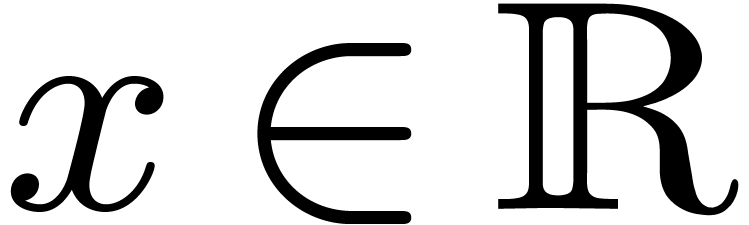 is given by an approximation algorithm which takes
is given by an approximation algorithm which takes 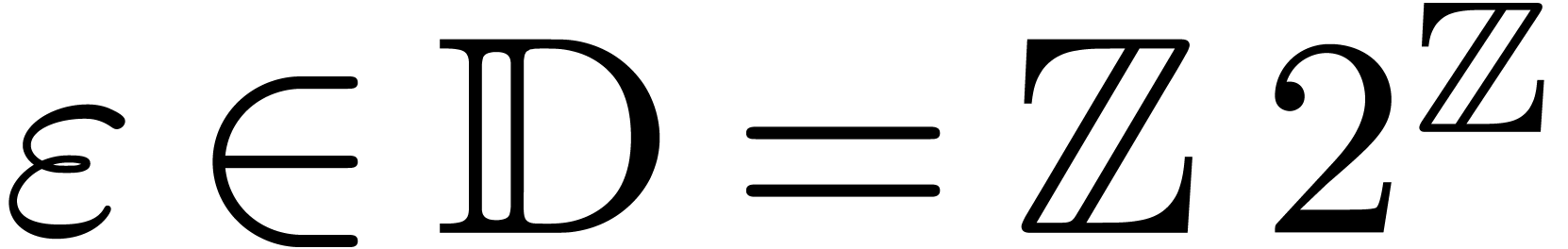 with
with  on input and which produces
an
on input and which produces
an  -approximation
-approximation
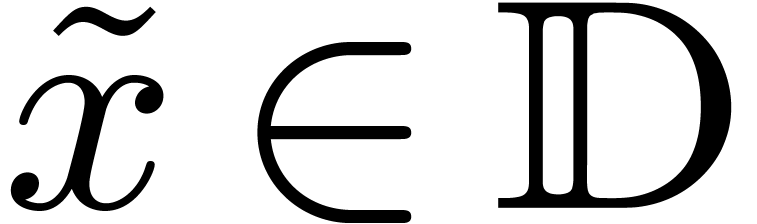 for
for 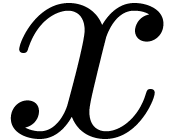 with
with 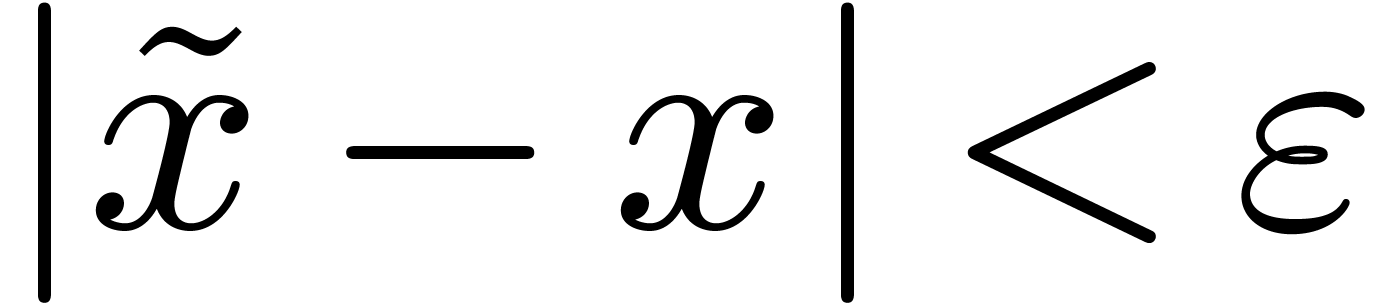 . One defines effective complex numbers in a
similar way.
. One defines effective complex numbers in a
similar way.
Mathématiques, CNRS
Bâtiment 425
Université Paris-Sud
91405 Orsay Cedex
France
Email: joris@texmacs.org
Web:
http://www.math.u-psud.fr/~vdhoeven
Effective real numbers in
July 9, 2006
Abstract
Until now, the area of symbolic computation has mainly focused on the
manipulation of algebraic expressions. Based on earlier, theoretical
work, the author has started to develop a systematic
Although the field of symbolic computation has given rise to several softwares for mathematically correct computations with algebraic expressions, similar tools for analytic computations are still somewhat inexistent.
Of course, a large amount of software for numerical analysis does exist, but the user generally has to make several error estimates by hand in order to guarantee the applicability of the method being used. There are also several systems for interval arithmetic, but the vast majority of them works only for fixed precisions. Finally, several systems have been developed for certified arbitrary precision computations with polynomial systems. However, such systems cannot cope with transcendental functions or differential equations.
The central concept of a systematic theory for certified computational
analysis is the notion of an effective real number [17,
22, 4]. Such a number
is given by an approximation algorithm which takes with on input and which produces
an -approximation
for with . One defines effective complex numbers in a
similar way.
Effective real and complex numbers are a bit tricky to manipulate:
although they can easily be added, multiplied, etc., there
exists no test for deciding whether an effective real number is
identically zero. Some interesting questions from a complexity point of
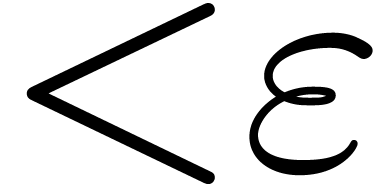
view are also raised: if we want to compute an -approximation of 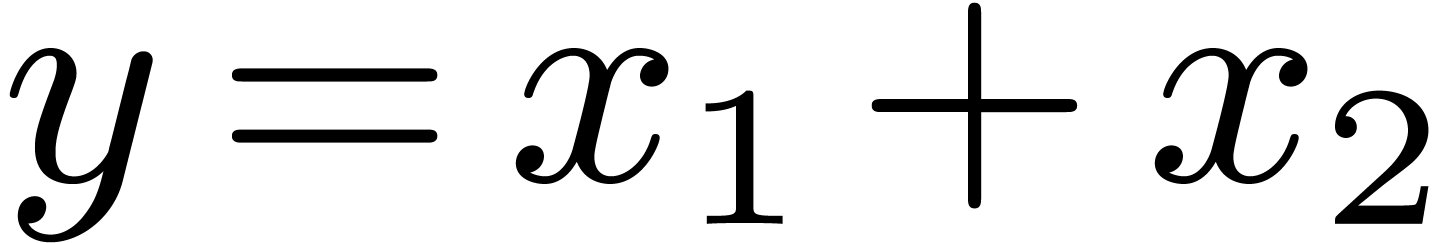 ,
how to determine
,
how to determine 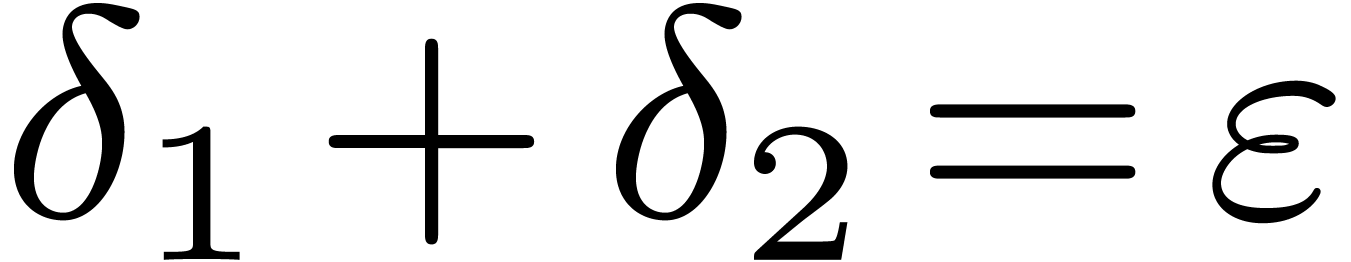 so that the computation of
so that the computation of
 -approximations of the
-approximations of the 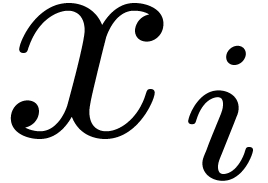 is most efficient?
is most efficient?
Concrete approaches and implementations for computations with effective
real numbers have been proposed, often independently, by several authors
[12, 3, 2, 13, 11, 14, 20]. A first step in these
approaches is often to implement some interval arithmetic [1,
16, 7, 15, 18]. As
an optional second step, one may then provide a class real
for which a real number is given by an
interval approximation algorithm which, given 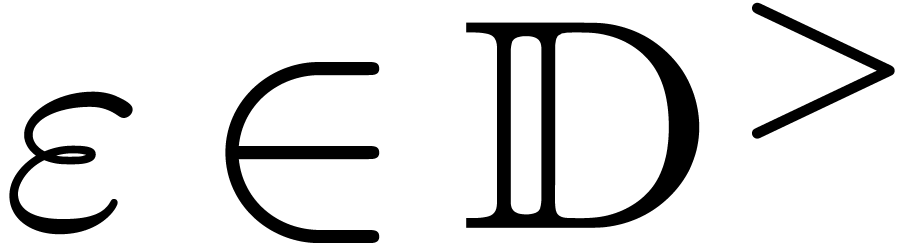 , computes a closed interval
, computes a closed interval  with endpoints in
with endpoints in  , of radius
, of radius
 .
.
In this paper, we report on the implementation of a C++ class for
effective real numbers in the
In section 2, we start by quickly reviewing interval
arithmetic and the computationally more efficient variant of “ball
arithmetic” (see also [1, 16, 2]).
We also try to establish a more precise semantics for this kind of
arithmetic in the multi-precision context and discuss the use of
interval classes as parameters of template classes such as complex
numbers, matrices or polynomials. Our implementation relies on the
In section 3, we mainly review previous work: equivalent definitions of effective real numbers, representation by dags and the different techniques for a priori and a posteriori error estimations. We also state improved versions of the “global approximation problem”, which serve as a base for the complexity analysis of our library. We finally correct an error which slipped into [20].
In section 4, we describe the current implementation, which is based on the sole use of a posteriori error estimates.
In section 5, we prove that our implementation is optimal up to a linear overhead in the input size (4) and a logarithmic overhead in the time complexity (3). It is interesting to compare these results with previous theoretical work on the complexity of interval arithmetic [5, 9].
In the last section, we indicate how to use a priori error estimates in a more efficient way than in [20]. In a forthcoming paper, we hope to work out the details and remove the linear overhead (4) in the input size, at least under certain additional assumptions.
Since real numbers cannot be stored in finite memory, a first
approach to certified computations with real numbers is to compute with
intervals instead of numbers. For instance, when using interval
arithmetic, a real number like 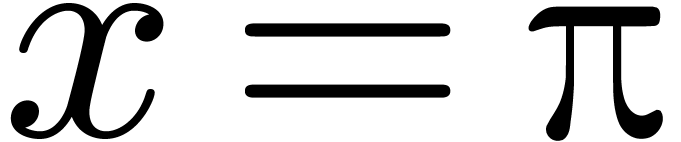 would be
approximated by an interval like
would be
approximated by an interval like 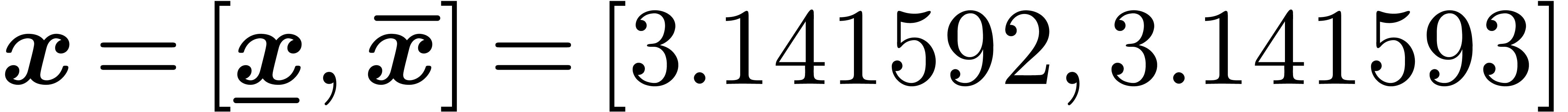 .
Evaluation of a real function
.
Evaluation of a real function 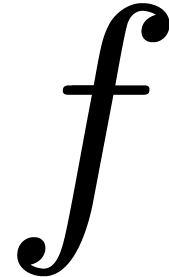 at a point
at a point 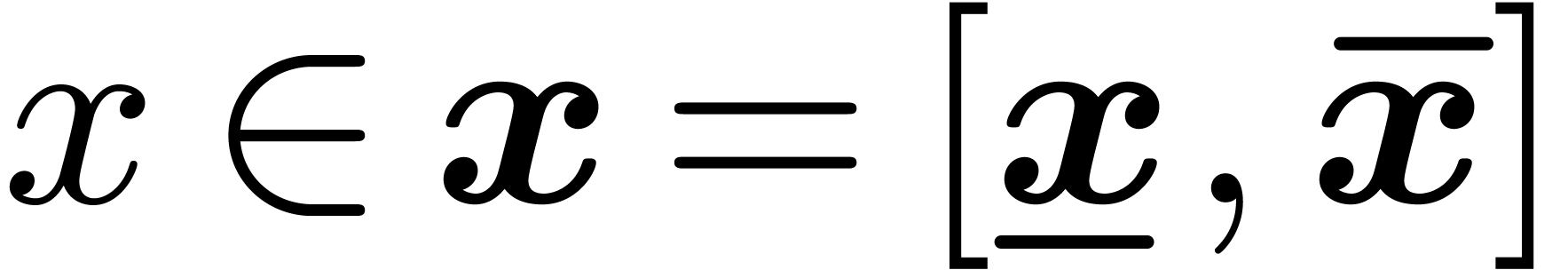 then corresponds to finding an interval
then corresponds to finding an interval 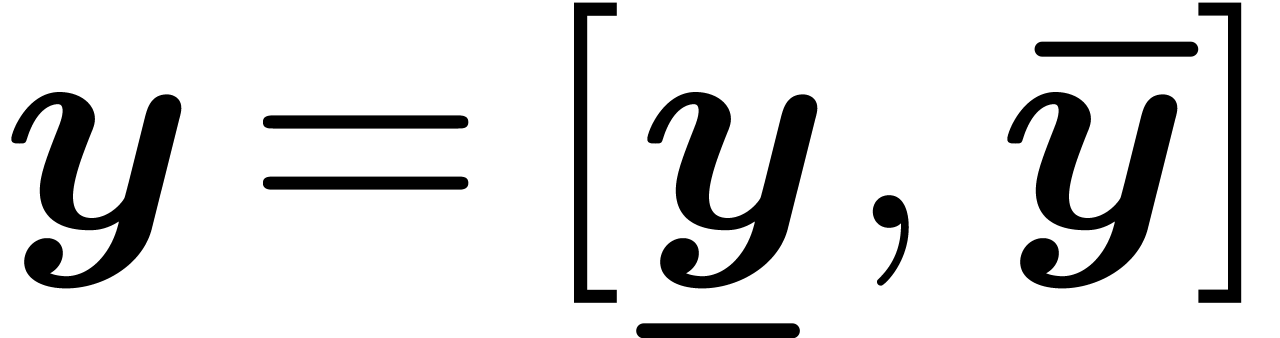 with
with 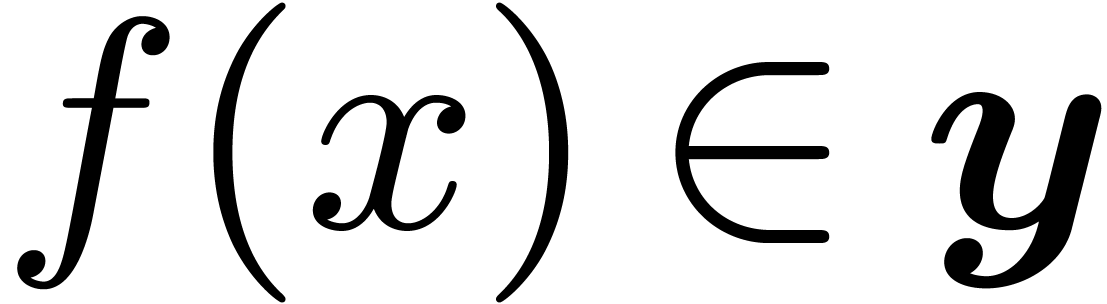 for all
for all  . When all functions under consideration are
Lipschitz continuous and when all computations are performed using a
sufficiently high precision, this technique provides arbitrarily good
approximations for the real numbers we want to compute.
. When all functions under consideration are
Lipschitz continuous and when all computations are performed using a
sufficiently high precision, this technique provides arbitrarily good
approximations for the real numbers we want to compute.
Our current interval library is based on MPFR [8], which
implements a generalization of the IEEE 754 standard. More precisely,
let  be the word precision of the computer under
consideration. Given a bit precision
be the word precision of the computer under
consideration. Given a bit precision 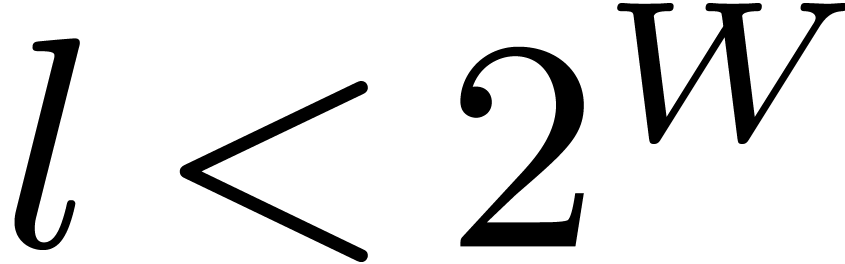 and a
maximal exponent
and a
maximal exponent 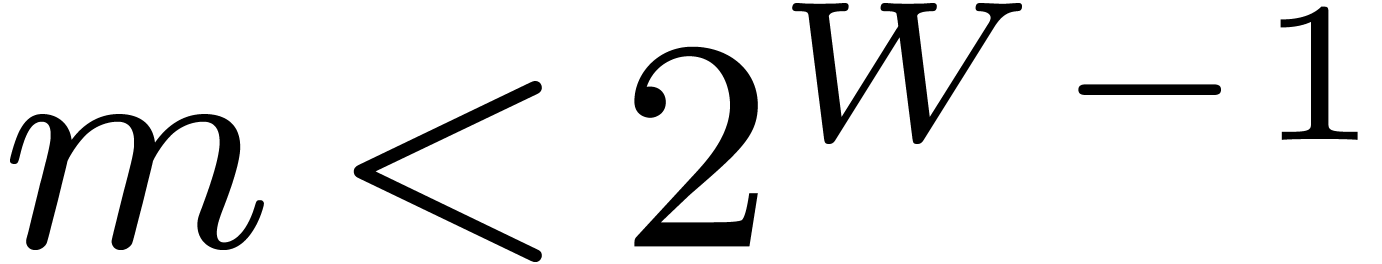 fixed by the user, the MPFR
library implements arithmetic on
fixed by the user, the MPFR
library implements arithmetic on  -bit
floating point numbers and exponents in the range
-bit
floating point numbers and exponents in the range 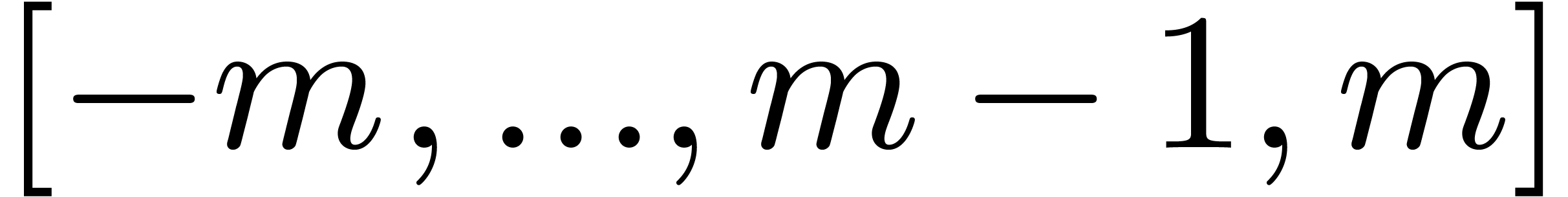 with exact rounding. We recall that the IEEE 754 norm (and thus MPFR)
includes special numbers
with exact rounding. We recall that the IEEE 754 norm (and thus MPFR)
includes special numbers 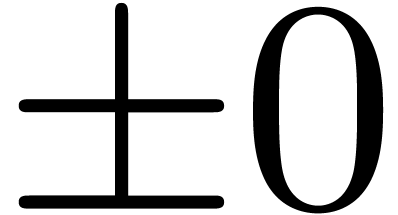 ,
,
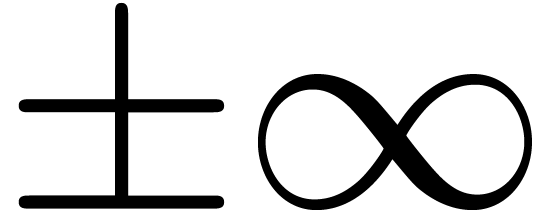 and
and 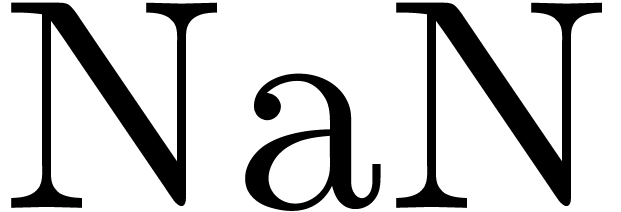 (not a number).
Assuming that
(not a number).
Assuming that  has been fixed once and for all,
we will denote by
has been fixed once and for all,
we will denote by  the set of -bit numbers. Several representations are
possible for the computation with -bit
intervals:
the set of -bit numbers. Several representations are
possible for the computation with -bit
intervals:
-bit
interval 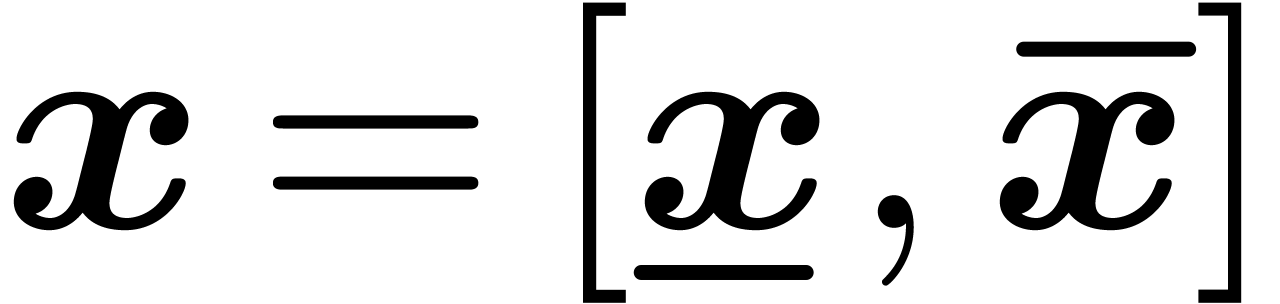 is determined by its end-points
is determined by its end-points 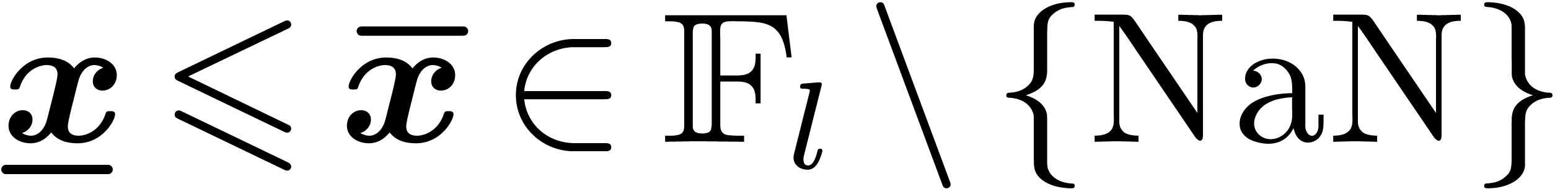 . We also allow for the
exceptional value
. We also allow for the
exceptional value  . Since
the MPFR library provides exact rounding, it is particularly simple to
base an interval library on it, when using this representation:
whenever a function is monotonic on a certain
range, it suffices to consider the values at the end-points with
opposite rounding modes. However, every high precision evaluation of
an interval function requires two high precision evaluations of
floating point numbers.
. Since
the MPFR library provides exact rounding, it is particularly simple to
base an interval library on it, when using this representation:
whenever a function is monotonic on a certain
range, it suffices to consider the values at the end-points with
opposite rounding modes. However, every high precision evaluation of
an interval function requires two high precision evaluations of
floating point numbers.
-bit
interval  is represented by a ball
is represented by a ball 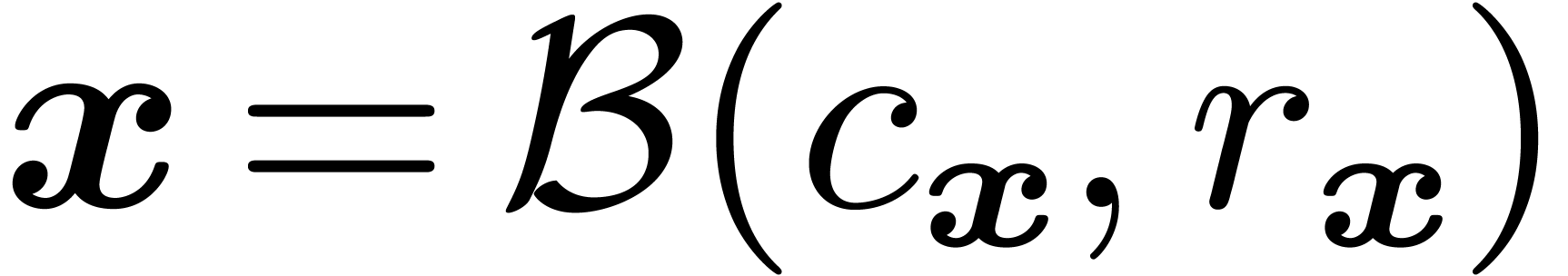 with center
with center  and radius
and radius 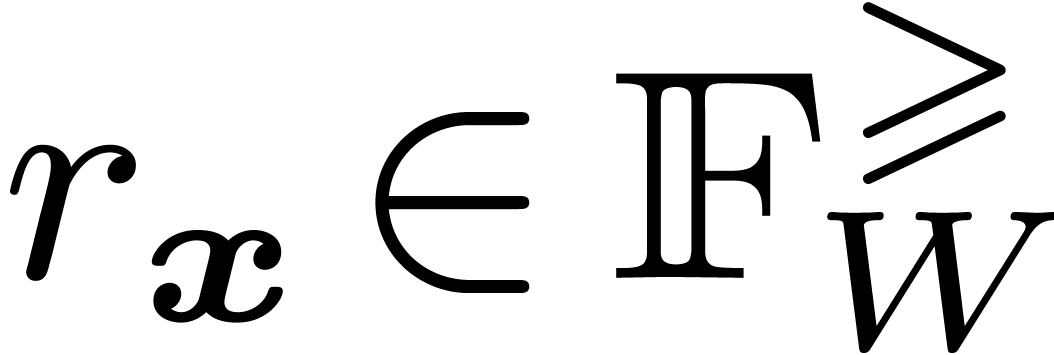 . If
. If  and
, then we also require that
the ball
and
, then we also require that
the ball 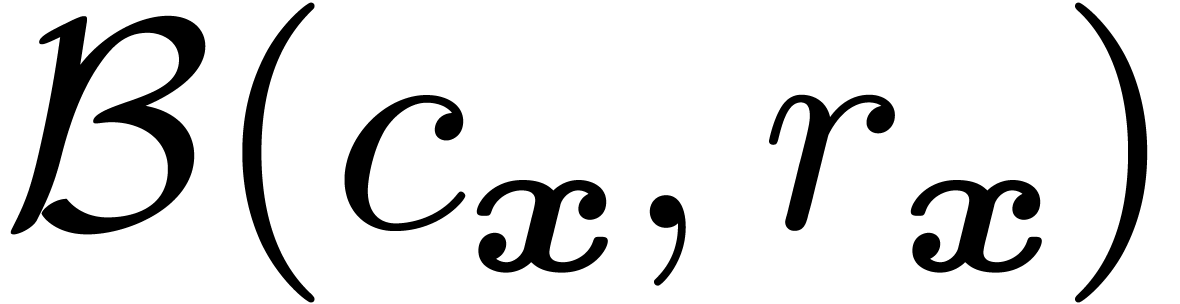 is normal in the sense that
is normal in the sense that
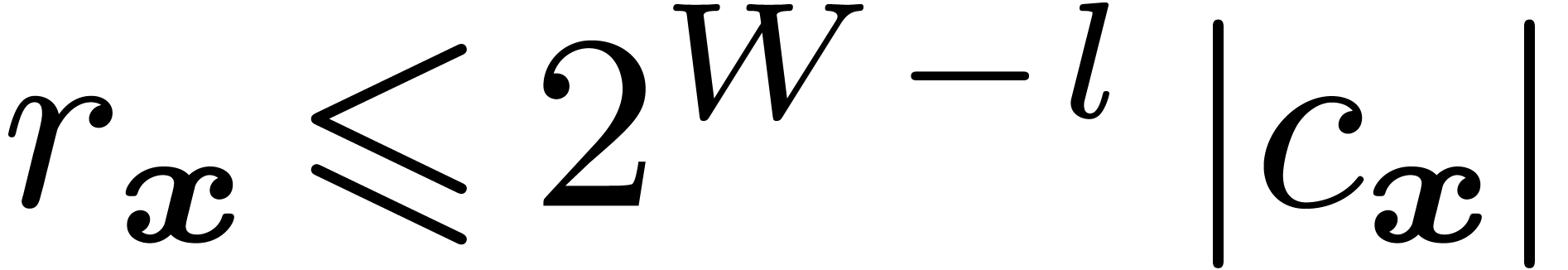 . The underlying idea is
that the endpoints of a high precision interval are usually identical
apart from a few bits at the end, whence it is more efficient to only
store the common part and the difference. As a consequence, one high
precision operation on balls reduces to one high precision operation
on floating point numbers and several operations on low precision
numbers.
