Calcul analytique |
| Cours pour les Journées Nationales du Calcul Formel |
|
| 29 novembre 2011 |
|
 . Ce travail a
été subventionné par le projet
. Ce travail a
été subventionné par le projet
Préface |
7 |
1Motivation |
9 |
1.1Vers un système de calcul formel/analytique |
9 |
1.2Exemples |
10 |
1.2.1Intégration numérique certifiée |
10 |
1.2.2Exemple : résolution polynomiale |
10 |
1.2.3Exemple : suivi de chemin |
11 |
1.2.4Exemple : nombres de Bell |
11 |
1.3Utilité du calcul analytique pour le calcul formel |
12 |
1.3.1Résolution de systèmes polynomiaux par homotopie |
12 |
1.3.2Groupe de Galois d'une fonction algébrique |
12 |
1.3.3Groupe de Galois différentiel |
13 |
Monodromie d'un opérateur différentiel |
13 |
Groupe de Galois différentiel |
13 |
1.4Utilité du calcul formel pour le calcul analytique |
14 |
1.5Outils communs pour calculs formel et analytique |
14 |
2Analyse calculable |
15 |
2.1Nombres réels calculables |
15 |
2.1.1Définition |
15 |
2.1.2Nombres réels calculables dans |
16 |
2.2Théorèmes classiques de non calculabilité |
16 |
2.2.1Théorème de Turing |
16 |
2.2.2Théorème de Grzegorczyk |
17 |
2.2.3Théorème de Denef et Lipschitz |
17 |
2.2.4Questionnaire |
17 |
2.3Semi calculabilité et typage |
18 |
2.3.1Autres types de calculabilité |
18 |
2.3.2Typage |
19 |
2.3.3Structures effectives |
19 |
2.3.4Approximateurs |
20 |
3Arithmétique de boules |
21 |
3.1Principes |
21 |
3.1.1Encadrements par des boules |
21 |
3.1.2Opérations |
22 |
3.1.3Opérations en précision limitée |
22 |
3.1.4Arithmétique d'intervalles |
23 |
3.1.5Prédicats |
24 |
3.1.6Estimations d'erreur a priori |
24 |
3.2Limiter la surestimation |
25 |
3.2.1L'ennemi |
25 |
3.2.2Le problème pour le calcul des puissances successives |
26 |
3.2.3Choix d'une bonne représentation par boules complexes |
26 |
3.2.4Minimisation de la profondeur du calcul |
27 |
3.2.5La méthode perturbative |
27 |
3.2.6Calcul d'une forme échelon certifiée dans
|
28 |
3.3Perte de précision intrinsèque et surestimation |
29 |
3.3.1Nombre de conditionnement et perte de précision |
29 |
3.3.2Extensions optimales et surestimation |
30 |
3.3.3Surestimation de l'arithmétique standard |
31 |
3.4Qualité versus efficacité |
32 |
3.4.1Le Graal : estimations efficaces et de qualité |
32 |
3.4.2Multiplication de matrices |
33 |
3.5Hiérarchie numérique |
34 |
4Arithmétique rapide |
37 |
4.1Rappels sur la complexité |
37 |
4.2Algorithmes sur les polynômes et sur les séries |
38 |
4.2.1Multiplication de polynômes |
38 |
4.2.2Multiplication de séries tronquées |
39 |
4.2.3Méthode de Newton |
39 |
4.2.4Évaluation multi-points |
40 |
4.3Calcul détendu |
41 |
4.3.1Principe du calcul détendue |
41 |
4.3.2Multiplication détendue naïve |
41 |
4.3.3Multiplication détendue par Karatsuba |
42 |
4.3.4Multiplication détendue rapide |
42 |
4.3.5Multiplication détendue super rapide |
43 |
4.3.6Exemple : nombres de Bell exacts |
43 |
4.4Méthodes multi-modulaires |
44 |
4.4.1Principes et variantes |
44 |
4.4.2Évaluation rapide de dags |
46 |
4.4.3Évaluation rapide de polynômes en plusieurs variables |
47 |
5Développements certifiés en série |
49 |
5.1Algorithmes rapides et numériquement stables |
49 |
5.1.1Instabilité numérique de la multiplication rapide |
49 |
5.1.2Préconditionnement par mise à l'échelle |
49 |
5.1.3Calcul numériquement stable des nombres de Bell |
50 |
5.2Certification du calcul des coefficients |
50 |
5.2.1Inversion |
50 |
5.2.2Exponentiation et résolution d'équations différentielles |
51 |
5.2.3Calcul certifié des nombres de Bell |
51 |
5.3Modèles de Taylor |
52 |
5.3.1Définition |
52 |
5.3.2Opérations |
52 |
5.3.3Généralisations |
53 |
5.4Réduction de la surestimation |
53 |
5.4.1L'idée sur un exemple |
53 |
5.4.2Application à la recherche de solutions réelles d'un système polynomial |
54 |
5.5Intégration de systèmes dynamiques |
54 |
5.5.1Algorithme de base |
55 |
5.5.2Effet d'enveloppement |
55 |
5.5.3Variante pour les modèles de Taylor |
56 |
5.5.4Qualité des estimations |
57 |
5.5.5Exemple dans |
58 |
6Calcul des racines d'un polynôme en une variable |
61 |
6.1Exemples pour différents types de polynômes |
62 |
6.1.1Polynômes tirés au hasard |
62 |
6.1.2Polynômes avec zéros de grandes multiplicités |
63 |
6.1.3Expérience à propos du conditionnement |
64 |
6.1.4Séries formelles tronquées |
65 |
6.2Quelques méthodes numériques classiques |
66 |
6.2.1Itération d'Aberth |
66 |
6.2.2Méthode par homotopie |
66 |
6.2.3Transformation de Graeffe |
66 |
6.3Polygone numérique de Newton |
67 |
6.3.1Exemple d'un polygone numérique de Newton |
67 |
6.3.2Évaluation du polynôme et polygone numérique de Newton |
68 |
6.4Stabilité numérique et efficacité : un mariage difficile |
69 |
6.5Évaluation multi-point rapide |
70 |
6.6Certification des racines |
70 |
6.6.1Racines simples |
70 |
6.6.2Racines multiples |
71 |
7Méthodes par homotopie |
73 |
7.1Introduction |
73 |
7.1.1Historique |
73 |
7.1.2Première difficulté : solutions partant vers l'infini |
74 |
7.1.3Deuxième difficulté : solutions multiples |
74 |
7.2Algorithmes de suivi de chemin |
75 |
7.2.1Cas purement numérique |
75 |
7.2.2Certification naïve par Krawczyk-Rump uniforme |
76 |
7.2.3Certification plus précise par modèles de Taylor |
76 |
7.3Racines multiples et suivi de troupeaux de solutions |
77 |
7.3.1La méthode sur un exemple |
77 |
7.3.2Le cas général |
78 |
7.4Comparaisons avec d'autres méthodes |
78 |
7.4.1Un exemple dans |
78 |
7.4.2Discussion et perspectives |
80 |
Références |
83 |
Ce cours est une adaptation des « slides » que j'avais présentés à mon cours sur le calcul analytique aux Journées Nationales de Calcul Formel, en novembre 2011 à Luminy. J'ai rajouté un peu de matériel supplémentaire et quelques explications plus détaillées par rapport à la présentation originale, sans toutefois avoir cherché la perfection d'un cours sur papier habituel.
Pourquoi un cours sur le calcul analytique ? Traditionnellement, on choisit le calcul formel pour la beauté du calcul symbolique ! Or, les techniques du calcul formel admettent de nombreuses applications en analyse, et le calcul numérique peut parfois permettre une résolution plus efficace ou directe de problèmes en calcul formel. Toutefois, quand j'ai commencé à m'intéresser à des problèmes plus analytiques, il me manquait la culture nécessaire en analyse calculable et en arithmétique d'intervalles. Ce cours cherche à exposer les techniques les plus utiles de ces domaines, tout en gardant le lien avec le calcul formel en filigrane.
Le document inclut un certain nombre de sessions du système
Remerciement. Merci à Jérémy Berthomieu pour ses commentaires sur le premier jet du manuscrit.
Le projet
L'approche du calcul formel est particulièrement bien
adaptée pour des objets de nature algébrique ou
combinatoire — algèbre linéaire, élimination
polynomiale, énumération combinatoire, théorie de
Galois, etc. En revanche, les systèmes numériques
classiques sont beaucoup plus efficaces pour des problèmes plus
analytiques, comme l'intégration d'équations
différentielles. Malheureusement, les systèmes
numériques actuels opèrent principalement en
précision fixe et incorporent peu d'outils pour certifier les
résultats. La session suivante en
maple> 1.000000000000000000000001 - 1;0.
Il est donc tentant de transposer l'esprit de calcul exact et garanti du calcul formel à l'analyse. Or le calcul formel et le calcul numérique sont encore dans une grande mesure des mondes distincts. D'une part, il y a peu d'intersections quant aux algorithmes de base utilisés (algèbre linéaire, polynômes, séries, etc.). D'autre part, il n'existe pas d'environnement de programmation convivial qui soit adapté aux deux mondes. En effet, les interactions actuelles se limitent surtout à des interfaces de type « boîte noire ».
Le calcul analytique se situe à la confluence de plusieurs domaines. L'analyse calculable, qui sera discutée dans le chapitre 2, propose une fondation réaliste au regard des architectures existantes d'ordinateurs. Un deuxième point théorique important concerne le développement d'algorithmes numériques certifiés, poursuivant des travaux classiques sur l'arithmétique des intervalles. Dans le chapitre 3, nous exposerons une variante de cette théorie : l'arithmétique de boules.
Évidemment, dans un système de calcul analytique, il est impératif de pouvoir approcher des nombres réels aussi précisément que nécessaire, donc de travailler en précision multiple. Ceci conduit à une pénalité énorme en efficacité par rapport à l'analyse numérique classique, et il convient de réduire cette pénalité autant que possible. Dans le chapitre 4, nous rappelons quelques résultats classiques en théorie de complexité. Dans les derniers chapitres 5, 6 et 7, nous combinons les différentes techniques en les appliquant à l'intégration de systèmes dynamiques et à la résolution polynomiale.
Pendule
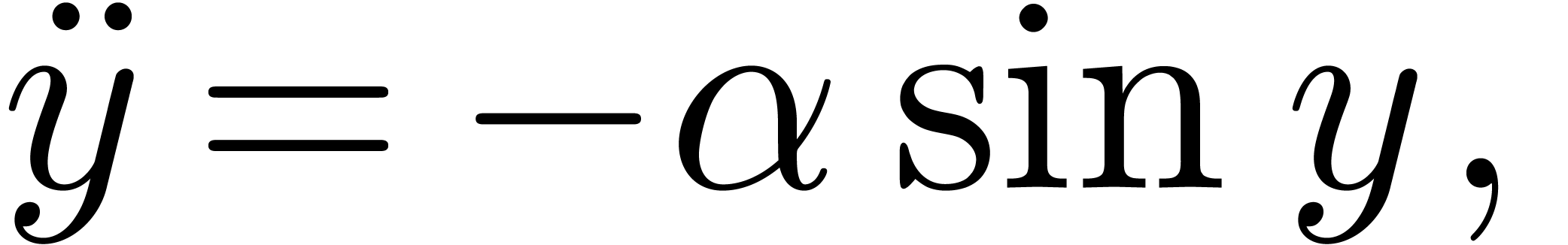
Pour 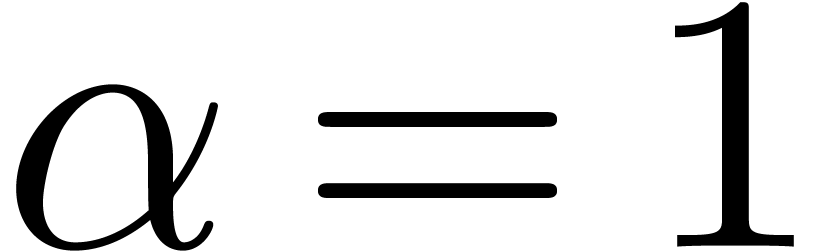 ,
, 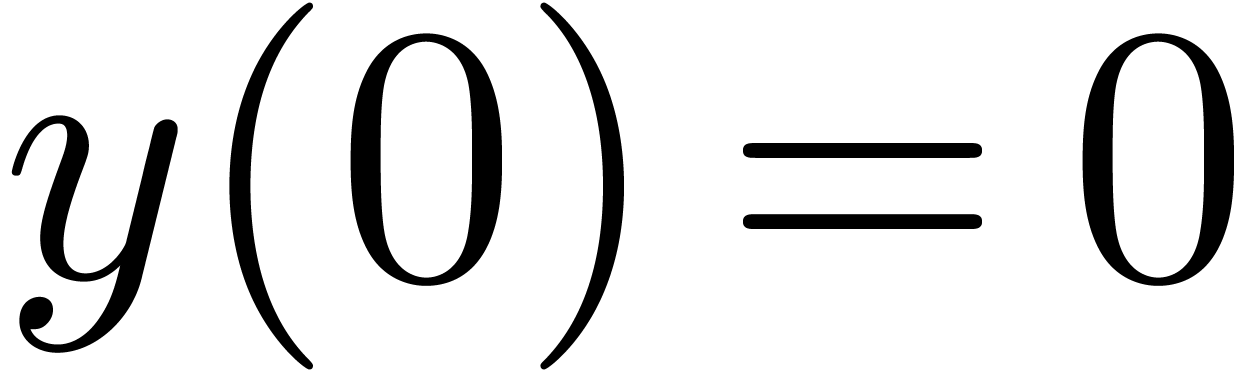 ,
, 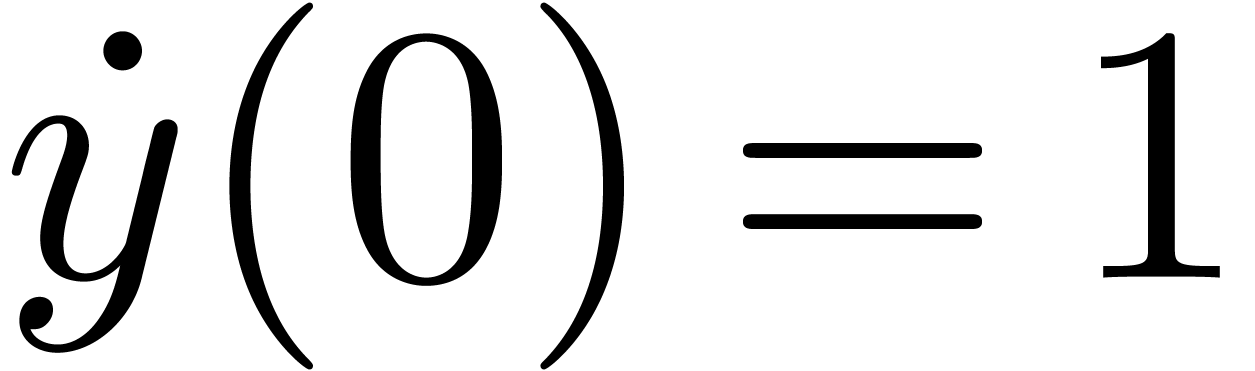 ,
calculer
,
calculer 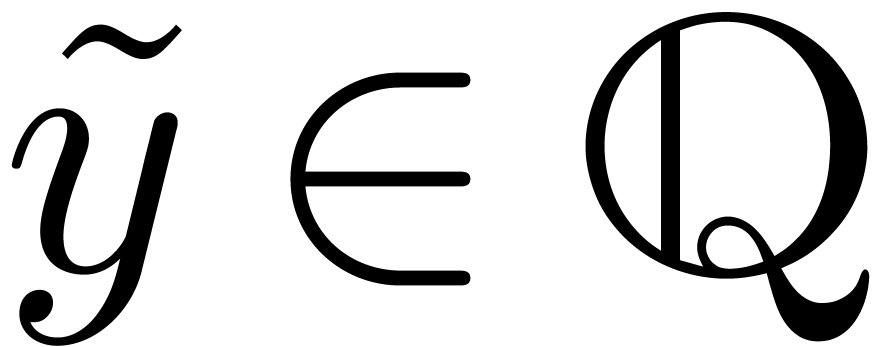 (ou
(ou 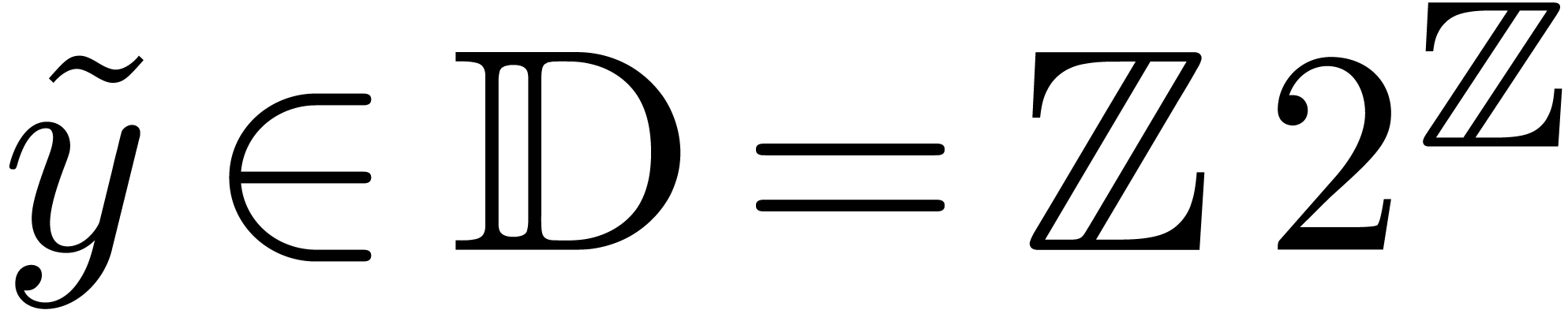 )
avec
)
avec
Systèmes dynamiques plus généraux
Soit 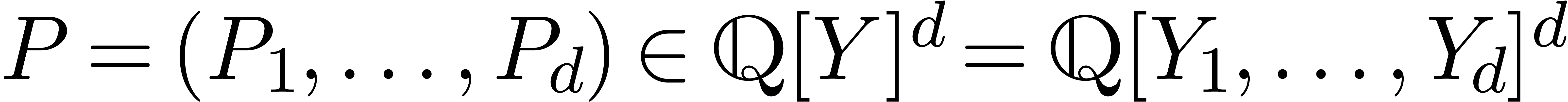 et considérons
et considérons
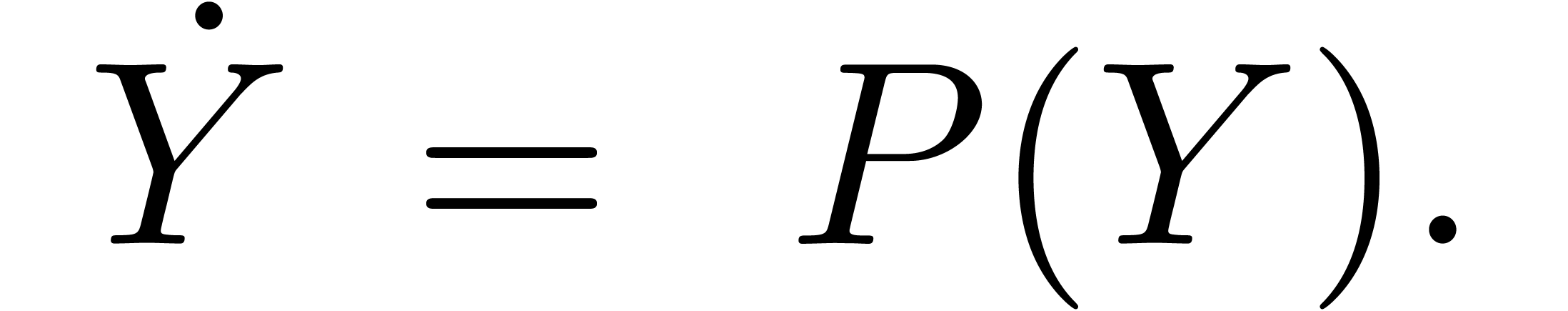
Pour 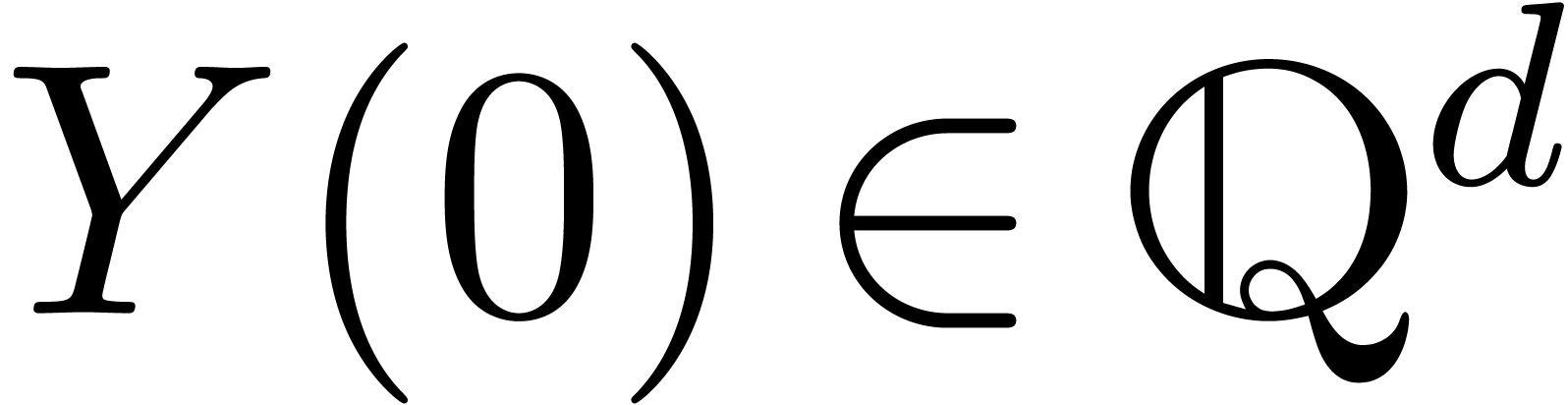 ,
, 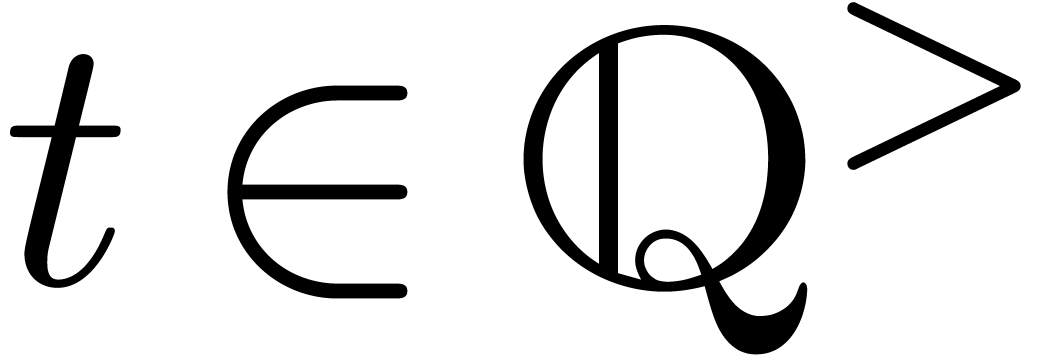 et
et 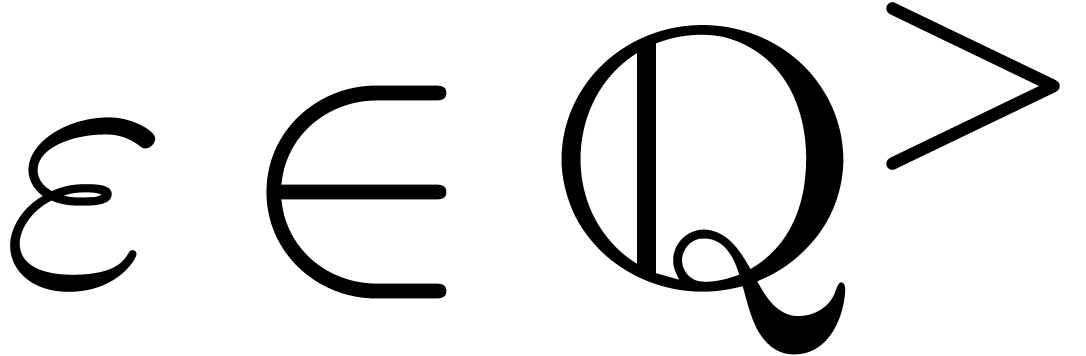 , calculer (si possible)
, calculer (si possible)
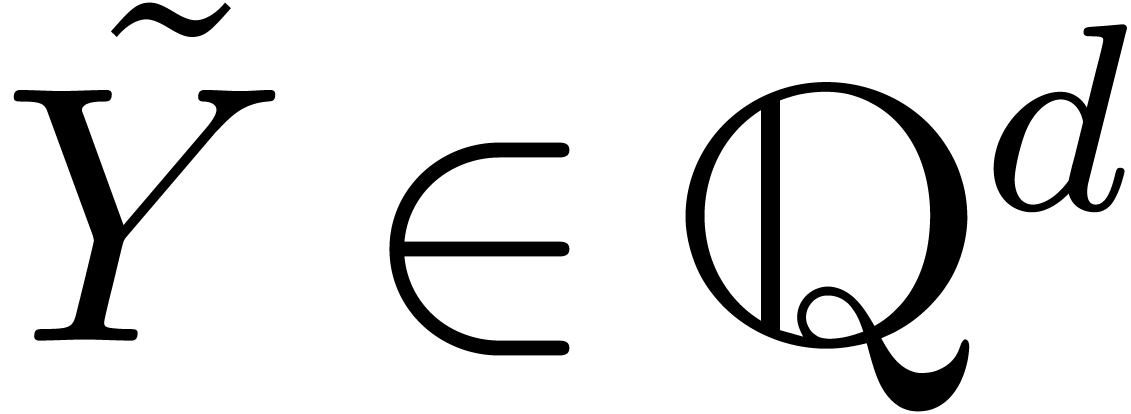 avec
avec

Fonctions spéciales
Fonctions élémentaires 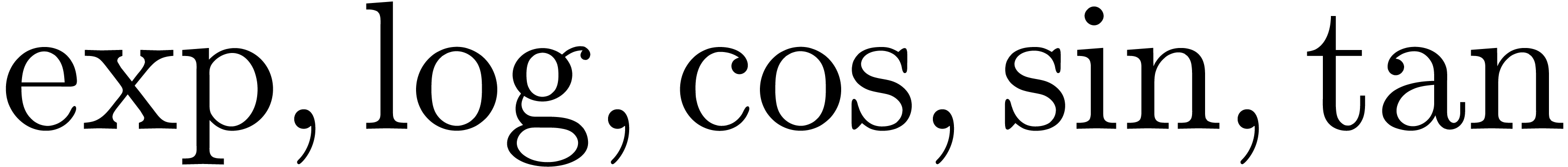 ,
etc.
,
etc.
Fonctions holonomes : 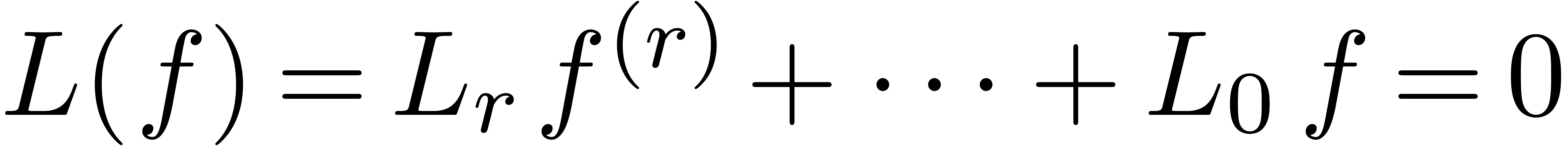 ,
,
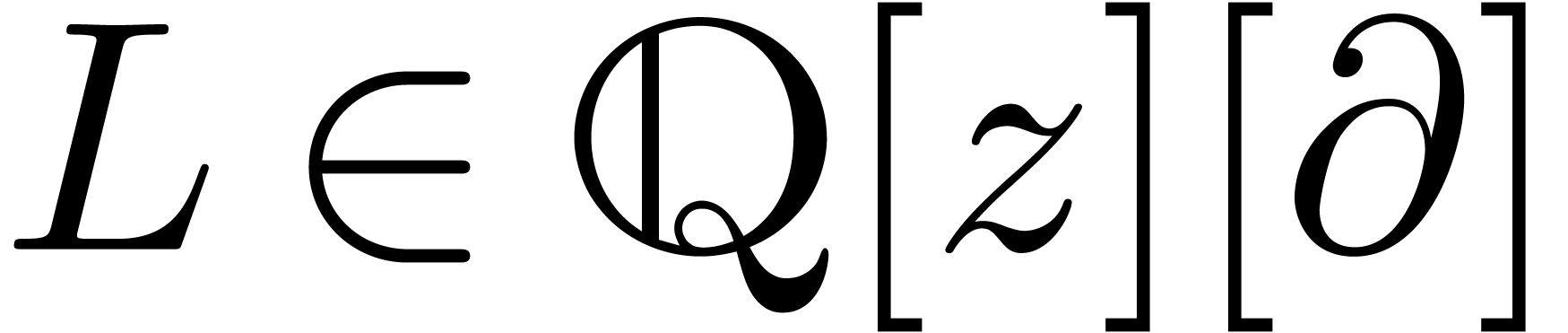 .
.
Autres :  , fonctions
thêta, fonctions de Matthieu, etc.
, fonctions
thêta, fonctions de Matthieu, etc.
Remarque 1.1. Il y a de nombreux autres exemples de fonctions
spéciales intéressantes en théorie de nombres.
Certaines de ces fonctions sont différentiellement
algébriques comme ci-dessus. D'autres, comme  ou
ou  se calculent par transformées
intégrales. Voir aussi le cours de Karim Belabas pour plus de
renseignements et l'utilité du calcul analytique dans ce domaine.
se calculent par transformées
intégrales. Voir aussi le cours de Karim Belabas pour plus de
renseignements et l'utilité du calcul analytique dans ce domaine.
Étant donné un système zéro-dimensionnel

avec 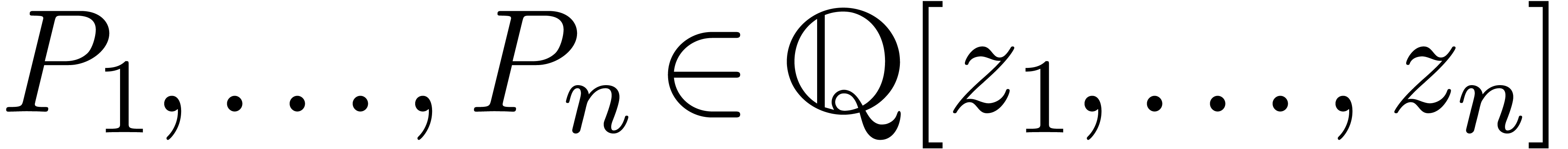 , trouver les
zéros “dans
, trouver les
zéros “dans  ”.
Plus précisément et ici encore, il faudrait pouvoir
approcher les zéros avec autant de précision que
souhaitée.
”.
Plus précisément et ici encore, il faudrait pouvoir
approcher les zéros avec autant de précision que
souhaitée.
Variante : prendre 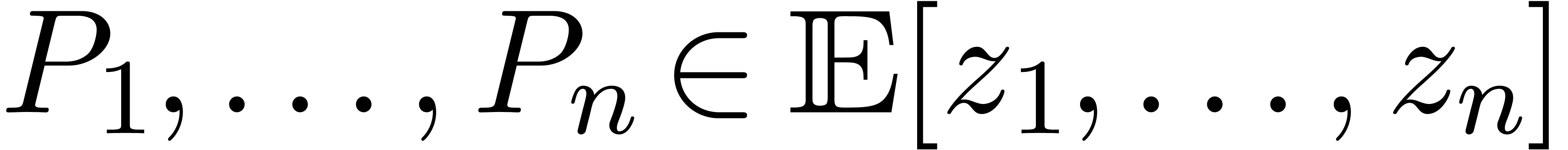 ,
où
,
où  désigne l'ensemble des
“constantes exp-log”, construits à partir de
désigne l'ensemble des
“constantes exp-log”, construits à partir de  en utilisant les opérations
en utilisant les opérations  et
et  .
.
Variante : chercher les racines dans 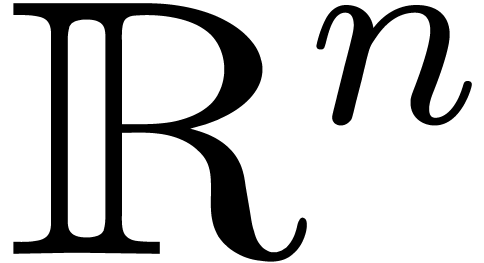 .
.
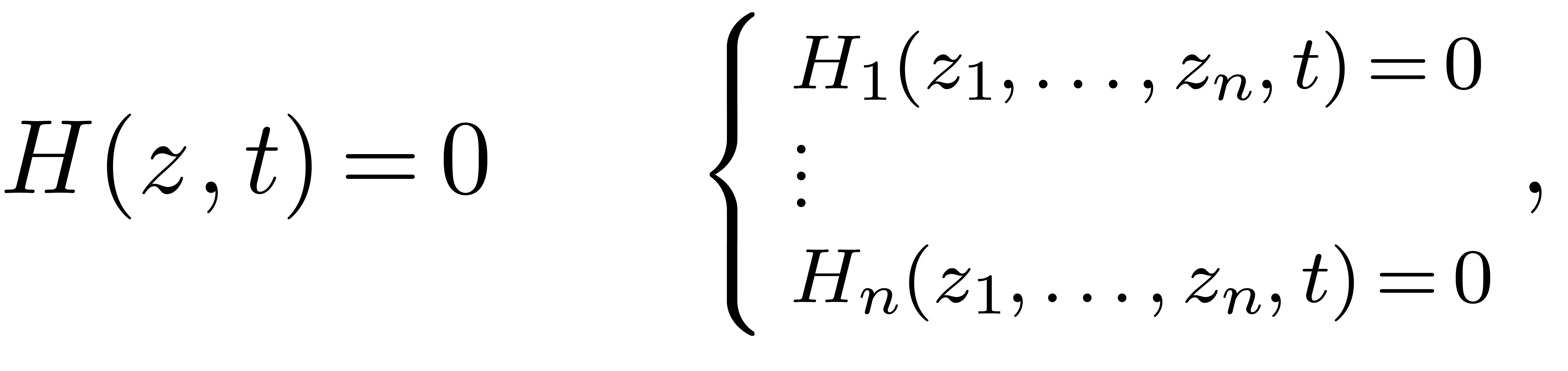
avec 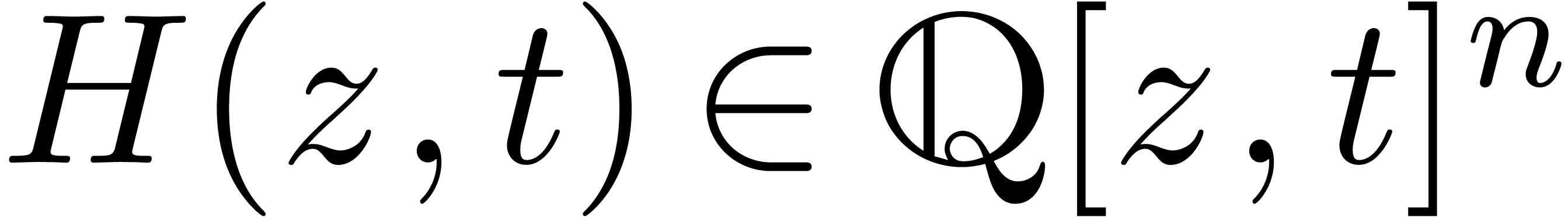 zéro-dimensionnel en
zéro-dimensionnel en  pour
pour  et
et  fini.
fini.
Étant donné 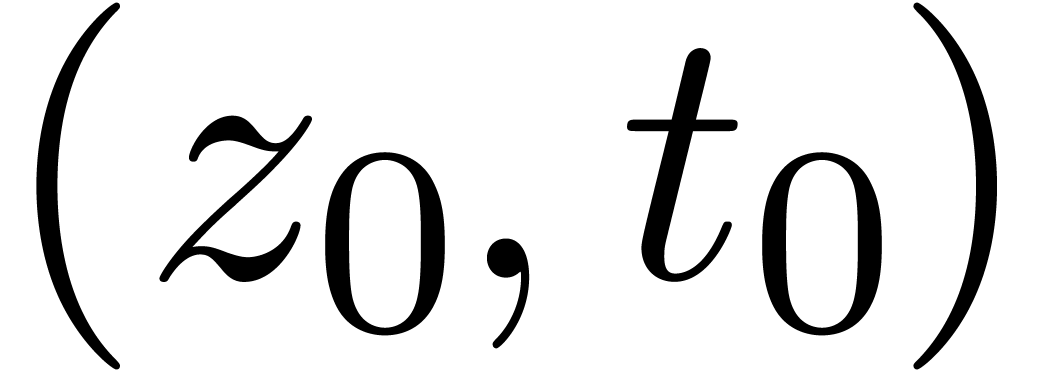 avec
avec 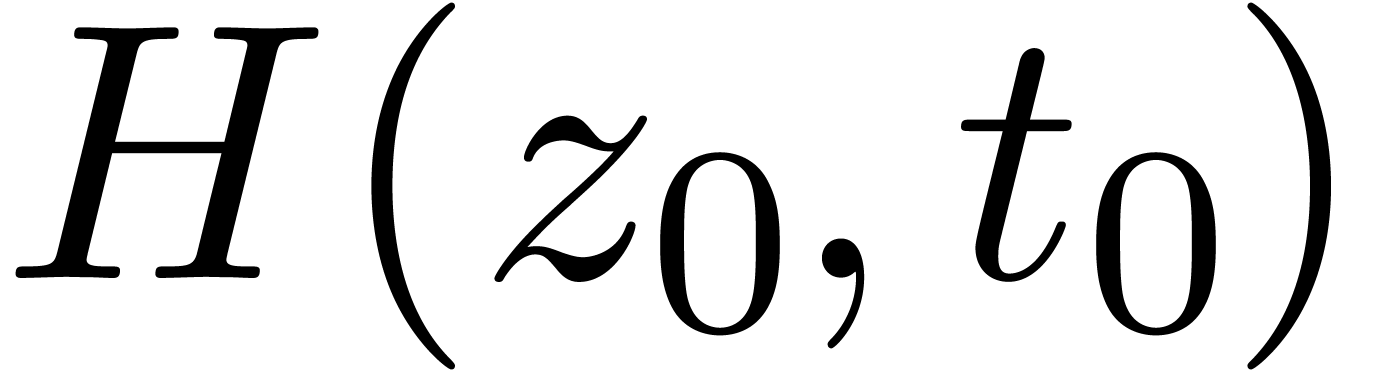 et un chemin
et un chemin 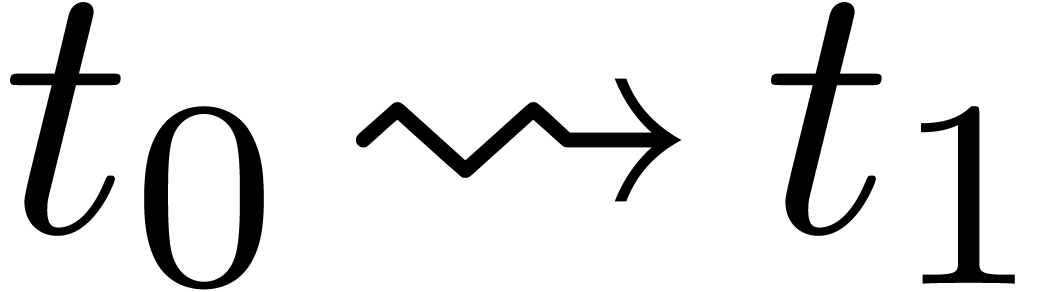 qui évite , calculer le chemin
qui évite , calculer le chemin 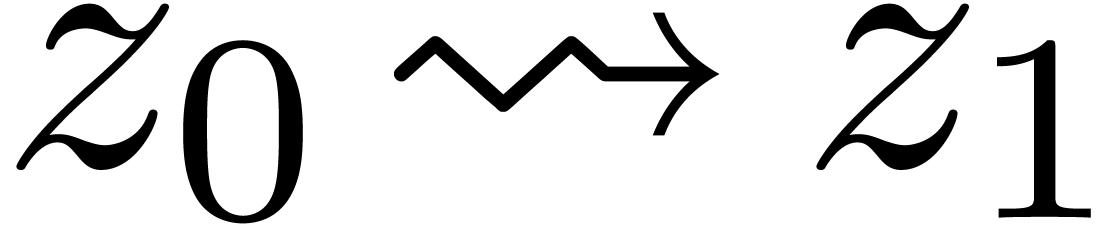 avec
avec  pour tout
pour tout  .
.
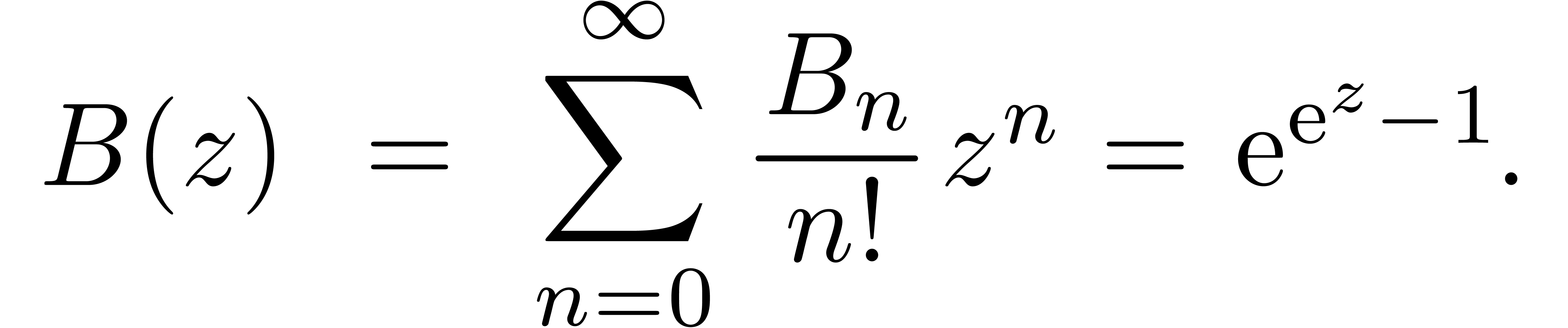
Problème 1 : calculer 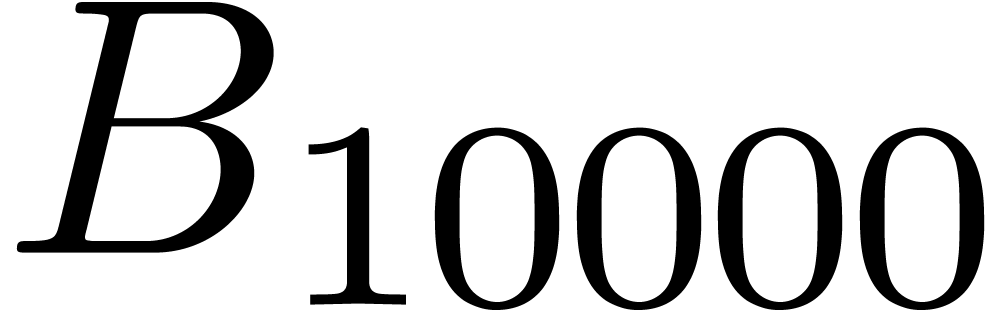 avec une erreur relative de
avec une erreur relative de 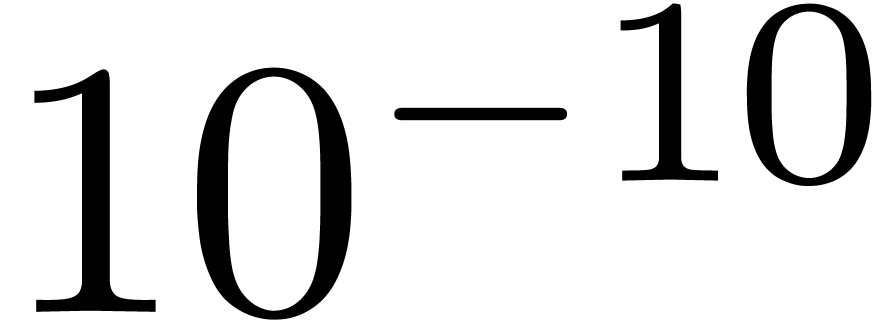 .
.
Problème 2 : trouver automatiquement le développement asymptotique
Problème 3 : pour 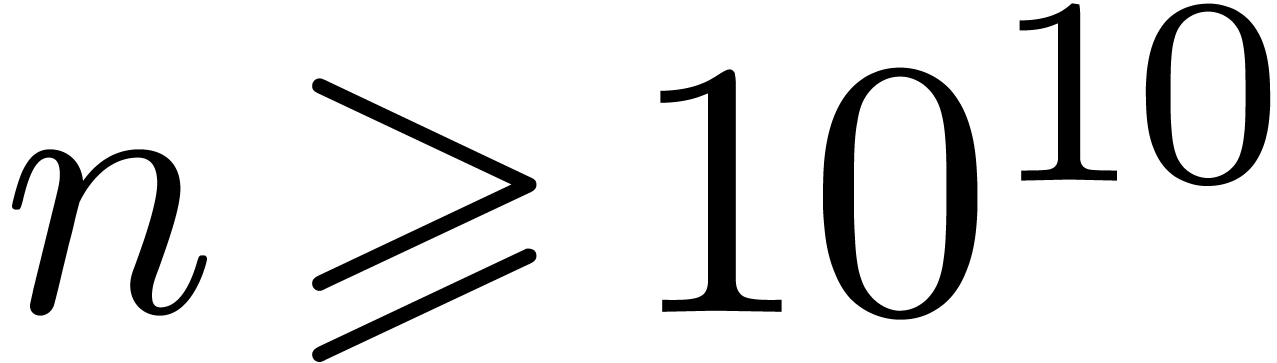 ,
trouver une constante explicite pour le
,
trouver une constante explicite pour le 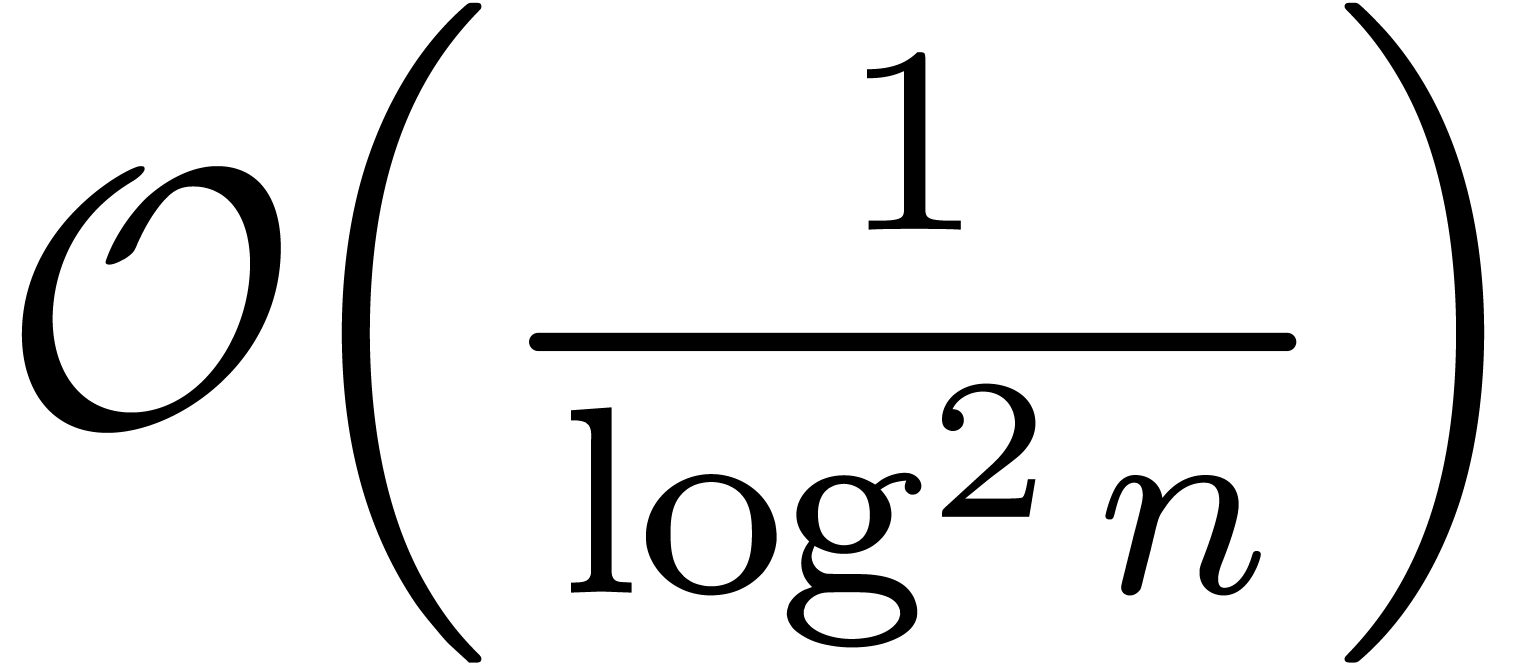 .
.
La technique incontestablement la plus importante en calcul analytique est la déformation. Une application astucieuse est la résolution de systèmes polynomiaux par homotopie. Supposons par exemple que l'on veuille résoudre un système
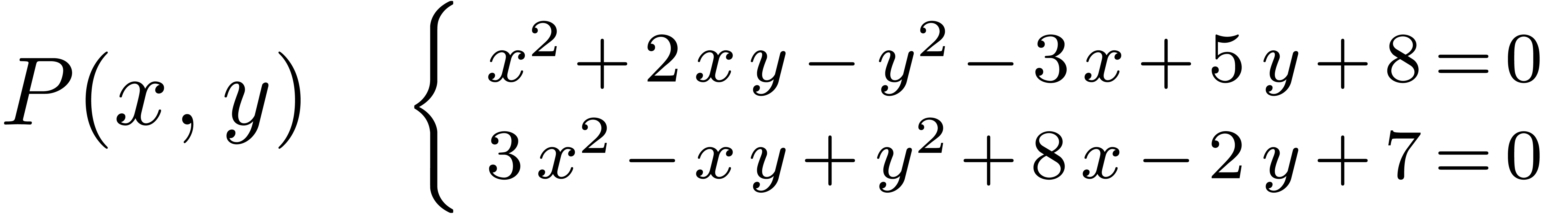
Ce système est suffisamment « générique
» pour que toutes ses solutions soient simples et pour qu'il y ait
exactement 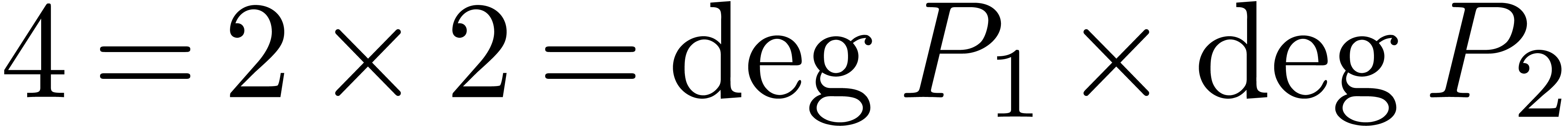 solutions (comme prédit par la
borne de Bézout). En particulier, le système «
ressemble » (en degré, nombre et nature des solutions) au
système beaucoup plus simple
solutions (comme prédit par la
borne de Bézout). En particulier, le système «
ressemble » (en degré, nombre et nature des solutions) au
système beaucoup plus simple
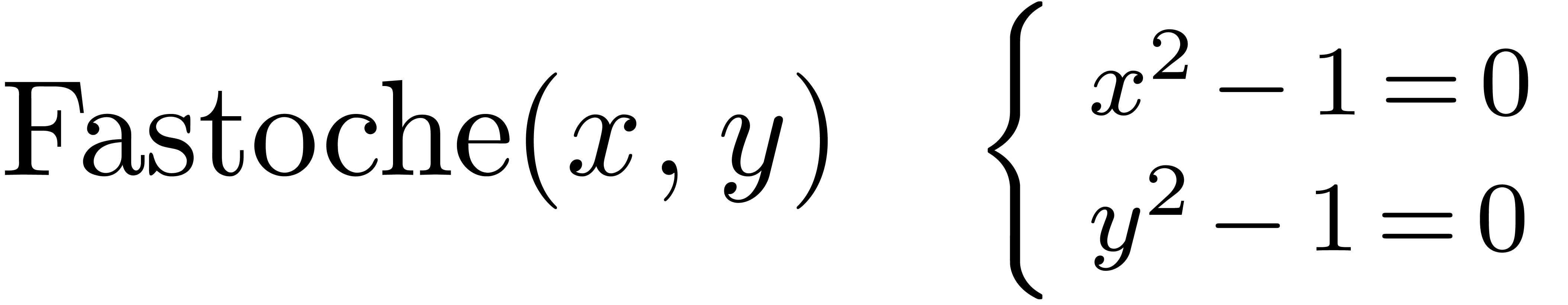
On considère maintenant l'homotopie
qui donne le système  en
en 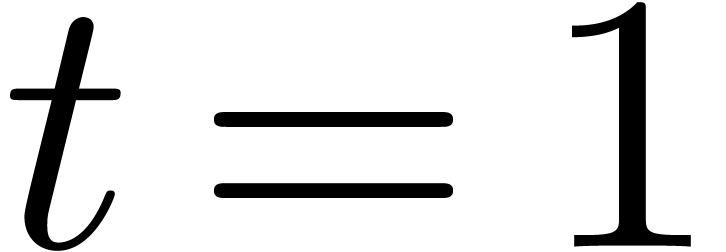 et le système du départ
et le système du départ  en
en 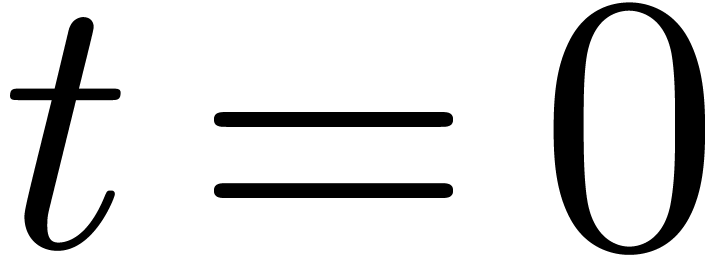 . Partant des solutions
. Partant des solutions  en , on obtient
donc les solutions de par déformation, en
suivant les solutions quand on fait bouger
en , on obtient
donc les solutions de par déformation, en
suivant les solutions quand on fait bouger 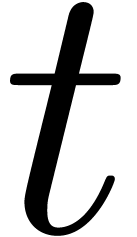 de
de
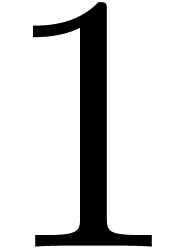 vers
vers 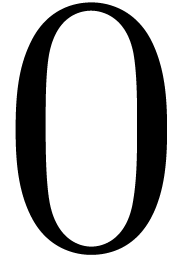 (voir la section 1.2.3 et le chapitre 7).
(voir la section 1.2.3 et le chapitre 7).
La technique de suivi de chemin est aussi utile pour le calcul du groupe
de Galois d'un polynôme  ,
vu comme polynôme en sur
,
vu comme polynôme en sur 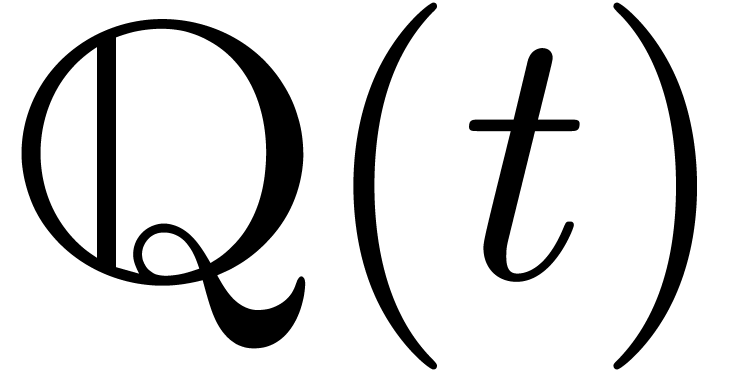 . On procède comme suit :
. On procède comme suit :
Soit l'ensemble des racines de 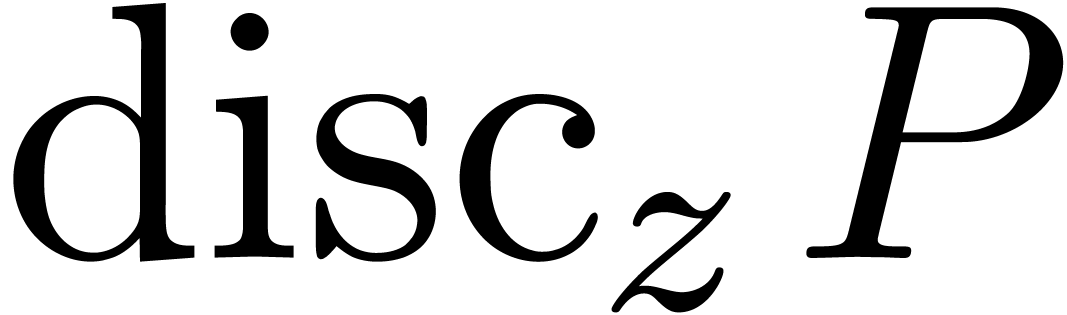 .
.
Soient  les racines de
en
les racines de
en  .
.
Pour tout  :
:
Construire un chemin  avec
avec  tournant autour de
tournant autour de  .
.
Remonter en un chemin  avec
avec  pour tout .
pour tout .
Calculer la permutation  de
de  avec
avec 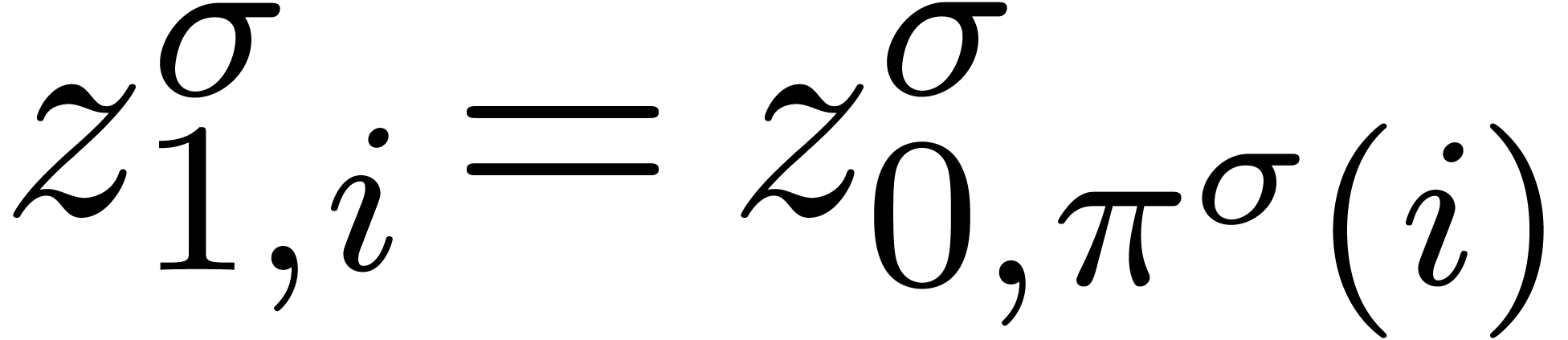 .
.
On montre que les génèrent 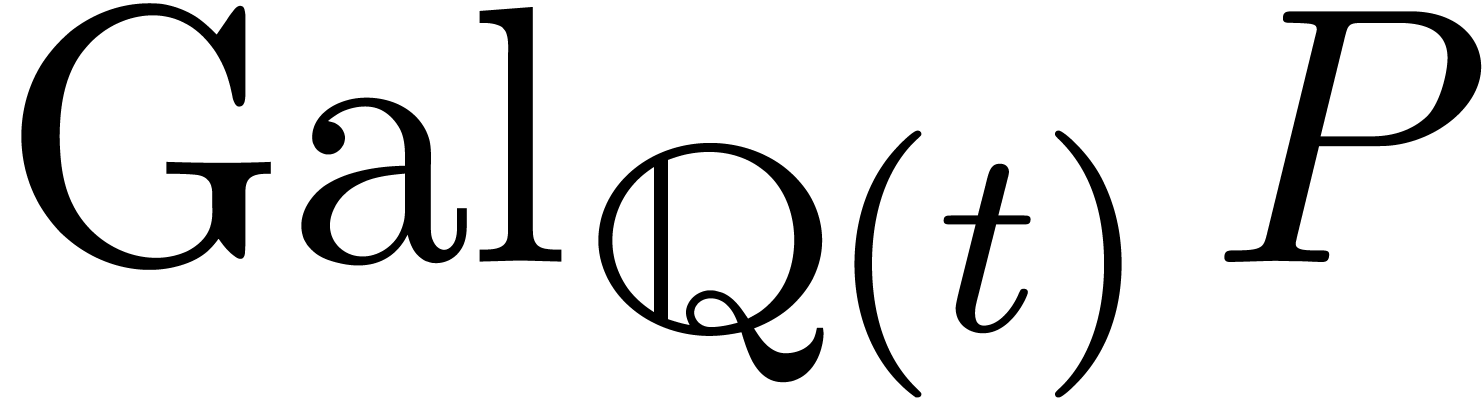 .
.
Prendre
|
|
L'algorithme pour calculer le groupe de Galois d'une fonction
algébrique s'adapte au cas des opérateurs
différentiels 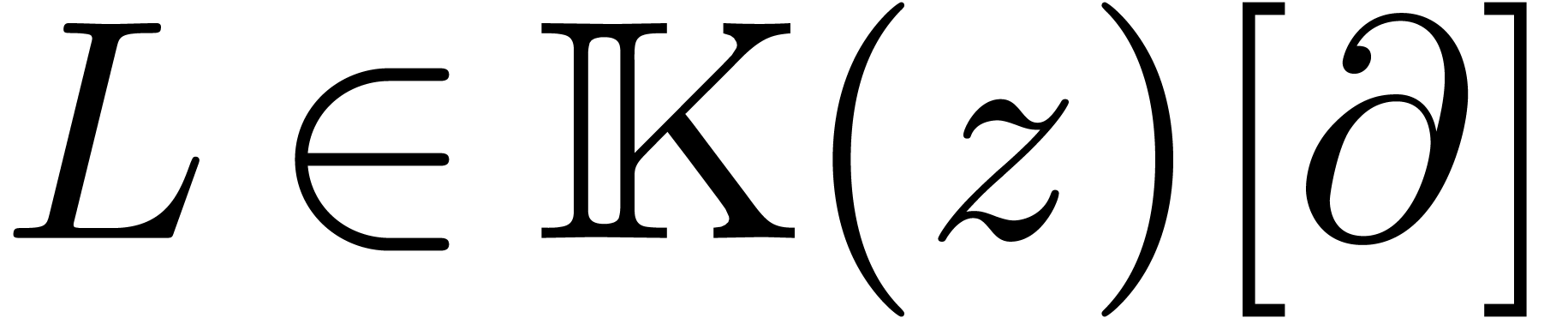 .
Considérons par exemple
.
Considérons par exemple
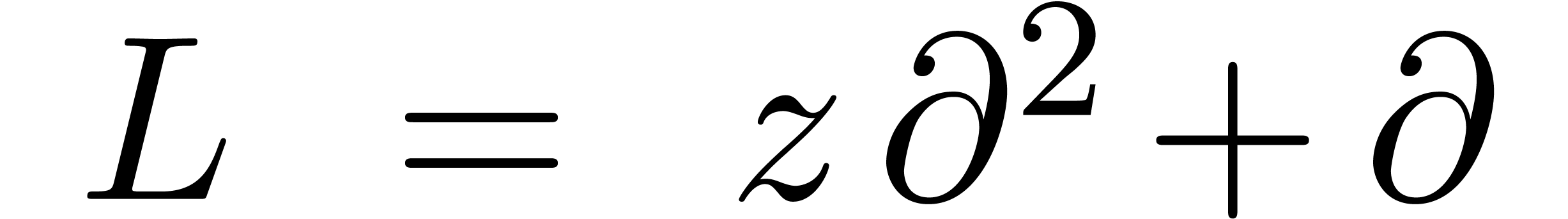
Base de solutions pour 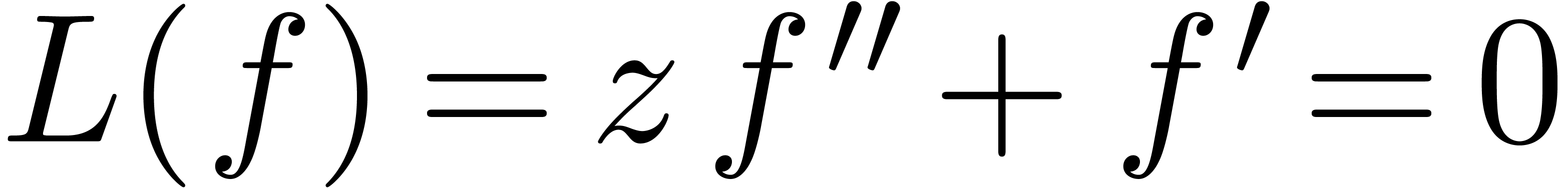 en
en 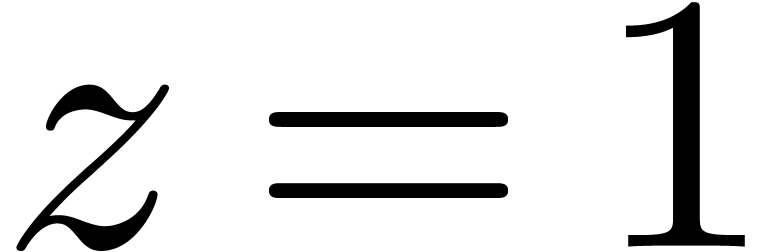 :
:
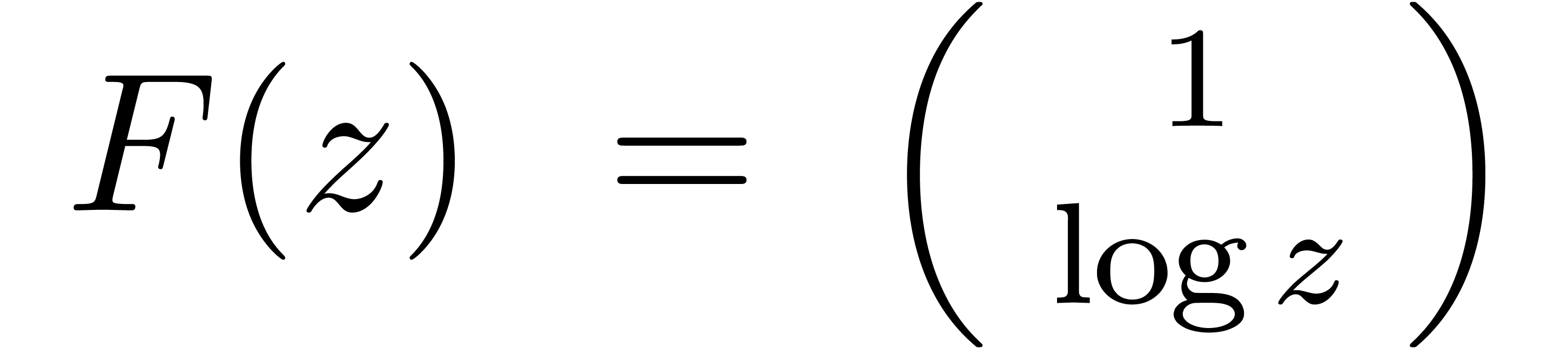
Prolongement analytique de la solution  autour de
:
autour de
:
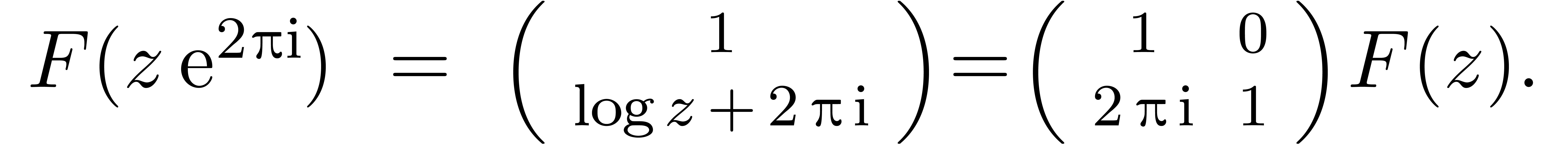
La matrice de monodromie 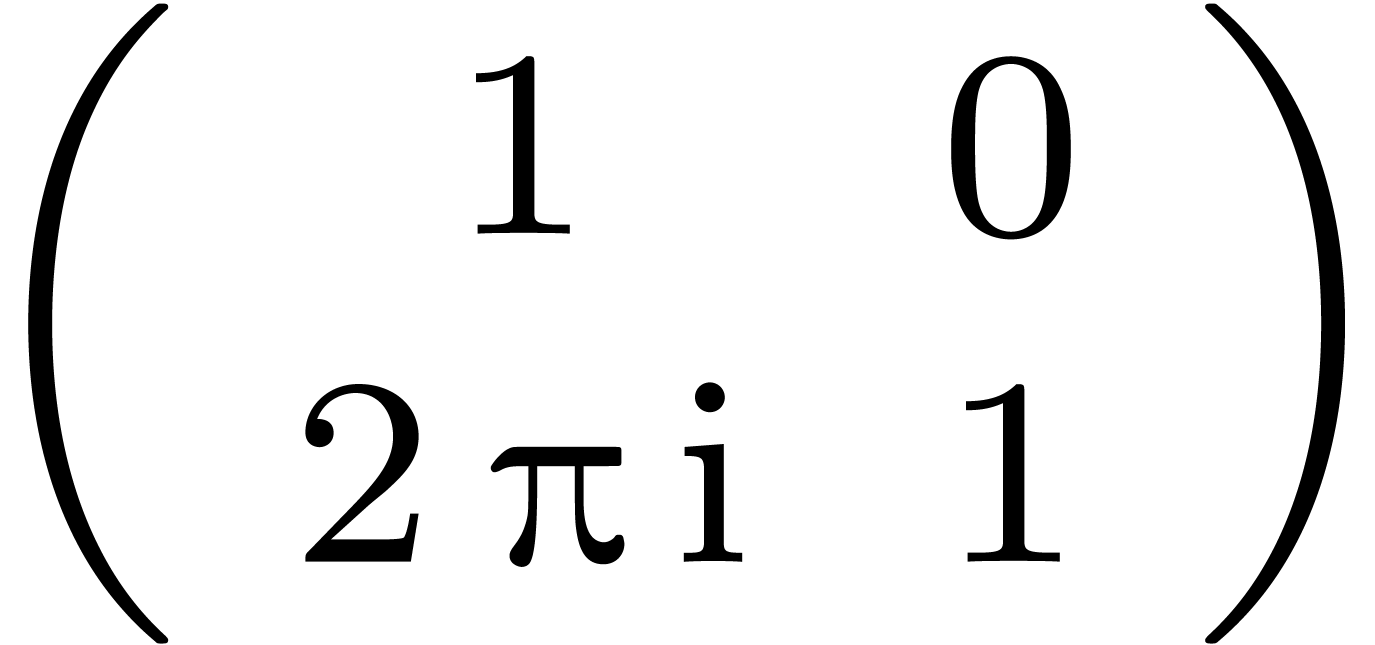 joue un rôle
analogue à la permutation
joue un rôle
analogue à la permutation 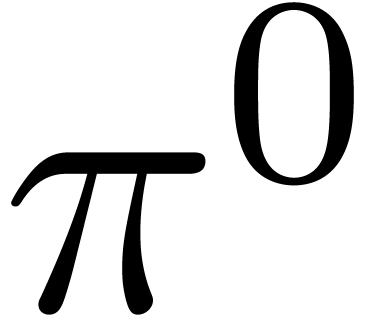 de l'exemple 1.2.
de l'exemple 1.2.
Soit 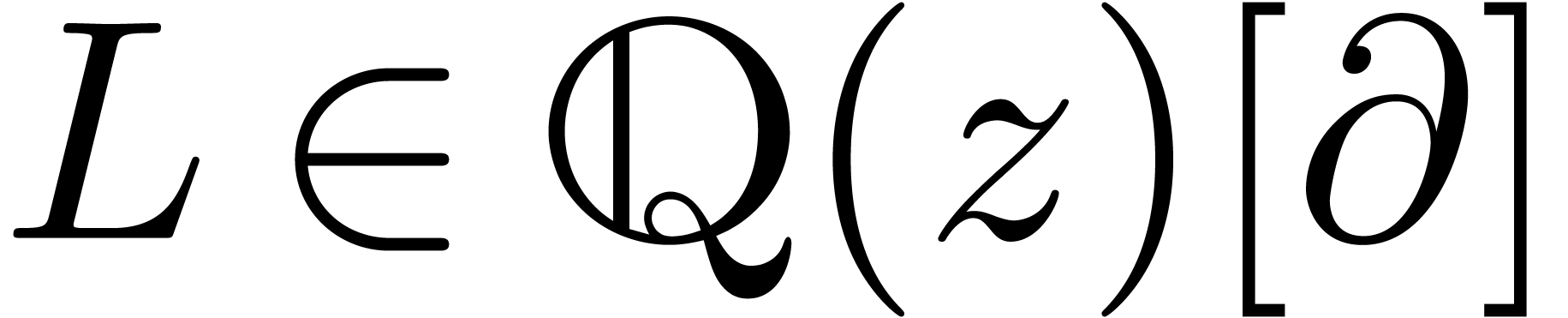 un opérateur différentiel
linéaire qui n'admet que des singularités
régulières. Alors son groupe de Galois différentiel
un opérateur différentiel
linéaire qui n'admet que des singularités
régulières. Alors son groupe de Galois différentiel
 est généré par ces matrices
de monodromie en tant que groupe de algébrique fermé ;
c'est le théorème de densité de Schlesinger [64, 65]. Dans le cas général, il
faut rajouter les matrices de Stokes et les matrices exponentielles ;
c'est le théorème de Martinet-Ramis [52].
est généré par ces matrices
de monodromie en tant que groupe de algébrique fermé ;
c'est le théorème de densité de Schlesinger [64, 65]. Dans le cas général, il
faut rajouter les matrices de Stokes et les matrices exponentielles ;
c'est le théorème de Martinet-Ramis [52].
Exemple 1.3. Dans l'exemple ci-dessus, le plus petit groupe
algébrique fermé qui contient la matrice 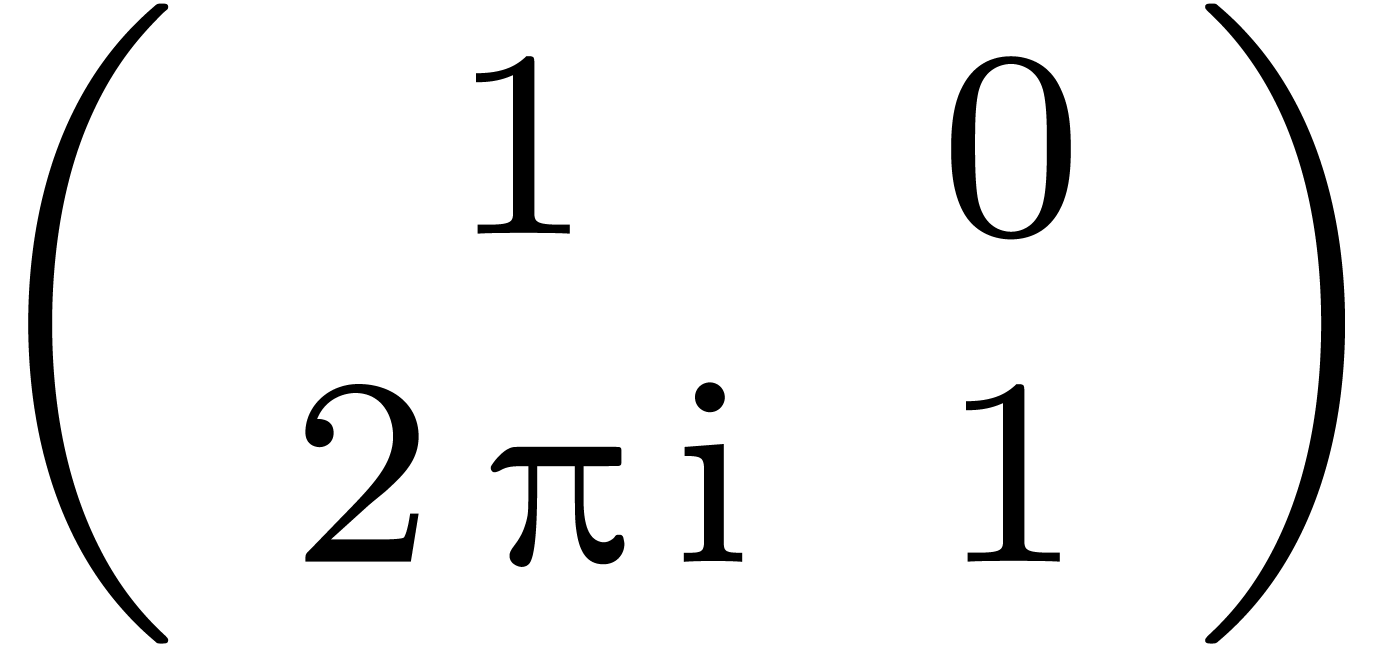 est constitué de toutes les matrices du type
est constitué de toutes les matrices du type 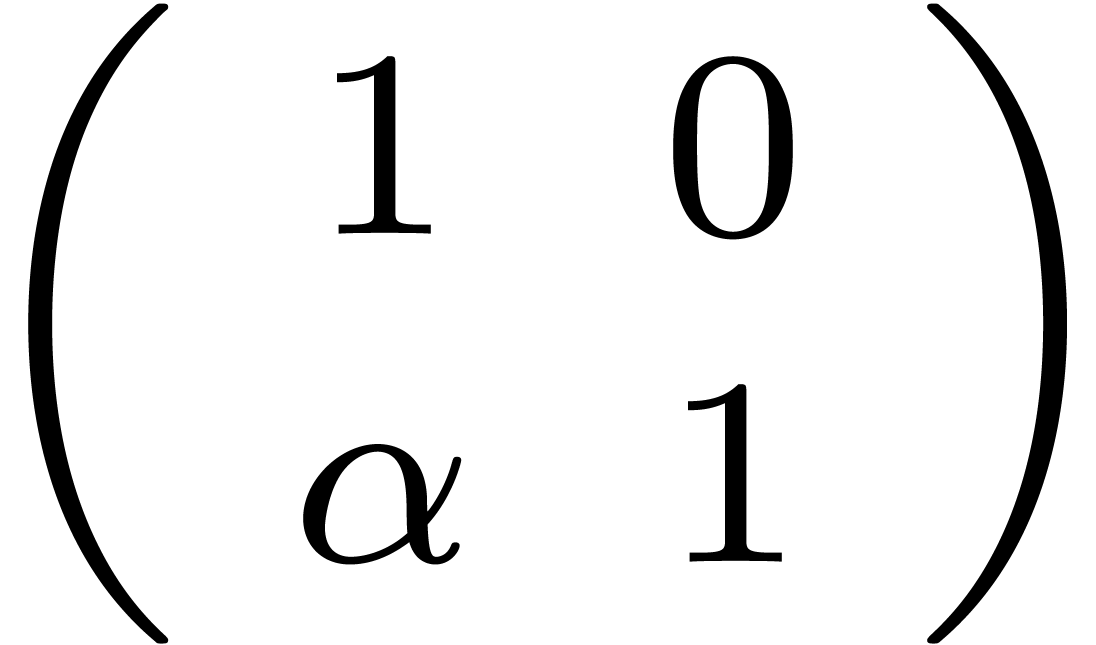 avec
avec 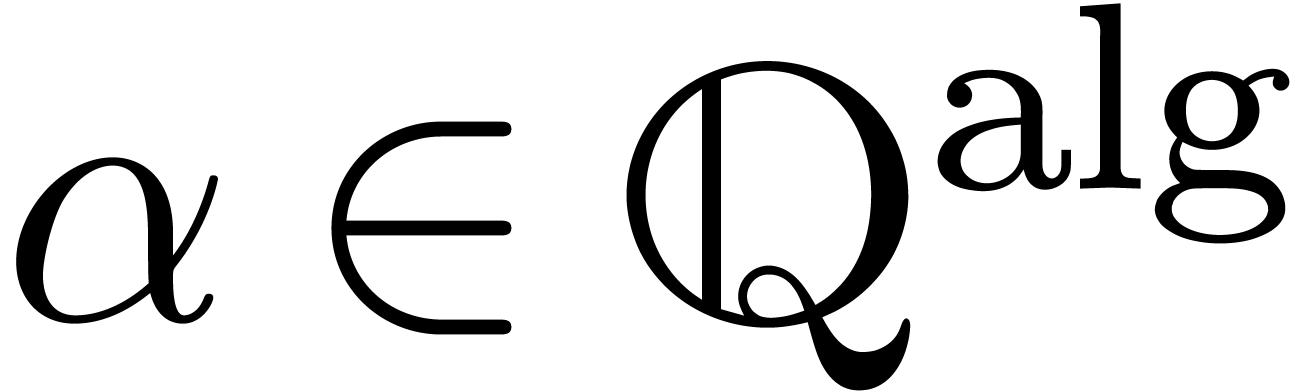 .
.
Toutes ces matrices de monodromie peuvent se calculer de façon
certifiée et en temps presque linéaire [18,
77, 78]. Ceci reste vrai pour les matrices
exponentielles et les matrices de Stokes [82], grace
à la théorie d'accéléro-sommation
d'Écalle [25, 26, 27, 12]. Pour une précision suffisamment grande de calcul,
ceci conduit a un algorithme pour calculer le groupe de Galois
différentiel [81]. En particulier, on obtient un
algorithme de factorisation de  .
.
Remarque 1.4. L'algorithme de factorisation marche grosso
modo comme ceci. Soit  un système
fondamental de solutions en un point non singulier
un système
fondamental de solutions en un point non singulier  et supposons que les matrices
et supposons que les matrices  générant
générant  ont été
calculées par rapport à .
L'opérateur
ont été
calculées par rapport à .
L'opérateur  se factorise si et seulement
si
se factorise si et seulement
si  admet un sous espace vectoriel stable non
trivial sous l'action de ,
c'est à dire sous l'action de l'algèbre
générée par .
admet un sous espace vectoriel stable non
trivial sous l'action de ,
c'est à dire sous l'action de l'algèbre
générée par .
Pour une précision de calcul donnée, si un tel espace  stable existe, il se calcule donc par algèbre
linéaire. Soit
stable existe, il se calcule donc par algèbre
linéaire. Soit  une base de . Alors l'opérateur
une base de . Alors l'opérateur 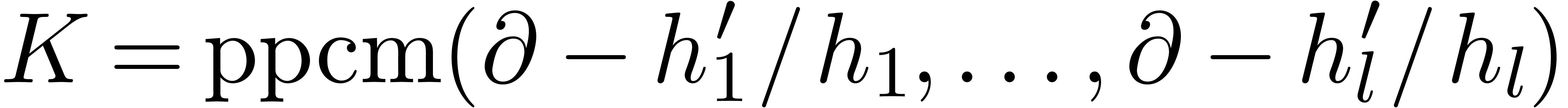 divise . Les coefficients de
divise . Les coefficients de
 sont présentés comme des
séries à coefficients dans
sont présentés comme des
séries à coefficients dans  ,
mais sont en réalité dans
,
mais sont en réalité dans  .
On obtient les coefficients en tant que fractions rationnelles dans par Padé-Hermite et développements en
fractions continues. On montre que pour une précision de calcul
suffisante, on obtient ou bien un qui divise
effectivement dans
.
On obtient les coefficients en tant que fractions rationnelles dans par Padé-Hermite et développements en
fractions continues. On montre que pour une précision de calcul
suffisante, on obtient ou bien un qui divise
effectivement dans  ,
ou bien un certificat numérique qu'il n'existe pas de sous-espace
vectoriel non trivial .
,
ou bien un certificat numérique qu'il n'existe pas de sous-espace
vectoriel non trivial .
Prétraitement symbolique  meilleure efficacité
meilleure efficacité
Plus généralement : asymptotique formelle
évaluation rapide de fonctions
De façon similaire, la résolution de systèmes algébriques surdéterminés peut bénéficier d'un prétraitement pour calculer une base de Gröbner ; ensuite on peut par exemple chercher les solutions numériques par méthode d'homotopie.
Calcul de schémas numériques rapides
Runge-Kutta à des ordres élevés
Bonnes bases de fonctions pour éléments finis
Bonnes bases d'ondelettes
Arithmétique rapide
Calcul rapide en multi-précision
Algorithmes denses rapides sur les polynômes, les matrices et les séries
Traitement efficace de structures creuses et en évaluation
Besoin d'un bon langage
Mathématiquement expressif
Sémantiquement propre
Interface conviviale
Compilé (au moins pour le calcul analytique)
Comme l'ensemble  des nombres réels est
non dénombrable, il est impossible de construire un type de
données susceptible de pouvoir représenter n'importe quel
nombre réel. Toutefois, au moins d'un point de vue
théorique, il serait utile de pouvoir calculer directement avec
des nombres réels, quitte à se restreindre à une
sous-classe de . Le choix le
plus naturel consiste à prendre la sous-classe des nombres que
l'on peut approcher aussi précisément que
nécessaire par des nombres rationnels :
des nombres réels est
non dénombrable, il est impossible de construire un type de
données susceptible de pouvoir représenter n'importe quel
nombre réel. Toutefois, au moins d'un point de vue
théorique, il serait utile de pouvoir calculer directement avec
des nombres réels, quitte à se restreindre à une
sous-classe de . Le choix le
plus naturel consiste à prendre la sous-classe des nombres que
l'on peut approcher aussi précisément que
nécessaire par des nombres rationnels :
Définition 2.1. Un nombre
réel 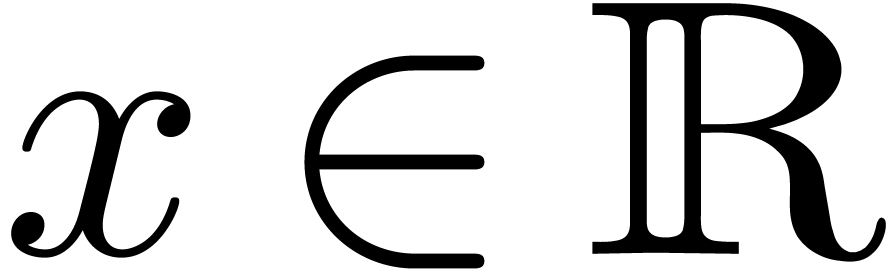 est calculable s'il
existe un algorithme qui prend en entrée
et qui produit une
est calculable s'il
existe un algorithme qui prend en entrée
et qui produit une  -approximation
-approximation
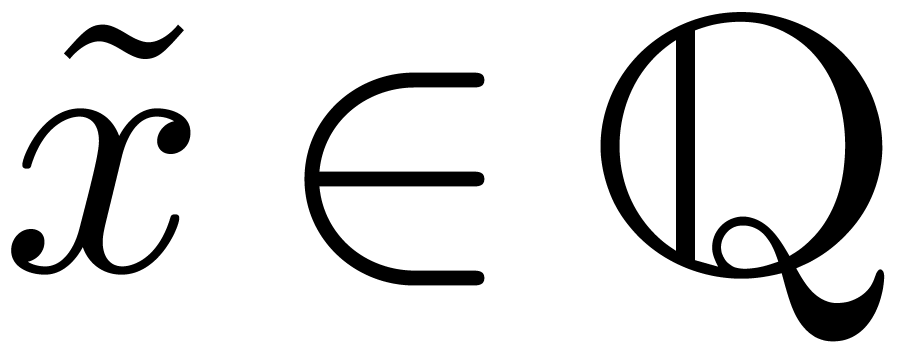 de
de  avec
avec 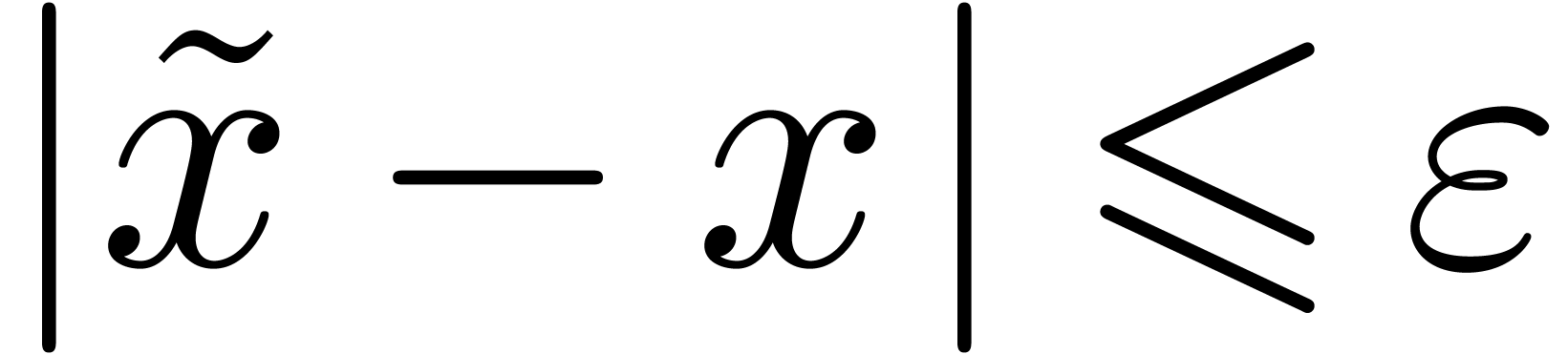 . On note
. On note  l'ensemble
des nombres réels calculables.
l'ensemble
des nombres réels calculables.
Ici, il est important d'intégrer le fait qu'un nombre est en
réalité un programme ou encore la
promesse de pouvoir trouver une approximation aussi fine que
souhaitée. Bien sûr, la définition admet de
nombreuses variantes, en jouant sur la façon d'approcher  . Par exemple :
. Par exemple :
On peut remplacer par l'ensemble des nombres
flottants
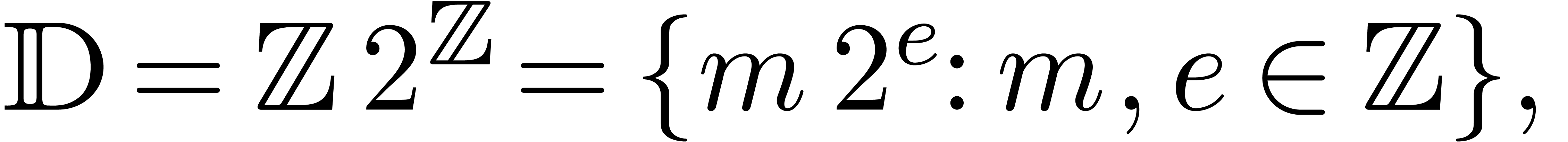
en autorisant une précision arbitraire pour les mantisses et les exposants.
 algorithme qui prend
algorithme qui prend 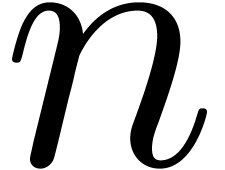 en entrée et calcule une
en entrée et calcule une  -approximation.
-approximation.
algorithme pour calculer 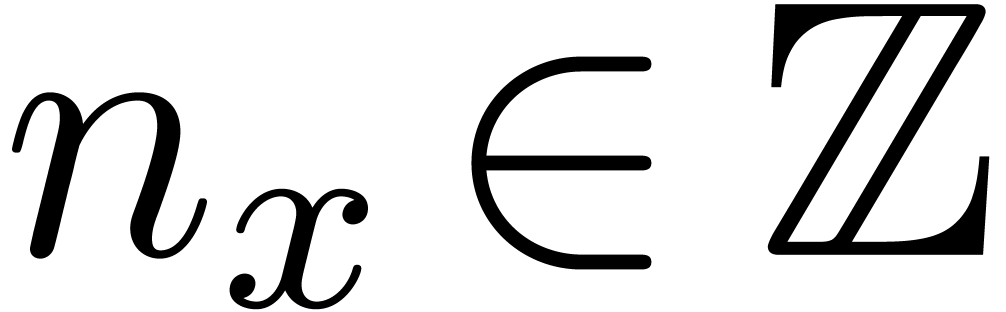 ,
, 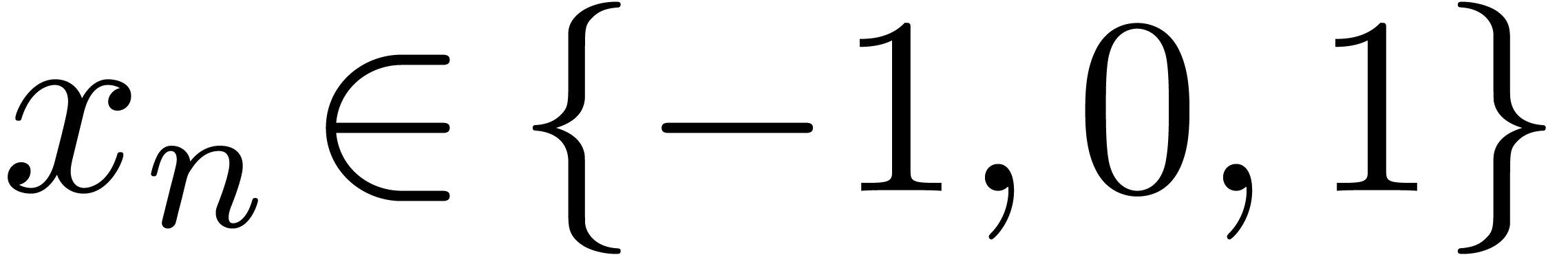 avec
avec 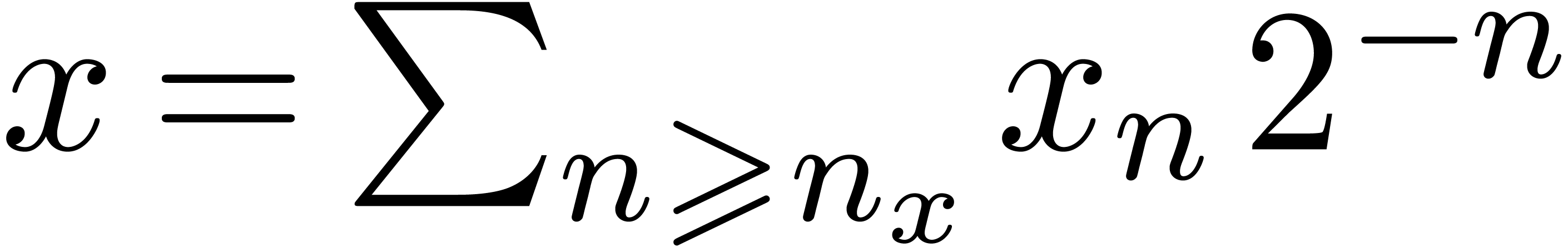
suites calculables  ,
, 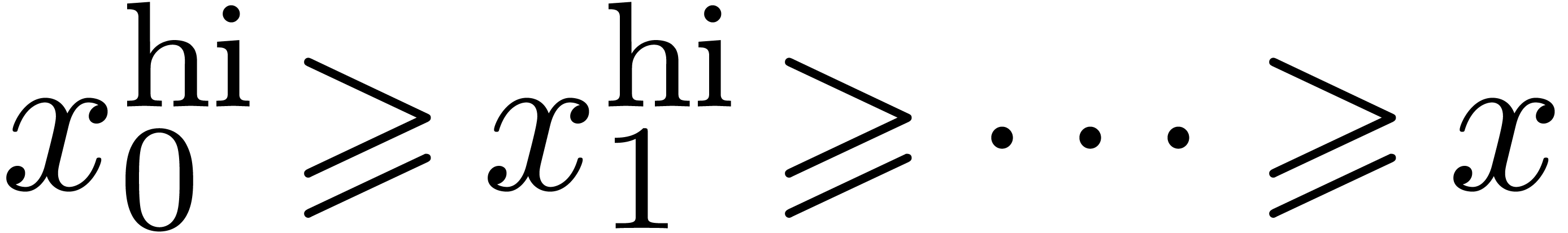 avec
avec 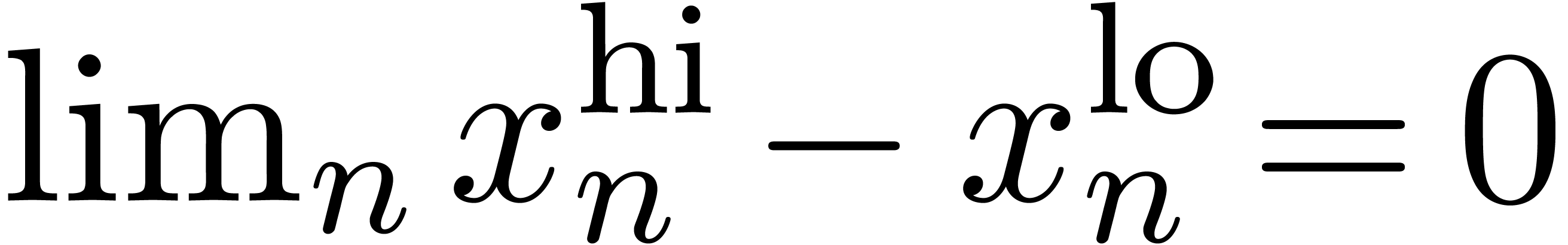
L'analyse calculable est le sujet qui se propose de « réécrire » l'analyse sous cet angle de la calculabilité [1, 93]. La encore, il y a des sujets voisins, comme l'analyse constructive [8].
Une autre approche [71, 72, 69,
70, 21] est de faire « comme si »
l'on pouvait représenter n'importe quel nombre réel et
effectuer des opérations habituelles  en
temps constant. Évidemment, ce modèle ne correspond encore
moins à des ordinateurs concrets que les machines de Turing.
Toutefois, ce modèle simplificateur n'est pas dénué
de sens si on calcule en précision fixe et il n'est pas inutile
d'adopter ce point de vue par moments, en particulier pour la
résolution de systèmes polynomiaux (voir les chapitres 6
et 7).
en
temps constant. Évidemment, ce modèle ne correspond encore
moins à des ordinateurs concrets que les machines de Turing.
Toutefois, ce modèle simplificateur n'est pas dénué
de sens si on calcule en précision fixe et il n'est pas inutile
d'adopter ce point de vue par moments, en particulier pour la
résolution de systèmes polynomiaux (voir les chapitres 6
et 7).
Mmx] |
use "asymptotix"; |
| Mmx] | type_mode? := true; |
Mmx] |
one: Approximator (Floating, Floating) == 1; |
Mmx] |
e == exp one |
 :
: 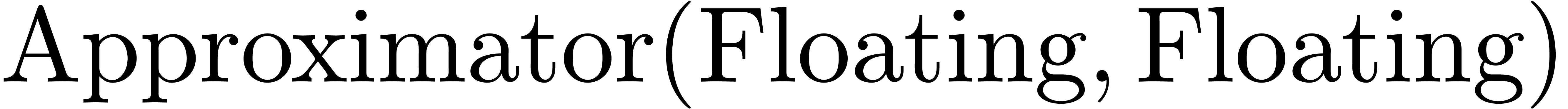
Mmx] |
approximate (e, 1.0e-1000) |
 :
: 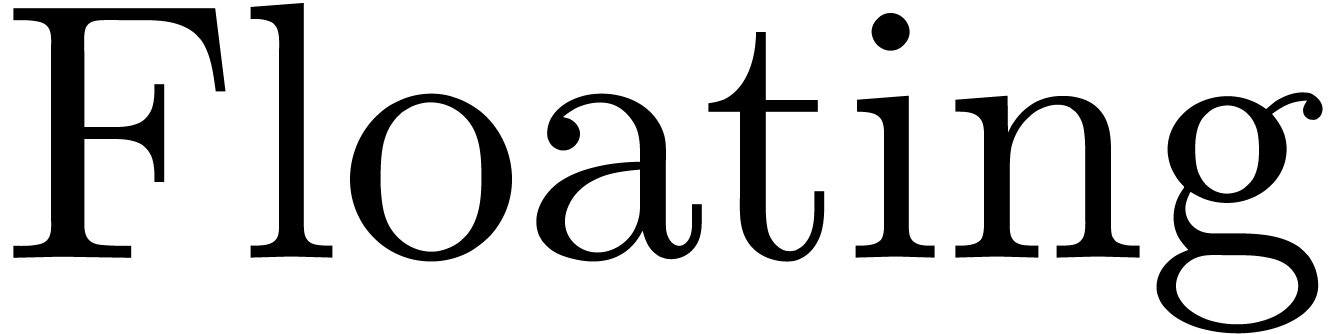
Le premier théorème de non calculabilité [75] parait naturel aujourd'hui. Or c'est ce théorème qui est à l'origine des machines de Turing et des premiers résultats de non calculabilité !
Théorème 2.2. Il n'existe pas de test
de nullité pour .
Asymmétrie. Soit 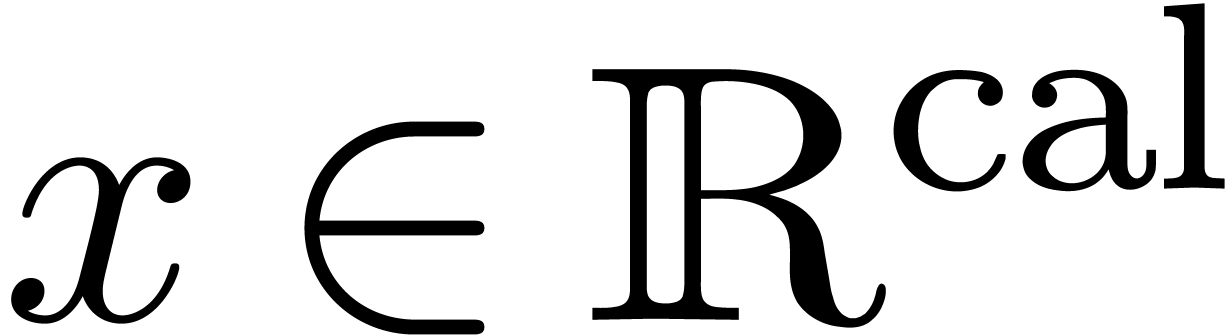 .
.
Si 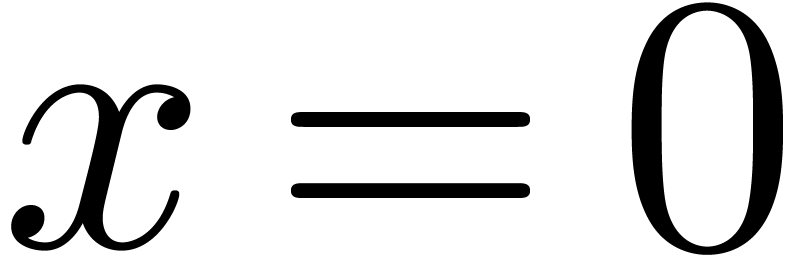 , alors on ne peut pas
forcément le démontrer en temps fini.
, alors on ne peut pas
forcément le démontrer en temps fini.
Si 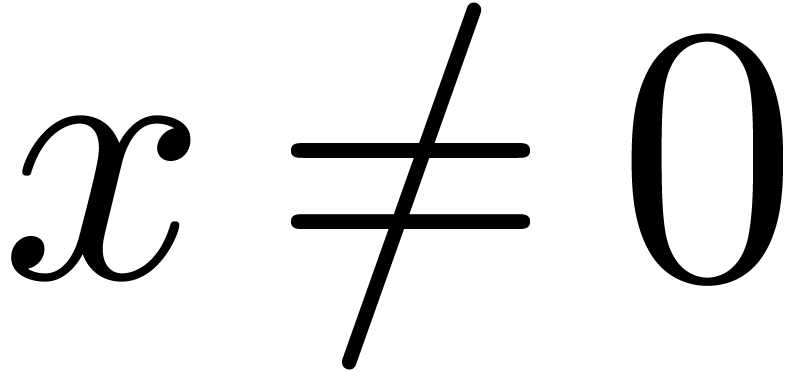 , alors on peut le
certifier en temps fini.
, alors on peut le
certifier en temps fini.
Restriction à des sous-classes.
Il existe un test de nullité pour  (nombres algébriques réels).
(nombres algébriques réels).
Il existe un test de nullité pour , modulo la conjecture de Schanuel.
Problème ouvert difficile : test de nullité pour les constantes holonomes.
Le deuxième théorème [36, 37, 38] de non calculabilité est un peu plus surprenant, du moins pour moi-même : ce n'est pas la peine de chercher à calculer des fonctions discontinues, puisque c'est impossible !
Théorème 2.3. Toute fonction
calculable  est continue.
est continue.
Démonstration. Considérons une machine de Turing
 pour calculer
pour calculer  .
.
Soit 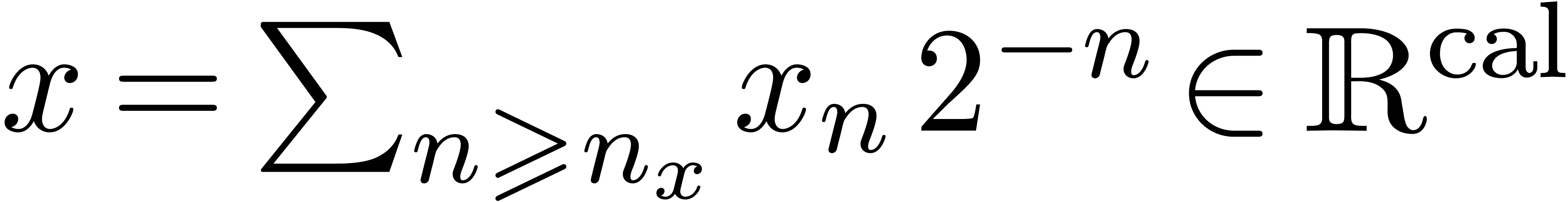 .
.
Sur l'entrée  , retourne
, retourne  avec
avec 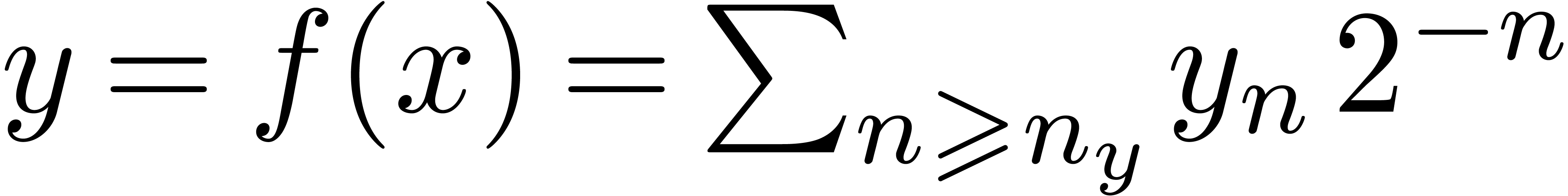 .
.
Soit  et
et 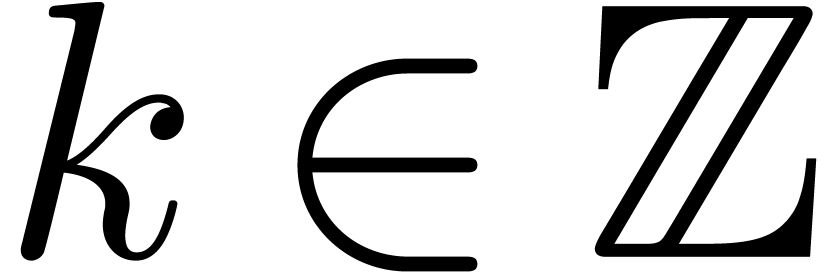 avec
avec 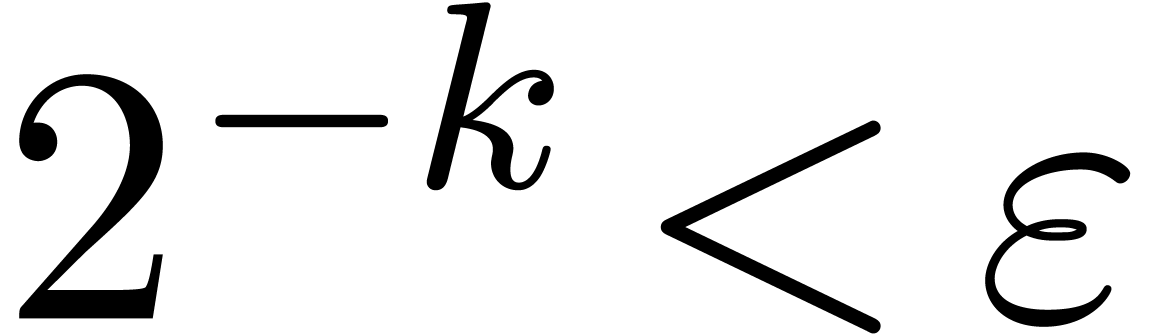 , considérons le calcul
fini de
, considérons le calcul
fini de  .
.
Soit 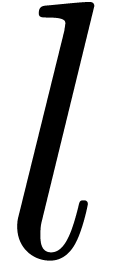 maximal, tel que
maximal, tel que 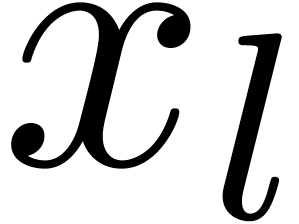 intervient dans ce calcul.
intervient dans ce calcul.
Alors 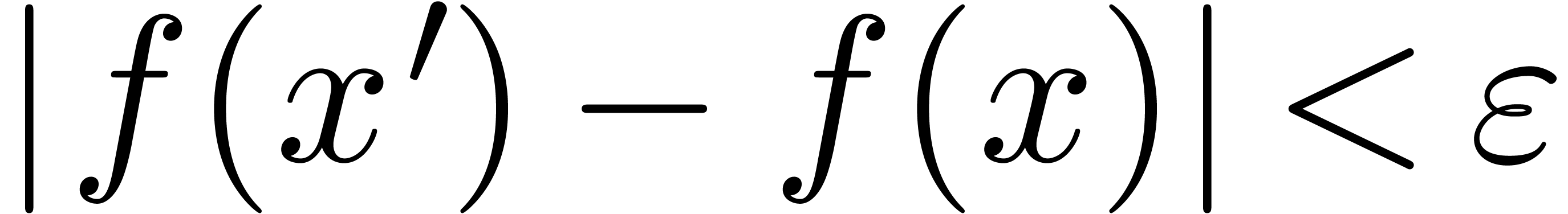 pour tout
pour tout  avec
avec
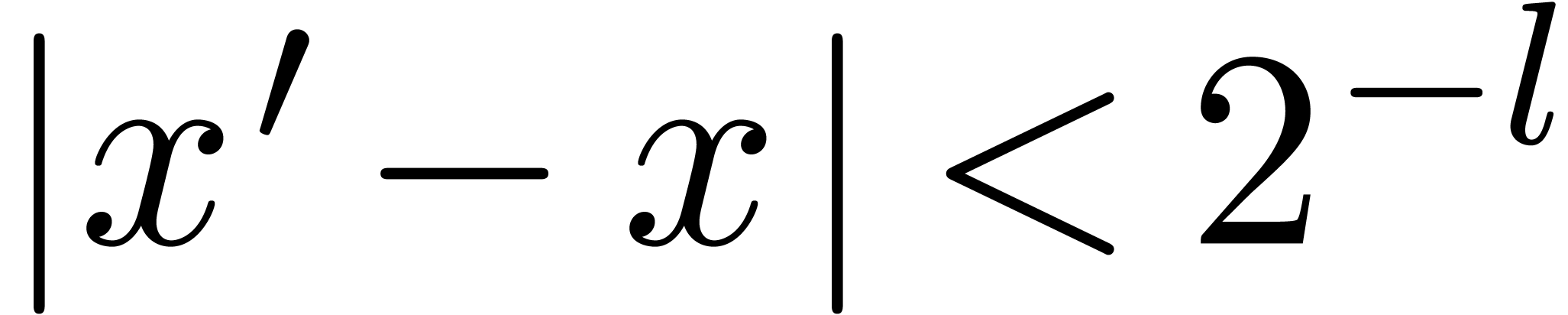 .
.
Le troisième théorème [22] de non
calculabilité est surprenant dans ce sens que les données
ne sont pas des nombres ou fonctions calculables, mais plutôt des
simples vecteurs et polynômes à coefficients dans . Le théorème pose
clairement des limites à ce que l'on pourra calculer dans la
théorie des systèmes dynamiques.
Théorème 2.4. Considérons un système dynamique avec conditions initiales
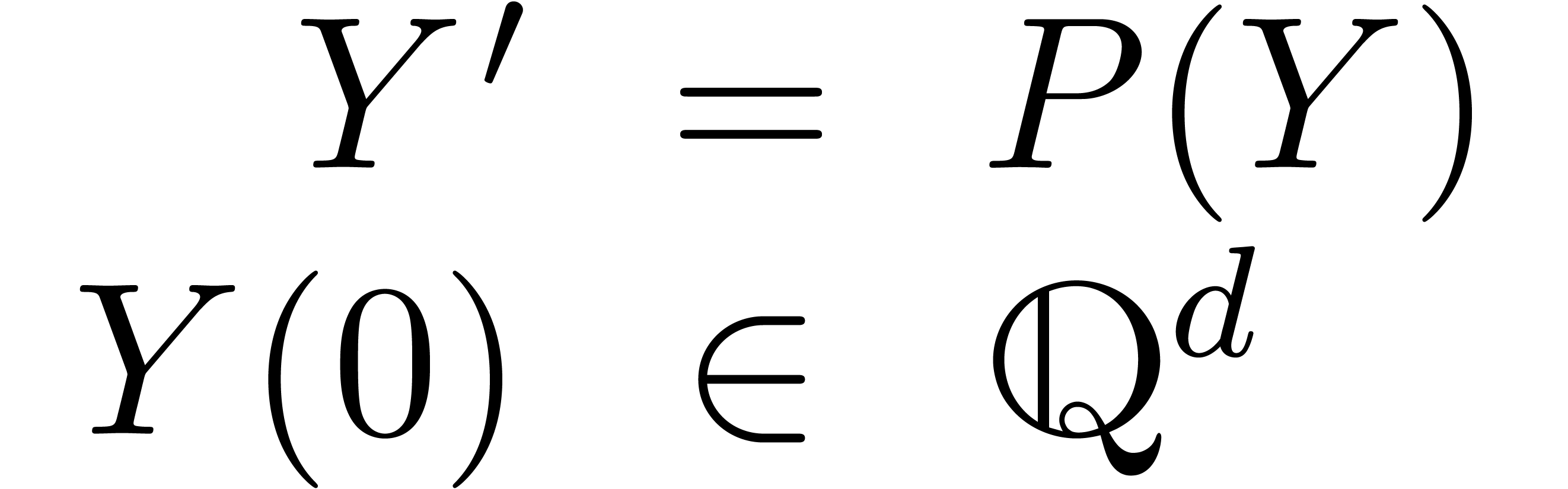
où 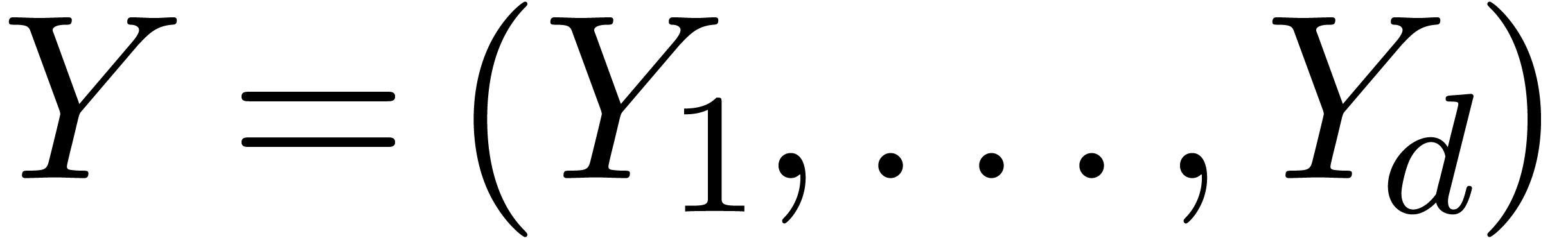 et
et 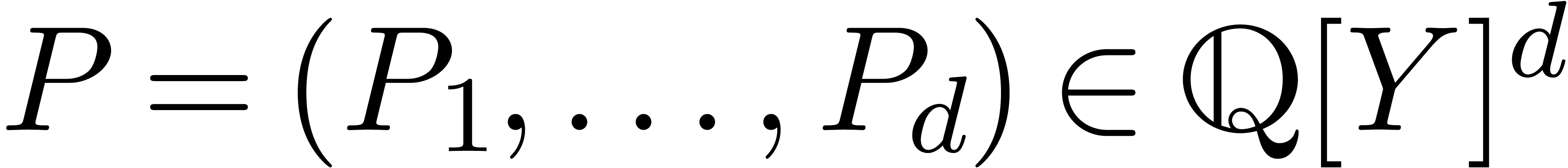 .
D'après Cauchy, ce système admet une unique solution
.
D'après Cauchy, ce système admet une unique solution 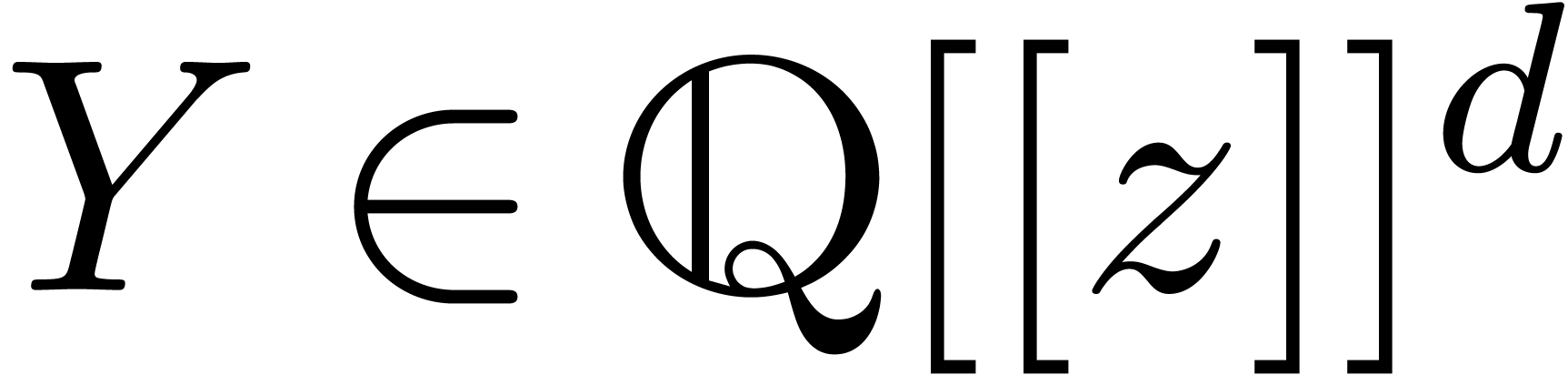 . Cette solution est convergente en
. Cette solution est convergente en
 .
.
Il n'existe pas d'algorithme pour calculer le rayon de convergence de
 .
.
Comme exercice, le lecteur pourra essayer de déterminer lesquels des problèmes suivants sont calculables :
Racines d'un polynôme unitaire à coefficients dans 
Racines réelles d'un polynôme unitaire à
coefficients dans
Racines complexes d'un système polynomial
zéro-dimensionnel sur 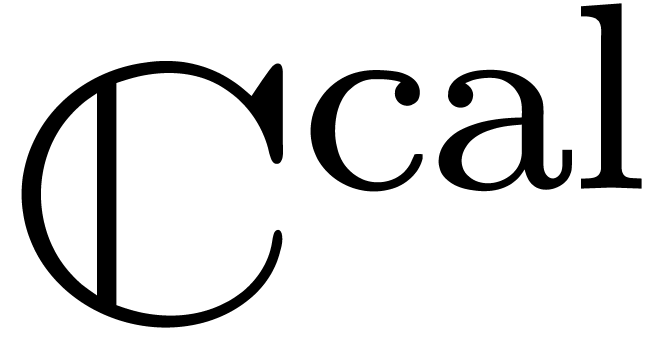
Vecteur propres d'une matrice à coefficients dans
Calcul d'une primitive d'une fonction calculable sur
Calcul de la dérivée d'une fonction  calculable sur
calculable sur
Calcul de la dérivée d'une fonction analytique
calculable sur
Calcul d'une racine de 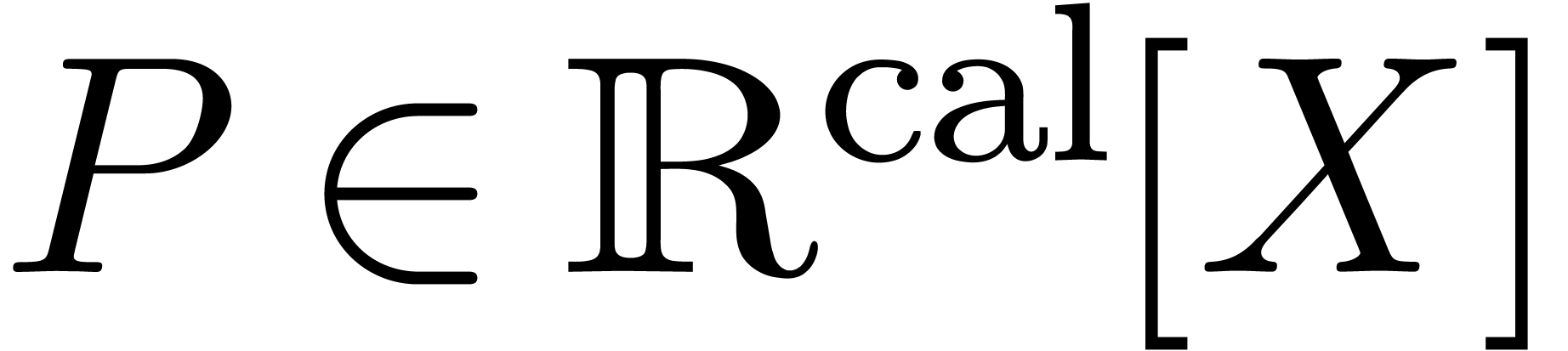 avec
avec 
Remarque 2.5. Subtilité concernant le dernier
problème : il existe une fonction qui prend en entrée une
représentation 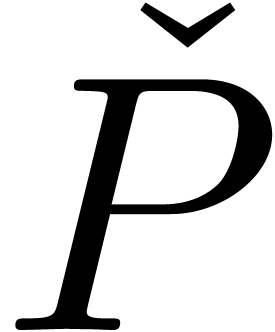 d'un
polynôme avec
d'un
polynôme avec 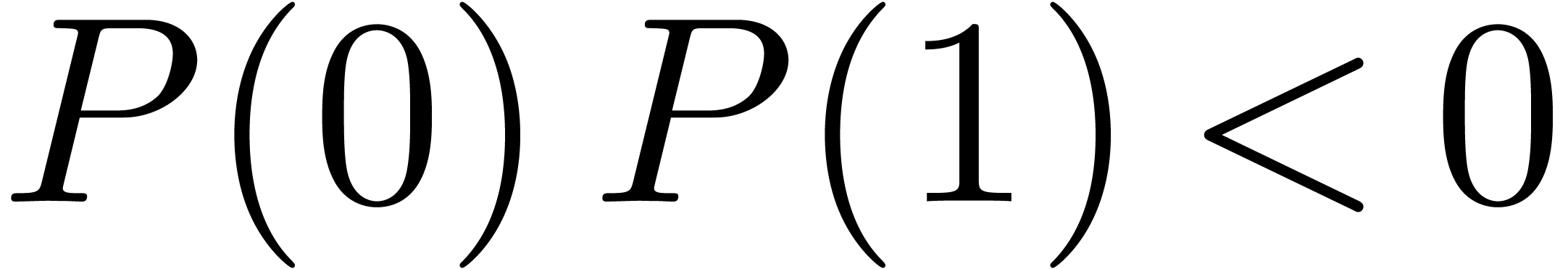 , et qui retourne une racine
, et qui retourne une racine 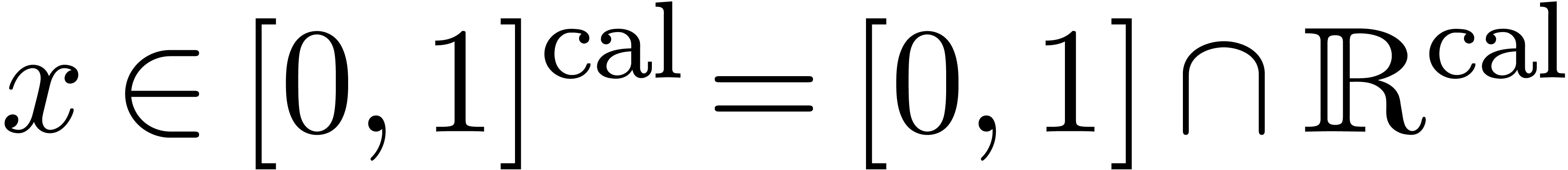 de
de  . Le hic réside
dans le fait que cette fonction peut retourner deux racines distinctes
pour deux représentations différentes du même
polynôme .
. Le hic réside
dans le fait que cette fonction peut retourner deux racines distinctes
pour deux représentations différentes du même
polynôme .
Les théorèmes de non calculabilité de la section 2.2 sont inutilement pessimistes. Par exemple, le
théorème de Turing ne rend pas compte du fait suivant :
étant donné un nombre ,
on peut démontrer en temps fini que ,
si tel est en effet le cas. Pour mieux cerner ce qui reste calculable,
il est utile d'introduire les ensembles de nombres réels
calculables à gauche et à droite, et qui reflètent
mieux l'asymmétrie profonde de l'analyse calculable entre
l'égalité et l'inégalité.
 s'il existe
s'il existe 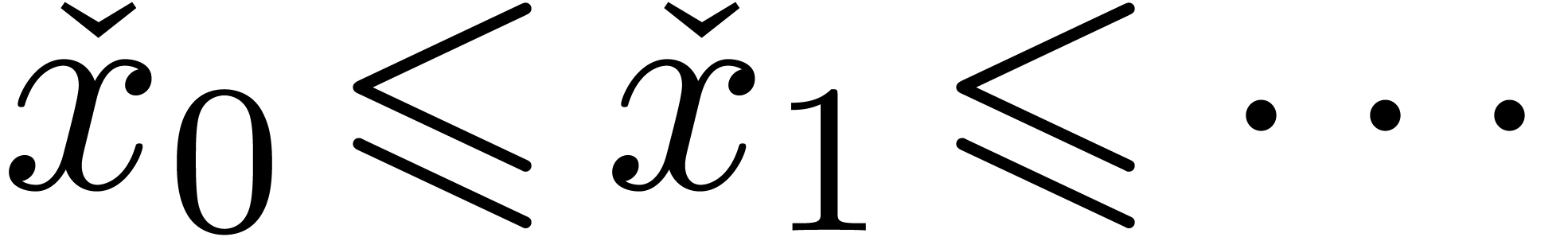 calculable avec
calculable avec  et
et 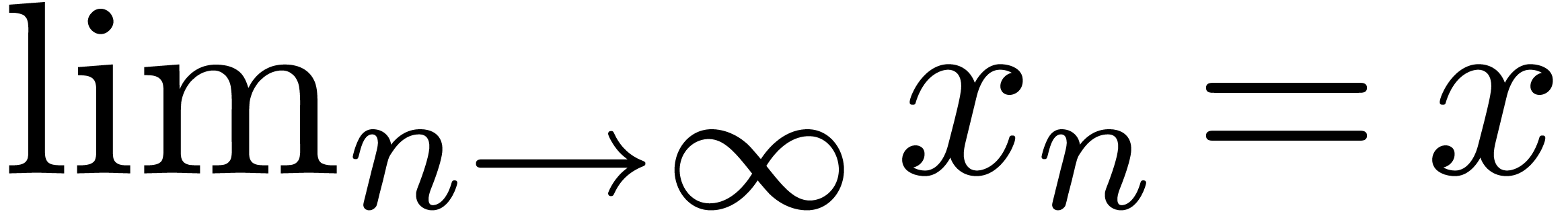
 si
si 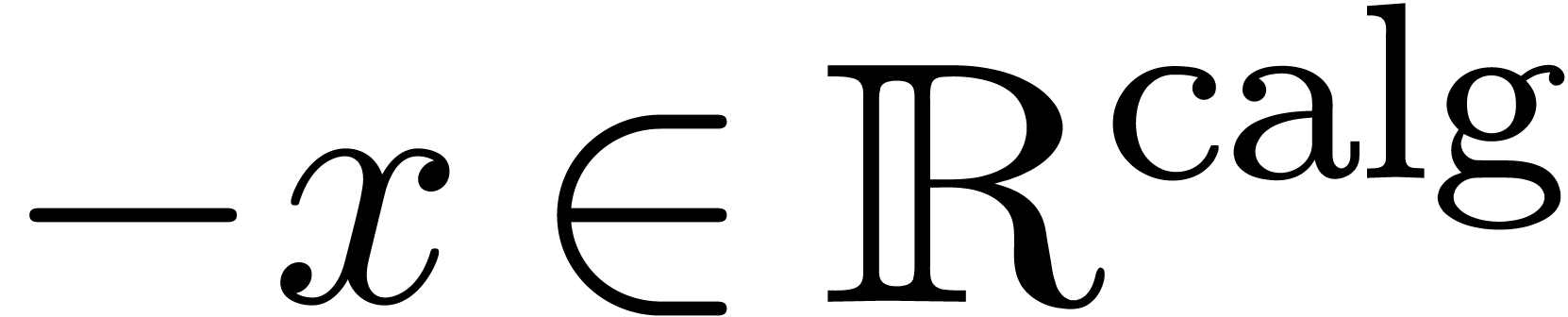 .
On a
.
On a 
On peut introduire une ribambelle de notions de calculabilité en poursuivant sur cette voie. Par exemple :
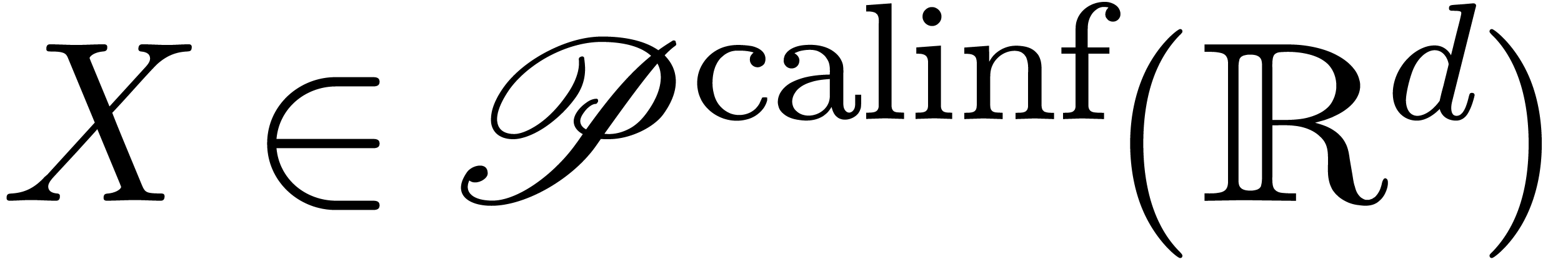 s'il existe
s'il existe  calculable avec
calculable avec 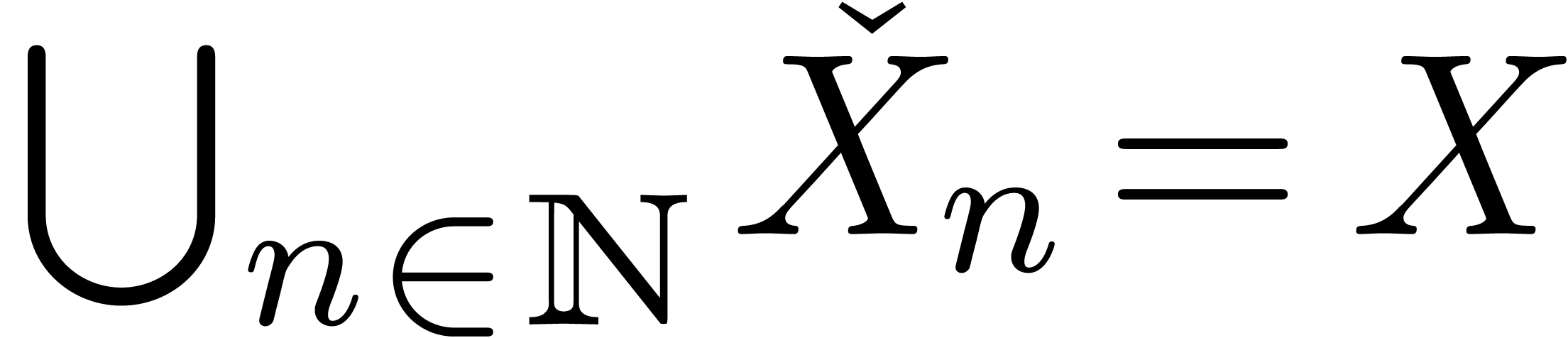 ,
où chaque
,
où chaque 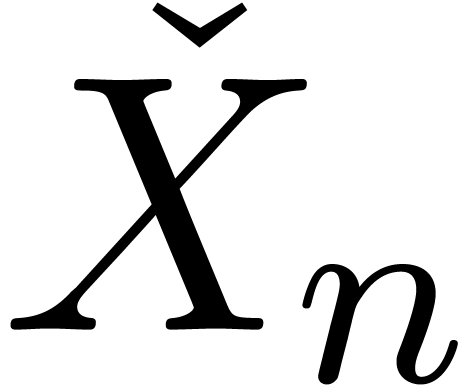 est une réunion
finie de « blocks » fermés à
extrémités dans
est une réunion
finie de « blocks » fermés à
extrémités dans 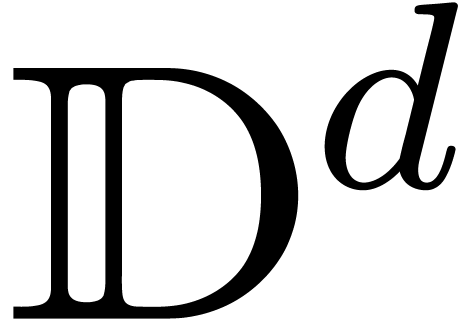
 si
si 
Il est utile de considérer des ensembles comme ,  ,
,
 ,
, 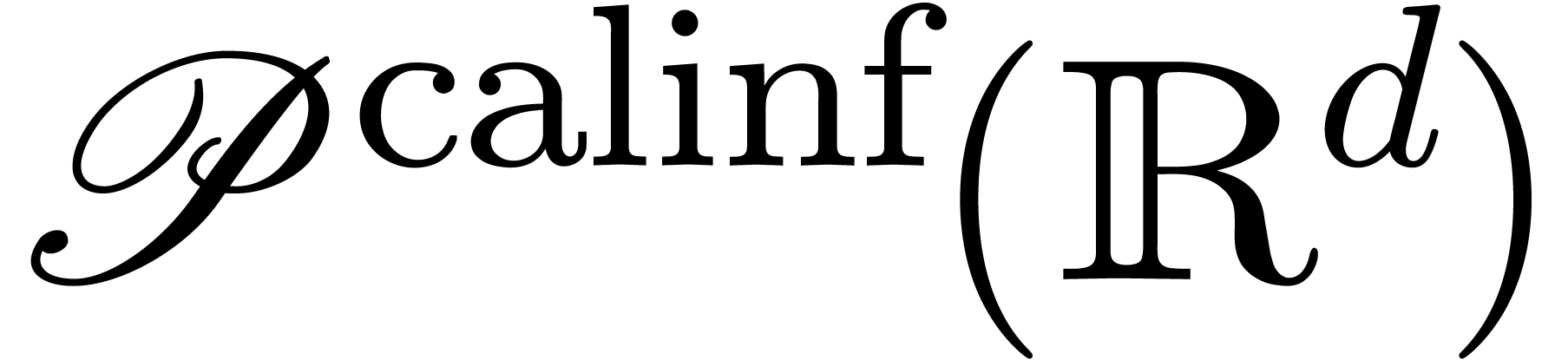 , etc. comme des types de données
concrets, pouvant intervenir dans des implantations. On peut
d'ailleurs construire plein d'autres types du même acabit, comme
les booléens à droite
, etc. comme des types de données
concrets, pouvant intervenir dans des implantations. On peut
d'ailleurs construire plein d'autres types du même acabit, comme
les booléens à droite  ou les
« booléens modulo la conjecture de Schanuel »
ou les
« booléens modulo la conjecture de Schanuel » 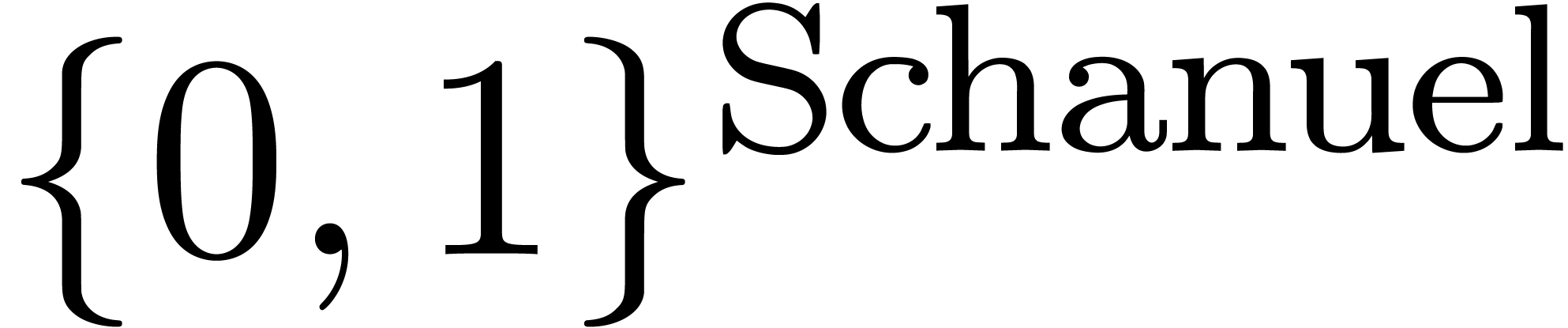 .
.
Ces types de données plus fins permettent de transformer les énoncés quelque peu négatives de la section 2.2 en assertions plus positives :
 calculable
calculable
calculable implique 
 calculable
calculable
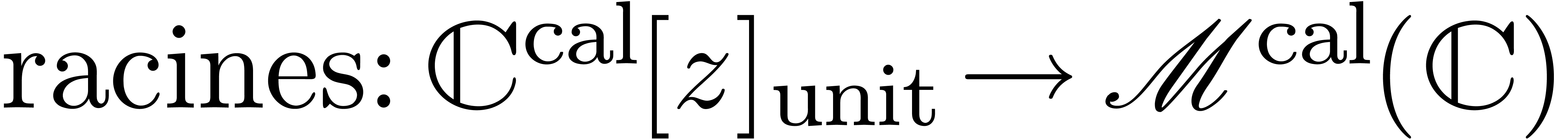 calculable (
calculable ( pour
multi-ensembles)
pour
multi-ensembles)
 calculable
calculable
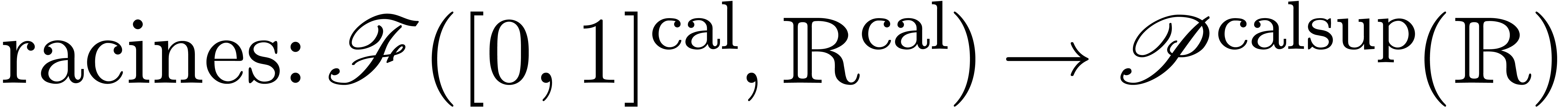 calculable
calculable
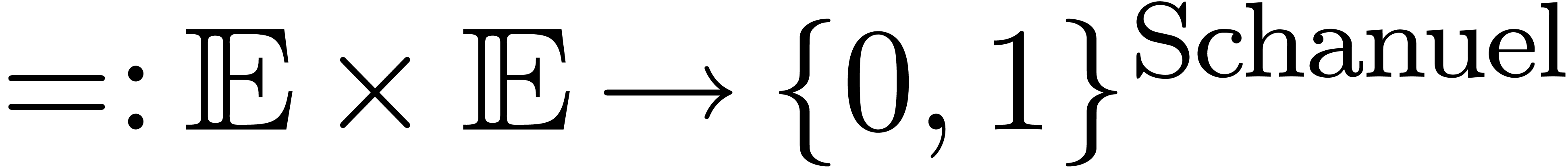 calculable (égalité modulo
conjecture de Schanuel)
calculable (égalité modulo
conjecture de Schanuel)
D'un point de vue logique, les types de données peuvent
être vu comme des « structures effectives » sur un
ensemble  . Chaque
élément de admet alors une
représentation dans un ensemble
. Chaque
élément de admet alors une
représentation dans un ensemble  de
représentations. Chaque représentation peut s'encoder
à son tour par un entier dans
de
représentations. Chaque représentation peut s'encoder
à son tour par un entier dans  ,
et donc être manipulée par des machines de Turing.
,
et donc être manipulée par des machines de Turing.

