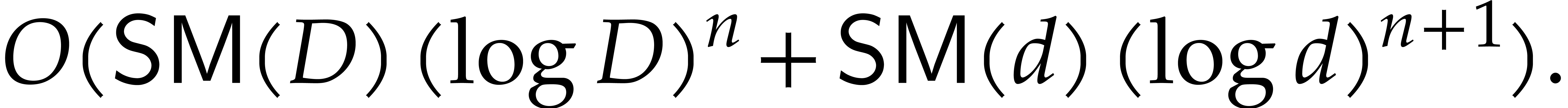| Amortized multi-point evaluation of multivariate polynomials   |
|
| Preliminary version of June 6, 2025 |
|
 . This paper is
part of a project that has received funding from the French
“Agence de l'innovation de défense”.
. This paper is
part of a project that has received funding from the French
“Agence de l'innovation de défense”.
 . This article has
been written using GNU TeXmacs [10].
. This article has
been written using GNU TeXmacs [10].
The evaluation of a polynomial at several points is called the problem of multi-point evaluation. Sometimes, the set of evaluation points is fixed and several polynomials need to be evaluated at this set of points. Several efficient algorithms for this kind of “amortized” multi-point evaluation have been developed recently for the special cases of bivariate polynomials or when the set of evaluation points is generic. In this paper, we extend these results to the evaluation of polynomials in an arbitrary number of variables at an arbitrary set of points. We prove a softly linear complexity bound when the number of variables is fixed. |
Let  be an effective field, so that we have
algorithms for the field operations. Given a polynomial
be an effective field, so that we have
algorithms for the field operations. Given a polynomial 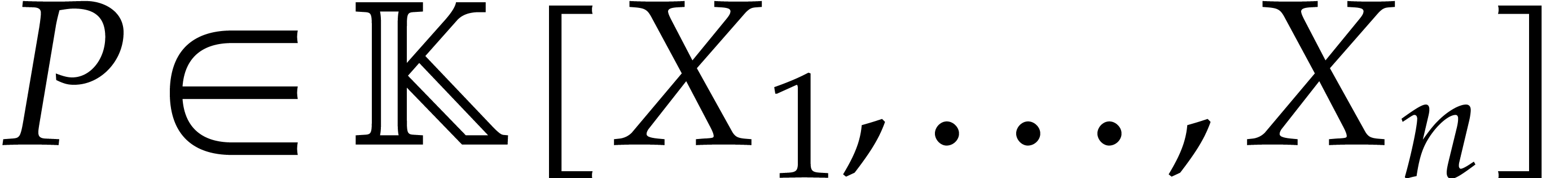 and a tuple
and a tuple  of points, the computation of
of points, the computation of  is called the problem of multi-point
evaluation.
is called the problem of multi-point
evaluation.
This problem naturally occurs in several areas of applied algebra. When solving a polynomial system, multi-point evaluation can for instance be used to check whether all points in a given set are indeed solutions of the system. In [16], we have shown that efficient algorithms for multi-point evaluation actually lead to efficient algorithms for polynomial system solving. Bivariate polynomial evaluation has also been used to compute generator matrices of algebraic geometry error correcting codes [20].
In the univariate case when 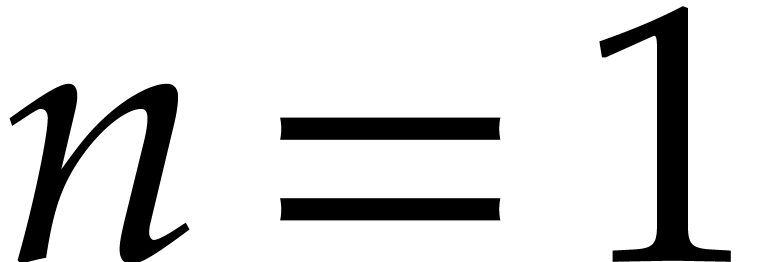 ,
it is well known that one may use so-called “remainder
trees” to compute multi-point evaluations in quasi-optimal time
[1, 2, 4, 8, 22]. More precisely, if
,
it is well known that one may use so-called “remainder
trees” to compute multi-point evaluations in quasi-optimal time
[1, 2, 4, 8, 22]. More precisely, if 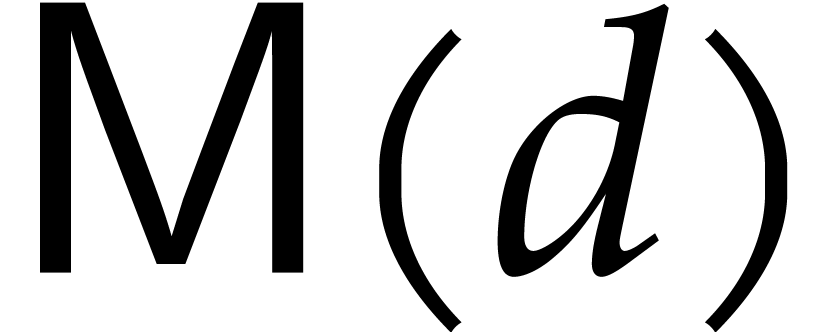 stands for the
cost to multiply two univariate polynomials of degree
stands for the
cost to multiply two univariate polynomials of degree 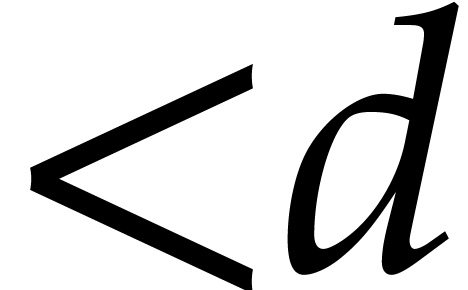 (in terms of the number of field operations in ), then the multi-point evaluation of a polynomial
of degree at
(in terms of the number of field operations in ), then the multi-point evaluation of a polynomial
of degree at  points can
be computed in time
points can
be computed in time 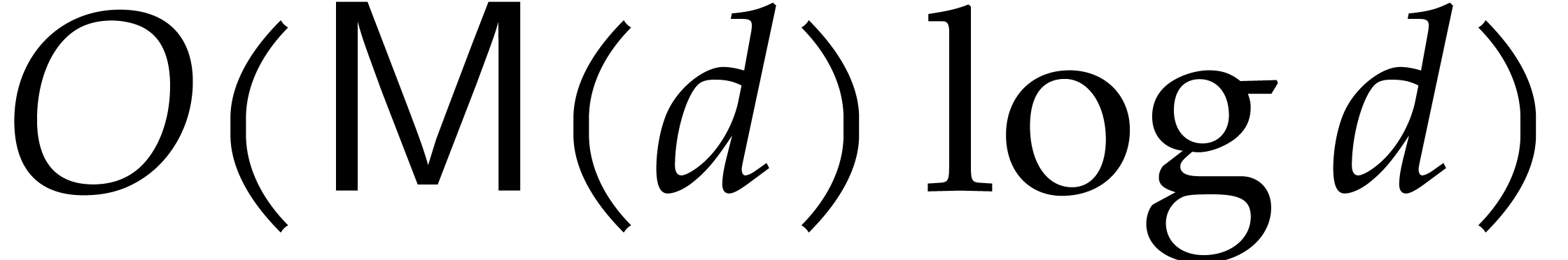 . Using a
variant of the Schönhage–Strassen algorithm [3,
27, 28], it is well known that
. Using a
variant of the Schönhage–Strassen algorithm [3,
27, 28], it is well known that 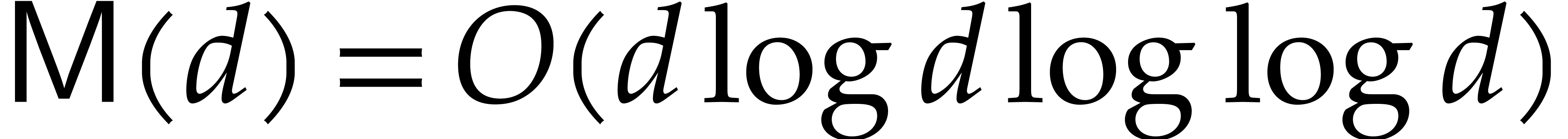 . If we restrict our attention to fields of positive characteristic, then we may take
. If we restrict our attention to fields of positive characteristic, then we may take 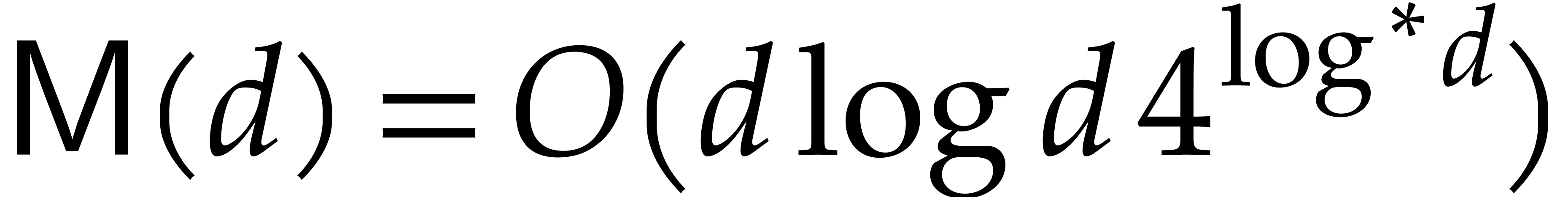 [5] and conjecturally even
[5] and conjecturally even 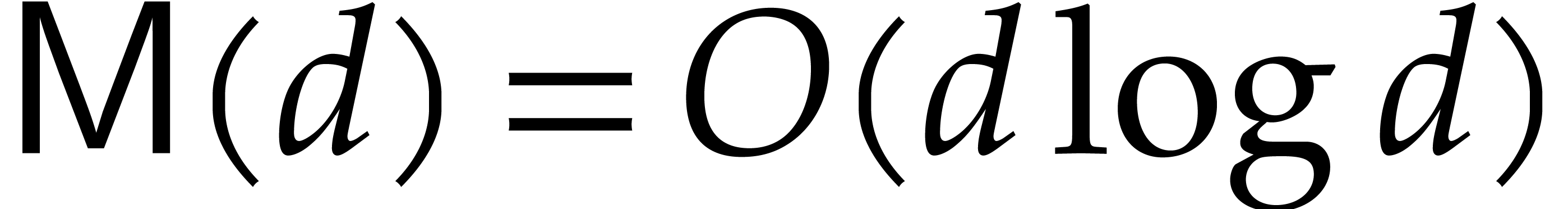 [6]. In the remainder of this paper, we make
the customary hypothesis that
[6]. In the remainder of this paper, we make
the customary hypothesis that 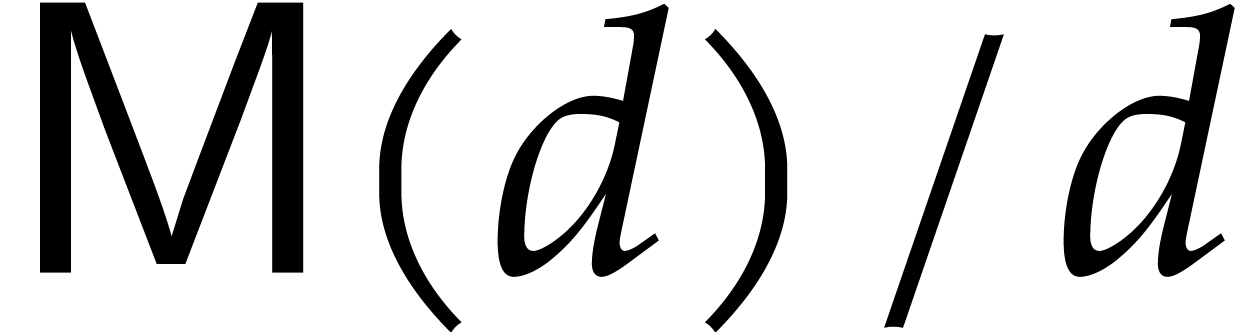 is a
non-decreasing function in .
is a
non-decreasing function in .