. The underlying idea is
that the endpoints of a high precision interval are usually identical
apart from a few bits at the end, whence it is more efficient to only
store the common part and the difference. As a consequence, one high
precision operation on balls reduces to one high precision operation
on floating point numbers and several operations on low precision
numbers.
However, the ball representation has essentially less expressive power.
For instance, it is impossible to represent the interval 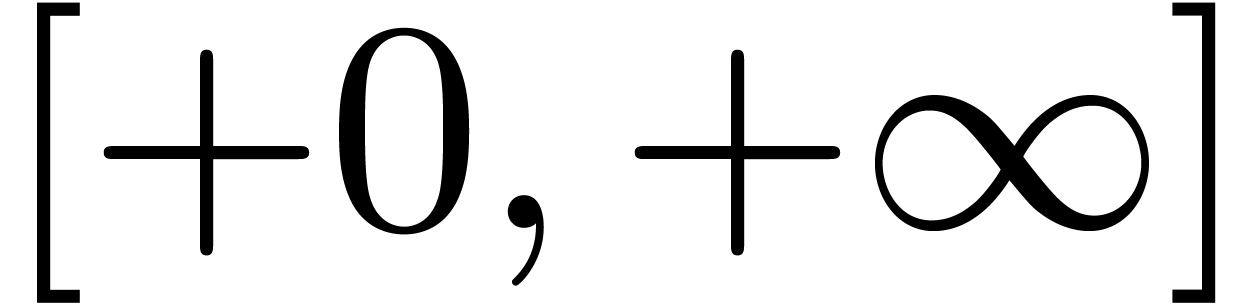 . Also, positivity is not naturally preserved
by addition if
. Also, positivity is not naturally preserved
by addition if  . This may be
problematic in the case we want to compute quantities like
. This may be
problematic in the case we want to compute quantities like  .
.
Remark 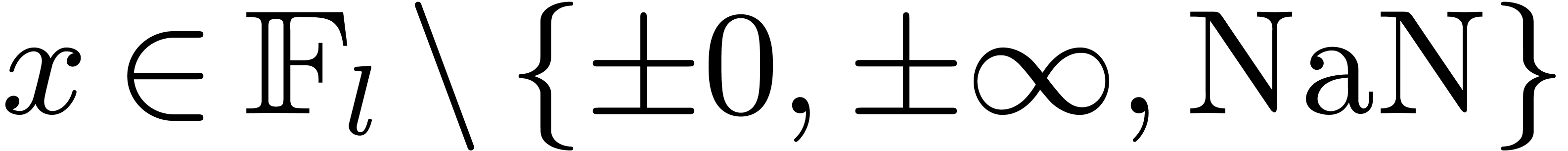 , we define the step
, we define the step  as the exponent of
as the exponent of 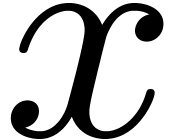 minus
minus 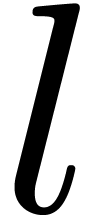 . A ball may then be called
normal if
. A ball may then be called
normal if 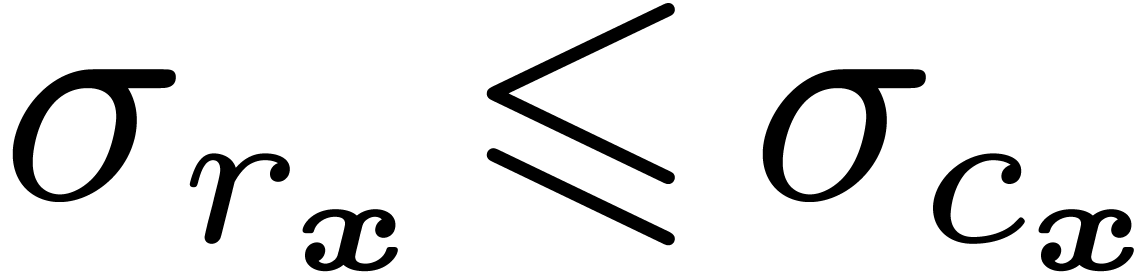 instead of
instead of 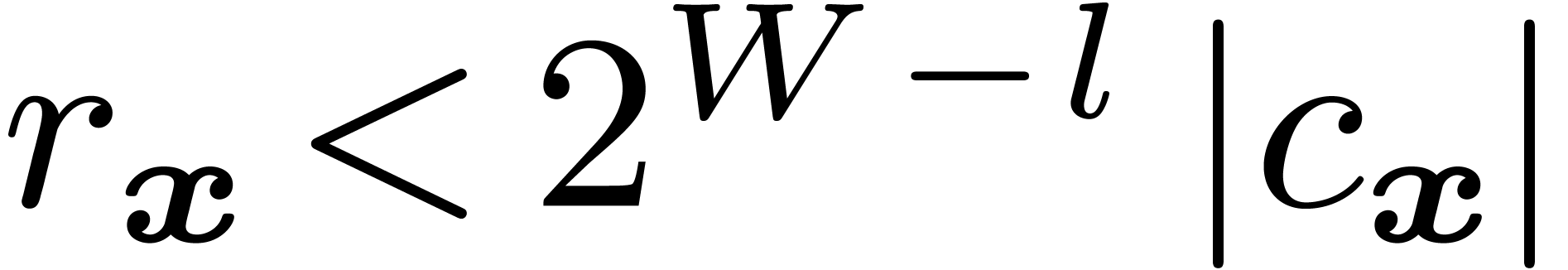 . Alternatively, one may require
. Alternatively, one may require 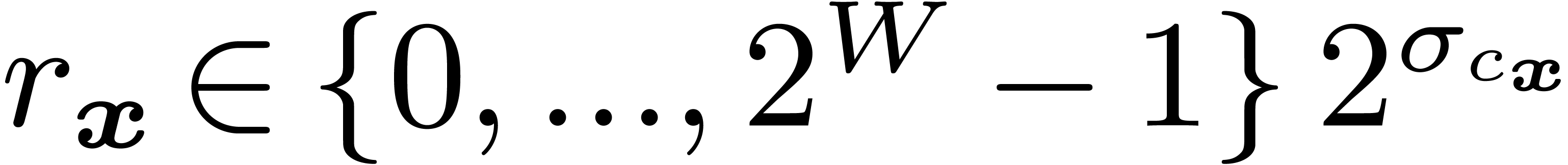 .
.
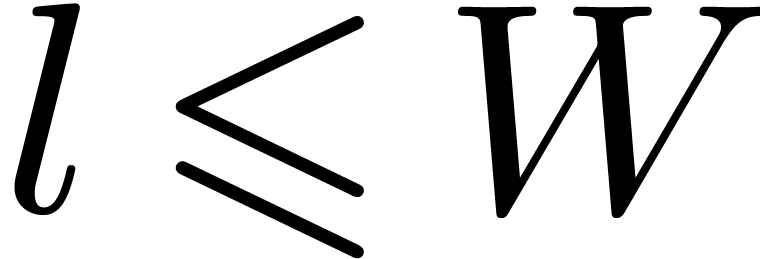 and
the ball representation for high precision numbers
and
the ball representation for high precision numbers 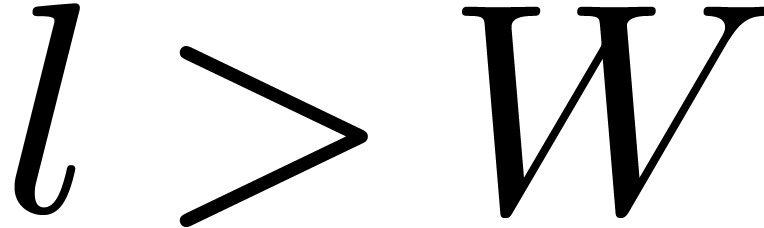 . Modulo some additional overhead, this
combines the advantages of both representations while removing their
drawbacks.
. Modulo some additional overhead, this
combines the advantages of both representations while removing their
drawbacks.
Let 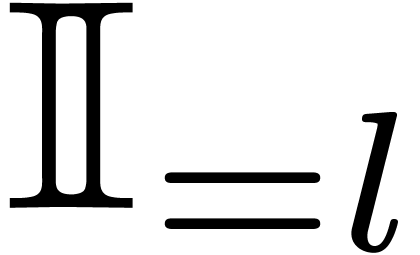 denote the set of -bit intervals for the hybrid representation. If
, then it should be noticed
that the set is not stable under the usual
arithmetic operations, due to the phenomenon of precision loss.
Indeed, the sum
denote the set of -bit intervals for the hybrid representation. If
, then it should be noticed
that the set is not stable under the usual
arithmetic operations, due to the phenomenon of precision loss.
Indeed, the sum  of
of 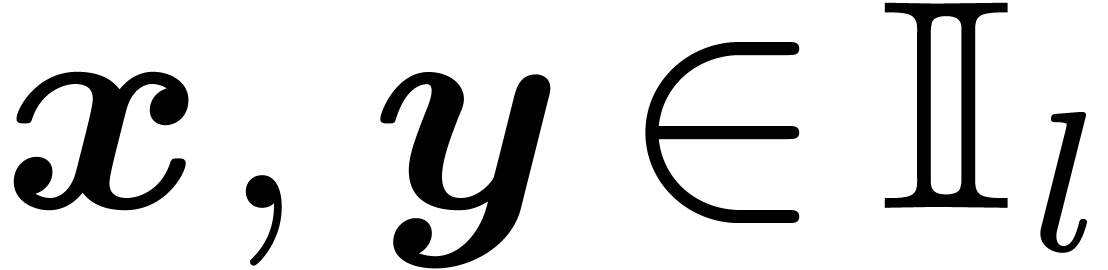 is
typically computed using
is
typically computed using 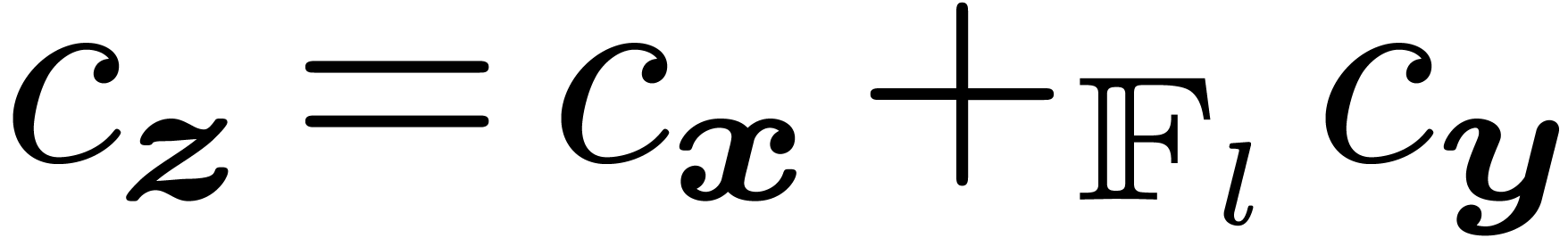 and
and 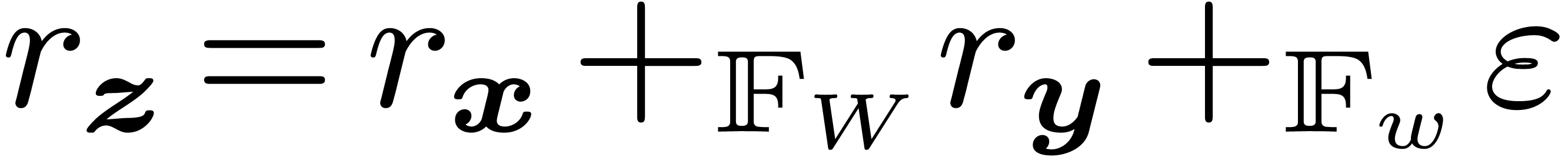 , where is a small
bound for the rounding error. However, if
, where is a small
bound for the rounding error. However, if 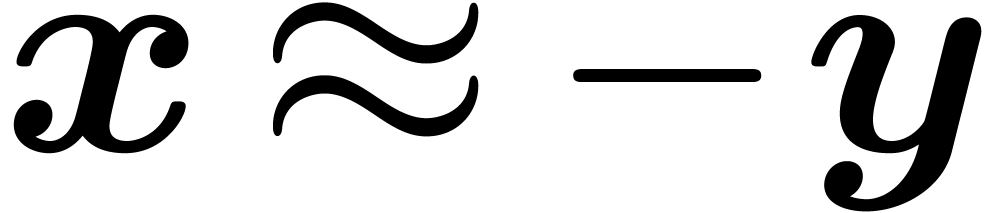 ,
then
,
then  is not necessarily normal.
is not necessarily normal.
Nevertheless, the set 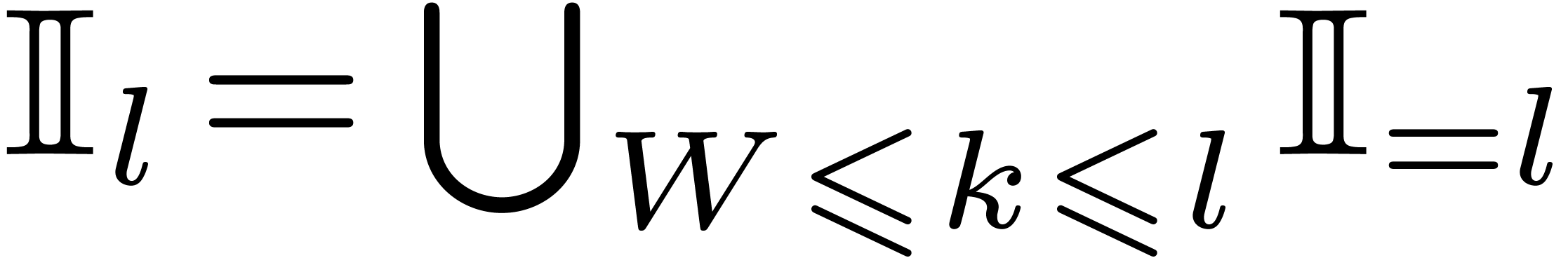 is stable under all usual
arithmetic operations. Indeed, any ball or interval
may be normalized by replacing
is stable under all usual
arithmetic operations. Indeed, any ball or interval
may be normalized by replacing 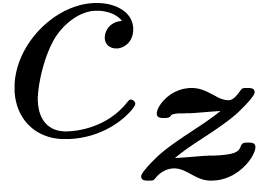 by a lower bit
approximation. More precisely, consider an abnormal interval
by a lower bit
approximation. More precisely, consider an abnormal interval 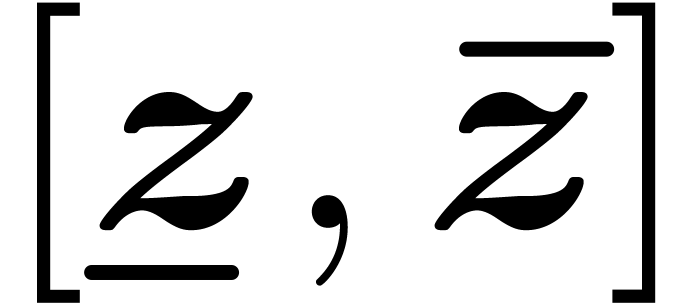 with
with  and
and 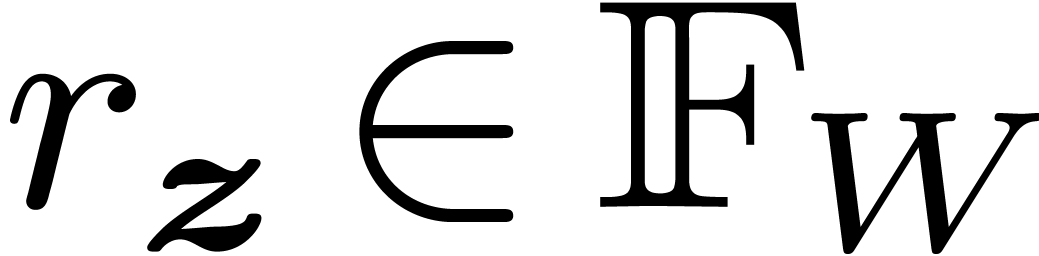 . Given
. Given 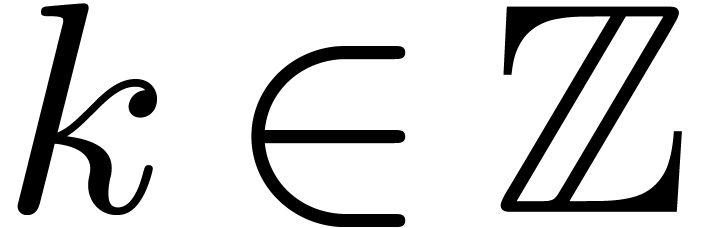 ,
let
,
let 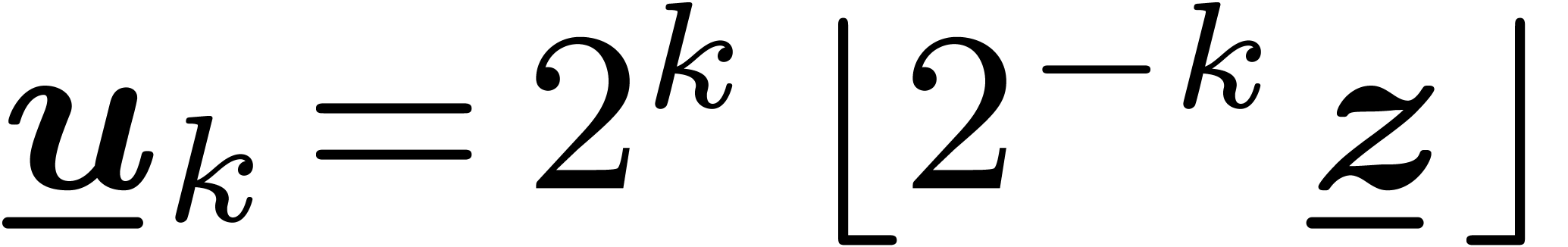 and
and 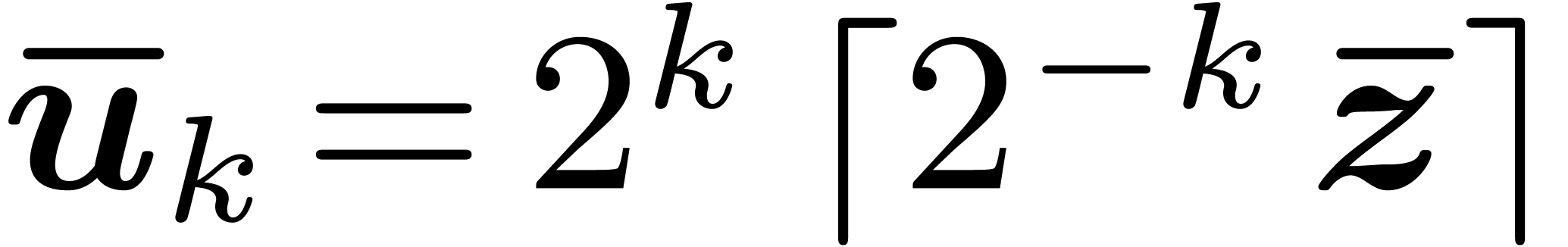 ,
so that
,
so that 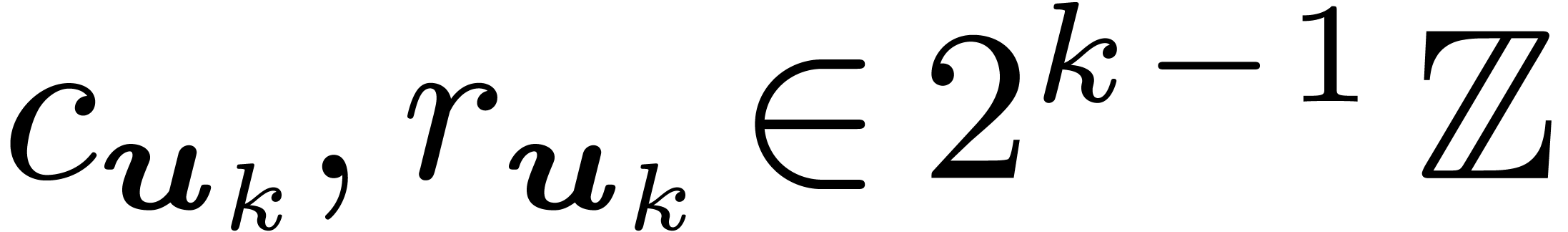 . Let be minimal such that
. Let be minimal such that  ,
,
 and
and 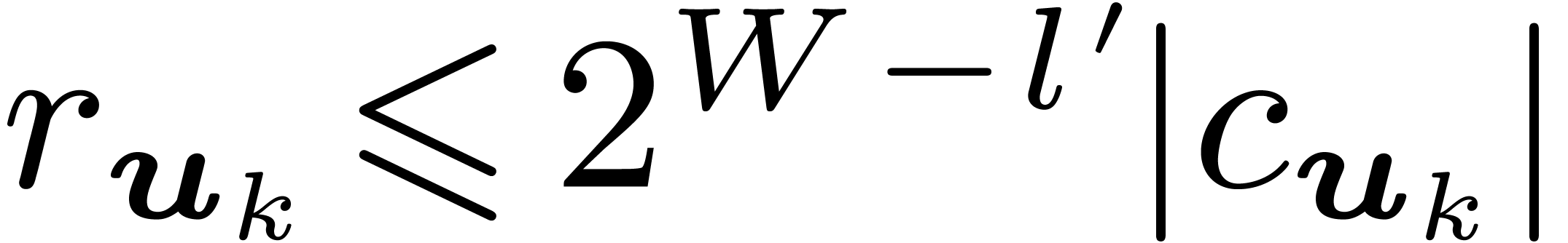 for some
for some  . Then
. Then 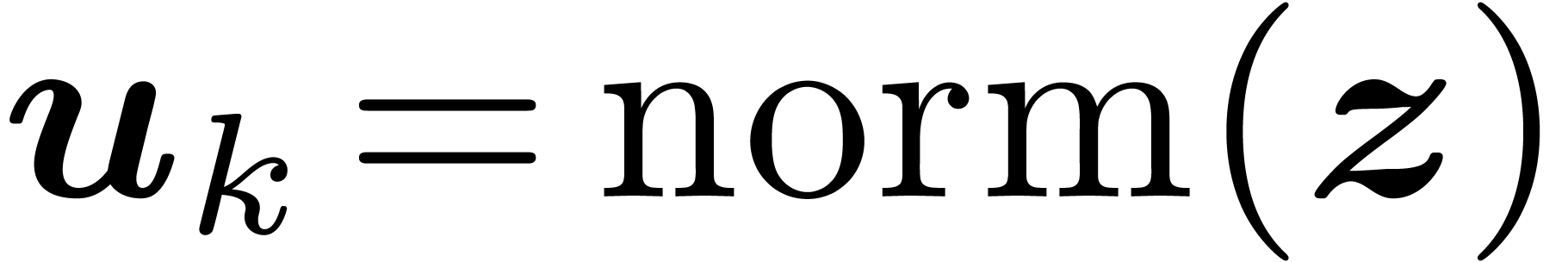 is
called the normalization of .
If no such
is
called the normalization of .
If no such 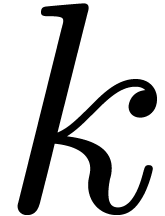 exists, then
exists, then  is defined to be the smallest interval with endpoints in
is defined to be the smallest interval with endpoints in  , which contains .
It can be shown that
, which contains .
It can be shown that 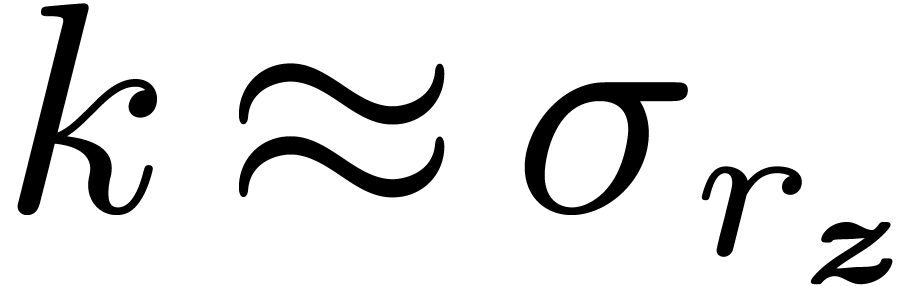 and
and 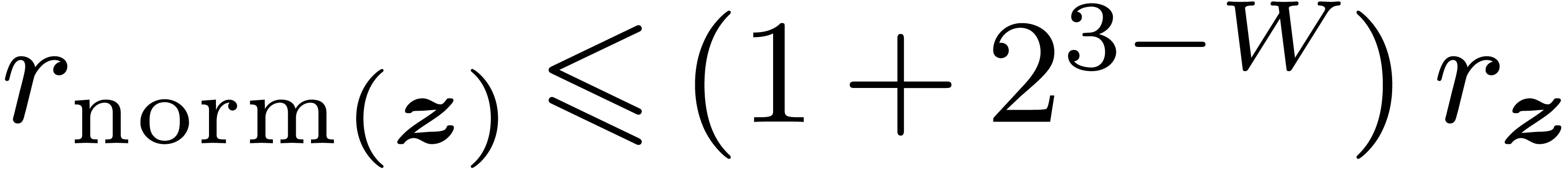 .
.
Remark 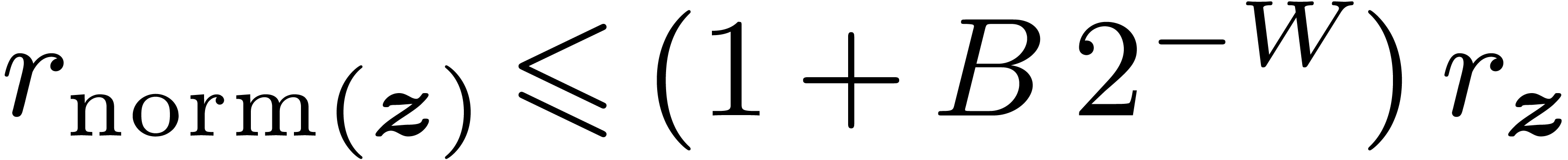 for some
small fixed constant
for some
small fixed constant  .
.
Dually, it may occur that the result of an operation can be given with
more precision than the argument. For instance, if 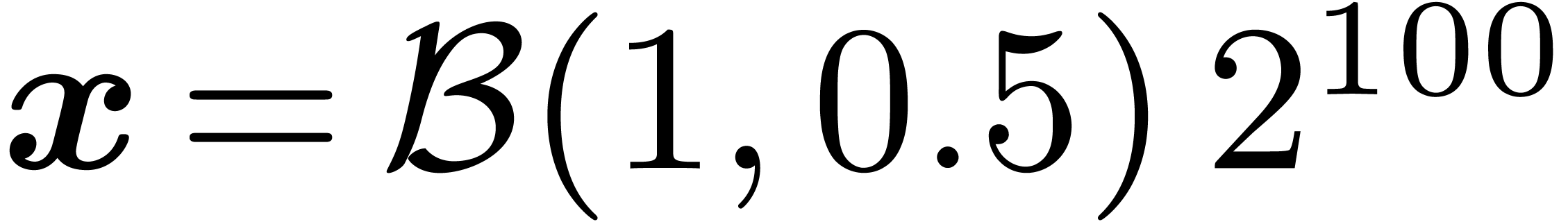 , then
, then  can be computed
with a precision of about
can be computed
with a precision of about 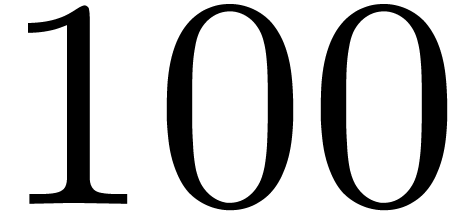 binary digits.
