| Polynomial multiplication over finite
fields in time 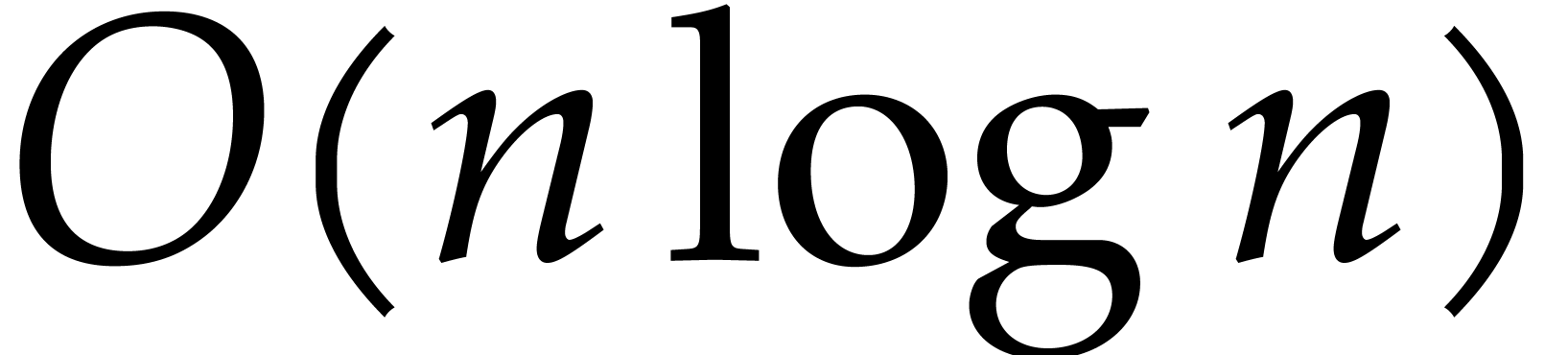 |
|
| March 18, 2019 |
|
Assuming a widely-believed hypothesis concerning the least prime
in an arithmetic progression, we show that two
|
Let 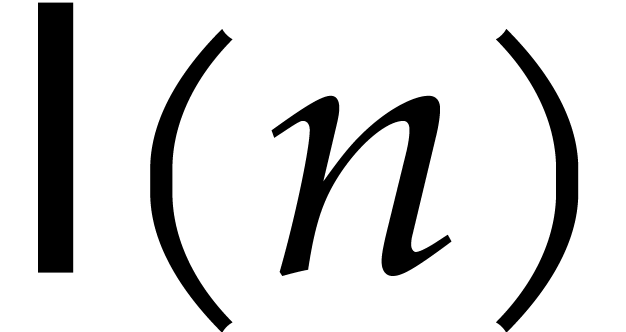 denote the bit complexity of multiplying two
integers of at most
denote the bit complexity of multiplying two
integers of at most 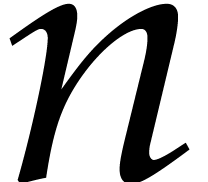 bits in the deterministic
multitape Turing model [16]. Similarly, let
bits in the deterministic
multitape Turing model [16]. Similarly, let 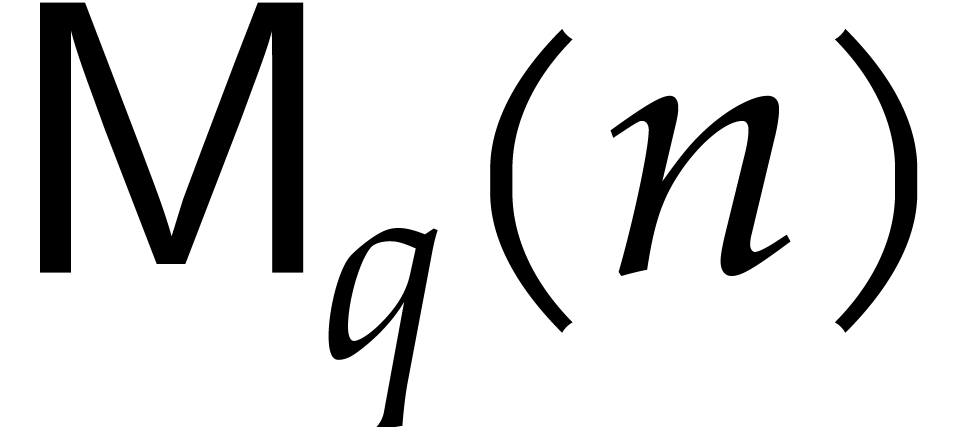 denote the bit complexity of multiplying two polynomials
of degree
denote the bit complexity of multiplying two polynomials
of degree 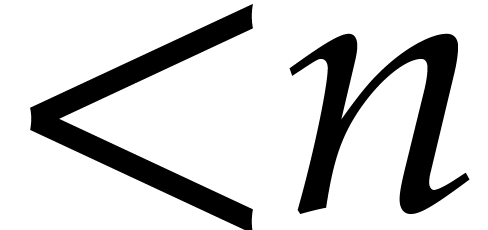 in
in 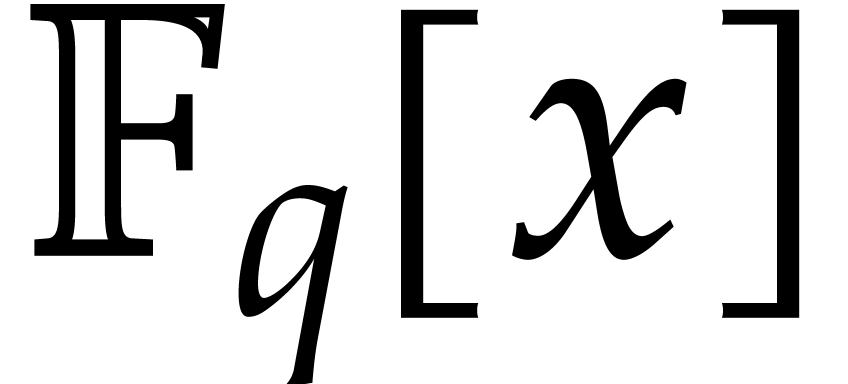 .
Here
.
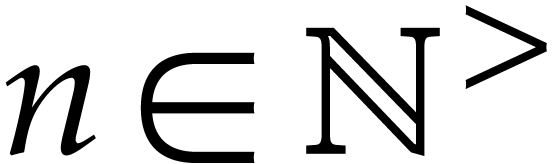
Here  is the finite field with
is the finite field with  elements, so that
elements, so that 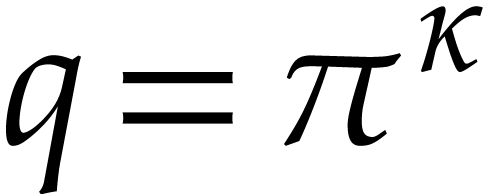 for some prime number
for some prime number  and integer
and integer 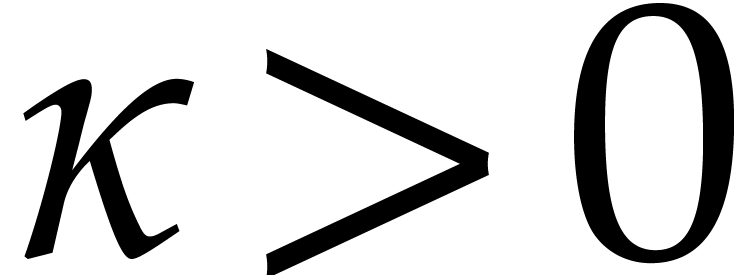 .
For computations over , we
tacitly assume that we are given a monic irreducible polynomial
.
For computations over , we
tacitly assume that we are given a monic irreducible polynomial 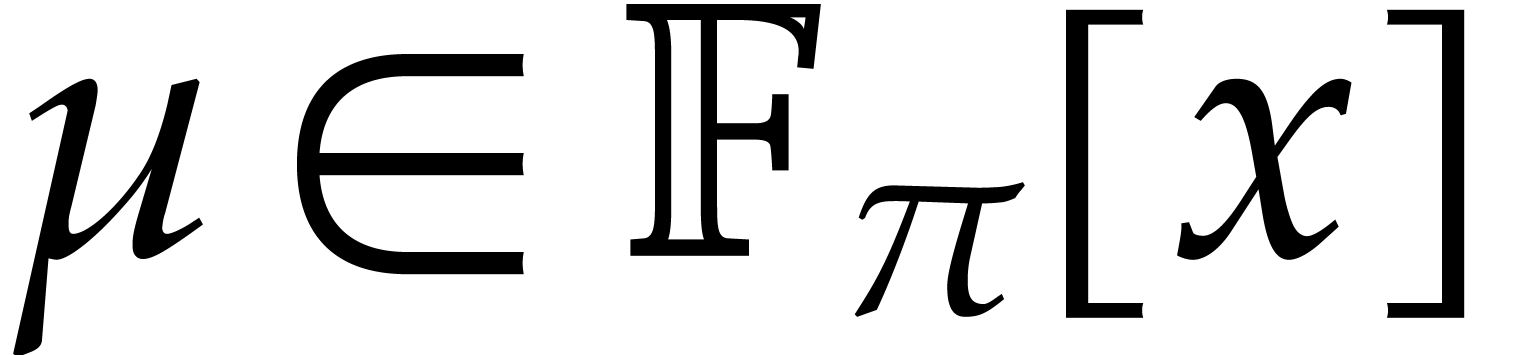 of degree
of degree  ,
and that elements of are represented by
polynomials in
,
and that elements of are represented by
polynomials in  of degree
of degree 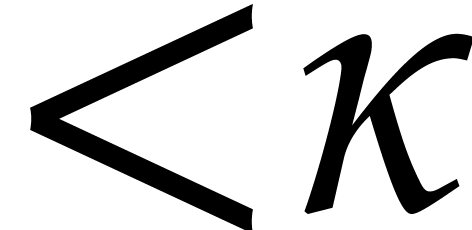 . Notice that multiplication in
can also be regarded as “carryless” integer multiplication
in base .
. Notice that multiplication in
can also be regarded as “carryless” integer multiplication
in base .
The best currently known bounds for and were obtained in [21] and [23].
For constants 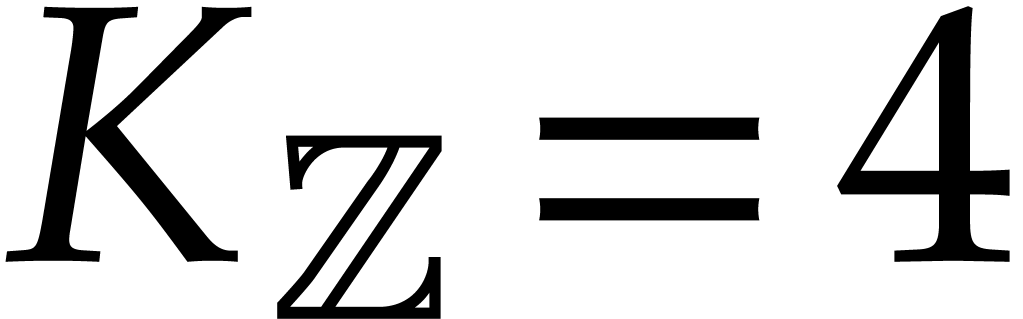 and
and 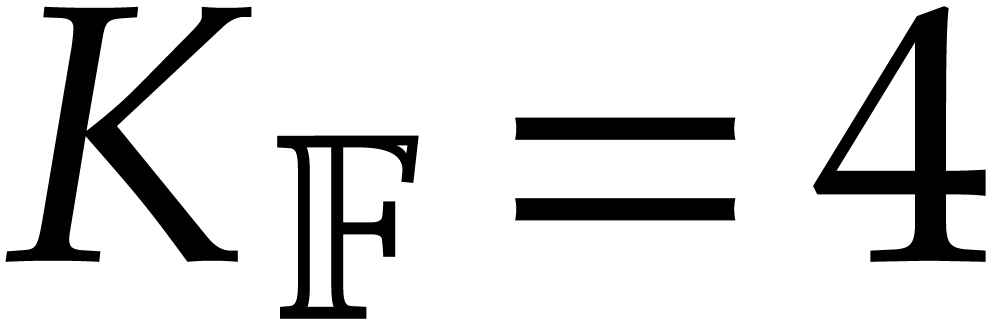 ,
we proved there that
,
we proved there that
where 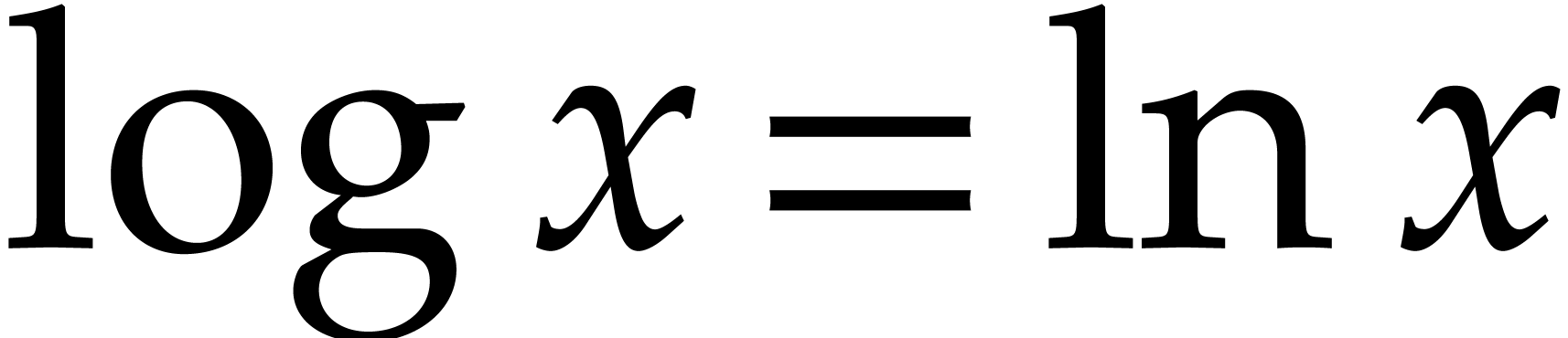 denotes the natural logarithm of
denotes the natural logarithm of  ,
,
and the bound (1.2) holds uniformly in .
For the statement of our new results, we need to recall the concept of a
“Linnik constant”. Given two integers  and
and  with
with 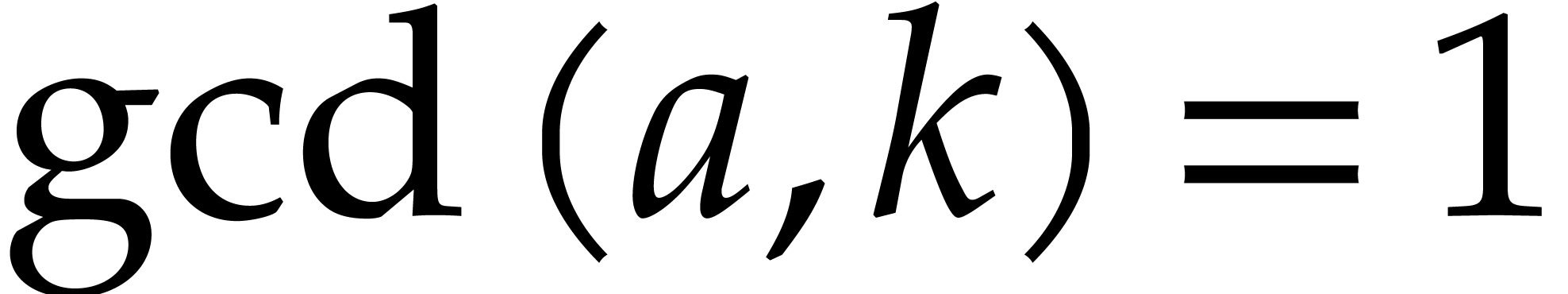 ,
we define
,
we define
We say that a number 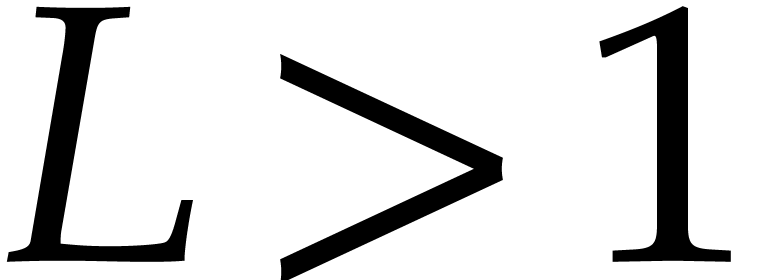 is a Linnik
constant if
is a Linnik
constant if 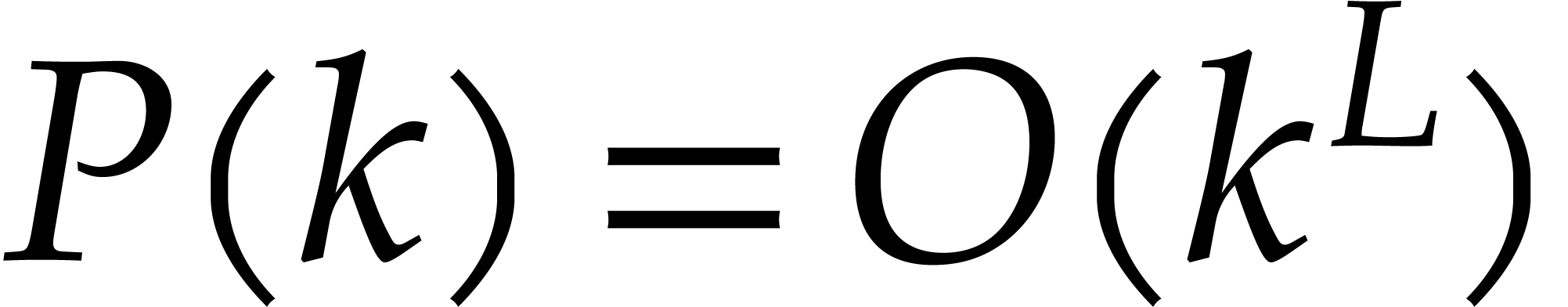 . The
smallest currently known Linnik constant
. The
smallest currently known Linnik constant  is due
to Xylouris [57]. It is widely believed that any number
is actually a Linnik constant; see section 5 for more details.
is due
to Xylouris [57]. It is widely believed that any number
is actually a Linnik constant; see section 5 for more details.
In this paper, we prove the following two results:
Theorem 1.2 is our main result. Notice that it implies 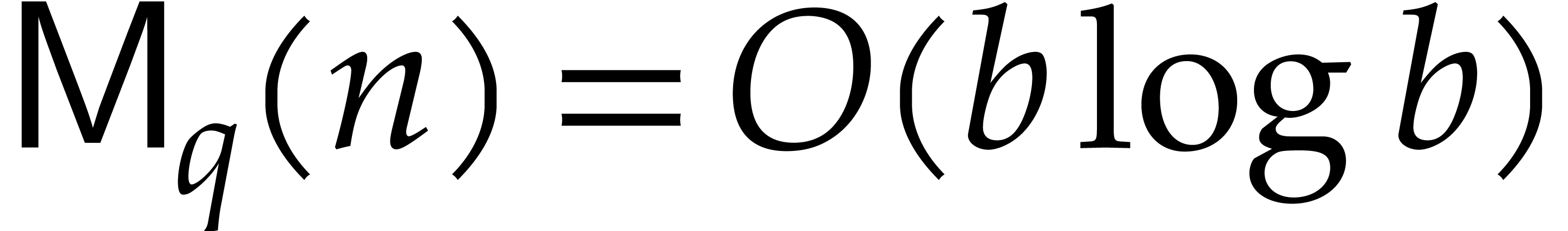 in terms of the bit-size
in terms of the bit-size 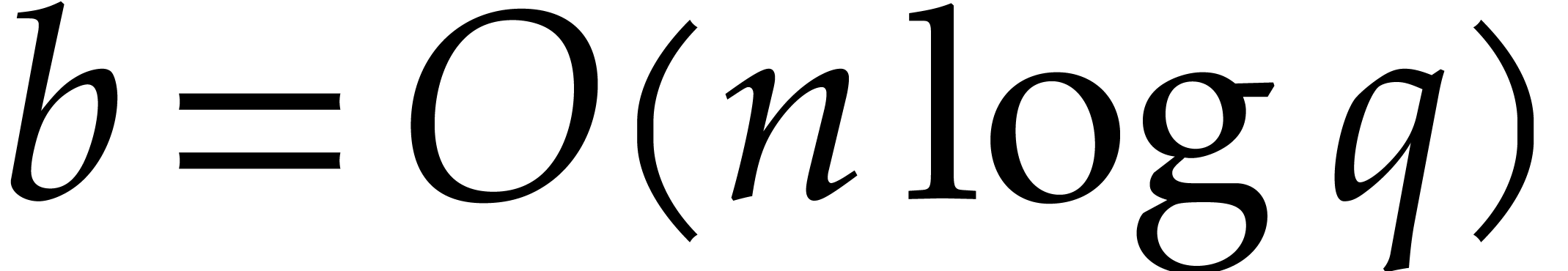 of
the inputs. In the companion paper [22], we show that the
bound
of
the inputs. In the companion paper [22], we show that the
bound 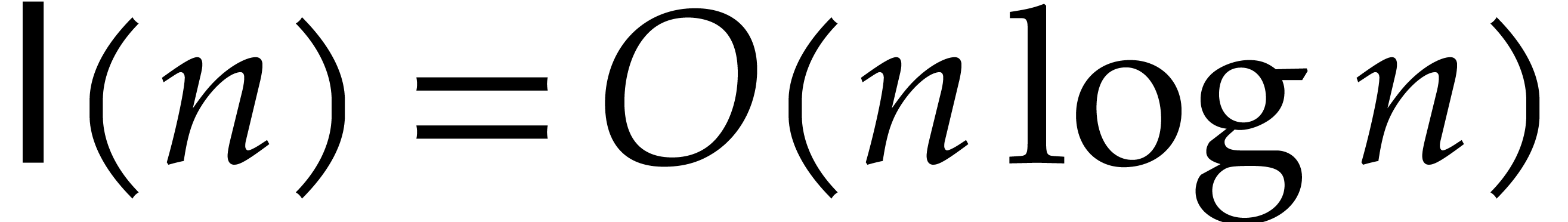 actually holds unconditionally, thereby
superseding Theorem 1.1. Since the proof of Theorem 1.1 is a good introduction to the proof of Theorem 1.2
and also somewhat shorter than the proof of the unconditional bound in [22], we decided to include it in the
present paper. The assumption
actually holds unconditionally, thereby
superseding Theorem 1.1. Since the proof of Theorem 1.1 is a good introduction to the proof of Theorem 1.2
and also somewhat shorter than the proof of the unconditional bound in [22], we decided to include it in the
present paper. The assumption 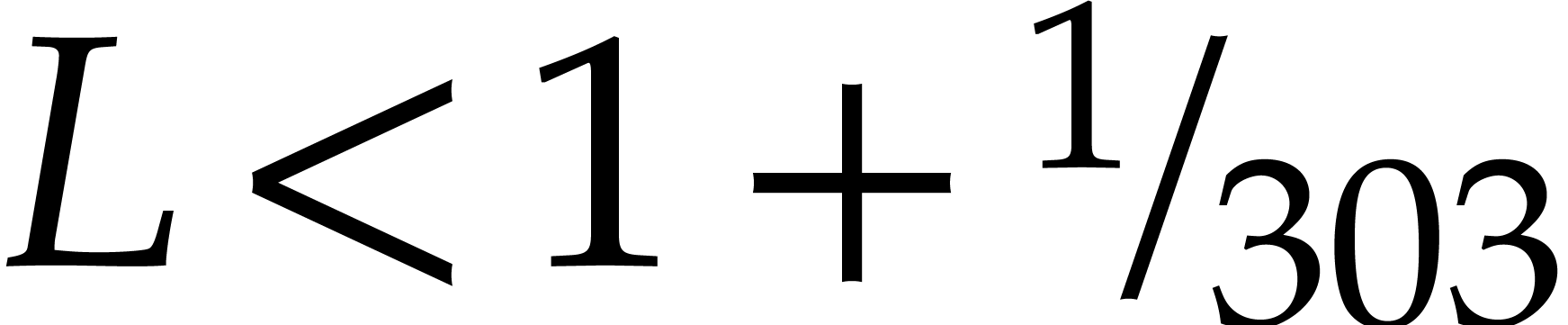 being satisfied
“in practice”, it is also conceivable that variants of the
corresponding algorithm may lead to faster practical implementations.
being satisfied
“in practice”, it is also conceivable that variants of the
corresponding algorithm may lead to faster practical implementations.
This companion paper [22] uses some of the techniques from the present paper, as well as a new ingredient: Gaussian resampling. This technique makes essential use of properties of real numbers, explaining why we were only able to apply it to integer multiplication. By contrast, the techniques of the present paper can be used in combination with both complex and number theoretic Fourier transforms. For our presentation, we preferred the second option, which is also known to be suitable for practical implementations [17]. It remains an open question whether Theorem 1.2 can be replaced by an unconditional bound.
In the sequel, we focus on the study of and from the purely theoretical perspective of asymptotic
complexity. In view of past experience [17, 26,
32], variants of our algorithms might actually be relevant
for machine implementations, but these aspects will be left aside for
now.
Integer multiplication.The
development of efficient methods for integer multiplication can be
traced back to the beginning of mathematical history. Multiplication
algorithms of complexity 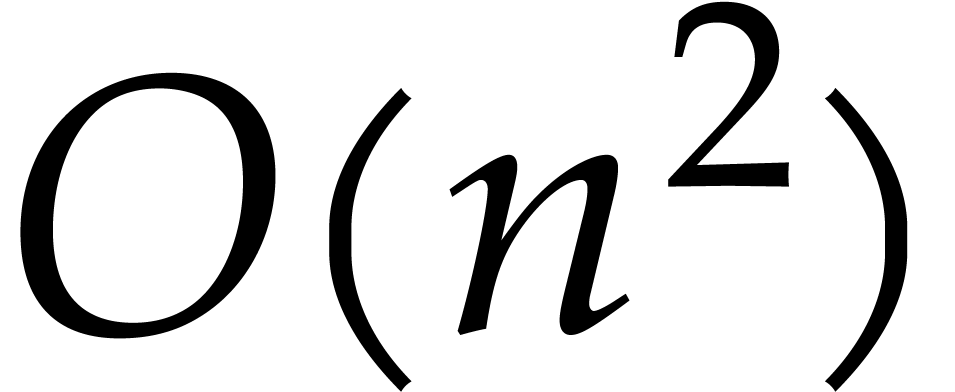 were already known in
ancient civilizations, whereas descriptions of methods close to the ones
that we learn at school appeared in Europe during the late Middle Ages.
For historical references, we refer to [54, section II.5]
and [41, 6].
were already known in
ancient civilizations, whereas descriptions of methods close to the ones
that we learn at school appeared in Europe during the late Middle Ages.
For historical references, we refer to [54, section II.5]
and [41, 6].
The first more efficient method for integer multiplication was discovered in 1962, by Karatsuba [34, 33]. His method is also the first in a family of algorithms that are based on the technique of evaluation-interpolation. The input integers are first cut into pieces, which are taken to be the coefficients of two integer polynomials. These polynomials are evaluated at several well-chosen points. The algorithm next recursively multiplies the obtained integer values at each point. The desired result is finally obtained by pasting together the coefficients of the product polynomial. This way of reducing integer multiplication to polynomial multiplication is also known as Kronecker segmentation [27, section 2.6].
Karatsuba's original algorithm cuts each input integer in two pieces and
then uses three evaluation points. This leads to an algorithm of
complexity 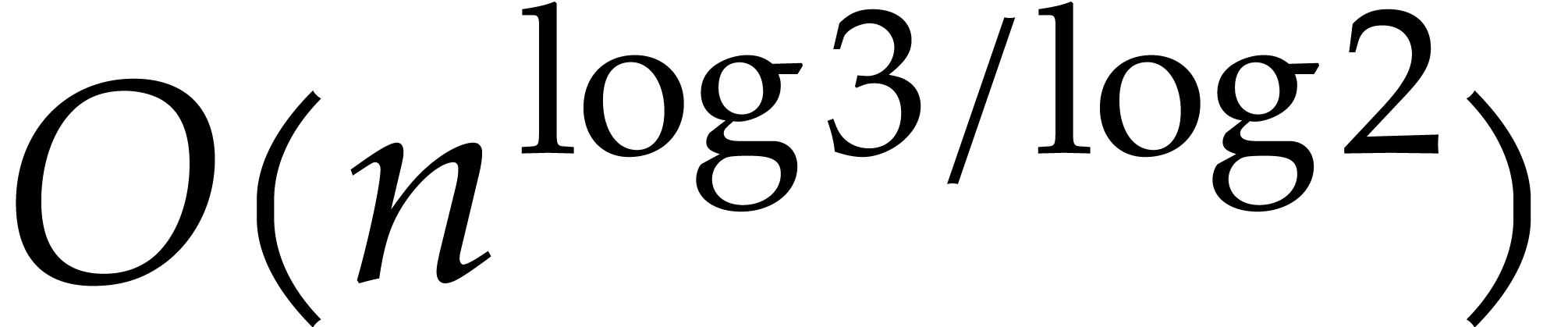 . Shortly after
the publication of Karatsuba's method, it was shown by Toom [56]
that the use of more evaluation points allowed for even better
complexity bounds, with further improvements by Schönhage [47]
and Knuth [35].
. Shortly after
the publication of Karatsuba's method, it was shown by Toom [56]
that the use of more evaluation points allowed for even better
complexity bounds, with further improvements by Schönhage [47]
and Knuth [35].
The development of efficient algorithms for the required evaluations and
interpolations at large sets of points then became a major bottleneck.
Cooley and Tukey's rediscovery [9] of the fast Fourier
transform (FFT) provided the technical tool to overcome this problem.
The FFT, which was essentially already known to Gauss [29],
can be regarded as a particularly efficient evaluation-interpolation
method for special sets of evaluation points. Consider a ring  with a principal
with a principal 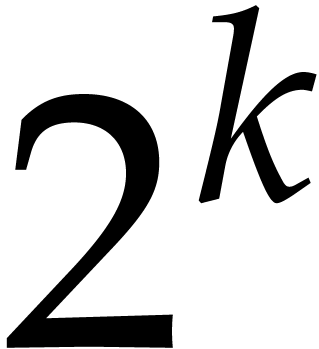 -th
root of unity
-th
root of unity  (see section 2.2 for
detailed definitions; if
(see section 2.2 for
detailed definitions; if 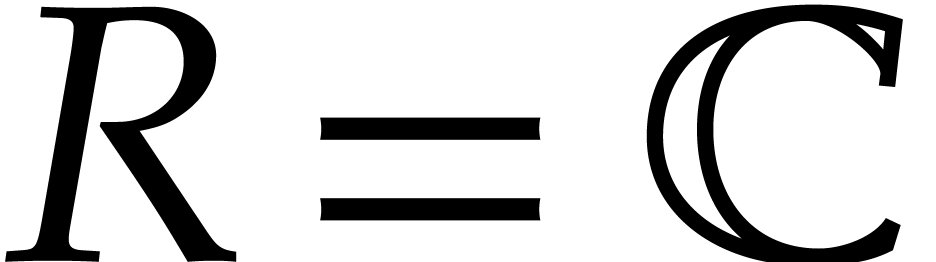 ,
then one may take
,
then one may take 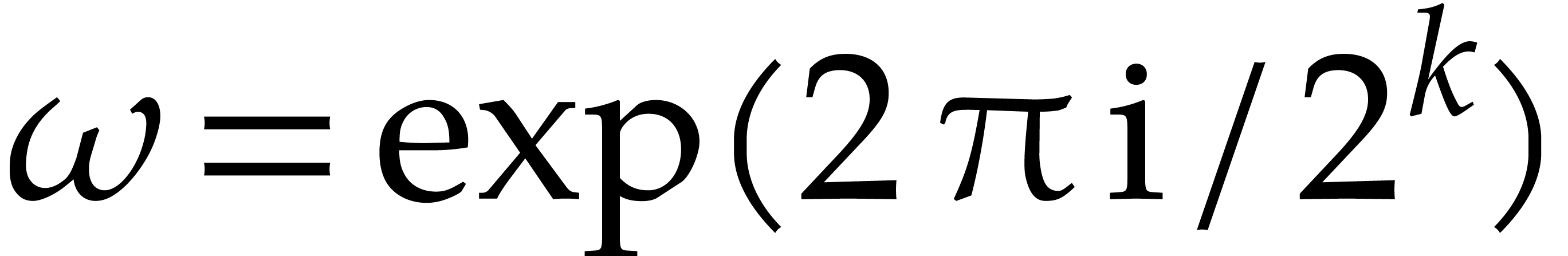 ). Then the
FFT permits evaluation at the points
). Then the
FFT permits evaluation at the points 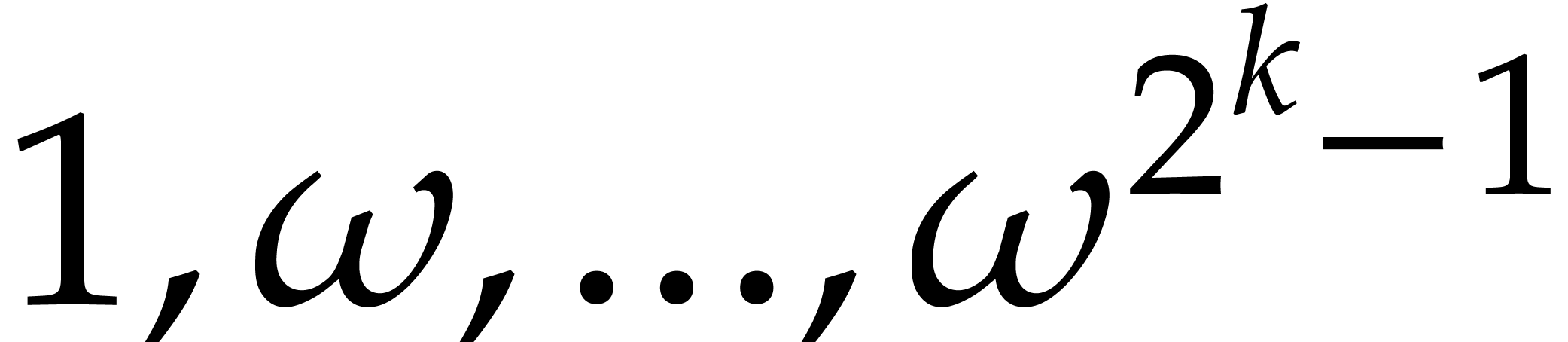 using only
using only
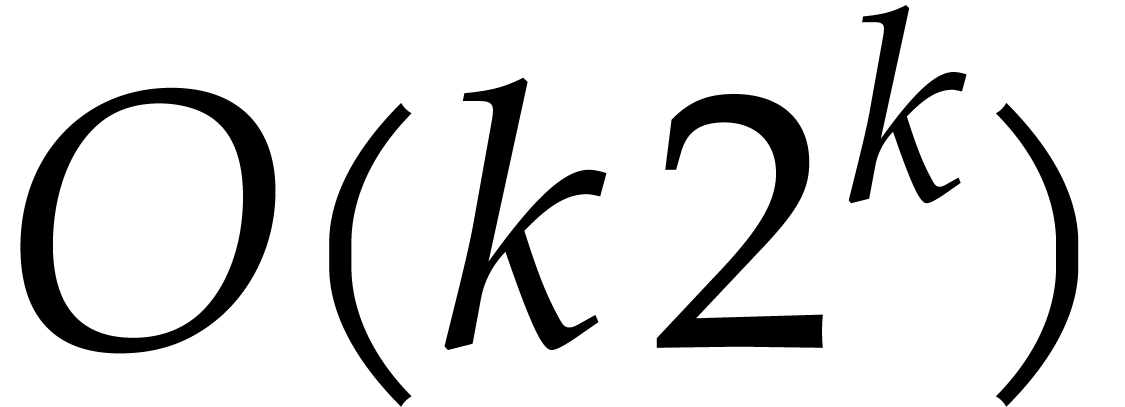 ring operations in .
The corresponding interpolations can be done with the same complexity,
provided that
ring operations in .
The corresponding interpolations can be done with the same complexity,
provided that  is invertible in . Given
is invertible in . Given  with
with 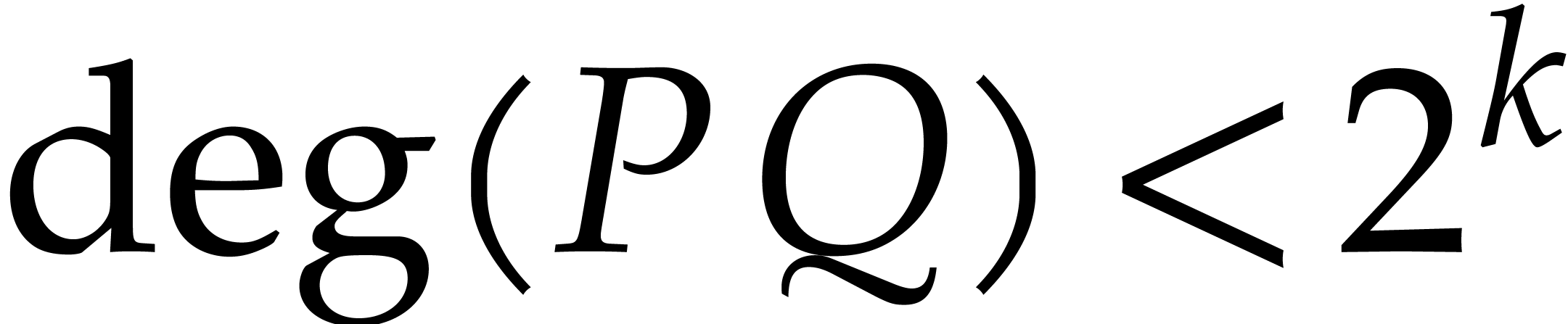 , it follows that the product
, it follows that the product  can be computed using ring
operations as well.
can be computed using ring
operations as well.
The idea to use fast Fourier transforms for integer multiplication is
independently due to Pollard [45] and
Schönhage–Strassen [49]. The simplest way to do
this is to take  and , while approximating elements of
and , while approximating elements of  with finite precision. Multiplications in itself
are handled recursively, through reduction to integer multiplications.
This method corresponds to Schönhage and Strassen's first algorithm
from [49] and they showed that it runs in time
with finite precision. Multiplications in itself
are handled recursively, through reduction to integer multiplications.
This method corresponds to Schönhage and Strassen's first algorithm
from [49] and they showed that it runs in time  for all
for all  .
Pollard's algorithm rather works with
.
Pollard's algorithm rather works with 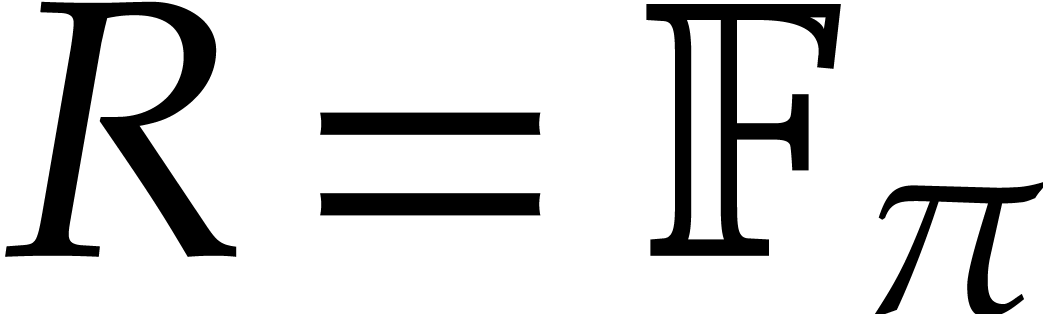 ,
where is a prime of the form
,
where is a prime of the form 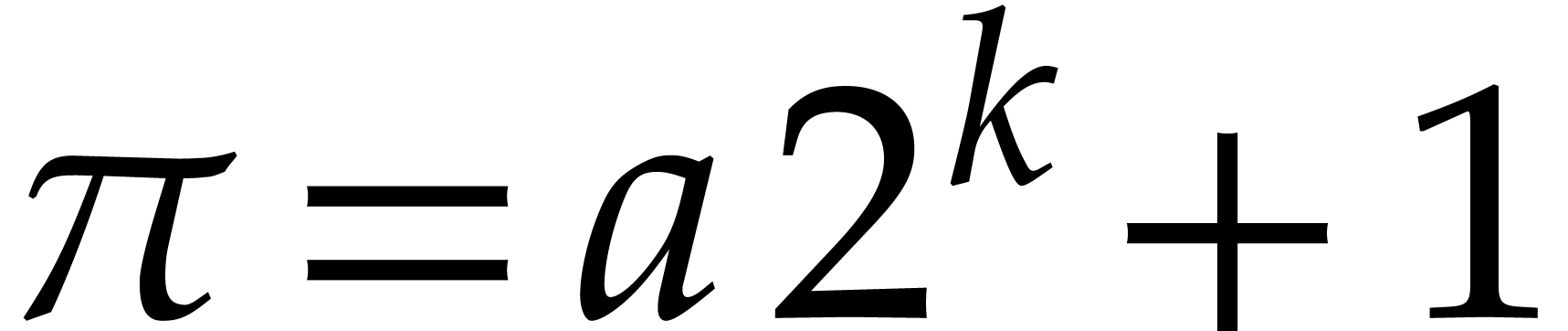 . The field
. The field 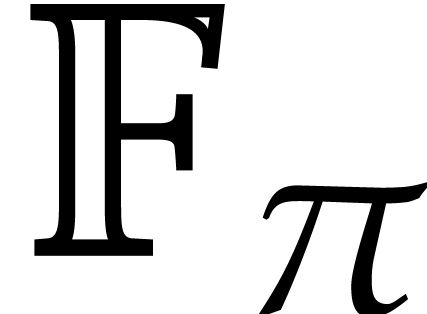 indeed
contains primitive -th roots
of unity and FFTs over such fields are sometimes called number theoretic
FFTs. Pollard did not analyze the asymptotic complexity of his method,
but it can be shown that its recursive use for the arithmetic in leads to a similar complexity bound as for
Schönhage–Strassen's first algorithm.
indeed
contains primitive -th roots
of unity and FFTs over such fields are sometimes called number theoretic
FFTs. Pollard did not analyze the asymptotic complexity of his method,
but it can be shown that its recursive use for the arithmetic in leads to a similar complexity bound as for
Schönhage–Strassen's first algorithm.
The paper [49] also contains a second method that achieves
the even better complexity bound 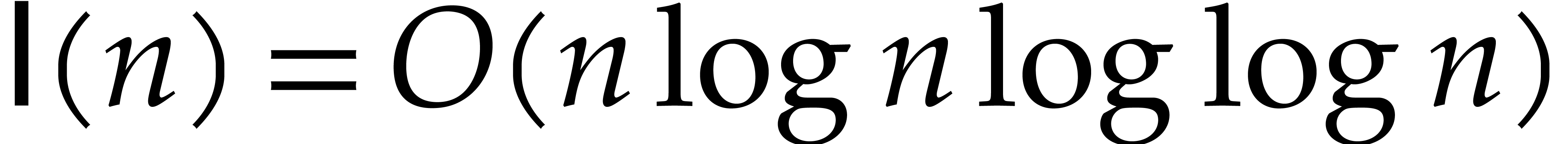 .
This algorithm is commonly known as the
Schönhage–Strassen algorithm. It works over
.
This algorithm is commonly known as the
Schönhage–Strassen algorithm. It works over 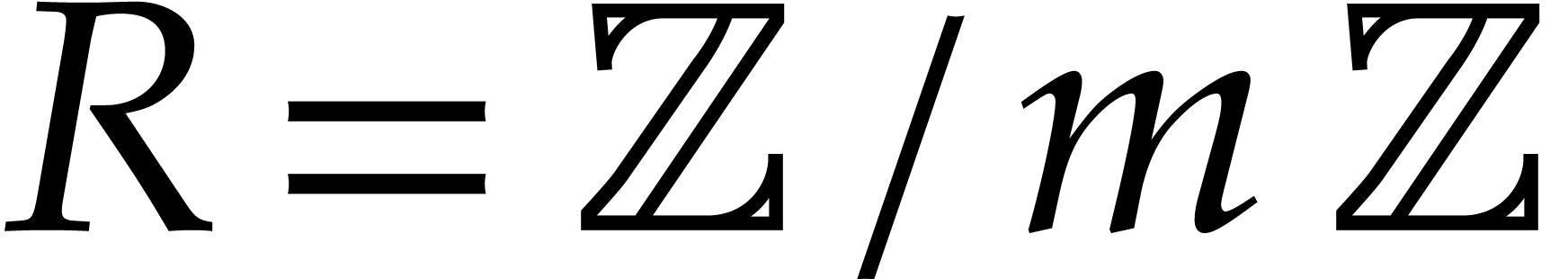 , where
, where 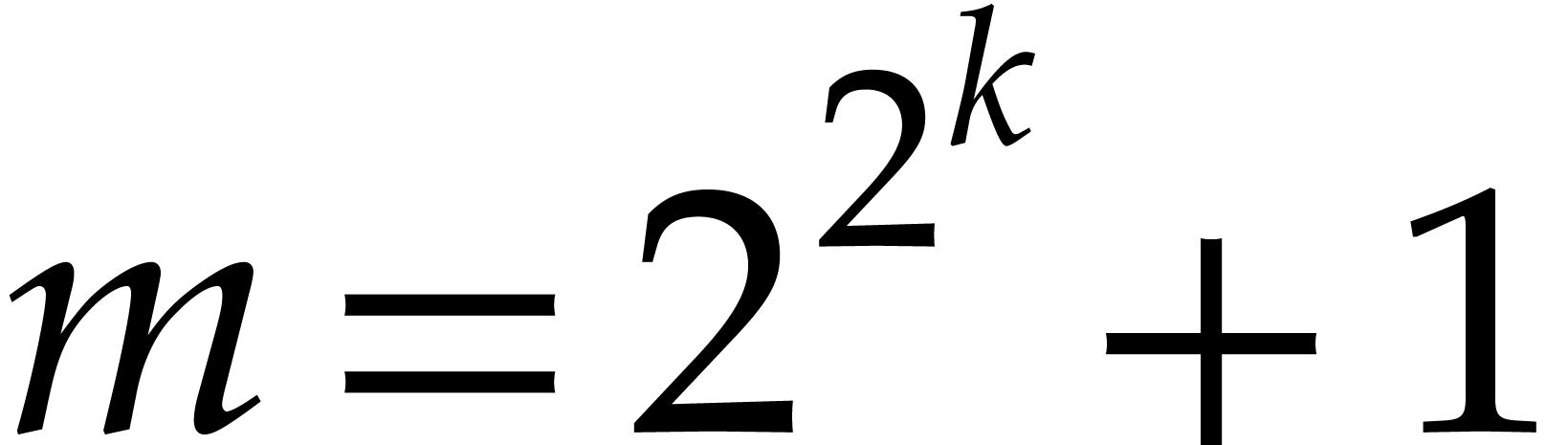 is a Fermat
number, and uses
is a Fermat
number, and uses 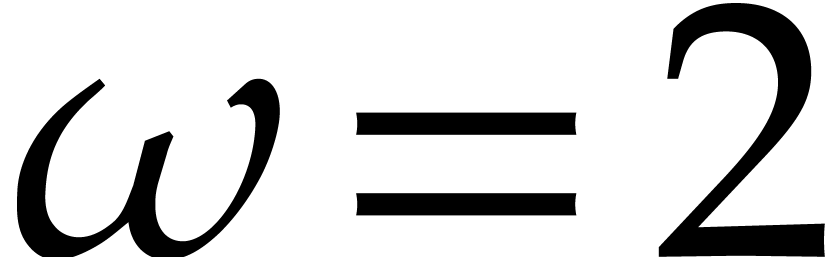 as a principal
as a principal 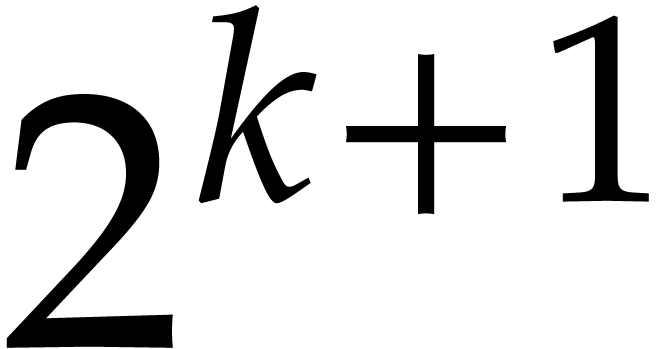 -th root of unity in . The increased speed is due to the fact that
multiplications by powers of
-th root of unity in . The increased speed is due to the fact that
multiplications by powers of  can be carried out
in linear time, as they correspond to simple shifts and negations.
can be carried out
in linear time, as they correspond to simple shifts and negations.
The Schönhage–Strassen algorithm remained the champion for
more than thirty years, before being superseded by Fürer's
algorithm [12]. In short, Fürer managed to combine the
advantages of the two algorithms from [49], to achieve the
bound (1.1) for some unspecified constant  . In [25, section 7], it has been
shown that an optimized version of Fürer's original algorithm
achieves
. In [25, section 7], it has been
shown that an optimized version of Fürer's original algorithm
achieves  . In a succession of
works [25, 18, 19, 21],
new algorithms were proposed for which
. In a succession of
works [25, 18, 19, 21],
new algorithms were proposed for which 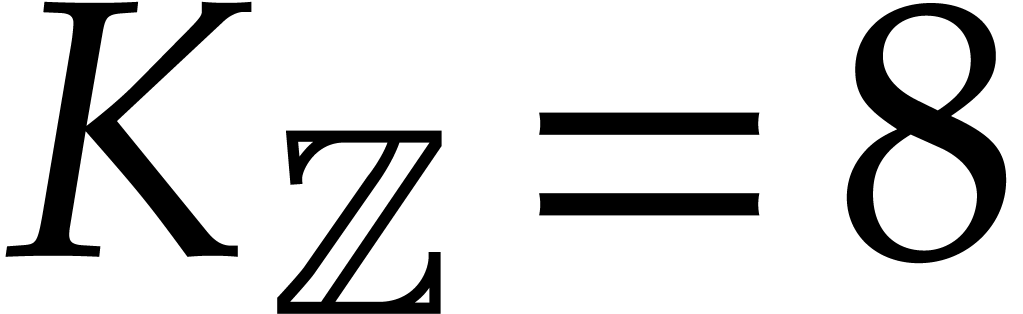 ,
,
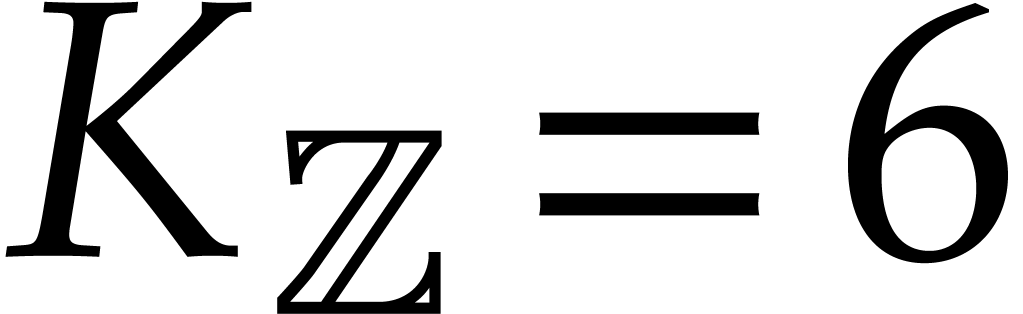 ,
, 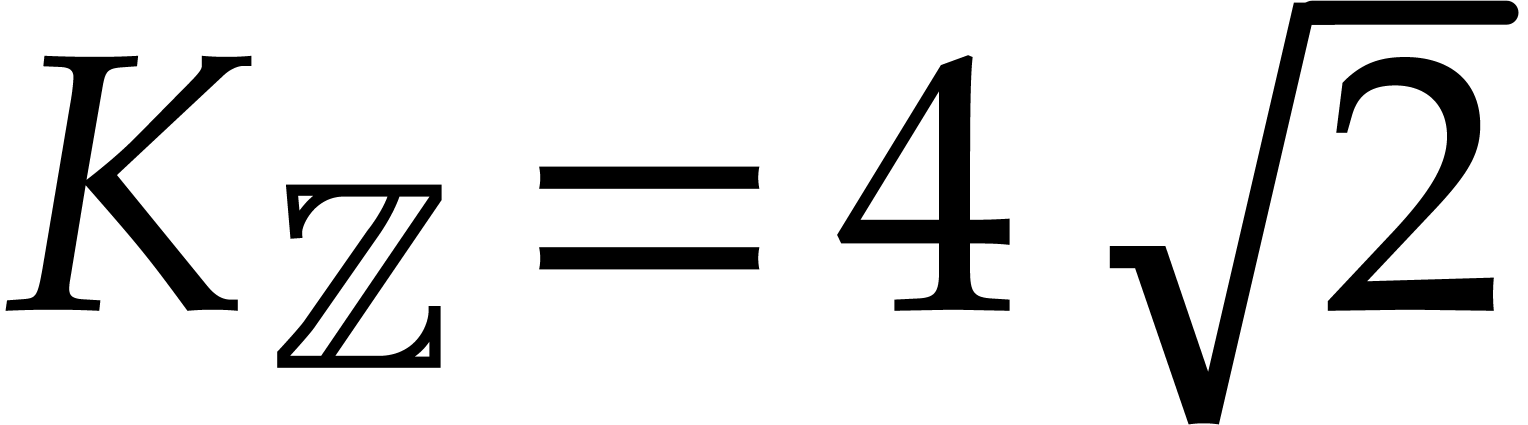 , and .
In view of the companion paper [22], we now know that .
, and .
In view of the companion paper [22], we now know that .
Historically speaking, we also notice that improvements on the lowest
possible values of and 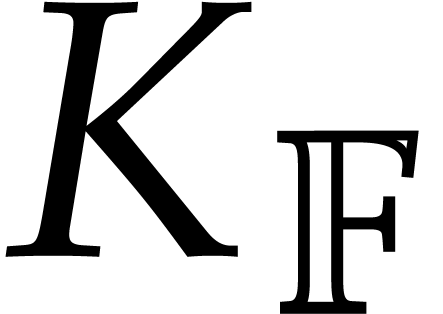 were often preceded by improvements modulo suitable number theoretic
assumptions. In [25, section 9], we proved that one may
take under the assumption that there exist
“sufficiently many” Mersenne primes [25,
Conjecture 9.1]. The same value was achieved in
[10] modulo the existence of sufficiently many generalized
Fermat primes. In [20], we again reached
under the assumption that
were often preceded by improvements modulo suitable number theoretic
assumptions. In [25, section 9], we proved that one may
take under the assumption that there exist
“sufficiently many” Mersenne primes [25,
Conjecture 9.1]. The same value was achieved in
[10] modulo the existence of sufficiently many generalized
Fermat primes. In [20], we again reached
under the assumption that 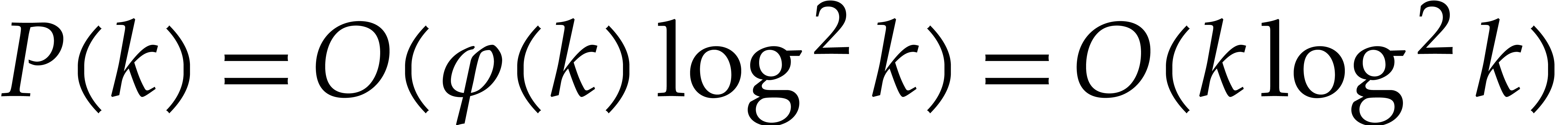 ,
where
,
where  is the Euler totient function.
is the Euler totient function.
Polynomial multiplication.To
a large extent, the development of more efficient algorithms for
polynomial multiplication went hand in hand with progress on integer
multiplication. The early algorithms by Karatsuba and Toom [34,
56], as well as Schönhage–Strassen's second
algorithm from [49], are all based on increasingly
efficient algebraic methods for polynomial multiplication over more or
less general rings .
More precisely, let 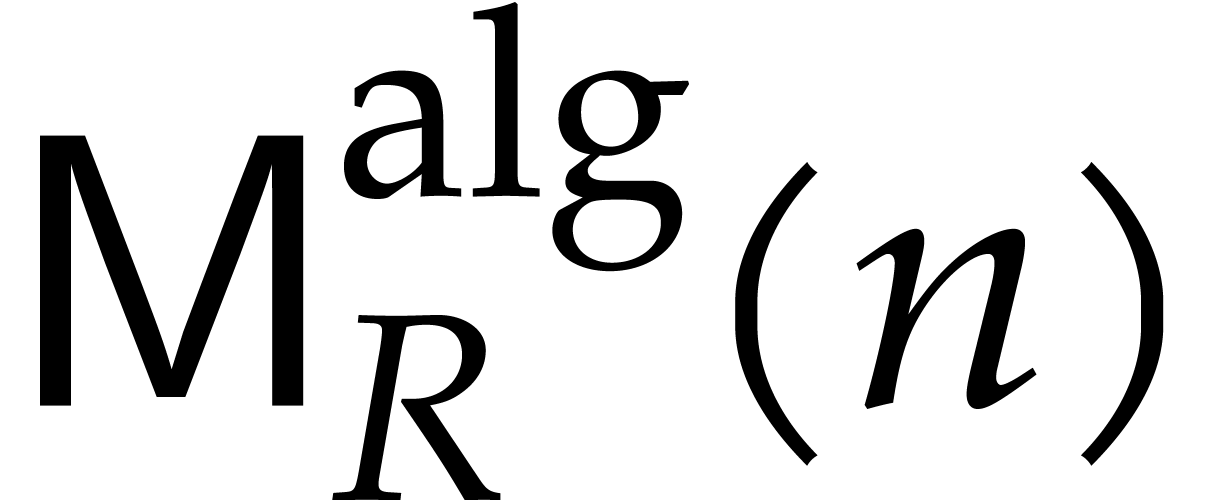 be the number of ring
operations in that are required for the
multiplication of two polynomials of degree in
be the number of ring
operations in that are required for the
multiplication of two polynomials of degree in
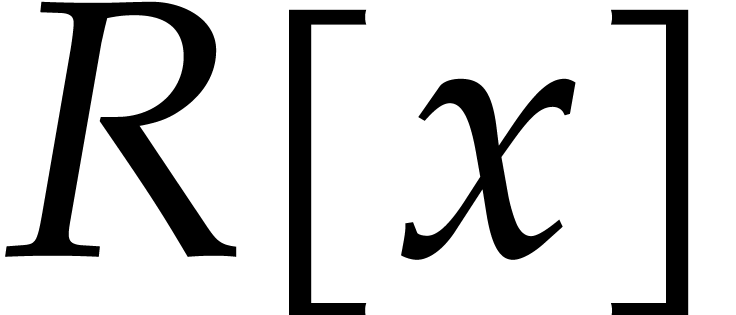 . A straightforward
adaptation of Karatsuba's algorithm for integer multiplication gives
rise to the algebraic complexity bound
. A straightforward
adaptation of Karatsuba's algorithm for integer multiplication gives
rise to the algebraic complexity bound 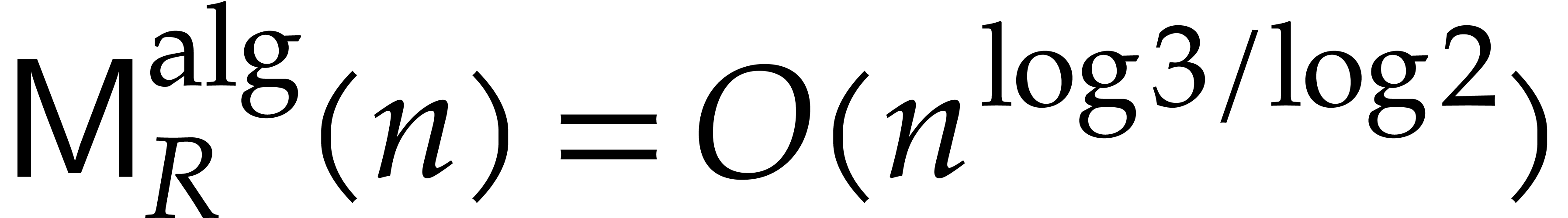 .
.
The subsequent methods typically require mild hypotheses on : since Toom's algorithm uses more than three
evaluation points, its polynomial analogue requires
to contain sufficiently many points. Similarly,
Schönhage–Strassen multiplication is based on
“dyadic” FFTs and therefore requires
to be invertible in .
Schönhage subsequently developed a “triadic” analogue
of their method that is suitable for polynomial multiplication over
fields of characteristic two [48]. The bound 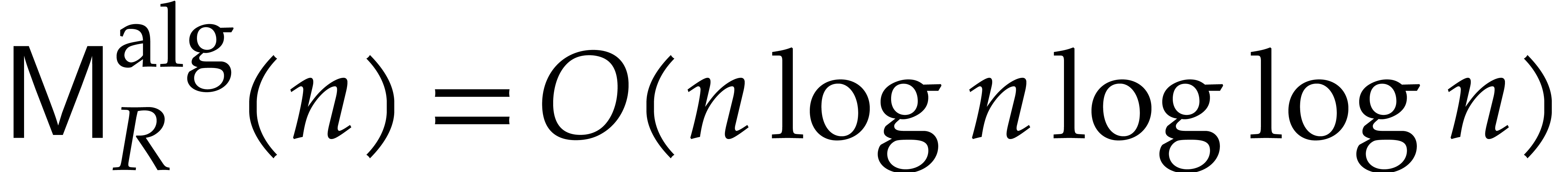 for general (not necessarily commutative) rings is due to Cantor and Kaltofen [8].
for general (not necessarily commutative) rings is due to Cantor and Kaltofen [8].
Let us now turn to the bit complexity of
polynomial multiplication over a finite field
with and where is prime.
Using Kronecker substitution, it is not hard to show that
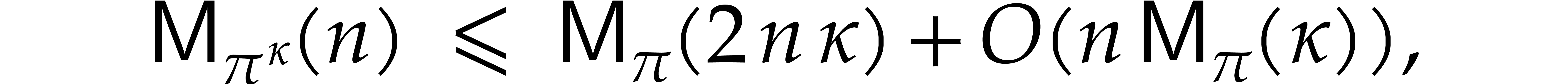
which allows us to reduce our study to the particular case when 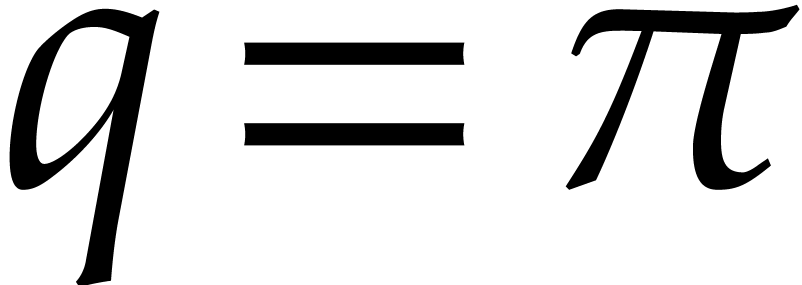 and
and 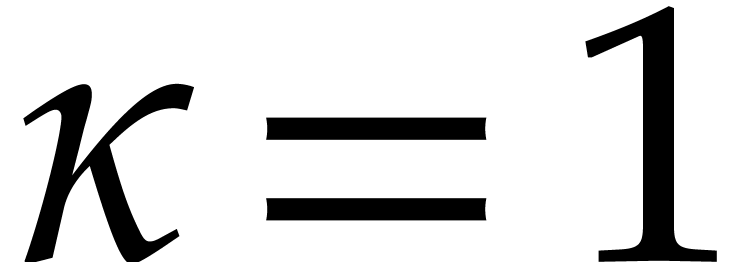 .
.
Now the multiplication of polynomials in of
small degree can be reduced to integer multiplication using Kronecker
substitution: the input polynomials are first lifted into polynomials
with integers coefficients in 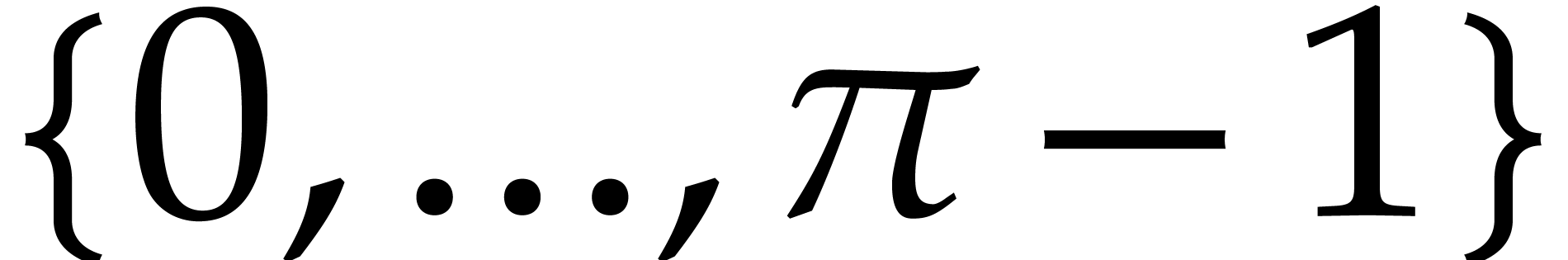 ,
and then evaluated at
,
and then evaluated at 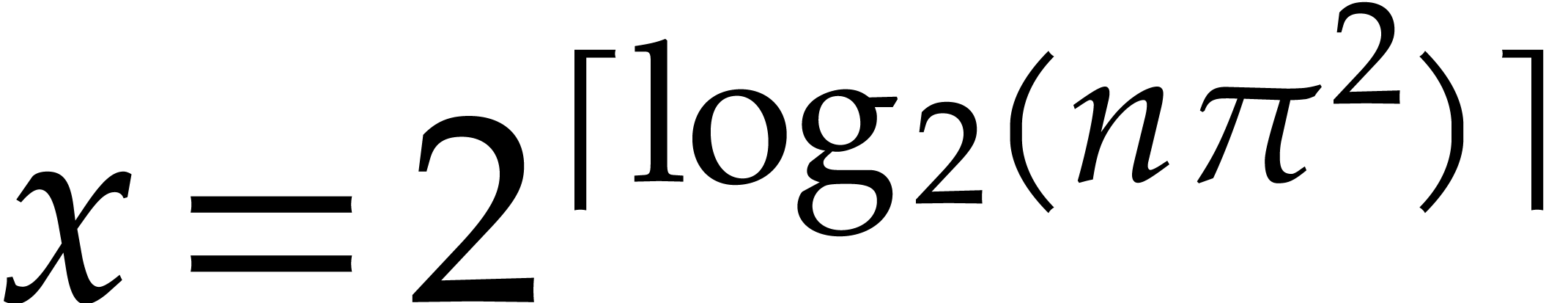 . The
desired result can finally be read off from the integer product of these
evaluations. If
. The
desired result can finally be read off from the integer product of these
evaluations. If  , this yields
, this yields
On the other hand, for 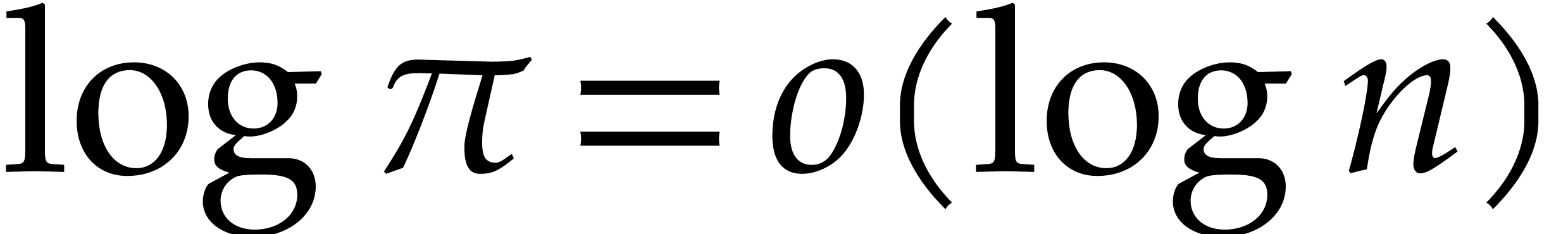 ,
adaptation of the algebraic complexity bound to
the Turing model yields
,
adaptation of the algebraic complexity bound to
the Turing model yields
where the first term corresponds to additions/subtractions in and the second one to multiplications. Notice that the
first term dominates for large .
The combination of (1.4) and (1.5) also
implies
For almost forty years, the bound (1.5) remained unbeaten.
Since Fürer's algorithm (alike Schönhage–Strassen's
first algorithm from [49]) essentially relies on the
availability of suitable roots of unity in the base field , it admits no direct algebraic analogue. In
particular, the existence of a Fürer-type bound of the form (1.2) remained open for several years. This problem got first
solved in [27] for 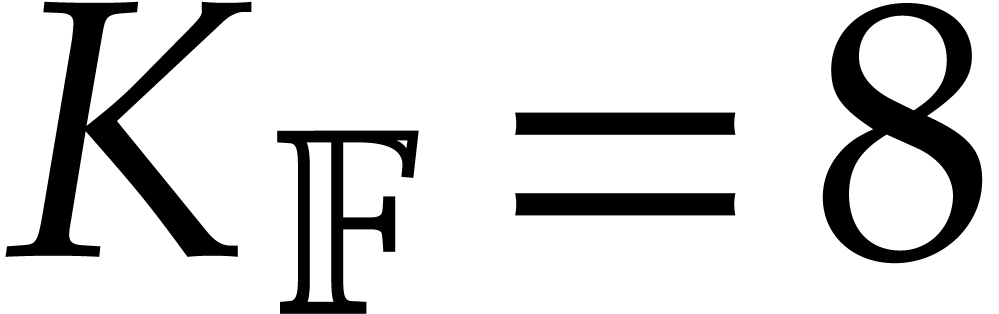 ,
but using an algorithm that is very different from Fürer's
algorithm for integer multiplication. Under suitable number theoretic
assumptions, it was also shown in the preprint version [24]
that one may take , a result
that was achieved subsequently without these assumptions [23].
,
but using an algorithm that is very different from Fürer's
algorithm for integer multiplication. Under suitable number theoretic
assumptions, it was also shown in the preprint version [24]
that one may take , a result
that was achieved subsequently without these assumptions [23].
Let us finally notice that it usually a matter of routine to derive
better polynomial multiplication algorithms over 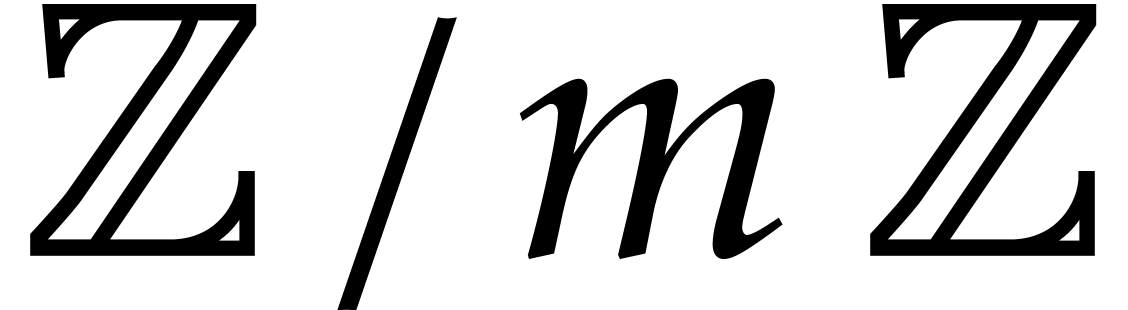 for integers
for integers 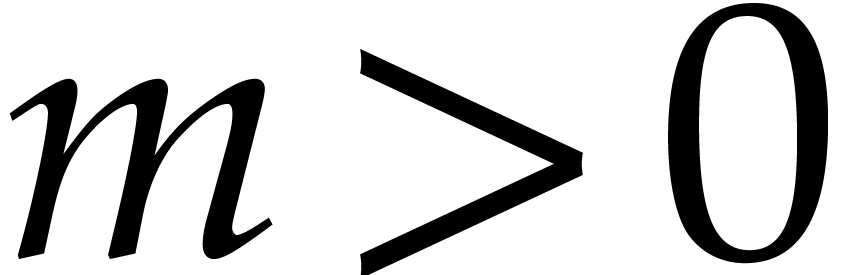 from better multiplication
algorithms over . These
techniques are detailed in [27, sections 8.1–8.3].
Denoting by
from better multiplication
algorithms over . These
techniques are detailed in [27, sections 8.1–8.3].
Denoting by 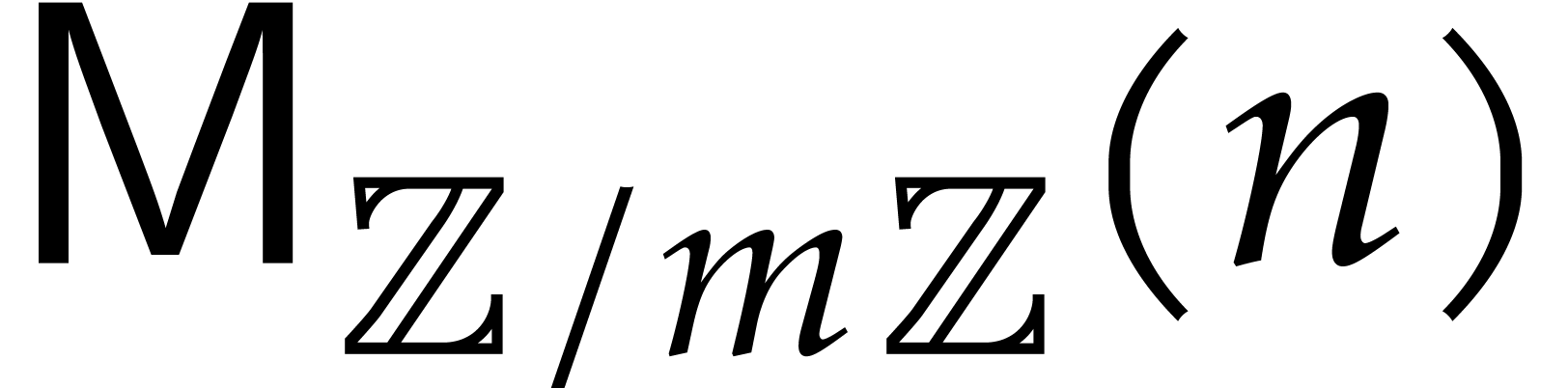 the bit complexity of multiplying
two polynomials of degree over , it is shown there that
the bit complexity of multiplying
two polynomials of degree over , it is shown there that
uniformly in 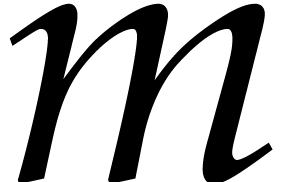 , and for . Exploiting the fact that finite
fields only contain a finite number of elements, it is also a matter of
routine to derive algebraic complexity bounds for
in the case when is a ring of finite
characteristic. We refer to [27, sections 8.4 and 8.5] for
more details.
, and for . Exploiting the fact that finite
fields only contain a finite number of elements, it is also a matter of
routine to derive algebraic complexity bounds for
in the case when is a ring of finite
characteristic. We refer to [27, sections 8.4 and 8.5] for
more details.
Related tools.In
order to prove Theorems 1.1 and 1.2, we will
make use of several other tools from the theory of discrete Fourier
transforms (DFTs). First of all, given a ring
and a composite integer 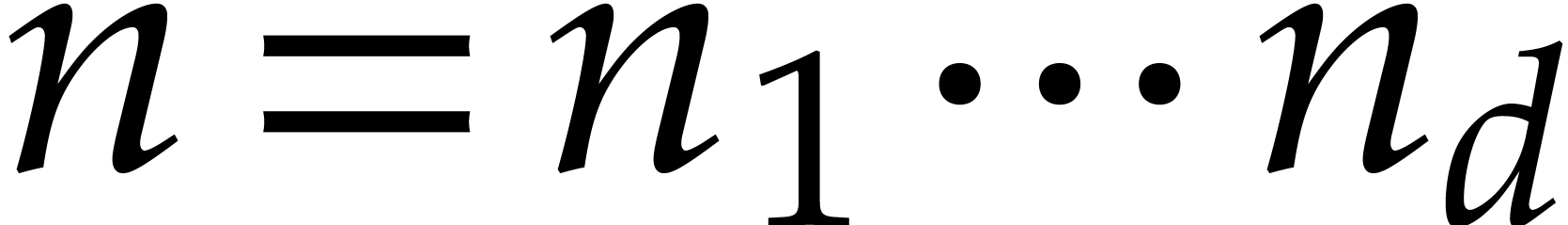 such that the
such that the 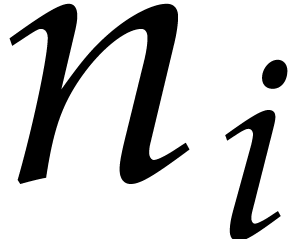 are mutually coprime, the Chinese remainder theorem gives
rise to an isomorphism
are mutually coprime, the Chinese remainder theorem gives
rise to an isomorphism
This was first observed in [1] and we will call the
corresponding conversions CRT transforms. The above isomorphism
also allows for the reduction of a univariate DFT of length to a multivariate DFT of length  . This observation is older and due to Good [15] and independently to Thomas [55].
. This observation is older and due to Good [15] and independently to Thomas [55].
Another classical tool from the theory of discrete Fourier transforms is
Rader reduction [46]: a DFT of prime length 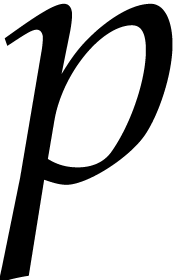 over a ring can be reduced to the
computation of a cyclic convolution of length
over a ring can be reduced to the
computation of a cyclic convolution of length 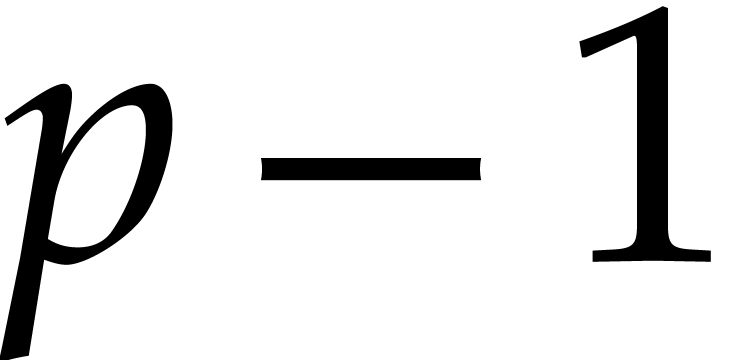 , i.e. a product in the ring
, i.e. a product in the ring 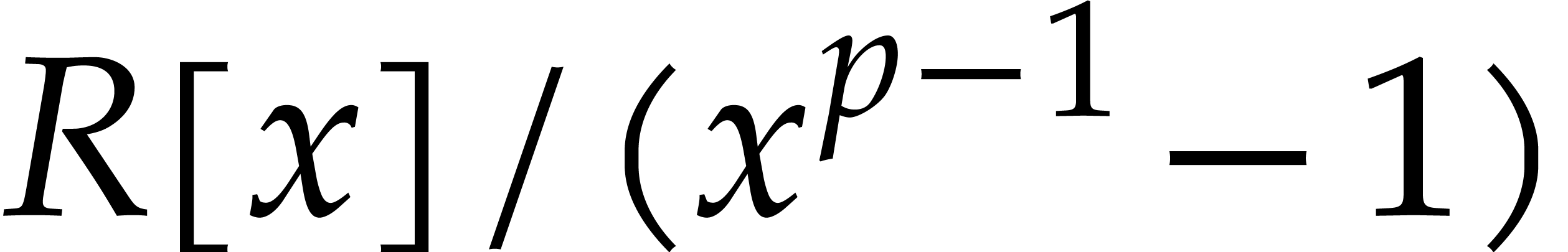 . In section 4, we
will also present a multivariate version of this reduction. In a similar
way, one may use Bluestein's chirp transform [4] to reduce
a DFT of general length over
to a cyclic convolution of the same length. Whereas FFT-multiplication
is a technique that reduces polynomial multiplications to the
computation of DFTs, Bluestein's algorithm (as well as Rader's algorithm
for prime lengths) can be used for reductions in the opposite direction.
In particular, Theorem 1.2 implies that a DFT of length
over a finite field can
be computed in time
. In section 4, we
will also present a multivariate version of this reduction. In a similar
way, one may use Bluestein's chirp transform [4] to reduce
a DFT of general length over
to a cyclic convolution of the same length. Whereas FFT-multiplication
is a technique that reduces polynomial multiplications to the
computation of DFTs, Bluestein's algorithm (as well as Rader's algorithm
for prime lengths) can be used for reductions in the opposite direction.
In particular, Theorem 1.2 implies that a DFT of length
over a finite field can
be computed in time 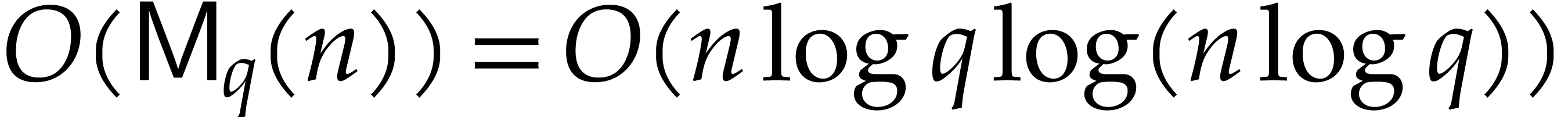 on a Turing machine.
on a Turing machine.
Nussbaumer polynomial transforms [42, 43]
constitute yet another essential tool for our new results. In a similar
way as in Schönhage–Strassen's second algorithm from [49], the idea is to use DFTs over a ring 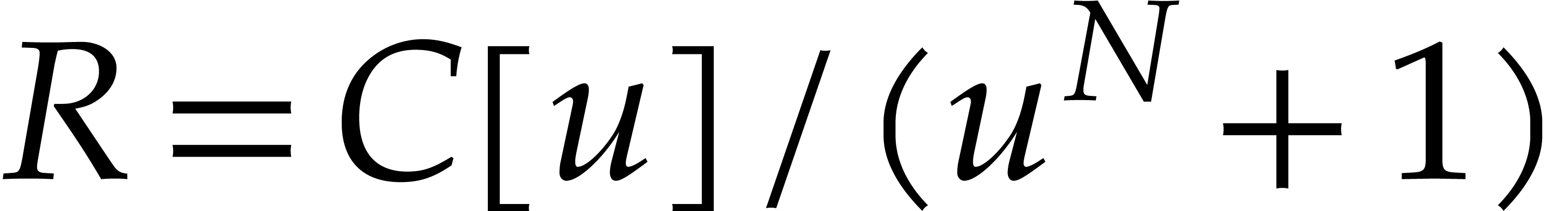 with
with 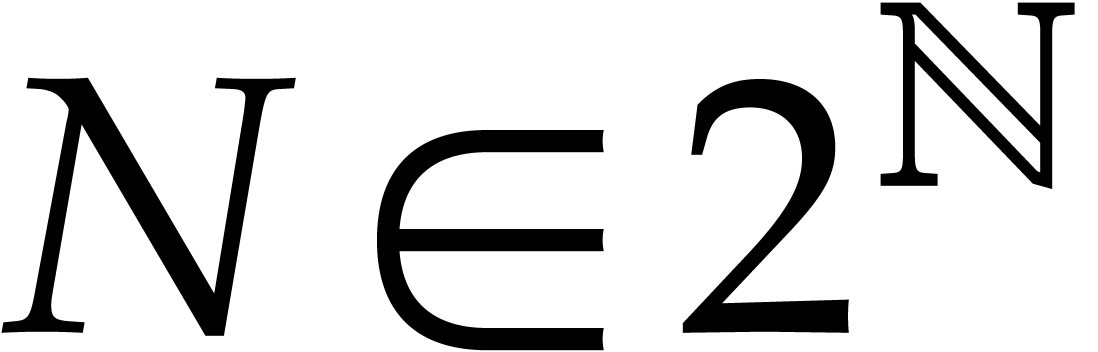 . This ring has the
property that
. This ring has the
property that  is a
is a  -th
principal root of unity and that multiplications by powers of can be computed in linear time. In particular, DFTs of
length
-th
principal root of unity and that multiplications by powers of can be computed in linear time. In particular, DFTs of
length 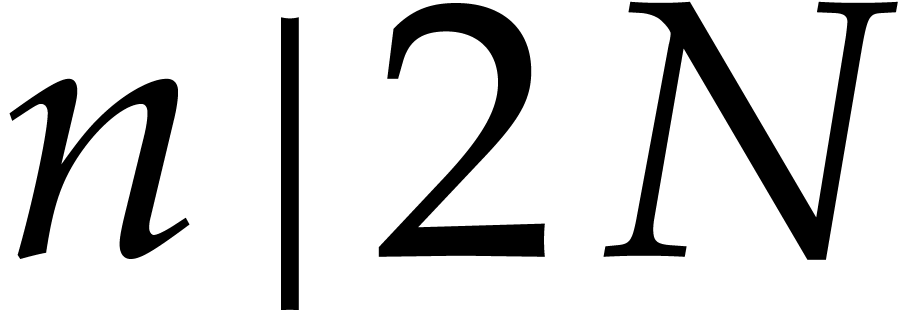 can be computed very efficiently using
only additions and subtractions. Nussbaumer's important observation is
that such transforms are especially interesting for the computation of
multidimensional DFTs (in [49] they are only used for
univariate DFTs). Now the lengths of these multidimensional DFTs should
divide in each direction. Following a suggestion
by Nussbaumer and Quandalle in [44, p. 141], this situation
can be forced using Rader reduction and CRT transforms.
can be computed very efficiently using
only additions and subtractions. Nussbaumer's important observation is
that such transforms are especially interesting for the computation of
multidimensional DFTs (in [49] they are only used for
univariate DFTs). Now the lengths of these multidimensional DFTs should
divide in each direction. Following a suggestion
by Nussbaumer and Quandalle in [44, p. 141], this situation
can be forced using Rader reduction and CRT transforms.
In order to prove Theorems 1.1 and 1.2, we
make use of a combination of well-known techniques from the theory of
fast Fourier transforms. We just surveyed these related tools; more
details are provided in sections 2, 3 and 4. Notice that part of section 2 contains
material that we adapted from previous papers [25, 27]
and included for convenience of the reader. In section 5,
the assumption on the existence of small Linnik constants  will also be discussed in more detail, together with a few
consequences. Throughout this paper, all computations are done in the
deterministic multitape Turing model [16] and execution
times are analyzed in terms of bit complexity. The appendix covers
technical details about the cost of data rearrangements when using this
model.
will also be discussed in more detail, together with a few
consequences. Throughout this paper, all computations are done in the
deterministic multitape Turing model [16] and execution
times are analyzed in terms of bit complexity. The appendix covers
technical details about the cost of data rearrangements when using this
model.
Integer multiplication.We prove Theorem 1.1 in section 6. The main idea of our new algorithm is to reduce integer multiplication to the computation of multivariate cyclic convolutions in a suitable algebra of the form
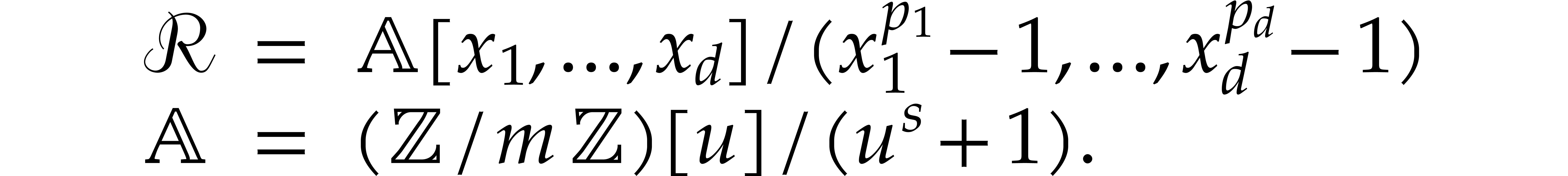
Here 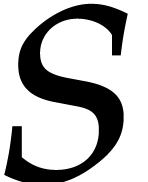 is a power of two and
is a power of two and  are the first
are the first  prime numbers in the arithmetic
progression
prime numbers in the arithmetic
progression 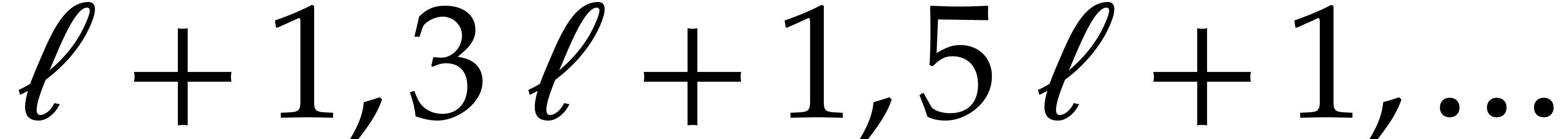 , where is another power of two with
, where is another power of two with 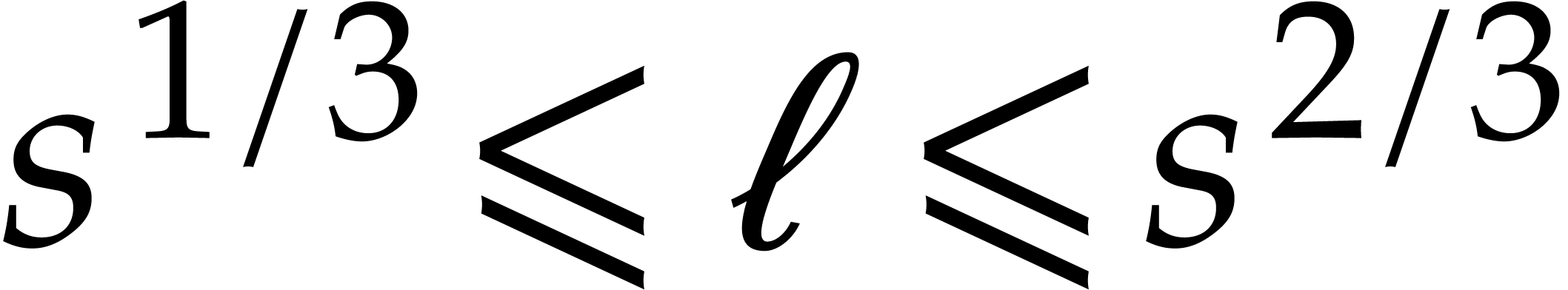 .
Setting
.
Setting 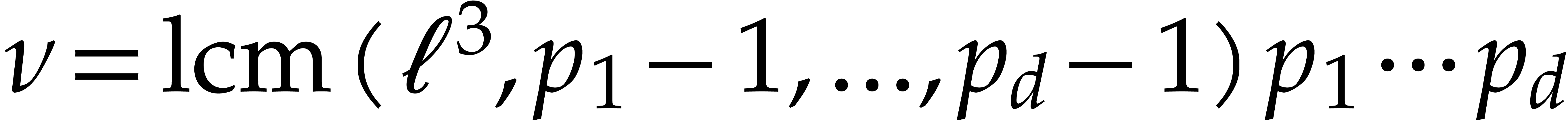 , we choose such that there exists a principal
, we choose such that there exists a principal 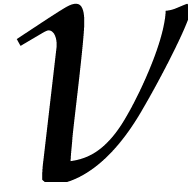 -th root of unity in that
makes it possible to compute products in the algebra
-th root of unity in that
makes it possible to compute products in the algebra  using fast Fourier multiplication. Concerning the dimension , it turns out that we may take
using fast Fourier multiplication. Concerning the dimension , it turns out that we may take  , although larger dimensions may allow for
speed-ups by a constant factor as long as
, although larger dimensions may allow for
speed-ups by a constant factor as long as  can be
kept small.
can be
kept small.
Using multivariate Rader transforms, the required discrete Fourier
transforms in essentially reduce to the
computation of multivariate cyclic convolutions in the algebra
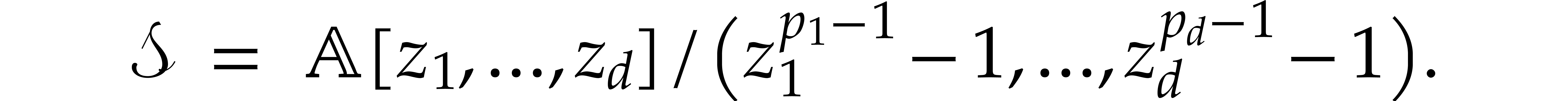
By construction, we may factor 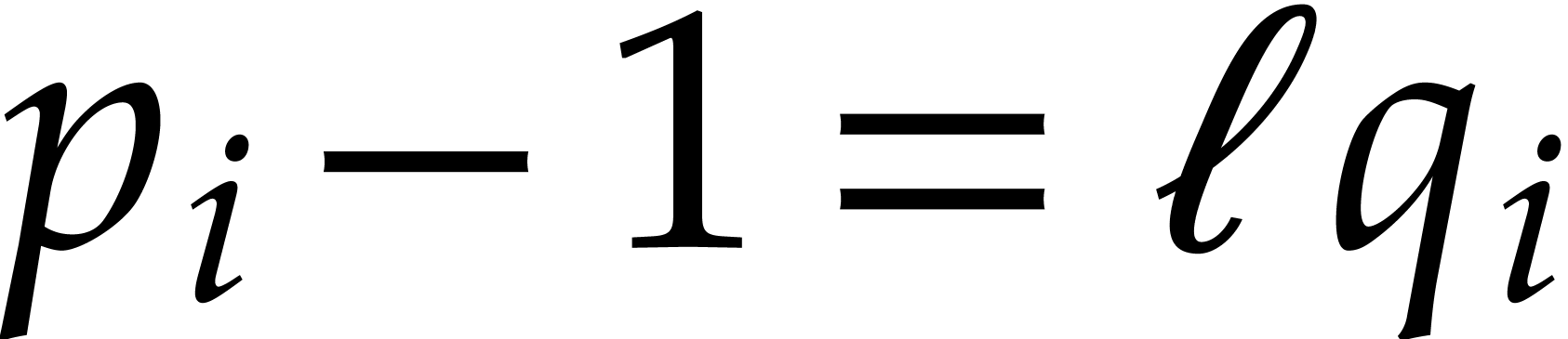 ,
where
,
where 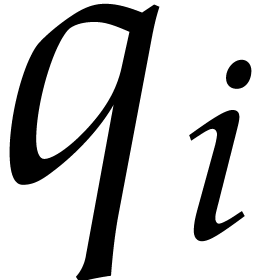 is an odd number that is small due the
hypothesis on the Linnik constant. Since
is an odd number that is small due the
hypothesis on the Linnik constant. Since 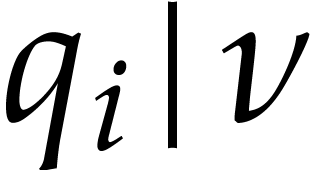 ,
we notice that contains a primitive -th root of unity. CRT transforms allow us to
rewrite the algebra
,
we notice that contains a primitive -th root of unity. CRT transforms allow us to
rewrite the algebra  as
as
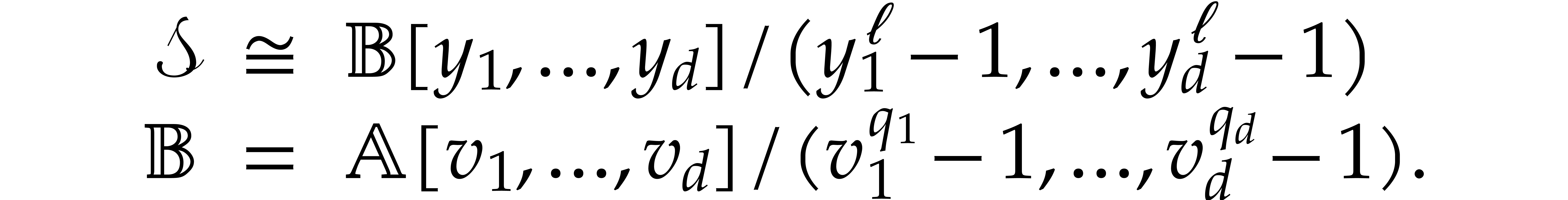
Now the important observation is that can be
considered as a “fast” principal 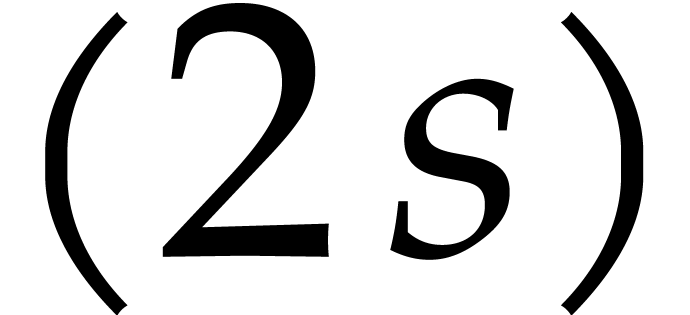 -th root of unity in both
-th root of unity in both  and
and  . This means that
products in can be computed using multivariate
Fourier multiplication with the special property that the discrete
Fourier transforms become Nussbaumer polynomial transforms. Since is a power of two, these transforms can be computed
in time . Moreover, for
sufficiently small Linnik constants ,
the cost of the “inner multiplications” in
can be mastered so that it only marginally contributes to the overall
cost.
. This means that
products in can be computed using multivariate
Fourier multiplication with the special property that the discrete
Fourier transforms become Nussbaumer polynomial transforms. Since is a power of two, these transforms can be computed
in time . Moreover, for
sufficiently small Linnik constants ,
the cost of the “inner multiplications” in
can be mastered so that it only marginally contributes to the overall
cost.
Polynomial multiplication.In
order to prove Theorem 1.2, we proceed in a similar manner;
see sections 7 and 8. It suffices to consider
the case that is prime. In section 7,
we first focus on ground fields of characteristic 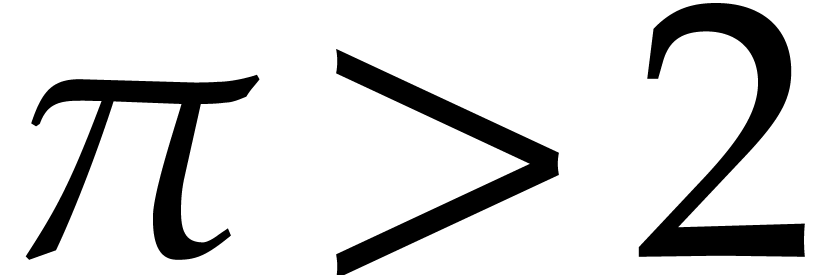 . This time, the ring needs
to be replaced by a suitable extension field
. This time, the ring needs
to be replaced by a suitable extension field  of
; in particular, we define
of
; in particular, we define
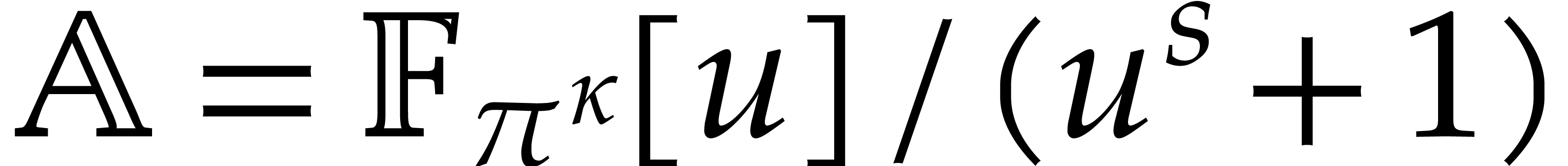 . More precisely, we take
. More precisely, we take
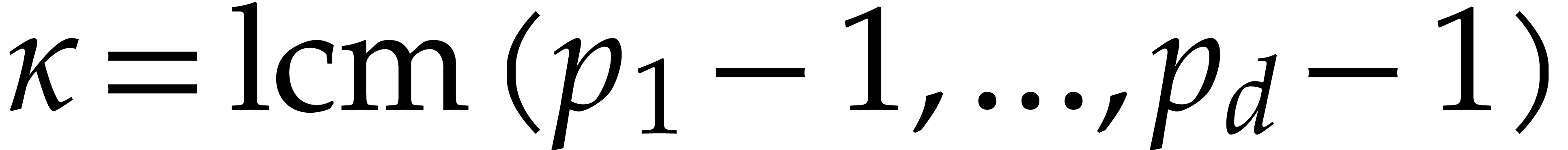 , which ensures the existence
of primitive
, which ensures the existence
of primitive  -th roots of
unity in
-th roots of
unity in  and .
and .
The finite field case gives rise to a few additional technical
difficulties. First of all, the bit size of an element of is exponentially larger than the bit size of an element of
. This makes the FFT-approach
for multiplying elements in not efficient
enough. Instead, we impose the additional requirement that  be pairwise coprime. This allows us to reduce
multiplications in to univariate multiplications
in
be pairwise coprime. This allows us to reduce
multiplications in to univariate multiplications
in 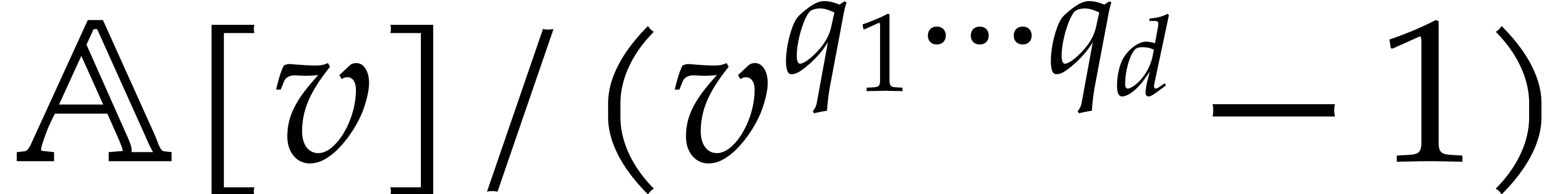 , but at the expense of
the much stronger hypothesis
, but at the expense of
the much stronger hypothesis 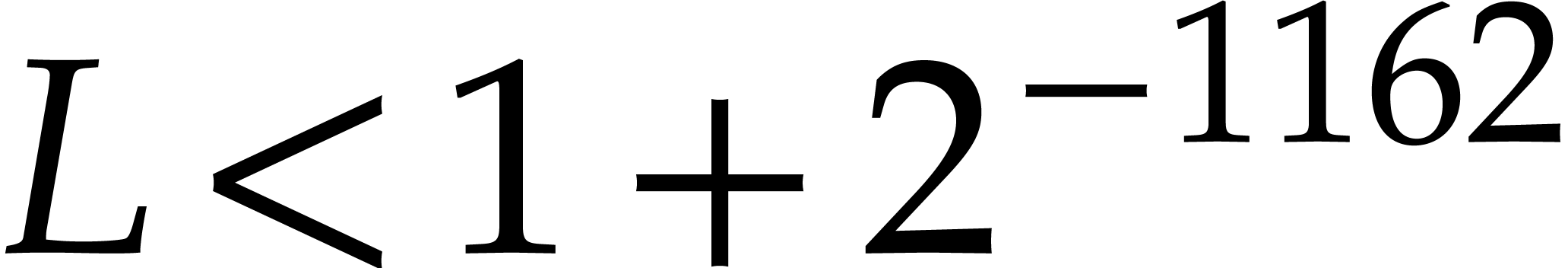 on .
on .
A second technical difficulty concerns the computation of a defining
polynomial for (i.e. an irreducible
polynomial 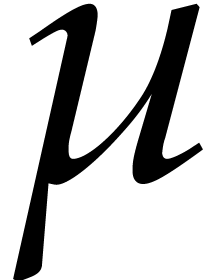 in of degree
), together with a primitive
-th root of unity
in of degree
), together with a primitive
-th root of unity 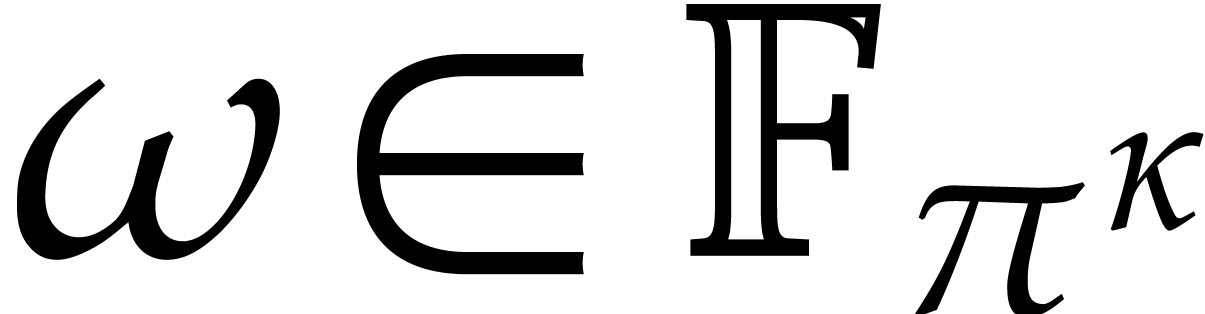 . For our choice of as a function of ,
and thanks to work by Shoup [51, 52], it turns
out that both and can be
precomputed in linear time
. For our choice of as a function of ,
and thanks to work by Shoup [51, 52], it turns
out that both and can be
precomputed in linear time 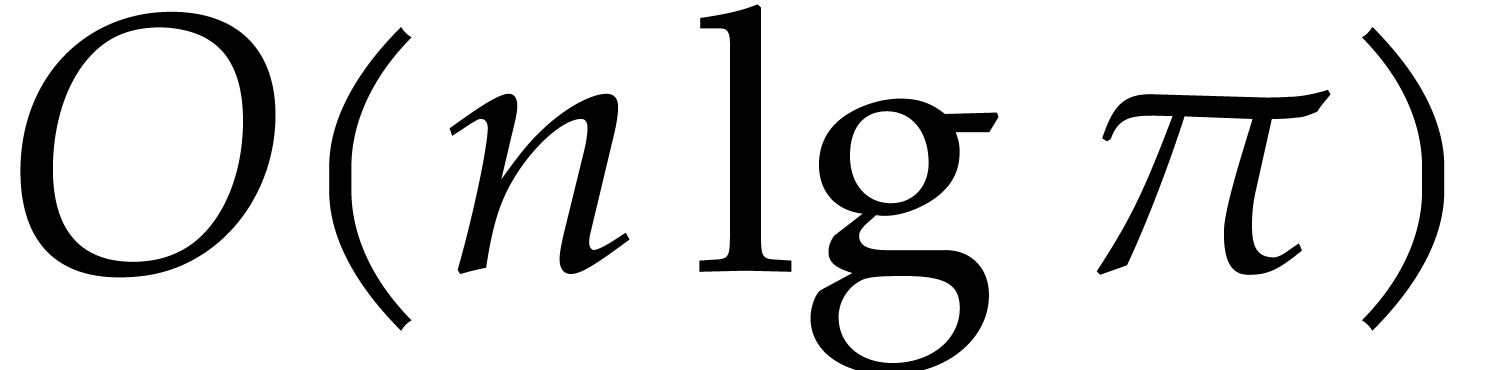 .
.
The case when 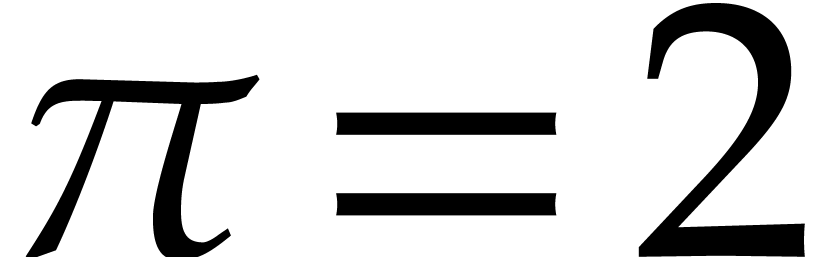 finally comes with its own
particular difficulties, so we treat it separately in section 8.
Since is no longer invertible, we cannot use DFT
lengths that are powers of two. Following
Schönhage [48], we instead resort to
“triadic” FFTs, for which becomes a
power of three. More annoyingly, since
finally comes with its own
particular difficulties, so we treat it separately in section 8.
Since is no longer invertible, we cannot use DFT
lengths that are powers of two. Following
Schönhage [48], we instead resort to
“triadic” FFTs, for which becomes a
power of three. More annoyingly, since 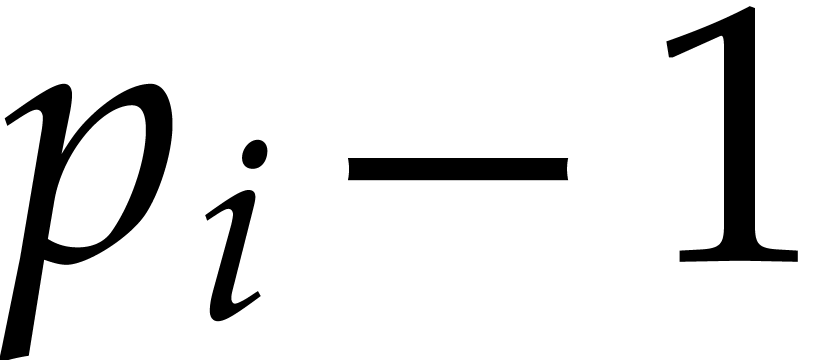 is
necessarily even for
is
necessarily even for 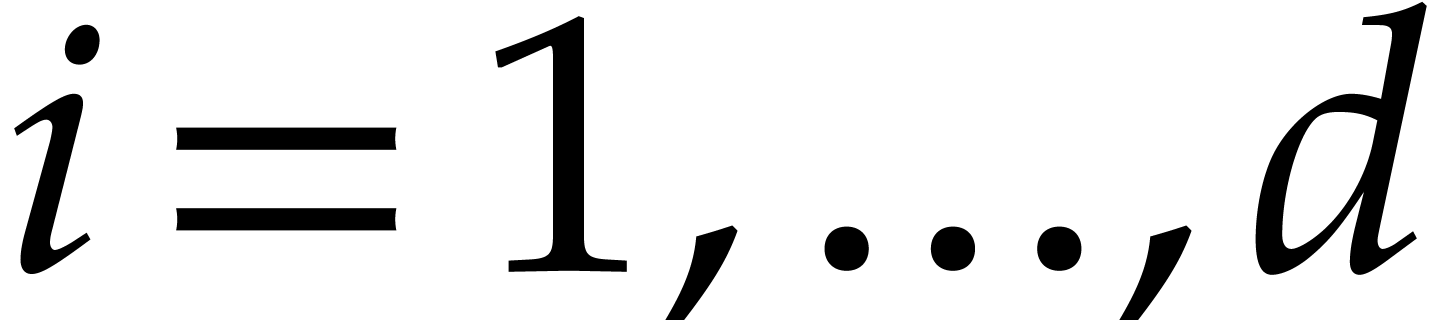 , this
also means that we now have to take
, this
also means that we now have to take 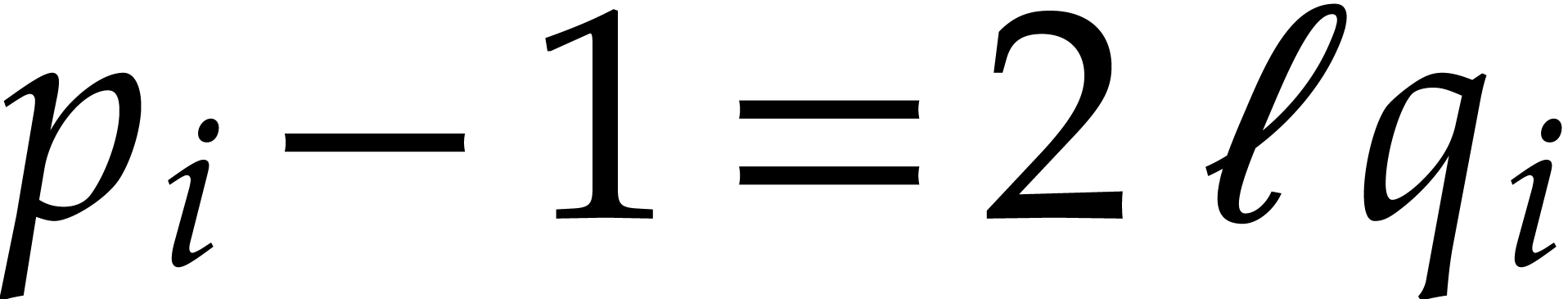 .
In a addition to the multivariate cyclic convolutions of lengths
.
In a addition to the multivariate cyclic convolutions of lengths 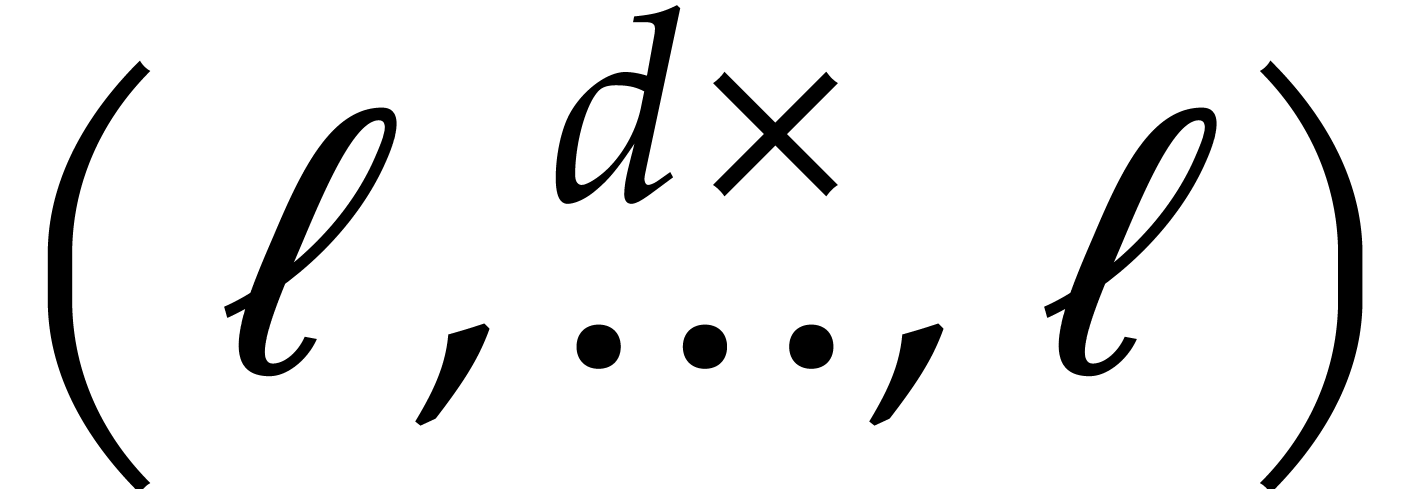 and
and  from before, this gives
rise to multivariate cyclic convolutions of length
from before, this gives
rise to multivariate cyclic convolutions of length 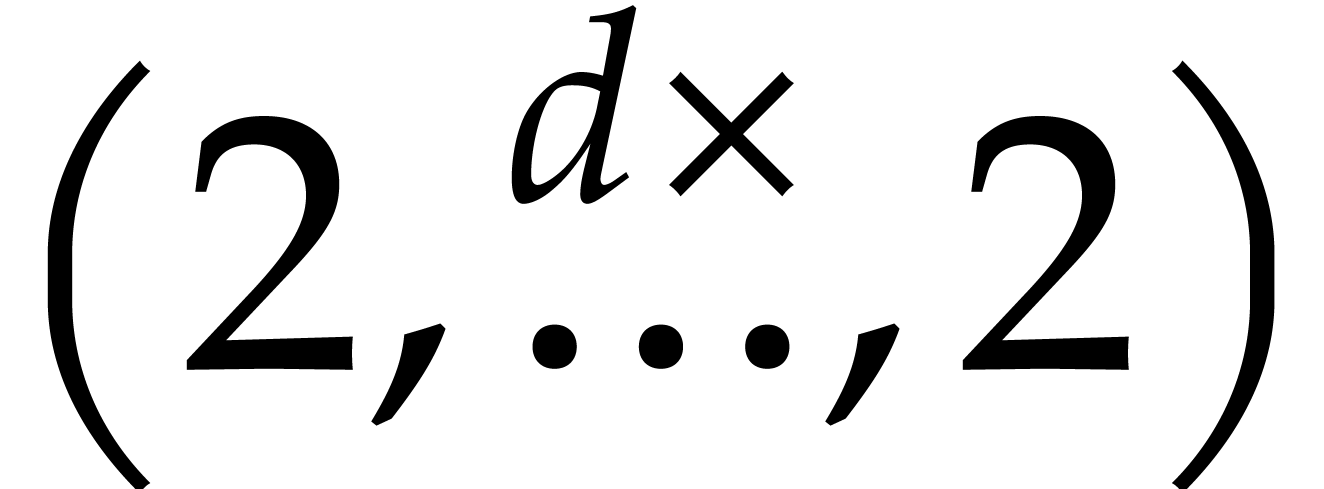 , which need to be handled separately. Although
the proof of Theorem 1.2 in the case when
is very similar to the case when
, which need to be handled separately. Although
the proof of Theorem 1.2 in the case when
is very similar to the case when 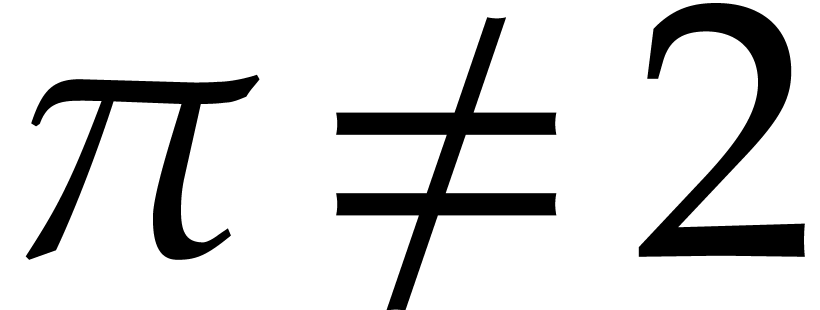 ,
the above complications lead to subtle changes in the choices of
parameters and coefficient rings. For convenience of the reader, we
therefore reproduced most of the proof from section 7 in
section 8, with the required adaptations.
,
the above complications lead to subtle changes in the choices of
parameters and coefficient rings. For convenience of the reader, we
therefore reproduced most of the proof from section 7 in
section 8, with the required adaptations.
Variants.The
constants 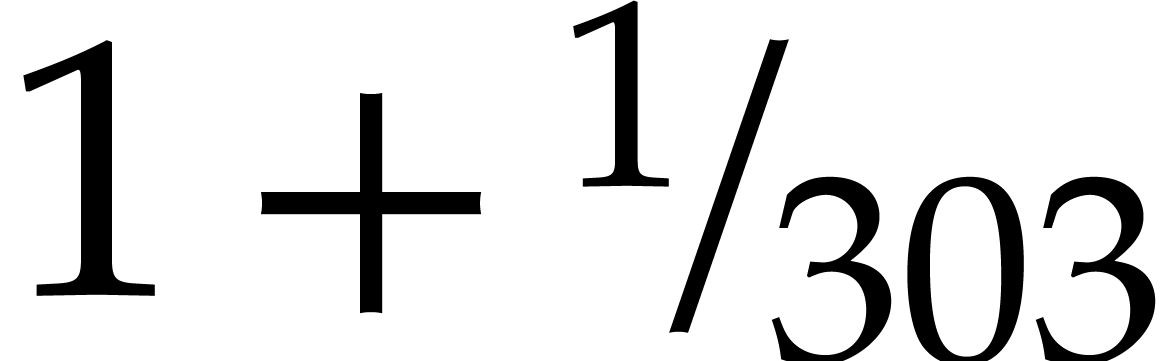 and
and 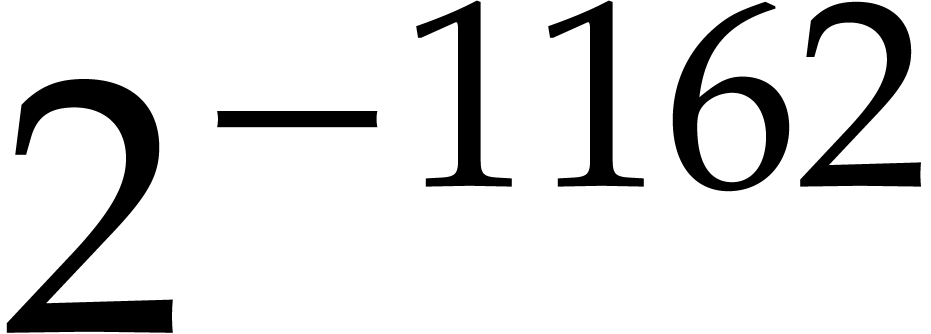 in
Theorems 1.1 and 1.2 are not optimal: we have
rather attempted to keep the proofs as simple as possible. Nevertheless,
our proofs do admit two properties that deserve to be highlighted:
in
Theorems 1.1 and 1.2 are not optimal: we have
rather attempted to keep the proofs as simple as possible. Nevertheless,
our proofs do admit two properties that deserve to be highlighted:
The hypothesis that there exists a Linnik constant that is sufficiently close to one is enough for obtaining our main complexity bounds.
The dimension of the multivariate Fourier
transforms can be kept bounded and does not need to grow with .
We refer to Remarks 6.1 and 7.1 for some ideas on how to optimize the thresholds for acceptable Linnik constants.
Our main algorithms admit several variants. It should for instance be
relatively straightforward to use approximate complex arithmetic in
section 6 instead of modular arithmetic. Due to the fact
that primitive roots of unity in are
particularly simple, the Linnik constants may also become somewhat
better, but additional care is needed for the numerical error analysis.
Using similar ideas as in [27, section 8], our
multiplication algorithm for polynomials over finite fields can also be
adapted to polynomials over finite rings and more general effective
rings of positive characteristic.
Another interesting question is whether there exist practically efficient variants that might outperform existing implementations. Obviously, this would require further fine-tuning, since the “crazy” constants in our proofs were not motivated by practical applications. Nevertheless, our approach combines several ideas from existing algorithms that have proven to be efficient in practice. In the case of integer multiplication, this makes us more optimistic than for the previous post-Fürer algorithms [12, 13, 11, 25, 10, 18, 19, 21]. In the finite field case, the situation is even better, since similar ideas have already been validated in practice [26, 32].
Applications.Assume
that there exist Linnik constants that are sufficiently close to 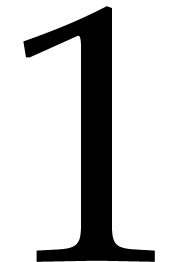 . Then Theorems 1.1
and 1.2 have many immediate consequences, as many
computational problems may be reduced to integer or polynomial
multiplication.
. Then Theorems 1.1
and 1.2 have many immediate consequences, as many
computational problems may be reduced to integer or polynomial
multiplication.
For example, Theorem 1.1 implies that the Euclidean
division of two -bit integers
can be performed in time 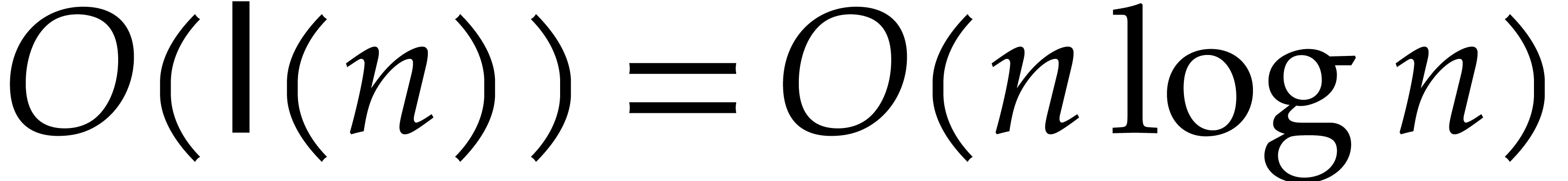 ,
whereas the gcd can be computed in time
,
whereas the gcd can be computed in time 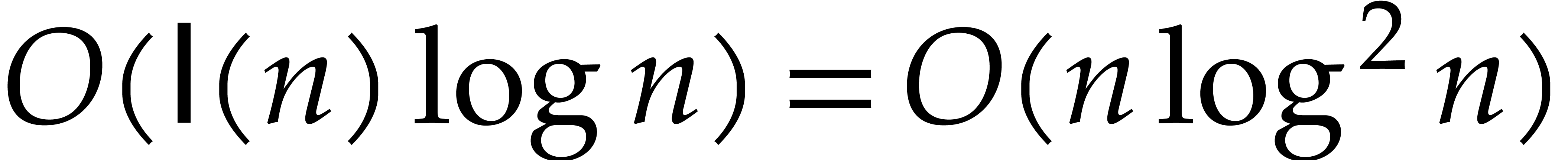 .
Many transcendental functions and constants can also be approximated
faster. For instance, binary digits of
.
Many transcendental functions and constants can also be approximated
faster. For instance, binary digits of  can be computed in time and the
result can be converted into decimal notation in time
can be computed in time and the
result can be converted into decimal notation in time 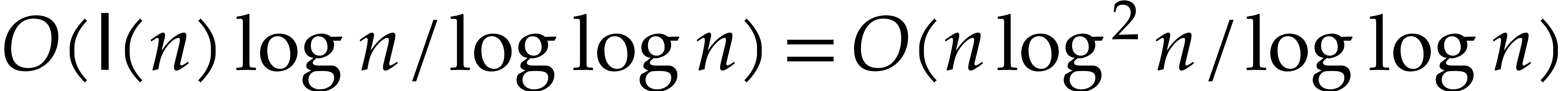 . For details and more examples, we refer to
[7, 31].
. For details and more examples, we refer to
[7, 31].
In a similar way, Theorem 1.2 implies that the Euclidean
division of two polynomials in with of degree can be performed in time
, whereas the extended gcd
admits bit-complexity 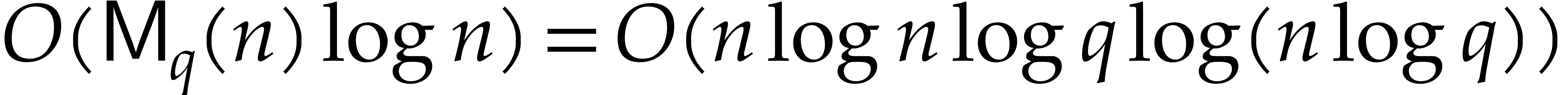 . Since
inversion of a non-zero element of boils down to
an extended gcd computation of degree over , this operation admits bit
complexity
. Since
inversion of a non-zero element of boils down to
an extended gcd computation of degree over , this operation admits bit
complexity 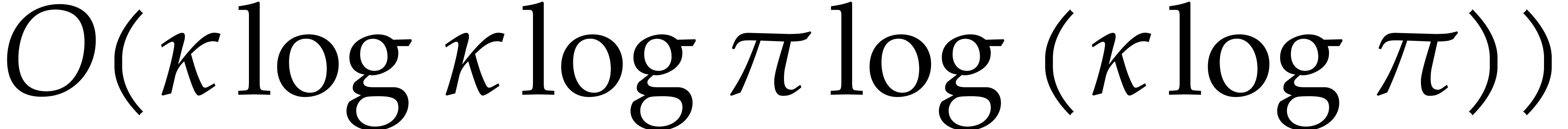 . The complexities
of many operations on formal power series over
can also be expressed in terms of .
We refer to [14, 30] for details and more
applications.
. The complexities
of many operations on formal power series over
can also be expressed in terms of .
We refer to [14, 30] for details and more
applications.
Let be a commutative ring with identity. Given
 , we define
, we define
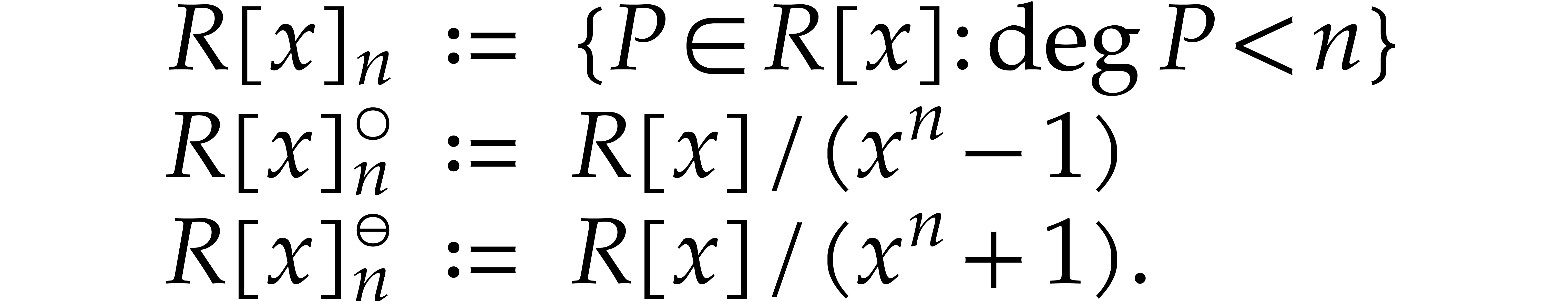
Elements of 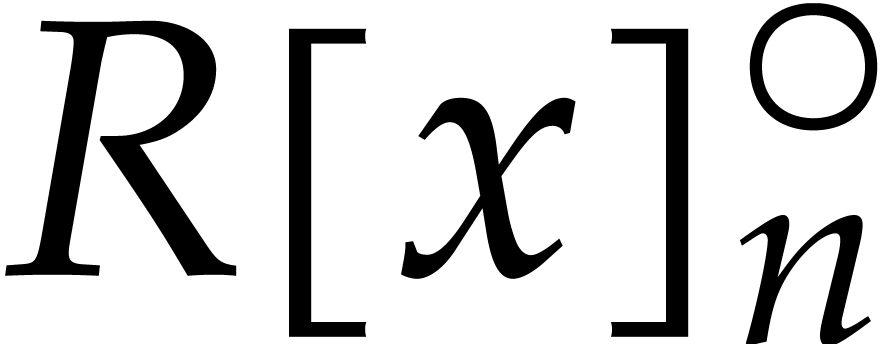 and
and 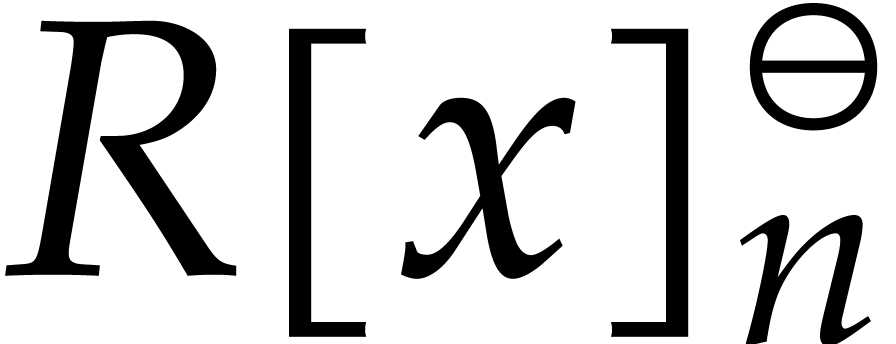 will be
called cyclic polynomials and negacyclic polynomials,
respectively. For subsets
will be
called cyclic polynomials and negacyclic polynomials,
respectively. For subsets  ,
it will be convenient to write
,
it will be convenient to write 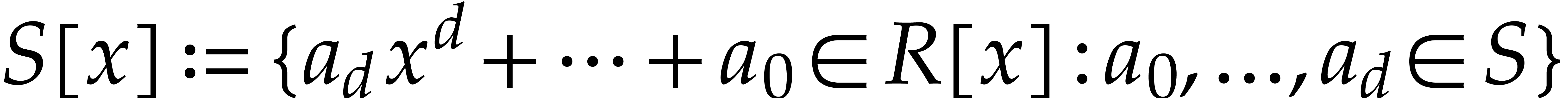 ,
and extend the above notations likewise. This is typically useful in the
case when
,
and extend the above notations likewise. This is typically useful in the
case when 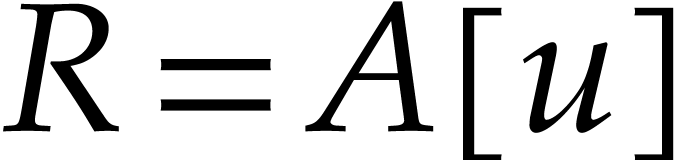 for some other ring
for some other ring  and
and  for some
for some 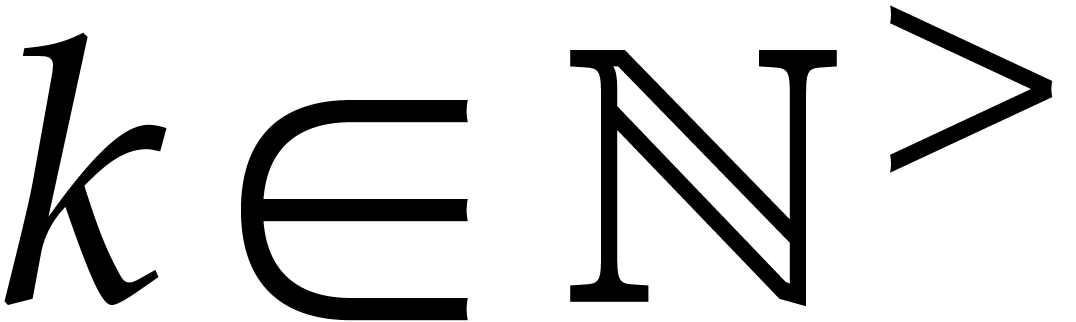 .
.
In our algorithms, we will only consider effective rings , whose elements can be represented
using data structures of a fixed bitsize  and
such that algorithms are available for the ring operations. We will
always assume that additions and subtractions can be computed in linear
time
and
such that algorithms are available for the ring operations. We will
always assume that additions and subtractions can be computed in linear
time 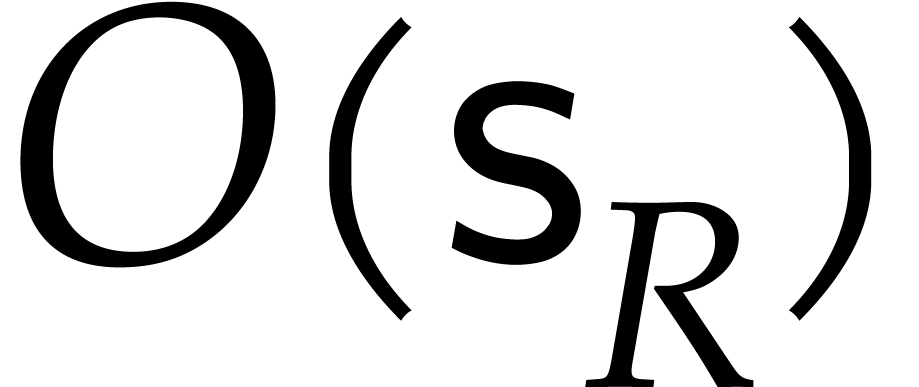 and we denote by
and we denote by 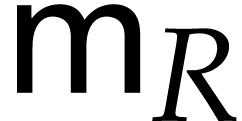 the bit complexity of multiplication in .
For some fixed invertible integer ,
we sometimes need to divide elements of by ; we define
the bit complexity of multiplication in .
For some fixed invertible integer ,
we sometimes need to divide elements of by ; we define 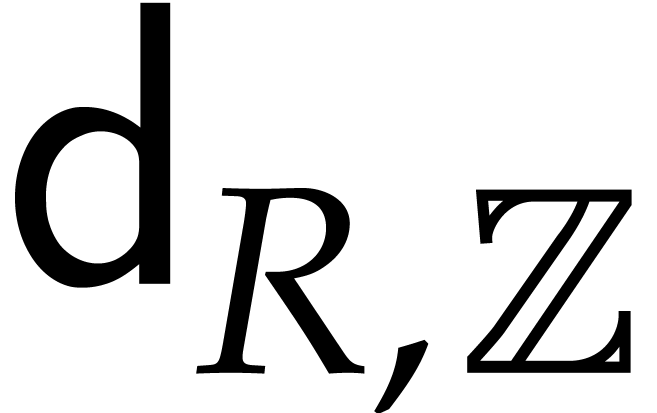 to be the cost of such a division (assuming that a pre-inverse of has been precomputed). If
with
to be the cost of such a division (assuming that a pre-inverse of has been precomputed). If
with  and prime, then we
have
and prime, then we
have  ,
, 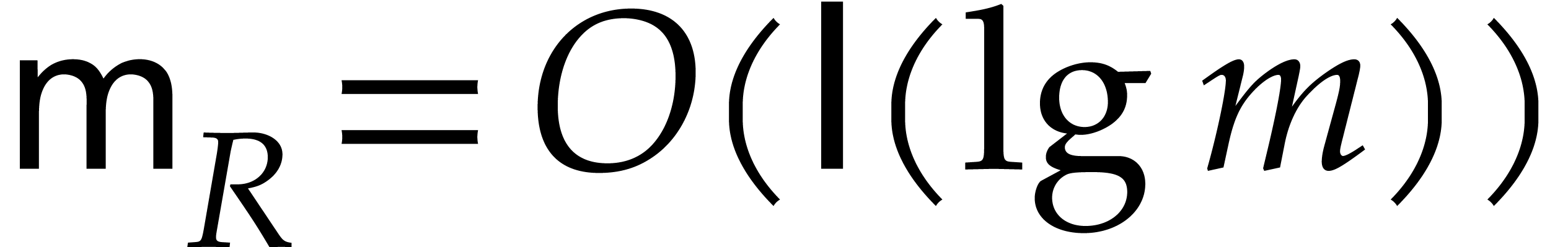 , and
, and 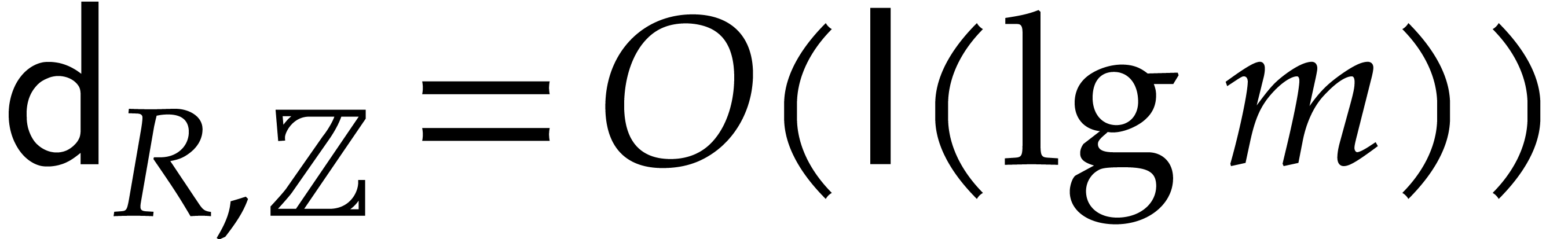 ,
where
,
where 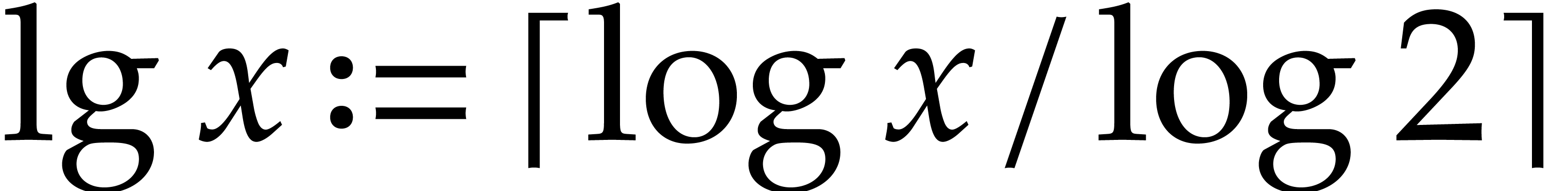 .
.
We write 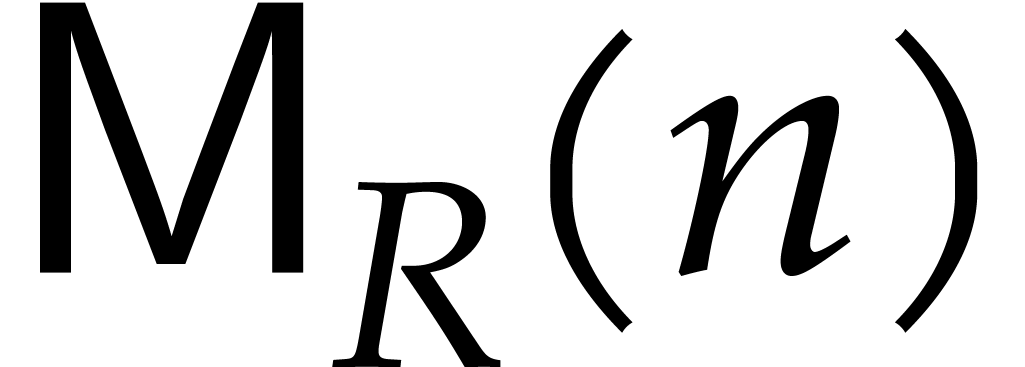 for the bit complexity of multiplying
two polynomials in
for the bit complexity of multiplying
two polynomials in 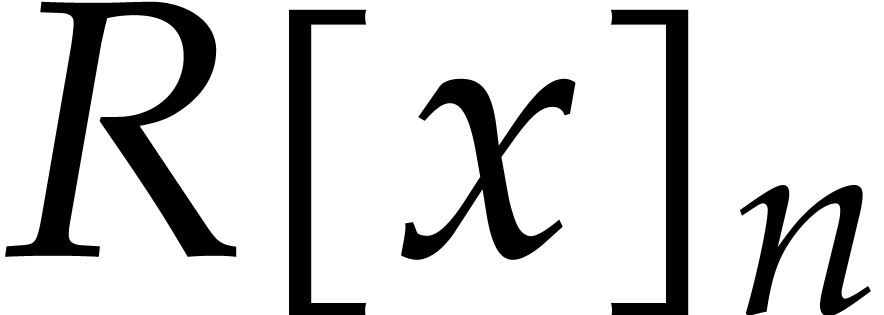 . We also
define
. We also
define 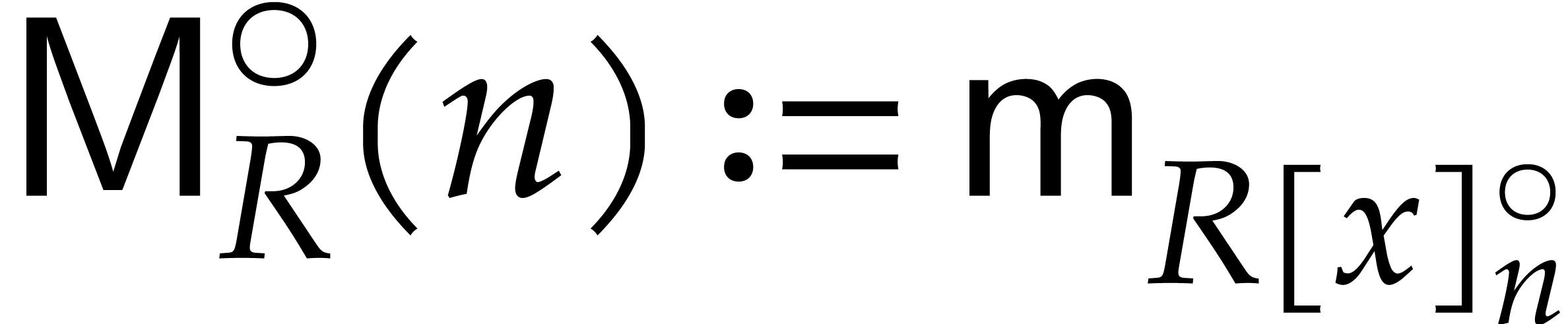 and
and 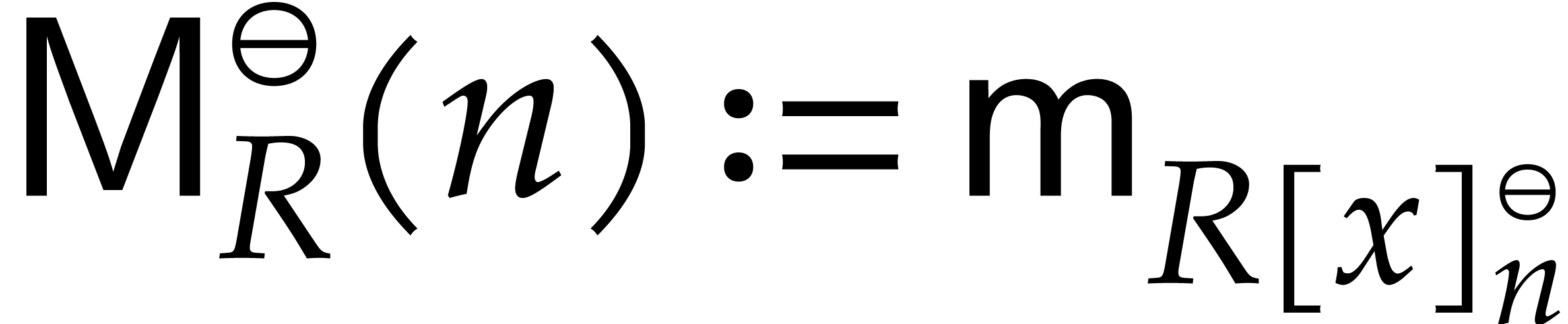 .
Multiplications in and
are also called cyclic convolutions and negacyclic
convolutions. Since reduction modulo
.
Multiplications in and
are also called cyclic convolutions and negacyclic
convolutions. Since reduction modulo 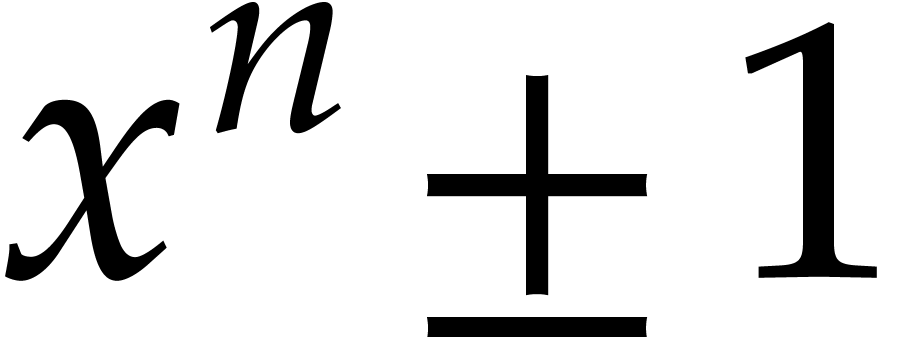 can be
performed using additions, we clearly have
can be
performed using additions, we clearly have
We also have
since  for all
for all 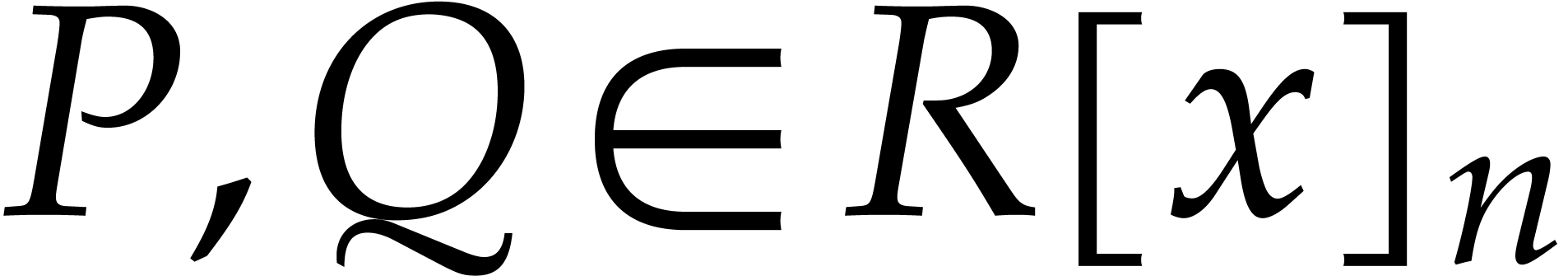 .
.
In this paper we will frequently convert between various
representations. Given a computable ring morphism
between two effective rings and 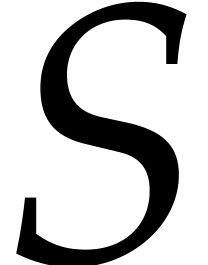 , we will write
, we will write 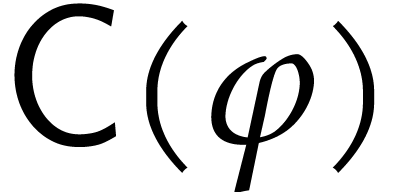 for the
cost of applying to an element of . If is an embedding of
into that is clear from
the context, then we will also write
for the
cost of applying to an element of . If is an embedding of
into that is clear from
the context, then we will also write 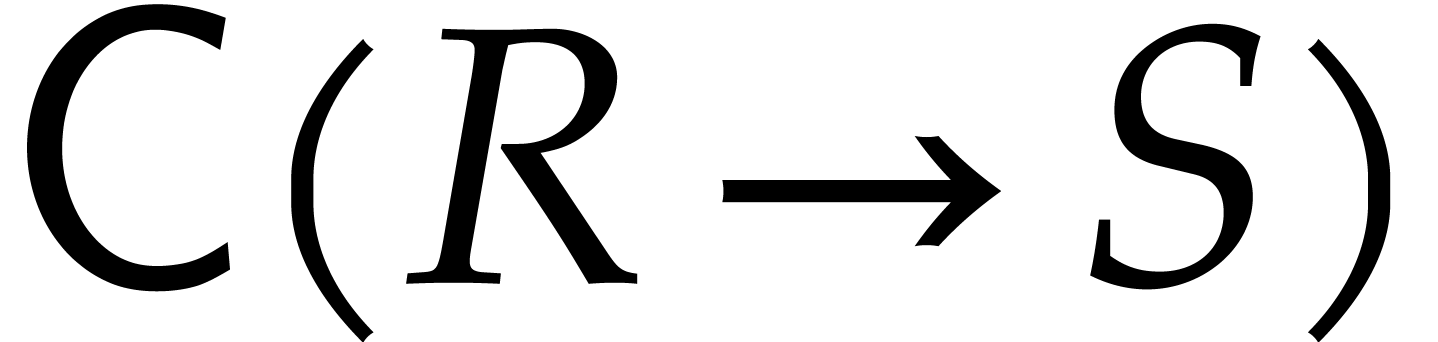 instead of
. If
and are isomorphic, with morphisms and
instead of
. If
and are isomorphic, with morphisms and 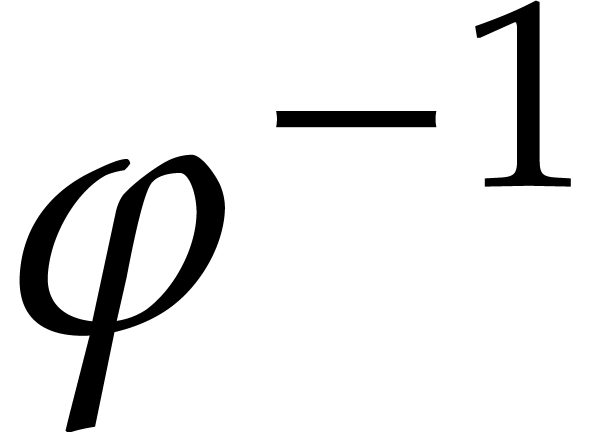 for performing the conversions
that are clear from context, then we define
for performing the conversions
that are clear from context, then we define  .
.
Let be a ring with identity and let be such that 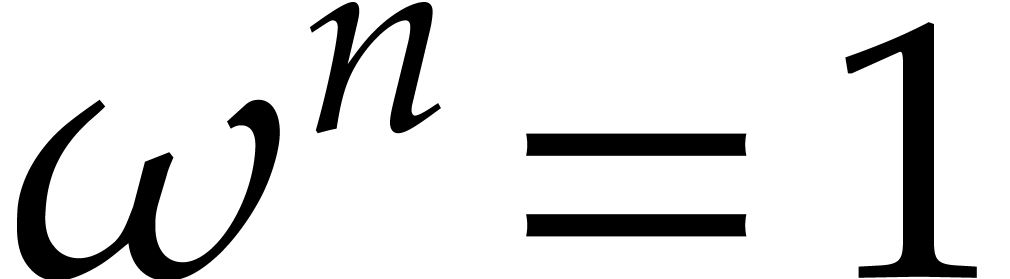 for some . Given a vector
for some . Given a vector 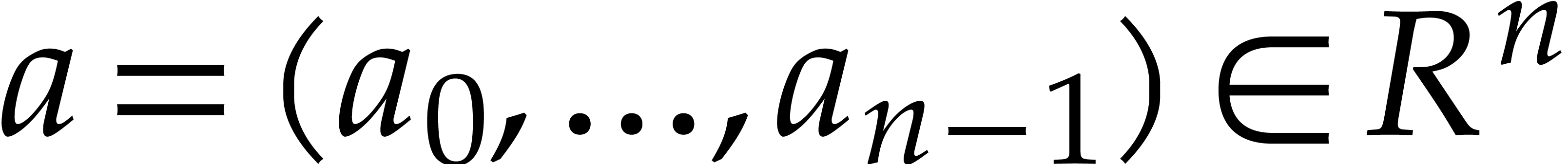 ,
we may form the polynomial
,
we may form the polynomial 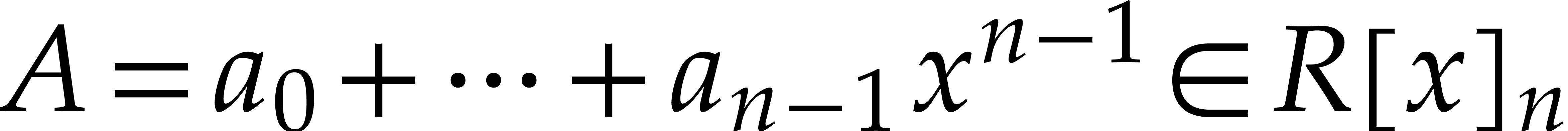 ,
and we define the discrete Fourier transform of
,
and we define the discrete Fourier transform of  with respect to to be the vector
with respect to to be the vector
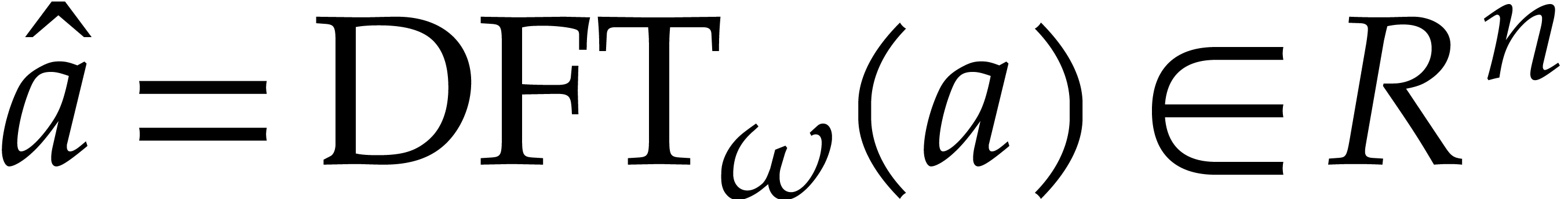 with
with 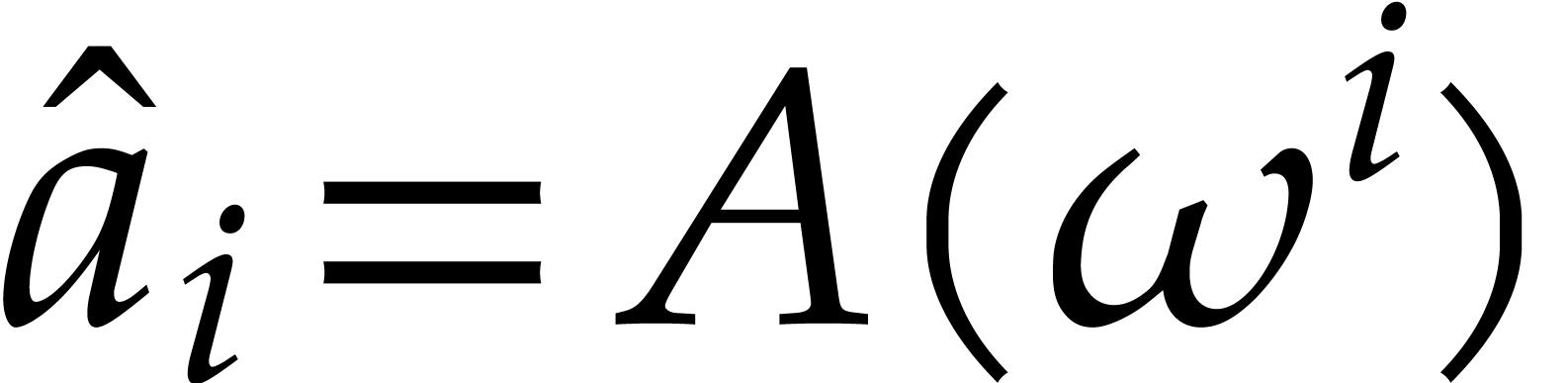 for all
for all 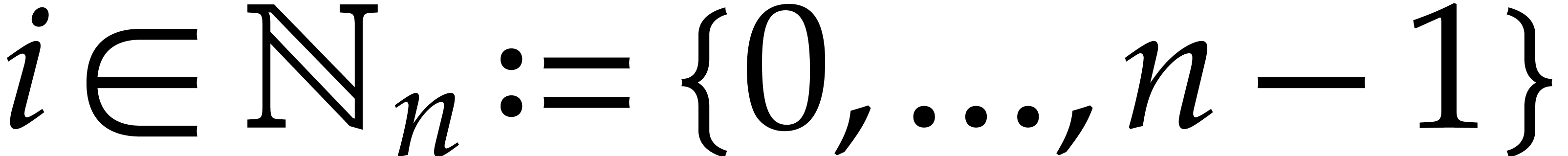 .
.
Assume now that is a principal -th root of unity, meaning that
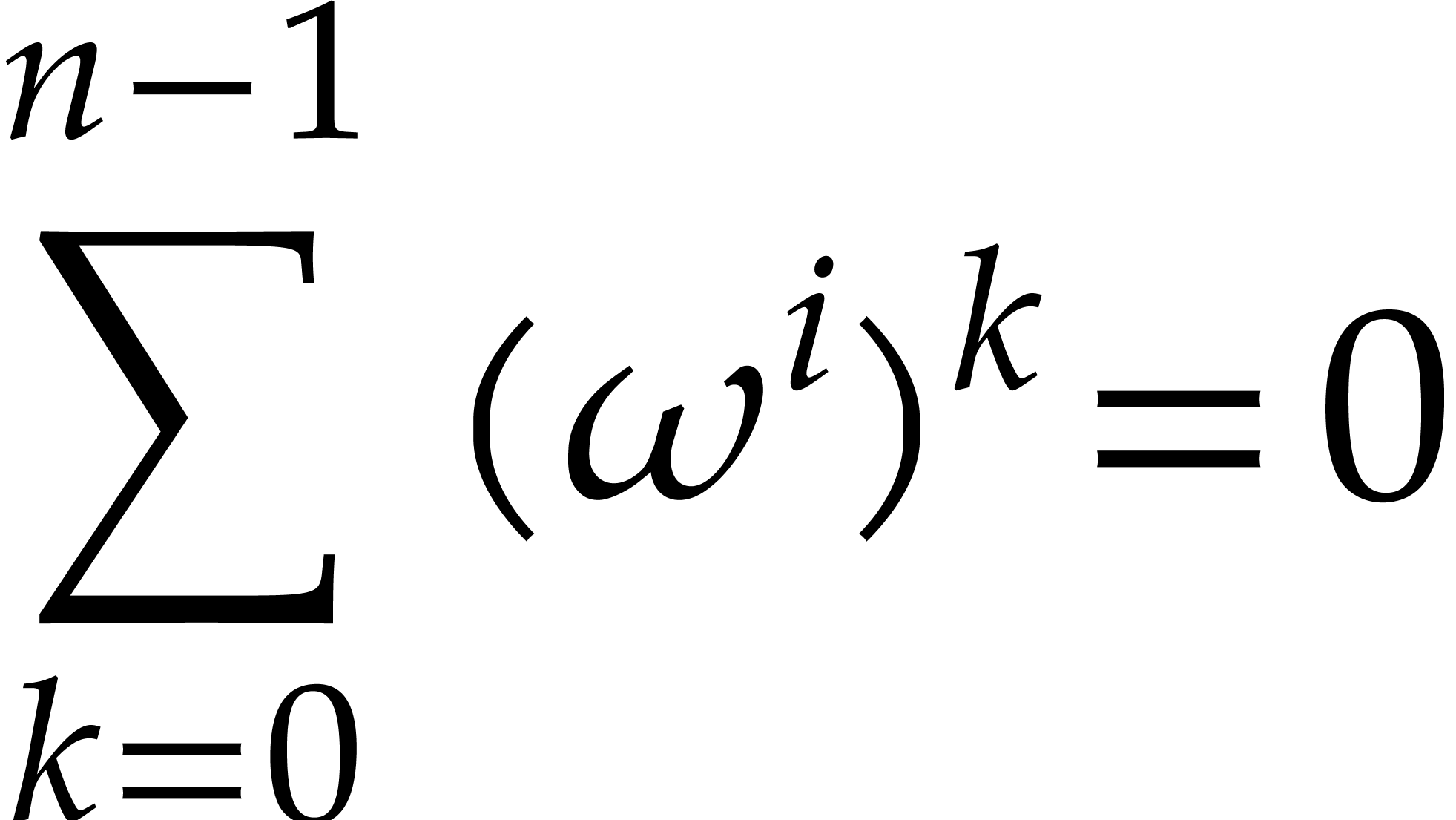 |
(2.5) |
for all  . Then
. Then 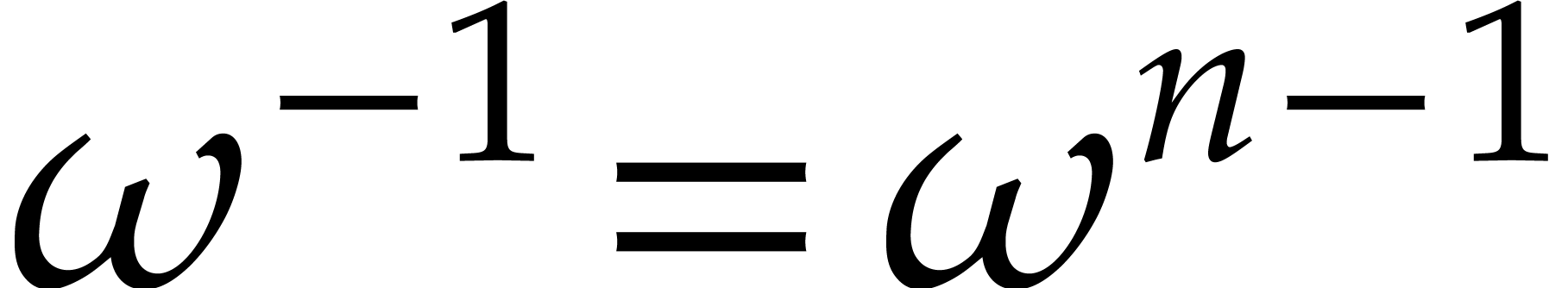 is again a principal -th
root of unity, and we have
is again a principal -th
root of unity, and we have
Indeed, writing 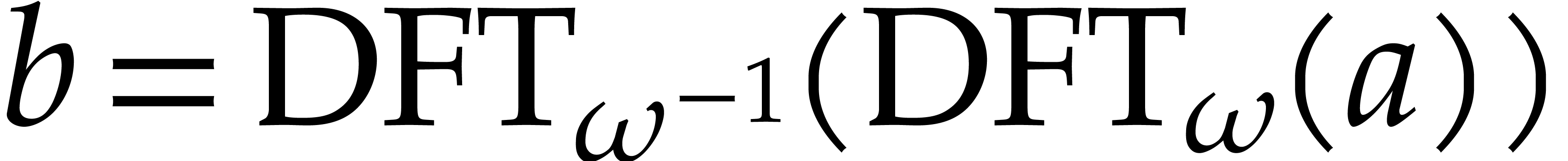 , the
relation (2.5) implies that
, the
relation (2.5) implies that
where 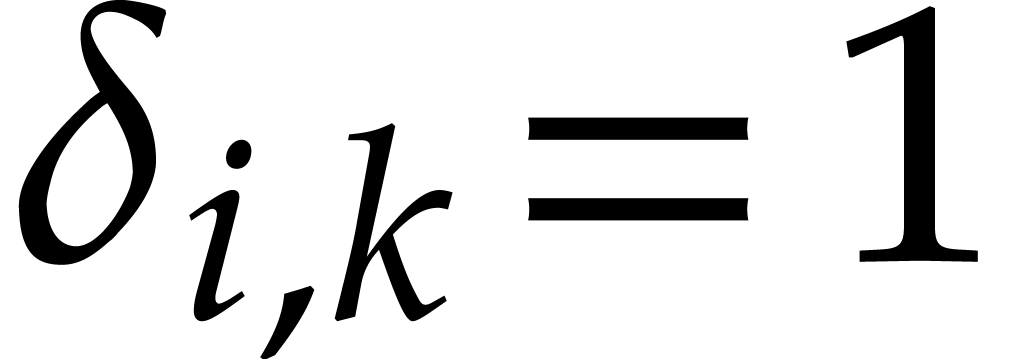 if
if 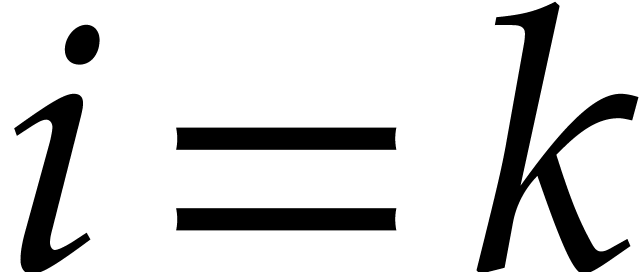 and
and 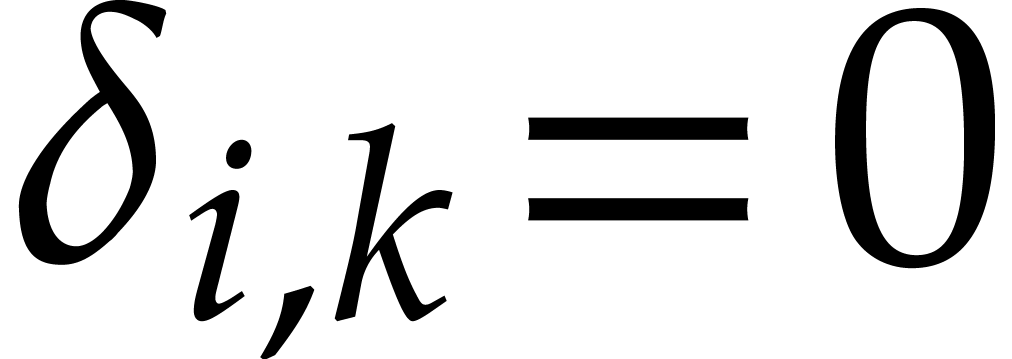 otherwise.
otherwise.
Consider any -th root of
unity 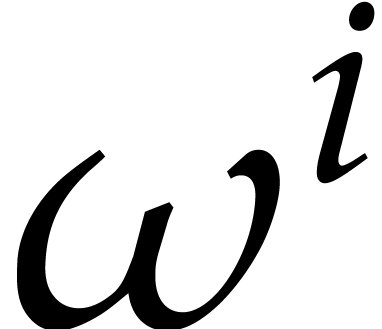 . Given a cyclic
polynomial
. Given a cyclic
polynomial 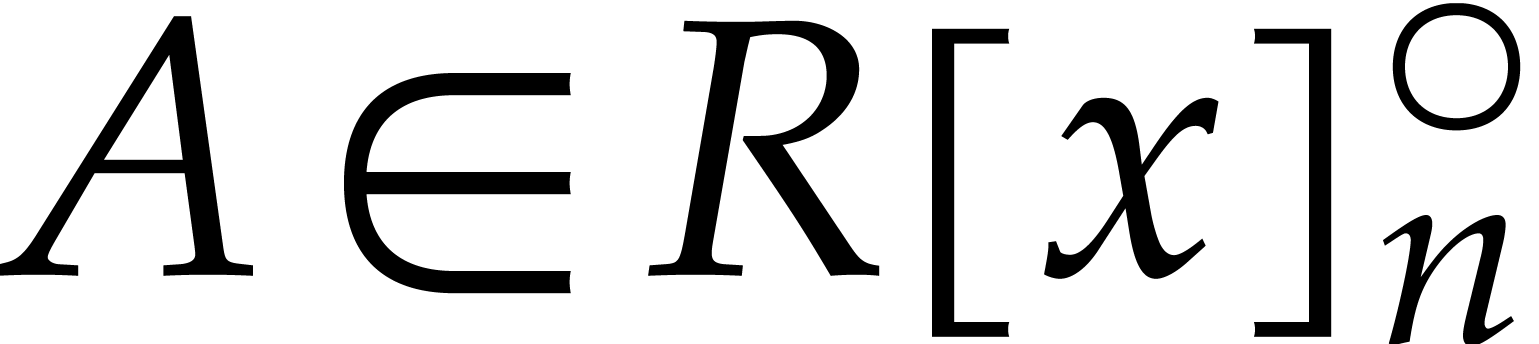 that is presented as the class of a
polynomial
that is presented as the class of a
polynomial  modulo
modulo 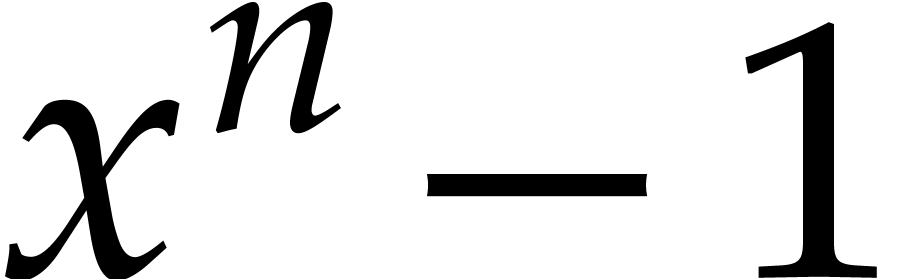 ,
the value
,
the value 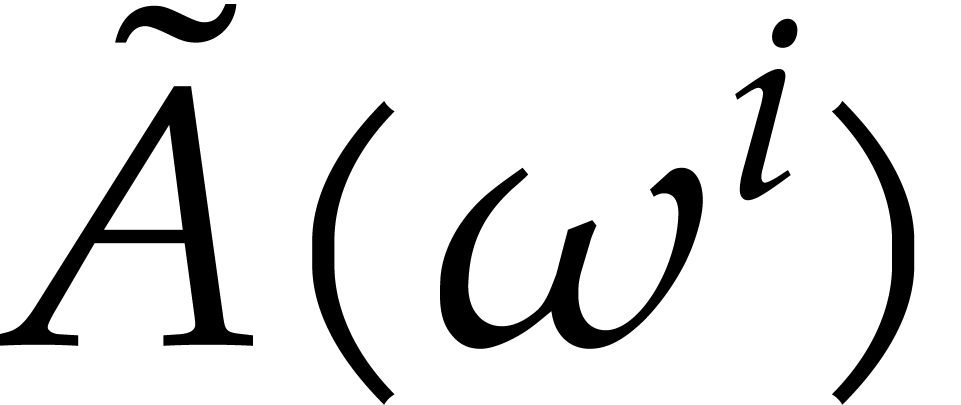 does not depend on the choice of
does not depend on the choice of  . It is therefore natural to
consider
. It is therefore natural to
consider 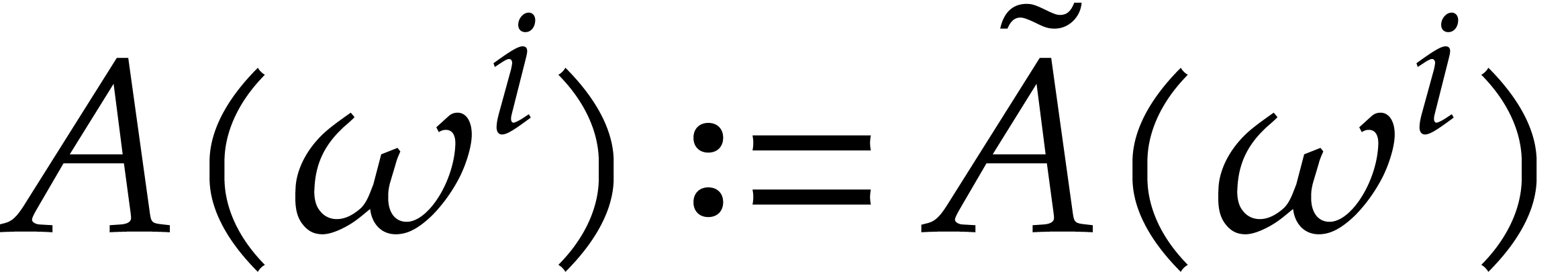 as the evaluation of
at . It is now convenient to
extend the definition of the discrete Fourier transform and set
as the evaluation of
at . It is now convenient to
extend the definition of the discrete Fourier transform and set 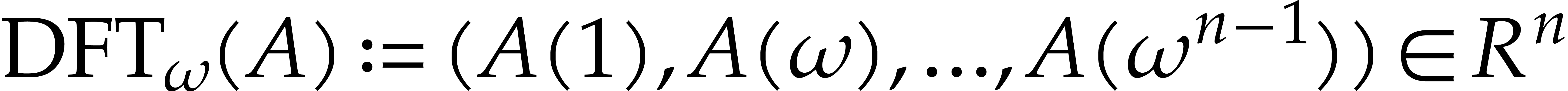 . If is
invertible in , then
. If is
invertible in , then  becomes a ring isomorphism between the rings and
becomes a ring isomorphism between the rings and 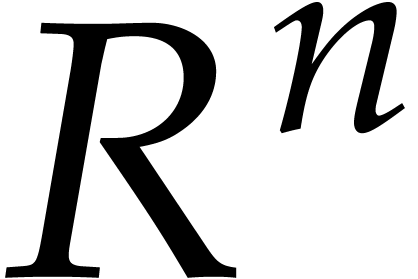 .
Indeed, for any
.
Indeed, for any 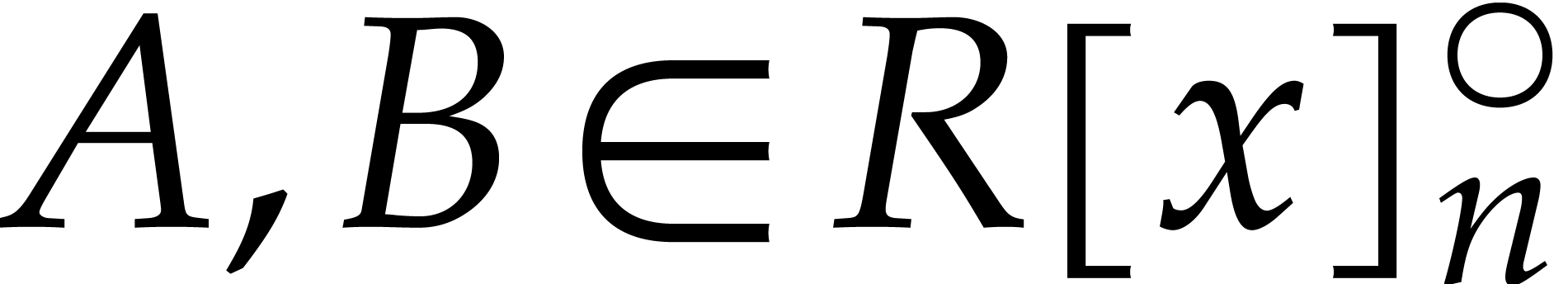 and
and  , we have
, we have 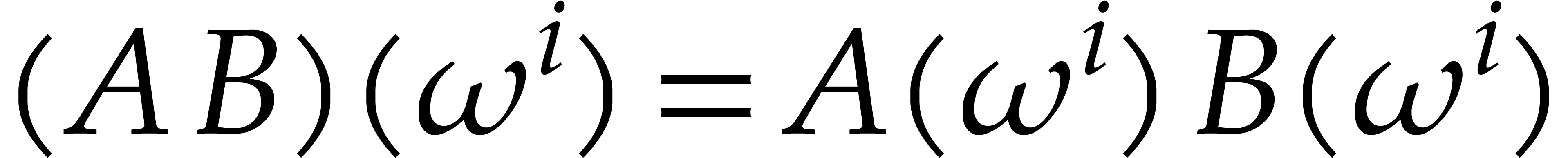 .
Furthermore, the relation (2.6) provides us with a way to
compute the inverse transform
.
Furthermore, the relation (2.6) provides us with a way to
compute the inverse transform 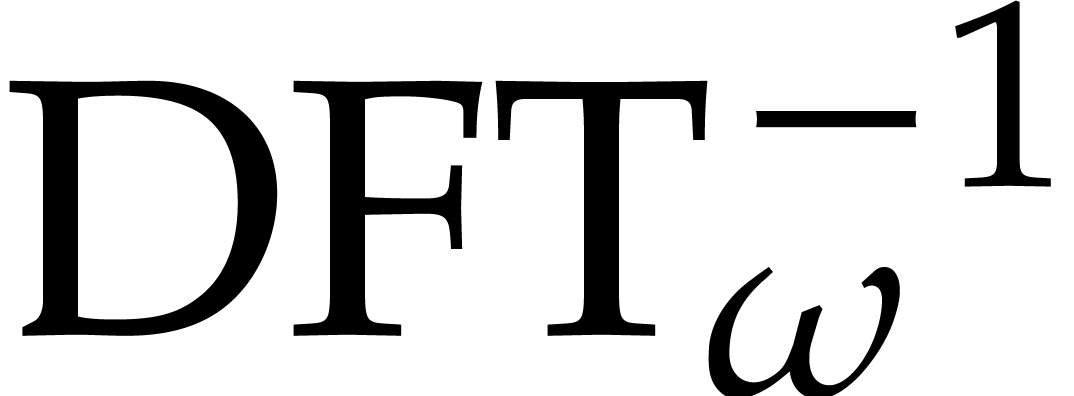 .
.
In particular, denoting by 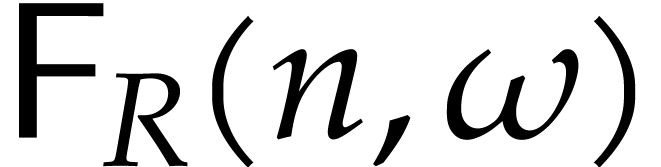 the cost of computing
a discrete Fourier transform of length with
respect to , we get
the cost of computing
a discrete Fourier transform of length with
respect to , we get
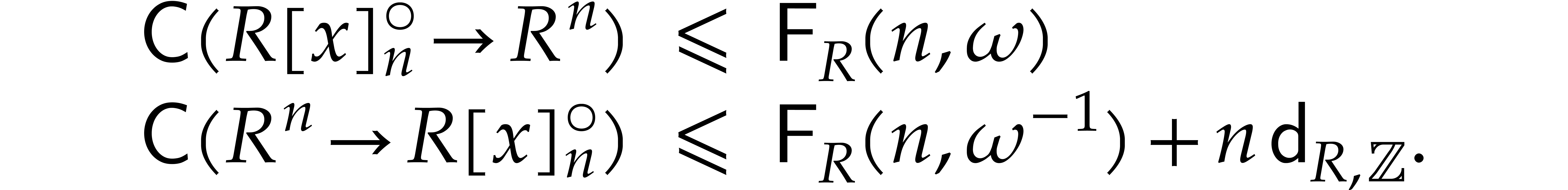
Since and 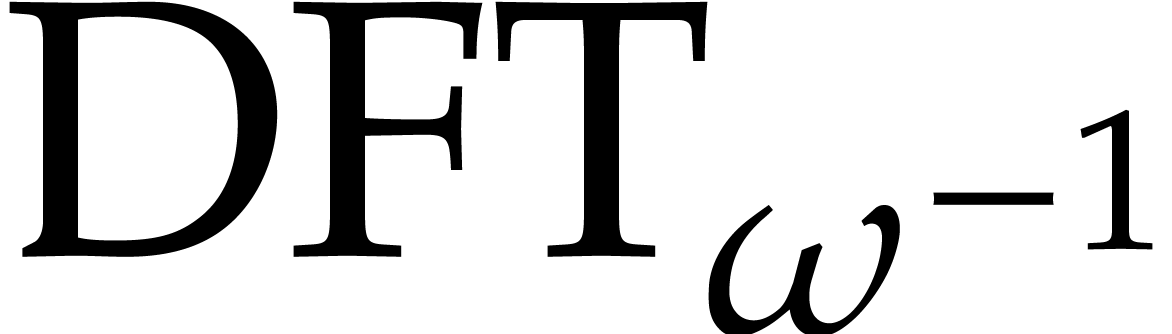 coincide up to
a simple permutation, we also notice that
coincide up to
a simple permutation, we also notice that 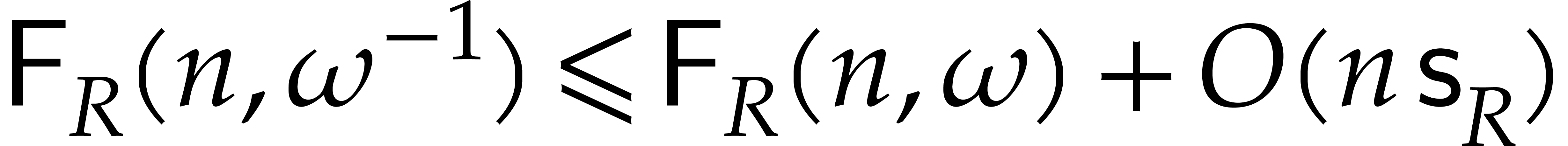 .
Setting
.
Setting 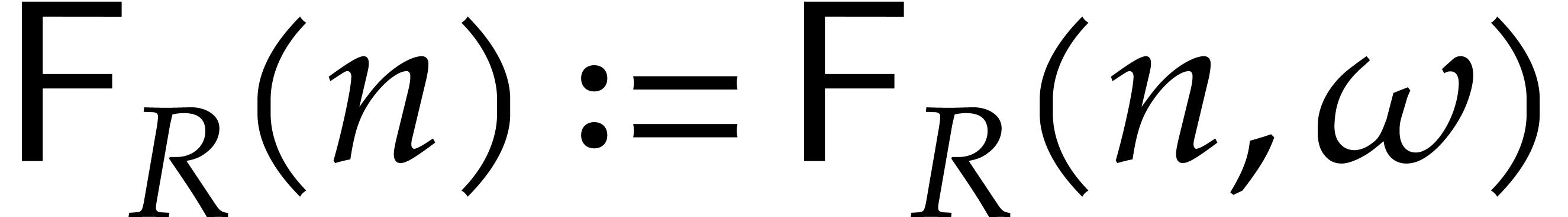 for some “privileged”
principal -th root of unity
(that will always be clear from the context), it
follows that
for some “privileged”
principal -th root of unity
(that will always be clear from the context), it
follows that 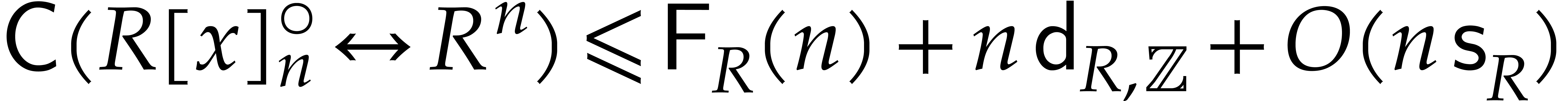 .
.
A well known application of this isomorphism is to compute cyclic
convolutions  for in using the formula
for in using the formula
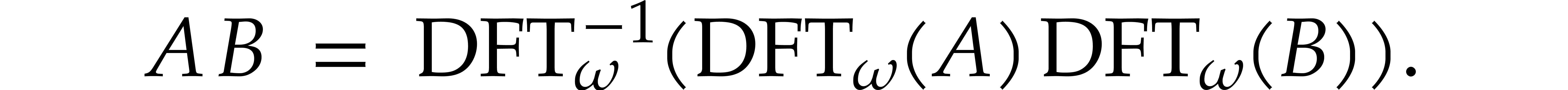
It follows that
Computing cyclic convolutions in this way is called fast Fourier multiplication.
Let be a principal -th
root of unity and let 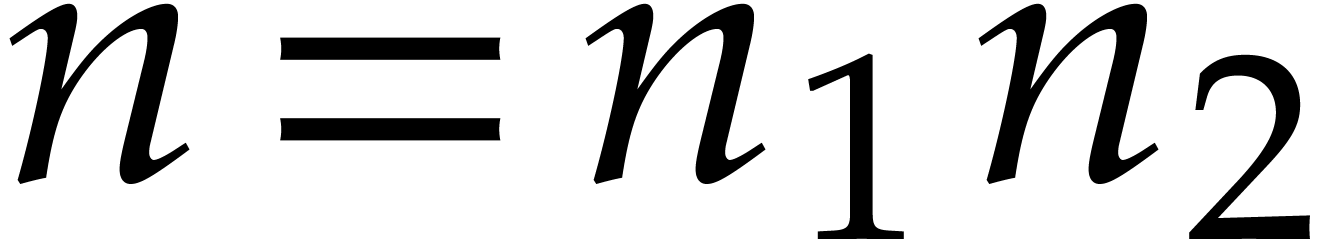 where
where 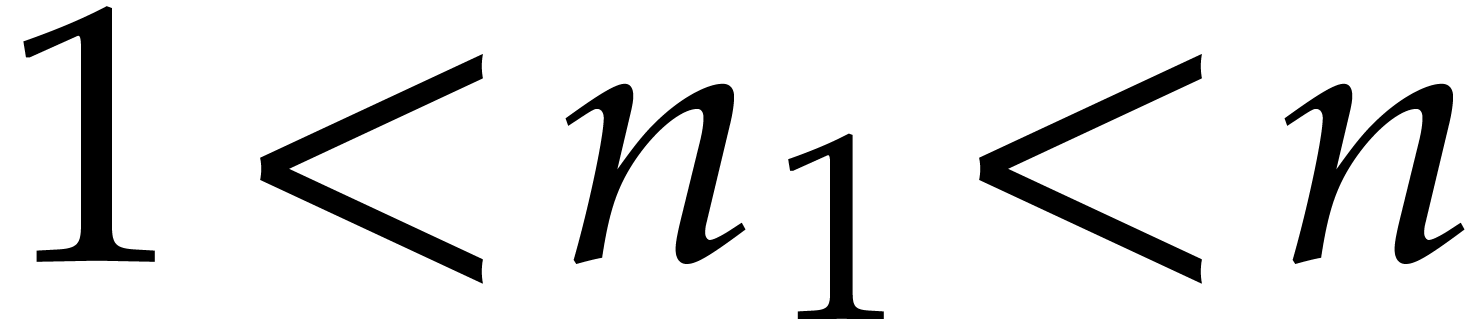 . Then
. Then  is a principal
is a principal
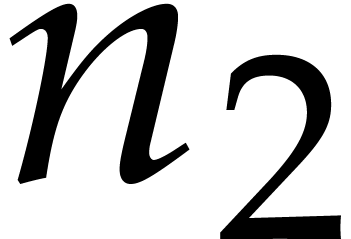 -th root of unity and
-th root of unity and 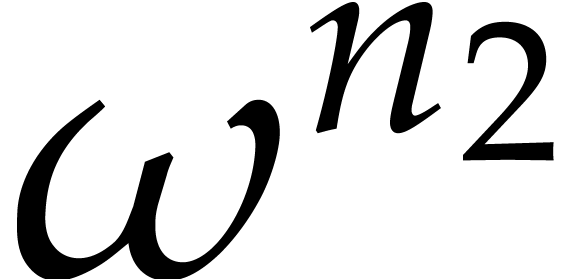 is a principal
is a principal 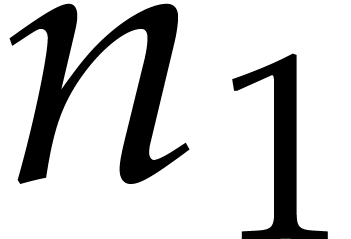 -th
root of unity. Moreover, for any
-th
root of unity. Moreover, for any  and
and  , we have
, we have
If  and
and  are algorithms
for computing DFTs of length and , then we may use
as follows.
are algorithms
for computing DFTs of length and , then we may use
as follows.
For each  , the sum inside the
brackets corresponds to the
, the sum inside the
brackets corresponds to the  -th
coefficient of a DFT of the -tuple
-th
coefficient of a DFT of the -tuple
 with respect to .
Evaluating these inner DFTs requires
calls to . Next, we multiply
by the twiddle factors
with respect to .
Evaluating these inner DFTs requires
calls to . Next, we multiply
by the twiddle factors 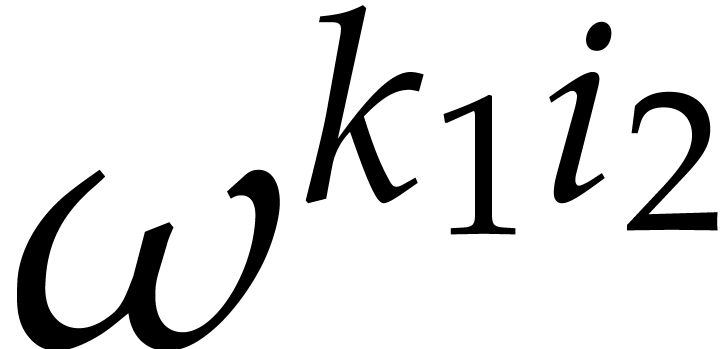 ,
at a cost of operations in . Finally, for each , the outer sum corresponds to the
,
at a cost of operations in . Finally, for each , the outer sum corresponds to the  -th coefficient of a DFT of an -tuple in
-th coefficient of a DFT of an -tuple in  with respect
to . These outer DFTs
require calls to .
On a Turing machine, the application of the
inner DFTs also requires us to reorganize into
consecutive vectors of size , and vice versa. This can be done in
time
with respect
to . These outer DFTs
require calls to .
On a Turing machine, the application of the
inner DFTs also requires us to reorganize into
consecutive vectors of size , and vice versa. This can be done in
time  using matrix transpositions (see section A.1 in the appendix).
using matrix transpositions (see section A.1 in the appendix).
Let  denote the cost of performing a DFT of
length , while assuming that
the twiddle factors
denote the cost of performing a DFT of
length , while assuming that
the twiddle factors 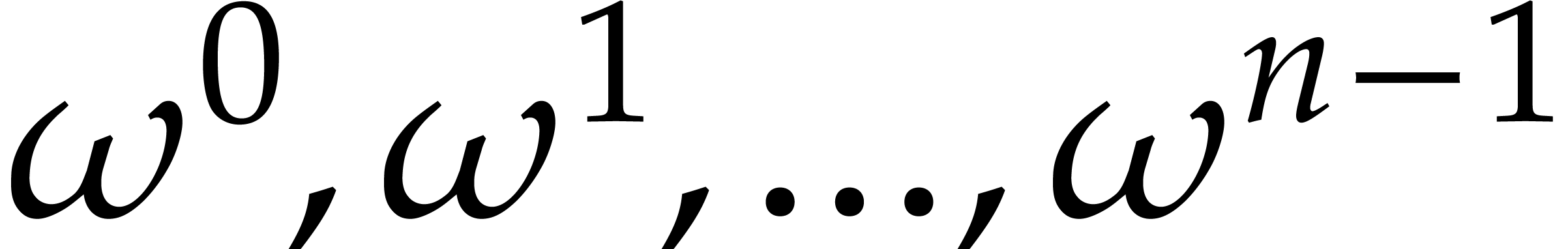 have been precomputed. Then
computing the DFT using the above Cooley–Tukey algorithm yields
the bound
have been precomputed. Then
computing the DFT using the above Cooley–Tukey algorithm yields
the bound
For a factorization , an easy
induction over then yields
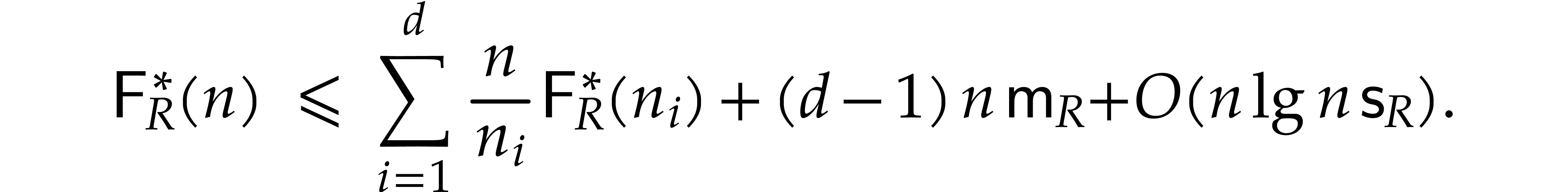
The twiddle factors can obviously be computed in time 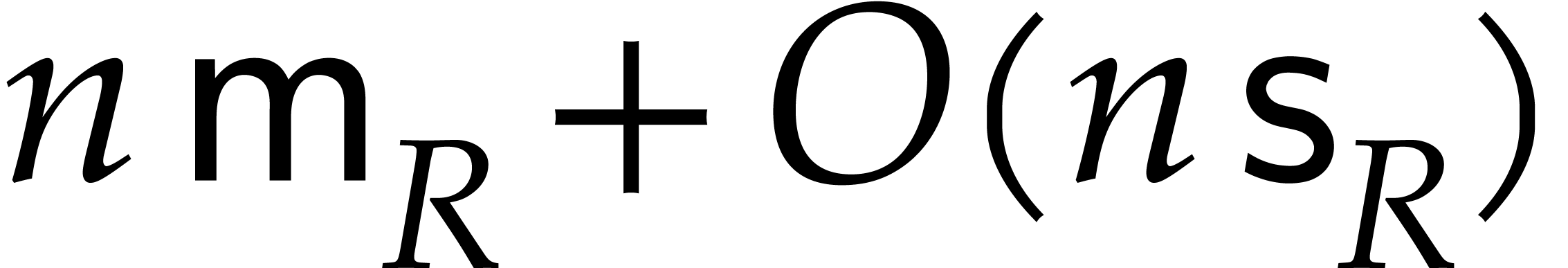 . Altogether, we obtain
. Altogether, we obtain
In the case that 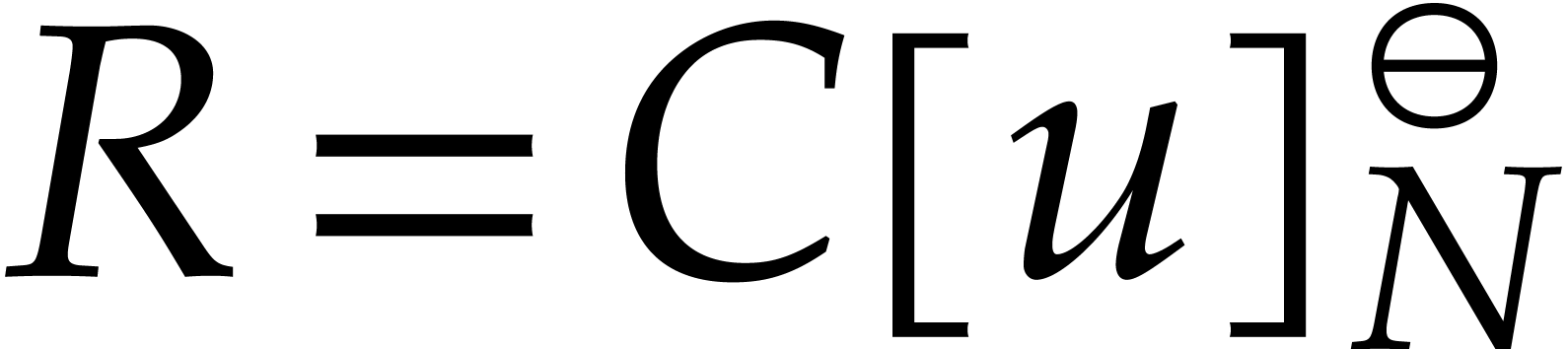 for some effective ring
for some effective ring  and power of two ,
the indeterminate is itself a principal
and power of two ,
the indeterminate is itself a principal 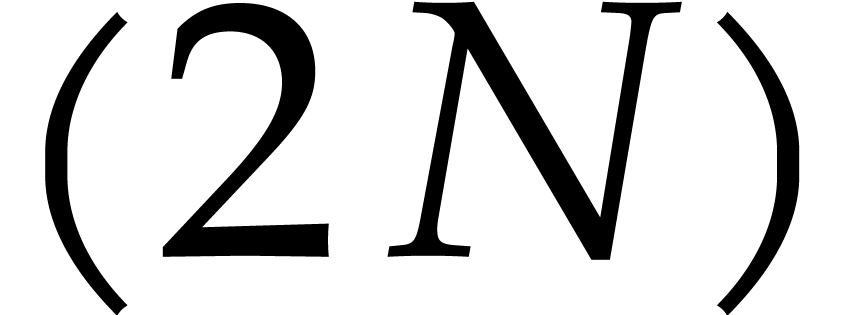 -th root of unity. Moreover,
multiplications by powers of can be computed in
linear time
-th root of unity. Moreover,
multiplications by powers of can be computed in
linear time 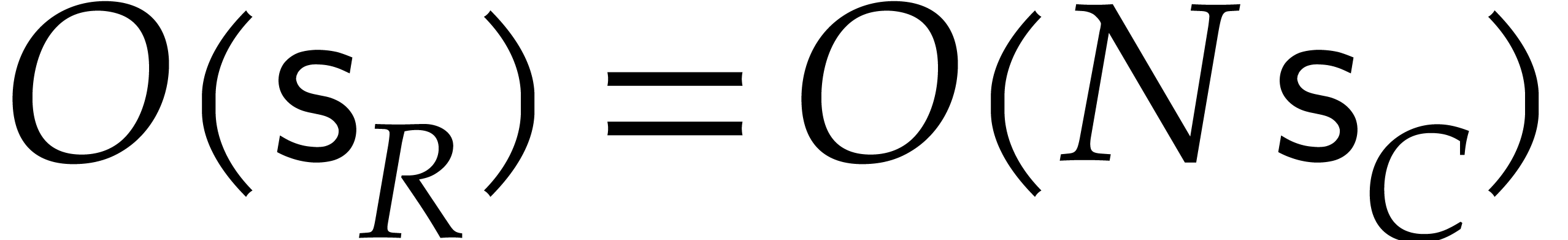 since
since