Par exemple, un nombre dans pourrait être
représenté par une suite calculable croissante :
Il est à noter que, de même que l'on peut définir
plusieurs structures de groupe sur un ensemble 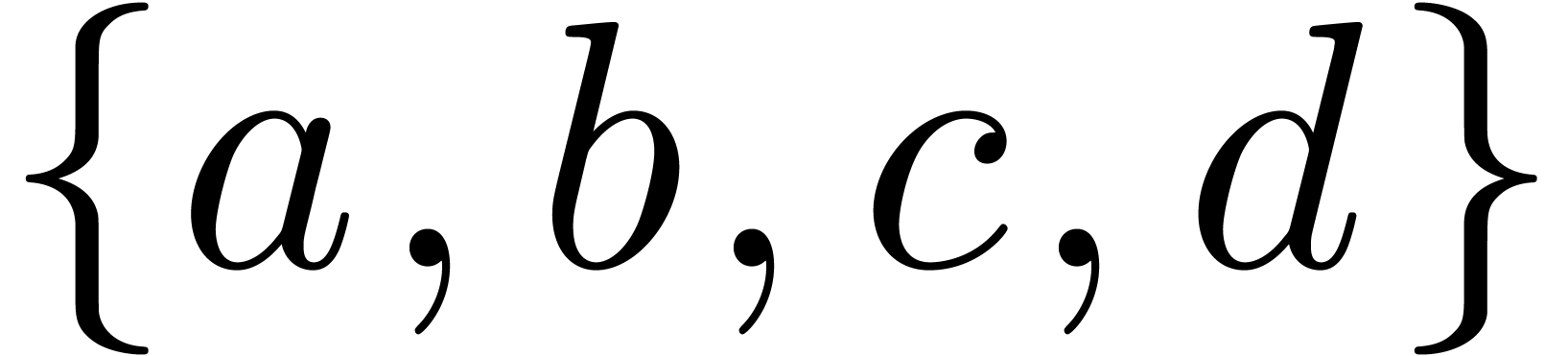 à quatre éléments, on peut définir plusieurs
structures effectives sur
à quatre éléments, on peut définir plusieurs
structures effectives sur 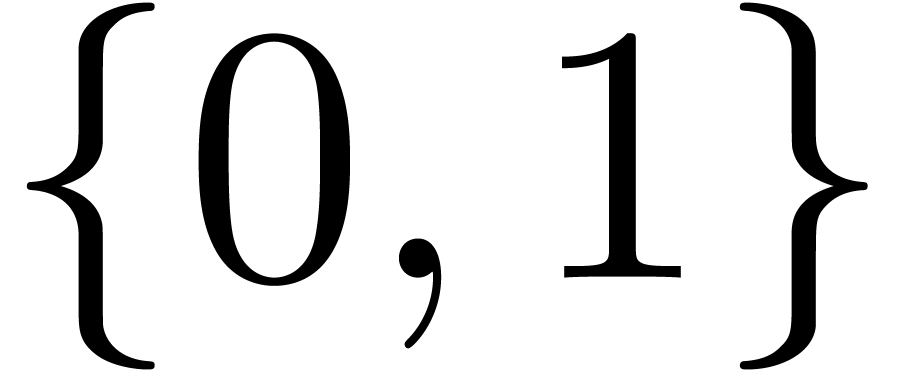 : on a bien sûr
: on a bien sûr
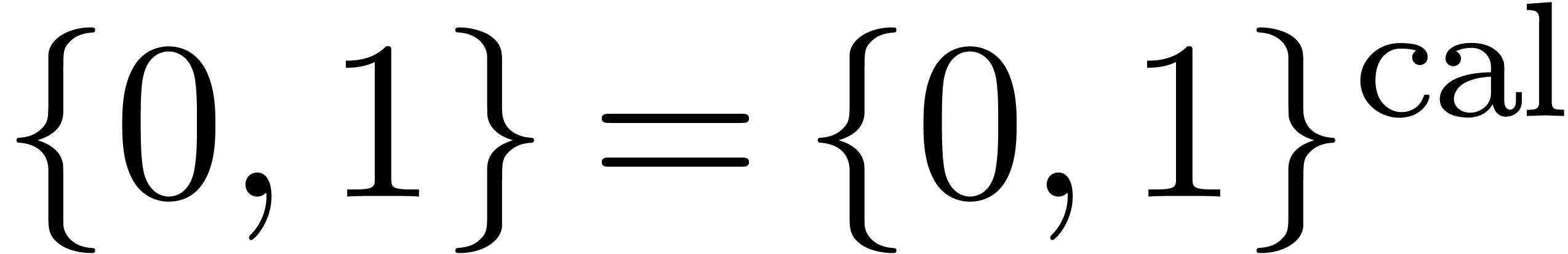 , mais aussi
, mais aussi  et
et 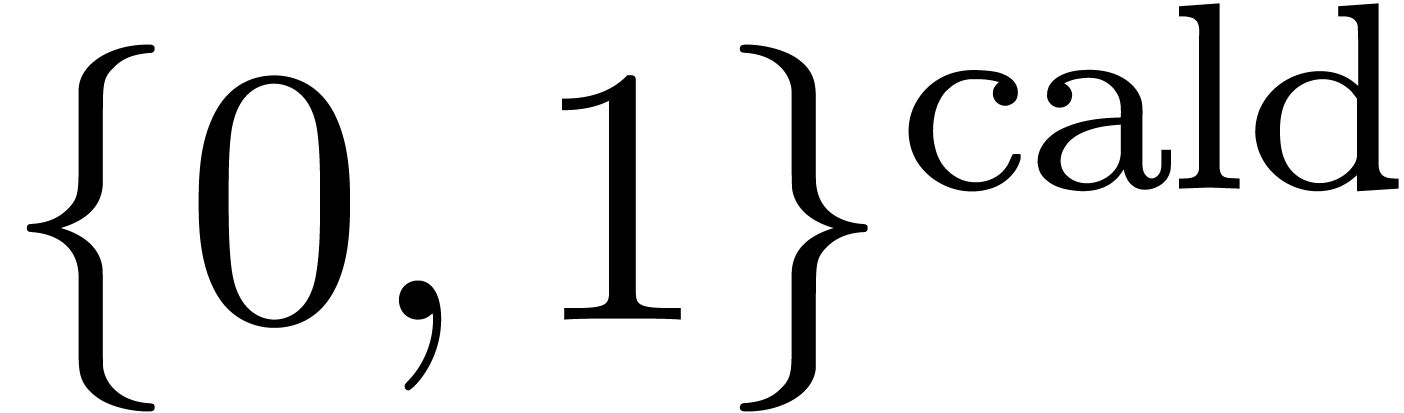 . La représentation
d'un élément de pourrait
être une fonction qui retourne un élément de si la conjecture de Schanuel est vraie.
. La représentation
d'un élément de pourrait
être une fonction qui retourne un élément de si la conjecture de Schanuel est vraie.
En analyse, les objets que l'on manipule correspondent généralement à des résultats de processus d'approximation. Il s'agit donc de structures effectives d'une nature particulière :
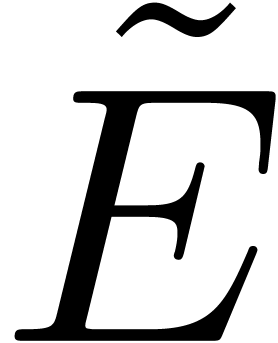 : ensemble abstrait d'approximations
d'éléments dans
: ensemble abstrait d'approximations
d'éléments dans
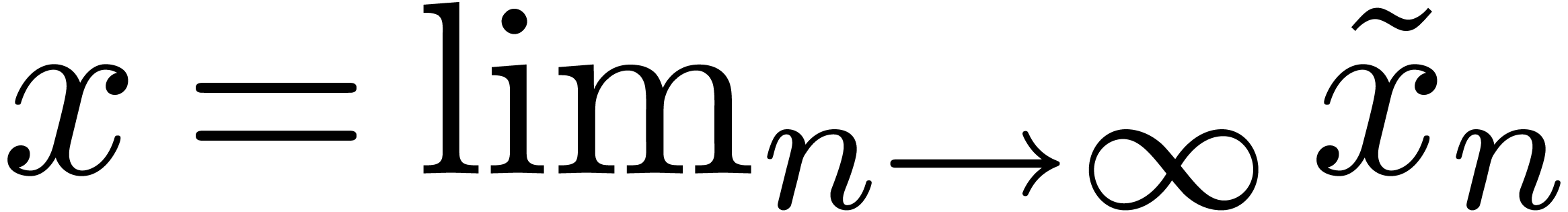 :
:  est la limite des
approximations
est la limite des
approximations 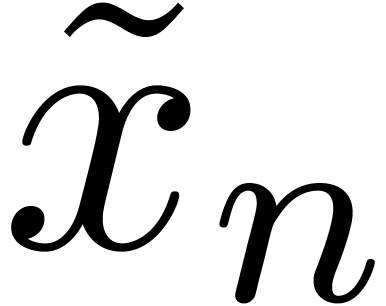
Le plus souvent, est constitué de parties
de (comme des intervalles ou des boules dans le
cas où  ) et la notion
de limite correspond à prendre une intersection. Par exemple :
) et la notion
de limite correspond à prendre une intersection. Par exemple :
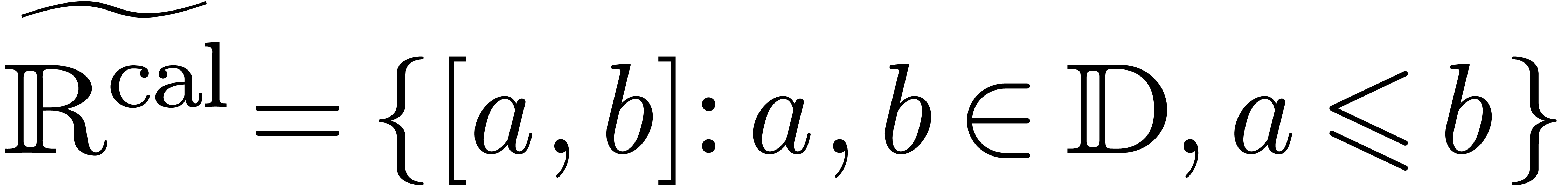
si 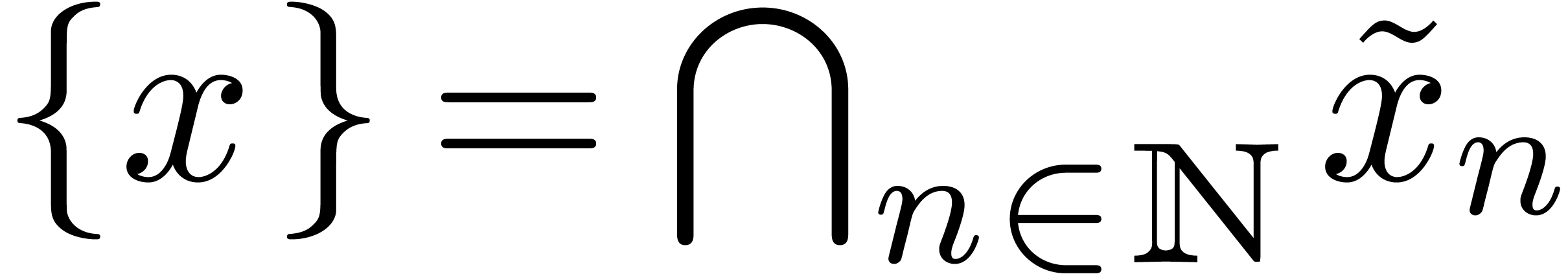
Toutefois, il faut parfois tordre un peu la notion de limite :
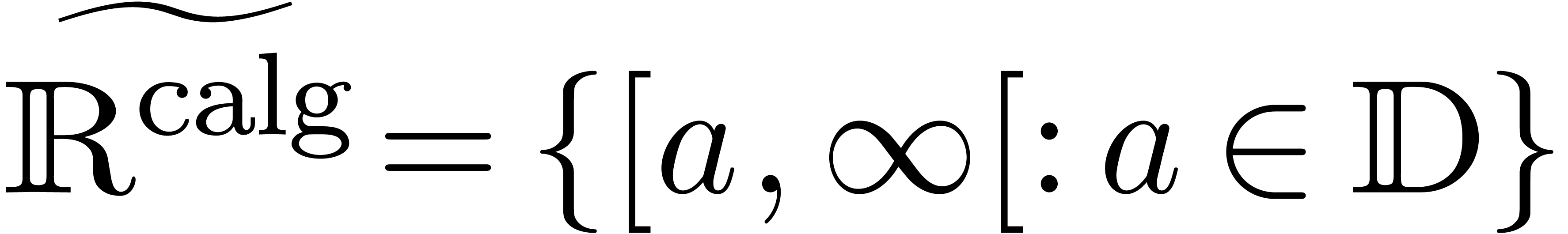
si 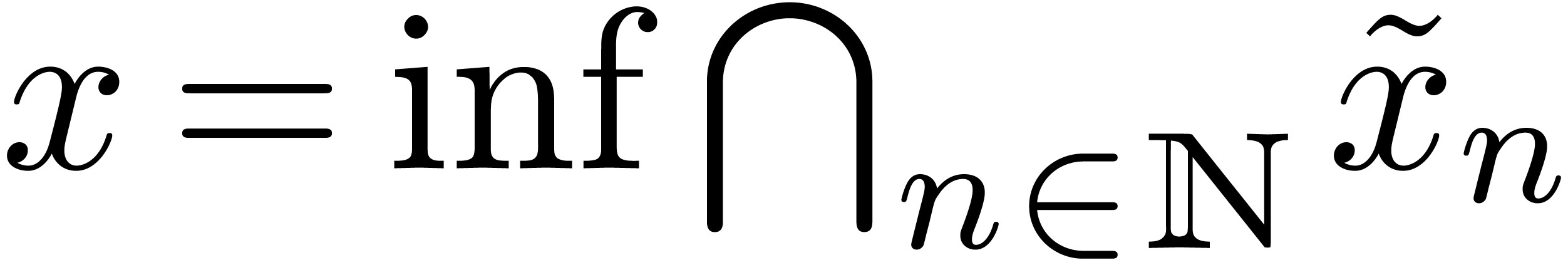
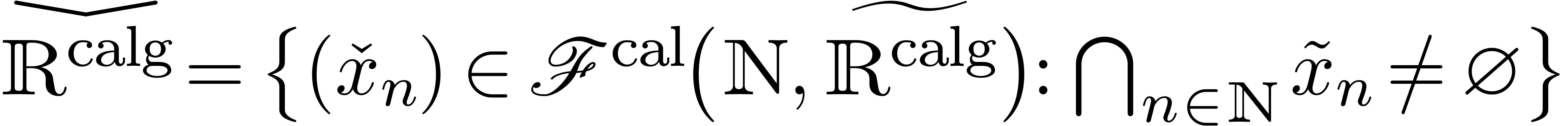
L'intérêt de cette formalisation est une certaine
fonctorialité. Par exemple, si on peut approcher les
éléments de et de , il en est de même pour les
éléments de  et les fonctions dans
et les fonctions dans
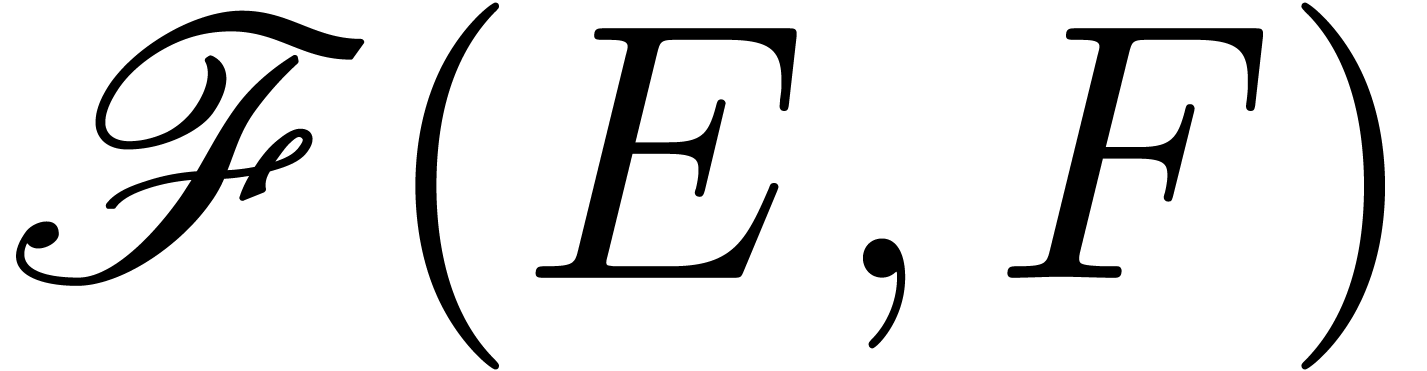 de vers
:
de vers
:

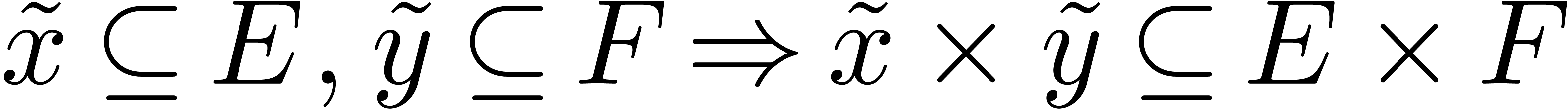
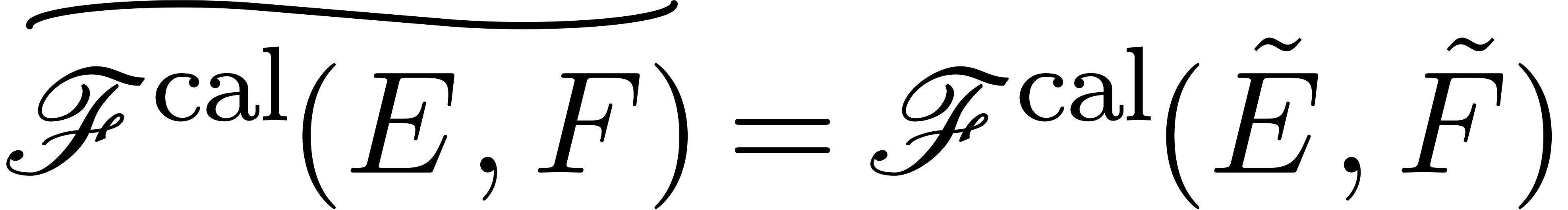
 si si |
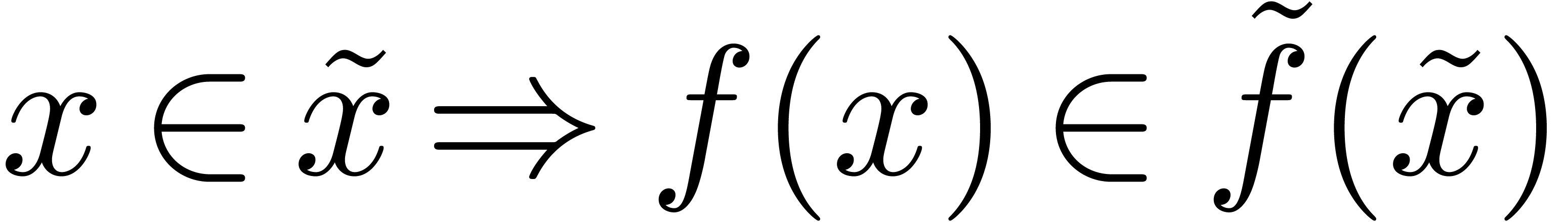 |
Dans la définition 2.1, nous avions choisi d'approcher les nombres réels par des rationnels. Malheureusement, de telles approximations ne sont pas des plus judicieuses si nous voulons borner de façon automatique les erreurs intervenant dans un calcul complexe.
Pour cette raison (voir aussi la section 2.3.4), il est
plus commode d'approcher un nombre réel donné 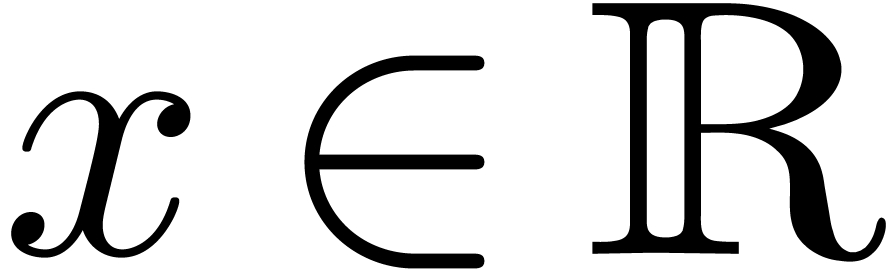 non pas par d'autres nombres
non pas par d'autres nombres 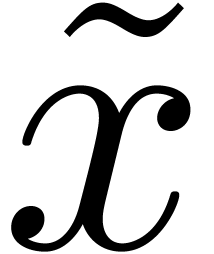 avec
avec
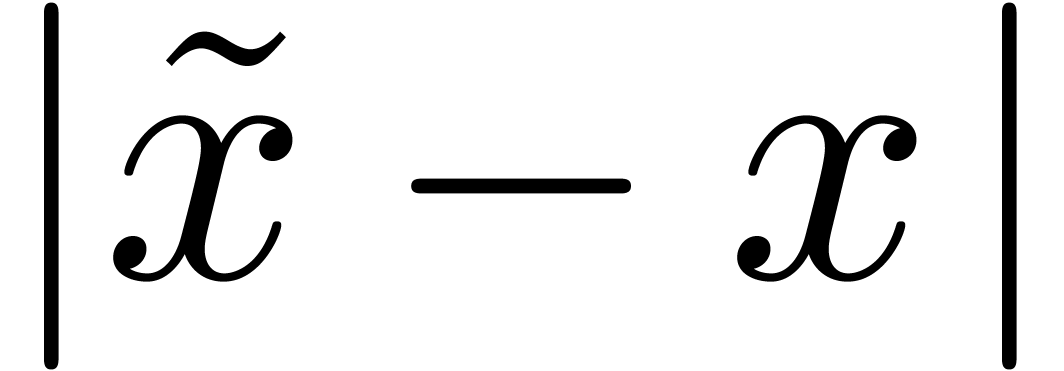 « petit », mais plutôt par des
boules fermées
« petit », mais plutôt par des
boules fermées  de la forme
de la forme
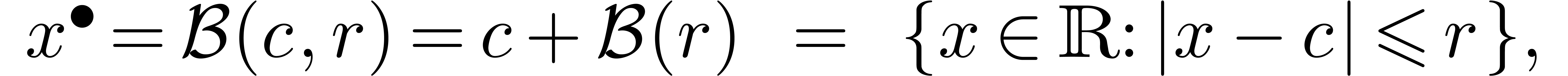
avec 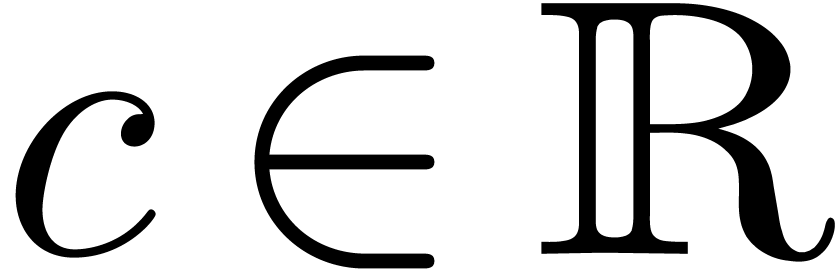 et
et  .
Ainsi, lorsque
.
Ainsi, lorsque  est le résultat d'un
calcul par arithmétique de boules, on est sûr que
le « vrai résultat » est dans
. On peut donc
interpréter une boule comme un «
nombre que l'on ne connait pas, mais pour lequel
on est sûr que
est le résultat d'un
calcul par arithmétique de boules, on est sûr que
le « vrai résultat » est dans
. On peut donc
interpréter une boule comme un «
nombre que l'on ne connait pas, mais pour lequel
on est sûr que 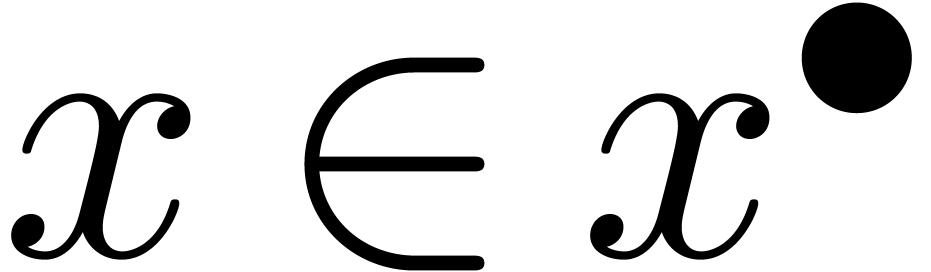 ».
».
Remarque 3.1. Ce principe de calcul n'est pas tout à fait
nouveau d'un point de vue historique. En effet, on peut observer que les
notations  et
et  de Landau
s'interprètent de la même manière. Par exemple, dans
de Landau
s'interprètent de la même manière. Par exemple, dans
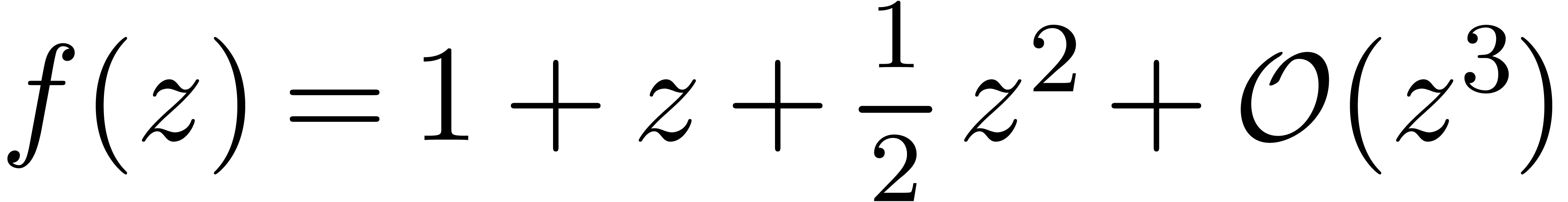 , le terme
, le terme 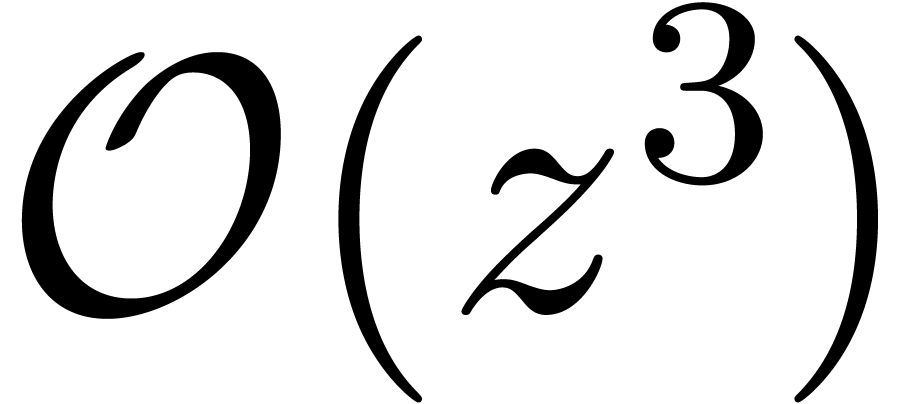 désigne « une quantité que
l'on ne connaît pas, mais pour lequel on est sûr que
désigne « une quantité que
l'on ne connaît pas, mais pour lequel on est sûr que 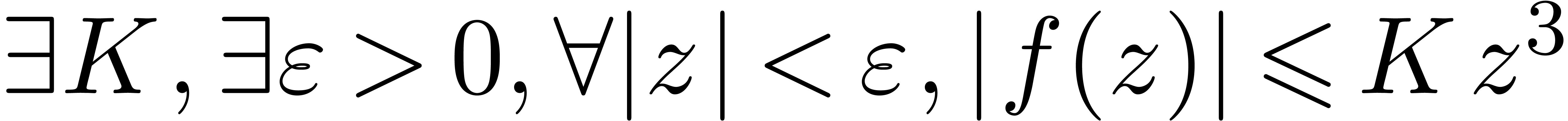 ».
».
Remarque 3.2. Au lieu d'encadrer les nombres
par des boules, on peut aussi les encadrer par des intervalles
fermées  . Ceci conduit
à l'arithmétique d'intervalles, qui est plus classique et
pour laquelle existe une littérature abondante [54,
2, 57, 40, 9, 63] ; voir la section 3.1.4 pour une comparaison.
L'arithmétique de boules est parfois appelé «
arithmétique d'intervalles par centres et rayons » ou
« arithmétique d'intervalles circulaires ». J'ai
préféré un nom plus court, d'autant plus qu'une
boule complexe (par exemple) n'a rien à voir avec des
intervalles.
. Ceci conduit
à l'arithmétique d'intervalles, qui est plus classique et
pour laquelle existe une littérature abondante [54,
2, 57, 40, 9, 63] ; voir la section 3.1.4 pour une comparaison.
L'arithmétique de boules est parfois appelé «
arithmétique d'intervalles par centres et rayons » ou
« arithmétique d'intervalles circulaires ». J'ai
préféré un nom plus court, d'autant plus qu'une
boule complexe (par exemple) n'a rien à voir avec des
intervalles.
Bien sûr, on peut prendre des boules dans des espaces
métriques plus généraux que , en commençant par  . En fait, il n'est même pas impératif
que les rayons des boules vivent dans un espace métrique au sens
classique. Plus tard, on verra par exemple l'utilité de
considerer des boules dont les centres sont des matrices dans
. En fait, il n'est même pas impératif
que les rayons des boules vivent dans un espace métrique au sens
classique. Plus tard, on verra par exemple l'utilité de
considerer des boules dont les centres sont des matrices dans 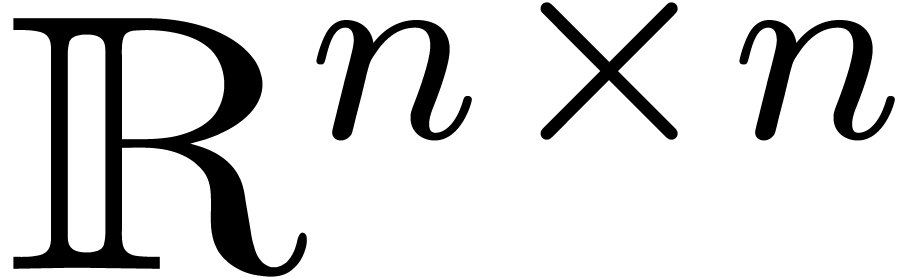 et dont les rayons sont également des matrices
à coefficients positifs dans
et dont les rayons sont également des matrices
à coefficients positifs dans 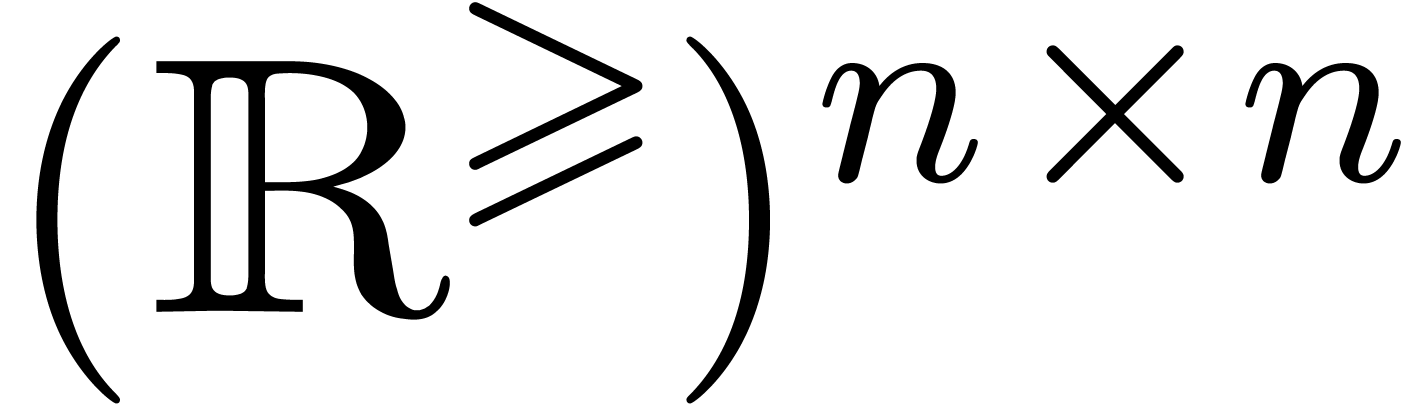 .
.
Dans la suite, étant donnés un ensemble  de centres et un ensemble
de centres et un ensemble 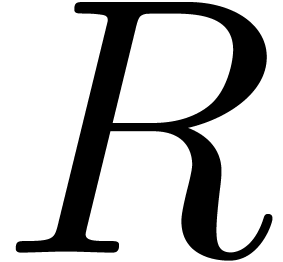 de rayons, on notera
par
de rayons, on notera
par 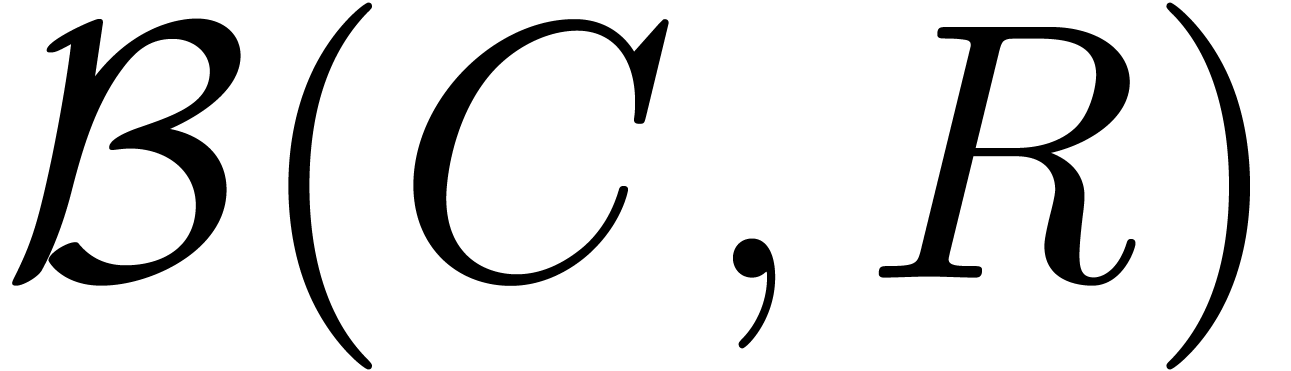 l'ensemble des boules avec des centres dans
et des rayons dans
l'ensemble des boules avec des centres dans
et des rayons dans 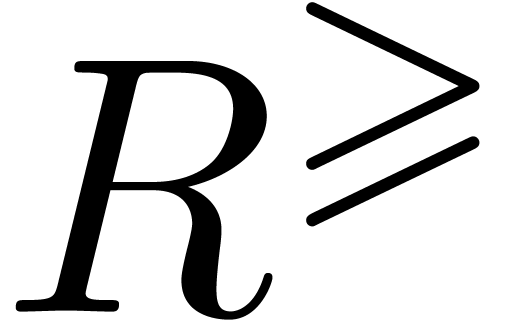 .
.
Soit 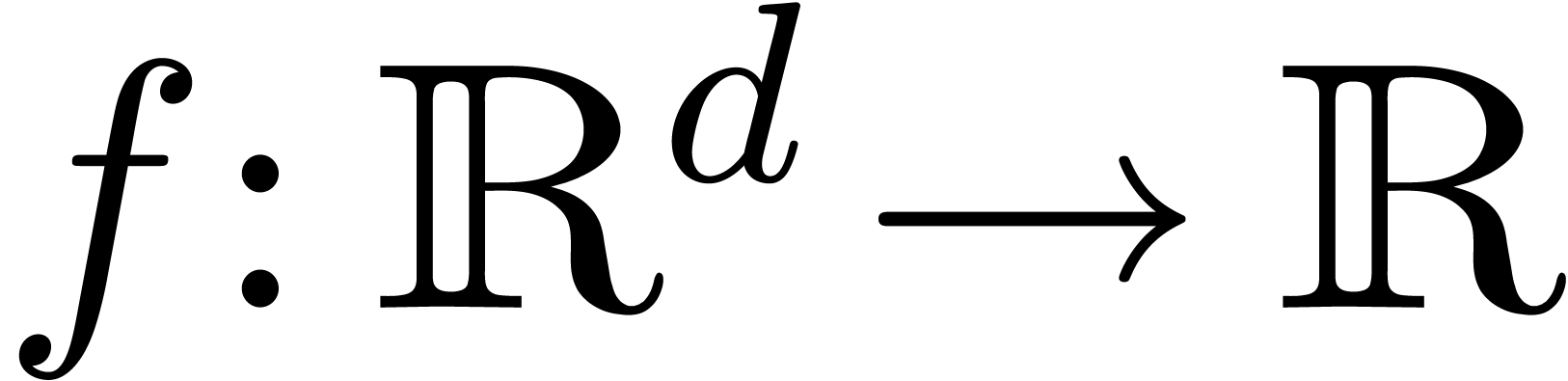 une fonction. Une fonction
une fonction. Une fonction 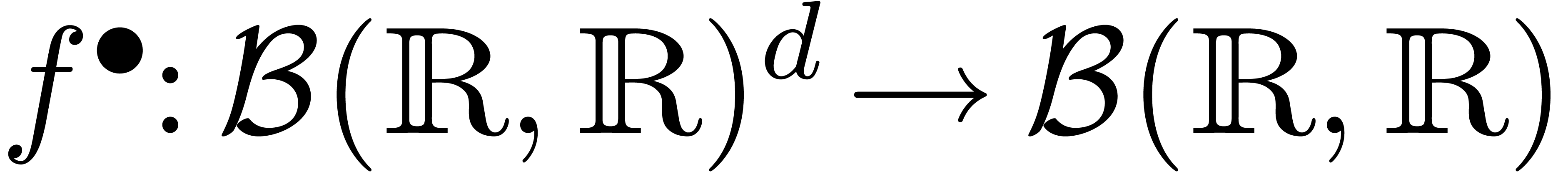 est appelée une extension de si
est appelée une extension de si
pour tous les 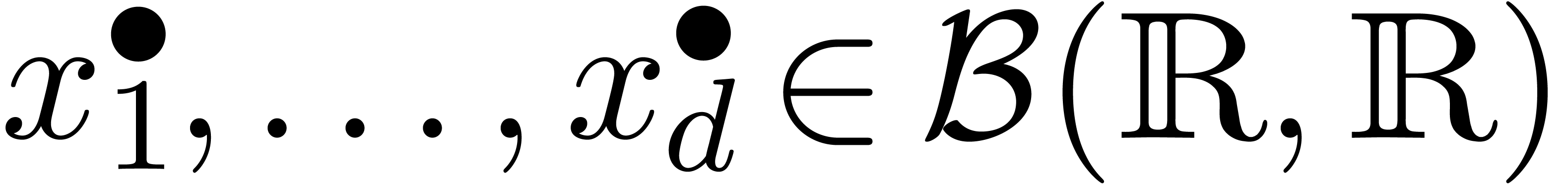 . Ainsi, si
. Ainsi, si
 , alors on peut être
sûr que
, alors on peut être
sûr que 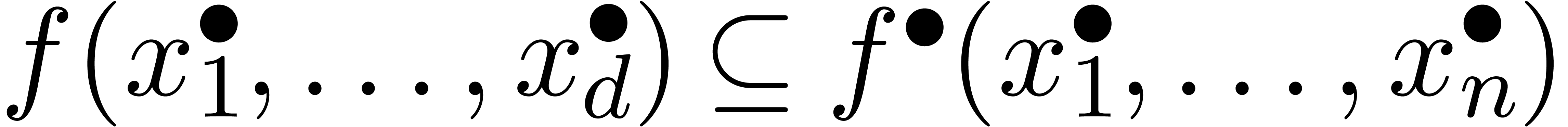 ,
conformément à la sémantique décrite dans la
section précédente.
,
conformément à la sémantique décrite dans la
section précédente.
On peut utiliser les formules suivantes pour les opérations élémentaires :
Il est à noter que la dernière formule est simple, mais
pas nécessairement optimale : par exemple, on trouve 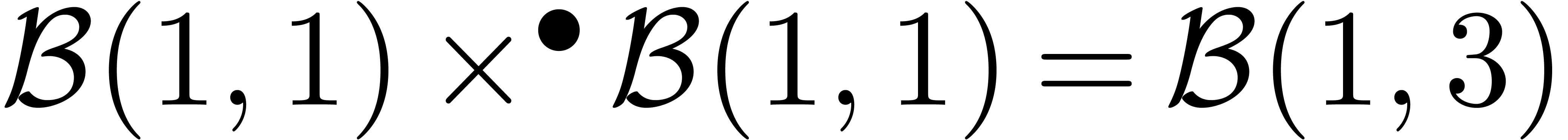 , alors que la boule
, alors que la boule 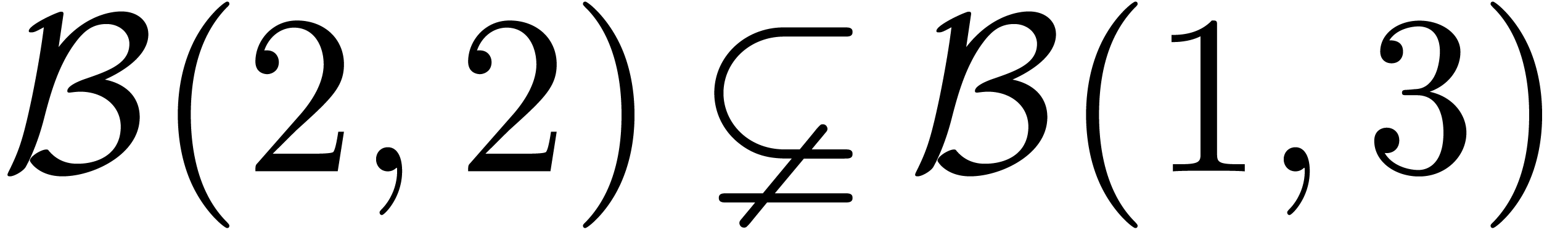 vérifie bien
vérifie bien  .
.
Pour des calculs concrets sur machine, on ne peut prendre les centres et
les rayons dans . Dans ce
cas, on considère plutôt des centres et des rayons dans
 , voire dans l'ensemble
, voire dans l'ensemble
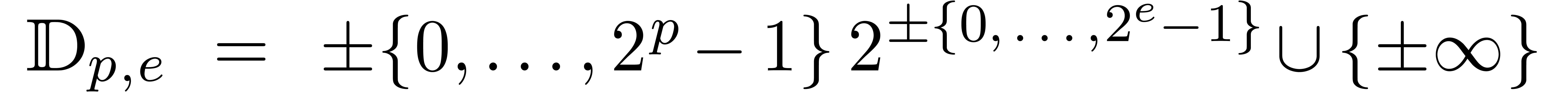
des nombres flottants avec un mantisse de  bits
et un exposant de
bits
et un exposant de  bits. Dans ce dernier cas, il
est à noter qu'il est impératif de rajouter la
possibilité de prendre des rayons infinis, afin de
représenter le résultat d'un overflow
(dépassement de précision).
bits. Dans ce dernier cas, il
est à noter qu'il est impératif de rajouter la
possibilité de prendre des rayons infinis, afin de
représenter le résultat d'un overflow
(dépassement de précision).
Quand on calcule avec en précisions et
fixes, le résultat exact 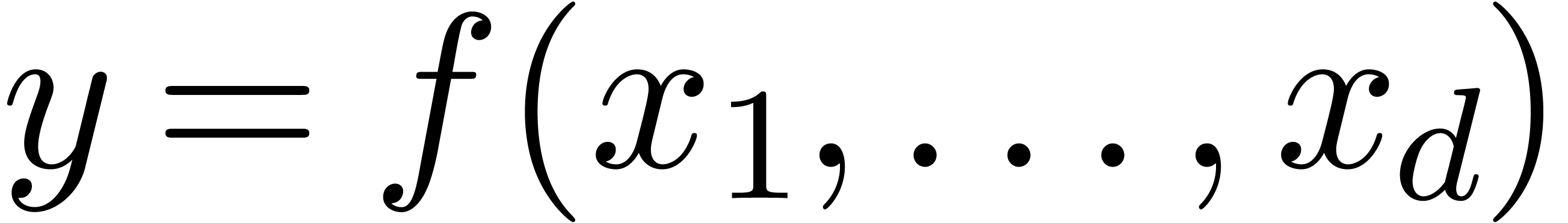 d'une opération sur des nombres
d'une opération sur des nombres  dans
dans  n'est pas nécessairement dans
et son approximation
n'est pas nécessairement dans
et son approximation  par un
élément dans induit donc une
erreur
par un
élément dans induit donc une
erreur 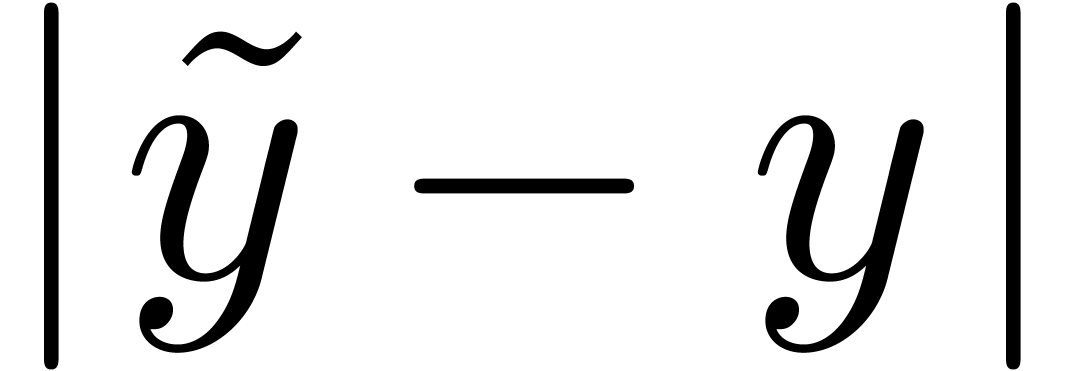 dont il faut tenir compte dans
l'implantation d'une arithmétique de boules.
dont il faut tenir compte dans
l'implantation d'une arithmétique de boules.
La norme IEEE [3, 56] pour le calcul avec des
nombres flottants spécifie que l'approximation
est obtenue en arrondissant le résultat exact  suivant un mode d'arrondi à spécifier. Nous utiliserons
les notations
suivant un mode d'arrondi à spécifier. Nous utiliserons
les notations  pour les modes d'arrondi vers le
haut, vers le bas et au plus près. En notant
pour les modes d'arrondi vers le
haut, vers le bas et au plus près. En notant  , nous notons que
, nous notons que 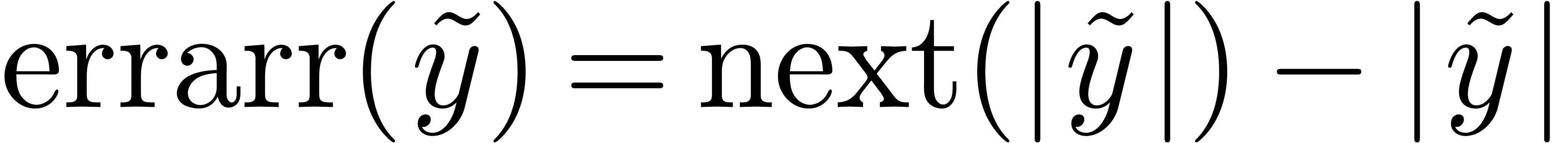 est
une borne supérieure pour l'erreur quelque soit le mode d'arrondi
choisi. Les formules (3.2), (3.3) et (3.4)
peuvent donc adaptées au cas du calcul en précision
limitée, en les remplaçant par
est
une borne supérieure pour l'erreur quelque soit le mode d'arrondi
choisi. Les formules (3.2), (3.3) et (3.4)
peuvent donc adaptées au cas du calcul en précision
limitée, en les remplaçant par
Il est à noter que la norme IEEE est désormais suivie par
la plupart des constructeurs de micro-processeurs.
On a déjà mentionné le fait que l'arithmétique de boules est classiquement considérée comme une variante de l'arithmétique d'intervalles. Pourquoi choisir l'une ou l'autre ? Voici quelques avantages et inconvénients des deux approches.
Quand les intervalles sont grands, l'arithmétique d'intervalles est généralement plus précises. Pour certaines applications, les intervalles sont grands par nature et donc plus adaptées. Par exemple, lors de la recherche de solutions d'un système d'équations dans une boîte, il est tout à fait adapté d'utiliser une méthode de découpage par dichotomie.
Toute fonction monotone 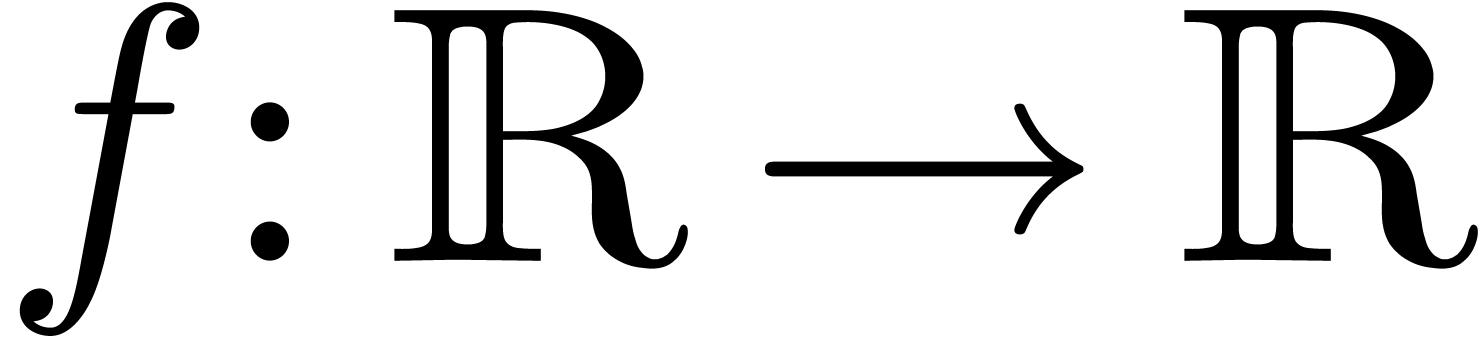 ,
disons croissante, admet une extension canonique
,
disons croissante, admet une extension canonique  en arithmétique d'intervalles :
en arithmétique d'intervalles : 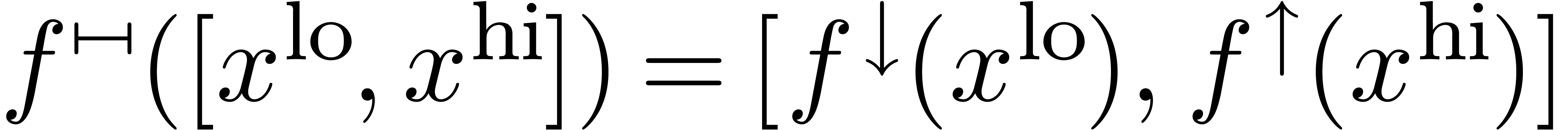 .
Ceci favorise la standardisation.
.
Ceci favorise la standardisation.
En implantant la norme IEEE, les processeurs modernes privilégient a priori l'efficacité de l'arithmétique d'intervalles. Attention toutefois : changer le mode d'arrondi peut s'avérer très coûteux en temps, auquel cas il faut adapter les algorithmes afin de pouvoir fonctionner avec n'importe quel mode d'arrondi [92, 45].
En précision multiple, les intervalles sont généralement petits, ce qui permet le stockage du centre en précision multiple et le rayon en précision simple. Ceci est deux fois plus efficace en temps et en espace par rapport à l'arithmétique d'intervalles qui oblige à stocker les deux extrémités en précision multiple. Si on cherche à approcher de plus en plus précisément des vrais nombres réels, il est donc plus naturel d'utiliser des boules.
L'arithmétique de boules donne une grande souplesse quant au choix des centres et des rayons. D'une part, ceci peut être utilisé pour améliorer la qualité des estimations (voir la section 3.2.3). D'autre part, ceci peut être utilisé pour améliorer la vectorisation et plus généralement l'efficacité des algorithmes (voir la section 3.4.2).
En mathématiques, les estimations d'erreur
s'établissent généralement via le
calcul  -
-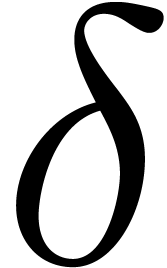 classique. Ce calcul correspond naturellement à
l'arithmétique de boules, ce qui facilite la conception
d'algorithmes certifiés. Ceci s'applique tout
particulièrement à tout argument par perturbation.
classique. Ce calcul correspond naturellement à
l'arithmétique de boules, ce qui facilite la conception
d'algorithmes certifiés. Ceci s'applique tout
particulièrement à tout argument par perturbation.
Une question intéressante concerne la sémantique des
prédicats comme  . Si
on interprète les boules comme un ensemble de « valeurs
possibles », alors le résultat d'un test
. Si
on interprète les boules comme un ensemble de « valeurs
possibles », alors le résultat d'un test 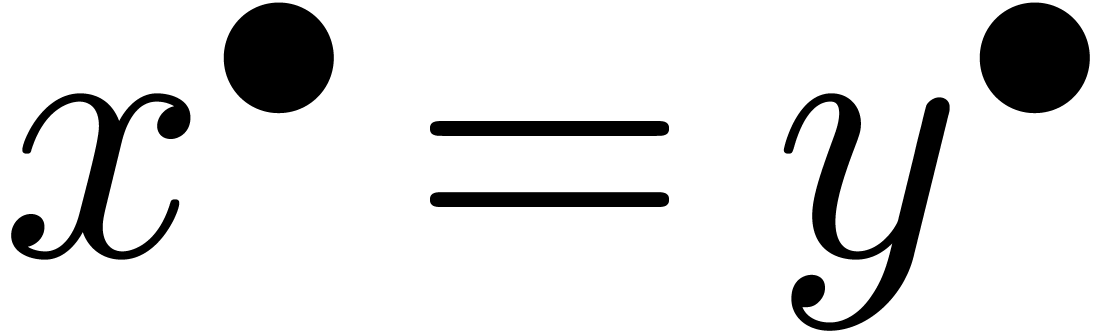 devrait être un intervalle
devrait être un intervalle 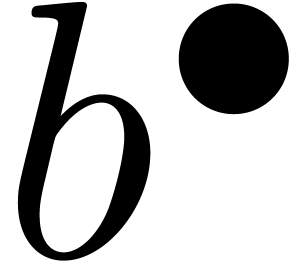 de
de 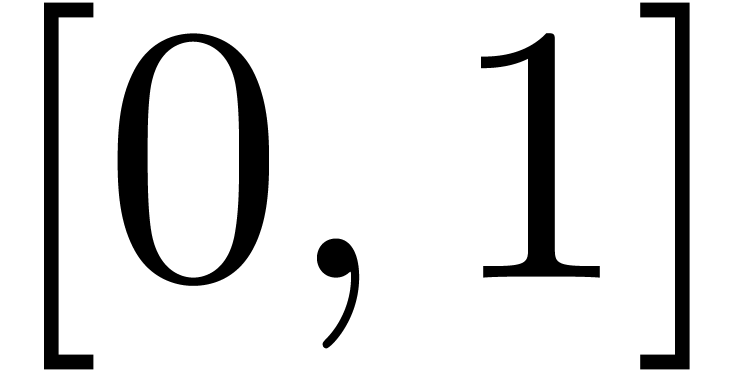 avec
avec
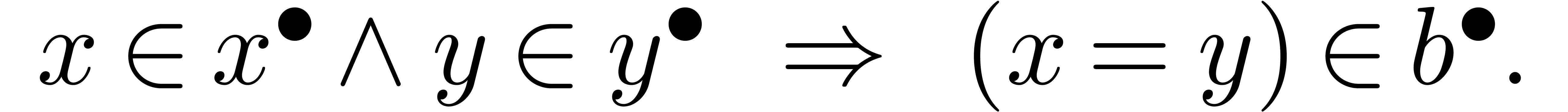
En revanche, si on interprète et  comme des approximation d'un vrai nombre réel
à une certaine précision, il est plus naturel de prendre
comme des approximation d'un vrai nombre réel
à une certaine précision, il est plus naturel de prendre

En effet, si  sont des nombres calculables
représentés par des suites calculables
décroissantes de boules
sont des nombres calculables
représentés par des suites calculables
décroissantes de boules 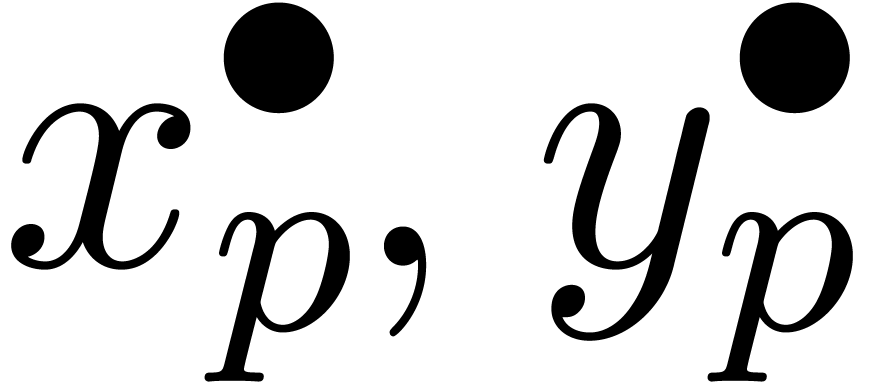 avec
avec 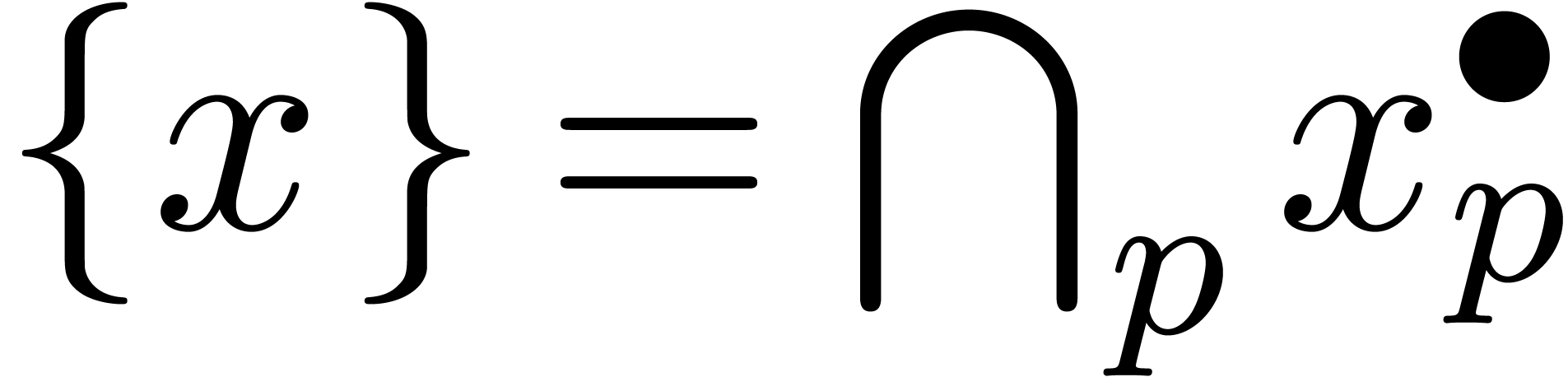 et
et 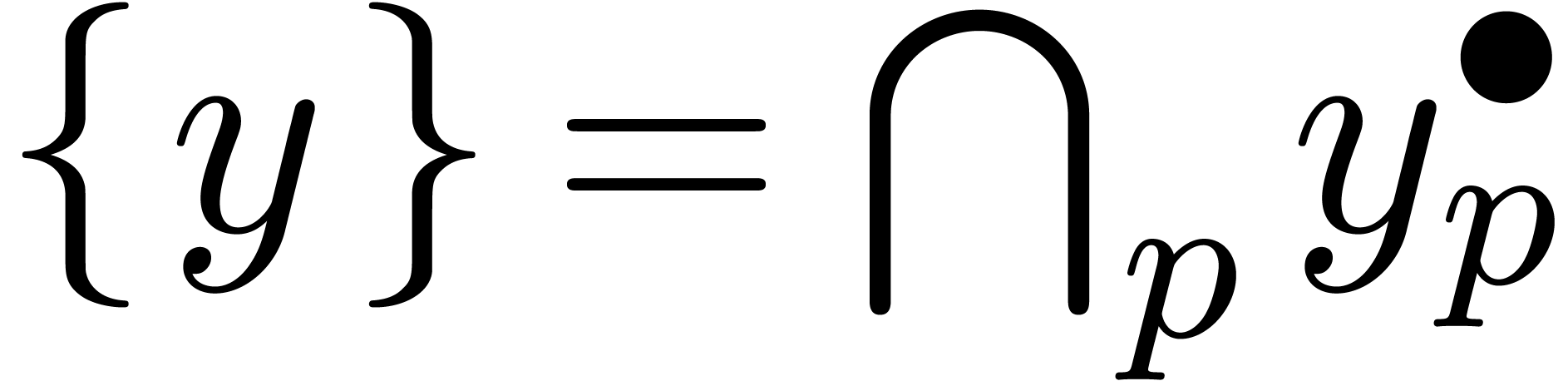 , alors la
suite
, alors la
suite 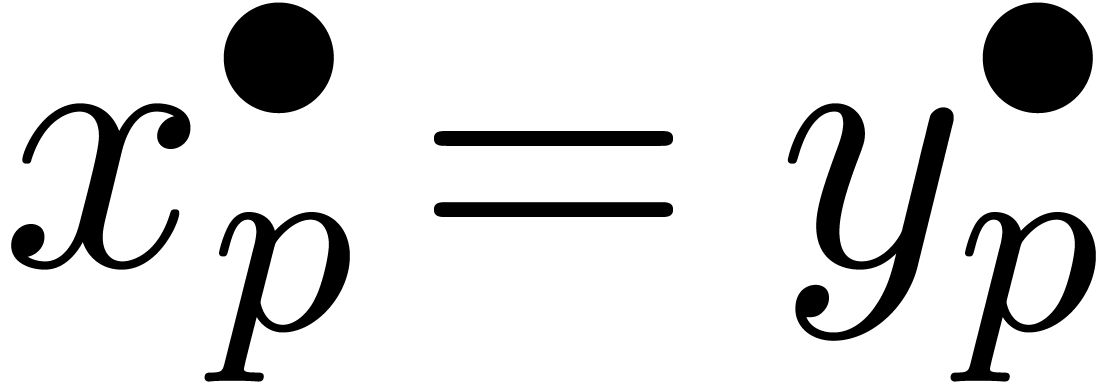 à valeurs dans
représente le résultat du test d'égalité
à valeurs dans
représente le résultat du test d'égalité
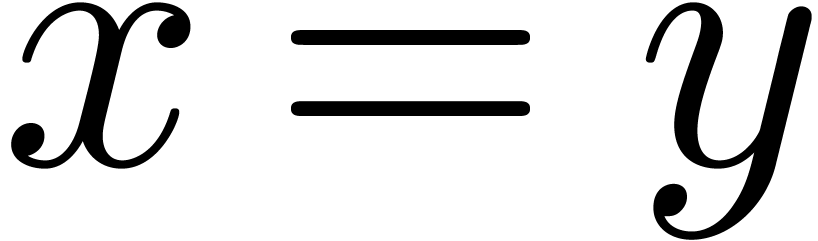 dans
dans 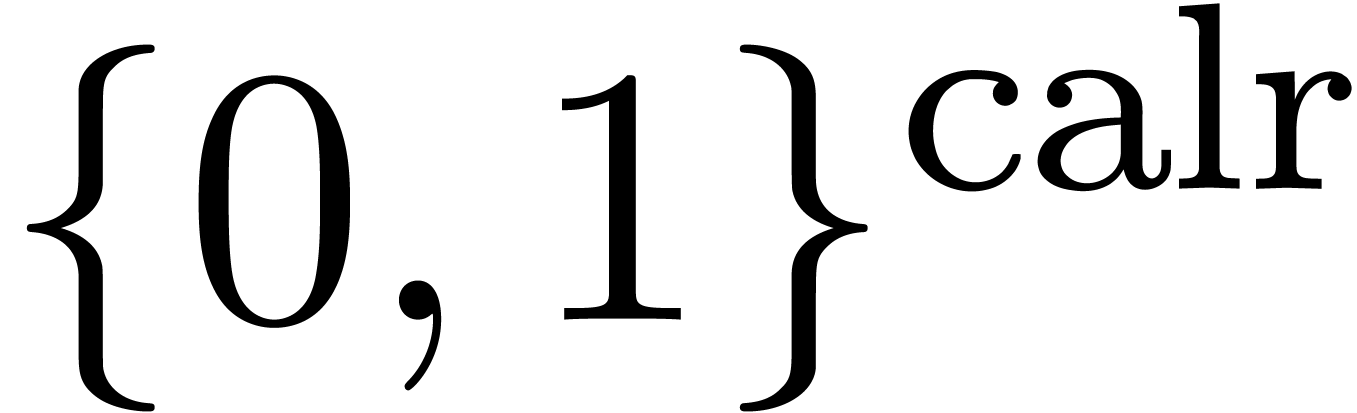 .
La deuxième définition reflète donc
l'asymmétrie profonde de l'égalité dans l'analyse
calculable.
.
La deuxième définition reflète donc
l'asymmétrie profonde de l'égalité dans l'analyse
calculable.
L'arithmétique des boules est basée sur une analyse a posteriori des erreurs : on effectue une opération en arithmétique de boules en utilisant une certaine précision que l'on augmentera jusqu'au moment où le rayon du résultat est suffisamment petit. Parfois, bien que rarement, on peut préférer une estimation a priori de l'erreur [80].
Exemple : calcul d'une -approximation
de 
Calculer des  -approximations
-approximations
 et
et  de
et
de
et 
Retourner 
Avantage : précision de calcul adaptatif dans le
case 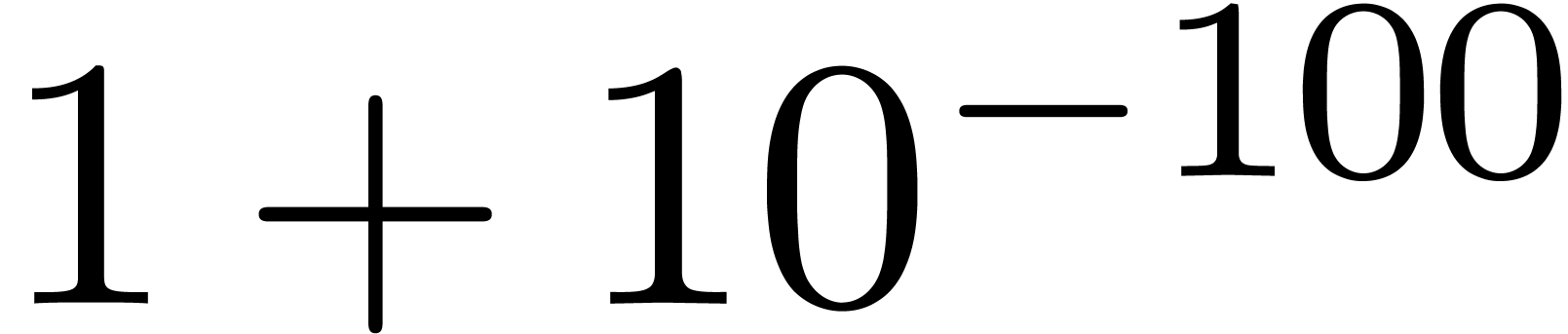
En effet, dans l'arithmétique de boules classique, on calcule
 et
et 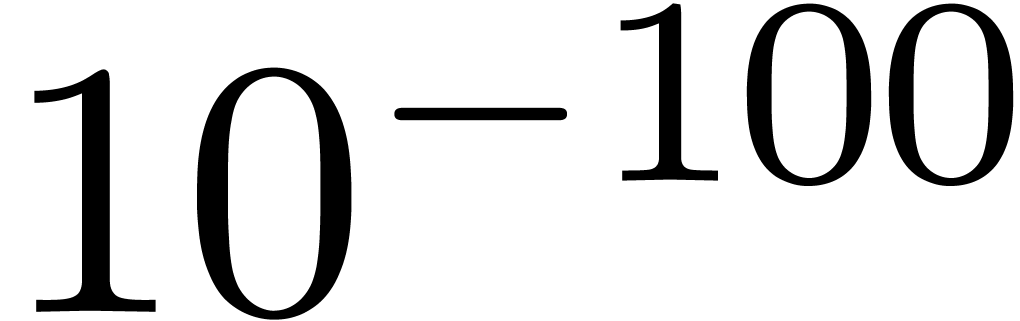 en utilisant la
même précision, alors que l'on peut simplement utiliser
en utilisant la
même précision, alors que l'on peut simplement utiliser
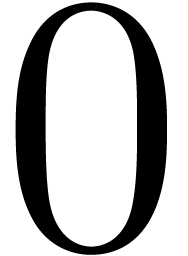 comme approximation de
tant que
comme approximation de
tant que 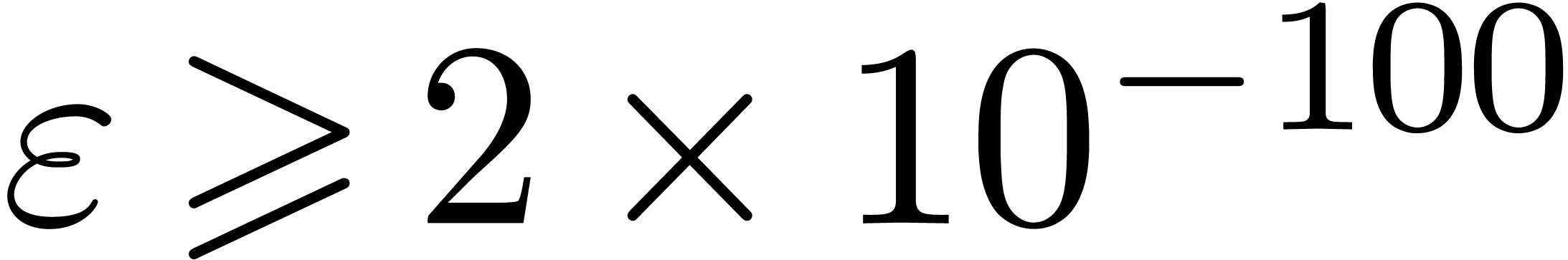 . Supposant que
est un nombre dont l'approximation est
très couteuse en temps, une estimation a priori de
l'erreur est donc plus efficace.
. Supposant que
est un nombre dont l'approximation est
très couteuse en temps, une estimation a priori de
l'erreur est donc plus efficace.
Problème : évaluation de  par Horner en
par Horner en 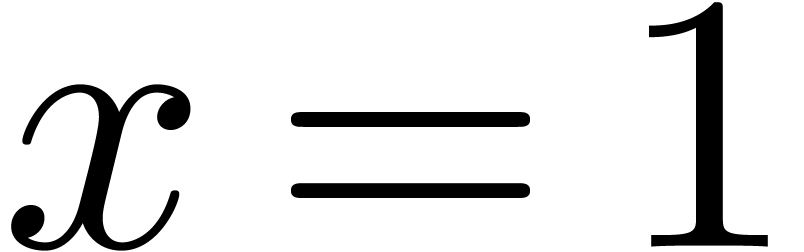
Calcul d'une 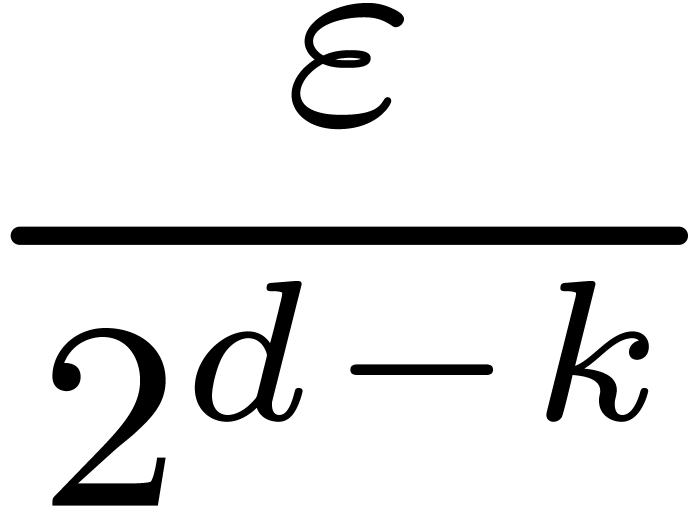 -approximation
de
-approximation
de 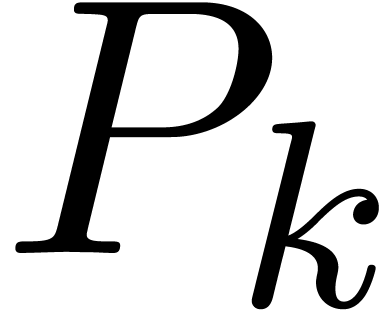 pour
pour 
 tolérance trop petite
tolérance trop petite
Équilibrage des tolérances : calcul d'une 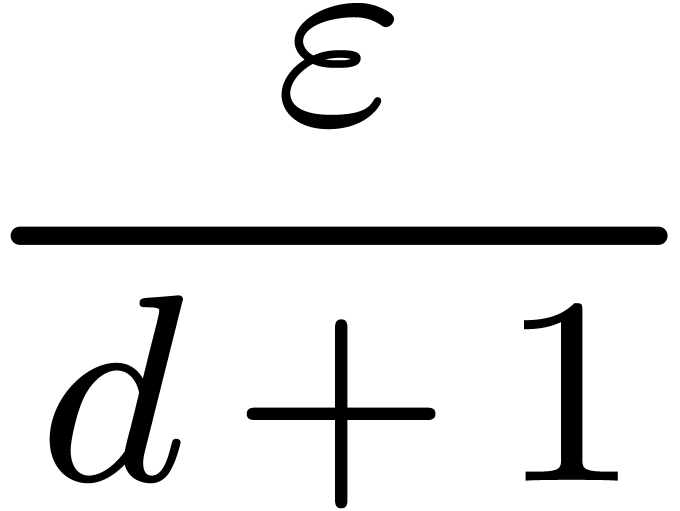 -approximation de
pour tout
-approximation de
pour tout 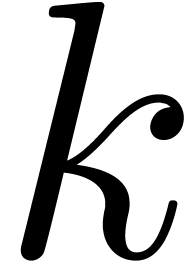
Problème : nécessite des « dags » (directed acyclic graphs) pour tous les résultats intermédiaires
Le problème principal de l'arithmétique de boules concerne
la surestimation des erreurs. Par exemple, l'évaluation de la
fonction 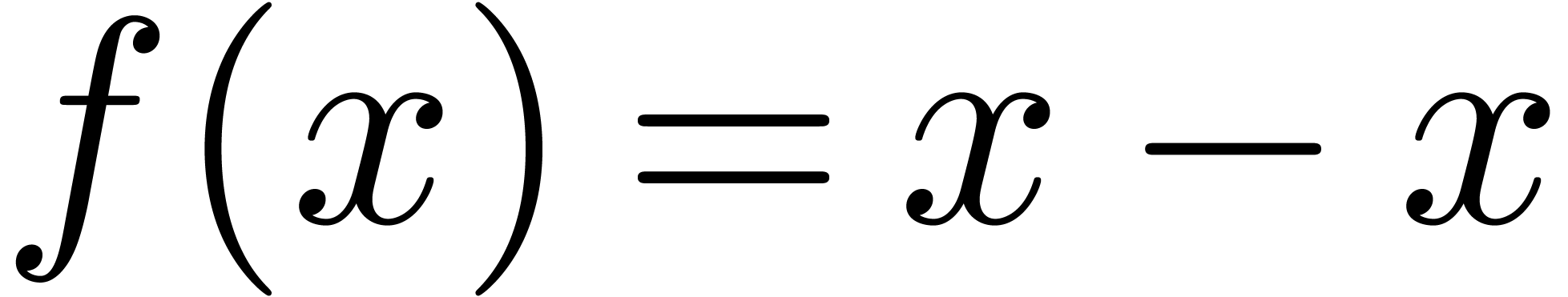 en
en 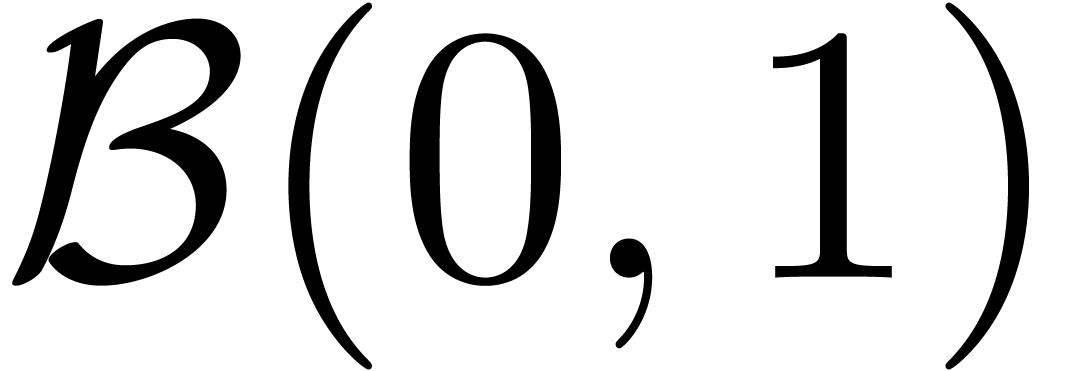 donne
donne
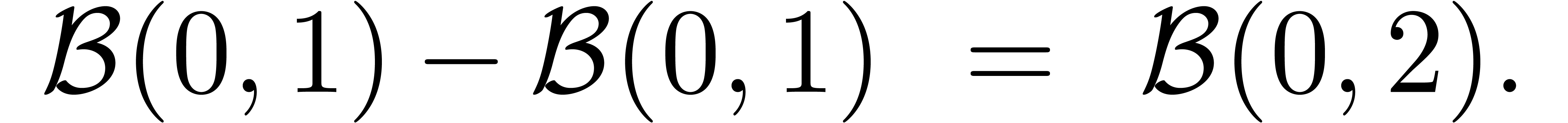
Plus généralement, ce problème intervient chaque fois qu'il y a des quantités qui s'annulent lors d'un calcul, sans que la méthode de calcul s'en rend compte.
Dans certain cas, la surestimation est due à notre façon
de représenter les encadrements. Par exemple, en
arithmétique d'intervalles standard, on encadre les nombres
complexes par des rectangles de la forme 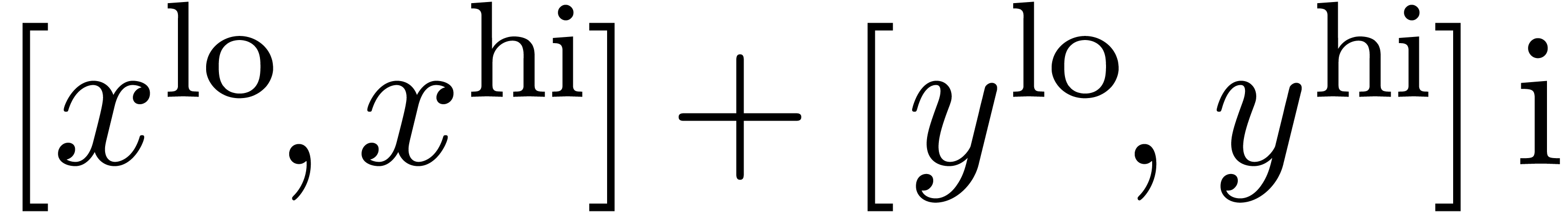 .
Ces rectangles ont tendance à se tourner lors de la
multiplication par un nombre complexe non réel, comme dans
l'exemple
.
Ces rectangles ont tendance à se tourner lors de la
multiplication par un nombre complexe non réel, comme dans
l'exemple
Ici l'inclusion du résultat dans un autre rectangle de la forme requise implique une perte automatique de précision. On appelle ceci l'effet d'enveloppement. Sur cet exemple précis, l'inconvénient disparaît lorsque l'on utilise l'arithmétique de boules, puisqu'une boule reste une boule si on la tourne. Toutefois, on verra un exemple plus complexe dans la section 5.5.2, où il faudra travailler plus pour résoudre le problème.

