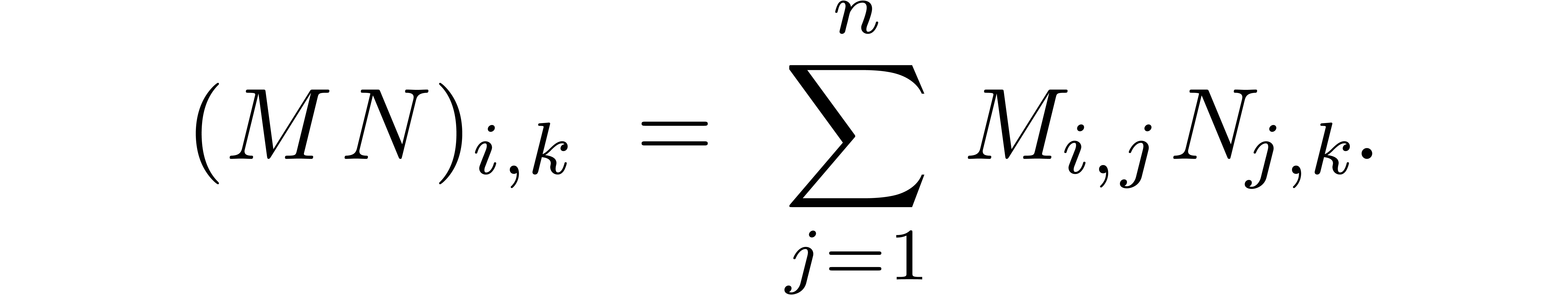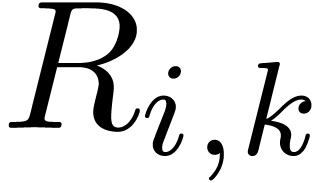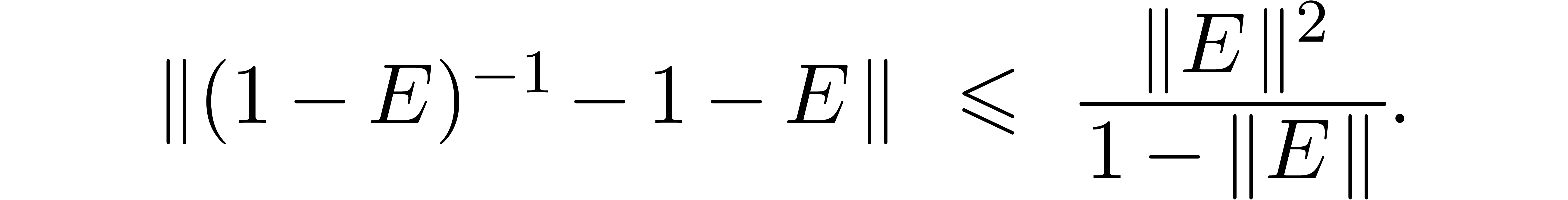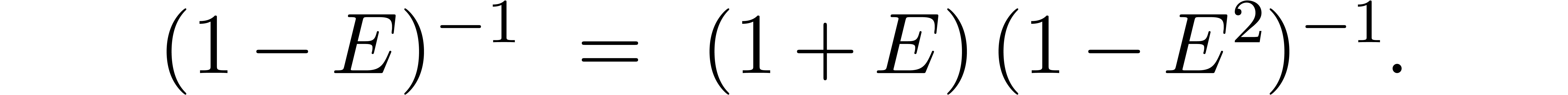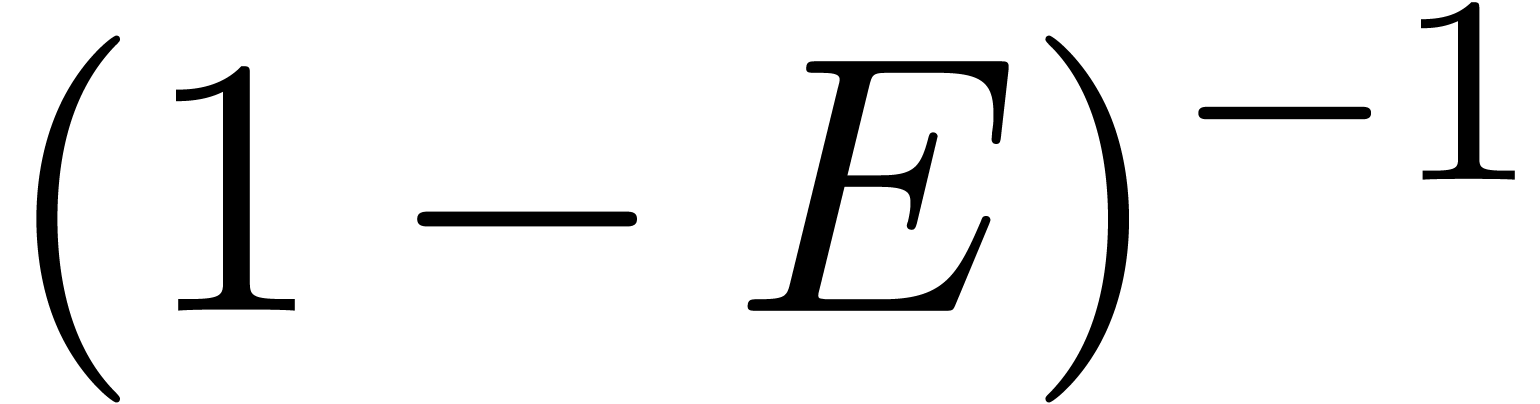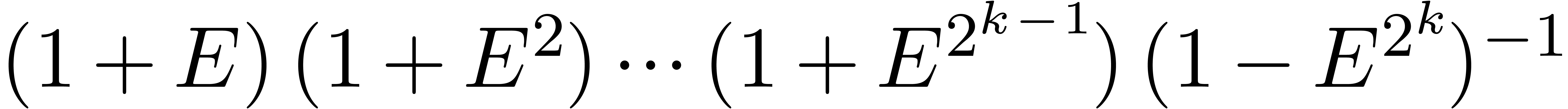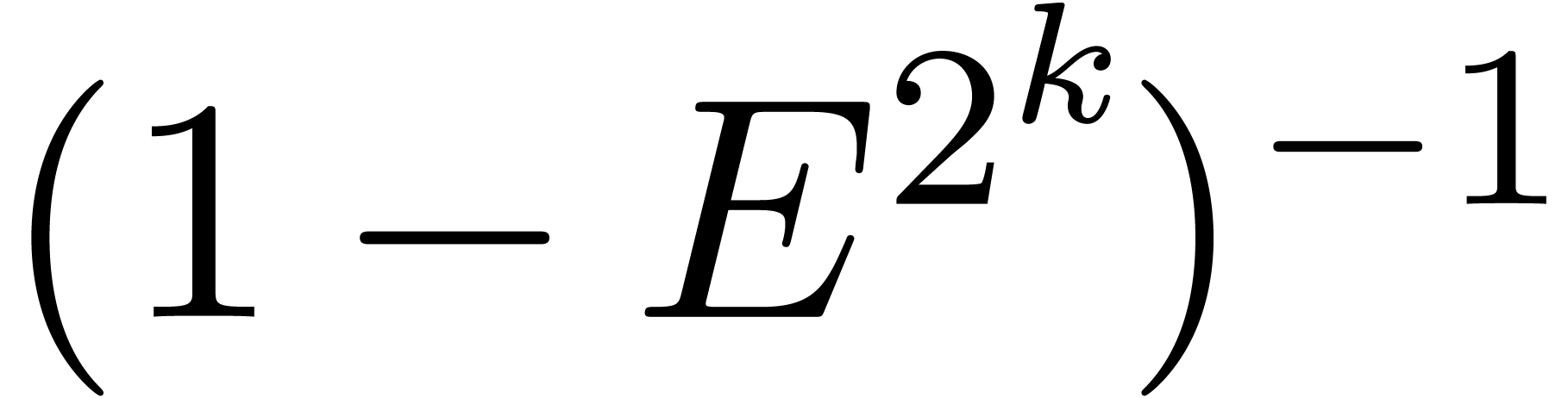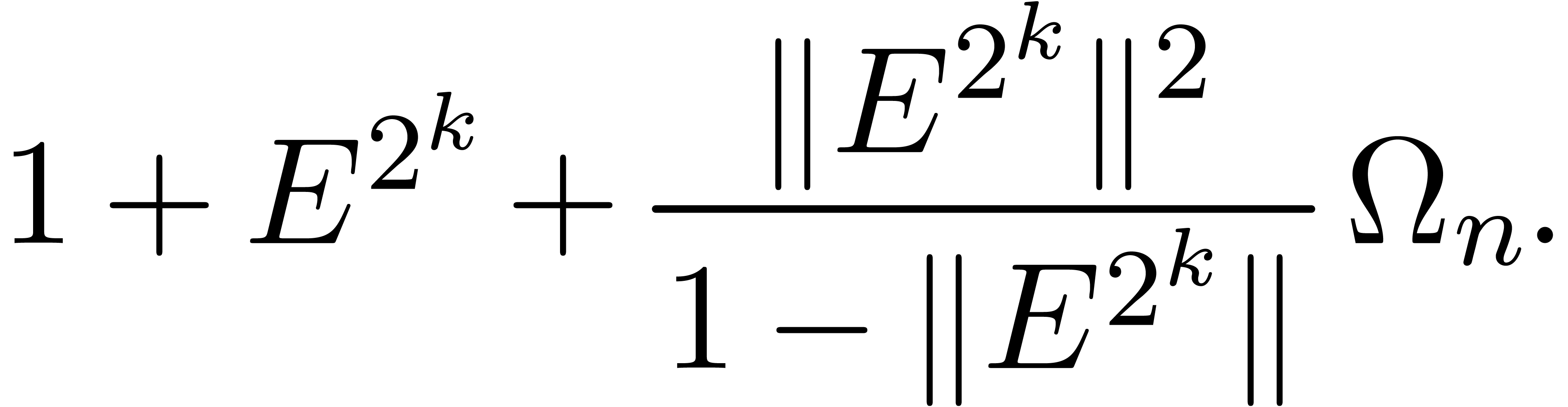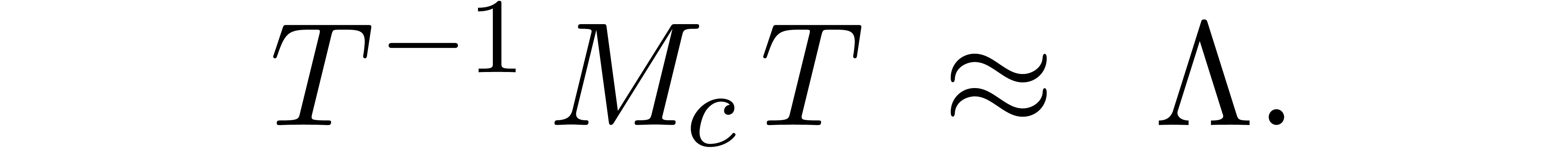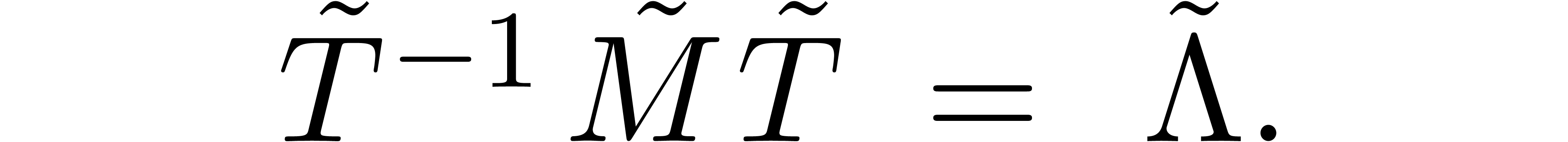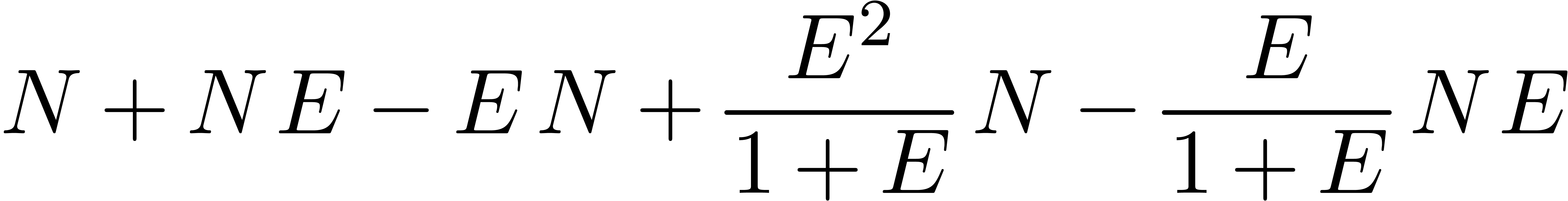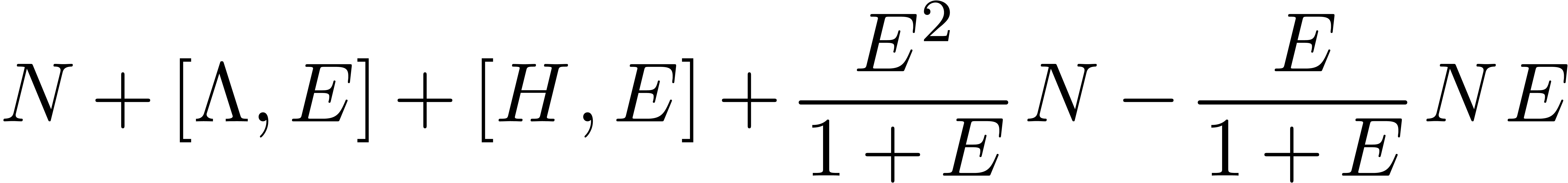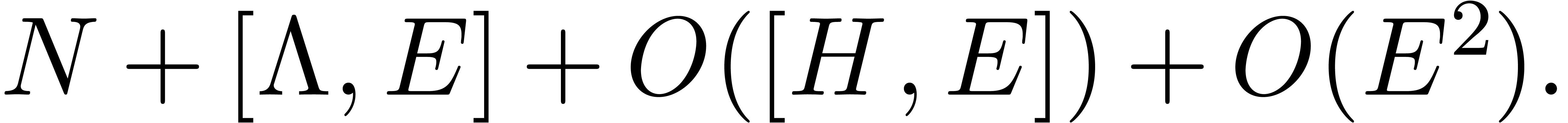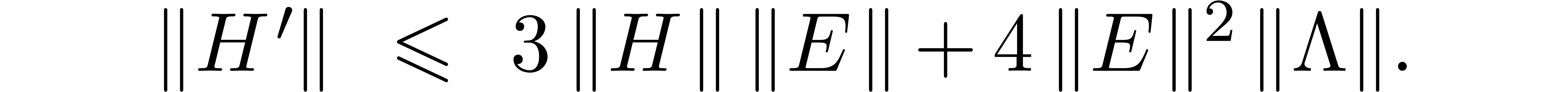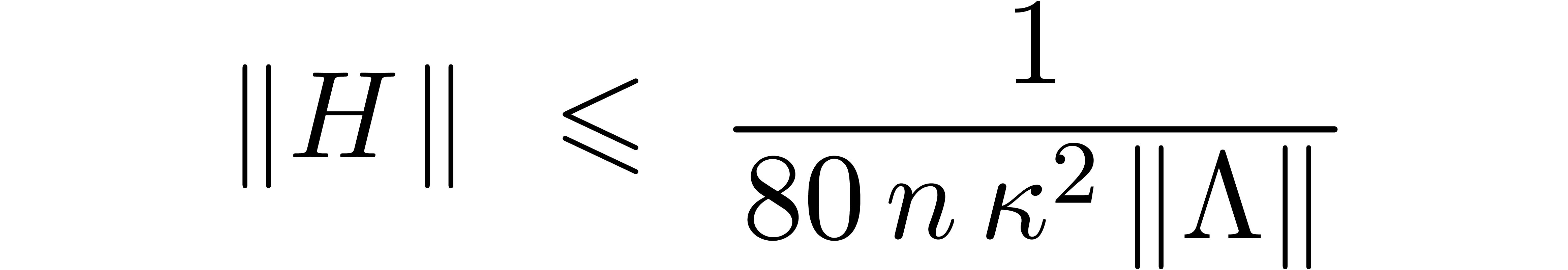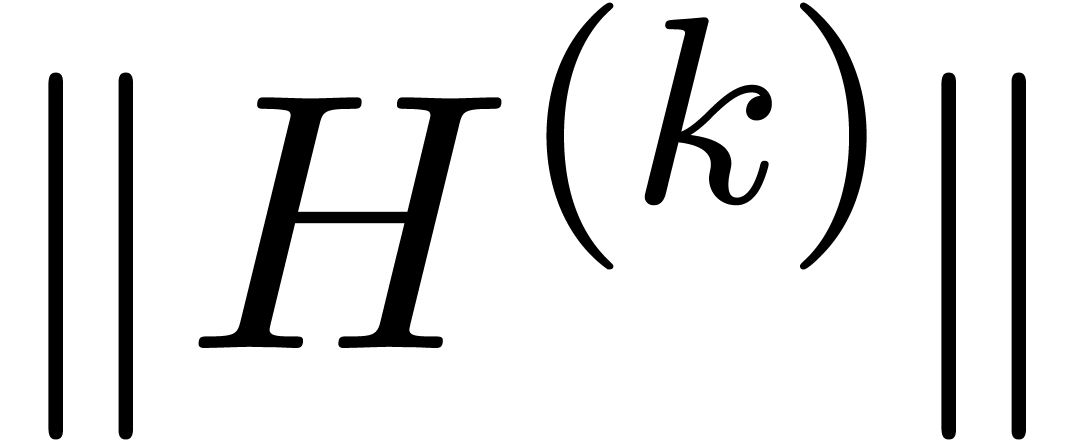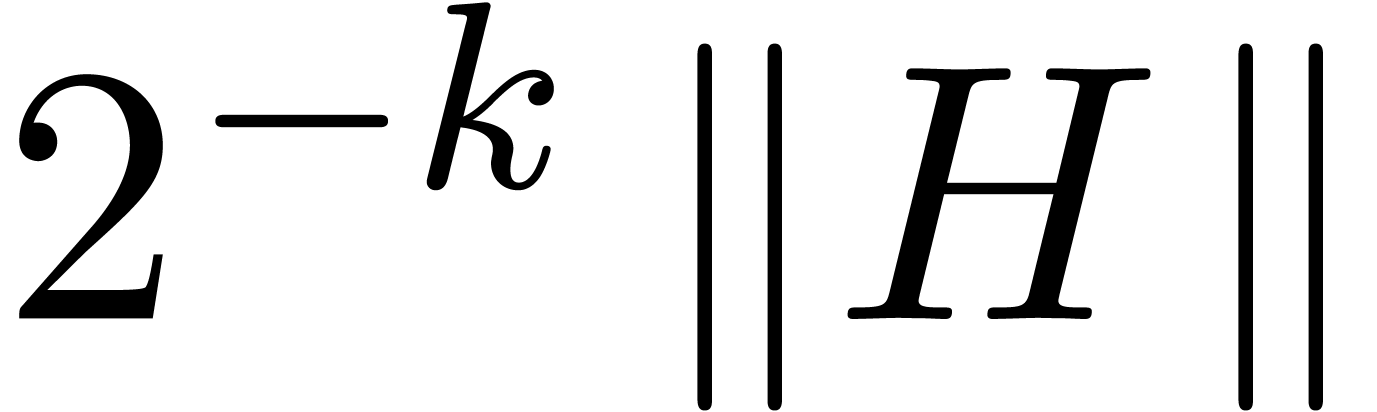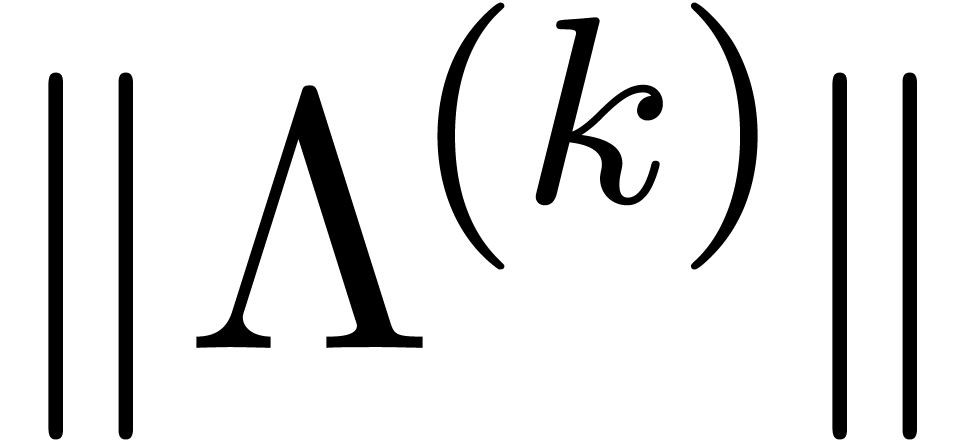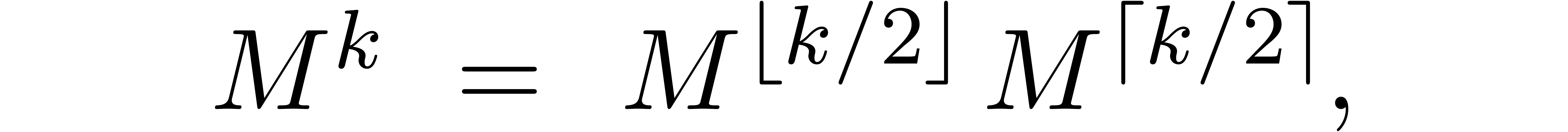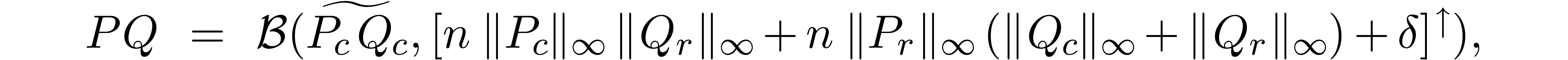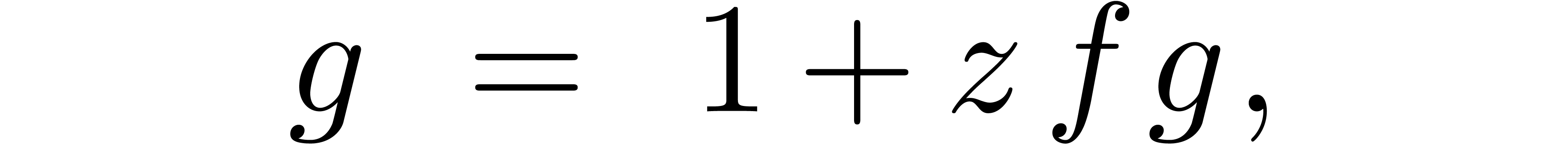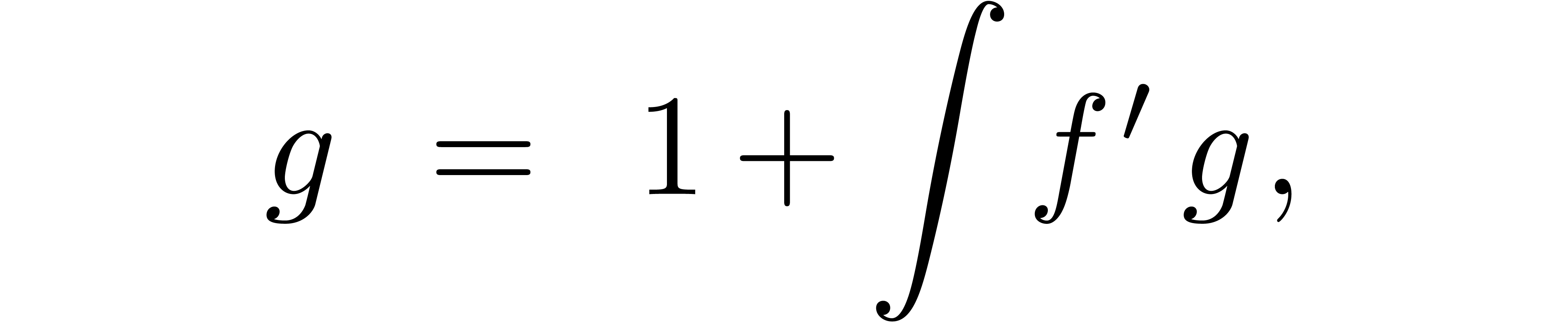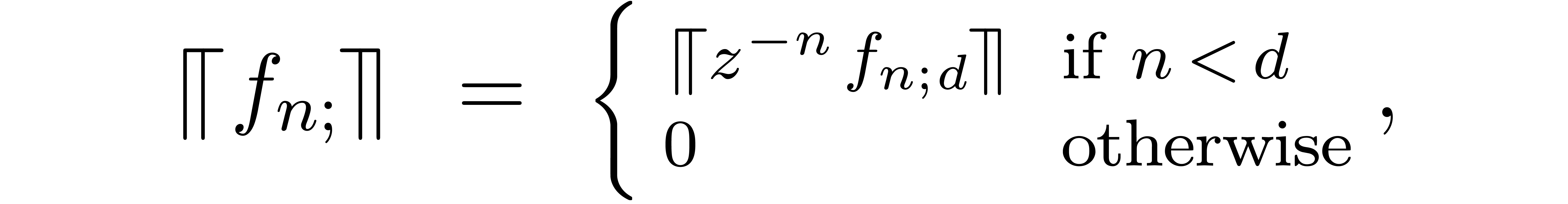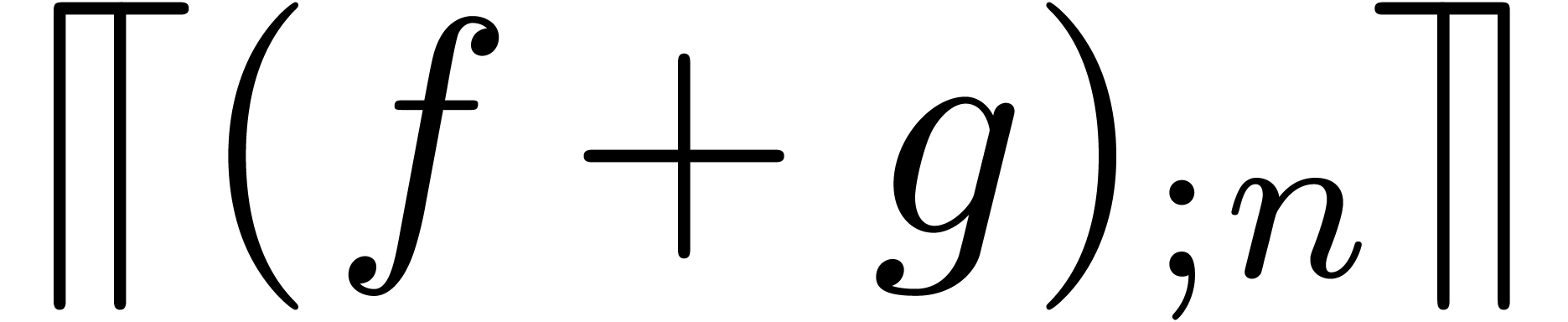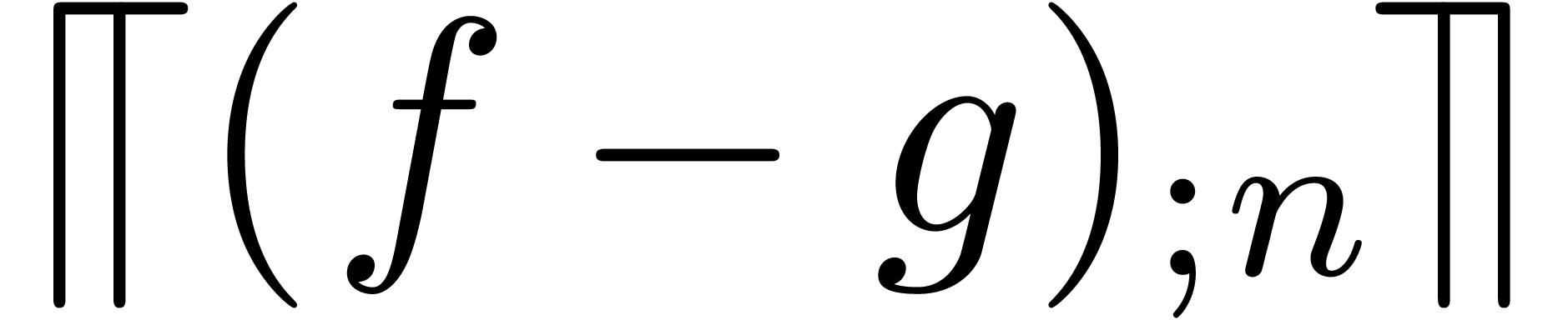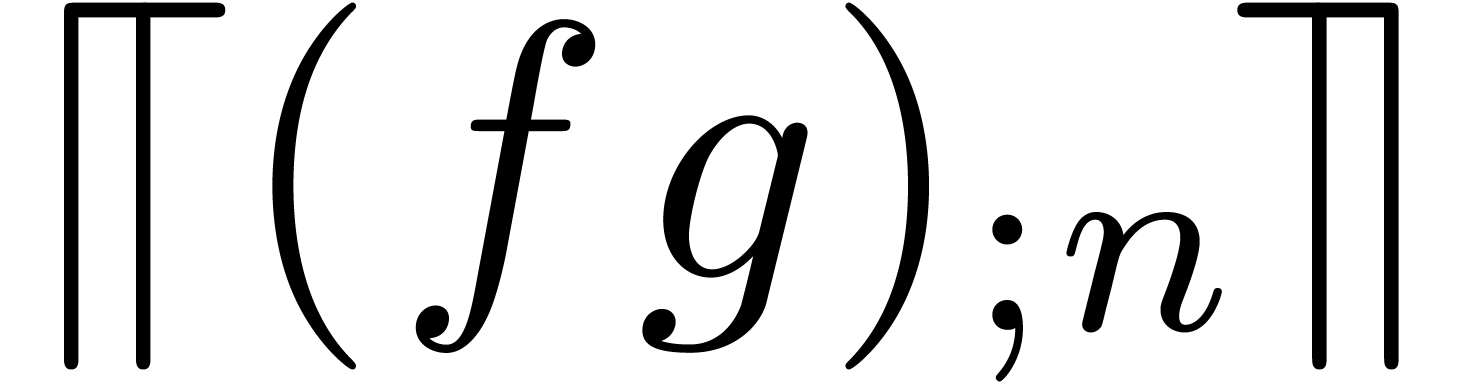Ball arithmetic |
|
| November 3, 2023 |
|
 . This work has
been supported by the ANR-09-JCJC-0098-01
. This work has
been supported by the ANR-09-JCJC-0098-01
The
|
Computer algebra systems are widely used today in order to perform mathematically correct computations with objects of algebraic or combinatorial nature. It is tempting to develop a similar system for analysis. On input, the user would specify the problem in a high level language, such as computable analysis [Wei00, BB85, Abe80, Tur36] or interval analysis [Moo66, AH83, Neu90, JKDW01, Kul08]. The system should then solve the problem in a certified manner. In particular, all necessary computations of error bounds must be carried out automatically.
There are several specialized systems and libraries which contain work
in this direction. For instance, Taylor models have been used with
success for the validated long term integration of dynamical systems [Ber98, MB96, MB04]. A fairly
complete
The
Most of the algorithms in this paper will be based on “ball arithmetic”, which provides a systematic tool for the automatic computation of error bounds. In section 3, we provide a short introduction to this topic and describe its relation with computable analysis. Although ball arithmetic is really a variant of interval arithmetic, we will give several arguments in section 4 why we actually prefer balls over intervals for most applications. Roughly speaking, balls should be used for the reliable approximation of numbers, whereas intervals are mainly useful for certified algorithms which rely on the subdivision of space. Although we will mostly focus on ball arithmetic in this paper, section 5 presents a rough overview of the other kinds of algorithms that are needed in a complete computer analysis system.
After basic ball arithmetic for real and complex numbers, the next challenge is to develop efficient algorithms for reliable linear algebra, polynomials, analytic functions, resolution of differential equations, etc. In sections 6 and 7 we will survey several basic techniques which can be used to implement efficient ball arithmetic for matrices and formal power series. Usually, there is a trade-off between efficiency and the quality of the obtained error bounds. One may often start with a very efficient algorithm which only computes rough bounds, or bounds which are only good in favourable well-conditioned cases. If the obtained bounds are not good enough, then we may switch to a more expensive and higher quality algorithm.
Of course, the main algorithmic challenge in the area of ball arithmetic
is to reduce the overhead of the bound computations as much as possible
with respect to the principal numeric computation. In favourable cases,
this overhead indeed becomes negligible. For instance, for high working
precisions  , the centers of
real and complex balls are stored with the full precision, but we only
need a small precision for the radii. Consequently, the cost of
elementary operations (
, the centers of
real and complex balls are stored with the full precision, but we only
need a small precision for the radii. Consequently, the cost of
elementary operations ( ,
,
 ,
,  ,
,  ,
etc.) on balls is dominated by the cost of the
corresponding operations on their centers. Similarly, crude error bounds
for large matrix products can be obtained quickly with respect to the
actual product computation, by using norm bounds for the rows and
columns of the multiplicands; see (21).
,
etc.) on balls is dominated by the cost of the
corresponding operations on their centers. Similarly, crude error bounds
for large matrix products can be obtained quickly with respect to the
actual product computation, by using norm bounds for the rows and
columns of the multiplicands; see (21).
Another algorithmic challenge is to use fast algorithms for the actual
numerical computations on the centers of the balls. In particular, it is
important to use existing high performance libraries, such as
The representations of objects should be chosen with care. For instance, should we rather work with ball matrices or matricial balls (see sections 6.4 and 7.1)?
If the result of our computation satisfies an equation, then we may first solve the equation numerically and only perform the error analysis at the end. In the case of matrix inversion, this method is known as Hansen's method; see section 6.2.
When considering a computation as a tree or dag, then the error tends to increase with the depth of the tree. If possible, algorithms should be designed so as to keep this depth small. Examples will be given in sections 6.4 and 7.5. Notice that this kind of algorithms are usually also more suitable for parallelization.
When combining the above approaches to the series of problems considered in this paper, we are usually able to achieve a constant overhead for sharp error bound computations. In favourable cases, the overhead becomes negligible. For particularly ill conditioned problems, we need a logarithmic overhead. It remains an open question whether we have been lucky or whether this is a general pattern.
In this paper, we will be easygoing on what is meant by “sharp
error bound”. Regarding algorithms as functions 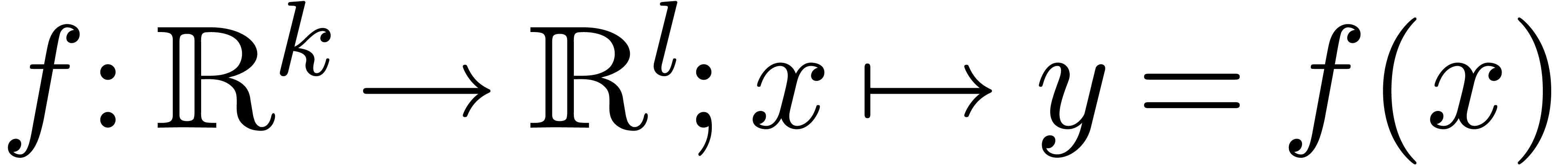 , an error
, an error 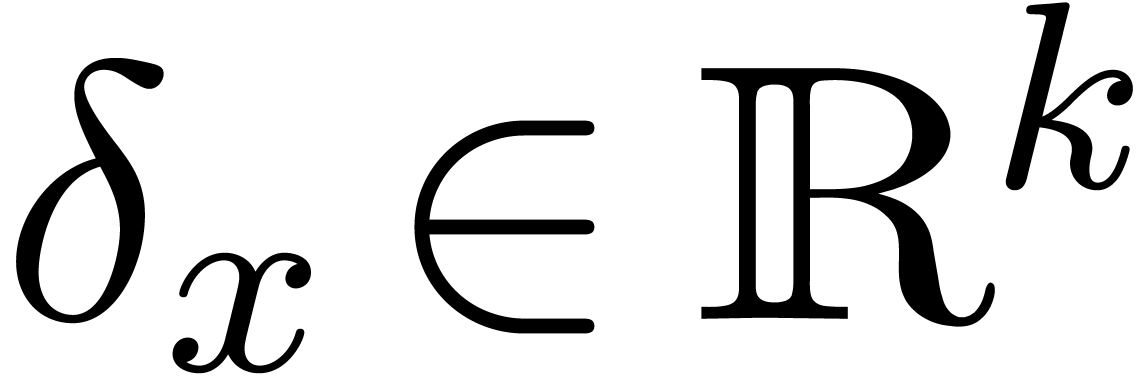 in the input
automatically gives rise to an error
in the input
automatically gives rise to an error 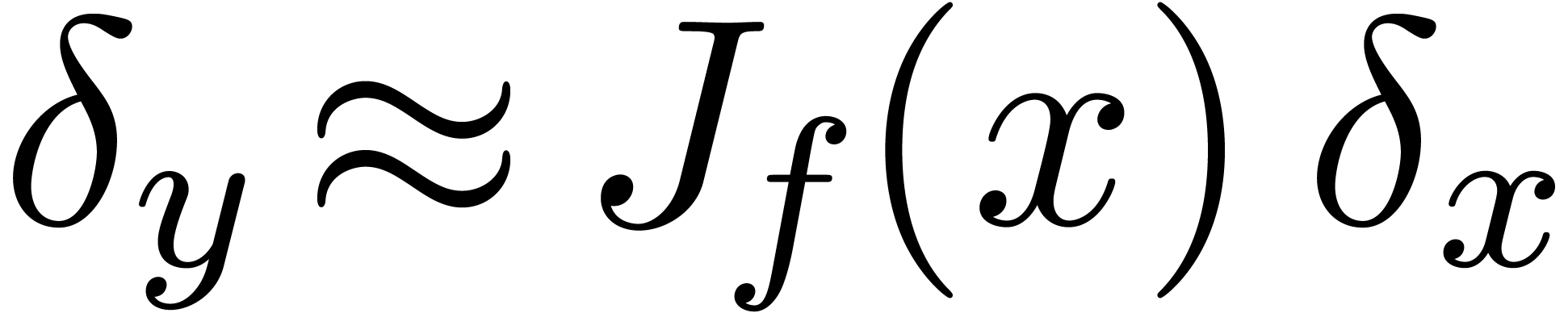 in the
output. When performing our computations with bit precision , we have to consider that the input error
in the
output. When performing our computations with bit precision , we have to consider that the input error 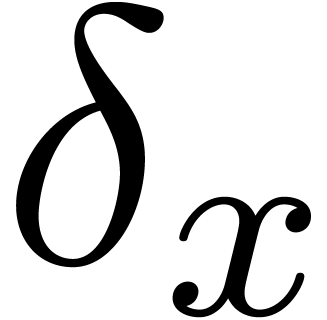 is as least of the order of
is as least of the order of 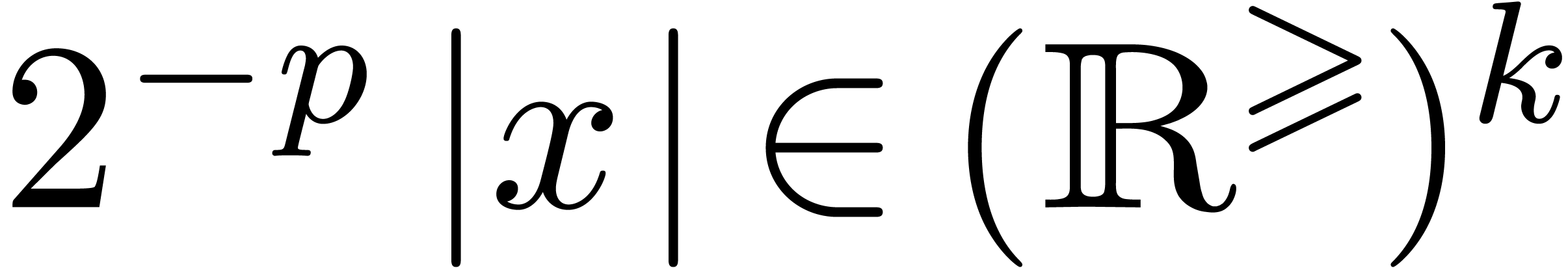 (where
(where 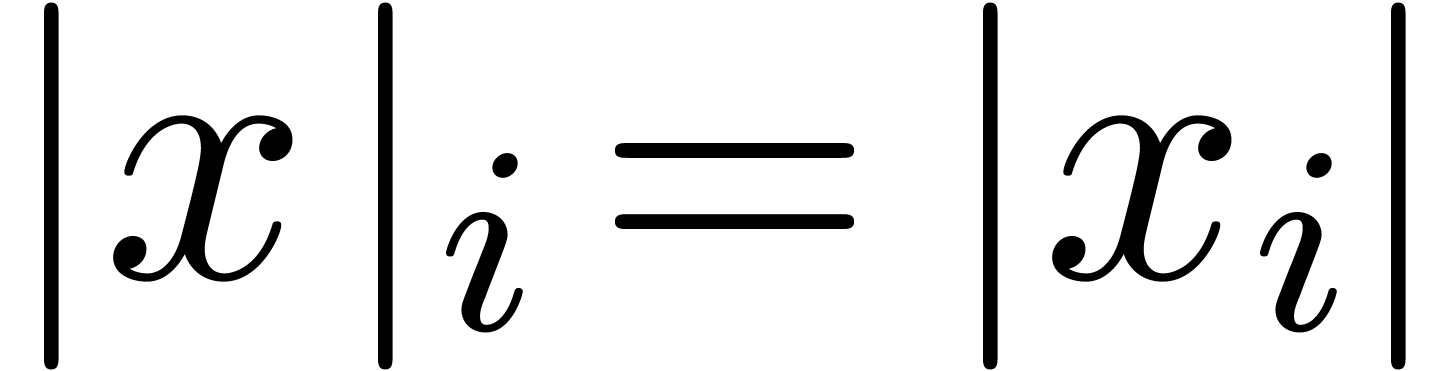 for all
for all  ).
Now given an error bound
).
Now given an error bound 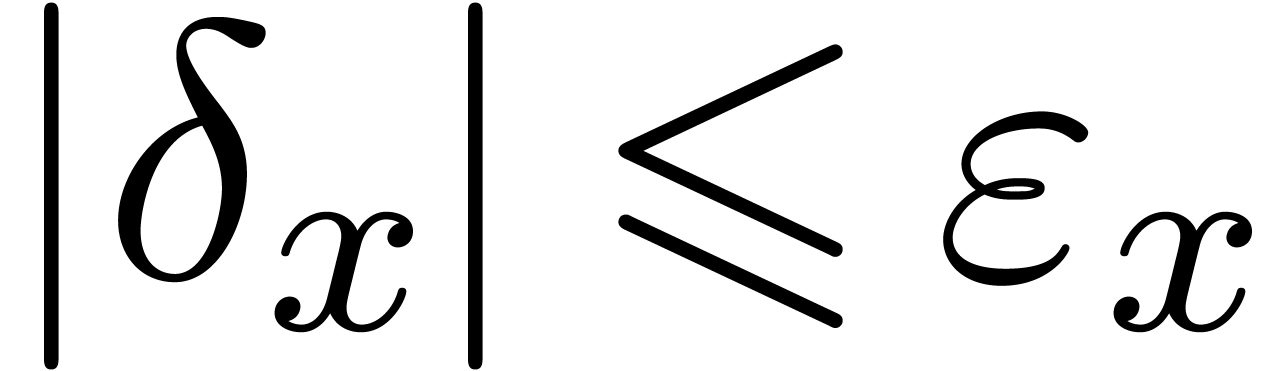 for the input, an error
bound
for the input, an error
bound 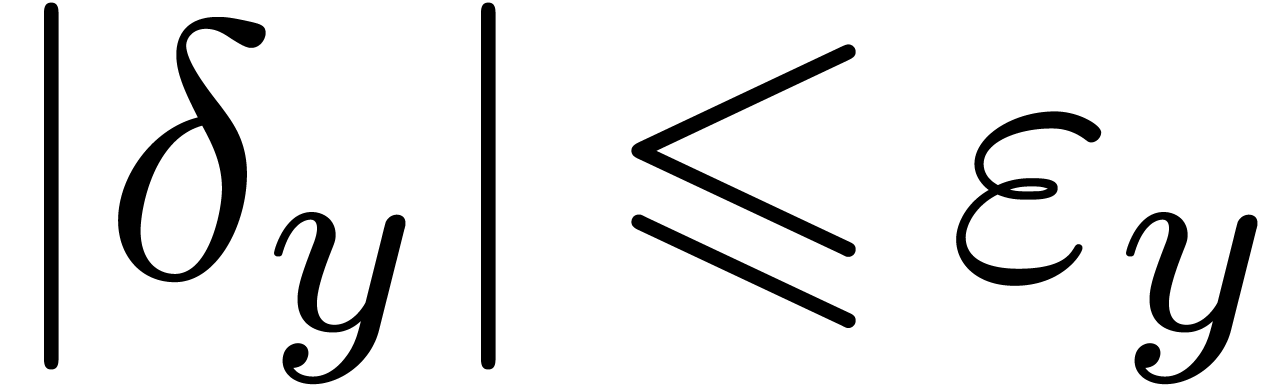 is considered to be sharp if
is considered to be sharp if 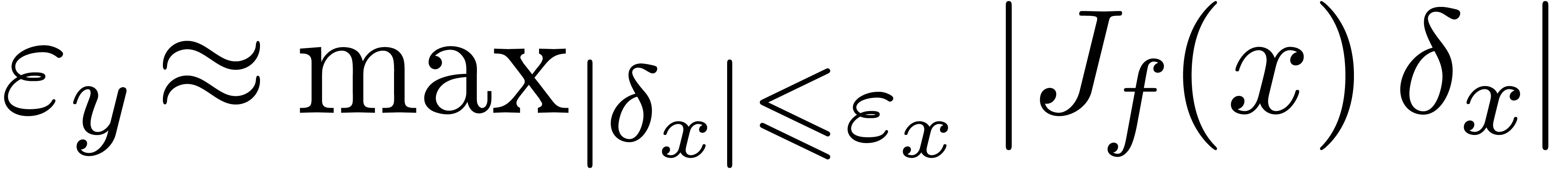 . More generally, condition numbers provide a
similar device for measuring the quality of error bounds. A detailed
investigation of the quality of the algorithms presented in this paper
remains to be carried out. Notice also that the computation of optimal
error bounds is usually NP-hard [KLRK97].
. More generally, condition numbers provide a
similar device for measuring the quality of error bounds. A detailed
investigation of the quality of the algorithms presented in this paper
remains to be carried out. Notice also that the computation of optimal
error bounds is usually NP-hard [KLRK97].
Of course, the development of asymptotically efficient ball arithmetic
presupposes the existence of the corresponding numerical algorithms.
This topic is another major challenge, which will not be addressed in
this paper. Indeed, asymptotically fast algorithms usually suffer from
lower numerical stability. Besides, switching from machine precision to
multiple precision involves a huge overhead. Special techniques are
required to reduce this overhead when computing with large compound
objects, such as matrices or polynomials. It is also recommended to
systematically implement single, double, quadruple and multiple
precision versions of all algorithms (see [BHL00, BHL01]
for a double-double and quadruple-double precision library). The
The aim of our paper is to provide a survey on how to implement an efficient library for ball arithmetic. Even though many of the ideas are classical in the interval analysis community, we do think that the paper sheds a new light on the topic. Indeed, we systematically investigate several issues which have received limited attention until now:
Using ball arithmetic instead of interval arithmetic, for a wide variety of center and radius types.
The trade-off between algorithmic complexity and quality of the error bounds.
The complexity of multiple precision ball arithmetic.
Throughout the text, we have attempted to provide pointers to existing literature, wherever appropriate. We apologize for possible omissions and would be grateful for any suggestions regarding existing literature.
We will denote by
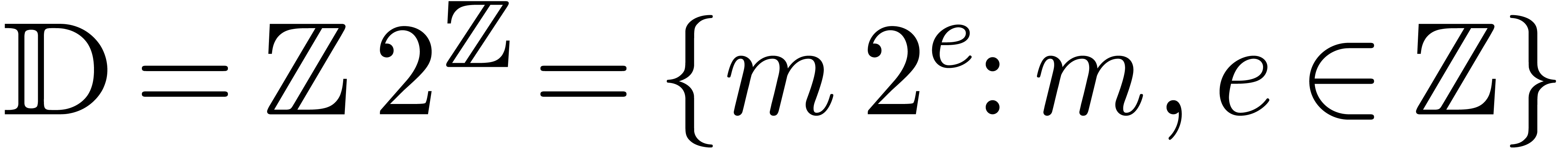
the set of dyadic numbers. Given fixed bit precisions  and
and 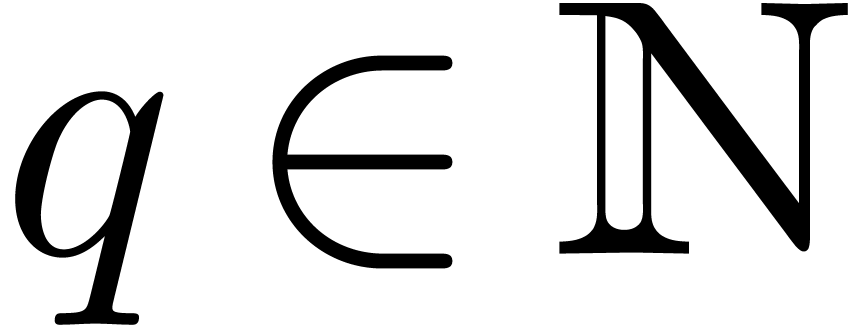 for the unsigned mantissa
(without the leading
for the unsigned mantissa
(without the leading  ) and
signed exponent, we also denote by
) and
signed exponent, we also denote by
the corresponding set of floating point numbers. Numbers in 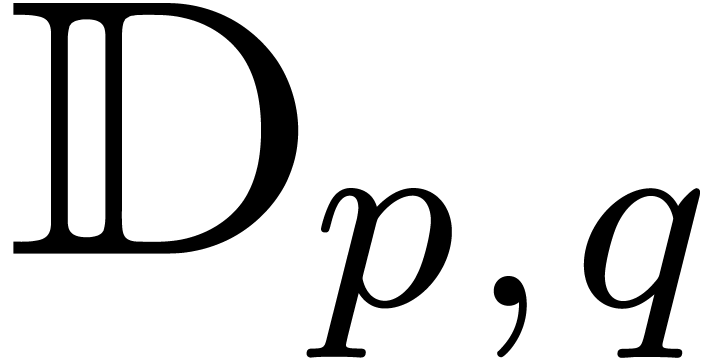 can be stored in
can be stored in 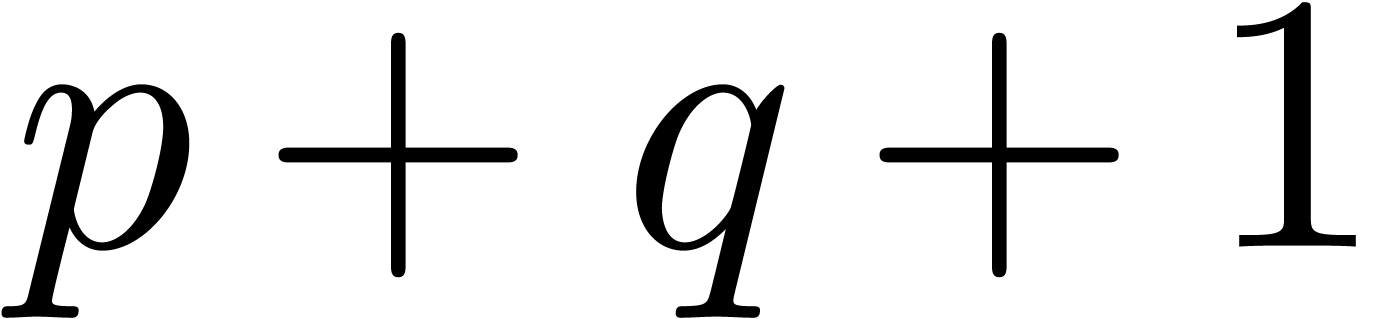 bit space and
correspond to “ordinary numbers” in the IEEE 754 norm [ANS08]. For double precision numbers, we have
bit space and
correspond to “ordinary numbers” in the IEEE 754 norm [ANS08]. For double precision numbers, we have 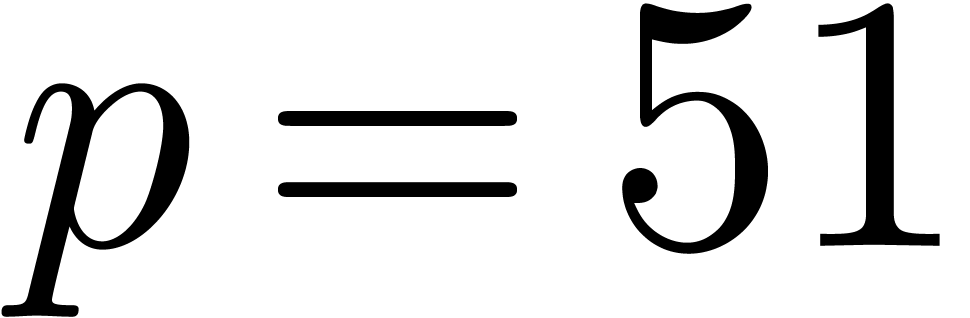 and
and 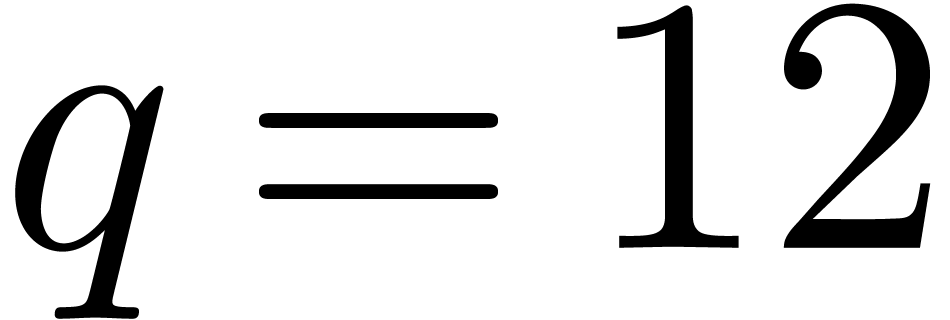 . For multiple precision
numbers, we usually take
. For multiple precision
numbers, we usually take  to be the size of a
machine word, say
to be the size of a
machine word, say 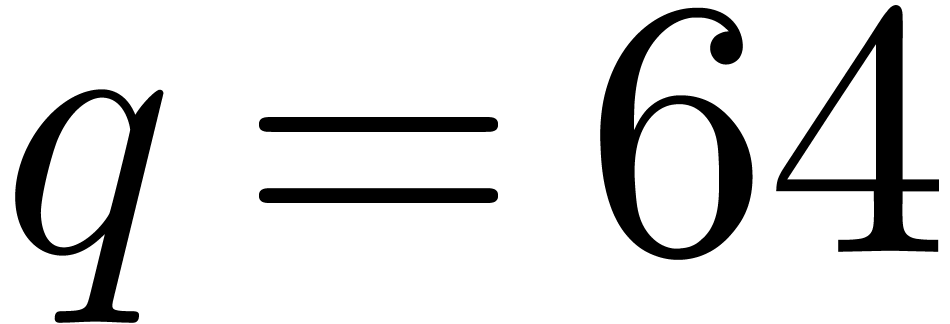 , and
denote
, and
denote 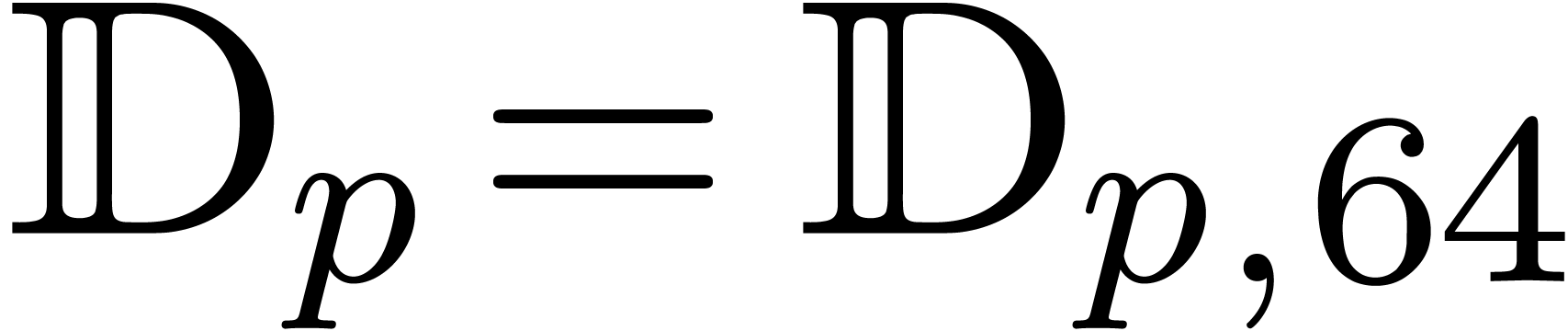 .
.
The IEEE 754 norm also defines several special numbers. The most
important ones are the infinities 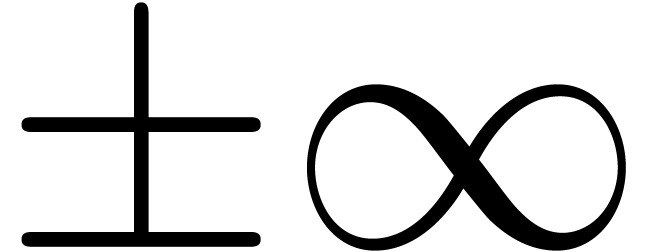 and “not
a number”
and “not
a number”  , which
corresponds to the result of an invalid operation, such as
, which
corresponds to the result of an invalid operation, such as 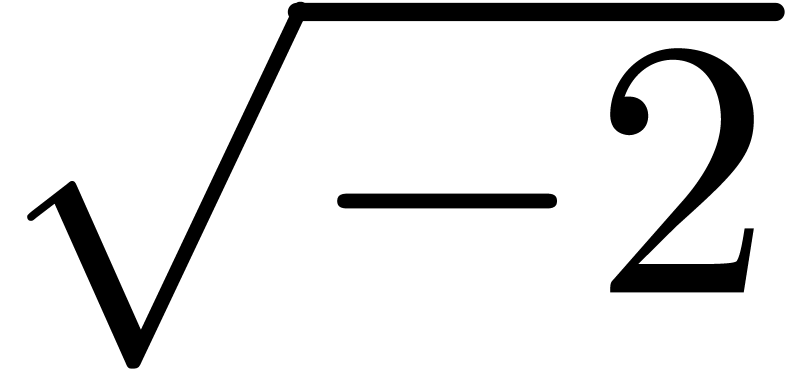 . We will denote
. We will denote
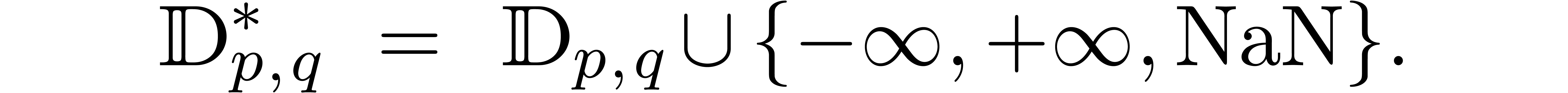
Less important details concern the specification of signed zeros 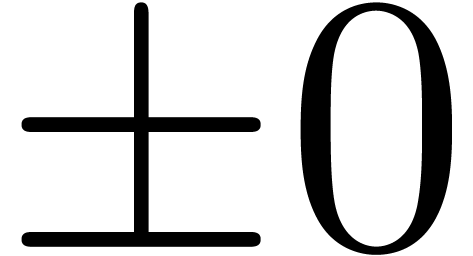 and several possible types of NaNs. For more details,
we refer to [ANS08].
and several possible types of NaNs. For more details,
we refer to [ANS08].
The other main feature of the IEEE 754 is that it specifies how to round
results of operations which cannot be performed exactly. There are four
basic rounding modes  (upwards),
(upwards),  (downwards),
(downwards),  (nearest) and
(nearest) and 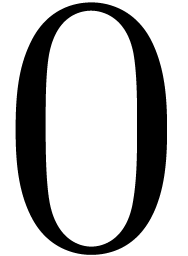 (towards zero). Assume that we have an operation
(towards zero). Assume that we have an operation 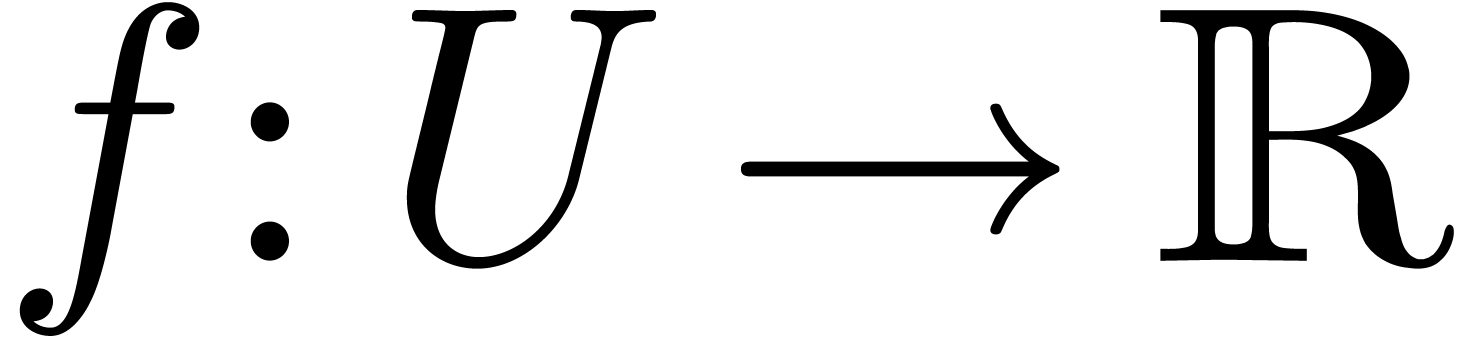 with
with 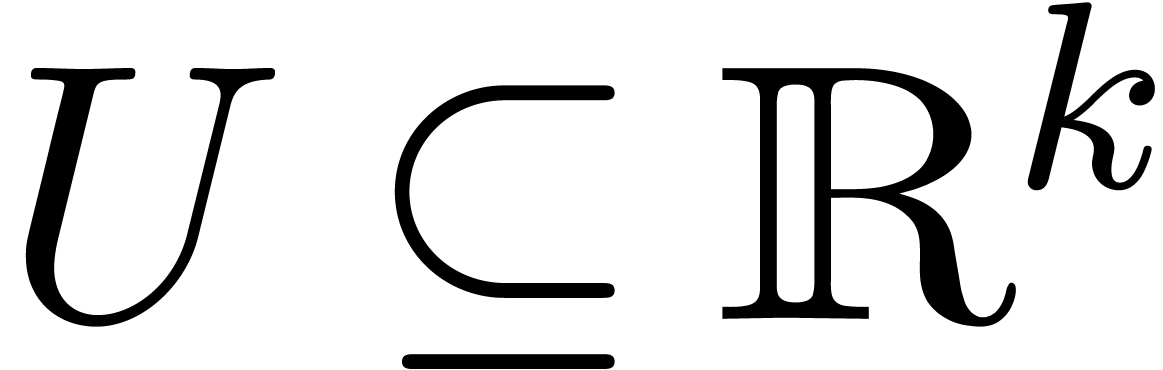 . Given
. Given  and
and  , we define
, we define 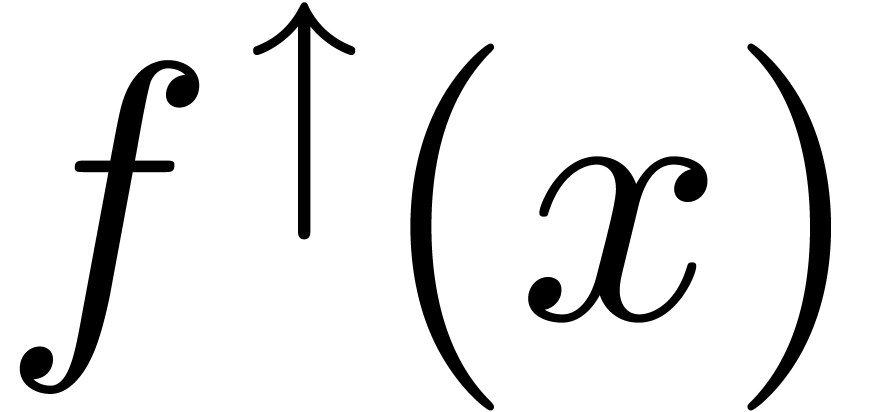 to be the smallest number
to be the smallest number 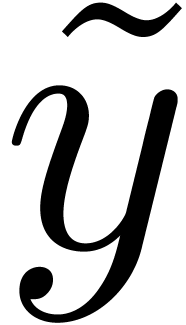 in
in  , such that
, such that 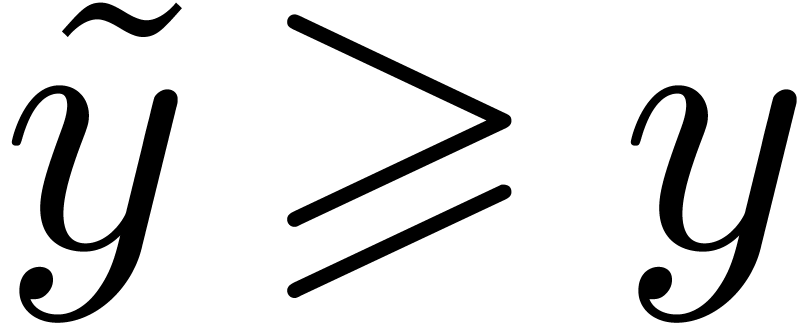 . More generally, we will use the notation
. More generally, we will use the notation 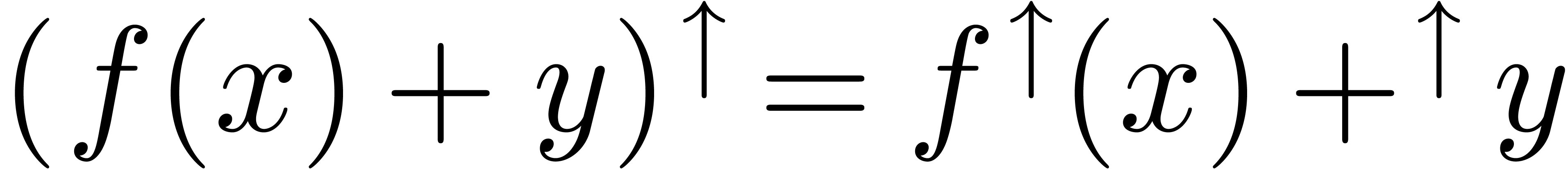 to indicate that all operations are performed by rounding
upwards. The other rounding modes are specified in a similar way. One
major advantage of IEEE 754 arithmetic is that it completely specifies
how basic operations are done, making numerical programs behave exactly
in the same way on different architectures. Most current microprocessors
implement the IEEE 754 norm for single and double precision numbers. A
conforming multiple precision implementation also exists [HLRZ00].
to indicate that all operations are performed by rounding
upwards. The other rounding modes are specified in a similar way. One
major advantage of IEEE 754 arithmetic is that it completely specifies
how basic operations are done, making numerical programs behave exactly
in the same way on different architectures. Most current microprocessors
implement the IEEE 754 norm for single and double precision numbers. A
conforming multiple precision implementation also exists [HLRZ00].
Using Schönhage-Strassen multiplication [SS71], it is
classical that the product of two -bit
integers can be computed in time 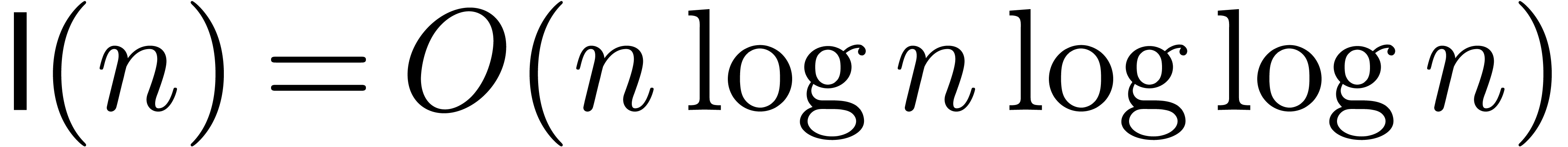 .
A recent algorithm by Fürer [Für07] further
improves this bound to
.
A recent algorithm by Fürer [Für07] further
improves this bound to 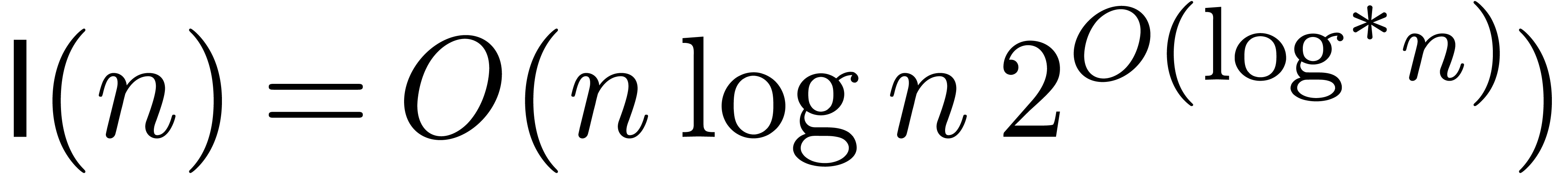 ,
where
,
where 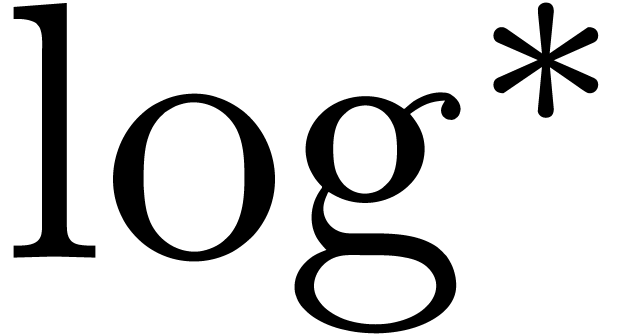 denotes the iterator of the logarithm (we
have
denotes the iterator of the logarithm (we
have 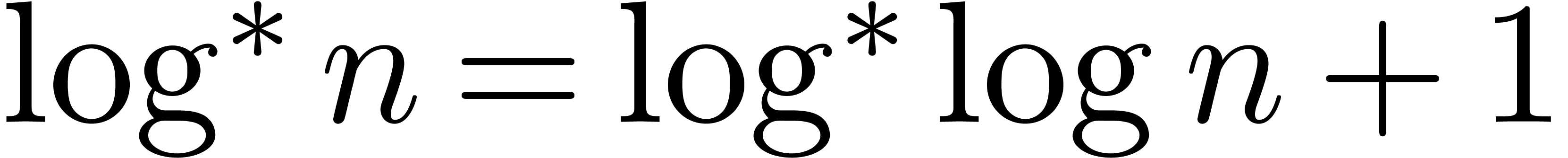 ). Other algorithms,
such as division two
). Other algorithms,
such as division two 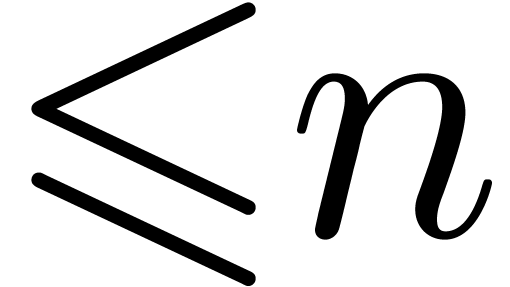 -bit
integers, have a similar complexity
-bit
integers, have a similar complexity 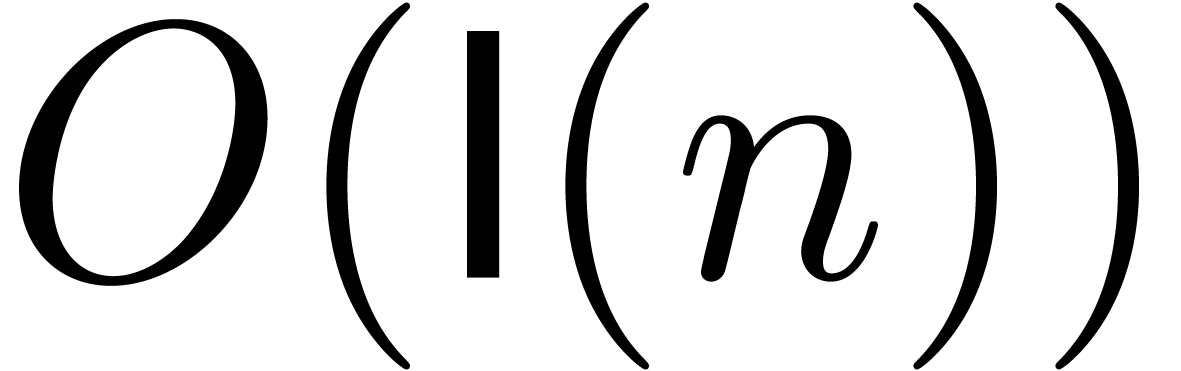 .
Given
.
Given 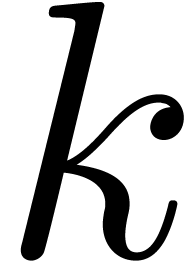 prime numbers
prime numbers  and
a number
and
a number 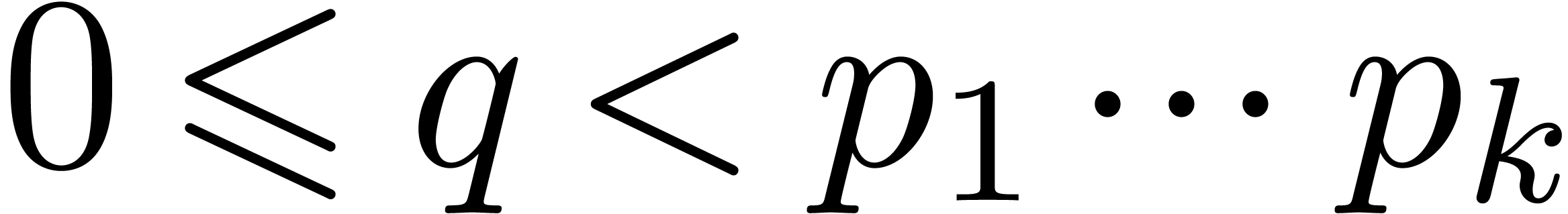 , the computation of
, the computation of
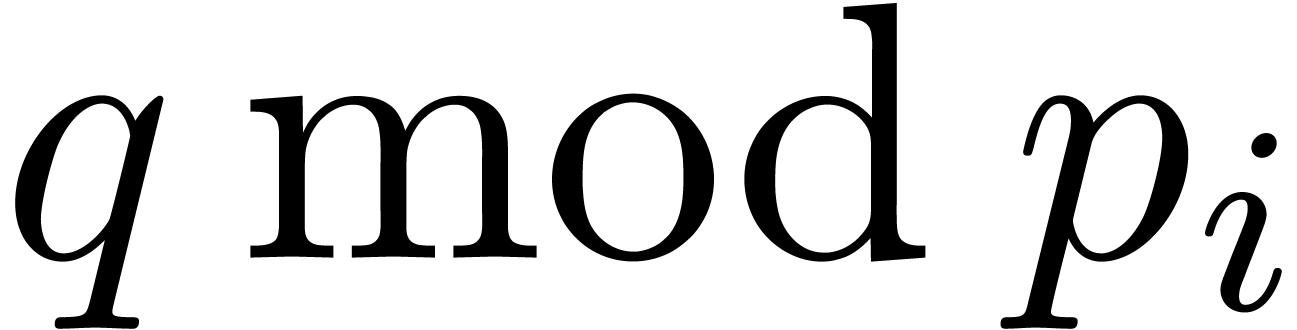 for
for 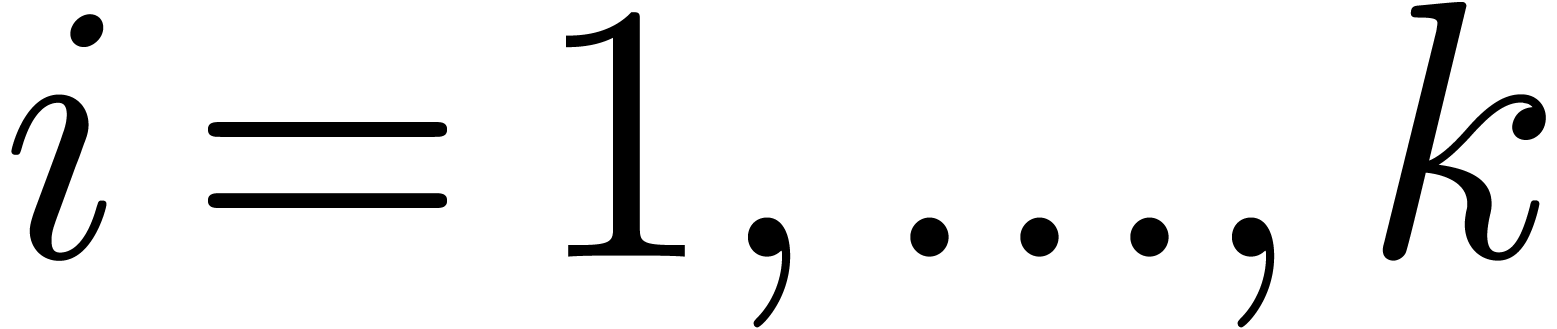 can be done in time
can be done in time
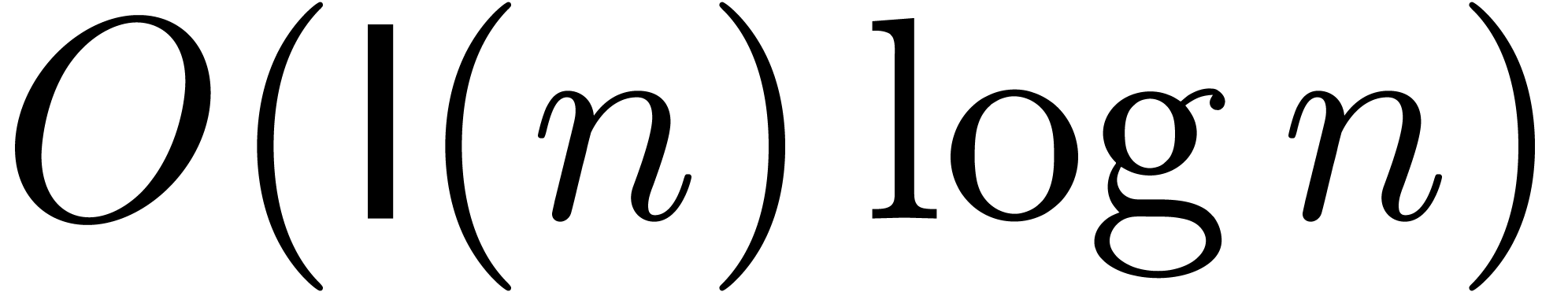 using binary splitting [GG02,
Theorem 10.25], where
using binary splitting [GG02,
Theorem 10.25], where 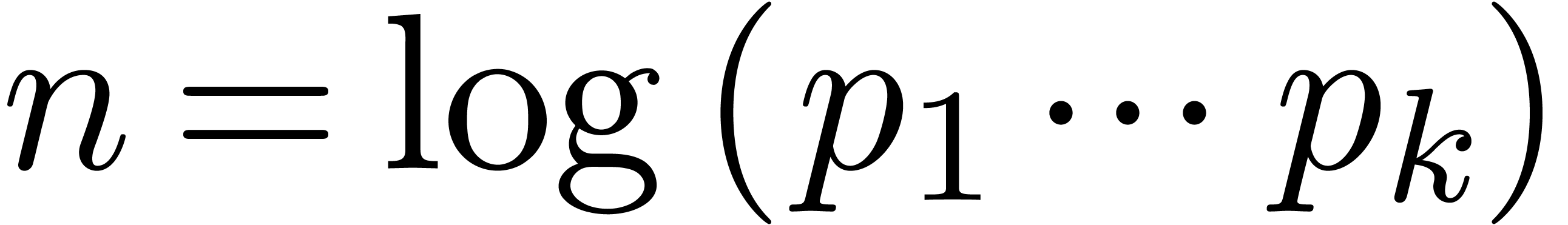 . It is
also possible to reconstruct from the remainders
in time .
. It is
also possible to reconstruct from the remainders
in time .
