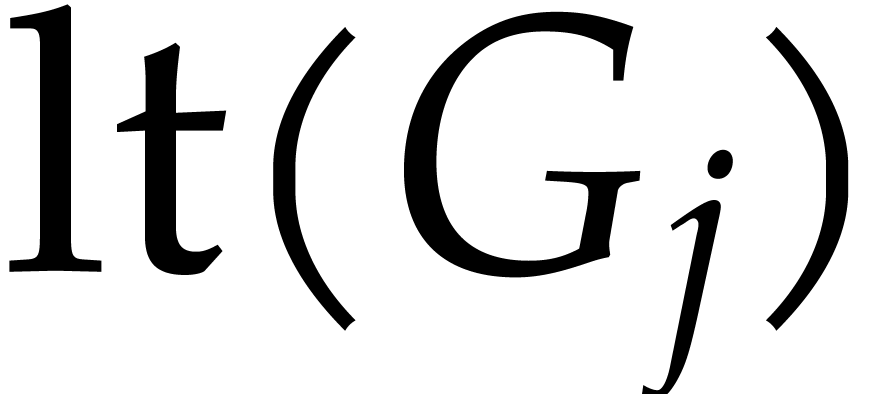 both divide
both divide  , then so does
, then so does 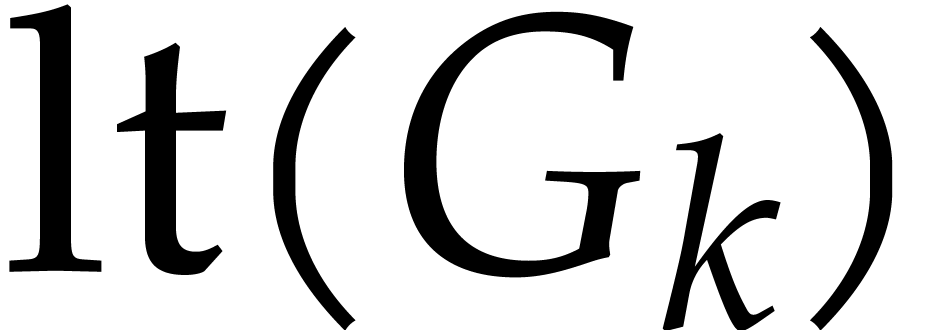 .
.
Intuitively, if
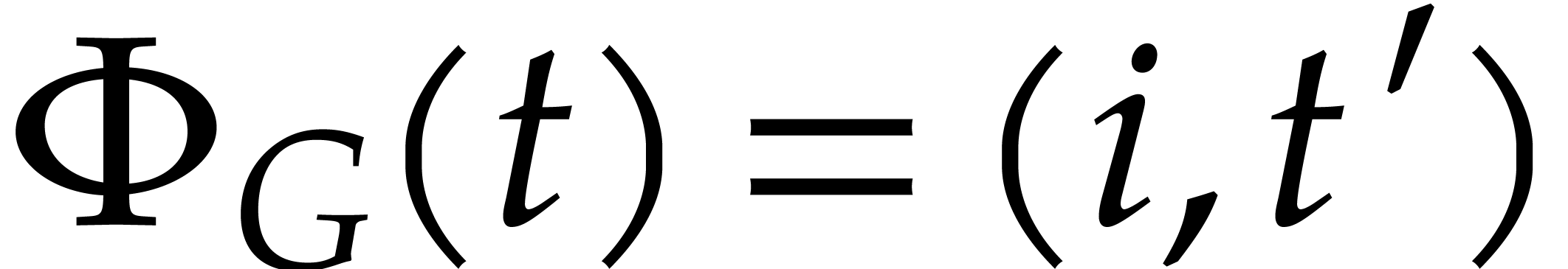 ,
then the term
is reduced against
and leads to the term
,
then the term
is reduced against
and leads to the term
 in
.
The case
in
.
The case
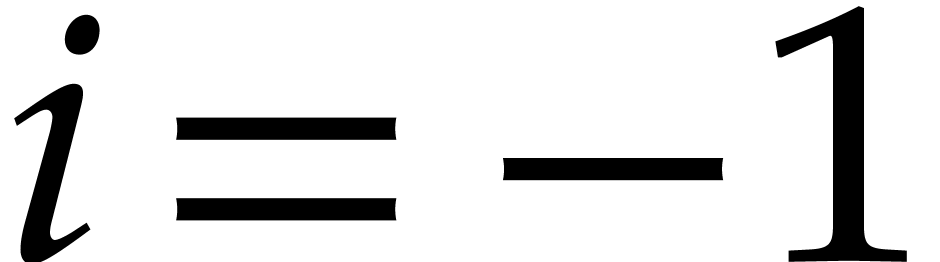 corresponds to monomials that are already in normal form with respect
to
.
corresponds to monomials that are already in normal form with respect
to
.
Proof. Let 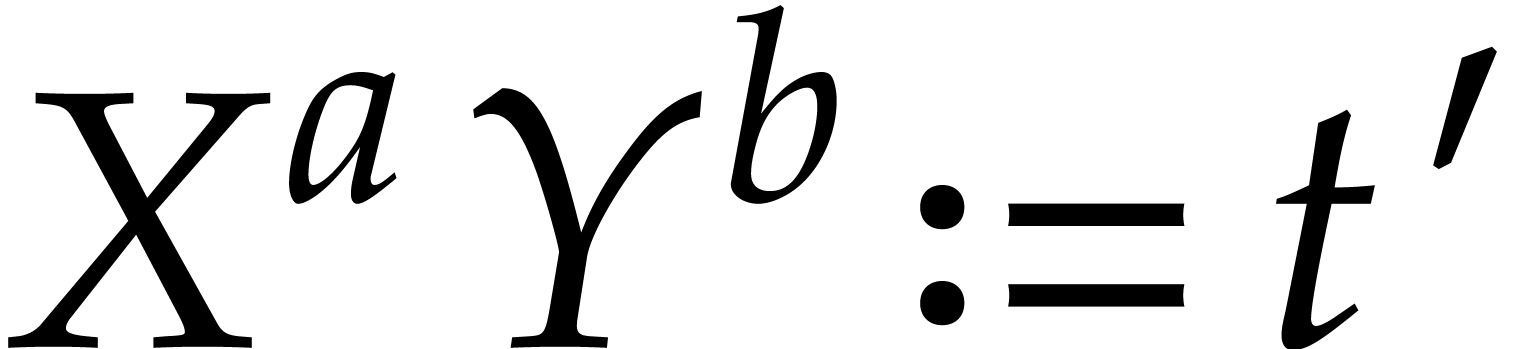 ,
and denote
,
and denote 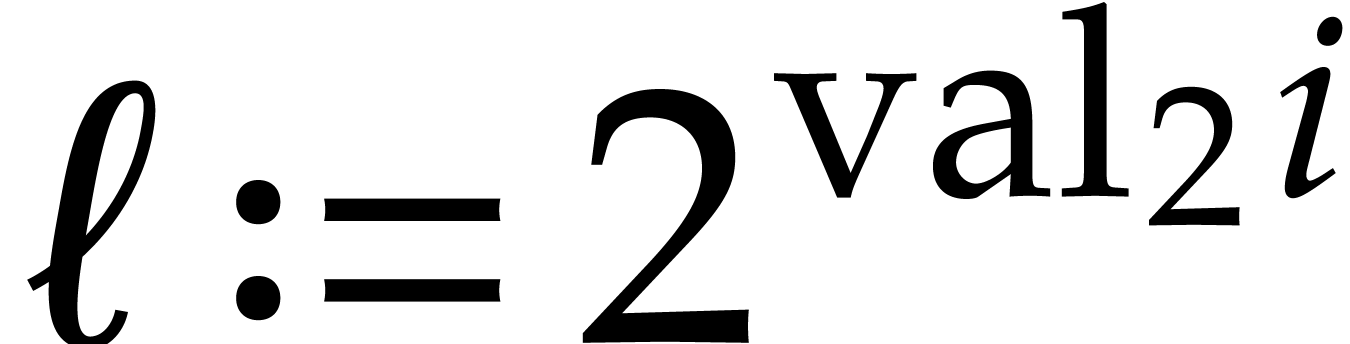 . Then we observe
that
. Then we observe
that  : if not, then
: if not, then 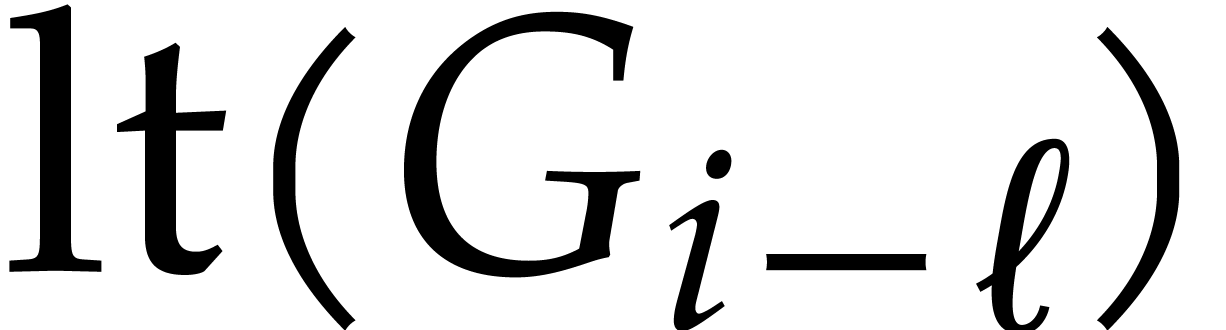 would divide
would divide  ,
whereas
,
whereas 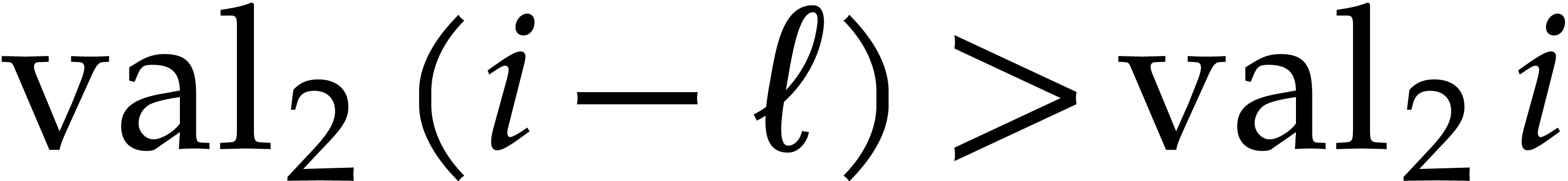 . A similar reasoning
with
. A similar reasoning
with 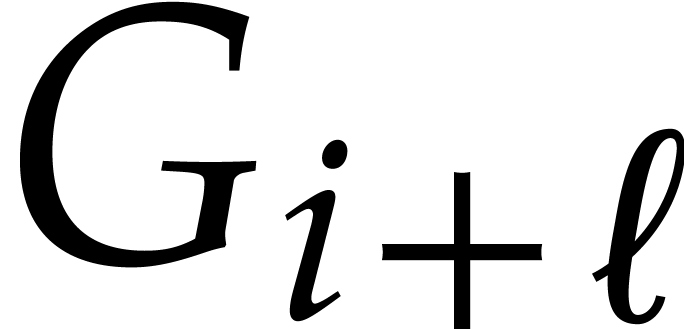 (or ,
whenever
(or ,
whenever 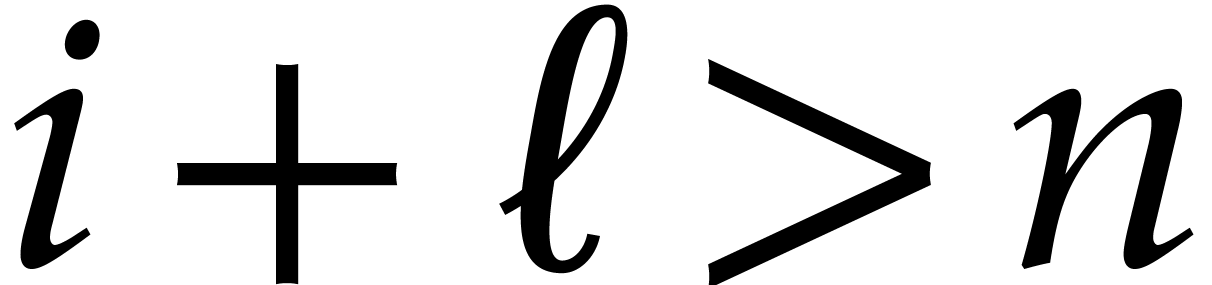 ) shows that
) shows that 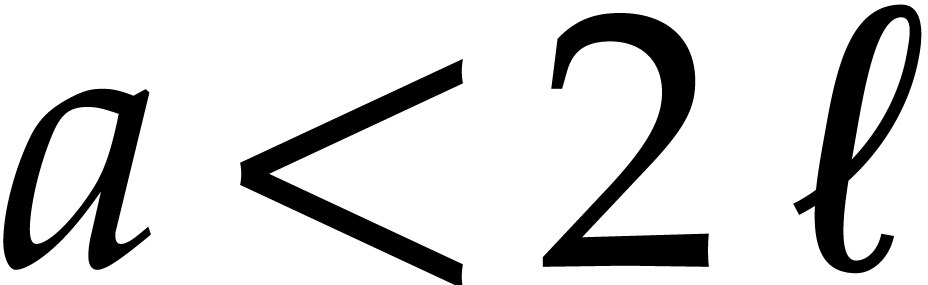 .
.
Recall that Definition 5 gives recurrence relations between
the : for any indices with , we
have
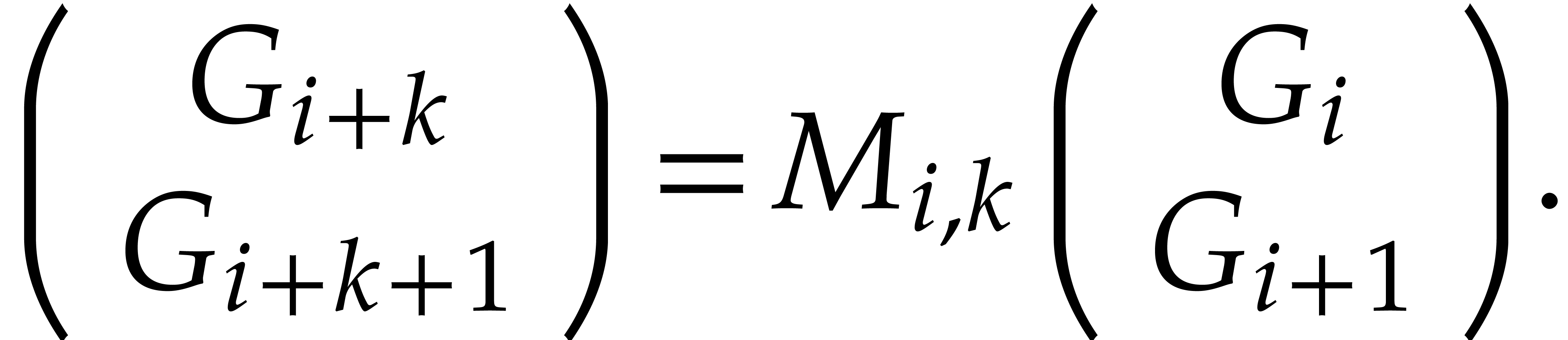 |
(6) |
This allows for substitutions in the expression
that are analogous to those used in the reduction algorithm from [17]. In our setting, the substitutions used in the reduction
algorithm are based on the following result:
be a Gröbner basis with recurrence
relations defined by the matrices as in
Definition 5 (for all indices
such that ). Given
quotients 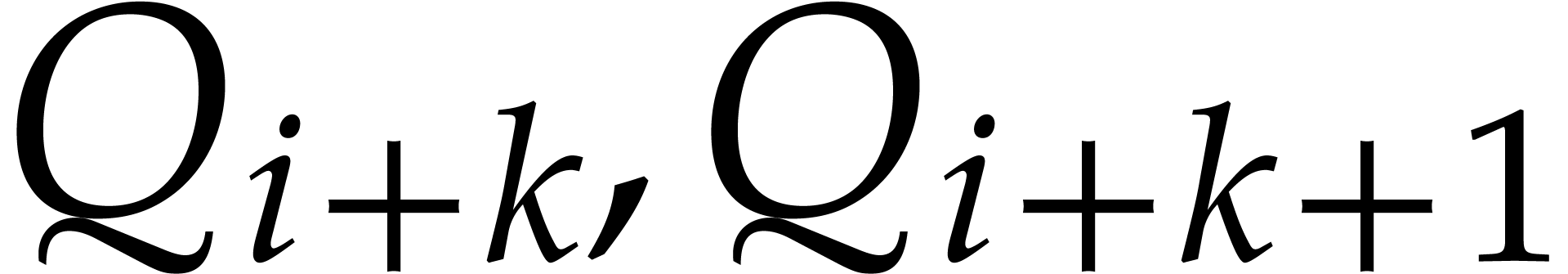 define
define
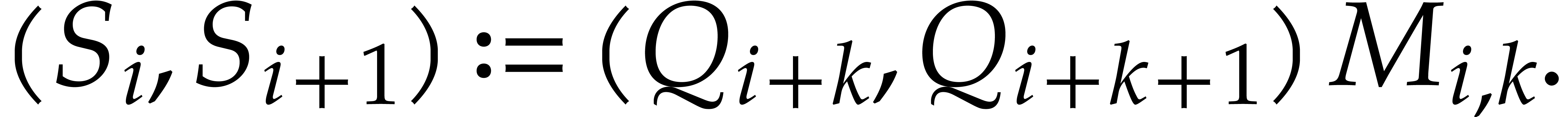
Then we have
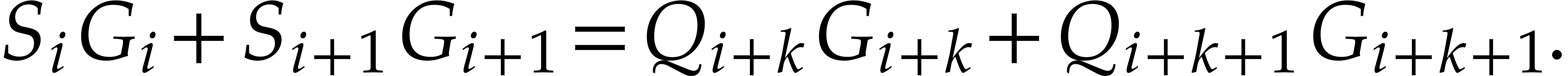 |
(7) |
Assume now that is such that have degree less than 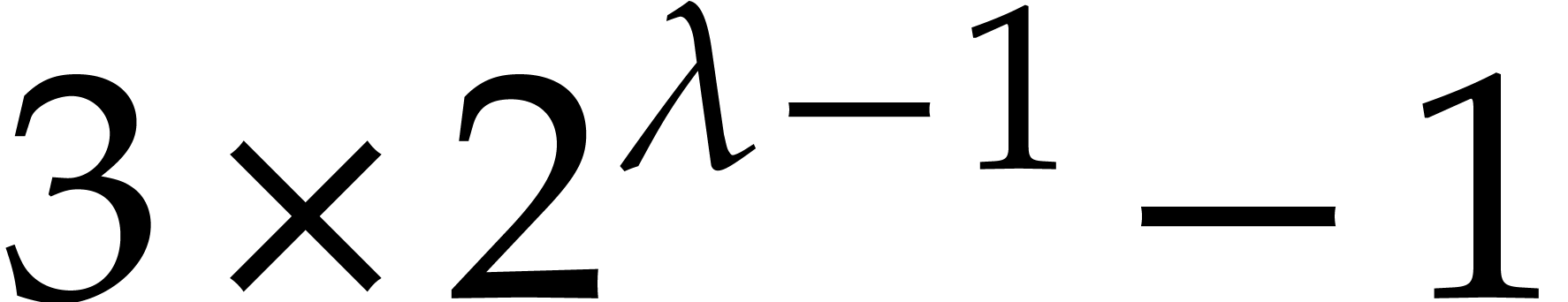 and
and 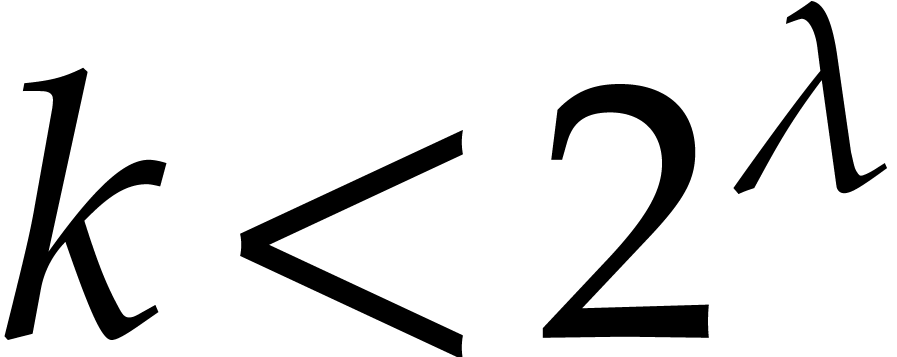 . Then:
. Then:
If  , then
, then  have degree less than
have degree less than 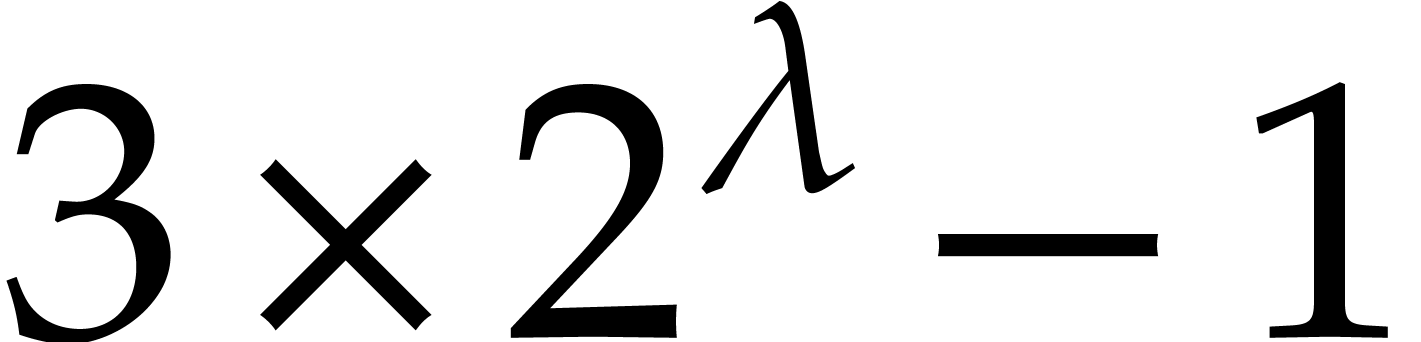 and
can be computed in time
and
can be computed in time  .