|
Fig. 3.1. Illustration de l'effet d'enveloppement pour l'exemple (3.5). |
Illustrons la perte de précision lorsque l'on calcule 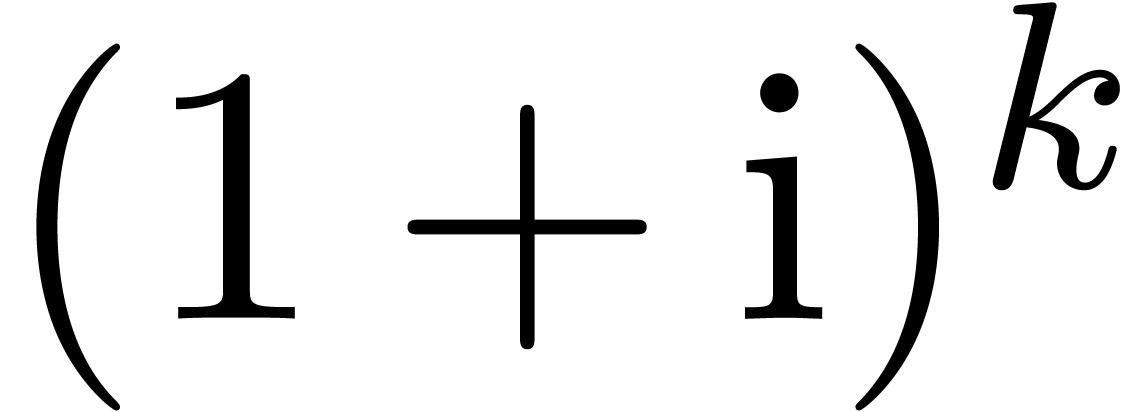 pour
pour  de façon naïve en
utilisant l'arithmétique d'intervalles. Dans la sortie, on
utilise la notation scientifique. Par exemple
de façon naïve en
utilisant l'arithmétique d'intervalles. Dans la sortie, on
utilise la notation scientifique. Par exemple 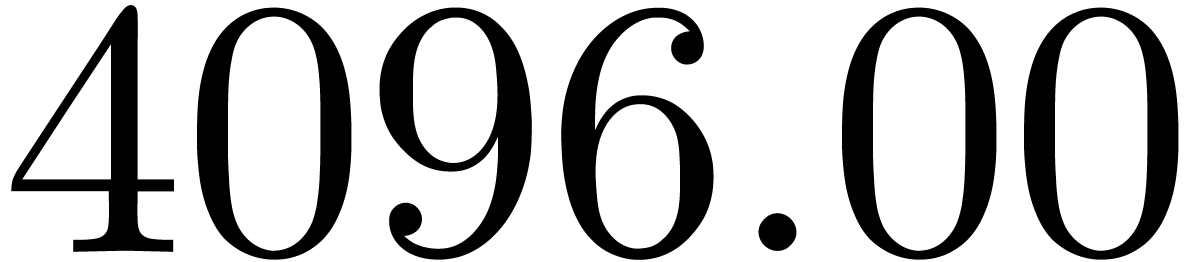 désigne un nombre compris entre
désigne un nombre compris entre  et
et  .
.
Mmx] |
use "algebramix"; |
Mmx] |
puissance (z, n) == if n = 1 then z else z * puissance (z, n-1); |
Mmx] |
z == complex (interval (1.0, 1.0000000001),
interval (1.0, 1.0000000001)) |

Mmx] |
[ puissance (z, 4*n) || n in 1 to 10 ] |

Comme on l'avait prédit, la perte de précision n'apparait pas lorsque l'on remplace l'arithmétique d'intervalles par l'arithmétique de boules.
Mmx] |
use "algebramix"; |
Mmx] |
puissance (z, n) == if n = 1 then z else z * puissance (z, n-1); |
Mmx] |
z == ball (complex (1.0, 1.0), 0.0000000001) |
Mmx] |
[ puissance (z, 4*n) || n in 1 to 10 ] |

Une autre technique pour limiter l'effet d'enveloppement consiste
à utiliser des algorithmes qui minimisent la profondeur du
calcul. En effet, dans la section 3.2.2, l'effet est
amplifié par le fait que l'on réinjecte
fois le résultat du calcul précédent dans
l'étape d'après, perdant ainsi 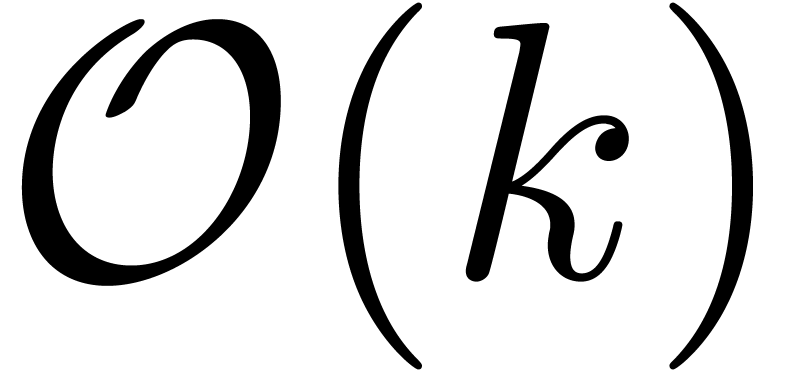 bits de précision. Si on utilise un algorithme diviser pour
régner pour calculer des puissances, la perte de précision
se limite à
bits de précision. Si on utilise un algorithme diviser pour
régner pour calculer des puissances, la perte de précision
se limite à 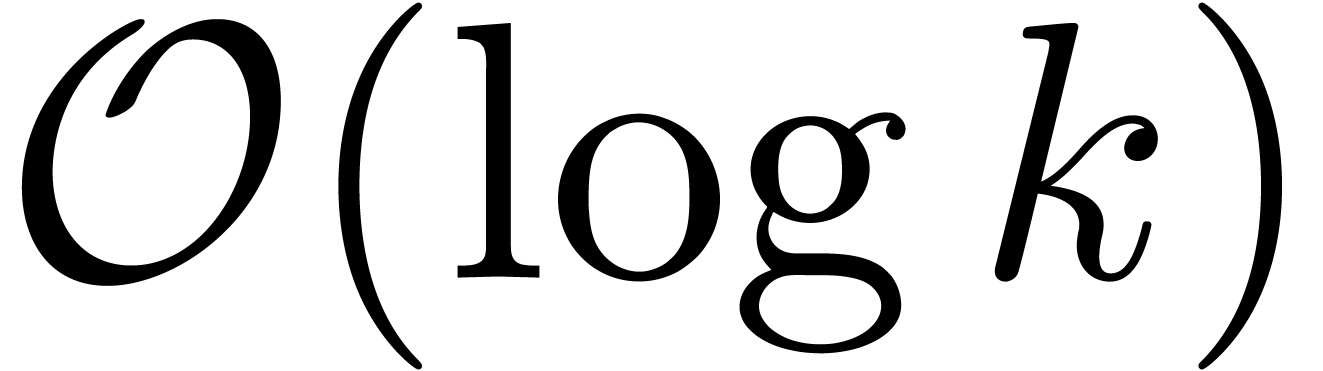 bits. À noter que ce
genre d'algorithmes sont intéressants de toute façon, car
ils se parallèlisent généralement mieux et ils se
comportent mieux vis à vis de la mémoire cache.
bits. À noter que ce
genre d'algorithmes sont intéressants de toute façon, car
ils se parallèlisent généralement mieux et ils se
comportent mieux vis à vis de la mémoire cache.
Mmx] |
use "algebramix"; |
Mmx] |
puissance (z, n) == if n = 1 then z else puissance (z, n quo 2) * puissance (z, n - (n quo 2)); |
Mmx] |
z == complex (interval (1.0, 1.0000000001), interval (1.0, 1.0000000001)) |
Mmx] |
[ puissance (z, 4*n) || n in 1 to 10 ] |

Nous avons déjà souligné l'importance des méthodes perturbatives en calcul analytique. Elles interviennent notamment lorsque l'on cherche à résoudre des équations et que l'on a déjà un moyen pour résoudre l'équation de façon approchée.
Considérons par exemple l'inversion d'une matrice 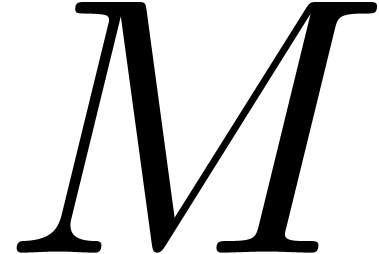 , qui correspond à la résolution
de l'équation
, qui correspond à la résolution
de l'équation  . Si
. Si
 est une matrice de boules,
réécrite comme une boule de centre
est une matrice de boules,
réécrite comme une boule de centre  et de rayon
et de rayon  , le calcul de
, le calcul de
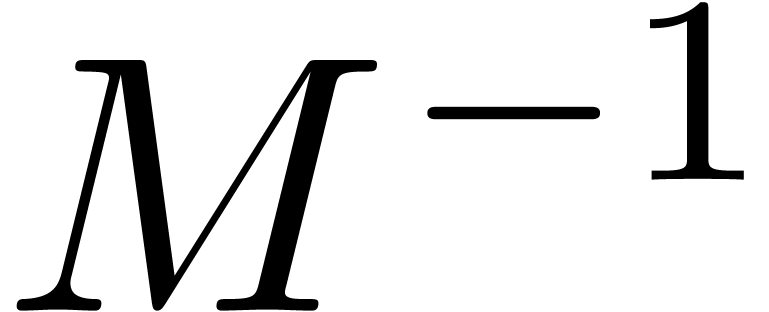 par pivot de Gauss naïf produit une
surestimation énorme. Or il existe de bons algorithmes
numériques pour inverser le centre de
façon approchée, produisant une matrice
par pivot de Gauss naïf produit une
surestimation énorme. Or il existe de bons algorithmes
numériques pour inverser le centre de
façon approchée, produisant une matrice  avec
avec 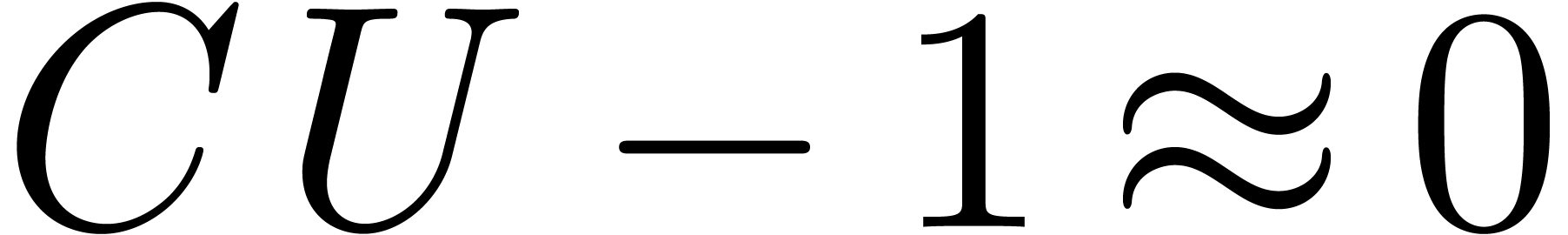 . Dès lors, il
suffit d'étudier de combien l'inverse de
peut bouger lorsque l'on fait varier .
Ceci conduit à l'algorithme suivant :
. Dès lors, il
suffit d'étudier de combien l'inverse de
peut bouger lorsque l'on fait varier .
Ceci conduit à l'algorithme suivant :
Algorithme (Hansen)

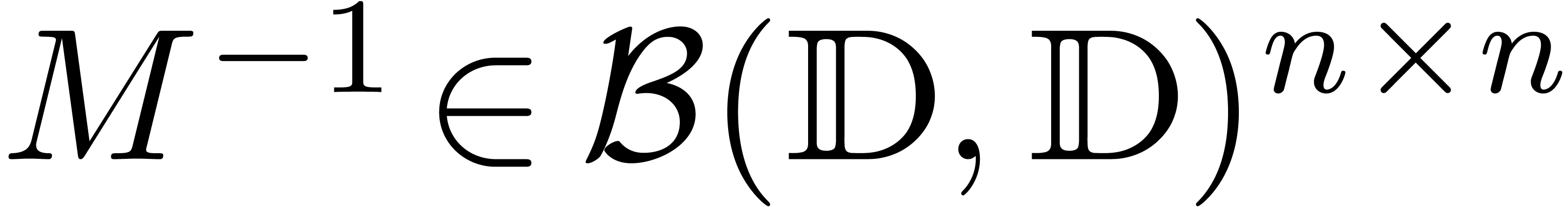 de
de
Écrire 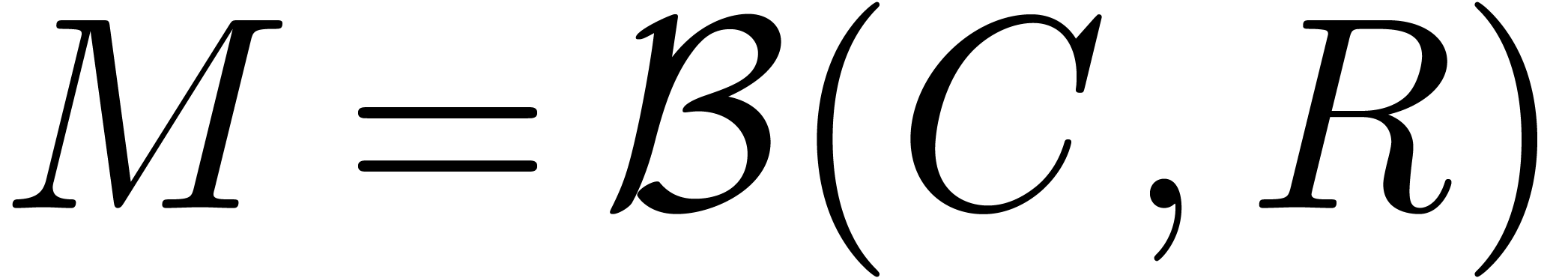 , avec
et
, avec
et 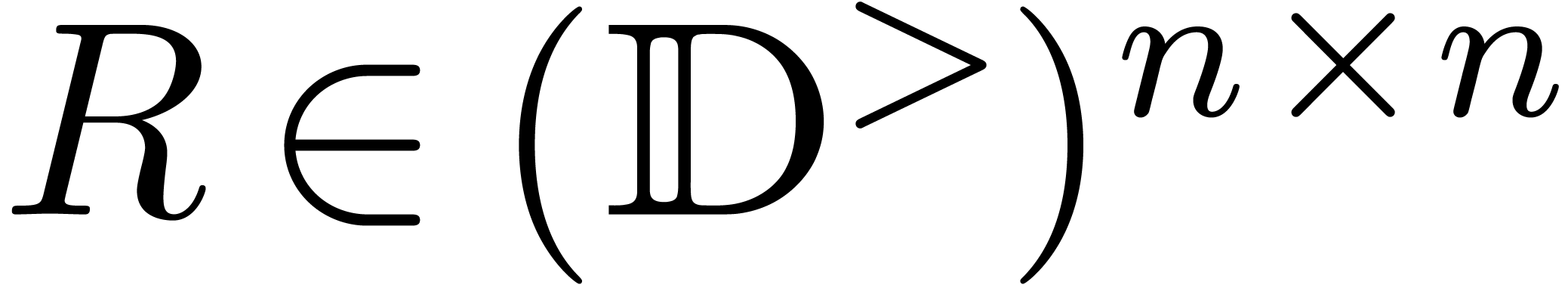
Inverser numériquement 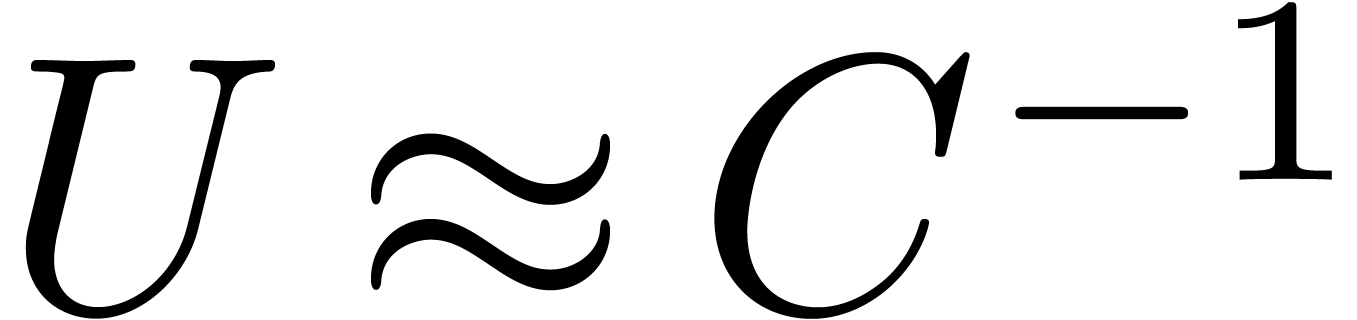
Calculer 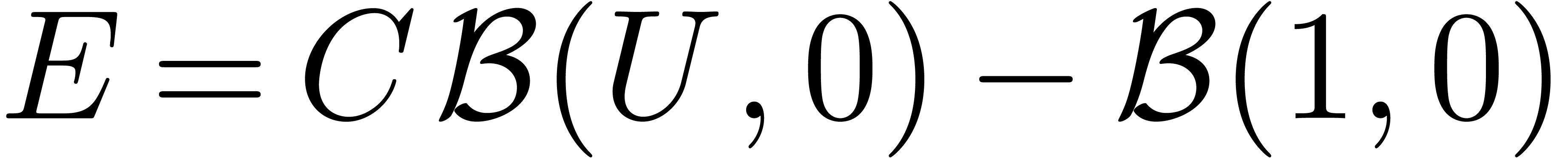
Calculer 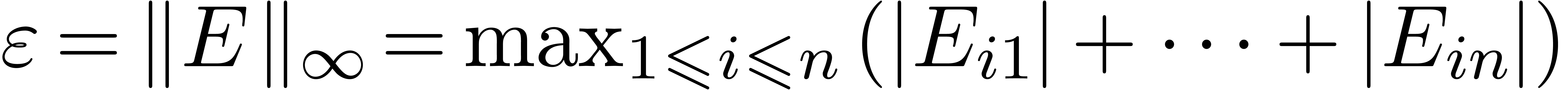 . On a :
. On a :
Soit  la matrice avec entrées
la matrice avec entrées 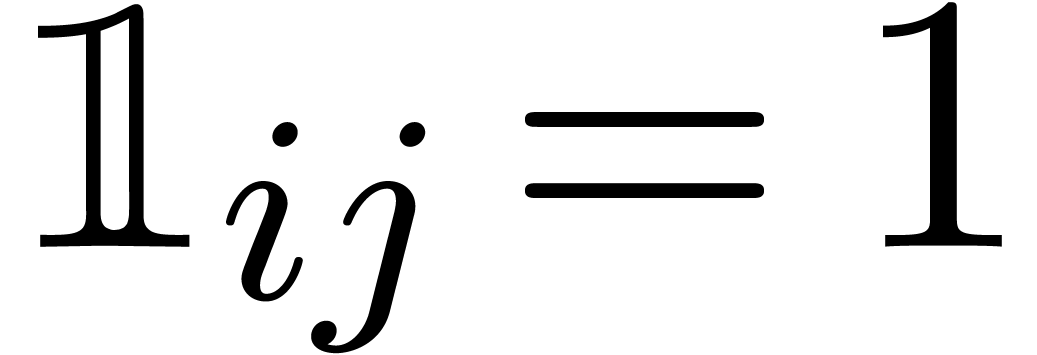
Retourner 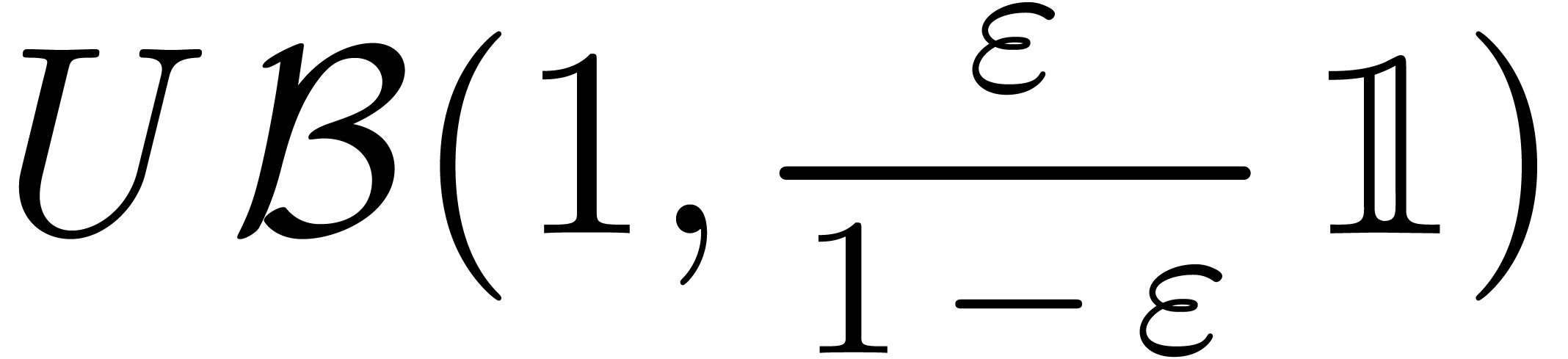
Remarque. De manière plus générale, la méthode perturbative appartient à la famille des algorithmes marchant par « prospection-validation ». Dans un premier temps, ces algorithmes cherchent à approcher, voire à diviner la bonne réponse. Lorsque l'on estime avoir accumulé suffisamment d'évidence pour que le résultat soit bon, on lance un nouvel algorithme pour la validation du résultat.
Bien sûr, la méthode perturbative s'applique à d'autres problèmes similaires, comme le calcul de la forme échelon. Montrons d'abord le calcul quand on utilise l'algorithme naïf qui consiste à directement appliquer le pivot de Gauss sur une matrice dont les coefficients sont des intervalles :
Mmx] |
use "analyziz" |
Mmx] |
rnd () == {
x == uniform_deviate (0.0, 1.0);
return interval (x - 0.0000001, x + 0.0000001);
}; |
Mmx] |
M == [ rnd () | j in 1 to 7 || i in 1 to 7 ] |
Mmx] |
row_echelon M |

On observe bien une déperdition de la précision au cours
de l'algorithme. Lorsque les coefficients de la matrice sont
remplacés par des boules,
Mmx] |
use "analyziz" |
Mmx] |
rnd () == {
x == uniform_deviate (0.0, 1.0);
return ball (x, 0.0000001);
}; |
Mmx] |
M == [ rnd () | j in 1 to 7 || i in 1 to 7 ] |
Mmx] |
row_echelon M |