Currently, the fastest general purpose algorithm for multivariate
multi-point evaluation is based on the “baby-step
giant-step” method; see e.g. [12,
section 3]. For a fixed dimension 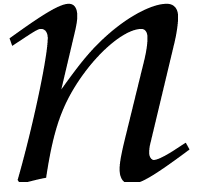 and
and 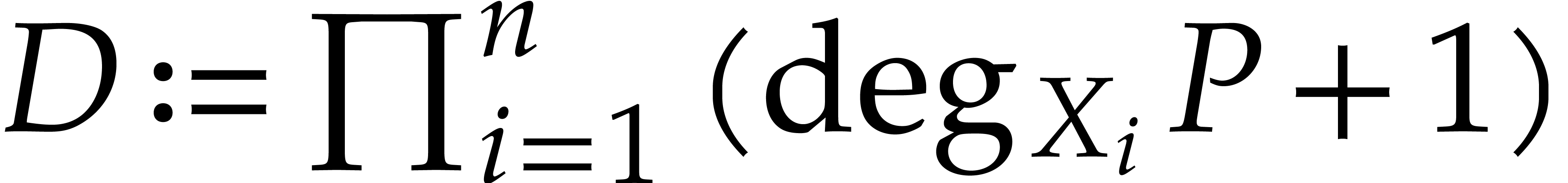 such that
such that  ,
this method requires
,
this method requires 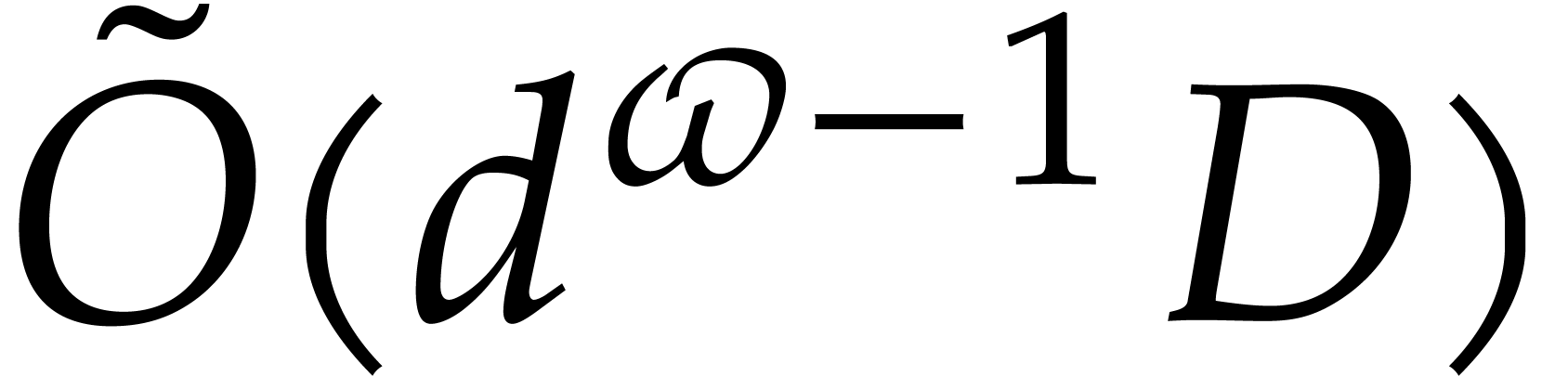 operations in (e.g. by taking
operations in (e.g. by taking 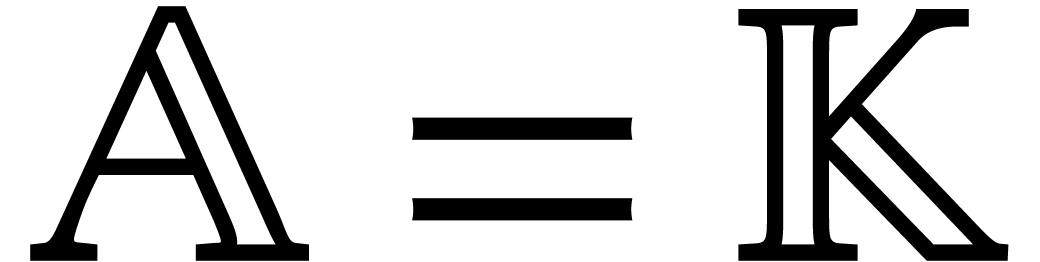 and
and
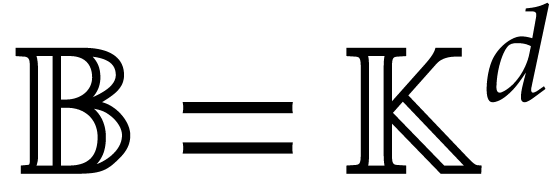 in [12, Proposition 3.3]). Here
in [12, Proposition 3.3]). Here
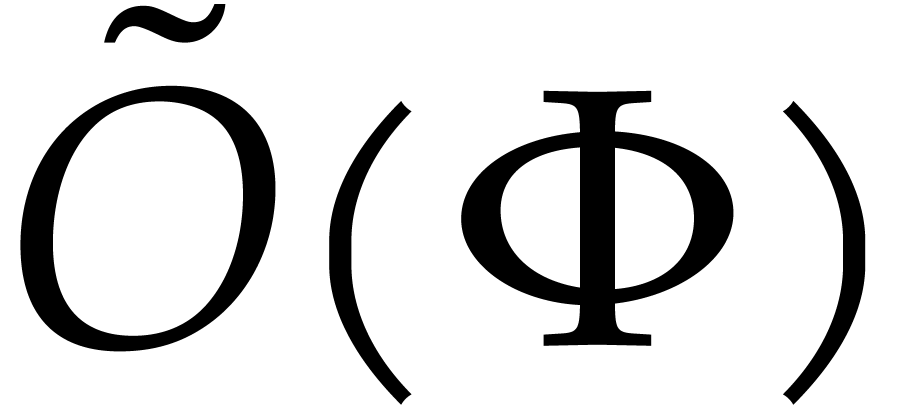 is a common abbreviation for
is a common abbreviation for 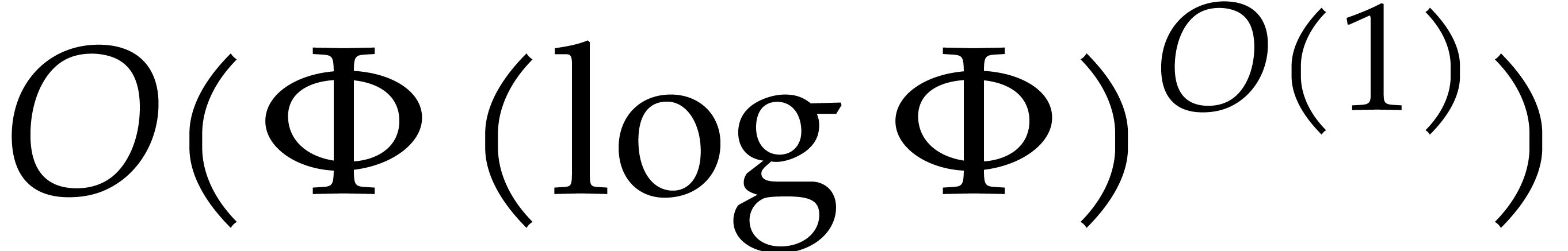 , and
, and 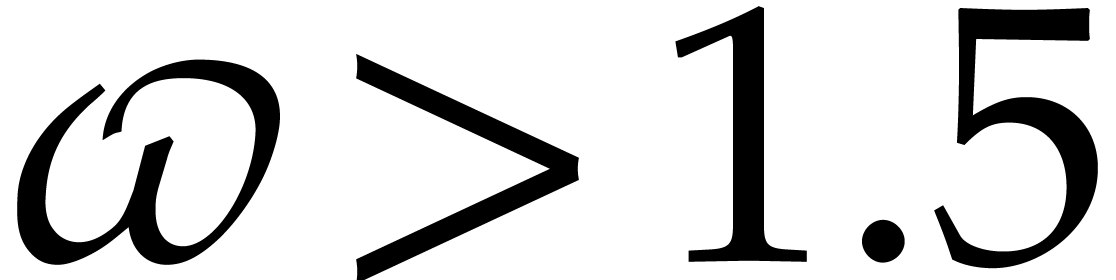 is a constant
such that two
is a constant
such that two  and
and 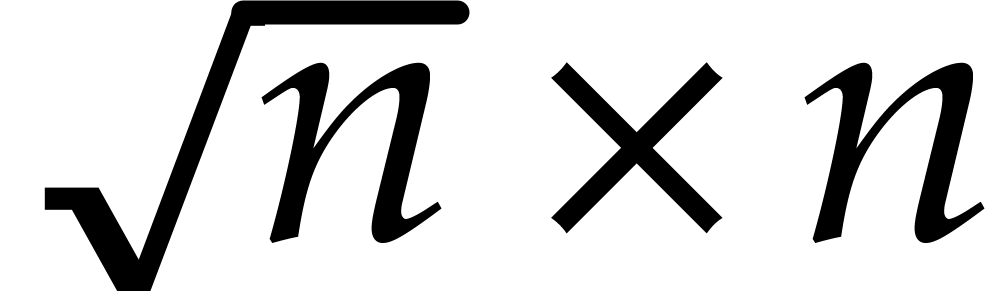 matrices with coefficients in can be multiplied
using
matrices with coefficients in can be multiplied
using 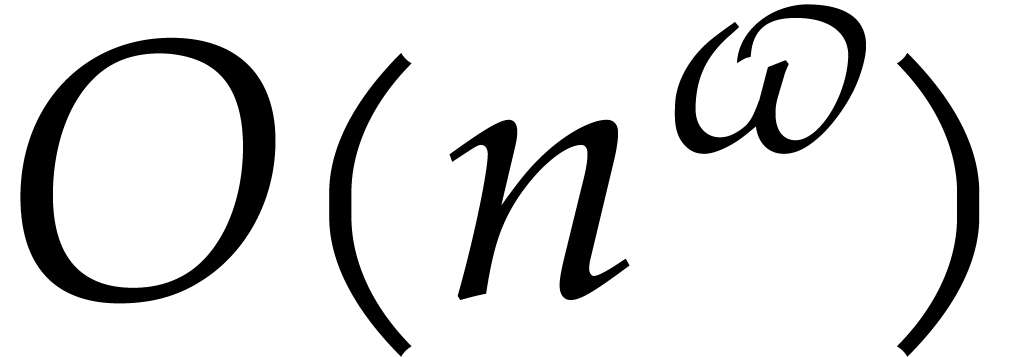 operations in . The best known theoretical bound is
operations in . The best known theoretical bound is 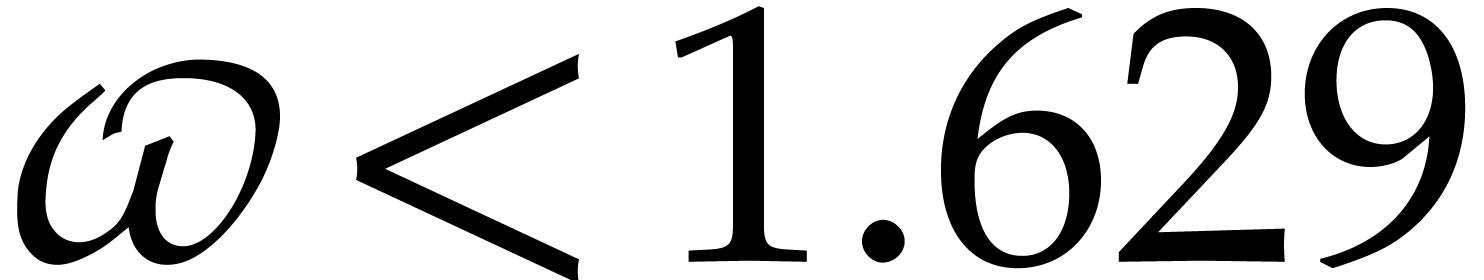 [21, Table 2, half of the upper bound for
[21, Table 2, half of the upper bound for
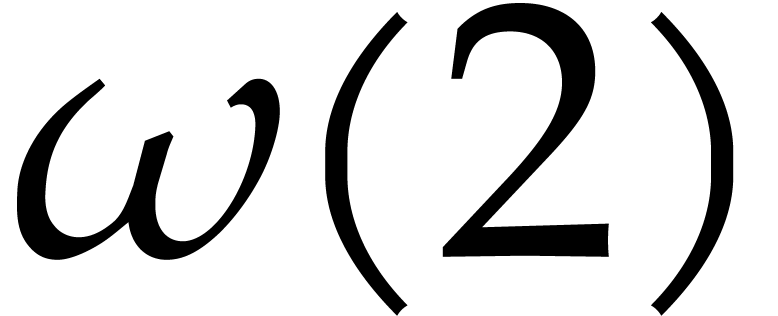 ] (combined with the tensor
permutation lemma [17, Corollary 7]). In the special case
when
] (combined with the tensor
permutation lemma [17, Corollary 7]). In the special case
when 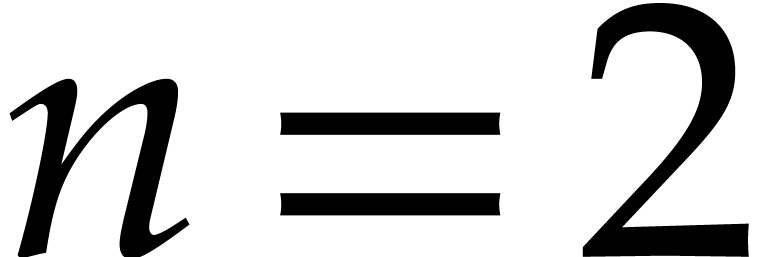 ,
, 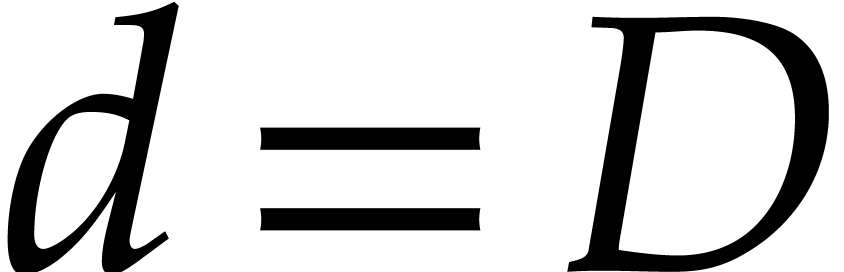 , and
, and 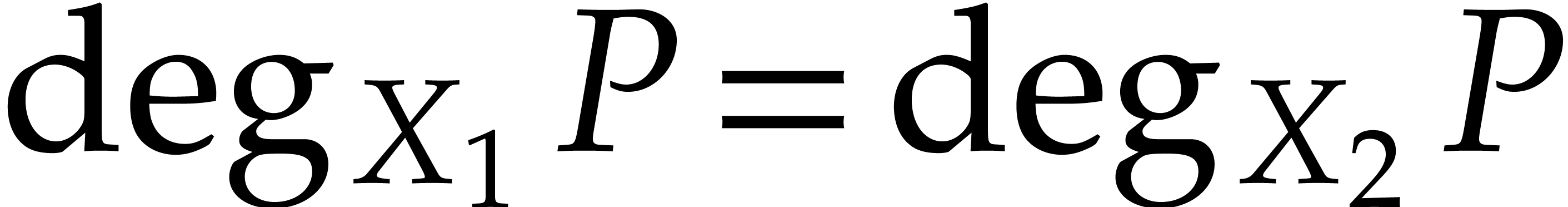 ,
Nüsken and Ziegler proved the sharper bound
,
Nüsken and Ziegler proved the sharper bound 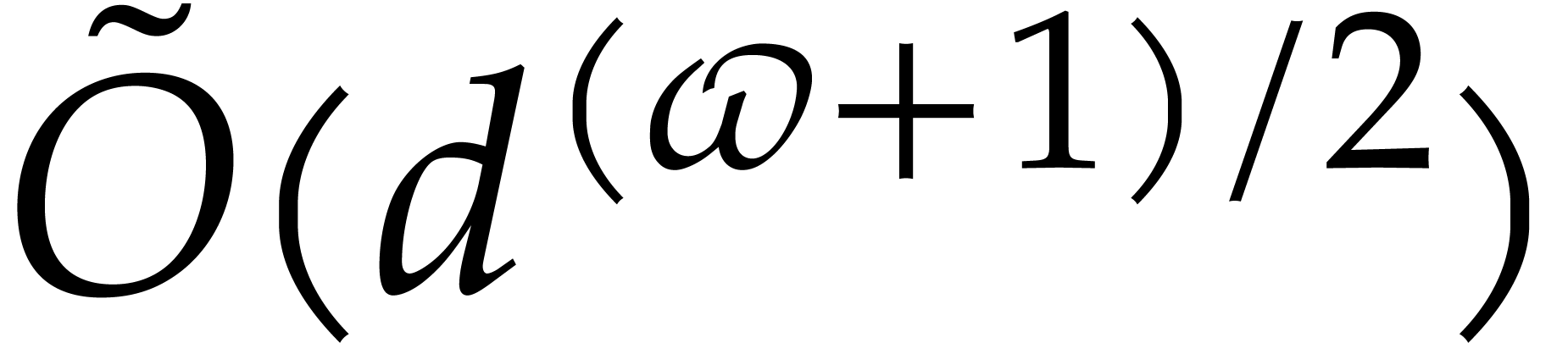 [24, particular case of Result 4].