for all 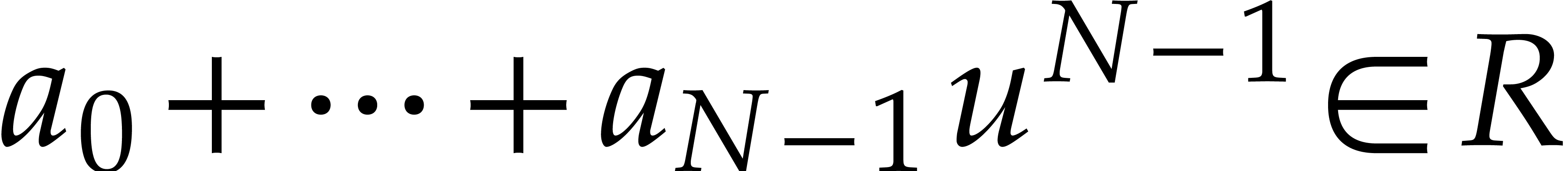 and
and 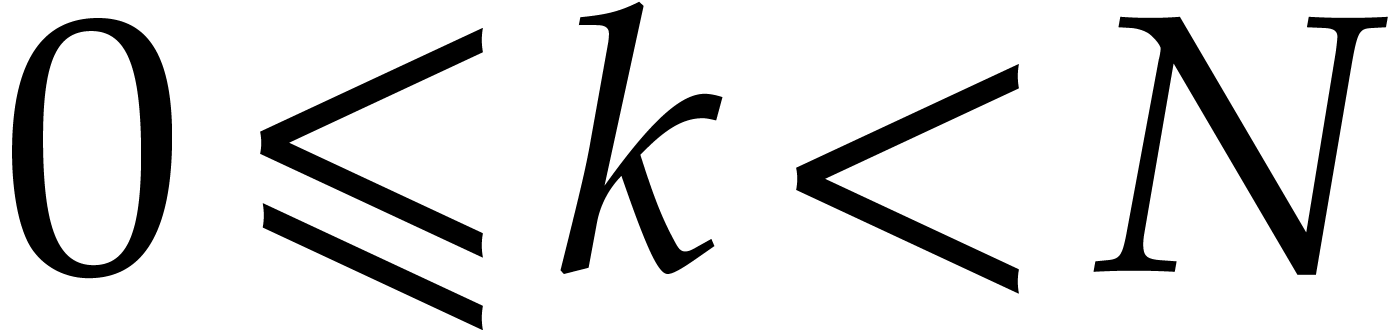 .
For this reason, is sometimes called a fast
principal root of unity.
.
For this reason, is sometimes called a fast
principal root of unity.
Now assume that we wish to compute a discrete Fourier transform of size
over .
Then we may use the Cooley–Tukey algorithm from the previous
subsection with 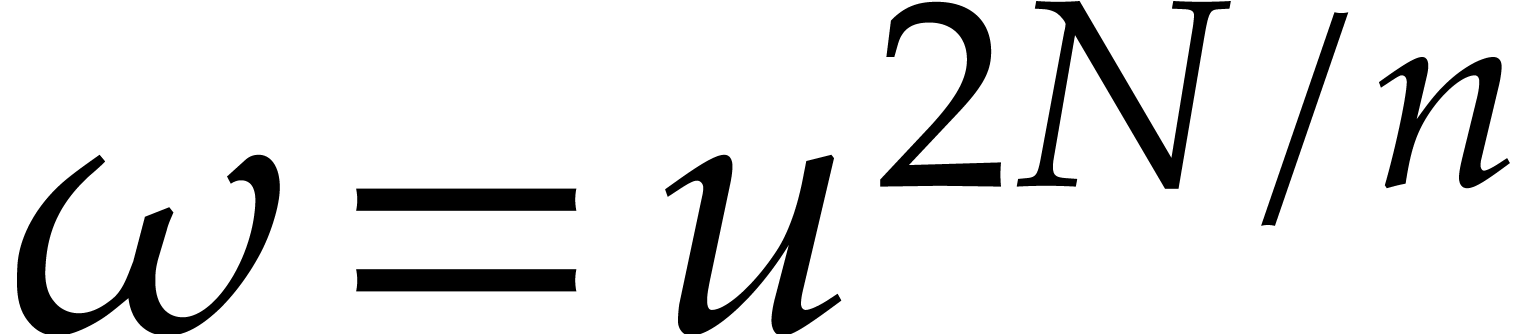 ,
, 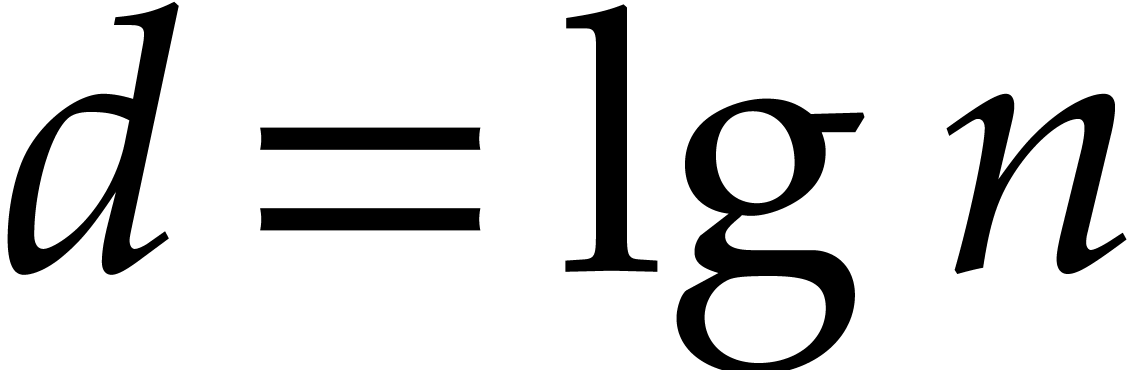 , and
, and  .
When using our faster algorithm for multiplications by twiddle factors,
the term
.
When using our faster algorithm for multiplications by twiddle factors,
the term  in (2.8) can be replaced
by
in (2.8) can be replaced
by  . Moreover, discrete
Fourier transforms of length just map pairs
. Moreover, discrete
Fourier transforms of length just map pairs  to pairs
to pairs  ,
so they can also be computed in linear time . Altogether, the bound (2.8) thus
simplifies into
,
so they can also be computed in linear time . Altogether, the bound (2.8) thus
simplifies into
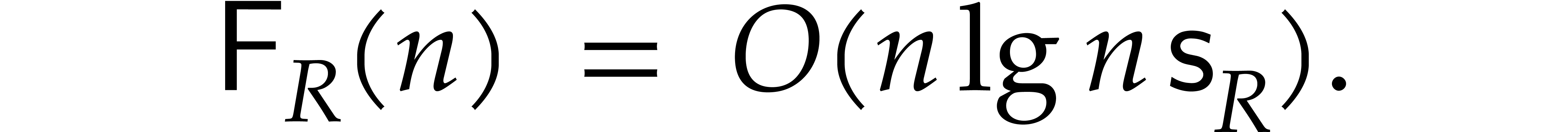
In terms of scalar operations in ,
this yields

