| On the bit-complexity of sparse polynomial and series multiplication  |
|
| December 1, 2010 |
|
 . This work has
been partly supported by the French
. This work has
been partly supported by the French
In this paper we present various algorithms for multiplying
multivariate polynomials and series. All algorithms have been
implemented in the C++ libraries of the For the sparse representation, we present new softly linear algorithms for the product whenever the destination support is known, together with a detailed bit-complexity analysis for the usual coefficient types. As an application, we are able to count the number of the absolutely irreducible factors of a multivariate polynomial with a cost that is essentially quadratic in the number of the integral points in the convex hull of the support of the given polynomial. We report on examples that were previously out of reach.
|
It is classical that the product of two integers, or two univariate
polynomials over any ring, can be performed in softly linear
time for the usual dense representations [SS71, Sch77, CK91, Für07]. More
precisely, two integers of bit-size at most  can
be multiplied in time
can
be multiplied in time  on a Turing machine, and
the product of two univariate polynomials can be done with
on a Turing machine, and
the product of two univariate polynomials can be done with  arithmetic operations in the coefficient ring. These
algorithms are widely implemented in computer algebra systems and turn
out to perform well even for problems of medium sizes.
arithmetic operations in the coefficient ring. These
algorithms are widely implemented in computer algebra systems and turn
out to perform well even for problems of medium sizes.
Concerning multivariate polynomials and series less effort has been dedicated towards such fast algorithms and implementations. One of the difficulties is that the polynomials and series behave differently according to their support. In this paper we propose several algorithms that cover a wide range of situations.
Representations of multivariate polynomials and series with their respective efficiencies have been discussed since the early ages of computer algebra; for historical references we refer the reader to [Joh74, Sto84, DST87, CGL92]. The representation is an important issue which conditions the performance in an intrinsic way. It is customary to distinguish three main types of representations: dense, sparse, and functional.
A dense representation is made of a compact description of the support of the polynomial and the sequence of its coefficients. The main example concerns block supports – it suffices to store the coordinates of two opposite vertices. In a dense representation all the coefficients of the considered support are stored, even if they are zero. In fact, if a polynomial has only a few of non-zero terms in its bounding block, we shall prefer to use a sparse representation which stores only the sequence of the non-zero terms as pairs of monomials and coefficients. Finally, a functional representation stores a function that can produce values of the polynomials at any given points. This can be a pure blackbox (which means that its internal structure is not supposed to be known) or a specific data structure such as straight-line programs (see Chapter 4 of [BCS97] for instance).
For dense representations with block supports, it is classical that the algorithms used for the univariate case can be naturally extended: the naive algorithm, Karatsuba's algorithm, and even fast Fourier transforms [CT65, SS71, CK91, Hoe04] can be applied recursively in each variable, with good performance. Another classical approach is the Kronecker substitution which reduces the multivariate product to one variable only. We refer the reader to classical books such as [BP94, GG02]. When the number of the variables is fixed and the partial degrees tend to infinity, these techniques lead to softly linear costs.
For sparse representations, the naive school book algorithm, that performs all the pairwise term products, is implemented in all the computer algebra systems and several other dedicated libraries. It is a matter of constant improvements in terms of data structures, memory management, vectorization and parallelization [Yan98, GL06, MP07, MP09a, MP09b] (see [Fat03] for some comparisons between several implementations available in 2003).
Multivariate dichotomic approaches have not been discussed much in the
literature. Let us for instance consider Karatsuba's algorithm (see [GG02, Chapter 8] for details). With one variable  only, the usual way the product is performed begins with
splitting
only, the usual way the product is performed begins with
splitting  and
and  into
into 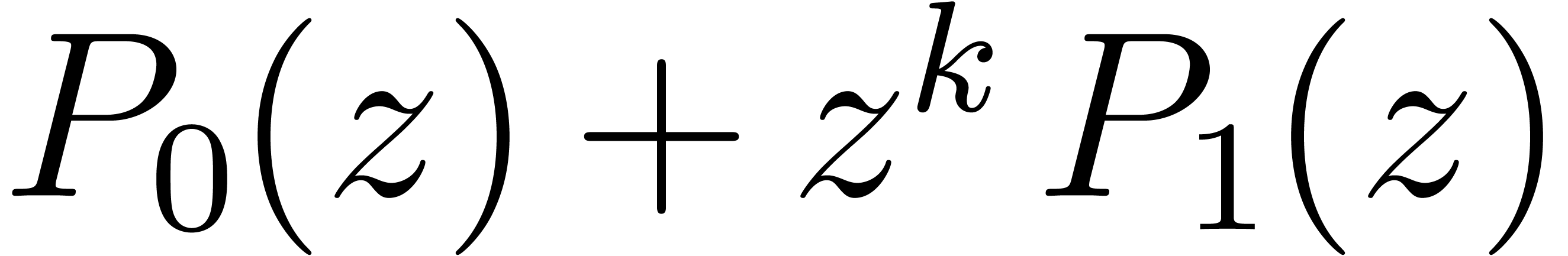 and
and  ,
respectively, where
,
respectively, where 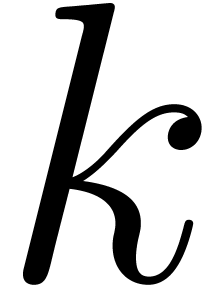 and
and  are half of the degrees of and . Then we compute recursively
are half of the degrees of and . Then we compute recursively 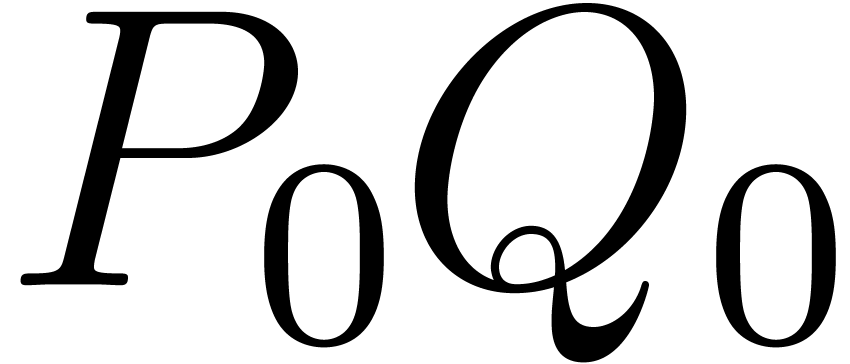 ,
, 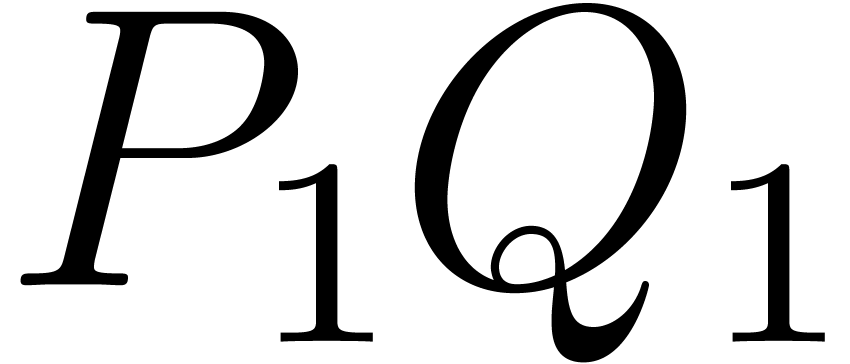 ,
and
,
and 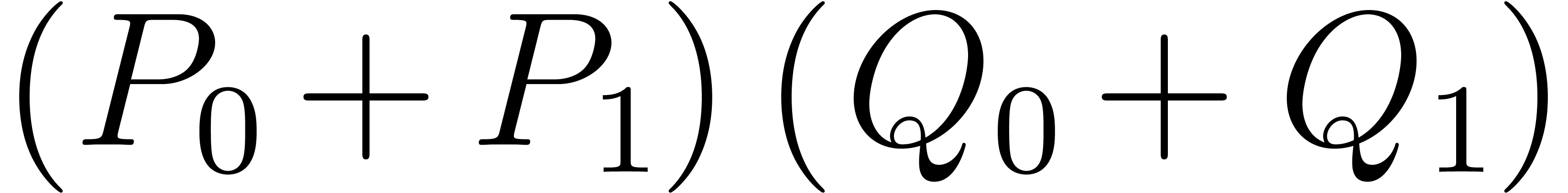 , and perform suitable
linear combinations to recover the result. This approach is efficient in
the dense block case because the sizes of the input are correctly
divided in each recursive call of the product. In the sparse case this
phenomenon hardly occurs, and it is commonly admitted that this approach
is useless (see for instance [Fat03, Section 3] or [MS04] for a cost analysis). Nevertheless block versions have
been suggested to be useful with several variables in [Hoe02,
Section 6.3.3], and refined in [Hoe06, Section 6], but
never tested in practice. Further improvements are under progress in [HL10].
, and perform suitable
linear combinations to recover the result. This approach is efficient in
the dense block case because the sizes of the input are correctly
divided in each recursive call of the product. In the sparse case this
phenomenon hardly occurs, and it is commonly admitted that this approach
is useless (see for instance [Fat03, Section 3] or [MS04] for a cost analysis). Nevertheless block versions have
been suggested to be useful with several variables in [Hoe02,
Section 6.3.3], and refined in [Hoe06, Section 6], but
never tested in practice. Further improvements are under progress in [HL10].
In the sparse case, the product can be decomposed into two subproblems:
(1) determine the support of  from those of and , (2)
compute the coefficients of .
These are independent in terms of complexity and applications. The
computation of the support is the most expensive part, that can be seen
as a special case of an even more difficult problem called sparse
interpolation. This is a cornerstone in higher level routines such
as the greatest common divisor: to compute the g.c.d. of
two polynomials in the sparse representation it is interesting to
specialize all the variables but one at several points, compute as many
univariate g.c.d.s, and interpolate the result without a
precise idea of the support (see for instance [KT90]). We
are not dealing with this problem in this paper, but most of the
literature in this topic hides fast algorithms for the sparse product of
polynomials as soon as the destination support is known, as explained in
the next paragraphs.
from those of and , (2)
compute the coefficients of .
These are independent in terms of complexity and applications. The
computation of the support is the most expensive part, that can be seen
as a special case of an even more difficult problem called sparse
interpolation. This is a cornerstone in higher level routines such
as the greatest common divisor: to compute the g.c.d. of
two polynomials in the sparse representation it is interesting to
specialize all the variables but one at several points, compute as many
univariate g.c.d.s, and interpolate the result without a
precise idea of the support (see for instance [KT90]). We
are not dealing with this problem in this paper, but most of the
literature in this topic hides fast algorithms for the sparse product of
polynomials as soon as the destination support is known, as explained in
the next paragraphs.
For coefficient fields of characteristic zero, it is proved in [CKL89] that the product of two polynomials in sparse representation can be computed in softly linear time in terms of operations over the ground field, once the destination support is known. This algorithm uses fast evaluation and interpolation at suitable points built from prime numbers. Unfortunately, the method hides an expensive growth of intermediate integers involved in the linear transformations, which prevents the algorithm from being softly linear in terms of bit-complexity. Indeed this algorithm was essentially a subroutine of the sparse interpolation algorithm of [BT88], with the suitable set of evaluation points borrowed from [GK87]. For more references on sparse interpolation in characteristic zero we refer the reader to [KL88, KLW90, KLL00, GS09].
For coefficients in a finite field, Grigoriev, Karpinski and Singer designed a specific sparse interpolation algorithm in [GKS90], which was then improved in [Wer94, GKS94]. These algorithms are based on special point-sets for evaluation and interpolation, built from a primitive element of the multiplicative subgroup of the ground field. As in [CKL89] a fast product might have been be deduced from this work, but to the best of our knowledge this has never been done until now.
The main contributions of this paper are practical algorithms for faster computations with multivariate polynomials and series. In Sections 2 and 3 we describe naive algorithms for the dense and sparse representations of polynomials, we recall the Kronecker substitution technique, and discuss bit-complexities with regards to practical performances. We show that our implementations are competitive with the best other software, and we discuss thresholds between sparse and dense representations. Section 4 is devoted to naive algorithms for power series.
In Section 5, we turn to the sparse case. Assuming the destination support to be known, we will focus on the computation of the coefficients. Our approach is similar to [CKL89], but relies on a different kind of evaluation points, which first appeared in [GKS90]. The fast product from [CKL89], which only applies in characteristic zero, suffers from the swell of the intermediate integers. In contrast, our method is primarily designed for finite fields. For integer coefficients we either rely on large primes or the multi-modular methods to deduce new bit-complexity bounds. Section ? is devoted to the bit-complexity for the most frequently encountered coefficient rings.
Of course, our assumption that the support of the product is known is very strong: in many cases, it can be feared that the computation of this support is actually the hardest part of the multiplication problem. Nevertheless, the computation of the support is negligible in many cases:
The coefficients of the polynomials are very large: the support can be computed with the naive algorithms, whereas the coefficients are deduced with the fast ones. A variant is when we need to compute the products of many pairs of polynomials with the same supports.
The destination support can be deduced by a simple geometric argument. A major example concerns dense formal power series, truncated by total degree. In Section 6 we adapt the method of [LS03] to our new evaluation-interpolation scheme. The series product of [LS03] applies in characteristic zero only and behaves badly in terms of bit-complexity. Our approach again starts with coefficient fields of positive characteristic and leads to much better bit-costs and useful implementations.
When searching for factors of a multivariate polynomial , the destination support is precisely the
support of . In Section
7 we present a new algorithm for counting the number of
absolutely irreducible factors of .
We will prove a new complexity bound in terms of the size of the
integral hull of the support of ,
and report on examples that were previously out of reach. In a
future work, we hope to extend our method into a full algorithm for
factoring .
Our fast product can be expected to admit several other applications, such as polynomial system solving, following [CKL89], but we have not tried.
Most of the algorithms presented in this paper have been implemented in
the C++ library multimix of the free
computer algebra system
In this section we recall several classical algorithms for computations with dense multivariate polynomials, using the so called “block representation”. We will also analyze the additional bit-complexity due to operations on the exponents.
The algorithms of this section do not depend on the type of the
coefficients. We let  be an effective ring, which
means that all ring operations can be performed by algorithm. We will
denote by
be an effective ring, which
means that all ring operations can be performed by algorithm. We will
denote by 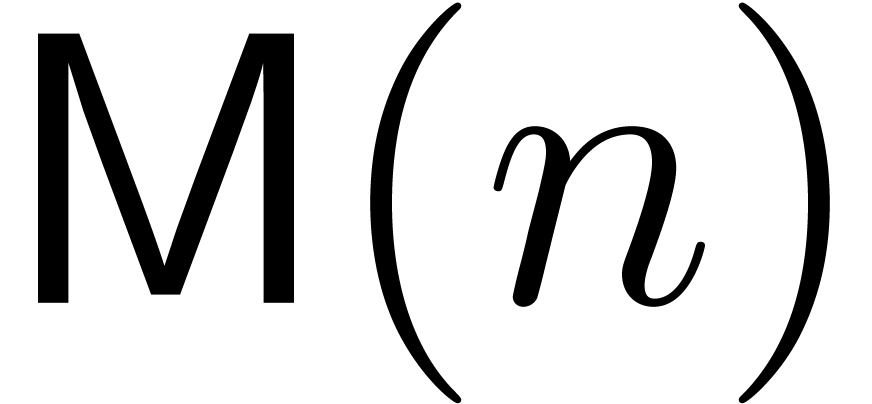 the cost for multiplying two
univariate polynomials of degree ,
in terms of the number of arithmetic operations in
the cost for multiplying two
univariate polynomials of degree ,
in terms of the number of arithmetic operations in  . Similarly, we denote by
. Similarly, we denote by 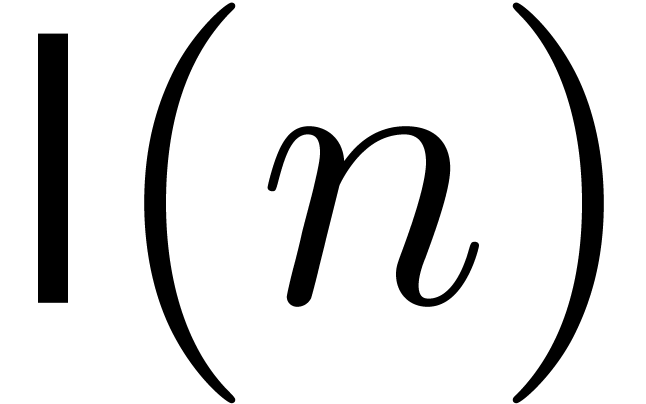 the time needed to multiply two integers of bit-size at most . One can take
the time needed to multiply two integers of bit-size at most . One can take 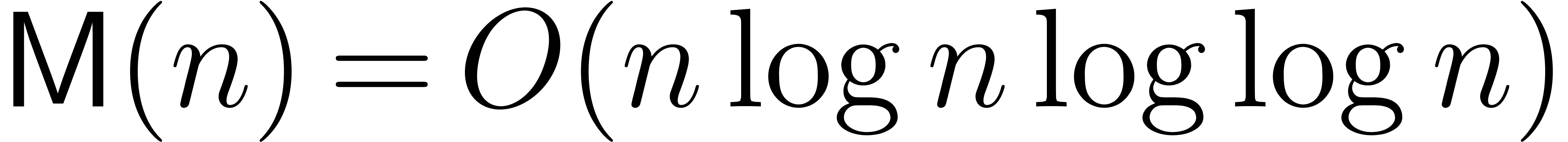 [CK91] and
[CK91] and  [Für07],
where
[Für07],
where 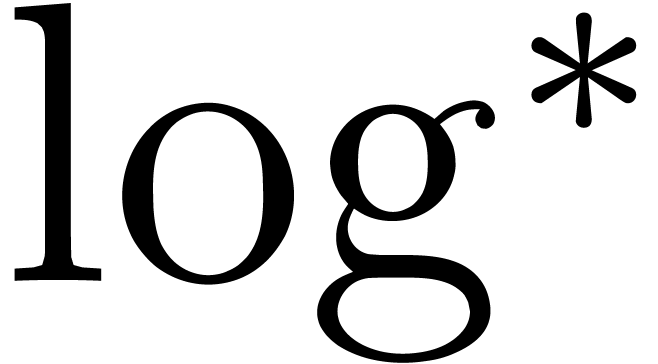 represents the iterated logarithm of . Throughout the paper, we will
assume that
represents the iterated logarithm of . Throughout the paper, we will
assume that 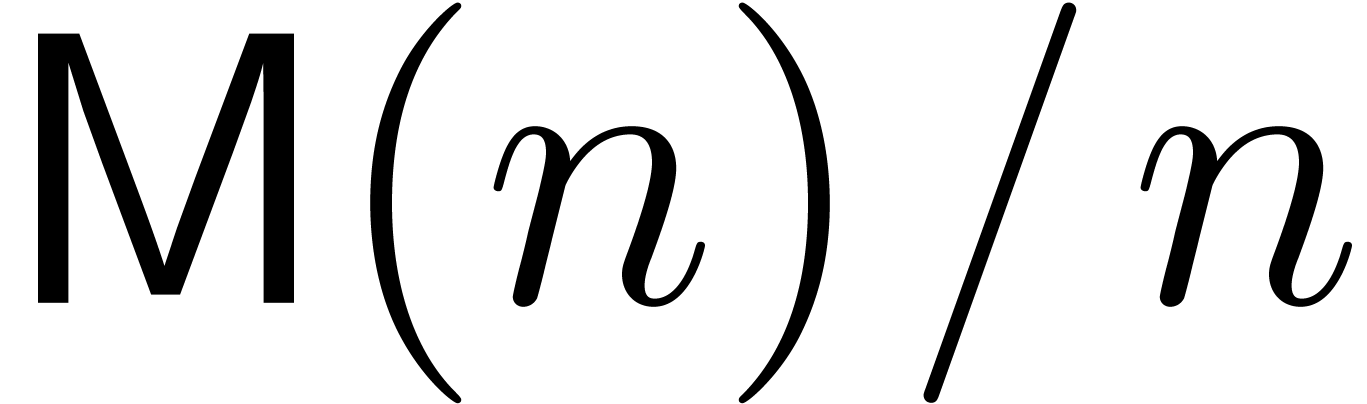 and
and 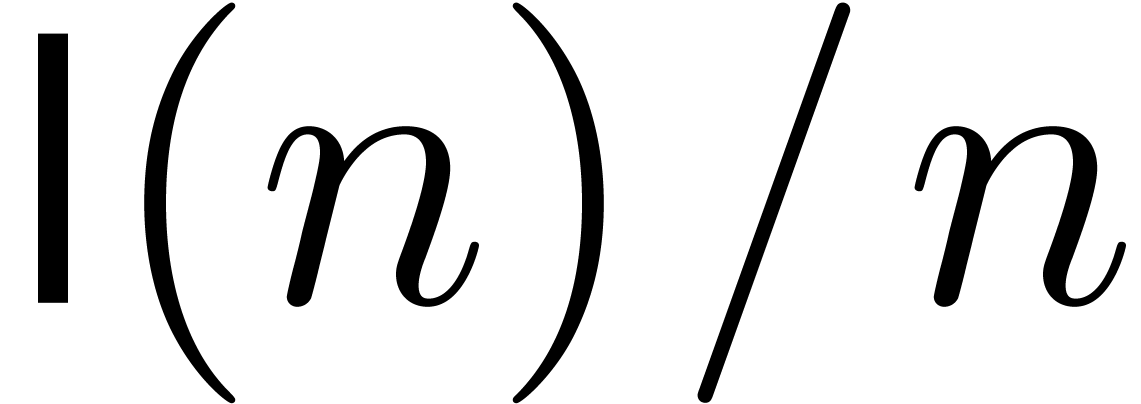 are
increasing. We also assume that
are
increasing. We also assume that  and
and  .
.
Any polynomial in 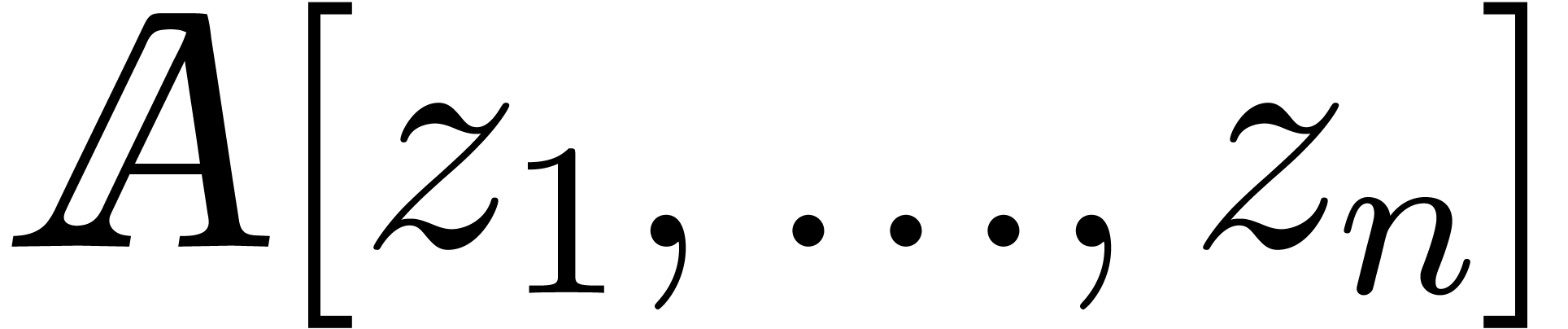 is
made of a sum of terms, with each term composed of a coefficient and an
exponent seen as a vector in
is
made of a sum of terms, with each term composed of a coefficient and an
exponent seen as a vector in  .
For an exponent
.
For an exponent  , the
monomial
, the
monomial  will be written
will be written  . For any
. For any 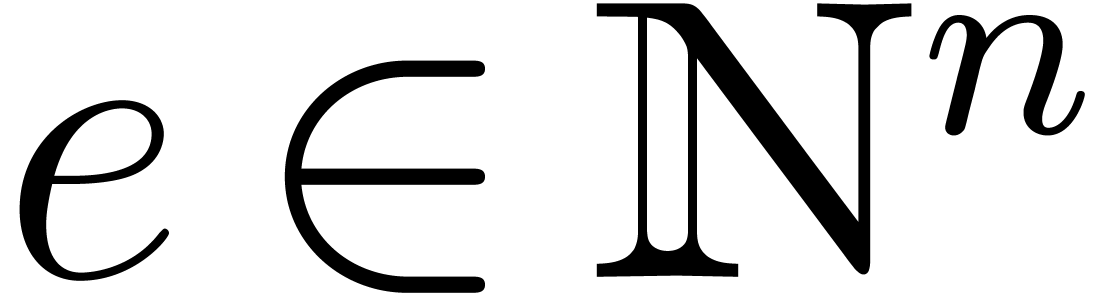 ,
we let
,
we let 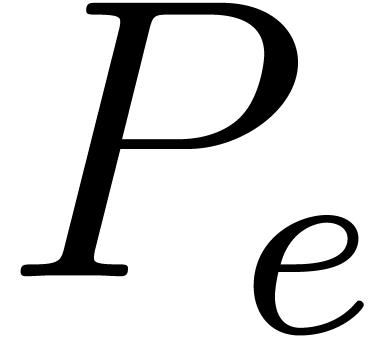 denote the coefficient of in . The
support of is defined by
denote the coefficient of in . The
support of is defined by 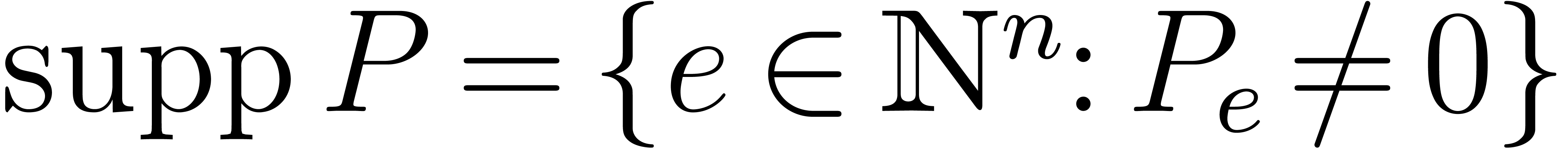 .
.
A block is a subset of of the form
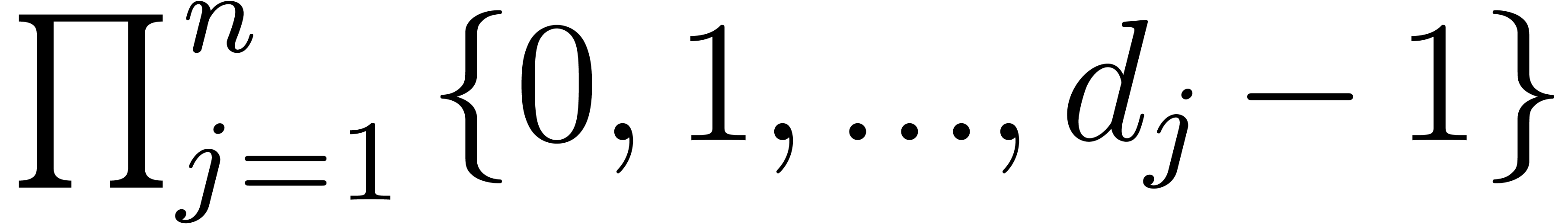 , with
, with 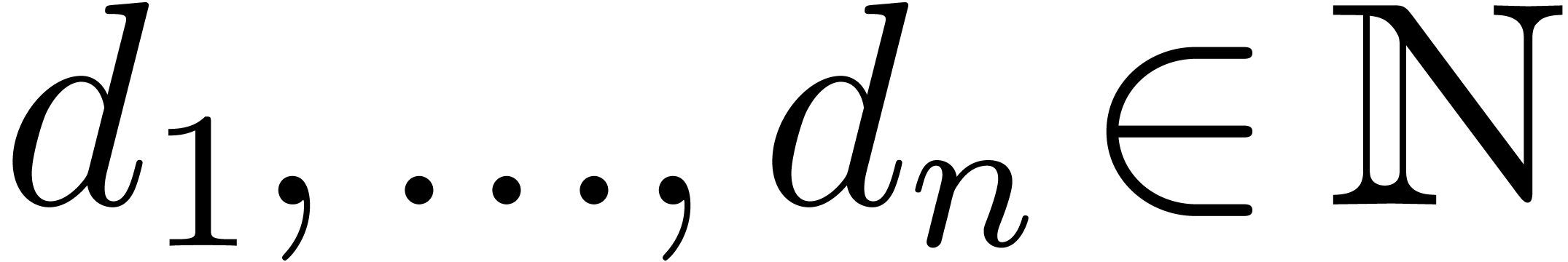 . Given a polynomial
. Given a polynomial  ,
its block support is the smallest block of the form
,
its block support is the smallest block of the form
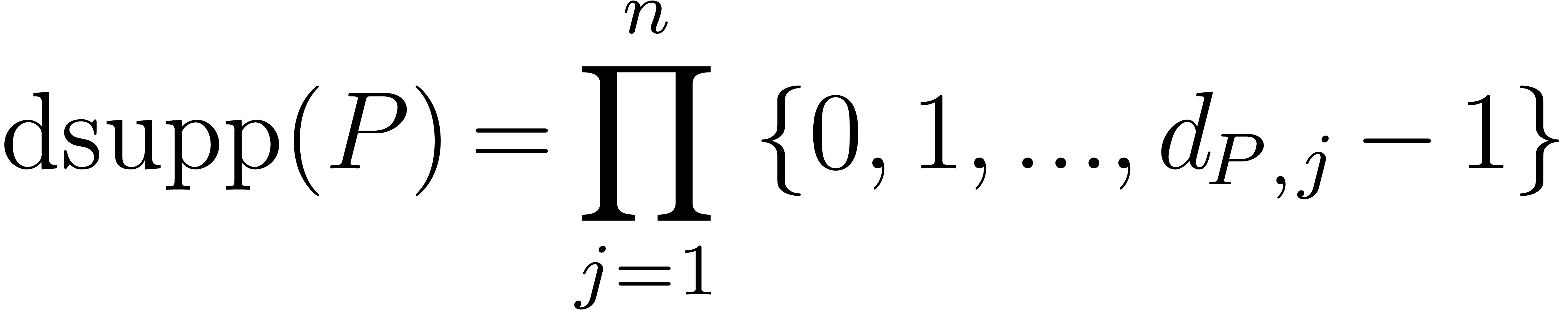
with 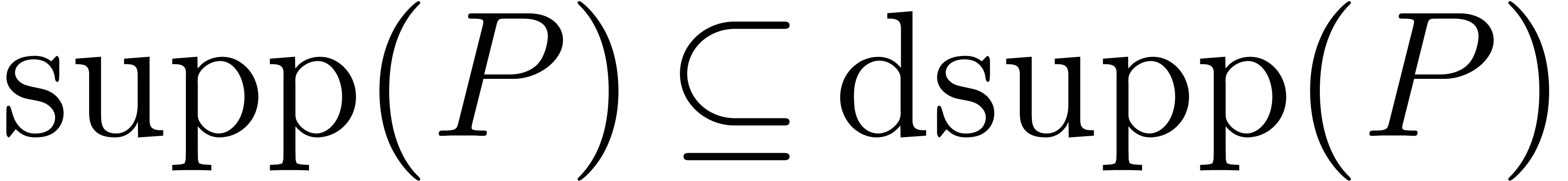 . In other words,
assuming
. In other words,
assuming 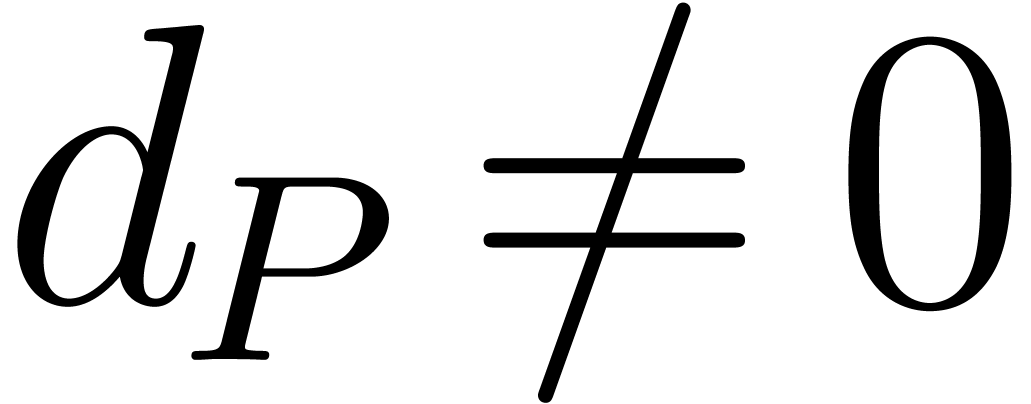 , we have
, we have 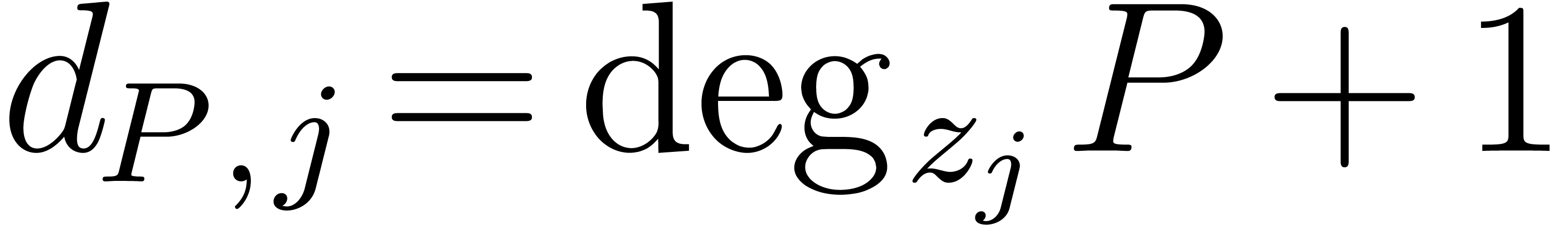 for
for 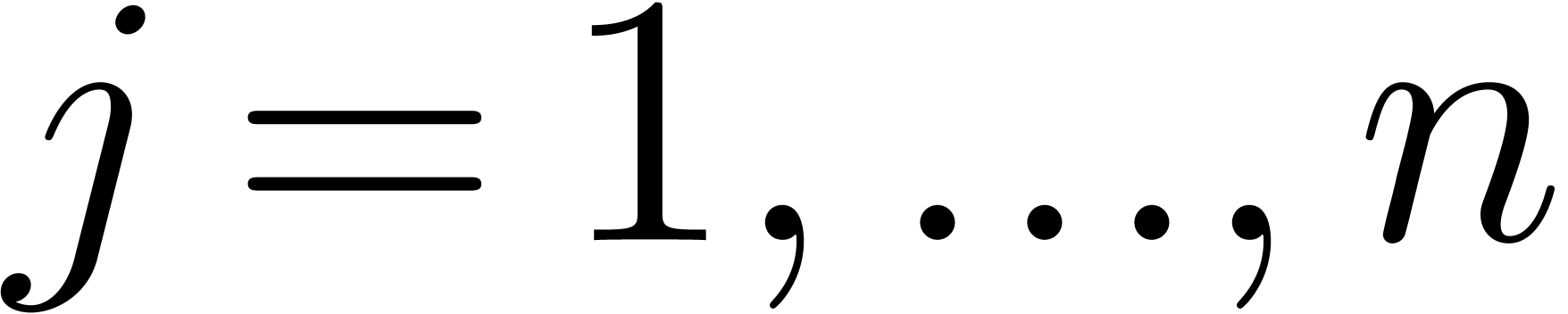 . We will
denote by
. We will
denote by 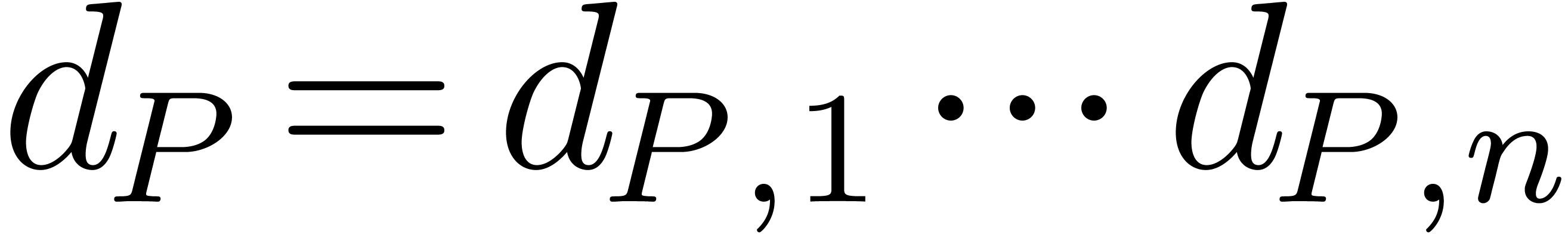 the cardinality of
the cardinality of 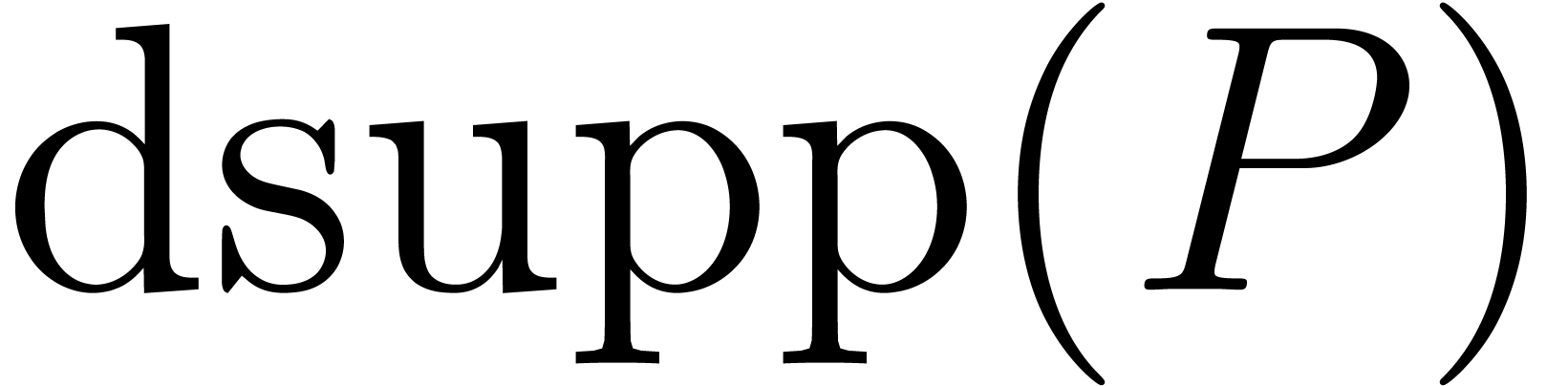 . In the dense block representation of
, we store the
. In the dense block representation of
, we store the 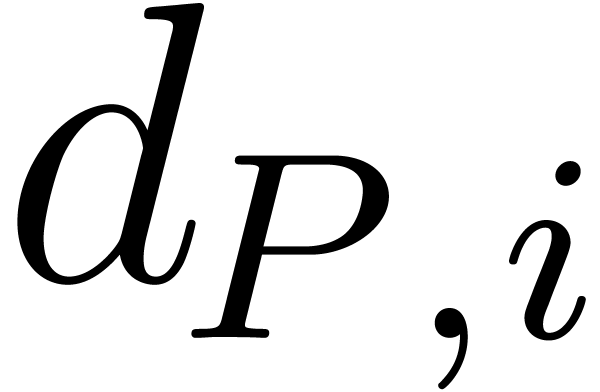 and all the coefficients corresponding to the monomials of
.
and all the coefficients corresponding to the monomials of
.
We order the exponents in the reverse lexicographic order, so that
In this way, the  -th exponent
-th exponent
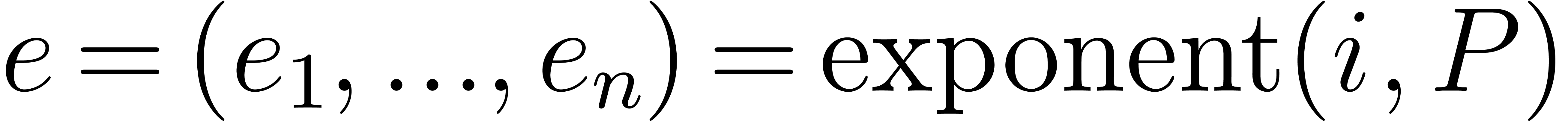 of is defined by
of is defined by
Conversely, we will write 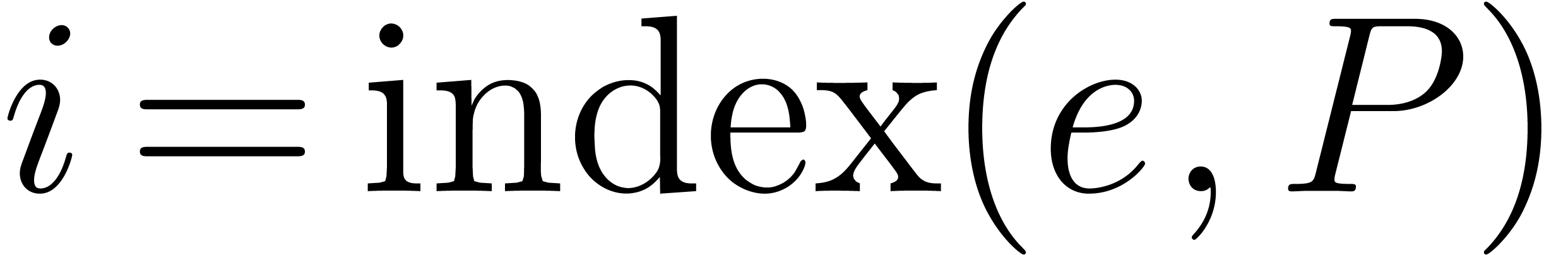 and call the index of
and call the index of  in . Notice that the index has values
from
in . Notice that the index has values
from  to
to 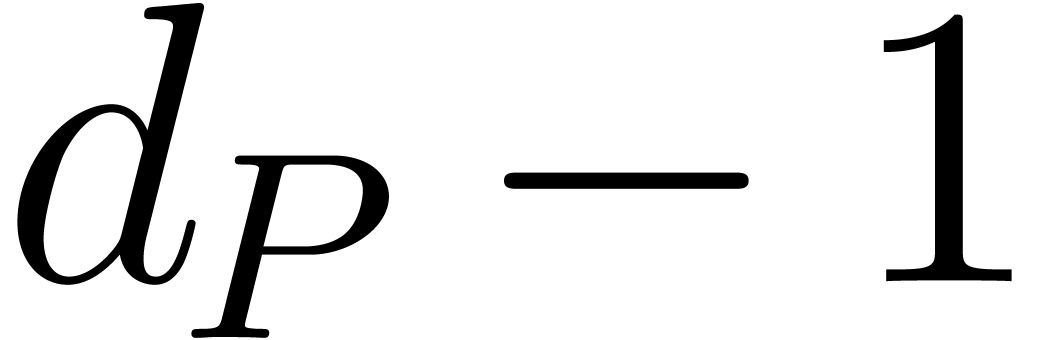 .
The coefficient of the exponent of index will be written
.
The coefficient of the exponent of index will be written 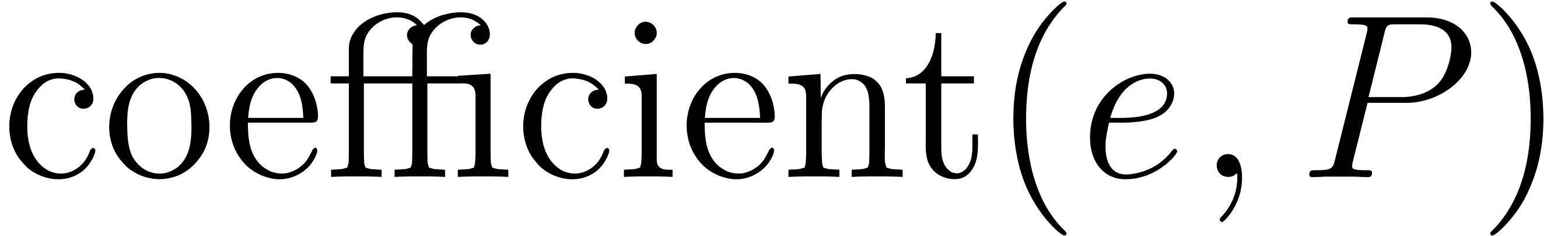 or
or  , according to the context.
, according to the context.
In the cost analysis of the algorithms below, we shall take into account
the number of operations in but also the
bit-cost involved by the arithmetic operations with the exponents.
Let and be the two
polynomials that we want to multiply. Their product 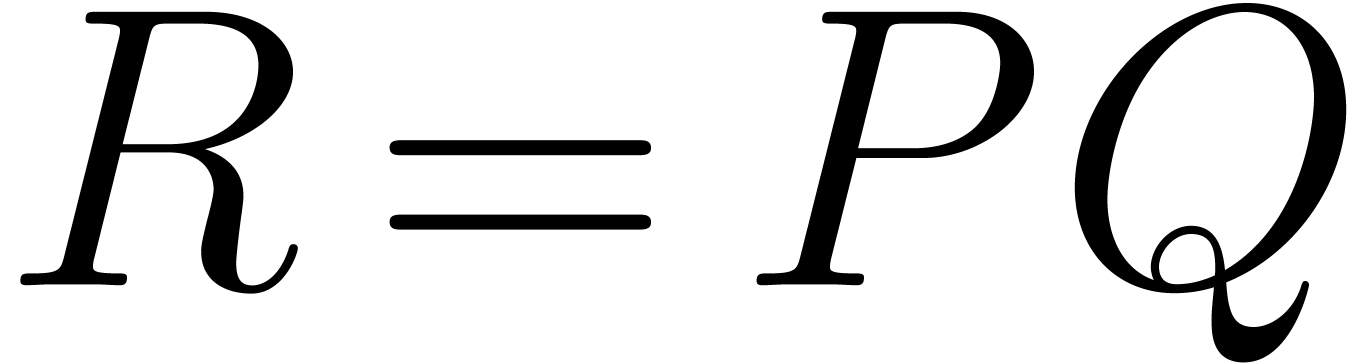 can be computed naively by performing the pairwise products of the terms
of and as follows:
can be computed naively by performing the pairwise products of the terms
of and as follows:
 of
of  and
and  can be computed using
can be computed using 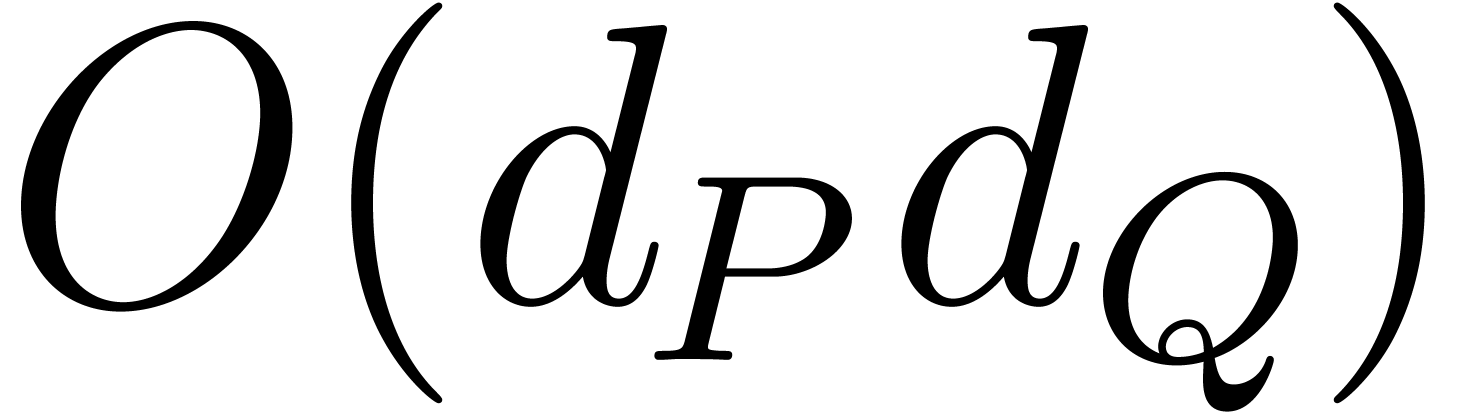 operations in
operations in  plus
plus 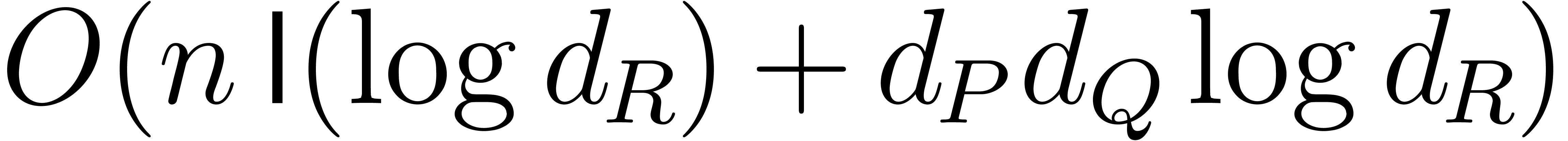 bit-operations.
bit-operations.
Proof. Before entering Algorithm 1
we compute all the 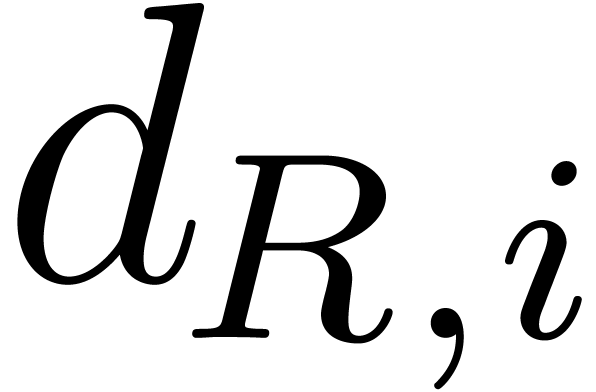 and discard all the variables
and discard all the variables
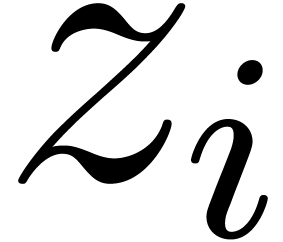 such that
such that  .
This takes no more that
.
This takes no more that 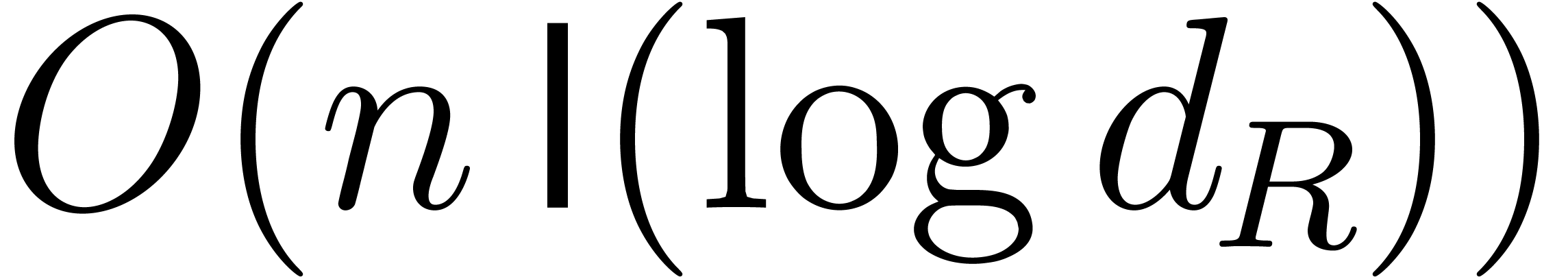 bit-operations. Then we
compute
bit-operations. Then we
compute 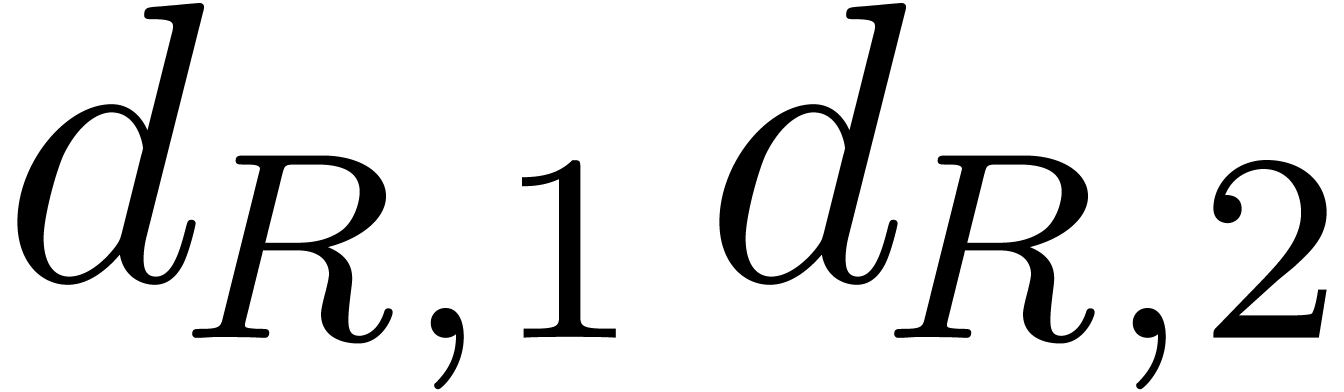 ,
, 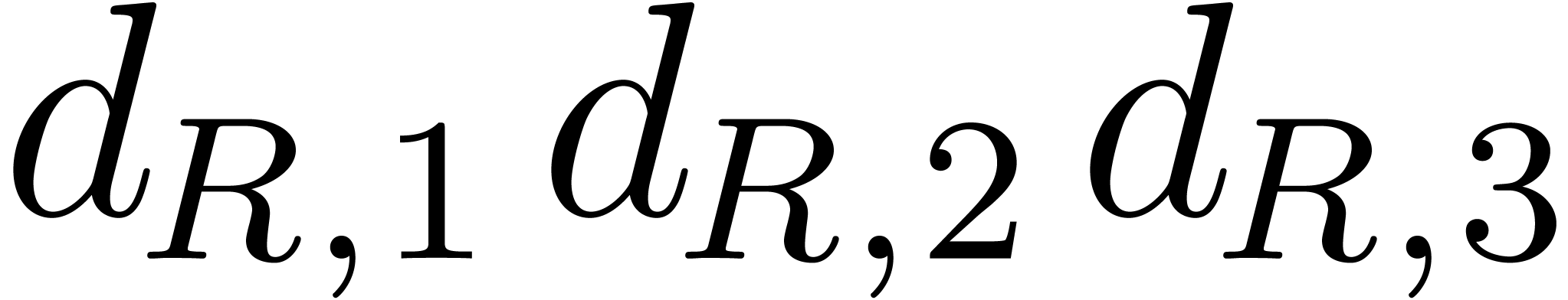 ,
,  ,
,
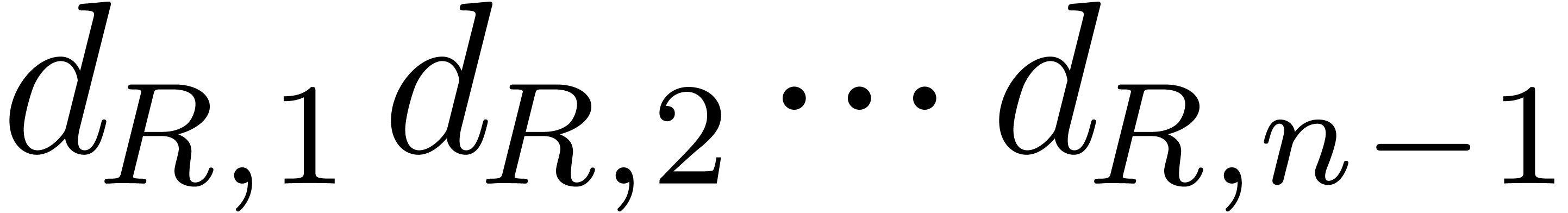 , as well as
, as well as 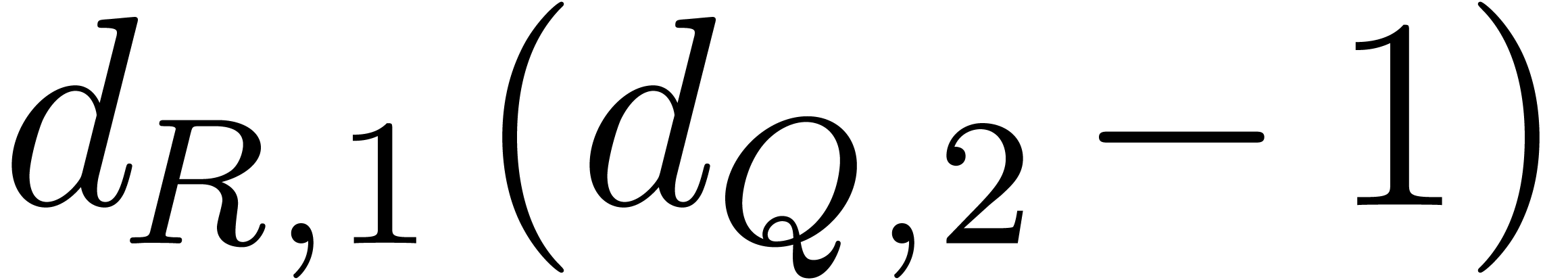 ,
, 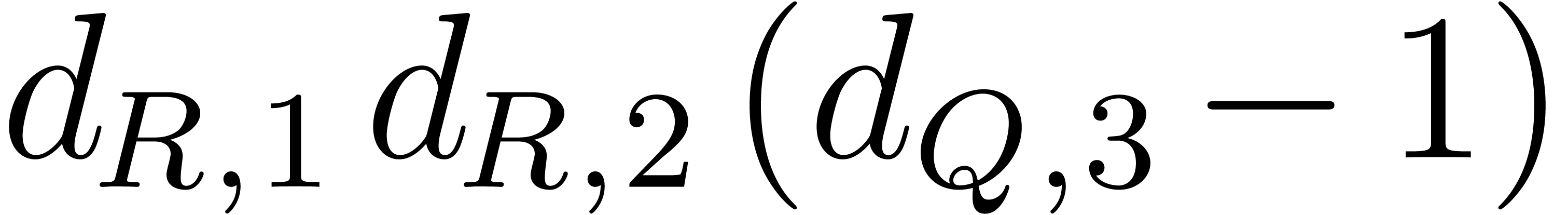 ,
,
,
, 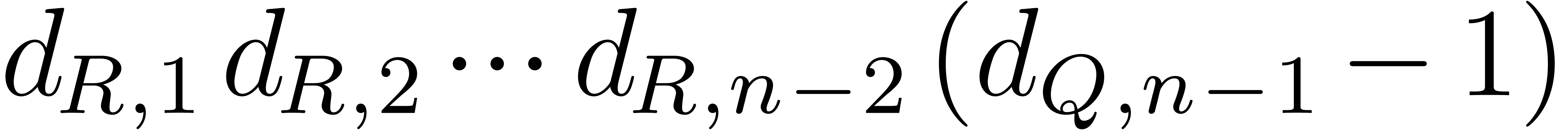 , and
, and 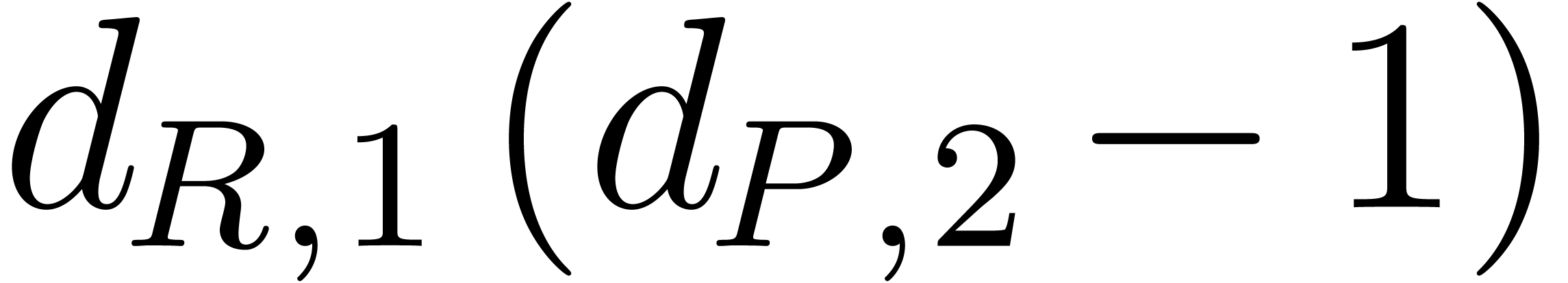 ,
,
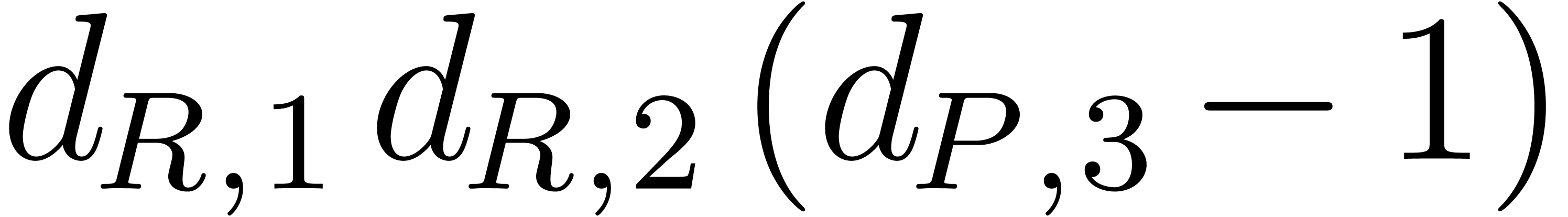 , ,
, , 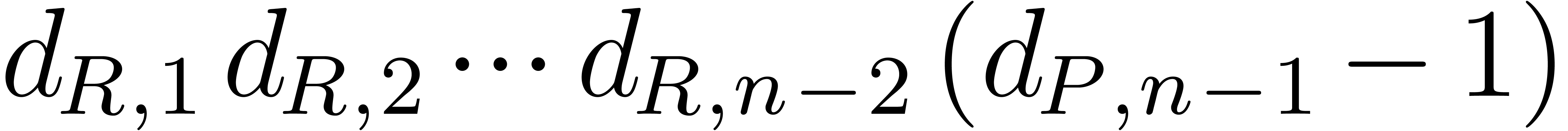 in
bit-operations.
in
bit-operations.
For computing efficiently the index  at step (i)
we make use of the enumeration strategy presented in Lemma 4
below. In fact, for each
at step (i)
we make use of the enumeration strategy presented in Lemma 4
below. In fact, for each  , we
compute
, we
compute 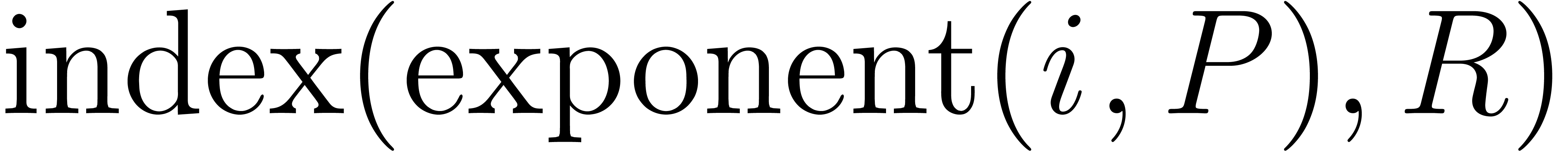 incrementally in the outer loop. Then
for each
incrementally in the outer loop. Then
for each  we also obtain
we also obtain 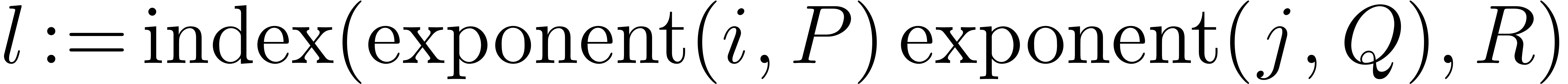 incrementally during the inner loop. The conclusion again follows from
Lemma 4.
incrementally during the inner loop. The conclusion again follows from
Lemma 4.
Notice that for small coefficients (in the field with two elements for instance), the bit-cost caused by the manipulation of the exponents is not negligible. This naive algorithm must thus be programmed carefully to be efficient with many variables in small degree.
For running efficiently over all the monomials of the source and the destination supports we use the following subroutine:
Input: 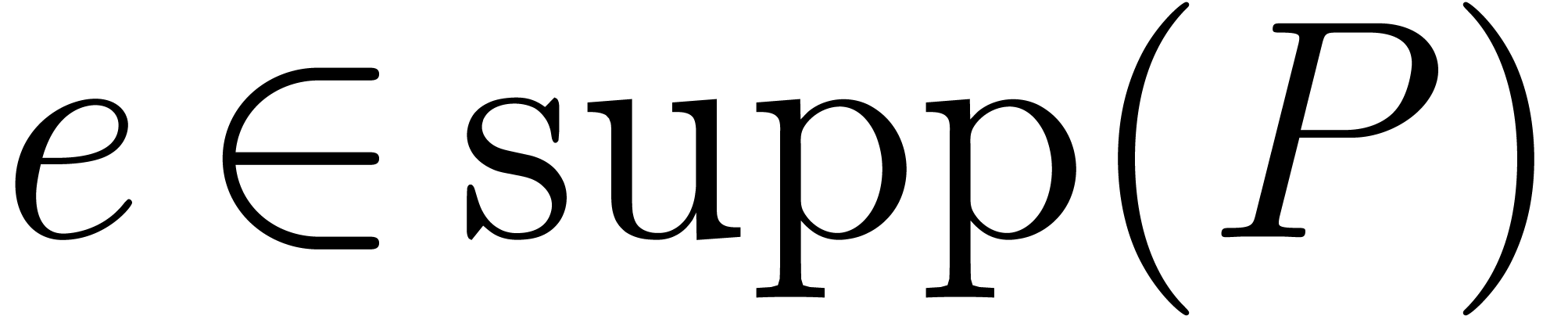 ,
, 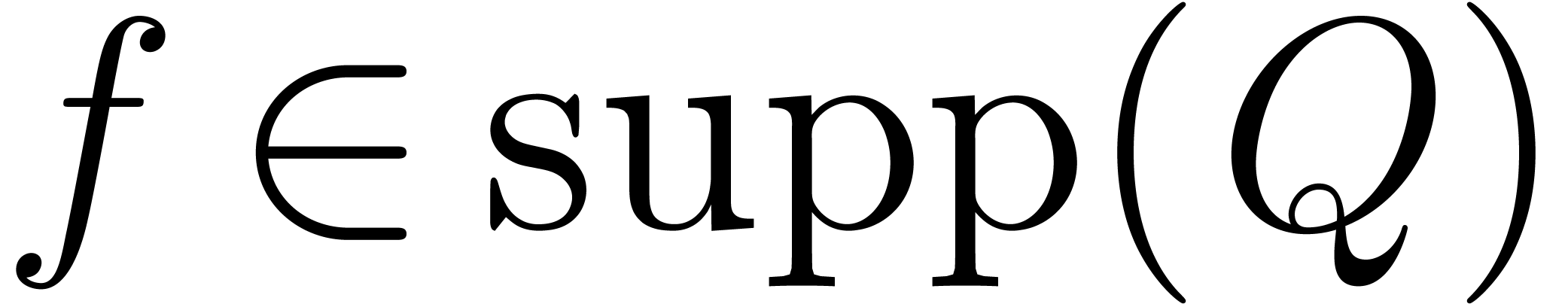 , and the index
, and the index 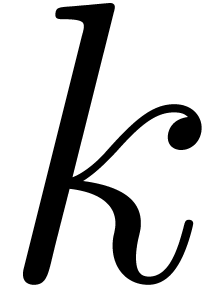 of
of  in
in 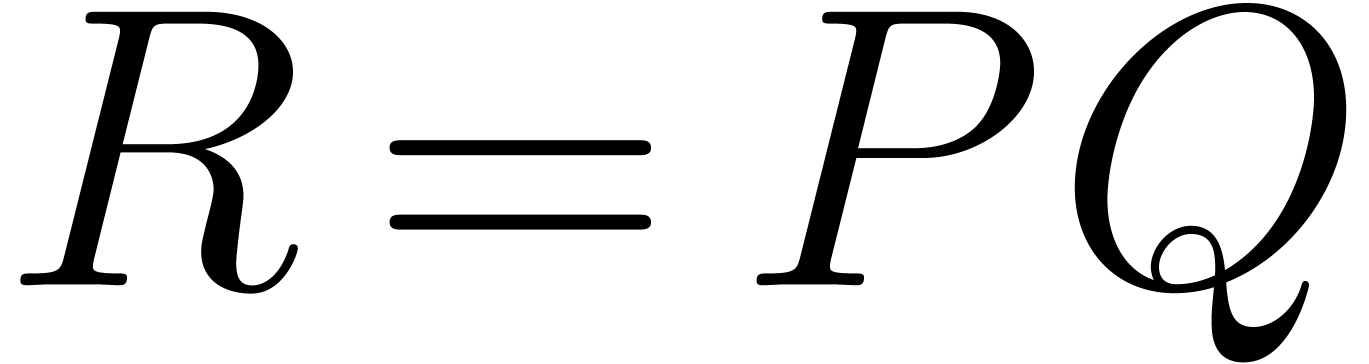 .
.
Output:  , and
, and
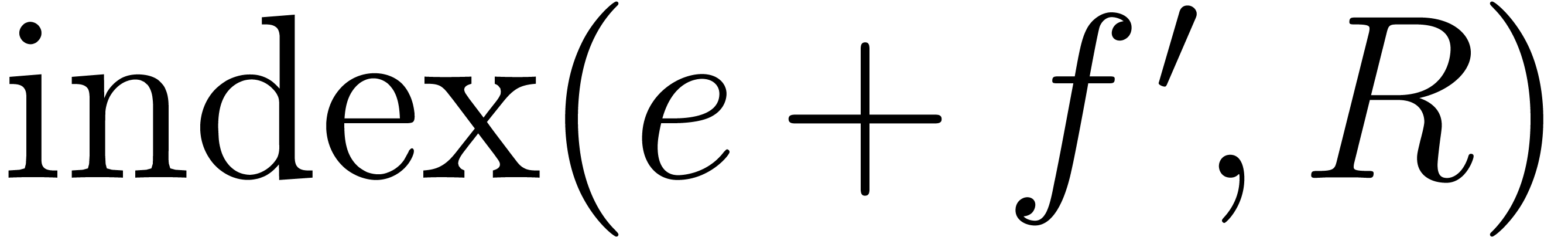 .
.