[24, particular case of Result 4].
In 2008, Kedlaya and Umans achieved a major breakthrough [18,
19]. On the one hand, they gave an algorithm of complexity
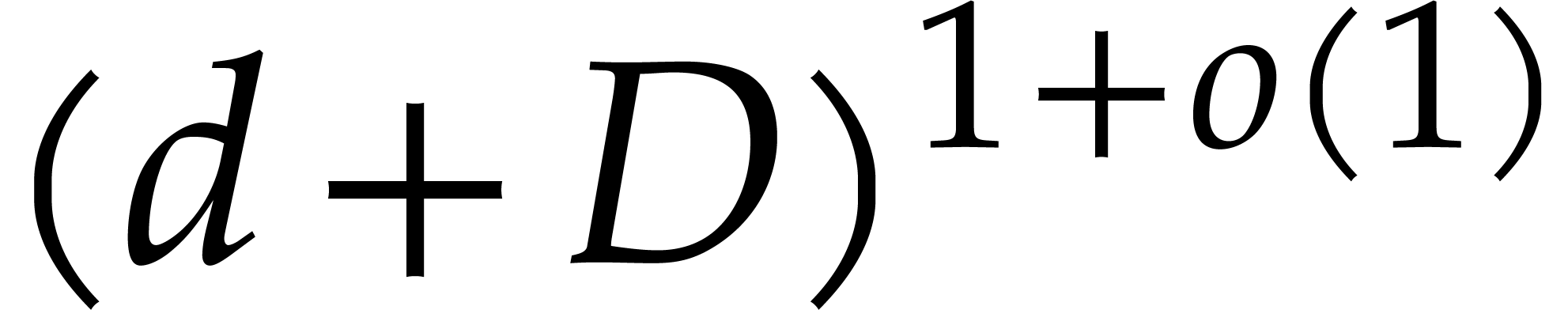 for the case when has
positive characteristic. On the other hand, they gave algorithms for
multi-point evaluations over
for the case when has
positive characteristic. On the other hand, they gave algorithms for
multi-point evaluations over 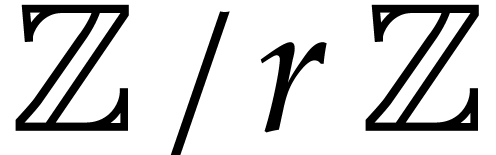 with quasi-optimal
bit-complexity exponents. Unfortunately, to the best of our knowledge,
these algorithms do not seem suitable for practical purposes, as
observed in [13, Conclusion]. Even in the case when the
dimension is fixed, we also note that the
algorithms by Kedlaya and Umans do not achieve a smoothly linear
complexity of the form
with quasi-optimal
bit-complexity exponents. Unfortunately, to the best of our knowledge,
these algorithms do not seem suitable for practical purposes, as
observed in [13, Conclusion]. Even in the case when the
dimension is fixed, we also note that the
algorithms by Kedlaya and Umans do not achieve a smoothly linear
complexity of the form 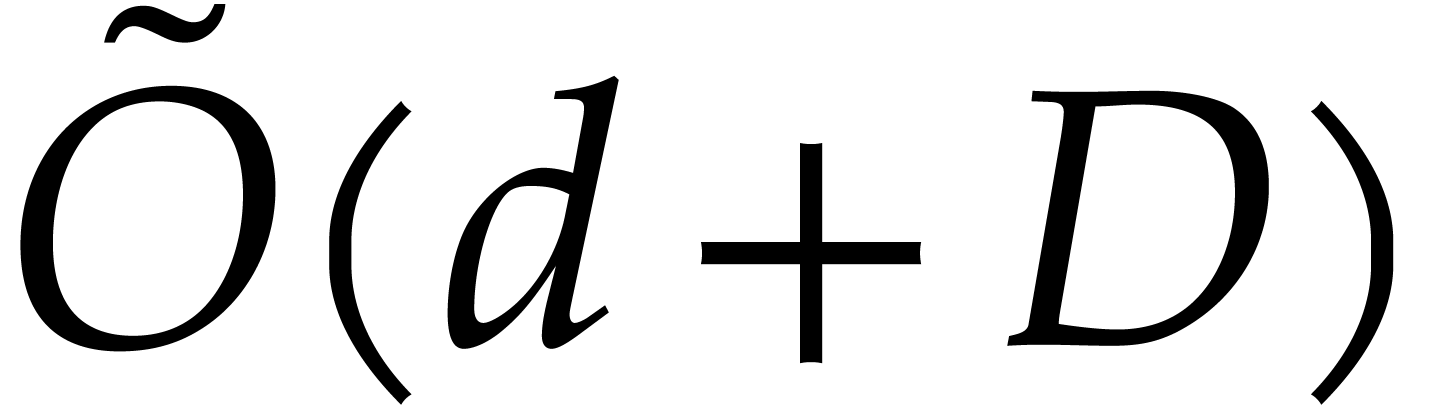 .
.
Recently, several algorithms have been proposed for multi-point
evaluation in the case when  is a fixed tuple of
points [15, 23]. These algorithms are
amortized in the sense that we allow for potentially expensive
precomputations as a function of .
The algorithms from [15, 23] are both
restricted to the case when is sufficiently
generic, whereas [14, 23] focus on the
bivariate case . In the
present paper, we deal with the general case when both
and are arbitrary. Our main result is the
following:
is a fixed tuple of
points [15, 23]. These algorithms are
amortized in the sense that we allow for potentially expensive
precomputations as a function of .
The algorithms from [15, 23] are both
restricted to the case when is sufficiently
generic, whereas [14, 23] focus on the
bivariate case . In the
present paper, we deal with the general case when both
and are arbitrary. Our main result is the
following:
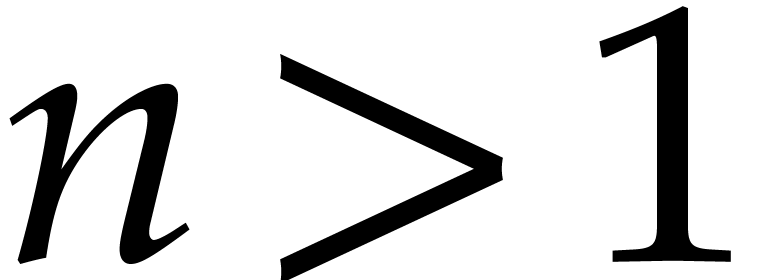 be a fixed dimension and let
be a fixed dimension and let 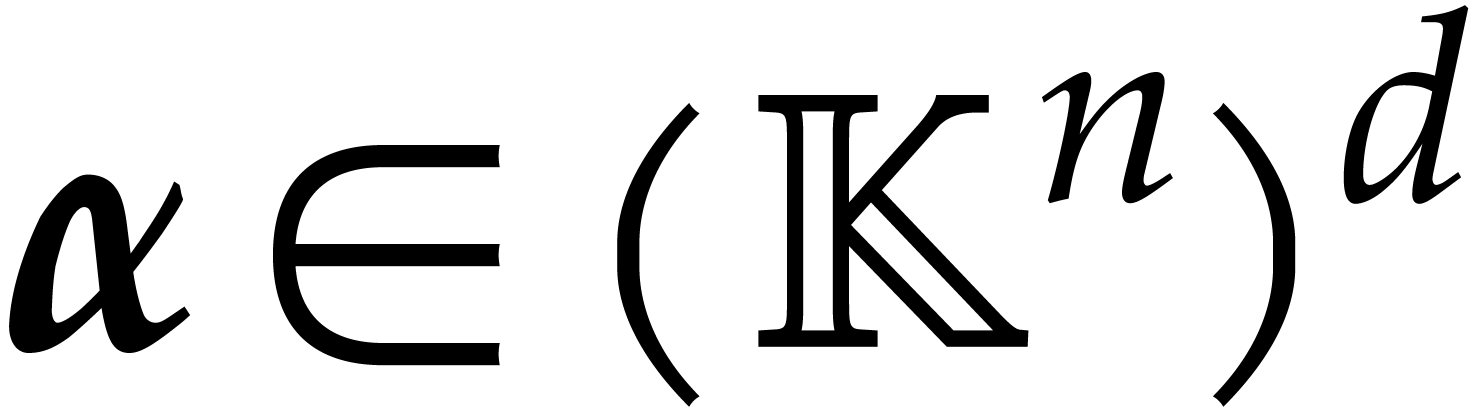 be a fixed set of points. Then, given a polynomial
with
be a fixed set of points. Then, given a polynomial
with 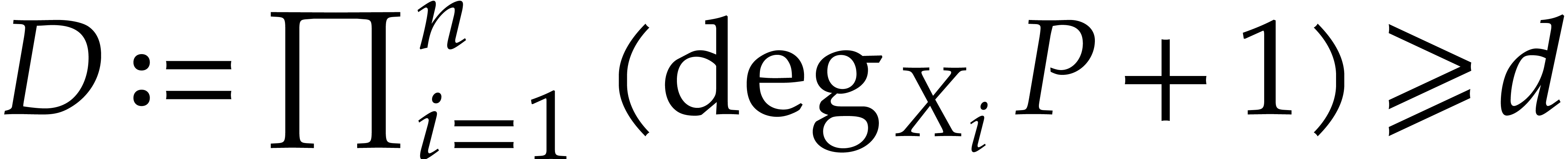 and an element of
and an element of
 of multiplicative order at least
of multiplicative order at least 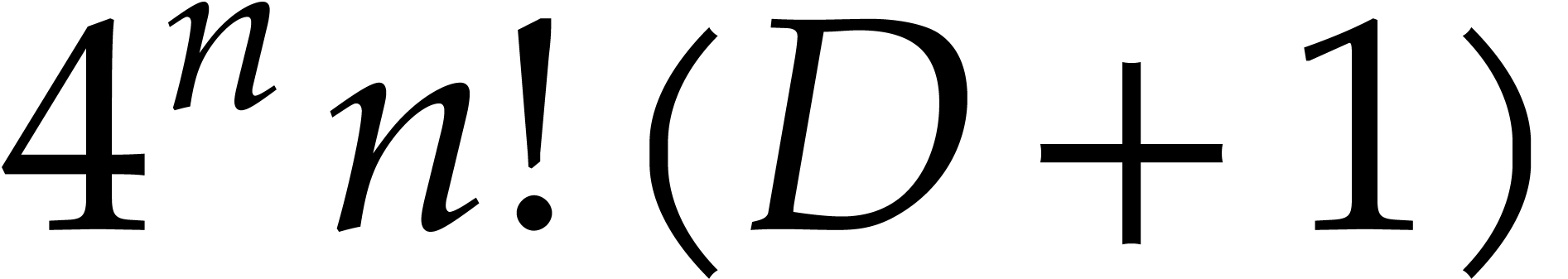 , we can compute
, we can compute 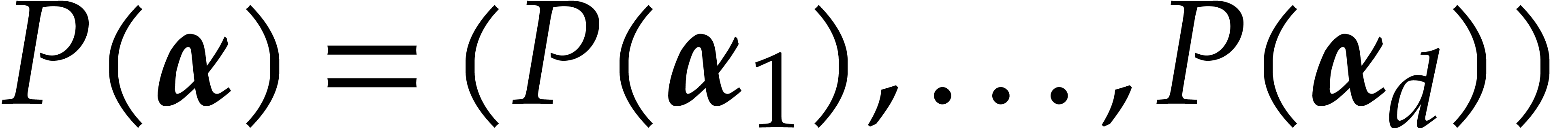 using
using
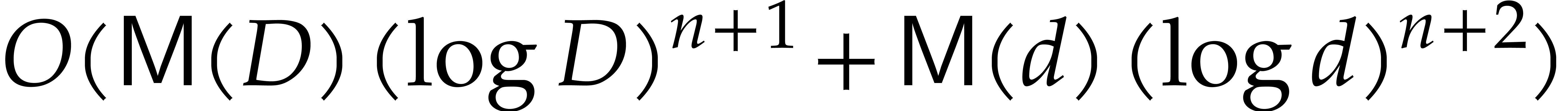
operations in .