Let  be an effective ring, in the sense that we
have algorithms for performing the ring operations in . If admits
be an effective ring, in the sense that we
have algorithms for performing the ring operations in . If admits 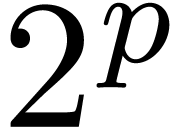 -th roots of unity for
-th roots of unity for 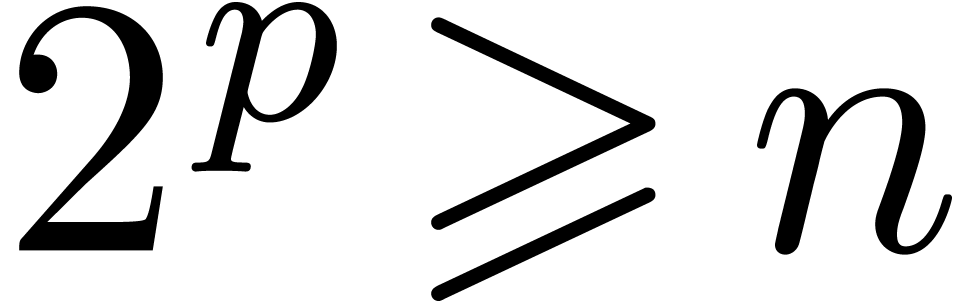 , then it is classical [CT65] that
the product of two polynomials
, then it is classical [CT65] that
the product of two polynomials 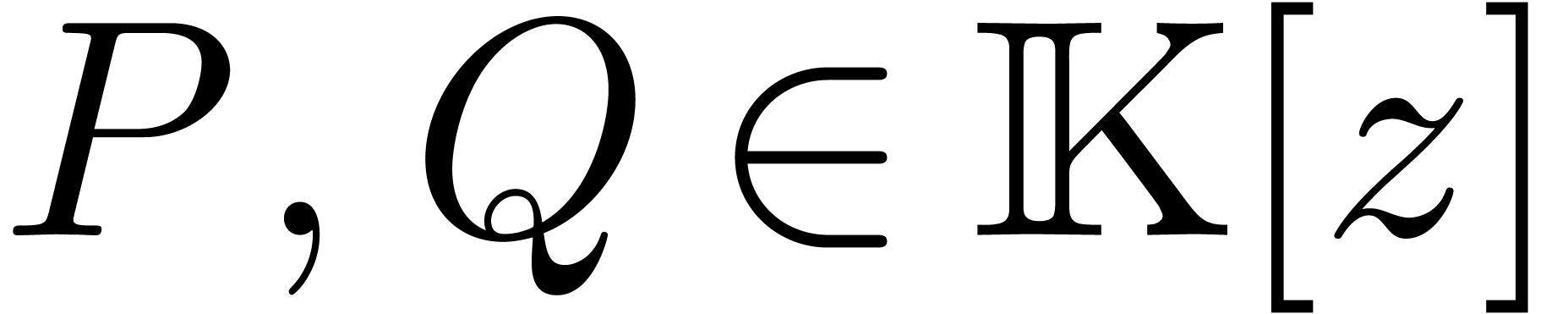 with
with 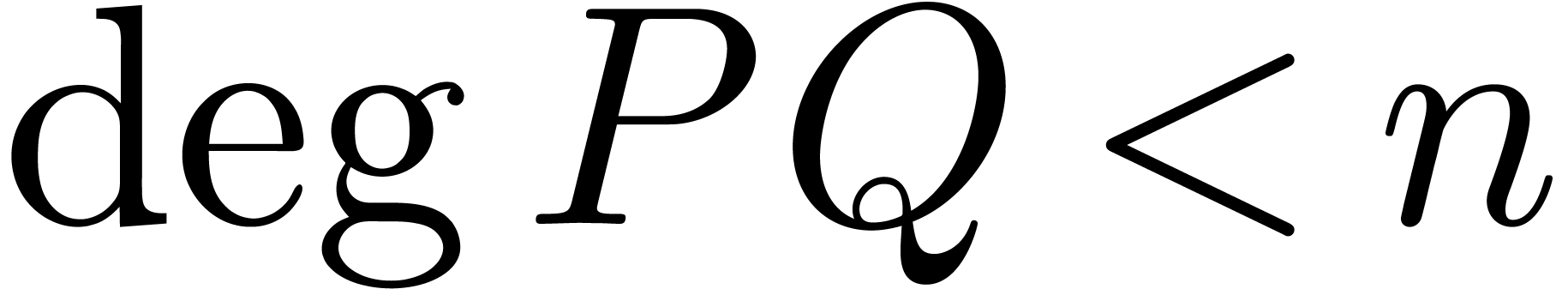 can be computed using
can be computed using 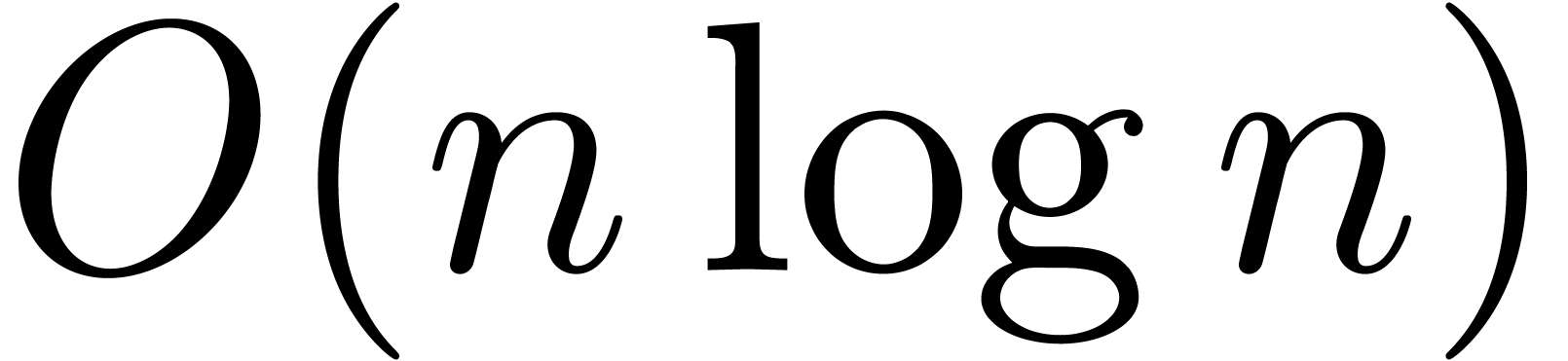 ring
operations in , using the
fast Fourier transform. For general rings, this product can be computed
using
ring
operations in , using the
fast Fourier transform. For general rings, this product can be computed
using 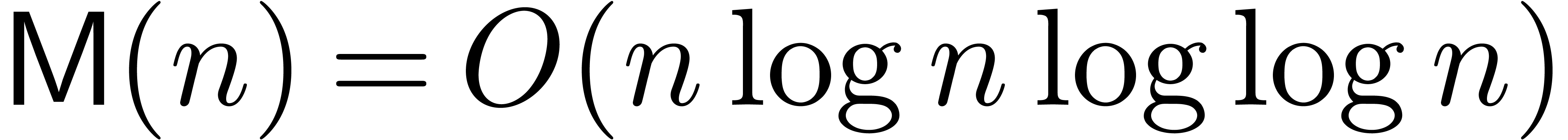 operations [CK91], using a
variant of Schönhage-Strassen multiplication.
operations [CK91], using a
variant of Schönhage-Strassen multiplication.
A formal power series  is said to be
computable, if there exists an algorithm which takes
is said to be
computable, if there exists an algorithm which takes  on input and which computes
on input and which computes  .
We denote by
.
We denote by 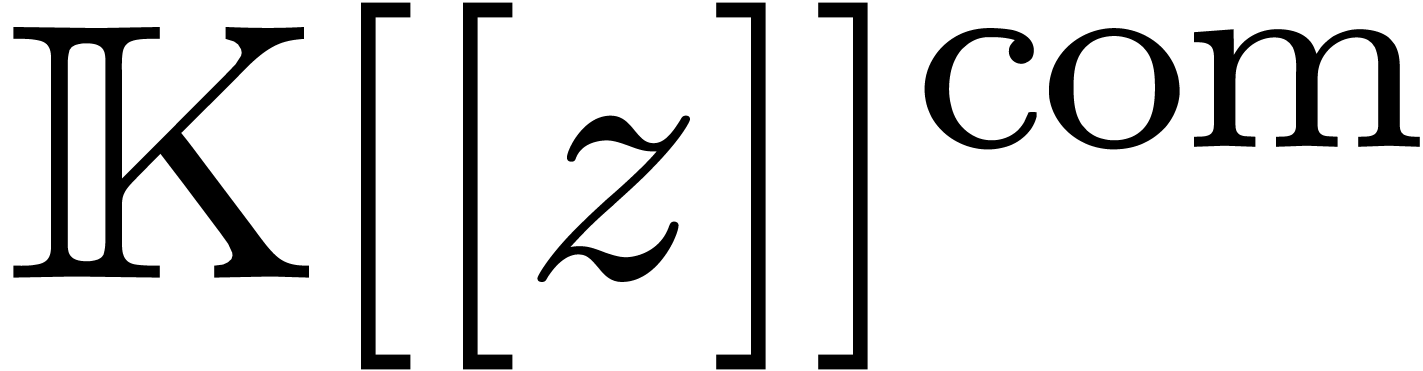 the set of computable power series.
Many simple operations on formal power series, such as multiplication,
division, exponentiation, etc., as well as the resolution
of algebraic differential equations can be done up till order
the set of computable power series.
Many simple operations on formal power series, such as multiplication,
division, exponentiation, etc., as well as the resolution
of algebraic differential equations can be done up till order 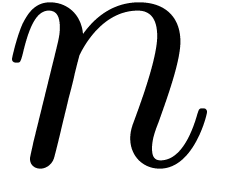 using a similar time complexity
using a similar time complexity 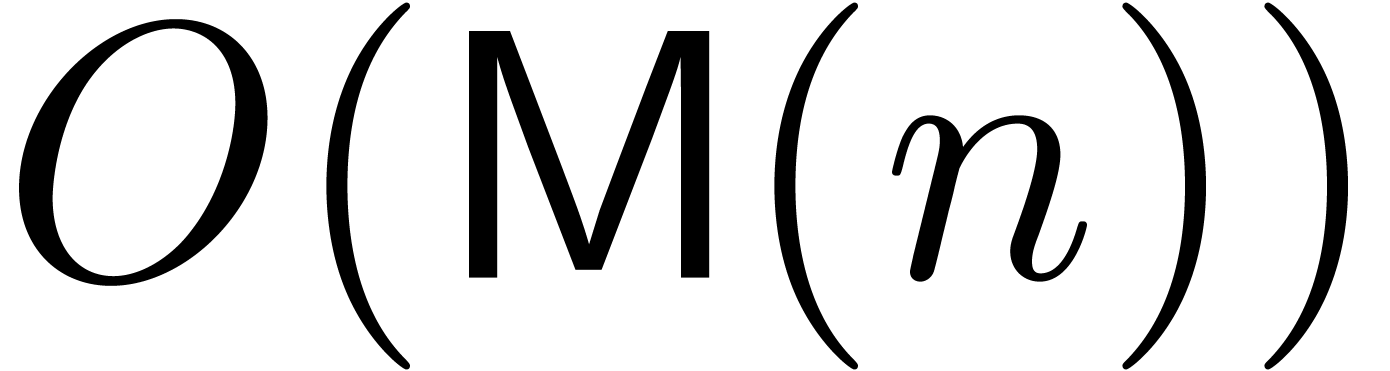 as
polynomial multiplication [BK78, BCO+06, vdH06b]. Alternative relaxed multiplication
algorithms of time complexity
as
polynomial multiplication [BK78, BCO+06, vdH06b]. Alternative relaxed multiplication
algorithms of time complexity  are given in [vdH02a, vdH07a]. In this case, the coefficients
are given in [vdH02a, vdH07a]. In this case, the coefficients
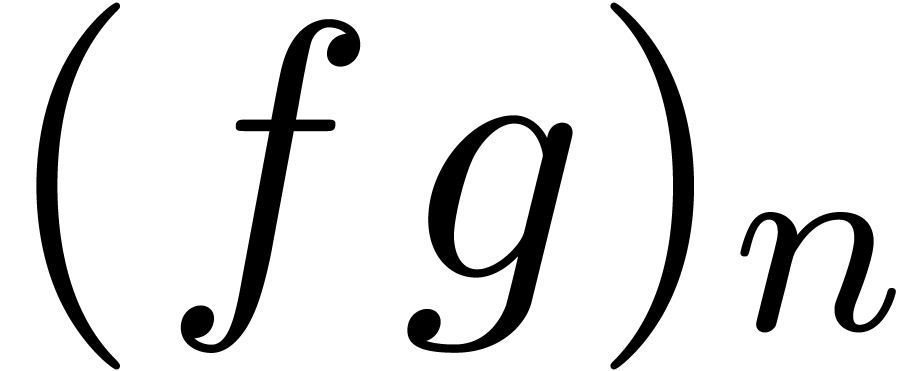 are computed gradually and
is output as soon as
are computed gradually and
is output as soon as  and
and  are known. This strategy is often most efficient for the resolution of
implicit equations.
are known. This strategy is often most efficient for the resolution of
implicit equations.
Let 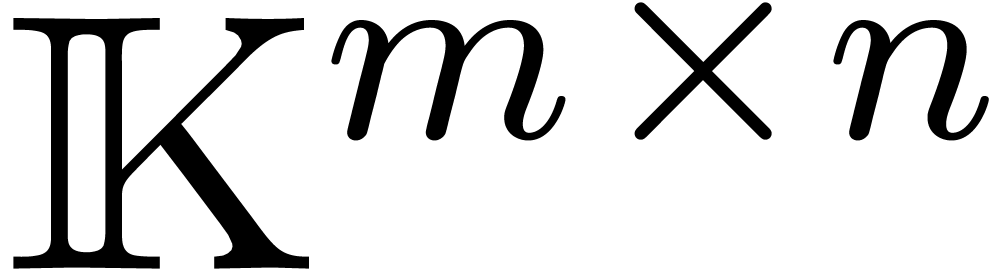 denote the set of
denote the set of  matrices with entries in .
Given two
matrices with entries in .
Given two  matrices
matrices  ,
the naive algorithm for computing
,
the naive algorithm for computing  requires
requires 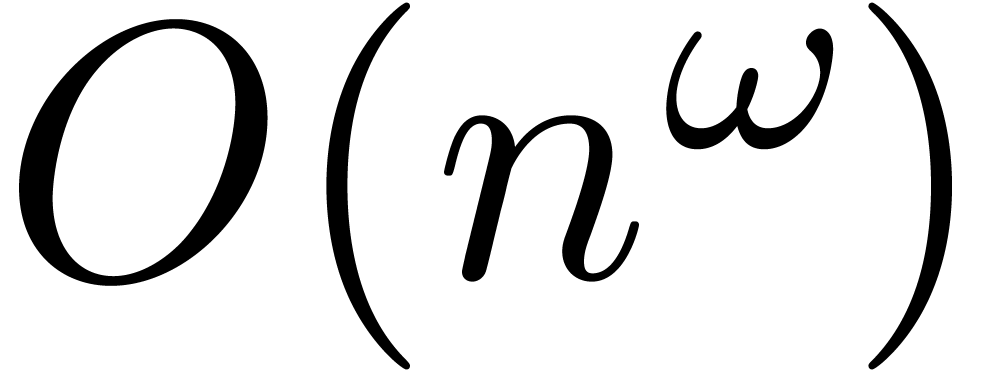 ring operations with
ring operations with 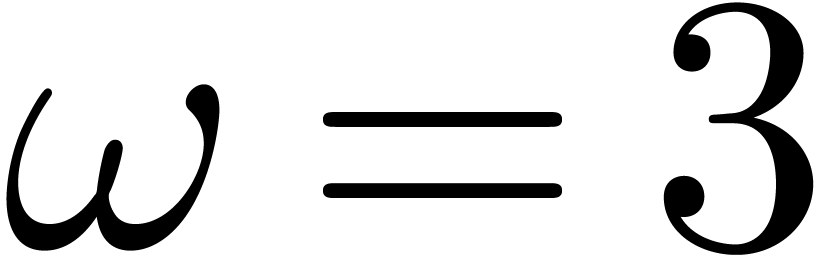 .
The exponent
.
The exponent  has been reduced by Strassen [Str69] to
has been reduced by Strassen [Str69] to 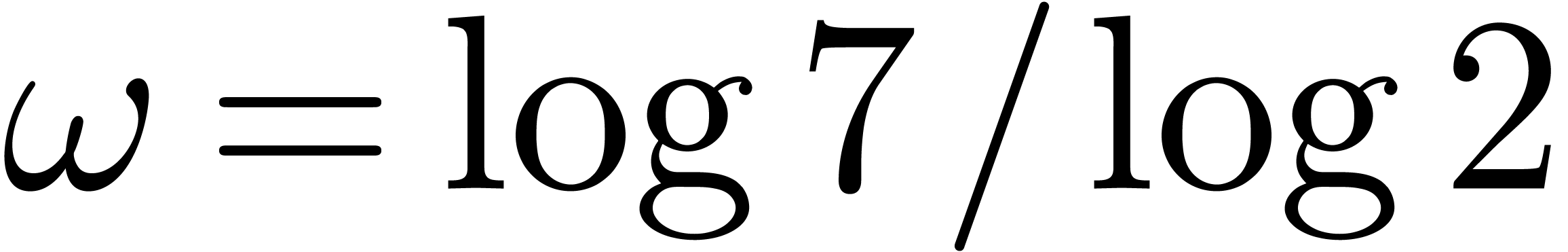 . Using
more sophisticated techniques, can be further
reduced to
. Using
more sophisticated techniques, can be further
reduced to 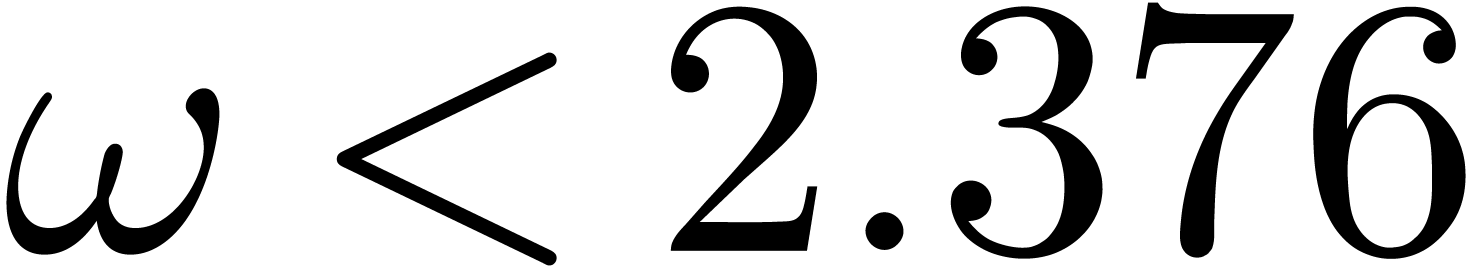 [Pan84, CW87].
However, this exponent has never been observed in practice.
[Pan84, CW87].
However, this exponent has never been observed in practice.
Given 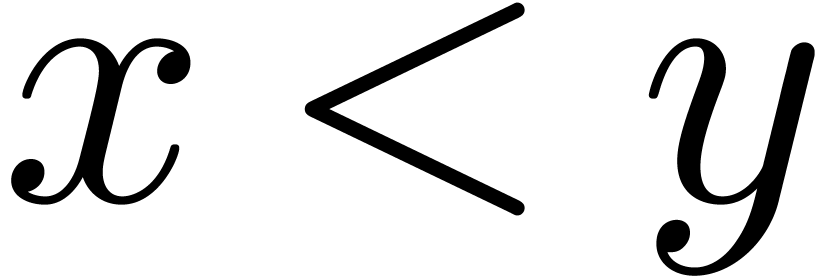 in a totally ordered set
in a totally ordered set  , we will denote by
, we will denote by 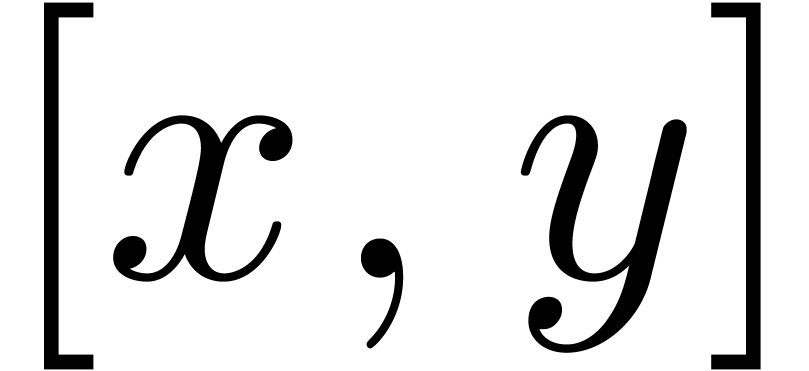 the
closed interval
the
closed interval
Assume now that is a totally ordered field and
consider a normed vector space  over . Given
over . Given 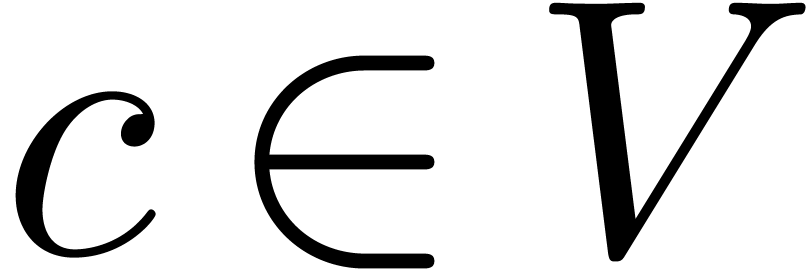 and
and 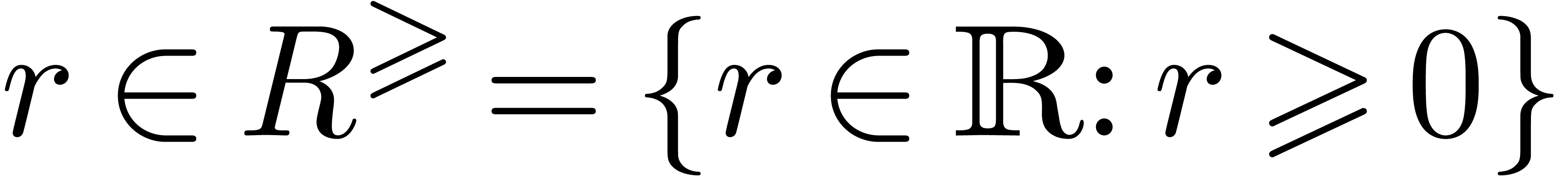 , we will denote by
, we will denote by
the closed ball with center  and radius
and radius 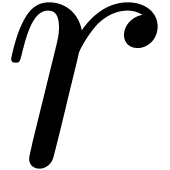 . Notice that we will never work
with open balls in what follows. We denote the set of all balls of the
form (2) by
. Notice that we will never work
with open balls in what follows. We denote the set of all balls of the
form (2) by 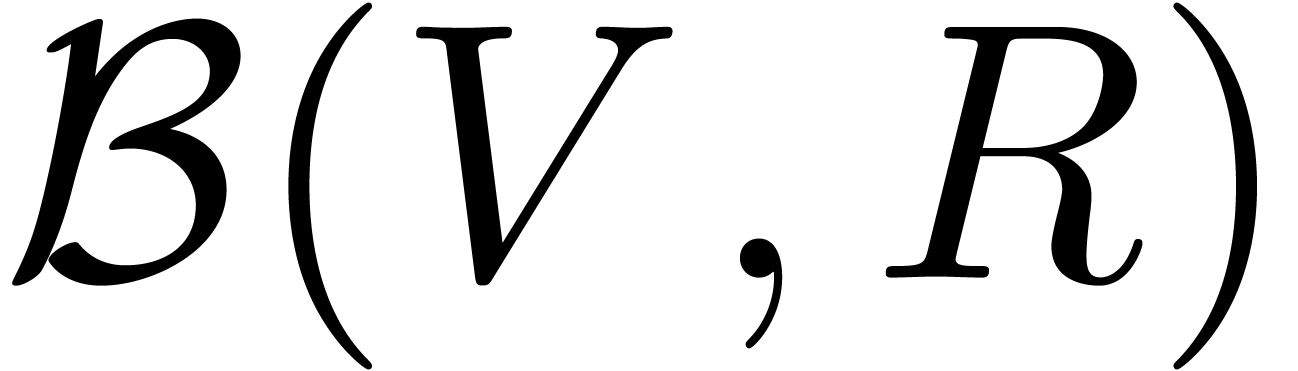 .
Given
.
Given 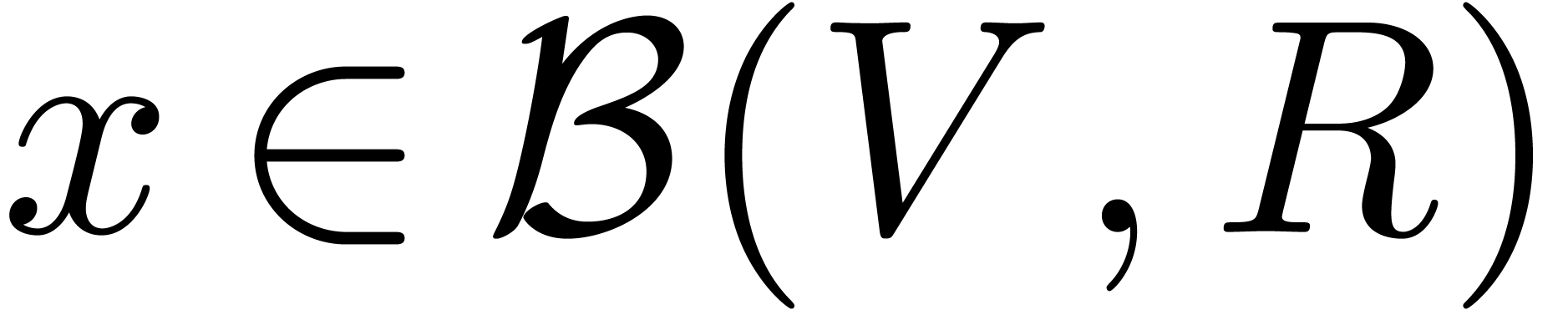 , we will denote by
, we will denote by
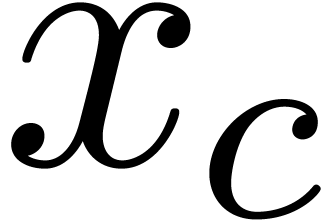 and
and 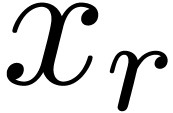 the center
resp. radius of
the center
resp. radius of  .
.
We will use the standard euclidean norm
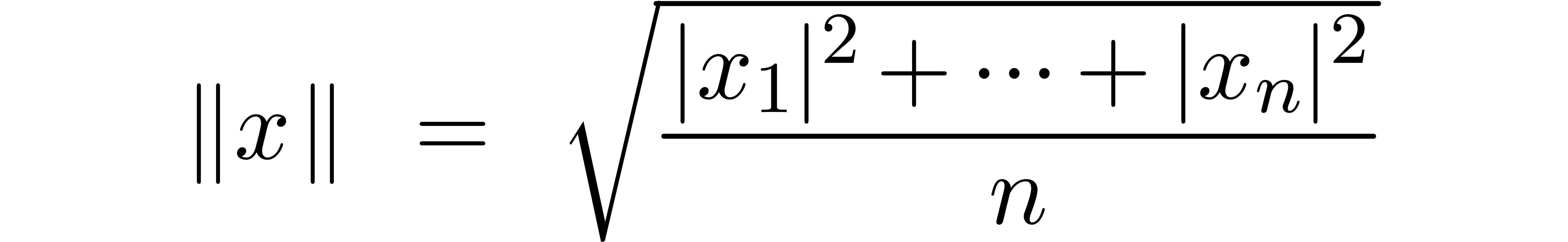
as the default norm on  and
and  . Occasionally, we will also consider the
max-norm
. Occasionally, we will also consider the
max-norm
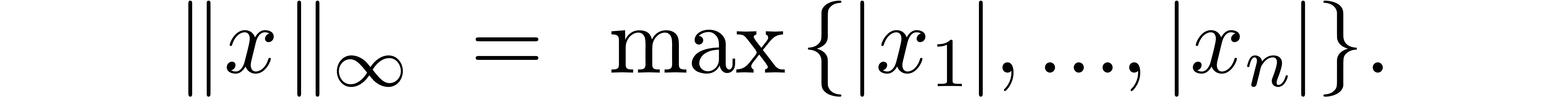
For matrices  or
or  ,
the default operator norm is defined by
,
the default operator norm is defined by
Occasionally, we will also consider the max-norm
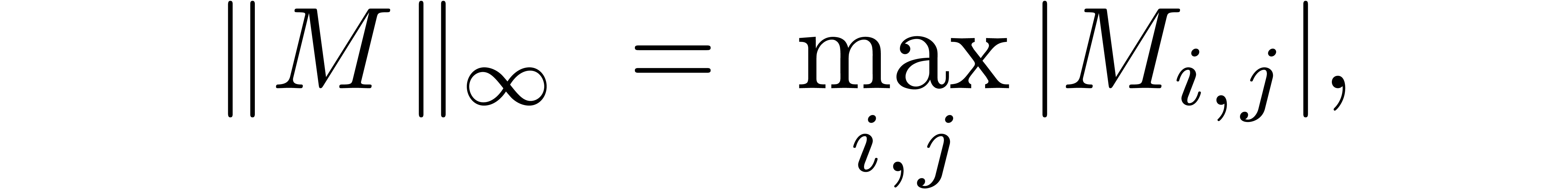
which satisfies
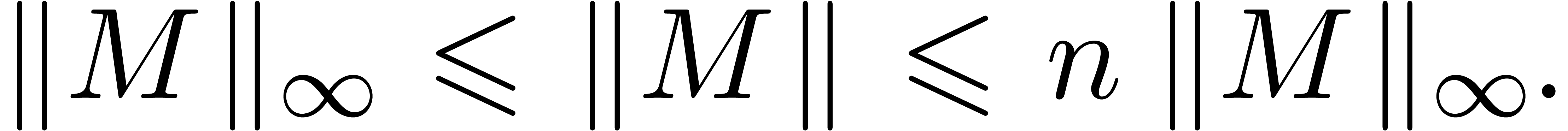
We also define the max-norm for polynomials 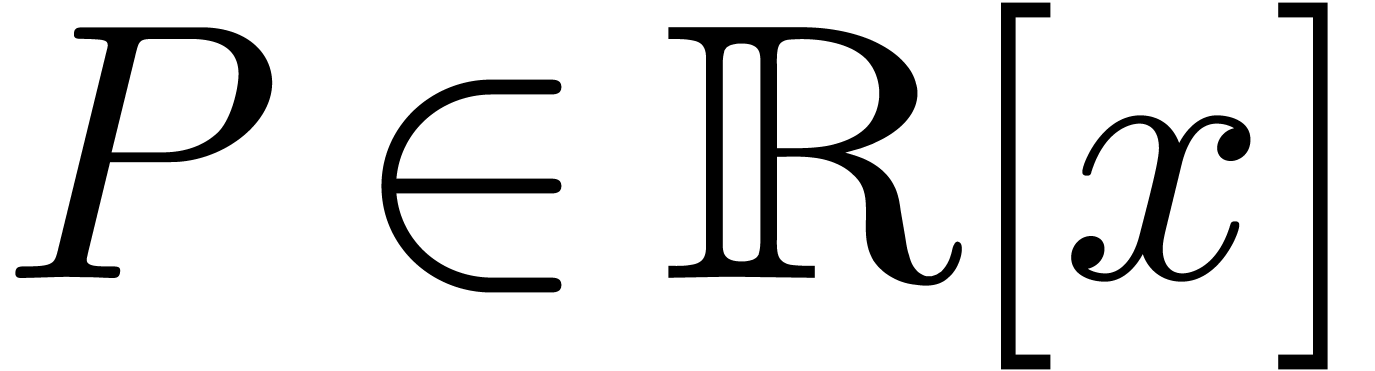 or
or
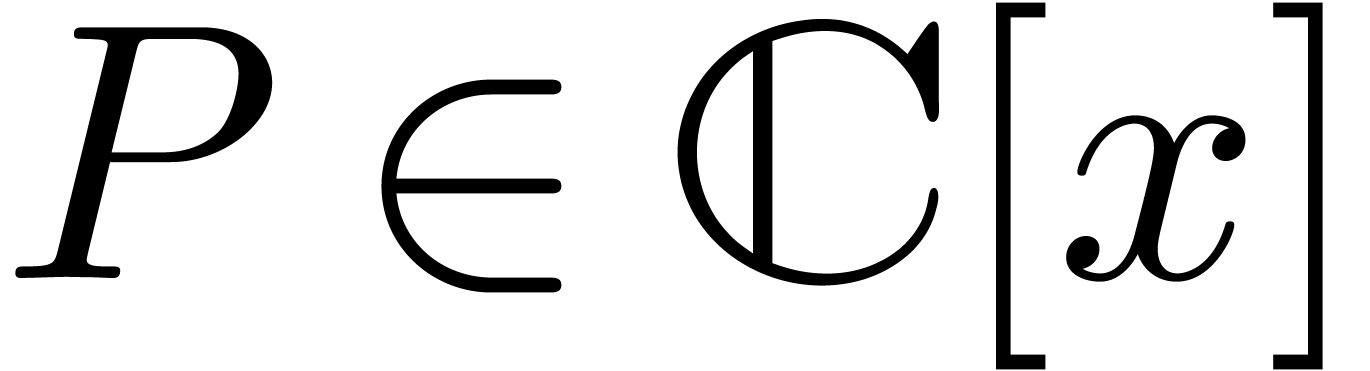 by
by
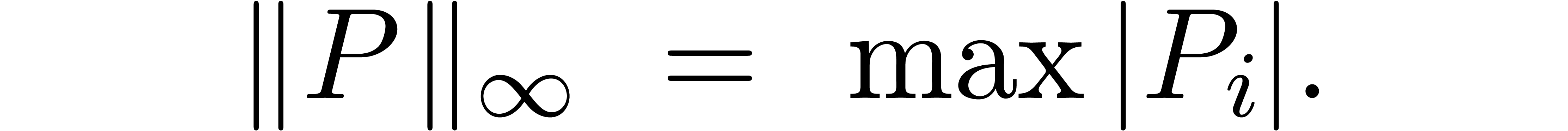
For power series  or
or  which converge on the compact disk
which converge on the compact disk 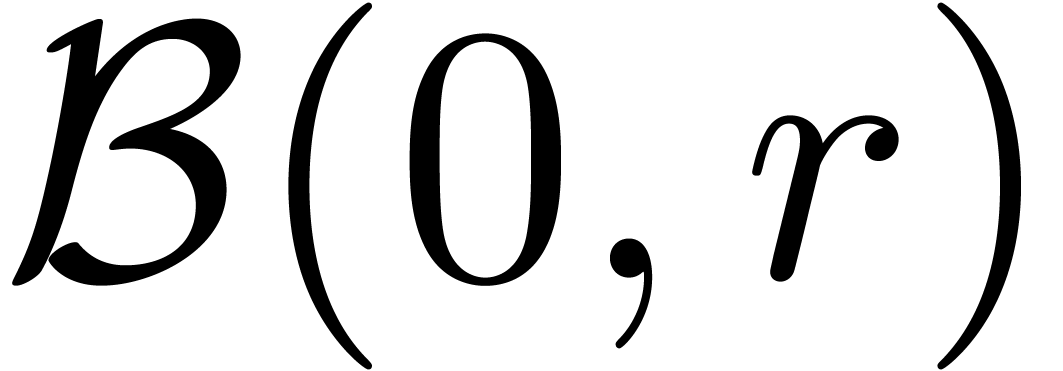 ,
we define the norm
,
we define the norm
After rescaling  , we will
usually work with the norm
, we will
usually work with the norm 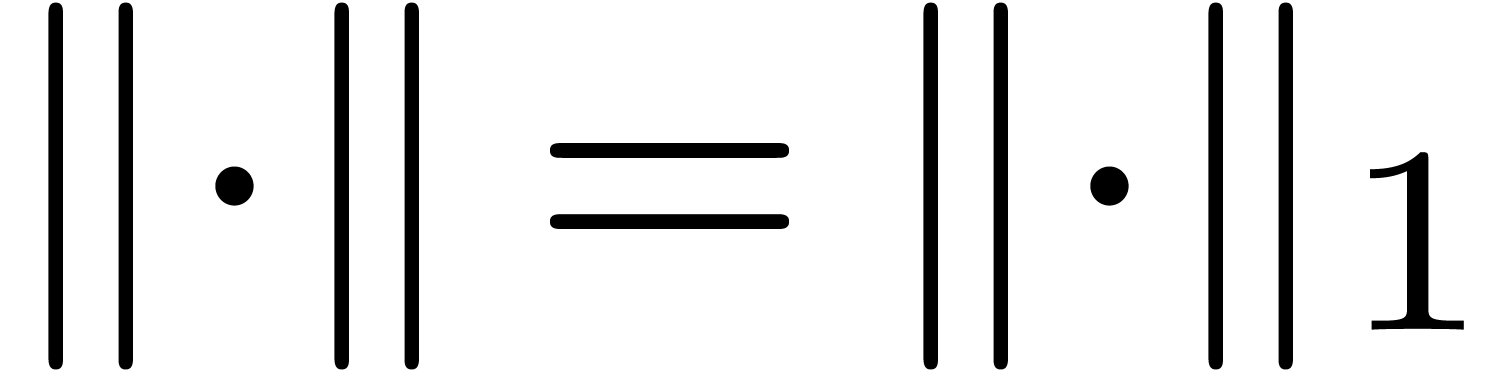 .
.
In some cases, it may be useful to generalize the concept of a ball and
allow for radii in partially ordered rings. For instance, a ball  stands for the set
stands for the set
The sets 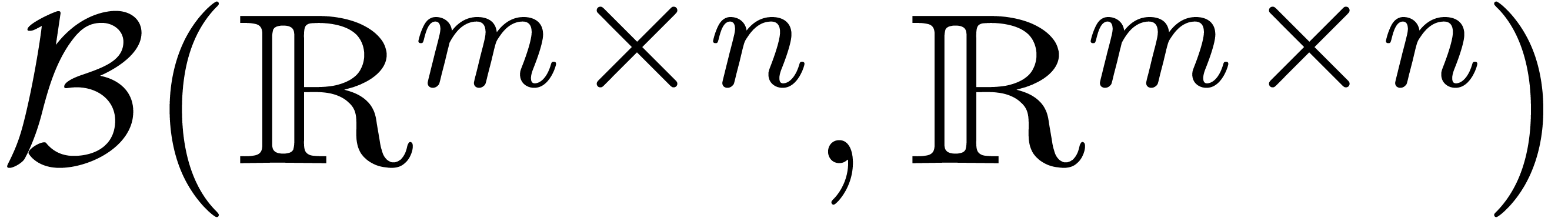 ,
,  ,
, 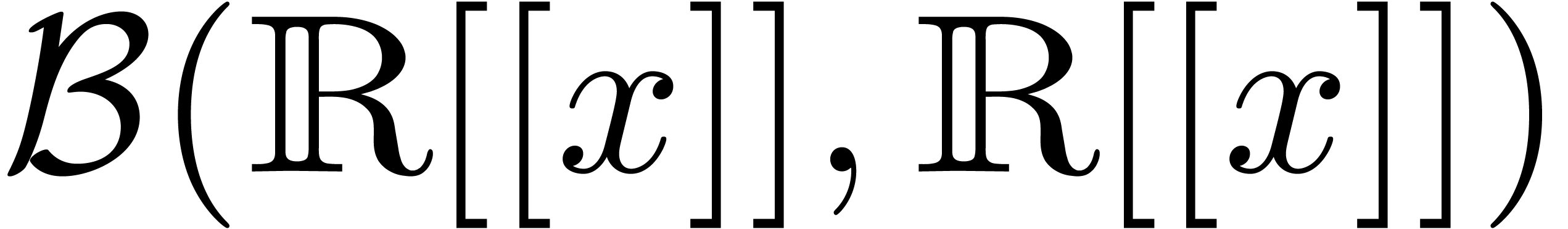 ,
etc. are defined in a similar component wise way. Given
,
etc. are defined in a similar component wise way. Given
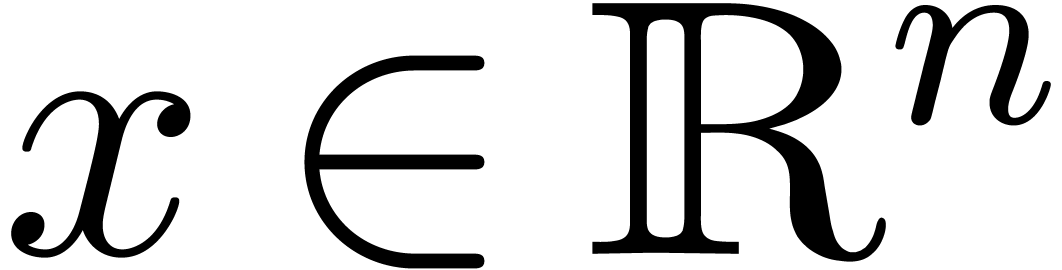 , it will also be convenient
to denote by
, it will also be convenient
to denote by  the vector with . For matrices ,
polynomials and power series
the vector with . For matrices ,
polynomials and power series 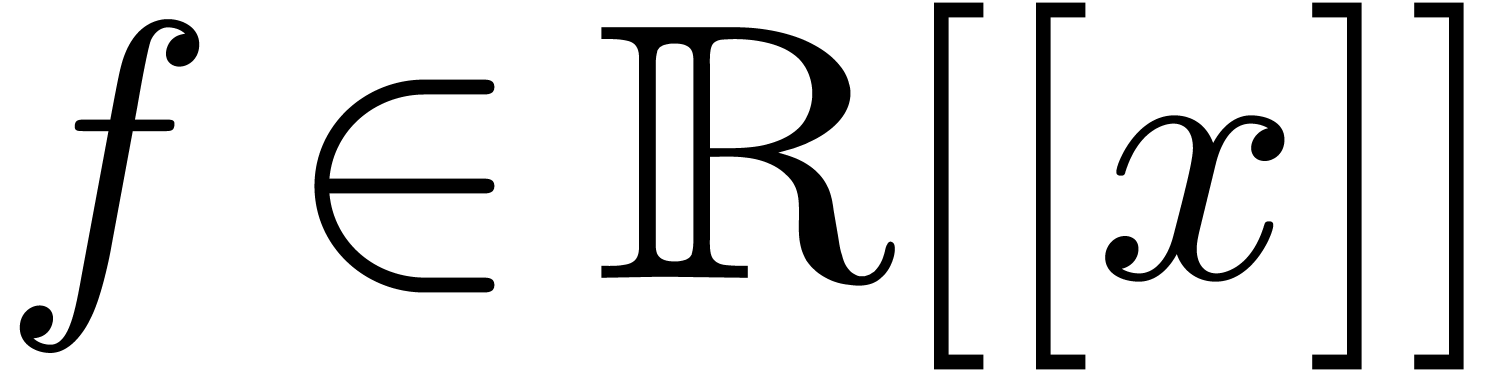 , we define
, we define  ,
,
 and
and  similarly.
similarly.
Let  be a normed vector space over
be a normed vector space over  and recall that
and recall that  stands for the set
of all balls with centers in and radii in . Given an operation
stands for the set
of all balls with centers in and radii in . Given an operation  , the operation is said to lift to an operation
, the operation is said to lift to an operation
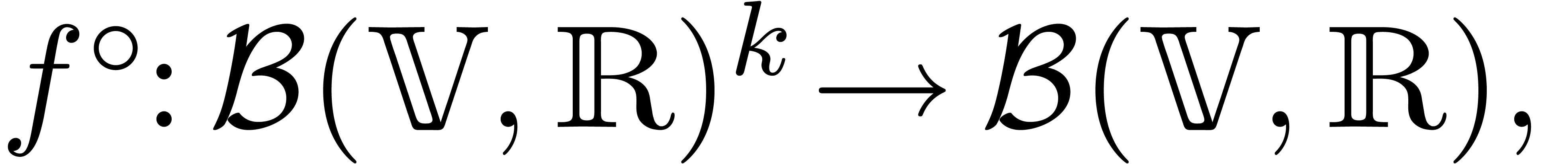
if we have

for all  . For instance, both
the addition
. For instance, both
the addition 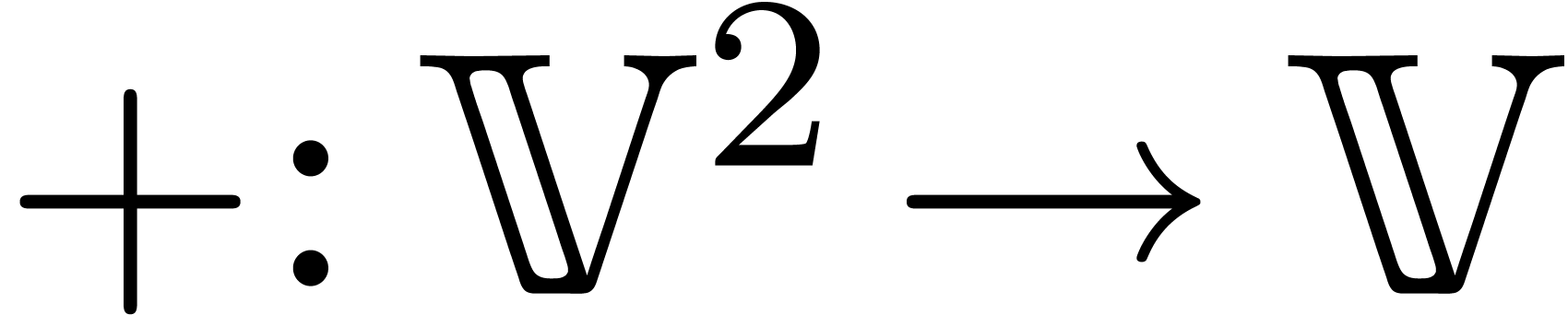 and subtraction
and subtraction 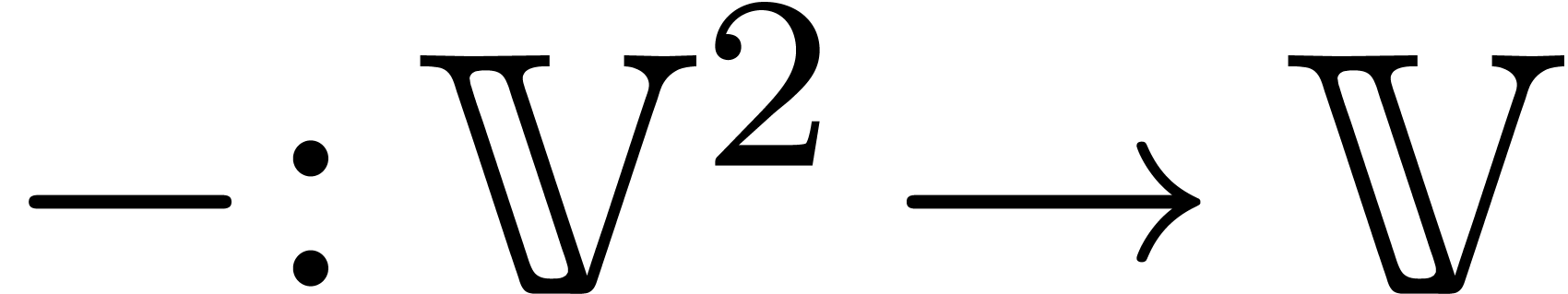 admits lifts
admits lifts
Similarly, if is a normed algebra, then the
multiplication lifts to
The lifts 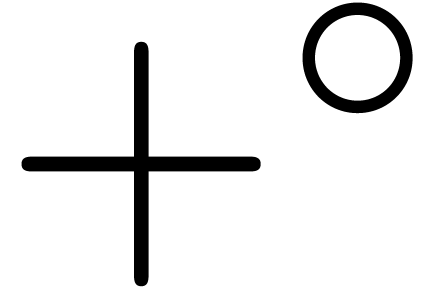 ,
,  ,
,  ,
etc. are also said to be the ball arithmetic counterparts
of addition, subtractions, multiplication, etc.
,
etc. are also said to be the ball arithmetic counterparts
of addition, subtractions, multiplication, etc.
Ball arithmetic is a systematic way for the computation of error bounds
when the input of a numerical operation is known only approximately.
These bounds are usually not sharp. For instance, consider the
mathematical function 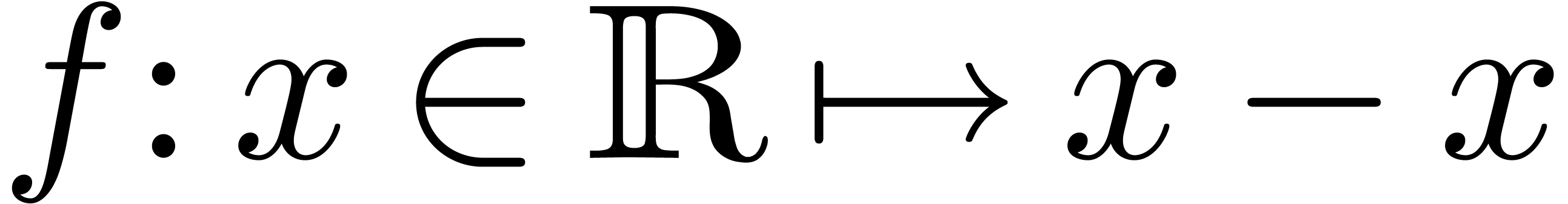 which evaluates to zero
everywhere, even if is only approximately known.
However, taking
which evaluates to zero
everywhere, even if is only approximately known.
However, taking 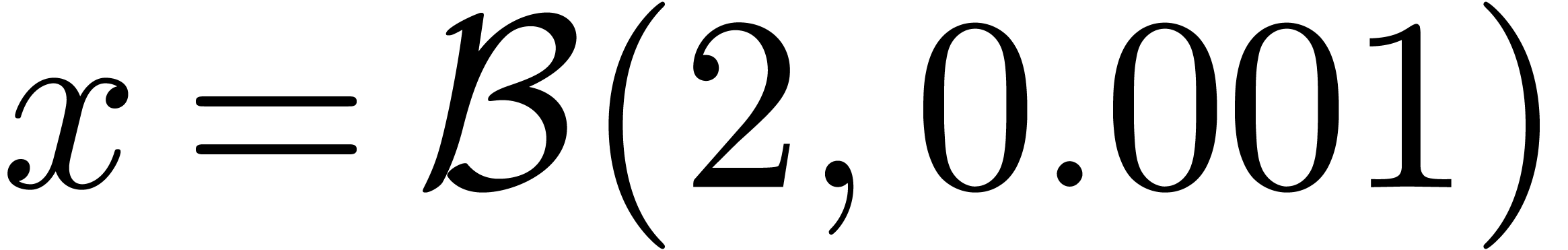 , we have
, we have
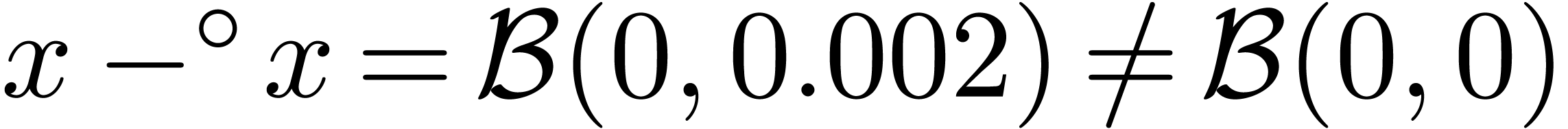 . This phenomenon is known as
overestimation. In general, ball algorithms have to be designed
carefully so as to limit overestimation.
. This phenomenon is known as
overestimation. In general, ball algorithms have to be designed
carefully so as to limit overestimation.
In the above definitions, can be replaced by a
subfield  ,
by an -vector space
,
by an -vector space  , and the domain of
, and the domain of 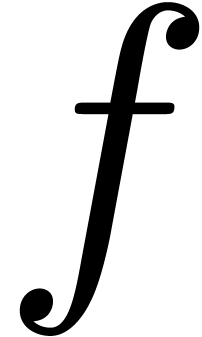 by an open subset of
by an open subset of  .
If and are
effective in the sense that we have algorithms for the
additions, subtractions and multiplications in
and , then basic ball
arithmetic in
.
If and are
effective in the sense that we have algorithms for the
additions, subtractions and multiplications in
and , then basic ball
arithmetic in 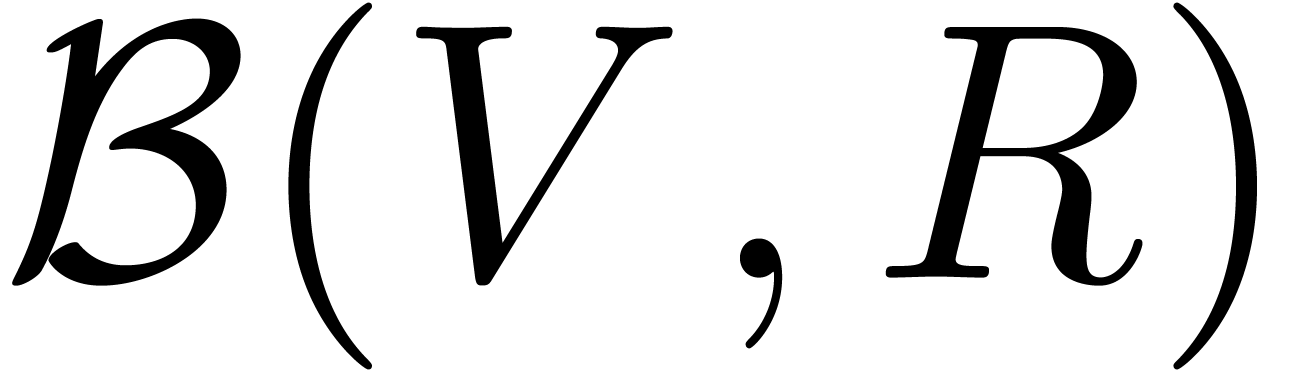 is again effective. If we are
working with finite precision floating point numbers in
rather than a genuine effective subfield ,
we will now show how to adapt the formulas (5), (6)
and (7) in order to take into account rounding errors; it
may also be necessary to allow for an infinite radius in this case.
is again effective. If we are
working with finite precision floating point numbers in
rather than a genuine effective subfield ,
we will now show how to adapt the formulas (5), (6)
and (7) in order to take into account rounding errors; it
may also be necessary to allow for an infinite radius in this case.
Let us detail what needs to be changed when using IEEE conform finite
precision arithmetic, say 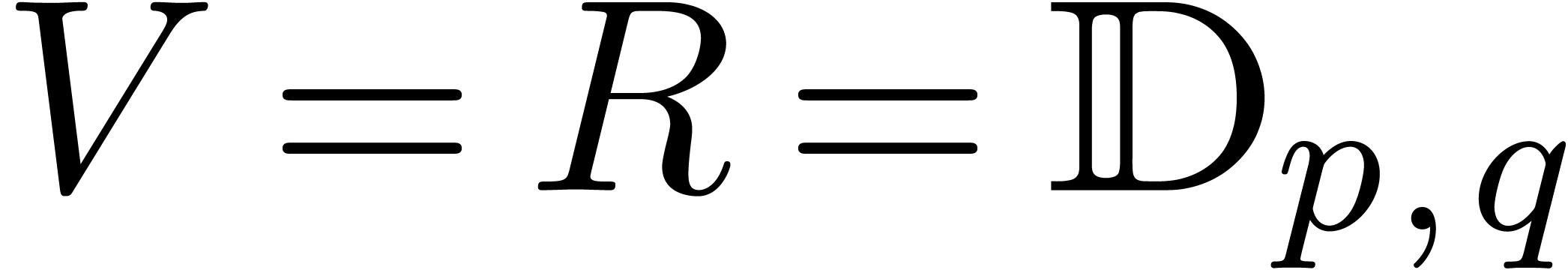 .
We will denote
.
We will denote
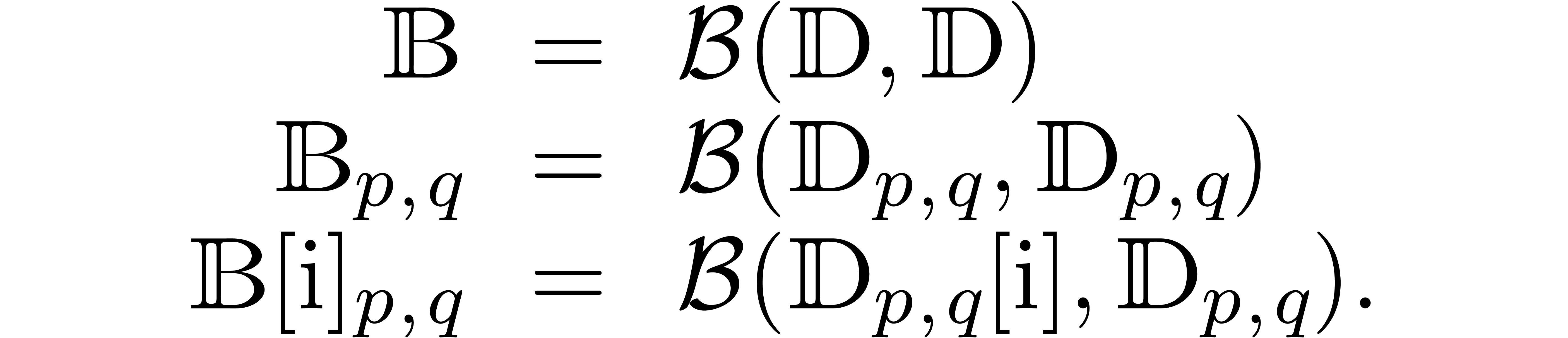
When working with multiple precision numbers, it usually suffices to use
low precision numbers for the radius type. Recalling that , we will therefore denote
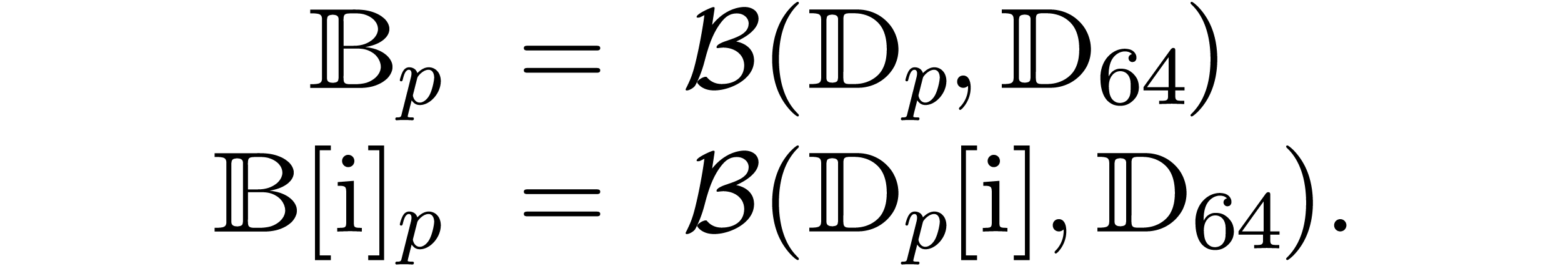
We will write 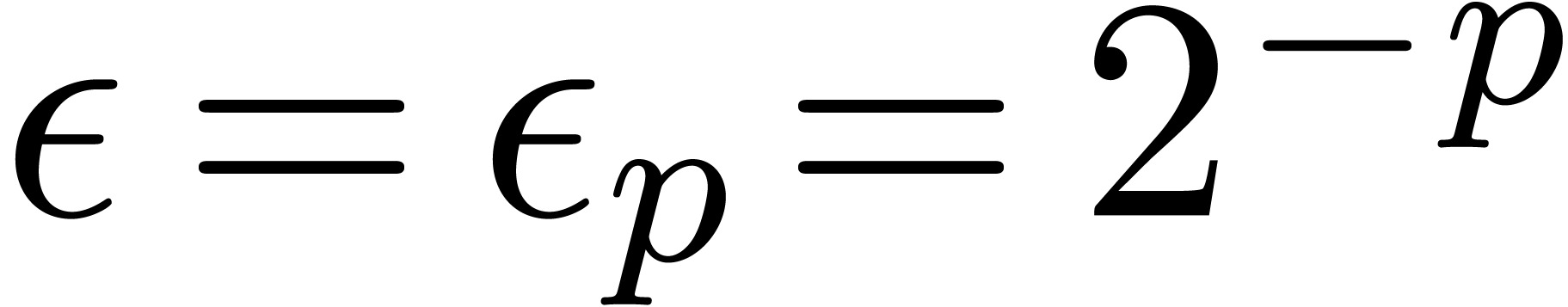 for the machine accuracy and
for the machine accuracy and 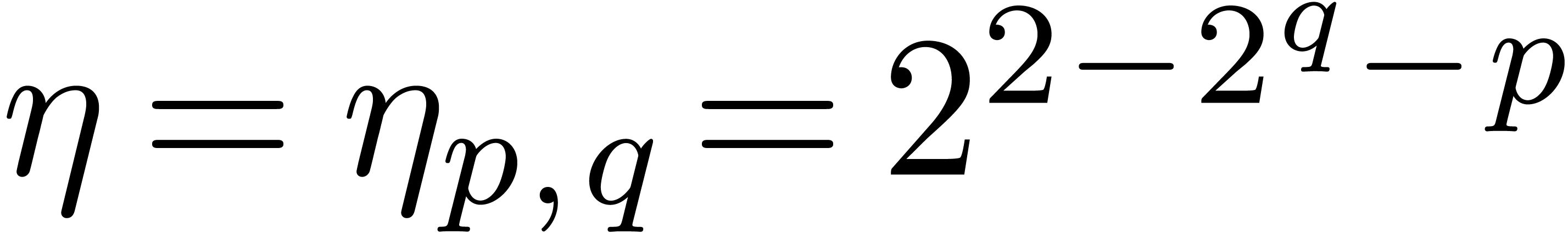 for the smallest representable positive number in
.
for the smallest representable positive number in
.
Given an operation 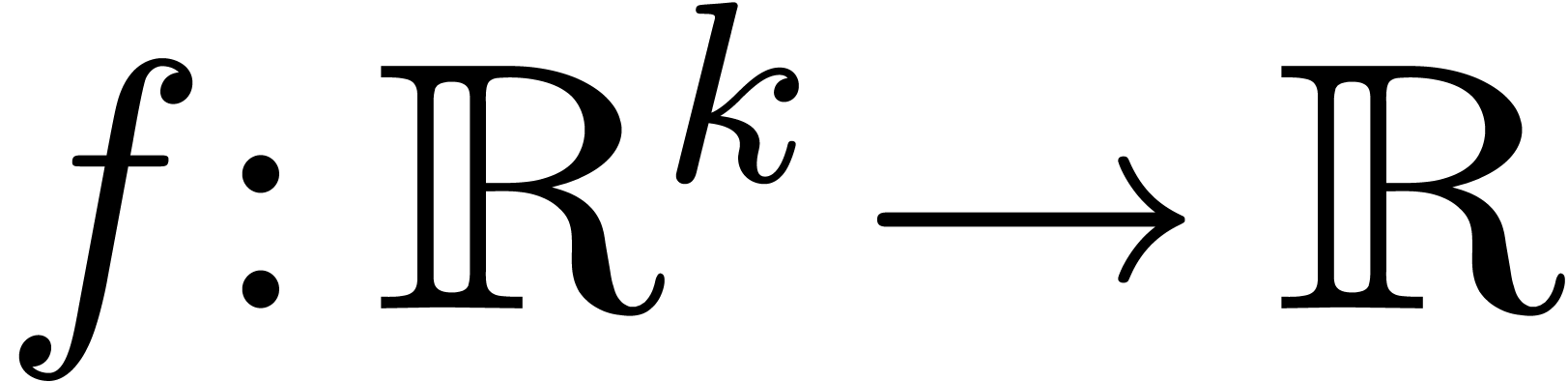 as in section 3.1,
together with balls
as in section 3.1,
together with balls 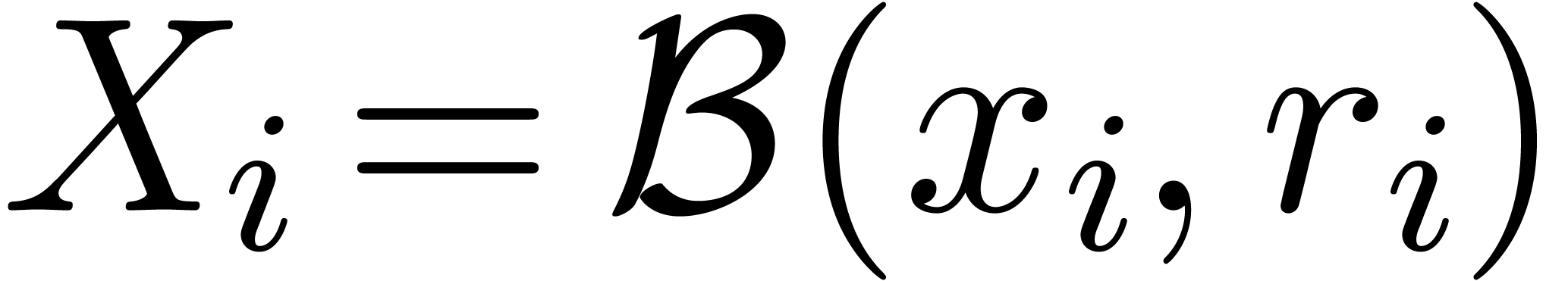 , it is
natural to compute the center
, it is
natural to compute the center  of
of
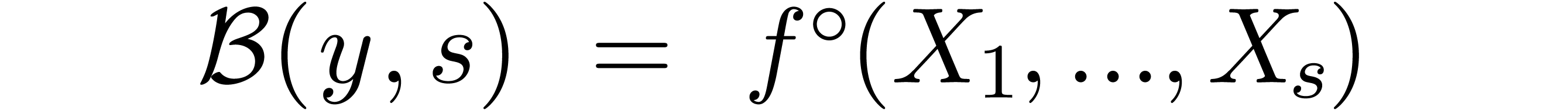
by rounding to the nearest:
One interesting point is that the committed error
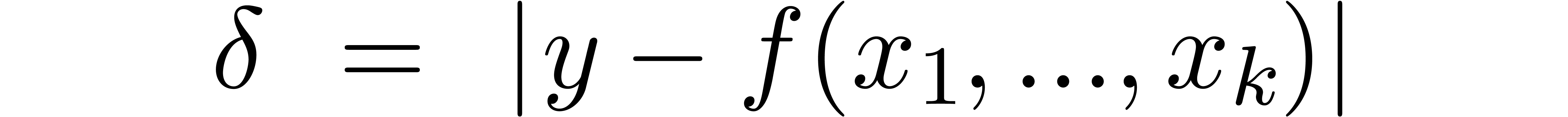
does not really depend on the operation itself:
we have the universal upper bound
It would be useful if this adjustment function  were present in the hardware.
were present in the hardware.
For the computation of the radius  ,
it now suffices to use the sum of
,
it now suffices to use the sum of  and the
theoretical bound formulas for the infinite precision case. For
instance,
and the
theoretical bound formulas for the infinite precision case. For
instance,
where  stands for the “adjusted
constructor”
stands for the “adjusted
constructor”
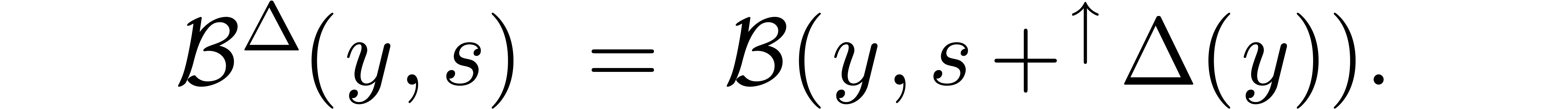
The approach readily generalizes to other “normed vector
spaces” over ,
as soon as one has a suitable rounded arithmetic in
and a suitable adjustment function attached to
it.
Notice that 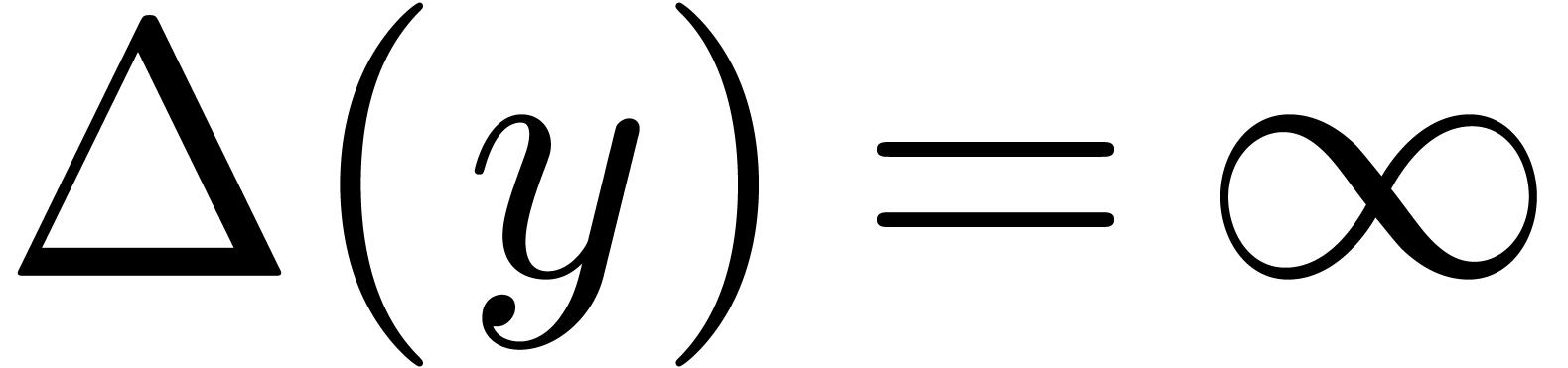 , if
, if 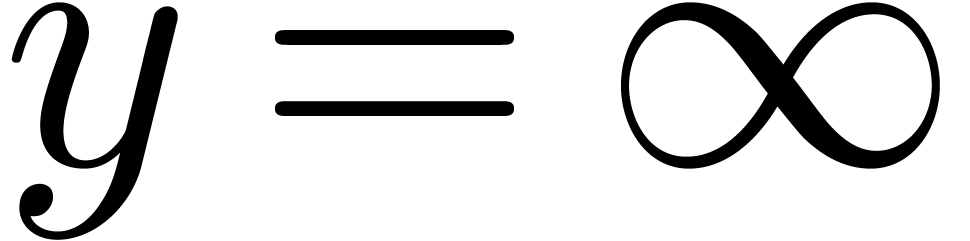 or is the largest representable
real number in .
Consequently, the finite precision ball computations naturally take
place in domains of the form
or is the largest representable
real number in .
Consequently, the finite precision ball computations naturally take
place in domains of the form  rather than
rather than  . Of course, balls with infinite
radius carry no useful information about the result. In order to ease
the reading, we will assume the absence of overflows in what follows,
and concentrate on computations with ordinary numbers in . We will only consider infinities if they are
used in an essential way during the computation.
. Of course, balls with infinite
radius carry no useful information about the result. In order to ease
the reading, we will assume the absence of overflows in what follows,
and concentrate on computations with ordinary numbers in . We will only consider infinities if they are
used in an essential way during the computation.
Similarly, if we want ball arithmetic to be a natural extension of the
IEEE 754 norm, then we need an equivalent of . One approach consists of introducing a  (not a ball) object, which could be represented by
(not a ball) object, which could be represented by 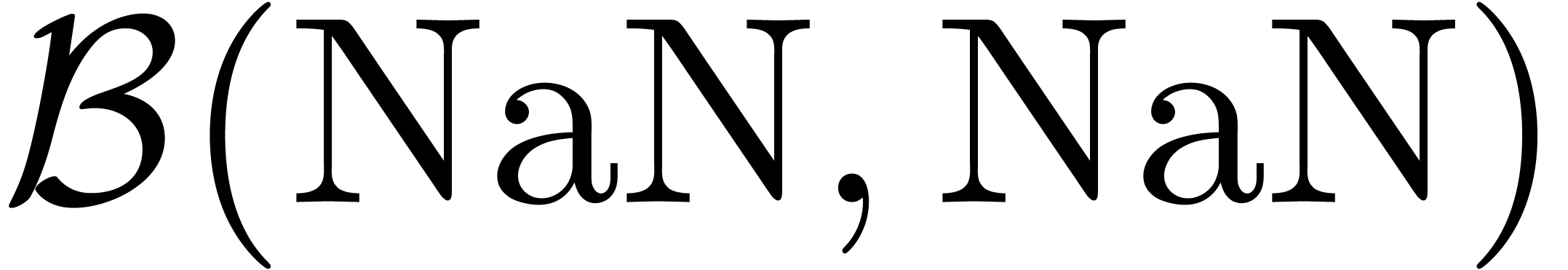 or
or 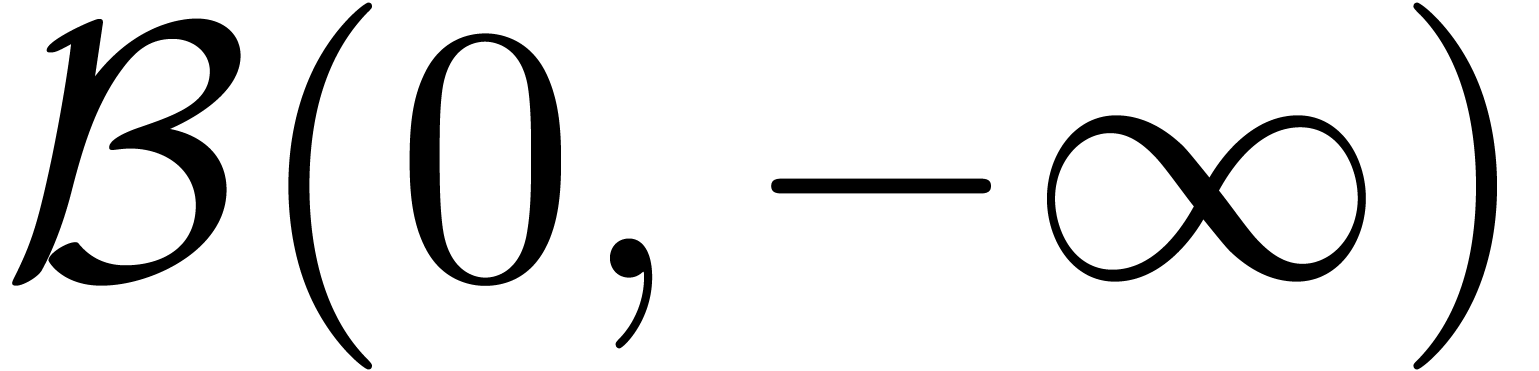 . A
ball function
. A
ball function 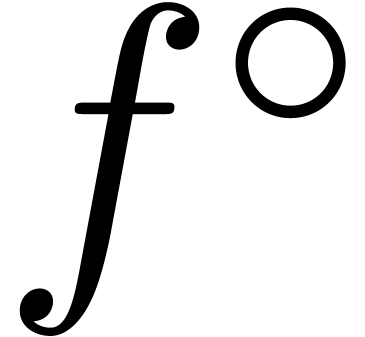 returns if
returns for one
selection of members of the input balls. For instance,
returns if
returns for one
selection of members of the input balls. For instance, 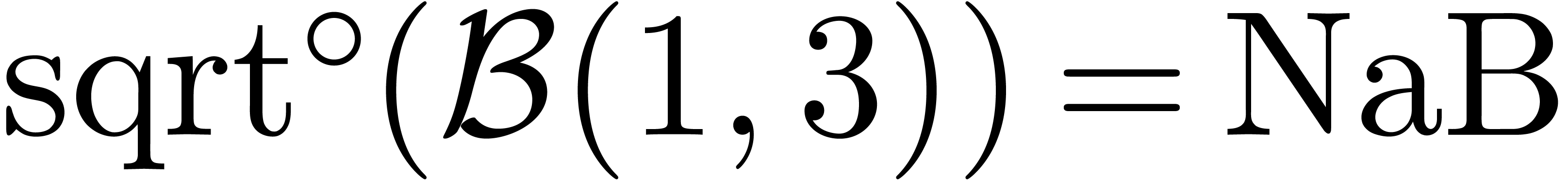 . An alternative approach consists of the
attachment of an additional flag to each ball object, which signals a
possible invalid outcome. Following this convention,
. An alternative approach consists of the
attachment of an additional flag to each ball object, which signals a
possible invalid outcome. Following this convention, 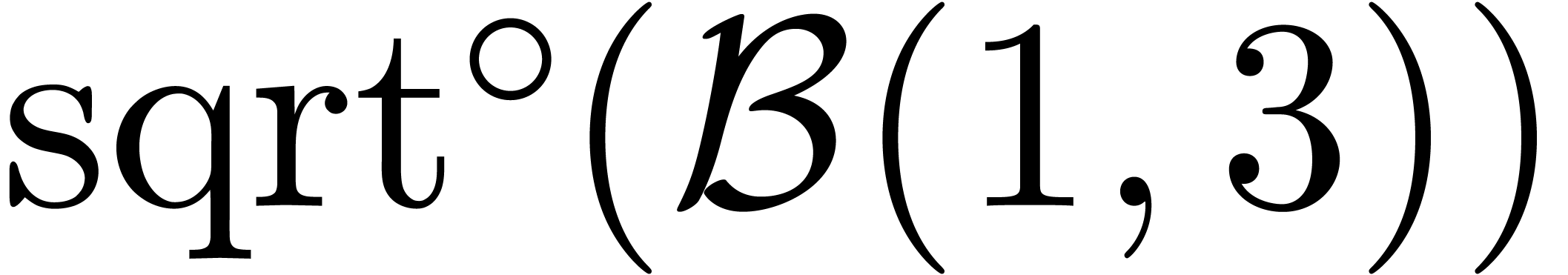 yields
yields 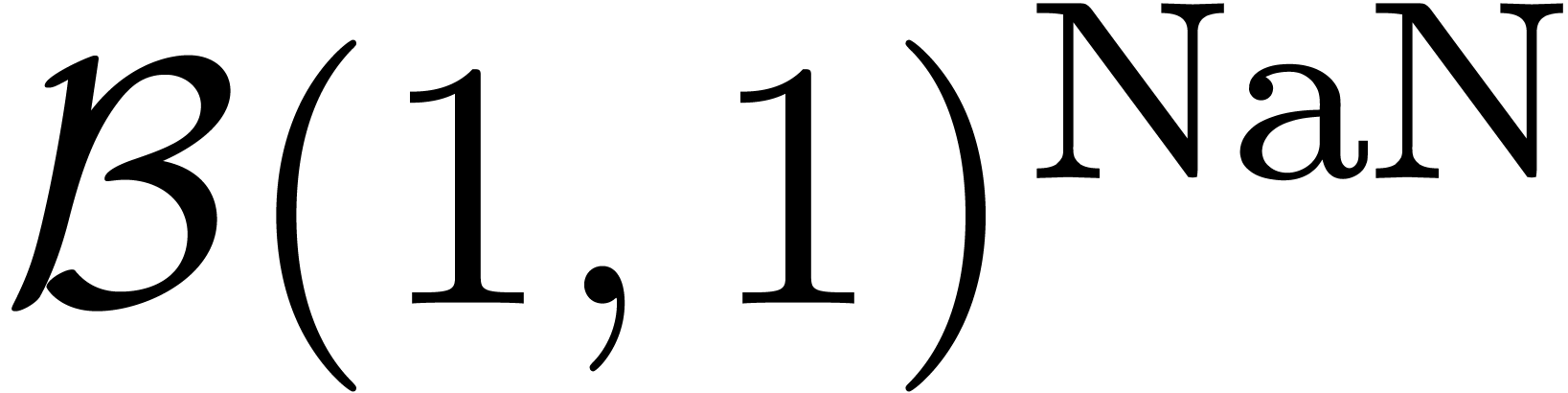 .
.
Using the formulas from the previous section, it is relatively
straightforward to implement ball arithmetic as a C++ template library,
as we have done in the
Multiple precision libraries such as
When computing with complex numbers  ,
one may again save several function calls. Moreover, it is possible
to regard
,
one may again save several function calls. Moreover, it is possible
to regard  as an element of
as an element of 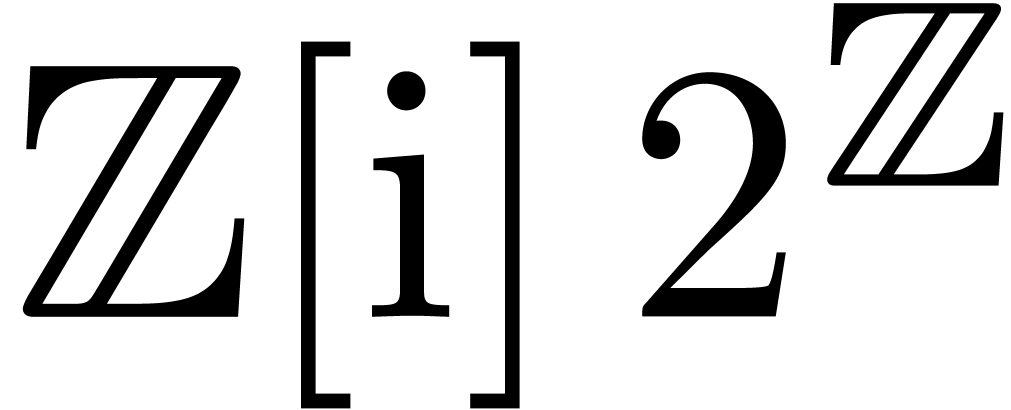 rather than
rather than 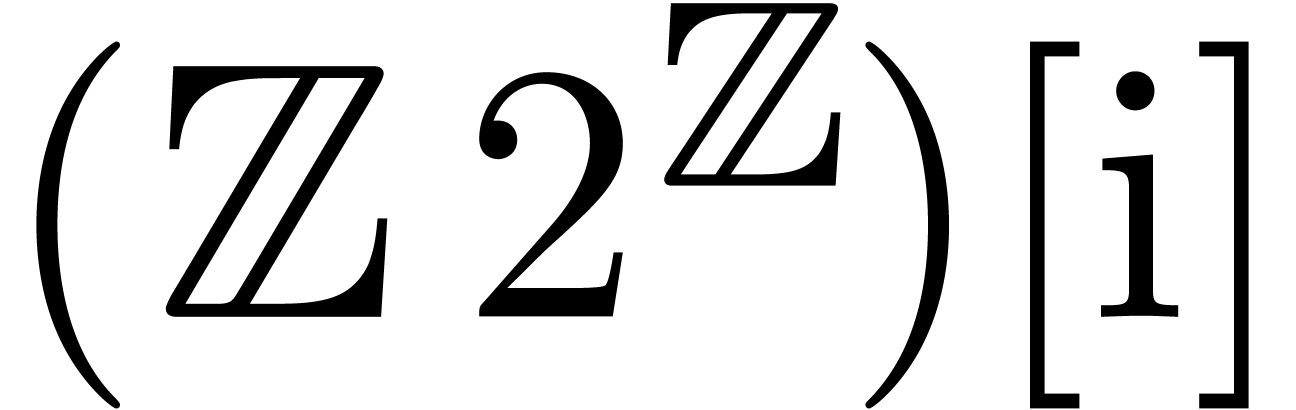 ,
i.e. use a single exponent for both the real and
imaginary parts of . This
optimization reduces the time spent on exponent computations and
mantissa normalizations.
,
i.e. use a single exponent for both the real and
imaginary parts of . This
optimization reduces the time spent on exponent computations and
mantissa normalizations.
Consider a ball 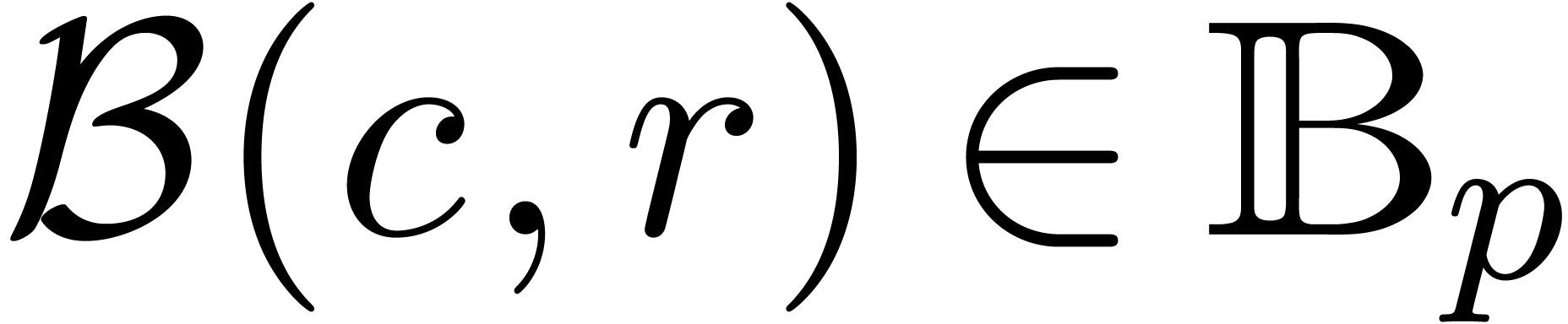 and recall that
and recall that 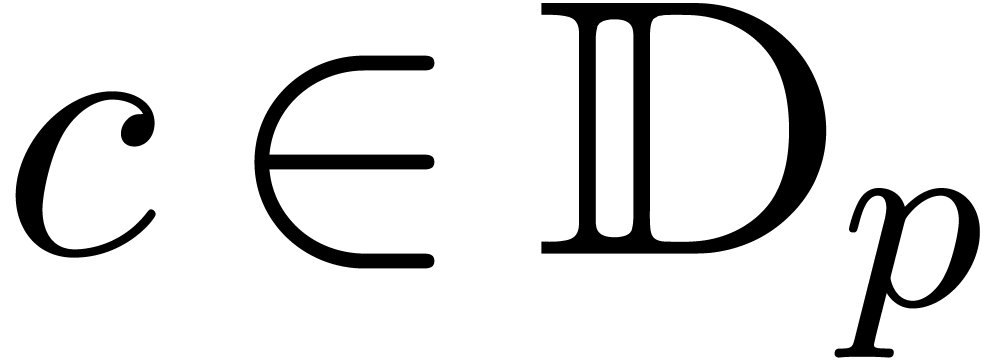 ,
, 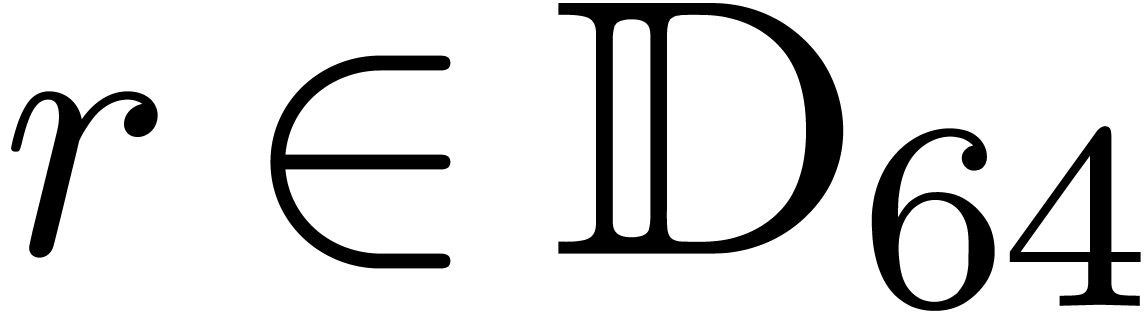 .