Let  ; Let
; Let  ;
;
For from  to do:
to do:
if 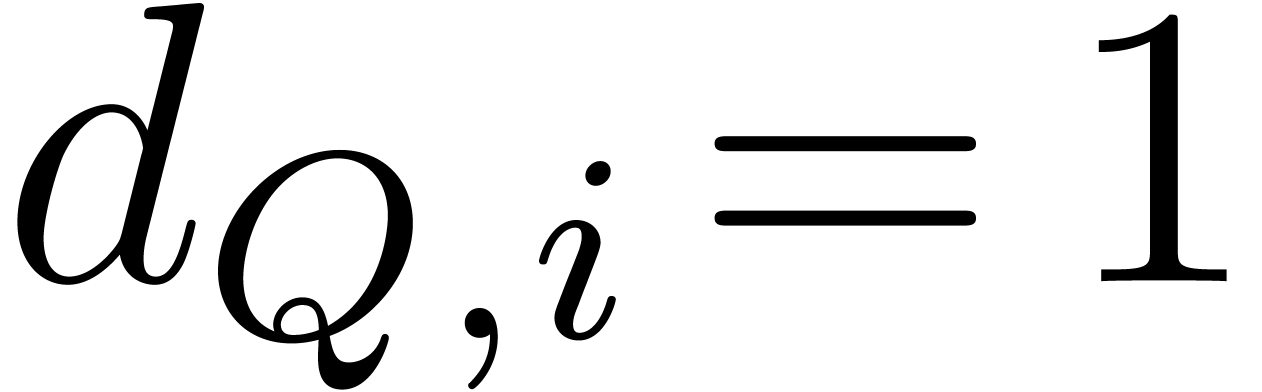 then continue;
then continue;
if 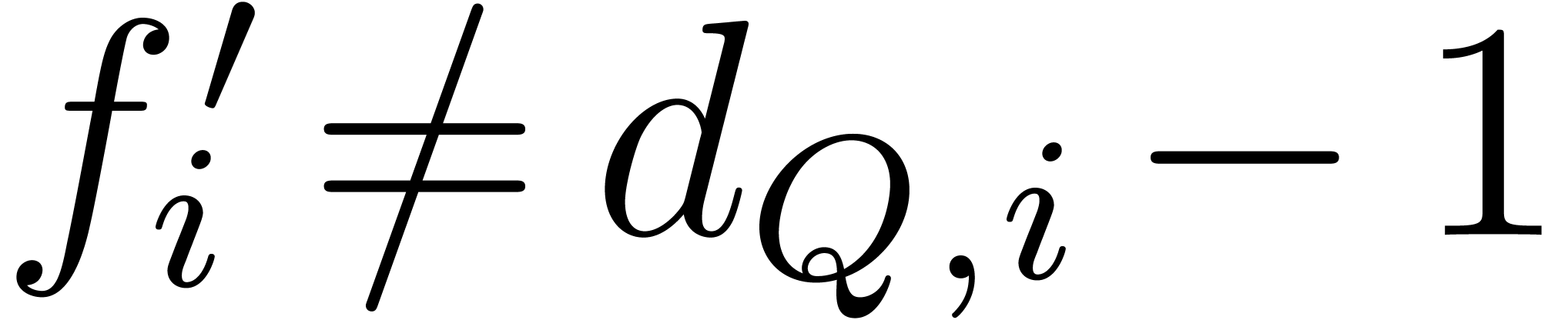 then return
then return 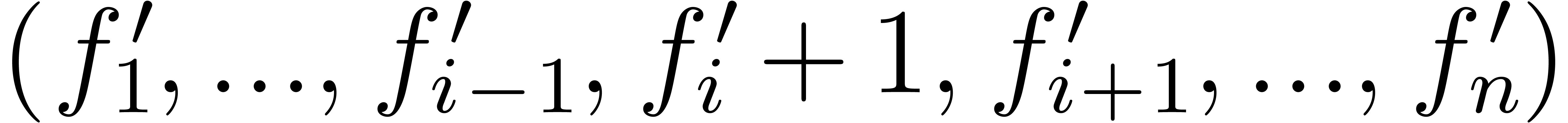 and
and 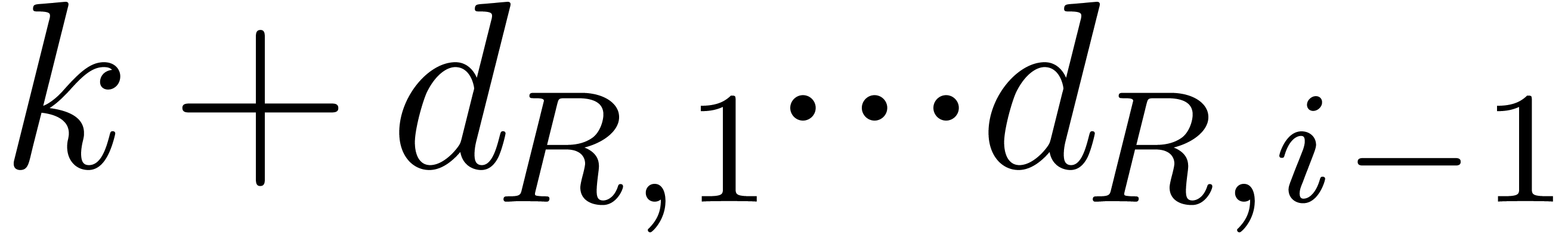 ;
;
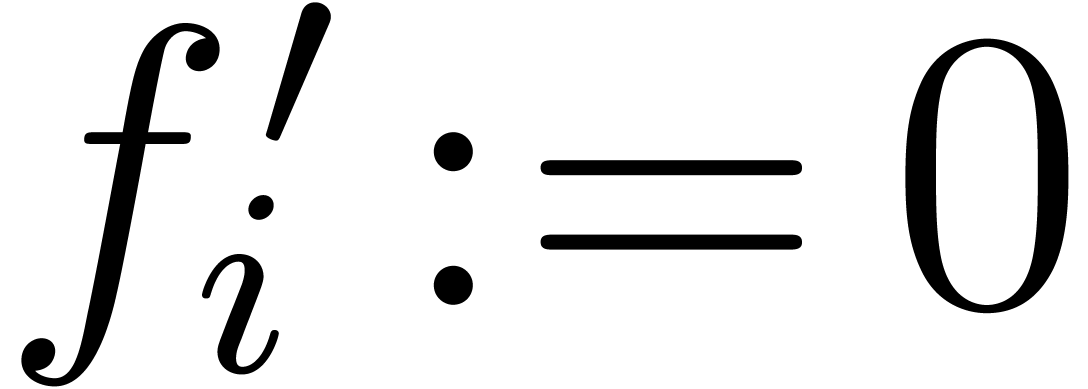 ;
; 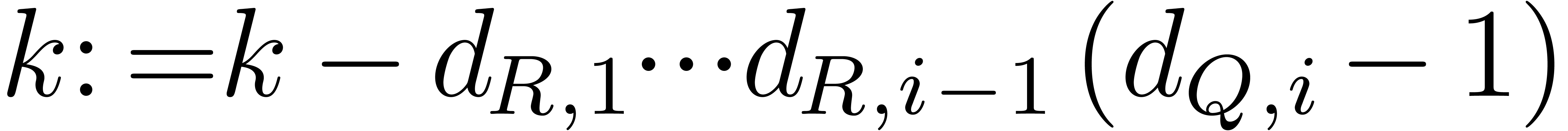 ;
;
Return an error.
The algorithm raises an error if, and only if,  is the last exponent of . The
proof of correctness is straightforward, hence is left to the reader. In
fact, we are interested in the total cost spent in the successive calls
of this routine to enumerate the indices of all the exponents of
is the last exponent of . The
proof of correctness is straightforward, hence is left to the reader. In
fact, we are interested in the total cost spent in the successive calls
of this routine to enumerate the indices of all the exponents of  in , for
any fixed exponent of :
in , for
any fixed exponent of :
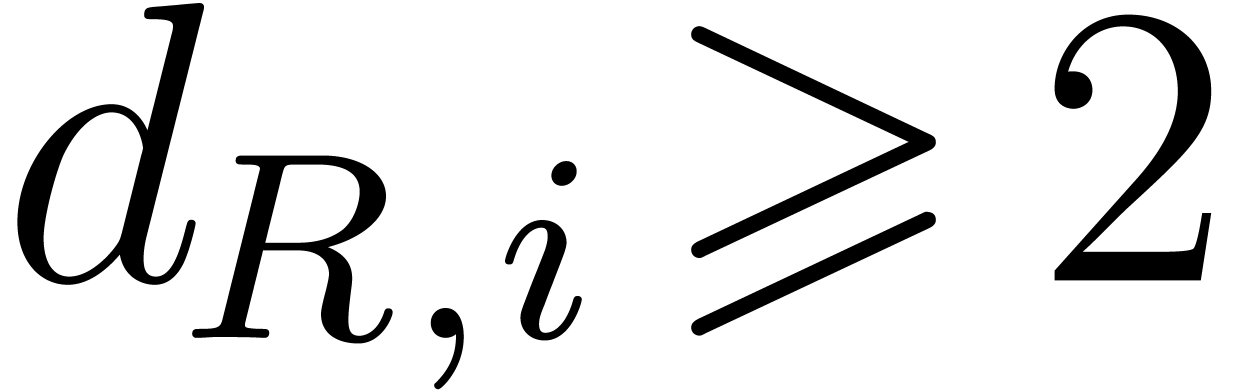 for all ,
and let
for all ,
and let  be an exponent of P. If , ,…,
and ,
, , are given, and if
be an exponent of P. If , ,…,
and ,
, , are given, and if 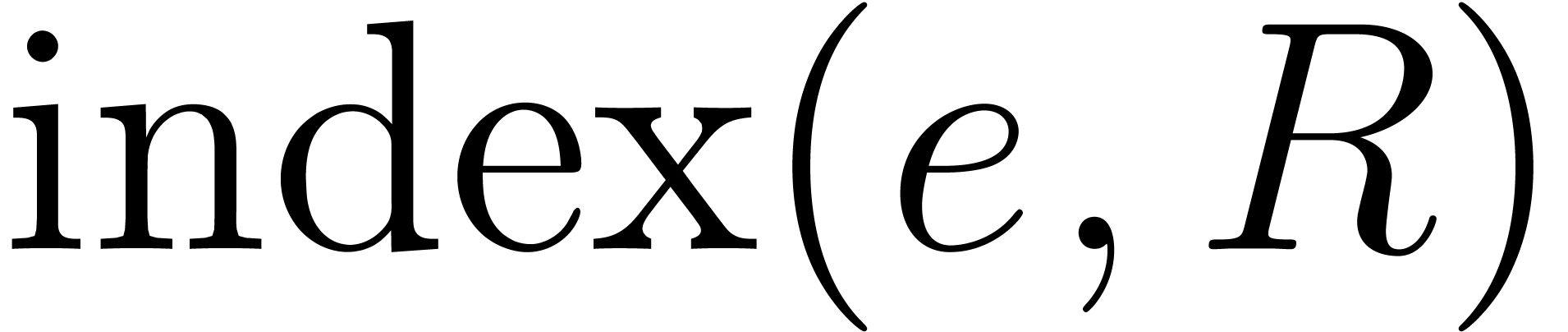 is known, then the indices in
of the exponents of can be enumerated in
increasing order with
is known, then the indices in
of the exponents of can be enumerated in
increasing order with 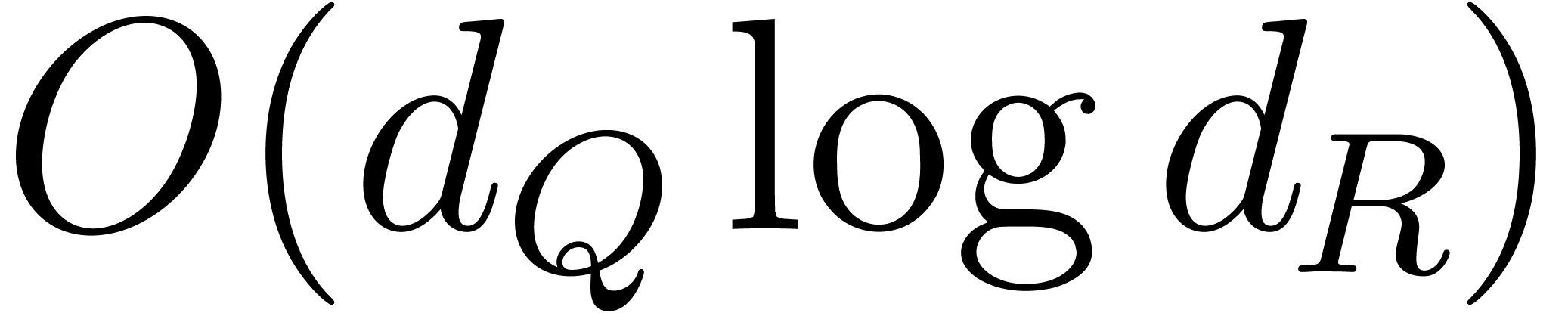 bit-operations.
bit-operations.
Proof. Let 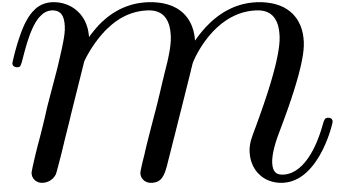 be the number
of the
be the number
of the 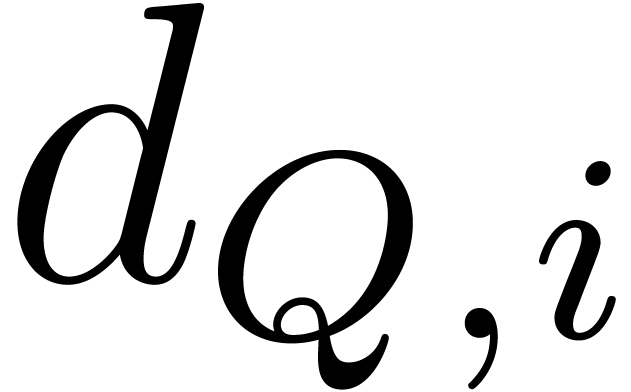 equal to
equal to 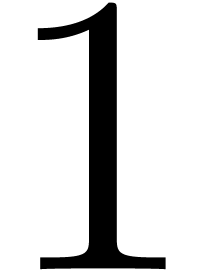 .
Each step of the loop of Algorithm 3 takes
.
Each step of the loop of Algorithm 3 takes 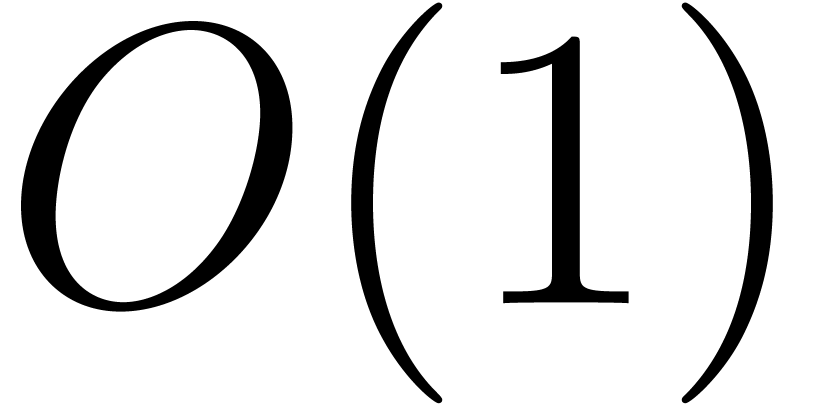 if or
if or 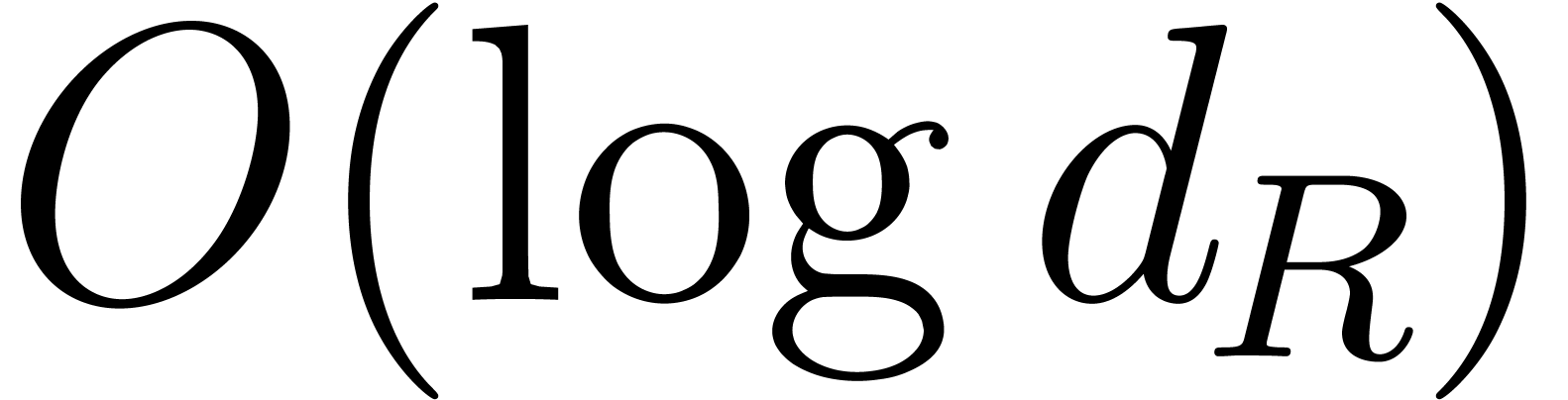 bit-operations
otherwise. Let
bit-operations
otherwise. Let 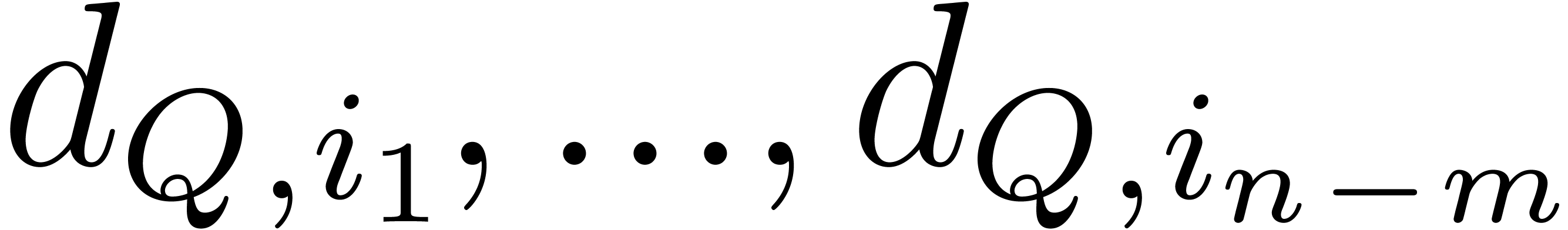 be the subsequence of
be the subsequence of 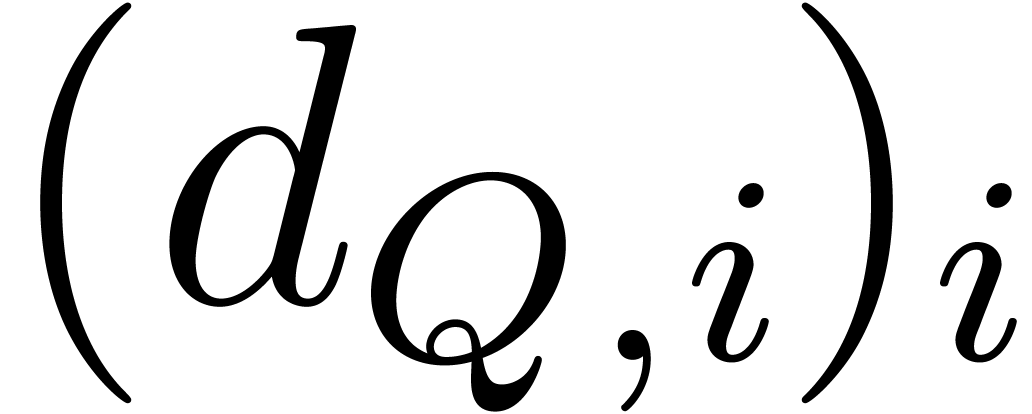 which are not .
which are not .
When running over all the successive exponents of  , this loop takes
, this loop takes 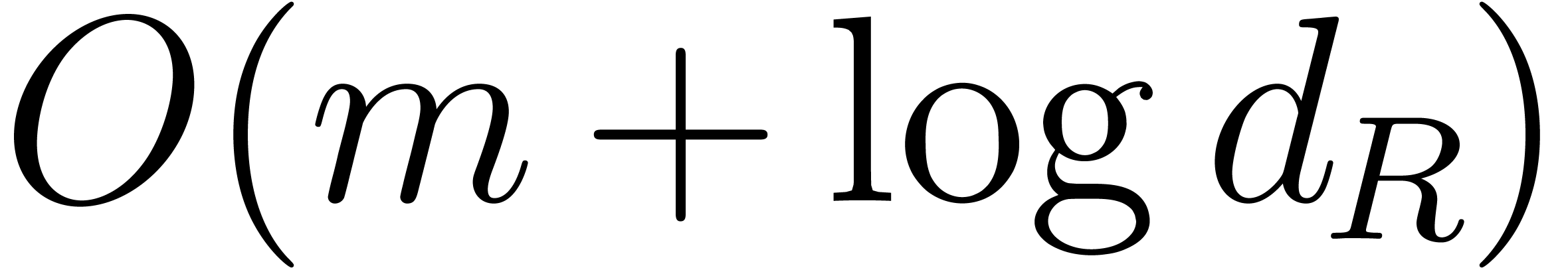 bit-operations for at most
bit-operations for at most  exponents, and
exponents, and 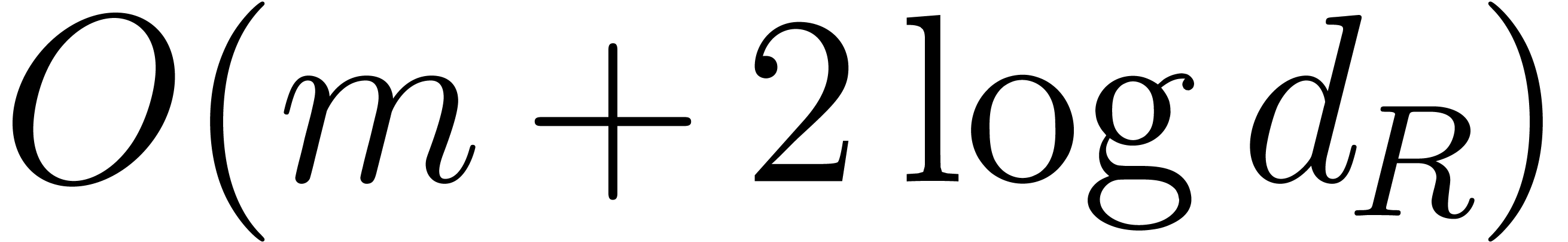 bit-operations for at most
bit-operations for at most  exponents, and
exponents, and 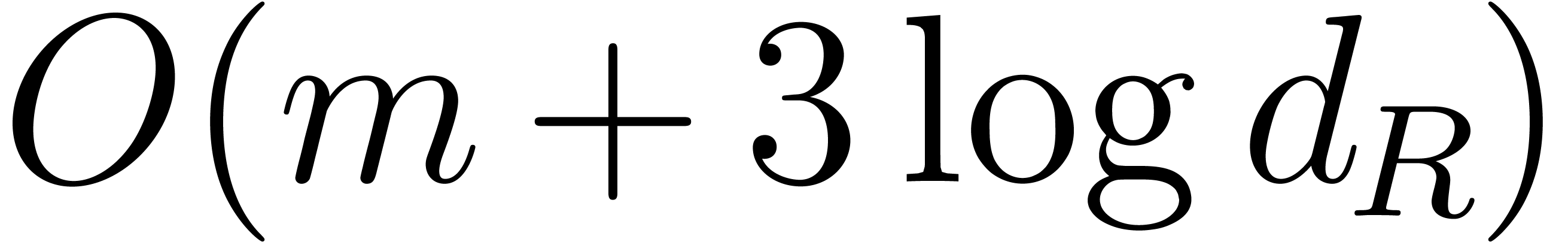 bit-operations for at most
bit-operations for at most  exponents, etc. Since the
exponents, etc. Since the 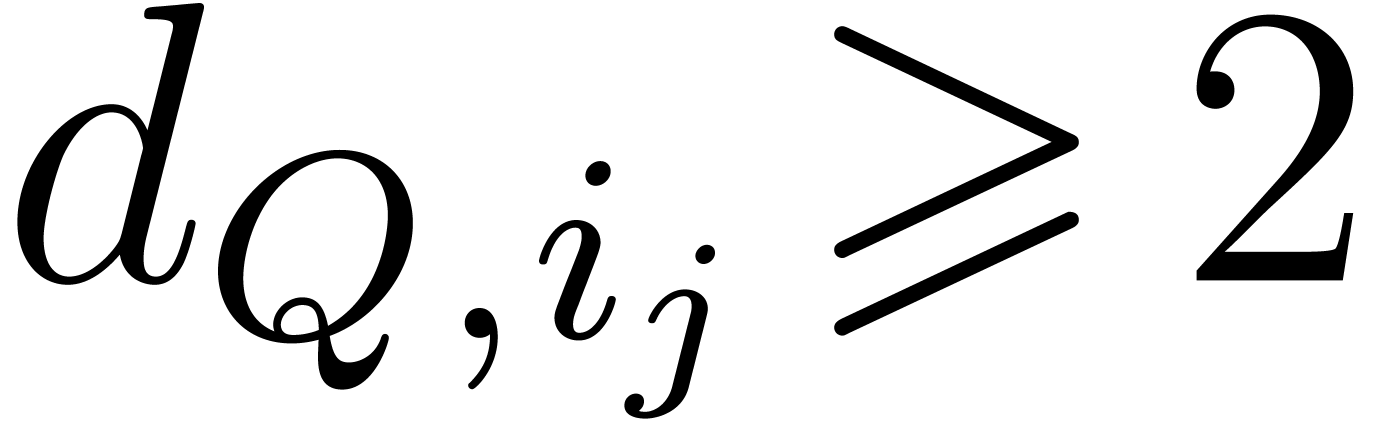 for
all , this amounts to
for
all , this amounts to 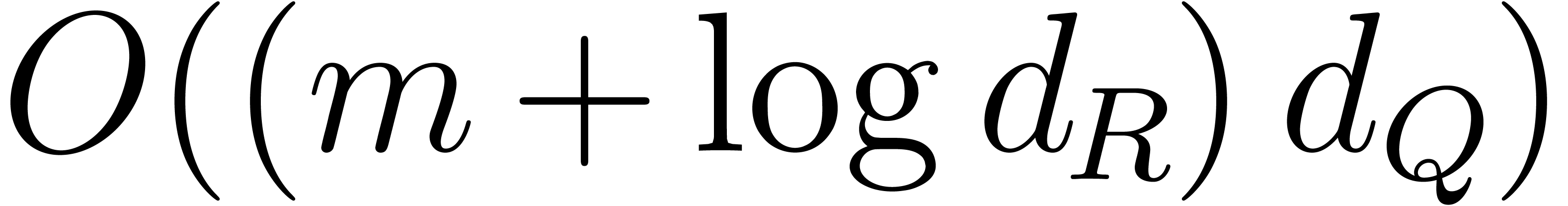 operations. Since the for all
, the conclusion follows from
operations. Since the for all
, the conclusion follows from
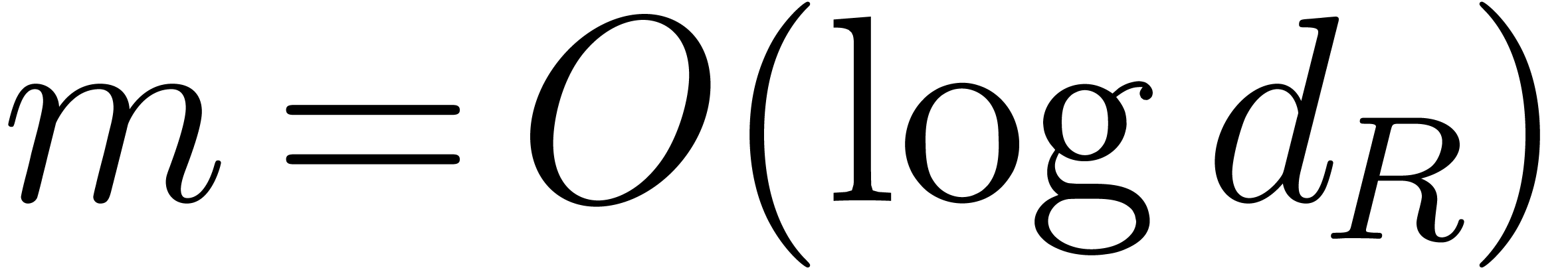 .
.
Let us briefly recall the Kronecker substitution. For computing , the Kronecker substitution we
need is defined as follows:
It suffices to compute 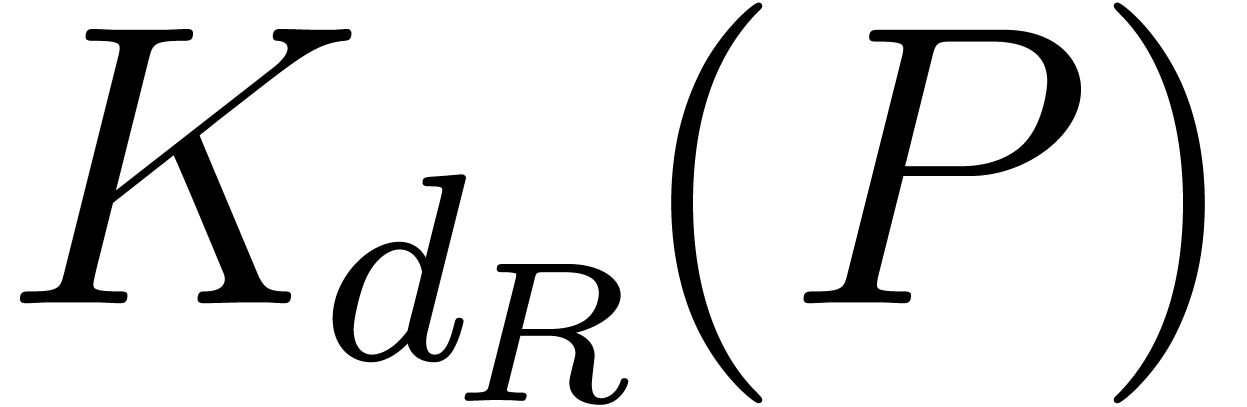 and
and 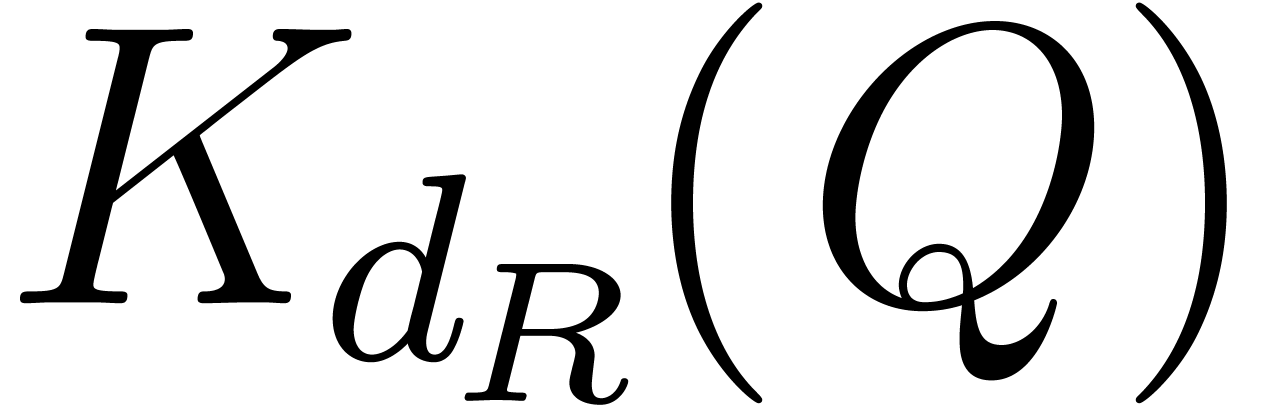 , perform their product, and recover by
, perform their product, and recover by
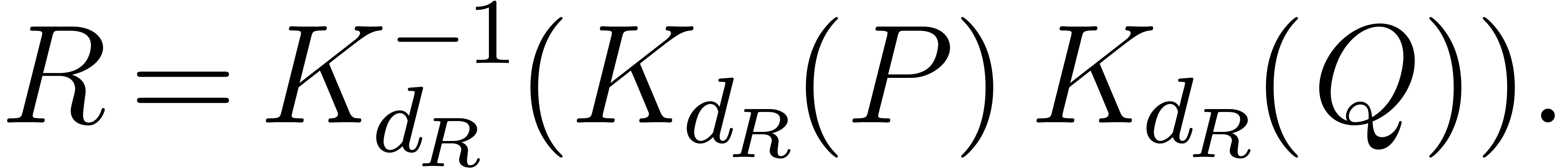
can be computed using 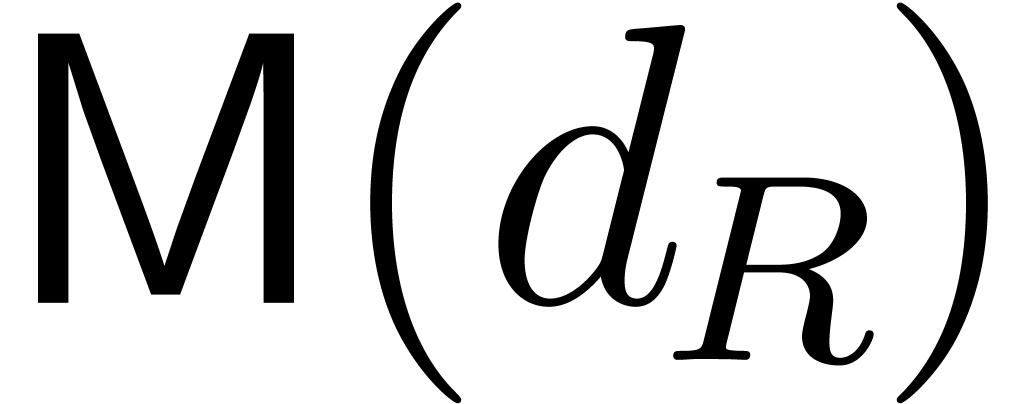 operations
in
operations
in  plus
plus 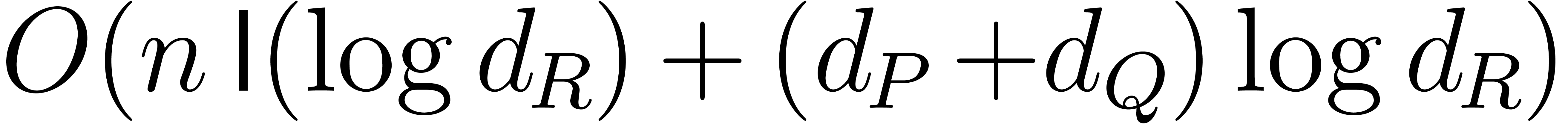 bit-operations.
bit-operations.
Proof. As for the naive approach we start with
computing all the and we discard all the
variables such that . Then we compute ,
, , and , , , and , ,
, . This takes bit-operations.
Thanks to Lemma 4, this allows to deduce
and with 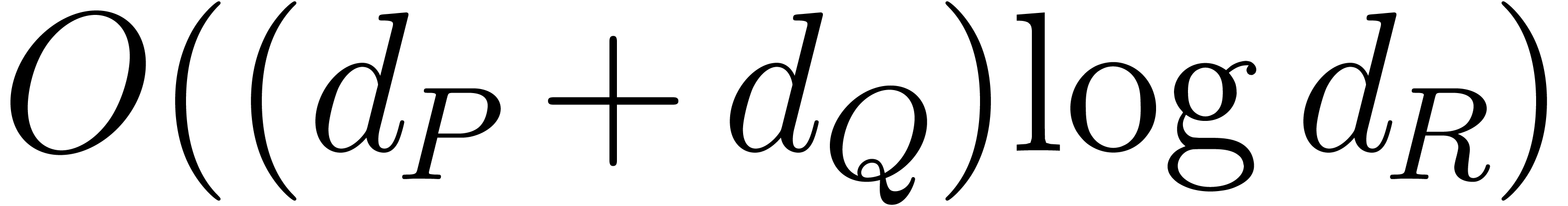 bit-operations.
Thanks to the reverse lexicographic ordering, the inverse
bit-operations.
Thanks to the reverse lexicographic ordering, the inverse 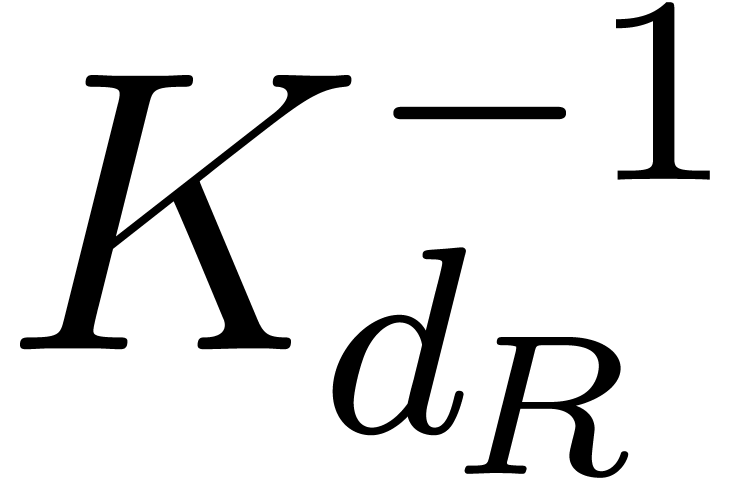 is for free.
is for free.
Remark has sufficiently
many 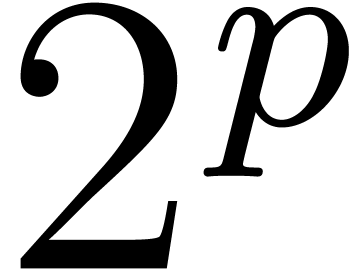 -th roots of unity, we
have
-th roots of unity, we
have 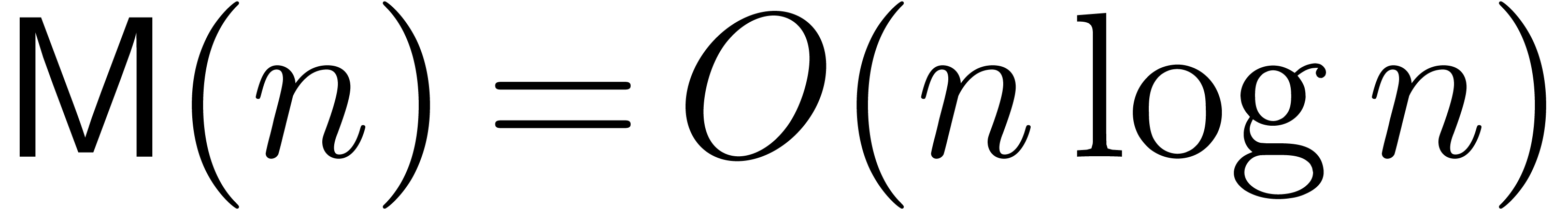 using FFT-multiplication. In the
multivariate case, the multiplication of and
essentially reduces to
using FFT-multiplication. In the
multivariate case, the multiplication of and
essentially reduces to  fast Fourier transforms of size
fast Fourier transforms of size  with respect to
each of the variables
with respect to
each of the variables  . This
amounts to a total number of
. This
amounts to a total number of 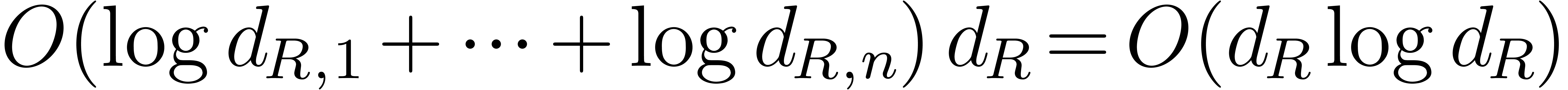 operations in .
operations in .
Over the integers, namely when  ,
one can further apply the Kronecker substitution to reduce to the
multiplication of two large integers. For any integer
,
one can further apply the Kronecker substitution to reduce to the
multiplication of two large integers. For any integer  we write
we write 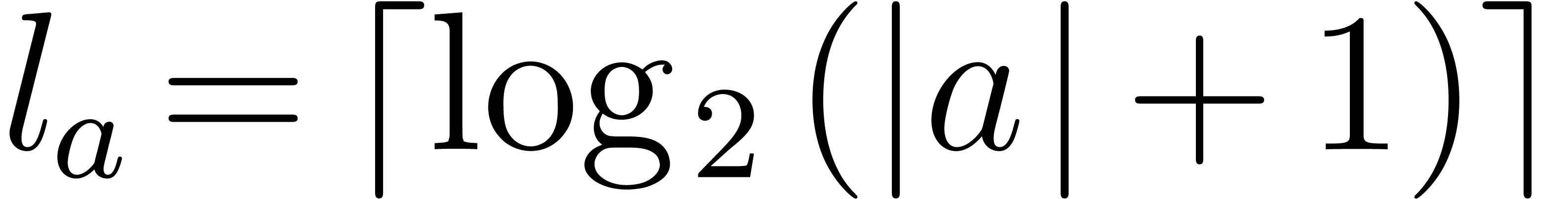 for its bit-size, and denote
by
for its bit-size, and denote
by  the maximal bit-length of the coefficients of
(and similarly for and
). Since
the maximal bit-length of the coefficients of
(and similarly for and
). Since
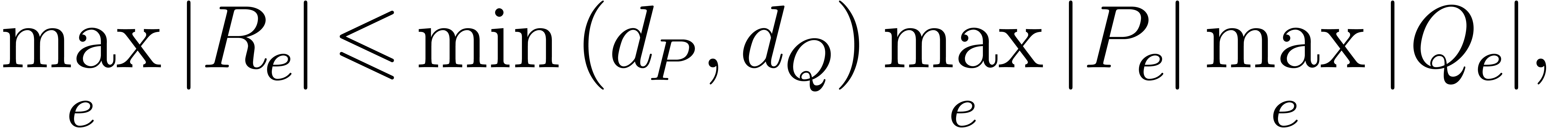
we have
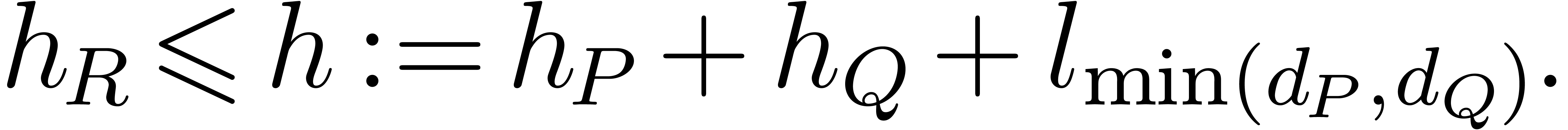
The coefficients of thus have bit-length at most
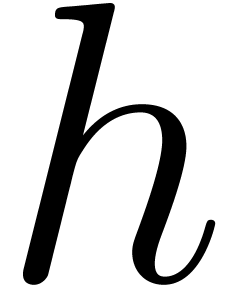 . We will be able to recover
them (with their signs) from an approximation modulo
. We will be able to recover
them (with their signs) from an approximation modulo 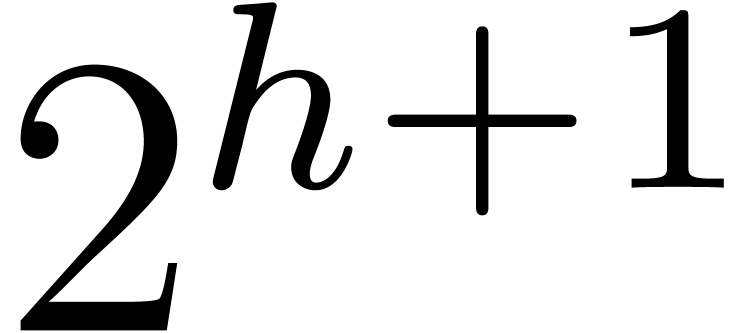 . The substitution works as follows:
. The substitution works as follows:
One thus computes 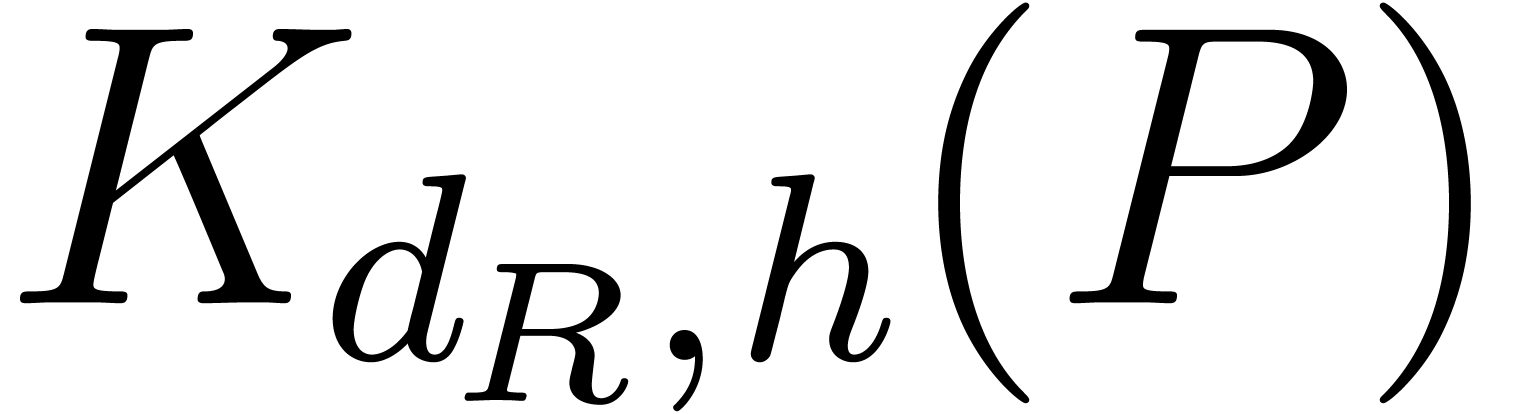 and
and 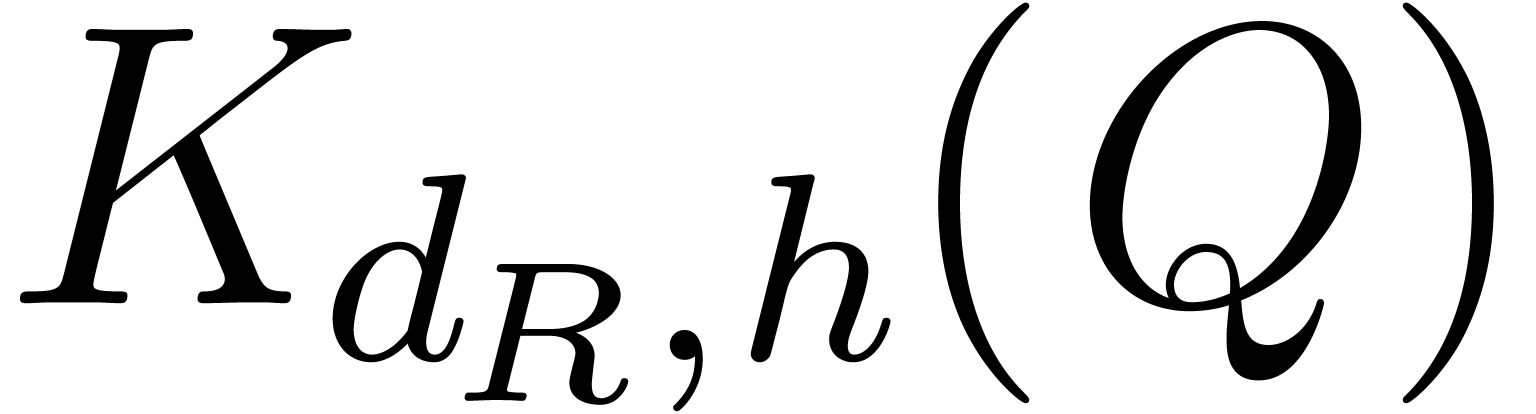 , does the integer product, and recovers
, does the integer product, and recovers
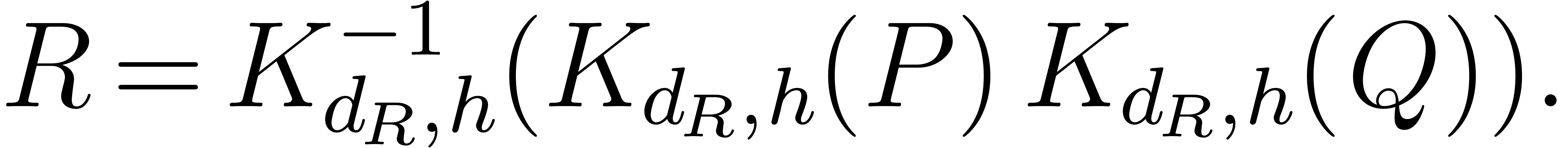
of times
in  takes
takes 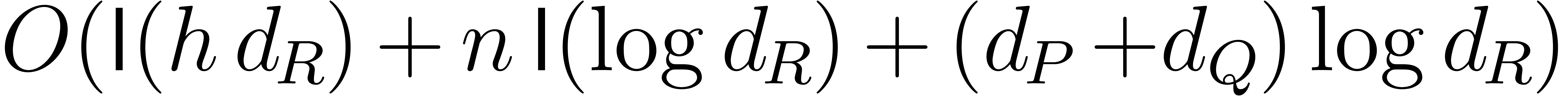 bit-operations.
bit-operations.
Proof. The evaluation at
takes linear time thanks to the binary representation of the integers
being used. The result thus follows from the previous proposition.
Remark 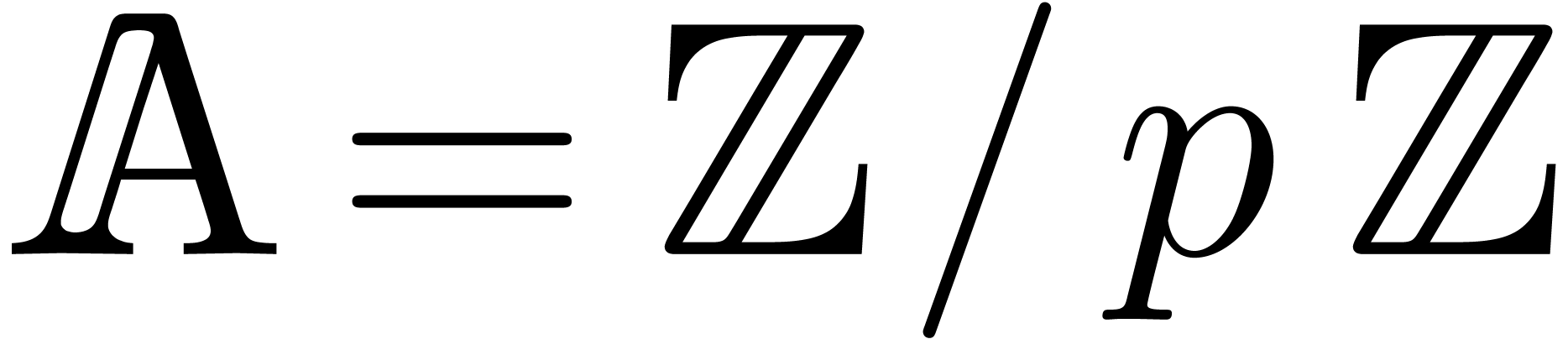 ,
,
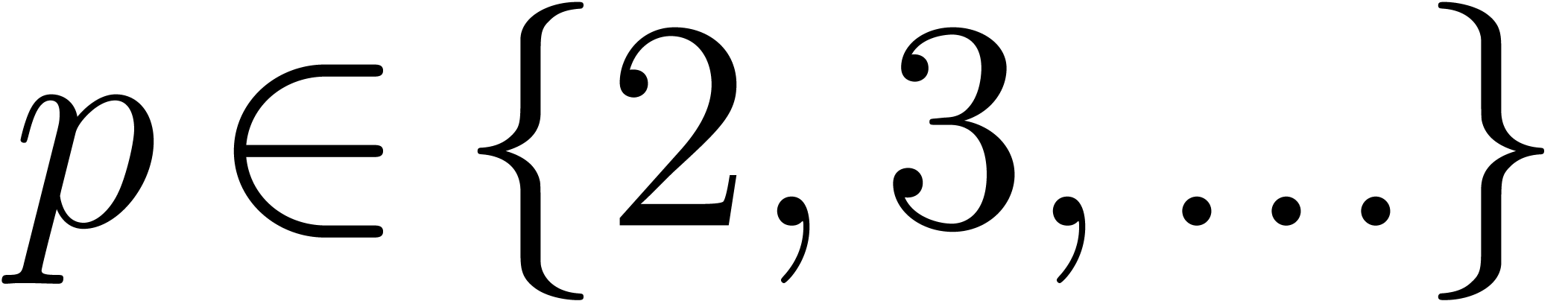 . Indeed, we first map
. Indeed, we first map 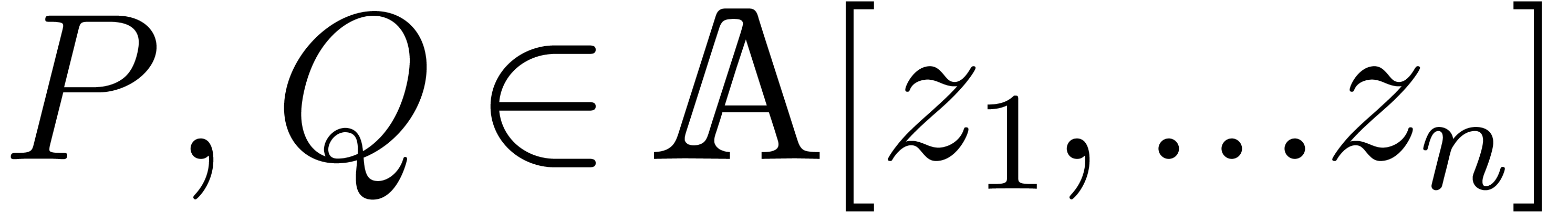 to polynomials in
to polynomials in  ,
multiply them as integer polynomials, and finally reduce modulo
,
multiply them as integer polynomials, and finally reduce modulo  .
.
In this paper we will often illustrate the performances of our
implementation for 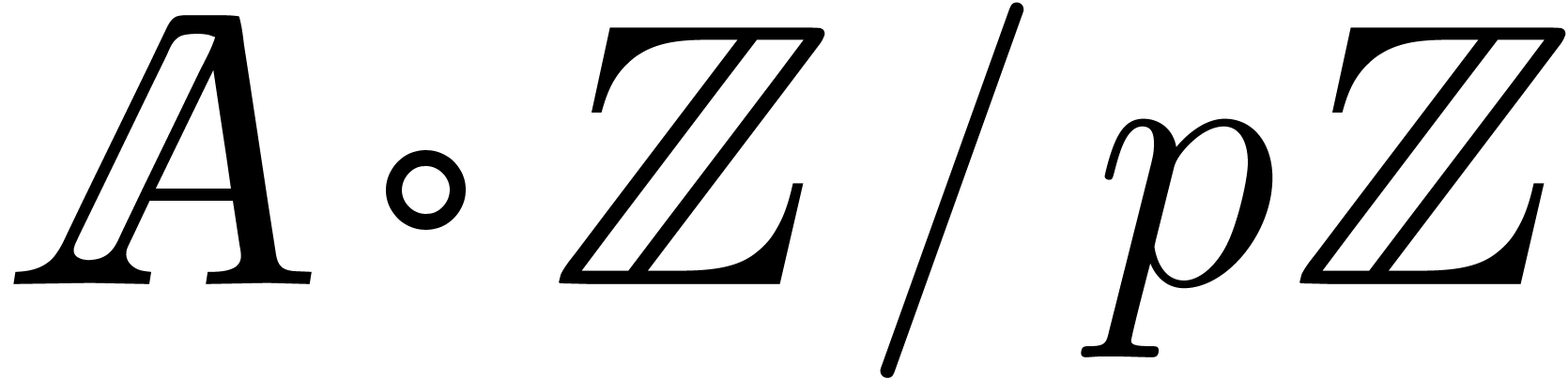 , with
, with
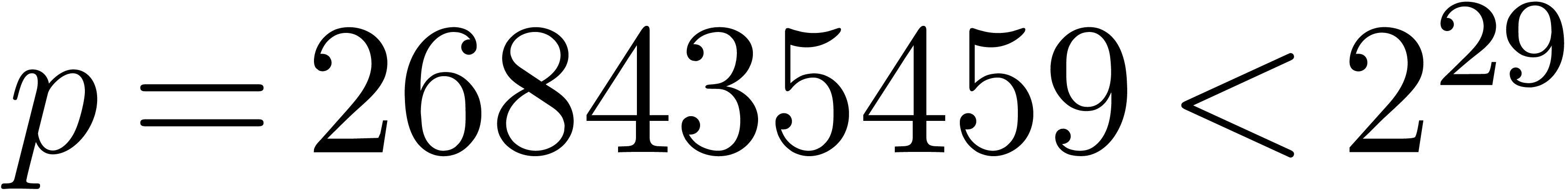 . Timings are measured in
seconds or milliseconds, using one core of an
. Timings are measured in
seconds or milliseconds, using one core of an  in the timing tables means that the time needed is
very high, and not relevant.
in the timing tables means that the time needed is
very high, and not relevant.
In Tables 1 and 2 we multiply dense
polynomials and with
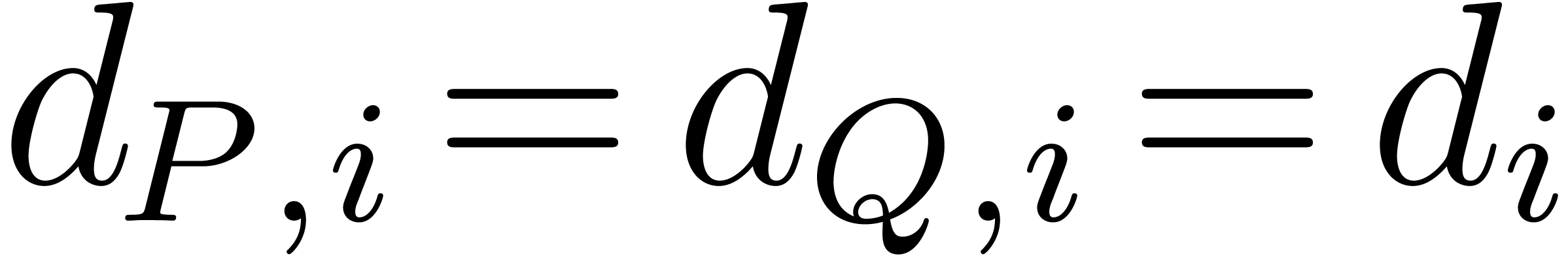 , for
, for 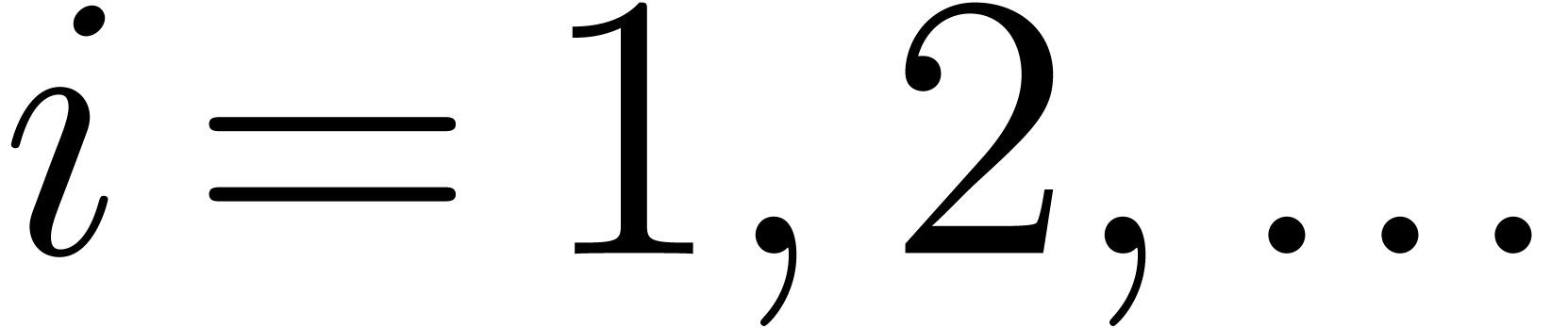 We observe that the Kronecker substitution is a very good strategy: it
involves less operations on the exponents, and fully benefits from the
performances of
We observe that the Kronecker substitution is a very good strategy: it
involves less operations on the exponents, and fully benefits from the
performances of
|
||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||
In this section, we will study the naive multiplication of multivariate polynomials using a sparse representation. Our naive implementation involves an additional dichotomy for increasing its cache efficiency.
In this paper, the sparse representation of a polynomial consists of a sequence of exponent-coefficient pairs
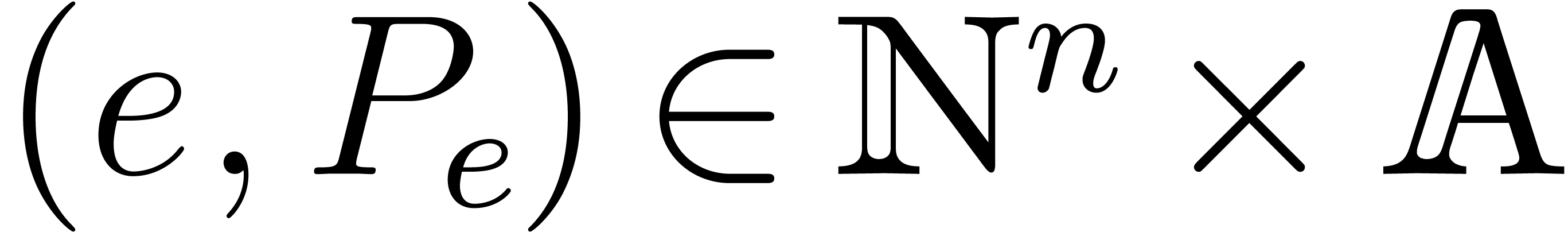 . This sequence is sorted
according to the reverse lexicographic order on the exponents, already
used for the block representation.
. This sequence is sorted
according to the reverse lexicographic order on the exponents, already
used for the block representation.
Natural numbers in the exponents are represented by their sequences of
binary digits. The total size of an exponent is
written 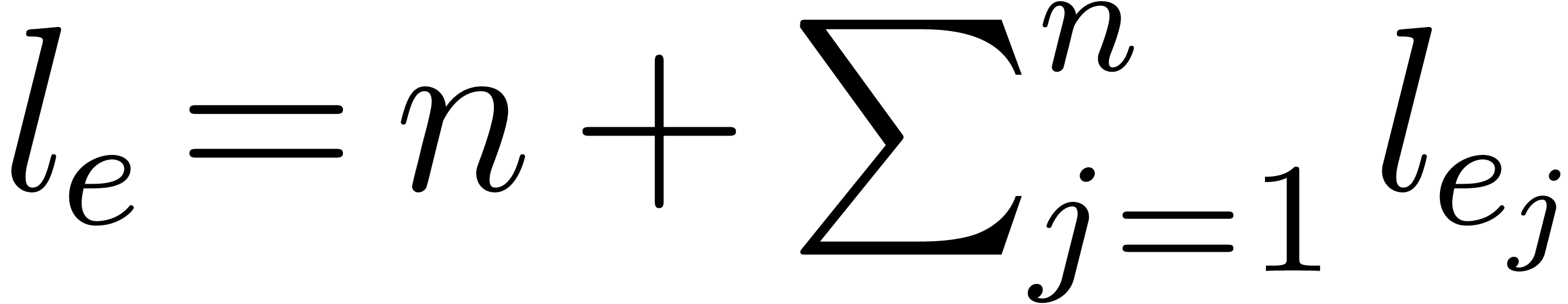 . We let
. We let 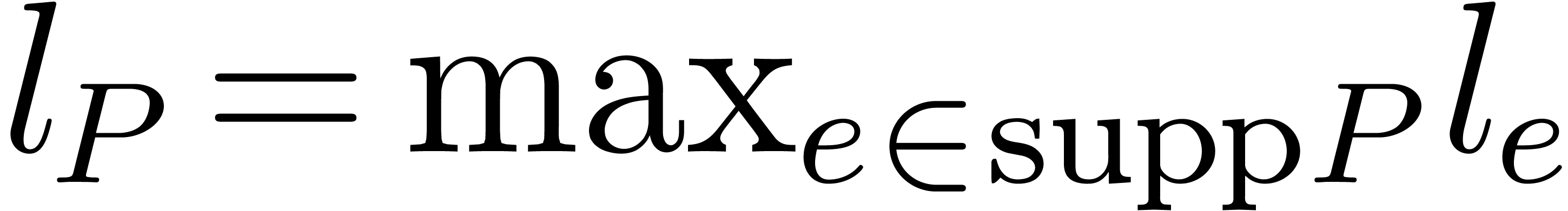 for the maximum size of the exponents of , and
for the maximum size of the exponents of , and  .
.
Comparing or adding two exponents and takes 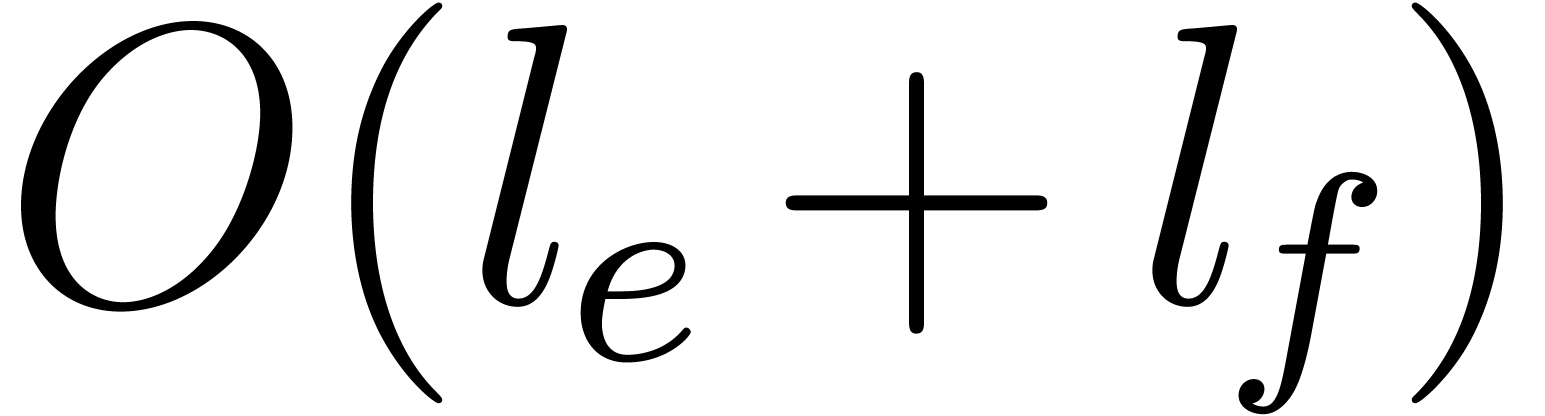 bit-operations. Therefore
reading the coefficient of a given exponent in
costs
bit-operations. Therefore
reading the coefficient of a given exponent in
costs  bit-operations by
a dichotomic search. Adding and
can be done with
bit-operations by
a dichotomic search. Adding and
can be done with 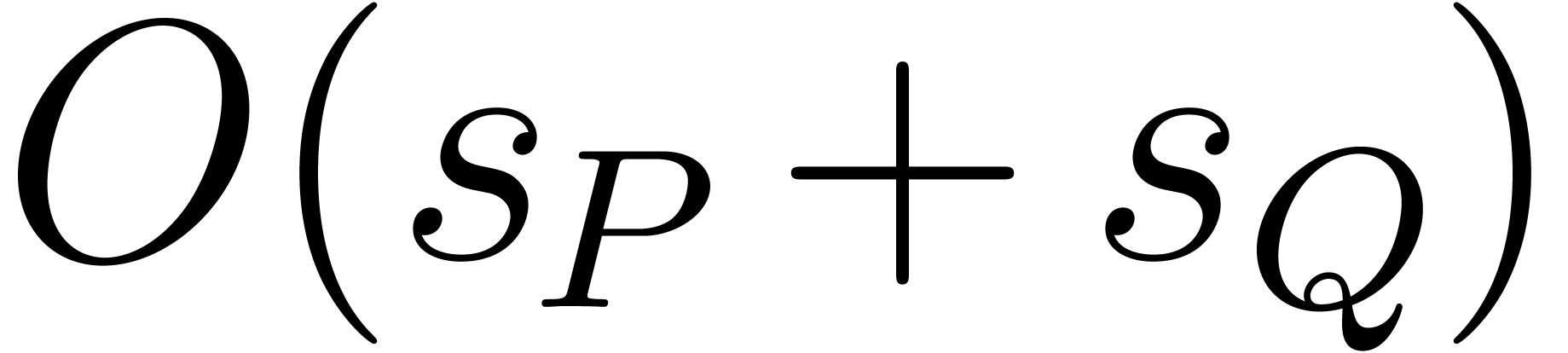 additions and copies in plus
additions and copies in plus 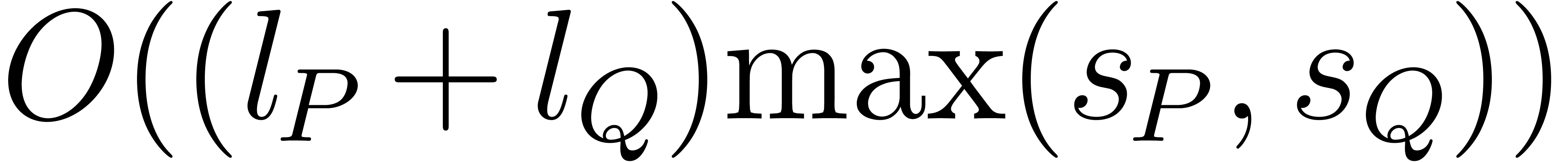 bit-operations. Now
consider the following algorithm for the computation of :
bit-operations. Now
consider the following algorithm for the computation of :
If 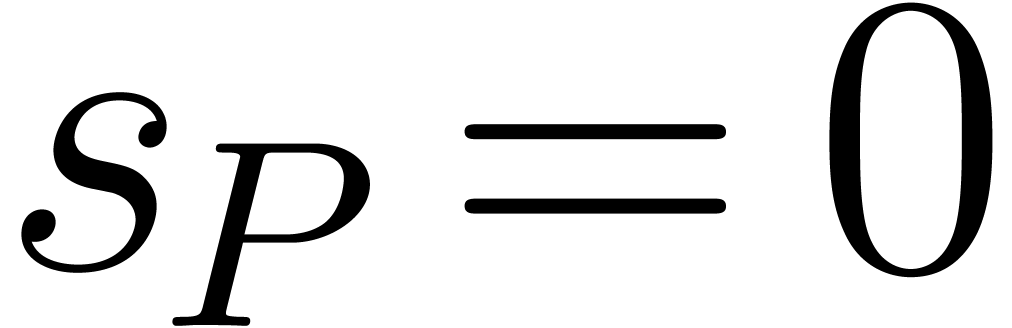 then return .
then return .
If 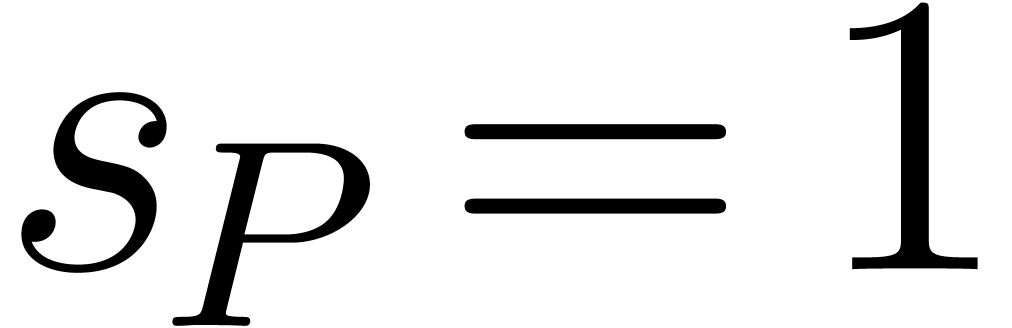 then return
then return 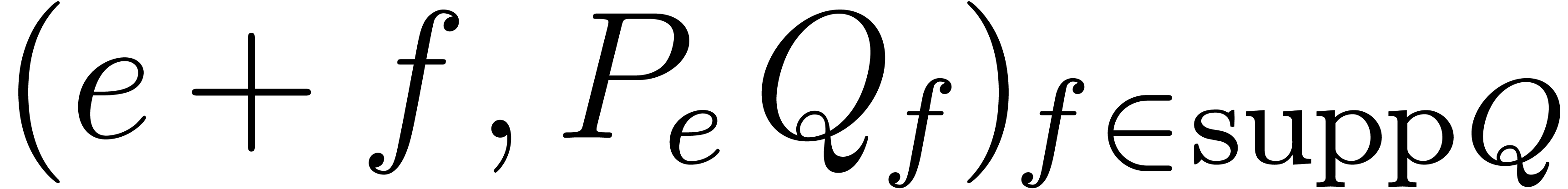 , where is the only
exponent of .
, where is the only
exponent of .
Split into  and
and
 with respective sizes
with respective sizes  and
and 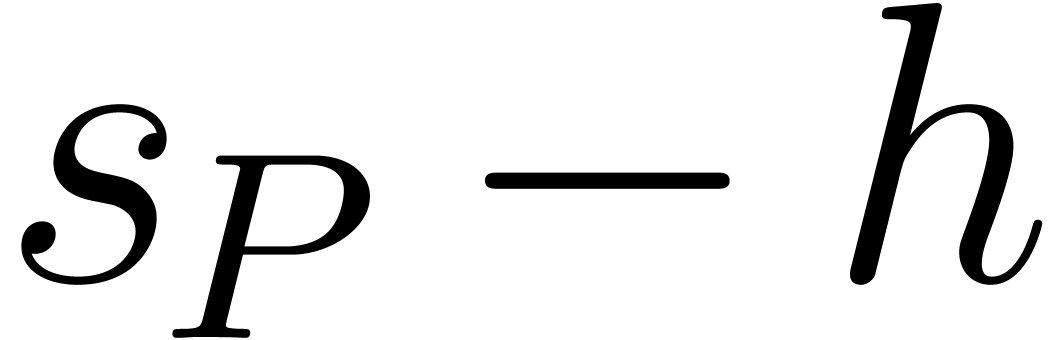 .
.