Remark  ,
, 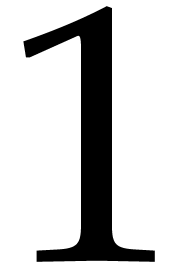 , and
, and
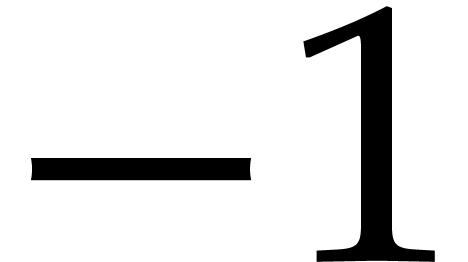 has infinite order. For finite fields
has infinite order. For finite fields 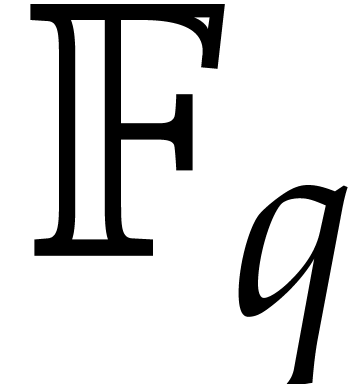 , working in an algebraic extension
, working in an algebraic extension
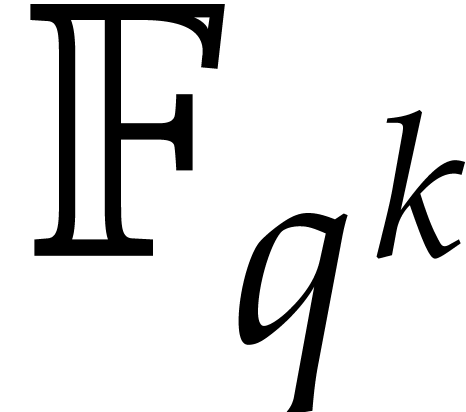 yields elements of order up to
yields elements of order up to 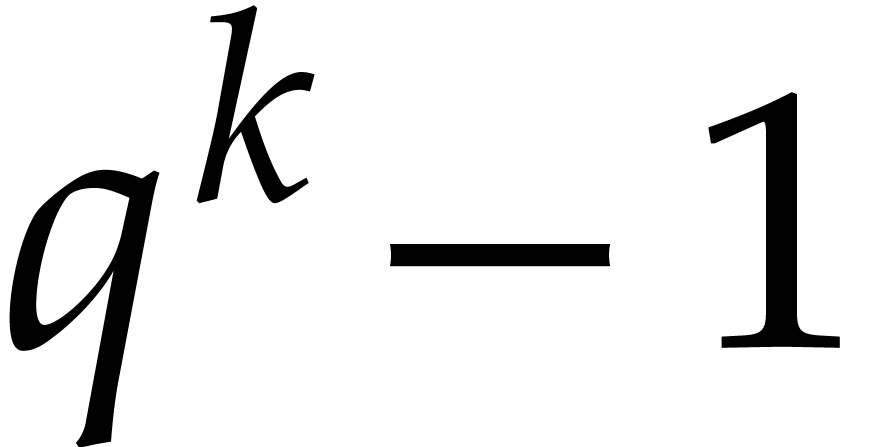 . Replacing by such an
extension induces an additional overhead of
. Replacing by such an
extension induces an additional overhead of 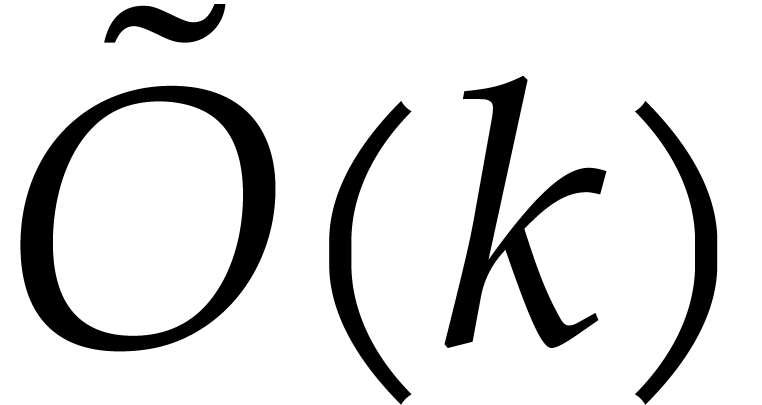 in
our complexity bound.
in
our complexity bound.
As in the generic case from [15], our algorithm heavily
relies on the relaxed algorithm for polynomial reduction from [9].
Given polynomials  , the
reduction algorithm computes
, the
reduction algorithm computes 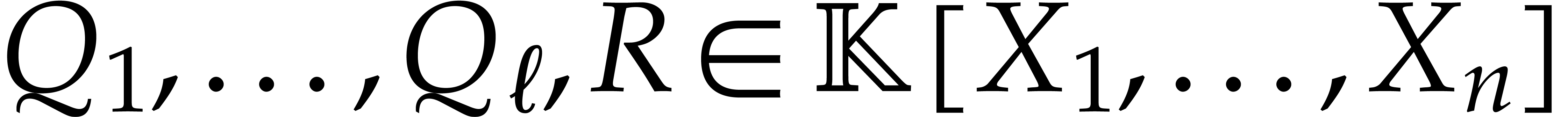 with
with
where  is reduced with respect to some admissible
ordering
is reduced with respect to some admissible
ordering  on monomials. The relaxed algorithm
from [9] essentially performs this reduction with the same
complexity (up to a logarithmic factor) as checking the relation.
on monomials. The relaxed algorithm
from [9] essentially performs this reduction with the same
complexity (up to a logarithmic factor) as checking the relation.
For our application to multi-point evaluation, the idea is to pick the
polynomials  in the vanishing ideal
in the vanishing ideal
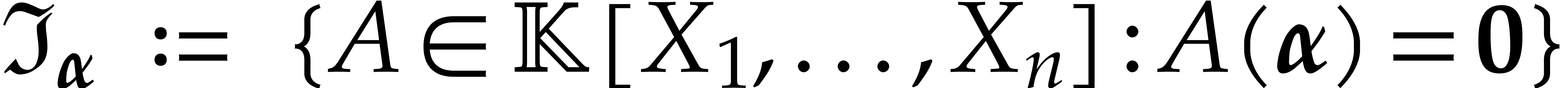
of , so 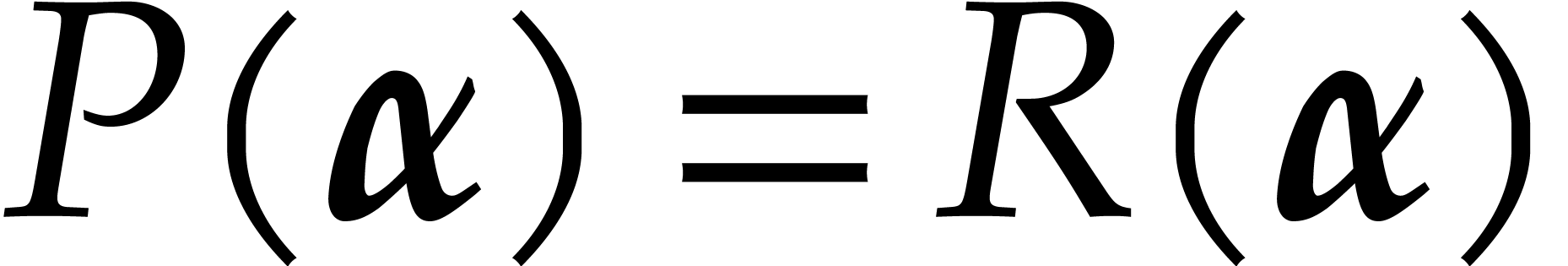 . We may next recursively split-up the tuple of
points into two halves and adopt a similar
strategy as in the univariate case.
. We may next recursively split-up the tuple of
points into two halves and adopt a similar
strategy as in the univariate case.
However, there are several technical problems with this idea. First of
all, it would be too costly to work with a full Gröbner basis  of
of 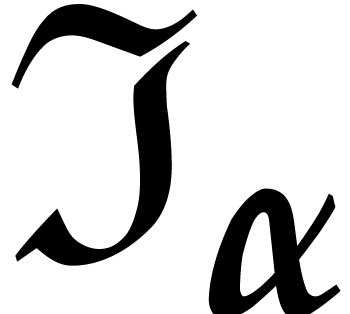 ,
because the mere storage of such a basis generally requires more than
,
because the mere storage of such a basis generally requires more than
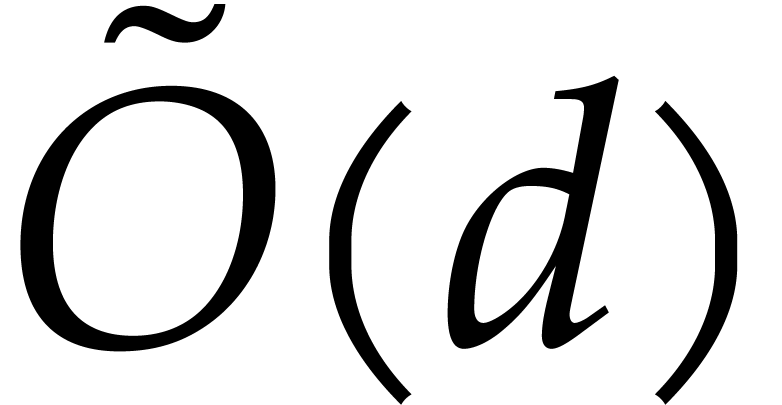 terms. In [15], we solved this
issue by working with respect to a so called “axial basis”
instead. In the case when is not generic, we
have the additional problem that the shape of a Gröbner basis may
become very irregular. This again has the consequence that the mere size
of all products
terms. In [15], we solved this
issue by working with respect to a so called “axial basis”
instead. In the case when is not generic, we
have the additional problem that the shape of a Gröbner basis may
become very irregular. This again has the consequence that the mere size
of all products 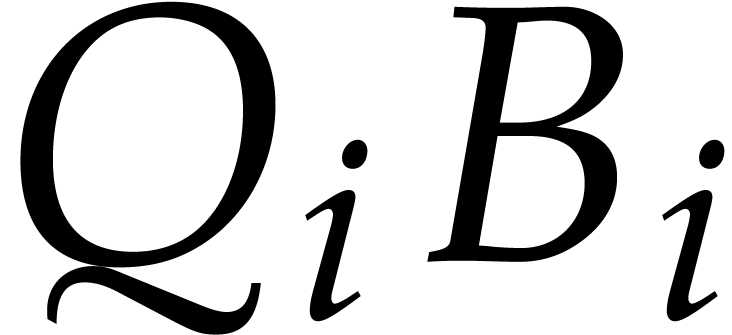 in
in 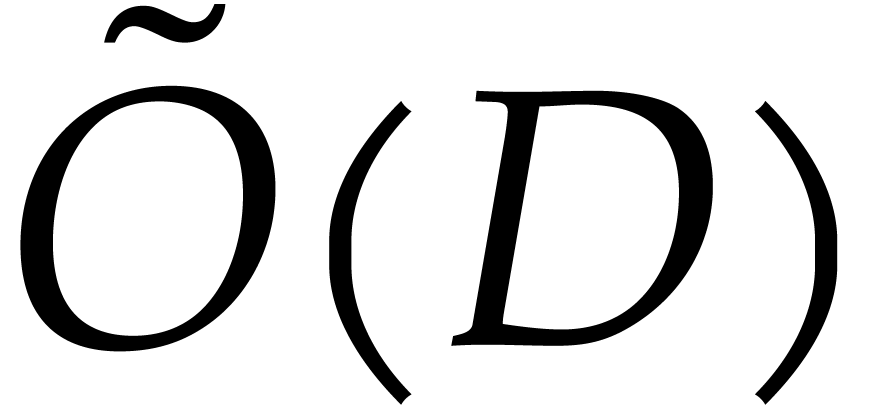 .
.
In this paper, we address these problems by introducing the new
technique of quasi-reduction. The idea is to work
simultaneously with several orderings on the monomials; in
particular, each belongs to a Gröbner basis
for with respect to a different admissible
ordering. The result of a quasi-reduction , but we will still be able
to control the size of .
Moreover, during the quasi-reduction process, we will be able to ensure
that the ratios

and

are similar for every  , which
further allows us to control the size of the products .
, which
further allows us to control the size of the products .
The constant factor in our complexity bound of Theorem 1.1
grows exponentially as a function of .
For the time being, we therefore expect our methods to be of practical
use only in low dimensions like or 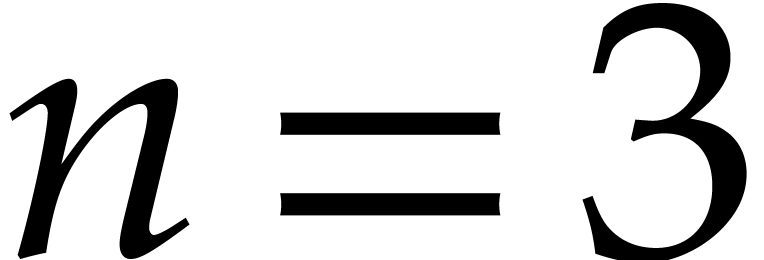 . Of course, the present paper focuses on worst
case bounds for potentially highly non-generic cases. There is hope to
drastically lower the constant factors for more common use cases.
. Of course, the present paper focuses on worst
case bounds for potentially highly non-generic cases. There is hope to
drastically lower the constant factors for more common use cases.
One major technical contribution of this paper is the introduction of
quasi-reduction and heterogeneous orderings. An interesting question for
future work is whether these concepts can be applied to other problems.
For instance, consider a zero-dimensional ideal 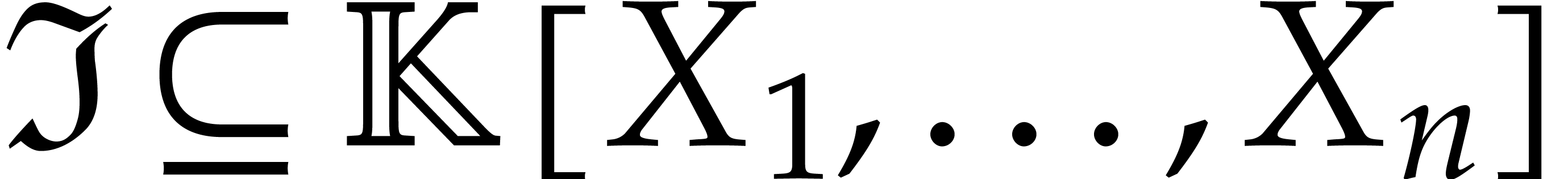 and two Gröbner bases for
and two Gröbner bases for  with respect to
different monomial orderings. Each Gröbner basis induces a
representation for elements of the quotient algebra
with respect to
different monomial orderings. Each Gröbner basis induces a
representation for elements of the quotient algebra  . Does there exist a smoothly linear time
algorithm to convert between these two representations?
. Does there exist a smoothly linear time
algorithm to convert between these two representations?