Similarly,
binary digits.
Similarly, 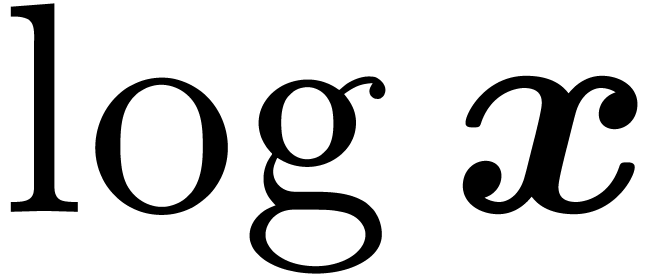 can be computed with a precision of
about
can be computed with a precision of
about  binary digits. We call this the phenomenon
of precision gain. The point here is that it is not necessarily
desirable to compute the results of and with the maximal possible precision.
binary digits. We call this the phenomenon
of precision gain. The point here is that it is not necessarily
desirable to compute the results of and with the maximal possible precision.
Taking into account the phenomena of precision loss and gain, we propose
the following “ideal” semantics for operations on intervals.
First of all, a default precision for
computations is fixed by the user. Now assume that we wish to evaluate
an 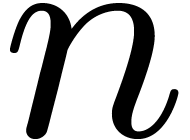 -ary function
-ary function 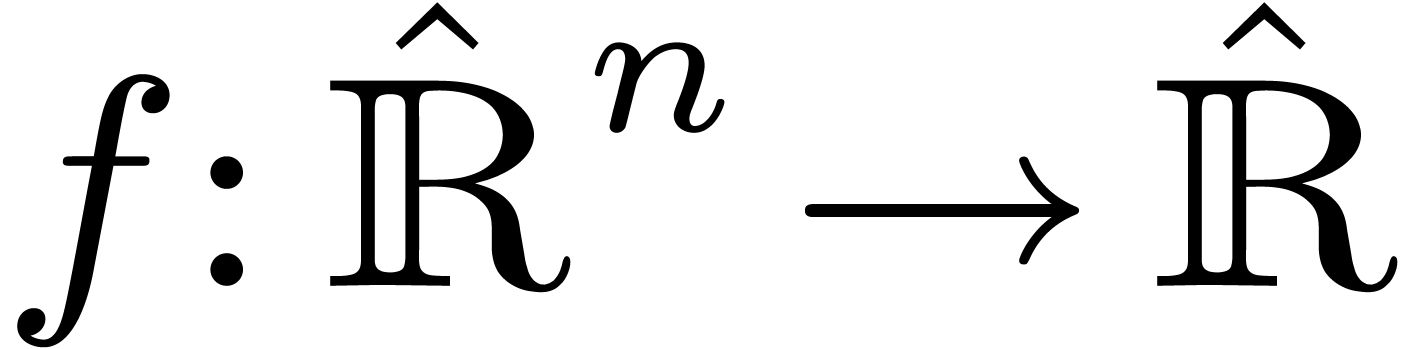 at intervals
at intervals 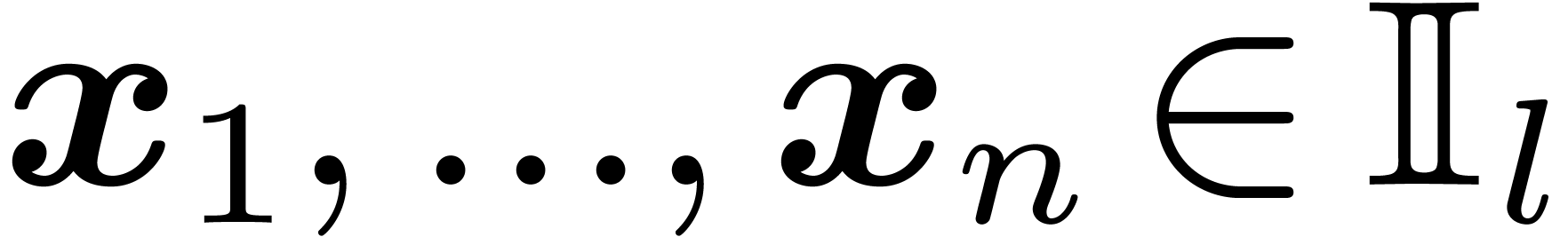 ,
where
,
where 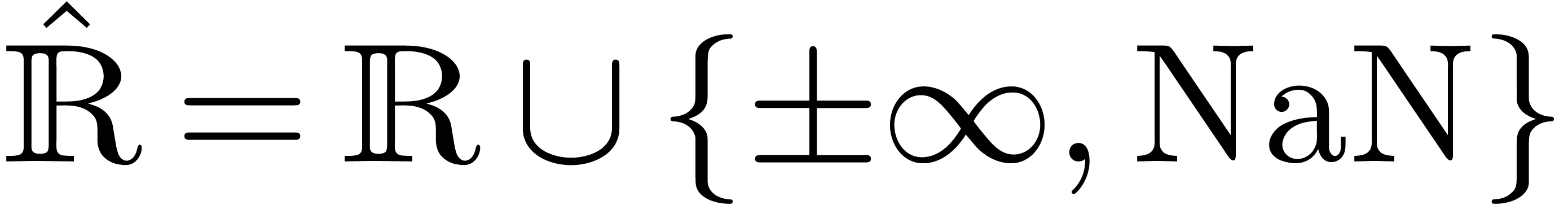 . Then there exists a
smallest interval
. Then there exists a
smallest interval  with
with 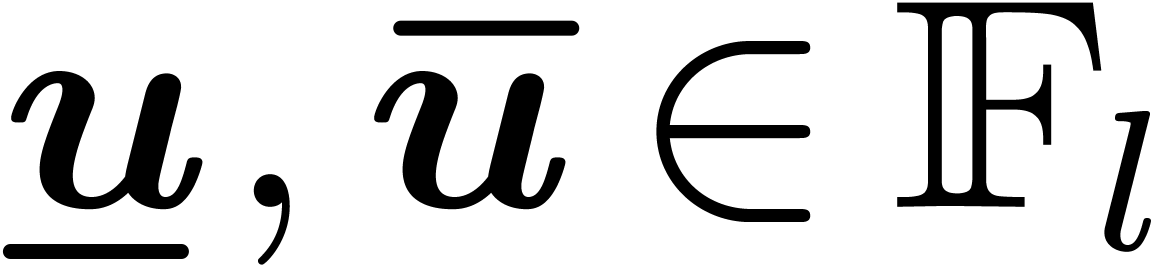 , which satisfies either
, which satisfies either
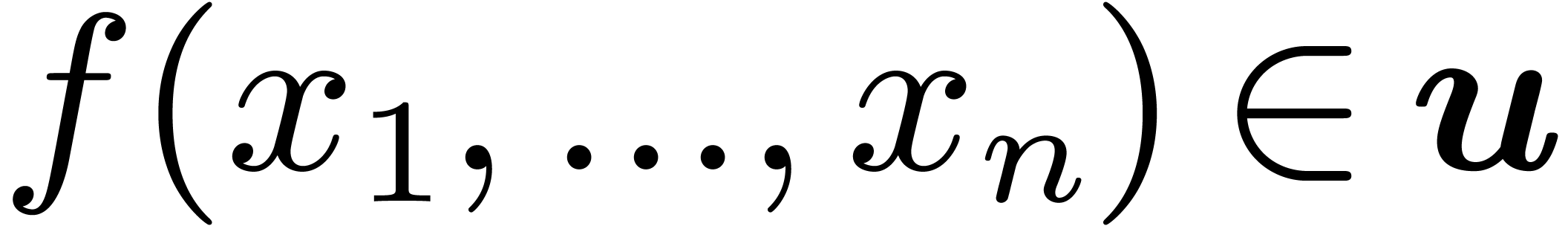 for all
for all  .
.
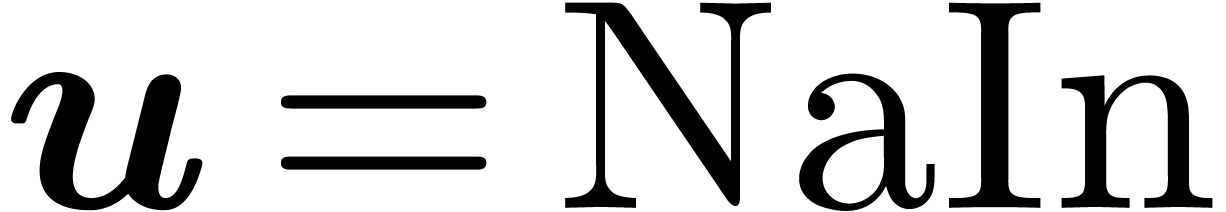 and
and 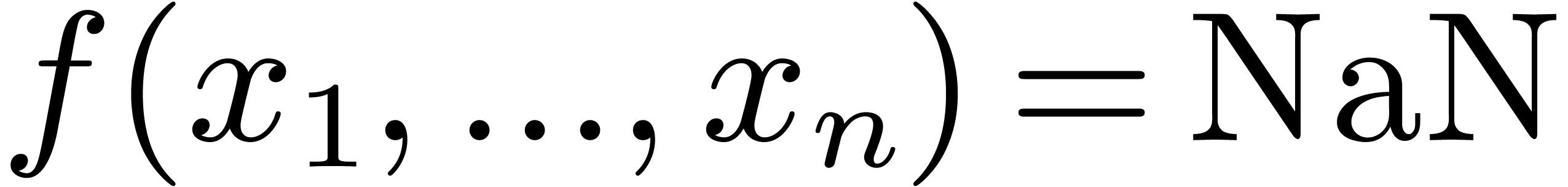 for some .
for some .
Whenever 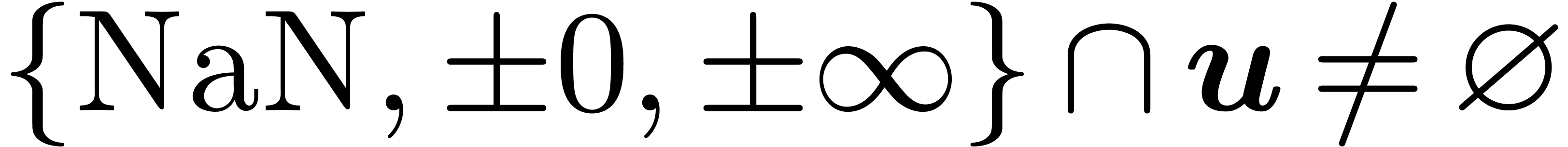 , then
, then 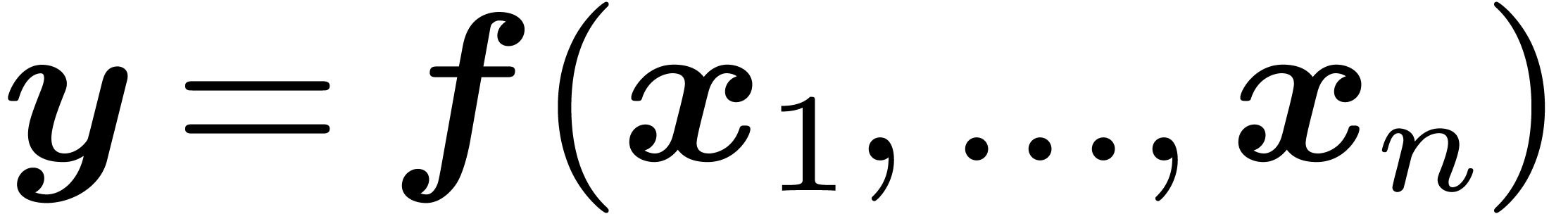 is taken to be the smallest interval of
which contains . Otherwise,
we take
is taken to be the smallest interval of
which contains . Otherwise,
we take  .
.
Remark  is the smallest interval which contains all non exceptional values.
is the smallest interval which contains all non exceptional values.
Since the normalization procedure is somewhat arbitrary (see remark 2), the ideal semantics may be loosened a little bit for
implementation purposes. Instead of requiring the optimal return value
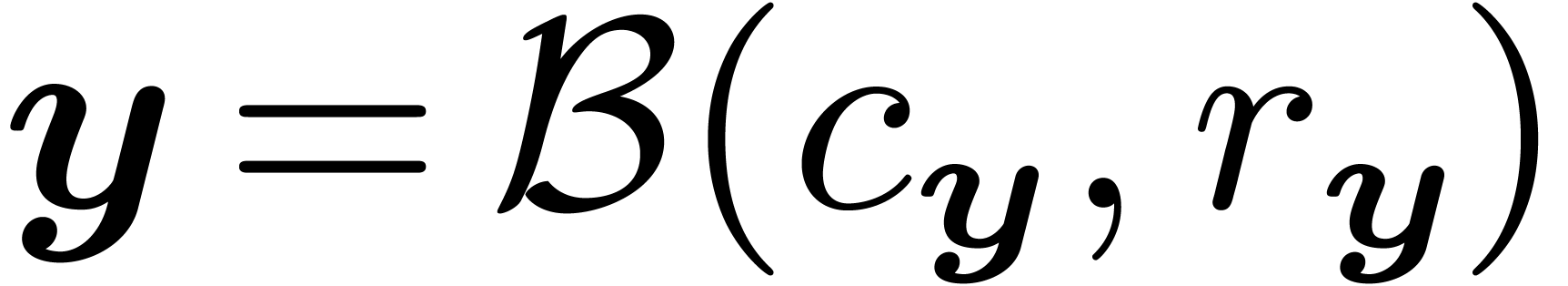 , we rather propose to
content oneself with a return value
, we rather propose to
content oneself with a return value  with
with  and
and 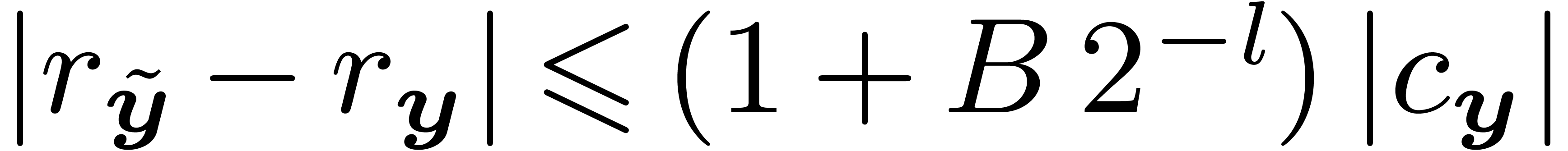 , for
some fixed small constant
, for
some fixed small constant  ,
in the case when
,
in the case when  has precision . This remark also applies to the underlying
MPFR layer: exact rounding is not really necessary for our purpose. It
would be sufficient to have a “looser” rounding mode,
guaranteeing results up to
has precision . This remark also applies to the underlying
MPFR layer: exact rounding is not really necessary for our purpose. It
would be sufficient to have a “looser” rounding mode,
guaranteeing results up to  times the last bit.
times the last bit.
A tempting way to implement the complex analogue of interval arithmetic
in C++ is to use the complex template class from the
standard library. Unfortunately, this approach leads to a lot of
overestimation for the bounding rectangles. In order to see this,
consider the complex rectangle 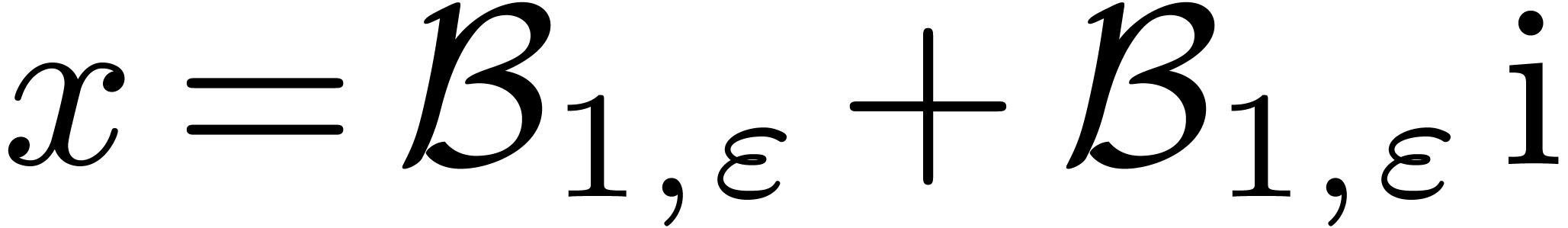 and the sequence
and the sequence
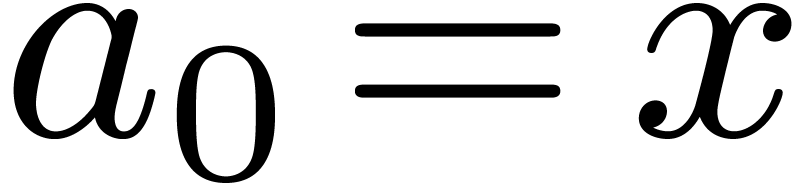 ,
, 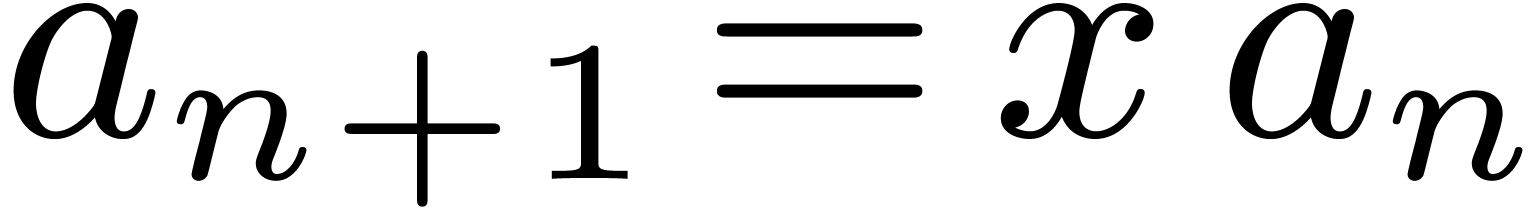 . Because multiplication with
. Because multiplication with  “turns” the bounding rectangle, the error
is roughly multiplied by
“turns” the bounding rectangle, the error
is roughly multiplied by 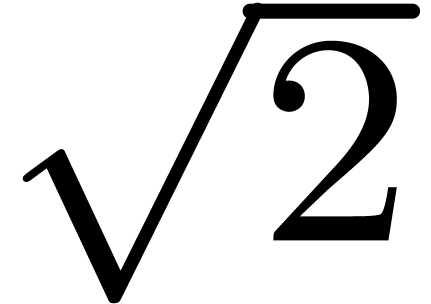 at each step. In other
words, we loose one bit of precision every two steps.
at each step. In other
words, we loose one bit of precision every two steps.
The above phenomenon can be reduced in two ways. First of all, one may
use a better algorithm for computing 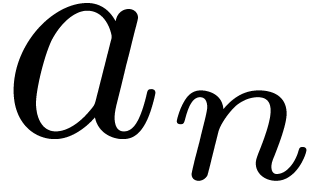 ,
like repeated squaring. In the case of complex numbers though, the best
solution is to systematically use complex ball representations. However,
standardization of the operations requires more effort. Indeed, given an
operation on balls
,
like repeated squaring. In the case of complex numbers though, the best
solution is to systematically use complex ball representations. However,
standardization of the operations requires more effort. Indeed, given an
operation on balls  of
precision
of
precision  , it can be
non-trivial to design an algorithm which computes a ball
, it can be
non-trivial to design an algorithm which computes a ball 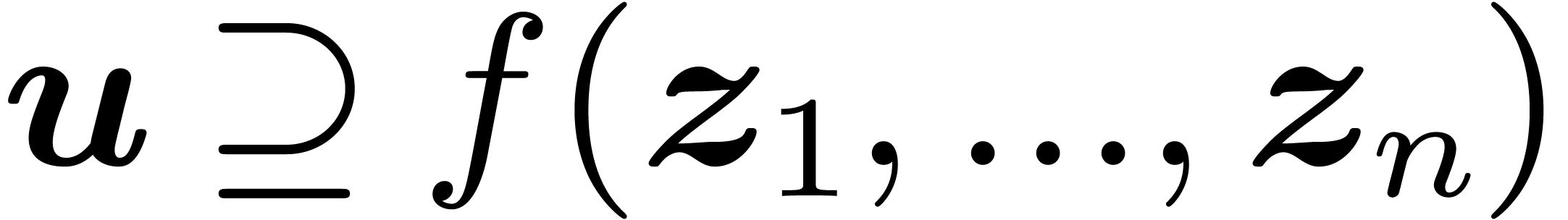 of almost minimal radius (up to
of almost minimal radius (up to 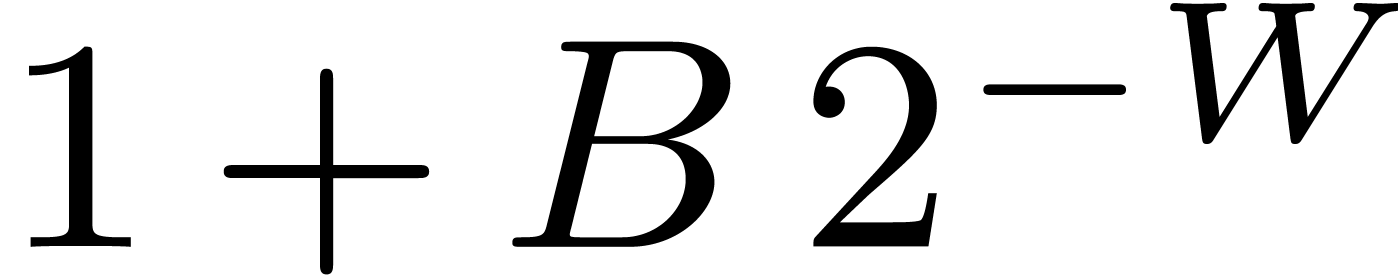 ).
).
The precision loss phenomenon is encountered more generally when
combining interval arithmetic with template types. The best remedy is
again to modify the algorithms and/or data types in a way that the
errors in the data are all of a similar order of magnitude. For
instance, when computing a monodromy matrix 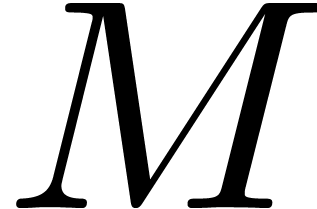 as a
product
as a
product  of connection matrices, it is best to
compute this product by dichotomy
of connection matrices, it is best to
compute this product by dichotomy 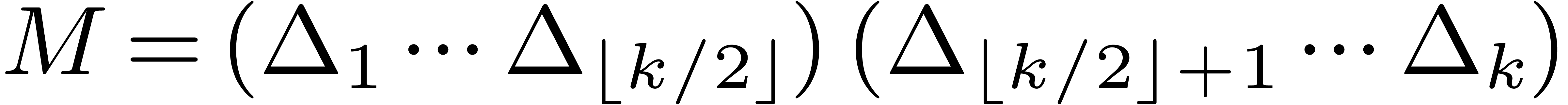 .
Similarly, when computing the product
.
Similarly, when computing the product 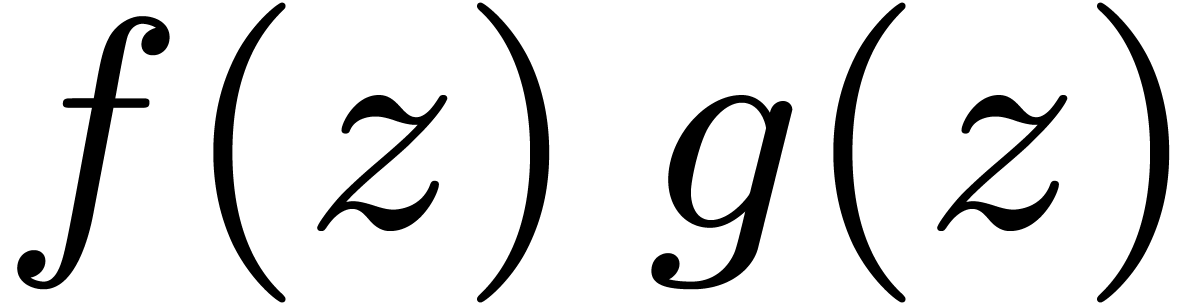 of two
truncated power series, it is good to first perform a change of
variables
of two
truncated power series, it is good to first perform a change of
variables 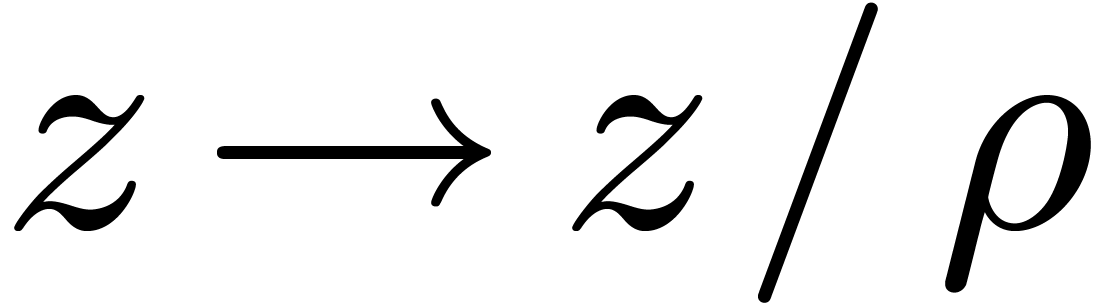 which makes the errors in the
coefficients of and
which makes the errors in the
coefficients of and  of
the same order of magnitude [19, Section 6.2]
of
the same order of magnitude [19, Section 6.2]
For users of computer algebra systems, it would be convenient to provide a data type for real numbers which can be used in a similar way as the types of rational numbers, polynomials, etc. Since interval arithmetic already provides a way to perform certified computations with “approximate real numbers”, this additional level of abstraction should mainly be thought of as a convenient interface. However, due to the fact that real numbers can only be represented by infinite structures like Cauchy sequences, their manipulation needs more care. Also, the actual implementation of a library of functions on effective real numbers raises several interesting computational complexity issues. In this section, we review some previous work on this matter.
Let 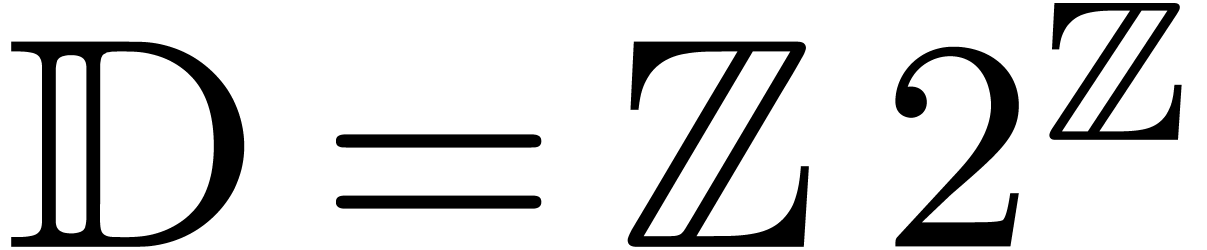 denote the set of dyadic numbers. Given and , we
recall from the introduction that an -approximation
of is a dyadic number
with . We say that is effective, if it admits an approximation
algorithm, which takes on input and which
returns an -approximation
for . The asymptotic time
complexity of such an approximation algorithm is the time it takes
to compute a
denote the set of dyadic numbers. Given and , we
recall from the introduction that an -approximation
of is a dyadic number
with . We say that is effective, if it admits an approximation
algorithm, which takes on input and which
returns an -approximation
for . The asymptotic time
complexity of such an approximation algorithm is the time it takes
to compute a  -approximation
for , when
-approximation
for , when  . We denote by
. We denote by  the set
of effective real numbers.
the set
of effective real numbers.