If
.
If 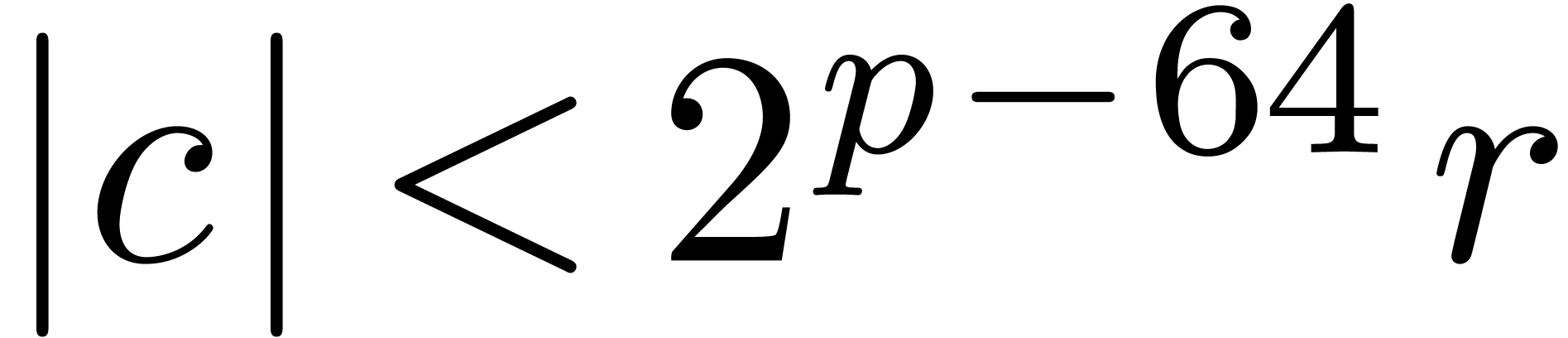 , then the
, then the 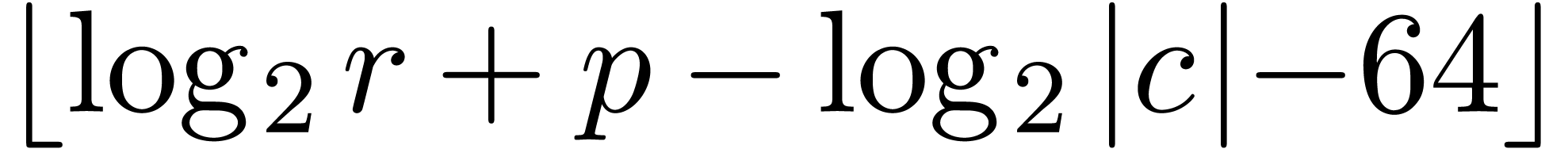 least significant binary digits of
are of little interest. Hence, we may replace
by its closest approximation in
least significant binary digits of
are of little interest. Hence, we may replace
by its closest approximation in 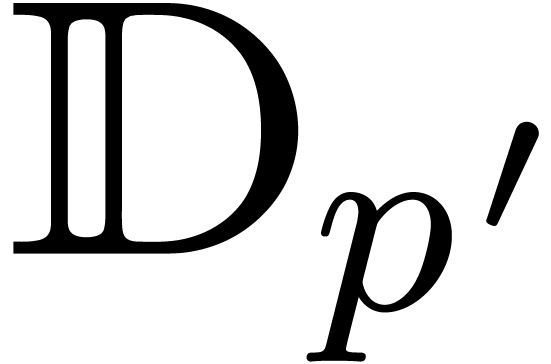 ,
with
,
with 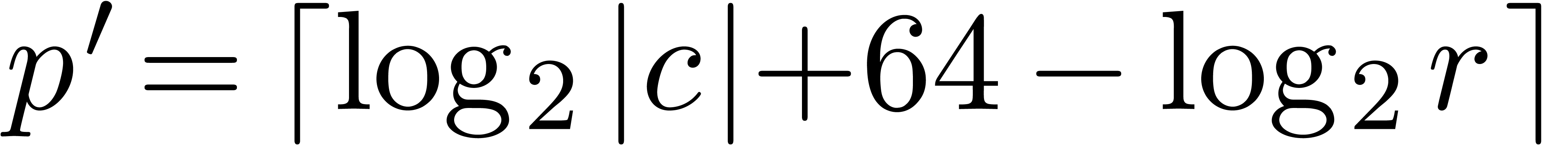 , and reduce the
working precision to
, and reduce the
working precision to  .
Modulo slightly more work, it is also possible to share the
exponents of the center and the radius.
.
Modulo slightly more work, it is also possible to share the
exponents of the center and the radius.
If we don't need large exponents for our multiple precision numbers,
then it is possible to use machine doubles 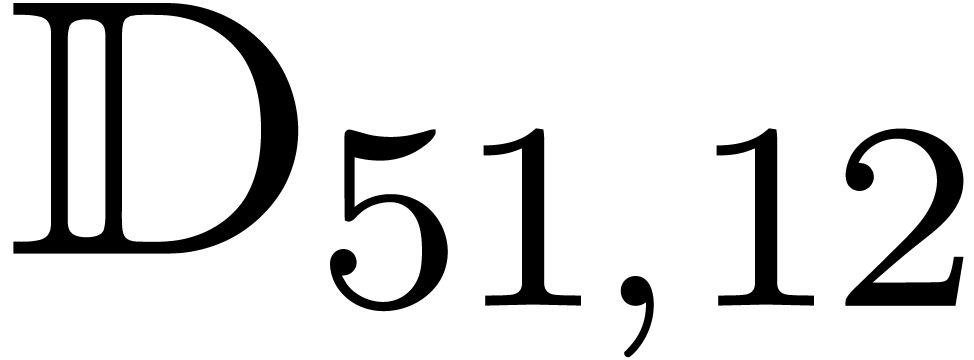 as our radius type and further reduce the overhead of bound
computations.
as our radius type and further reduce the overhead of bound
computations.
When combining the above optimizations, it can be hoped that multiple precision ball arithmetic can be implemented almost as efficiently as standard multiple precision arithmetic. However, this requires a significantly higher implementation effort.
Given 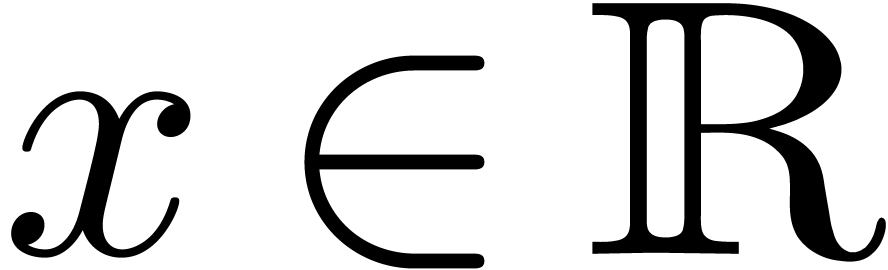 ,
, 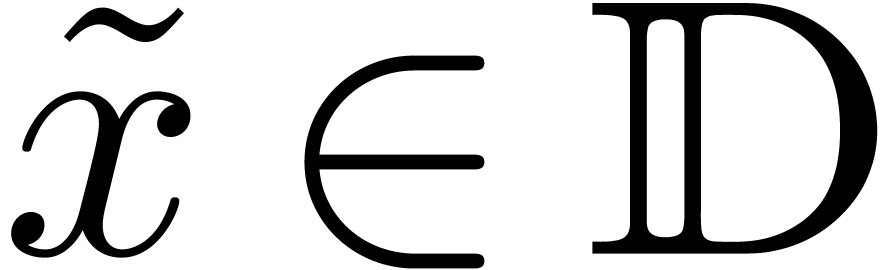 and
and 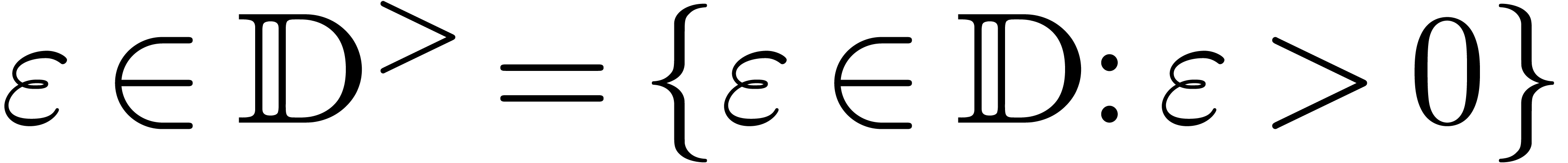 , we say that
, we say that 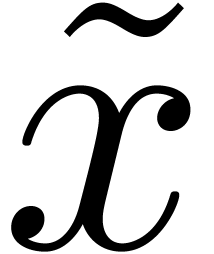 is an
is an  -approximation
of if
-approximation
of if 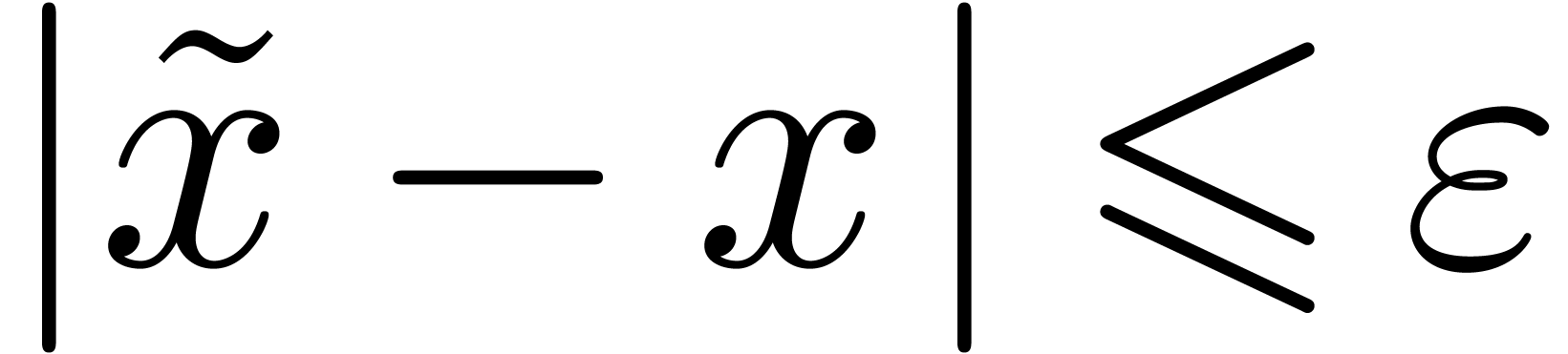 .
A real number is said to be computable
[Tur36, Grz57, Wei00] if there
exists an approximation algorithm which takes an absolute
tolerance
.
A real number is said to be computable
[Tur36, Grz57, Wei00] if there
exists an approximation algorithm which takes an absolute
tolerance 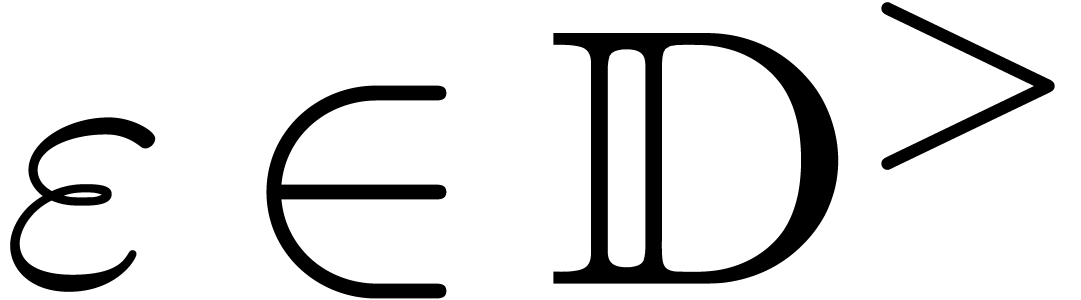 on input and which returns an -approximation of . We denote by
on input and which returns an -approximation of . We denote by  the set
of computable real numbers. We may regard as a
data type, whose instances are represented by approximation algorithms
(this is also known as the Markov representation [Wei00,
Section 9.6]).
the set
of computable real numbers. We may regard as a
data type, whose instances are represented by approximation algorithms
(this is also known as the Markov representation [Wei00,
Section 9.6]).
In practice, it is more convenient to work with so called ball
approximation algorithms: a real number is computable if and only if it
admits a ball approximation algorithm, which takes a working
precision on input and returns a ball
approximation 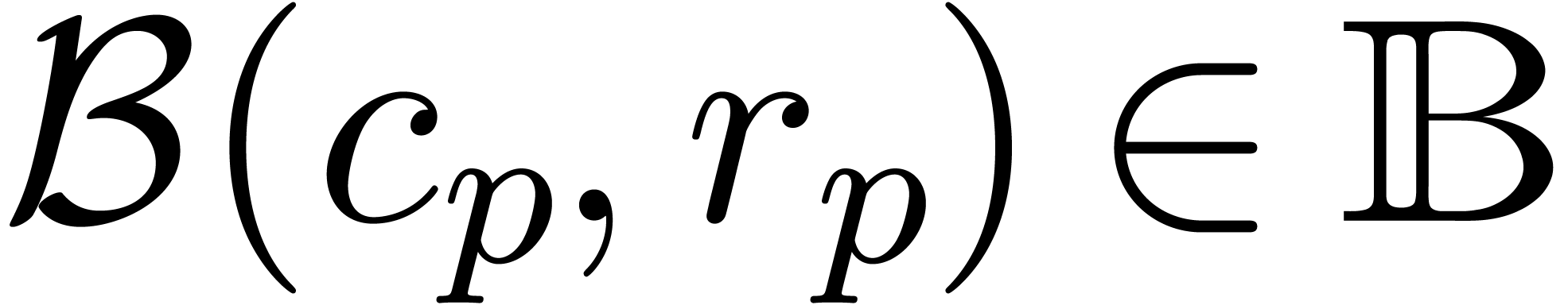 with
with 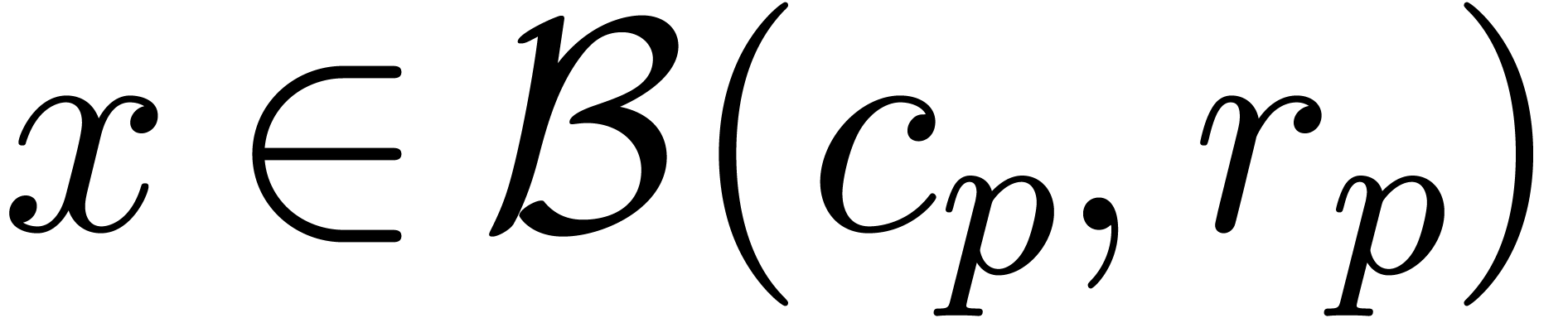 and
and 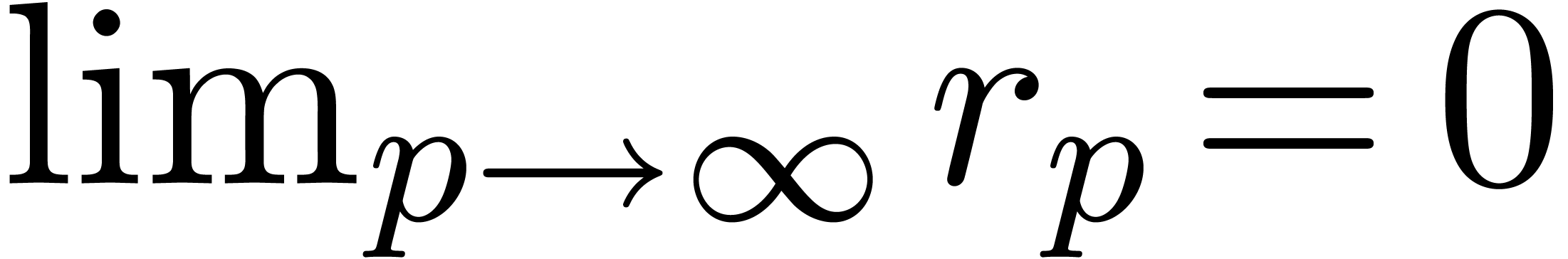 . Indeed, assume that we
have a ball approximation algorithm. In order to obtain an -approximation, it suffices to compute ball
approximations at precisions
. Indeed, assume that we
have a ball approximation algorithm. In order to obtain an -approximation, it suffices to compute ball
approximations at precisions  which double at
every step, until
which double at
every step, until 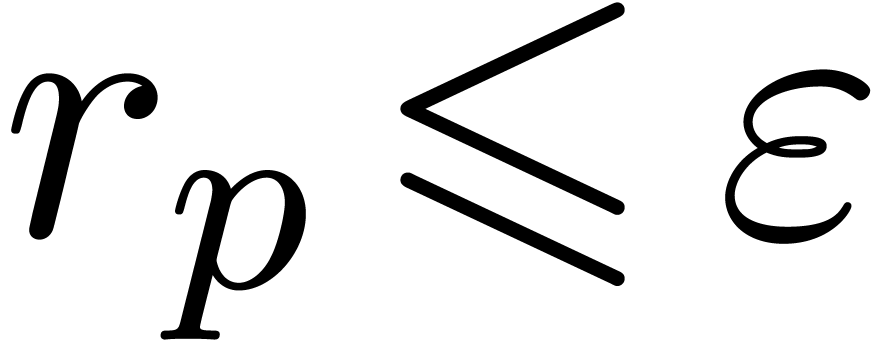 .
Conversely, given an approximation algorithm
.
Conversely, given an approximation algorithm 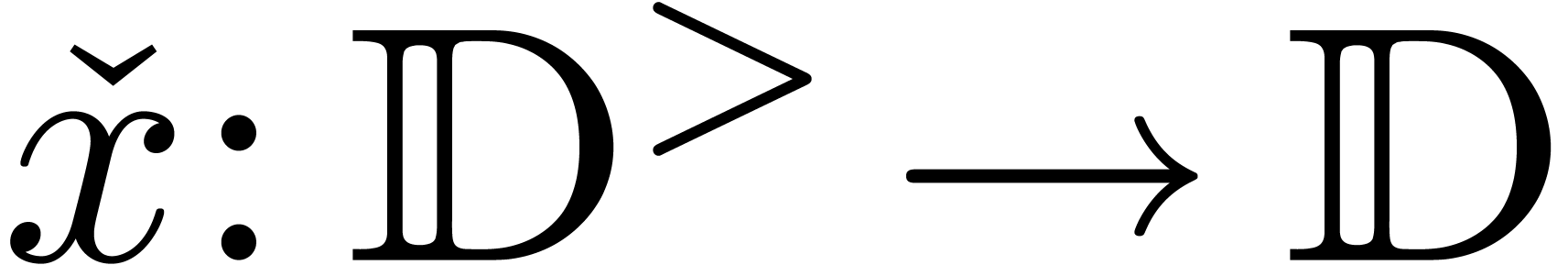 of
of
 , we obtain a ball
approximation algorithm
, we obtain a ball
approximation algorithm 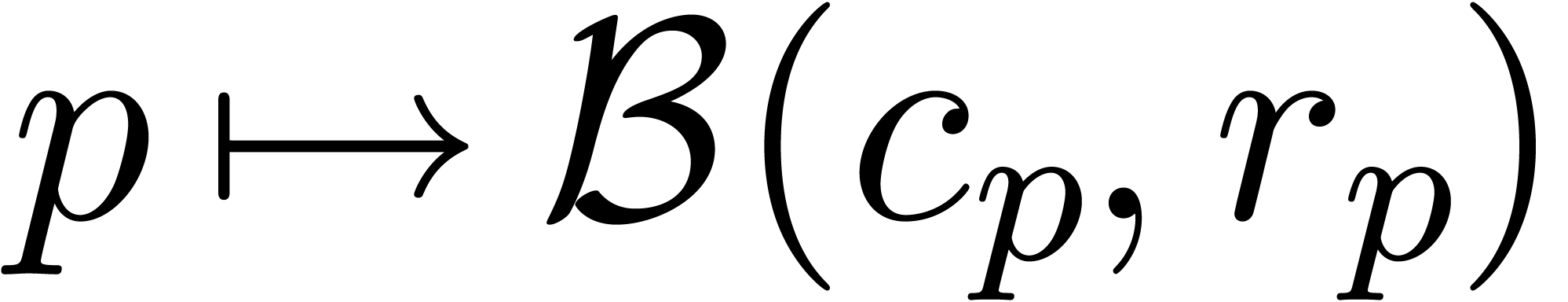 by taking
by taking  and
and 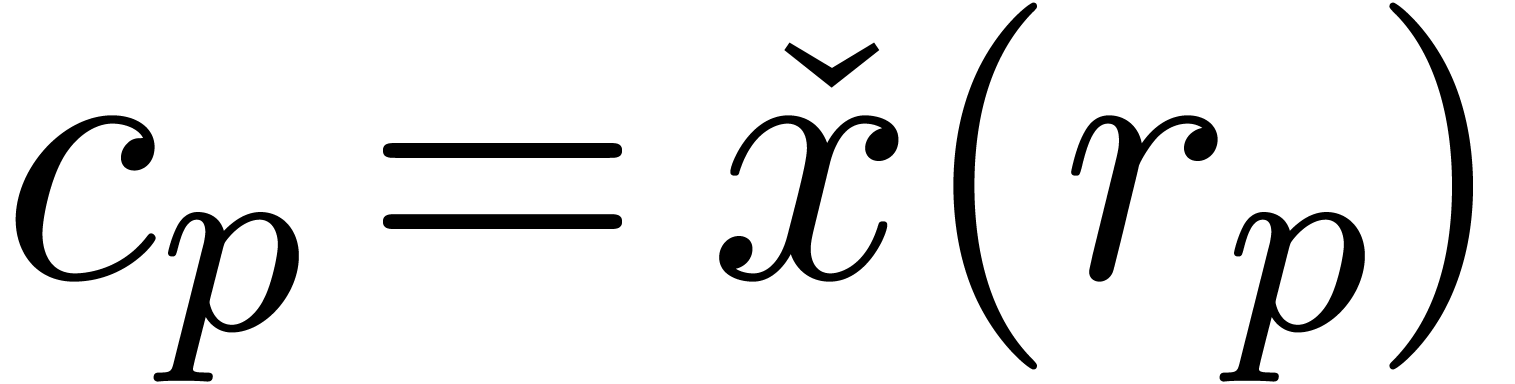 .
.
Given 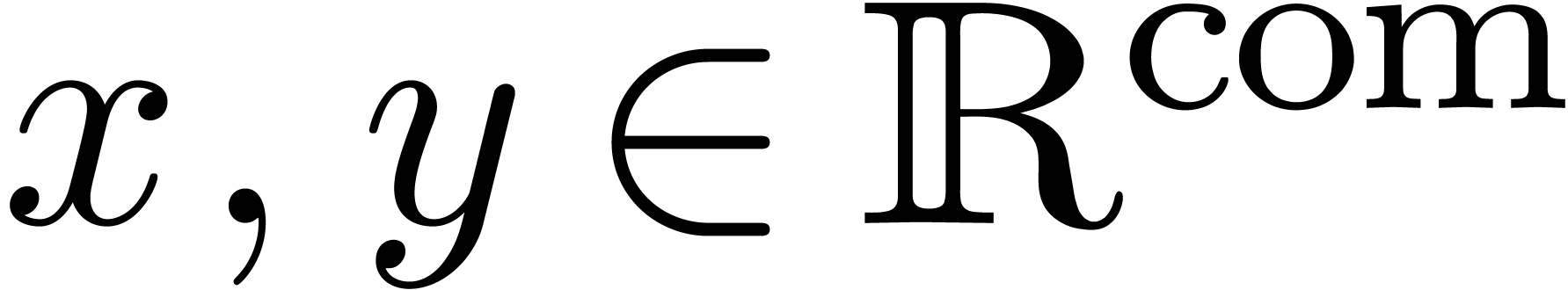 with ball approximation algorithms
with ball approximation algorithms  , we may compute ball approximation
algorithms for
, we may compute ball approximation
algorithms for 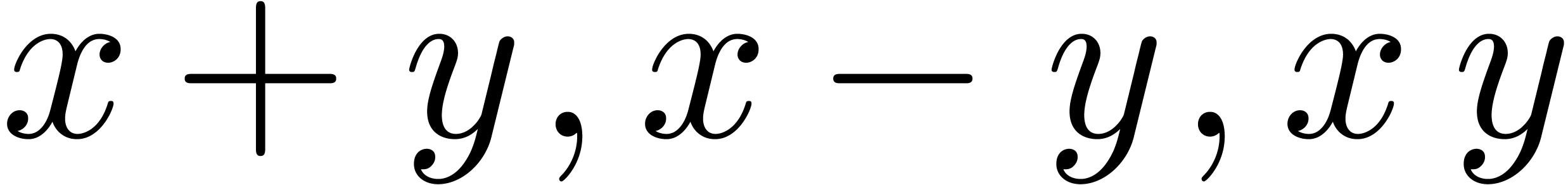 simply by taking
simply by taking
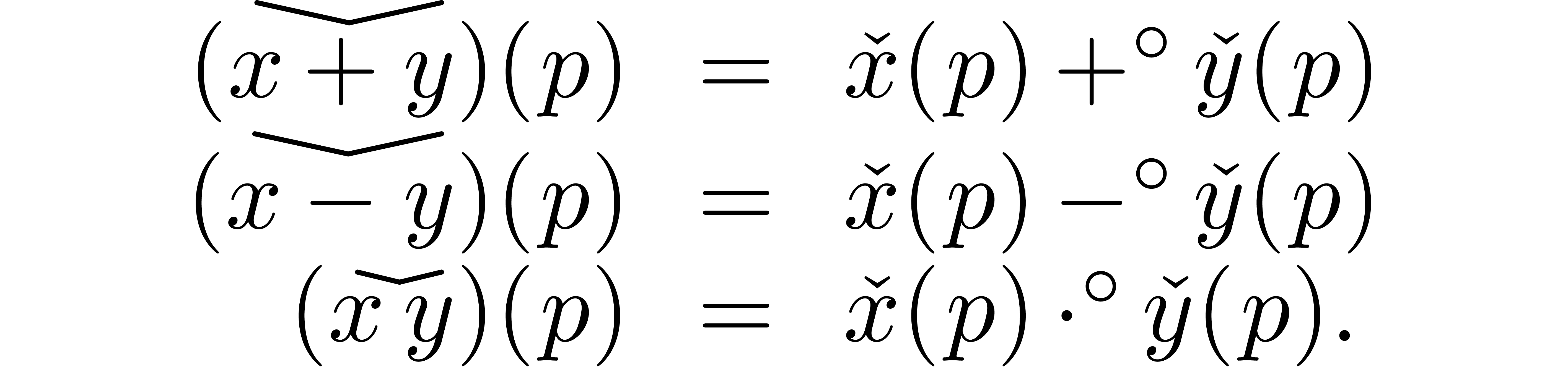
More generally, assuming a good library for ball arithmetic, it is usually easy to write a wrapper library with the corresponding operations on computable numbers.
From the efficiency point of view, it is also convenient to work with
ball approximations. Usually, the radius  satisfies
satisfies
or at least
for some  . In that case,
doubling the working precision until a
sufficiently good approximation is found is quite efficient. An even
better strategy is to double the “expected running time” at
every step [vdH06a, KR06]. Yet another
approach will be described in section 3.6 below.
. In that case,
doubling the working precision until a
sufficiently good approximation is found is quite efficient. An even
better strategy is to double the “expected running time” at
every step [vdH06a, KR06]. Yet another
approach will be described in section 3.6 below.
The concept of computable real numbers readily generalizes to more
general normed vector spaces. Let be a normed
vector space and let 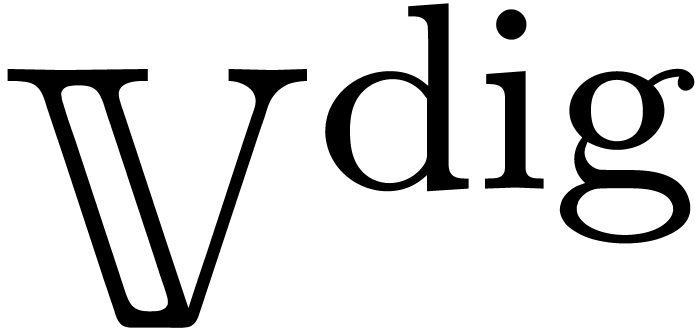 be an effective subset of
digital points in ,
i.e. the elements of admit a
computer representation. For instance, if
be an effective subset of
digital points in ,
i.e. the elements of admit a
computer representation. For instance, if 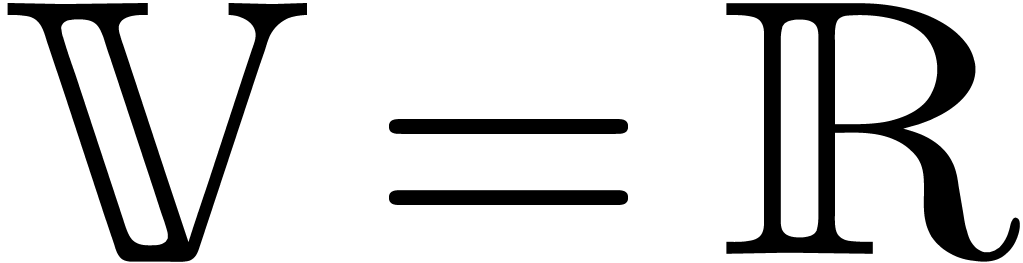 ,
then we take
,
then we take 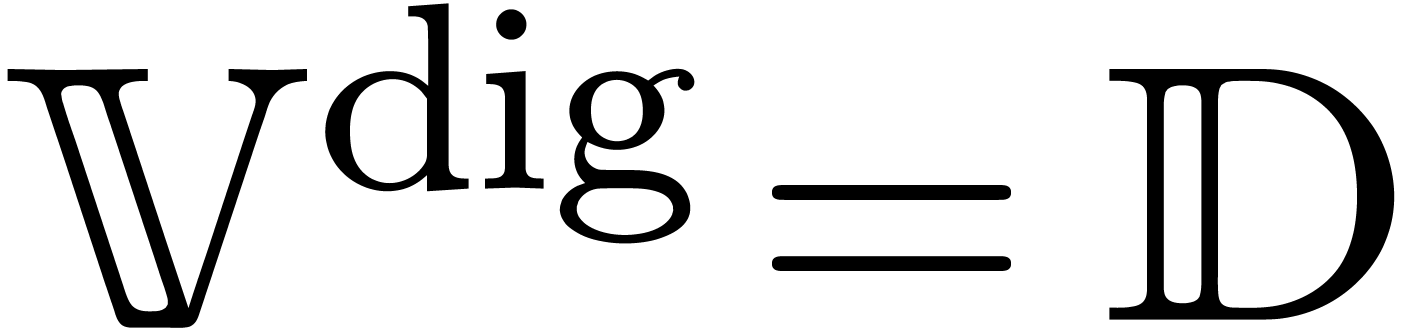 . Similarly, if
. Similarly, if
 is the set of real
matrices, with one of the matrix norms from section 2.3,
then it is natural to take
is the set of real
matrices, with one of the matrix norms from section 2.3,
then it is natural to take 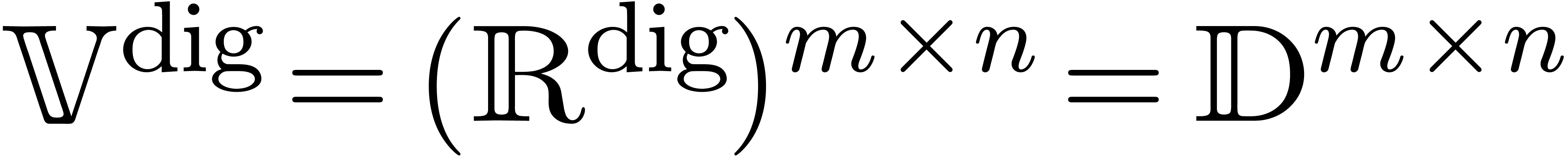 .
A point
.
A point 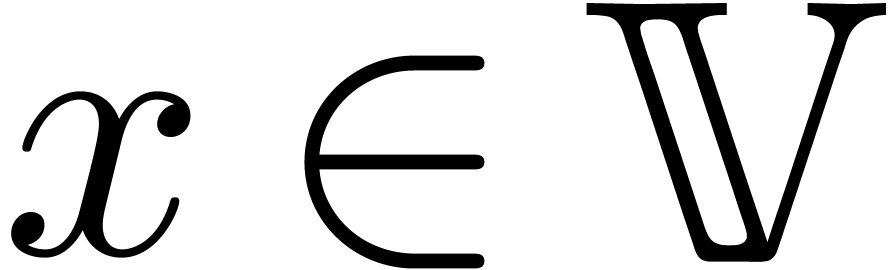 is said to be computable, if it
admits an approximation algorithm which takes
on input, and returns an -approximation
is said to be computable, if it
admits an approximation algorithm which takes
on input, and returns an -approximation
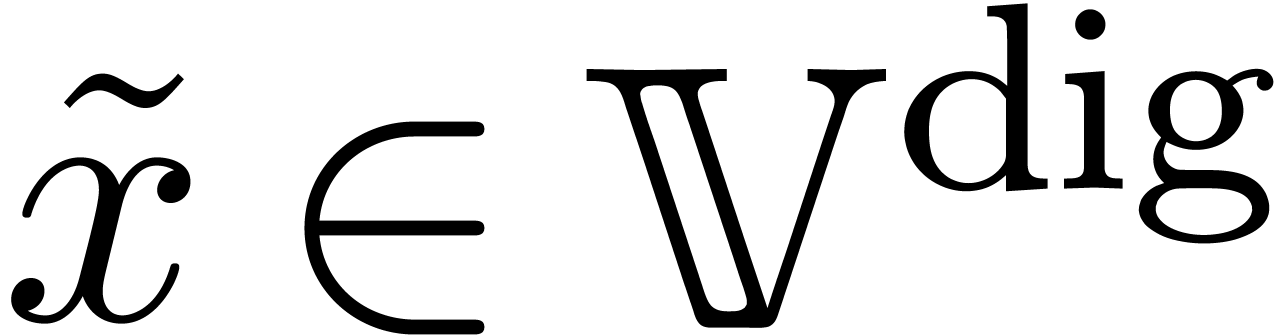 of (satisfying
of (satisfying 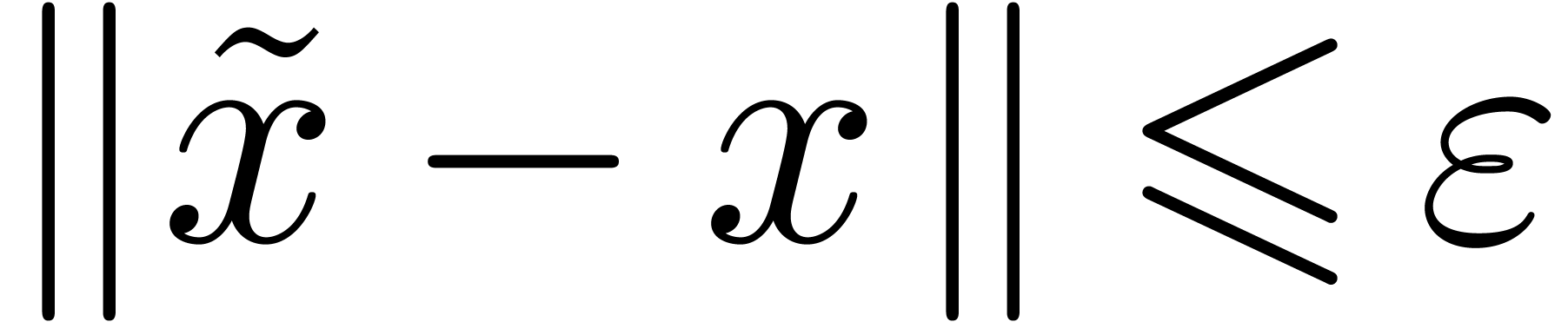 , as above).
, as above).
A real number is said to be left
computable if there exists an algorithm for computing an increasing
sequence  with
with 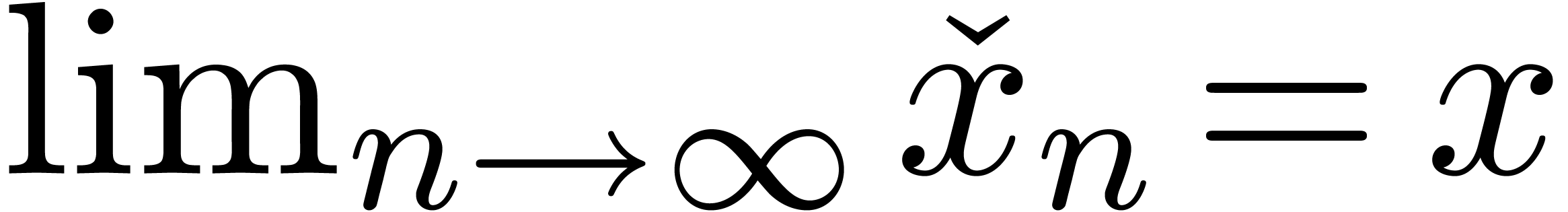 (and
(and  is called a left approximation algorithm). Similarly,
is said to be right computable if
is called a left approximation algorithm). Similarly,
is said to be right computable if  is left computable. A real number is computable if
and only if it is both left and right computable. Left computable but
non computable numbers occur frequently in practice and correspond to
“computable lower bounds” (see also [Wei00, vdH07b]).
is left computable. A real number is computable if
and only if it is both left and right computable. Left computable but
non computable numbers occur frequently in practice and correspond to
“computable lower bounds” (see also [Wei00, vdH07b]).
We will denote by 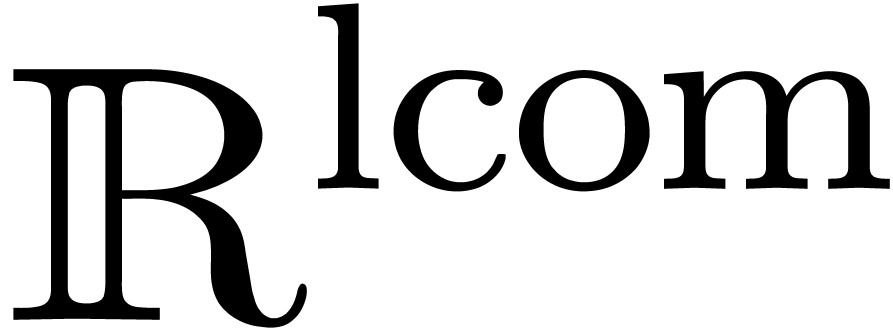 and
and 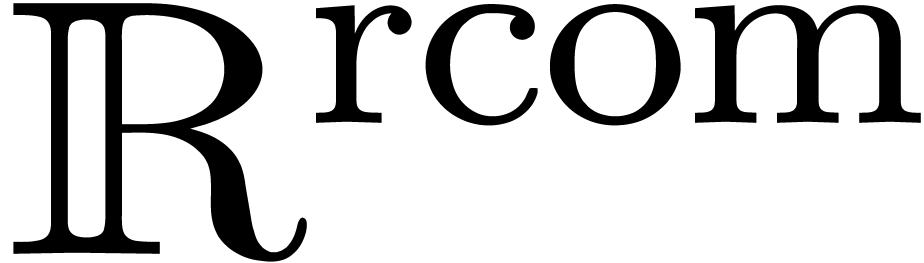 the data types of left and right computable real numbers. It is
convenient to specify and implement algorithms in computable analysis in
terms of these data types, whenever appropriate [vdH07b].
For instance, we have computable functions
the data types of left and right computable real numbers. It is
convenient to specify and implement algorithms in computable analysis in
terms of these data types, whenever appropriate [vdH07b].
For instance, we have computable functions
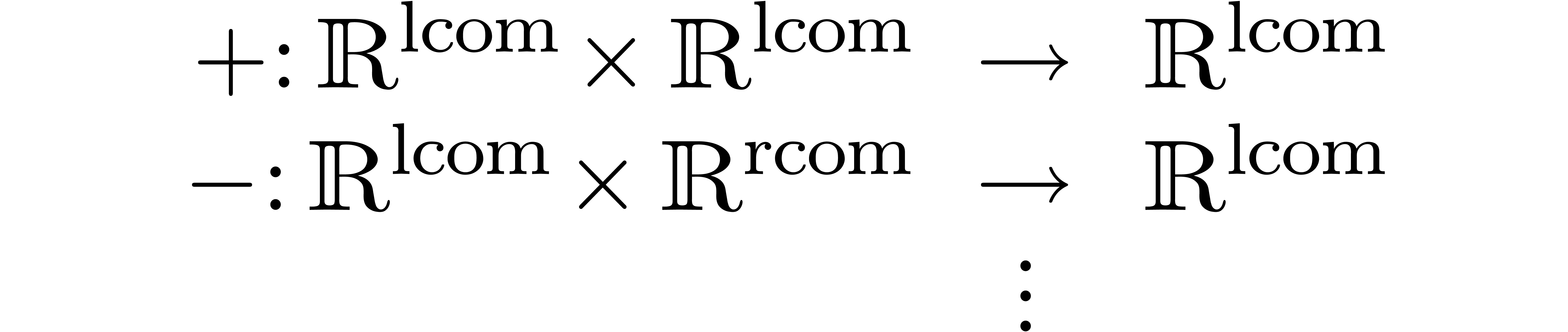
More generally, given a subset 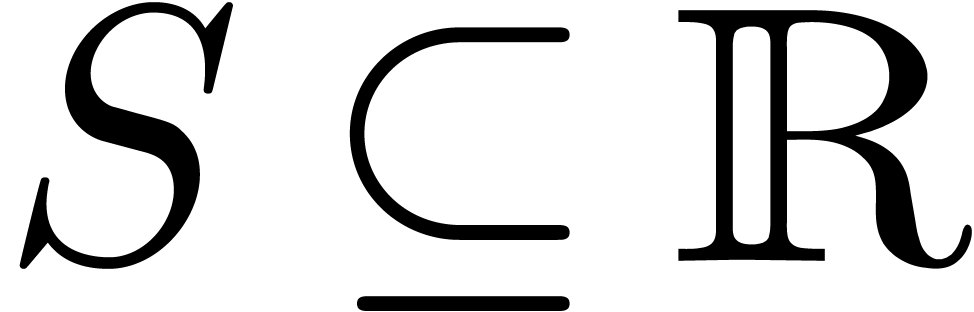 ,
we say that
,
we say that  is left computable in
is left computable in  if there exists a left approximation algorithm
if there exists a left approximation algorithm 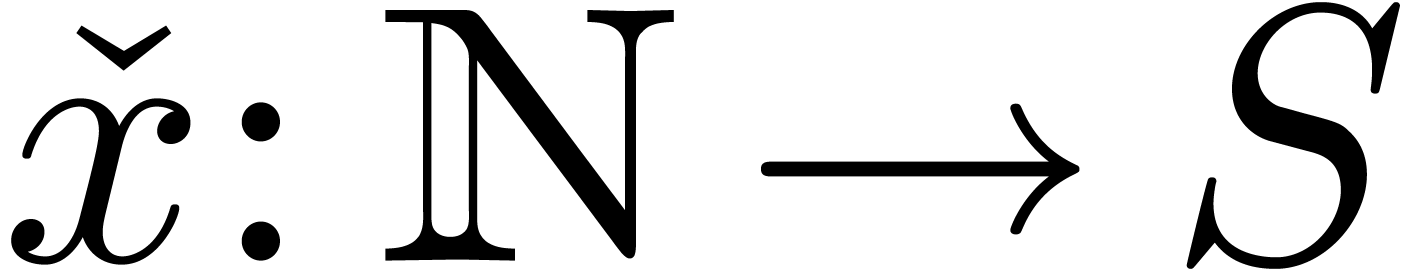 for . We will
denote by
for . We will
denote by  and
and  the data
types of left and computable numbers in ,
and define
the data
types of left and computable numbers in ,
and define  .
.
Identifying the type of boolean numbers  with
with
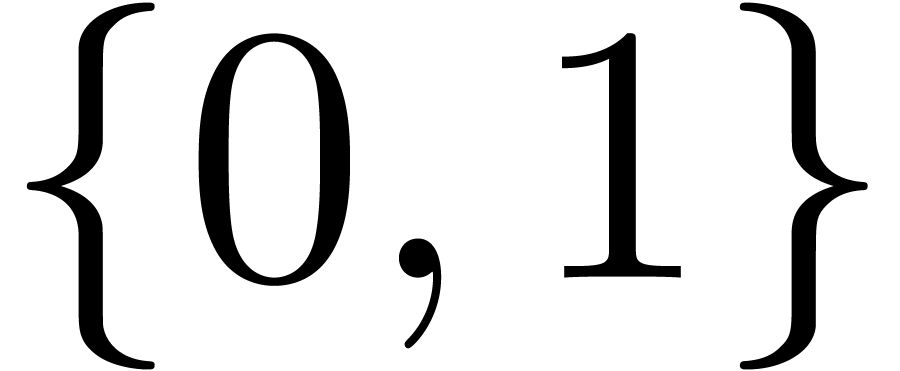 , we have
, we have  as sets, but not as data types. For instance, it is well known
that equality is non computable for computable real numbers [Tur36].
Nevertheless, equality is “ultimately computable”
in the sense that there exists a computable function
as sets, but not as data types. For instance, it is well known
that equality is non computable for computable real numbers [Tur36].
Nevertheless, equality is “ultimately computable”
in the sense that there exists a computable function
Indeed, given with ball approximation algorithms
and  ,
we may take
,
we may take
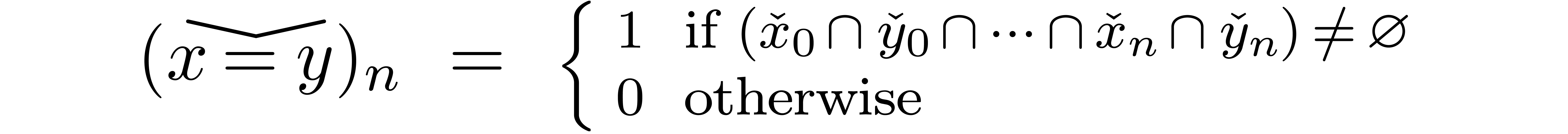
Similarly, the ordering relation 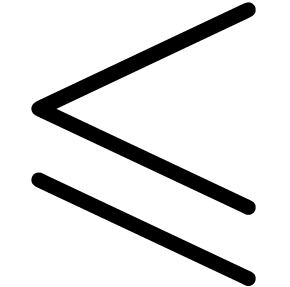 is ultimately
computable.
is ultimately
computable.
This asymmetric point of view on equality testing also suggest a
semantics for the relations  ,
, etc. on balls.
For instance, given balls
,
, etc. on balls.
For instance, given balls 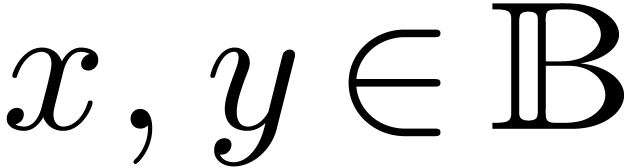 ,
it is natural to take
,
it is natural to take
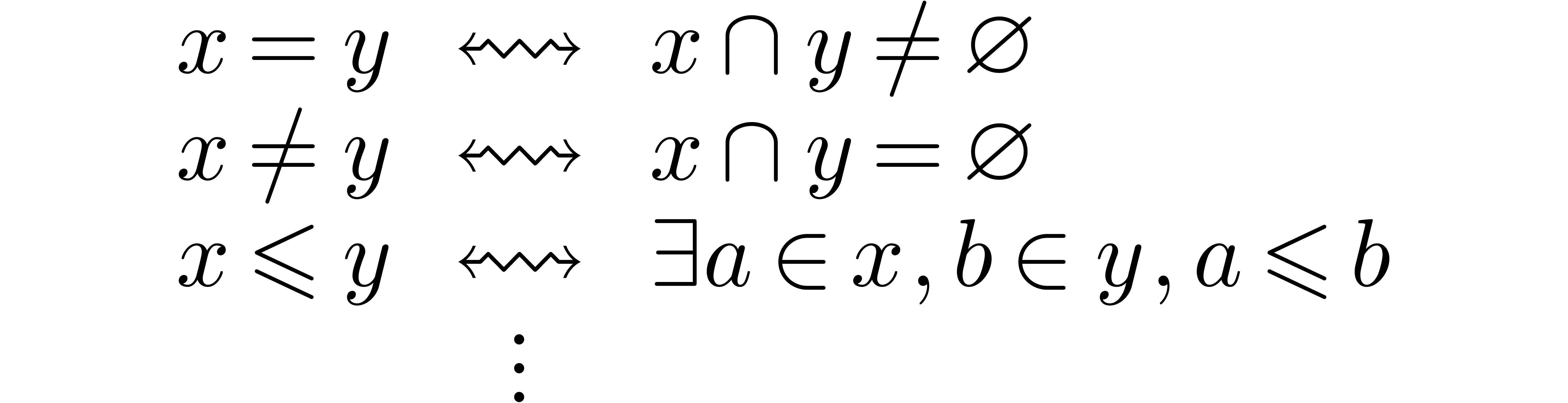
These definitions are interesting if balls are really used as successive approximations of a real number. An alternative application of ball arithmetic is for modeling non-deterministic computations: the ball models a set of possible values and we are interested in the set of possible outcomes of an algorithm. In that case, the natural return type of a relation on balls becomes a “boolean ball”. In the area of interval analysis, this second interpretation is more common [ANS09].
Remark
Given a computable function 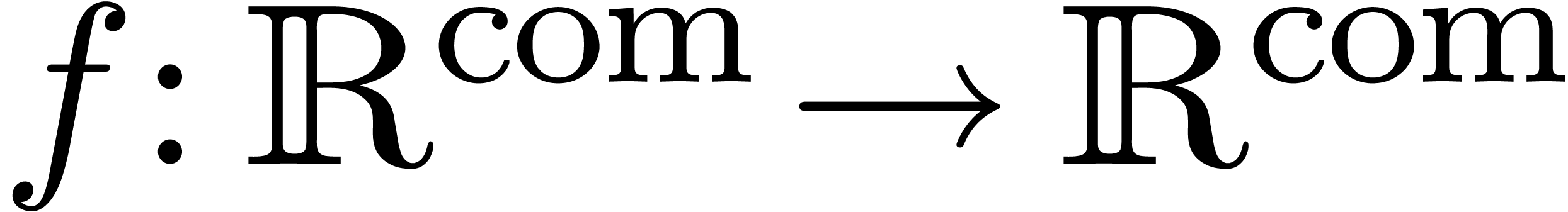 ,
and ,
let us return to the problem of efficiently computing an approximation
,
and ,
let us return to the problem of efficiently computing an approximation
 of with
of with  . In section 3.4, we suggested to
compute ball approximations of at precisions
which double at every step, until a sufficiently precise approximation
is found. This computation involves an implementation
. In section 3.4, we suggested to
compute ball approximations of at precisions
which double at every step, until a sufficiently precise approximation
is found. This computation involves an implementation 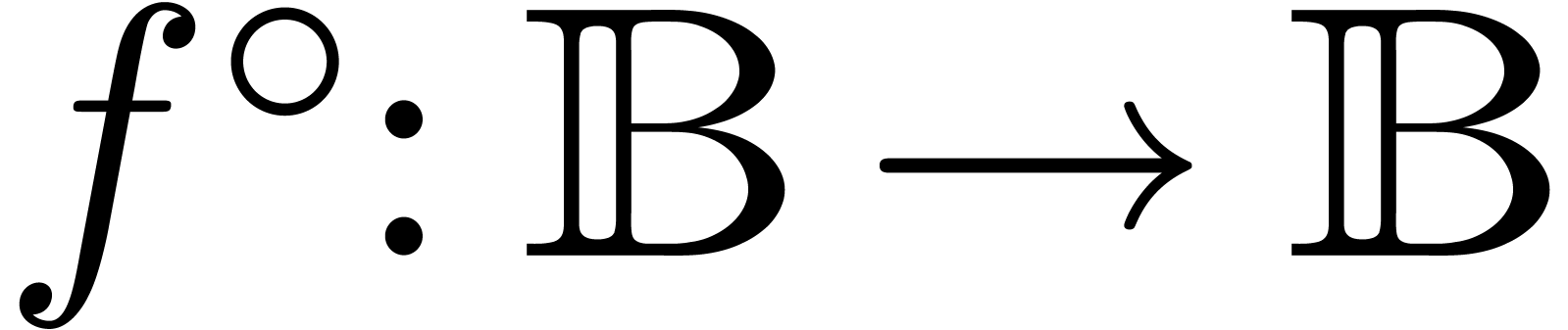 of on the level of balls, which satisfies
of on the level of balls, which satisfies
for every ball  . In practice,
is often differentiable, with
. In practice,
is often differentiable, with 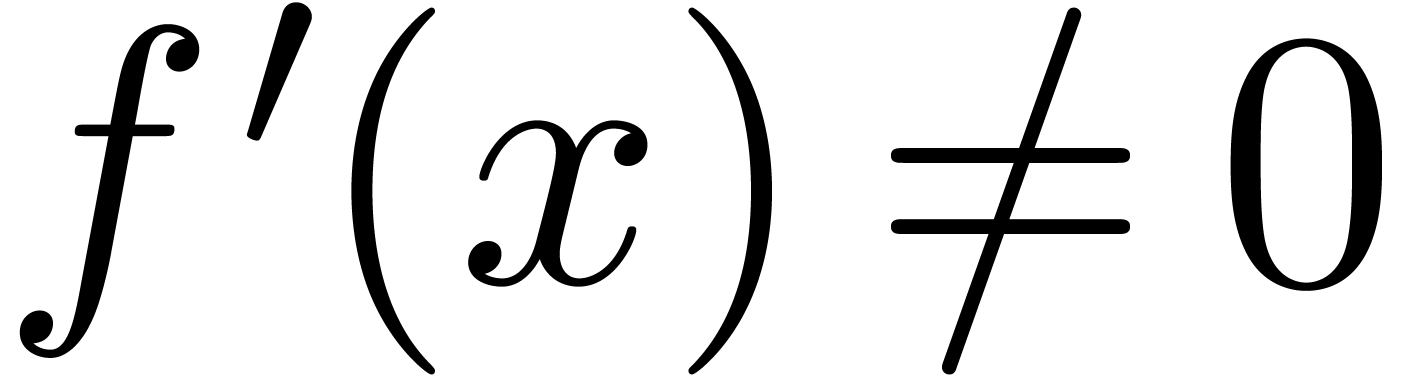 . In that case, given a ball approximation
. In that case, given a ball approximation 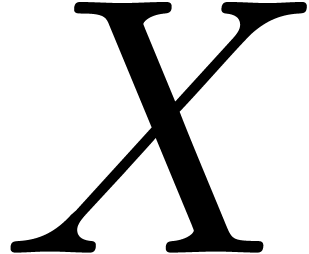 of , the
computed ball approximation
of , the
computed ball approximation 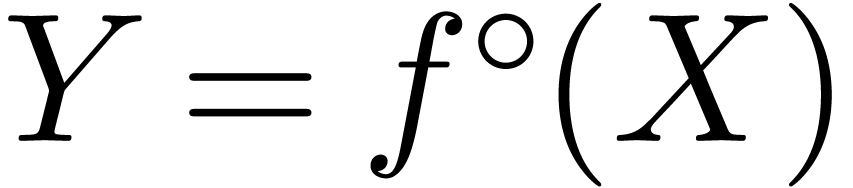 of
typically has a radius
of
typically has a radius
for 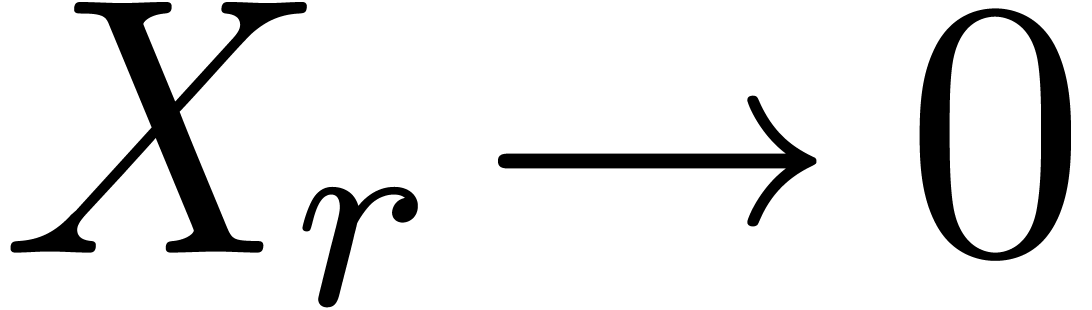 . This should make it
possible to directly predict a sufficient precision at which
. This should make it
possible to directly predict a sufficient precision at which 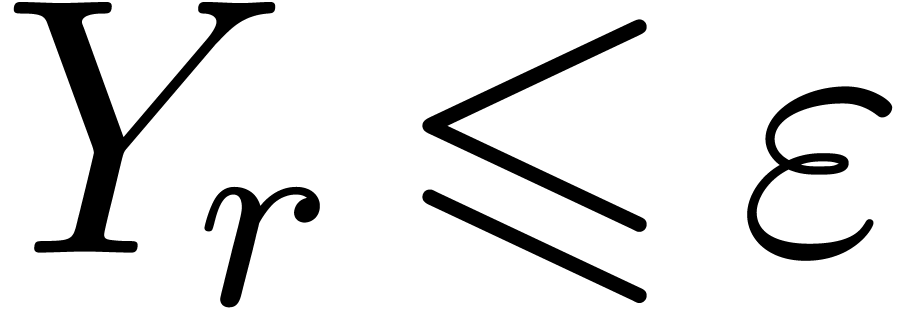 . The problem is that (14)
needs to be replaced by a more reliable relation. This can be done on
the level of ball arithmetic itself, by replacing the usual condition
(13) by
. The problem is that (14)
needs to be replaced by a more reliable relation. This can be done on
the level of ball arithmetic itself, by replacing the usual condition
(13) by
Similarly, the multiplication of balls is carried out using
instead of (7). A variant of this kind of “Lipschitz
ball arithmetic” has been implemented in [M0].
Although a constant factor is gained for high precision computations at
regular points , the
efficiency deteriorates near singularities (i.e. the
computation of 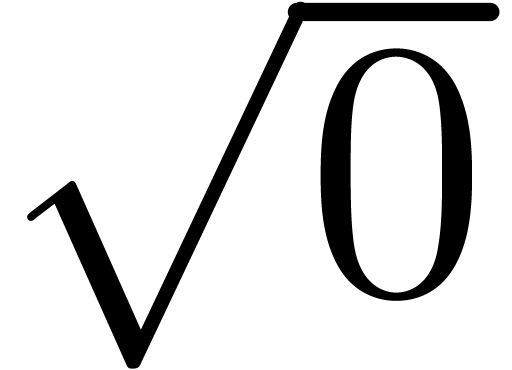 ).
).
In the area of reliable computation, interval arithmetic has for long been privileged with respect to ball arithmetic. Indeed, balls are often regarded as a more or less exotic variant of intervals, based on an alternative midpoint-radius representation. Historically, interval arithmetic is also preferred in computer science because it is easy to implement if floating point operations are performed with correct rounding. Since most modern microprocessors implement the IEEE 754 norm, this point of view is well supported by hardware.
Not less historically, the situation in mathematics is inverse: whereas
intervals are the standard in computer science, balls are the standard
in mathematics, since they correspond to the traditional -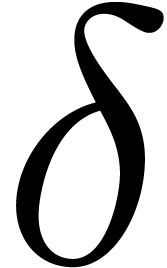 -calculus.
Even in the area of interval analysis, one usually resorts (at least
implicitly) to balls for more complex computations, such as the
inversion of a matrix [HS67, Moo66]. Indeed,
balls are more convenient when computing error bounds using perturbation
techniques. Also, we have a great deal of flexibility concerning the
choice of a norm. For instance, a vectorial ball is not necessarily a
Cartesian product of one dimensional balls.
-calculus.
Even in the area of interval analysis, one usually resorts (at least
implicitly) to balls for more complex computations, such as the
inversion of a matrix [HS67, Moo66]. Indeed,
balls are more convenient when computing error bounds using perturbation
techniques. Also, we have a great deal of flexibility concerning the
choice of a norm. For instance, a vectorial ball is not necessarily a
Cartesian product of one dimensional balls.
In this section, we will give a more detailed account on the respective advantages and disadvantages of interval and ball arithmetic.
One advantage of interval arithmetic is that the IEEE 754 norm suggests
a natural and standard implementation. Indeed, let
be a real function which is increasing on some interval  . Then the natural interval lift
. Then the natural interval lift  of is given by
of is given by
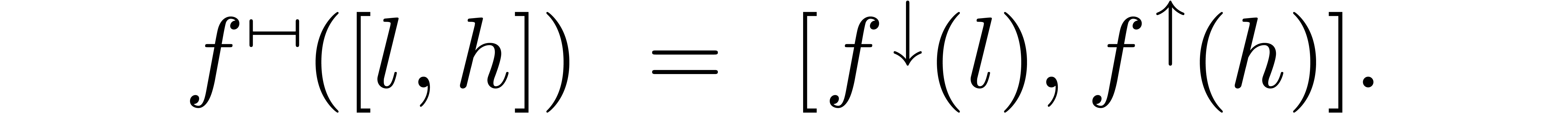
This implementation has the property that 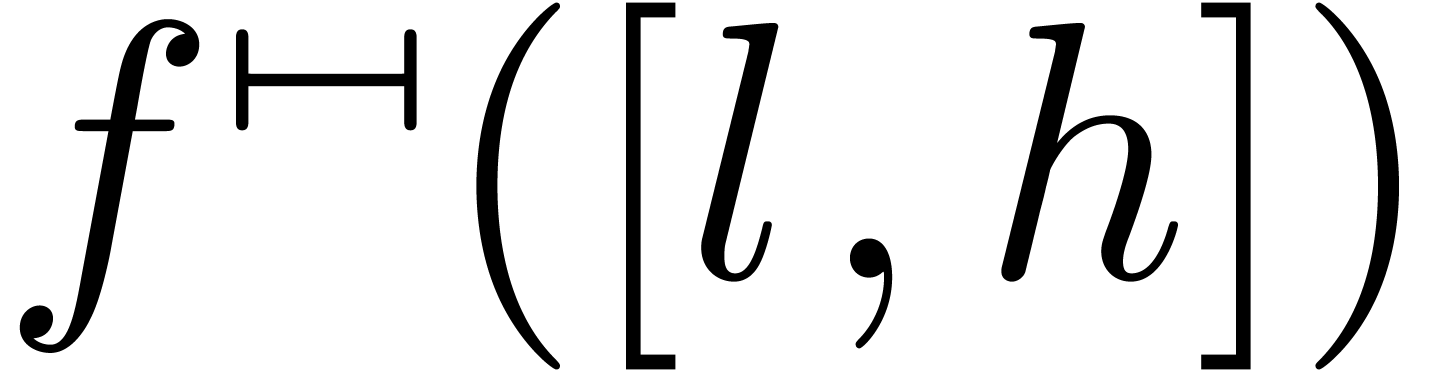 is the
smallest interval with end-points in
is the
smallest interval with end-points in 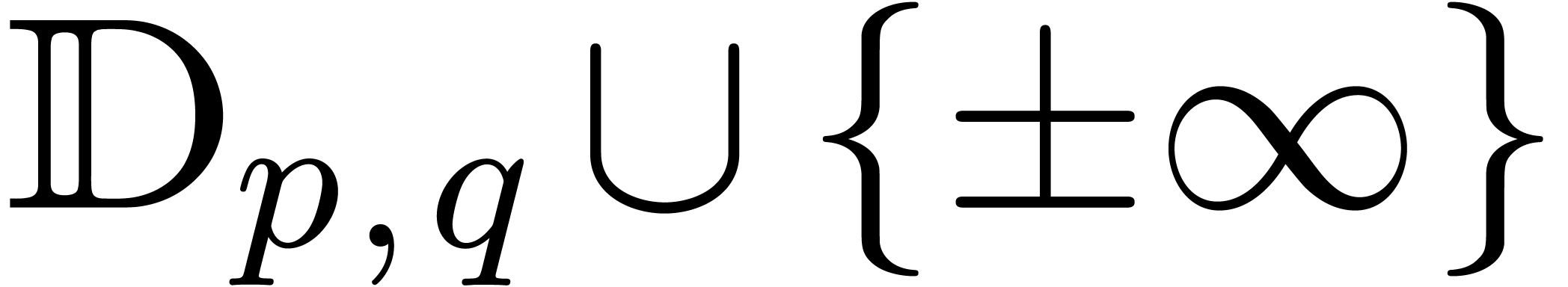 ,
which satisfies
,
which satisfies
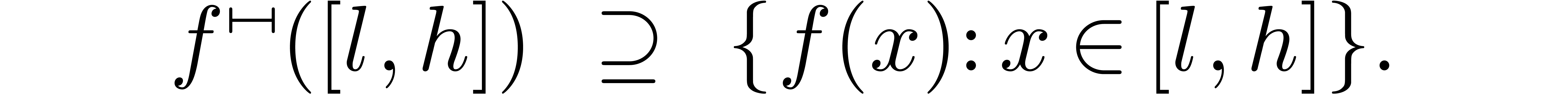
For not necessarily increasing functions this
property can still be used as a requirement for the
“standard” implementation of .
For instance, this leads to the following implementation of the cosine
function on intervals:
Such a standard implementation of interval arithmetic has the convenient property that programs will execute in the same way on any platform which conforms to the IEEE 754 standard.
By analogy with the above approach for standardized interval arithmetic,
we may standardize the ball implementation of
by taking
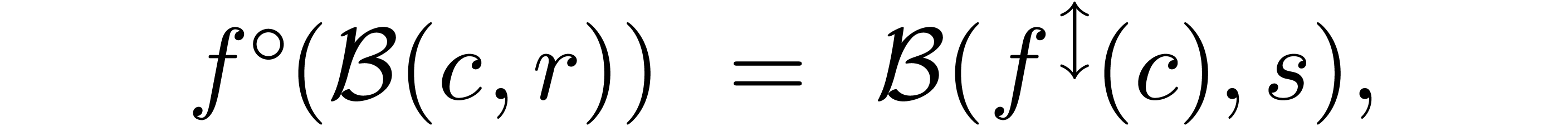
where the radius is smallest in 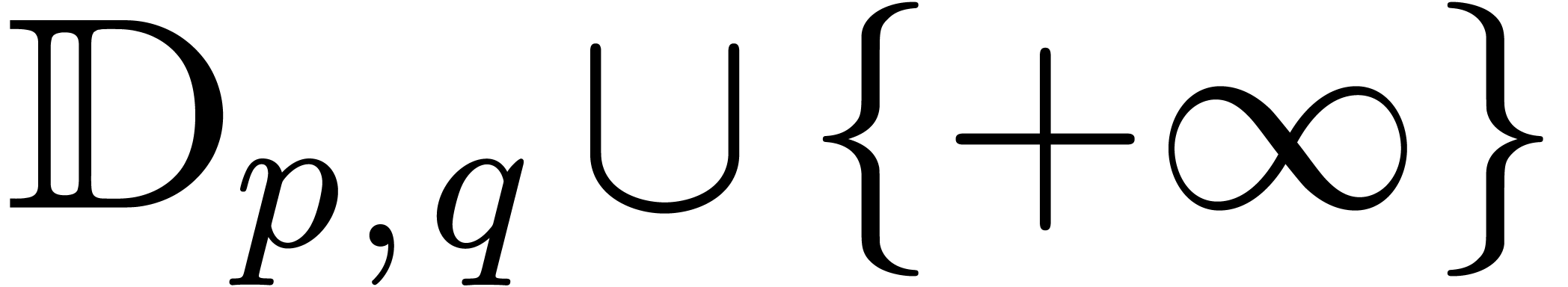 with
with
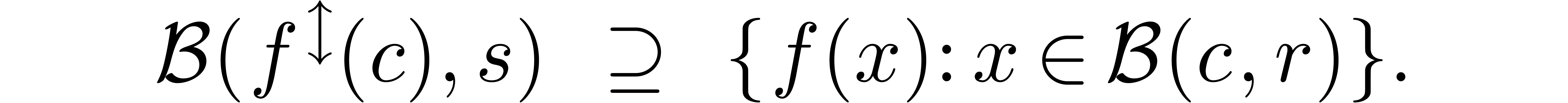
Unfortunately, the computation of such an optimal
is not always straightforward. In particular, the formulas (10),
(11) and (12) do not necessarily realize this
tightest bound. In practice, it might therefore be better to achieve
standardization by fixing once and for all the formulas by which ball
operations are performed. Of course, more experience with ball
arithmetic is required before this can happen.
The respective efficiencies of interval and ball arithmetic depend on the precision at which we are computing. For high precisions and most applications, ball arithmetic has the advantage that we can still perform computations on the radius at single precision. By contrast, interval arithmetic requires full precision for operations on both end-points. This makes ball arithmetic twice as efficient at high precisions.
When working at machine precision, the efficiencies of both approaches
essentially depend on the hardware. A priori, interval
arithmetic is better supported by current computers, since most of them
respect the IEEE 754 norm, whereas the function
from (9) usually has to be implemented by hand. However,
changing the rounding mode is often highly expensive (over hundred
cycles). Therefore, additional gymnastics may be required in order to
always work with respect to a fixed rounding mode. For instance, if is our current rounding mode, then we may take
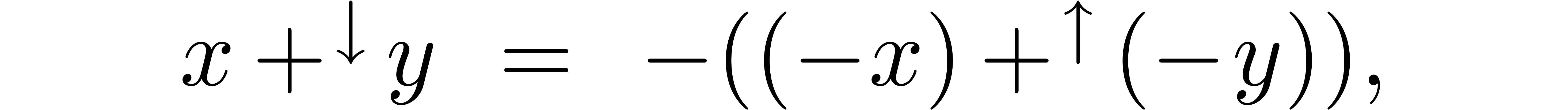
since the operation  is always exact
(i.e. does not depend on the rounding mode). As a
consequence, interval arithmetic becomes slightly more expensive. By
contrast, when releasing the condition that centers of balls are
computed using rounding to the nearest, we may replace (8)
by
is always exact
(i.e. does not depend on the rounding mode). As a
consequence, interval arithmetic becomes slightly more expensive. By
contrast, when releasing the condition that centers of balls are
computed using rounding to the nearest, we may replace (8)
by
and (9) by
Hence, ball arithmetic already allows us to work with respect to a fixed rounding mode. Of course, using (17) instead of (8) does require to rethink the way ball arithmetic should be standardized.
An alternative technique for avoiding changes in rounding mode exists when performing operations on compound types, such as vectors or matrices. For instance, when adding two vectors, we may first add all lower bounds while rounding downwards and next add the upper bounds while rounding upwards. Unfortunately, this strategy becomes more problematic in the case of multiplication, because different rounding modes may be needed depending on the signs of the multiplicands. As a consequence, matrix operations tend to require many conditional parts of code when using interval arithmetic, with increased probability of breaking the processor pipeline. On the contrary, ball arithmetic highly benefits from parallel architecture and it is easy to implement ball arithmetic for matrices on top of existing libraries: see [Rum99a] and section 6 below.
Besides the efficiency of ball and interval arithmetic for basic
operations, it is also important to investigate the quality of the
resulting bounds. Indeed, there are usually differences between the sets
which are representable by balls and by intervals. For instance, when
using the extended IEEE 754 arithmetic with infinities, then it is
possible to represent 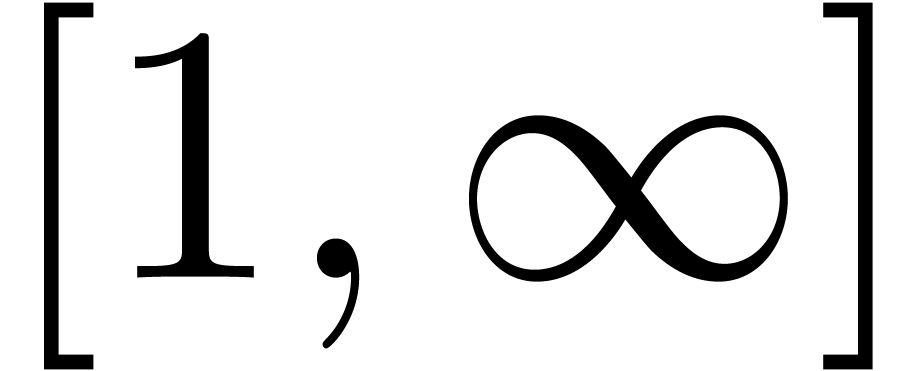 as an interval, but not as
a ball.
as an interval, but not as
a ball.
These differences get more important when dealing with complex numbers
or compound types, such as matrices. For instance, when using interval
arithmetic for reliable computations with complex numbers, it is natural
to enclose complex numbers by rectangles 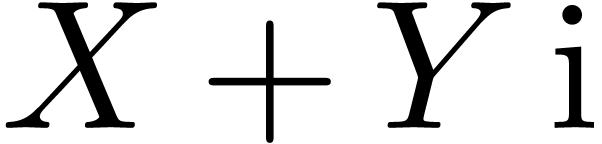 ,
where and
,
where and 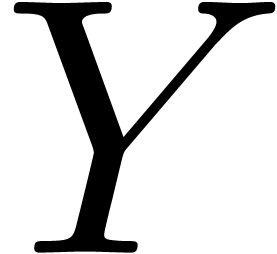 are intervals.
For instance, the complex number
are intervals.
For instance, the complex number 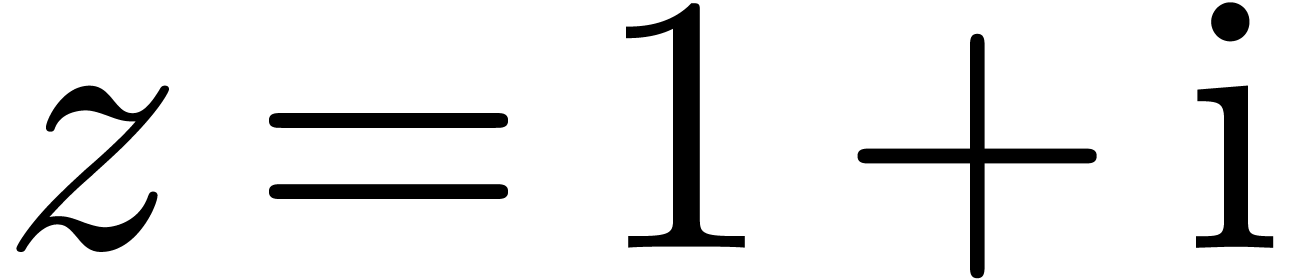 may be enclosed
by
may be enclosed
by

for some small number . When
using ball arithmetic, we would rather enclose
by
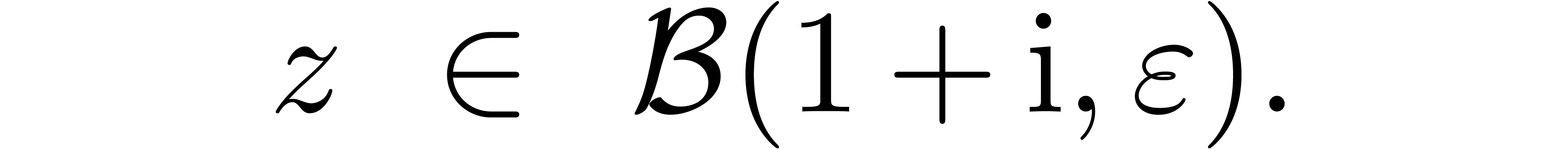
Now consider the computation of 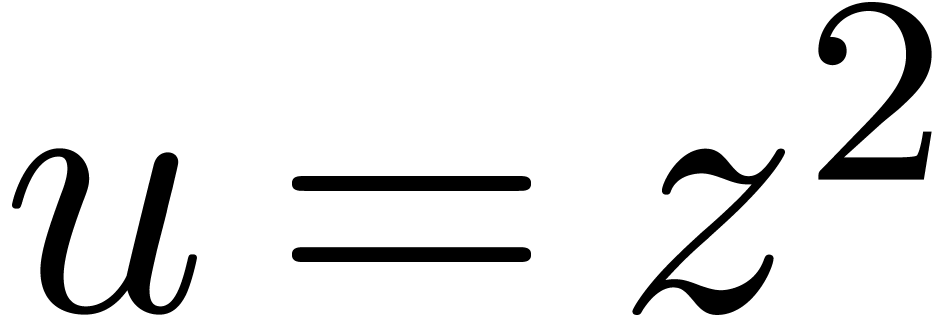 .
The computed rectangular and ball enclosures are given by
.
The computed rectangular and ball enclosures are given by
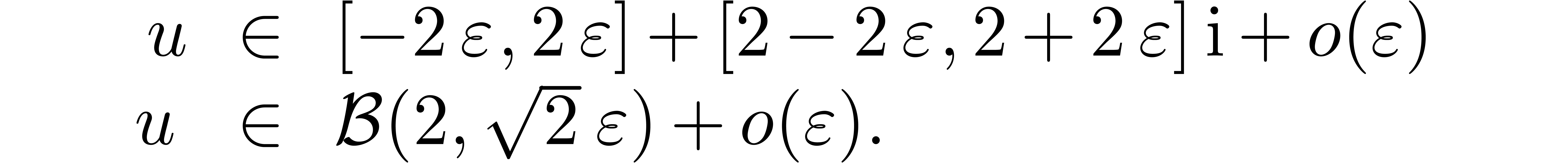
Consequently, ball arithmetic yields a much better bound, which is due
to the fact that multiplication by 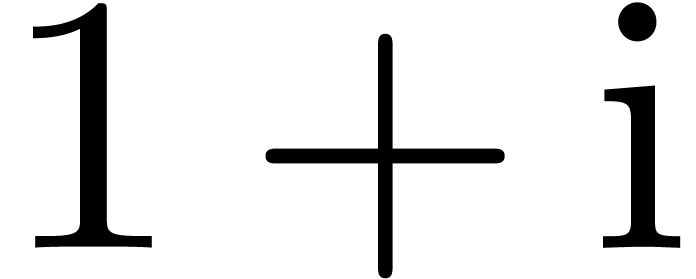 turns the
rectangular enclosure by
turns the
rectangular enclosure by  degrees, leading to an
overestimation by a factor
degrees, leading to an
overestimation by a factor 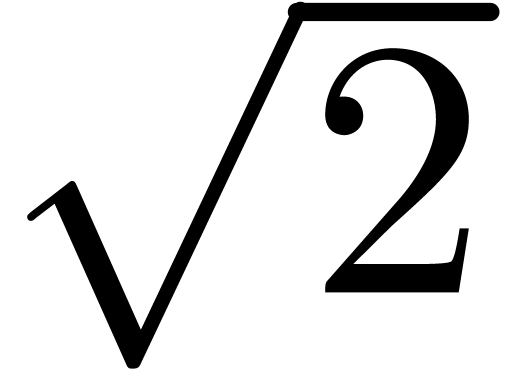 when re-enclosing the
result by a horizontal rectangle (see figure 1).
when re-enclosing the
result by a horizontal rectangle (see figure 1).
This is one of the simplest instances of the wrapping effect [Moo66]. For similar reasons, one may prefer to compute the square of the matrix
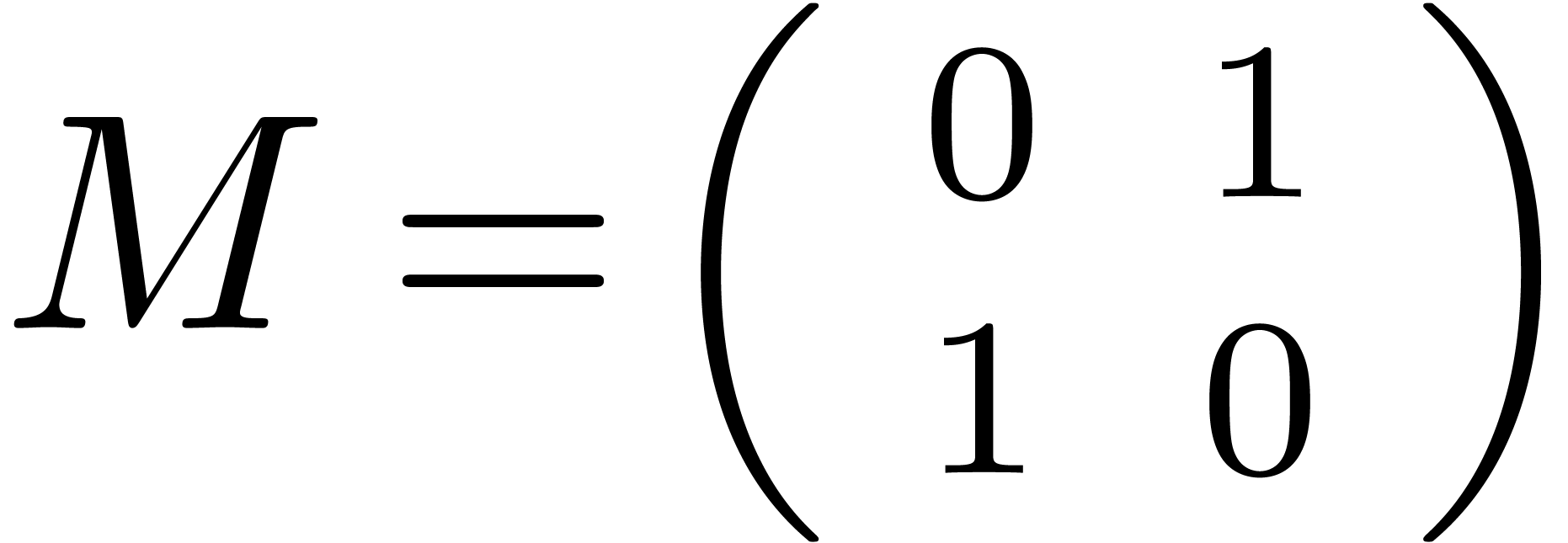 |
(18) |
in 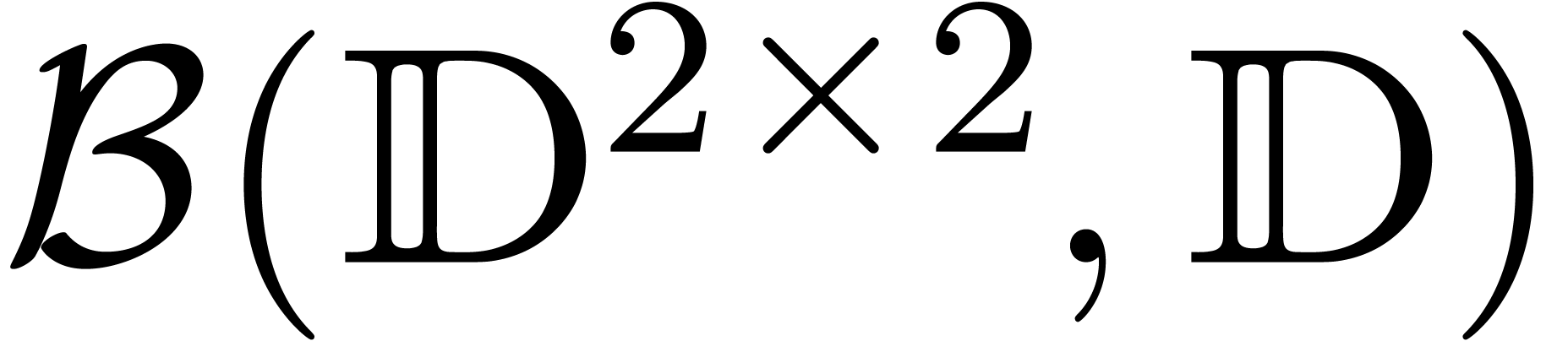 rather than
rather than 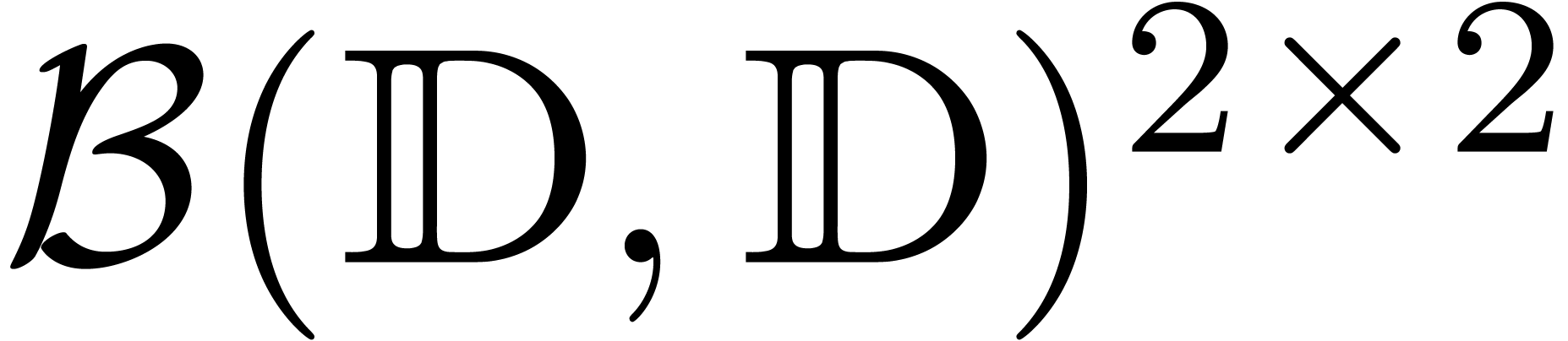 ,
while using the operator norm (3) for matrices. This
technique highlights another advantage of ball arithmetic: we have a
certain amount of flexibility regarding the choice of the radius type.