In this section we recall and extend some results from [9] to the context of this paper.
Let  be the set of monomials
be the set of monomials  with
with 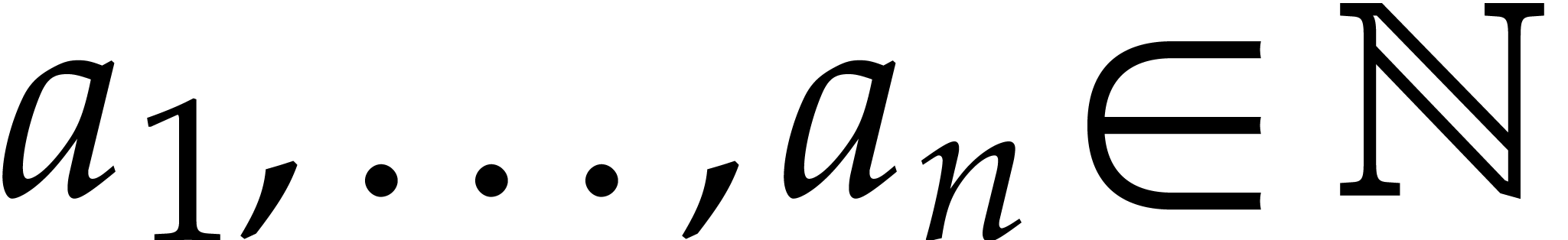 . Any polynomial can uniquely be written as a linear combination
. Any polynomial can uniquely be written as a linear combination
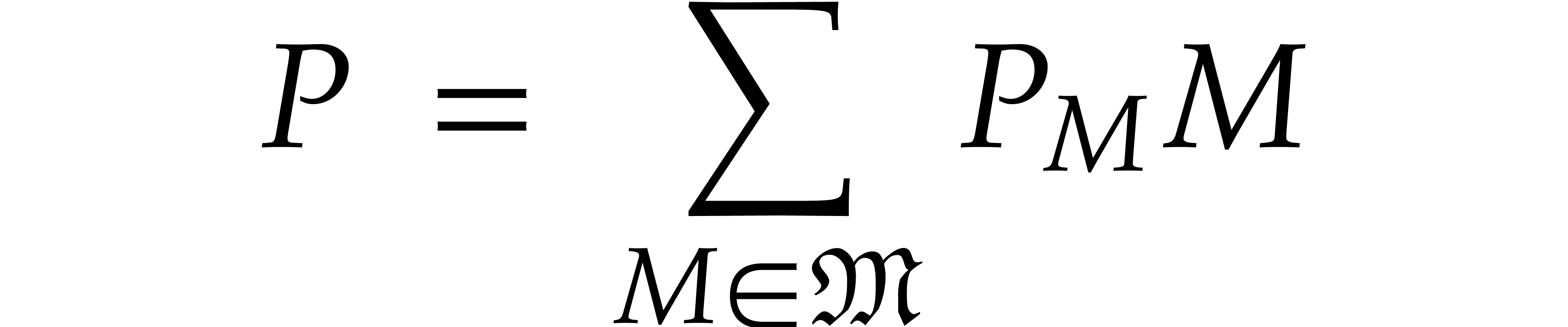
with coefficients  in and
finite support
in and
finite support
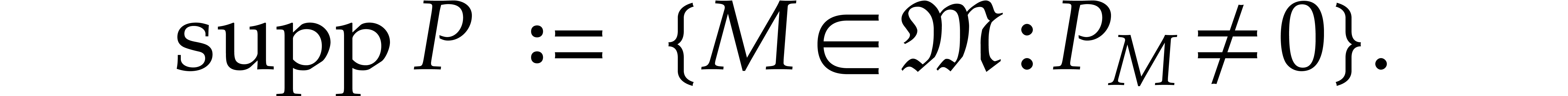
Given a total ordering on , the support of any non-zero polynomial 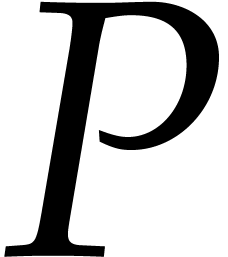 admits a unique maximal element
admits a unique maximal element 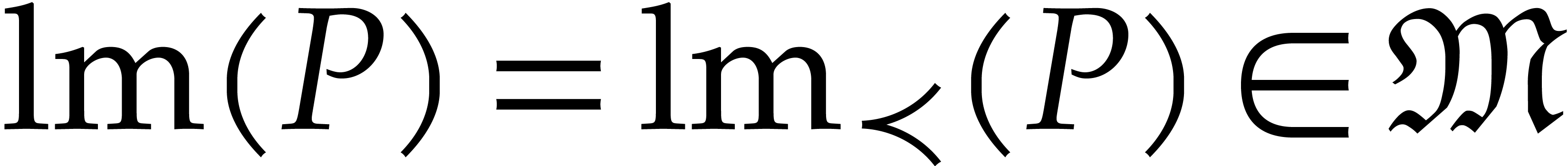 that is called the leading monomial of ; the corresponding coefficient
that is called the leading monomial of ; the corresponding coefficient 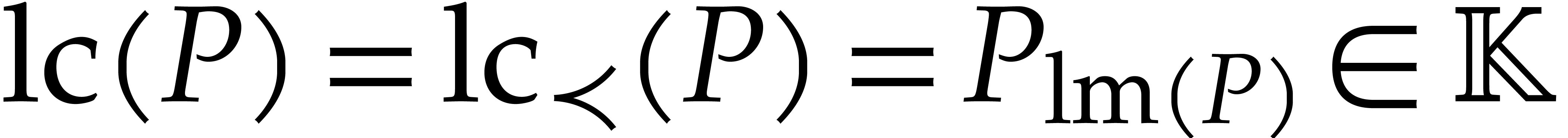 is called the leading coefficient of .
is called the leading coefficient of .
A total ordering on is
said to be admissible if
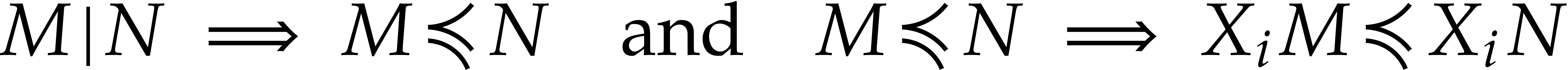
for all monomials 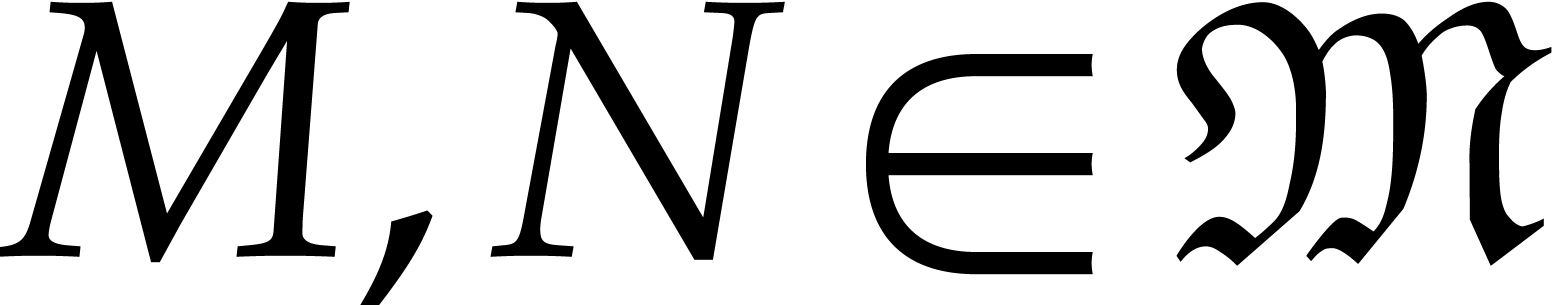 and
and  . In particular, the lexicographical ordering
. In particular, the lexicographical ordering 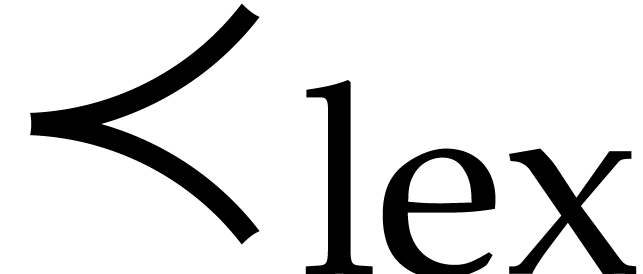 defined by
defined by

is admissible.
A sparse representation of a polynomial
in  is a data structure that stores the set of
the non-zero terms of . Each
such term is a pair made of a coefficient and a degree vector. In an
algebraic complexity model the bit size of the exponents counts for
free, so the relevant size of such a polynomial is the cardinality of
its support.
is a data structure that stores the set of
the non-zero terms of . Each
such term is a pair made of a coefficient and a degree vector. In an
algebraic complexity model the bit size of the exponents counts for
free, so the relevant size of such a polynomial is the cardinality of
its support.
Consider two polynomials and 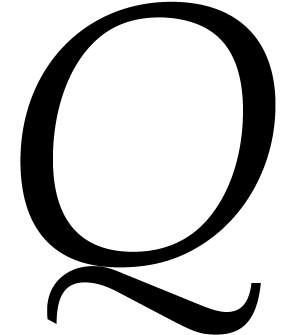 of in sparse representation. An extensive
literature exists on the general problem of multiplying
and ; see [26]
for a recent survey. For the purposes of this paper, a superset
of in sparse representation. An extensive
literature exists on the general problem of multiplying
and ; see [26]
for a recent survey. For the purposes of this paper, a superset  for the support of
for the support of  will
always be known. Then we define
will
always be known. Then we define 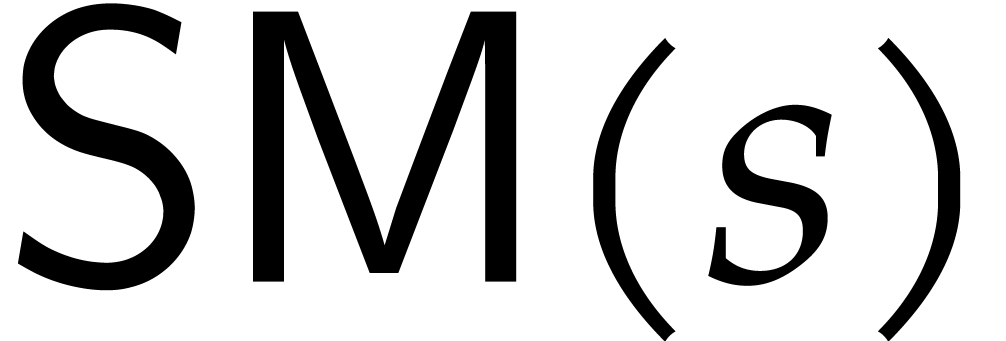 to be the cost
to compute , where
to be the cost
to compute , where  is the maximum of the sizes of and
the supports of and . We will assume that
is the maximum of the sizes of and
the supports of and . We will assume that  is a
non-decreasing function in .
Under suitable assumptions, the following proposition will allow us to
take
is a
non-decreasing function in .
Under suitable assumptions, the following proposition will allow us to
take 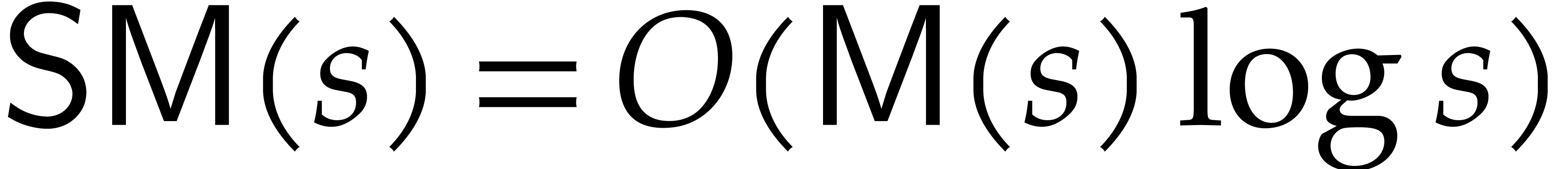 in our multivariate evaluation algorithm.
in our multivariate evaluation algorithm.
 be positive integers
and let
be positive integers
and let  in be of
multiplicative order at least
in be of
multiplicative order at least  .
.
The set  of all products
of all products 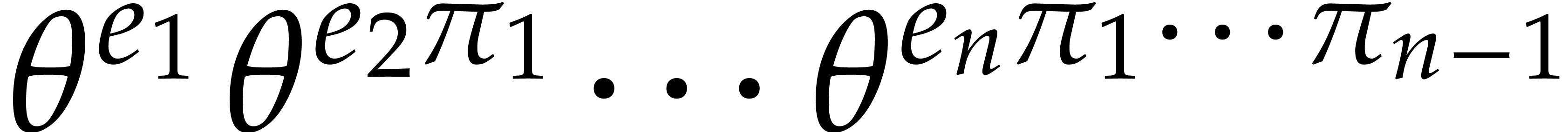 for
for 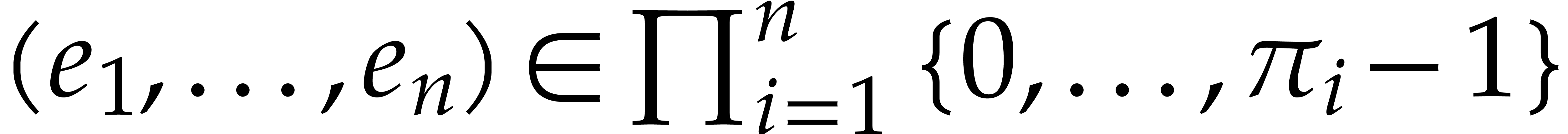 can be computed using
can be computed using  operations in .
operations in .