En calcul numérique, la précision relative du résultat est généralement moindre que la précision relative des données. On pourrait appeler la différence entre ces deux précisions la « déperdition de précision ». Cette déperdition admet deux sources tout à fait distinctes :
Une partie de la déperdition est intrinsèque et liée au conditionnement du problème.
L'autre partie est due à l'algorithme de calcul choisi, et on peut espérer la réduire autant que possible en cherchant un bon algorithme.
Fixons une norme  sur et
soit
sur et
soit  une fonction. On définit le
nombre de conditionnement
une fonction. On définit le
nombre de conditionnement 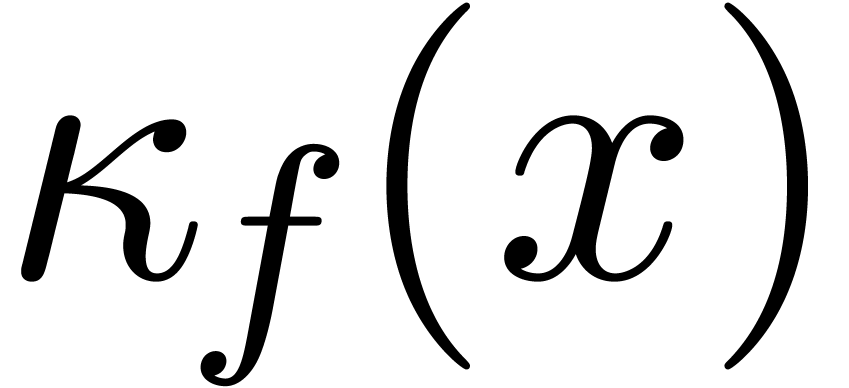 de
de  en
en 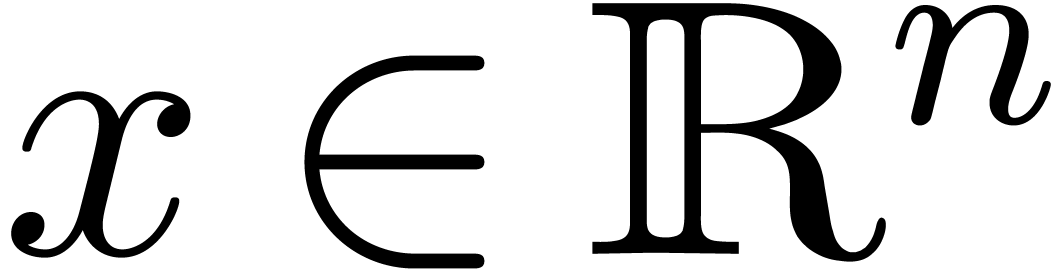 par
par
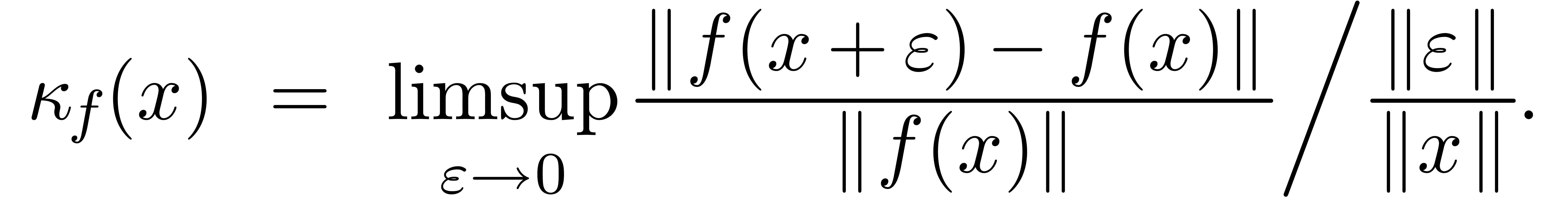
Le logarithme 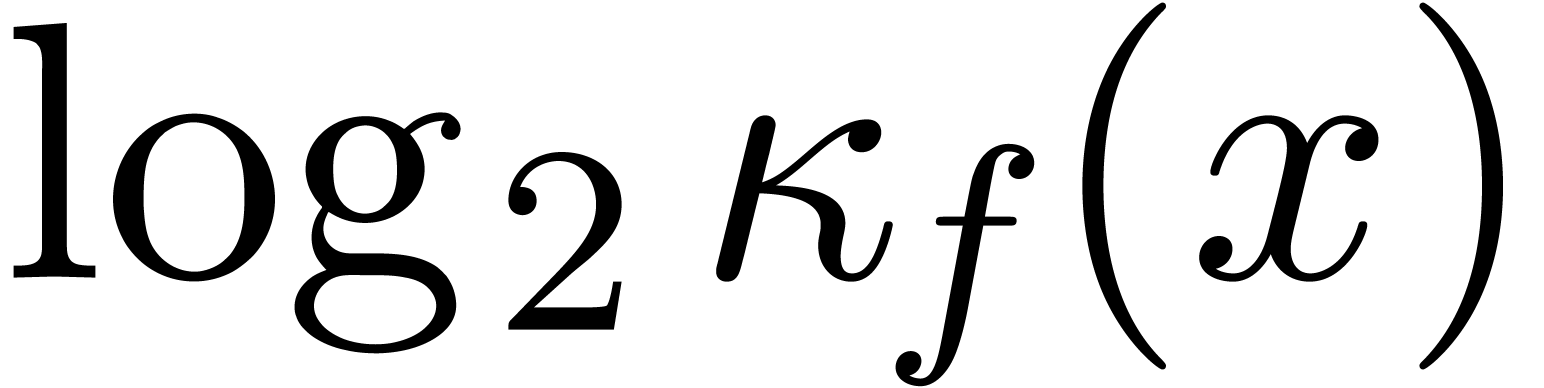 en base deux mesure donc la
déperdition intrinsèque de précision pour
l'évaluation de en . En algèbre linéaire, on
définit aussi le nombre de conditionnement d'une matrice par
en base deux mesure donc la
déperdition intrinsèque de précision pour
l'évaluation de en . En algèbre linéaire, on
définit aussi le nombre de conditionnement d'une matrice par
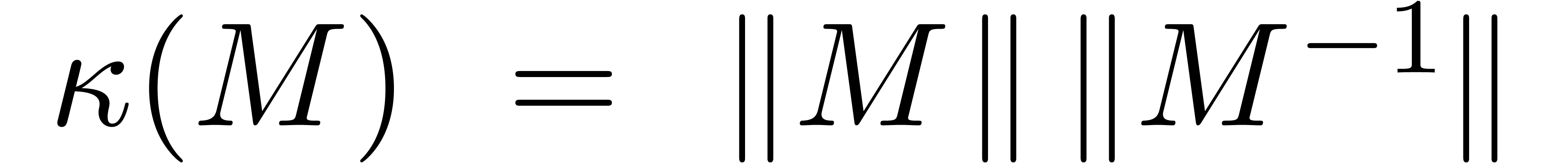
Ceci correspond au maximum des pour , où 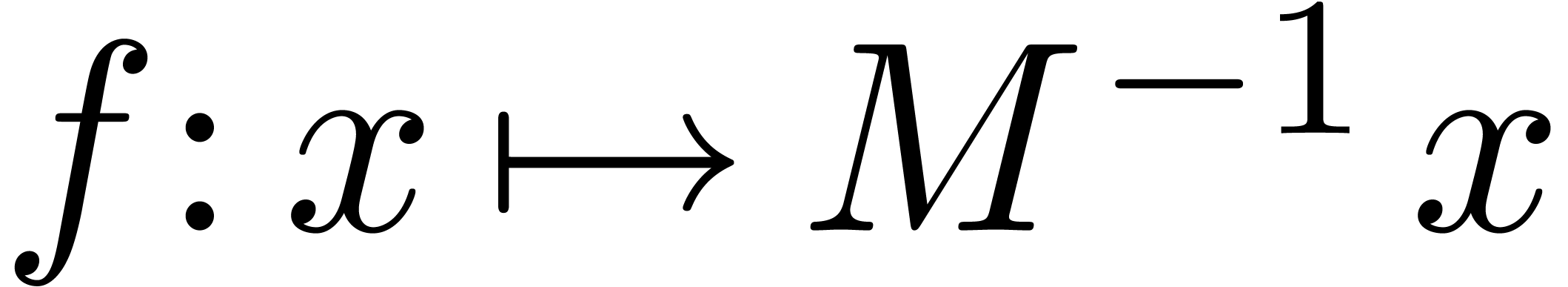 .
.
Supposons maintenant que l'on cherche à approcher par  , en
calculant avec une précision de bits. On
définit le facteur d'éloignement de
, en
calculant avec une précision de bits. On
définit le facteur d'éloignement de  en
en 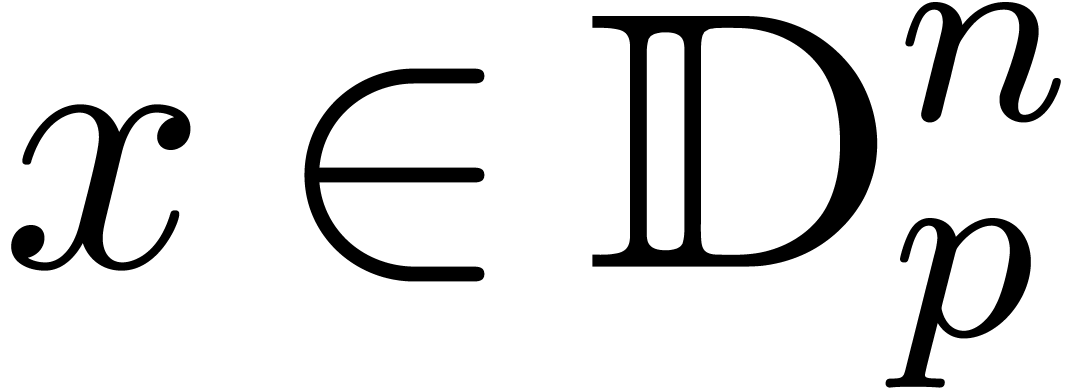 par
par
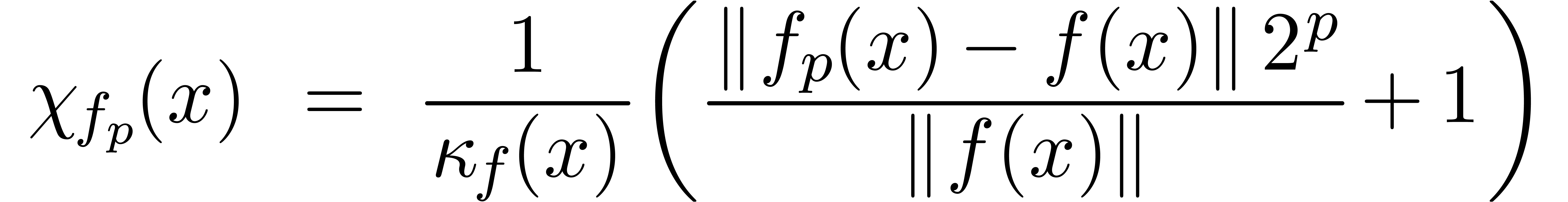
Quand on calcule en on
perd donc environ bits de précision de
façon intrinsèque et environ 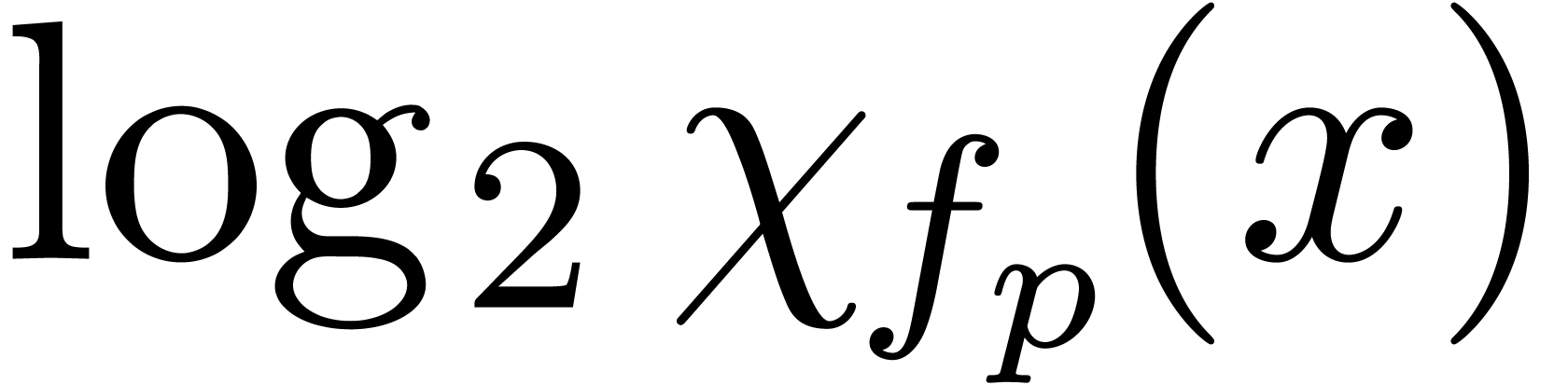 bits
additionnels à cause de l'algorithme employé.
bits
additionnels à cause de l'algorithme employé.
Essayons maintenant de transposer l'esprit de la section précédente à l'arithmétique de boules. Le nombre de conditionnement n'a pas de contre-partie directe. En revanche, on la notion d'une « extension optimale » :
Soit 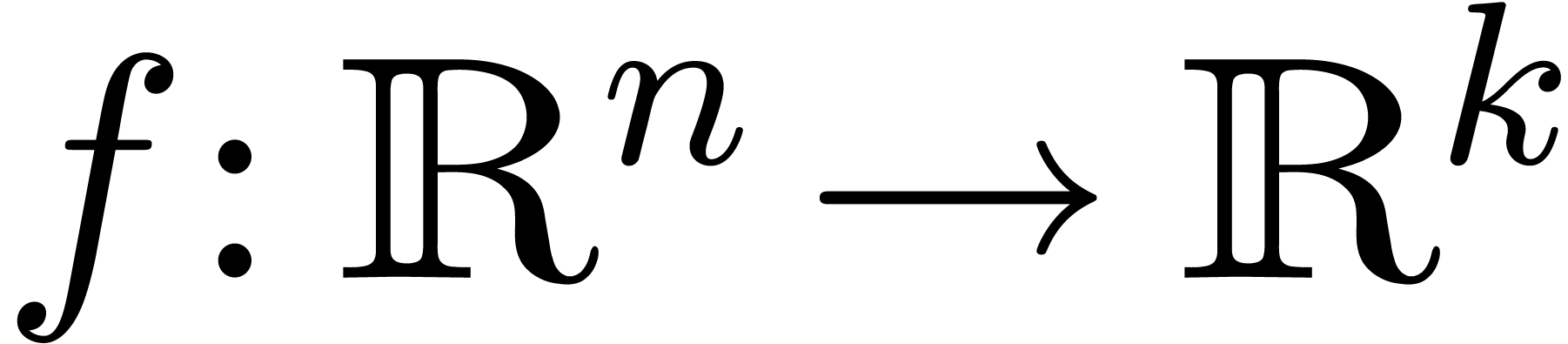 une fonction. Nous avons déjà
signalé l'existence a priori d'une multitude
d'extensions
une fonction. Nous avons déjà
signalé l'existence a priori d'une multitude
d'extensions 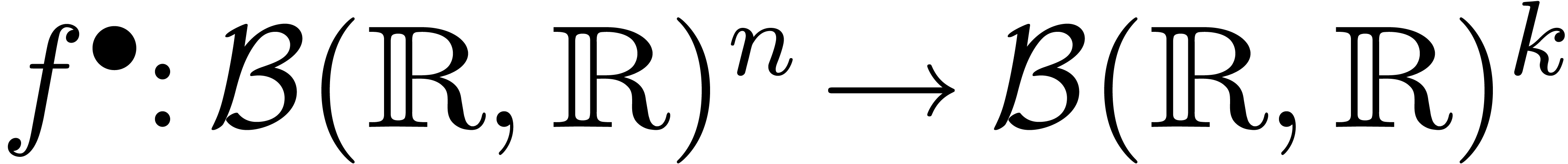 de
vérifiant la relation
de
vérifiant la relation
pour tous les 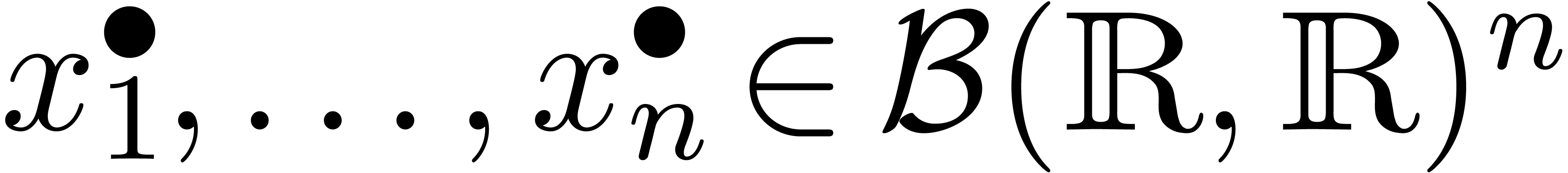 .
Néanmoins, si on impose la contrainte supplémentaire que
.
Néanmoins, si on impose la contrainte supplémentaire que
 est de la forme
est de la forme  pour un
certain
pour un
certain 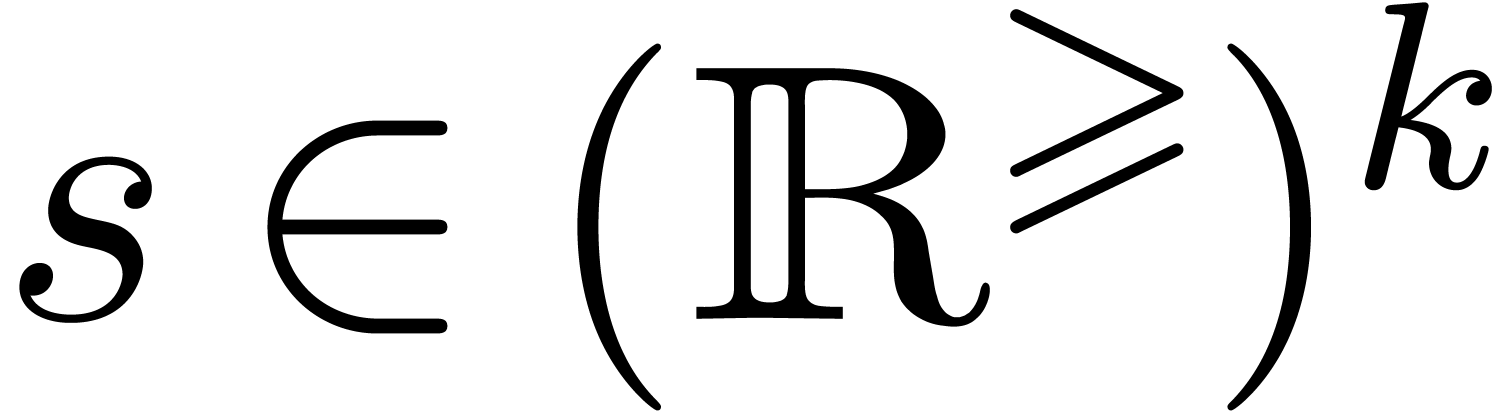 , alors il existe une
unique extension optimale
, alors il existe une
unique extension optimale  ,
définie par
,
définie par
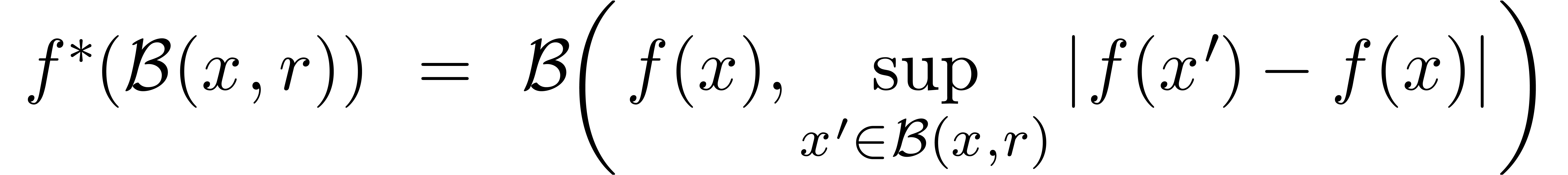
Ici, on utilise la notation vectorielle. Par exemple 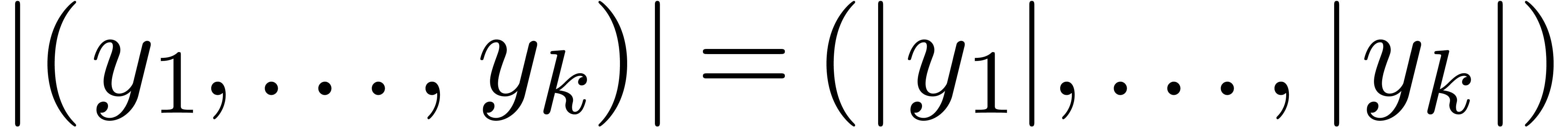 .
.
Maintenant, nous pouvons définir la surestimation d'une extension
 arbitraire de façon naturelle par rapport
à l'extension optimale .
Plus précisément, étant donnée une boule
arbitraire de façon naturelle par rapport
à l'extension optimale .
Plus précisément, étant donnée une boule
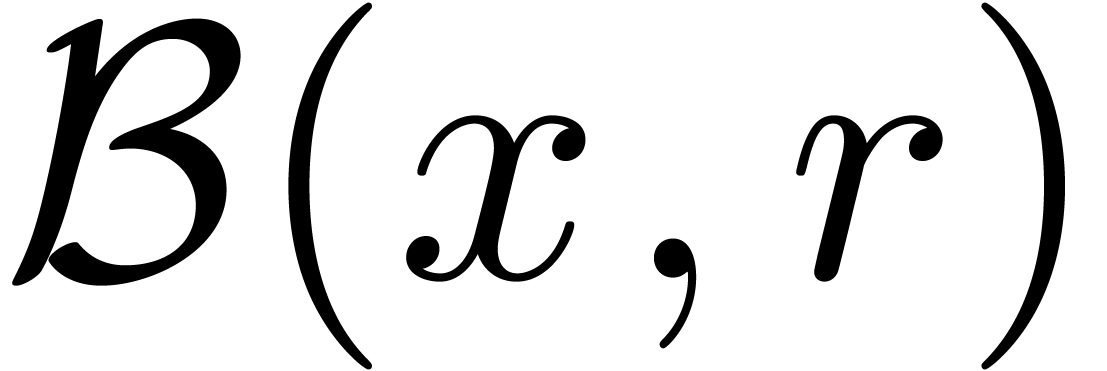 , on définit la
surestimation de en
par
, on définit la
surestimation de en
par
On définit également la surestimation ponctuelle
de en par
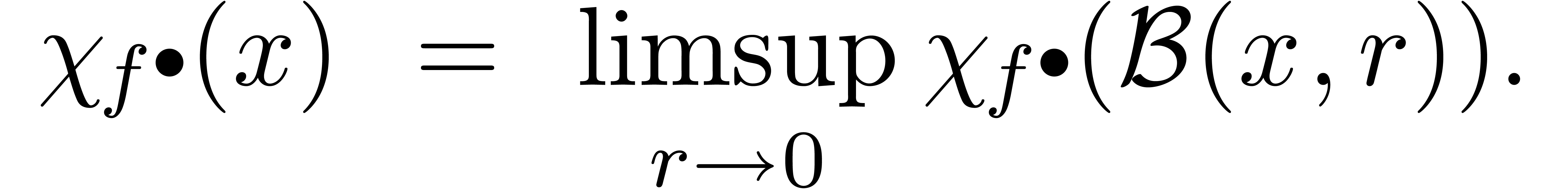
Nous allons voir maintenant que cette surestimation ponctuelle est souvent simple à calculer. De la même manière qu'il est bon pour un algorithme numérique de surveiller le nombre de conditionnement et le facteur d'éloignement, c'est généralement une bonne idée pour un algorithme certifié de surveiller la surestimation. En effet, si la surestimation devient trop importante, il est souvent possible de déclencher un autre algorithme a priori plus couteux, mais plus précis.
Supposons que l'on ait une expression construite
à partir de constantes dans ,
d'un nombre fini d'indéterminées  et les opérations
et les opérations 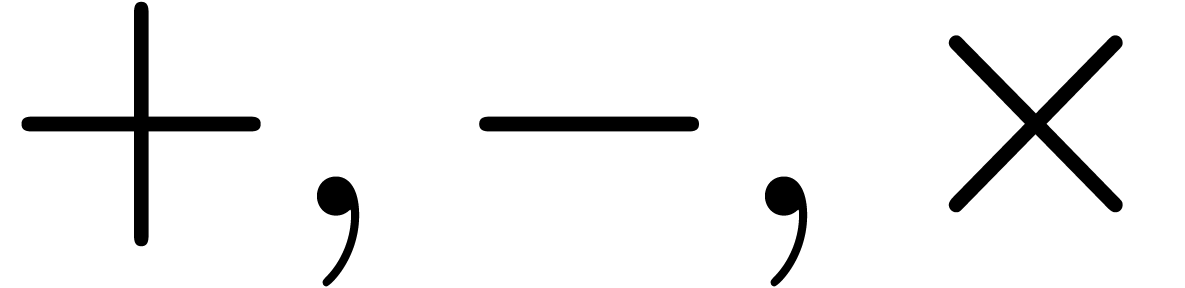 .
D'une part, on peut interpréter comme une
fonction
.
D'une part, on peut interpréter comme une
fonction 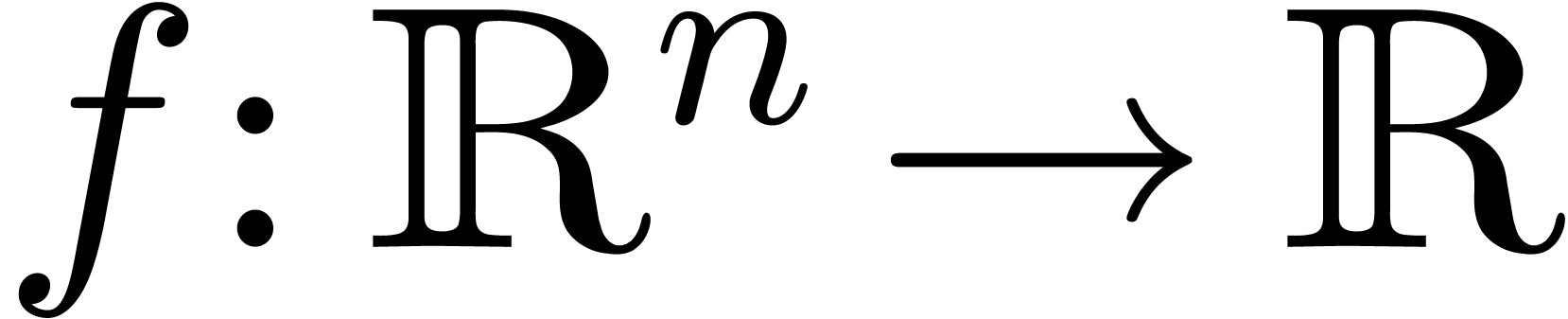 . D'autre part, en
utilisant l'arithmétique de boules standard (3.2–3.4), l'expression donne naturellement
lieu à une fonction
. D'autre part, en
utilisant l'arithmétique de boules standard (3.2–3.4), l'expression donne naturellement
lieu à une fonction 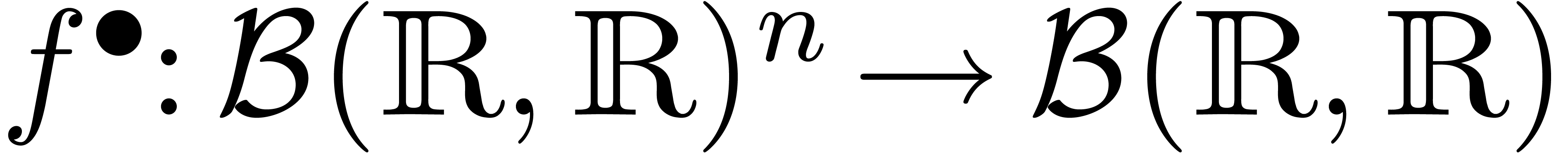 .
Il n'est pas difficile de montrer que la surestimation ponctuelle de
se calcule explicitement par
.
Il n'est pas difficile de montrer que la surestimation ponctuelle de
se calcule explicitement par
où l'opérateur  de « gradient
majoré » est défini par
de « gradient
majoré » est défini par
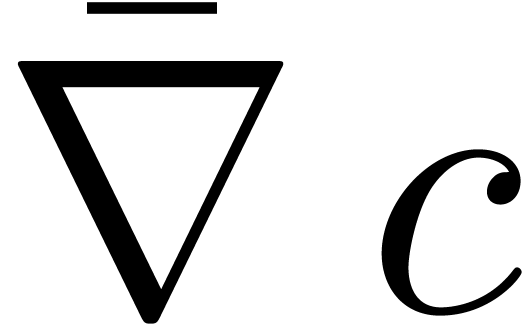 |
 |
 |
(c∈ℝ) |
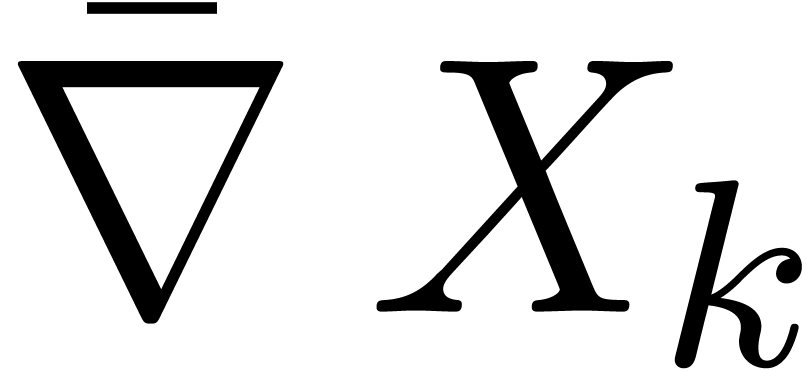 |
|
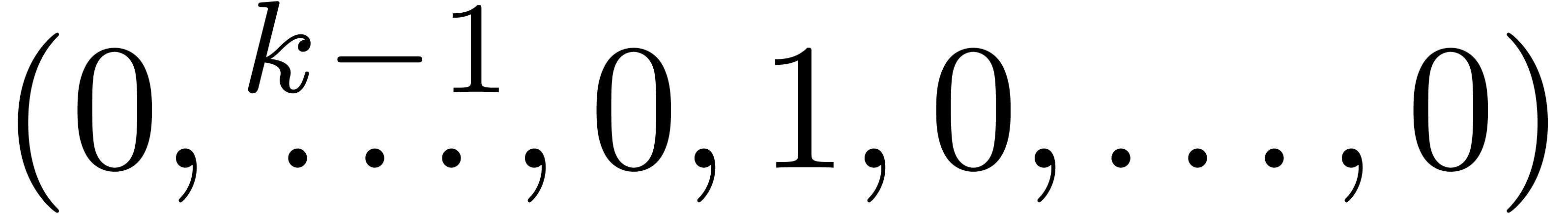 |
(k∈{1,…,n}) |
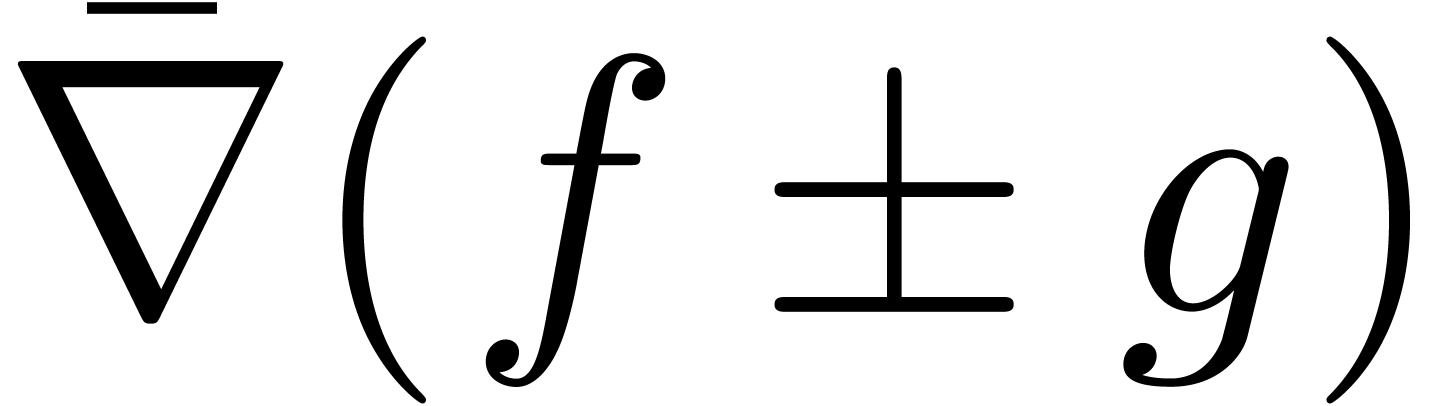 |
|
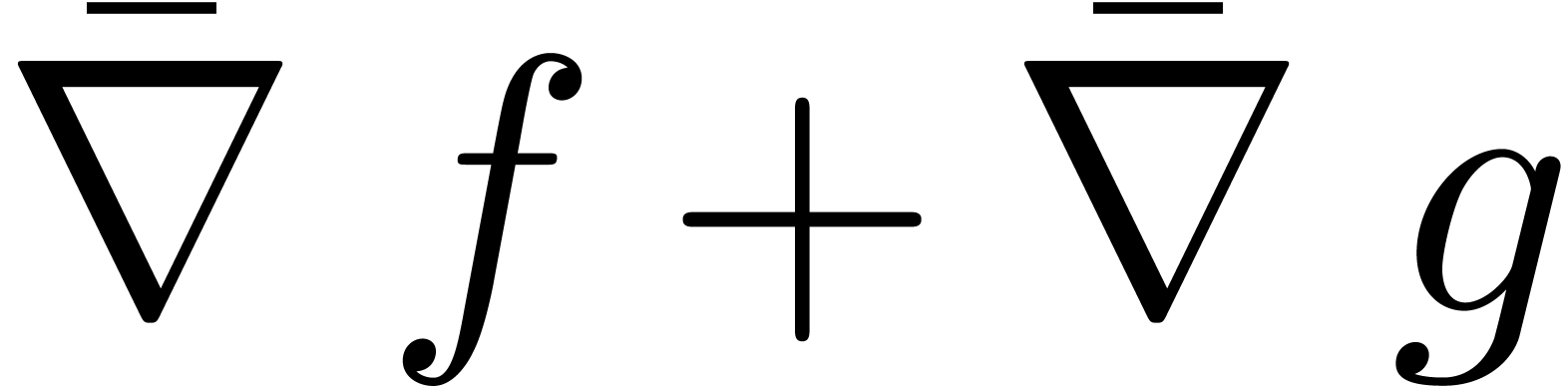 |
|
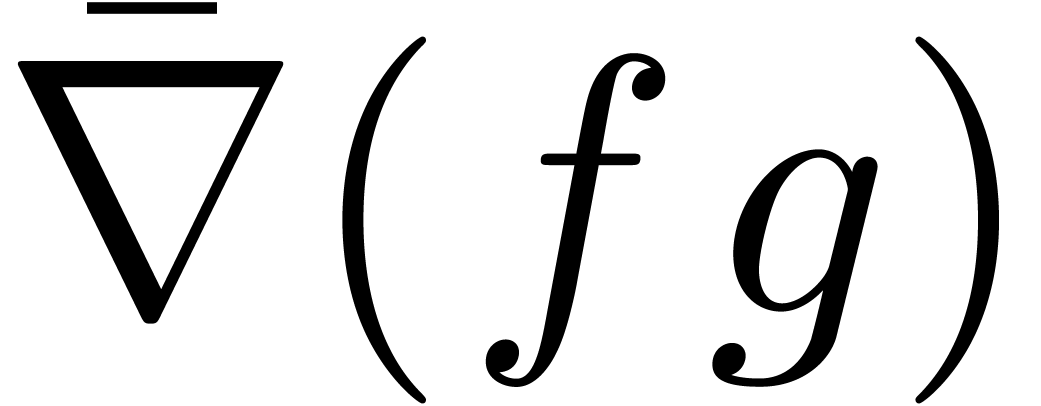 |
|
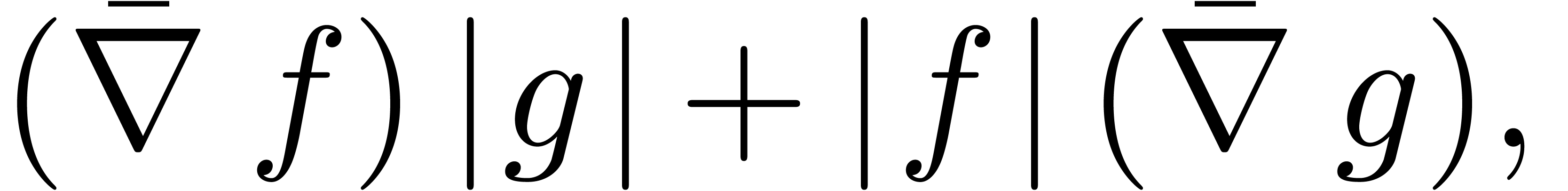 |
Lorsque 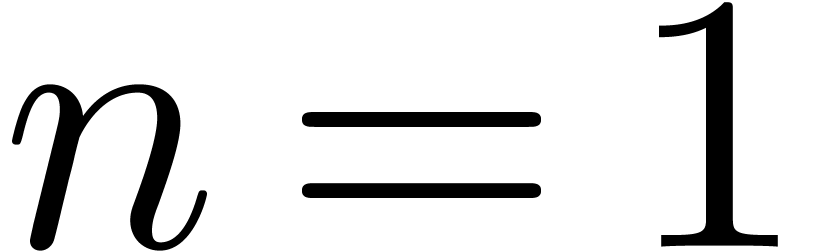 , la formule (3.6) se simplifie en
, la formule (3.6) se simplifie en
Exemple 3.3. Prenons l'exemple
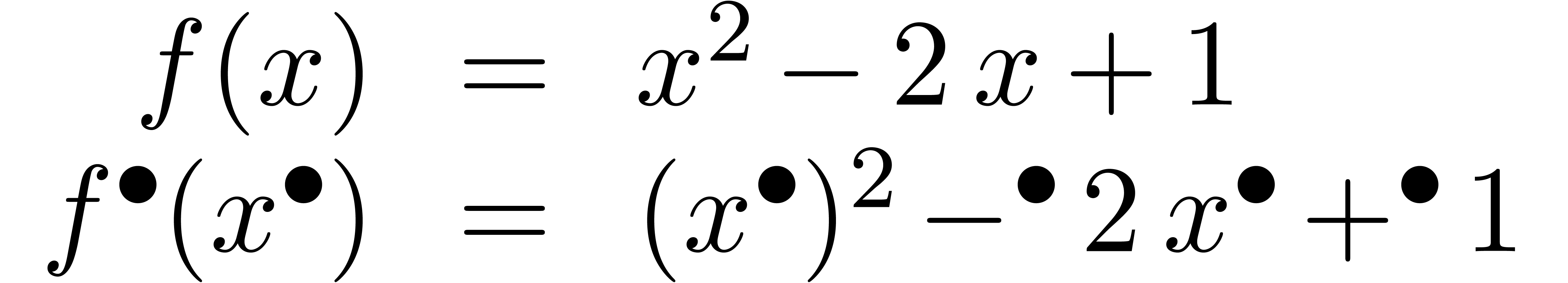
L'extension optimale de est la même que
pour la fonction 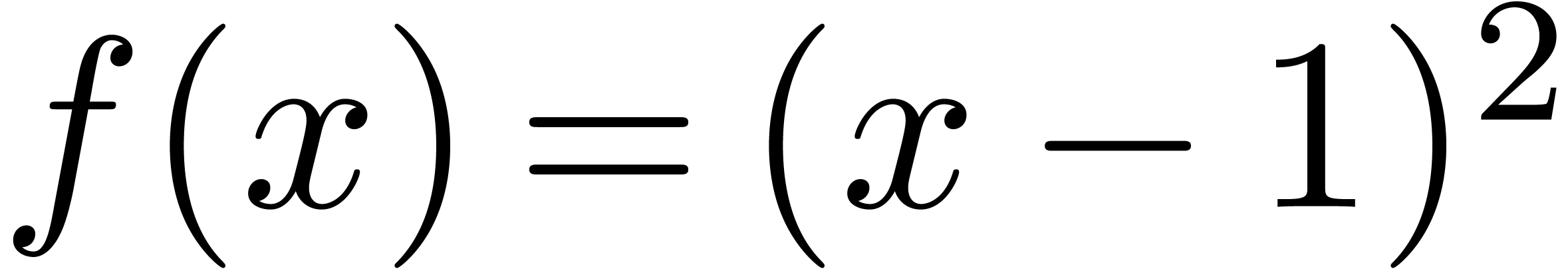 :
:
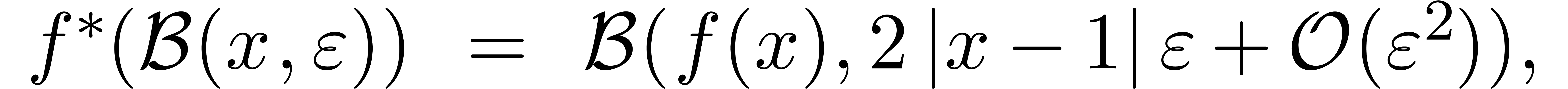
alors que l'extension standard donne
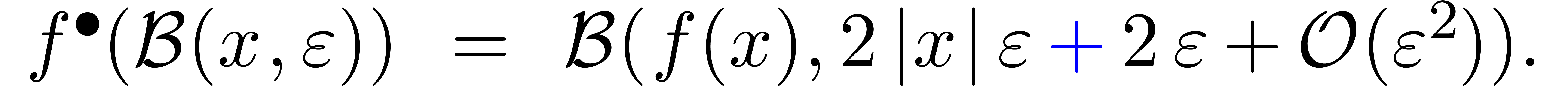
Par conséquent,
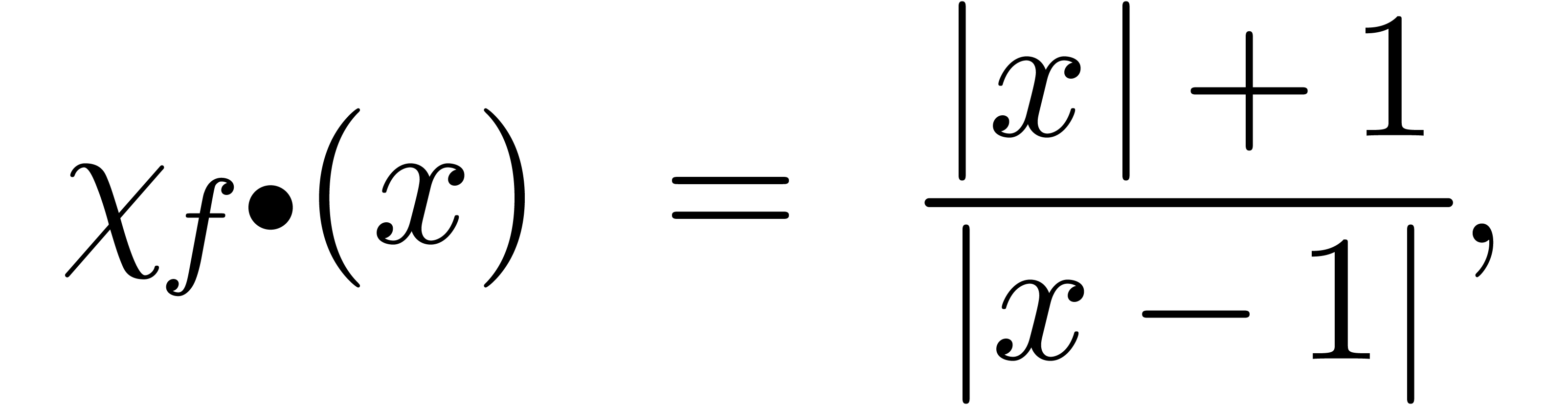
conformément à la formule (3.7).
Cette formule a une conséquence importante pour des algorithmes
par subdivision qui cherchent des zéros de
dans un ensemble donné. En effet, lorsque l'on utilise
l'arithmétique de boules (ou d'intervalles) naïve pour
certifier l'absence de zéros dans des boîtes, on est
forcé de prendre des boîtes 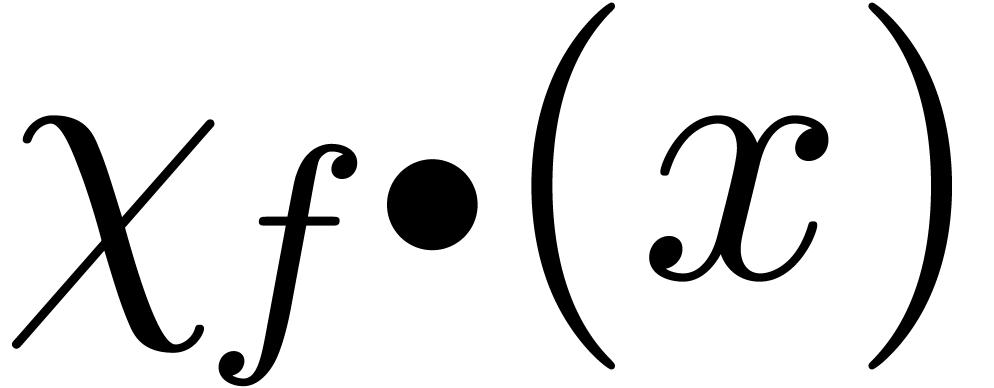 fois plus petites que nécéssaire. En dimension
fois plus petites que nécéssaire. En dimension  , cela multiplie le coût de
l'algorithme par un facteur
, cela multiplie le coût de
l'algorithme par un facteur  vis à vis un
algorithme théorique optimal. Dans la section 5.4,
nous verrons une méthode systématique pour réduire
la surestimation afin de remédier à ce problème.
vis à vis un
algorithme théorique optimal. Dans la section 5.4,
nous verrons une méthode systématique pour réduire
la surestimation afin de remédier à ce problème.
Toujours pour l'arithmétique de boules standard, une problème intéressant est de pouvoir calculer ou au moins estimer la surestimation sur une boule générale par rapport à la surestimation ponctuelle. Voici une question plus précise qui semble abordable :
Question. Pour construite
à partir de  , est-ce
que
, est-ce
que
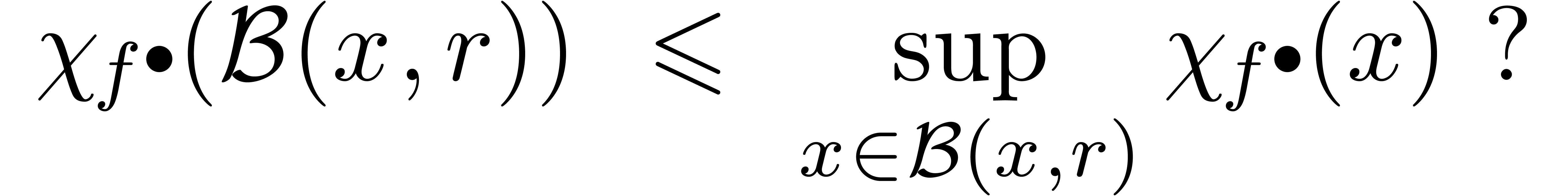
Ayant défini la surestimation d'un algorithme de façon
précise, la question est maintenant comment construire des
algorithmes à la fois efficaces et de bonne qualité (c'est
à dire, avec une surestimation proche de ). Bien évidemment, il s'agit de deux
objectifs contraires, donc il faudra chercher un compromis.
Par exemple, en rendant systématiquement la boule 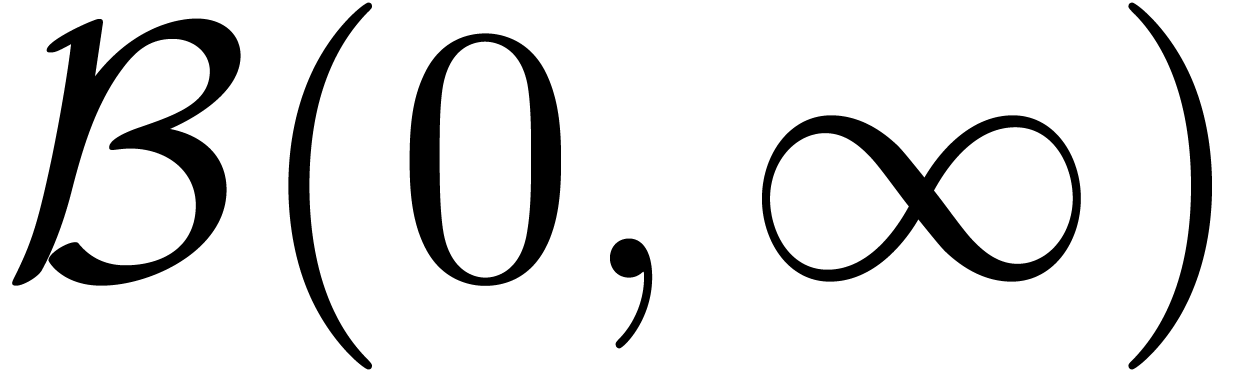 comme résultat, on obtient un algorithme
très efficace, mais sans intérêt.
Réciproquement, dans de nombreux cas, l'obtention de bornes
optimales est NP complet ou pire [44].
Généralement, les algorithmes qui nous intéressent
introduisent un facteur constant dans la complexité pour calculer
des bornes de qualité acceptable, ou des petits facteurs
logarithmiques ou polynomiaux pour avoir un algorithme avec une
surestimation proche de .
comme résultat, on obtient un algorithme
très efficace, mais sans intérêt.
Réciproquement, dans de nombreux cas, l'obtention de bornes
optimales est NP complet ou pire [44].
Généralement, les algorithmes qui nous intéressent
introduisent un facteur constant dans la complexité pour calculer
des bornes de qualité acceptable, ou des petits facteurs
logarithmiques ou polynomiaux pour avoir un algorithme avec une
surestimation proche de .
On rappelle aussi qu'il est souvent possible d'appliquer la stratégie de la « terminaison précoce » : on commence avec un algorithme rapide et a priori de faible qualité. Seulement si la qualité du résultat est jugée insuffisante, on lance des algorithmes plus lents, mais de meilleure qualité.
La recherche d'un compromis entre efficacité et qualité
s'illustre bien sur le problème de la multiplication de deux
matrices 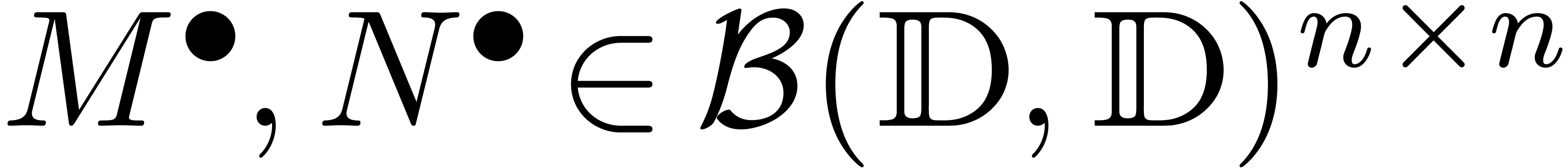 .
.
On calcule le produit par l'algorithme classique en utilisant 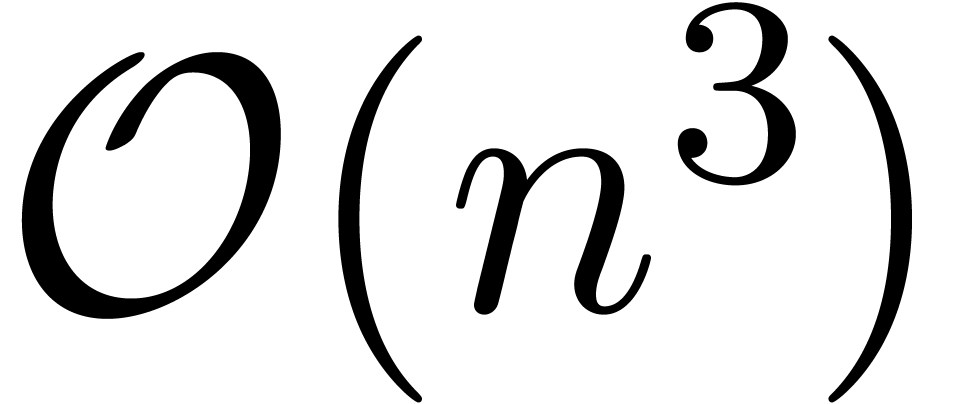 opérations en arithmétique de
boules. C'est un algorithme de bonne qualité, mais assez
lent.
opérations en arithmétique de
boules. C'est un algorithme de bonne qualité, mais assez
lent.
On réinterprète  comme des
boules avec des centres et des rayons dans
comme des
boules avec des centres et des rayons dans 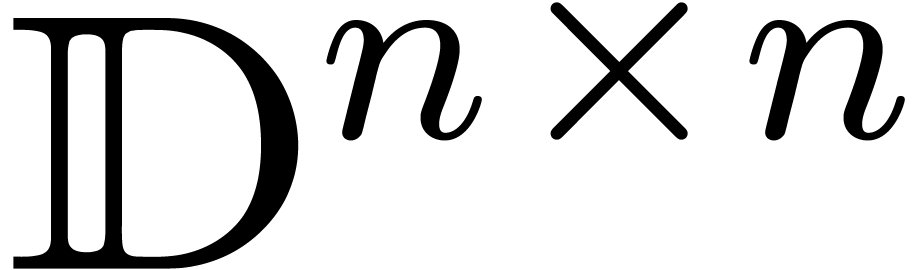 . Dès lors, on peut utiliser la formule
(3.4) pour la multiplication, quitte à
rajouter le nécessaire pour les erreurs d'arrondi.
. Dès lors, on peut utiliser la formule
(3.4) pour la multiplication, quitte à
rajouter le nécessaire pour les erreurs d'arrondi.
L'avantage principal de cette méthode est que l'on s'appuie
directement sur la multiplication matricielle dans au lieu de faire toutes les opérations sur
les coefficients un par un dans l'arithmétique des boules.
En effet, la multiplication dans est
généralement hautement optimisée (en
précision machine, on peut par exemple utiliser des
Dans la méthode précédente, on majore le
rayon du produit par la somme de deux produits de matrices dans
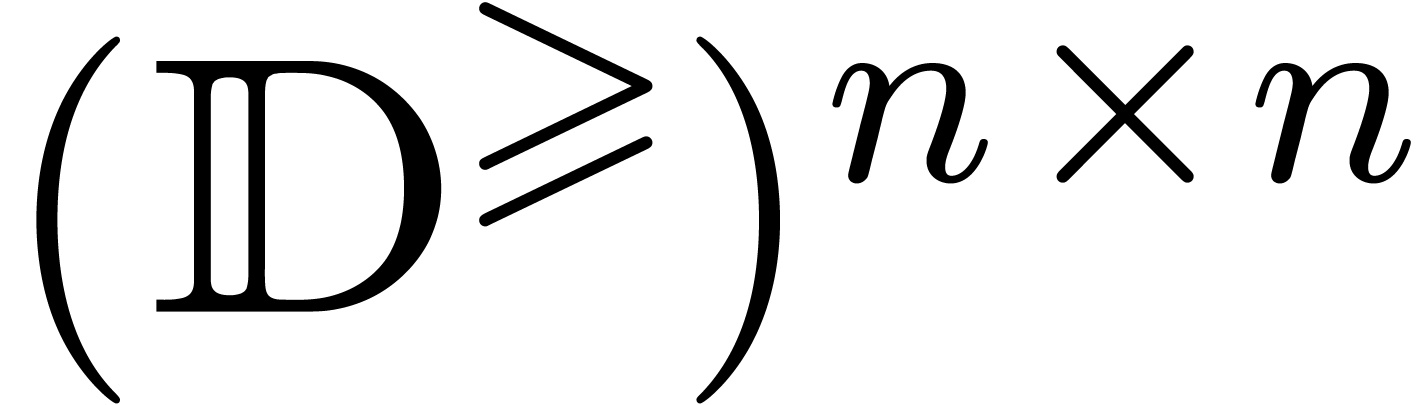 . Étant
données deux matrices
. Étant
données deux matrices 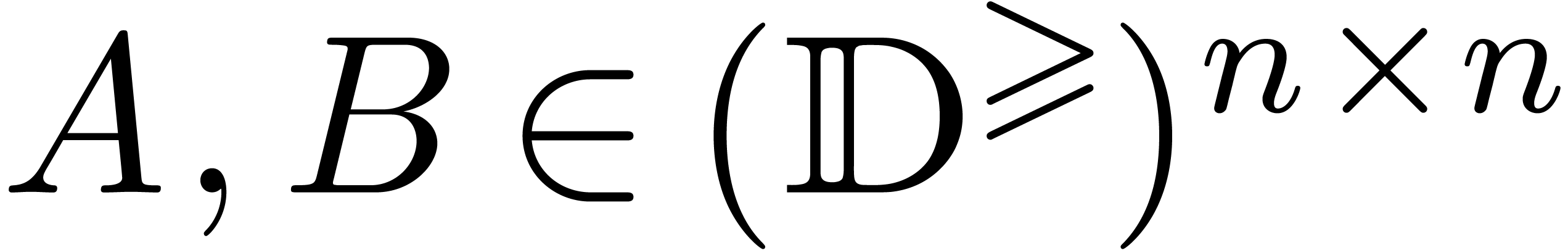 ,
il est souvent possible d'obtenir une majoration raisonnable du
produit
,
il est souvent possible d'obtenir une majoration raisonnable du
produit  en faisant seulement
en faisant seulement  opérations.
opérations.
En effet, supposons qu'après préconditionnement, on
peut s'arranger pour que les entrées de chaque ligne de
 et de chaque colonne de
et de chaque colonne de  soient du même ordre de grandeur. Dans ce cas, on peut
utiliser la formule
soient du même ordre de grandeur. Dans ce cas, on peut
utiliser la formule
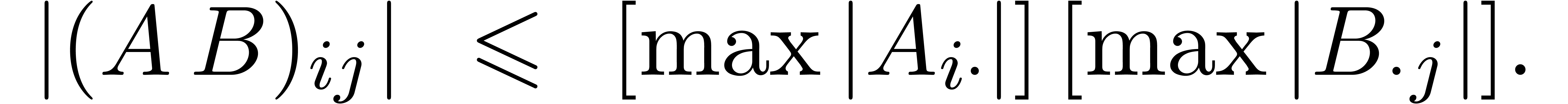
Dans la pratique, il arrive souvent que les entrées d'une
matrice soient localement du même ordre de grandeur, mais
pas globalement, même après
préconditionnement. Dans ce cas, on peut découper la
matrice en petits blocs de matrices  ,
utiliser des majorations brutales sur ces petits blocs et un
algorithme plus naïf pour la matrice toute entière.
Ceci conduit à un algorithme de coût
,
utiliser des majorations brutales sur ces petits blocs et un
algorithme plus naïf pour la matrice toute entière.
Ceci conduit à un algorithme de coût 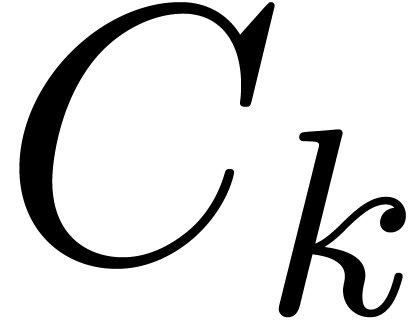 supérieur à la multiplication dans , avec
supérieur à la multiplication dans , avec  .
.
De manière générale, on observe aussi que le
coût de certification des calculs tend souvent à devenir
négligeable pour des gros problèmes. Par exemple, pour la
multiplication dans  ,
l'estimation des erreurs se fait généralement en simple
précision. En grande précision, le coût de deux
multiplications en simple précision devient négligeable
devant le coût d'une grosse multiplication dans
,
l'estimation des erreurs se fait généralement en simple
précision. En grande précision, le coût de deux
multiplications en simple précision devient négligeable
devant le coût d'une grosse multiplication dans  . De même, dans des cas bien
conditionnés où on peut utiliser la méthode des
majorations brutales pour la multiplication des matrices, le coût
des opérations pour estimer les erreurs
est négligeable devant le coût pour
la multiplication des centres.
. De même, dans des cas bien
conditionnés où on peut utiliser la méthode des
majorations brutales pour la multiplication des matrices, le coût
des opérations pour estimer les erreurs
est négligeable devant le coût pour
la multiplication des centres.
À présent, nous avons vu les types de base pour le calcul
analytique. D'un point de vue haut niveau, nous avons les nombres
calculables de , , ,
etc. Juste en-dessous suit l'arithmétique de boules qui permet le
calcul certifié avec des approximations. Tout en bas, nous avons
le calcul numérique classique avec des nombres en virgule
flottante et l'arithmétique rapide pour les mantisses en
précision arbitraire.
Cette division en quatre niveaux de la « hiérarchie numérique » est pertinente pour la plupart des algorithmes en calcul analytique. Dans le cas d'une multiplication de matrices par exemple, on procède comme suit :
Au niveau conceptuel, nous partons de deux matrices  à multiplier. Une telle matrice est constituée de
à multiplier. Une telle matrice est constituée de  promesses d'approximation. Pour gagner en
efficacité il vaut mieux réécrire
promesses d'approximation. Pour gagner en
efficacité il vaut mieux réécrire  .
.
Pour une précision donnée, on
approche et  par des
matrices de boules , ou
mieux, encore pour des raisons d'efficacité, comme des boules
matricielles
par des
matrices de boules , ou
mieux, encore pour des raisons d'efficacité, comme des boules
matricielles  .
.
L'arithmétique de boules dans  conduit
à l'arithmétique en virgule flottante standard dans
sur les centres et les rayons. Si est petit, on peut utiliser des nombres machines et
des BLAS rapides.
conduit
à l'arithmétique en virgule flottante standard dans
sur les centres et les rayons. Si est petit, on peut utiliser des nombres machines et
des BLAS rapides.
Si est plus grand, et si on cherche à
multiplier efficacement des matrices 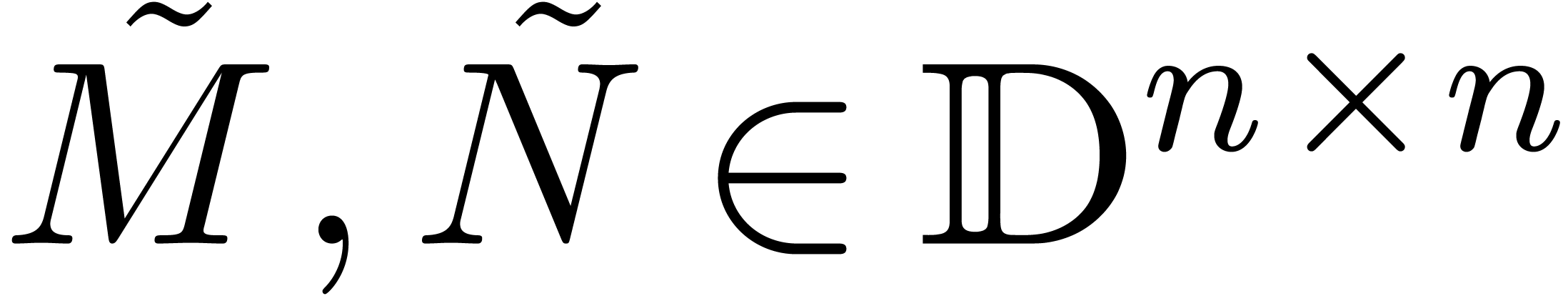 ,
il est souvent possible de les préconditionner et ensuite
à les écrire par rapport à un même
exposant :
,
il est souvent possible de les préconditionner et ensuite
à les écrire par rapport à un même
exposant :  . On peut
alors employer un algorithme de multiplication de matrices rapide
dans
. On peut
alors employer un algorithme de multiplication de matrices rapide
dans 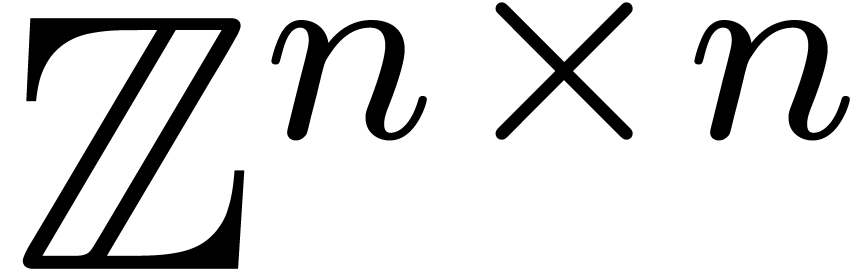 .
.
L'algorithmique rapide est un sujet classique en calcul formel. Nous ferons quelques rappels, sans chercher à être exhaustif. Voir par exemple [31, 6] pour deux références classiques.
L'opération clef à comprendre pour des analyses en complexité est la multiplication, que ça soit sur les entiers, sur les nombres flottants, les polynômes, les matrices, ou encore les séries. Les complexités d'autres opérations (division, racine carrée, etc.) s'expriment généralement en fonction du coût de la multiplication. Voici quelques complexités classiques concernant la multiplication :
chiffres
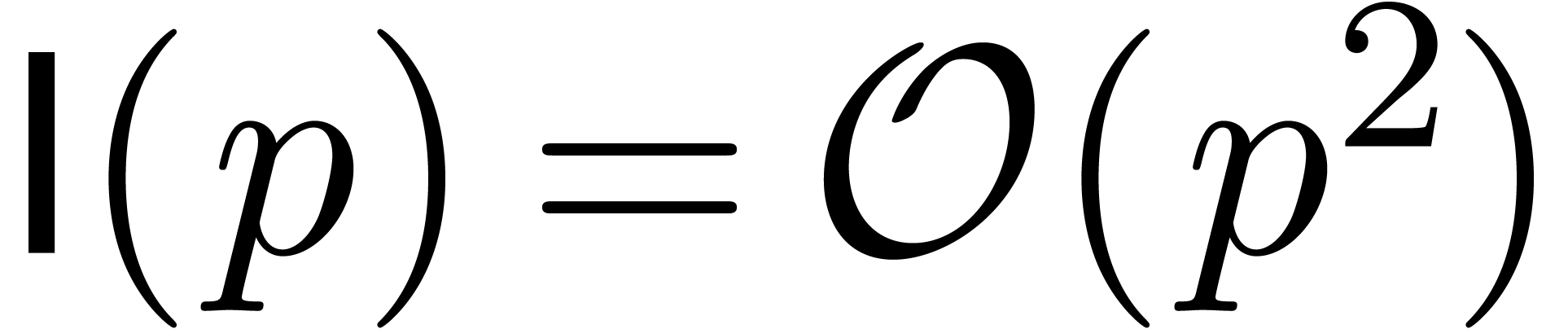 : multiplication
naïve.
: multiplication
naïve.
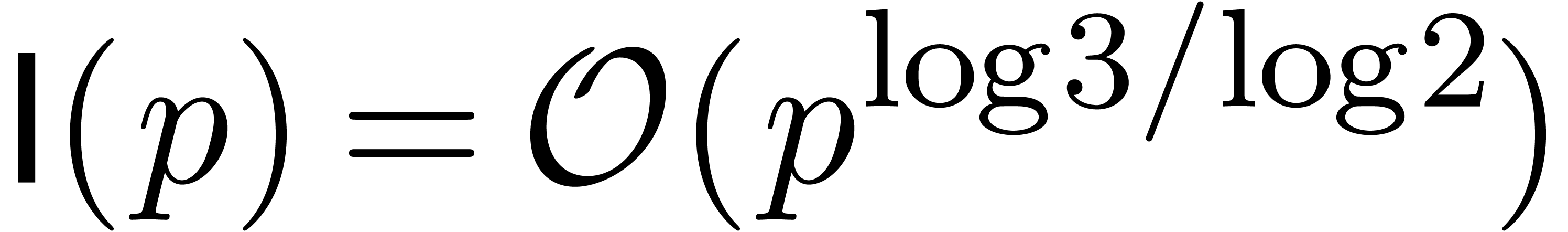 : multiplication de
Karatsuba [41].
: multiplication de
Karatsuba [41].
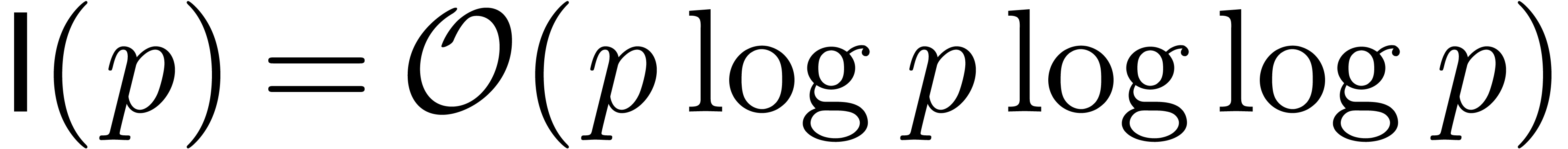 : multiplication de
Schönhage-Strassen [67].
: multiplication de
Schönhage-Strassen [67].
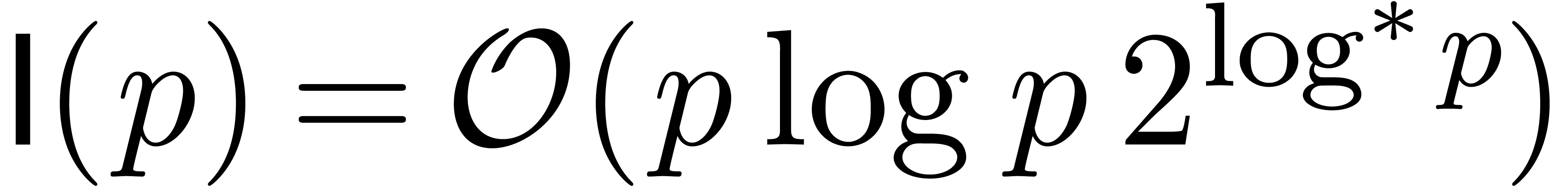 : multiplication de
Fürer [30].
: multiplication de
Fürer [30].
 de degré
de degré
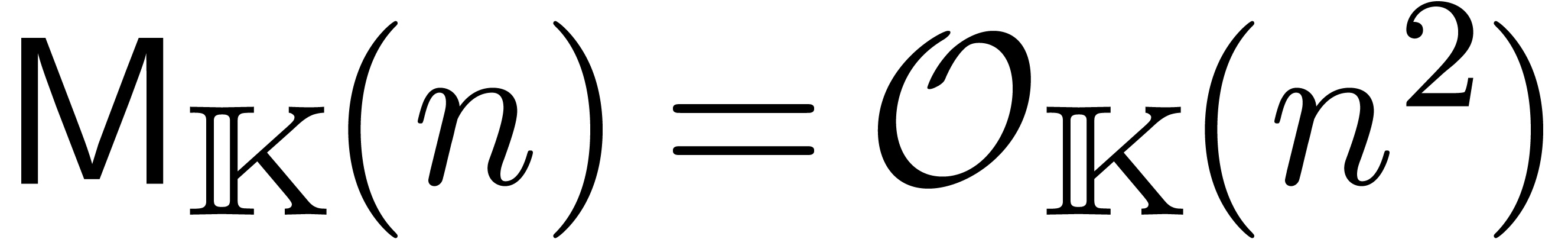 : multiplication
naïve (on compte le nombre d'opérations dans ).
: multiplication
naïve (on compte le nombre d'opérations dans ).
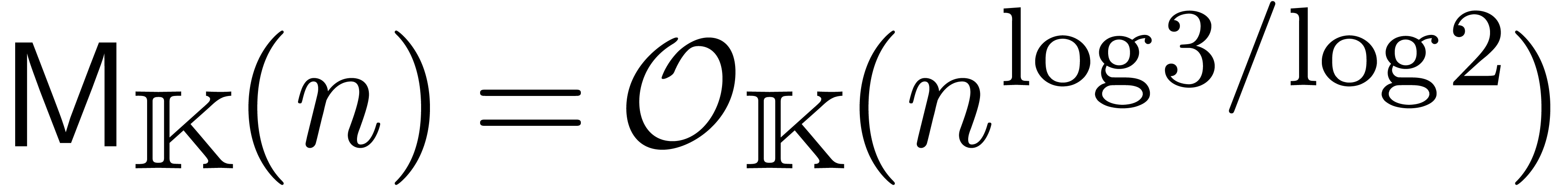 : multiplication de
Karatsuba [41].
: multiplication de
Karatsuba [41].
 si admet
suffisamment de racines
si admet
suffisamment de racines  -ièmes
de l'unité [19].
-ièmes
de l'unité [19].
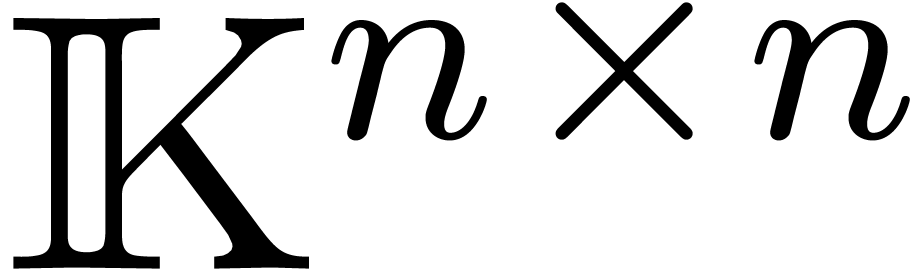
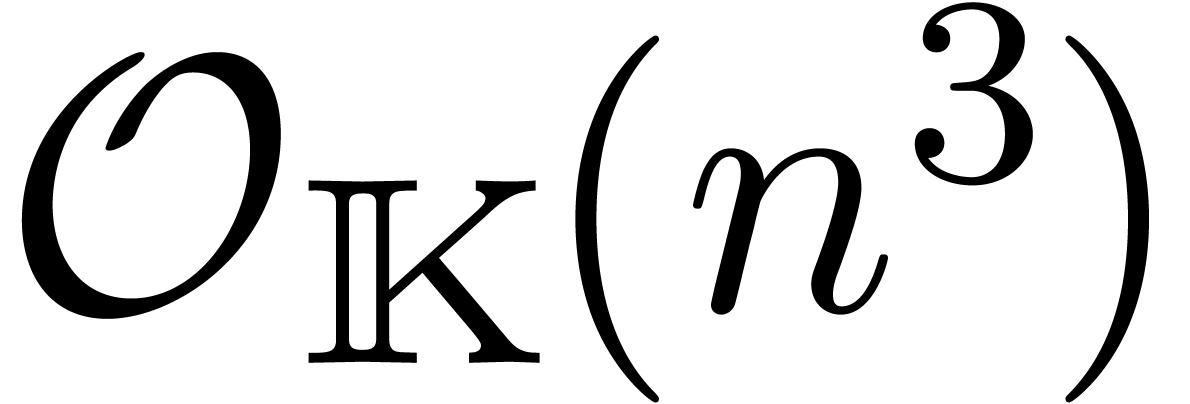 : multiplication
naïve.
: multiplication
naïve.
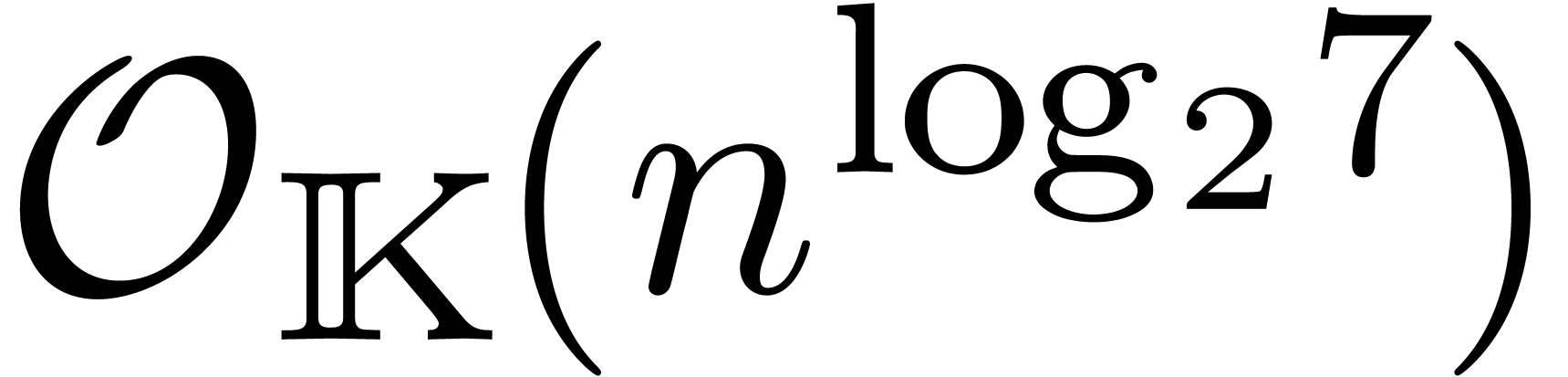 : multiplication de
Strassen [74].
: multiplication de
Strassen [74].
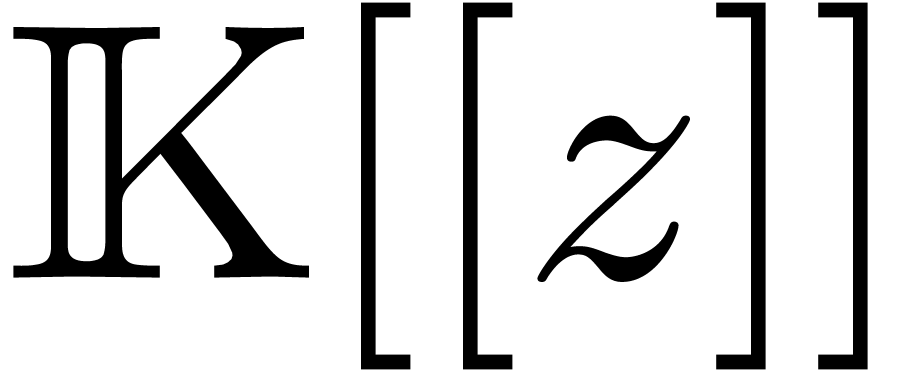 à l'ordre (voir la section
4.3)
à l'ordre (voir la section
4.3)
 : multiplication
naïve.
: multiplication
naïve.
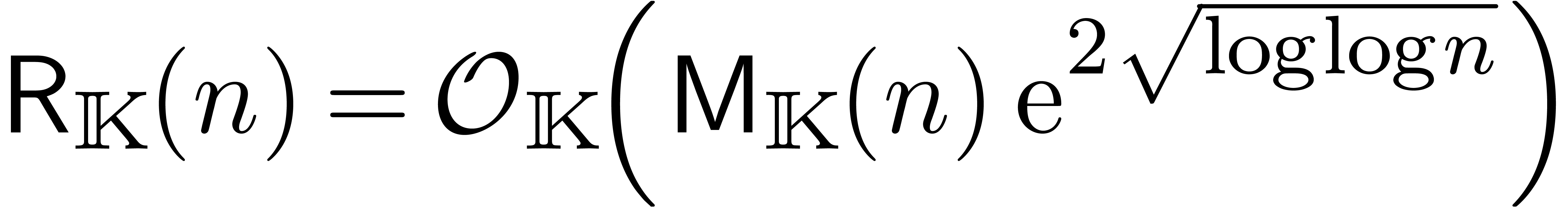 si admet
suffisamment de racines -ièmes
de l'unité [83].
si admet
suffisamment de racines -ièmes
de l'unité [83].
avec des coefficients de
chiffres
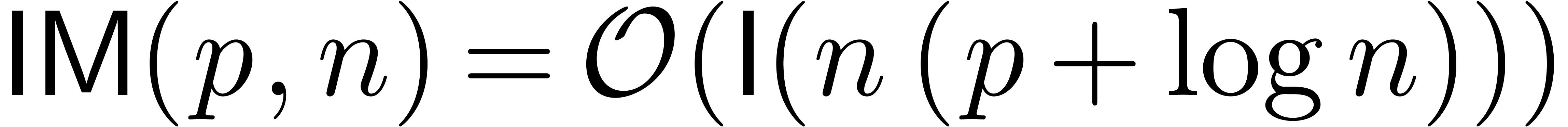 : Kronecker [31].
: Kronecker [31].
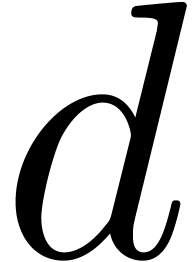 avec des coefficients dans
avec des coefficients dans
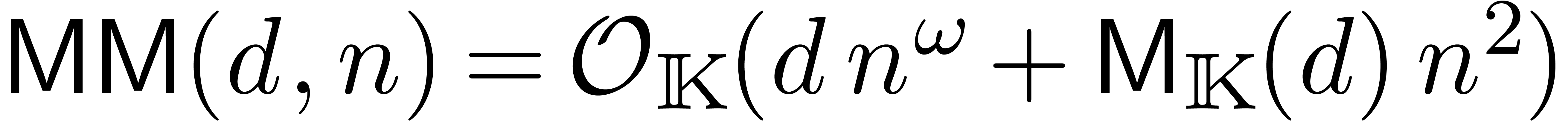 si la complexité
si la complexité 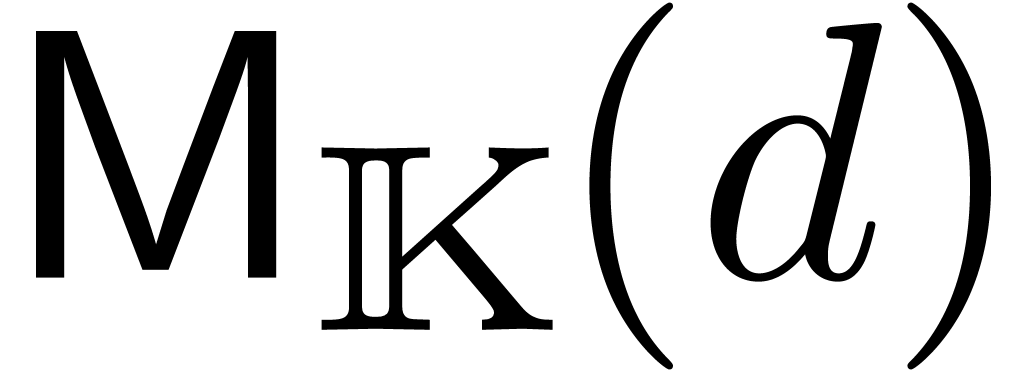 pour la multiplication est obtenue par
évaluation-interpolation en
pour la multiplication est obtenue par
évaluation-interpolation en  de
points.
de
points.
Il existe deux variantes pour multiplier deux polynômes 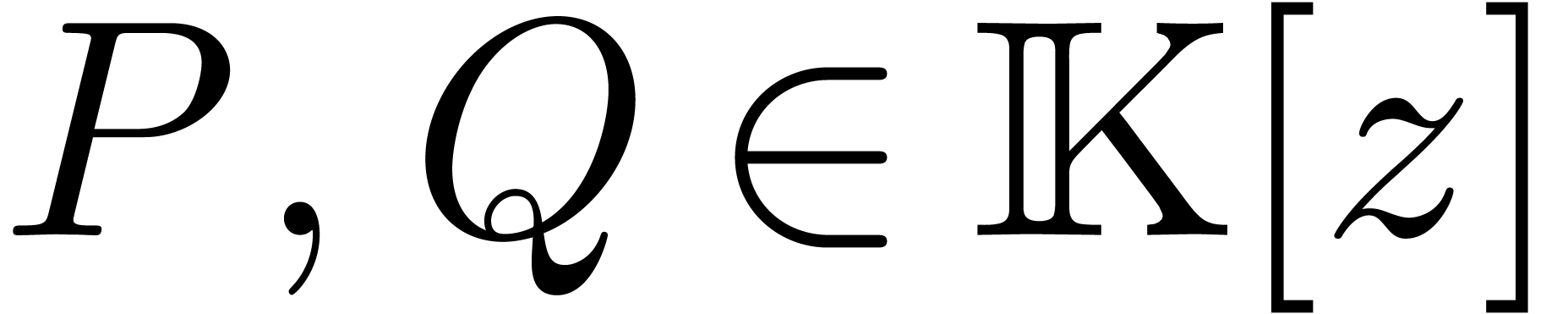 de degrés
de degrés 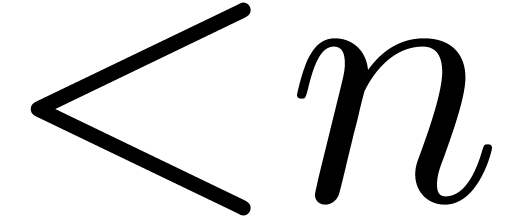 .
On peut couper les polynômes en deux à l'exposant
.
On peut couper les polynômes en deux à l'exposant 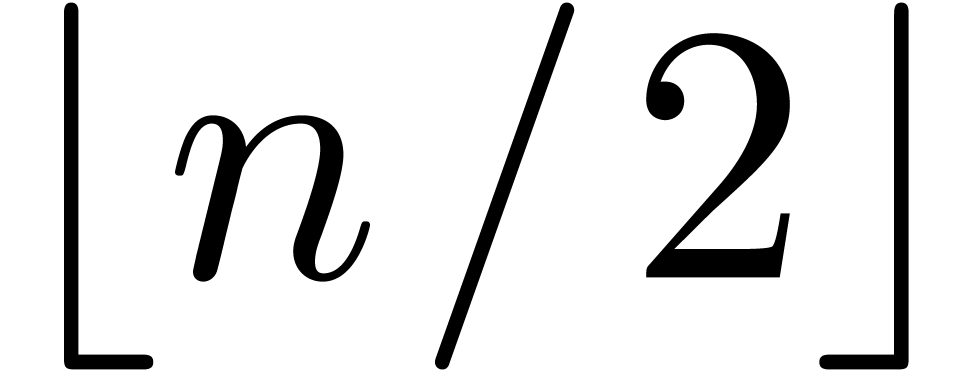 , ou par exposants pairs-impairs.
L'algorithme pair-impair est généralement plus stable d'un
point de vue numérique :
, ou par exposants pairs-impairs.
L'algorithme pair-impair est généralement plus stable d'un
point de vue numérique :
Multiplication FFT
La multiplication de Karatsuba est un algorithme « multi-modulaire
» classique, procédant par évaluation-interpolation
dans les points 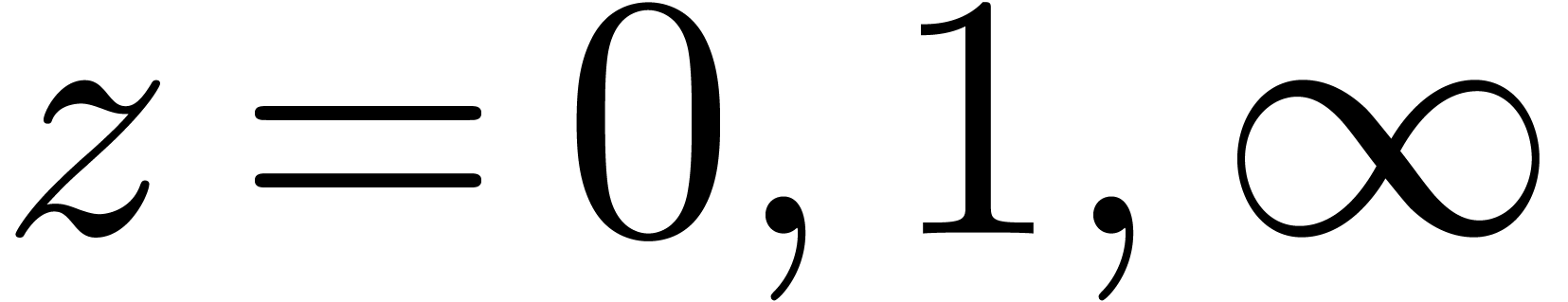 (en projectif). Si admet une racine primitive de l'unité
(en projectif). Si admet une racine primitive de l'unité  d'ordre
d'ordre 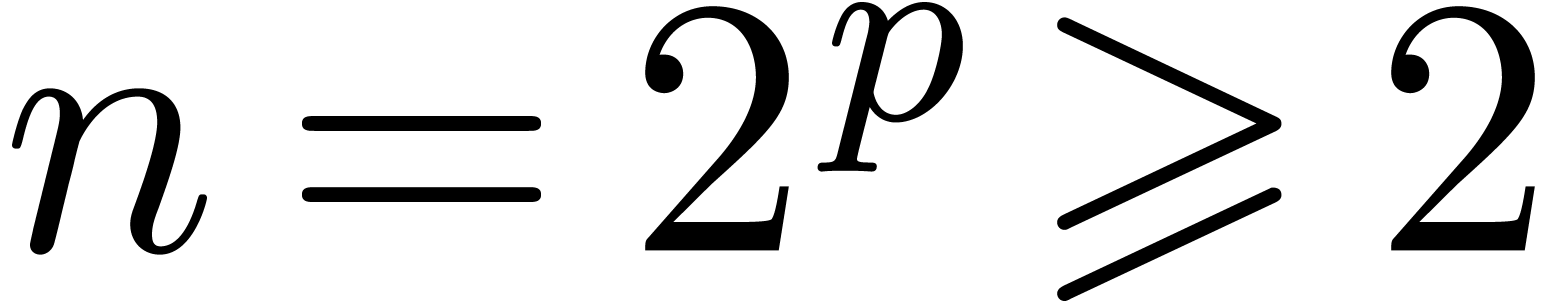 (donc
(donc 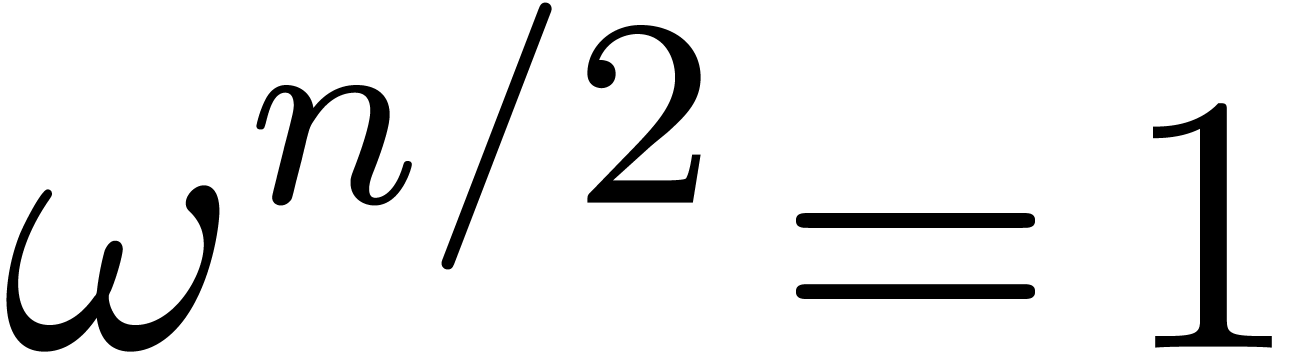 ), une stratégie multi-modulaire plus
efficace est basée sur la transformation de Fourier
discrète rapide (FFT). Pour un polynôme
), une stratégie multi-modulaire plus
efficace est basée sur la transformation de Fourier
discrète rapide (FFT). Pour un polynôme 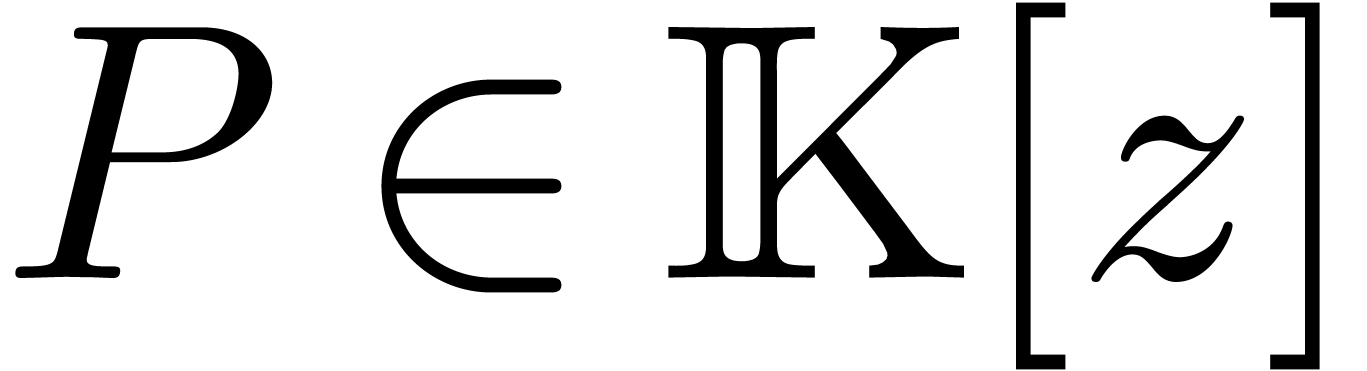 avec
avec 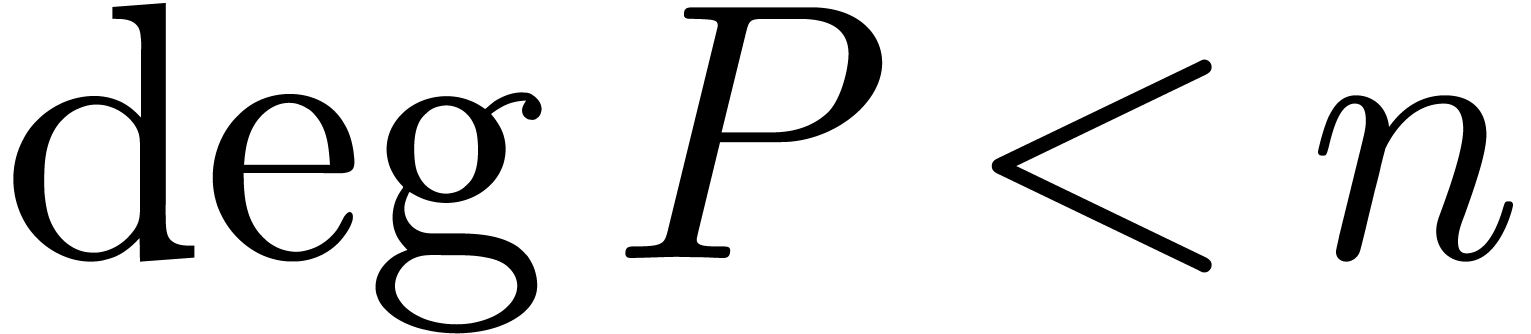 , on définit
, on définit 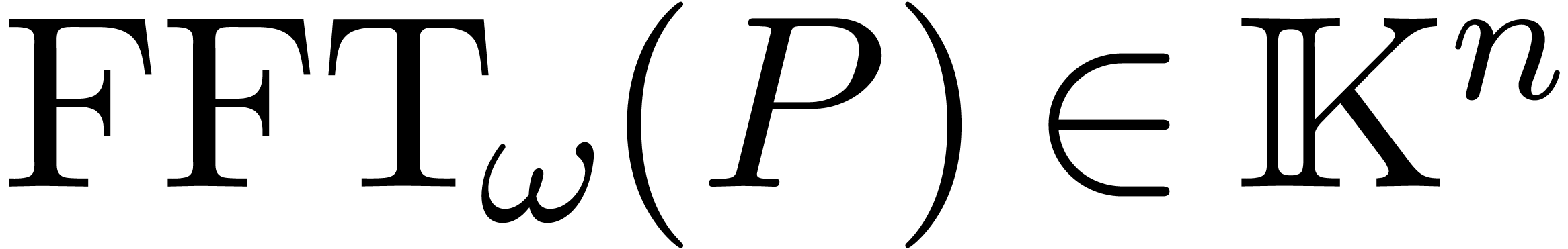 par
par
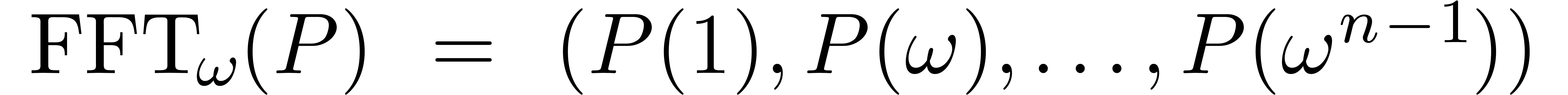
et il est classique [19] que l'on peut calculer  et son inverse
et son inverse 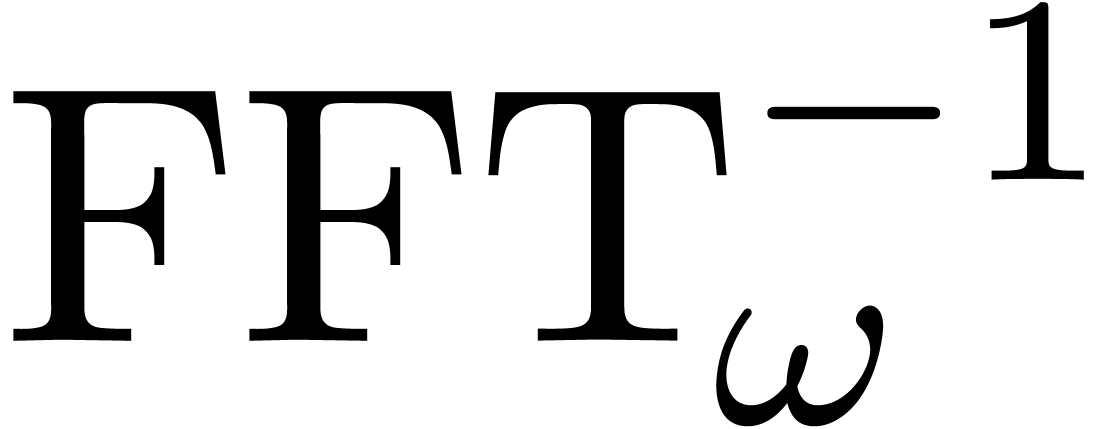 en temps
en temps 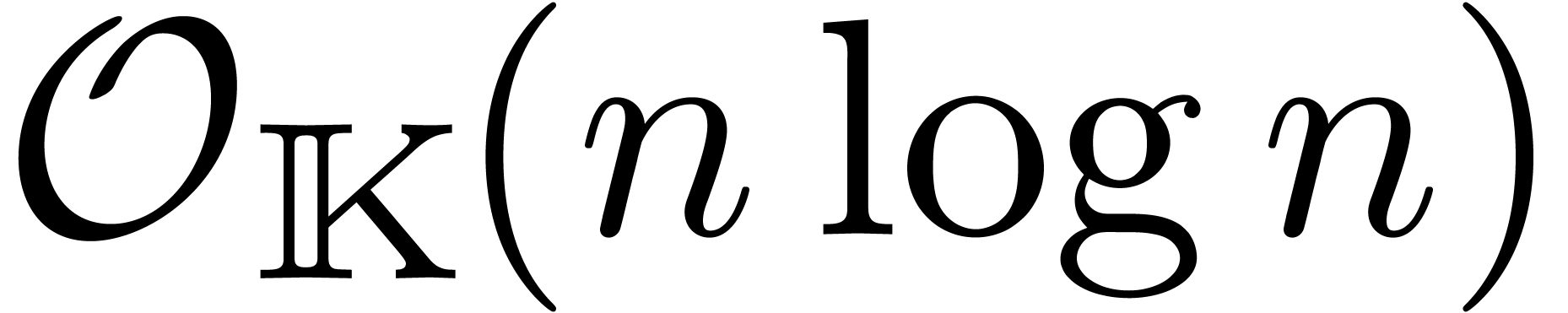 . Étant donné deux
polynômes avec
. Étant donné deux
polynômes avec 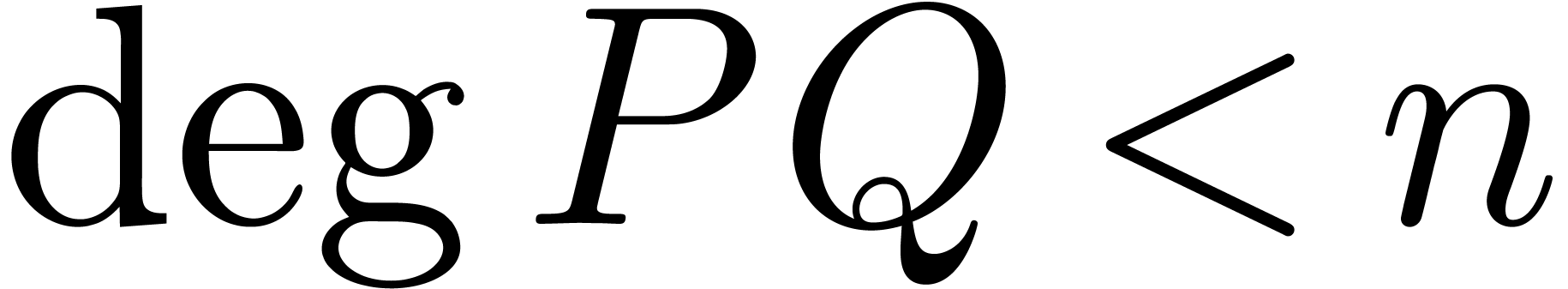 on
peut donc calculer leur produit en temps
on
peut donc calculer leur produit en temps 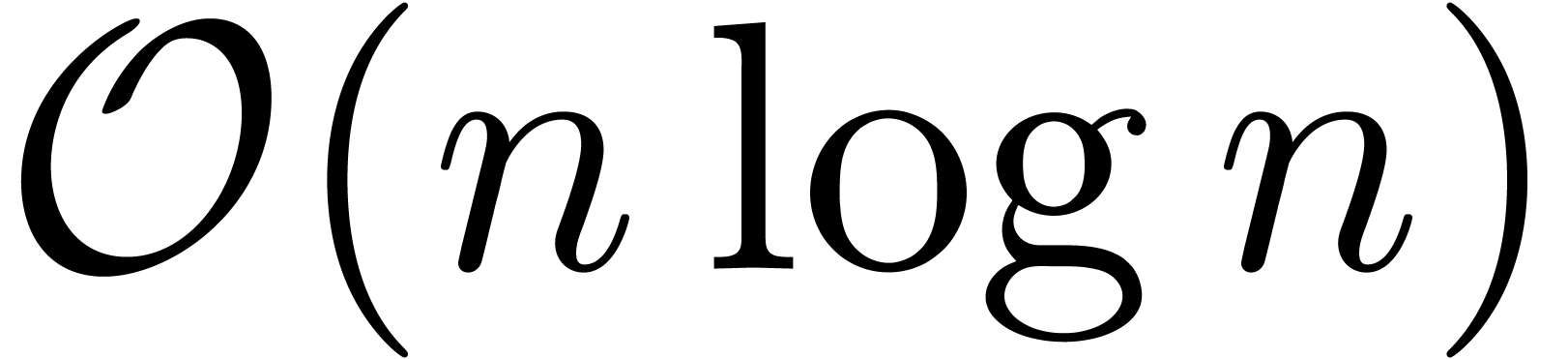 par la
formule
par la
formule
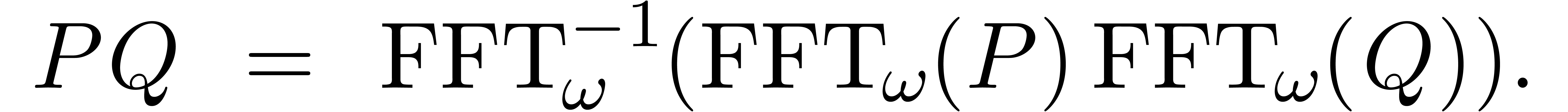
Un point de vue naturel pour calculer avec des séries dans est de calculer systématiquement avec des
séries à l'ordre 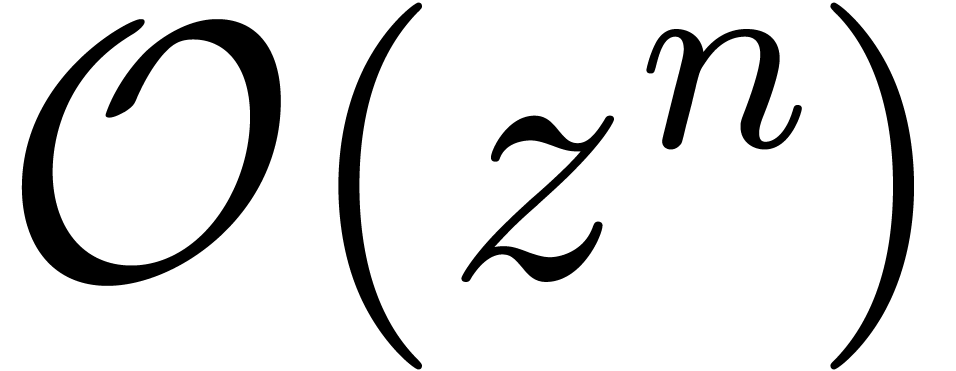 .
Pour multiplier deux telles séries, il suffit de multiplier les
séries tronquées en tant que polynômes et de
tronquer le résultat. Toutefois, si on utilise la multiplication
naïve, ceci conduit à faire environ deux fois trop de
travail. C'est un problème ouvert de savoir si on peut faire
mieux en général :
.
Pour multiplier deux telles séries, il suffit de multiplier les
séries tronquées en tant que polynômes et de
tronquer le résultat. Toutefois, si on utilise la multiplication
naïve, ceci conduit à faire environ deux fois trop de
travail. C'est un problème ouvert de savoir si on peut faire
mieux en général :
Question. Est-ce qu'il existe un algorithme de
multiplication tronquée avec de complexité en temps 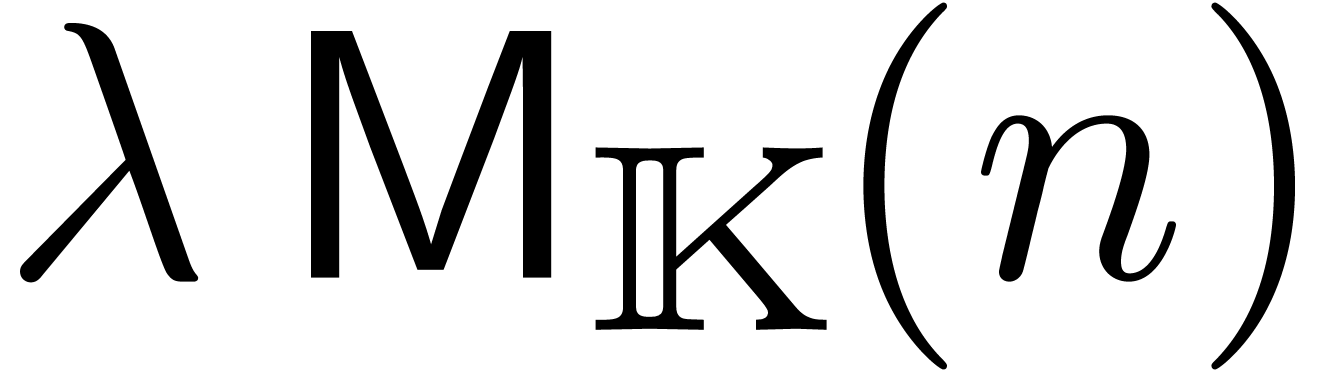 avec
avec 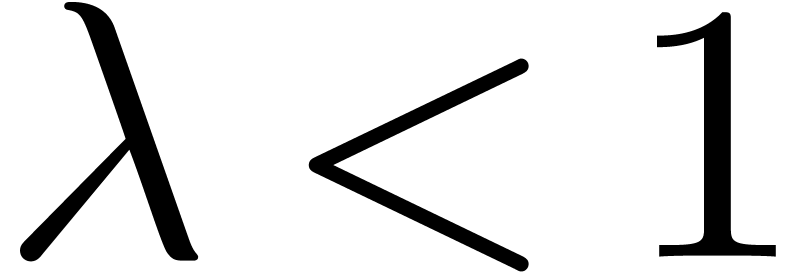 ?
?
On a déjà signalé le fait que la complexité de la plupart des opérations plus complexes, comme la division, la racine carrée, l'exponentielle, etc. s'expriment en fonction de la complexité de la multiplication. Une technique puissante pour démontrer ceci est la méthode de Newton.
Supposons par exemple que l'on veuille inverser une série  avec
avec 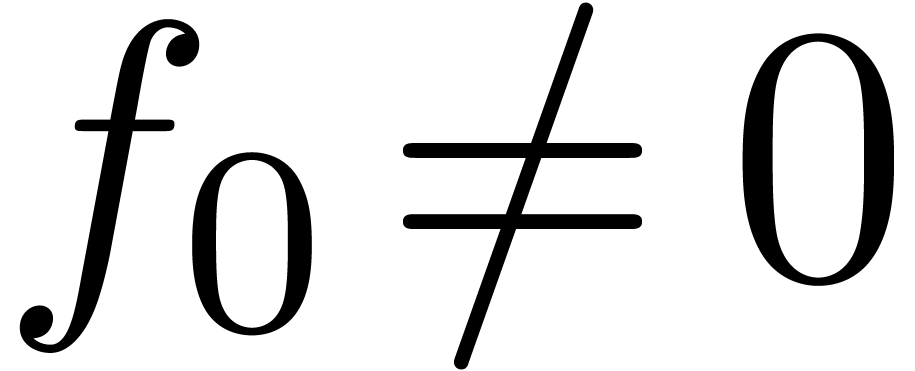 à l'ordre . En d'autres mots, étant
donnés les coefficients
à l'ordre . En d'autres mots, étant
donnés les coefficients  ,
on voudrait calculer les coefficients
,
on voudrait calculer les coefficients  de
de 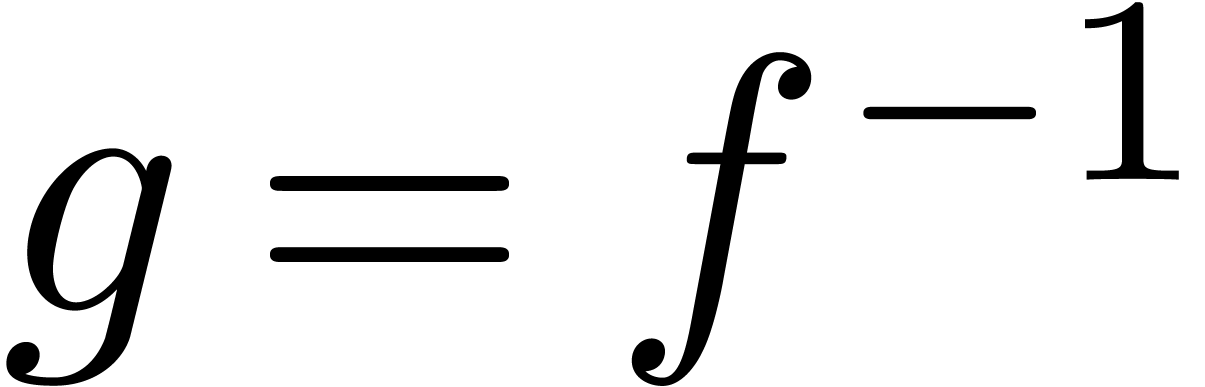 . La méthode de Newton
appliquée à l'équation
. La méthode de Newton
appliquée à l'équation 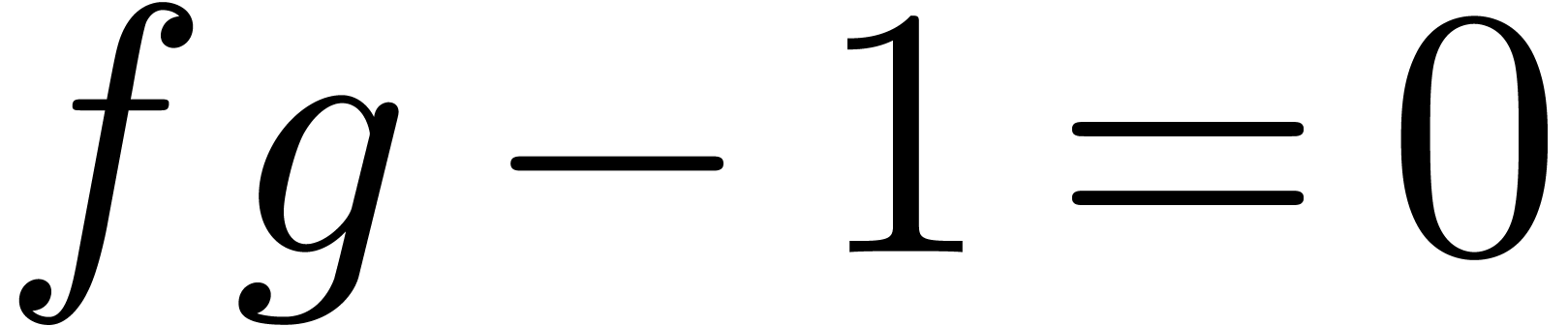 donne l'itération
donne l'itération
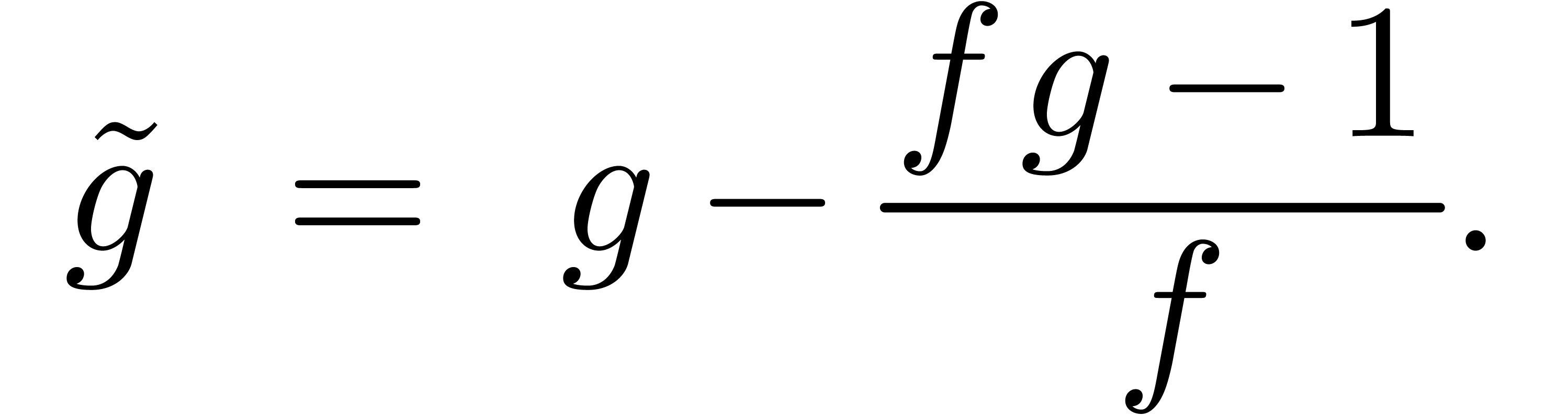
Comme on ne connait pas encore 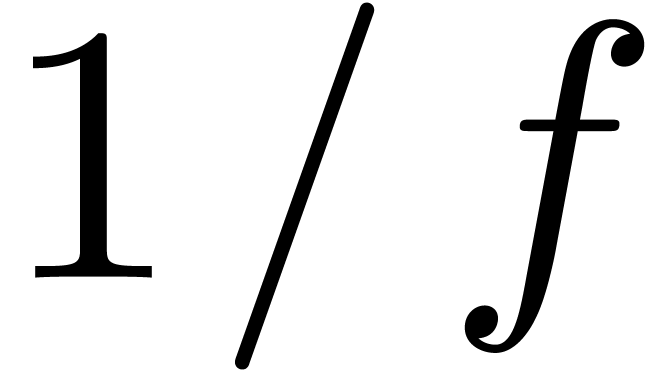 dans cette
itération, on utilisera plutôt l'itération
dans cette
itération, on utilisera plutôt l'itération
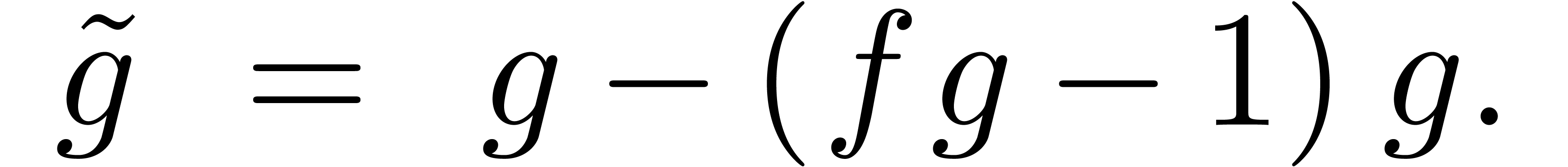
Si  est bon jusqu'à l'ordre :
est bon jusqu'à l'ordre :
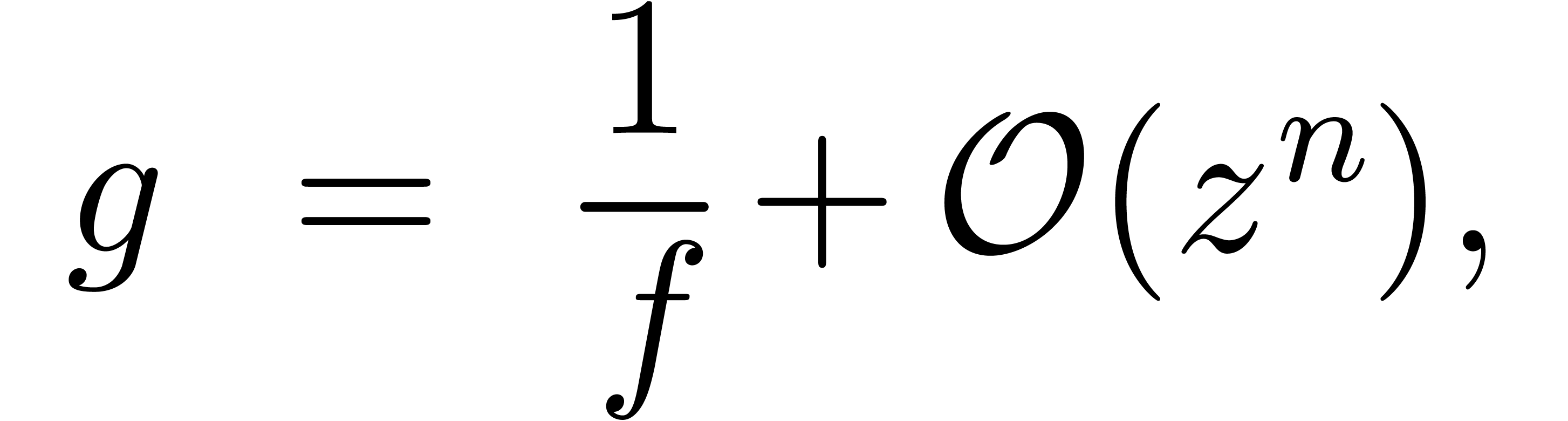
la nouvelle valeur  sera bonne jusqu'à
l'ordre
sera bonne jusqu'à
l'ordre 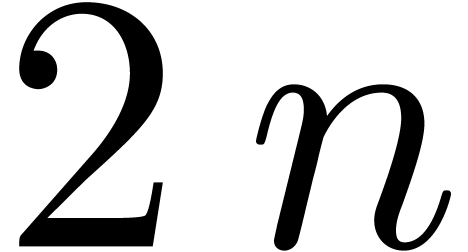 , puisque
, puisque
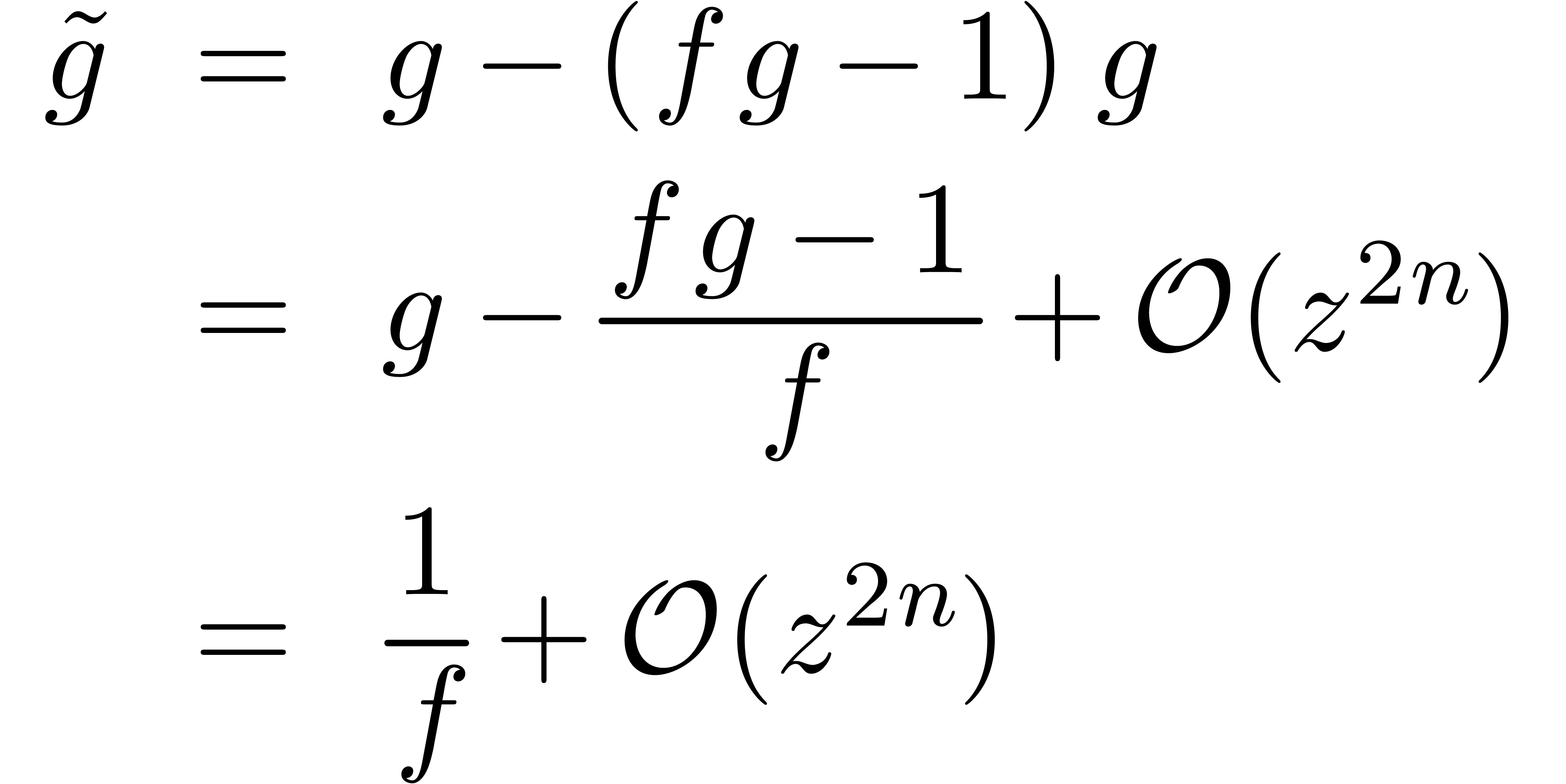
Si  désigne le coût de la division
à l'ordre , ceci donne
désigne le coût de la division
à l'ordre , ceci donne
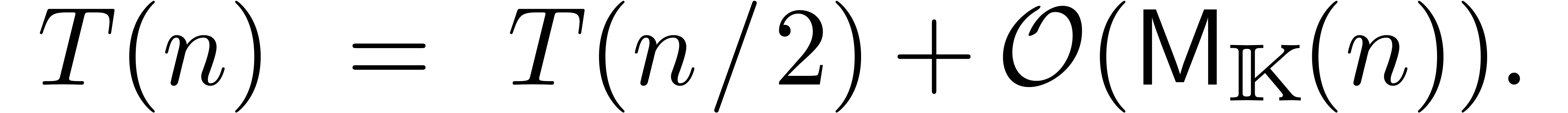
En supposant que 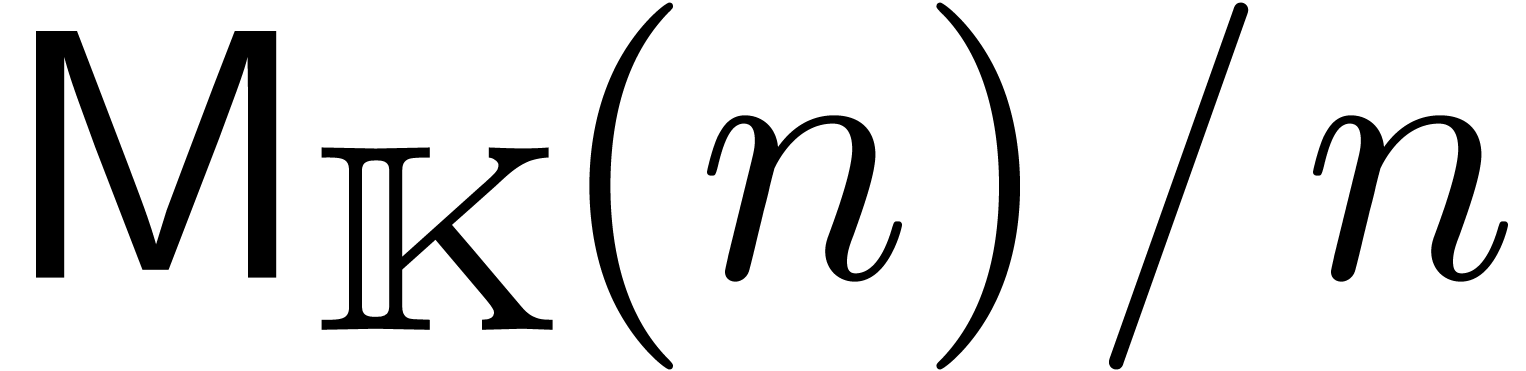 est croissante, on laisse au
soin du lecteur de vérifier que ceci implique
est croissante, on laisse au
soin du lecteur de vérifier que ceci implique 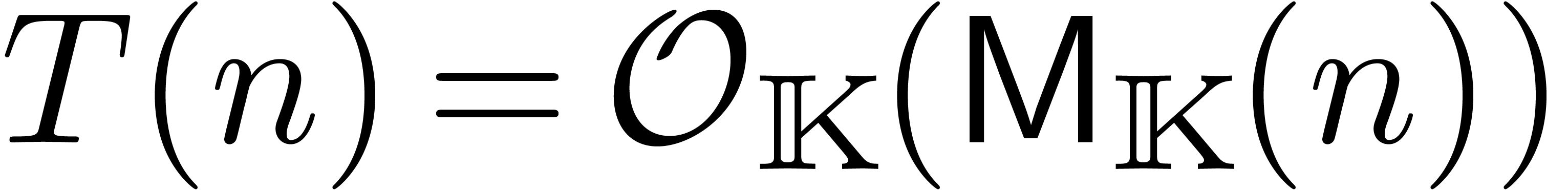 . On déduit aussi aisément que le
calcul du quotient et du reste de la division euclidienne d'un
polynôme de degré
par un polynôme
. On déduit aussi aisément que le
calcul du quotient et du reste de la division euclidienne d'un
polynôme de degré
par un polynôme  de degré se calcule en temps
de degré se calcule en temps 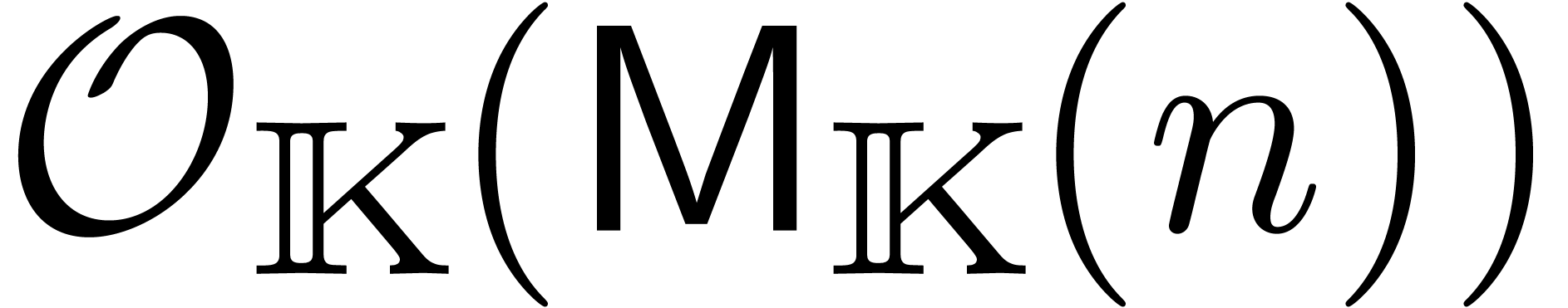 .
.
L'utilisation de la méthode de Newton dans ce cadre remonte
à Hensel et se généralise pour des équations
polynomiales plus générale (à la fois dans les
séries et les nombres -adiques
d'ailleurs). Brent et Kung ont remarqué [13, 15] que la même technique peut être
utilisée pour composer des séries formelles, calculer
leurs inverses fonctionnelles, ou résoudre des équations
différentielles. Par exemple, l'exponentielle 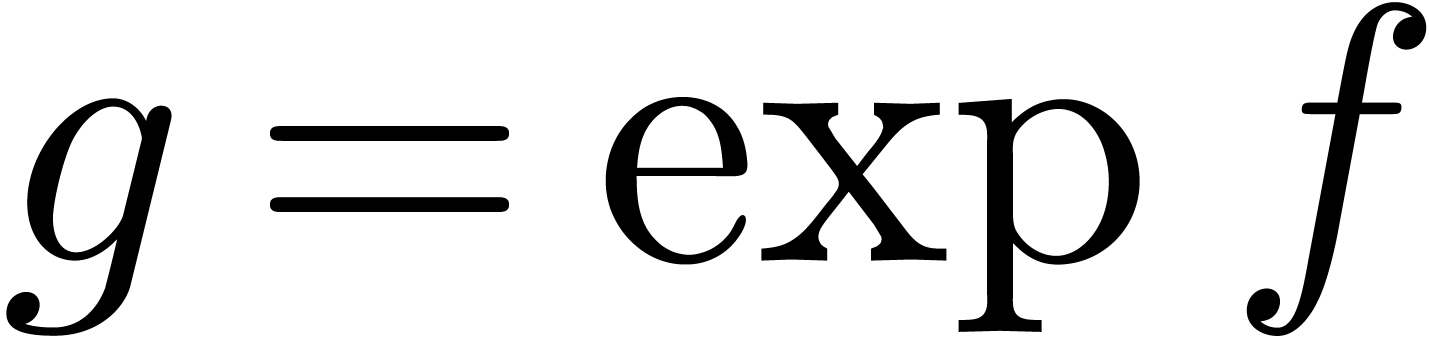 de avec
de avec 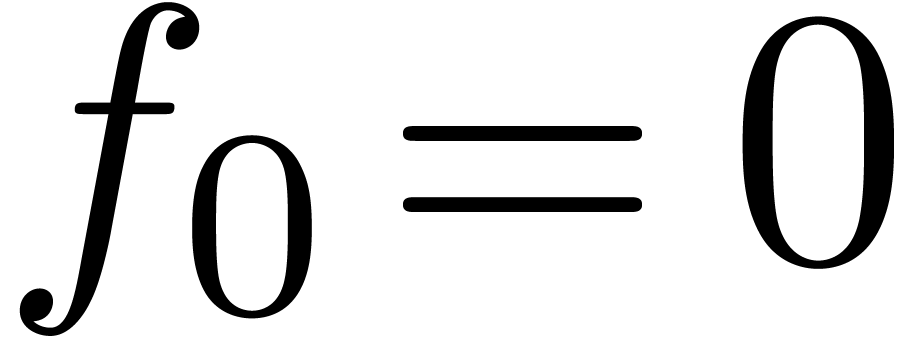 se calcule par
l'itération
se calcule par
l'itération
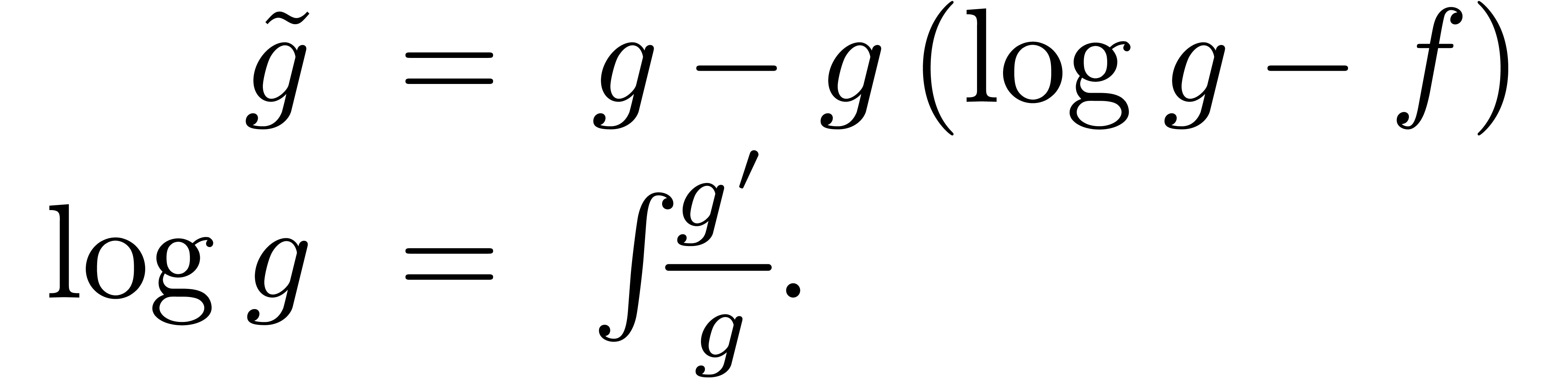
Une méthode efficace pour la résolution d'équations différentielles algébriques plus générales a été proposée par Sedoglavic [68, 10, 86].
Il y a de nombreux autres opérations sur les polynômes (racine carrée, pgcd, ppcm, etc.) qui peuvent se calculer en temps presque linéaire. Nous donnons un dernier exemple qui est utile pour le calcul des zéros d'un polynôme. En effet, si on dispose déjà de bonnes approximations pour les racines, l'évaluation multi-point rapide permet d'appliquer la méthode de Newton pour améliorer toutes ces approximations de façon simultanée.
Algorithme évaluation multi-point rapide
avec
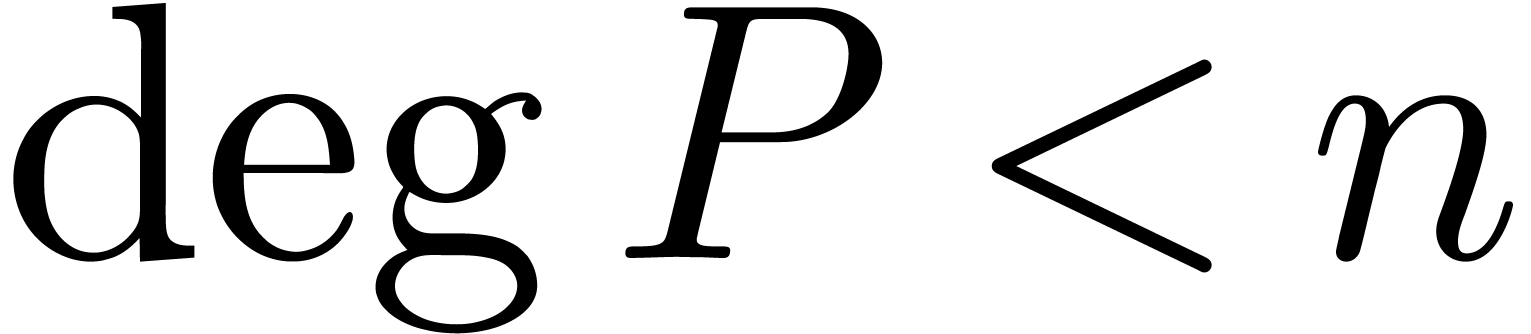 et points
et points 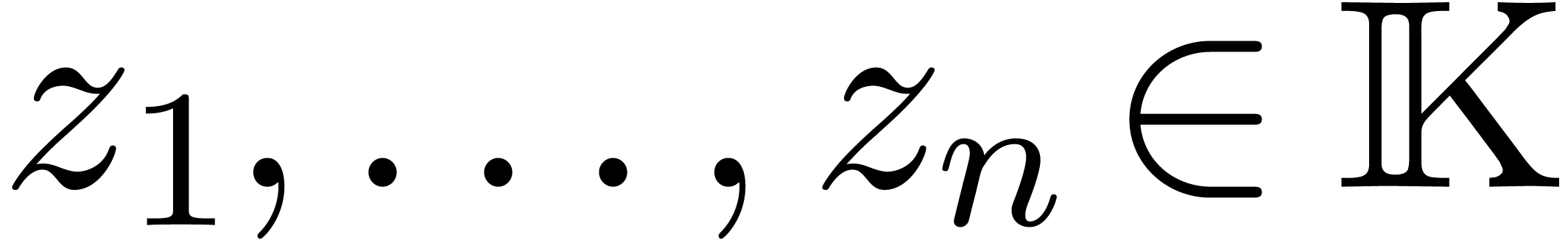
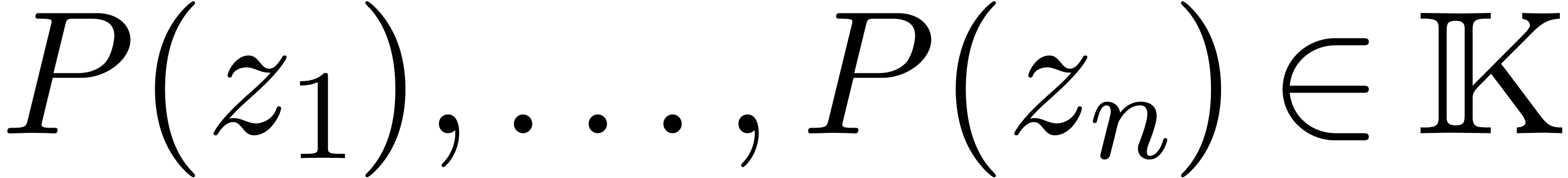
On précalcule tous les polynômes dans l'arbre suivant :
On utilise la méthode dichotomique suivante pour calculer le résultat :
Si , retourner
Sinon, soient  et
et 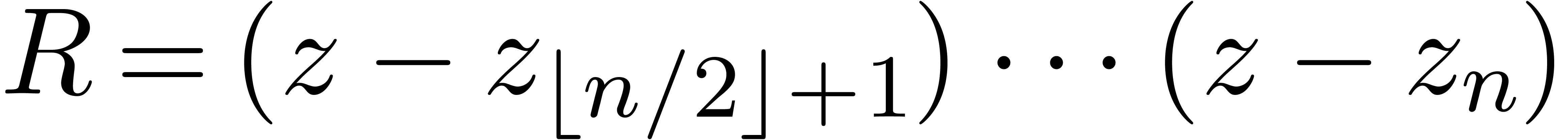
Evaluer  en
en 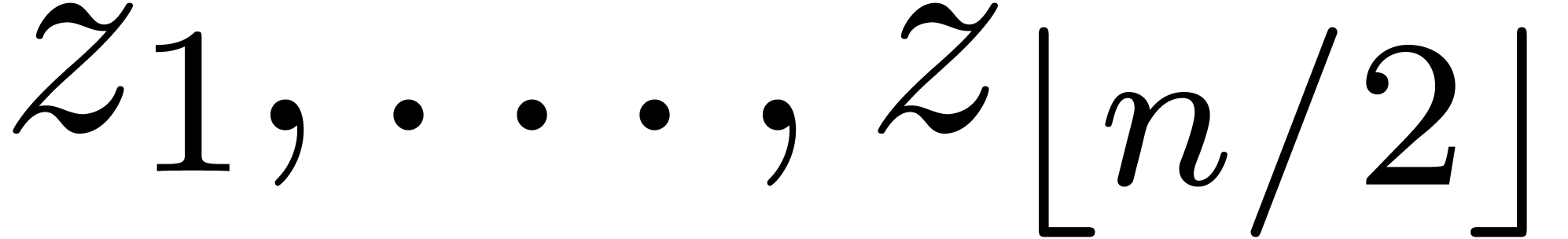 et
et  en
en 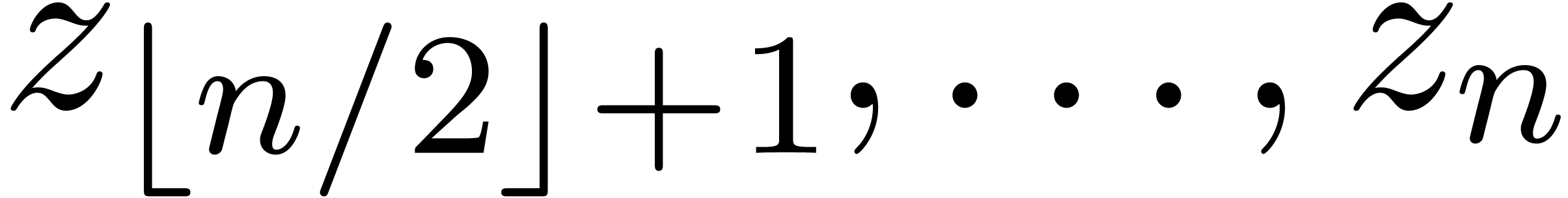
On remarque que la complexité du précalcul et de la dichotomie proprement dite vérifient une estimation du type
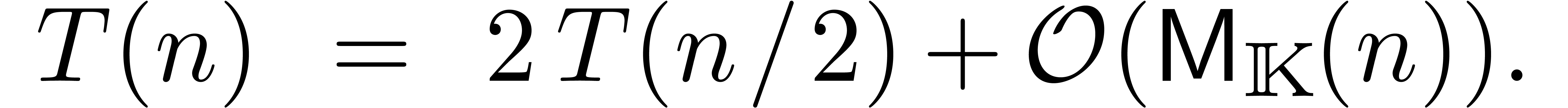
En supposant que est croissante, on laisse au
soin du lecteur de vérifier que ceci implique 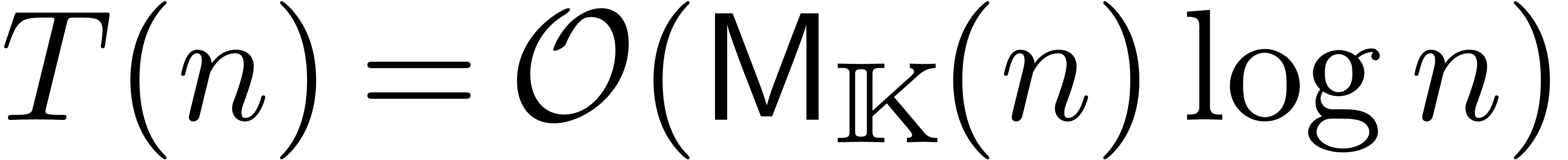 . On peut encore gagner un facteur constant sur
l'algorithme présenté ici [11].
. On peut encore gagner un facteur constant sur
l'algorithme présenté ici [11].
Nous avons vu comment calculer avec des séries en les tronquant
à un certain ordre .
Une autre approche consiste à considérer les séries
comme des « flots de coefficients » qui sont calculés
un par un. Ce point de vue détendu impose une contrainte sur
notre façon de concevoir les opérations sur les
séries. Par exemple, la multiplication détendue  de deux séries
de deux séries 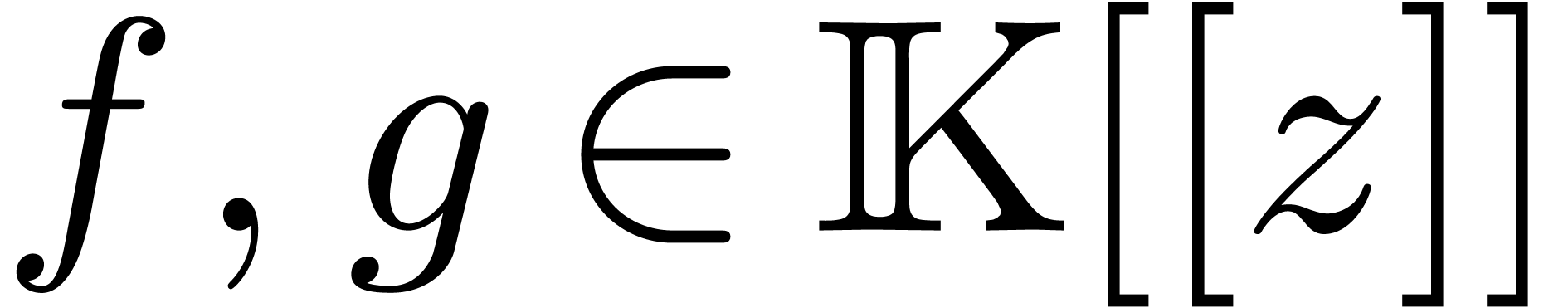 impose la
sortie de
impose la
sortie de  dès que
dès que  sont connus. Par conséquent, on ne peut pas
directement appliquer certains algorithmes rapides, comme la
multiplication FFT. L'avantage du calcul détendu est qu'il permet
naturellement de résoudre des équations «
récursives »
sont connus. Par conséquent, on ne peut pas
directement appliquer certains algorithmes rapides, comme la
multiplication FFT. L'avantage du calcul détendu est qu'il permet
naturellement de résoudre des équations «
récursives »

où l'extraction du coefficient en 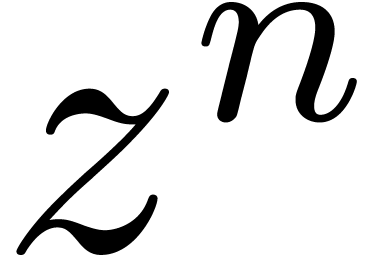 de
de 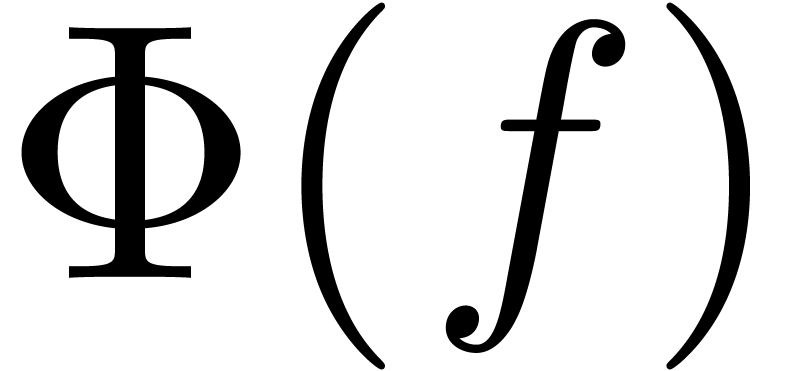 ne fait intervenir que les coefficients de . Voici deux
exemples :
ne fait intervenir que les coefficients de . Voici deux
exemples :
de 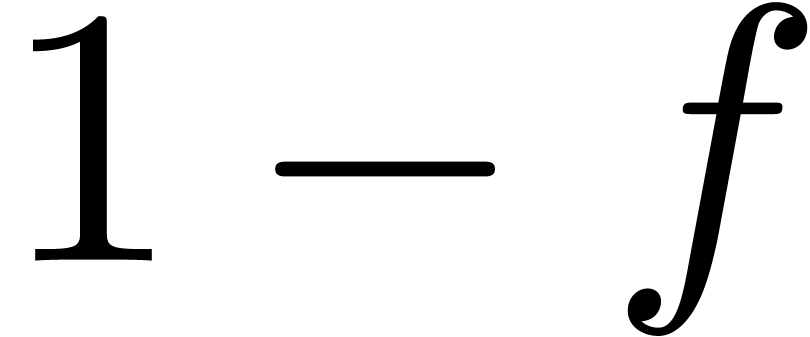 avec
avec 
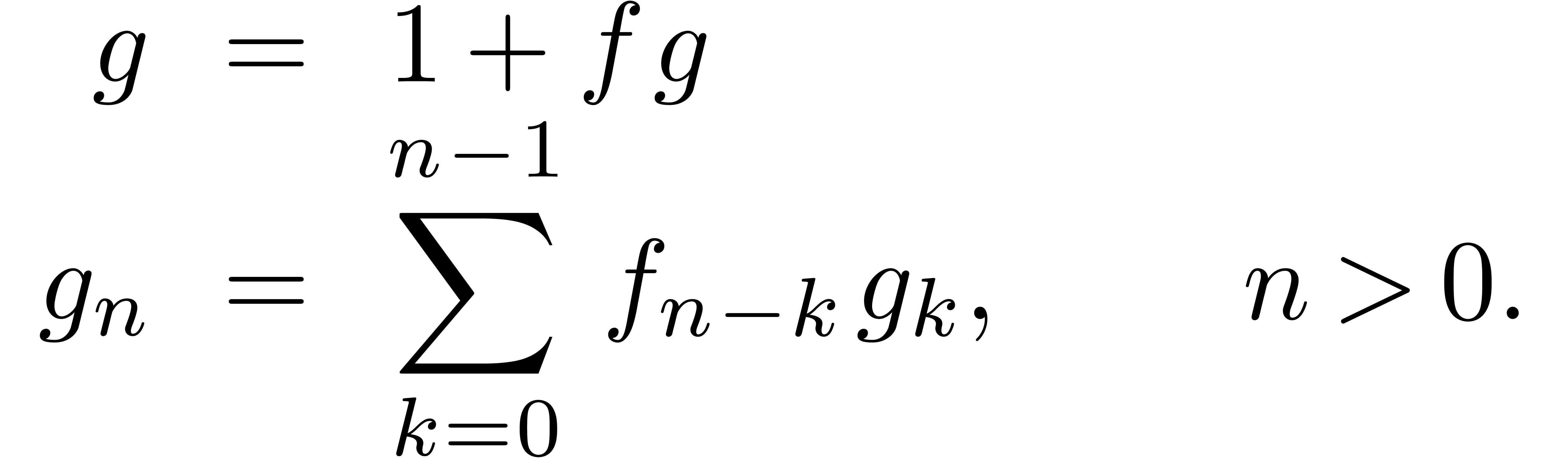
de
avec 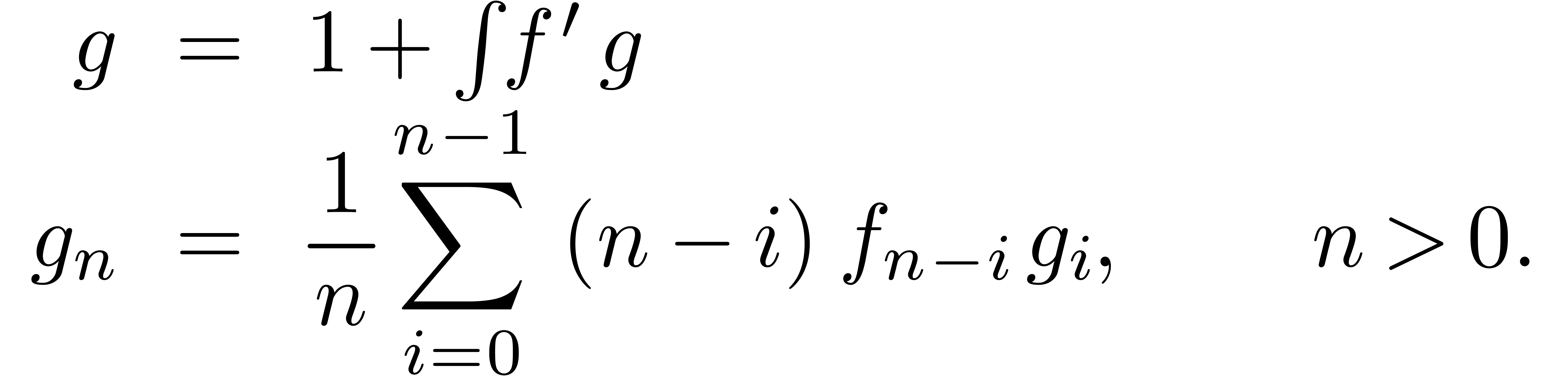
La stratégie la plus naïve pour calculer le coefficient d'un produit est d'utiliser
la formule classique de convolution
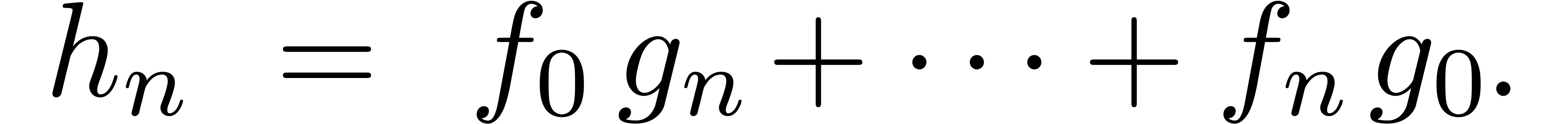
Pour un calcul jusqu'à l'ordre ,
cela donne une complexité 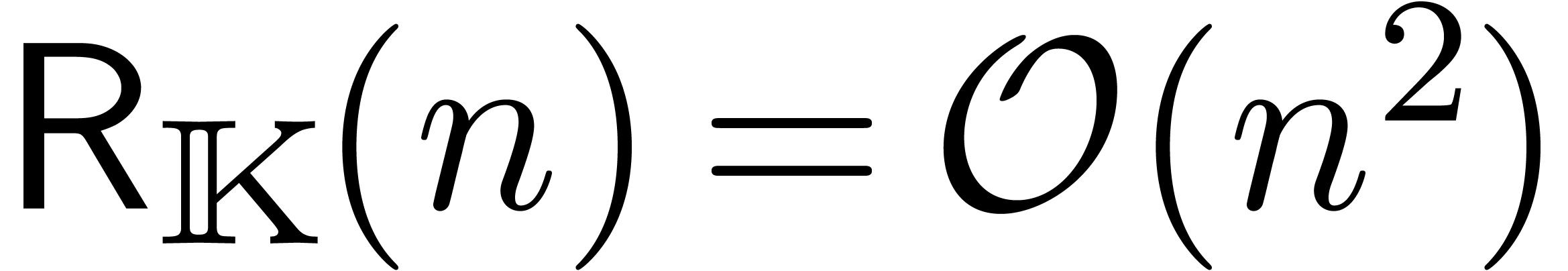 .
Dans la figure 4.1, on montre les étapes successives
du calcul détendu de l'exponentielle
.
Dans la figure 4.1, on montre les étapes successives
du calcul détendu de l'exponentielle 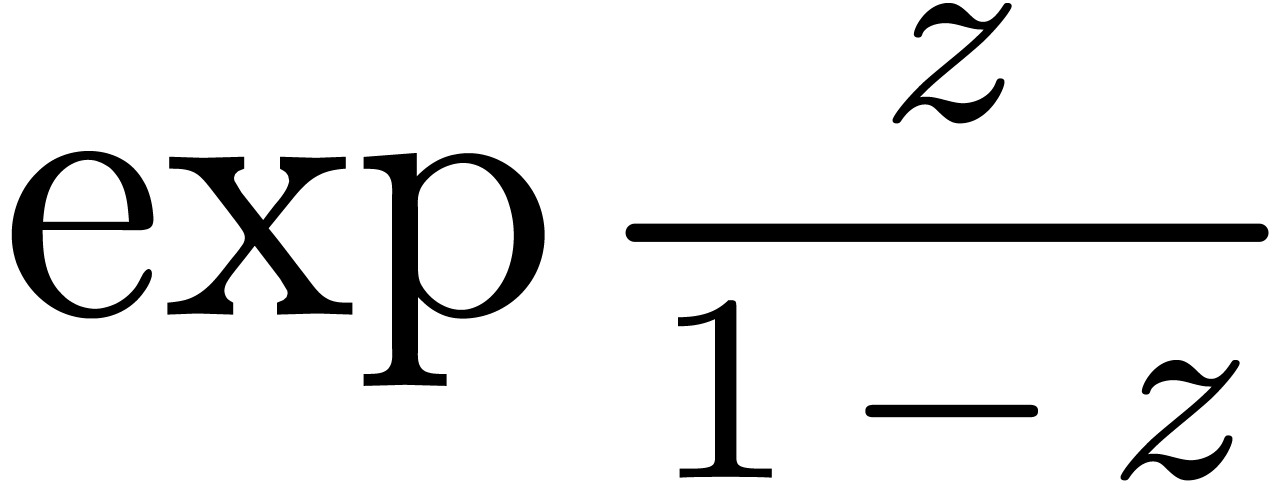 .
.
Lorsque l'on applique l'algorithme de Karatsuba sur des polynômes
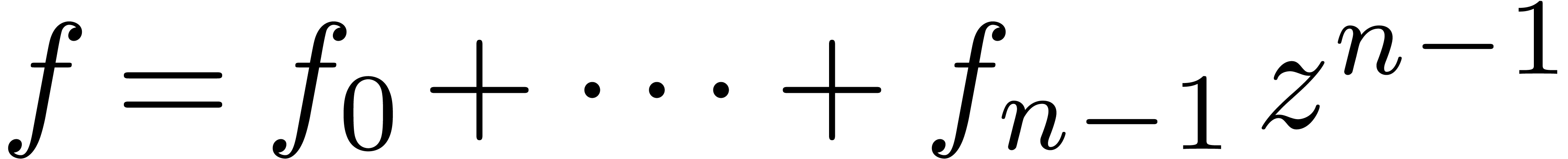 et
et 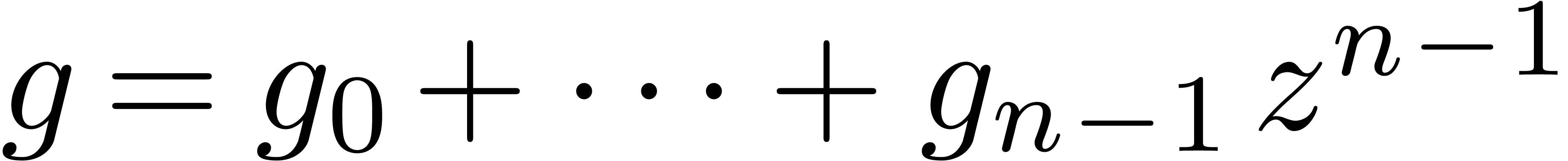 avec , où on considère
avec , où on considère 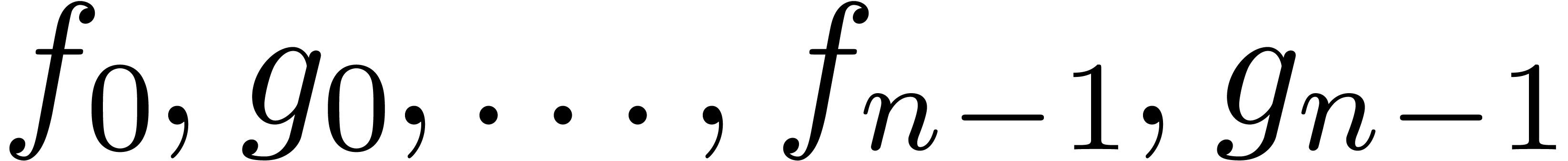 comme des paramètres formels, on observe que la
formule pour
comme des paramètres formels, on observe que la
formule pour 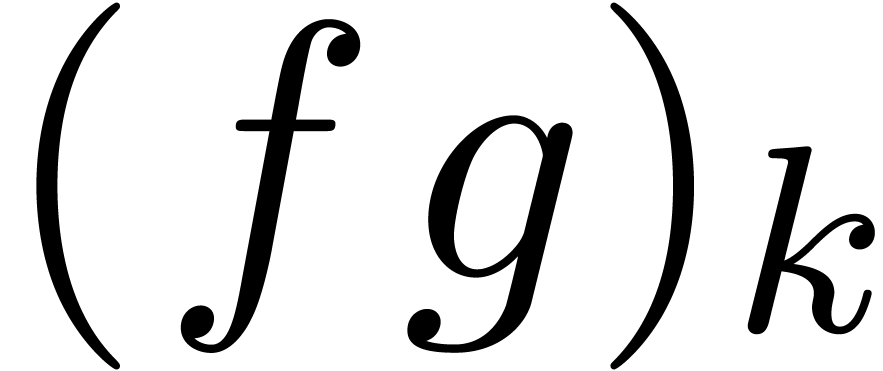 ne dépend que de
ne dépend que de  pour chaque .
En d'autres termes, l'algorithme de Karatsuba est naturellement
détendu, si on fait les calculs dans le bon ordre. Ceci montre
qu'il existe un algorithme de multiplication détendue de
complexité
pour chaque .
En d'autres termes, l'algorithme de Karatsuba est naturellement
détendu, si on fait les calculs dans le bon ordre. Ceci montre
qu'il existe un algorithme de multiplication détendue de
complexité  .
.
On peut encore faire mieux en anticipant des calculs à venir. Par
exemple lorsque  et
et  sont
connus, on peut calculer la contribution de
sont
connus, on peut calculer la contribution de  au
produit
au
produit 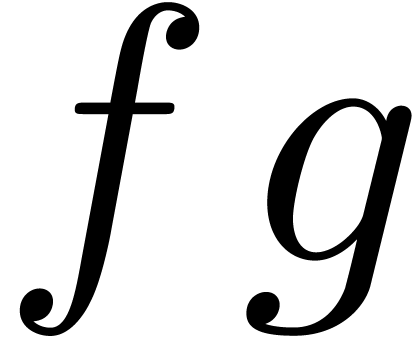 par n'importe quel algorithme de
multiplication rapide pour les polynômes. De même, lorsque
l'on connait
par n'importe quel algorithme de
multiplication rapide pour les polynômes. De même, lorsque
l'on connait  et
et  ,
on peut calculer la contribution de
,
on peut calculer la contribution de  au produit
de façon rapide. En exploitant cette
idée, les contributions de tous les grands carrés dans la
figure 4.2 peuvent se calculer par un algorithme rapide. Il
s'ensuit [76, 79] que
au produit
de façon rapide. En exploitant cette
idée, les contributions de tous les grands carrés dans la
figure 4.2 peuvent se calculer par un algorithme rapide. Il
s'ensuit [76, 79] que
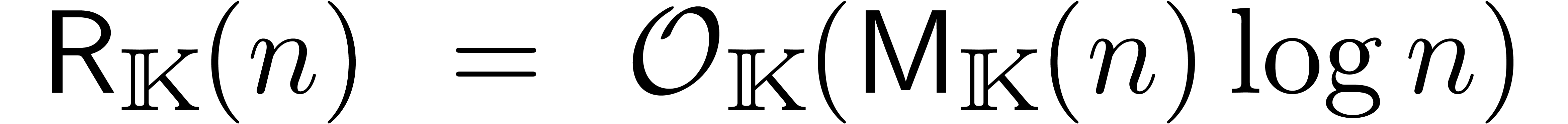
Est-ce que l'on peut faire encore mieux ? Si
admet suffisamment de racines -ièmes
de l'unité, on montre [83] que :
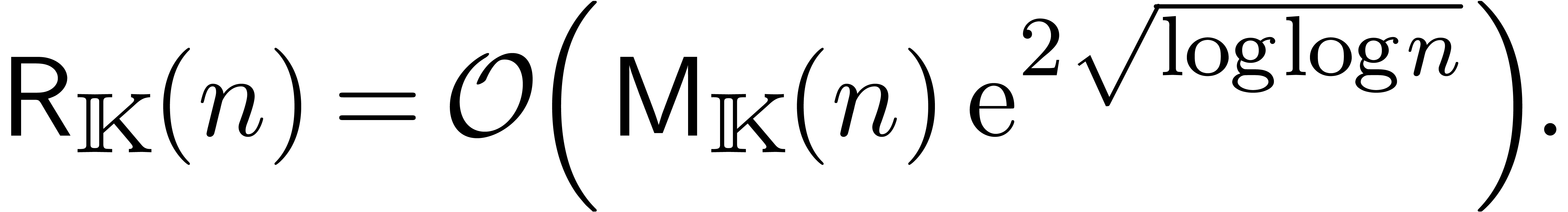
Dans le cas général, la question reste ouverte :
Question. Pour n'importe quel anneau effectif  , est-ce qu'il existe un algorithme
de multiplication détendue dont la complexité est
meilleure que
, est-ce qu'il existe un algorithme
de multiplication détendue dont la complexité est
meilleure que
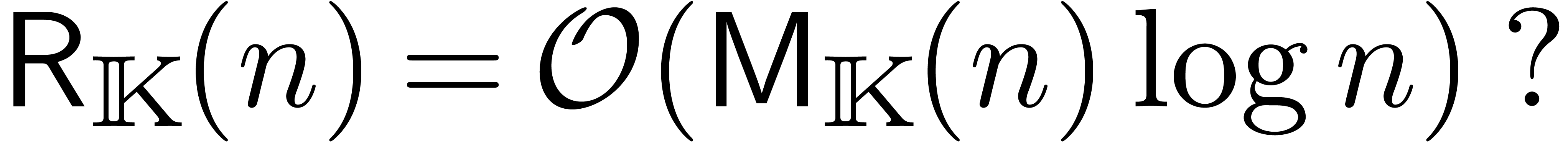
Mmx] |
use "algebramix" |
Mmx] |
z == series (0, 1); |
Mmx] |
B == exp (exp z - 1) |
Mmx] |
B[1000] * 1000! |