By choosing a simple radius type, we do not only reduce the wrapping
effect, but also improve the efficiency: when computing with complex
balls in
,
while using the operator norm (3) for matrices. This
technique highlights another advantage of ball arithmetic: we have a
certain amount of flexibility regarding the choice of the radius type.
By choosing a simple radius type, we do not only reduce the wrapping
effect, but also improve the efficiency: when computing with complex
balls in 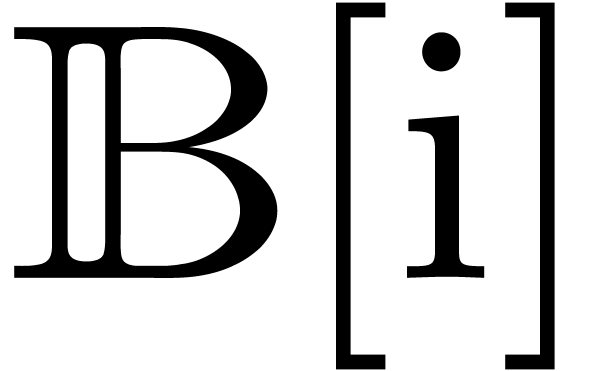 , we only need to
bound one radius instead of two for every basic operation. More
precisely, we replace (8) and (9) by
, we only need to
bound one radius instead of two for every basic operation. More
precisely, we replace (8) and (9) by
On the negative side, generalized norms may be harder to compute, even
though a rough bound often suffices (e.g. replacing 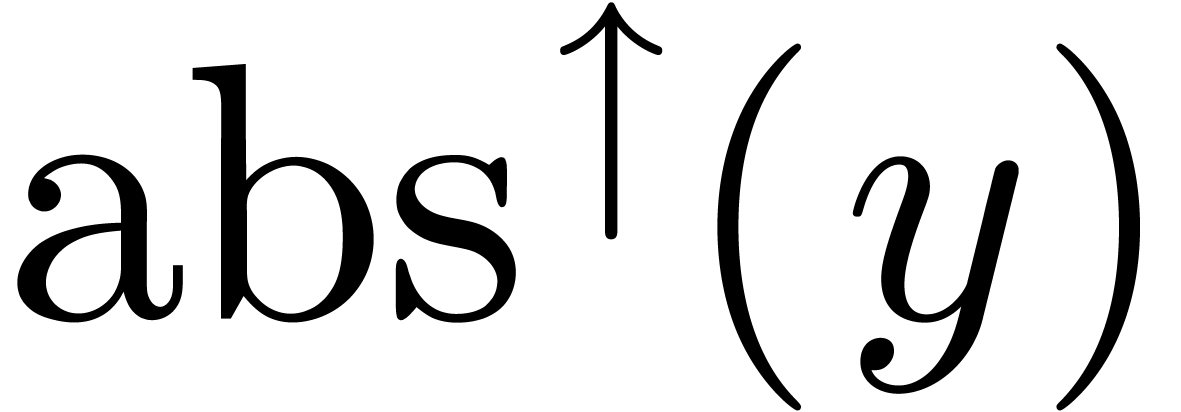 by
by  in the above formula). In
the case of matricial balls, a more serious problem concerns
overestimation when the matrix contains entries of different orders of
magnitude. In such badly conditioned situations, it is better to work in
in the above formula). In
the case of matricial balls, a more serious problem concerns
overestimation when the matrix contains entries of different orders of
magnitude. In such badly conditioned situations, it is better to work in
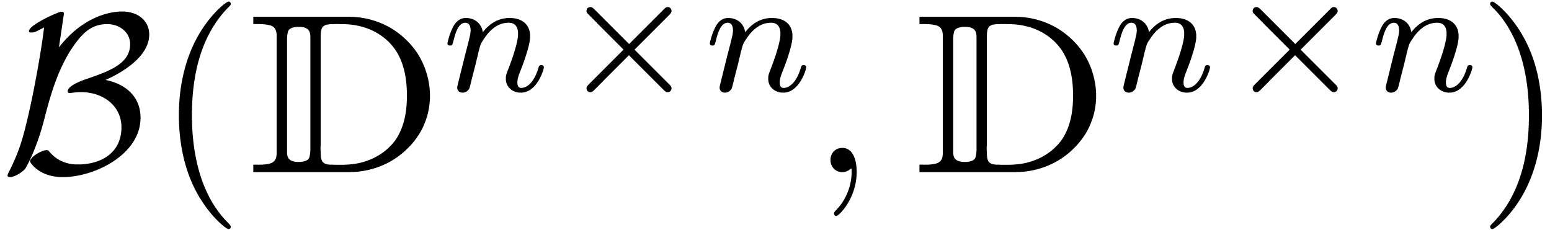 rather than
rather than 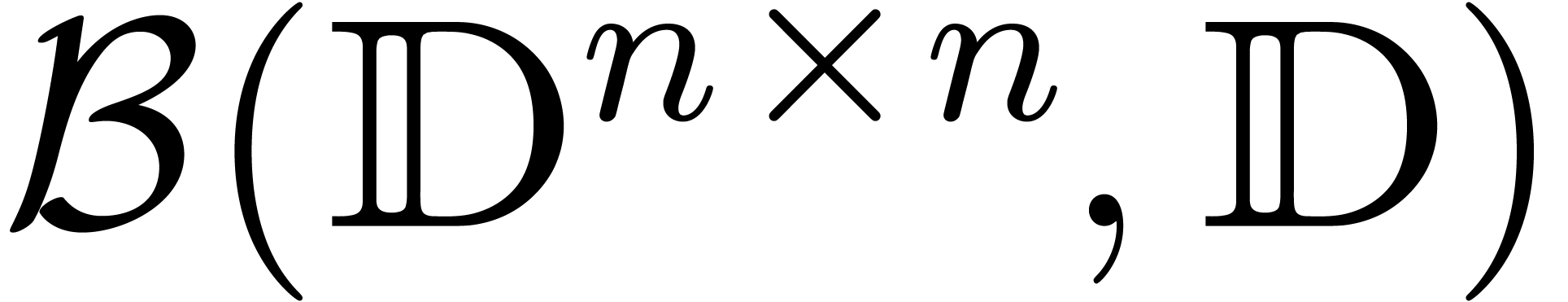 .
Another more algorithmic technique for reducing the wrapping effect will
be discussed in sections 6.4 and 7.5 below.
.
Another more algorithmic technique for reducing the wrapping effect will
be discussed in sections 6.4 and 7.5 below.
Even though personal taste in the choice between balls and intervals cannot be discussed, the elegance of the chosen approach for a particular application can partially be measured in terms of the human time which is needed to establish the necessary error bounds.
We have already seen that interval enclosures are particularly easy to
obtain for monotonic real functions. Another typical algorithm where
interval arithmetic is more convenient is the resolution of a system of
equations using dichotomy. Indeed, it is easier to cut an -dimensional block  into
into
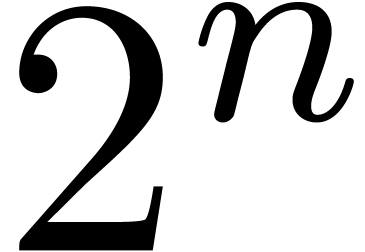 smaller blocks than to perform a similar
operation on balls.
smaller blocks than to perform a similar
operation on balls.
For most other applications, ball representations are more convenient. Indeed, error bounds are usually obtained by perturbation methods. For any mathematical proof where error bounds are explicitly computed in this way, it is generally easy to derive a certified algorithm based on ball arithmetic. We will see several illustrations of this principle in the sections below.
Implementations of interval arithmetic often rely on floating point arithmetic with correct rounding. One may question how good correct rounding actually is in order to achieve reliability. One major benefit is that it provides a simple and elegant way to specify what a mathematical function precisely does at limited precision. In particular, it allows numerical programs to execute exactly in the same way on many different hardware architectures.
On the other hand, correct rounding does have a certain cost. Although
the cost is limited for field operations and elementary functions [Mul06], the cost increases for more complex special functions,
especially if one seeks for numerical methods with a constant operation
count. For arbitrary computable functions on , correct rounding even becomes impossible. Another
disadvantage is that correct rounding is lost as soon we perform more
than one operation: in general,  and
and 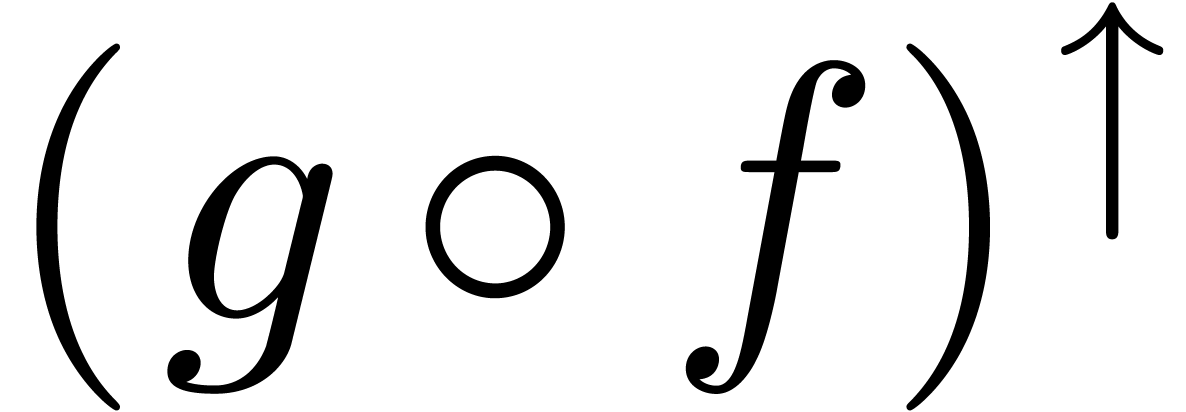 do not coincide.
do not coincide.
In the case of ball arithmetic, we only require an upper bound for the error, not necessarily the best possible representable one. In principle, this is just as reliable and usually more economic. Now in an ideal world, the development of numerical codes goes hand in hand with the systematic development of routines which compute the corresponding error bounds. In such a world, correct rounding becomes superfluous, since correctness is no longer ensured at the micro-level of hardware available functions, but rather at the top-level, via mathematical proof.
Computable analysis provides a good high-level framework for the
automatic and certified resolution of analytic problems. The user states
the problem in a formal language and specifies a required absolute or
relative precision. The program should return a numerical result which
is certified to meet the requirement on the precision. A simple example
is to compute an -approximation
for  , for a given .
, for a given .
The
In order to address this efficiency problem, the computable real matrices. The
numerical hierarchy turns out to be a convenient framework for more
complex problems as well, such as the analytic continuation of the
solution to a dynamical system. As a matter of fact, the framework
incites the developer to restate the original problem at the different
levels, which is generally a good starting point for designing an
efficient solution.
matrices 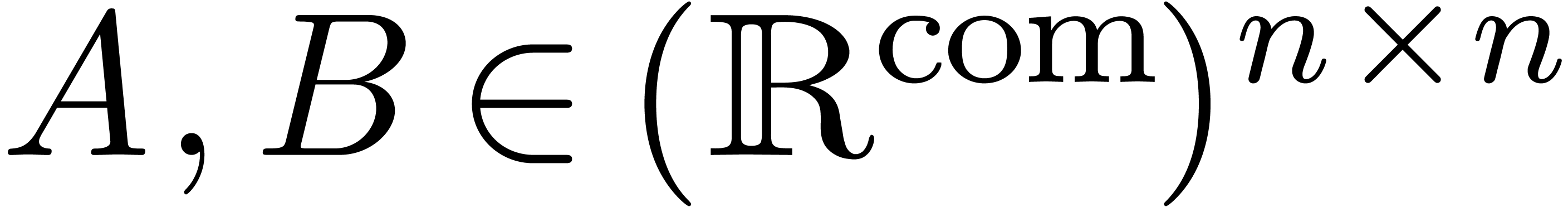 and an absolute
error . The aim is to
compute -approximations for
all entries of the product
and an absolute
error . The aim is to
compute -approximations for
all entries of the product 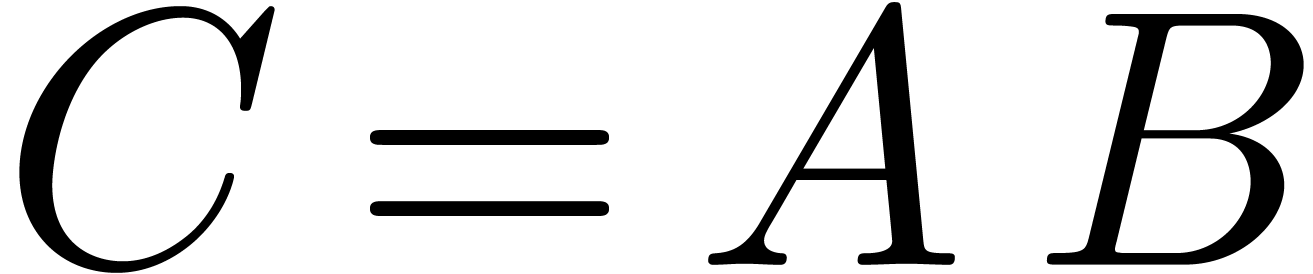 .
.
The simplest approach to this problem is to use a generic formal matrix
multiplication algorithm, using the fact that is
an effective ring. However, as stressed above, instances of are really functions, so that ring operations in are quite expensive. Instead, when working at precision
, we may first compute ball
approximations for all the entries of  and
and  , after which we form two
approximation matrices
, after which we form two
approximation matrices 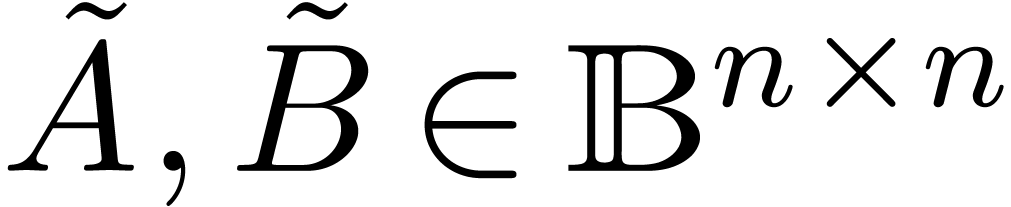 . The
multiplication problem then reduces to the problem of multiplying two
matrices in
. The
multiplication problem then reduces to the problem of multiplying two
matrices in 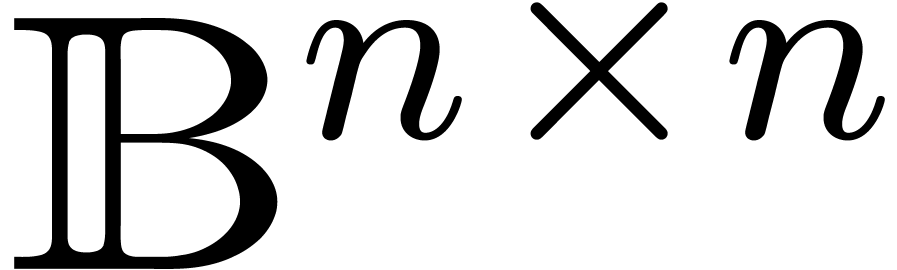 . This approach
has the advantage that
. This approach
has the advantage that 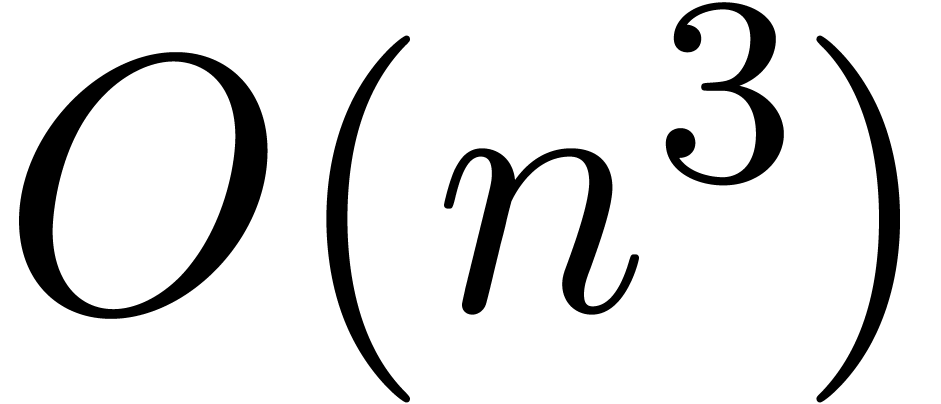 operations on
“functions” in are replaced by a
single multiplication in .
operations on
“functions” in are replaced by a
single multiplication in .
When operating on non-scalar objects, such as matrices of balls, it is
often efficient to rewrite the objects first. For instance, when working
in fixed point arithmetic (i.e. all entries of and admit similar orders of
magnitude), a matrix in may also be considered
as a matricial ball in for the matrix
norm  . We multiply two such
balls using the formula
. We multiply two such
balls using the formula
which is a corrected version of (7), taking into account
that the matrix norm only satisfies 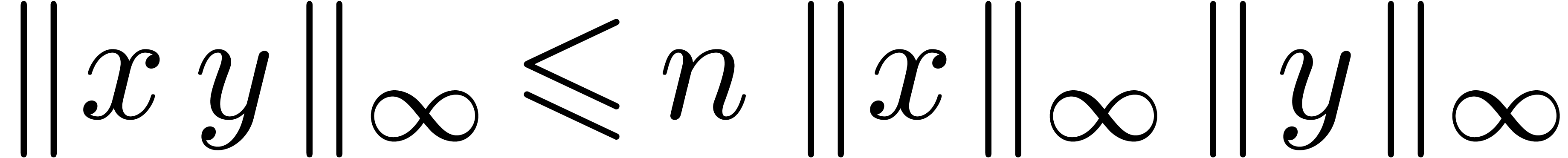 . Whereas the naive multiplication in involves
. Whereas the naive multiplication in involves 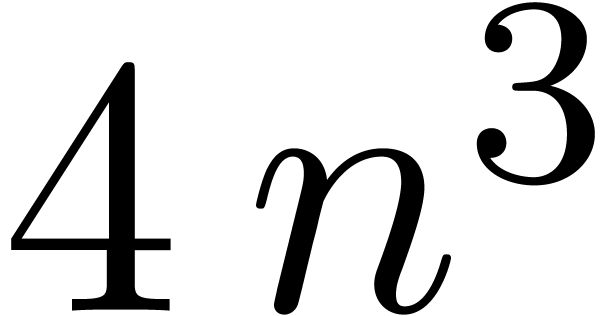 multiplications in
multiplications in  , the new method reduces this
number to
, the new method reduces this
number to 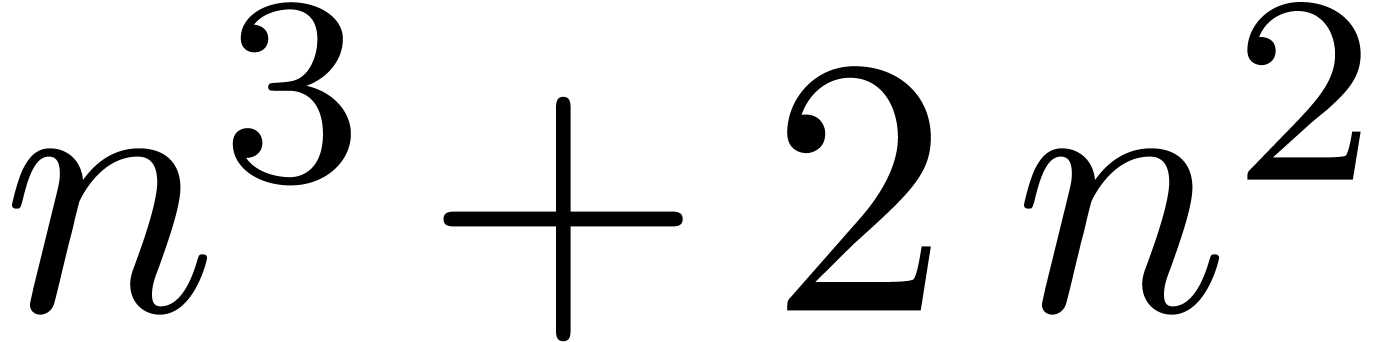 : one
“expensive” multiplication in
: one
“expensive” multiplication in 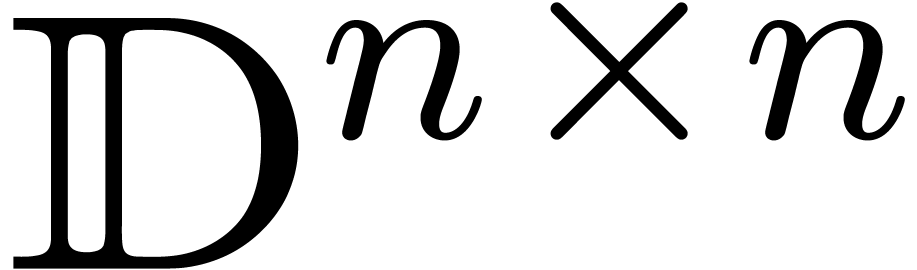 and
two scalar multiplications of matrices by numbers. This type of tricks
will be discussed in more detail in section 6.4 below.
and
two scalar multiplications of matrices by numbers. This type of tricks
will be discussed in more detail in section 6.4 below.
Essentially, the new method is based on the isomorphism

A similar isomorphism exists on the mathematical level:

As a variant, we directly may use the latter isomorphism at the top
level, after which ball approximations of elements of 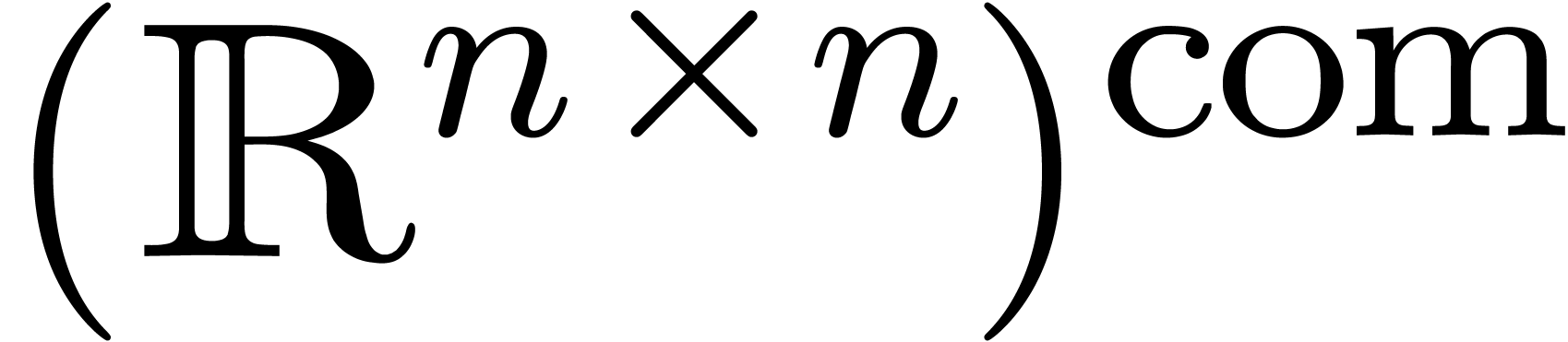 are already in .
are already in .
. In single or
double precision, we may usually rely on highly efficient numerical
libraries (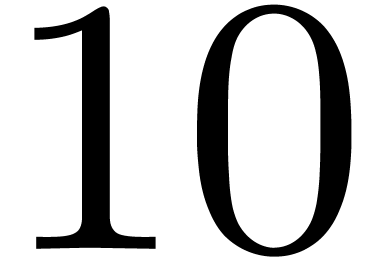 and
and 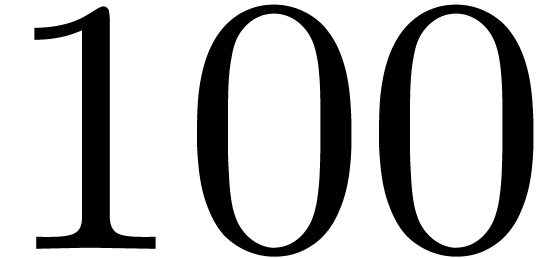 .
.
When working with matrices with multiple precision floating point entries, this overhead can be greatly reduced by putting the entries under a common exponent using the isomorphism
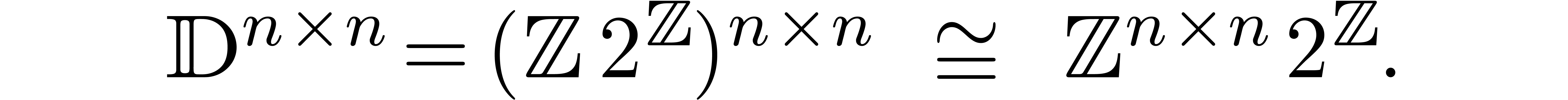
This reduces the matrix multiplication problem for floating point numbers to a purely arithmetic problem. Of course, this method becomes numerically unstable when the exponents differ wildly; in that case, row preconditioning of the first multiplicand and column preconditioning of the second multiplicand usually helps.
matrices in 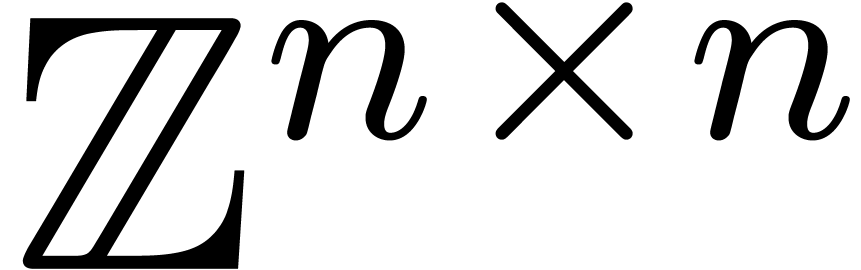 . The efficient
resolution of this problem for all possible
and integer bit lengths is again non-trivial.
. The efficient
resolution of this problem for all possible
and integer bit lengths is again non-trivial.
Indeed, libraries such as 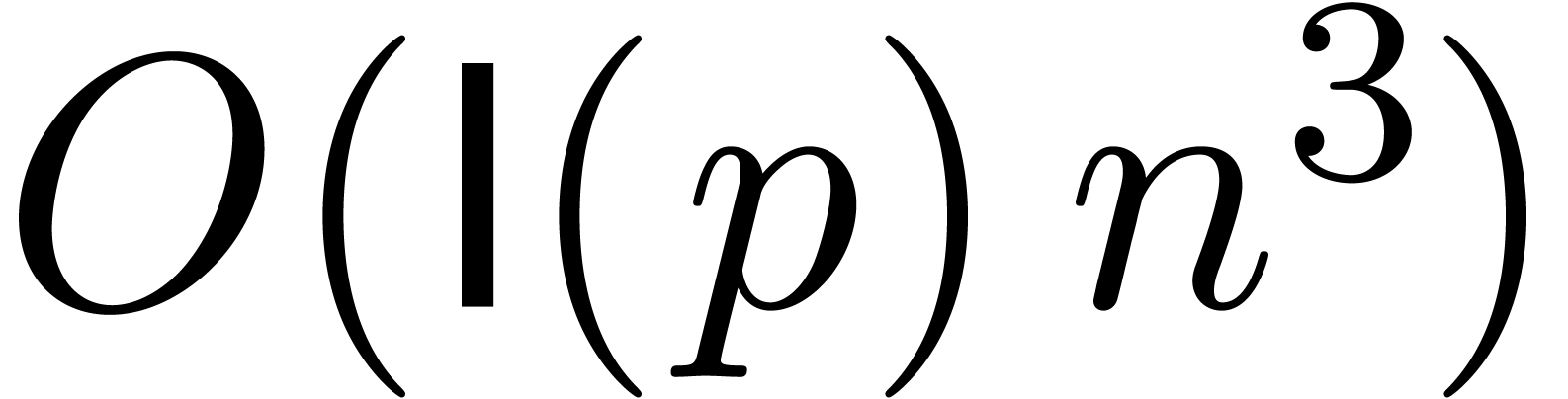 , which is far from optimal for
large values of .
, which is far from optimal for
large values of .
Indeed, for large , it is
better to use multi-modular methods. For instance, choosing sufficiently
many small primes 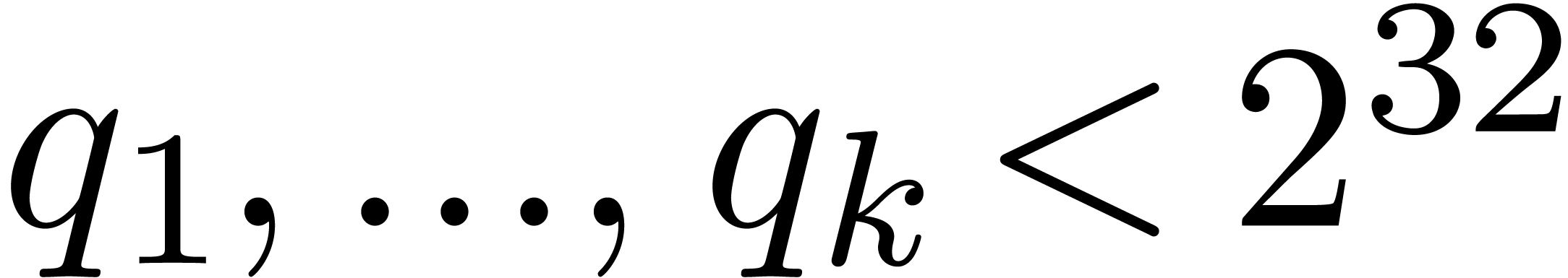 (or
(or  ) with
) with  ,
the multiplication of the two integer matrices can be reduced to multiplications of matrices in
,
the multiplication of the two integer matrices can be reduced to multiplications of matrices in 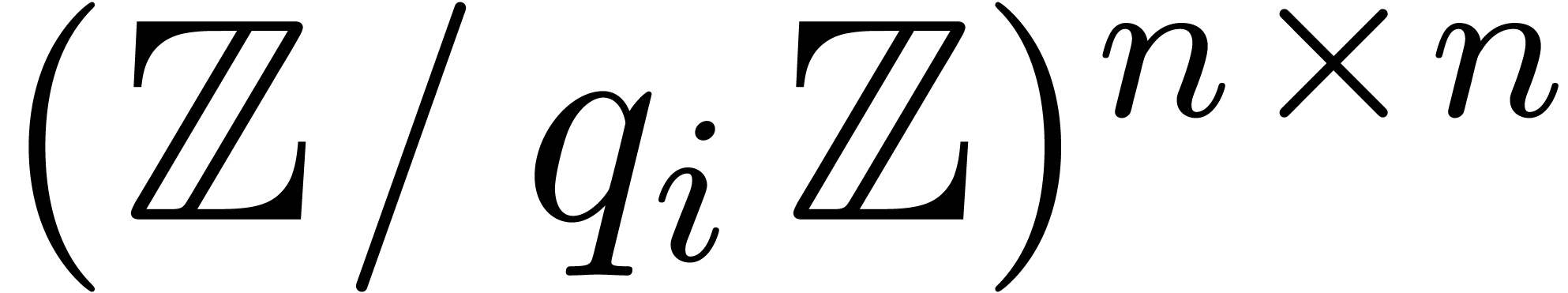 . Recall that a
. Recall that a 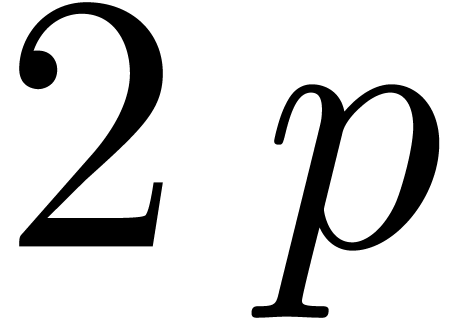 -bit
number can be reduced modulo all the
-bit
number can be reduced modulo all the 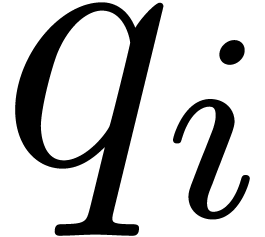 and
reconstructed from these reductions in time
and
reconstructed from these reductions in time 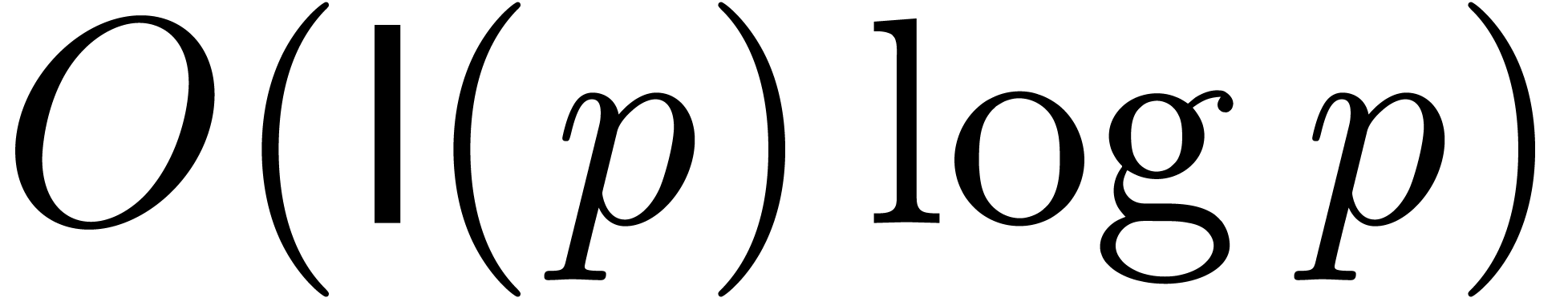 . The improved matrix multiplication algorithm
therefore admits a time complexity
. The improved matrix multiplication algorithm
therefore admits a time complexity 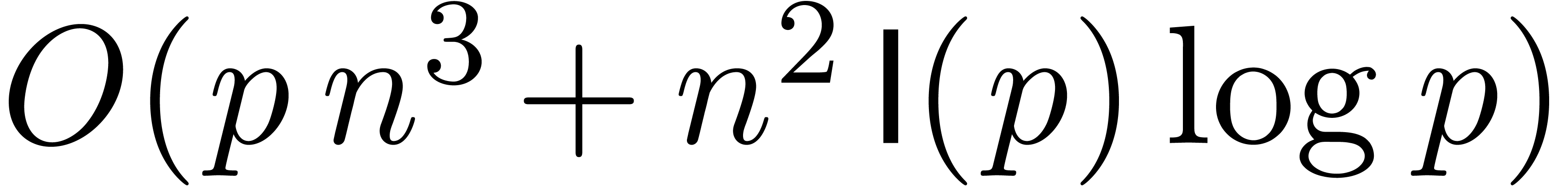 and has been
implemented in
and has been
implemented in 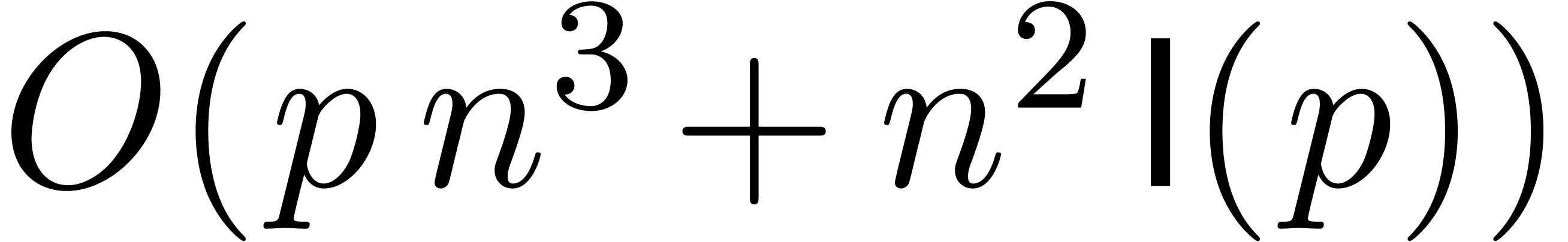 when and are of the same order of magnitude.
when and are of the same order of magnitude.
In this section, we will start the study of ball arithmetic for non
numeric types, such as matrices. We will examine the complexity of
common operations, such as matrix multiplication, linear system solving,
and the computation of eigenvectors. Ideally, the certified variants of
these operations are only slightly more expensive than the non certified
versions. As we will see, this objective can sometimes be met indeed. In
general however, there is a trade-off between the efficiency of the
certification and its quality, i.e. the sharpness of the
obtained bound. As we will see, the overhead of bound computations also
tends to diminish for increasing bit precisions .
Let us first consider the multiplication of two
double precision matrices
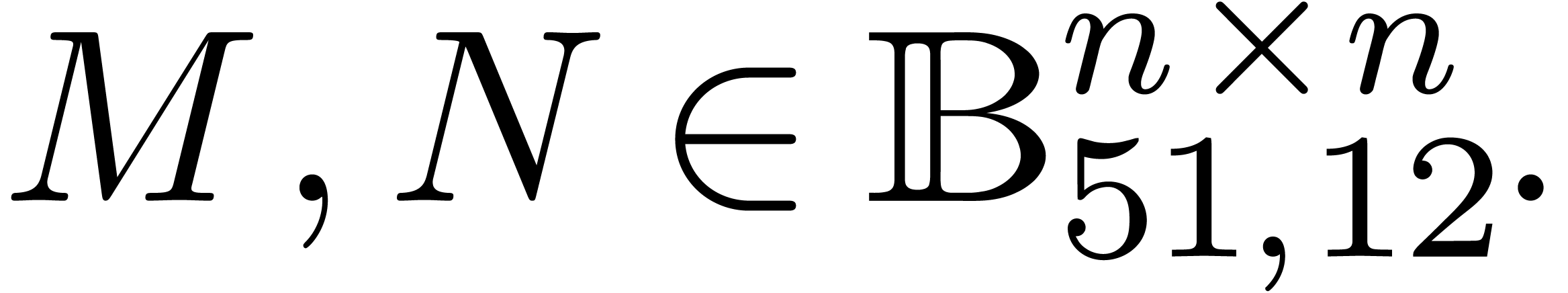
using the naive symbolic formula
Although this strategy is efficient for very small , it has the disadvantage that we cannot profit
from high performance
 and
and  as
balls with matricial radii
as
balls with matricial radii
we may compute using
where is given by  .
A similar approach was first proposed in [Rum99a]. Notice
that the additional term
.
A similar approach was first proposed in [Rum99a]. Notice
that the additional term 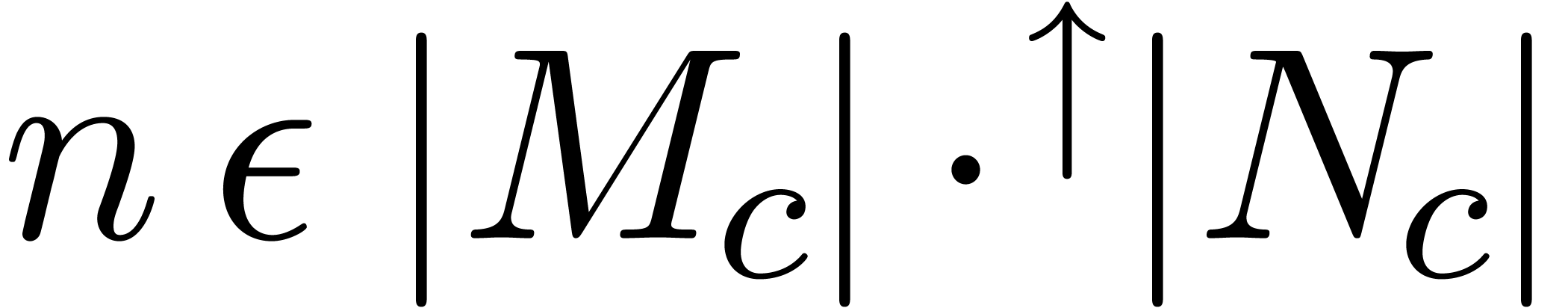 replaces
replaces 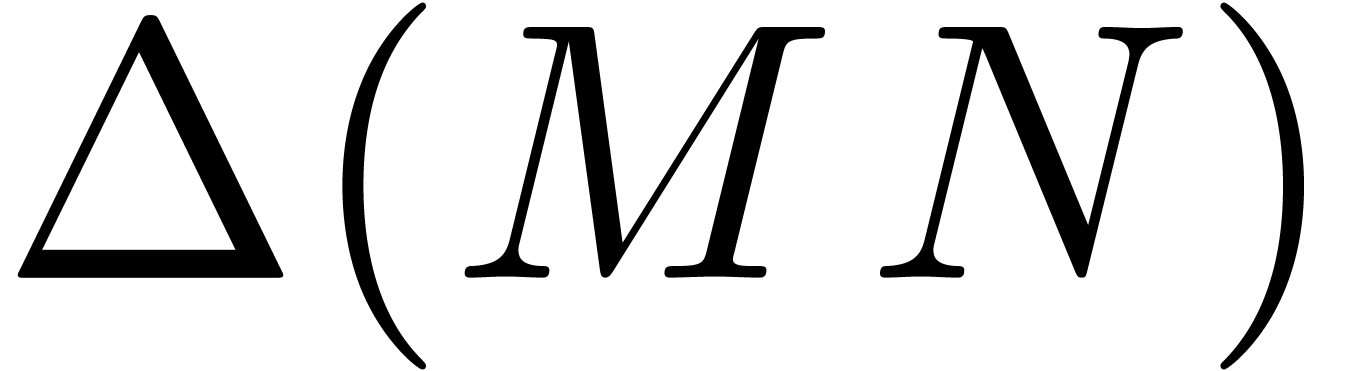 . This extra product is really required: the
computation of
. This extra product is really required: the
computation of 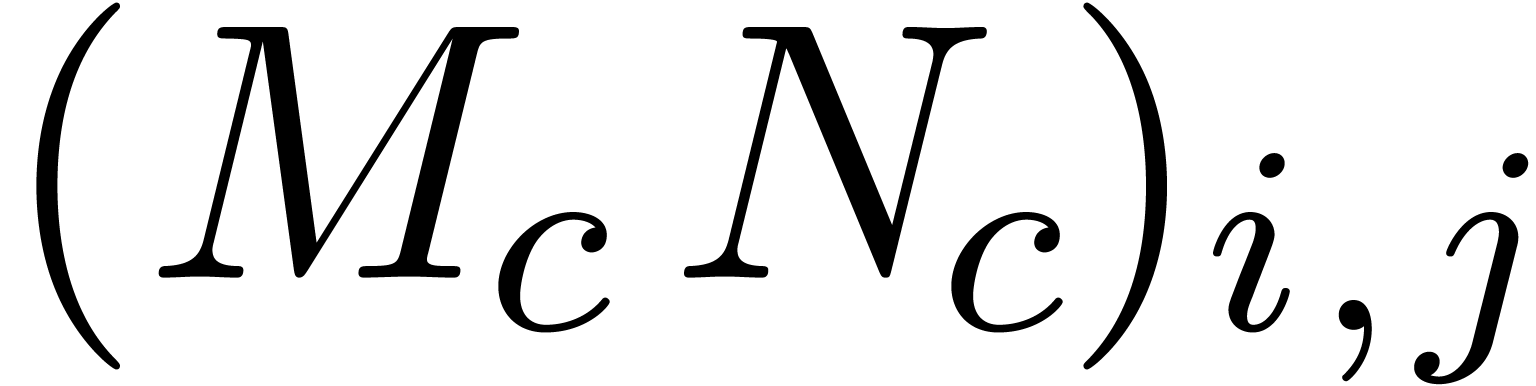 may involve cancellations, which
prevent a bound for the rounding errors to be read off from the
end-result. The formula (20) does assume that the
underlying
may involve cancellations, which
prevent a bound for the rounding errors to be read off from the
end-result. The formula (20) does assume that the
underlying  using the naive formula (19) and correct rounding, with the
possibility to compute the sums in any suitable order. Less naive
schemes, such as Strassen multiplication [Str69], may give
rise to additional rounding errors.
using the naive formula (19) and correct rounding, with the
possibility to compute the sums in any suitable order. Less naive
schemes, such as Strassen multiplication [Str69], may give
rise to additional rounding errors.
matrix products in  . If and
are well-conditioned, then the following
formula may be used instead:
. If and
are well-conditioned, then the following
formula may be used instead:
where 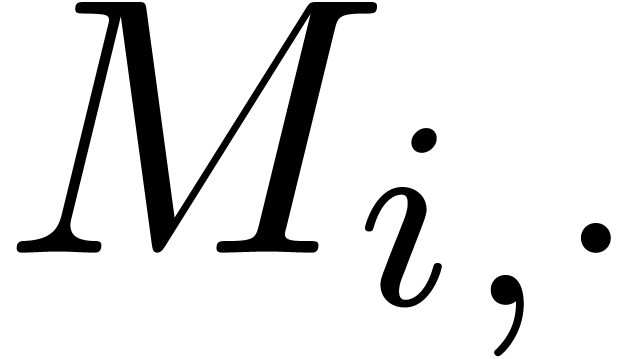 and
and 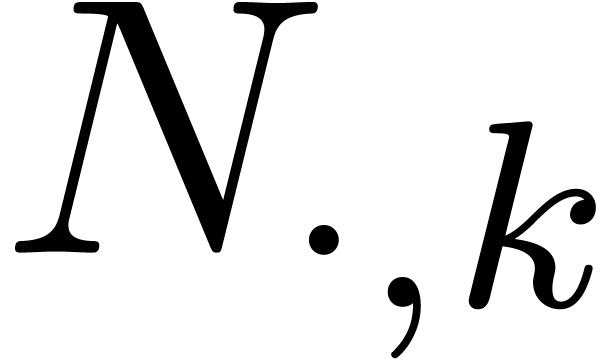 stand for the
-th row of
and the -th column of . Since the
stand for the
-th row of
and the -th column of . Since the  norms can be computed using only
norms can be computed using only  operations, the
cost of the bound computation is asymptotically negligible with respect
to the cost of the multiplication .
operations, the
cost of the bound computation is asymptotically negligible with respect
to the cost of the multiplication .
matrices, chances increase that or gets badly conditioned,
in which case the quality of the error bound (22)
decreases. Nevertheless, we may use a compromise between the naive and
the fast strategies: fix a not too small constant  , such as
, such as  ,
and rewrite and as
,
and rewrite and as
 matrices whose entries are
matrices whose entries are  matrices. Now multiply and
using the revisited naive strategy, but use the fast strategy on each
of the block coefficients. Being able to
choose , the user has an
explicit control over the trade-off between the efficiency of matrix
multiplication and the quality of the computed bounds.
matrices. Now multiply and
using the revisited naive strategy, but use the fast strategy on each
of the block coefficients. Being able to
choose , the user has an
explicit control over the trade-off between the efficiency of matrix
multiplication and the quality of the computed bounds.
As an additional, but important observation, we notice that the user often has the means to perform an “a posteri quality check”. Starting with a fast but low quality bound computation, we may then check whether the computed bound is suitable. If not, then we recompute a better bound using a more expensive algorithm.
 . Computing
using (20) requires one expensive multiplication in
. Computing
using (20) requires one expensive multiplication in  and three cheap multiplications in
and three cheap multiplications in  . For large ,
the bound computation therefore induces no noticeable overhead.
. For large ,
the bound computation therefore induces no noticeable overhead.
Assume that we want to invert an ball matrix
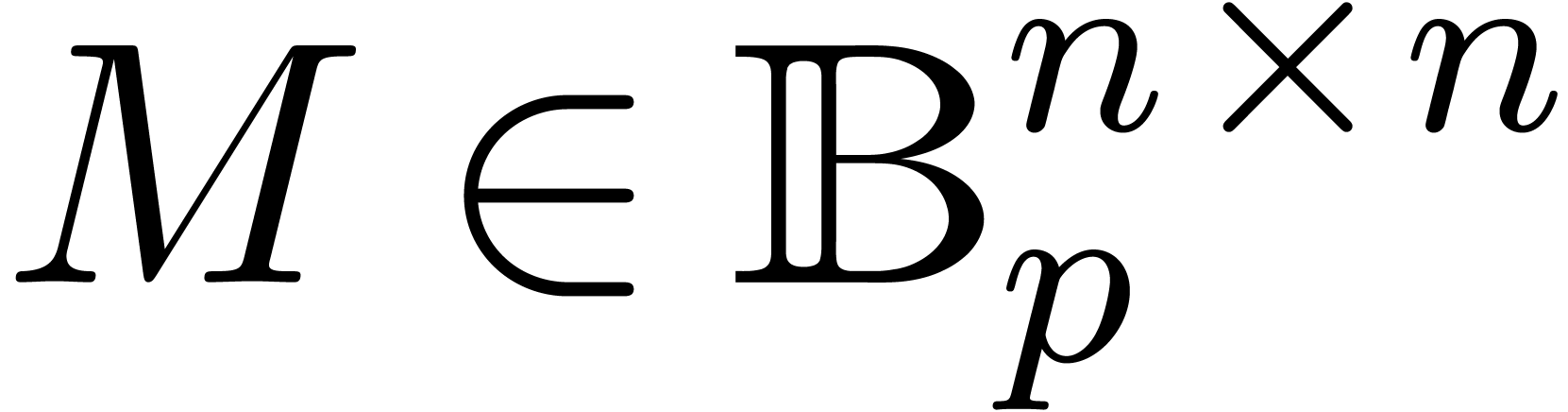 . This a typical situation
where the naive application of a symbolic algorithm (such as gaussian
elimination or LR-decomposition) may lead to overestimation. An
efficient and high quality method for the inversion of
is called Hansen's method [HS67, Moo66]. The
main idea is to first compute the inverse of
. This a typical situation
where the naive application of a symbolic algorithm (such as gaussian
elimination or LR-decomposition) may lead to overestimation. An
efficient and high quality method for the inversion of
is called Hansen's method [HS67, Moo66]. The
main idea is to first compute the inverse of 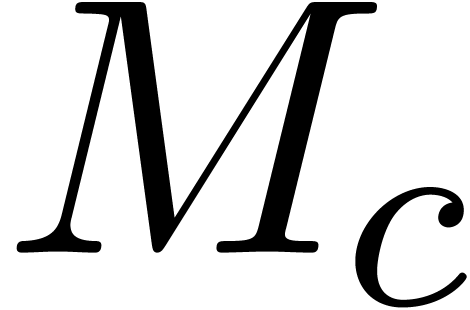 using a standard numerical algorithm. Only at the end, we estimate the
error using a perturbative analysis. The same technique can be used for
many other problems.
using a standard numerical algorithm. Only at the end, we estimate the
error using a perturbative analysis. The same technique can be used for
many other problems.
More precisely, we start by computing an approximation 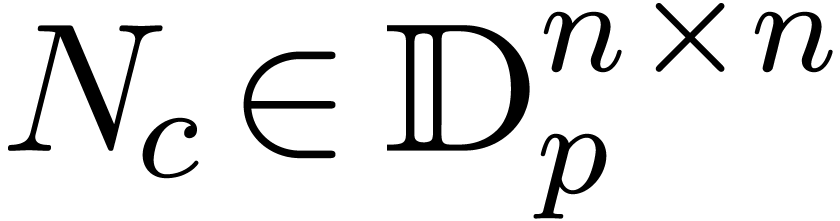 of
of  . Putting
. Putting 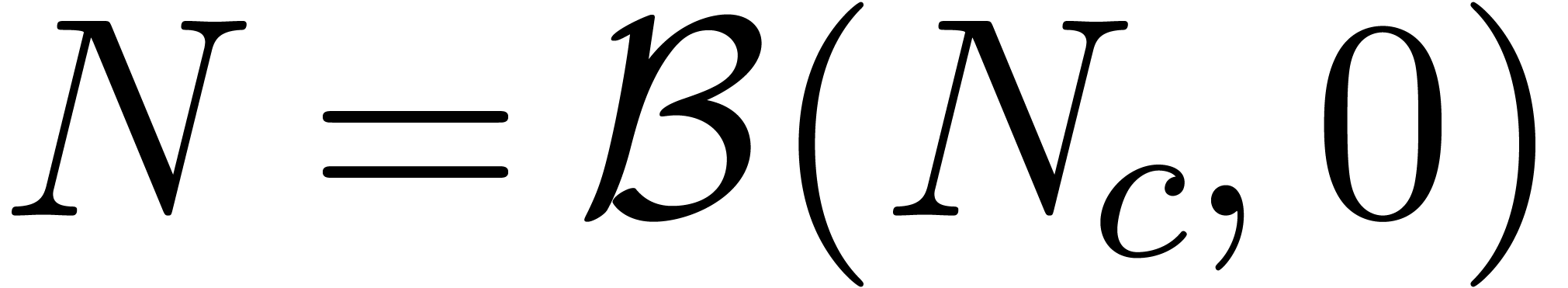 , we next compute the product
using ball arithmetic. This should yield a matrix of the form
, we next compute the product
using ball arithmetic. This should yield a matrix of the form 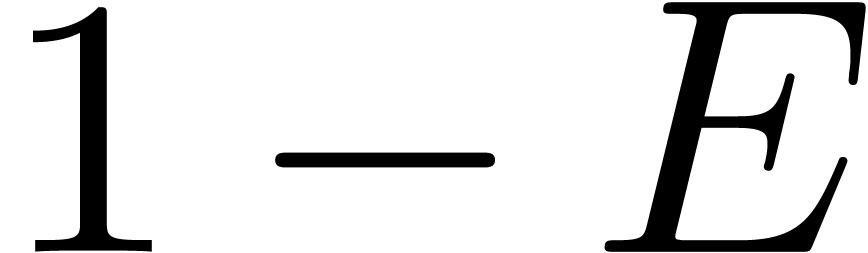 , where
, where  is
small. If is indeed small, say
is
small. If is indeed small, say 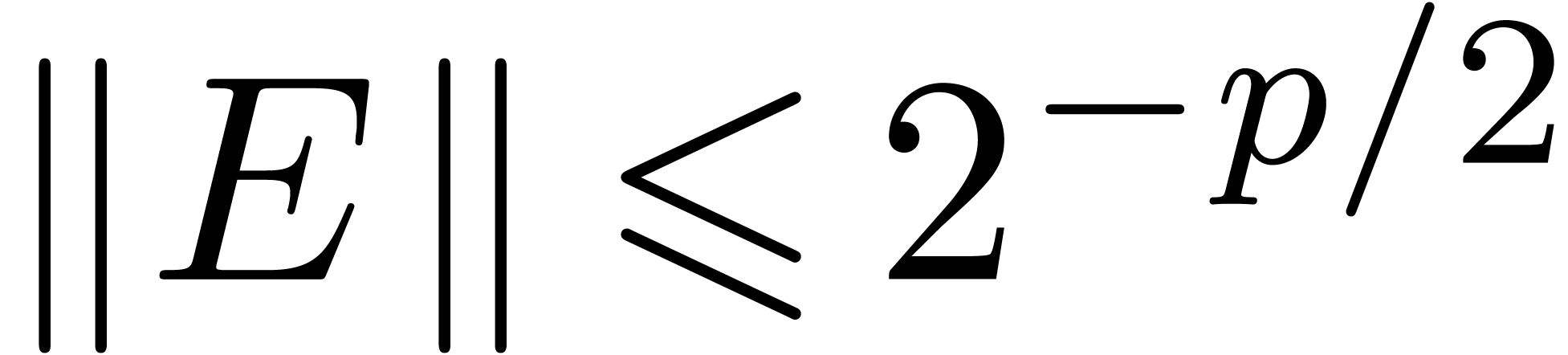 , then
, then
Denoting by 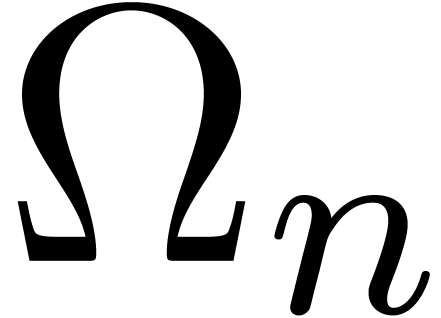 the matrix
whose entries are all
the matrix
whose entries are all 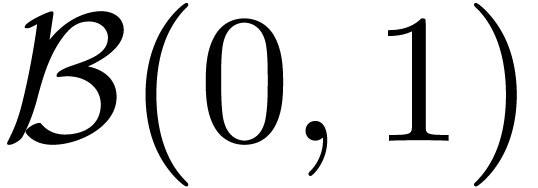 , we
may thus take
, we
may thus take
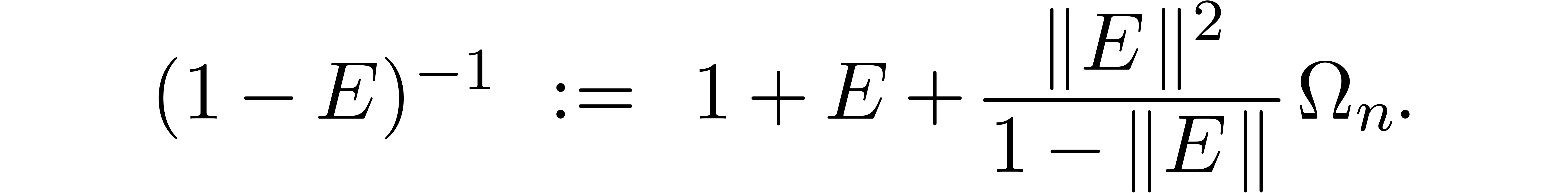
Having inverted , we may
finally take 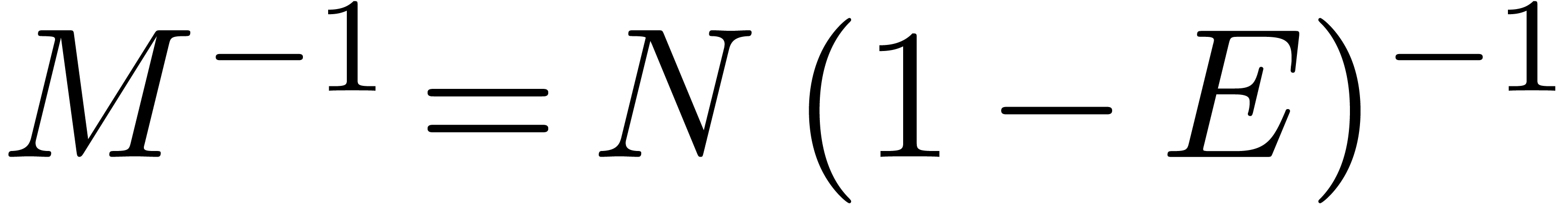 . Notice that
the computation of
. Notice that
the computation of  can be quite expensive. It is
therefore recommended to replace the check by a
cheaper check, such as
can be quite expensive. It is
therefore recommended to replace the check by a
cheaper check, such as 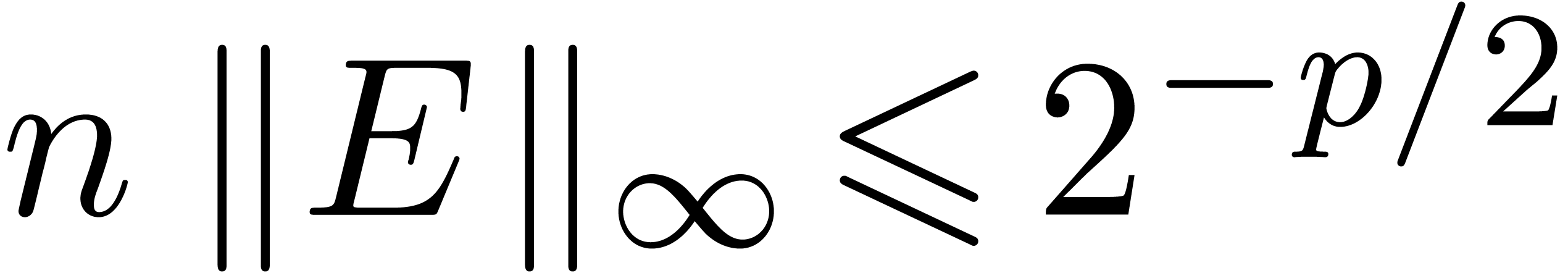 .
.
Unfortunately, the matrix is not always small,
even if is nicely invertible. For instance,
starting with a matrix of the form
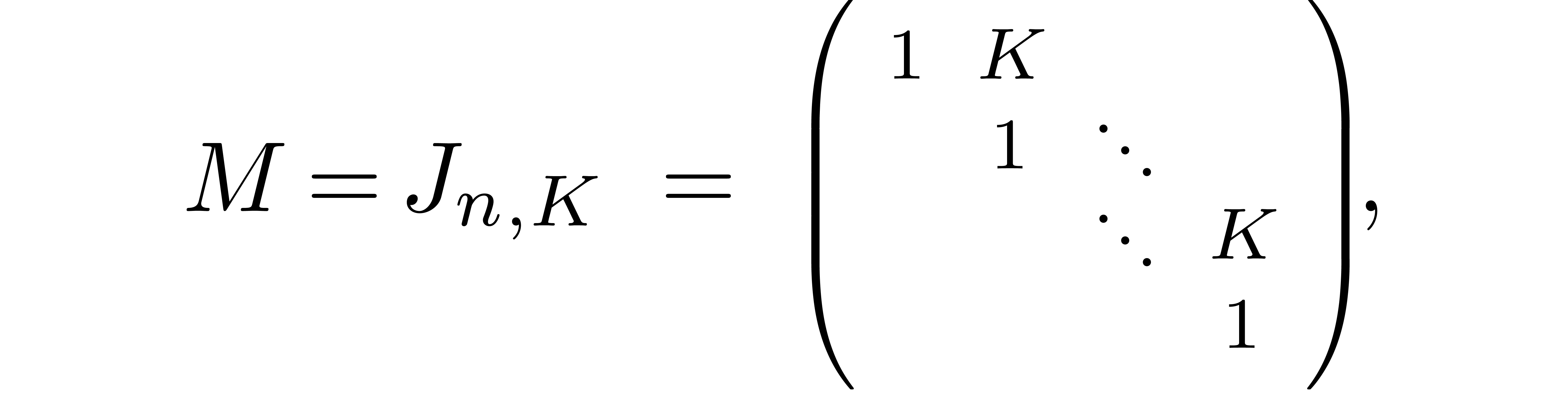
with large, we have
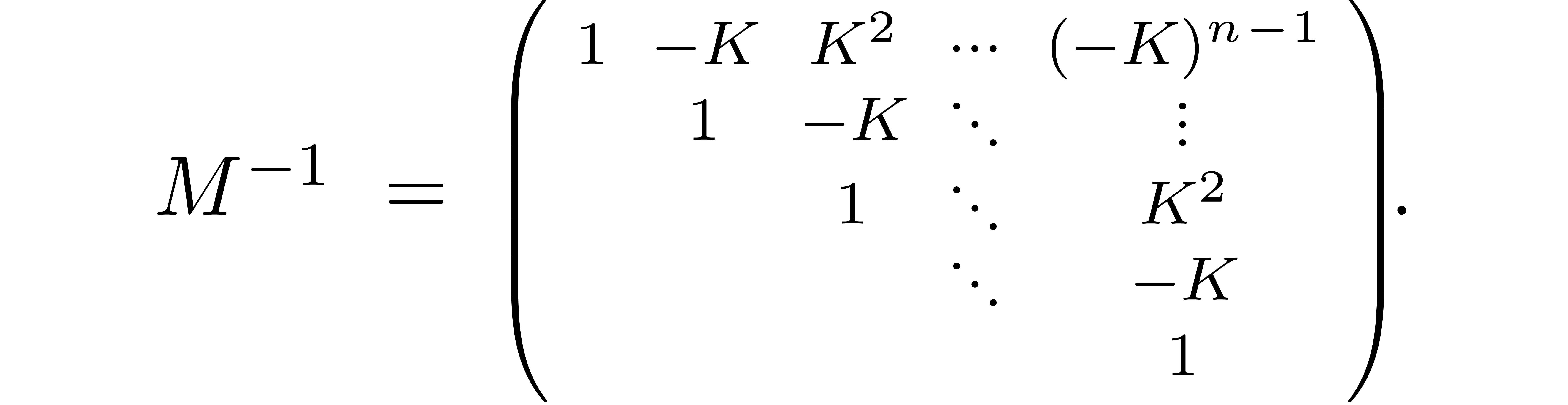
Computing using bit precision , this typically leads to
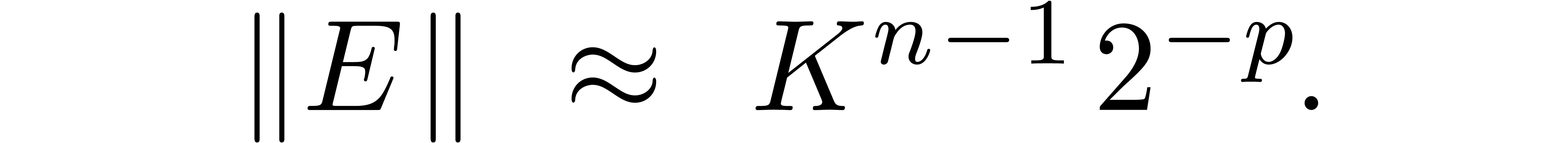
In such cases, we rather reduce the problem of inverting to the problem of inverting 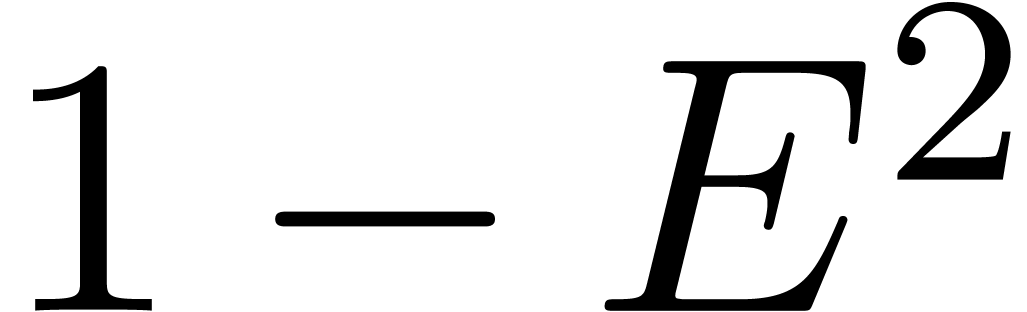 ,
using the formula
,
using the formula
More precisely, applying this trick recursively, we compute 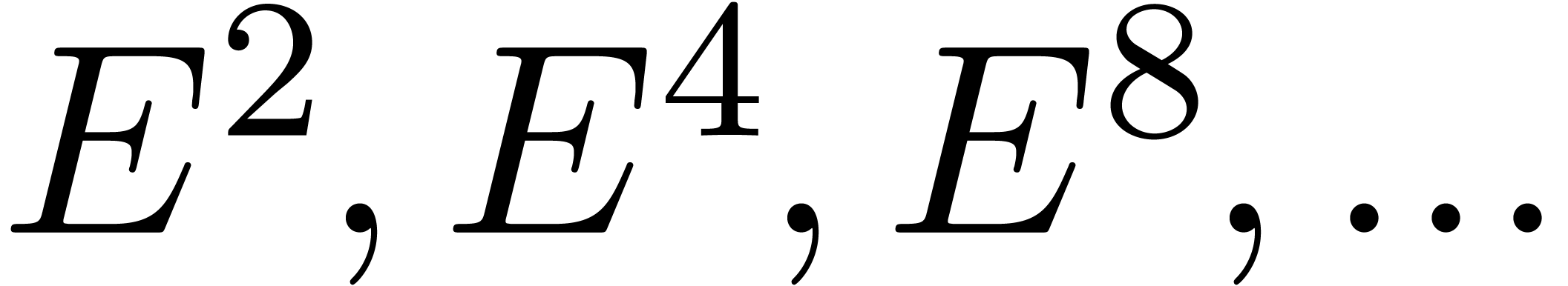 until
until 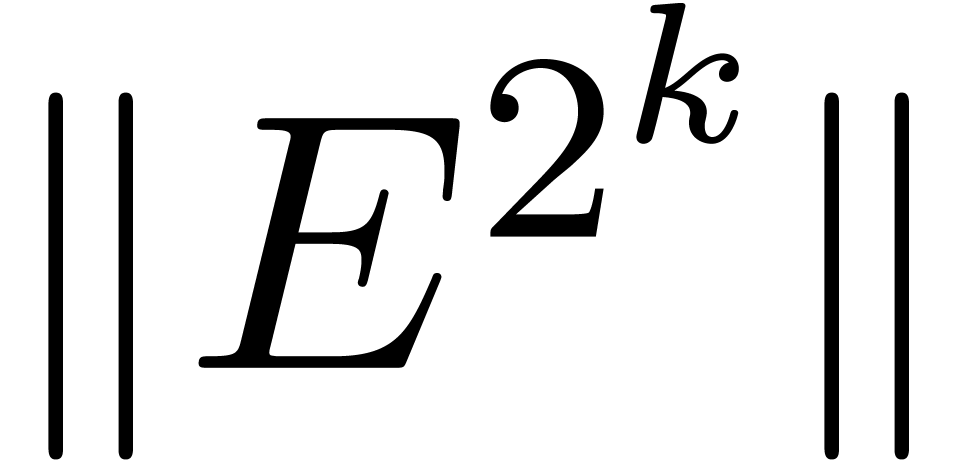 becomes small (say
becomes small (say 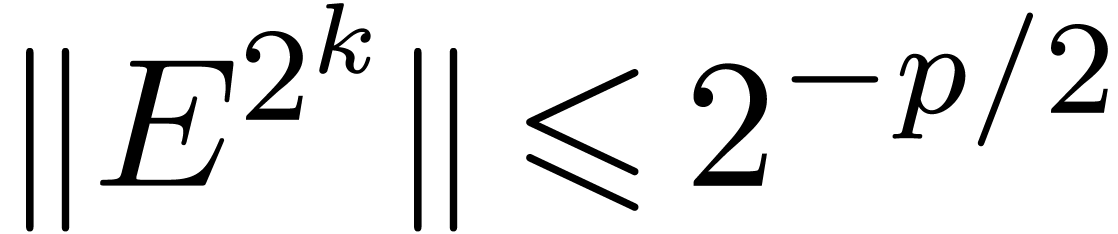 ) and use the formula
) and use the formula
We may always stop the algorithm for 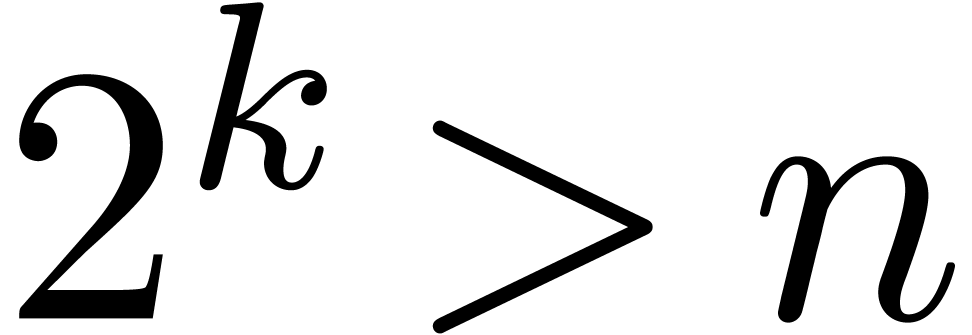 ,
since
,
since 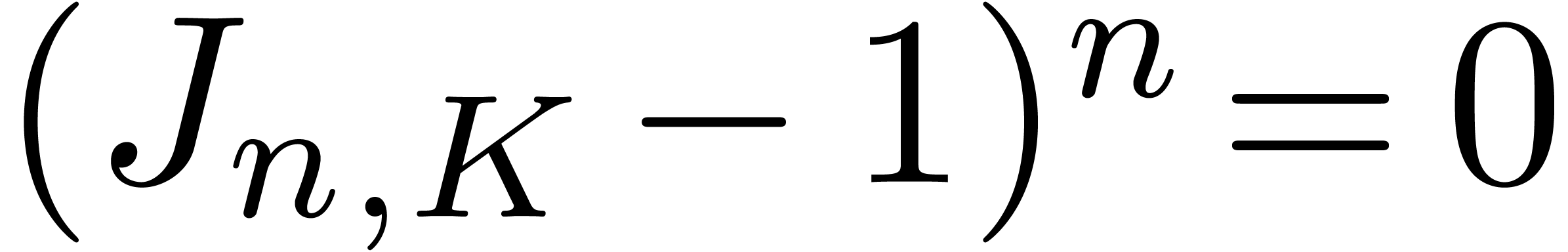 . We may also stop the
algorithm whenever
. We may also stop the
algorithm whenever 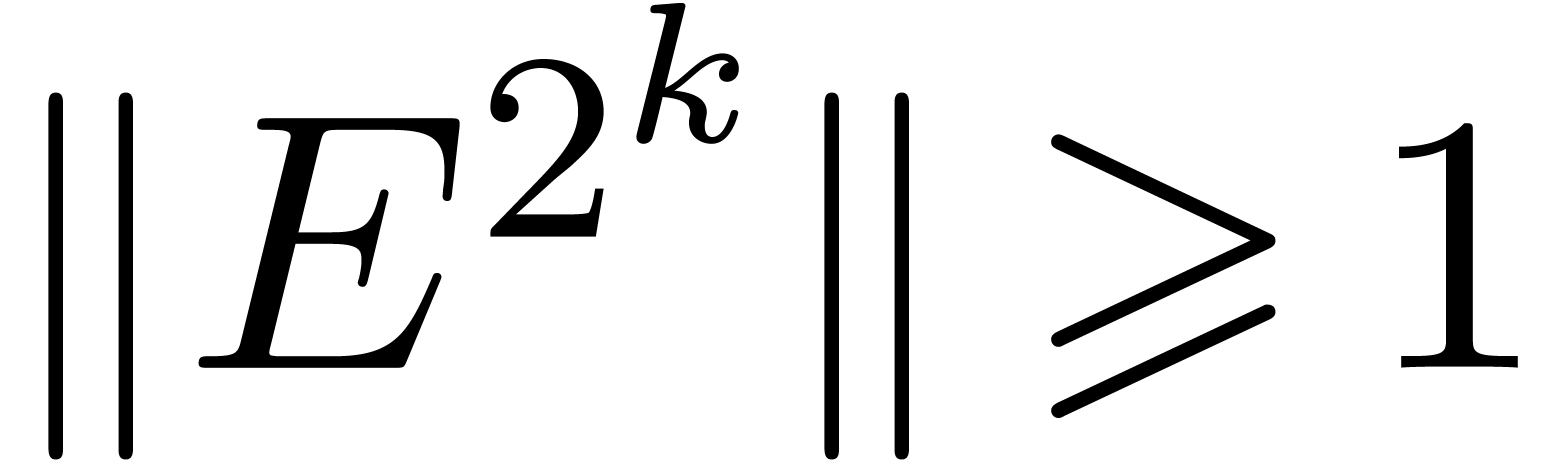 and
and  , since usually fails to be
invertible in that case.
, since usually fails to be
invertible in that case.
In general, the above algorithm requires 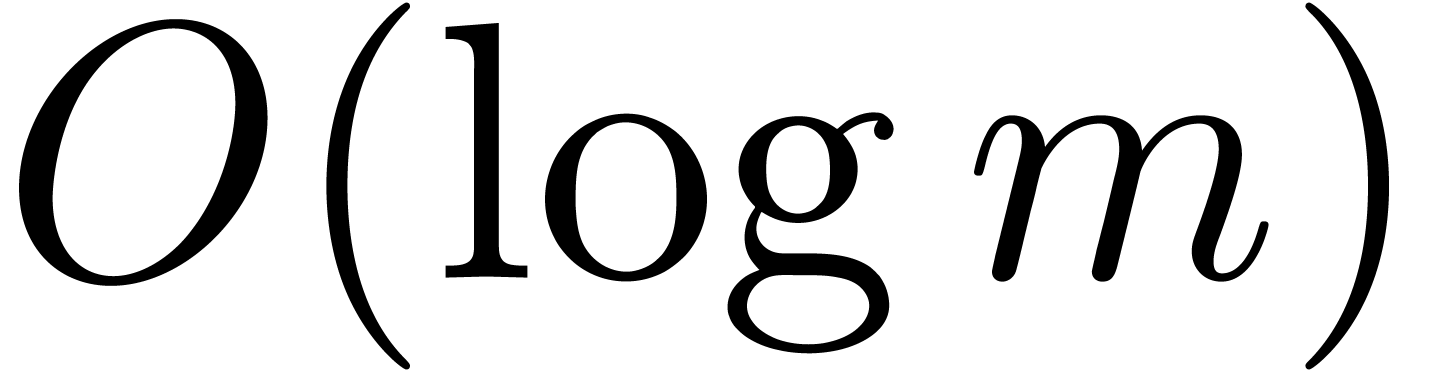 ball
matrix multiplications, where
ball
matrix multiplications, where 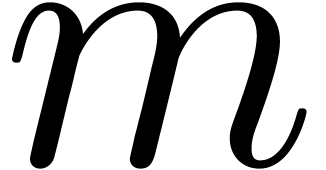 is the size of the largest block of the kind
is the size of the largest block of the kind 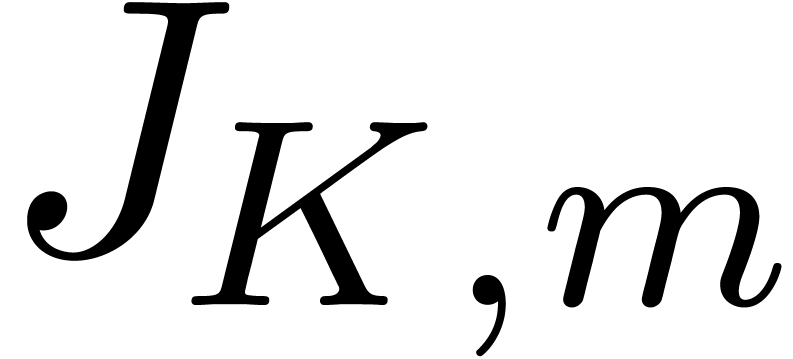 in
the Jordan decomposition of .
The improved quality therefore requires an additional
in
the Jordan decomposition of .
The improved quality therefore requires an additional 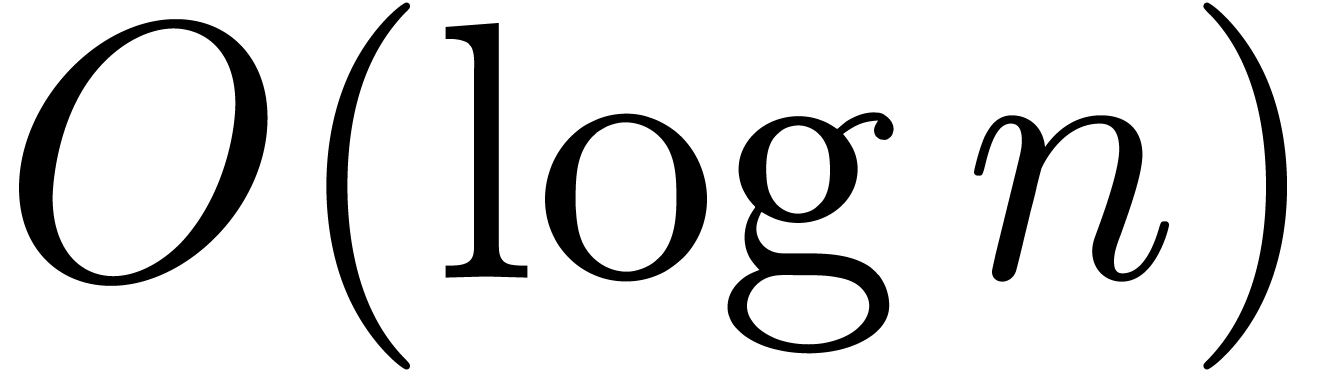 overhead in the worst case. Nevertheless, for a fixed matrix and
overhead in the worst case. Nevertheless, for a fixed matrix and 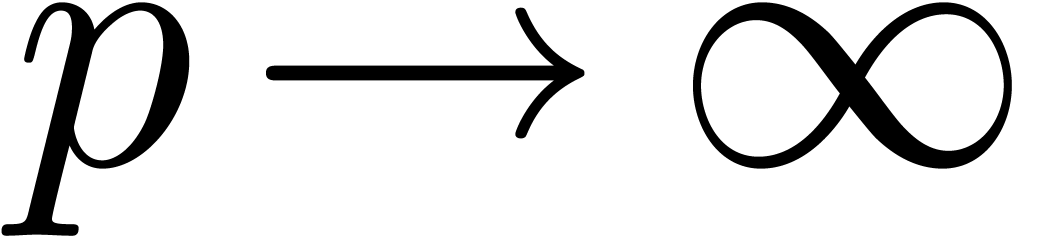 , the norm
will eventually become sufficiently small
(i.e.