The above definition admits numerous variants [22, section
4.1]. For instance, instead of require an approximation algorithm, one
may require the existence of an algorithm which associates a closed
interval 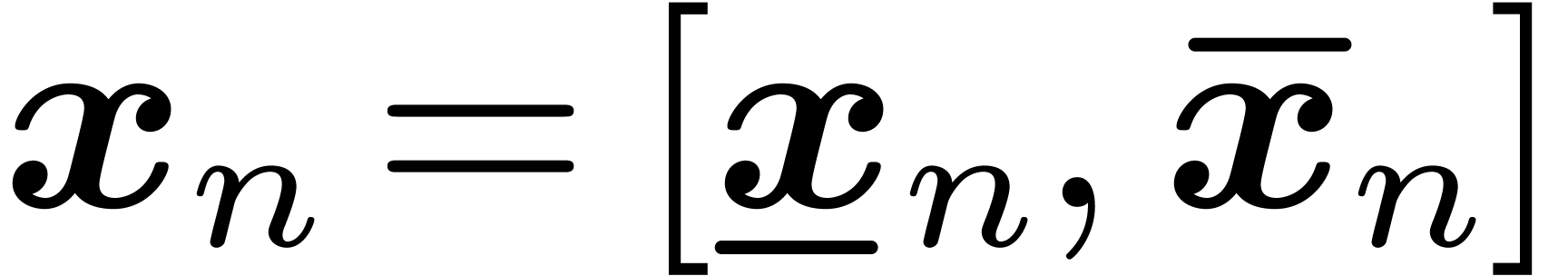 with end-points in
to each
with end-points in
to each 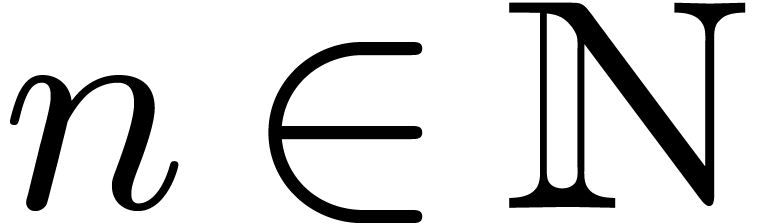 , such that
, such that 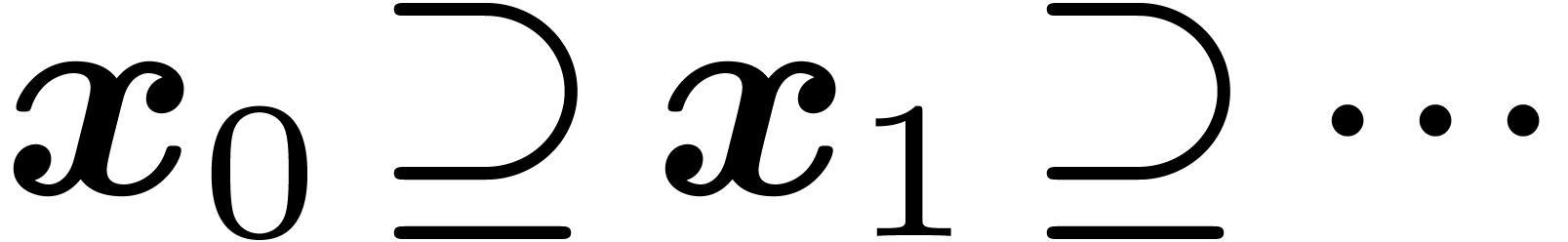 and
and 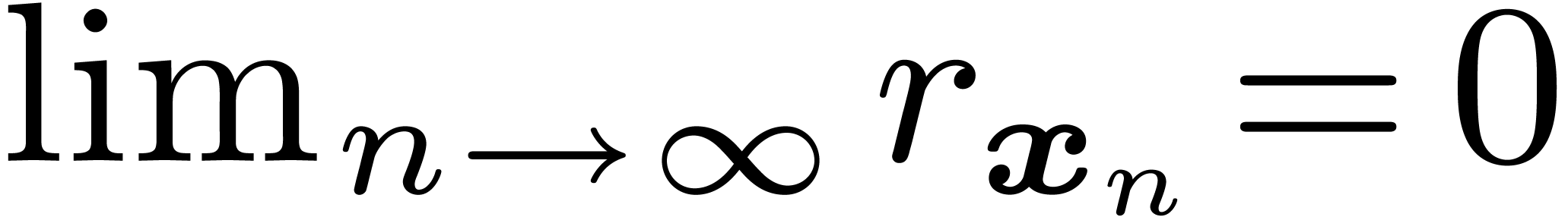 (an interval
with end-points in will also be called an
-bounding interval
for ). Similarly, one may
require the existence of an effective and rapidly converging Cauchy
sequence
(an interval
with end-points in will also be called an
-bounding interval
for ). Similarly, one may
require the existence of an effective and rapidly converging Cauchy
sequence  for which there exists a number
for which there exists a number 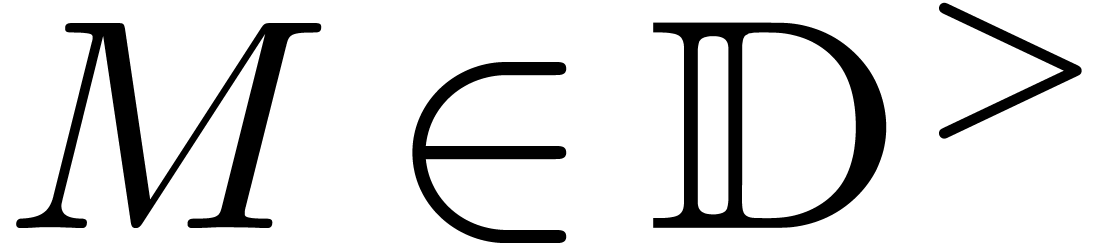 with
with  for all .
for all .
All these definitions have in common that an effective real number is determined by an algorithm which provides more and
more precise approximations of on demand. In an
object oriented language like
Since effective real numbers should be thought of as algorithms, the
zero-test problem in can be reduced to the
halting problem for Turing machines. Consequently, there exist no
algorithms for the basic relations 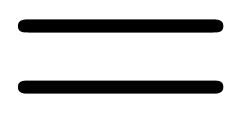 ,
,
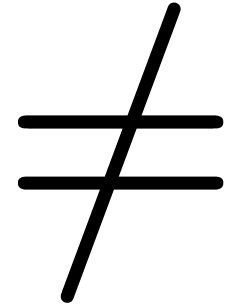 ,
,  ,
, 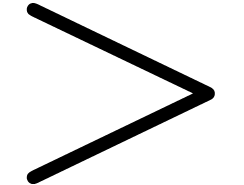 ,
, 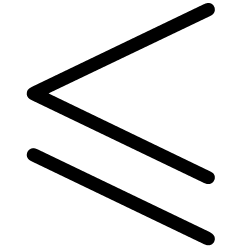 and
and 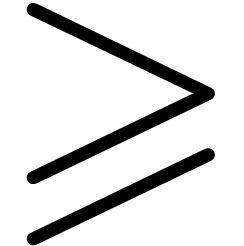 on .
on .
Given an open domain  of
of 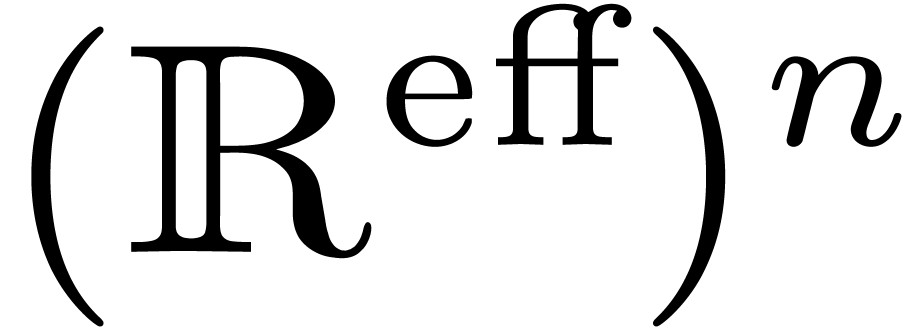 , a real function
, a real function 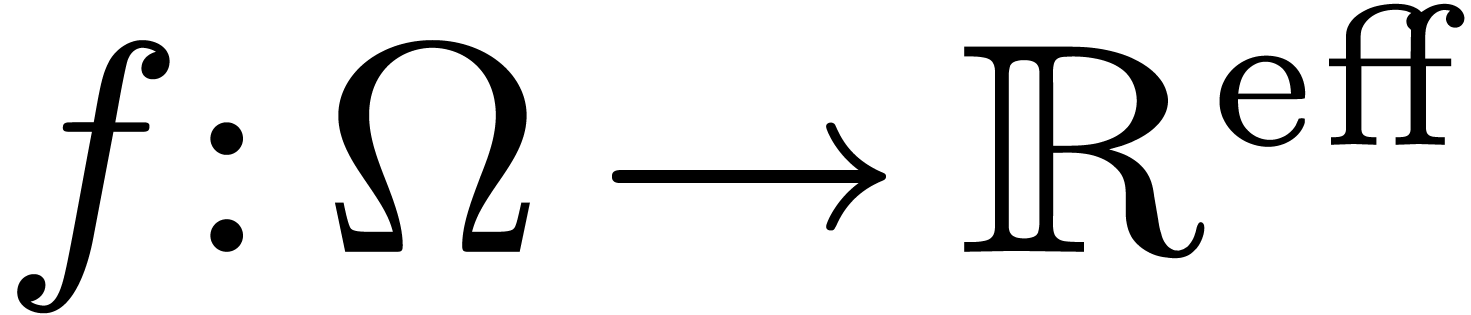 is said to
be effective if there exists an algorithm
is said to
be effective if there exists an algorithm 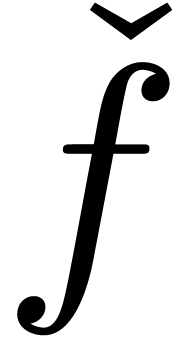 which takes an approximation algorithm
which takes an approximation algorithm 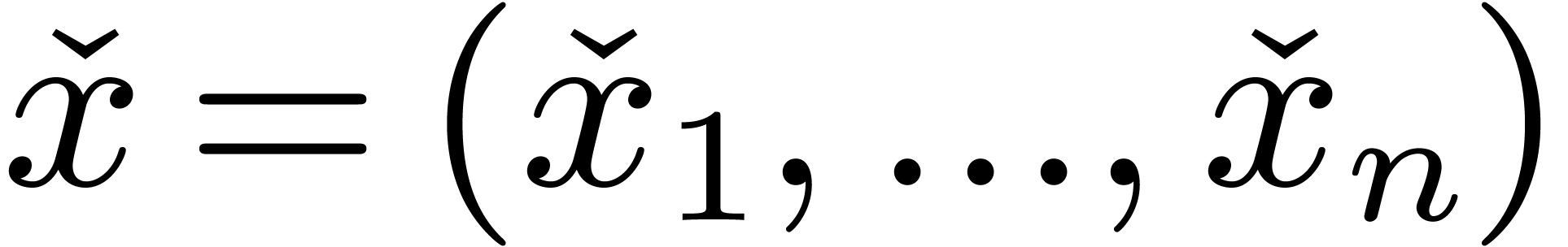 for
for  on input and which produces an approximation
algorithm
on input and which produces an approximation
algorithm 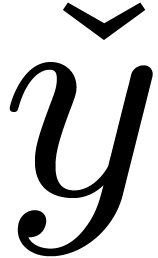 for
for 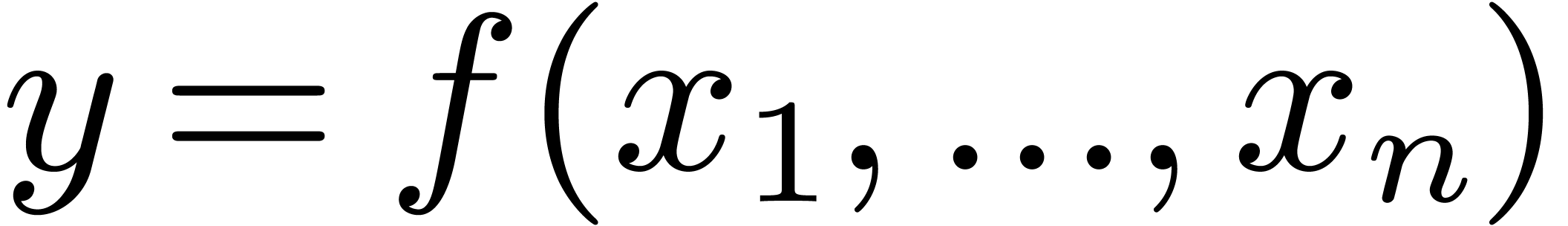 .
Here we understand that
.
Here we understand that 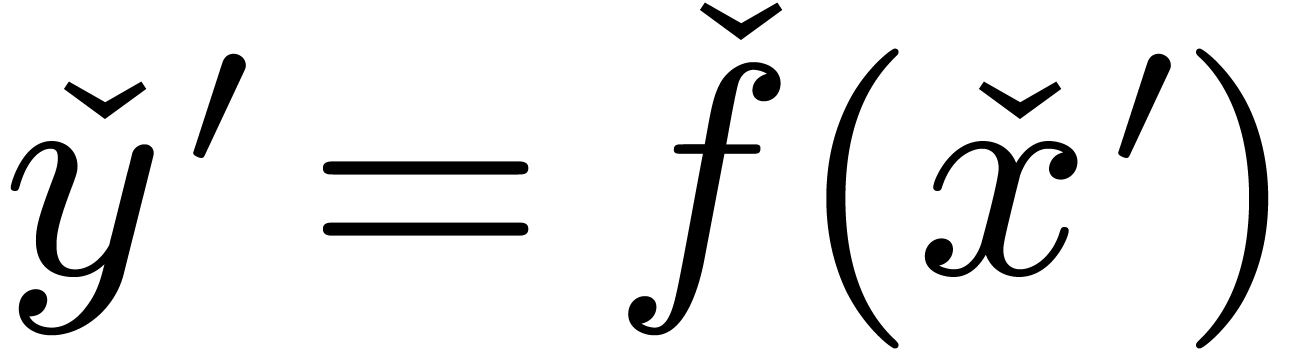 approximates the same
number
approximates the same
number  , if
, if 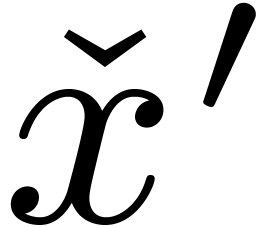 is another approximation algorithm for .
is another approximation algorithm for .
Most common operations, like  ,
,
 ,
,  ,
,  ,
, 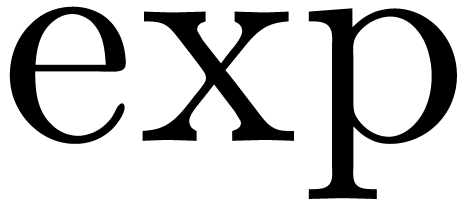 ,
, 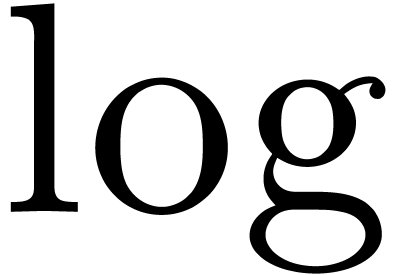 ,
,
 ,
, 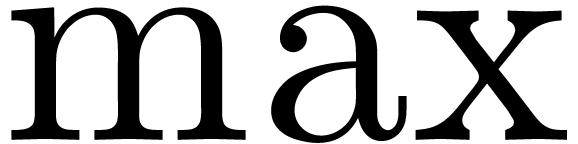 , etc., can easily shown to be
effective. On the other hand, without any of the operations for
comparison, it seems more difficult to implement functions like
, etc., can easily shown to be
effective. On the other hand, without any of the operations for
comparison, it seems more difficult to implement functions like 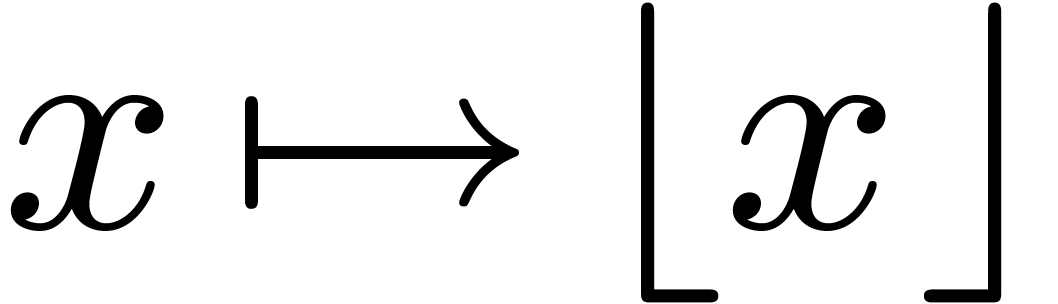 . In fact, it turns out that
effective real functions are necessarily continuous [22,
theorem 1.3.4].
. In fact, it turns out that
effective real functions are necessarily continuous [22,
theorem 1.3.4].
A concrete library for computations with effective real
numbers consists of a finite number of functions like 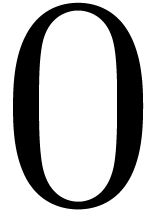 ,
, 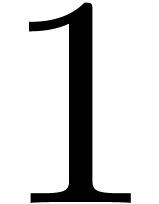 ,
, , , , etc. Given inputs
,
, , , , etc. Given inputs  of type real, such an operation should
produce a new instance
of type real, such an operation should
produce a new instance 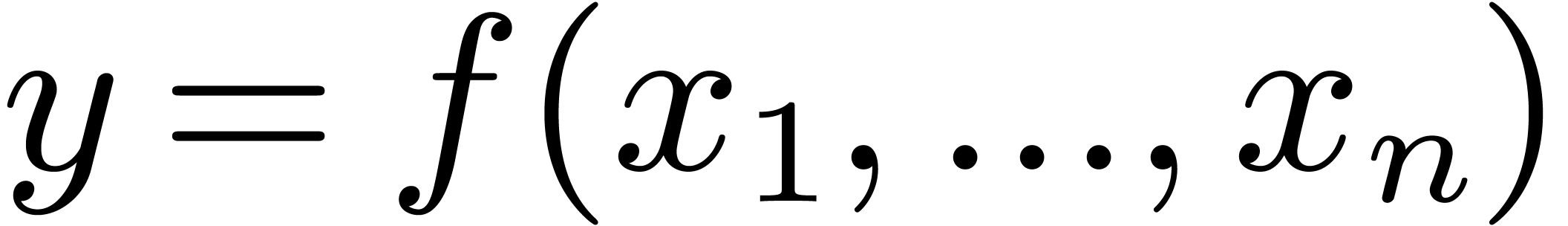 of real.
Usually, the representation class for in
particular contains members for ,
which can then be used in the method which implements the approximation
algorithm for . For instance,
a very simple implementation of addition might look as follows:
of real.
Usually, the representation class for in
particular contains members for ,
which can then be used in the method which implements the approximation
algorithm for . For instance,
a very simple implementation of addition might look as follows:
class add_real_rep: public real_rep {
real x, y;
public:
add_real_rep (const real& x2, const real& y2):
x (x2), y (y2) {}
dyadic approximate (const dyadic& err) {
return x->approximate (err/2) + y->approximate (err/2);
}
};
When implementing a library of effective real functions 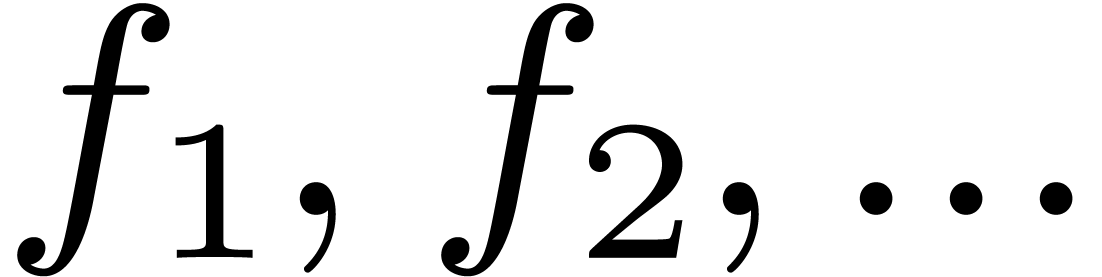 in this way, we notice in particular that any effective real number
computed by the library reproduces the expression by which it was
computed in memory. Such effective real numbers may therefore be modeled
faithfully by rooted dags (directed acyclic graphs)
in this way, we notice in particular that any effective real number
computed by the library reproduces the expression by which it was
computed in memory. Such effective real numbers may therefore be modeled
faithfully by rooted dags (directed acyclic graphs)  , whose nodes are labeled by . More generally, finite sets of effective real
numbers can be modeled by general dags of this type. Figure 1
shows an example of such a dag, together with some parameters for
measuring its complexity.
, whose nodes are labeled by . More generally, finite sets of effective real
numbers can be modeled by general dags of this type. Figure 1
shows an example of such a dag, together with some parameters for
measuring its complexity.
Since storing entire computations in memory may require a lot of space, the bulk of computations should not be done on the effective real numbers themselves, but rather in their approximation methods. In particular, real should not be thought of as some kind of improved double type, which can be plugged into existing numerical algorithms: the real class rather provides a user-friendly high-level interface, for which new algorithms need to be developed.
Let be a library of effective real functions as
in the previous section, based on a corresponding library 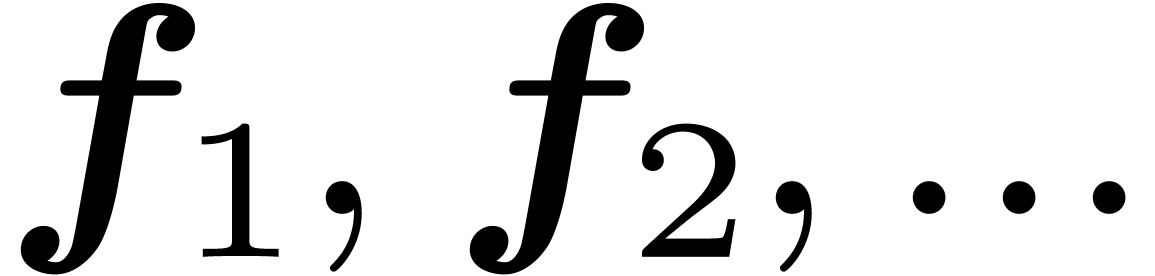 of functions on intervals. In order to study the
efficiency of our library, it is important to have a good model for the
computational complexity. In this section, we will describe a static and
a dynamic version of the global approximation problem, which
are two attempts to capture the computational complexity issues in a
precise manner.
of functions on intervals. In order to study the
efficiency of our library, it is important to have a good model for the
computational complexity. In this section, we will describe a static and
a dynamic version of the global approximation problem, which
are two attempts to capture the computational complexity issues in a
precise manner.
In its static version, the input of the global approximation problem consists of
A dag , whose nodes are
labeled by
A challenge  for each node
for each node  .
.
Denoting by  the function associated to the node
the function associated to the node
 and by
and by  its children, we
may recursively associate a real value
its children, we
may recursively associate a real value 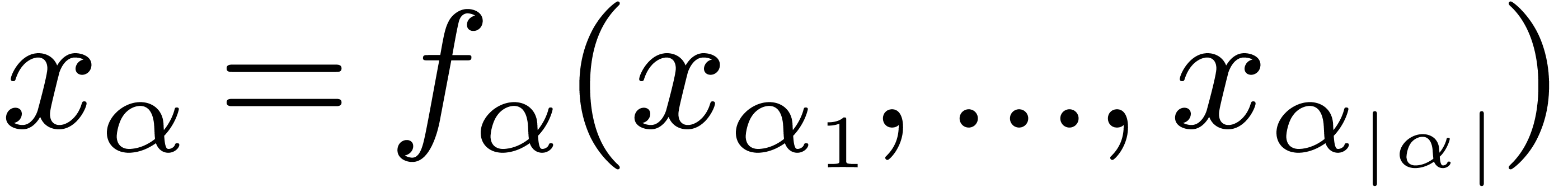 to . On output, we require for each
node
to . On output, we require for each
node 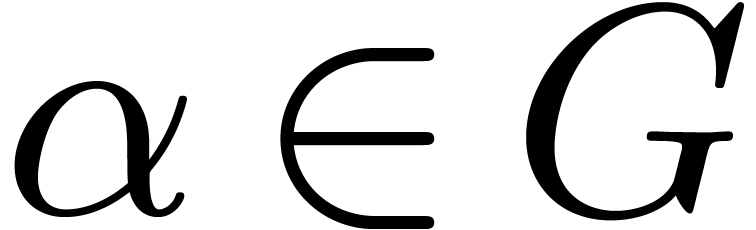 an interval
an interval  with
endpoints in , such that
with
endpoints in , such that
 and
and  .
.
For certain  , we have
, we have
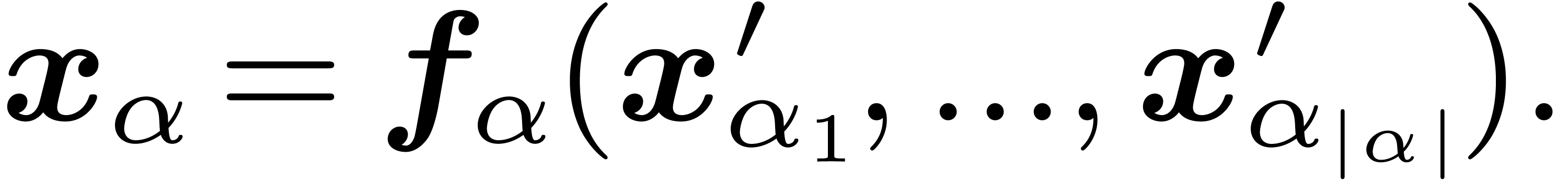
Notice that the second condition implies in particular that 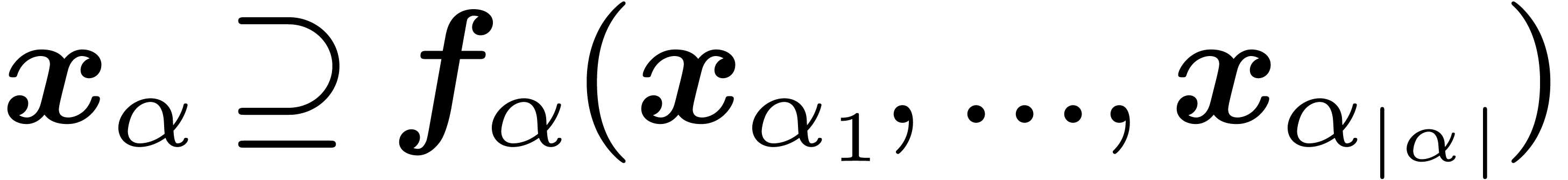 .
.
The dynamic version of the global approximation problem consists of a
sequence of static global approximation problems for a fixed labeled dag
, when we incrementally add
challenges  for nodes . More precisely, we are given
for nodes . More precisely, we are given
A dag , whose nodes are
labeled by
A finite sequence  of pairs
of pairs 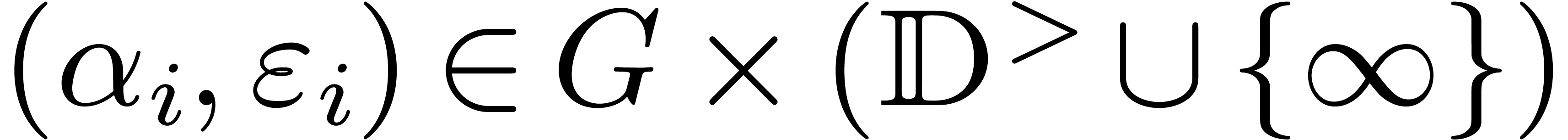 .
.
On output, we require for each 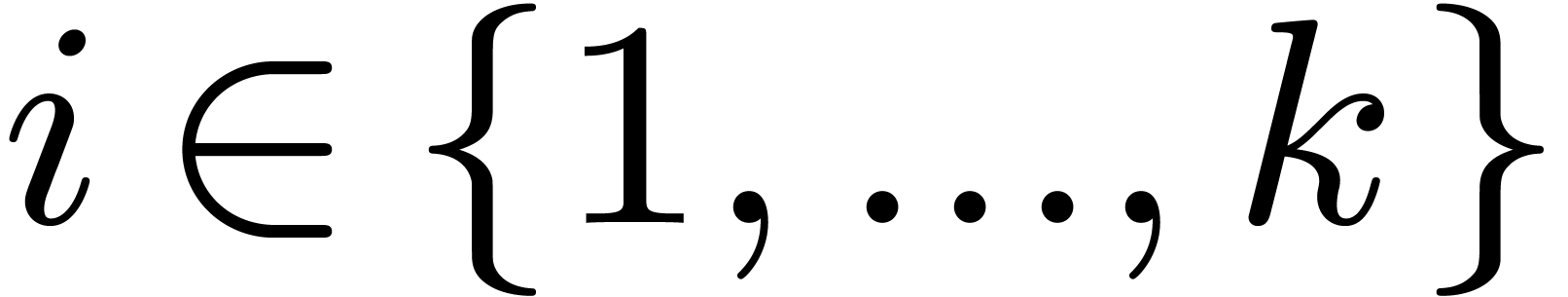 a solution to the
a solution to the
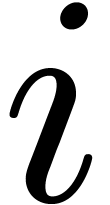 -th static global
approximation problem, which consists of the labeled dag with challenges
-th static global
approximation problem, which consists of the labeled dag with challenges 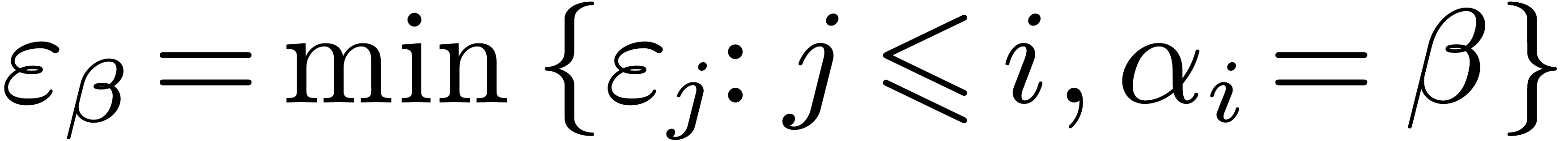 .