Compute 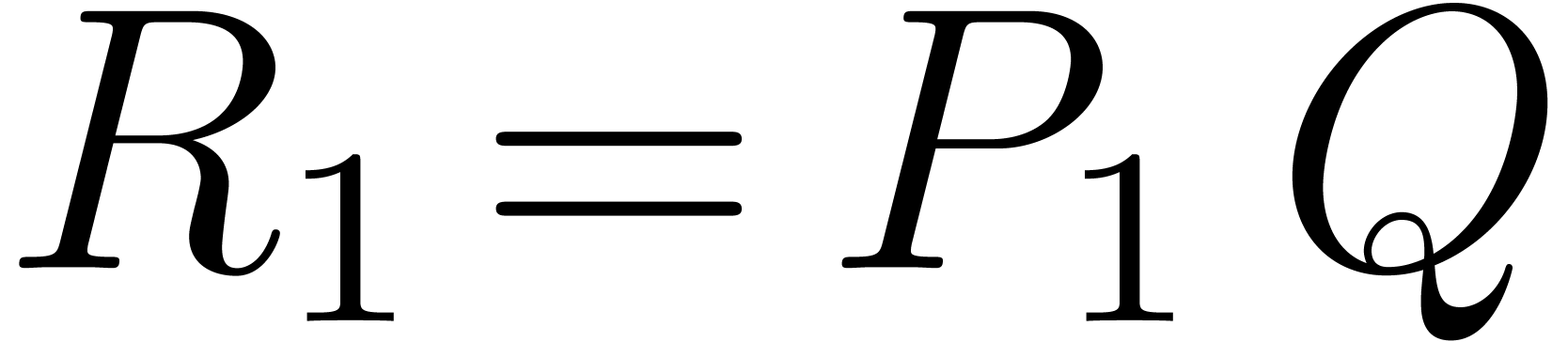 and
and 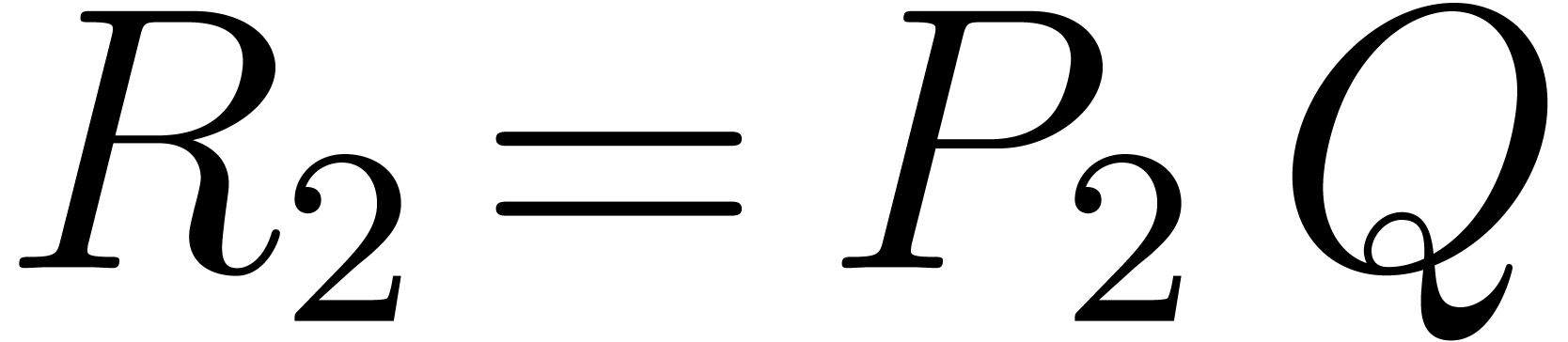 recursively.
recursively.
Return  .
.
can be computed using
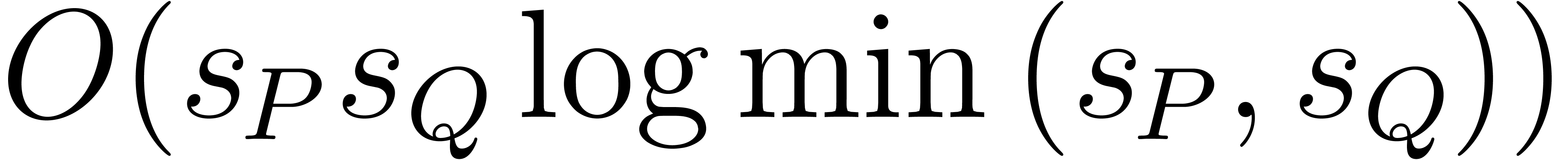 operations in ,
plus
operations in ,
plus 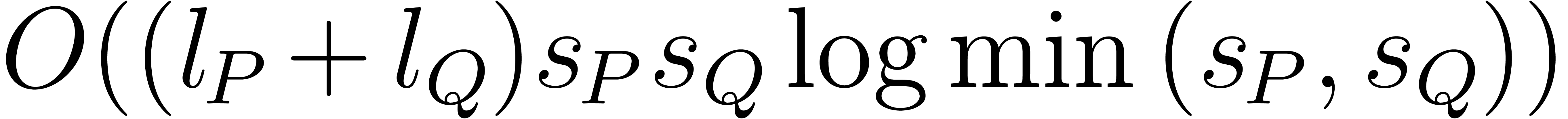 bit-operations.
bit-operations.
Proof. We can assume that 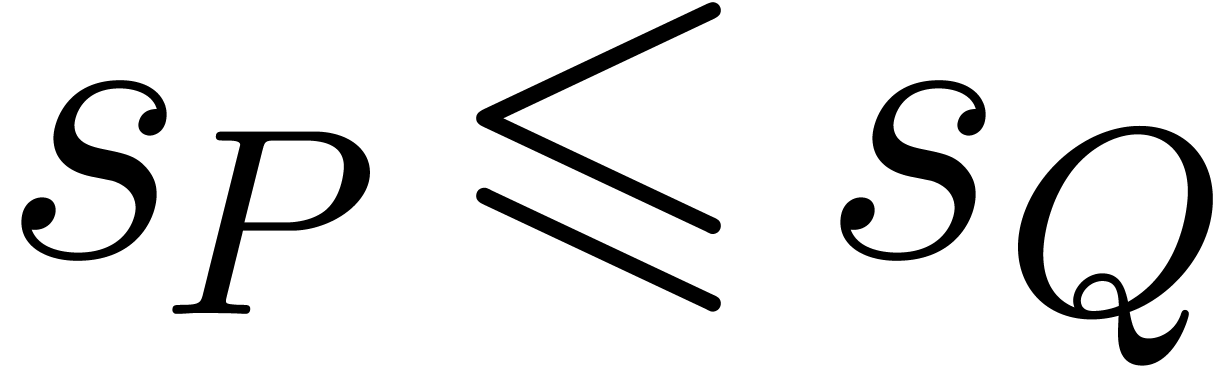 from the outset. The number of operations in is
clear because the depth of the recurrence is
from the outset. The number of operations in is
clear because the depth of the recurrence is 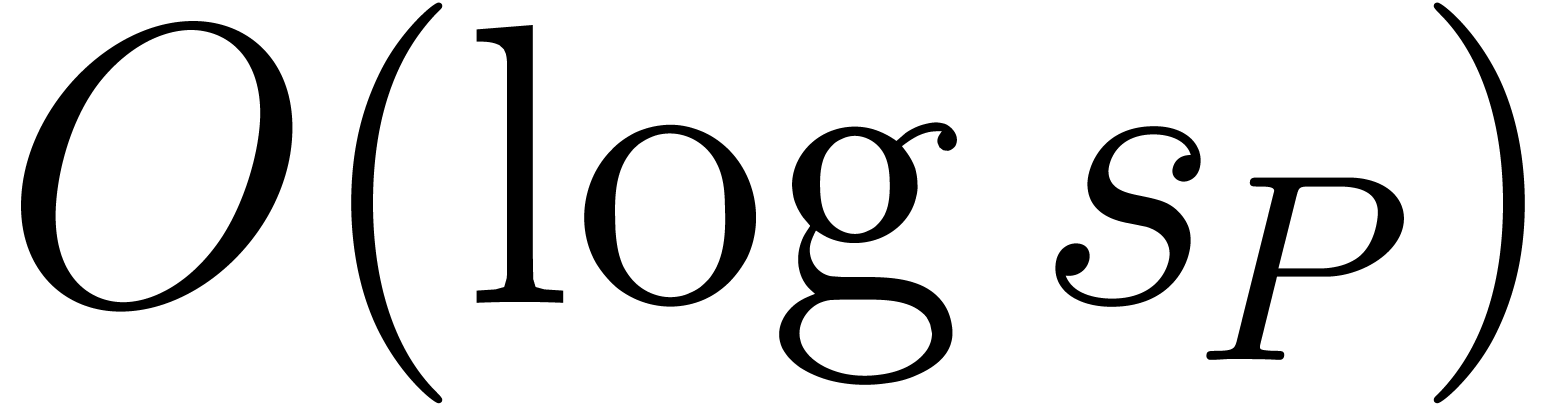 . Addition of exponents only appears in the leaves
of the recurrence. The total cost of step 2 amounts to
. Addition of exponents only appears in the leaves
of the recurrence. The total cost of step 2 amounts to 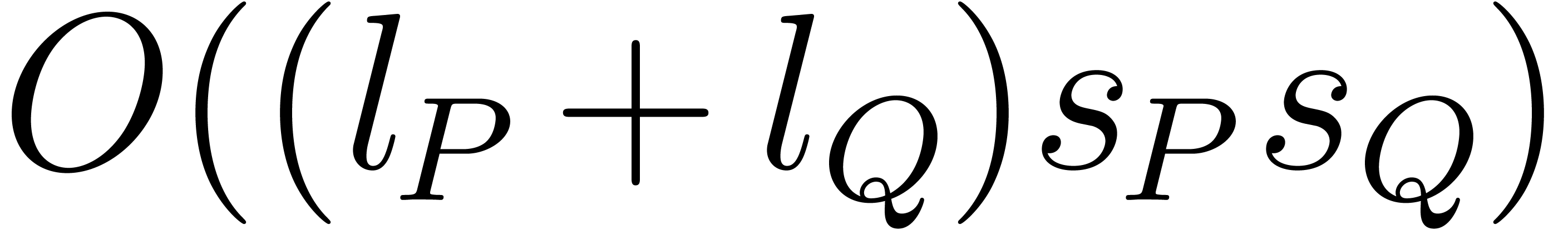 . The maximum bit-size of the exponents of the
polynomials in
. The maximum bit-size of the exponents of the
polynomials in  and
and  in
step 4 never exceeds
in
step 4 never exceeds 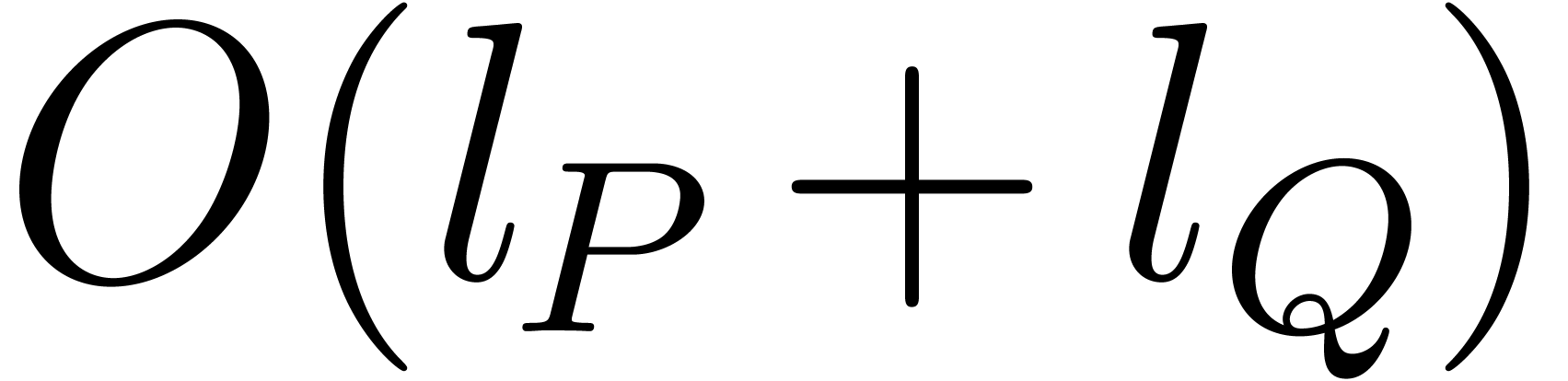 , which
yields the claimed bound.
, which
yields the claimed bound.
Remark  tends to be quite pessimistic in
practice. Especially in the case when
tends to be quite pessimistic in
practice. Especially in the case when 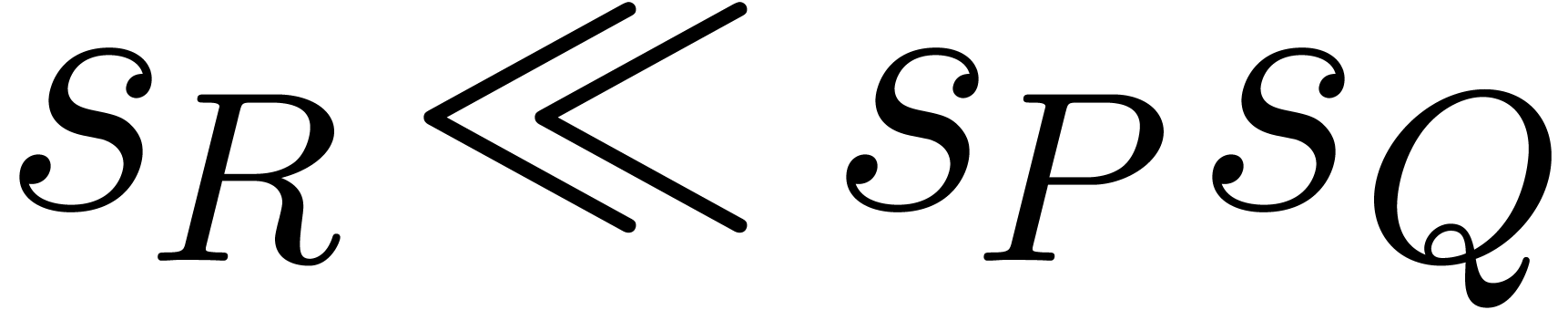 ,
the observed complexity is rather
,
the observed complexity is rather 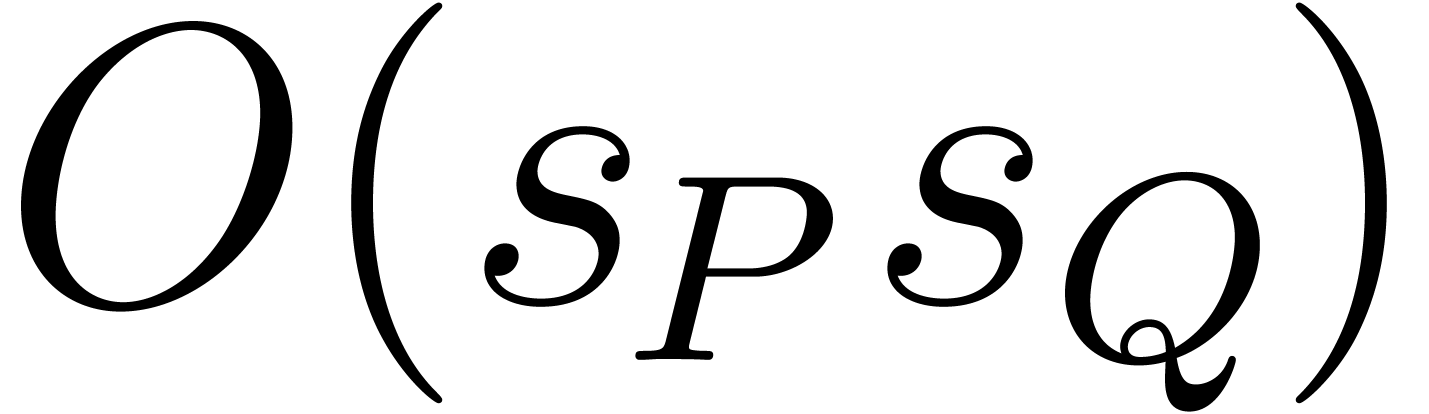 .
Moreover, the constant corresponding to this complexity is quite small,
due to the cache efficiency of the dichotomic approach.
.
Moreover, the constant corresponding to this complexity is quite small,
due to the cache efficiency of the dichotomic approach.
Remark in order to ensure that
fits in the cache, most of the time.
In the next tables we provide timings for ,
with  . For Table 3
we pick up
. For Table 3
we pick up 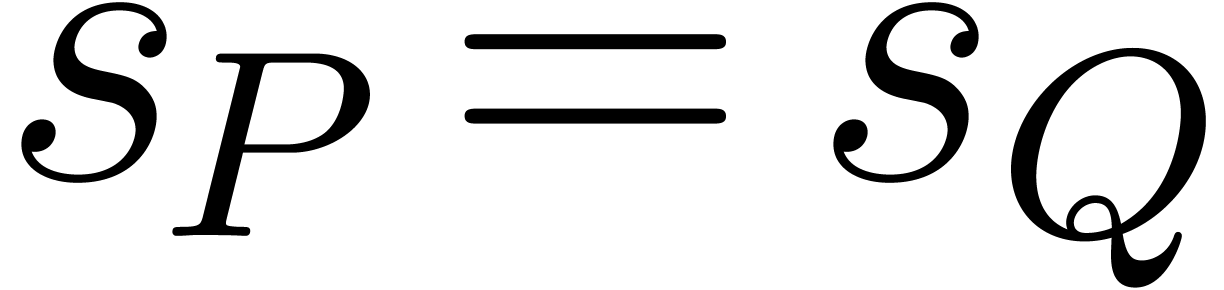 random monomials in the block
random monomials in the block  , with random coefficients. Here
the exponents are “packed” into a single machine word if
possible. This is a classical useful trick for when the coefficients are
small that was already used in [Joh74]. For
, with random coefficients. Here
the exponents are “packed” into a single machine word if
possible. This is a classical useful trick for when the coefficients are
small that was already used in [Joh74]. For 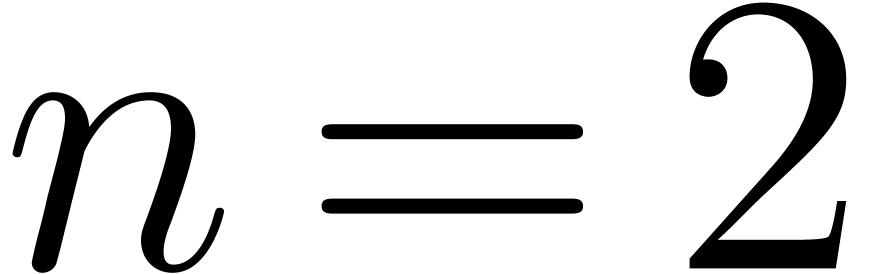 and
and 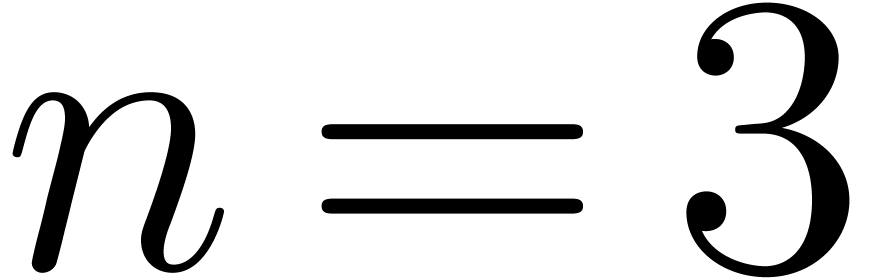 the exponents are packed into
a 64 bits word. But for
the exponents are packed into
a 64 bits word. But for 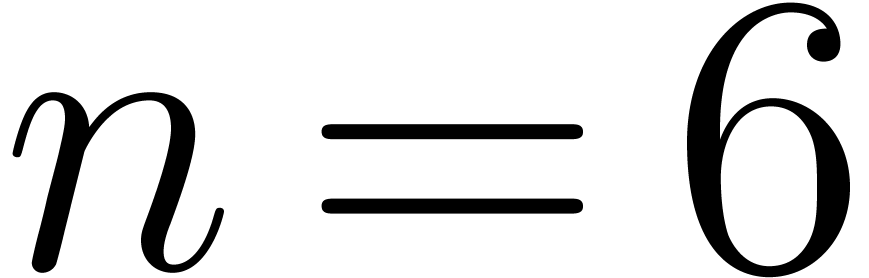 , the
packing requires
, the
packing requires 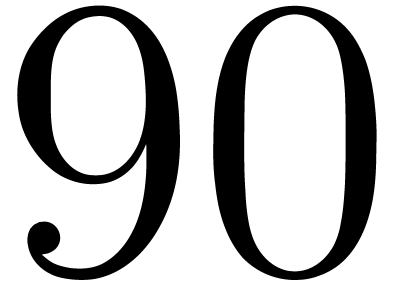 bits, and thus we operate
directly on the vector representation.
bits, and thus we operate
directly on the vector representation.
|
||||||||||||||||||||||||||||||||||||
In the following table we give the timings of same computations with
|
||||||||||||||||||||||||||||||||||||
These timings confirm that our implementation of the naive algorithms is
already competitive. In the next table we consider polynomials with
increasing size in a fixed bounding hypercube 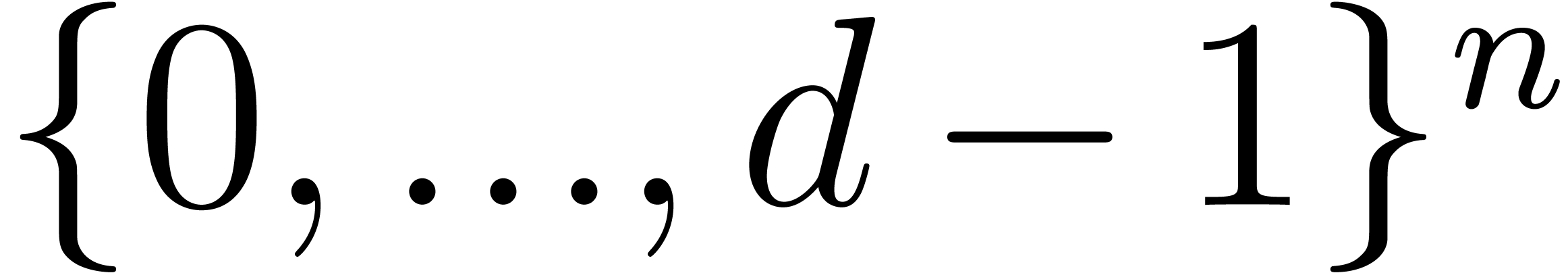 . The row “density” indicates the ratio
of non-zero terms with exponent in .
. The row “density” indicates the ratio
of non-zero terms with exponent in .
|
||||||||||||||||||||||||
In Table 5, we see that the Kronecker substitution is
faster from 5 % of density in the first case and 3 % in the second case.
Roughly speaking, in order to determine which algorithm is faster one
needs to compare 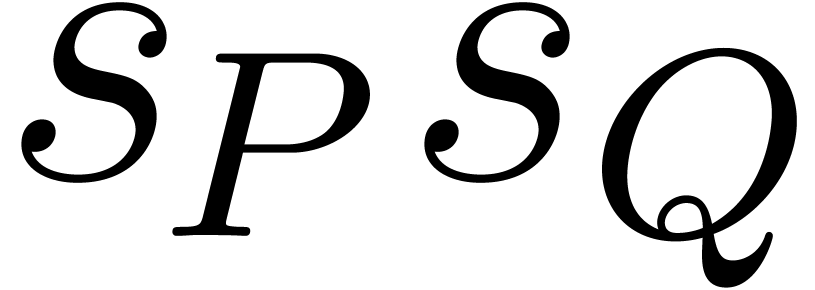 to
to  . The efficiency of the Kronecker substitution
relies on the underlying univariate arithmetic.
. The efficiency of the Kronecker substitution
relies on the underlying univariate arithmetic.
Let us also consider the following example with , borrowed from [Fat03]:
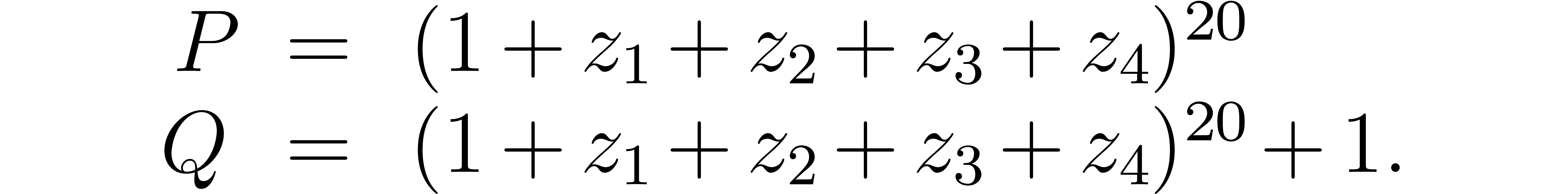
This example has been very recently used in [MP09b] as a
benchmark to compare the new implementation that will be available in
Firstly the Kronecker substitution takes 3.5 s, which is already faster
than all other software they tested. The drawback of the Kronecker
substitution is the memory consumption, but the direct call of the naive
product takes 377 s: the coefficients of the product have at most 83
bits, and the overhead involved by 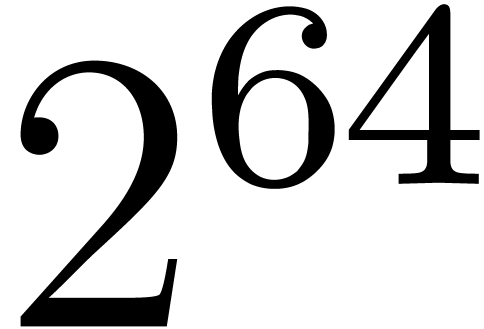 and
and 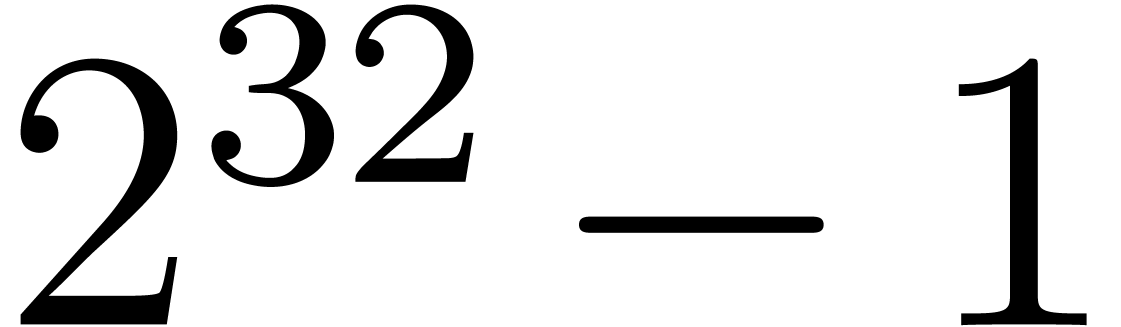 ,
for which the remainders are very cheap, the multiplication time is
reduced to 4 s.
,
for which the remainders are very cheap, the multiplication time is
reduced to 4 s.
We shall consider multivariate series truncated in total degree. Such a
series to order 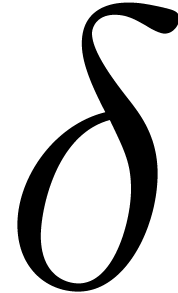 is represented by the sequence
of its homogeneous components up to degree
is represented by the sequence
of its homogeneous components up to degree  .
For each component we use a sparse representation. Let
.
For each component we use a sparse representation. Let 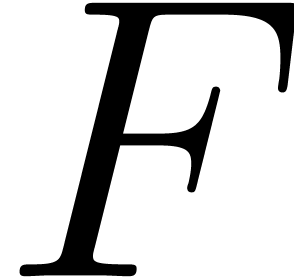 and
and  be two series to order . The homogeneous component of degree in is written
be two series to order . The homogeneous component of degree in is written  .
.
The naive algorithm for computing their product  works as follows:
works as follows:
The number of non-zero terms in is denoted by
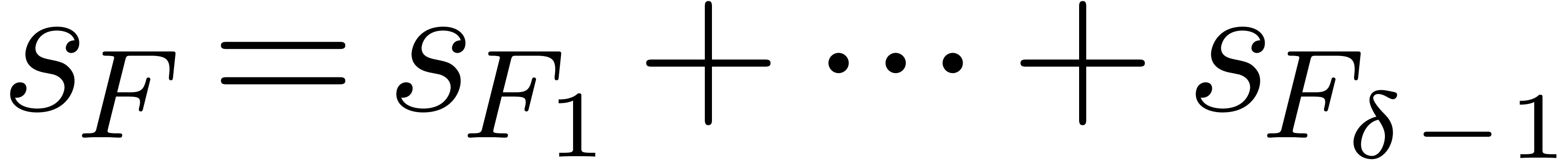 . The maximum size of the
exponents of
. The maximum size of the
exponents of 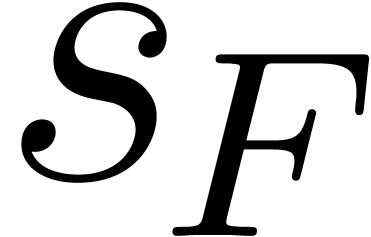 is represented by
is represented by 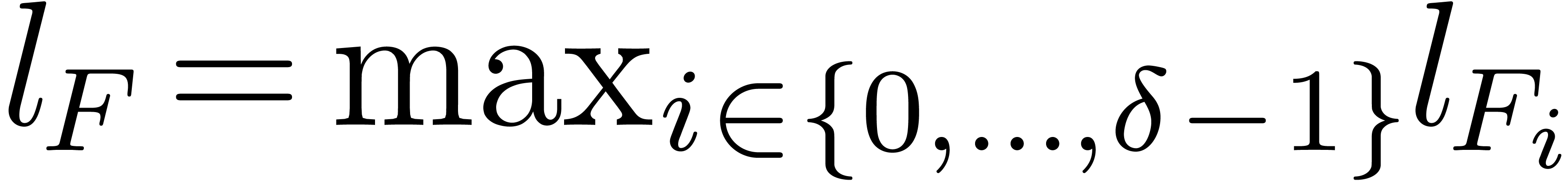 .
.
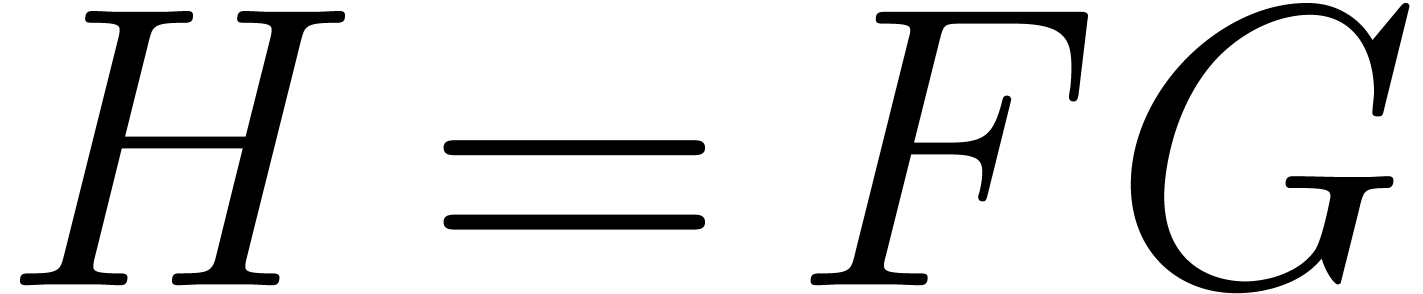 can be done with
can be done with 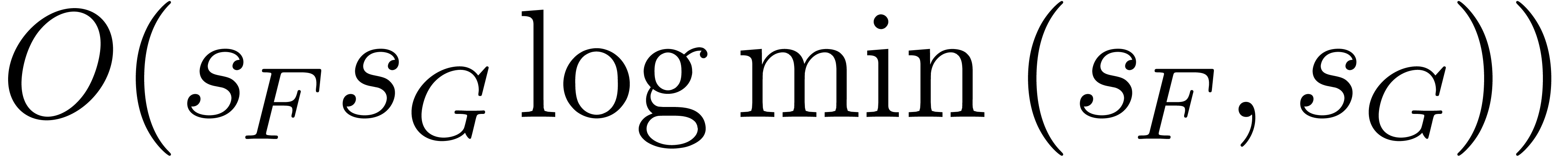 operations in , plus
operations in , plus 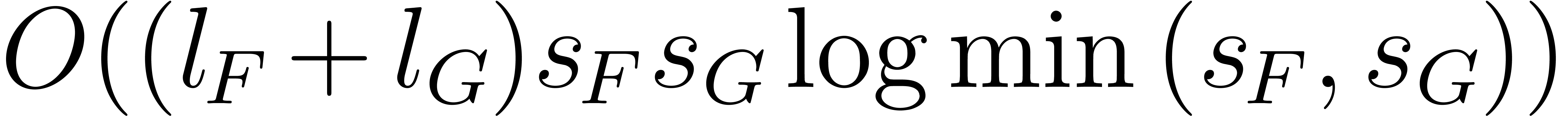 bit-operations.
bit-operations.
Proof. By Proposition 10, the total
number of operations in is in
and the total bit-cost follows in the same way.
Remark
Let 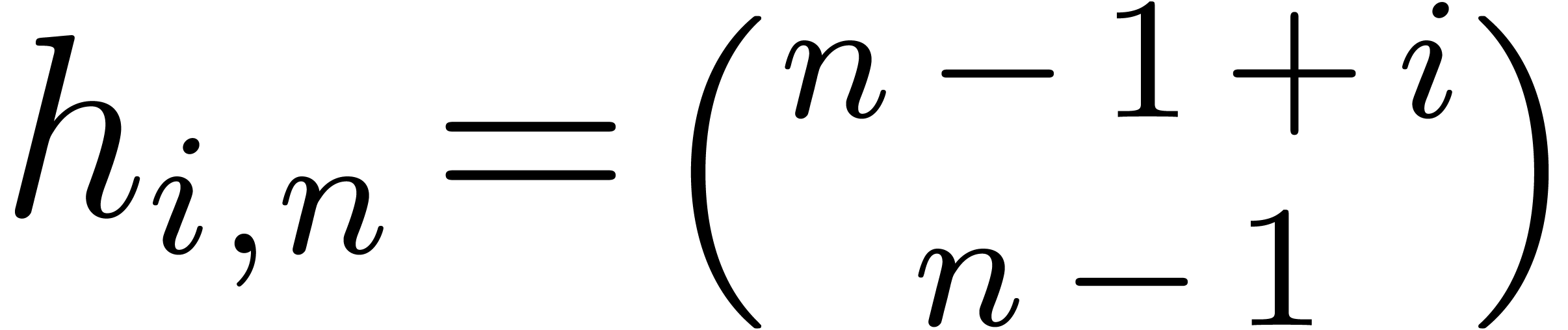 represent the number of the monomials of
degree with variables,
and let
represent the number of the monomials of
degree with variables,
and let 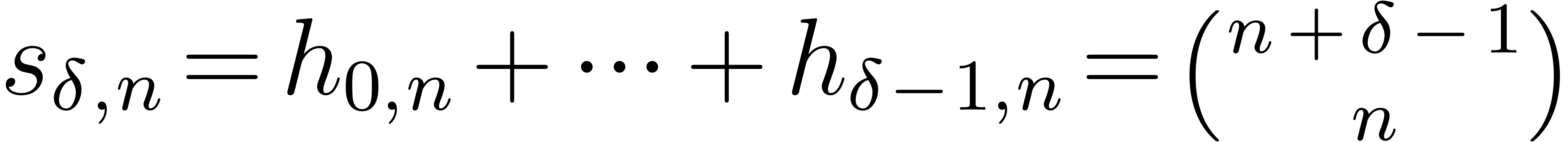 be the number of the monomials of degree
at most . We shall consider
the product in the densest situation, when
be the number of the monomials of degree
at most . We shall consider
the product in the densest situation, when 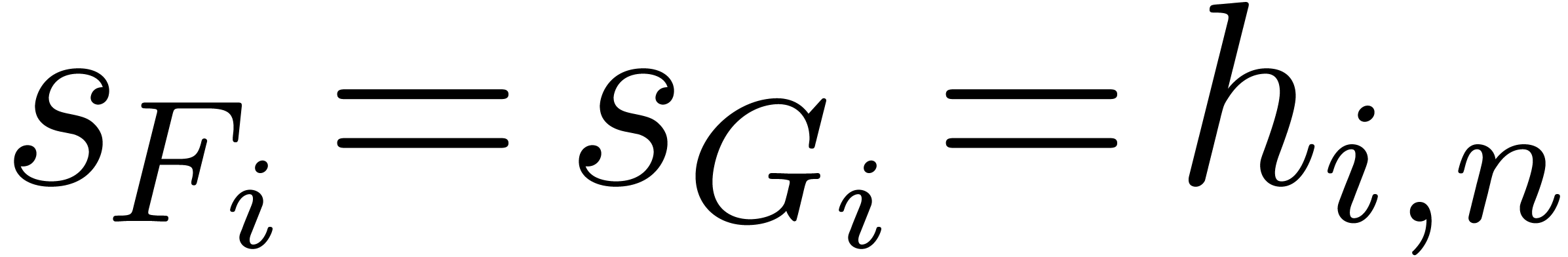 for
all .
for
all .
up till order  takes
takes 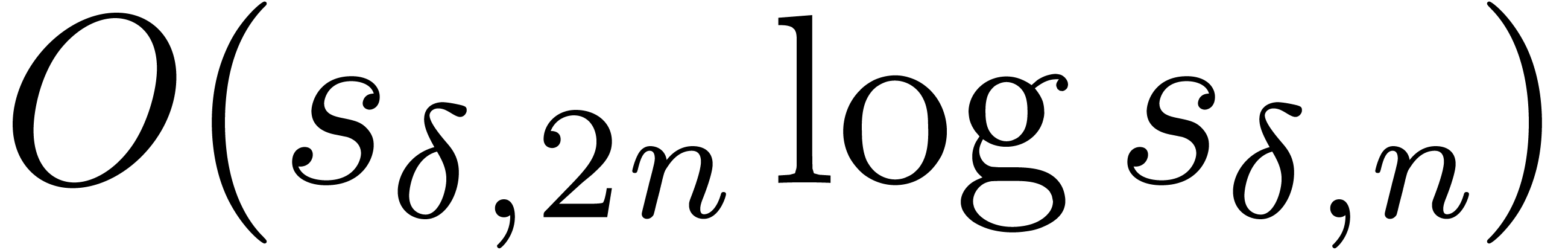 operations in , plus
operations in , plus 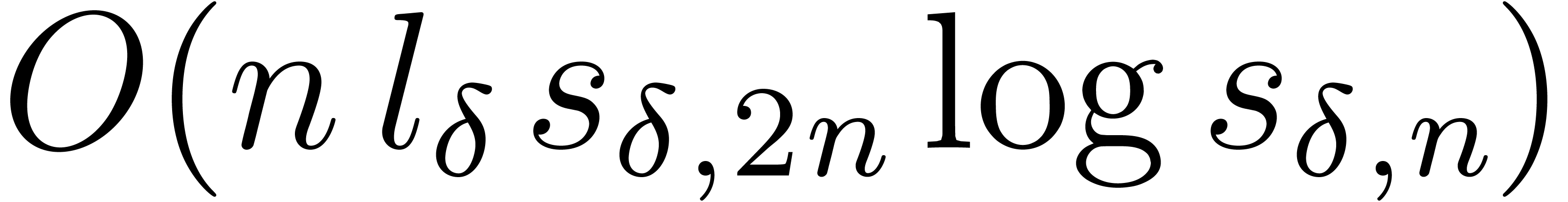 bit-operations.
bit-operations.
Proof. The result follows as in proposition 14 thanks to the following identity:
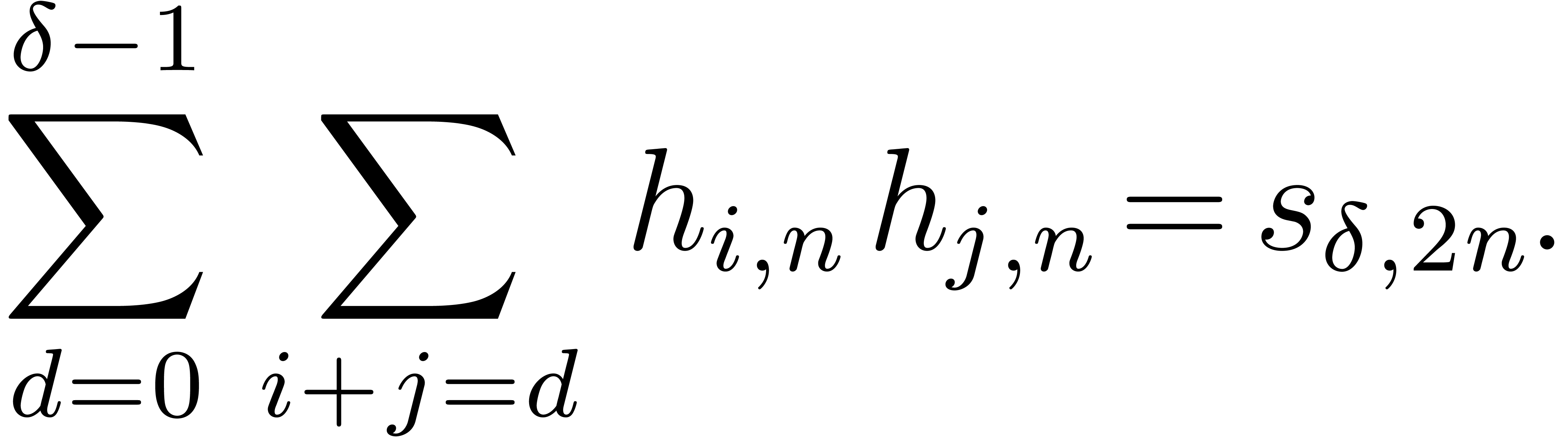 |
(1) |
This identity is already given in [Hoe06, Section 6] for a
similar purpose. We briefly recall its proof for completeness. Let 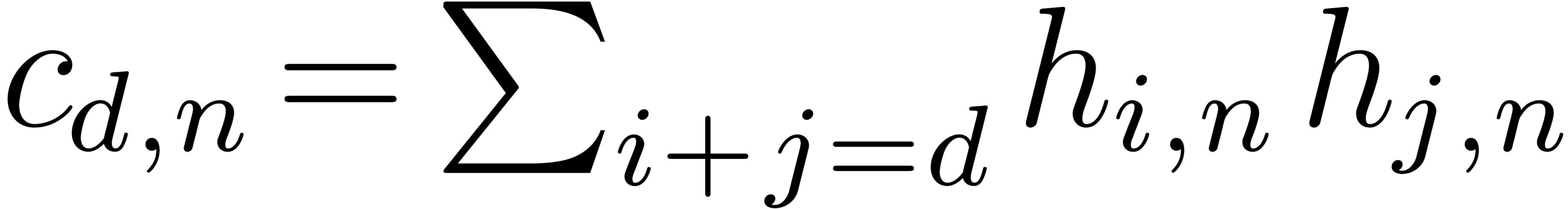 , let
, let 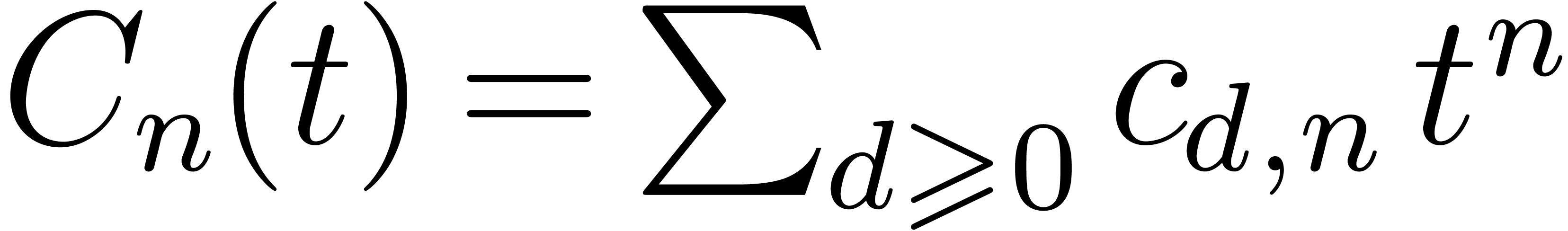 for
the generating series, and let also
for
the generating series, and let also 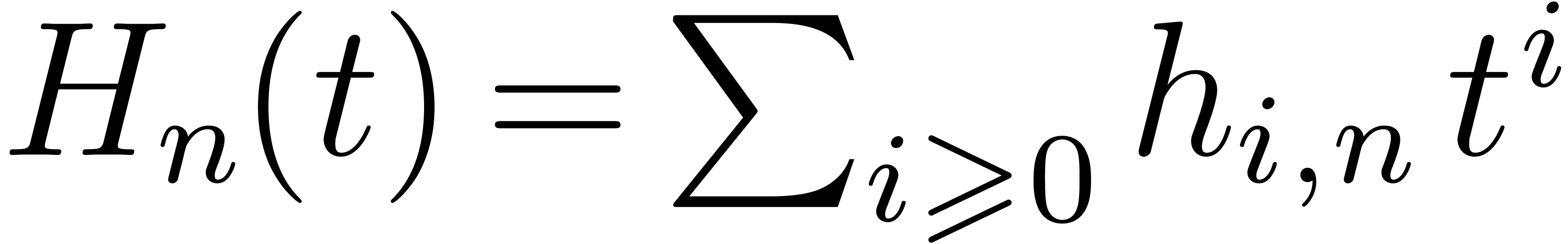 .
On one hand, we have
.
On one hand, we have 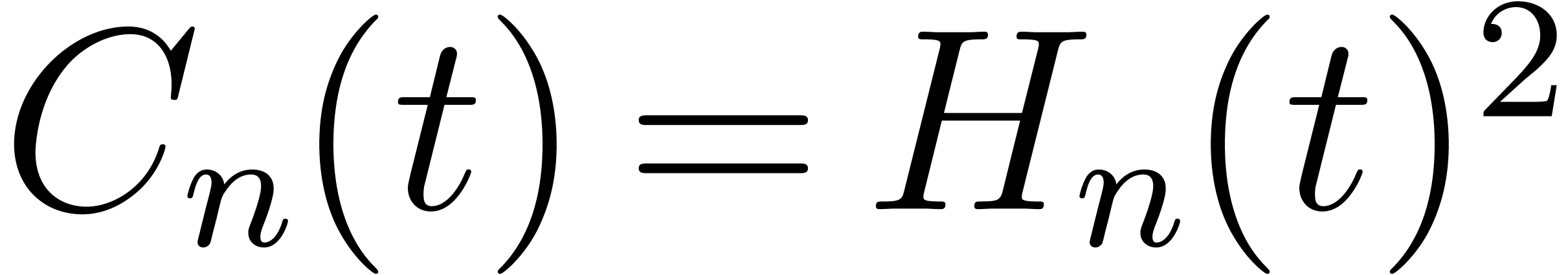 . On the
other hand,
. On the
other hand, 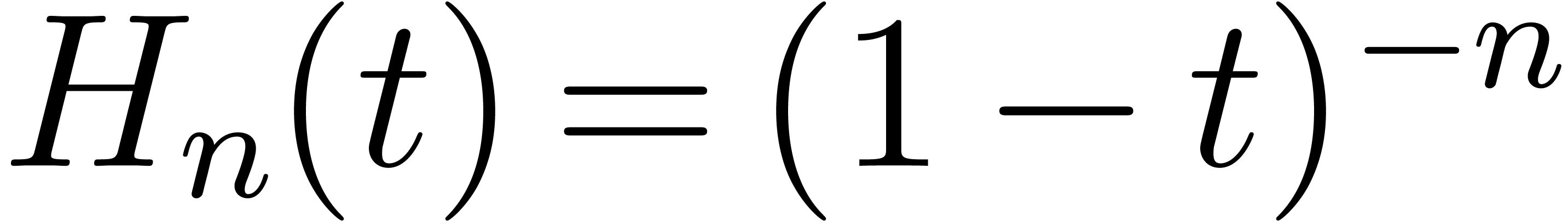 . It follows that
. It follows that
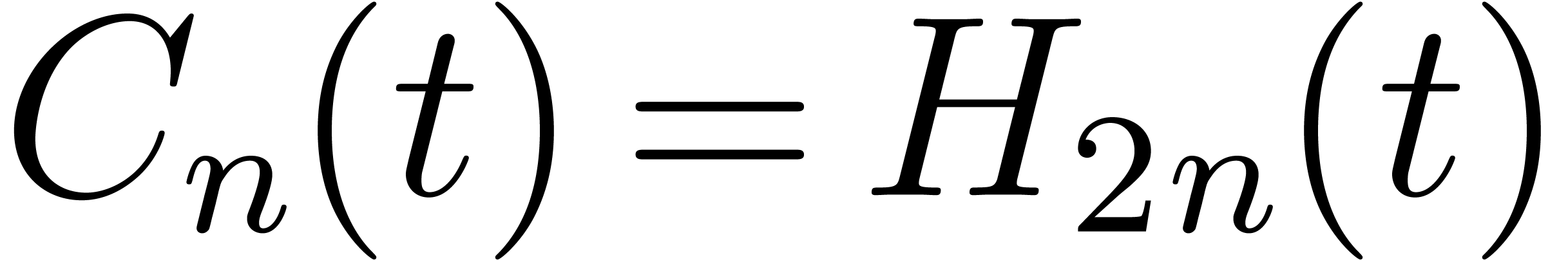 , and that
, and that 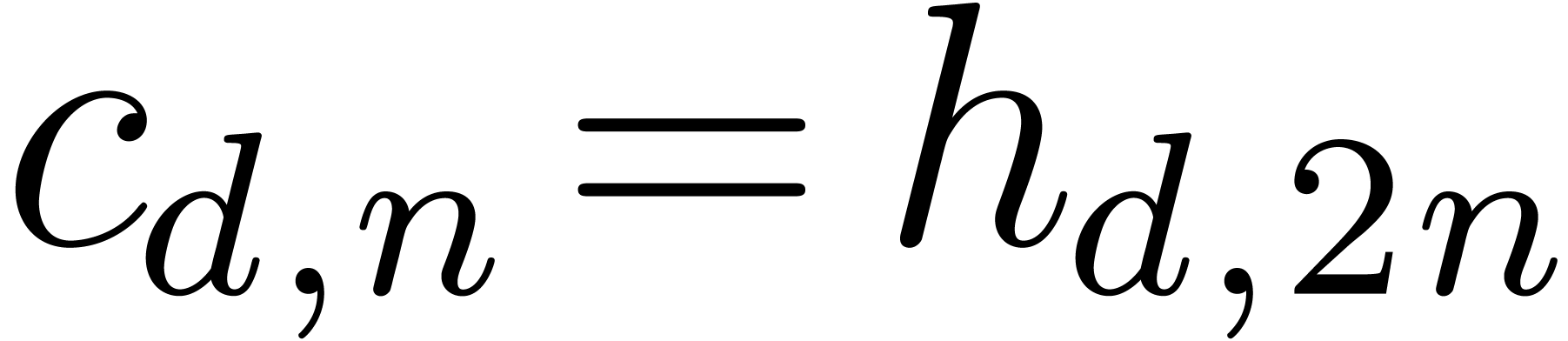 , whence (1). Finally the bit-cost
follows in the same way with
, whence (1). Finally the bit-cost
follows in the same way with 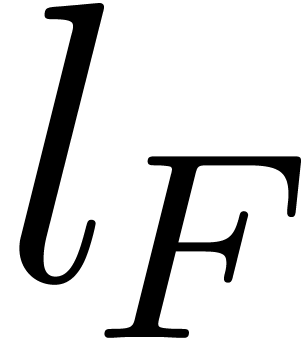 and
and  being bounded by
being bounded by 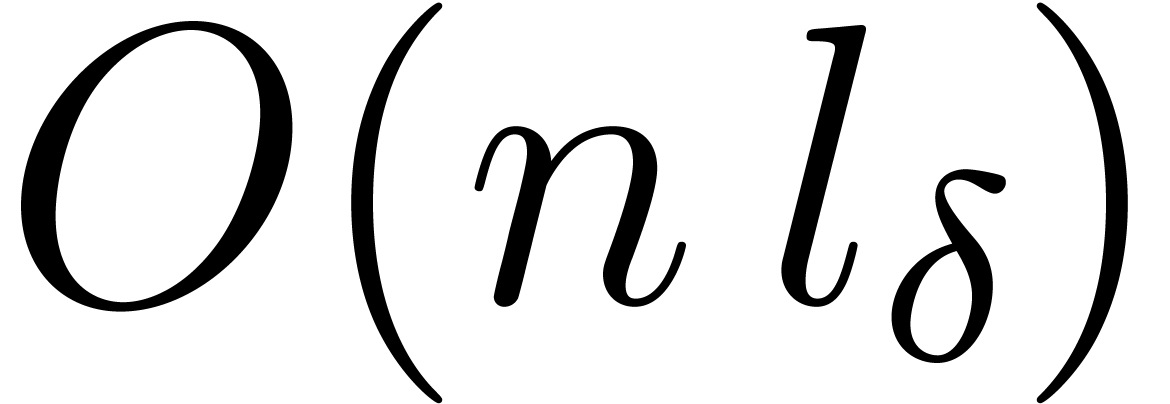 .
.
If  , then
, then  and
and 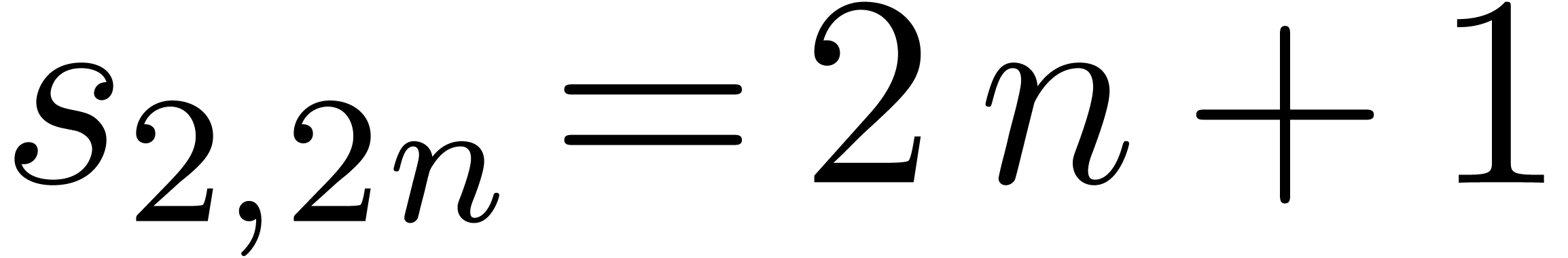 , so the naive sparse
product is softly optimal when grows to
infinity. If
, so the naive sparse
product is softly optimal when grows to
infinity. If 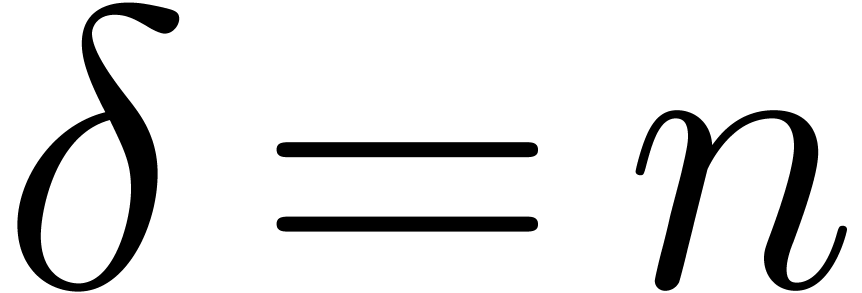 and is
large, then
and is
large, then
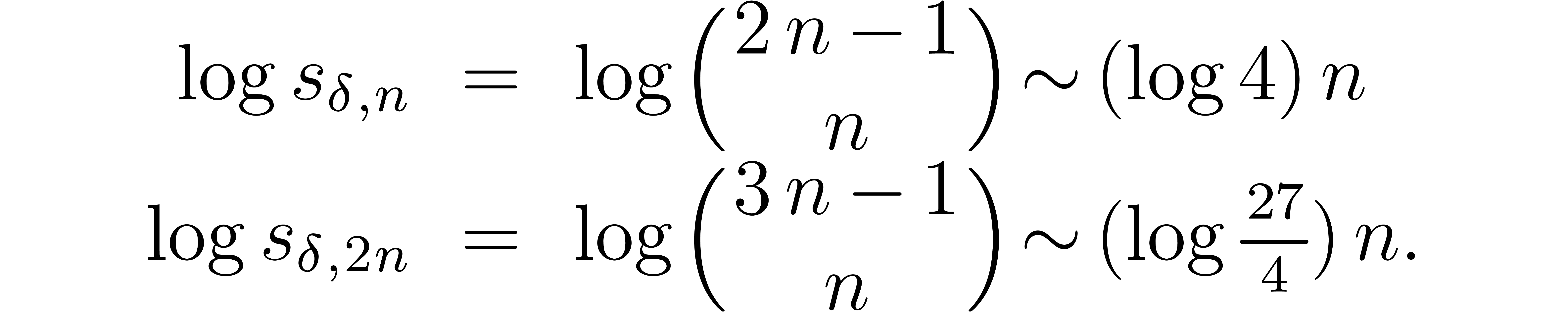
In particular, we observe that the naive algorithm has a subquadratic
complexity in this case. In general, for fixed
and for when tends to infinity, the cost is
quadratic since the ratio
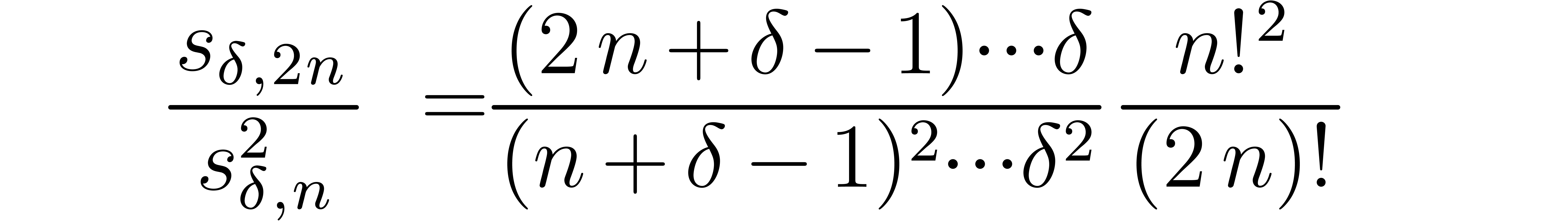
tends to 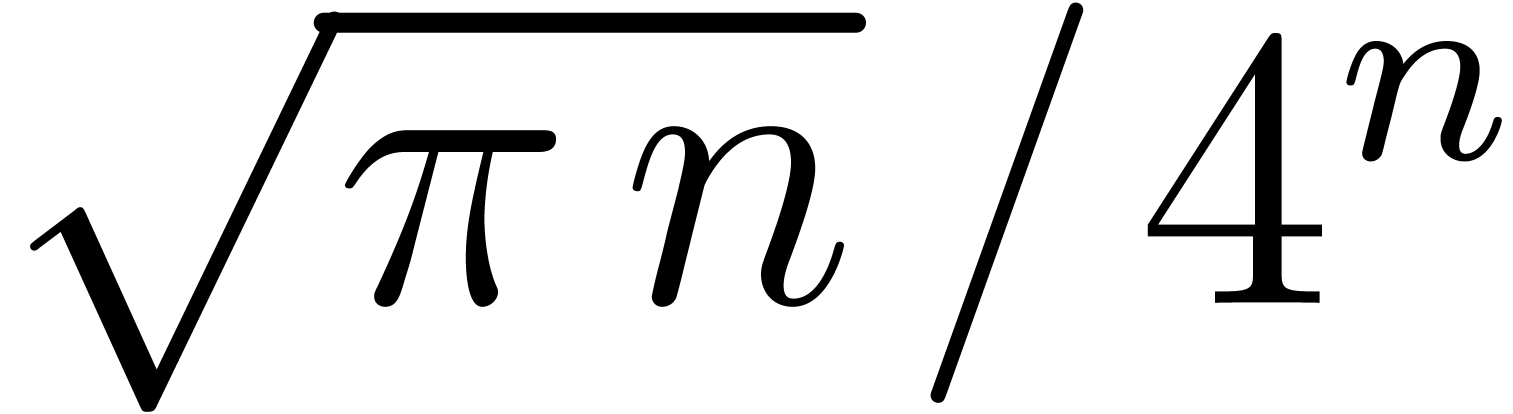 .
.
Remark that we do not propose a specific dense representation for the series. This could be possible as we did for polynomials and gain in memory space (but not so much with respect to the “packed exponent” technique). However one can not expect more because there is no straightforward generalization of the fast algorithms for series to several variables such as the Kronecker substitution.
In Table ? we report on timings for , with .
Comparing with Tables 1 and 2, we observe
that, for small , Kronecker
substitution quickly becomes the most efficient strategy. However, it
computes much more and its memory consumption is much higher. For small
, one could also benefit from
the truncated Fourier transform, as explained in Section 6 of [Hoe06].
In higher dimensions, say and order 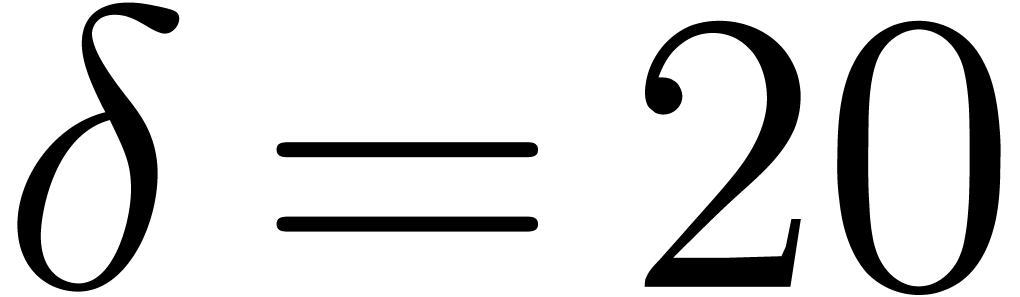 , the Kronecker substitution is hopeless: the
size of the univariate polynomials to be multiplied is
, the Kronecker substitution is hopeless: the
size of the univariate polynomials to be multiplied is  .
.
|
||||||||||||||||||||||||||||||||||||||||||
Let be an effective algebra over an effective
field 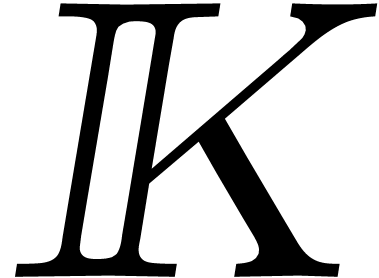 , i.e. all
algebra and field operations can be performed by algorithm. Let and still be two multivariate
polynomials in we want to multiply, and let
, i.e. all
algebra and field operations can be performed by algorithm. Let and still be two multivariate
polynomials in we want to multiply, and let 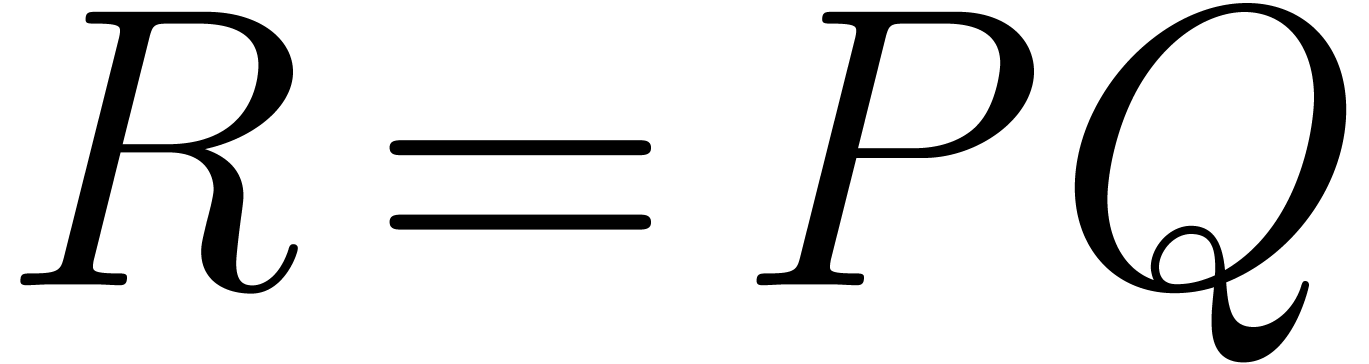 be their product.
be their product.
We assume we are given a subset 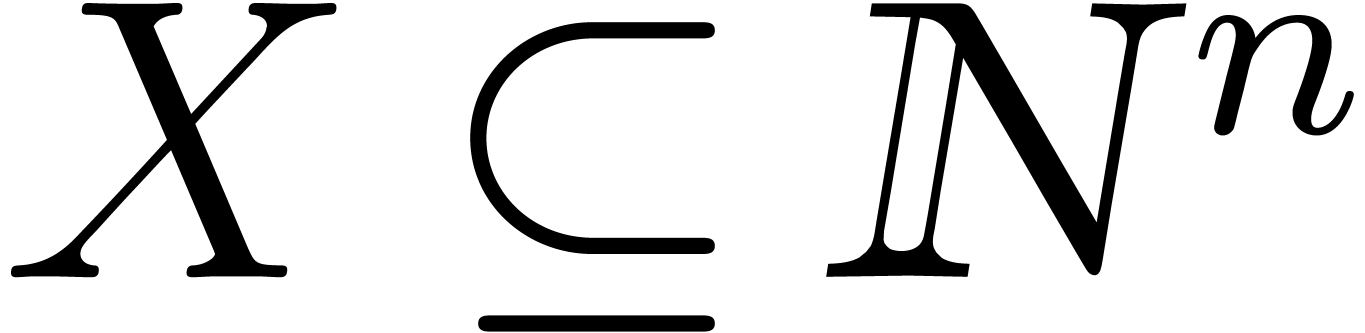 of size
of size  that contains the support of . We let
that contains the support of . We let 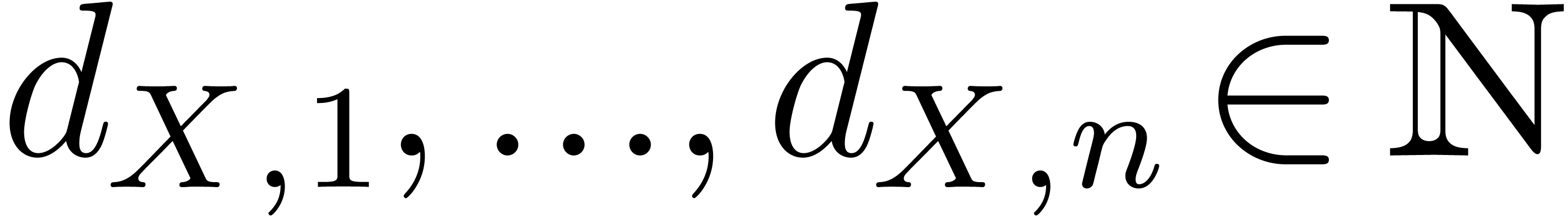 be the minimal
numbers with
be the minimal
numbers with 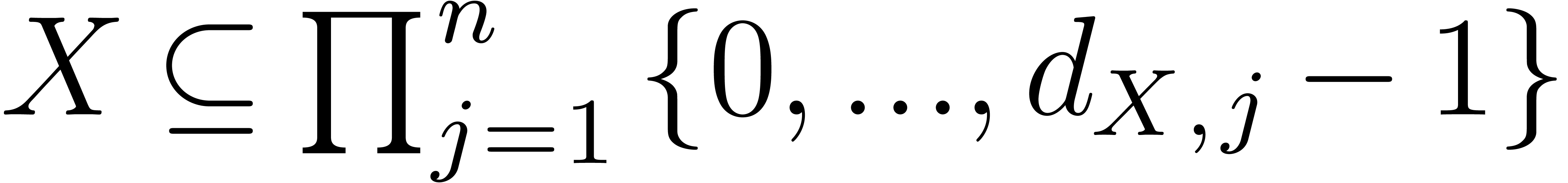 . With no loss
of generality we can assume that
. With no loss
of generality we can assume that 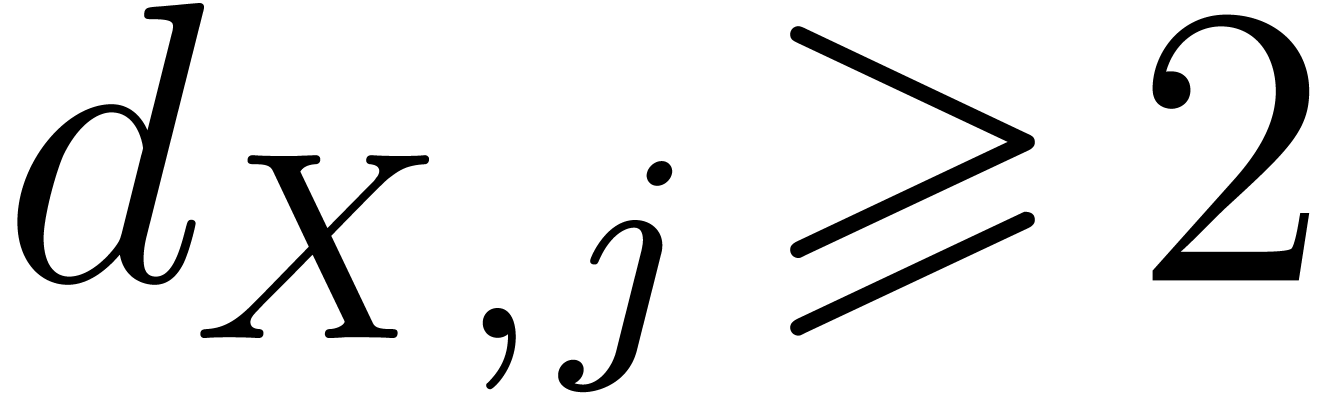 for all
for all  .
.
To analyze the algorithms of this section we shall use the quantities
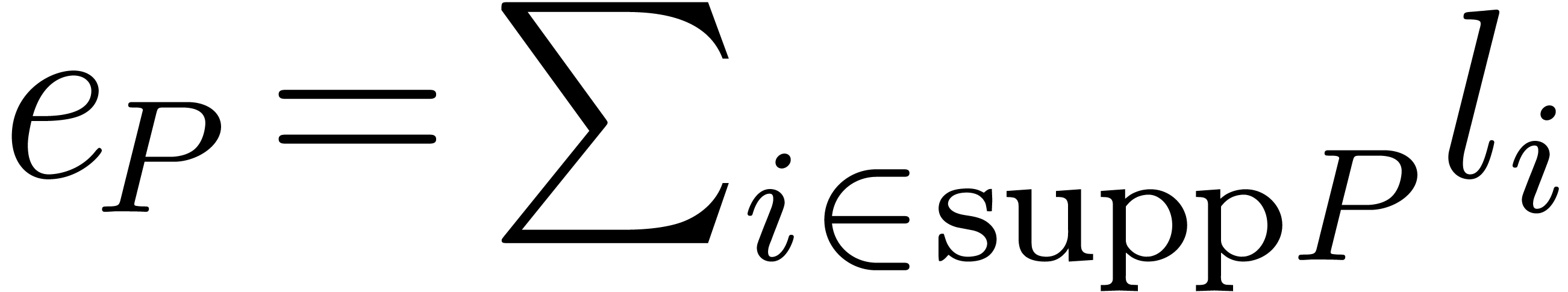 ,
, 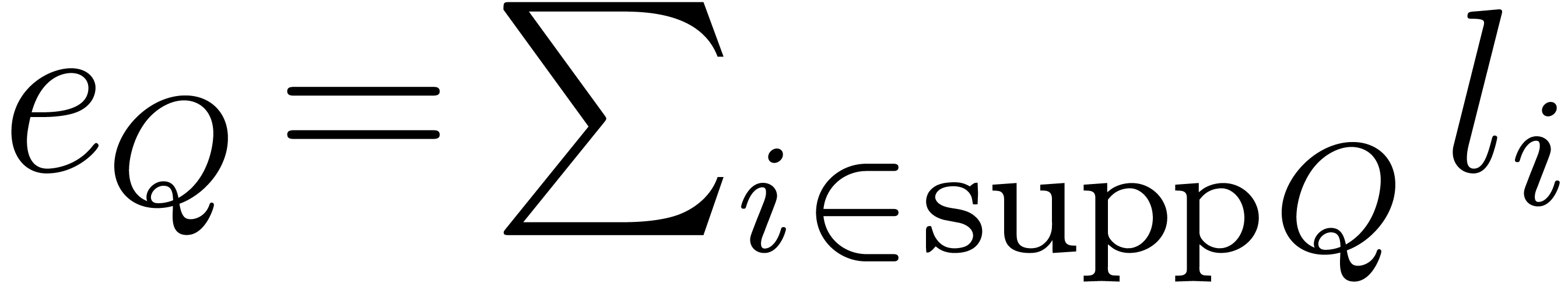 and
and
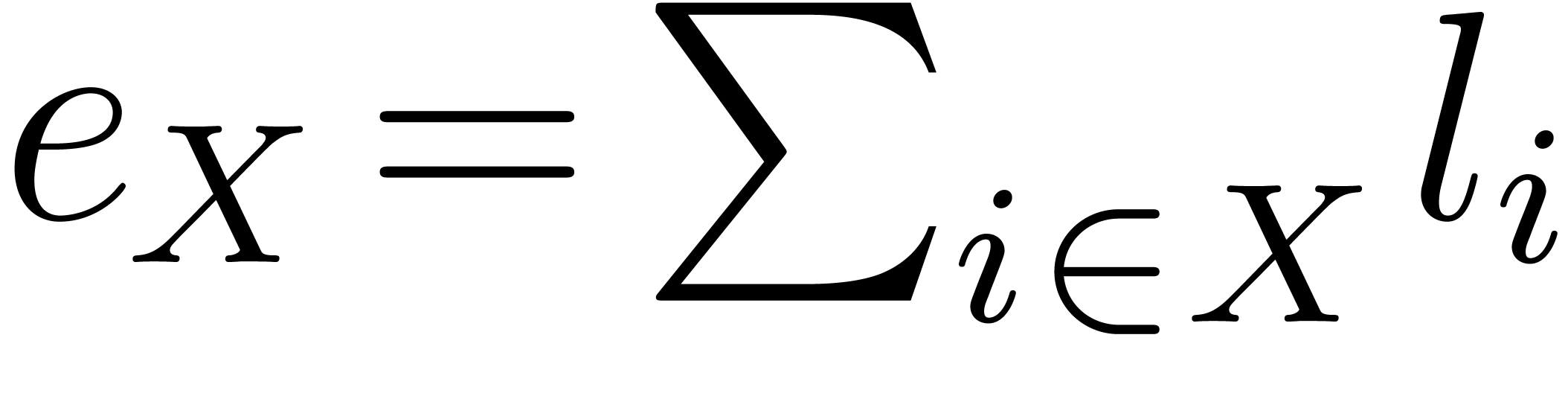 . We also introduce
. We also introduce 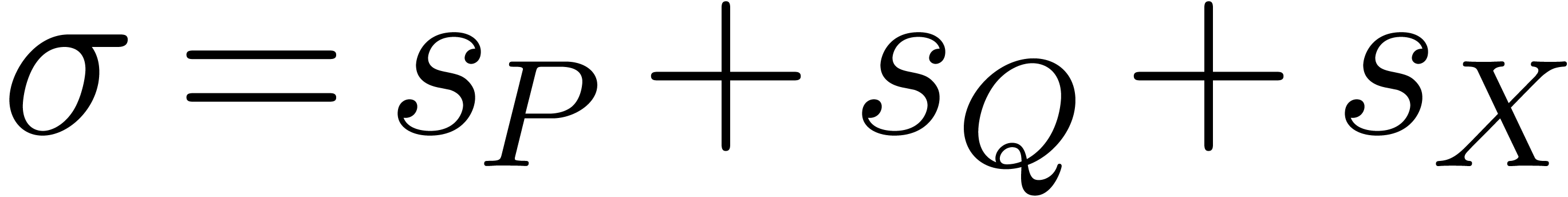 and
and  , and
, and 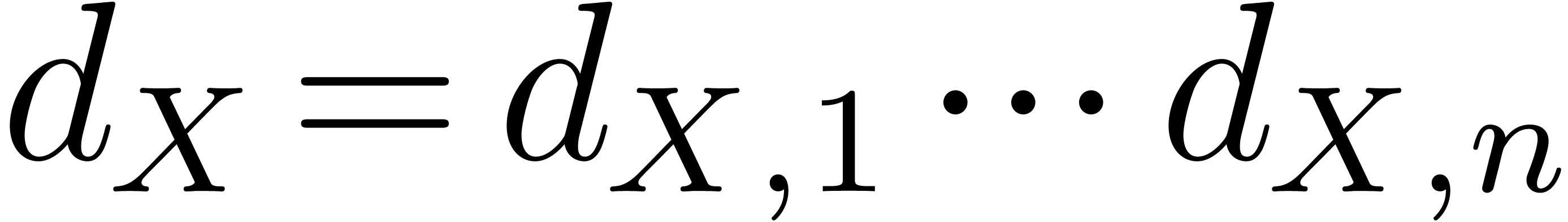 .