Let and be in
, in sparse
representation. Let be a superset of the
support of with 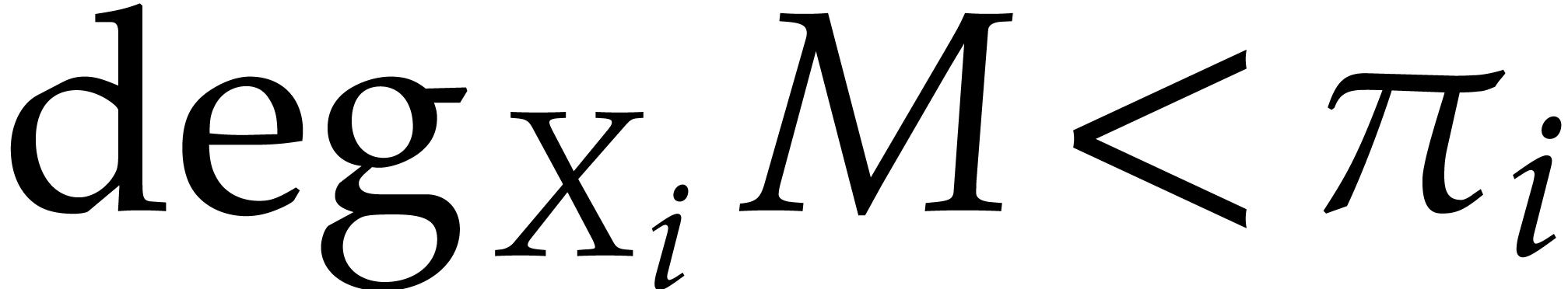 for all
for all  and
and  . Assume that has
been precomputed. Then the product
. Assume that has
been precomputed. Then the product  can
be computed using
can
be computed using 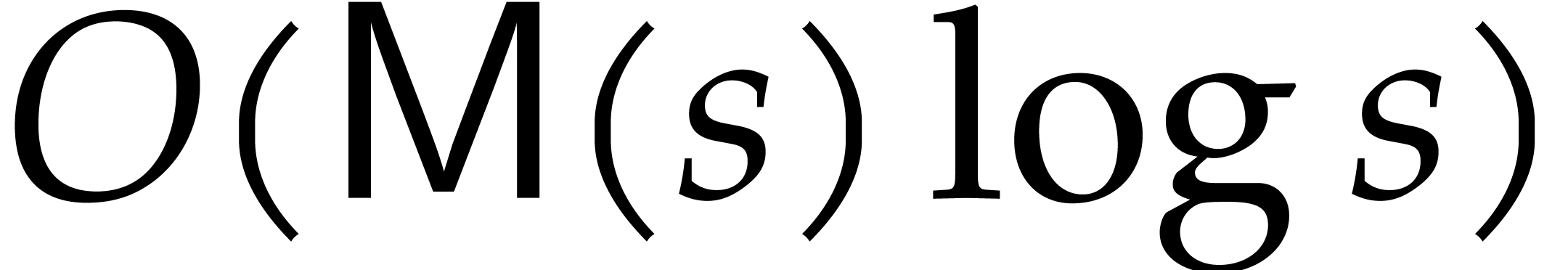 operations in , where
denotes the maximum of the sizes of and
the supports of and .
operations in , where
denotes the maximum of the sizes of and
the supports of and .
Proof. The first statement is straightforward.
The second one is an adapted version of [11, Proposition
6].
We assume that the reader is familiar with the technique of relaxed
power series evaluations [7], which is an efficient way to
solve so-called recursive power series equations. In [9],
this technique was generalized to multivariate Laurent series that are
expanded according to some admissible ordering .
Given a general admissible ordering ,
we know from [25] that there exist real vectors 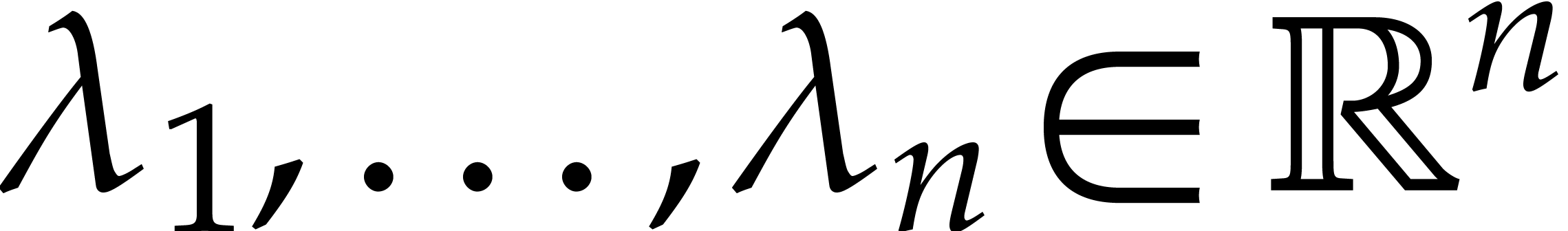 , such that
, such that
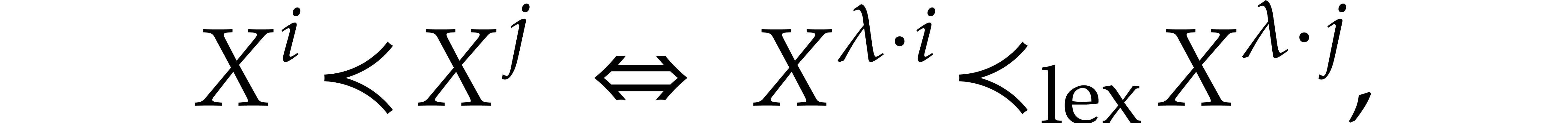
where
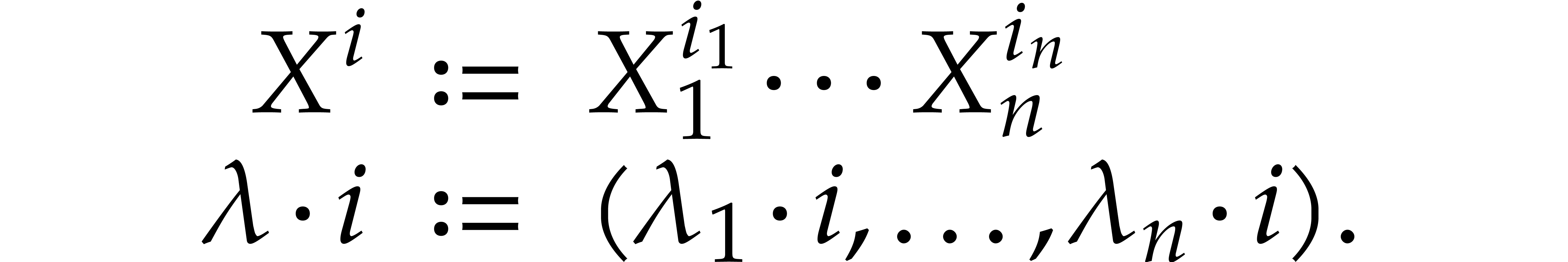
For clarity we sometimes denote this ordering by
 . In [9], it is
always assumed that
. In [9], it is
always assumed that 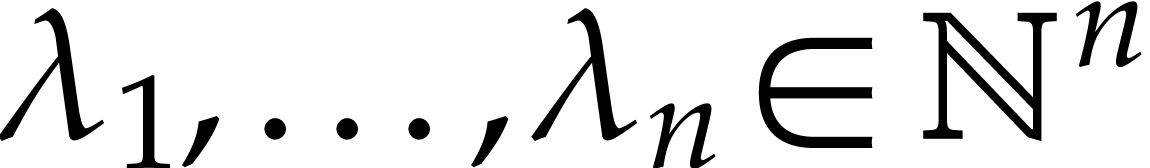 and
and  for all .
for all .
Example 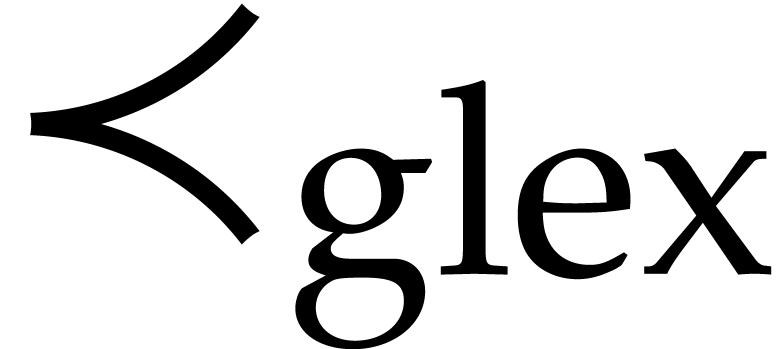 is obtained by taking
is obtained by taking
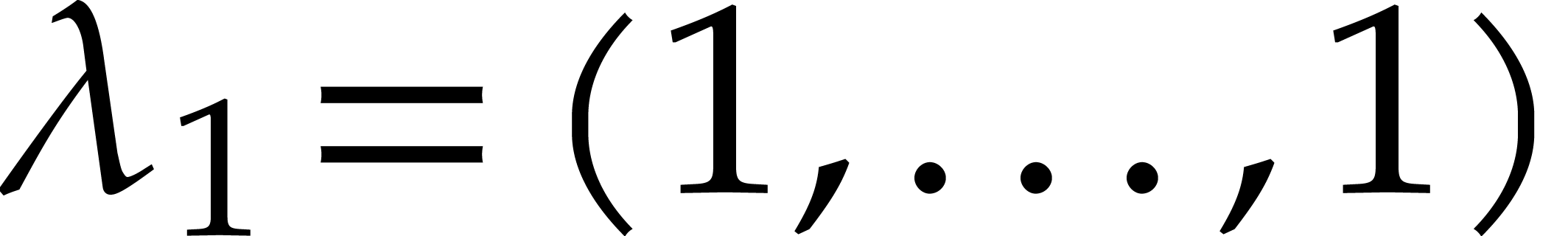 ,
, 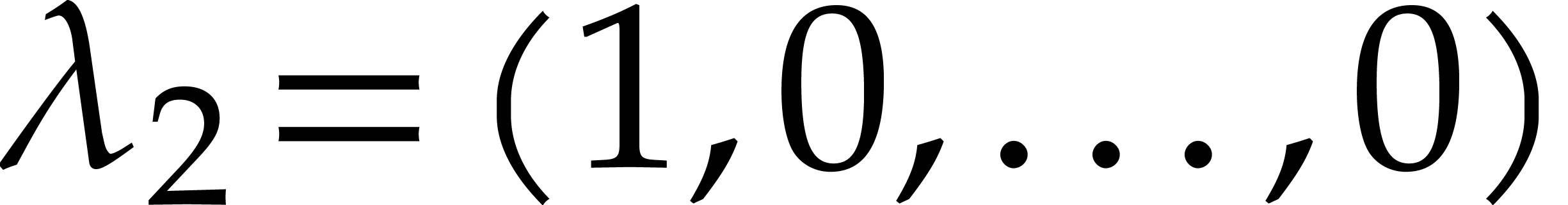 ,
, 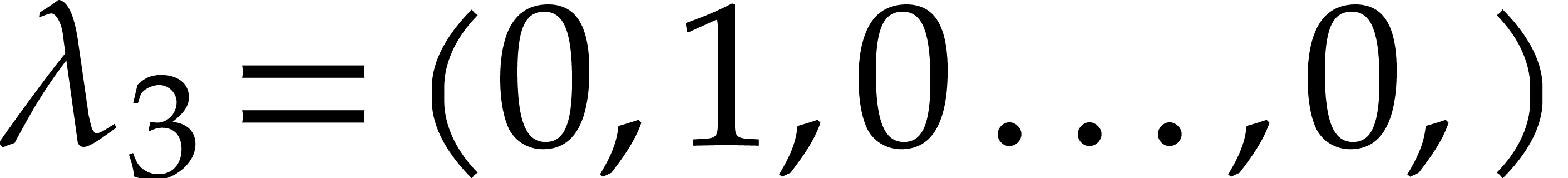 ,
,  ,
,  .
.