Here we understand that a solution at the stage
.
Here we understand that a solution at the stage  may be presented as the set of changes w.r.t. the solution
at stage .
may be presented as the set of changes w.r.t. the solution
at stage .
Let us explain why we think that the dynamic global approximation
problem models the complexity of the library in an adequate way. For
this, consider a computation by the library. The set of all effective
real numbers constructed during the computation forms a labeled dag
. The successive calls of the
approximation methods of these numbers naturally correspond to the
sequence  .
.
It is reasonable to assume that the library itself does not construct
any real numbers, i.e. all nodes of
correspond to explicit creations of real numbers by the user. Indeed, if
new numbers are created from inside an approximation method, then all
computations which are done with these numbers can be seen as parts of
the approximation method, so they should not be taken into account
during the complexity analysis. Similarly, if the constructor of a
number  induces the construction of other real
numbers, then may be expressed in terms of more
basic real functions, so we may consider as a
function outside our library.
induces the construction of other real
numbers, then may be expressed in terms of more
basic real functions, so we may consider as a
function outside our library.
Now assume that another, possibly better library were used for the same
computation. It is reasonable to assume that the corresponding dag 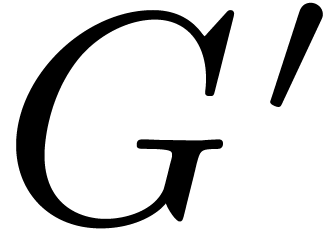 and challenges
and challenges  coincide with
the previous ones. Indeed, even though it might happen that the first
and second library return different bounding intervals
and
coincide with
the previous ones. Indeed, even though it might happen that the first
and second library return different bounding intervals
and 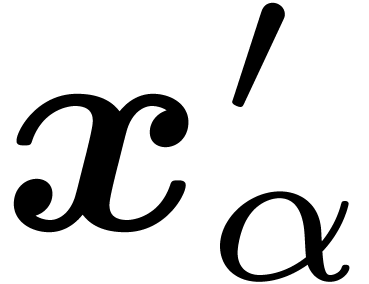 for a given challenge
for a given challenge 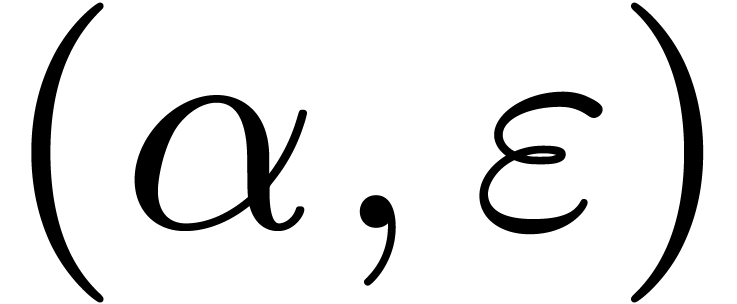 , the libraries cannot know what the user wants to
do with the result. Hence, for a fair comparison between the first and
second library, we should assume that the user does not take advantage
out of possible differences between and
, the libraries cannot know what the user wants to
do with the result. Hence, for a fair comparison between the first and
second library, we should assume that the user does not take advantage
out of possible differences between and 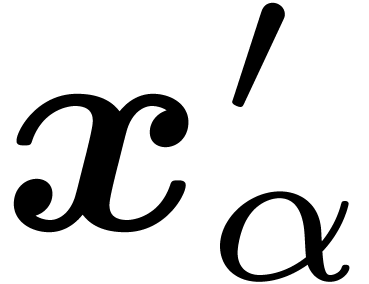 . This reduces to assuming that
. This reduces to assuming that
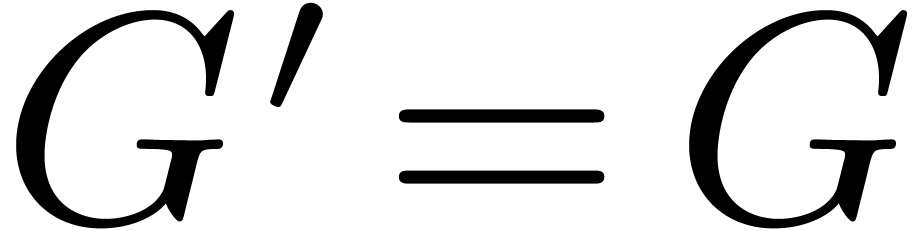 ,
, 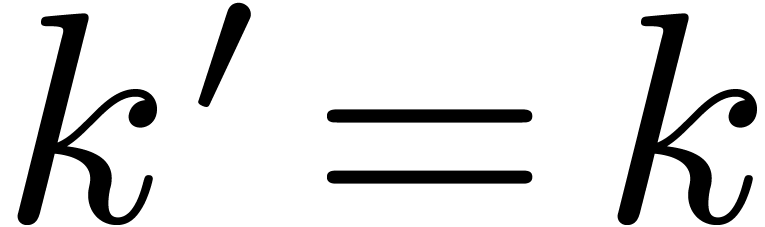 and
and
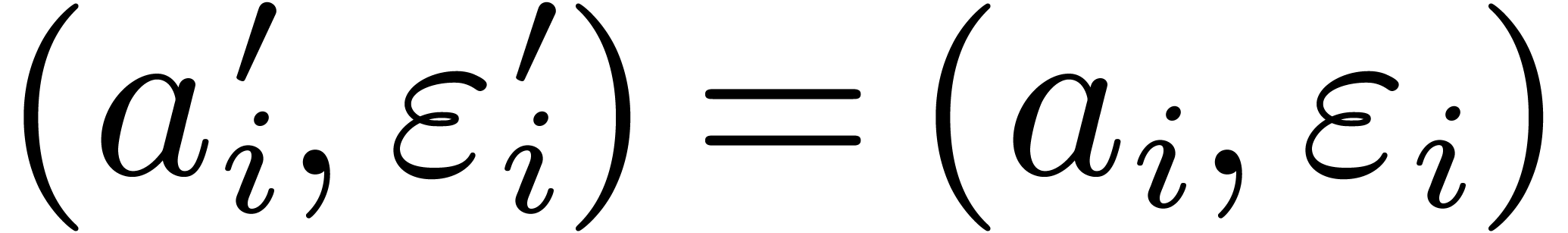 for all .
for all .
Finally, it is reasonable to assume that all actual approximations of the 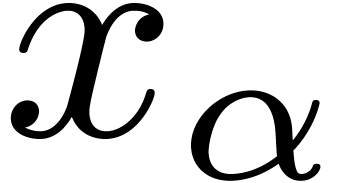 are done using a fixed
interval library . This means
for instance that the second library has no better algorithms for
multiplication, exponentiation, etc. than the first one.
When putting all our “reasonable assumptions” together, the
time of the computation which was spent in the library now corresponds
to the time which was required to solve the corresponding dynamic global
approximation problem.
are done using a fixed
interval library . This means
for instance that the second library has no better algorithms for
multiplication, exponentiation, etc. than the first one.
When putting all our “reasonable assumptions” together, the
time of the computation which was spent in the library now corresponds
to the time which was required to solve the corresponding dynamic global
approximation problem.
Let us now consider the problem of obtaining an -approximation for the result of an operation 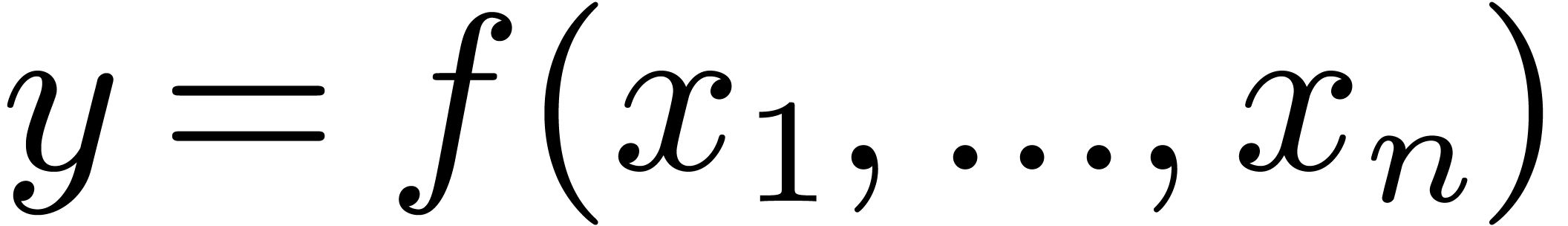 . For simplicity, we will focus on
the case of addition
. For simplicity, we will focus on
the case of addition 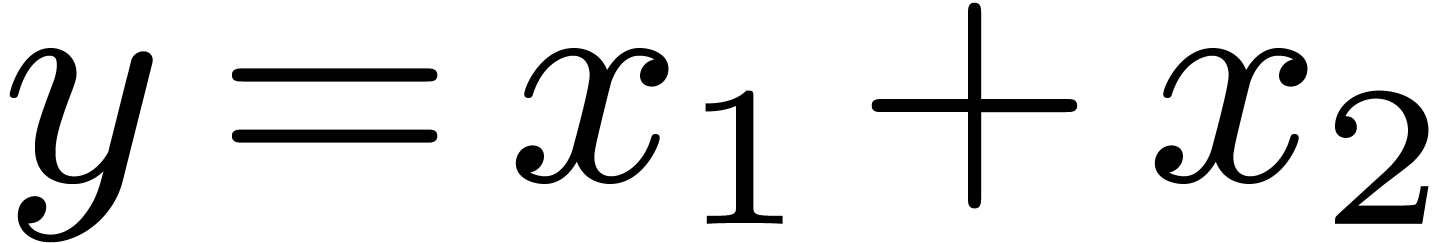 . In
this and the next section, we briefly recall several strategies, which
are discussed in more detail in [20].
. In
this and the next section, we briefly recall several strategies, which
are discussed in more detail in [20].
In the case of a priori error estimates, the tolerance is distributed a priori over 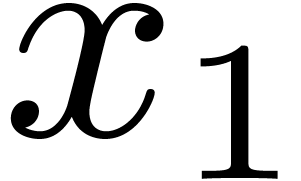 and
and 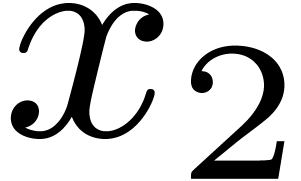 . In other
words, we first determine
. In other
words, we first determine 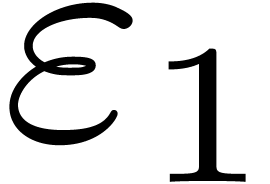 and
and  with
with 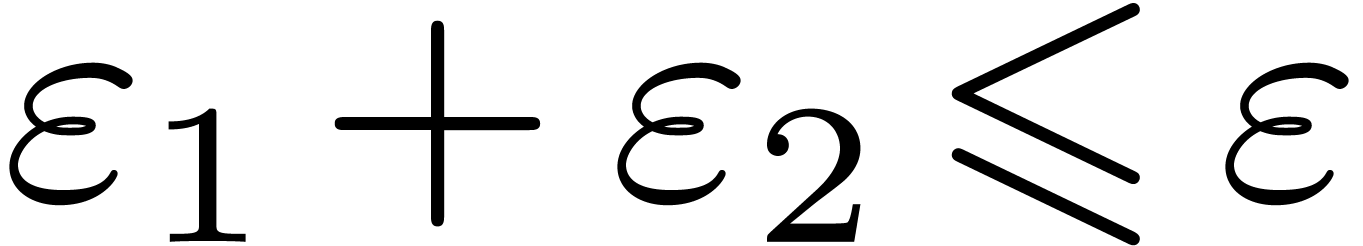 , next compute
, next compute  -approximations for the , and finally add the results. The
systematic choice of
-approximations for the , and finally add the results. The
systematic choice of 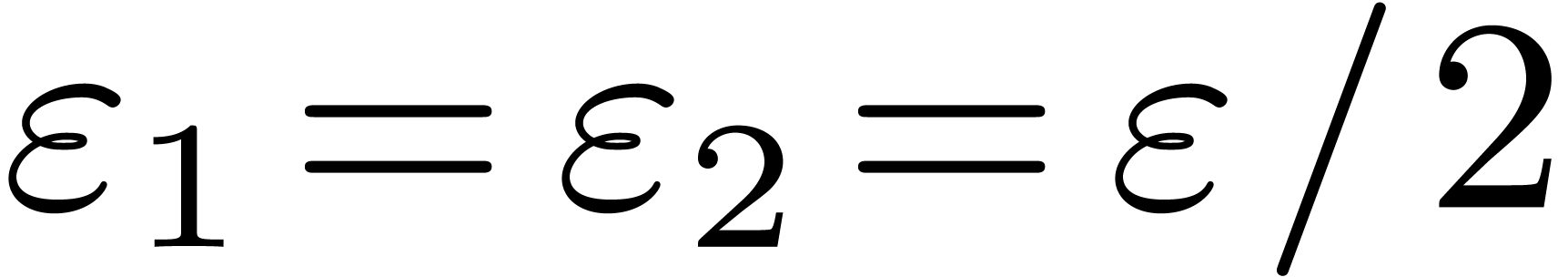 can be very inefficient: in
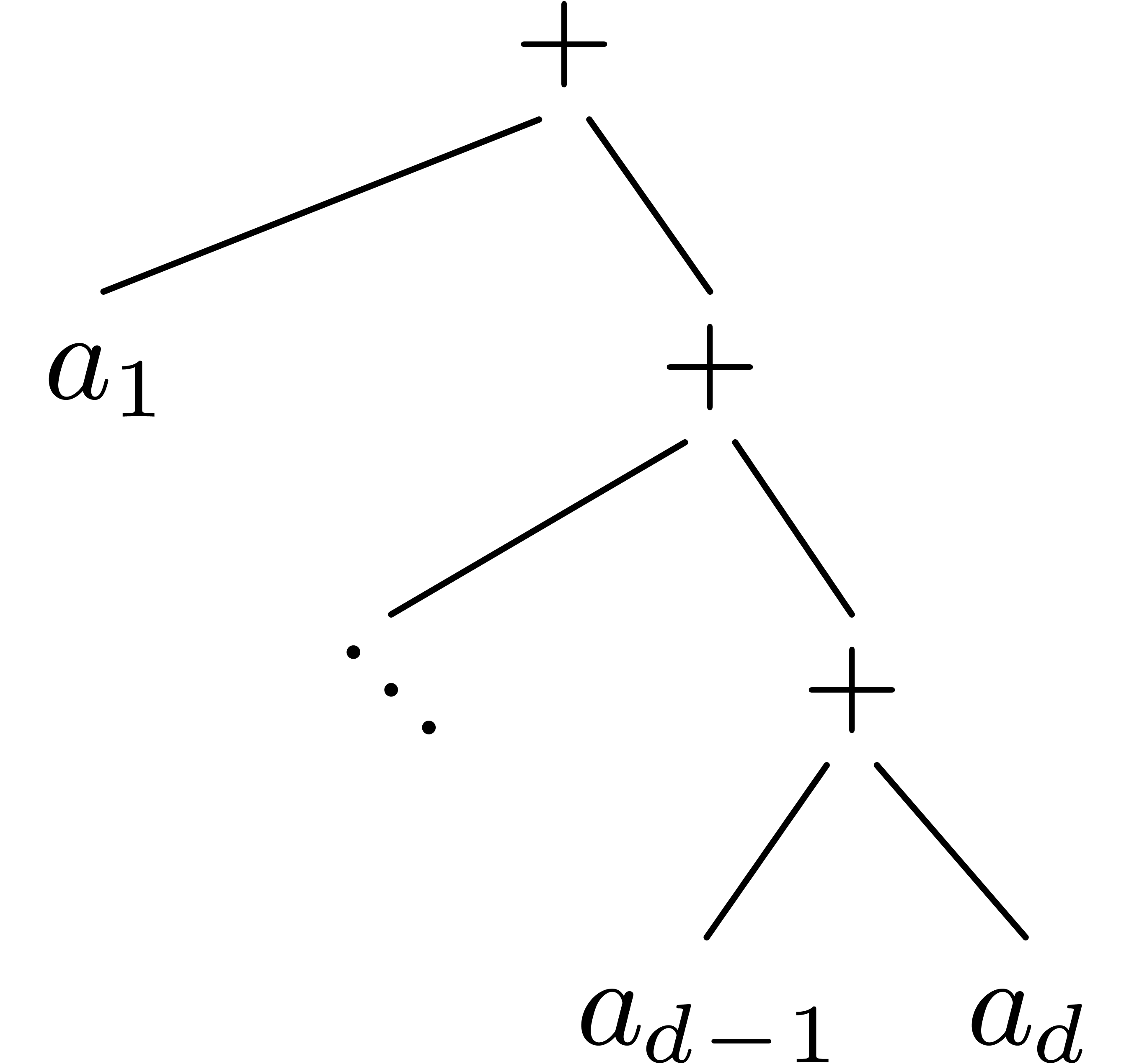
the case of badly balanced trees like in figure 2 (this
occurs in practice when evaluating polynomials using Horner's rule),
this requires the approximation of
can be very inefficient: in
the case of badly balanced trees like in figure 2 (this
occurs in practice when evaluating polynomials using Horner's rule),
this requires the approximation of 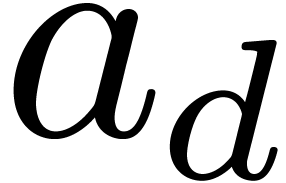 with a much
lower tolerance than
with a much
lower tolerance than 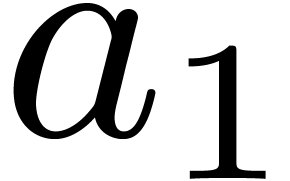 (
(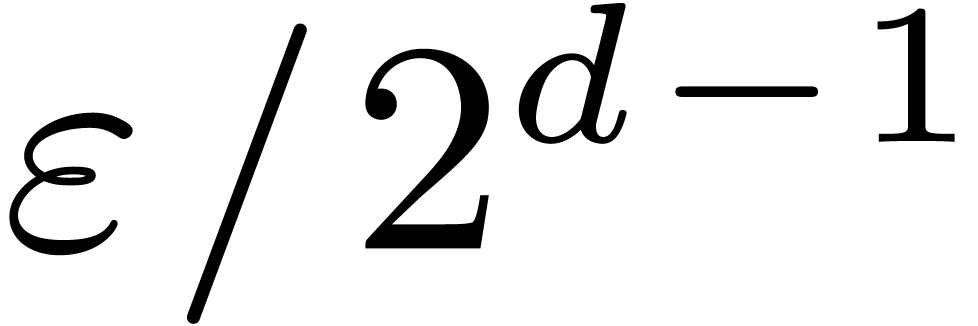 versus
versus 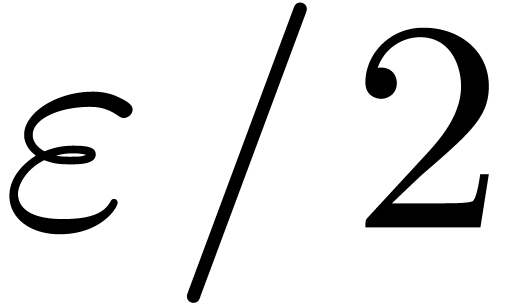 ).
).
This problem can be removed by balancing the error according to the
weights 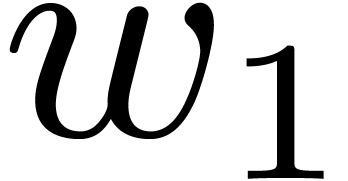 and
and 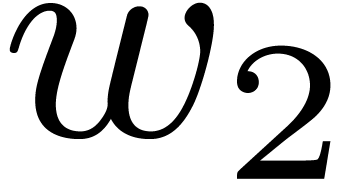 of and (i.e., by taking
of and (i.e., by taking
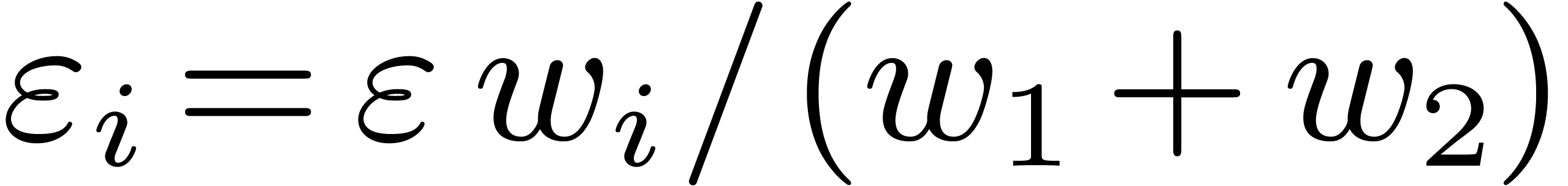 ). For “non
degenerate” cases of the global approximation problem for a dag of
weight
). For “non
degenerate” cases of the global approximation problem for a dag of
weight  and size
and size  ,
it can be shown this technique requires tolerances which are never worse
than
,
it can be shown this technique requires tolerances which are never worse
than 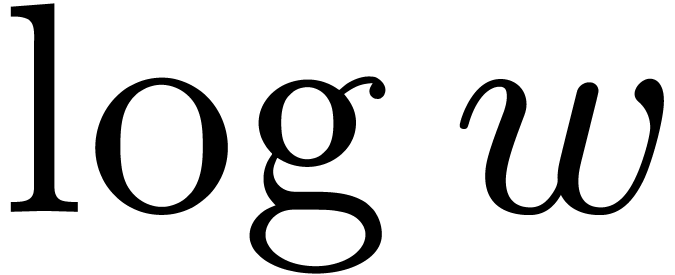 times the optimal ones.
times the optimal ones.
Unfortunately, while implementing the algorithms from [20],
it turned out that is often of the same order as
and therefore far from good enough. This is for
instance the case when the expressions are obtained via some
iterative process or as the coefficient of a lazy power series. For this
reason, we have currently abandoned the use of a priori error
estimates in our implementation. However, this situation is quite
unsatisfactory, since this technique is still most efficient in many
cases. We will come back to this problem in section 6.
 |
A second strategy consists of computing error estimates a
posteriori: if we want to compute an -approximation
for , we start with the
computation of a bounding interval for at
precision . As long as the
obtained result is not sufficiently precise, we keep doubling the
precision and repeating the same computation.
As explained in [20], this strategy can be optimized in two
ways. First of all, the strategy may be carried out locally, by storing
a “best available approximation” (together with the
corresponding precision) for each instance of real.
Indeed, when increasing the precision for the computation of , sufficiently precise
approximations for and
might already be known, in which case their recomputation is
unnecessary.
Secondly, instead of doubling the precision at each step, it is better
to double the expected computation time. For instance, consider the
computation of 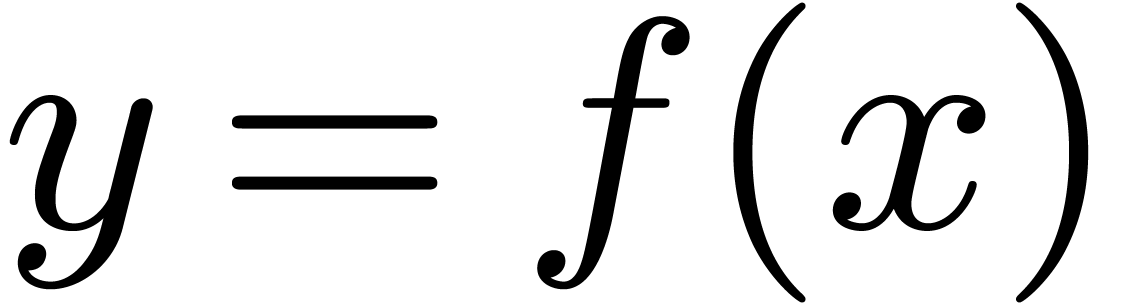 , where has time complexity
, where has time complexity 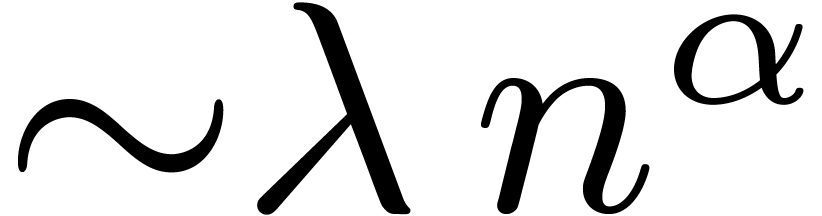 (i.e. admits an
(i.e. admits an 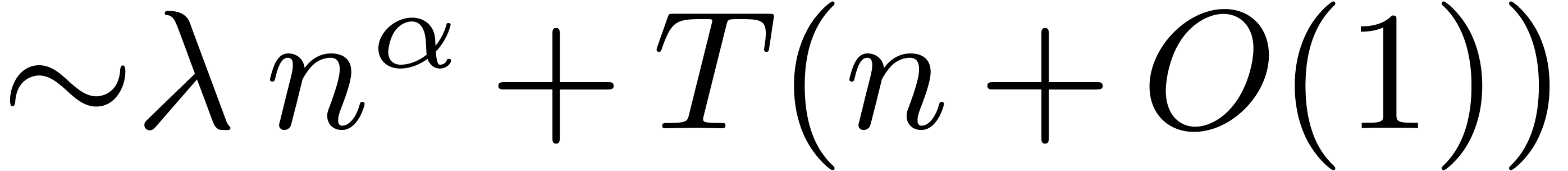 approximation algorithm, whenever admits a
approximation algorithm, whenever admits a 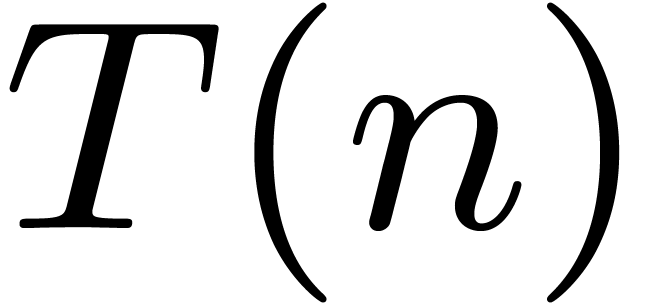 approximation algorithm). Evaluate
at successive precisions
approximation algorithm). Evaluate
at successive precisions 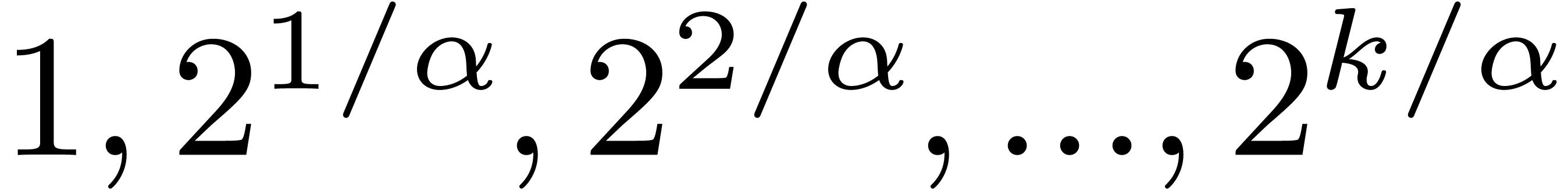 ,
where
,
where 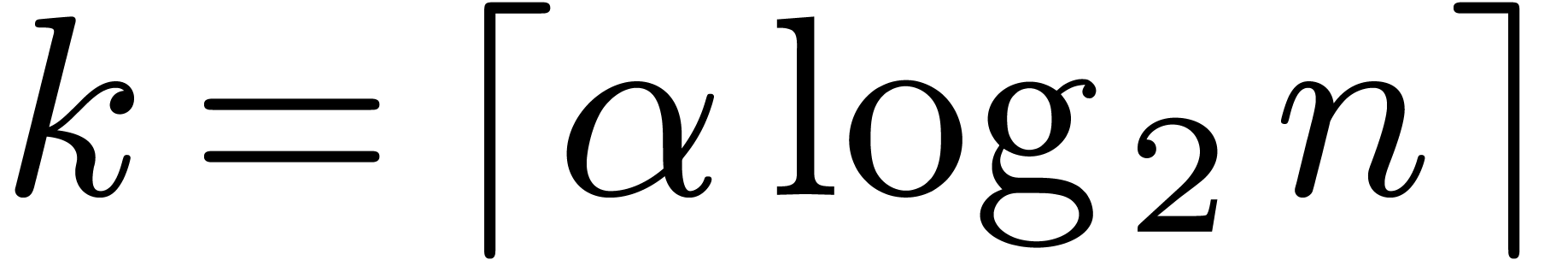 and is the
smallest precision at which the evaluation yields a sufficiently precise
result. Then the total computation time
and is the
smallest precision at which the evaluation yields a sufficiently precise
result. Then the total computation time  never
exceeds
never
exceeds 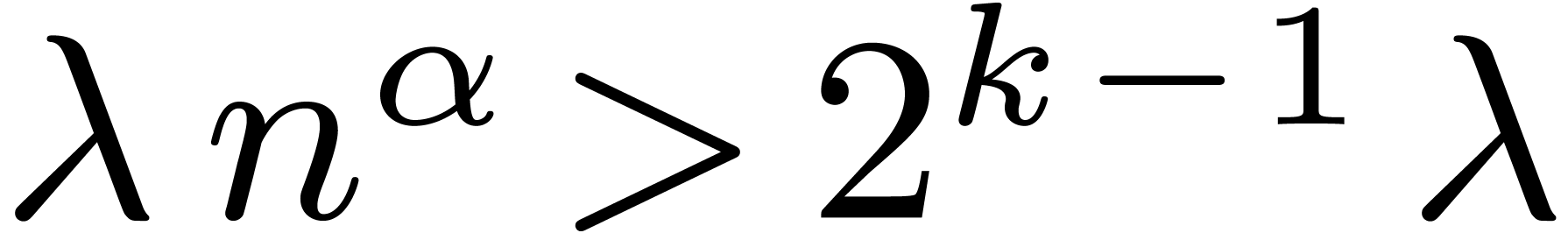 by a factor more than
by a factor more than  (see also [10]).