Discrete Fourier transforms over rings of the
type considered in this subsection are sometimes qualified as
Nussbaumer polynomial transforms.
If is invertible in the effective ring from the previous subsection, then so is , and we can compute the inverse DFT of length
using
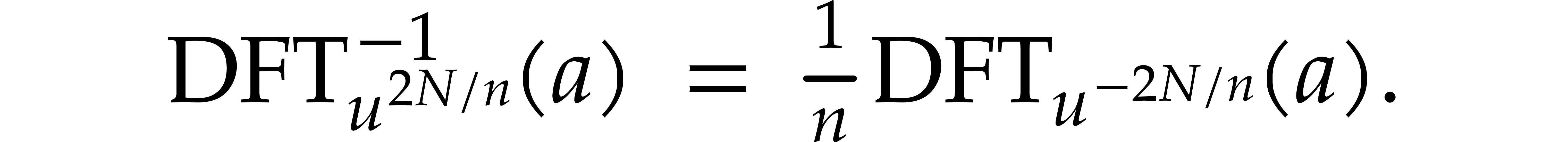
However, if has characteristic
(i.e.  in ), then this is no longer possible, and we need to
adapt the method if we want to use it for polynomial multiplication.
in ), then this is no longer possible, and we need to
adapt the method if we want to use it for polynomial multiplication.
Following Schönhage [48], the remedy is to use triadic
DFTs. More precisely, assuming that 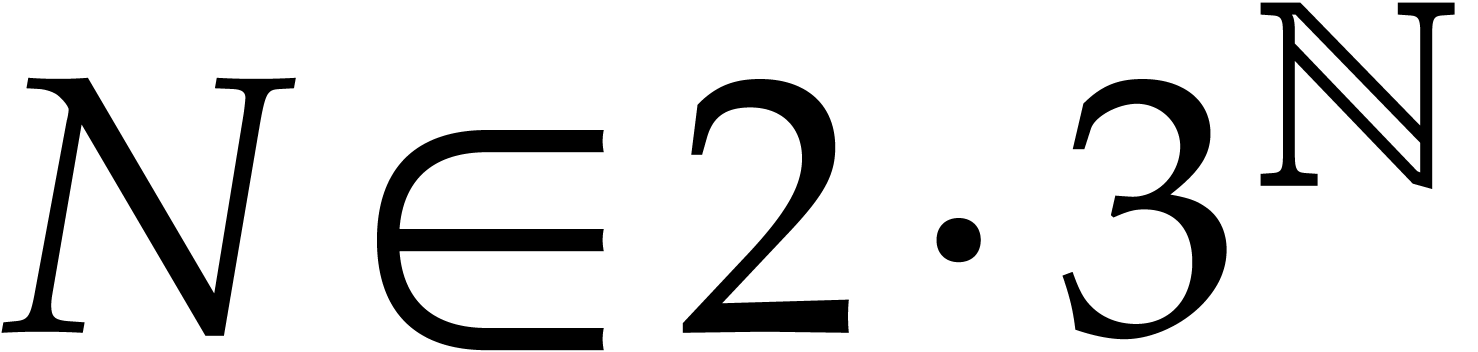 ,
we now work over the ring
,
we now work over the ring 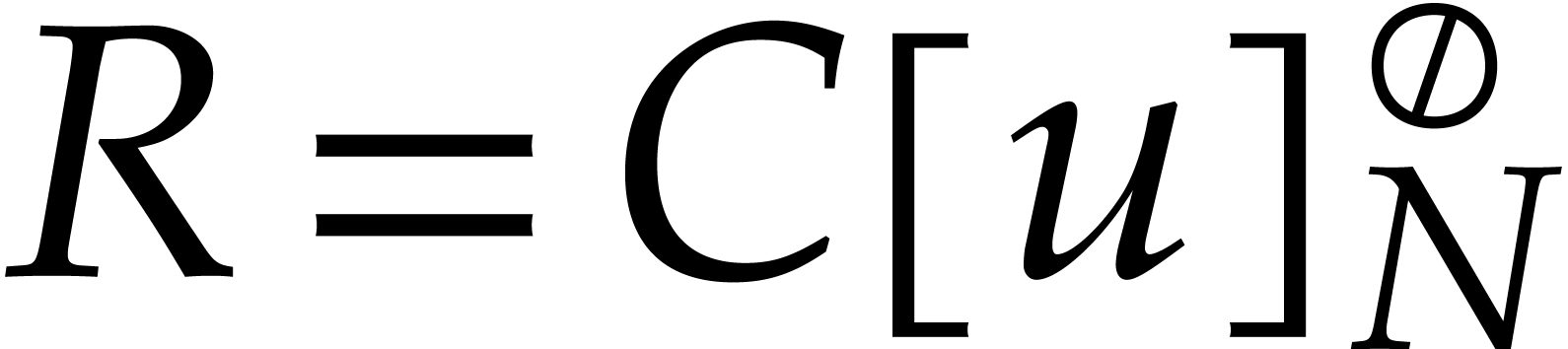 instead of , where
instead of , where
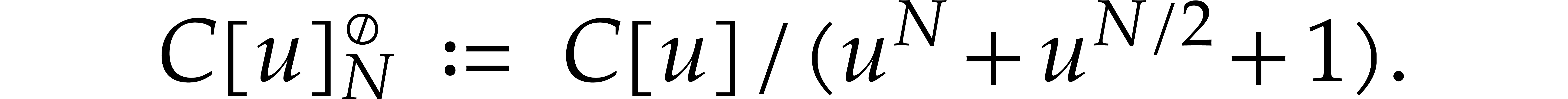
It is easily verified that is a principal  -th root of unity in
-th root of unity in 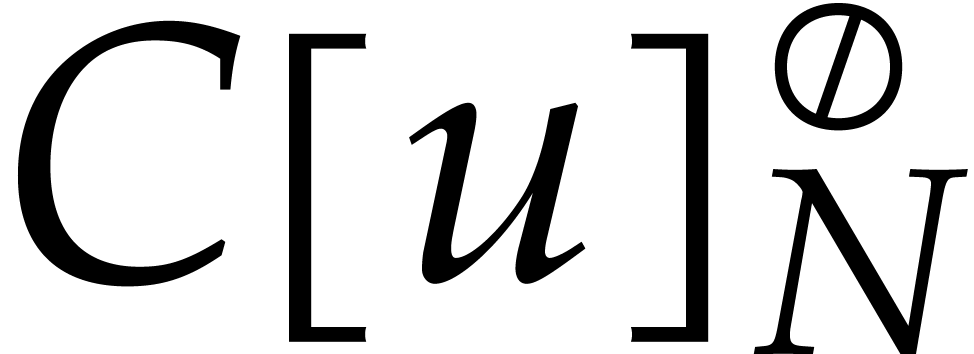 . Moreover, multiplications of elements in with powers of can still be
computed in linear time
. Moreover, multiplications of elements in with powers of can still be
computed in linear time  .
Indeed, given
.
Indeed, given 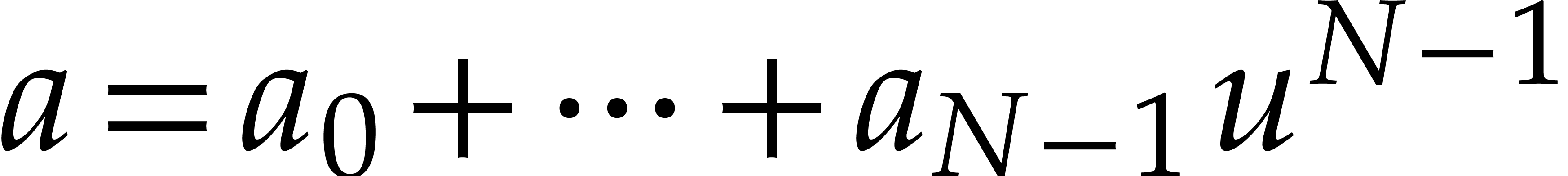 and
and  ,
we have
,
we have
Multiplications with 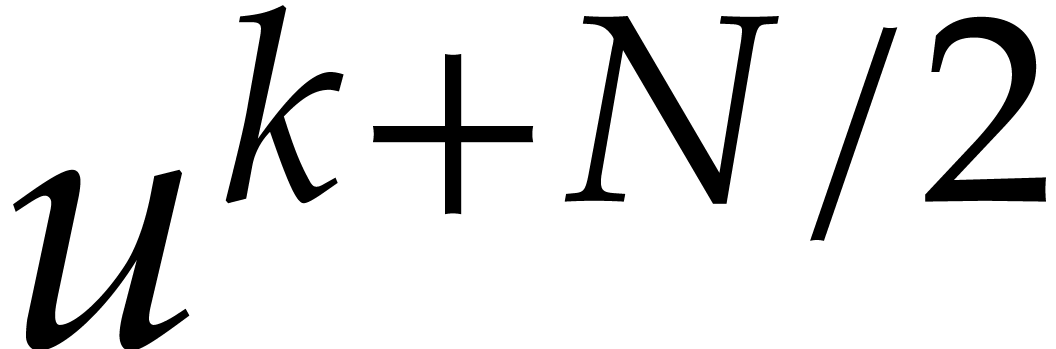 (resp.
(resp. 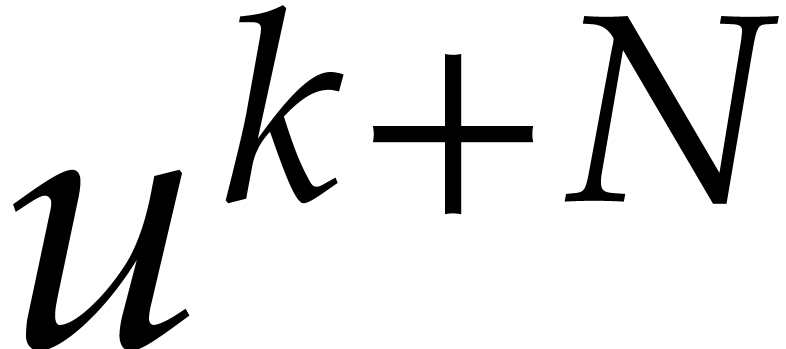 ) can be reduced to this case, by regarding
them as two multiplications with
) can be reduced to this case, by regarding
them as two multiplications with  and
and  (resp. three multiplications with , ,
and ). Using similar
formulas, polynomials in
(resp. three multiplications with , ,
and ). Using similar
formulas, polynomials in  of degree
of degree  can be reduced in linear time
can be reduced in linear time 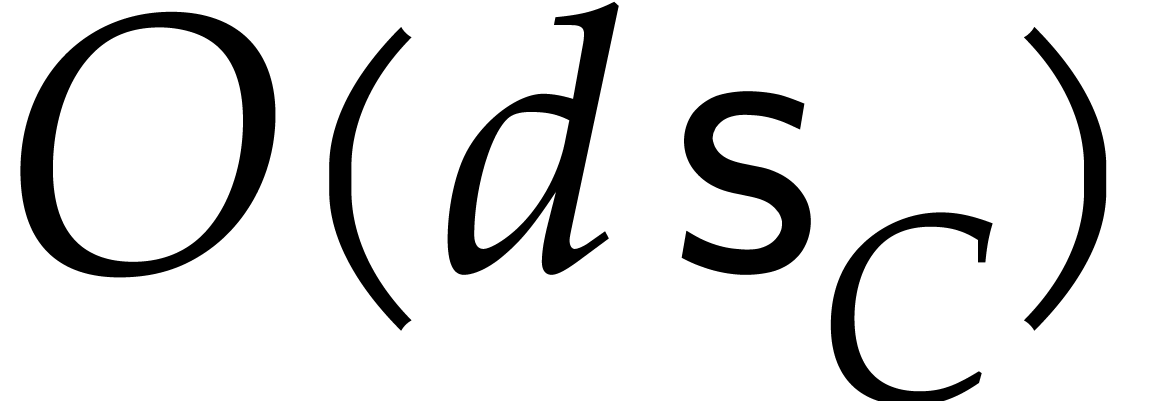 modulo
modulo 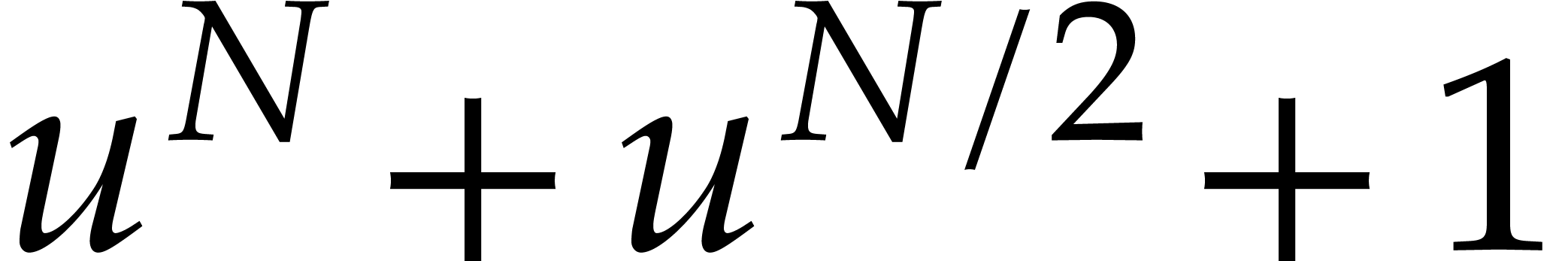 .
.
Now assume that we wish to compute a discrete Fourier transform of size
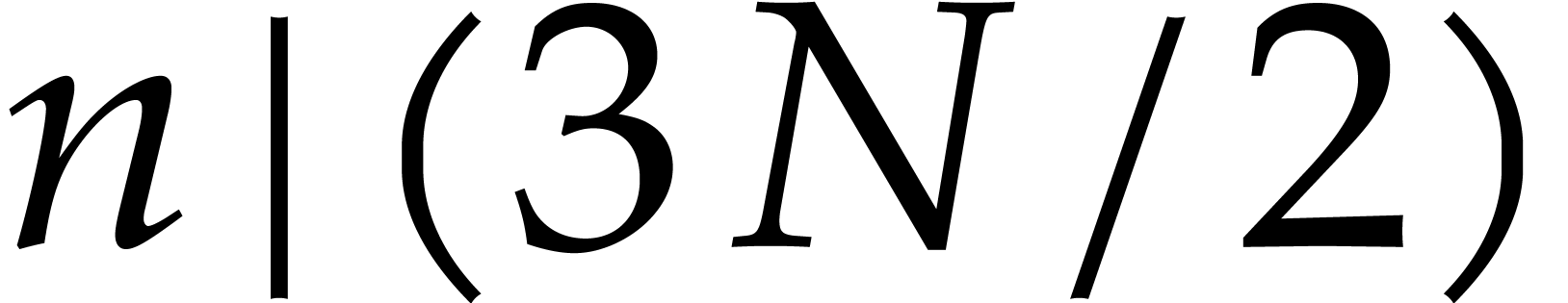 over .
Discrete Fourier transforms of length
over .
Discrete Fourier transforms of length  now map
triples
now map
triples 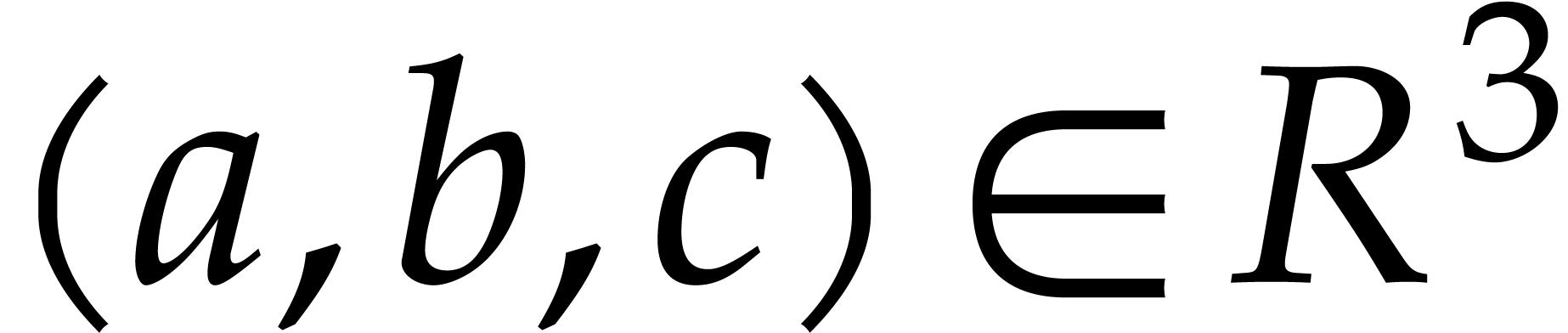 to triples
to triples 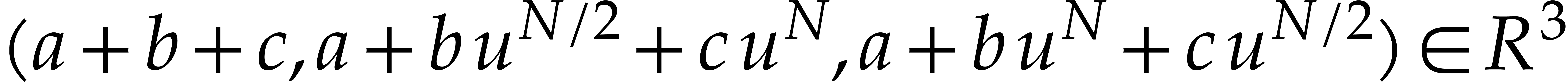 ,
so they can be computed in linear time .
Using the Cooley–Tukey algorithm with
,
so they can be computed in linear time .
Using the Cooley–Tukey algorithm with 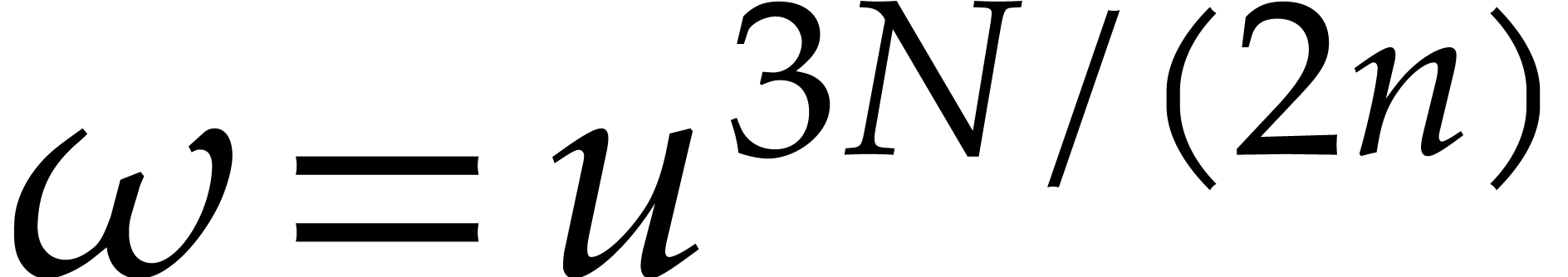 ,
, 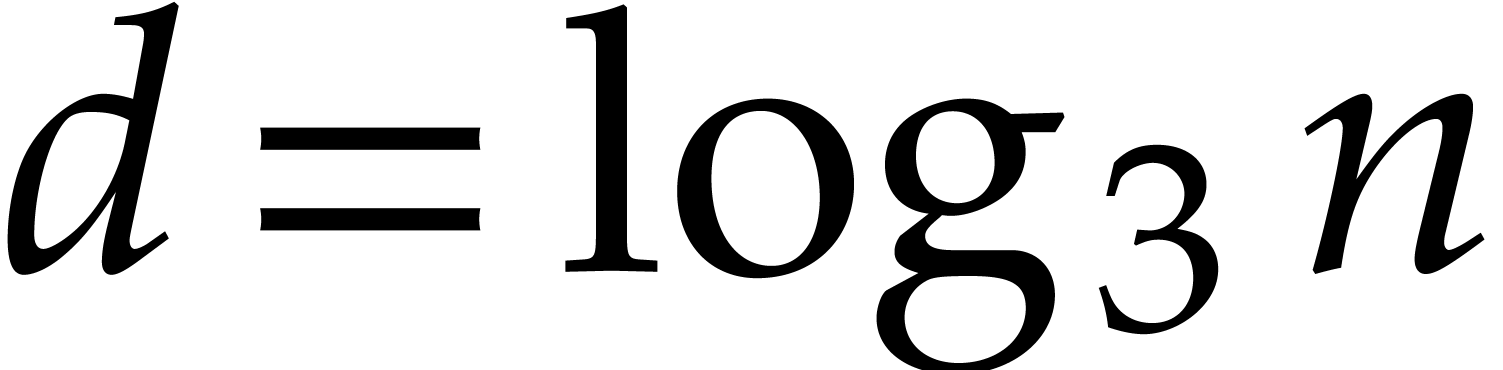 , and
, and
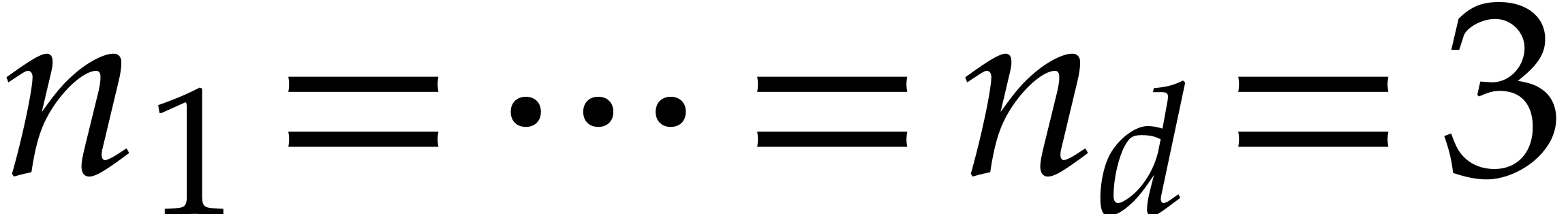 , similar considerations as
in the previous subsection again allows us to conclude that
, similar considerations as
in the previous subsection again allows us to conclude that
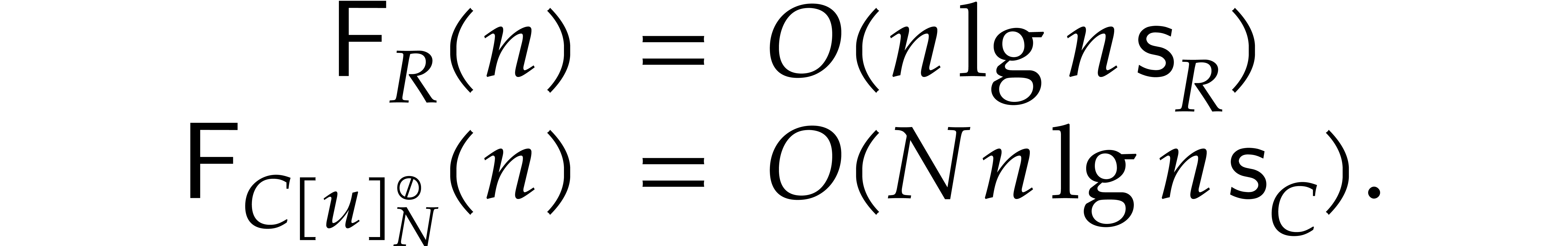
We will qualify discrete Fourier transforms over rings
of this type as triadic Nussbaumer polynomial transforms.
We have shown above how to multiply polynomials using DFTs. Inversely, it is possible to reduce the computation of DFTs — of arbitrary length, not necessarily a power of two — to polynomial multiplication [4], as follows.
Let be a principal -th
root of unity. If is even, then we assume that
there exists some 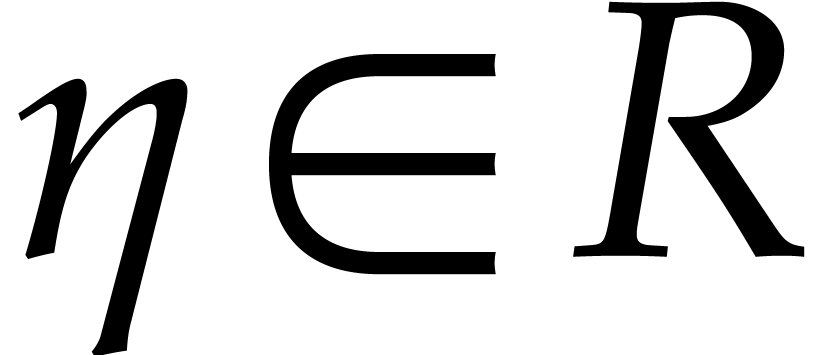 with
with 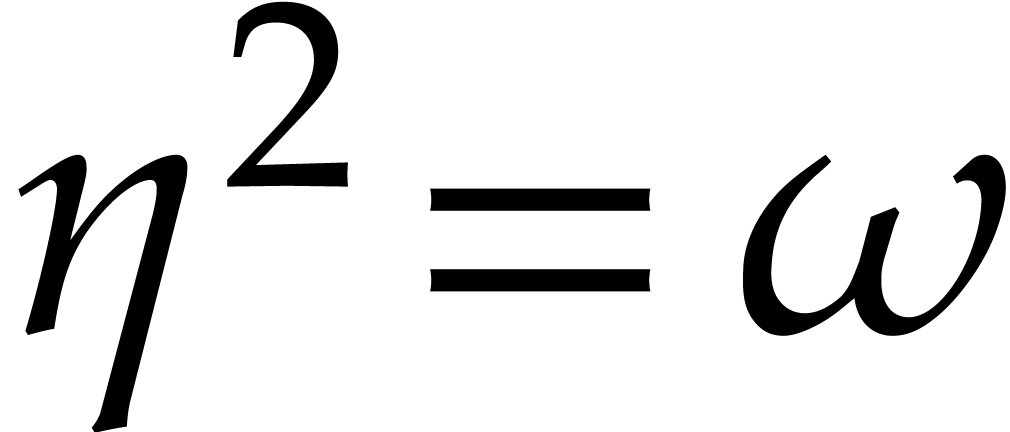 . If is odd, then we take
. If is odd, then we take
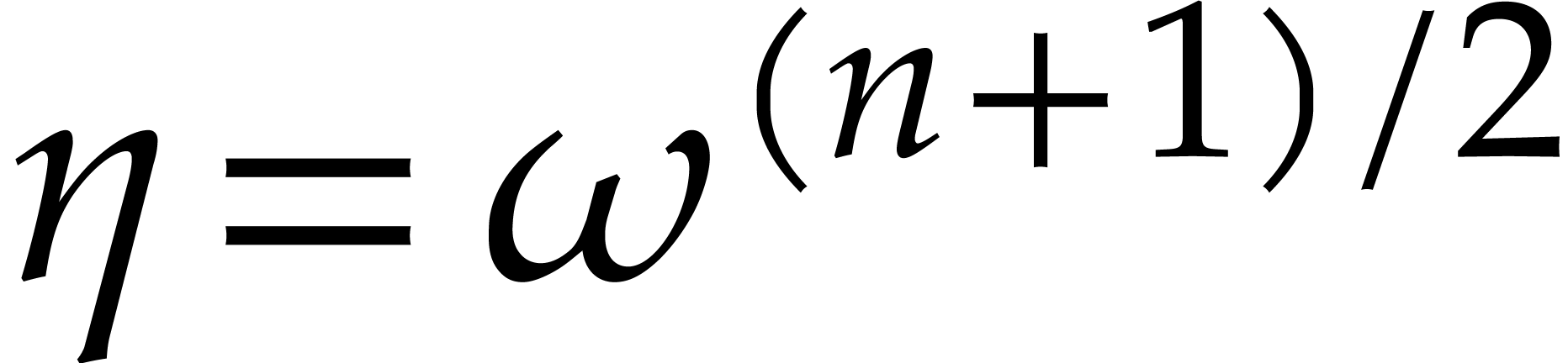 , so that
and
, so that
and 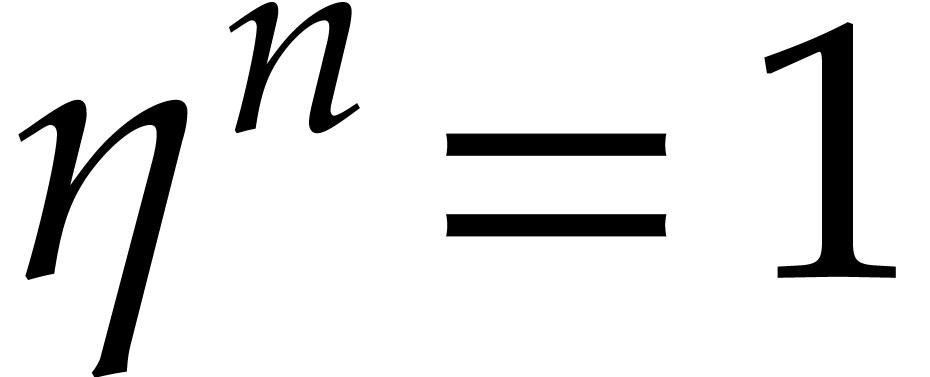 . Consider the sequences
. Consider the sequences

Then 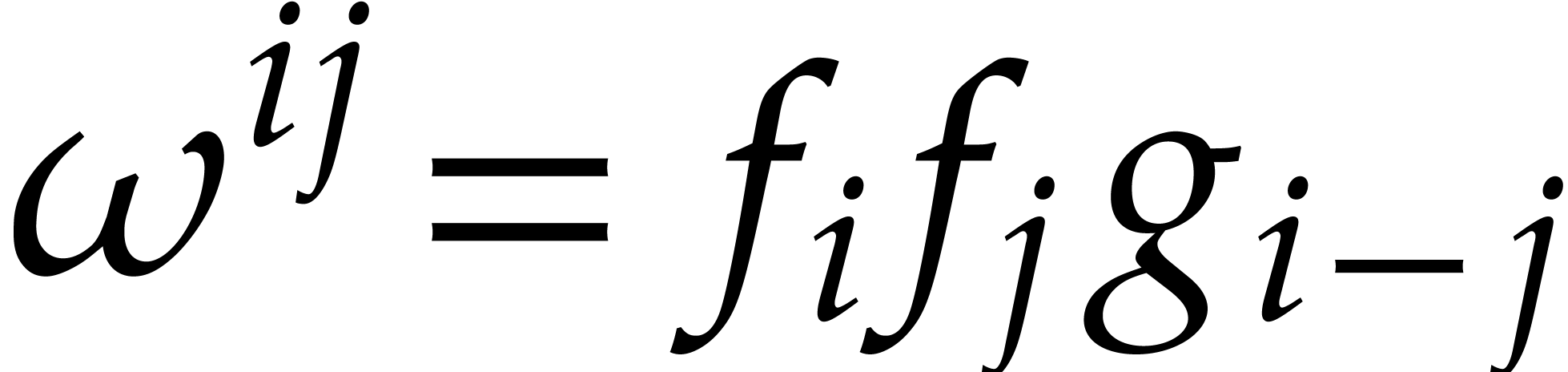 , so for any
, so for any 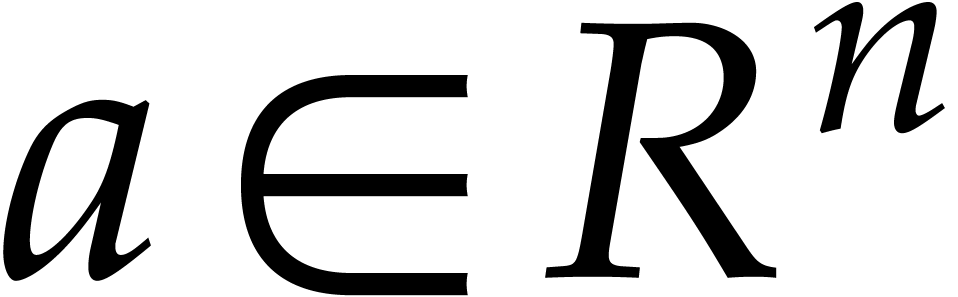 we have
we have
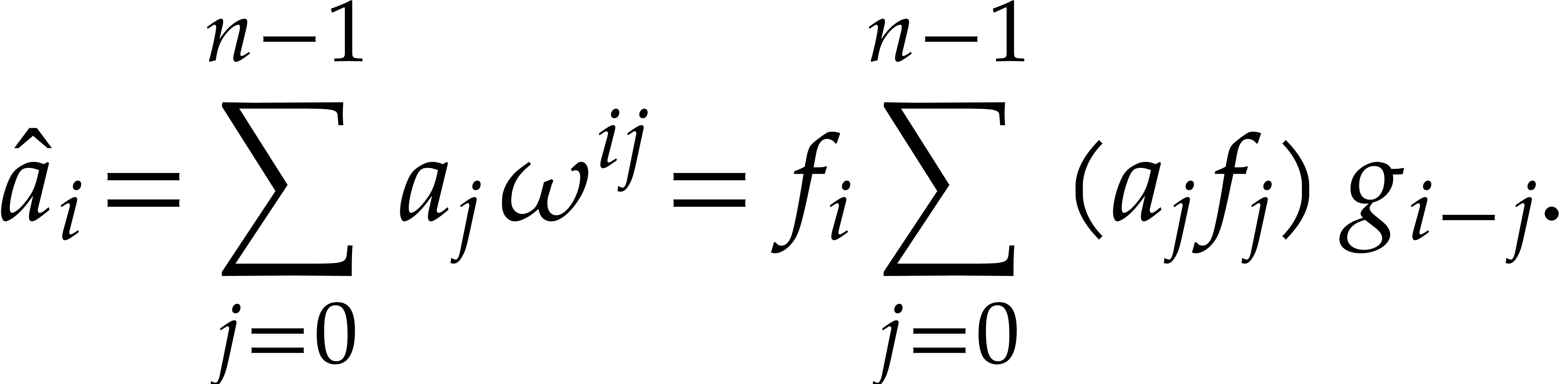 |
(2.9) |
If is even, then we have
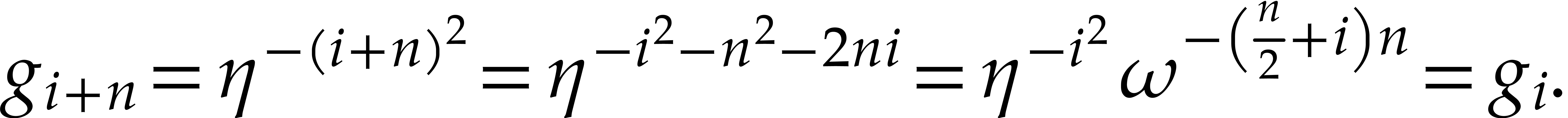
If is odd, then we also have
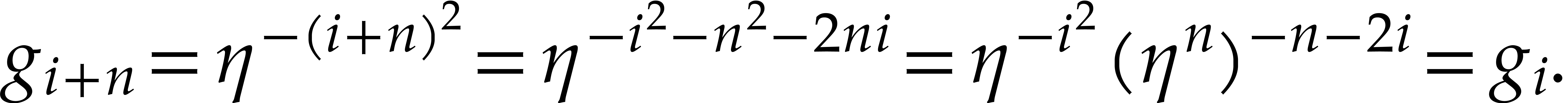
Now let 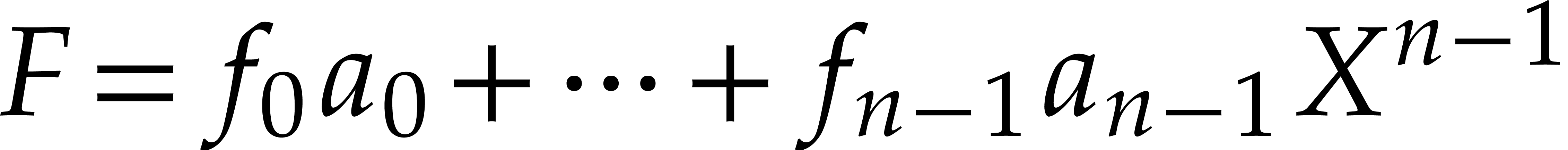 ,
, 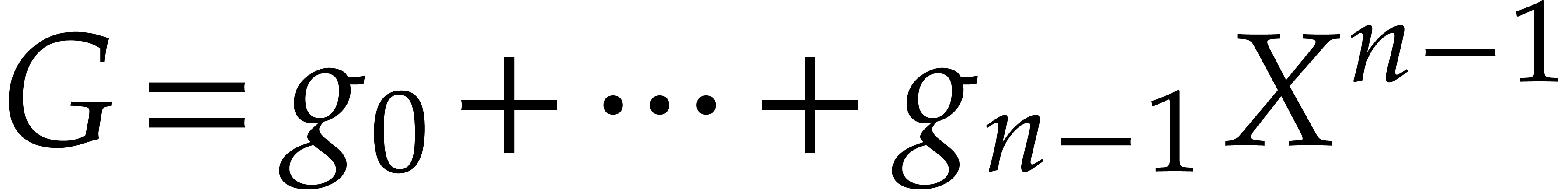 and
and 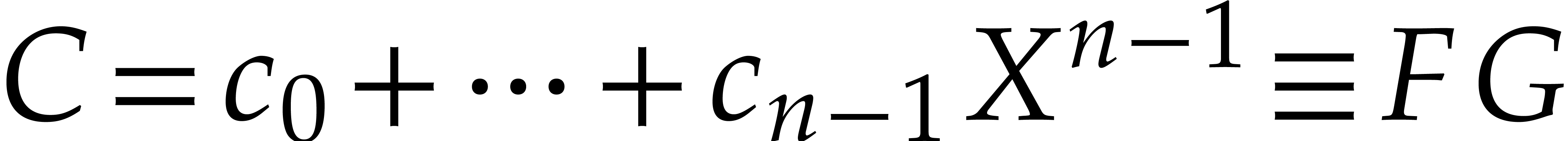 modulo
modulo 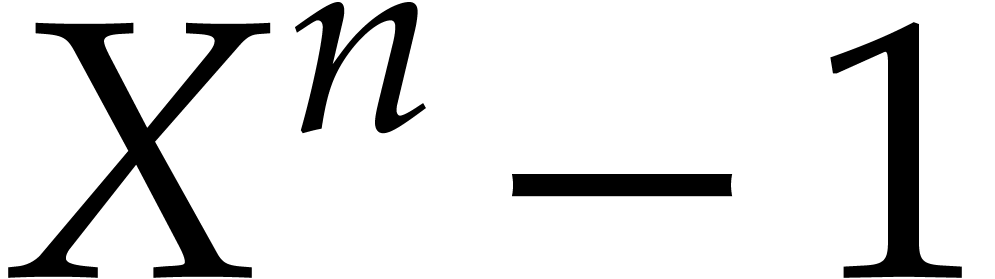 .
Then (2.9) implies that
.
Then (2.9) implies that 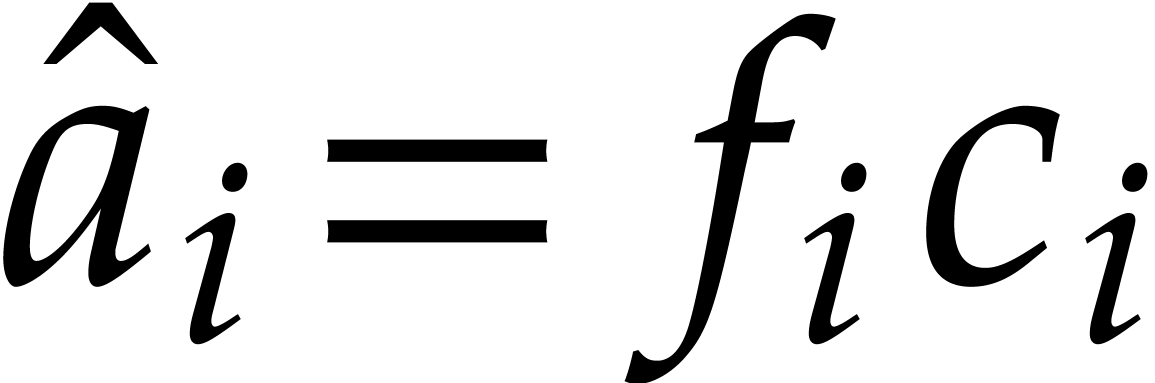 for all
. In other words, the
computation of a DFT of even length reduces to a
cyclic convolution product of the same length, together with
for all
. In other words, the
computation of a DFT of even length reduces to a
cyclic convolution product of the same length, together with 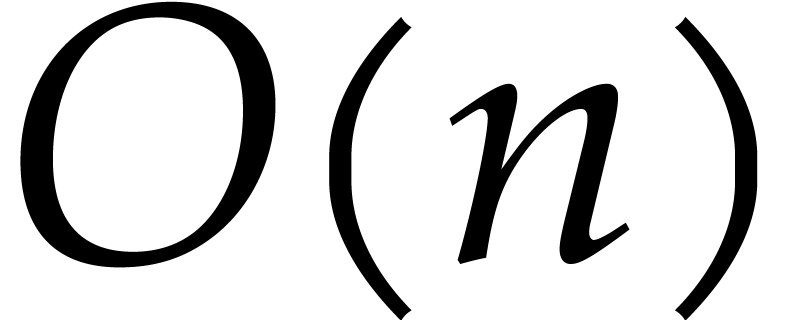 additional operations in :
additional operations in :
Notice that the polynomial  is fixed and
independent of in this product. The
is fixed and
independent of in this product. The  (and
(and  ) can be
computed in time
) can be
computed in time 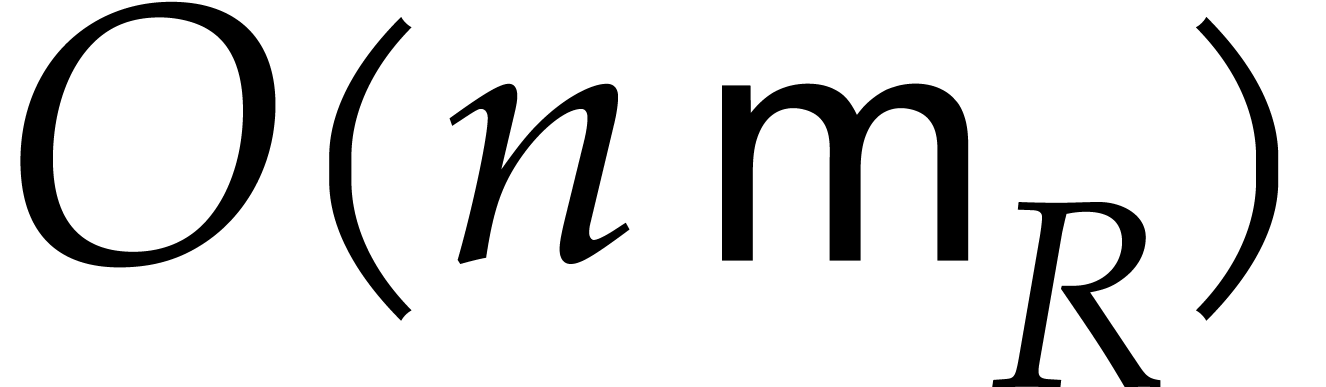 via the identity
via the identity 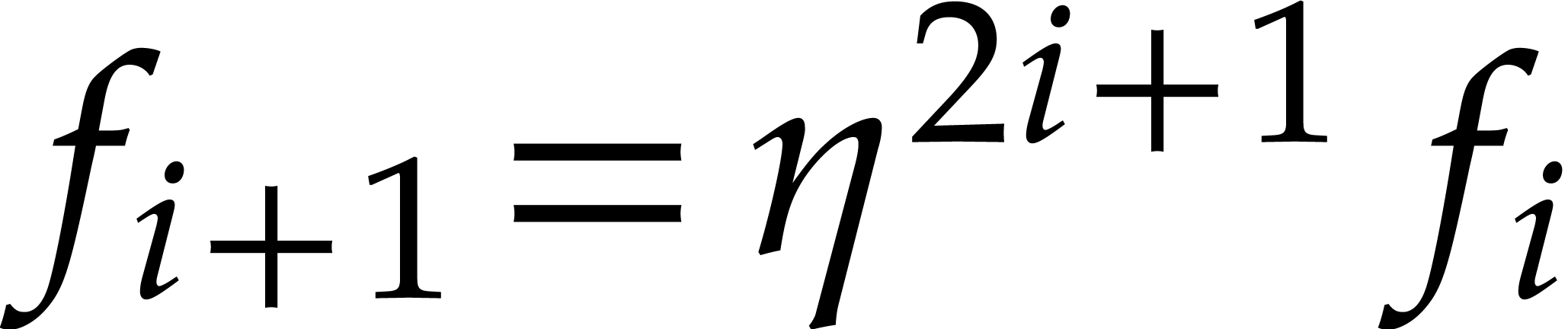 .
.
It is well known that multivariate Fourier transforms can be interpreted as tensor products of univariate Fourier transforms. Since we will also need another type of multivariate “Rader transform” in the next section, it will be useful to recall this point of view. We refer to [37, Chapter XVI] for an abstract introduction to tensor products.
Let be a commutative ring and let and 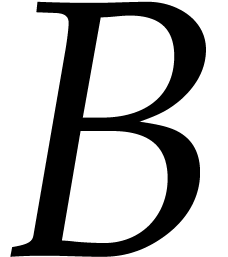 be two -modules. The tensor product
be two -modules. The tensor product  of and is
an -module together with a
bilinear mapping
of and is
an -module together with a
bilinear mapping 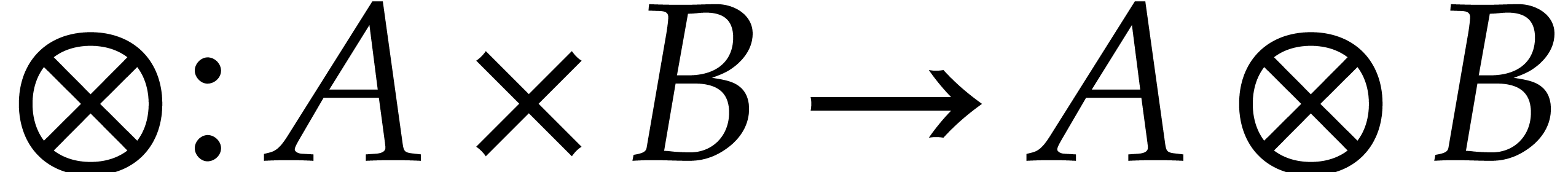 . This
bilinear mapping satisfies the universal property that for any other
-module
together with a bilinear mapping
. This
bilinear mapping satisfies the universal property that for any other
-module
together with a bilinear mapping 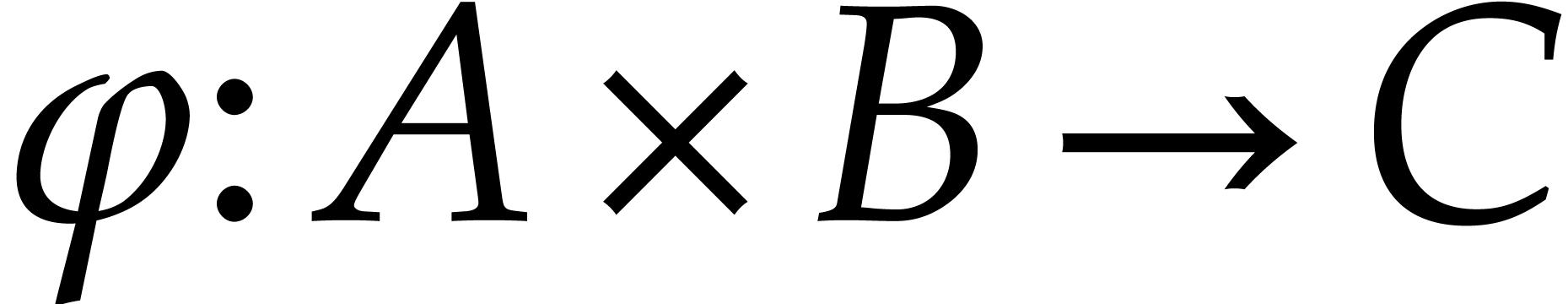 ,
there exists a unique linear mapping
,
there exists a unique linear mapping 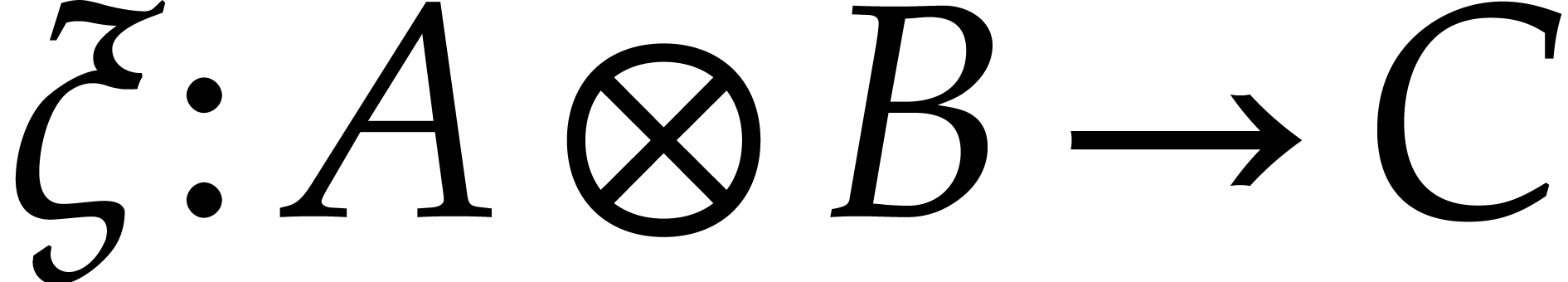 with
with 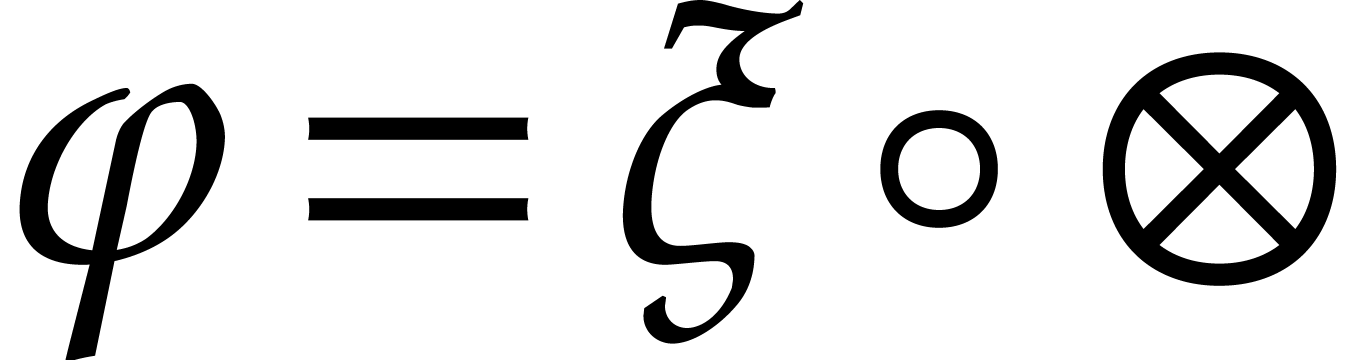 . Up to natural isomorphisms, it
can be shown that the tensor product operation
. Up to natural isomorphisms, it
can be shown that the tensor product operation  is associative and distributive with respect to the direct sum operation
is associative and distributive with respect to the direct sum operation
 .
.
Besides modules, it is also possible to tensor linear mappings. More
precisely, given two linear mappings 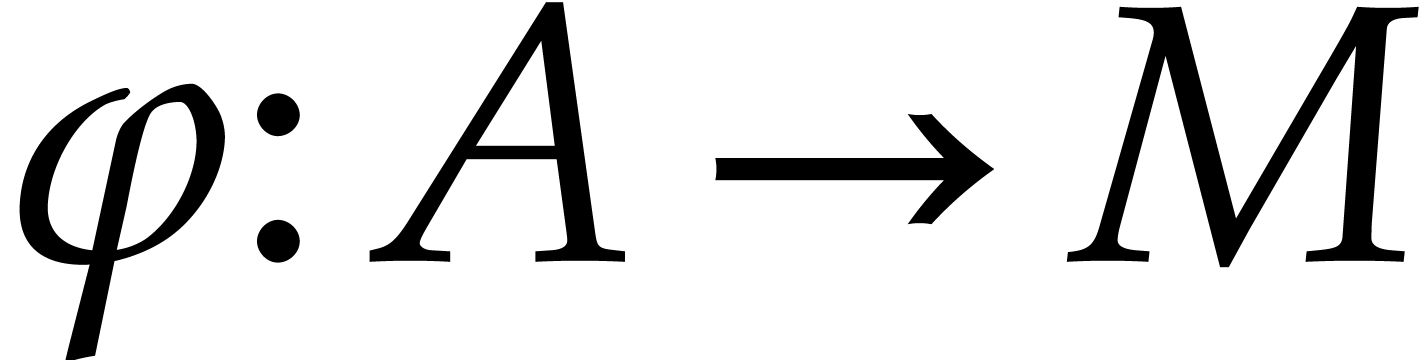 and
and 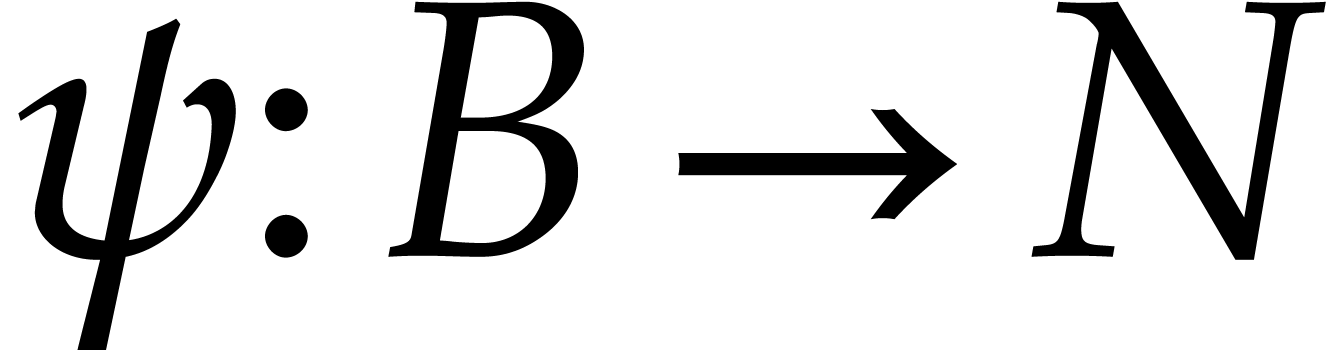 , the mapping that sends
, the mapping that sends  to
to  is clearly bilinear. This means
that there exists a unique mapping
is clearly bilinear. This means
that there exists a unique mapping 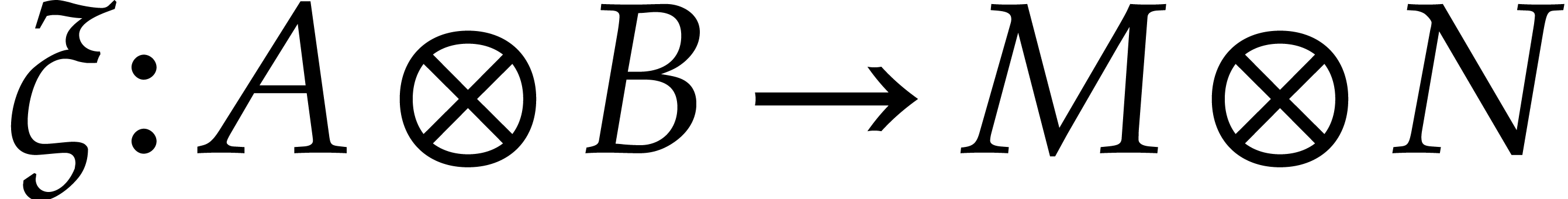 such that
such that
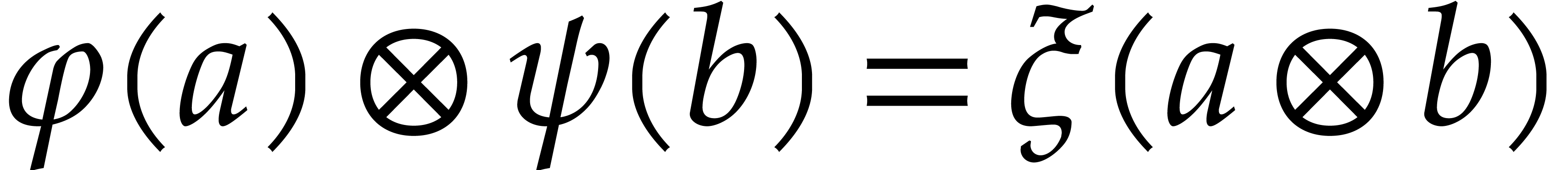 for all .
We call
for all .
We call  the tensor product of and
the tensor product of and  .
.
Assume now that and are
free -modules of finite rank,
say 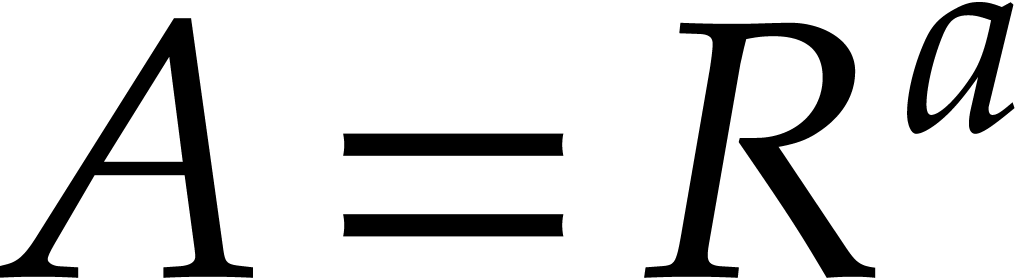 and
and  .
Then is again a free -module that can be identified with the set
.
Then is again a free -module that can be identified with the set  of bidimensional arrays of size
of bidimensional arrays of size  and with coefficients in .
The tensor product of two vectors
and with coefficients in .
The tensor product of two vectors  and
and  is given by the array
is given by the array  with entries
with entries
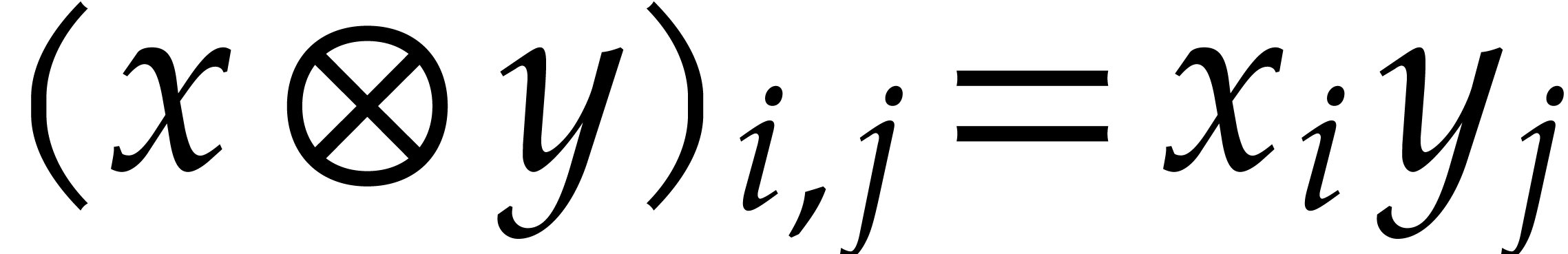 .
.
Let 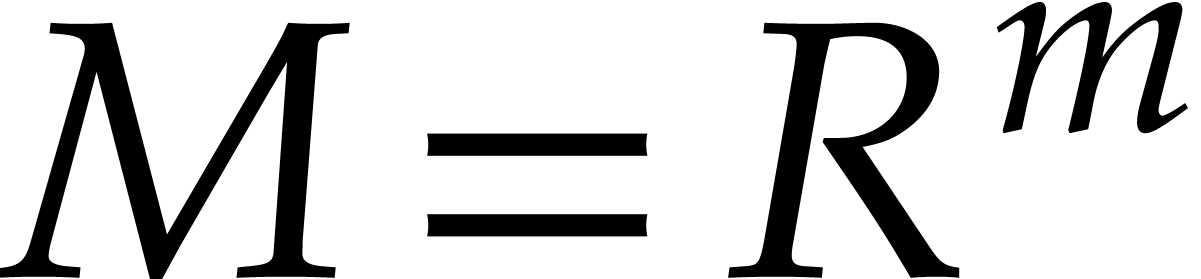 and
and 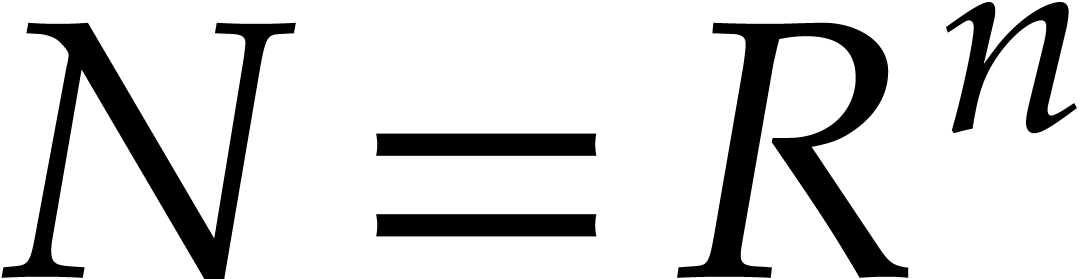 be two more free
-modules of finite rank.
Assume that we are given two linear mappings and
that can be computed by an algorithm. Then
be two more free
-modules of finite rank.
Assume that we are given two linear mappings and
that can be computed by an algorithm. Then  can be computed as follows. Given
can be computed as follows. Given 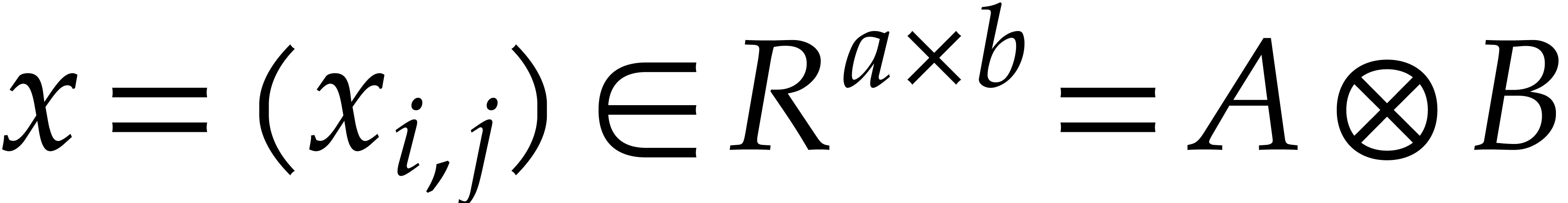 , we first apply to
each of the rows
, we first apply to
each of the rows  . This
yields a new array
. This
yields a new array 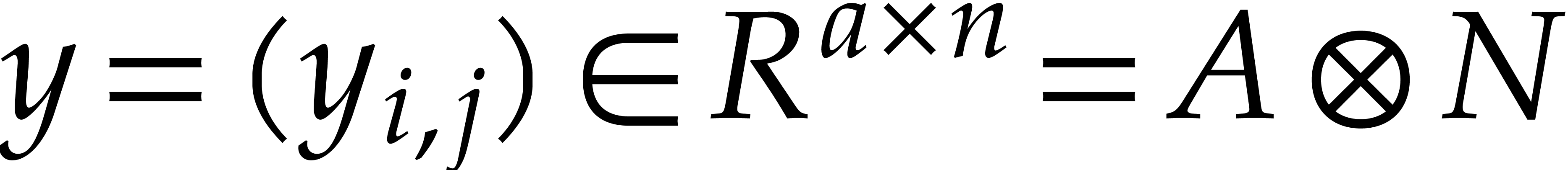 with
with  for all
for all  . We next apply to each of the columns
. We next apply to each of the columns  .
This yields an array
.
This yields an array 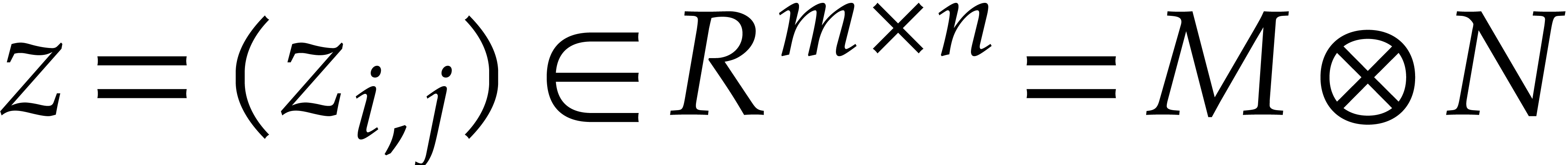 with
with  for all
for all  . We claim that
. We claim that  . Indeed, if
. Indeed, if  , then
, then  and
and 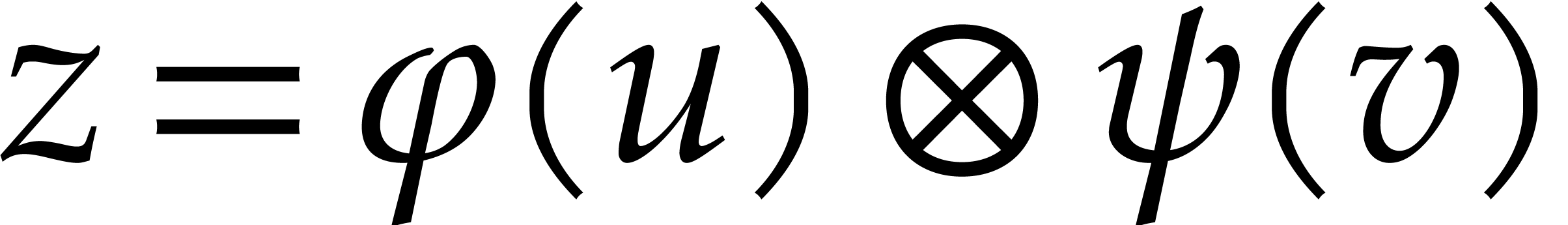 , whence the claim follows by linearity.
, whence the claim follows by linearity.
Given  , the above algorithm
then allows us to compute
, the above algorithm
then allows us to compute 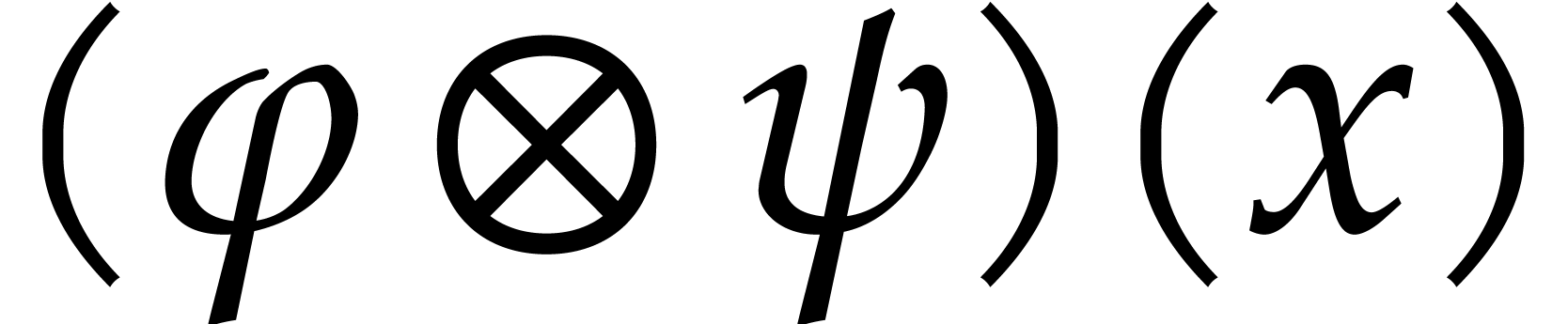 in time
in time
More generally, given linear mappings  , a similar complexity analysis as
in the case of the Cooley–Tukey algorithm yields
, a similar complexity analysis as
in the case of the Cooley–Tukey algorithm yields
where  for
for  .
.
For working with multivariate polynomials, it is convenient to introduce
a few notations. Let 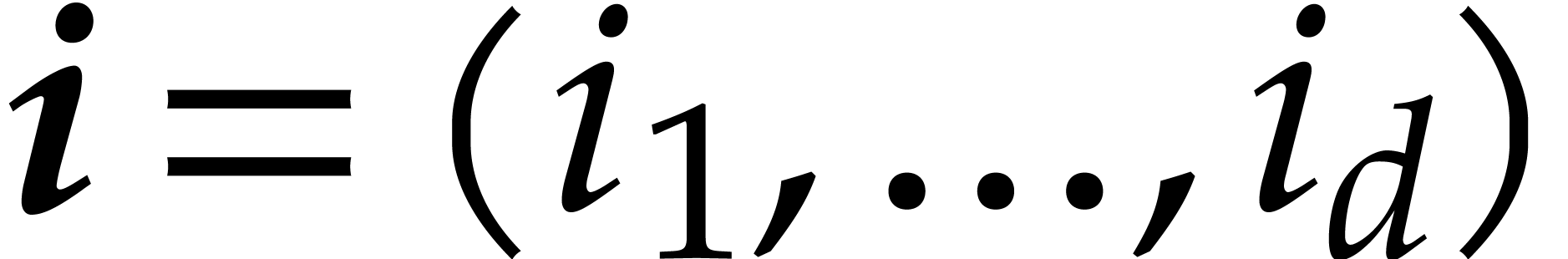 and
and 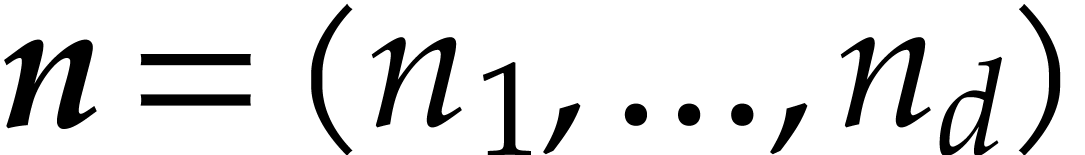 be -tuples in
be -tuples in  . We define
. We define
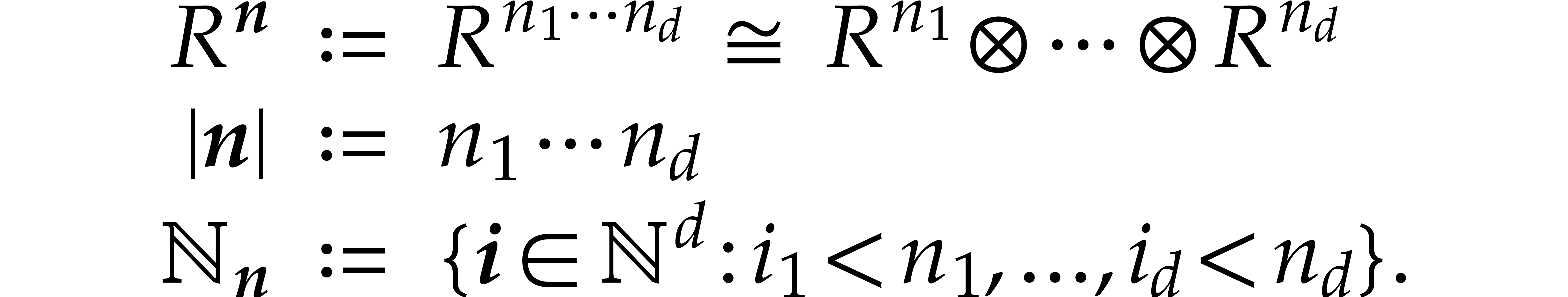
Notice that 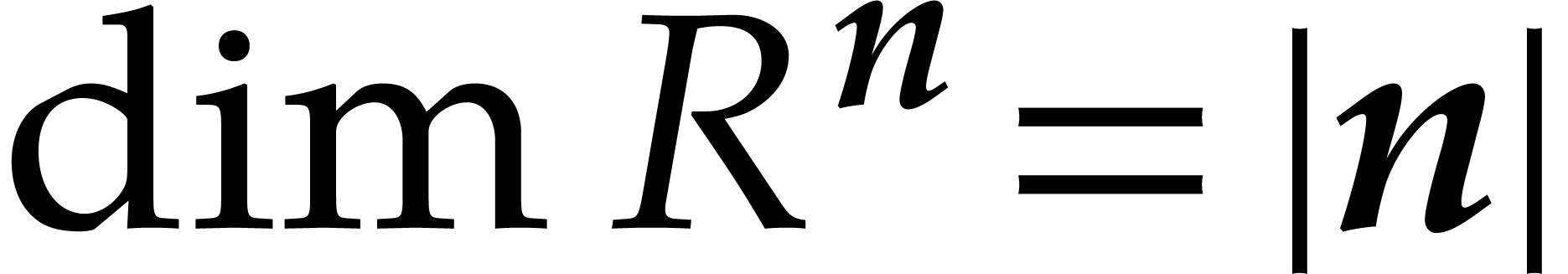 . Elements in
. Elements in
 can be regarded as
arrays. On a Turing tape, we recursively represent them as vectors of
size
can be regarded as
arrays. On a Turing tape, we recursively represent them as vectors of
size  with entries in
with entries in  .
.
Given a -tuple of
indeterminates  , we define
, we define
The first tensor product is understood in the sense of -modules and we regard 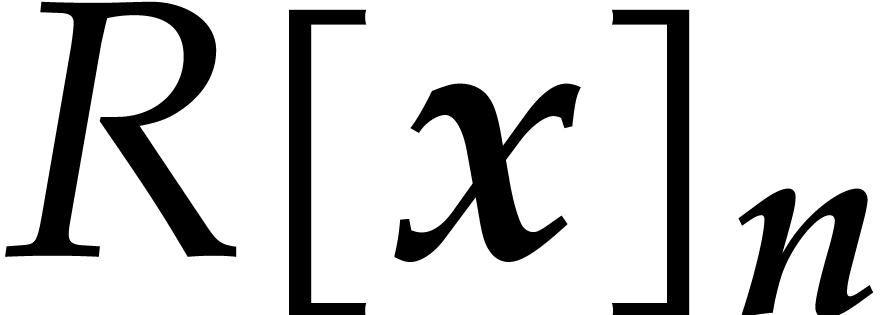 as a subset of
as a subset of 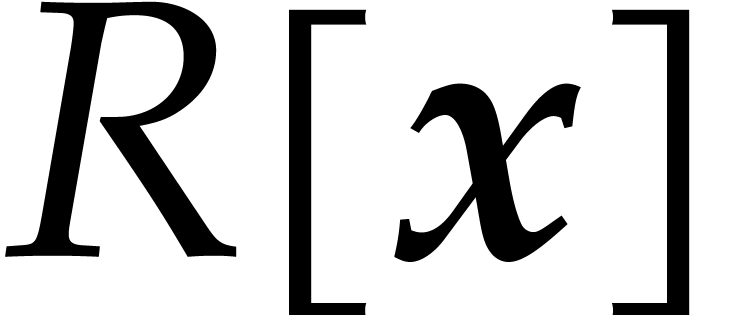 . The second
tensor product is understood in the sense of -algebras. Any polynomial in
(or cyclic polynomial in
. The second
tensor product is understood in the sense of -algebras. Any polynomial in
(or cyclic polynomial in 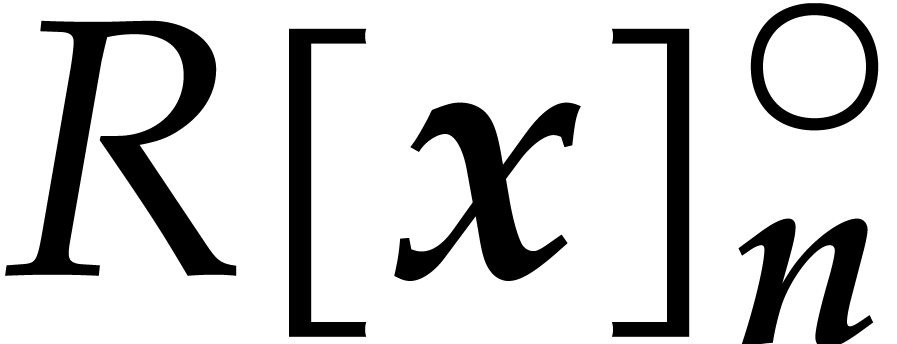 ) can uniquely be written as a sum
) can uniquely be written as a sum
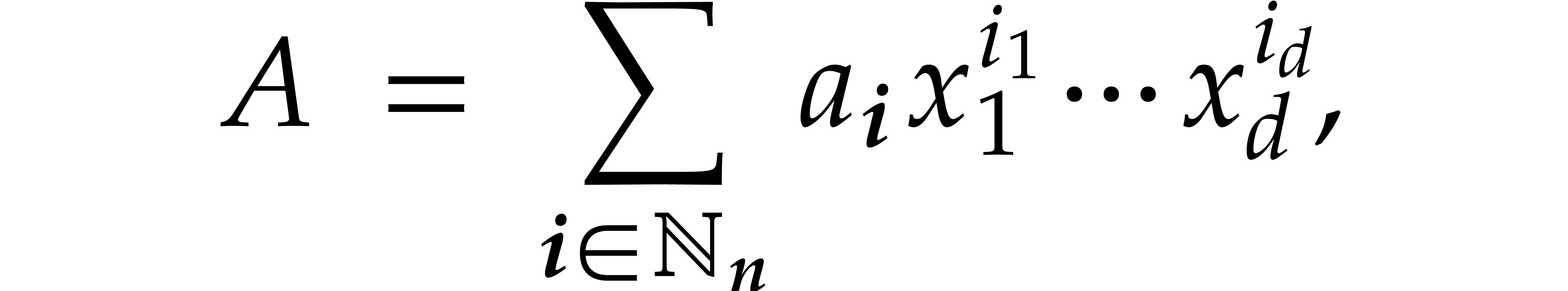
where  is the vector of coefficients of . We write
is the vector of coefficients of . We write 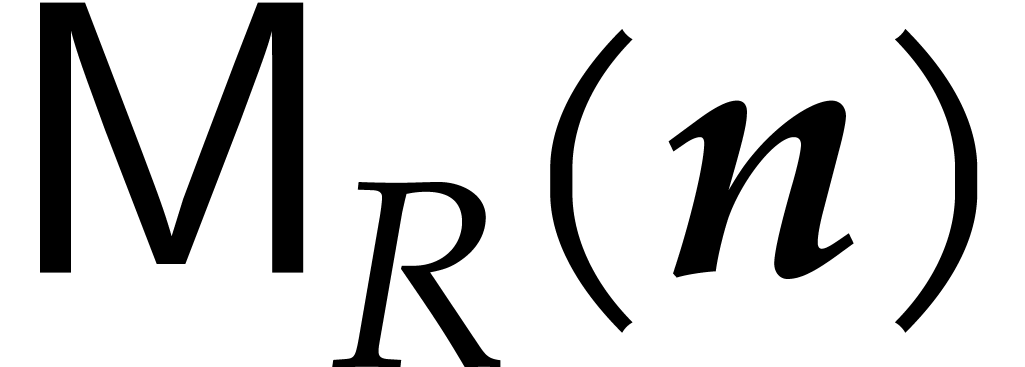 for the complexity of multiplying two polynomials in
and also define
for the complexity of multiplying two polynomials in
and also define 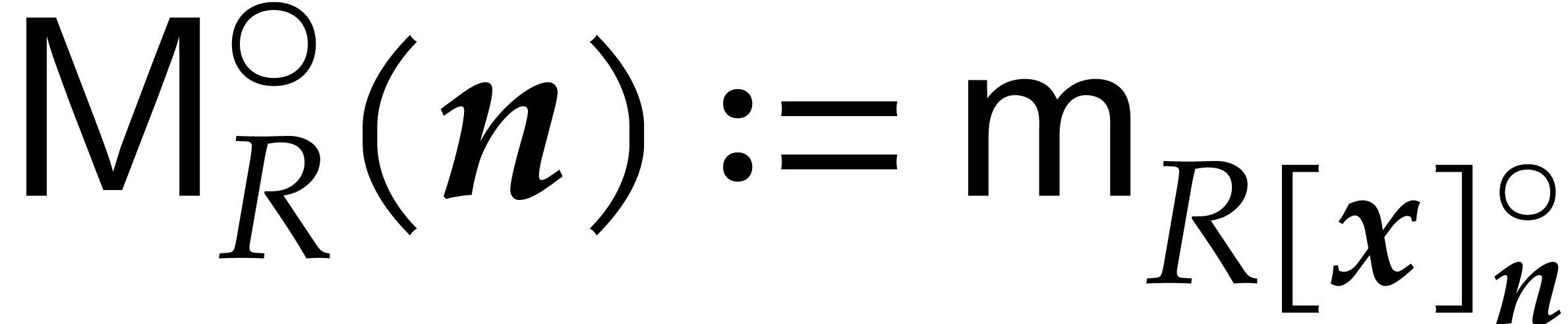 .
.
Assume now that  is such that
is such that  is a principal -th root of
unity for and invertible positive integers
is a principal -th root of
unity for and invertible positive integers  . As in the univariate case, cyclic
polynomials
. As in the univariate case, cyclic
polynomials  can naturally be evaluated at points
of the form
can naturally be evaluated at points
of the form 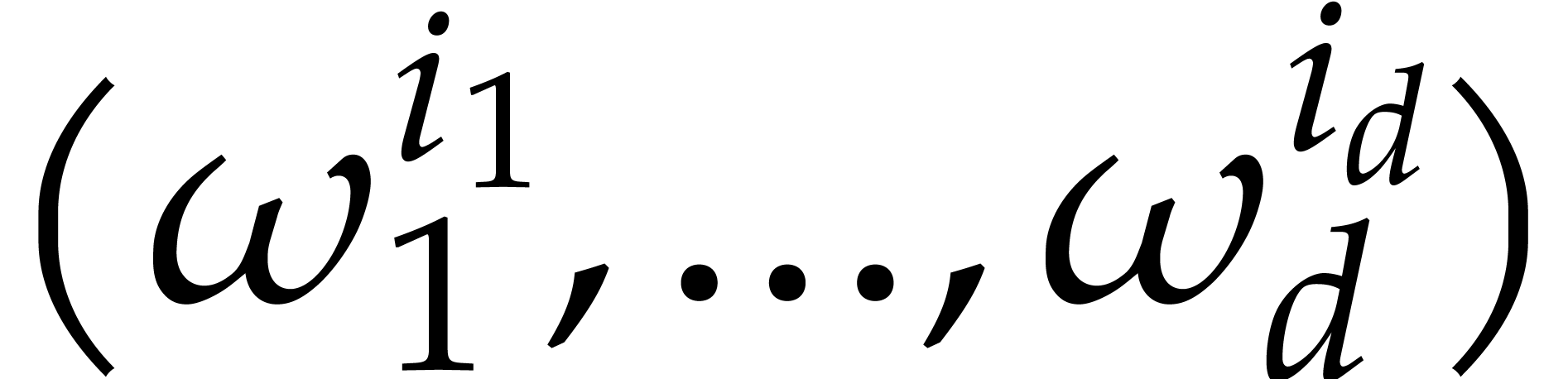 . We now define
the discrete Fourier transform of to be the
vector
. We now define
the discrete Fourier transform of to be the
vector 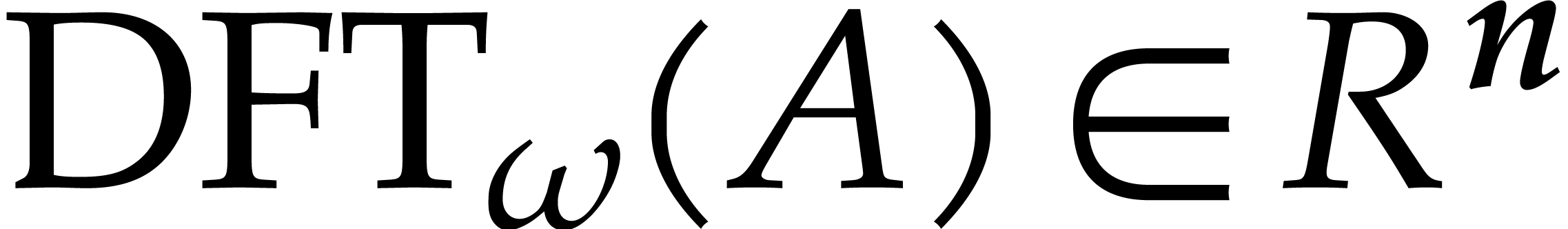 with
with
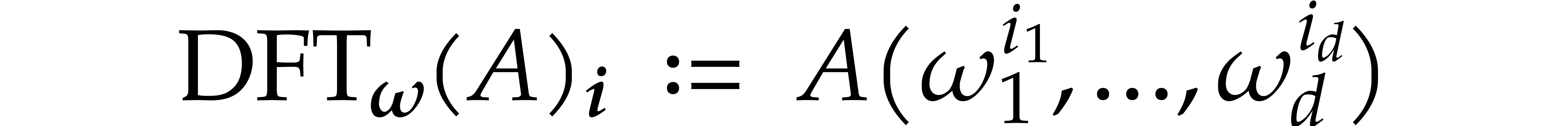
for all 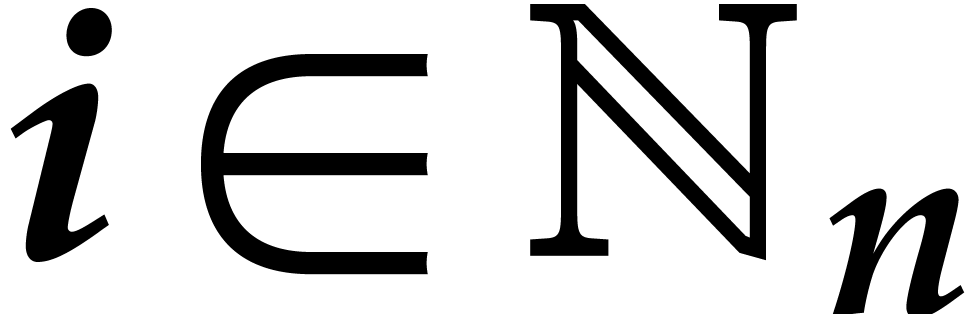 . Multivariate
Fourier transforms again provide us with an isomorphism between and .
Writing
. Multivariate
Fourier transforms again provide us with an isomorphism between and .
Writing 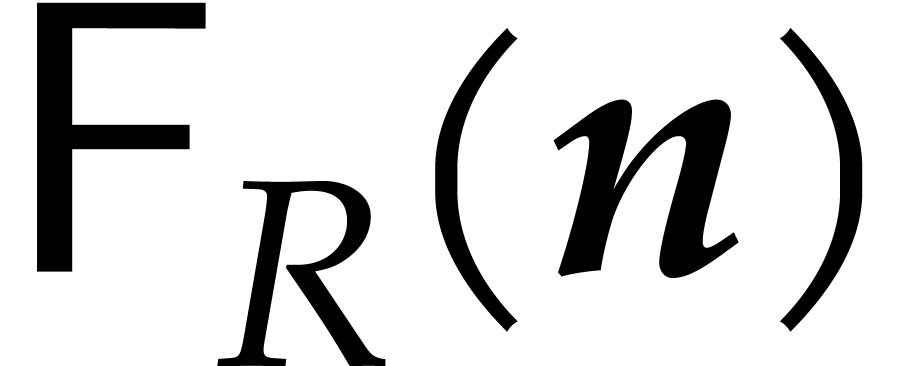 for the cost to compute such a transform
with respect to a most suitable
for the cost to compute such a transform
with respect to a most suitable  ,
we thus have
,
we thus have 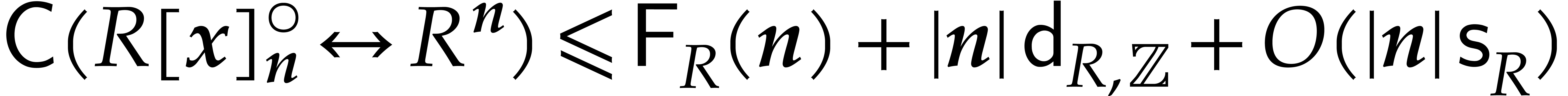 .
.
We claim that multivariate Fourier transforms can be regarded as the tensor product of univariate Fourier transforms with respect to each of the variables, that is,
Indeed, given a vector 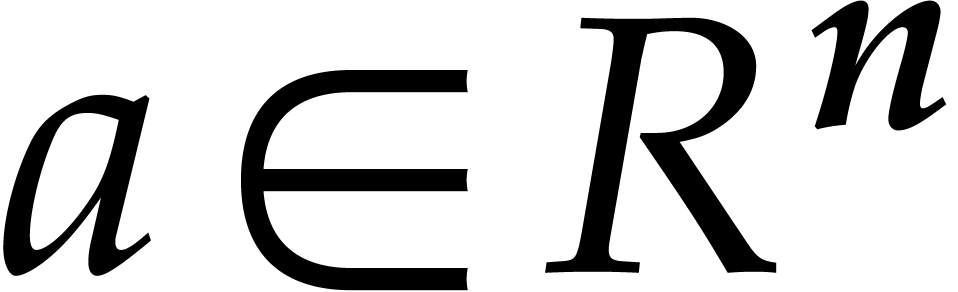 of the form
of the form  with
with 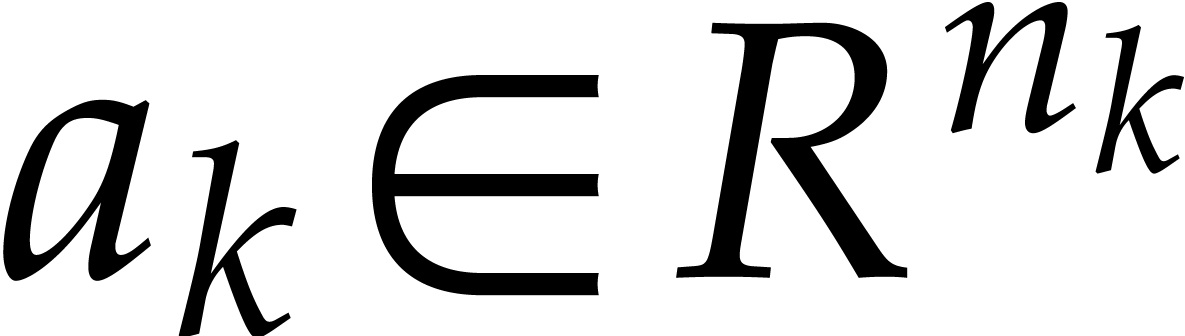 for each
for each  , we have
, we have
where 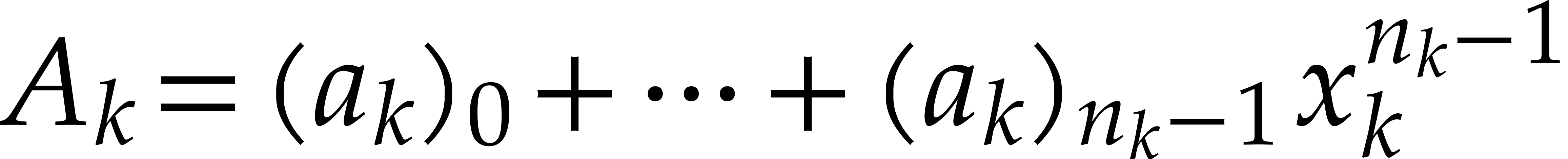 for each ,
and is as above. The relation (3.5)
follows from (3.6) by linearity, since the
of the form
for each ,
and is as above. The relation (3.5)
follows from (3.6) by linearity, since the
of the form  span .
span .
In particular, in order to compute a multivariate Fourier transform, it suffices to compute univariate Fourier transforms with respect to each of the variables, as described in section 3.1. It follows that
The technique of FFT-multiplication from section 2.2 also
naturally generalizes to multivariate polynomials in . This yields the bound
If , as in section 2.4,
and all divide ,
then (3.7) and (3.8) become simply
Let be a tuple of pairwise coprime numbers and
. The Chinese remainder
theorem provides us with an isomorphism of abelian groups
Any such isomorphism induces an isomorphism of -algebras
that boils down to a permutation of coefficients when using the usual
power bases for 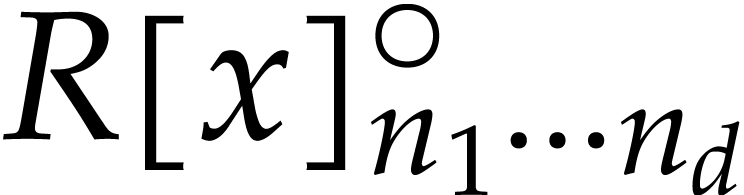 and
and  . For a suitable choice of
. For a suitable choice of  , we show in section A.3 of the
appendix that this permutation can be computed efficiently on Turing
machines, which yields
, we show in section A.3 of the
appendix that this permutation can be computed efficiently on Turing
machines, which yields
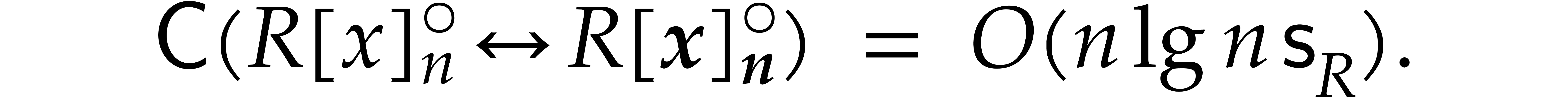
We will also need a multivariate generalization of this formula: let
 ,
, 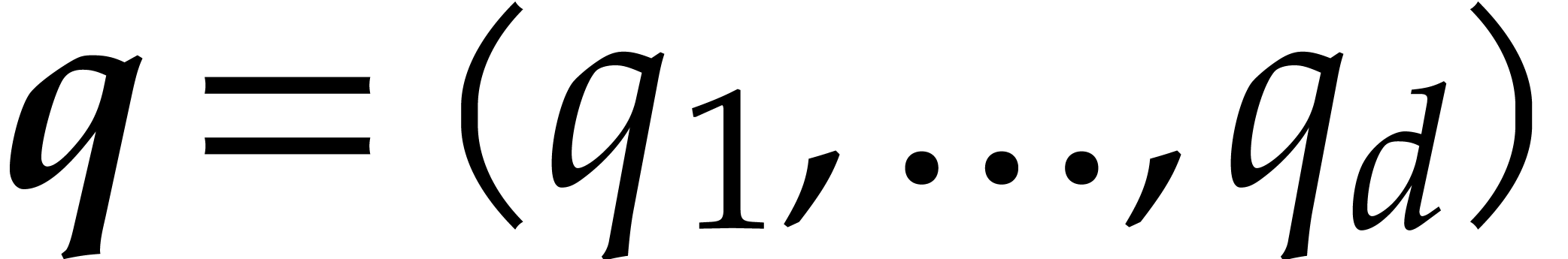 and
and
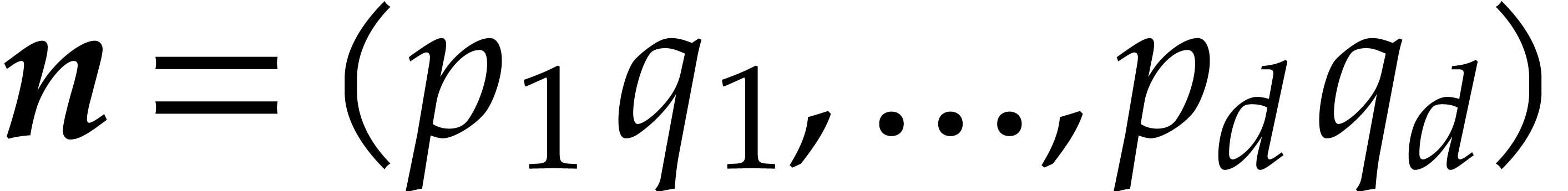 be such that
be such that 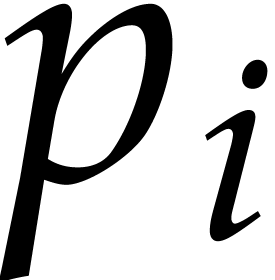 and are coprime for .
Then
and are coprime for .
Then
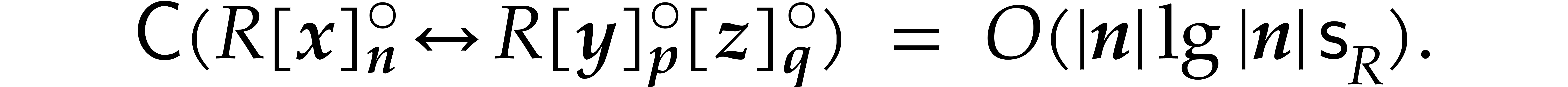
This is a result of Corollary A.8 in the appendix.
Assume now that 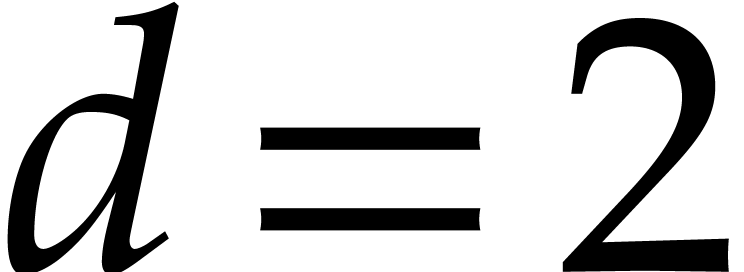 and let , where and
are coprime and is odd. Then we have
isomorphisms of -algebras
and let , where and
are coprime and is odd. Then we have
isomorphisms of -algebras
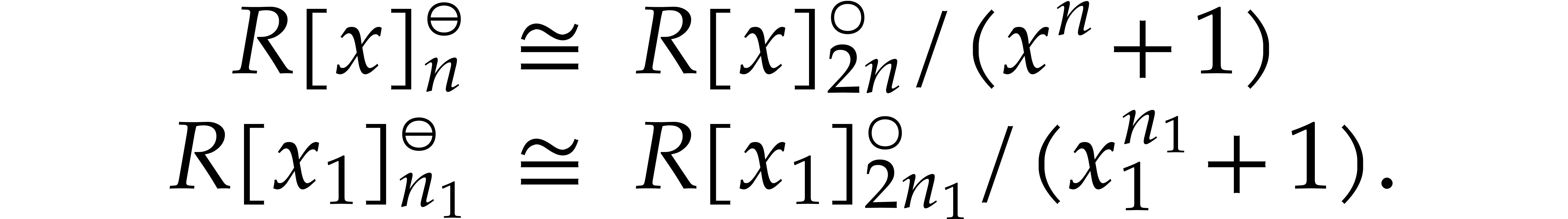
Given 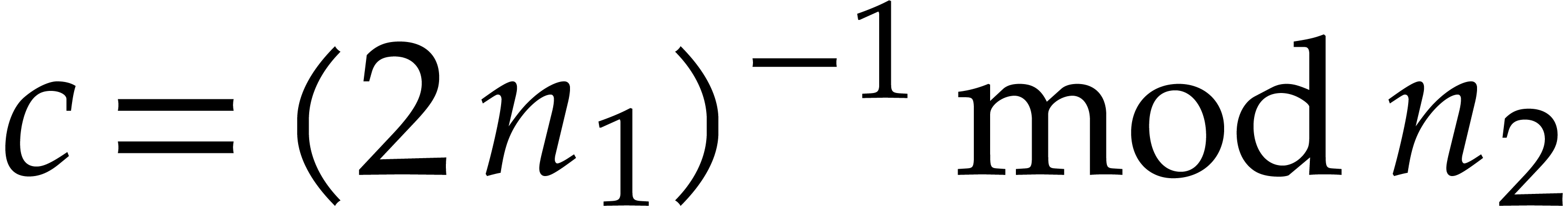 , the map
, the map 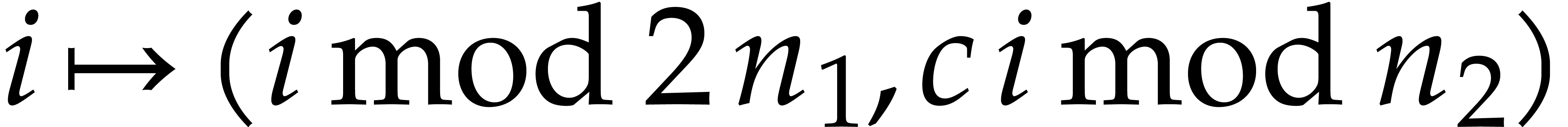 determines an isomorphism of abelian groups between
determines an isomorphism of abelian groups between 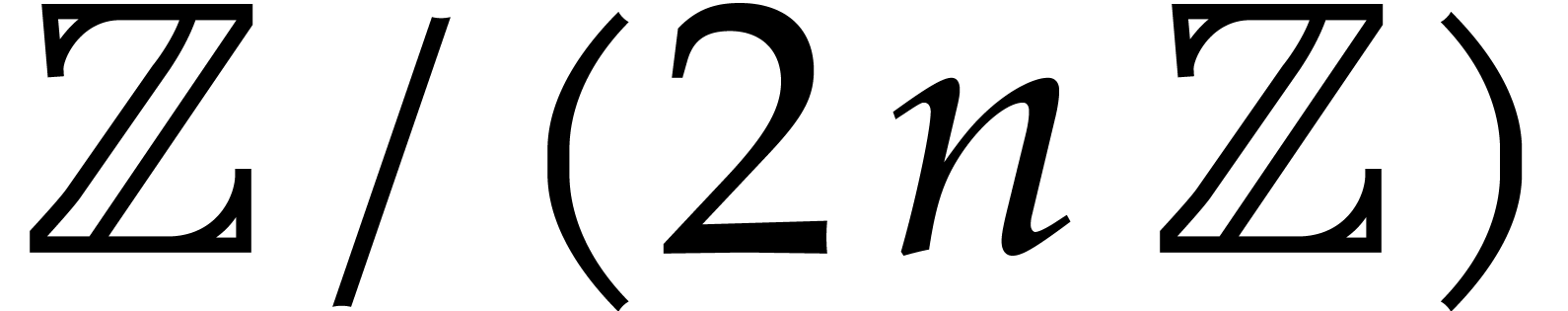 and
and 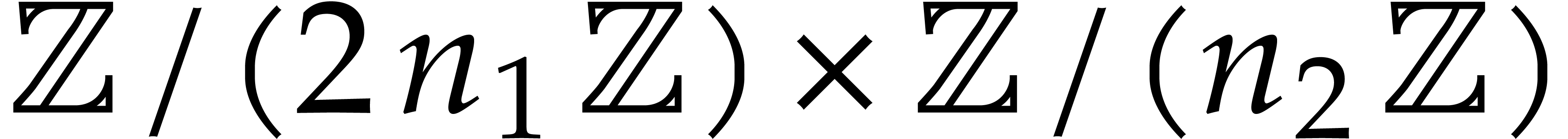 . As
explained in the previous subsection, this gives rise to an isomorphism
of -algebras
. As
explained in the previous subsection, this gives rise to an isomorphism
of -algebras
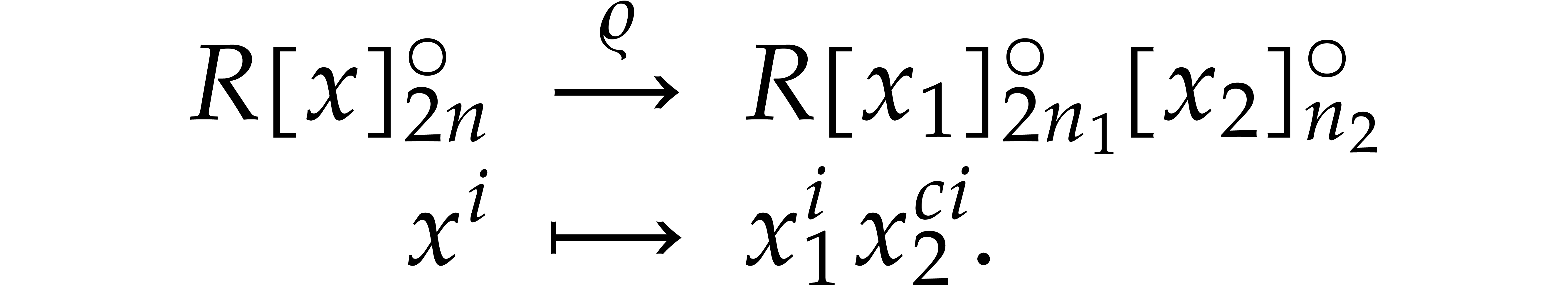
In view of Lemma A.4, this isomorphism can be computed
efficiently. Moreover, 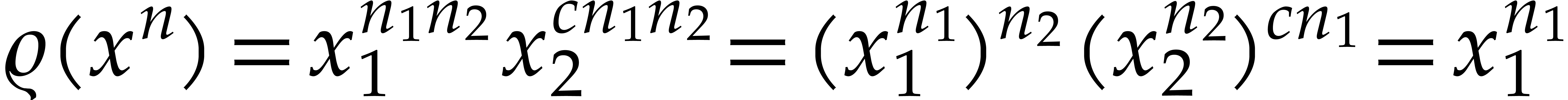 ,
since is odd and
,
since is odd and 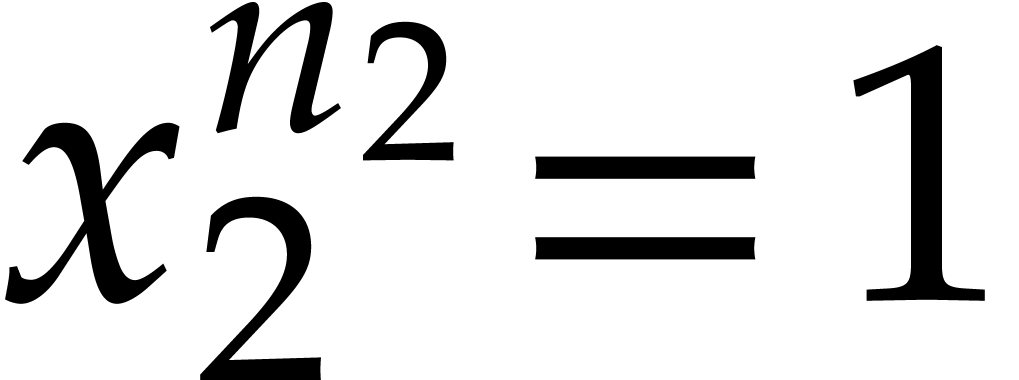 .
This yields a natural isomorphism
.
This yields a natural isomorphism 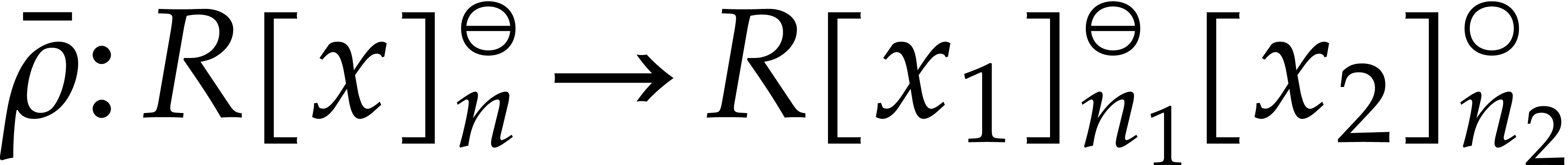 of -algebras such that the following
diagram commutes:
of -algebras such that the following
diagram commutes:
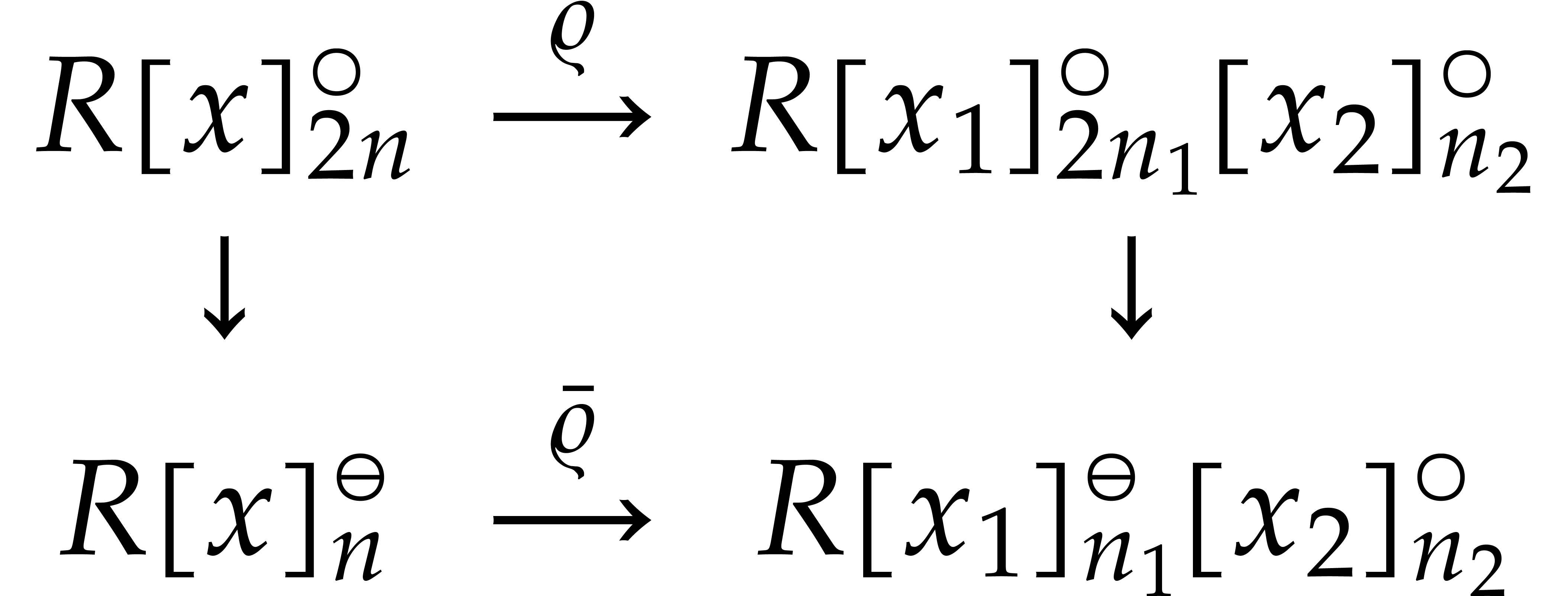
The projection 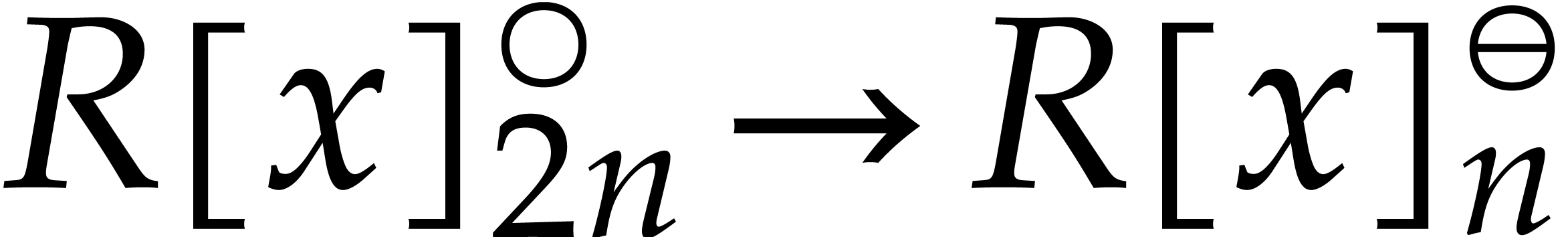 admits an obvious right inverse
that sends a polynomial
admits an obvious right inverse
that sends a polynomial 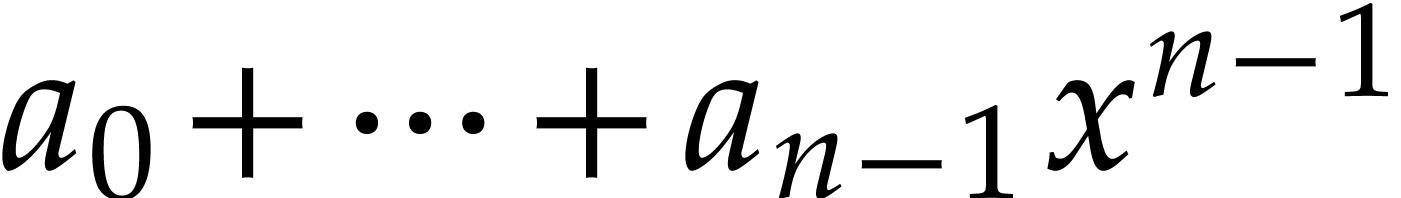 modulo
modulo 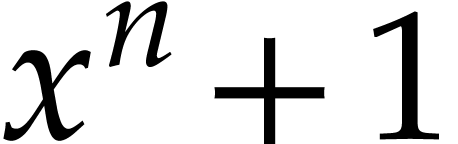 to . This lift can clearly be
computed in linear time, so we again obtain
to . This lift can clearly be
computed in linear time, so we again obtain
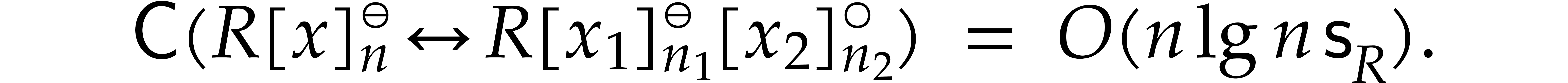
Alternatively, one may compute  in a similar way
as the isomorphism of -algebras
between
in a similar way
as the isomorphism of -algebras
between 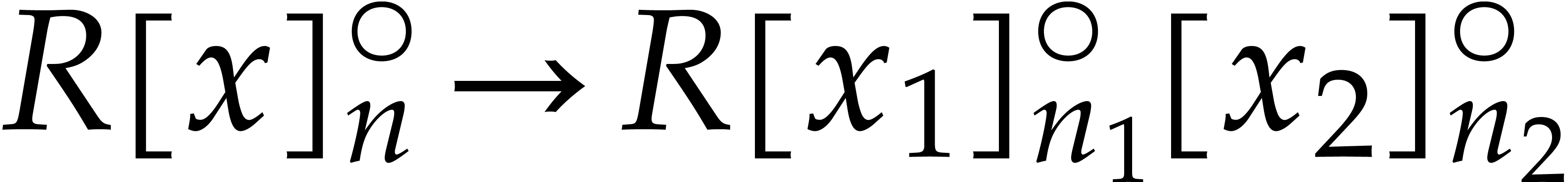 from the previous subsection, while
inverting signs whenever appropriate.
from the previous subsection, while
inverting signs whenever appropriate.
In section 8, we will also need a triadic variant of the
negacyclic CRT transforms from the previous subsection. More precisely,
assume that , where and are coprime,
is even, and is not divisible by . Then we have isomorphisms of -algebras
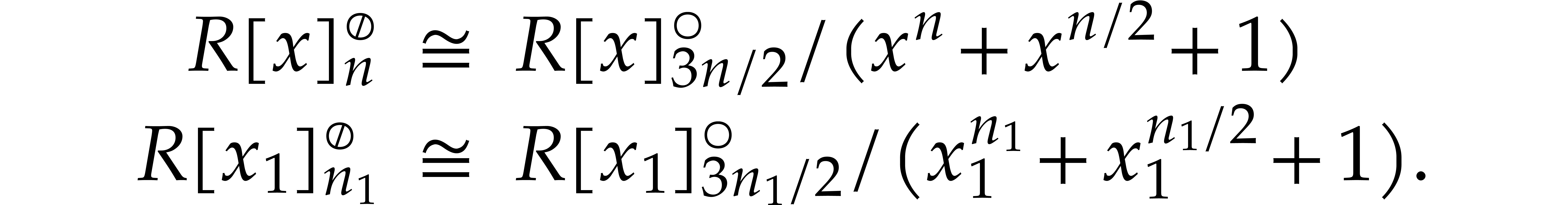
Given 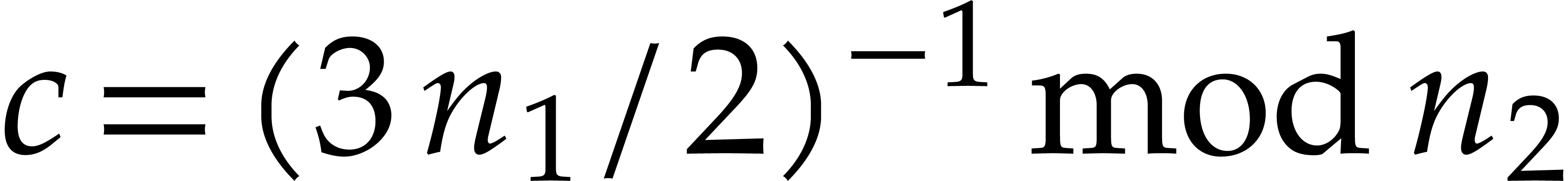 , the map
, the map 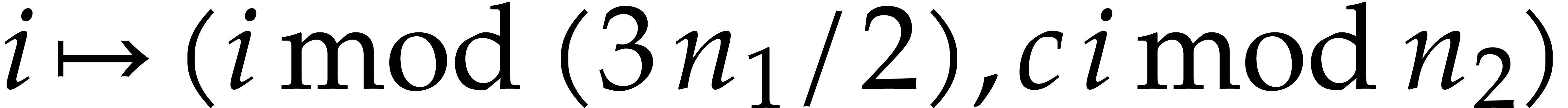 determines an isomorphism of abelian groups between
determines an isomorphism of abelian groups between 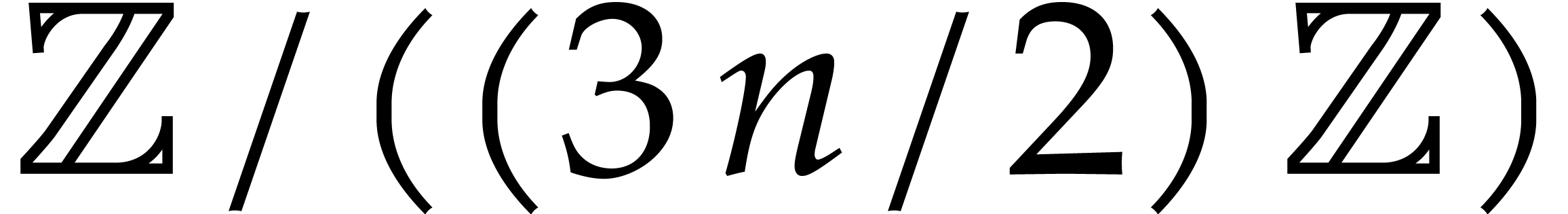 and
and 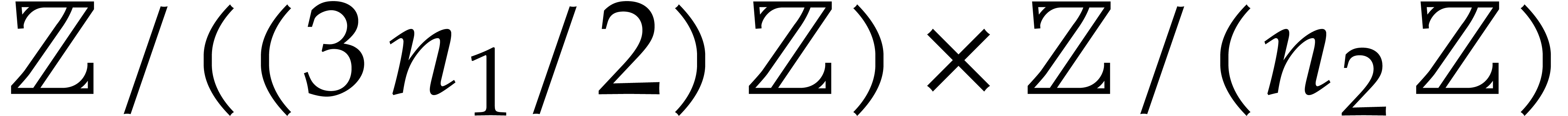 . In a
similar way as in the previous subsection, this leads to an isomorphism
of -algebras
. In a
similar way as in the previous subsection, this leads to an isomorphism
of -algebras