La multiplication FFT de la section 4.2.1 est un exemple classique d'algorithme multi-modulaire. En effet, elle repose en réalité sur l'isomorphisme
entre les polynômes modulo 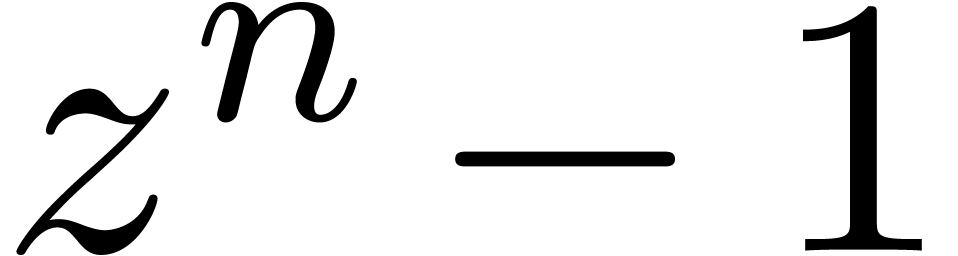 et les réductions de modulo
les
et les réductions de modulo
les 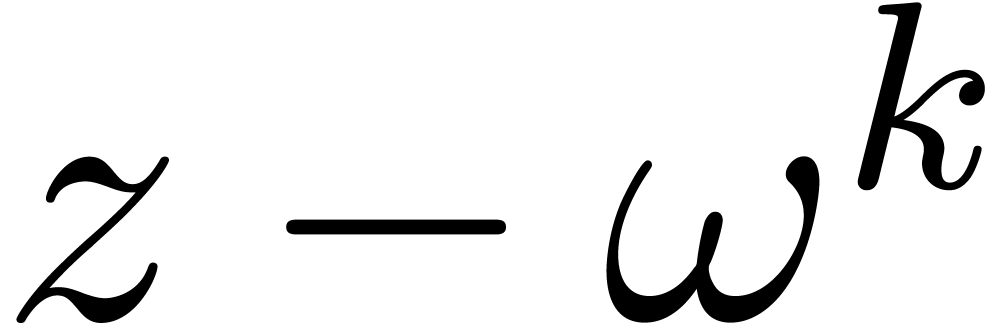 avec
avec  .
De la même manière, étant donnés
.
De la même manière, étant donnés  nombres premiers
nombres premiers  mutuellement
distincts, le théorème des restes chinois nous fournit un
isomorphisme
mutuellement
distincts, le théorème des restes chinois nous fournit un
isomorphisme
Dans chaque cas, le calcul multi-modulaire repose sur un changement de
représentation, où un objet dans  ou
ou  où la multiplication coûte cher
est remplacé par un vecteur d'objets pour lesquels la
multiplication coûte moins cher.
où la multiplication coûte cher
est remplacé par un vecteur d'objets pour lesquels la
multiplication coûte moins cher.
Comme les changements de représentation coûtent
généralement cher aussi, il est recommandé
d'effectuer un maximum de calculs dans le modèle multi-modulaire.
Supposons par exemple que l'on veuille multiplier deux matrices et dans 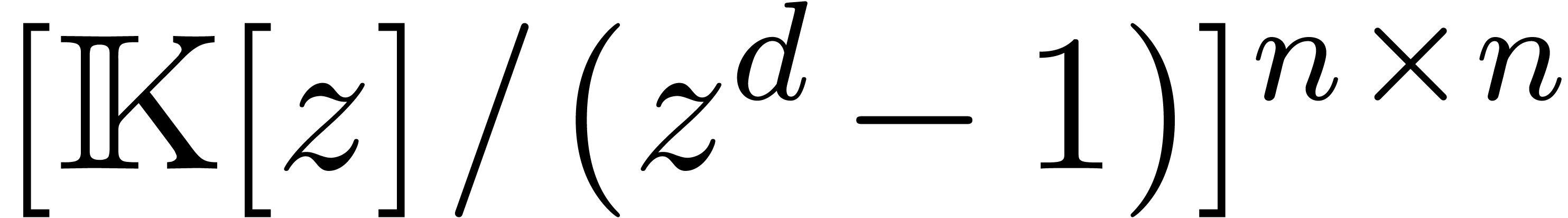 . Au lieu de faire
. Au lieu de faire  opérations dans
opérations dans 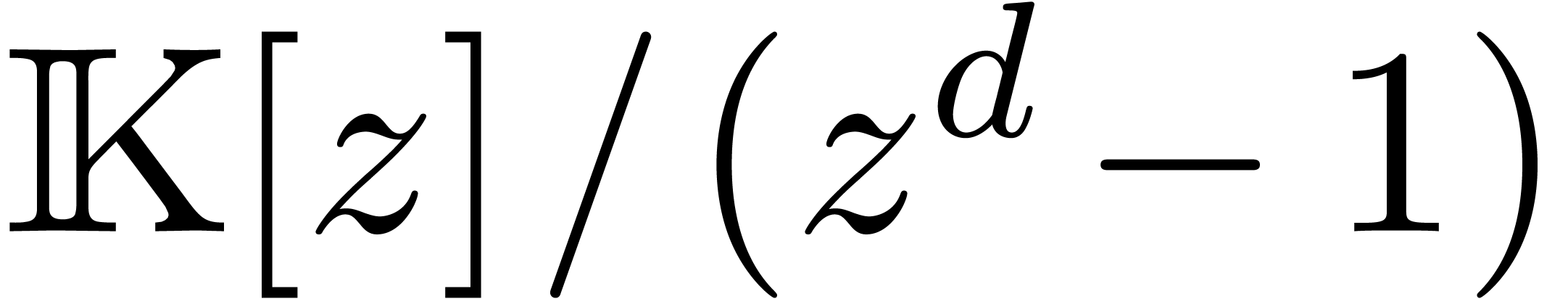 , de
coût
, de
coût 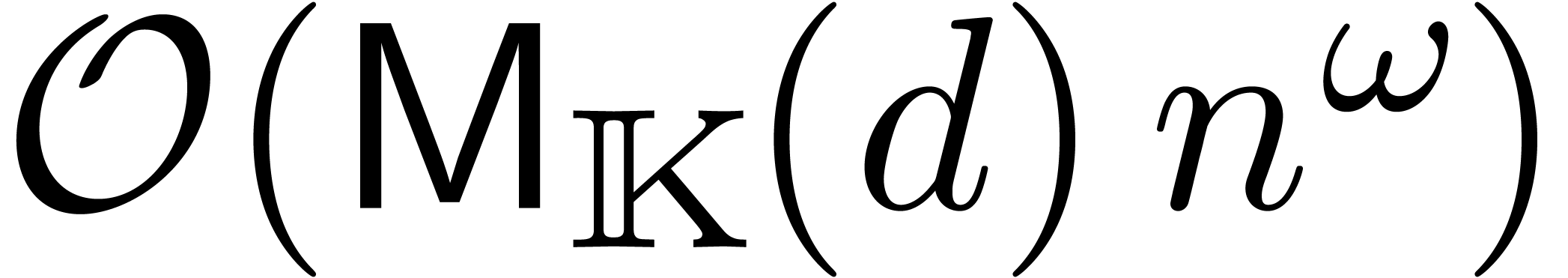 , il vaut mieux
utiliser la formule
, il vaut mieux
utiliser la formule

qui correspond à mettre tous les coefficients de
et dans le modèle FFT, de multiplier matrices scalaires dans ,
et de faire la transformation inverse. En effet, cet algorithme admet
une complexité 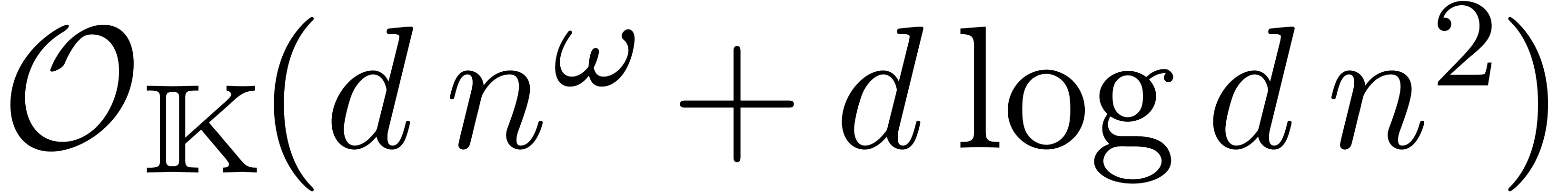 bien meilleure.
bien meilleure.
Il y a plusieurs variantes pour les méthodes multi-modulaires. Chaque variante admet ses caractéristiques propres quant au nombre de moduli utilisés et quant au coût de la réduction et de la reconstruction. Les méthodes les plus utilisées sont les suivantes :
Cette méthode permet grosso modo d'encoder un
entier d'environ mots machines en
utilisant seulement moduli. En revanche,
les coûts de la réduction et de la reconstruction
sont en 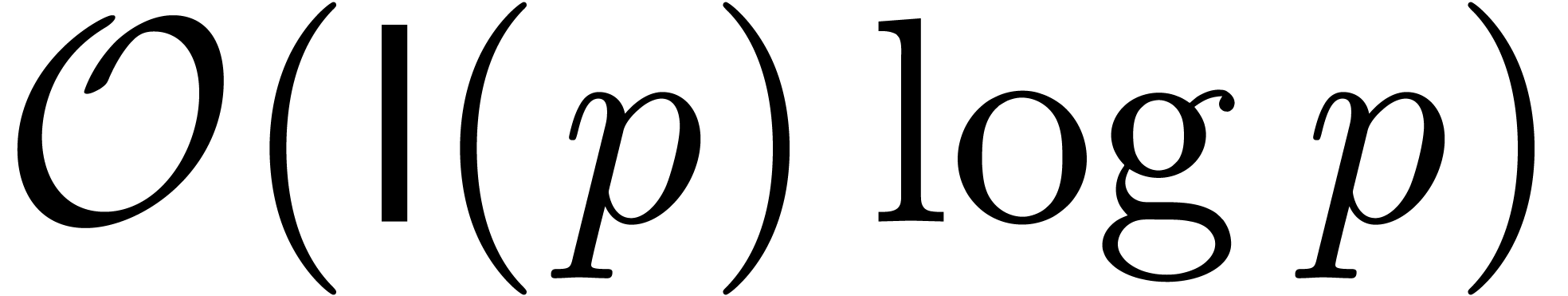 pour un entier de taille .
pour un entier de taille .
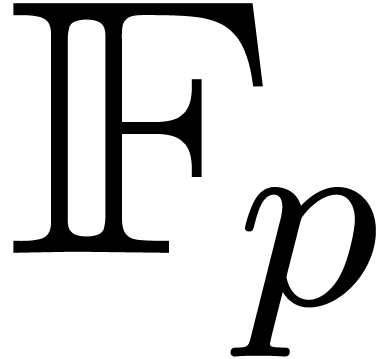 avec beaucoup de racines
avec beaucoup de racines  -ièmes de l'unité
-ièmes de l'unité
Certains nombres premiers comme  admettent
des racines primitives de l'unité d'un ordre avec grand. Cela permet
d'utiliser la multiplication FFT pour des polynômes de
degrés importants à coefficients dans . Par ailleurs, tout nombre dans
admettent
des racines primitives de l'unité d'un ordre avec grand. Cela permet
d'utiliser la multiplication FFT pour des polynômes de
degrés importants à coefficients dans . Par ailleurs, tout nombre dans  peut se coder par
peut se coder par  avec
avec
 . En prenant
. En prenant  , on peut aussi ramener la
multiplication dans à la
multiplication dans
, on peut aussi ramener la
multiplication dans à la
multiplication dans  pour des nombres pas
trop grands. Par rapport aux restes chinois, ceci revient à
prendre plus de moduli, mais aussi à gagner sur le
coûts de réduction et de reconstruction. On peut
d'ailleurs combiner les deux approches.
pour des nombres pas
trop grands. Par rapport aux restes chinois, ceci revient à
prendre plus de moduli, mais aussi à gagner sur le
coûts de réduction et de reconstruction. On peut
d'ailleurs combiner les deux approches.
Lorsque l'on calcule avec des nombres flottants complexes, on peut
directement calculer avec une racine -ième
de l'unité approchée. En encadrant les erreurs
d'arrondi avec soin, ceci conduit à des algorithmes de
multiplication rapide dans 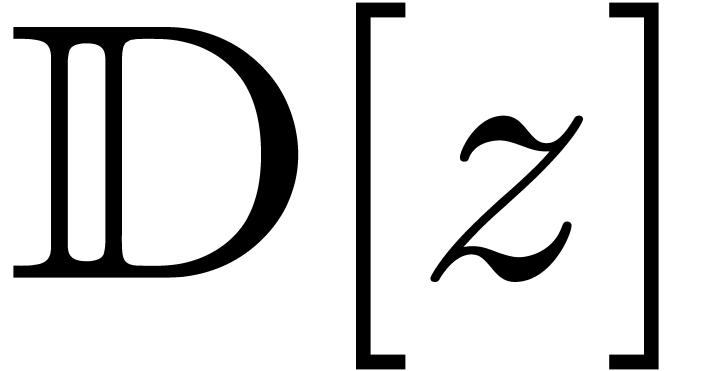 et qui ont des avantages et inconvénients
semblables par rapport à la méthode
précédente.
et qui ont des avantages et inconvénients
semblables par rapport à la méthode
précédente.
En cas d'absence de racines -ièmes
de l'unité pour suffisamment grand,
on peut les synthétiser. Supposons par exemple,
que l'on veuille multiplier des polynômes dans  et prenons
et prenons 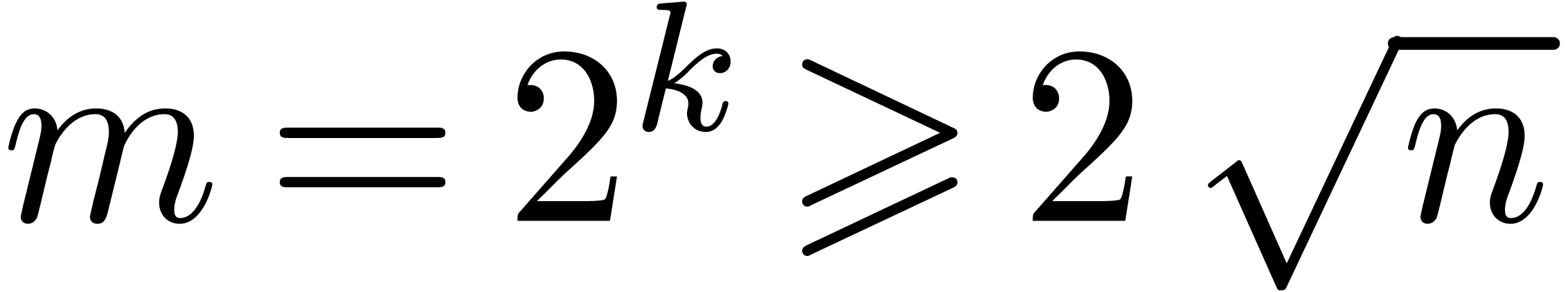 .
Alors est une racine
.
Alors est une racine  -ième primitive de l'unité
dans
-ième primitive de l'unité
dans 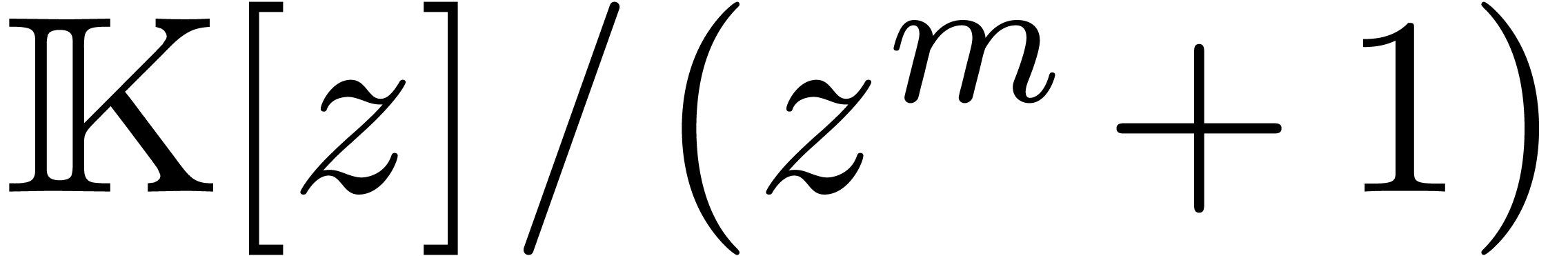 et montre que la multiplication dans
se ramène à une
multiplication de polynômes à coefficients dans . En outre, la FFT à
coefficients dans est très
efficace, car elle ne nécessite que des additions et des
soustractions dans .
Par ailleurs, la méthode est parfaitement
générale, et marche encore pour des grands entiers.
Le seul point noir de l'approche est qu'elle nécessite plus
de moduli que les méthodes précédentes.
et montre que la multiplication dans
se ramène à une
multiplication de polynômes à coefficients dans . En outre, la FFT à
coefficients dans est très
efficace, car elle ne nécessite que des additions et des
soustractions dans .
Par ailleurs, la méthode est parfaitement
générale, et marche encore pour des grands entiers.
Le seul point noir de l'approche est qu'elle nécessite plus
de moduli que les méthodes précédentes.
Un problème qui revient fréquemment est
l'évaluation rapide d'un vecteur de polynômes en plusieurs
variables 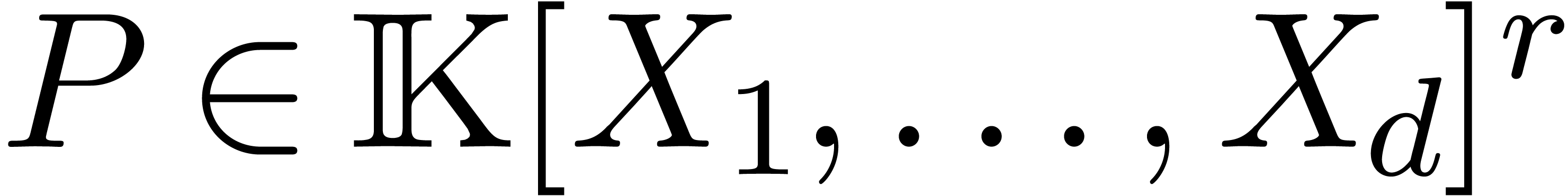 dans une -algèbre
dans une -algèbre
 . En effet, ce
problème intervient dans l'intégration de système
dynamiques
. En effet, ce
problème intervient dans l'intégration de système
dynamiques 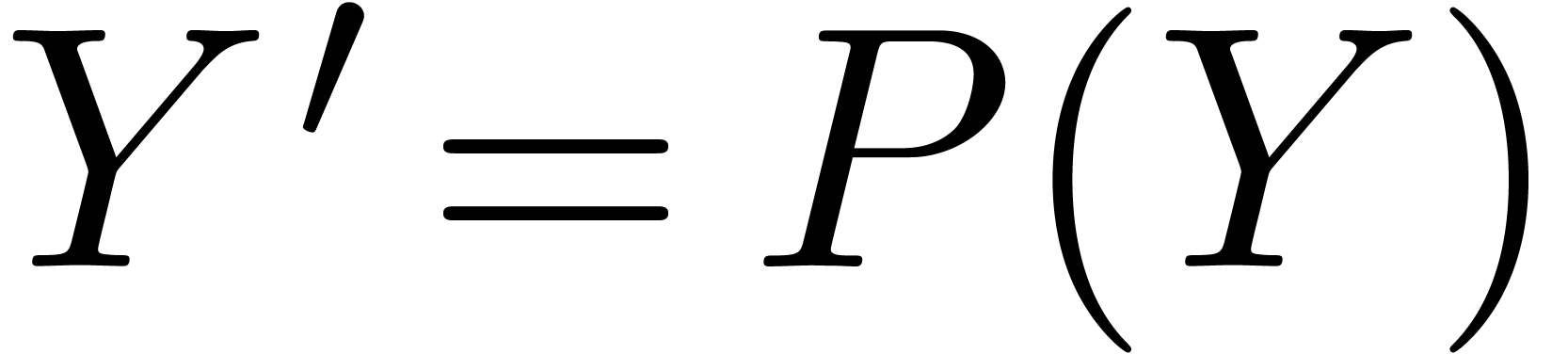 ou encore dans des méthodes
algébriques par homotopie. En outre, il n'est pas rare que l'on
veuille évaluer à la fois et sa
matrice jacobienne
ou encore dans des méthodes
algébriques par homotopie. En outre, il n'est pas rare que l'on
veuille évaluer à la fois et sa
matrice jacobienne  .
.
Nous allons nous concentrer sur le cas  ,
en supposant que la multiplication dans
s'effectue par un algorithme multi-modulaire avec
,
en supposant que la multiplication dans
s'effectue par un algorithme multi-modulaire avec 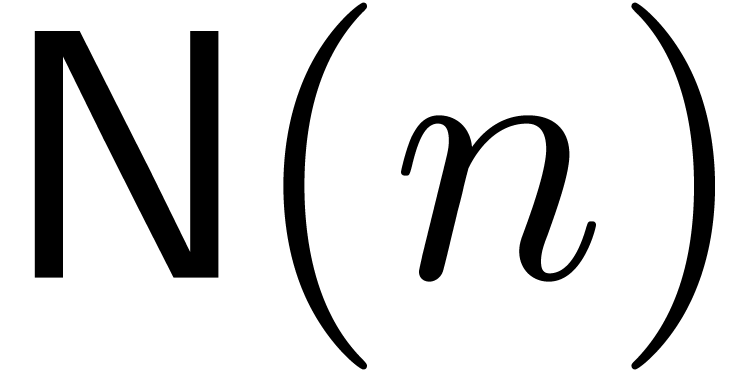 moduli et avec un coût de réduction-reconstruction de
moduli et avec un coût de réduction-reconstruction de 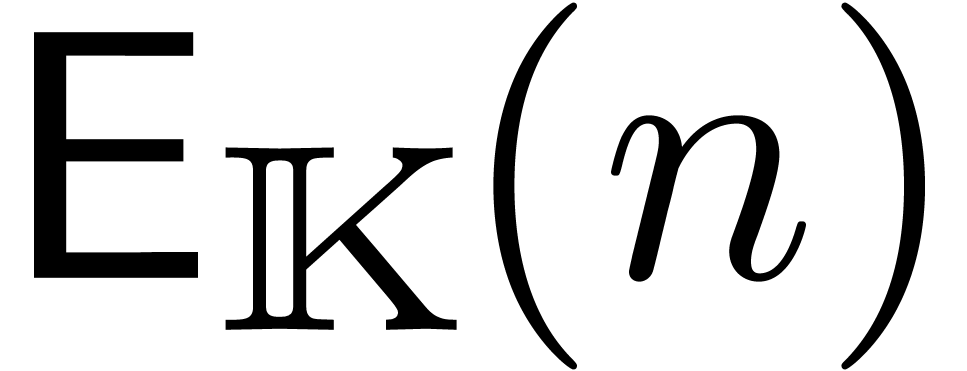 opérations dans .
opérations dans .
Considérons d'abord le cas où les polynômes sont
donnés par des expressions avec éventuellement des
sous-expressions communes. En d'autres termes,
est représenté par un « dag » (directed
acyclic graph). La figure 4.3 montre un dag typique,
correspondant au vecteur 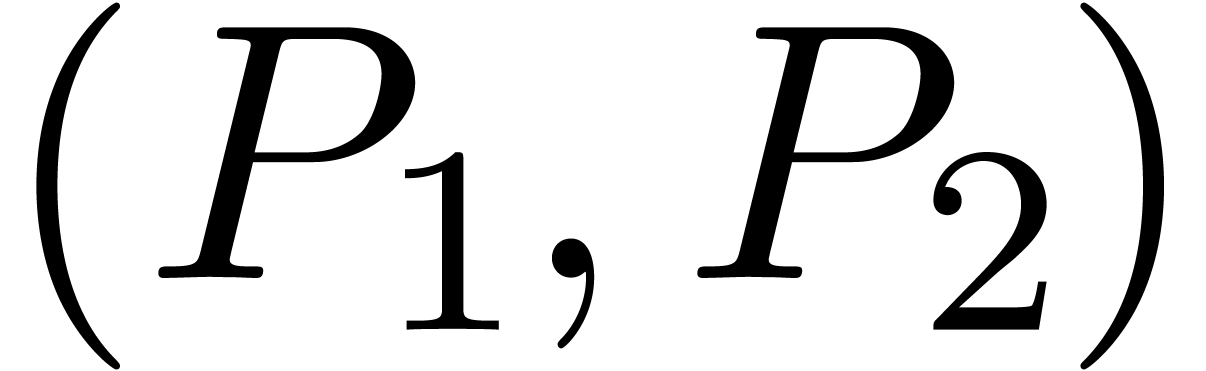 avec
avec
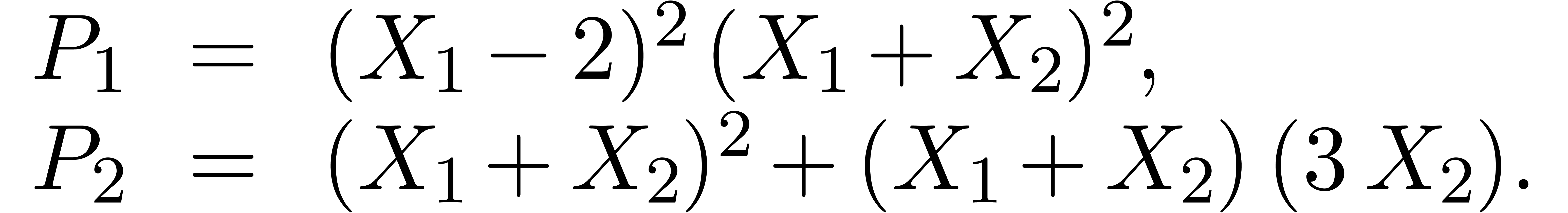
Un sous-dag de est dit scalaire s'il ne
fait pas intervenir les  .
Dans la figure 4.3, les seuls sous-dags scalaires sont
.
Dans la figure 4.3, les seuls sous-dags scalaires sont  et
et  . Un
sous-dag multiplicatif de de la forme
. Un
sous-dag multiplicatif de de la forme
 est dit
est dit
 ou
ou  est scalaire ;
est scalaire ;
 n'est pas un sous-dag d'un
autre sous-dag multiplicatif de ;
n'est pas un sous-dag d'un
autre sous-dag multiplicatif de ;
Dans notre exemple, les ensembles de sous-dags multiplicatifs
homothétiques, terminaux et actifs sont respectivement 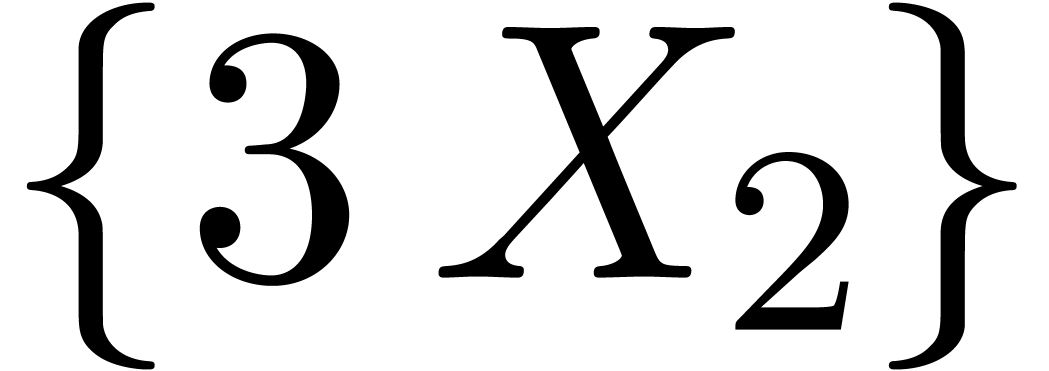 ,
, 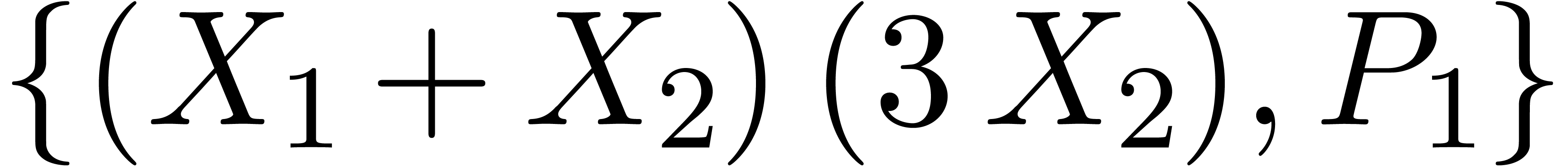 et
et 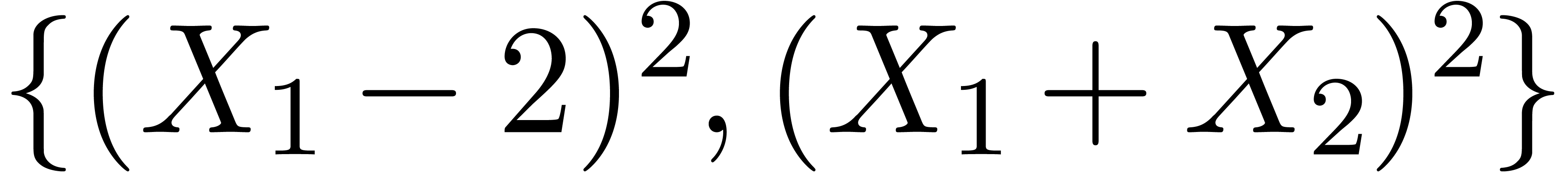 . On a :
. On a :
Proposition 4.1. Soit
un dag de taille totale 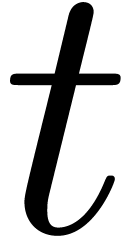 et avec
et avec 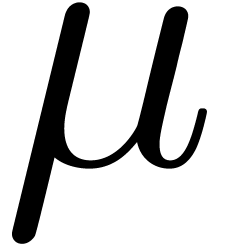 sous-dags multiplicatifs actifs. Alors pour des séries
tronquées
sous-dags multiplicatifs actifs. Alors pour des séries
tronquées 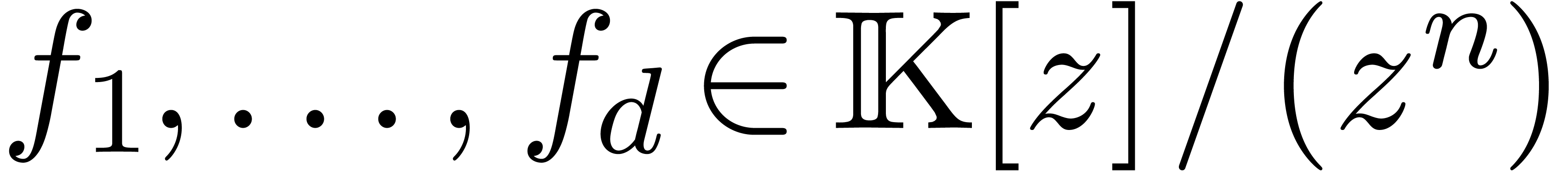 , on peut
évaluer
, on peut
évaluer  en utilisant au plus
en utilisant au plus  opérations dans .
opérations dans .
Démonstration. On commence par réduire les
entrées  (coût
(coût 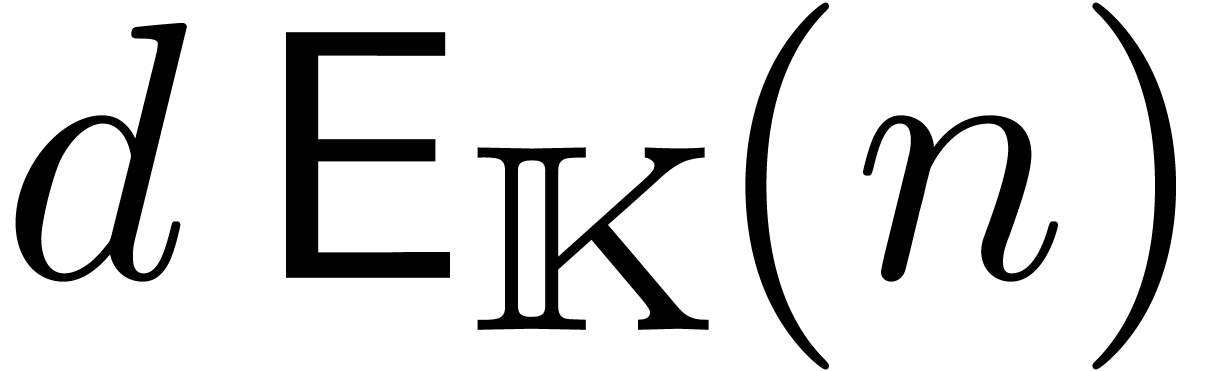 ). De façon récursive, et
travaillant avec la représentation multi-modulaire, on
évalue chaque sous-dag non multiplicatif ou non actif en
utilisant
). De façon récursive, et
travaillant avec la représentation multi-modulaire, on
évalue chaque sous-dag non multiplicatif ou non actif en
utilisant 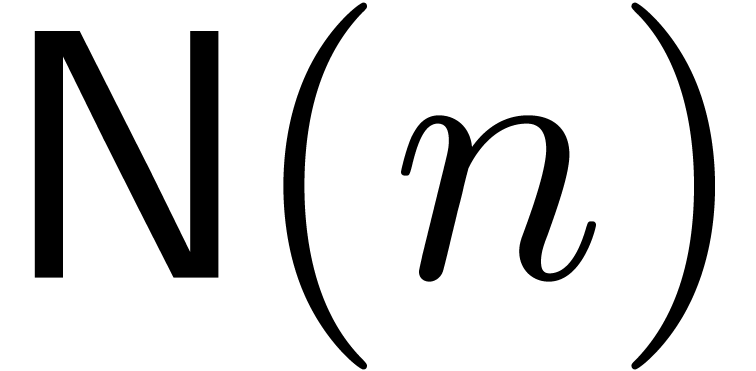 opérations dans . On évalue chaque sous-dag
multiplicatif actif en faisant un produit scalaire en
représentation multi-modulaire (coût ), une reconstruction d'un polynôme dans
opérations dans . On évalue chaque sous-dag
multiplicatif actif en faisant un produit scalaire en
représentation multi-modulaire (coût ), une reconstruction d'un polynôme dans 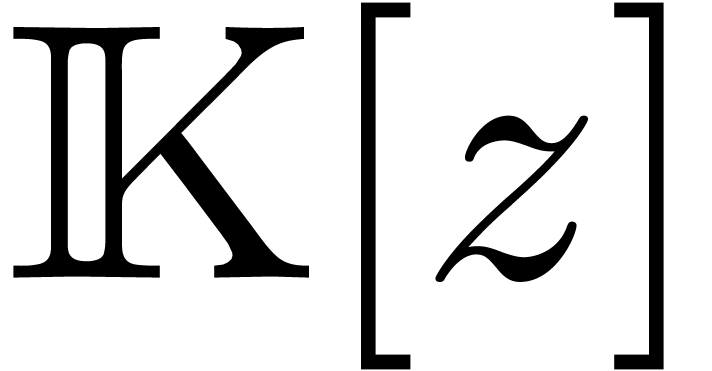 de degré
de degré 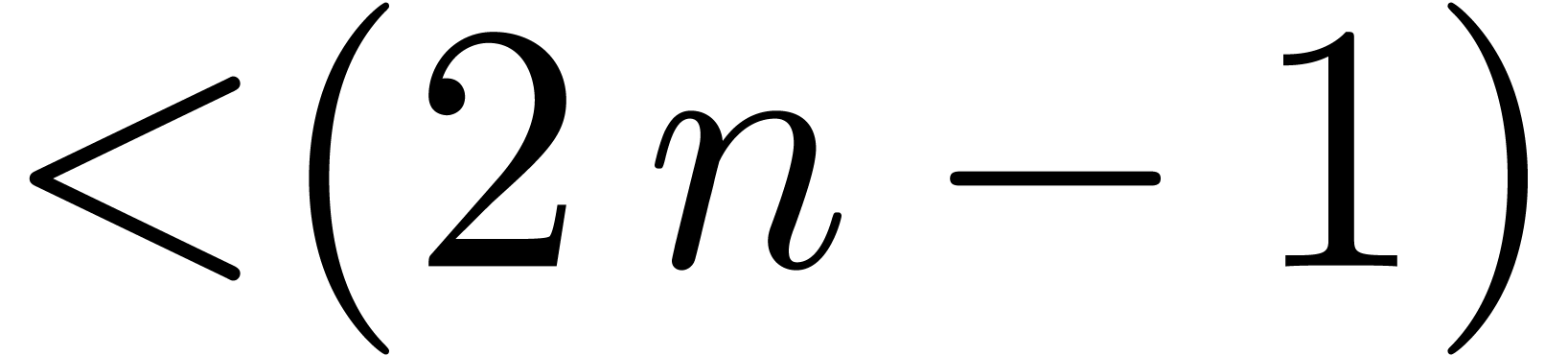 ,
dont on réduit à nouveau la troncature à l'ordre
(coût
,
dont on réduit à nouveau la troncature à l'ordre
(coût 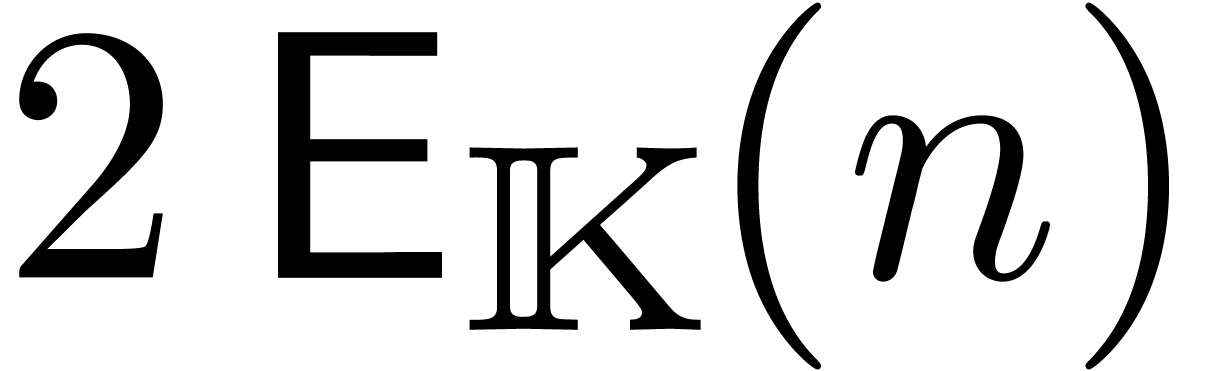 ).
Enfin, on reconstruit les évaluations de
).
Enfin, on reconstruit les évaluations de  à partir de leurs réductions (coût
à partir de leurs réductions (coût 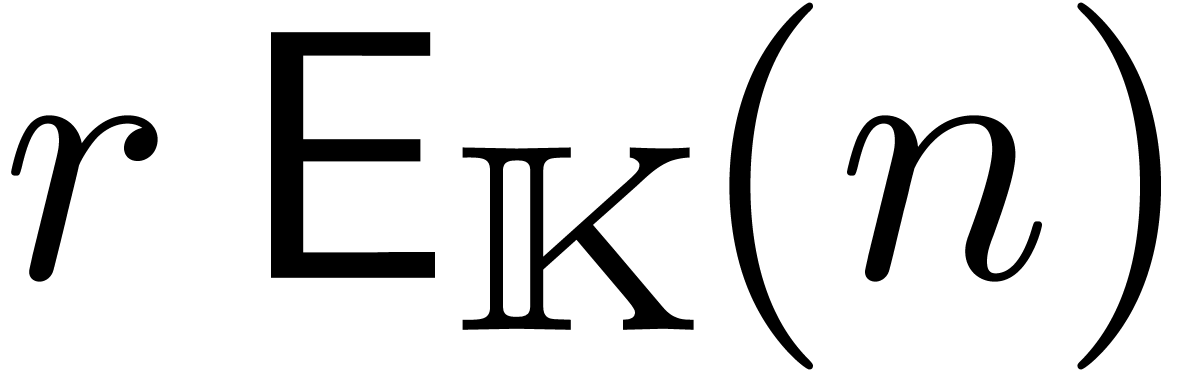 ). Le résultat suit en rajoutant les
différents coûts.
). Le résultat suit en rajoutant les
différents coûts.
Corollaire. Si est
quadratique, on peut l'évaluer utilisant 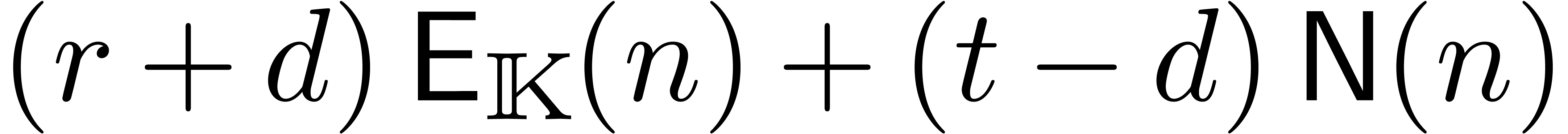 opérations dans .
opérations dans .
Si les polynômes sont donnés comme
combinaisons linéaires de monômes dans  , alors il faut construire un dag pour avant d'appliquer la proposition 4.1.
Ceci conduit au problème comment trouver un dag pour lequel le
nombre de sous-dags multiplicatifs actifs est minimal. Bien sûr,
ce problème de nature plutôt combinatoire est assez
délicat, donc on cherche plutôt de bonnes stratégies
pour s'approcher du minimum.
, alors il faut construire un dag pour avant d'appliquer la proposition 4.1.
Ceci conduit au problème comment trouver un dag pour lequel le
nombre de sous-dags multiplicatifs actifs est minimal. Bien sûr,
ce problème de nature plutôt combinatoire est assez
délicat, donc on cherche plutôt de bonnes stratégies
pour s'approcher du minimum.
Soit  l'ensemble des monômes dans apparaissant dans .
La question se réduit essentiellement à la nouvelle
question comment trouver deux sous-ensembles
l'ensemble des monômes dans apparaissant dans .
La question se réduit essentiellement à la nouvelle
question comment trouver deux sous-ensembles 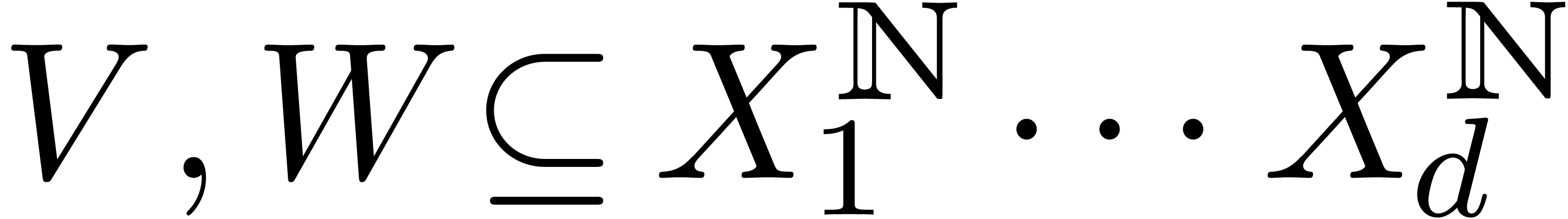 tels que
tels que 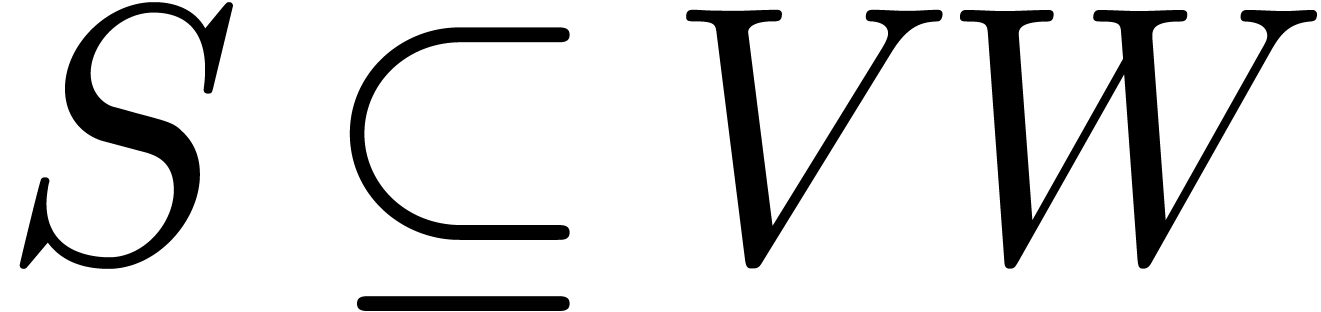 et tels que le cardinal
et tels que le cardinal  soit minimal. Deux approches heuristiques semblent
raisonnables :
soit minimal. Deux approches heuristiques semblent
raisonnables :
Pour chaque partie 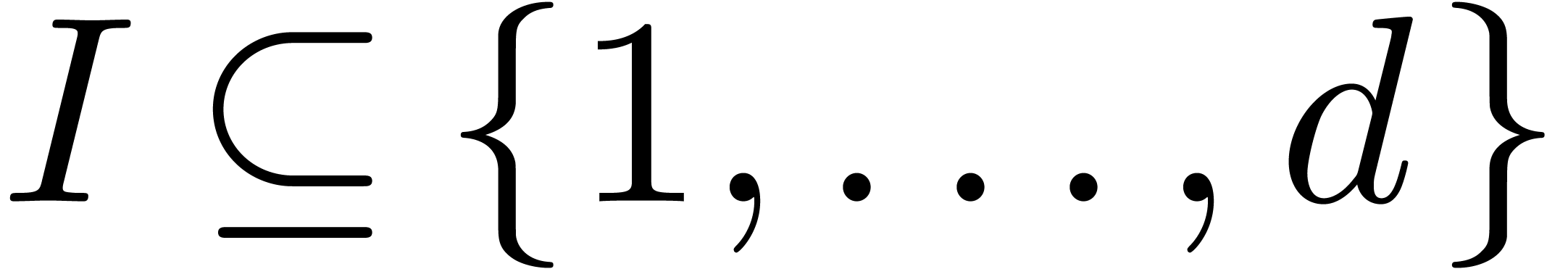 de fonction
caractéristique
de fonction
caractéristique  , on a
une projection naturelle
, on a
une projection naturelle
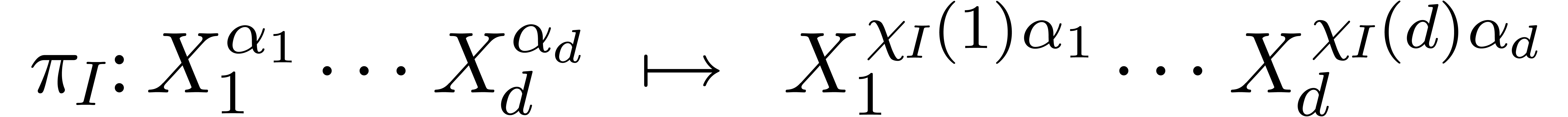
La projection 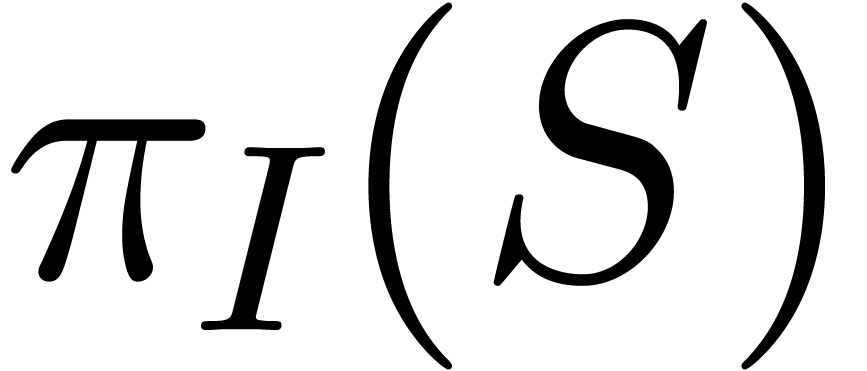 peut se calculer en temps
linéaire. L'idée est maintenant de prendre
peut se calculer en temps
linéaire. L'idée est maintenant de prendre 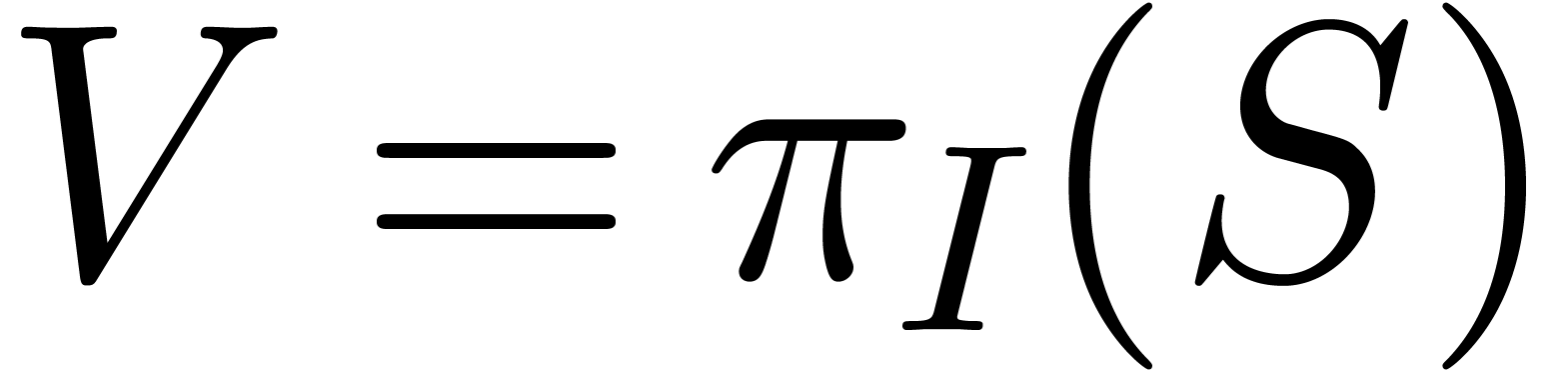 et
et  pour un
pour un  qui minimise . Si est grand, ce calcul peut encore devenir trop cher, auquel
cas on peut se restreindre aux parties de la
forme
qui minimise . Si est grand, ce calcul peut encore devenir trop cher, auquel
cas on peut se restreindre aux parties de la
forme 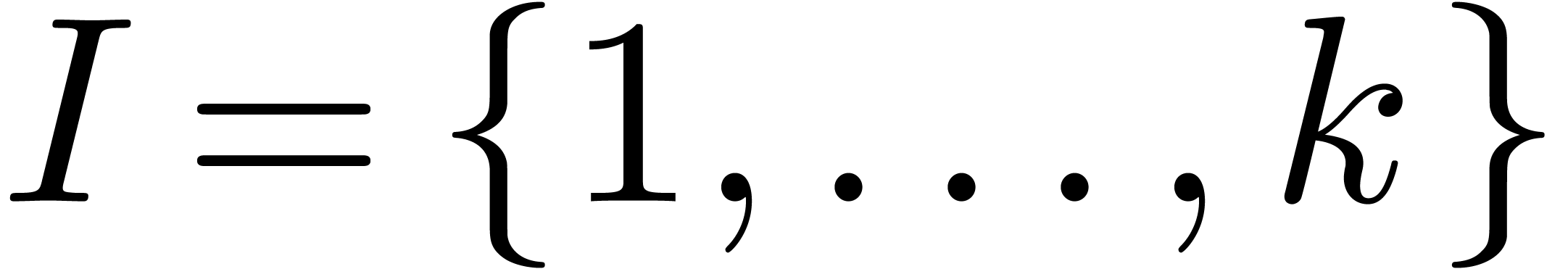 avec
avec 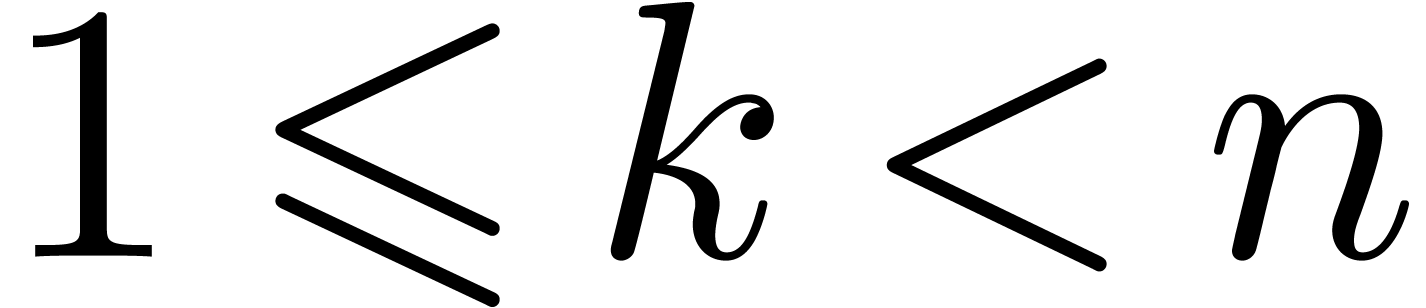 .
.
Étant donnés des entiers  ,
on peut considérer les projections
,
on peut considérer les projections
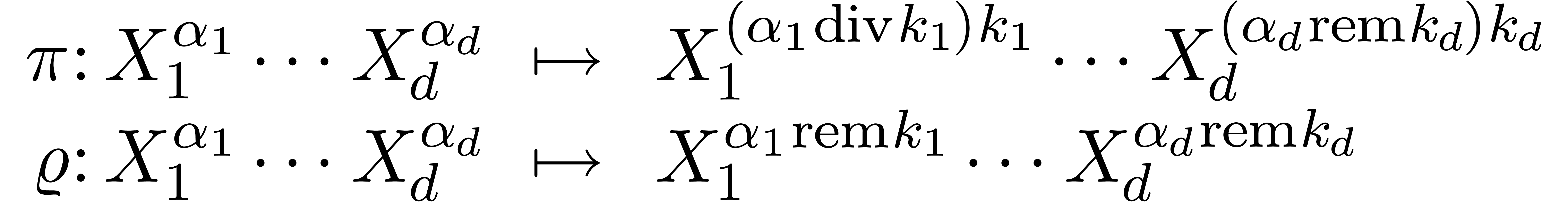
avec 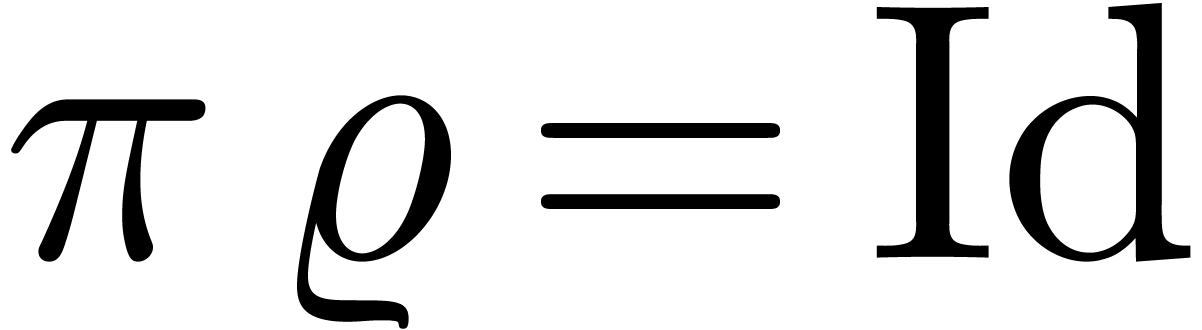 . L'idée est
alors de prendre
. L'idée est
alors de prendre 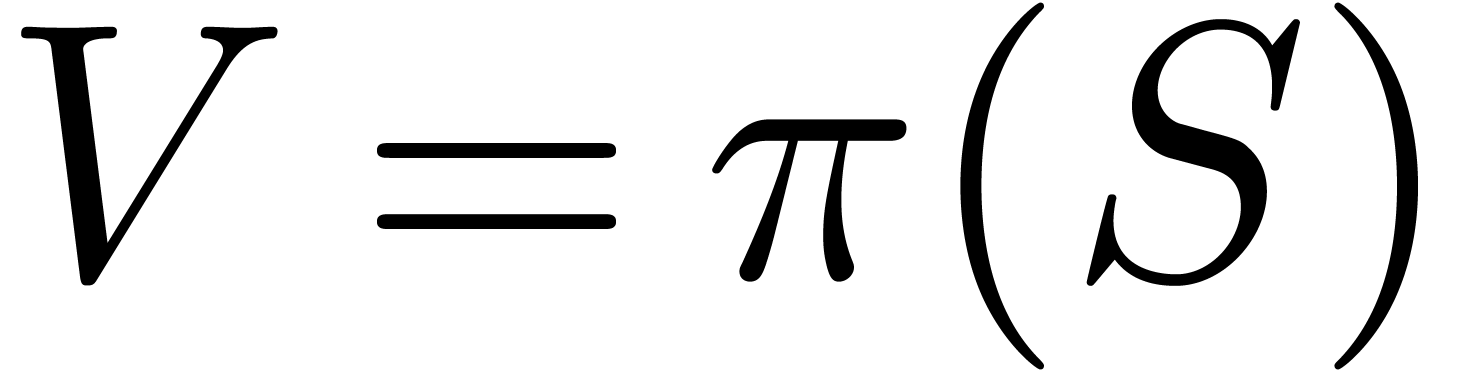 et
et 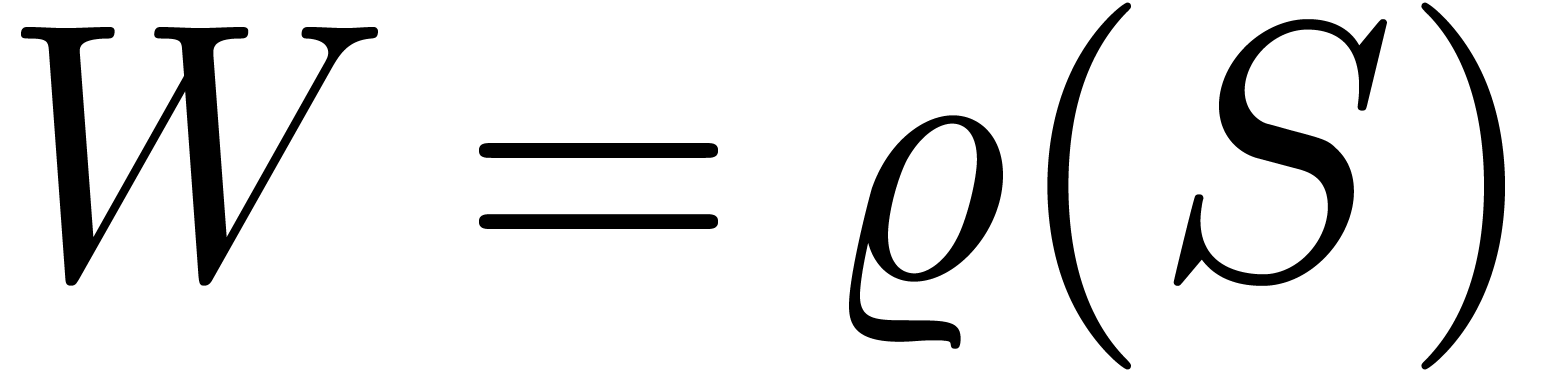 pour
des entiers
pour
des entiers  bien choisis. On peut trouver ces
entiers en commençant avec
bien choisis. On peut trouver ces
entiers en commençant avec 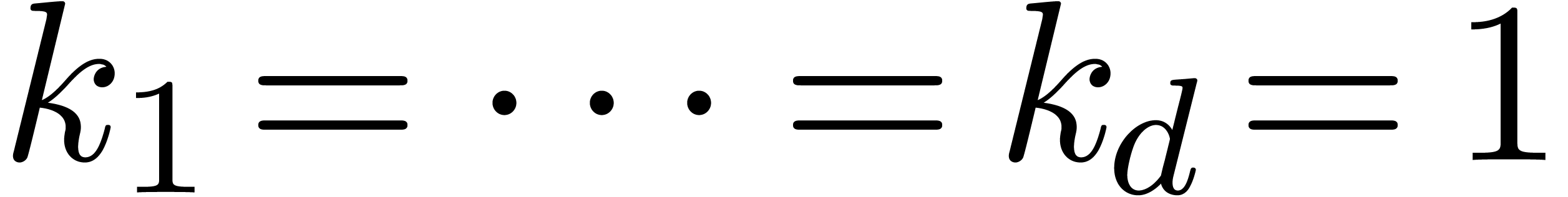 et en doublant
l'un des entiers tant que cela fait chuter la cardinalité de
et en doublant
l'un des entiers tant que cela fait chuter la cardinalité de
 .
.
Exemple. Un exemple particulièrement important est quand
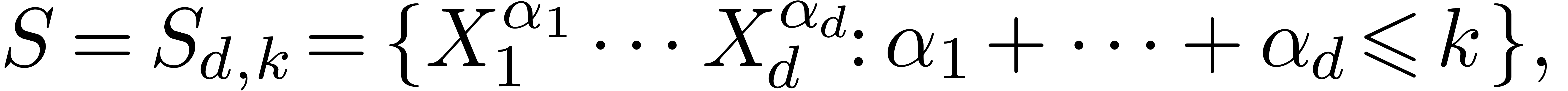
avec
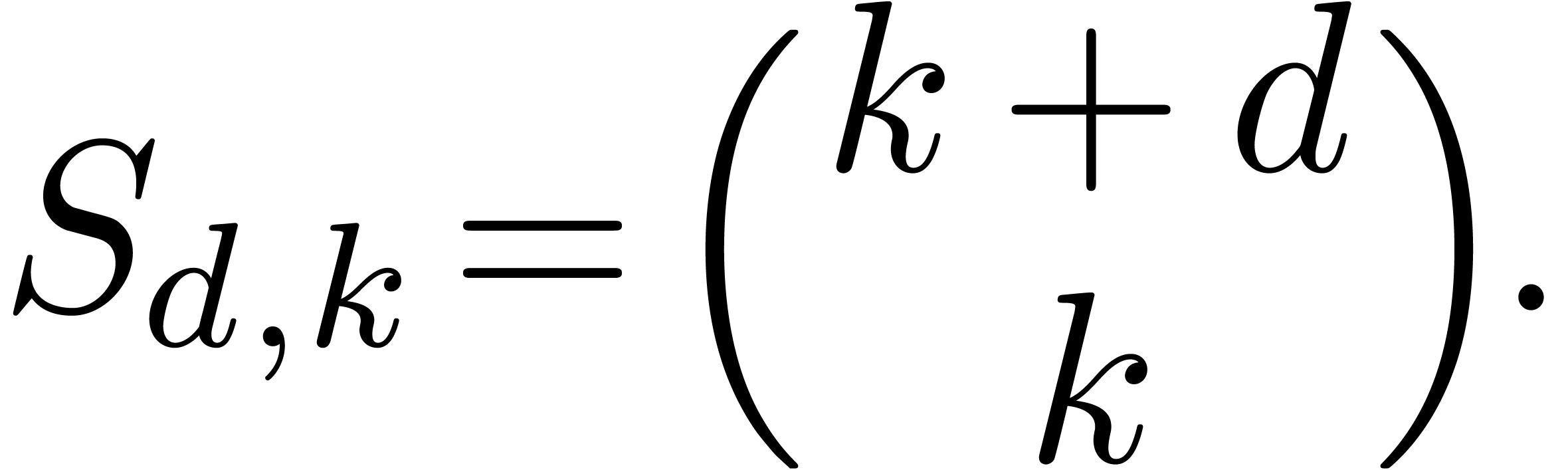
Pour 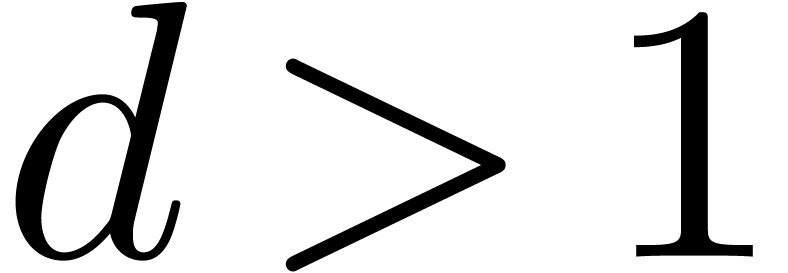 la première stratégie donne
la première stratégie donne
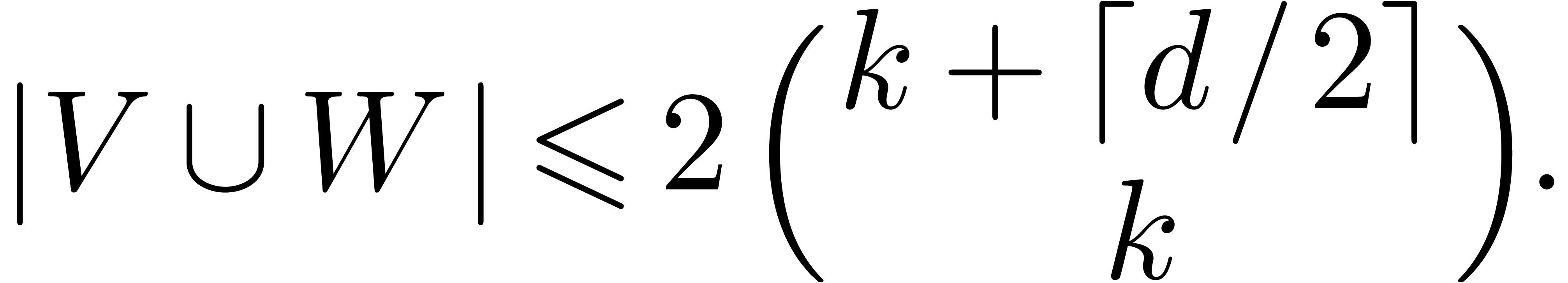
Si on peut utiliser la multiplication FFT dans , la proposition 4.1 implique donc que
l'on peut évaluer en 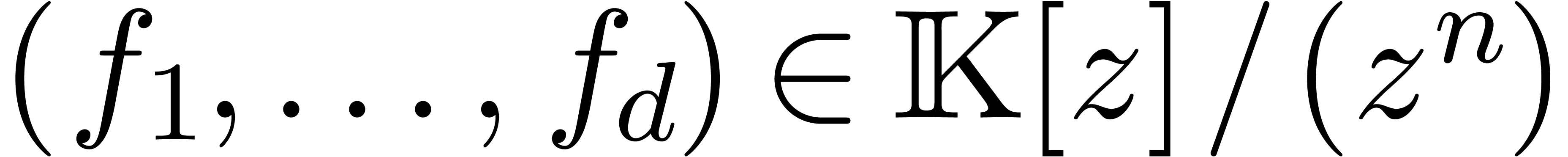 en temps
en temps  pour
pour 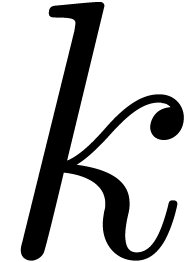 suffisamment grand. Pour quelques autres résultats
intéressants sur la composition de séries formelles en
plusieurs variables, nous renvoyons vers [14].
suffisamment grand. Pour quelques autres résultats
intéressants sur la composition de séries formelles en
plusieurs variables, nous renvoyons vers [14].
Malheureusement, les algorithmes asymptotiquement rapides pour
multiplier des polynômes à coefficients flottants sont
numériquement instables dans le cas général. Par
exemple, considérons le calcul suivant d'un carré par la
méthode de Karatsuba, en utilisant une précision de  chiffres binaires :
chiffres binaires :
On voit bien que le fait d'avoir ajouté et soustrait des
coefficients d'ordres de grandeur différents a pollué le
calcul, de manière à rendre le coefficient en du résultat incorrect.
Une manière simple pour régler le problème de la
section précédente est de rendre tous les coefficients de
de même ordre de grandeur modulo une
postcomposition par  pour une «
échelle »
pour une «
échelle »  bien choisie :
bien choisie :
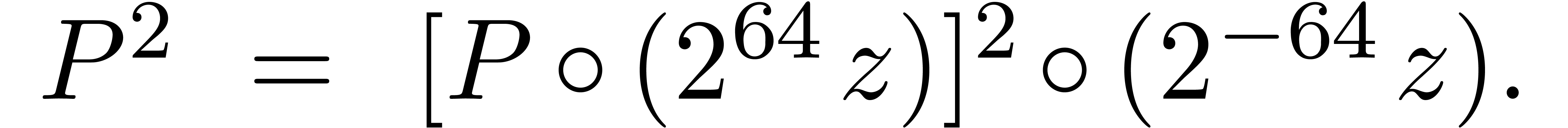
Malheureusement, cela ne règle pas le problème dans le cas
général, car le choix d'un bon
peut être ambigu. Par exemple, si
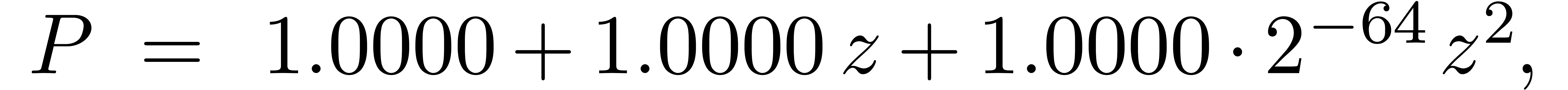
il faudrait prendre 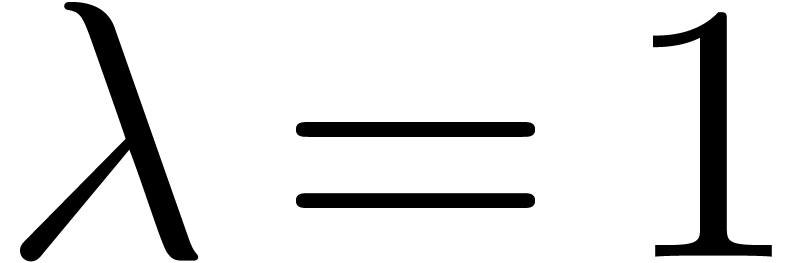 pour que
et
pour que
et 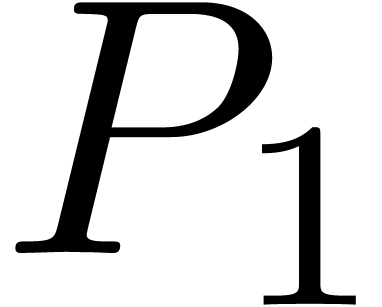 soient du même ordre de grandeur, mais
soient du même ordre de grandeur, mais
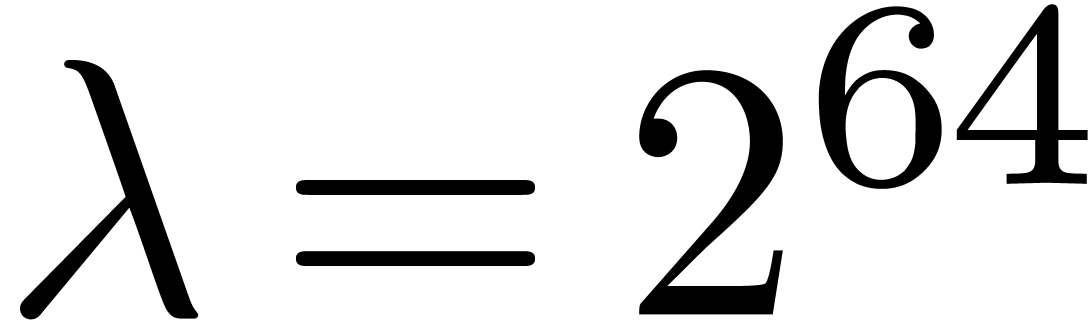 pour que et
pour que et 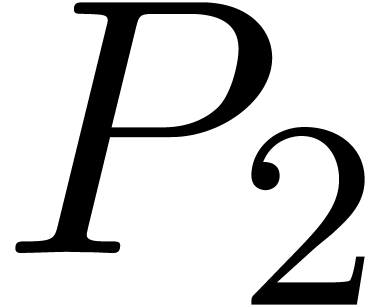 le soient.
le soient.
Heureusement, dans le cas d'une série  , le comportent des
, le comportent des  est
généralement assez régulière pour
est
généralement assez régulière pour  , car dicté par la nature de
la singularité de qui est la plus proche
de l'origine. Dans de nombreux cas (et notamment quand
est algébrique avec une unique singularité dominante), on
a par exemple
, car dicté par la nature de
la singularité de qui est la plus proche
de l'origine. Dans de nombreux cas (et notamment quand
est algébrique avec une unique singularité dominante), on
a par exemple

où  est le rayon de convergence de . Dès lors, l'existence
d'une bonne échelle
est le rayon de convergence de . Dès lors, l'existence
d'une bonne échelle  est garantie pour
tout polynôme
est garantie pour
tout polynôme  avec
et suffisamment grands. D'un point de vue
pratique, s'approche bien, en considérant
la pente au milieu du polygone numérique de Newton (voir la
section 6.3).
avec
et suffisamment grands. D'un point de vue
pratique, s'approche bien, en considérant
la pente au milieu du polygone numérique de Newton (voir la
section 6.3).
Afin de vérifier la stabilité numérique de la méthode de préconditionnement par mise à l'échelle, il suffit d'effectuer le même calcul avec des précisions différentes. Bien entendu, cela ne garantit rien, mais ça indique que tout se passe comme prévu.
Mmx] |
use "analyziz" |
Mmx] |
bit_precision := 64; |
Mmx] |
z == series (0.0, 1.0); |
Mmx] |
B == exp (exp z - 1) |
Mmx] |
B[10000] |
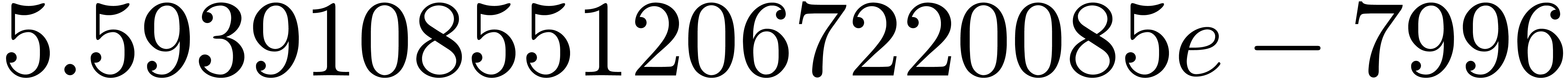
Mmx] |
bit_precision := 128; |
Mmx] |
z == series (0.0, 1.0); |
Mmx] |
B == exp (exp z - 1); |
Mmx] |
B[10000] |
Pour une séries  à coefficients
dans
à coefficients
dans 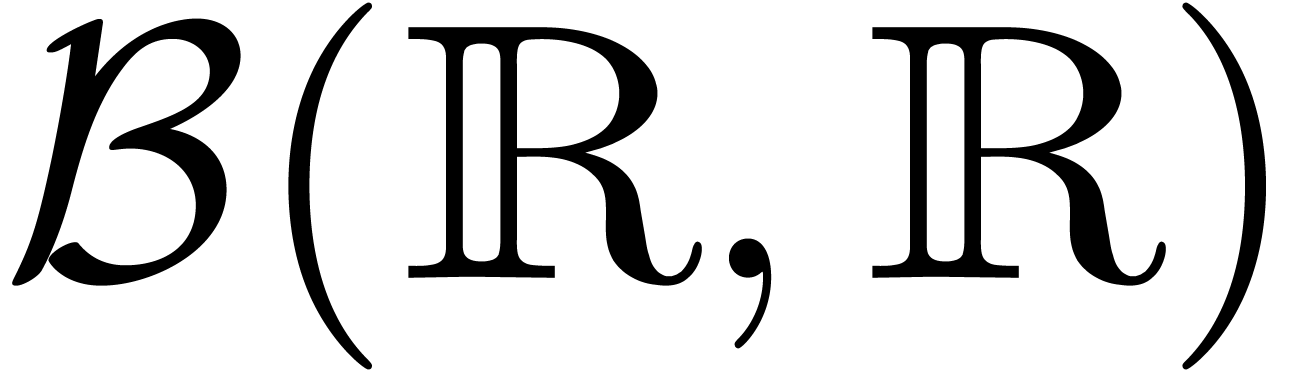 , obtenue comme le
résultat d'un calcul naïf comme
, obtenue comme le
résultat d'un calcul naïf comme
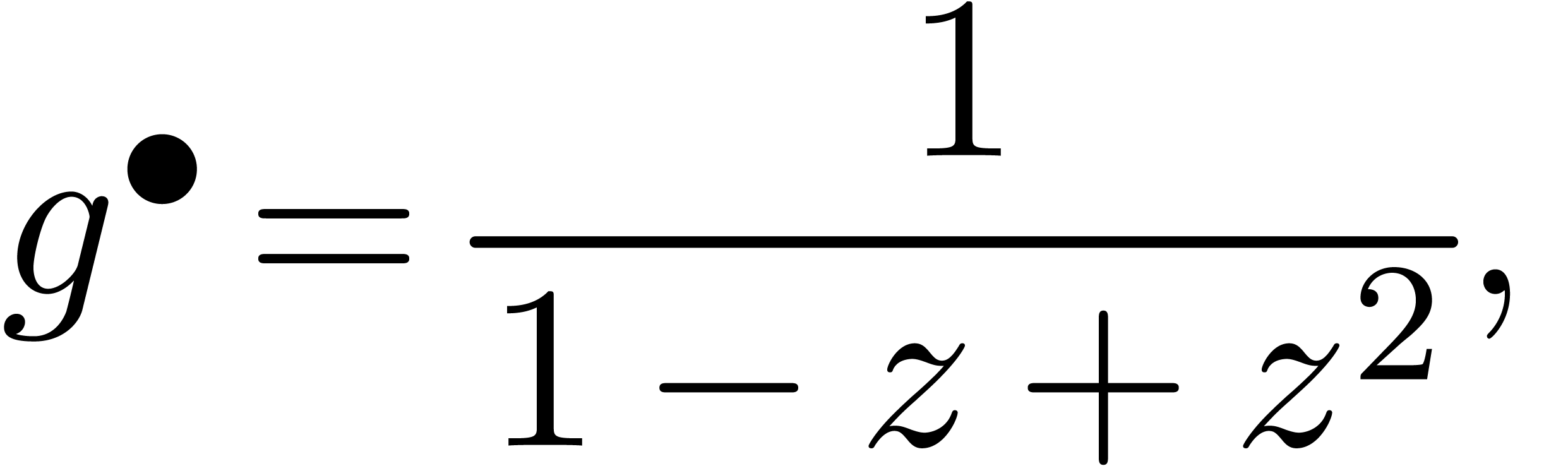
il est instructif d'étudier le comportement des rayons 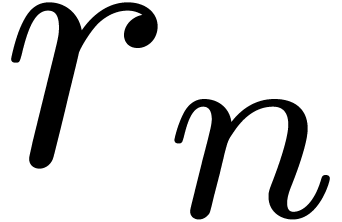 des
des 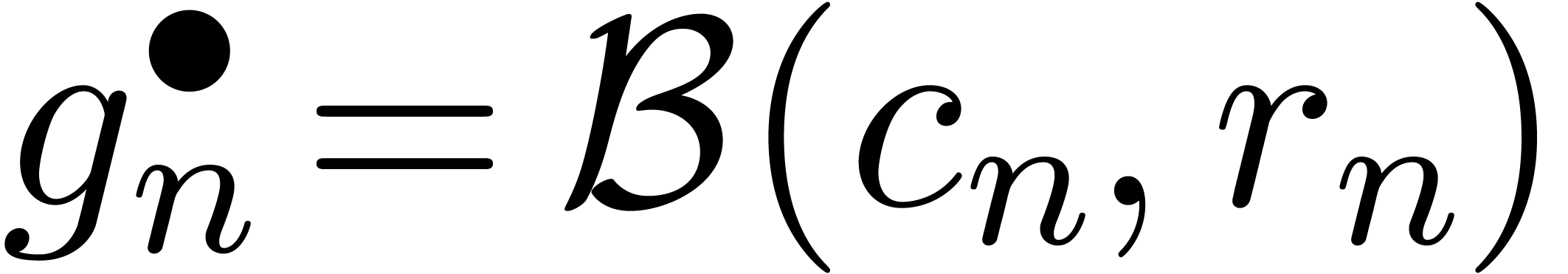 par rapport à celui des
centres
par rapport à celui des
centres 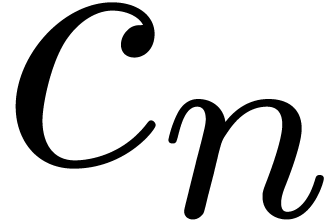 . La
différence principale entre les calculs de
et est que « tous les
. La
différence principale entre les calculs de
et est que « tous les  ont été remplacés par des
ont été remplacés par des  » dans les formules de récurrence. En effet, dans notre
exemple, on a
» dans les formules de récurrence. En effet, dans notre
exemple, on a
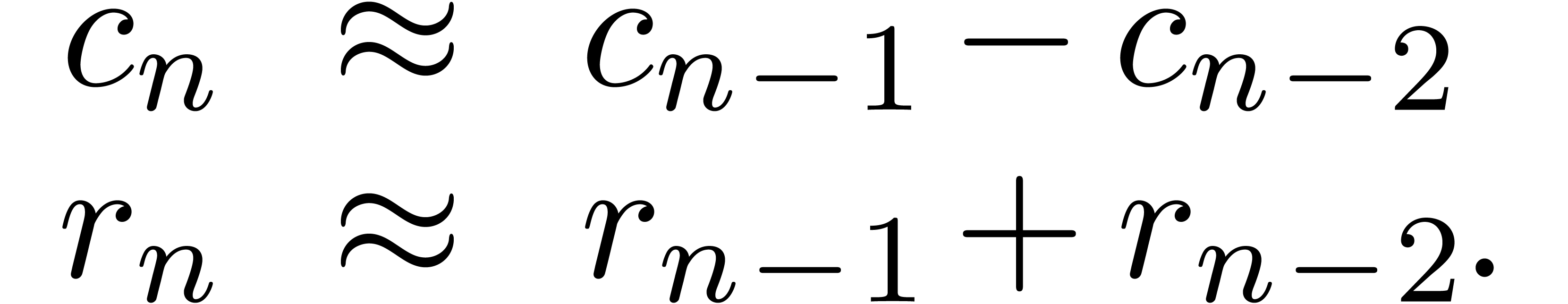
Par conséquent, si on calcule avec une précision de chiffres binaires, on obtient
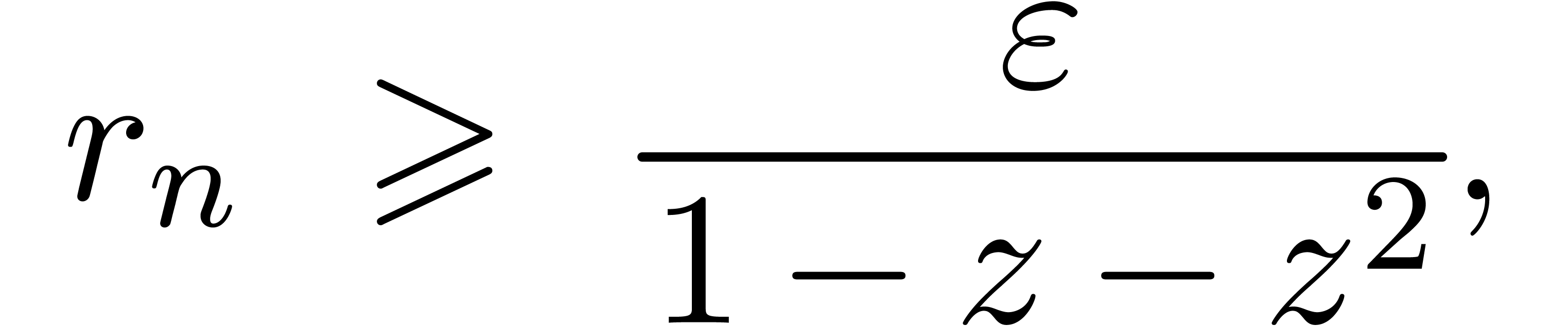
pour un certain 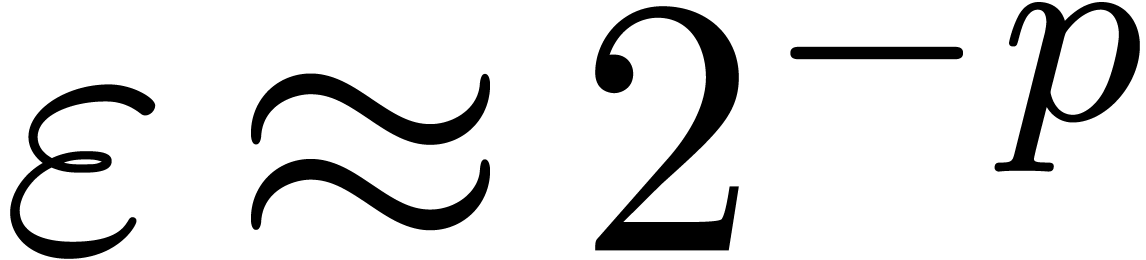 . Comme le
rayon de convergence de la série
. Comme le
rayon de convergence de la série 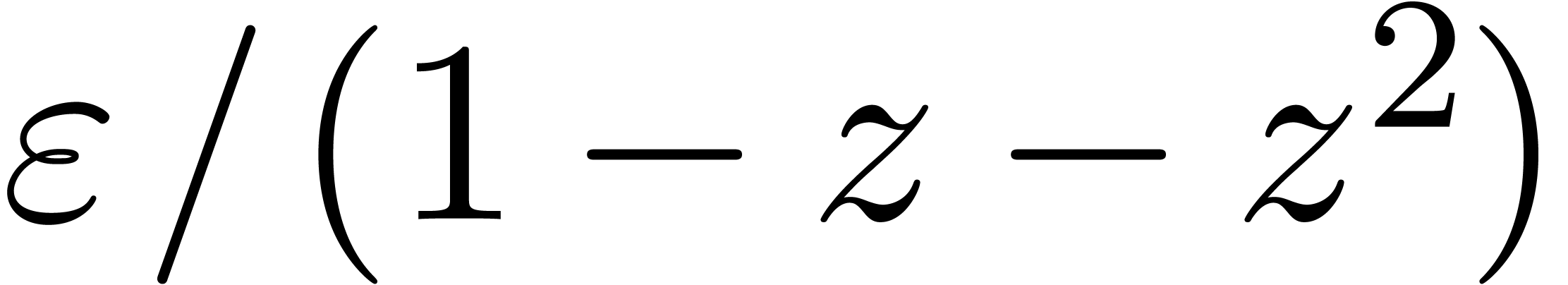 est plus
petite que le rayon de convergence de
est plus
petite que le rayon de convergence de 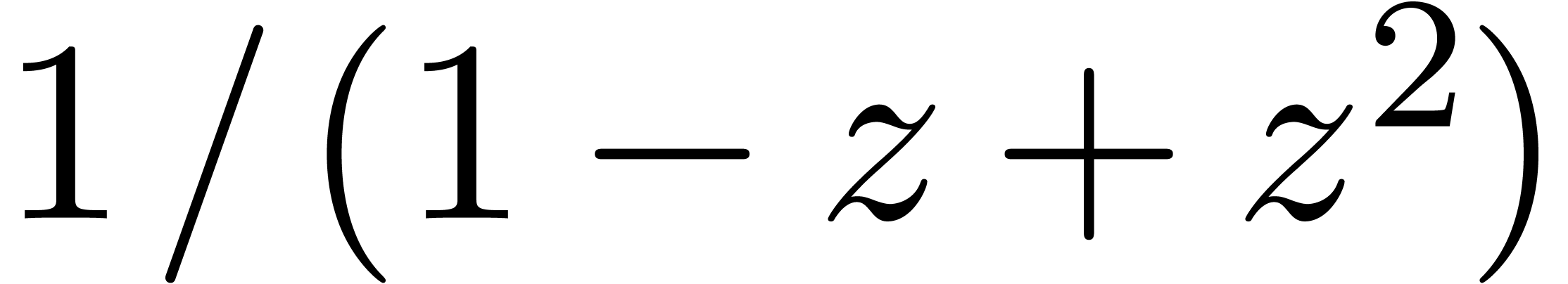 ,
il s'en suit qu'il existe une constante
,
il s'en suit qu'il existe une constante  telle
que l'algorithme d'inversion naïf perd toute sa précision
pour
telle
que l'algorithme d'inversion naïf perd toute sa précision
pour 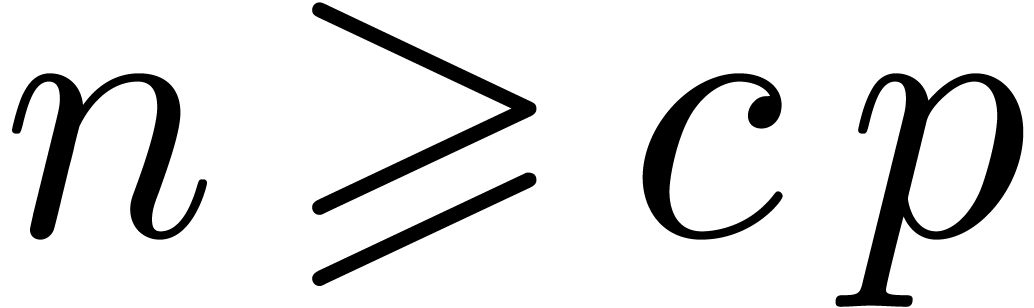 .
.
Le remède est pareil que pour l'inversion des matrices dans la
section 3.2.5 : supposons que l'on veuille inverser une
série 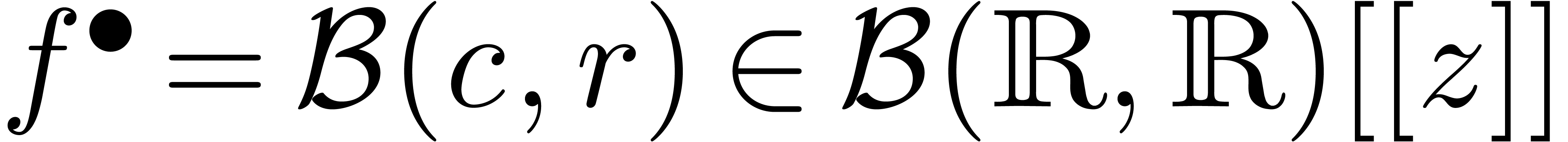 . Alors on
calcule un inverse numérique approché
. Alors on
calcule un inverse numérique approché  de , et on prend
de , et on prend 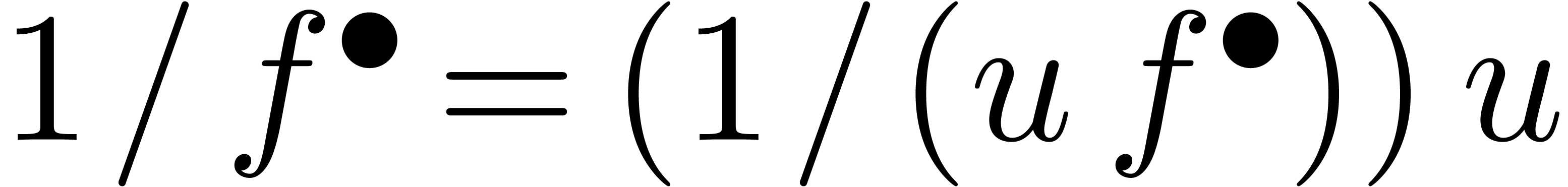 , où
, où 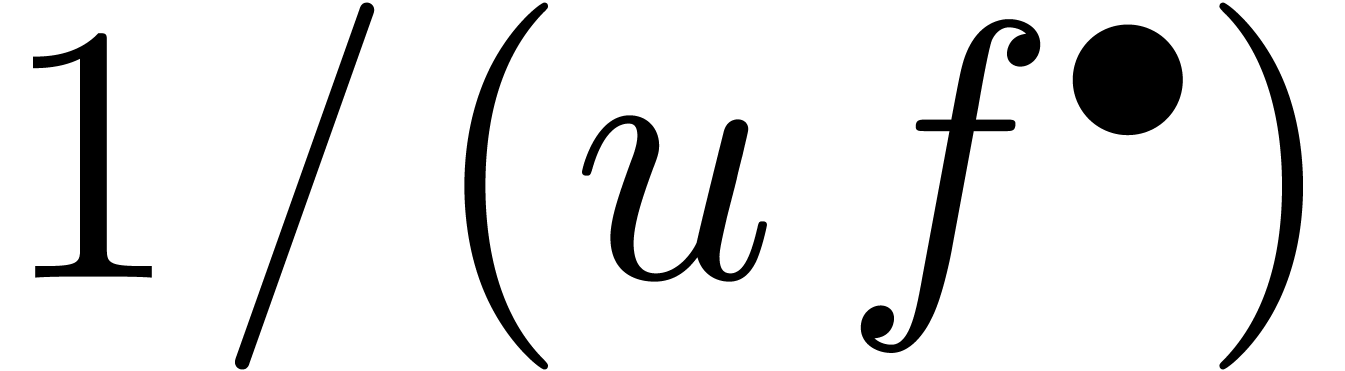 est
calculé utilisant une méthode détendue
générique.
est
calculé utilisant une méthode détendue
générique.
Considérons maintenant le cas du calcul certifié d'une
exponentielle 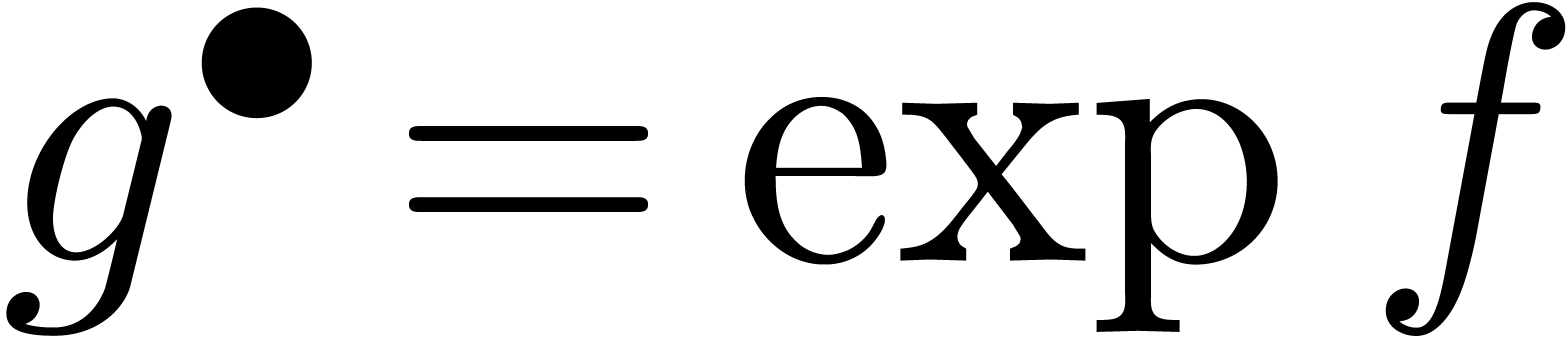 . Si on fait
une analyse similaire à celle de la section
précédente, on se rend compte que les séries
génératrices et
. Si on fait
une analyse similaire à celle de la section
précédente, on se rend compte que les séries
génératrices et  formées par les centres et rayons des coefficients vérifient cette fois-ci
formées par les centres et rayons des coefficients vérifient cette fois-ci
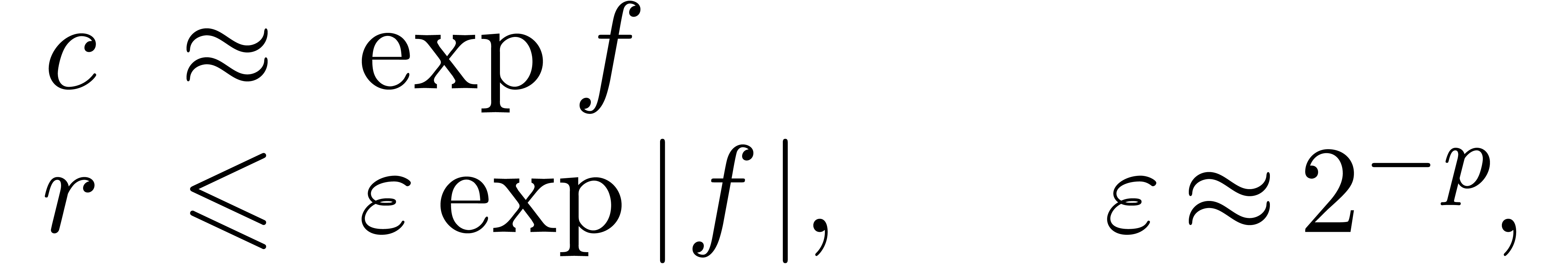
où  est la série
génératrice avec
est la série
génératrice avec 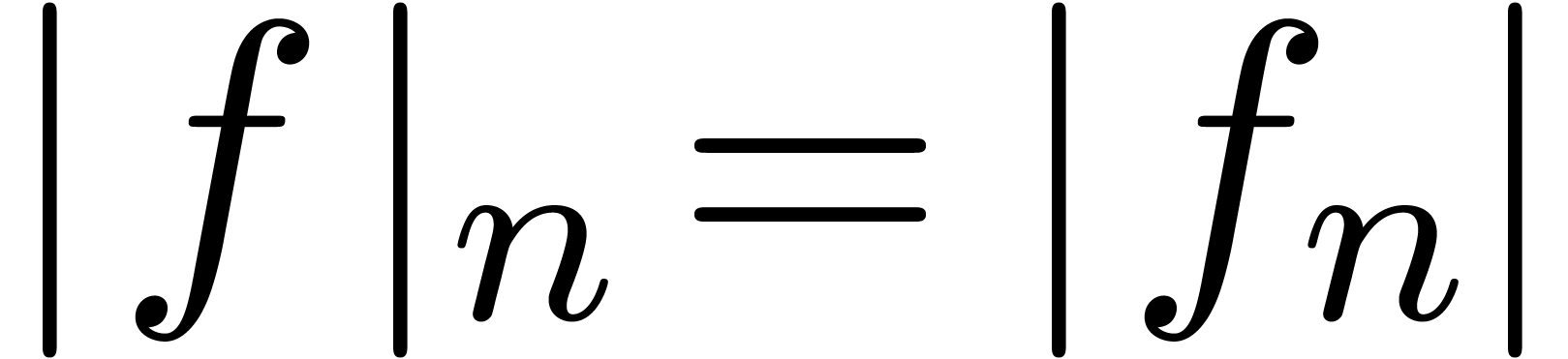 .
Or les rayons de convergence de et sont les mêmes et les singularités dominantes
généralement de même nature. Par magie, on observe
donc rarement de la surestimation dans ce cas ! Cette observation
s'étend d'ailleurs aux intégrales de systèmes
dynamiques plus générales.
.
Or les rayons de convergence de et sont les mêmes et les singularités dominantes
généralement de même nature. Par magie, on observe
donc rarement de la surestimation dans ce cas ! Cette observation
s'étend d'ailleurs aux intégrales de systèmes
dynamiques plus générales.
Ceci dit, dans les rares cas où on observe quand même de la
surestimation, on peut bien sûr adapter la méthode
perturbative. En effet, pour le calcul de 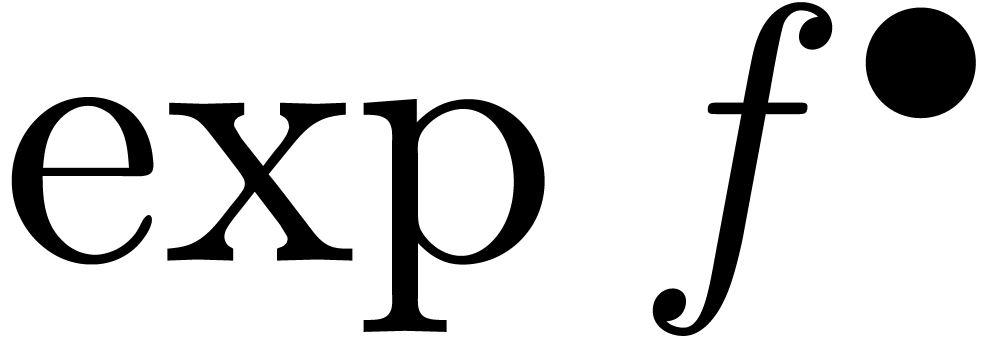 avec
avec
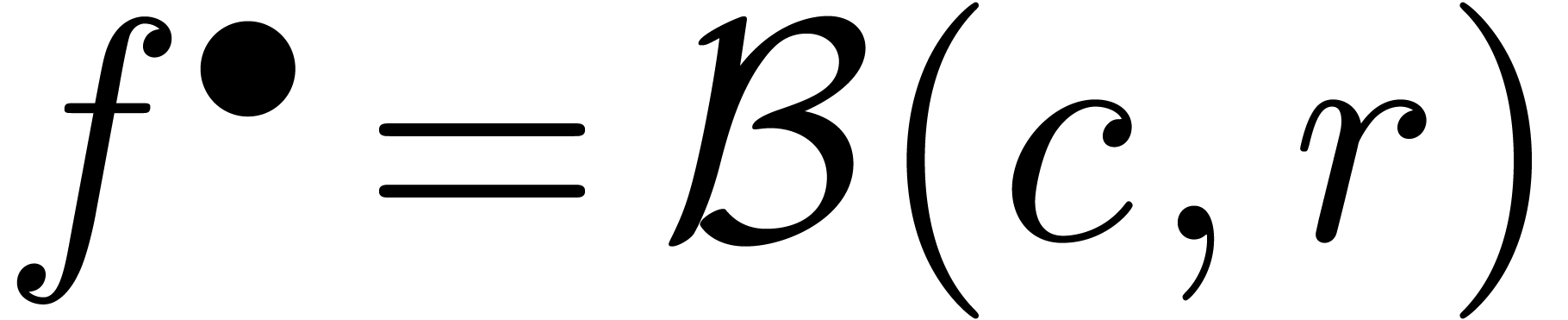 , il suffit de prendre
, il suffit de prendre 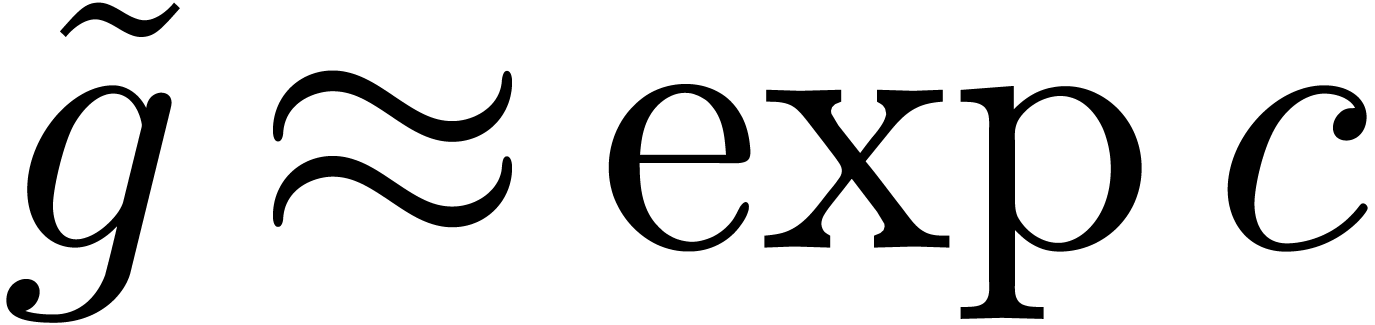 , après quoi la fonction
, après quoi la fonction
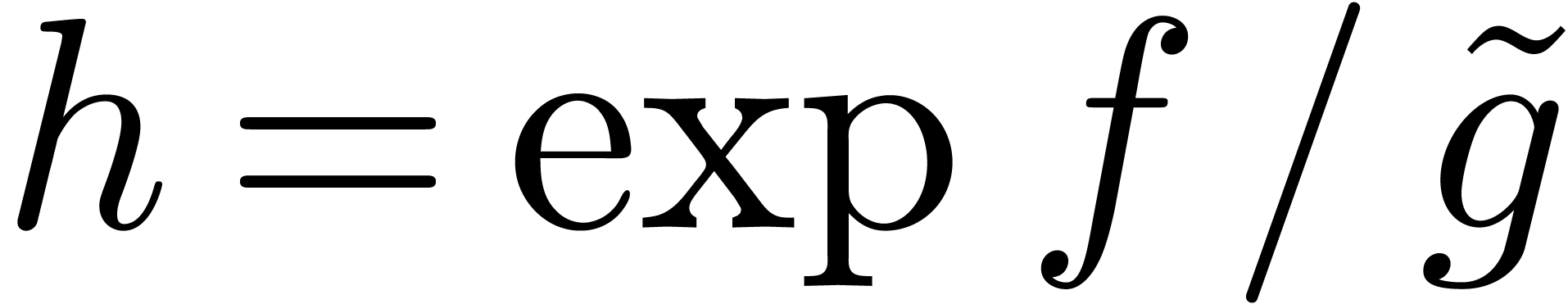 se calcule en intégrant le système
dynamique
se calcule en intégrant le système
dynamique  .
.
Mmx] |
use "analyziz" |
Mmx] |
bit_precision := 64; |
Mmx] |
z == series (0.0, 1.0); |
Mmx] |
B == exp (exp z - 1); |
Mmx] |
B[10000] |
Mmx] |
z == series (ball 0.0, ball 1.0); |
Mmx] |
B == exp (exp z - 1); |
Mmx] |
B[10000] |