(see also [10]).
Unfortunately, an error slipped into [20], because the
successive recursive approximations of may not
be sufficiently precise in order to allow for evaluations of at successive precisions .
For instance, if is given by an algorithm of
exponential time complexity 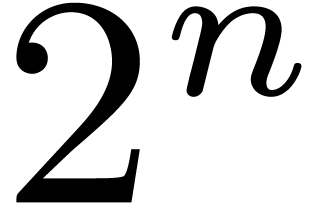 ,
then successive approximations of will only
yield one more bit at every step. This error can be repaired up to a
logarithmic factor in two ways. First of all, we notice that the error
only concerns the cumulative cost of the successive reevaluation of
. In section 5,
we will prove that the total cost of reevaluating all nodes of
the dag remains good.
,
then successive approximations of will only
yield one more bit at every step. This error can be repaired up to a
logarithmic factor in two ways. First of all, we notice that the error
only concerns the cumulative cost of the successive reevaluation of
. In section 5,
we will prove that the total cost of reevaluating all nodes of
the dag remains good.
Secondly, it is possible to adapt the technique of relaxed formal power
series to real numbers. Roughly speaking, this approach relies on the
recursive decomposition of a “relaxed mantissa” of length into a fixed part of length 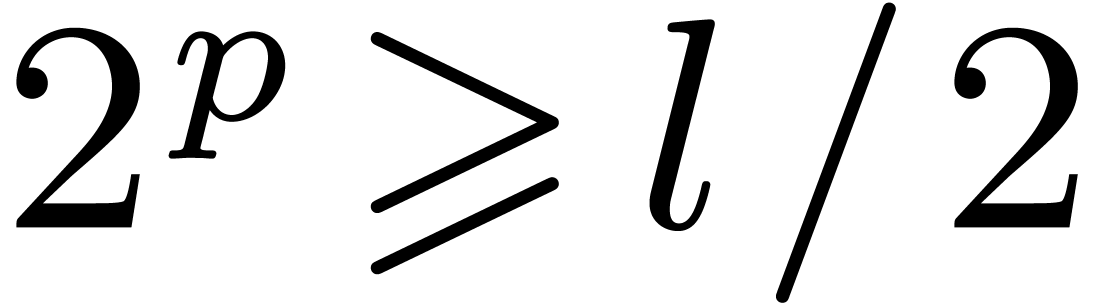 and a relaxed
remainder (so that
and a relaxed
remainder (so that 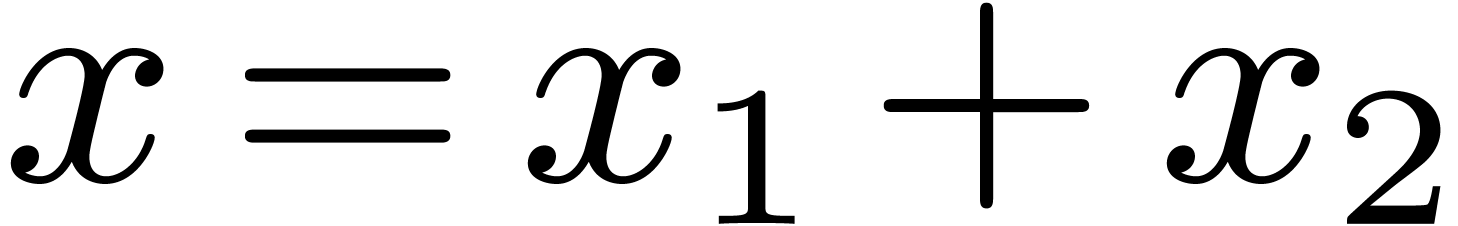 ).
Given an operation , we then
compute
).
Given an operation , we then
compute 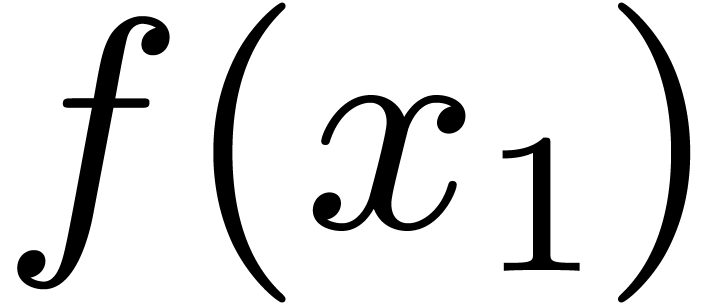 and
and 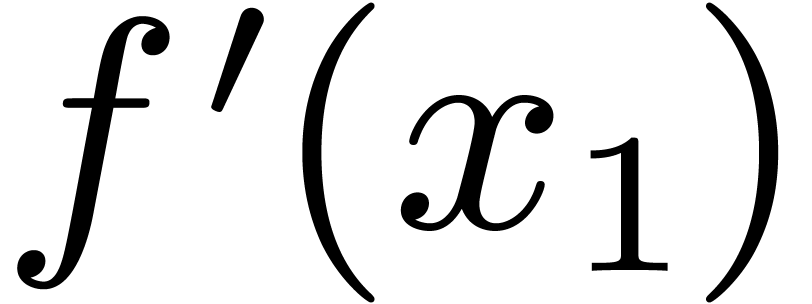 at precision
at precision
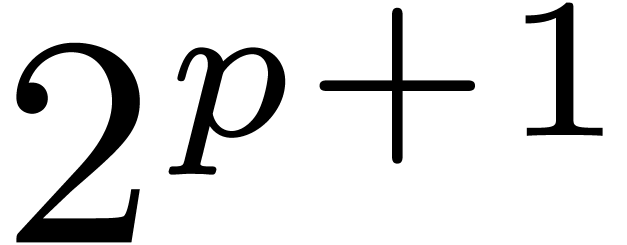 and obtain a formula for the relaxed
decomposition
and obtain a formula for the relaxed
decomposition 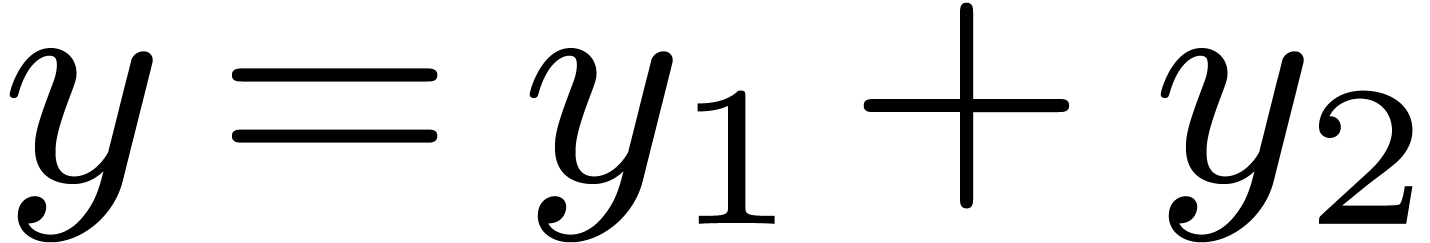 , since
, since  is a truncation of and
is a truncation of and 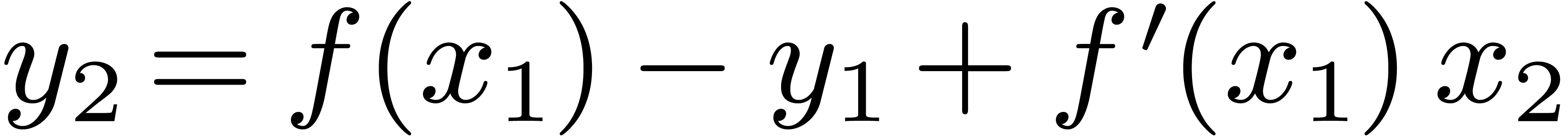 . As soon as the precision of exceeds
. As soon as the precision of exceeds  ,
we take a new value for and recompute and at a doubled precision.
Working out the details of this construction shows that most common real
functions can be evaluated in a relaxed way with the same complexity as
usual, multiplied by an
,
we take a new value for and recompute and at a doubled precision.
Working out the details of this construction shows that most common real
functions can be evaluated in a relaxed way with the same complexity as
usual, multiplied by an 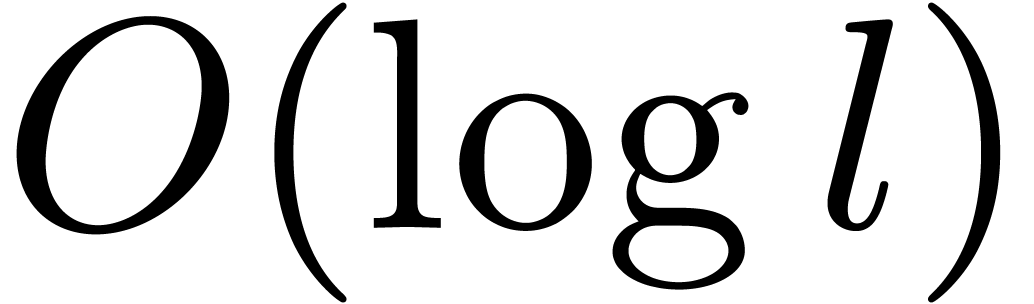 overhead.
overhead.
However, the relaxed strategy accounts for a lot of additional implementation work and no noticeable improvement with respect to the global bound (3) which will be proved in section 5. Therefore, it is mainly interesting from a theoretical point of view.
Inside are represented using generalized floating point
numbers in , where is bounded by a precision of the order of 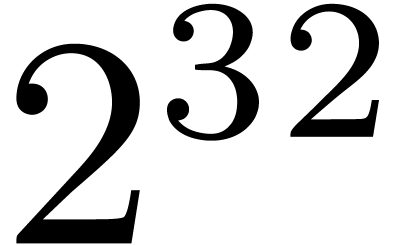 or
or 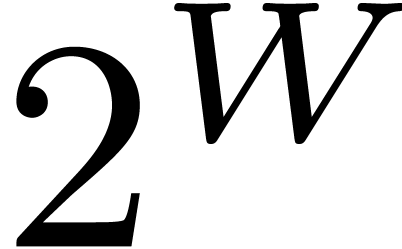 .
.
Effective real numbers (of type real) are implemented as
pointers to an abstract representation class real_rep
with a virtual method for the computation of -bounding intervals. Usually, such a number is of
the form , where is an effective real function and
are other effective real numbers. The number is
concretely represented by an instance of a class f_real_rep
which derives from real_rep and with fields
corresponding to .
The current implementation is based on the technique of a posteriori error bounds from section 3.5 with the two optimizations mentioned there: remembering the best currently available approximations for each real number and doubling computations times instead of precisions. These strategies are reflected as follows in the real_rep data type:
class real_rep {
protected:
double cost;
interval best;
real_rep (): cost (1.0) { compute (); }
virtual int as_precision (double cost);
virtual interval compute ();
public:
interval improve (double new_cost);
interval approximate (const dyadic& err);
};
The field best corresponds to the best currently
available bounding interval for .
The value of best is recomputed several times by the
purely virtual method compute at increasing
intended costs, the last one of which is stored in cost.
More precisely, best is recomputed as a function of
approximations  of at the
same costs. When these approximations are sufficiently precise, then the
cost of the computation of best will be more or less
equal to cost. Otherwise, the actual computation may
take less time (see the discussion at the end of section 3.5).
of at the
same costs. When these approximations are sufficiently precise, then the
cost of the computation of best will be more or less
equal to cost. Otherwise, the actual computation may
take less time (see the discussion at the end of section 3.5).
The costs are normalized (we start with 1.0) and doubled at each iteration. The purely virtual method as_precision is used to convert an intended cost to the corresponding intended precision.
The user interface is given by the routines improve and
approximate. The first one computes an approximation of
at intended cost new_cost:
interval real_rep::improve (double new_cost) {
if (new_cost <= cost) return best;
cost= max (new_cost, 2.0 * cost);
set_precision (as_precision (cost));
best= compute ();
restore_precision ();
return best;
}
The method approximate returns an -bounding interval for as a function of :
interval real_rep::approximate (const dyadic& eps) {
while (radius (best) >= eps)
(void) improve (2.0 * cost);
return best;
}
Remark
Let us illustrate the mechanism from the previous section in
the case of exponentiation. The exponential 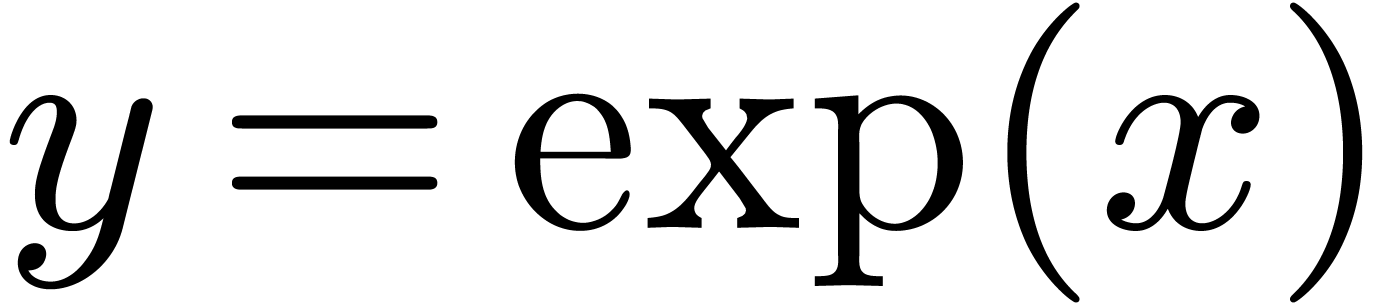 of a
number is represented by an instance of
of a
number is represented by an instance of
class exp_real_rep: public real_rep {
real x;
int as_precision (double cost);
interval compute ();
public:
exp_real_rep (const real& x2): x (x2) {}
};
The computation of bits of
takes a time proportional to 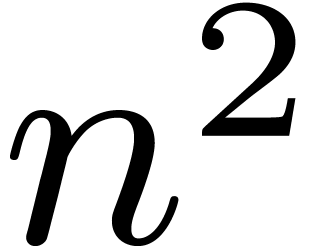 for small values of
and a more or less linear time for large values
of . Therefore, a simple
implementation of as_precision would be as follows:
for small values of
and a more or less linear time for large values
of . Therefore, a simple
implementation of as_precision would be as follows:
int exp_real_rep::as_precision (double cost) {
if (cost <= 256.0) return (int) sqrt (cost);
return min (MAX_PREC, (int) cost/16.0);
}
Of course, this is a very rough approximation of the real time
complexity of . For the
theoretical bounds in the next sections, better approximations are
required. In practice however, a simple implementation like the above
one is quite adequate. If necessary, one may implement a more precise
algorithm, based on benchmarks. One may also gradually increase
precisions and use a timer. The actual approximation of
is done using the overloaded function exp on intervals:
interval exp_real_rep::compute () {
return exp (x->improve (cost));
}
In the case of functions with arity more than one it is often possible to avoid unnecessarily precise computations of one of the arguments, when the approximations of the other argument are far less precise. For instance, in the case of addition, compute may be implemented as follows:
interval add_real_rep::compute () {
dyadic eps= pow (2.0, -BITS_IN_WORD)
if (radius (y->best) < eps * radius (x->best)) {
(void) x->improve (cost);
while (y->cost < cost &&
radius (y->best) >= eps * radius (x->best))
(void) y->improve (2.0 * y->cost);
}
else symmetric case with x and y interchanged
else return x->improve (cost) + y->improve (cost);
}
Notice that our and then either compute an
-approximation for each , or successive -approximations for each
(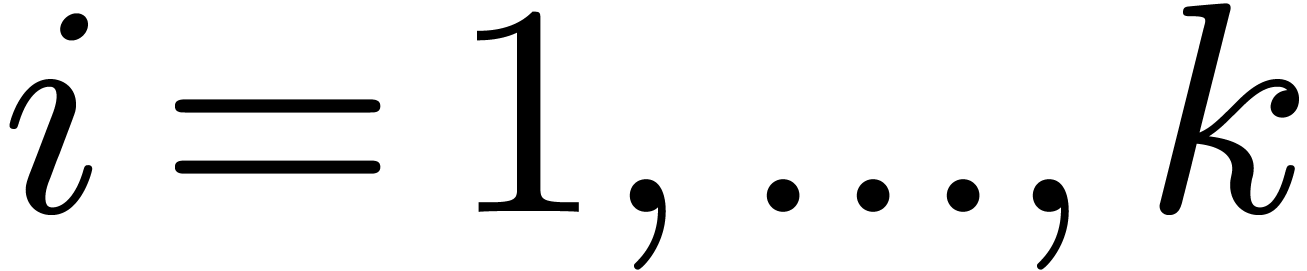 ). In this section, we
examine the efficiency of this approach.
). In this section, we
examine the efficiency of this approach.
Since is approximated several times
during our algorithm, let us first study the difference between the
total computation time and the time taken by the final and most precise
approximations of the .
For each node , let  be the successive timings for the approximation of . We will also denote by
be the successive timings for the approximation of . We will also denote by  the intended computation times and precisions. By
construction, we have
the intended computation times and precisions. By
construction, we have 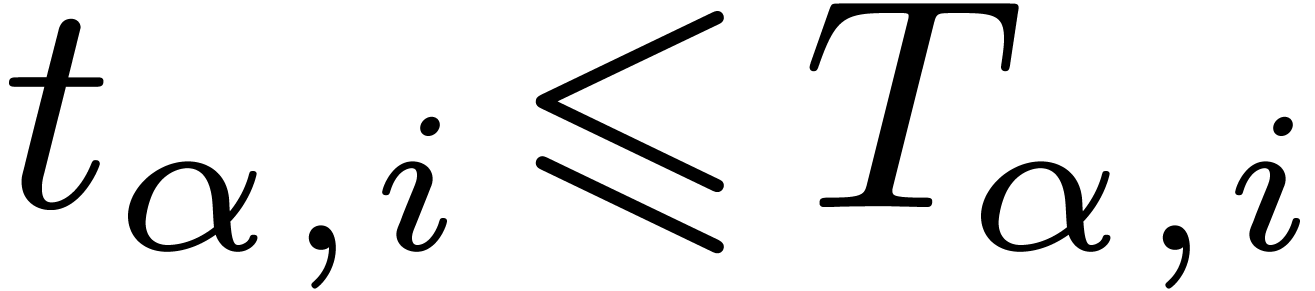 for all
and
for all
and 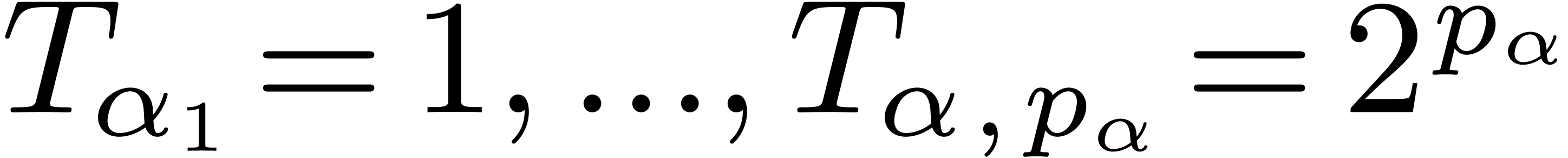 . For each , let
. For each , let 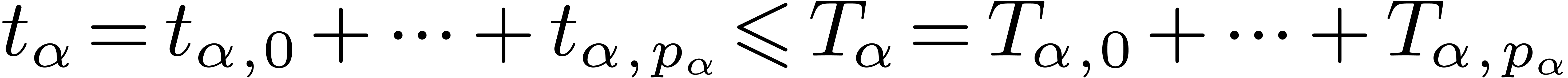 and
and 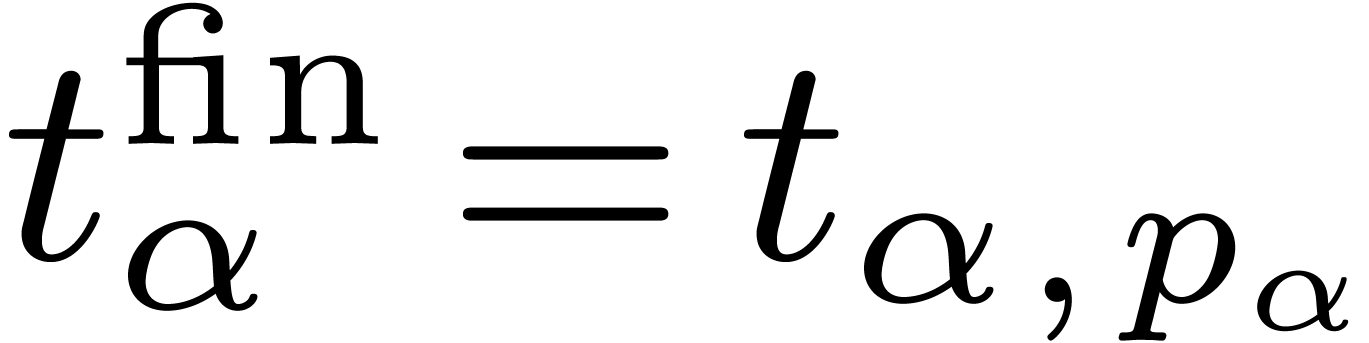 . We define
. We define  ,
,
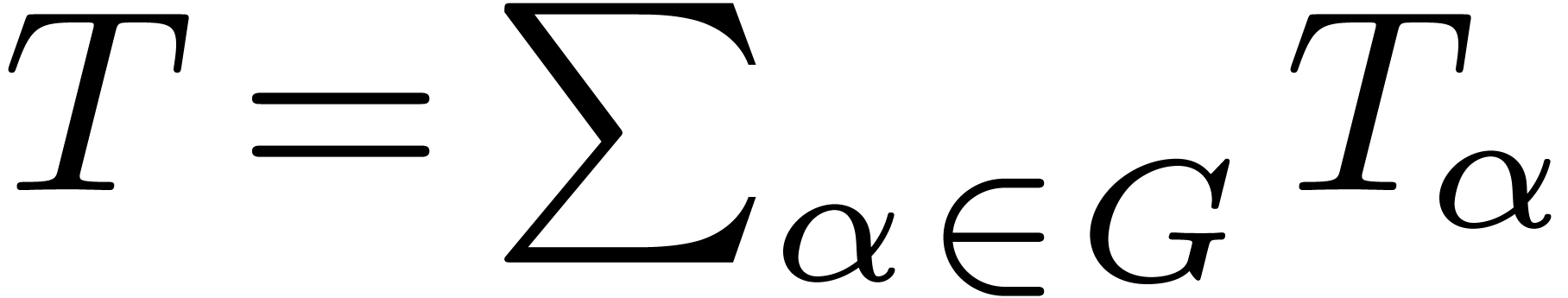 and
and 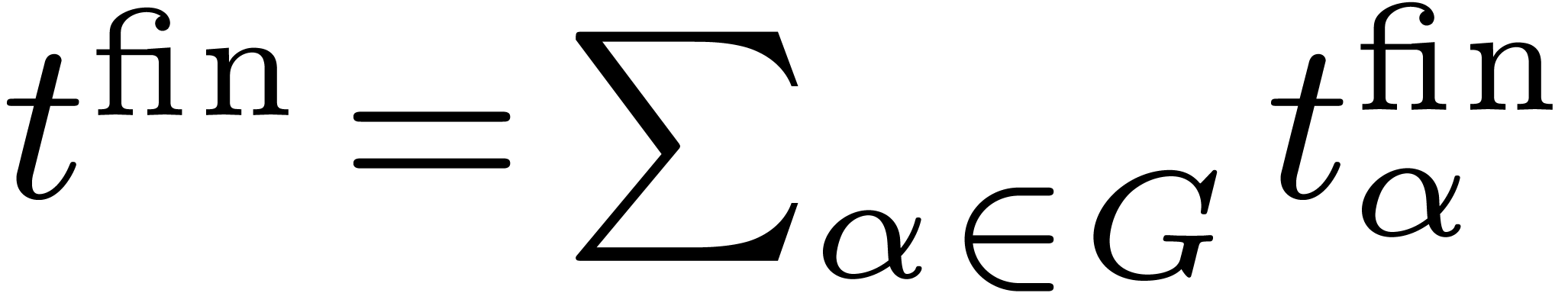 .
.