and a commutative diagram
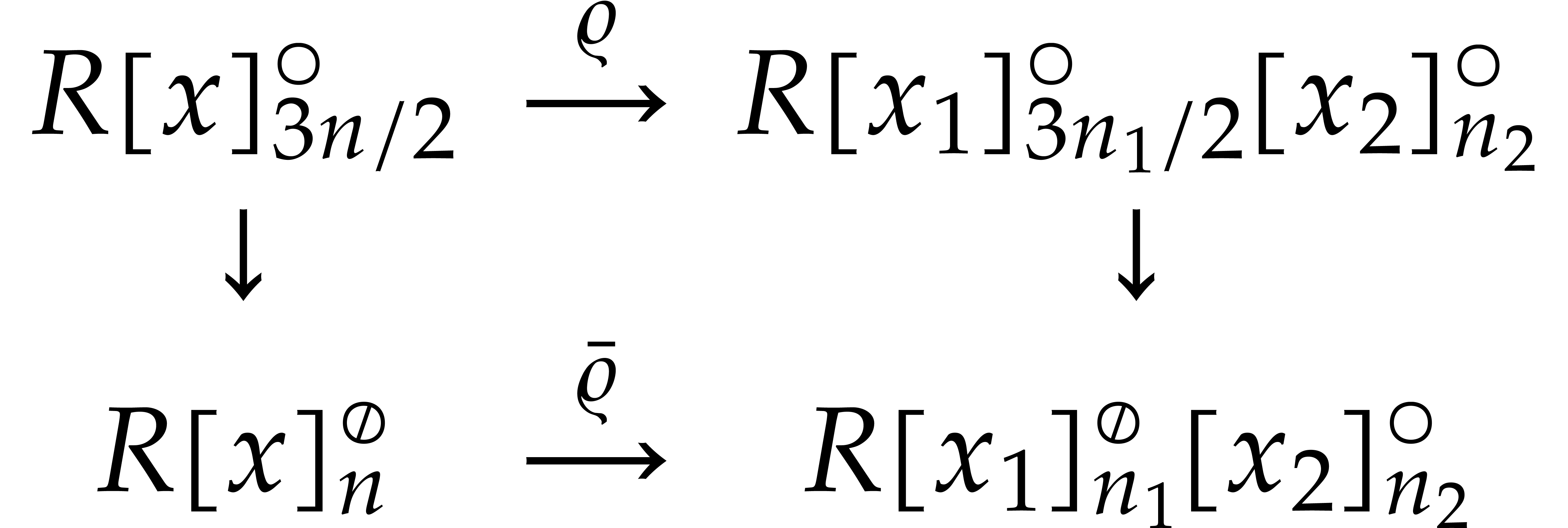
in which all maps and their right inverses can be computed efficiently. This again yields
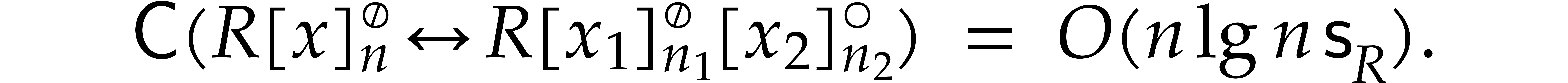
We will qualify this kind of conversions between 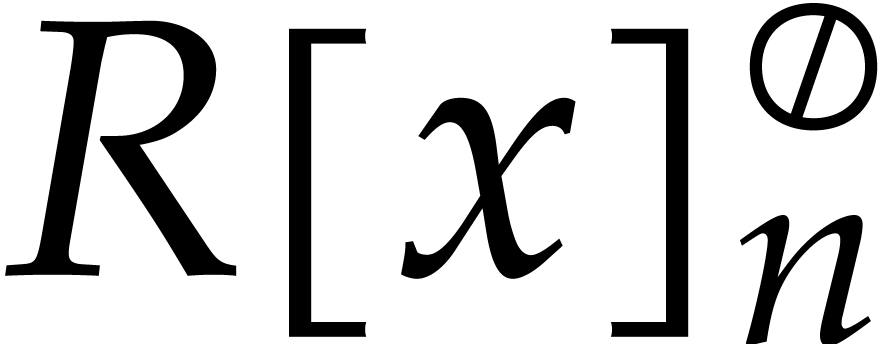 and
and 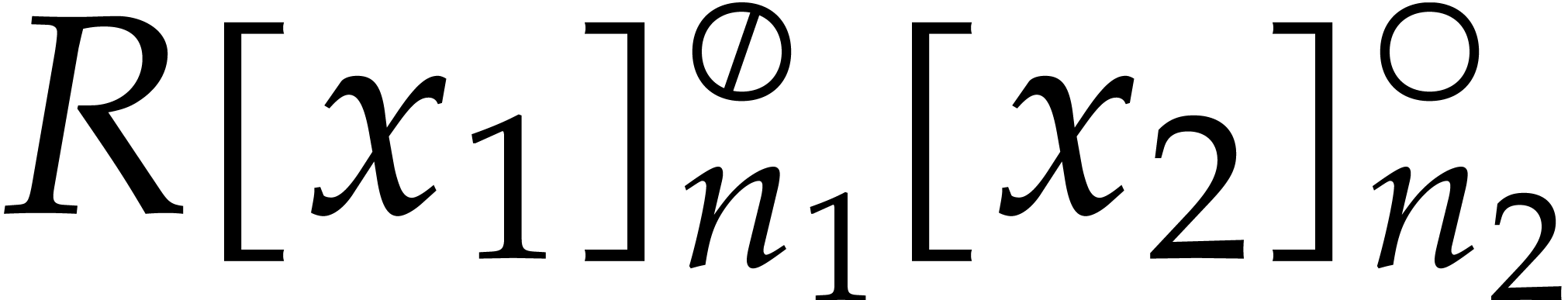 as tricyclic CRT transforms.
as tricyclic CRT transforms.
Let be a ring and let be
a principal -th root of unity
for some prime number . The
multiplicative group  is cyclic, of order . Let
is cyclic, of order . Let  be
such that
be
such that 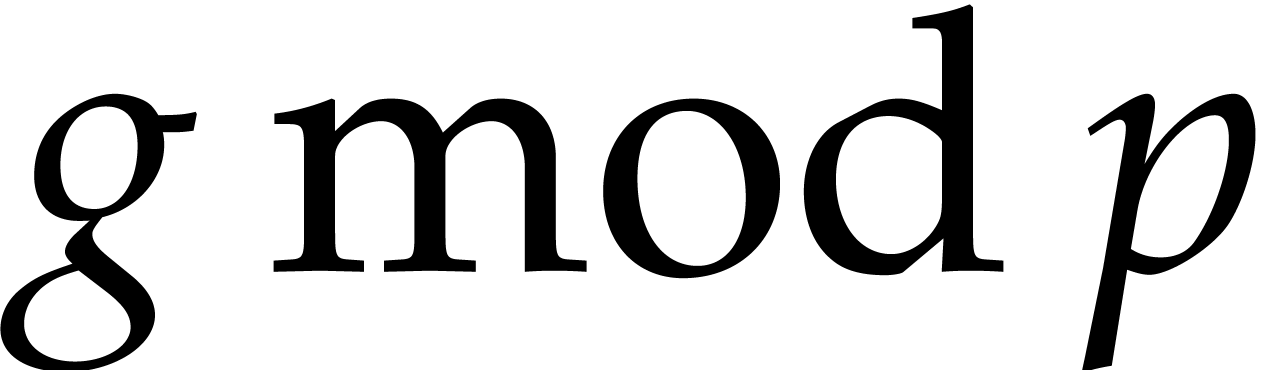 is a generator of this cyclic group.
Given a polynomial
is a generator of this cyclic group.
Given a polynomial 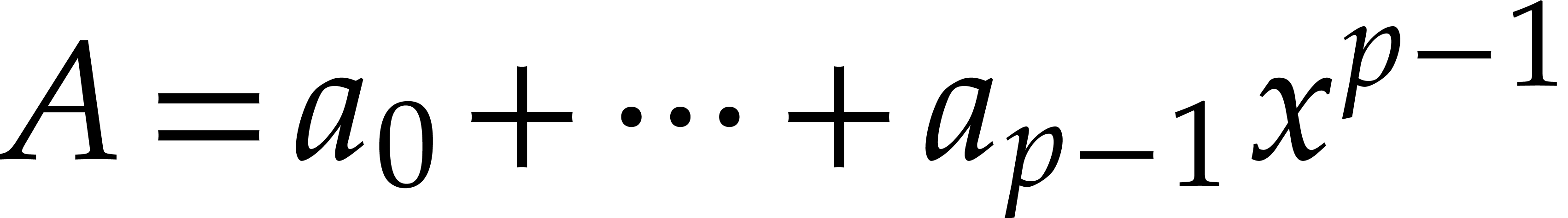 and
and  with
with 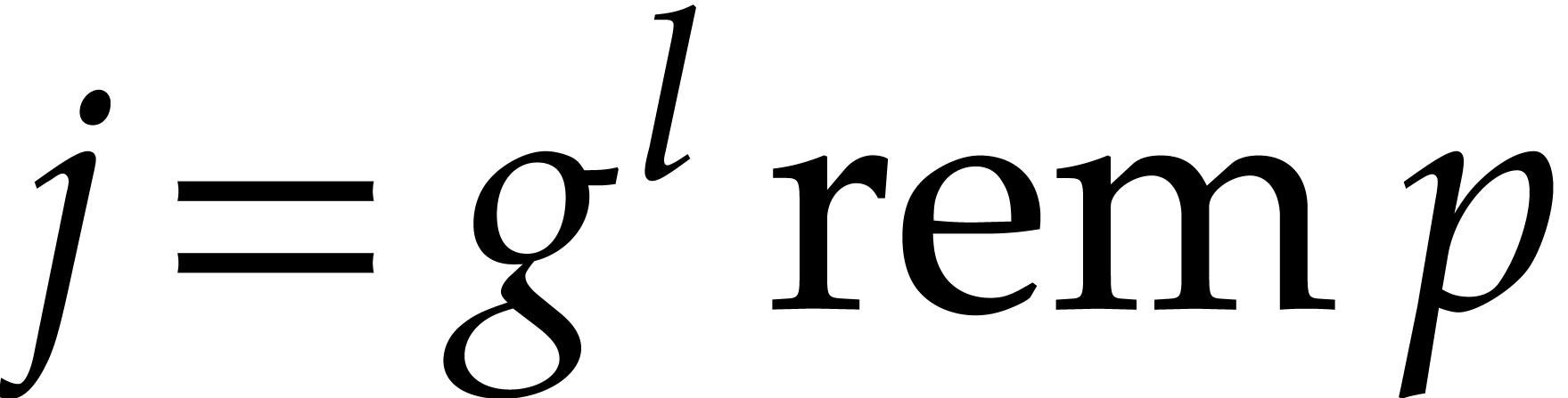 , we have
, we have
Setting
it follows that 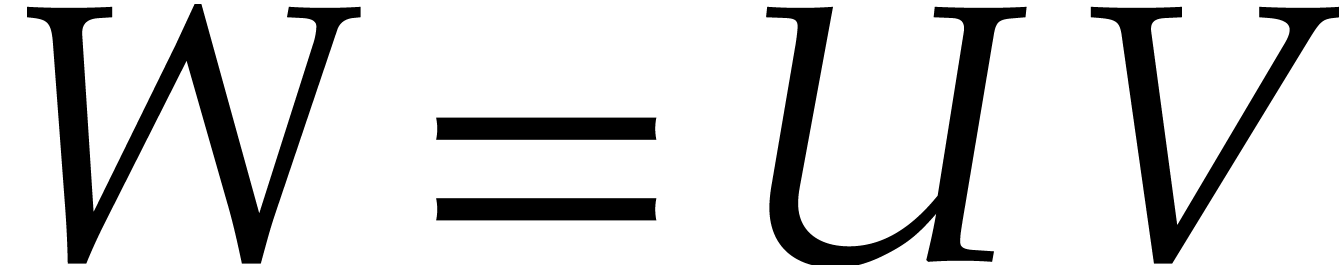 , when
regarding
, when
regarding  ,
,  and
and  as elements of
as elements of 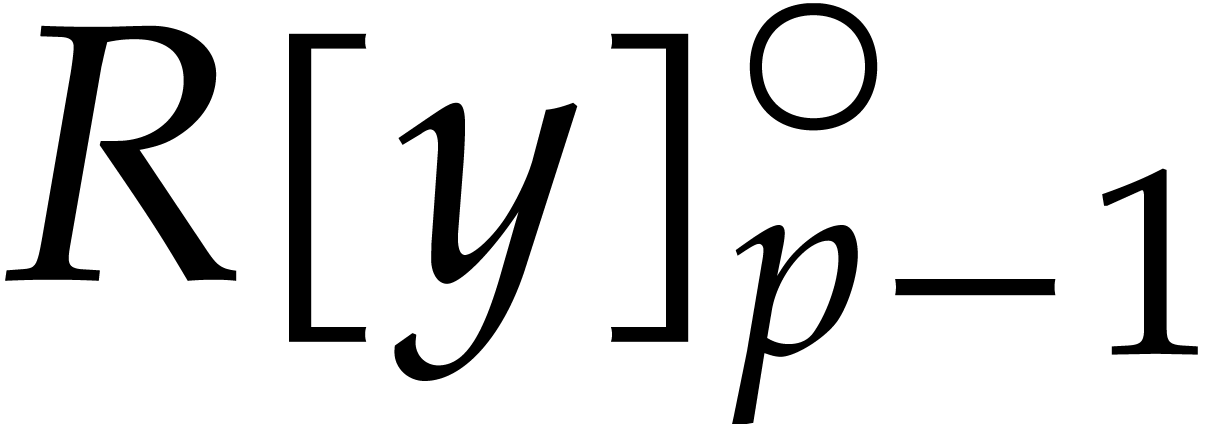 ,
since
,
since
Notice that the vector can be precomputed since
it does not depend on .
In summary, we have reduced the computation of a discrete Fourier
transform of length to a cyclic convolution of
length and 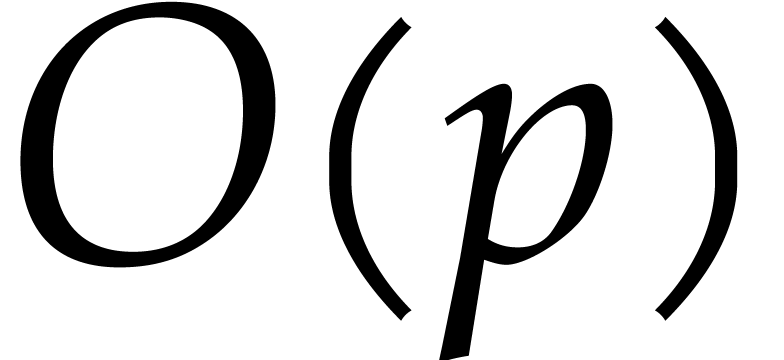 additions in
. This reduction is due to
Rader [46], except for the minor twist that we subtract
additions in
. This reduction is due to
Rader [46], except for the minor twist that we subtract
 in the definition of
in the definition of  . As far as we are aware, this twist is essentially
due to Nussbaumer [43, section 5.2.2]. In the next
subsection, it allows us to compute Rader transforms without increasing
the dimension from to
. As far as we are aware, this twist is essentially
due to Nussbaumer [43, section 5.2.2]. In the next
subsection, it allows us to compute Rader transforms without increasing
the dimension from to  .
.
Let us now show how to present Rader reduction using suitable linear
transforms, called left, right and inverse Rader transforms (LRT, RRT
and IRT). These transforms depend on the choice of  ; from now on, we assume that
has been fixed once and for all. Given
; from now on, we assume that
has been fixed once and for all. Given  and , let ,
and be as in section 4.1. Setting
and , let ,
and be as in section 4.1. Setting
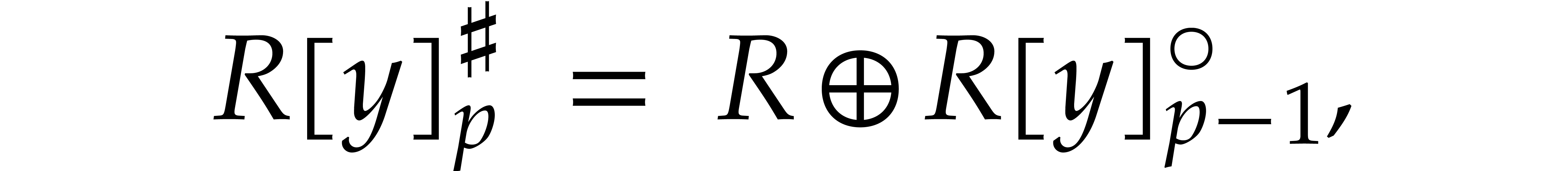
we first introduce the distinguished element 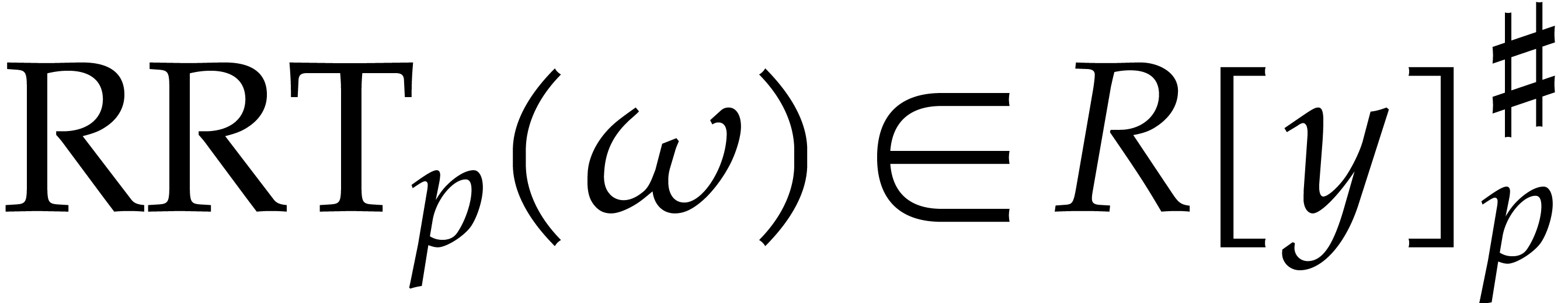 by
by
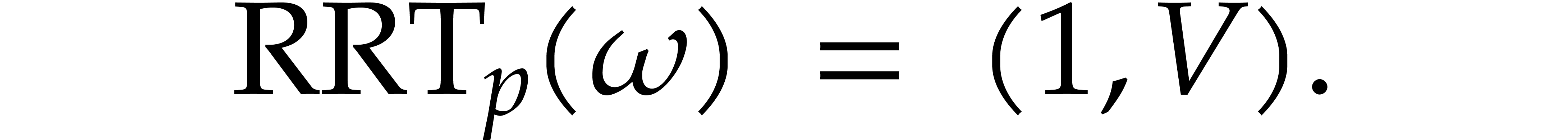
We also define 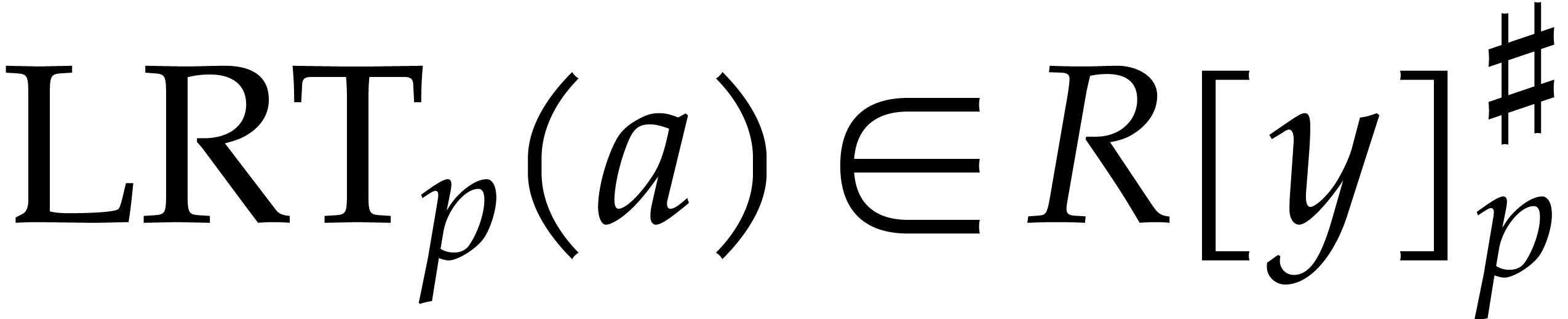 by
by
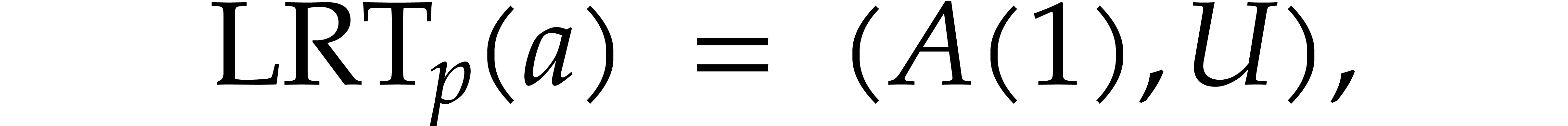
so that 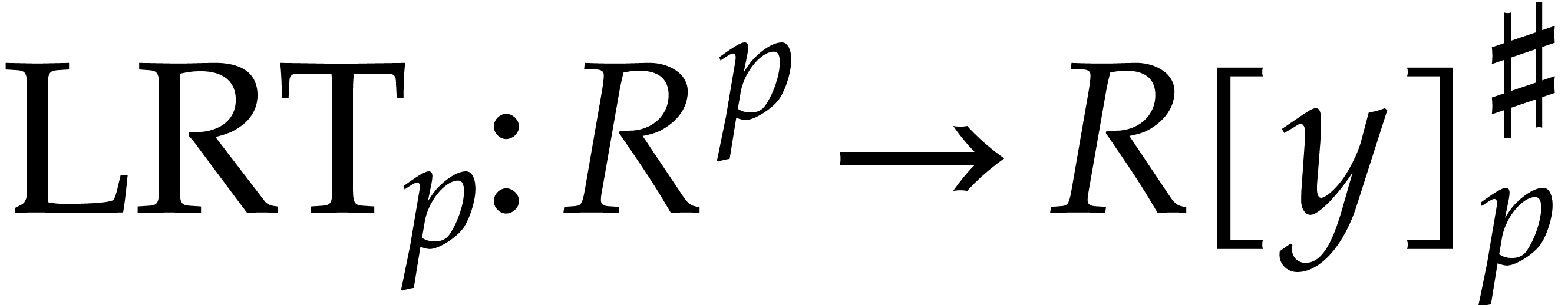 is a linear mapping. We can retrieve
is a linear mapping. We can retrieve
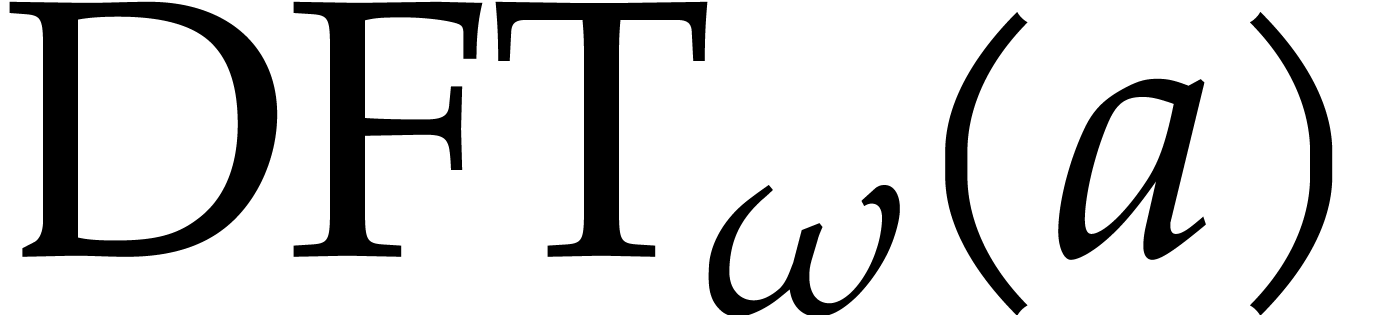 from the product
from the product  using
using
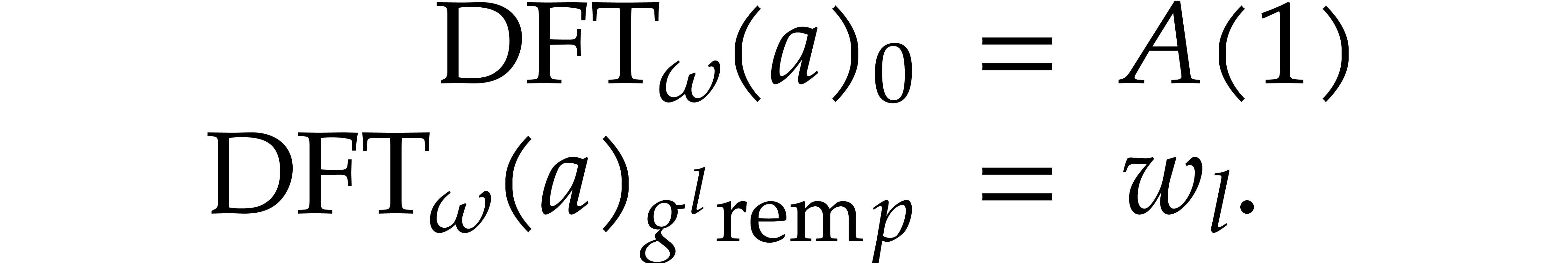
We denote by 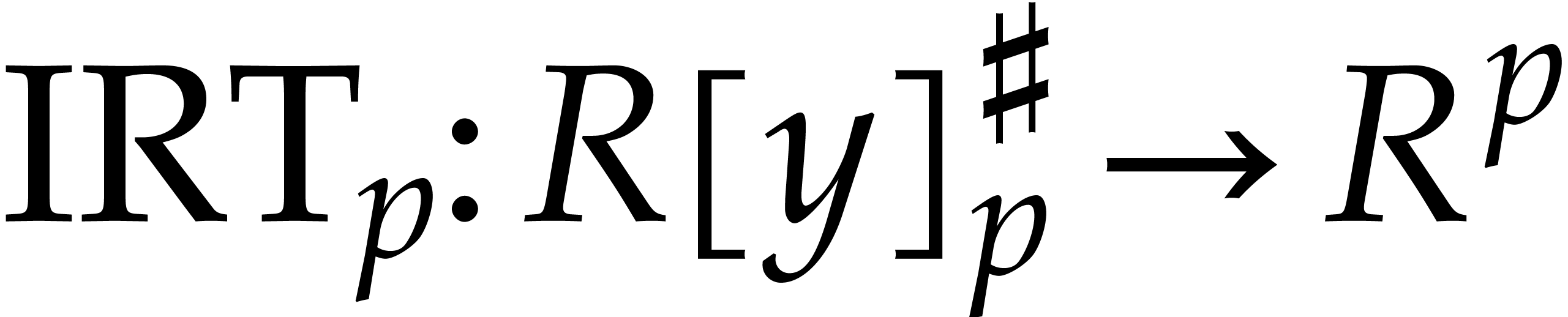 the linear mapping with
the linear mapping with 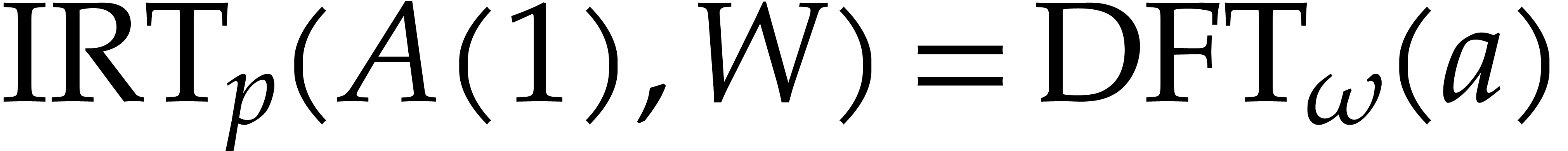 . Altogether, we have
. Altogether, we have
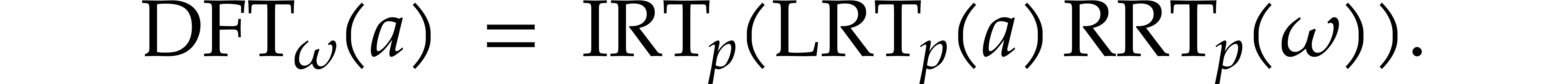
The linear mappings  and
and  boil down to permutations and a linear number of additions and
subtractions. Now permutations can be computed efficiently on Turing
machines, as recalled in section A.1 of the appendix. More
precisely, since is a principal root of unity of
order , we necessarily have
boil down to permutations and a linear number of additions and
subtractions. Now permutations can be computed efficiently on Turing
machines, as recalled in section A.1 of the appendix. More
precisely, since is a principal root of unity of
order , we necessarily have
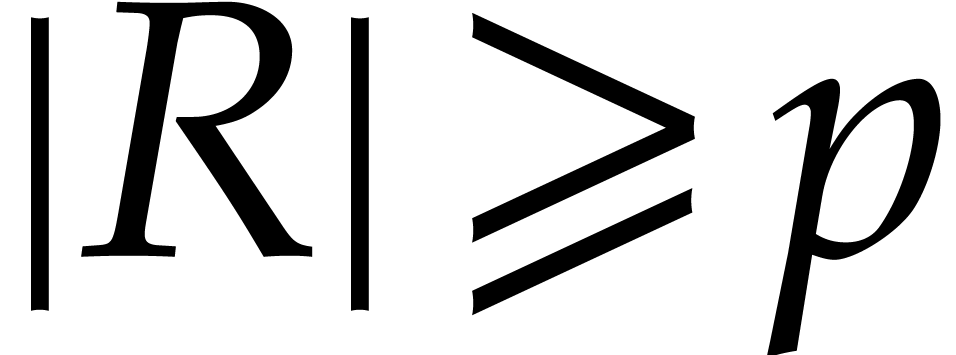 . Then the permutation of
coefficients in of
bitsize
. Then the permutation of
coefficients in of
bitsize 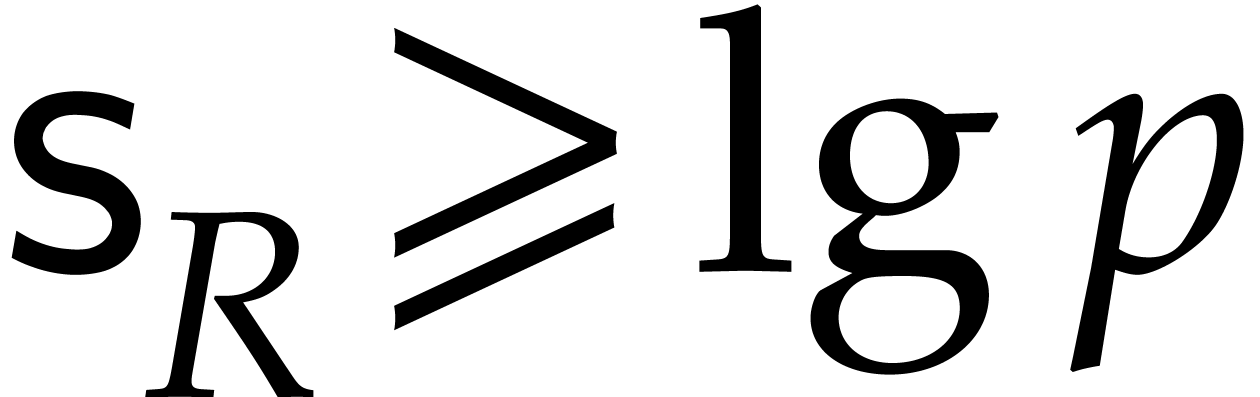 can be done using a merge sort in time
can be done using a merge sort in time
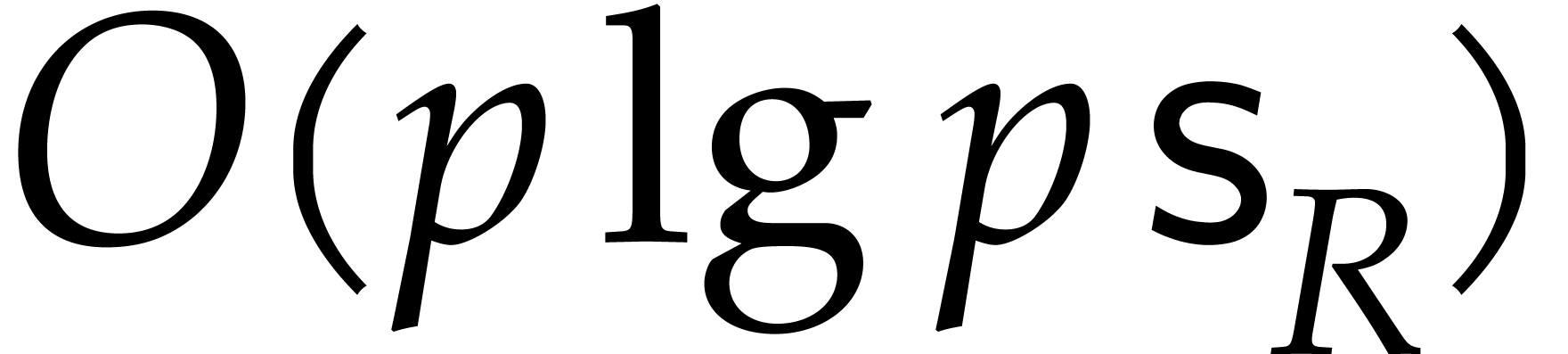 , whence
, whence
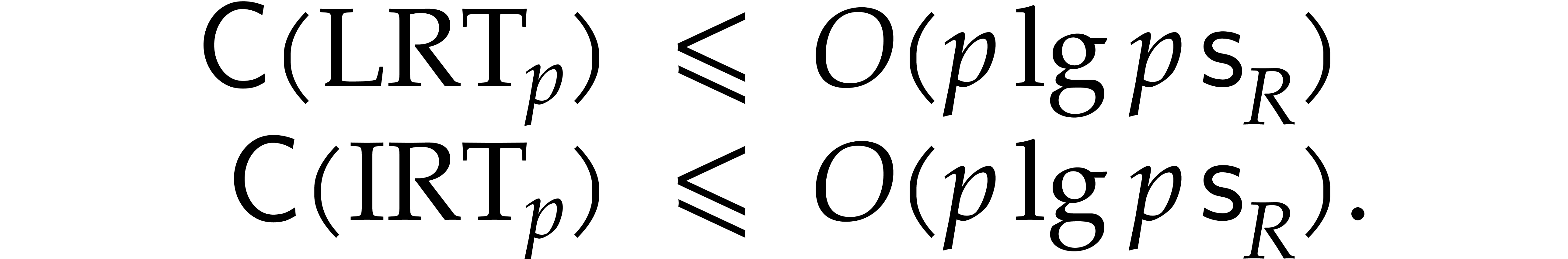
It follows that
In this bound, the cost 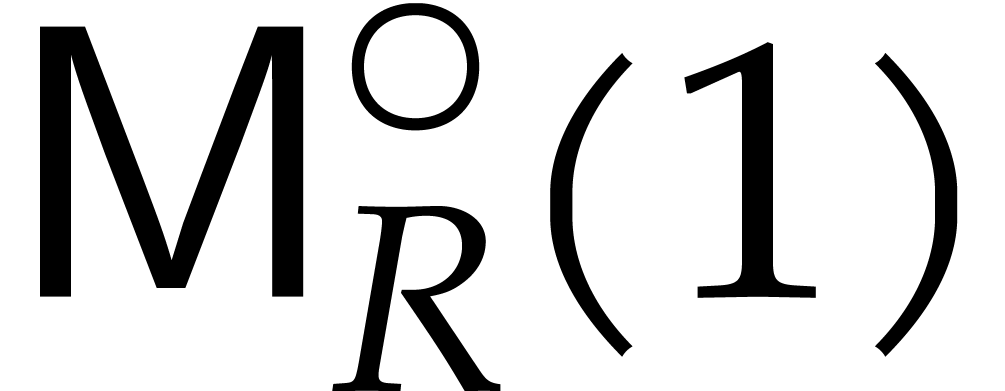 corresponds to the
trivial multiplication
corresponds to the
trivial multiplication 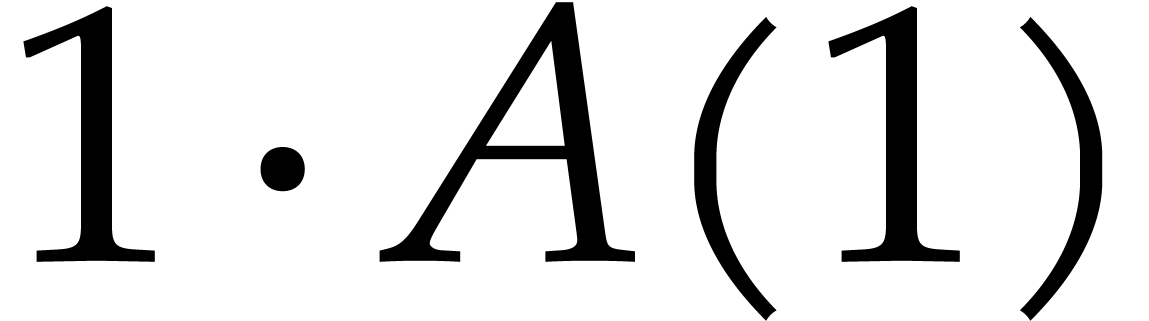 . We
included this term in anticipation of the multivariate generalization
(4.3) below. We also recall that we assumed to be precomputed. This precomputation can be done in time
. We
included this term in anticipation of the multivariate generalization
(4.3) below. We also recall that we assumed to be precomputed. This precomputation can be done in time
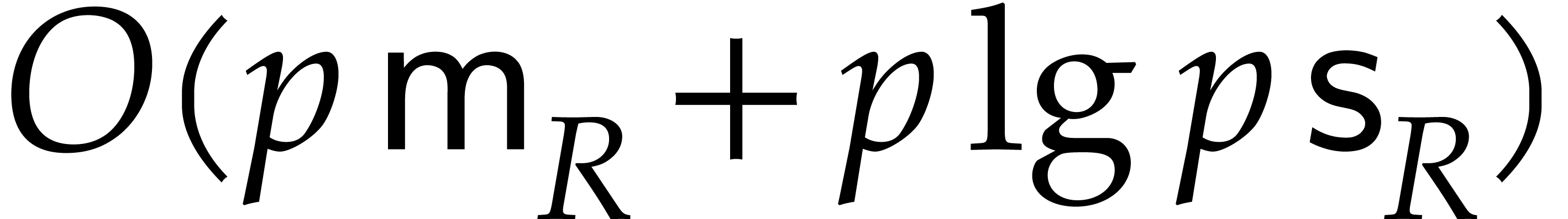 : we first compute the powers
for
: we first compute the powers
for  and then permute
them appropriately.
and then permute
them appropriately.
Assume now that are prime numbers, that we have
fixed generators  for the cyclic groups
for the cyclic groups 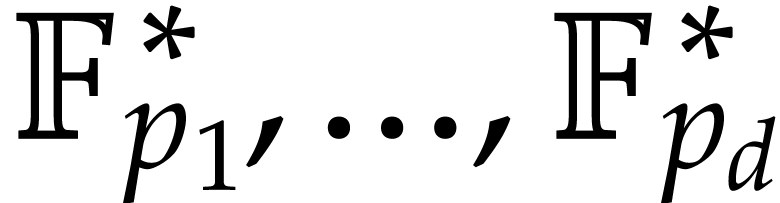 , and that
, and that 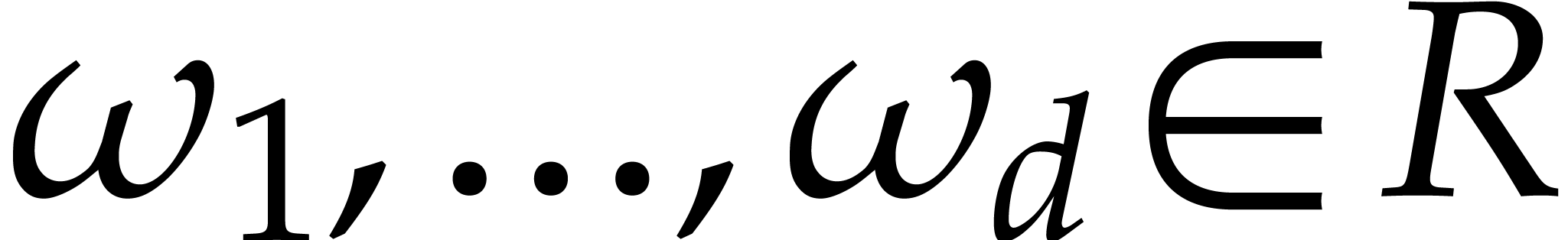 are such that is a principal -th root of unity for . Let ,
are such that is a principal -th root of unity for . Let ,
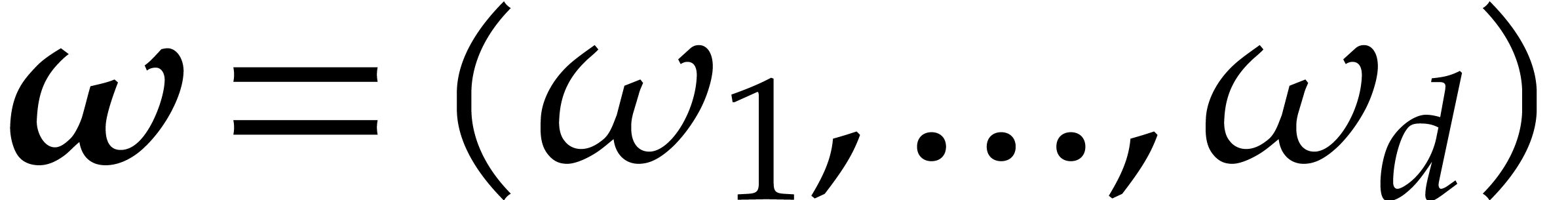 , and
, and
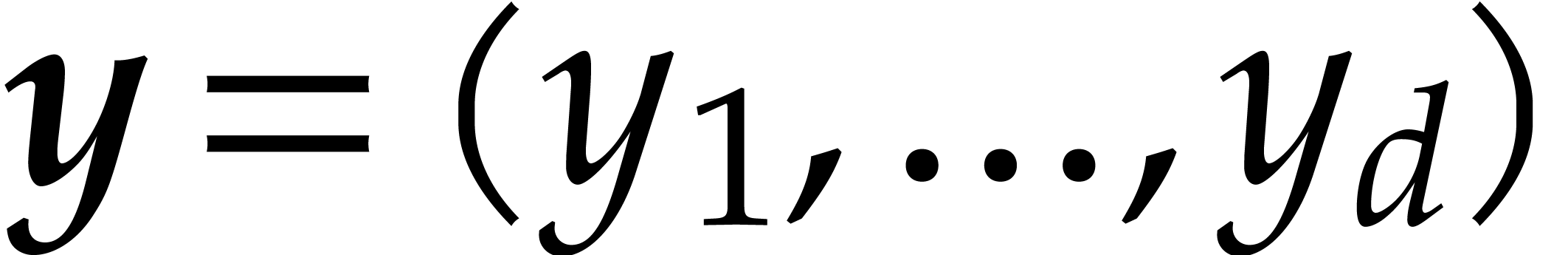 . We define
. We define
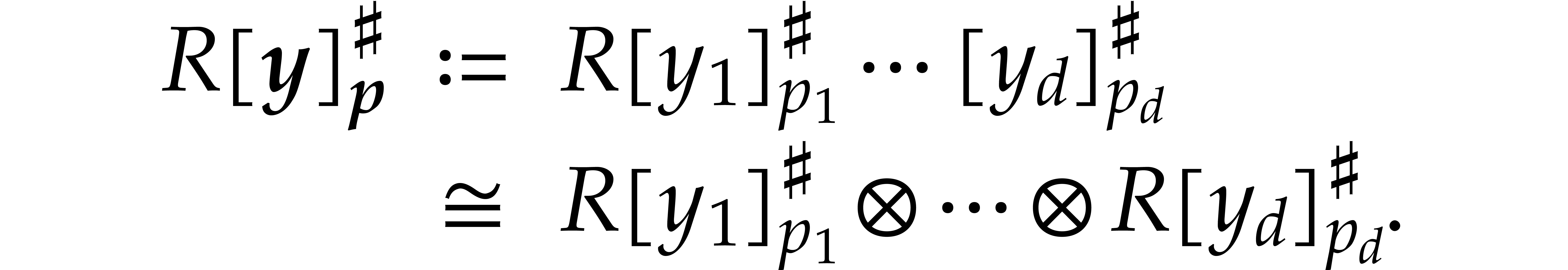
Using the distributivity of with respect to
, the algebra 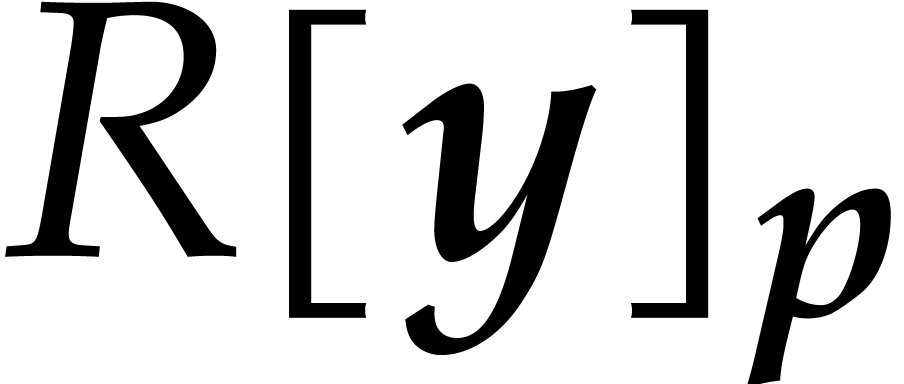 is a direct sum of algebras of cyclic multivariate
polynomials. More precisely, let
is a direct sum of algebras of cyclic multivariate
polynomials. More precisely, let  .
For each index
.
For each index  , let
, let 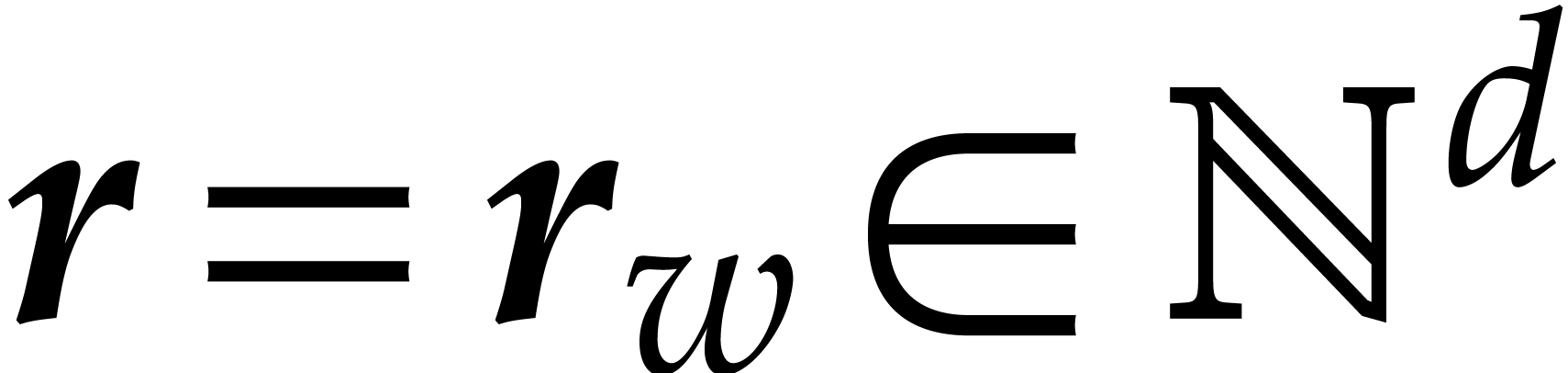 be such that
be such that 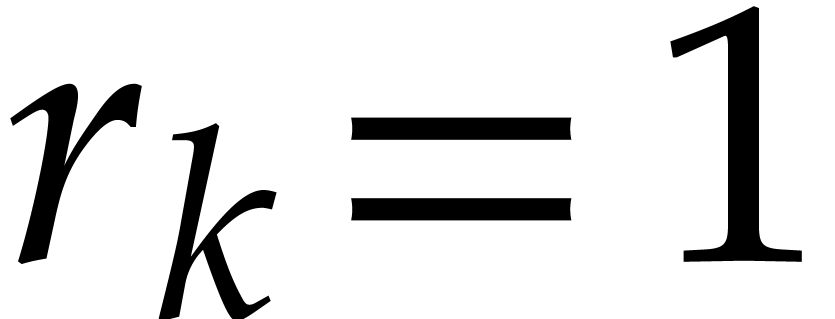 if
if 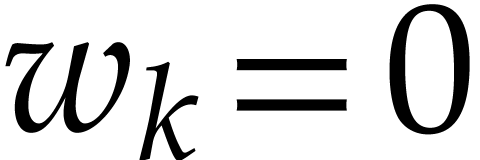 and
and 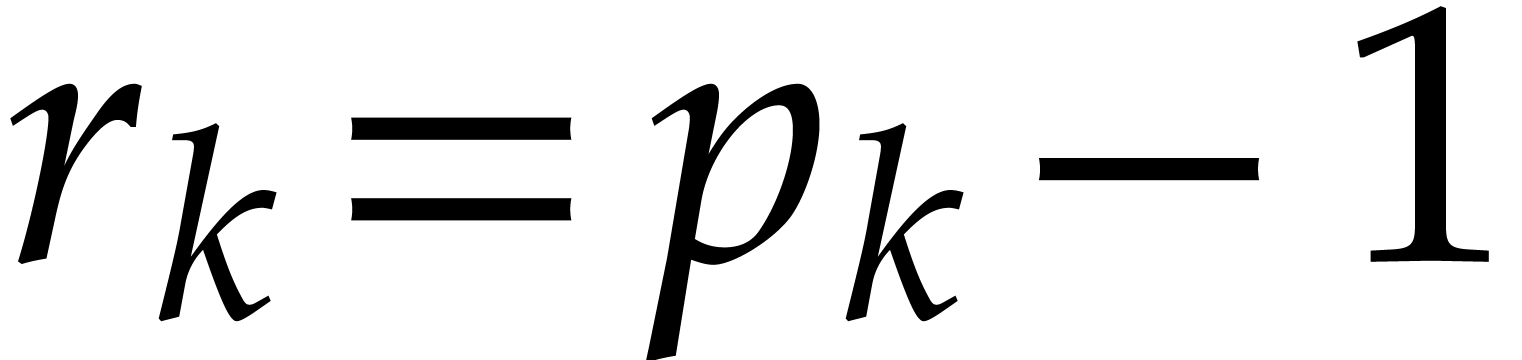 if
if 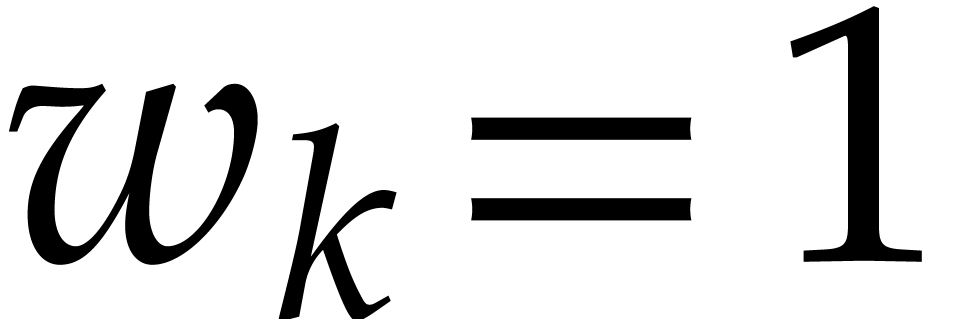 for
for
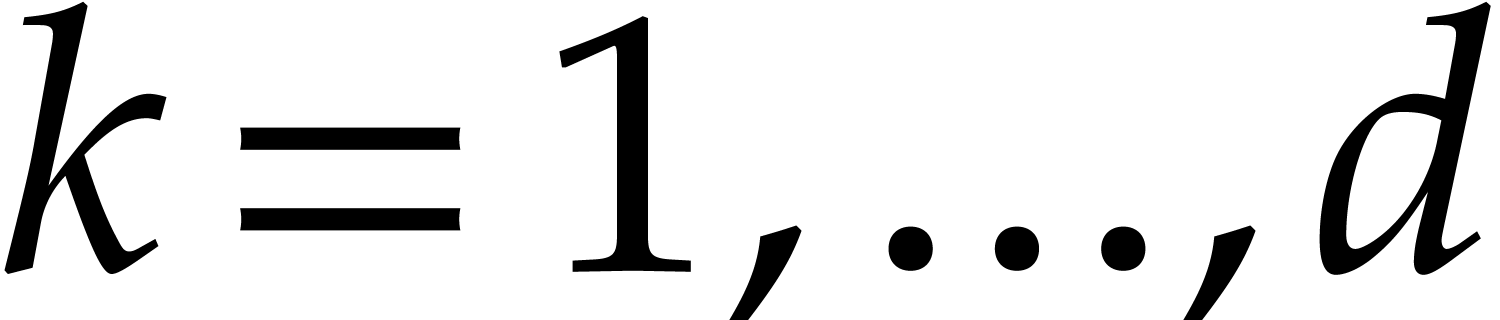 . Then
. Then

Notice that
Elements in  correspond to sums
correspond to sums 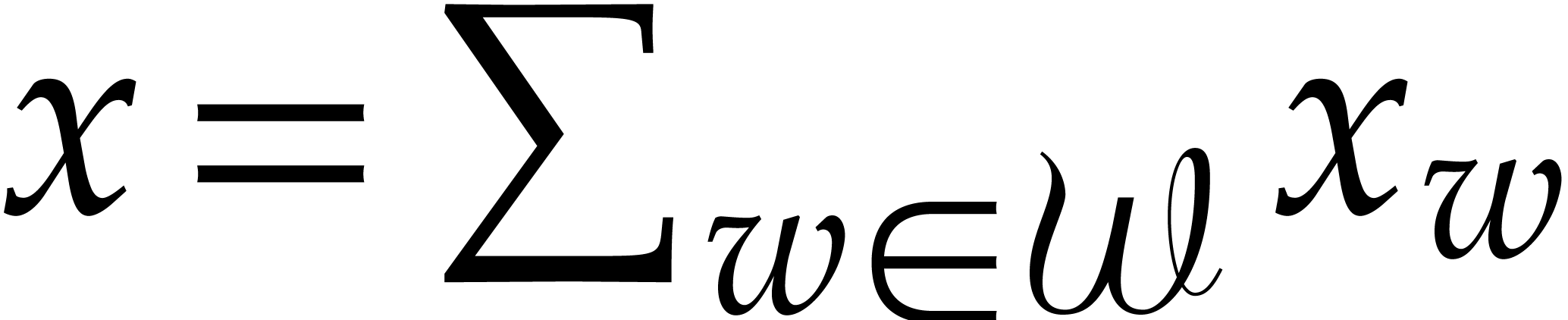 with
with 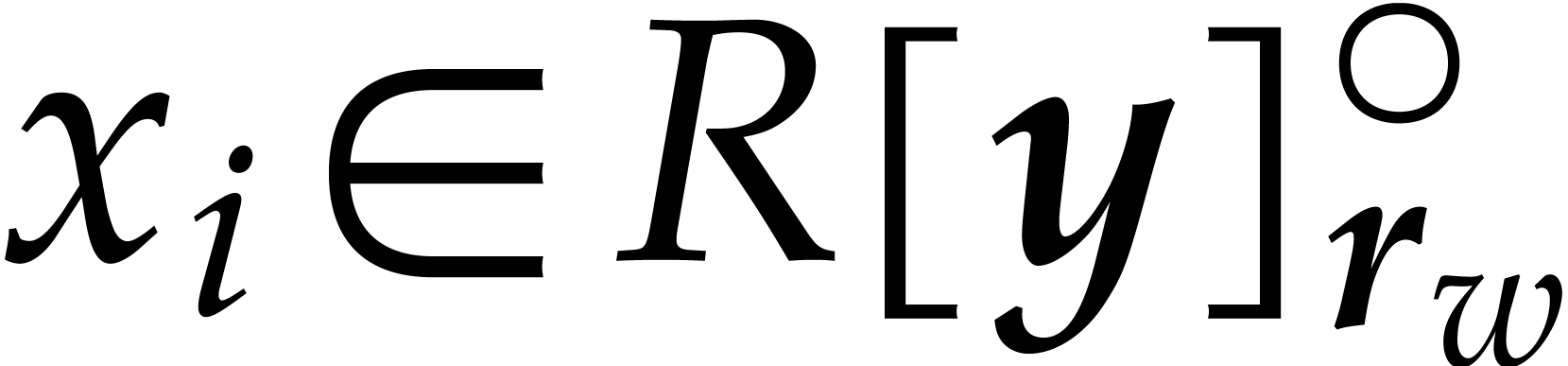 . Assuming the
lexicographical ordering on
. Assuming the
lexicographical ordering on  ,
such sums are represented on a Turing tape by concatenating the
representations of the components
,
such sums are represented on a Turing tape by concatenating the
representations of the components  :
see section A.5 in the appendix for details. We have
:
see section A.5 in the appendix for details. We have
by Lemma A.9 (we may take  ).
).
The tensor product of the mappings 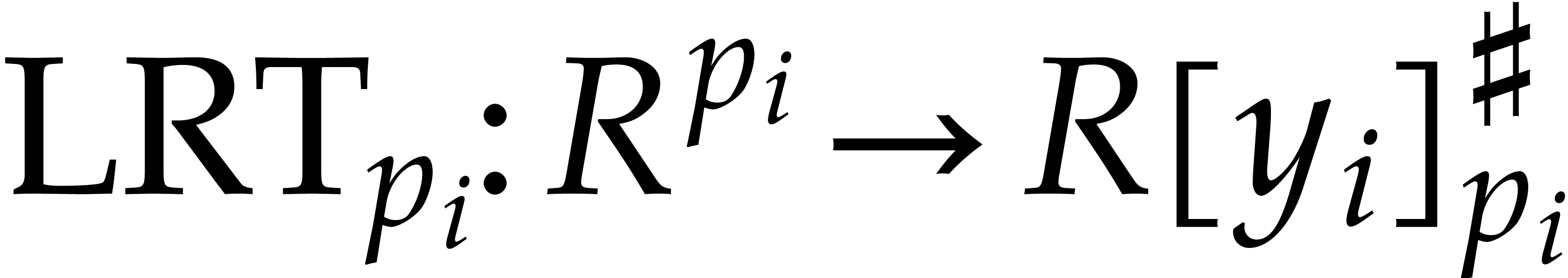 provides us
with a mapping
provides us
with a mapping

Similarly, we obtain a mapping

and a distinguished element
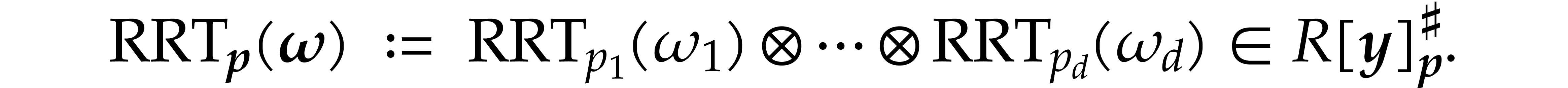
For any  and
and  ,
we now have
,
we now have
By linearity, it follows that
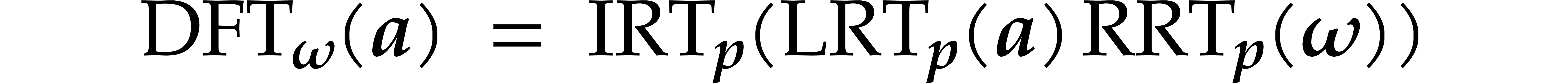
for all  .
.
From the complexity point of view, the relation (3.2) implies
Using (4.2) and 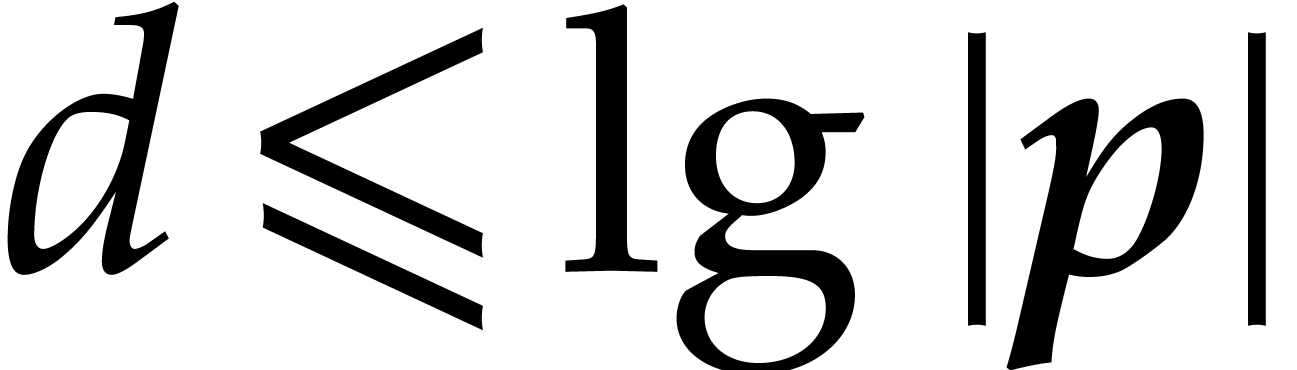 ,
this leads to the following multivariate analogue of (4.1):
,
this leads to the following multivariate analogue of (4.1):
As in the case of (4.1), this bound does not include the
cost of the precomputation of 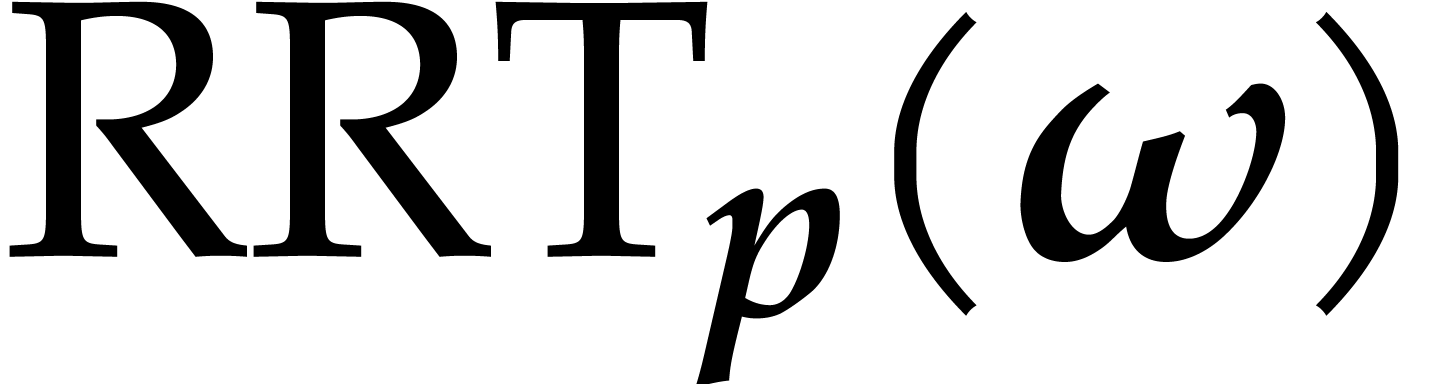 .
This precomputation can be performed in time
.
This precomputation can be performed in time 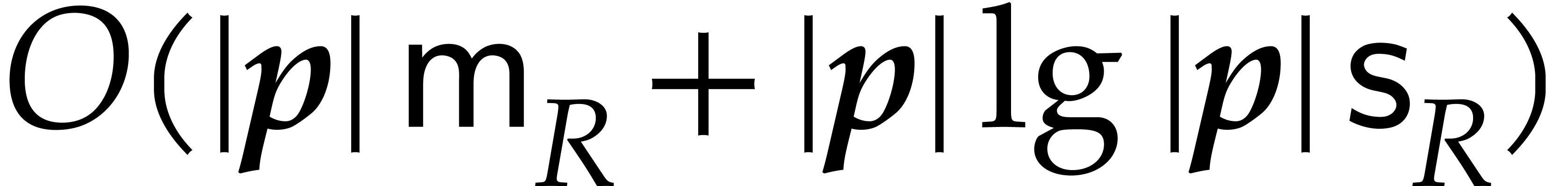 using the same “list and sort” technique as in the
univariate case.
using the same “list and sort” technique as in the
univariate case.
Let  be the set of all prime numbers. Given two
integers and
be the set of all prime numbers. Given two
integers and  with
with 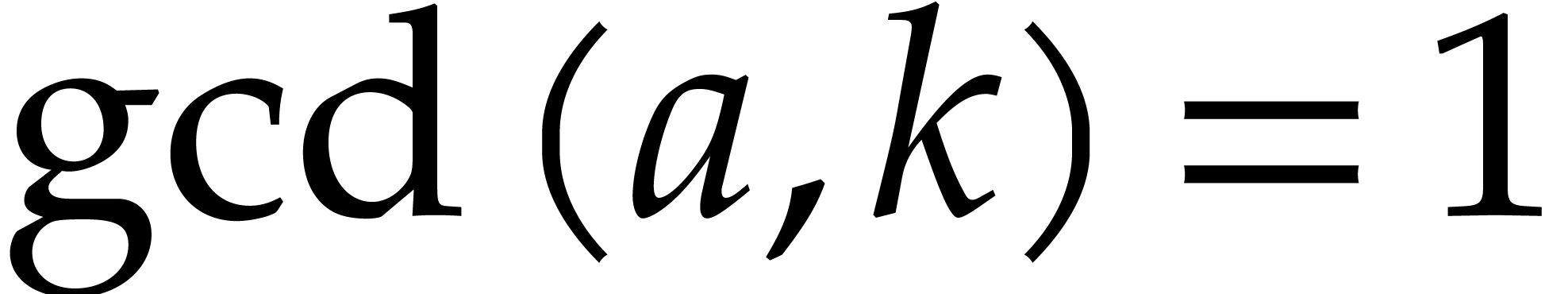 , we define
, we define 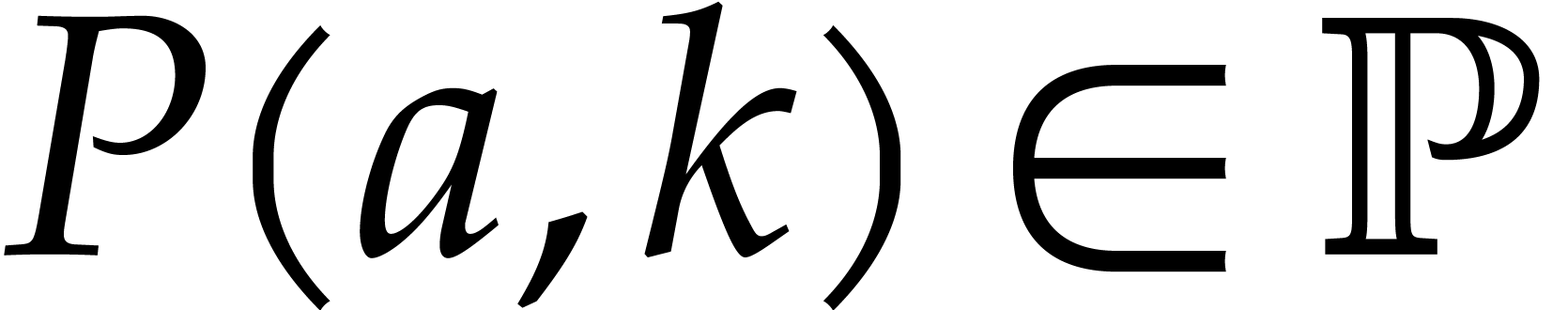 and
and 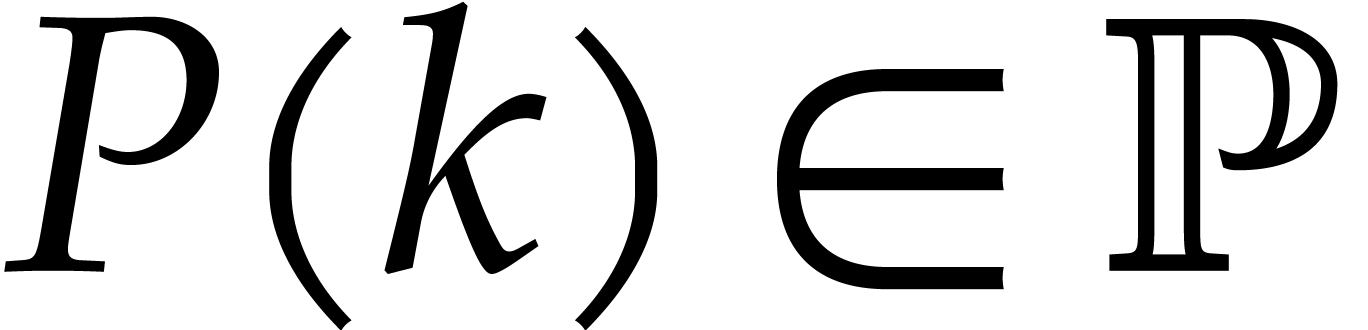 by
by
A constant with the property that is called a Linnik constant (notice that we allow
the implicit constants 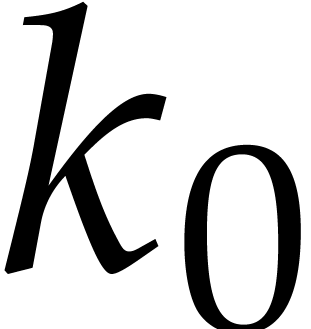 and
with
and
with 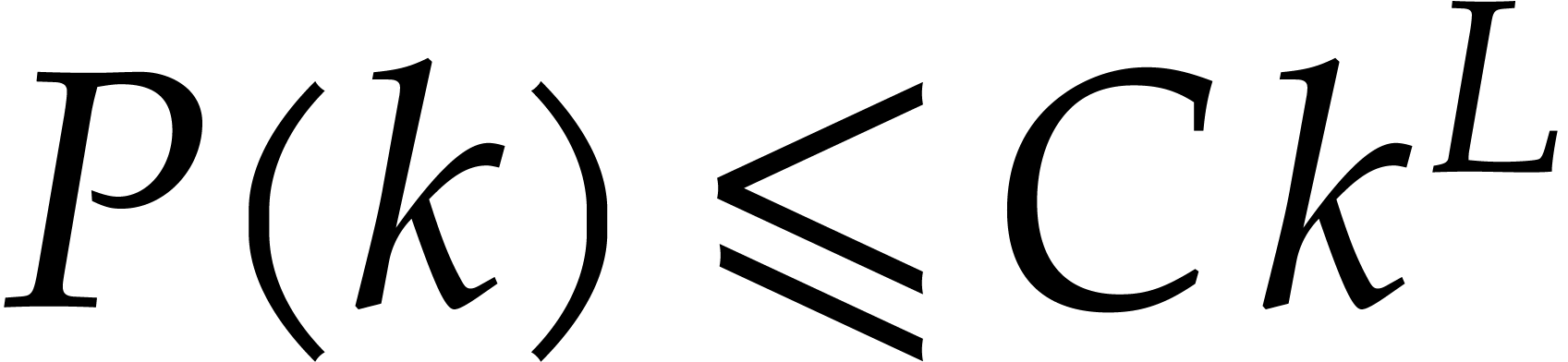 for
for 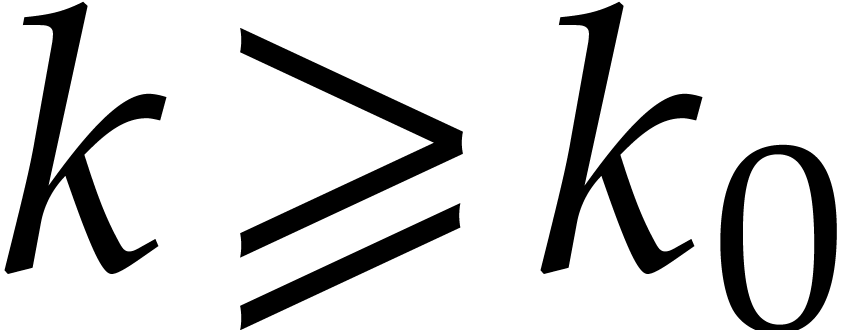 to depend on
).
to depend on
).
The existence of a Linnik constant was shown by
Linnik [39, 40]. The smallest currently known
value is due to Xylouris [57].
Assuming the Generalized Riemann Hypothesis (GRH), it is known that any
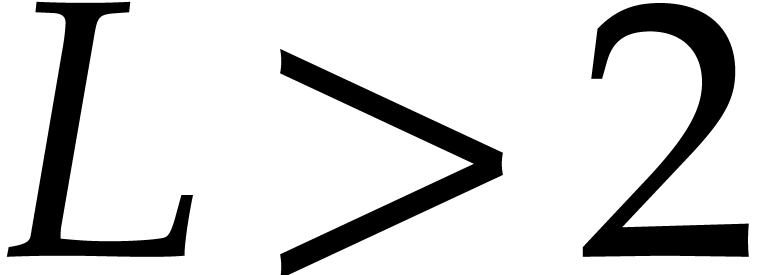 is a Linnik constant [28].
Unfortunately, these bounds are still too weak for our purposes.
is a Linnik constant [28].
Unfortunately, these bounds are still too weak for our purposes.
Both heuristic probabilistic arguments and numerical evidence indicate
that 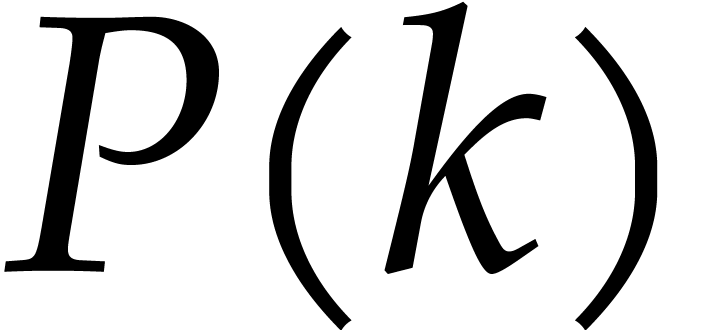 satisfies the much sharper bound , where
stands for Euler's totient function. More precisely, based on such
evidence [38], Li, Pratt and Shakan conjecture that
satisfies the much sharper bound , where
stands for Euler's totient function. More precisely, based on such
evidence [38], Li, Pratt and Shakan conjecture that

Unfortunately, a proof of this conjecture currently seems to be out of
reach. At any rate, this conjecture is much stronger than the assumption
that in Theorem 1.2.
Given integers , 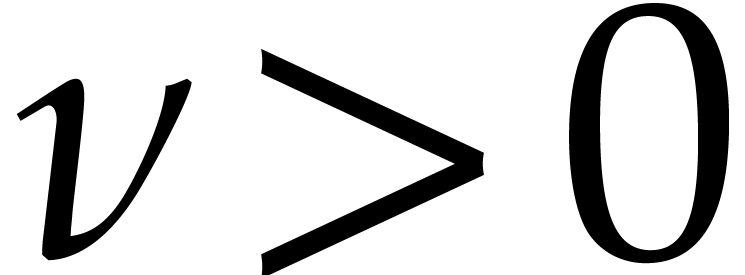 , and
, and  with , let
with , let 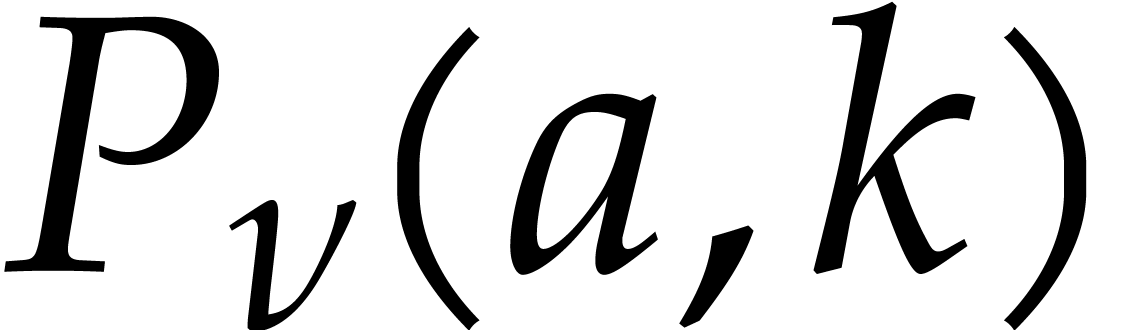 denote the -th prime number in the arithmetic
progression
denote the -th prime number in the arithmetic
progression 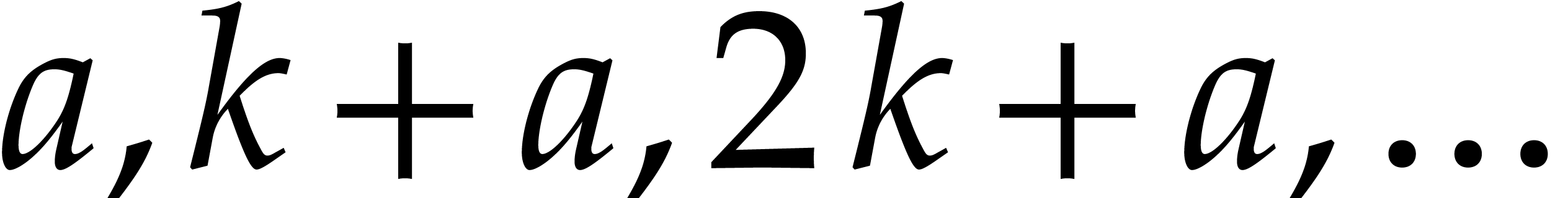 , so that
, so that 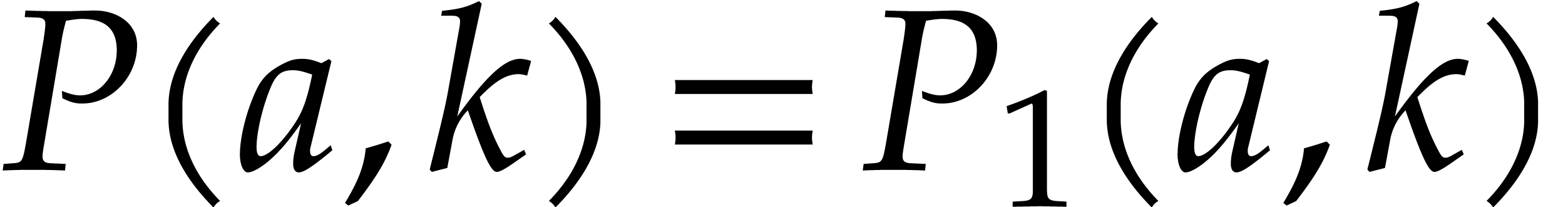 . Also define
. Also define 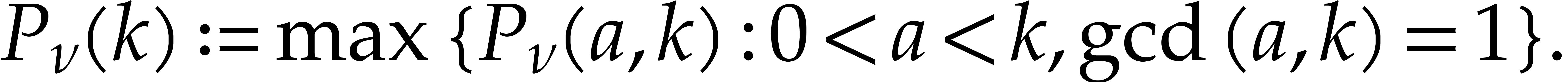
Remark. Note that the implied big-Oh constant
depends on  ; a similar remark
applies to Lemma 5.4 below.
; a similar remark
applies to Lemma 5.4 below.
Proof. Let 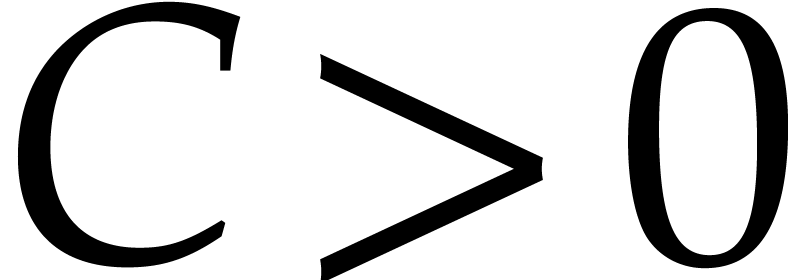 be an
absolute constant with
be an
absolute constant with 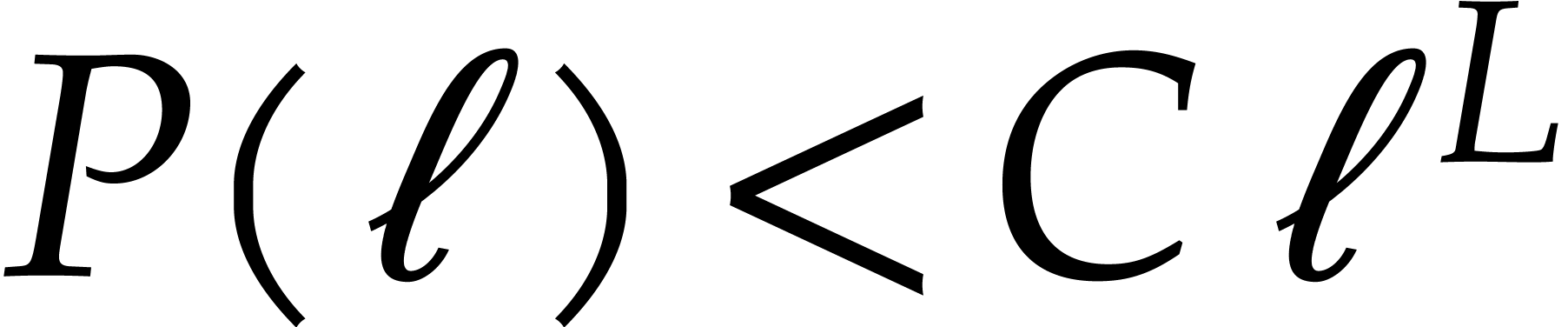 for all
for all  . Let
. Let 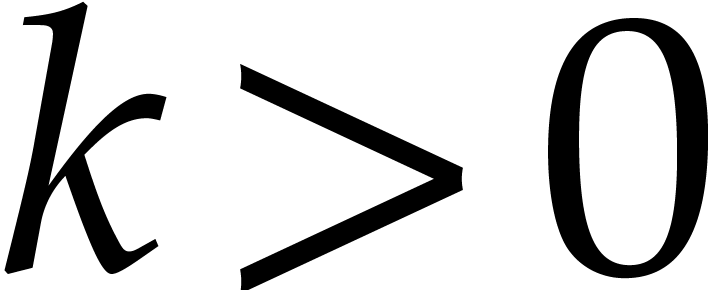 be given and let
be a fixed remainder class with .
be given and let
be a fixed remainder class with .
Let 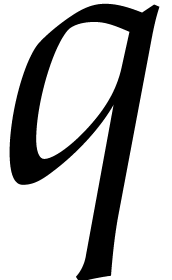 be the smallest prime number such that
be the smallest prime number such that  and
and  . The
prime number theorem implies that
. The
prime number theorem implies that  .
For each
.
For each  , let
, let  be such that
be such that 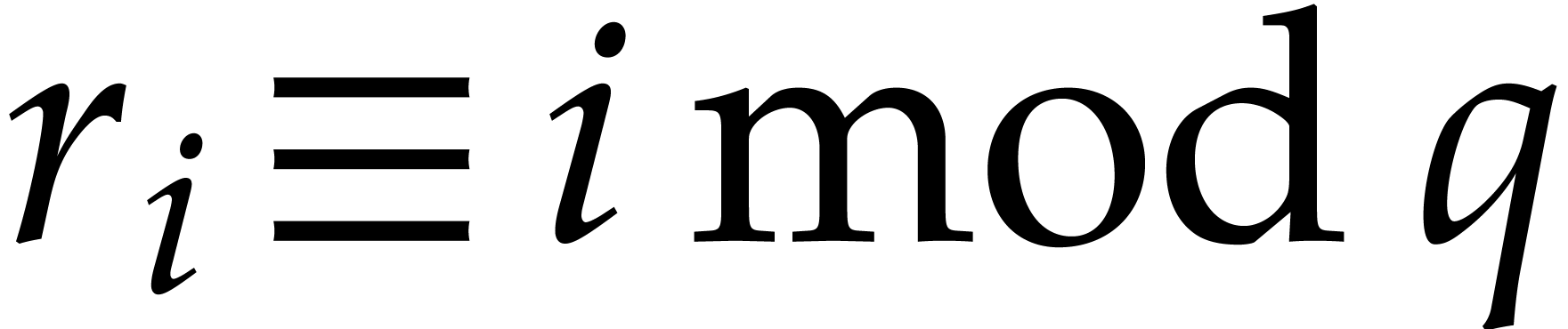 and
and 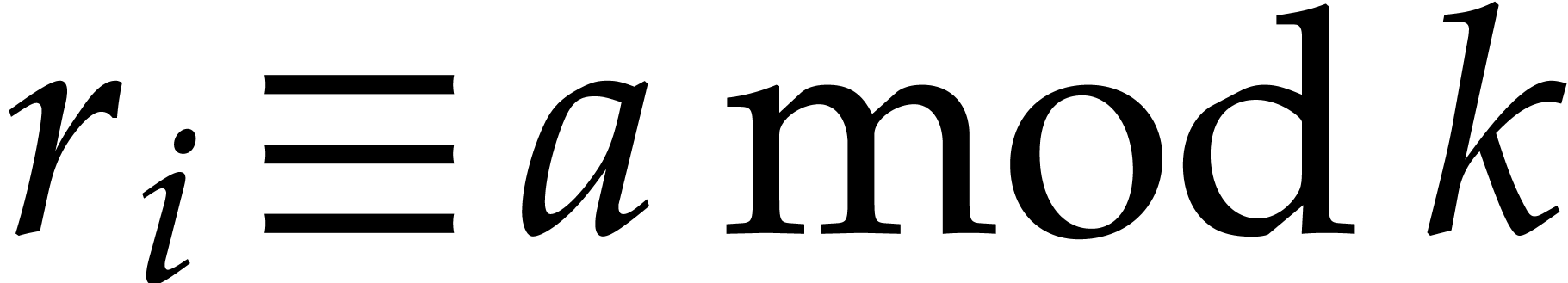 . Such an integer exists since
and
. Such an integer exists since
and 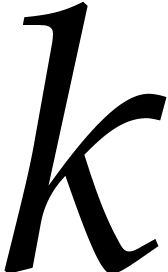 are coprime. Notice also that
are coprime. Notice also that 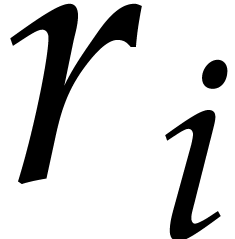 and
and 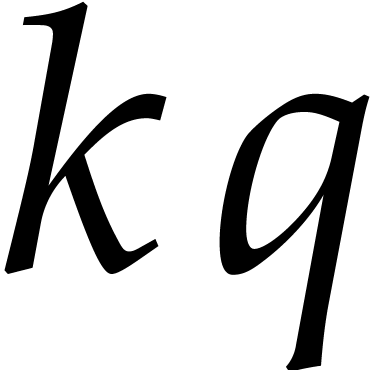 are coprime. Now consider the
prime numbers
are coprime. Now consider the
prime numbers 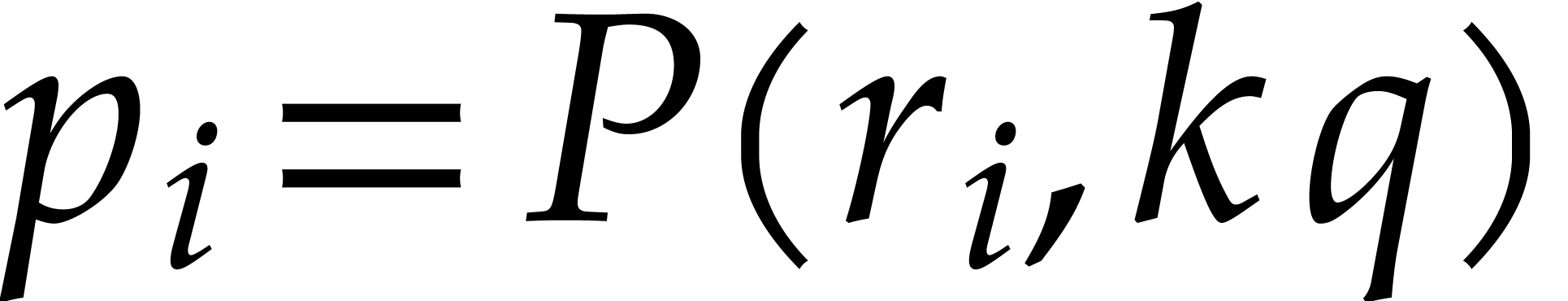 for
for 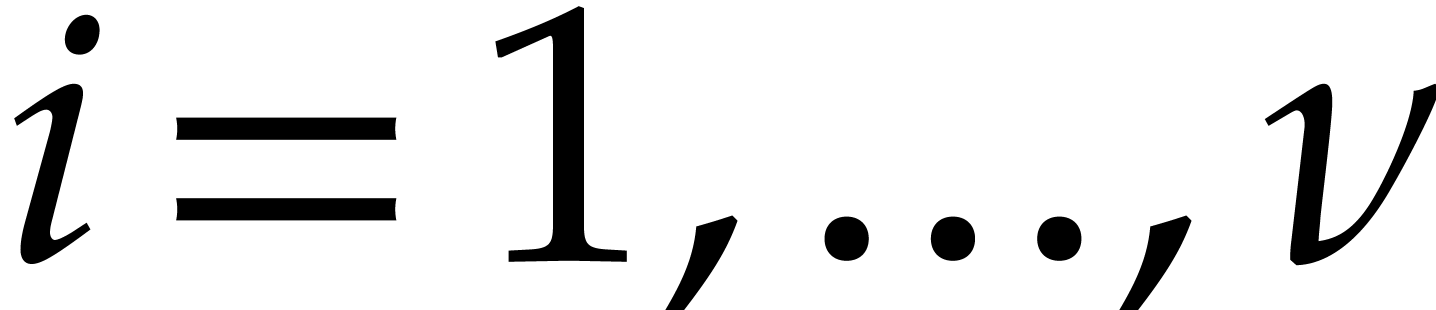 .
By construction, we have
.
By construction, we have 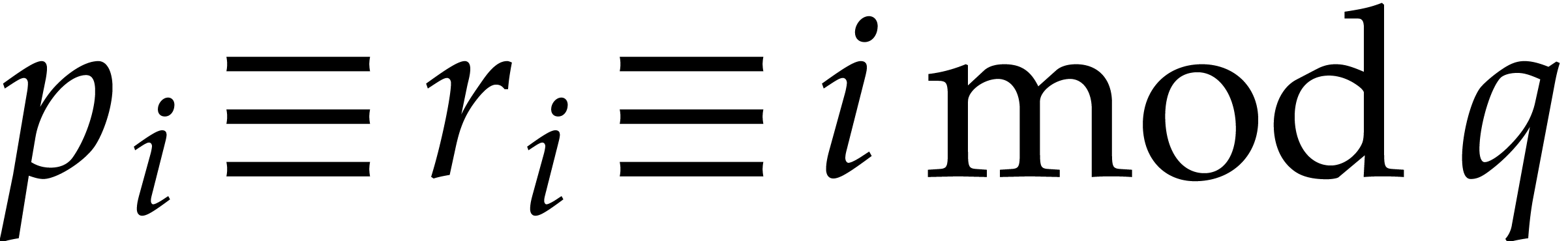 , so
the numbers are pairwise distinct. We also have
, so
the numbers are pairwise distinct. We also have
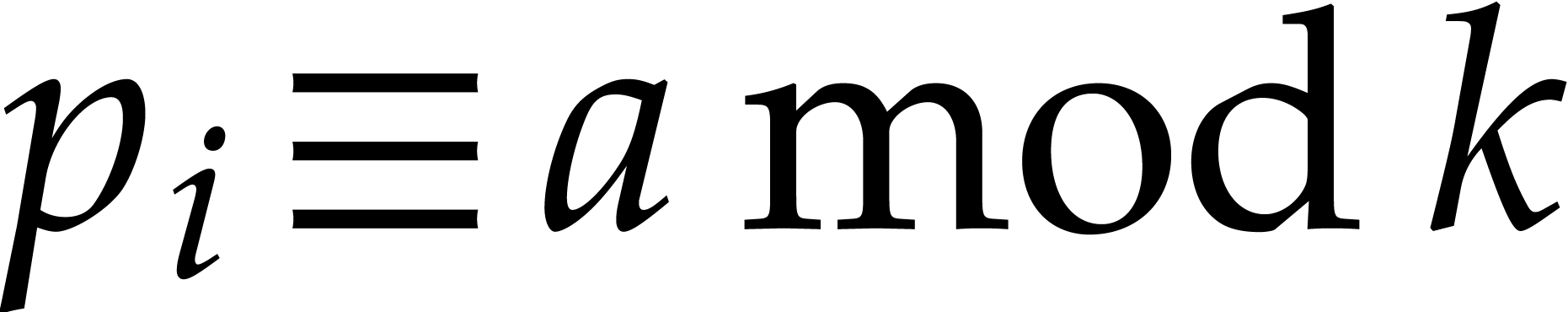 and
and 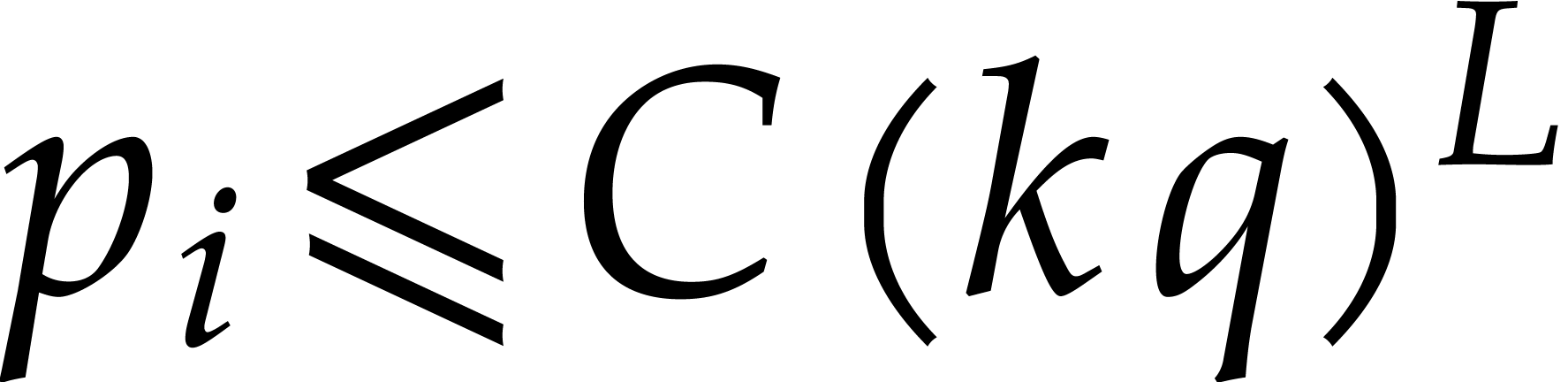 ,
whence
,
whence 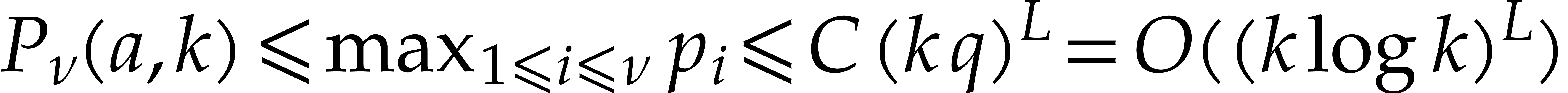 .
.
Remark with a bounded number of prime factors,
we actually have  in the proof of Lemma 5.1,
which leads to the sharper bound
in the proof of Lemma 5.1,
which leads to the sharper bound 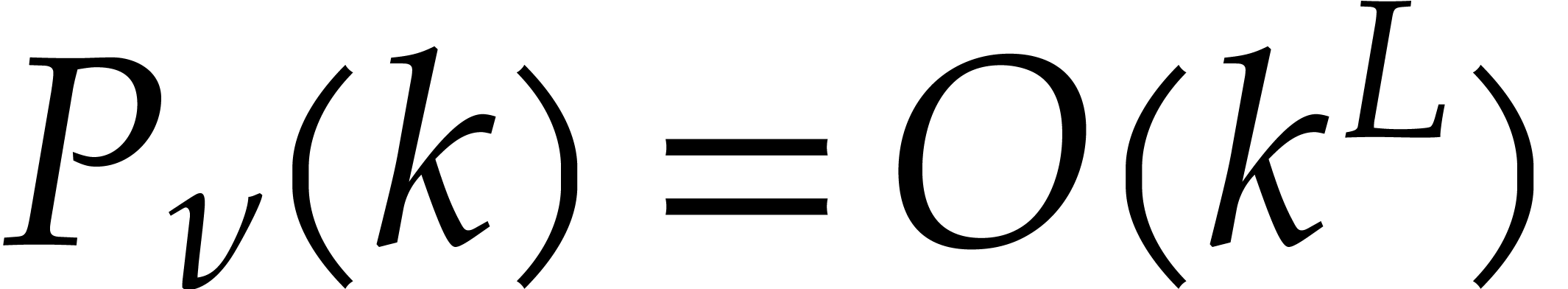 .
It is possible that the bound always holds, but
we were unable to prove this so far. If is no
longer fixed, then it is not hard to see that
.
It is possible that the bound always holds, but
we were unable to prove this so far. If is no
longer fixed, then it is not hard to see that 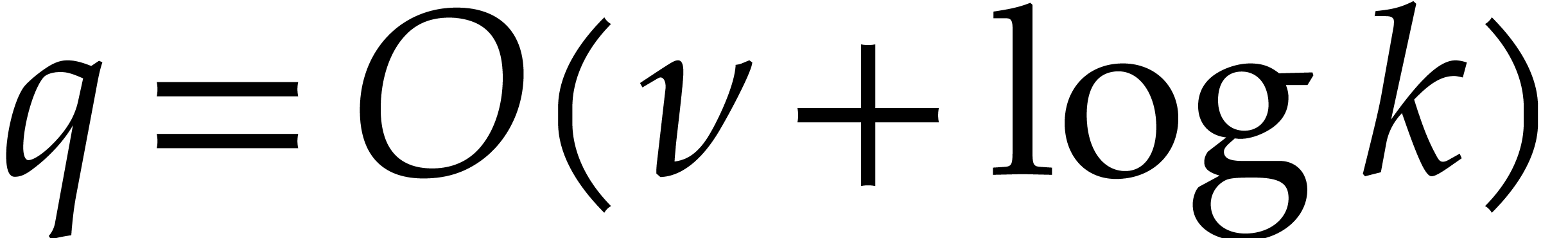 , which yields
, which yields 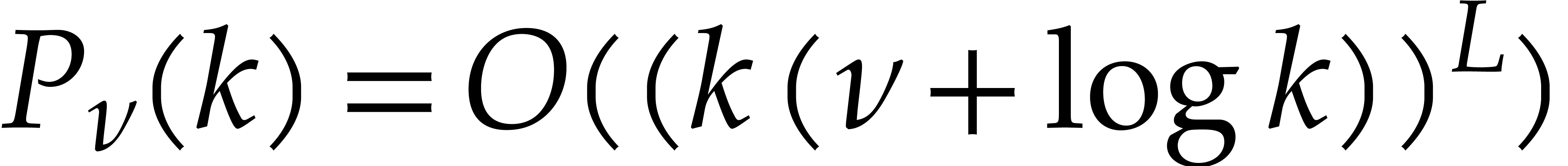 .
Concerning a generalization of the Li–Pratt–Shakan
conjecture, it is likely that there exist constants
.
Concerning a generalization of the Li–Pratt–Shakan
conjecture, it is likely that there exist constants 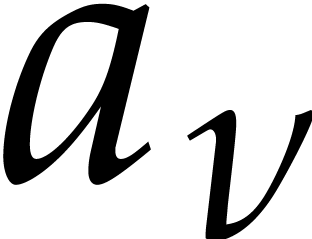 and
and 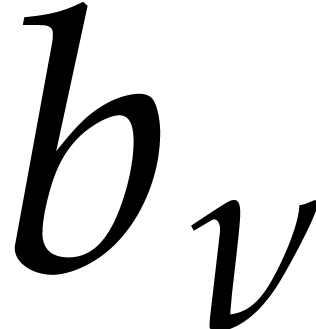 with
with