Pour l'instant, on a surtout vu des boules scalaires dans ou  et des boules qui
opèrent coefficient par coefficient, comme des boules dans
et des boules qui
opèrent coefficient par coefficient, comme des boules dans 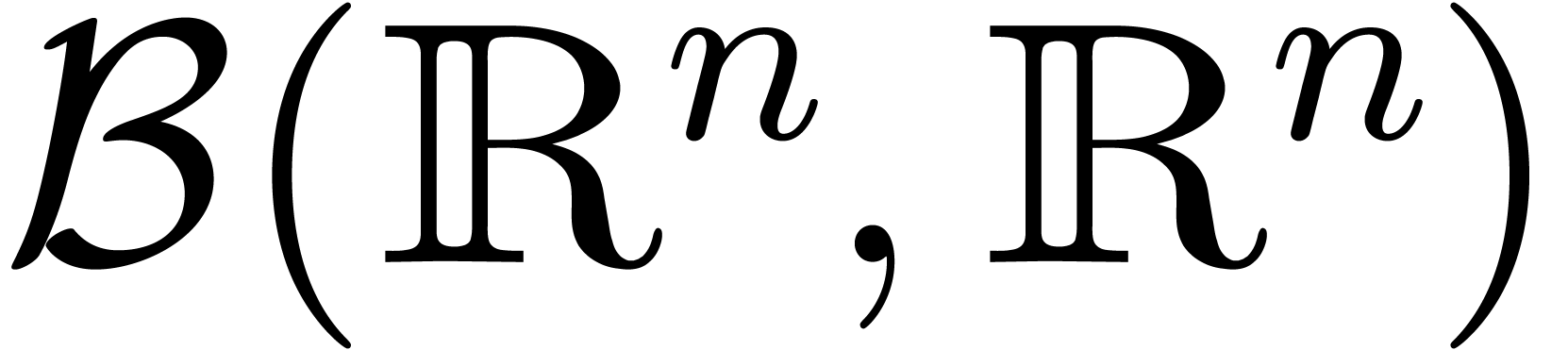 ou
ou 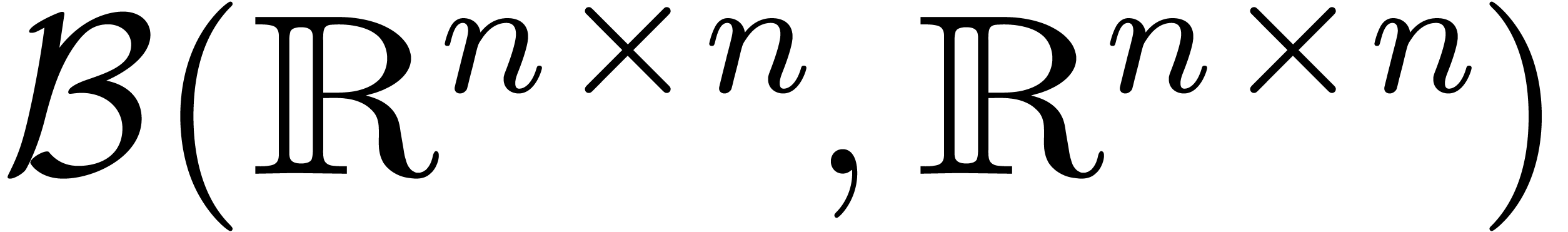 . Il
est maintenant temps d'étendre les principes du calcul à
des espaces un peu plus sophistiqués comme l'ensemble
. Il
est maintenant temps d'étendre les principes du calcul à
des espaces un peu plus sophistiqués comme l'ensemble 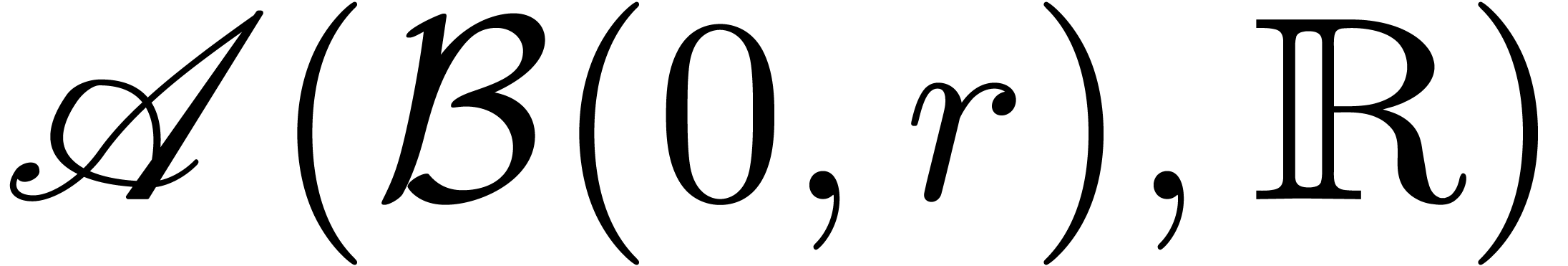 des fonctions réelles analytiques sur la boule
des fonctions réelles analytiques sur la boule
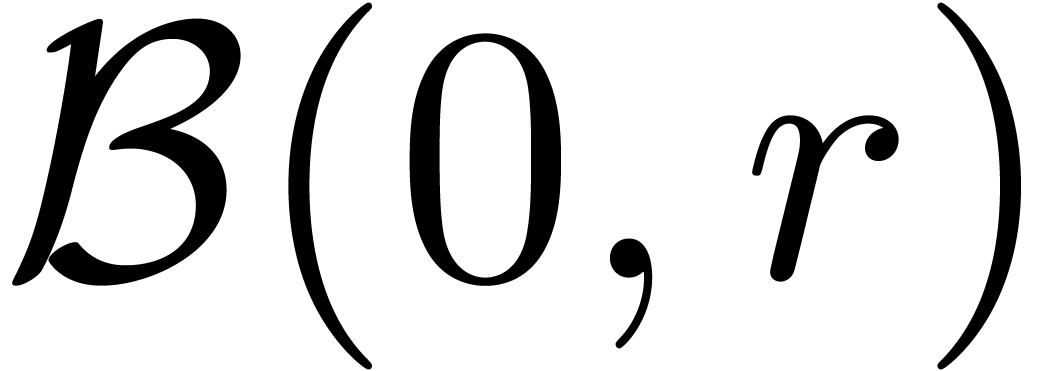 . La norme naturelle sur cet
espace est donnée par
. La norme naturelle sur cet
espace est donnée par
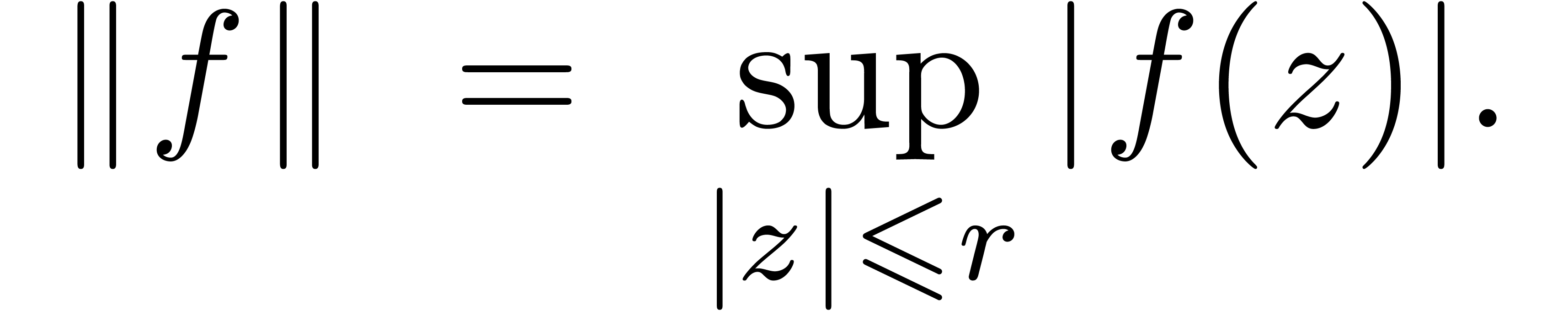
Pour 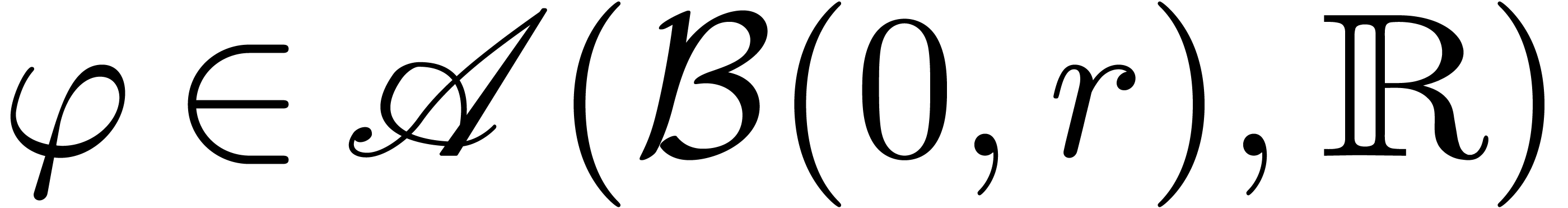 et
et 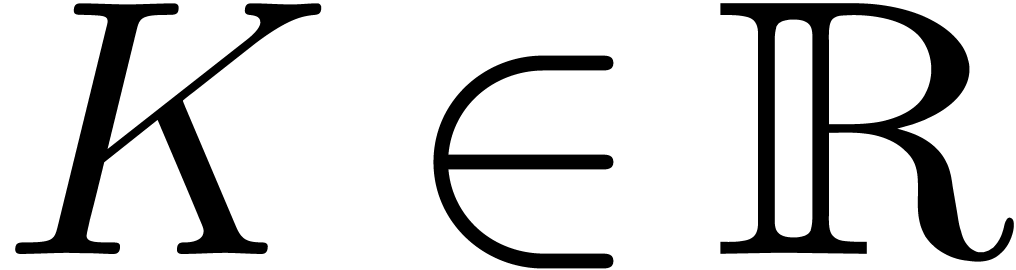 ,
on peut donc considérer la boule fermée
,
on peut donc considérer la boule fermée
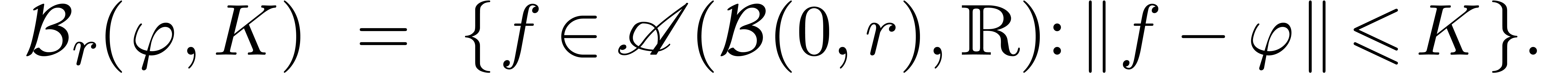
Étant donné un ordre 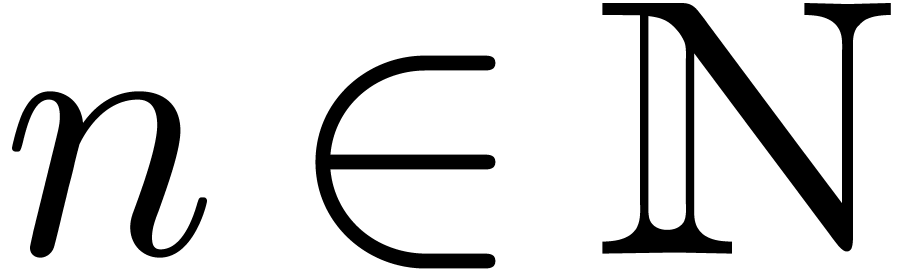 ,
on peut ensuite prendre les centres dans l'ensemble
,
on peut ensuite prendre les centres dans l'ensemble
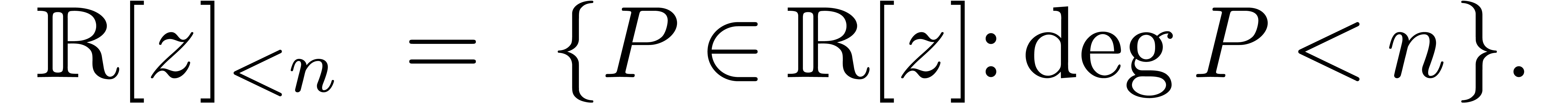
Une boule 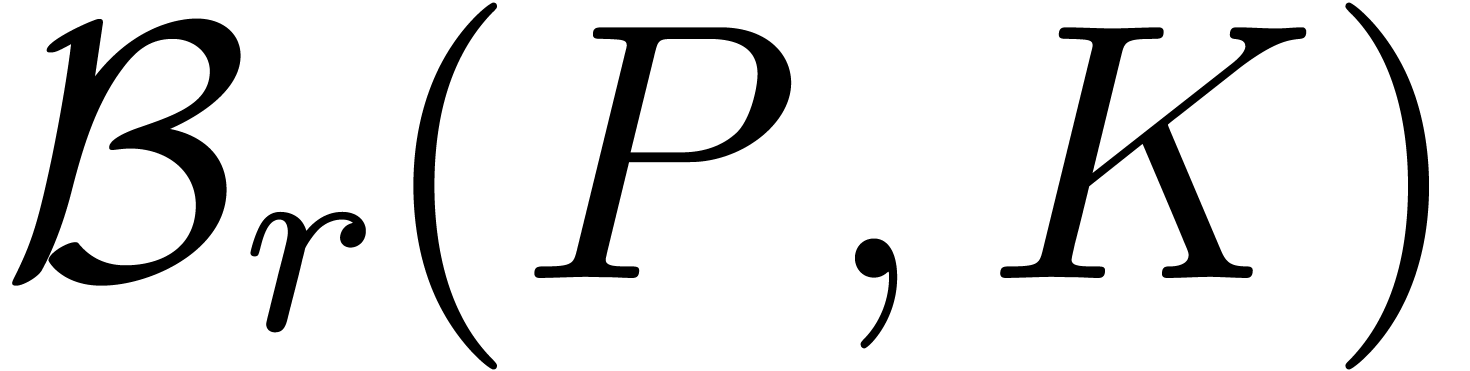 avec
avec 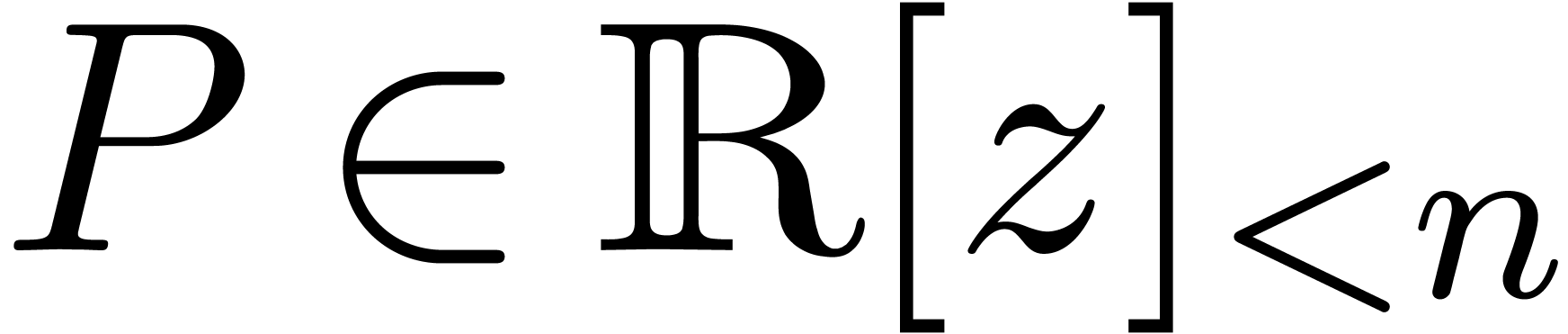 et
et 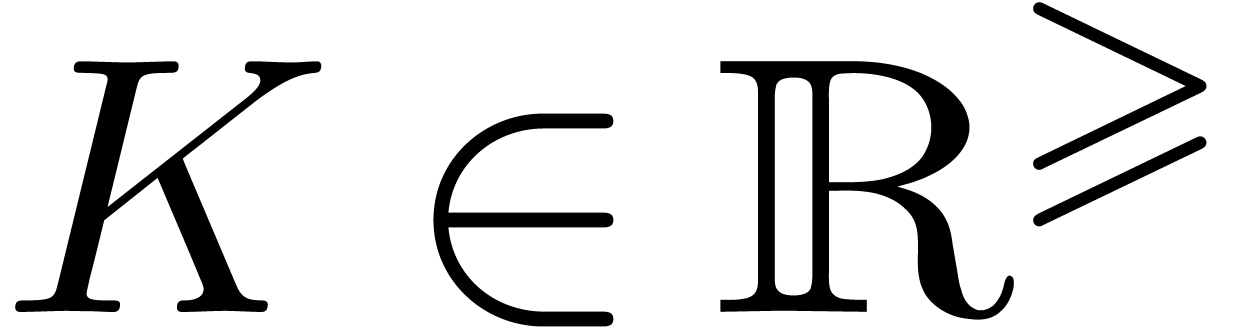 est appelé un modèle de Taylor
d'ordre sur la boule . On note par
est appelé un modèle de Taylor
d'ordre sur la boule . On note par 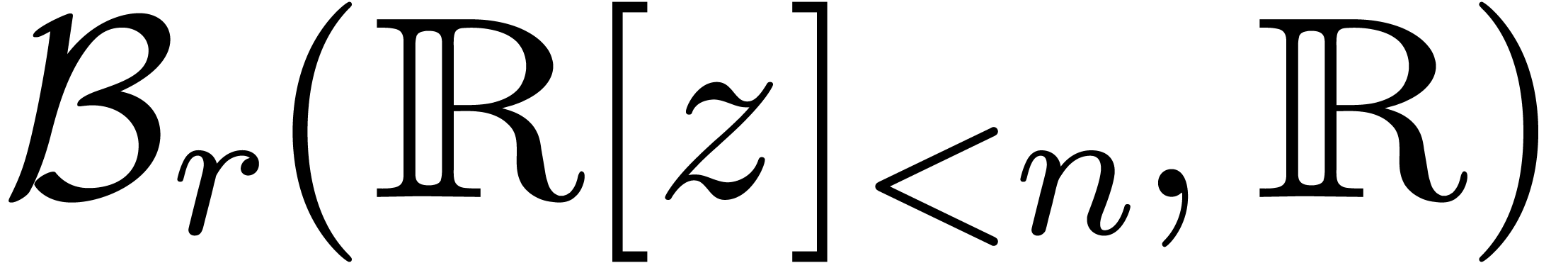 l'ensemble des
modèles de Taylor de ce type. Pour des calculs sur machine, on
peut évidemment définir la variante
l'ensemble des
modèles de Taylor de ce type. Pour des calculs sur machine, on
peut évidemment définir la variante 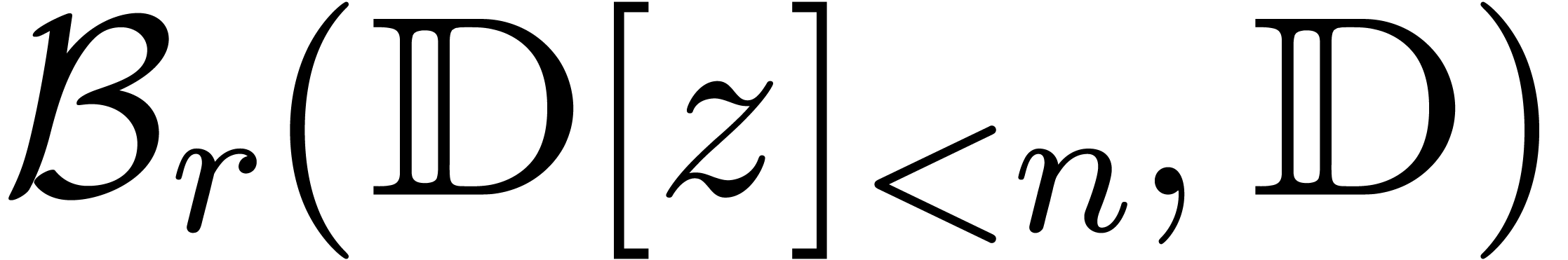 .
.
La multiplication doit être définie avec un peu plus de soin pour les modèles de Taylor :
Si on calcule avec des flottants de précision , il faut en plus prendre en compte les erreurs
d'arrondi, par exemple en rajoutant
au rayon en utilisant systématiquement le mode d'arrondi vers le
haut pour les estimations d'erreur. Dans tous les cas, on observe que le
calcul des erreurs est négligeable devant le coût de la
multiplication polynomiale tronquée pour
pas trop petit.
Contrairement au boules traditionnelles, les modèles de Taylor permettent aussi l'implantation d'opérations fonctionnelles comme l'intégration :
Ici, on utilise le fait que 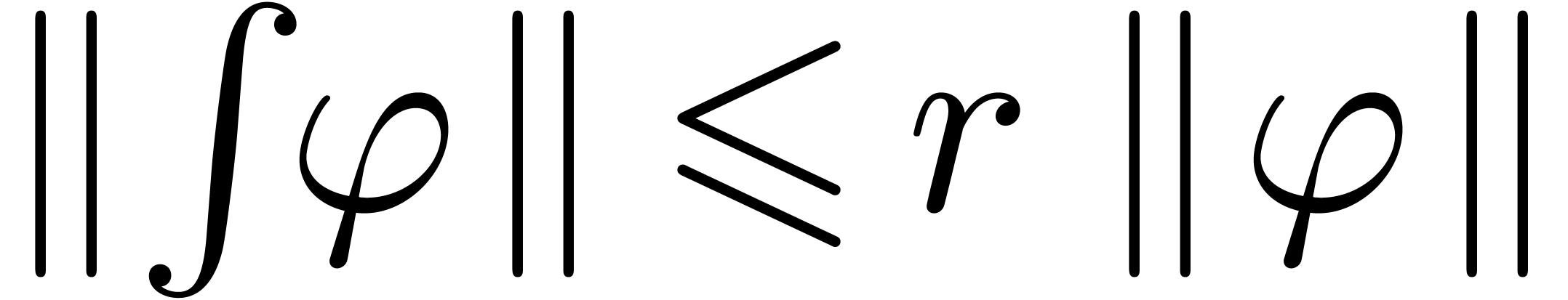 pour tout .
pour tout .
Les définitions se généralisent naturellement aux
cas des fonctions analytiques complexes et des fonctions analytiques en
variables sur un polydisque
avec  . Les centres d'un
modèle de Taylor en plusieurs variables vivent
généralement dans un ensemble du type
. Les centres d'un
modèle de Taylor en plusieurs variables vivent
généralement dans un ensemble du type
avec 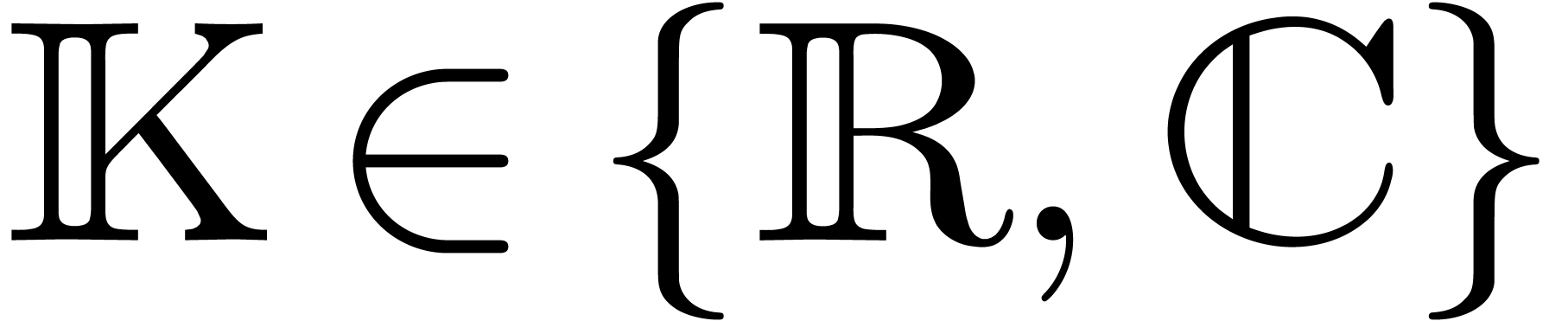 ,
et
,
et  .
.
Une application importante des modèles concerne la réduction de la surestimation quand on évalue une fonction en arithmétique de boules. Revenons à l'exemple 3.3 :
Considérons maintenant l'évaluation de l'expression 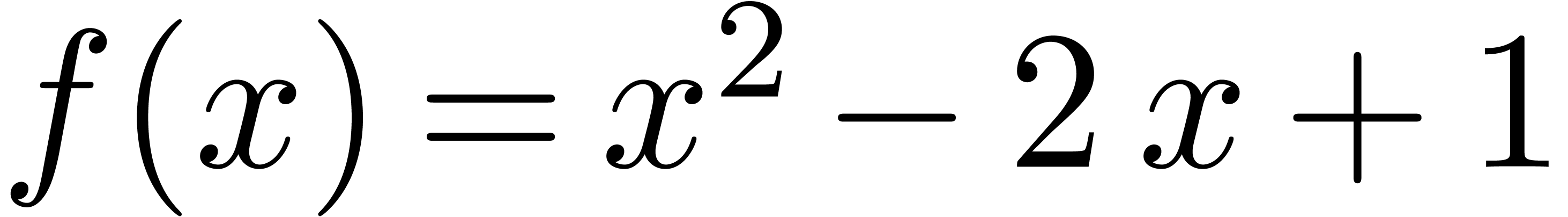 en un modèle de Taylor d'ordre (ou plus) :
en un modèle de Taylor d'ordre (ou plus) :

Pour tout 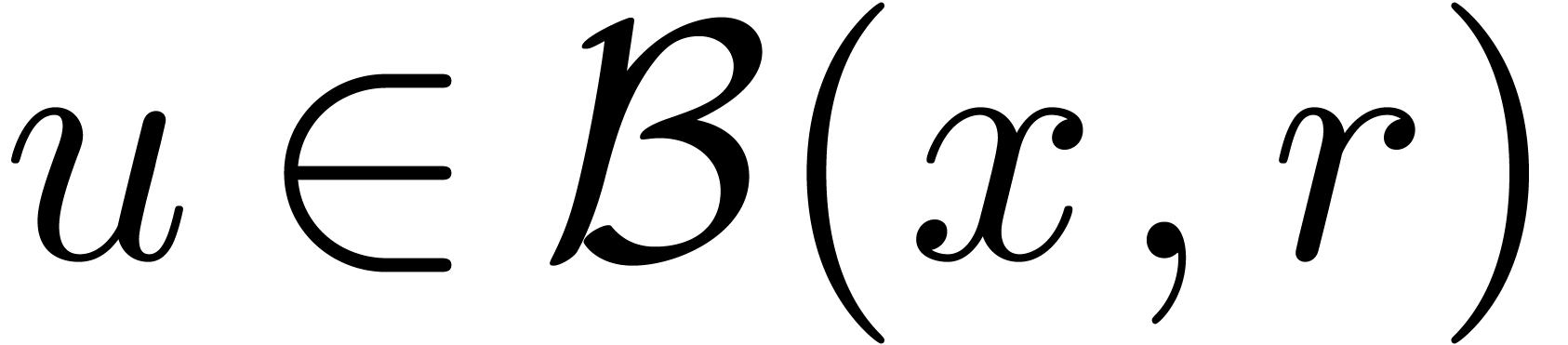 on a donc
on a donc 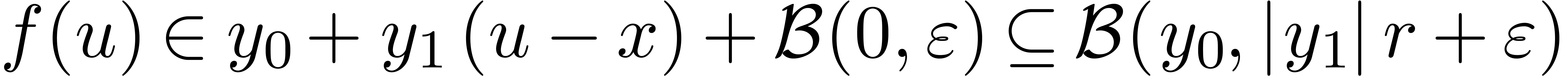 , ce qui nous permet de définir une meilleure
extension
, ce qui nous permet de définir une meilleure
extension 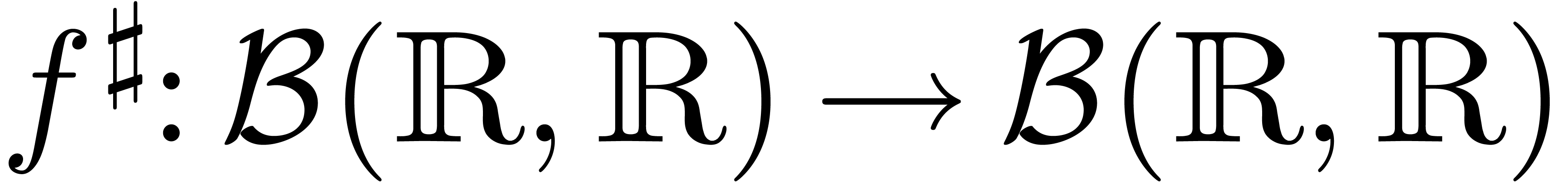 de par
de par
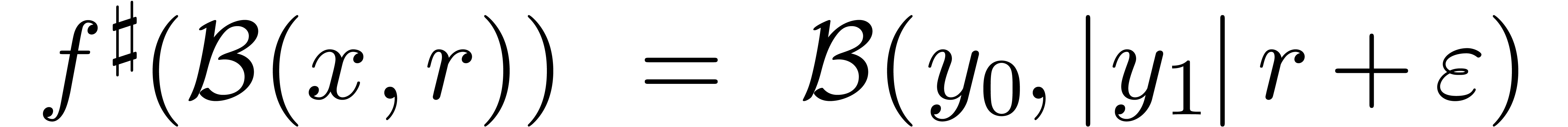
Il est facile de vérifier que cette extension est ponctuellement optimale dans le sens que
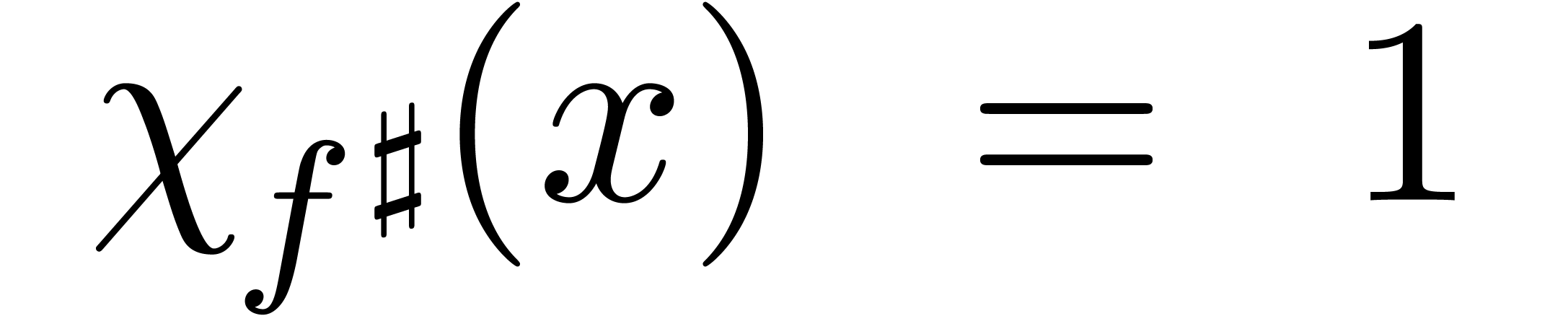
pour tout . Bien sûr,
il faudra recourir à des modèles de Taylor d'ordre au
moins  si présente
des racines de multiplicité (ou
lorsqu'une petite perturbation de
présente de telles racines).
si présente
des racines de multiplicité (ou
lorsqu'une petite perturbation de
présente de telles racines).
Considérons un système de polynômes réels
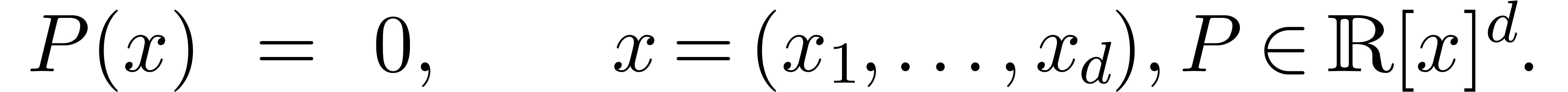
Un algorithme classique pour trouver les solutions de ce système
dans une « boîte » 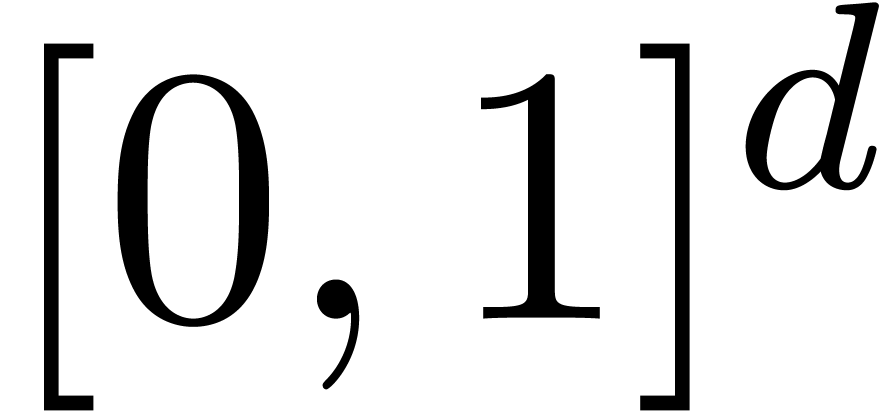 est de la
découper en des boîtes de plus en
plus petites jusqu'au moment où l'une des deux situations
suivantes se présente :
est de la
découper en des boîtes de plus en
plus petites jusqu'au moment où l'une des deux situations
suivantes se présente :
On a 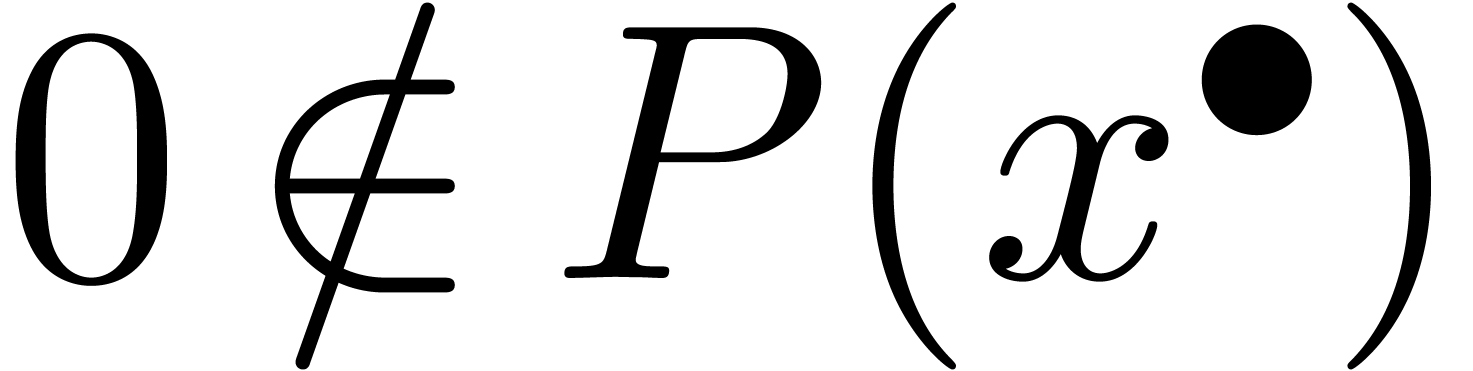 , et donc n'admet pas de racines sur .
, et donc n'admet pas de racines sur .
On peut démontrer que admet une
unique solution dans (par exemple, en
utilisant la méthode de Krawczyk-Rump qui sera exposée
dans la section 6.6.1).
Si n'admet que des racines simples dans , alors cet algorithme simpliste
termine. Toutefois, en présence de racines multiples, ou racines
proches (éventuellement dans des voisinages imaginaires),
l'évaluation de 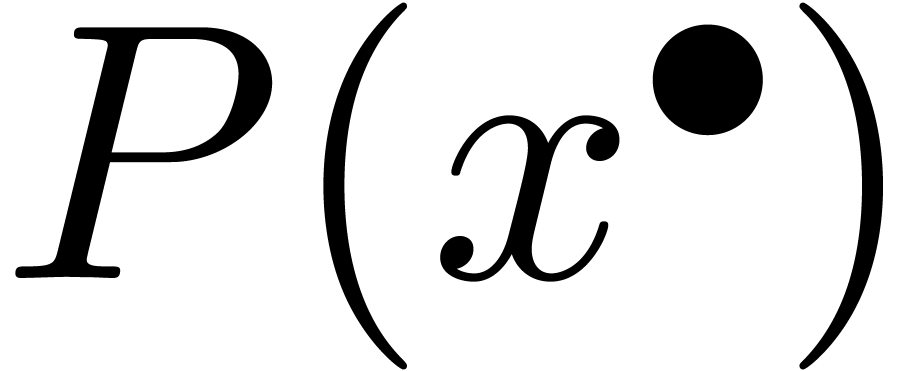 présentera une
surestimation qui rend la méthode inutilisable.
présentera une
surestimation qui rend la méthode inutilisable.
En utilisant les modèles de Taylor, on aimerait donc
réduire cette surestimation. Le principal problème est
alors de trouver un ordre de troncature adéquat. Ceci peut se
faire de façon heuristique. Afin de simplifier l'exposition,
considérons le cas de dimension un. Supposons que l'on a
calculé un encadrement 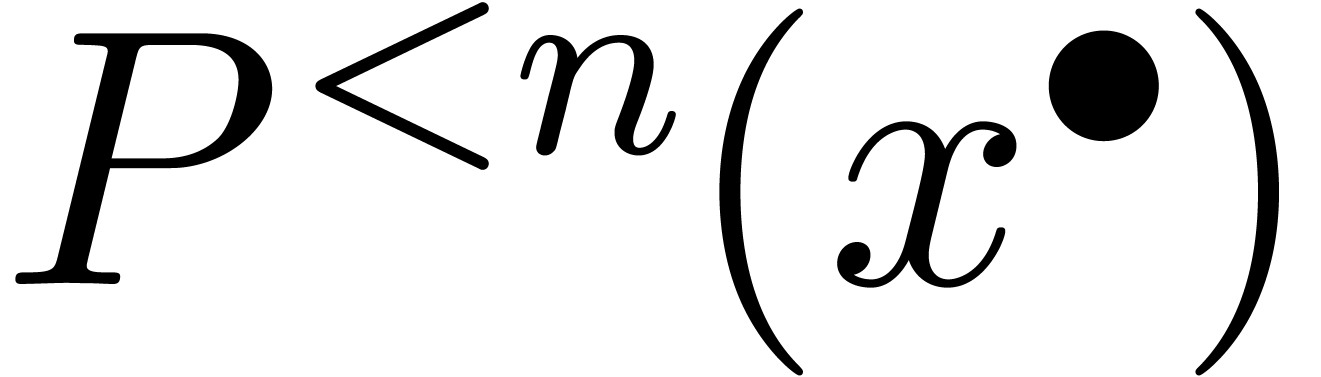 de sur en utilisant des
modèles de Taylor à l'ordre .
Pour un coût
de sur en utilisant des
modèles de Taylor à l'ordre .
Pour un coût 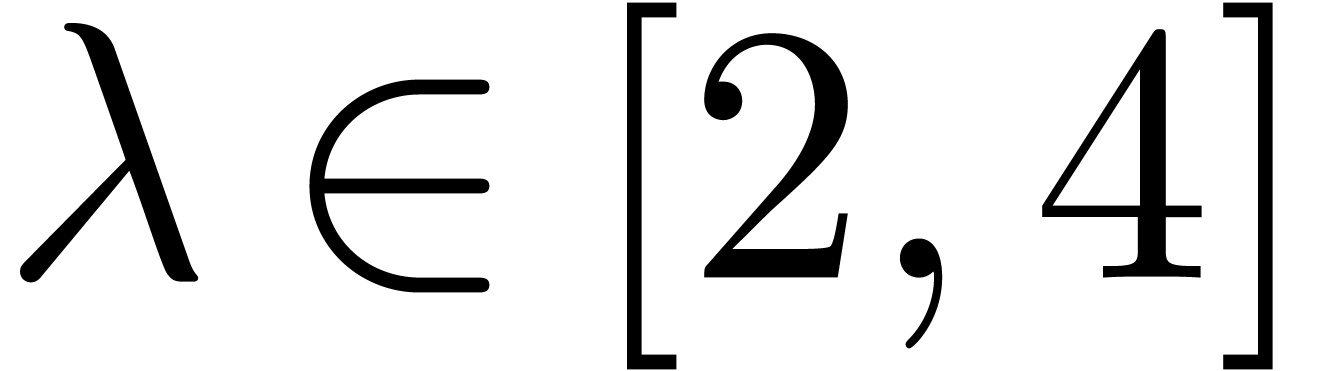 plus grand on peut aussi
calculer un encadrement
plus grand on peut aussi
calculer un encadrement 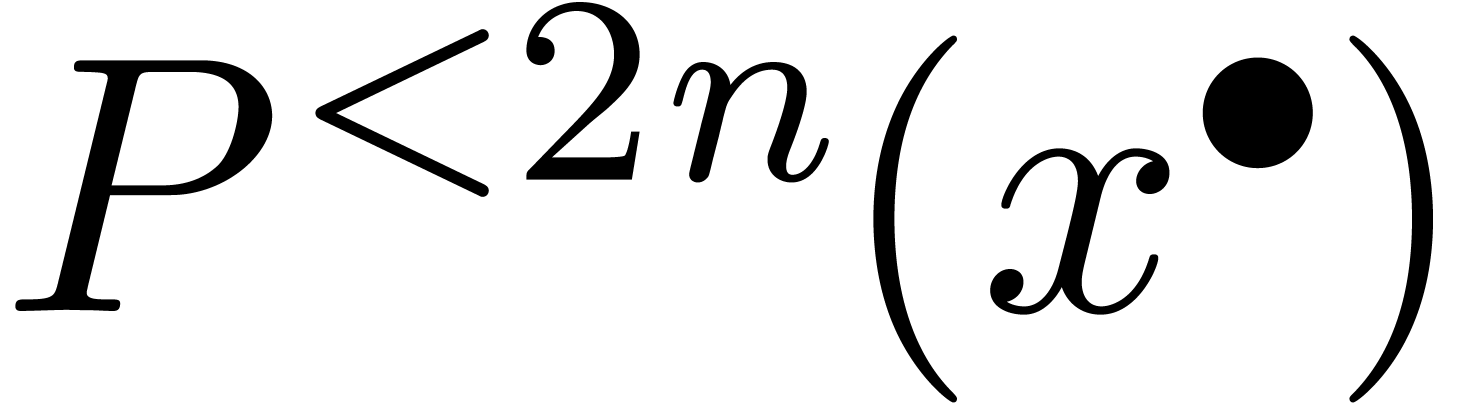 en utilisant des
modèles de Taylor à l'ordre .
Même si on ne connait pas les surestimations
en utilisant des
modèles de Taylor à l'ordre .
Même si on ne connait pas les surestimations 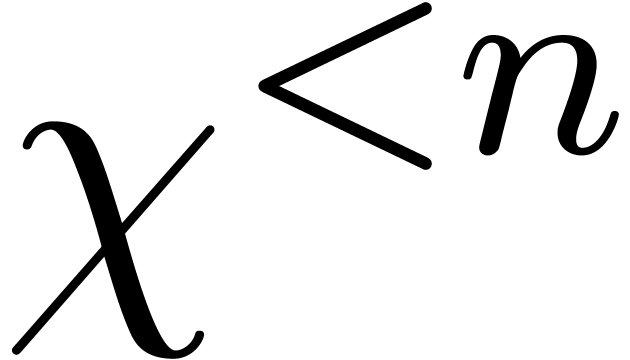 et
et 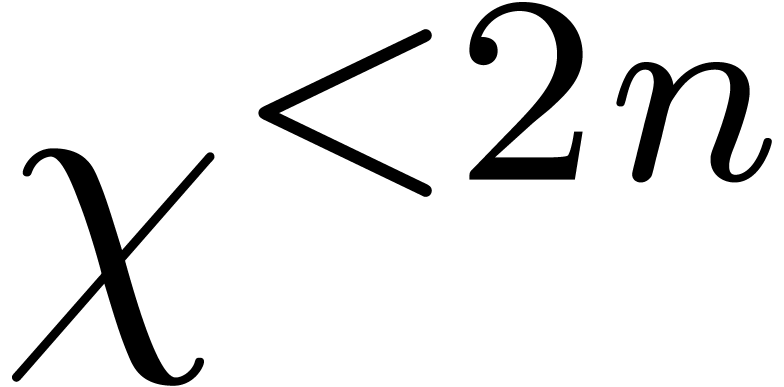 de et dans l'absolu, le quotient entre les rayons de
et de nous fournit le
ratio
de et dans l'absolu, le quotient entre les rayons de
et de nous fournit le
ratio 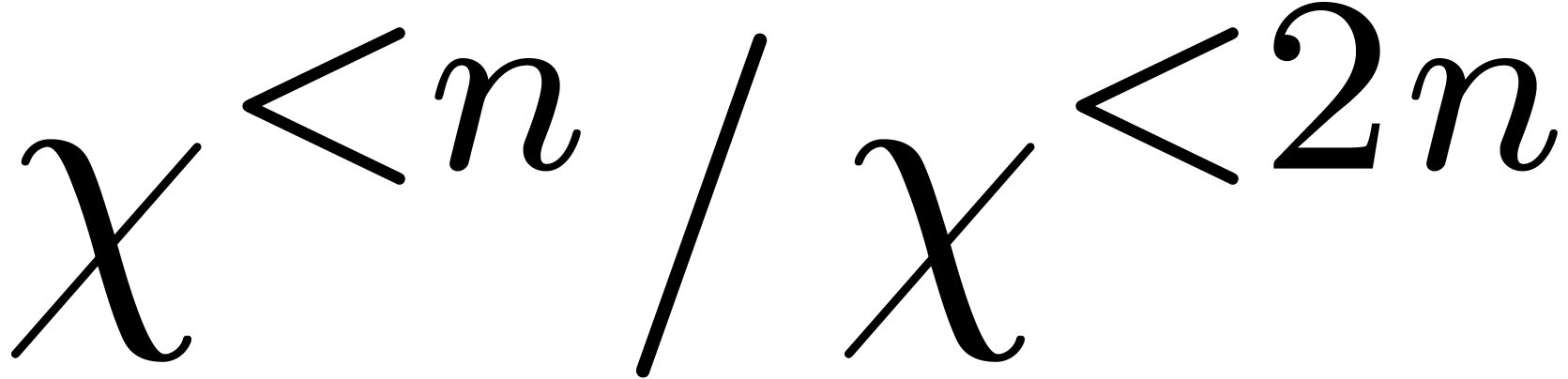 . On s'attend donc
à ce que l'on doive découper la boîte en des boîtes fois plus
petites en utilisant des modèle de Taylor d'ordre plutôt que .
Lorsque
. On s'attend donc
à ce que l'on doive découper la boîte en des boîtes fois plus
petites en utilisant des modèle de Taylor d'ordre plutôt que .
Lorsque 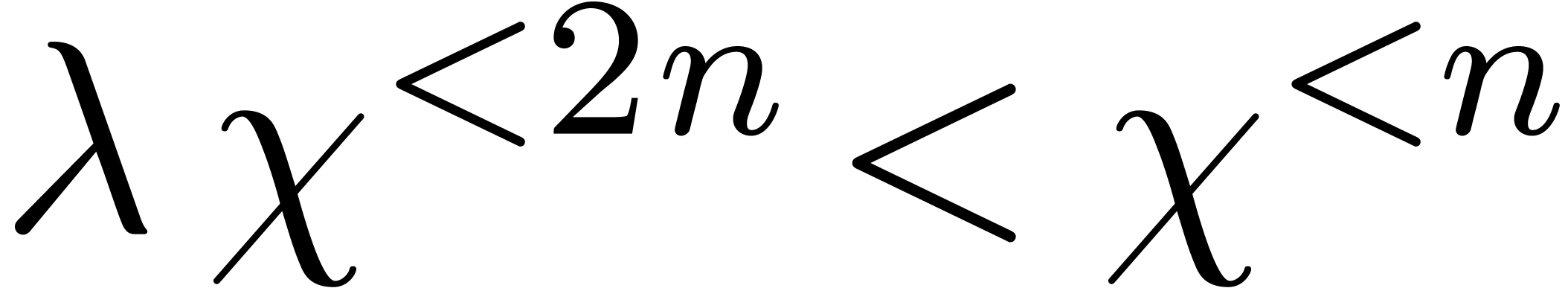 , on a donc
intérêt à prendre des modèles de Taylor
d'ordre plutôt que des modèles
d'ordre . Ce critère
nous permet de trouver un ordre à peu près optimal.
, on a donc
intérêt à prendre des modèles de Taylor
d'ordre plutôt que des modèles
d'ordre . Ce critère
nous permet de trouver un ordre à peu près optimal.
Nous notons en outre que les modèles de Taylor en plusieurs variables nous permettent en principe des prendre des boîtes qui ne sont pas forcément parallèles aux axes (voir aussi la section 7.2.3) et donc de mieux suivre la géométrie du problème. En fait, les boîtes ont même le droit de devenir courbées, si cela peut arranger les estimations d'erreur.
L'intégration certifiée de systèmes dynamiques utilisant la technique des modèles de Taylor a été proposé par Berz et Makino [49, 50]. Un grand avantage de ces méthodes est qu'ils permettent d'étudier la dépendance du flot par rapport aux conditions initiales pour des conditions initiales dans des domaines relativement grands. Bien sûr, ceci nécessite de recourir à des modèles de Taylor en plusieurs variables, c'est à dire par rapport au temps et par rapport aux conditions initiales. Dans cette section, nous allons plutôt nous intéresser à des techniques qui continuent à marcher en haute précision. Dans ce cadre, les conditions initiales sont forcément spécifiées de façon très précise, donc on peut se contenter de modèles de Taylor en une variable. Dans la section 5.5.2, on aura juste besoin d'étudier la dépendance du flot par rapport aux conditions initiales à l'ordre un.
Supposons que l'on veuille intégrer le système dynamique
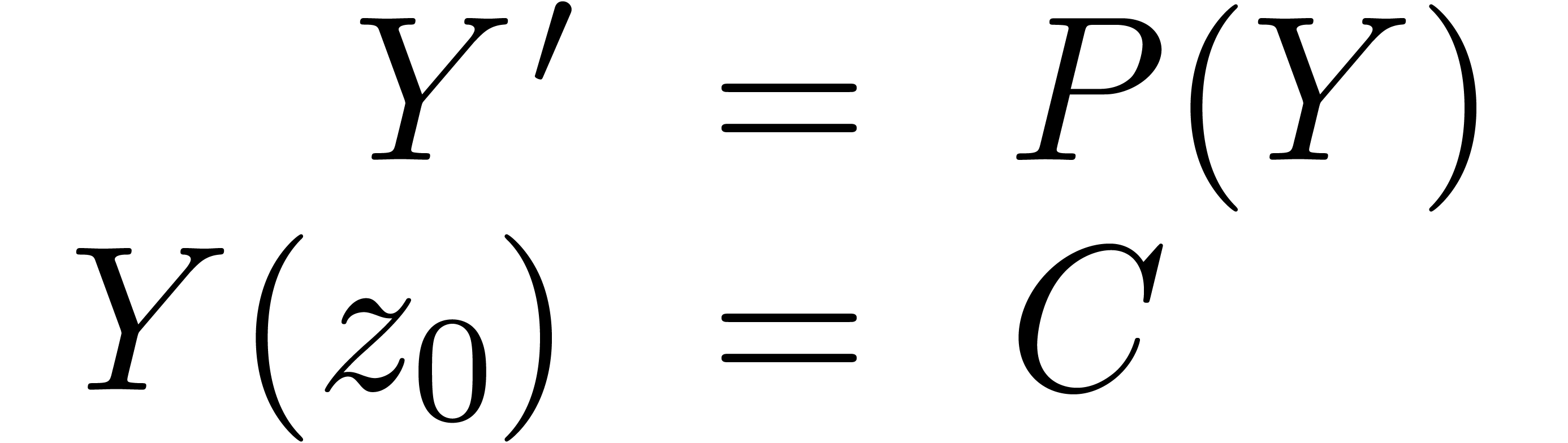
avec  ,
,  ,
, 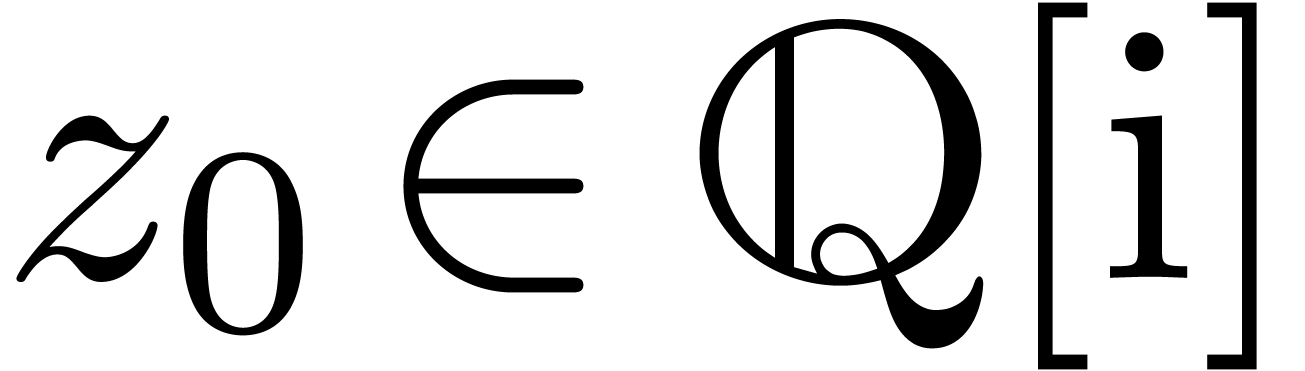 et
et 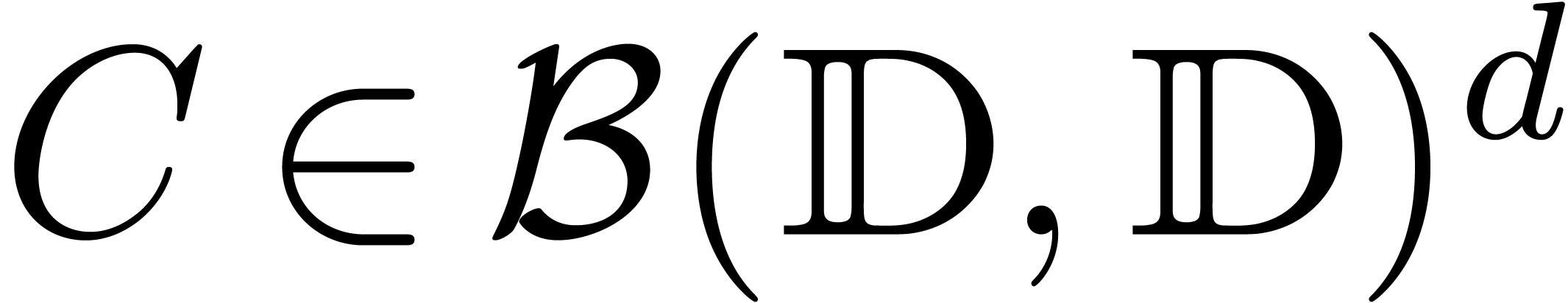 . Plus précisément, supposons que l'on
veuille calculer la valeur
. Plus précisément, supposons que l'on
veuille calculer la valeur 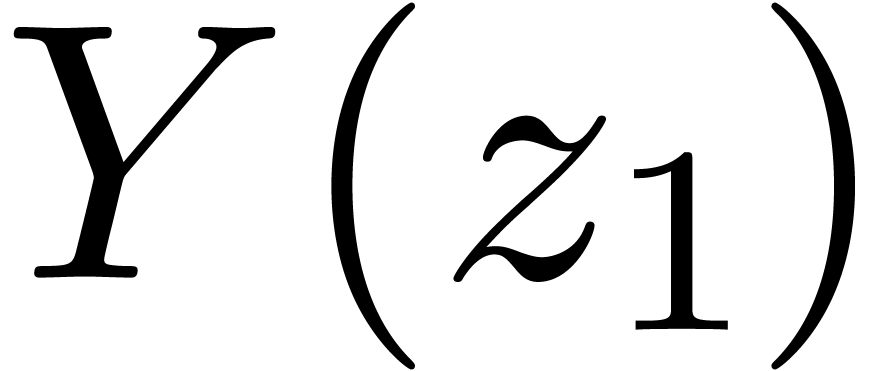 de
de  en
en 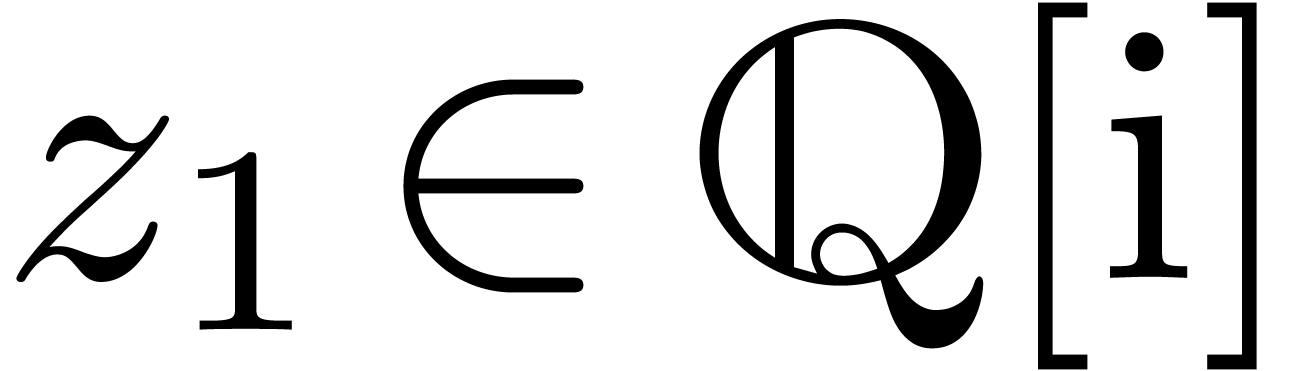 . Alors on peut utiliser
la méthode suivante :
. Alors on peut utiliser
la méthode suivante :
Comme le système ne dépend pas du temps, on peut
supposer sans perdre de généralité que 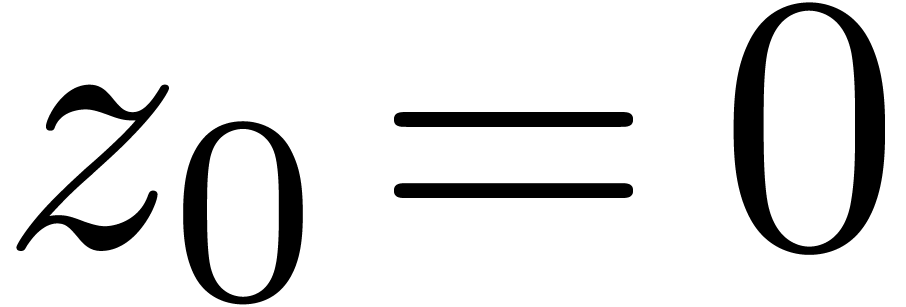 .
.
Supposant que l'on calcule avec une précision de chiffres binaires, on sélectionne un ordre
de développement proportionnel
à (disons 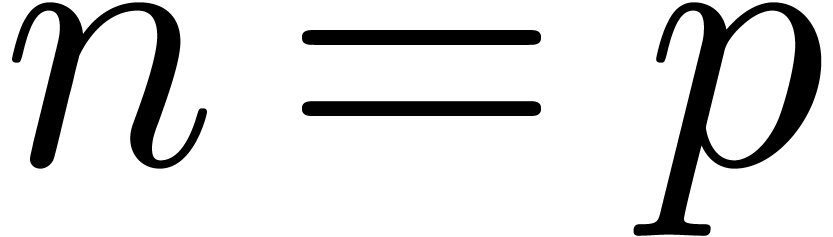 ), et on calcule une approximation
numérique de la solution autour de
), et on calcule une approximation
numérique de la solution autour de 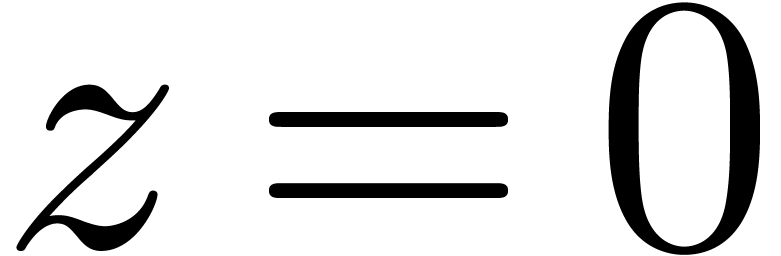 :
:
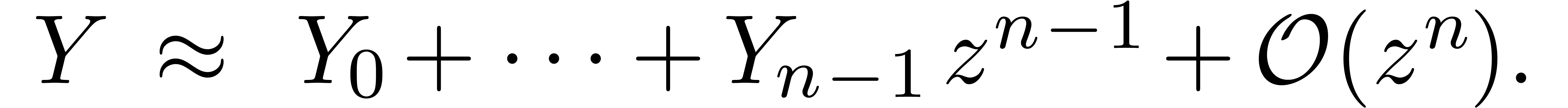
Pour  , où
, où  est une constante dont le calcul sera
détaillé plus bas, on évalue
est une constante dont le calcul sera
détaillé plus bas, on évalue 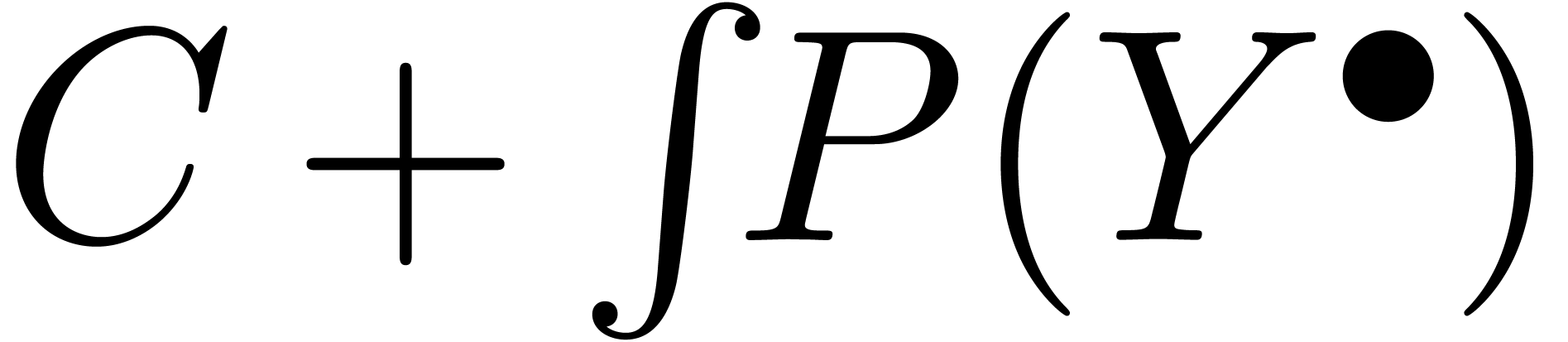 utilisant l'arithmétique pour les modèles de Taylor.
Si
utilisant l'arithmétique pour les modèles de Taylor.
Si
alors on retourne  .
.
Sinon, on calcule récursivement  , puis en fonction de
.
, puis en fonction de
.
Vérifions que cette méthode est correcte. En effet, si on
a l'inclusion (5.1), alors l'opérateur de 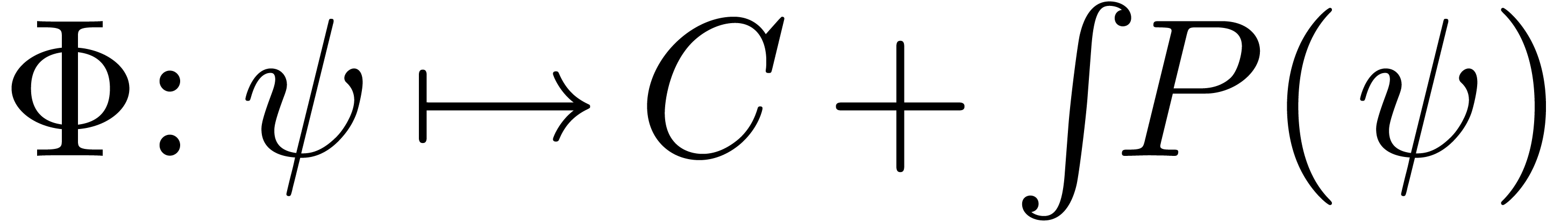 envoie la boule
envoie la boule 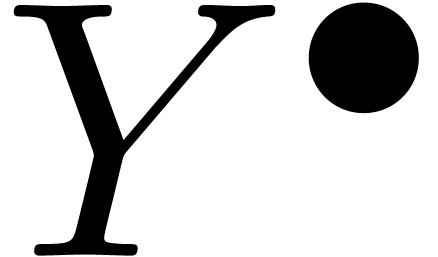 dans lui
même. Comme est une boule compacte dans un
espace de Banach, il s'en suit que
dans lui
même. Comme est une boule compacte dans un
espace de Banach, il s'en suit que  admet un
point fixe. Or il existe une unique façon de calculer les
coefficients en série d'un tel point fixe, donc ce point fixe est
nécessairement unique.
admet un
point fixe. Or il existe une unique façon de calculer les
coefficients en série d'un tel point fixe, donc ce point fixe est
nécessairement unique.
Il nous reste à montrer comment calculer la constante . L'idée est tout simplement
de commencer avec 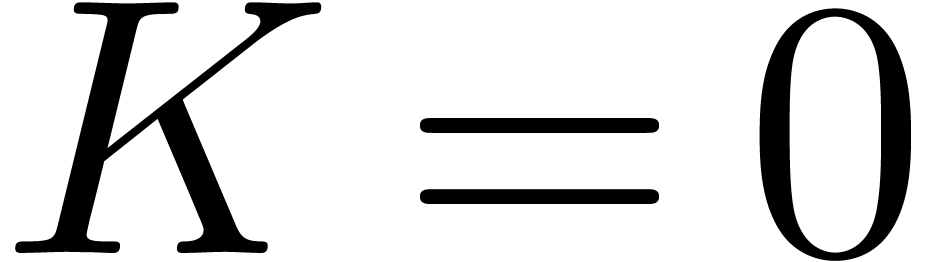 et d'itérer quelque
fois le processus suivant : on calcule
et d'itérer quelque
fois le processus suivant : on calcule 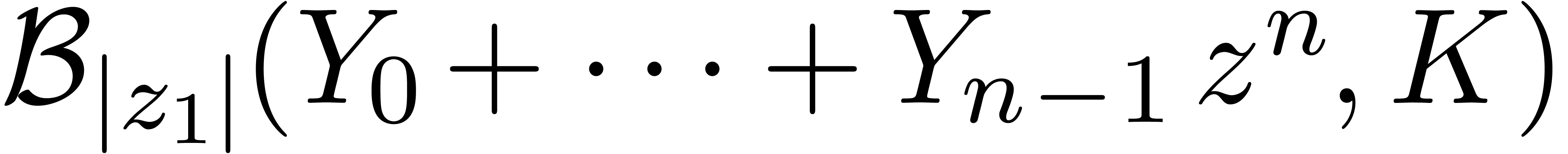 et on
remplace par le supremum de
et le rayon du résultat. Si cette itération diverge
numériquement, alors on arrête et (5.1) ne
sera pas vérifier. Sinon, on continue jusqu'au moment où
ne bouge plus trop, disons
et on
remplace par le supremum de
et le rayon du résultat. Si cette itération diverge
numériquement, alors on arrête et (5.1) ne
sera pas vérifier. Sinon, on continue jusqu'au moment où
ne bouge plus trop, disons 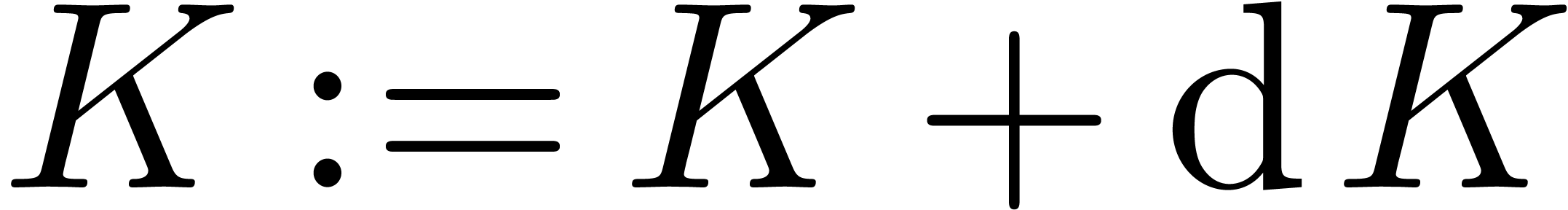 , et on refait une nouvelle fois avant de finir.
, et on refait une nouvelle fois avant de finir.
Si on applique l'algorithme de la section précédente tel quel dans le cas du système
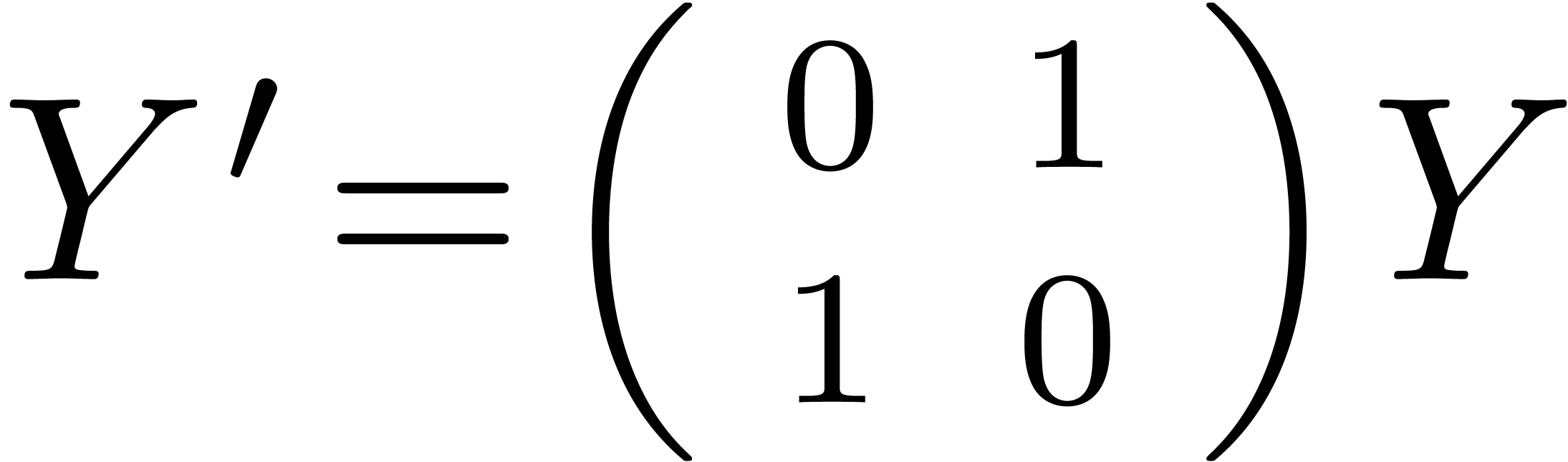
on observe un effet d'enveloppement similaire au calcul de puissances successives d'un nombre complexe (voir la section 3.2.2, ainsi que la figure 5.1). Pour y remédier, on utilise les idées suivantes [53].
Idée 1 : calculer la dependence en fonction de la condition initiale
Idée 2 : encadrements de l'erreur dans des
coordonnées déterminées par 
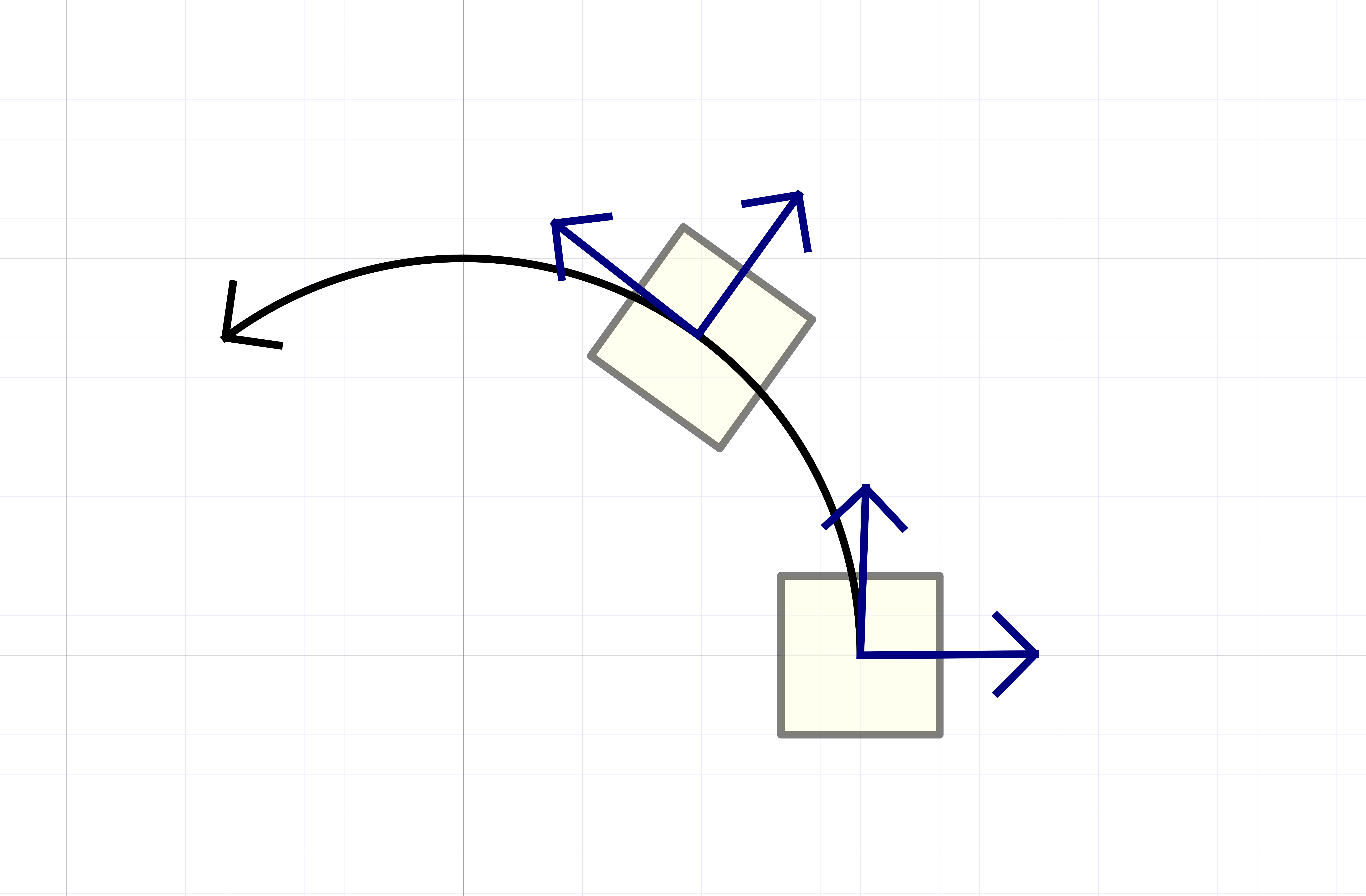 |
Il est naturel de se demander s'il ne faudrait pas remplacer la
définition de l'ensemble des modèles de Taylor sur le
disque et d'ordre par
quelque chose d'un peu plus fin, comme
Bien sûr, la définition classique est plus simple, ce qui
rend les opérations de base plus efficaces. Toutefois, en grande
précision, le calcul avec des boules dans  ne coûte pas sensiblement plus cher que le calcul avec des
flottants dans . Par
ailleurs, la définition alternative admet aussi quelques
avantages :
ne coûte pas sensiblement plus cher que le calcul avec des
flottants dans . Par
ailleurs, la définition alternative admet aussi quelques
avantages :
Avant tout, les bornes obtenues sont souvent de meilleure
qualité. Par exemple, dans le cas de l'intégration, on
profite d'une division par  :
:
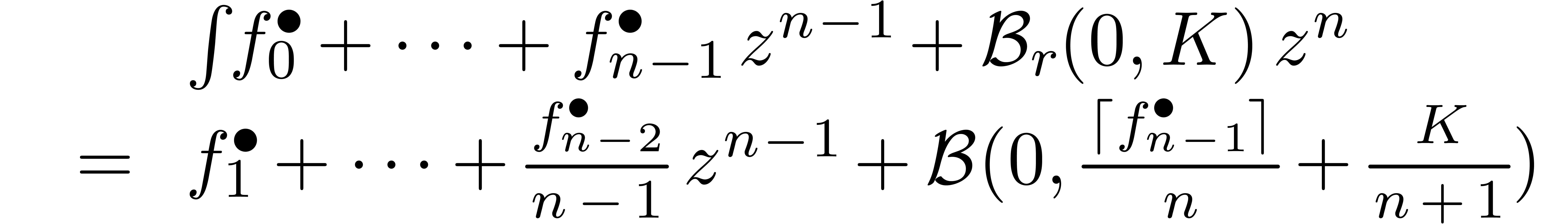
Comme on le verra dans la section suivante, cette amélioration n'est pas anodine.
Il n'est pas nécessaire de calculer avec une précision
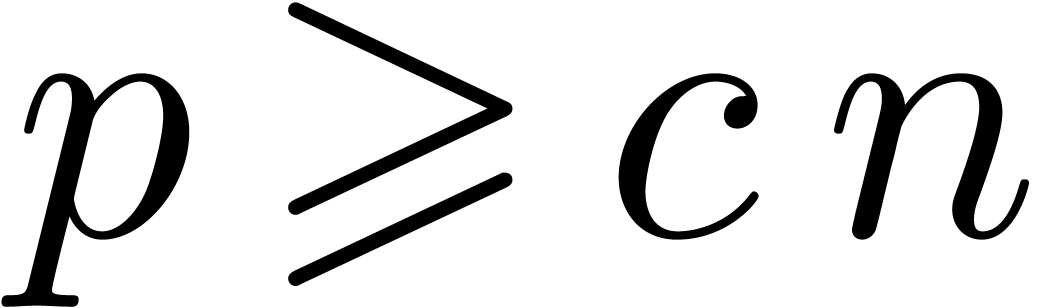 pour avoir des bornes précises pour
le reste
pour avoir des bornes précises pour
le reste 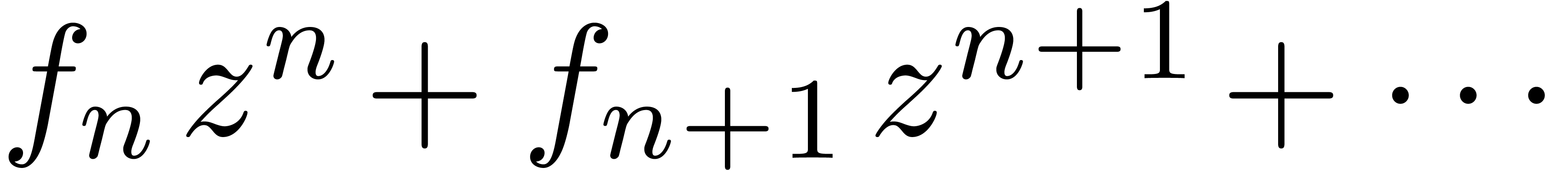 .
.
Les bornes obtenues donnent des bornes plus fines quand on restreint
le domaine du modèle de Taylor
à une boule 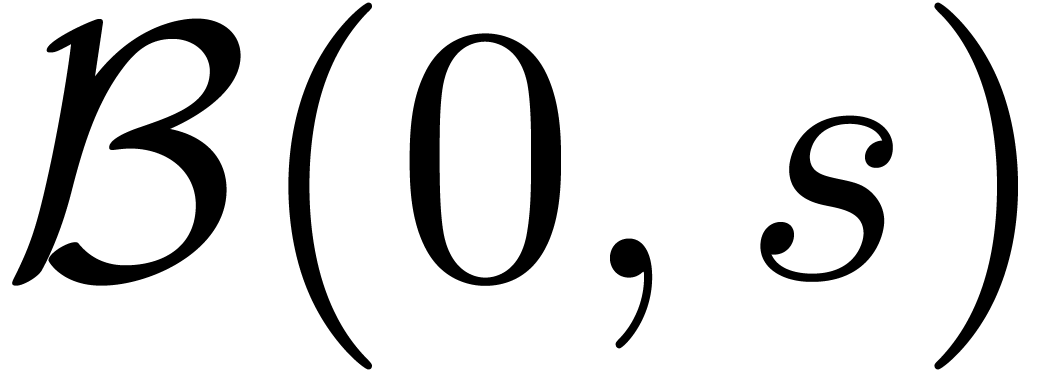 plus petite.
plus petite.
Examinons plus en détails la qualité des estimations
lorsque l'on utilise la variante des modèles de Taylor de la
section précédente. On suppose que l'on a calculé
des encadrements  pour les coefficients de la
solution jusqu'à l'ordre
et on pose
pour les coefficients de la
solution jusqu'à l'ordre
et on pose
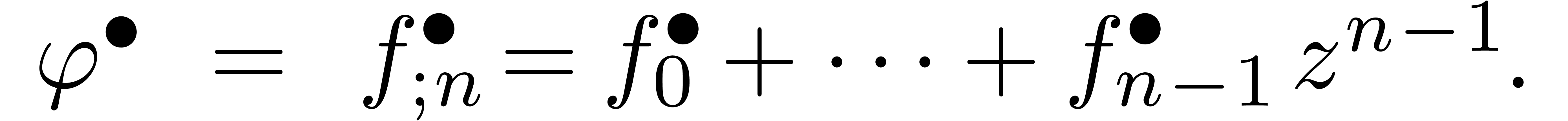
Notre but est d'obtenir un encadrement  pour le
reste
pour le
reste
Soit la fonctionnelle définie par

En calculant  en utilisant l'arithmétique
pour les modèles de Taylor, on trouve une boule
en utilisant l'arithmétique
pour les modèles de Taylor, on trouve une boule 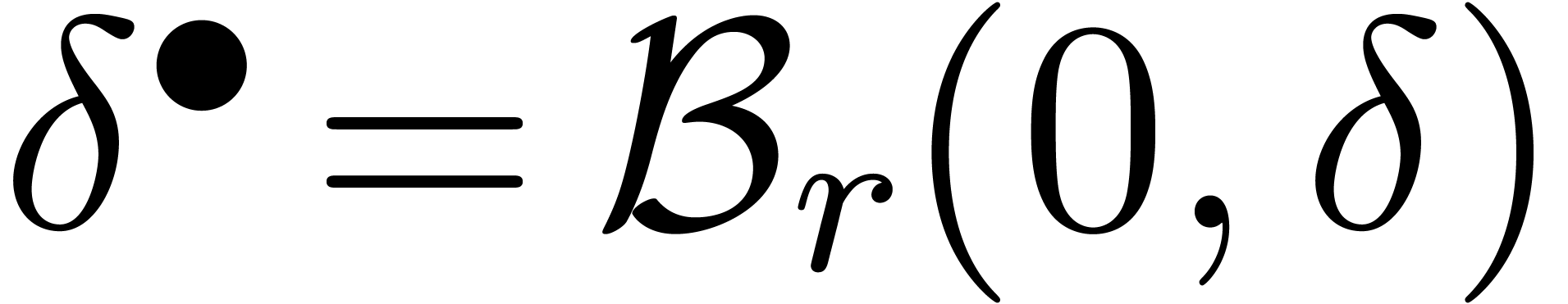 avec
avec

Rappelons que notre but était de trouver un encadrement pour avec

Or
Nous en sommes donc réduit à trouver un
avec

Supposant que
il suffit alors de prendre
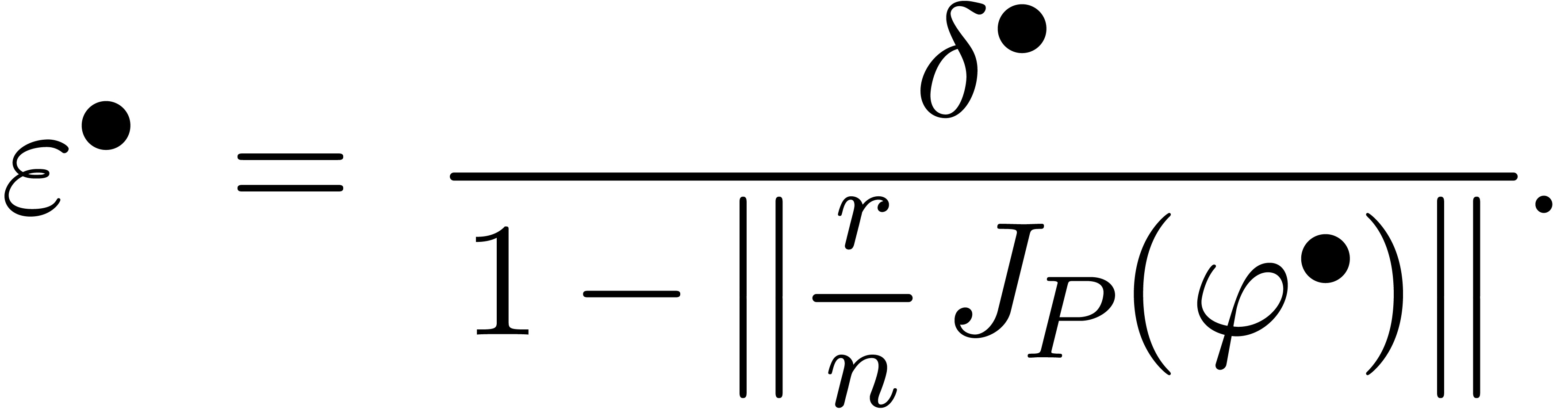 |
(5.3) |
L'intérêt de majorer le reste par
une expression de la forme 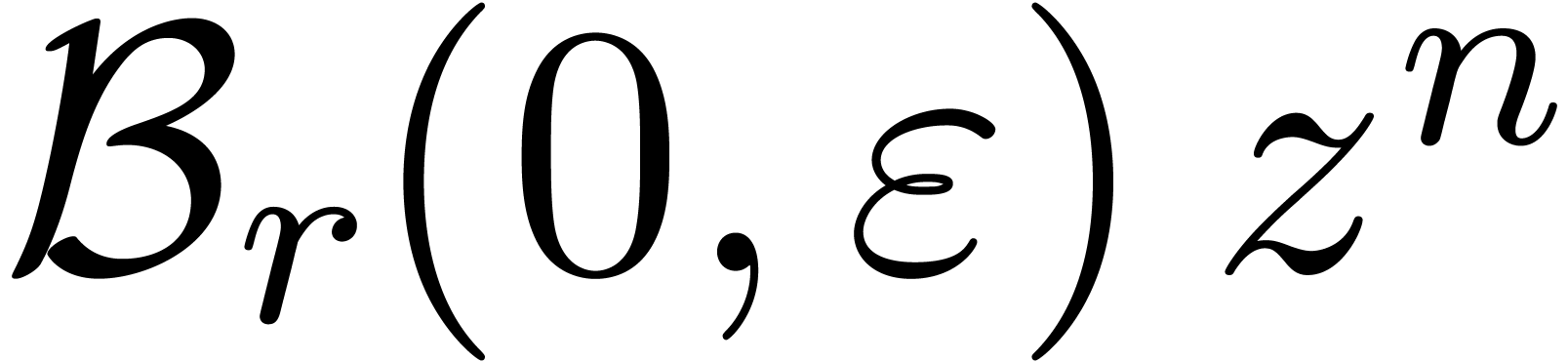 et non pas par une
boule de la forme
et non pas par une
boule de la forme 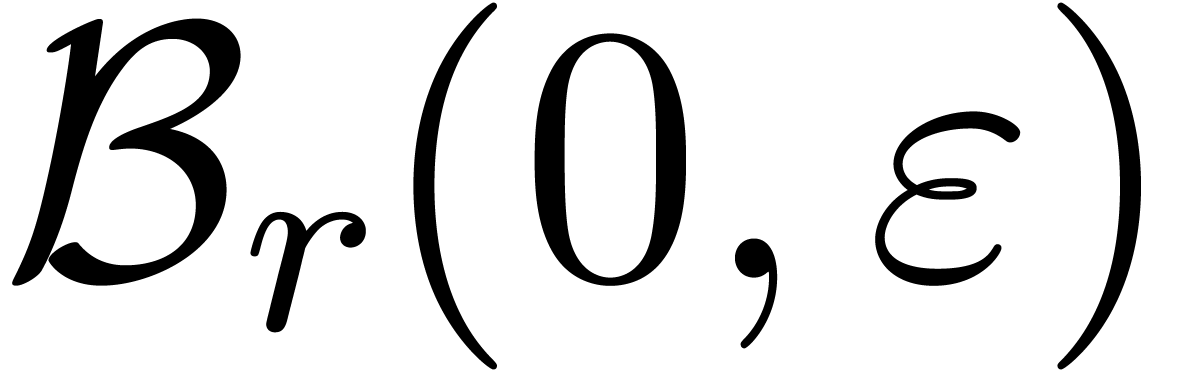 saute désormais au yeux
: dans le deuxième cas, il aurait fallu demander que
saute désormais au yeux
: dans le deuxième cas, il aurait fallu demander que
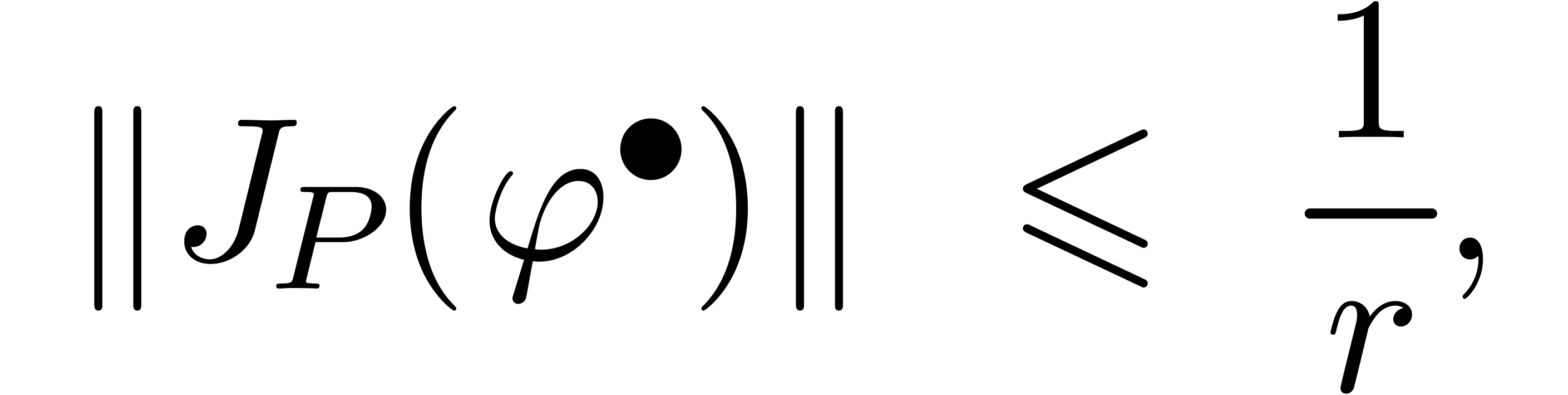
et on aurait dû se résoudre à prendre
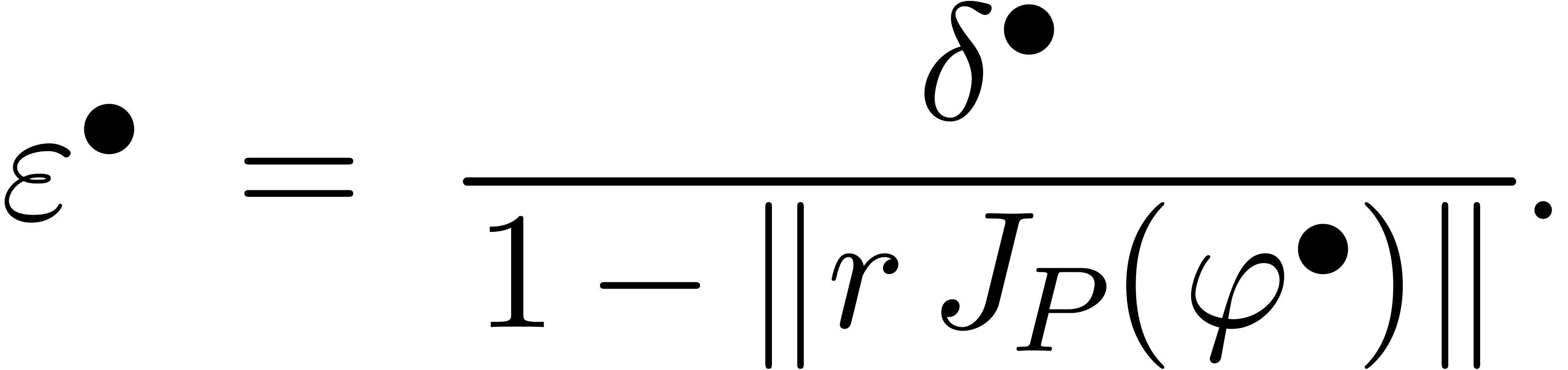
La taille de nos pas aurait donc été environ fois trop pessimiste.
La formule (5.3) montre aussi qu'il est intéressant
de rendre 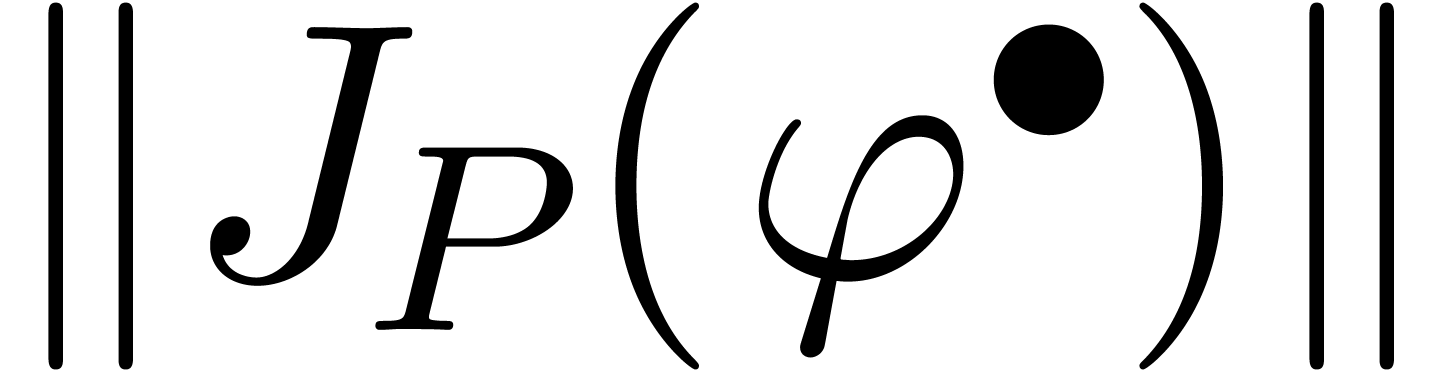 aussi petit que possible. Ceci
suggère de ne pas chercher des majorations directes dans les
coordonnées d'origine, mais plutôt des majorations de la
forme
aussi petit que possible. Ceci
suggère de ne pas chercher des majorations directes dans les
coordonnées d'origine, mais plutôt des majorations de la
forme 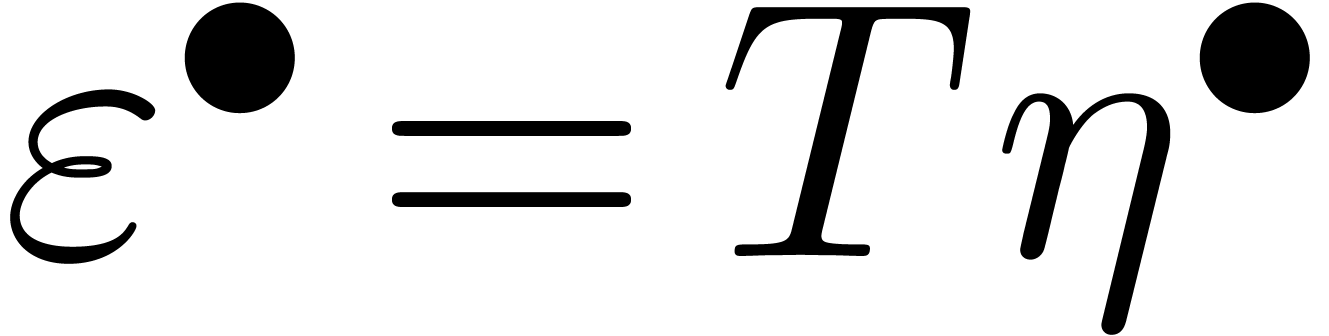 tel que
tel que  soit
petit.
soit
petit.
On observe enfin que la condition (5.2) est
vérifiée en prenant suffisamment
grand. À partir de cette observation, on montre que le rayon pour lequel on peut certifier l'existence d'une borne
tend vers le rayon de convergence  de lorsque l'on fait tendre et vers l'infini. Dans la terminologie du chapitre 2, cela implique
de lorsque l'on fait tendre et vers l'infini. Dans la terminologie du chapitre 2, cela implique 
L'équation de Volterra est souvent utilisée comme
benchmark pour des systèmes d'intégration
certifiés. L'implantation des modèles de Taylor est en
cours dans
Mmx] |
use "continewz" |
Mmx] |
type_mode? := false; |
Mmx] |
x: Coordinate == coordinate ('x); |
Mmx] |
y: Coordinate == coordinate ('y); |
Mmx] |
sys: Vector MVPolynomial Rational == [ 2 * x * (1 - y), - y * (1 - x) ] |
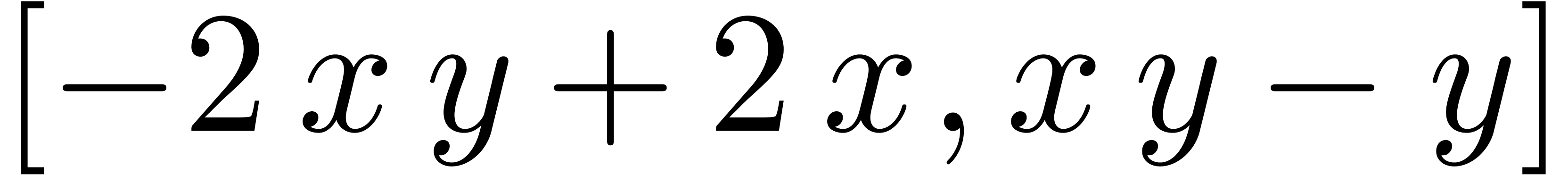
Mmx] |
coords: Vector Coordinate == [ x, y ] |
Mmx] |
init == [ as_double 1.0, as_double 3.0 ] |
Mmx] |
ode_order := 48; |
Mmx] |
ode_precision := 48; |
Mmx] |
significant_digits := 4; |
Mmx] |
solve_ode_taylor (sys, coords, init) |
Mmx] |
first_variation_taylor (sys, coords, init) |
Mmx] |
Mmx] |
significant_digits := 0; |
Mmx] |
period == as_double 5.48813846815; |
Mmx] |
[ @integrate_ode_taylor (sys, coords, init, period * (t / 15)) || t in 0 to 15 ] |
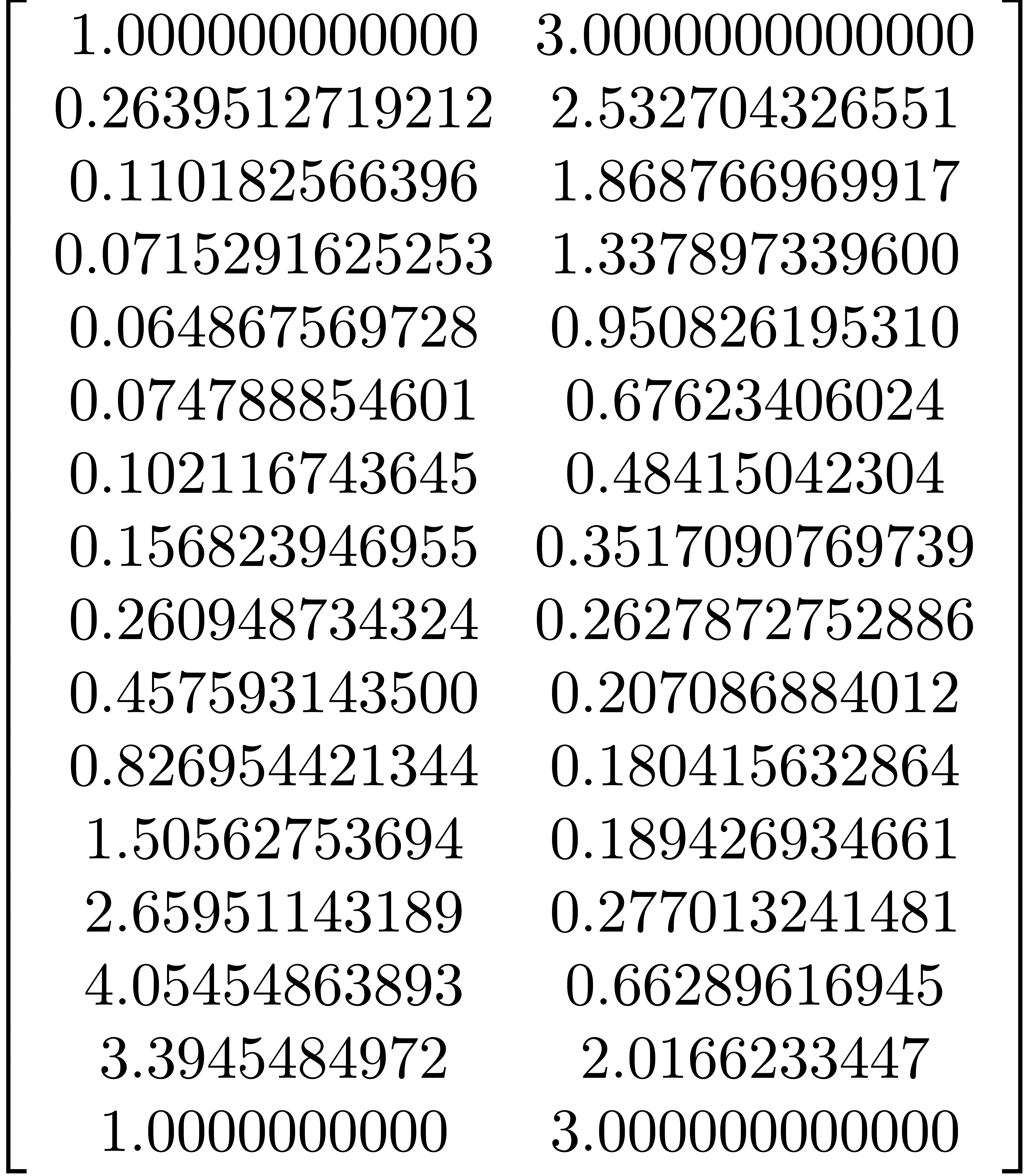
Mmx] |
Mmx] |
integrate_ode_taylor (sys, coords, init, period) |
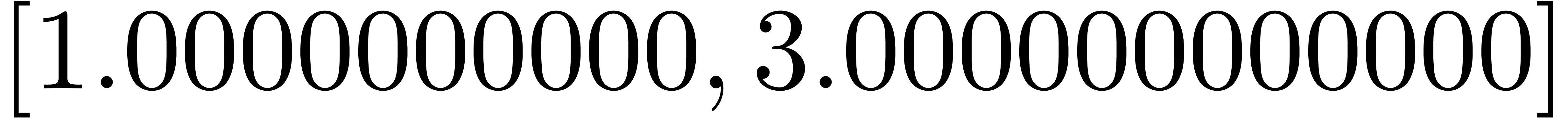
Mmx] |
integrate_ode_taylor (sys, coords, init, 2 * period) |
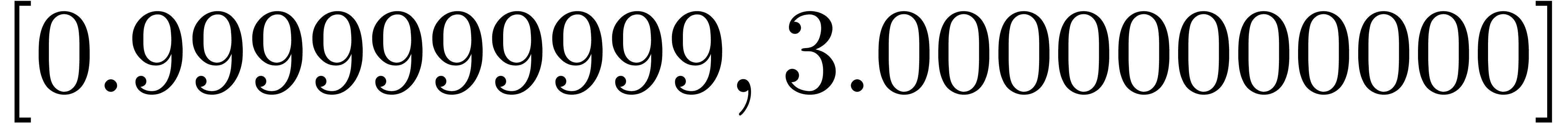
Mmx] |
integrate_ode_taylor (sys, coords, init, 5 * period) |
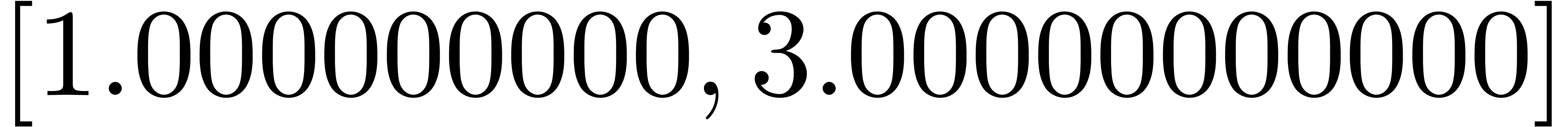
Mmx] |
integrate_ode_taylor (sys, coords, init, 10 * period) |
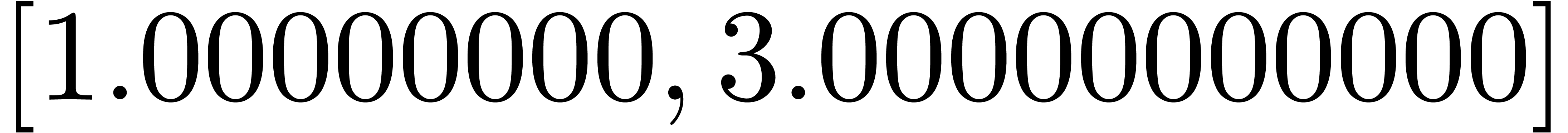
Mmx] |
integrate_ode_taylor (sys, coords, init, 20 * period) |
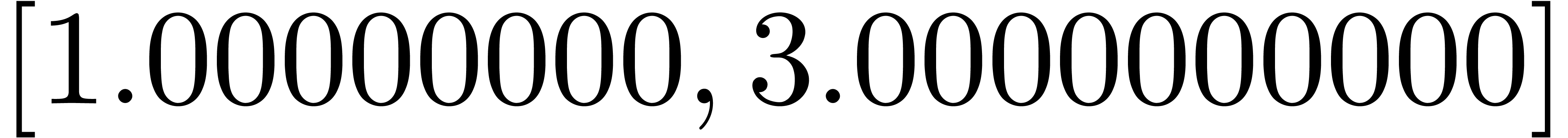
Mmx] |
integrate_ode_taylor (sys, coords, init, 50 * period) |
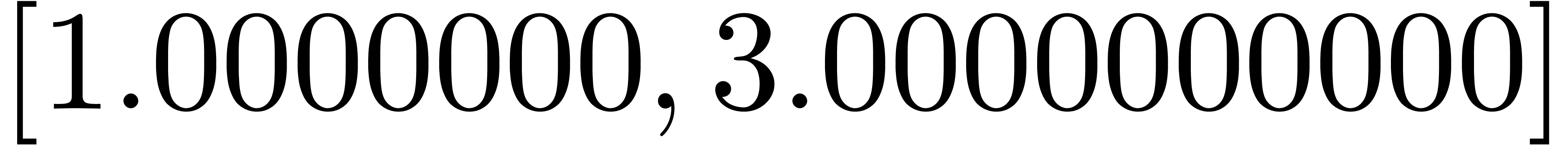
Mmx] |
integrate_ode_taylor (sys, coords, init, 100 * period) |
Mmx] |
integrate_ode_taylor (sys, coords, init, 200 * period) |
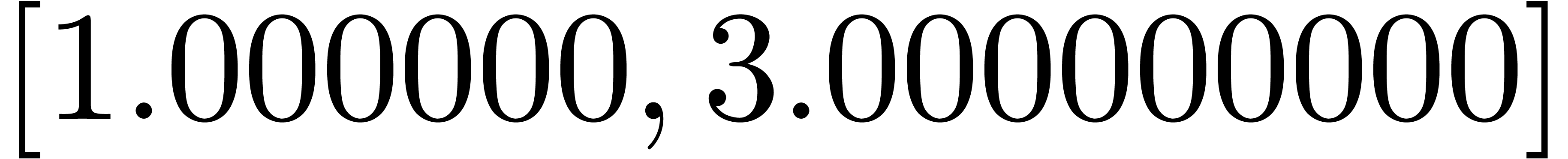
Mmx] |
integrate_ode_taylor (sys, coords, init, 500 * period) |
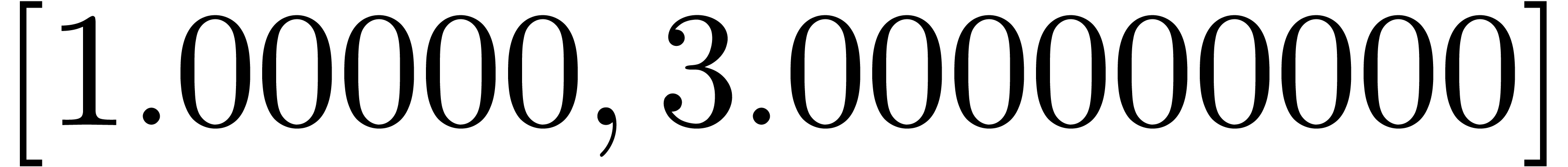
D'une part, il existe des algorithmes d'une bonne complexité théorique pour calculer les racines d'un polynôme en une variable [66, 59, 60]. D'autre part, il existe des bons implantations [35, 7]. La messe est-elle dite ? Malheureusement, l'état de l'art présente encore plusieurs défauts.
D'une part, les algorithmes asymptotiquement rapides marchent bien quand
la précision de calcul excède le
degré du polynôme. Or une précision bien moindre
suffit généralement pour isoler la plupart des racines.
Par ailleurs, il est souvent plus rapide d'appliquer des algorithmes
numériques brutaux en précision machine, plutôt que
de payer un grand facteur constant pour l'utilisation d'une
arithmétique « rapide » en précision multiple.
D'autant plus que ces algorithmes brutaux sont
généralement plus faciles à parallèliser.
Manifestement le passage des algorithmes naïfs mais
asymptotiquement mauvais à des algorithmes intelligents mais
asymptotiquement bons pose encore un problème dans ce domaine.
En outre, trouver toutes les racines dans le cas général pose de sérieux problèmes techniques : souvent les bonnes idées ne s'appliquent que dans certains cas et il est difficile de les combiner. D'ailleurs, les algorithmes de Pan attendent toujours à être implantés.
Enfin, il est fort probable que les mesures de complexité traditionnels ne soient pas tout à fait opérationnels pour ce problème. En effet, il existe de nombreux types de polynômes (voir la section 6.1) et l'efficacité et la qualité des solveurs dépend grandement de la répartition géométrique des racines. Faudrait-il des nombres de conditionnement plus fins pour exprimer la vraie complexité ? Est-ce qu'il vaudrait mieux considérer un autre problème, comme la factorisation en deux facteurs de degrés deux fois moindre ? Je ne connais pas les réponses pour l'instant, d'où le caractère plus « expérimental » de ce chapitre.
| Mmx] | use "analyziz"; |
| Mmx] | include "graphix/points.mmx"; |
Mmx] |
pi == 4.0 * arctan 1.0; |
Mmx] |
rnd () == exp (complex (0.0, uniform_deviate (0.0, 2*pi))); |
Mmx] |
p == polynomial (rnd () | i in 0 to 100); |
Mmx] |
$points roots p |

Meilleur conditionnement :
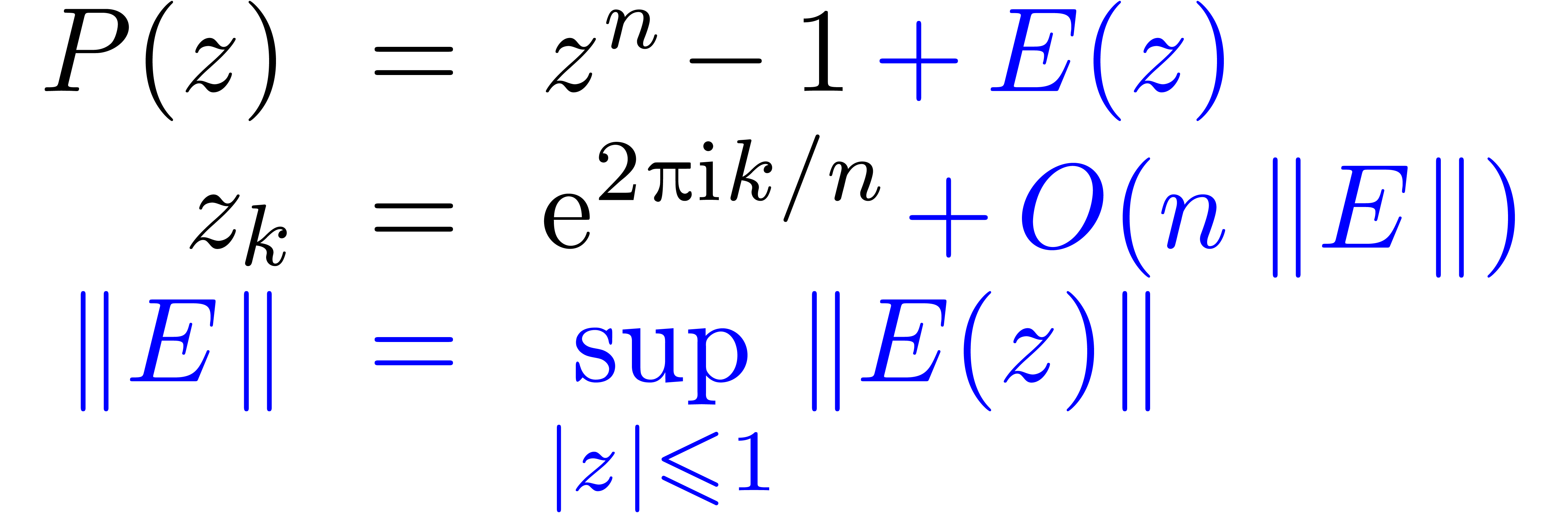
Mmx] |
p == poly (1.0, -1.0)^100; |
Mmx] |
$points (roots p) |
Pire conditionnement :
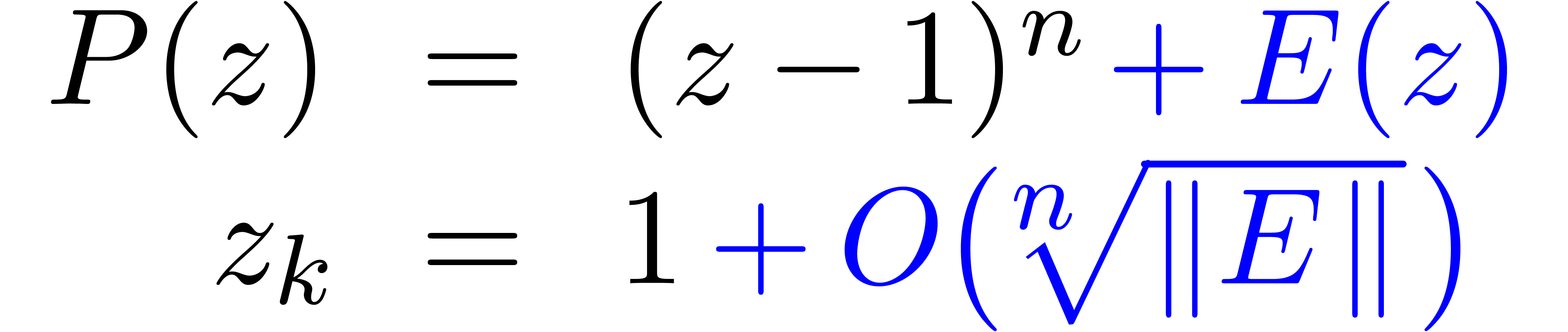
Pour différentes multiplicités :
On pourrait penser que le mauvais conditionnement est lié
à la présence d'une racine de grande multiplicité
(modulo petites perturbations du moins). L'exemple qui suit montre qu'il
n'en est rien : des polynômes dont toutes les racines sont
similaires en norme et dans le même demi plan sont à peu
près aussi mal conditionnés qu'un polynôme de la
forme 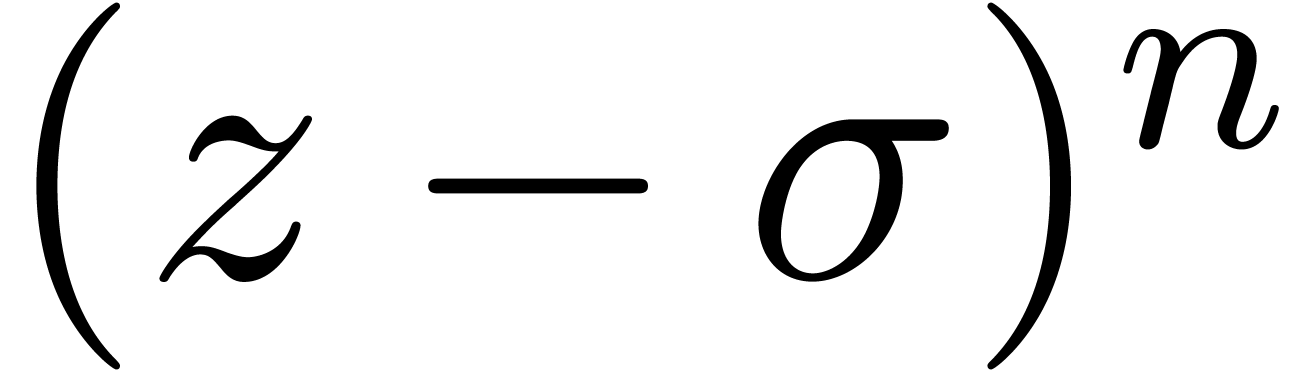 .
.
Mmx] |
v == [ rnd () | i in 1 to 100 ]; |
Mmx] |
p == annulator v; |
Mmx] |
$points (roots p) |