.
If 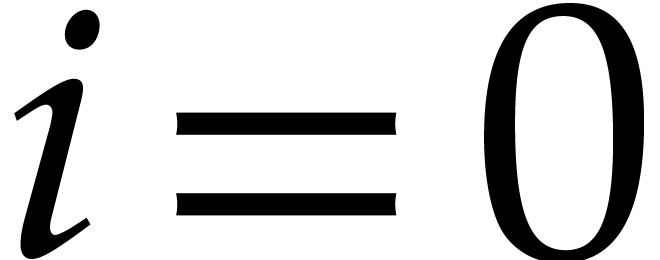 , then
, then 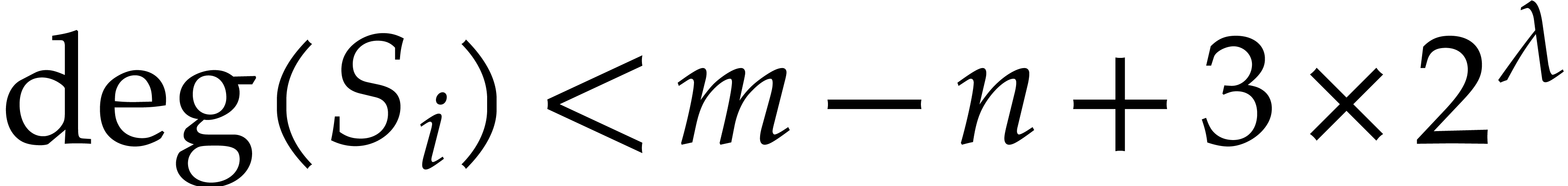 ,
, 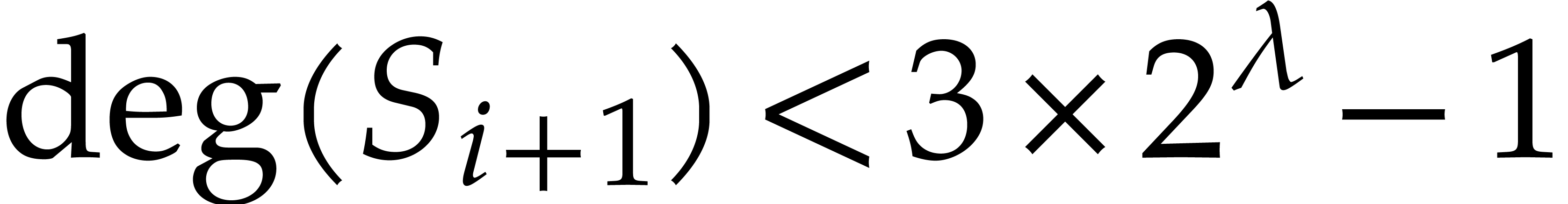 and they can be computed in time
and they can be computed in time 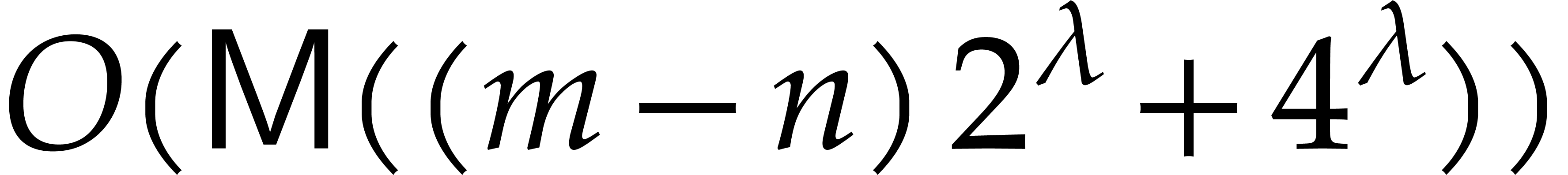 .
.
Proof. Equation (7) is an immediate
consequence of the recurrence relations (6) between the
. Similarly, the bounds on
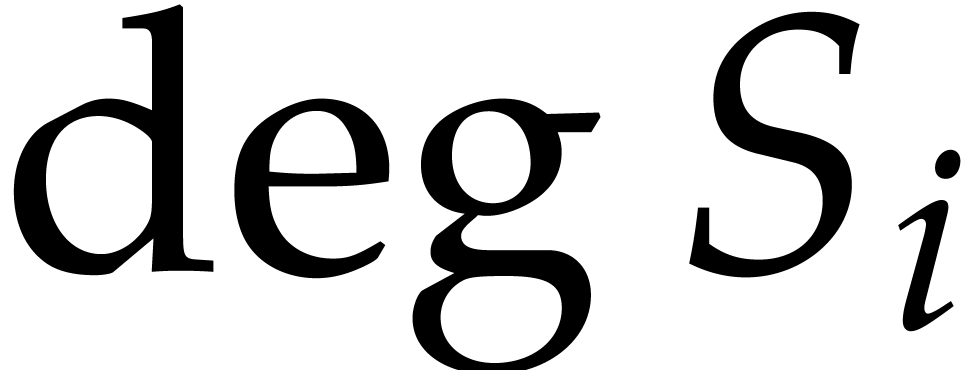 are consequences of the degree bounds from
Proposition 6.
are consequences of the degree bounds from
Proposition 6.
We can now adapt the extended reduction algorithm from [16] to perform these replacements during the computation.
Algorithm
Input: 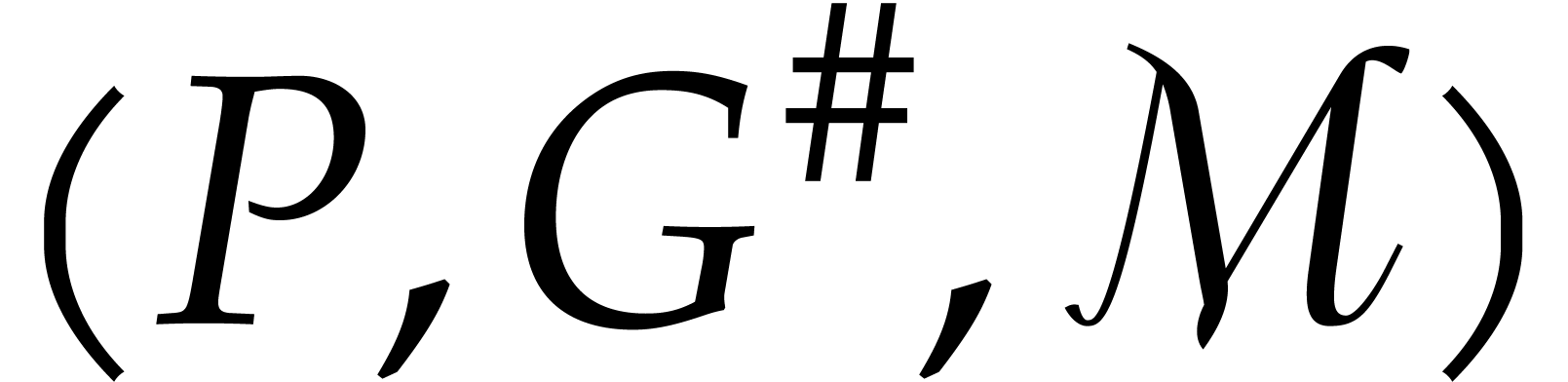 ,
where is a bivariate polynomial of degree
, and
is the concise representation of a Gröbner basis
,
where is a bivariate polynomial of degree
, and
is the concise representation of a Gröbner basis  (as in Definition 8).
(as in Definition 8).
Output: 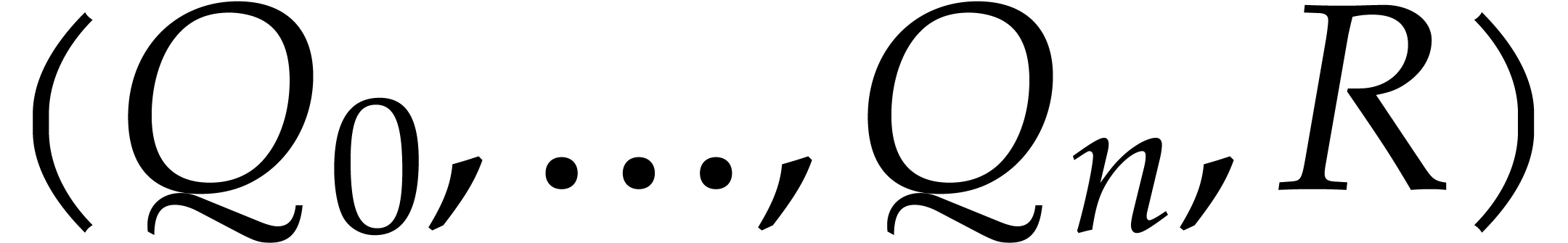 , the
extended reduction of with respect to .
, the
extended reduction of with respect to .
Set 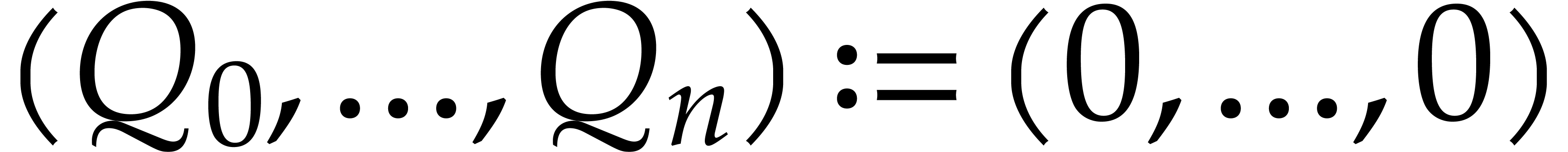
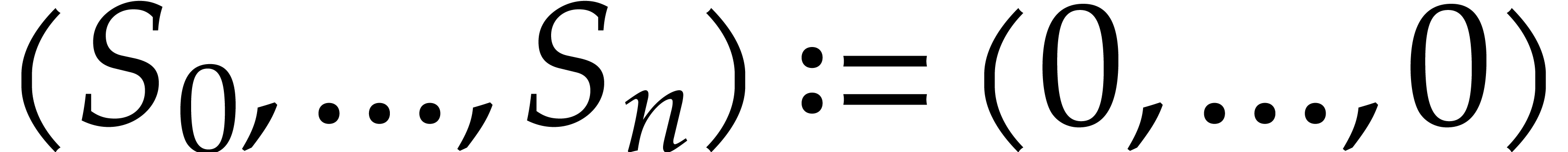
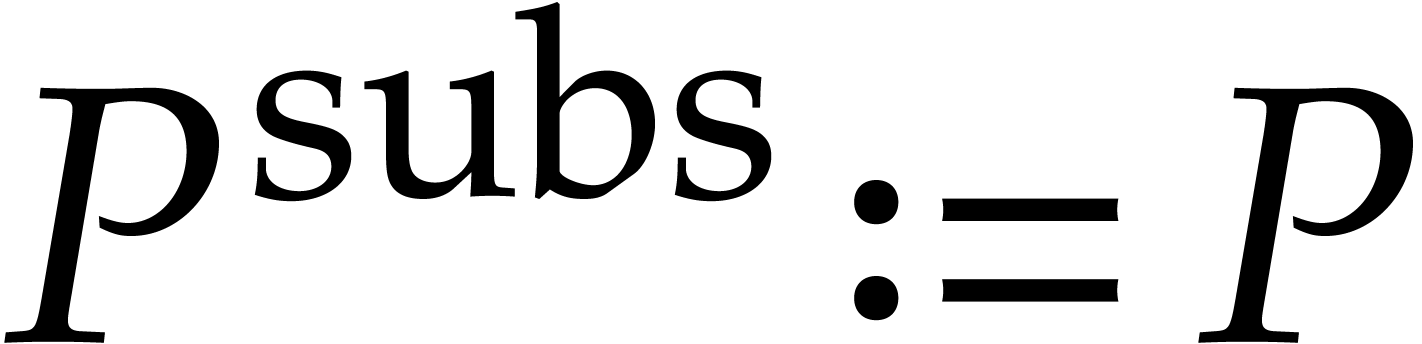 and
and 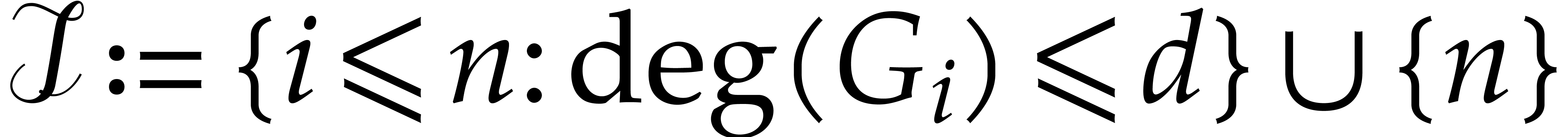
 : active indices for
relaxed multiplications
: active indices for
relaxed multiplications
For 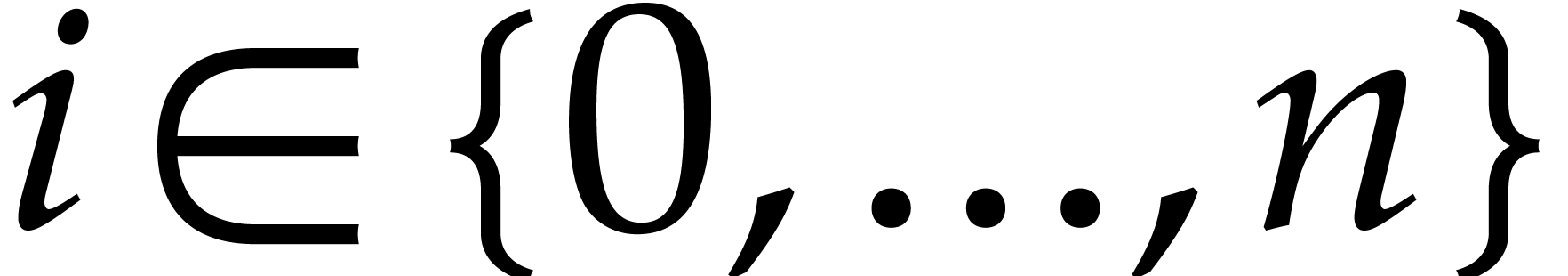 , set
, set 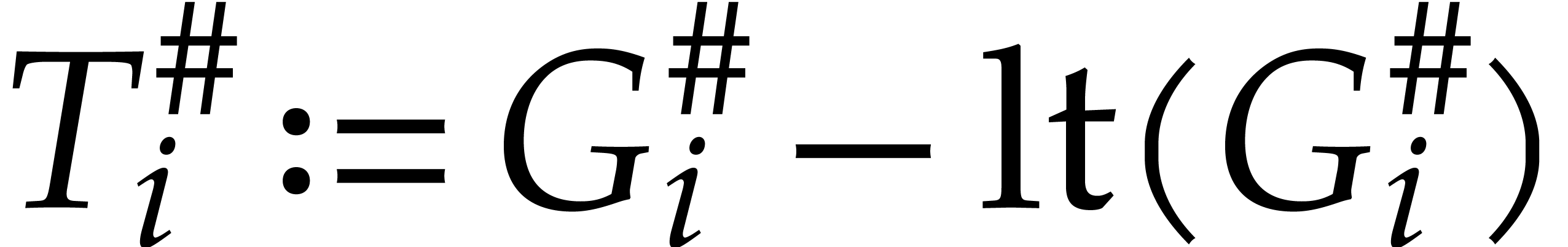 .
.
For 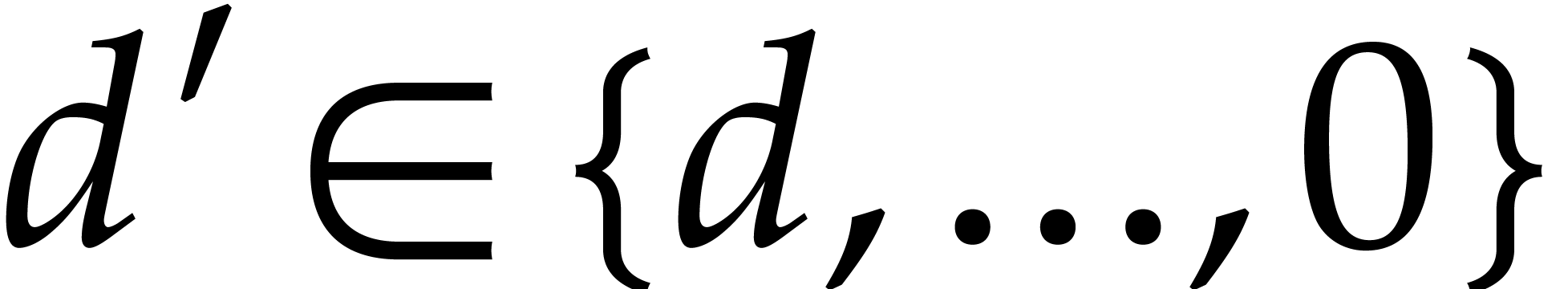 :
:
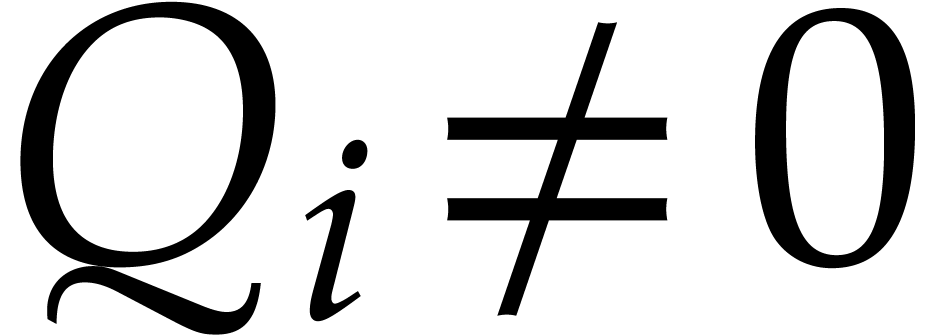
For 
Let be the term of  in
in
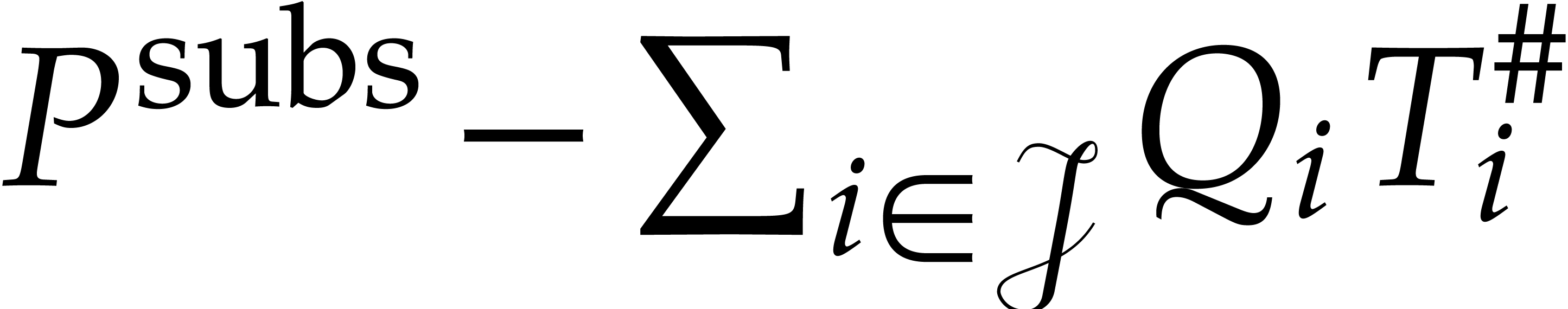 , computed using relaxed
multiplications.
, computed using relaxed
multiplications.