.
Since the support of the product is now given, we will neglect the bit-cost due to computations on the exponents.
Given  pairwise distinct points
pairwise distinct points 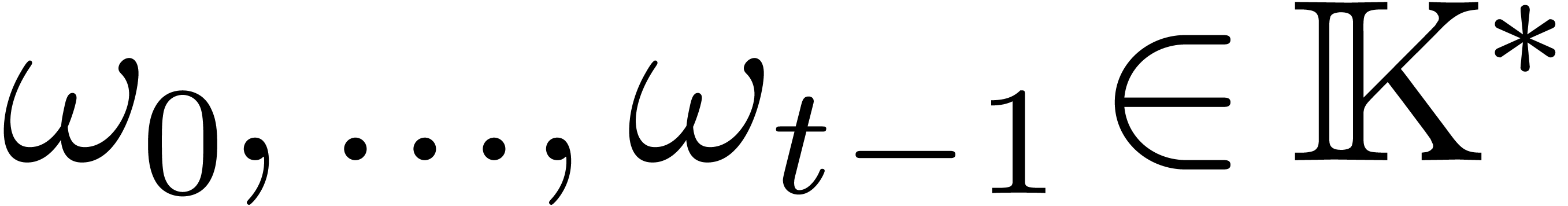 and
and  , let
, let 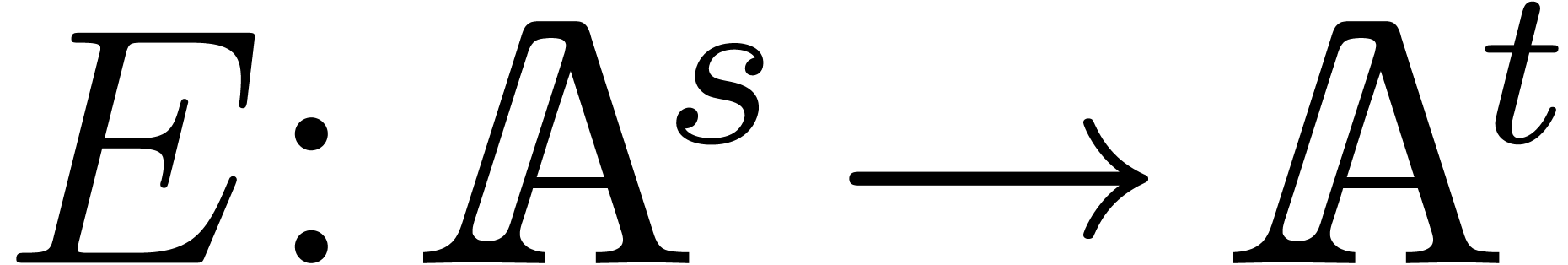 be the linear map which sends
be the linear map which sends  to
to  , with
, with  .
In the canonical basis, this map corresponds to left multiplication by
the generalized Vandermonde matrix
.
In the canonical basis, this map corresponds to left multiplication by
the generalized Vandermonde matrix
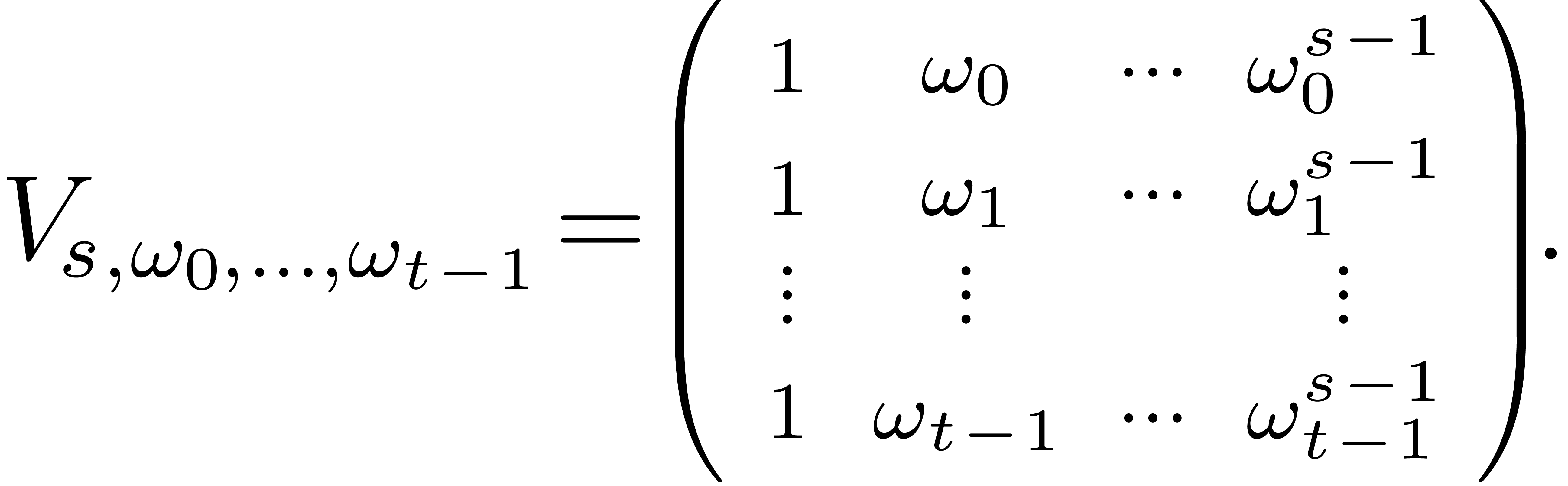
The computation of  and its inverse
and its inverse 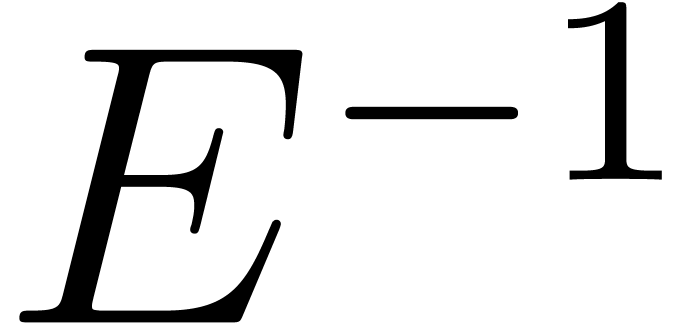 (if
(if  )
correspond to the problems of multi-point evaluation and interpolation
of a polynomial. Using binary splitting, it is classical [BM72,
Str73, BM74] that both problems can be solved
in time
)
correspond to the problems of multi-point evaluation and interpolation
of a polynomial. Using binary splitting, it is classical [BM72,
Str73, BM74] that both problems can be solved
in time  ; see also [GG02,
Chapter 10] for a complete description. Notice that the algorithms only
require vectorial operations in (additions,
subtractions and multiplications with elements in
; see also [GG02,
Chapter 10] for a complete description. Notice that the algorithms only
require vectorial operations in (additions,
subtractions and multiplications with elements in  ).
).
The algorithms of this section rely on the efficient computations of the
transpositions 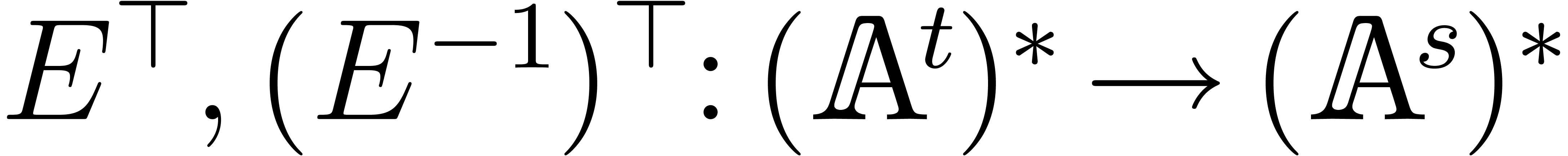 of and
. The map
of and
. The map  corresponds to left multiplication by
corresponds to left multiplication by
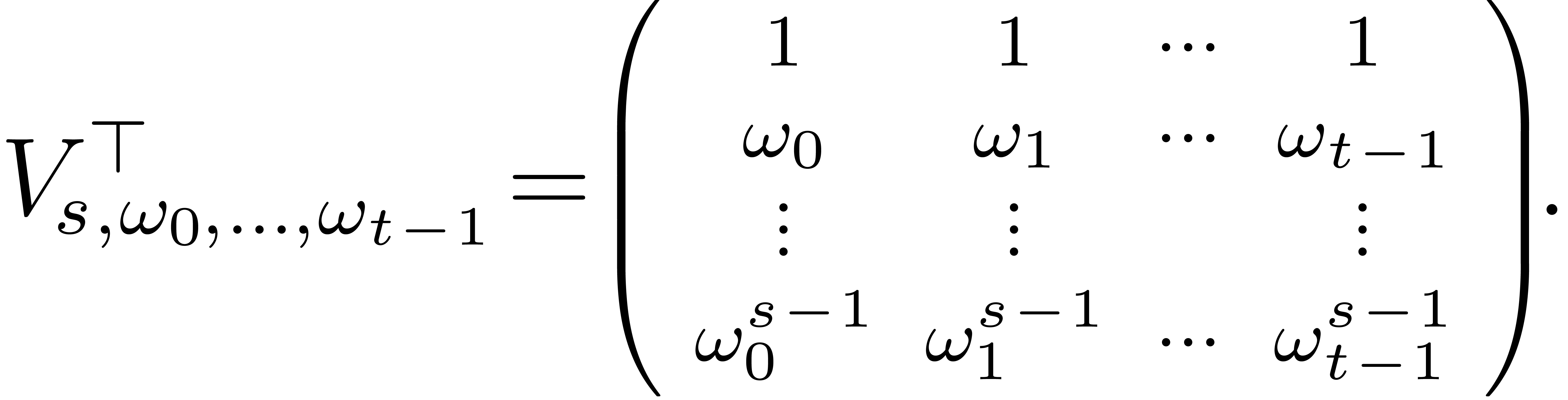
By the transposition principle [Bor56, Ber],
the operations and 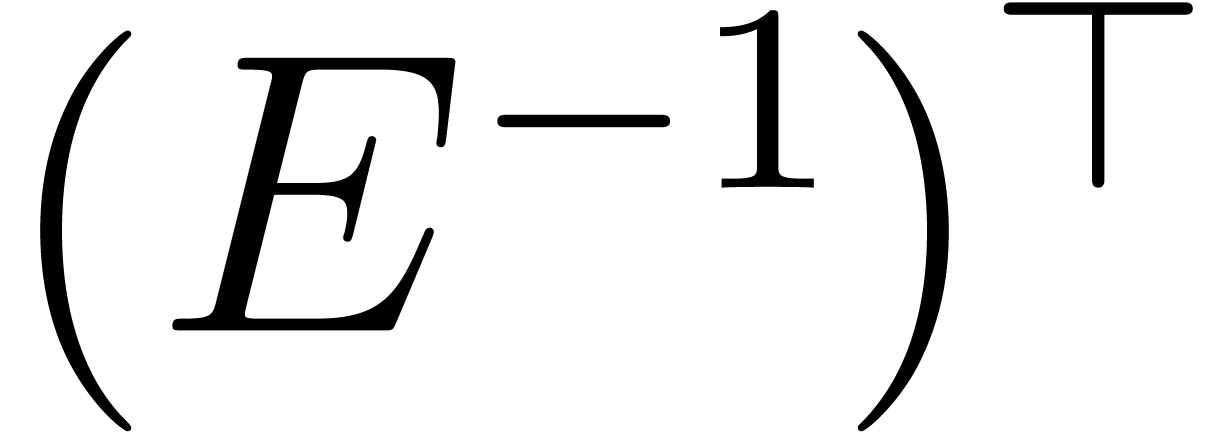 can
again be computed in time
can
again be computed in time  .
.
There is an efficient direct approach for the computation of [BLS03]. Given a vector 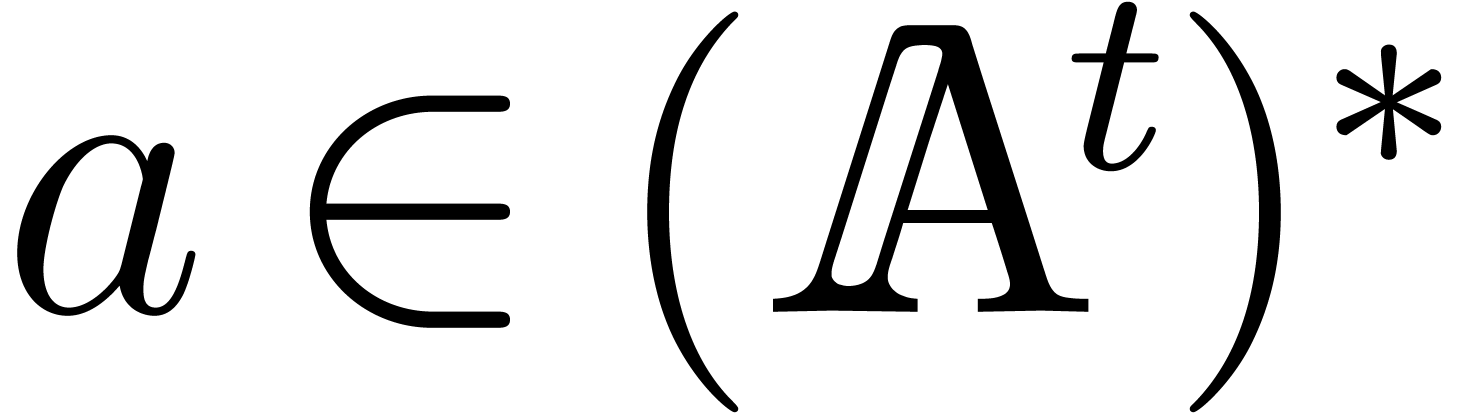 with entries
with entries  , the entries
, the entries
 of
of 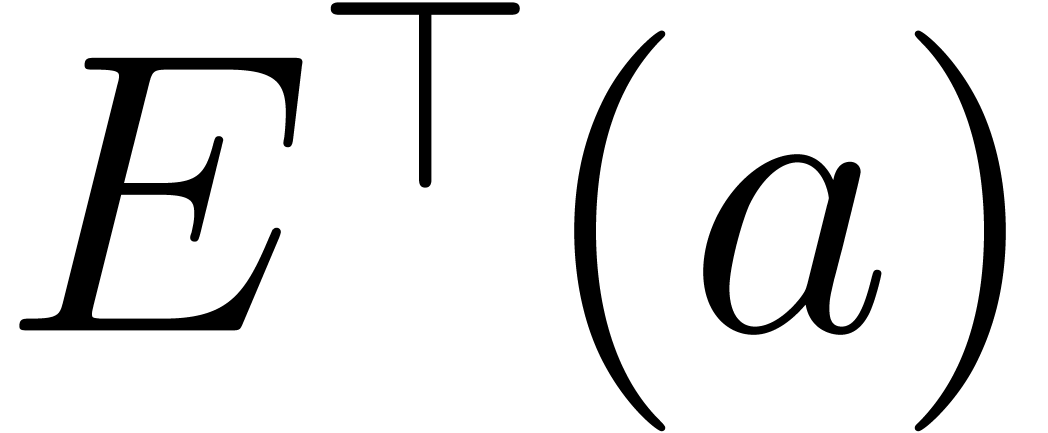 are identical to the
first
are identical to the
first  coefficients of the power series
coefficients of the power series
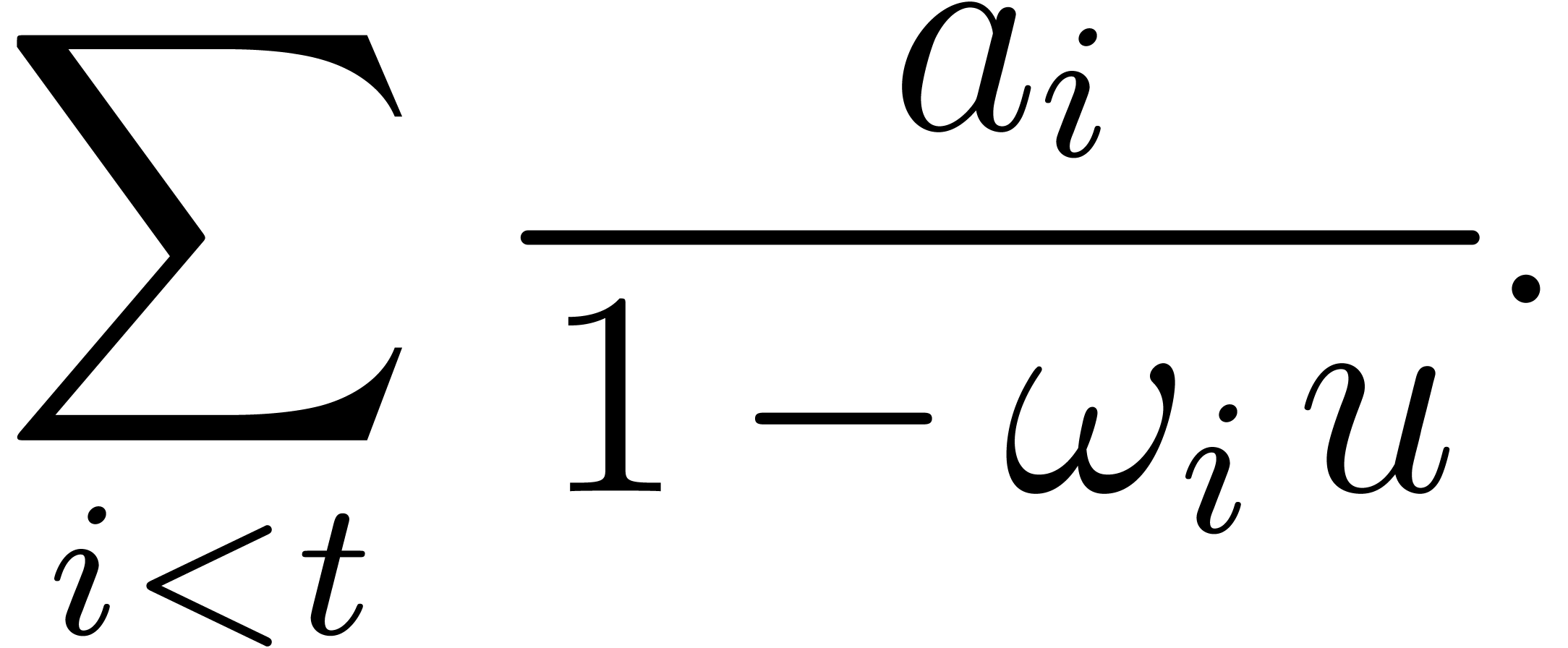
The numerator and denominator of this rational function can be computed
using the classical divide and conquer technique, as described in [GG02, Algorithm 10.9]. If 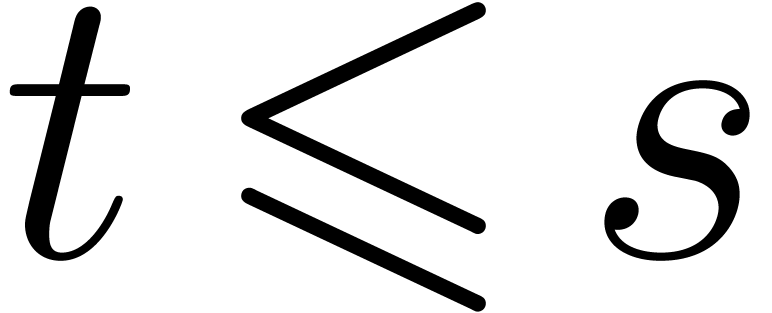 ,
then this requires
,
then this requires  vectorial operations in [GG02, Theorem 10.10]. The truncated
division of the numerator and denominator at order
requires
vectorial operations in [GG02, Theorem 10.10]. The truncated
division of the numerator and denominator at order
requires 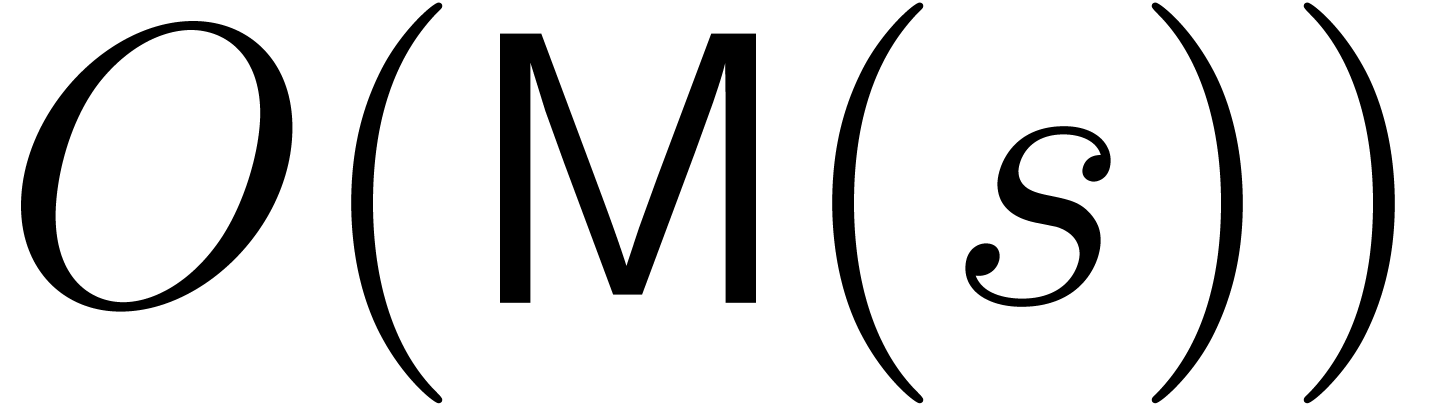 vectorial operations in . If
vectorial operations in . If 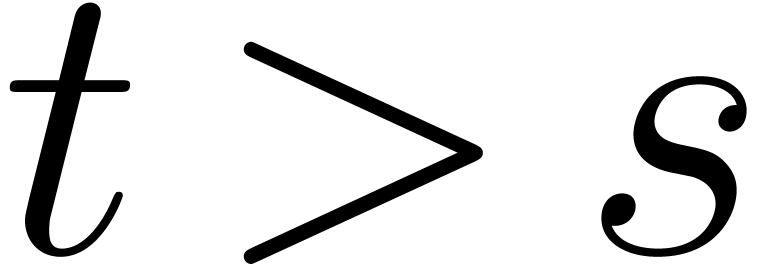 ,
then we cut the sum into
,
then we cut the sum into 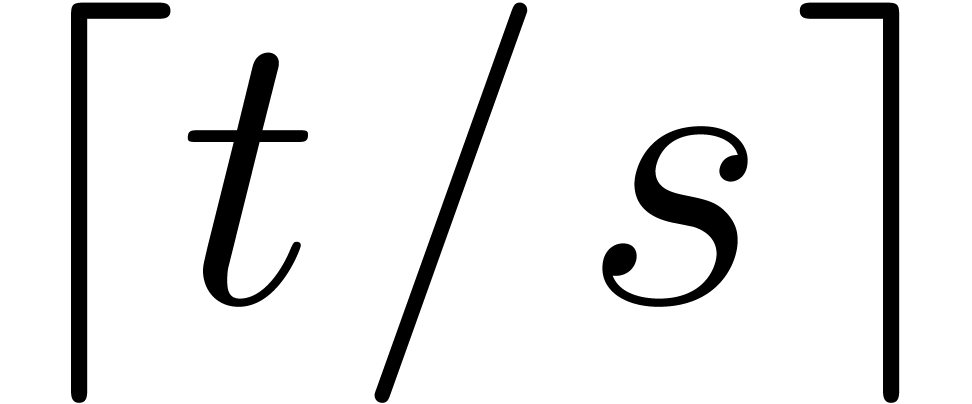 parts of size
parts of size 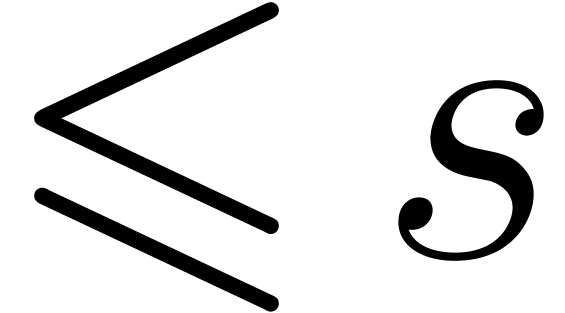 , and obtain the complexity bound
.
, and obtain the complexity bound
.
Inversely, assume that we wish to recover  from
, when . For simplicity, we assume that the
from
, when . For simplicity, we assume that the  are non-zero (this will be the case in the sequel).
Setting
are non-zero (this will be the case in the sequel).
Setting  ,
, 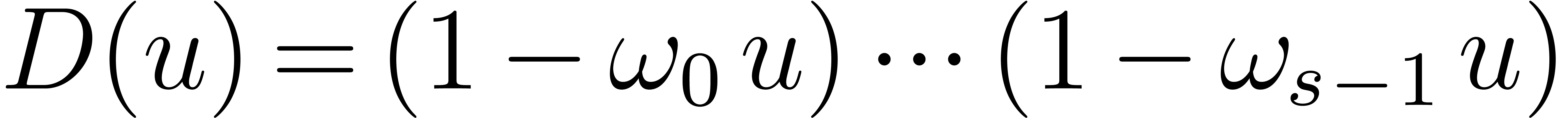 and
and  , we notice that
, we notice that  for all .
Hence, the computation of the
for all .
Hence, the computation of the  reduces to two
multi-point evaluations of
reduces to two
multi-point evaluations of  and
and 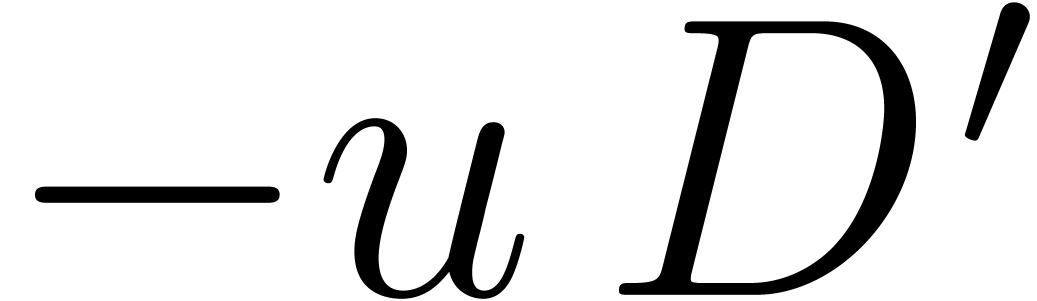 at
at  and divisions. This
amounts to a total of vectorial operations in
and
and divisions. This
amounts to a total of vectorial operations in
and  divisions in .
divisions in .
The Kronecker substitution 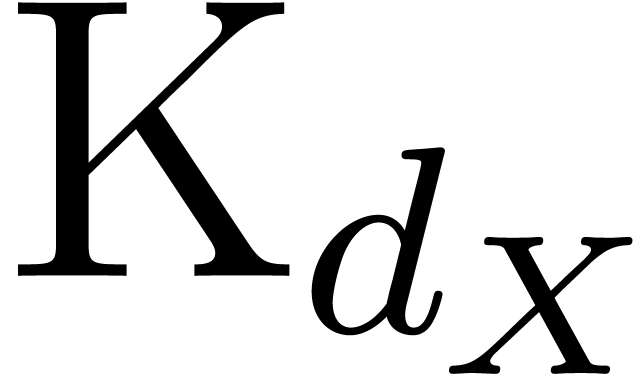 ,
introduced in Section 2.3, sends any monomial
,
introduced in Section 2.3, sends any monomial  to
to 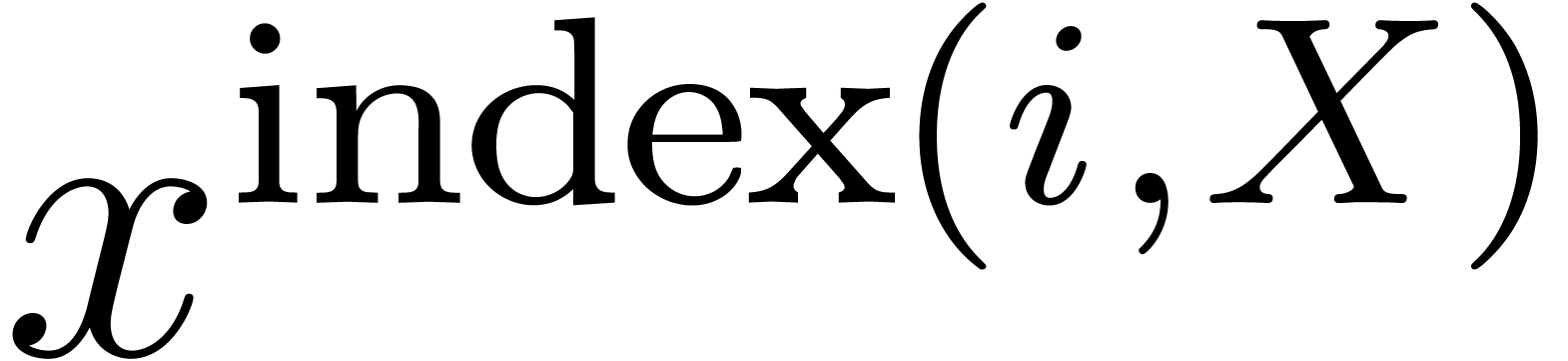 , where
, where
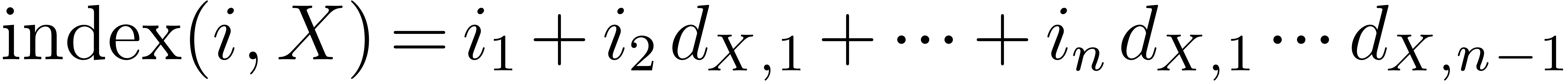 . It defines an isomorphism
between polynomials with supports in
. It defines an isomorphism
between polynomials with supports in  and
univariate polynomials of degrees at most
and
univariate polynomials of degrees at most 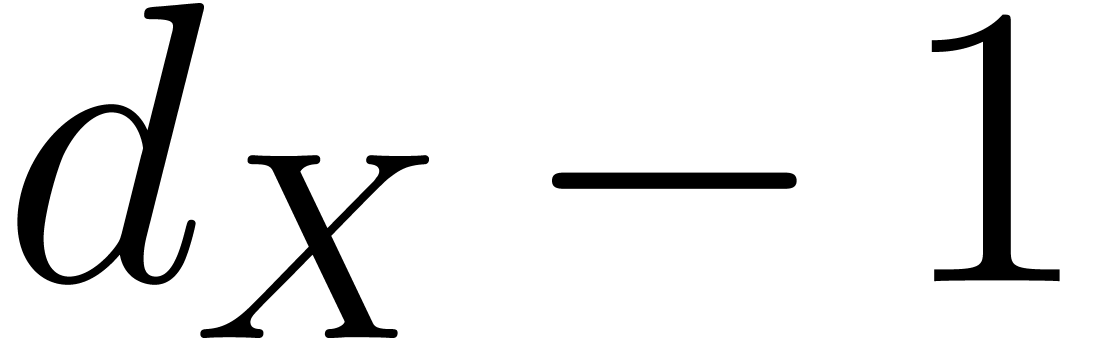 ,
so that
,
so that 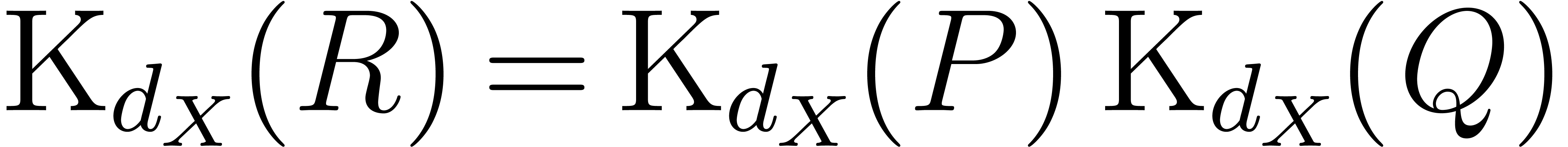 .
.
Assume now that we are given an element 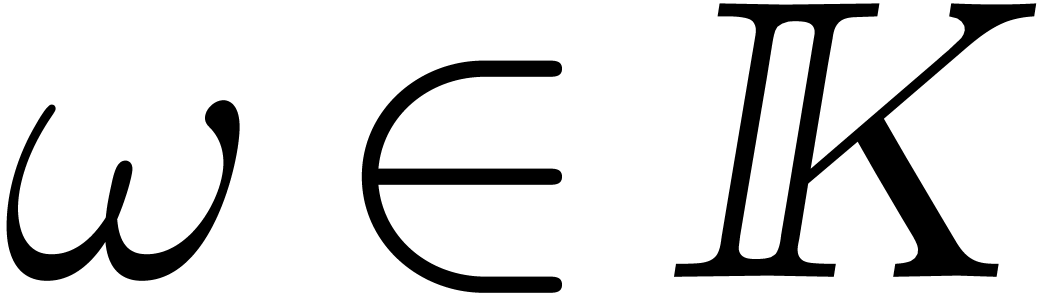 of
multiplicative order at least
of
multiplicative order at least  and consider the
following evaluation map
and consider the
following evaluation map
We propose to compute though the equality 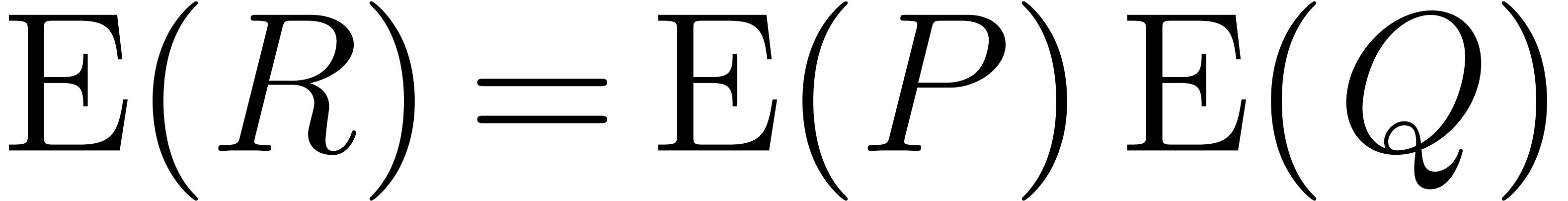 .
.
Given 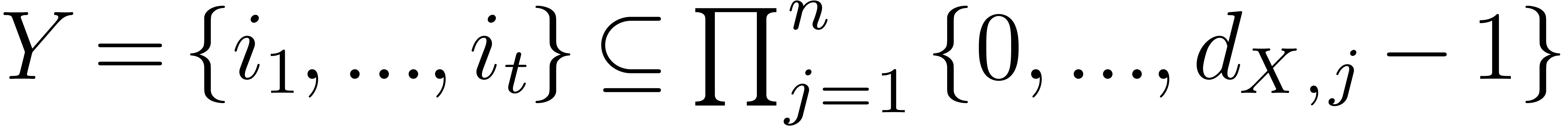 , let
, let 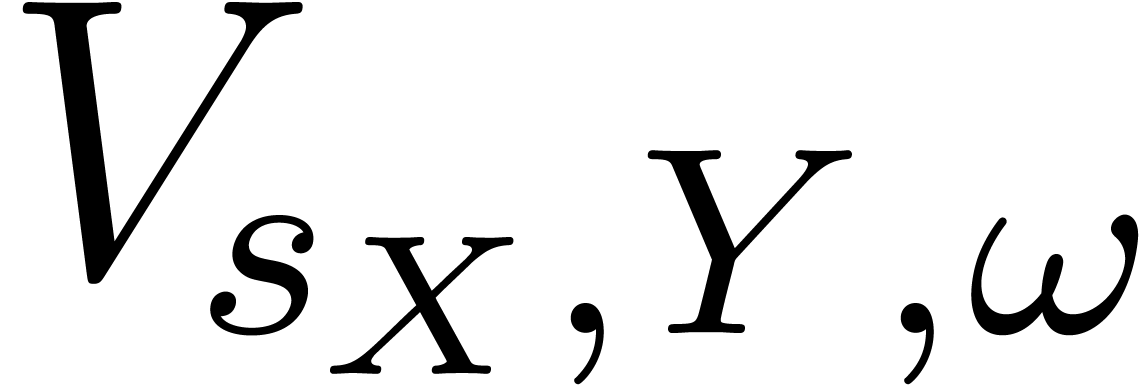 be the matrix of
be the matrix of  restricted to the space of
polynomials with support included in
restricted to the space of
polynomials with support included in 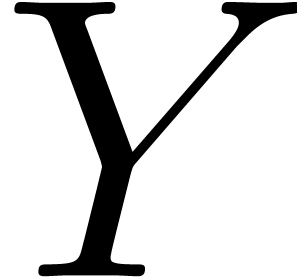 .
Setting
.
Setting 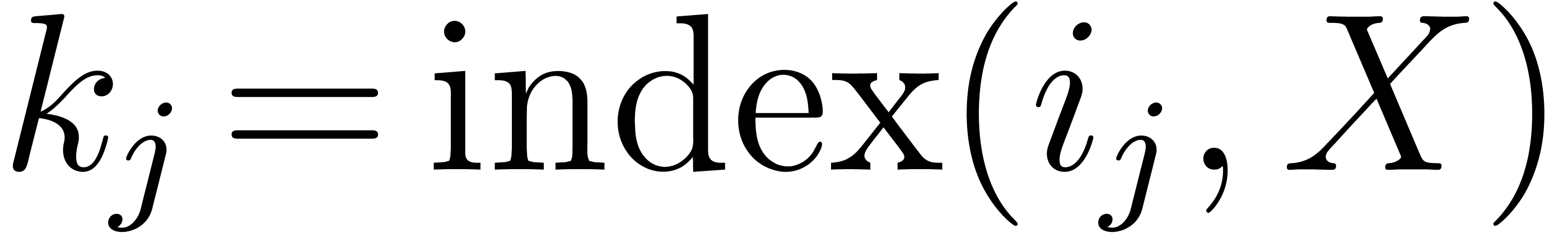 , we have
, we have
Taking  , resp.
, resp.
 , this allows us to compute
, this allows us to compute
 and
and  using our algorithm
for transposed multi-point evaluation from the preceding subsection. We
obtain
using our algorithm
for transposed multi-point evaluation from the preceding subsection. We
obtain 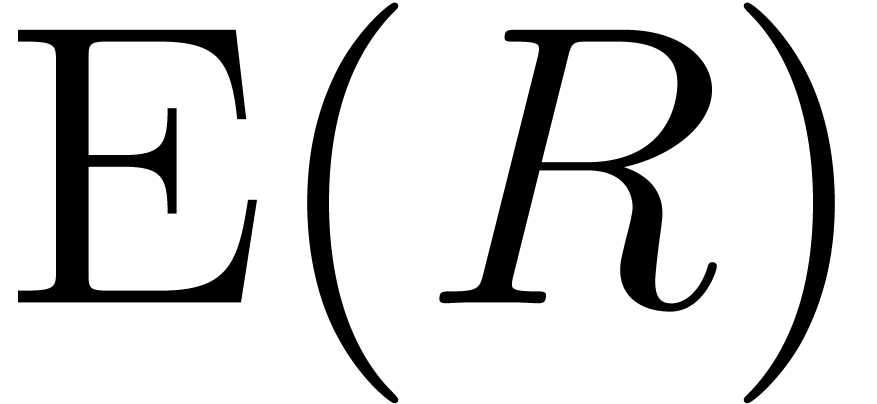 using one Hadamard product
using one Hadamard product 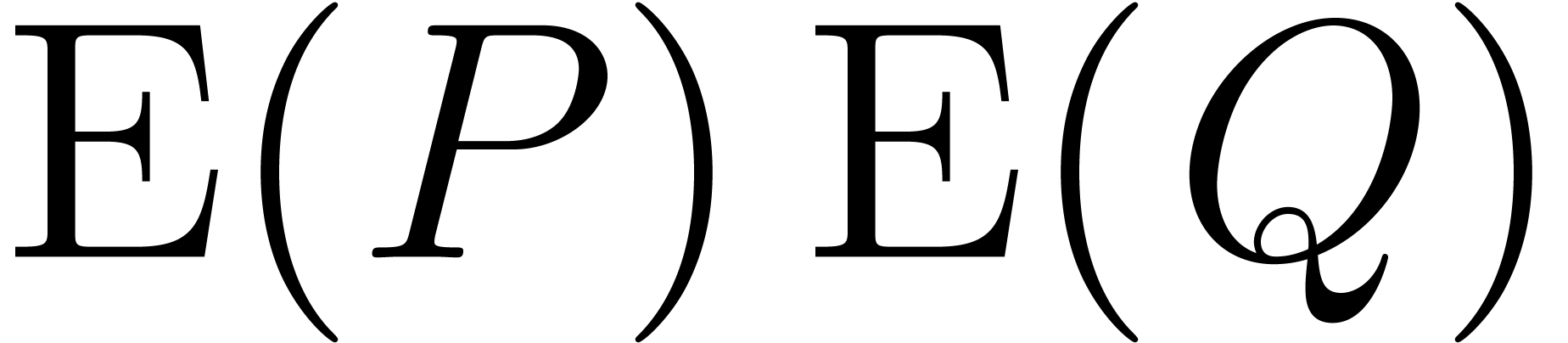 . Taking
. Taking  ,
the points
,
the points  are pairwise distinct, since the
are pairwise distinct, since the  are smaller than the order of
are smaller than the order of  . Hence
. Hence  is invertible and we
recover from using
transposed multi-point interpolation.
is invertible and we
recover from using
transposed multi-point interpolation.
and in 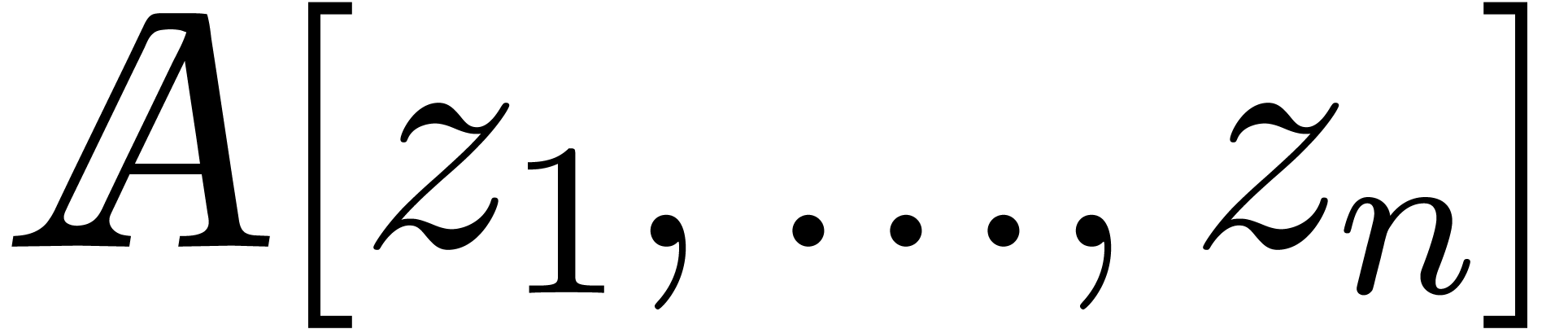 and an element
and an element
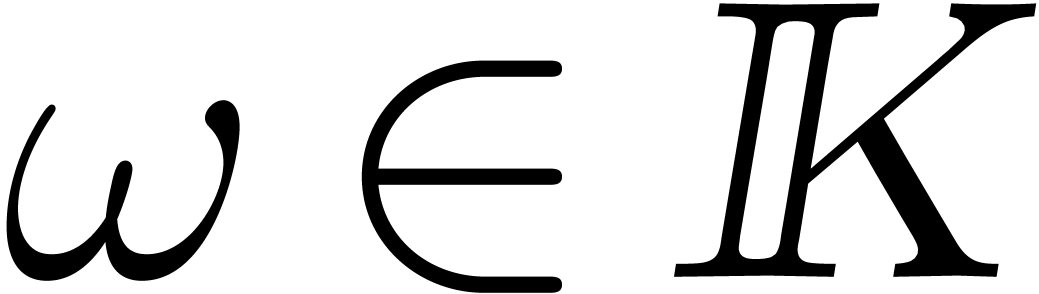 of order at least , then the product
of order at least , then the product 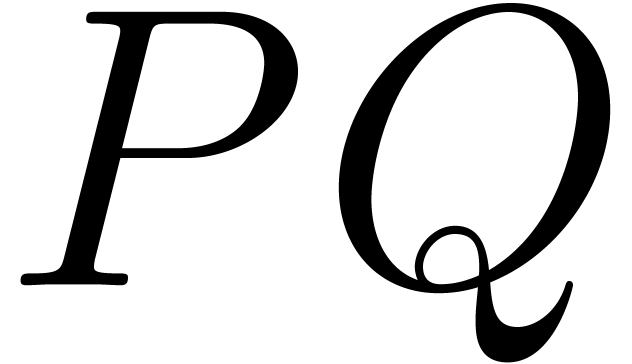 can be
computed using:
can be
computed using:
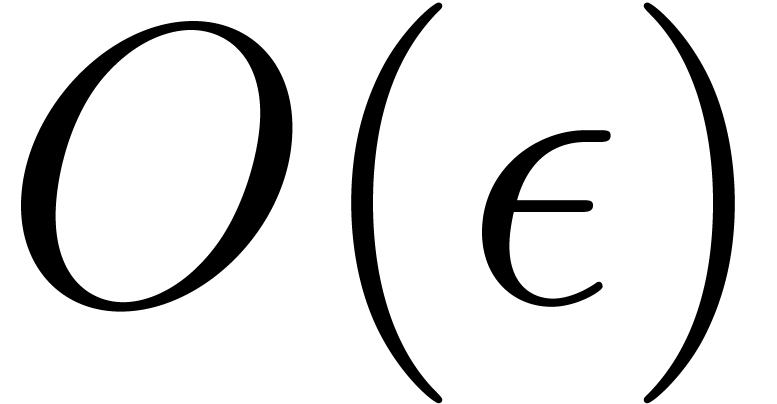 products in that
only depend on
products in that
only depend on 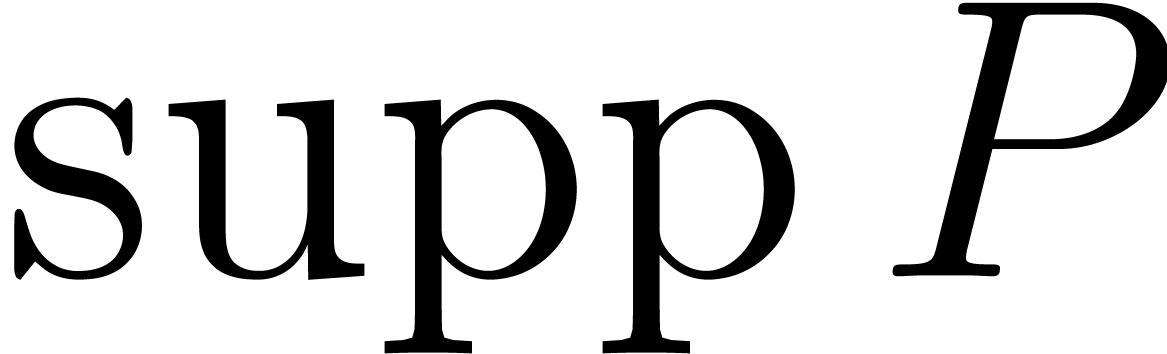 ,
, 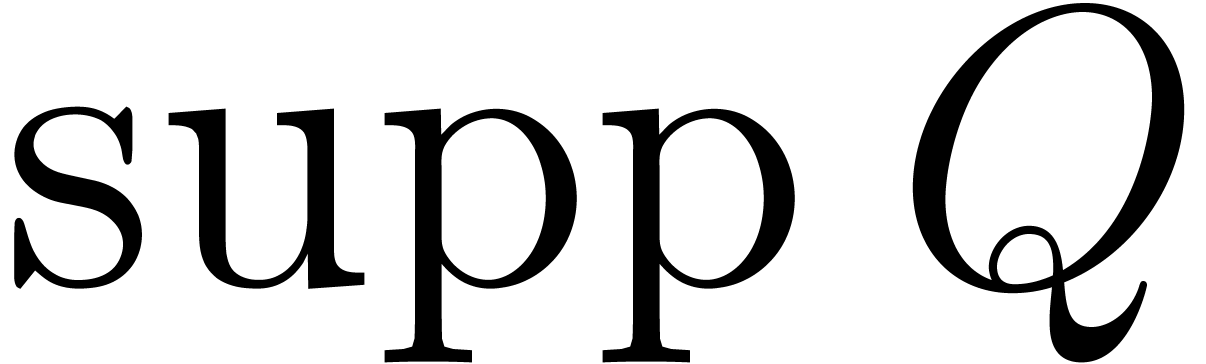 and ;
and ;
 inversions in , products in , and
inversions in , products in , and 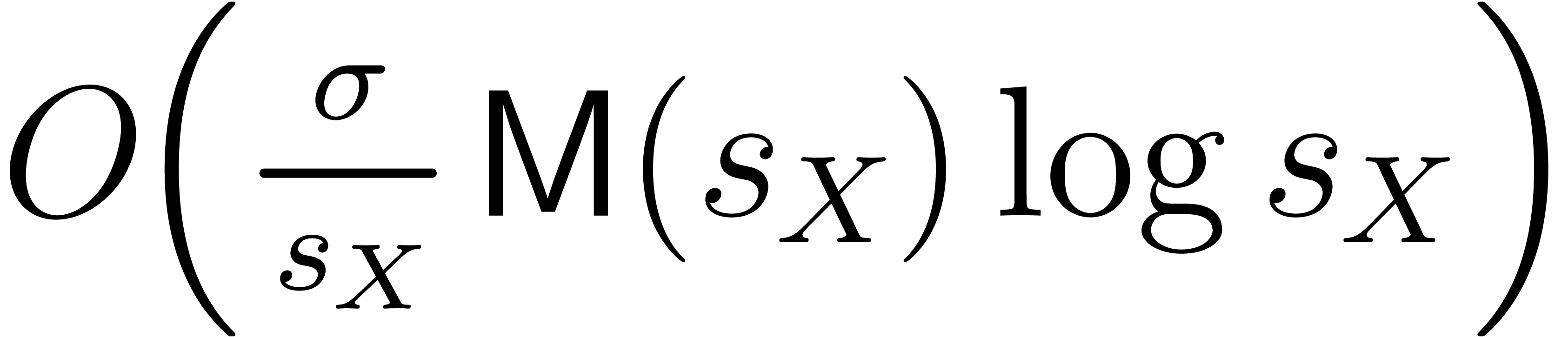 vectorial operations in .
vectorial operations in .
Proof. By classical binary powering, the
computation of the sequence  takes
takes 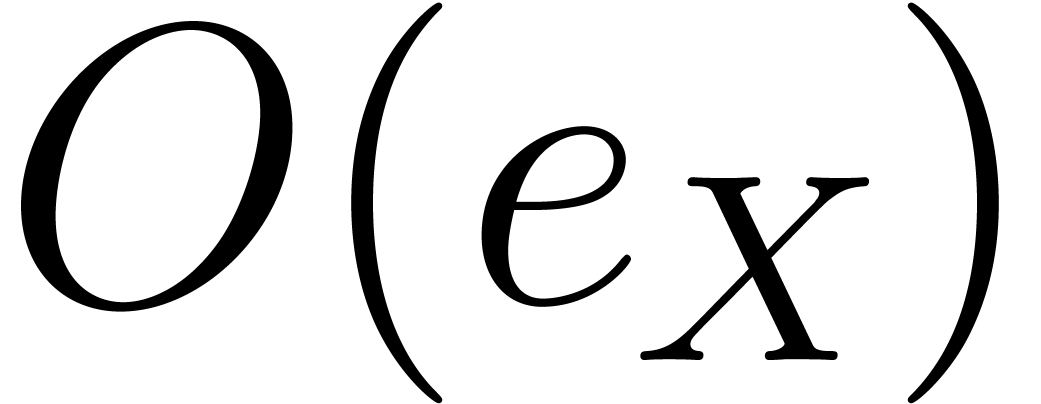 operations in
operations in  because each
because each  does appear in the entries of
does appear in the entries of  . Then the computation of all the
. Then the computation of all the 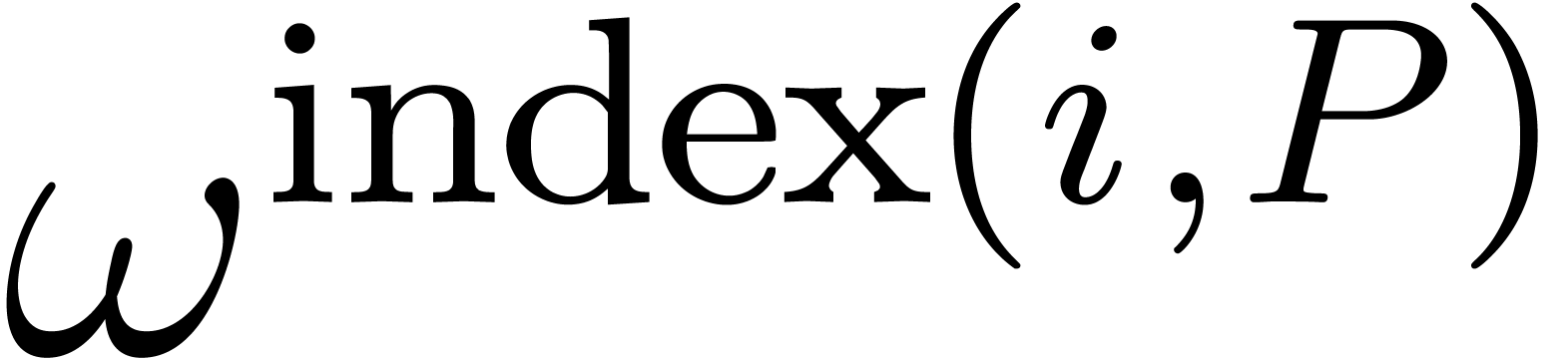 for
for 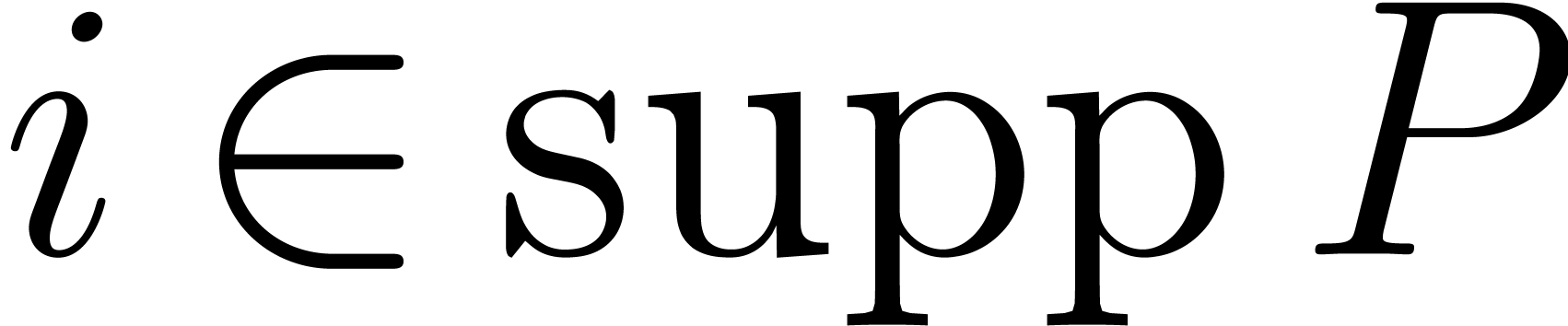 (resp.
(resp. 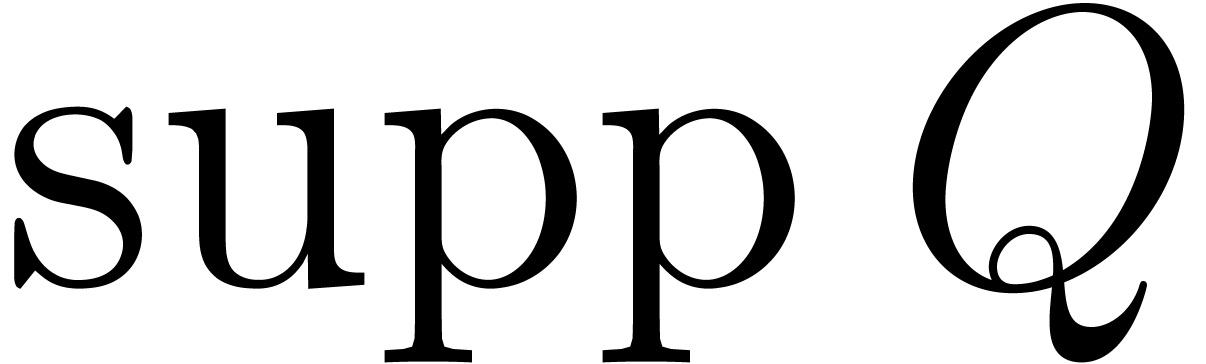 and ) requires
and ) requires  (resp.
(resp. 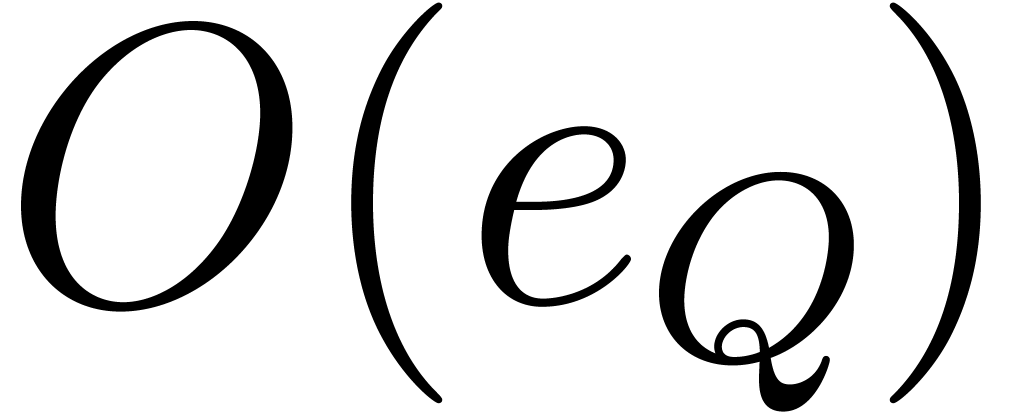 and )
products in .
and )
products in .
Using the complexity results from Section 5.1, we may
compute and using 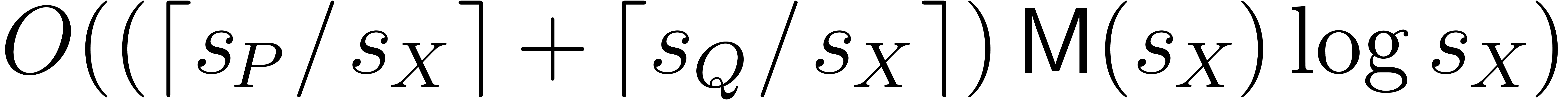 vectorial operations in .
We deduce using more
multiplications in . Again
using the results from Section 5.1, we retrieve the
coefficients
vectorial operations in .
We deduce using more
multiplications in . Again
using the results from Section 5.1, we retrieve the
coefficients 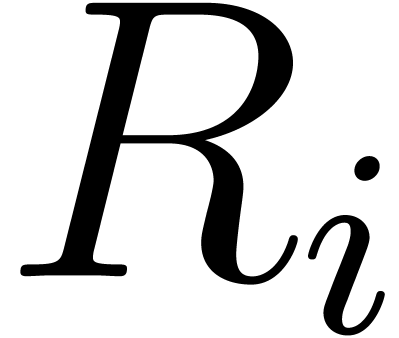 after
after 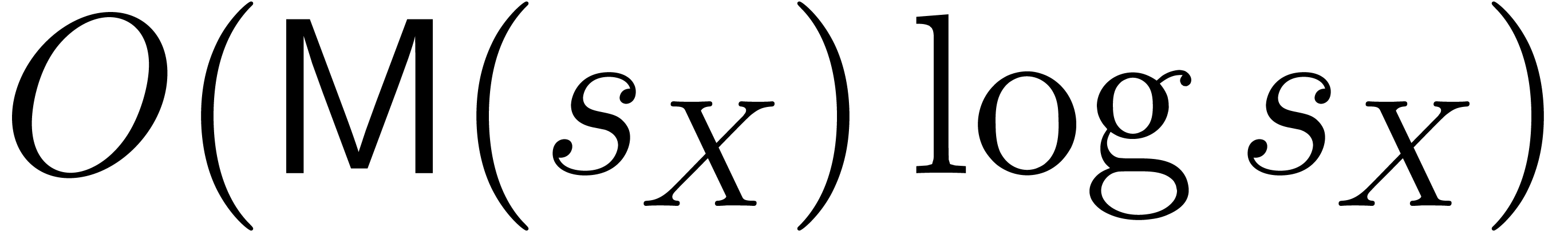 further vectorial operations in and divisions in
further vectorial operations in and divisions in  .
Adding up the various contributions, we obtain the theorem.
.
Adding up the various contributions, we obtain the theorem.
For when the supports of and
and also are fixed all the necessary powers of
can be shared and seen as a pretreatment, so
that each product can be done in softly linear time. This situation
occurs in the algorithm for counting the number of absolutely
irreducible factors of a given polynomial, that we study in Section 7.
Similar to FFT multiplication, our algorithm falls into the general category of multiplication algorithms by evaluation and interpolation. This makes it possible to work in the so-called “transformed model” for several other operations besides multiplication.
In the rest of this section we describe how to implement the present algorithm for the usual coefficient rings and fields. We analyze the bit-cost in each case.
If  is the finite field
is the finite field 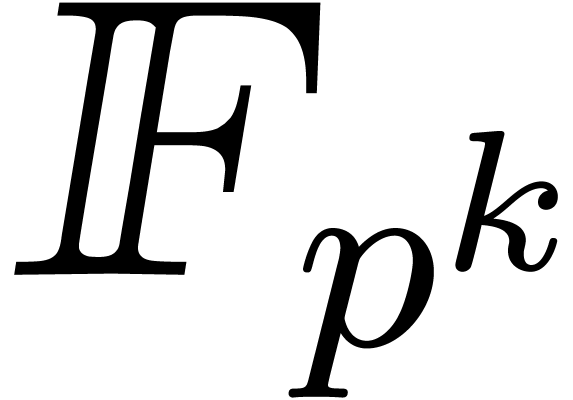 with
with 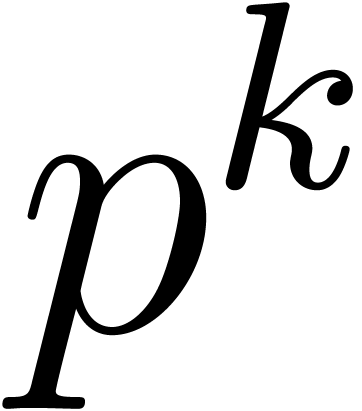 elements, then its multiplicative group is
cyclic of order
elements, then its multiplicative group is
cyclic of order 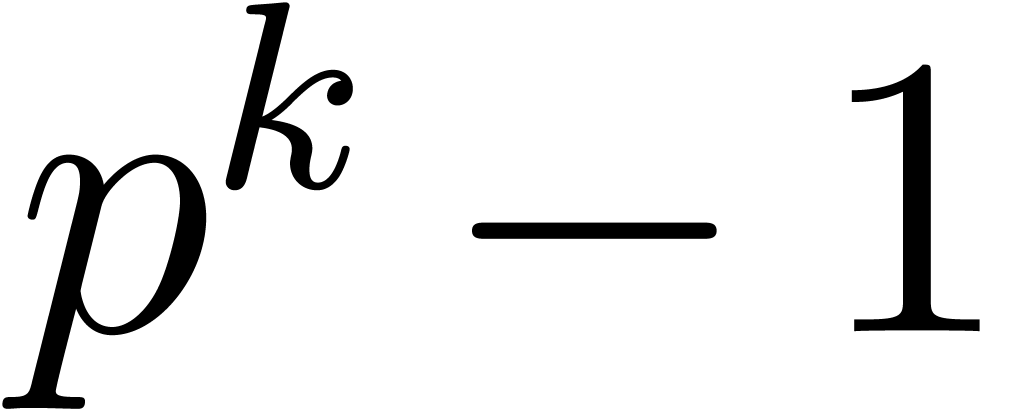 . Whenever
. Whenever
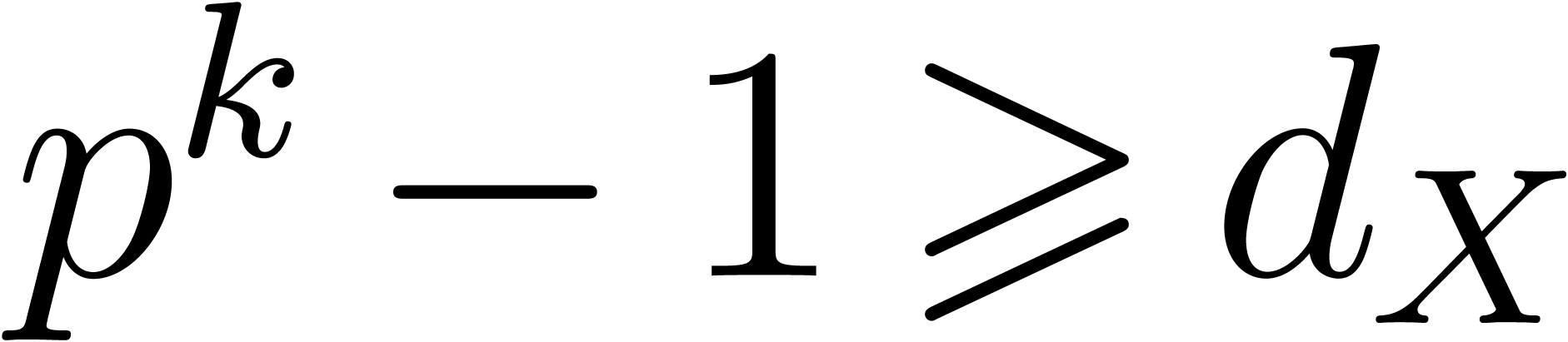 , Proposition 17
applies for any primitive element of this group.
We assume that
, Proposition 17
applies for any primitive element of this group.
We assume that 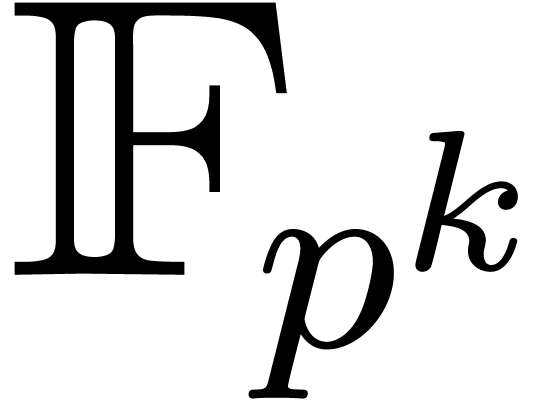 is given as the quotient
is given as the quotient 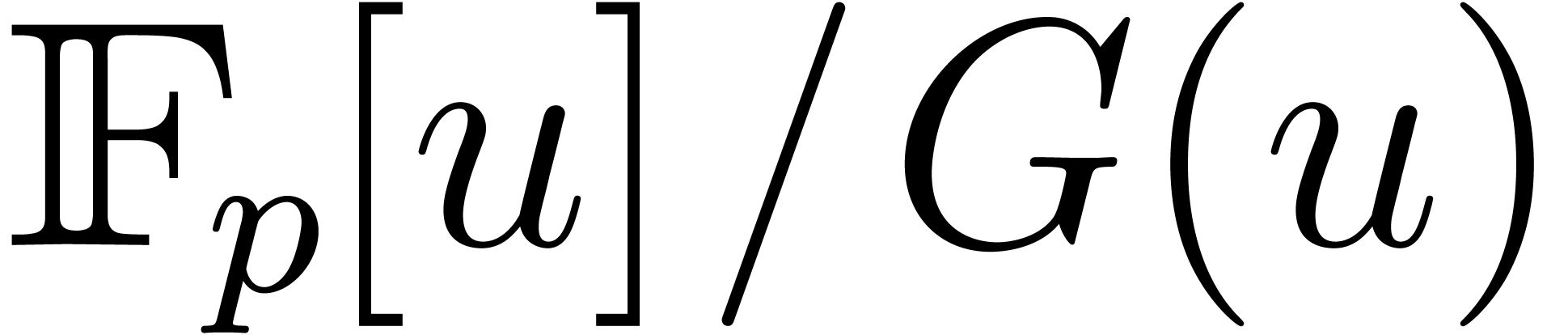 for some monic and irreducible polynomial of degree .
for some monic and irreducible polynomial of degree .
, and assume
given a primitive element  of
of 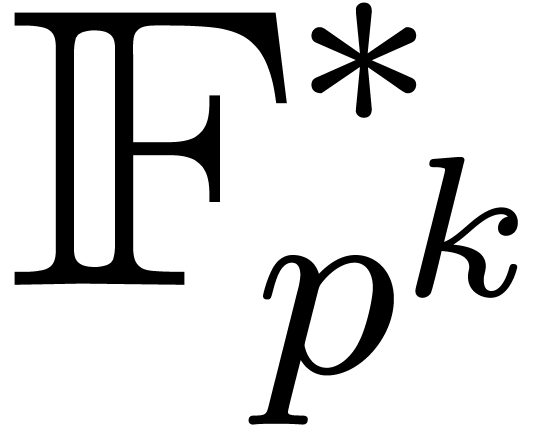 . Given
. Given  ,
the product can be computed using
,
the product can be computed using
 ring operations in
ring operations in  that only depend on ,
and ;
that only depend on ,
and ;
 ring operations in
and inversions in .
ring operations in
and inversions in .