Mmx] |
v == [ sqrt rnd () | i in 1 to 100 ]; |
Mmx] |
p == annulator v; |
Mmx] |
$points (roots p) |
Mmx] |
z == series (0.0, 1.0); |
Mmx] |
B == exp (exp z - 1); |
Mmx] |
p == B[0,100]; |
Mmx] |
$points (0.5 * roots p) |
Mmx] |
z == series (0.0, 1.0); |
Mmx] |
f == integrate exp (-z*z); |
Mmx] |
p == f[0,200]; |
Mmx] |
$points (0.2 * roots p) |
Un algorithme numérique classique et efficace pour trouver les racines d'un polynôme

est la méthode d'Aberth. On part d'un ansatz 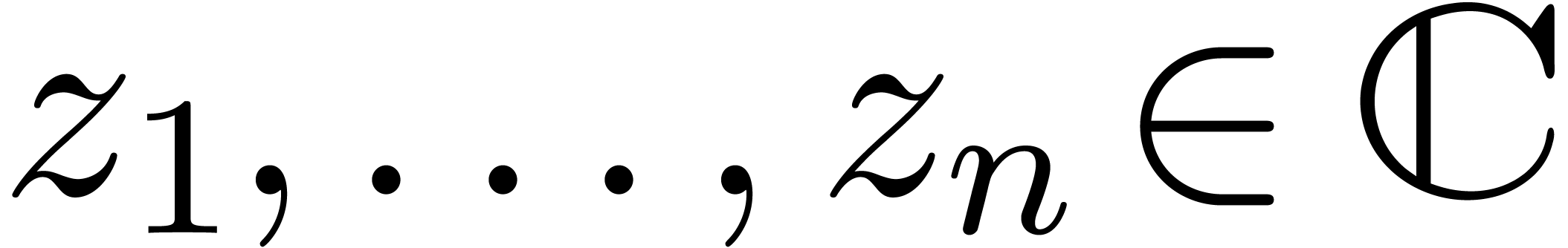 pour les racines, comme
pour les racines, comme
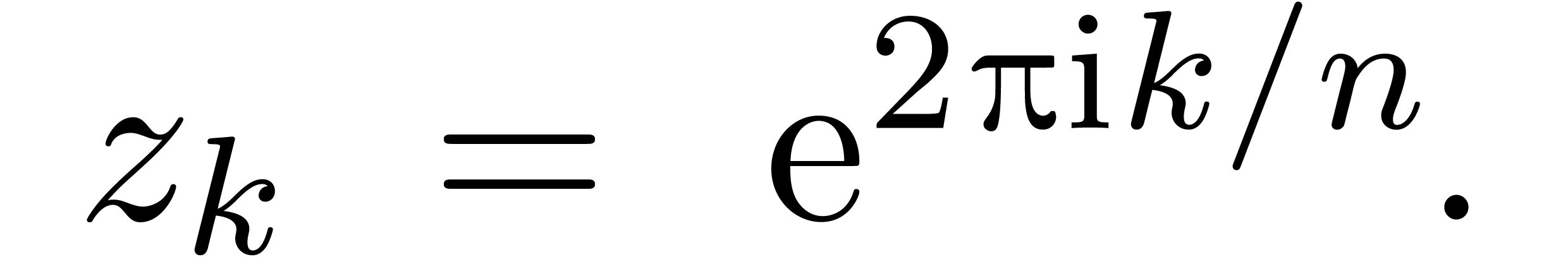
L'idée est ensuite d'appliquer pour chaque
la méthode de Newton à la fonction
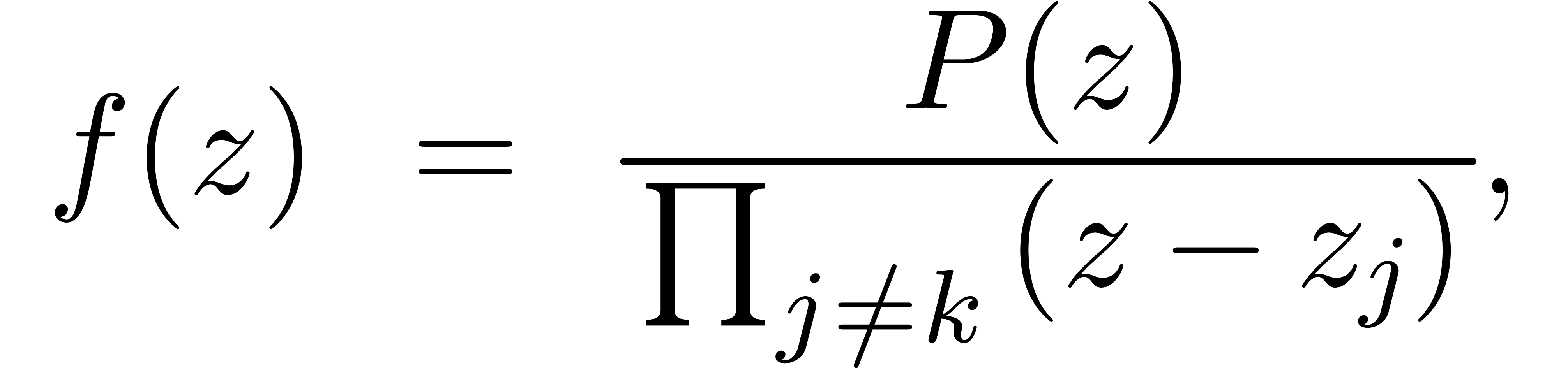
ce qui conduit à l'itération
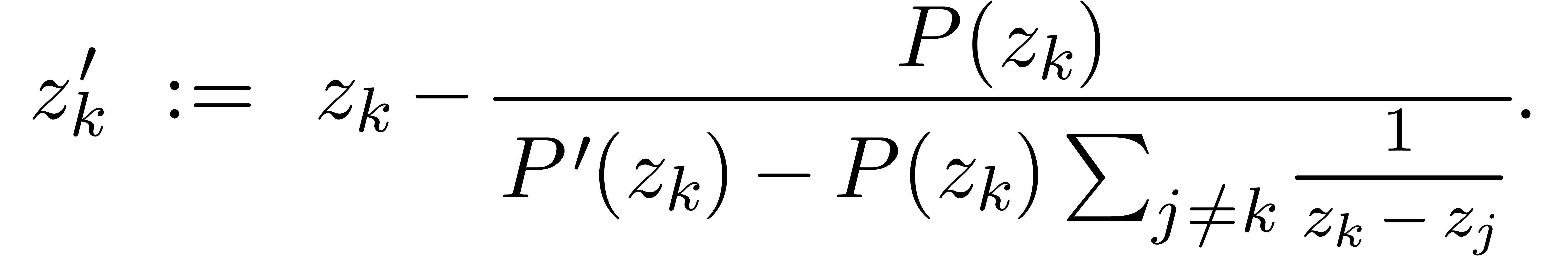
Une propriété intéressante de cet algorithme est le
fait que dès que l'on a trouvé des bonnes approximations
de 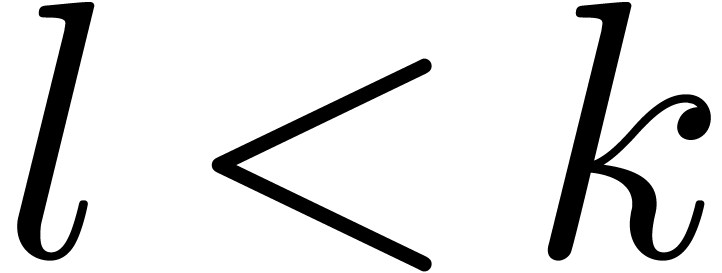 racines de ,
disons
racines de ,
disons  , alors les
itérations suivantes appliquent essentiellement la méthode
d'Aberth pour le polynôme
, alors les
itérations suivantes appliquent essentiellement la méthode
d'Aberth pour le polynôme
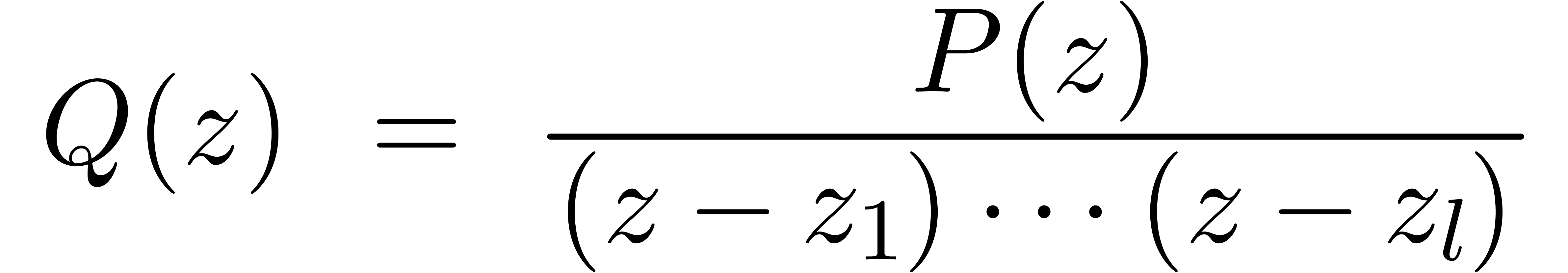
et les racines restantes  . La
méthode est particulièrement efficace quand on l'applique
de façon naïve en précision machine (avec une
complexité de calcul en )
; c'est une des raisons de l'efficacité du logiciel
. La
méthode est particulièrement efficace quand on l'applique
de façon naïve en précision machine (avec une
complexité de calcul en )
; c'est une des raisons de l'efficacité du logiciel
La méthode par homotopie est un autre exemple d'une méthode qui est efficace quand on l'applique de façon naïve en précision machine. L'itération est un peu différente que pour la méthode d'Aberth, mais son efficacité est du même ordre de grandeur. On y reviendra dans un contexte plus général dans le chapitre 7. Voir aussi [71].
La plupart des algorithmes asymptotiquement efficaces font intervenir la
transformation de Graeffe  ,
dont voici la définition :
,
dont voici la définition :
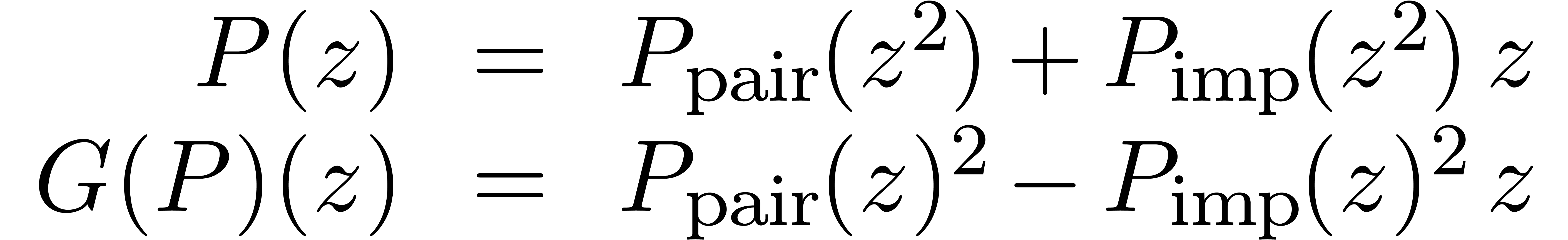
On vérifie que
Il s'en suit la propriété fondamentale que  et
et

En d'autres termes, la transformation est un séparateur puissant
de racines, au moins en norme : si  pour deux
racines
pour deux
racines 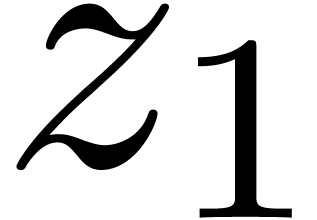 et
et 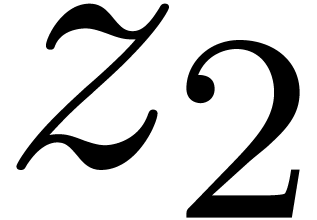 de , alors
de , alors 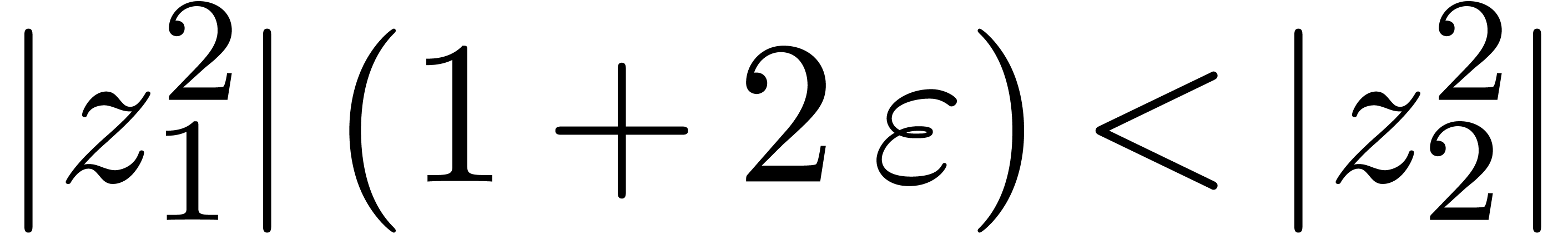 pour les racines
pour les racines 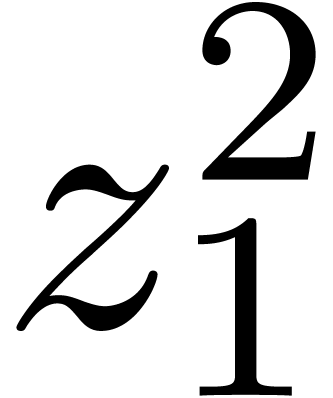 et
et  de
de
 . Or, lorsque les racines
. Or, lorsque les racines
 de sont très
différents en module, disons
de sont très
différents en module, disons  ,
alors on a
,
alors on a 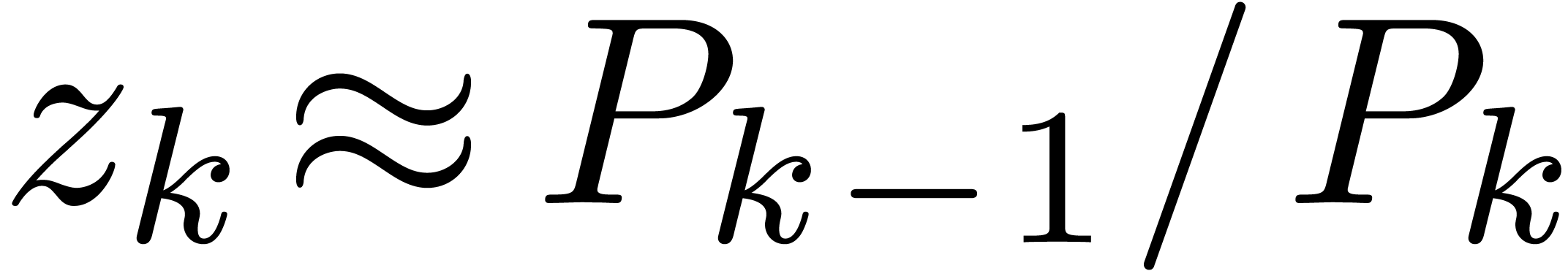 pour chaque
pour chaque 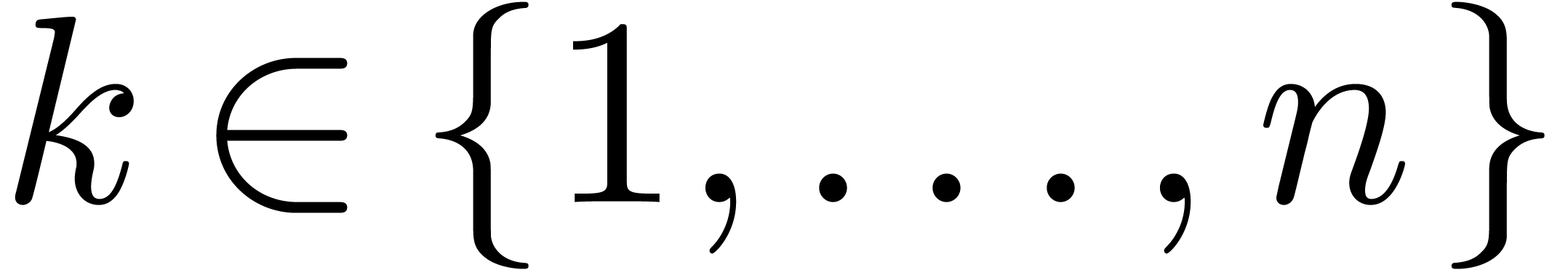 . Si les racines de sont toutes différentes en module, il suffit
donc de quelques transformations de Graeffe pour obtenir
. Si les racines de sont toutes différentes en module, il suffit
donc de quelques transformations de Graeffe pour obtenir  pour un certain .
pour un certain .
Reste le problème comment retrouver
à partir de . On peut
utiliser une astuce pour cela qui consiste à calculer avec des
« nombres tangents » dans 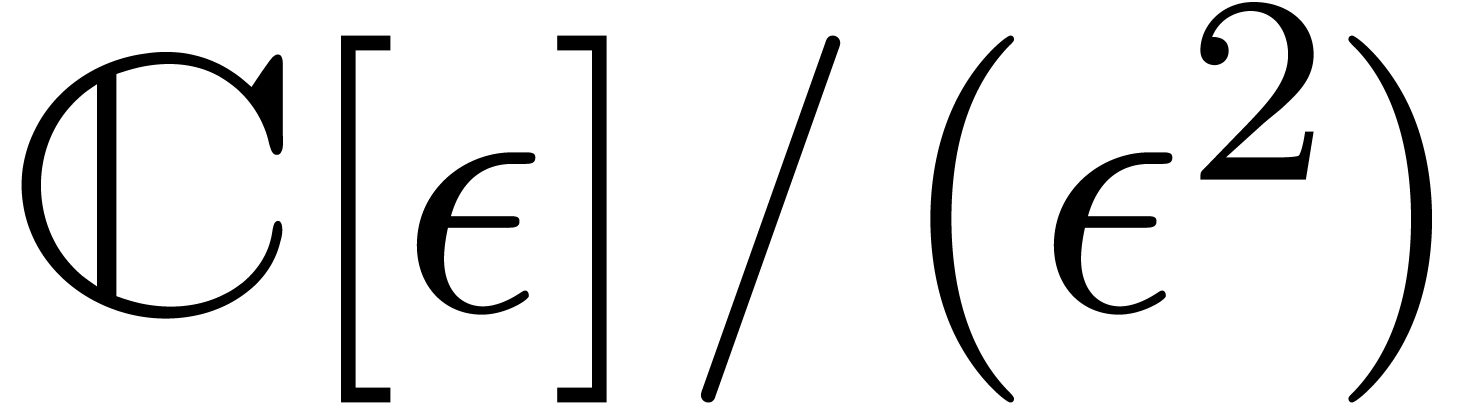 au lieu de
simples coefficients dans .
En effet, lorsque l'on fait le remplacement
au lieu de
simples coefficients dans .
En effet, lorsque l'on fait le remplacement
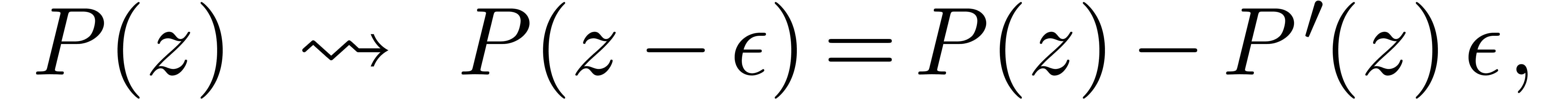
et que l'on calcule les puissances -ièmes
des racines de  en faisant quelques
transformations de Graeffe, on obtient pour chaque racine
en faisant quelques
transformations de Graeffe, on obtient pour chaque racine  :
:
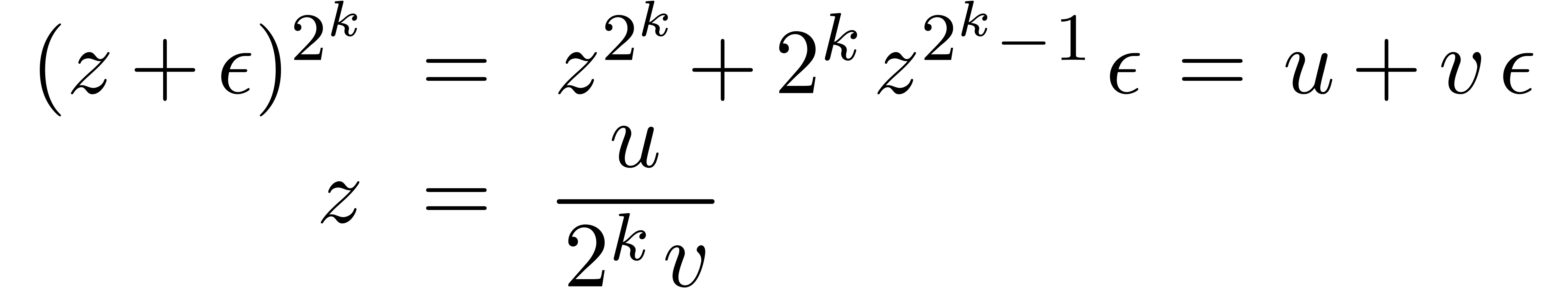
Nous venons de voir l'importance de l'étude des normes des
racines du polynôme au delà de leur
calcul à proprement parler. Le polygone numérique de
Newton nous fournit les valeurs approximatives de ces normes,
directement à partir des coefficients du polynôme.
Le polygone de Newton intervient aussi lorsque l'on veut
développer une arithmétique efficace et
numériquement stable pour les polynômes. Une telle
arithmétique reste typiquement précis pour le calcul de
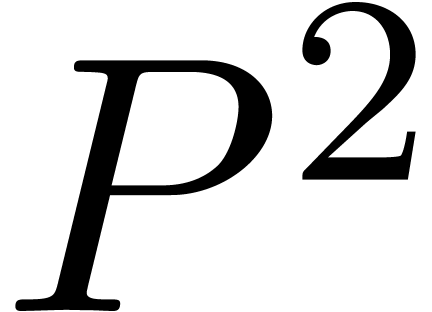 avec
avec  .
Un tel algorithme de multiplication est donné dans [85],
mais la borne (3) dans ce papier est fausse.
.
Un tel algorithme de multiplication est donné dans [85],
mais la borne (3) dans ce papier est fausse.
Le polygone numérique de Newton de  est
défini comme l'enveloppe convexe de l'ensemble
est
défini comme l'enveloppe convexe de l'ensemble

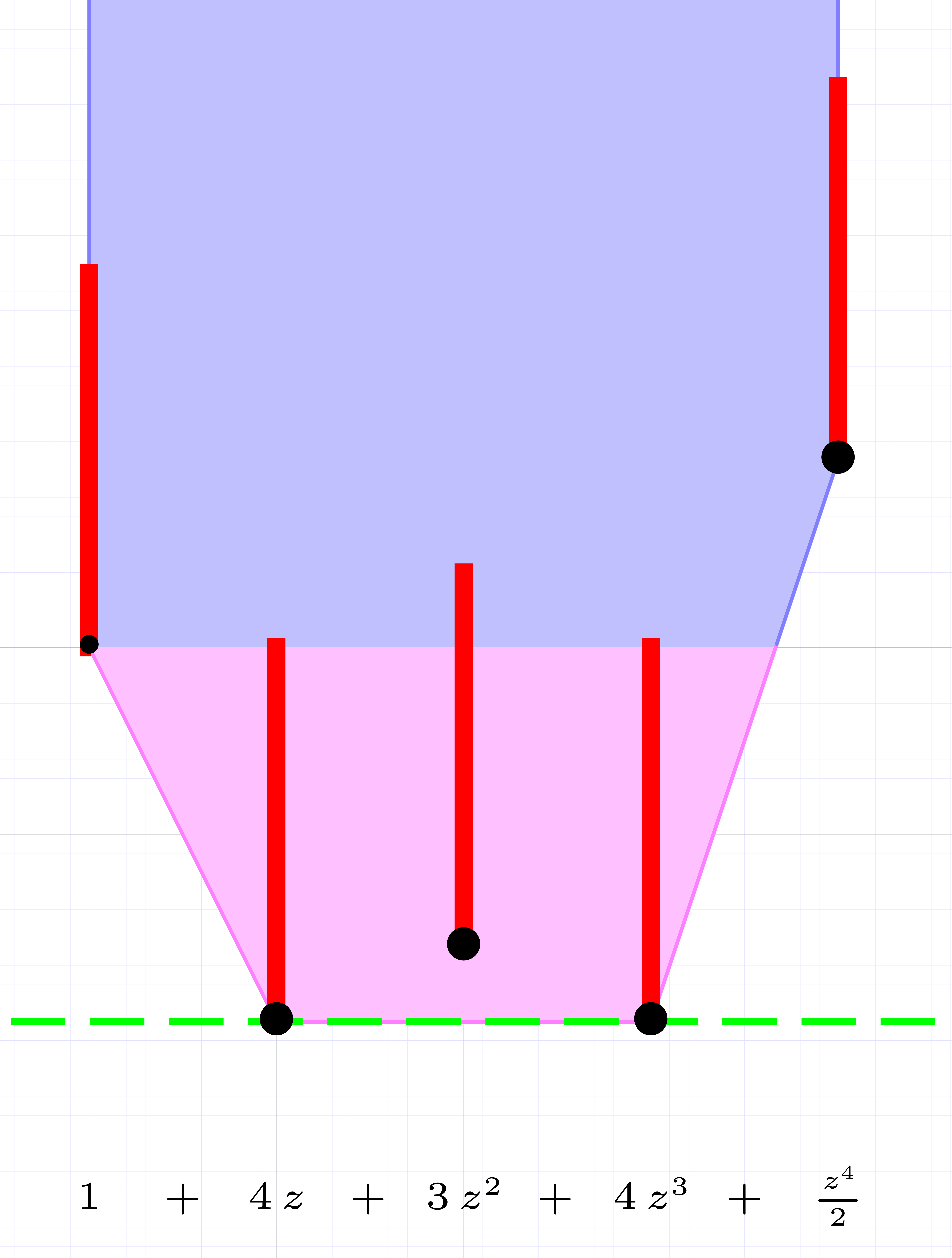  |
Moralité : Polygone de Newton  Comportement en évaluation
Comportement en évaluation
En particulier : Pentes du polygone de Newton
Modules des racines
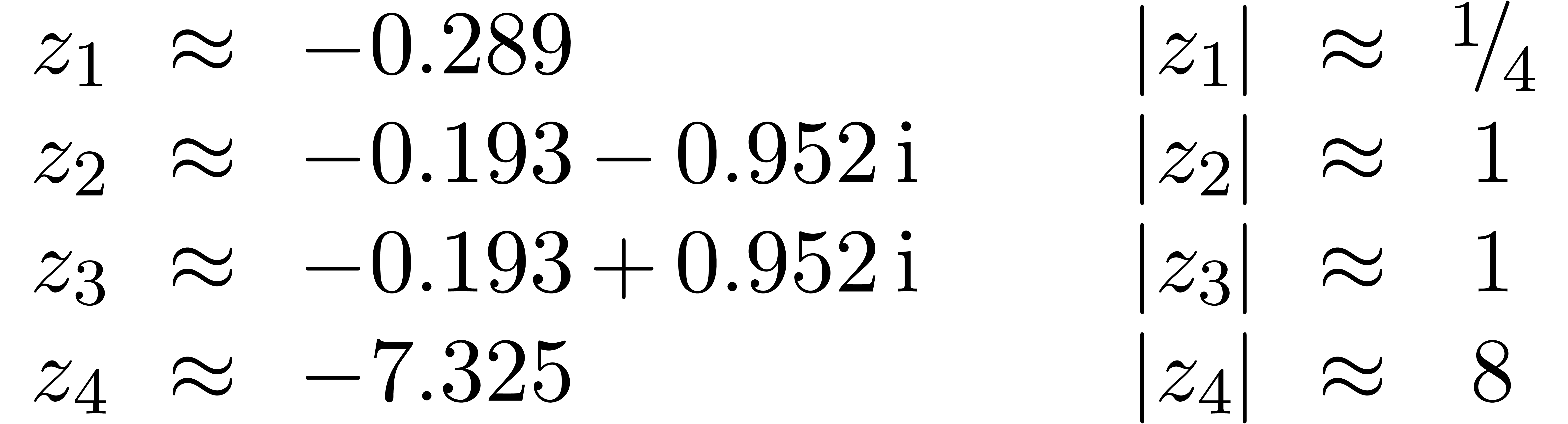
La question suivante semble ouverte et abordable :
Question. Supposons des pentes  et des racines :
et des racines :  .
.
Est-ce qu'il existe une constante 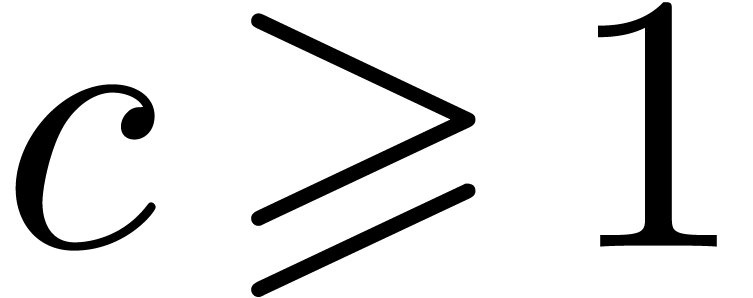 universelle
avec :
universelle
avec :
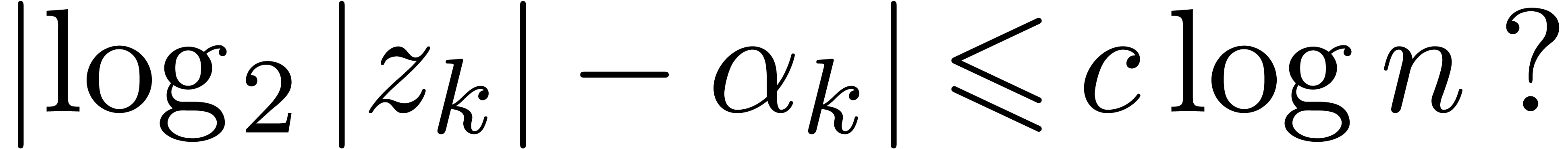
Problème. Meilleure approximation possible des
racines de pour précision 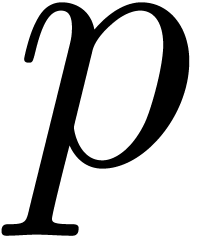 donnée.
donnée.
Note. Sans perdre en généralité, on peut
perturber les coefficients de par des nombres
d'erreur relative 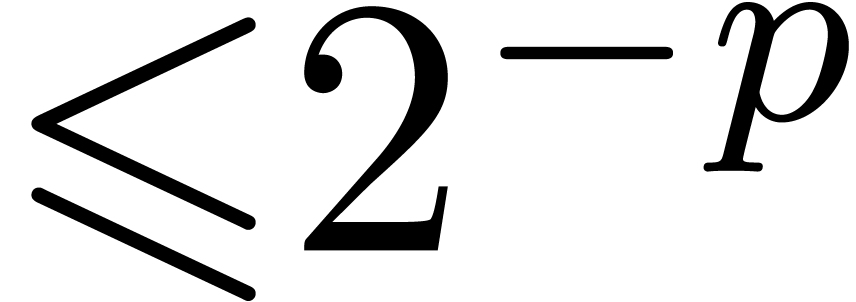 . Ceci peut
par exemple être utile si on veut éviter que toutes les
racines soient de même module.
. Ceci peut
par exemple être utile si on veut éviter que toutes les
racines soient de même module.
Arithmétique naïve en précision machine
Algorithme en temps 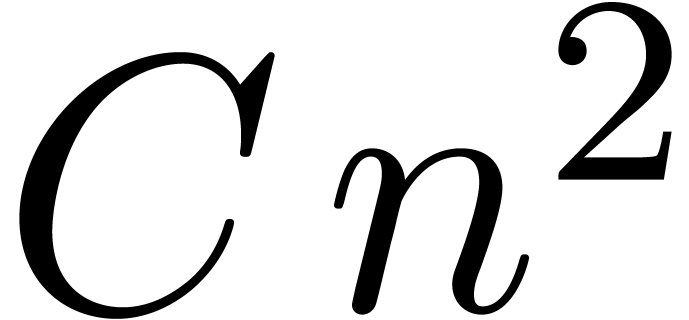 avec petit ?
avec petit ?
Arithmétique rapide en précision multiple
Nécessite une précision d'au moins 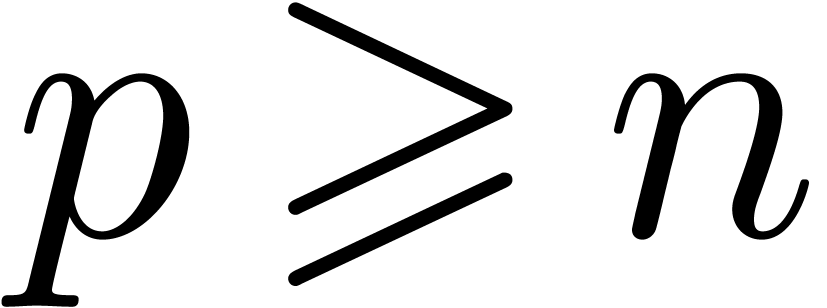
Algorithme en temps 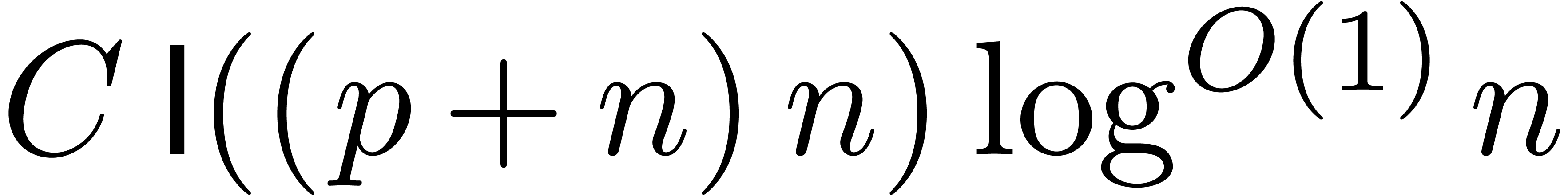 ,
avec pas trop grand ?
,
avec pas trop grand ?
Compromis lorsque 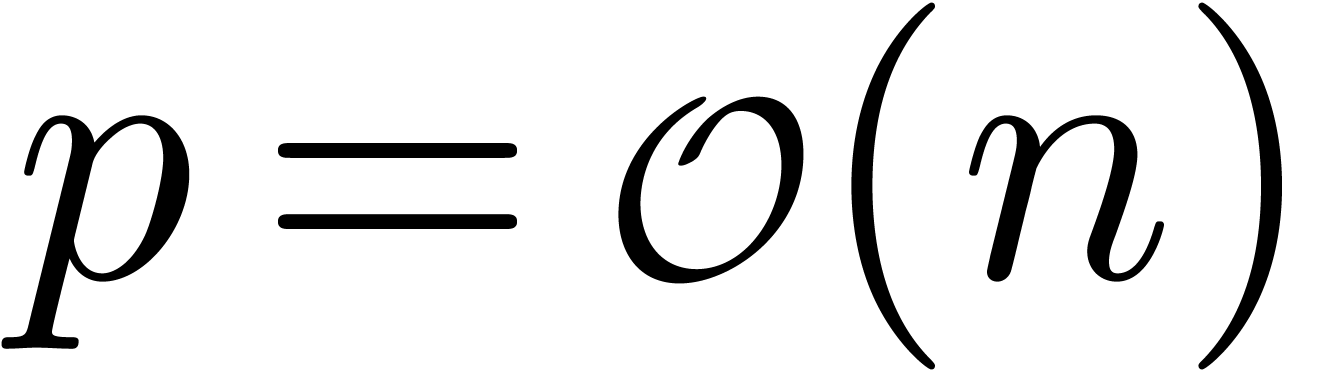 ?
?
Pour un certain facteur 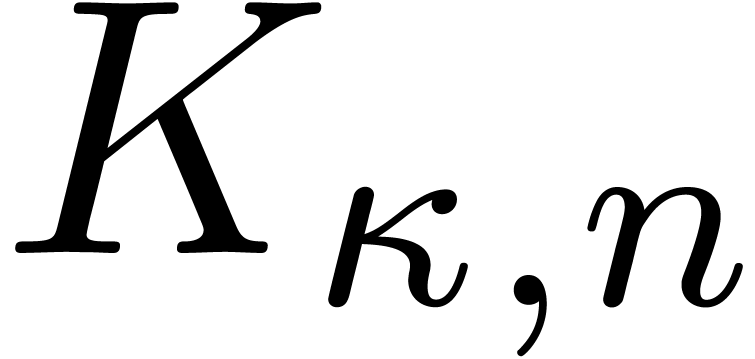 dépendant
du conditionnement
dépendant
du conditionnement  et de
:
et de
:
Arithmétique naïve en précision machine
Algorithme en temps 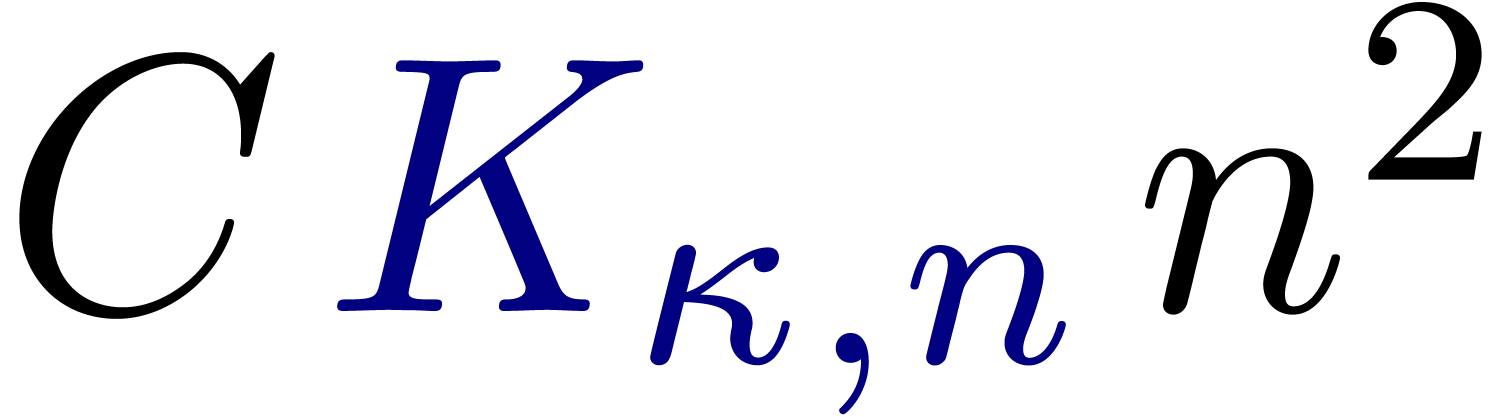 avec petit ?
avec petit ?
Arithmétique rapide en précision multiple
Algorithme en temps 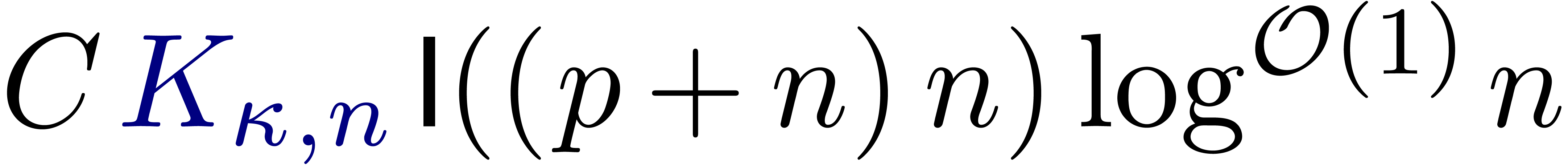 ,
avec pas trop grand ?
,
avec pas trop grand ?
Compromis lorsque ?
Exemple d'un théorème précis :
Théorème 6.1. 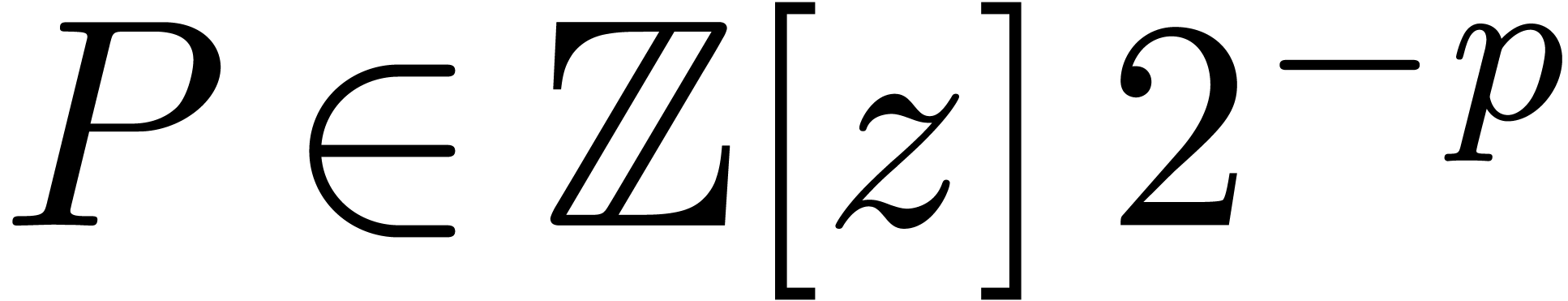 avec
avec
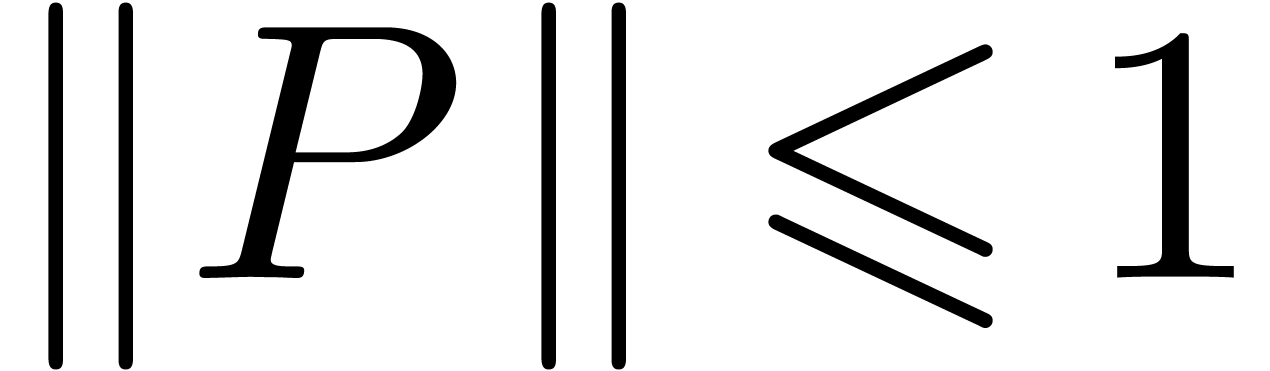 , on peut calculer en temps
, on peut calculer en temps
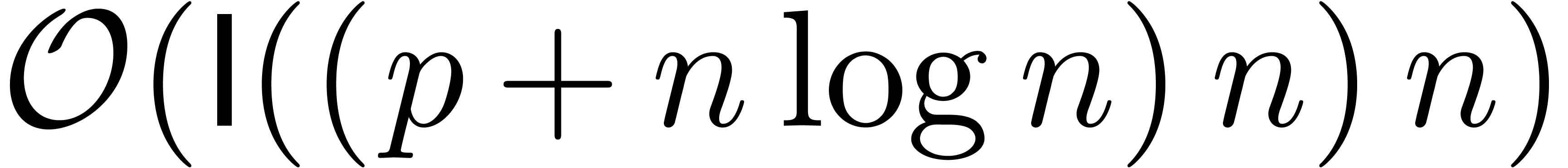 des nombres
des nombres  avec
avec
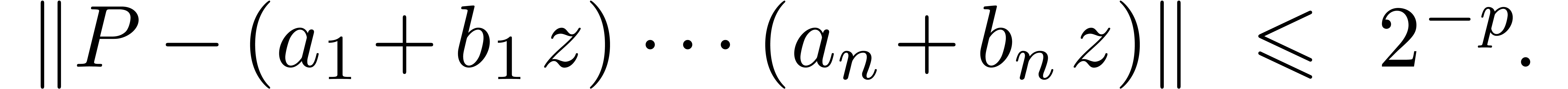
Remarque. Gourdon a implanté la méthode de Schönhage [35]. D'autres résultats de complexité ont été donné par Pan [59, 60].
C'est le problème inverse de la recherche des racines. En effet,
ce problème est important lorsque l'on veut raffiner une
approximation pour une précision en une
meilleure approximation pour la précision 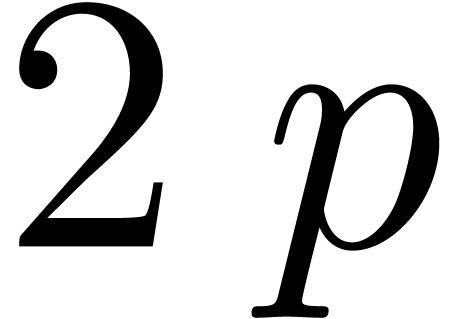 (par exemple, en utilisant la méthode de Newton).
(par exemple, en utilisant la méthode de Newton).
Coût 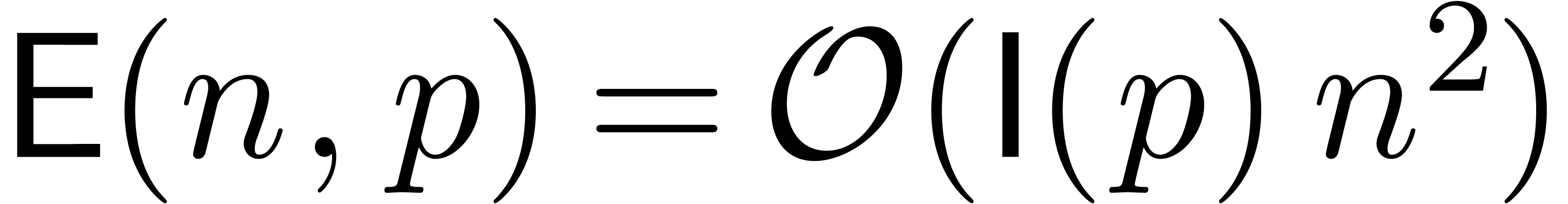 , en
appliquant fois Horner.
, en
appliquant fois Horner.
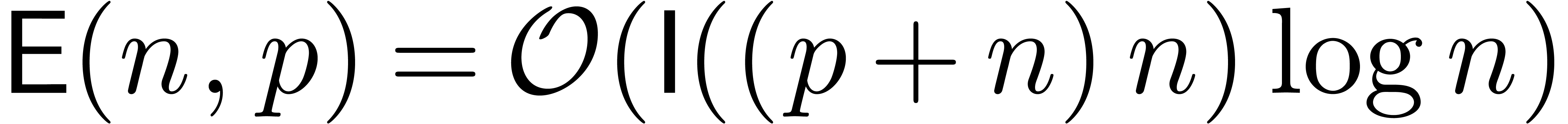
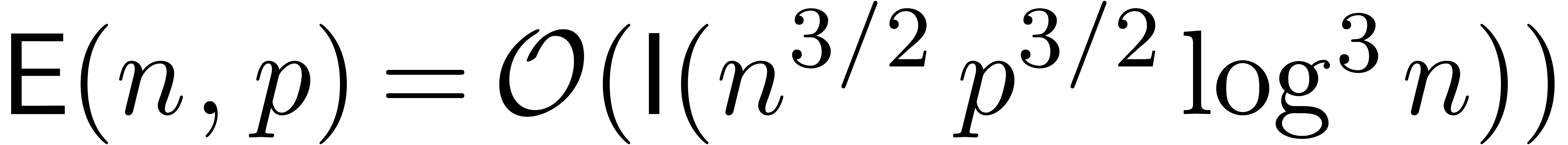 , en faisant des FFT
massives sur différents cercles de centre
[84]. Cet algorithme est meilleur que les
précédents lorsque
, en faisant des FFT
massives sur différents cercles de centre
[84]. Cet algorithme est meilleur que les
précédents lorsque 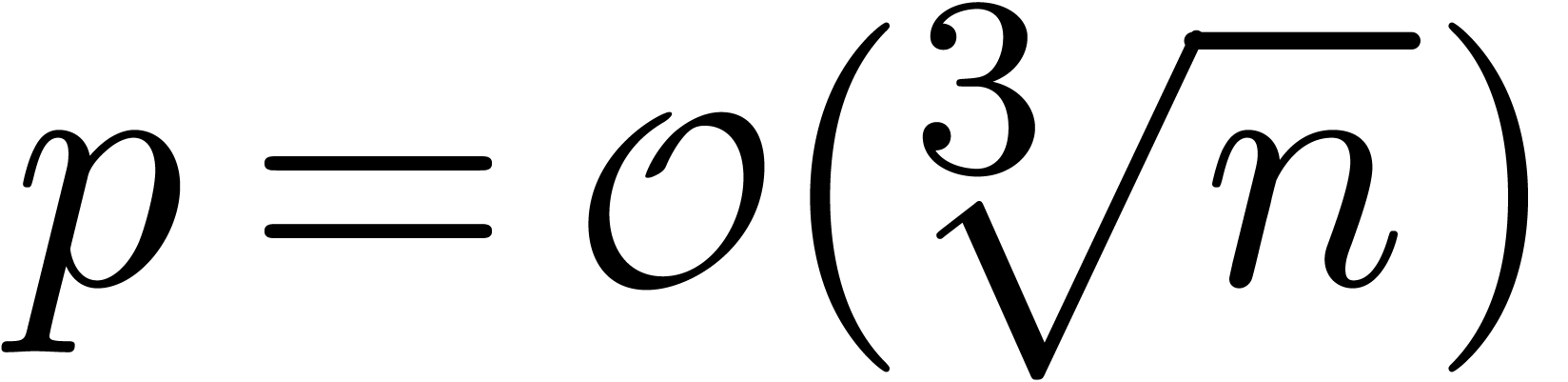 .
.
Question. Peut-on faire mieux lorsque 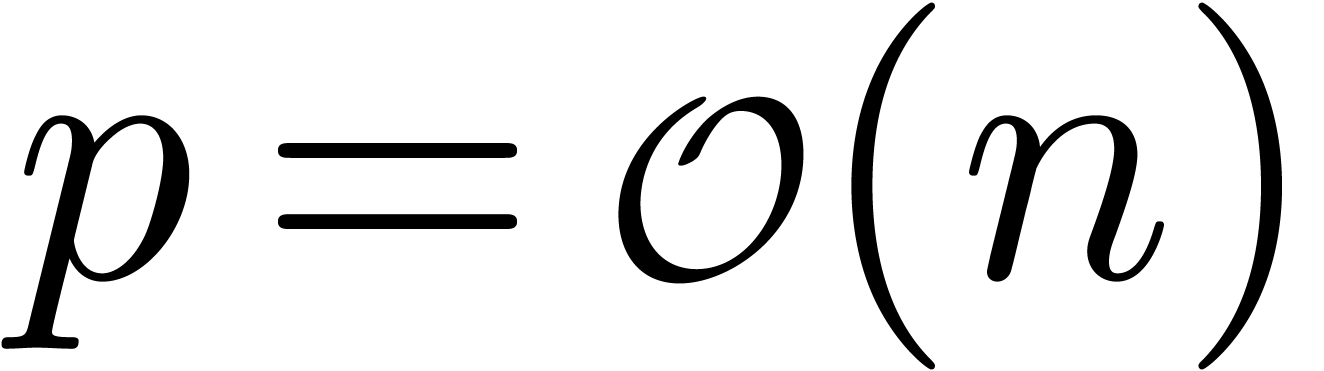 ?
?
Les algorithmes de Schönhage et de Pan, qui admettent les meilleures complexités actuelles, certifient déjà les résultats. Toutefois, en suivant la même philosophie que dans les autres chapitres, il peut être utile de découpler les étapes de calcul et la certification des résultats.
Certification par la méthode de Krawczyk [43], présentée pour le cas de fonctions en plusieurs variables :
Théorème 6.2. Si 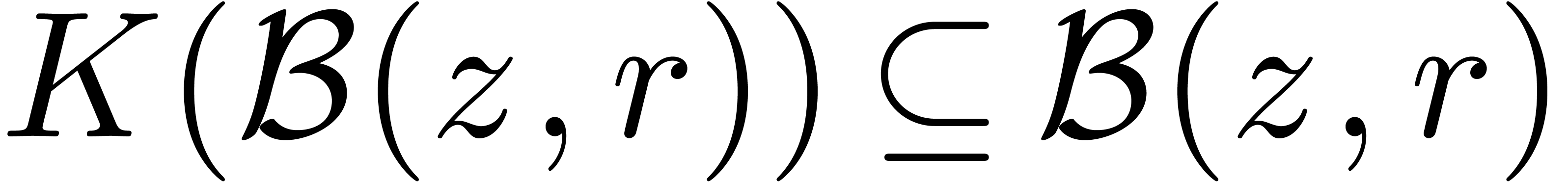 , alors
, alors  pour un certain
pour un certain
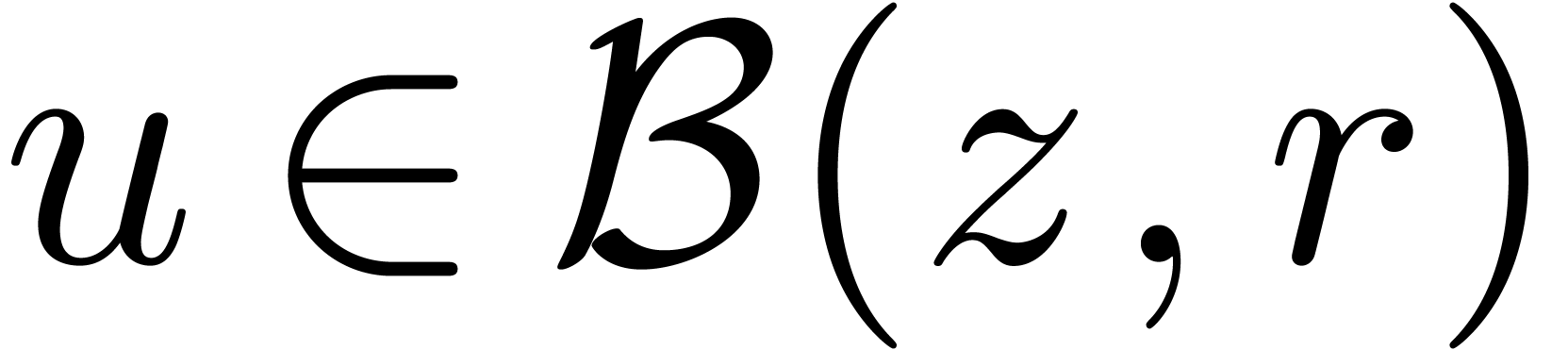 .
.
Démonstration. Soit 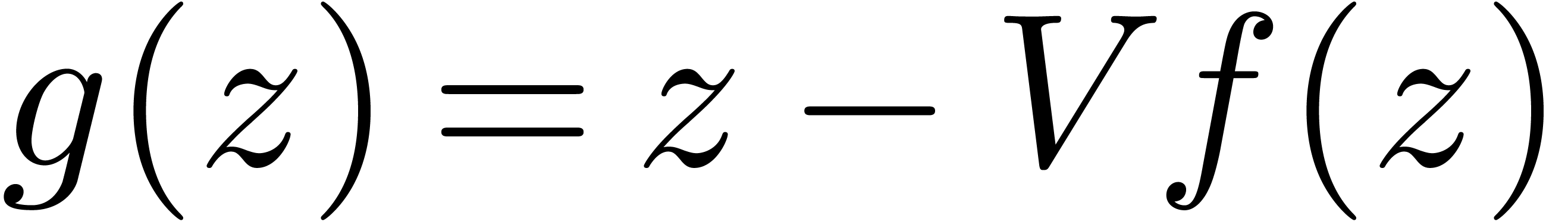 .
Pour , on a
.
Pour , on a
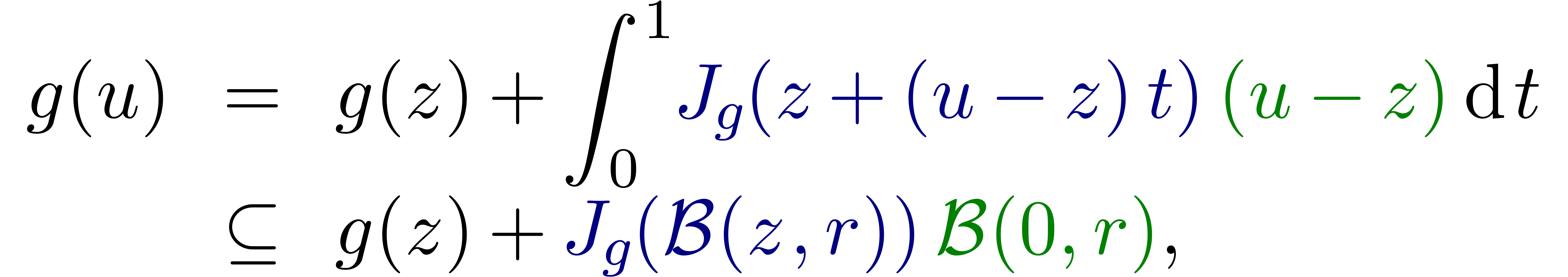
puisque 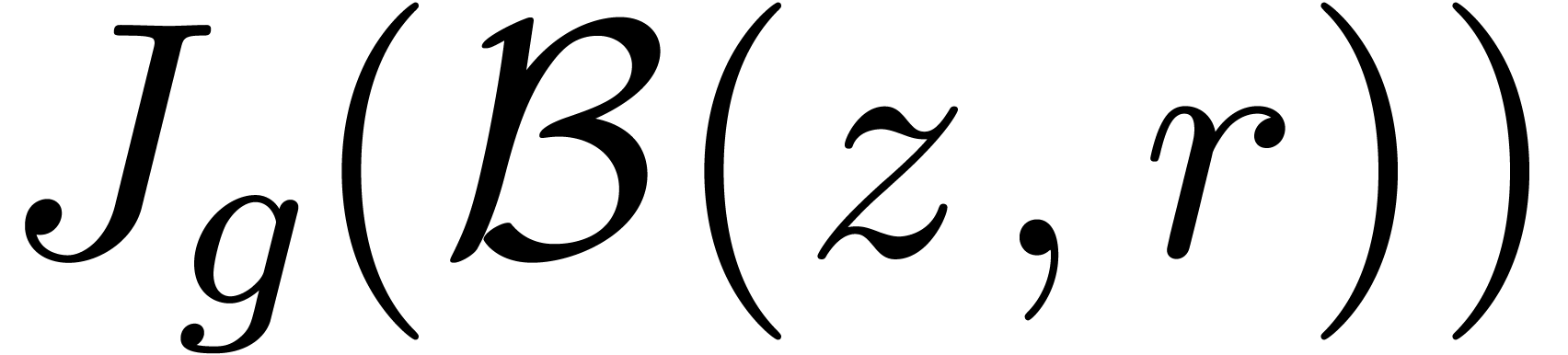 est convexe. Donc
est convexe. Donc
et  admet un point fixe, grace à la
compacité de
admet un point fixe, grace à la
compacité de 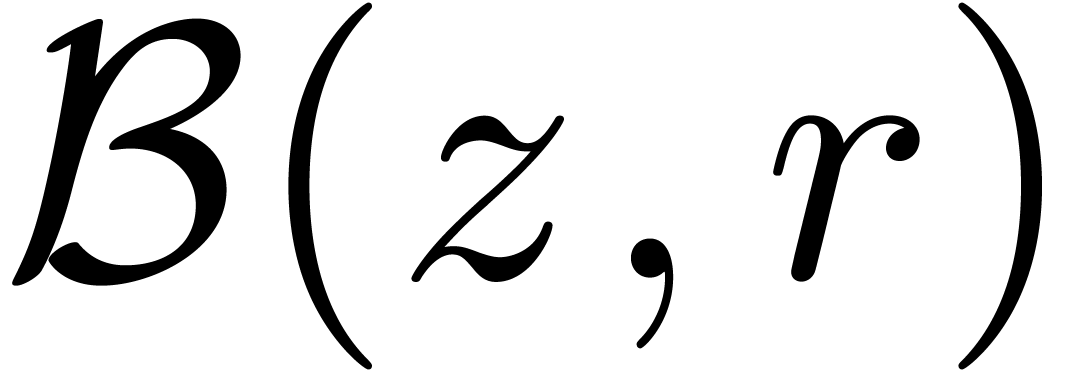 .
.
Ce théorème ne garantit pas l'unicité de la racine. Rump [61, 63] a donné une version plus fine du théorème qui garantit aussi l'unicité :
Théorème 6.3. Si 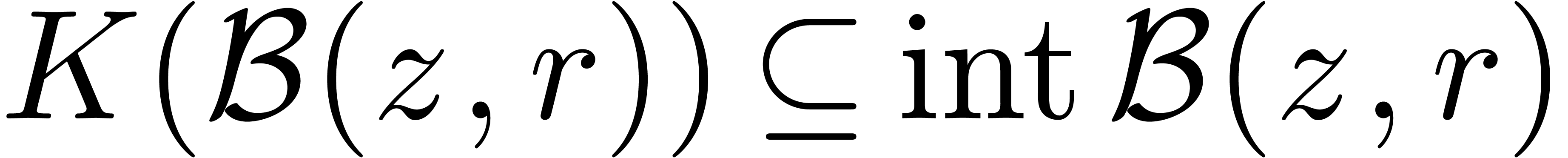 , alors pour un unique
.
, alors pour un unique
.
Pour trouver , faire
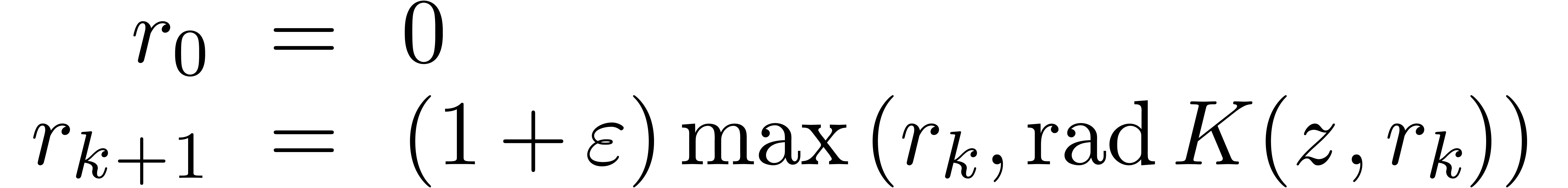
Méthode de -inflation
de Rump [61, 63].
Problème. Soit un
polynôme avec un comportement
pour 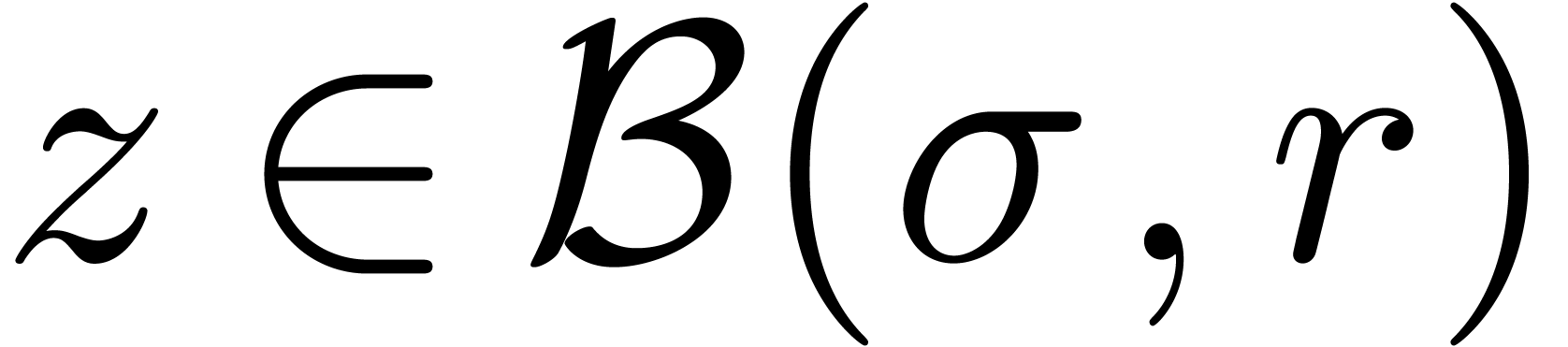 . Comment montrer que
admet exactement racines
sur
. Comment montrer que
admet exactement racines
sur 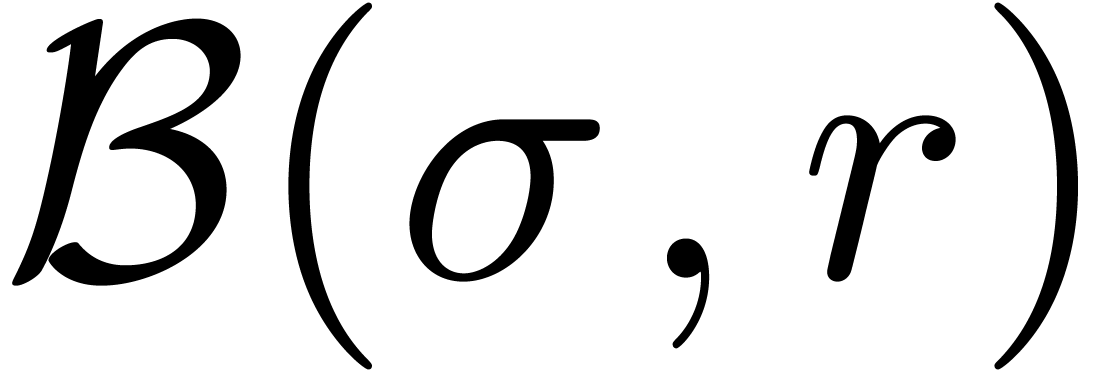 ?
?
Prendre  pour
pour 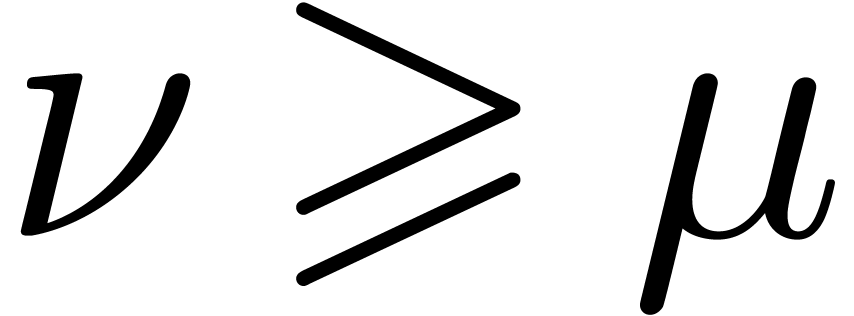 et
évaluer
et
évaluer
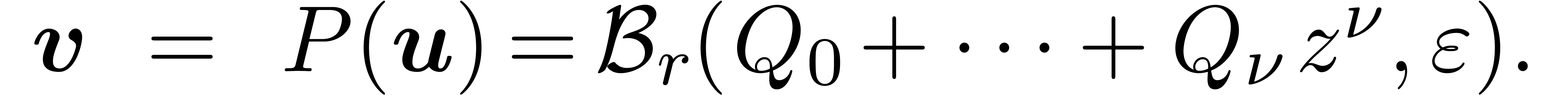
Montrer que tout  admet
racines dans .
admet
racines dans .
Par exemple, il suffit de vérifier que
et d'appliquer le théorème de Rouché. Voir [87] pour des variantes de cette méthode.
Approche par déflation
Une autre approche consiste à examiner de combien il faut
déformer le polynôme 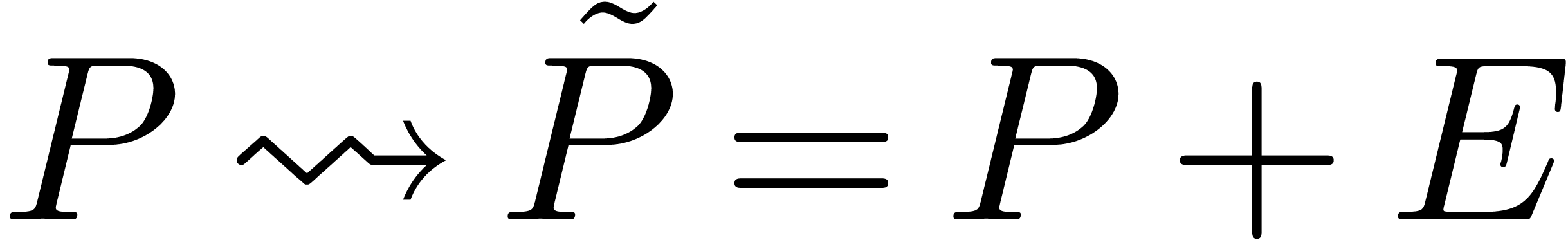 pour qu'il
admette exactement une racine de multiplicité . Cette approche « par
déflation » [63] permet de se ramener à
la théorie de la section 6.6.1 en cherchant à
résoudre simultanément les équations
pour qu'il
admette exactement une racine de multiplicité . Cette approche « par
déflation » [63] permet de se ramener à
la théorie de la section 6.6.1 en cherchant à
résoudre simultanément les équations 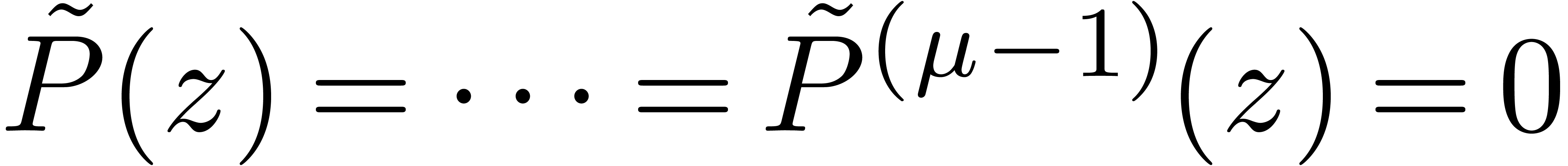 . Toutefois, l'astuce introduit un facteur
. Toutefois, l'astuce introduit un facteur  dans la complexité en temps.
dans la complexité en temps.
Remarque 6.4. Voir aussi la section 7.3 pour un point de vue différent sur la question.
Dans la section 1.3.1, nous avons esquissé comment
résoudre des systèmes polynomiaux par homotopie. Cette
technique ancienne remonte à la démonstration par Gauss
que est algébriquement clos. En relation
avec des implantations concrètes, les méthodes par
homotopie apparaissent dans plusieurs contextes différents mais
liés :
Les homotopies numériques non certifiés ont
été étudié par de nombreux auteurs.
Voir par exemple [23, 55, 90,
73] et les références dans ces
documents. Quelques logiciels connus pour des homotopies
numériques sont
La complexité théorique des méthodes par homotopie a été analysé dans [71, 72, 69, 70, 21, 5]. Ces travaux donnent une justification théorique pourquoi les méthodes par homotopie marchent aussi vite, tout en faisant des hypothèses assez fortes sur le modèle de calcul.
Au lieu de calculer avec des nombres flottants, on peut aussi définir les trajectoires de manière algébrique. Ce point de vue a donné lieu à la méthode de Kronecker [34, 33, 24], qui admet également une implantation concrète [46]. Par construction, cette méthode est algébrique donc certifiée, bien qu'elle ne tire pas profit de l'efficacité du calcul numérique pur. Par ailleurs, ce point de vue évite les chemins partant vers l'infini ; voir la section 7.1.2 plus bas.
Il est naturel de chercher à certifier les méthodes
numériques par homotopie, mais curieusement, peu d'efforts
ont été déployés dans ce sens.
Quelques exceptions : [42, 47, 88].
Des implantations partielles sont présentes dans
Les méthodes par homotopie ne viennent pas sans leur lot de
problèmes. D'une part, si le système est
surdéterminé, le problème est mal posé d'un
point de vue numérique. Dans ce cas, le problème est
intrinsèquement irrésoluble par des voies exclusivement
numériques, du moins si on souhaite certifier les solutions. Or,
même en excluant des systèmes surdéterminés,
et en considérant exclusivement des systèmes zéro
dimensionnels avec équations et inconnus, les méthodes par homotopie comportent
plusieurs inconvénients.
Premièrement, il est crucial que le système initial « facile à résoudre » ressemble autant que possible au système final qui nous intéresse réellement. En particulier, en prenant un système du même multi-degré, on espère que les deux systèmes admettent le même nombre de solutions. Malheureusement, tel n'est pas toujours le cas, comme on le voit sur l'exemple
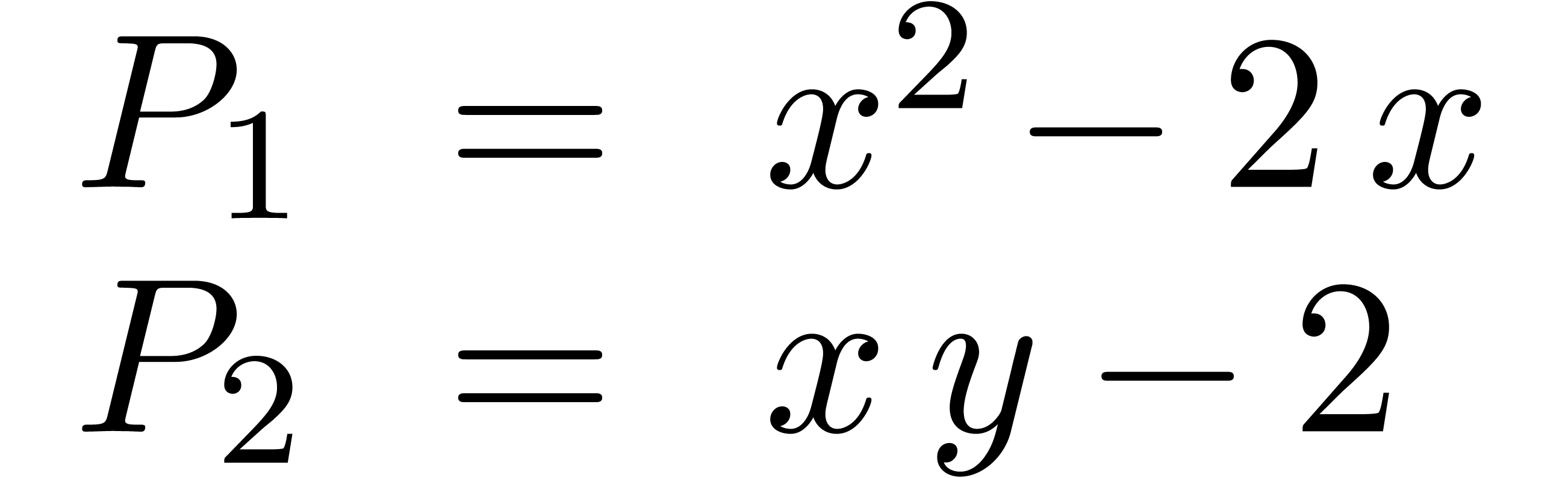
qui admet seulement une solution  au lieu de
au lieu de
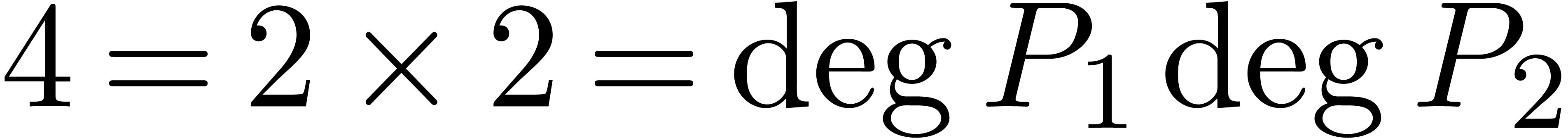 . Dans ce cas, trois des
quatre chemins de l'homotopie partent vers l'infini. On peut
remédier au problème des chemins qui partent vers l'infini
en homogénéisant le système et en coupant par un
hyperplan affine générique :
. Dans ce cas, trois des
quatre chemins de l'homotopie partent vers l'infini. On peut
remédier au problème des chemins qui partent vers l'infini
en homogénéisant le système et en coupant par un
hyperplan affine générique :
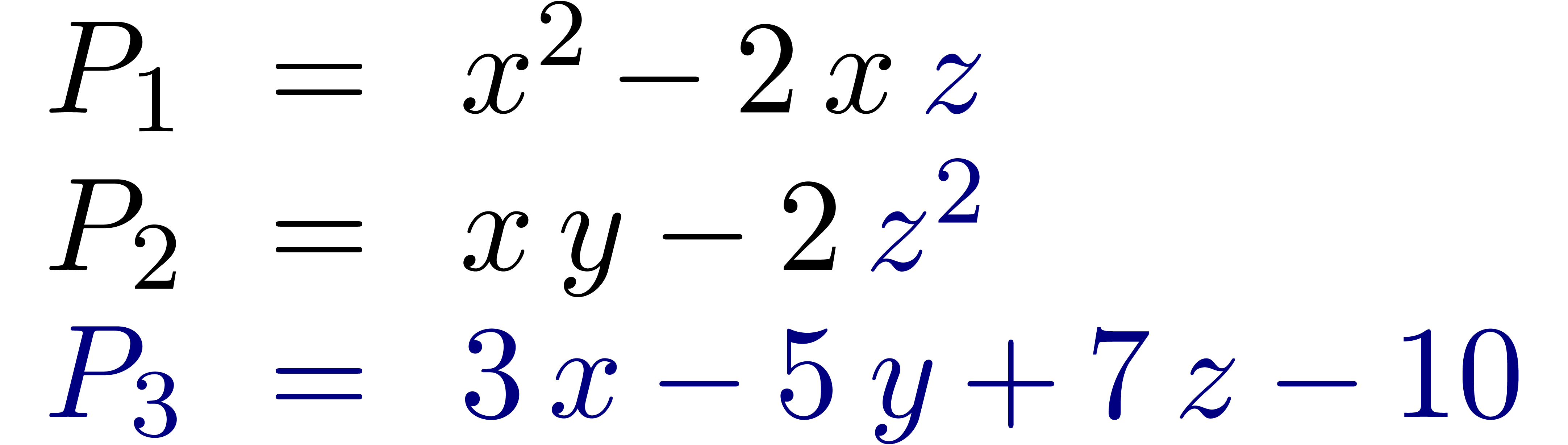
Pour ce nouveau système, il n'y a plus de chemins qui partent à l'infini, mais il existe toujours trois chemin qui tendent vers une racine multiple qui nous intéresse pas.
Dans ce cas précis, il aurait été possible d'éviter ces trois chemins parasites, en prenant des systèmes initiaux et finaux qui ne se ressemblent pas seulement en degré mais aussi quant à leurs polytopes de Newton. Pour plus de détails, voir par exemple [90] et des travaux plus récents du même auteur. En général, il est difficile de trouver un système initial à résoudre qui ressemble suffisamment au système final pour que chaque solution du système initial se déforme en une unique solution du système final.
Une deuxième difficulté concerne les systèmes
dégénérés avec des racines multiples.
Reprenons l'exemple 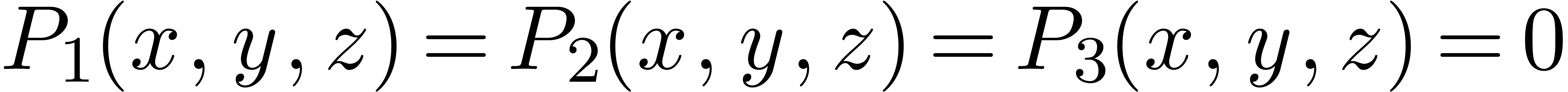 de la section
précédente dans
de la section
précédente dans
Mmx] |
use "continewz" |
Mmx] |
include "continewz/homotopy_solve.mmx" |
Mmx] |
type_mode? := false; |
Mmx] |
time_mode? := false; |
Mmx] |
significant_digits := 4; |
Mmx] |
x == coordinate ('x); |
Mmx] |
y == coordinate ('y); |
Mmx] |
z == coordinate ('z); |
Mmx] |
p == x*x - 2*x*z; |
Mmx] |
q == x*y - 2*z*z; |
Mmx] |
r == 3*x - 5*y + 7*z - 10; |
Mmx] |
homotopy_solve ([p,q,r], [x,y,z], 1.0) |
Pour une précision fixée, l'algorithme peine à
converger vers la solution triple 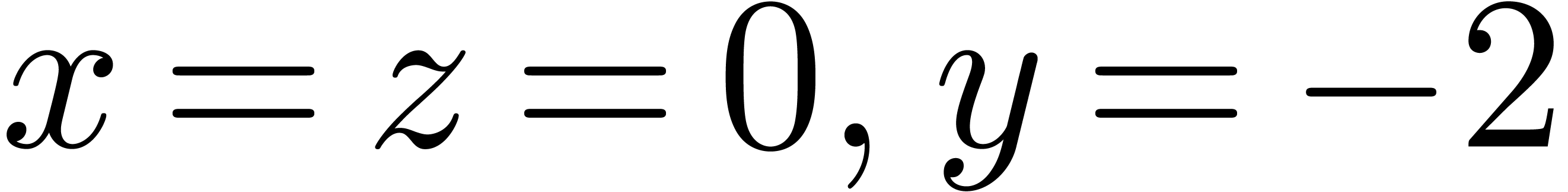 ,
et s'arrête bien avant d'avoir atteint une bonne qualité
d'approximation. Ceci tient au fait que les méthodes naïves
de suivi de chemin sont à convergence quadratique pour des
solutions simples, mais seulement à convergence linéaire
pour des solutions multiples. Une technique pour remédier
à ce problème sera discutée dans la section 7.3.
,
et s'arrête bien avant d'avoir atteint une bonne qualité
d'approximation. Ceci tient au fait que les méthodes naïves
de suivi de chemin sont à convergence quadratique pour des
solutions simples, mais seulement à convergence linéaire
pour des solutions multiples. Une technique pour remédier
à ce problème sera discutée dans la section 7.3.
Méthode « prédicteur-correcteur »
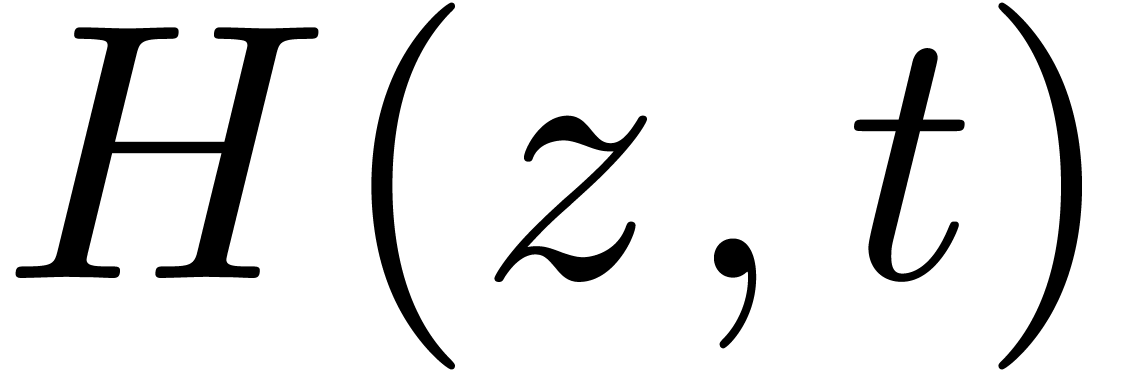 |
 |
 |
|
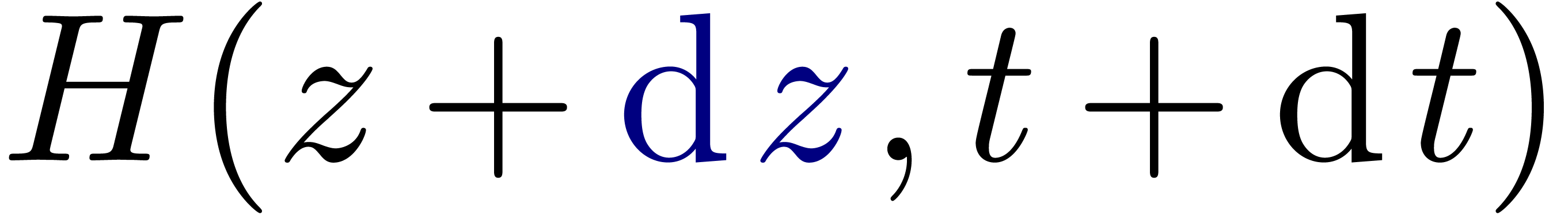 |
|
|
|
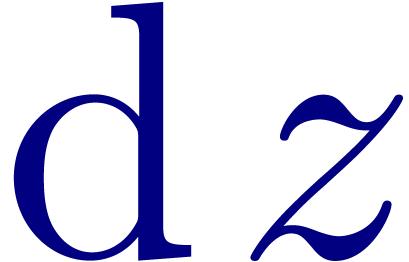 |
|
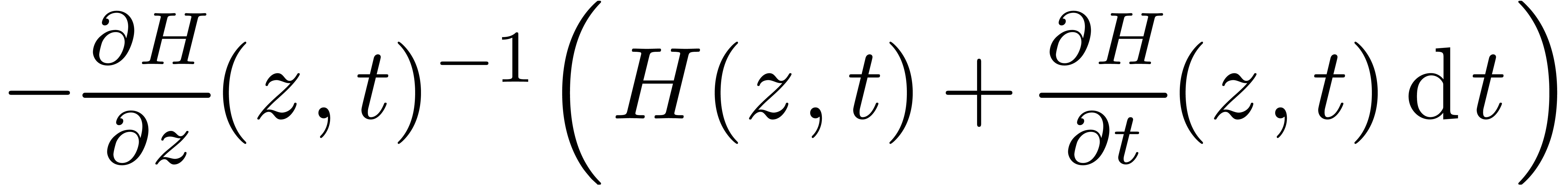 |
(prédiction) |
|
 |
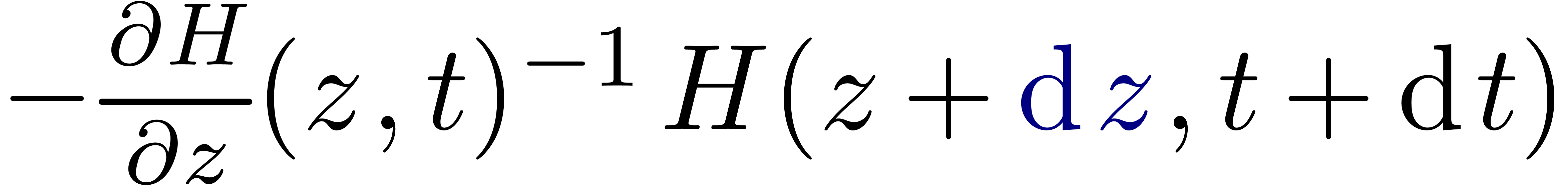 |
(correction) |
Contrôle de pas
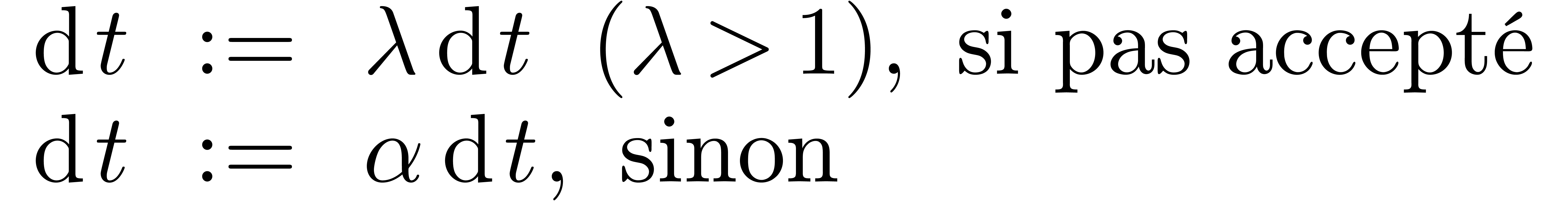
Critère numérique d'acceptation
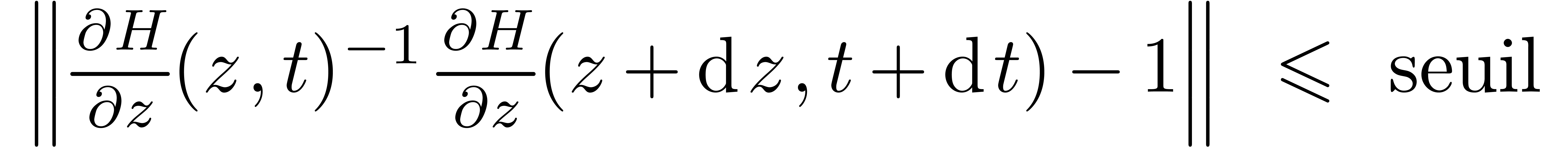
Contrôle de la précision
Surestimation  pour un certain seuil
pour un certain seuil  .
.
Toute méthode de certification d'une racine simple d'un
système polynomial donne lieu à une méthode de
certification pour des algorithmes de suivi de chemin en
remplaçant les scalaires par des petite boules qui bornent la
dépendance en de façon uniforme.
On peut par exemple utiliser la méthode de Krawczyk-Rump de la
section 6.6.1 ou [42].
Géométriquement parlant, ceci revient à certifier
que, pour des dans une certaine boule, le chemin
 à suivre reste dans une certaine
boîte comme dans la figure 7.1.
à suivre reste dans une certaine
boîte comme dans la figure 7.1.
Remarque 7.1. Afin de certifier les zéros d'un système, il n'est pas forcément nécessaire de certifier les algorithmes de suivi de chemin : si l'algorithme numérique de suivi de chemin produit un nombre suffisant de solutions distinctes, on peut directement utiliser la méthode de Krawczyk-Rump pour les certifier.
La méthode de la section précédente conduit
à des tailles de pas 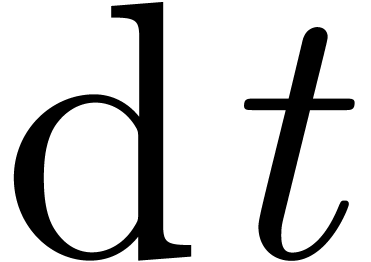 inutilement
pessimistes. En effet à cause de la forme
géométrique des encadrements, on ne souffre pas seulement
de la surestimation de l'erreur due à la variation de , mais aussi de la surestimation en
. Afin de réduire la
surestimation en , il vaut
mieux encadrer le chemin par un ensemble qui suit mieux la courbe. Dans
[88, section 6.3], je montre comment faire cela en
évaluant l'homotopies
inutilement
pessimistes. En effet à cause de la forme
géométrique des encadrements, on ne souffre pas seulement
de la surestimation de l'erreur due à la variation de , mais aussi de la surestimation en
. Afin de réduire la
surestimation en , il vaut
mieux encadrer le chemin par un ensemble qui suit mieux la courbe. Dans
[88, section 6.3], je montre comment faire cela en
évaluant l'homotopies  non pas en des
boules, mais en des modèles de Taylor d'un type particulier.
non pas en des
boules, mais en des modèles de Taylor d'un type particulier.
Considérons une homotopie générale
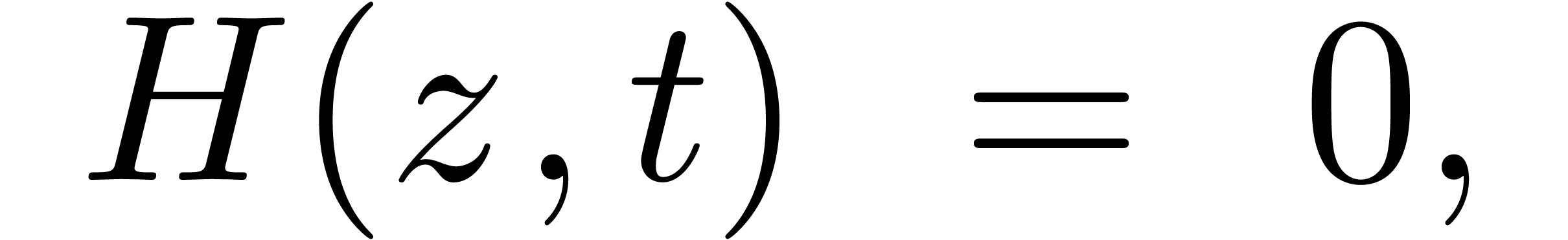
avec  et
et 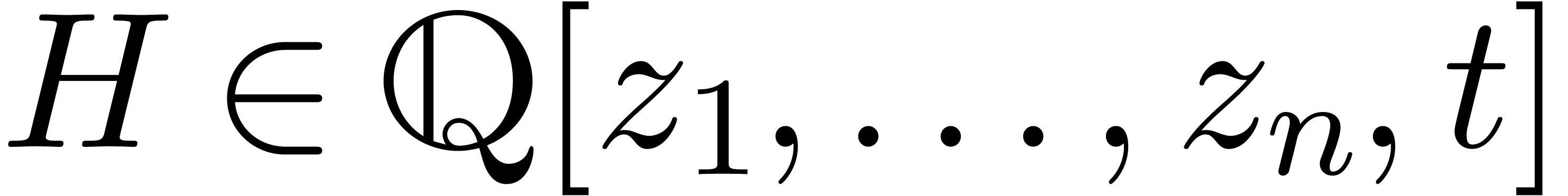 .
Pour
.
Pour 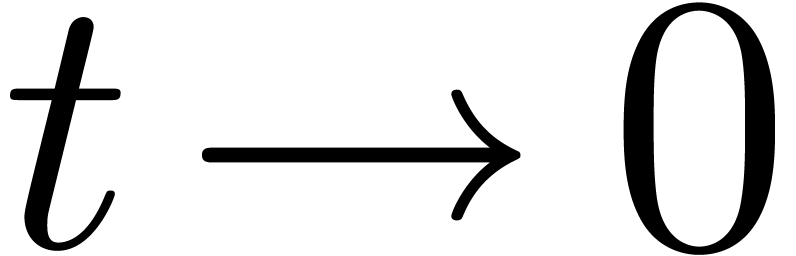 , toute solution est donnée par une série de Laurent
algébrique
, toute solution est donnée par une série de Laurent
algébrique
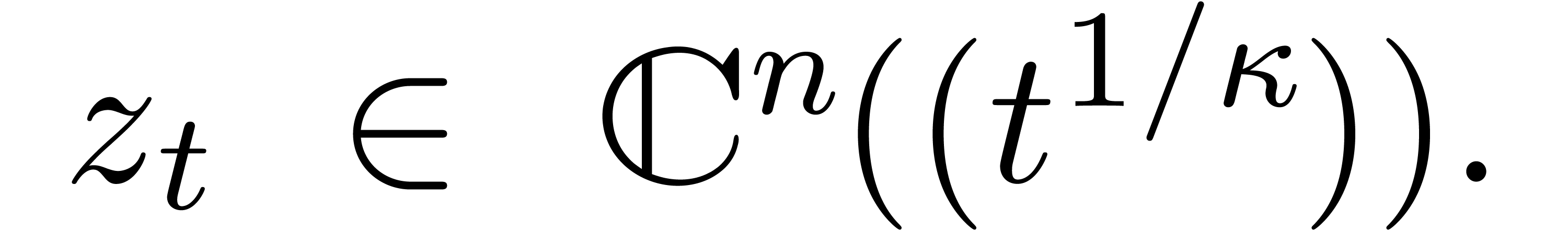
En particulier, en remplaçant par 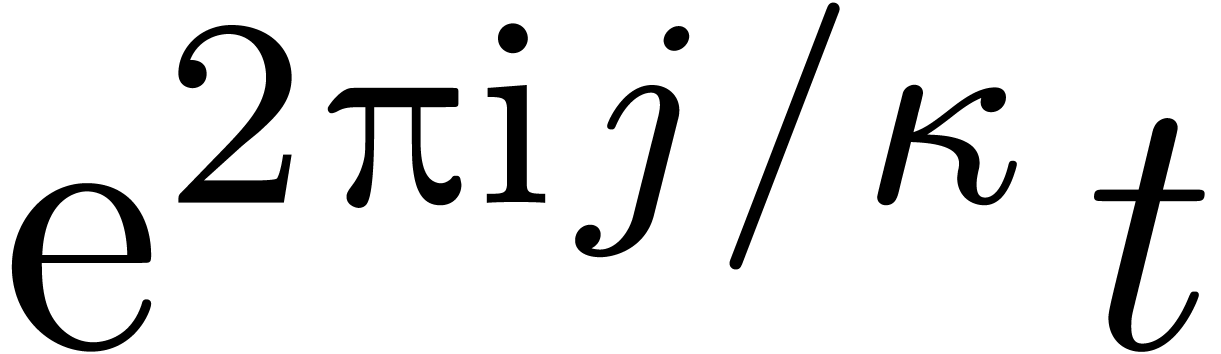 avec
avec  , on
obtient un « troupeau » de
solutions. Une méthode [88, section 7.2] pour
approcher des solutions multiples consiste à considerer tout le
troupeau comme un unique chemin dans un nouvel espace. Cette
méthode admet à la fois les avantages d'une
déflation [48, 51] et des
éclatements (des chemins distincts modulo
, on
obtient un « troupeau » de
solutions. Une méthode [88, section 7.2] pour
approcher des solutions multiples consiste à considerer tout le
troupeau comme un unique chemin dans un nouvel espace. Cette
méthode admet à la fois les avantages d'une
déflation [48, 51] et des
éclatements (des chemins distincts modulo 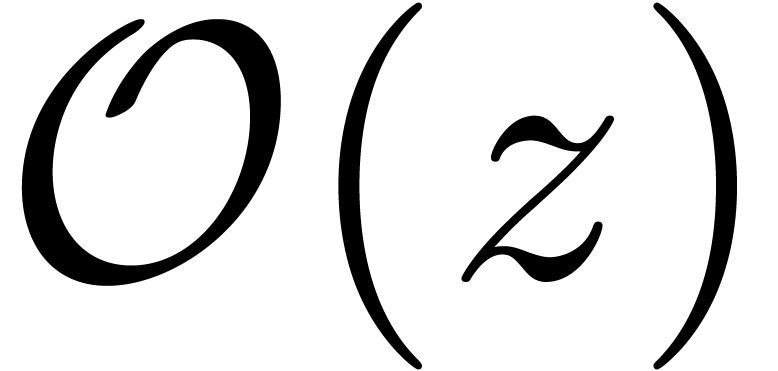 et de même multiplicité ont des
limites distinctes dans le nouvel espace). En utilisant la FFT, les
troupeaux se suivent également bien d'un point de vue
numérique [88, section 5.2].
et de même multiplicité ont des
limites distinctes dans le nouvel espace). En utilisant la FFT, les
troupeaux se suivent également bien d'un point de vue
numérique [88, section 5.2].
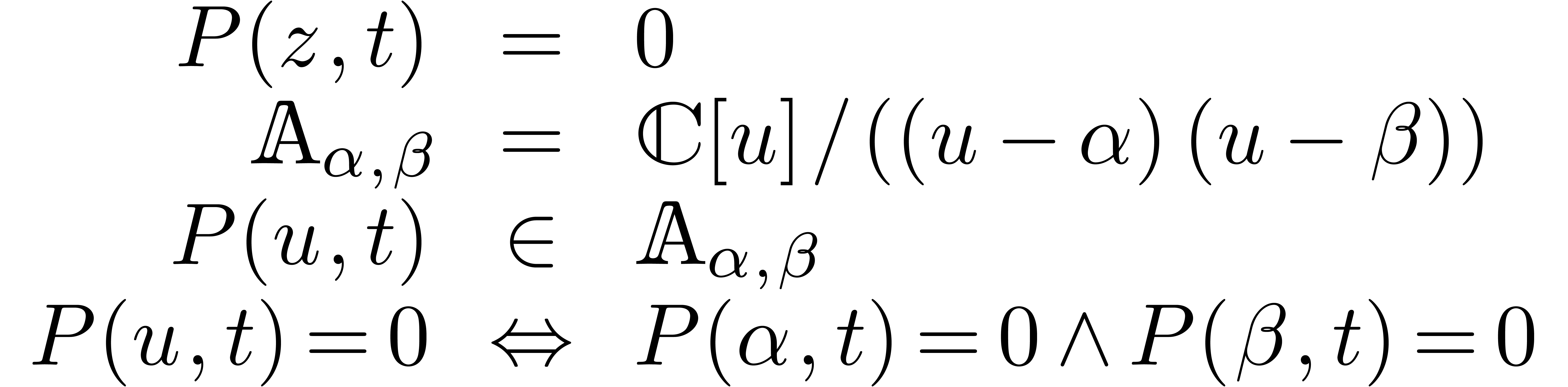
Idée : Considérer 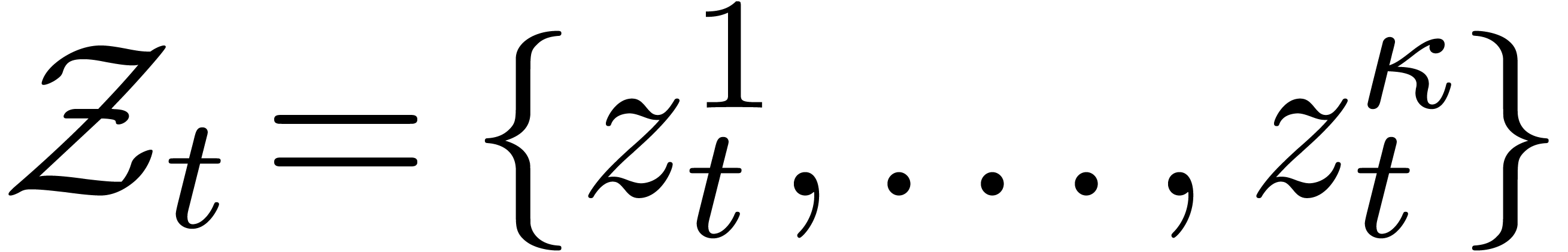 comme « chemin » avec idéal
comme « chemin » avec idéal 
Représentation de (en
position générale)
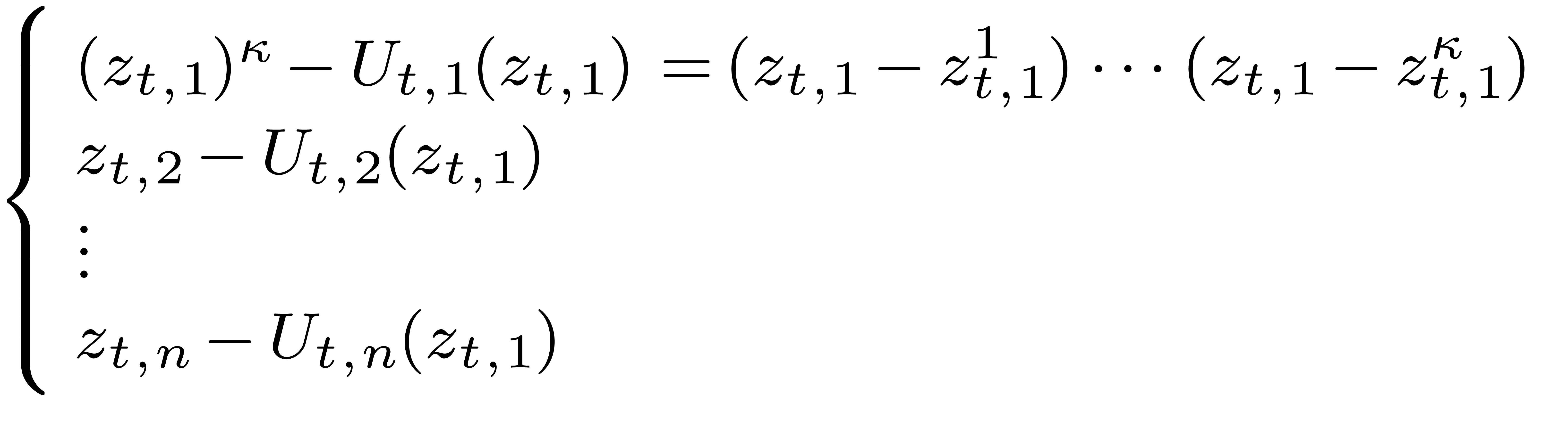
Relever l'homotopie
Évaluer en 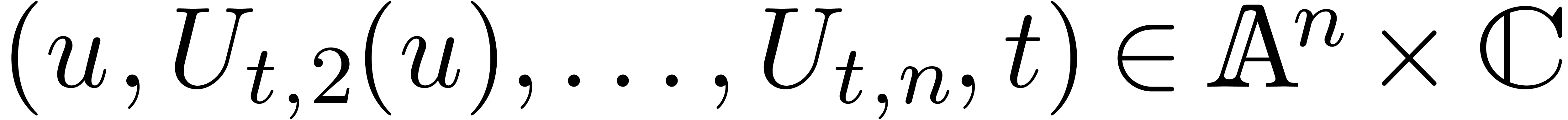 avec
avec
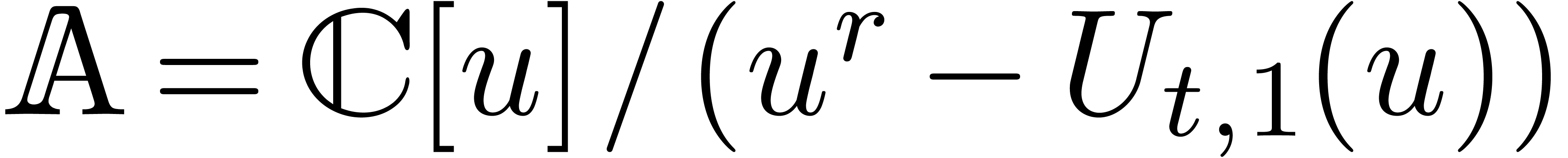
Une question naturelle est de savoir quelle est l'efficacité des
méthodes par homotopie par rapport à des algorithmes
rapides pour calculer des bases de Gröbner [16, 32, 28]. La session  solutions, on observe que le résultat du calcul des
solutions certifiées prend environ une page, alors que la base de
Gröbner en prend plus de
solutions, on observe que le résultat du calcul des
solutions certifiées prend environ une page, alors que la base de
Gröbner en prend plus de  (pour des raisons
d'espace, nous avons tronqué les résultats ici). Plus
qu'il y a de solutions, plus que ce ratio entre les tailles tend
à devenir grand.
(pour des raisons
d'espace, nous avons tronqué les résultats ici). Plus
qu'il y a de solutions, plus que ce ratio entre les tailles tend
à devenir grand.
Mmx] |
use "continewz" |
Mmx] |
include "continewz/homotopy_solve.mmx" |
Mmx] |
type_mode? := false; |
Mmx] |
time_mode? := true; |
Mmx] |
bit_precision := 128; |
Mmx] |
significant_digits := 5; |
Mmx] |
x == coordinate ('x); |
Mmx] |
y == coordinate ('y); |
Mmx] |
z == coordinate ('z); |
Mmx] |
p == 5*x*x*x*x - x*x*x*y + x*y*y*x - z*z*y + x*x - 3*x + y + 5; |
Mmx] |
q == 8*y*y*y*y + 3*y*y*z*z - x*y*z - 2*z*z*z + 23*x - y + 11; |
Mmx] |
r == 9*z*z*z - 3*x*x*x - x*y*z - x*y*x + y*y - x + z + 80; |
Mmx] |
homotopy_solve ([p,q,r], [x,y,z], ball 1.0) |
Computed in
 ms
ms
Mmx] |
set_ordering graded_reverse_lex_ordering () |
Mmx] |
|