Let 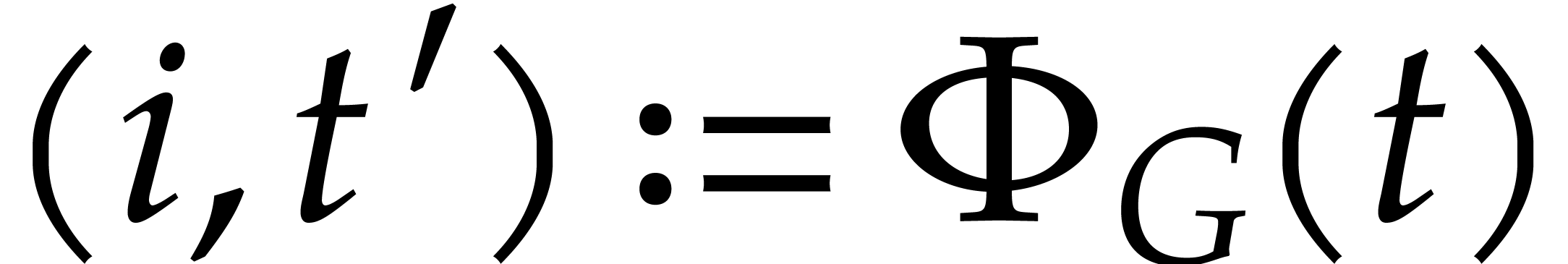 .
.
If 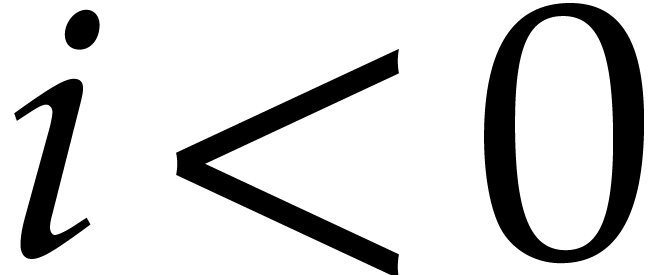 , then update
, then update 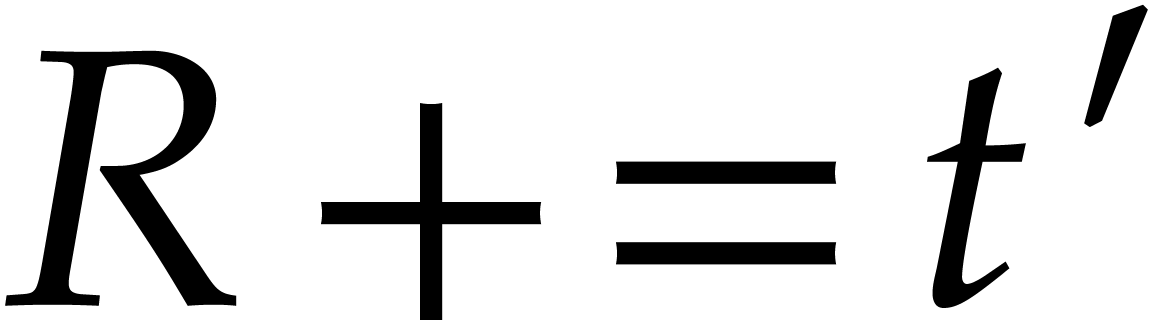 , else update
, else update  .
.
 such that
such that 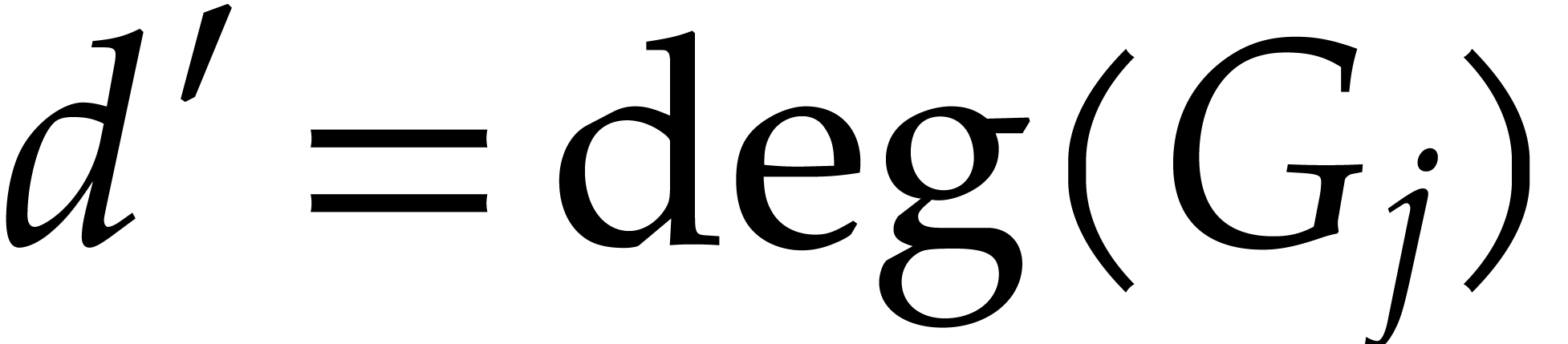 :
:
If 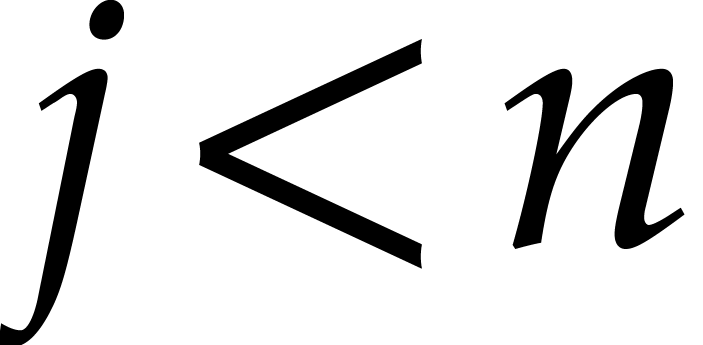 , then update
, then update 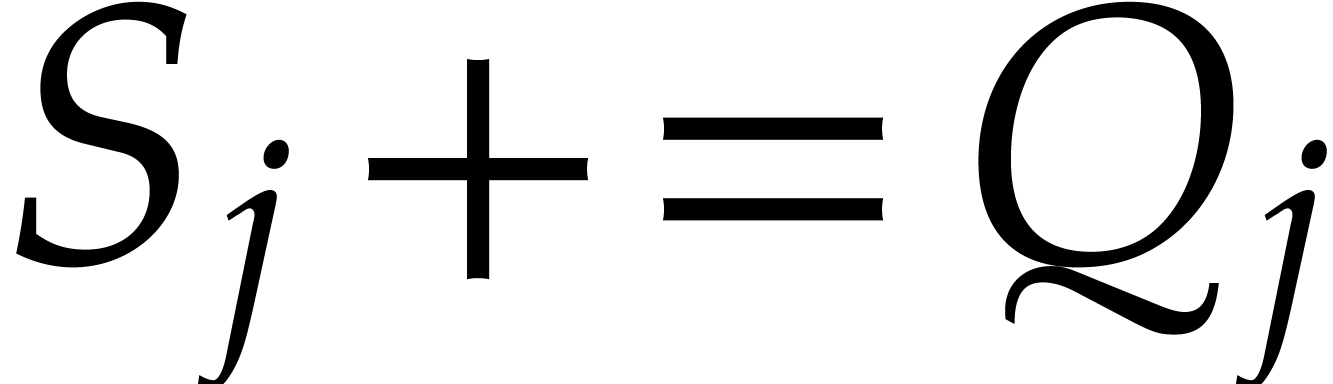 and
and 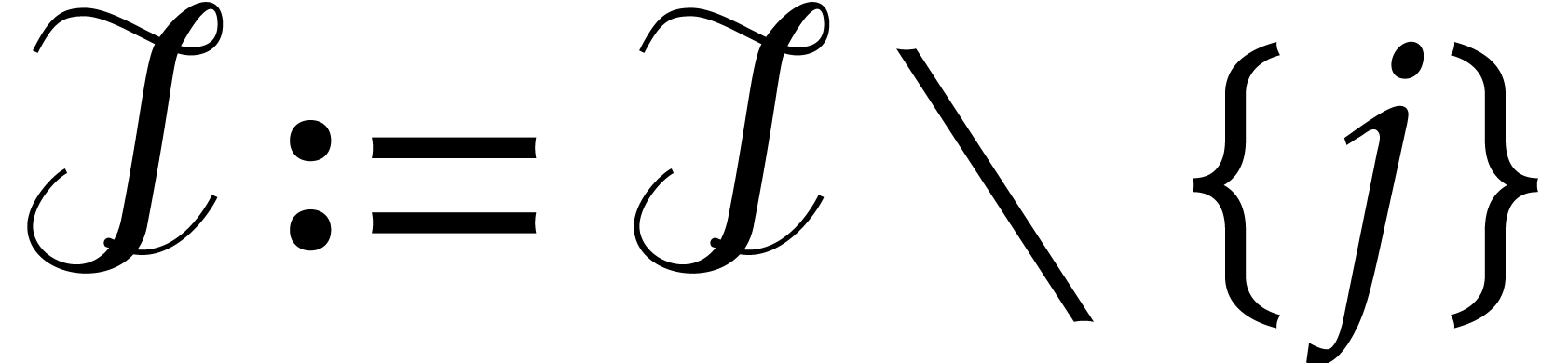 and
and 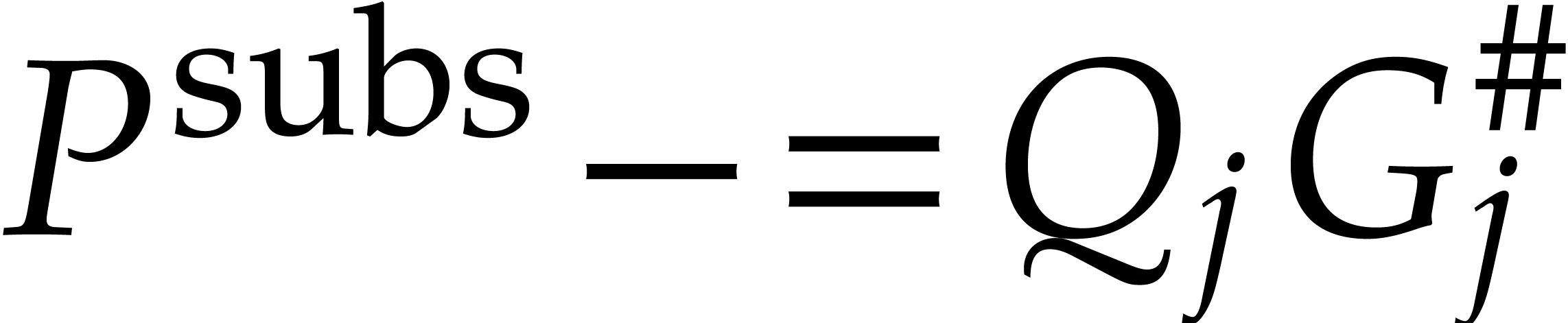
If 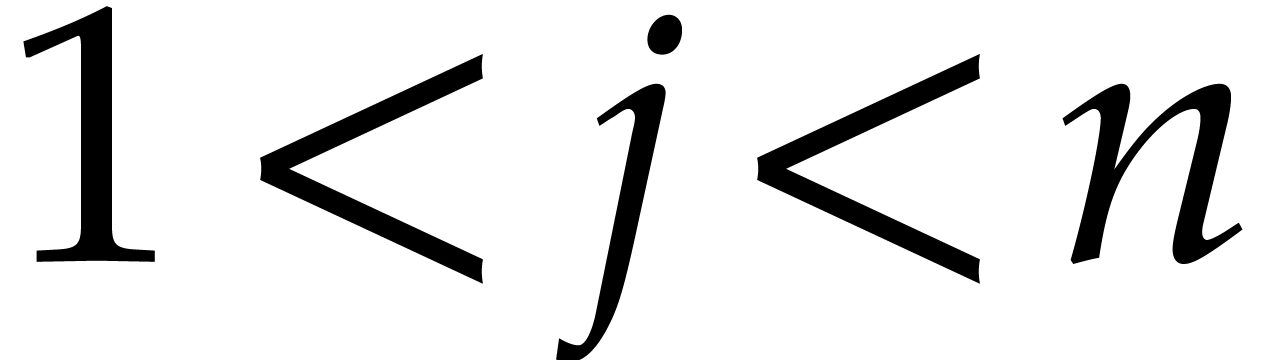 and
and 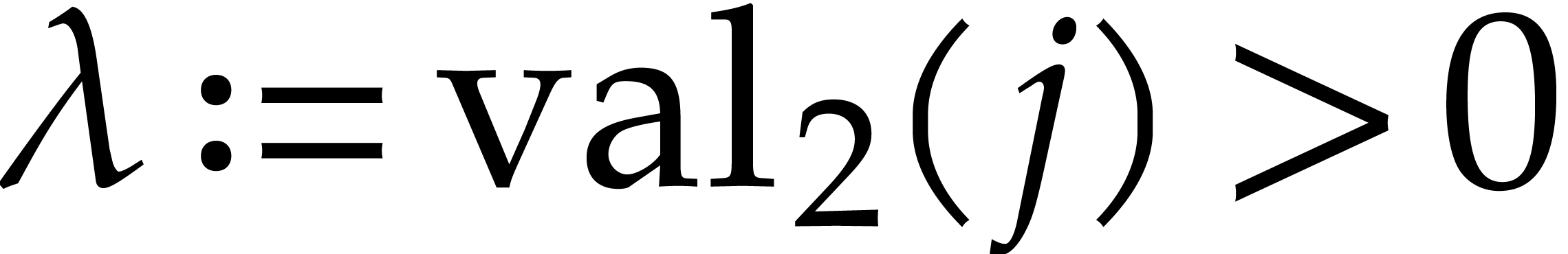 ,
then:
,
then:
Set 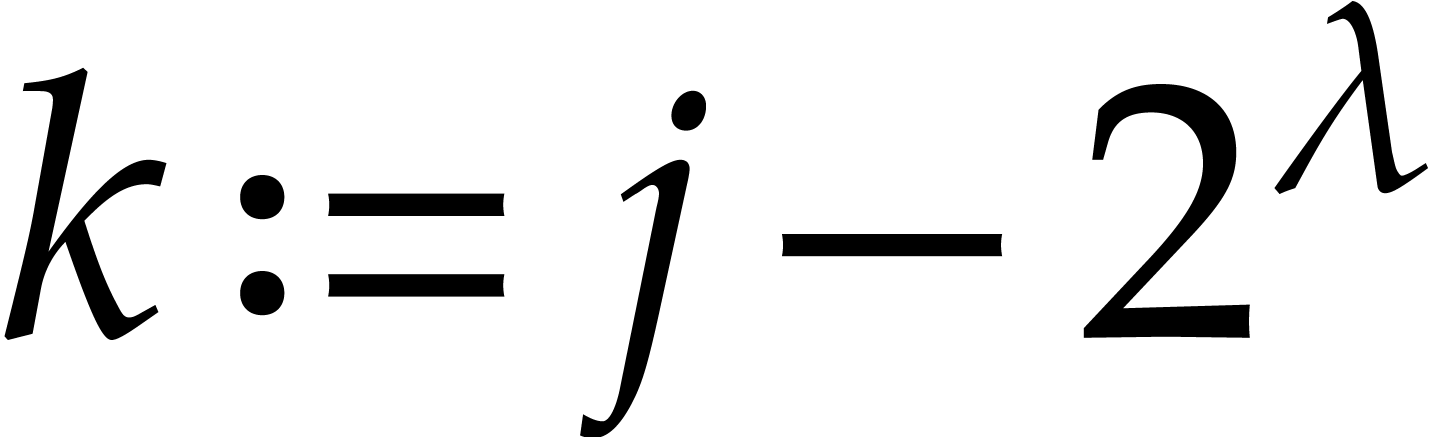 .
.
Set 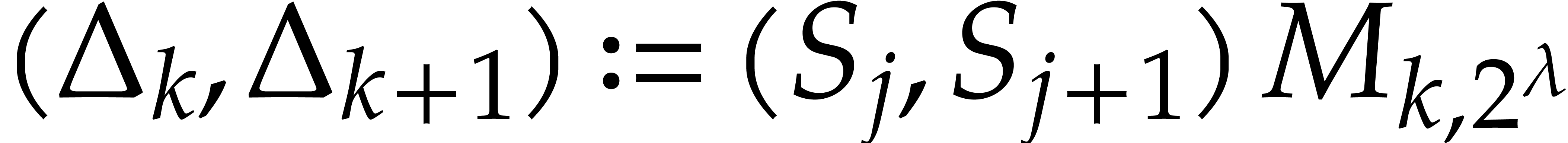 .
.
Update 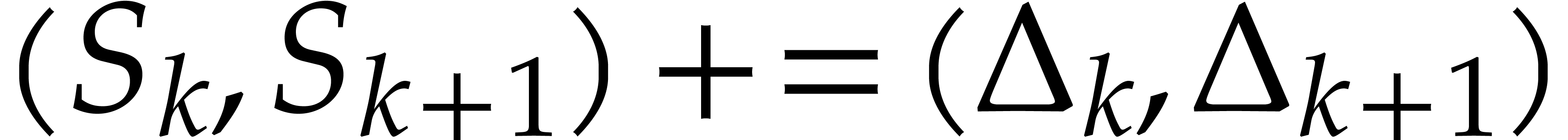 .
.
Update 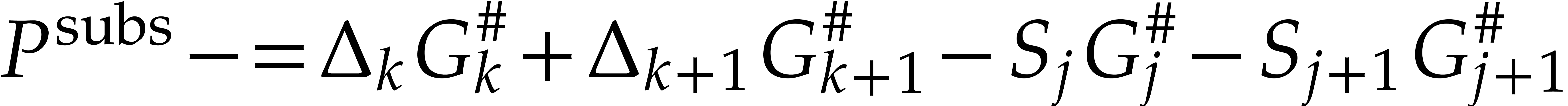
Set 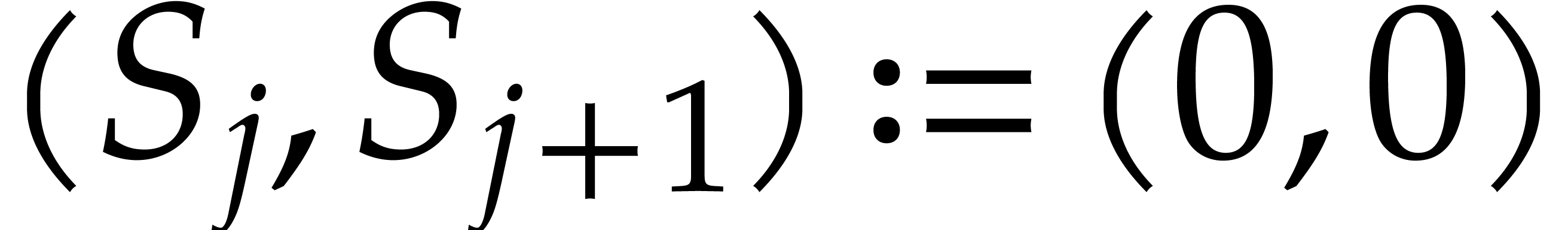 .
.
Return
Remark has degree  and has degree
and has degree 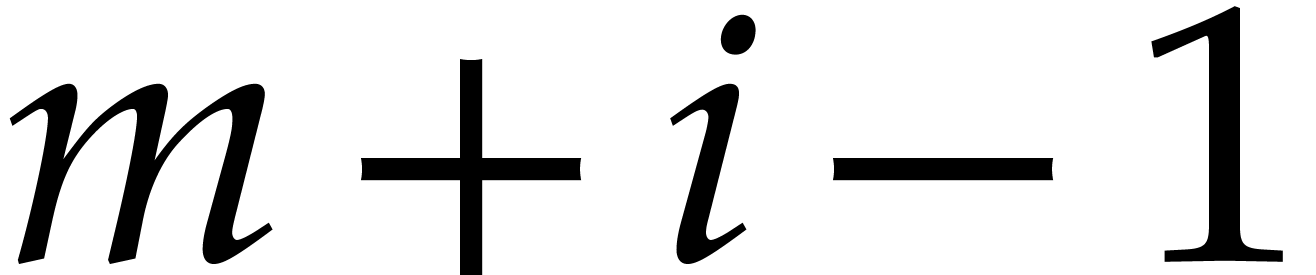 for
for  . Therefore, the loop on
such that is trivial: the set of such contains at most 1 element, except when
. Therefore, the loop on
such that is trivial: the set of such contains at most 1 element, except when 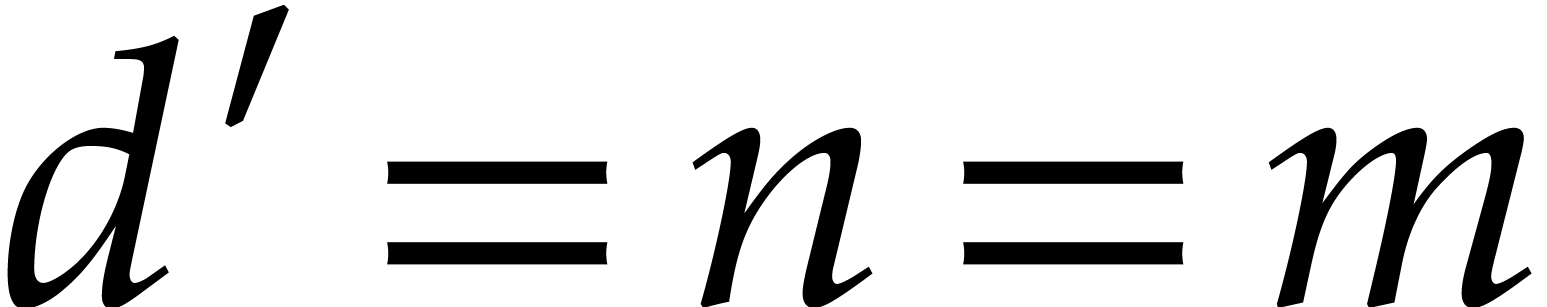 , in which case there are 2 elements
, in which case there are 2 elements  and
and 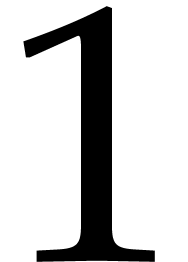 .