Example 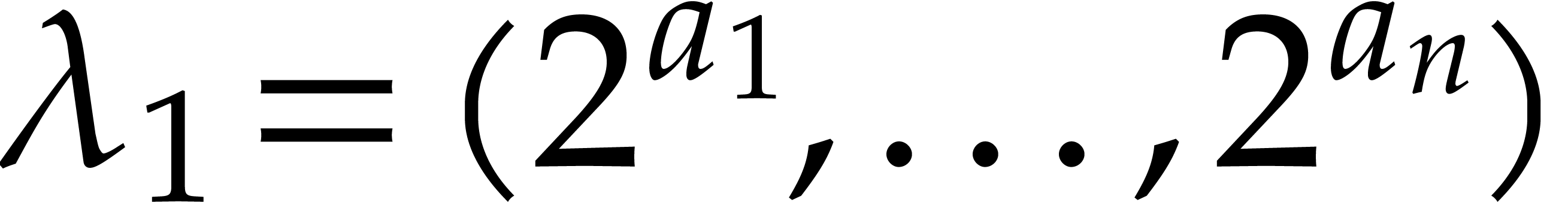 for certain
for certain 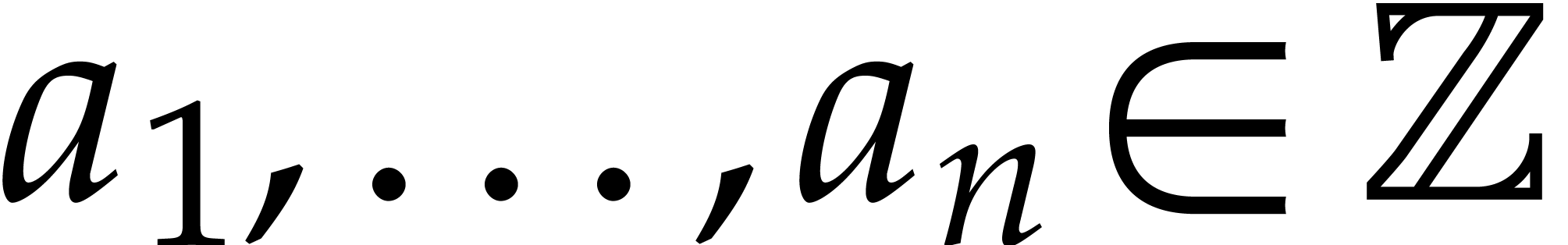 and
and  . In fact, we note that
. In fact, we note that 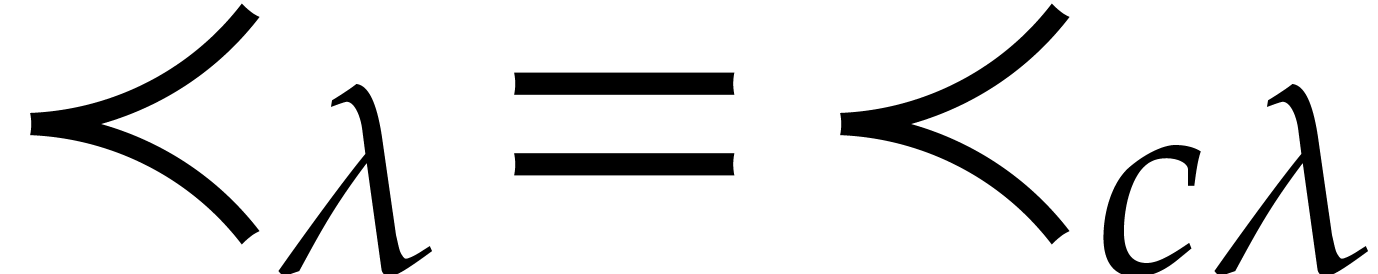 for any
for any 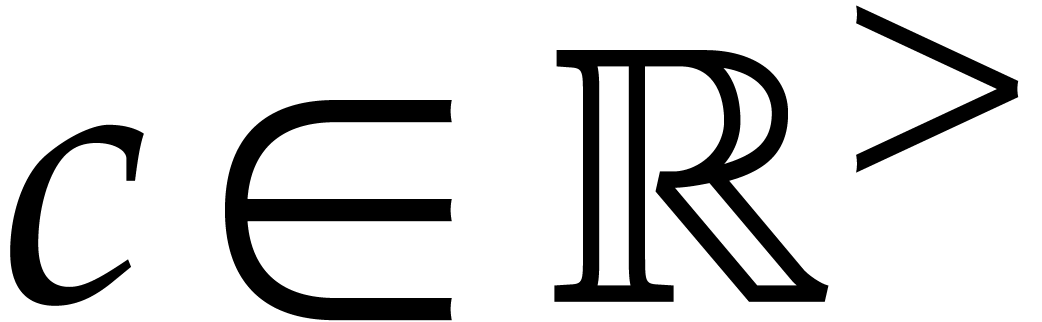 , so modulo the
replacement of
, so modulo the
replacement of  by
by  ,
we may assume without loss of generality that , whenever we wish to apply the theory from [9].
,
we may assume without loss of generality that , whenever we wish to apply the theory from [9].
In order to analyze the complexity of relaxed products in this
multivariate context, we need to introduce the following quantities for
finite subsets  :
:
We also define 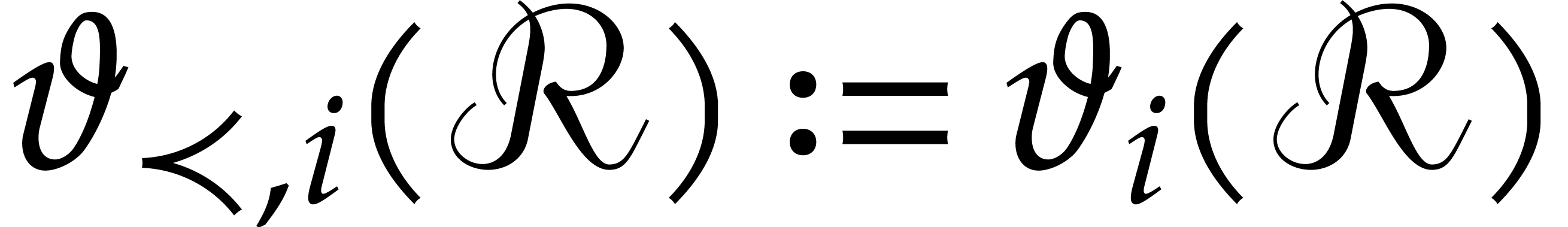 and
and 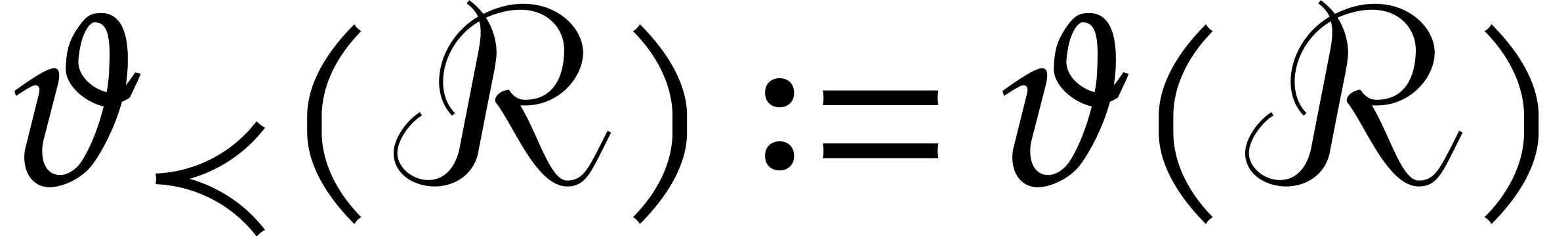 when
we need to emphasize the dependence on .
when
we need to emphasize the dependence on .
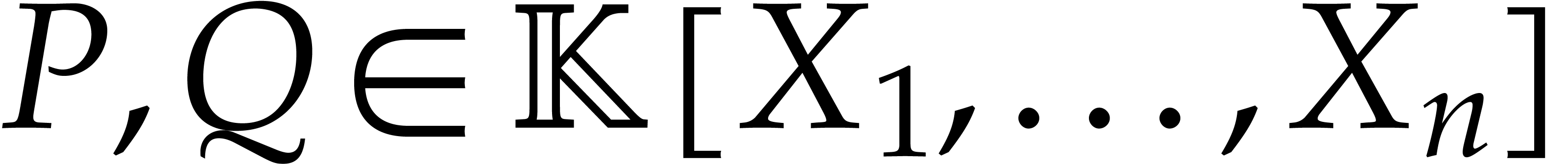 and a set
and a set  with
with  , the relaxed product
, the relaxed product  can be computed in time
can be computed in time
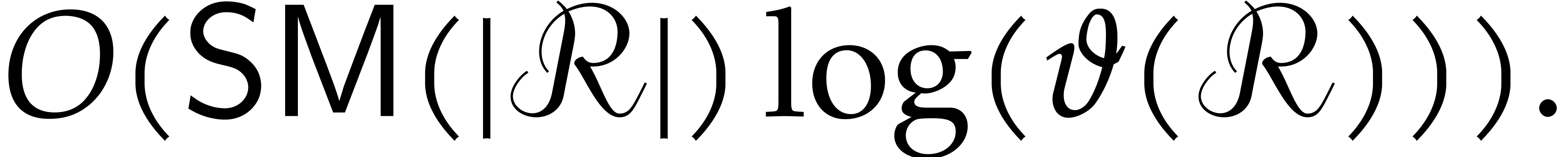
Let be a total ordering on
and consider a finite family 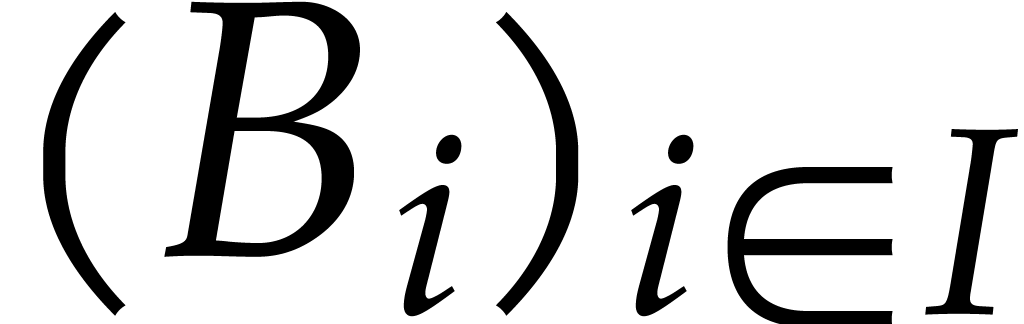 of non-zero
polynomials in . Each comes with a distinguished monomial
of non-zero
polynomials in . Each comes with a distinguished monomial  (that will play the role of the leading monomial) and we define
(that will play the role of the leading monomial) and we define 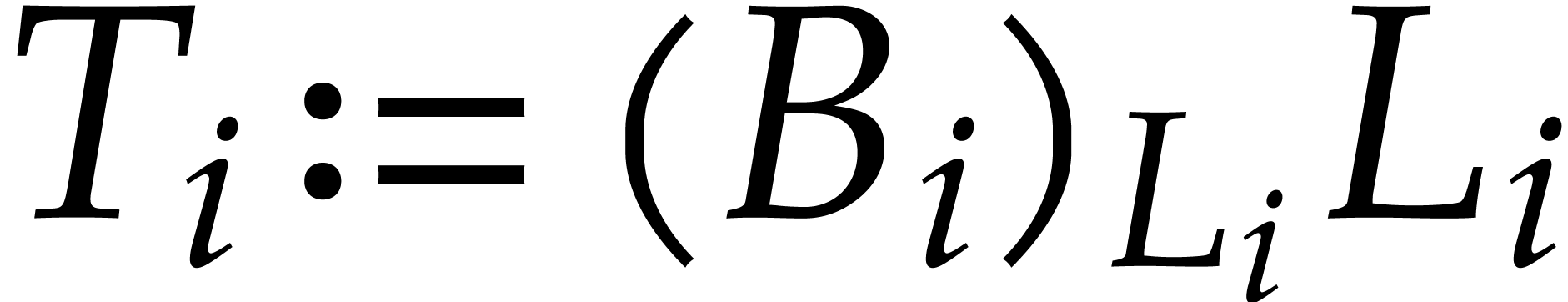 . The family
is equipped with a selection strategy, that is a function
. The family
is equipped with a selection strategy, that is a function

For each 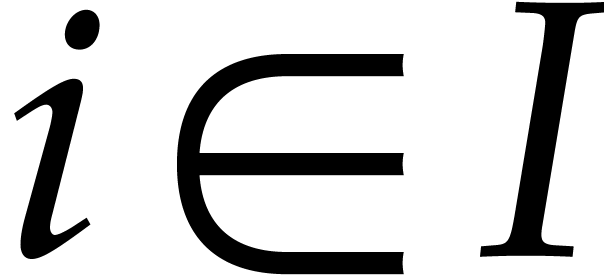 , we also assume
that we have fixed the set
, we also assume
that we have fixed the set 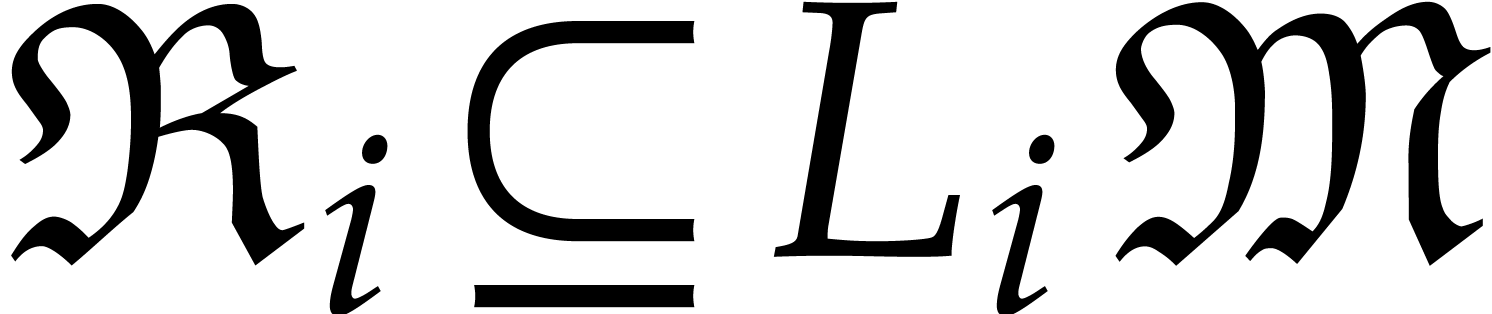 of monomials that
will be selected for reduction with respect to , for .
We assume that the
of monomials that
will be selected for reduction with respect to , for .