, the norm
will eventually become sufficiently small
(i.e. 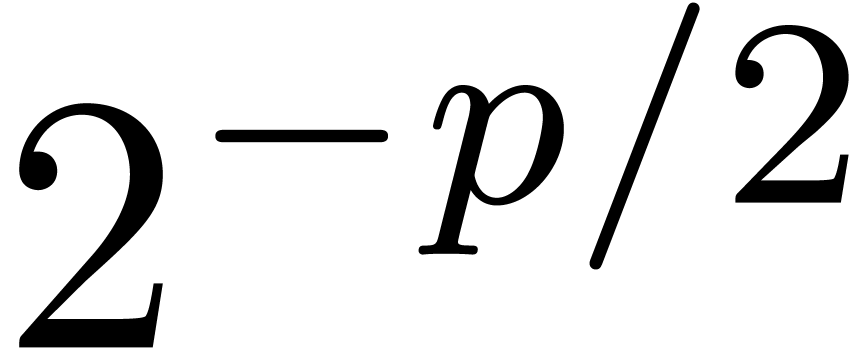 ) for (23) to apply. Again, the complexity thus tends to improve for
high precisions. An interesting question is whether we can avoid the
ball matrix multiplication
) for (23) to apply. Again, the complexity thus tends to improve for
high precisions. An interesting question is whether we can avoid the
ball matrix multiplication  altogether, if gets really large. Theoretically, this can be
achieved by using a symbolic algorithm such as Gaussian elimination or
LR-decomposition using ball arithmetic. Indeed, even though the
overestimation is important, it does not depend on the precision . Therefore, we have
altogether, if gets really large. Theoretically, this can be
achieved by using a symbolic algorithm such as Gaussian elimination or
LR-decomposition using ball arithmetic. Indeed, even though the
overestimation is important, it does not depend on the precision . Therefore, we have 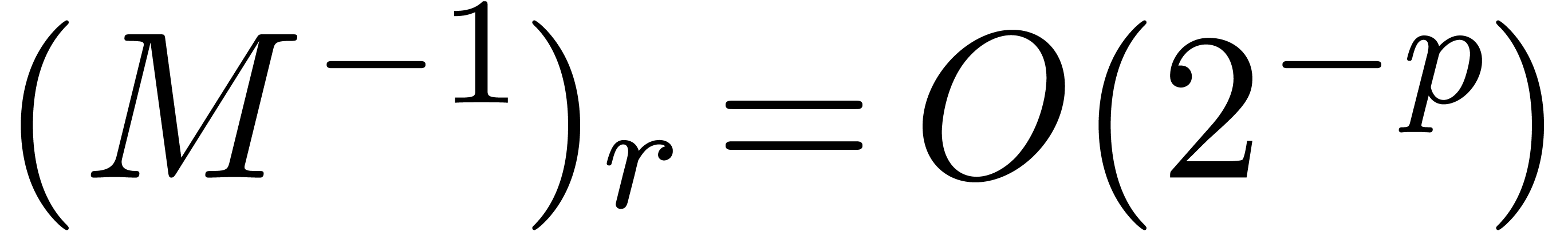 and the cost of the bound computations becomes negligible
for large .
and the cost of the bound computations becomes negligible
for large .
Let us now consider the problem of computing the eigenvectors of a ball
matrix 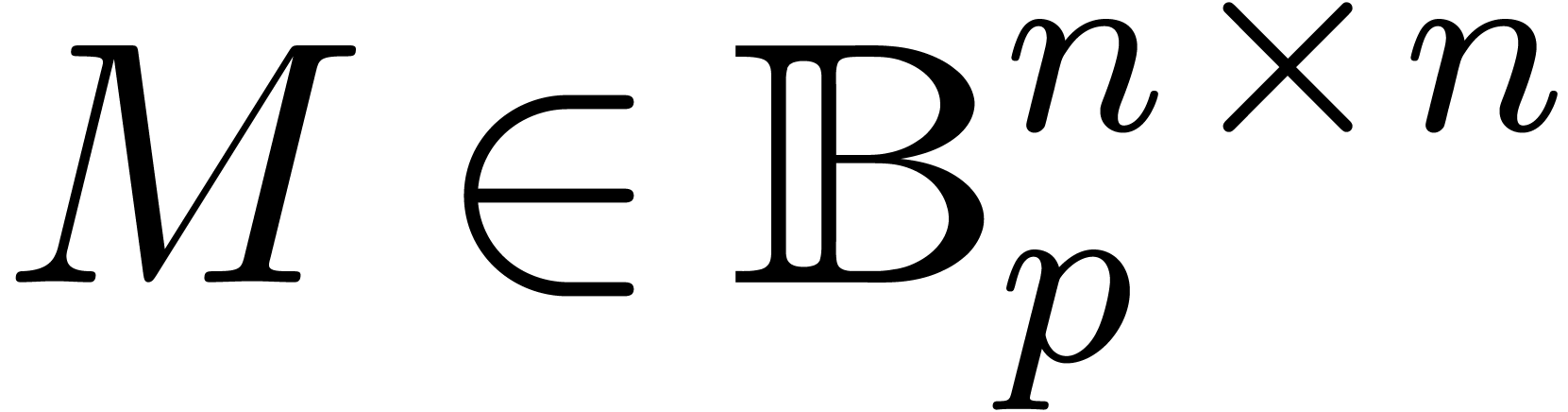 , assuming for
simplicity that the corresponding eigenvalues are non zero and pairwise
distinct. We adopt a similar strategy as in the case of matrix
inversion. Using a standard numerical method, we first compute a
diagonal matrix
, assuming for
simplicity that the corresponding eigenvalues are non zero and pairwise
distinct. We adopt a similar strategy as in the case of matrix
inversion. Using a standard numerical method, we first compute a
diagonal matrix 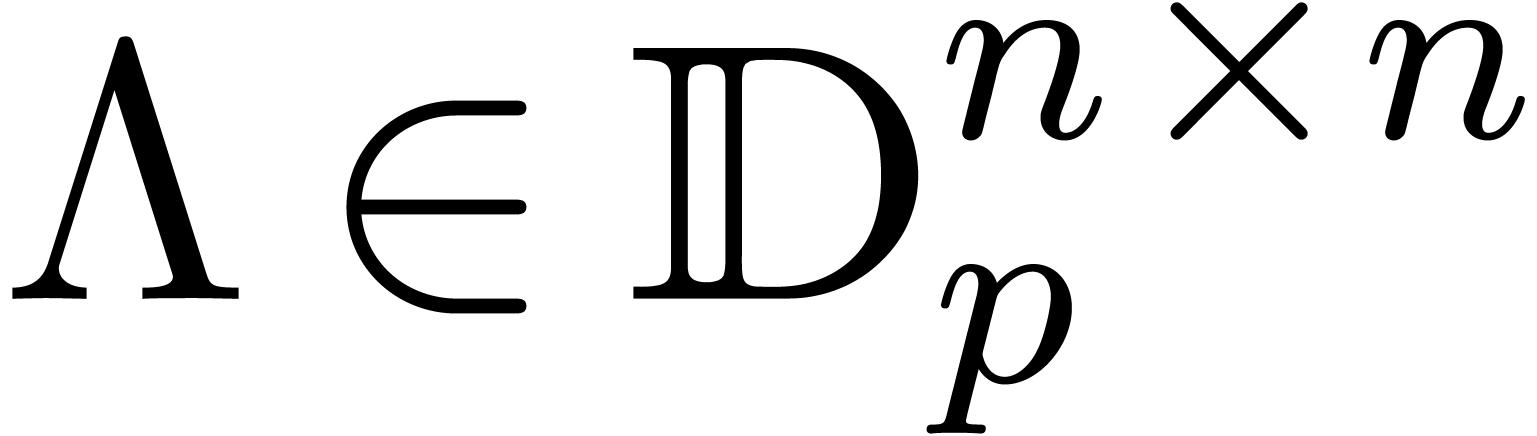 and an invertible transformation
matrix
and an invertible transformation
matrix 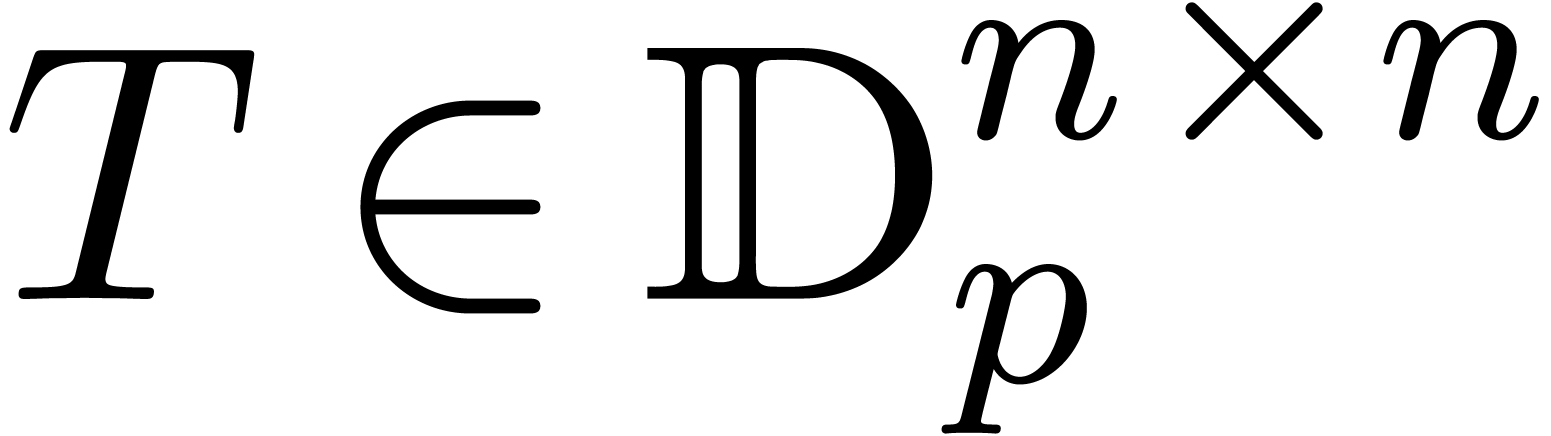 , such that
, such that
The main challenge is to find reliable error bounds for this
computation. Again, we will use the technique of small perturbations.
The equation (26) being a bit more subtle than  , this requires more work than in the case of
matrix inversion. In fact, we start by giving a numerical method for the
iterative improvement of an approximate solution. A variant of the same
method will then provide the required bounds. Again, this idea can often
be used for other problems. The results of this section are work in
common with
, this requires more work than in the case of
matrix inversion. In fact, we start by giving a numerical method for the
iterative improvement of an approximate solution. A variant of the same
method will then provide the required bounds. Again, this idea can often
be used for other problems. The results of this section are work in
common with
Given 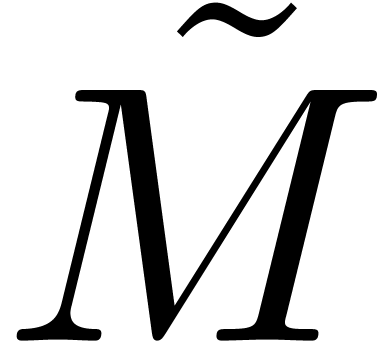 close to ,
we have to find
close to ,
we have to find  close to
close to  and
and  close to
close to  ,
such that
,
such that
Putting
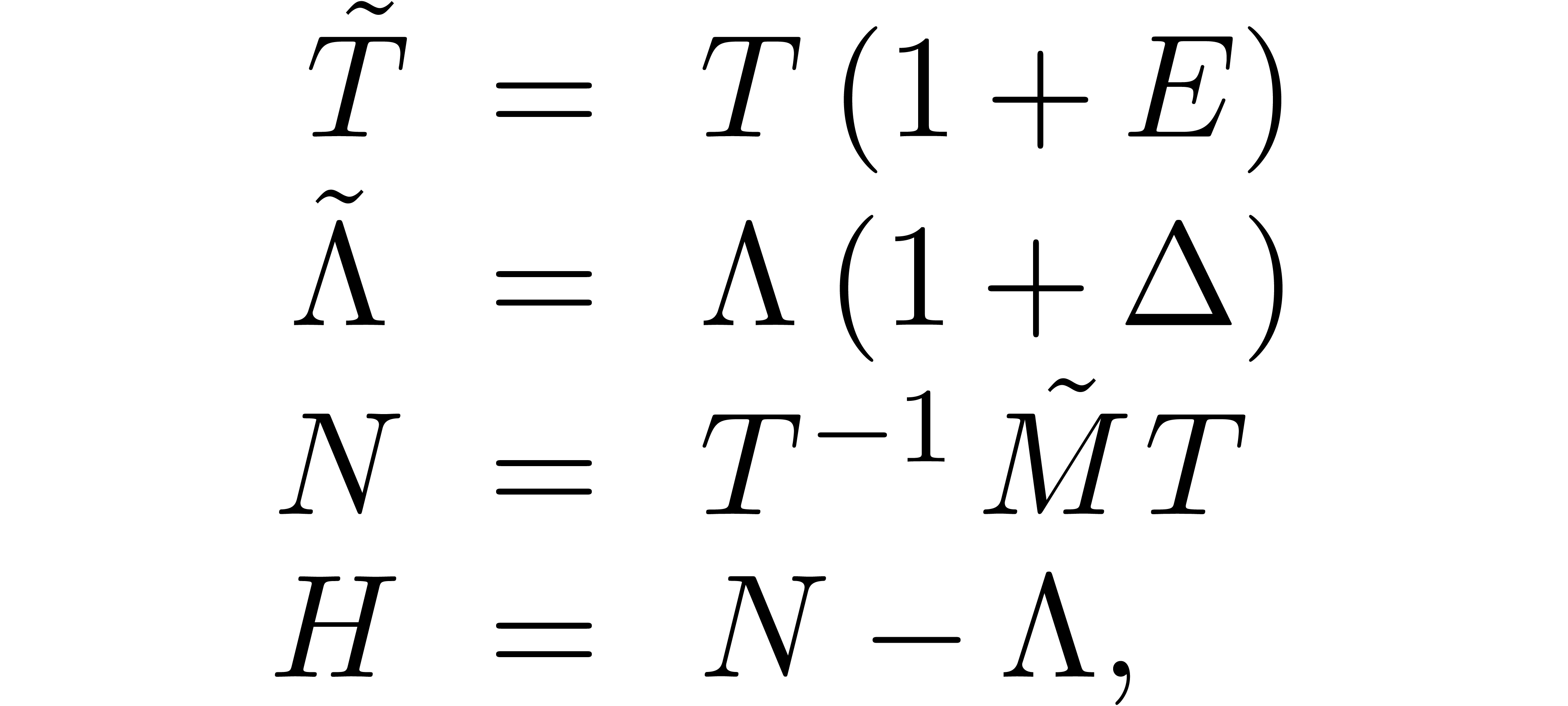
this yields the equation
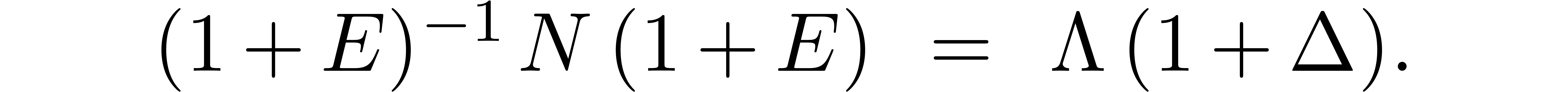
Expansion with respect to yields
Forgetting about the non-linear terms, the equation
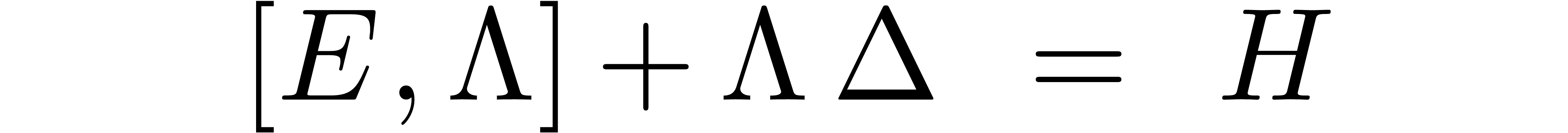
admits a unique solution
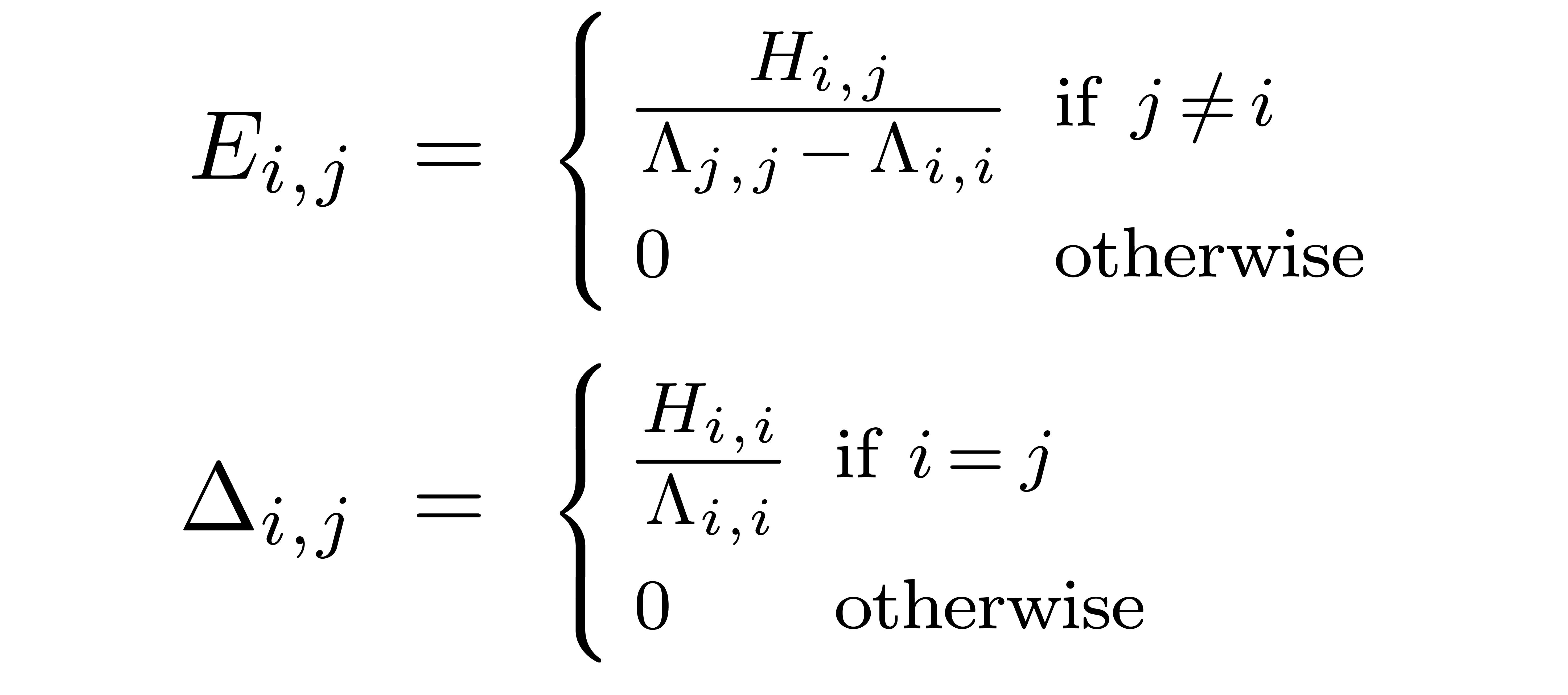
Setting
it follows that
Setting 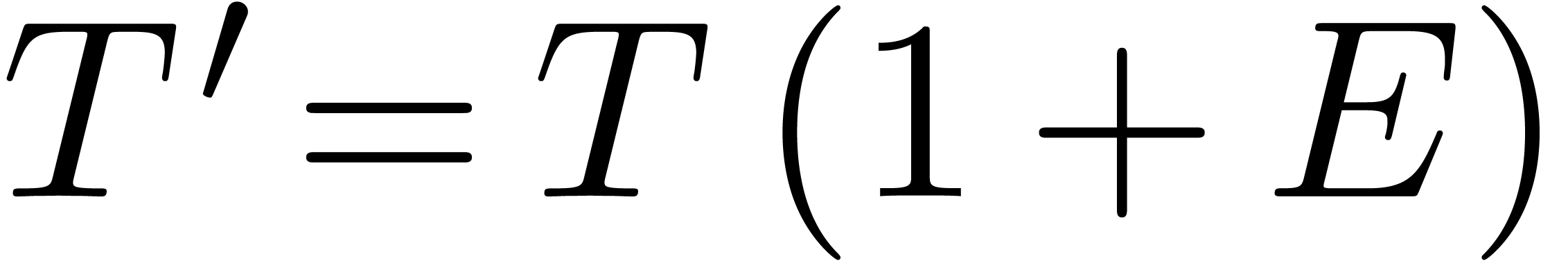 ,
, 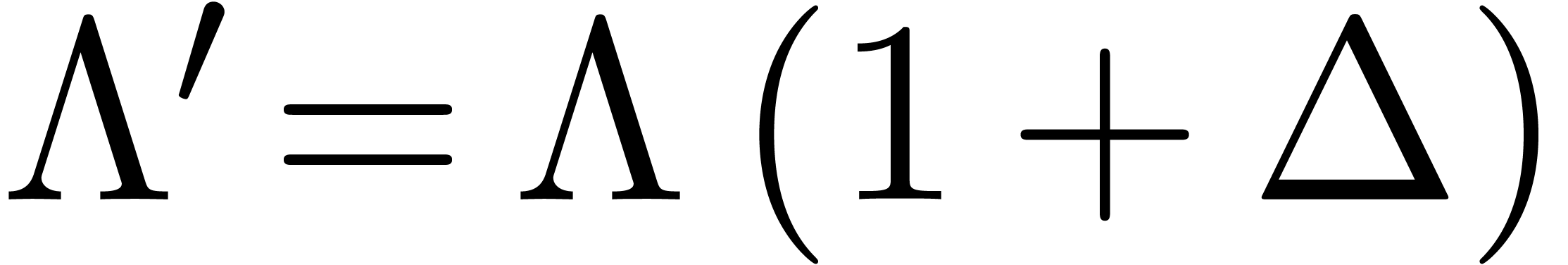 and
and 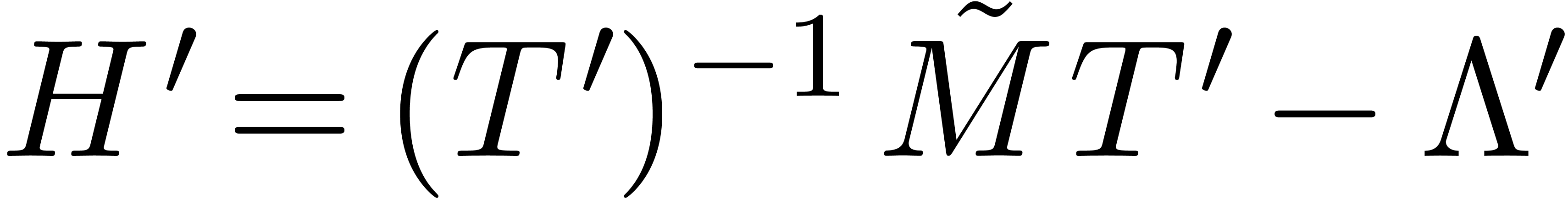 , the relation (28)
also implies
, the relation (28)
also implies
Under the additional condition 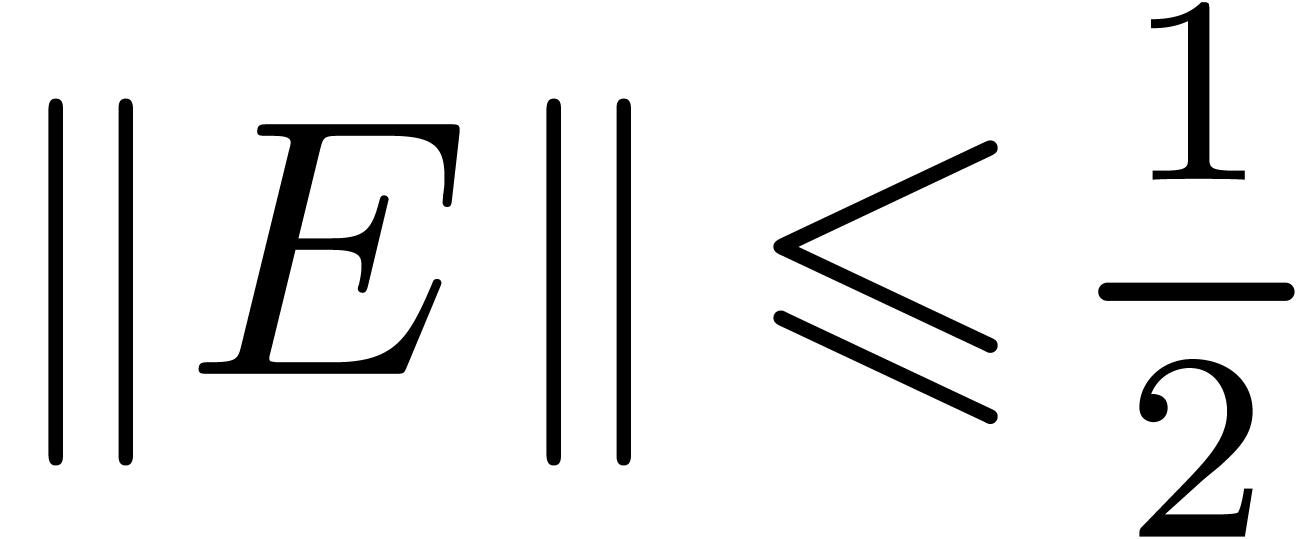 ,
it follows that
,
it follows that
For sufficiently small  , we
claim that iteration of the mapping
, we
claim that iteration of the mapping 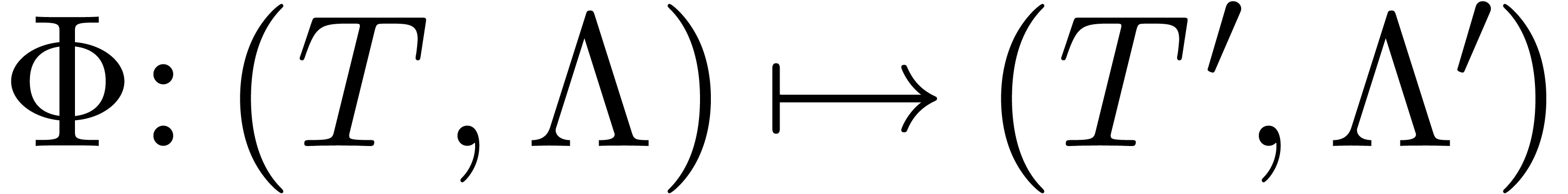 converges to
a solution of (27).
converges to
a solution of (27).
Let us denote 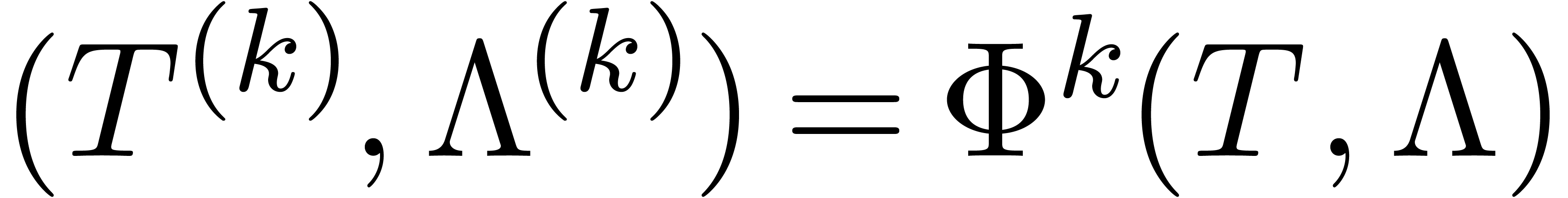 ,
, 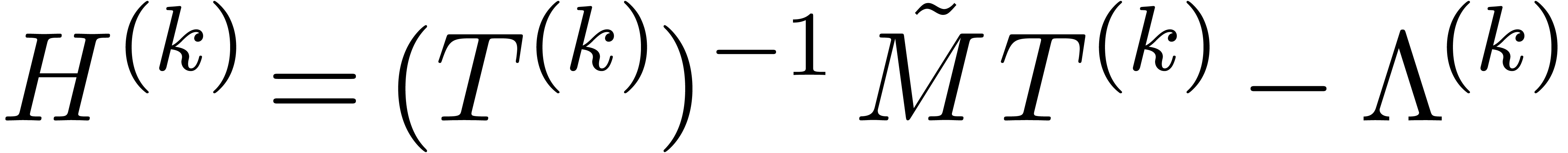 and let
and let  be such that
be such that 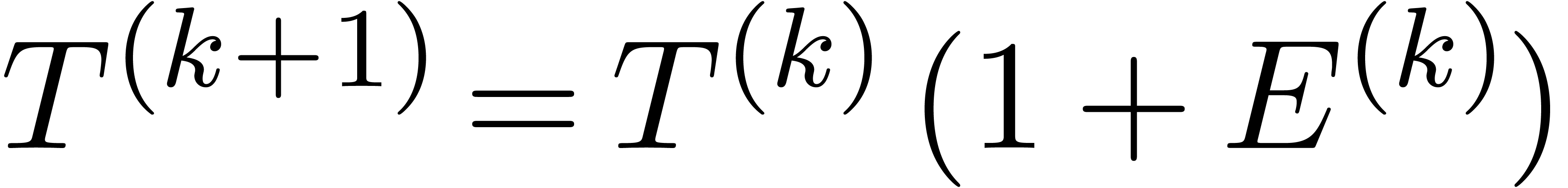 and
and 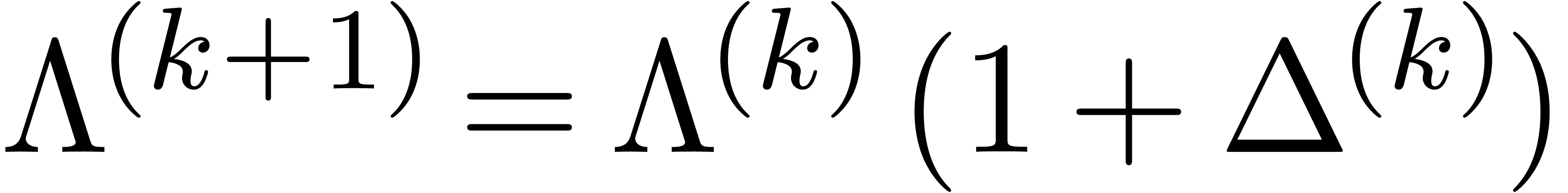 . Assume
that
. Assume
that
and let us prove by induction over that
This is clear for 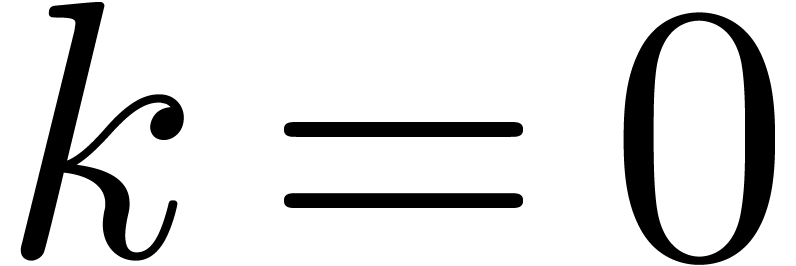 , so assume
that
, so assume
that  . In a similar way as
(30), we have
. In a similar way as
(30), we have
Using the induction hypotheses and  ,
it follows that
,
it follows that
which proves (32). Now let 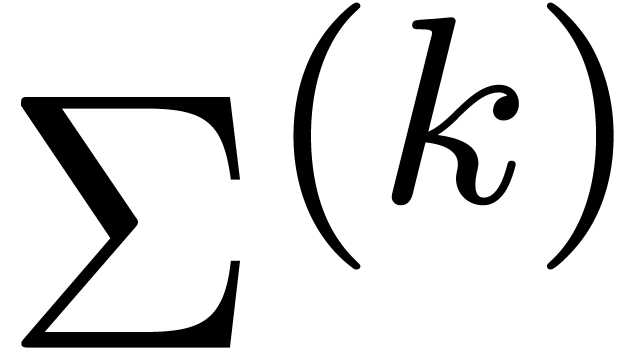 be such
that
be such
that
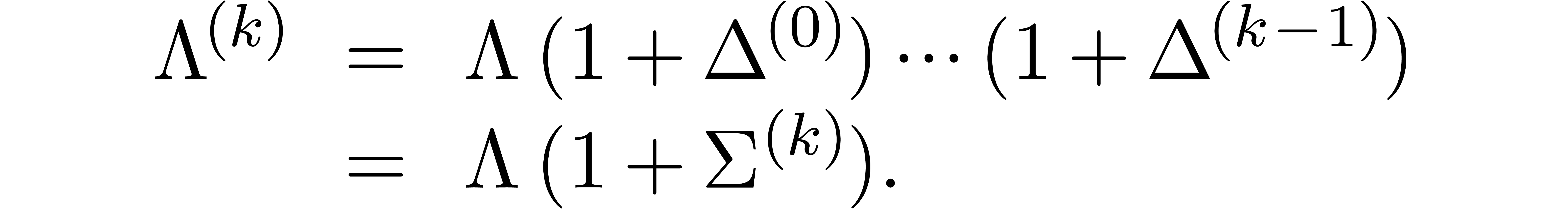
From (34), it follows that
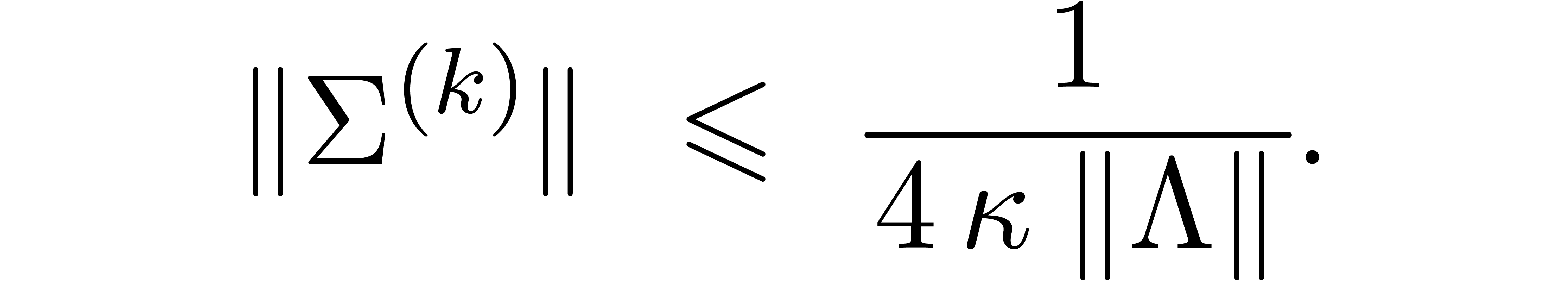
On the one hand, this implies (33). On the other hand, it follows that
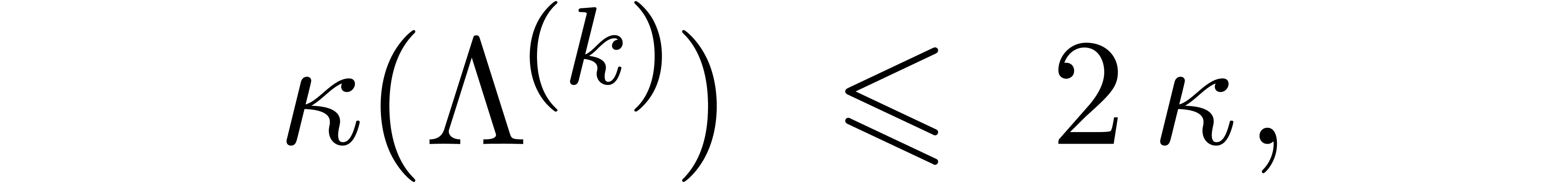
whence (29) generalizes to (34). This
completes the induction and the linear convergence of 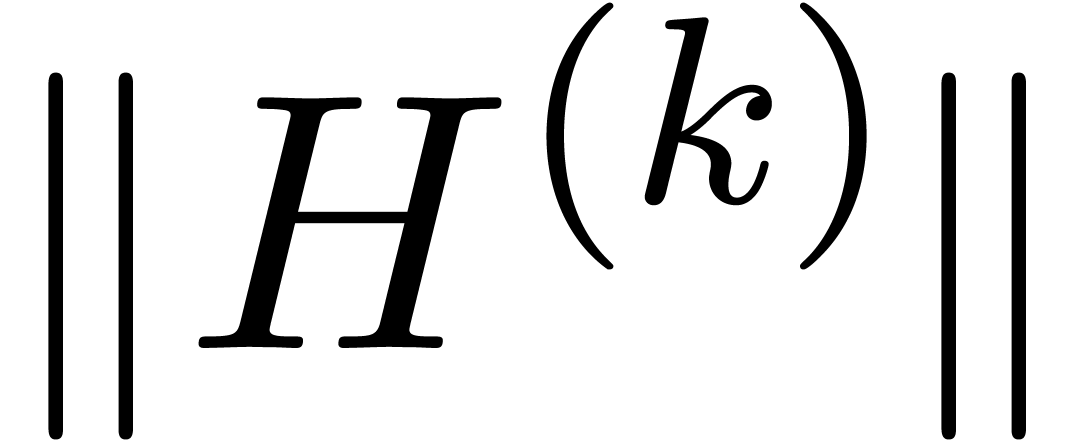 to zero. In fact, the combination of (34) and (35)
show that we even have quadratic convergence.
to zero. In fact, the combination of (34) and (35)
show that we even have quadratic convergence.
Let us now return to the original bound computation problem. We start
with the computation of 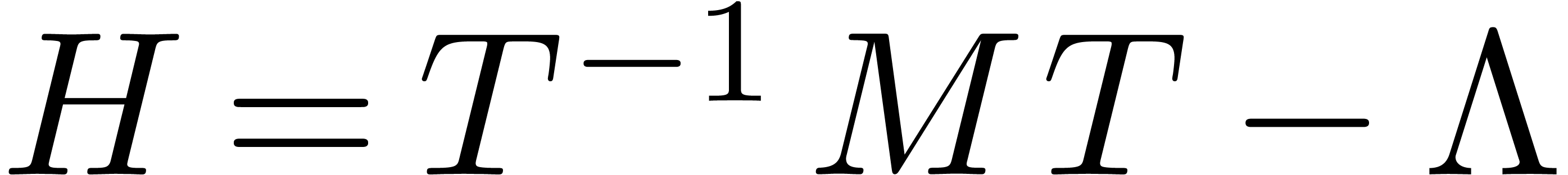 using ball arithmetic.
If the condition (31) is met (using the most pessimistic
rounding), the preceding discussion shows that for every
using ball arithmetic.
If the condition (31) is met (using the most pessimistic
rounding), the preceding discussion shows that for every  (in the sense that
(in the sense that  for all
for all  ), the equation (27)
admits a solution of the form
), the equation (27)
admits a solution of the form
with

for all . It follows that
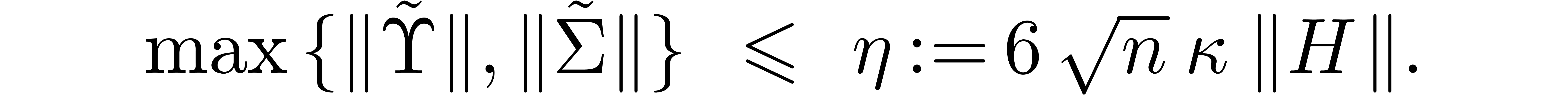
We conclude that
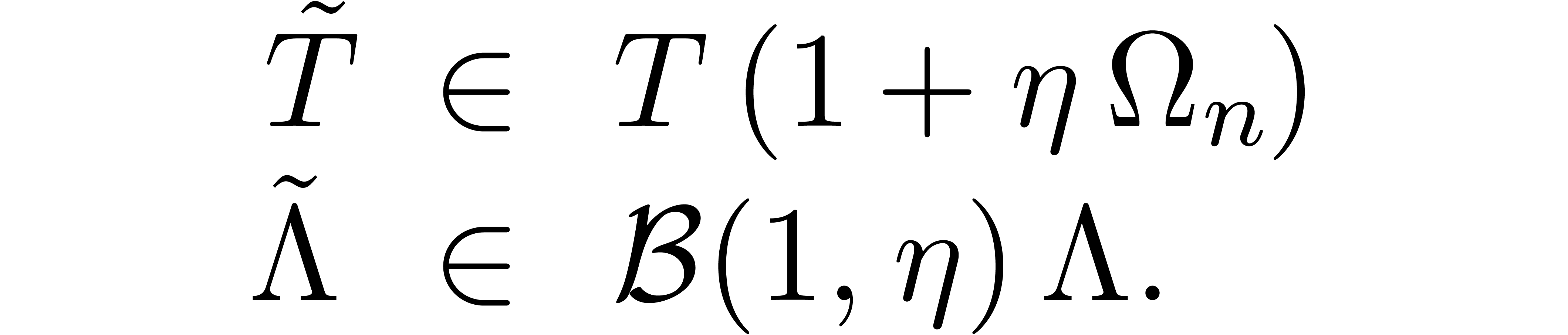
We may thus return 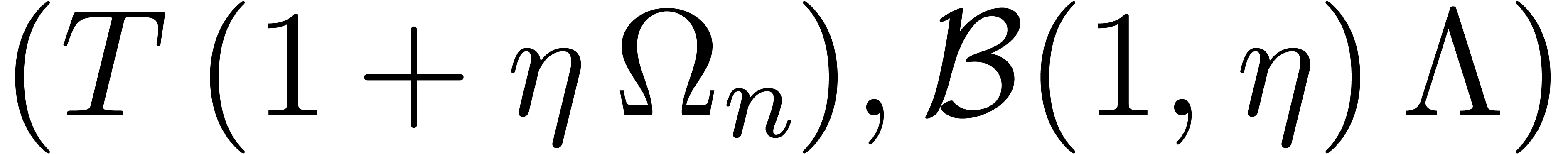 as the solution to the
original eigenproblem associated to the ball matrix .
as the solution to the
original eigenproblem associated to the ball matrix .
The reliable bound computation essentially reduces to the computation of
three matrix products and one matrix inversion. At low precisions, the
numerical computation of the eigenvectors is far more expensive in
practice, so the overhead of the bound computation is essentially
negligible. At higher precisions ,
the iteration 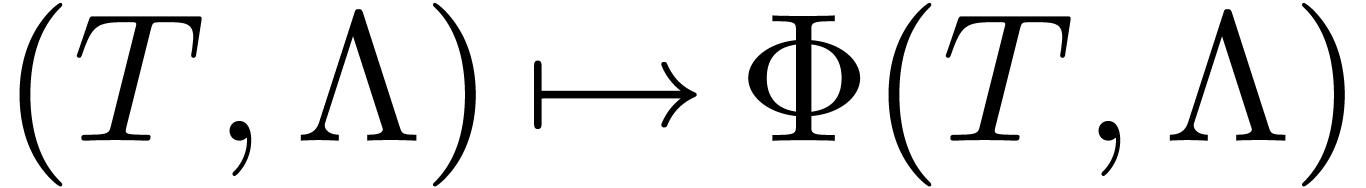 actually provides an efficient way
to double the precision of a numerical solution to the eigenproblem at
precision
actually provides an efficient way
to double the precision of a numerical solution to the eigenproblem at
precision 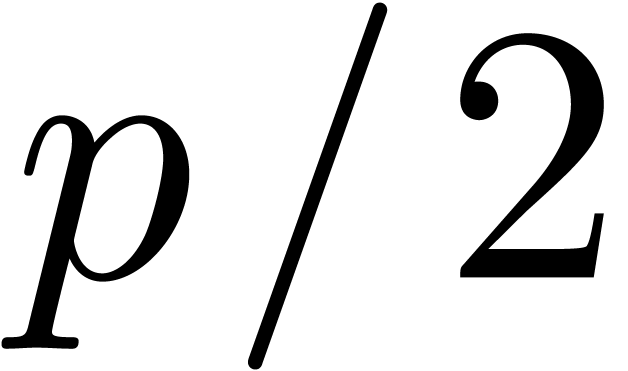 . In particular,
even if the condition (31) is not met initially, then it
usually can be enforced after a few iterations and modulo a slight
increase of the precision. For fixed and , it also follows that the
numerical eigenproblem essentially reduces to a few matrix products. The
certification of the end-result requires a few more products, which
induces a constant overhead. By performing a more refined error
analysis, it is probably possible to make the cost certification
negligible, although we did not investigate this issue in detail.
. In particular,
even if the condition (31) is not met initially, then it
usually can be enforced after a few iterations and modulo a slight
increase of the precision. For fixed and , it also follows that the
numerical eigenproblem essentially reduces to a few matrix products. The
certification of the end-result requires a few more products, which
induces a constant overhead. By performing a more refined error
analysis, it is probably possible to make the cost certification
negligible, although we did not investigate this issue in detail.
In section 4.3, we have already seen that matricial balls
in often provide higher quality error bounds
than ball matrices in 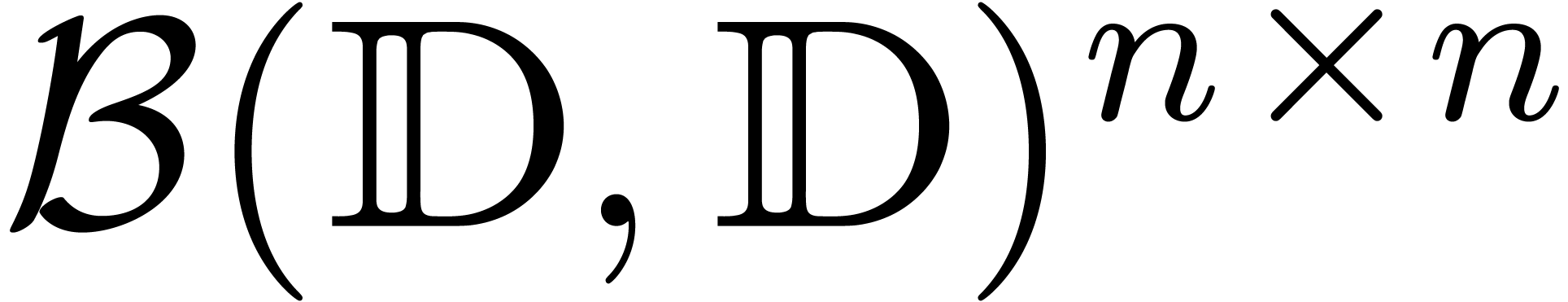 or essentially equivalent
variants in . However, ball
arithmetic in
or essentially equivalent
variants in . However, ball
arithmetic in 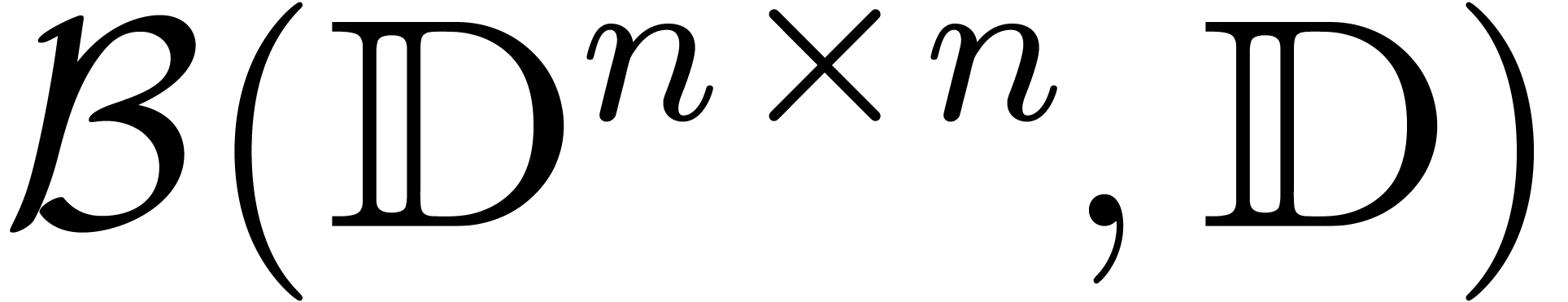 relies on the possibility to
quickly compute a sharp upper bound for the operator norm
relies on the possibility to
quickly compute a sharp upper bound for the operator norm 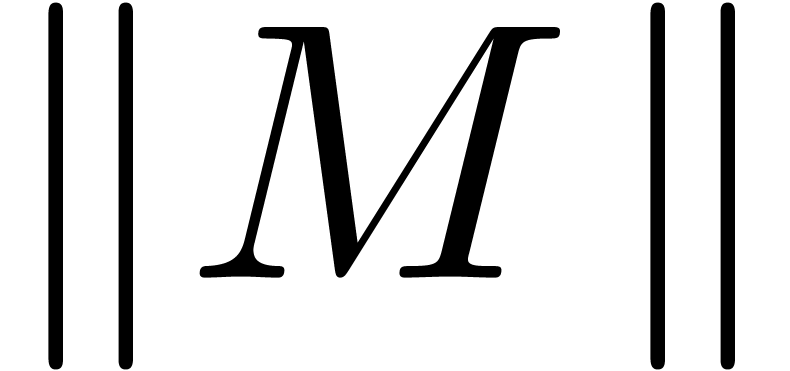 of a matrix
of a matrix  .
Unfortunately, we do not know of any really efficient algorithm for
doing this.
.
Unfortunately, we do not know of any really efficient algorithm for
doing this.
One expensive approach is to compute a reliable singular value
decomposition of , since coincides with the largest singular value.
Unfortunately, this usually boils down to the resolution of the
eigenproblem associated to 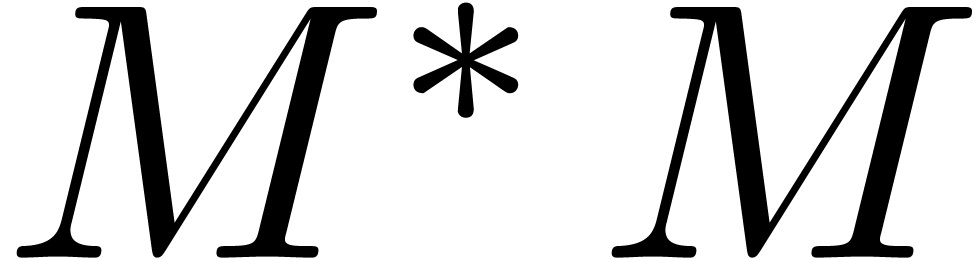 ,
with a few possible improvements (for instance, the dependency of the
singular values on the coefficients of is less
violent than in the case of a general eigenproblem).
,
with a few possible improvements (for instance, the dependency of the
singular values on the coefficients of is less
violent than in the case of a general eigenproblem).
Since we only need the largest singular value, a faster approach is to
reduce the computation of to the computation of
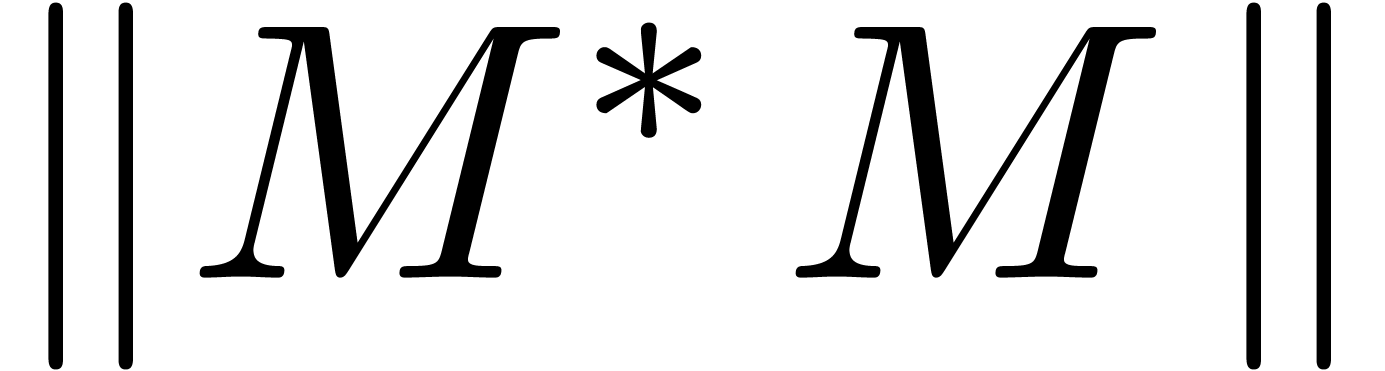 , using the formula
, using the formula
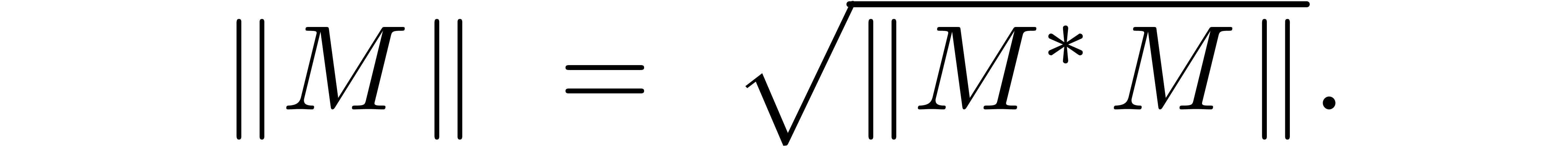
Applying this formula times and using a naive
bound at the end, we obtain
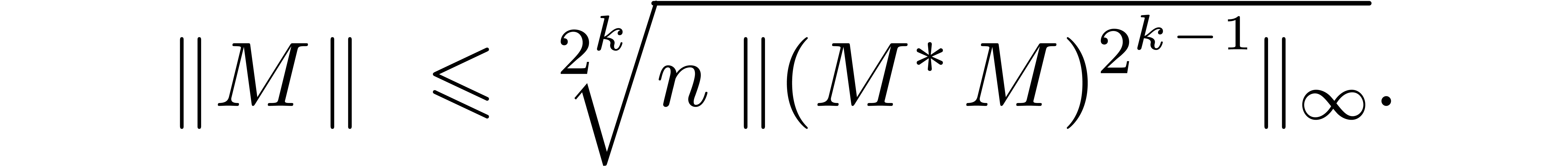
This bound has an accuracy of 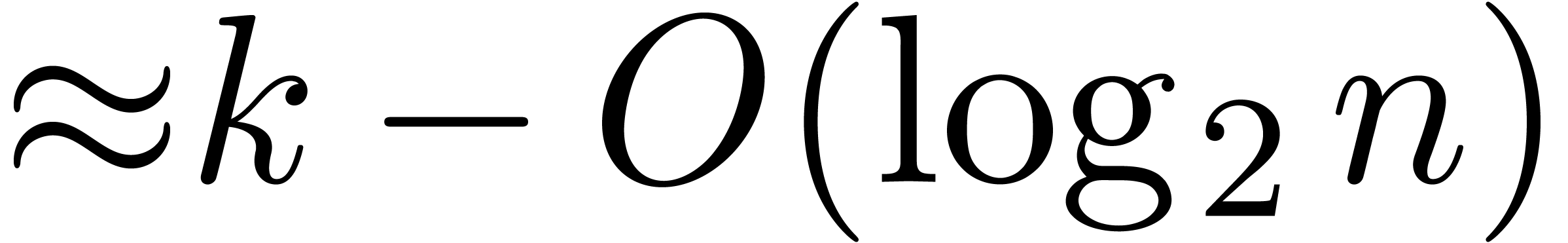 bits. Since is symmetric, the
bits. Since is symmetric, the  repeated
squarings of only correspond to about
repeated
squarings of only correspond to about 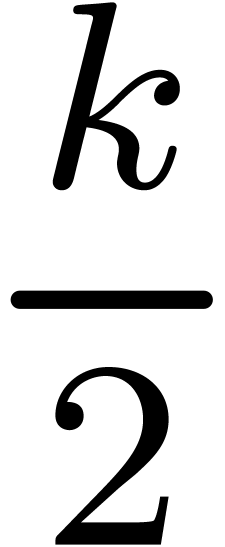 matrix multiplications. Notice also that it is wise to
renormalize matrices before squaring them, so as to avoid overflows and
underflows.
matrix multiplications. Notice also that it is wise to
renormalize matrices before squaring them, so as to avoid overflows and
underflows.
The approach can be speeded up further by alternating steps of
tridiagonalization and squaring. Indeed, for a symmetric tridiagonal
matrix 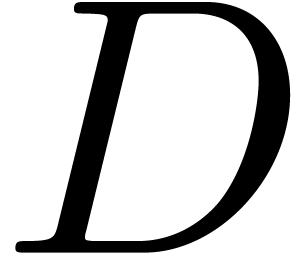 , the computation of
, the computation of
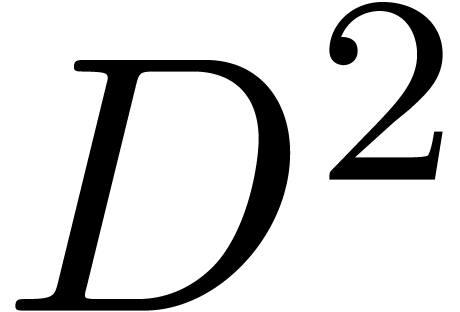 and its tridiagonalization only take steps instead of for a full matrix
product. After a few
and its tridiagonalization only take steps instead of for a full matrix
product. After a few 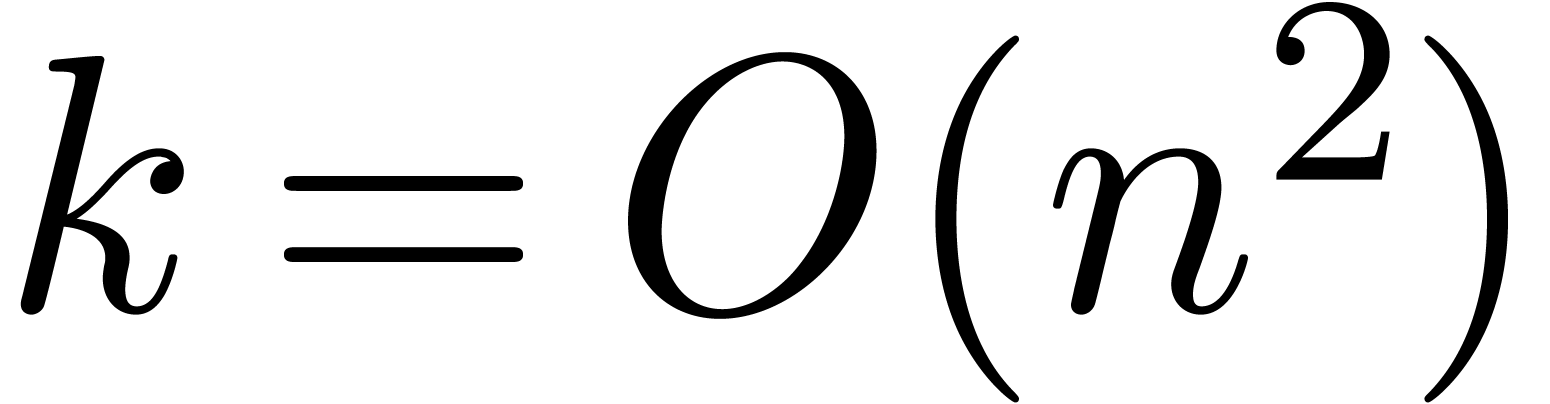 steps of this kind, one
obtains a good approximation
steps of this kind, one
obtains a good approximation 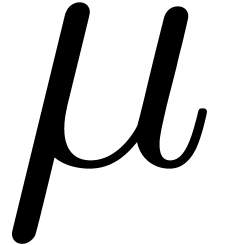 of
of 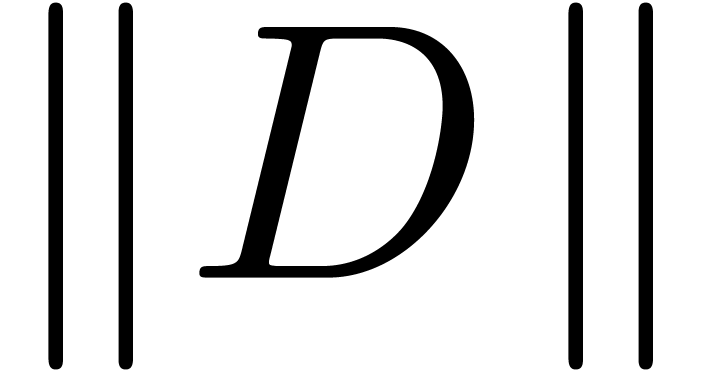 . One may complete the algorithm by applying an
algorithm with quadratic convergence for finding the smallest
eigenvalues of
. One may complete the algorithm by applying an
algorithm with quadratic convergence for finding the smallest
eigenvalues of  . In the lucky
case when has an isolated maximal eigenvalue, a
certification of this method will provide sharp upper bounds for in reasonable time.
. In the lucky
case when has an isolated maximal eigenvalue, a
certification of this method will provide sharp upper bounds for in reasonable time.
Even after the above improvements, the computation of sharp upper bounds
for remains quite more expensive than ordinary
matrix multiplication. For this reason, it is probably wise to avoid
ball arithmetic in except if there are good
reasons to expect that the improved quality is really useful for the
application in mind.
Moreover, when using ball arithmetic in ,
it is often possible to improve algorithms in ways to reduce
overestimation. When interpreting a complete computation as a dag, this
can be achieved by minimizing the depth of the dag, i.e. by
using an algorithm which is better suited for parallelization. Let us
illustrate this idea for the computation of the -th power 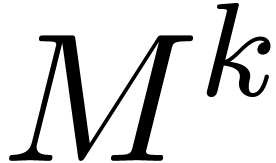 of a matrix . When using Horner's method
(multiply the identity matrix times by ), we typically observe an
overestimation of
of a matrix . When using Horner's method
(multiply the identity matrix times by ), we typically observe an
overestimation of 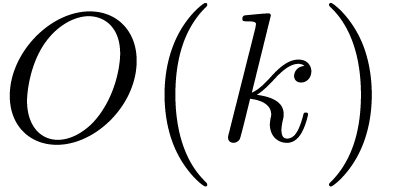 bits (as for the example (18)). If we use binary powering, based on the rule
bits (as for the example (18)). If we use binary powering, based on the rule
then the precision loss drops down to 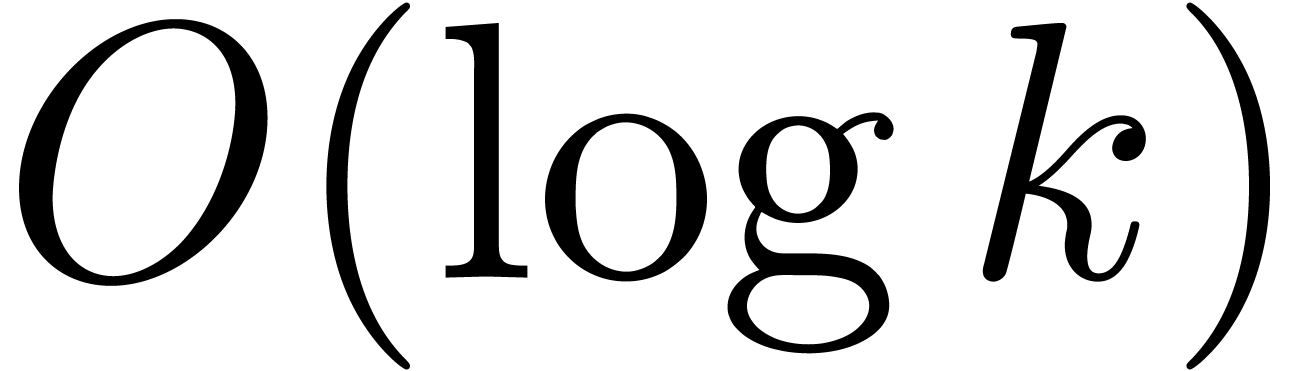 bits. We
will encounter a less obvious application of the same idea in section 7.5 below.
bits. We
will encounter a less obvious application of the same idea in section 7.5 below.
There are two typical applications of power series
or with certified error bounds. When occurs as a generating function in a counting problem or
random object generator, then we are interested in the computation of
the coefficients 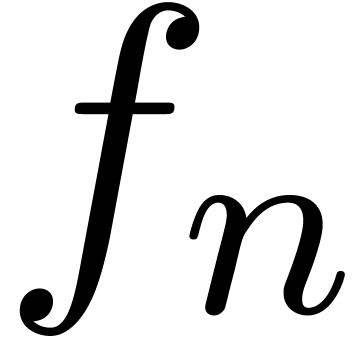 for large , together with reliable error bounds. A
natural solution is to systematically work with computable power series
with ball coefficients in
for large , together with reliable error bounds. A
natural solution is to systematically work with computable power series
with ball coefficients in 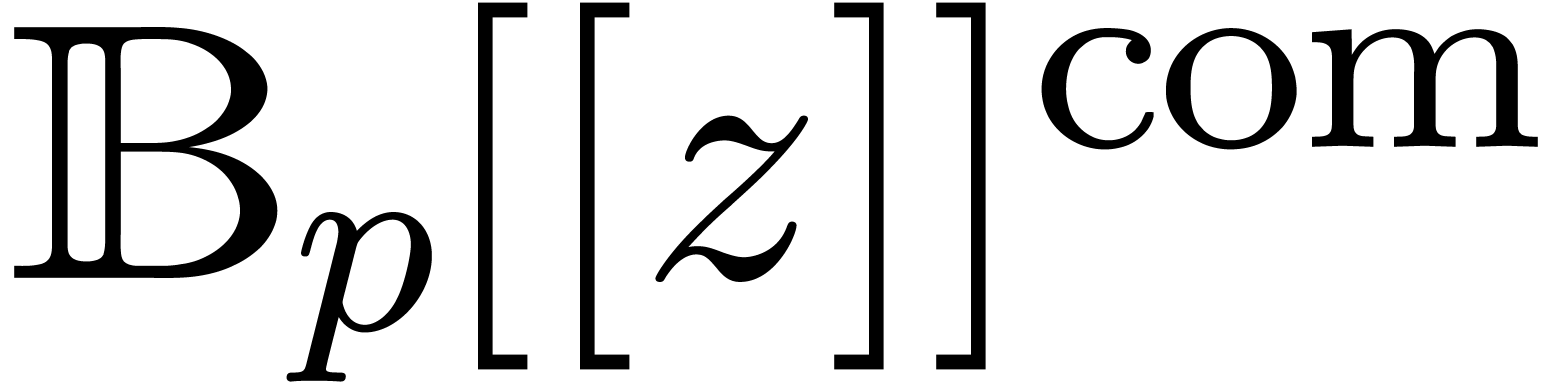 .
For many applications, we notice that is fixed,
whereas
.
For many applications, we notice that is fixed,
whereas 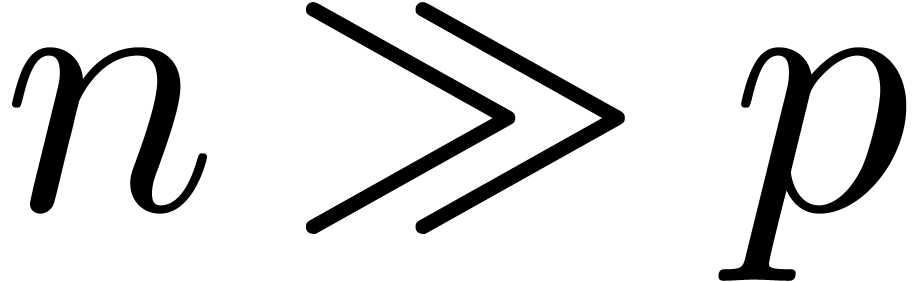 may become very large.
may become very large.
The second typical application is when is the
local expansion of an analytic function on a disk 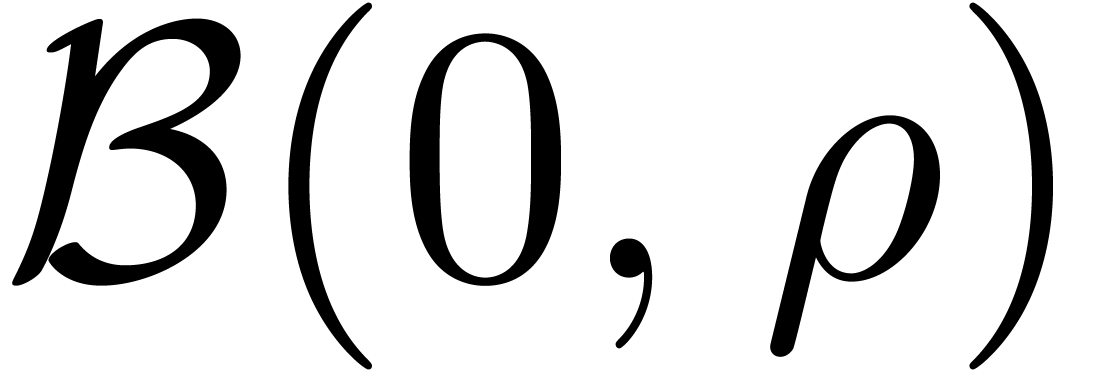 and we wish to evaluate at a point with
and we wish to evaluate at a point with 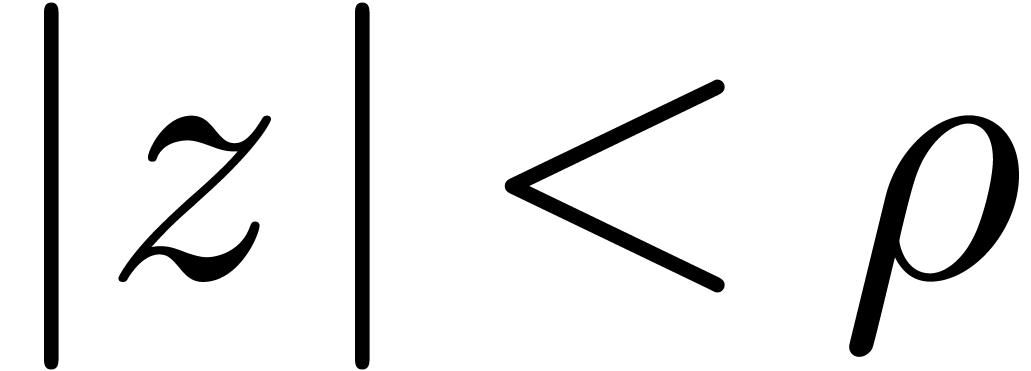 . The
geometric decrease of
. The
geometric decrease of 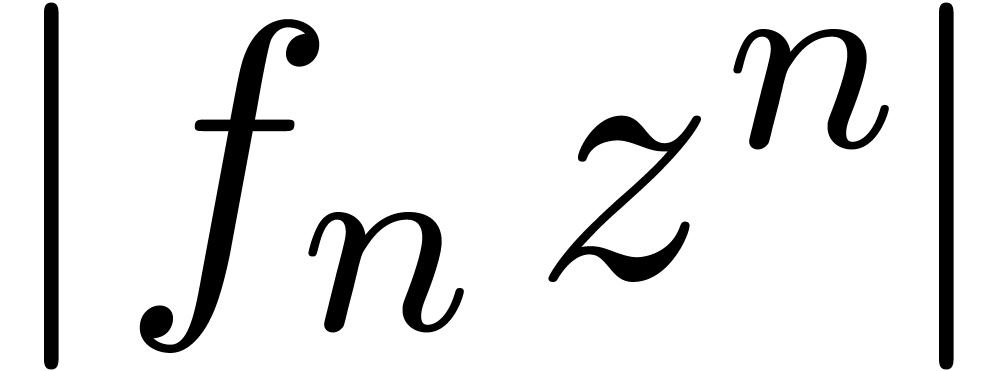 implies that we will need
only
implies that we will need
only 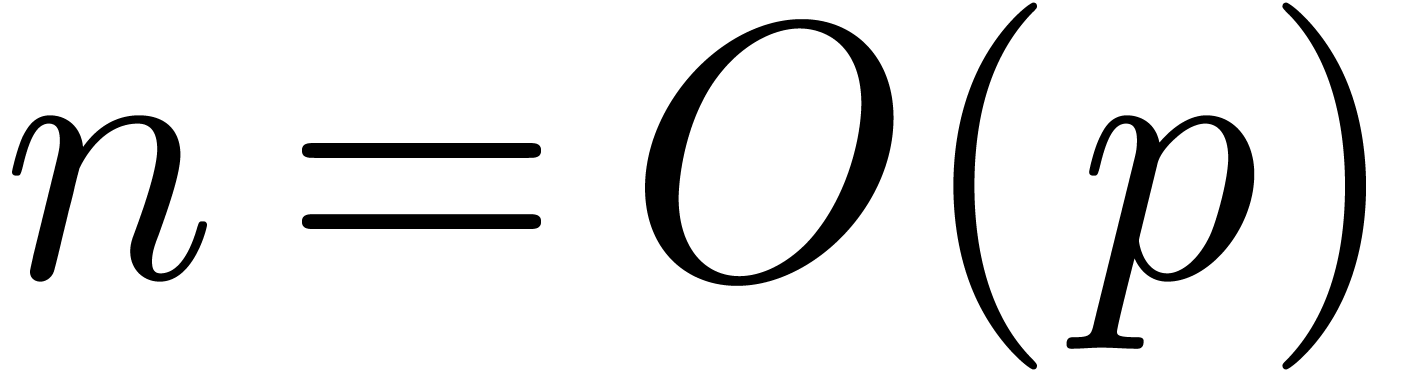 coefficients of the series. In order to
bound the remaining error using Cauchy's formula, we do not only need
bounds for the individual coefficients ,
but also for the norm
coefficients of the series. In order to
bound the remaining error using Cauchy's formula, we do not only need
bounds for the individual coefficients ,
but also for the norm 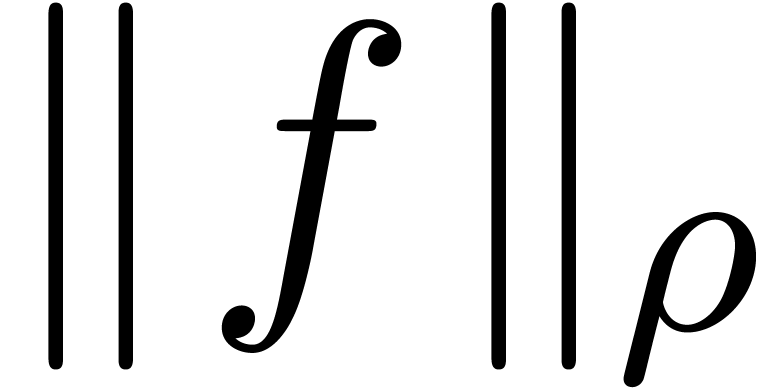 defined in (4).
Hence, it is more natural to work with serial balls in
defined in (4).
Hence, it is more natural to work with serial balls in  , while using the
, while using the 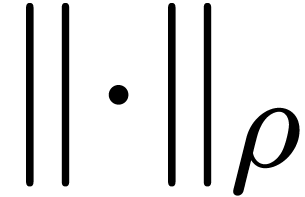 norm.
Modulo a rescaling
norm.
Modulo a rescaling  , it will
be convenient to enforce
, it will
be convenient to enforce 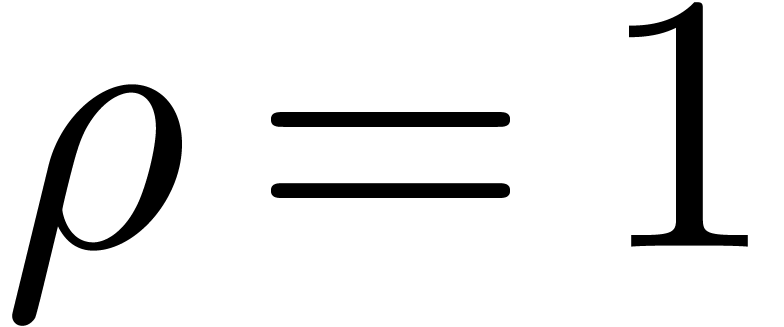 . In
order to compute sharp upper bounds
. In
order to compute sharp upper bounds 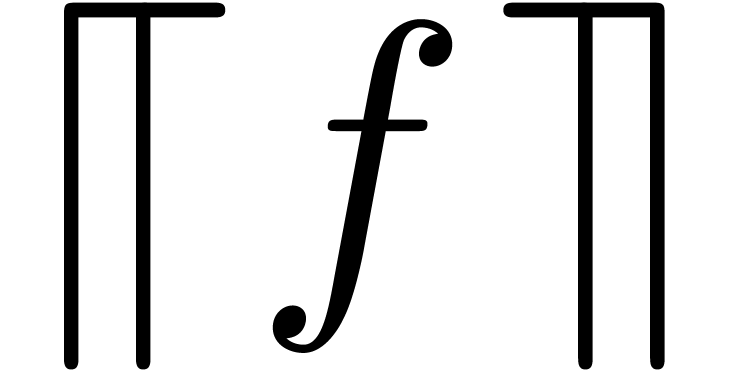 for
for 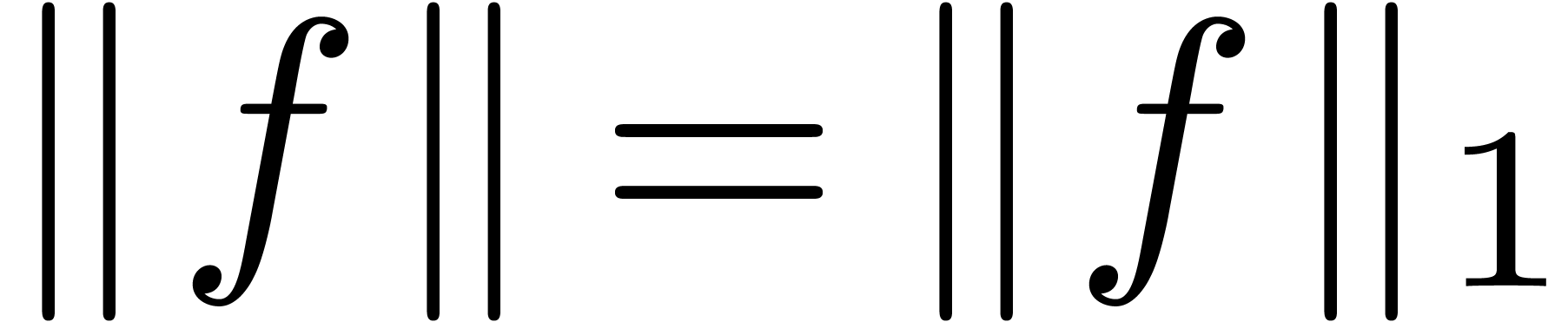 , it will also be convenient to
have an algorithm which computes bounds
, it will also be convenient to
have an algorithm which computes bounds 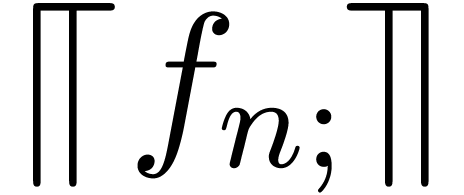 for the
tails
for the
tails
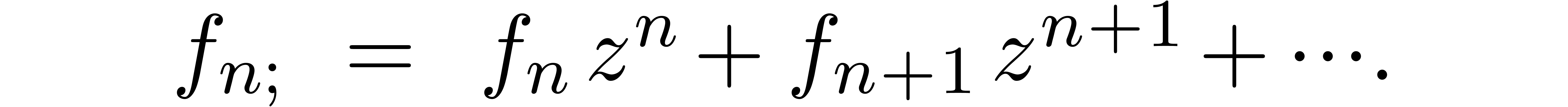
Compared to the computation of the corresponding head

we will show in section 7.4 that the computation of such a tail bound is quite cheap.
Again the question arises how to represent 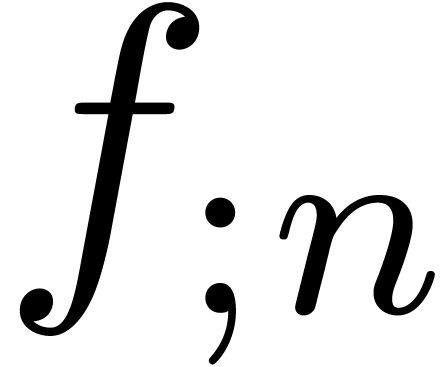 in a
reliable way. We may either store a global upper bound for the error, so
that
in a
reliable way. We may either store a global upper bound for the error, so
that  , or compute individual
bounds for the errors, so that
, or compute individual
bounds for the errors, so that 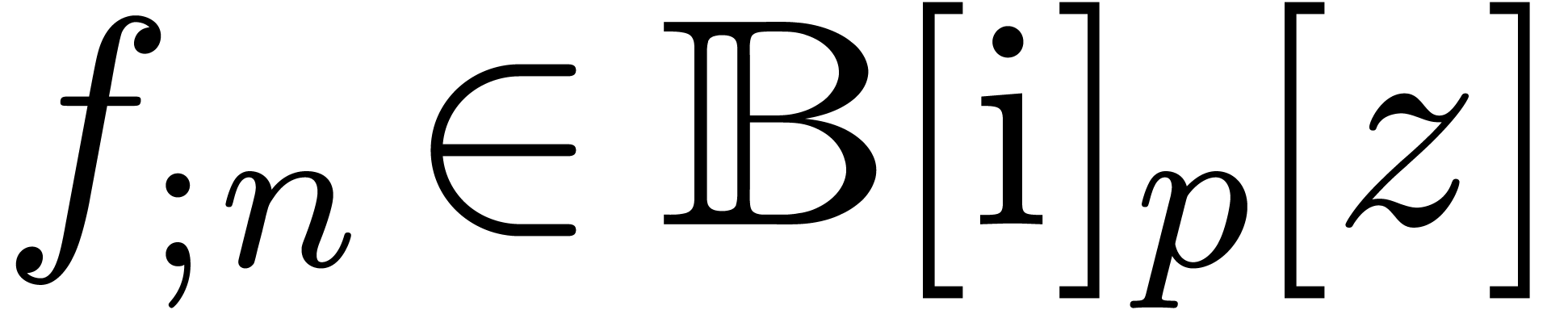 .
If our aim is to evaluate at a point with
.