.
Proof. Let us first explain why the relaxed
strategy can indeed be used. We regard the quotients
as streams of coefficients. These coefficients are produced by the
updates and consumed in the relaxed evaluation
of the products 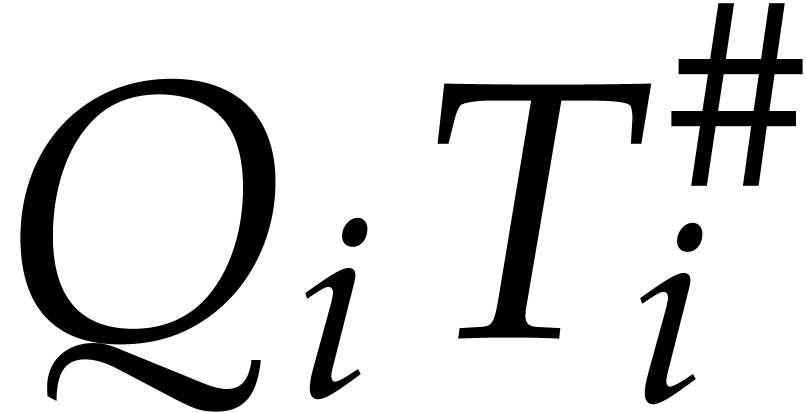 . Since our
reduction process is essentially based on the same recursive functional
equation as in [16], the production of coefficients always
occurs before their consumption.
. Since our
reduction process is essentially based on the same recursive functional
equation as in [16], the production of coefficients always
occurs before their consumption.
We will show that Algorithm 3 computes the same result as
the traditional relaxed reduction algorithm from [16],
because the term that is considered at each step
is the same in both cases. More precisely, we must show that for each
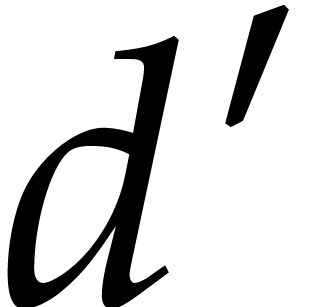 , at the start of each
iteration of the loop on
, at the start of each
iteration of the loop on  , we
have
, we
have
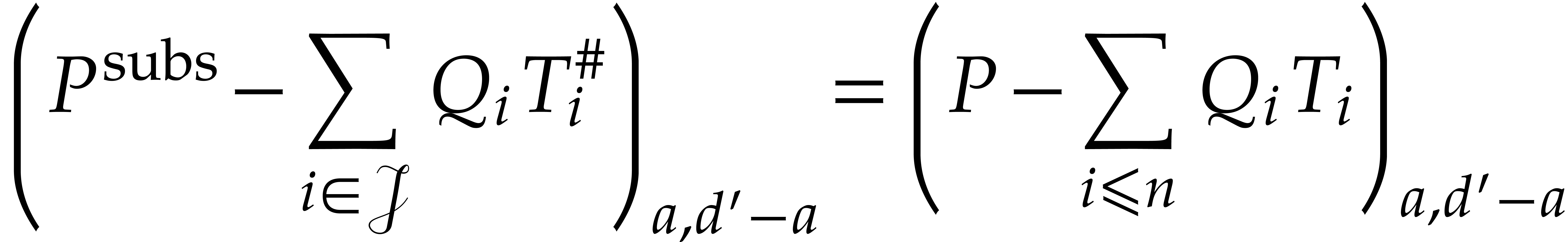 |
(8) |
where 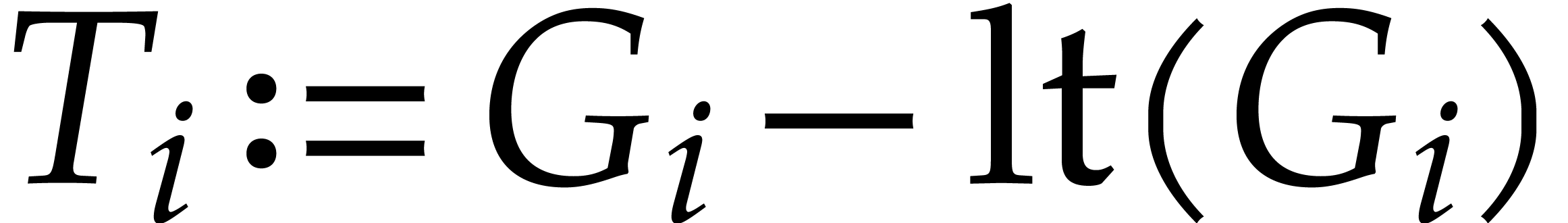 is the non-truncated analogous of
is the non-truncated analogous of 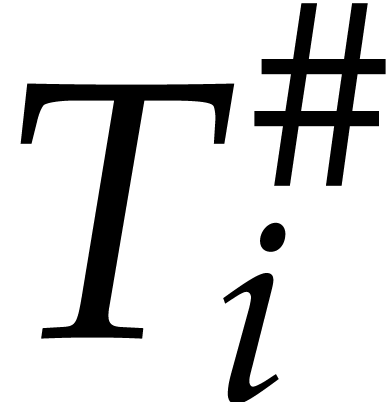 .
.
Let us start with the description of a few invariants at the start of
the main loop on  To avoid case distinctions, let
To avoid case distinctions, let
 be the function on
be the function on  defined by
defined by
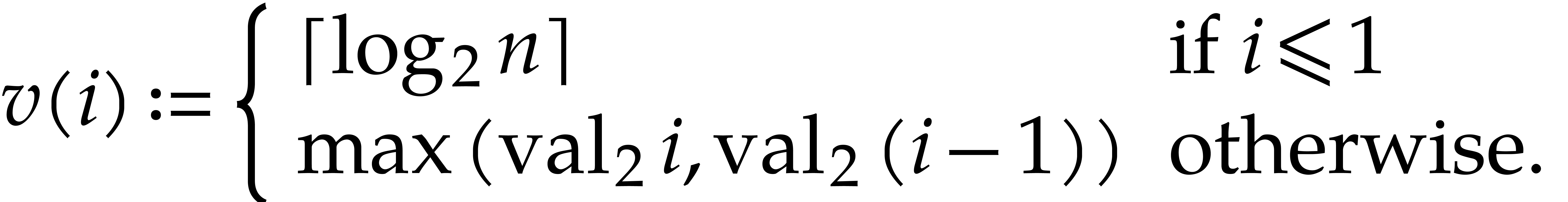
Then the following invariants hold:
Invariant 1 is immediate. Invariants 2 and 3 follow from Lemma 13, using 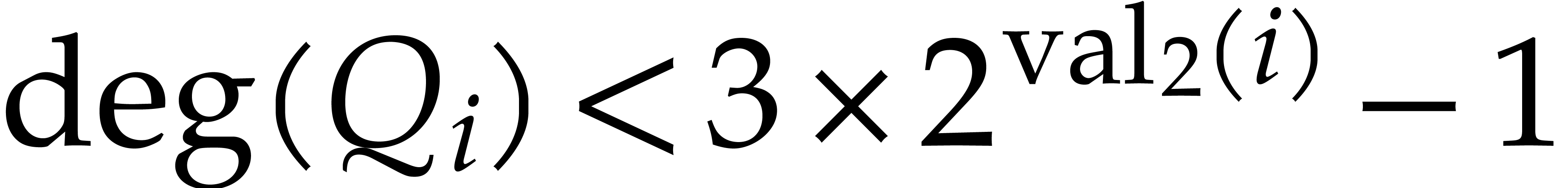 by Lemma 12. For invariant 4, we recall that
by Lemma 12. For invariant 4, we recall that
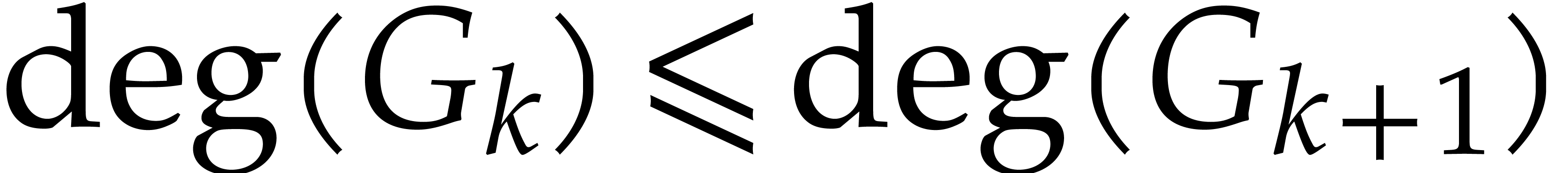 for all
for all 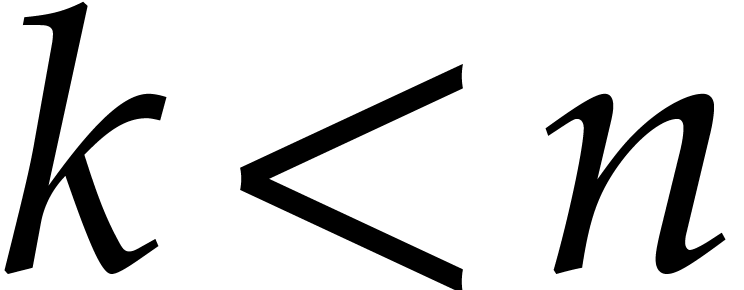 .
Finally, invariant 5 is an immediate consequence of the
definition of the index .
.
Finally, invariant 5 is an immediate consequence of the
definition of the index .
Let us now prove the main claim (8). Notice first that if
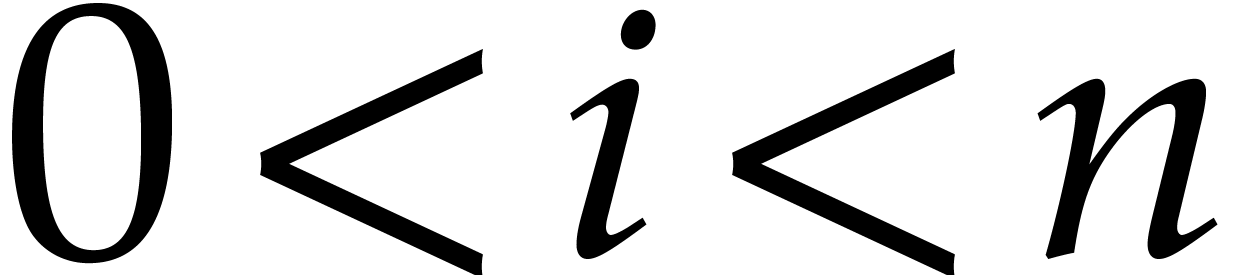 and
and 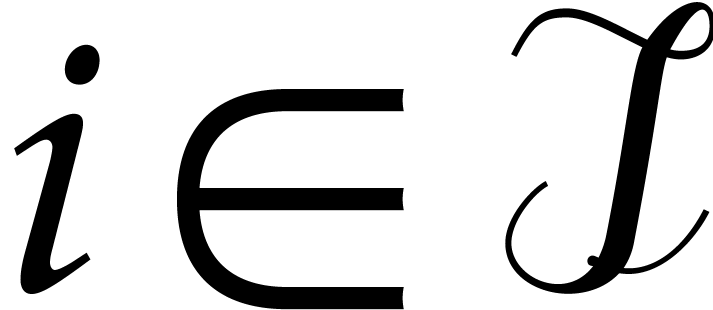 ,
then
,
then 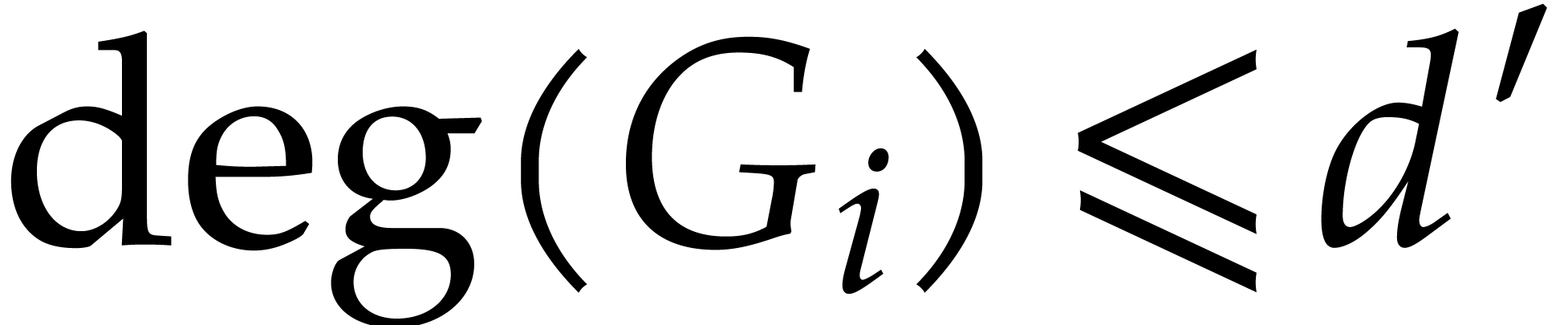 . Recall also that for . This
means
. Recall also that for . This
means 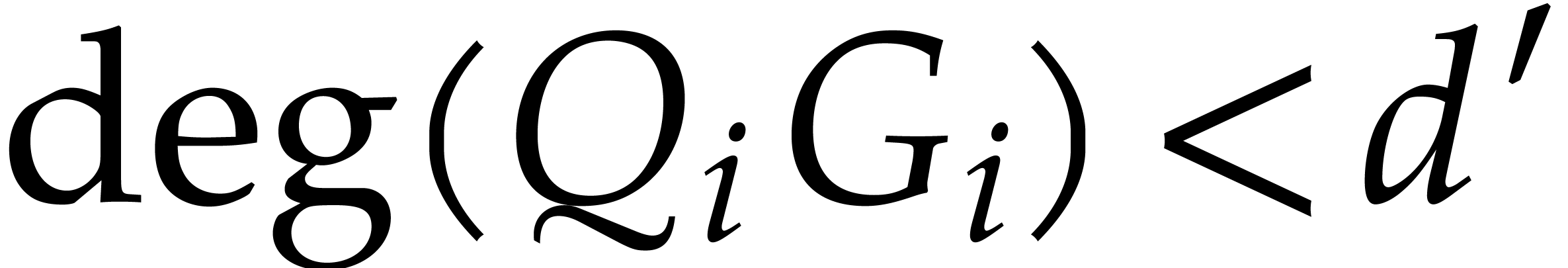 for
for 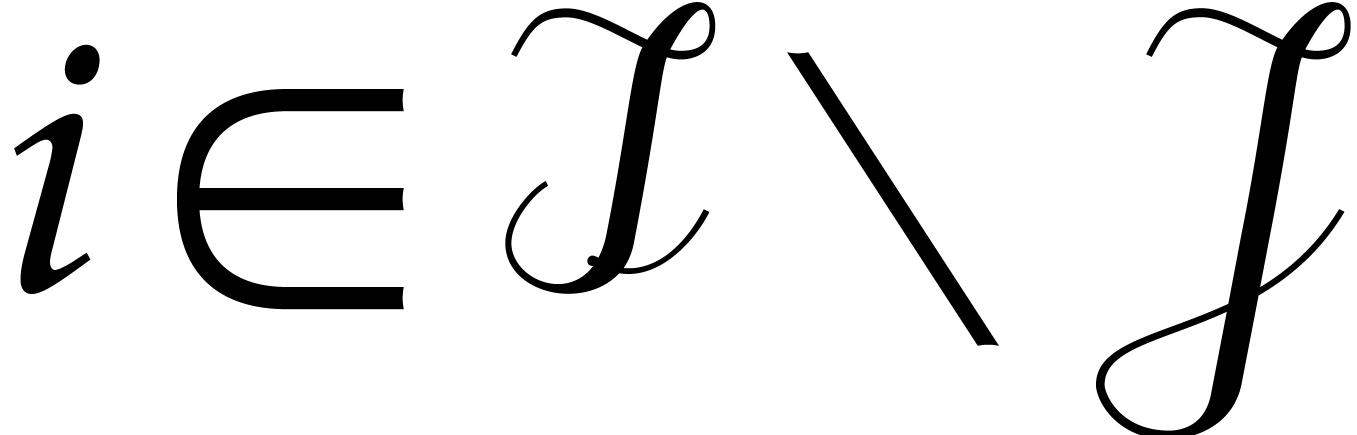 .
Since by definition
.
Since by definition
we deduce that
To complete the proof (by invariant 1), we show that
For the first identity, we contend that 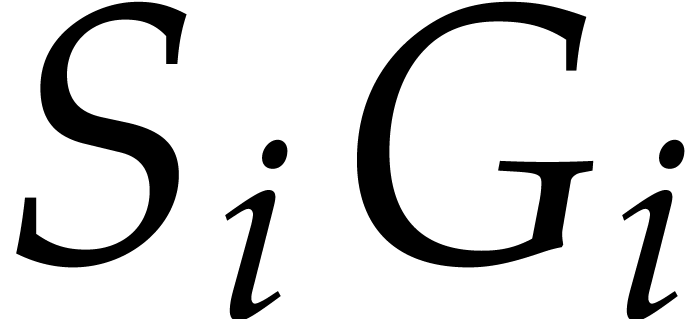 and
and 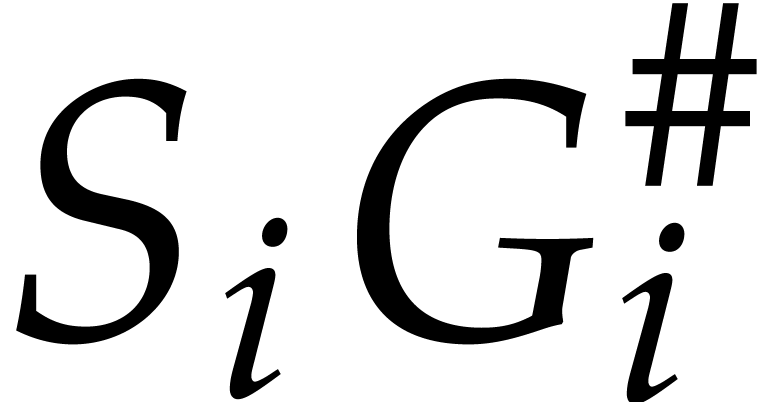 have the same terms of degree
because of invariants 3 and 5. This is clear
if
have the same terms of degree
because of invariants 3 and 5. This is clear
if 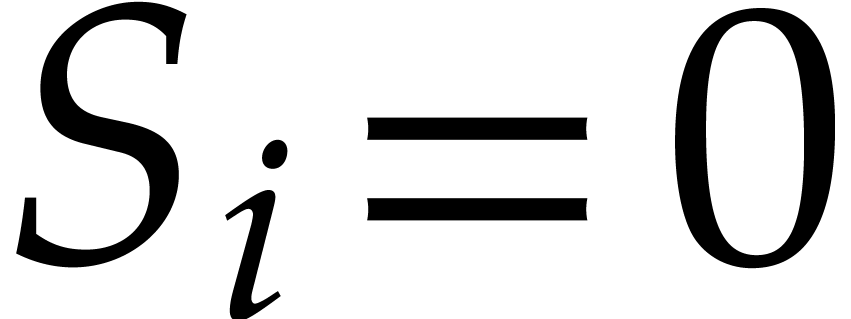 , or if
, or if  since
since 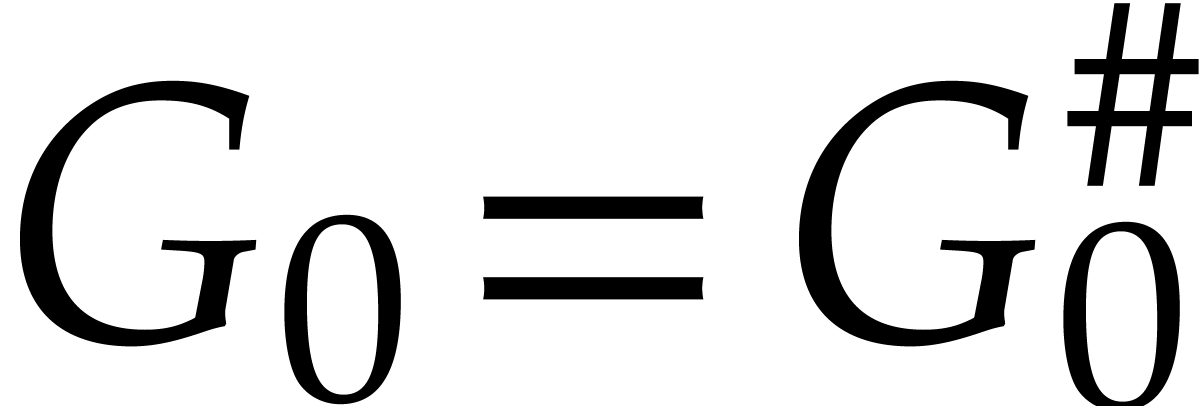 and
and 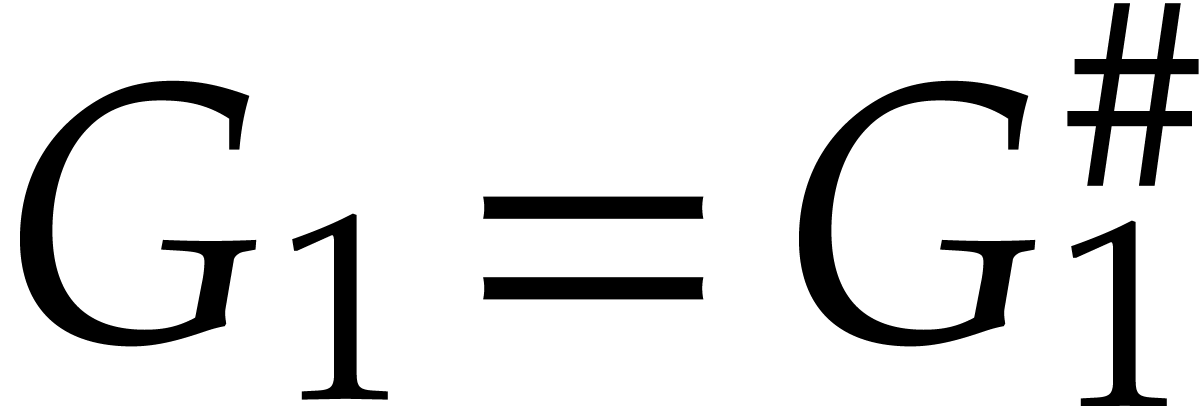 .