Proof. A multiplication in  amounts to
amounts to  ring operations in
ring operations in 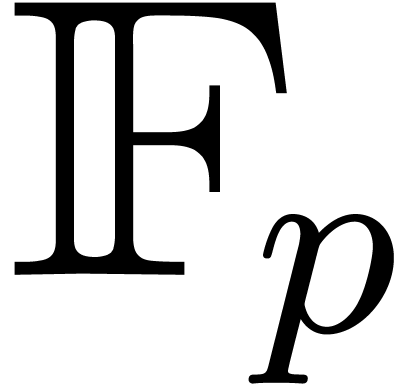 . An inversion in
requires an extended g.c.d. computation in
. An inversion in
requires an extended g.c.d. computation in 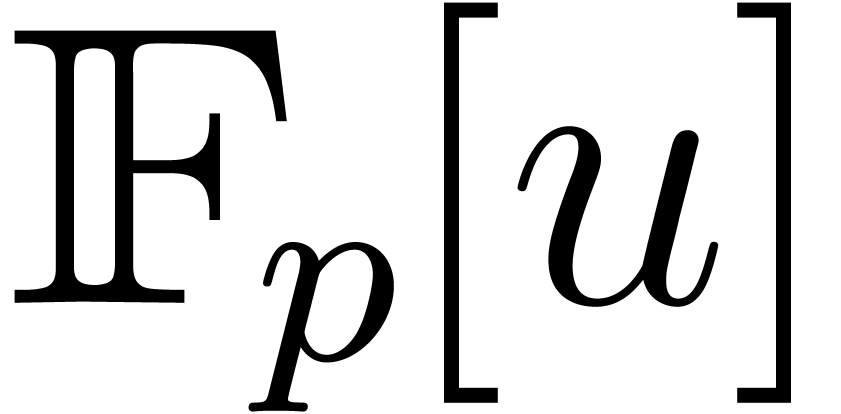 and gives rise to
and gives rise to 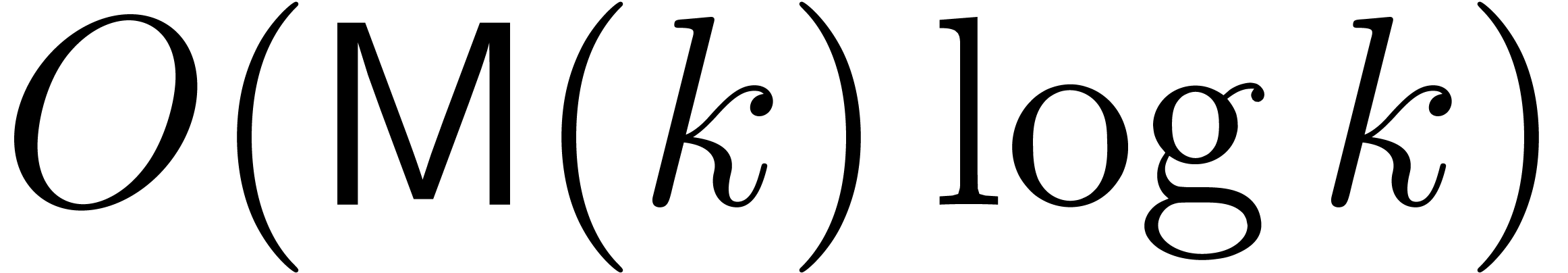 ring operations in and one inversion: this can be achieved with the fast
Euclidean algorithm [GG02, Chapter 11], with using
pseudo-divisions instead of divisions. Using the Kronecker substitution,
one product in
ring operations in and one inversion: this can be achieved with the fast
Euclidean algorithm [GG02, Chapter 11], with using
pseudo-divisions instead of divisions. Using the Kronecker substitution,
one product in 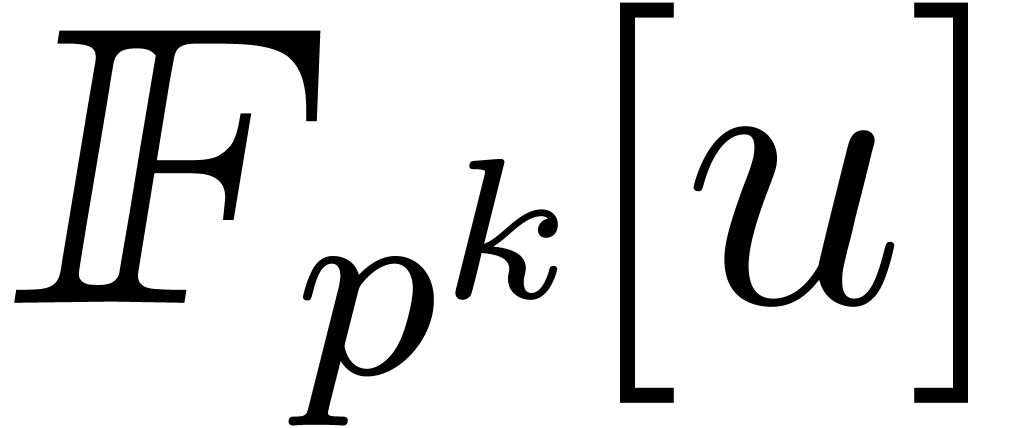 in size
in size 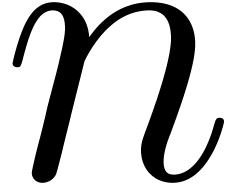 takes
takes 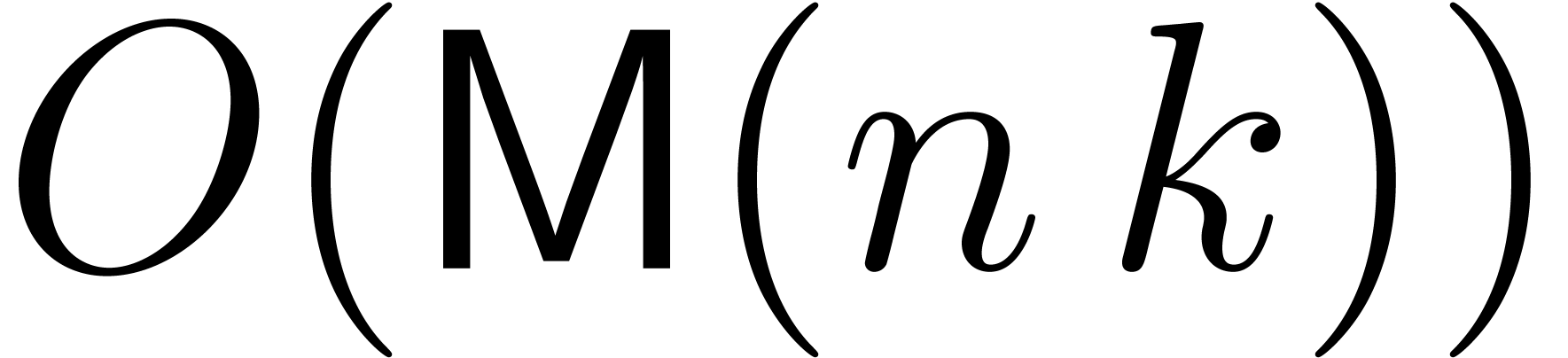 operations in . The conclusion thus follows from Proposition 17.
operations in . The conclusion thus follows from Proposition 17.
Applying the general purpose algorithm from [CK91], two
polynomials of degree over
can be multiplied in time 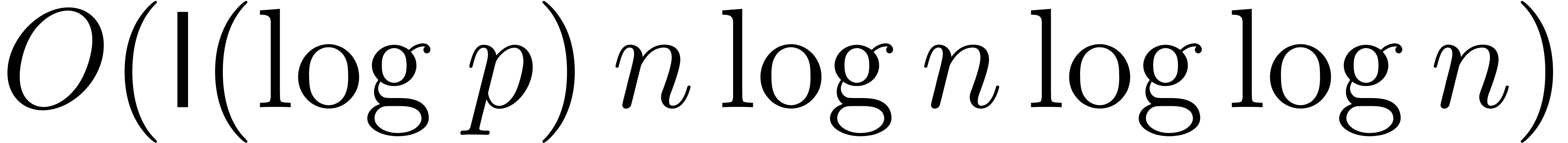 .
Alternatively, we may lift the multiplicands to polynomials in
.
Alternatively, we may lift the multiplicands to polynomials in 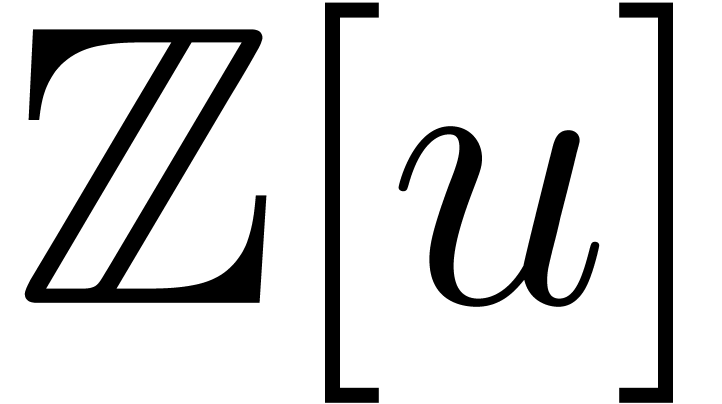 , use Kronecker multiplication and
reduce modulo
, use Kronecker multiplication and
reduce modulo 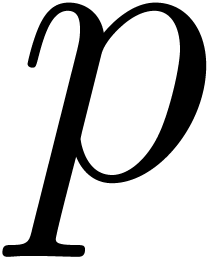 . As long as
. As long as
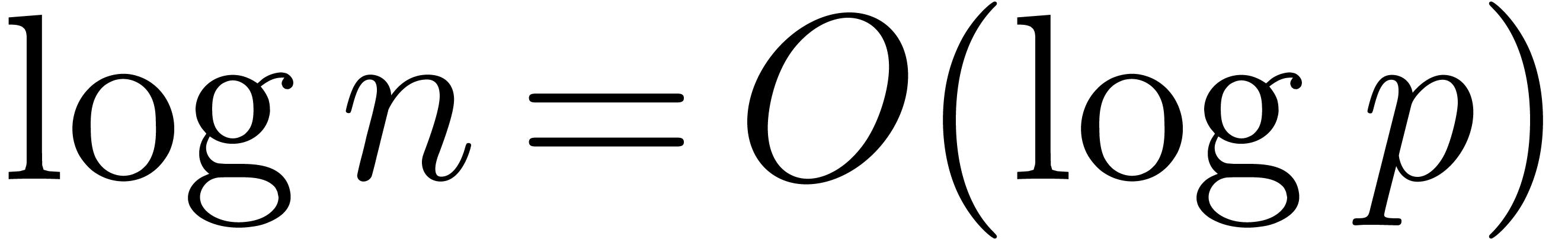 , this yields the better
complexity bound
, this yields the better
complexity bound 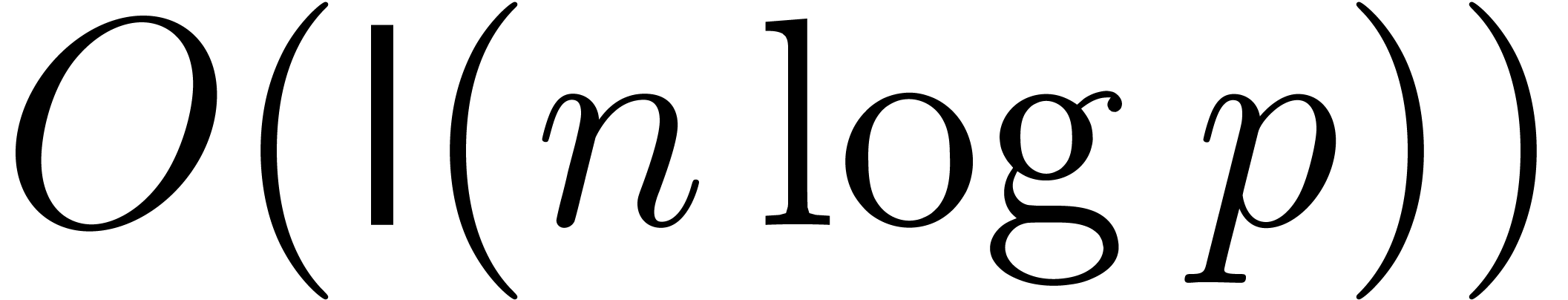 . Corollary
18 therefore further implies:
. Corollary
18 therefore further implies:
and 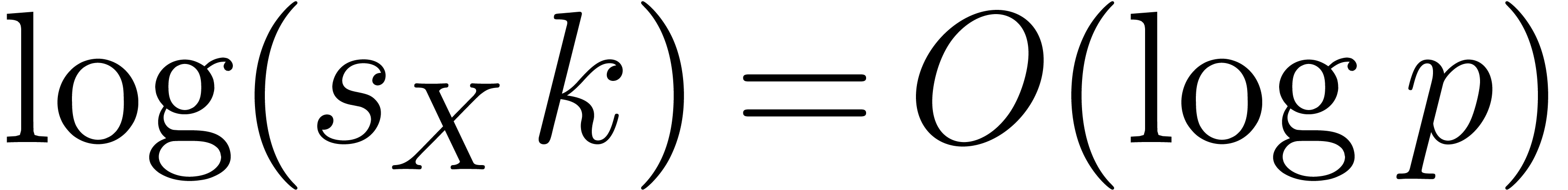 , and assume given a primitive element of . Given
two polynomials and in
, and assume given a primitive element of . Given
two polynomials and in
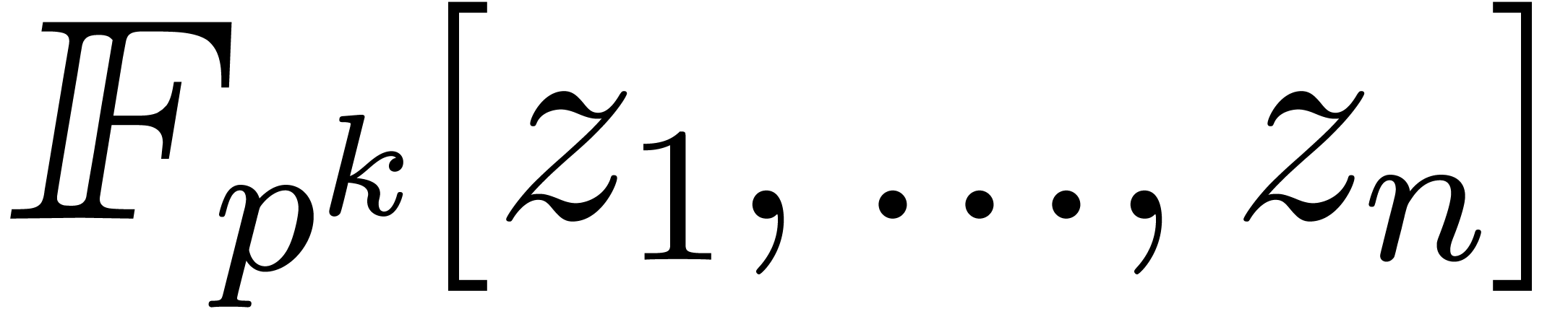 , the product can be computed using
, the product can be computed using
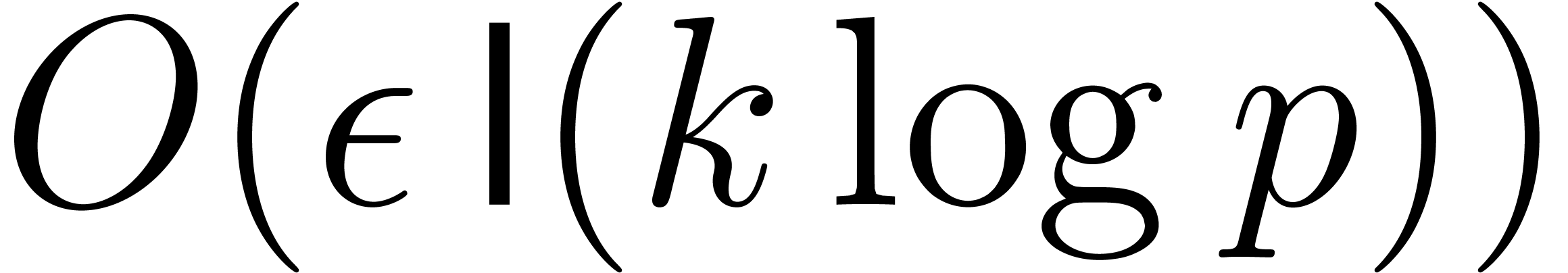 bit-operations that only depend on ,
and ;
bit-operations that only depend on ,
and ;
 bit-operations.
bit-operations.
If 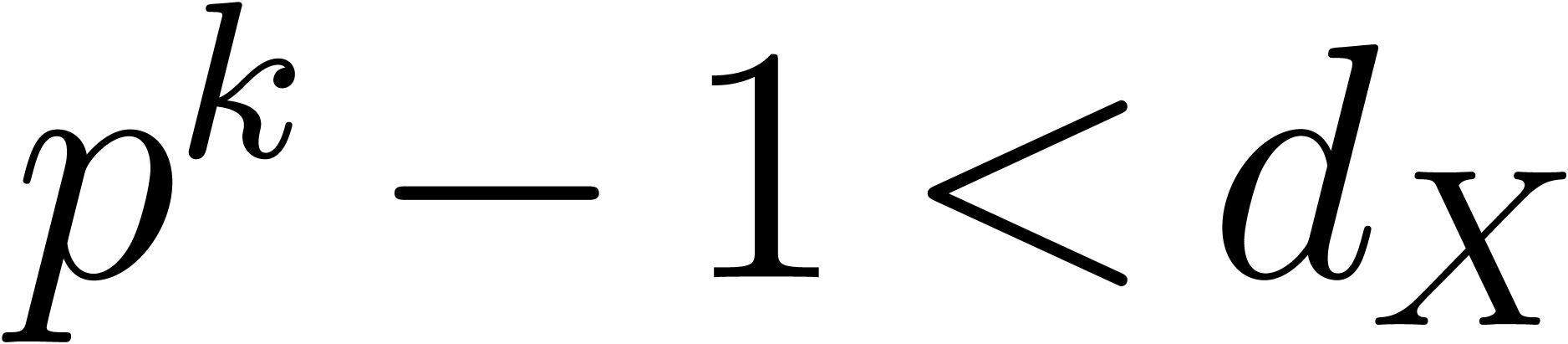 then it is always possible to build an
algebraic extension of suitable degree in order
to apply the corollary. Such constructions are classical, see for
instance [GG02, Chapter 14]. We need to have
then it is always possible to build an
algebraic extension of suitable degree in order
to apply the corollary. Such constructions are classical, see for
instance [GG02, Chapter 14]. We need to have 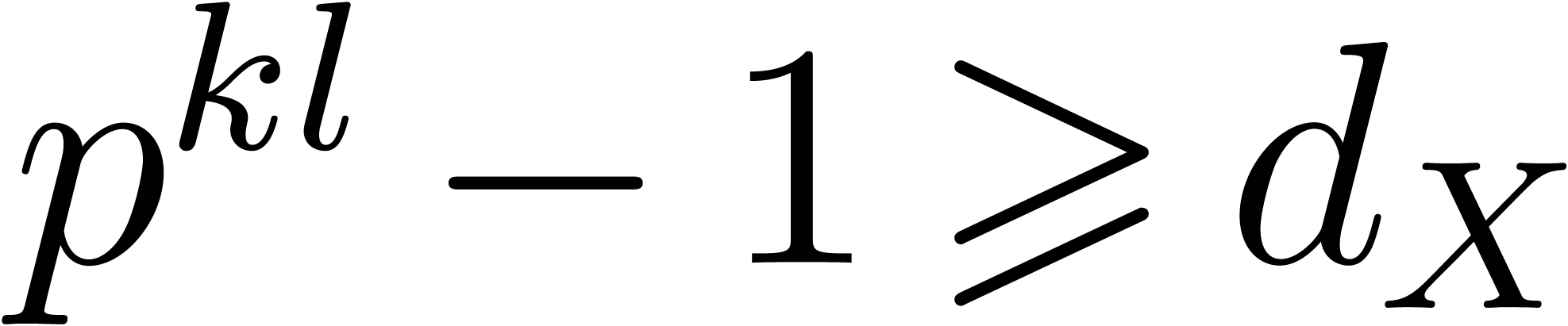 , so should be taken of
the order
, so should be taken of
the order 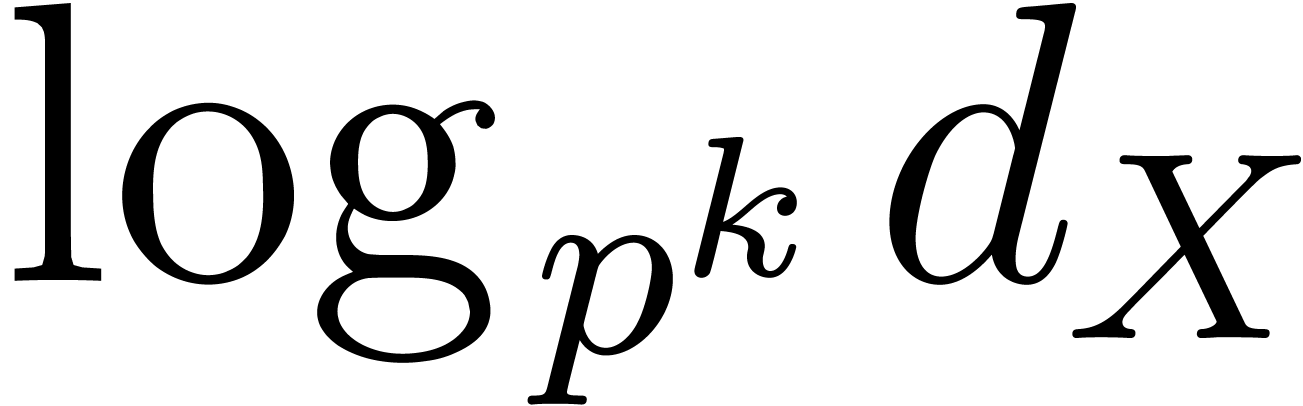 , which also
corresponds to the additional overhead induced by this method. If exceeds
, which also
corresponds to the additional overhead induced by this method. If exceeds 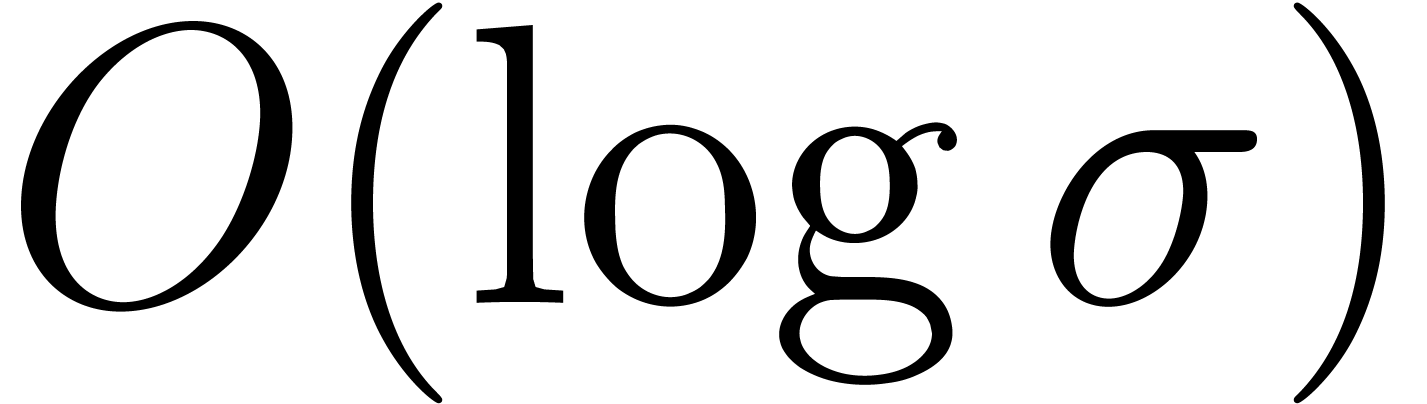 and
and 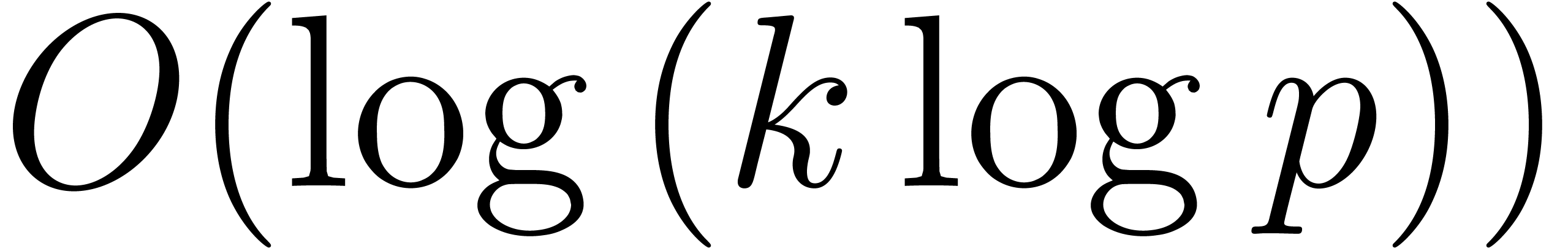 , then we notice that the softly linear cost is
lost. This situation may occur for instance for polynomials over
, then we notice that the softly linear cost is
lost. This situation may occur for instance for polynomials over  .
.
In practice, the determination of the primitive element
is a precomputation that can be done fast with randomized algorithms.
Theoretically speaking, assuming the generalized Riemann hypothesis, and
given the prime factorization of ,
a primitive element in 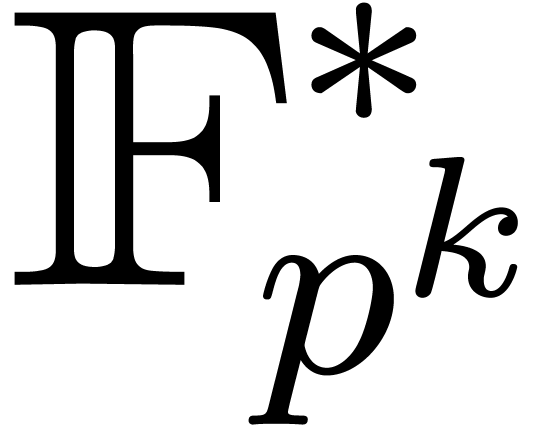 can be constructed in
polynomial time [BS91, Section 1, Applications].
can be constructed in
polynomial time [BS91, Section 1, Applications].
Let 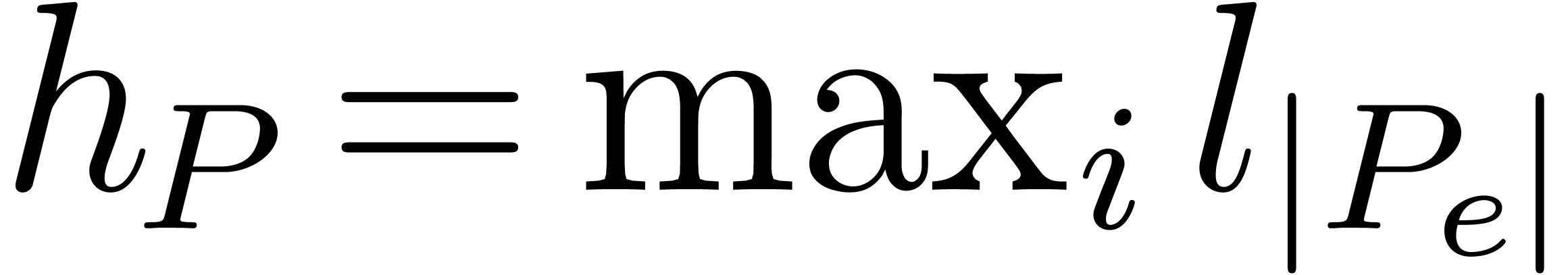 denote the maximal bit-size of the
coefficients of and similarly for and . Since
denote the maximal bit-size of the
coefficients of and similarly for and . Since
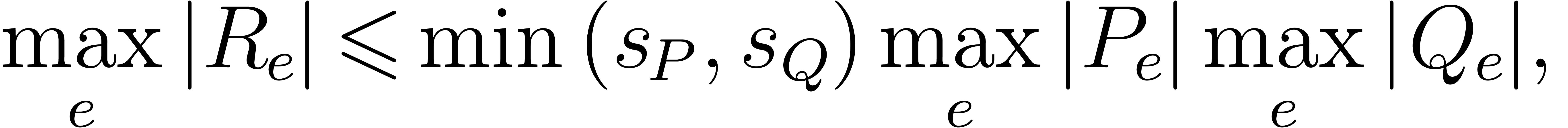
we have
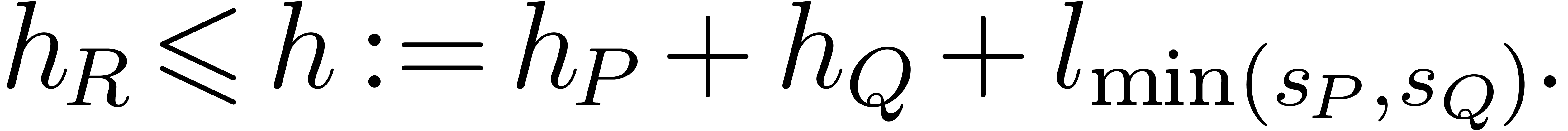
One approach for the multiplication of
polynomials with integer coefficients is to reduce the problem modulo a
suitable prime number . This
prime number should be sufficiently large such that
can be read off from 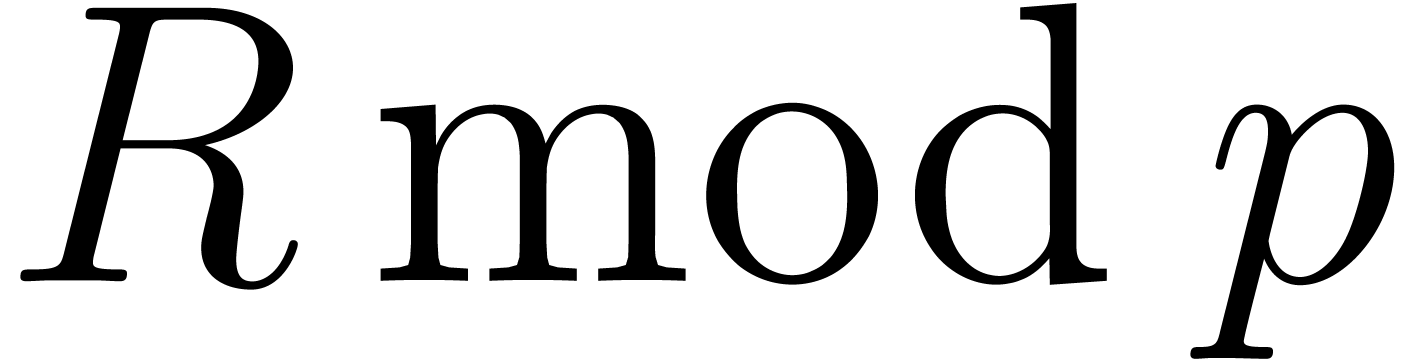 and such that admits elements of order at least . It suffices to take
and such that admits elements of order at least . It suffices to take 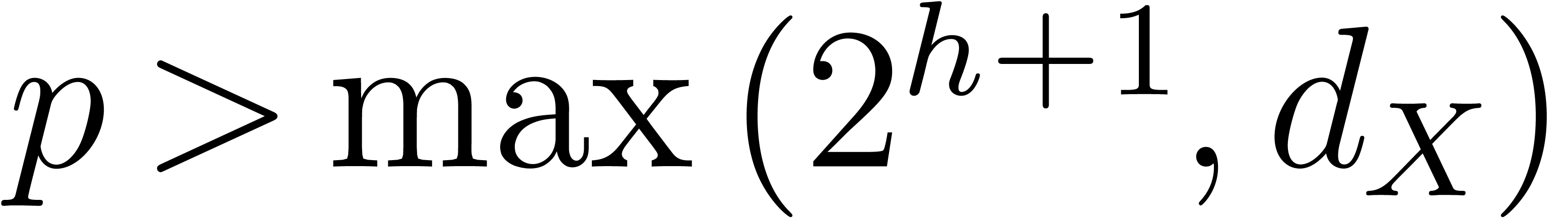 ,
so Corollary 19 now implies:
,
so Corollary 19 now implies:
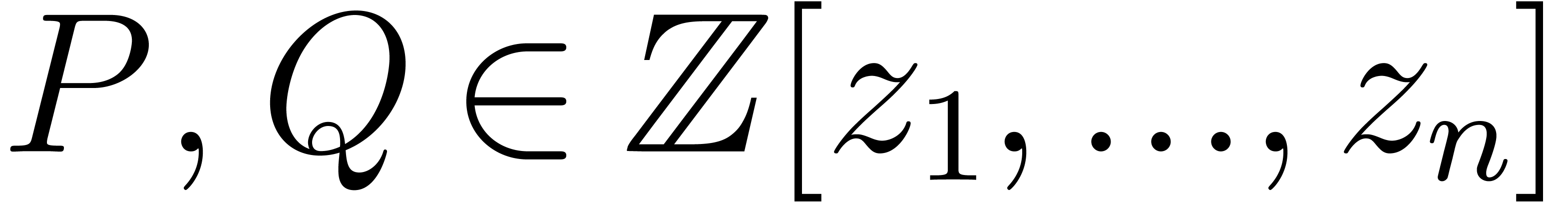 , a prime
number and a primitive element of
, a prime
number and a primitive element of 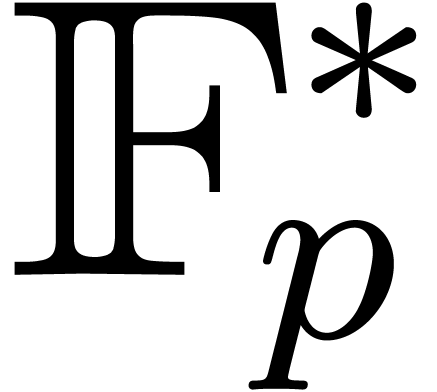 , we can
compute with
, we can
compute with
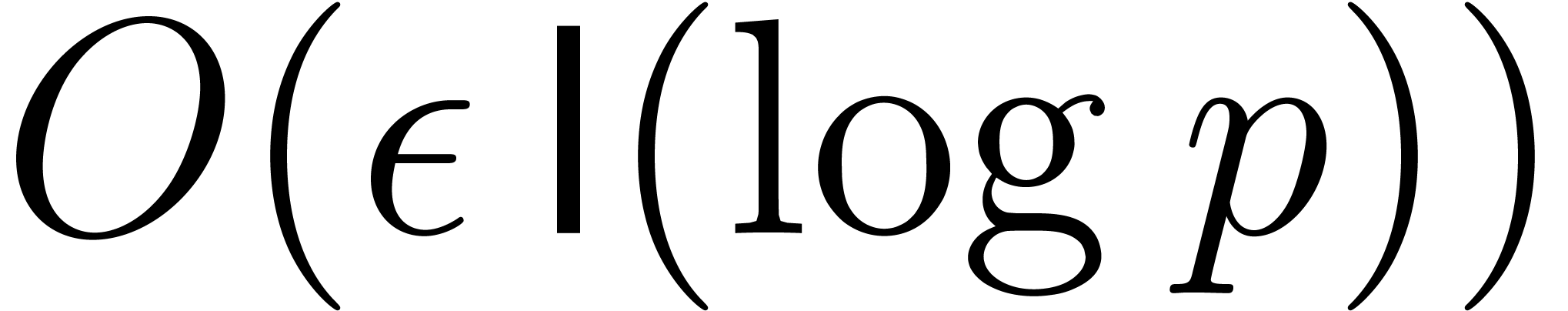 bit-operations that only depend on , , and ;
bit-operations that only depend on , , and ;
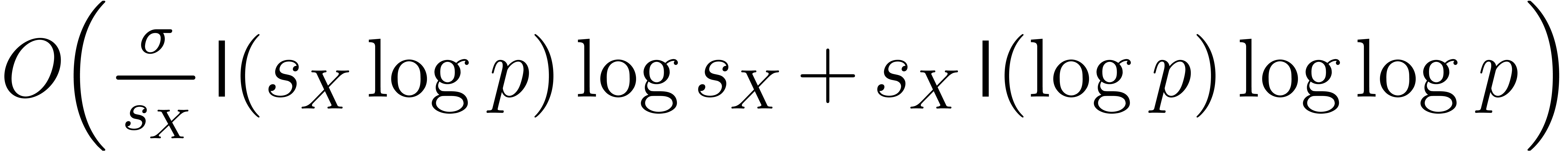 bit-operations.
bit-operations.
Let 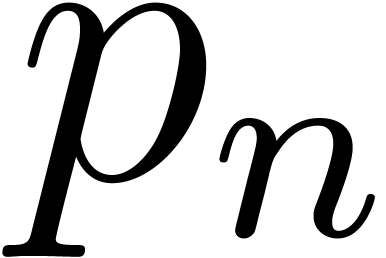 denote the -th
prime number. The prime number theorem implies that
denote the -th
prime number. The prime number theorem implies that 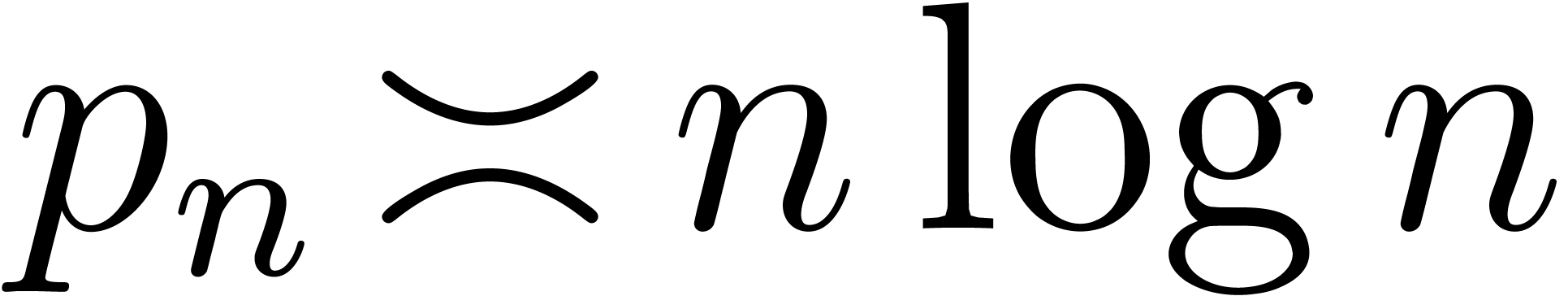 . Cramér's conjecture [Cra36,
Sha64] states that
. Cramér's conjecture [Cra36,
Sha64] states that
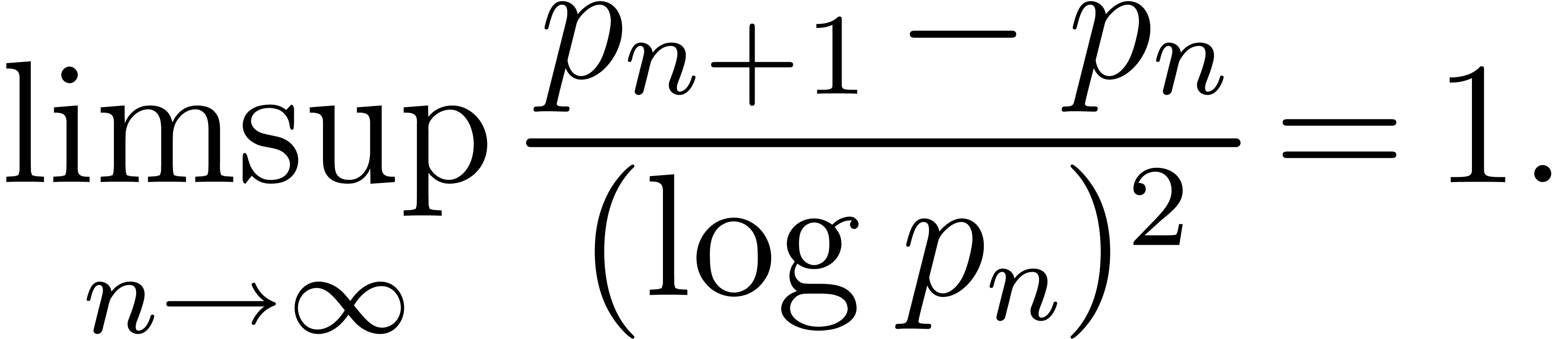
This conjecture is supported by numerical evidence, which is sufficient
for our practical purposes. Setting 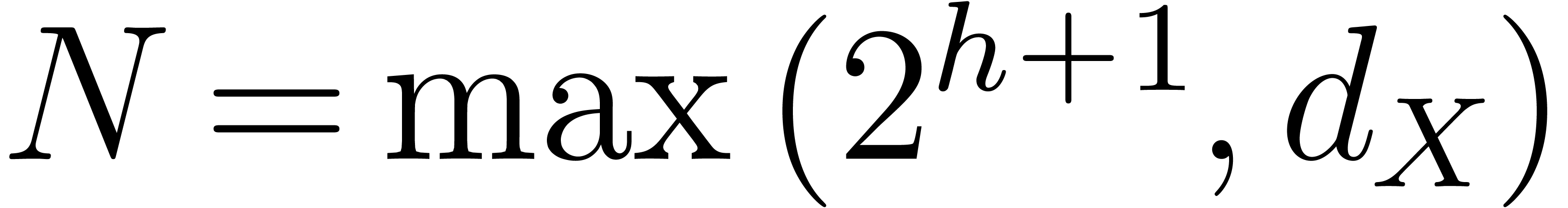 ,
the conjecture implies that the smallest prime number
with
,
the conjecture implies that the smallest prime number
with 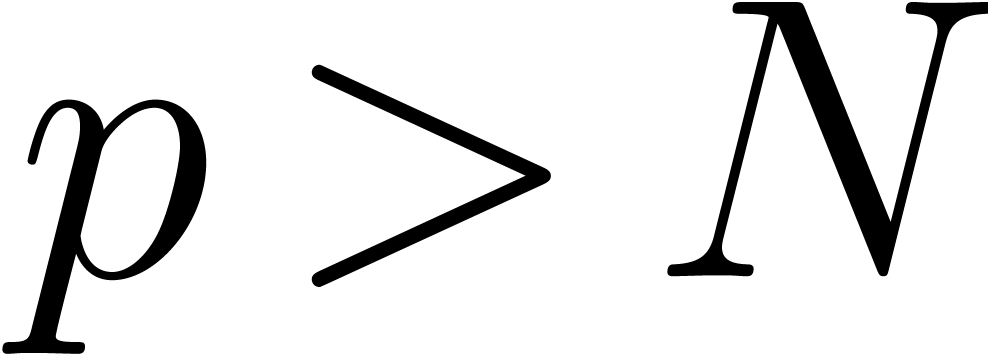 satisfies
satisfies  .
Using a polynomial time primality test [AKS04], it follows
that this number can be computed by brute force in time
.
Using a polynomial time primality test [AKS04], it follows
that this number can be computed by brute force in time 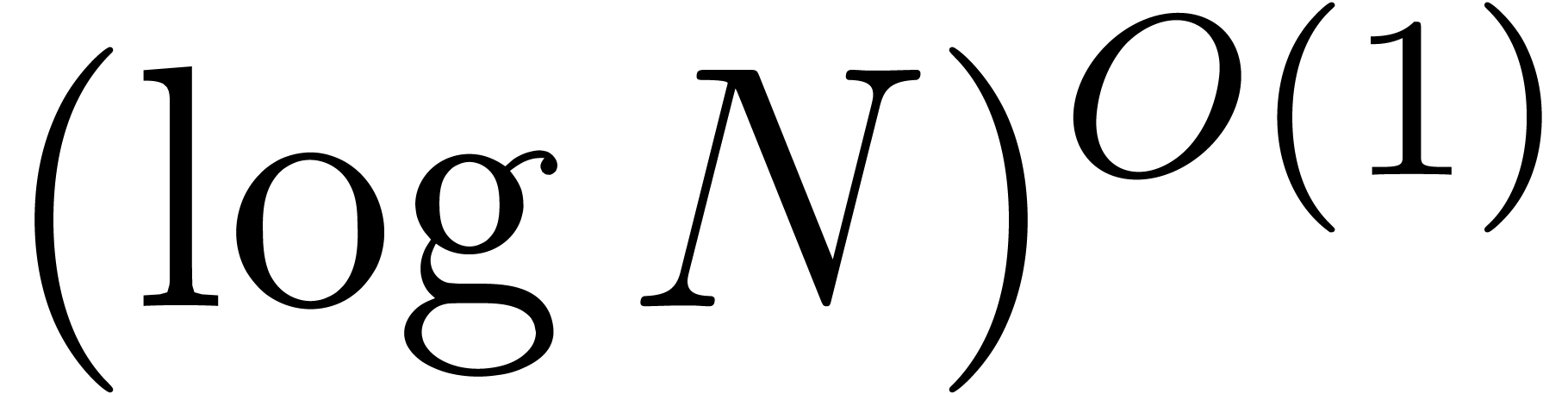 . In practice, in order to satisfy the
complexity bound it suffices to tabulate prime numbers of sizes 2, 4, 8,
16, etc.
. In practice, in order to satisfy the
complexity bound it suffices to tabulate prime numbers of sizes 2, 4, 8,
16, etc.
In our algorithm and Corollary 20, we regard the
computation of a prime number 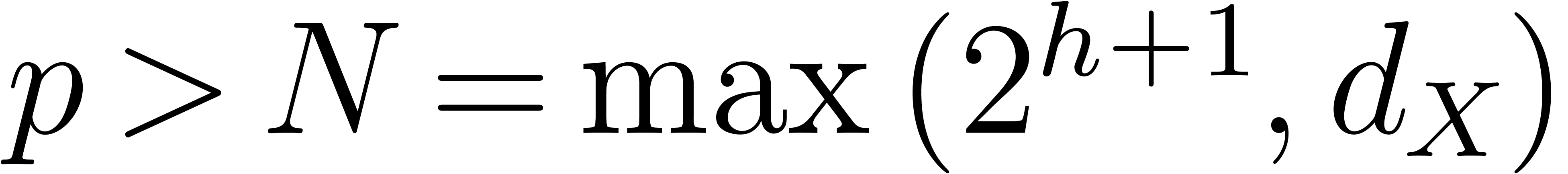 as a
precomputation. This is reasonable if
as a
precomputation. This is reasonable if 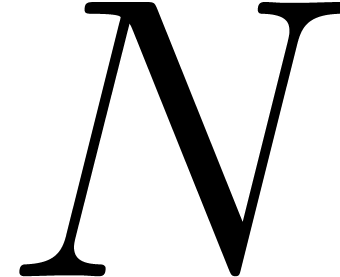 is not too
large. Now the quantity
is not too
large. Now the quantity 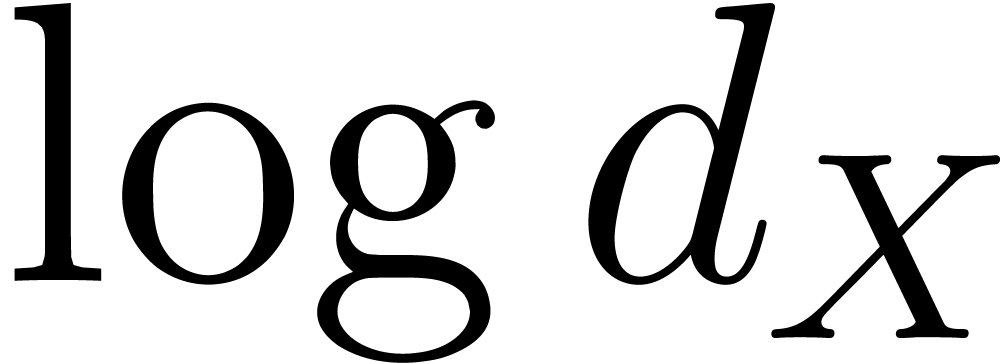 usually remains
reasonably small. Hence, our assumption that is
not too large only gets violated if
usually remains
reasonably small. Hence, our assumption that is
not too large only gets violated if  becomes
large. In that case, we will rather use Chinese remaindering. We first
compute
becomes
large. In that case, we will rather use Chinese remaindering. We first
compute 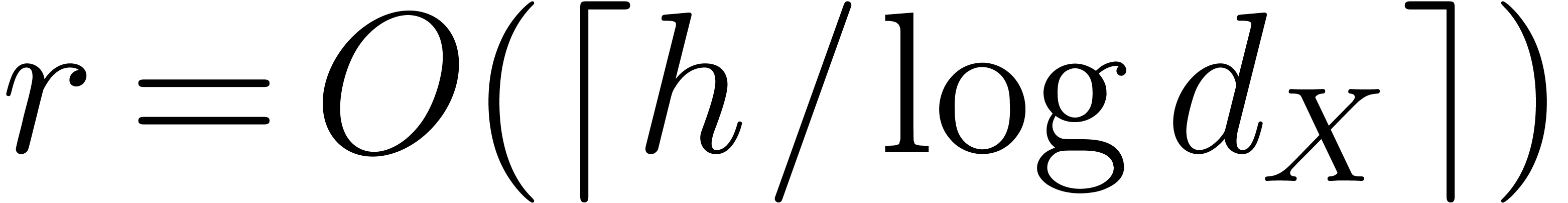 prime numbers
prime numbers  with
with
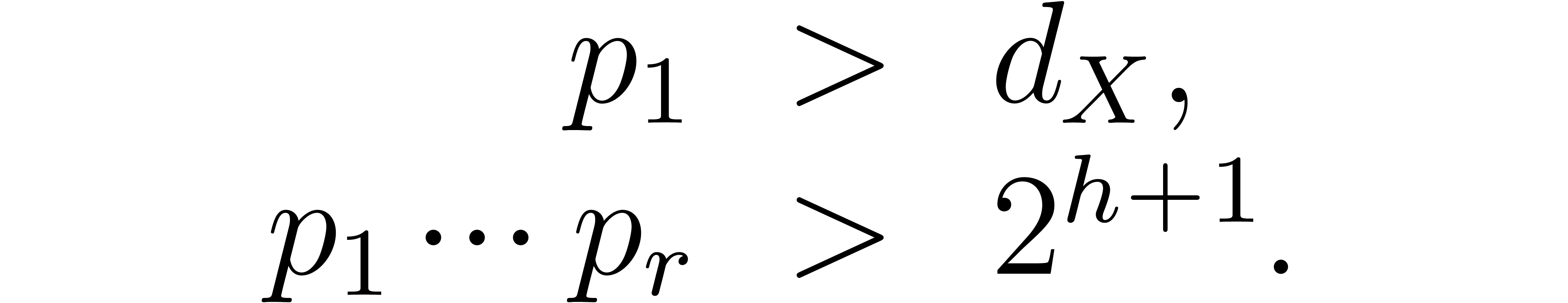
Such a sequence is said to be a reduced sequence of prime
moduli with order and capacity , if, in addition, we have that 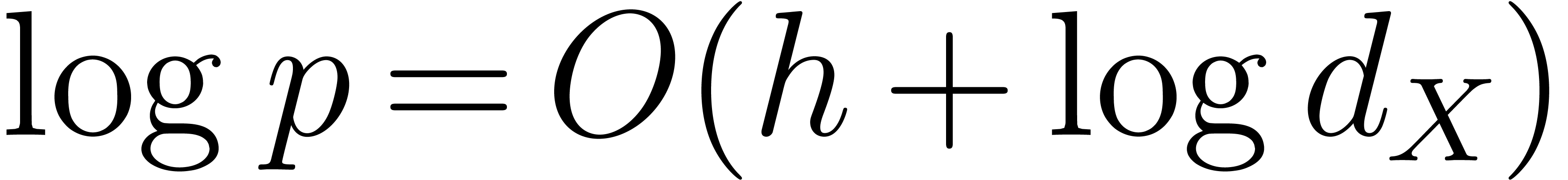 , where
, where 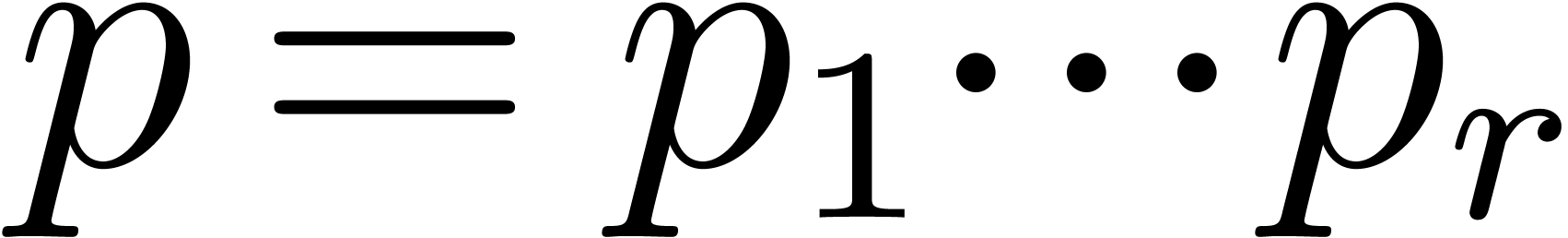 .
.
In fact Bertrand's postulate [HW79, Chapter 12, Theorem
1.3] ensures us that there exists 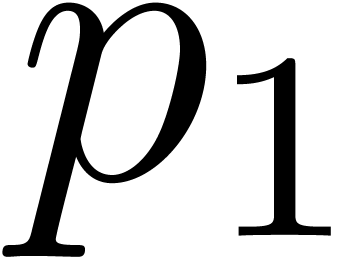 between
between 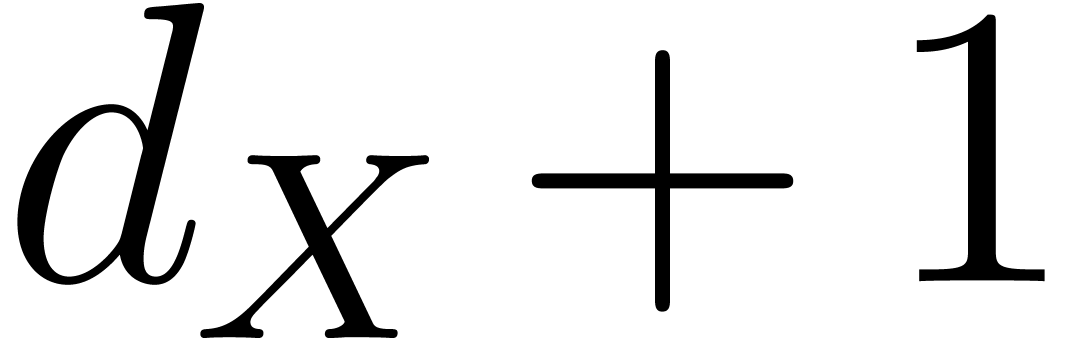 and
and 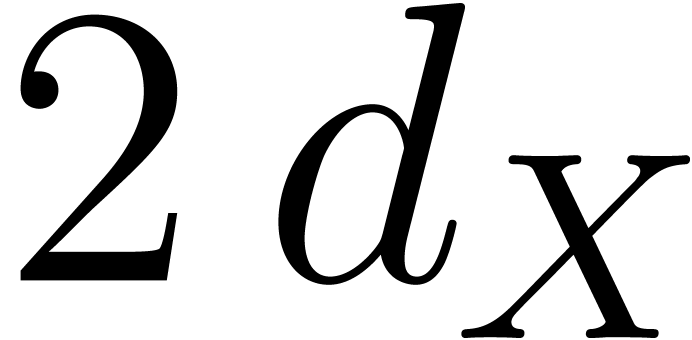 , then
one can take
, then
one can take 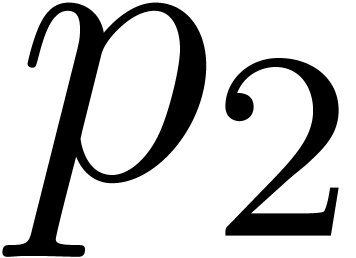 between
between 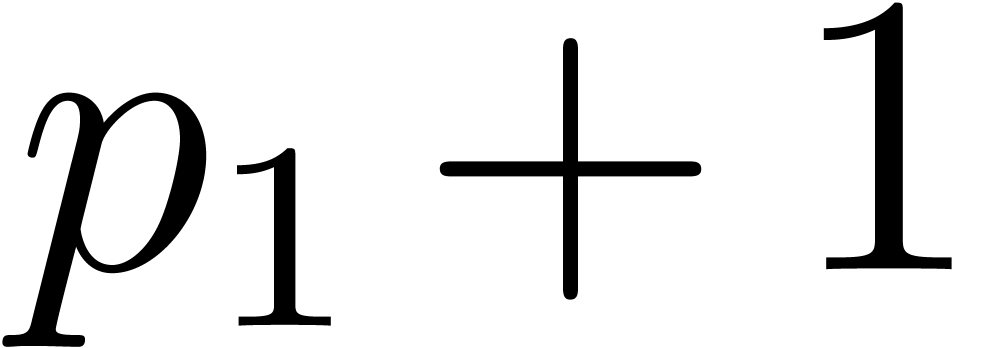 and
and
 , etc, so that
, etc, so that  . We stop this construction with
. We stop this construction with 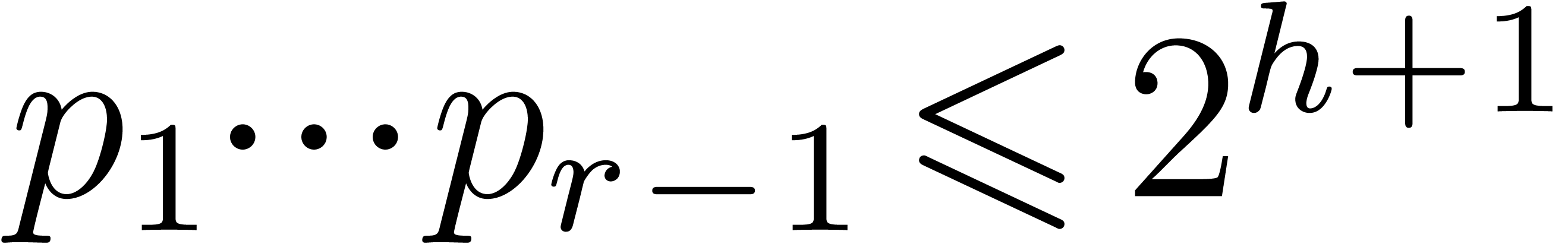 and
and 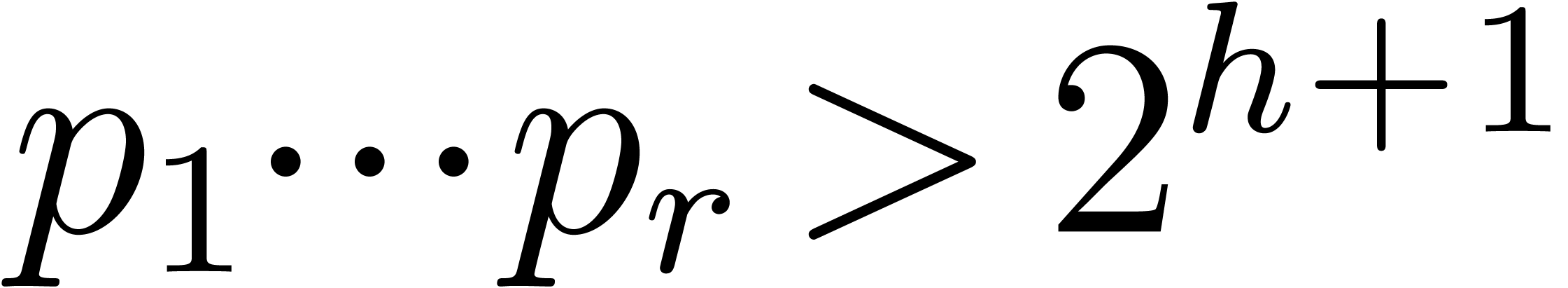 , hence
with . This proves that such
reduced sequences actually exist. Of course Bertrand's postulate is
pessimistic, and in practice all the
, hence
with . This proves that such
reduced sequences actually exist. Of course Bertrand's postulate is
pessimistic, and in practice all the  are very
close to .
are very
close to .
Each  contains a primitive root of unity
contains a primitive root of unity  of order at least .
We next proceed as before, but with
of order at least .
We next proceed as before, but with 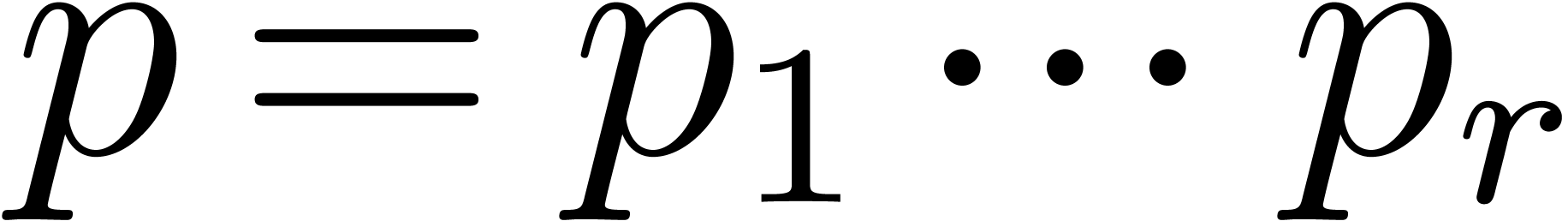 and
and 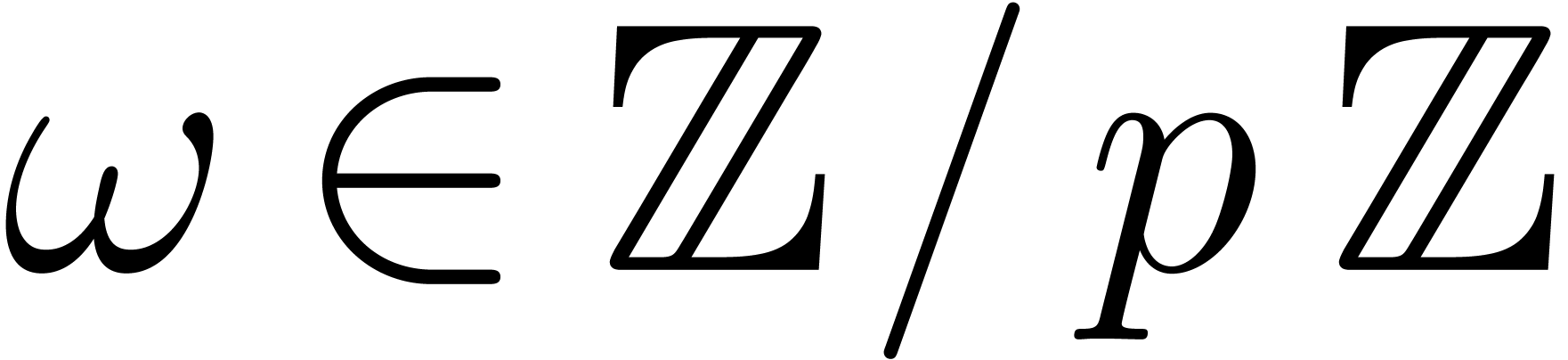 such that
such that  for each . Indeed, even though
for each . Indeed, even though 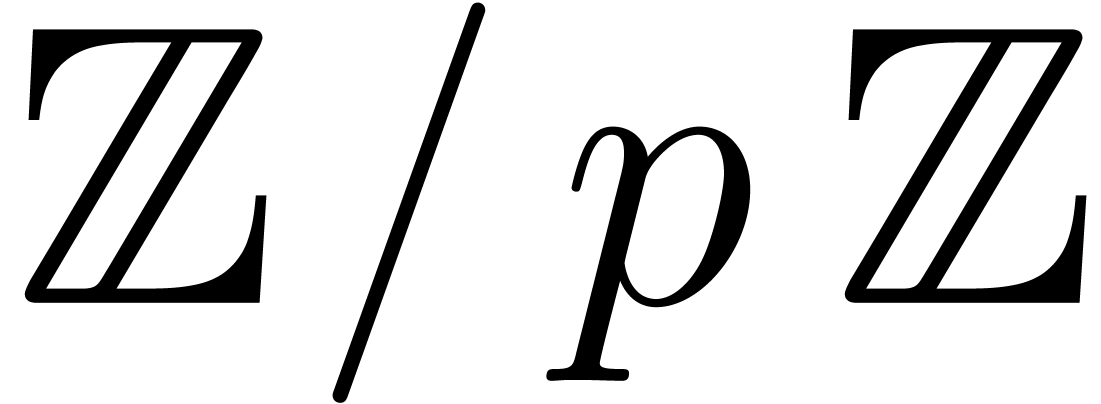 is not a field, the fact that each
is not a field, the fact that each  is invertible implies that is invertible, which
is sufficient for our purposes.
is invertible implies that is invertible, which
is sufficient for our purposes.
, a reduced
sequence of prime moduli with order and capacity and an element 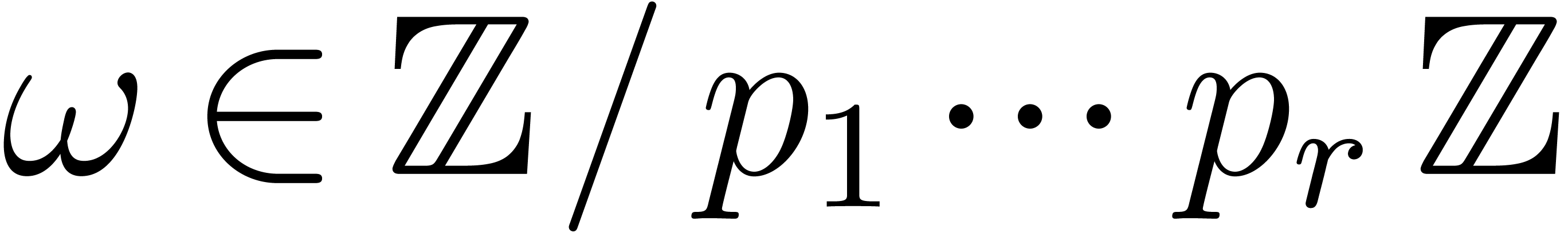 of order at least ,
we can compute with
of order at least ,
we can compute with
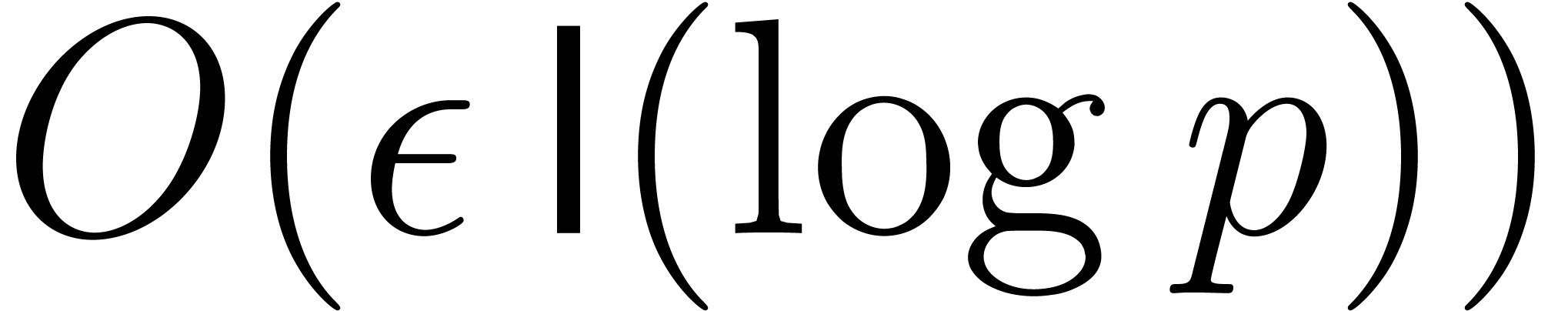 bit-operations that only depend on , , and ;
bit-operations that only depend on , , and ;
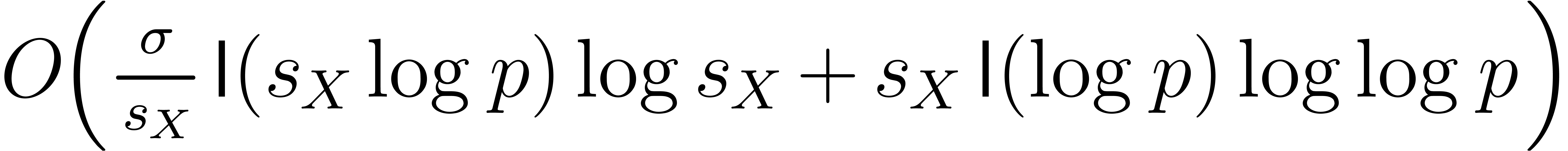 bit-operations.
bit-operations.
Proof. This follows from Proposition 17,
following the proofs of Corollaries 18 and 19,
mutatis mutandis.
Whenever 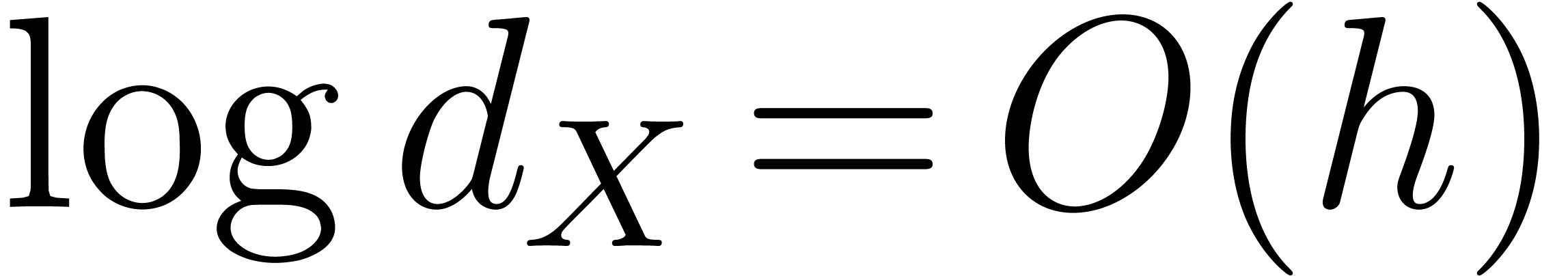 we have that
we have that 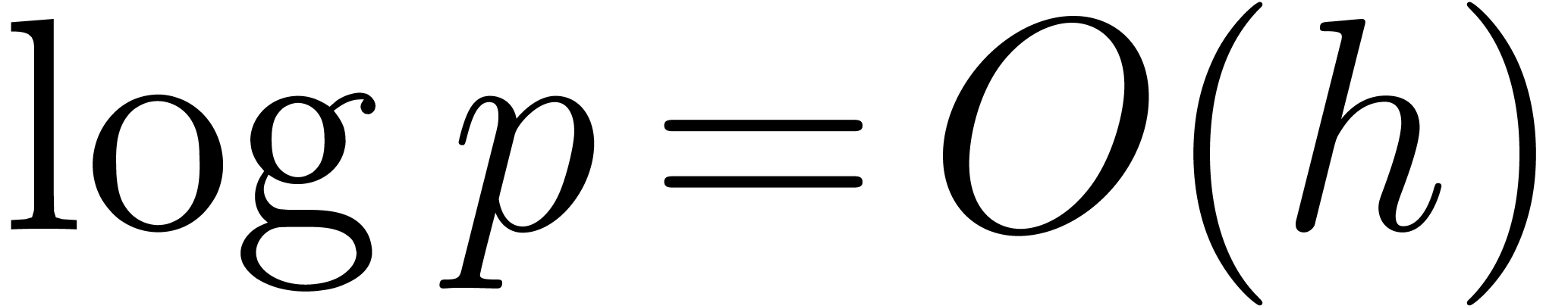 . Therefore, for fixed supports of
and , and fixed , this method allows us to compute several
products in softly linear time. Remark that for moderate sizes of the
coefficients it is even more interesting to compute the products modulo
each in parallel, and then use Chinese
remaindering to reconstruct the result.
. Therefore, for fixed supports of
and , and fixed , this method allows us to compute several
products in softly linear time. Remark that for moderate sizes of the
coefficients it is even more interesting to compute the products modulo
each in parallel, and then use Chinese
remaindering to reconstruct the result.
An important kind of sparse polynomials are power series in several
variables, truncated by total degree. Such series are often used in long
term integration of dynamical systems [MB96, MB04],
in which case their coefficients are floating point numbers rather than
integers. Assume therefore that and are polynomials with floating coefficients with a
precision of 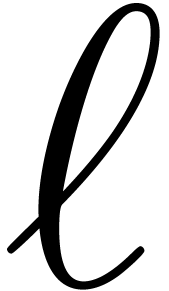 bits.
bits.