If our aim is to evaluate at a point with  , then
both representations
, then
both representations 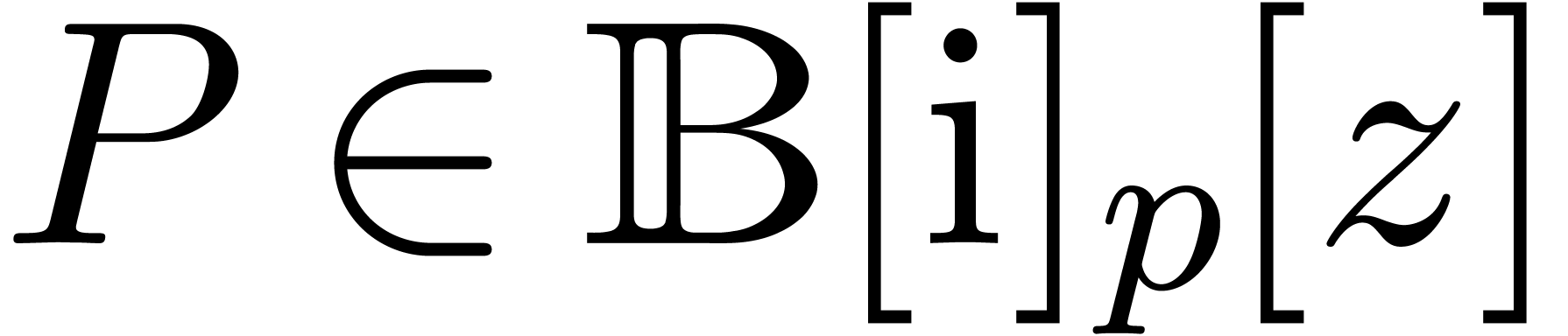 and
and 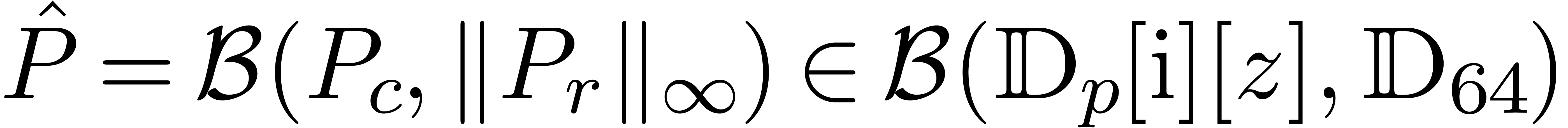 give rise to evaluations
give rise to evaluations 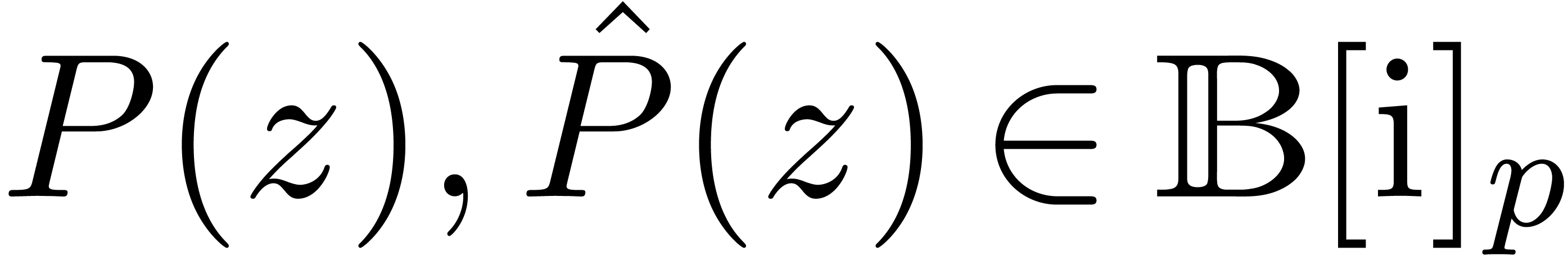 with equally precise
error bounds. Since the manipulation of global error bounds is more
efficient, the corresponding representation should therefore be
preferred in this case. In the multivariate case, one has the additional
benefit that “small” coefficients
with equally precise
error bounds. Since the manipulation of global error bounds is more
efficient, the corresponding representation should therefore be
preferred in this case. In the multivariate case, one has the additional
benefit that “small” coefficients 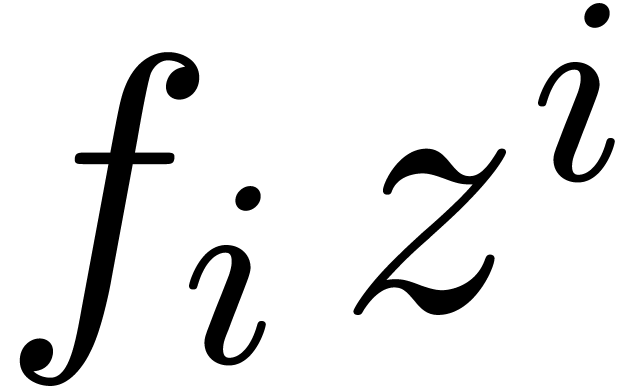 (e.g.
(e.g. 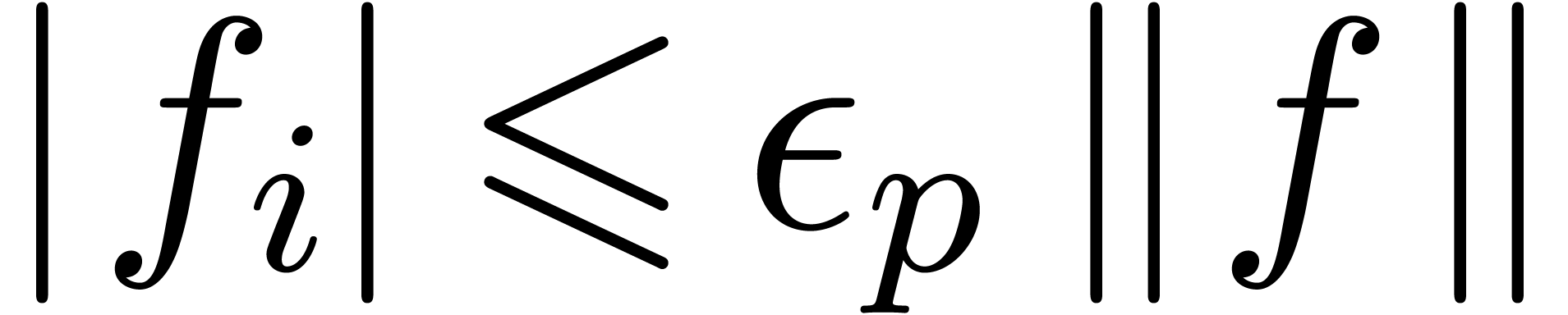 ) can
simply be replaced by a global error
) can
simply be replaced by a global error 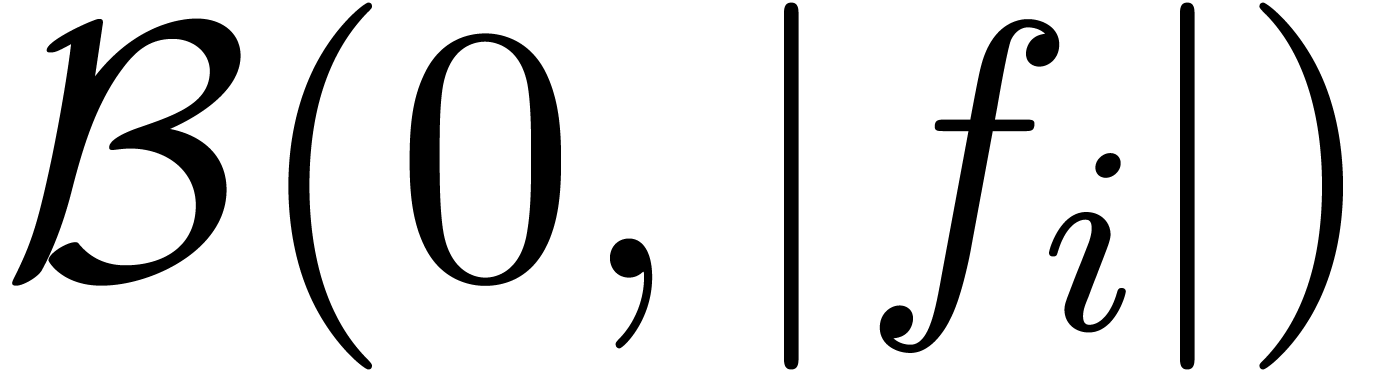 ,
thereby increasing the sparsity of .
On the other hand, individual error bounds admit the advantage that
rescaling
,
thereby increasing the sparsity of .
On the other hand, individual error bounds admit the advantage that
rescaling  is cheap. If we suddenly find out that
is actually convergent on a larger disk and want
to evaluate at a point
with
is cheap. If we suddenly find out that
is actually convergent on a larger disk and want
to evaluate at a point
with  , then we will not have
to recompute the necessary error bounds for from
scratch.
, then we will not have
to recompute the necessary error bounds for from
scratch.
Serial ball representations similar to what has been described above are
frequently used in the area of Taylor models [MB96, MB04] for the validated long term integration of dynamical
systems. In the case of Taylor models, there is an additional twist:
given a dynamical system of dimension  ,
we not only compute a series expansion with respect to the time
,
we not only compute a series expansion with respect to the time  , but also with respect to small
perturbations
, but also with respect to small
perturbations  of the initial conditions. In
particular, we systematically work with power series in several
variables. Although such computations are more expensive, the extra
information may be used in order to increase the sharpness of the
computed bounds. A possible alternative is to compute the expansions in
only up to the first order and to use binary
splitting for the multiplication of the resulting Jacobian matrices on
the integration path. This approach will be detailed in section 7.5.
of the initial conditions. In
particular, we systematically work with power series in several
variables. Although such computations are more expensive, the extra
information may be used in order to increase the sharpness of the
computed bounds. A possible alternative is to compute the expansions in
only up to the first order and to use binary
splitting for the multiplication of the resulting Jacobian matrices on
the integration path. This approach will be detailed in section 7.5.
In order to study the reliable multiplication of series
and  , let us start with the
case when
, let us start with the
case when  , using the
sup-norm on the unit disk. We may take
, using the
sup-norm on the unit disk. We may take
where 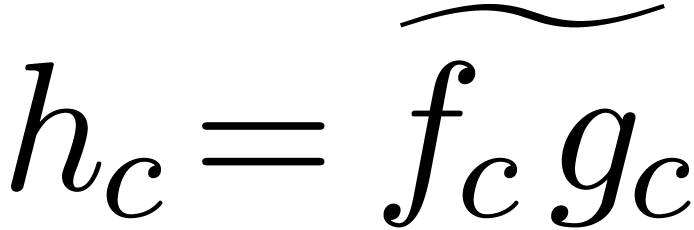 stands for a -approximation
of
stands for a -approximation
of  . Since
. Since  is really a numeric algorithm for the computation of its coefficients,
the difficulty resides in the fact that has to
be chosen once and for all, in such a way that the bound
is really a numeric algorithm for the computation of its coefficients,
the difficulty resides in the fact that has to
be chosen once and for all, in such a way that the bound 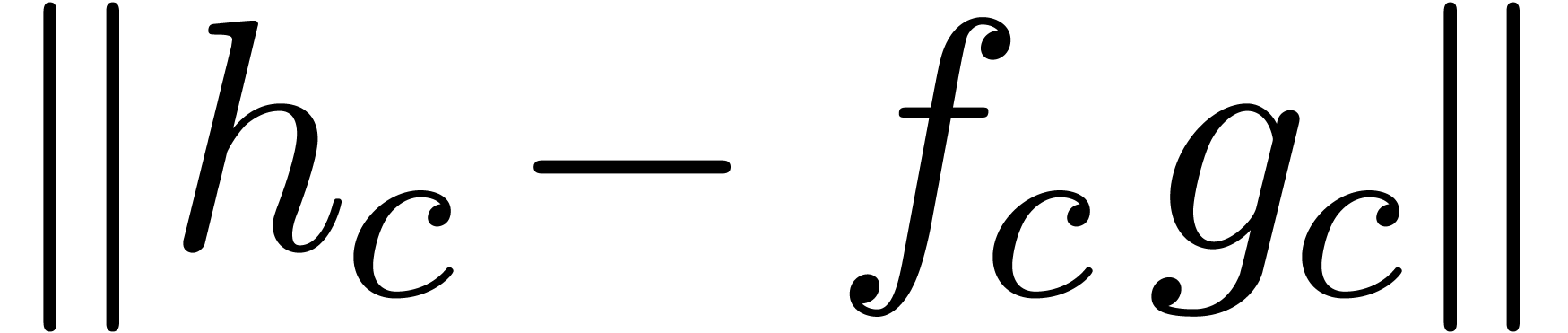 will be respected at the limit. A reasonable choice is
will be respected at the limit. A reasonable choice is
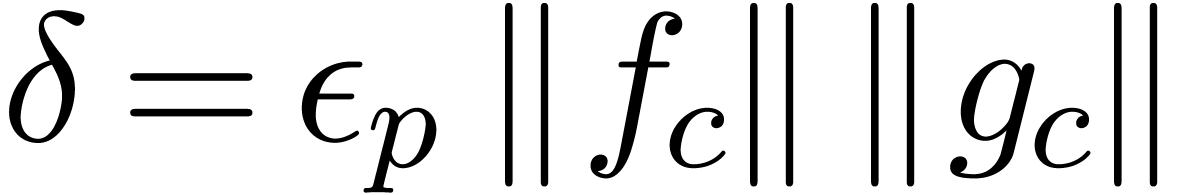 . We next distribute this
error over the infinity of coefficients: picking some
. We next distribute this
error over the infinity of coefficients: picking some  , each coefficient
, each coefficient  is
taken to be an
is
taken to be an 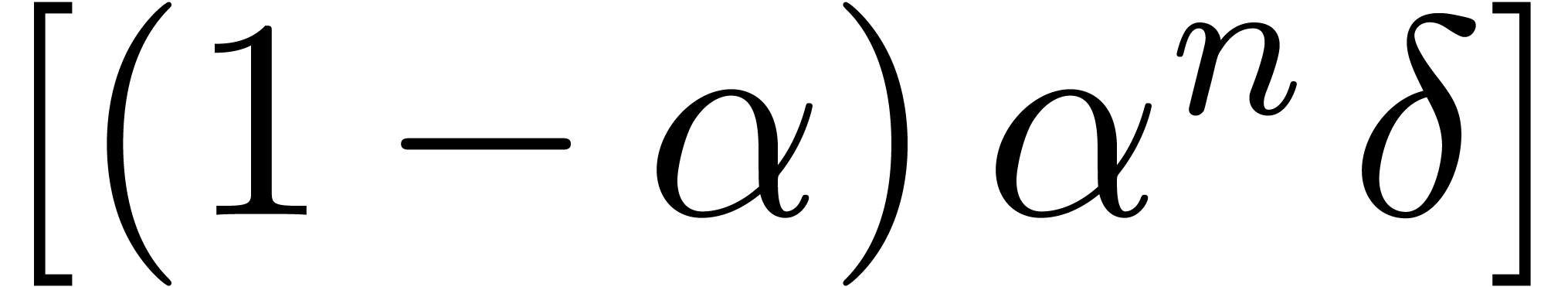 -approximation
of . Of course, these
computation may require a larger working precision than . Nevertheless, and
are actually convergent on a slightly larger
disk . Picking
-approximation
of . Of course, these
computation may require a larger working precision than . Nevertheless, and
are actually convergent on a slightly larger
disk . Picking 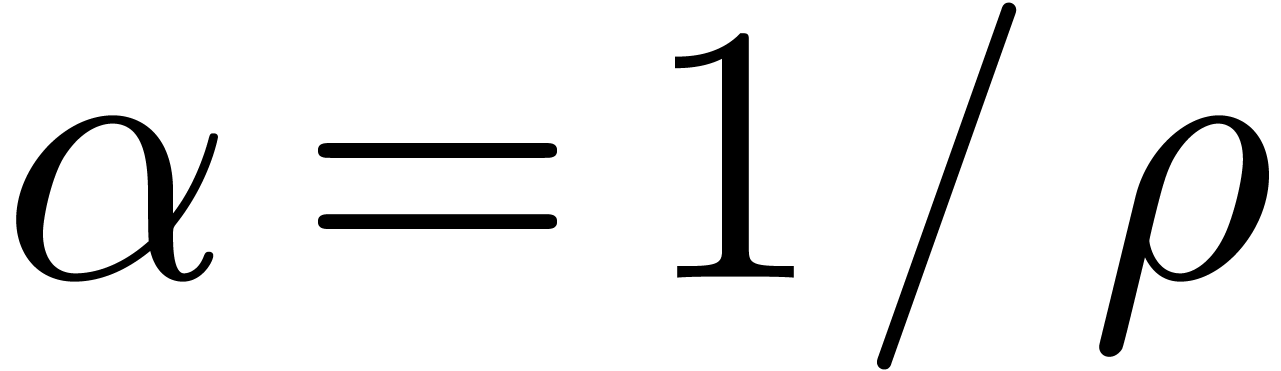 , the required increase of the working
precision remains modest.
, the required increase of the working
precision remains modest.
Let us now turn our attention to the multiplication of two computable
series 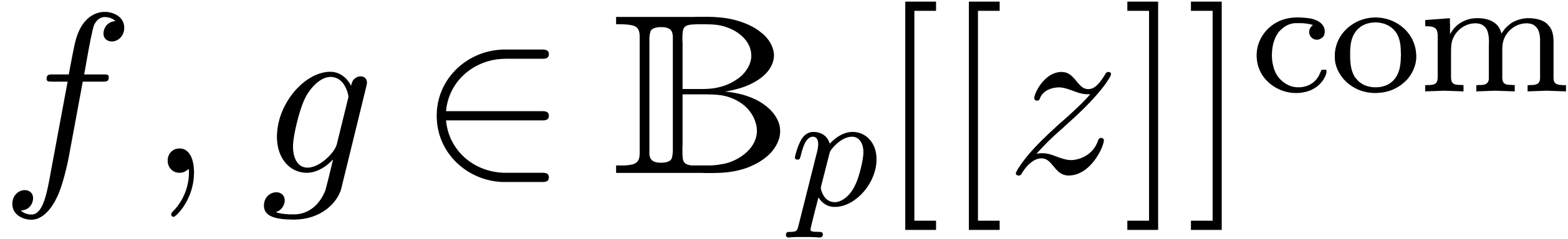 with ball coefficients. Except for naive
power series multiplication, based on the formula
with ball coefficients. Except for naive
power series multiplication, based on the formula 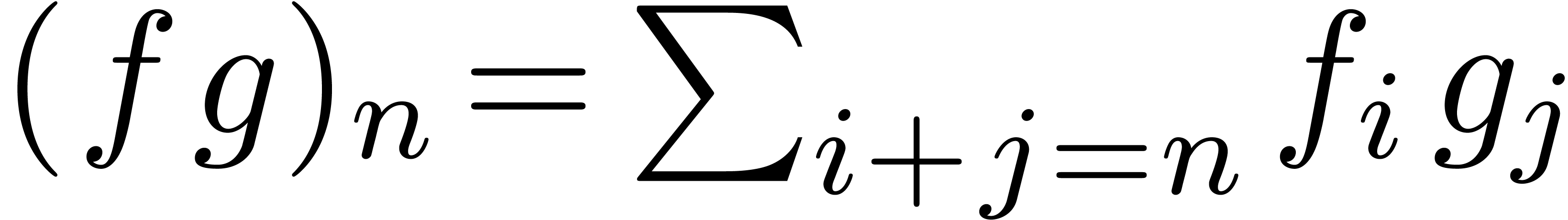 , most other multiplication algorithms (whether
relaxed or not) use polynomial multiplication as a subalgorithm. We are
thus left with the problem of finding an efficient and high quality
algorithm for multiplying two polynomials
, most other multiplication algorithms (whether
relaxed or not) use polynomial multiplication as a subalgorithm. We are
thus left with the problem of finding an efficient and high quality
algorithm for multiplying two polynomials 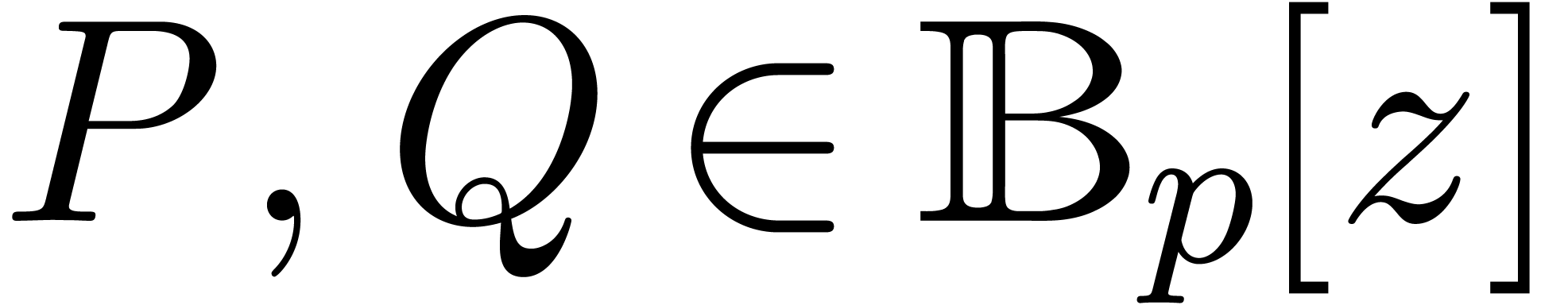 of
degrees
of
degrees 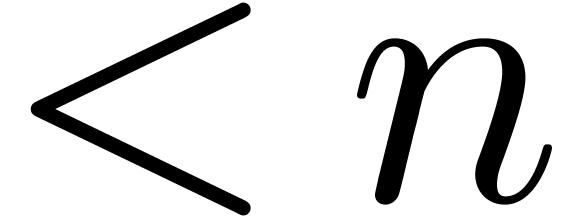 . In order to
simplify the reading, we will assume that
. In order to
simplify the reading, we will assume that  are
all non-zero.
are
all non-zero.
As in the case of matrix multiplication, there are various approaches
with different qualities, efficiencies and aptitudes to profit from
already available fast polynomial arithmetic in 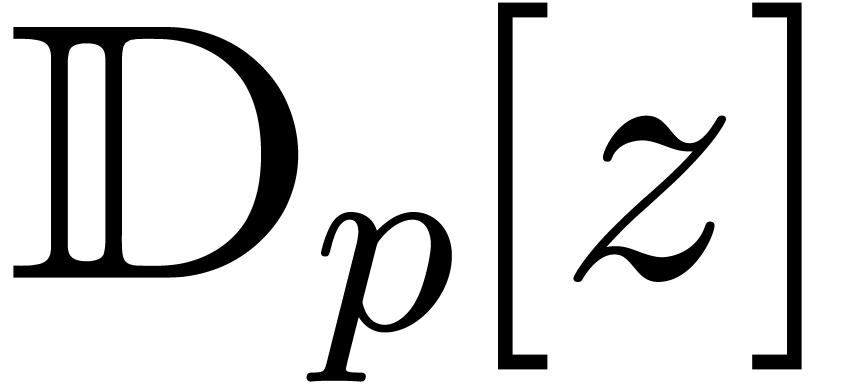 . Again, the naive approach
provides almost optimal numerical stability and qualities for the error
bounds. However, this approach is both slow from an asymptotic point of
view and unable to rely on existant multiplication algorithms in .
. Again, the naive approach
provides almost optimal numerical stability and qualities for the error
bounds. However, this approach is both slow from an asymptotic point of
view and unable to rely on existant multiplication algorithms in .
If the coefficients of  and
and  are all of the same order of magnitude, then we may simply convert and into polynomial balls in
are all of the same order of magnitude, then we may simply convert and into polynomial balls in
 for the norm and use the
following crude formula for their multiplication:
for the norm and use the
following crude formula for their multiplication:
where  stands for a -approximation
of
stands for a -approximation
of  . In other words, we may
use any efficient multiplication algorithm in
for the approximation of ,
provided that we have a means to compute a certified bound for the error.
. In other words, we may
use any efficient multiplication algorithm in
for the approximation of ,
provided that we have a means to compute a certified bound for the error.
In our application where and
correspond to ranges of coefficients in the series
and , we usually have 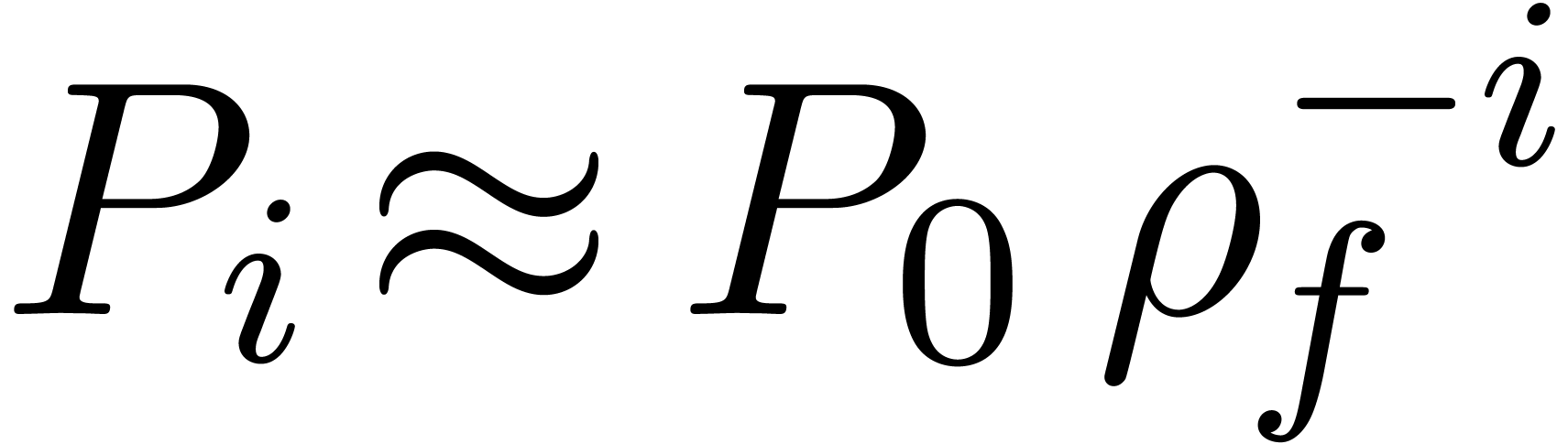 and
and 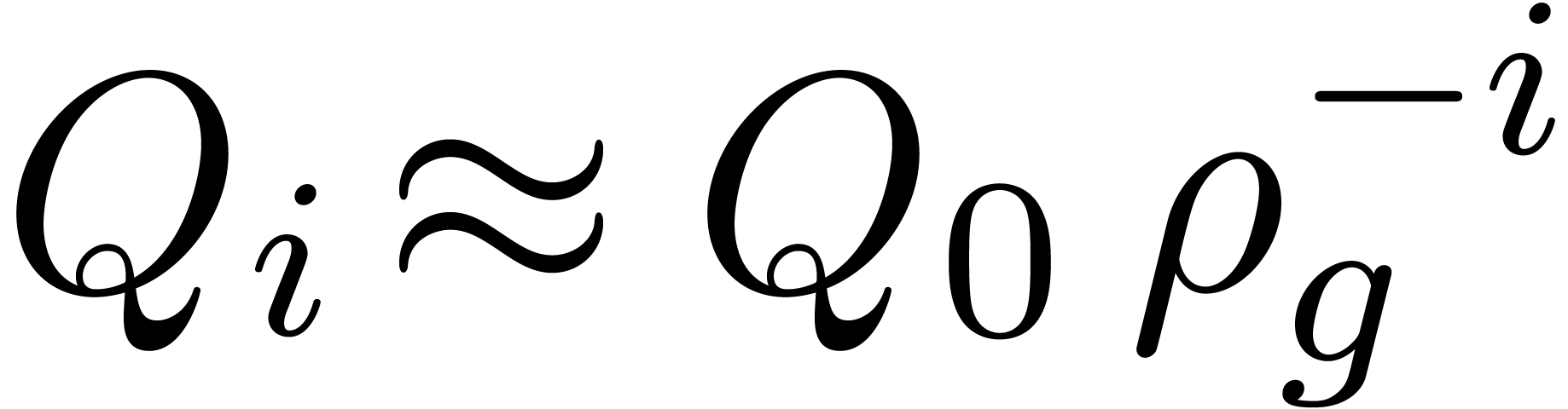 for the convergence radii
for the convergence radii
 and
and  of
and . In order to use (37), it is therefore important to scale
of
and . In order to use (37), it is therefore important to scale 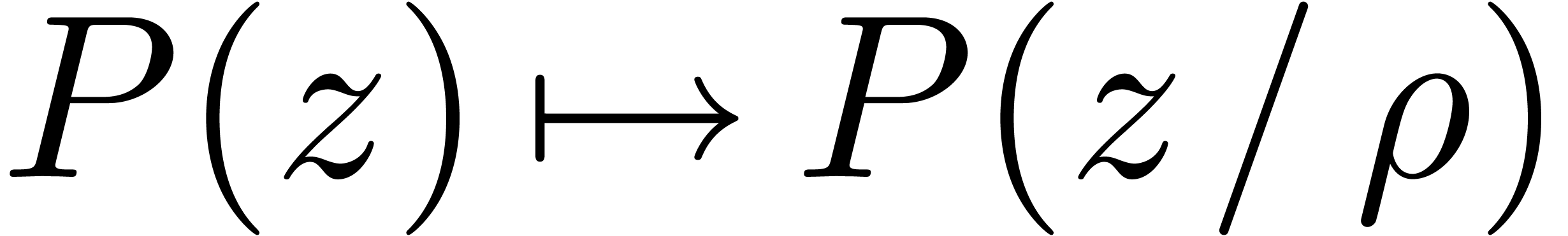 and
and  for a suitable
for a suitable  .
If we are really interested in the evaluation of
.
If we are really interested in the evaluation of  at points in a disk , then we may directly take
at points in a disk , then we may directly take  . In we are rather interested in the coefficients of
, then
. In we are rather interested in the coefficients of
, then 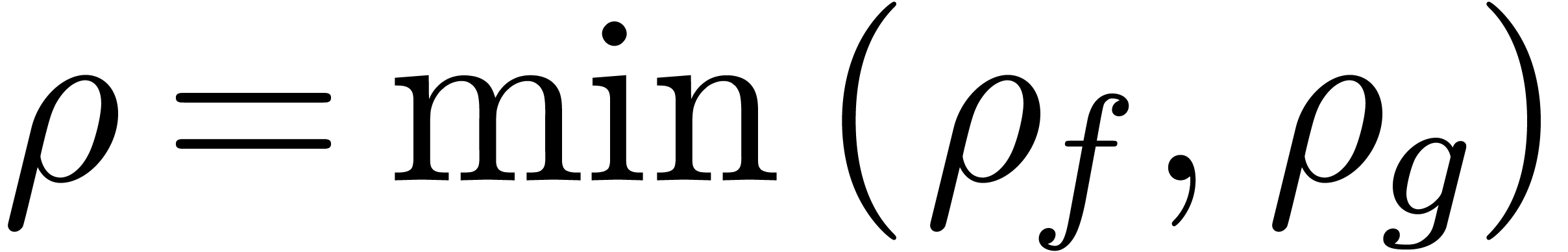 is the natural choice. However, since and are usually unknown, we first have to compute
suitable approximations for them, based on the available coefficients of
and .
A good heuristic approach is to determine indices
is the natural choice. However, since and are usually unknown, we first have to compute
suitable approximations for them, based on the available coefficients of
and .
A good heuristic approach is to determine indices 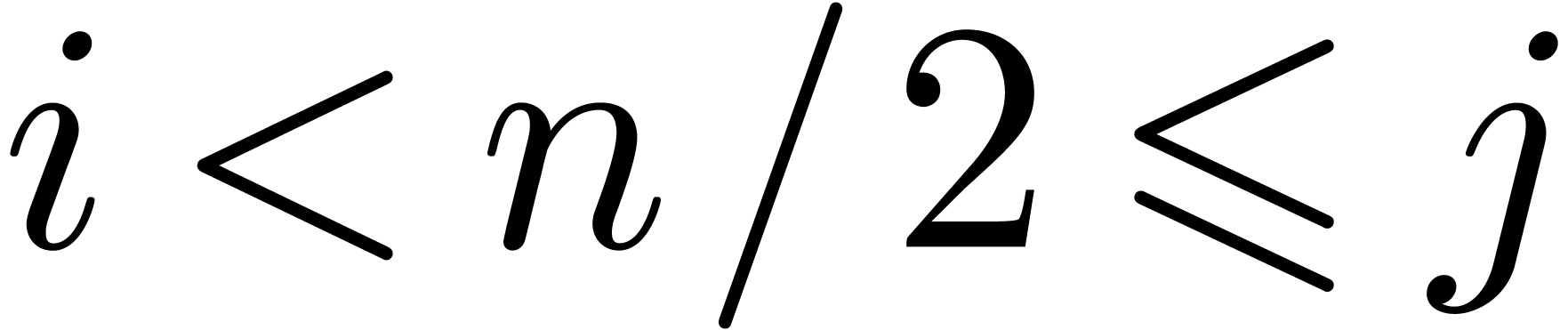 such that
such that
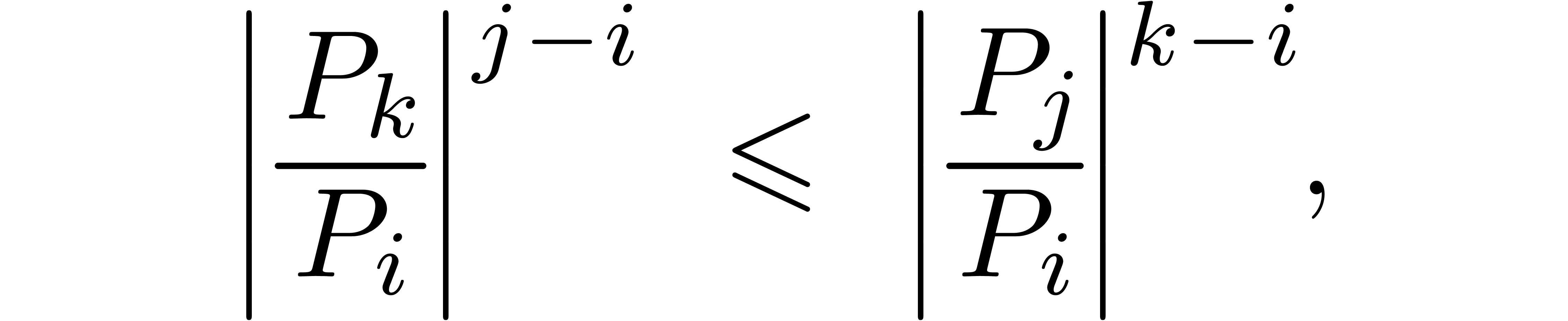
for all , and to take
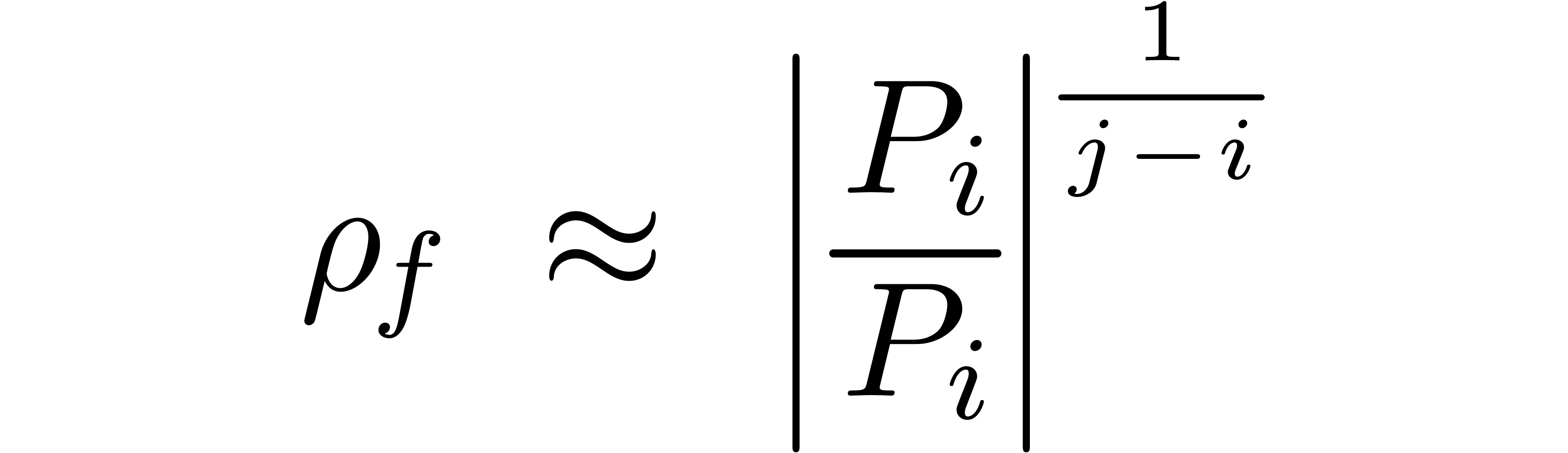
as the approximation for .
Recall that the numerical Newton polygon of  is
the convex hull of all points
is
the convex hull of all points  with
with  . Consider the edge of
whose projection on the -axis
contains
. Consider the edge of
whose projection on the -axis
contains  . Then and
. Then and  are precisely the extremities
of this projection, so they can be computed in linear time.
are precisely the extremities
of this projection, so they can be computed in linear time.
For large precisions , the
scaling algorithm is both very efficient and almost of an optimal
quality. For small and large , there may be some precision loss which
depends on the nature of the smallest singularities of
and . Nevertheless, for many
singularities, such as algebraic singularities, the precision loss is
limited to bits. For a more detailed discussion,
we refer to [vdH02a, Section 6.2].
In other applications, where and are not obtained from formal power series, it is usually
insufficient to scale using a single factor . This is already the case when multiplying 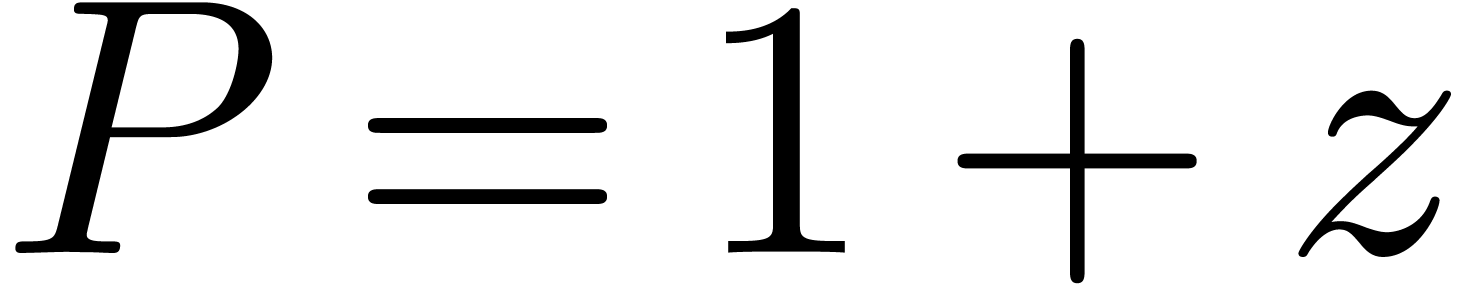 and
and 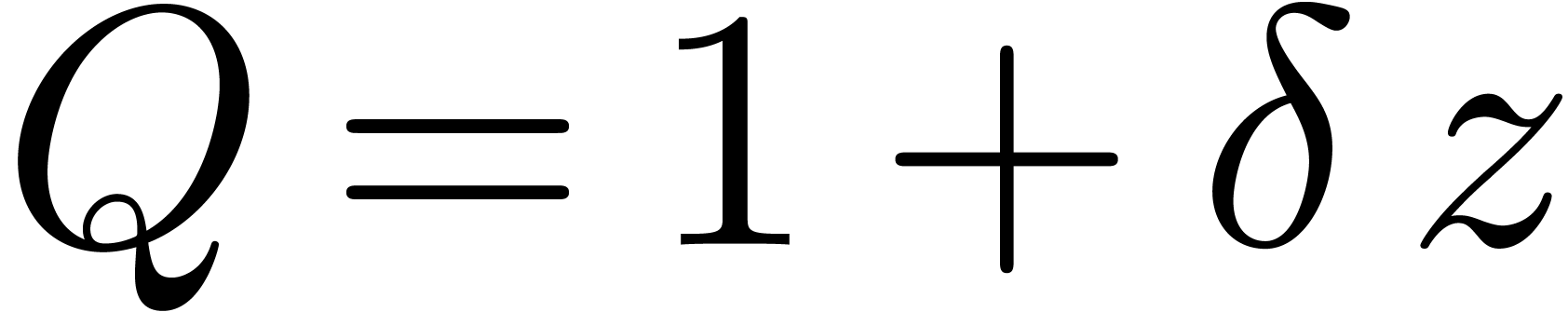 for small
for small  , since the error bound for
, since the error bound for 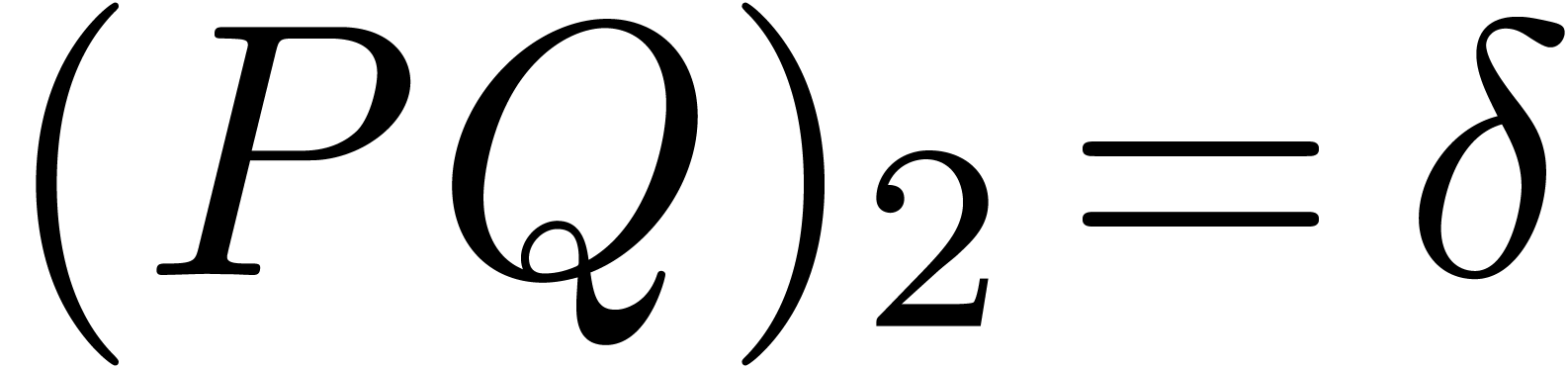 exceeds
exceeds  . One possible remedy
is to “precondition” and according to their numerical Newton polygons and use the
fact that
. One possible remedy
is to “precondition” and according to their numerical Newton polygons and use the
fact that  is close to the Minkowski sum
is close to the Minkowski sum  .
.
More precisely, for each ,
let  denote the number such that
denote the number such that  lies on one of the edges of .
Then
lies on one of the edges of .
Then 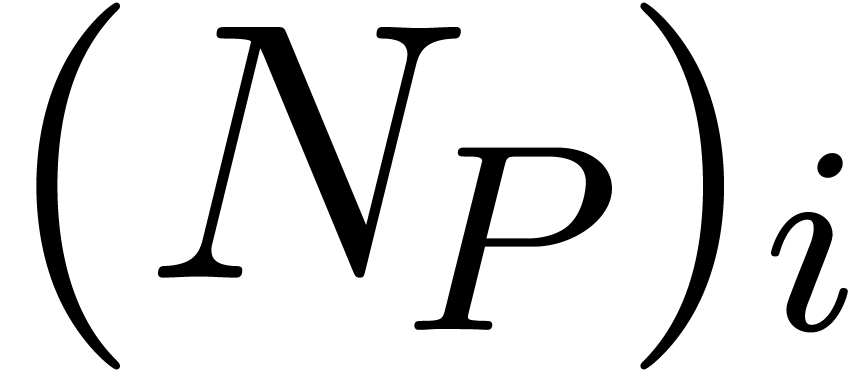 is of the same order of magnitude as
is of the same order of magnitude as 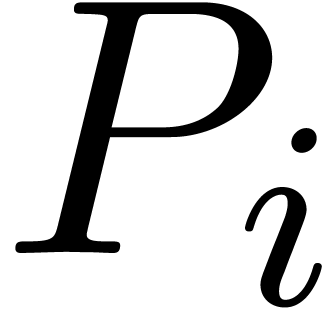 , except for indices for which is small “by accident”. Now consider the
preconditioned relative error
, except for indices for which is small “by accident”. Now consider the
preconditioned relative error
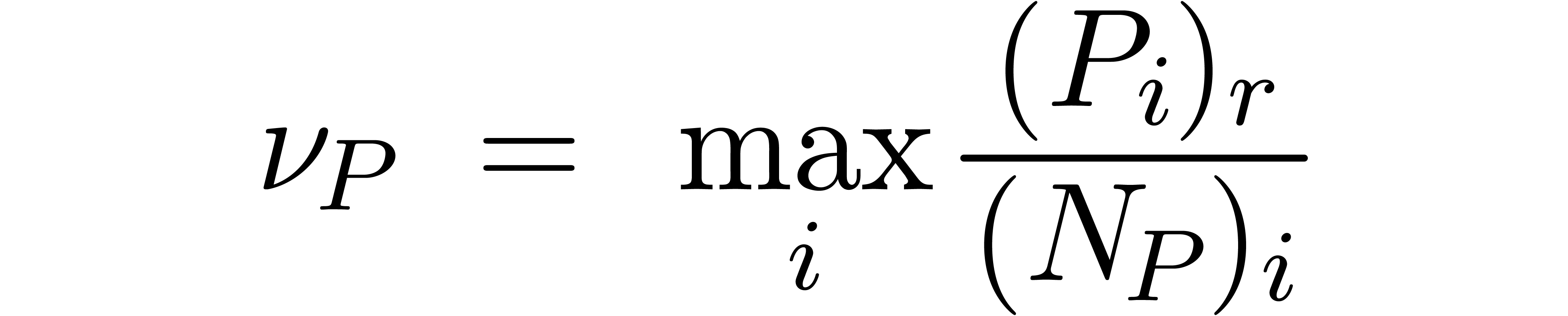
and similarly for . Then
if  is computed using infinite precision ball
arithmetic. Assuming a numerically stable multiplication algorithm for
the centers, as proposed in [vdH08a], and incorporating the
corresponding bound for the additional errors into the right hand side
of (38), we thus obtain an efficient way to compute an
upper bound for
is computed using infinite precision ball
arithmetic. Assuming a numerically stable multiplication algorithm for
the centers, as proposed in [vdH08a], and incorporating the
corresponding bound for the additional errors into the right hand side
of (38), we thus obtain an efficient way to compute an
upper bound for 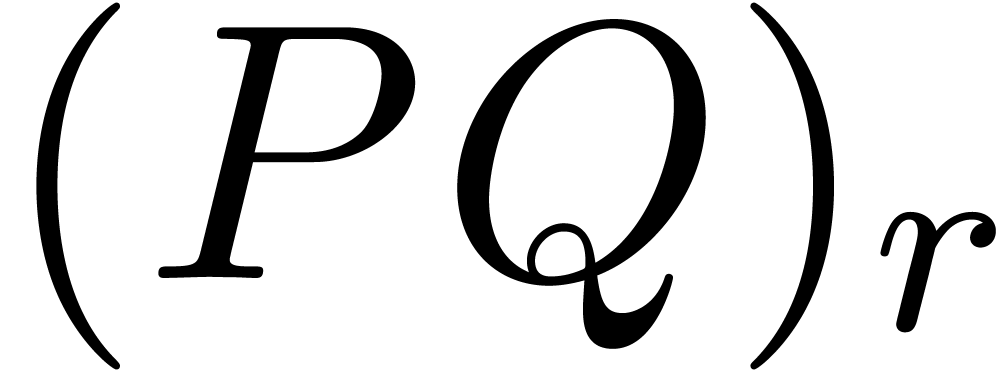 .
.
Notice that the numerical Newton polygon has a
close relation to the orders of magnitudes of the roots of . Even though the error bounds for some
“accidentally small” coefficients  may be bad for the above method, the error bounds have a good quality if
we require them to remain valid for small perturbations of the roots of
.
may be bad for the above method, the error bounds have a good quality if
we require them to remain valid for small perturbations of the roots of
.
The algorithms from the previous section can in particular be used for
the relaxed multiplication of two ball power series . In particular, using the implicit equation
this yields a way to compute 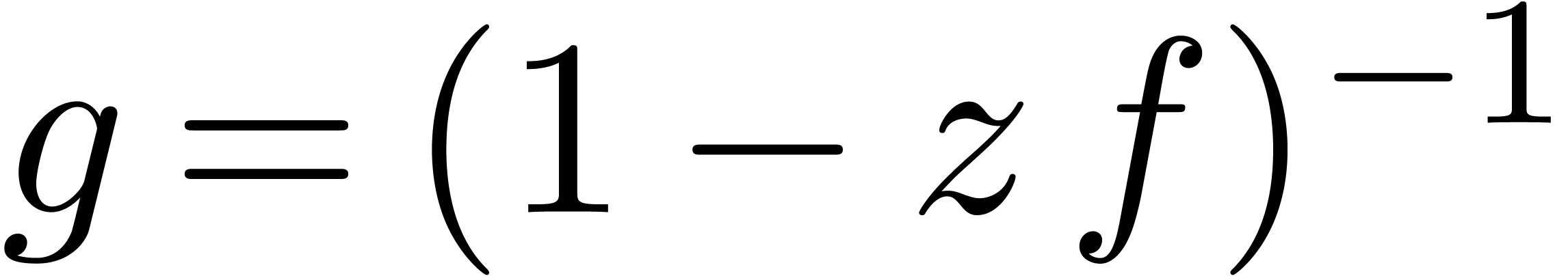 .
Unfortunately, the direct application of this method leads to massive
overestimation. For instance, the computed error bounds for the inverses
of
.
Unfortunately, the direct application of this method leads to massive
overestimation. For instance, the computed error bounds for the inverses
of
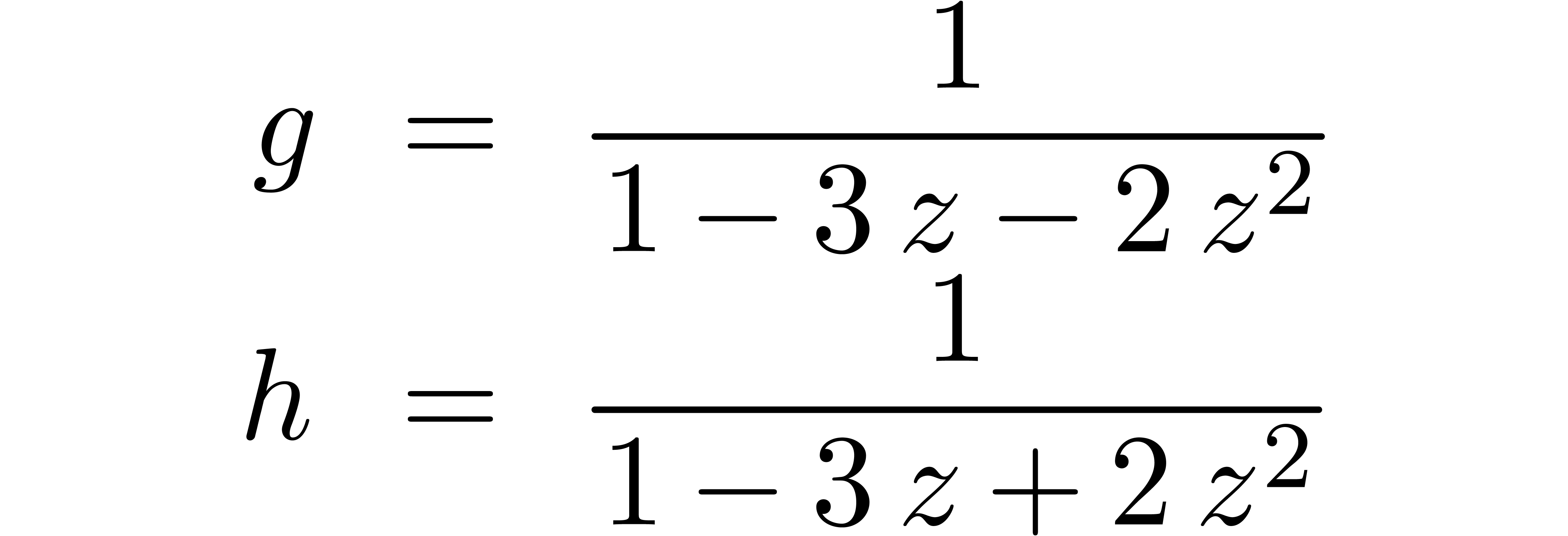
coincide. Indeed, even when using a naive relaxed multiplication, the
coefficients of and  are
computed using the recurrences
are
computed using the recurrences
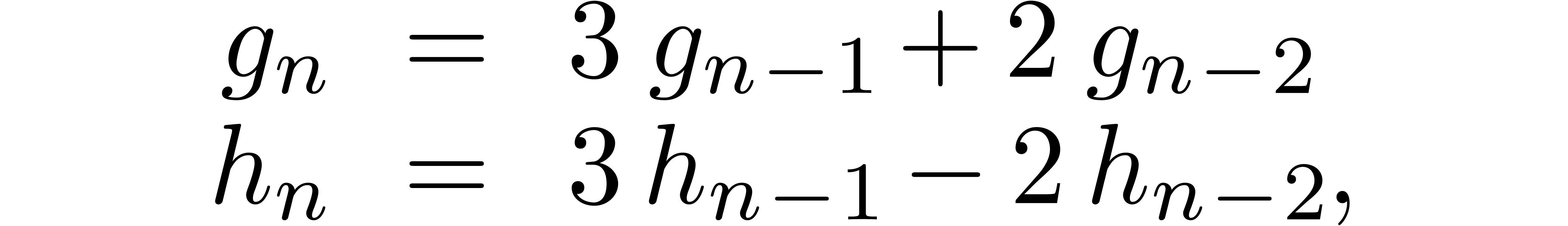
but the error bound  for
for 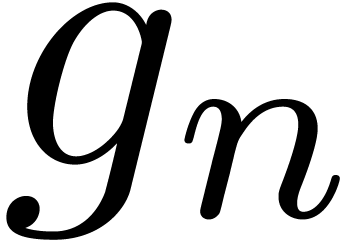 and
and 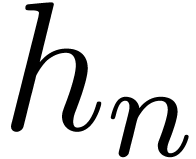 is computed using the same recurrence
is computed using the same recurrence
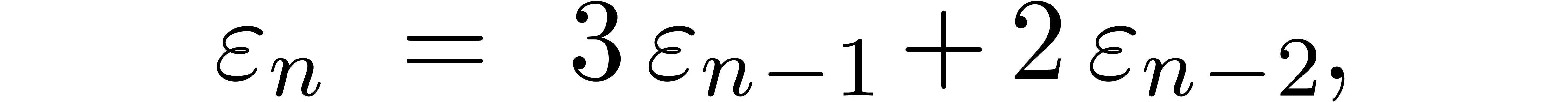
starting with  . For
. For  , it follows that
, it follows that 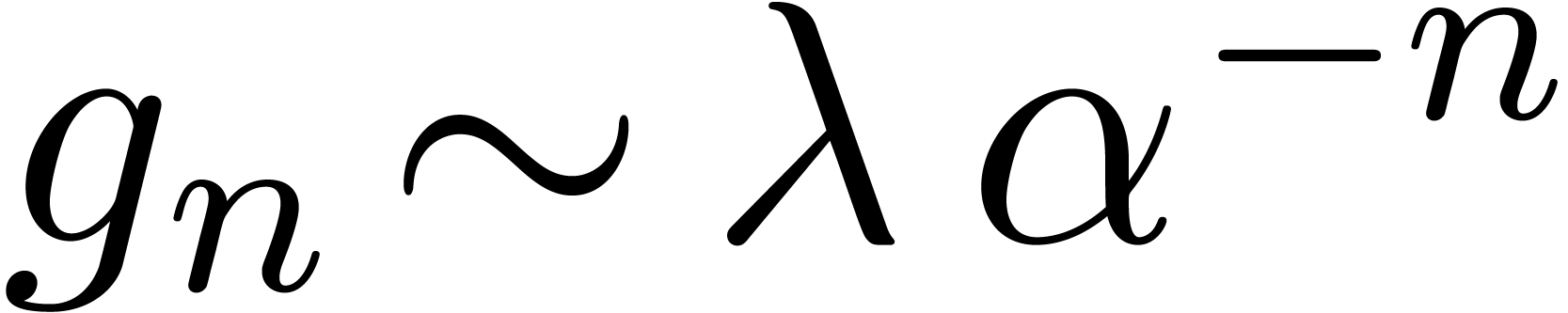 and
and 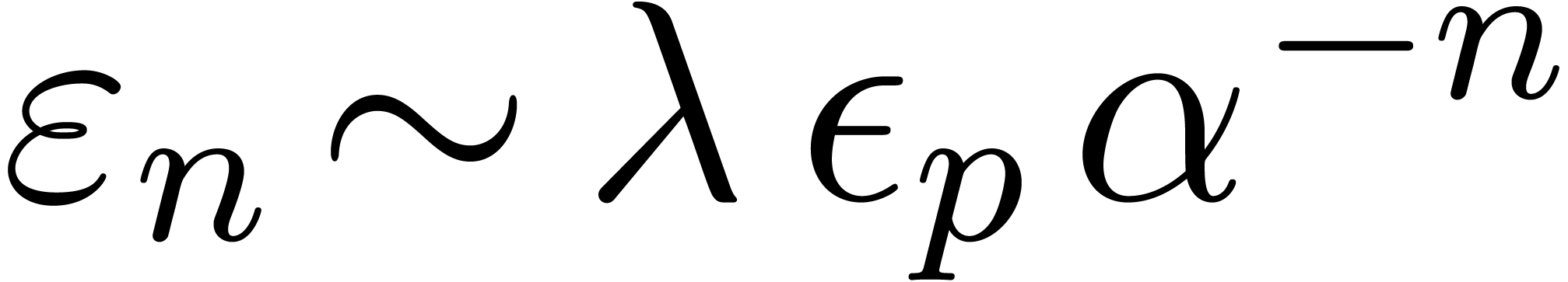 for some
for some  ,
where
,
where  is the smallest root of
is the smallest root of 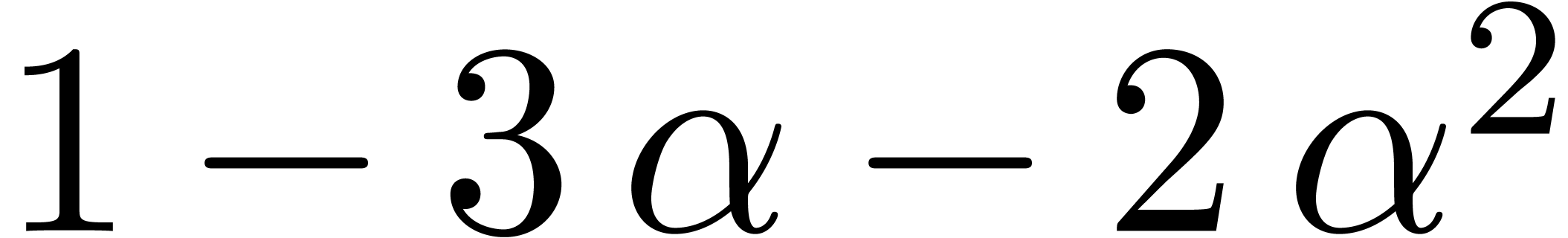 . Hence the error bound for
is sharp. On the other hand,
. Hence the error bound for
is sharp. On the other hand, 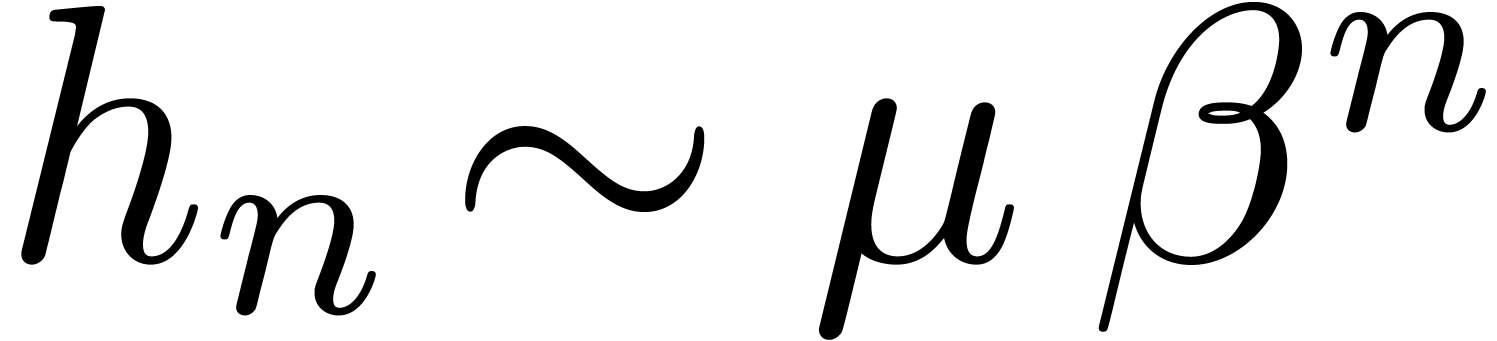 for some , where
for some , where 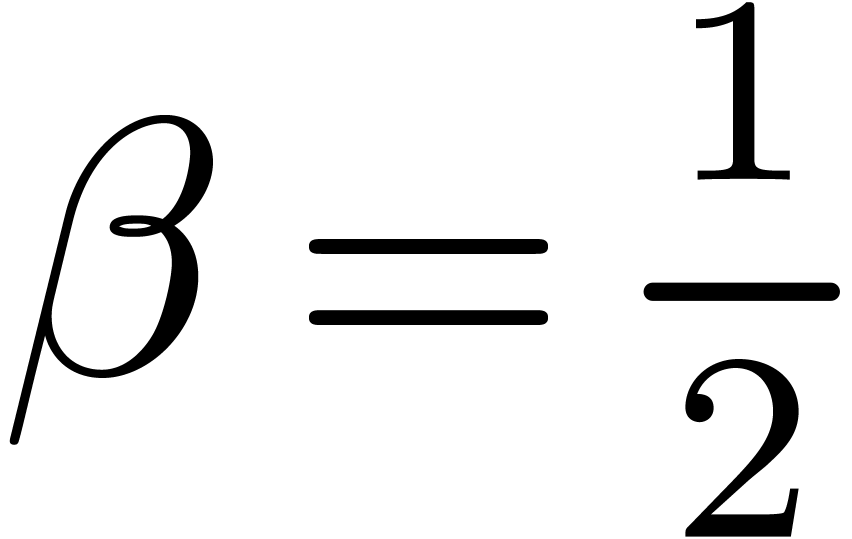 is
the smallest root of
is
the smallest root of 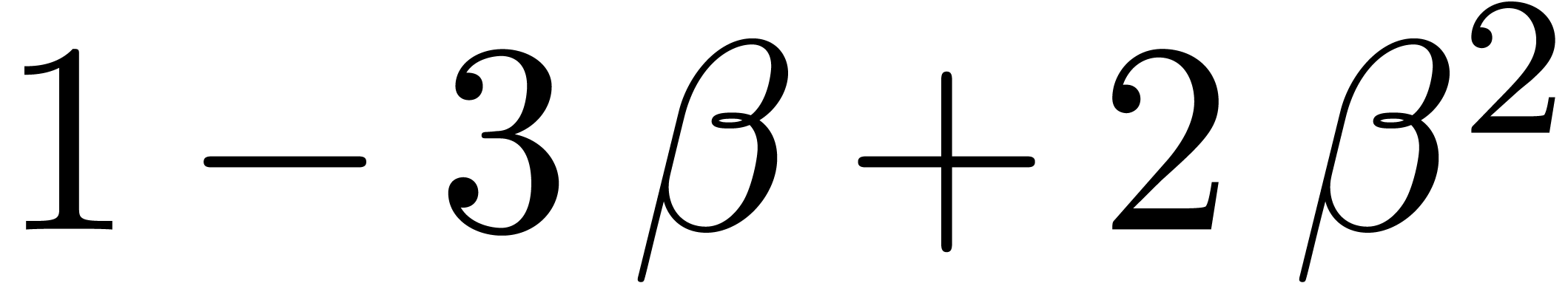 . Hence,
the error bound is
. Hence,
the error bound is 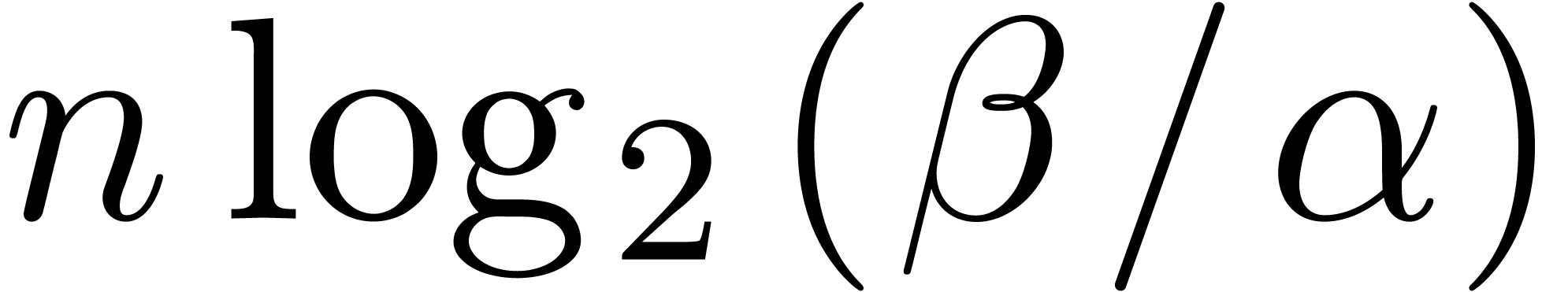 bits
too pessimistic in the case of .
The remedy is similar to what we did in the case of matrix inversion. We
first introduce the series
bits
too pessimistic in the case of .
The remedy is similar to what we did in the case of matrix inversion. We
first introduce the series
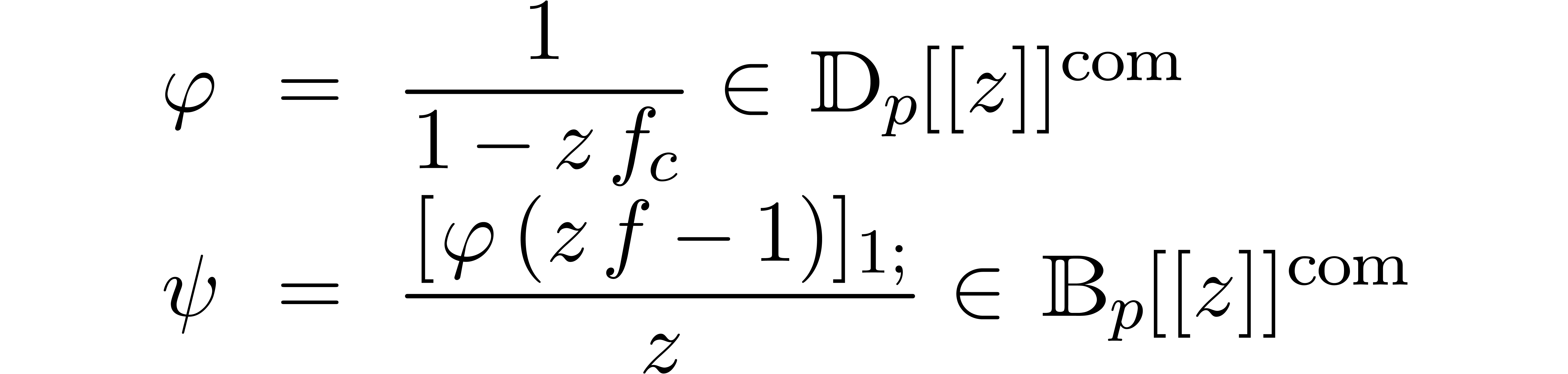
and next compute using
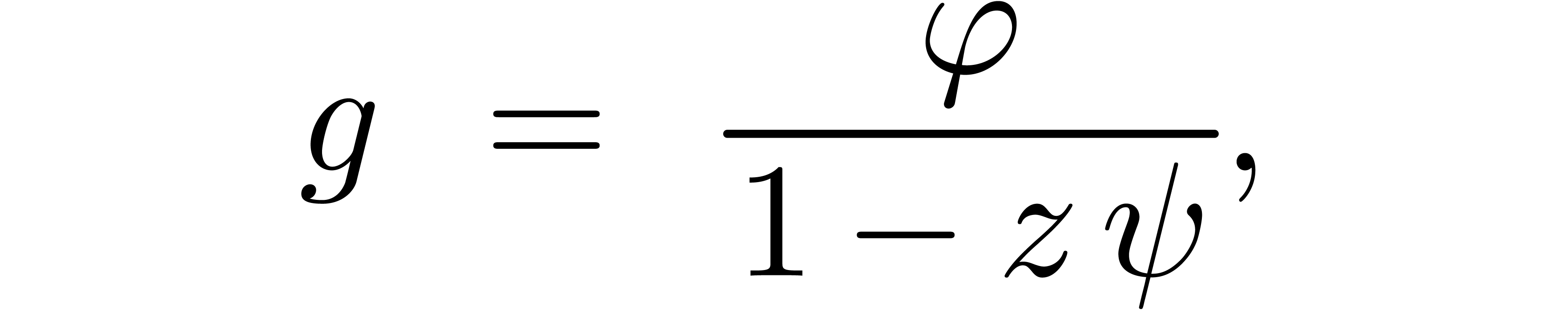
where 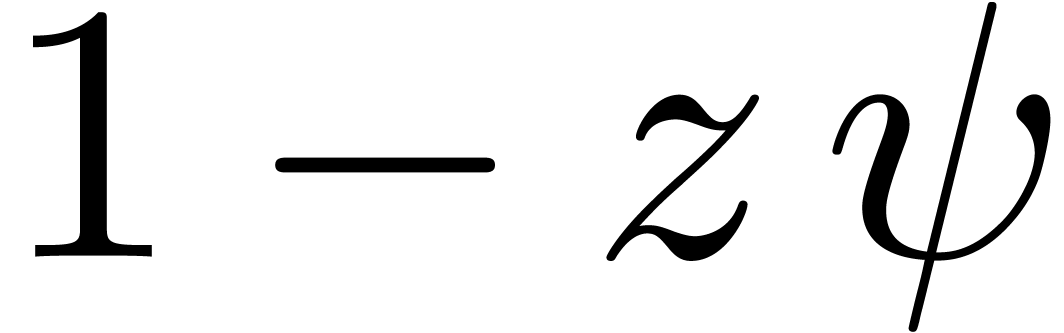 is inverted using the formula (39).
This approach has the advantage of being compatible with relaxed power
series expansion and it yields high quality error bounds.
is inverted using the formula (39).
This approach has the advantage of being compatible with relaxed power
series expansion and it yields high quality error bounds.
Another typical operation on power series is exponentiation. Using
relaxed multiplication, we may compute the exponential
of an infinitesimal power series 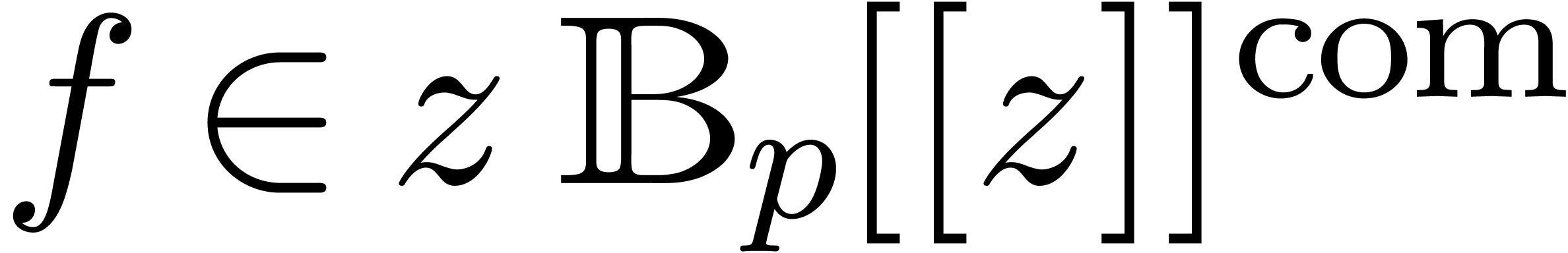 using the
implicit equation
using the
implicit equation
where  stands for “distinguished
integration” in the sense that
stands for “distinguished
integration” in the sense that 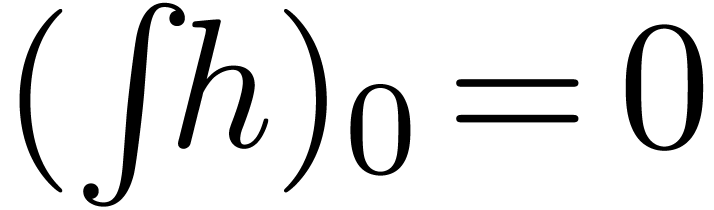 for all
. Again, one might fear that
this method leads to massive overestimation. As a matter of fact, it
usually does not. Indeed, assume for simplicity that
for all
. Again, one might fear that
this method leads to massive overestimation. As a matter of fact, it
usually does not. Indeed, assume for simplicity that 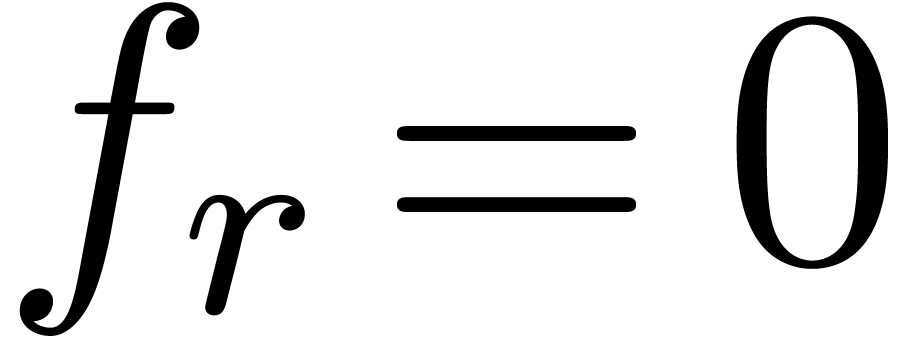 , so that
, so that 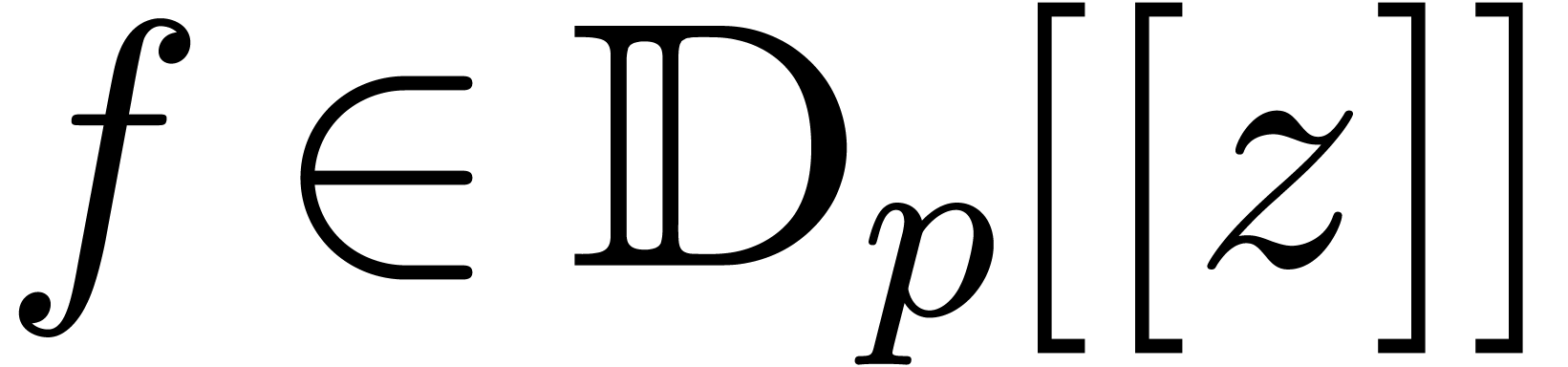 .
Recall that denotes the power series with
.
Recall that denotes the power series with 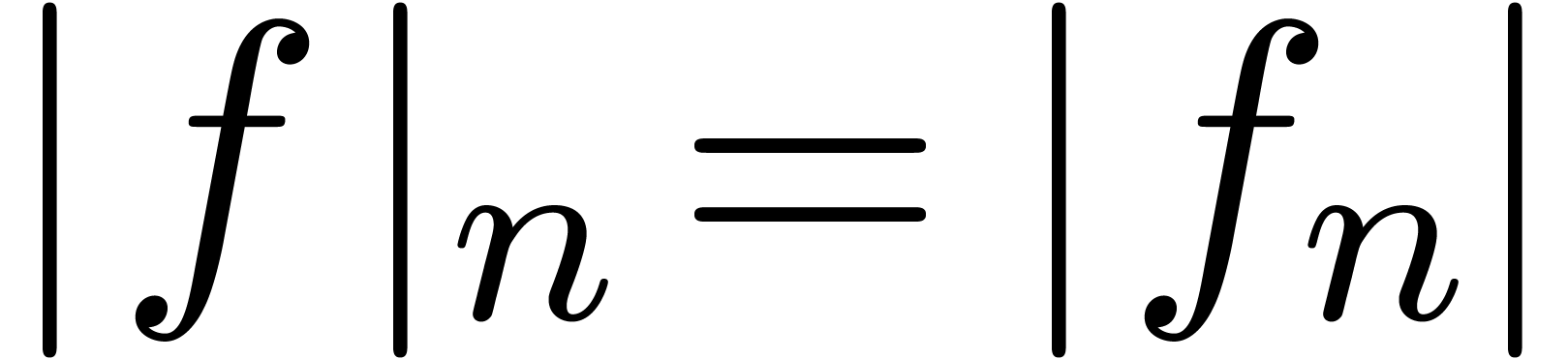 . Roughly speaking, the error bound
for , when computed using the
formula (40) will be the coefficient
of the power series
. Roughly speaking, the error bound
for , when computed using the
formula (40) will be the coefficient
of the power series 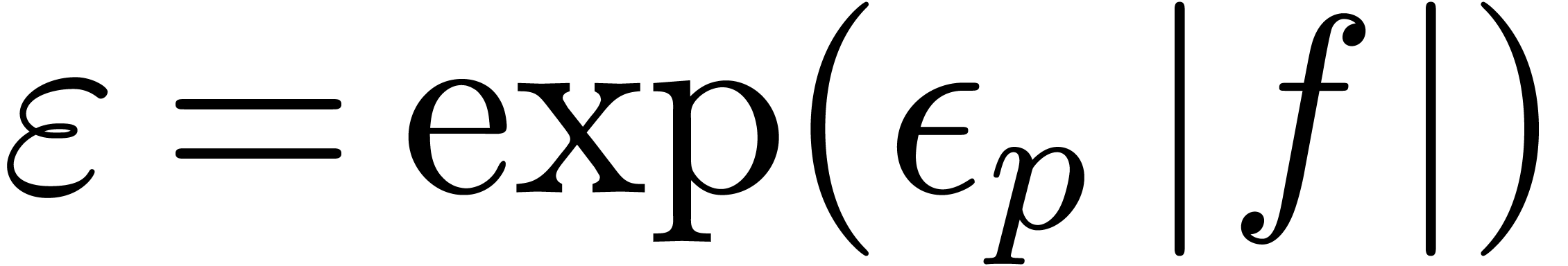 . Since
has the same radius of convergence as , it directly follows that the bit
precision loss is sublinear
. Since
has the same radius of convergence as , it directly follows that the bit
precision loss is sublinear  .
Actually, the dominant singularity of often has
the same nature as the dominant singularity of . In that case, the computed error bounds usually
become very sharp. The observation generalizes to the resolution of
linear differential equations, by taking a square matrix of power series
for .
.
Actually, the dominant singularity of often has
the same nature as the dominant singularity of . In that case, the computed error bounds usually
become very sharp. The observation generalizes to the resolution of
linear differential equations, by taking a square matrix of power series
for .
In the previous sections, we have seen various reliable algorithms for
the computation of the expansion of a power
series up till a given order . Such expansions are either regarded as ball
polynomials in 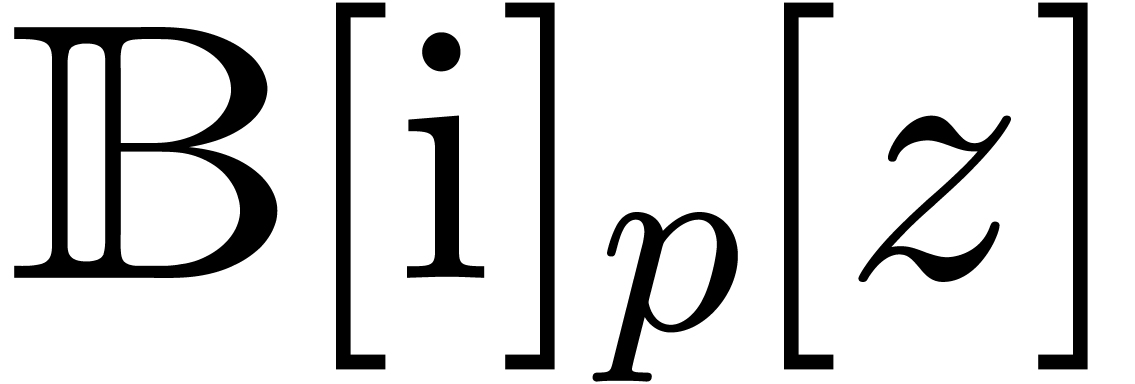 or as polynomial balls in
or as polynomial balls in 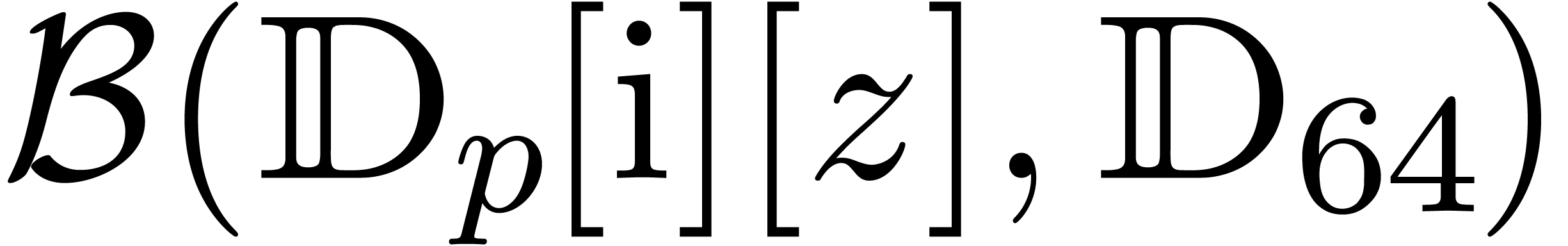 . Assuming that
is convergent on the closed unit disk ,
it remains to be shown how to compute tail bounds . We will follow [vdH07b]. Given a ball
polynomial , then we notice
that reasonably sharp upper and lower bounds
. Assuming that
is convergent on the closed unit disk ,
it remains to be shown how to compute tail bounds . We will follow [vdH07b]. Given a ball
polynomial , then we notice
that reasonably sharp upper and lower bounds  and
and
 for can be obtained
efficiently by evaluating at
for can be obtained
efficiently by evaluating at 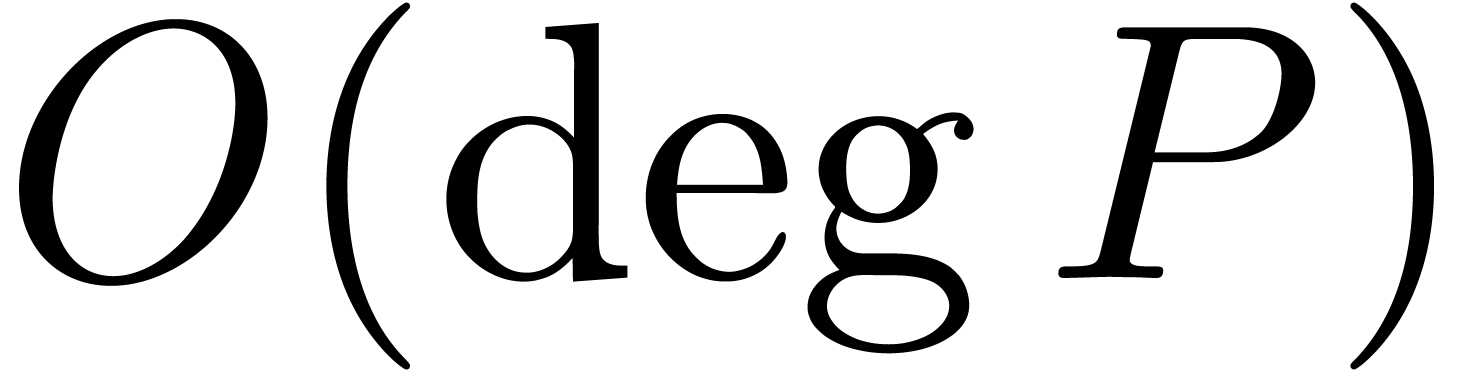 primitive roots of unity using fast Fourier transforms [vdH07b,
Section 6.2].
primitive roots of unity using fast Fourier transforms [vdH07b,
Section 6.2].