Assume therefore that
.
Assume therefore that 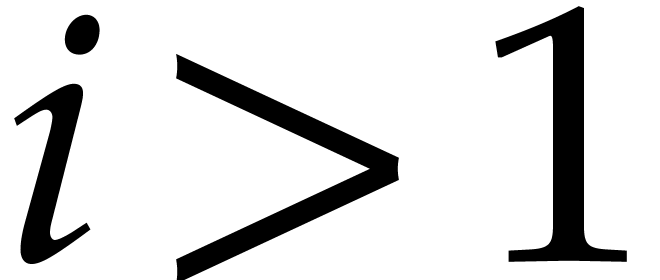 and
and 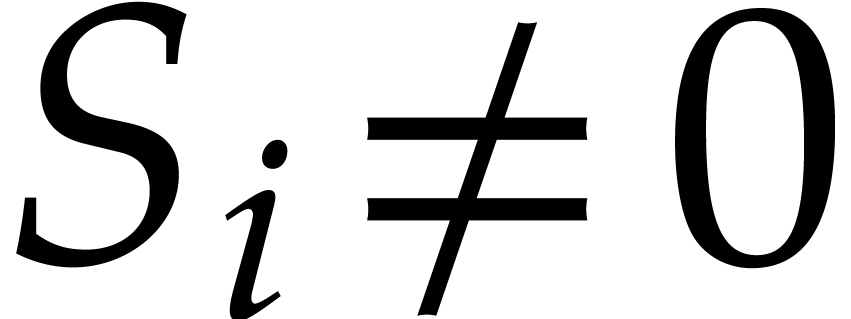 . By invariant 5, the index
. By invariant 5, the index 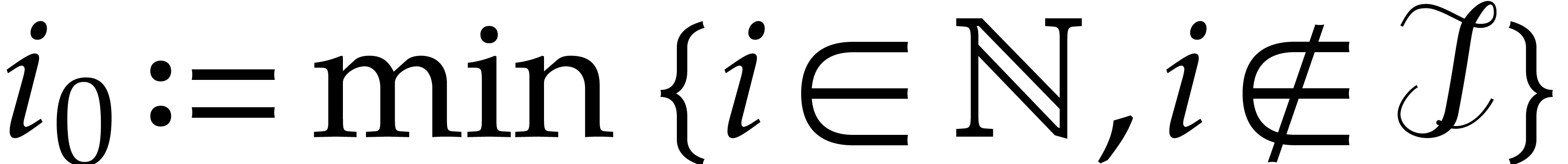 verifies
verifies 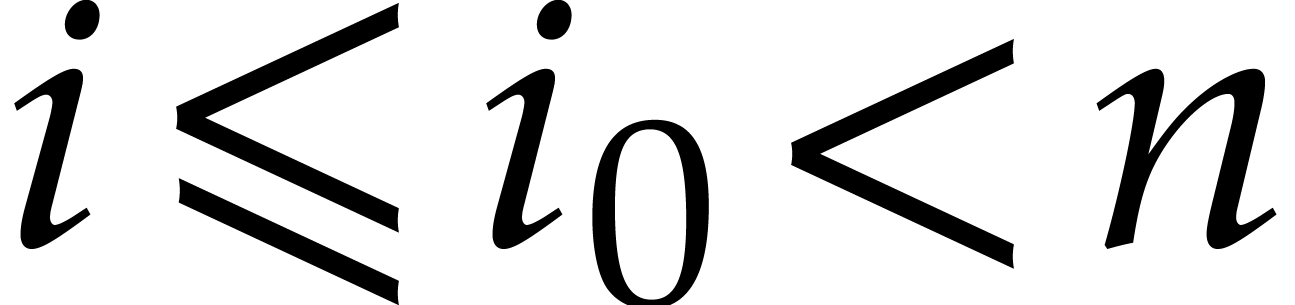 ,
hence
,
hence  was removed from
was removed from  during a previous iteration of the loop on .
Since
during a previous iteration of the loop on .
Since 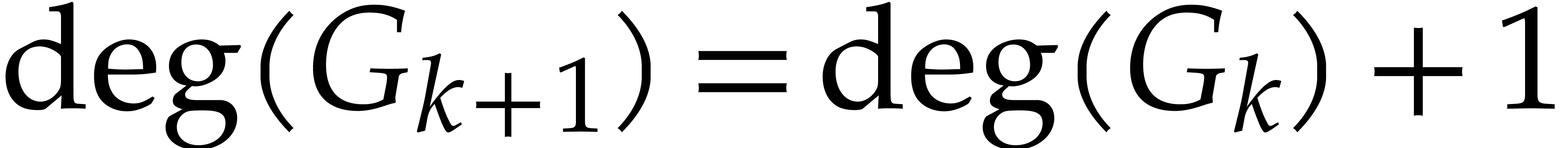 for all
for all  ,
this actually happened during the previous iteration (with
,
this actually happened during the previous iteration (with 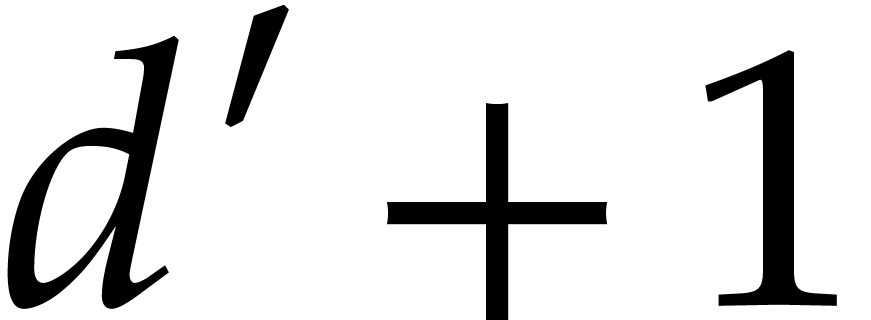 instead of ).
It follows that
instead of ).
It follows that  . By
definition of and invariant 3, the
polynomials and have the
same terms of degree at least
. By
definition of and invariant 3, the
polynomials and have the
same terms of degree at least 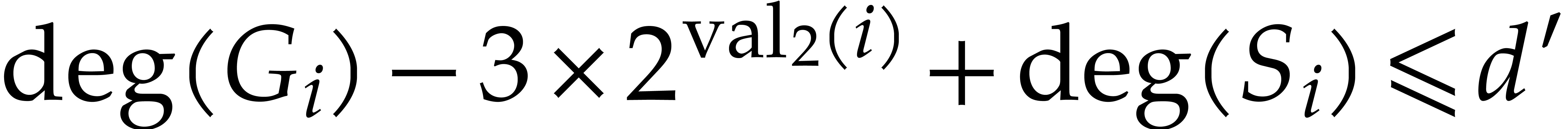 .
.
The second identity follows immediately from invariant 2.
The last identity follows from the implication  , so that
, so that 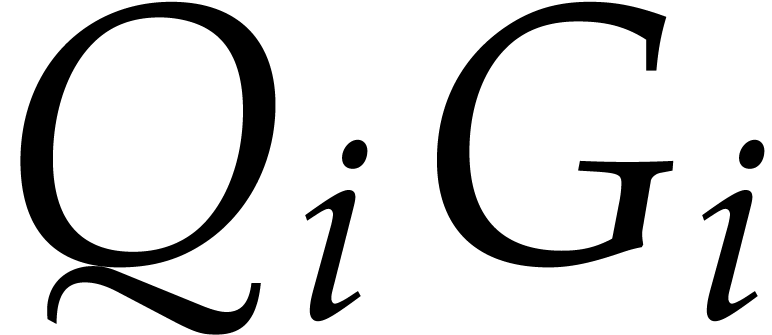 and
and 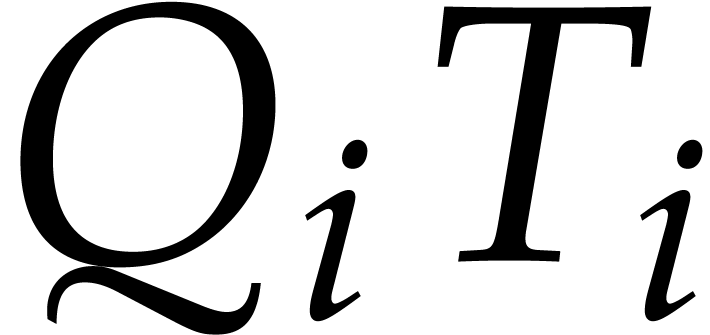 have the same terms of degree .
have the same terms of degree .
For the complexity, relaxed multiplications are used to compute the
coefficients of the 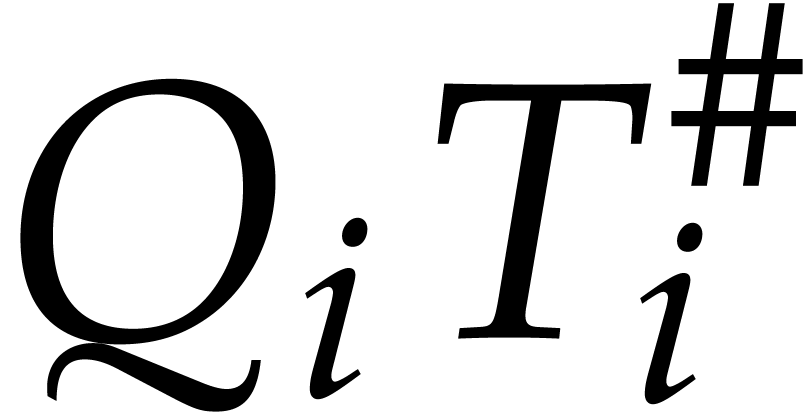 , whose
support is a subset of the support of
, whose
support is a subset of the support of  .
Then the relaxed multiplications take time
.
Then the relaxed multiplications take time
It remains to evaluate the cost of the zealous multiplications during
the rewriting steps. For each index  with even, and for each
with even, and for each  ,
there is an update of
,
there is an update of  at a cost of , followed by an evaluation of the products
at a cost of , followed by an evaluation of the products
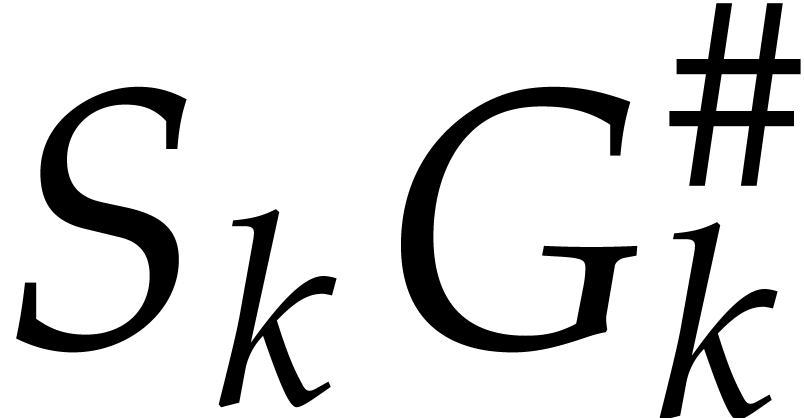 and
and 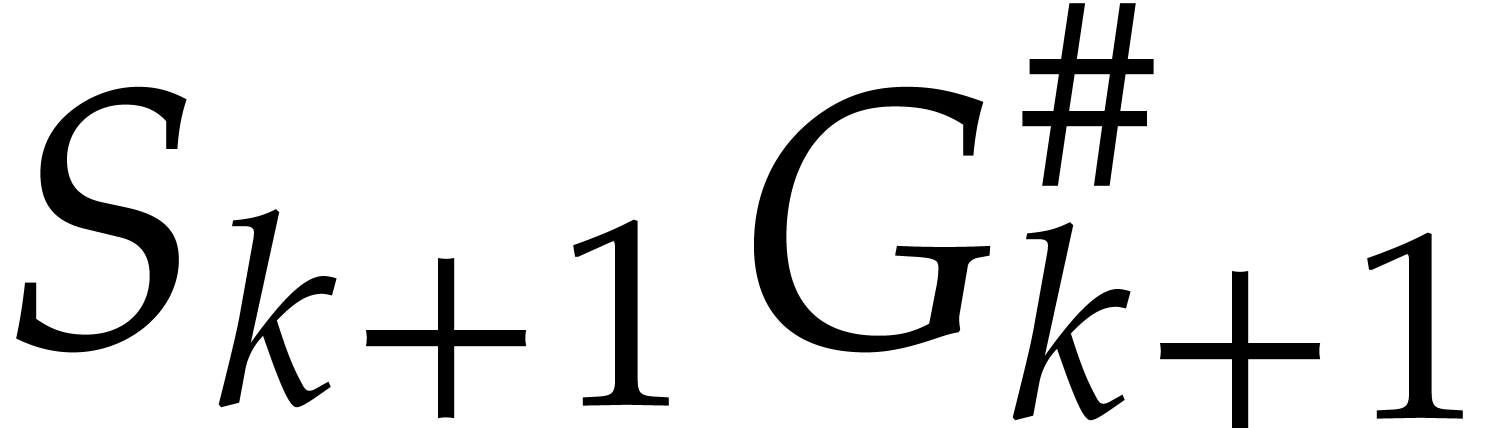 at a cost of
at a cost of 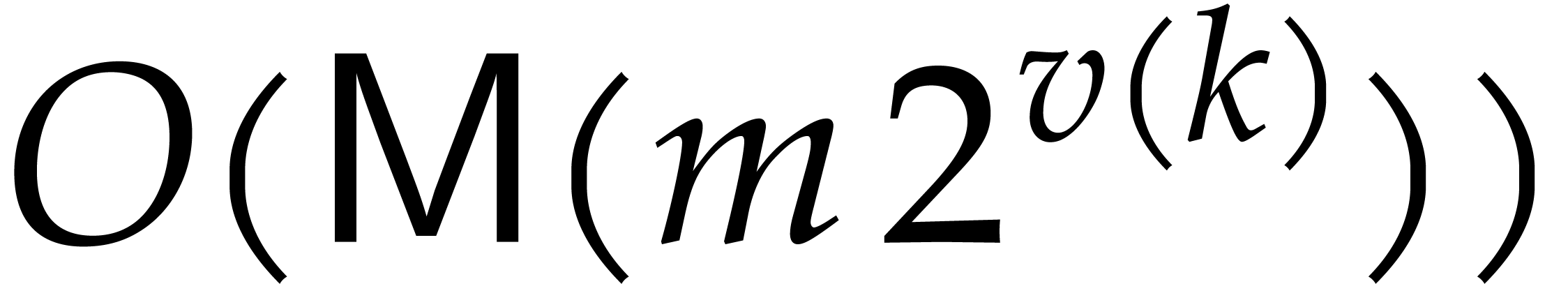 operations. This totals for
operations. This totals for 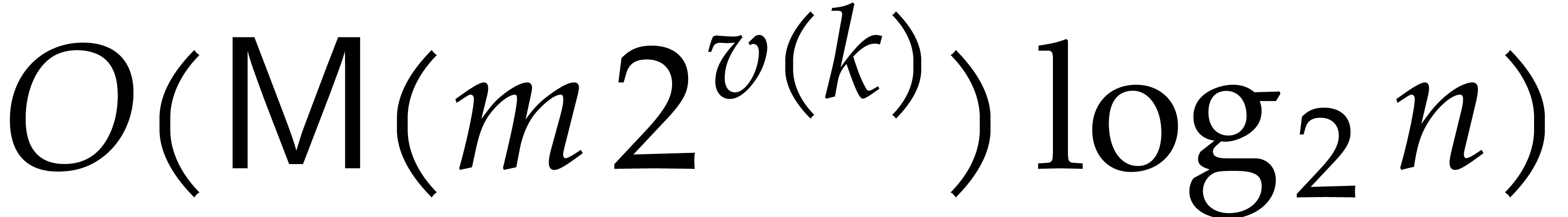 operations. Summing for all ,
we get a total cost of
operations. Summing for all ,
we get a total cost of 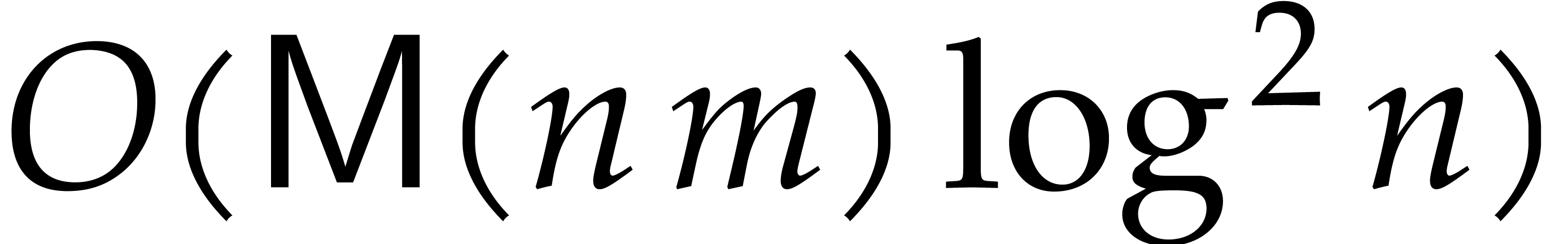 for all rewriting steps.
This fits in the announced complexity bound, by our assumption that
for all rewriting steps.
This fits in the announced complexity bound, by our assumption that
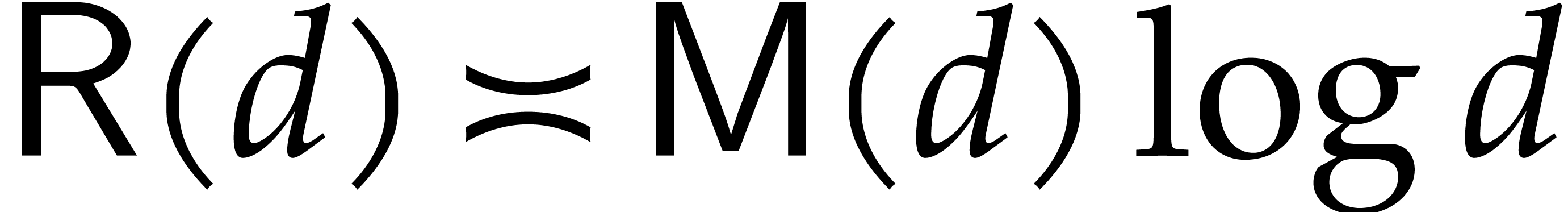 .
.
Remark 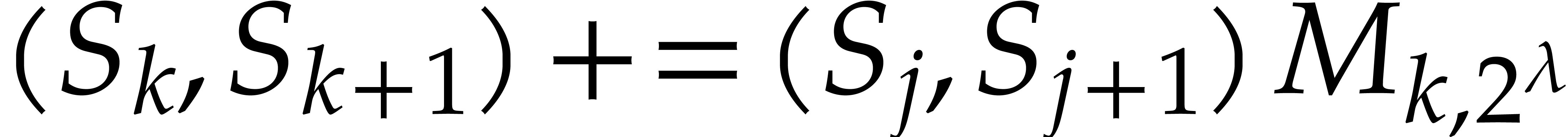 until more quotients are known. This allows to
decrease by a logarithmic factor the number of products
until more quotients are known. This allows to
decrease by a logarithmic factor the number of products 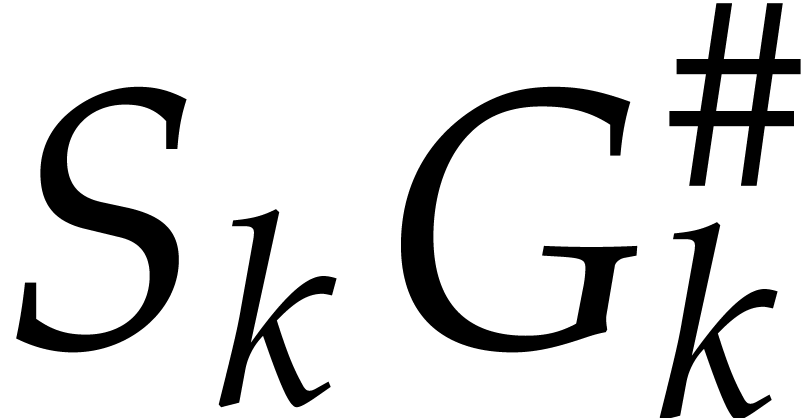 , but leads to various technical complications.