It is actually even likely that 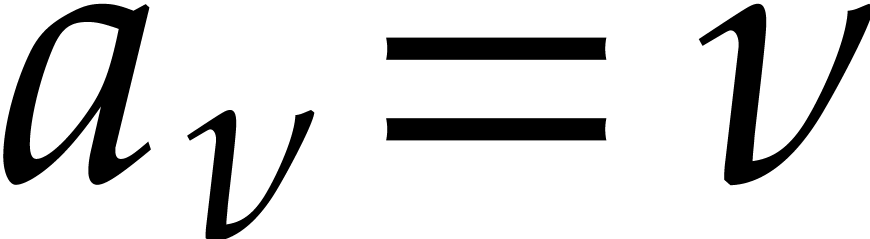 and
and 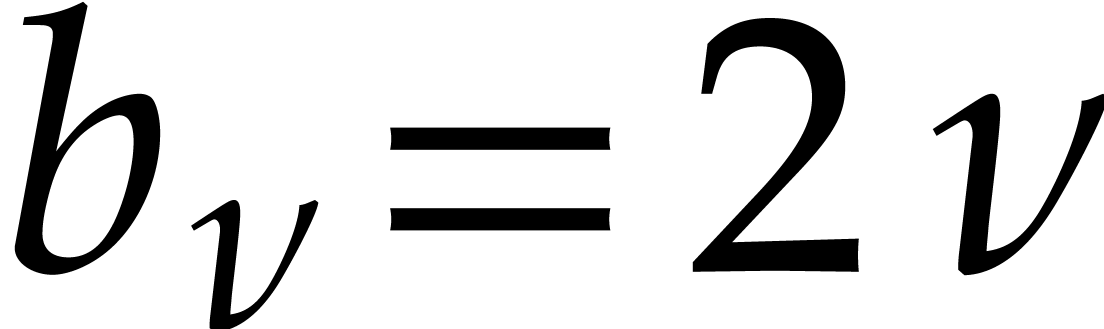 . At any rate, it would be interesting to
empirically determine and
via numerical experiments.
. At any rate, it would be interesting to
empirically determine and
via numerical experiments.
When searching for multiple prime numbers 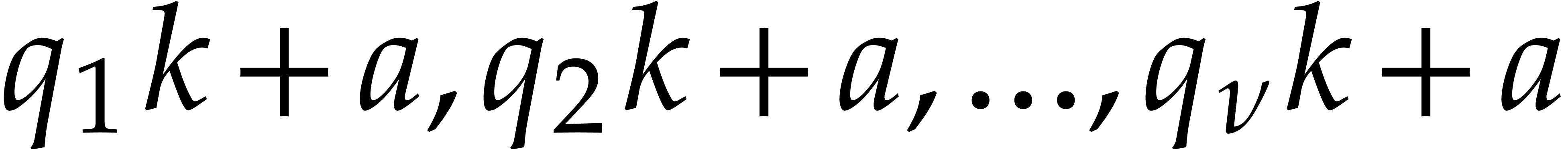 in an
arithmetic progression, as in the previous subsection, it will be useful
in sections 7 and 8 to insist that the
multipliers
in an
arithmetic progression, as in the previous subsection, it will be useful
in sections 7 and 8 to insist that the
multipliers  be pairwise coprime. The simplest
way to force this is to define the by induction
for
be pairwise coprime. The simplest
way to force this is to define the by induction
for 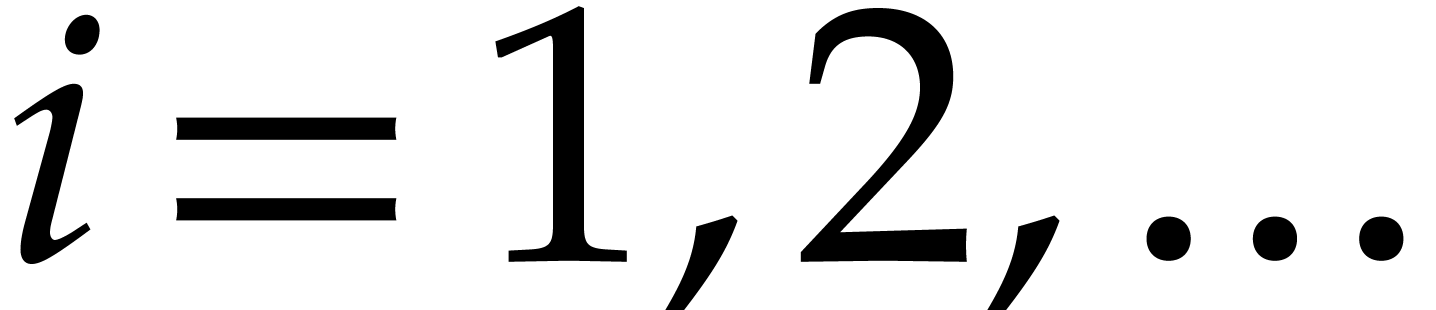 using
using
(In Lemma 5.3 below, we will show that such a value of  exists for all ,
provided that is even.) We then define
exists for all ,
provided that is even.) We then define 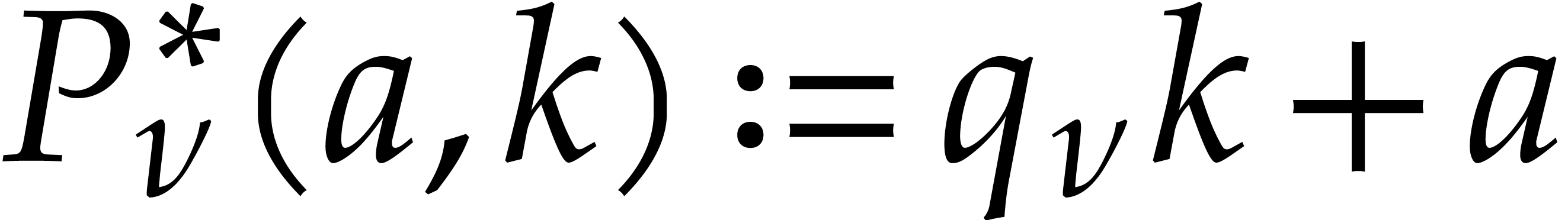 and
and 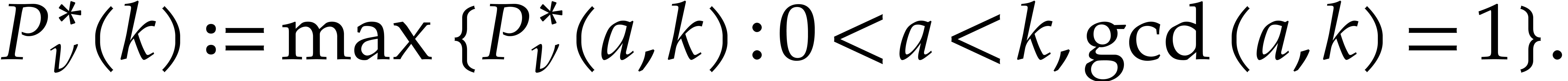
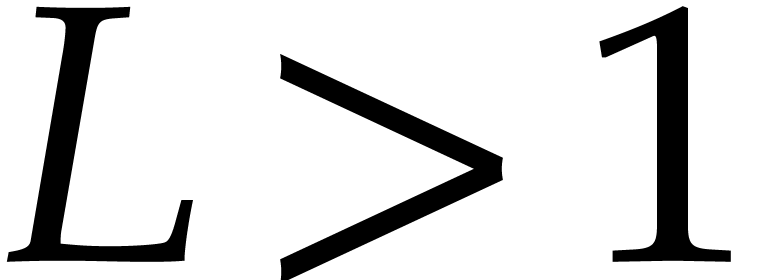 be a Linnik constant and assume
that is even. Given an integer
be a Linnik constant and assume
that is even. Given an integer  , there exists an integer
, there exists an integer 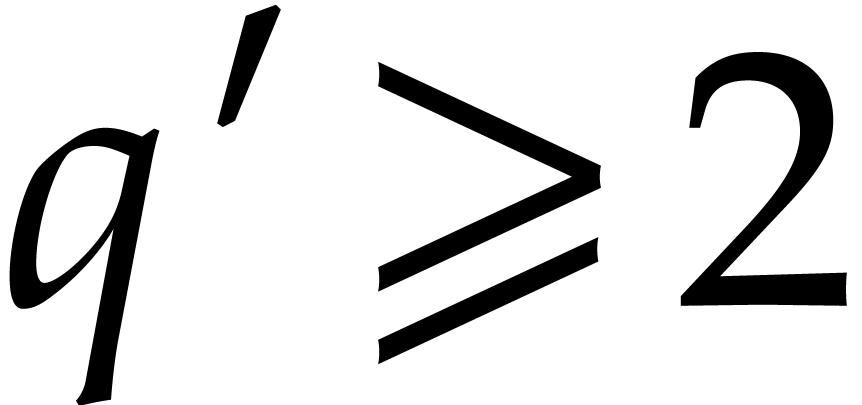 such that
such that 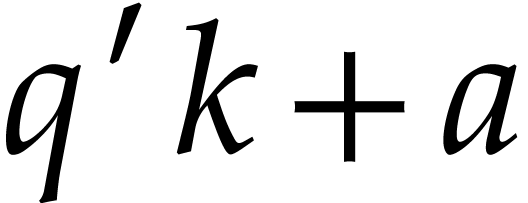 is prime,
is prime, 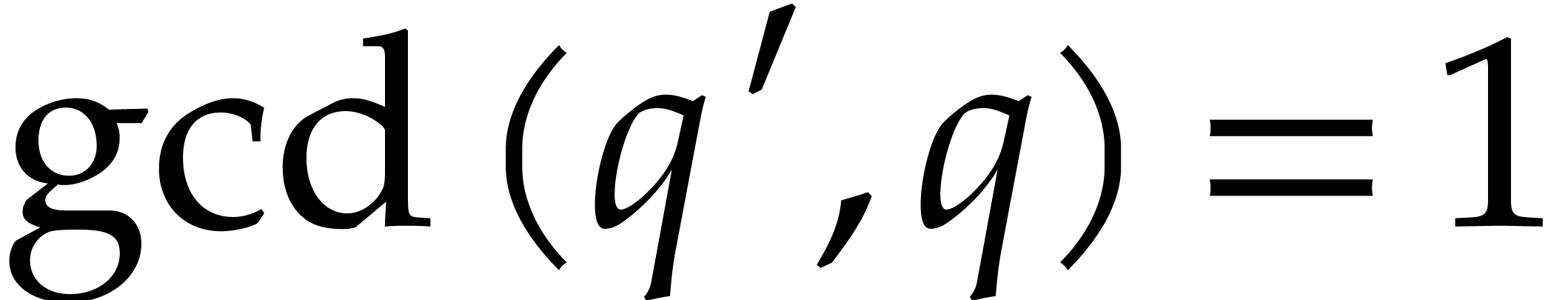 , and
, and
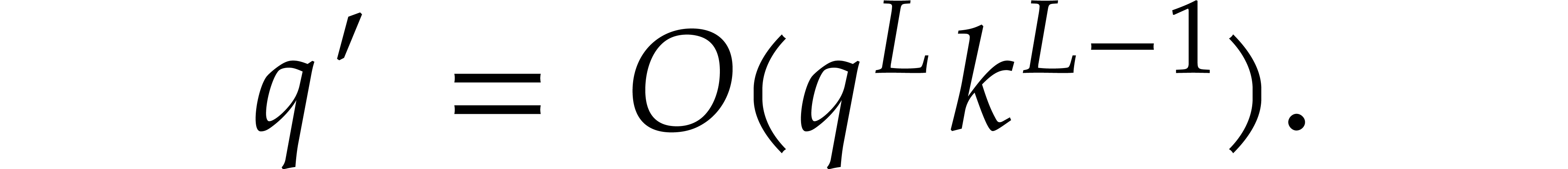
Proof. Modulo the replacement of by  , we may
assume without loss of generality that
, we may
assume without loss of generality that  .
First we show that for each prime
.
First we show that for each prime  ,
there exists an integer
,
there exists an integer 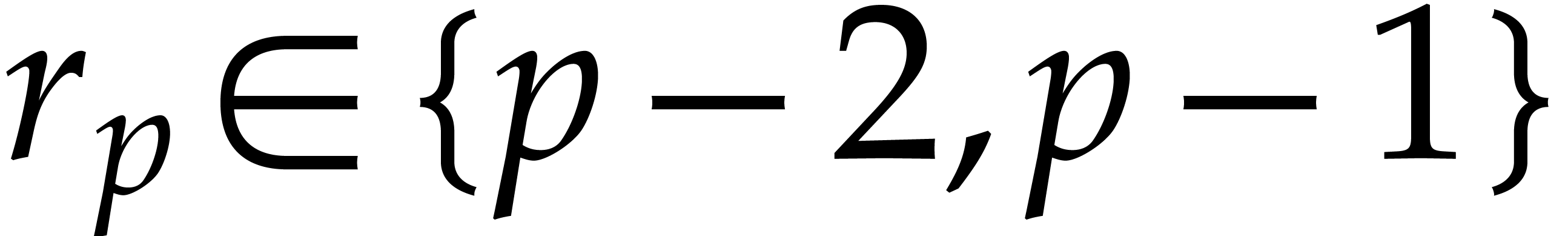 such that
such that  and
and  . Indeed,
if
. Indeed,
if  then
then  so we may take
so we may take
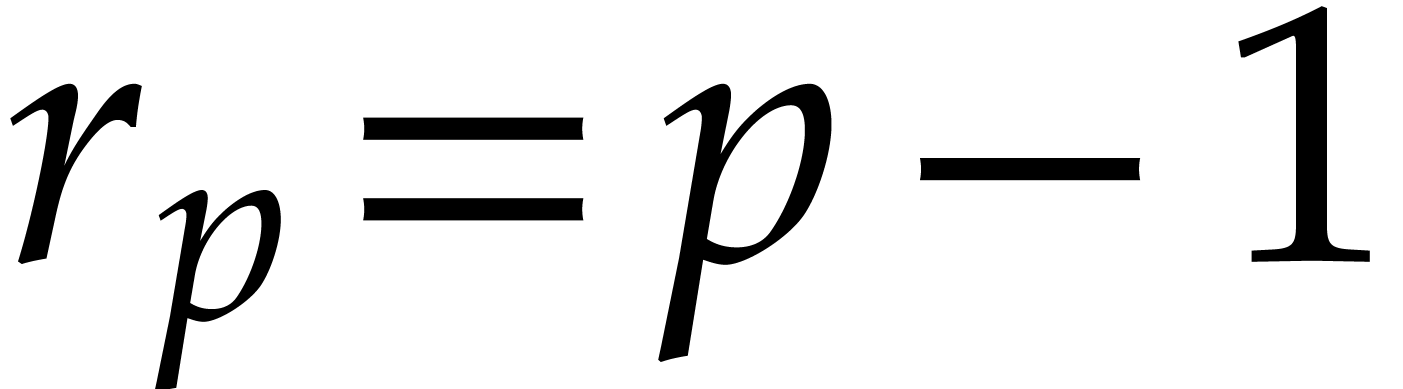 ; if
; if  , then
, then  ,
so at least one satisfies
,
so at least one satisfies  and
and  . Now, using the Chinese
remainder theorem, we may construct an integer
. Now, using the Chinese
remainder theorem, we may construct an integer 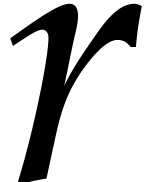 such that
such that 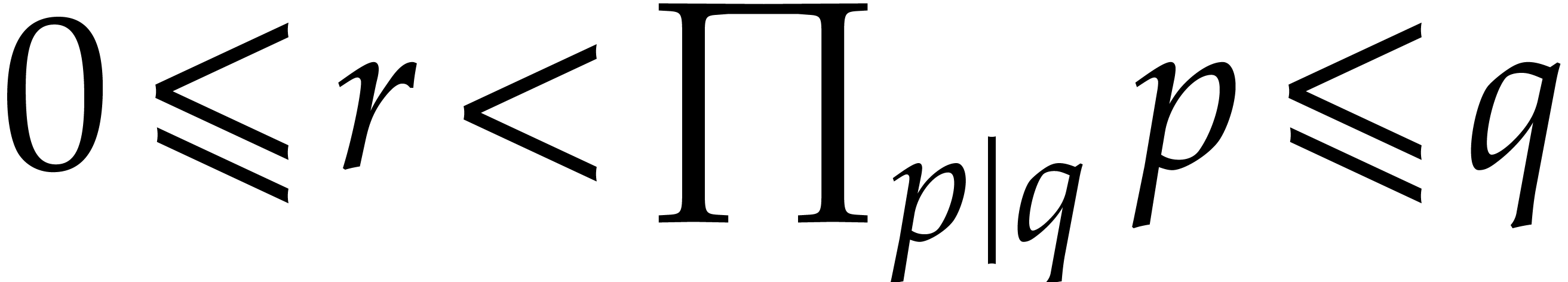 and
and 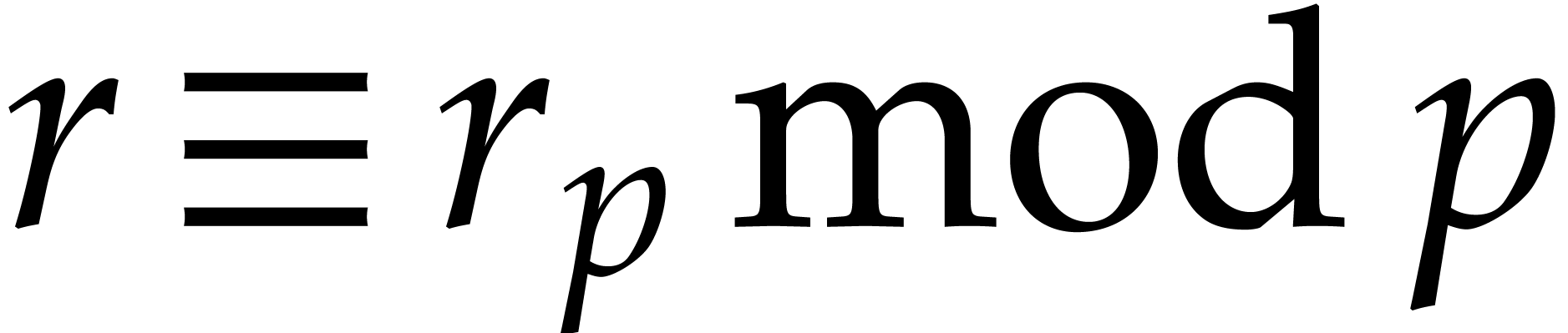 for all
. Then we have
for all
. Then we have 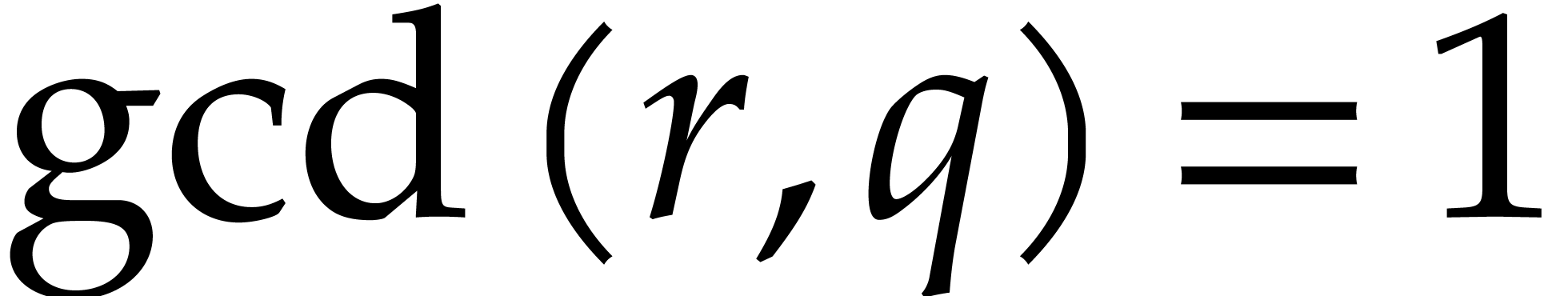 and
and 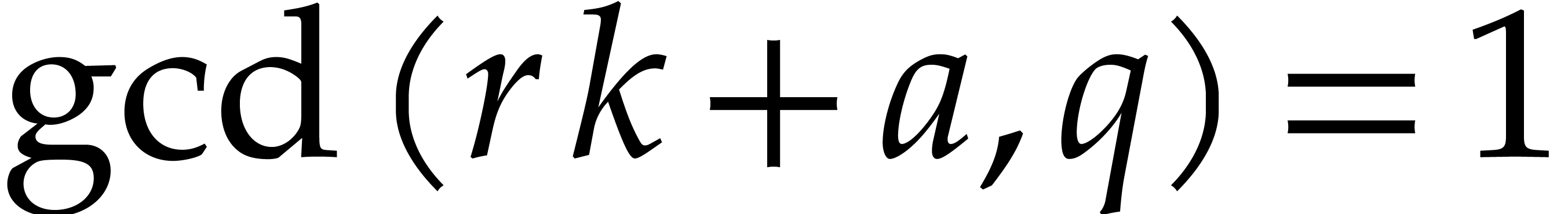 . Since
. Since
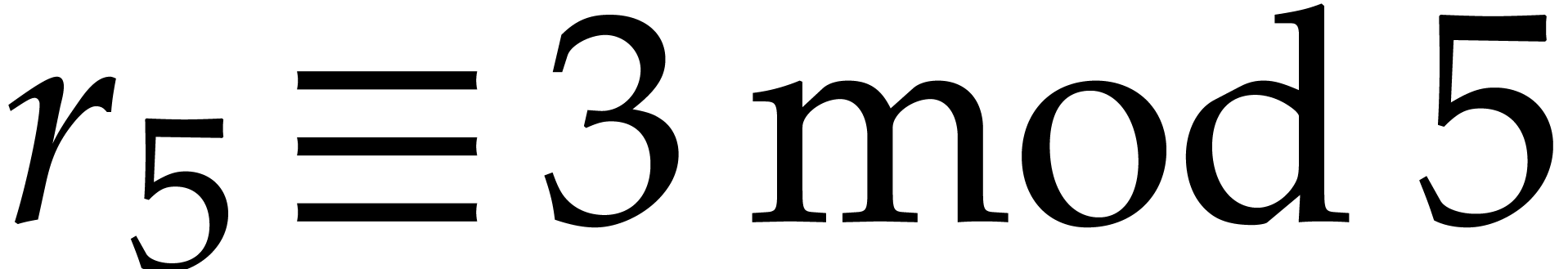 or
or 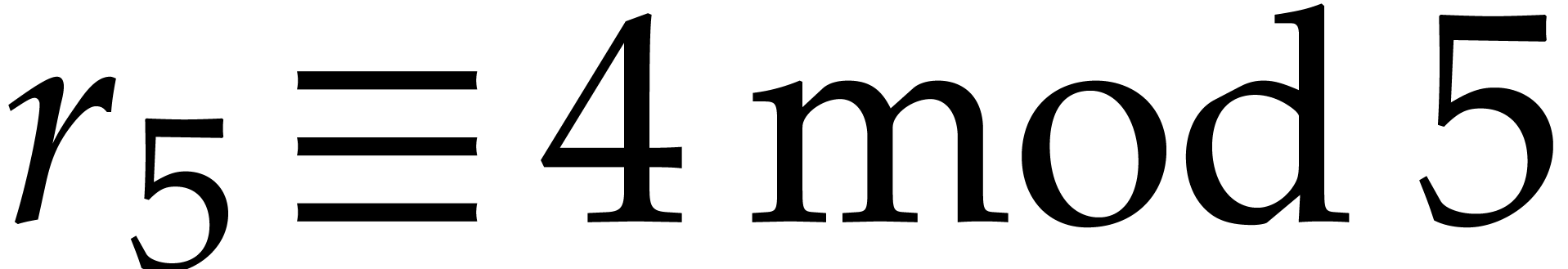 ,
we also must have
,
we also must have  .
.
Now 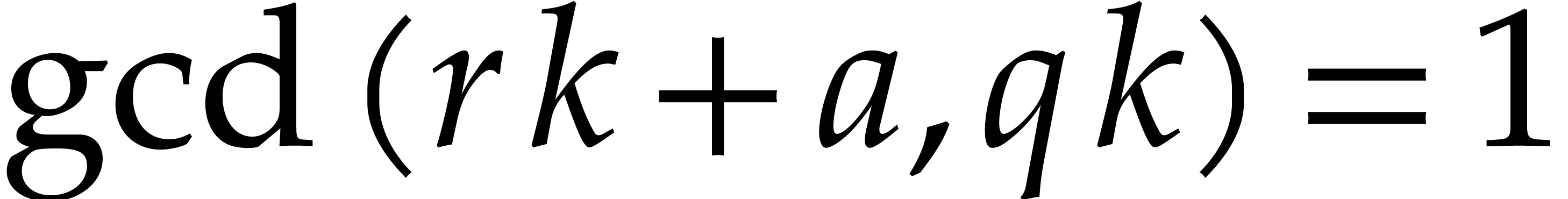 , since
and
, since
and 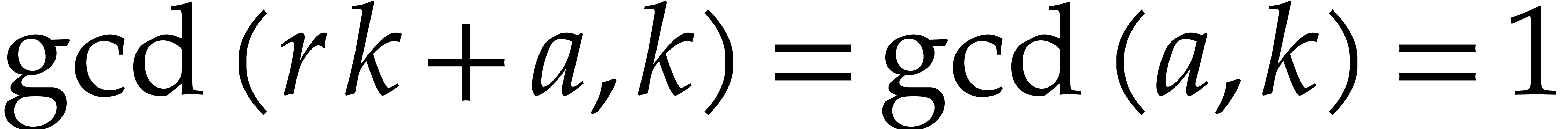 . It follows that
. It follows that 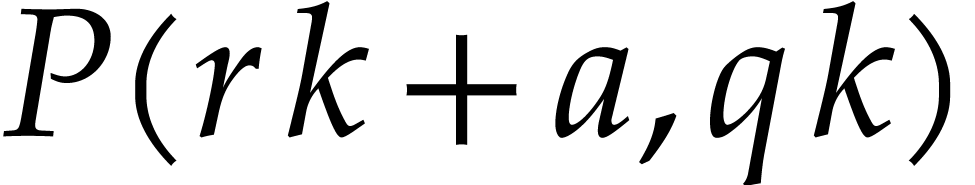 is well defined. Let
is well defined. Let  be the
integer with
be the
integer with 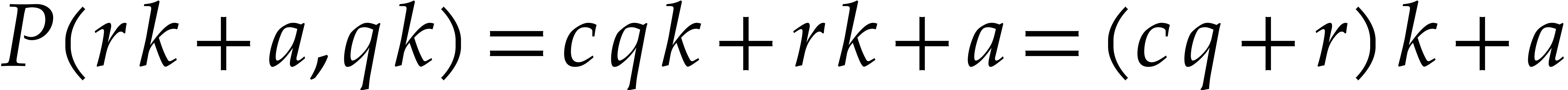 and take
and take 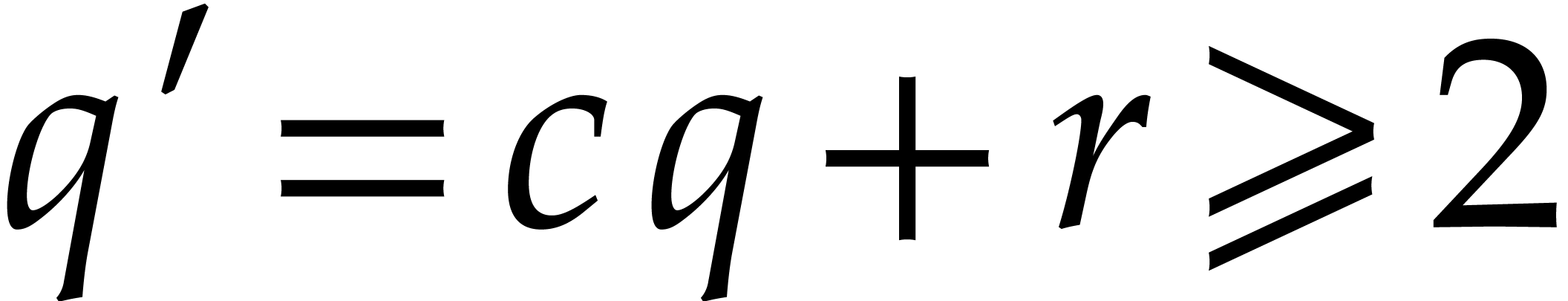 , so that
, so that 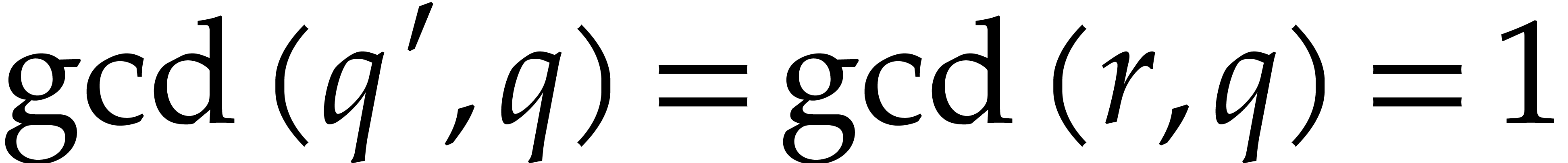 .
We conclude by observing that
.
We conclude by observing that 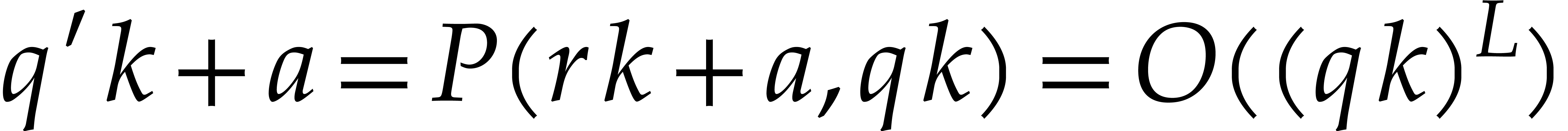 ,
whence
,
whence 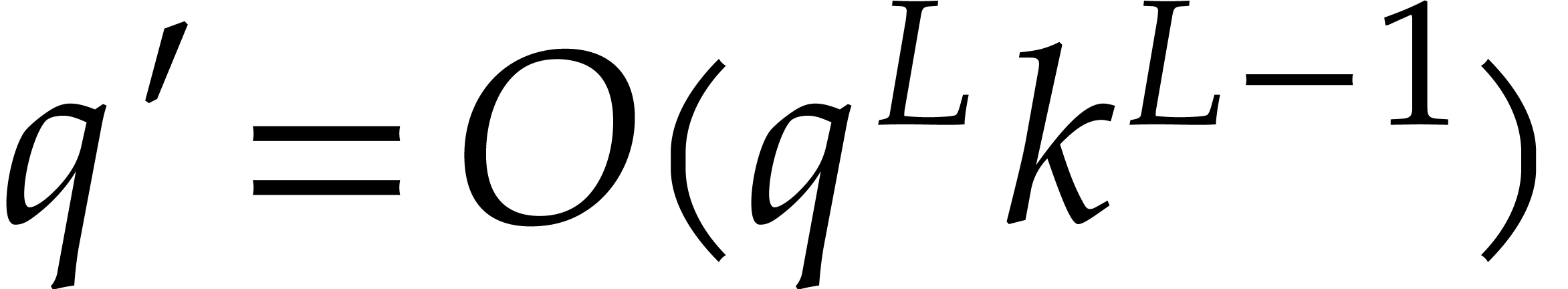 .
.
Proof. Let us prove by induction on  that defined as in (5.1)
satisfies
that defined as in (5.1)
satisfies
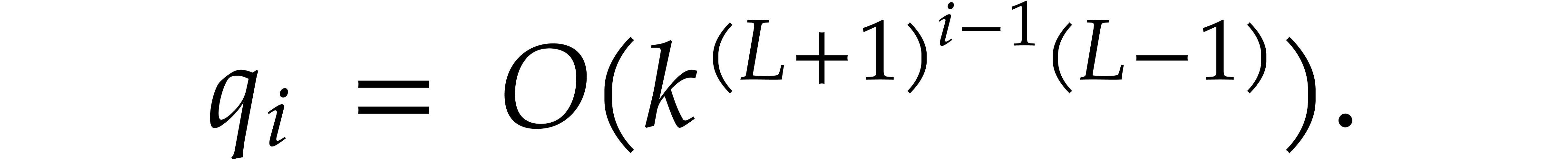
Indeed, setting 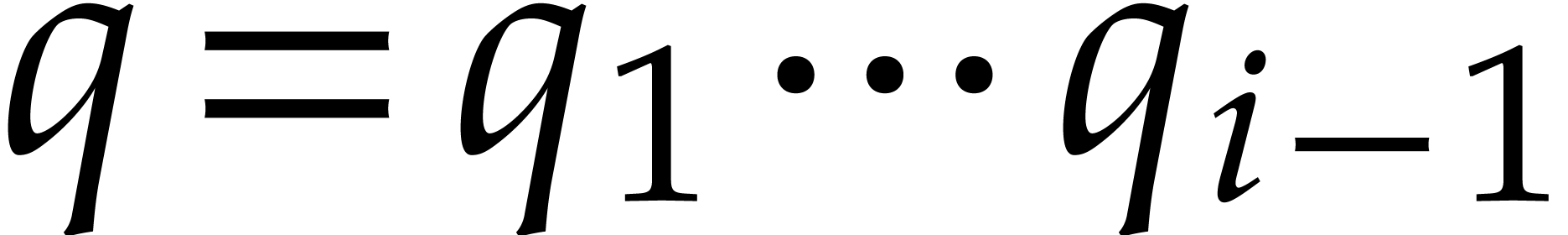 , the
induction hypothesis implies
, the
induction hypothesis implies
Lemma 5.3 then yields
whence the result.
Remark 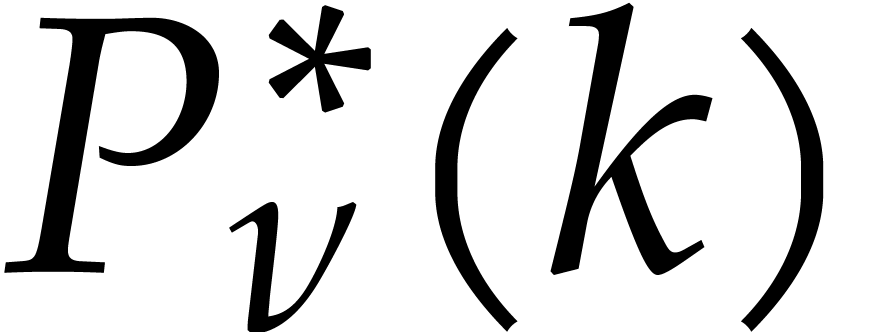 seems overly pessimistic. It is possible that a
bound
seems overly pessimistic. It is possible that a
bound 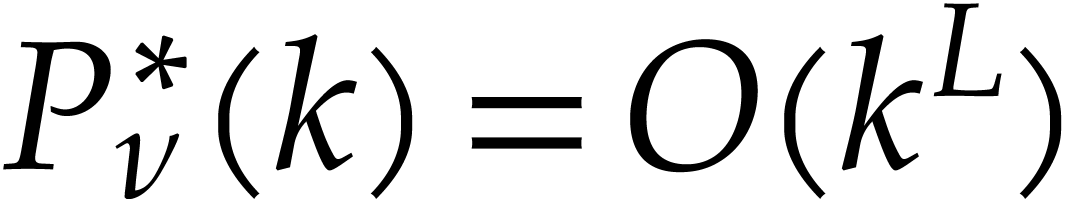 or
or 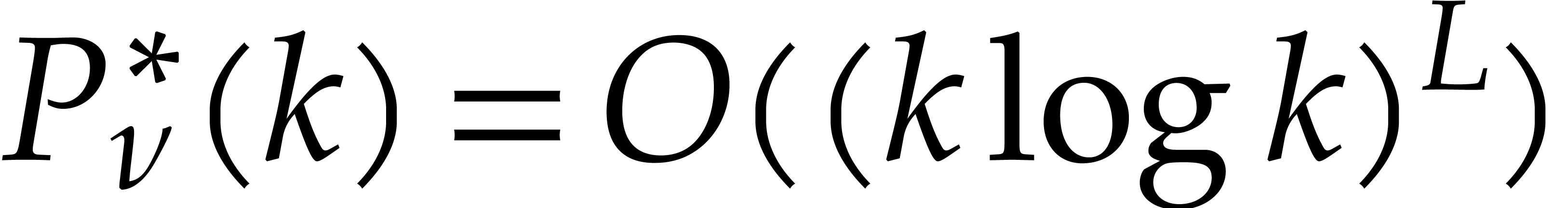 always holds,
but we were unable to prove this so far. It would also be interesting to
investigate counterparts of the Li–Pratt–Shakan conjecture.
always holds,
but we were unable to prove this so far. It would also be interesting to
investigate counterparts of the Li–Pratt–Shakan conjecture.
Let be a Linnik constant with . Our algorithm proceeds as follows.
Step 0: setting up the parameters. Assume that we wish to
multiply two -bit integers.
For sufficiently large 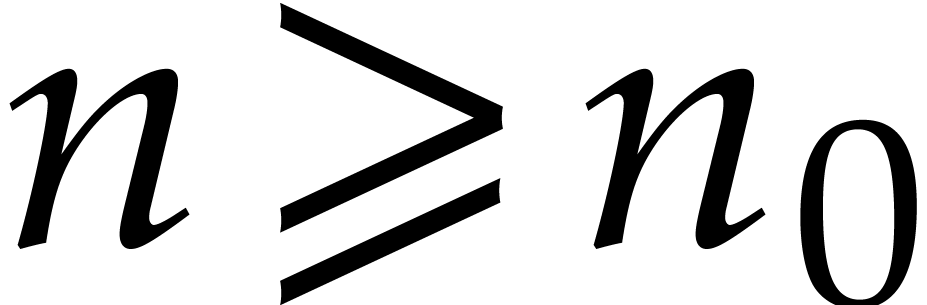 and suitable parameters
, , , we
will reduce this problem to a multiplication problem in
and suitable parameters
, , , we
will reduce this problem to a multiplication problem in 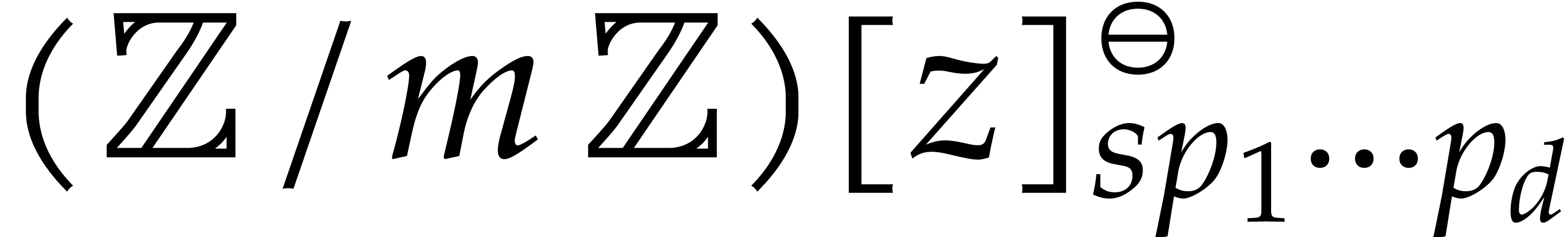 . If
. If 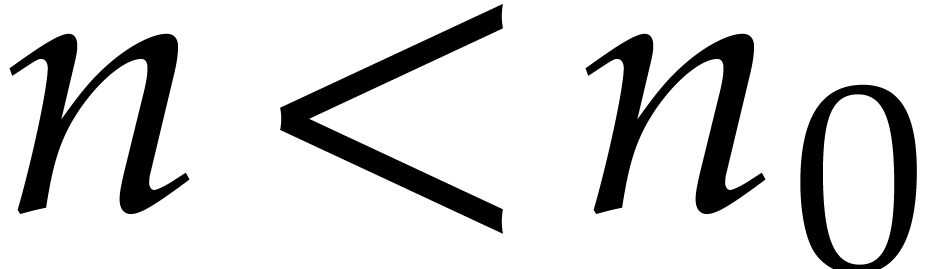 ,
then any traditional multiplication algorithm can be used. The threshold
,
then any traditional multiplication algorithm can be used. The threshold
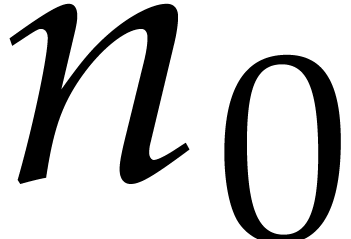 should be chosen such that various asymptotic
relations encountered in the proof below hold for all . The other parameters are chosen as follows:
should be chosen such that various asymptotic
relations encountered in the proof below hold for all . The other parameters are chosen as follows:
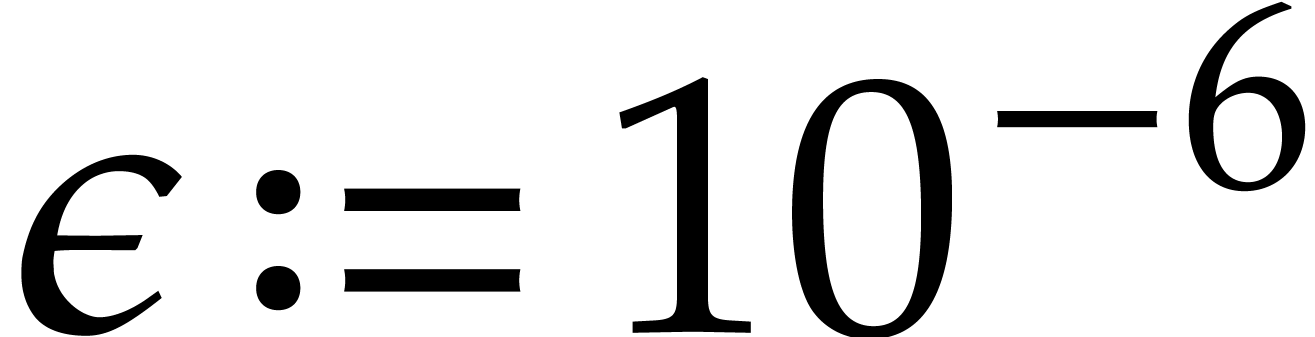 .
.
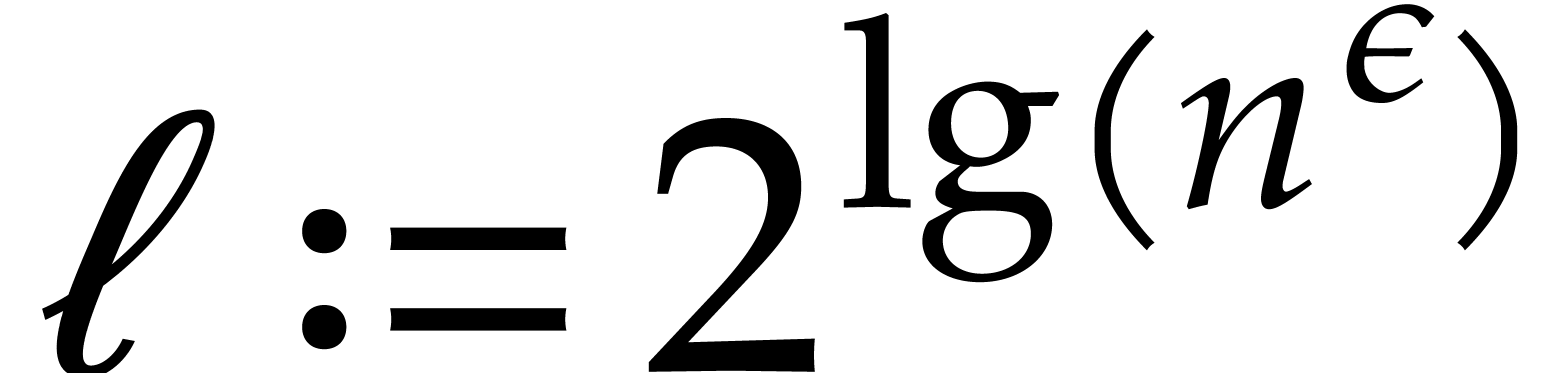 is the smallest power of two with
is the smallest power of two with 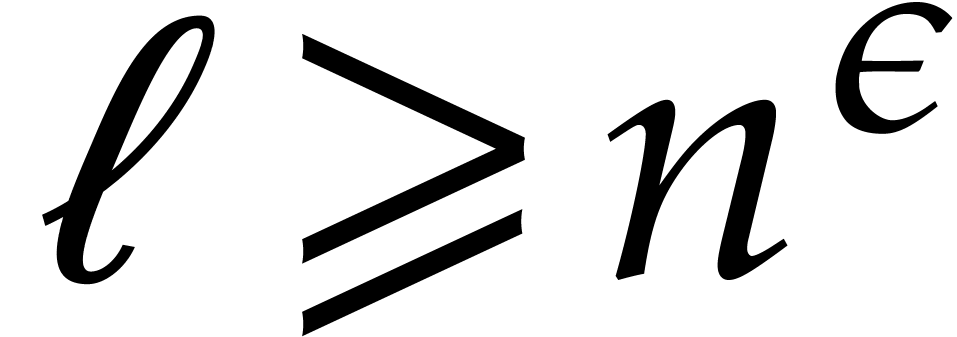 .
.
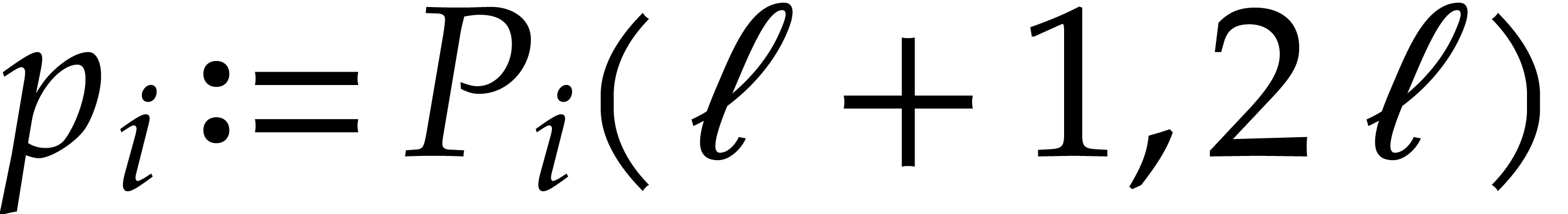 for
for
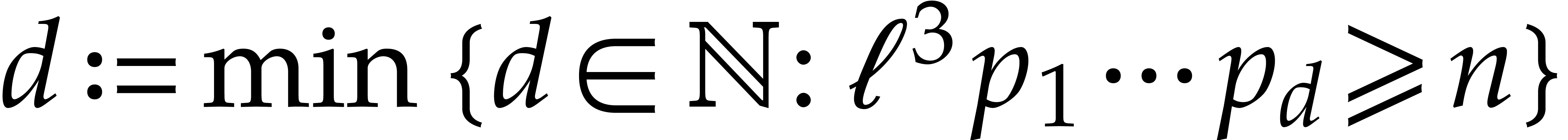 .
.
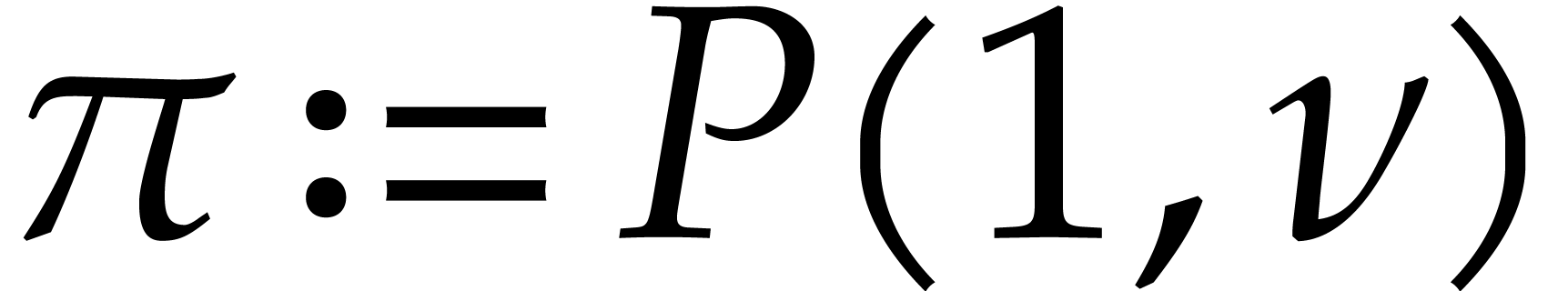 , where
, where 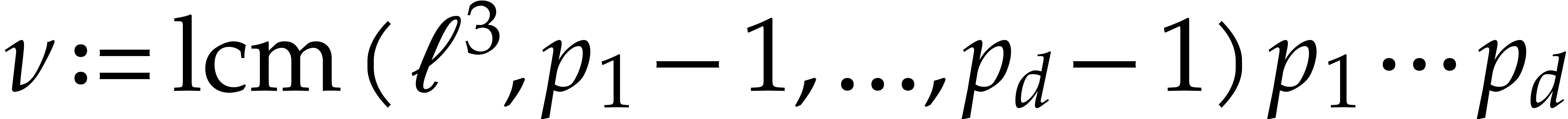 .
.
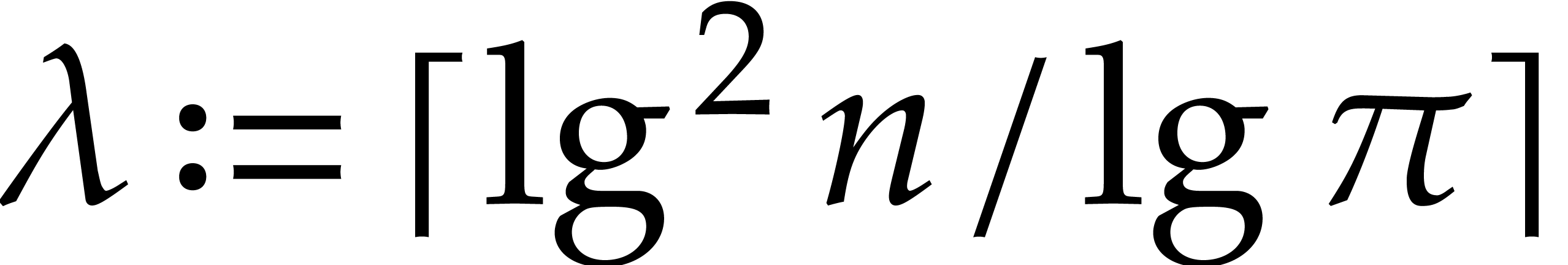 and
and 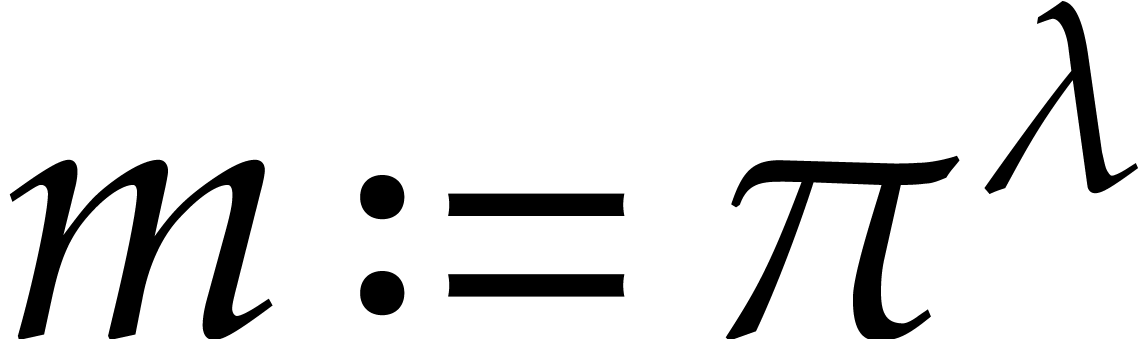 .
.
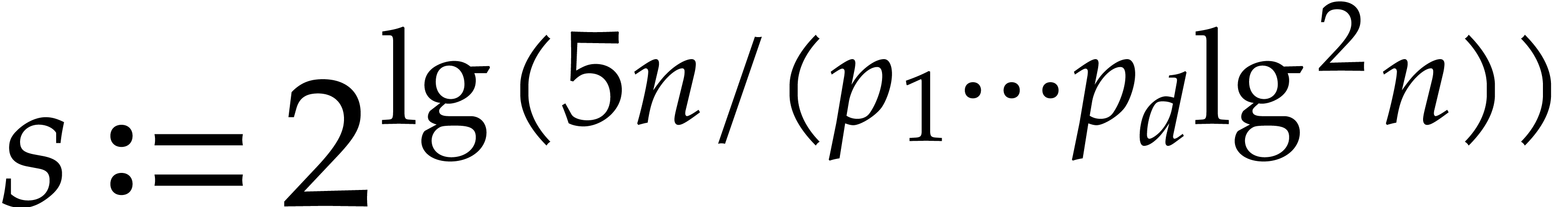
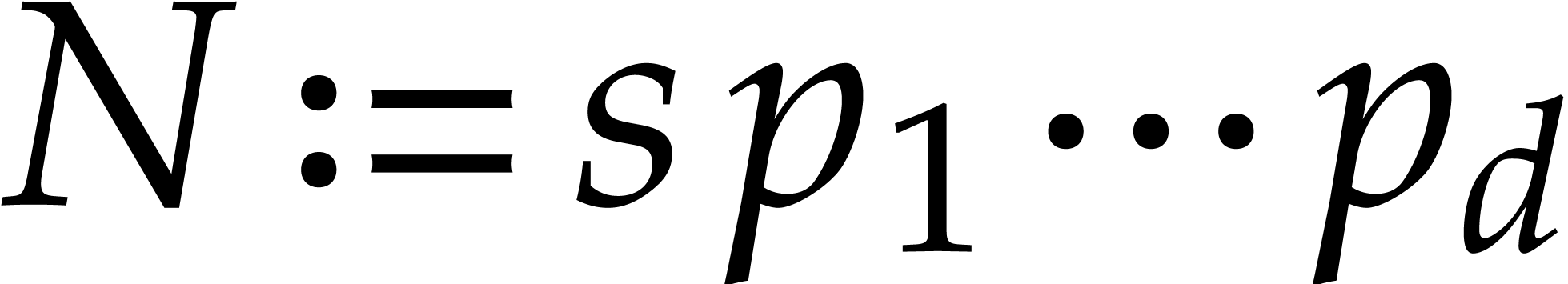 .
.
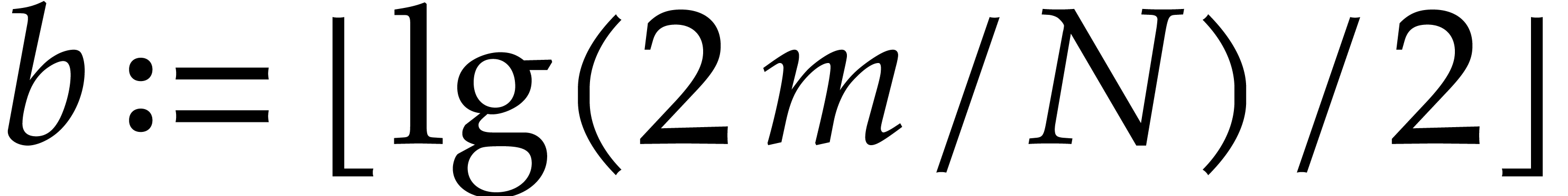 is maximal with
is maximal with 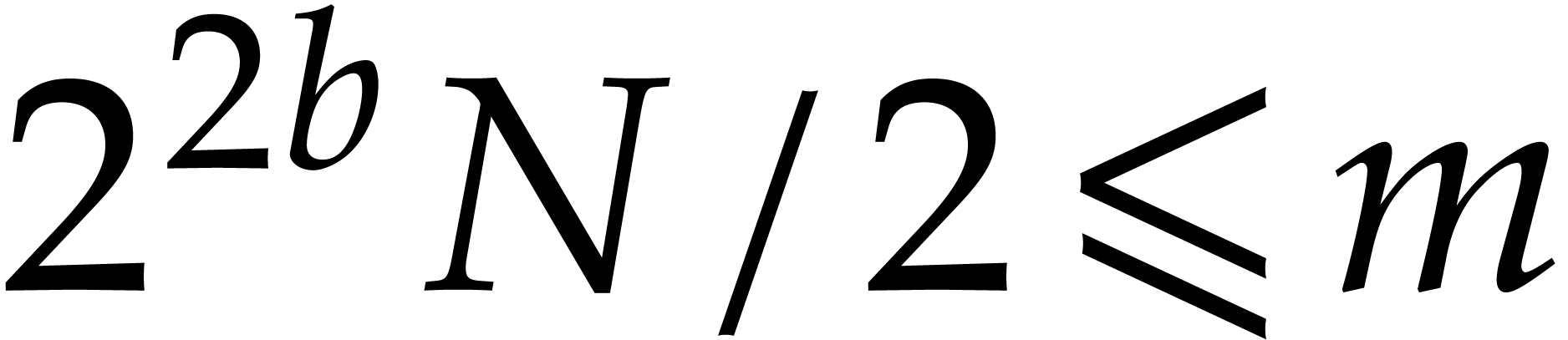 .
.
We claim that and the rest of these parameters
can be computed in linear time .
Recall from [2] that we can test whether a 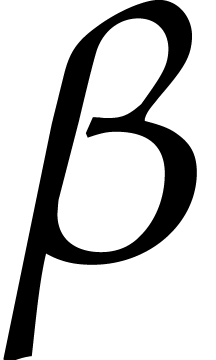 -bit integer is prime in time
-bit integer is prime in time 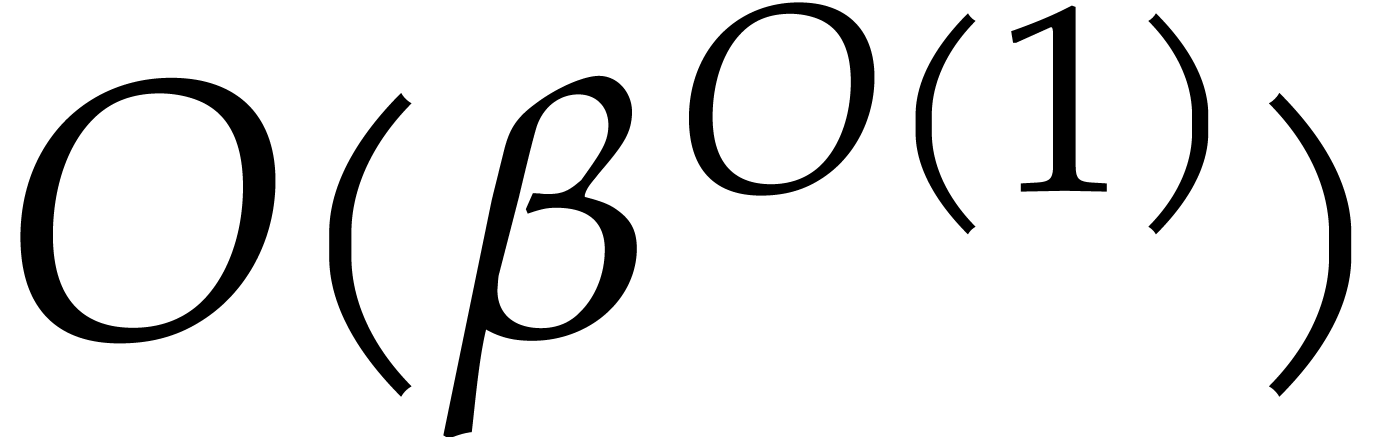 . We clearly have
. We clearly have 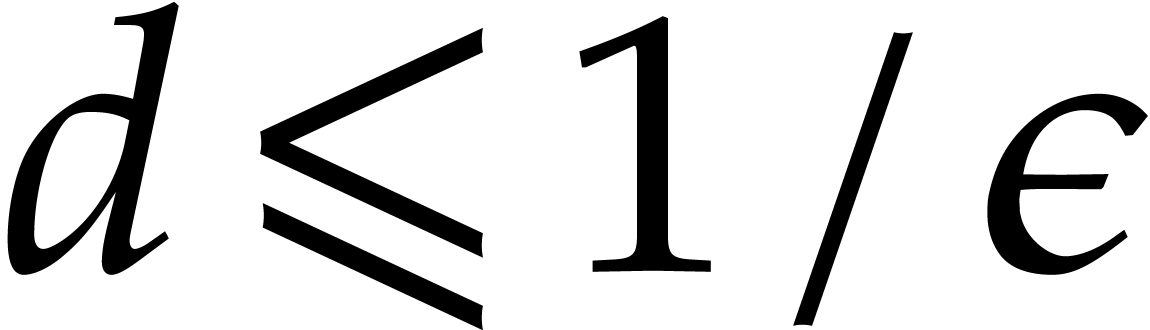 ,
whence
,
whence 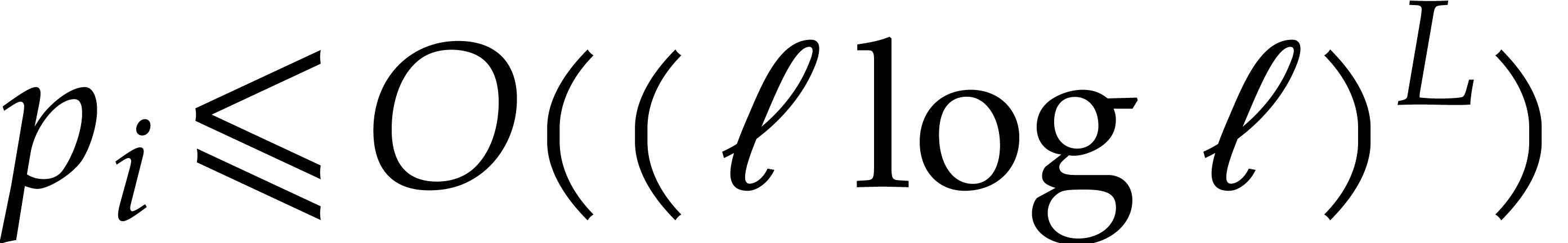 for ,
by Lemma 5.1. For sufficiently large , this means that
for ,
by Lemma 5.1. For sufficiently large , this means that

The brute force computation of requires 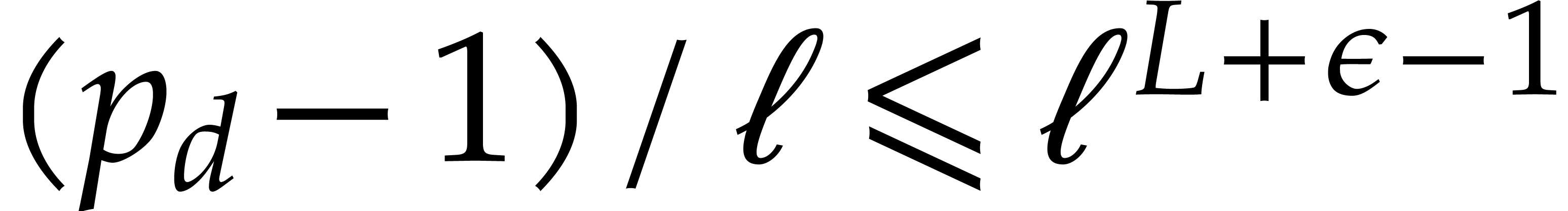 primality tests of total cost
primality tests of total cost 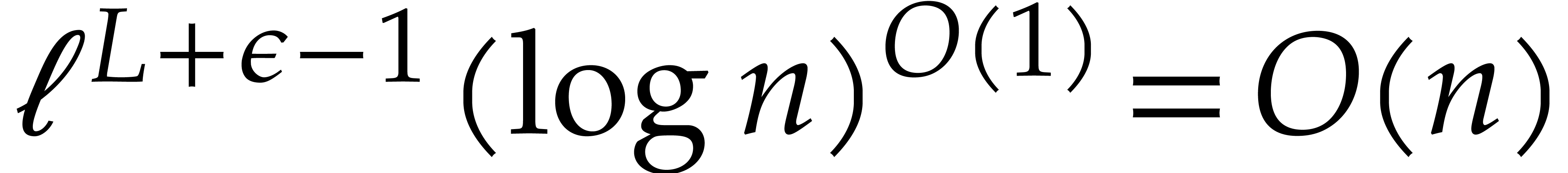 . From ,
we also deduce
. From ,
we also deduce  and
and 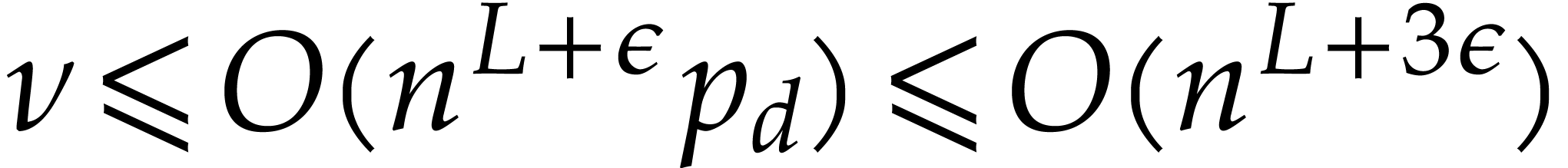 .
In particular,
.
In particular, 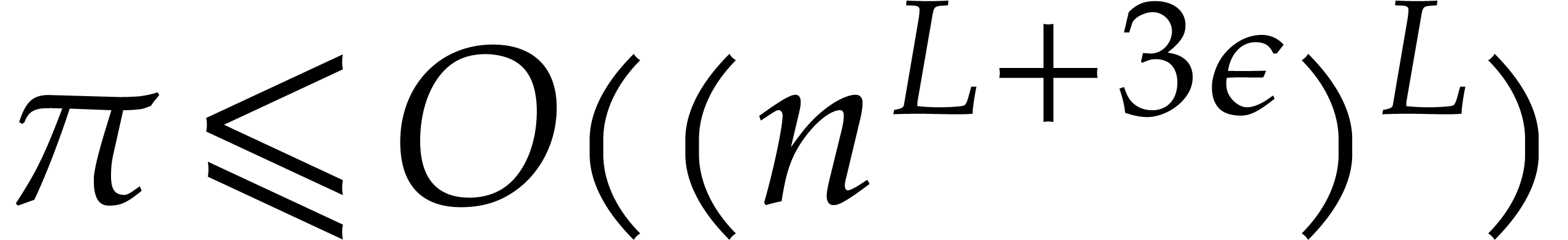 ; for sufficiently large, we thus get
; for sufficiently large, we thus get
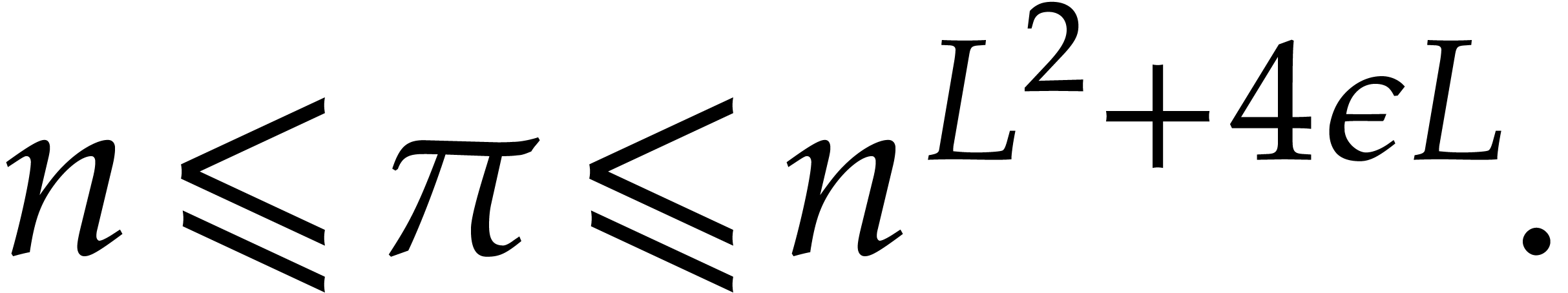
In order to compute , we need
to perform 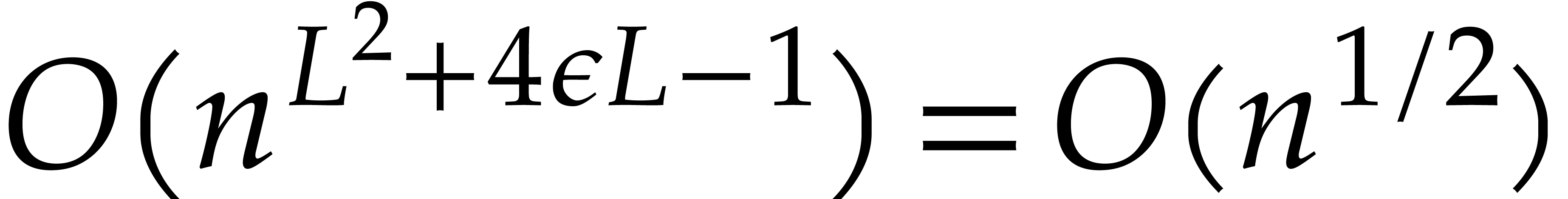 primality tests of total cost
primality tests of total cost 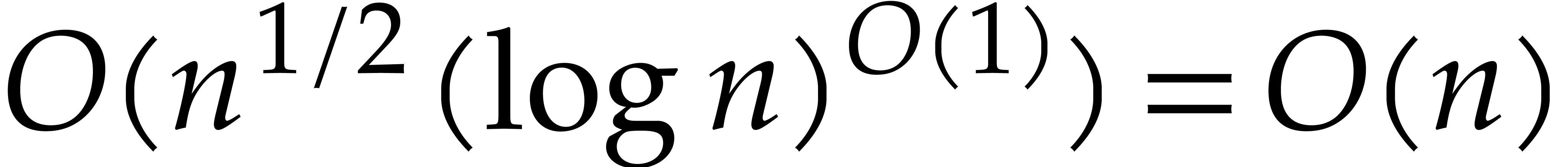 . This completes the proof of our
claim.
. This completes the proof of our
claim.
Let us proceed with a few useful bounds. From 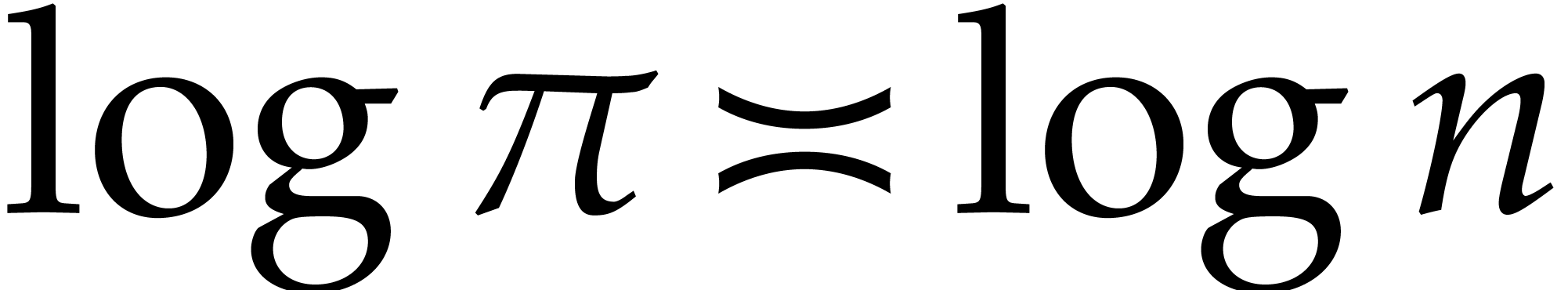 we
get
we
get
which in turn yields
Since 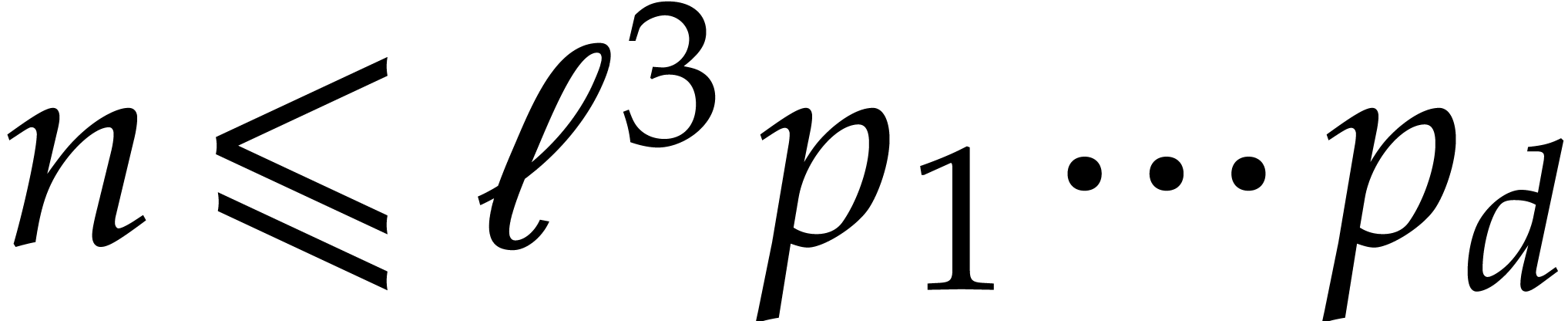 , we also have
, we also have
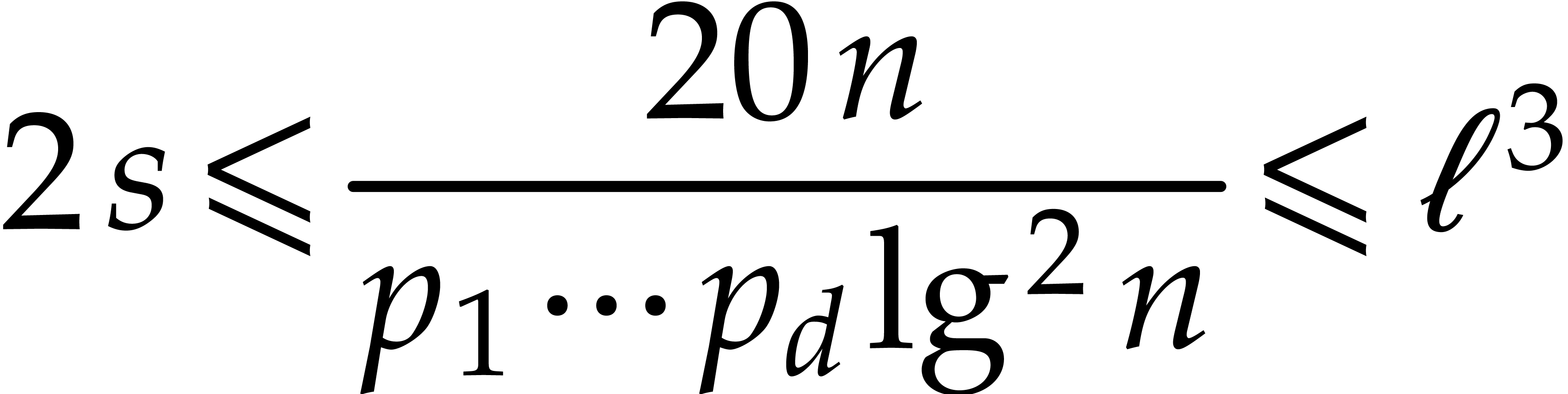
and 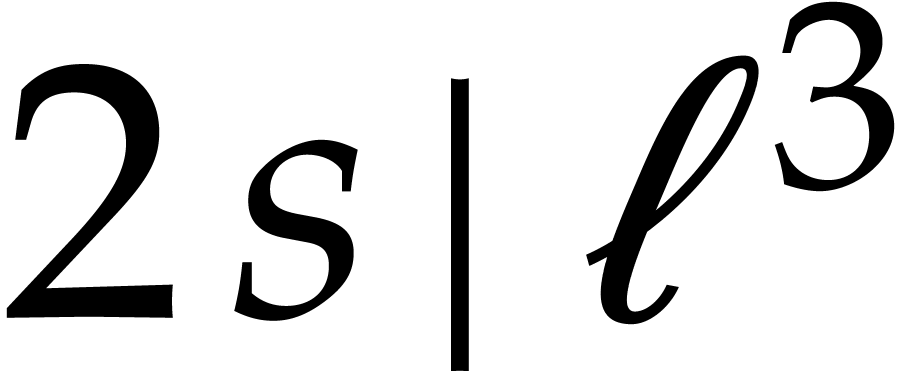 , for sufficiently large
. Inversely,
, for sufficiently large
. Inversely, 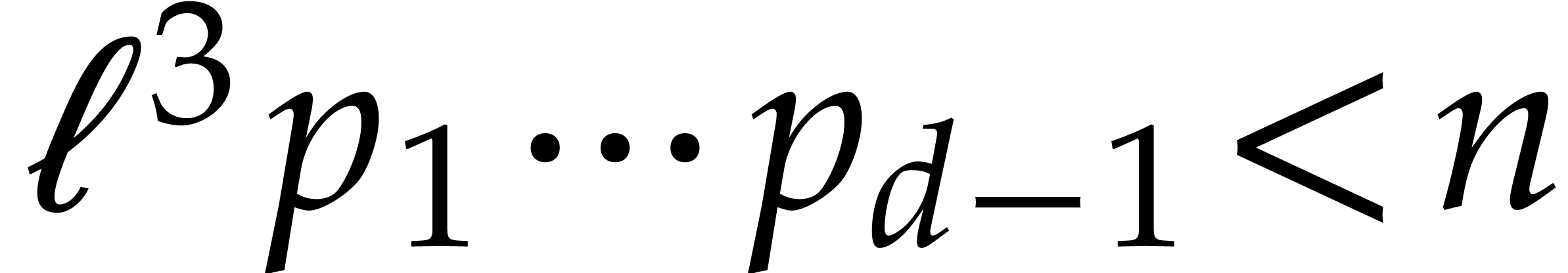 implies
implies
Notice finally that
Step 1: Kronecker segmentation. For sufficiently large , the last inequality implies that
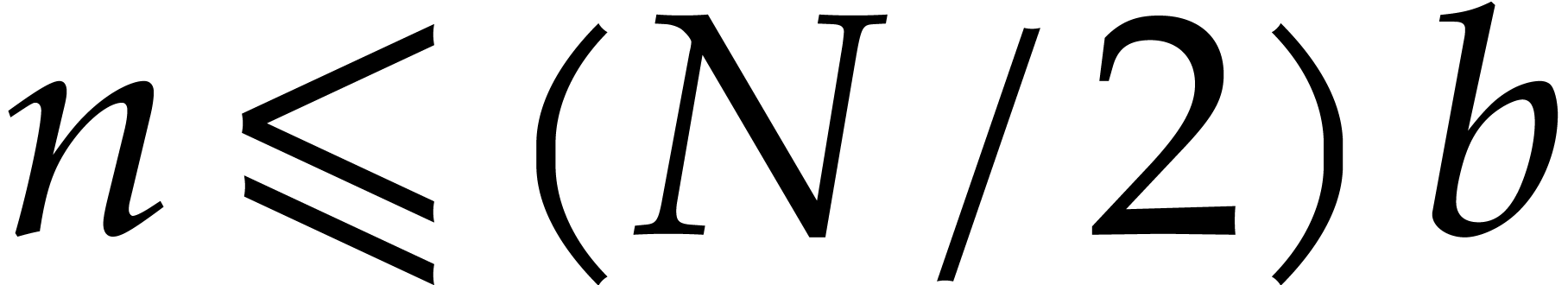 . In order to multiply two
-bit integers and , we expand
them in base
. In order to multiply two
-bit integers and , we expand
them in base 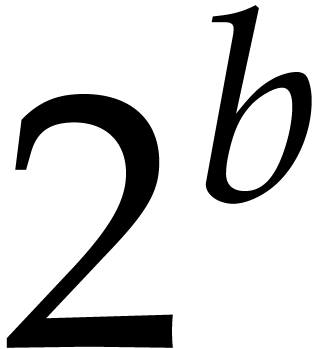 ,
i.e.
,
i.e.
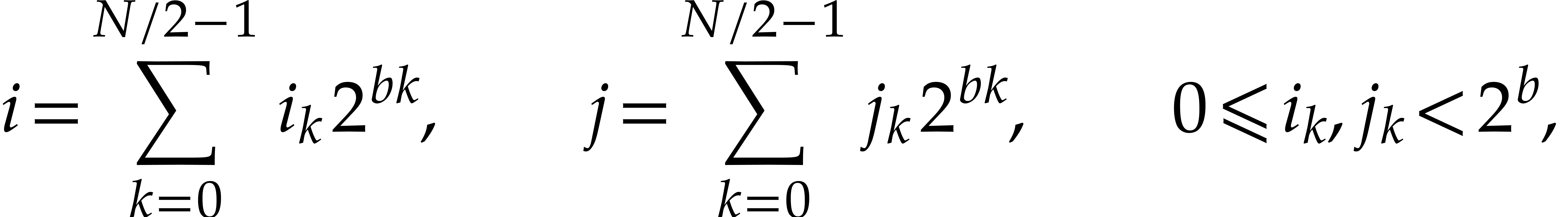
and form the polynomials
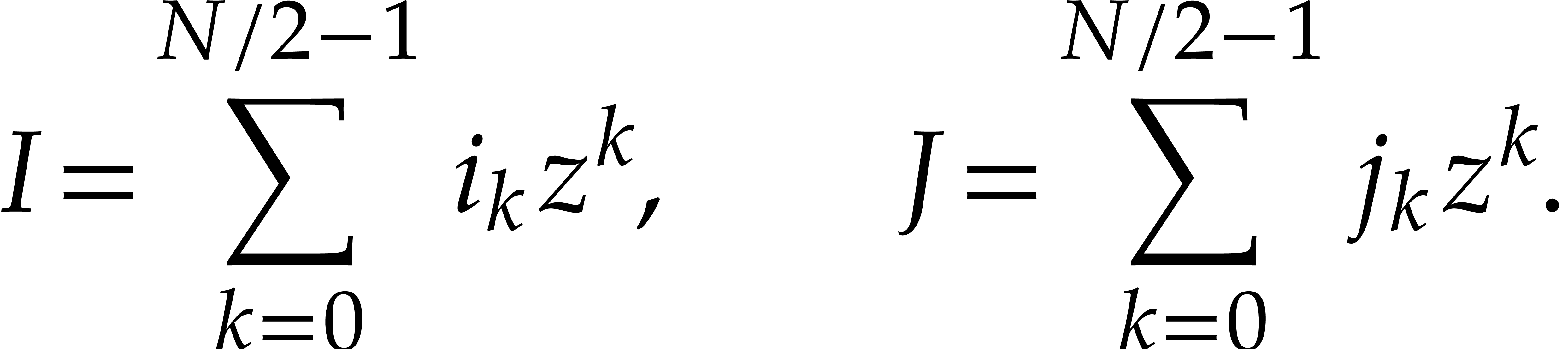
Let 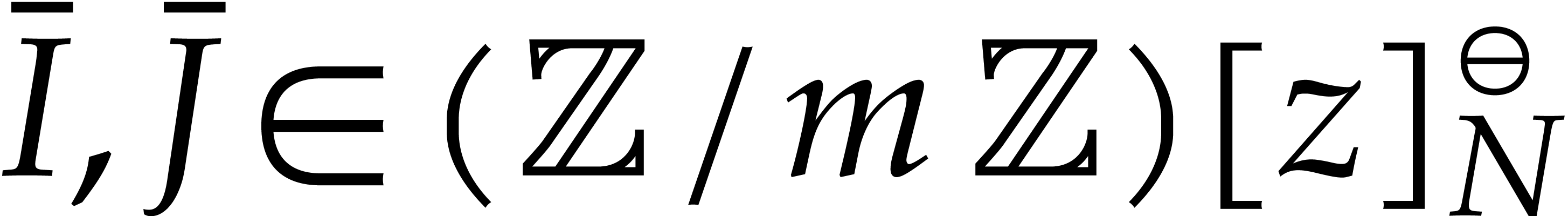 be the reductions of these polynomials
modulo and
be the reductions of these polynomials
modulo and 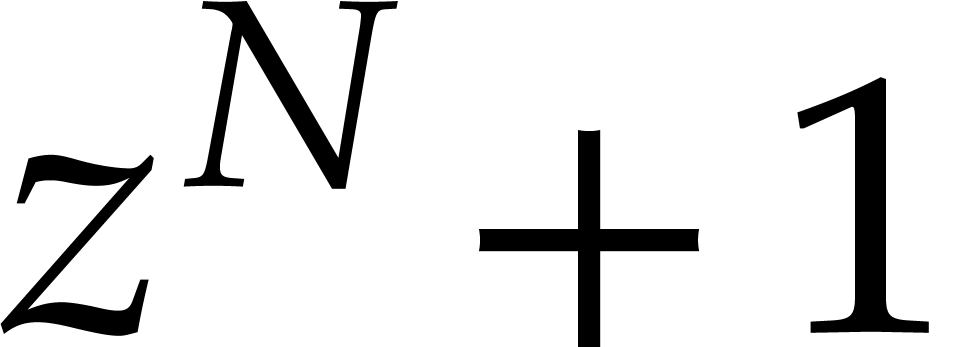 .
Since
.
Since 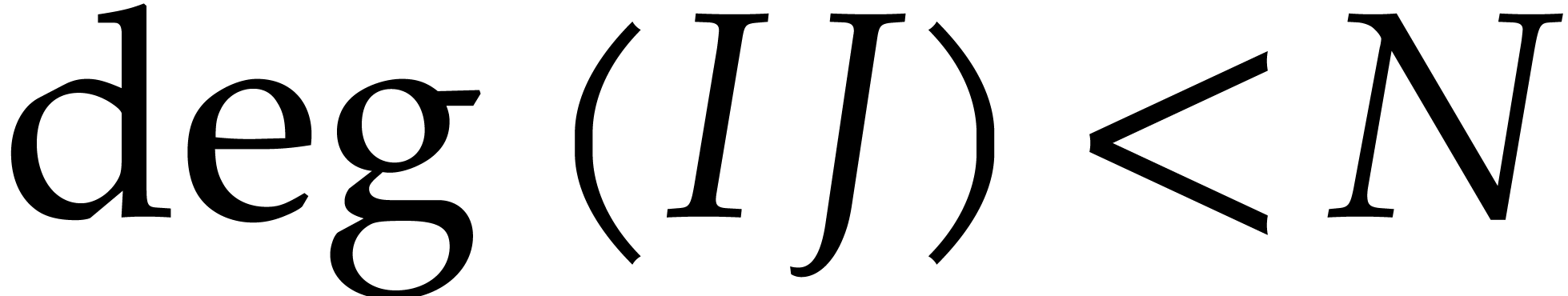 and
and 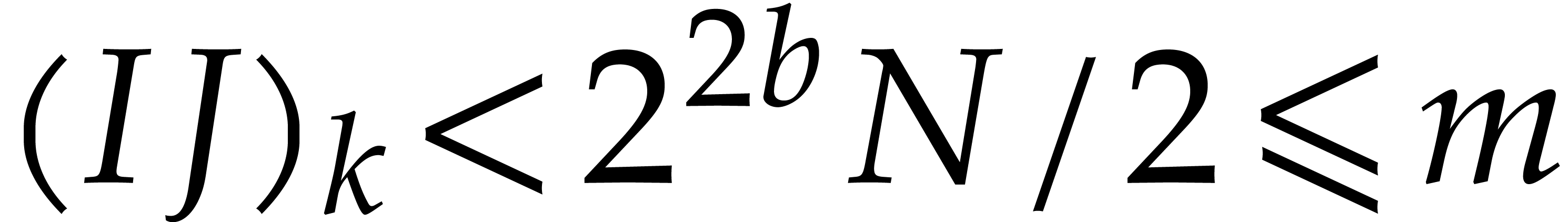 for
for  , we can read off the product
, we can read off the product  from the product
from the product 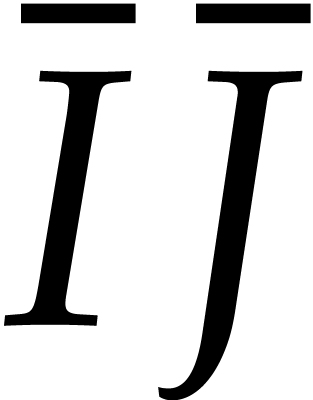 ,
after which
,
after which 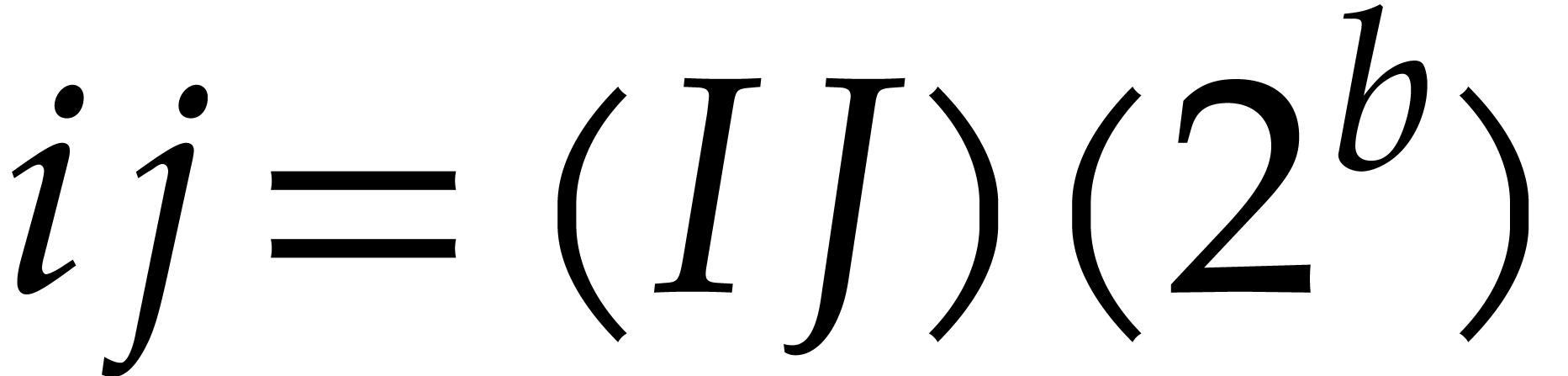 . Computing
. Computing 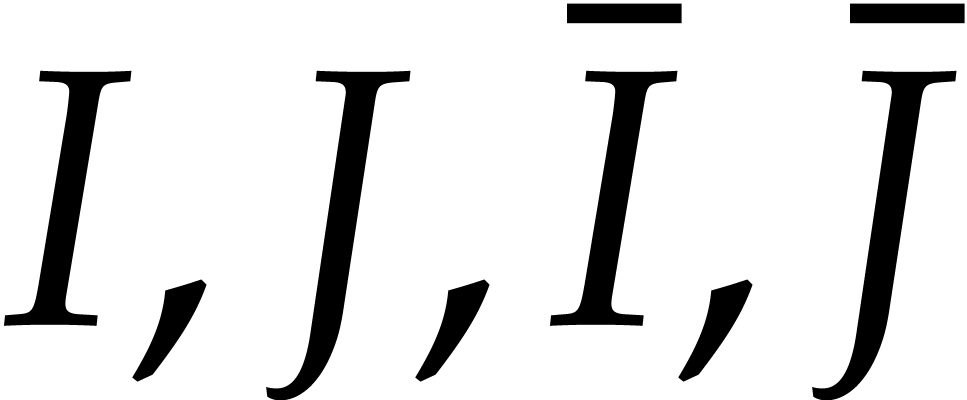 from and
clearly takes linear time ,
and so does the retrieval of and
from and
clearly takes linear time ,
and so does the retrieval of and 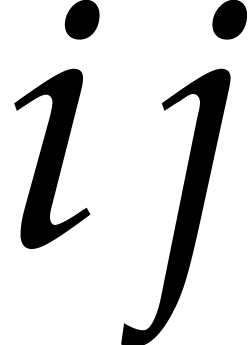 from . In other
words, we have shown that
from . In other
words, we have shown that
Step 2: CRT transforms. At a second stage, we use negacyclic
CRT transforms (section 3.5) followed by traditional CRT
transforms (section 3.4) in order to reduce multiplication
in 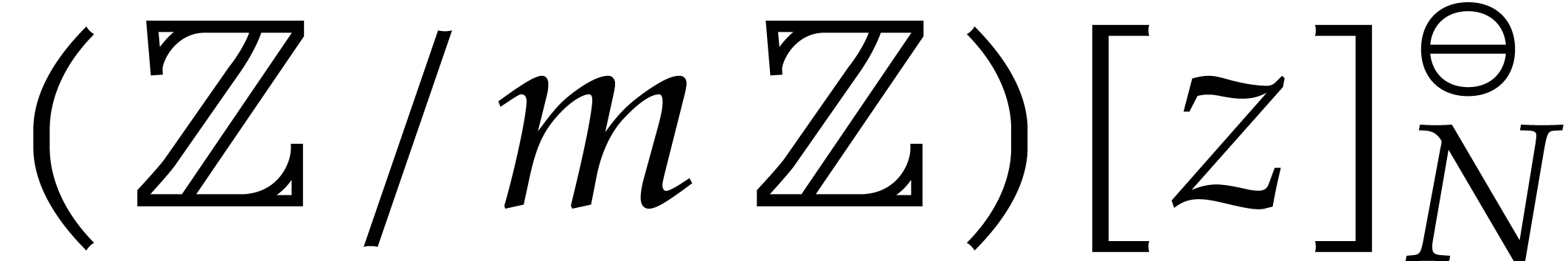 to multiplication in
to multiplication in  , where ,
, and
, where ,
, and 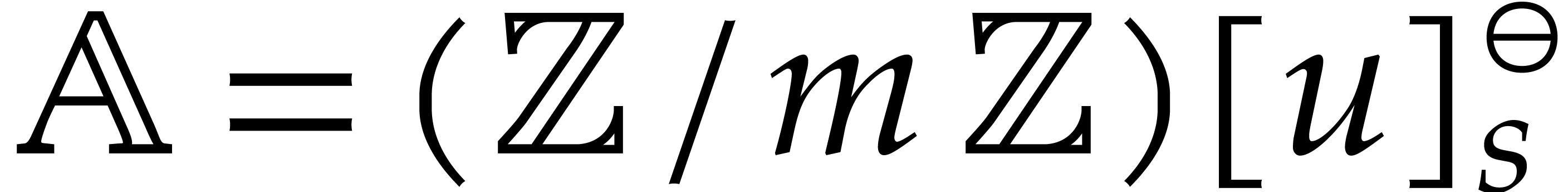 :
:
Since  , this yields
, this yields