Let  be the maximal exponent of the coefficients
of . For a so called
discrepancy
be the maximal exponent of the coefficients
of . For a so called
discrepancy  , fixed
by the user, we let
, fixed
by the user, we let  be the integer polynomial
with
be the integer polynomial
with
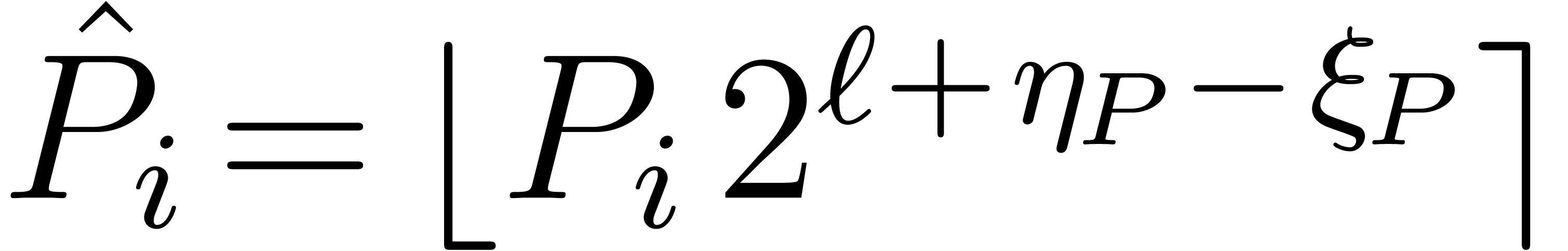
for all . We have  and
and
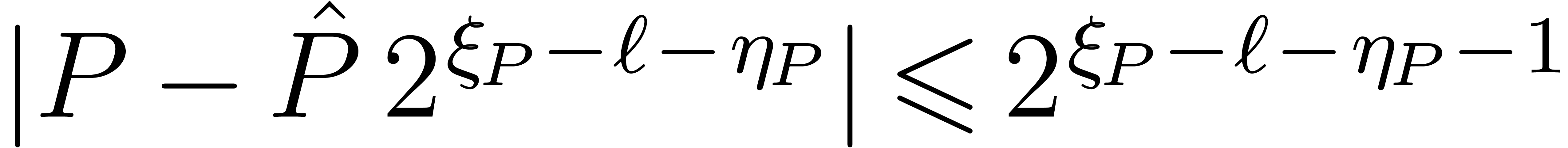
for the sup-norm on the coefficients. If all coefficients of have a similar order of magnitude, in the sense that the
minimal exponent of the coefficients is at least 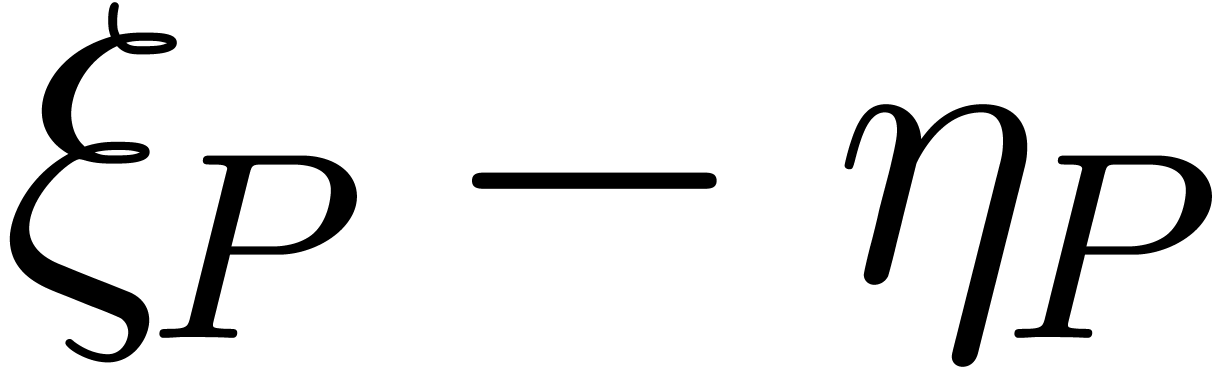 , then we actually have
, then we actually have 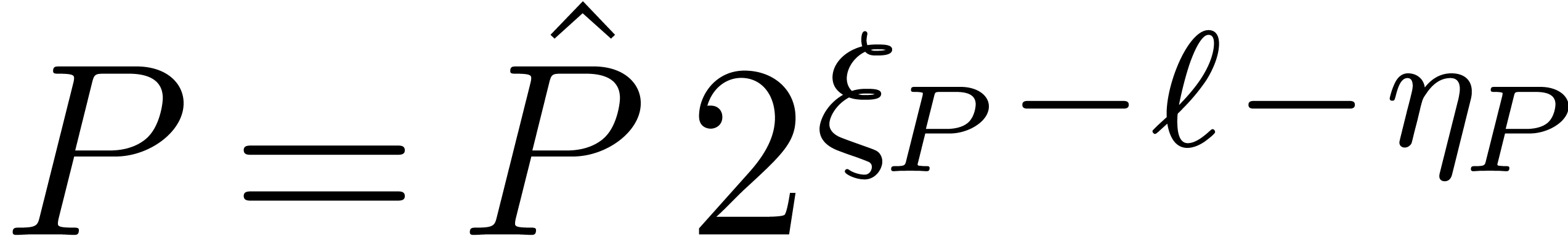 . Applying a similar decomposition to , we may compute the product
. Applying a similar decomposition to , we may compute the product
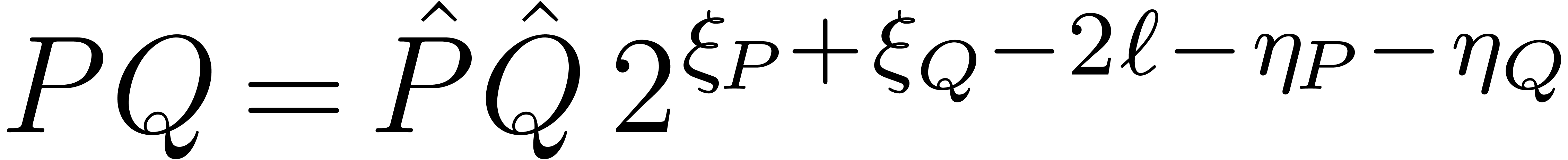
using the preceding algorithms and convert the resulting coefficients back into floating point format.
Usually, the coefficients 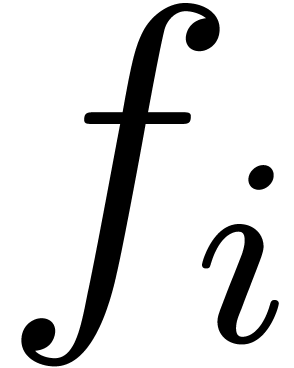 of a univariate power
series
of a univariate power
series  are approximately in a geometric
progression
are approximately in a geometric
progression 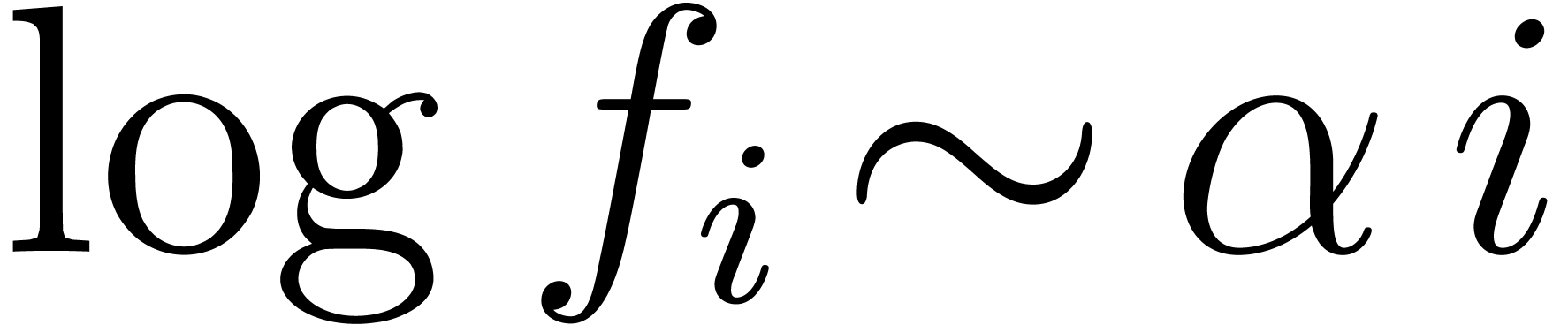 . In that case,
the coefficients of the power series
. In that case,
the coefficients of the power series 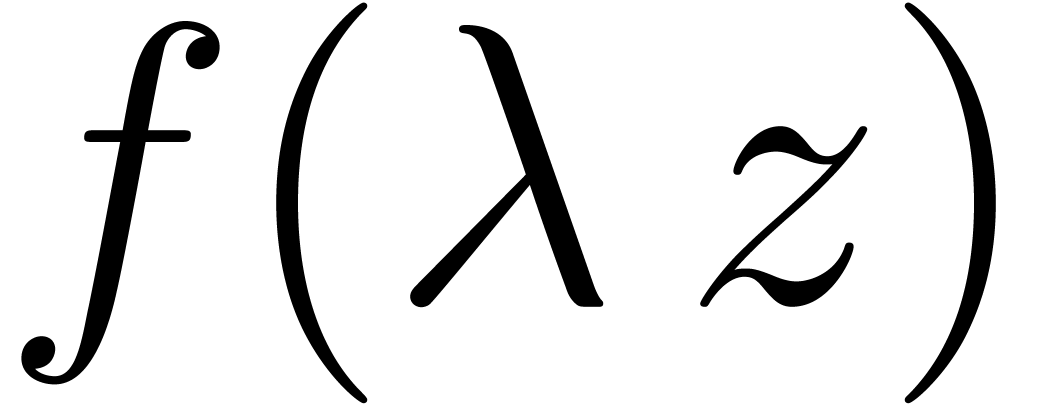 with
with 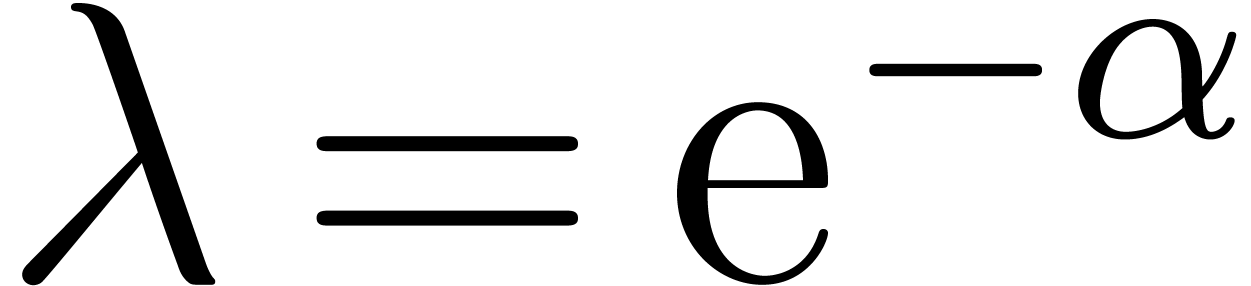 are approximately of the same order of magnitude. In
the multivariate case, the coefficients still have a geometric increase
on diagonals
are approximately of the same order of magnitude. In
the multivariate case, the coefficients still have a geometric increase
on diagonals 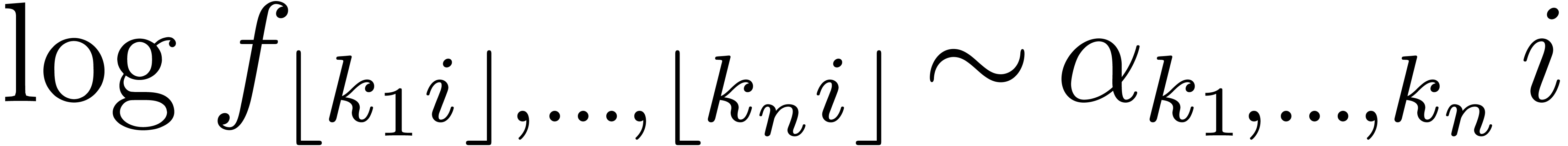 , but the
parameter
, but the
parameter 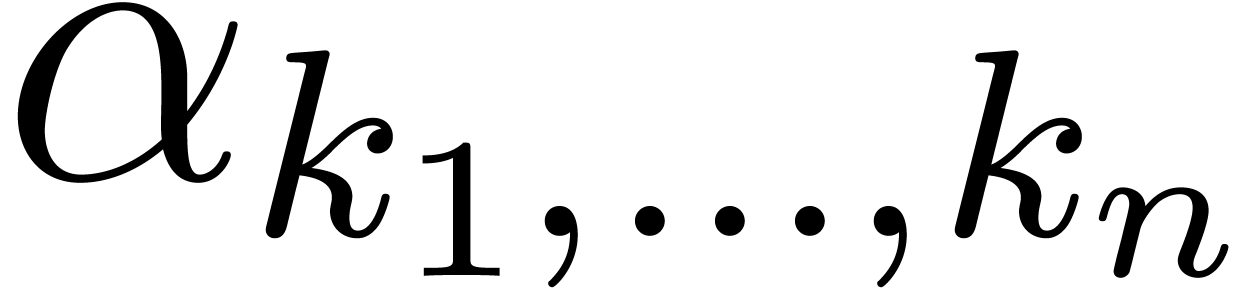 depends on the diagonal. After a
suitable change of variables
depends on the diagonal. After a
suitable change of variables 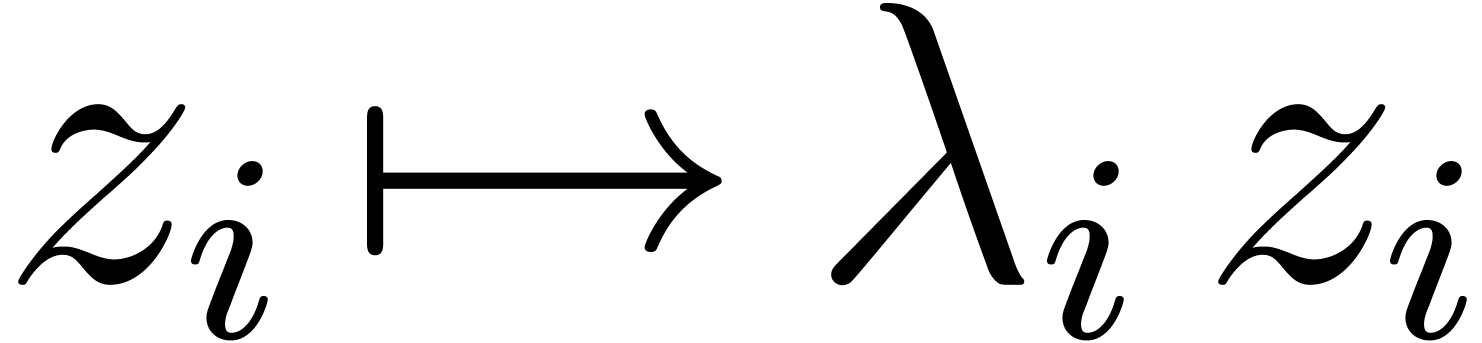 ,
the coefficients in a big zone near the main diagonal become of
approximately the same order of magnitude. However, the discrepancy
usually needs to be chosen proportional to the total truncation degree
in order to ensure sufficient accuracy elsewhere.
,
the coefficients in a big zone near the main diagonal become of
approximately the same order of magnitude. However, the discrepancy
usually needs to be chosen proportional to the total truncation degree
in order to ensure sufficient accuracy elsewhere.
Let us now consider the case when  .
Let
.
Let  and
and  denote the least
common multiples of the denominators of the coefficients of resp. .
One obvious way to compute
denote the least
common multiples of the denominators of the coefficients of resp. .
One obvious way to compute  is to set
is to set  ,
, 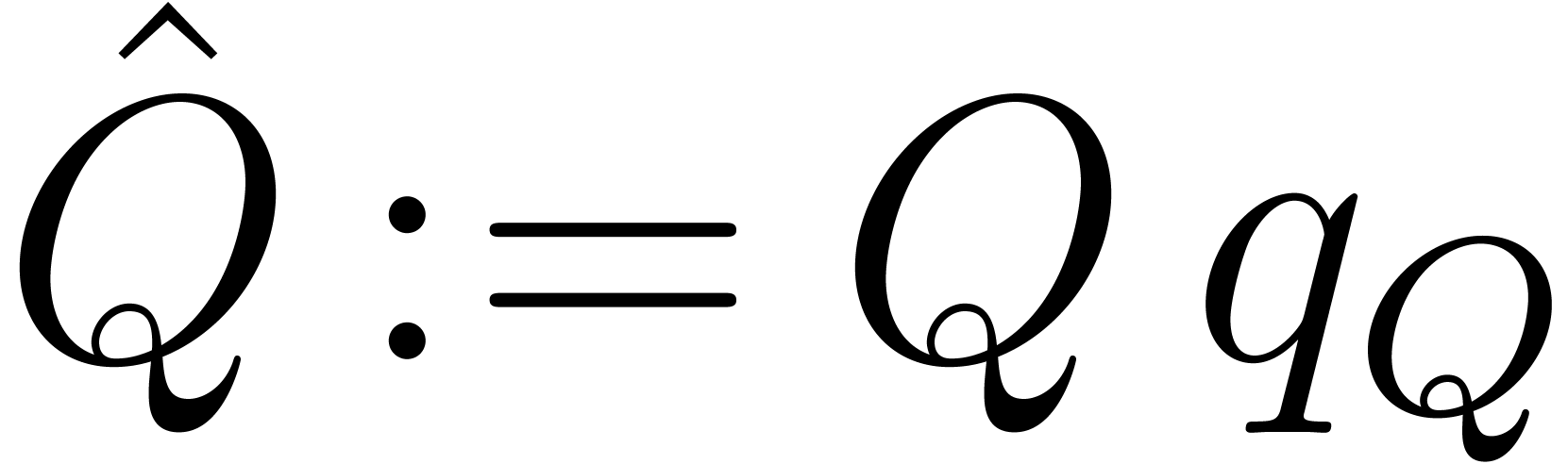 ,
and compute
,
and compute  using one of the methods from
Section 5.4. This approach works well in many cases
(e.g. when and
are truncations of exponential generating series). Unfortunately, this
approach is deemed to be very slow if the size of
or is much larger than the size of any of the
coefficients of .
using one of the methods from
Section 5.4. This approach works well in many cases
(e.g. when and
are truncations of exponential generating series). Unfortunately, this
approach is deemed to be very slow if the size of
or is much larger than the size of any of the
coefficients of .
An alternative, more heuristic approach is the following. Let 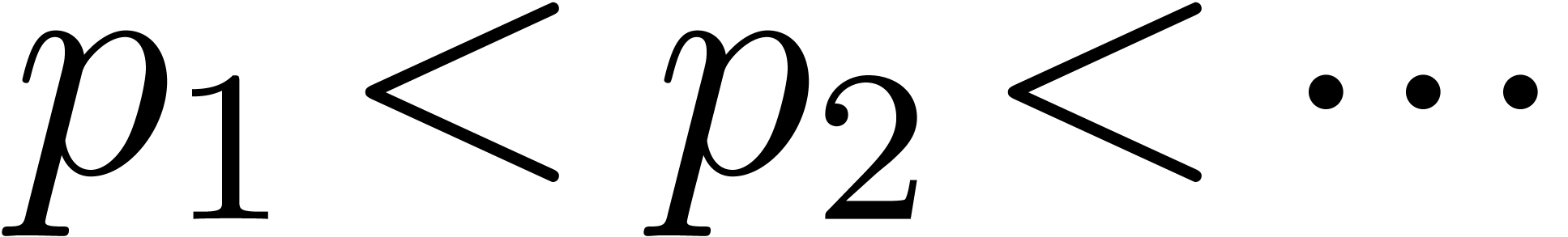 be an increasing sequence of prime numbers with
be an increasing sequence of prime numbers with  and such that each
and such that each 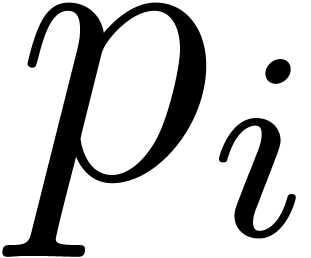 is relatively
prime to the denominators of each of the coefficients of and . For each
, we may then multiply
is relatively
prime to the denominators of each of the coefficients of and . For each
, we may then multiply 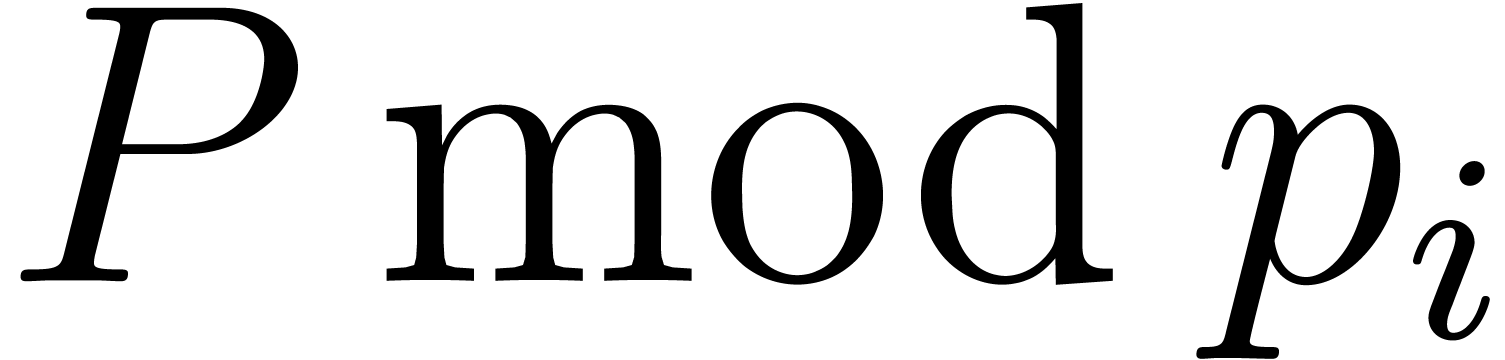 and
and 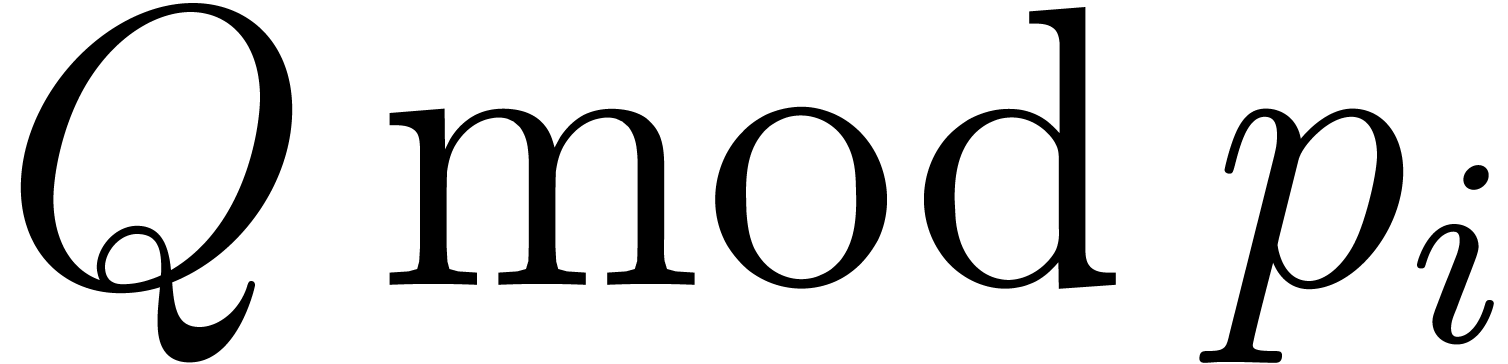 using the algorithm from
Section ?. For
using the algorithm from
Section ?. For  ,
we may recover
,
we may recover 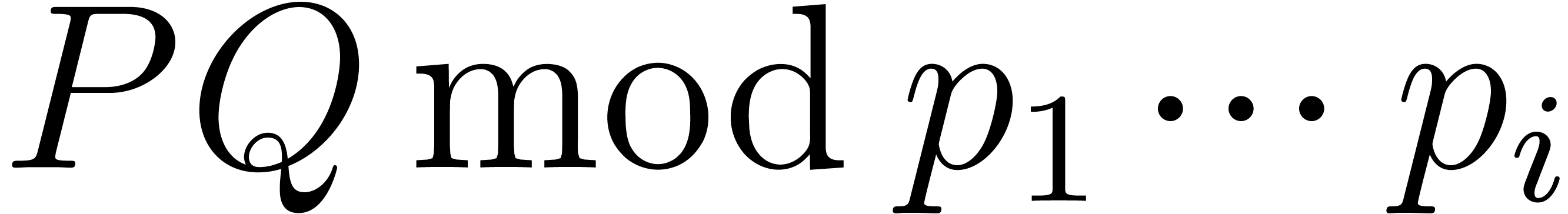 using Chinese remaindering and
attempt to reconstruct from
using rational number reconstruction [GG02, Chapter 5]. If
this yields the same result for a given and
using Chinese remaindering and
attempt to reconstruct from
using rational number reconstruction [GG02, Chapter 5]. If
this yields the same result for a given and
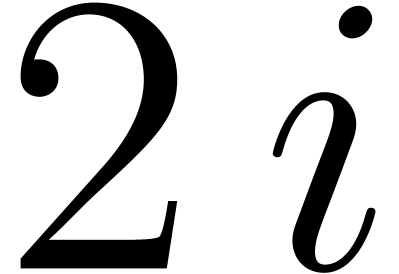 , then the reconstructed is likely to be correct at those stages. This
strategy is well-suited to probabilistic algorithms, for polynomial
factorization, polynomial system solving, etc.
, then the reconstructed is likely to be correct at those stages. This
strategy is well-suited to probabilistic algorithms, for polynomial
factorization, polynomial system solving, etc.
Of course, if we have an a priori bound on the bit sizes of the
coefficients of , then we may
directly take a sufficient number of primes such
that can be reconstructed from its reduction
modulo  .
.
We illustrate the performances of the algorithms of this section for a
prime finite field, which is the central case to optimize. We take , with 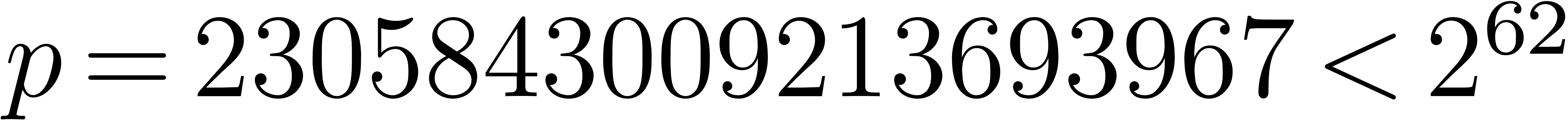 . If the size of the product is of the order of then the naive algorithm is already softly optimal.
If the polynomials are close to being dense then the Kronecker
substitution is the most efficient in practice. Here we consider a case
which lies in between these two extremes.
. If the size of the product is of the order of then the naive algorithm is already softly optimal.
If the polynomials are close to being dense then the Kronecker
substitution is the most efficient in practice. Here we consider a case
which lies in between these two extremes.
More precisely, we pick polynomials with terms of total degree at most
and at least  with random
coefficients in . The subset
can be easily taken as the set of the monomials
of degree at most
with random
coefficients in . The subset
can be easily taken as the set of the monomials
of degree at most 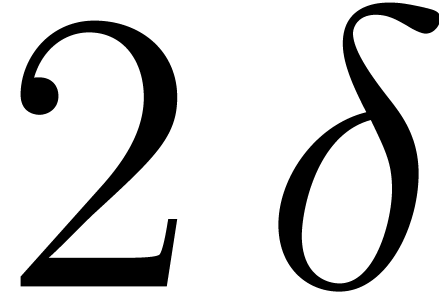 and at least
and at least 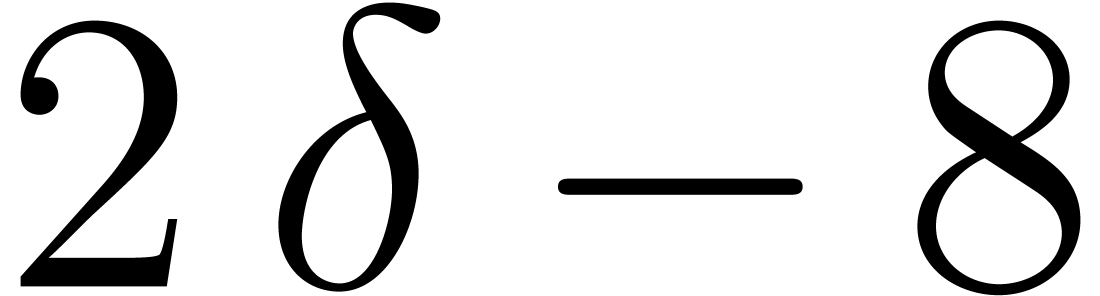 . In Table 7 we compare the fast
algorithm of Section 5.3 to the naive one of Section 3 and the direct use of the Kronecker substitution.
. In Table 7 we compare the fast
algorithm of Section 5.3 to the naive one of Section 3 and the direct use of the Kronecker substitution.
|
||||||||||||||||||||||||||||||||||||||||||||||||||
With 2 (and also with 3 variables) the theoretical asymptotic behaviours are already well reflected. But the fast algorithm only gains for very large sizes. When sharing the same supports in several product the benefit of the fast product can be observed earlier. We shall illustrate this situation in Section 7, for a similar family of examples.
In this section, we show how to build a multiplication algorithm for formal power series on top of the fast polynomial product from the previous section. We will only consider power series which are truncated with respect to the total degree.
Given 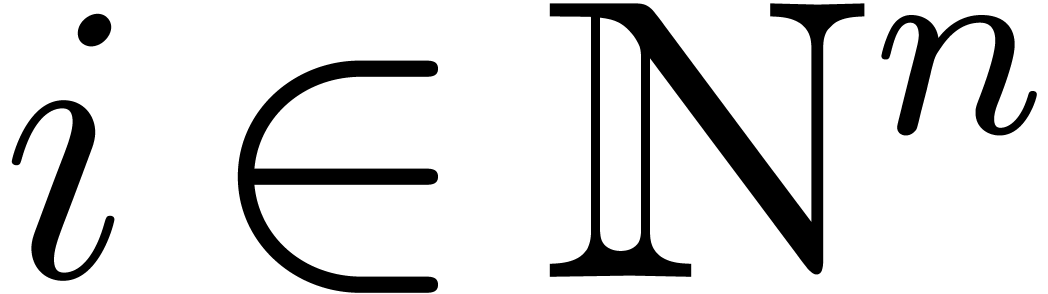 , we let
, we let  . The total degree of a polynomial
. The total degree of a polynomial
 is defined by
is defined by  .
Given a subset
.
Given a subset 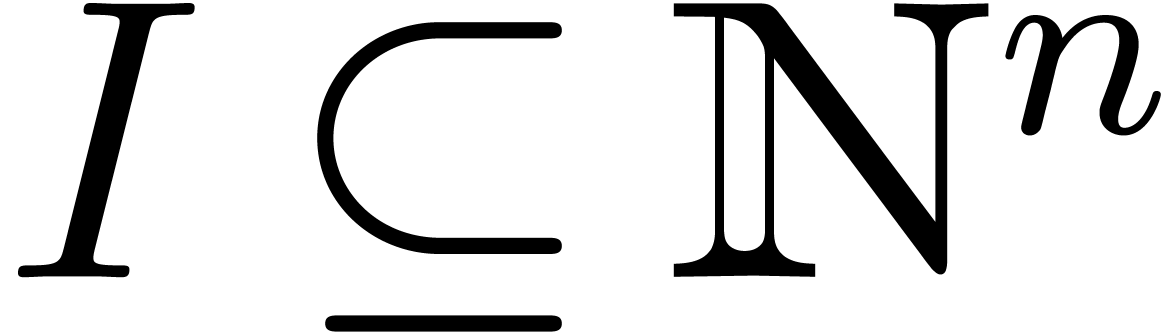 , we define
the restriction
, we define
the restriction 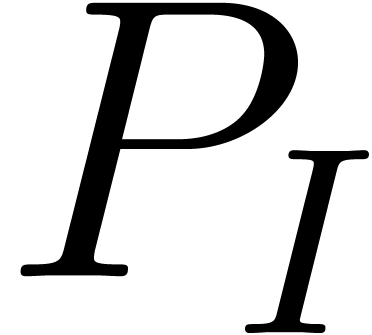 of
to
of
to 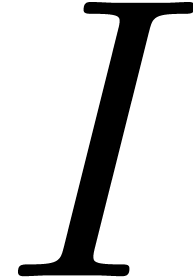 by
by
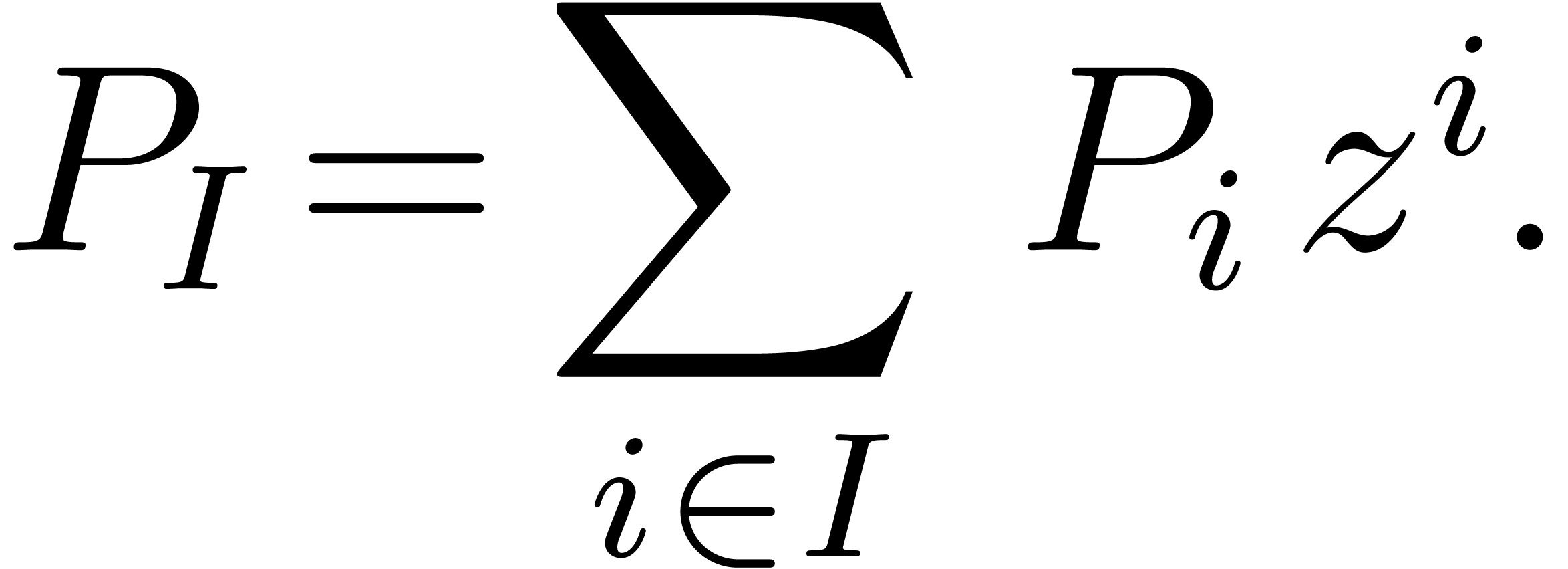
For  , we define the initial
segments
, we define the initial
segments 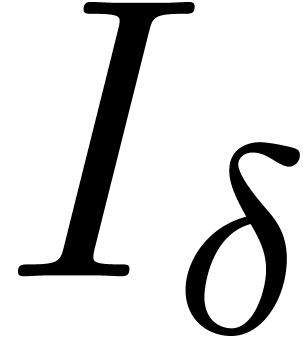 of by
of by 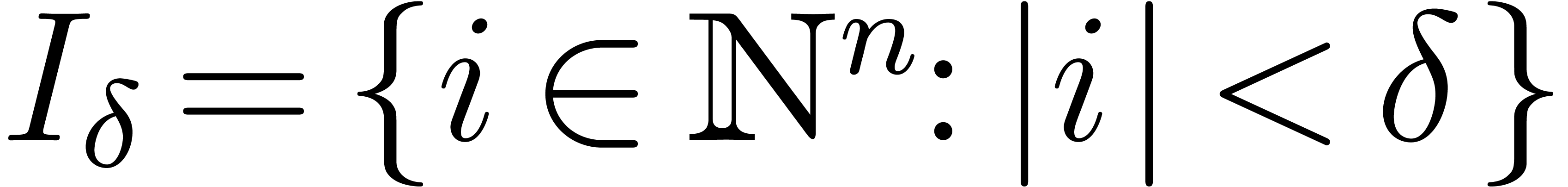 . Then
. Then
is the set of polynomials of total degree 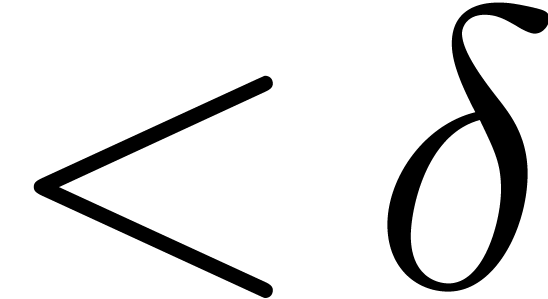 .
Given
.
Given 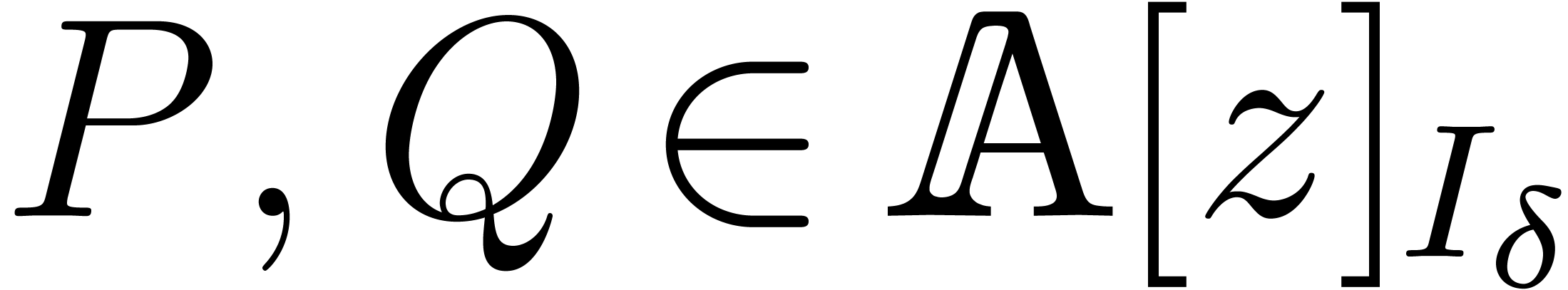 , the aim of this
section is to describe efficient algorithms for the computation of
, the aim of this
section is to describe efficient algorithms for the computation of 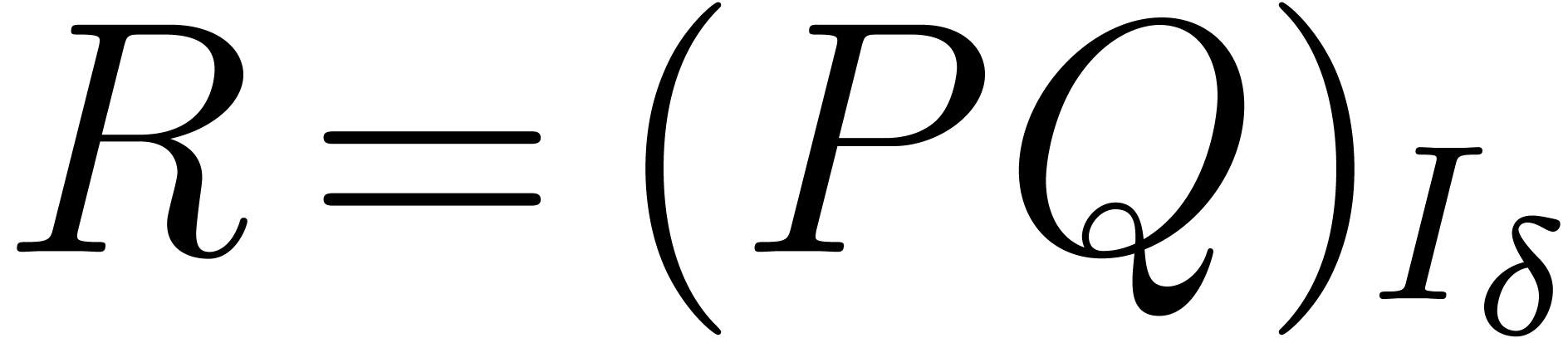 . We will follow and extend the
strategy described in [LS03].
. We will follow and extend the
strategy described in [LS03].
Remark  with
with  , but for the sake of simplicity,
we will stick to ordinary total degrees.
, but for the sake of simplicity,
we will stick to ordinary total degrees.
Given a polynomial , we
define its projective transform 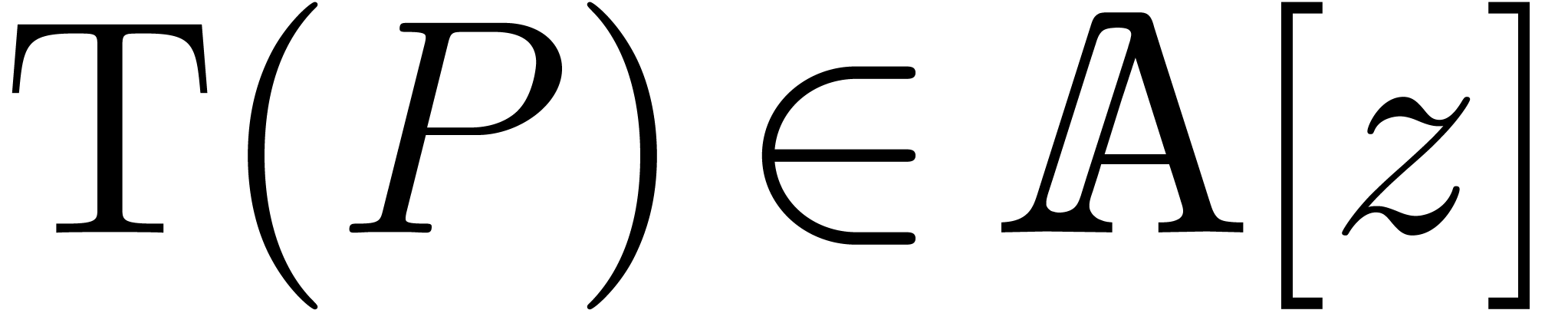 by
by
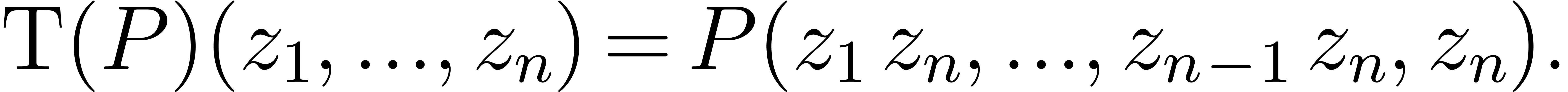
If 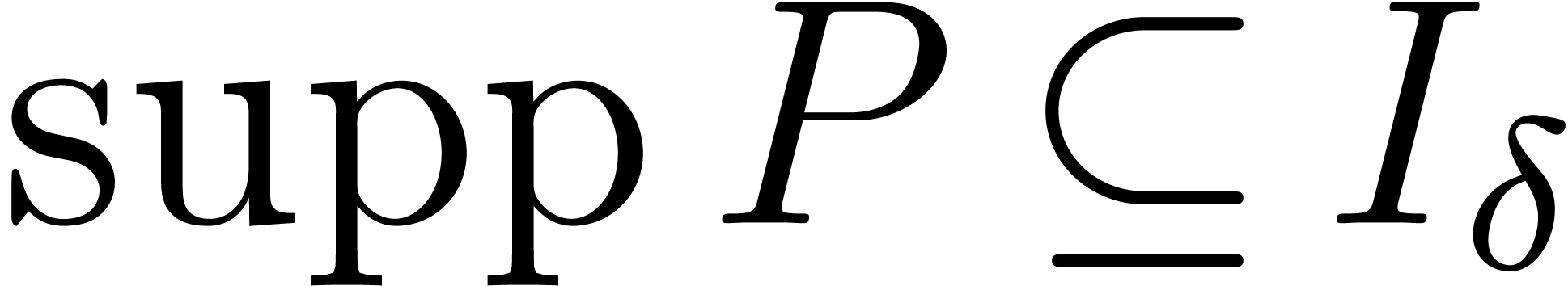 , then
, then 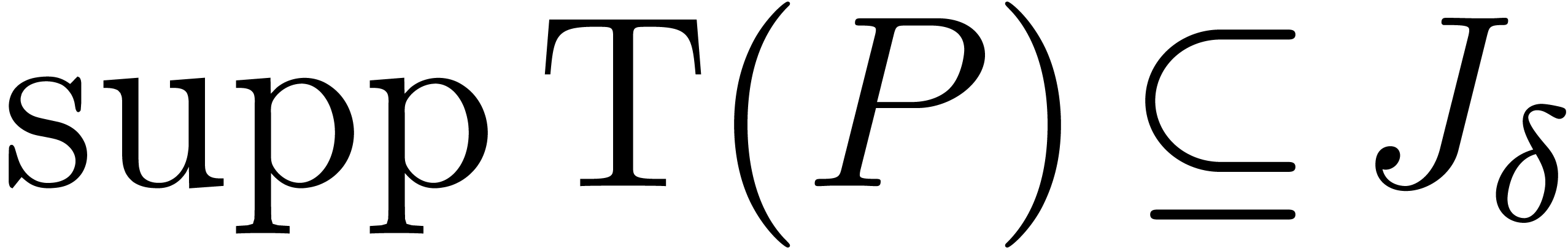 , where
, where
Inversely, for any  , there
exists a unique
, there
exists a unique 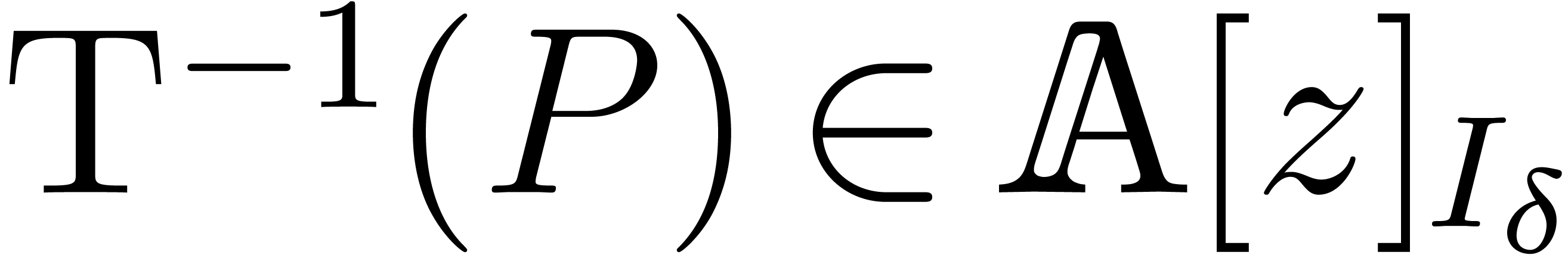 with
with 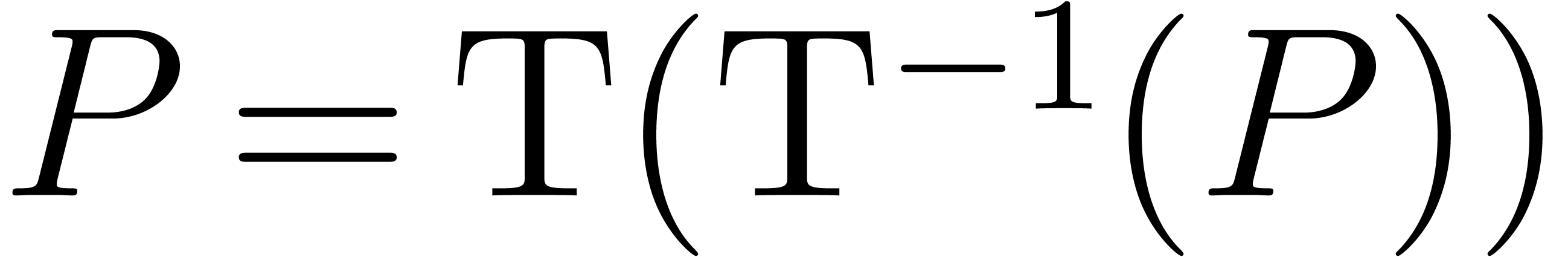 . The transformation
. The transformation  is an
injective morphism of -algebras.
Consequently, given
is an
injective morphism of -algebras.
Consequently, given 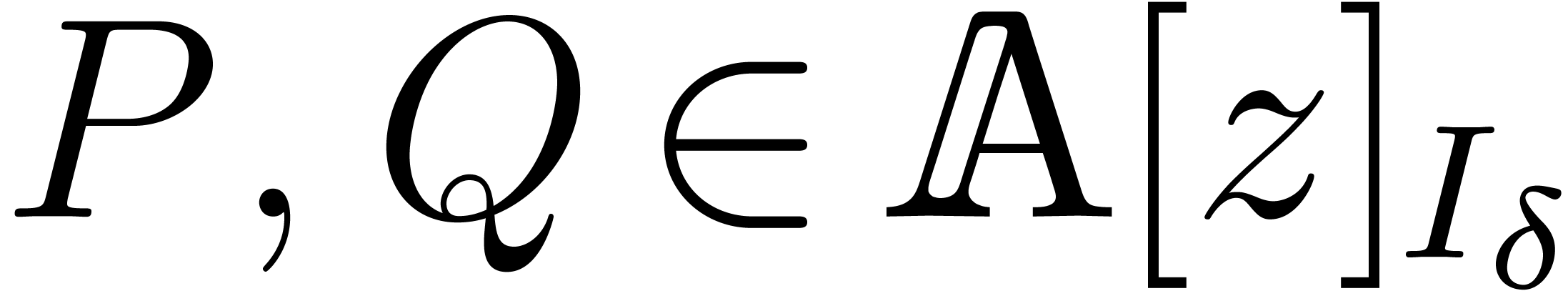 , we will
compute the truncated product
, we will
compute the truncated product 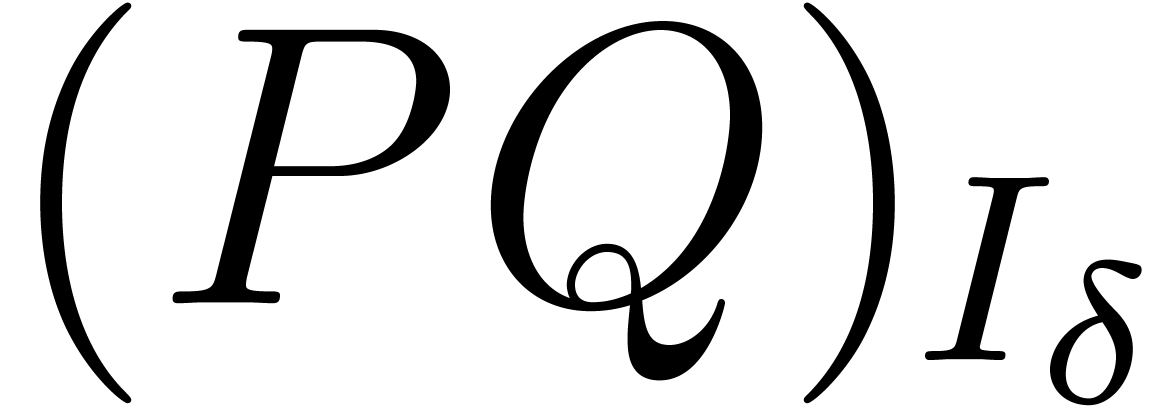 using
using
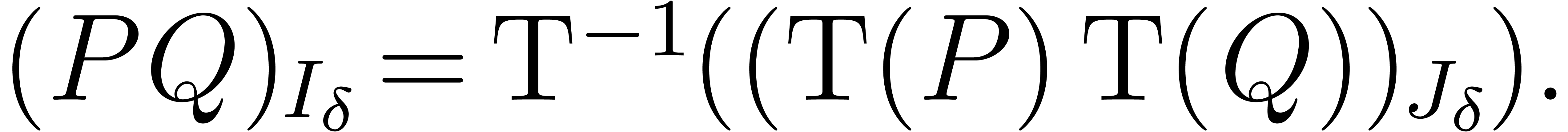
Given a polynomial and 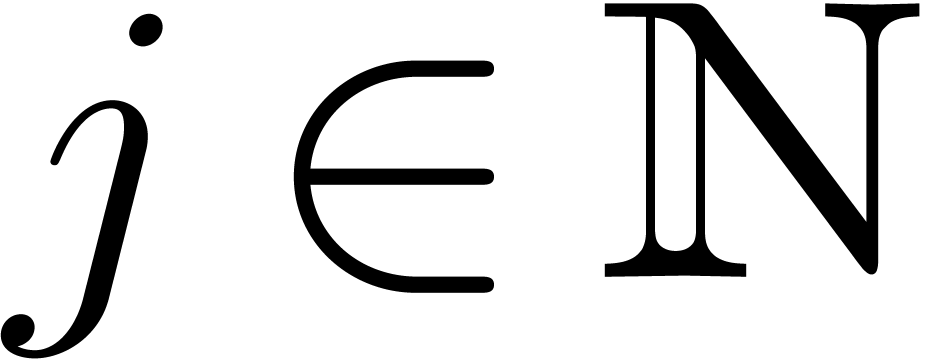 , let
, let
If 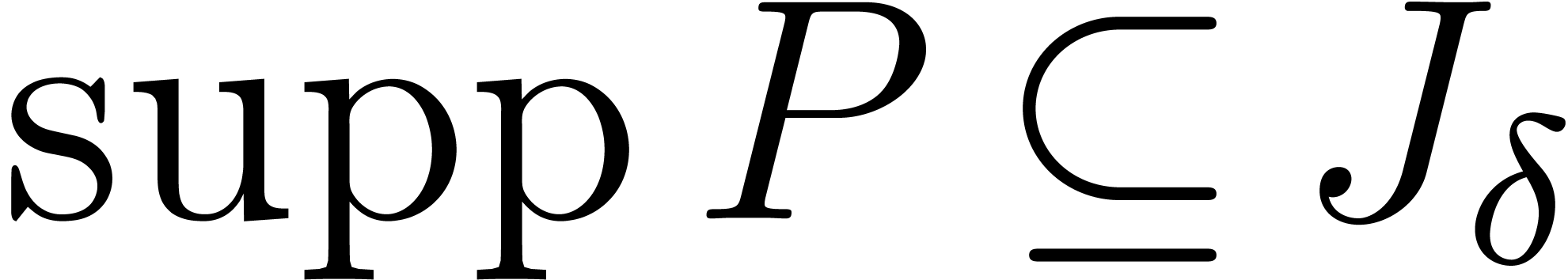 , then
, then 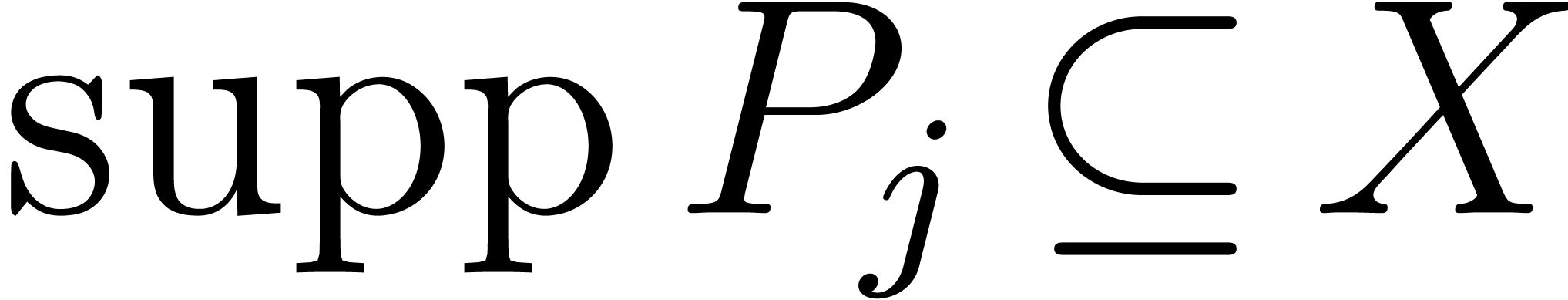 , with
, with
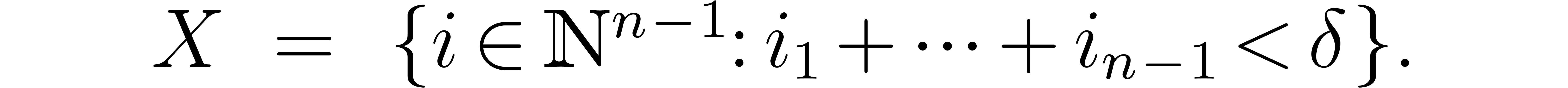
Let be an element of of
order at least 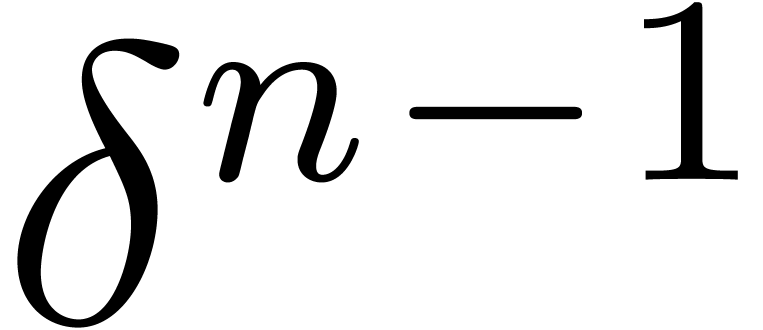 . Taking as above, the construction in Section ?
yields a -linear and
invertible evaluation mapping
. Taking as above, the construction in Section ?
yields a -linear and
invertible evaluation mapping
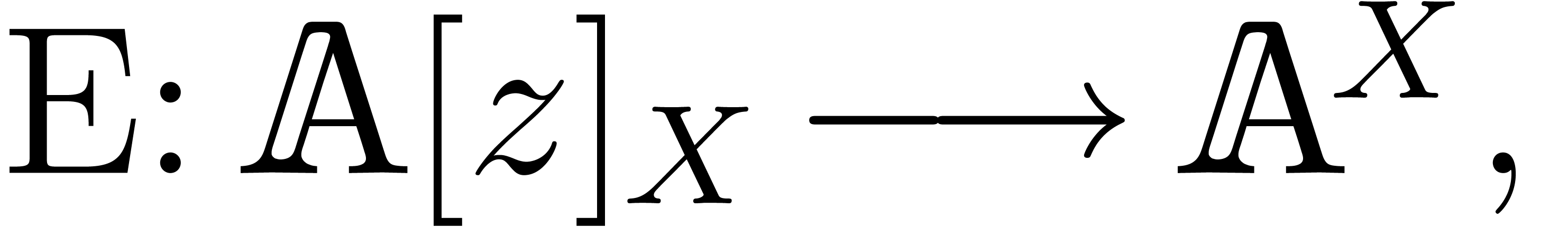
such that for all 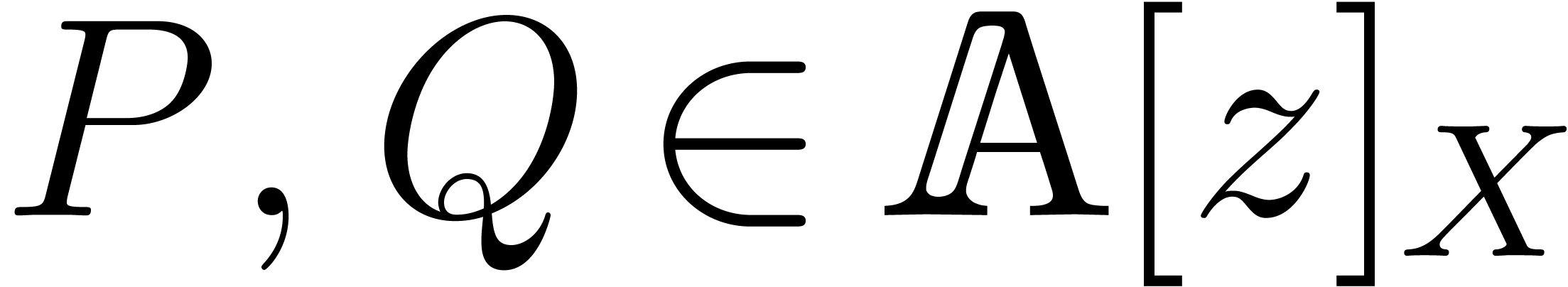 with
with 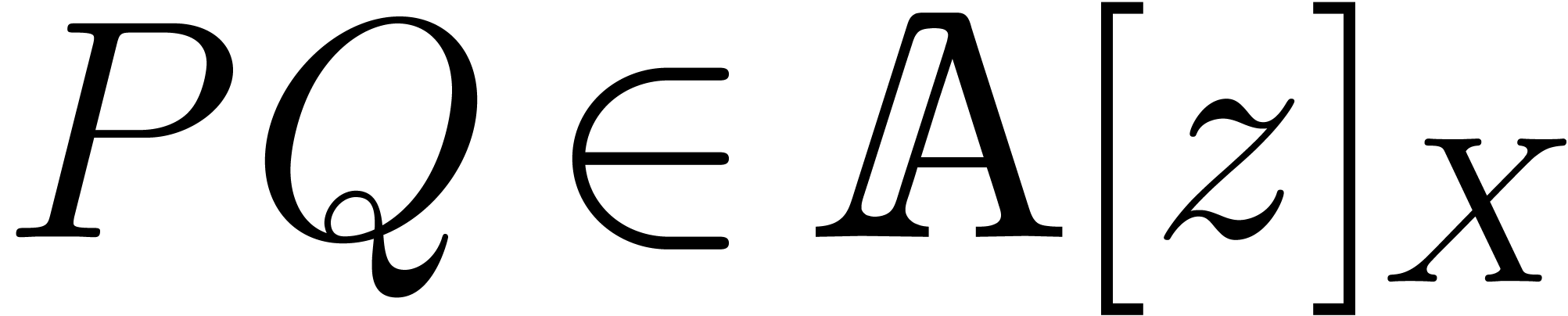 , we have
, we have
 |
(2) |
This map extends to 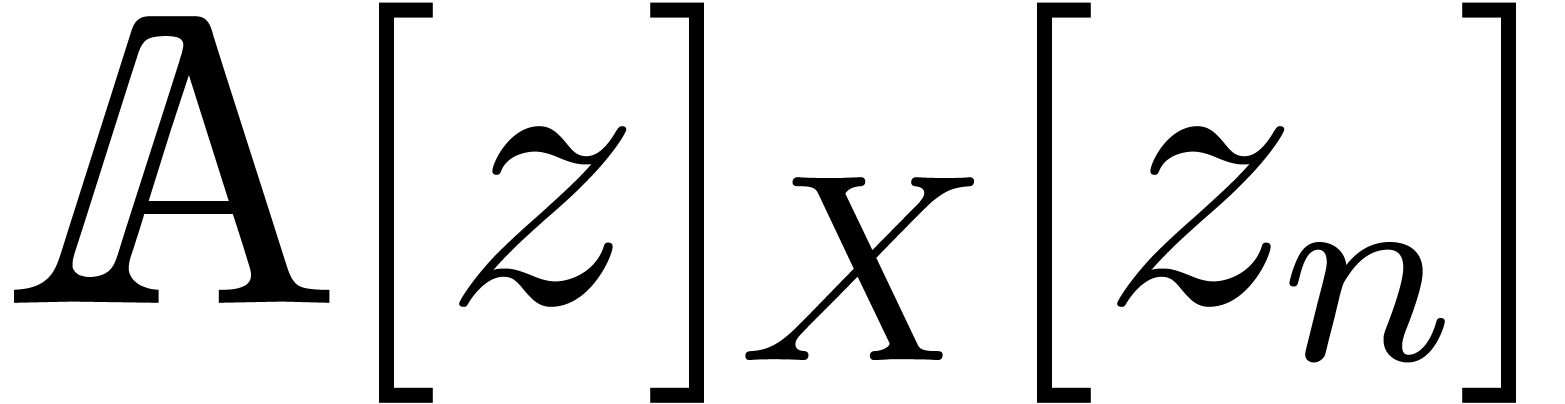 using
using
Given 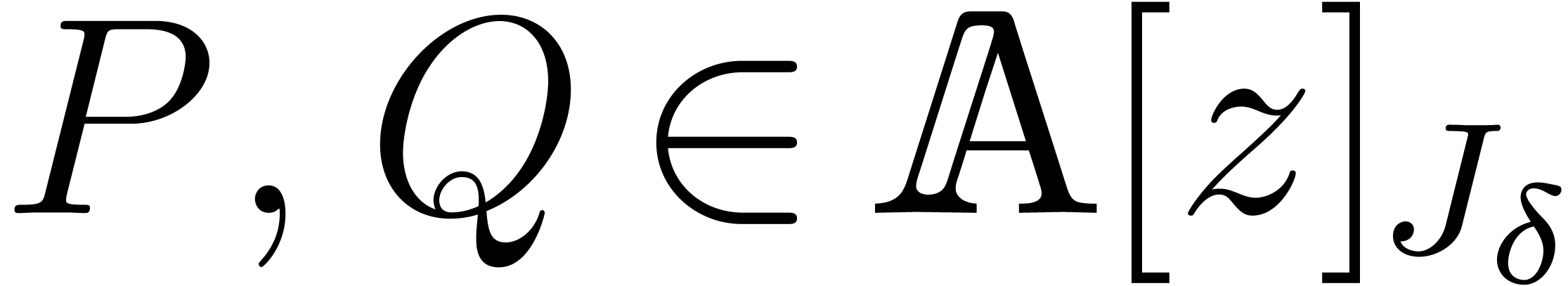 and
and  ,
the relation (2) yields
,
the relation (2) yields
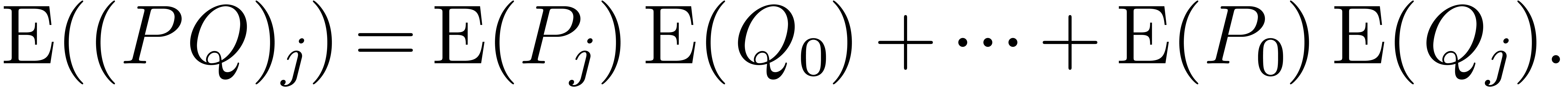
In particular, if  , then
, then
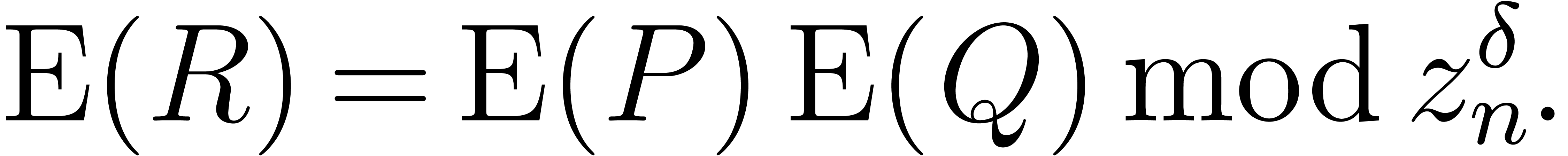
Since is invertible, this yields an efficient
way to compute .
The number of coefficients of a truncated series in 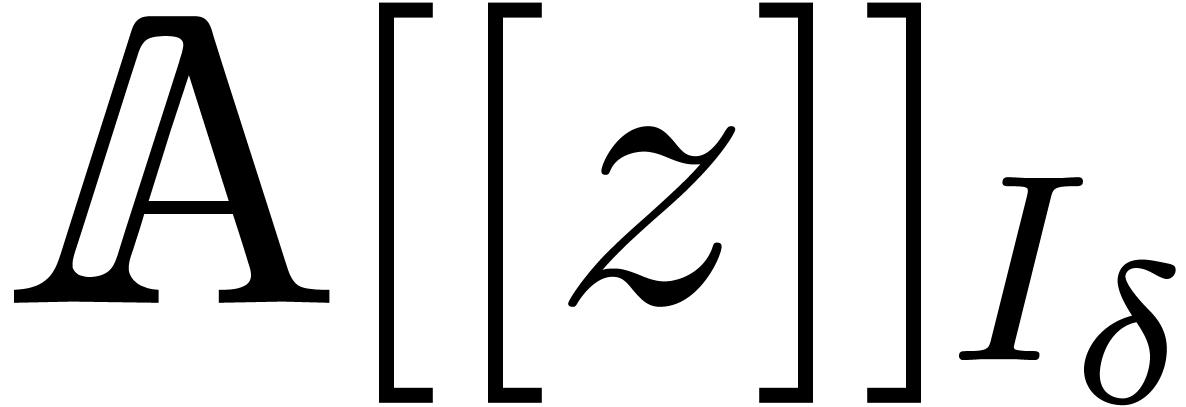 is given by
is given by
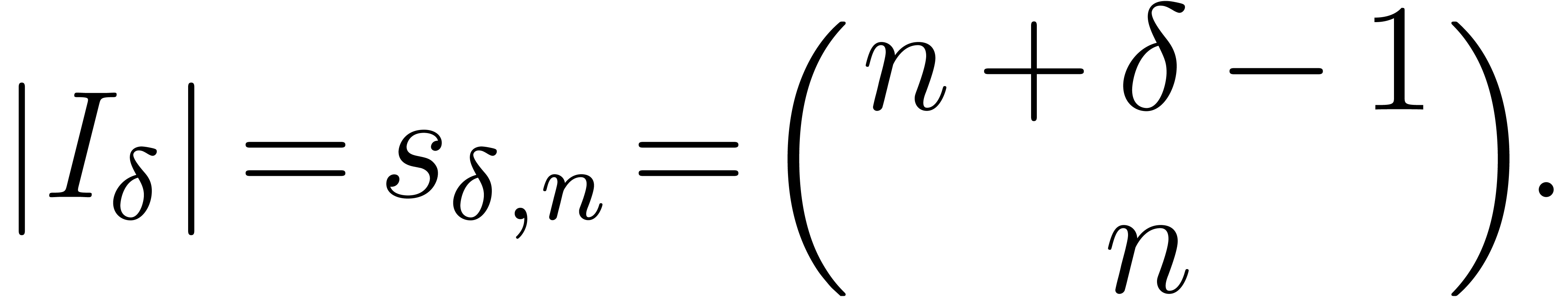
The size  of is smaller
by a factor between and :
of is smaller
by a factor between and :
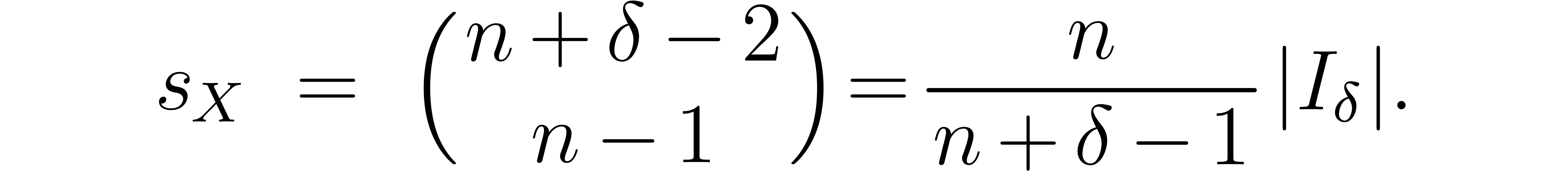
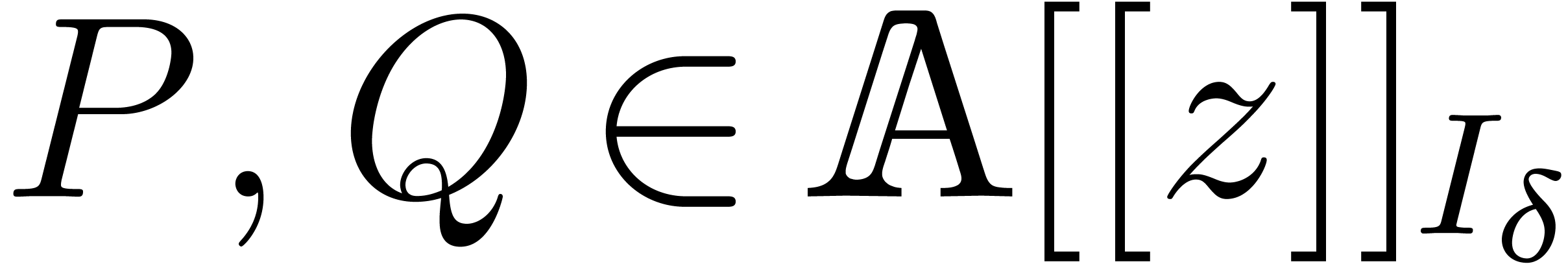 and an element
and an element
 of order at least , we can compute using
of order at least , we can compute using
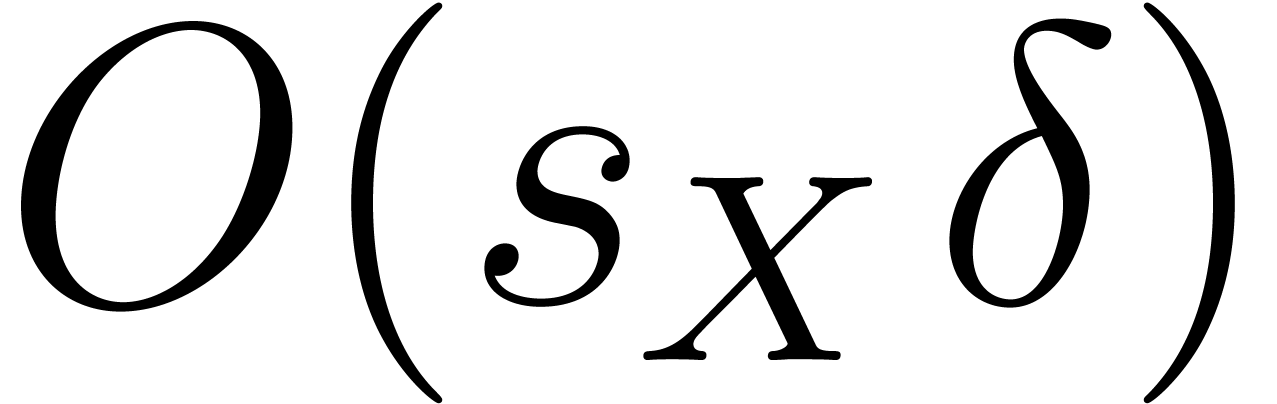 inversions in ,
inversions in ,
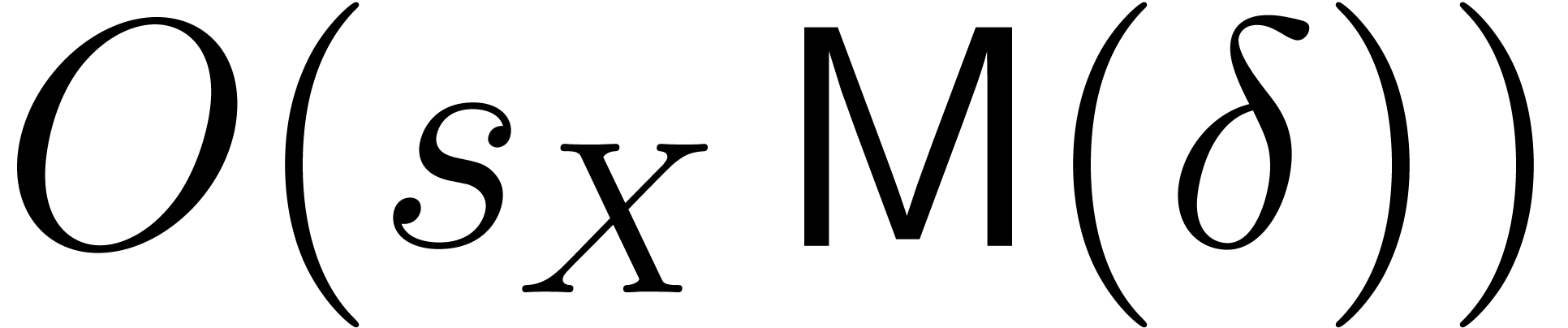 ring operations in , and
ring operations in , and 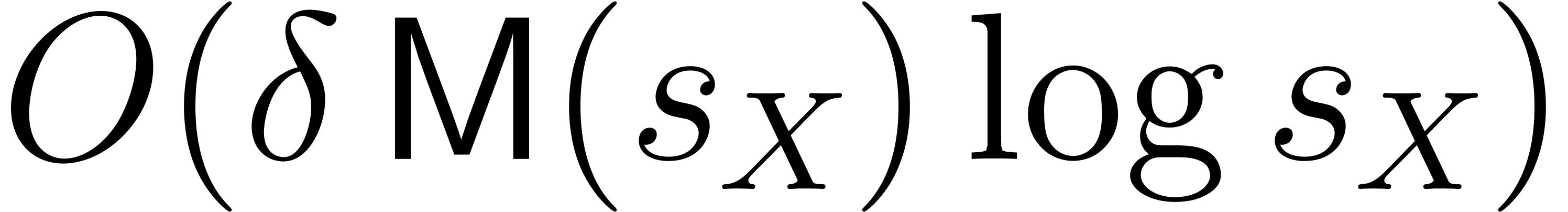 vectorial operations
in .
vectorial operations
in .