We already warned against the possibility that 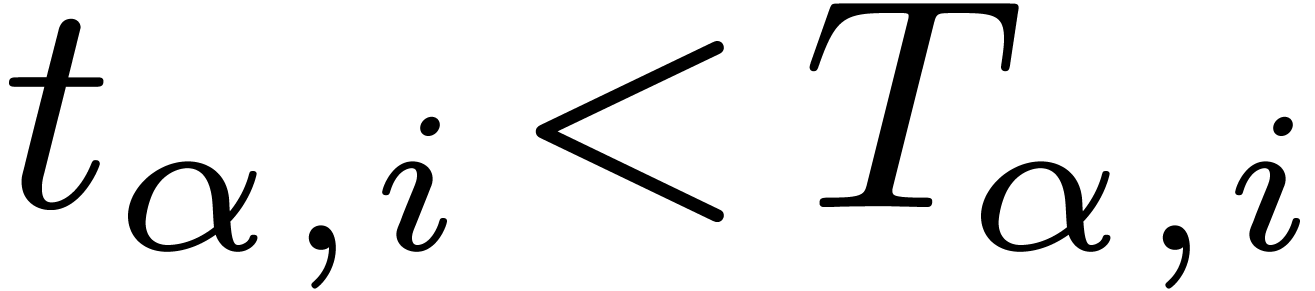 . Nevertheless, we necessarily have
. Nevertheless, we necessarily have 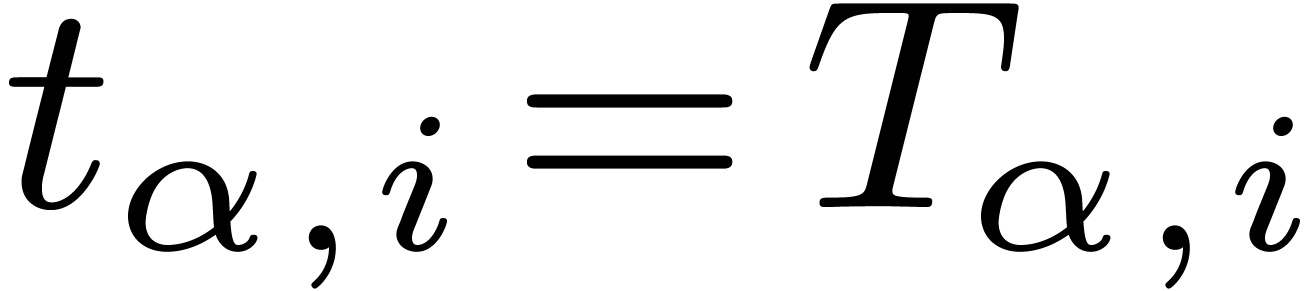 if is a leaf. Also, any operation of cost
if is a leaf. Also, any operation of cost 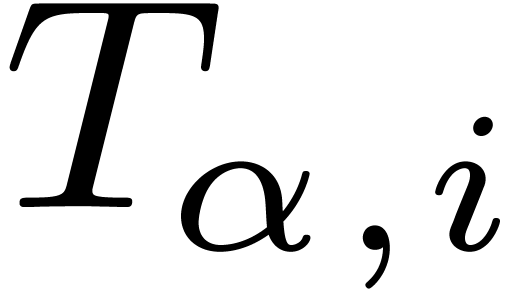 triggers an operation of
cost for one of the children of . By induction, it follows that there exists at
least one leaf
triggers an operation of
cost for one of the children of . By induction, it follows that there exists at
least one leaf 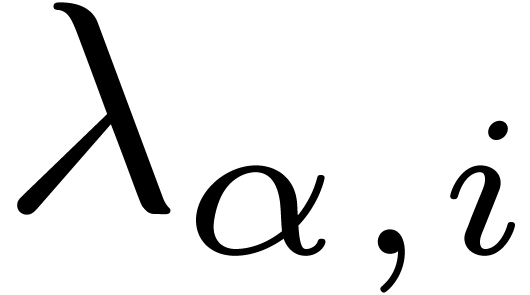 descending from
which really spends a time
descending from
which really spends a time 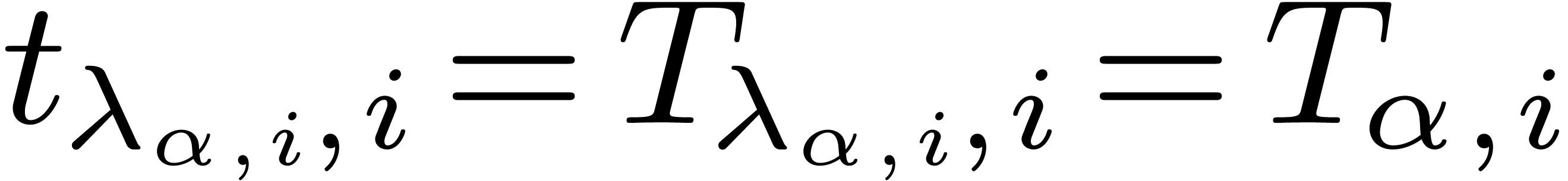 .
Hence, denoting by
.
Hence, denoting by  the ancestrality of the dag
and by
the ancestrality of the dag
and by  its subset of leaves, we have
its subset of leaves, we have
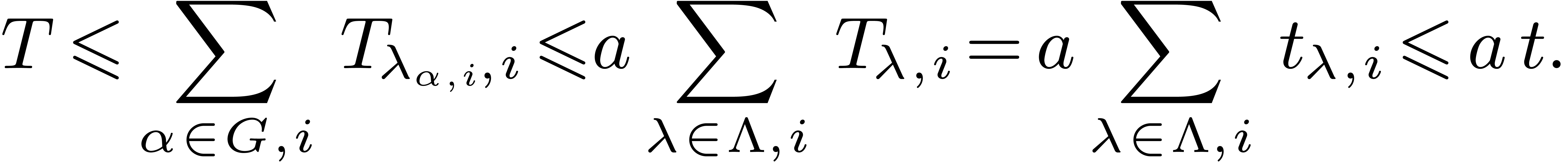 |
(1) |
We also have 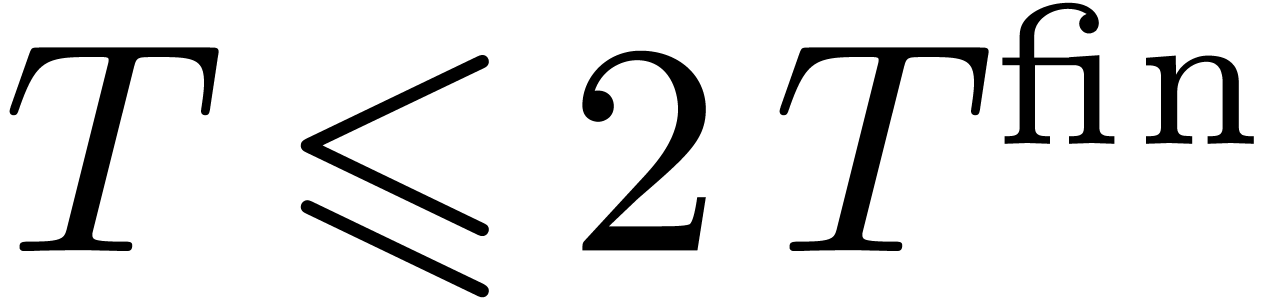 since
since 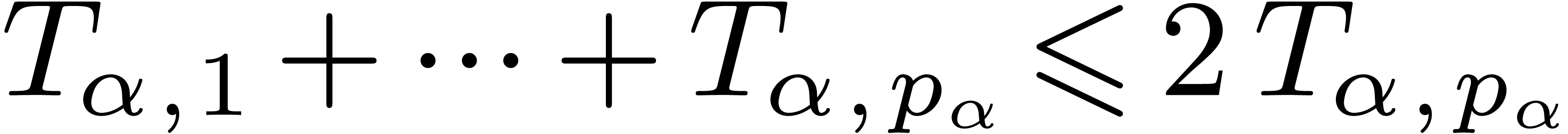 for
all . Consequently,
for
all . Consequently,
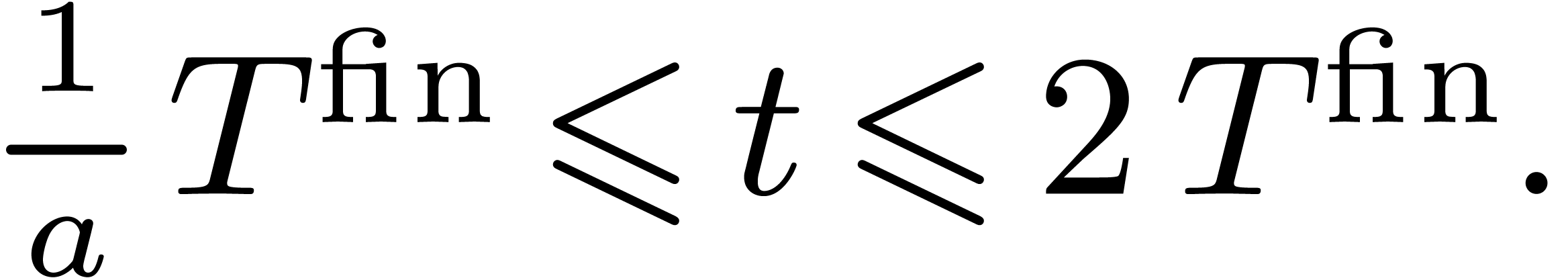 |
(2) |
The bound (1) is sharp in the case when the dag has only
one leaf 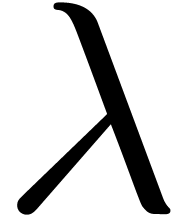 and a) the computation of an
digit approximation of
and a) the computation of an
digit approximation of 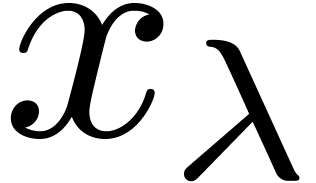 requires exponential time; b) all other operations can be
performed in linear or polynomial time. A similar situation occurs when
cancellations occur during the computation of , in which case the computation of
requires exponential time; b) all other operations can be
performed in linear or polynomial time. A similar situation occurs when
cancellations occur during the computation of , in which case the computation of 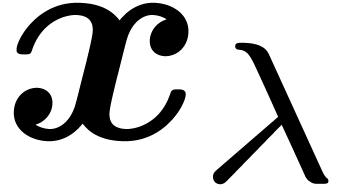 at many bits precision still produces a -bit
result.
at many bits precision still produces a -bit
result.
A variant of (2), which is usually better, is obtained as
follows. Since the precision of the result of an operation on intervals
increases with the precision of the arguments, and similarly for the
computation times, we have  .
Let be a node (which can be assumed to be a leaf
by what precedes) for which
.
Let be a node (which can be assumed to be a leaf
by what precedes) for which 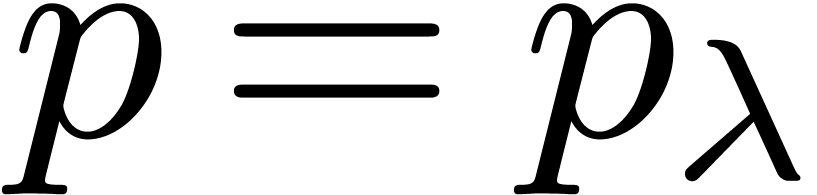 is maximal. Then
is maximal. Then
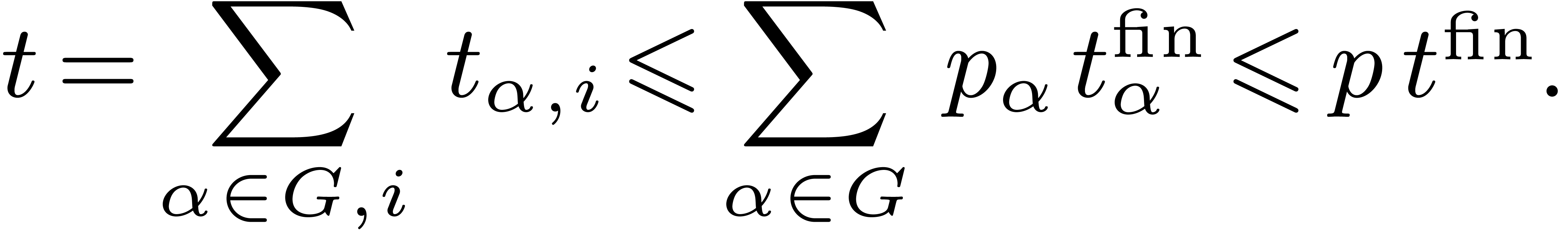
It follows that
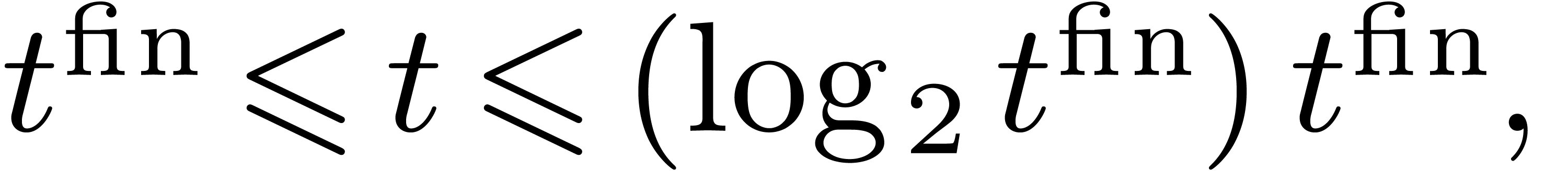 |
(3) |
since 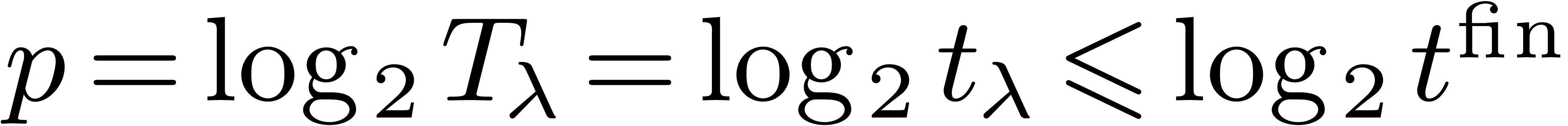 .
.
Let us now compare 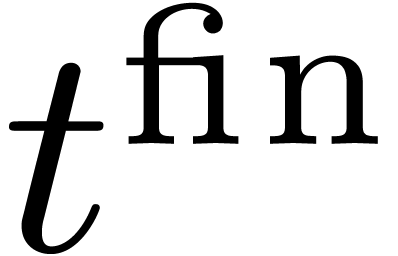 with the
computation time
with the
computation time 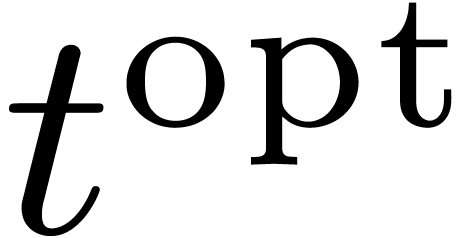 for an optimal solution to the
global approximation problem. In fact, it suffices to compare with an
optimal solution for the static version: in the dynamic case, we
consider the last static global approximation problem.
for an optimal solution to the
global approximation problem. In fact, it suffices to compare with an
optimal solution for the static version: in the dynamic case, we
consider the last static global approximation problem.
Denote by 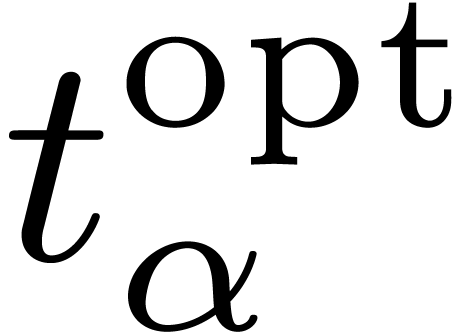 the computation time at each node for a fixed optimal solution, so that
the computation time at each node for a fixed optimal solution, so that 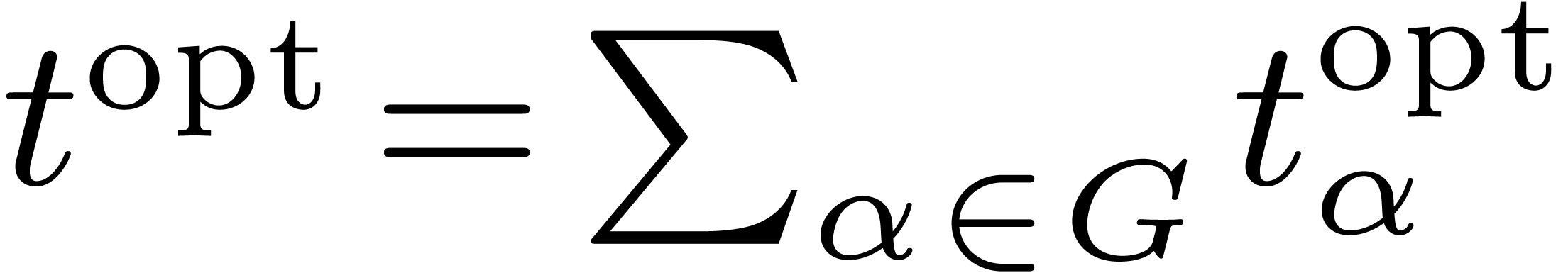 . If is the size of the
dag, then we claim that
. If is the size of the
dag, then we claim that
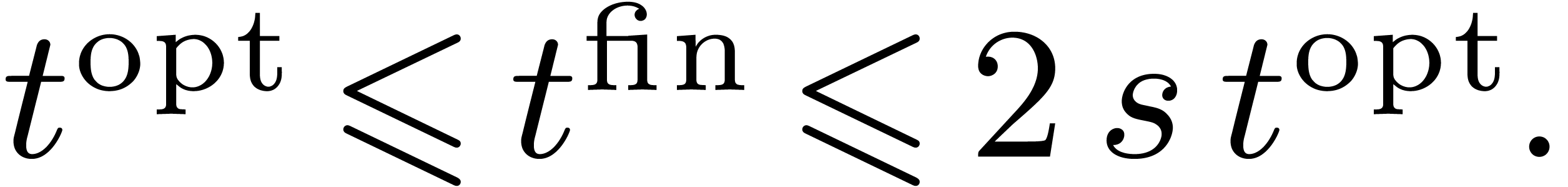 |
(4) |
For simplicity, we will assume that 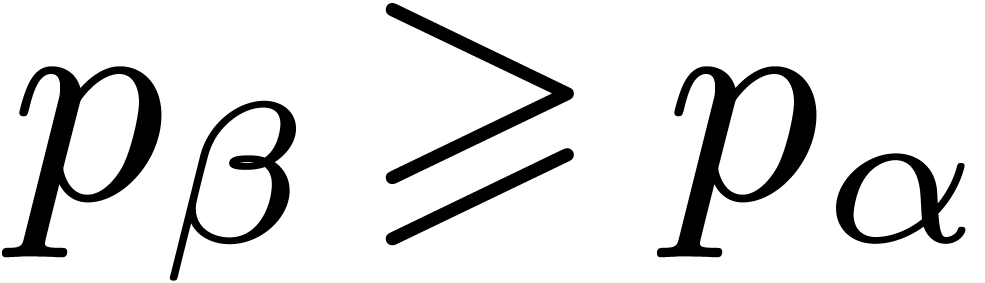 whenever
whenever
 is a descendant from . This is no longer the case if we apply the
optimization from the end of section 4.1, but the reasoning
can probably be adapted to that case.
is a descendant from . This is no longer the case if we apply the
optimization from the end of section 4.1, but the reasoning
can probably be adapted to that case.
Assume for contradiction that (4) does not hold. Now
consider the moment during the execution at which we first call improve with a maximal cost 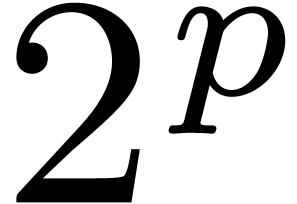 for some
node . At that point, the
current cost
for some
node . At that point, the
current cost  of each of the descendants of is
of each of the descendants of is 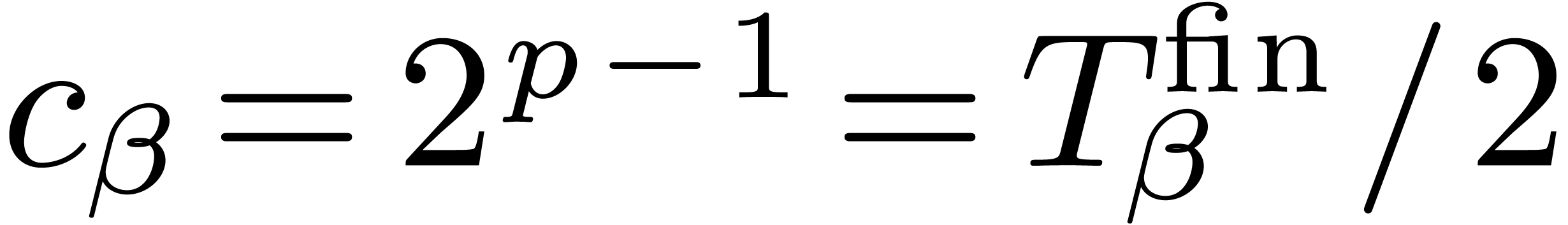 . When such a is a leaf, it
follows that
. When such a is a leaf, it
follows that 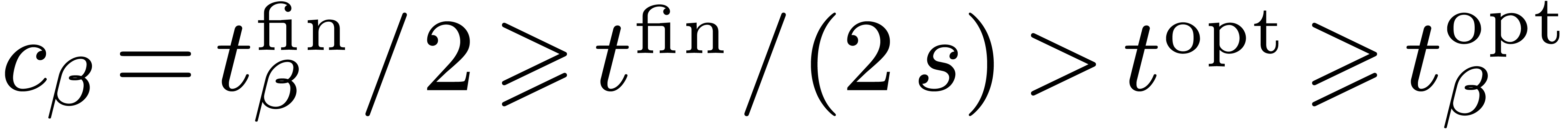 . By structural
induction over the descendants of , it follows that
. By structural
induction over the descendants of , it follows that 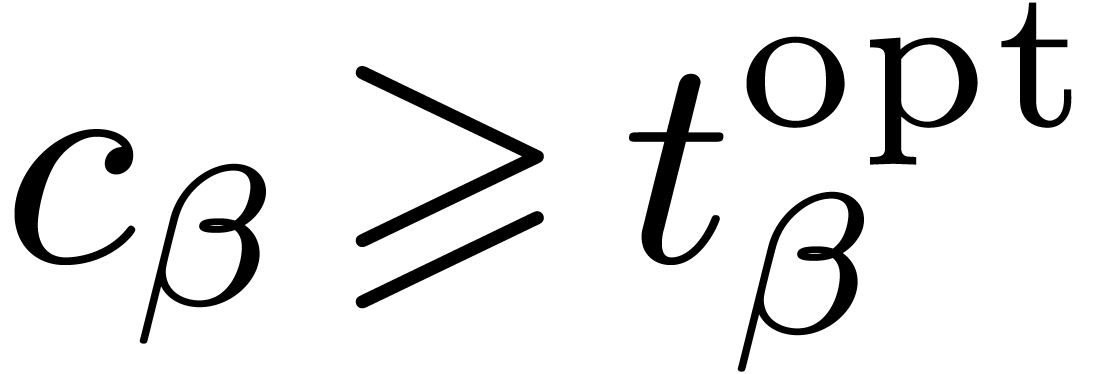 and
the best available (resp. optimal) approximation
and
the best available (resp. optimal) approximation 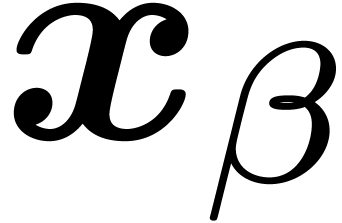 (resp.
(resp.  )
for
)
for 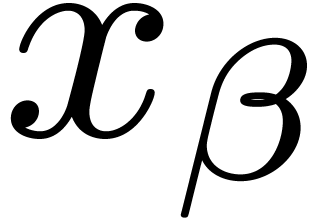 satisfies
satisfies 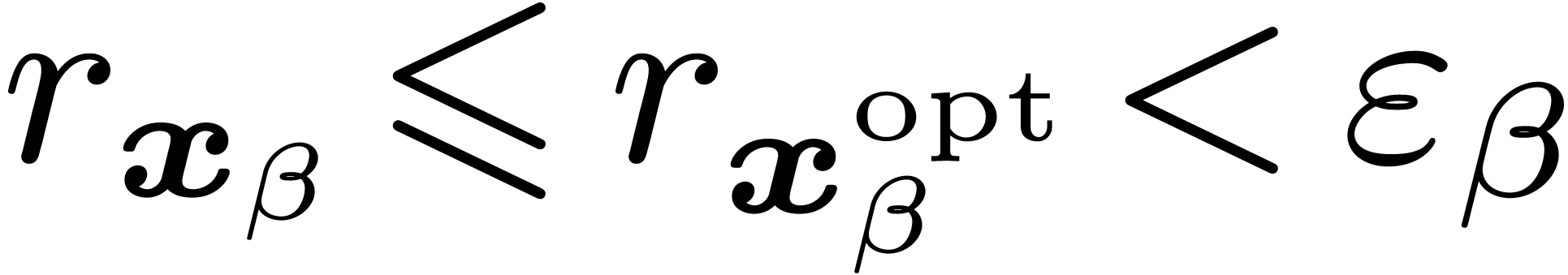 .
In particular . On the other
hand, the first call of improve with a maximal cost was necessarily triggered by approximate,
whence
.
In particular . On the other
hand, the first call of improve with a maximal cost was necessarily triggered by approximate,
whence 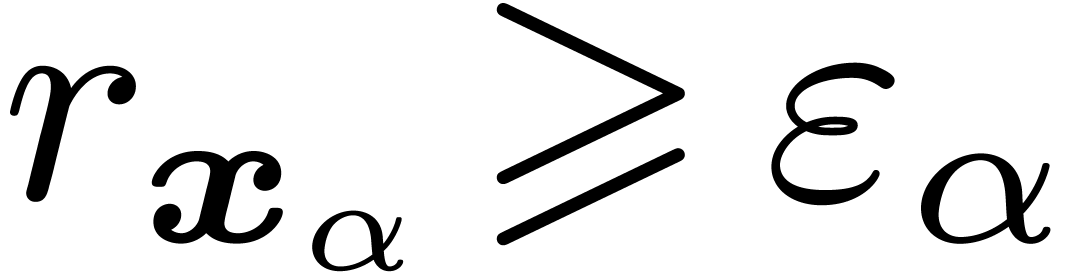 . This contradiction
proves our claim.
. This contradiction
proves our claim.
Up to a constant factor, the bound (4) is sharp. Indeed,
consider the case of a multiplication  of numbers which are all zero. When gradually increasing
the precisions for the computation of ,
it can happen that one of the produces bounding
intervals
of numbers which are all zero. When gradually increasing
the precisions for the computation of ,
it can happen that one of the produces bounding
intervals 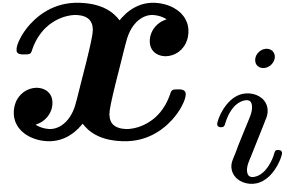 whose radii quickly converge to zero,
contrary to each of the other
whose radii quickly converge to zero,
contrary to each of the other 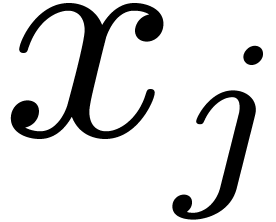 .
In that case, the time spent on improving each of the
(
.
In that case, the time spent on improving each of the
(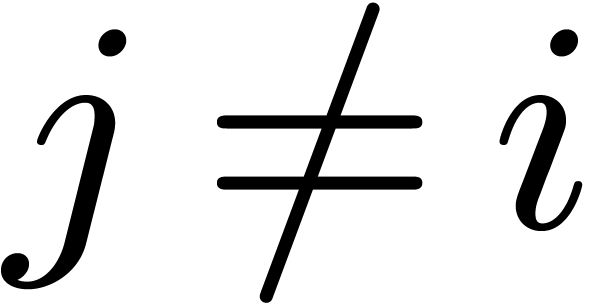 ) is a waste, whence we
loose a factor with respect to the optimal
solution. On the other hand, without additional knowledge about the
functions
) is a waste, whence we
loose a factor with respect to the optimal
solution. On the other hand, without additional knowledge about the
functions 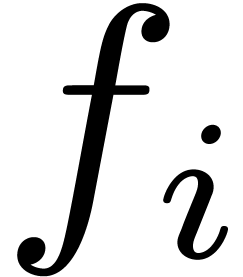 , it is impossible
to design a deterministic procedure for choosing the most efficient
index . In this sense, our
current solution is still optimal. However, under additional
monotonicity hypotheses on the cost functions, efficient indices can be found, by taking into account the “cost
per digit”.
, it is impossible
to design a deterministic procedure for choosing the most efficient
index . In this sense, our
current solution is still optimal. However, under additional
monotonicity hypotheses on the cost functions, efficient indices can be found, by taking into account the “cost
per digit”.
Although the approach from the previous section has the
advantage of never being extremely bad and rather easy to implement on
top of an existing layer for interval arithmetic, there are even simple
cases in which the factor in the bound (3)
is not necessary: in the truncated power series evaluation 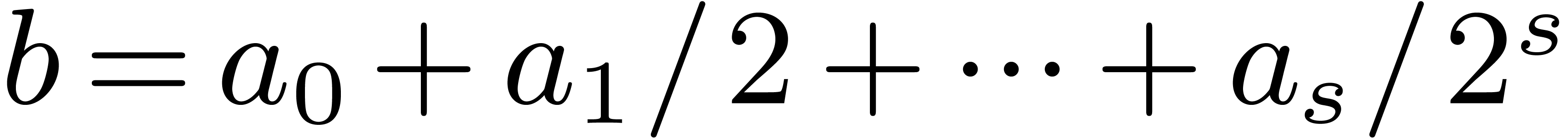 with
with 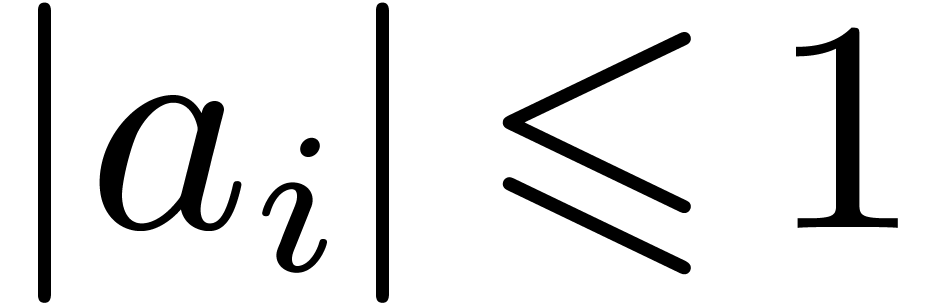 for all , the computation of a -approximation of
for all , the computation of a -approximation of  induces
the computation of -bit
approximations of each of the
induces
the computation of -bit
approximations of each of the  .