A priori, this does not change the asymptotic complexity;
however, with a bound for relaxed multiplication better than , these zealous products would
become predominant without this optimization.
, but leads to various technical complications.
A priori, this does not change the asymptotic complexity;
however, with a bound for relaxed multiplication better than , these zealous products would
become predominant without this optimization.
Under some regularity assumptions, we provided a quasi-linear algorithm
for polynomial reduction, but unlike in [17], it does not
rely on expensive precomputations. This leads to significant
improvements in the asymptotic complexity for various problems. To
illustrate the gain, let us assume to simplify that 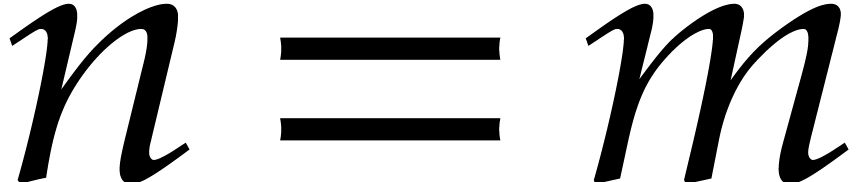 , and neglect logarithmic factors. Then, ideal
membership test and modular multiplication are essentially quadratic in
, and neglect logarithmic factors. Then, ideal
membership test and modular multiplication are essentially quadratic in
 . Also, computing the reduced
Gröbner basis has cubic complexity. In all these examples, the
bound is intrinsically optimal, and corresponds to a speed-up by a
factor compared to the best previously known
algorithms.
. Also, computing the reduced
Gröbner basis has cubic complexity. In all these examples, the
bound is intrinsically optimal, and corresponds to a speed-up by a
factor compared to the best previously known
algorithms.
From any fast algorithms for Gröbner basis computation and (multivariate) polynomial reduction, it is immediate to construct an ideal membership test:
Algorithm
Output: true if 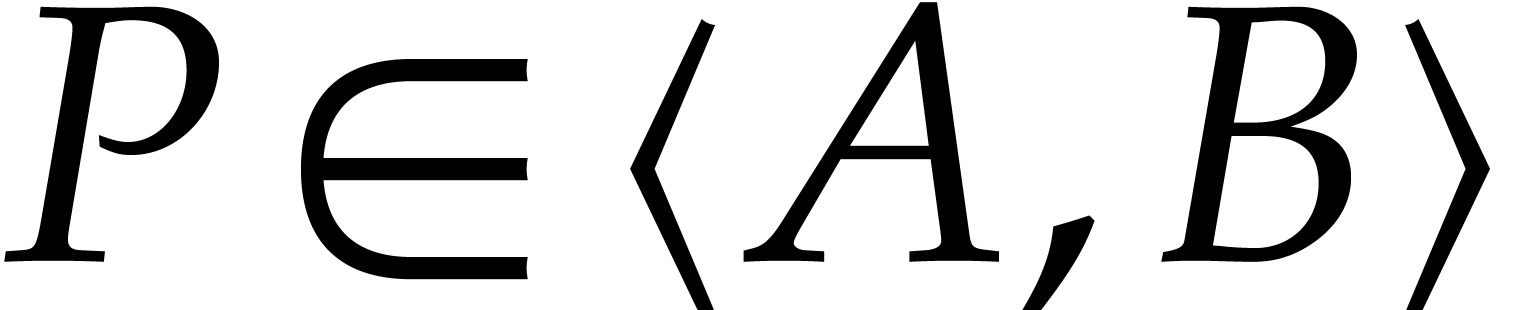 ,
false otherwise.
,
false otherwise.
Let be the concise representation of the
Gröbner basis of 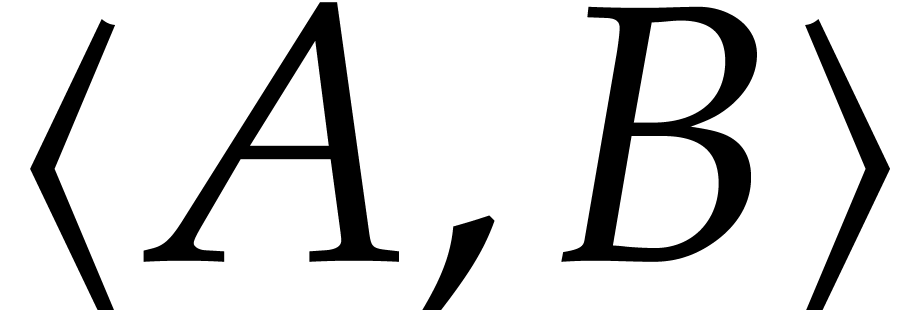 with respect to , computed
using Algorithm 2.
with respect to , computed
using Algorithm 2.
Let be an extended reduction of modulo ,
computed using Algorithm 3.
Return true if 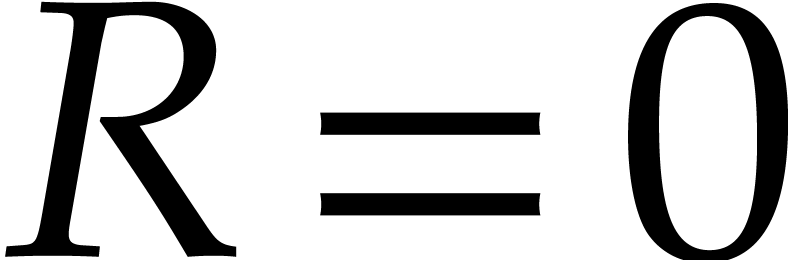 ,
false otherwise.
,
false otherwise.
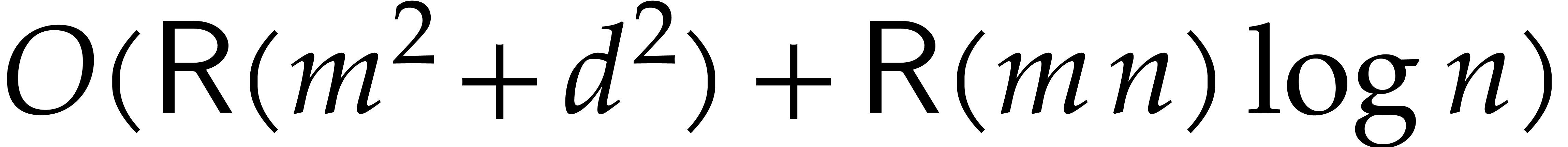 .
.
We designed a practical representation of the quotient algebra 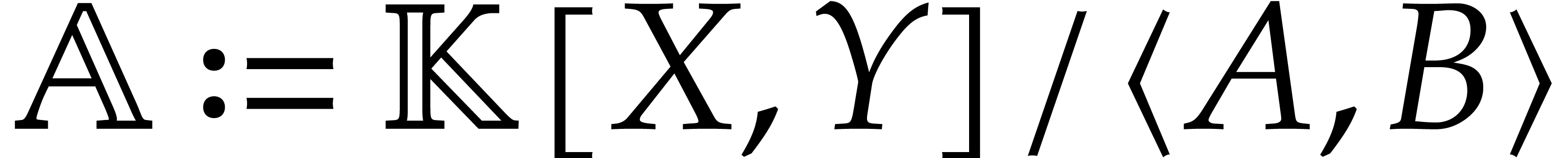 that does not need more space (up to logarithmic factors)
than the algebra itself, while still allowing for efficient computation.
The main difference with the terse representation from [17]
is that said representation is easy to compute, so that multiplication
in
that does not need more space (up to logarithmic factors)
than the algebra itself, while still allowing for efficient computation.
The main difference with the terse representation from [17]
is that said representation is easy to compute, so that multiplication
in  can be done in quasi-linear time, including
the cost for the precomputation:
can be done in quasi-linear time, including
the cost for the precomputation:
Algorithm
Input: 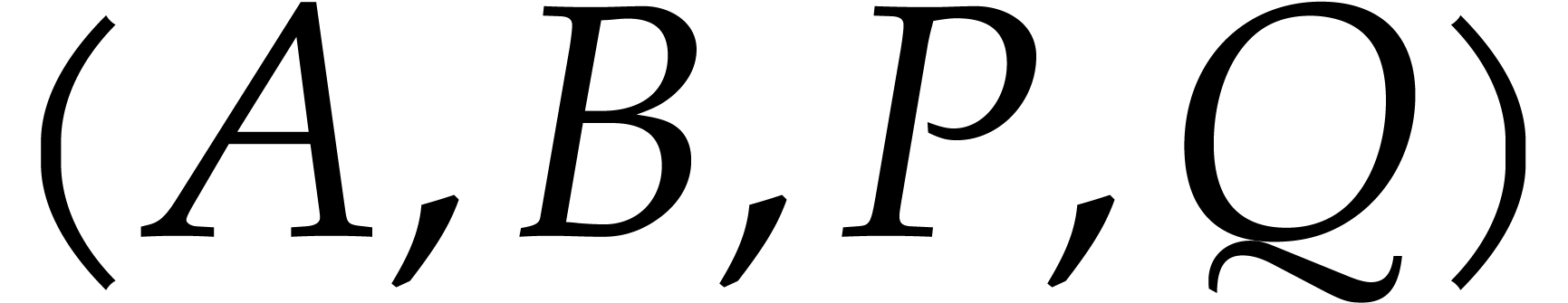 ,
bivariate polynomials, with generic of degrees
,
bivariate polynomials, with generic of degrees
 and
and  of degree at most
of degree at most
 (typically in normal form).
(typically in normal form).
Output:  in normal form.
in normal form.
Let be the concise representation of the
Gröbner basis of
with respect to , computed
using Algorithm 2.
Compute  using any (zealous) multiplication
algorithm.
using any (zealous) multiplication
algorithm.
Let be an extended reduction of modulo ,
computed using Algorithm 3.
Return  .
.
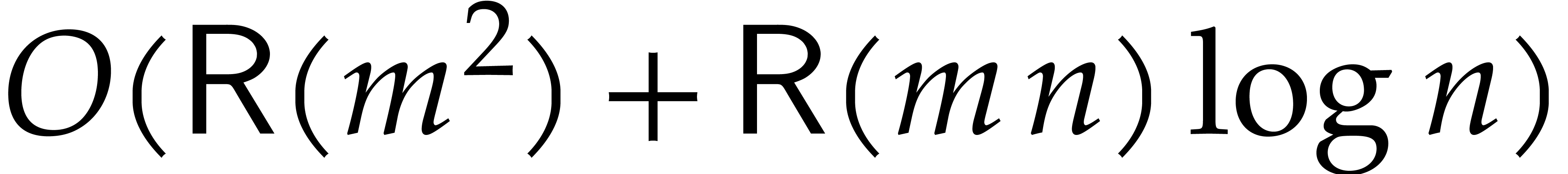 .
.
Remark 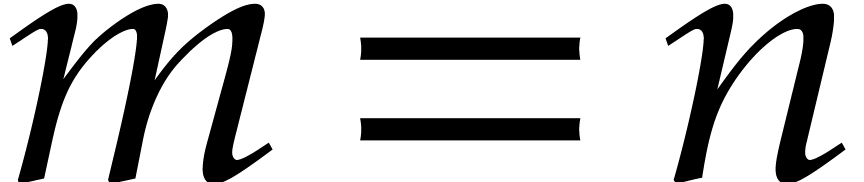 or simply
or simply  , then the algebra
, then the algebra  has
dimension
has
dimension 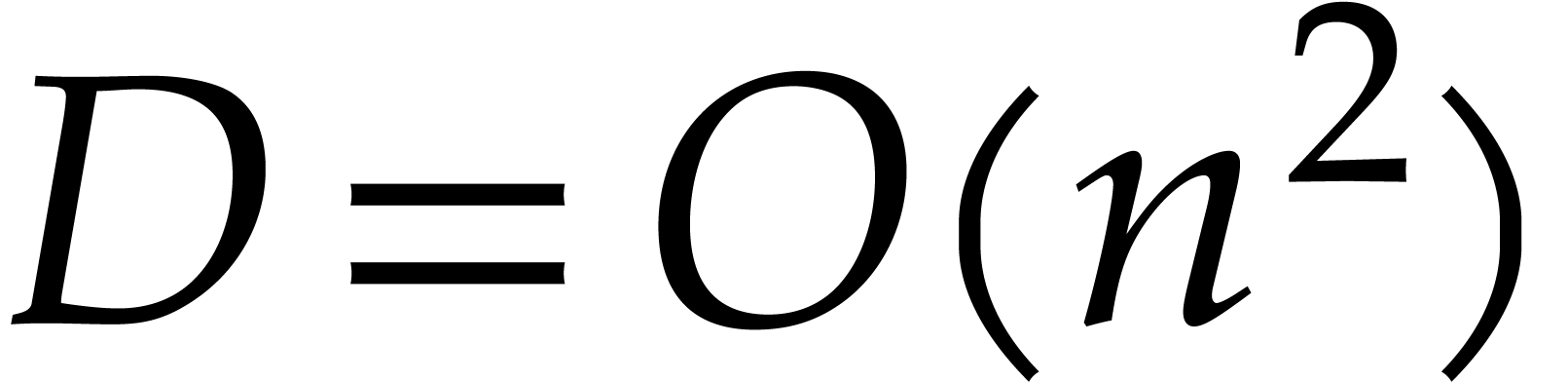 and the above bound can be rewritten
and the above bound can be rewritten
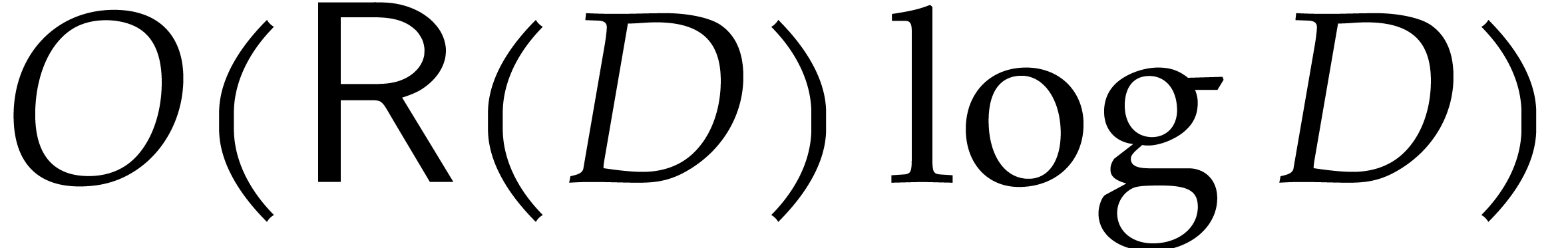 . In the general case, we
have
. In the general case, we
have 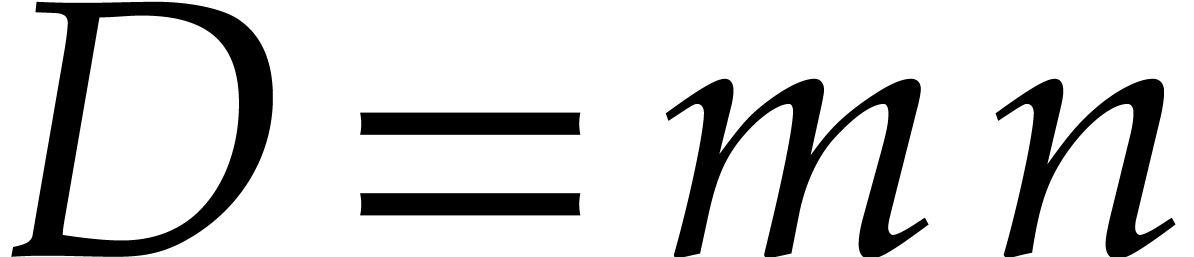 , and one might wish to
discard the term
, and one might wish to
discard the term 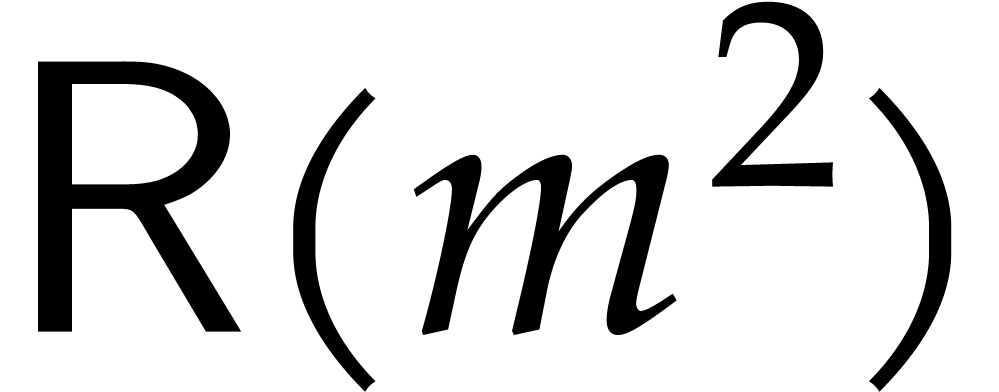 to achieve complexity
to achieve complexity 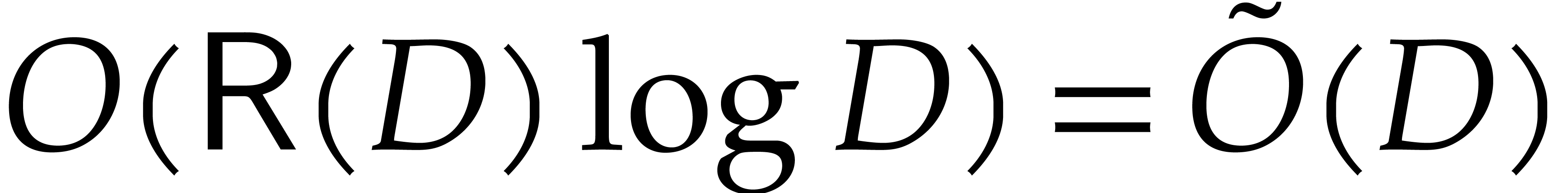 . This term includes the
computation of
. This term includes the
computation of  during the call to Algorithm 2 (which can be seen as precomputation), the multiplication
, and the term
during the call to Algorithm 2 (which can be seen as precomputation), the multiplication
, and the term 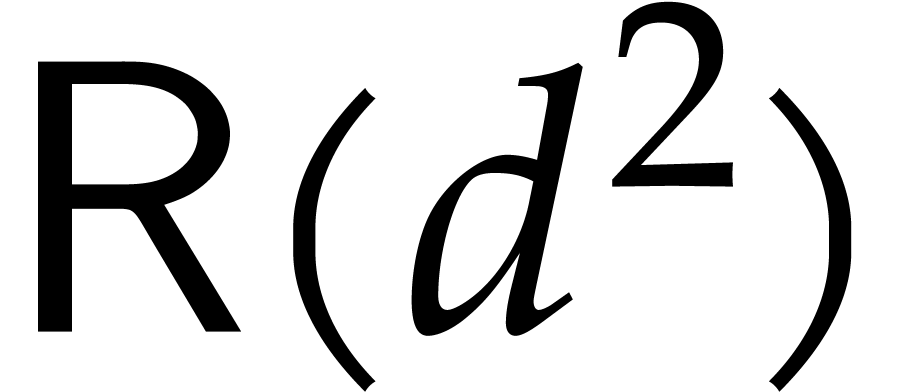 in the complexity of the reduction (since here
in the complexity of the reduction (since here 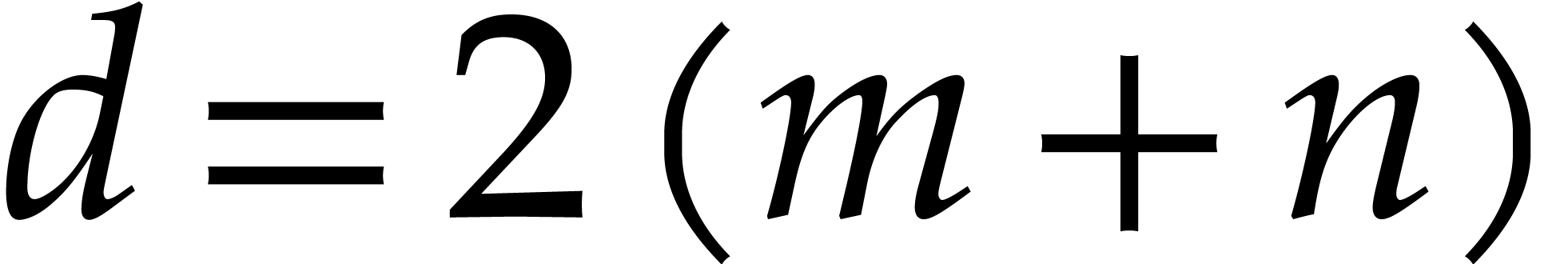 ). If and
). If and
 are given in normal form with respect to , then has
in fact degree
are given in normal form with respect to , then has
in fact degree 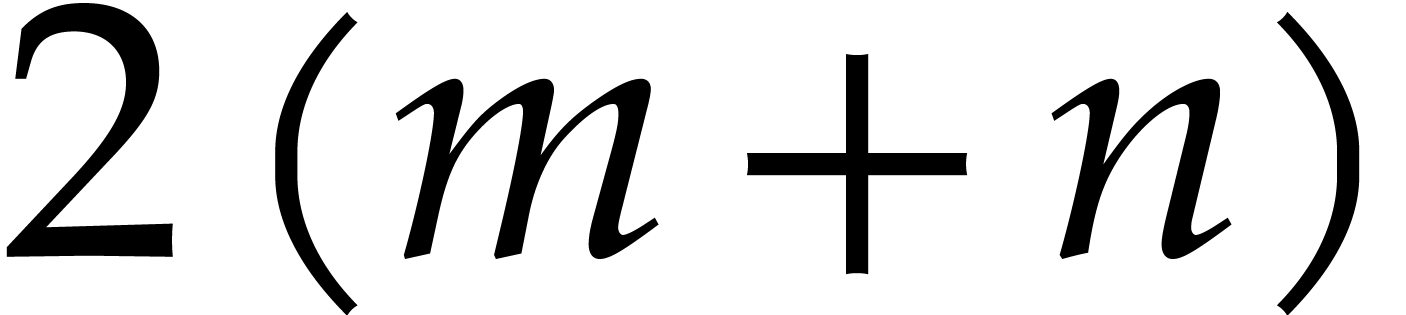 in the variable
and only
in the variable
and only  in .