We will assume that the series is either an
explicit series, the result of an operation on other power series or the
solution of an implicit equation. Polynomials are the most important
examples of explicit series. Assuming that is a
polynomial of degree  , we may
simply take
, we may
simply take
where
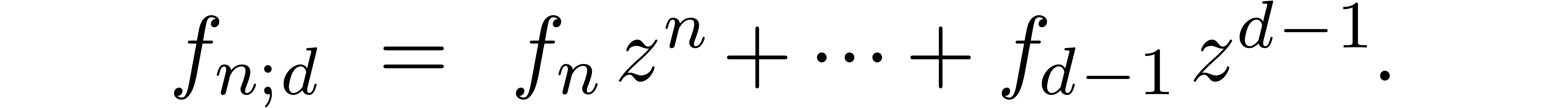
For simple operations on power series, we may use the following bounds:
where
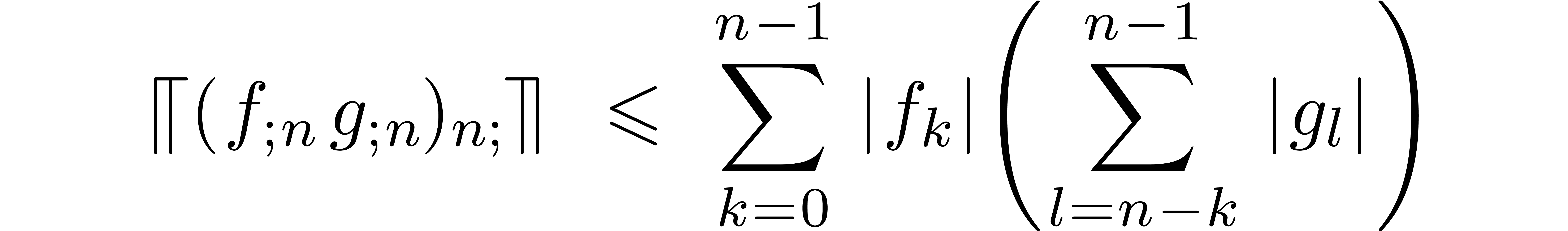
can be computed in time . Due
to possible overestimation, division has to be treated with care. Given
an infinitesimal power series and
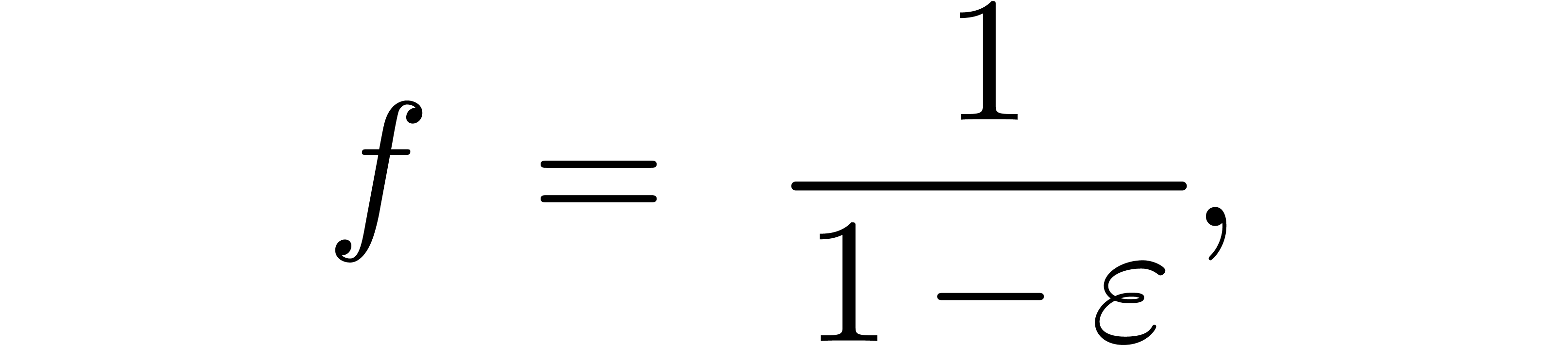
so that
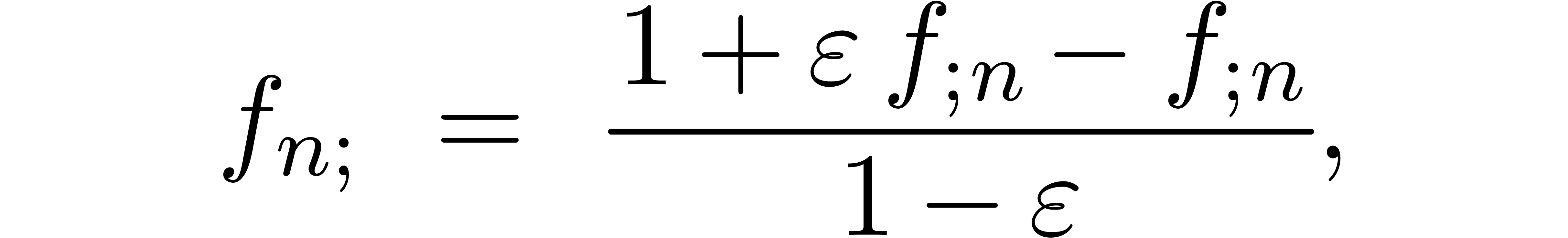
we take
where  is computed using (44).
is computed using (44).
Let  be an expression which is constructed from
and polynomials, using the ring operations and
distinguished integration (we exclude division in order to keep the
discussion simple). Assume that each coefficient
be an expression which is constructed from
and polynomials, using the ring operations and
distinguished integration (we exclude division in order to keep the
discussion simple). Assume that each coefficient 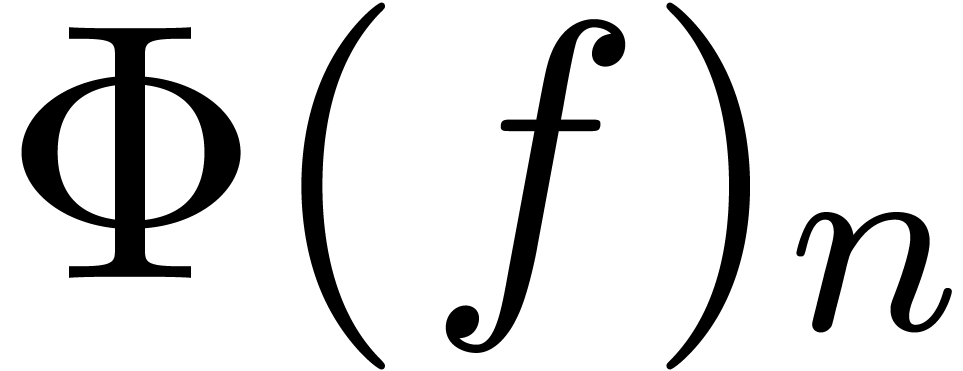 only depends on the previous coefficients
only depends on the previous coefficients 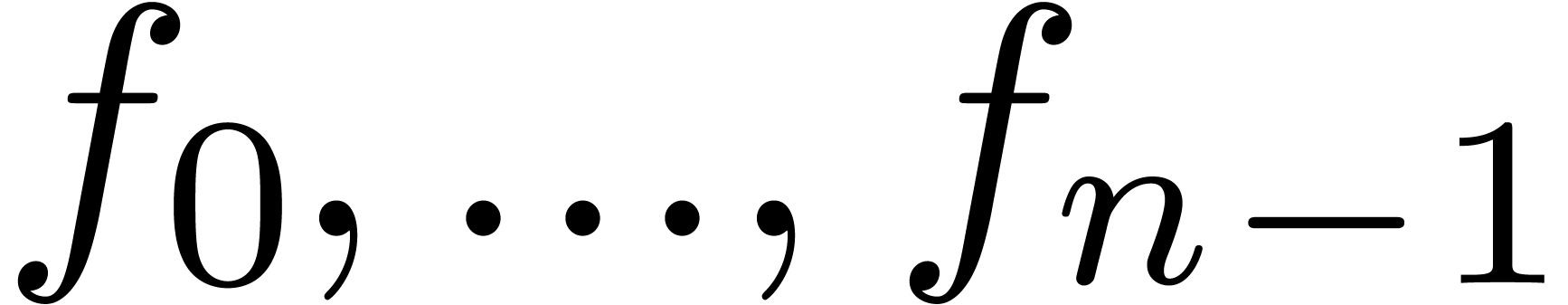 of
and not on
of
and not on 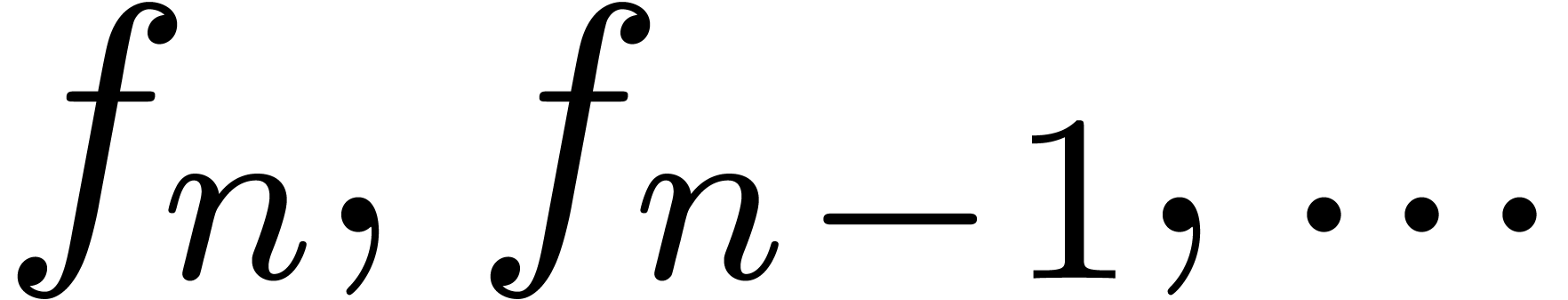 .
Then the sequence
.
Then the sequence  tends to the unique solution
of the implicit equation
tends to the unique solution
of the implicit equation
Moreover, 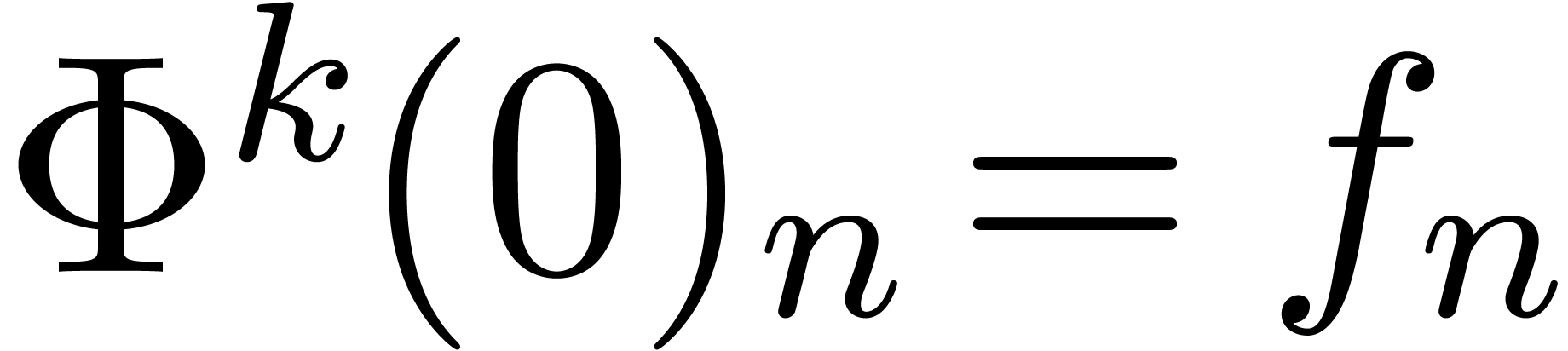 for any
for any 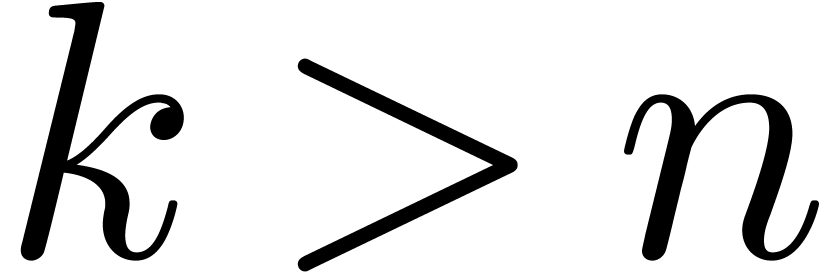 .
In (39) and (40), we have already seen two
examples of implicit equations of this kind.
.
In (39) and (40), we have already seen two
examples of implicit equations of this kind.
The following technique may be used for the computation of tail bounds
. Given 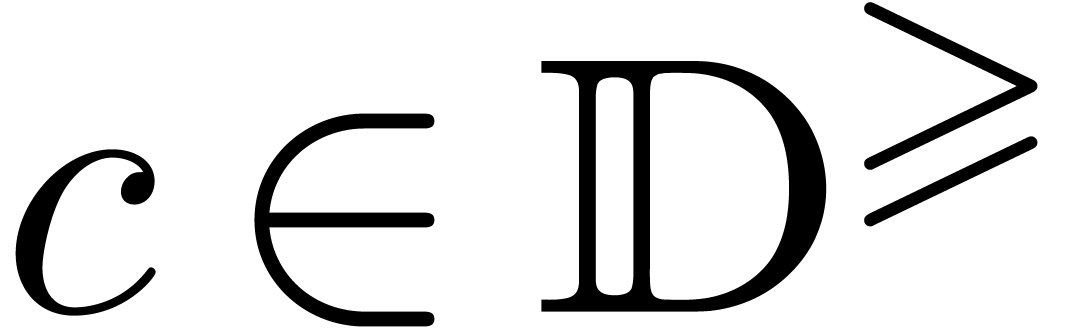 and assuming that
and assuming that 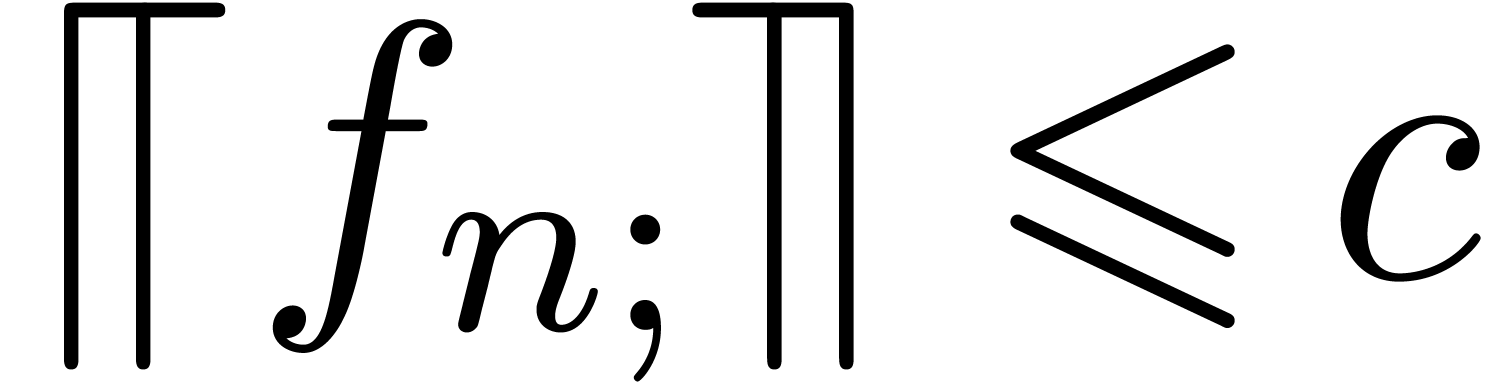 , we may
use the rules (41–46) in order to
compute a “conditional tail bound”
, we may
use the rules (41–46) in order to
compute a “conditional tail bound” 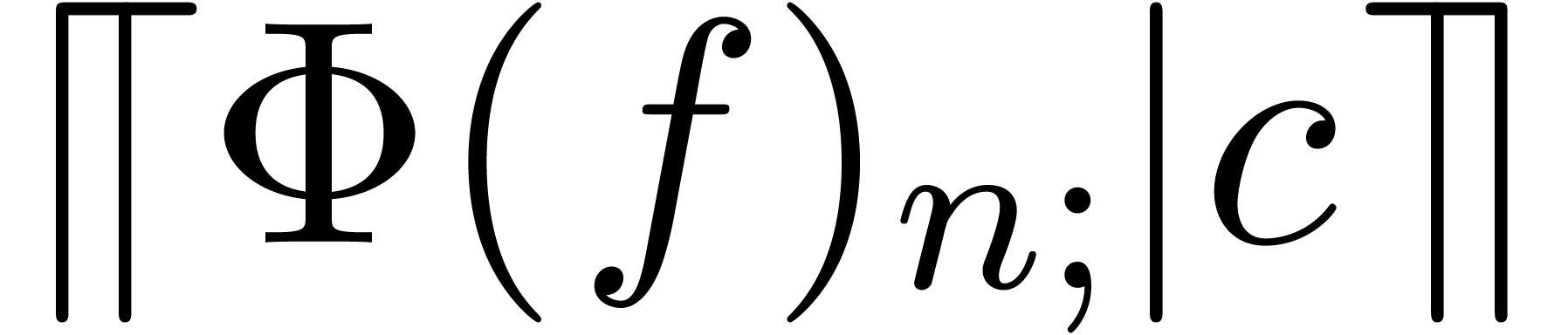 for
for 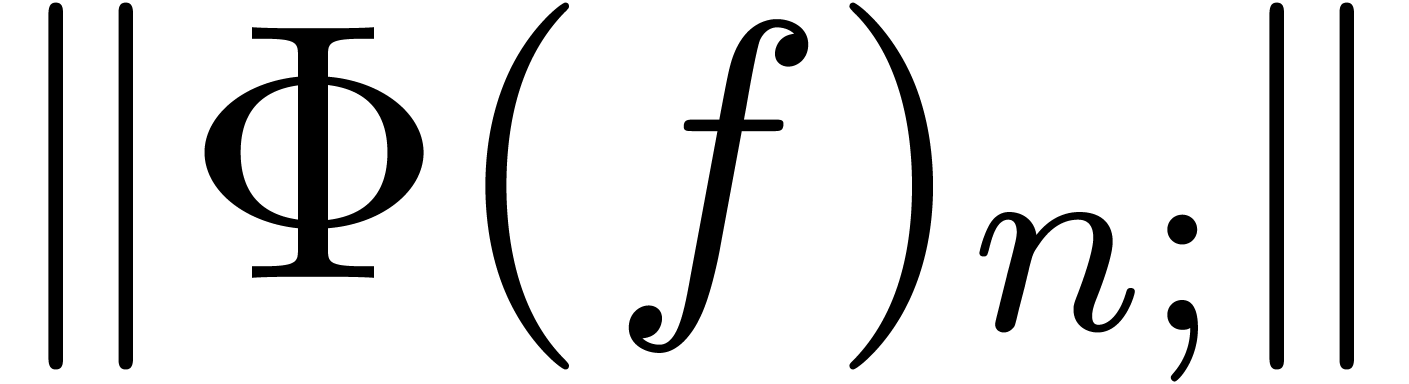 . Mathematically
speaking, this bound has the property that for any power series with
. Mathematically
speaking, this bound has the property that for any power series with 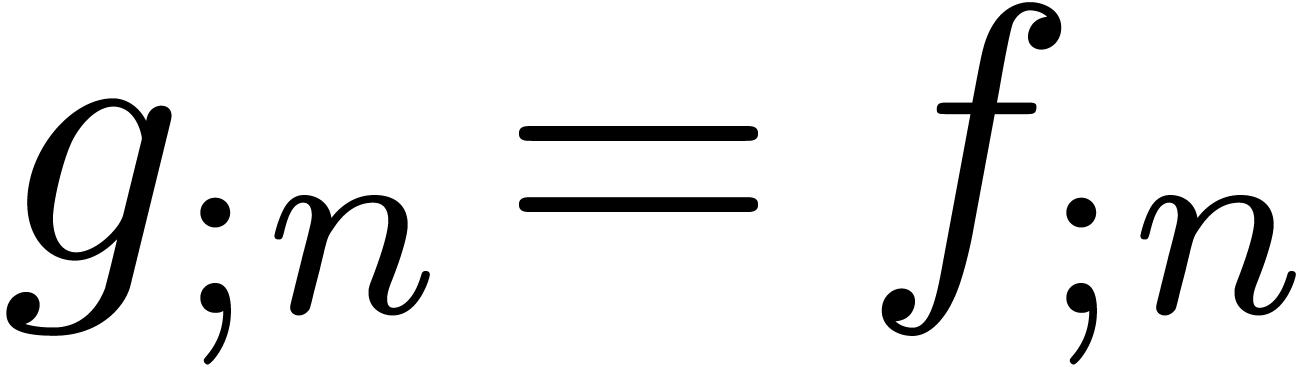 and
and 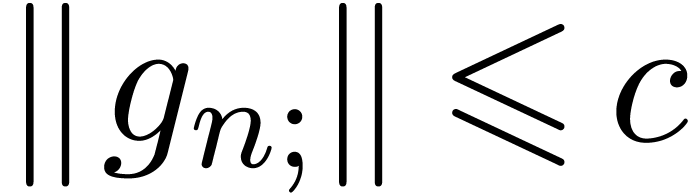 , we have
, we have  .
If
.
If 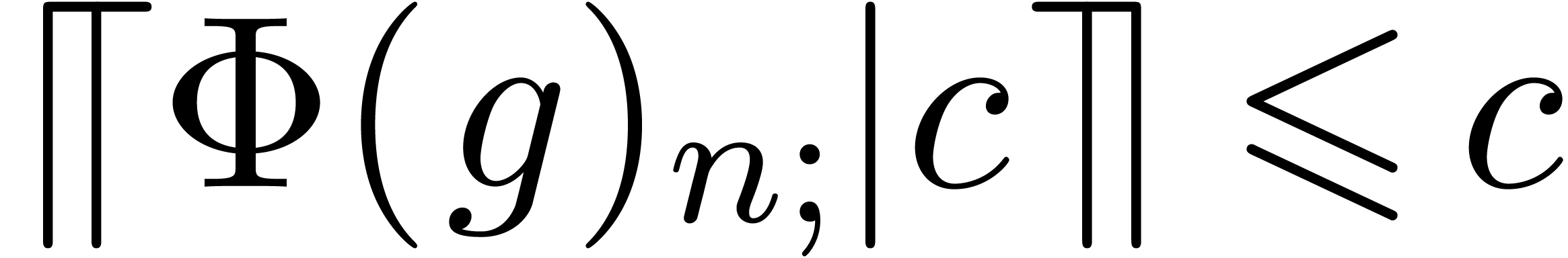 , then it follows that
, then it follows that
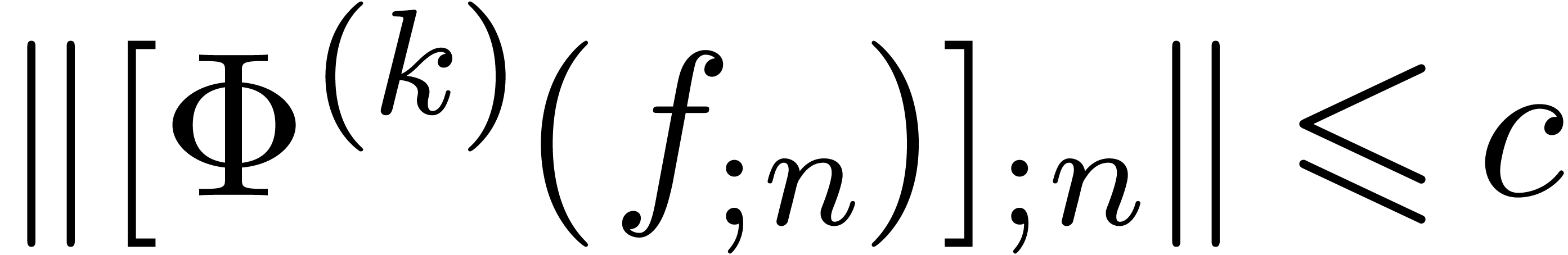 for all .
Given any disk with
for all .
Given any disk with 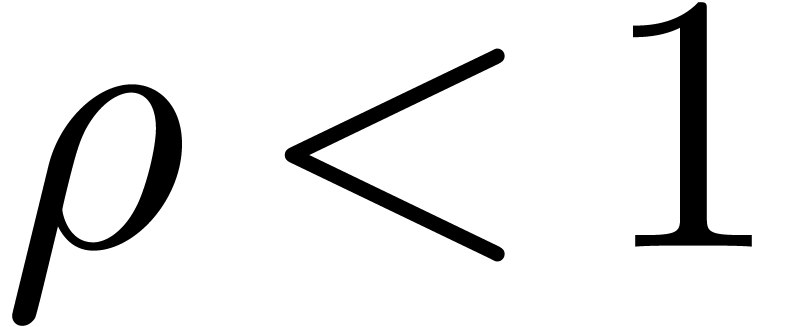 , it follows that
, it follows that 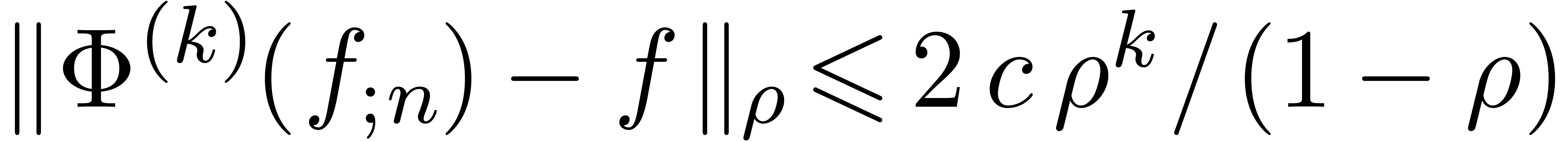 for any
for any
 , since
, since 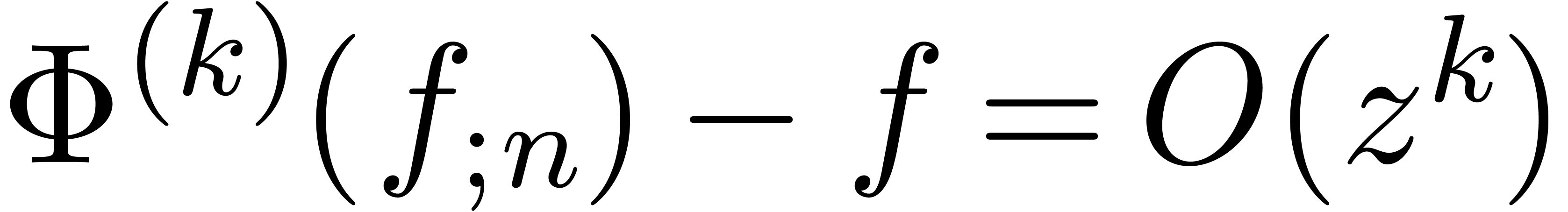 . In other words,
. In other words, 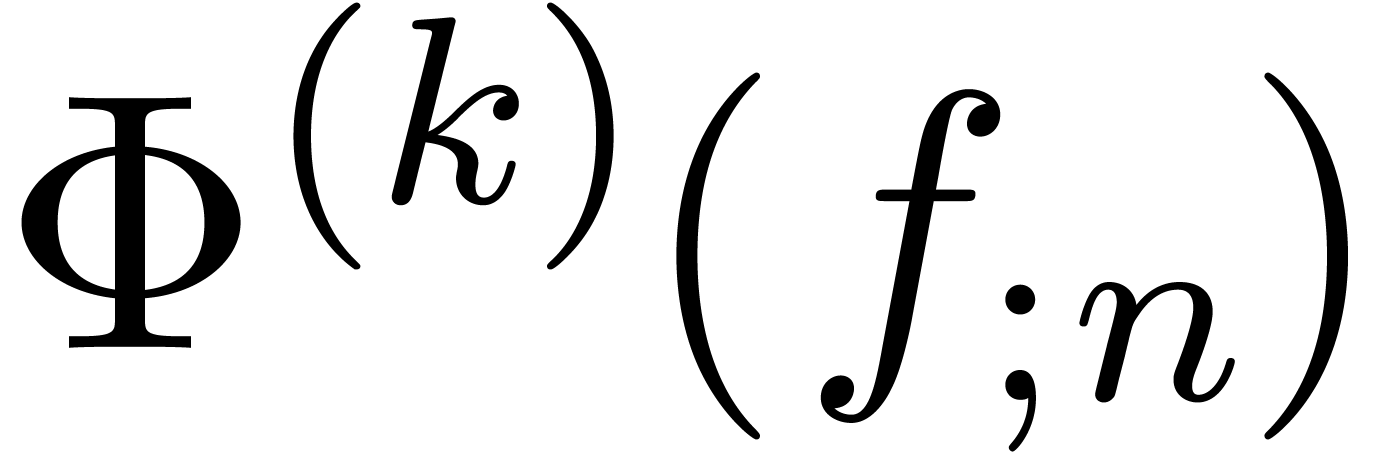 uniformly converges to on . Therefore,
uniformly converges to on . Therefore, 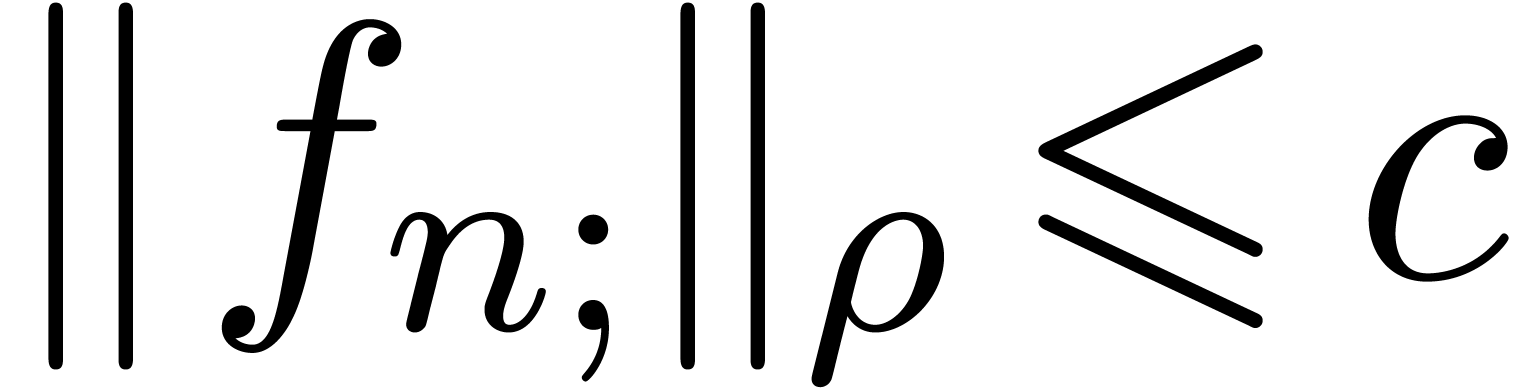 and
and 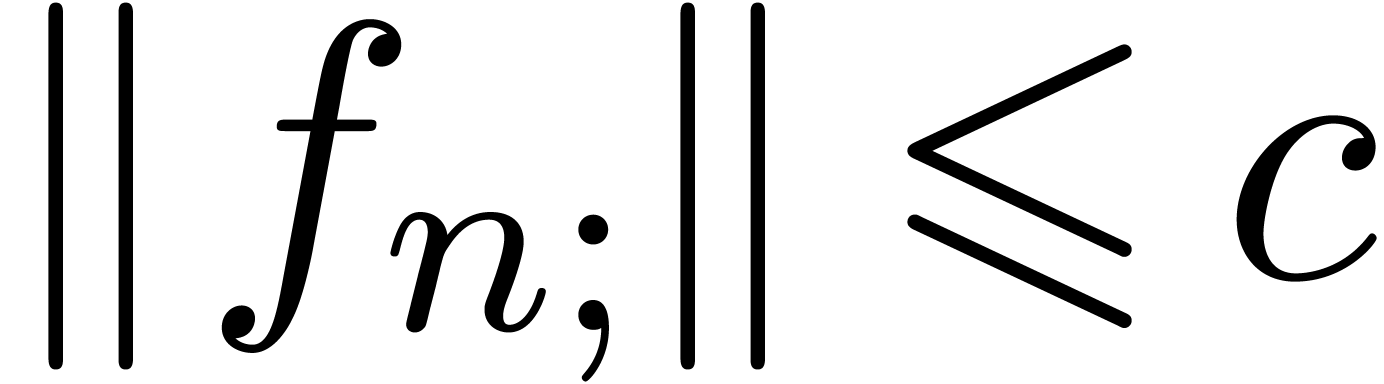 , by letting
, by letting 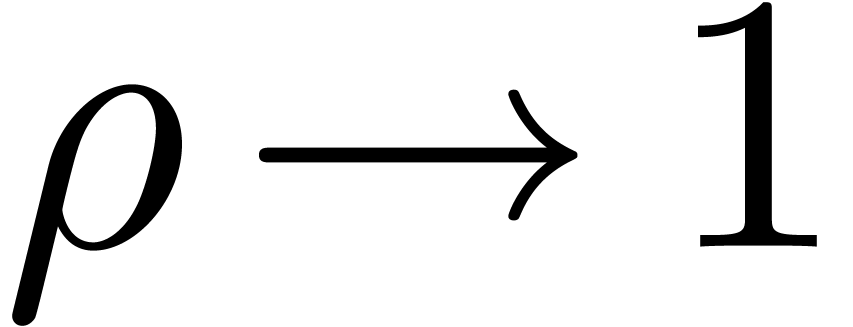 .
.
Let us now consider the mapping  and assume that
and assume that
 involves no divisions. When computing using infinite precision and the rules (41–44), we notice that
involves no divisions. When computing using infinite precision and the rules (41–44), we notice that  is a real analytic
function, whose power series expansion contains only positive
coefficients. Finding the smallest with
is a real analytic
function, whose power series expansion contains only positive
coefficients. Finding the smallest with  thus reduces to finding the smallest fixed point
thus reduces to finding the smallest fixed point  of , if
such a fixed point exists. We may use the secant method:
of , if
such a fixed point exists. We may use the secant method:
If 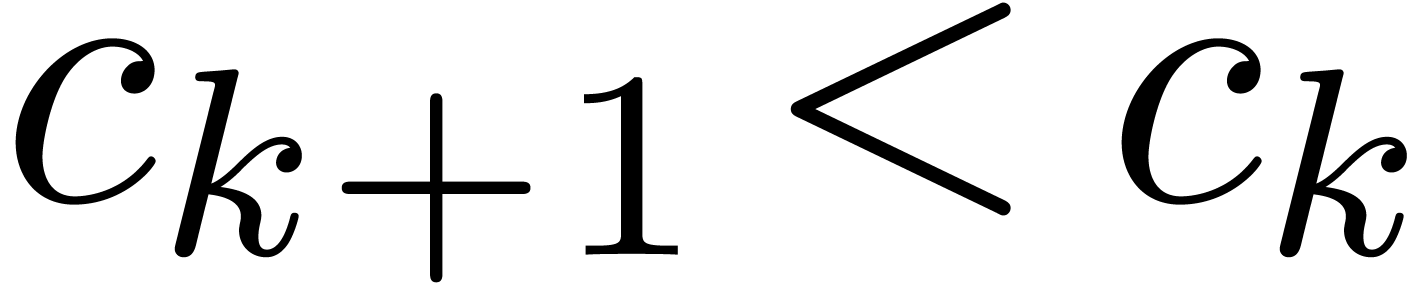 for some or if exceeds a given threshold , then the method fails and we set
for some or if exceeds a given threshold , then the method fails and we set  . Otherwise,
. Otherwise, 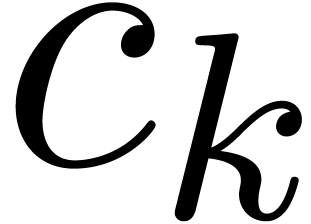 converges
quadratically to . As soon as
converges
quadratically to . As soon as
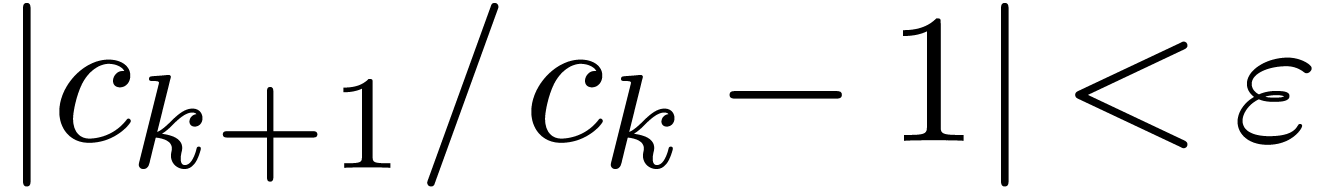 , for some given
, for some given  , we check whether
, we check whether  for
for
 , in which case we stop. The
resulting
, in which case we stop. The
resulting  is an approximation of with relative accuracy .
is an approximation of with relative accuracy .
Assuming that 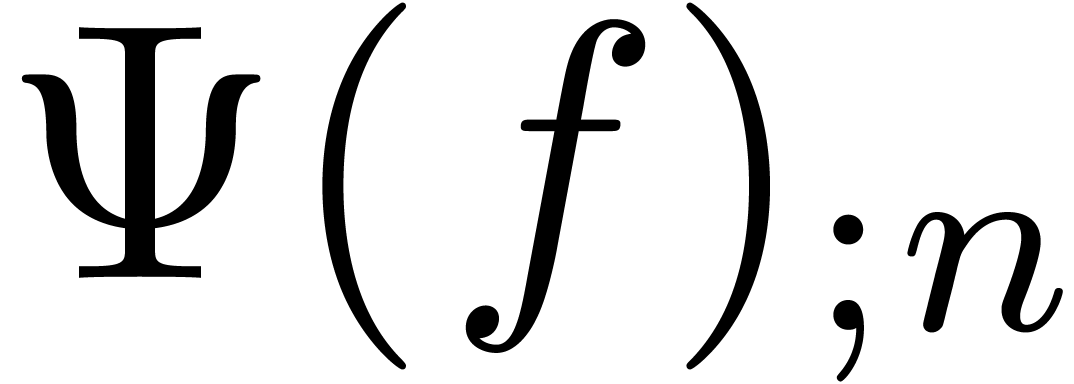 has been computed for every
subexpression of , we notice
that the computation of only requires
has been computed for every
subexpression of , we notice
that the computation of only requires 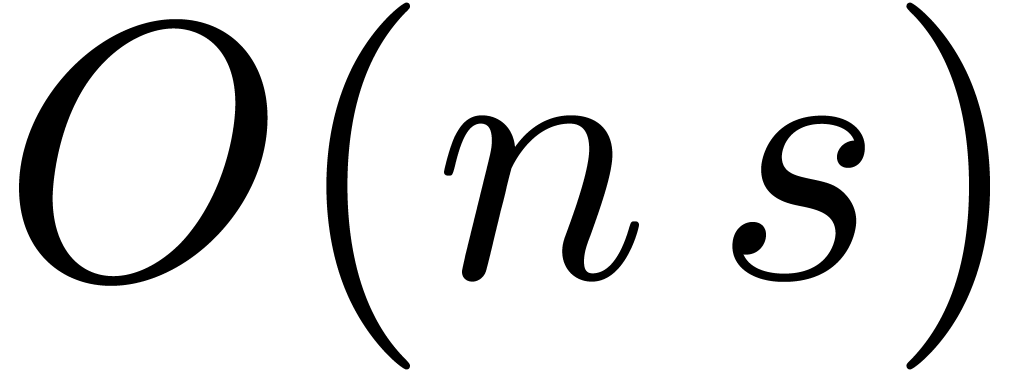 floating point operations, where
is the size of as an expression. More generally,
the evaluation of
floating point operations, where
is the size of as an expression. More generally,
the evaluation of  for
different hypotheses
for
different hypotheses  only requires
only requires 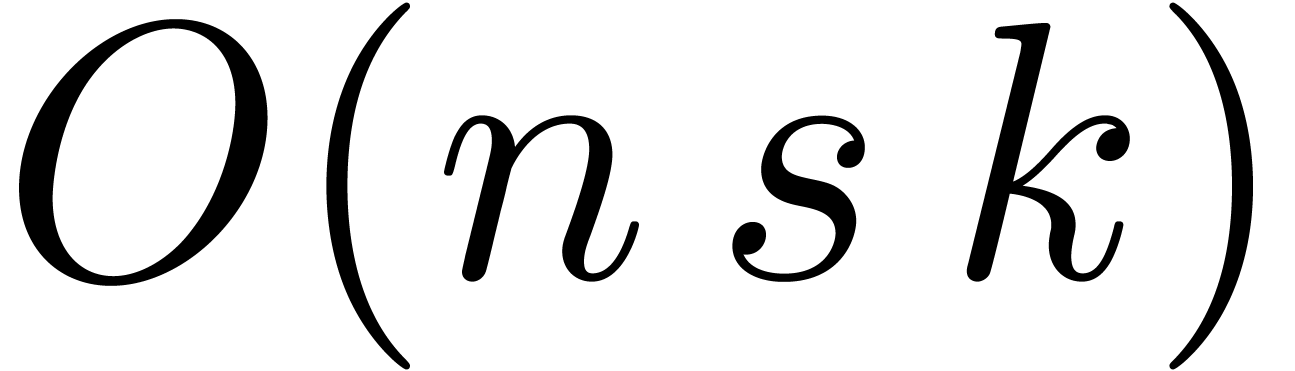 operations, since the heads do not
need to be recomputed. Our algorithm for the computation of therefore requires at most
operations, since the heads do not
need to be recomputed. Our algorithm for the computation of therefore requires at most 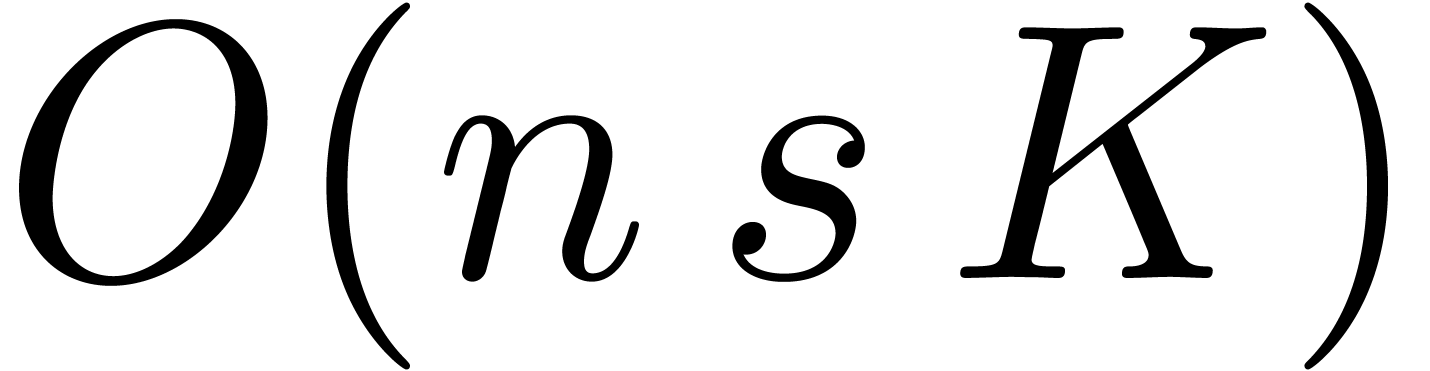 floating point operations. Taking
floating point operations. Taking 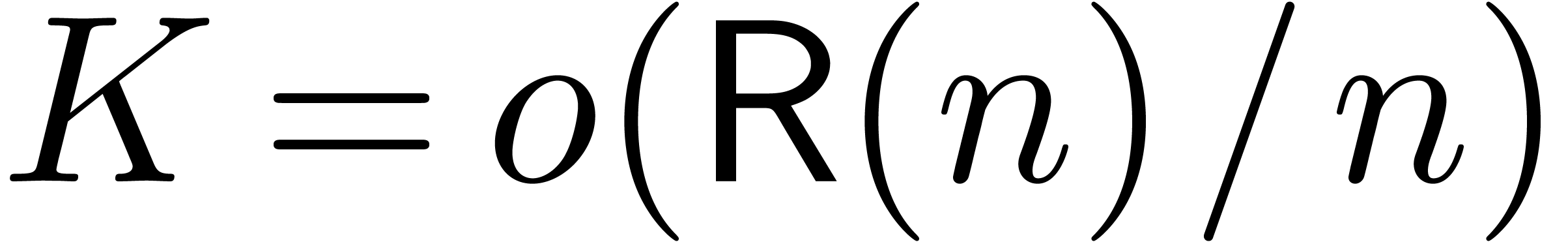 ,
it follows that the cost of the tail bound computation remains
negligible with respect to the series expansion itself.
,
it follows that the cost of the tail bound computation remains
negligible with respect to the series expansion itself.
The approach generalizes to the case when is a
vector or matrix of power series, modulo a more involved method for the
fixed point computation [vdH07b, Section 6.3]. If is indeed convergent on ,
then it can also be shown that indeed admits a
fixed point if is sufficiently large.
Let us now consider a dynamical system
where is a vector of
unknown complex power series, 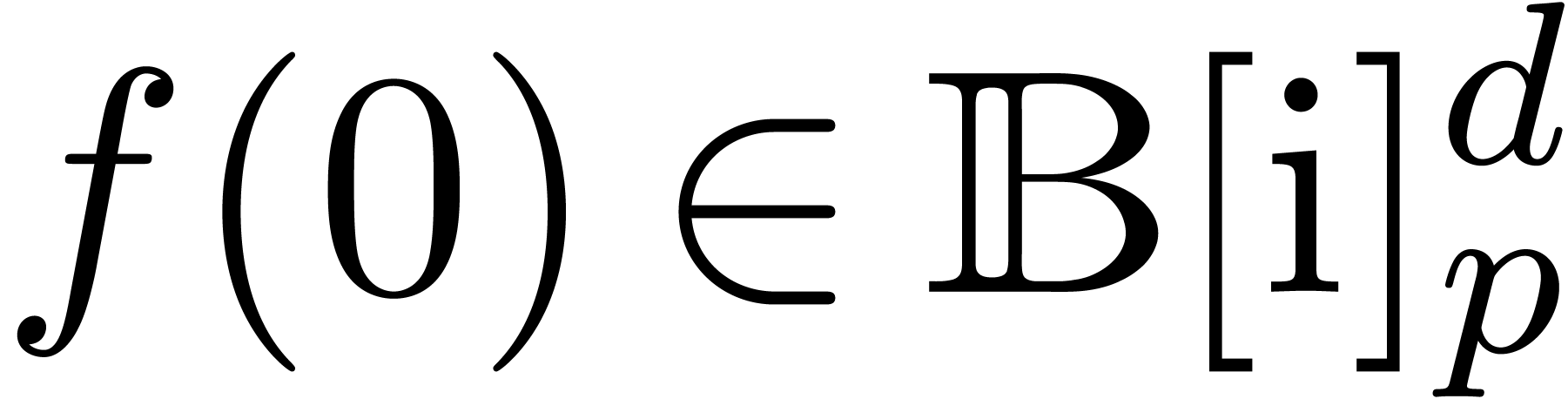 ,
and an expression built up from the entries of
and polynomials in
,
and an expression built up from the entries of
and polynomials in 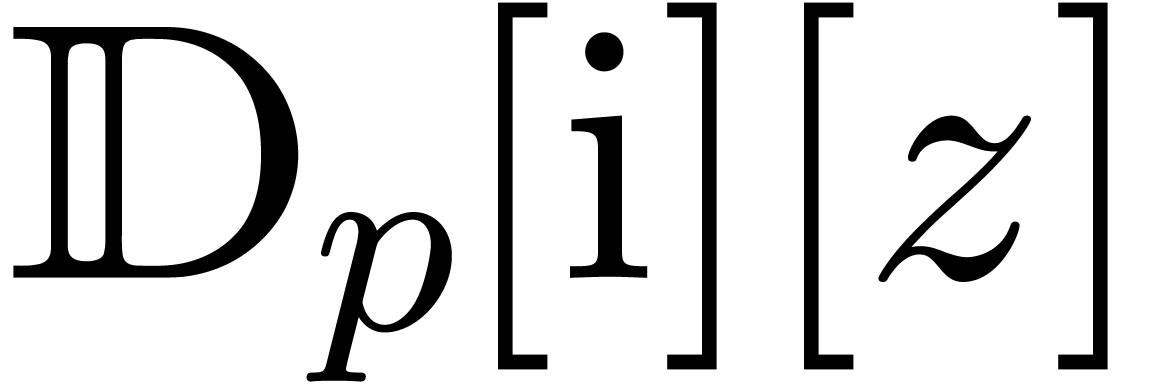 using
the ring operations. Given
using
the ring operations. Given  ,
denote by
,
denote by 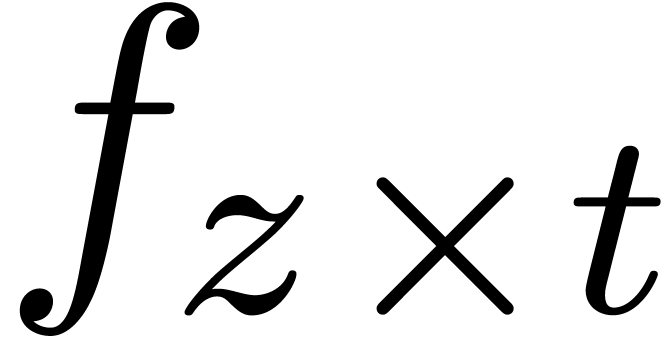 the scaled power series
the scaled power series 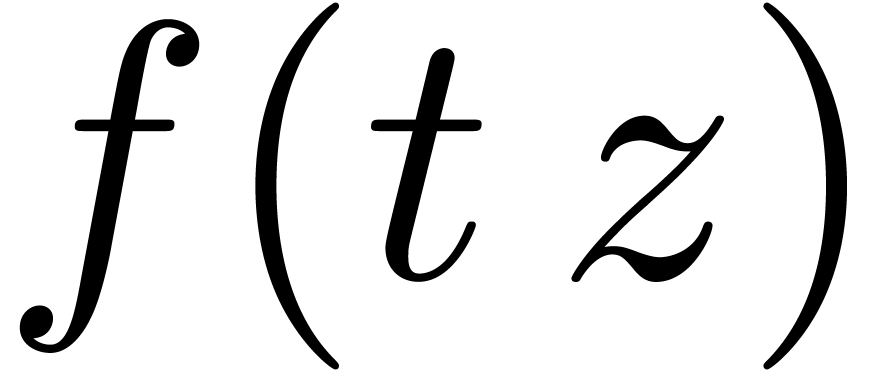 and by
and by 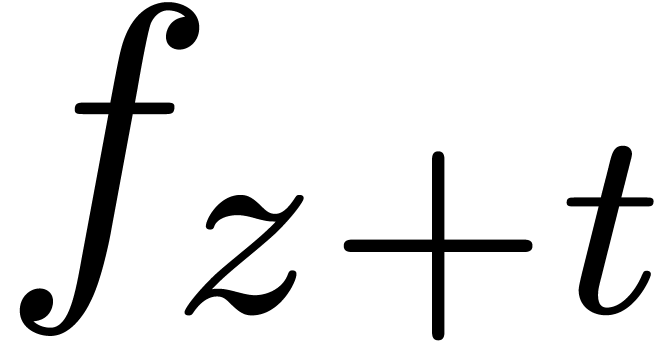 the shifted power series
the shifted power series
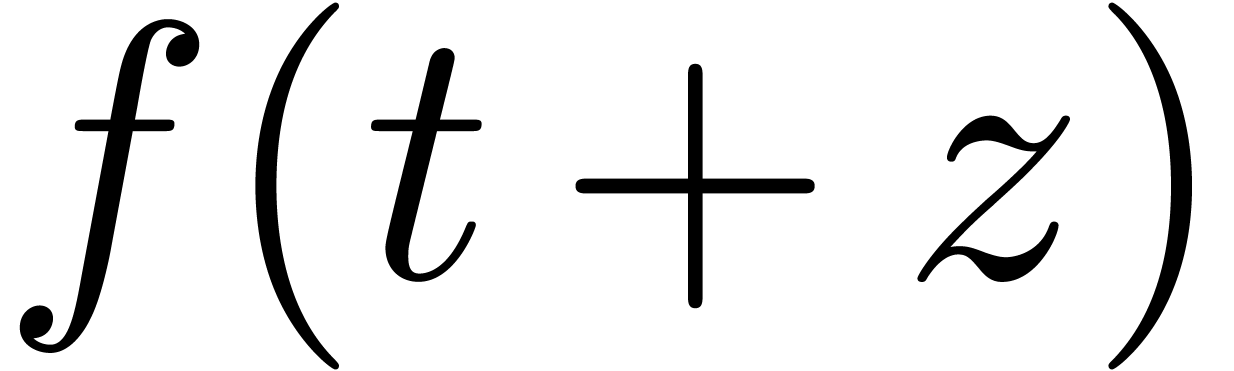 , assuming that converges at .
Also denote by
, assuming that converges at .
Also denote by 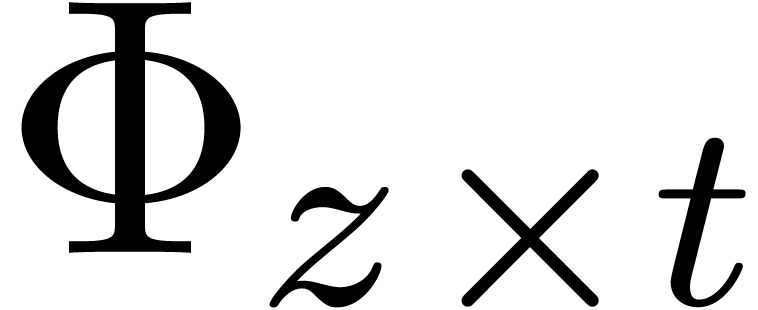 and
and 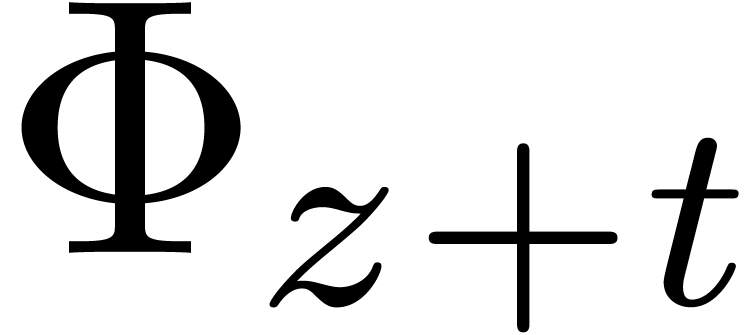 the
expressions which are obtained when replacing each polynomial in by
the
expressions which are obtained when replacing each polynomial in by 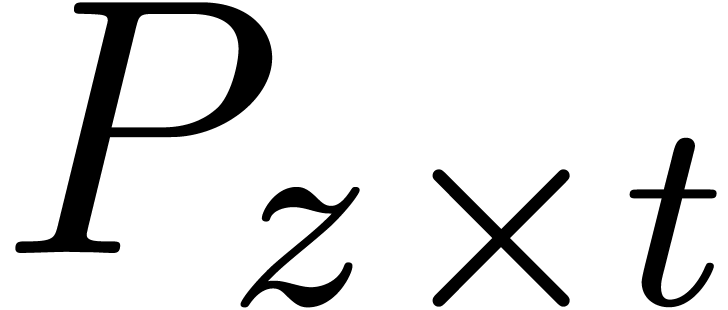 resp.
resp. 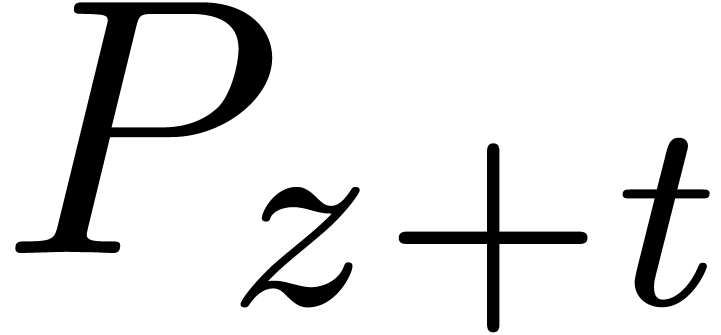 . Then
and satisfy
. Then
and satisfy
Since (48) is a particular case of an implicit equation of
the form (47), we have an algorithm for the computation of
tail bounds 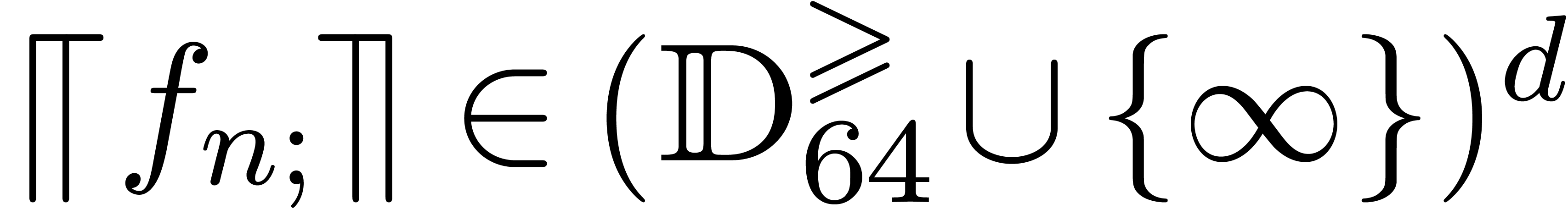 for on . Modulo rescaling (49),
we may also compute tail bounds
for on . Modulo rescaling (49),
we may also compute tail bounds 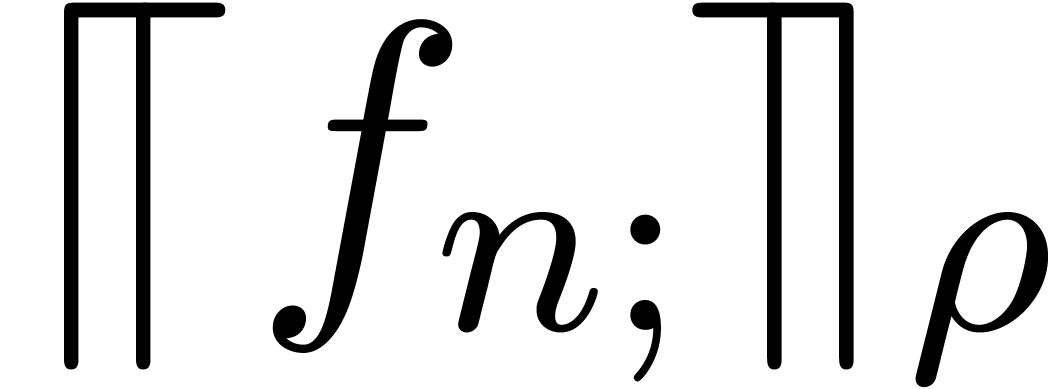 on more general
disks
on more general
disks  .
.
Assume that we want to integrate (48) along the real axis,
as far as possible, and performing all computations with an approximate
precision of bits. Our first task is to find a
suitable initial step size and evaluate at . Since
we require a relative precision of approximately
bits, we roughly want to take  ,
where is the radius of convergence of , and evaluate the power series
up to order
,
where is the radius of convergence of , and evaluate the power series
up to order  .
We thus start by the numerical computation of
.
We thus start by the numerical computation of 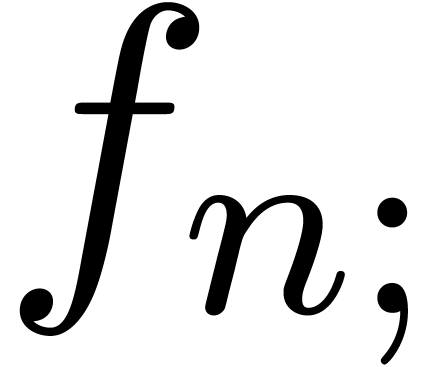 and the estimation
and the estimation 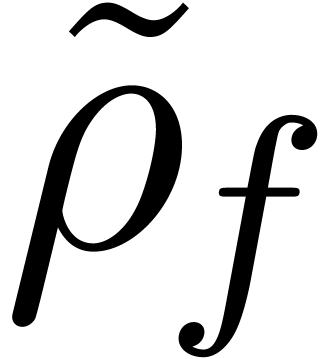 of , based on the numerical Newton polygon of . Setting
of , based on the numerical Newton polygon of . Setting 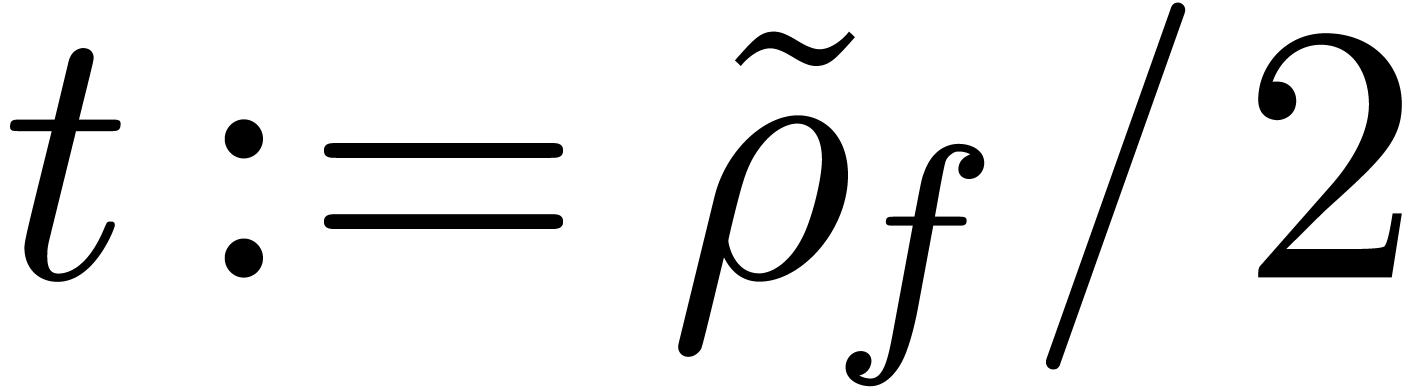 , we next compute a tail bound
, we next compute a tail bound 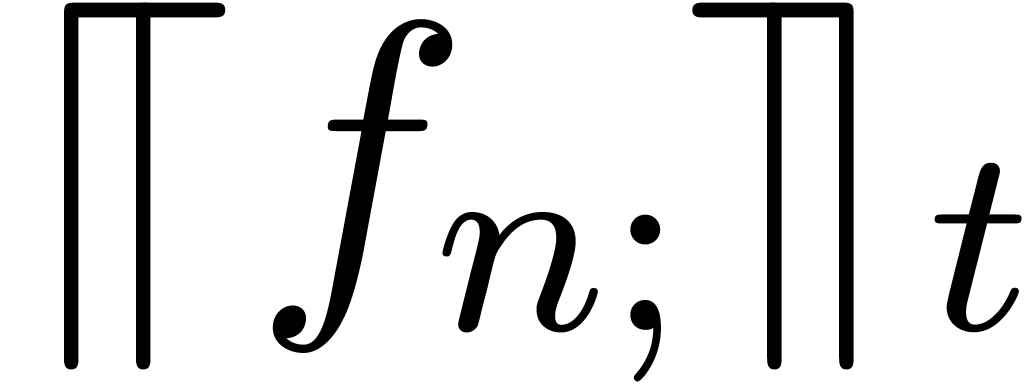 . This bound is considered to be of an
acceptable quality if
. This bound is considered to be of an
acceptable quality if

In the contrary case, we keep setting 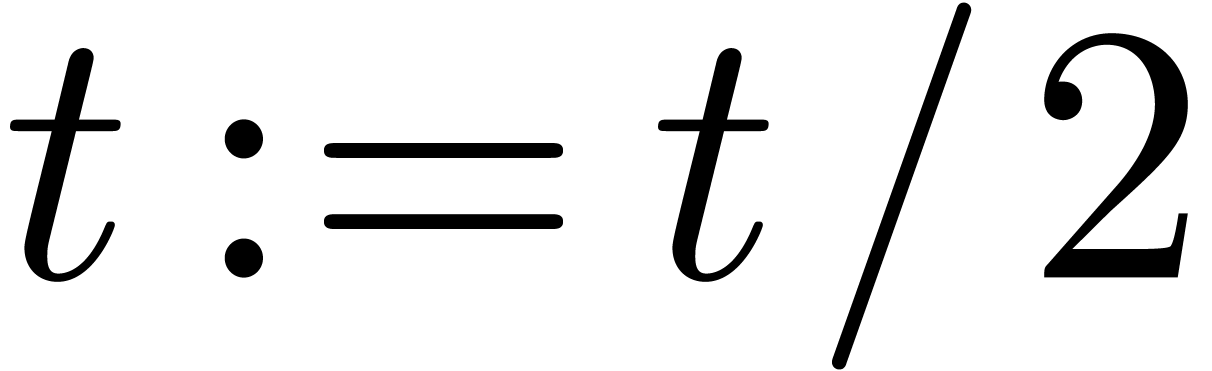 and
recomputing , until we find a
bound of acceptable quality. It can be shown [vdH07b] that
this process ultimately terminates, when is
sufficiently large. We thus obtain an appropriate initial step size which allows us to compute a -approximation of
and
recomputing , until we find a
bound of acceptable quality. It can be shown [vdH07b] that
this process ultimately terminates, when is
sufficiently large. We thus obtain an appropriate initial step size which allows us to compute a -approximation of 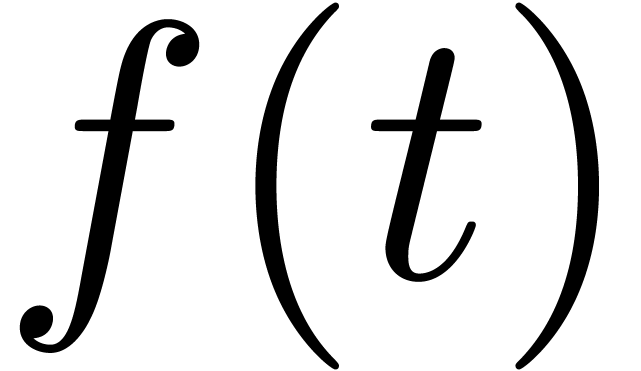 with
with  .
.
In principle, we may now perform the translation  and repeat the analytic continuation process using the equation (50). Unfortunately, this approach leads to massive
overestimation. Indeed, if the initial condition
and repeat the analytic continuation process using the equation (50). Unfortunately, this approach leads to massive
overestimation. Indeed, if the initial condition 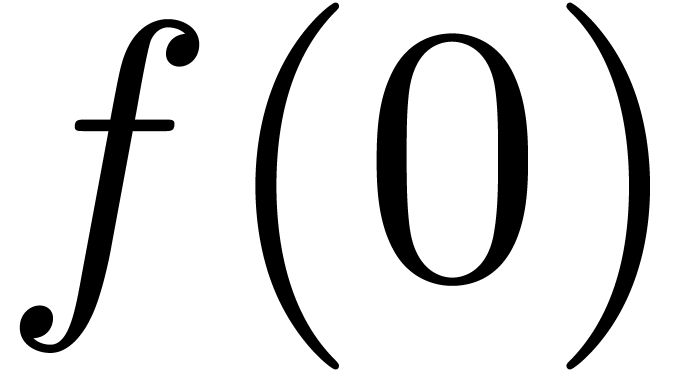 is given with relative precision
is given with relative precision  ,
then the relative precisions of the computed coefficients
,
then the relative precisions of the computed coefficients  are typically a non trivial factor times larger than , as well as the next
“initial condition” at . Usually, we therefore lose
are typically a non trivial factor times larger than , as well as the next
“initial condition” at . Usually, we therefore lose  bits of precision at every step.
bits of precision at every step.
One remedy is the following. Let 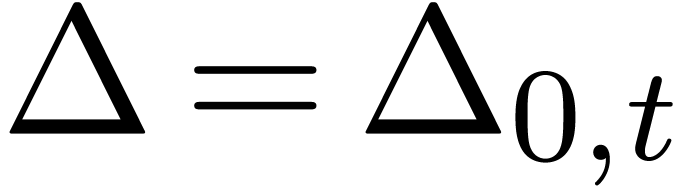 be the analytic
continuation operator which takes an initial condition
be the analytic
continuation operator which takes an initial condition 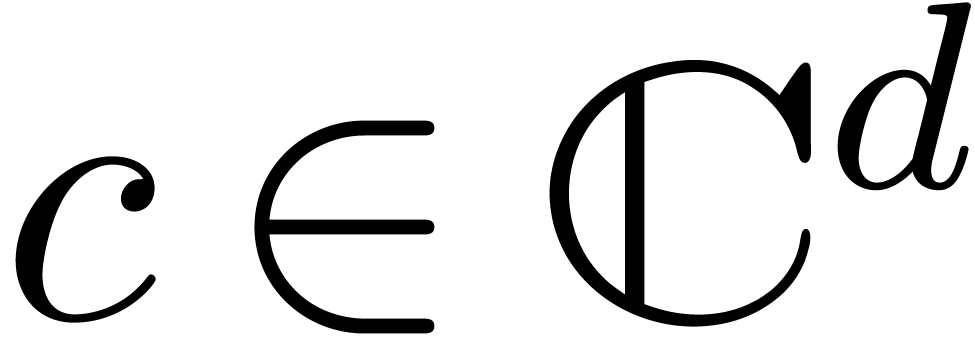 on input and returns the evaluation
on input and returns the evaluation 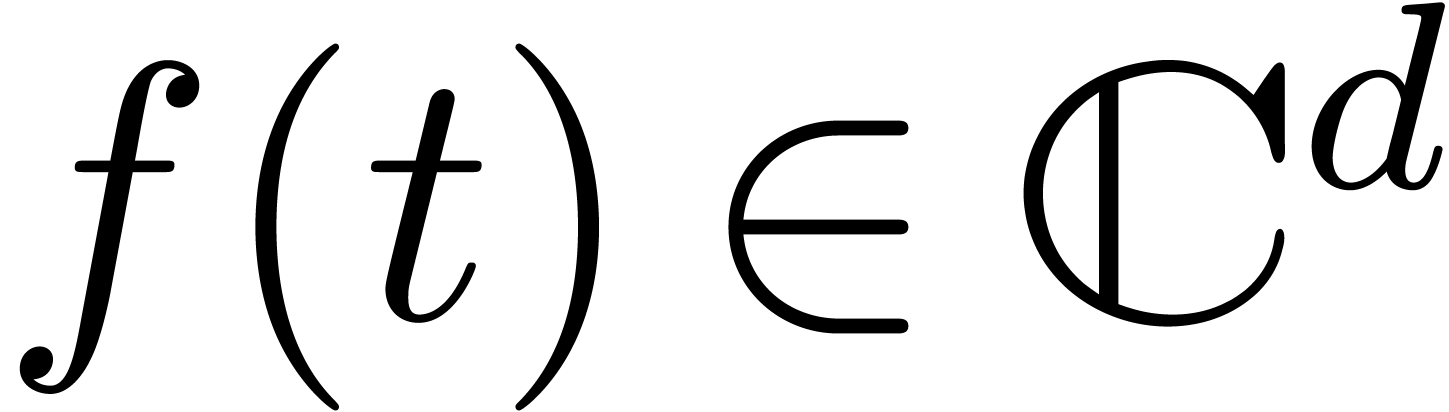 of the
unique solution to (48) with
of the
unique solution to (48) with 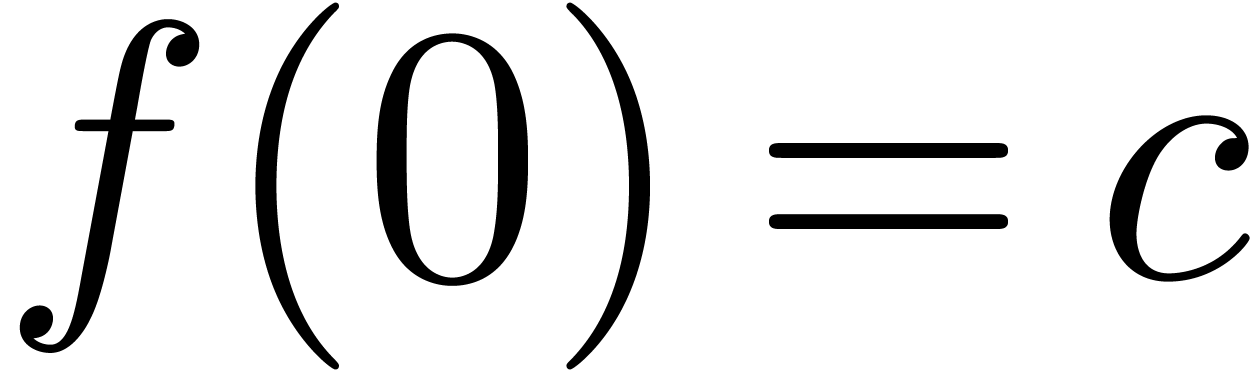 .
Now instead of computing using a ball initial
condition , we rather use its
center
.
Now instead of computing using a ball initial
condition , we rather use its
center 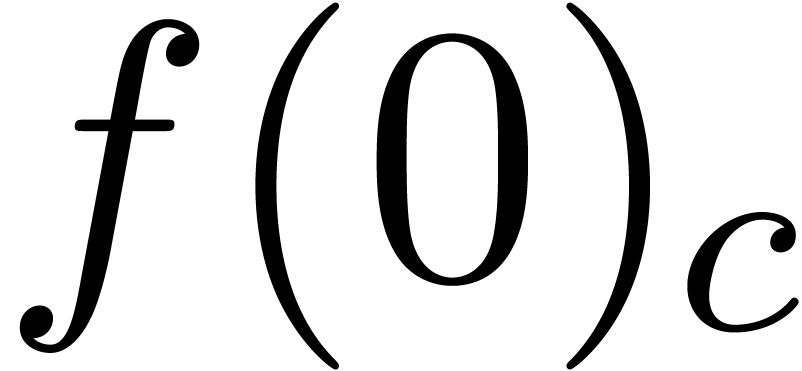 as our initial condition and compute
as our initial condition and compute  using ball arithmetic. In order to obtain a reliable
error bound for , we also
compute the Jacobian
using ball arithmetic. In order to obtain a reliable
error bound for , we also
compute the Jacobian  of
at using ball arithmetic, and take
of
at using ball arithmetic, and take
The Jacobian can either be computed using the technique of automatic differentiation [BS83] or using series with coefficients in a jet space of order one.
With this approach is computed with an almost
optimal -bit accuracy, and
 with an accuracy which is slightly worse than
the accuracy of the initial condition. In the lucky case when is almost diagonal, the accuracy of
will therefore be approximately the same as the accuracy of . However, if is not
diagonal, such as in (18), then the multiplication
with an accuracy which is slightly worse than
the accuracy of the initial condition. In the lucky case when is almost diagonal, the accuracy of
will therefore be approximately the same as the accuracy of . However, if is not
diagonal, such as in (18), then the multiplication 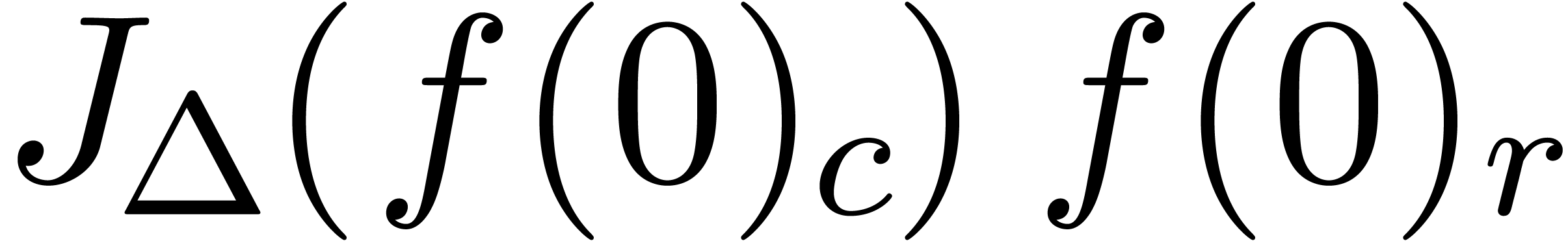 may lead to overestimation. This case may already
occur for simple linear differential equations such as
may lead to overestimation. This case may already
occur for simple linear differential equations such as
and the risk is again that we lose bits of
precision at every step.
Let us describe a method for limiting the harm of this manifestation of
the wrapping effect. Consider the analytic continuations of at successive points 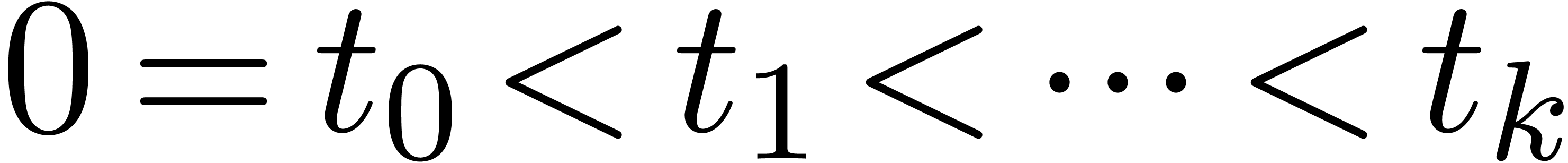 and denote
and denote
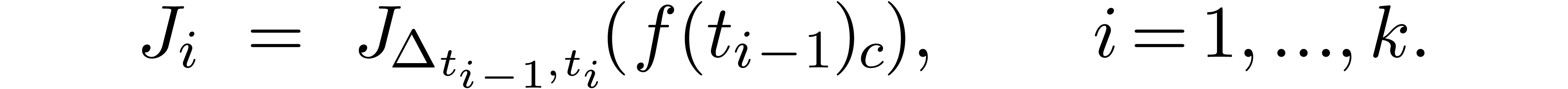
Instead of computing the error at 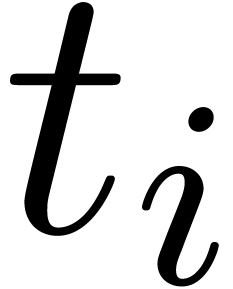 due to
perturbation of the initial condition using the
formula
due to
perturbation of the initial condition using the
formula
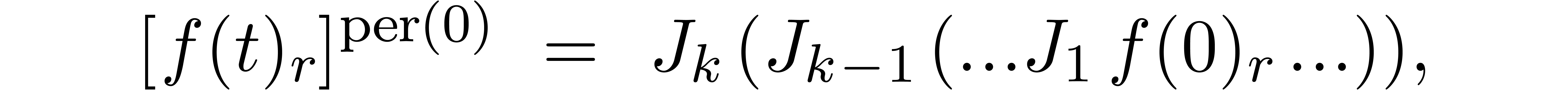
we may rather use the formula
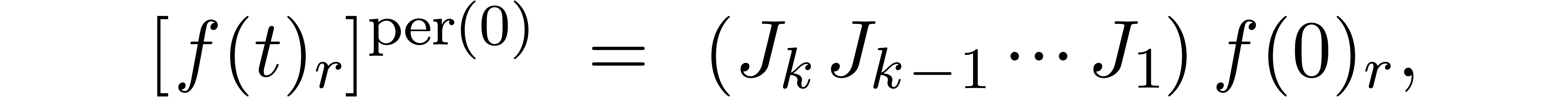
where matrix chain products are computed using a variant of binary powering (36):
In order to be complete, we also have to take into account the
additional error  , which
occurs during the computation of
, which
occurs during the computation of 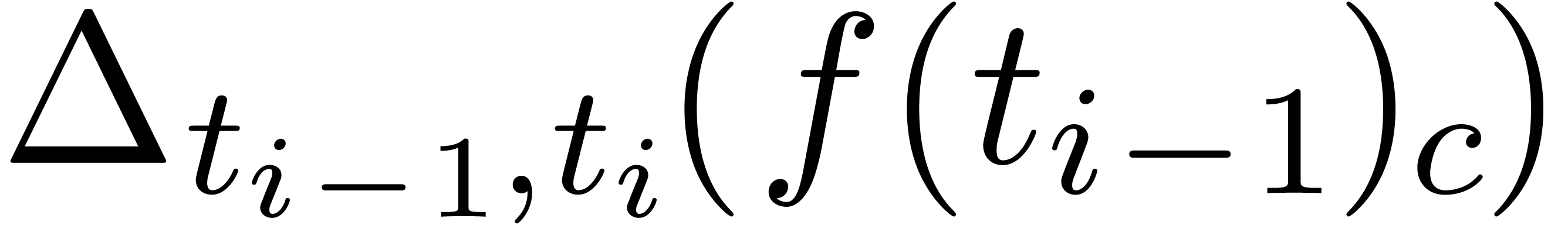 .
Setting
.
Setting 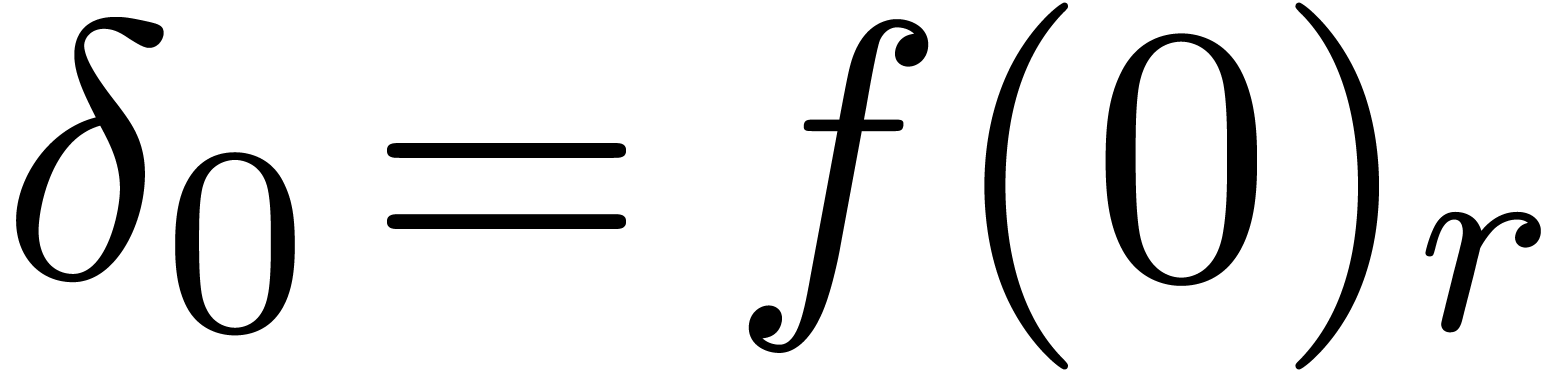 , we thus take
, we thus take
When using this algorithm, at least in the case of simple systems such
as (51), the precision loss at step
will be limited to bits. Notice that we benefit
from the fact that the Jacobian matrices remain accurate as long as the
initial conditions remain accurate.