Bien sûr, la comparaison que nous venons de faire est favorable aux méthodes par homotopie. Toutefois, elle met en lumière un problème de fond concernant les bases de Gröbner : au moins sur certains exemples, la taille du résultat est beaucoup plus grande que nécessaire.
En outre, si on souhaite avoir une solution numérique, le simple
calcul d'une base de Gröbner n'est pas suffisant. Même si on
dispose n'une base pour l'ordre lexicographique, il faudra encore
trouver les racines d'un gros polynôme en une variable. Or ce
dernier problème pourrait se révéler plus dur que
le problème de départ. En effet, il y a moins d'espace
pour les racines dans que dans , ce qui nous impose de calculer avec une plus
grande précision ,
comme on l'avait déjà constaté dans le chapitre 6.
Par contraste, la précision machine suffit dans de nombreux cas,
lorsque l'on applique des méthodes par homotopie sur le
système de départ.
Toutefois, les systèmes surdéterminés et les chemins partant vers l'infini forment deux problèmes importants pour les méthodes par homotopie. Il est donc fort probable qu'il n'existe pas une technique unique idéale pour la résolution de systèmes polynomiaux.
Ce qui soulève les questions de pouvoir combiner plusieurs méthodes, et, plus modestement, de rendre les résultats d'une méthode utilisables pour d'autres méthodes. À l'intérieur des systèmes de calcul de bases de Gröbner, on dispose par exemple de l'algorithme FGLM pour passer d'un ordre sur les monômes à un autre [29]. De la même manière, on pourra vouloir faire des conversions entre bases de Gröbner, représentations de Kronecker, systèmes triangulaires et des représentations numériques certifiées des variétés de solutions.
Par exemple, lorsque l'on dispose des racines  approchées d'un polynôme unitaire
approchées d'un polynôme unitaire 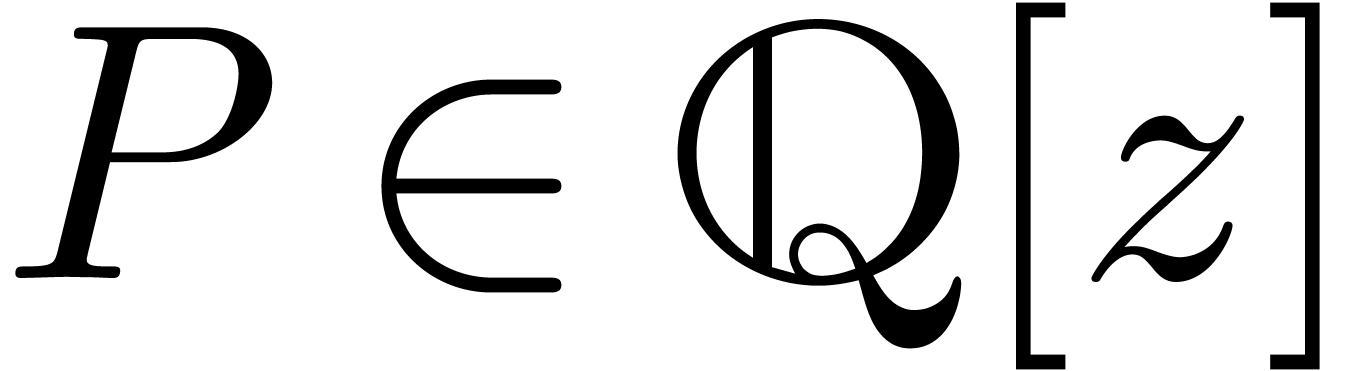 , il est facile de reconstituer le polynôme en
calculant
, il est facile de reconstituer le polynôme en
calculant 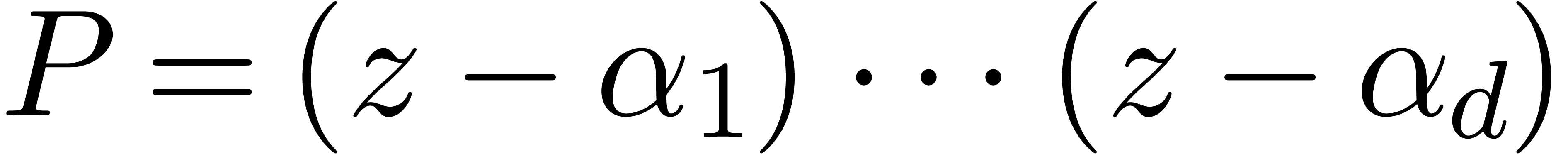 et en retrouvant les coefficients par
développement en fractions continues. Cette approche se
généralise aux polynômes en plusieurs variables, et
permet le calcul d'une représentation de Kronecker à
partir de l'ensemble des solutions d'un système
zéro-dimensionnel [88, section 7.4]. Ceci permet en
particulier l'utilisation de méthodes numériques par
homotopie pour la résolution de systèmes
surdéterminés.
et en retrouvant les coefficients par
développement en fractions continues. Cette approche se
généralise aux polynômes en plusieurs variables, et
permet le calcul d'une représentation de Kronecker à
partir de l'ensemble des solutions d'un système
zéro-dimensionnel [88, section 7.4]. Ceci permet en
particulier l'utilisation de méthodes numériques par
homotopie pour la résolution de systèmes
surdéterminés.
O. Aberth. Computable analysis. McGraw-Hill, New York, 1980.
G. Alefeld and J. Herzberger. Introduction to interval analysis. Academic Press, New York, 1983.
ANSI/IEEE. IEEE standard for binary floating-point arithmetic. Technical report, ANSI/IEEE, New York, 2008. ANSI-IEEE Standard 754-2008. Revision of IEEE 754-1985, approved on June 12, 2008 by IEEE Standards Board.
D. Bates, J. Hauenstein, A. Sommese, and C. Wampler. Bertini: Software for numerical algebraic geometry. http://www.nd.edu/~sommese/bertini/, 2006.
C. Beltrán and L.M. Pardo. Smale's 17th problem: Average polynomial time to compute affine and projective solutions. Journal of the AMS, 2008. To appear.
D. Bini and V.Y. Pan. Polynomial and matrix computations. Vol. 1. Birkhäuser Boston Inc., Boston, MA, 1994. Fundamental algorithms.
D. A. Bini and G. Fiorentino. Design, analysis, and implementation of a multiprecision polynomial rootfinder. Numerical Algorithms, 23:127–173, 2000.
E. Bishop and D. Bridges. Foundations of constructive analysis. Die Grundlehren der mathematische Wissenschaften. Springer, Berlin, 1985.
J. Blanck, V. Brattka, and P. Hertling, editors. Computability and complexity in analysis, volume 2064 of Lect. Notes in Comp. Sc., Berlin, Heidelberg, 2001. Springer.
A. Bostan, F. Chyzak, F. Ollivier, B. Salvy, É. Schost, and A. Sedoglavic. Fast computation of power series solutions of systems of differential equations. In Proceedings of the 18th ACM-SIAM Symposium on Discrete Algorithms, pages 1012–1021, New Orleans, Louisiana, U.S.A., January 2007.
A. Bostan, G. Lecerf, and É. Schost. Tellegen's principle into practice. In Proceedings of ISSAC 2003, pages 37–44. ACM, 2003.
B.L.J. Braaksma. Multisummability and Stokes multipliers of linear meromorphic differential equations. J. Diff. Eq, 92:45–75, 1991.
R.P. Brent and H.T. Kung. 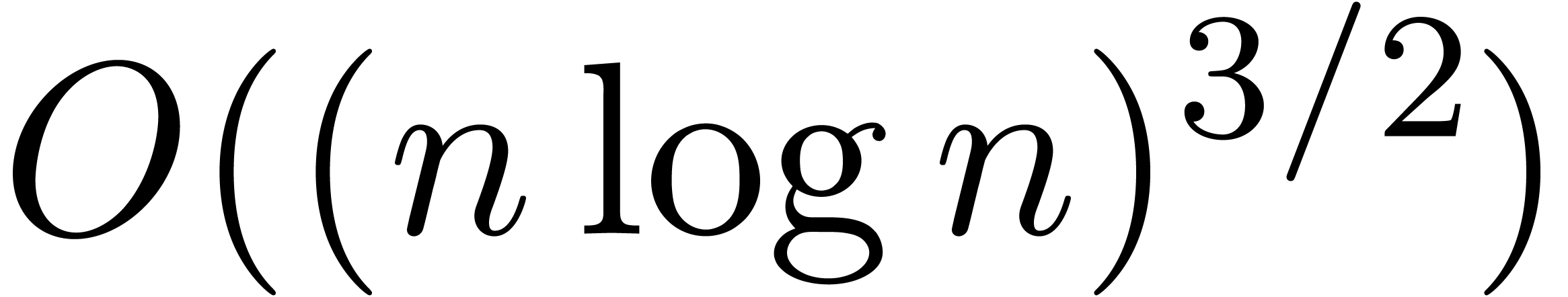 algorithms for composition and reversion of power series. In
J.F. Traub, editor, Analytic Computational Complexity,
Pittsburg, 1975. Proc. of a symposium on analytic computational
complexity held by Carnegie-Mellon University.
algorithms for composition and reversion of power series. In
J.F. Traub, editor, Analytic Computational Complexity,
Pittsburg, 1975. Proc. of a symposium on analytic computational
complexity held by Carnegie-Mellon University.
R.P. Brent and H.T. Kung. Fast algorithms for composition and reversion of multivariate power series. In Proc. Conf. Th. Comp. Sc., pages 149–158, Waterloo, Ontario, Canada, August 1977. University of Waterloo.
R.P. Brent and H.T. Kung. Fast algorithms for manipulating formal power series. Journal of the ACM, 25:581–595, 1978.
B. Buchberger. Ein Algorithmus zum auffinden der Basiselemente des Restklassenringes nach einem null-dimensionalen Polynomideal. PhD thesis, University of Innsbruck, 1965.
D.G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28:693–701, 1991.
D.V. Chudnovsky and G.V. Chudnovsky. Computer algebra in the service of mathematical physics and number theory (computers in mathematics, stanford, ca, 1986). In Lect. Notes in Pure and Applied Math., volume 125, pages 109–232, New-York, 1990. Dekker.
J.W. Cooley and J.W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
D. Coppersmith and S. Winograd. Matrix multiplication
via arithmetic progressions. In Proc. of the  Annual Symposium on Theory of Computing, pages 1–6,
New York City, may 25–27 1987.
Annual Symposium on Theory of Computing, pages 1–6,
New York City, may 25–27 1987.
Jean-Pierre Dedieu. Points fixes, zéros et la méthode de Newton. Number 54 in Mathématiques et Applications. SMAI-Springer Verlag.
J. Denef and L. Lipshitz. Decision problems for differential equations. The Journ. of Symb. Logic, 54(3):941–950, 1989.
F.J. Drexler. Eine Methode zur Berechnung sämtlicher Lösungen von Polynomgleichungssystemen. Numer. Math., 29(1):45–58, 1977.
C. Durvye. Algorithmes pour la décomposition primaire des idéaux polynomiaux de dimension nulle donnés en évaluation. PhD thesis, Univ. de Versailles (France), 2008.
J. Écalle. L'accélération des fonctions résurgentes (survol). Unpublished manuscript, 1987.
J. Écalle. Introduction aux fonctions analysables et preuve constructive de la conjecture de Dulac. Hermann, collection: Actualités mathématiques, 1992.
J. Écalle. Six lectures on transseries, analysable functions and the constructive proof of Dulac's conjecture. In D. Schlomiuk, editor, Bifurcations and periodic orbits of vector fields, pages 75–184. Kluwer, 1993.
J.-C. Faugère. A new efficient algorithm for computing Gröbner bases (F4). Journal of Pure and Applied Algebra, 139(1–3):61–88, 1999.
J.C. Faugère, P. Gianni, D. Lazard, and T. Mora. Efficient computation of zero-dimensional Gröbner bases by change of ordering. Journal of Symbolic Computation, 16(4):329–344, 1993.
M. Fürer. Faster integer multiplication. In Proceedings of the Thirty-Ninth ACM Symposium on Theory of Computing (STOC 2007), pages 57–66, San Diego, California, 2007.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, 2-nd edition, 2002.
A. Giovini, T. Mora, G. Niesi, L. Robbiano, and C. Traverso. “one sugar cube, please” or selection strategies in the buchberger algorithm. In S. Watt, editor, Proc. ISSACâĂŹ91, pages 49–54, New York, 1991. ACM Press.
M. Giusti, K. Hägele, J. Heintz, J.E. Morais, J.L Monta na, and L.M. Pardo. Lower bounds for diophantine approximation. Journal of Pure and Applied Algebra, 117–118:277–317, 1997.
M. Giusti, J. Heintz, J.E. Morais, and L.M. Pardo. When polynomial equation systems can be solved fast? In G. Cohen, M. Giusti, and T. Mora, editors, Proc. AAECC'11, volume 948 of Lecture Notes in Computer Science. Springer Verlag, 1995.
X. Gourdon. Combinatoire, algorithmique et géométrie des polynômes. PhD thesis, École polytechnique, 1996.
A. Grzegorczyk. Computable functionals. Fund. Math., 42:168–202, 1955.
A. Grzegorczyk. On the definition of computable functionals. Fund. Math., 42:232–239, 1955.
A. Grzegorczyk. On the definitions of computable real continuous functions. Fund. Math., 44:61–71, 1957.
G. Hanrot, V. Lefèvre, K. Ryde, and P. Zimmermann. MPFR, a C library for multiple-precision floating-point computations with exact rounding. http://www.mpfr.org, 2000.
L. Jaulin, M. Kieffer, O. Didrit, and E. Walter. Applied interval analysis. Springer, London, 2001.
A. Karatsuba and J. Ofman. Multiplication of multidigit numbers on automata. Soviet Physics Doklady, 7:595–596, 1963.
R.B. Kearfott. An interval step control for continuation methods. SIAM J. Numer. Anal., 31(3):892–914, 1994.
R. Krawczyk. Newton-algorithmen zur bestimmung von nullstellen mit fehler-schranken. Computing, 4:187–201, 1969.
V. Kreinovich, A.V. Lakeyev, J. Rohn, and P.T. Kahl. Computational Complexity and Feasibility of Data Processing and Interval Computations. Springer, 1997.
B. Lambov. Interval arithmetic using sse-2. In Peter Hertling, Christoph Hoffmann, Wolfram Luther, and Nathalie Revol, editors, Reliable Implementation of Real Number Algorithms: Theory and Practice, volume 5045 of Lecture Notes in Computer Science, pages 102–113. Springer Berlin/Heidelberg, 2008.
G. Lecerf. Une alternative aux méthodes de
réécriture pour la résolution des syst es algébriques.
PhD thesis, École polytechnique, 2001.
es algébriques.
PhD thesis, École polytechnique, 2001.
A. Leykin. NAG. http://www.math.uic.edu/~leykin/NAG4M2, 2009. Macaulay 2 package for numerical algebraic geometry.
Anton Leykin, Jan Verschelde, and Ailing Zhao. Algorithms in algebraic geometry, chapter Higher-order deflation for polynomial systems with isolated singular solutions, pages 79–97. Springer, New York, 2008.
K. Makino and M. Berz. Remainder differential algebras and their applications. In M. Berz, C. Bischof, G. Corliss, and A. Griewank, editors, Computational differentiation: techniques, applications and tools, pages 63–74, SIAM, Philadelphia, 1996.
K. Makino and M. Berz. Suppression of the wrapping effect by Taylor model-based validated integrators. Technical Report MSU Report MSUHEP 40910, Michigan State University, 2004.
A. Mantzaflaris and B. Mourrain. Deflation and certified isolation of singular zeros of polynomial systems. In A. Leykin, editor, Proc. ISSAC'11, pages 249–256, San Jose, CA, US, Jun 2011. ACM New York.
J. Martinet and J.-P. Ramis. Elementary acceleration and multisummability. Ann. Inst. Henri Poincaré, 54(4):331–401, 1991.
R.E. Moore. Automatic local coordinate transformations to reduce the growth of error bounds in interval computation of solutions to ordinary differential equation. In L.B. Rall, editor, Error in Digital Computation, volume 2, pages 103–140. John Wiley, 1965.
R.E. Moore. Interval Analysis. Prentice Hall, Englewood Cliffs, N.J., 1966.
A.P. Morgan. Solving polynomial systems using continuation for] engineering and scientific problems. Prentice-Hall, Englewood Cliffs, N.J., 1987.
Jean-Michel Muller. Elementary Functions, Algorithms and Implementation. Birkhauser Boston, Inc., 2006.
A. Neumaier. Interval methods for systems of equations. Cambridge university press, Cambridge, 1990.
V. Pan. How to multiply matrices faster, volume 179 of Lect. Notes in Math. Springer, 1984.
V. Y. Pan. Optimal and nearly optimal algorithms for approximating polynomial zeros. Comput. Math. Appl., 31(12):97–138, 1996.
V. Y. Pan. Univariate polynomials: nearly optimal algorithms for numerical factorization and root-finding. J. Symbolic Comput., 33(5):701–733, 2002.
S.M. Rump. Kleine Fehlerschranken bei Matrixproblemen. PhD thesis, Universität Karlsruhe, 1980.
S.M. Rump. Fast and parallel interval arithmetic. BIT, 39(3):534–554, 1999.
S.M. Rump. Verification methods: Rigorous results using floating-point arithmetic. Acta Numerica, 19:287–449, 2010.
L. Schlesinger. Handbuch der Theorie der linearen Differentialgleichungen, volume I. Teubner, Leipzig, 1895.
L. Schlesinger. Handbuch der Theorie der linearen Differentialgleichungen, volume II. Teubner, Leipzig, 1897.
A. Schönhage. The fundamental theorem of algebra in terms of computational complexity. Technical report, Math. Inst. Univ. of Tübingen, 1982.
A. Schönhage and V. Strassen. Schnelle Multiplikation grosser Zahlen. Computing, 7:281–292, 1971.
Alexandre Sedoglavic. Méthodes seminumériques en algèbre différentielle ; applications à l'étude des propriétés structurelles de systèmes différentiels algébriques en automatique. PhD thesis, École polytechnique, 2001.
M. Shub and S. Smale. Computational complexity. On the geometry of polynomials and a theory of cost. I. Ann. Sci. École Norm. Sup. (4), 18(1):107–142, 1985.
M. Shub and S. Smale. Computational complexity: on the geometry of polynomials and a theory of cost. II. SIAM J. Comput., 15(1):145–161, 1986.
S. Smale. The fundamental theorem of algebra and complexity theory. Bull. Amer. Math. Soc. (N.S.), 4(1):1–36, 1981.
S. Smale. Newton method estimates from data at one point. In R. E. Ewing, K. I. Gross, and C. F. Martin, editors, In the Merging of Disciplines: New Directions in Pure, Applied, and Computational Mathematics, pages 185–196. Springer-Verlag, 1986.
A.J. Sommese and C.W. Wampler. The Numerical Solution of Systems of Polynomials Arising in Engineering and Science. World Scientific, 2005.
V. Strassen. Gaussian elimination is not optimal. Numer. Math., 13:352–356, 1969.
A. Turing. On computable numbers, with an application to the Entscheidungsproblem. Proc. London Maths. Soc., 2(42):230–265, 1936.
J. van der Hoeven. Lazy multiplication of formal power series. In W. W. Küchlin, editor, Proc. ISSAC '97, pages 17–20, Maui, Hawaii, July 1997.
J. van der Hoeven. Fast evaluation of holonomic functions. TCS, 210:199–215, 1999.
J. van der Hoeven. Fast evaluation of holonomic functions near and in singularities. JSC, 31:717–743, 2001.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven. Computations with effective real numbers. TCS, 351:52–60, 2006.
J. van der Hoeven. Around the numeric-symbolic computation of differential Galois groups. JSC, 42:236–264, 2007.
J. van der Hoeven. Efficient accelero-summation of holonomic functions. JSC, 42(4):389–428, 2007.
J. van der Hoeven. New algorithms for relaxed multiplication. JSC, 42(8):792–802, 2007.
J. van der Hoeven. Fast composition of numeric power series. Technical Report 2008-09, Université Paris-Sud, Orsay, France, 2008.
J. van der Hoeven. Making fast multiplication of polynomials numerically stable. Technical Report 2008-02, Université Paris-Sud, Orsay, France, 2008.
J. van der Hoeven. Newton's method and FFT trading. JSC, 45(8):857–878, 2010.
J. van der Hoeven. Efficient root counting for analytic functions on a disk. Technical report, HAL, 2011. http://hal.archives-ouvertes.fr/hal-00583139/fr/.
J. van der Hoeven. Reliable homotopy continuation. Technical report, HAL, 2011. http://hal.archives-ouvertes.fr/hal-00589948/fr/.
J. van der Hoeven, G. Lecerf, B. Mourain, et al. Mathemagix, 2002. http://www.mathemagix.org.
J. Verschelde. Homotopy continuation methods for solving polynomial systems. PhD thesis, Katholieke Universiteit Leuven, 1996.
J. Verschelde. PHCpack: A general-purpose solver for polynomial systems by homotopy continuation. ACM Transactions on Mathematical Software, 25(2):251–276, 1999. Algorithm 795.
J.W. von Gudenberg. Interval arithmetic on multimedia architectures. Reliable Computing, 8(4), 2002.
K. Weihrauch. Computable analysis. Springer-Verlag, Berlin/Heidelberg, 2000.
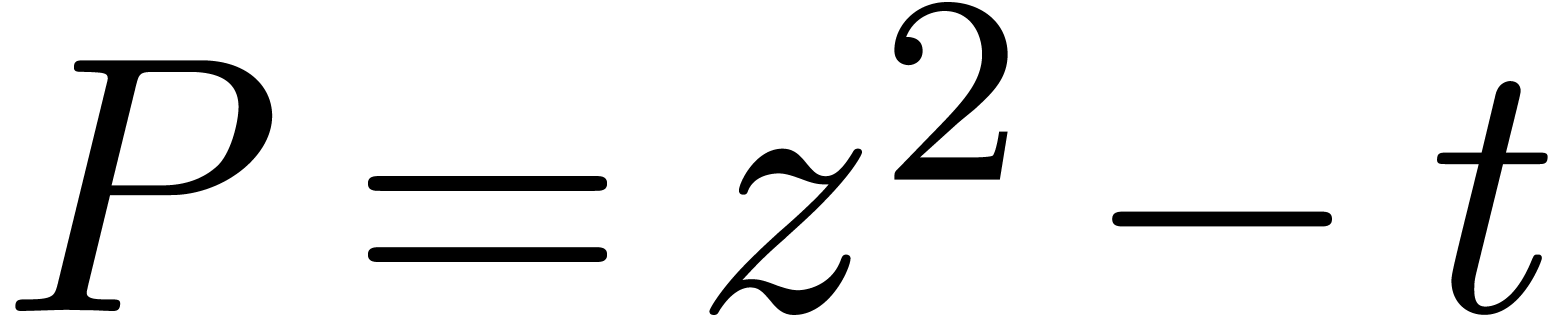 .
. ,
, ,
, .
.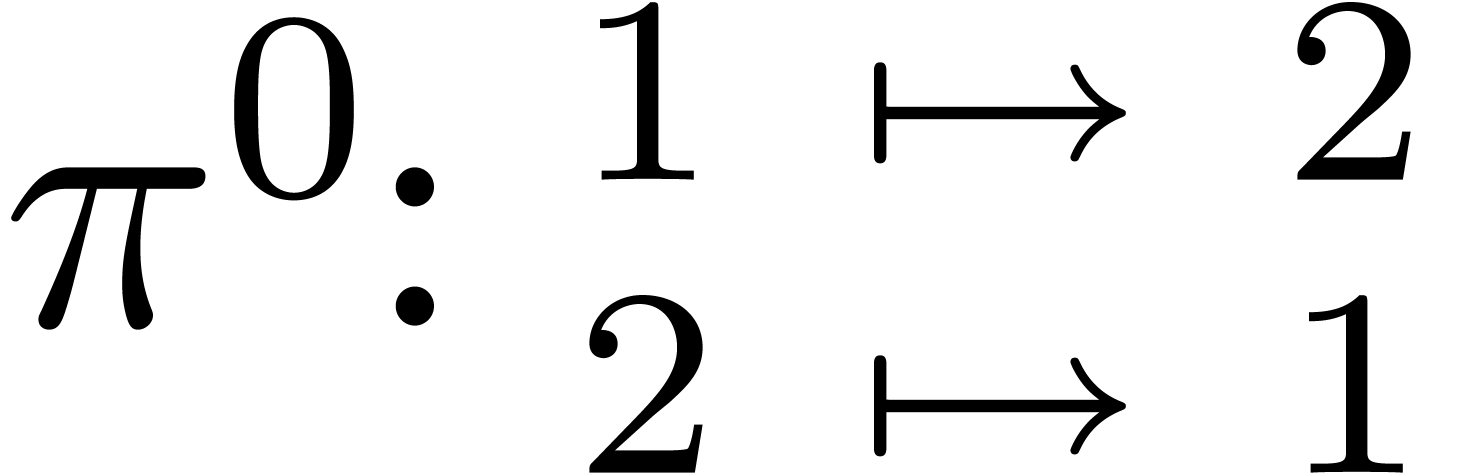 ,
,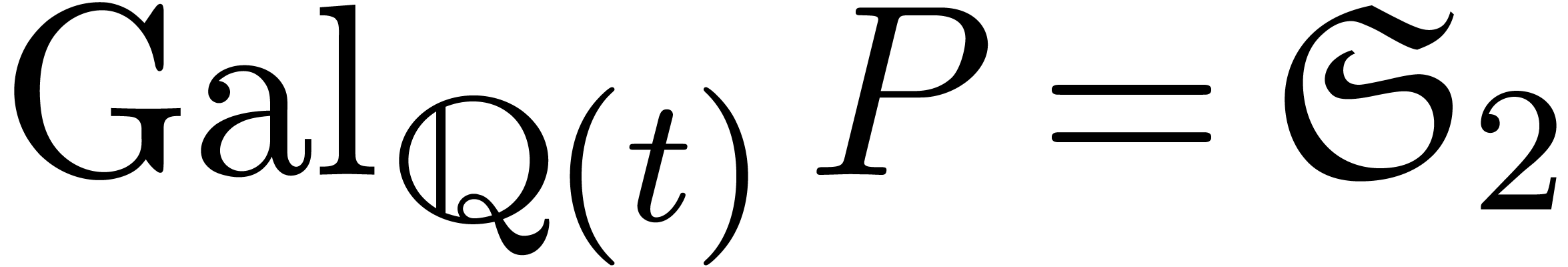 .
.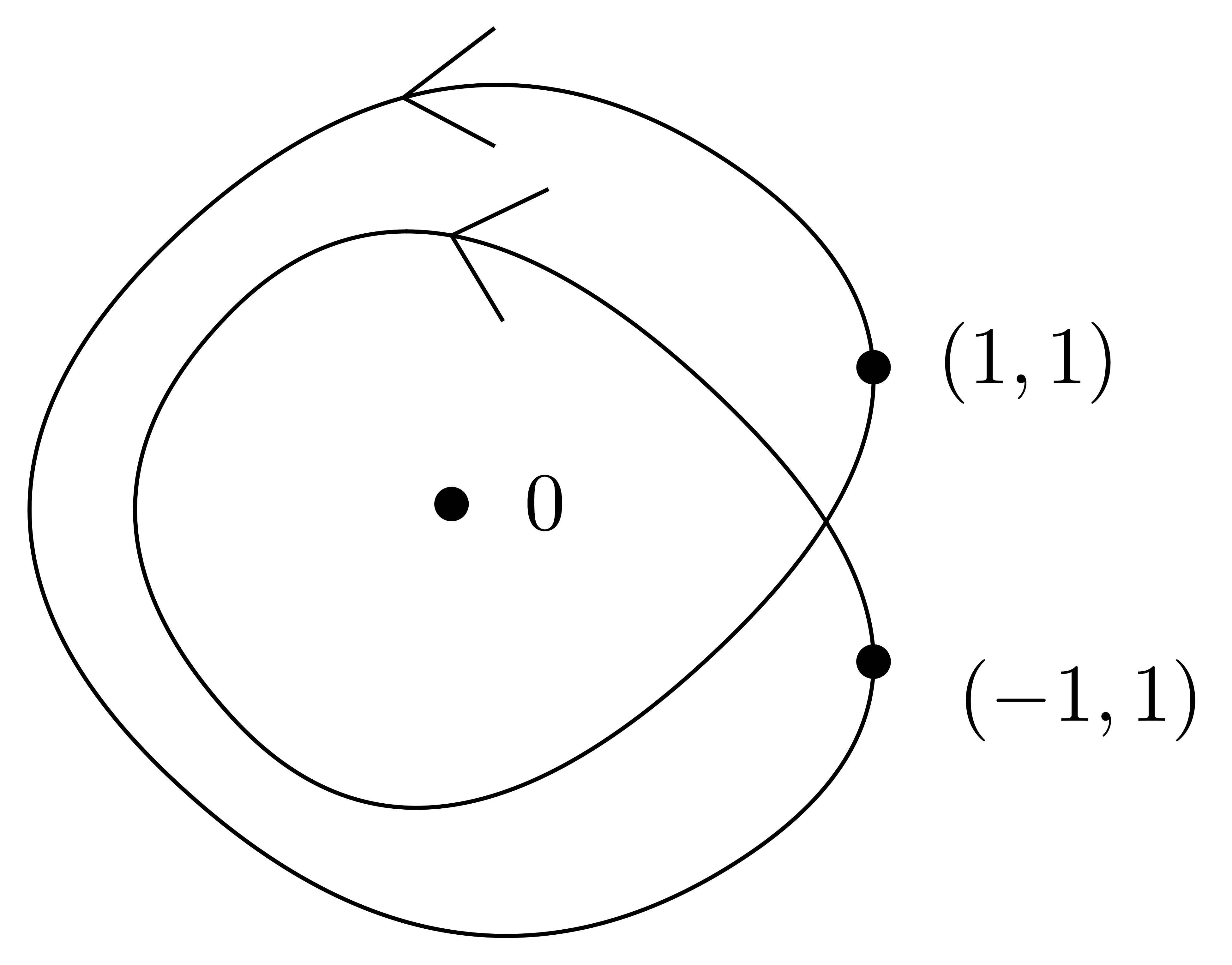

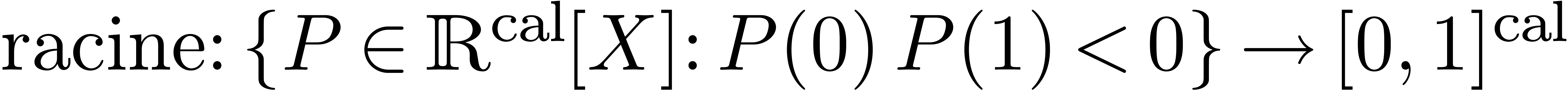
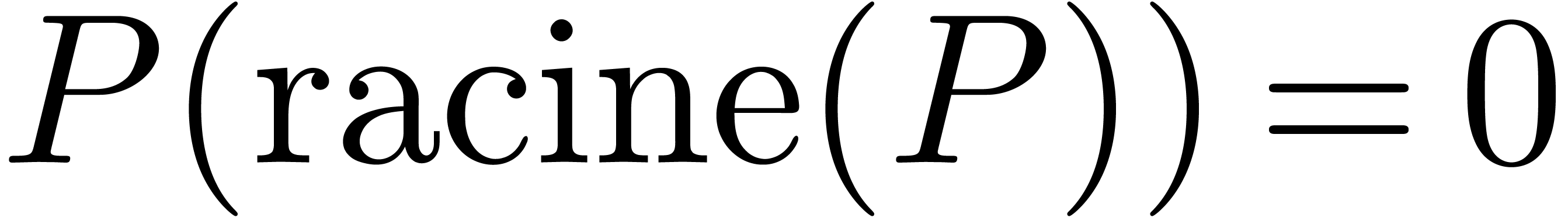 .
.

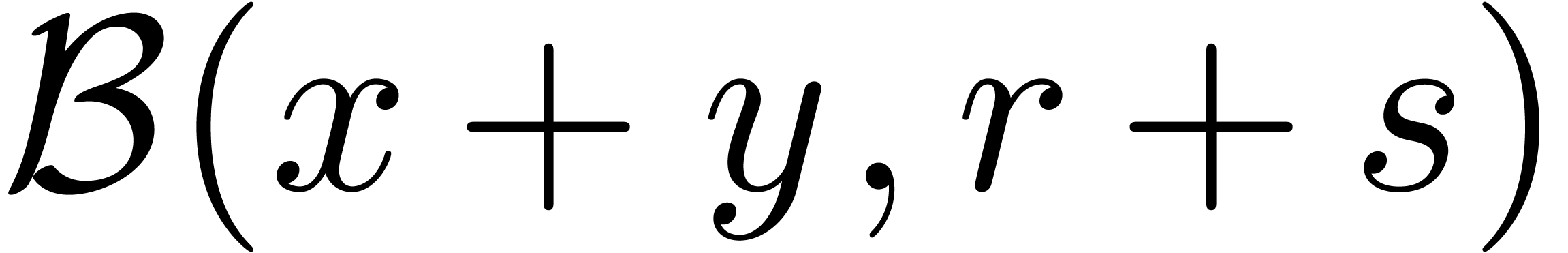

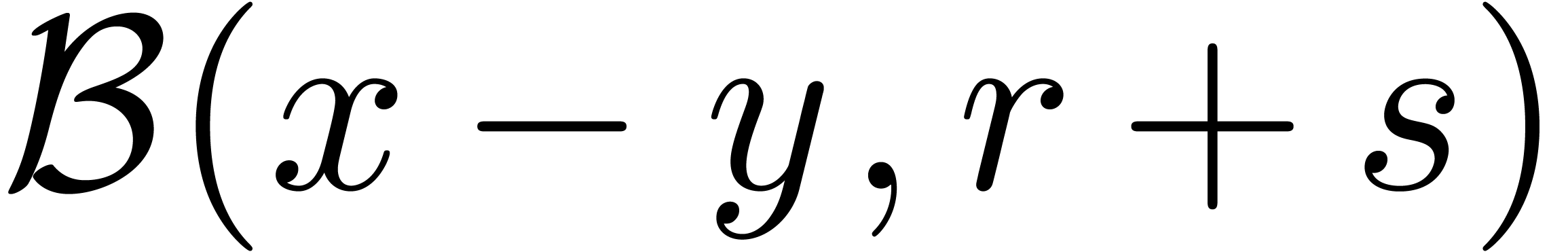

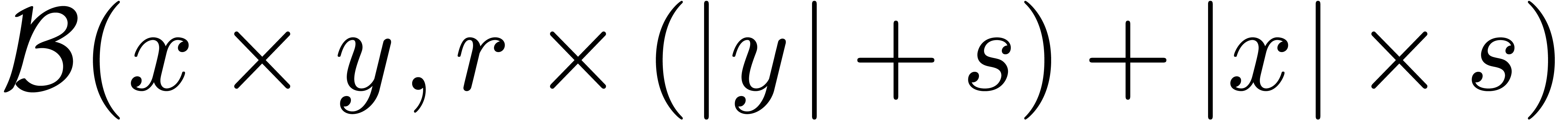
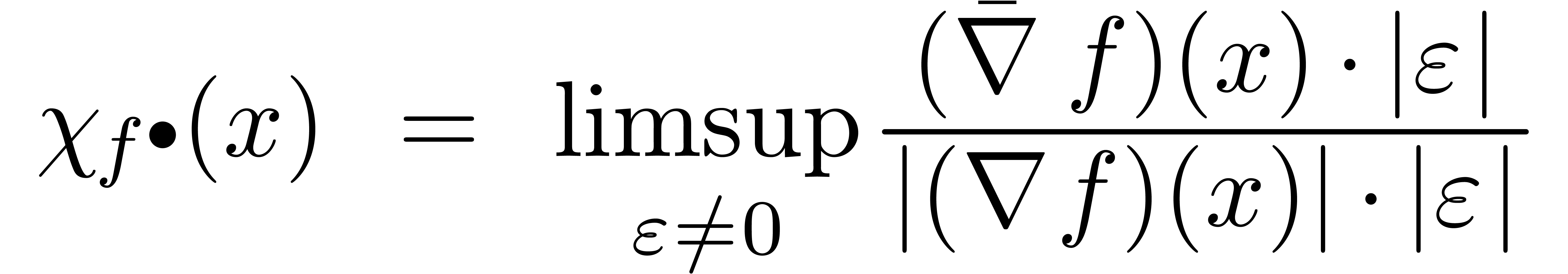
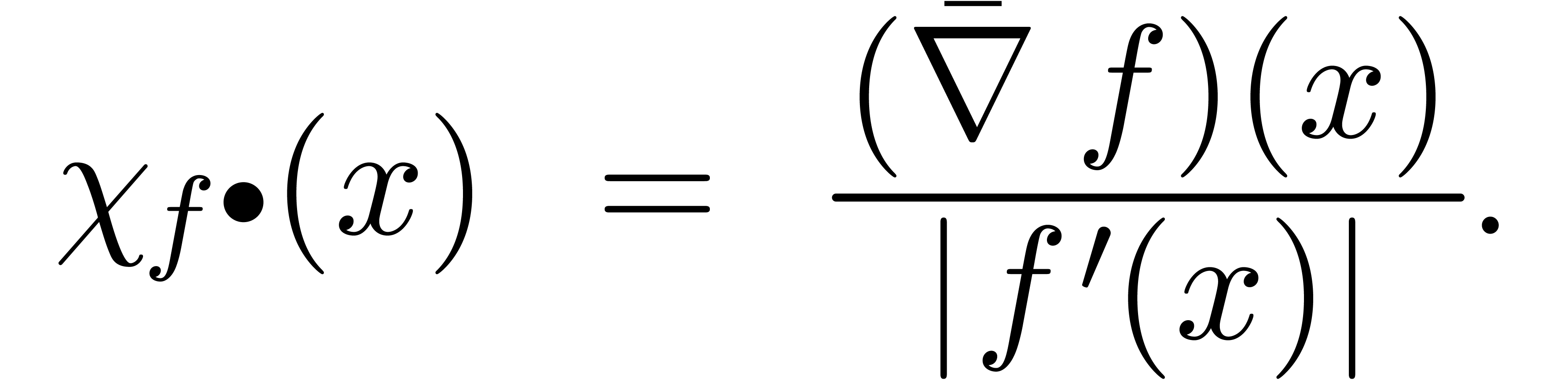

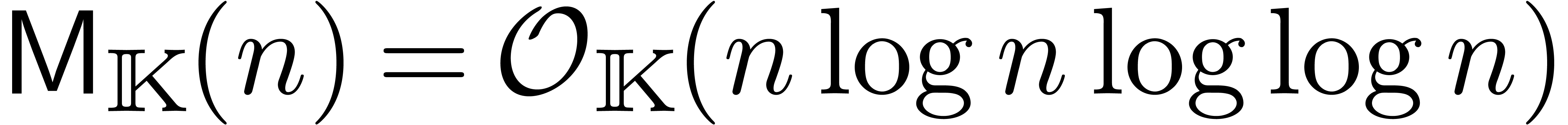 :
: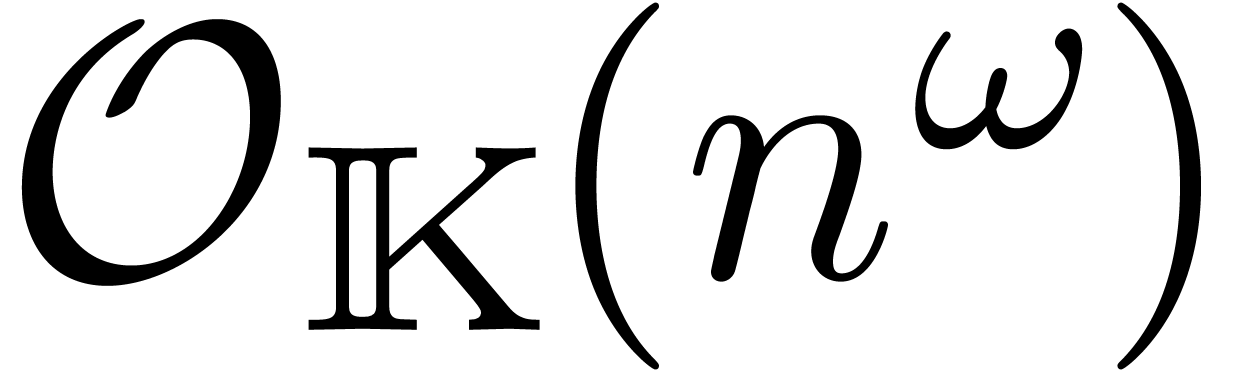 avec
avec 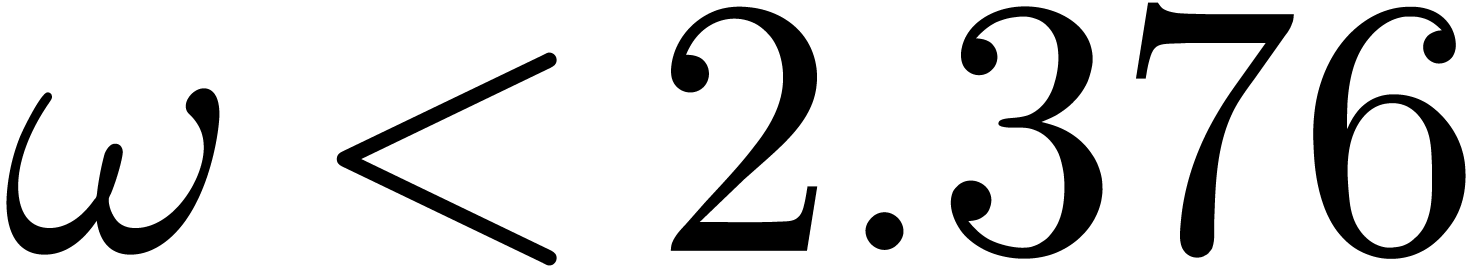 :
: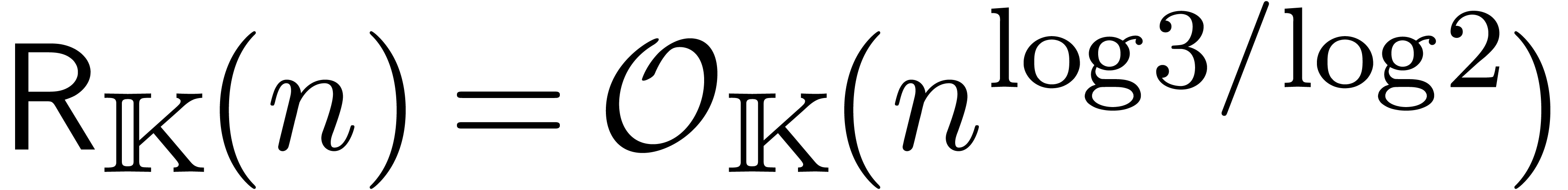 :
: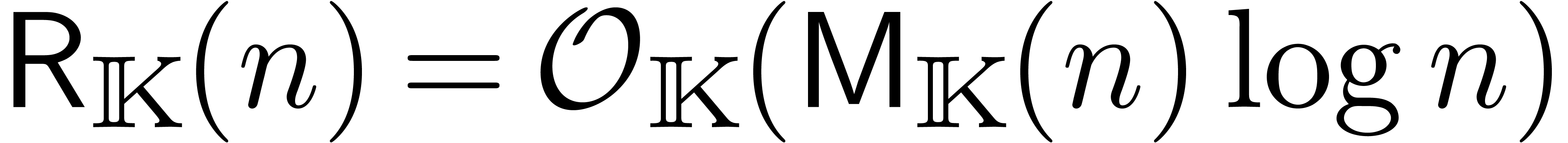 :
: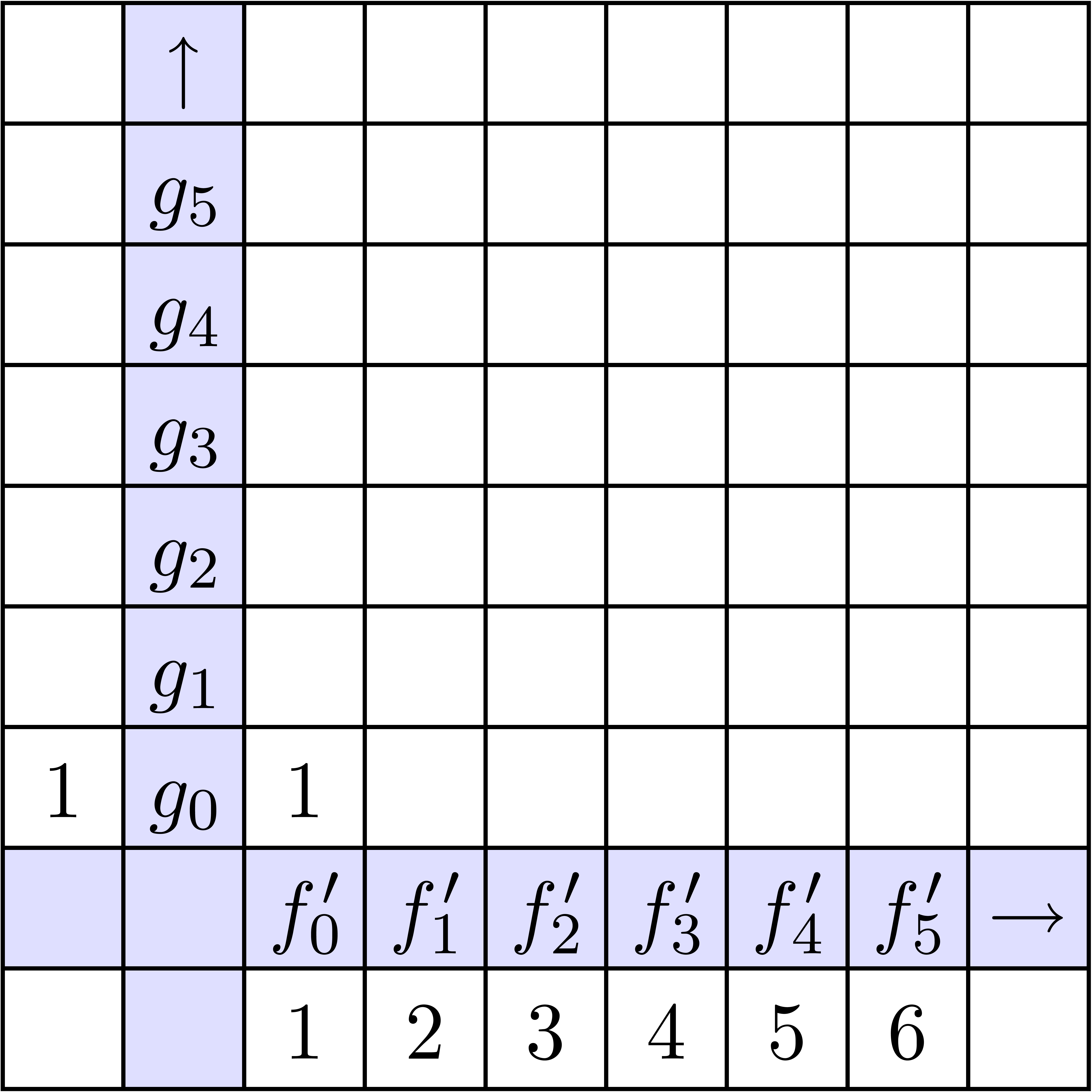
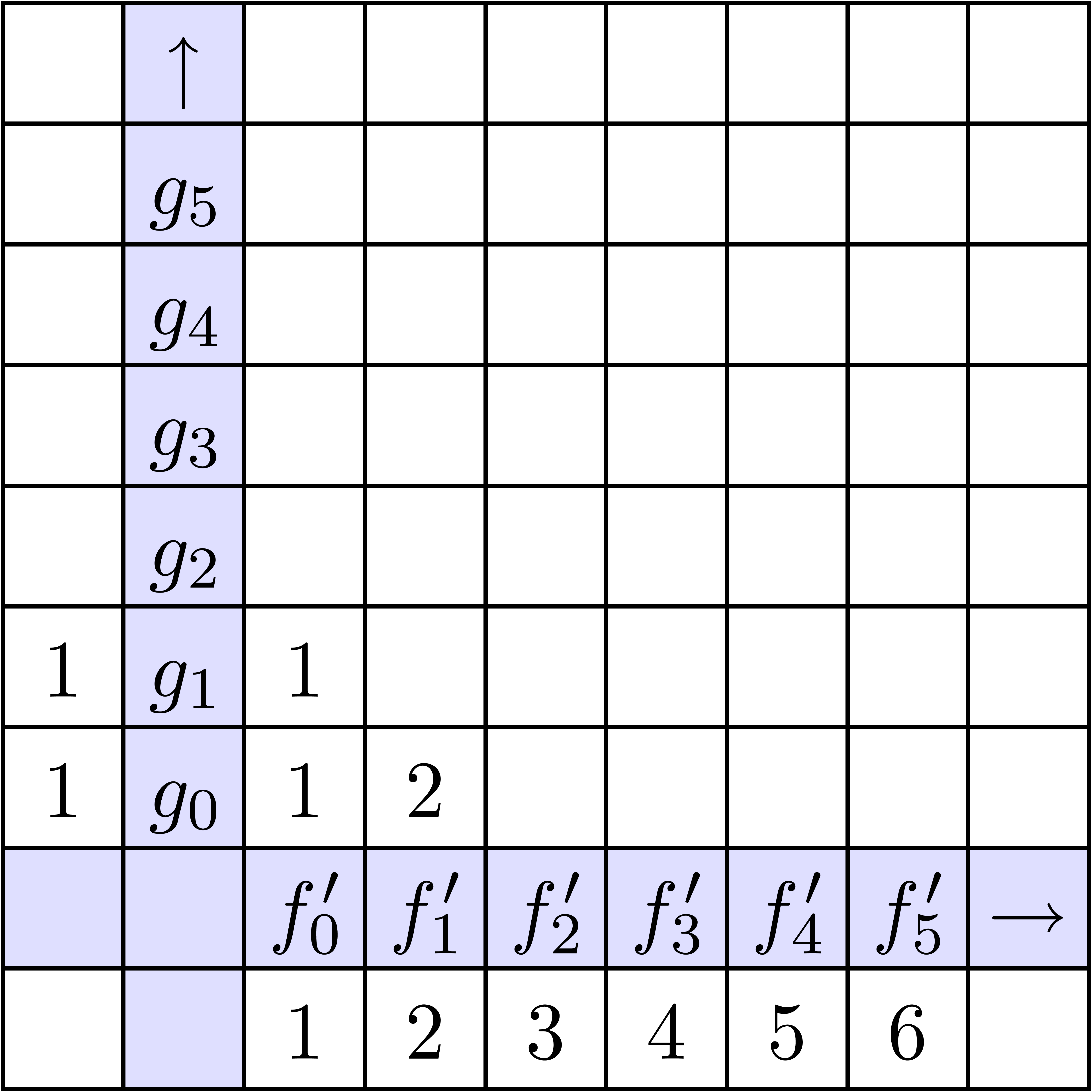
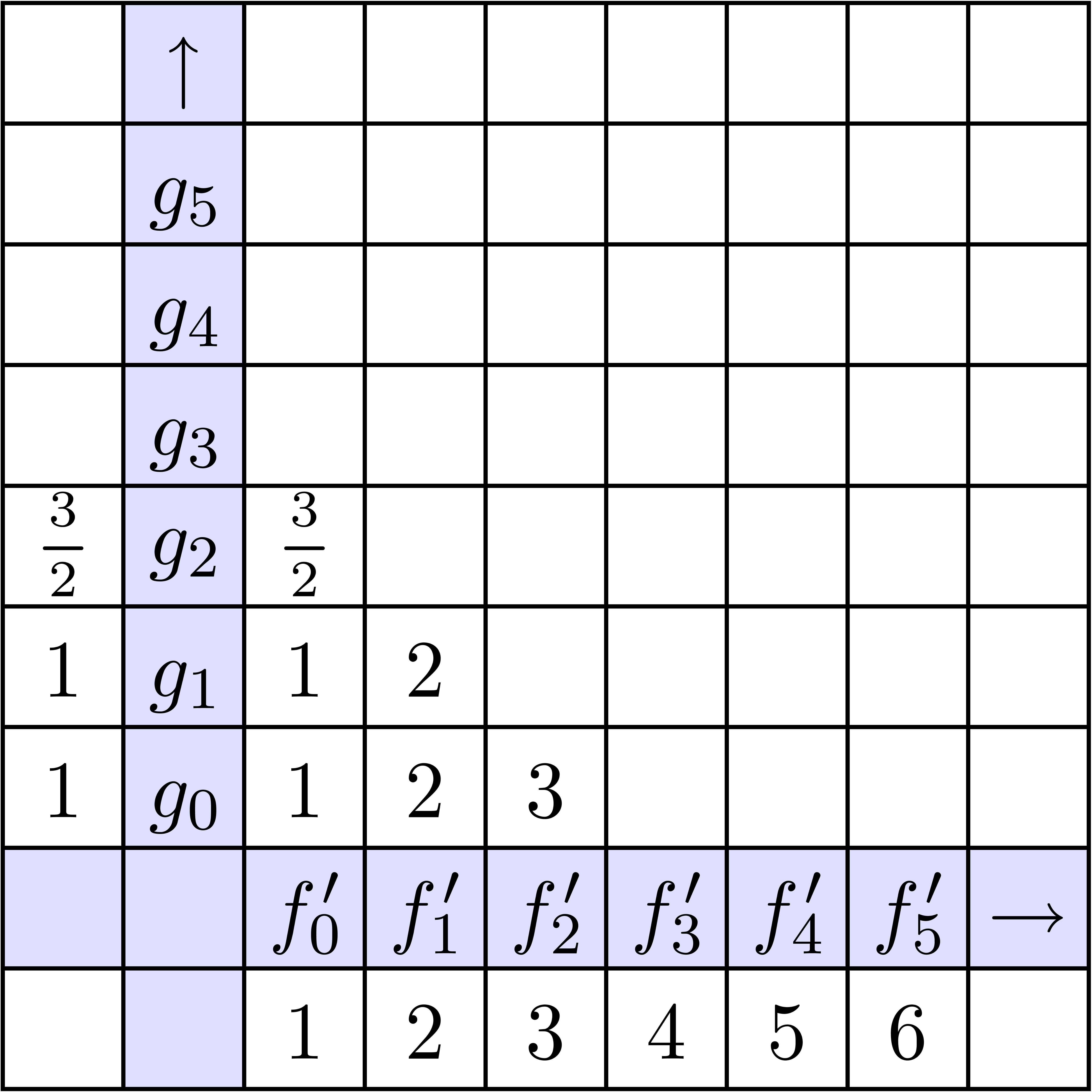
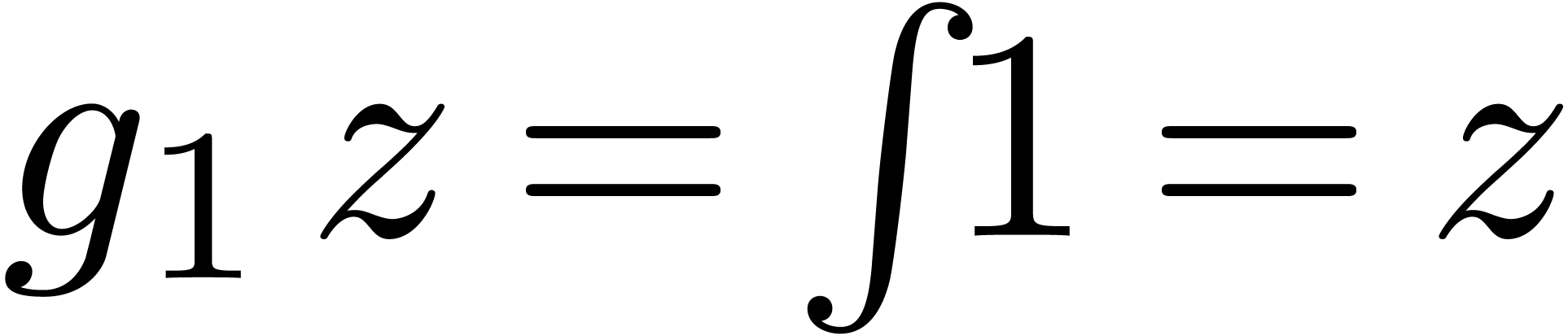
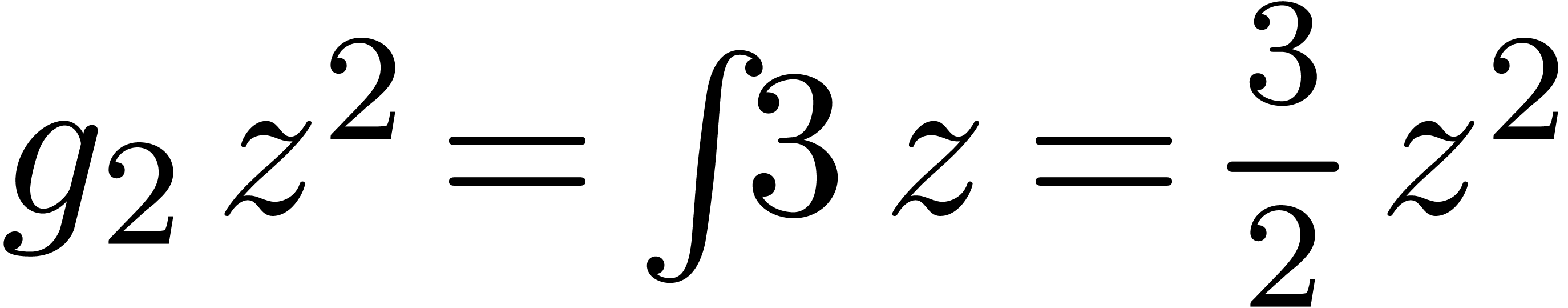
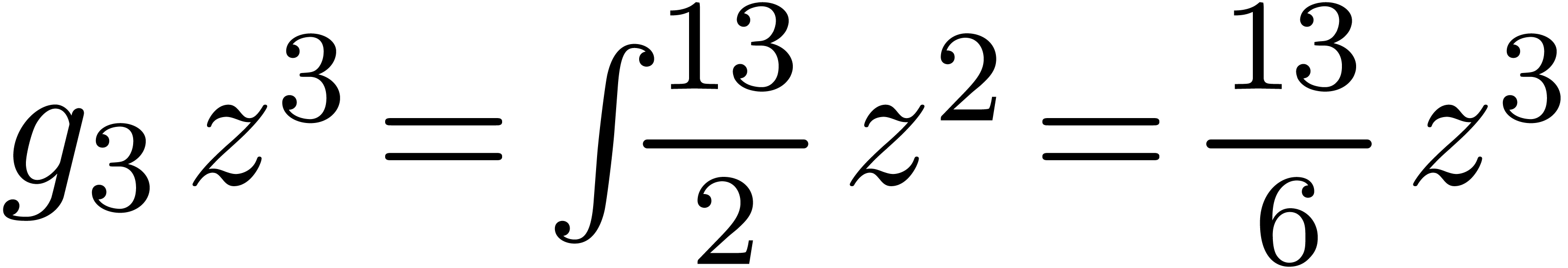
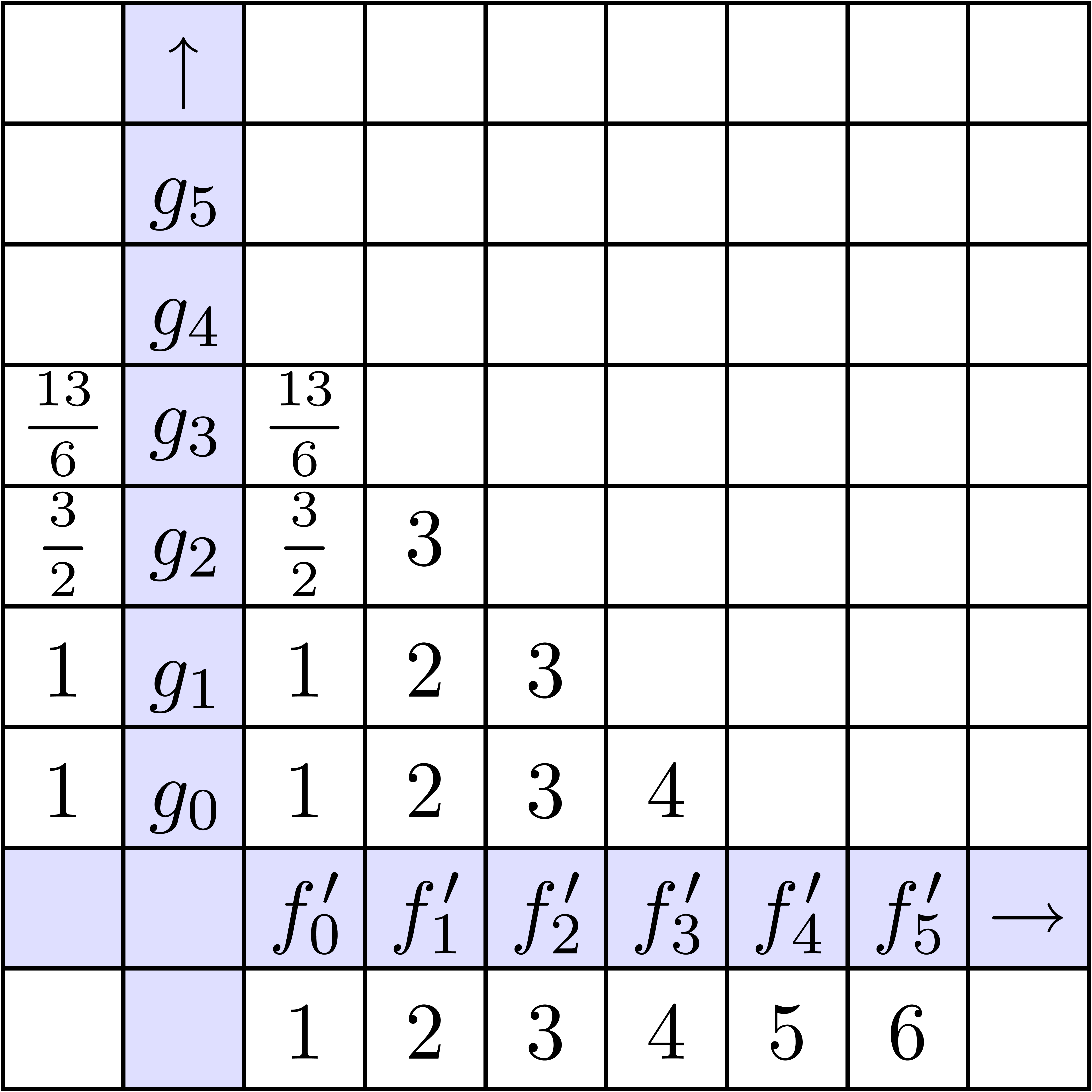
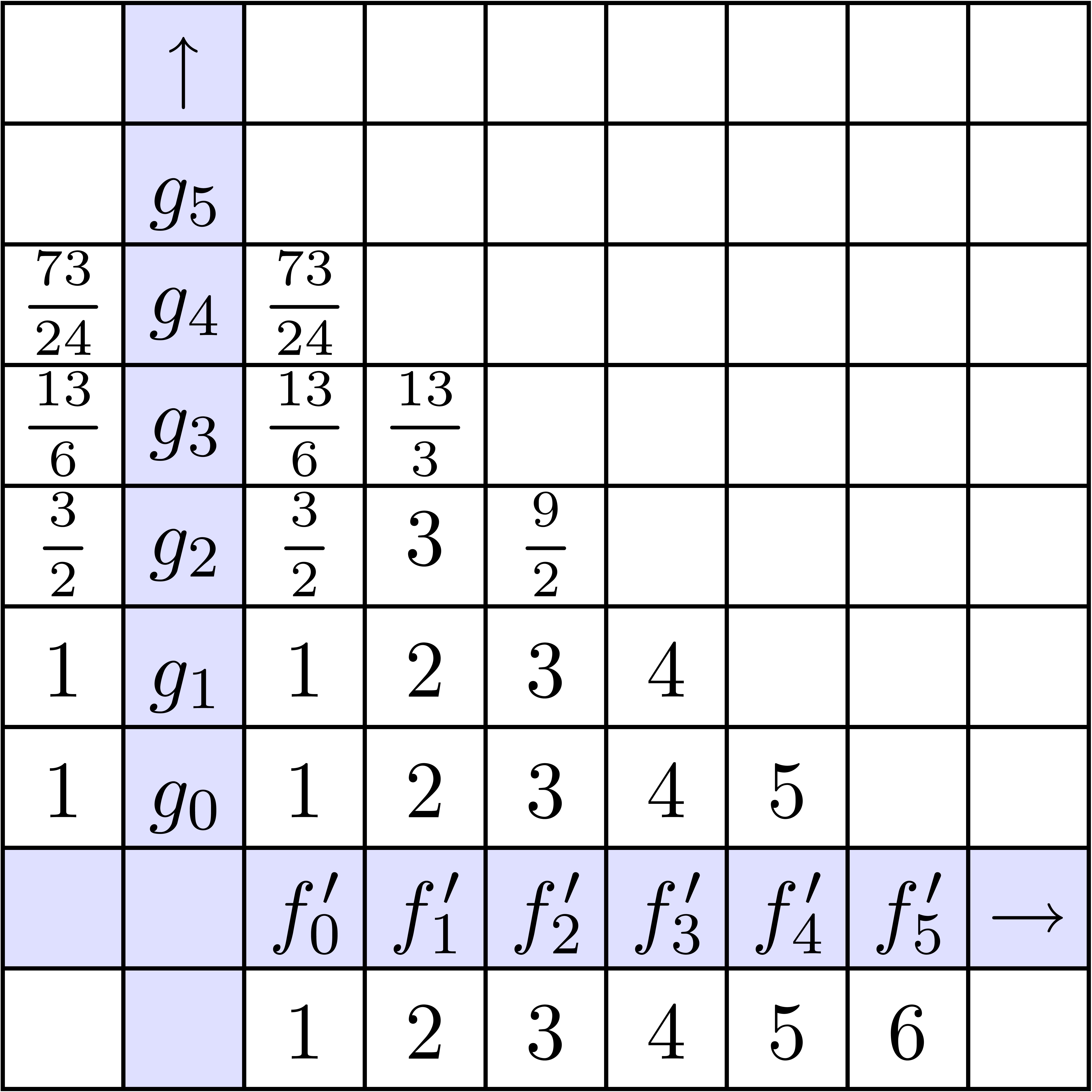
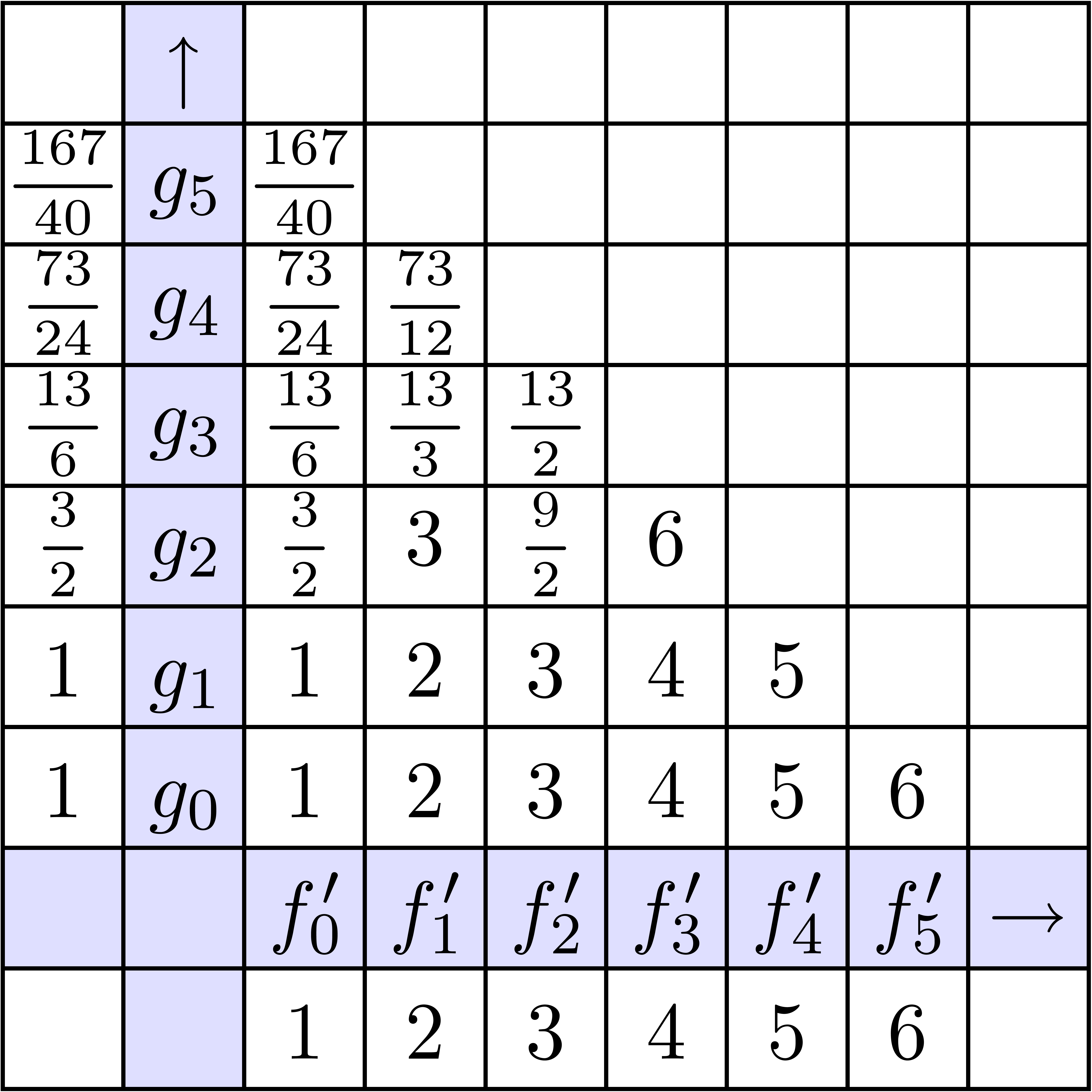
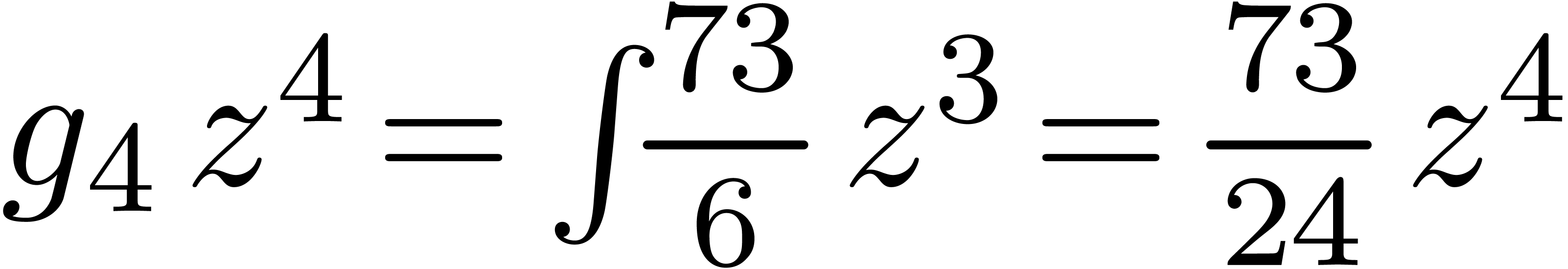
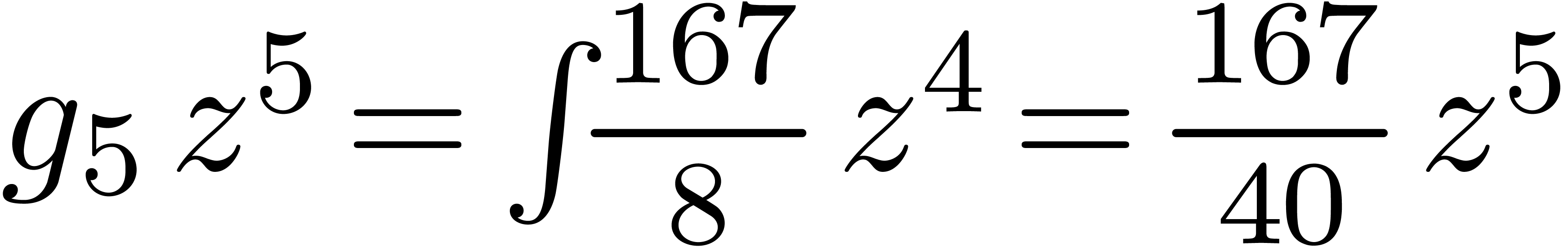
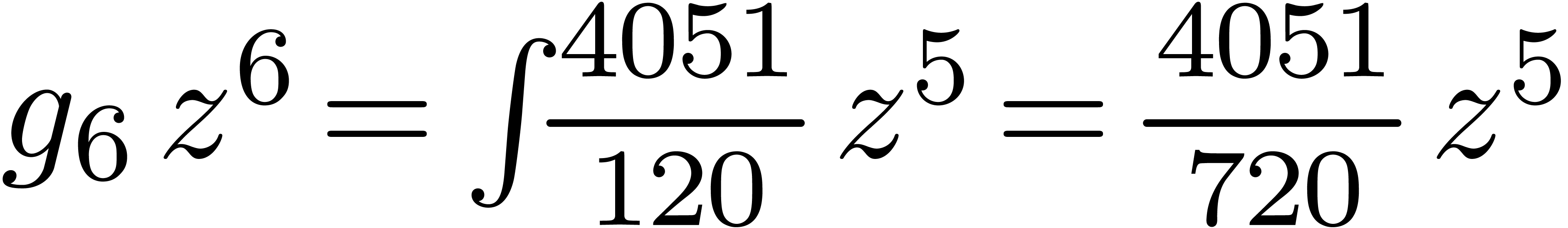
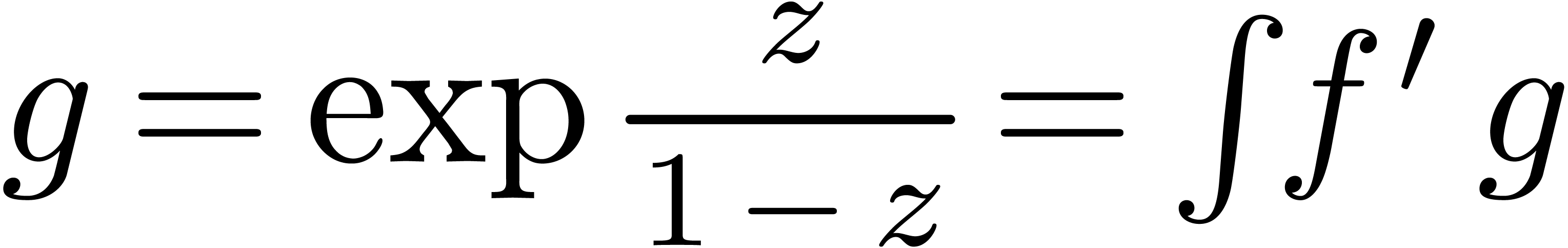 par multiplication détendue de
par multiplication détendue de  et
et 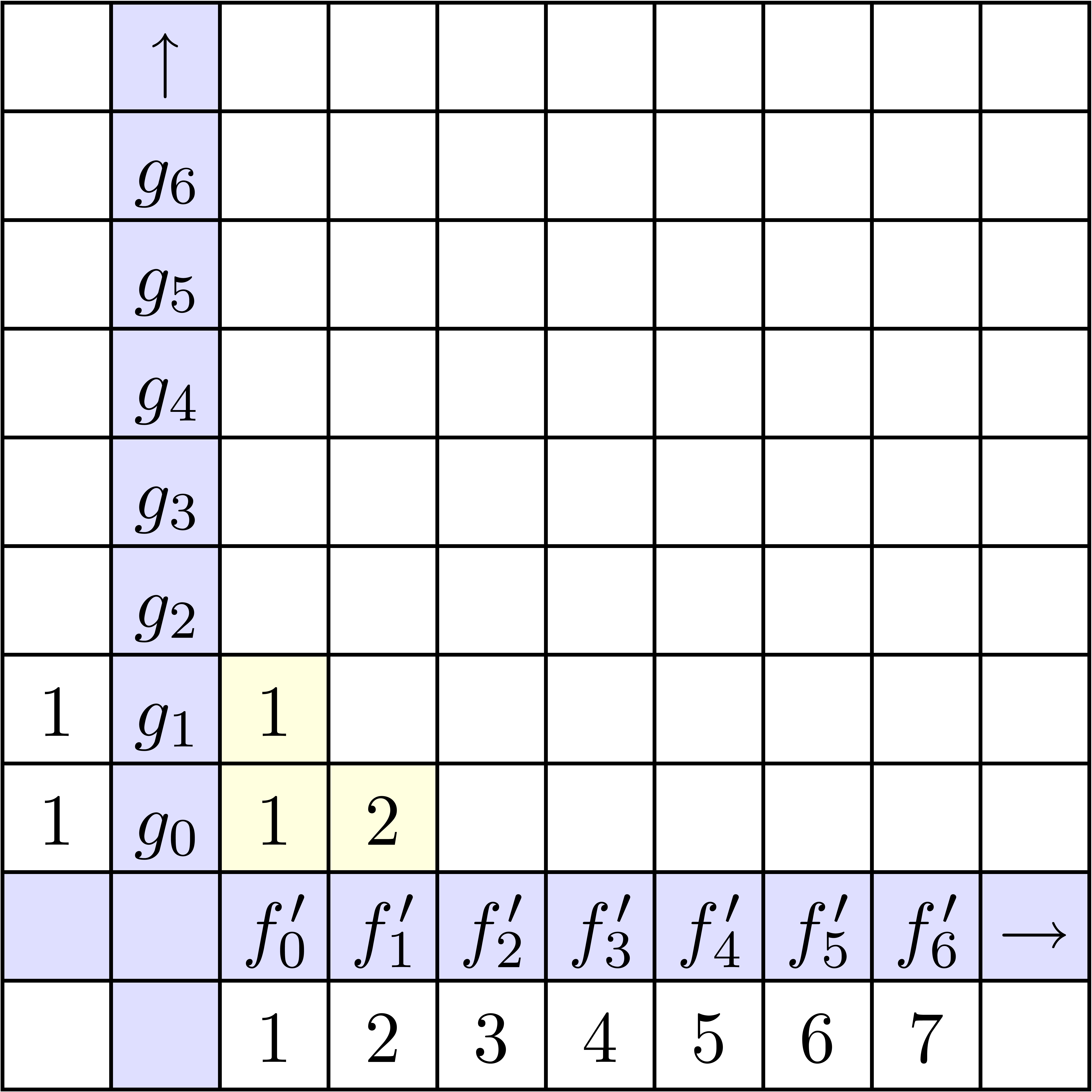
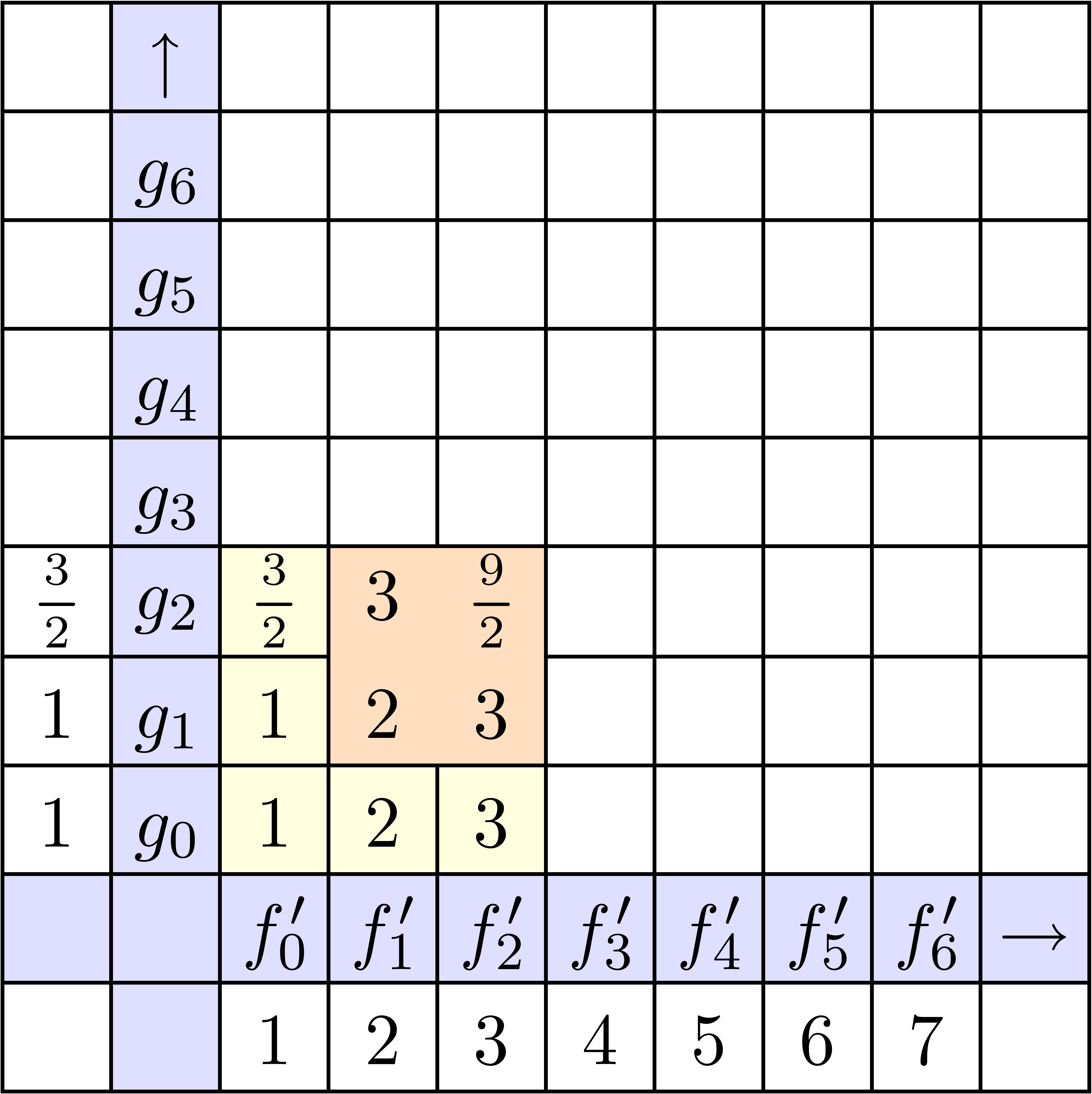
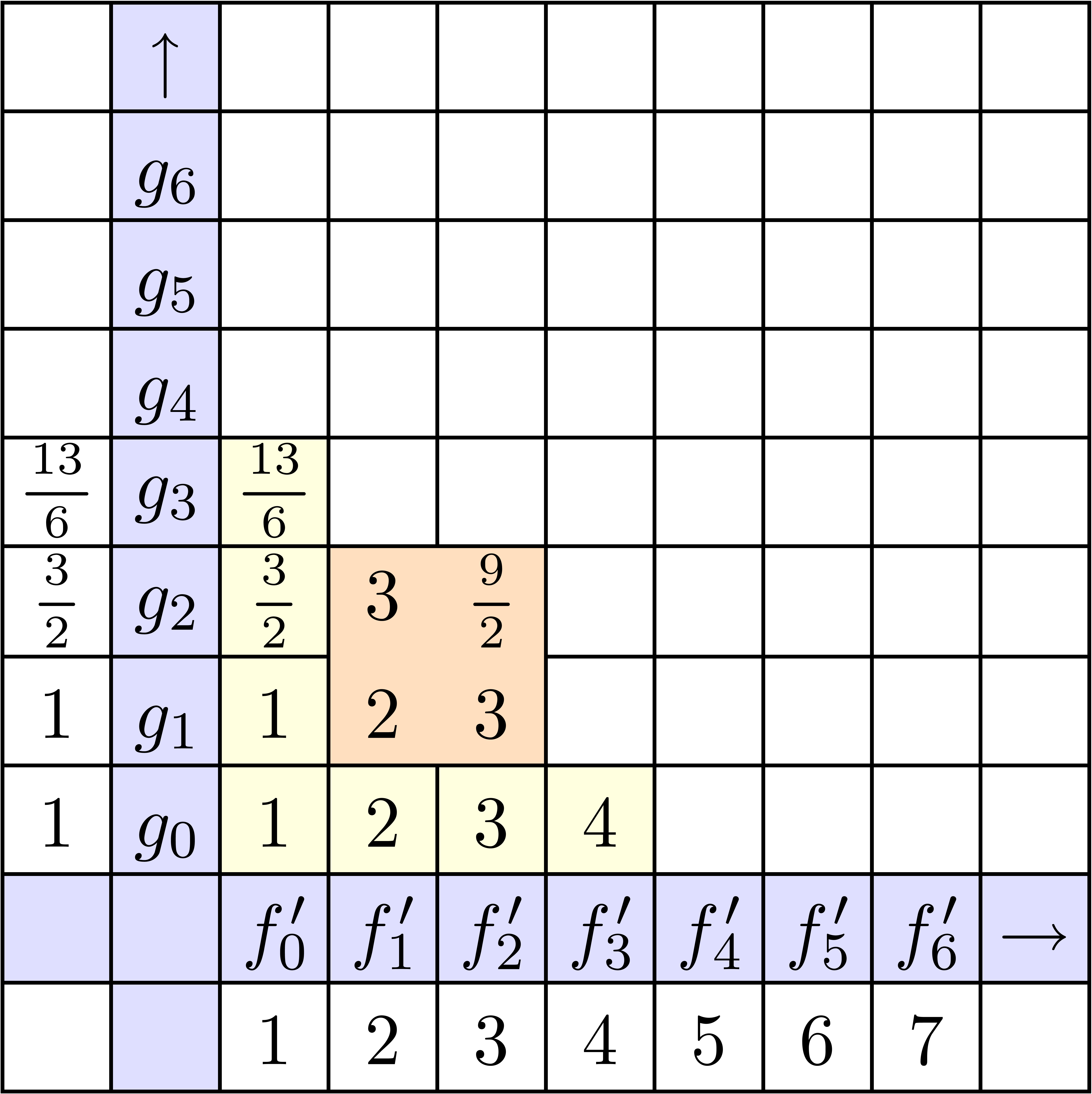
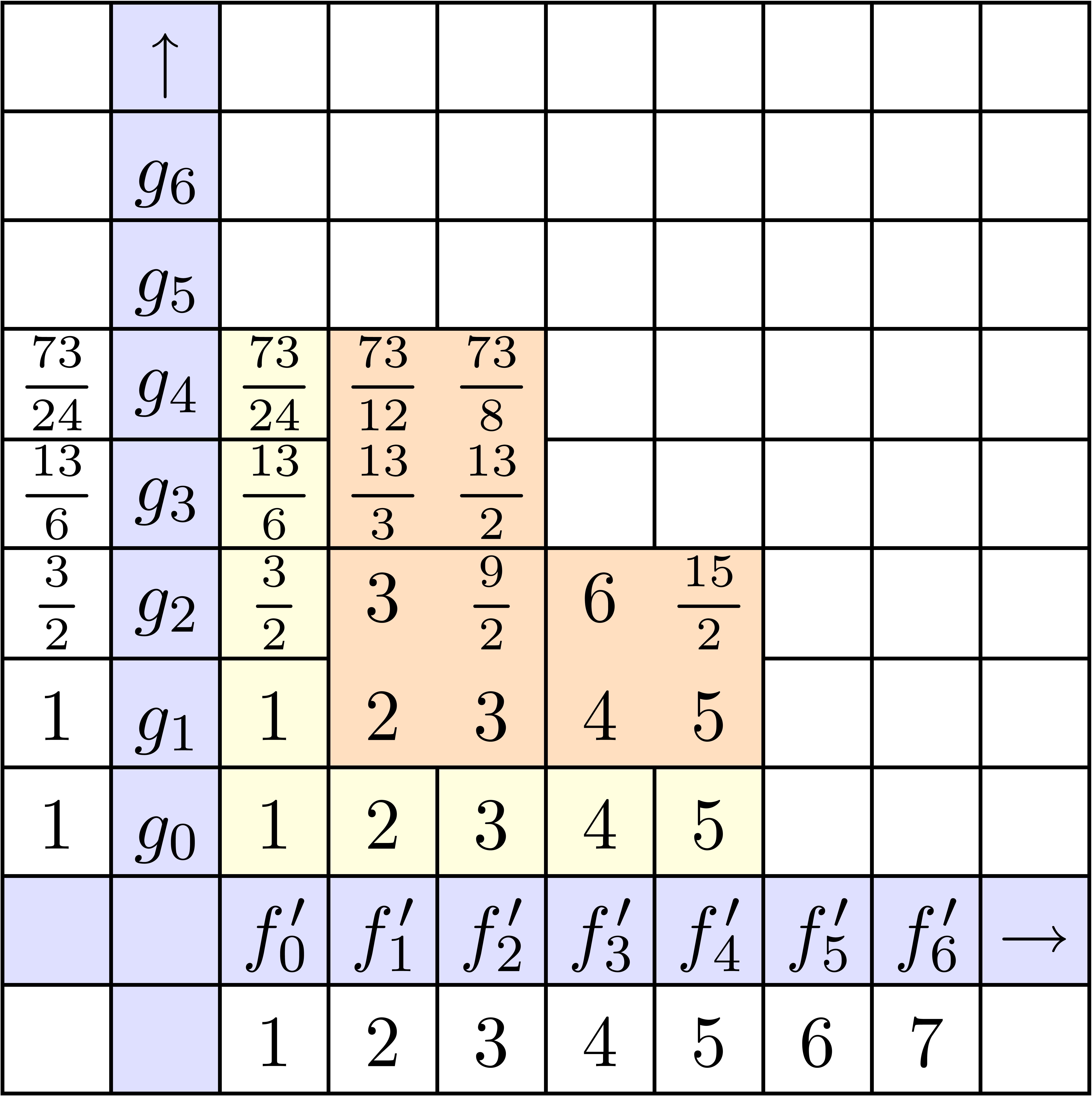
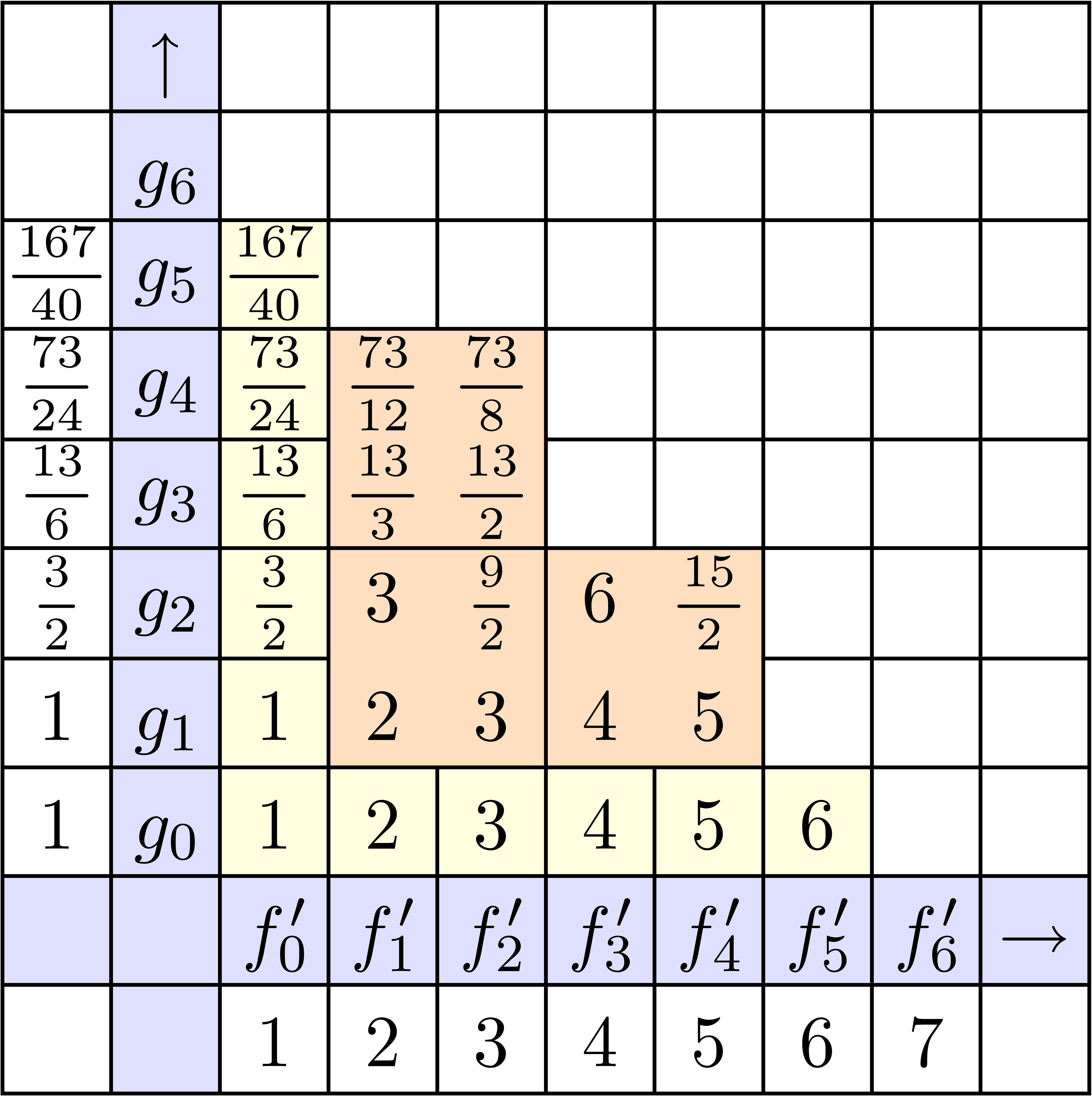
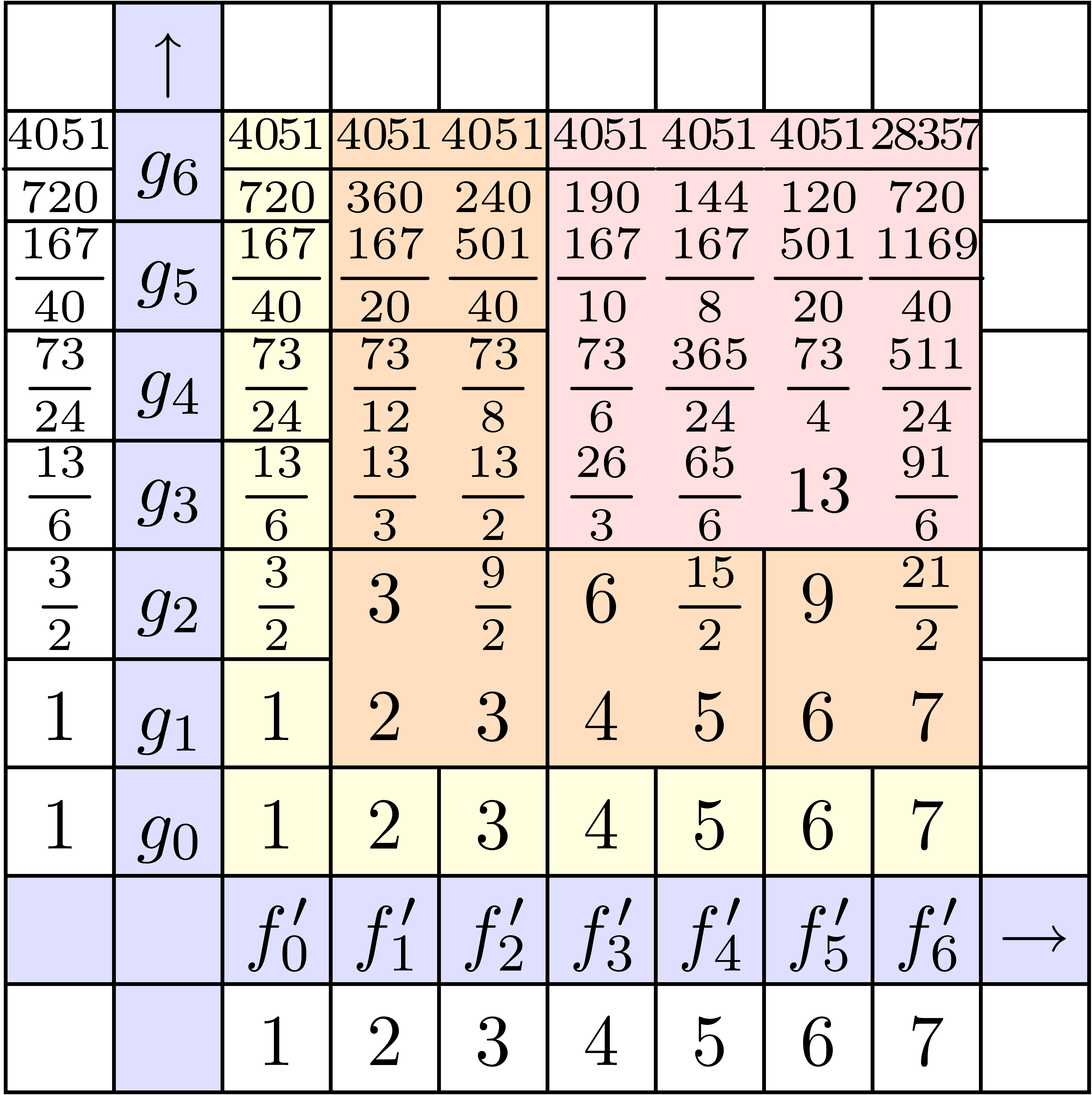







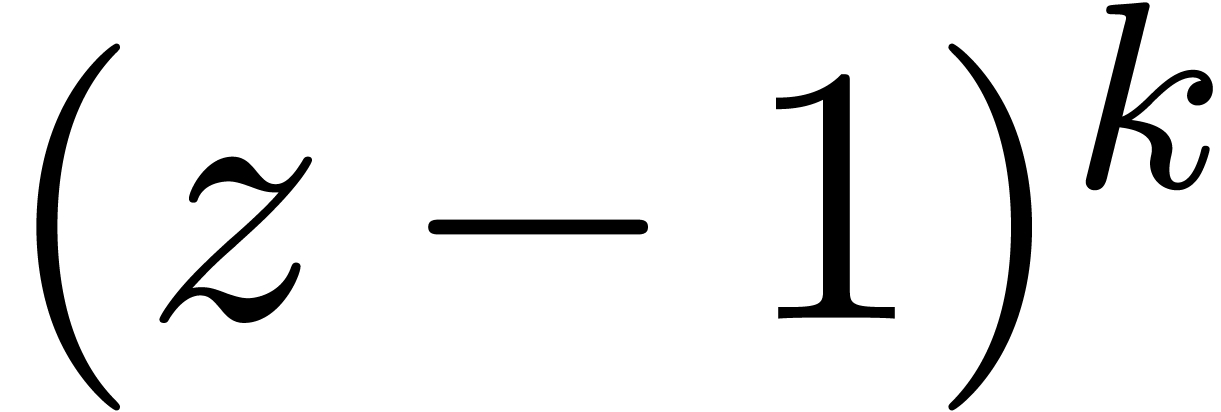 pour
pour  et en calculant avec une
précision de
et en calculant avec une
précision de  bits.
bits.
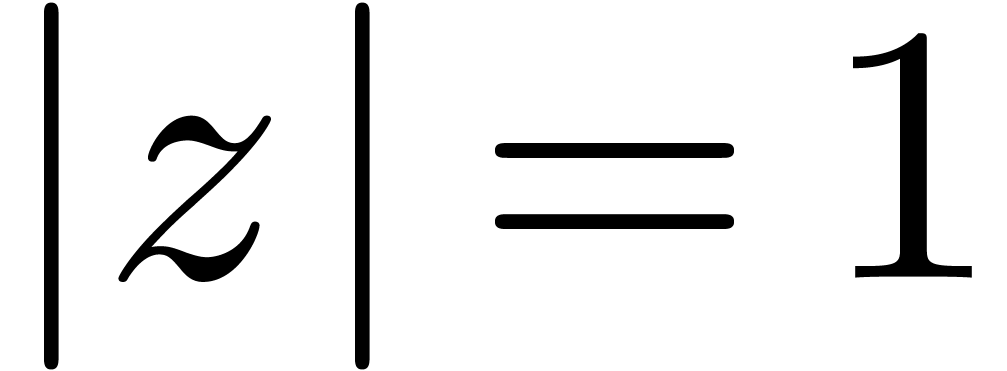 (à gauche) ou
(à gauche) ou 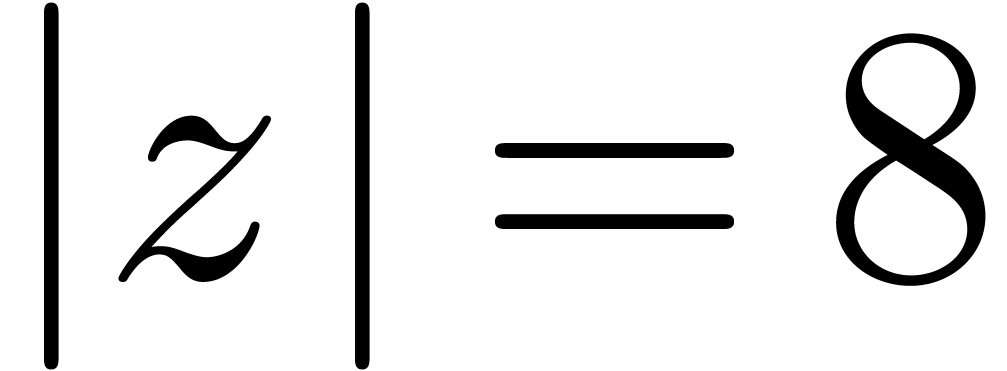 ,
,