Proof. We apply the algorithm described in the
previous subsection. The transforms  and
and 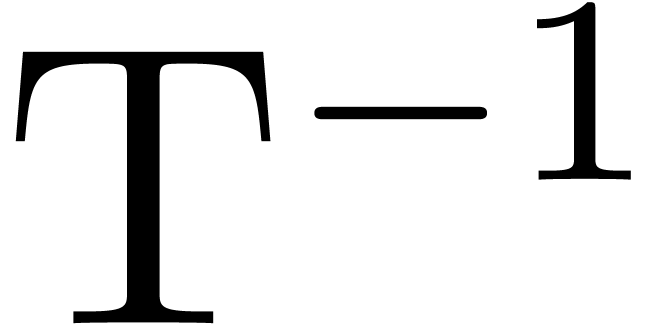 require a negligible amount of time. The computation
of the evaluation points
require a negligible amount of time. The computation
of the evaluation points 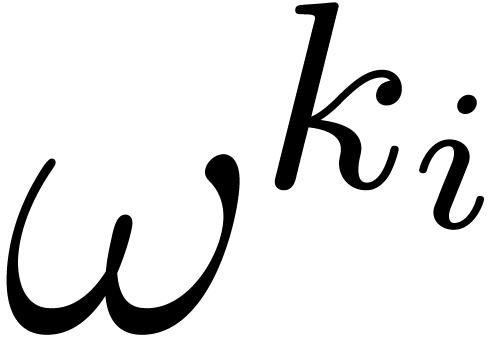 only involves products in ,
when exploiting the fact that is an initial
segment. The computation of
only involves products in ,
when exploiting the fact that is an initial
segment. The computation of 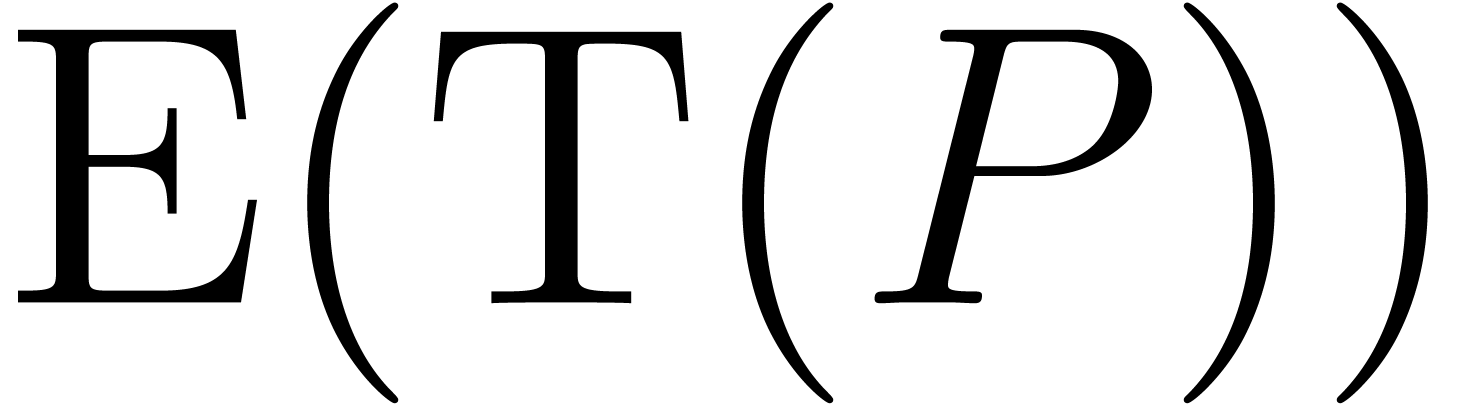 and
and 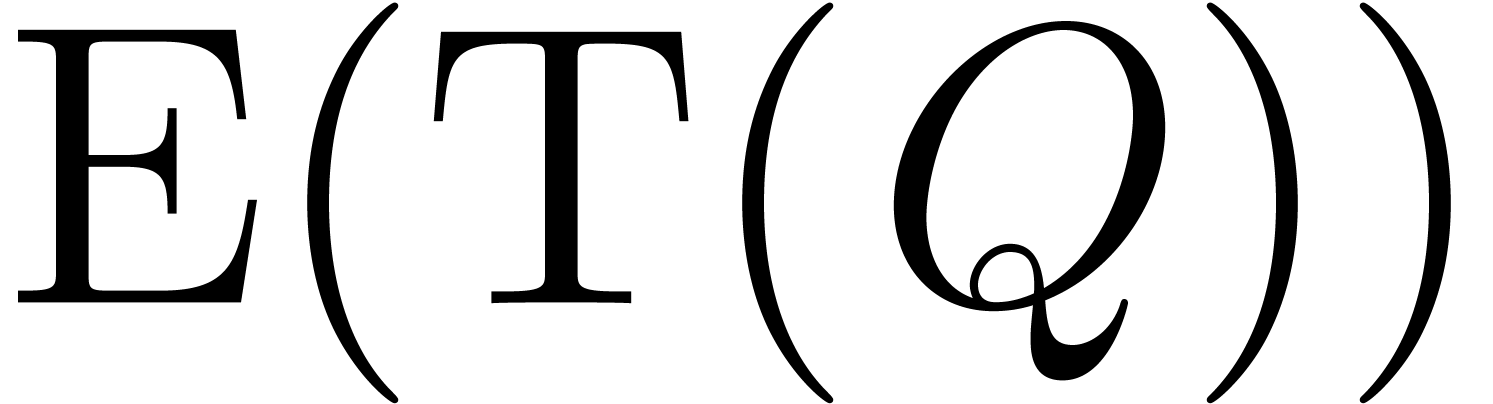 requires vectorial operations in , as recalled in Section 5.1. The
computation of
requires vectorial operations in , as recalled in Section 5.1. The
computation of 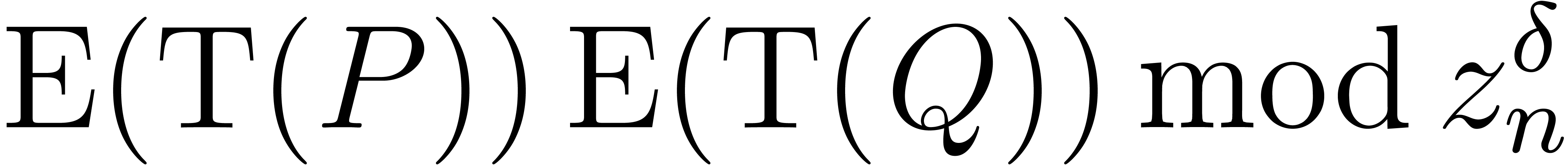 can be done using ring operations in .
Recovering again requires
vectorial operations in , as
well as inversions in .
can be done using ring operations in .
Recovering again requires
vectorial operations in , as
well as inversions in .
Remark 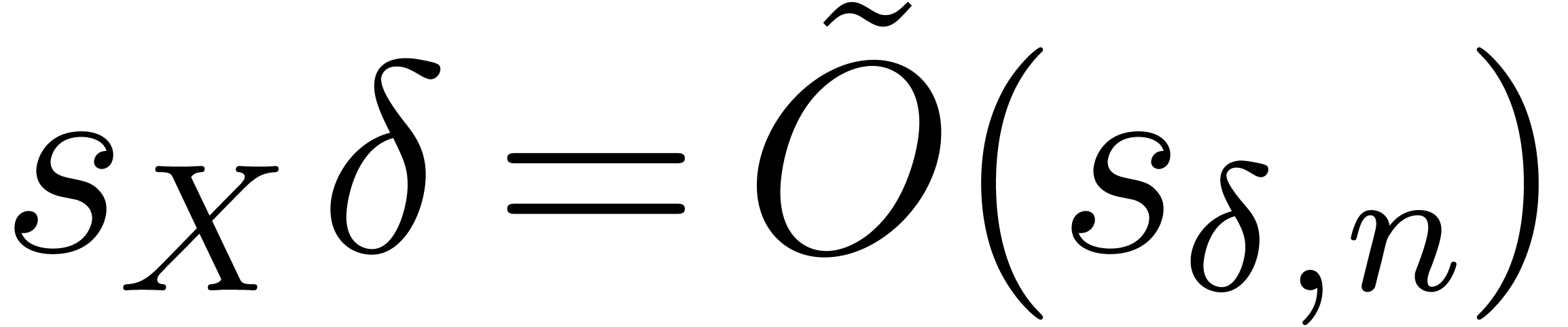 by [LS03, Lemma 3], Proposition 23
ensures that power series can be multiplied in softly linear time, when
truncating with respect to the total degree.
by [LS03, Lemma 3], Proposition 23
ensures that power series can be multiplied in softly linear time, when
truncating with respect to the total degree.
In the finite field case when  ,
the techniques from Section 5.3 lead to the following
consequence of Proposition 23.
,
the techniques from Section 5.3 lead to the following
consequence of Proposition 23.
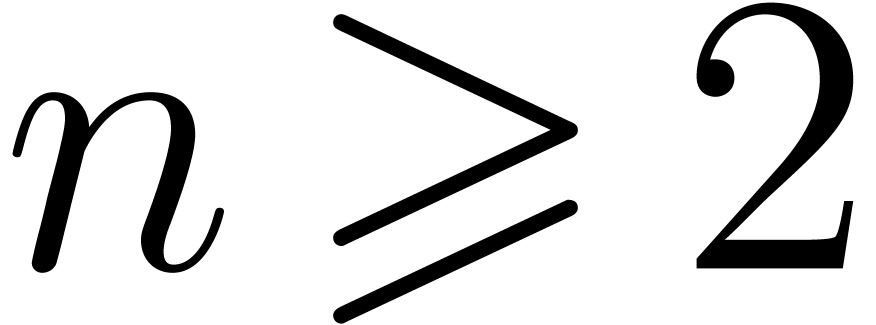 ,
, 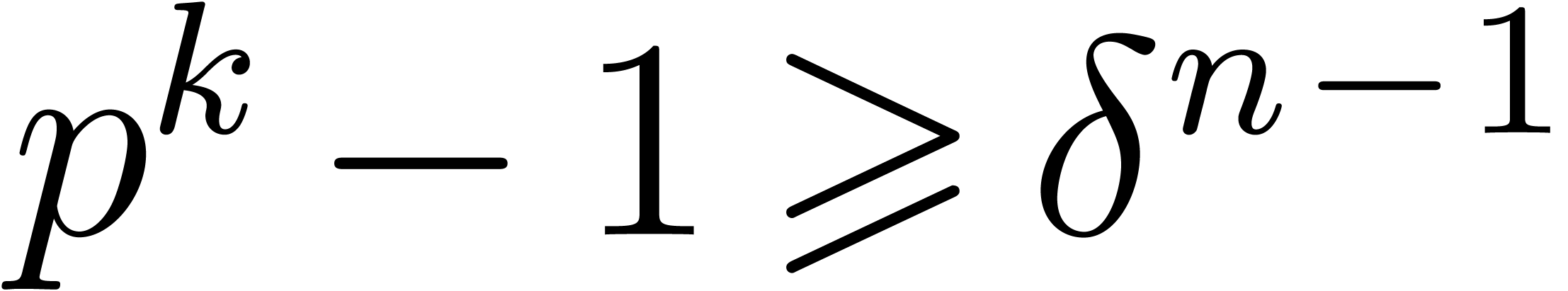 and , and
assume given a primitive element of . Given , we can compute using
and , and
assume given a primitive element of . Given , we can compute using
bit-operations.
Proof. The  inversions in
take
inversions in
take 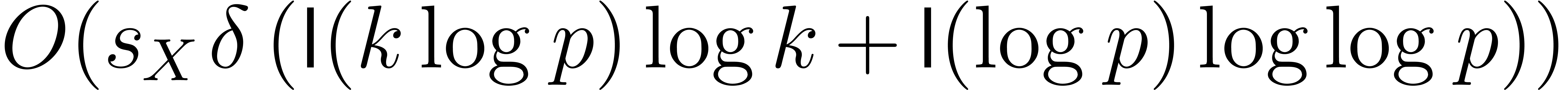 bit-operations,
when using Kronecker substitution. The ring
operations in amount to
bit-operations,
when using Kronecker substitution. The ring
operations in amount to 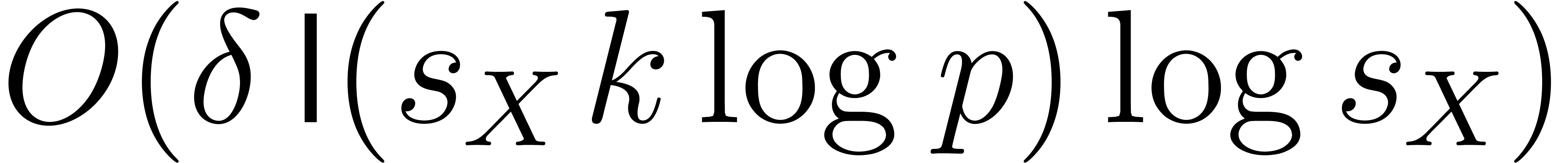 more bit-operations. Since we have
more bit-operations. Since we have 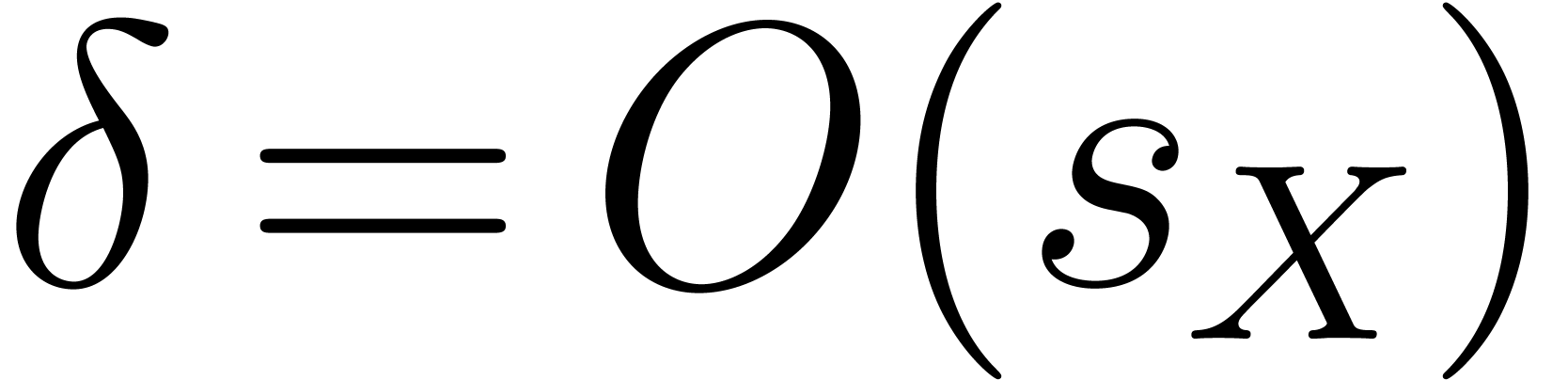 , which implies
, which implies 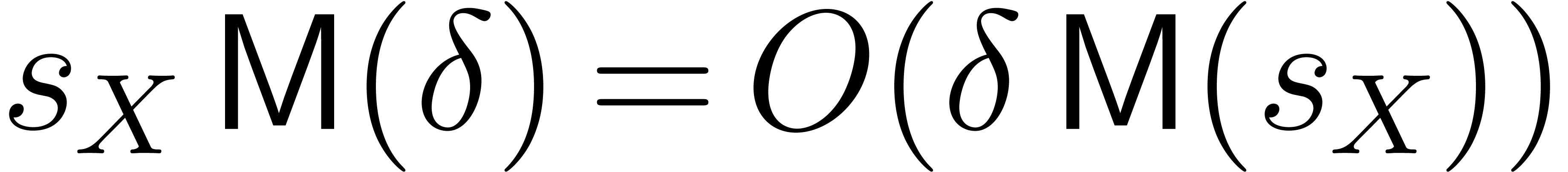 .
The conclusion thus follows from Proposition 23.
.
The conclusion thus follows from Proposition 23.
If 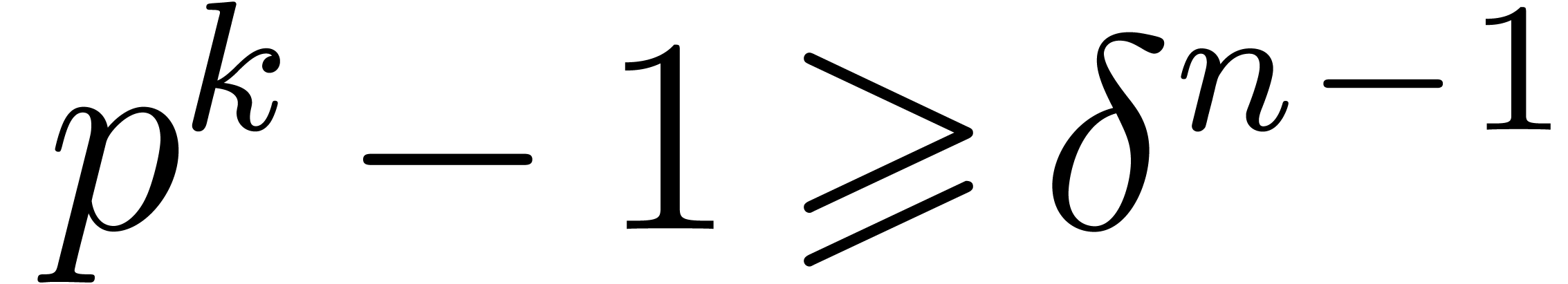 does not hold, then it is possible to perform
the product in an extension of degree
does not hold, then it is possible to perform
the product in an extension of degree 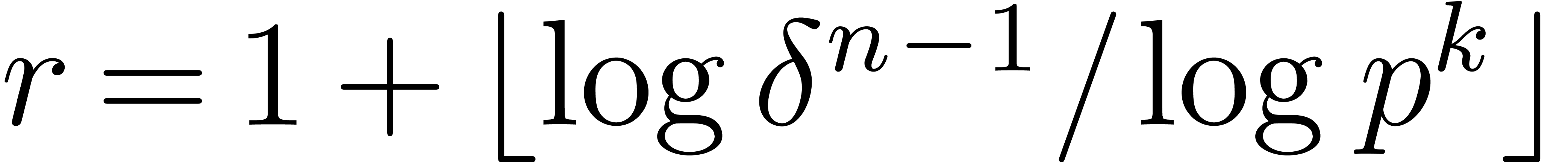 of , so that
of , so that 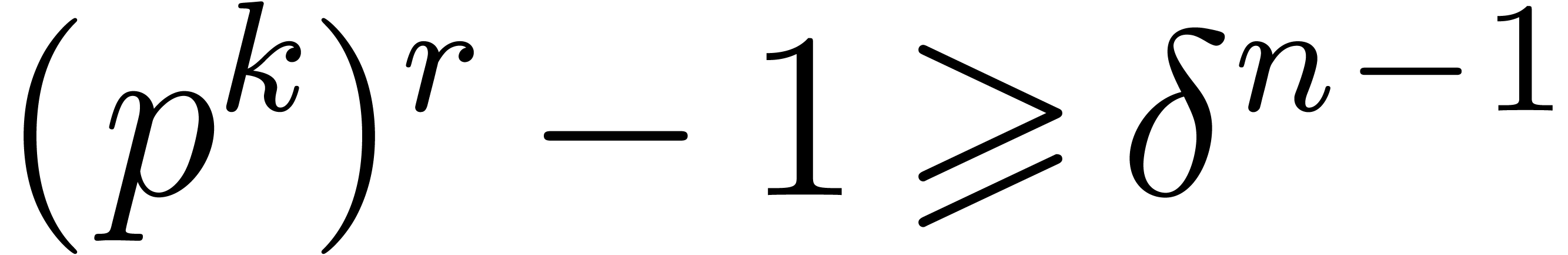 . Doing so, the cost of the product requires
. Doing so, the cost of the product requires 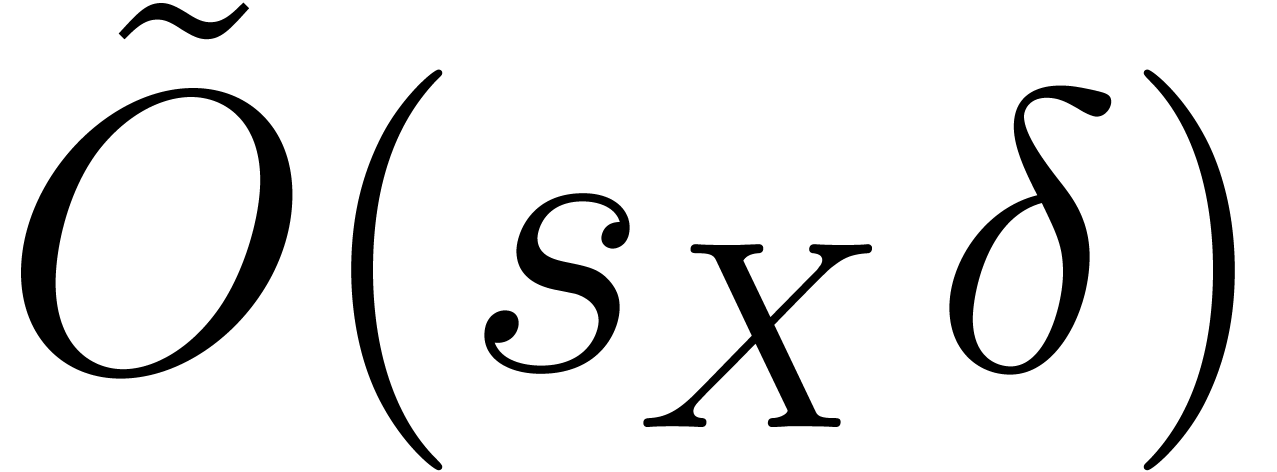 operations in
operations in 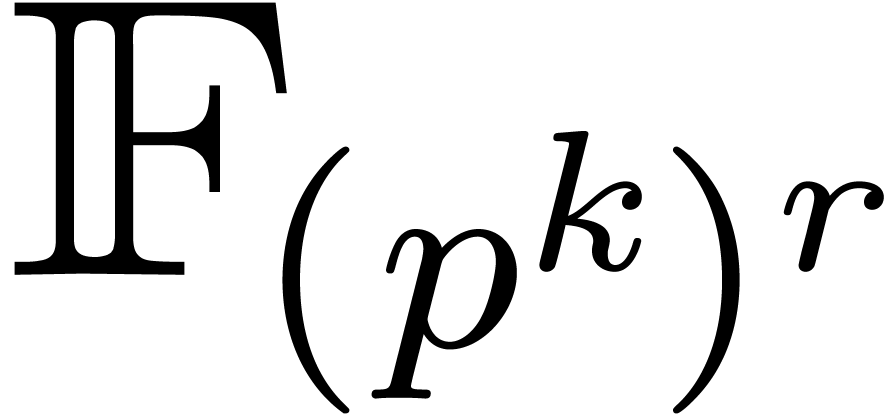 ,
which further reduces to
,
which further reduces to 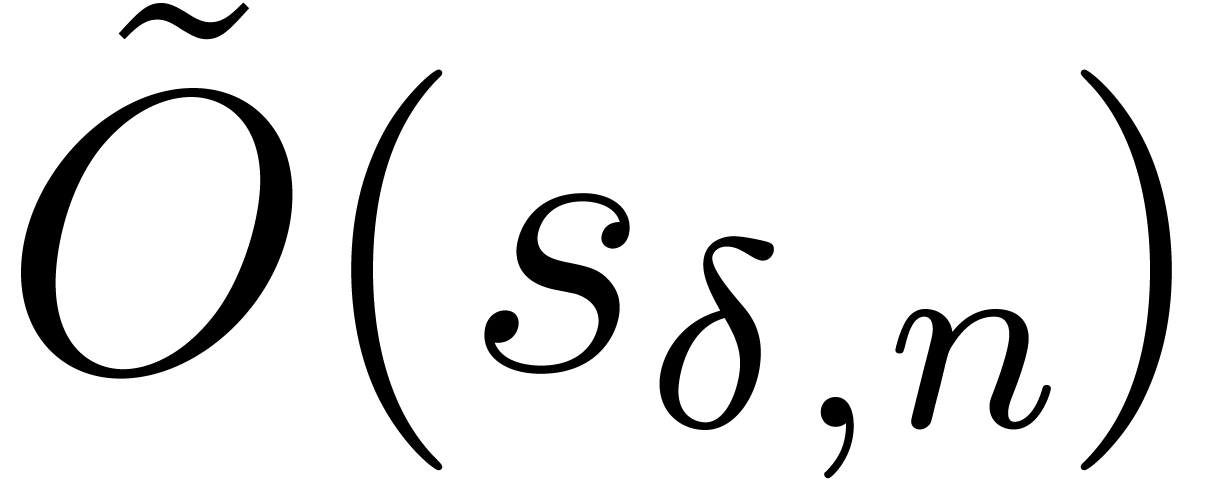 by [LS03,
Lemma 3]. The field extension and the construction of the needed can be seen as precomputations for they only depend
on , , and . Since
by [LS03,
Lemma 3]. The field extension and the construction of the needed can be seen as precomputations for they only depend
on , , and . Since 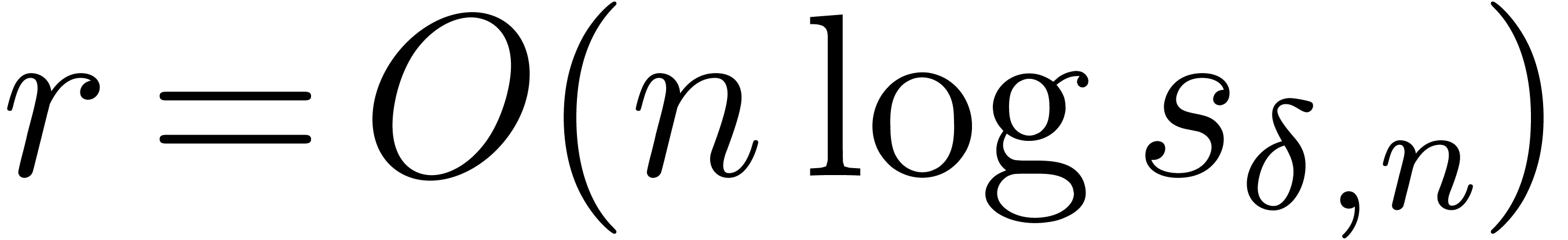 ,
we have therefore obtained a softly optimal uniform complexity bound in
the finite field case.
,
we have therefore obtained a softly optimal uniform complexity bound in
the finite field case.
Notice that the direct use of Kronecker substitution for multiplying
and yields 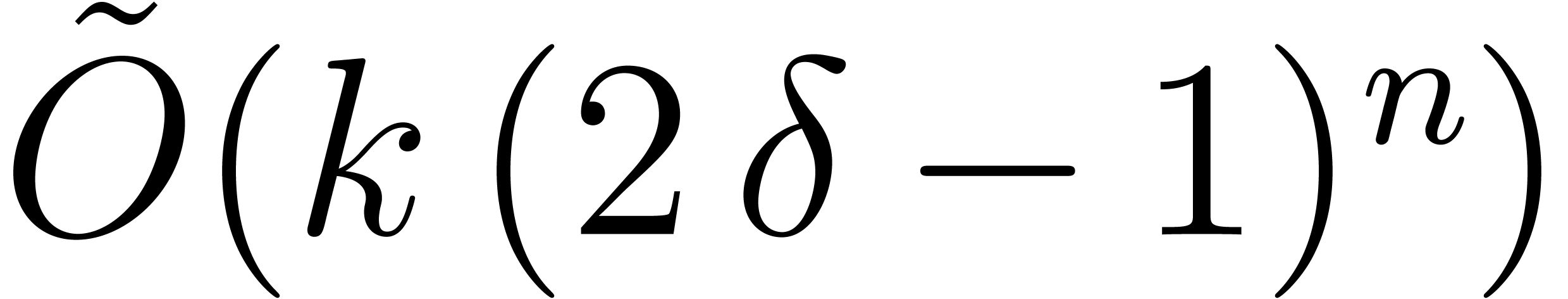 operations in .
In terms of the dense size of and , the latter bound becomes of order
operations in .
In terms of the dense size of and , the latter bound becomes of order 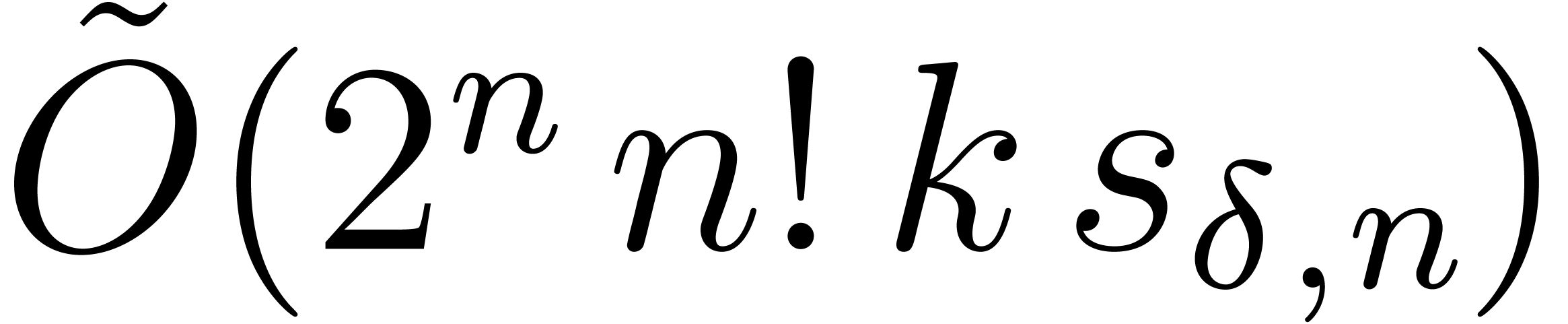 , which is more expensive than the
present algorithm.
, which is more expensive than the
present algorithm.
If 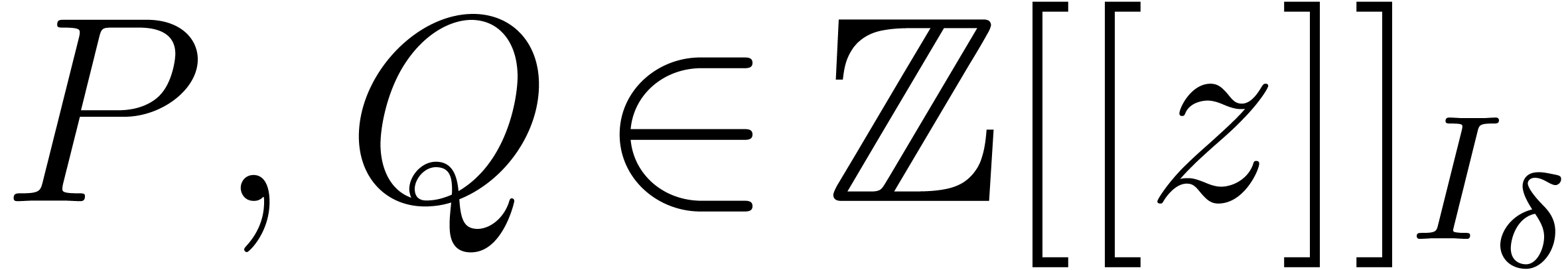 , then the assumption
, then the assumption
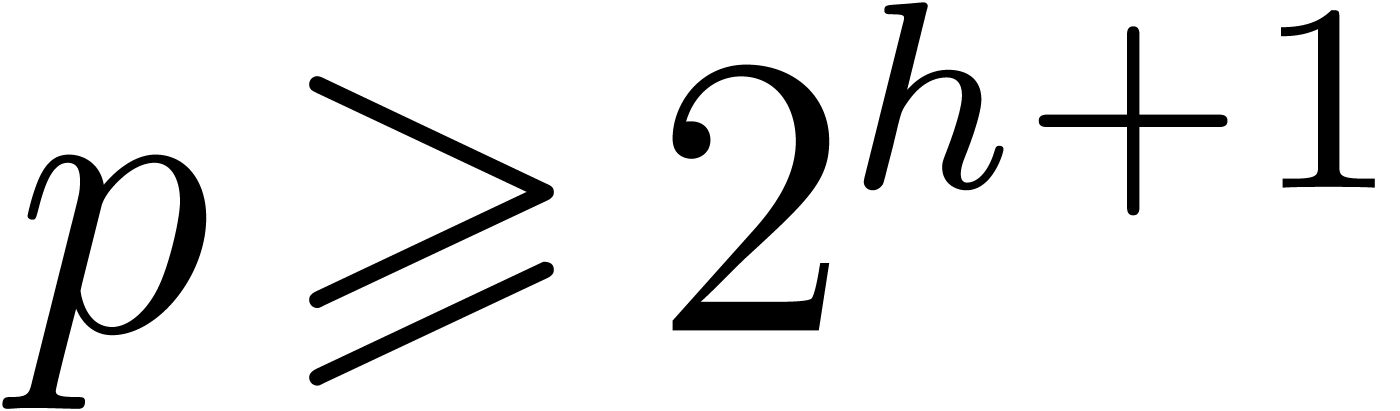 , with
, with 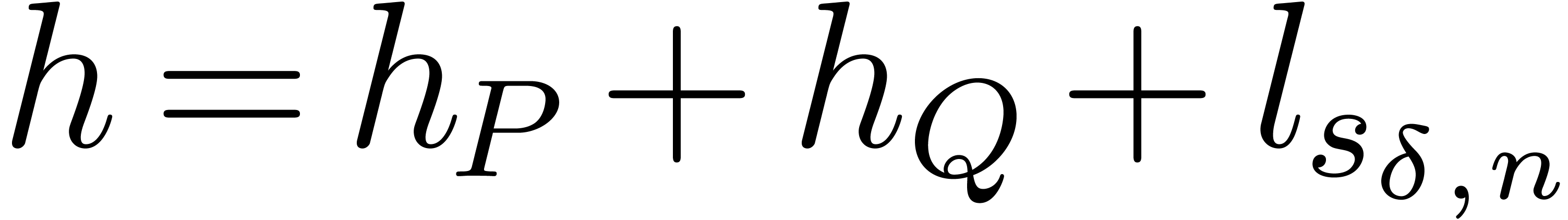 , guarantees that the coefficients of the result
can be reconstructed from their reductions
modulo . If
, guarantees that the coefficients of the result
can be reconstructed from their reductions
modulo . If  , and if we are given a prime number
, and if we are given a prime number 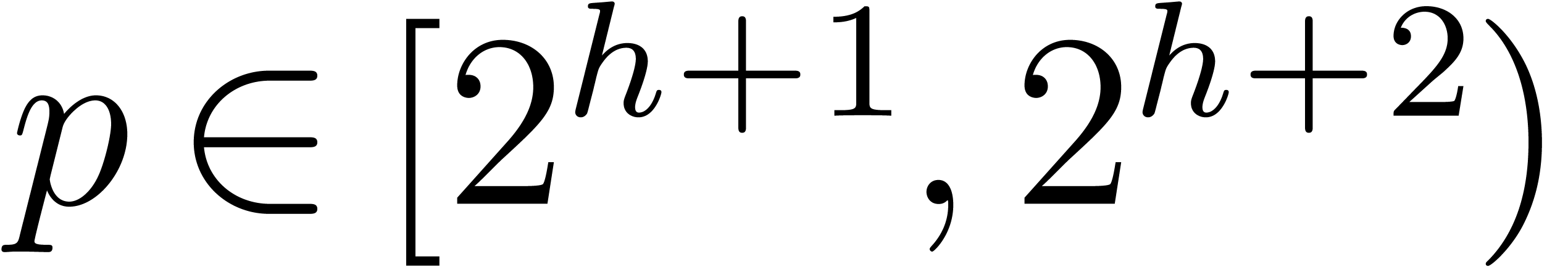 and a primitive element of
and a primitive element of 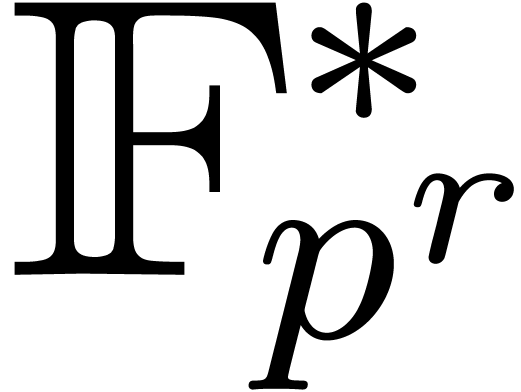 , where , then can be computed using
, where , then can be computed using
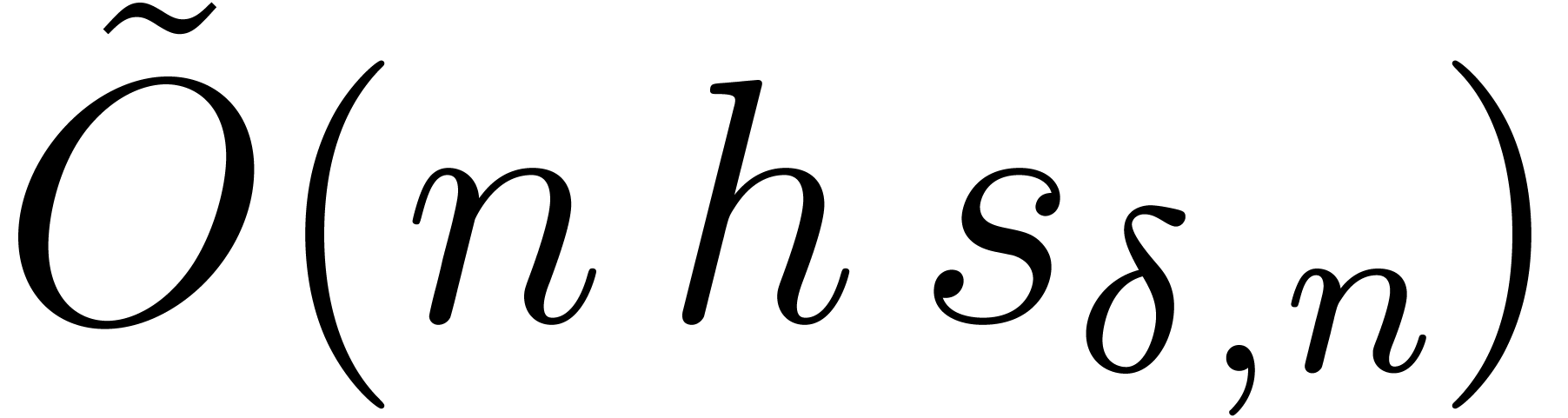 bit-operations, by Corollary 25.
Otherwise, in the same way we did for polynomials in Section 5.4,
Chinese remaindering leads to:
bit-operations, by Corollary 25.
Otherwise, in the same way we did for polynomials in Section 5.4,
Chinese remaindering leads to:
, that
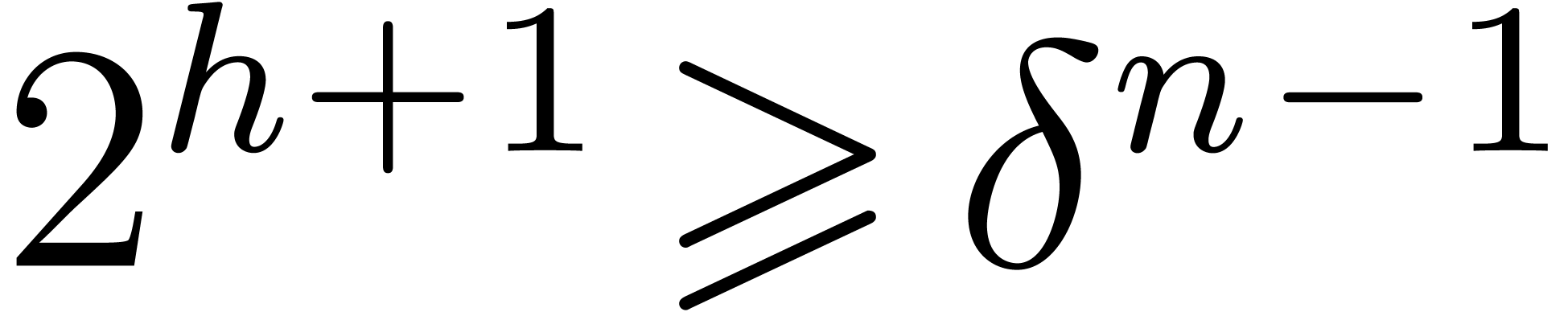 , and that we are given a
reduced sequence of prime moduli with order
and capacity ,
and an element of order at least . Given
, and that we are given a
reduced sequence of prime moduli with order
and capacity ,
and an element of order at least . Given 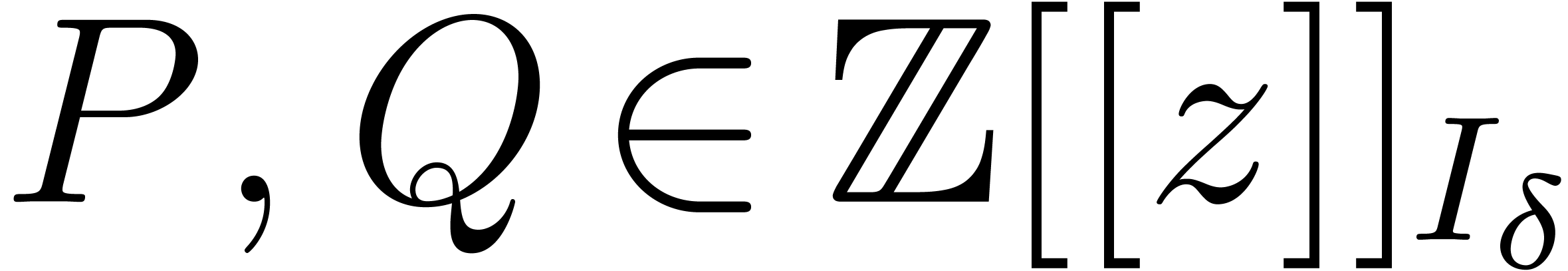 ,
we can compute using
,
we can compute using
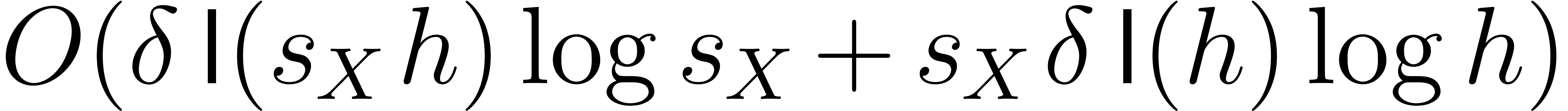
bit-operations.
Proof. Let .
Since 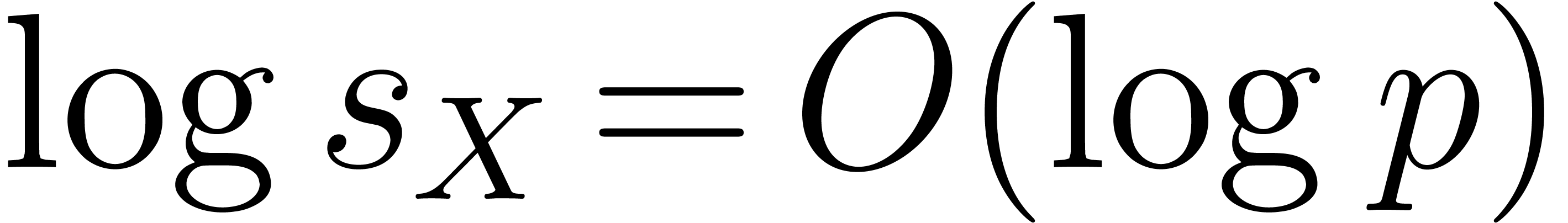 , we can use the
Kronecker substitution with the algorithm underlying Proposition 23 over
, we can use the
Kronecker substitution with the algorithm underlying Proposition 23 over 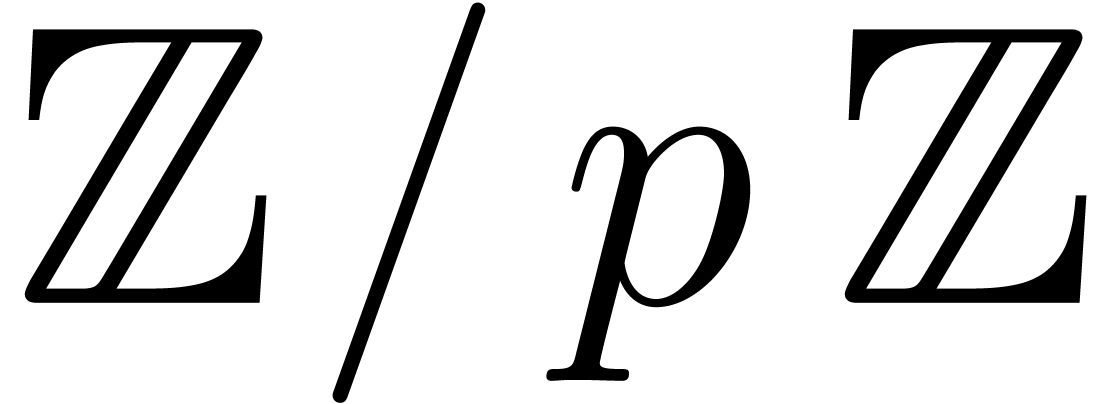 to perform the truncated
product of and with
to perform the truncated
product of and with  bit-operations. The conclusion thus follows from
.
bit-operations. The conclusion thus follows from
.
Remark that the bound in Corollary 26 is softly optimal,
namely 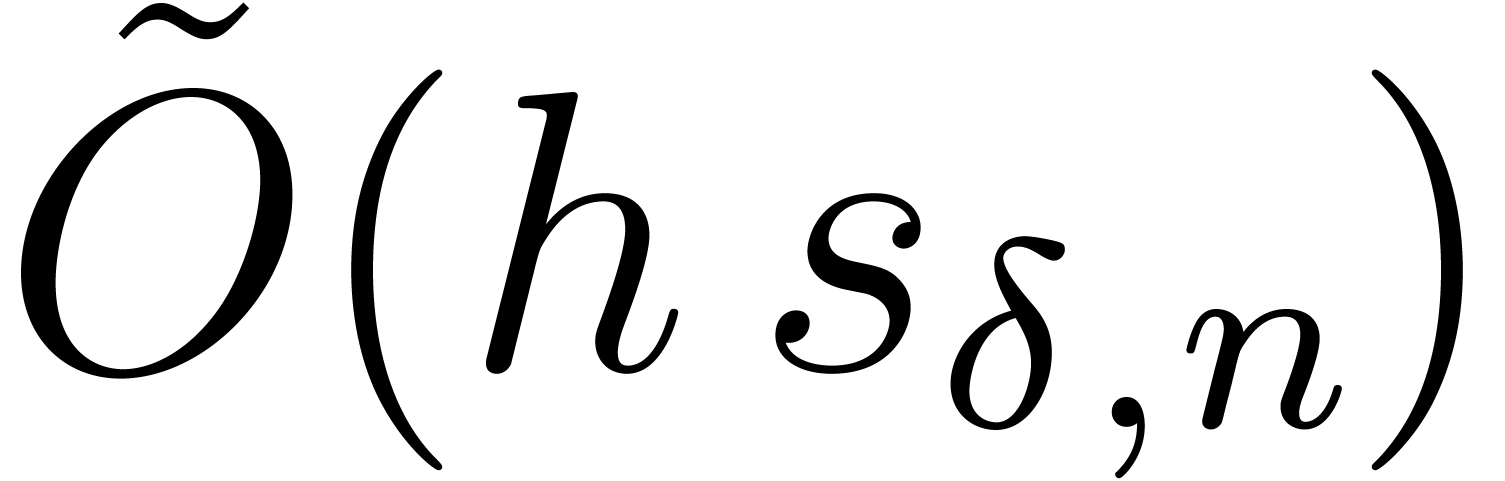 , which is much better
than a direct use of Kronecker substitution when
becomes large.
, which is much better
than a direct use of Kronecker substitution when
becomes large.
We take , with . The following tables demonstrate that the the
theoretical softly linear asymptotic costs can really be
observed.
|
||||||||||||||||||
When comparing Tables 8 and 6, we see that our fast product does not compete with the naive algorithm up to order 160 in the bivariate case. For three variables we observe that it outperforms the naive approach at large orders, but that it is still slower than Kronecker substitution (see Table 2).
|
||||||||||||||||||||
For 4 variables we see in Table 9 that the Kronecker product is slower than the naive approach (it also consumes a huge quantity of memory). The naive algorithm is fastest for small orders, but our fast algorithm wins for large orders.
For 5 and more variables the truncation order can not grow very large, and the naive algorithm becomes subquadratic, so that the threshold for the fast algorithm is much higher:
|
||||||||||||||||||||||||||||
Let be a field, and let 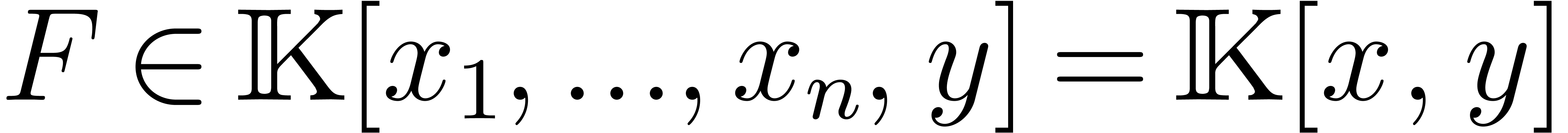 . In this section we are interested to count the
number of the absolutely irreducible factors of , i.e. number of irreducible
factors of over the algebraic closure
. In this section we are interested to count the
number of the absolutely irreducible factors of , i.e. number of irreducible
factors of over the algebraic closure  of .
of .
Let  denote the total degree in the variables
denote the total degree in the variables
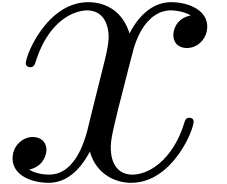 , and let
, and let 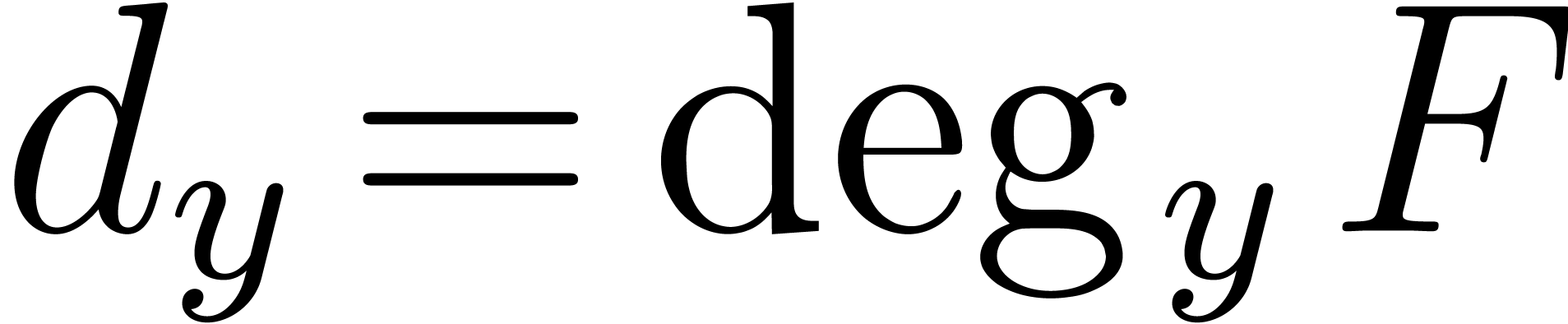 . The integral hull of
. The integral hull of 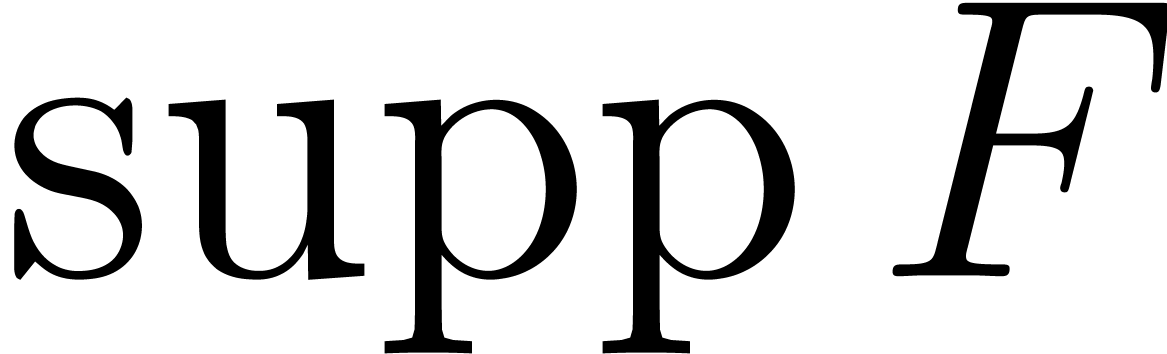 , which we will denote by , is the intersection of
, which we will denote by , is the intersection of 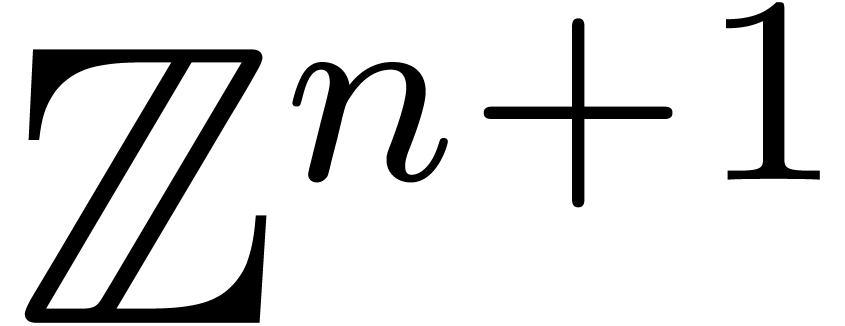 and the convex hull of as a subset of
and the convex hull of as a subset of 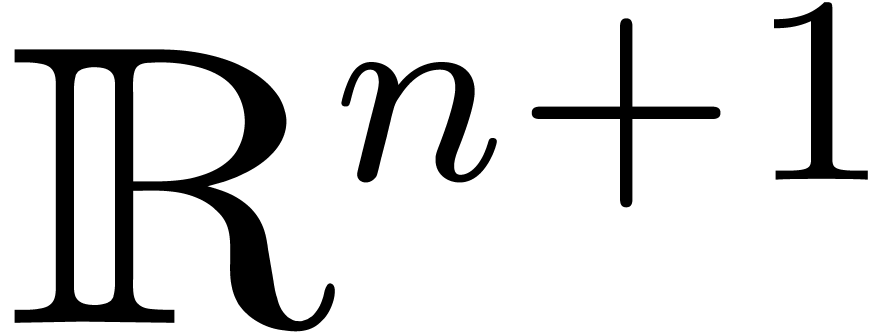 . The method we are to use is not
new, but combined with our fast algorithms of Section 5, we
obtain a new complexity bound, essentially (for fixed values of ) quadratic in terms of the size of
S .
. The method we are to use is not
new, but combined with our fast algorithms of Section 5, we
obtain a new complexity bound, essentially (for fixed values of ) quadratic in terms of the size of
S .
Besides the support of , we
need to introduce
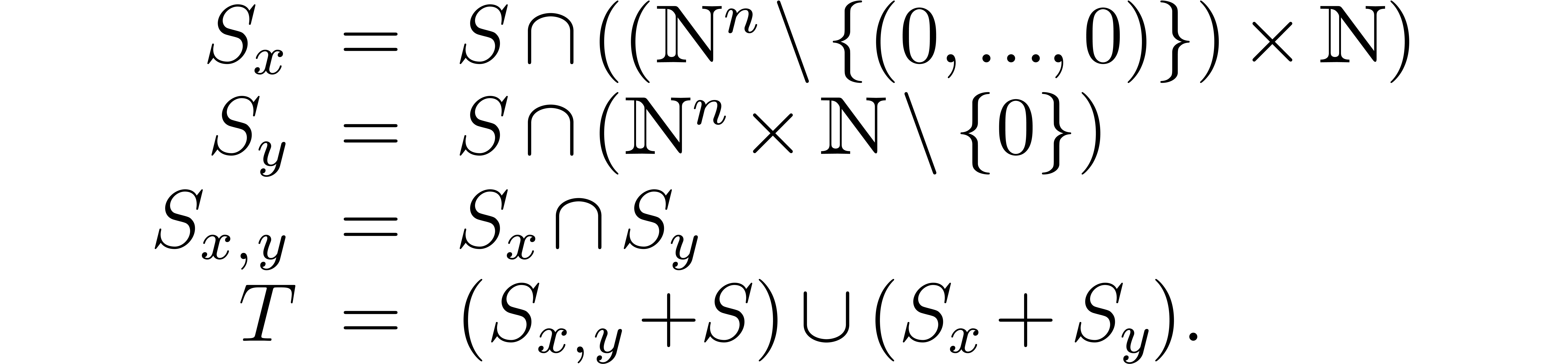
Notice that  consists of the elements
consists of the elements 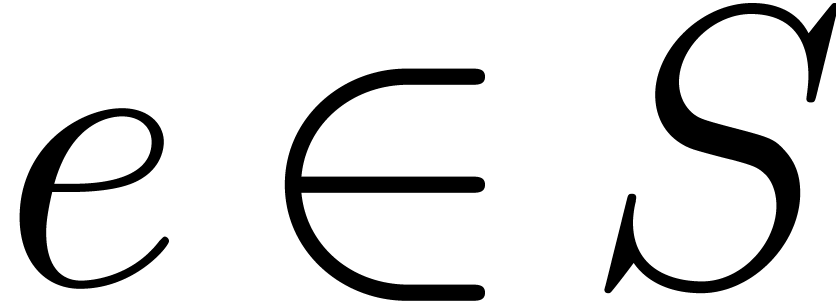 with
with  . The set
. The set
 contains the support of
contains the support of
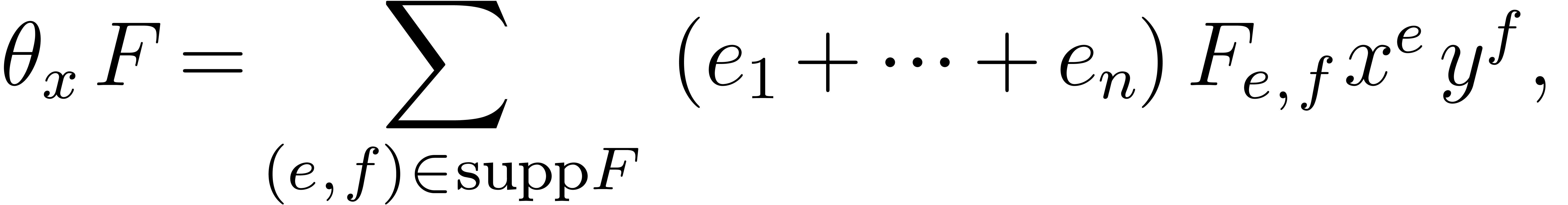
the set contains the support of
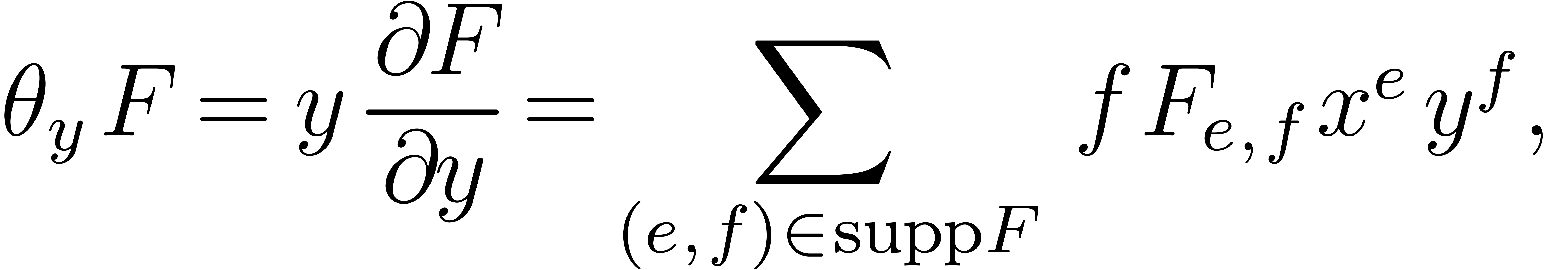
and 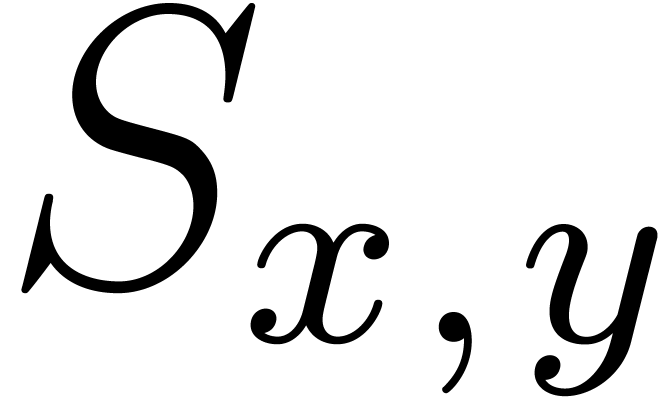 contains
contains 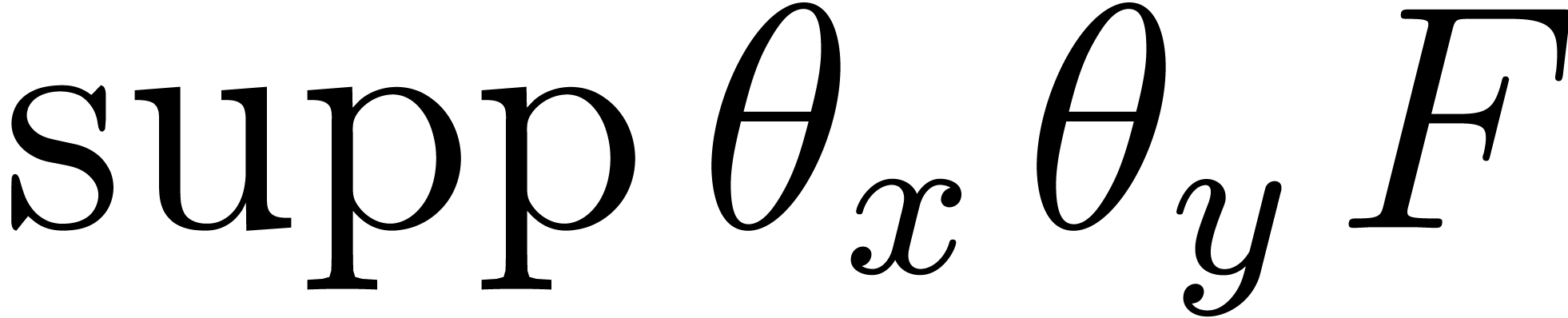 .
.
The absolute factorization of mainly reduces to
linear algebra by considering the following map:
where 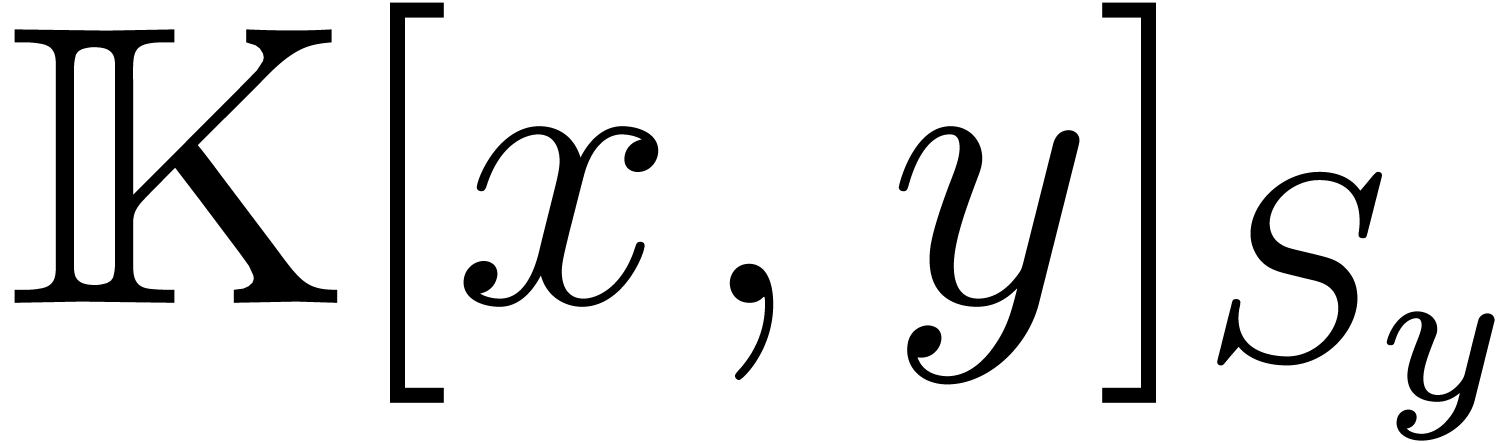 represents the subset of the polynomials
with support in (and similarly for , ,
and
represents the subset of the polynomials
with support in (and similarly for , ,
and  ).
).
has
characteristic 0 or at least 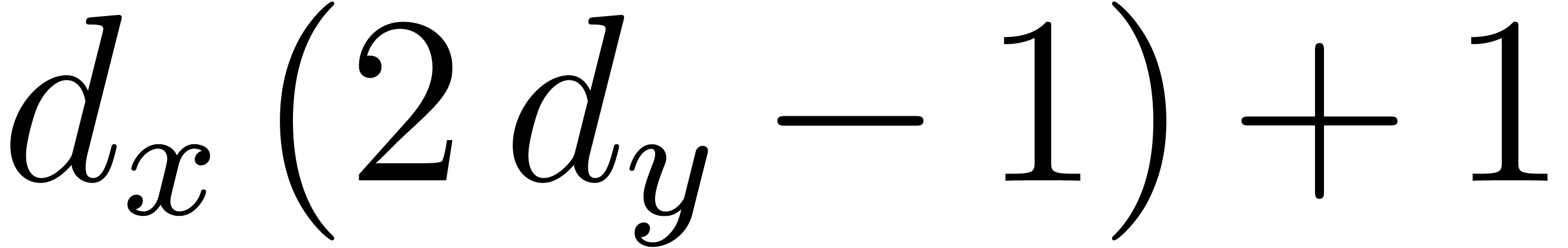 ,
that
,
that  is primitive in
is primitive in 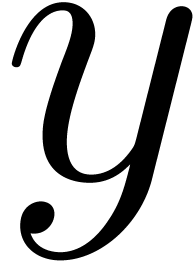 , and that the discriminant of
in is non-zero. Then the number of the
absolutely irreducible factors of equals the
dimension of the kernel of
, and that the discriminant of
in is non-zero. Then the number of the
absolutely irreducible factors of equals the
dimension of the kernel of 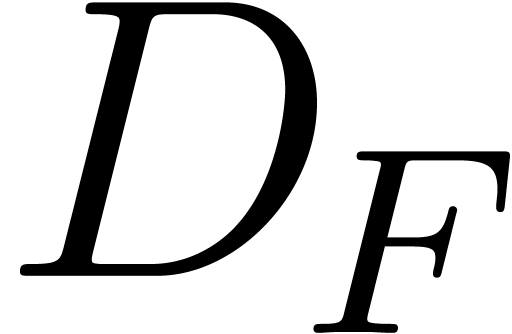 .
.