Although we have reduced the wrapping effect, the asymptotic complexity
of the above algorithm is cubic or at least quadratic in when evaluating (52) using a binary splitting
version of Horner's method. Let us now describe the final method which
requires only 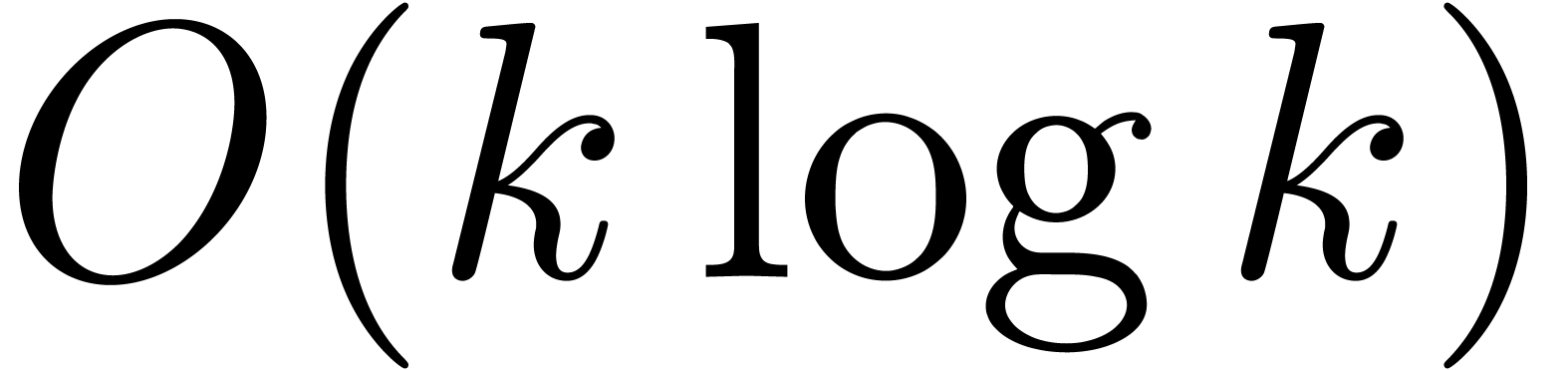 matrix multiplications up till
step . For
matrix multiplications up till
step . For 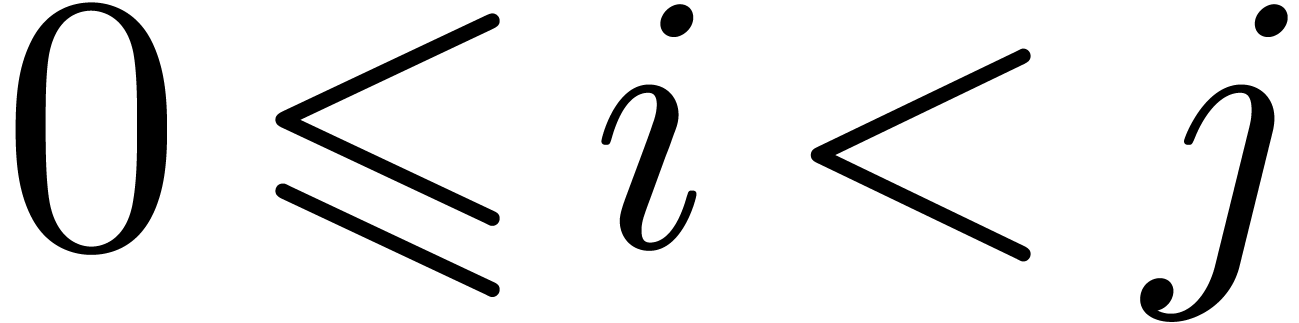 , we define
, we define
where 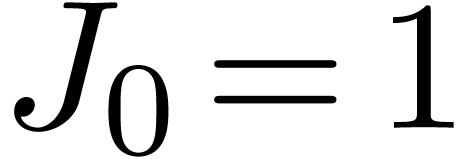 . At stage
. At stage 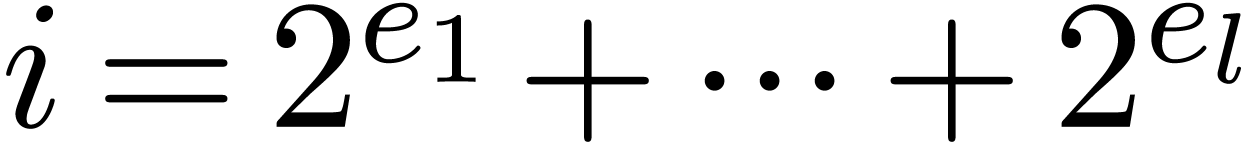 with
with  , we
assume that
, we
assume that
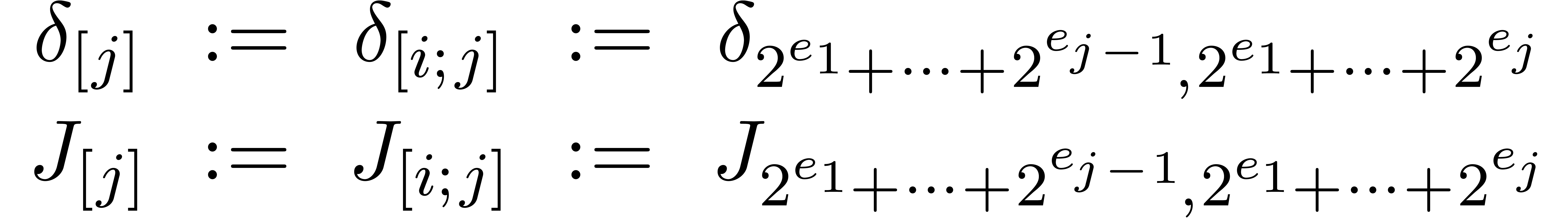
are stored in memory for all 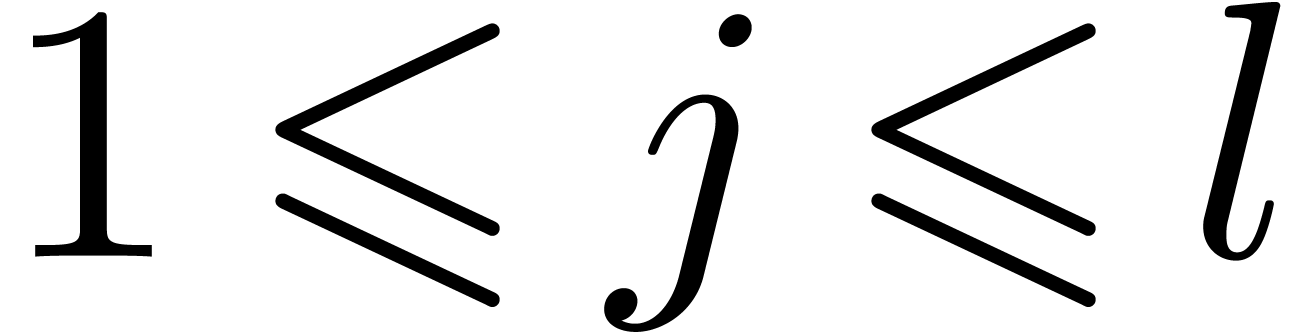 .
From these values, we may compute
.
From these values, we may compute
using only 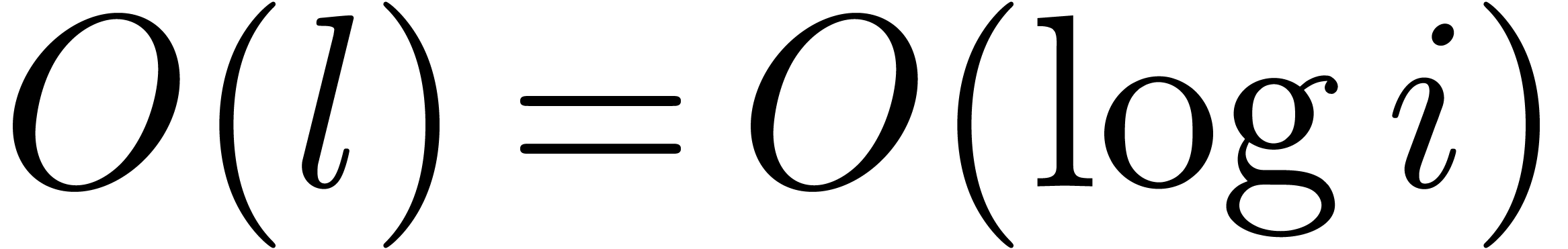 matrix multiplications. Now assume
that we go to the next stage
matrix multiplications. Now assume
that we go to the next stage 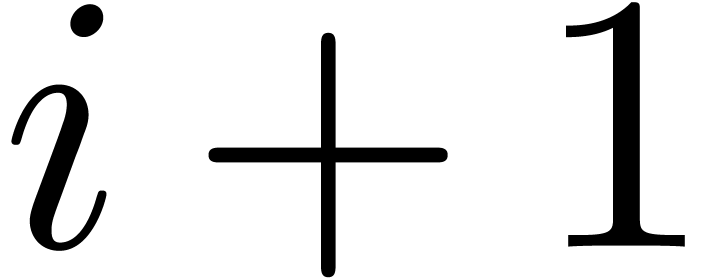 .
If is maximal such that
.
If is maximal such that  divides , then
divides , then  . Consequently,
. Consequently,  and
and
 for
for  and
and
Hence, the updated lists 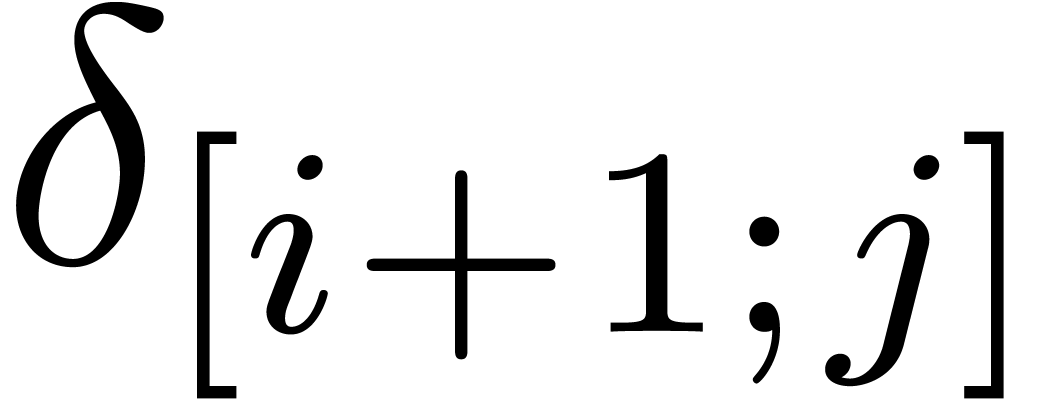 and
and 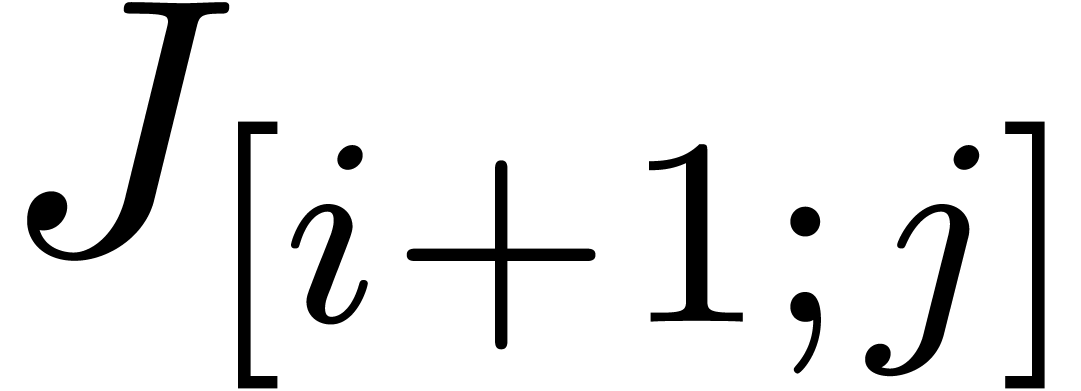 can be computed using
can be computed using 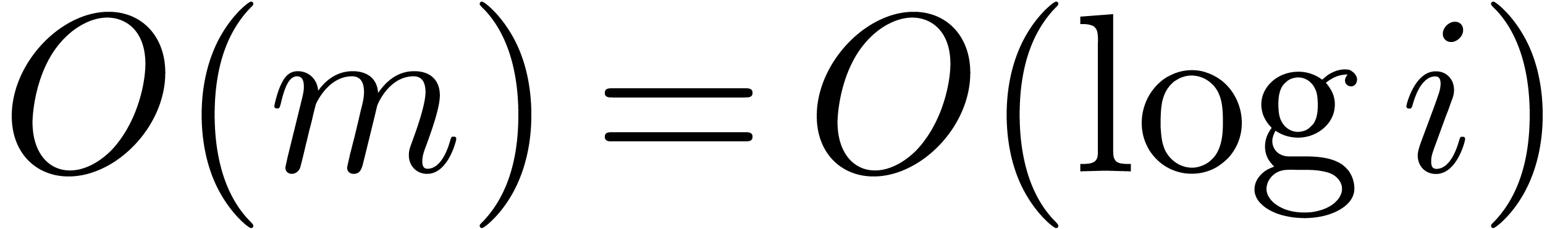 matrix multiplications.
Furthermore, we only need to store
matrix multiplications.
Furthermore, we only need to store 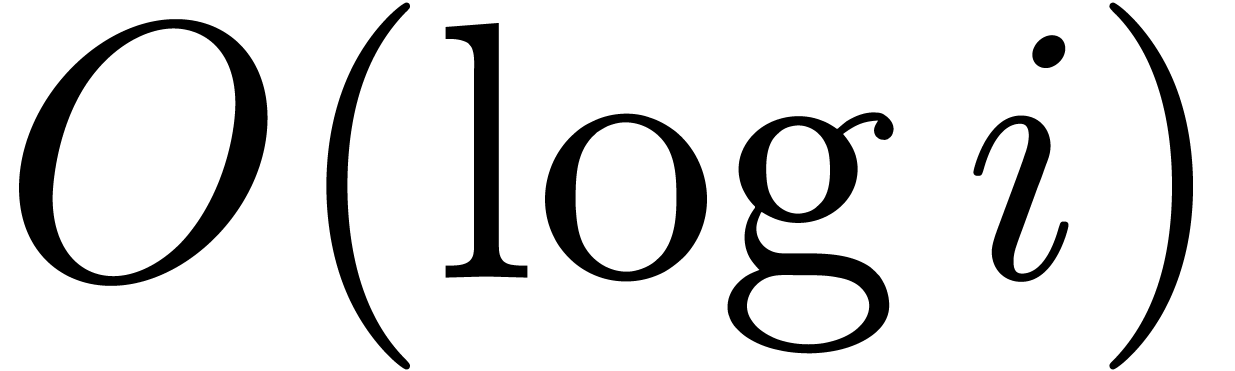 auxiliary
matrices at step .
auxiliary
matrices at step .
There is a vast literature on validated integration of dynamical systems and reduction of the wrapping effect [Moo65, Moo66, Nic85, Loh88, GS88, Neu93, K8, Loh01, Neu02, MB04]. We refer to [Loh01] for a nice review. Let us briefly discuss the different existing approaches.
The wrapping effect was noticed in the early days of interval arithmetic
[Moo65] and local coordinate transformations were proposed
as a remedy. The idea is to work as much as possible with respect to
coordinates in which all errors are parallel to axes. Hence, instead of
considering blocks 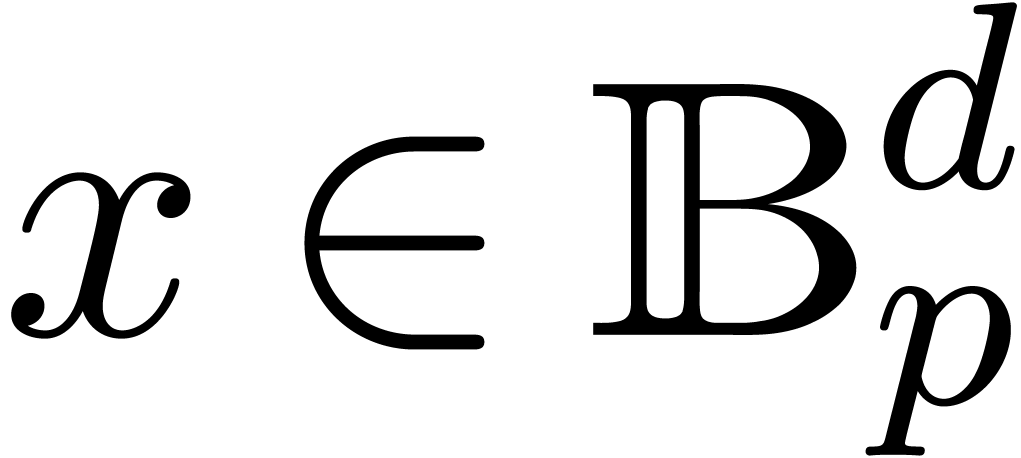 , we
rather work with parallelepipeds
, we
rather work with parallelepipeds 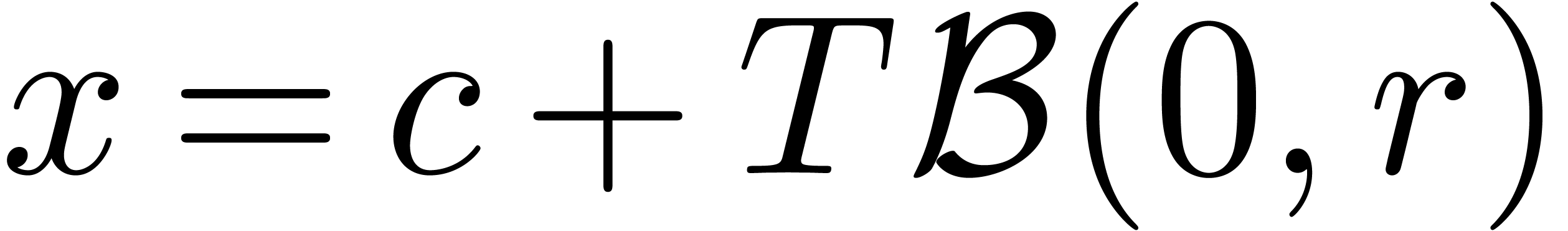 ,
with
,
with 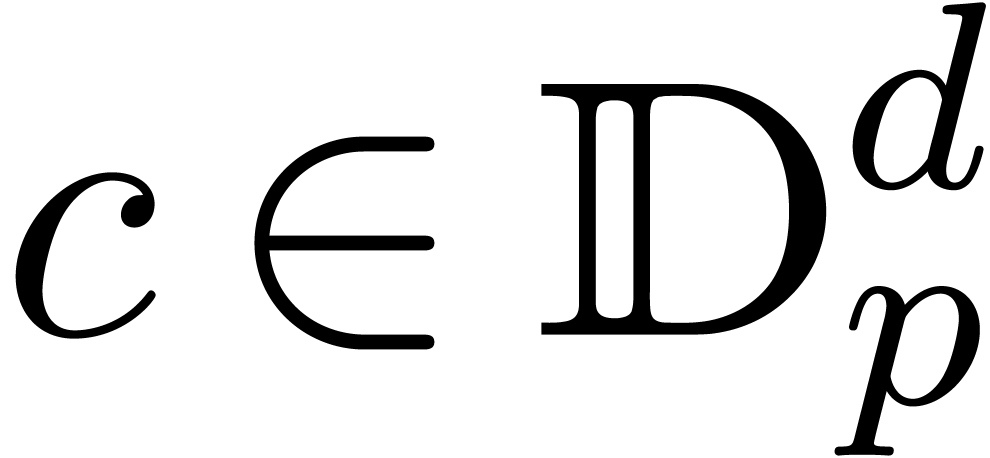 ,
, 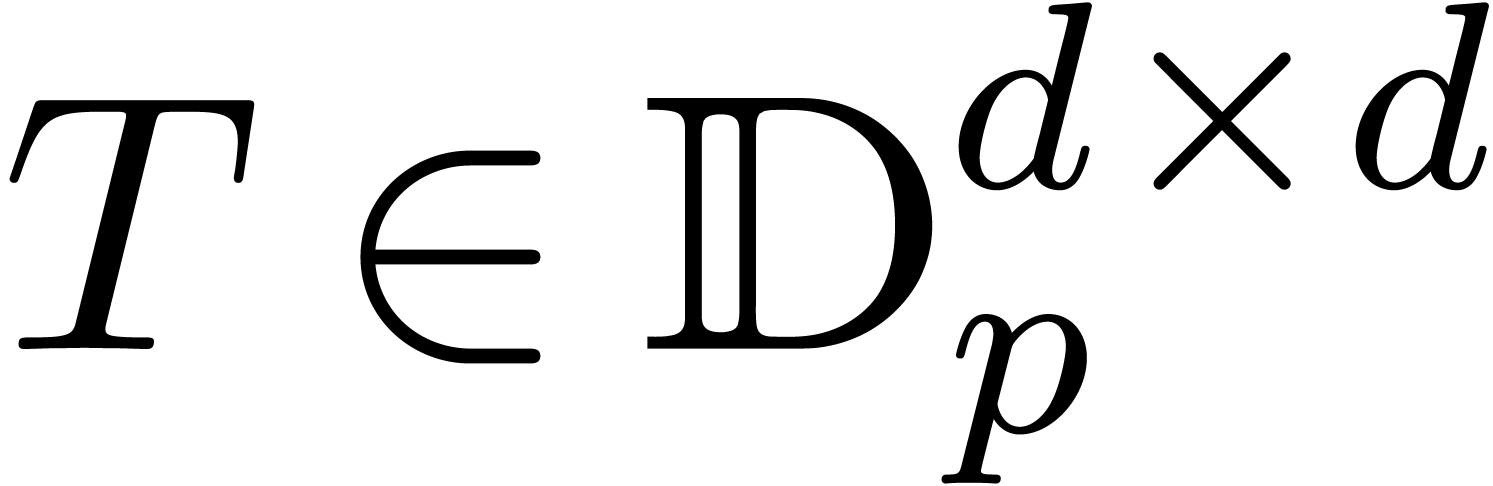 and
and 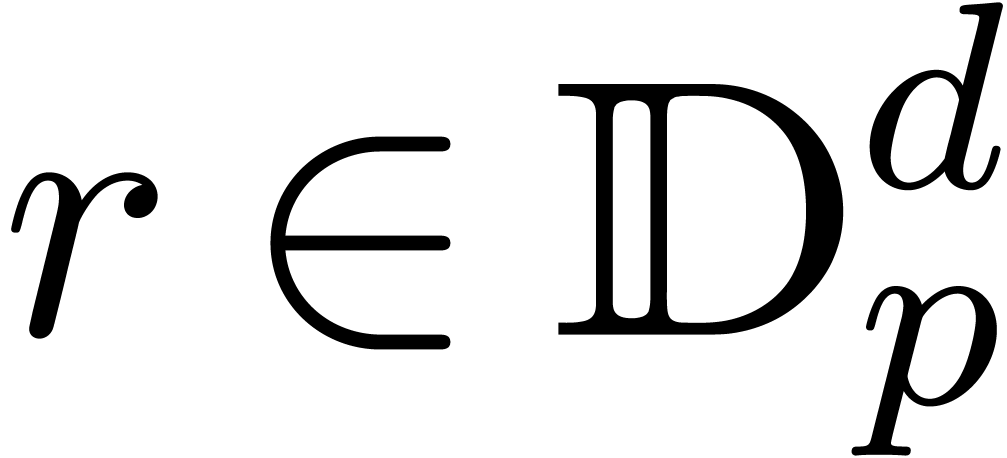 . A natural choice for
after steps is
. A natural choice for
after steps is 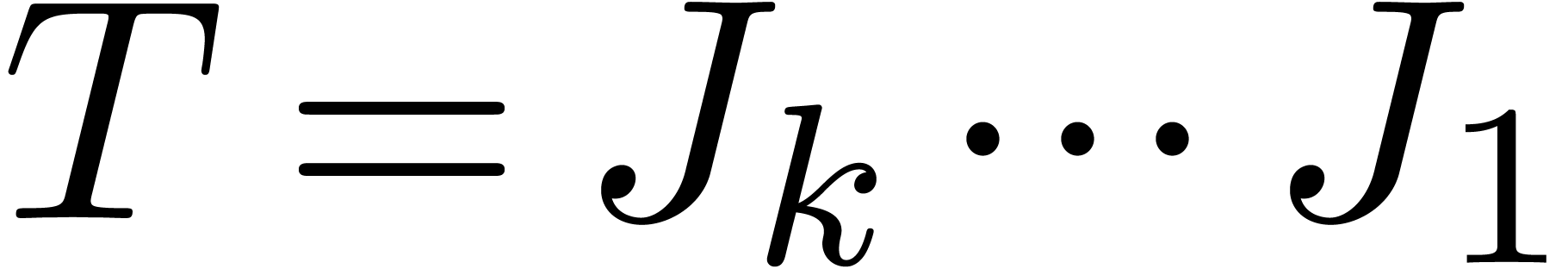 , but more elaborate choices may be
preferred [Loh88]. Other geometric shapes for the
enclosures have been advanced in the literature, such as ellipsoids [Neu93], which are also invariant under linear transformations,
and zonotopes [K8]. However, as long as we integrate (48) using a straightforward iterative method, and even if we
achieve a small average loss
, but more elaborate choices may be
preferred [Loh88]. Other geometric shapes for the
enclosures have been advanced in the literature, such as ellipsoids [Neu93], which are also invariant under linear transformations,
and zonotopes [K8]. However, as long as we integrate (48) using a straightforward iterative method, and even if we
achieve a small average loss  of the bit
precision at a single step, the precision loss after
steps will be of the form
of the bit
precision at a single step, the precision loss after
steps will be of the form 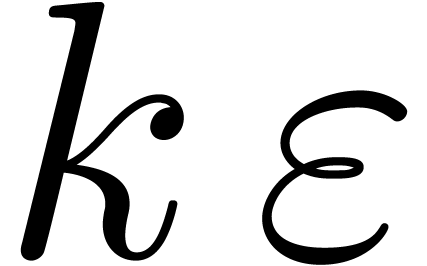 .
.
The idea of using dichotomic algorithms in order to reduce the wrapping
effect was first described in the case of linear differential equations
[GS88]. The previous section shows how to adapt that
technique to non linear equations. We notice that the method may very
well be combined with other geometric shapes for the enclosures: this
will help to reduce the precision loss to 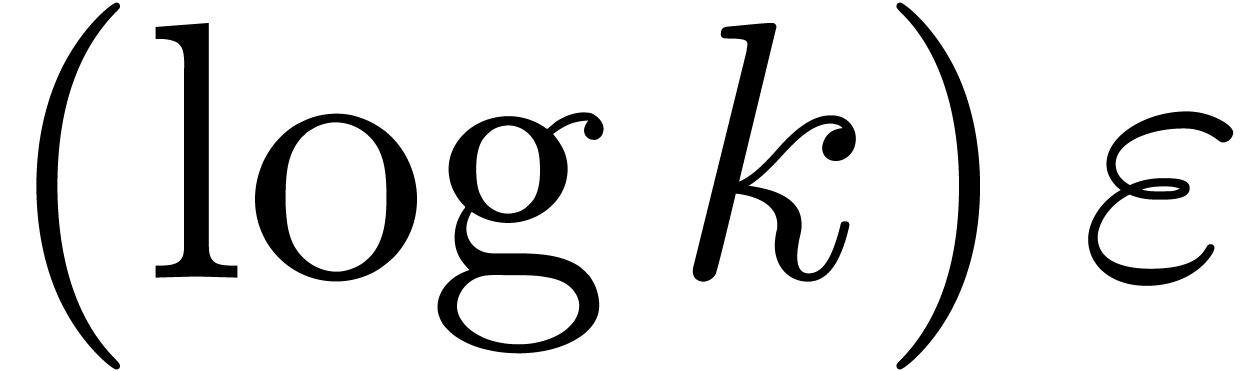 instead of in the above discussion.
instead of in the above discussion.
Notice that there are two common misunderstandings about the dichotomic
method. Contrary to what we have shown above (see also [GS88]
in the linear case), it is sometimes believed that we need to keep all
matrices  in memory and that we have to
reevaluate products
in memory and that we have to
reevaluate products  over and over again.
Secondly, one should not confuse elimination and
reduction of the wrapping effect: if is
the
over and over again.
Secondly, one should not confuse elimination and
reduction of the wrapping effect: if is
the  rotation matrix by a
rotation matrix by a 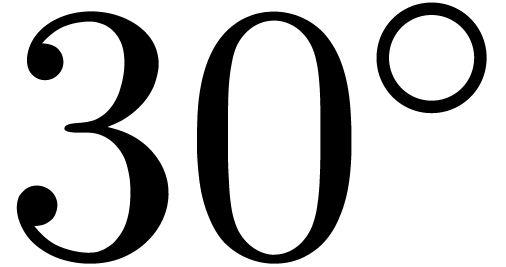 angle, then none of its repeated squarings
angle, then none of its repeated squarings 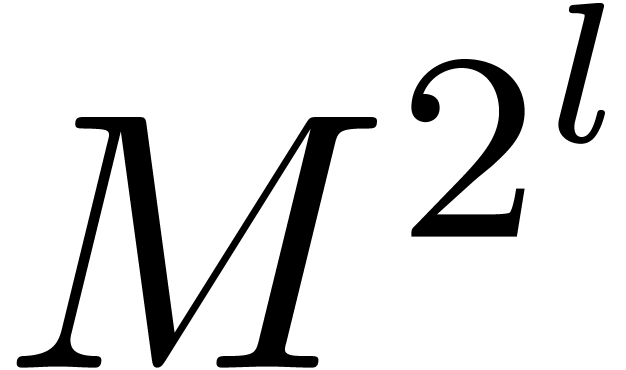 will
be the identity matrix, so every squaring
will
be the identity matrix, so every squaring 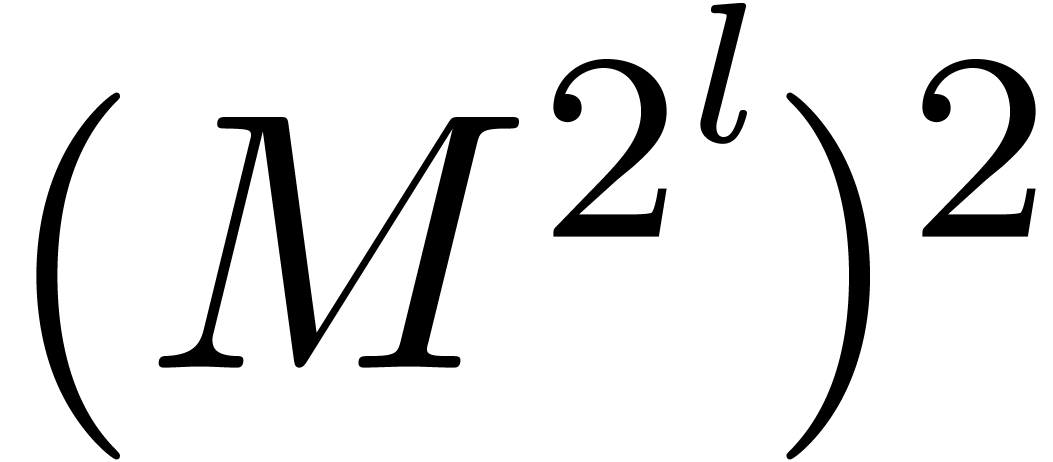 will
involve a wrapping. Even though we have not eliminated the
wrapping effect, we did achieve to reduce the number of
wrappings to
will
involve a wrapping. Even though we have not eliminated the
wrapping effect, we did achieve to reduce the number of
wrappings to  instead of
instead of 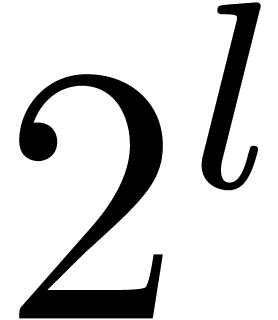 .
.
Taylor models are another approach for the validated long term
integration of dynamical systems [EKW84, EMOK91,
MB96, MB04]. The idea is to rely on higher
-th order expansions of the
continuation operator . This
allows for real algebraic enclosures which are determined by polynomials
of degree . Such enclosures
are a priori more precise for non linear problems. However, the
method requires us to work in order jet spaces
in variables; the mere storage of such a jet
involves  coefficients. From a theoretical point
of view it is also not established that Taylor methods eliminate the
wrapping effect by themselves. Nevertheless, Taylor models can be
combined with any of the above methods and the non linear enclosures
seem to be more adapted in certain cases. For a detailed critical
analysis, we refer to [Neu02].
coefficients. From a theoretical point
of view it is also not established that Taylor methods eliminate the
wrapping effect by themselves. Nevertheless, Taylor models can be
combined with any of the above methods and the non linear enclosures
seem to be more adapted in certain cases. For a detailed critical
analysis, we refer to [Neu02].
Let us finally investigate how sharp good error bounds actually may be.
If 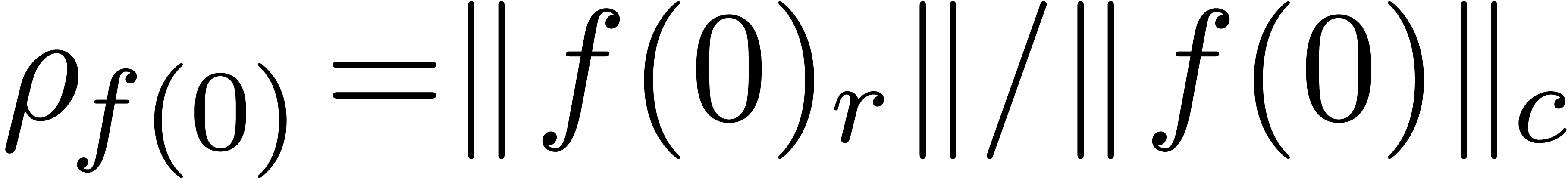 denotes the relative precision of the initial
condition at the start and
denotes the relative precision of the initial
condition at the start and 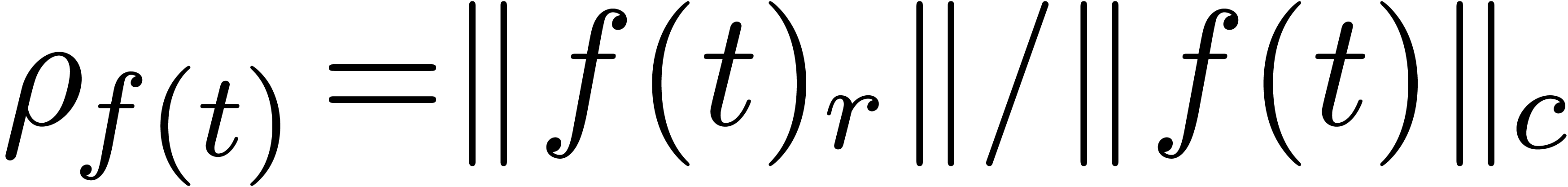 the relative
precision of the final result, then it is classical that
the relative
precision of the final result, then it is classical that
where 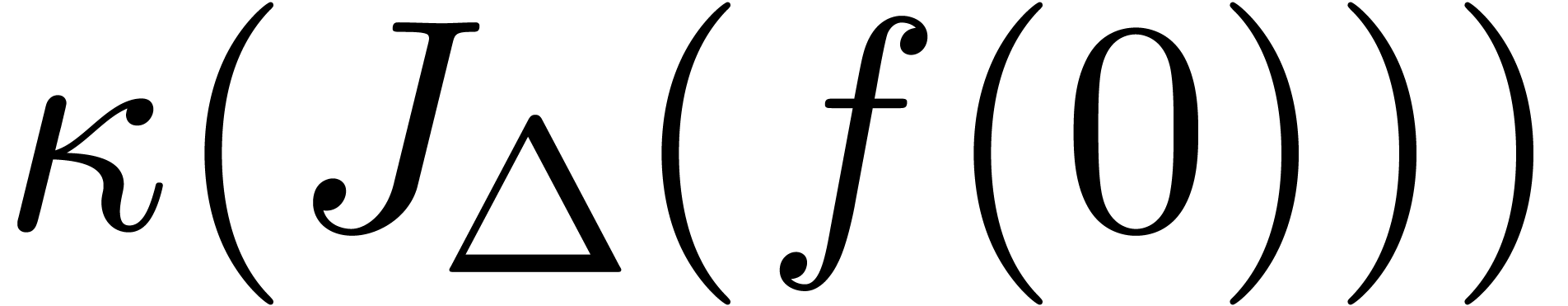 is the condition number of the matrix
is the condition number of the matrix
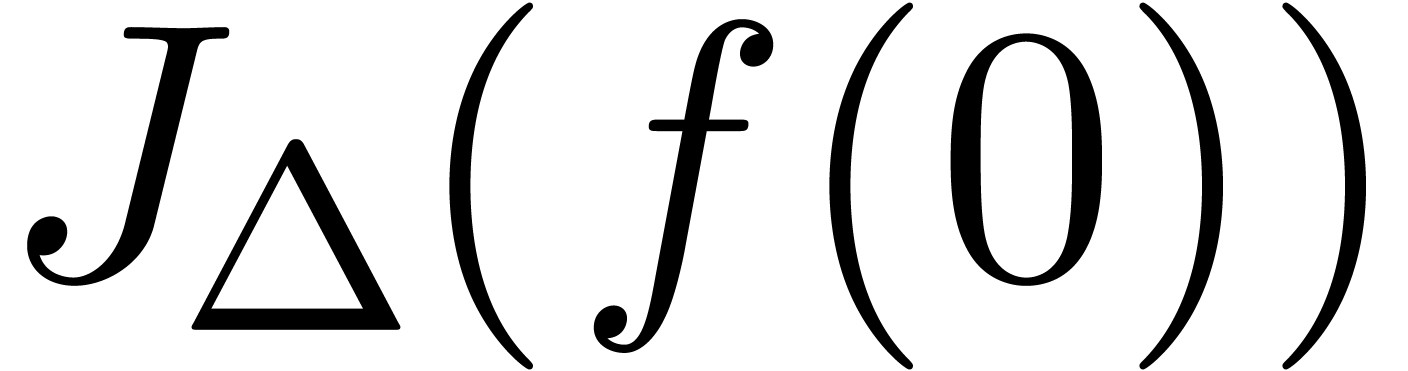 . We propose to define the
condition number
. We propose to define the
condition number 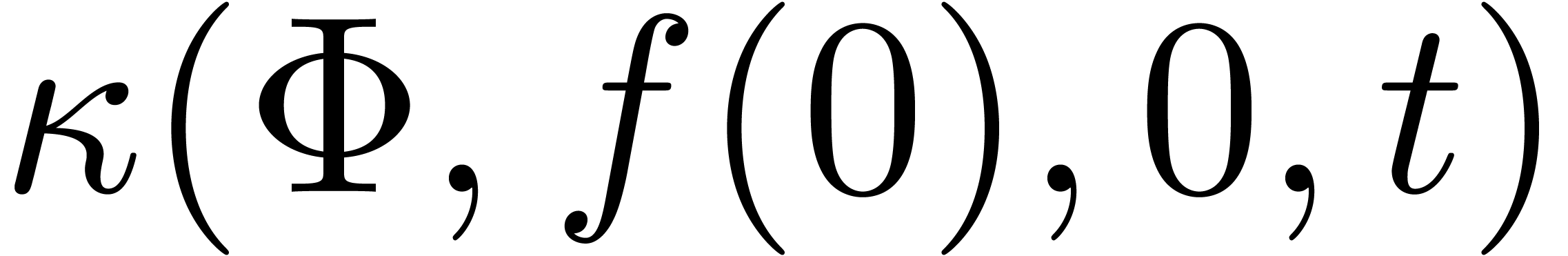 for the integration problem (48) on
for the integration problem (48) on 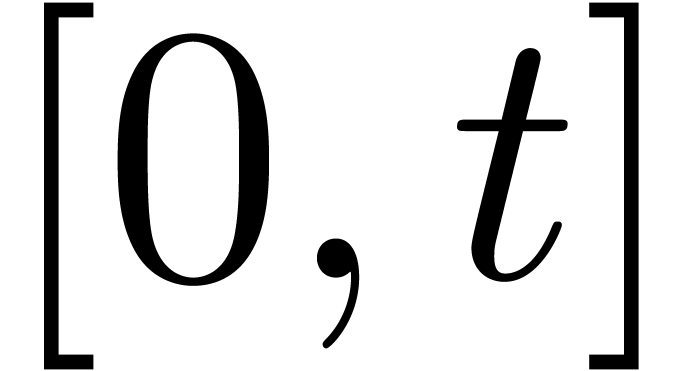 by
by
Indeed, without using any particular mathematical properties of or , we
somehow have to go through the whole interval . Of course, it may happen that
is indeed special. For instance, if 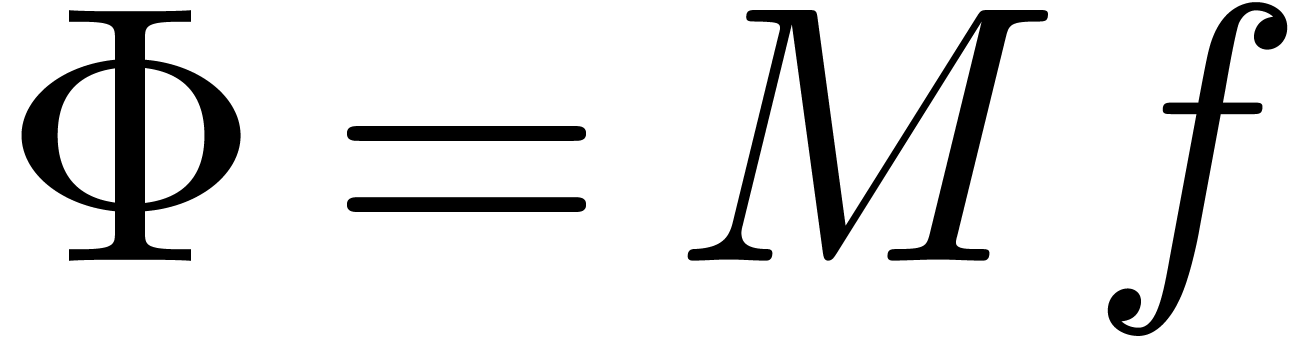 for a matrix
with a special triangular or diagonal form, then
special arguments may be used to improve error bounds and more dedicated
condition numbers will have to be introduced.
for a matrix
with a special triangular or diagonal form, then
special arguments may be used to improve error bounds and more dedicated
condition numbers will have to be introduced.
However, in general, we suspect that a precision loss of 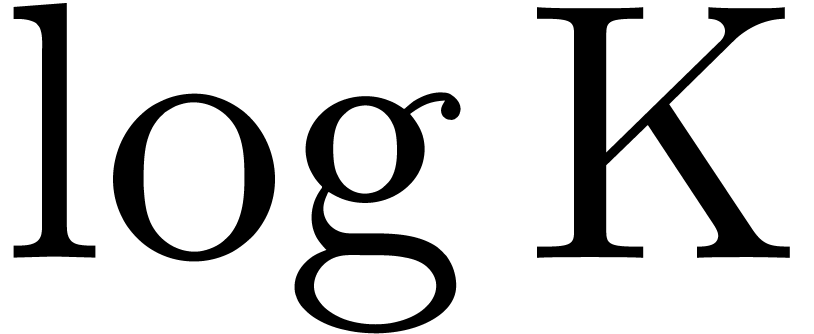 cannot be avoided. If
cannot be avoided. If  gets large,
the only real way to achieve long term stability is to take
gets large,
the only real way to achieve long term stability is to take 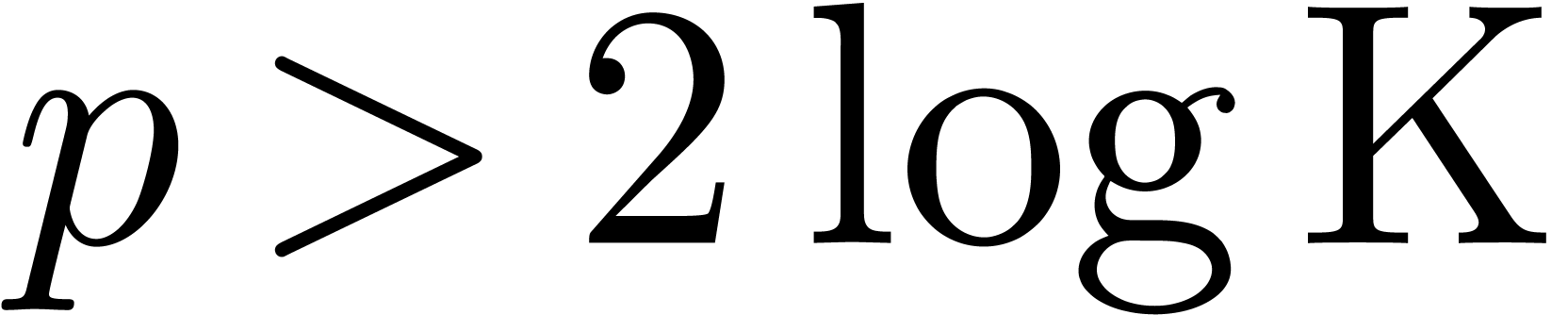 (say), whence the interest of efficient multiple precision
and high order ball algorithms. It seems to us that the parallelepiped
method should manage to keep the precision loss bounded by , for and
(say), whence the interest of efficient multiple precision
and high order ball algorithms. It seems to us that the parallelepiped
method should manage to keep the precision loss bounded by , for and  . The algorithm from section 7.5
(without coordinate transformations) only achieves a
. The algorithm from section 7.5
(without coordinate transformations) only achieves a 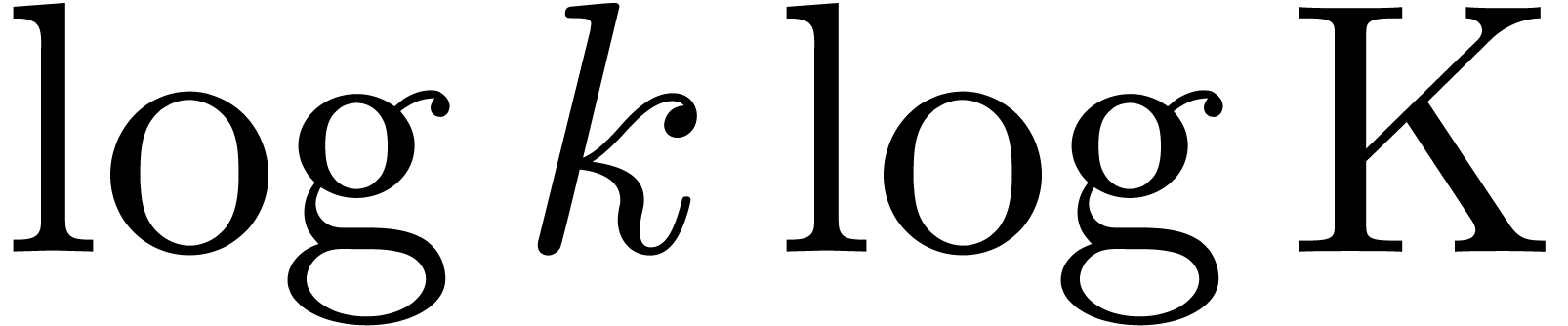 in the worst case, although a bound is probably
obtained in many cases of interest. We plan to carry out a more detailed
analysis once we will have finished a first efficient multiple precision
implementation.
in the worst case, although a bound is probably
obtained in many cases of interest. We plan to carry out a more detailed
analysis once we will have finished a first efficient multiple precision
implementation.
O. Aberth. Computable analysis. McGraw-Hill, New York, 1980.
G. Alefeld and J. Herzberger. Introduction to interval analysis. Academic Press, New York, 1983.
ANSI/IEEE. IEEE standard for binary floating-point arithmetic. Technical report, ANSI/IEEE, New York, 2008. ANSI-IEEE Standard 754-2008. Revision of IEEE 754-1985, approved on June 12, 2008 by IEEE Standards Board.
ANSI/IEEE. IEEE interval standard working group -
p1788.
http://grouper.ieee.org/groups/1788/,
2009.
E. Bishop and D. Bridges. Foundations of constructive analysis. Die Grundlehren der mathematische Wissenschaften. Springer, Berlin, 1985.
Andrea Balluchi, Alberto Casagrande, Pieter Collins, Alberto Ferrari, Tiziano Villa, and Alberto L. Sangiovanni-Vincentelli. Ariadne: a framework for reachability analysis of hybrid automata. In Proceedings of the 17th International Symposium on the Mathematical Theory of Networks and Systems, pages 1269âĂŞ–1267, Kyoto, July 2006.
A. Bostan, F. Chyzak, F. Ollivier, B. Salvy, É. Schost, and A. Sedoglavic. Fast computation of power series solutions of systems of differential equation. preprint, april 2006. submitted, 13 pages.
M. Berz. Cosy infinity version 8 reference manual. Technical Report MSUCL-1088, Michigan State University, East Lansing, 1998.
D. A. Bini and G. Fiorentino. Design, analysis, and implementation of a multiprecision polynomial rootfinder. Numerical Algorithms, 23:127–173, 2000.
D.H. Bailey, Y. Hida, and X.S. Li. QD, a C/C++/Fortran library for double-double and quad-double arithmetic. http://crd.lbl.gov/~dhbailey/mpdist/, 2000.
D.H. Bailey, Y. Hida, and X.S. Li. Algorithms for quad-double precision floating point arithmetic. In 15th IEEE Symposium on Computer Arithmetic, pages 155–162, June 2001.
R.P. Brent and H.T. Kung. Fast algorithms for manipulating formal power series. Journal of the ACM, 25:581–595, 1978.
Walter Baur and Volker Strassen. The complexity of partial derivatives. Theor. Comput. Sci., 22:317–330, 1983.
D.G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28:693–701, 1991.
J.W. Cooley and J.W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
D. Coppersmith and S. Winograd. Matrix multiplication
via arithmetic progressions. In Proc. of the  Annual Symposium on Theory of Computing, pages 1–6,
New York City, may 25–27 1987.
Annual Symposium on Theory of Computing, pages 1–6,
New York City, may 25–27 1987.
J.-G. Dumas, T. Gautier, M. Giesbrecht, P. Giorgi, B. Hovinen, E. Kaltofen, B. D. Saunders, W. J. Turner, and G. Villard. Linbox: A generic library for exact linear algebra. In First Internat. Congress Math. Software ICMS, pages 40–50, Beijing, China, 2002.
J.-G. Dumas, T. Gautier, M. Giesbrecht, P. Giorgi, B. Hovinen, E. Kaltofen, B. D. Saunders, W. J. Turner, and G. Villard. Project linbox: Exact computational linear algebra. http://www.linalg.org/, 2002.
U.W. Kulisch et al. Scientific computing with validation, arithmetic requirements, hardware solution and language support. http://www.math.uni-wuppertal.de/~xsc/, 1967.
J.-P. Eckmann, H. Koch, and P. Wittwer. A computer-assisted proof of universality in area-preserving maps. Memoirs of the AMS, 47(289), 1984.
J.-P. Eckmann, A. Malaspinas, and S. Oliffson-Kamphorst. A software tool for analysis in function spaces. In K. Meyer and D. Schmidt, editors, Computer aided proofs in analysis, pages 147–166. Springer, New York, 1991.
M. Fürer. Faster integer multiplication. In Proceedings of the Thirty-Ninth ACM Symposium on Theory of Computing (STOC 2007), pages 57–66, San Diego, California, 2007.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, 2-nd edition, 2002.
T. Granlund et al. GMP, the GNU multiple precision
arithmetic library.
http://www.swox.com/gmp,
1991.
A. Grzegorczyk. On the definitions of computable real continuous functions. Fund. Math., 44:61–71, 1957.
T.N. Gambill and R.D. Skeel. Logarithmic reduction of the wrapping effect with application to ordinary differential equations. SIAM J. Numer. Anal., 25(1):153–162, 1988.
B. Haible. CLN,a Class Library for Numbers. http://www.ginac.de/CLN/cln.html, 1995.
G. Hanrot, V. Lefèvre, K. Ryde, and P. Zimmermann. MPFR, a C library for multiple-precision floating-point computations with exact rounding. http://www.mpfr.org, 2000.
E. Hansen and R. Smith. Interval arithmetic in matrix computations, part ii. Siam J. Numer. Anal., 4:1–9, 1967.
L. Jaulin, M. Kieffer, O. Didrit, and E. Walter. Applied interval analysis. Springer, London, 2001.
W. Kühn. Rigourously computed orbits of dynamical systems without the wrapping effect. Computing, 61:47–67, 1998.
V. Kreinovich, A.V. Lakeyev, J. Rohn, and P.T. Kahl. Computational Complexity and Feasibility of Data Processing and Interval Computations. Springer, 1997.
A. Karatsuba and J. Ofman. Multiplication of multidigit numbers on automata. Soviet Physics Doklady, 7:595–596, 1963.
V. Kreinovich and S. Rump. Towards optimal use of multi-precision arithmetic: a remark. Technical Report UTEP-CS-06-01, UTEP-CS, 2006.
U.W. Kulisch. Computer Arithmetic and Validity. Theory, Implementation, and Applications. Number 33 in Studies in Mathematics. de Gruyter, 2008.
B. Lambov. Reallib: An efficient implementation of exact real arithmetic. Mathematical Structures in Computer Science, 17(1):81–98, 2007.
R. Lohner. Einschließung der Lösung gewöhnlicher Anfangs- und Randwertaufgaben und Anwendugen. PhD thesis, Universität Karlsruhe, 1988.
R. Lohner. On the ubiquity of the wrapping effect in the computation of error bounds. In U. Kulisch, R. Lohner, and A. Facius, editors, Perspectives on enclosure methods, pages 201–217, Wien, New York, 2001. Springer.
N. Müller. iRRAM, exact arithmetic in C++. http://www.informatik.uni-trier.de/iRRAM/, 2000.
K. Makino and M. Berz. Remainder differential algebras and their applications. In M. Berz, C. Bischof, G. Corliss, and A. Griewank, editors, Computational differentiation: techniques, applications and tools, pages 63–74, SIAM, Philadelphia, 1996.
K. Makino and M. Berz. Suppression of the wrapping effect by Taylor model-based validated integrators. Technical Report MSU Report MSUHEP 40910, Michigan State University, 2004.
R.E. Moore. Automatic local coordinate transformations to reduce the growth of error bounds in interval computation of solutions to ordinary differential equation. In L.B. Rall, editor, Error in Digital Computation, volume 2, pages 103–140. John Wiley, 1965.
R.E. Moore. Interval Analysis. Prentice Hall, Englewood Cliffs, N.J., 1966.
Jean-Michel Muller. Elementary Functions, Algorithms and Implementation. Birkhauser Boston, Inc., 2006.
A. Neumaier. Interval methods for systems of equations. Cambridge university press, Cambridge, 1990.
A. Neumaier. The wrapping effect, ellipsoid arithmetic, stability and confedence regions. Computing Supplementum, 9:175–190, 1993.
A. Neumaier. Taylor forms - use and limits. Reliable Computing, 9:43–79, 2002.
K. Nickel. How to fight the wrapping effect. In Springer-Verlag, editor, Proc. of the Intern. Symp. on interval mathematics, pages 121–132, 1985.
V. Pan. How to multiply matrices faster, volume 179 of Lect. Notes in Math. Springer, 1984.
N. Revol. MPFI, a multiple precision interval arithmetic library. http://perso.ens-lyon.fr/nathalie.revol/software.html, 2001.
S.M. Rump. Fast and parallel inteval arithmetic. BIT, 39(3):534–554, 1999.
S.M. Rump. INTLAB - INTerval LABoratory. In Tibor Csendes, editor, Developments in Reliable Computing, pages 77–104. Kluwer Academic Publishers, Dordrecht, 1999. http://www.ti3.tu-harburg.de/rump/.
A. Schönhage and V. Strassen. Schnelle Multiplikation grosser Zahlen. Computing, 7:281–292, 1971.
V. Strassen. Gaussian elimination is not optimal. Numer. Math., 13:352–356, 1969.
A. Turing. On computable numbers, with an application to the Entscheidungsproblem. Proc. London Maths. Soc., 2(42):230–265, 1936.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven et al. Mathemagix, 2002. http://www.mathemagix.org.
J. van der Hoeven. Computations with effective real numbers. TCS, 351:52–60, 2006.
J. van der Hoeven. Newton's method and FFT trading. Technical Report 2006-17, Univ. Paris-Sud, 2006. Submitted to JSC.
J. van der Hoeven. New algorithms for relaxed multiplication. JSC, 42(8):792–802, 2007.
J. van der Hoeven. On effective analytic continuation. MCS, 1(1):111–175, 2007.
J. van der Hoeven. Making fast multiplication of polynomials numerically stable. Technical Report 2008-02, Université Paris-Sud, Orsay, France, 2008.
J. van der Hoeven. Meta-expansion of transseries. In Y. Boudabbous and N. Zaguia, editors, ROGICS '08: Relations Orders and Graphs, Interaction with Computer Science, pages 390–398, Mahdia, Tunesia, May 2008.
J. van der Hoeven, B. Mourrain, and Ph. Trébuchet. Efficient and reliable resolution of eigenproblems. In preparation.
K. Weihrauch. Computable analysis. Springer-Verlag, Berlin/Heidelberg, 2000.
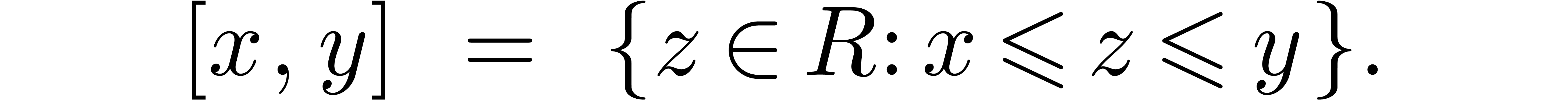
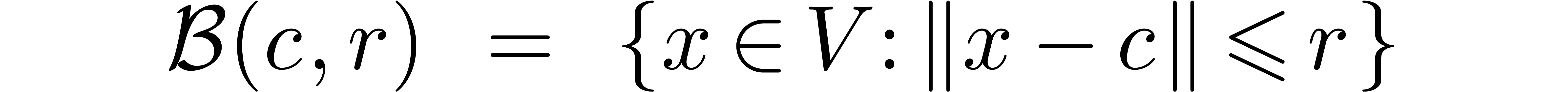
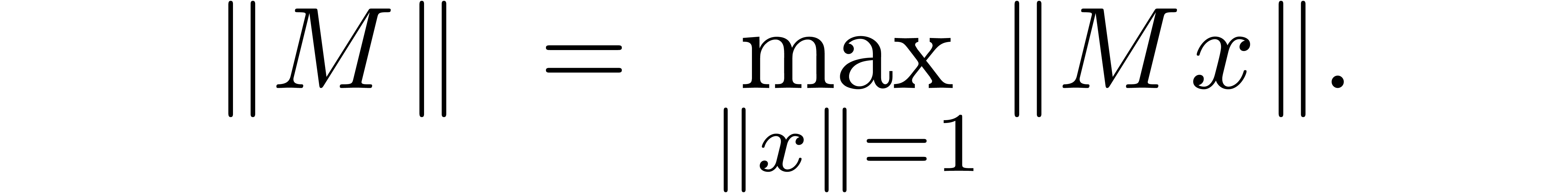
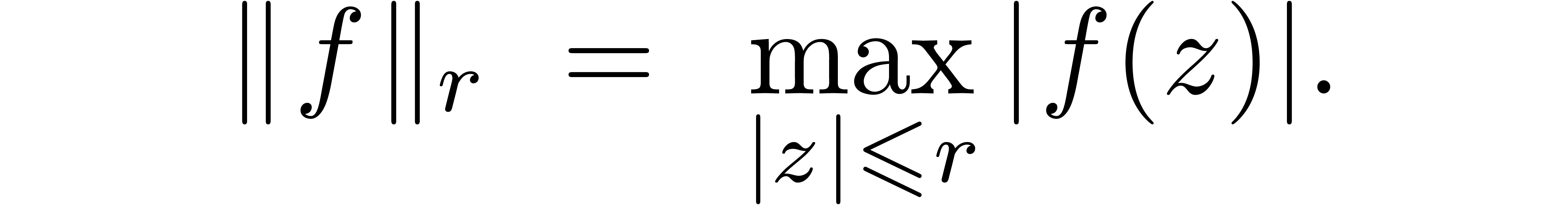
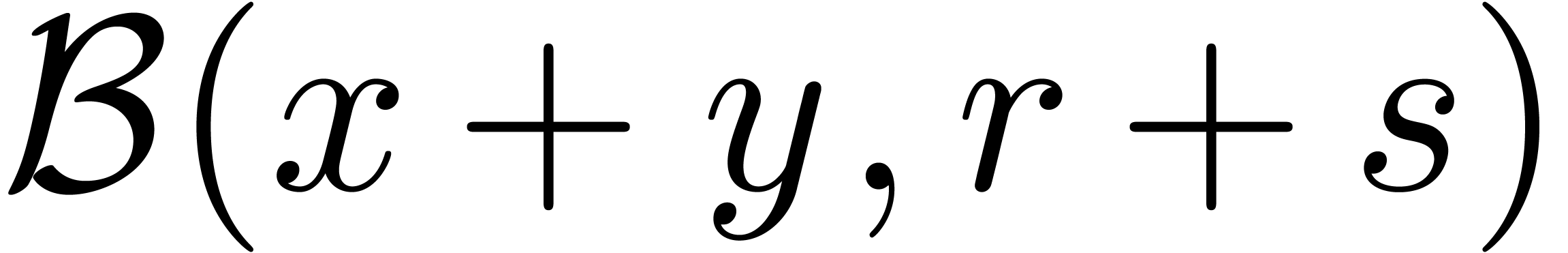
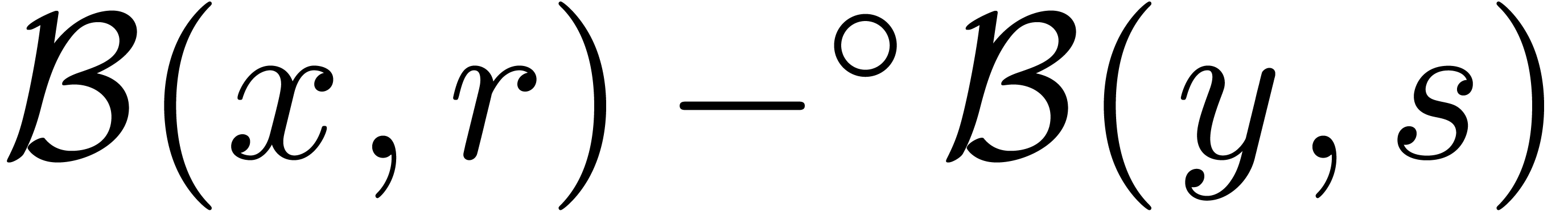
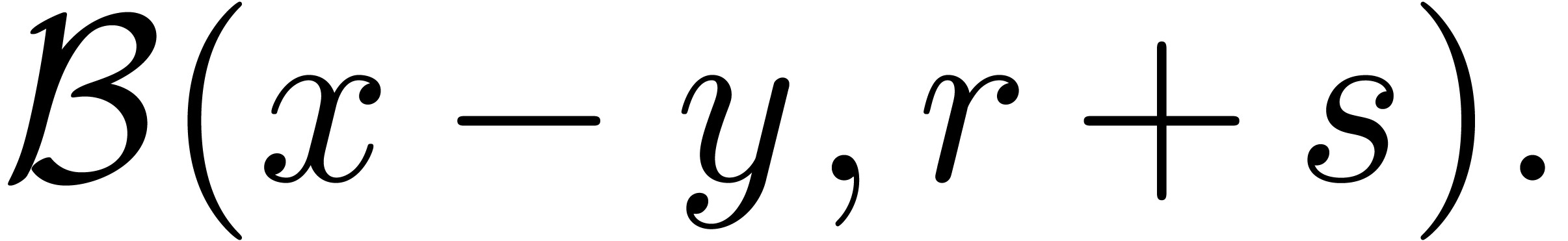
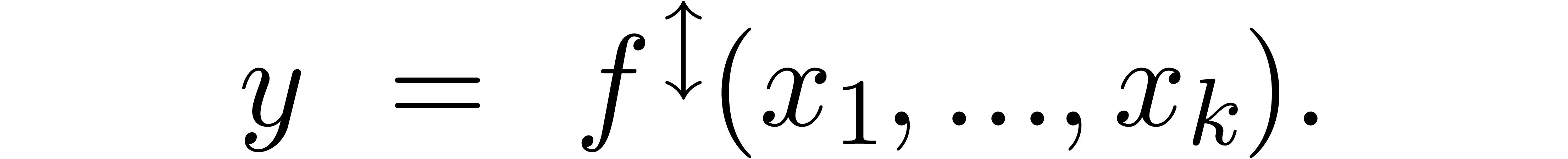
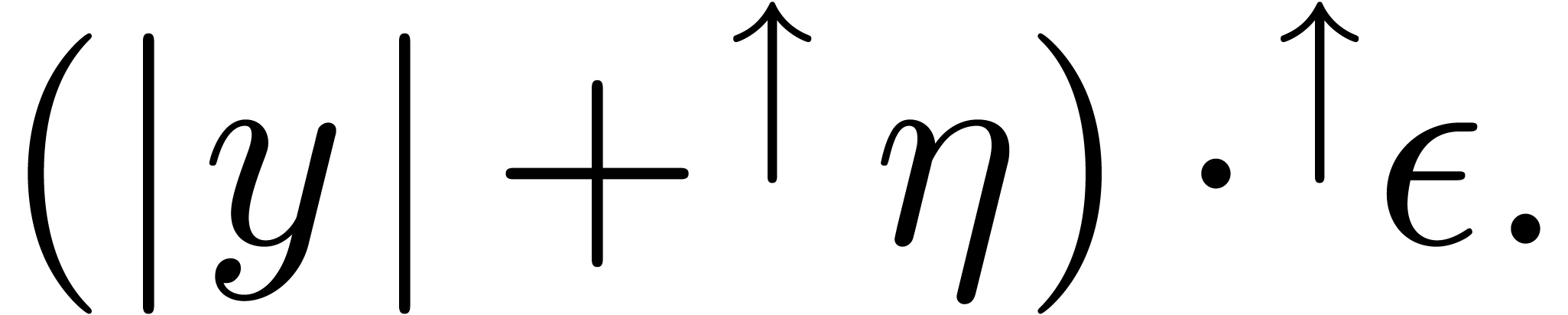
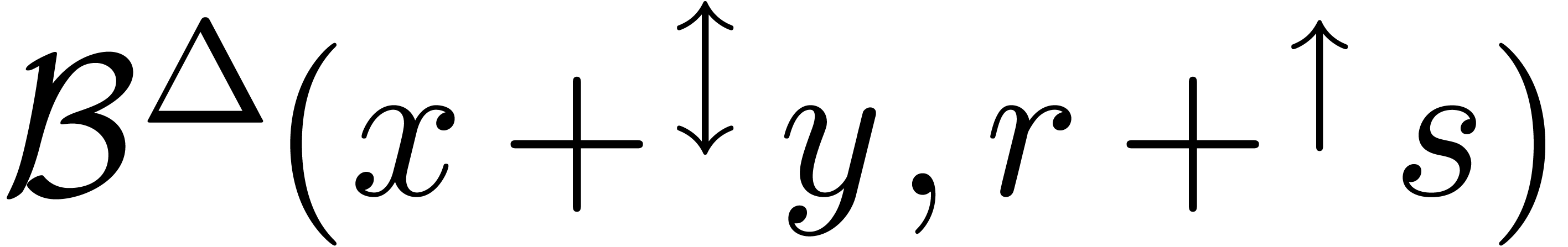
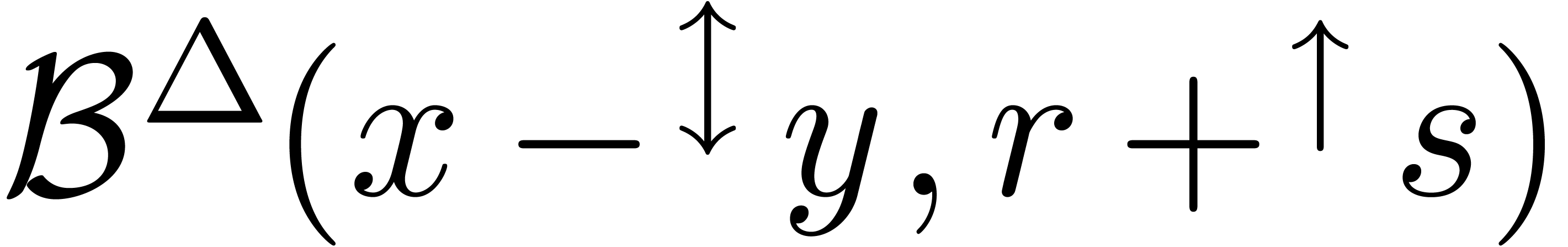

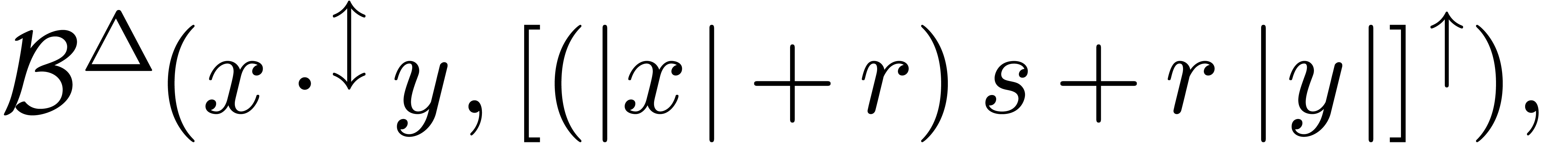
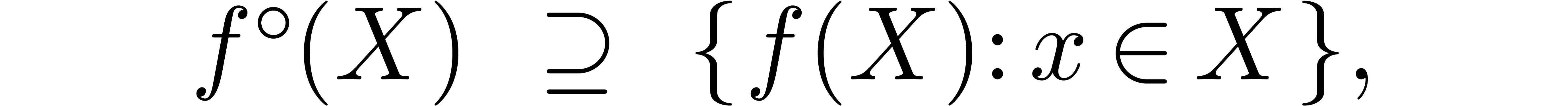
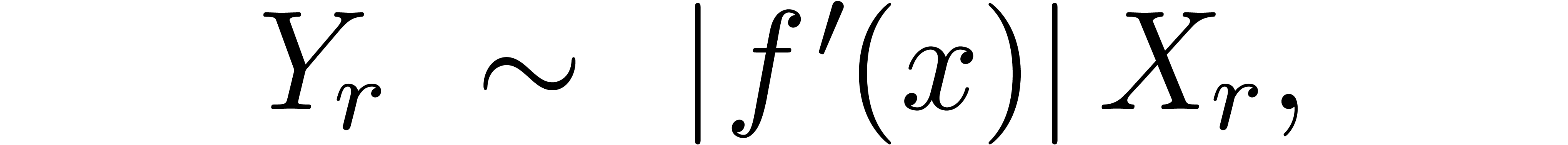
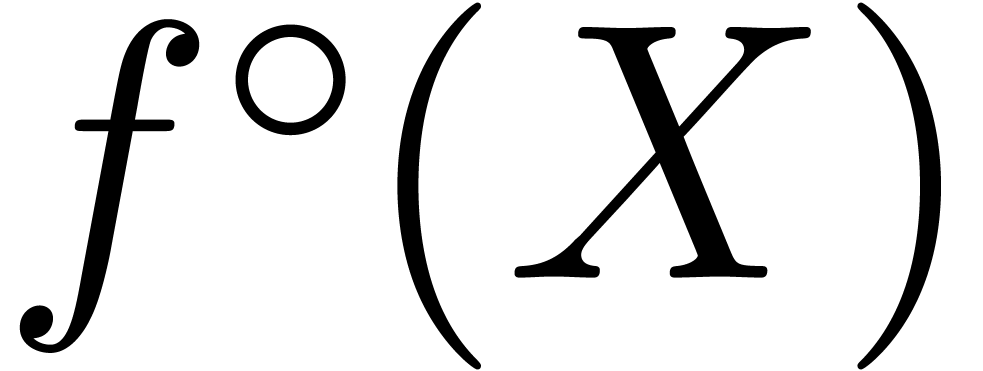
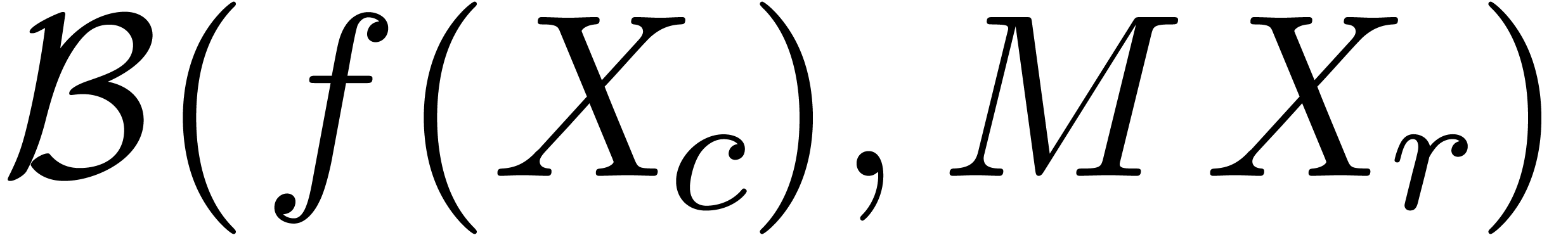
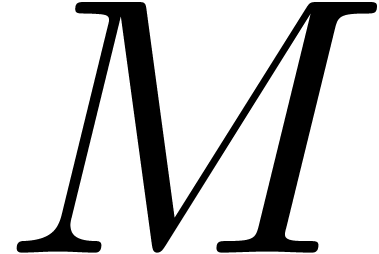
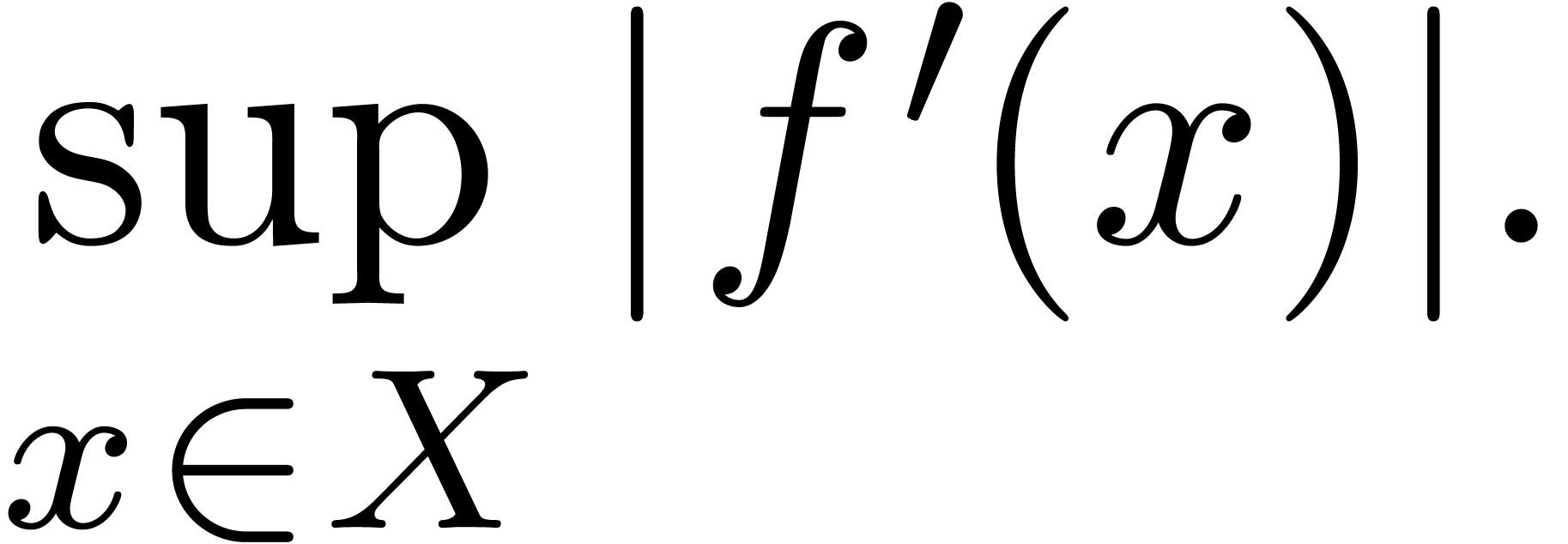
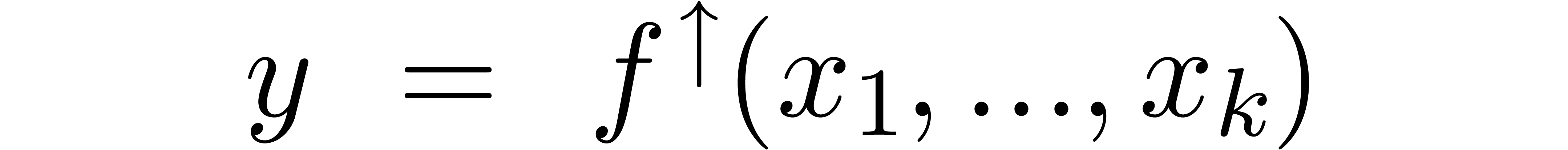
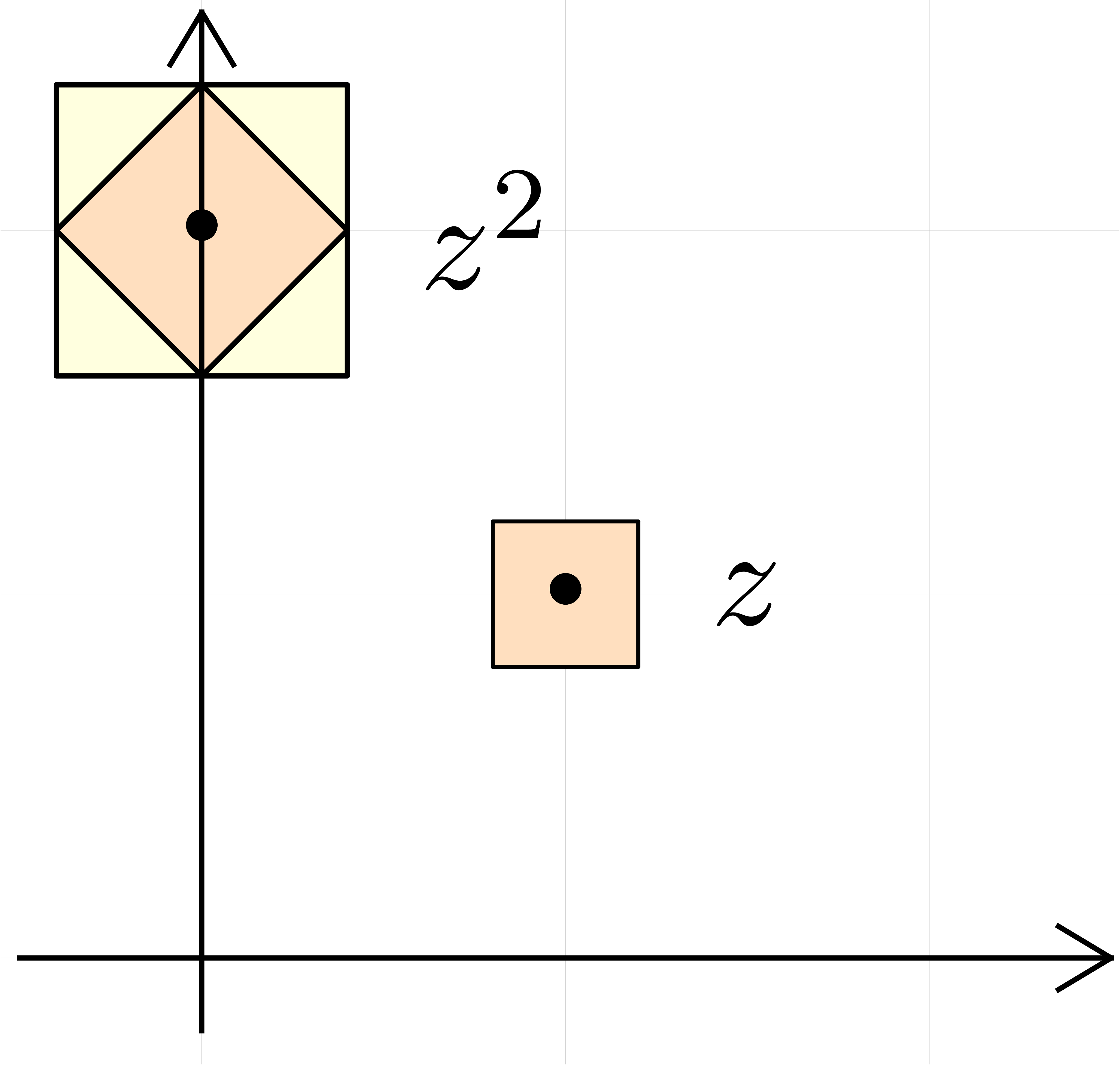
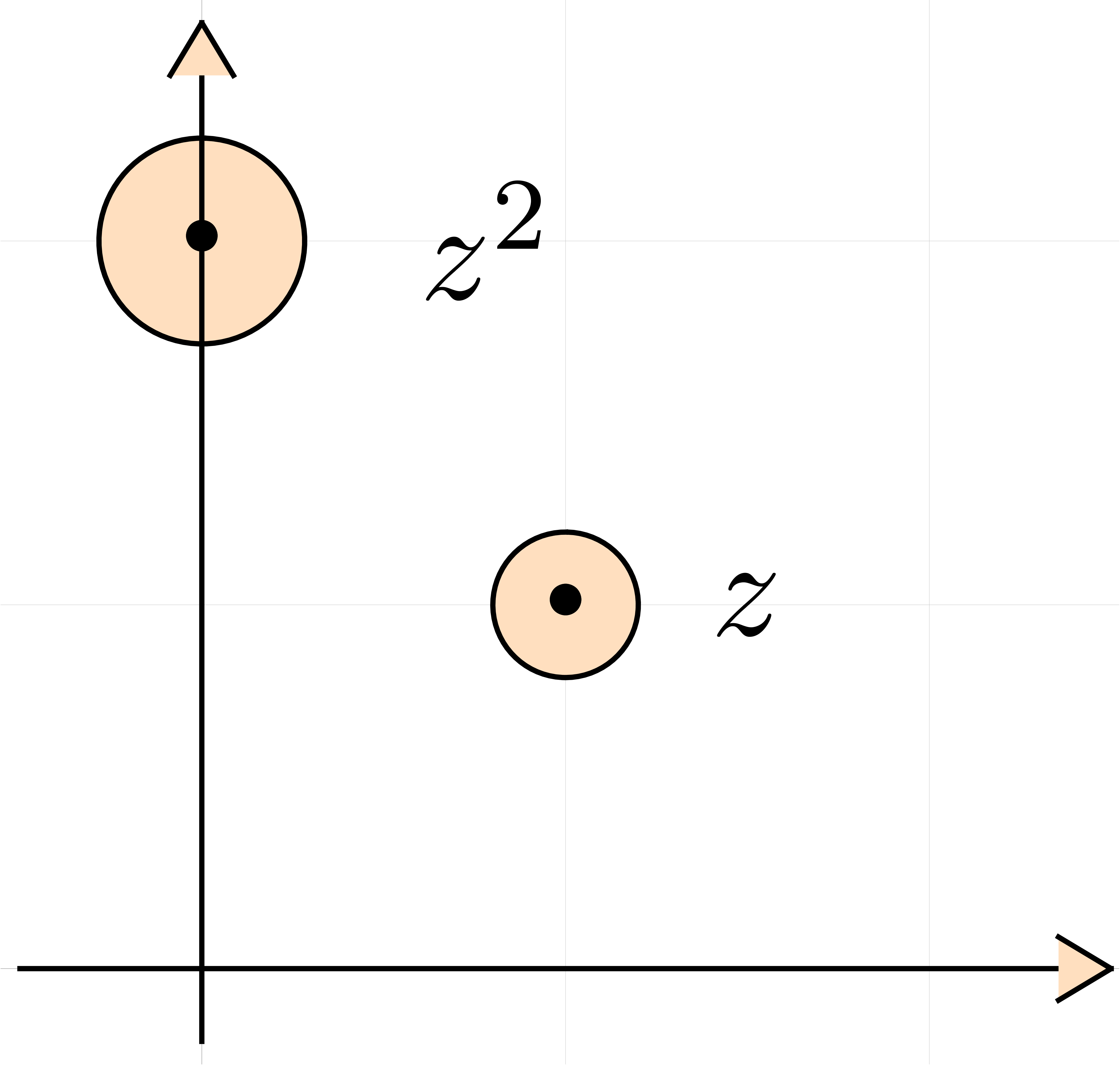
 using interval and ball
arithmetic, for
using interval and ball
arithmetic, for  .
.