The computation of a generator of the cyclic group  can be done in time
can be done in time 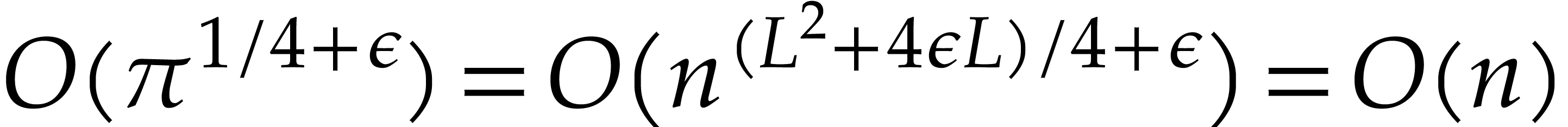 , by [53]. The lift of the
, by [53]. The lift of the 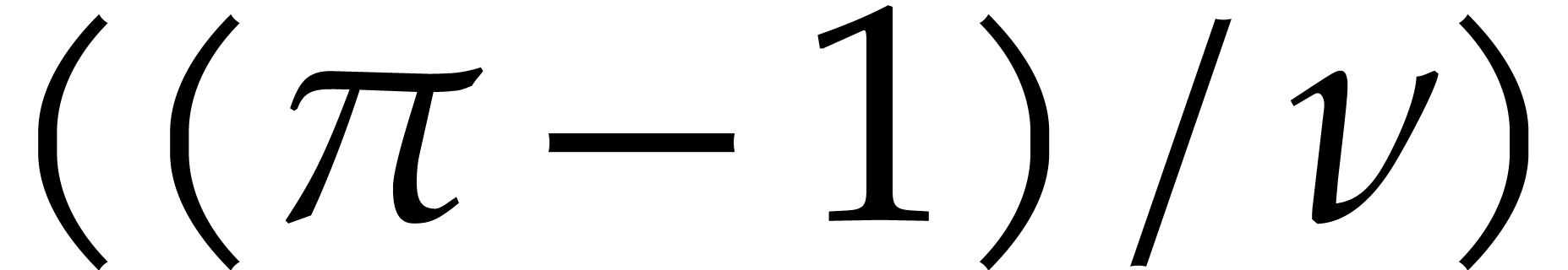 -th
power of this generator to can be computed in
time
-th
power of this generator to can be computed in
time 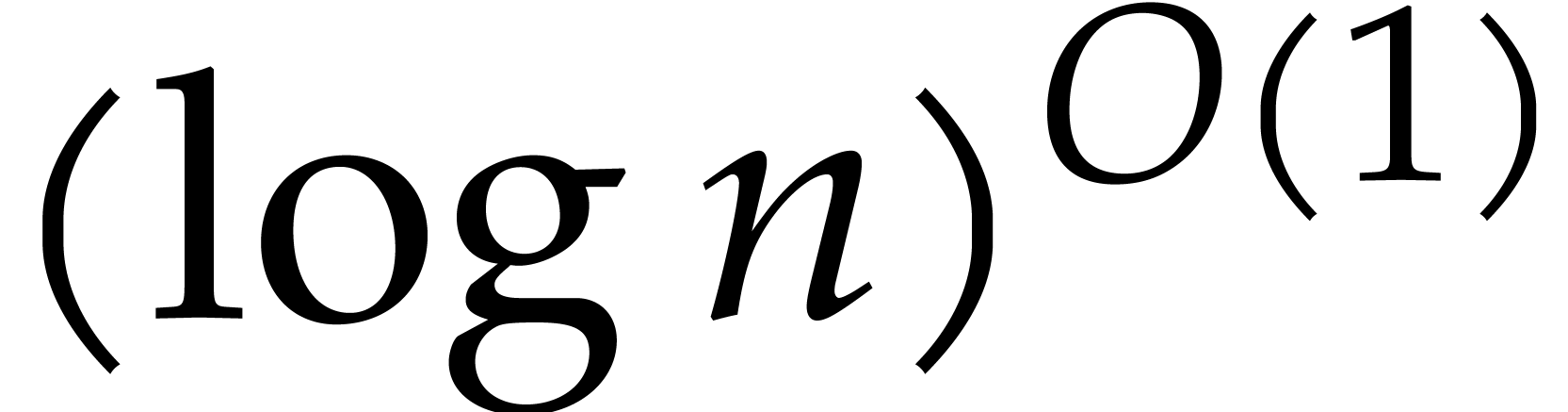 and yields a primitive -th root of unity
and yields a primitive -th root of unity 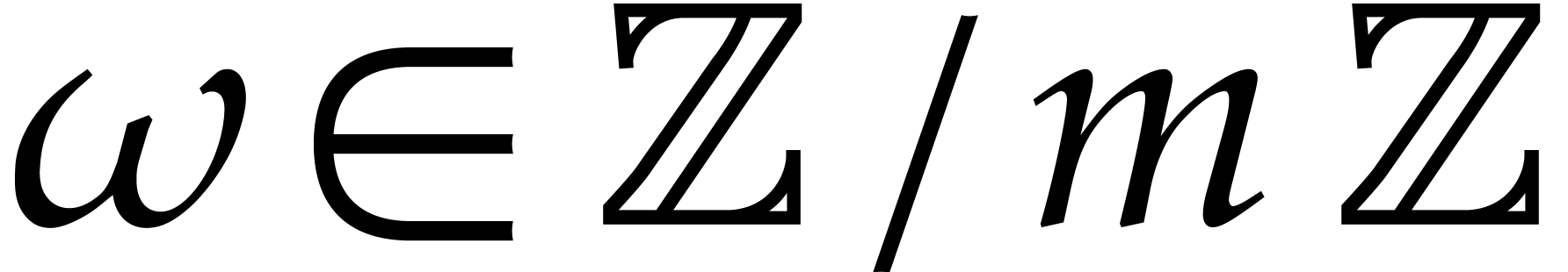 .
We perform the multivariate cyclic convolutions in
using fast Fourier multiplication, where the discrete Fourier transforms
are computed with respect to
.
We perform the multivariate cyclic convolutions in
using fast Fourier multiplication, where the discrete Fourier transforms
are computed with respect to 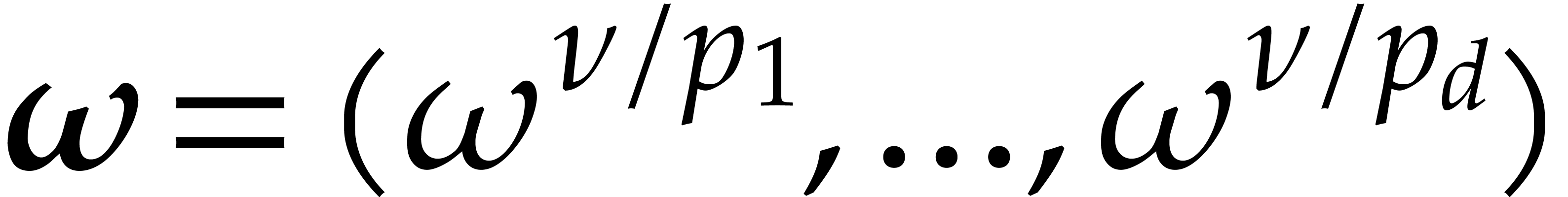 .
In view of (3.8), this leads to
.
In view of (3.8), this leads to
Indeed, scalar divisions by integers in can be
performed in time
using Schönhage–Strassen's algorithm for integer
multiplication. Now we observe that 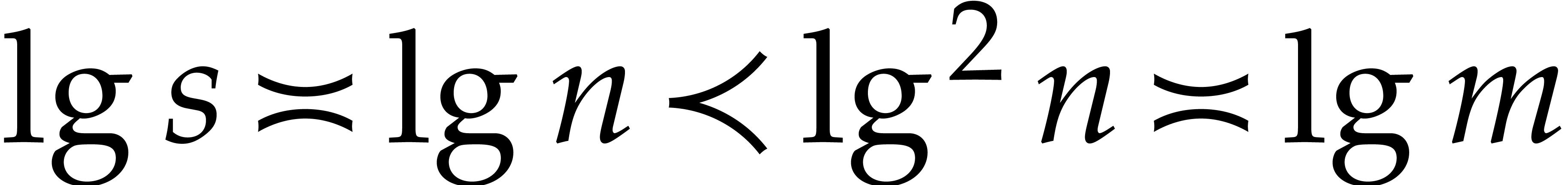 and
and 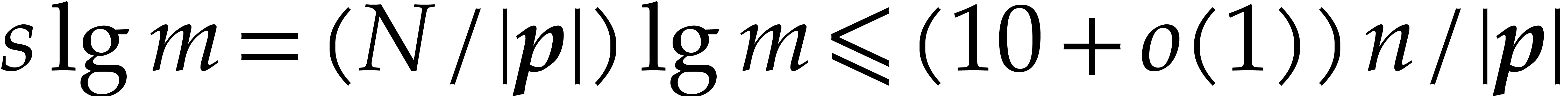 , whence
, whence 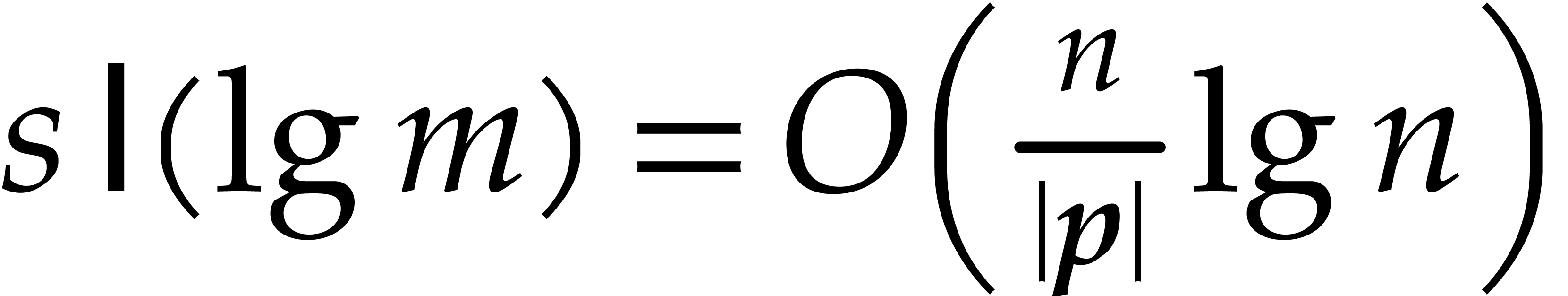 , again using Schönhage–Strassen
multiplication. Performing multiplications in
using Kronecker multiplication, it also follows that
, again using Schönhage–Strassen
multiplication. Performing multiplications in
using Kronecker multiplication, it also follows that
for sufficiently large . We
conclude that
Step 3: multivariate Rader reduction. We compute the
multivariate discrete Fourier transforms using Rader reduction. For each
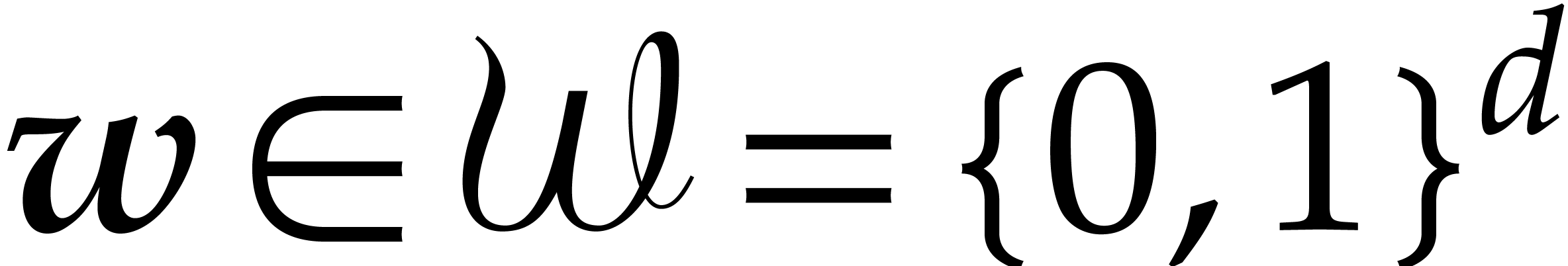 , let
, let  be such that
be such that  if and
if and  if for . Then (4.3) implies
if for . Then (4.3) implies
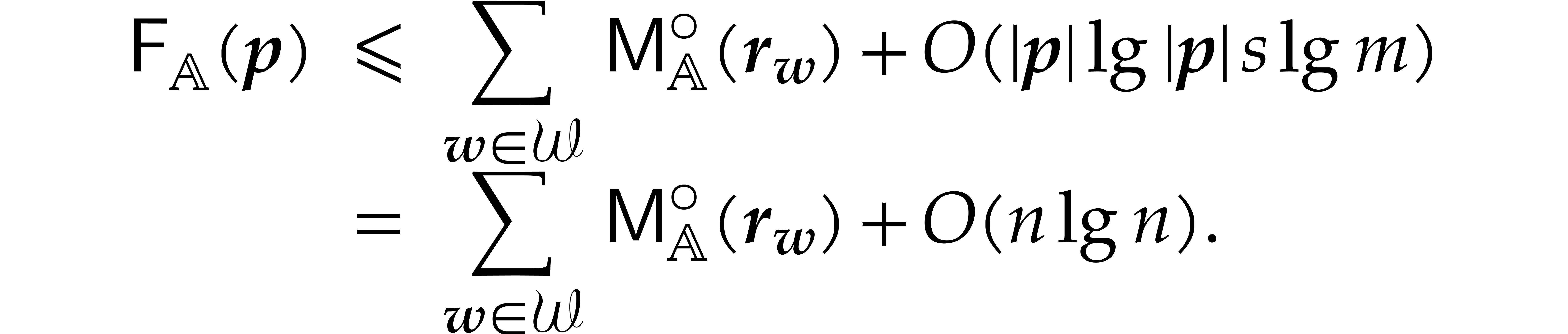
The necessary precomputations for each of the 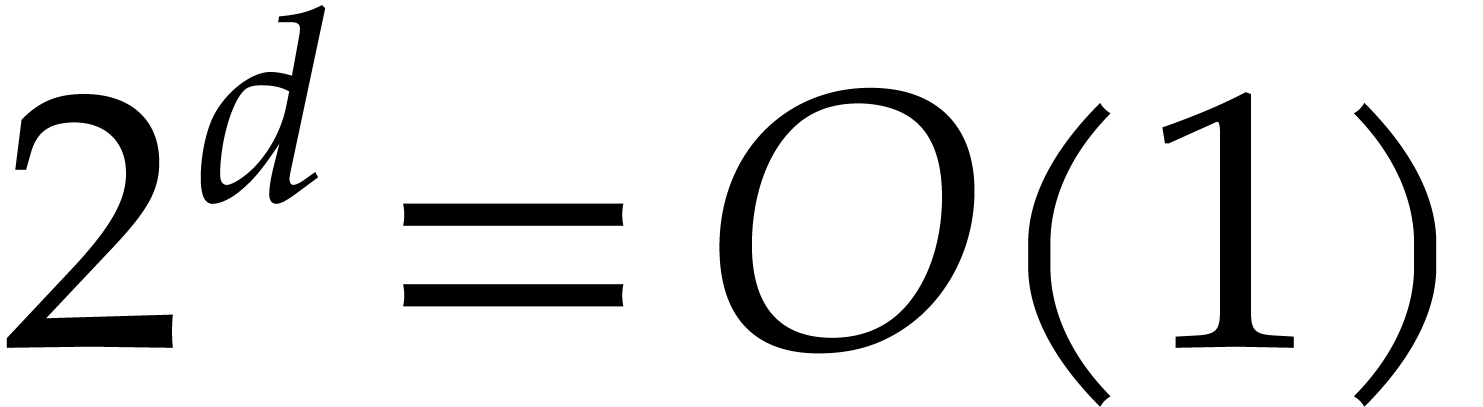 Rader reductions can be performed over instead
of . Using
Schönhage–Strassen multiplication, this can be done in time
Rader reductions can be performed over instead
of . Using
Schönhage–Strassen multiplication, this can be done in time
since
Now for any 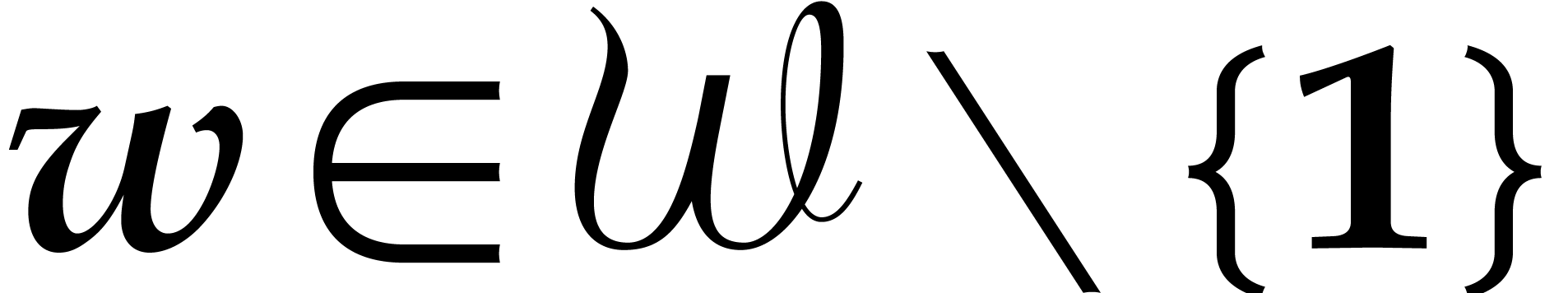 , we have
, we have 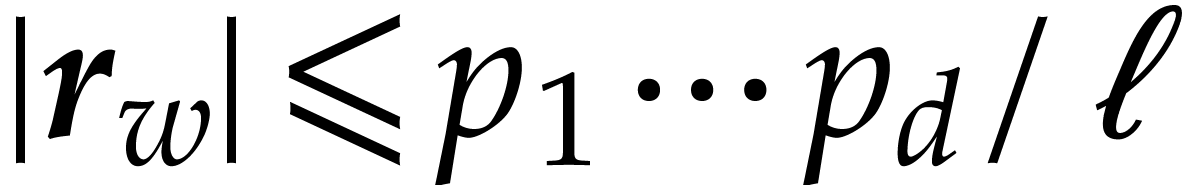 . Performing multiplications in
. Performing multiplications in
 using -fold
Kronecker substitution and Cantor–Kaltofen's variant of
Schönhage–Strassen multiplication over , this yields
using -fold
Kronecker substitution and Cantor–Kaltofen's variant of
Schönhage–Strassen multiplication over , this yields
whence
Since 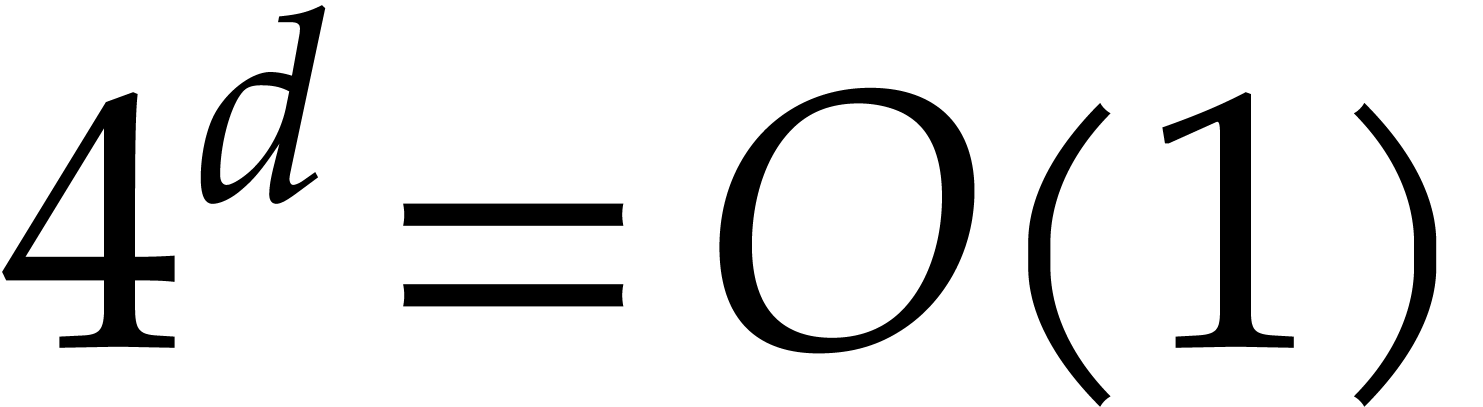 and
and 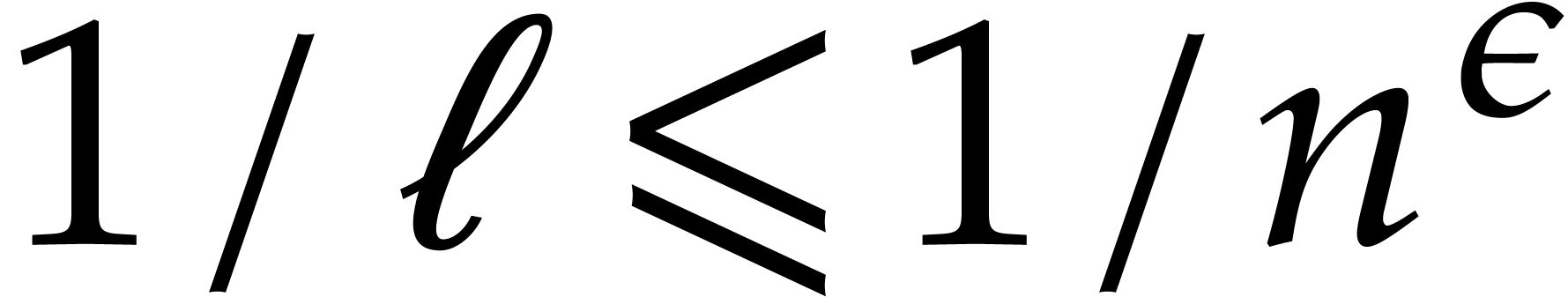 ,
the right hand side is bounded by ,
whence
,
the right hand side is bounded by ,
whence
Step 4: second CRT transforms. For , we may decompose 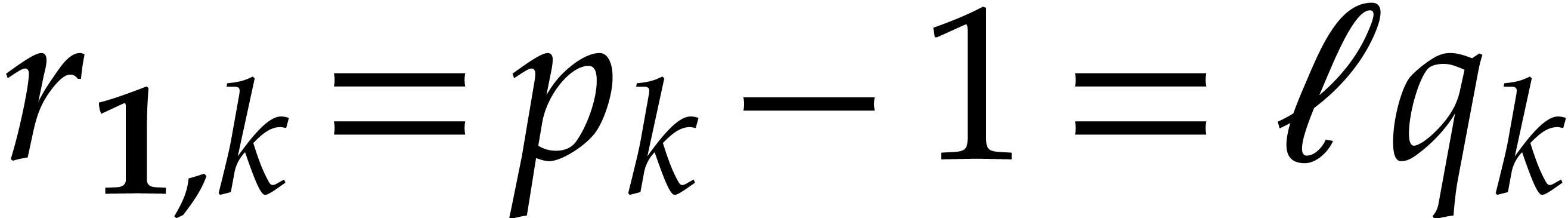 ,
where
,
where  is odd. Using multivariate CRT transforms
(Corollary A.8), this yields
is odd. Using multivariate CRT transforms
(Corollary A.8), this yields
Setting  and
and 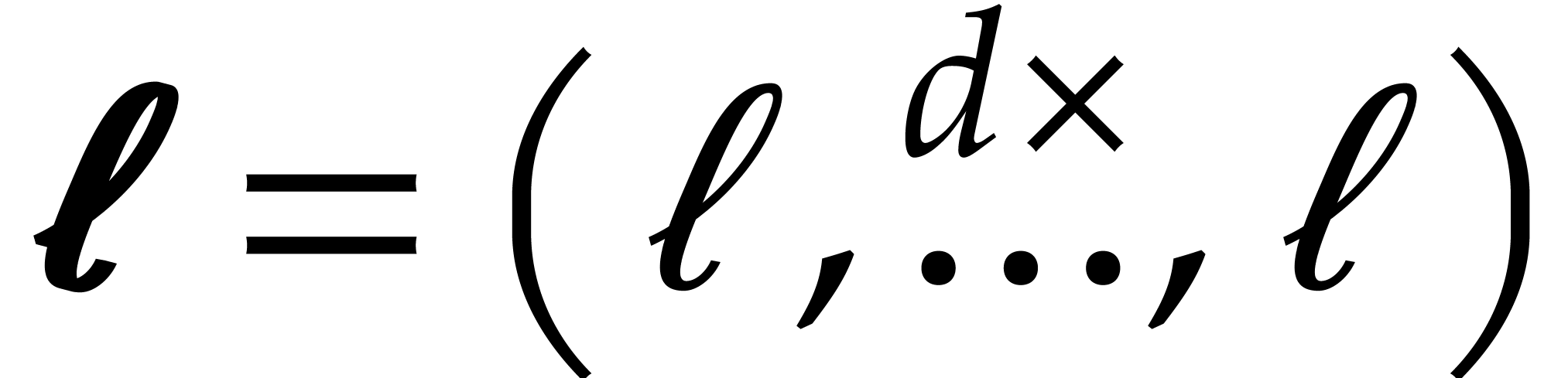 ,
this relation can be rewritten as
,
this relation can be rewritten as
Step 5: Nussbaumer polynomial transforms. Since  , we have a fast root of unity
, we have a fast root of unity 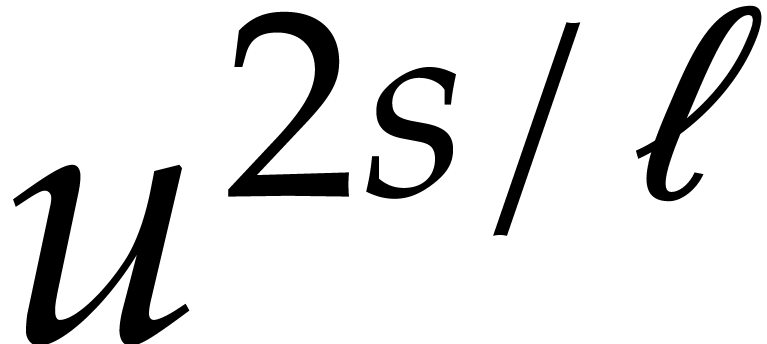 of order in and in . We may thus compute polycyclic
convolutions of order
of order in and in . We may thus compute polycyclic
convolutions of order  over
using fast Fourier multiplication, with Nussbaumer polynomial transforms
in the role of discrete Fourier transforms. From (3.10), it
follows that
over
using fast Fourier multiplication, with Nussbaumer polynomial transforms
in the role of discrete Fourier transforms. From (3.10), it
follows that
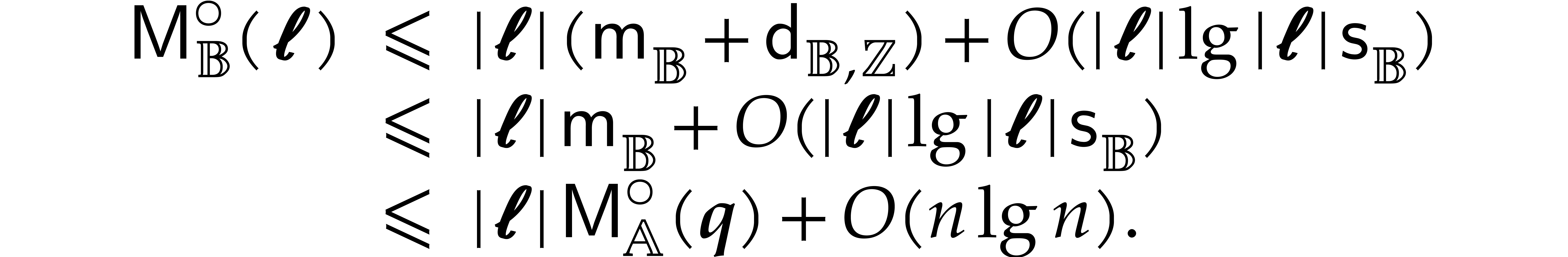
Here we used the bound 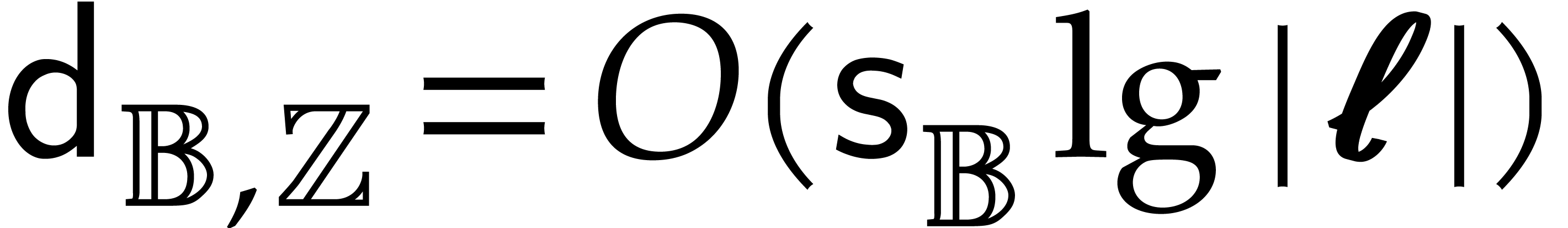 ,
which is shown in a similar way as above. Modulo a change of variables
,
which is shown in a similar way as above. Modulo a change of variables
 where
where 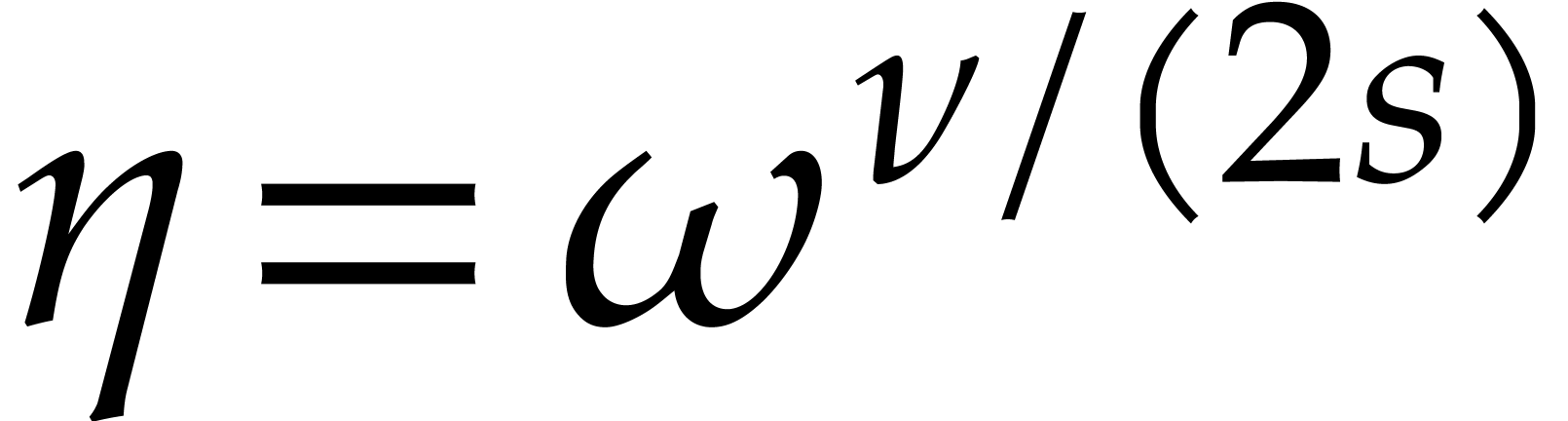 is a principal
-th root of unity in , negacyclic convolutions in
is a principal
-th root of unity in , negacyclic convolutions in 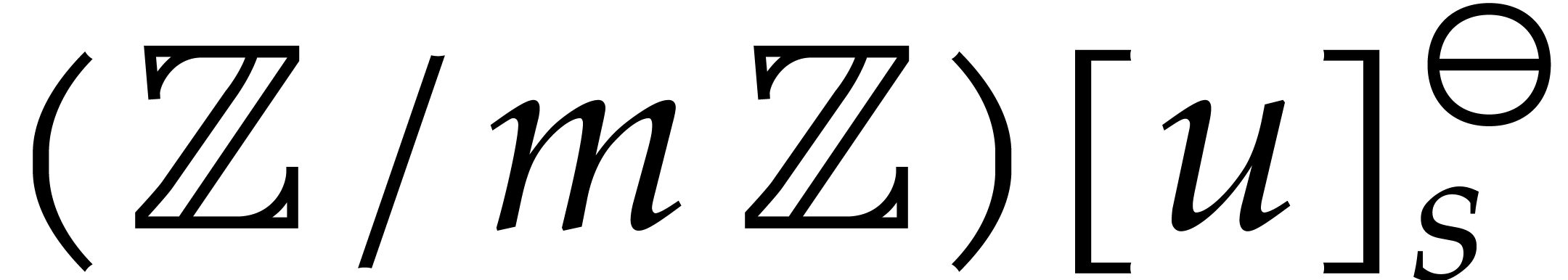 reduce to cyclic convolutions in
reduce to cyclic convolutions in 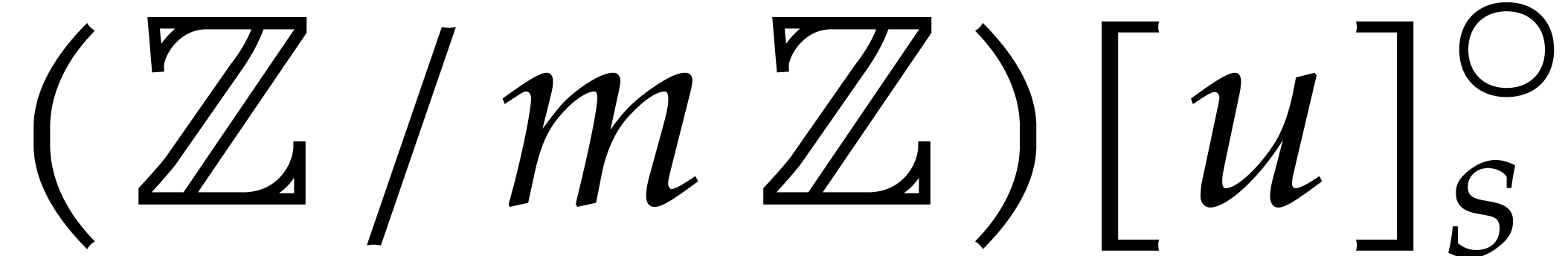 . Combining this with the above relations, this
yields
. Combining this with the above relations, this
yields
The bound  follows from (1.1).
follows from (1.1).
Step 6: residual cyclic convolutions. By construction, contains principal roots of unity of orders 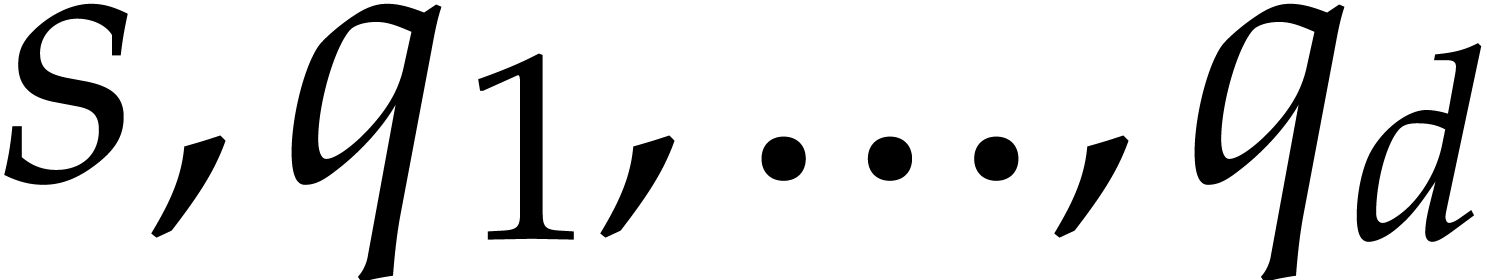 , which can again be computed in
time using a similar method as above. We may
thus compute cyclic convolutions of order
, which can again be computed in
time using a similar method as above. We may
thus compute cyclic convolutions of order  over
using fast Fourier multiplication. Since
over
using fast Fourier multiplication. Since  and
and  , we
obtain
, we
obtain
Using Bluestein reduction (2.10), the univariate discrete Fourier transforms can be transformed back into cyclic products:
We perform the cyclic products using Kronecker substitution. Since  is increasing (by definition), this yields
is increasing (by definition), this yields
Step 7: recurse. Combining the relations (6.1),
(6.2), (6.3), (6.4) and (6.5),
while using the fact that 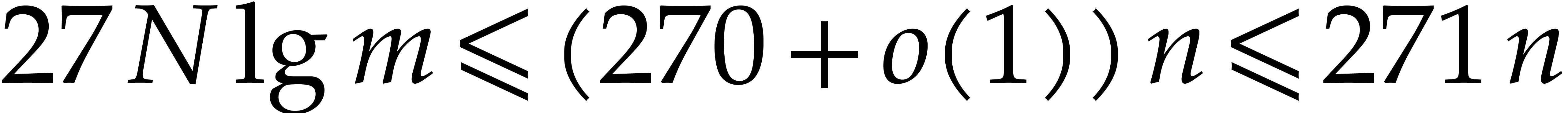 for sufficiently large
, we obtain
for sufficiently large
, we obtain
Using that 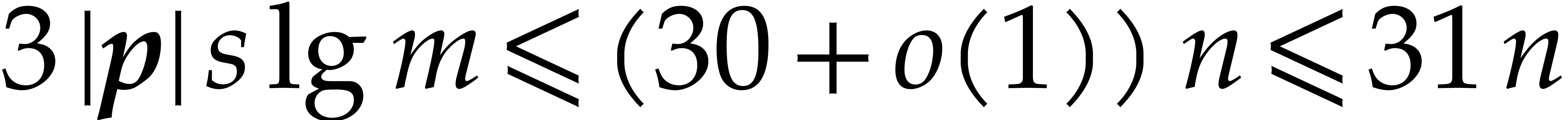 , this relation
simplifies to
, this relation
simplifies to
In terms of the normalized cost function
and 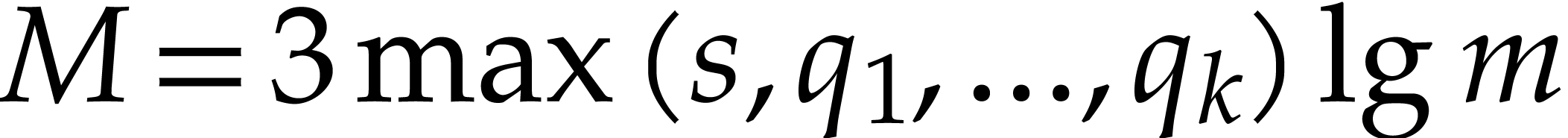 , this relation becomes
, this relation becomes
By Lemma 5.1, we have 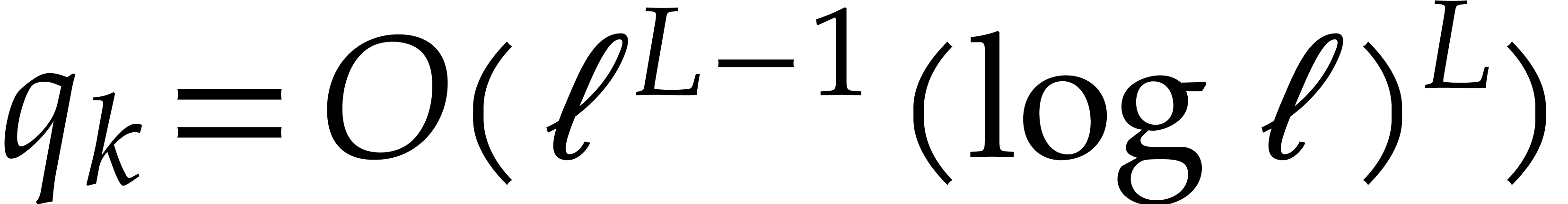 for all . For sufficiently large , this means that
for all . For sufficiently large , this means that 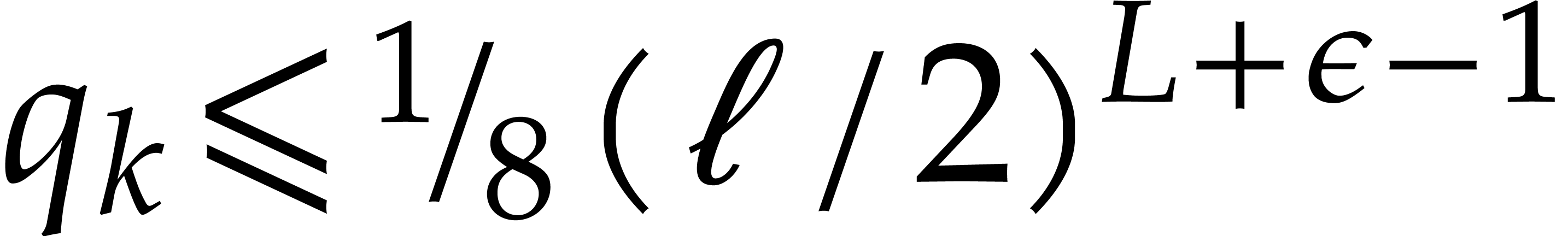 , whence
, whence 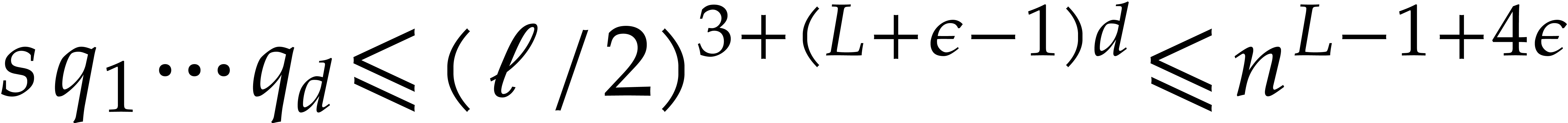 and
and 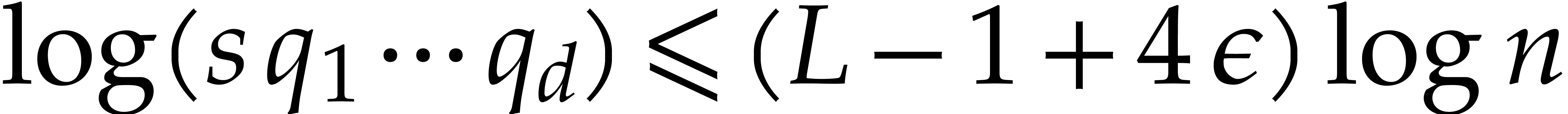 . Using that
. Using that 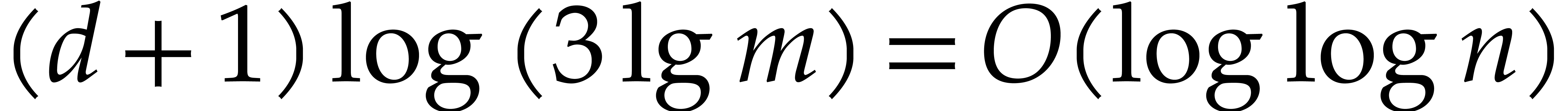 , the latest bound on
, the latest bound on  therefore further simplifies into
therefore further simplifies into
for some suitable universal constant 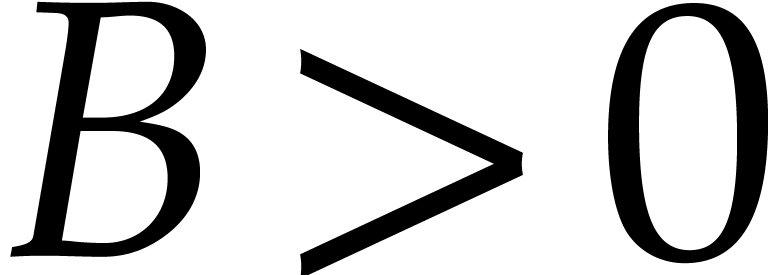 .
For sufficiently large ,
using our assumptions , we
have
.
For sufficiently large ,
using our assumptions , we
have 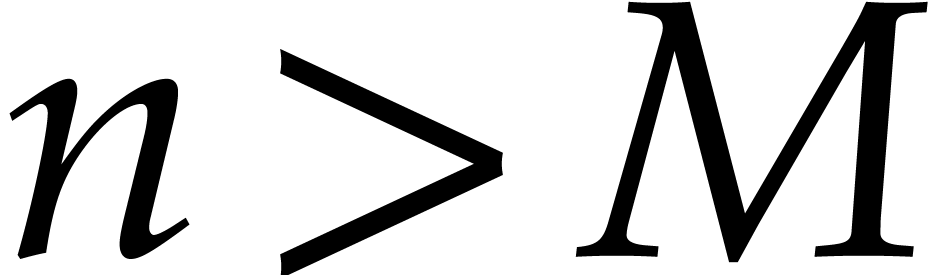 and
and 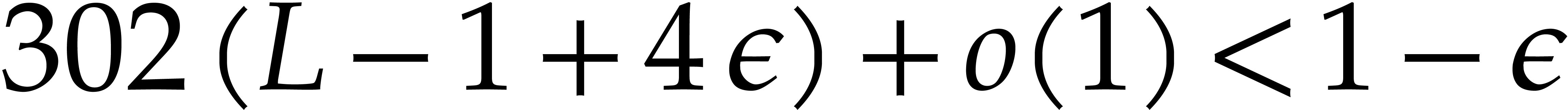 ,
whence
,
whence
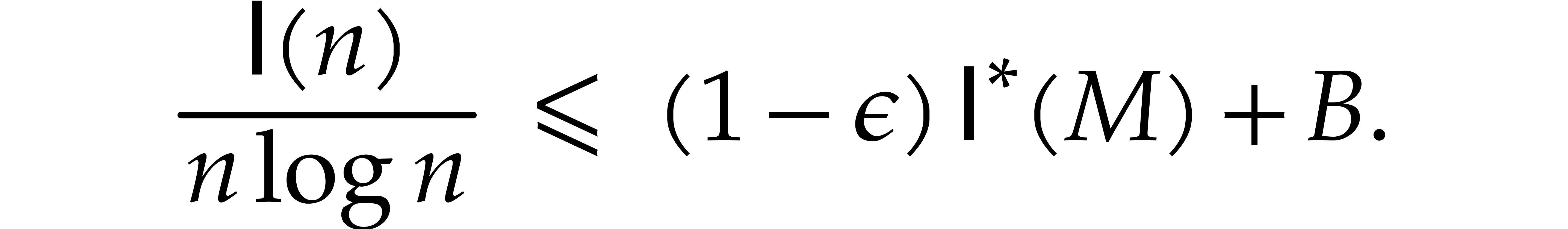
Let us show by induction over that this implies
 for all .
This is clear for
for all .
This is clear for  , so assume
that
, so assume
that  . Then the above
inequality yields
. Then the above
inequality yields
Consequently,  . This
completes the induction and we conclude that
. This
completes the induction and we conclude that 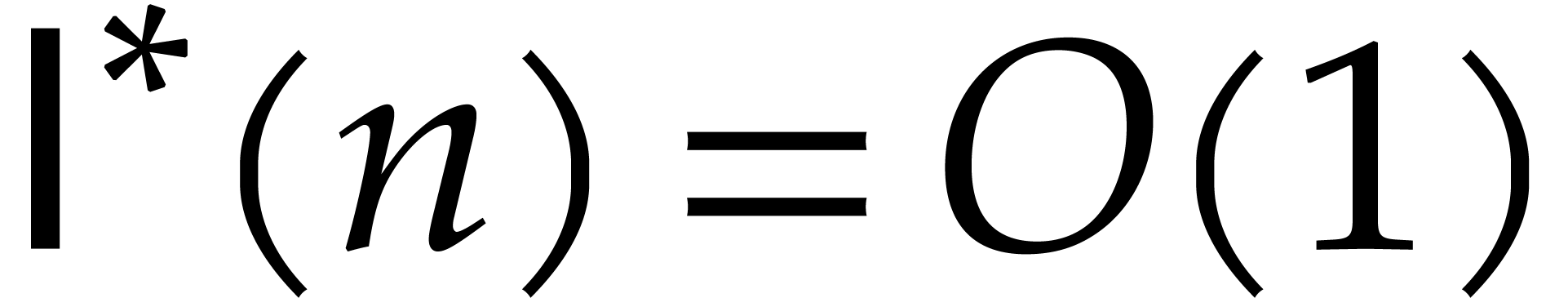 , whence .
, whence .
Remark  . With a bit more work, it should be possible
to achieve any constant larger than
. With a bit more work, it should be possible
to achieve any constant larger than  ,
as follows:
,
as follows:
On three occasions, we used the crude estimate 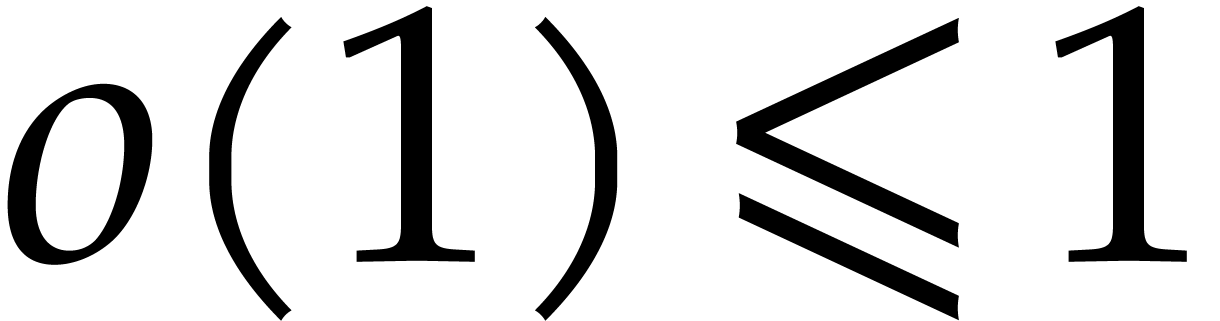 for large ; this explains
the increase from
for large ; this explains
the increase from  to
to  .
.
Taking 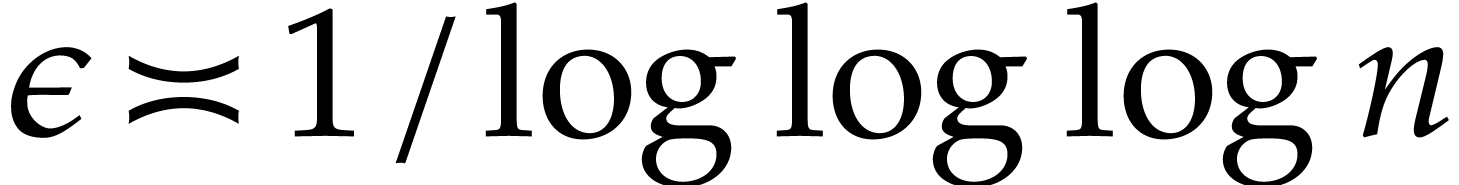 , the cost of the
pointwise multiplications in (6.2) becomes negligible,
so there is no further increase from
, the cost of the
pointwise multiplications in (6.2) becomes negligible,
so there is no further increase from  to
to  in the last step. Since this also means that the
dimension is no longer constant, a few
adaptations are necessary. For instance, we need Remark 5.2
that and at the end of step 3, we only have
in the last step. Since this also means that the
dimension is no longer constant, a few
adaptations are necessary. For instance, we need Remark 5.2
that and at the end of step 3, we only have
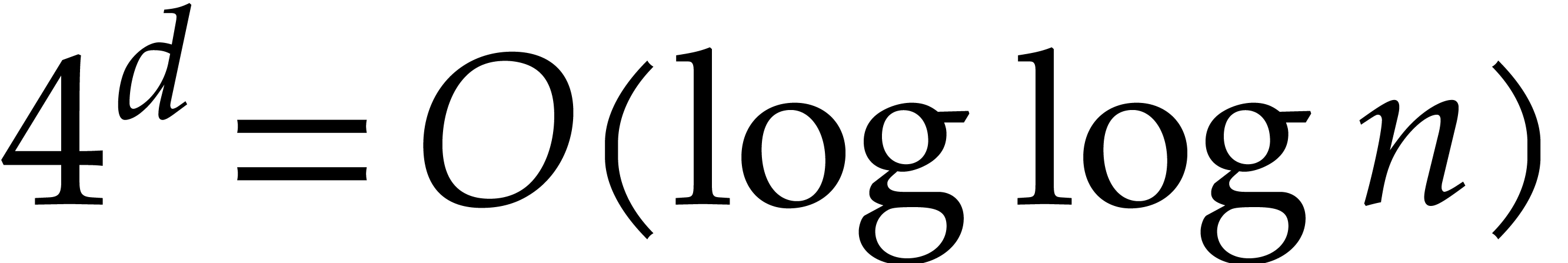 .
.
Taking 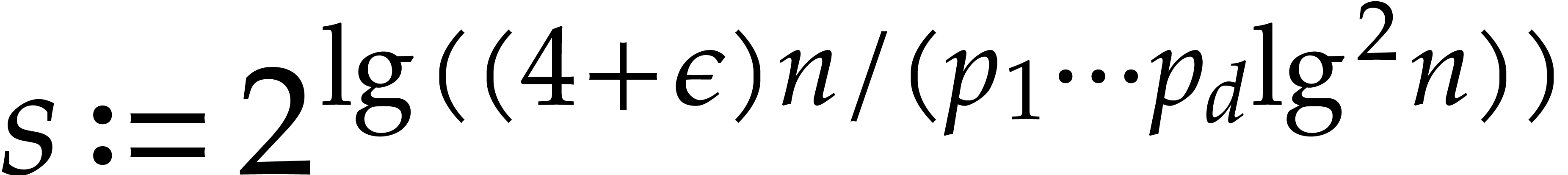 one gains a factor
one gains a factor  .
.
In recursive FFT-multiplications, one argument is always fixed (due
to the fact that one of the multipliers in the Bluestein and Rader
reductions is fixed). In a similar way as in [25], this
makes it possible to save one fast Fourier transform out of three.
Since this observation can be used twice in steps 2 and 6, a further
factor of  can be gained in this way.
can be gained in this way.
In step 6, we used the crude bound 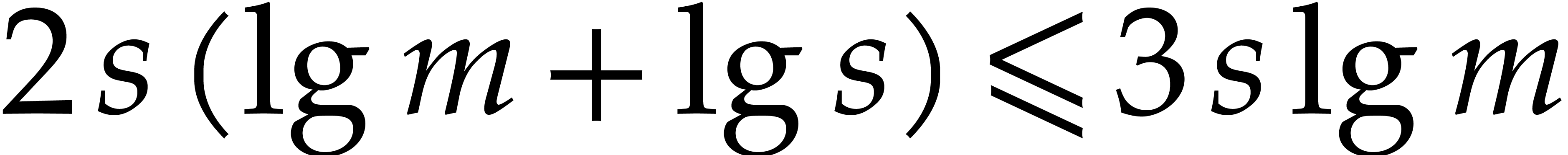 .
Replacing the right-hand side by
.
Replacing the right-hand side by 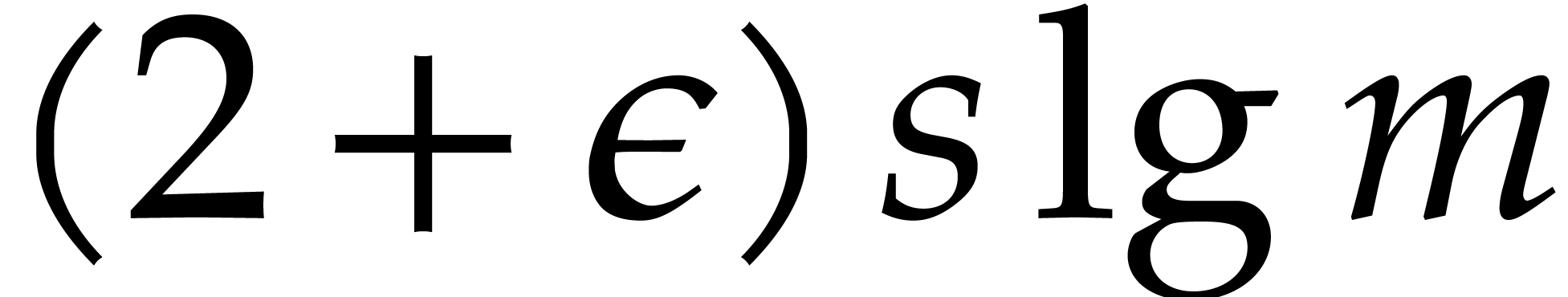 ,
we save another factor
,
we save another factor 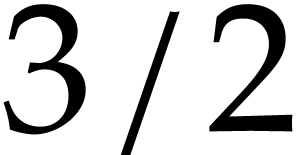 .
.
By allowing to contain some small odd
factors, we may further improve the inequality 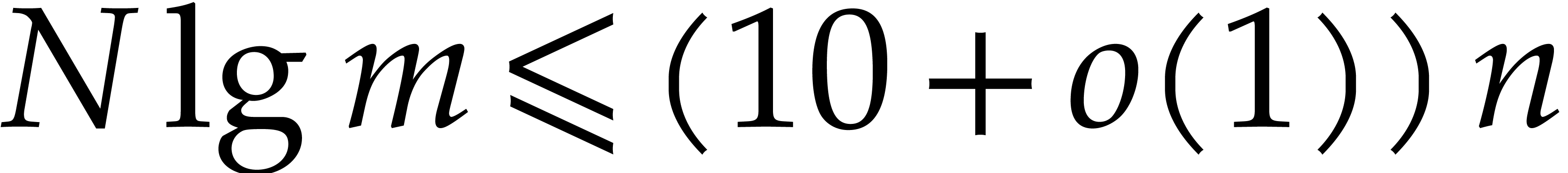 in step 7 to become
in step 7 to become  .
This saves another factor of two.
.
This saves another factor of two.
We finally recall that we opted to present our algorithm for number
theoretic FFTs. When switching to approximate complex FFTs, one
advantage is that one may work more extensively with primitive roots of
power of two orders. This should also allow for the use of
Crandall–Fagin's reduction (in a similar way as in [25])
to further release the assumption on the Linnik constant to 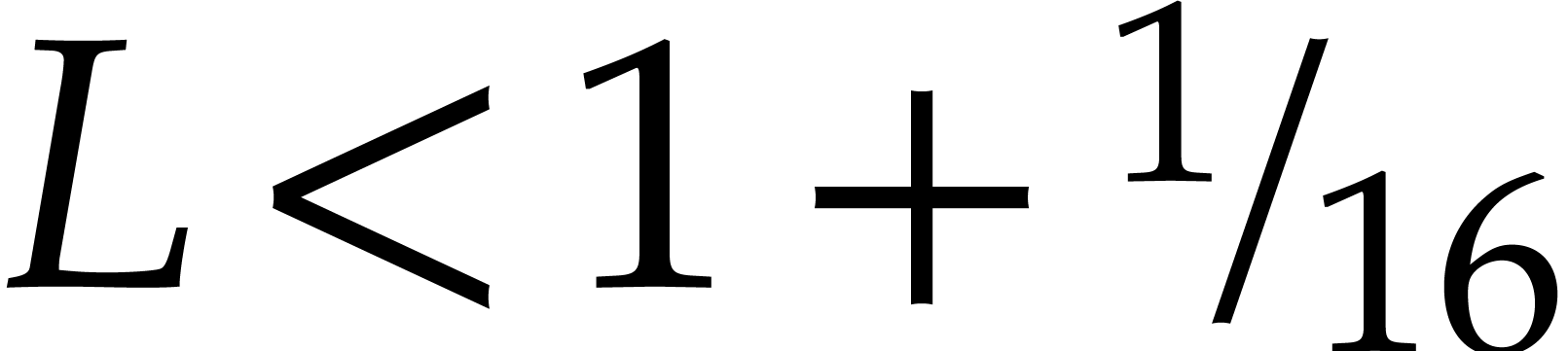 .
.
Recall that elements of the finite field are
represented as remainder classes of polynomials in 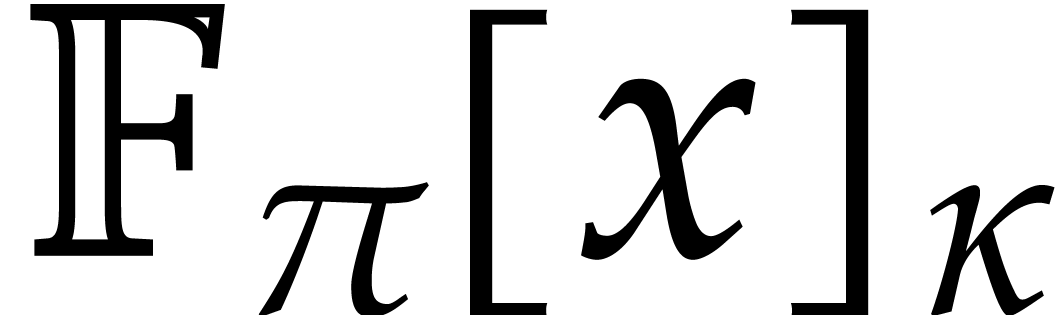 modulo , for some given monic
irreducible polynomial of degree . Using Kronecker substitution and
segmentation, one has the following well known complexity bounds [27, section 3]:
modulo , for some given monic
irreducible polynomial of degree . Using Kronecker substitution and
segmentation, one has the following well known complexity bounds [27, section 3]:
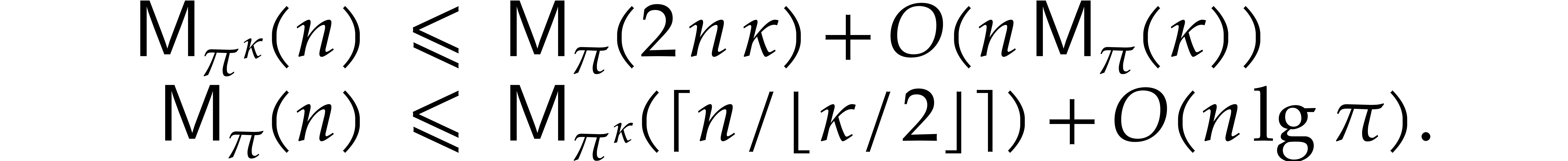
In order to establish Theorem 1.2, it therefore suffices to
consider the case when is a prime number. In
this section, we first prove the theorem in the case when . The case is treated
in the next section. If  ,
then it is well known that
,
then it is well known that 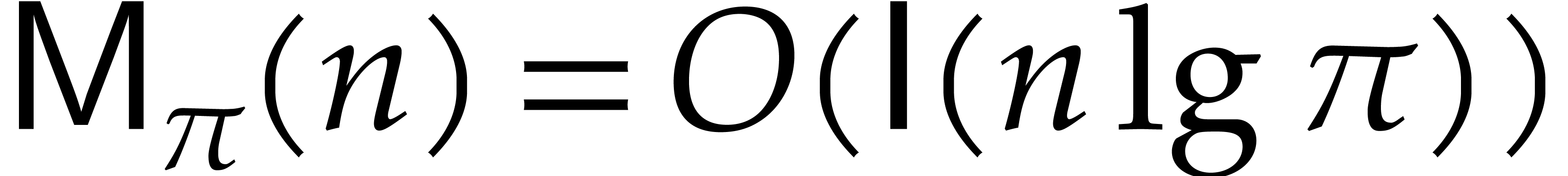 ,
again using Kronecker substitution. In this particular case, Theorem 1.2 therefore follows from Theorem 1.1. Let be a Linnik constant with
,
again using Kronecker substitution. In this particular case, Theorem 1.2 therefore follows from Theorem 1.1. Let be a Linnik constant with  . Our algorithm proceeds as follows.
. Our algorithm proceeds as follows.
Step 0: setting up the parameters. Assume that we wish to
multiply two polynomials of degree in . For  with
with
 and suitable parameters
and
and suitable parameters
and 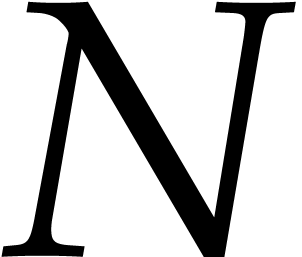 , we will reduce this
problem to a multiplication problem in
, we will reduce this
problem to a multiplication problem in 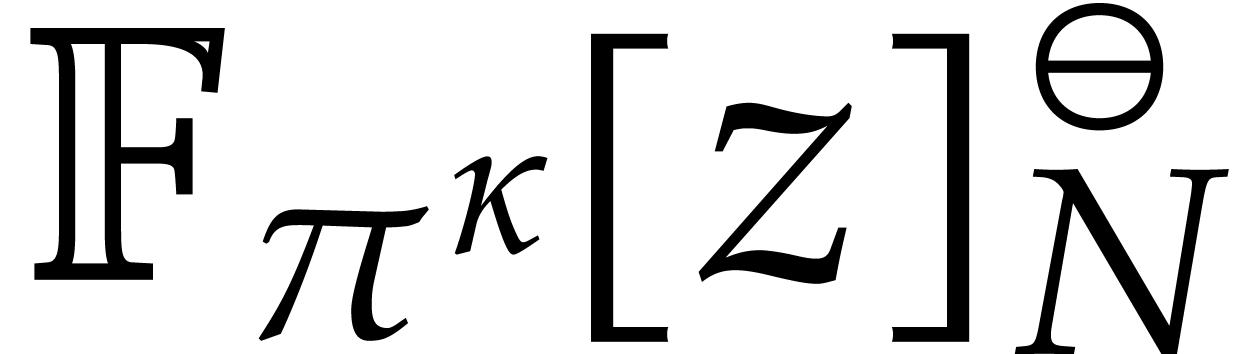 .
If , then we use Kronecker
multiplication. The factor
.
If , then we use Kronecker
multiplication. The factor  is a sufficiently
large absolute constant such that various asymptotic inequalities
encountered during the proof hold for all .
The other parameters are determined as follows:
is a sufficiently
large absolute constant such that various asymptotic inequalities
encountered during the proof hold for all .
The other parameters are determined as follows:
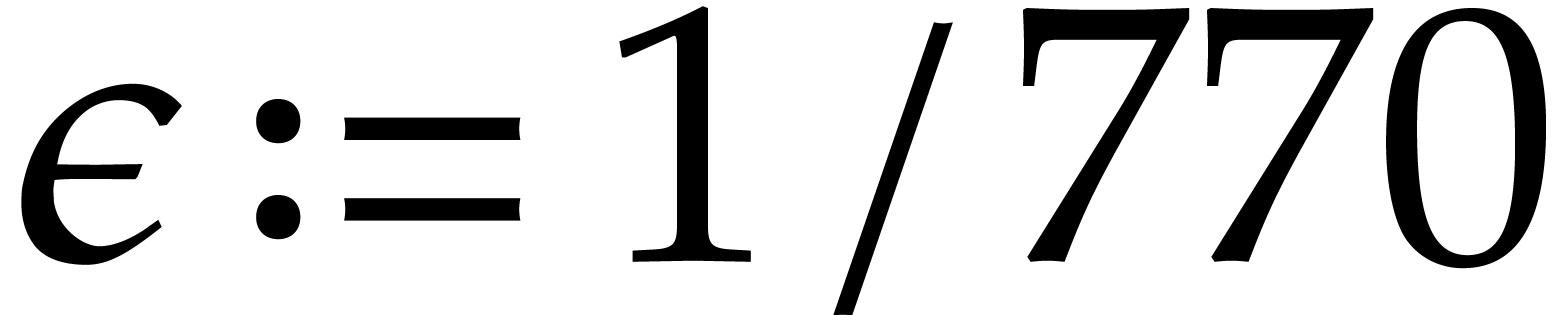 .
.
is the smallest power of two with 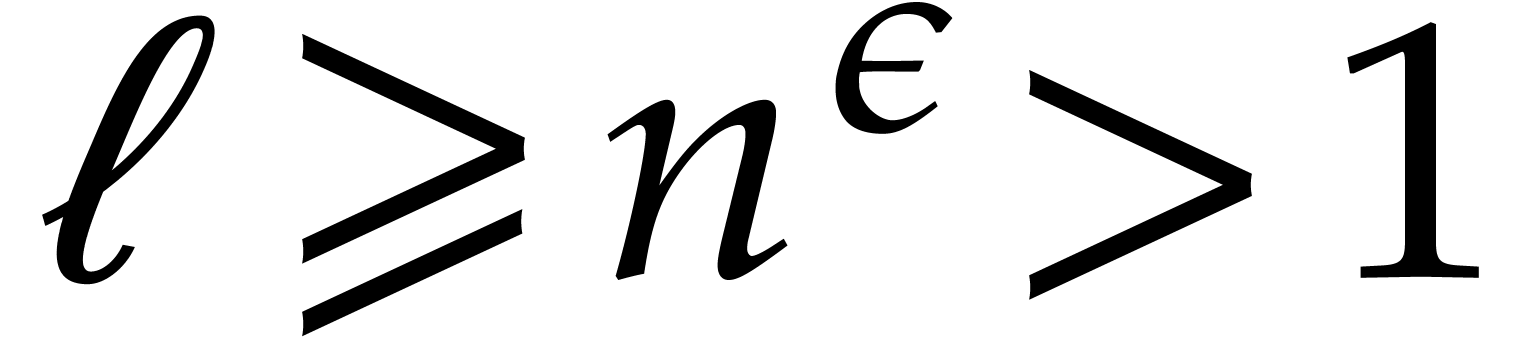 .
.
With the notations from section 5.3 and for each , let 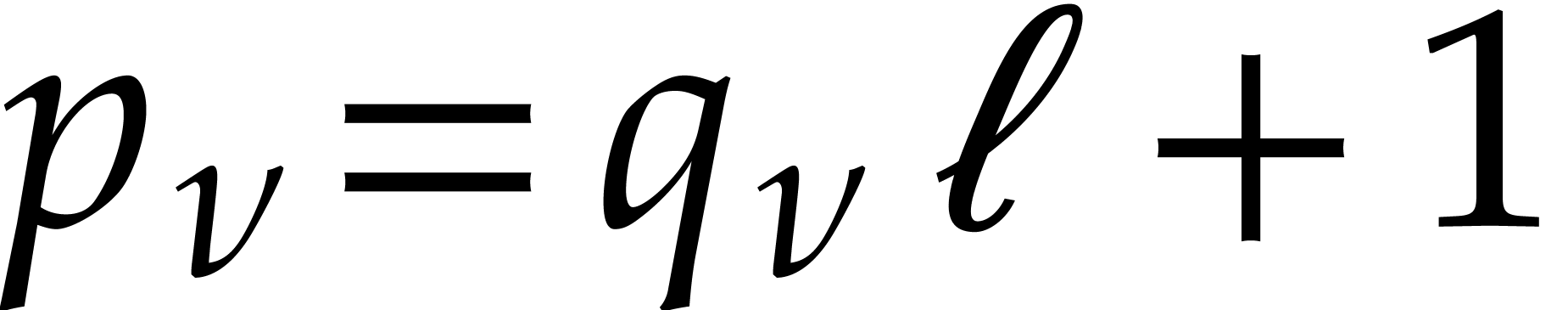 be the -th element in the
list
be the -th element in the
list  with
with  and
and 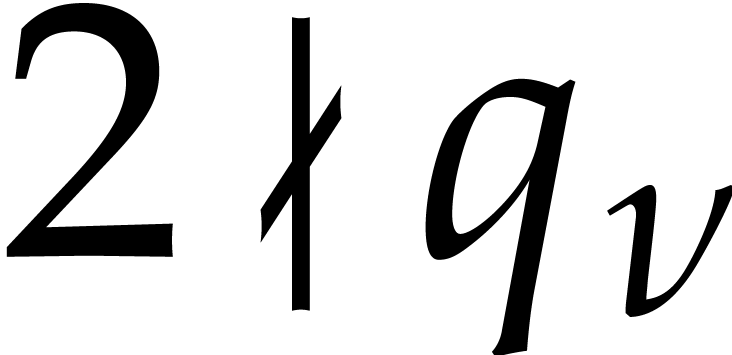 .
.
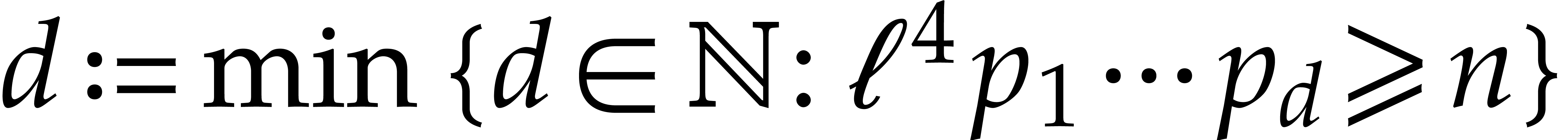 .
.
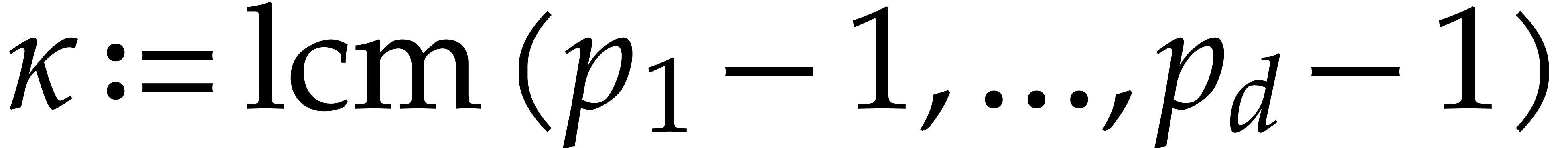 .
.
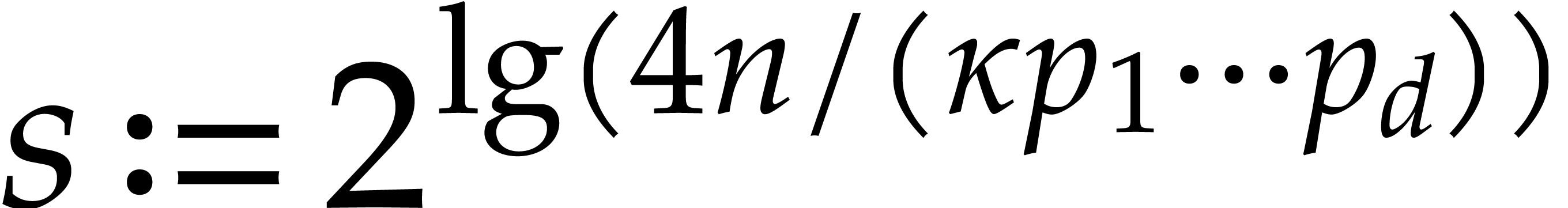 .
.
.
Since 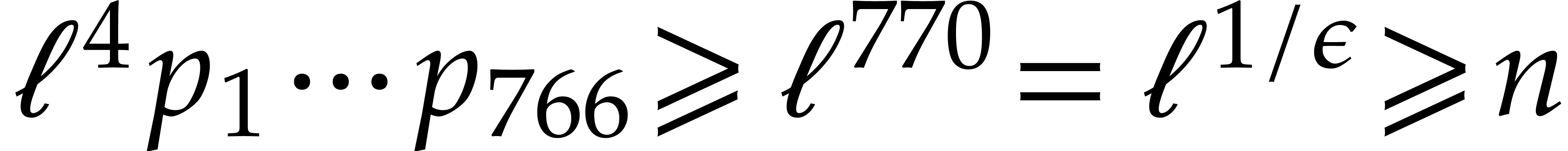 , we must have
, we must have  . From Lemma 5.4, we
get
. From Lemma 5.4, we
get
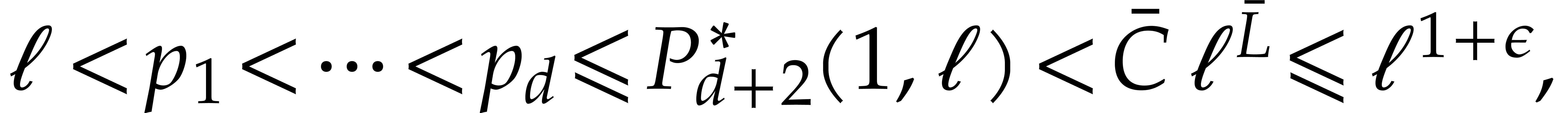
for sufficiently large ,
where
and  is a constant. As in the previous section,
the prime numbers and the rest of the parameters
can be computed in linear time .
Let us proceed with a few useful bounds that hold for sufficiently large
. From the definitions of
and ,
we clearly have
is a constant. As in the previous section,
the prime numbers and the rest of the parameters
can be computed in linear time .
Let us proceed with a few useful bounds that hold for sufficiently large
. From the definitions of
and ,
we clearly have
From 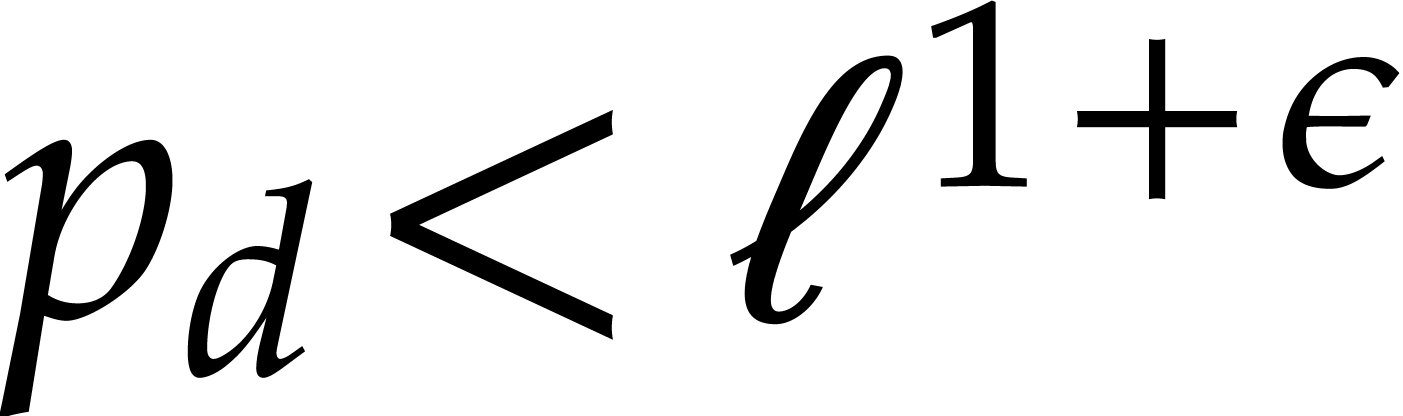 and
and 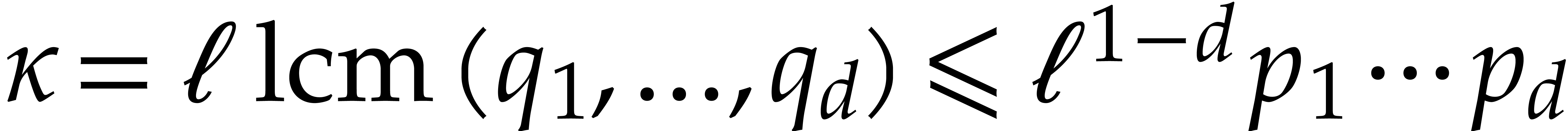 ,
we get
,
we get
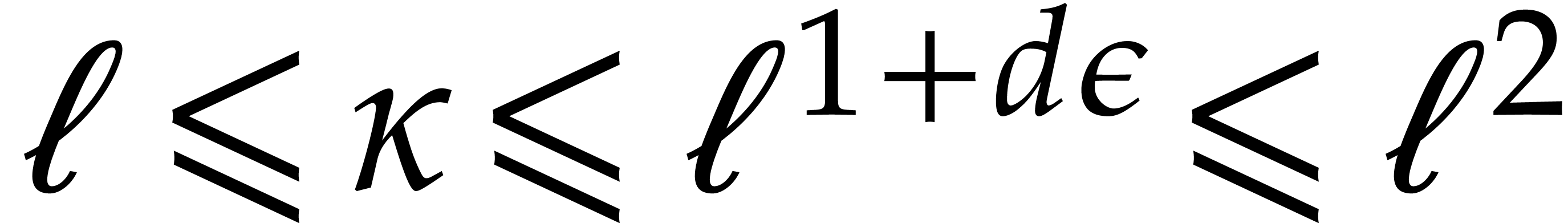
and
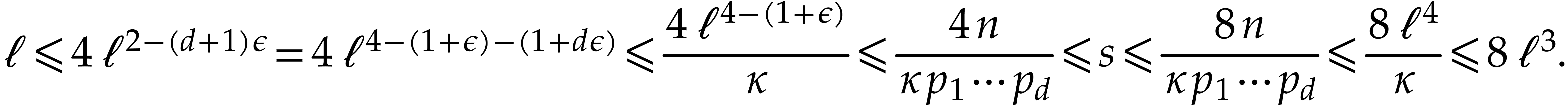
Step 0, continued: setting up the FFT field. Notice that  . Elements of the field will be represented as polynomials in
modulo , where is a monic irreducible polynomial of degree . By [51, Theorem 3.2], such a
polynomial can be computed in time
. Elements of the field will be represented as polynomials in
modulo , where is a monic irreducible polynomial of degree . By [51, Theorem 3.2], such a
polynomial can be computed in time  ,
where we used the assumption that
,
where we used the assumption that  .
.
Setting 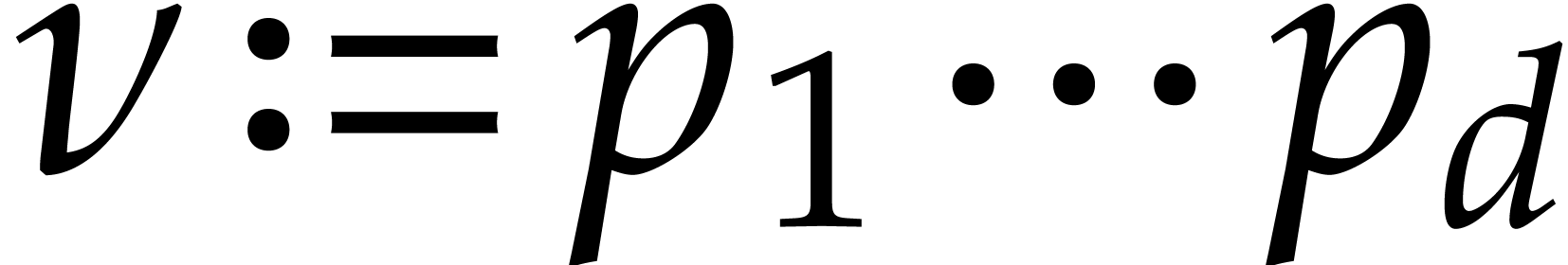 , we claim that the
field admits a primitive -th root of unity ,
that can also be computed in time .
Indeed, divides for each
, we claim that the
field admits a primitive -th root of unity ,
that can also be computed in time .
Indeed, divides for each
 and
and  ,
whence
,
whence 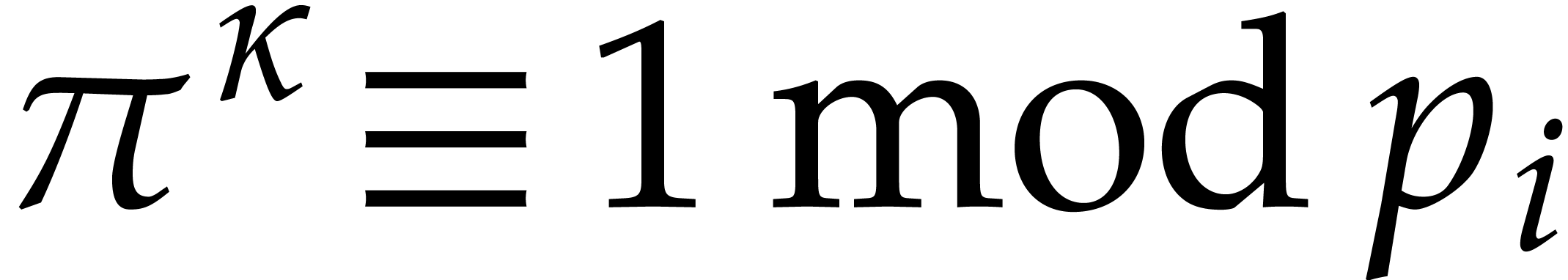 , so that
, so that 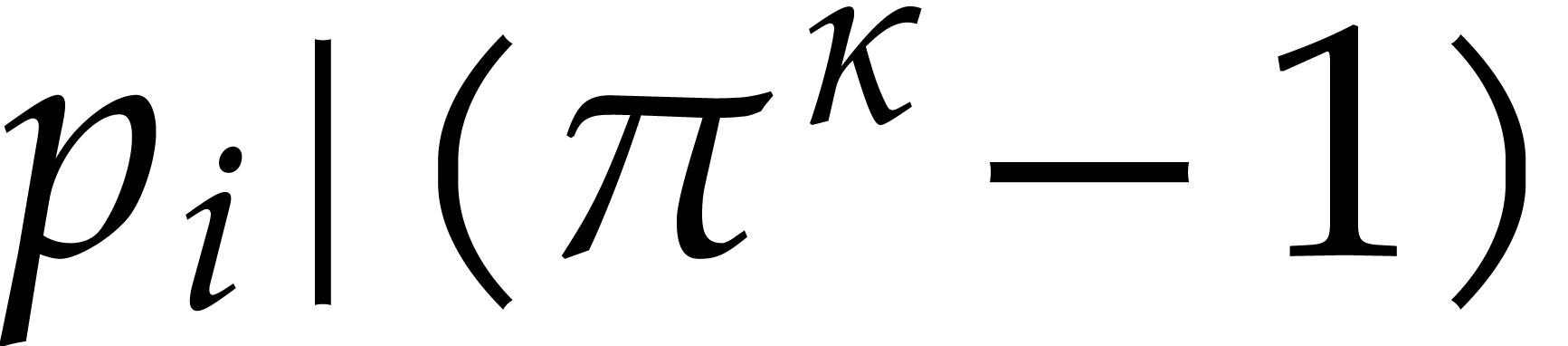 . We compute by brute
force: for all polynomials
. We compute by brute
force: for all polynomials  ,
starting with those of smallest degree, we check whether
,
starting with those of smallest degree, we check whether 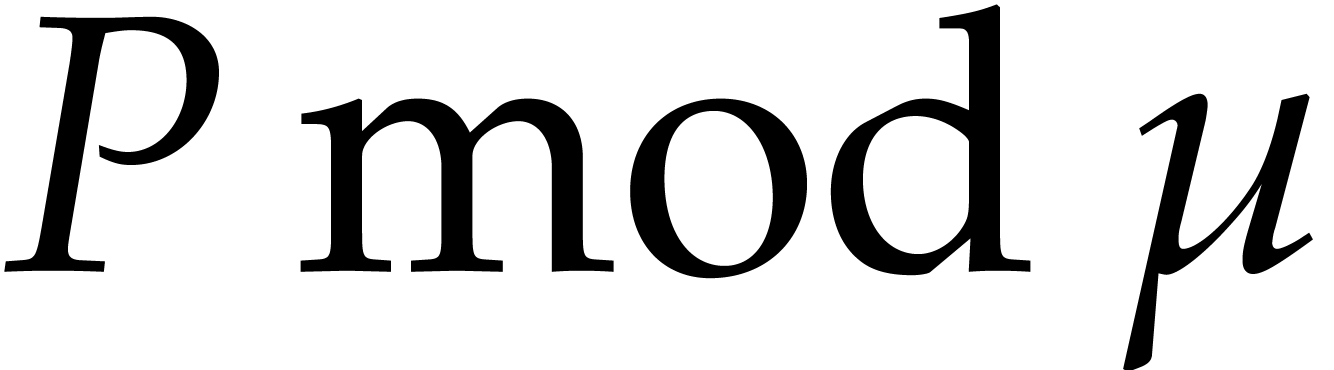 is a primitive -th
root. By [52, Theorem 1.1,
is a primitive -th
root. By [52, Theorem 1.1, 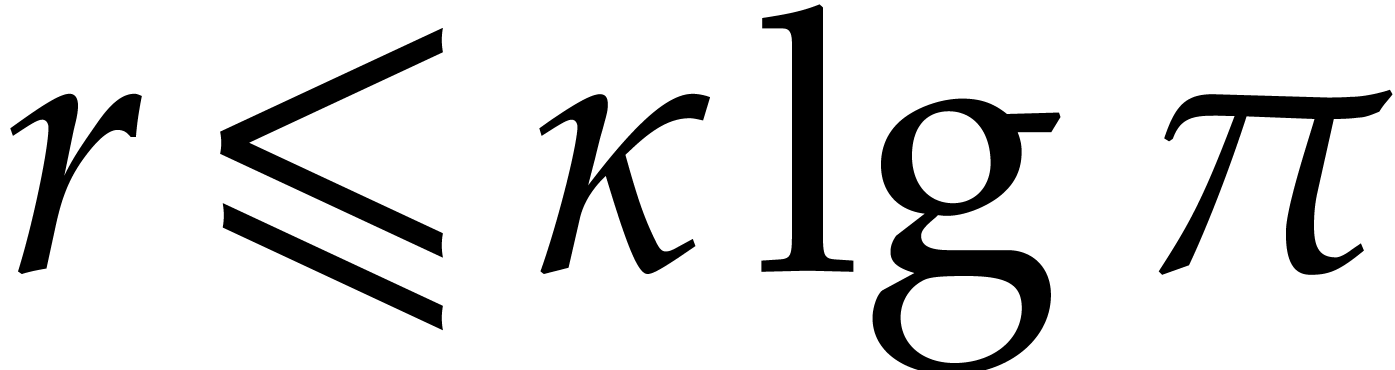 ],
this procedure succeeds after at most
],
this procedure succeeds after at most 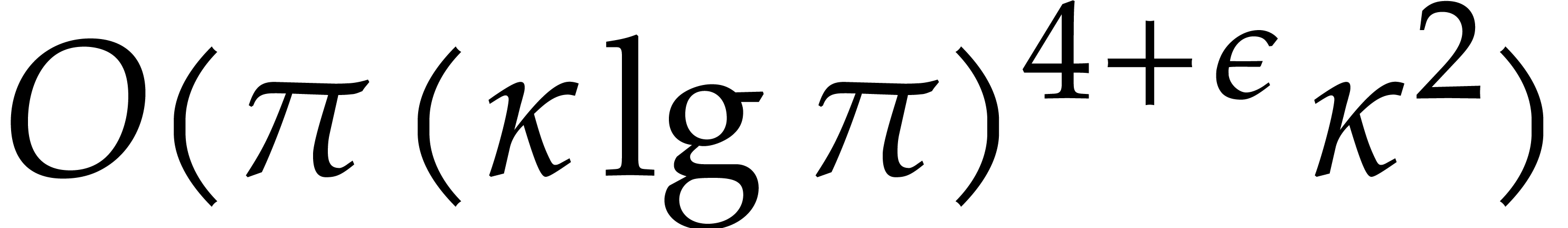 checks. In
order to check whether a given
checks. In
order to check whether a given 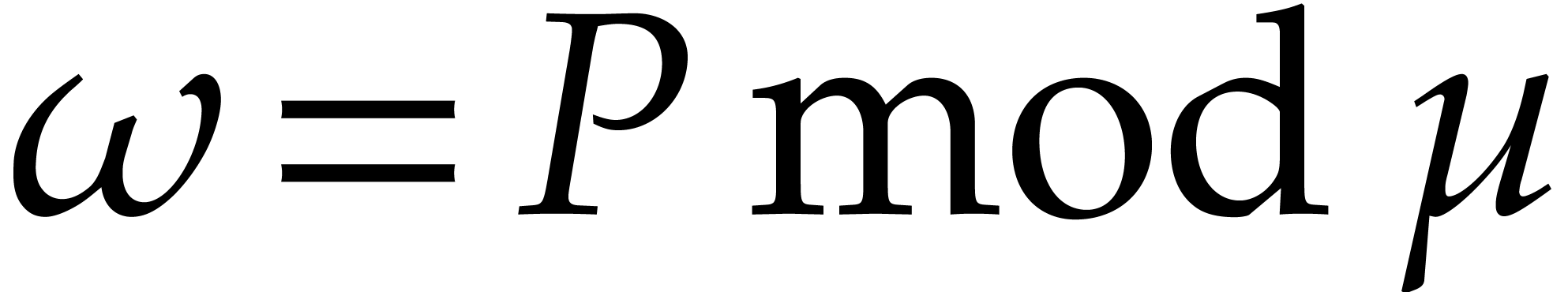 is a primitive
-th root of unity, it
suffices to verify that
is a primitive
-th root of unity, it
suffices to verify that 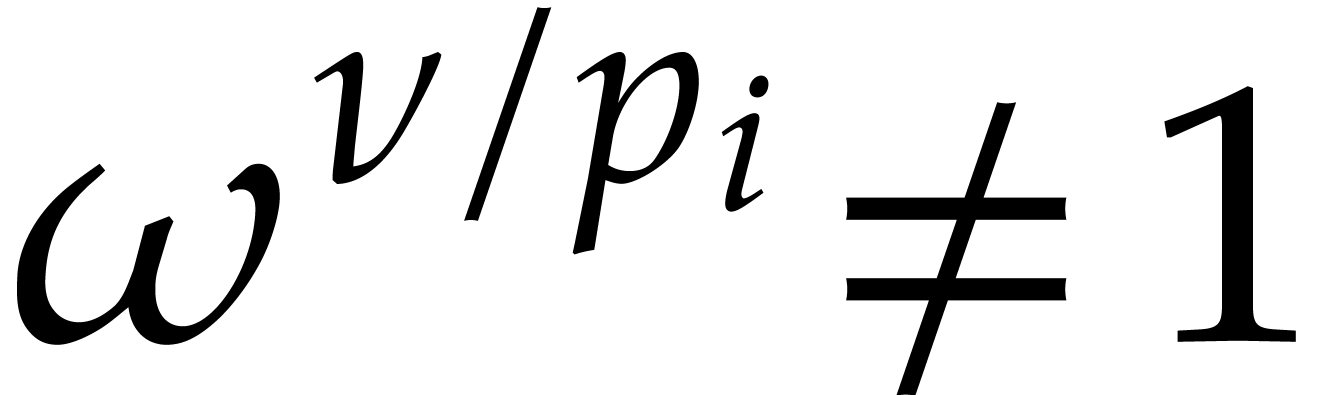 for each
for each  , which can be done in time
, which can be done in time 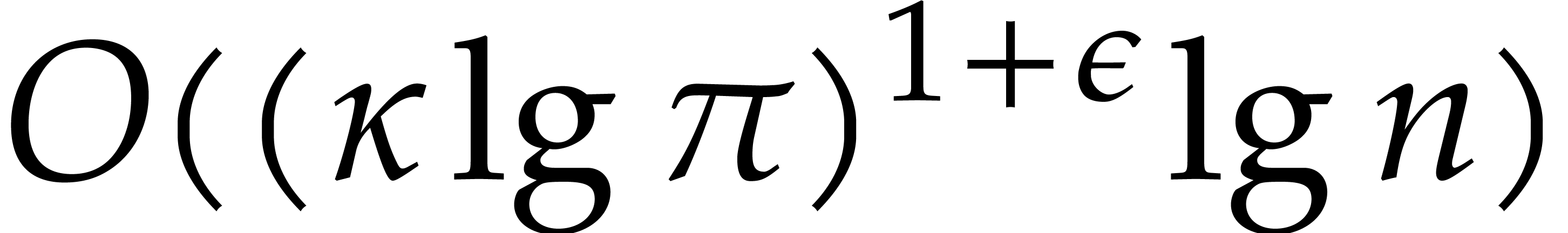 using binary powering. The total time to compute a suitable is therefore bounded by
using binary powering. The total time to compute a suitable is therefore bounded by  ,
using our assumption that
,
using our assumption that 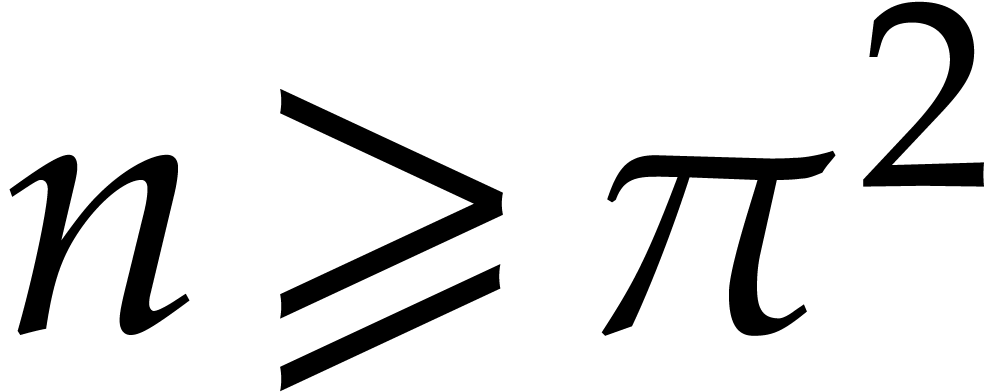 .
.
Step 1: Kronecker segmentation. Recall that 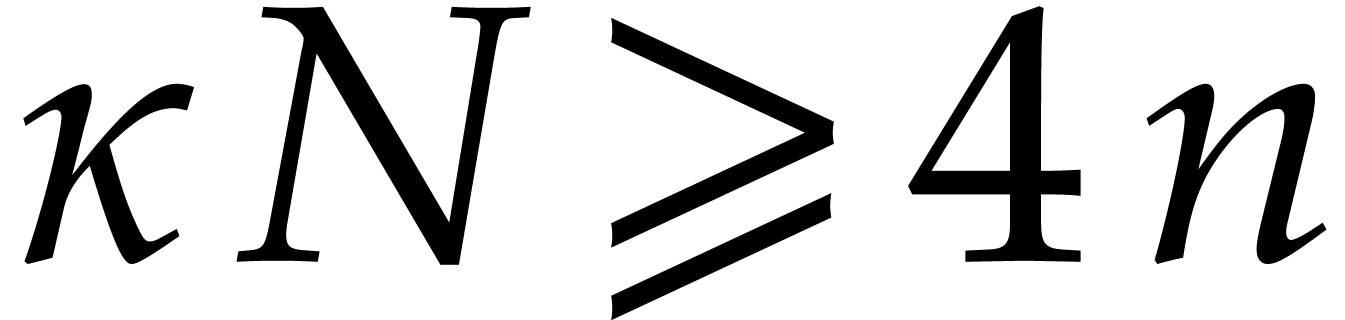 . In order to multiply two polynomials
. In order to multiply two polynomials 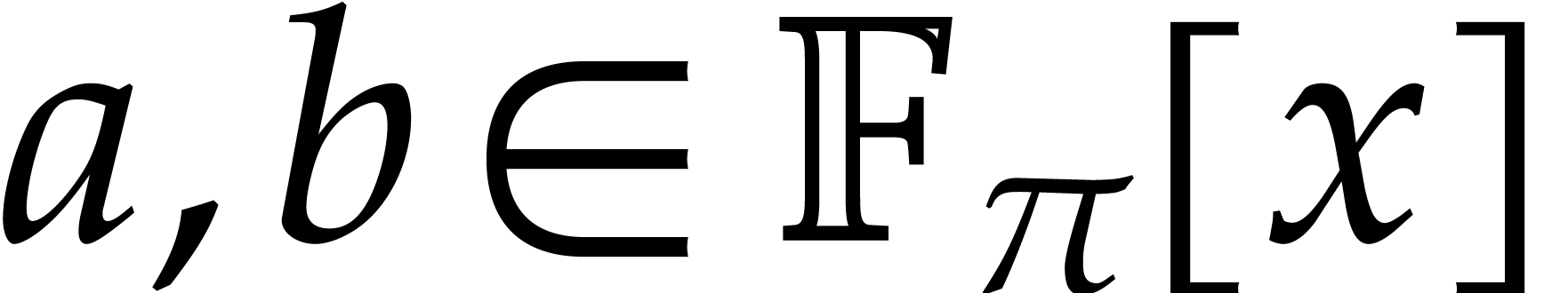 of degree ,
we cut them in chunks
of degree ,
we cut them in chunks 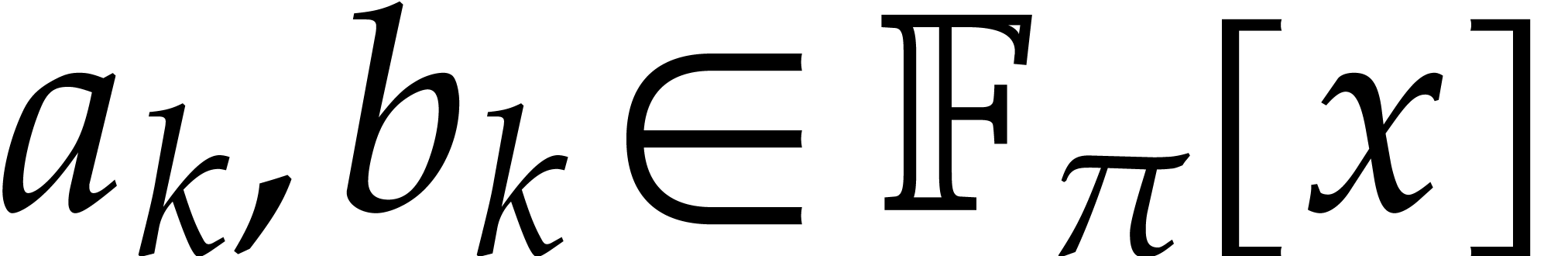 of degree
of degree  , i.e.
, i.e.
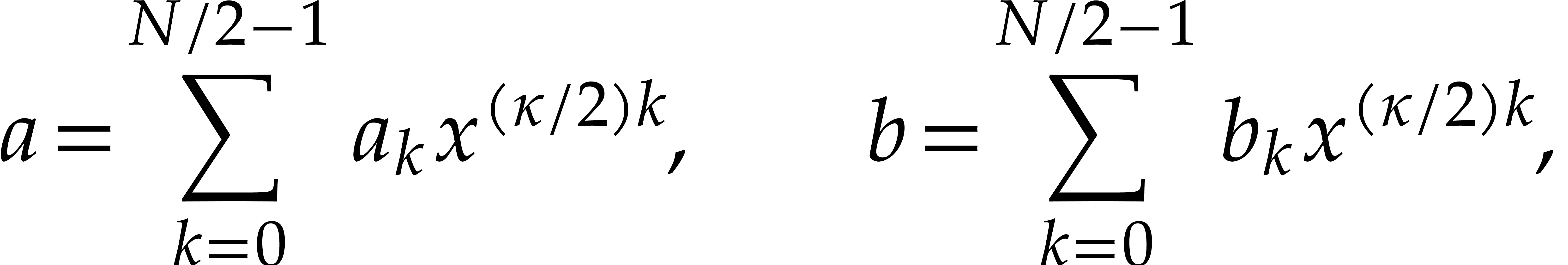
and form the polynomials
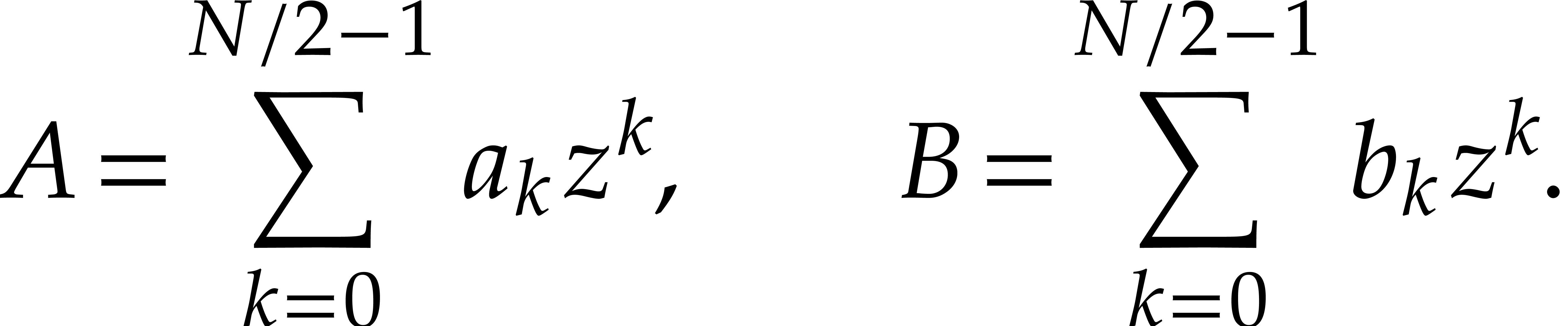
Let 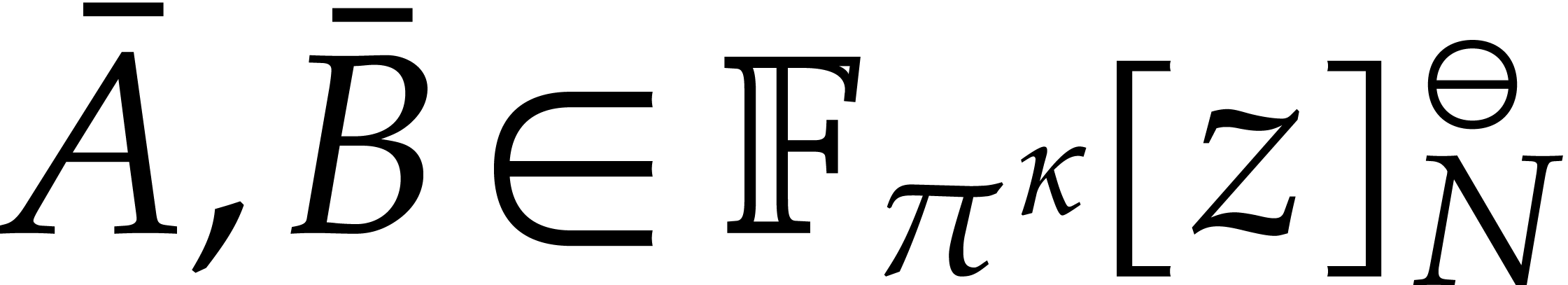 be the reductions of these polynomials
modulo and .
Since
be the reductions of these polynomials
modulo and .
Since  and
and  ,
we can read off the product from the product
,
we can read off the product from the product
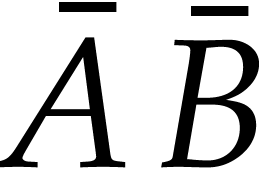 , after which
, after which  . Computing
. Computing 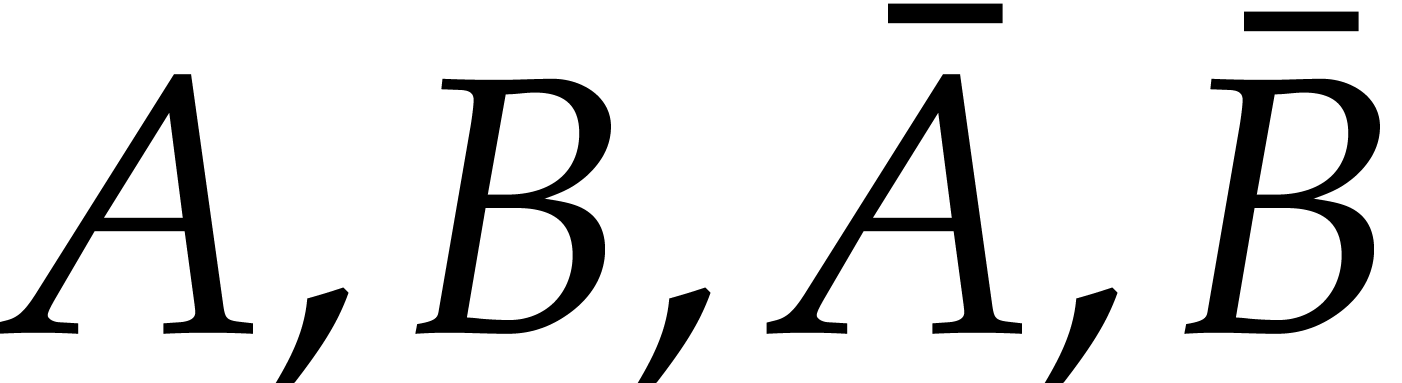 from and
from and  clearly takes linear time
, and so does the retrieval
of and
clearly takes linear time
, and so does the retrieval
of and  from . In other words, we have shown that
from . In other words, we have shown that
Step 2: CRT transforms. At a second stage, we use negacyclic
CRT transforms followed by traditional CRT transforms in order to reduce
multiplication in to multiplication in , where , , and
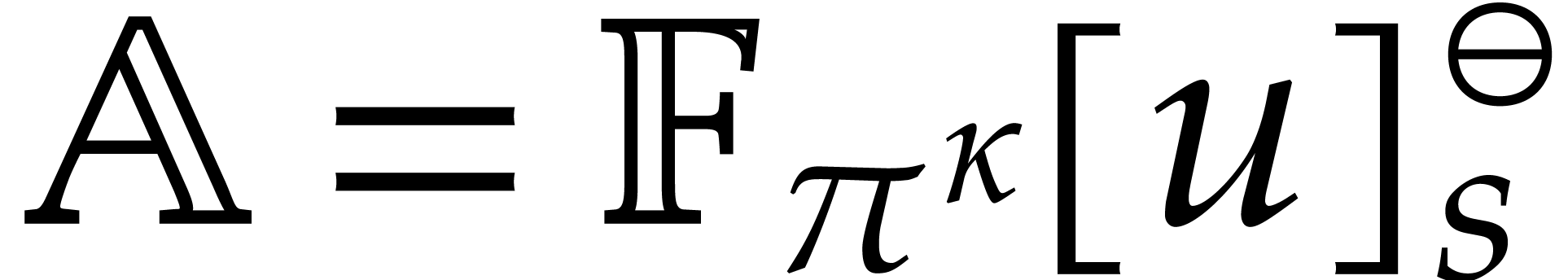 :
:
Since  , this yields
, this yields
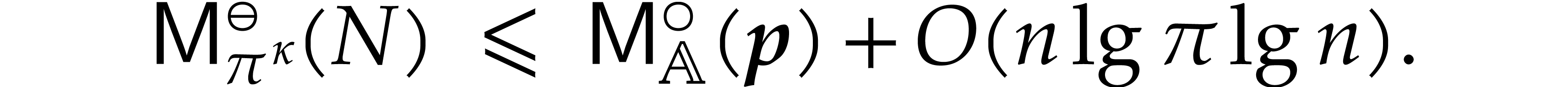
We perform the multivariate cyclic convolutions in
using fast Fourier multiplication, where the discrete Fourier transforms
are computed with respect to 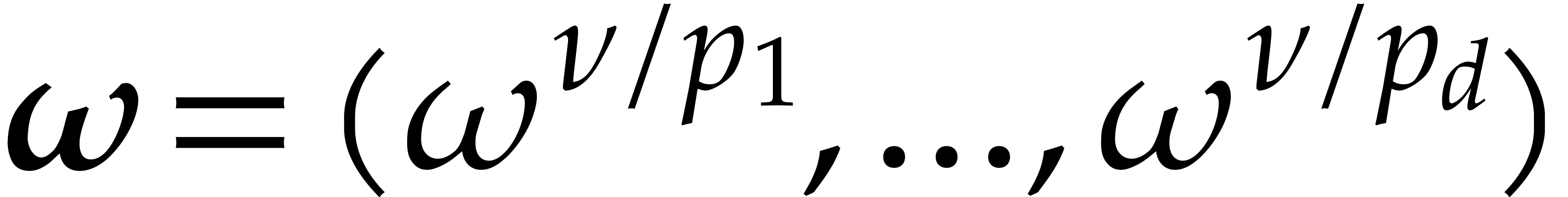 .
In view of (3.8) and
.
In view of (3.8) and
this yields
The reduction of a polynomial of degree  in modulo using Barrett's
algorithm [3] essentially requires two polynomial
multiplications in of degree , modulo the precomputation of a preinverse in
time
in modulo using Barrett's
algorithm [3] essentially requires two polynomial
multiplications in of degree , modulo the precomputation of a preinverse in
time 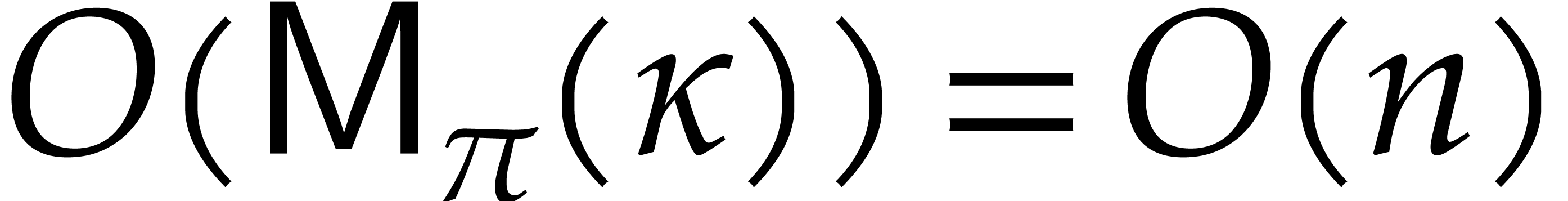 . Performing
multiplications in using Kronecker substitution,
we thus have
. Performing
multiplications in using Kronecker substitution,
we thus have
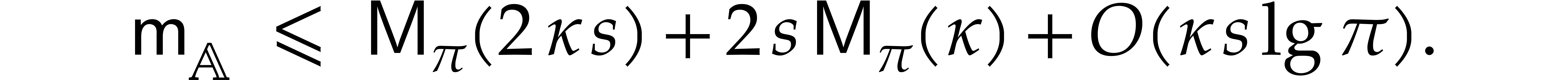
For sufficiently large , we
conclude that
Step 3: multivariate Rader reduction. We compute the
multivariate discrete Fourier transforms using Rader reduction. For each
, let
be such that if and if for . Then
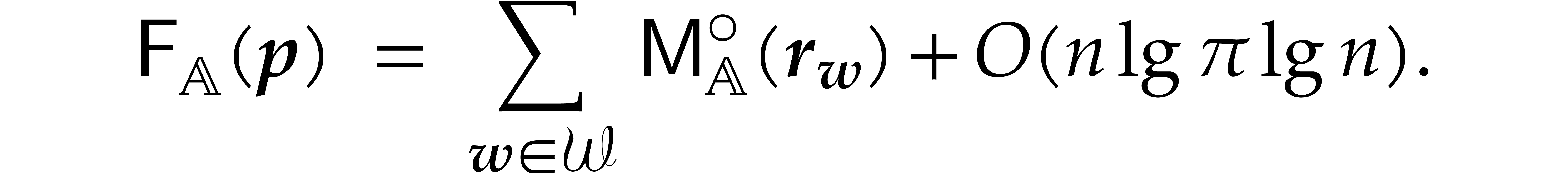
The necessary precomputations for each of the
Rader reductions can be performed over instead
of , in time
Now for any , we have . Performing multiplications in
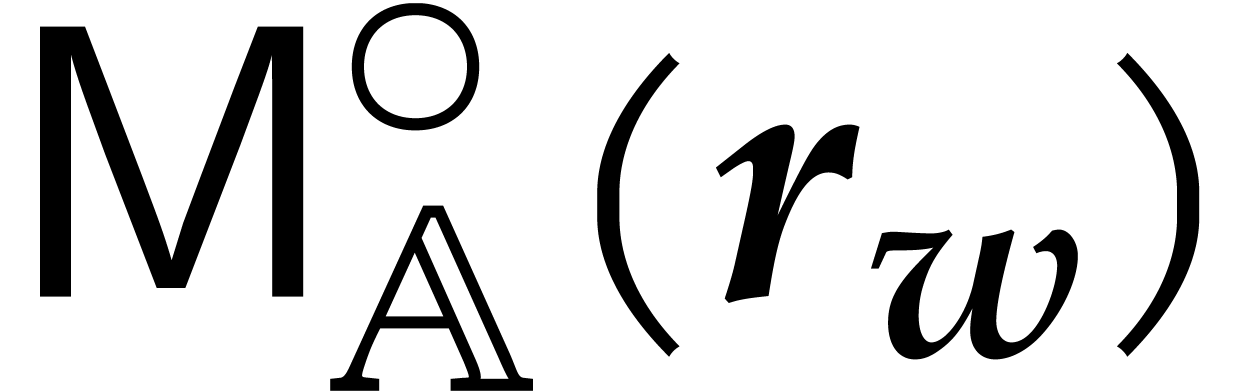 using -fold
Kronecker substitution and (1.6), this yields
using -fold
Kronecker substitution and (1.6), this yields
whence
Since , , and 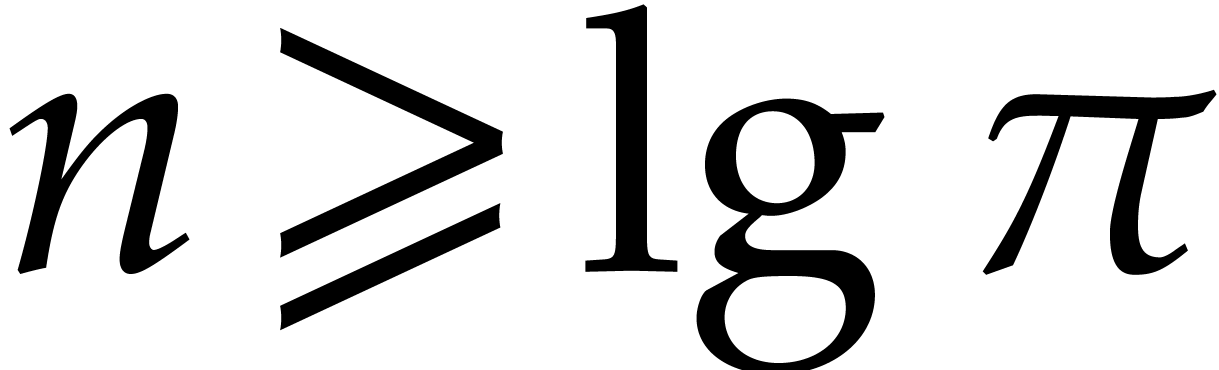 ,
the right hand side is bounded by ,
whence
,
the right hand side is bounded by ,
whence
Step 4: second CRT transforms. For , we may decompose ,
where is odd. Using multivariate CRT transforms,
this yields
Setting and ,
this relation can be rewritten as
Step 5: Nussbaumer polynomial transforms. Since , we have a fast root of unity
of order in and in . We may thus compute polycyclic
convolutions of order over
using fast Fourier multiplication, with Nussbaumer polynomial transforms
in the role of discrete Fourier transforms:
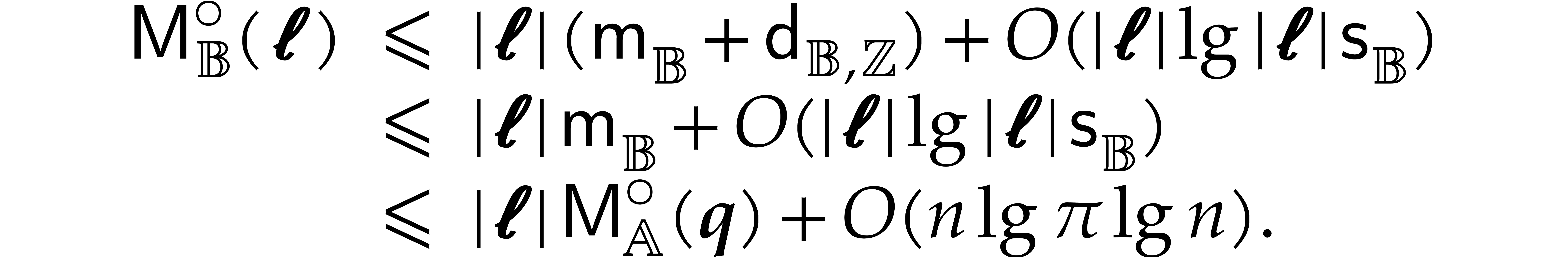
Step 6: residual cyclic convolutions. This time, we convert the
residual multivariate cyclic convolutions of length  back into univariate cyclic convolutions of length
back into univariate cyclic convolutions of length  using CRT transforms the other way around. This is possible since are pairwise coprime, and we get
using CRT transforms the other way around. This is possible since are pairwise coprime, and we get
whence
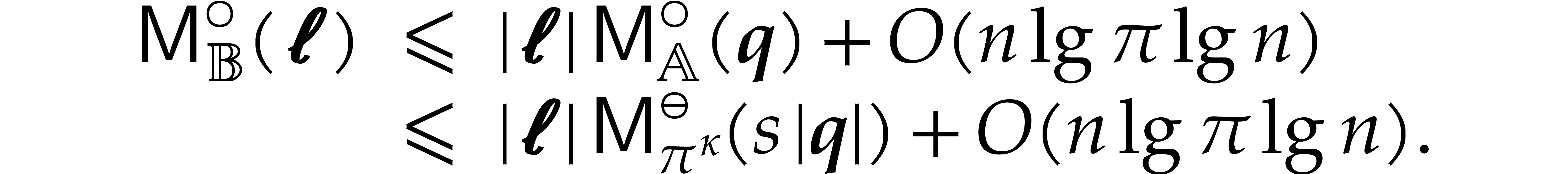
We perform the univariate cyclic products using Kronecker substitution.
Since reductions of polynomials in 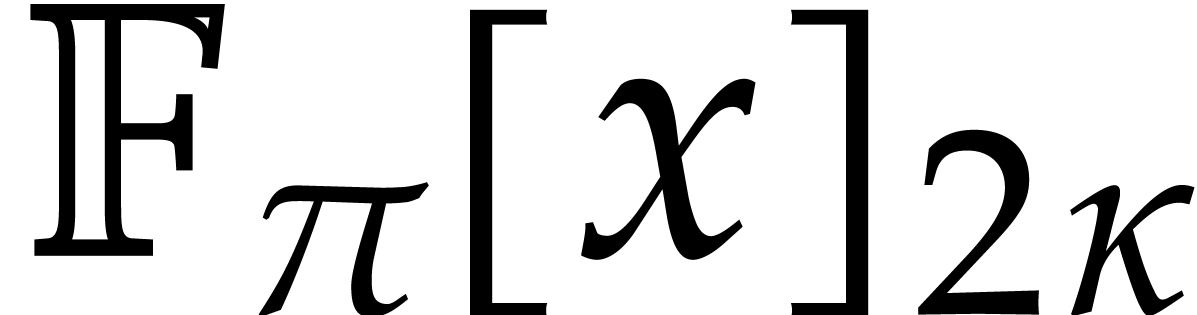 modulo can be done in time
modulo can be done in time 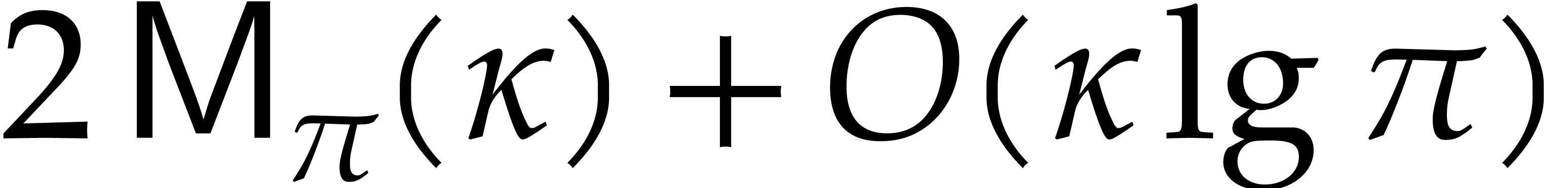 ,
this yields
,
this yields
Step 7: recurse. Combining the relations (7.1),
(7.2), (7.3), (7.4) and (7.5),
while using the fact that 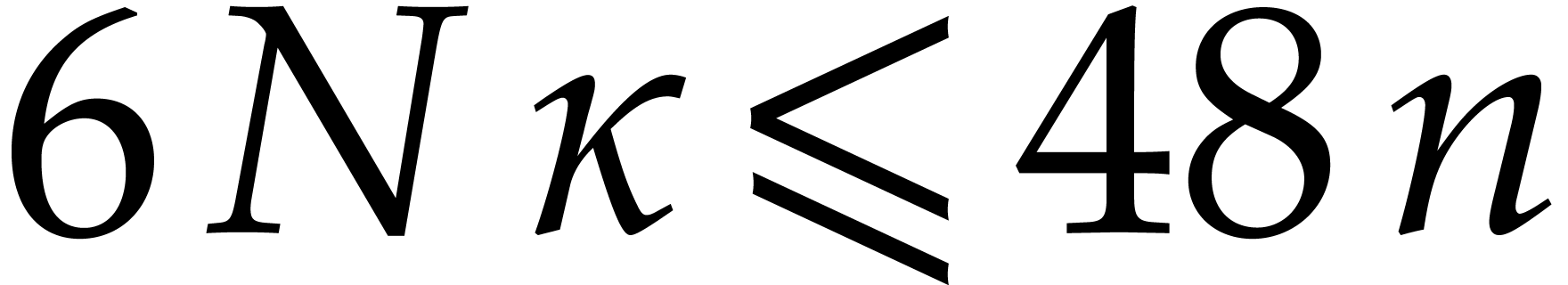 ,
we obtain
,
we obtain
In terms of the normalized cost function
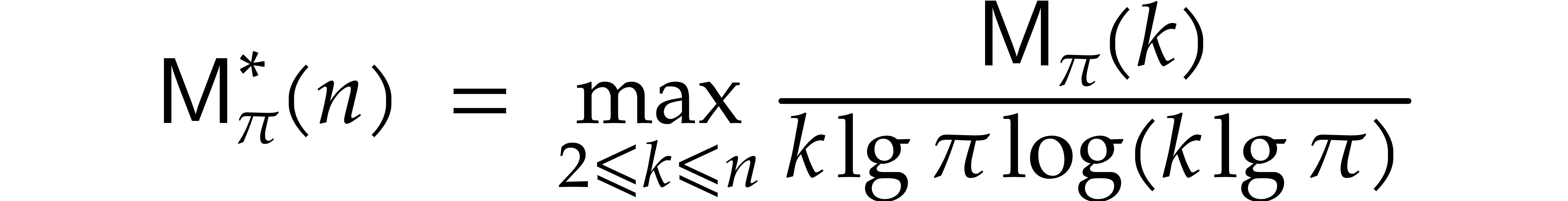
and  , this relation becomes
, this relation becomes
where we used the fact that  .
Recall that
.
Recall that 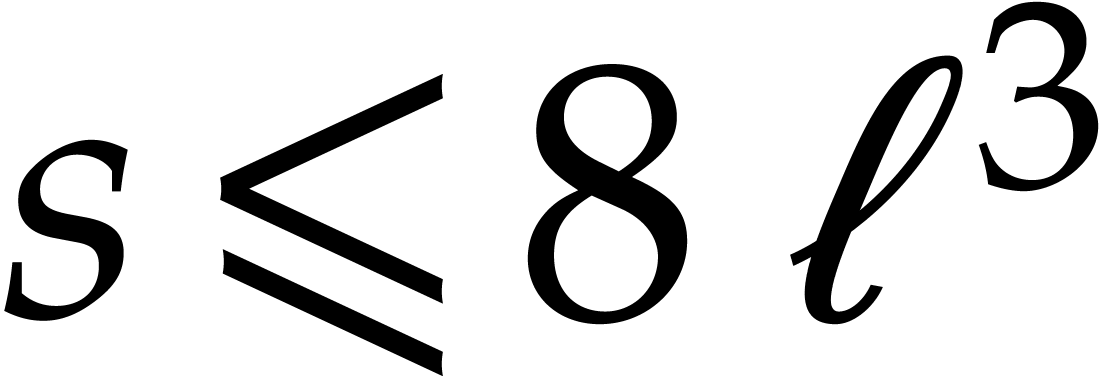 and
and  for
for
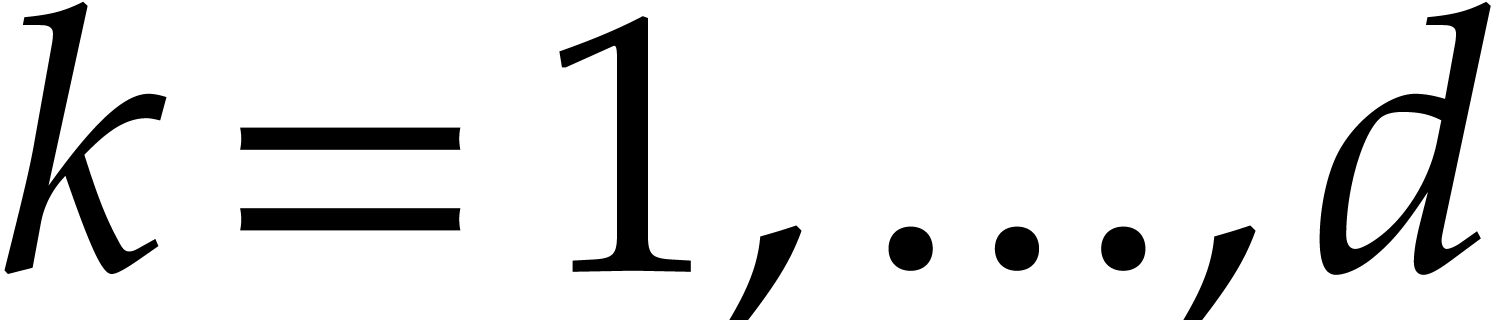 , whence
, whence 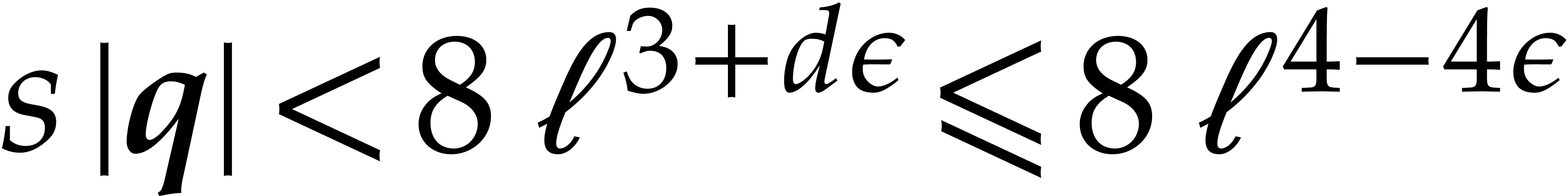 , whereas
, whereas 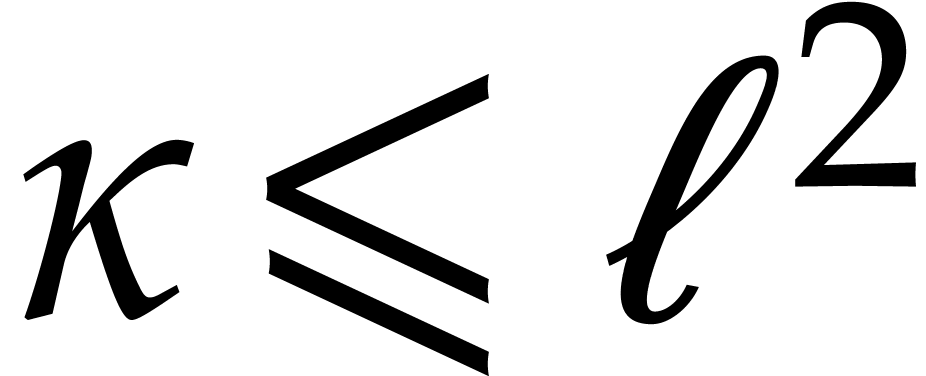 .
Consequently, for large , we
have
.
Consequently, for large , we
have
For some suitable universal constant ,
this yields
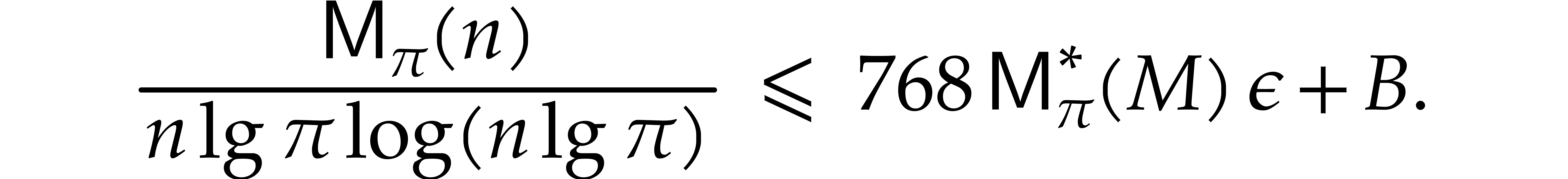
For sufficiently large , we
have 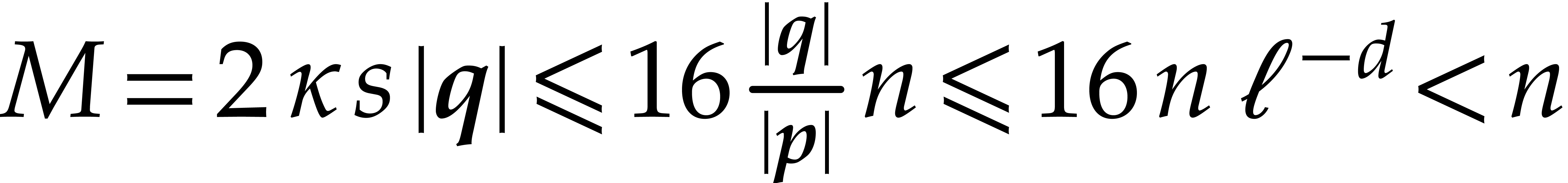 and
and  ,
whence
,
whence
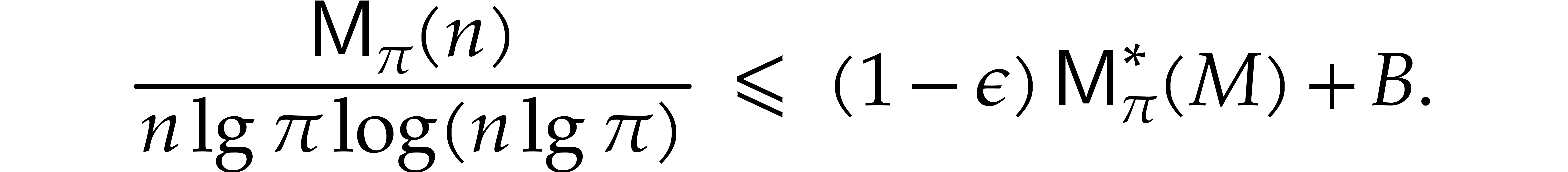
In a similar way as in the previous section, this implies 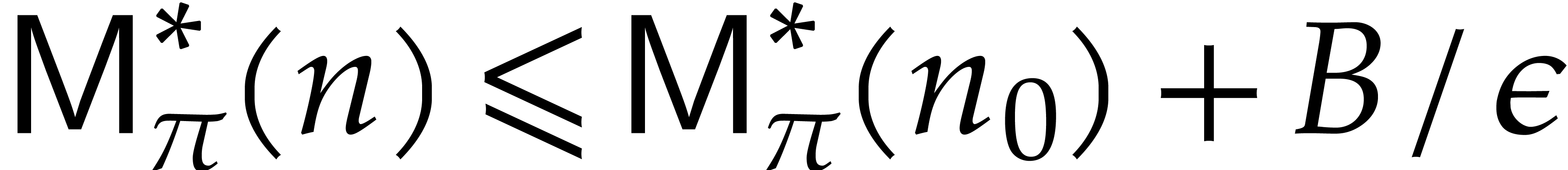 for all . Now
recall that Kronecker substitution and Theorem 1.1 imply
for all . Now
recall that Kronecker substitution and Theorem 1.1 imply
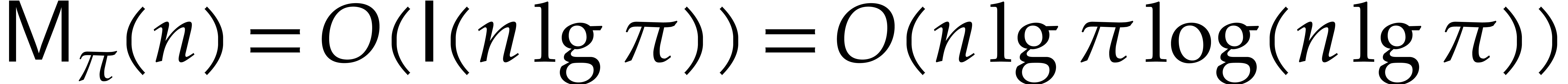 for all
for all 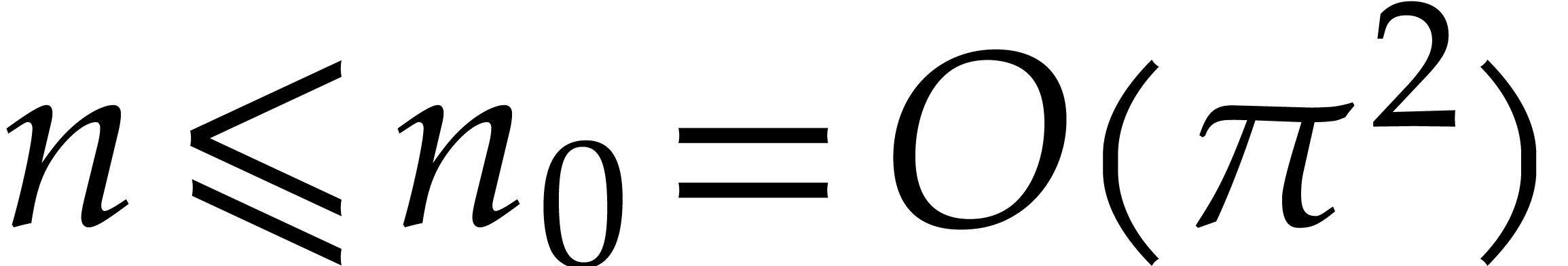 ,
whence
,
whence 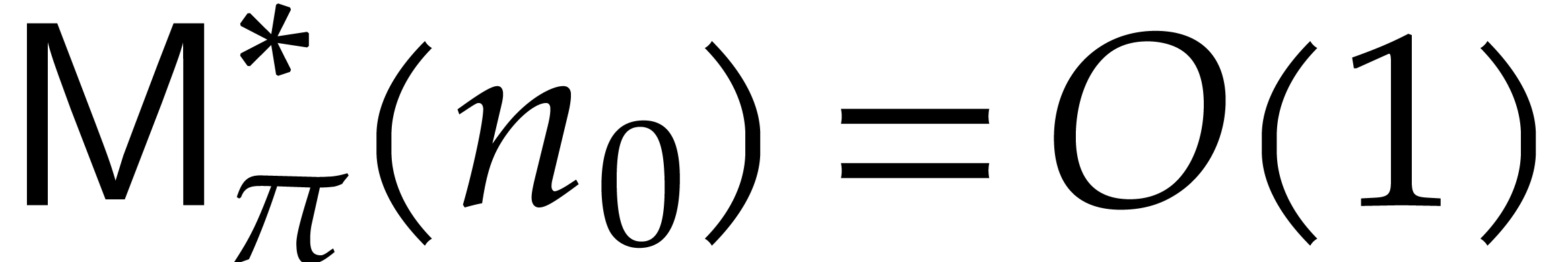 . We conclude that
. We conclude that
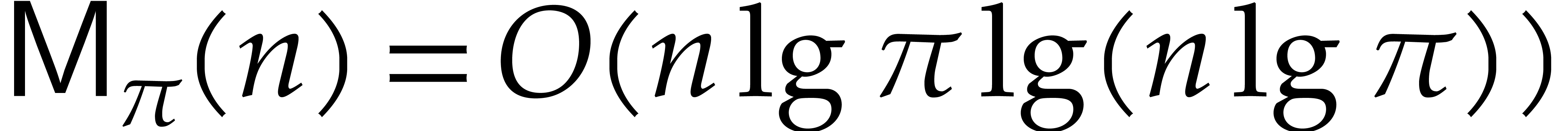 .
.
Remark is very pessimistic and mainly due to
the way we reduce the residual multivariate cyclic convolutions back to
univariate ones. Our assumption that the be
pairwise coprime clearly makes this back-reduction very easy.
Nevertheless, with more work, we expect that this assumption can
actually be released. We intend to come back to this issue in a separate
paper on the computation of multivariate cyclic convolution products.
The proof of Theorem 1.2 in the case when
is similar to the one from the previous section, with two important
changes:
Following Schönhage [48], we need to use triadic
DFTs instead of dyadic ones. In particular, 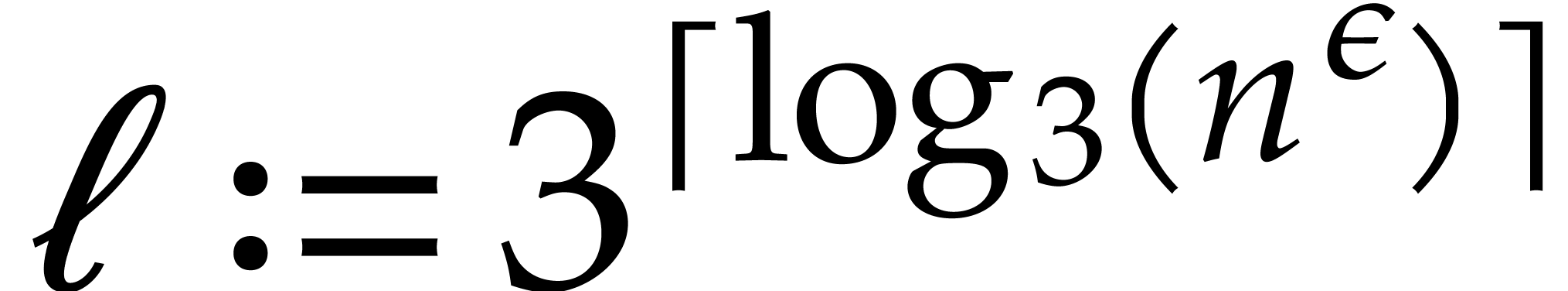 will now be a power of three.
will now be a power of three.
The transform lengths are unavoidably even.
This time, we will therefore have 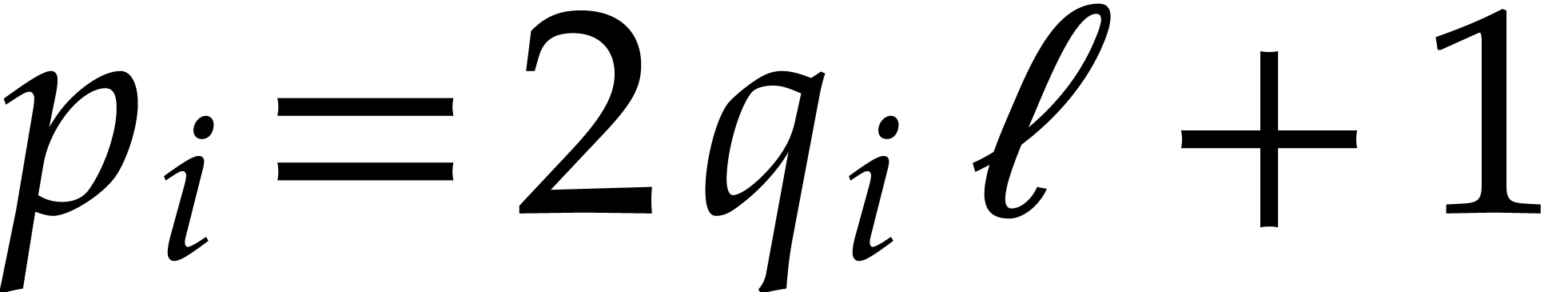 ,
where the are pairwise coprime. As a
consequence, we will need a separate mechanism to deal with residual
polycyclic convolution products of length in
each variable.
,
where the are pairwise coprime. As a
consequence, we will need a separate mechanism to deal with residual
polycyclic convolution products of length in
each variable.
Given a ring and an integer  , it will be convenient to define
, it will be convenient to define
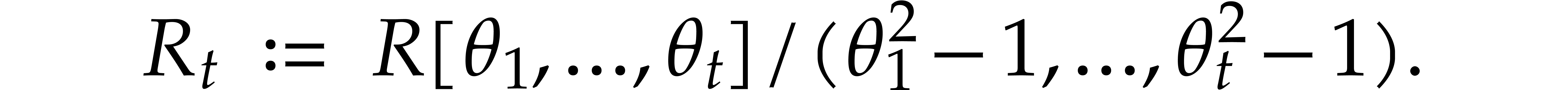
We will also use the abbreviations 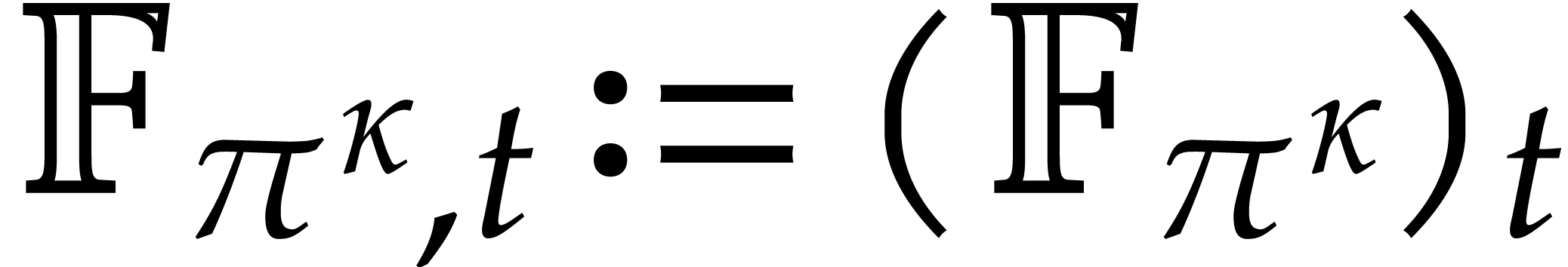 ,
,
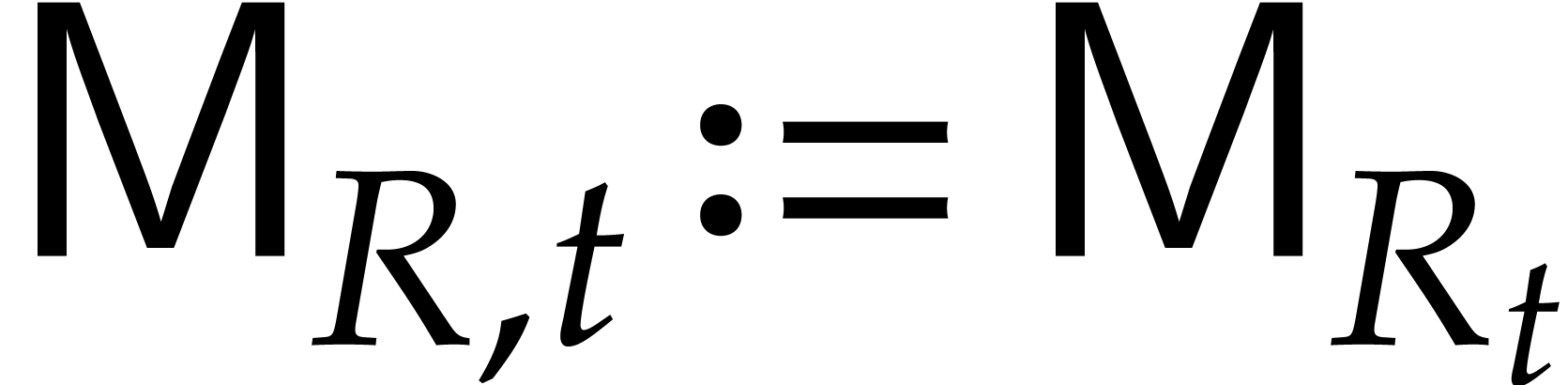 ,
, 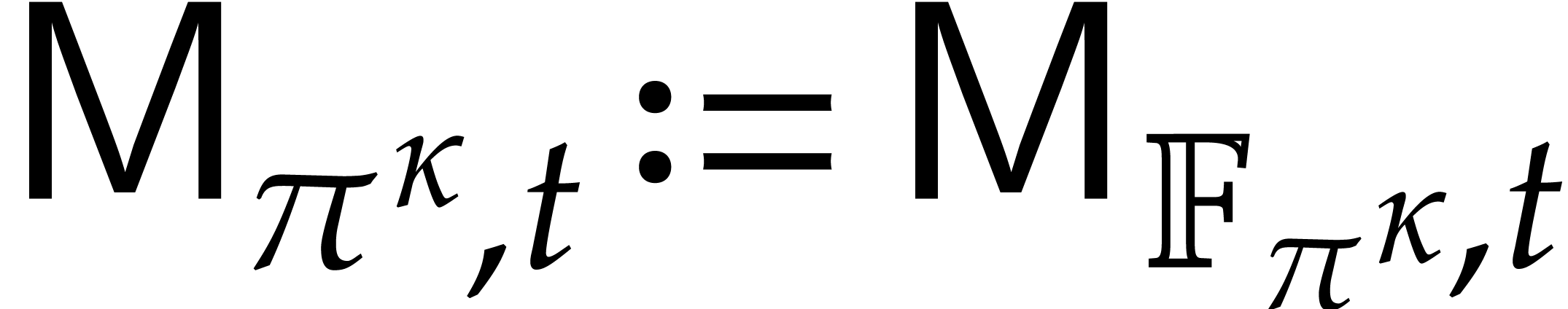 , and so on. Throughout this section, we assume that
is a Linnik constant with . Our algorithm proceeds as follows.
, and so on. Throughout this section, we assume that
is a Linnik constant with . Our algorithm proceeds as follows.
Step 0: setting up the parameters. Let
and assume that we wish to multiply two polynomials of degree in 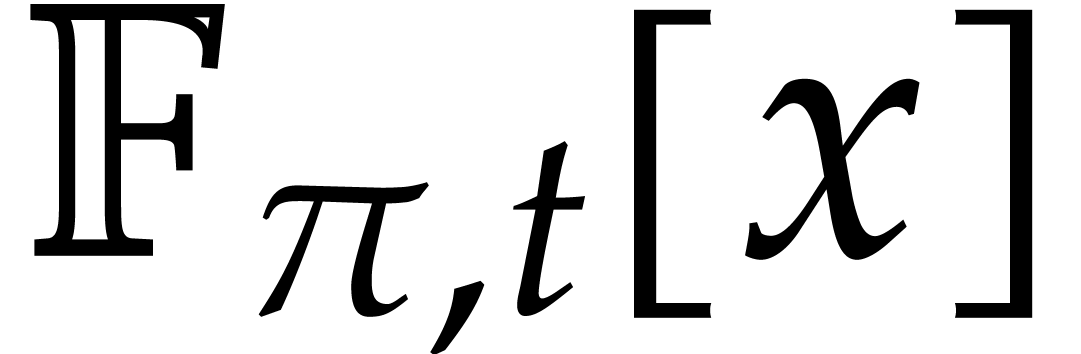 . For with
. For with 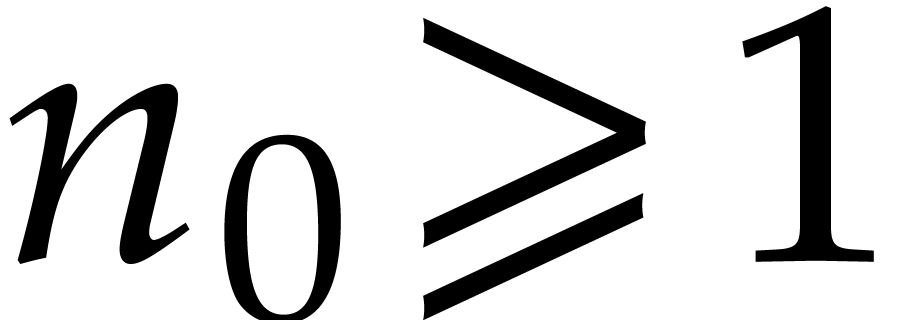 and suitable parameters
and ,
we will reduce this problem to a multiplication problem in
and suitable parameters
and ,
we will reduce this problem to a multiplication problem in 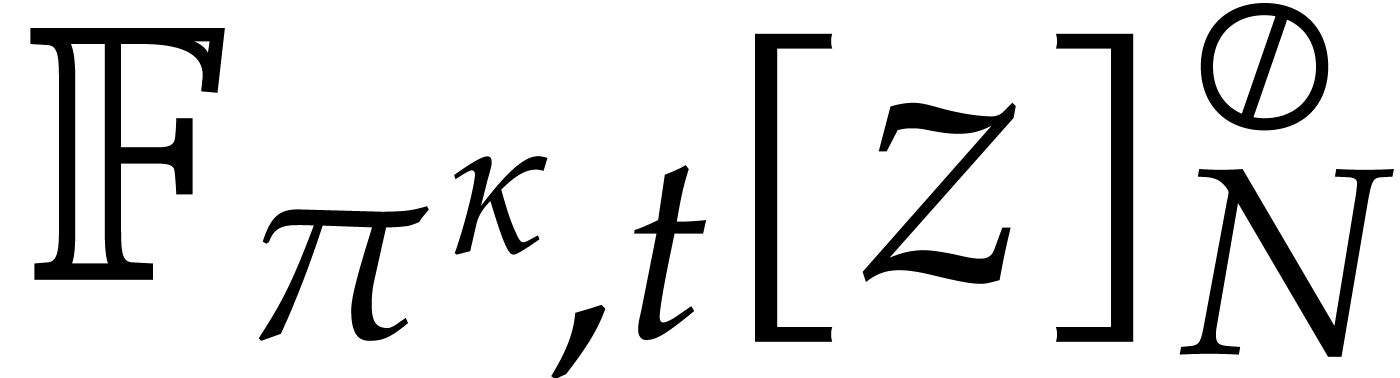 . If ,
then we use a naive multiplication algorithm. The threshold is a sufficiently large absolute constant such that
various asymptotic inequalities encountered during the proof hold for
all . The other parameters
are determined as follows:
. If ,
then we use a naive multiplication algorithm. The threshold is a sufficiently large absolute constant such that
various asymptotic inequalities encountered during the proof hold for
all . The other parameters
are determined as follows:
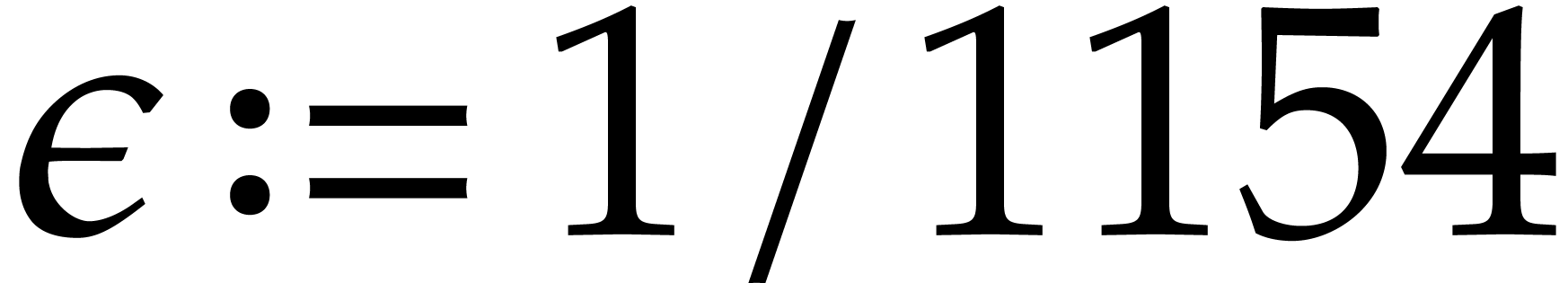 .
.
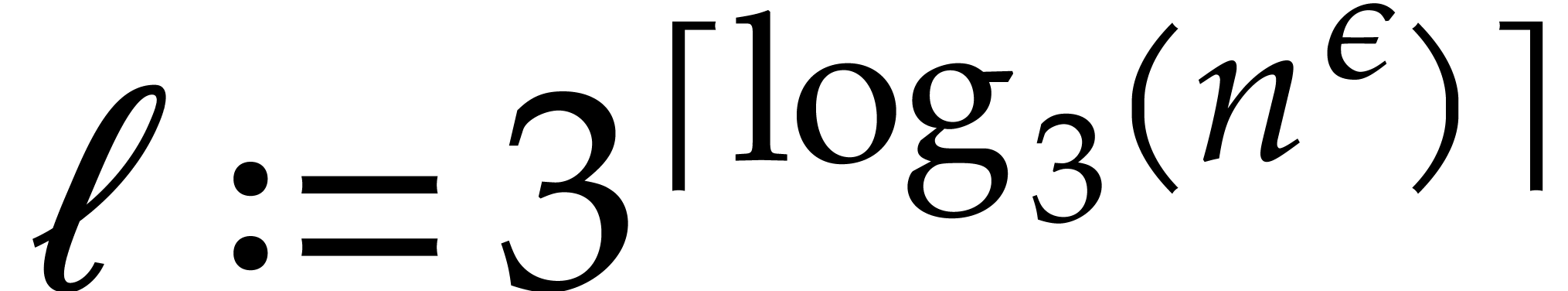 is the smallest power of three with .
is the smallest power of three with .
With the notations from section 5.3 and for each , let 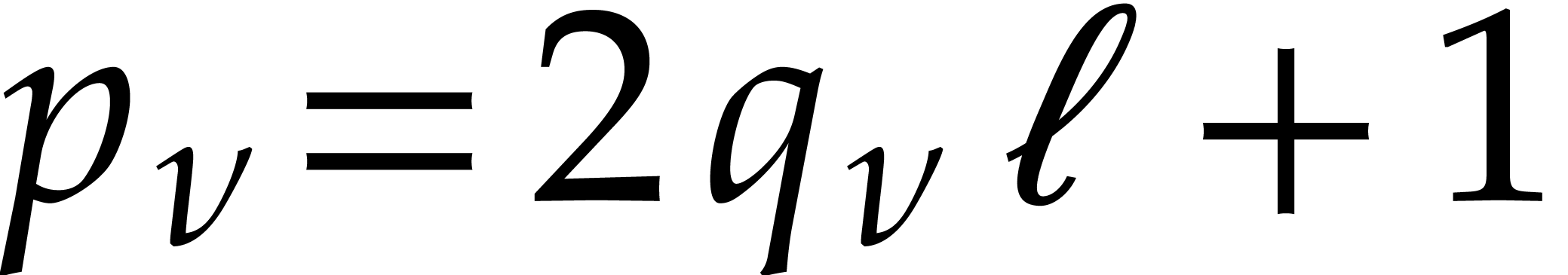 be the -th element in the
list
be the -th element in the
list  with
with 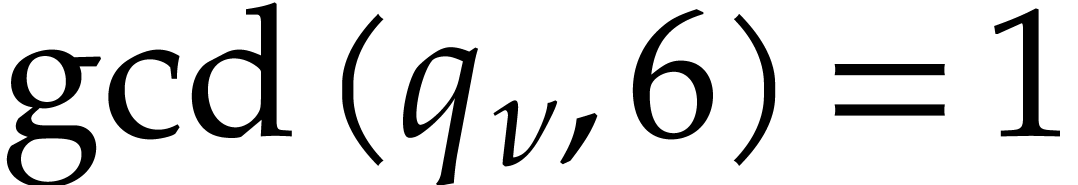 .
.
.
.
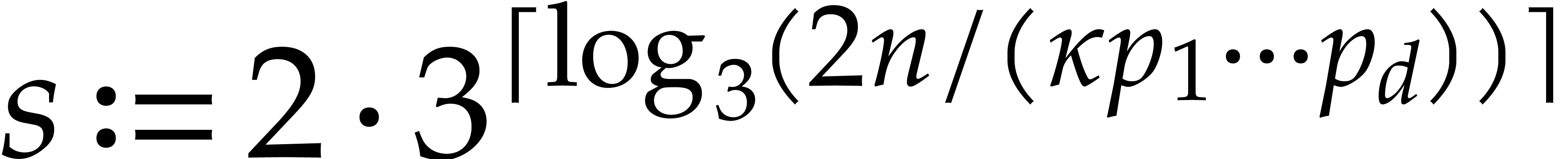 is smallest in
is smallest in 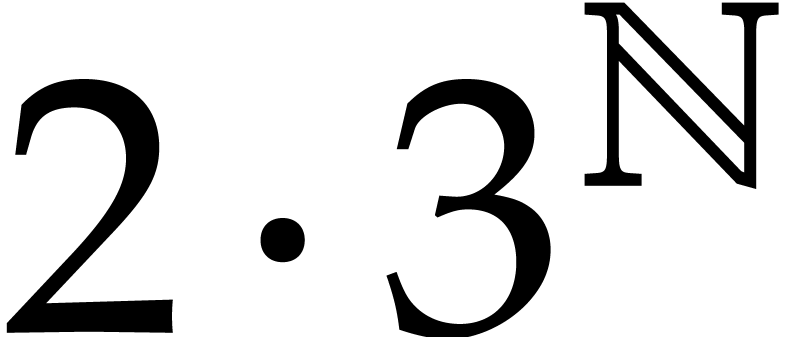 with
with
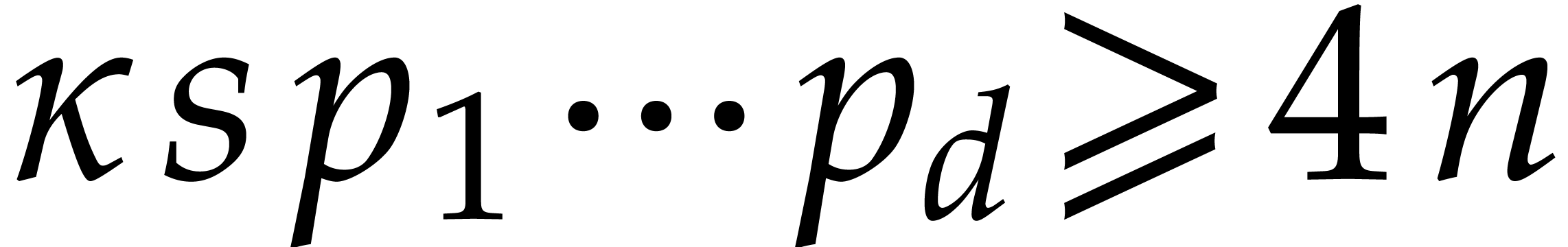 .
.
.
Since 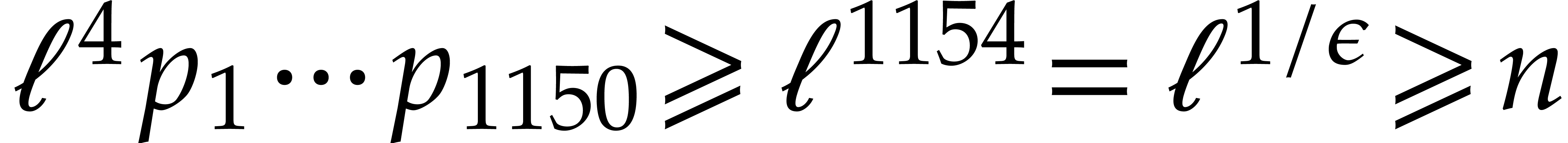 , we must have
, we must have 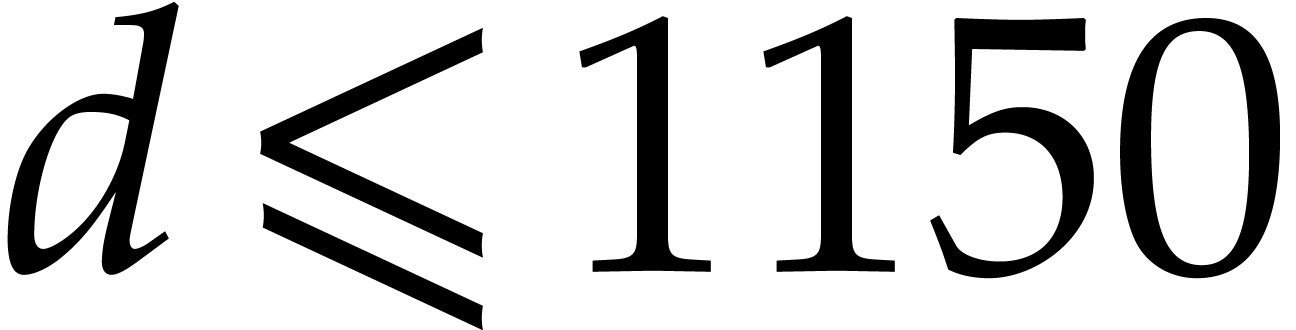 . From Lemma 5.4, we
get
. From Lemma 5.4, we
get
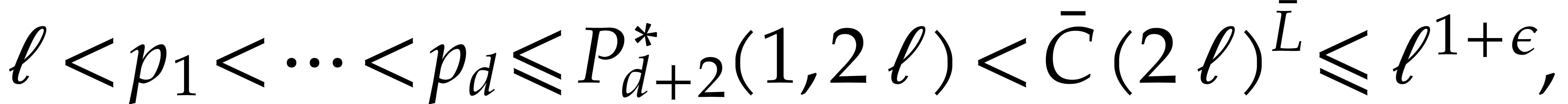
for sufficiently large ,
where
and is a constant. As before, the prime numbers
and the rest of the parameters can be computed
in linear time . Let us
proceed with a few useful bounds that hold for sufficiently large . From the definitions of and , we
clearly have
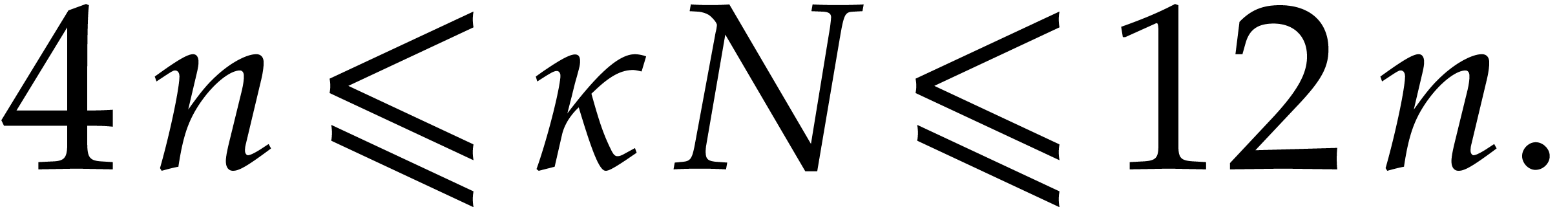
From and 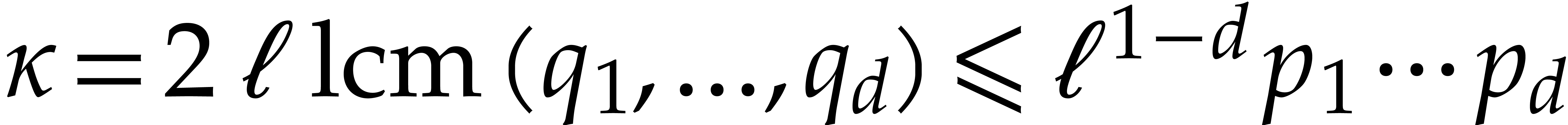 ,
we get
,
we get
and
Step 0, continued: setting up the FFT field. As in the previous
section, setting , the
defining polynomial for
and a primitive -th root of
unity can both be computed in time .
Step 1: Kronecker segmentation. Recall that . In order to multiply two polynomials 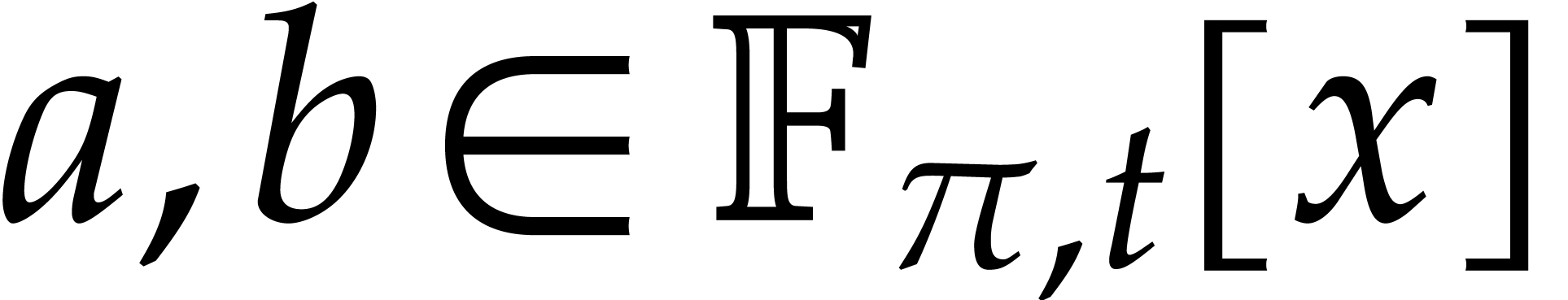 of degree ,
we cut them in chunks
of degree ,
we cut them in chunks 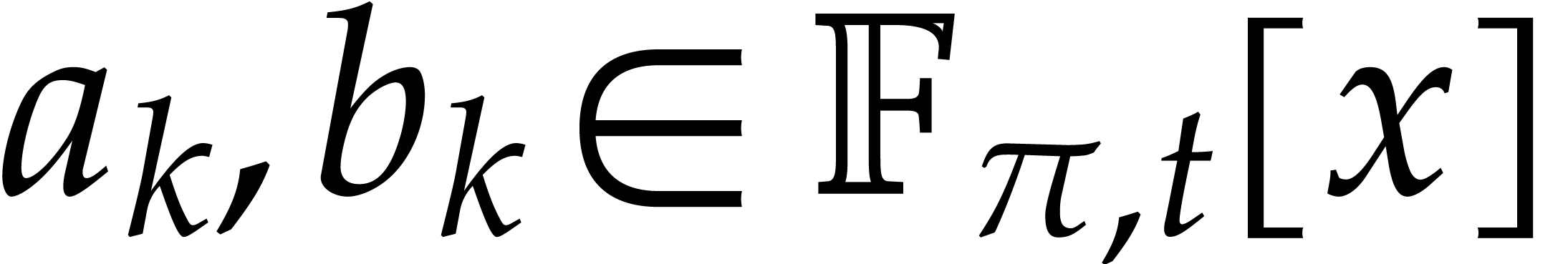 of degree , i.e.
of degree , i.e.
and form the polynomials
Let 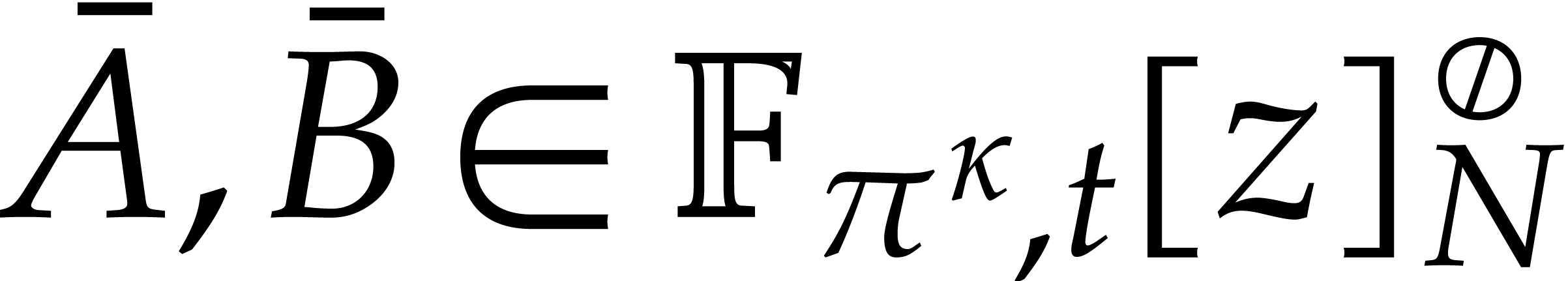 be the reductions of these polynomials
modulo and
be the reductions of these polynomials
modulo and  .
Since and ,
we can read off the product from the product
, after which . Computing from and clearly takes linear time
.
Since and ,
we can read off the product from the product
, after which . Computing from and clearly takes linear time
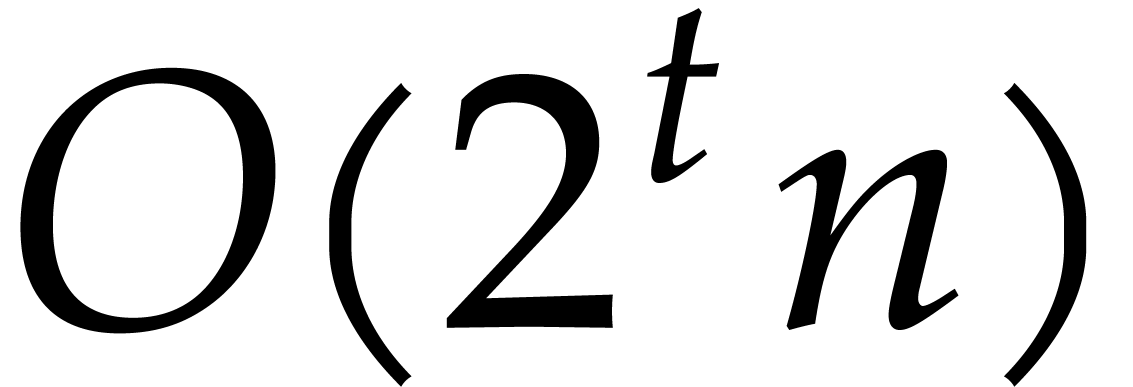 , and so does the retrieval
of and from . In other words, we have shown that
, and so does the retrieval
of and from . In other words, we have shown that
Step 2: CRT transforms. At a second stage, we use tricyclic CRT
transforms followed by traditional CRT transforms in order to reduce
multiplication in to multiplication in 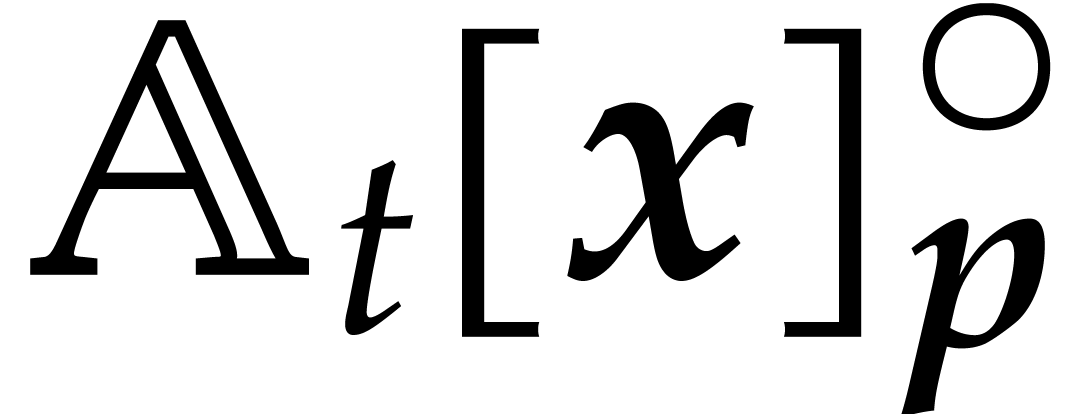 , where , , and
, where , , and
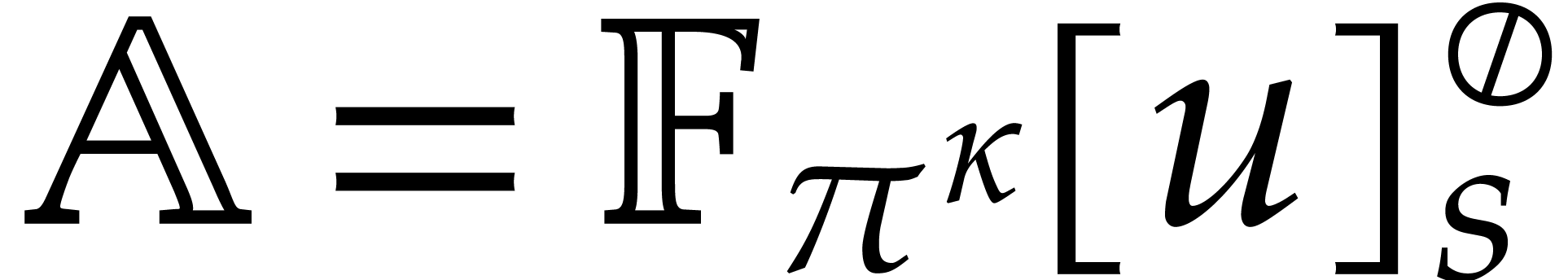 :
:
Since  , this yields
, this yields
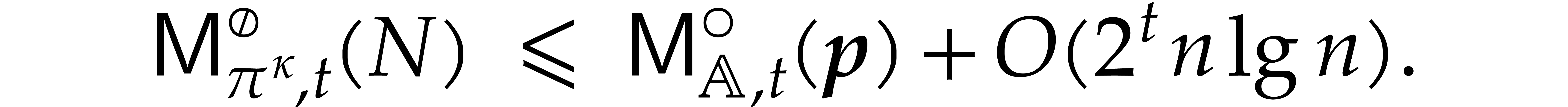
We perform the multivariate cyclic convolutions in
using fast Fourier multiplication, where the discrete Fourier transforms
are computed with respect to .
Since the only possible divisions of elements in
by integers are divisions by one, they come for free, so (3.8)
yields
The multivariate DFTs can be performed on the 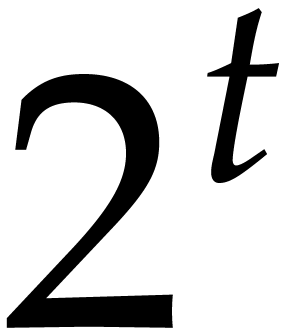 coefficients over in parallel:
coefficients over in parallel:
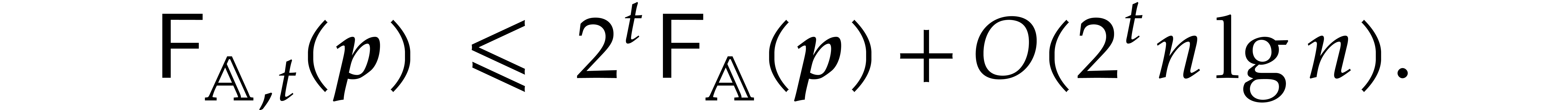
The reduction of a polynomial of degree in modulo using Barrett's
algorithm [3] essentially requires two polynomial
multiplications in of degree , modulo the precomputation of a preinverse in
time . Performing
multiplications in  using Kronecker substitution,
we thus have
using Kronecker substitution,
we thus have
For sufficiently large , we
conclude that
Step 3: multivariate Rader reduction. This step is essentially
the same as in section 7; setting 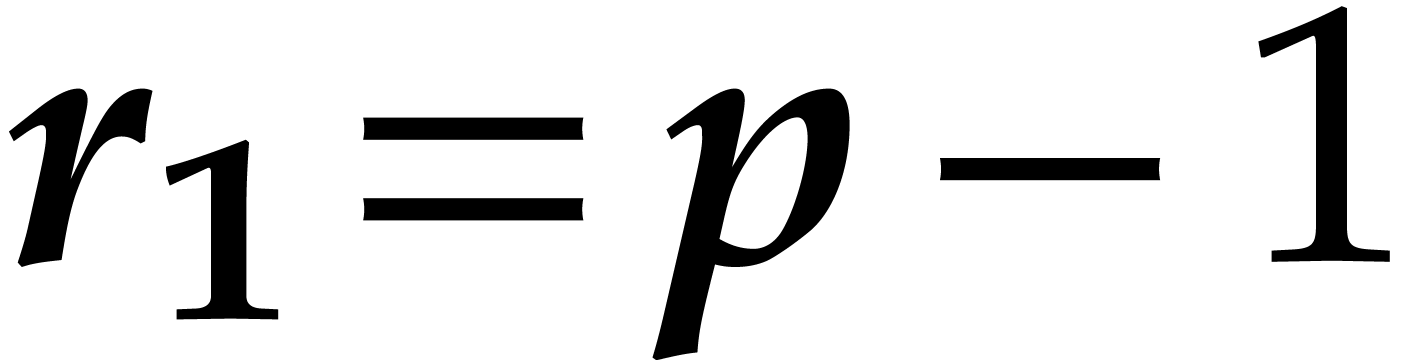 , we obtain the bound
, we obtain the bound
Step 4: second CRT transforms. For , we may decompose 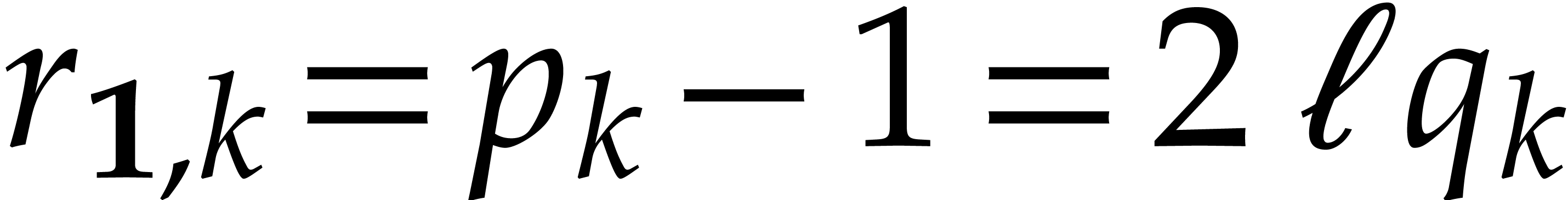 ,
where is coprime with
,
where is coprime with  . Using multivariate CRT transforms, this yields
. Using multivariate CRT transforms, this yields
Setting 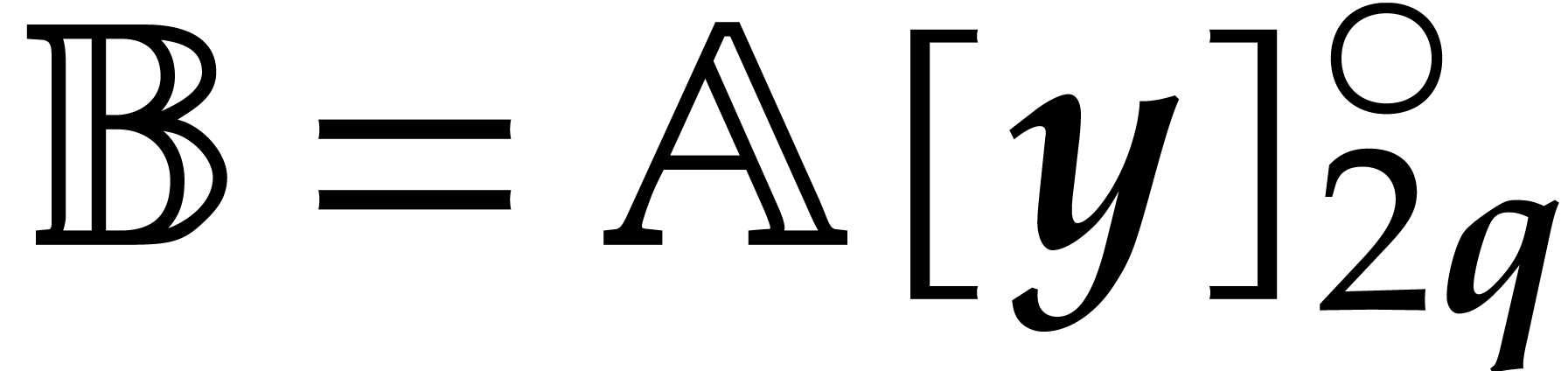 and ,
this relation can be rewritten as
and ,
this relation can be rewritten as
Step 5: Nussbaumer polynomial transforms. Since  , we have a fast root of unity
, we have a fast root of unity  of order in and in . We may thus compute polycyclic
convolutions of order over
using fast Fourier multiplication, with triadic Nussbaumer polynomial
transforms in the role of discrete Fourier transforms. Using that
divisions by integers are again for free in , this yields
of order in and in . We may thus compute polycyclic
convolutions of order over
using fast Fourier multiplication, with triadic Nussbaumer polynomial
transforms in the role of discrete Fourier transforms. Using that
divisions by integers are again for free in , this yields
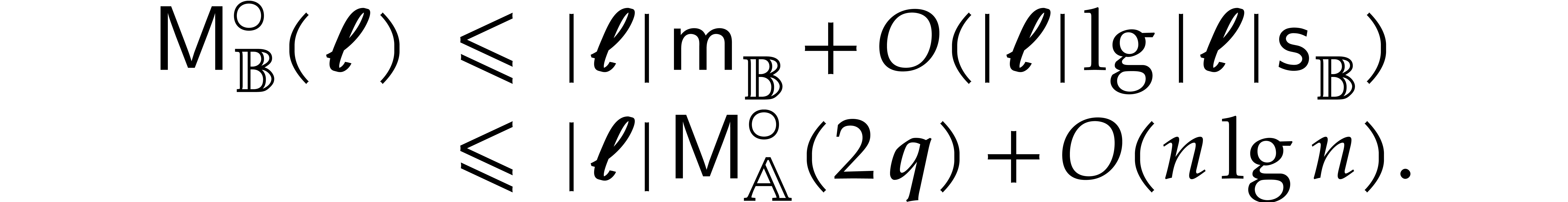
Step 6: residual cyclic convolutions. Using CRT transforms, the
residual multivariate cyclic convolutions of length  are successively transformed into multivariate cyclic convolutions of
lengths
are successively transformed into multivariate cyclic convolutions of
lengths 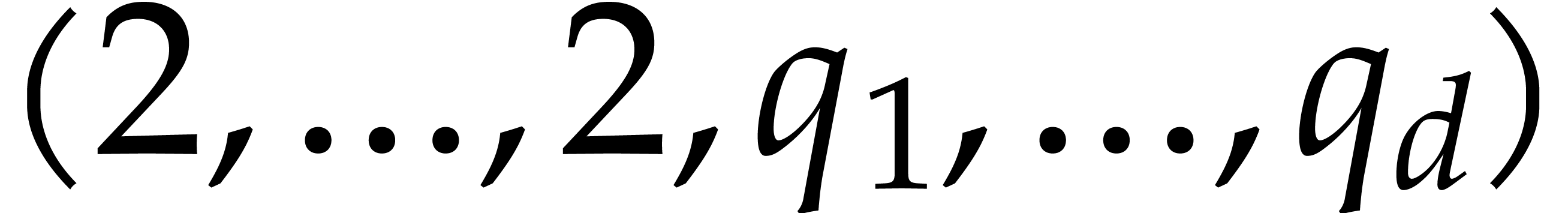 and then
and then 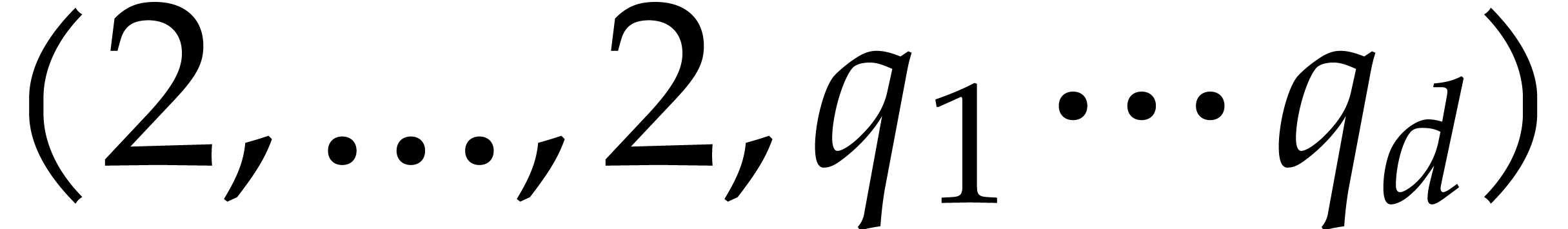 .
Using that are pairwise coprime, we get
.
Using that are pairwise coprime, we get
whence
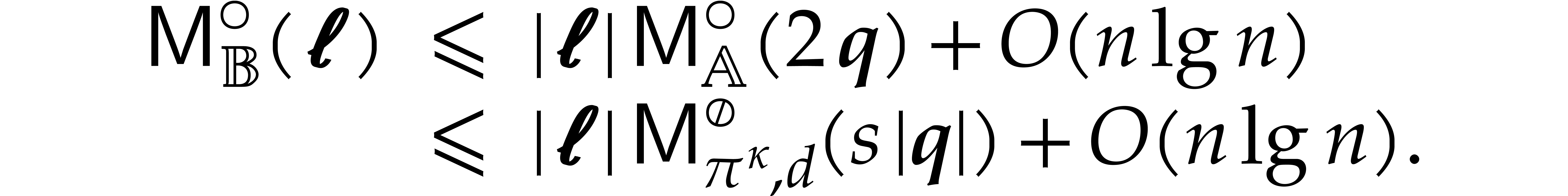
We perform the univariate cyclic products using Kronecker substitution.
Since reductions of polynomials in modulo can be done in time 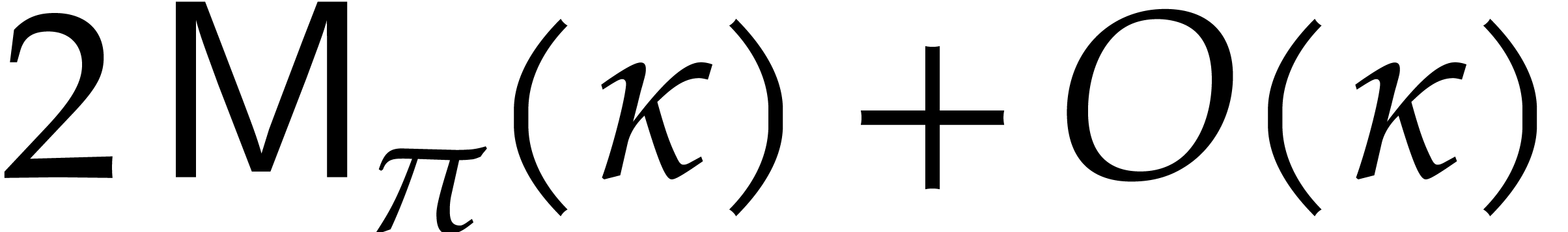 ,
this yields
,
this yields
Step 7: recurse. Combining the relations (8.1),
(8.2), (8.3), (8.4) and (8.5),
while using the fact that 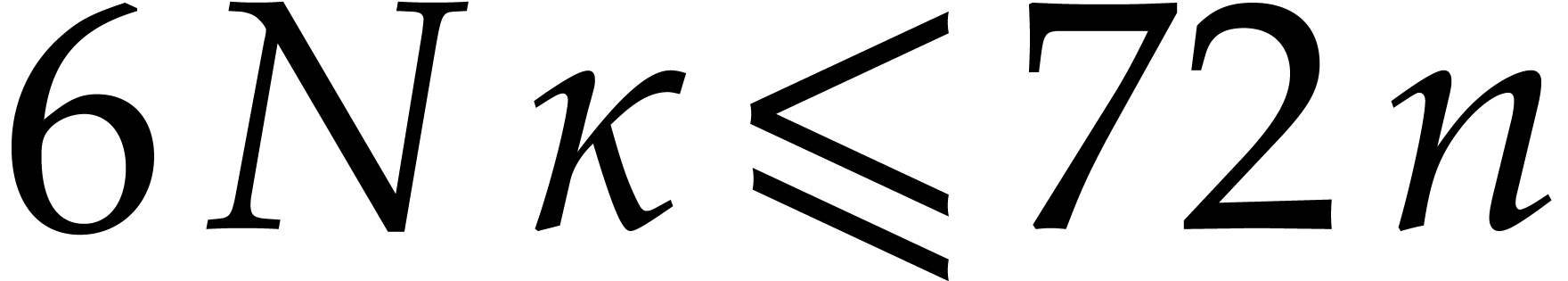 ,
we obtain
,
we obtain
In terms of the normalized cost functions
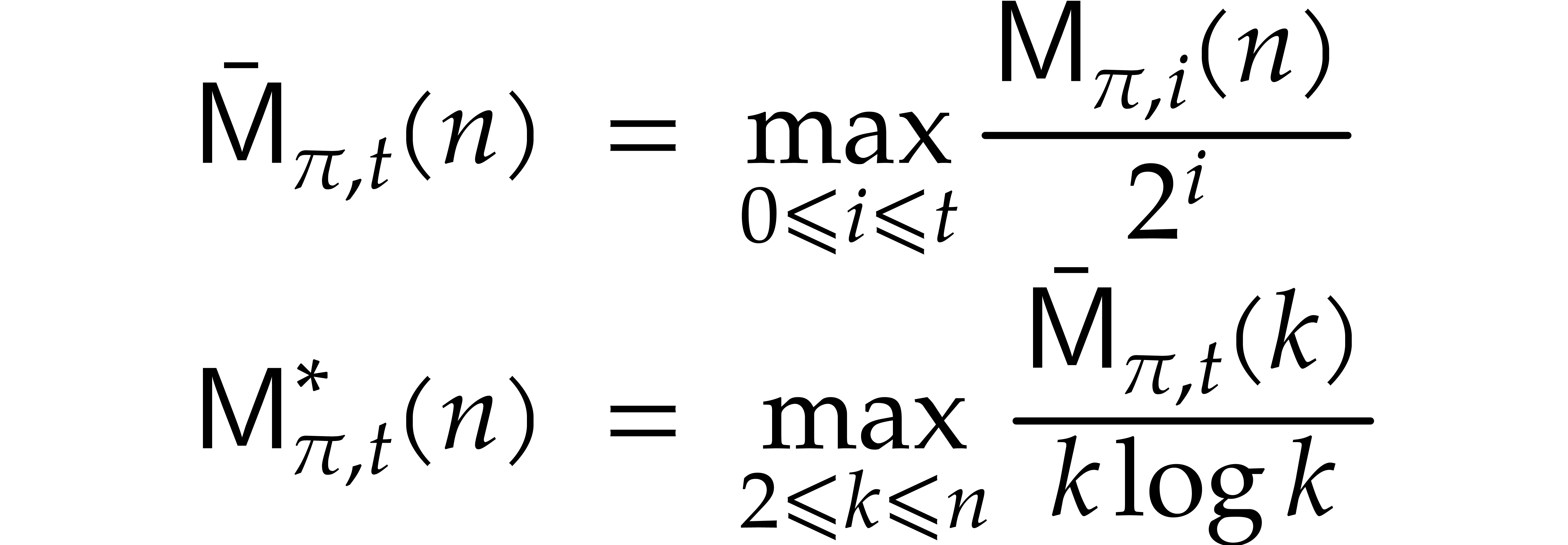
and , the above relation
implies
where we used the fact that 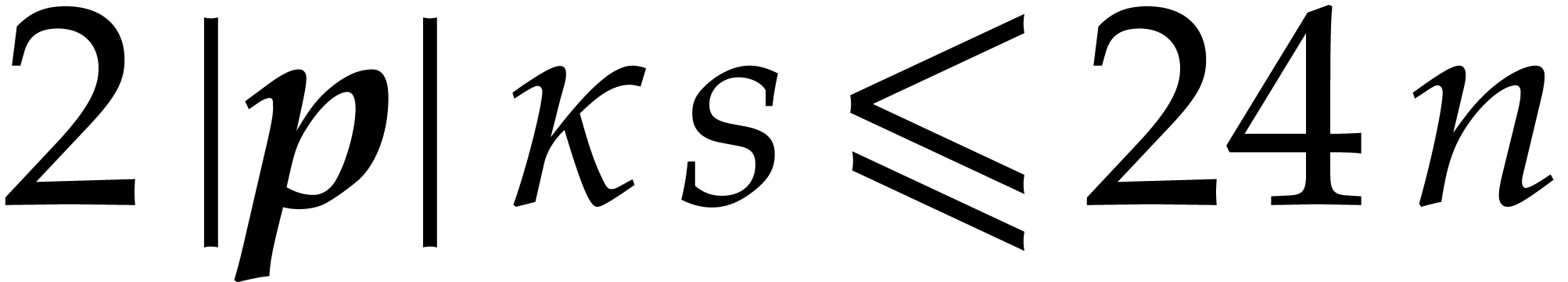 .
Taking
.
Taking  , so that
, so that 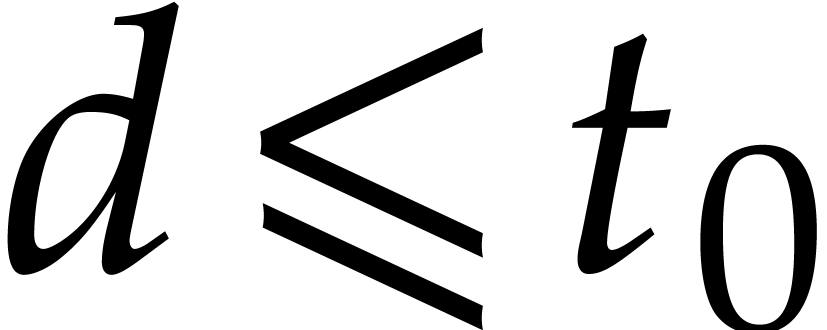 , this yields
, this yields
Recall that 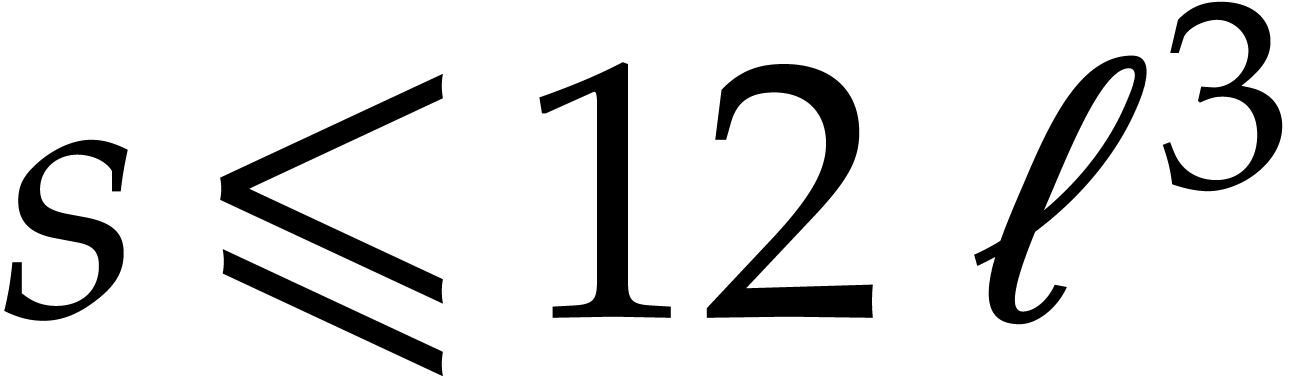 and for
, whence
and for
, whence 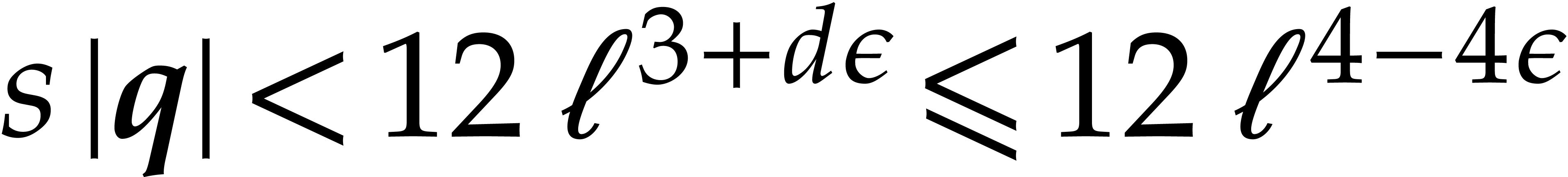 , whereas .
Consequently,
, whereas .
Consequently,
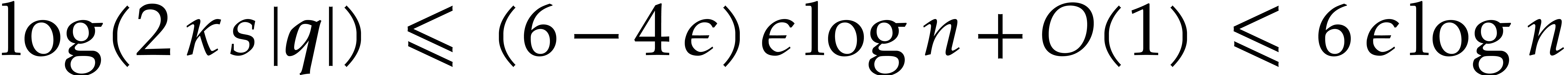
for large . For some suitable
universal constant , this
yields
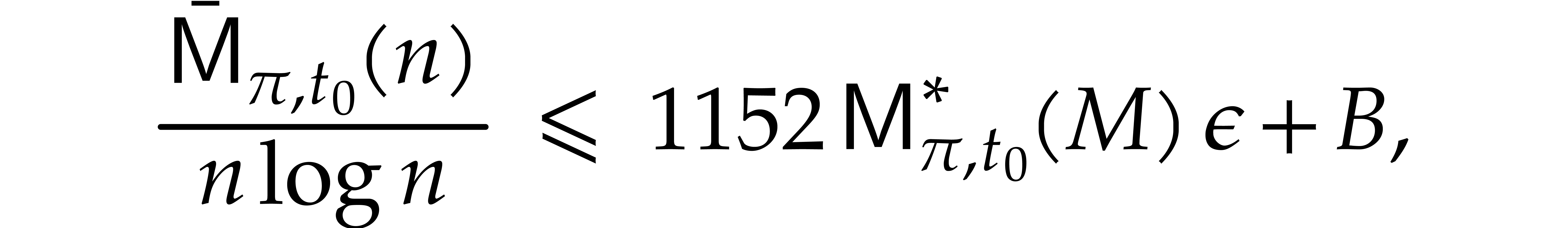
For sufficiently large , we
have 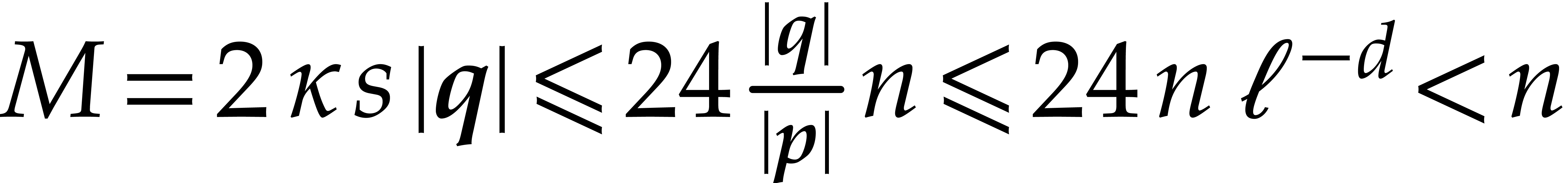 and
and 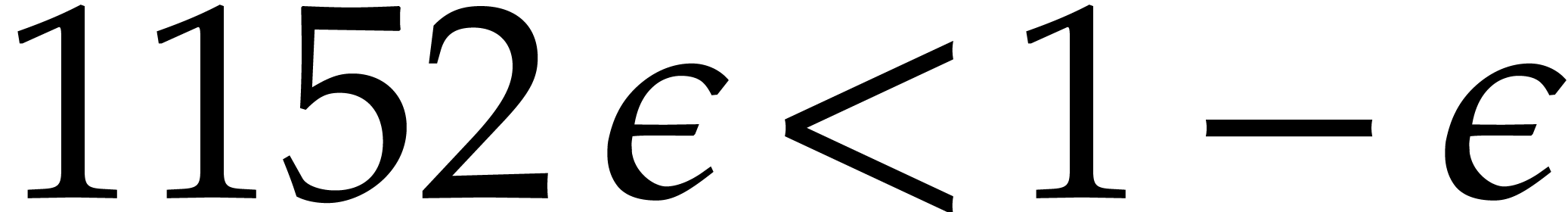 ,
whence
,
whence
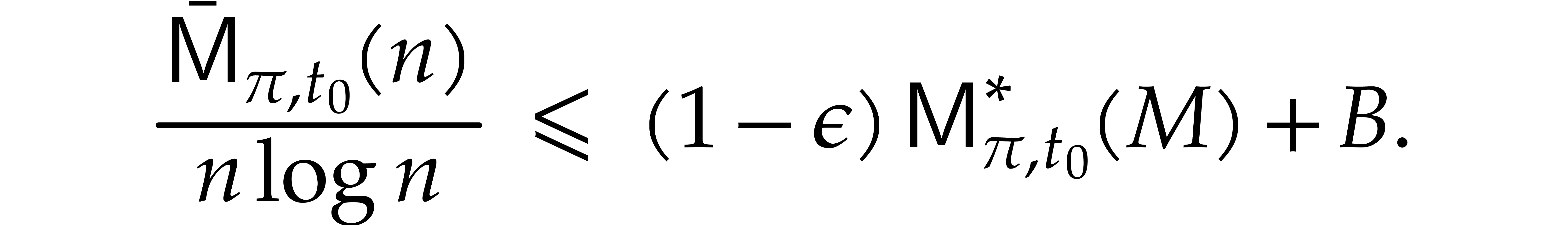
In a similar way as in the previous sections, this implies 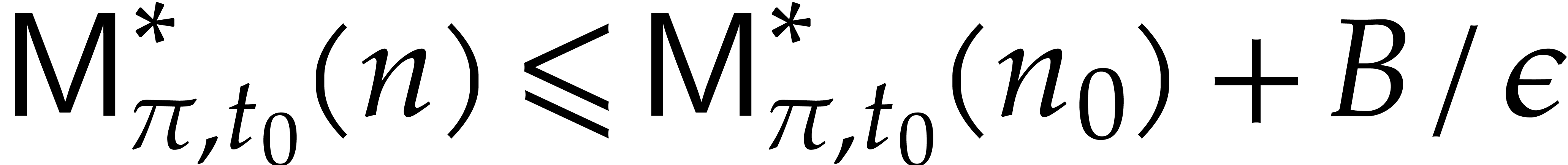 for all ,
whence
for all ,
whence  .
.
Remark  is bounded in
our proof, we can pay ourselves the luxury to use a naive algorithm for
polynomial multiplications over
is bounded in
our proof, we can pay ourselves the luxury to use a naive algorithm for
polynomial multiplications over 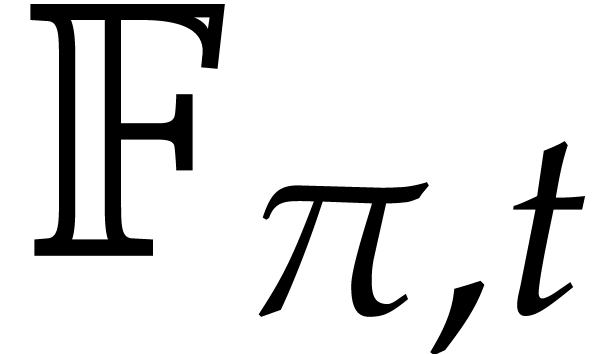 of bounded
degree
of bounded
degree 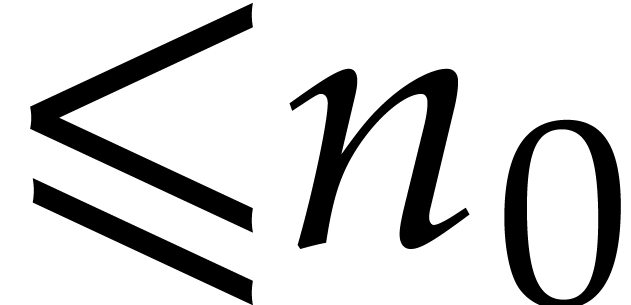 . It is an interesting
question how to do such multiplications more efficiently. First of all,
we notice that
. It is an interesting
question how to do such multiplications more efficiently. First of all,
we notice that
via the the change of variables  .
The bound (3.2) implies that this change of variables can
be performed in time
.
The bound (3.2) implies that this change of variables can
be performed in time 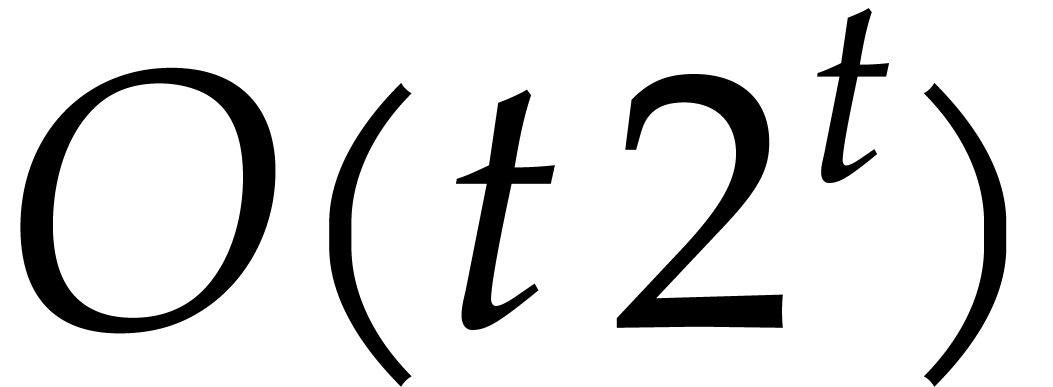 . In [50], Schost designed an efficient algorithm for multiplication
in the truncated power series ring
. In [50], Schost designed an efficient algorithm for multiplication
in the truncated power series ring 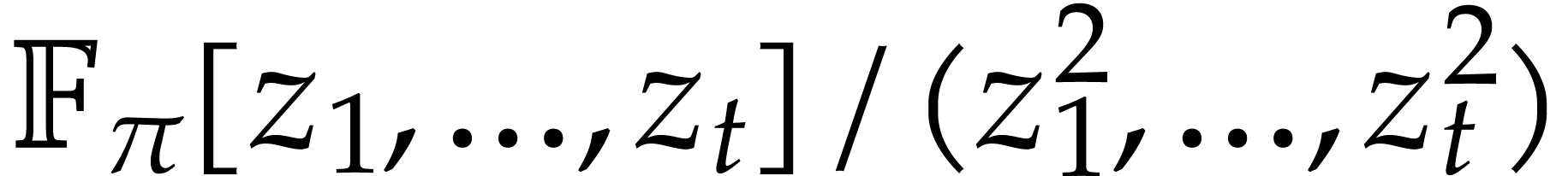 .
The idea is to embed this ring inside
.
The idea is to embed this ring inside
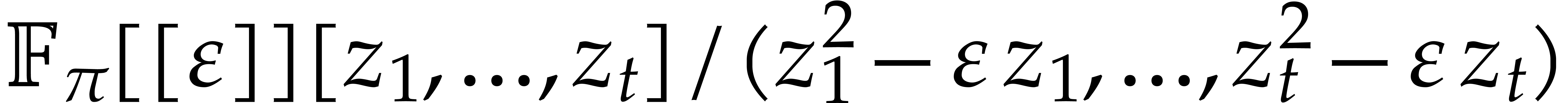
and then to use multipoint evaluation and interpolation at  . It turns out that it suffices to compute with
series of precision
. It turns out that it suffices to compute with
series of precision  in order to obtain the
desired product. Altogether, this leads to an algorithm of bit
complexity
in order to obtain the
desired product. Altogether, this leads to an algorithm of bit
complexity 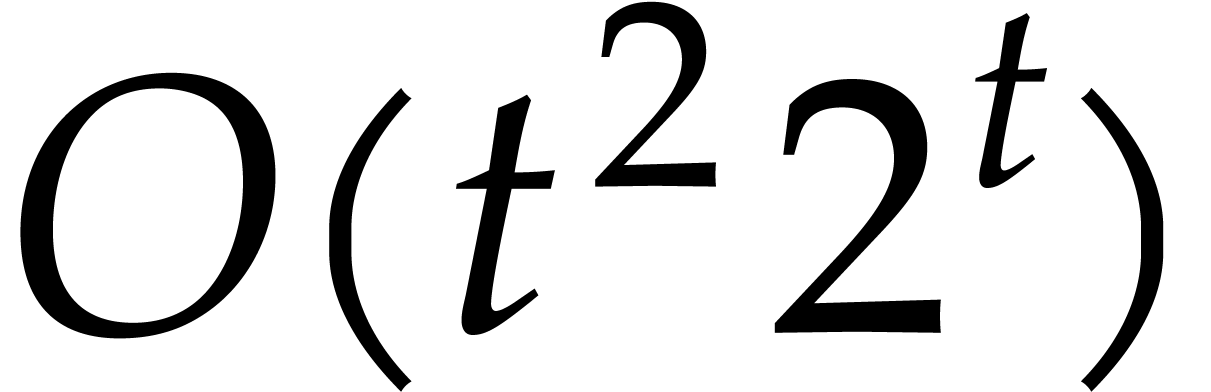 .
.
There are several variants and generalizations of Theorem 1.2 along similar lines as the results in [27, section 8]. First of all, we have the following:
and let 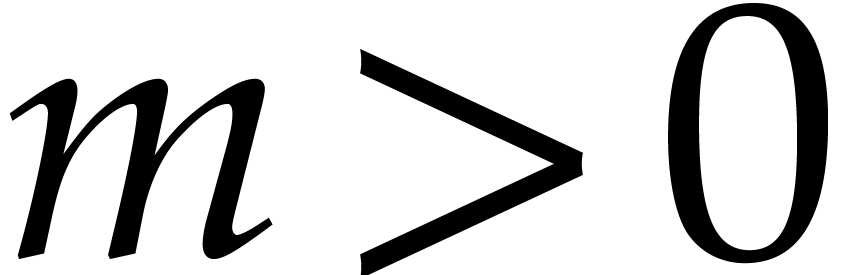 .
Then the bit complexity
.
Then the bit complexity 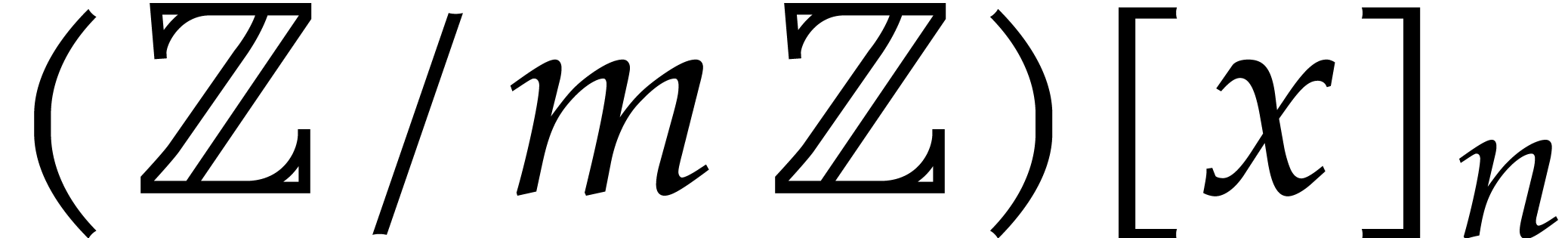 of multiplying two
polynomials in
of multiplying two
polynomials in  satisfies
satisfies