In this case, can be computed in time
in .
In this case, can be computed in time 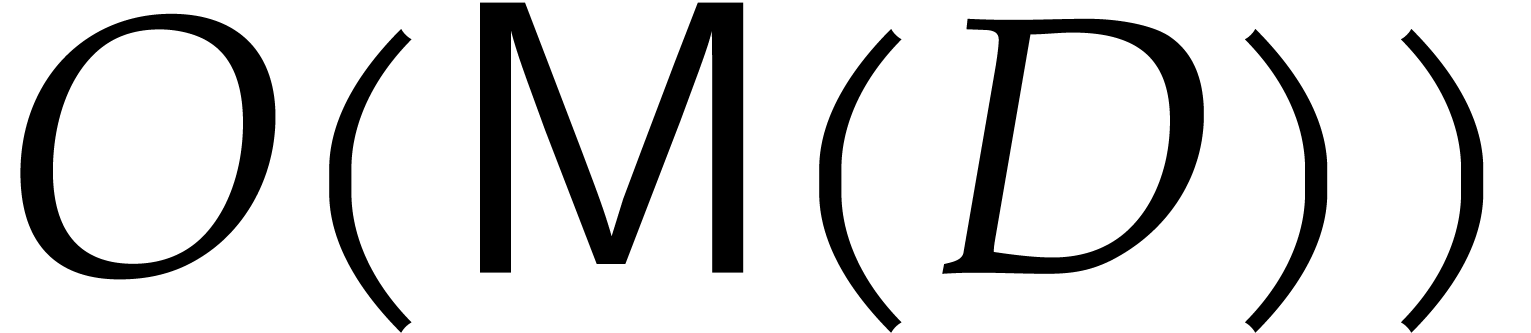 , and a refined analysis of the
reduction algorithm should reduce the term to
, and a refined analysis of the
reduction algorithm should reduce the term to
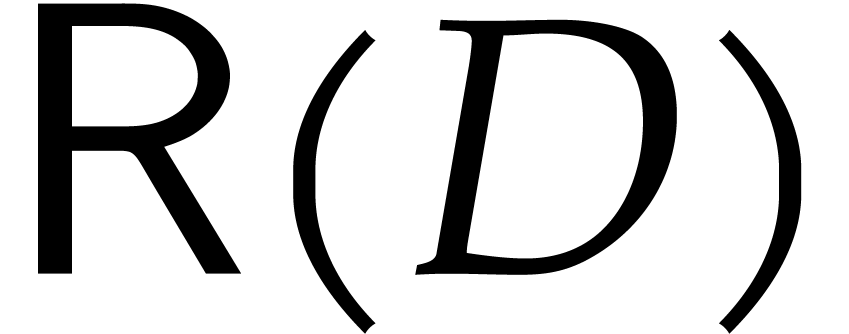 by observing that the degree in
remains
by observing that the degree in
remains 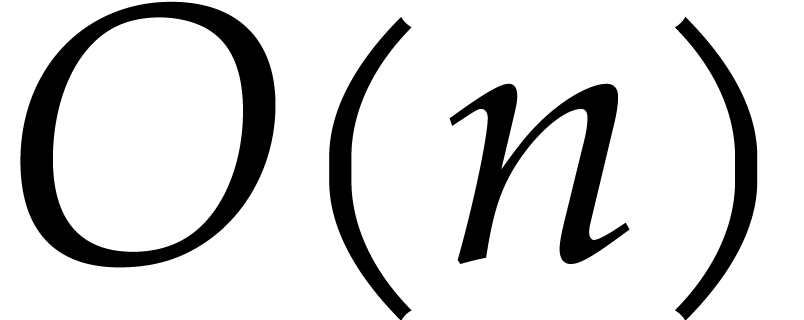 .
.
Since we can reduce polynomials in quasi-linear time, we deduce a new method to compute the reduced Gröbner basis: first compute the non-reduced basis, together with additional information to allow the efficient reduction (which can be done fast); then reduce each element with respect to the others.
Algorithm
Output: 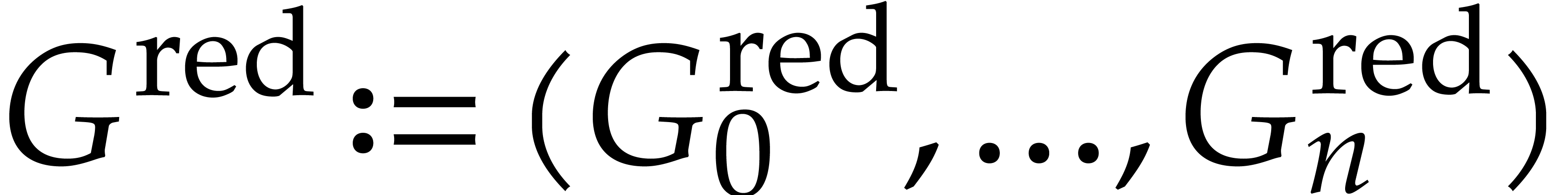 the reduced Gröbner basis
of with respect to .
the reduced Gröbner basis
of with respect to .
Let be the concise representation of , computed using Algorithm 2.
For all :
Set 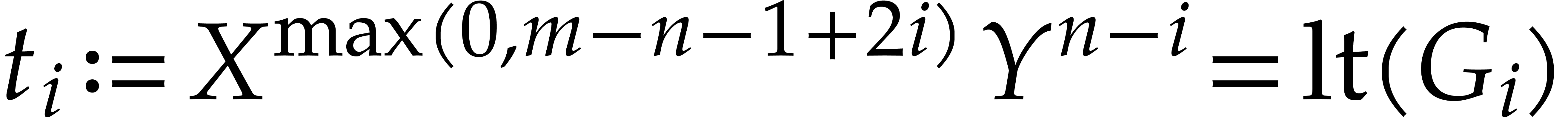 .
.
Let  be an extended reduction of
be an extended reduction of 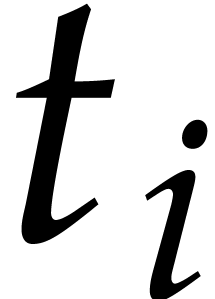 modulo ,
computed using Algorithm 3.
modulo ,
computed using Algorithm 3.
Set 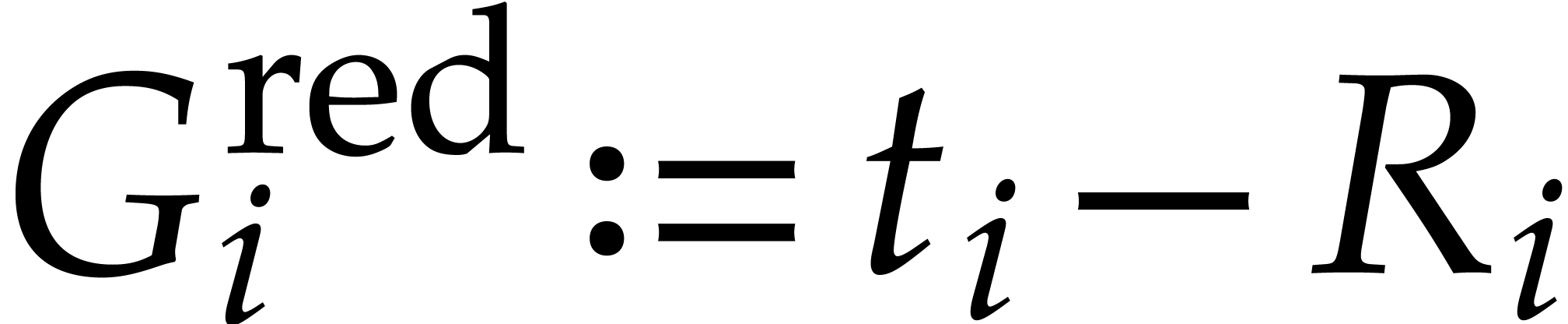 .
.
Return  .
.
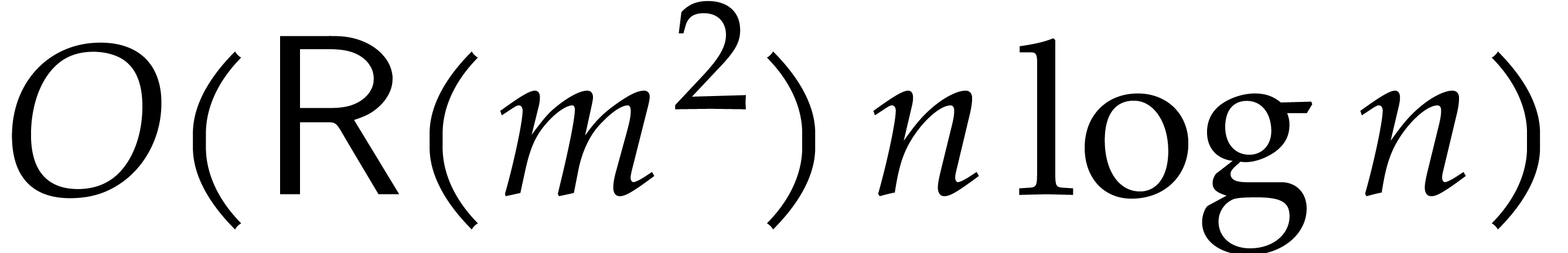 .
.
Proof. Clearly is in the
ideal and has the same leading monomial as .
Moreover, is monic and none of its terms is
divisible by the leading term of any ,
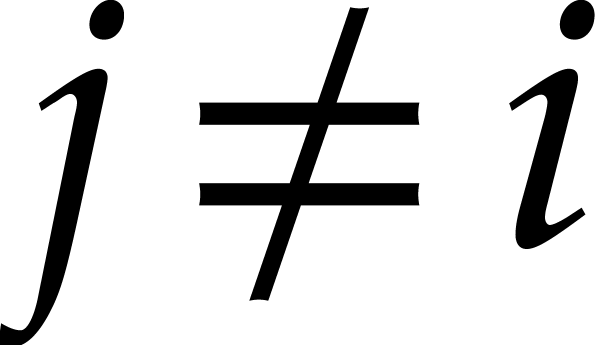 . This proves is indeed the reduced Gröbner basis of with respect to .
. This proves is indeed the reduced Gröbner basis of with respect to .
For the complexity, the call to Algorithm 2 takes time
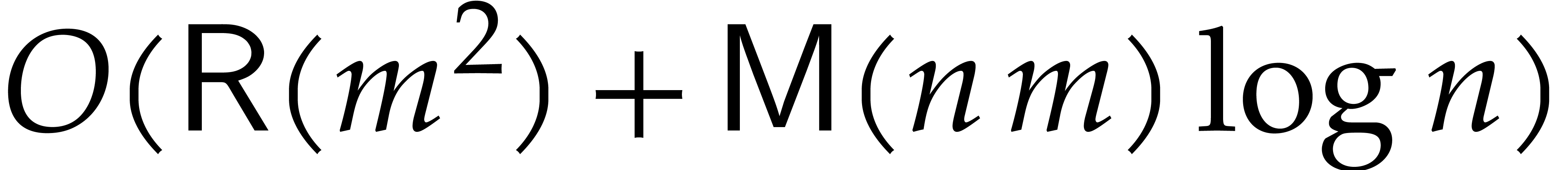 . Then, for each , the reduction requires
. Then, for each , the reduction requires 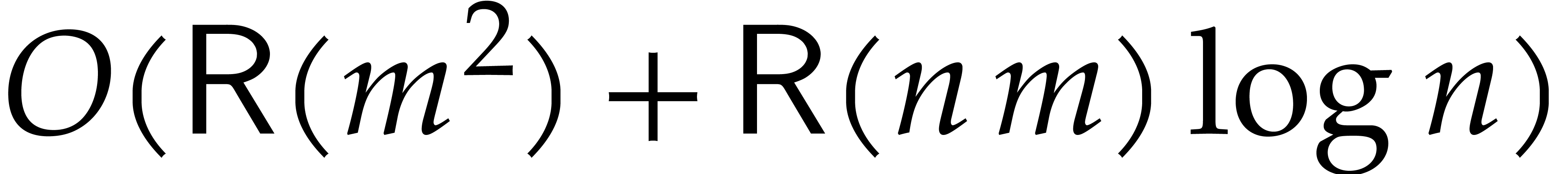 operations. The assumption now yields the
desired bound.
operations. The assumption now yields the
desired bound.
Remark has size 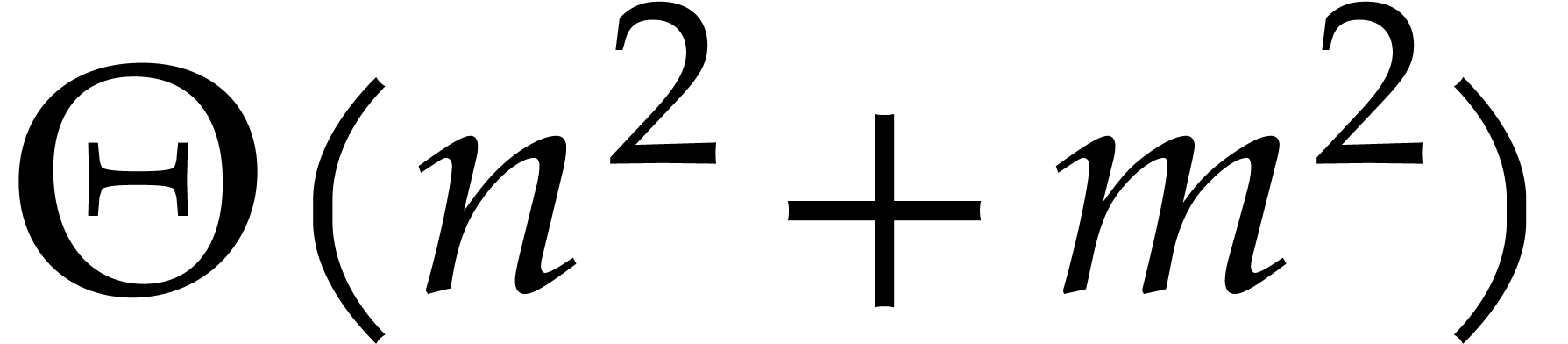 ,
and the output needs
,
and the output needs 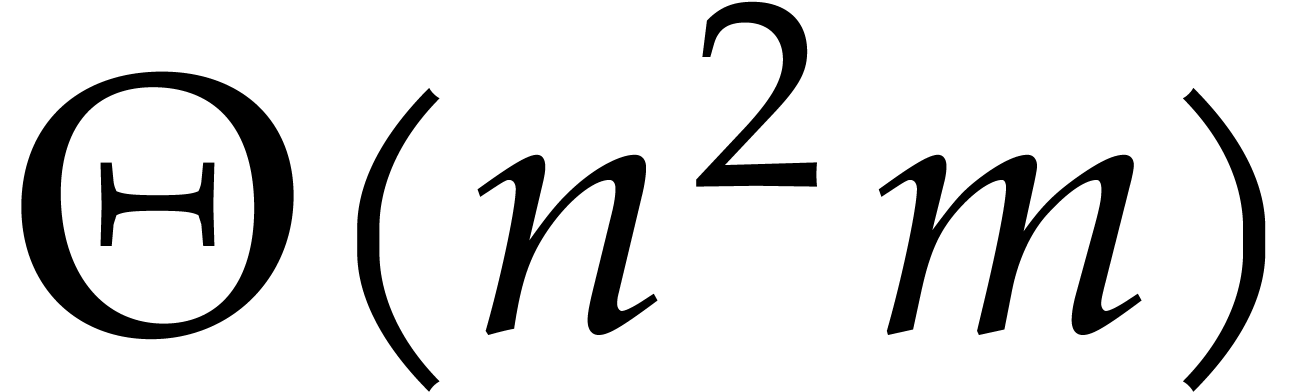 , while Algorithm 6 runs in time
, while Algorithm 6 runs in time 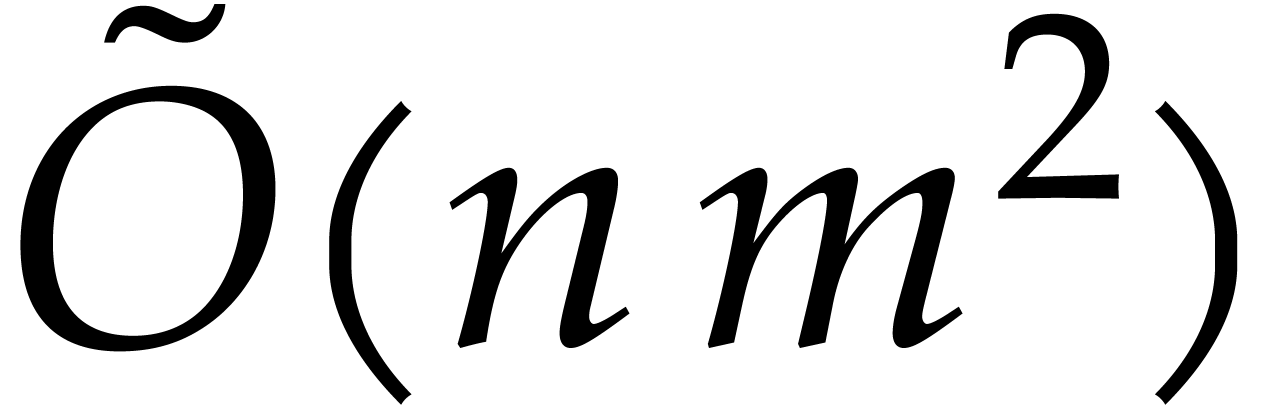 . Our complexity bound is therefore
quasi-optimal only if
. Our complexity bound is therefore
quasi-optimal only if  . We
expect that a truly quasi-linear bound can still be obtained in general
through a refined analysis (as for Remark 19).
. We
expect that a truly quasi-linear bound can still be obtained in general
through a refined analysis (as for Remark 19).
As we noted in different remarks, the announced bounds could be slightly
improved at the expense of some technicalities. For example, the
optimization mentioned in Remark 16 would lead to a tighter
bound when considering even faster relaxed multiplication (as in [19]). Also, as noted in Remarks 19 and 21,
a refined analysis is required when  to give a
truly quasi-linear complexity. Apart from this, several more
theoretically challenging extensions can be considered.
to give a
truly quasi-linear complexity. Apart from this, several more
theoretically challenging extensions can be considered.
First we notice that Algorithm 2 fails if the Euclidean algorithm raises a quotient with degree larger than 1. Generically, this should not happen, but this restriction can be limiting in practice, especially in the case of small finite fields. It is then natural to ask how to handle the case of non-normal degree sequences. We conjecture that our algorithm extends (and remains quasi-linear) to the case where the quotients have a bounded degree, with only a logarithmic number of them being larger than 1.
It would also be interesting to extend our ideas to the case of  variables. Whishful thinking suggests that this might
possible for fixed
variables. Whishful thinking suggests that this might
possible for fixed  , but with
a dependency polynomial in
, but with
a dependency polynomial in  (as the ratio between
the volumes of a pyramid and a parallelepiped based on the same
vectors). Extending the dichotomic selection strategy to higher
dimension is rather straightforward, but the question of the successive
substitutions is more subtle.
(as the ratio between
the volumes of a pyramid and a parallelepiped based on the same
vectors). Extending the dichotomic selection strategy to higher
dimension is rather straightforward, but the question of the successive
substitutions is more subtle.
Magali Bardet, Jean-Charles Faugère, and Bruno Salvy. On the complexity of the F5 Gröbner basis algorithm. Journal of Symbolic Computation, pages 1–24, sep 2014.
Thomas Becker and Volker Weispfenning. Gröbner bases: a computational approach to commutative algebra, volume 141 of Graduate Texts in Mathematics. Springer-Verlag, New York, 1993.