Proof. This result is not original, but for a
lack of an exact reference in the literature, we provide the reader with
a sketch of the proof adapted from the bivariate case. Let  represent the distinct roots of in
represent the distinct roots of in
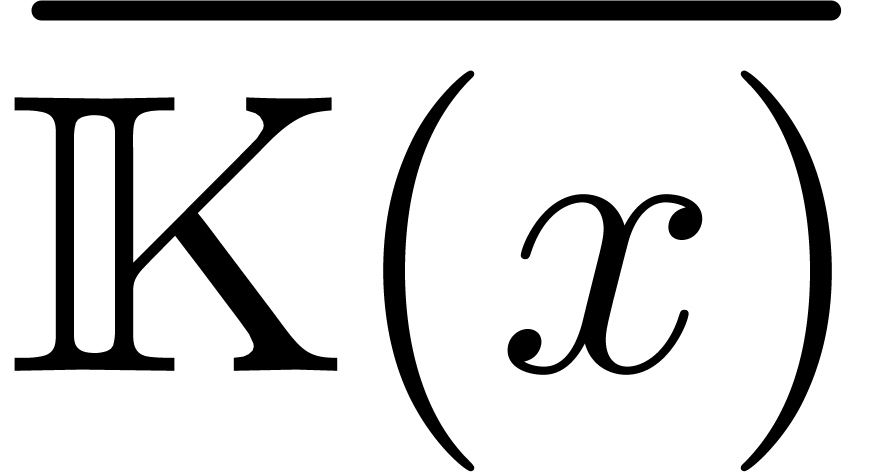 . The assumption on the
discriminant of ensures that all are simple. Now
consider the partial fraction decompositions of
. The assumption on the
discriminant of ensures that all are simple. Now
consider the partial fraction decompositions of 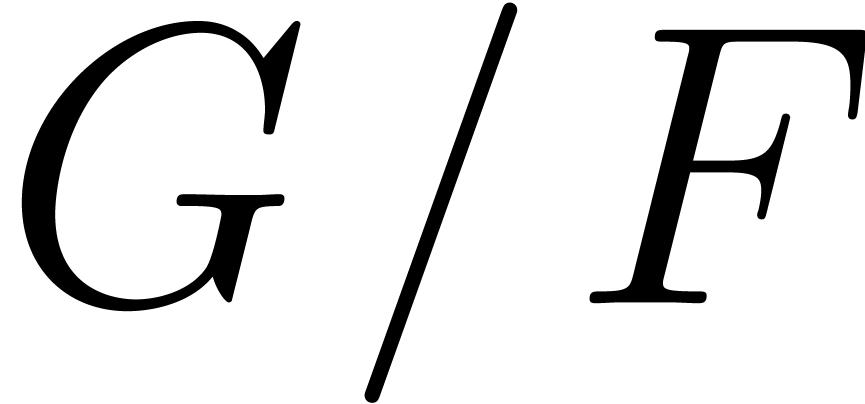 and
and  :
:
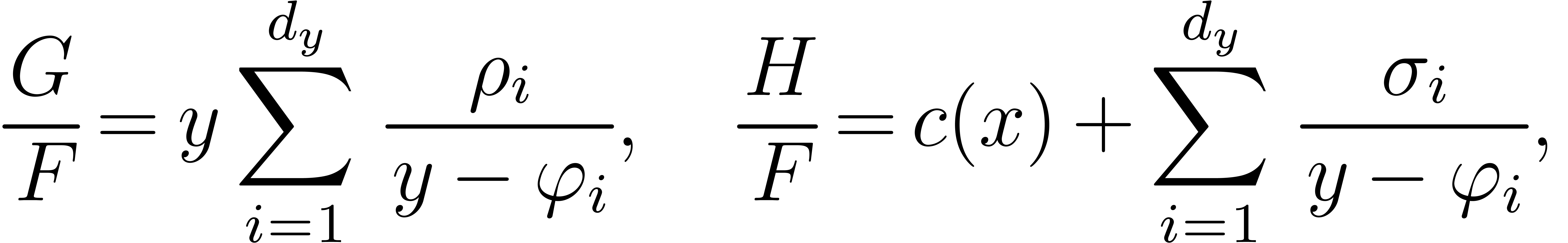
where  and
and 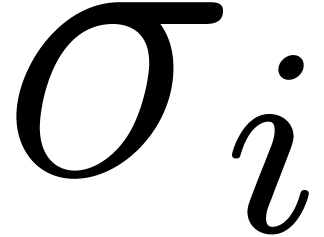 belong to and
belong to and 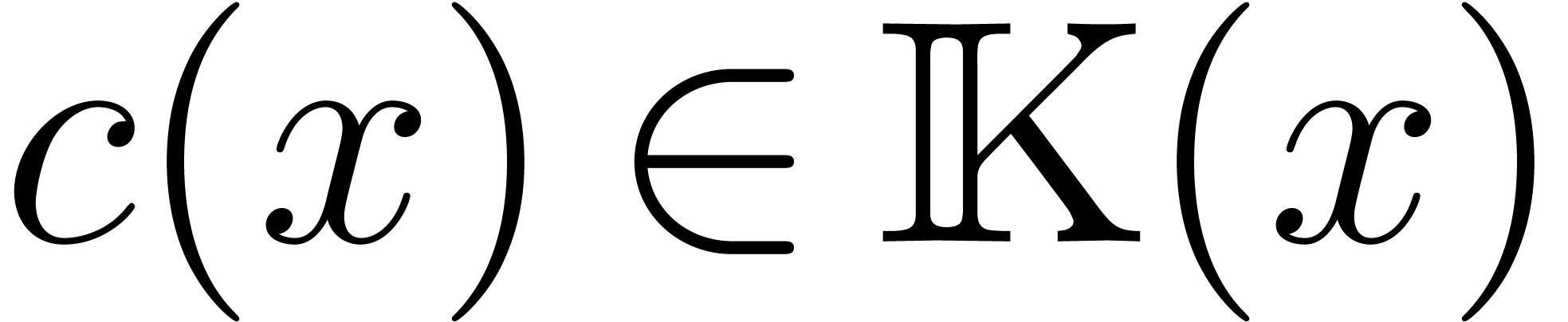 . The
fact that
. The
fact that 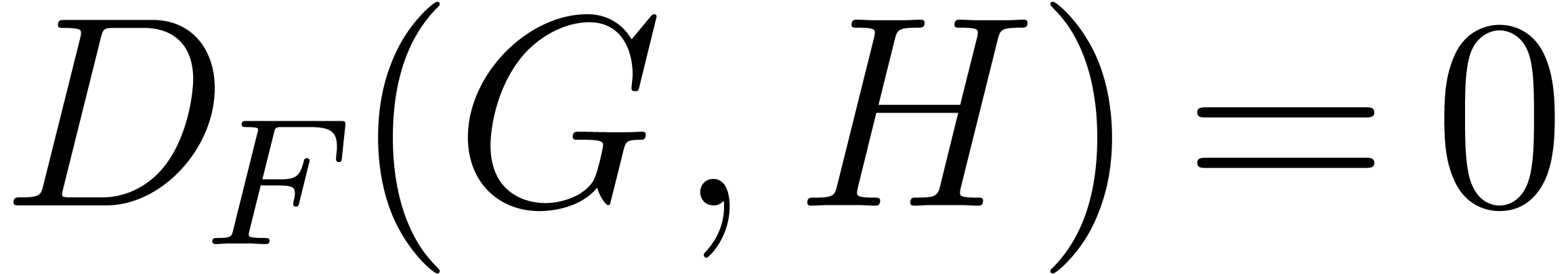 is equivalent to
is equivalent to
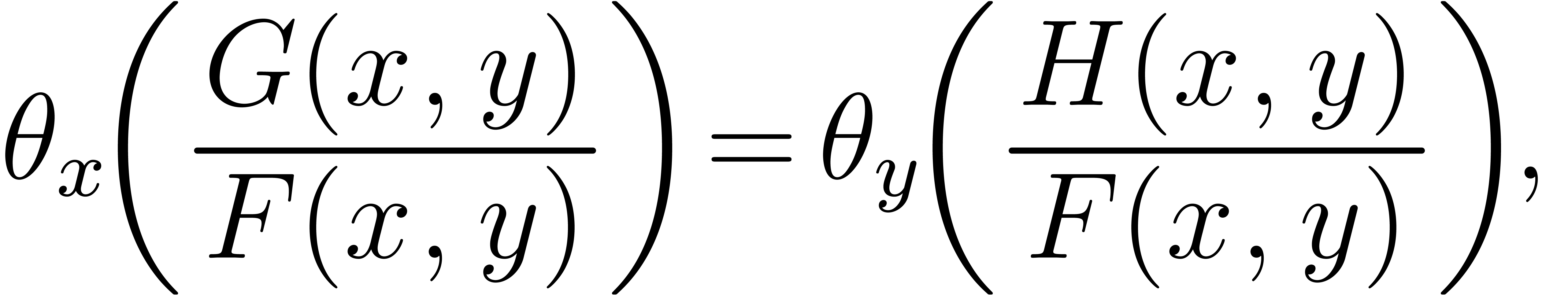
which rewrites into:
Therefore 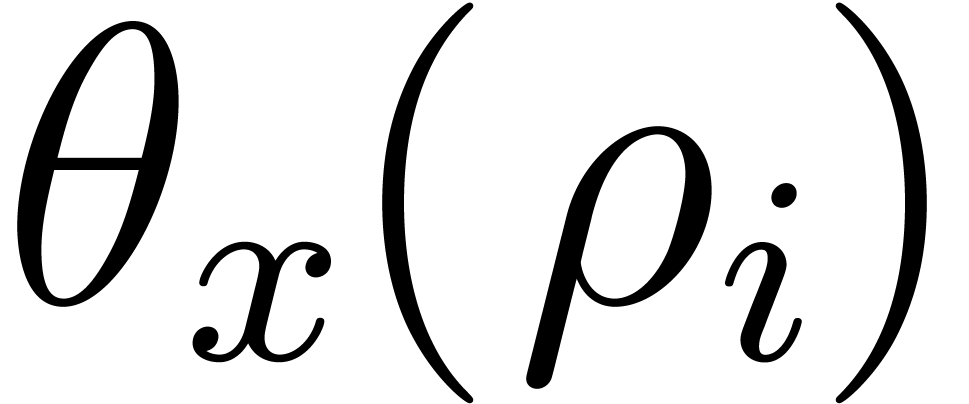 must vanish for all . In characteristic 0, this implies that the
actually belong to
must vanish for all . In characteristic 0, this implies that the
actually belong to  .
If the characteristic is least this still holds
by the same arguments as in Lemma 2.4 of [Gao03]. Let
.
If the characteristic is least this still holds
by the same arguments as in Lemma 2.4 of [Gao03]. Let  denote the absolutely irreducible factors of , and let
denote the absolutely irreducible factors of , and let 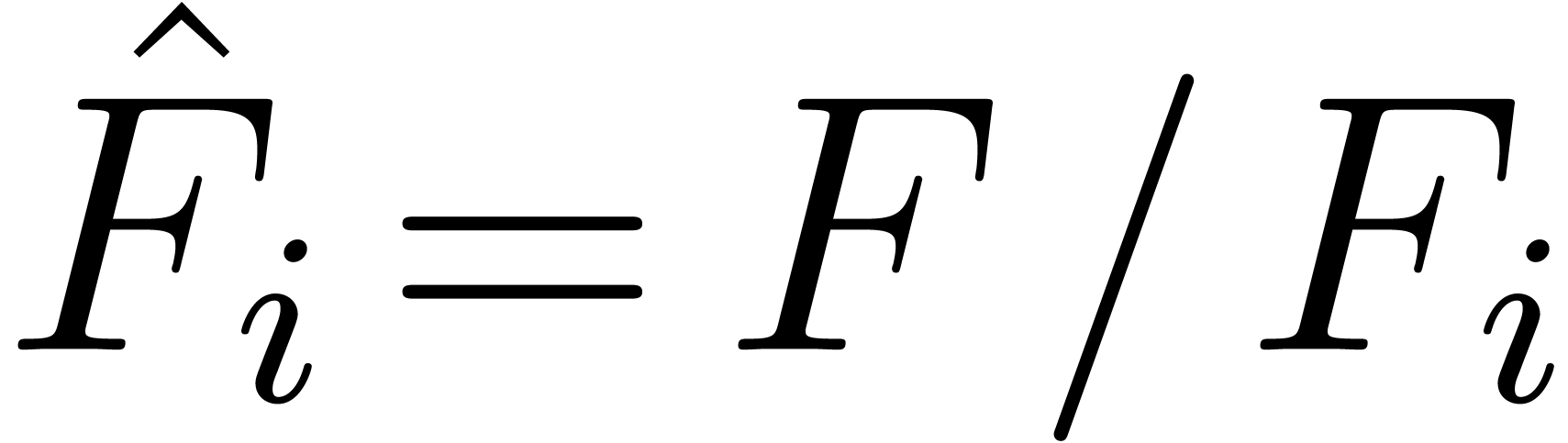 . By applying classical facts on partial fraction
decomposition, such as [GG02, Theorem 22.8] or [CL07,
Appendix A] for instance, we deduce that
. By applying classical facts on partial fraction
decomposition, such as [GG02, Theorem 22.8] or [CL07,
Appendix A] for instance, we deduce that  is a
linear combination of the
is a
linear combination of the 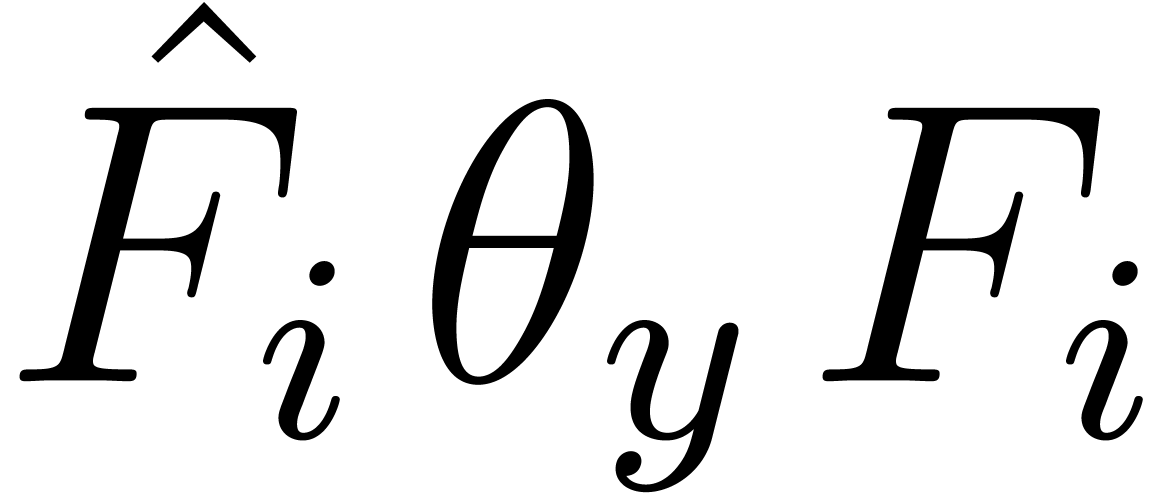 ,
hence that
,
hence that  belongs to the space spanned by the
belongs to the space spanned by the
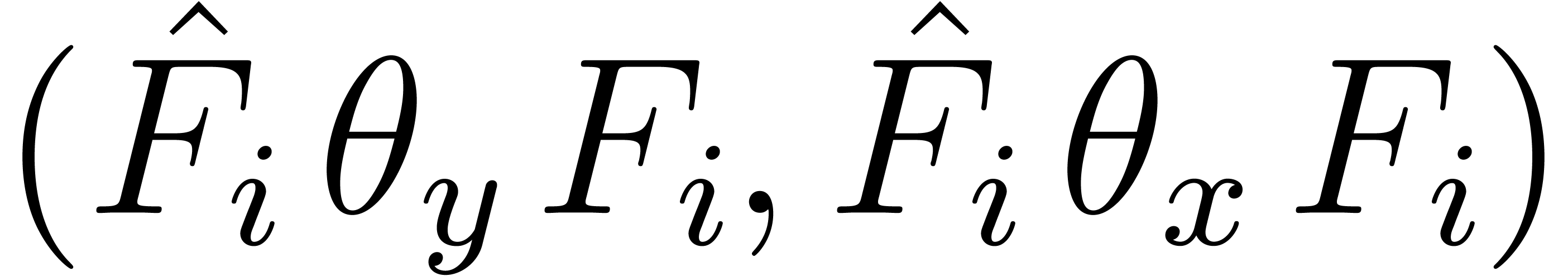 over ,
for
over ,
for 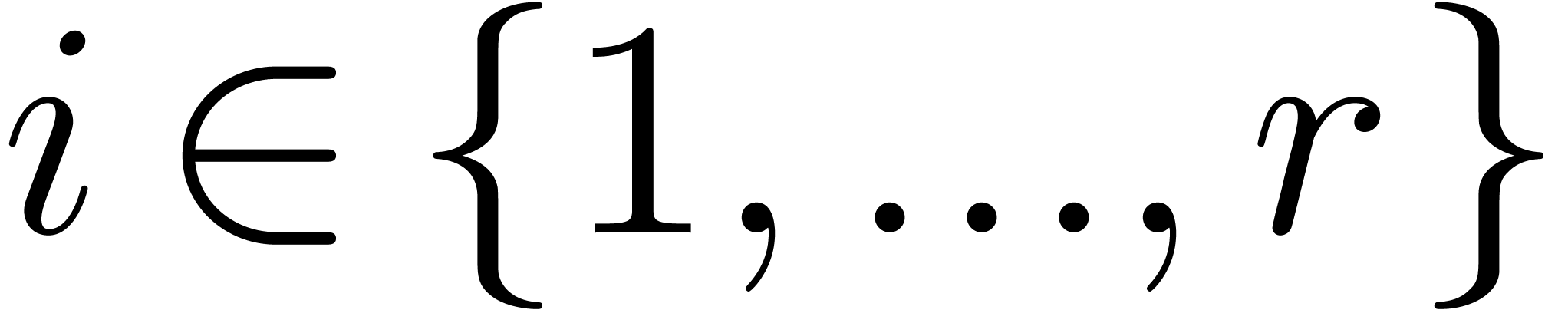 .
.
Since 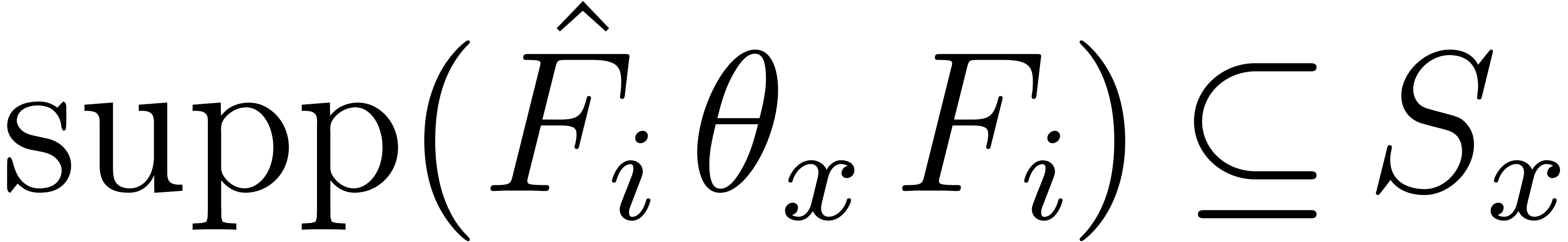 and
and 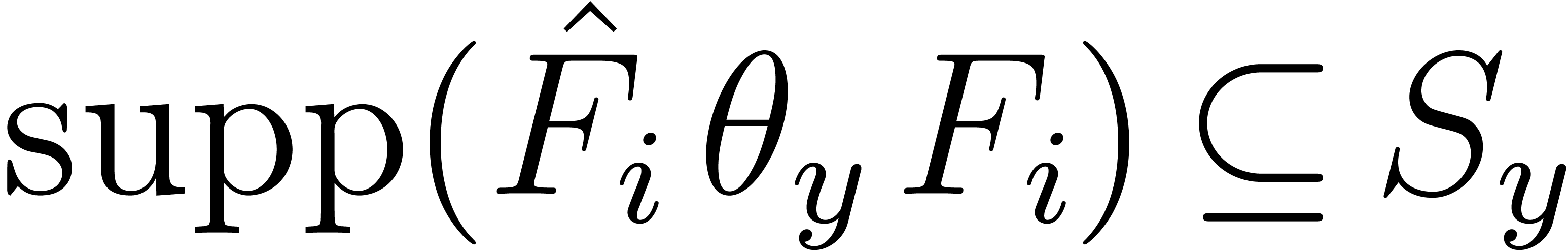 ,
the couples form a basis of the kernel of over ,
which concludes the proof.
,
the couples form a basis of the kernel of over ,
which concludes the proof.
Proposition 27 was first stated in [Gao03] in
the bivariate case for the dense representation of the polynomials, and
then in terms of the actual support of in [GR03] but still for two variables. For several variables and
block supports, generalizations have been proposed in [GKM+04,
Remark 2.3] but they require computing the partial derivatives in all
the variables separately, which yields more linear equations to be
solved than with the present approach. Let us recall that the kernel of
is nothing else than the first De Rham
cohomology group of the complementary of the hypersurface defined by
(this was pointed out in [Lec07],
we refer the reader to [Sha09] for the details).
For a complete history of the algorithms designed for the absolute
factorization we refer the reader to the introduction of [CL07].
In fact, the straightforward resolution of the linear system defined by
by Gaussian elimination requires 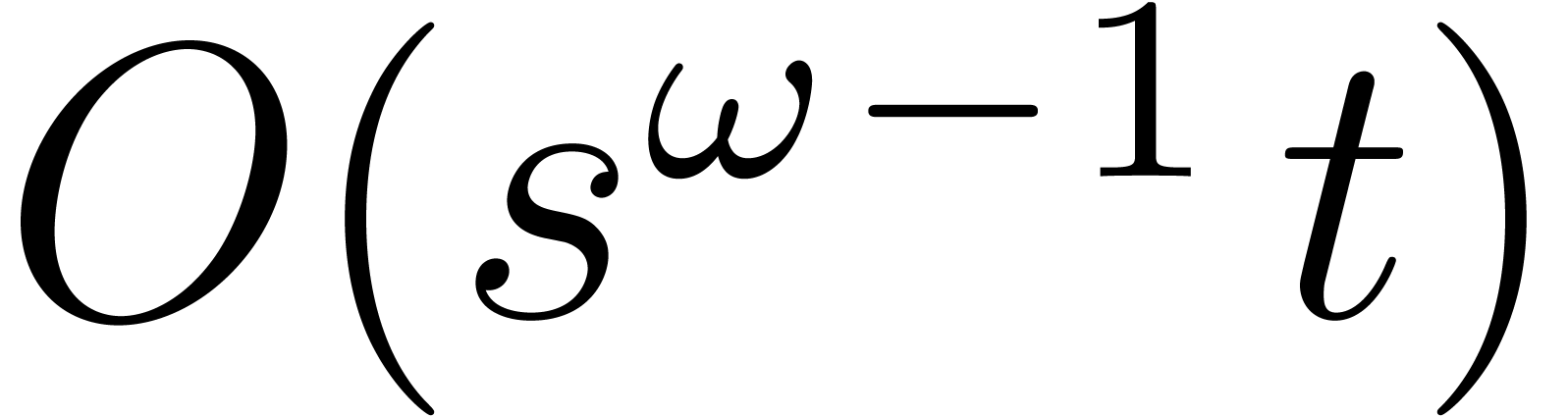 operations in ,
where
operations in ,
where 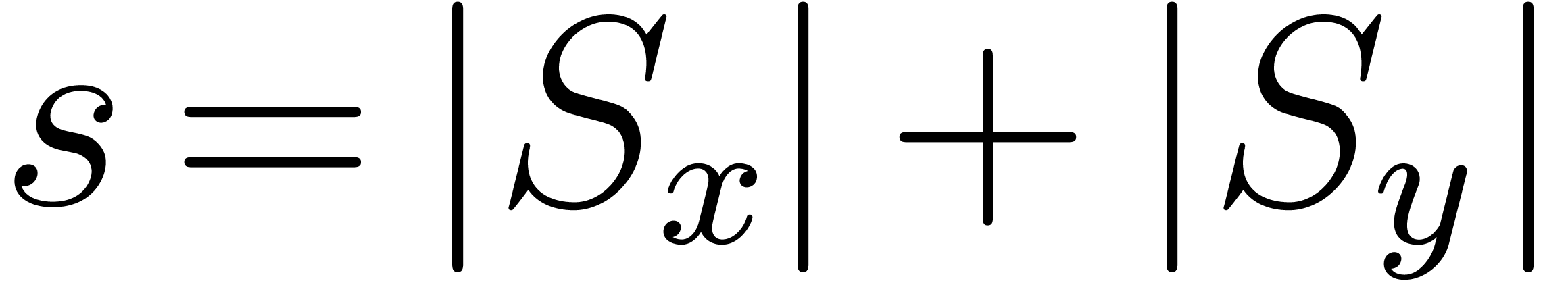 is the number of the unknowns and
is the number of the unknowns and 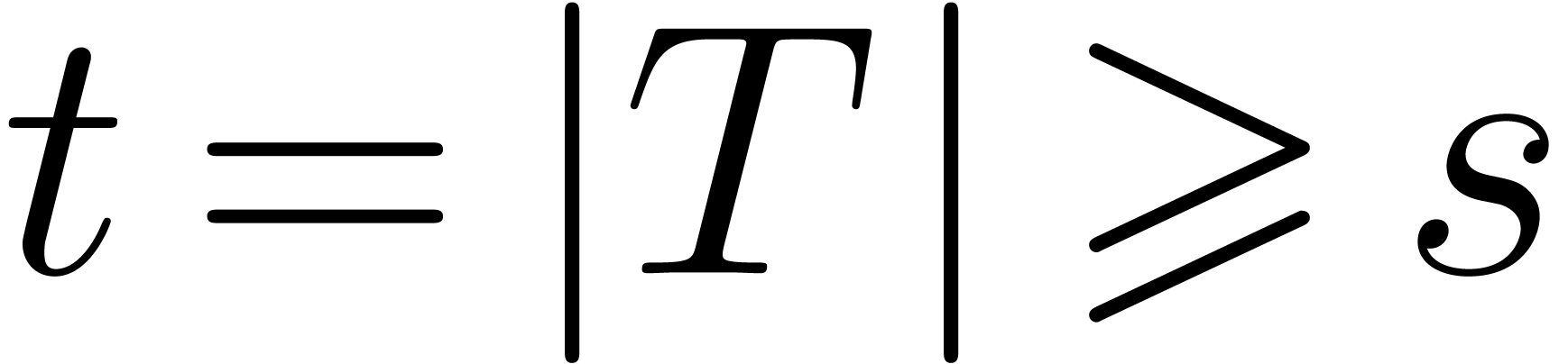 is the number of equations [Sto00,
Proposition 2.11]. Here is a real number at most
3 such that the product of two matrices of size
is the number of equations [Sto00,
Proposition 2.11]. Here is a real number at most
3 such that the product of two matrices of size  can be done with
can be done with  operations in . In practice is close
to
operations in . In practice is close
to  , so that Gaussian
elimination leads to a cost more than quadratic.
, so that Gaussian
elimination leads to a cost more than quadratic.
In [Gao03], Gao suggested to compute the kernel of using Wiedemann's algorithm: roughly speaking this
reduces to compute the image by of at most  vectors. With a block support, and for when the
dimension is fixed, the Kronecker substitution can be used so that a
softly quadratic cost can be achieved in this way. In the next
subsection we extend this idea for general supports by using the fast
polynomial product of Section 5.
vectors. With a block support, and for when the
dimension is fixed, the Kronecker substitution can be used so that a
softly quadratic cost can be achieved in this way. In the next
subsection we extend this idea for general supports by using the fast
polynomial product of Section 5.
The algorithm we propose for computing the number of the absolutely
irreducible factors of summarizes as follows:
.
Compute the integral hull of the support
of . Deduce , , ,
and .
Pre-compute all the intermediate data necessary to the
evaluation of by means of the fast
polynomial product of Section 5.
Compute the dimension of the kernel of
with the randomized algorithm of [KS91, Section 4],
all the necessary random values being taken in a given subset
 of .
of .
For simplicity, the following complexity analysis will not take into account the bit-cost involved by operations with the exponents and the supports.
has characteristic 0 or
at least , that is primitive in ,
that the discriminant of in
is non-zero, that we are given an element in
of order at least 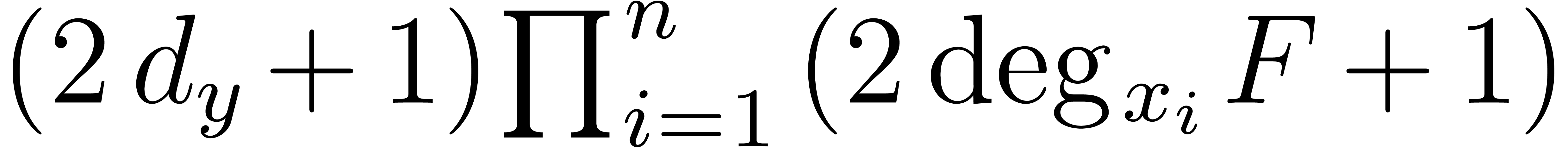 , and that the given set
, and that the given set  contains at least
contains at least 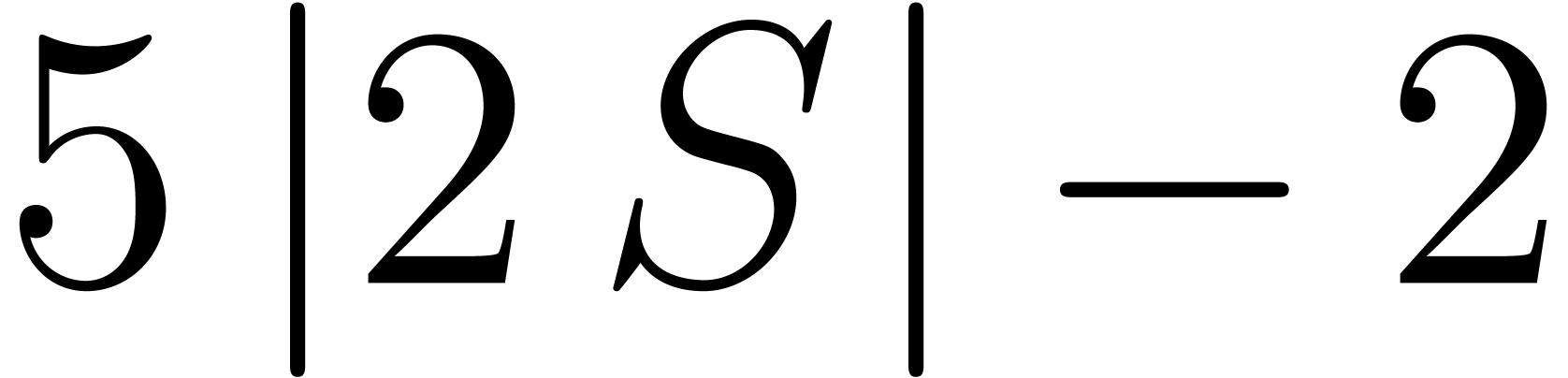 elements.
elements.
Then Algorithm 28 performs the computation of the
integral hull  of
of 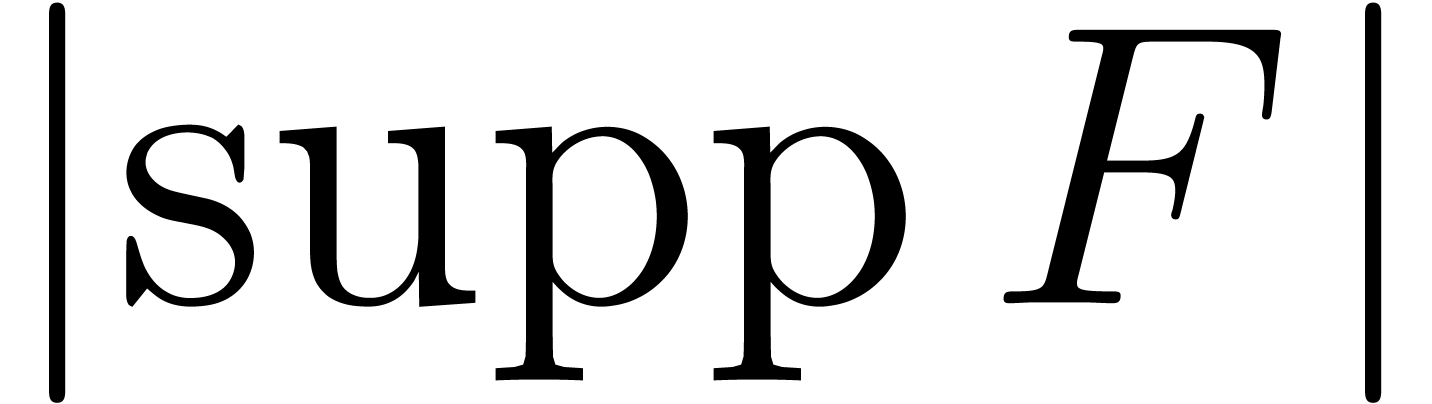 points of bit-size at most ,
plus the computation of
points of bit-size at most ,
plus the computation of  ,
plus
,
plus 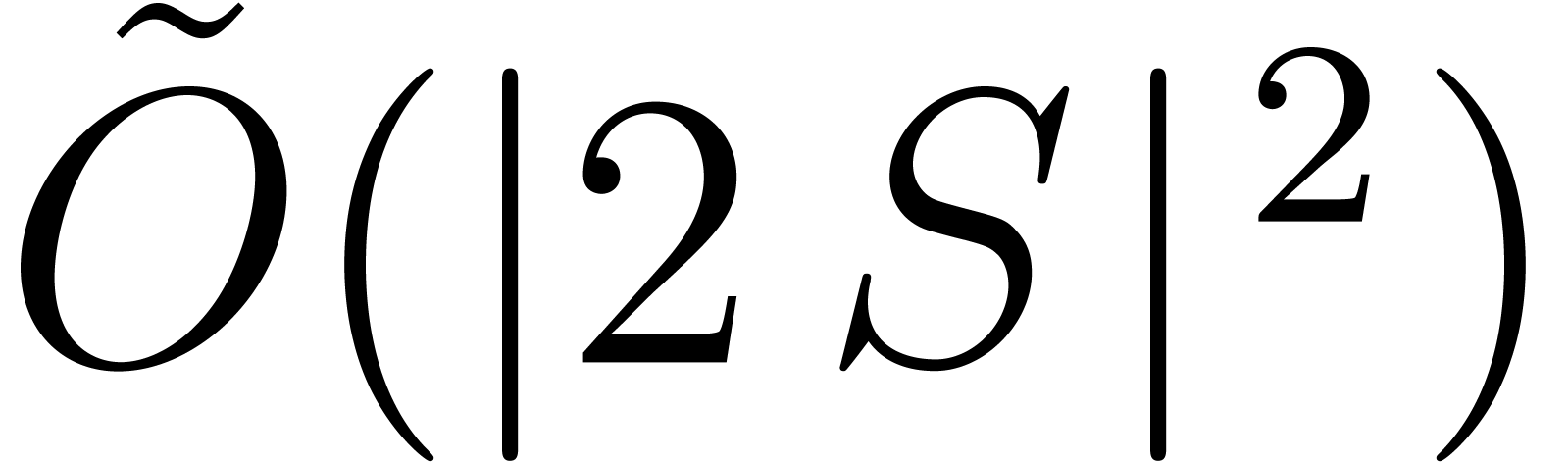 operations in . It returns a correct answer with a probability
at least
operations in . It returns a correct answer with a probability
at least 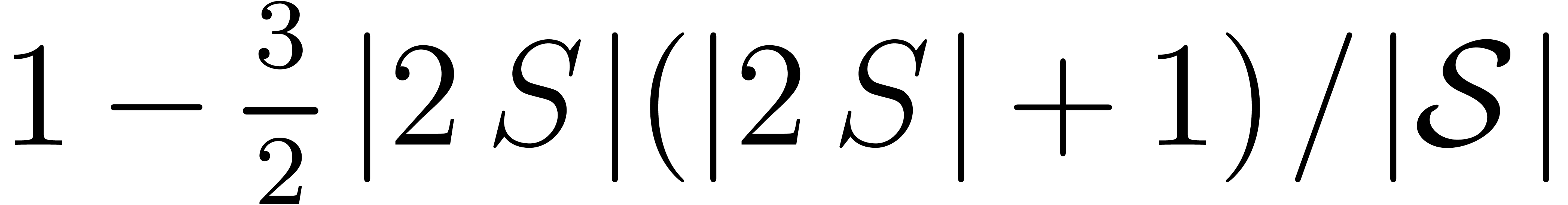 .
.
Proof. Since is included
in  , the assumption on the
order of allows us to apply Proposition 17.
In the second step, we thus compute all the necessary powers of to evaluate :
because the supports are convex, this only amounts to
, the assumption on the
order of allows us to apply Proposition 17.
In the second step, we thus compute all the necessary powers of to evaluate :
because the supports are convex, this only amounts to 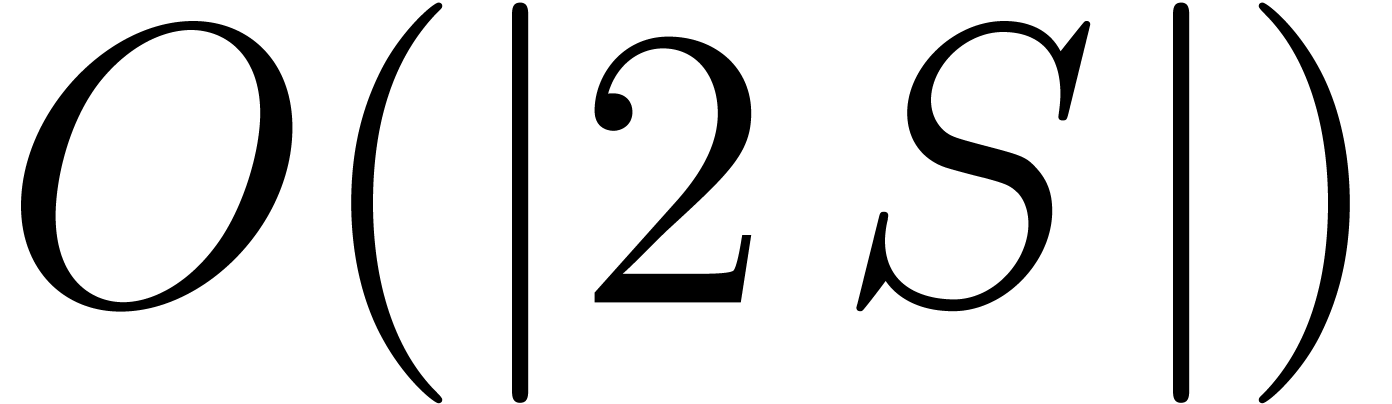 operations in . Then for any
couple
operations in . Then for any
couple 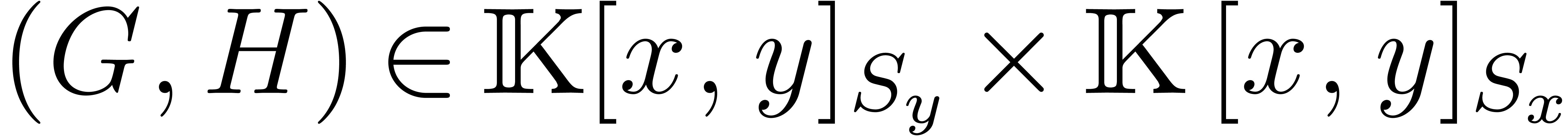 , the vector
, the vector 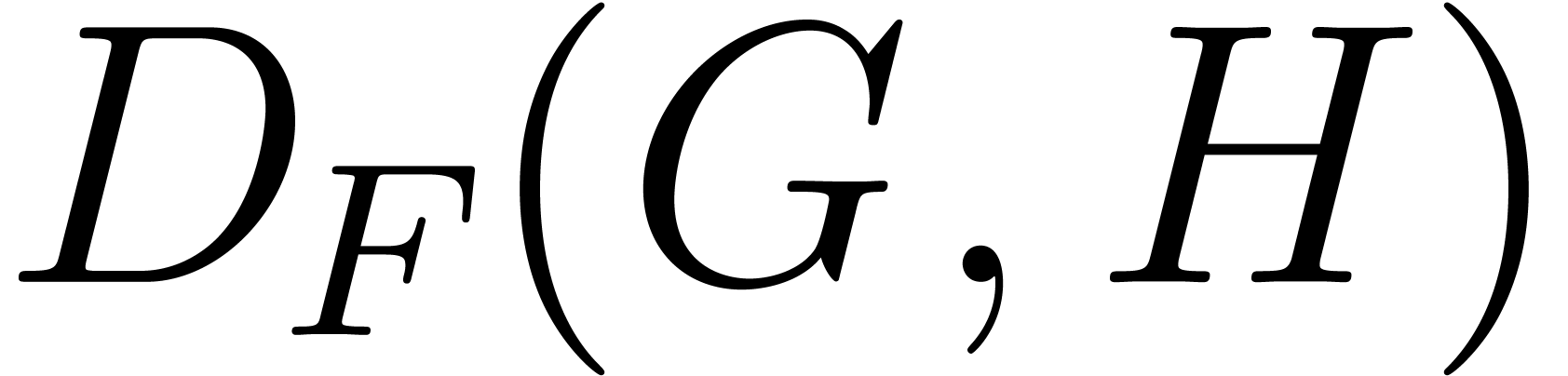 can be computed with
can be computed with 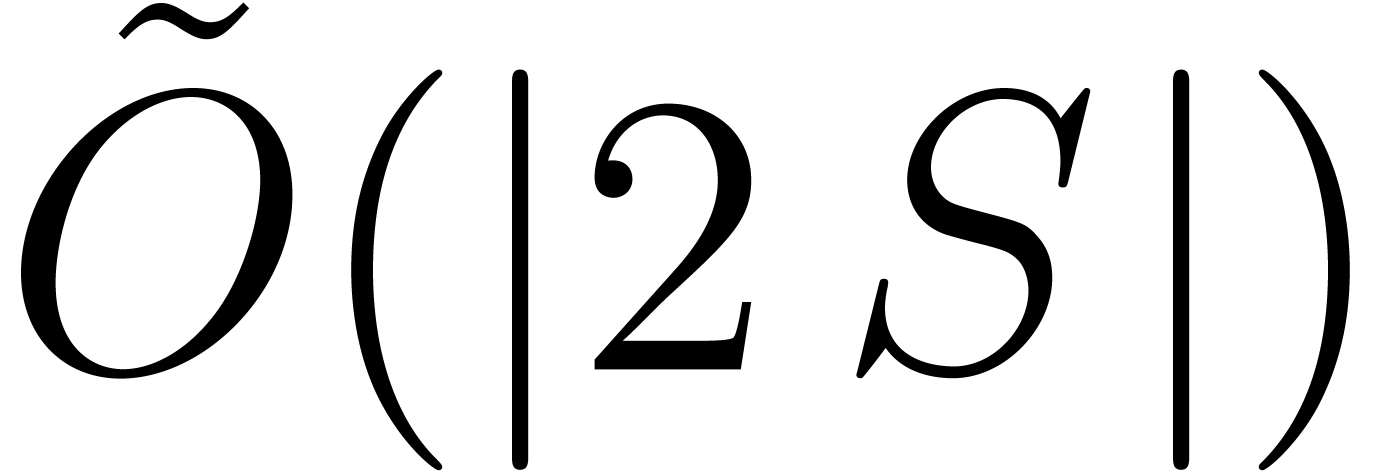 operations.
operations.
Now, by Theorem 3 of [KS91], we can chose
elements at random in and compute the dimension
of the kernel of with
evaluations of and 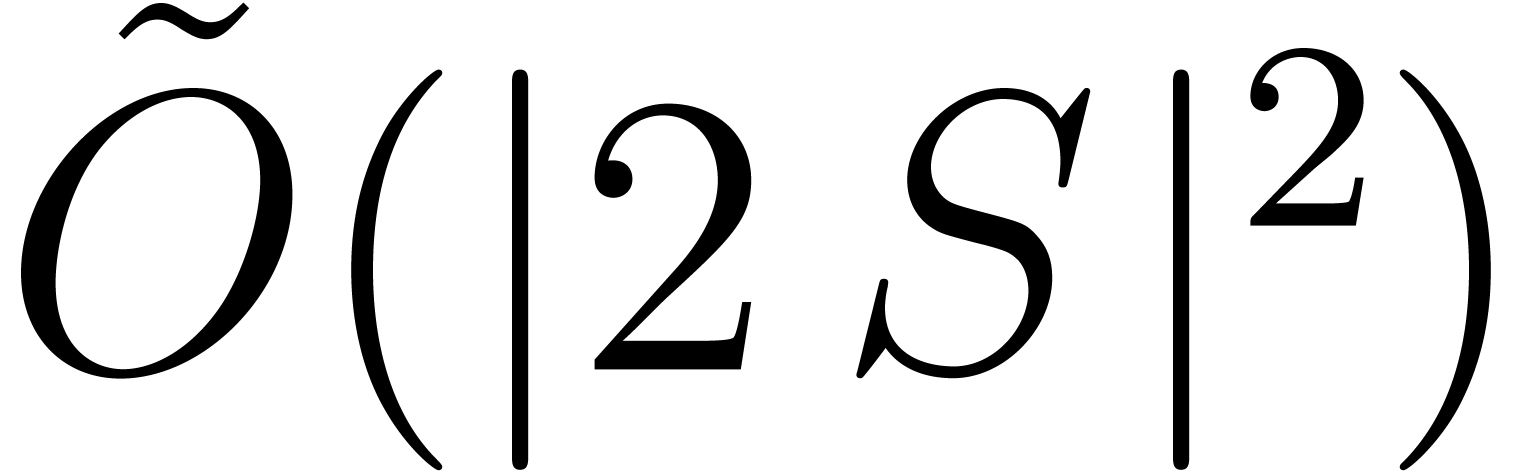 more
operations in . The
probability of success being at least ,
this concludes the proof.
more
operations in . The
probability of success being at least ,
this concludes the proof.
Once is known, the set
can be obtained by means of the naive polynomial product with 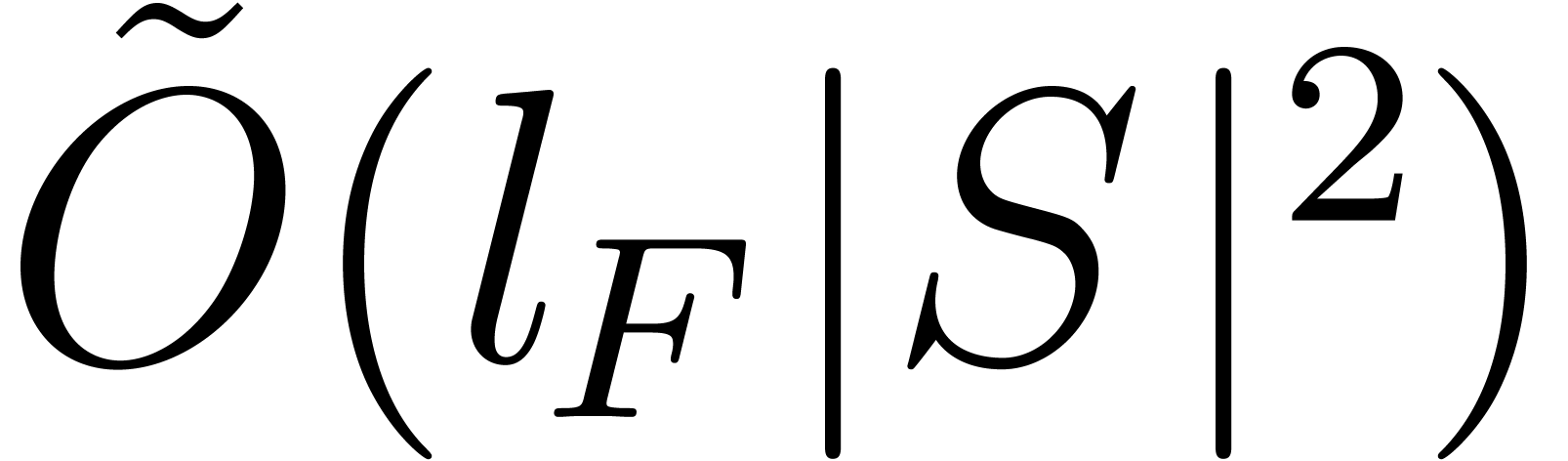 bit-operations by Proposition 10. When the
dimension is fixed and is non-degenerated then
bit-operations by Proposition 10. When the
dimension is fixed and is non-degenerated then
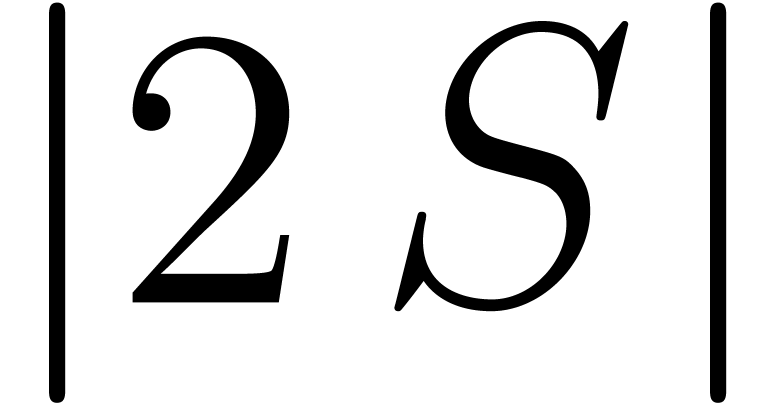 grows linearly with
grows linearly with  , whence our algorithm becomes softly quadratic in
, in terms of the number of
operations in . This new
complexity bound is to be compared to a recent algorithm by Weimann that
computes the irreducible factorization of a bivariate polynomial within
a cost that grows with
, whence our algorithm becomes softly quadratic in
, in terms of the number of
operations in . This new
complexity bound is to be compared to a recent algorithm by Weimann that
computes the irreducible factorization of a bivariate polynomial within
a cost that grows with 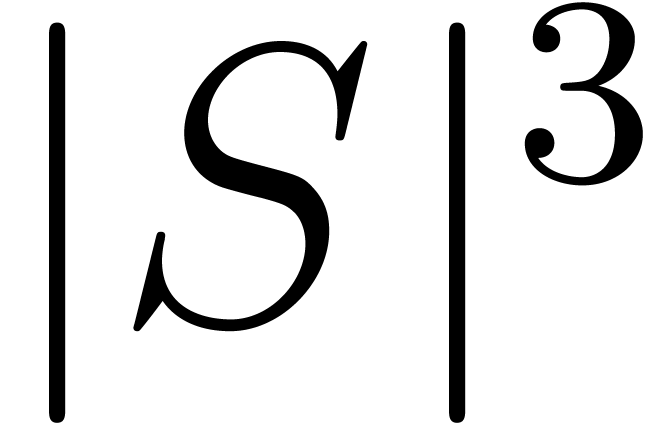 [Wei09a, Wei09b].
[Wei09a, Wei09b].
In practice, the computation of the integral hull is not negligible when
the dimension becomes large. The known algorithms for computing the
integral hull of start by computing the convex
hull. The latter problem is classical and can be solved in softly linear
time in dimensions 2 and 3 (see for instance [PS85]). In
higher dimensions, the size of the convex hull grows exponentially in
the worst case and it can be the bottleneck of our algorithm. With the
fastest known algorithms, the convex hull can be computed in time 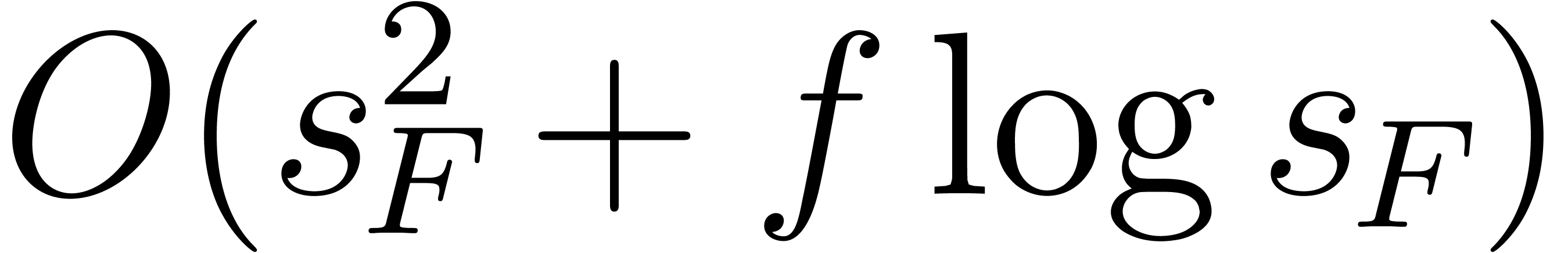 where is the number of faces
of the hull [Sei86] (improvements are to be found in [MS92]). In our implementation, we programmed the naive
“gift-wrapping” method, which turned out to be sufficient
for the examples below.
where is the number of faces
of the hull [Sei86] (improvements are to be found in [MS92]). In our implementation, we programmed the naive
“gift-wrapping” method, which turned out to be sufficient
for the examples below.
In order to enumerate the points with integer coordinates in the convex hull, we implemented a classical subdivision method. This turned out to be sufficient for our purposes. But let us mention that there exist specific and faster algorithms for this task such as in [Bar94b, Bar94a, LZ05] for instance. Discussing these aspects longer would lead us too far from the purposes of the present paper.
We chose the following family of examples in two variables, which
depends on a parameter  :
:
Here  are taken at random, with . In Table 11 below, we indicate
the size of ,
the size of the matrix , and
the time spent for computing the integral hull. Then we compare the time
taken by the Wiedemann method with the naive and the fast polynomial
products. As expected we observe a softly cubic cost with the naive
product, and a softly quadratic cost with the fast product. Notice that
the supports are rather sparse, so that Kronecker substitution does not
compete here.
are taken at random, with . In Table 11 below, we indicate
the size of ,
the size of the matrix , and
the time spent for computing the integral hull. Then we compare the time
taken by the Wiedemann method with the naive and the fast polynomial
products. As expected we observe a softly cubic cost with the naive
product, and a softly quadratic cost with the fast product. Notice that
the supports are rather sparse, so that Kronecker substitution does not
compete here.
|
||||||||||||||||||||||||||||||
The goal of these examples is less the absolute factorization problem
itself than the demonstration of the usefulness of the fast polynomial
product on a real application. Let us finally mention that the algorithm
with the smallest asymptotic cost, given in [CL07], will
not gain on our family 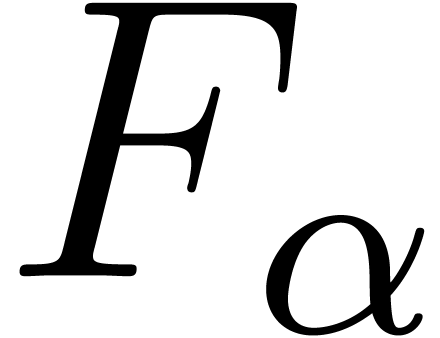 ,
because it starts with performing a random linear change of the
variables. To the best of our knowledge, no other software is able to
run the present examples faster.
,
because it starts with performing a random linear change of the
variables. To the best of our knowledge, no other software is able to
run the present examples faster.
We have presented classical and new algorithms for multiplying polynomials and series in several variables with a special focus on asymptotic complexity. It turns out that the new algorithms lead to substantial speed-ups in specific situations, but are not competitive in a general manner. Of course, the fast algorithms involve many subalgorithms, which make them harder to optimize. With an additional implementation effort, some of the thresholds in our tables might become more favourable for the new algorithms.
In our implementation, all the variants are available independently from one to another, but they can also be combined with given thresholds. This allows the user to finetune the software whenever it is known whether the polynomials are rather dense (which occur if a random change of the variables is done for instance), strictly sparse, etc. In the near future, we hope to extend the present techniques to the division and higher level operations such as the g.c.d. and polynomial factorization.
M. Agrawal, N. Kayal, and N. Saxena. PRIMES is in P. Annals of Mathematics, 160(2):781–793, 2004.
A. I. Barvinok. Computing the Ehrhart polynomial of a convex lattice polytope. Discrete Comput. Geom., 12(1):35–48, 1994.
A. I. Barvinok. A polynomial time algorithm for counting integral points in polyhedra when the dimension is fixed. Math. Oper. Res., 19(4):769–779, 1994.
P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic complexity theory. Springer-Verlag, 1997.
D. Bernstein. The transposition principle. Available
from
http://cr.yp.to/transposition.html.
A. Bostan, G. Lecerf, and É. Schost. Tellegen's principle into practice. In Proceedings of ISSAC 2003, pages 37–44. ACM, 2003.
A. Borodin and R.T. Moenck. Fast modular transforms via division. In Thirteenth annual IEEE symposium on switching and automata theory, pages 90–96, Univ. Maryland, College Park, Md., 1972.
A. Borodin and R.T. Moenck. Fast modular transforms. Journal of Computer and System Sciences, 8:366–386, 1974.
J. L. Bordewijk. Inter-reciprocity applied to electrical networks. Applied Scientific Research B: Electrophysics, Acoustics, Optics, Mathematical Methods, 6:1–74, 1956.
D. Bini and V. Pan. Polynomial and matrix computations (vol. 1): fundamental algorithms. Birkhauser, 1994.
J. Buchmann and V. Shoup. Constructing nonresidues in finite fields and the extended Riemann hypothesis. In STOC '91: Proceedings of the twenty-third annual ACM symposium on Theory of computing, pages 72–79, New York, NY, USA, 1991. ACM.
M. Ben-Or and P. Tiwari. A deterministic algorithm for sparse multivariate polynomial interpolation. In STOC '88: Proceedings of the twentieth annual ACM symposium on Theory of computing, pages 301–309, New York, NY, USA, 1988. ACM.
S. Czapor, K. Geddes, and G. Labahn. Algorithms for Computer Algebra. Kluwer Academic Publishers, 1992.
D. G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28:693–701, 1991.
J. Canny, E. Kaltofen, and Y. Lakshman. Solving systems of non-linear polynomial equations faster. In Proc. ISSAC '89, pages 121–128, Portland, Oregon, A.C.M., New York, 1989. ACM Press.
G. Chèze and G. Lecerf. Lifting and recombination techniques for absolute factorization. J. Complexity, 23(3):380–420, 2007.
H. Cramér. On the order of magnitude of the difference between consecutive prime numbers. Acta Arithmetica, 2:23–46, 1936.
J.W. Cooley and J.W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
J. H. Davenport, Y. Siret, and É. Tournier. Calcul formel : systèmes et algorithmes de manipulations algébriques. Masson, Paris, France, 1987.
R. Fateman. Comparing the speed of programs for sparse polynomial multiplication. SIGSAM Bull., 37(1):4–15, 2003.
M. Fürer. Faster integer multiplication. In Proceedings of the Thirty-Ninth ACM Symposium on Theory of Computing (STOC 2007), pages 57–66, San Diego, California, 2007.
S. Gao. Factoring multivariate polynomials via partial differential equations. Math. Comp., 72(242):801–822, 2003.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, 2-nd edition, 2002.
D. Y. Grigoriev and M. Karpinski. The matching problem for bipartite graphs with polynomially bounded permanents is in NC. In Proceedings of the 28th IEEE Symposium on the Foundations of Computer Science, pages 166–172, 1987.
S. Gao, E. Kaltofen, J. May, Z. Yang, and L. Zhi. Approximate factorization of multivariate polynomials via differential equations. In ISSAC '04: Proceedings of the 2004 international symposium on Symbolic and algebraic computation, pages 167–174, New York, NY, USA, 2004. ACM.
D. Y. Grigoriev, M. Karpinski, and M. F. Singer. Fast parallel algorithms for sparse multivariate polynomial interpolation over finite fields. SIAM J. Comput., 19(6):1059–1063, 1990.
D. Grigoriev, M. Karpinski, and M. F. Singer. Computational complexity of sparse rational interpolation. SIAM J. Comput., 23(1):1–11, 1994.
M. Gastineau and J. Laskar. Development of TRIP: Fast sparse multivariate polynomial multiplication using burst tries. In Proceedings of ICCS 2006, LNCS 3992, pages 446–453. Springer, 2006.
S. Gao and V. M. Rodrigues. Irreducibility of
polynomials modulo via Newton polytopes.
J. Number Theory, 101(1):32–47, 2003.
T. Granlund et al. GMP, the GNU multiple precision
arithmetic library.
http://gmplib.org,
1991.
S. Garg and É. Schost. Interpolation of polynomials given by straight-line programs. Theoretical Computer Science, 410(27-29):2659–2662, 2009.
J. van der Hoeven et al. Mathemagix, 2002. http://www.mathemagix.org.
J. van der Hoeven and G. Lecerf. Divide and conquer products for multivariate polynomial and series. Work in progress, 2010.
J. van der Hoeven. Relax, but don't be too lazy. J. Symbolic Comput., 34:479–542, 2002.
J. van der Hoeven. The truncated Fourier transform and applications. In J. Gutierrez, editor, Proc. ISSAC 2004, pages 290–296, Univ. of Cantabria, Santander, Spain, July 4–7 2004.
J. van der Hoeven. Newton's method and FFT trading. Technical Report 2006-17, Univ. Paris-Sud, 2006. To appear in JSC.
G. H. Hardy and E. M. Wright. An introduction to the theory of numbers. Oxford University Press, 1979.
S. C. Johnson. Sparse polynomial arithmetic. SIGSAM Bull., 8(3):63–71, 1974.
E. Kaltofen and Y. N. Lakshman. Improved sparse multivariate polynomial interpolation algorithms. In ISSAC '88: Proceedings of the international symposium on Symbolic and algebraic computation, pages 467–474. Springer Verlag, 1988.
E. Kaltofen, W. Lee, and A. A. Lobo. Early termination in Ben-Or/Tiwari sparse interpolation and a hybrid of Zippel's algorithm. In ISSAC '00: Proceedings of the 2000 international symposium on Symbolic and algebraic computation, pages 192–201, New York, NY, USA, 2000. ACM.
E. Kaltofen, Y. N. Lakshman, and J.-M. Wiley. Modular rational sparse multivariate polynomial interpolation. In ISSAC '90: Proceedings of the international symposium on Symbolic and algebraic computation, pages 135–139, New York, NY, USA, 1990. ACM.
E. Kaltofen and B. D. Saunders. On Wiedemann's method of solving sparse linear systems. In H. F. Mattson, T. Mora, and T. R. N. Rao, editors, Proceedings of AAECC-9, volume 539 of Lect. Notes Comput. Sci., pages 29–38. Springer-Verlag, 1991.
E. Kaltofen and B. M. Trager. Computing with polynomials given by black boxes for their evaluations: greatest common divisors, factorization, separation of numerators and denominators. J. Symbolic Comput., 9(3):301–320, 1990.
G. Lecerf. Improved dense multivariate polynomial factorization algorithms. J. Symbolic Comput., 42(4):477–494, 2007.
G. Lecerf and É. Schost. Fast multivariate power series multiplication in characteristic zero. SADIO Electronic Journal on Informatics and Operations Research, 5(1):1–10, September 2003.
J. B. Lasserre and E. S. Zeron. An alternative algorithm for counting lattice points in a convex polytope. Math. Oper. Res., 30(3):597–614, 2005.
K. Makino and M. Berz. Remainder differential algebras and their applications. In M. Berz, C. Bischof, G. Corliss, and A. Griewank, editors, Computational differentiation: techniques, applications and tools, pages 63–74, SIAM, Philadelphia, 1996.
K. Makino and M. Berz. Suppression of the wrapping effect by Taylor model-based validated integrators. Technical Report MSU Report MSUHEP 40910, Michigan State University, 2004.
M. Monagan and R. Pearce. Polynomial division using dynamic arrays, heaps, and packed exponent vectors. In Proc. of CASC 2007, pages 295–315. Springer, 2007.
M. Monagan and R. Pearce. Parallel sparse polynomial multiplication using heaps. In ISSAC '09: Proceedings of the 2009 international symposium on Symbolic and algebraic computation, pages 263–270, New York, NY, USA, 2009. ACM.
M. Monagan and R. Pearce. Sparse polynomial multiplication and division in Maple 14. Available from http://www.cecm.sfu.ca/CAG/products2009.shtml, 2009.
J. Matoušek and O. Schwarzkopf. Linear optimization queries. In SCG '92: Proceedings of the eighth annual symposium on Computational geometry, pages 16–25, New York, NY, USA, 1992. ACM.
G. I. Malaschonok and E. S. Satina. Fast multiplication and sparse structures. Programming and Computer Software, 30(2):105–109, 2004.
F. P. Preparata and M. I. Shamos. Computational Geometry: An Introduction. Springer-Verlag, 1985.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Informatica, 7:395–398, 1977.
R. Seidel. Constructing higher-dimensional convex hulls at logarithmic cost per face. In STOC '86: Proceedings of the eighteenth annual ACM symposium on Theory of computing, pages 404–413, New York, NY, USA, 1986. ACM.
D. Shanks. On maximal gaps between successive primes. Math. Comp., 18(88):646–651, 1964.
H. Shaker. Topology and factorization of polynomials. Math. Scand., 104(1):51–59, 2009.
A. Schönhage and V. Strassen. Schnelle Multiplikation grosser Zahlen. Computing, 7:281–292, 1971.
D. R. Stoutmeyer. Which polynomial representation is best? In Proceedings of the 1984 MACSYMA Users' Conference: Schenectady, New York, July 23–25, 1984, pages 221–243, 1984.
A. Storjohann. Algorithms for matrix canonical forms. PhD thesis, ETH, Zürich, Switzerland, 2000.
V. Strassen. Die Berechnungskomplexität von elementarsymmetrischen Funktionen und von Interpolationskoeffizienten. Numer. Math., 20:238–251, 1973.
M. Weimann. Algebraic osculation and factorization of sparse polynomials. Available from http://arxiv.org/abs/0904.0178, 2009.
M. Weimann. A lifting and recombination algorithm for rational factorization of sparse polynomials. Available from http://arxiv.org/abs/0912.0895, 2009.
K. Werther. The complexity of sparse polynomial interpolation over finite fields. Appl. Algebra Engrg. Comm. Comput., 5(2):91–103, 1994.
T. Yan. The geobucket data structure for polynomials. J. Symbolic Comput., 25(3):285–293, 1998.
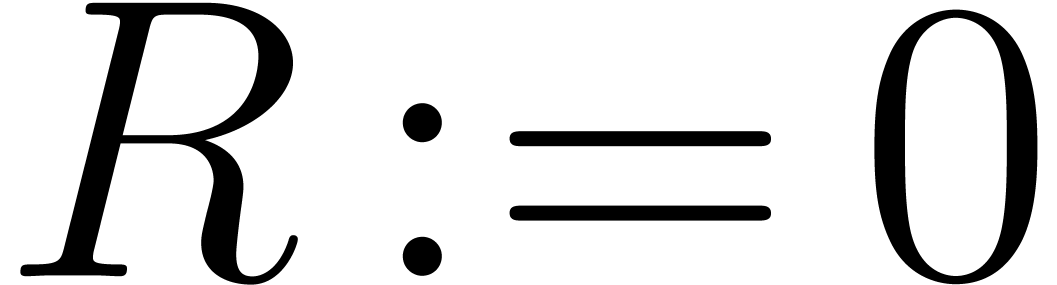
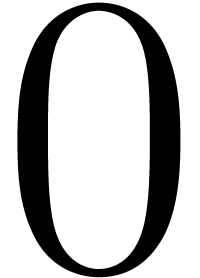 to
to 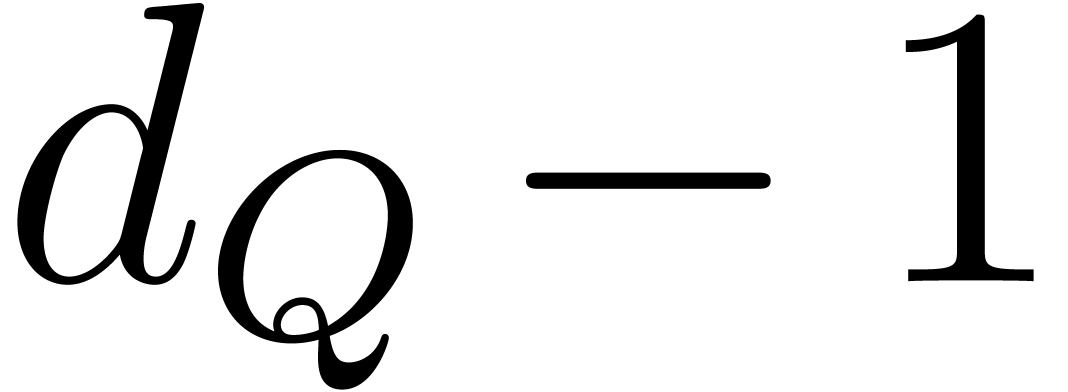 do:
do:
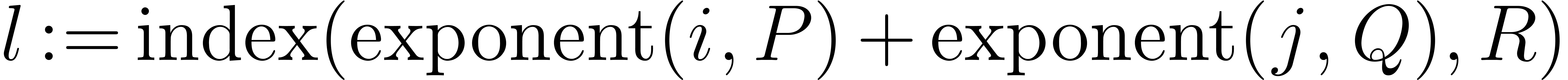 ;
;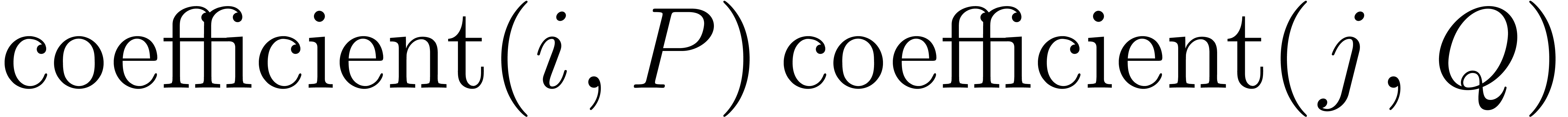 to
to  ;
;
 ,
,
 ,
, ,
,
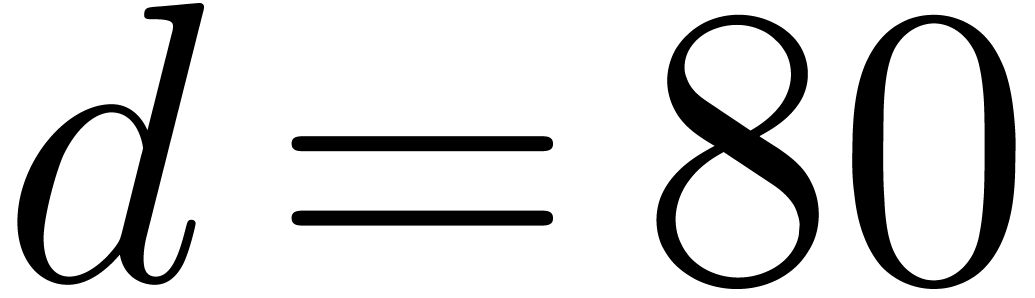
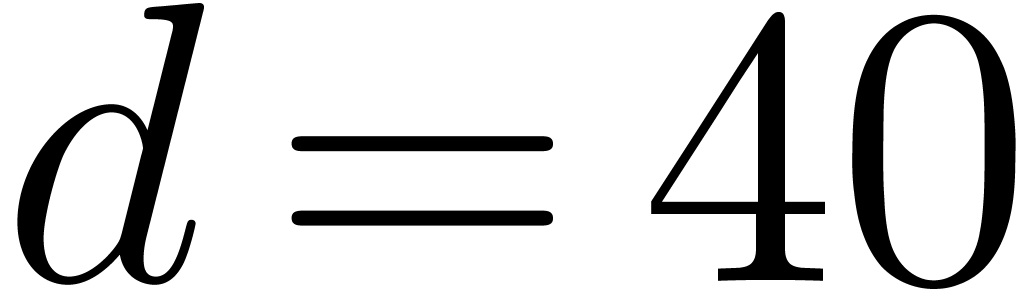
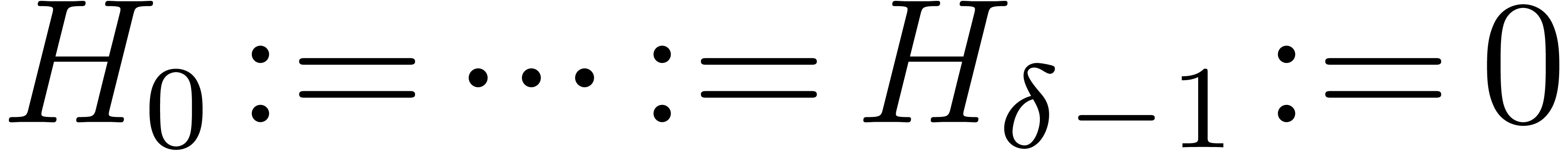 .
.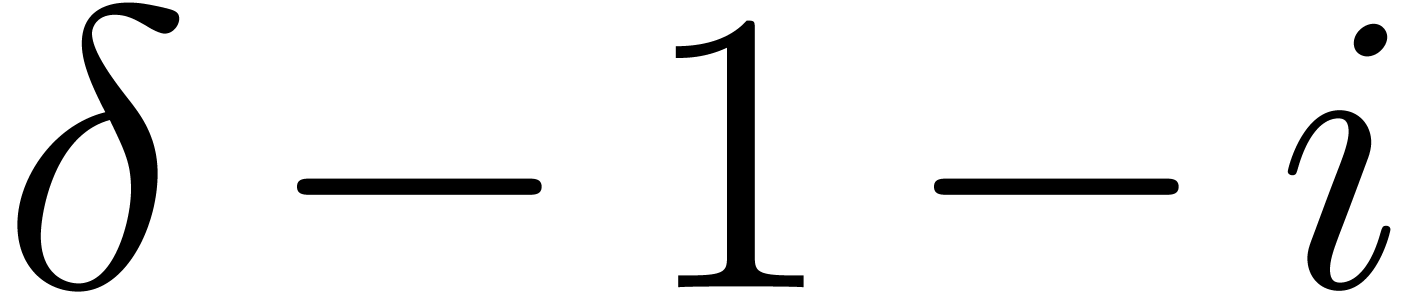 do
do
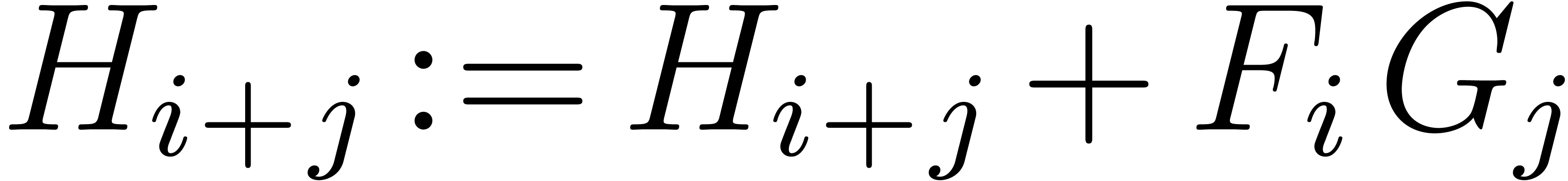 .
.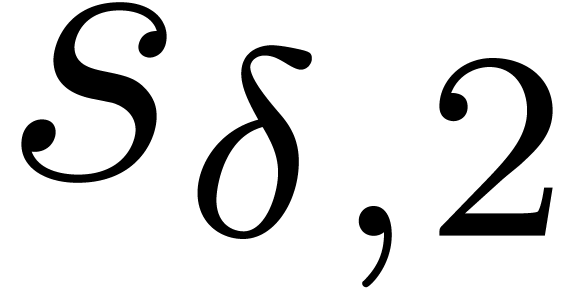
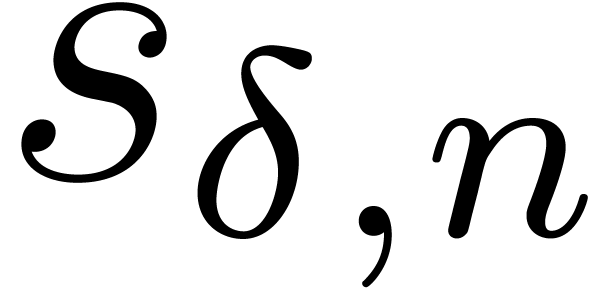
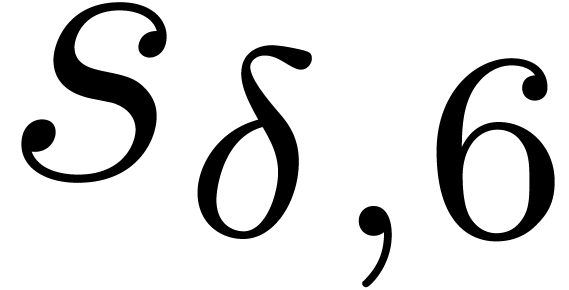
 to
to