If
.
If 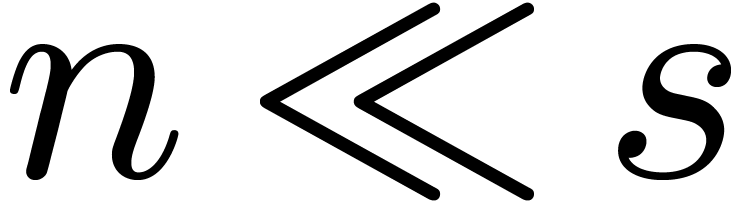 , this means that we spend
a time
, this means that we spend
a time 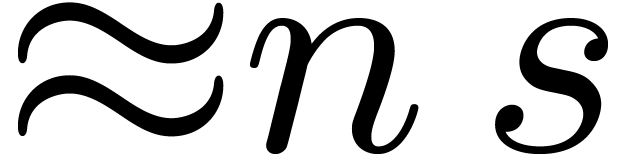 instead of
instead of 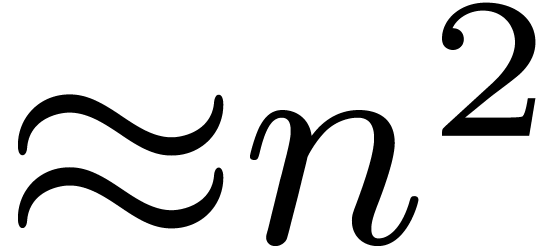 .
.
In order to remedy to this problem, we suggest to improve the balanced
a priori estimate technique from [20] and cleverly
recombine it with the current approach. In this section, we will briefly
sketch how this could be done. The results are based on joint ideas with
Let us start by isolating those situations in which a priori
error estimates should be efficient. Consider a labeled dag so that admits an initial interval
approximation  for each . Assume also that for each node
and each child
for each . Assume also that for each node
and each child 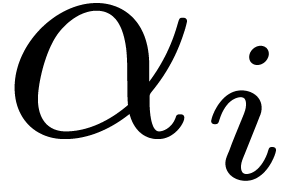 of ,
we have an interval
of ,
we have an interval 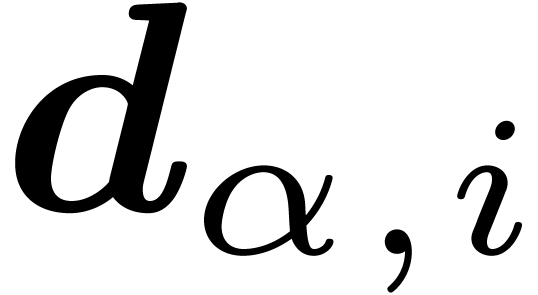 with
with 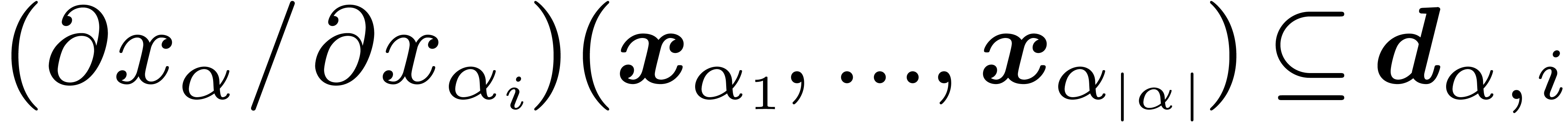 . If
. If 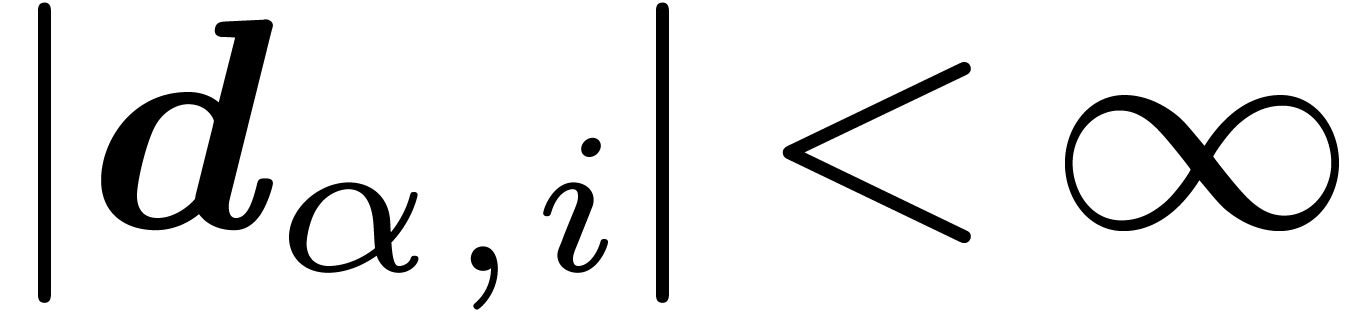 ,
then we say that (together with the ) is a Lipschitz dag. If, in addition,
we have
,
then we say that (together with the ) is a Lipschitz dag. If, in addition,
we have 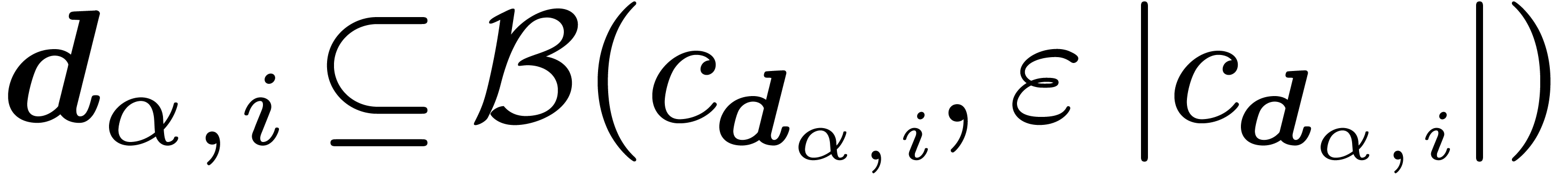 for some
for some  and all
and all
 , then we say that is -rigid.
, then we say that is -rigid.
A typical obstruction to the Lipschitz property occurs in dags like
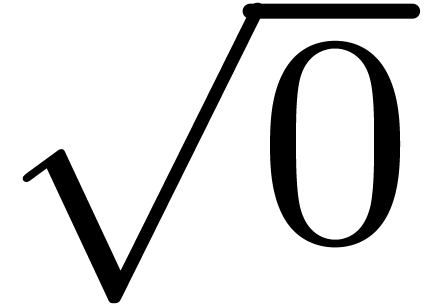 . Similarly, a dag like
. Similarly, a dag like  is typically Lipschitz, but not rigid. Given a
Lipschitz dag, a variant of automatic differentiation provides us with
bounds for the error in in terms of the errors
in the , where ranges over the leaves below .
If is -rigid,
and especially when
is typically Lipschitz, but not rigid. Given a
Lipschitz dag, a variant of automatic differentiation provides us with
bounds for the error in in terms of the errors
in the , where ranges over the leaves below .
If is -rigid,
and especially when 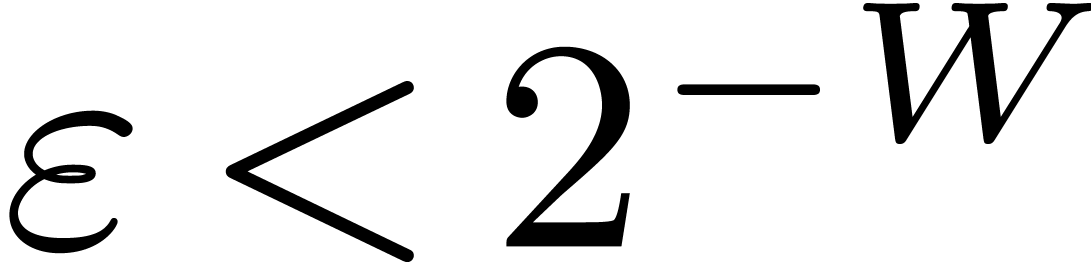 , then
these bounds actually become very sharp.
, then
these bounds actually become very sharp.
For instance, given a rooted Lipschitz dag and a challenge at the root  ,
one may compute a sufficient precision for
obtaining an -approximation
of
,
one may compute a sufficient precision for
obtaining an -approximation
of 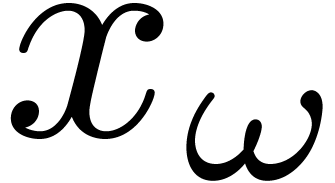 as follows. Let
as follows. Let 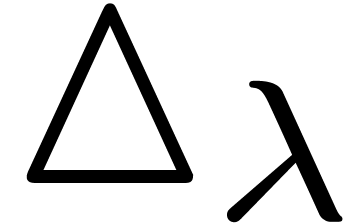 be
the error in at each leaf , when computing with precision . We have
be
the error in at each leaf , when computing with precision . We have 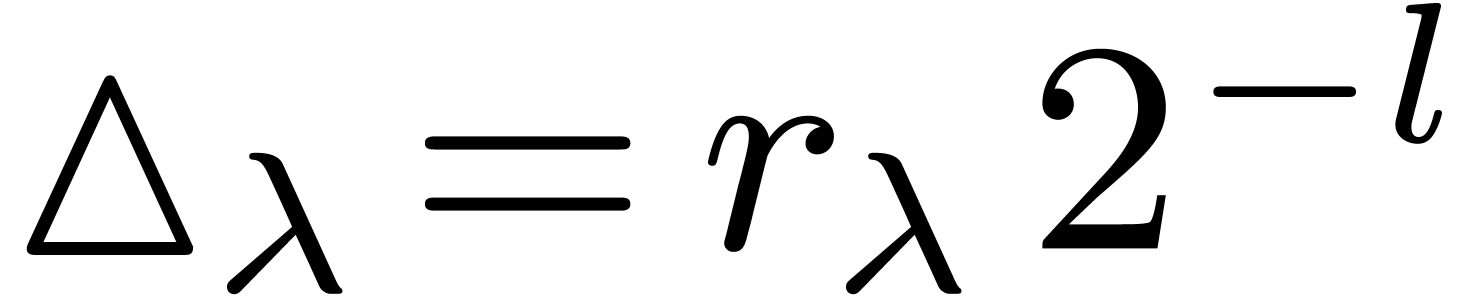 for some
for some 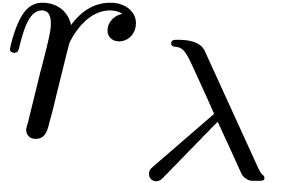 which depends on .
Then we recursively estimate the error
which depends on .
Then we recursively estimate the error  at each
node by
at each
node by
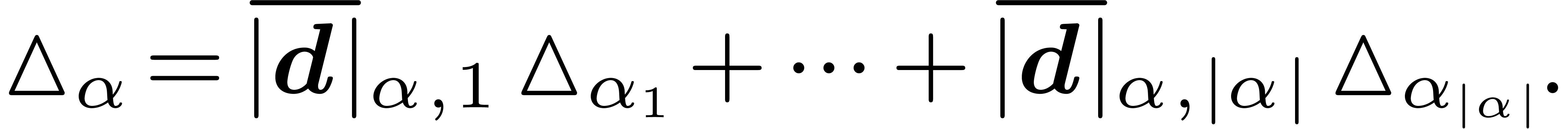
This provides us with a bound of the form 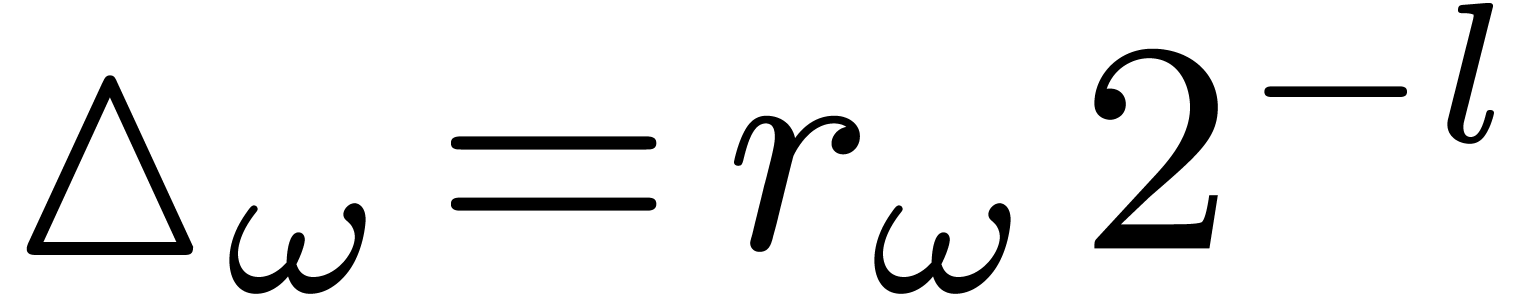 for
the error at the root . We
may thus take
for
the error at the root . We
may thus take 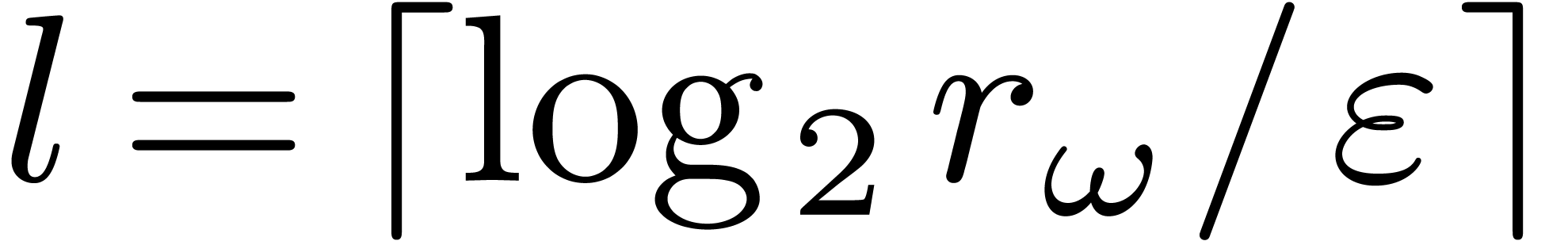 . The approach
can be further improved using similar ideas as in the implementation of
addition in section 4.2.
. The approach
can be further improved using similar ideas as in the implementation of
addition in section 4.2.
Instead of working with a fixed precision ,
a better idea is to compute the contribution  of
the error at each leaf to the error
of
the error at each leaf to the error 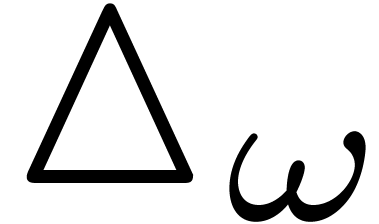 at . This
problem is dual to the problem of automatic differentiation, since it
requires us to look at the opposite dag
at . This
problem is dual to the problem of automatic differentiation, since it
requires us to look at the opposite dag 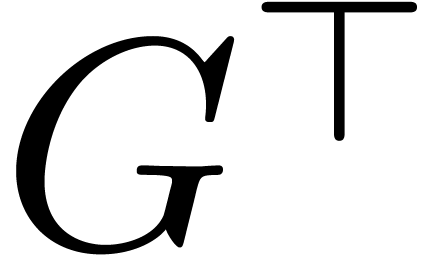 of , which is obtained by inverting
the direction of the edges. Indeed, if
of , which is obtained by inverting
the direction of the edges. Indeed, if  denote
all parents of a node , and
if is the
denote
all parents of a node , and
if is the  -th
child of
-th
child of  for each
for each  ,
then we take
,
then we take
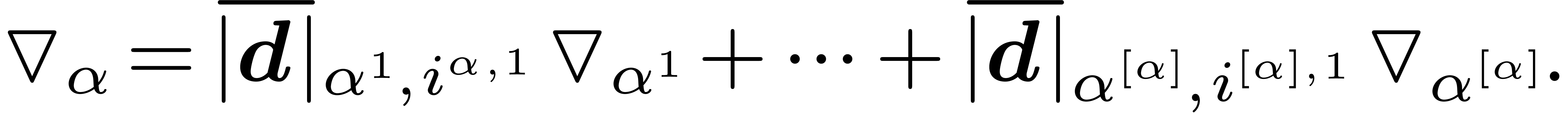
Together with the initial condition 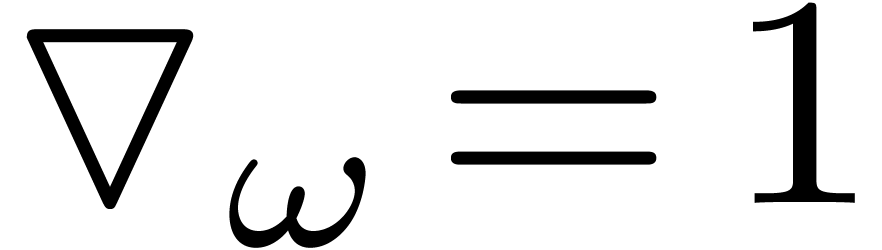 ,
this allows us to compute
,
this allows us to compute  for all leafs . In order to compute with error
for all leafs . In order to compute with error  , we
may now balance over the leaves
according to the
, we
may now balance over the leaves
according to the 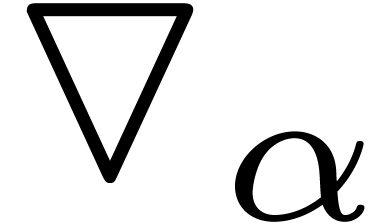 . More
precisely, we compute an
. More
precisely, we compute an 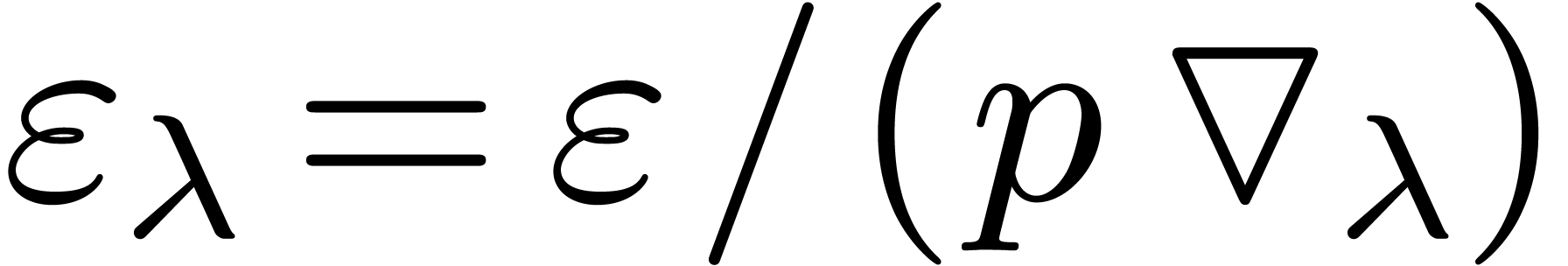 -approximation
of each , where
-approximation
of each , where 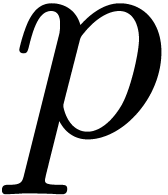 is the number of leaves, and recompute all other nodes
using interval arithmetic. As an additional optimization, one may try to
balance according to the computational complexities of the
is the number of leaves, and recompute all other nodes
using interval arithmetic. As an additional optimization, one may try to
balance according to the computational complexities of the 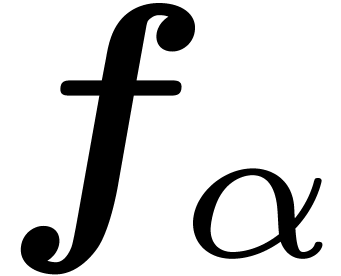 .
.
The above strategy is a bit trickier to implement in an incremental way.
Indeed, in the dynamic global approximation problem, we ask for -approximations at different nodes
and, since good previous approximations may
already be present, it is not always necessary to compute the complete
dag below . A solution to
this problem is to keep track of the “creation date” of each
node and to compute the
from the top down to the leaves, while first considering nodes with the
latest creation date (i.e. by means of a heap). Whenever
the computed is so small that the current error
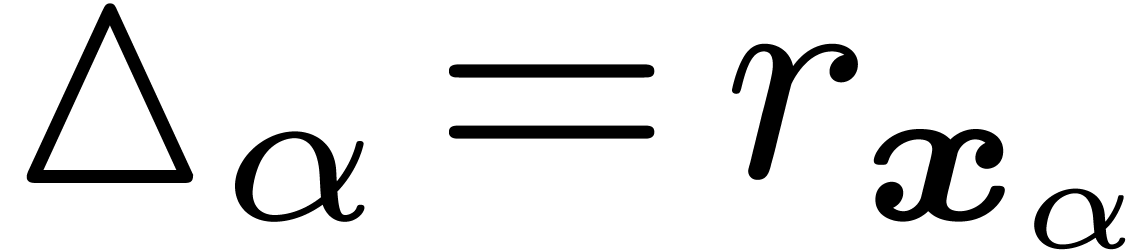 at contributes only
marginally to the error at the top
(i.e.
at contributes only
marginally to the error at the top
(i.e.  ), then it
is not necessary to consider the descendants of .
), then it
is not necessary to consider the descendants of .
G. Alefeld and J. Herzberger. Introduction to interval analysis. Academic Press, 1983.
J. Blanck. General purpose exact real arithmetic. Technical Report CSR 21-200, Luleå University of Technology, Sweden, 2002. http://www.sm.luth.se/~jens/.
J. Blanck, V. Brattka, and P. Hertling, editors. Computability and complexity in analysis, volume 2064 of Lect. Notes in Comp. Sc. Springer, 2001.
A. Edalat and P. Sünderhauf. A domain-theoretic approach to real number computation. TCS, 210:73–98, 1998.
A. Gaganov. Computational complexity of the range of the polynomial in several variables. Cybernetics, pages 418–425, 1985.
T. Granlund et al. GMP, the GNU multiple precision arithmetic library. http://www.swox.com/gmp, 1991–2006.
M. Grimmer, K. Petras, and N. Revol. Multiple precision interval packages: Comparing different approaches. Technical Report RR 2003-32, LIP, École Normale Supérieure de Lyon, 2003.
G. Hanrot, V. Lefèvre, K. Ryde, and P. Zimmermann. MPFR, a C library for multiple-precision floating-point computations with exact rounding. http://www.mpfr.org, 2000–2006.
V. Kreinovich. For interval computations, if absolute accuracy is NP-hard, then so is relative accuracy+optimization. Technical Report UTEP-CS-99-45, UTEP-CS, 1999.
V. Kreinovich and S. Rump. Towards optimal use of multi-precision arithmetic: a remark. Technical Report UTEP-CS-06-01, UTEP-CS, 2006.
B. Lambov. The RealLib project. http://www.brics.dk/~barnie/RealLib, 2001–2006.
V. Ménissier-Morain. Arbitrary precision real arithmetic: design and algorithms. http://www-calfor.lip6.fr/~vmm/documents/submission_JSC.ps.gz, 1996.
N. Müller. iRRAM, exact arithmetic in C++. http://www.informatik.uni-trier.de/iRRAM/, 2000–2006.
R. O'Connor. A monadic, functional implementation of real numbers. Technical report, Institute for Computing and Information Science, Radboud University Nijmegen, 2005.
N. Revol. MPFI, a multiple precision interval arithmetic library. http://perso.ens-lyon.fr/nathalie.revol/software.html, 2001–2006.
S. Rump. Fast and parallel inteval arithmetic. BIT, 39(3):534–554, 1999.
A. Turing. On computable numbers, with an application to the Entscheidungsproblem. Proc. London Maths. Soc., 2(42):230–265, 1936.
J. van der Hoeven. GMPX, a C-extension library for gmp. http://www.math.u-psud.fr/~vdhoeven/, 1999. No longer maintained.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven. Computations with effective real numbers. TCS, 351:52–60, 2006.
J. van der Hoeven et al. Mmxlib: the standard library for Mathemagix, 2002–2006. http://www.mathemagix.org/mml.html.
K. Weihrauch. Computable analysis. Springer-Verlag, Berlin/Heidelberg, 2000.
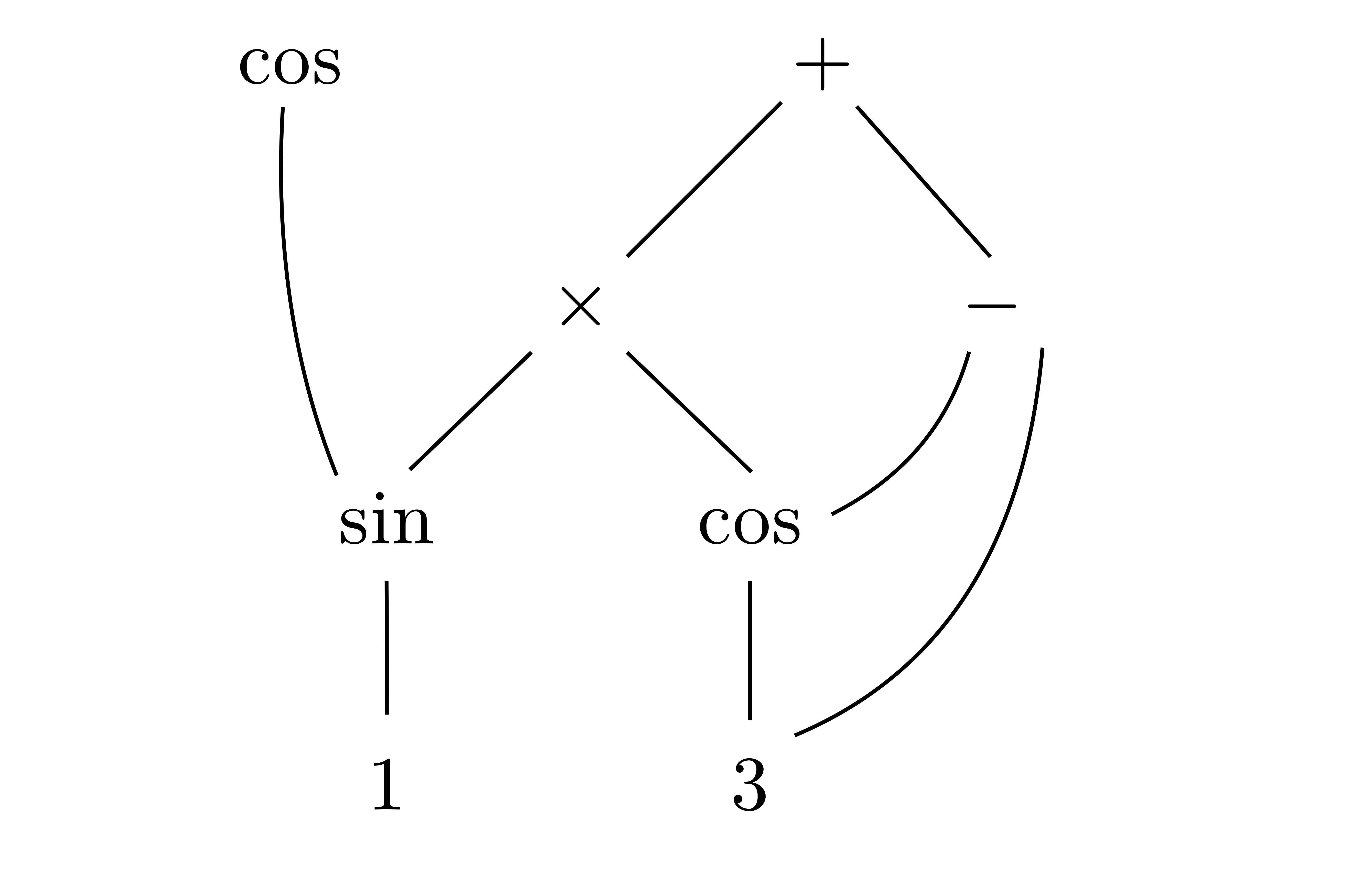
 roots. The dag has size
roots. The dag has size 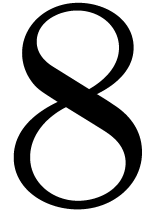 (i.e. the total number of nodes)
and depth 3 (i.e. the longest path from a
root to a leaf). The weight of the dag corresponds to
the sum of the sizes of the trees obtained by
“copying” each of the roots. In our example, the
weight is
(i.e. the total number of nodes)
and depth 3 (i.e. the longest path from a
root to a leaf). The weight of the dag corresponds to
the sum of the sizes of the trees obtained by
“copying” each of the roots. In our example, the
weight is 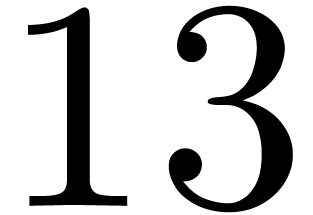 .
. .
.