Proof. Routine adaptation of the proofs of [27, Theorems 8.2 and 8.3].
Until now, we have systematically worked in the bit complexity model for implementations on a multitape Turing machine. But it is a matter of routine to adapt Theorem 1.2 to other complexity models. In the straight-line program (SLP) model, the most straightforward adaptation of [27, Theorem 8.4] goes as follows:
. Let  be
an -algebra, where
be
an -algebra, where 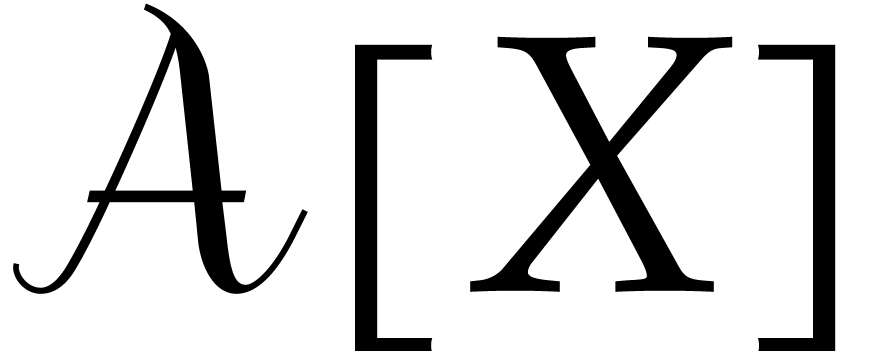 is prime. We may multiply two polynomials in
is prime. We may multiply two polynomials in 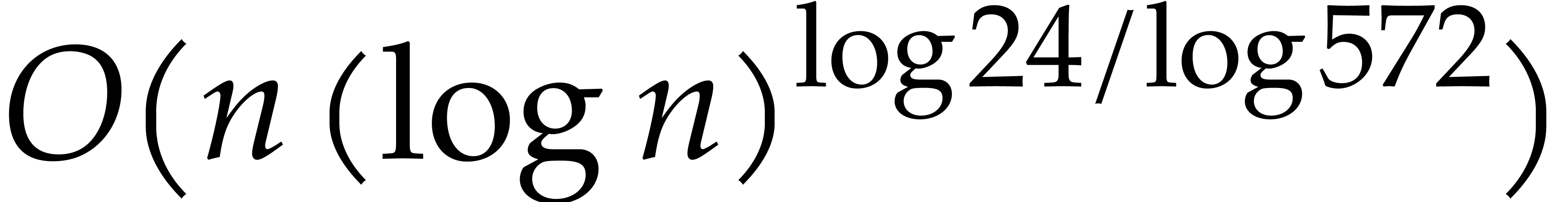 of degree less than
of degree less than  using
additions, subtractions, and scalar
multiplications, and
using
additions, subtractions, and scalar
multiplications, and  non-scalar
multiplications. These bounds are uniform over all primes and all -algebras
.
non-scalar
multiplications. These bounds are uniform over all primes and all -algebras
.
Proof. With respect to the proof of [27,
Theorem 8.4], the only non-trivial thing to check concerns the number of
non-scalar multiplications. These are due to the innermost
multiplications of our recursive FFT-multiplications, when unrolling the
recursion. Assume first that 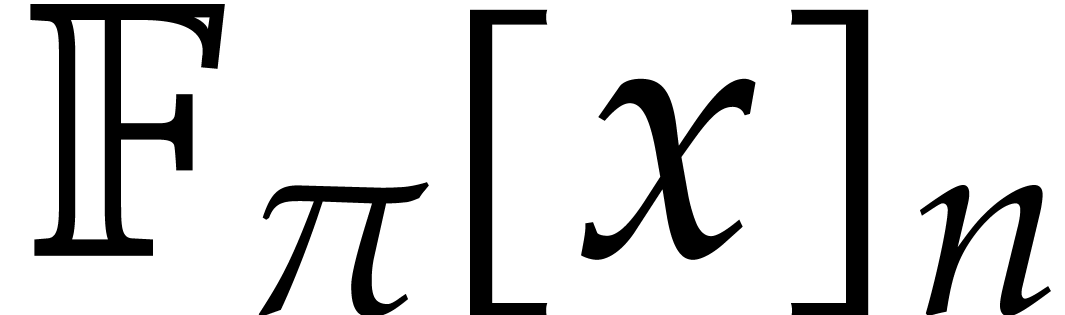 .
Then one level of our recursion reduces the multiplication of two
polynomials in
.
Then one level of our recursion reduces the multiplication of two
polynomials in  to
to  multiplications in , whence
to
multiplications in , whence
to  multiplications in . By construction, we have
multiplications in . By construction, we have 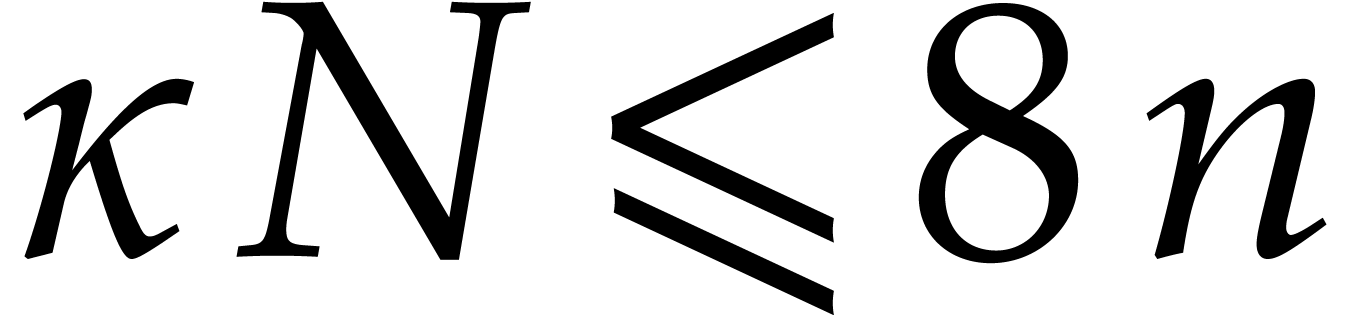 and
and  . Each recursive step
therefore expands the data size by a factor at most
. Each recursive step
therefore expands the data size by a factor at most 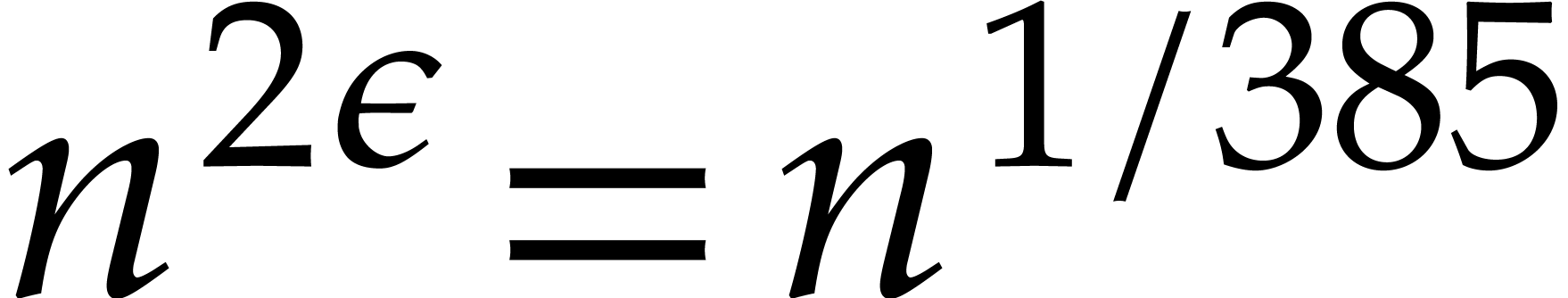 while passing from degree to degree roughly
while passing from degree to degree roughly
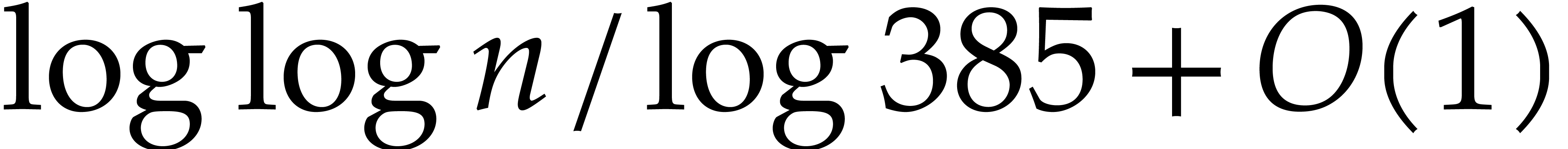 . The algorithm therefore
requires
. The algorithm therefore
requires 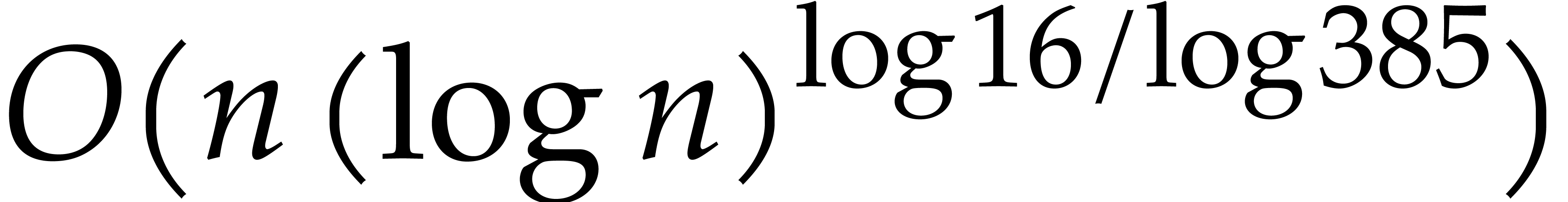 recursive steps and
recursive steps and  non-scalar multiplications. In the case when , the reasoning is similar: this time, the data size
is expanded by a factor at most
non-scalar multiplications. In the case when , the reasoning is similar: this time, the data size
is expanded by a factor at most  at each
recursive step (since
at each
recursive step (since  ),
whereas the degree in
),
whereas the degree in 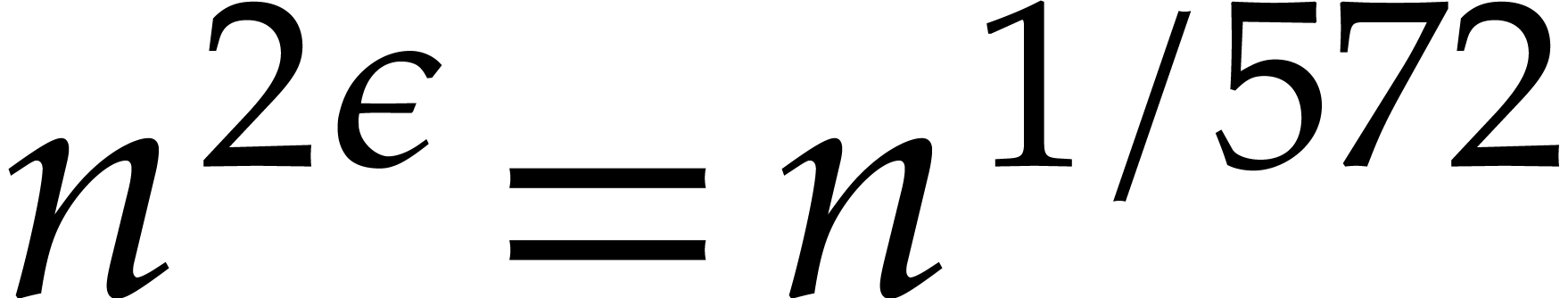 descends from to at most
descends from to at most 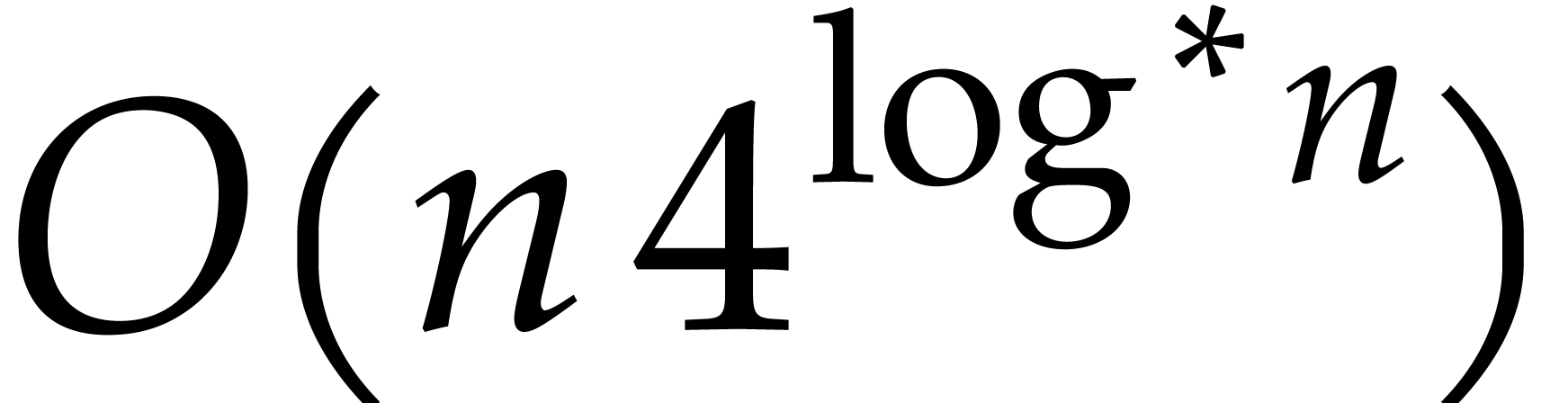 .
This leads to the announced complexity bound.
.
This leads to the announced complexity bound.
We notice that the number of non-scalar multiplications is far larger
than 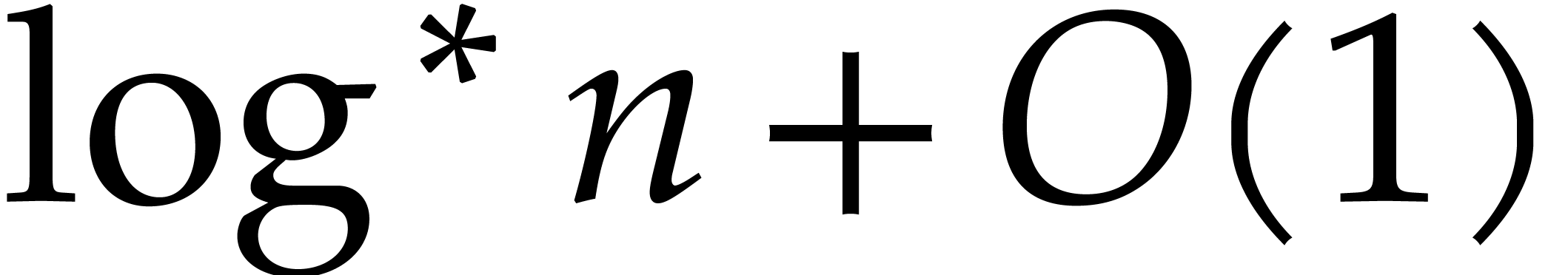 , as for the algorithm
from [27, Theorem 8.4]. Ideally speaking, we would like to
take exponentially smaller than , which requires a sharper bound on than the one from Lemma 5.4. Assuming that
this is possible (modulo stronger number theoretic assumptions), the
number of recursive steps would go down to
, as for the algorithm
from [27, Theorem 8.4]. Ideally speaking, we would like to
take exponentially smaller than , which requires a sharper bound on than the one from Lemma 5.4. Assuming that
this is possible (modulo stronger number theoretic assumptions), the
number of recursive steps would go down to 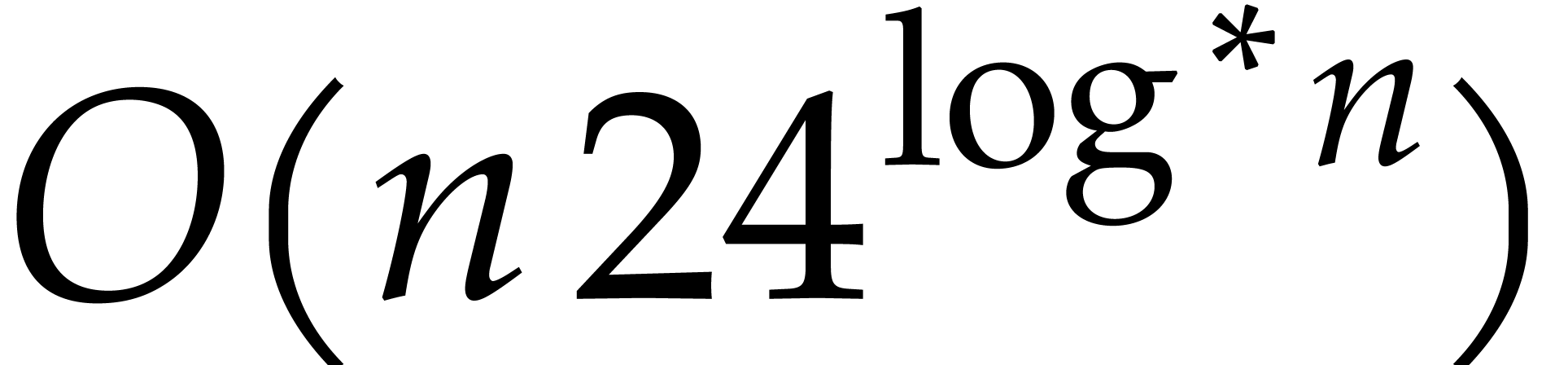 ,
and the number of non-scalar multiplications to
,
and the number of non-scalar multiplications to  . With more work, it is plausible that the constant
. With more work, it is plausible that the constant
 can be further reduced.
can be further reduced.
It is also interesting to observe that the bulk of the other -vector space operations are
additions and subtractions: for some constant  with
with 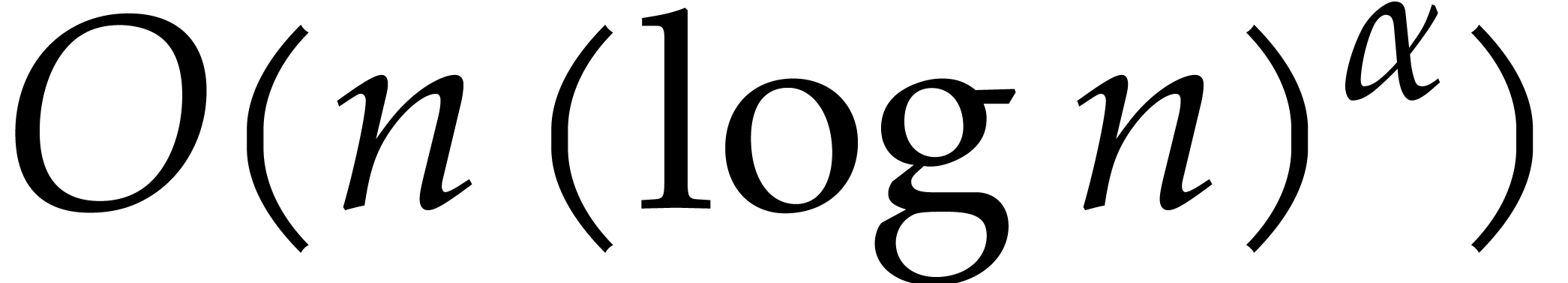 , the algorithm only
uses
, the algorithm only
uses 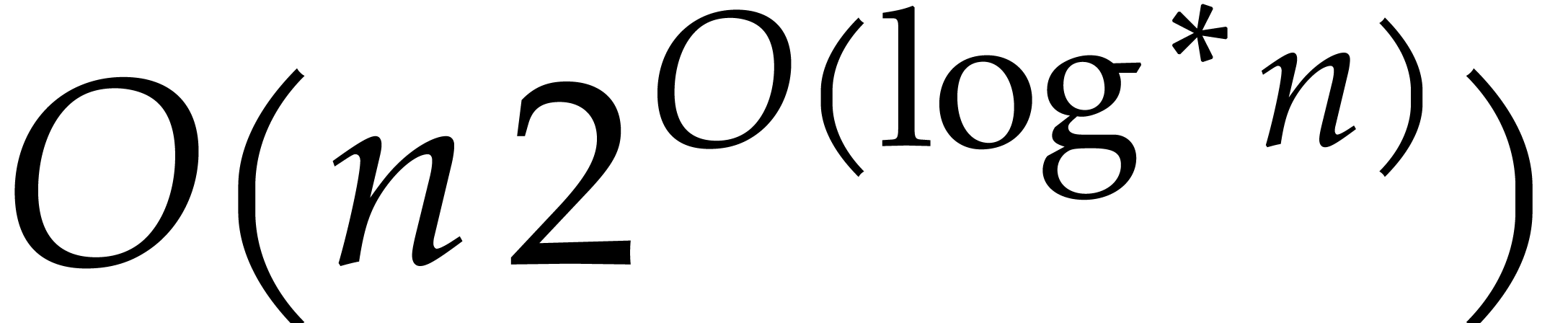 scalar multiplications. In a similar way as
above, this number goes down to
scalar multiplications. In a similar way as
above, this number goes down to  modulo stronger
number theoretic assumptions. For bounded
modulo stronger
number theoretic assumptions. For bounded  ,
we also notice that scalar multiplications theoretically reduce to
,
we also notice that scalar multiplications theoretically reduce to  additions.
additions.
Recall that all computations in this paper are done in the deterministic multitape Turing model [16]. In this appendix, we briefly review the cost of various basic types of data rearrangements when working in this model.
Let be a data type whose instances take bits. An array  of elements in is stored as a
linear array of
of elements in is stored as a
linear array of  bits. We generally assume that
the elements are ordered lexicographically by
bits. We generally assume that
the elements are ordered lexicographically by  .
.
What is significant from a complexity point of view is that occasionally
we must switch representations, to access an array (say 2-dimensional)
by “rows” or by “columns”. In the Turing model,
we may transpose an  matrix of elements in in time
matrix of elements in in time
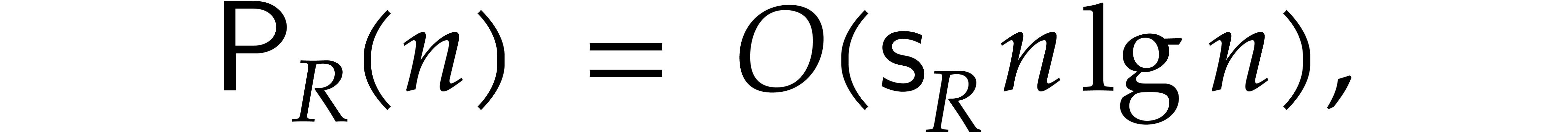
using the algorithm of [5, appendix]. Briefly, the idea is to split the matrix into two halves along the “short” dimension, and transpose each half recursively.
We will also require more complex rearrangements of data, for which we
resort to sorting. Suppose that we can compare elements of in linear time .
Then an array of elements of
may be sorted in time

using merge sort [36], which can be implemented efficiently on a Turing machine.
Let us now consider a general permutation  .
We assume that is represented by the array
.
We assume that is represented by the array 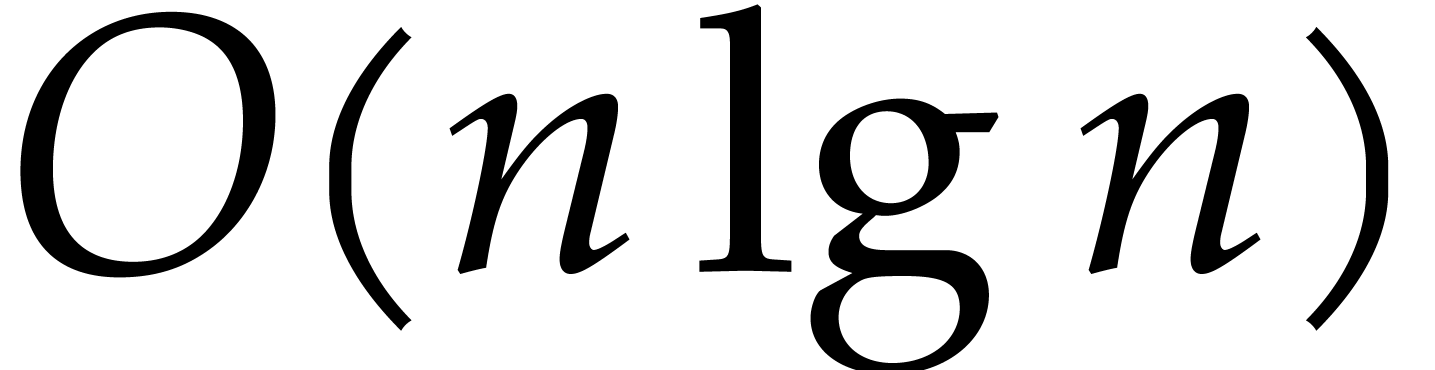 , which takes space
, which takes space 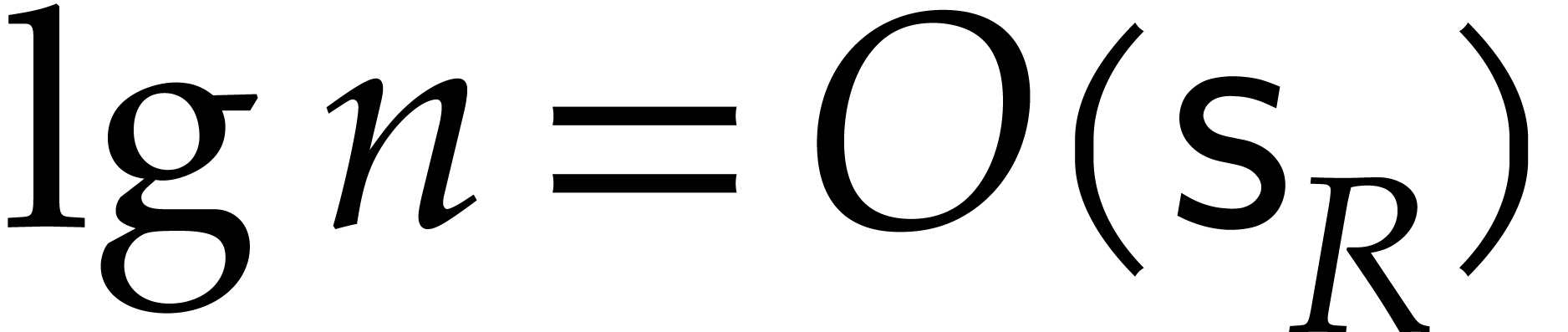 on a Turing tape. Given a general data type , the permutation naturally acts on arrays of
length with entries in . As
long as
on a Turing tape. Given a general data type , the permutation naturally acts on arrays of
length with entries in . As
long as 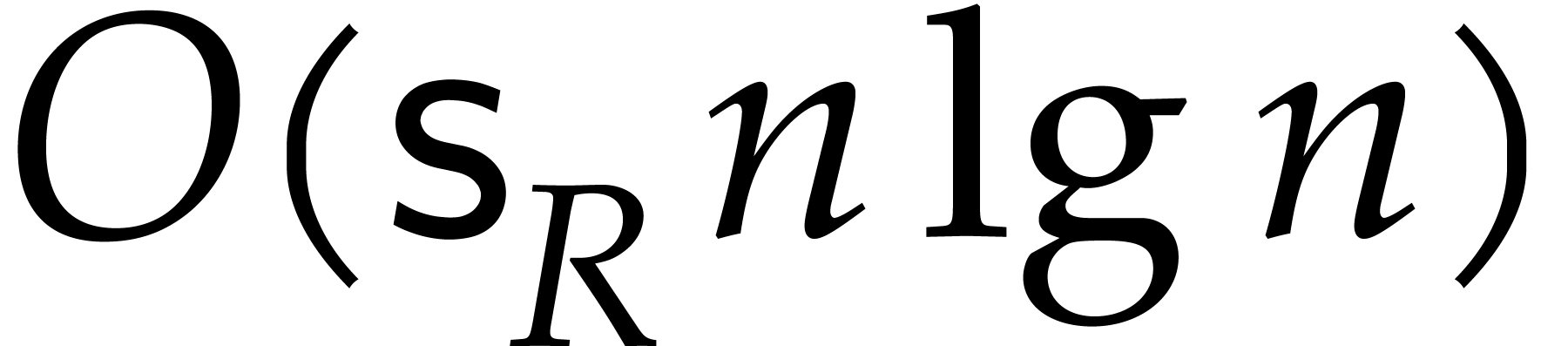 , this action can be
computed in time
, this action can be
computed in time 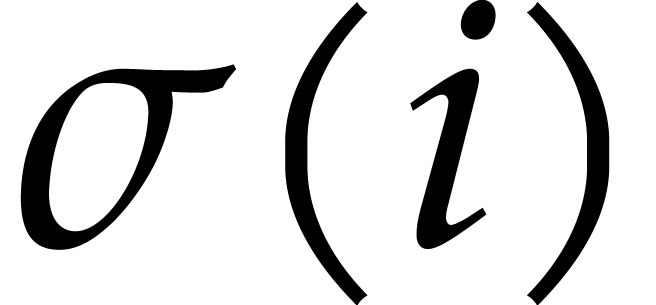 , by tagging
the -th entry of the array by
, by tagging
the -th entry of the array by
 , sorting the tagged entries,
and then removing the tags.
, sorting the tagged entries,
and then removing the tags.
Unfortunately, for some of the data rearrangements in this paper, we do
not have . Nevertheless,
certain special kinds of permutations can still be performed in time
. Transpositions are one
important example. In the next subsections, we will consider a few other
examples.
Proof. Let be an
absolute constant with 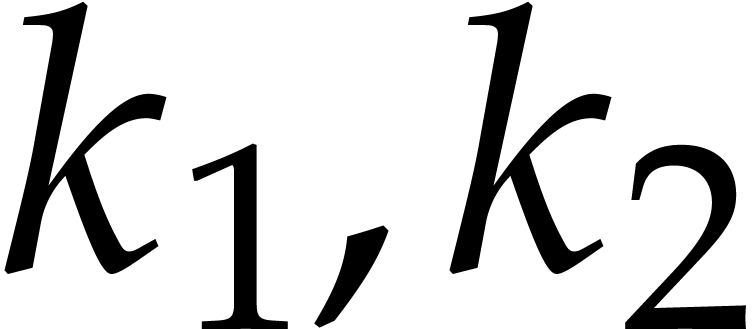 for all
for all  . Let us prove by induction on
that
. Let us prove by induction on
that 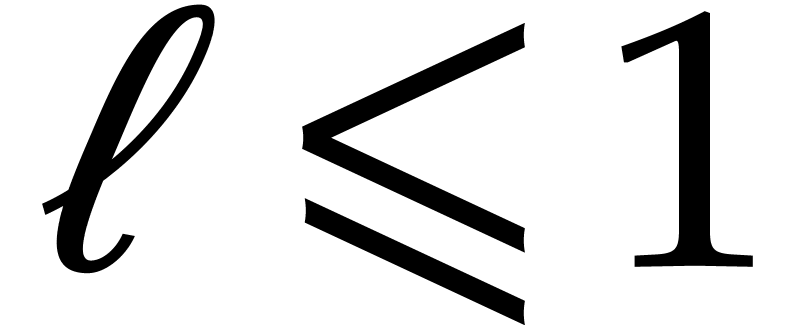 . For
. For 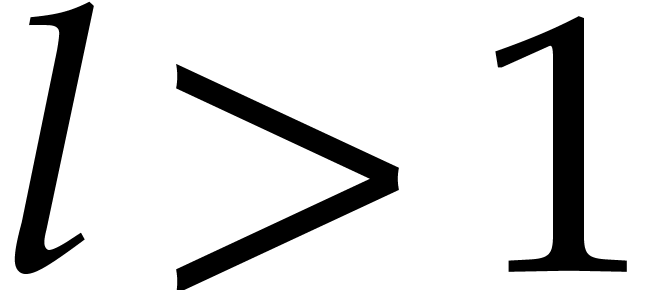 , the result is clear, so assume that
, the result is clear, so assume that 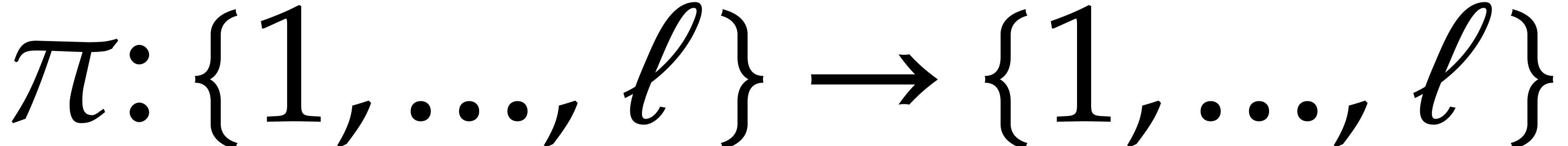 . Let
. Let  be
the mapping with
be
the mapping with  ,
,  and
and  for
for 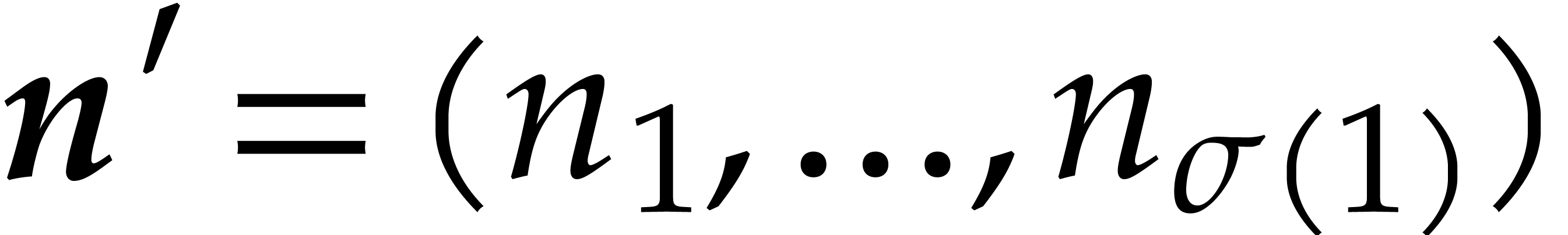 . Setting
. Setting  ,
,
 and
and  ,
the natural isomorphism between
,
the natural isomorphism between  and
and 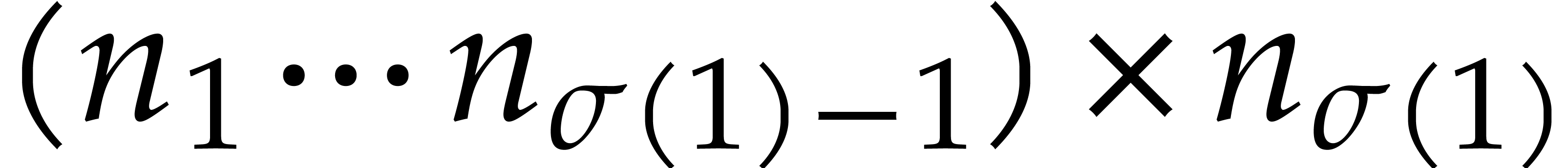 corresponds to the transposition of an
corresponds to the transposition of an  matrix with coefficients in
matrix with coefficients in  .
Since conversions between and
.
Since conversions between and  amount to
amount to  such transpositions, it follows that
such transpositions, it follows that
By the induction hypothesis, we also have
whence

as desired.
 ,
the conversions
,
the conversions
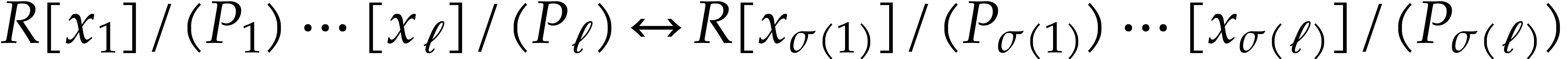
can be performed in time ,
where 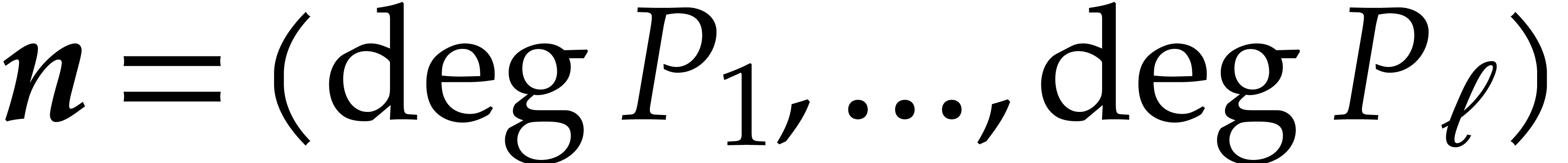 .
.
Proof. Setting  ,
we may naturally represent elements in
,
we may naturally represent elements in

by -variate arrays in . Similarly, elements of
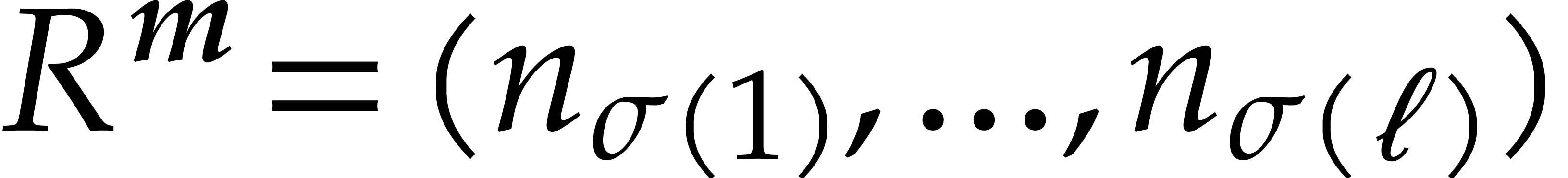
are represented by arrays in 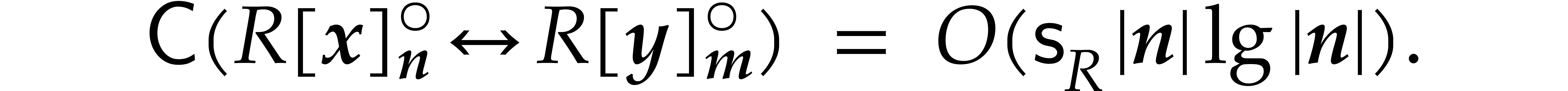 .
We now apply the lemma.
.
We now apply the lemma.