Bruno Buchberger. Ein Algorithmus zum Auffinden der Basiselemente des Restklassenrings nach einem nulldimensionalen Polynomideal. PhD thesis, Universitat Innsbruck, Austria, 1965.
David G Cantor and Erich Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28(7):693–701, 1991.
Jean-Charles Faugère. A new efficient algorithm for computing Gröbner bases (F4). Journal of Pure and Applied Algebra, 139(1–3):61–88, 1999.
Jean-Charles Faugère. A new efficient algorithm for computing Gröbner bases without reduction to zero (F5). In Proceedings of the 2002 international symposium on Symbolic and algebraic computation, ISSAC '02, pages 75–83. New York, NY, USA, 2002. ACM.
Jean-Charles Faugère, Pierrick Gaudry, Louise Huot, and Guénaël Renault. Polynomial systems solving by fast linear algebra. ArXiv preprint arXiv:1304.6039, 2013.
Jean-Charles Faugère, Patrizia Gianni, Daniel Lazard, and Teo Mora. Efficient computation of zero-dimensional Gröbner bases by change of ordering. Journal of Symbolic Computation, 16(4):329–344, 1993.
M. J. Fischer and L. J. Stockmeyer. Fast on-line integer multiplication. Proc. 5th ACM Symposium on Theory of Computing, 9:67–72, 1974.
Ralf Fröberg and Joachim Hollman. Hilbert series for ideals generated by generic forms. Journal of Symbolic Computation, 17(2):149 – 157, 1994.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, 3rd edition, 2013.
Vladimir P. Gerdt and Yuri A. Blinkov. Involutive bases of polynomial ideals. Mathematics and Computers in Simulation, 45(5):519–541, 1998.
D. Harvey and J. van der Hoeven. Faster integer and polynomial multiplication using cyclotomic coefficient rings. Technical Report, ArXiv, 2017. http://arxiv.org/abs/1712.03693.
David Harvey, Joris van der Hoeven, and Grégoire Lecerf. Faster polynomial multiplication over finite fields. Technical Report, ArXiv, 2014. http://arxiv.org/abs/1407.3361.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven. On the complexity of polynomial reduction. In I. Kotsireas and E. Martínez-Moro, editors, Proc. Applications of Computer Algebra 2015, volume 198 of Springer Proceedings in Mathematics and Statistics, pages 447–458. Cham, 2015. Springer.
J. van der Hoeven and R. Larrieu. Fast reduction of bivariate polynomials with respect to sufficiently regular Gröbner bases. Technical Report, HAL, 2018. http://hal.archives-ouvertes.fr/hal-01702547.
J. van der Hoeven and É. Schost. Multi-point evaluation in higher dimensions. AAECC, 24(1):37–52, 2013.
Joris van der Hoeven. Faster relaxed multiplication. In Proc. ISSAC '14, pages 405–412. Kobe, Japan, Jul 2014.
Romain Lebreton, Eric Schost, and Esmaeil Mehrabi. On the complexity of solving bivariate systems: the case of non-singular solutions. In ISSAC: International Symposium on Symbolic and Algebraic Computation, pages 251–258. Boston, United States, Jun 2013.
Ernst Mayr. Membership in polynomial ideals over q is exponential space complete. STACS 89, pages 400–406, 1989.
Guillermo Moreno-Socías. Degrevlex gröbner bases of generic complete intersections. Journal of Pure and Applied Algebra, 180(3):263 – 283, 2003.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Infor., 7:395–398, 1977.
A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.
 be two bivariate polynomials over an
effective field
be two bivariate polynomials over an
effective field  ,
, with respect to the usual degree
lexicographic order. Assuming
with respect to the usual degree
lexicographic order. Assuming  .
.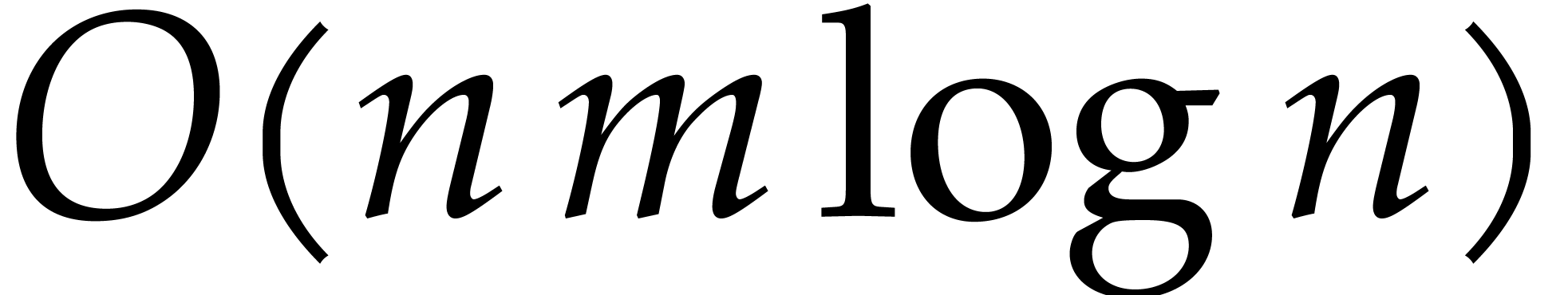 .
.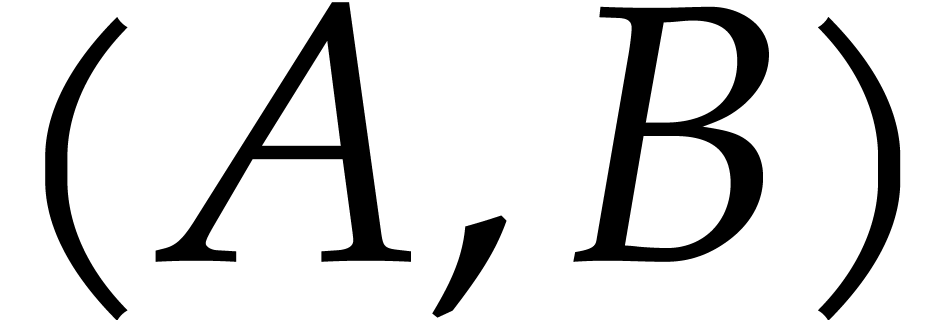 ,
,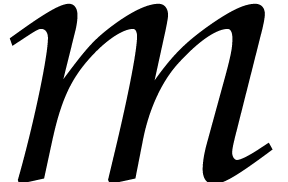 with
with 
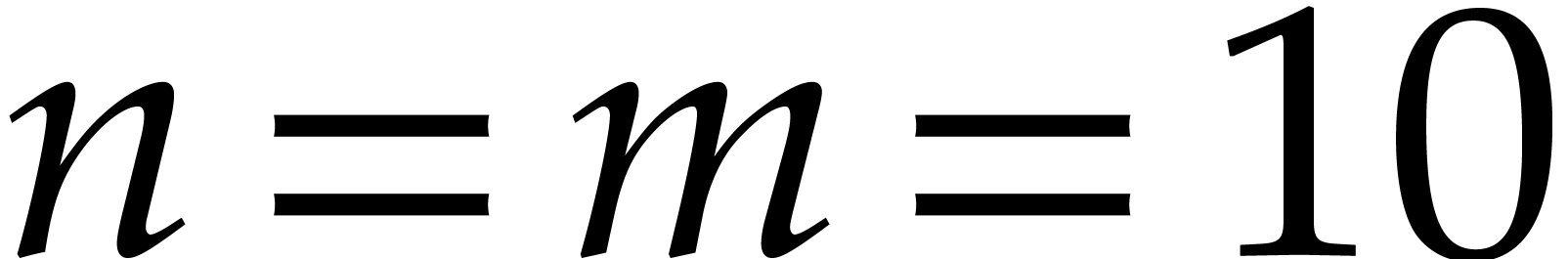 ):
):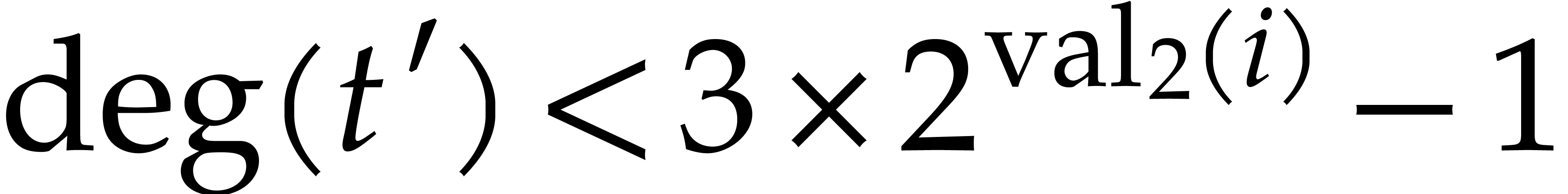 .
.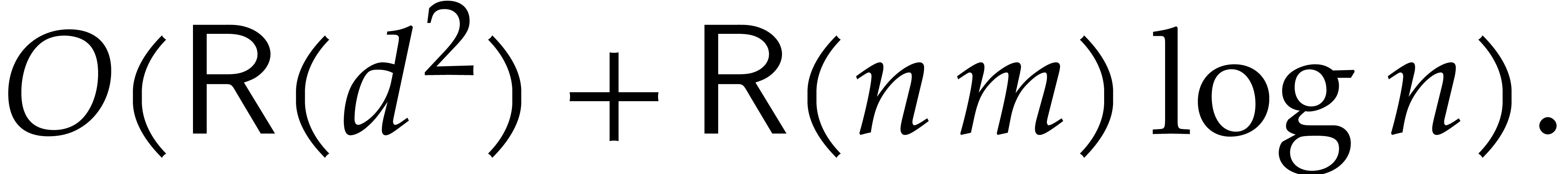
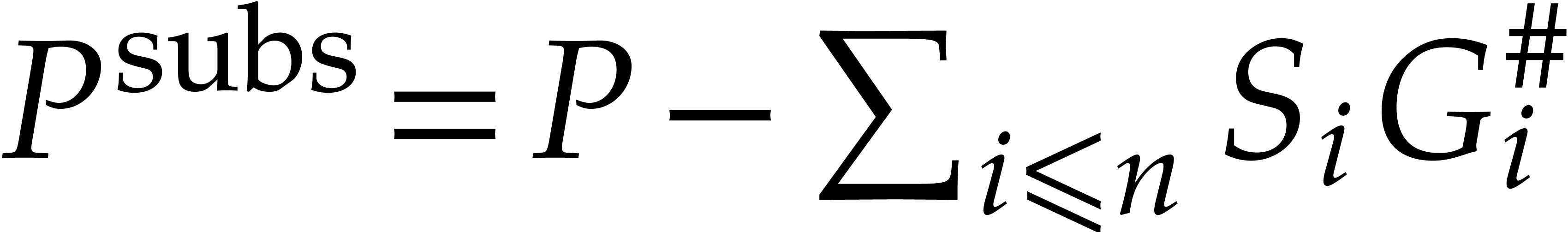 .
.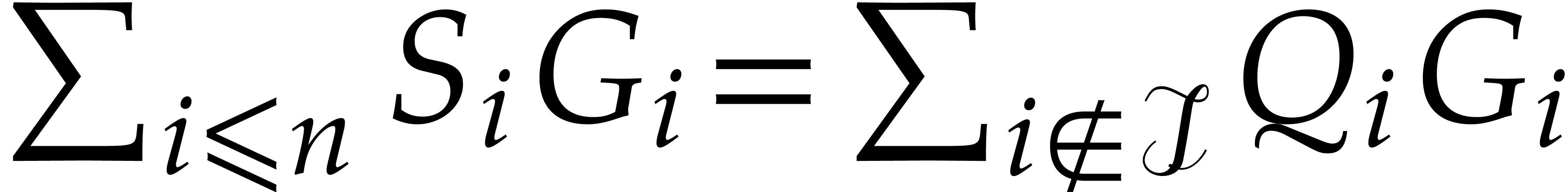 .
.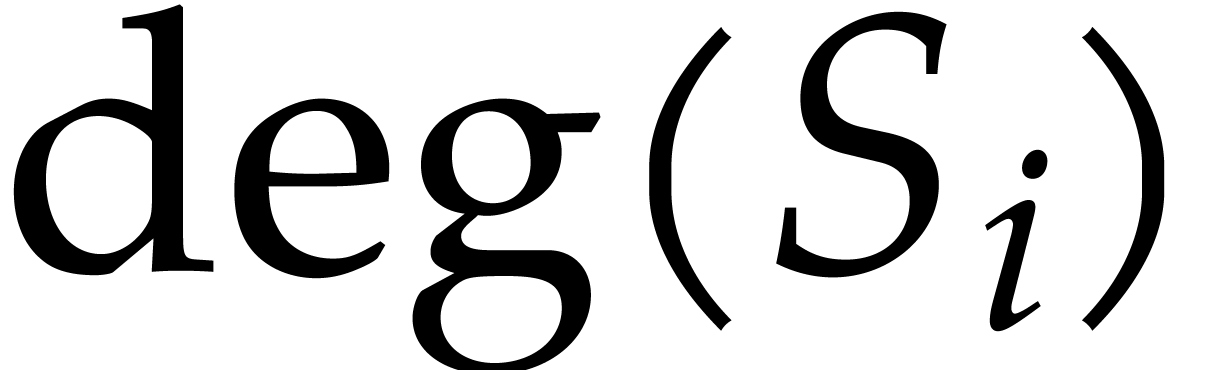 and
and 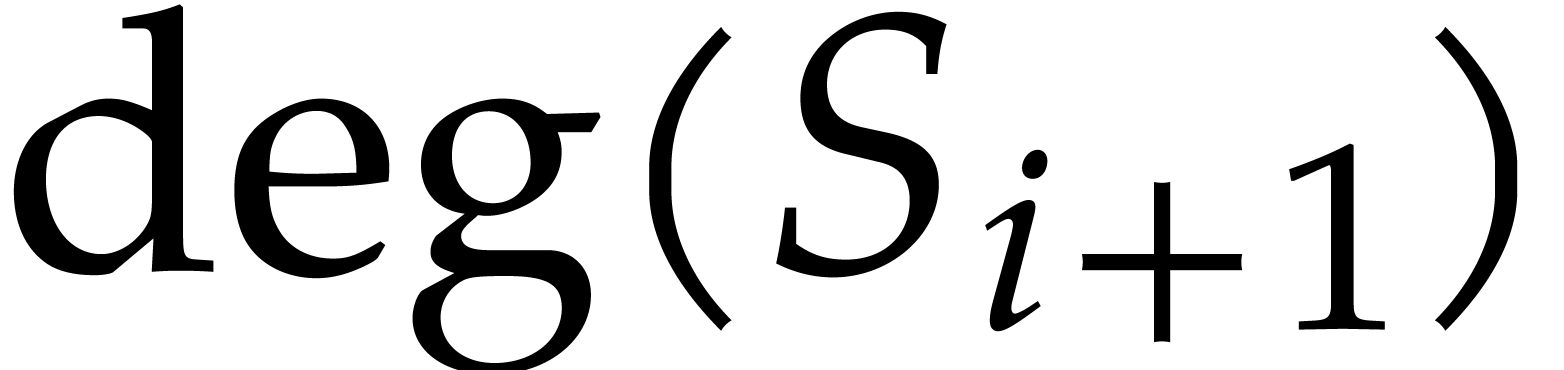 are
at most
are
at most 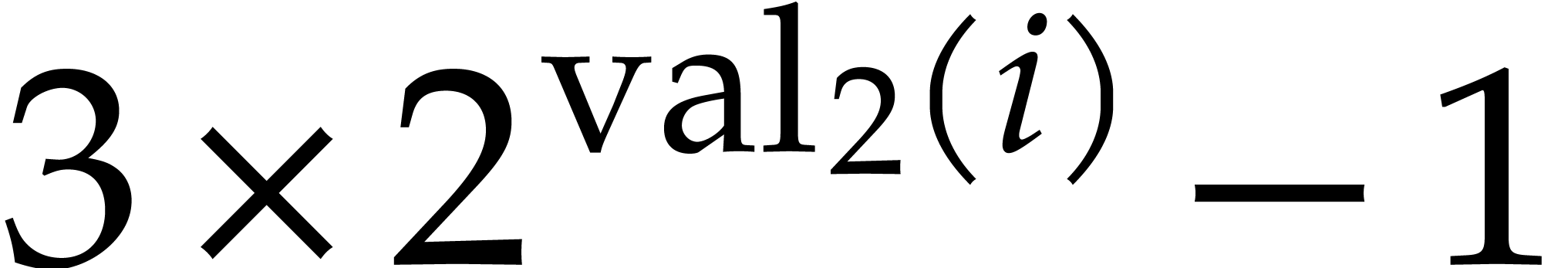 for all even
for all even  .
. ,
,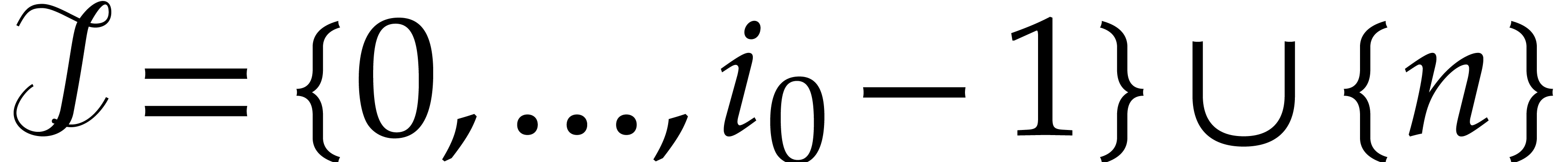 .
.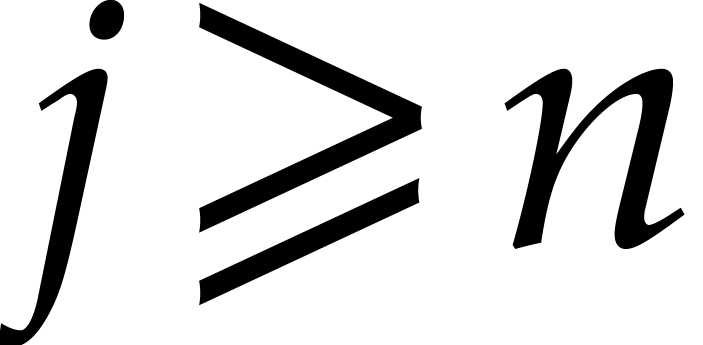 or
or 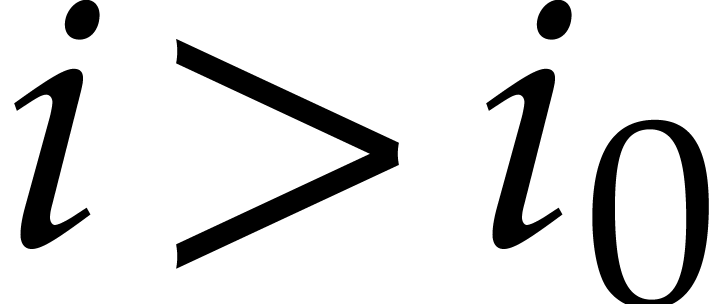 or (
or (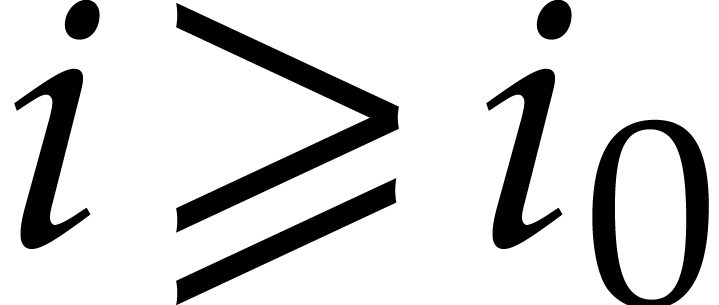 with
with 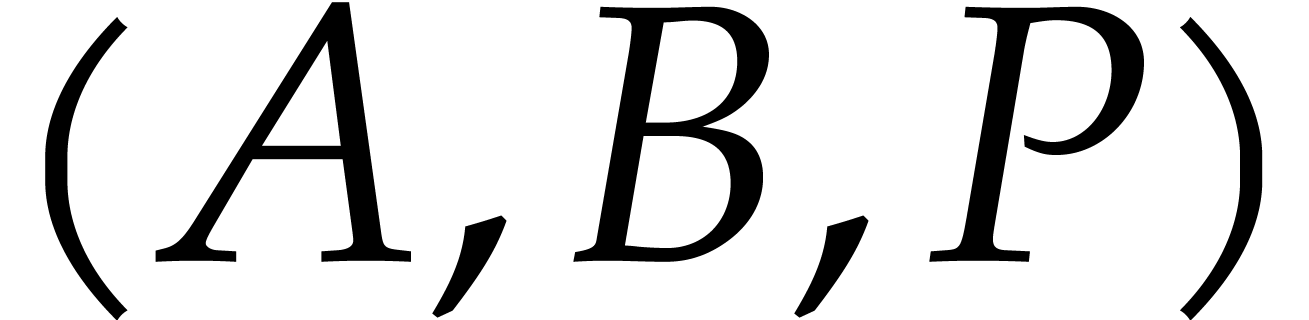 ,
,