Proof. Take 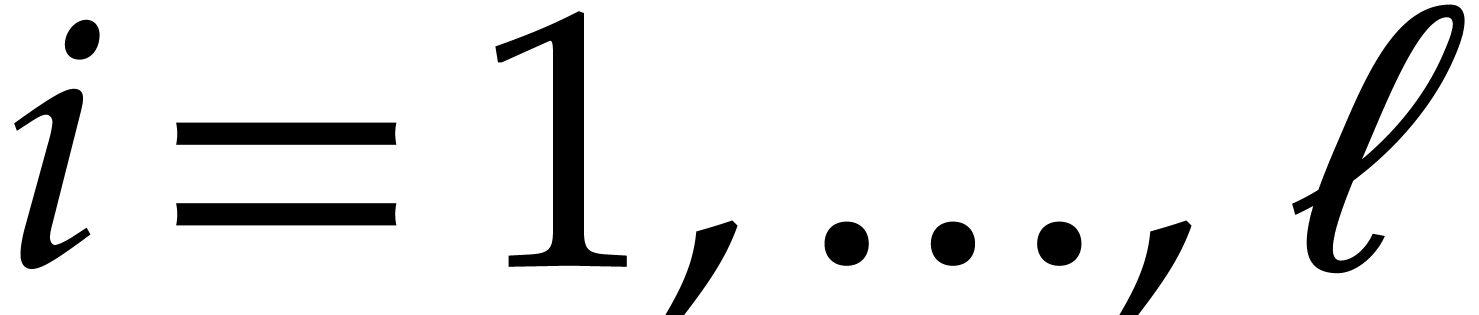 for
for 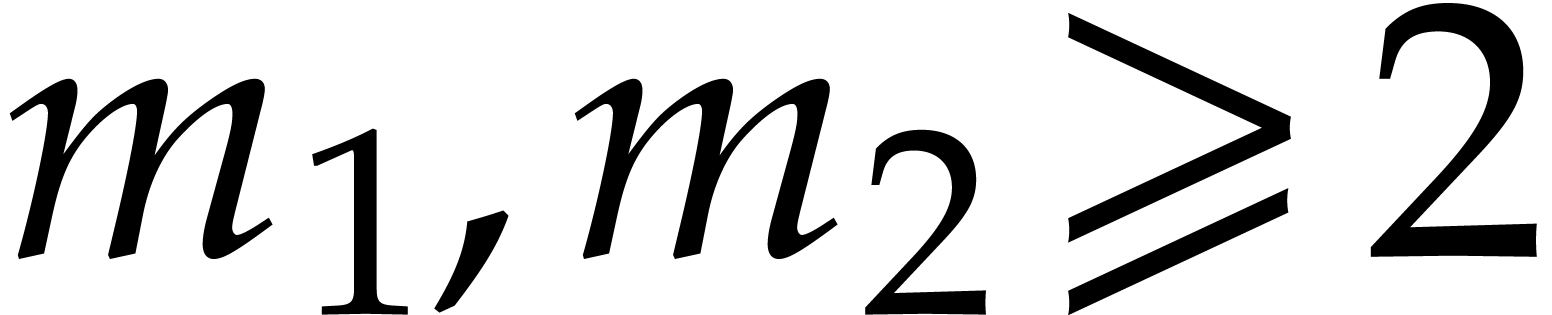 .
.
We start with two lemmas from [23, section 2.4]. For convenience we reproduce the proofs here.
Proof. Let 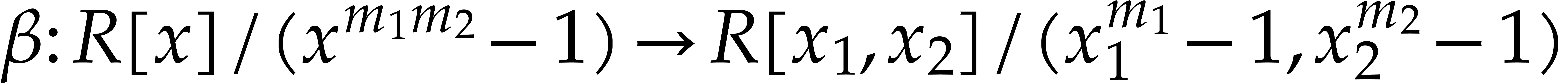 ,
and let
,
and let
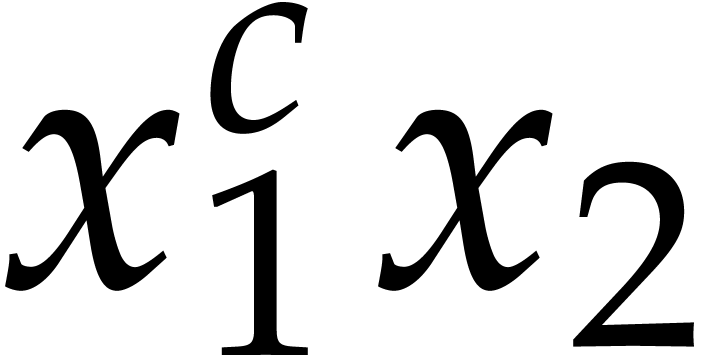
denote the homomorphism that maps to 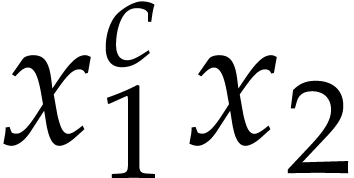 , and acts as the identity on . Suppose that we wish to compute
, and acts as the identity on . Suppose that we wish to compute
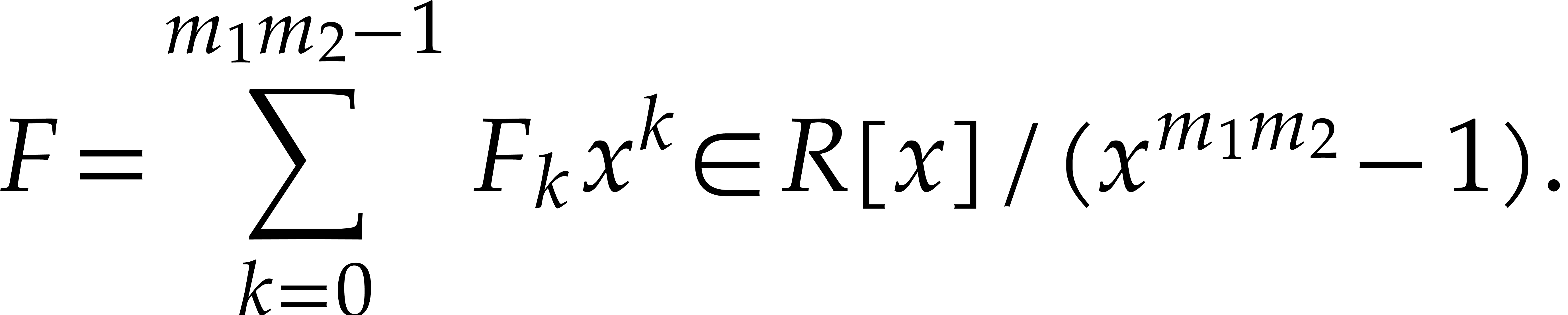 for some input polynomial
for some input polynomial
Interpreting the list  as an
as an  array, the
array, the 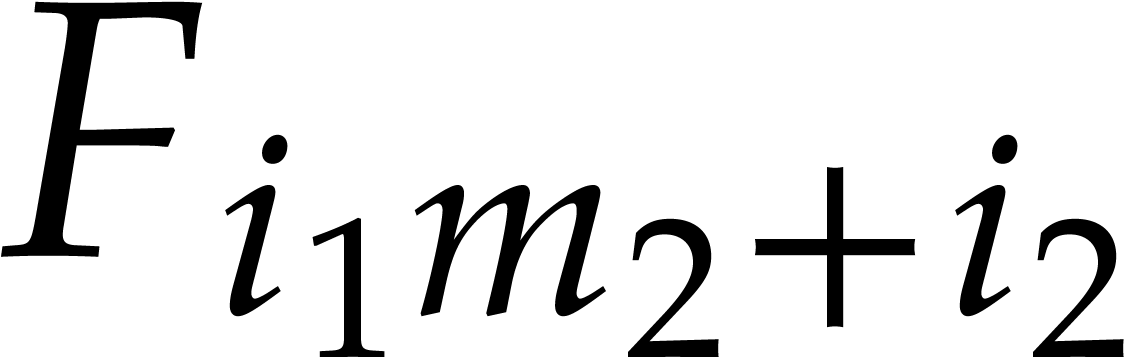 -th entry
corresponds to
-th entry
corresponds to 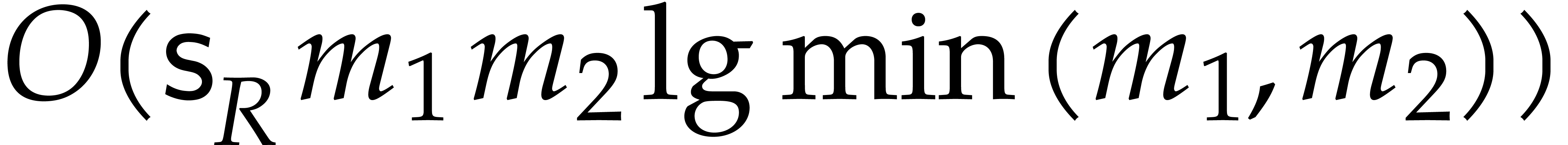 . After
transposing the array, which costs
. After
transposing the array, which costs  bit
operations, we have an
bit
operations, we have an 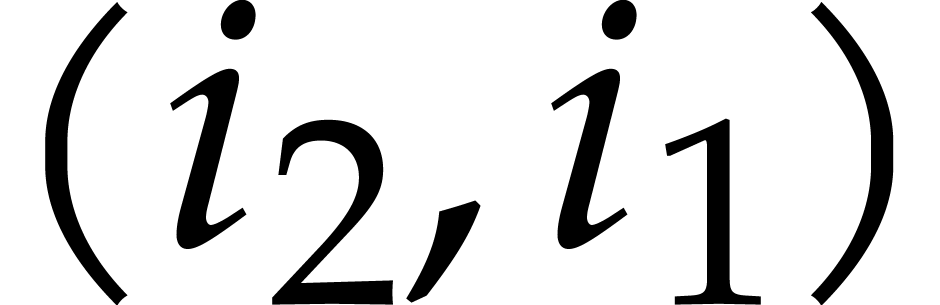 array, whose
array, whose  -th entry is .
Now for each , cyclically
permute the -th row by
-th entry is .
Now for each , cyclically
permute the -th row by 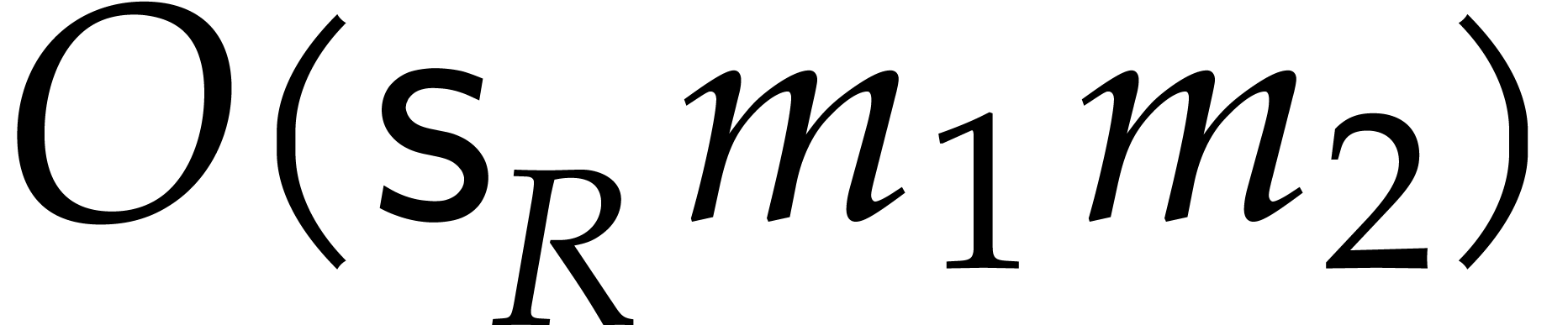 slots; altogether this uses only
slots; altogether this uses only  bit operations. The result is an array whose
-th entry is
bit operations. The result is an array whose
-th entry is 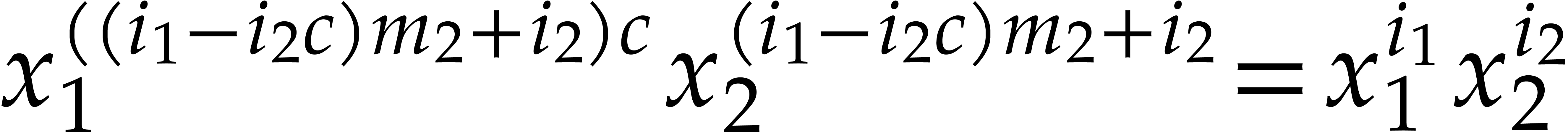 , which is exactly the coefficient of
, which is exactly the coefficient of
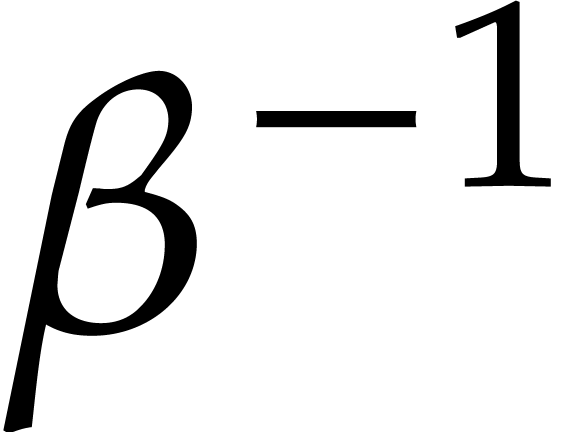
in . The inverse map  may be computed by reversing this procedure.
may be computed by reversing this procedure.
Proof. Using Lemma A.4, we construct a sequence of isomorphisms
the -th of which may be
computed in 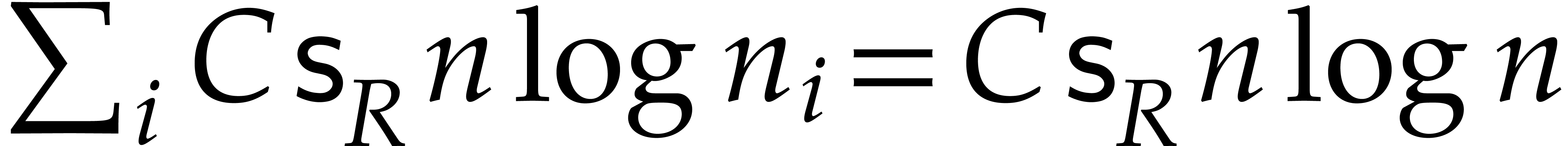 bit operations for some universal
constant . The overall cost
is
bit operations for some universal
constant . The overall cost
is 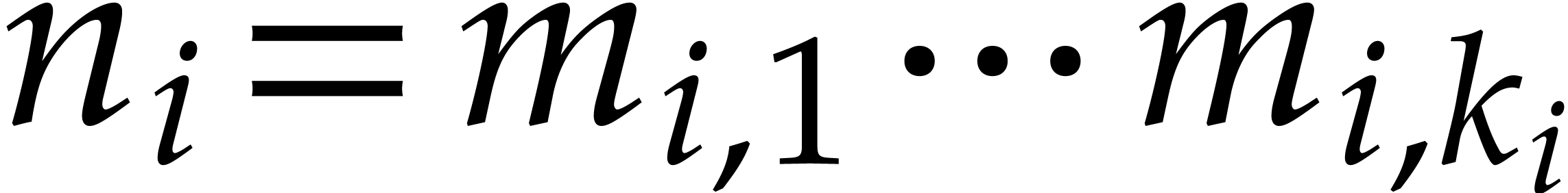 bit operations.
bit operations.
Proof. We prove the assertion by induction over
. For , the result follows from Lemma A.5, so
assume that . Denote  ,
,  ,
and
,
and 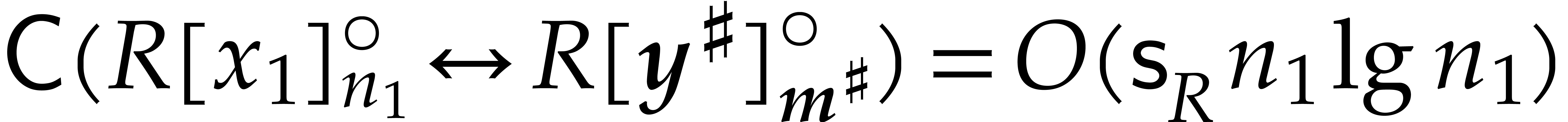 . Lemma A.5
yields
. Lemma A.5
yields  , whence
, whence
The induction hypothesis also yields
Adding up the these two bounds, the result follows.
Given 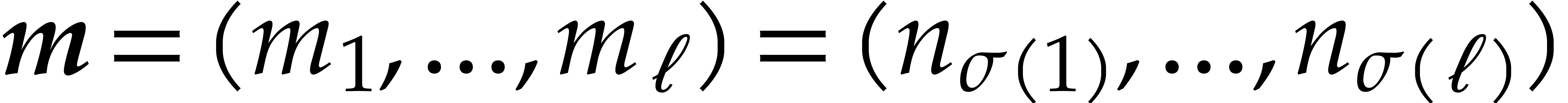 , we recall that the
classification of finite abelian groups implies the existence of a
unique tuple
, we recall that the
classification of finite abelian groups implies the existence of a
unique tuple  with
with  ,
,
 ,
,  , and
, and
We call  the normal form of
the normal form of  and say that is in normal form if
and say that is in normal form if  .
.
is the normal form of 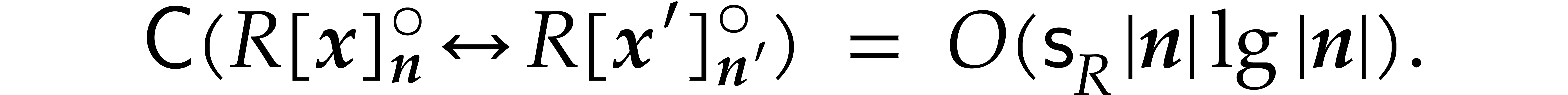 , then
, then
Proof. Let  and
and 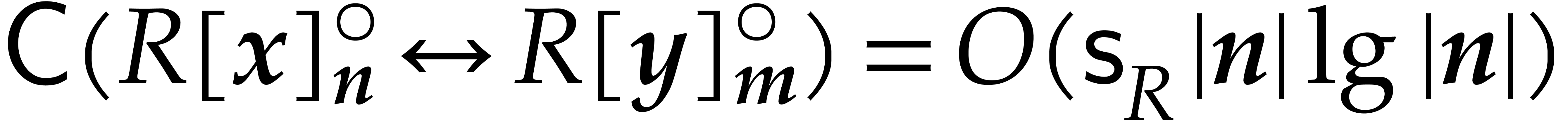 be the tuples obtained when performing the entry-wise
prime power factorizations of and as in Lemma A.6. From Lemma A.6
it follows that
be the tuples obtained when performing the entry-wise
prime power factorizations of and as in Lemma A.6. From Lemma A.6
it follows that  and
and 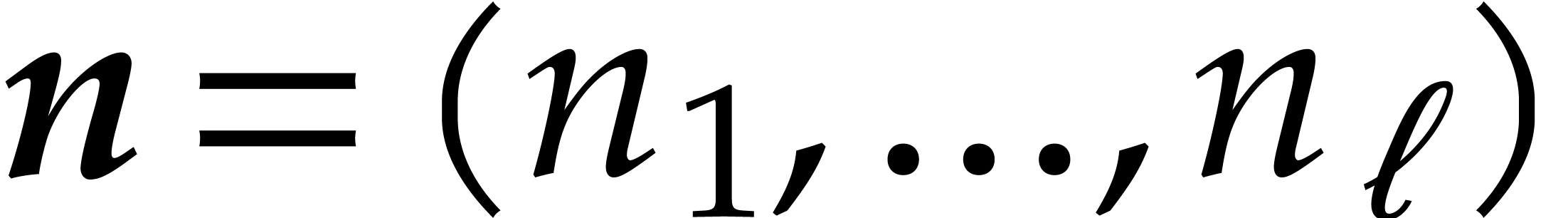 . Since is a permutation of
, the result follows from
Lemma A.1.
. Since is a permutation of
, the result follows from
Lemma A.1.
We say that two tuples 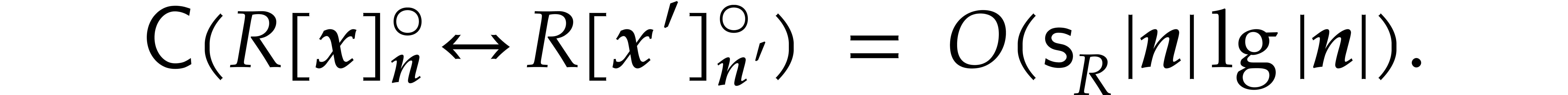 and
are equivalent if they admit the same normal form.
and
are equivalent if they admit the same normal form.
Consider an -algebra of the
form  , where
, where  is finite and totally ordered
is finite and totally ordered 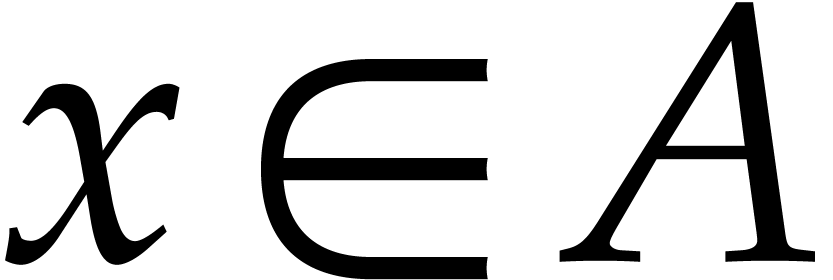 . Elements
. Elements  are of the form
are of the form 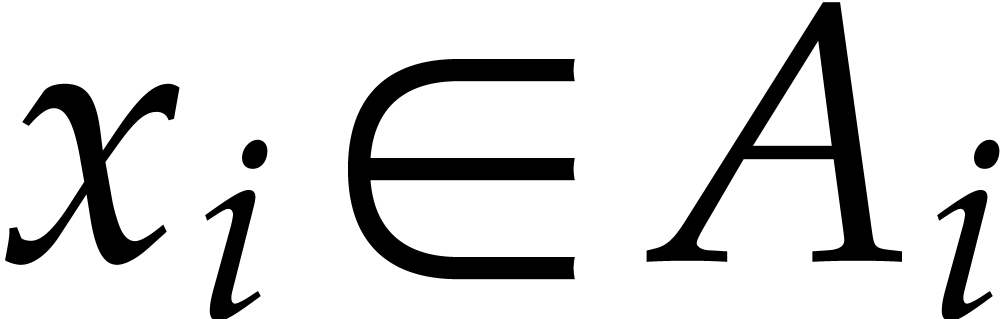 with
with  , so we may naturally represent
them on a Turing tape by concatenating the representations of
, so we may naturally represent
them on a Turing tape by concatenating the representations of 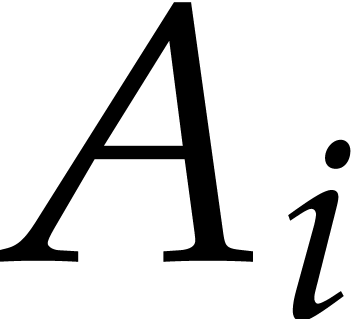 . In particular, if each
. In particular, if each 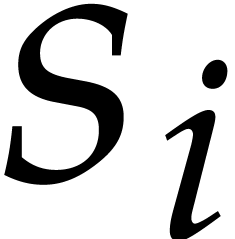 is an -algebra
of dimension
is an -algebra
of dimension 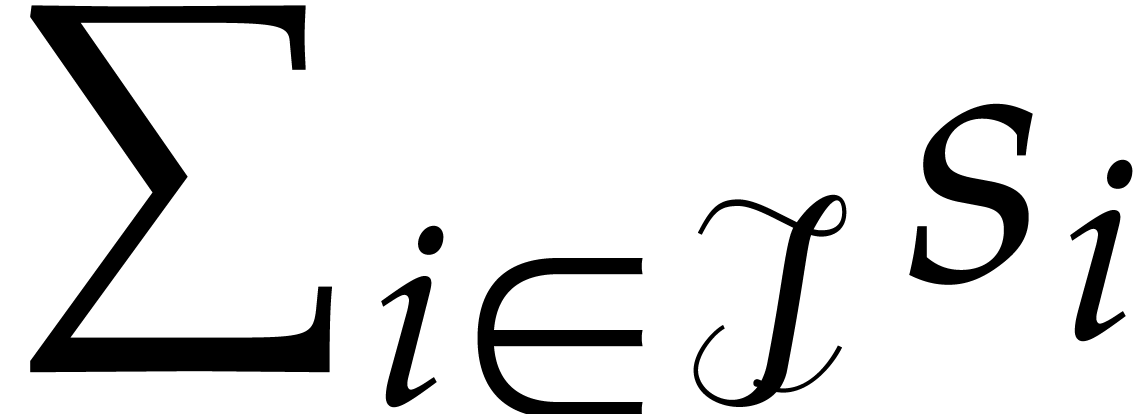 whose elements are represented by
vectors of size with entries in , then elements in are
simply represented as vectors of size
whose elements are represented by
vectors of size with entries in , then elements in are
simply represented as vectors of size  with
entries in .
with
entries in .
Now consider such algebras 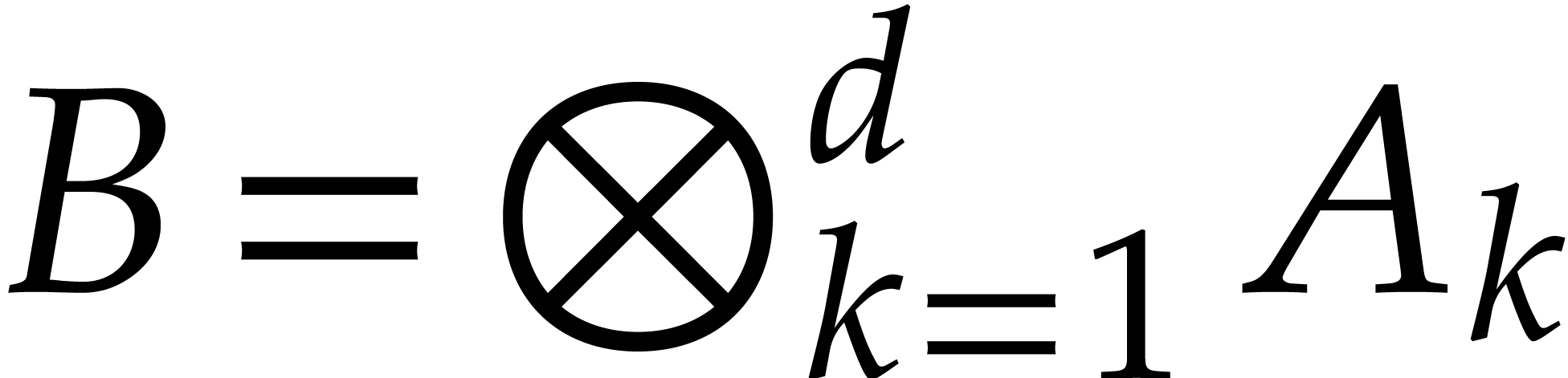 and let us form their tensor product
and let us form their tensor product 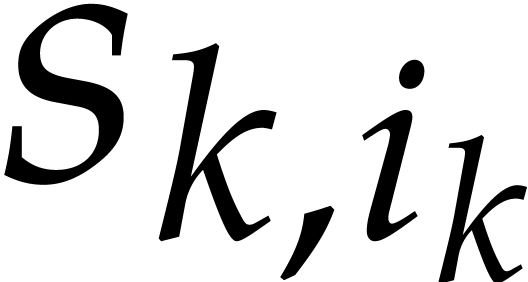 .
Let
.
Let 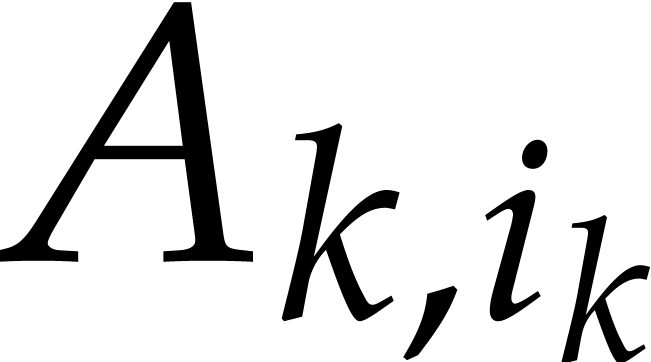 be the dimension of the -subalgebra
be the dimension of the -subalgebra 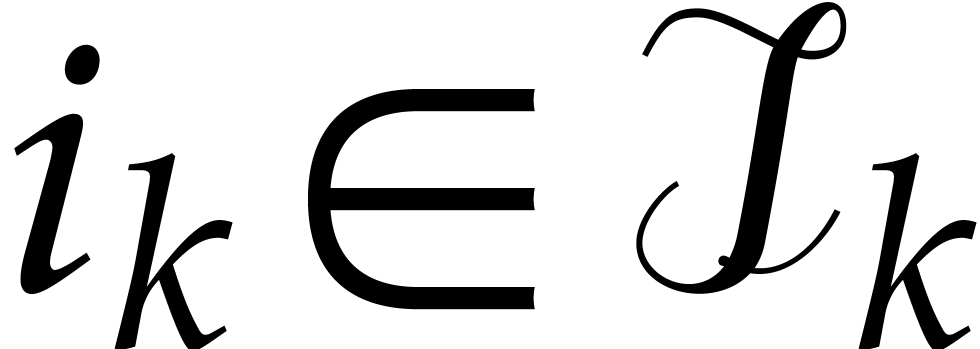 for and
for and  . Then
elements in are recursively represented as
vectors of size
. Then
elements in are recursively represented as
vectors of size 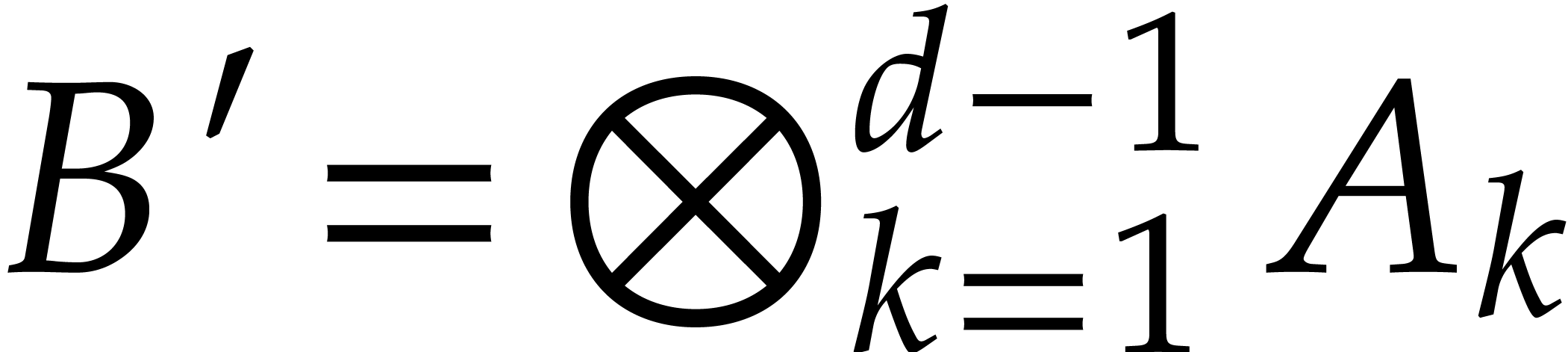 with entries in
with entries in 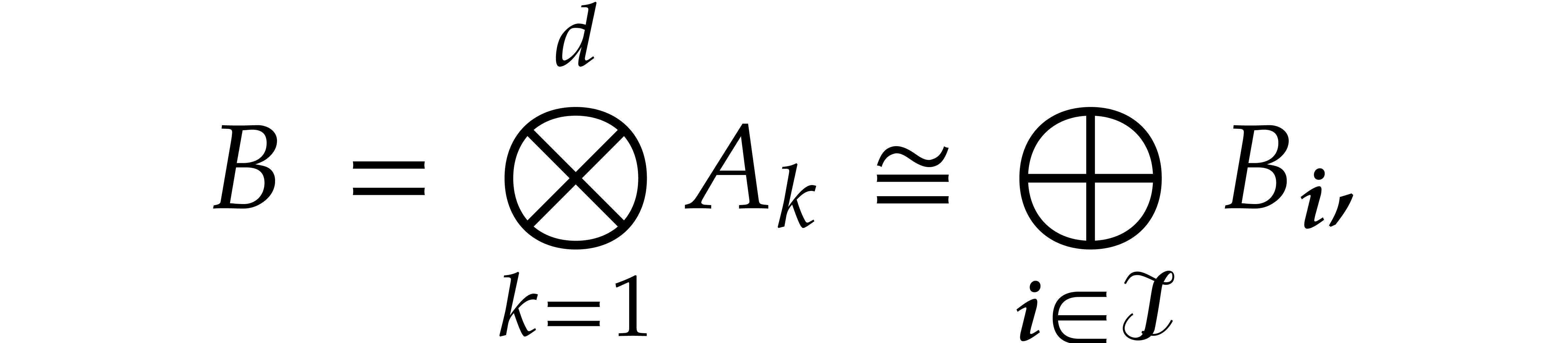 . Using the distributivity of
over , we have a natural
isomorphism
. Using the distributivity of
over , we have a natural
isomorphism
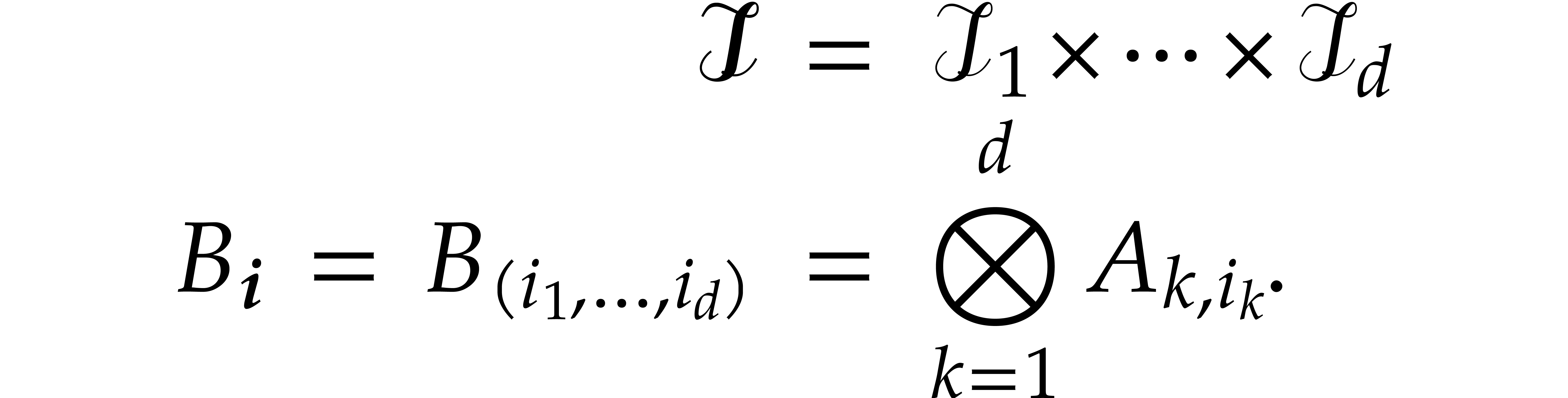
where
When endowing the index set 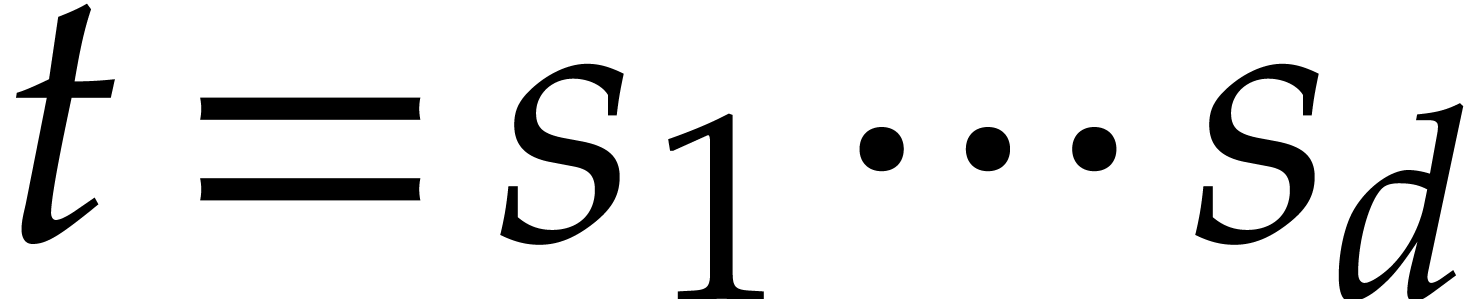 with the
lexicographical ordering, this isomorphism requires some reordering of
data on Turing tapes, but we can compute it reasonably efficiently as
follows:
with the
lexicographical ordering, this isomorphism requires some reordering of
data on Turing tapes, but we can compute it reasonably efficiently as
follows:
Proof. Let us prove the assertion by induction
on 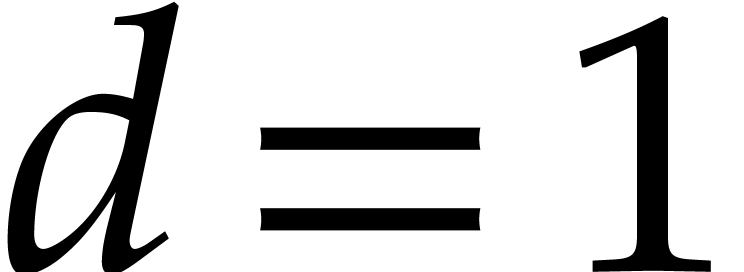 . For
. For 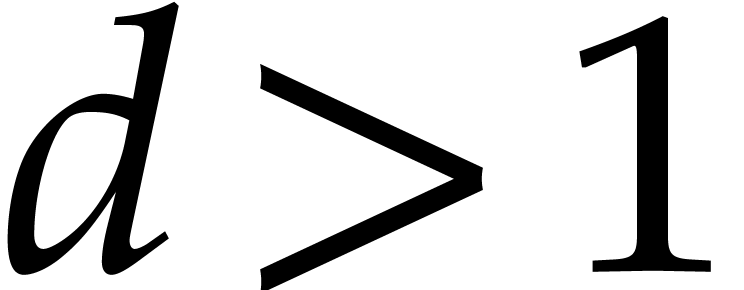 , we have nothing to do, so assume that
, we have nothing to do, so assume that  . We may consider an element
. We may consider an element  of
of  as a vector of size
as a vector of size  with coefficients in
with coefficients in  .
For each
.
For each 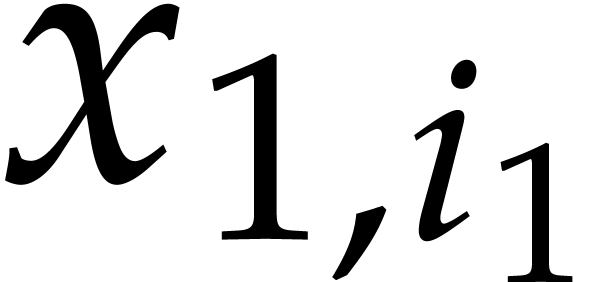 , we may compute the
projection
, we may compute the
projection 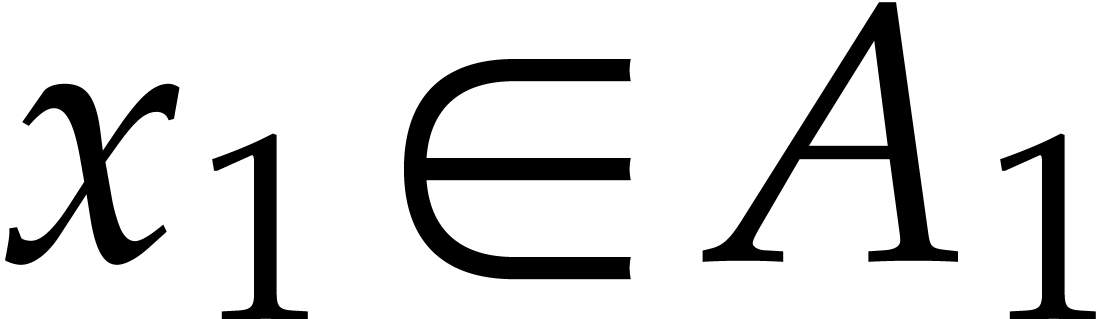 of
of 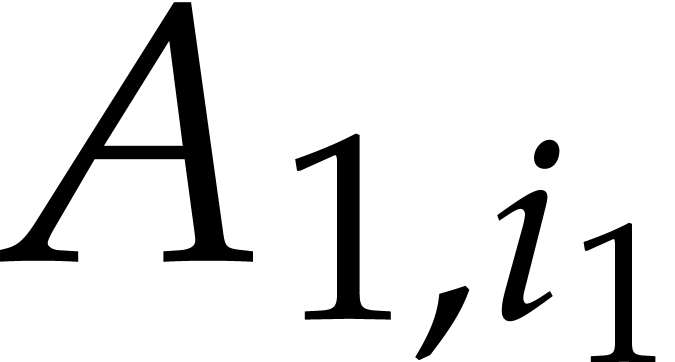 on
on 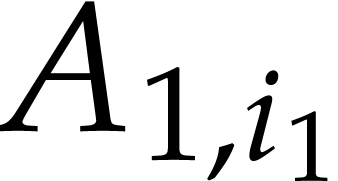 in time
in time 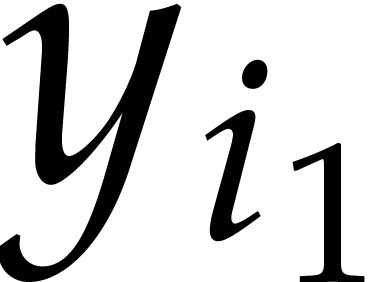 .
Doing this for all entries of , we obtain an element
.
Doing this for all entries of , we obtain an element  of
of

This computation takes a time 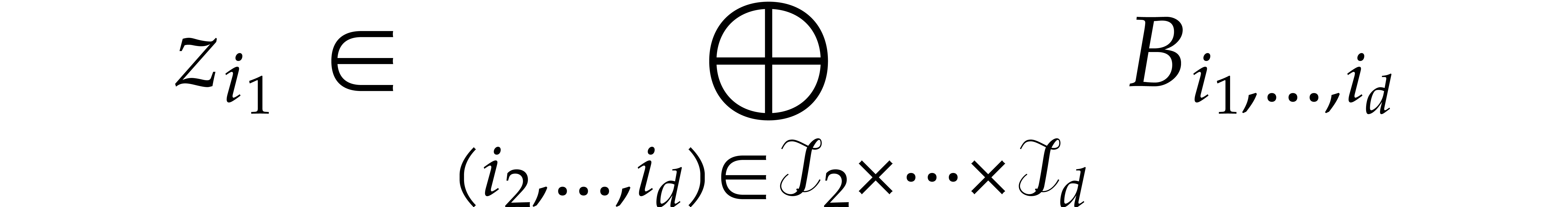 .
Using the induction hypothesis, we can convert
into an element
.
Using the induction hypothesis, we can convert
into an element
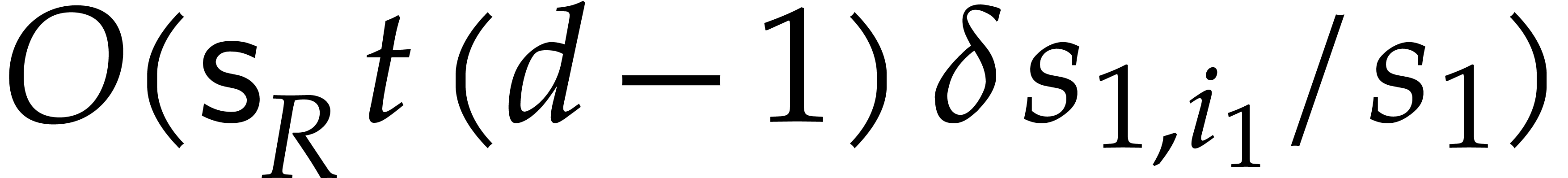
in time 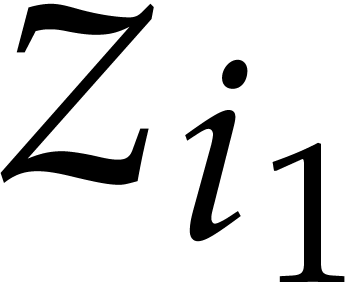 . Doing this in order
for all and concatenating the resulting
. Doing this in order
for all and concatenating the resulting  , we obtain the conversion of as an element of
, we obtain the conversion of as an element of  .
The total computation time is bounded by
.
The total computation time is bounded by
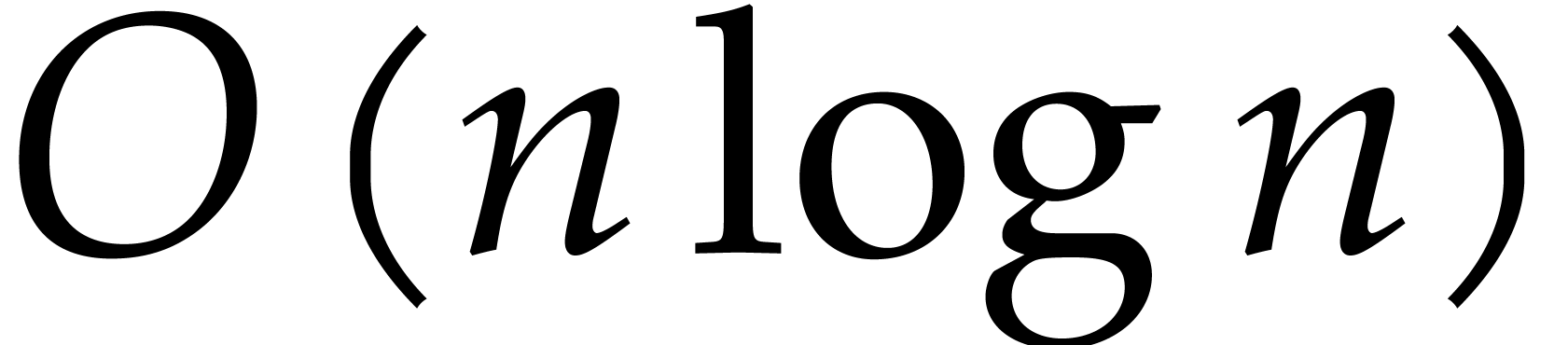
The conversion in the opposite direction can be computed in the same
time by reversing the algorithm.
R. Agarwal and J. Cooley. New algorithms for digital convolution. IEEE Transactions on Acoustics, Speech, and Signal Processing, 25(5):392–410, 1977.
M. Agrawal, N. Kayal, and N. Saxena. PRIMES is in P. Annals of Math., 160(2):781–793, 2004.
P. Barrett. Implementing the Rivest Shamir and Adleman public key encryption algorithm on a standard digital signal processor. In A. M. Odlyzko, editor, Advances in Cryptology — CRYPTO' 86, pages 311–323. Berlin, Heidelberg, 1987. Springer Berlin Heidelberg.
L. I. Bluestein. A linear filtering approach to the computation of discrete Fourier transform. IEEE Transactions on Audio and Electroacoustics, 18(4):451–455, 1970.
A. Bostan, P. Gaudry, and É. Schost. Linear recurrences with polynomial coefficients and application to integer factorization and Cartier-Manin operator. SIAM J. Comput., 36:1777–1806, 2007.
C. B. Boyer. A History of Mathematics. Princeton Univ. Press, First paperback edition, 1985.
R. P. Brent and P. Zimmermann. Modern Computer Arithmetic. Cambridge University Press, 2010.
D. G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28:693–701, 1991.
J.W. Cooley and J.W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
S. Covanov and E. Thomé. Fast integer multiplication using generalized Fermat primes. Math. Comp., 88:1449–1477, 2019.
A. De, P. P. Kurur, C. Saha, and R. Saptharishi. Fast integer multiplication using modular arithmetic. SIAM J. Comput., 42(2):685–699, 2013.
M. Fürer. Faster integer multiplication. In Proceedings of the Thirty-Ninth ACM Symposium on Theory of Computing, STOC 2007, pages 57–66. New York, NY, USA, 2007. ACM Press.
M. Fürer. Faster integer multiplication. SIAM J. Comput., 39(3):979–1005, 2009.
J. von zur Gathen and J. Gerhard. Modern computer algebra. Cambridge University Press, New York, 3rd edition, 2013.
I. J. Good. The interaction algorithm and practical Fourier analysis. Journal of the Royal Statistical Society, Series B. 20(2):361–372, 1958.
C. H.Papadimitriou. Computational Complexity. Addison-Wesley, 1994.
D. Harvey. Faster arithmetic for number-theoretic transforms. J. Symbolic Comput., 60:113–119, 2014.
D. Harvey. Faster truncated integer multiplication. https://arxiv.org/abs/1703.00640, 2017.
D. Harvey and J. van der Hoeven. Faster integer and polynomial multiplication using cyclotomic coefficient rings. Technical Report, ArXiv, 2017. http://arxiv.org/abs/1712.03693.
D. Harvey and J. van der Hoeven. Faster integer multiplication using plain vanilla FFT primes. Math. Comp., 88(315):501–514, 2019.
D. Harvey and J. van der Hoeven. Faster integer multiplication using short lattice vectors. In R. Scheidler and J. Sorenson, editors, Proc. of the 13-th Algorithmic Number Theory Symposium, Open Book Series 2, pages 293–310. Mathematical Sciences Publishes, Berkeley, 2019.
D. Harvey and J. van der Hoeven. Integer
multiplication in time  .
Technical Report, HAL, 2019. http://hal.archives-ouvertes.fr/hal-02070778.
.
Technical Report, HAL, 2019. http://hal.archives-ouvertes.fr/hal-02070778.
D. Harvey and J. van der Hoeven. Faster polynomial multiplication over finite fields using cyclotomic coefficient rings. Shortened version of [19]. Accepted for publication in J. of Complexity.
D. Harvey, J. van der Hoeven, and G. Lecerf. Faster polynomial multiplication over finite fields. Technical Report, ArXiv, 2014. http://arxiv.org/abs/1407.3361. Preprint version of [27].
D. Harvey, J. van der Hoeven, and G. Lecerf. Even faster integer multiplication. Journal of Complexity, 36:1–30, 2016.
D. Harvey, J. van der Hoeven, and G. Lecerf. Fast
polynomial multiplication over  .
In Proc. ISSAC '16, pages 255–262. New York, NY,
USA, 2016. ACM.
.
In Proc. ISSAC '16, pages 255–262. New York, NY,
USA, 2016. ACM.
D. Harvey, J. van der Hoeven, and G. Lecerf. Faster polynomial multiplication over finite fields. J. ACM, 63(6), 2017. Article 52.
D. R. Heath-Brown. Zero-free regions for Dirichlet L-functions, and the least prime in an arithmetic progression. Proc. London Math. Soc., 64(3):265–338, 1992.
M. T. Heideman, D. H. Johnson, and C. S. Burrus. Gauss and the history of the fast Fourier transform. Arch. Hist. Exact Sci., 34(3):265–277, 1985.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven. Faster Chinese remaindering. Technical Report, HAL, 2016. http://hal.archives-ouvertes.fr/hal-01403810.
J. van der Hoeven, R. Larrieu, and G. Lecerf. Implementing fast carryless multiplication. In J. Blömer, I. S. Kotsireas, T. Kutsia, and D. E. Simos, editors, Proc. MACIS 2017, Vienna, Austria, Lect. Notes in Computer Science, pages 121–136. Cham, 2017. Springer International Publishing.
A. A. Karatsuba. The complexity of computations. Proc. of the Steklov Inst. of Math., 211:169–183, 1995. English translation; Russian original at pages 186–202.
A. Karatsuba and J. Ofman. Multiplication of multidigit numbers on automata. Soviet Physics Doklady, 7:595–596, 1963.
D. E. Knuth. The Art of Computer Programming, volume 2: Seminumerical Algorithms. Addison-Wesley, 1969.
D. E. Knuth. The Art of Computer Programming, volume 3: Sorting and Searching. Addison-Wesley, Reading, MA, 1998.
J. Li, K. Pratt, and G. Shakan. A lower bound for the least prime in an arithmetic progression. The Quarterly Journal of Mathematics, 68(3):729–758, 2017.
Yu. V. Linnik. On the least prime in an arithmetic progression I. The basic theorem. Rec. Math. (Mat. Sbornik) N.S., 15(57):139–178, 1944.
Yu. V. Linnik. On the least prime in an arithmetic progression II. The Deuring-Heilbronn phenomenon. Rec. Math. (Mat. Sbornik) N.S., 15(57):347–368, 1944.
O. Neugebauer. The Exact Sciences in Antiquity. Brown Univ. Press, Providence, R.I., 1957.
H. J. Nussbaumer. Fast polynomial transform algorithms for digital convolution. IEEE Trans. Acoust. Speech Signal Process., 28(2):205–215, 1980.
H. J. Nussbaumer. Fast Fourier Transforms and Convolution Algorithms. Springer-Verlag, 2nd edition, 1982.
H. J. Nussbaumer and P. Quandalle. Computation of convolutions and discrete Fourier transforms by polynomial transforms. IBM J. Res. Develop., 22(2):134–144, 1978.
J. M. Pollard. The fast Fourier transform in a finite field. Mathematics of Computation, 25(114):365–374, 1971.
C. M. Rader. Discrete Fourier transforms when the number of data samples is prime. Proc. IEEE, 56:1107–1108, 1968.
A. Schönhage. Multiplikation großer Zahlen. Computing, 1(3):182–196, 1966.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Infor., 7:395–398, 1977.
A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.
É. Schost. Multivariate power series multiplication. In Manuel Kauers, editor, ISSAC '05, pages 293–300. New York, NY, USA, 2005. ACM Press.
V. Shoup. New algorithms for finding irreducible polynomials over finite fields. Math. Comp., 189:435–447, 1990.
V. Shoup. Searching for primitive roots in finite fields. Math. Comp., 58:369–380, 1992.
I. Shparlinski. On finding primitive roots in finite fields. Theoret. Comput. Sci., 157(2):273–275, 1996.
L. H. Thomas. Using computers to solve problems in physics. Applications of digital computers, 458:42–57, 1963.
A. L. Toom. The complexity of a scheme of functional elements realizing the multiplication of integers. Soviet Mathematics, 4(2):714–716, 1963.
T. Xylouris. On the least prime in an arithmetic progression and estimates for the zeros of Dirichlet L-functions. Acta Arith., 1:65–91, 2011.
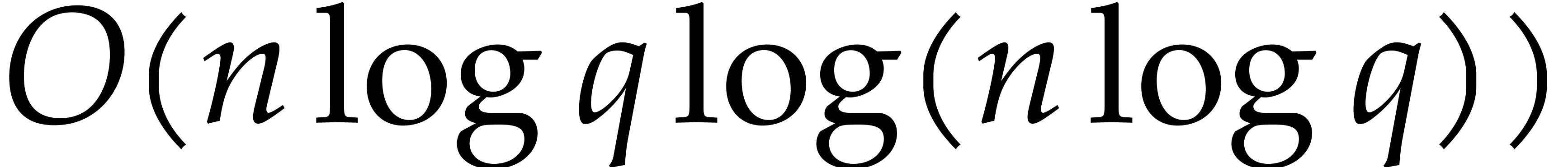 ,
,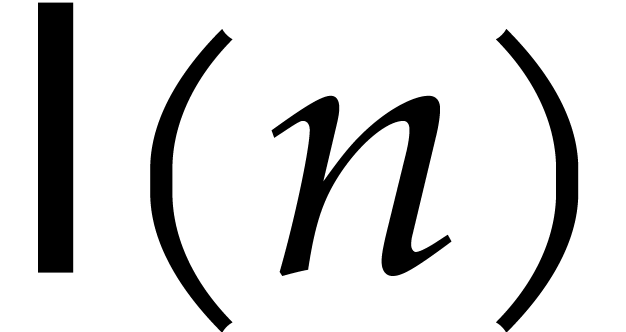

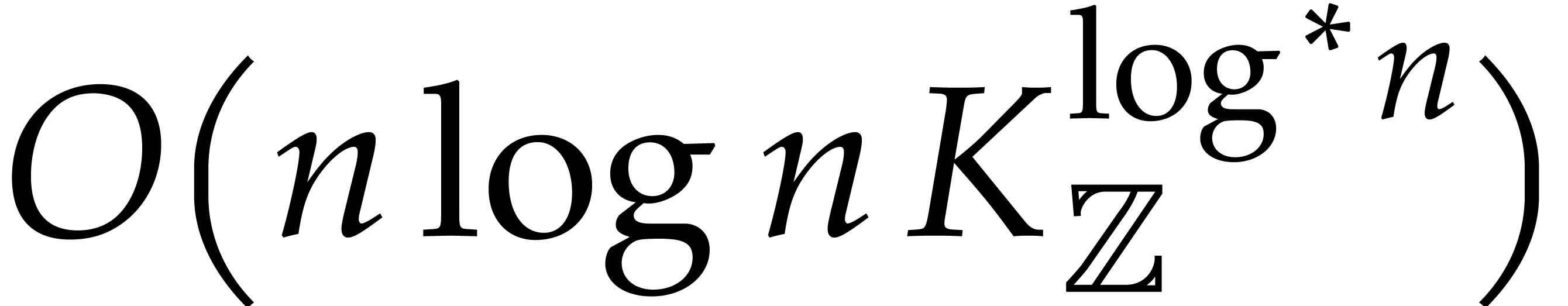
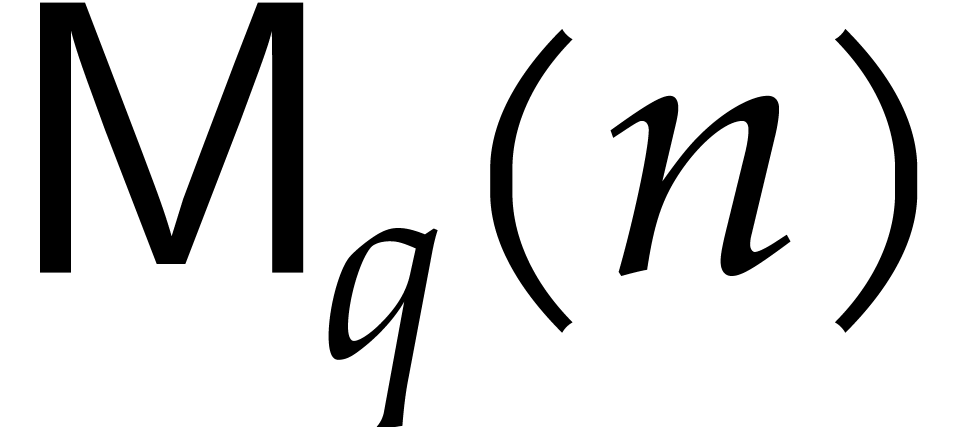
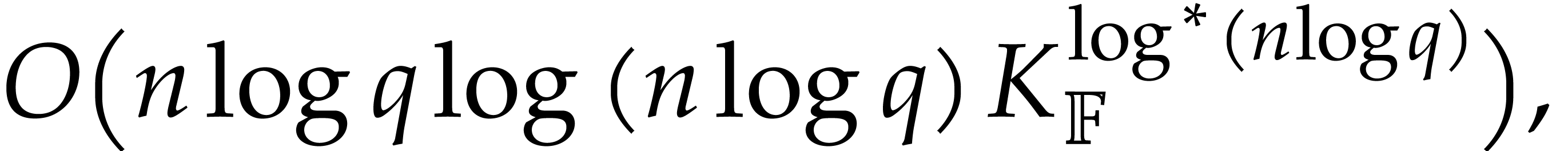

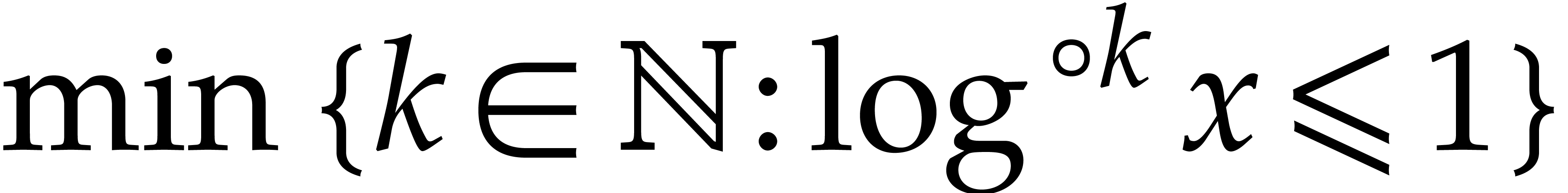
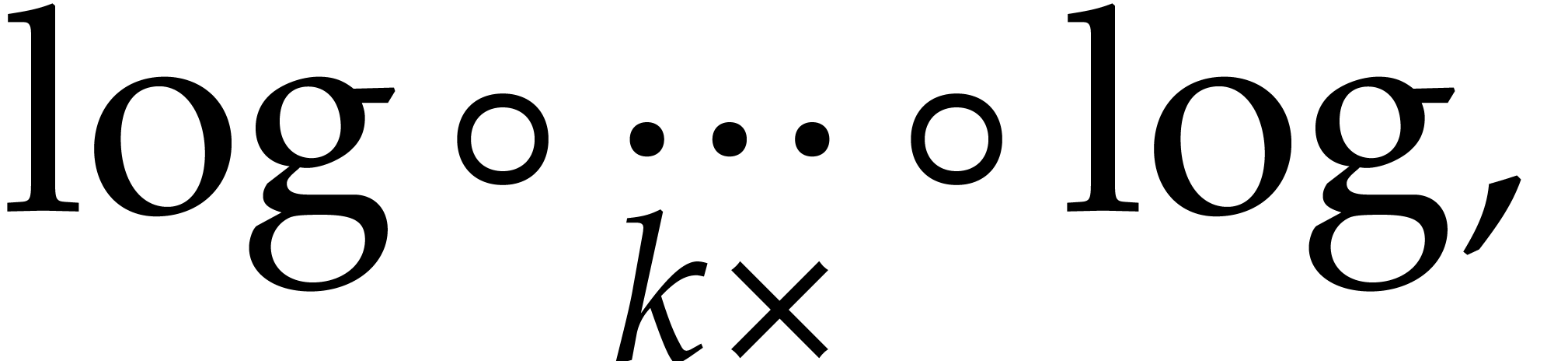
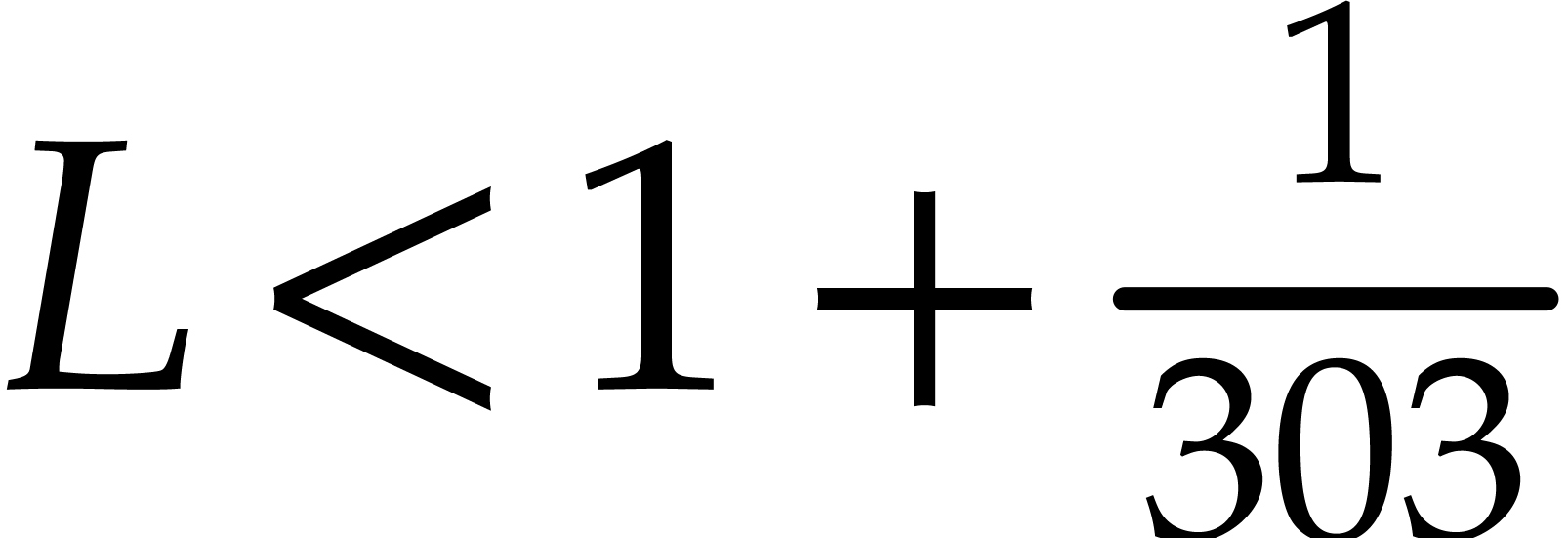 .
.
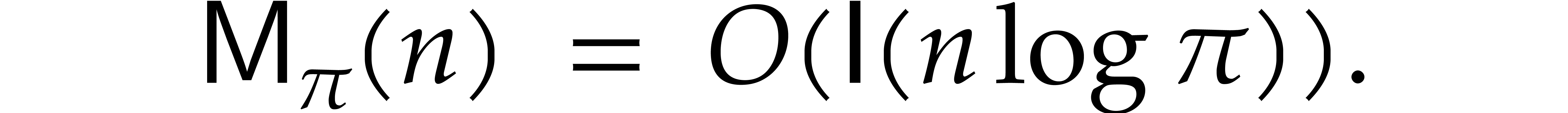
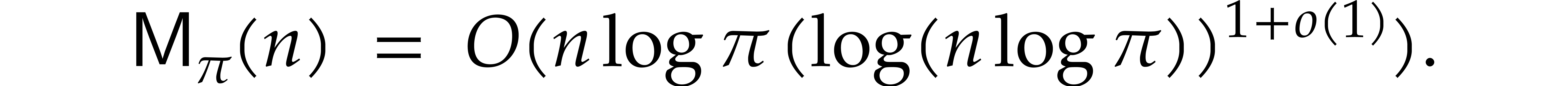
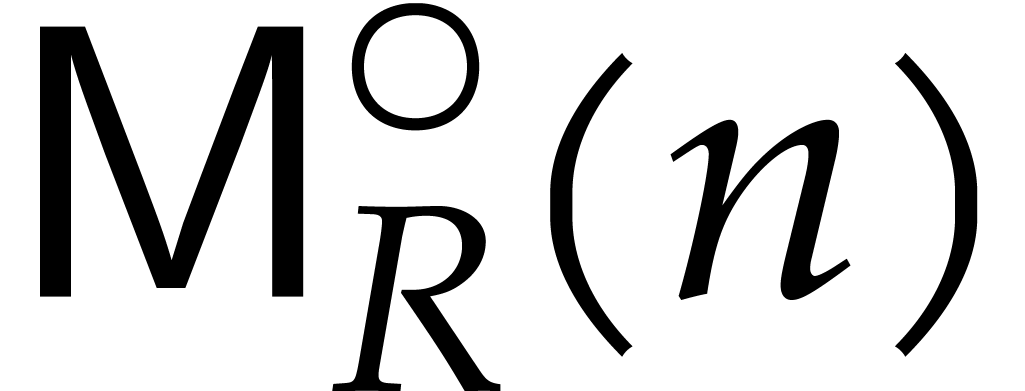
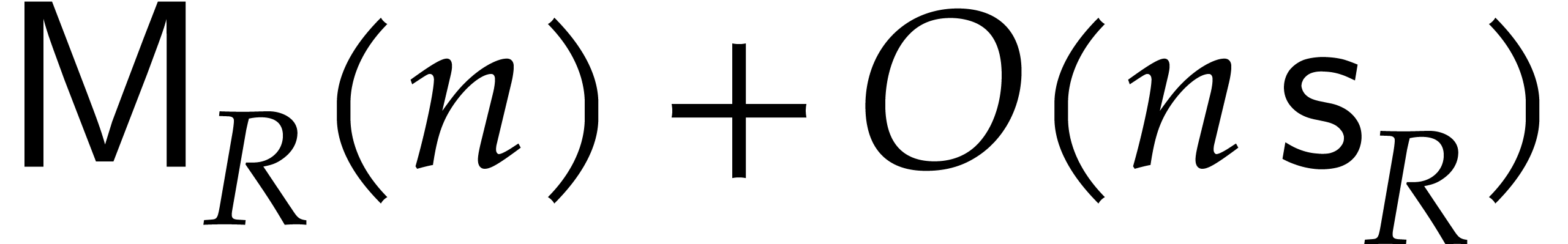
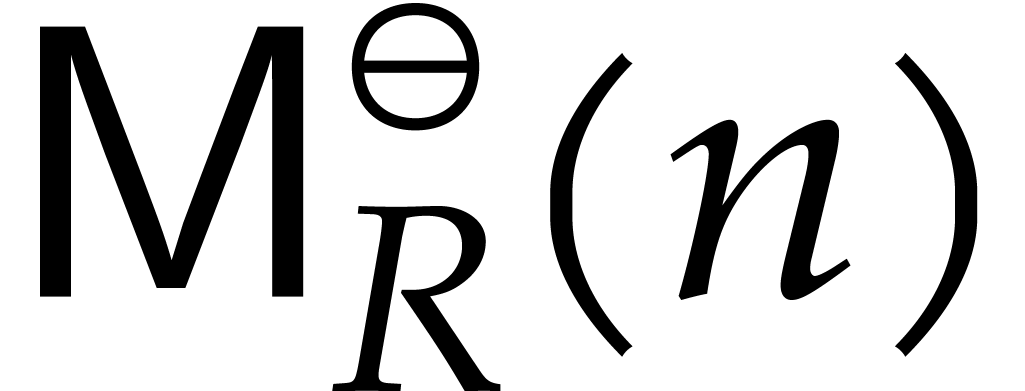
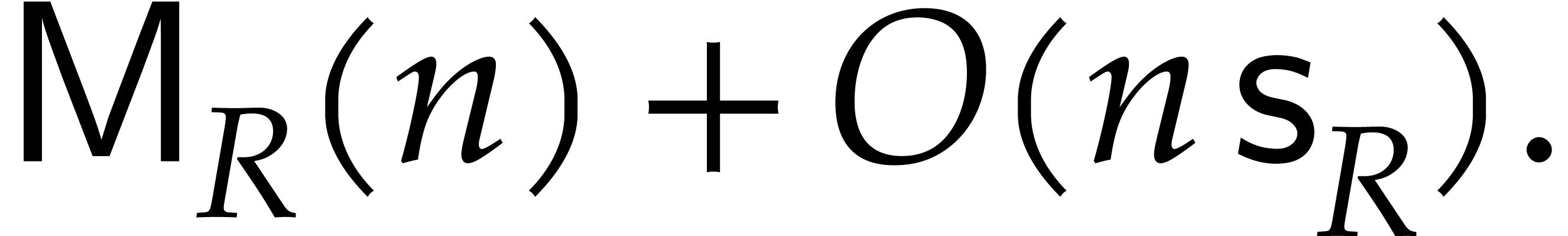
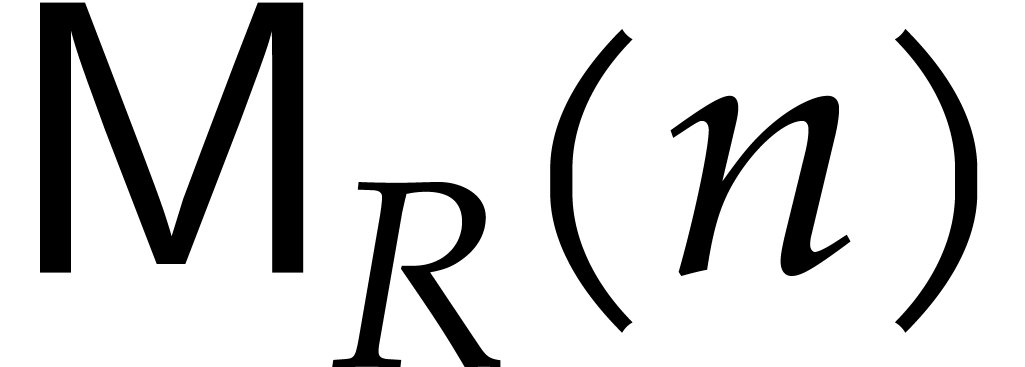
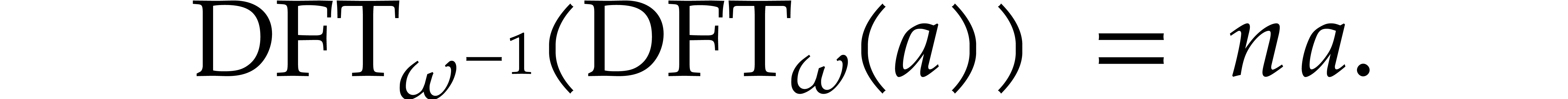
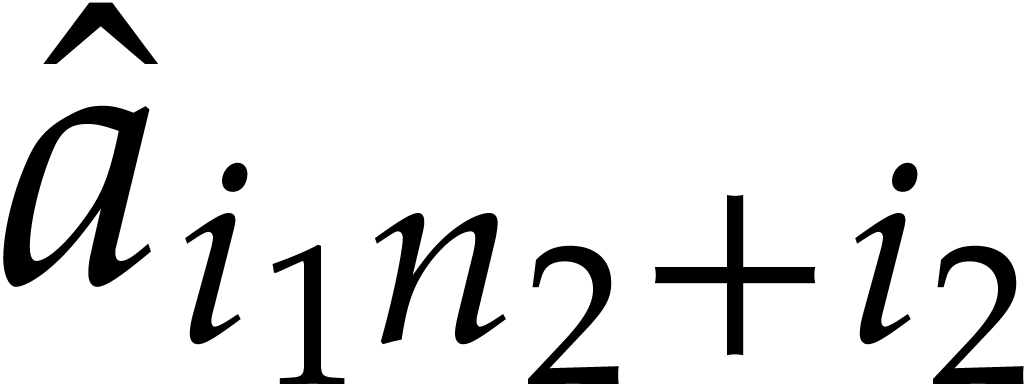
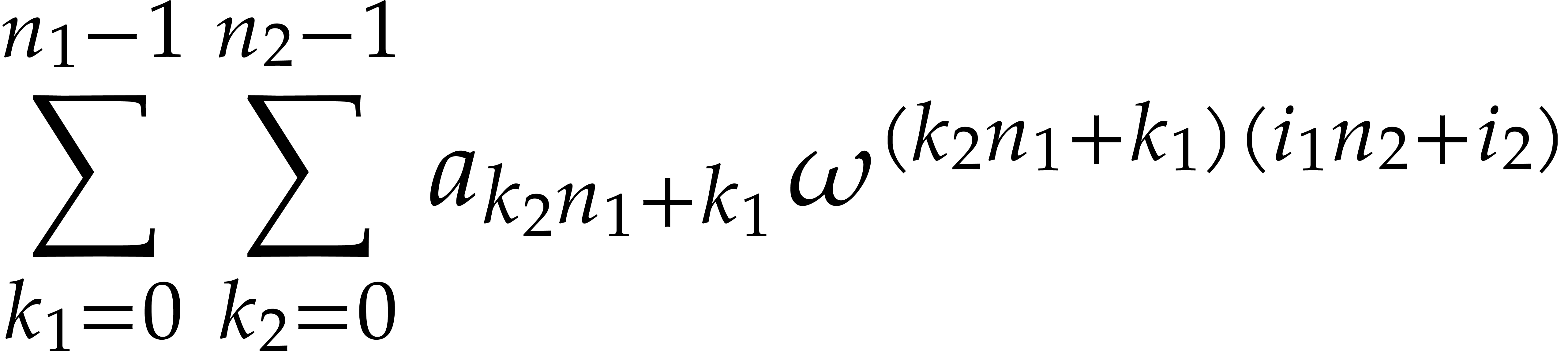
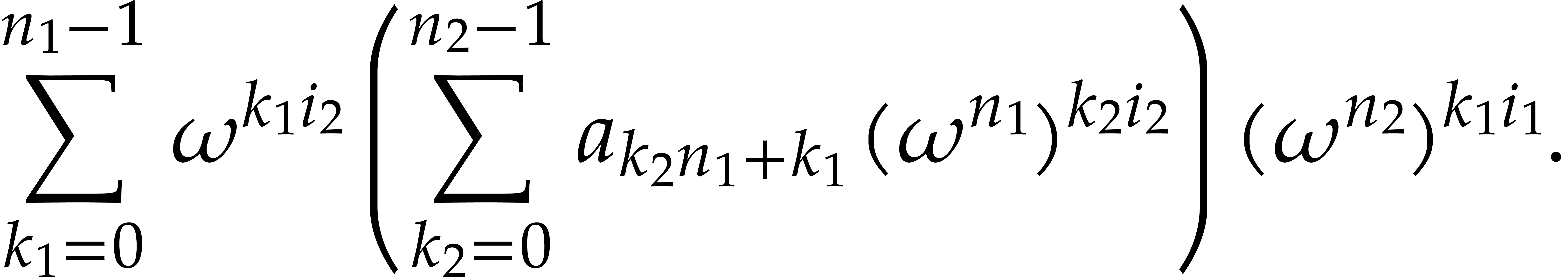
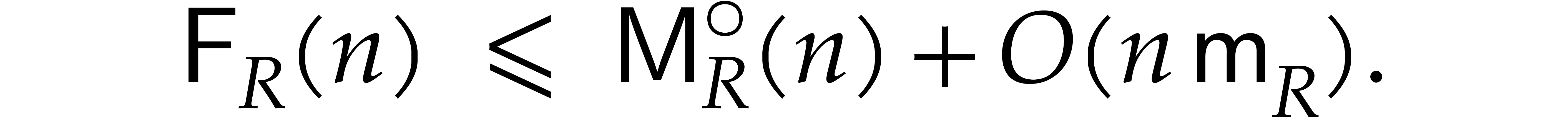
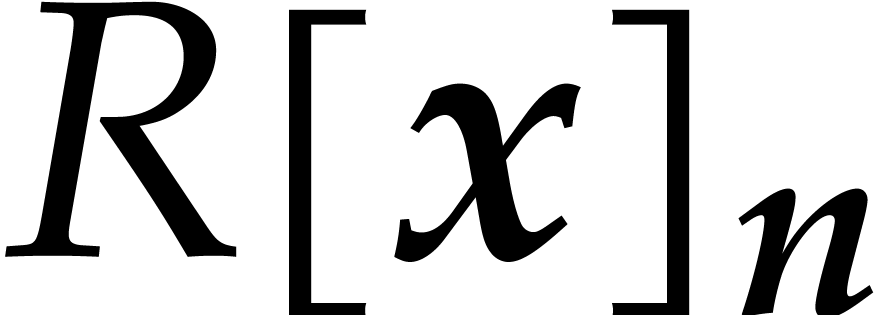
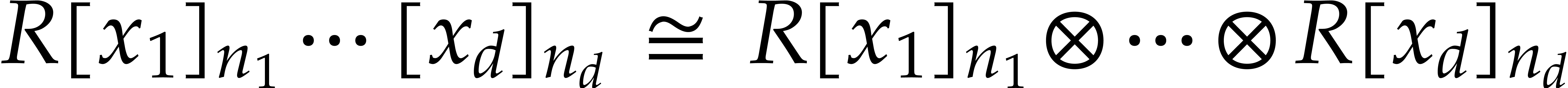
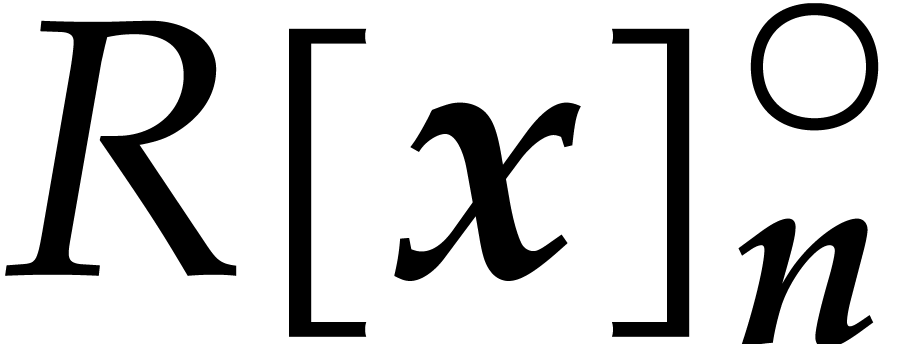
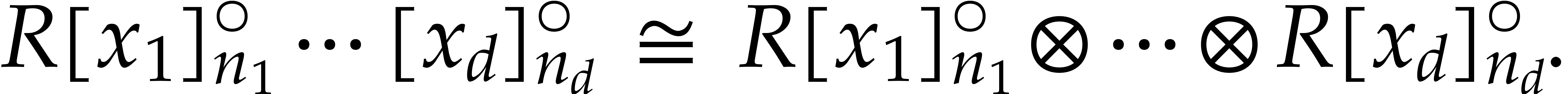
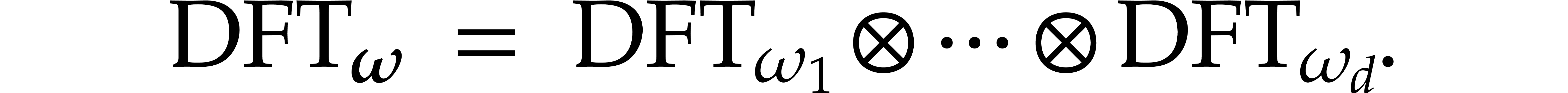
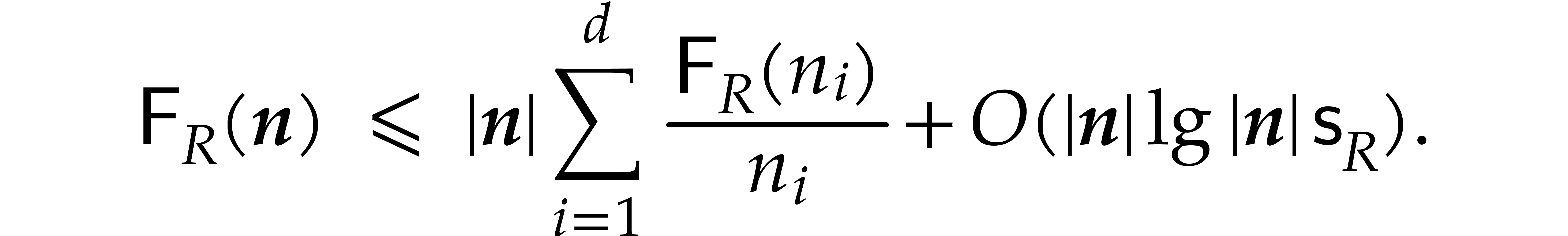
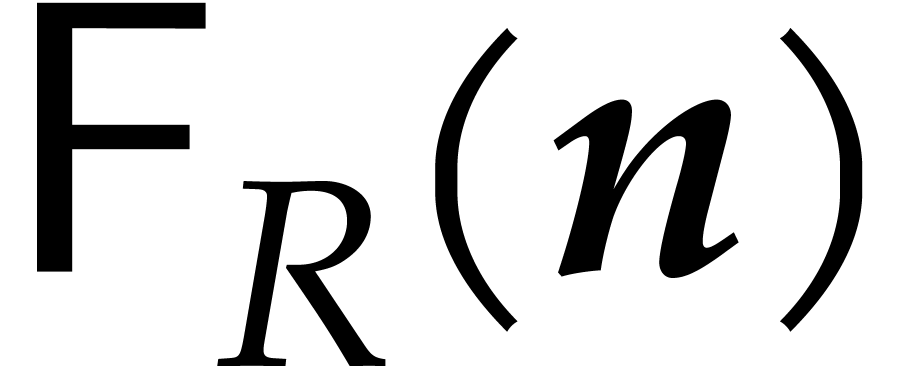
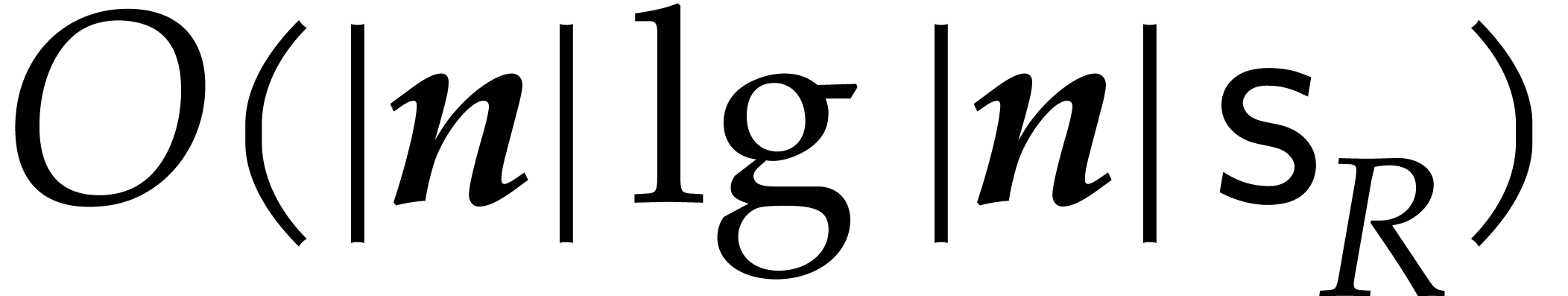
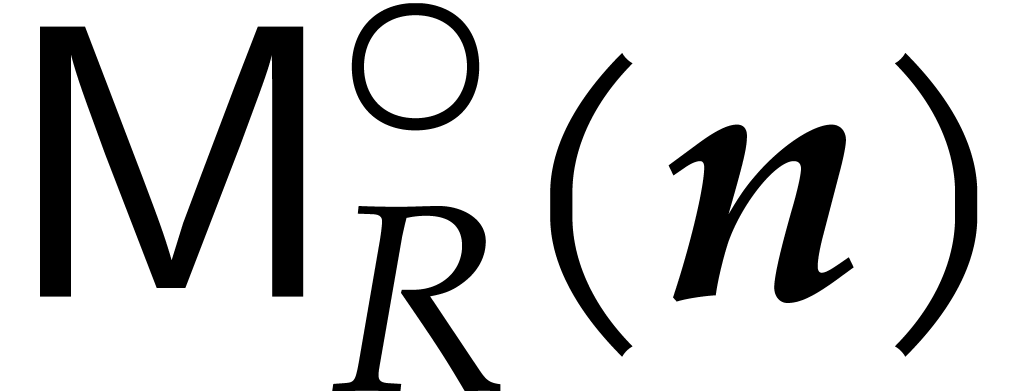
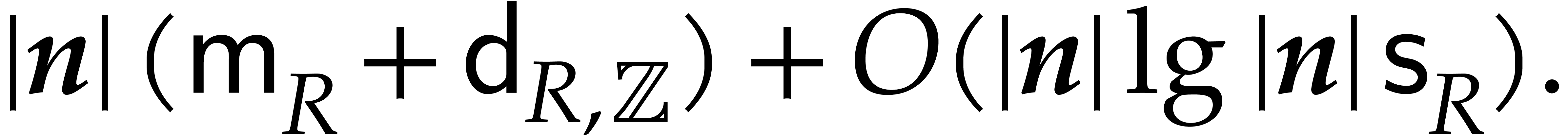
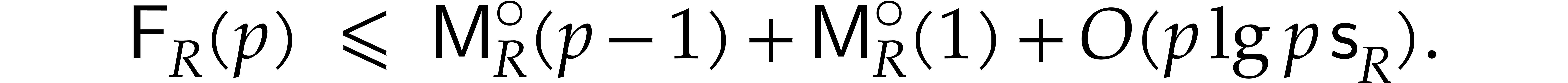
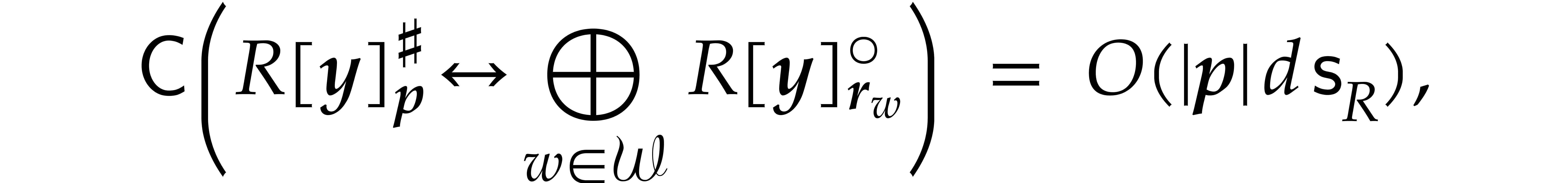
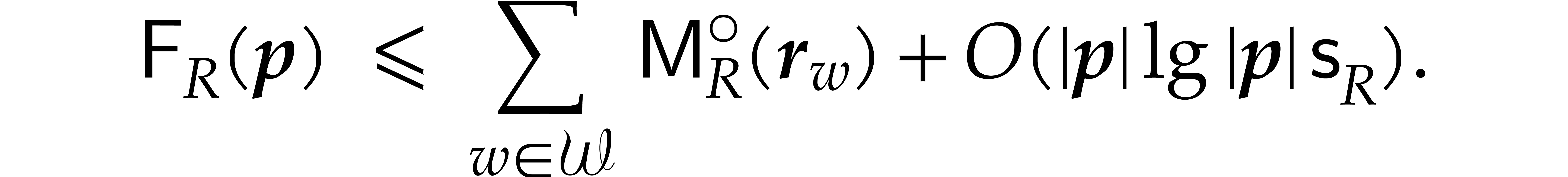
 be a Linnik constant. Then for any
fixed integer
be a Linnik constant. Then for any
fixed integer  ,
,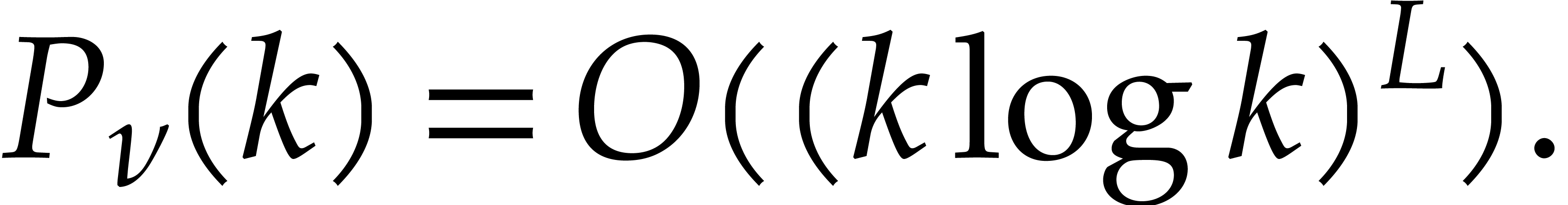
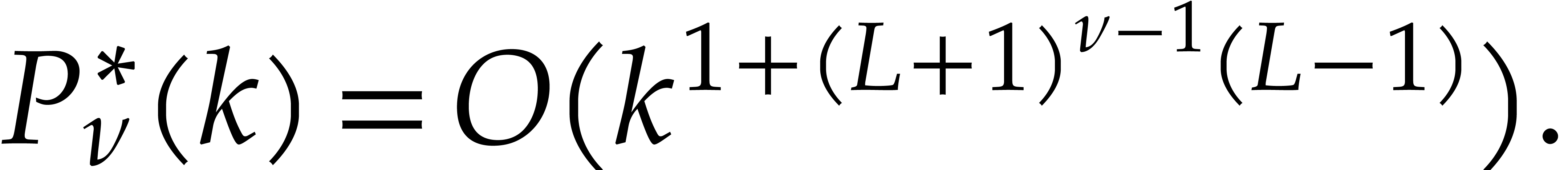
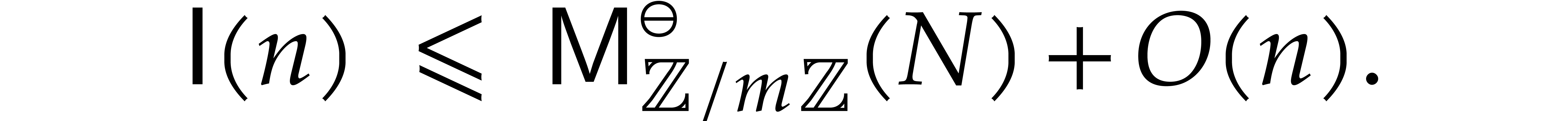
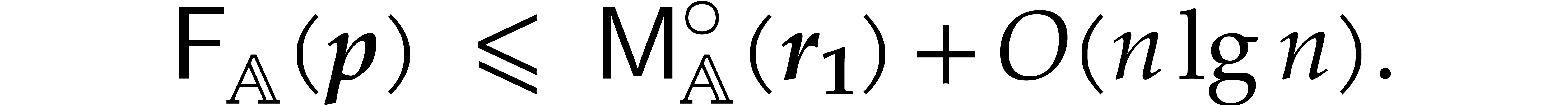

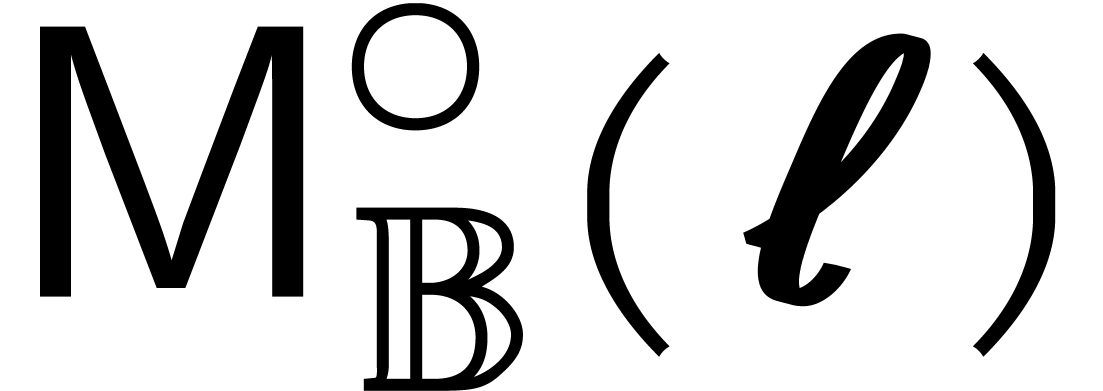
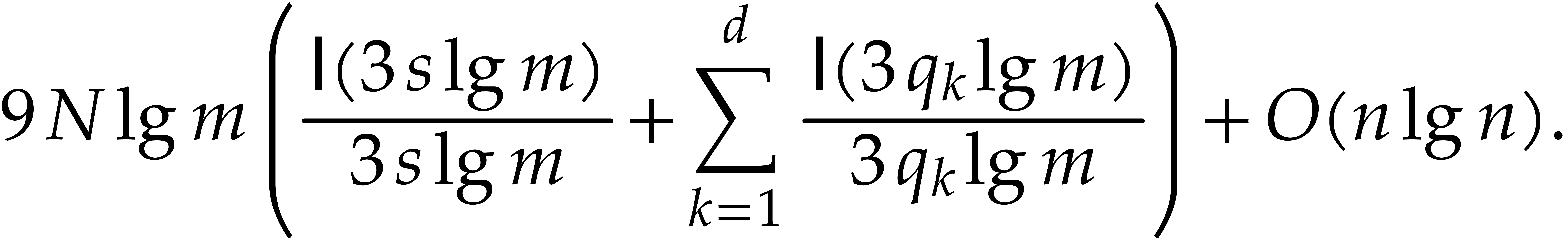
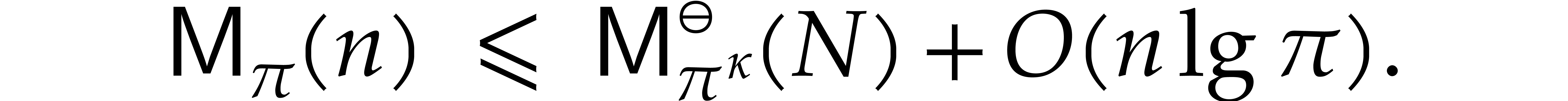
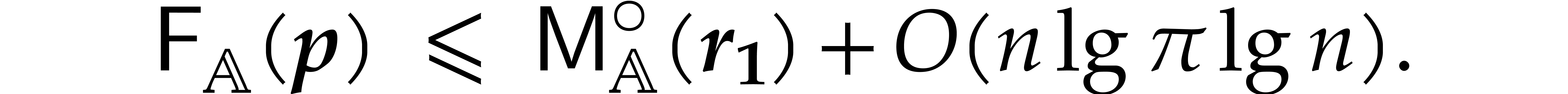
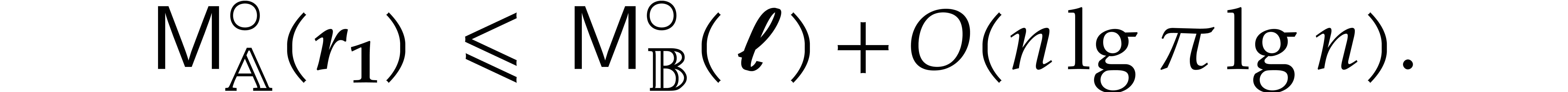
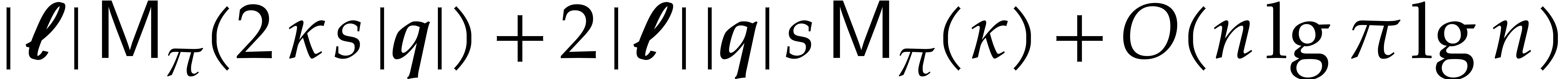
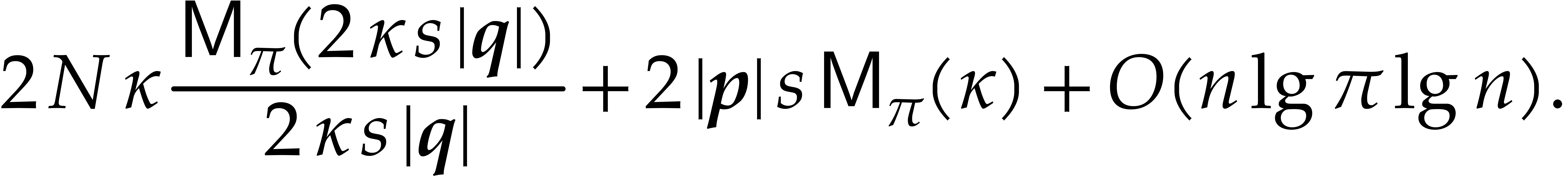
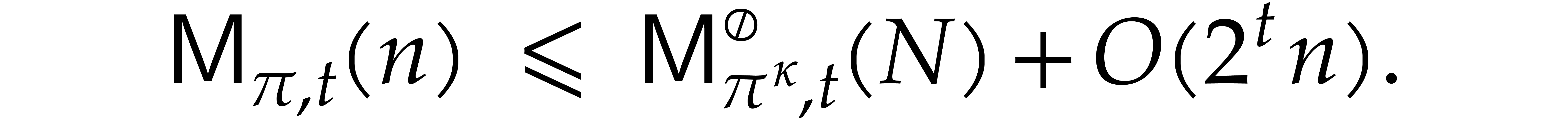
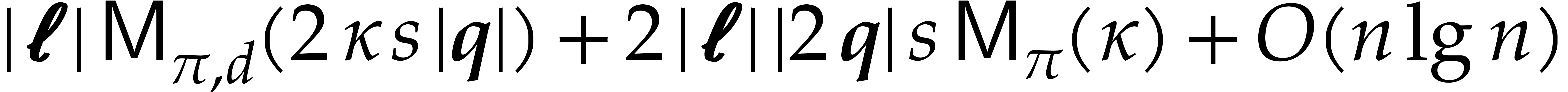
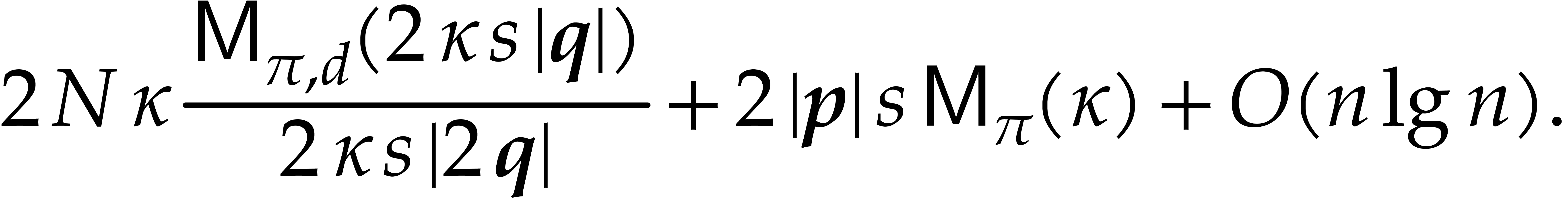
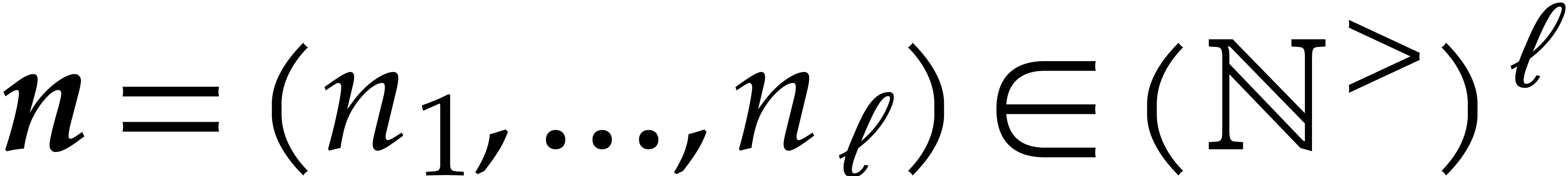 .
.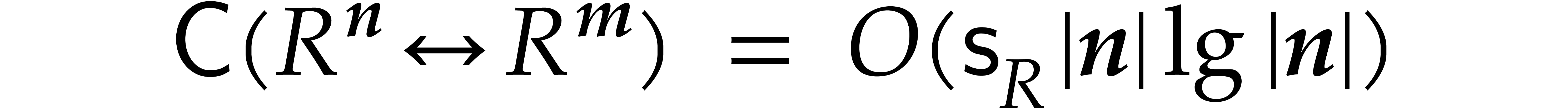 .
.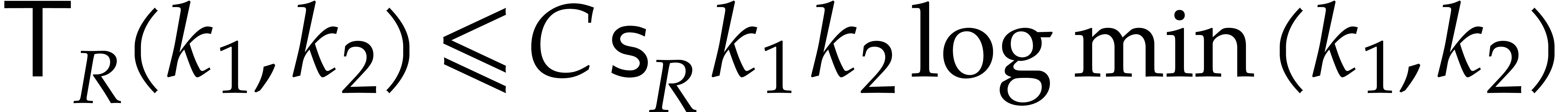
 be relatively prime and
be relatively prime and  .
.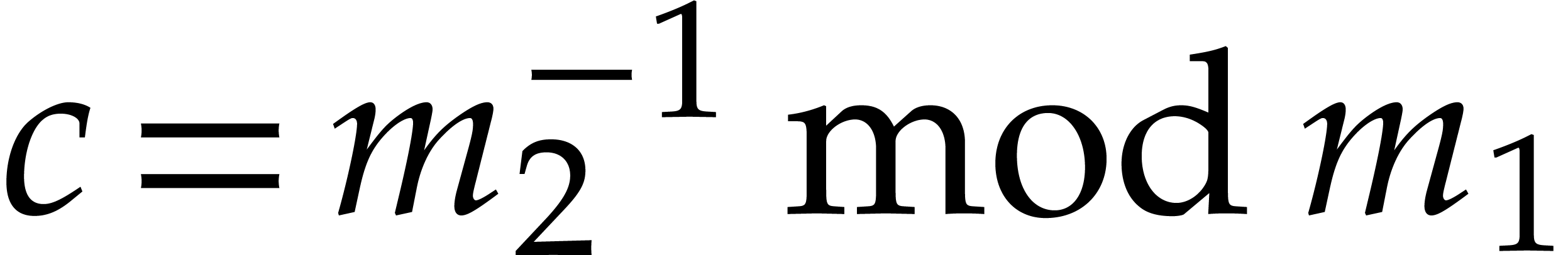
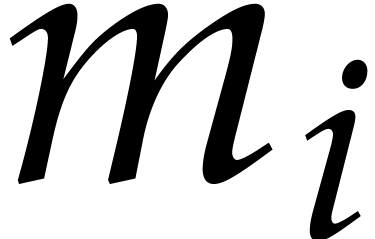 where the
where the  are pairwise coprime. Then
are pairwise coprime. Then
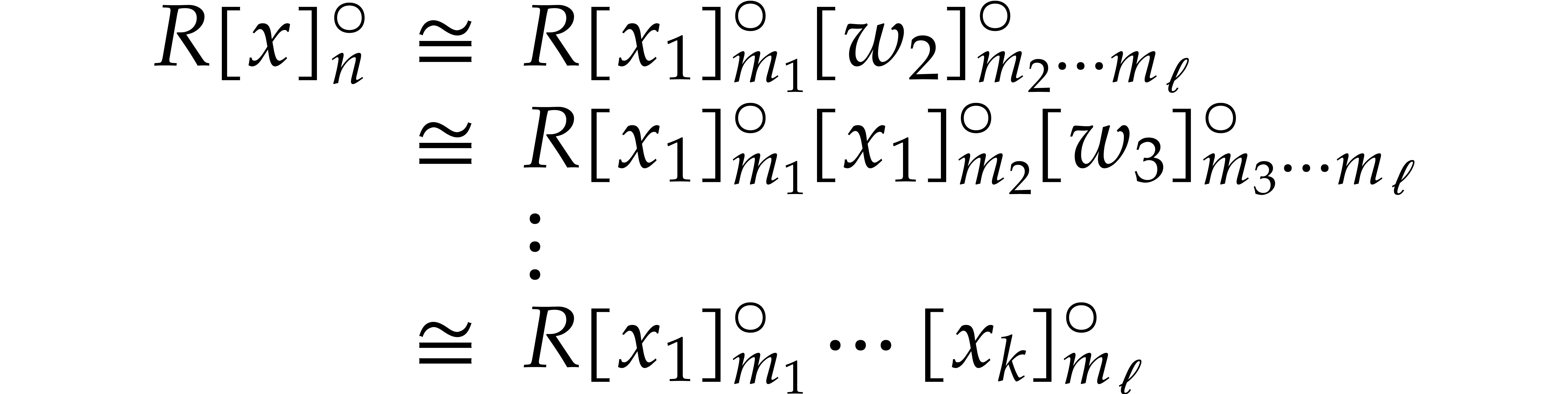
 be
the prime power factorization of each
be
the prime power factorization of each  ,
,
 ,
,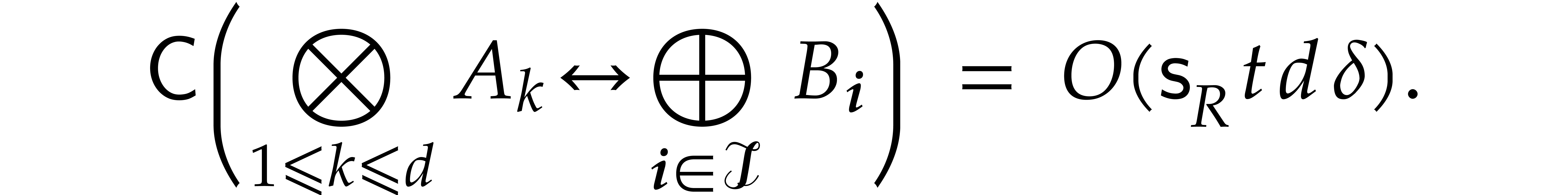 ,
,