We assume that the  are pairwise disjoint and we
set
are pairwise disjoint and we
set
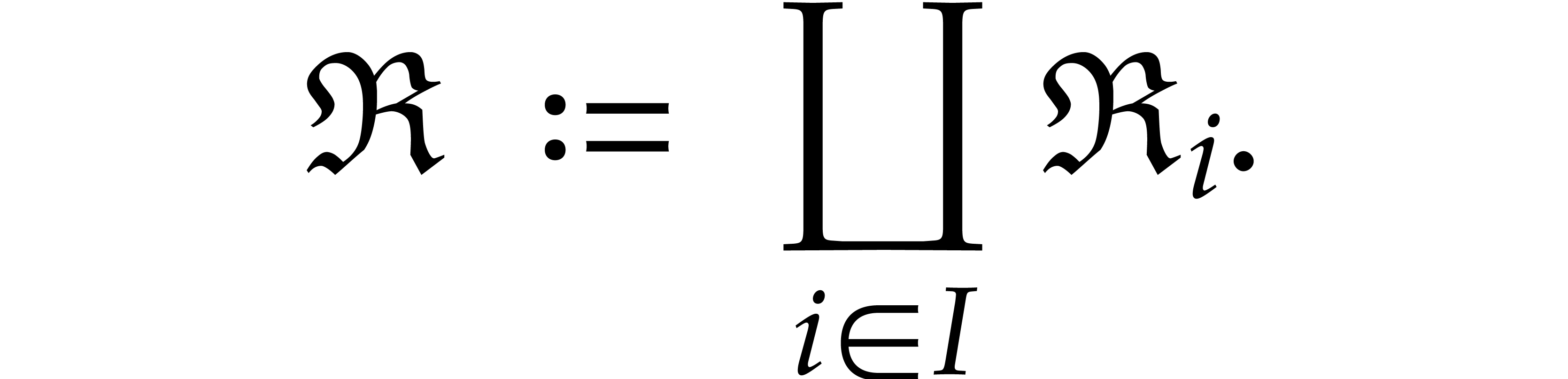
Note that this corresponds to fixing a selection strategy, although we
do not require that 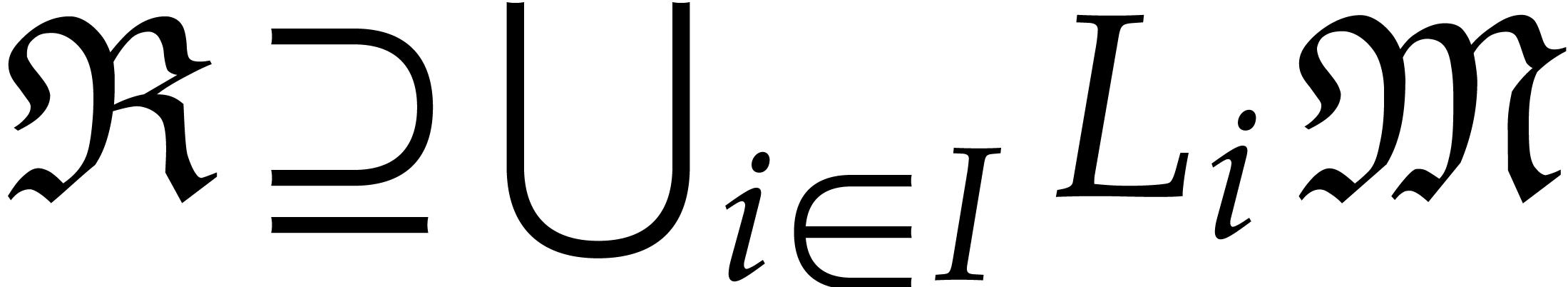 (which explains the
terminology “quasi-reduction” below). For our application
later in this paper, the complement
(which explains the
terminology “quasi-reduction” below). For our application
later in this paper, the complement 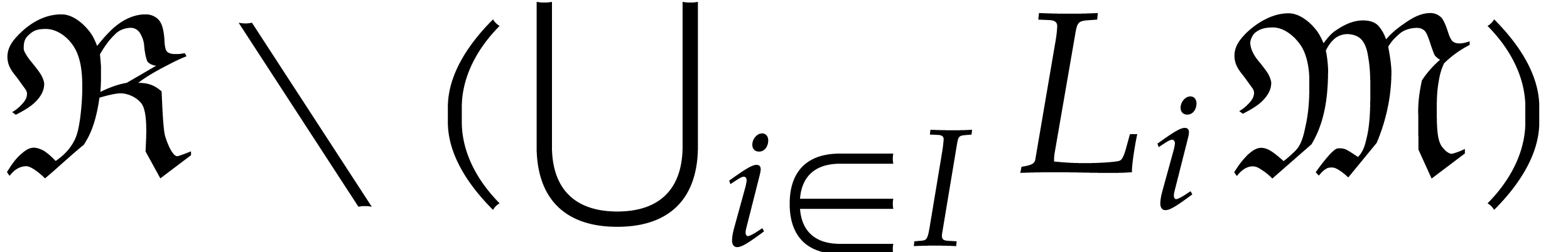 will be a
“rather relatively small” finite set.
will be a
“rather relatively small” finite set.
We say that is quasi-reduced if 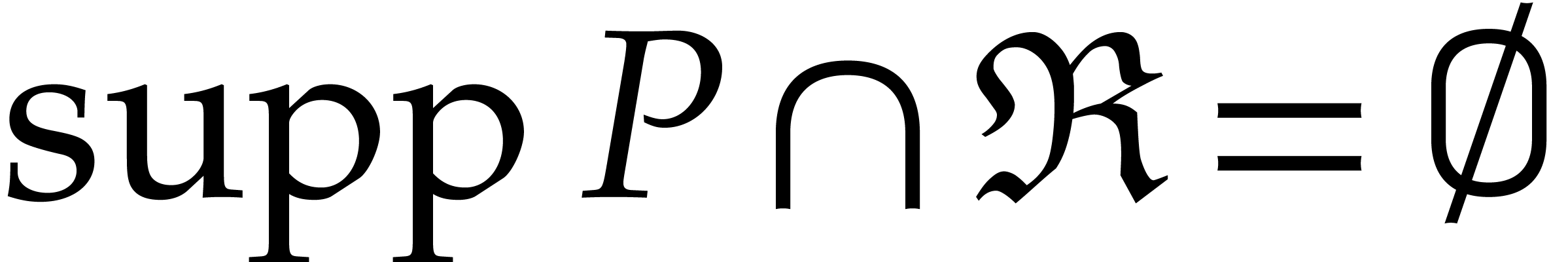 . We say that a total ordering on is
quasi-admissible (with respect to our choices of ,
. We say that a total ordering on is
quasi-admissible (with respect to our choices of , 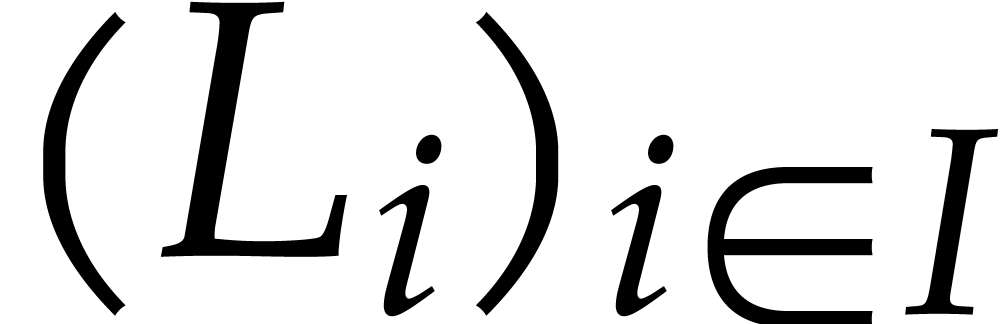 and the selection
strategy
and the selection
strategy  ) if
) if  for all and if
for all and if
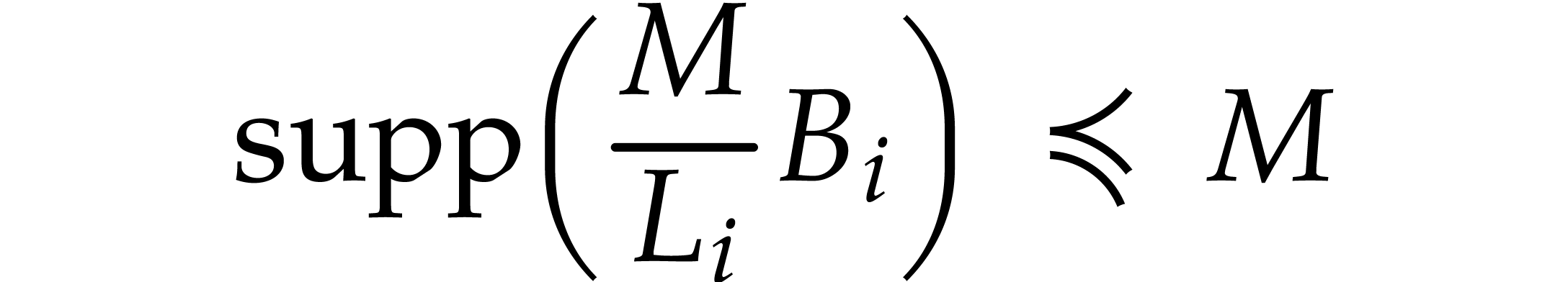
for any and any  .
.
Polynomials that are not quasi-reduced are said to be
quasi-reducible. In order to quasi-reduce
with respect to we may use Algorithm 2.1
below. This yields the relation
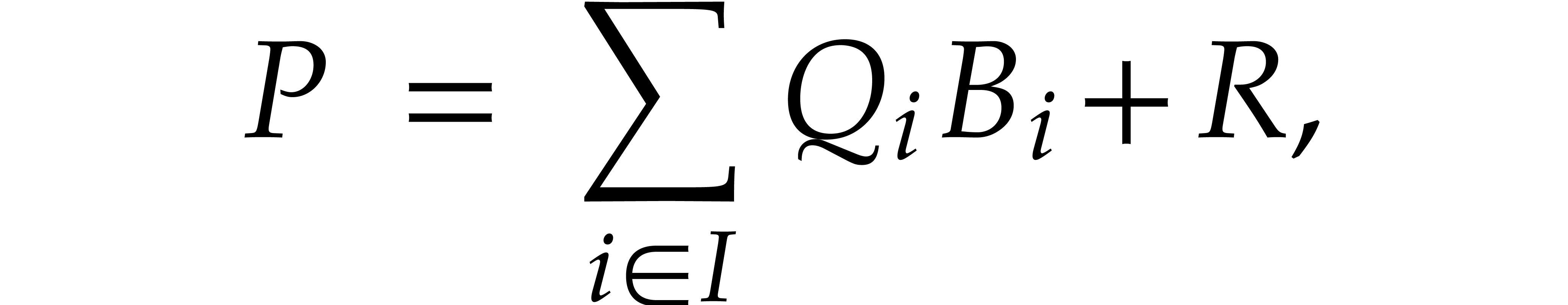
such that is quasi-reduced with respect to . We call 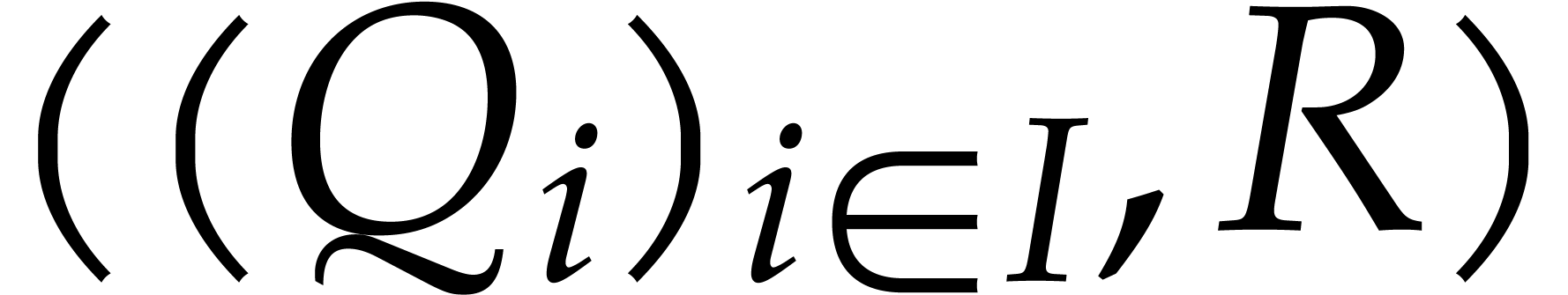 the extended quasi-reduction of with
respect to .
the extended quasi-reduction of with
respect to .
Algorithm |
|
By construction, we have
for all .
The main contribution of [9] is a relaxed algorithm for the computation of extended reductions. This algorithm generalizes to our setting as follows and provides an alternative for Algorithm 2.1 with a better computational complexity.
For each  , let
, let  be the -th
canonical basis vector
be the -th
canonical basis vector
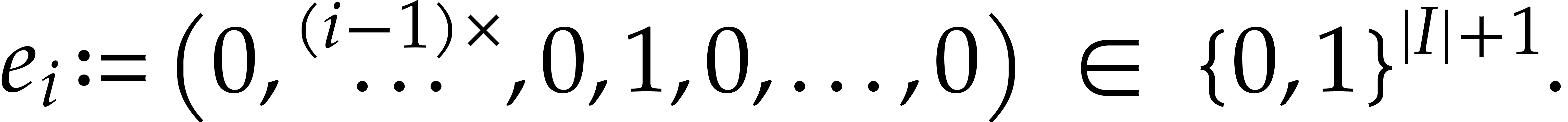
We first define the operator  on monomials:
on monomials:
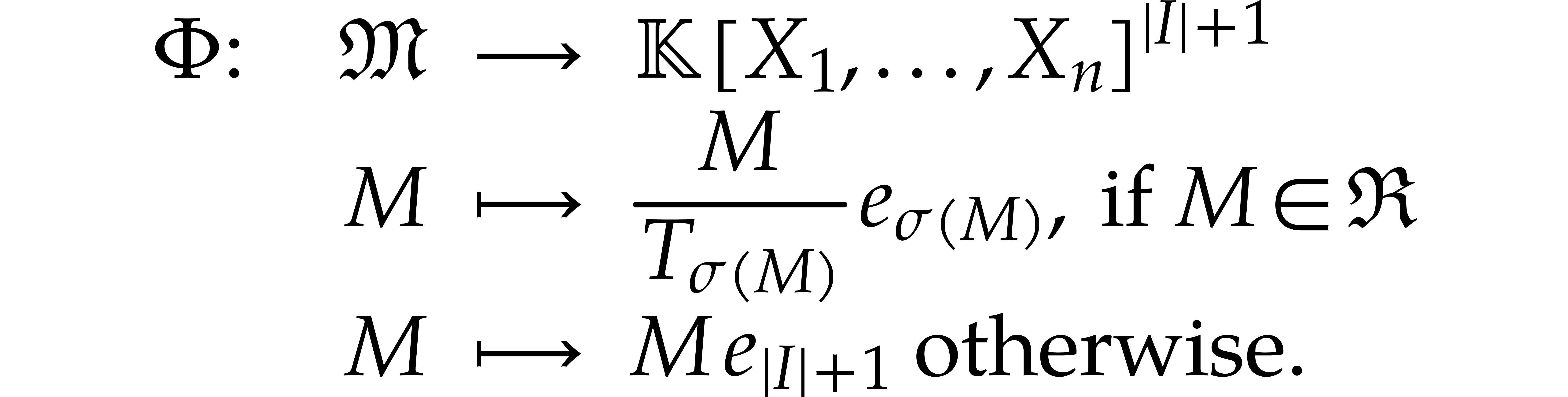
By linearity we next extend to :
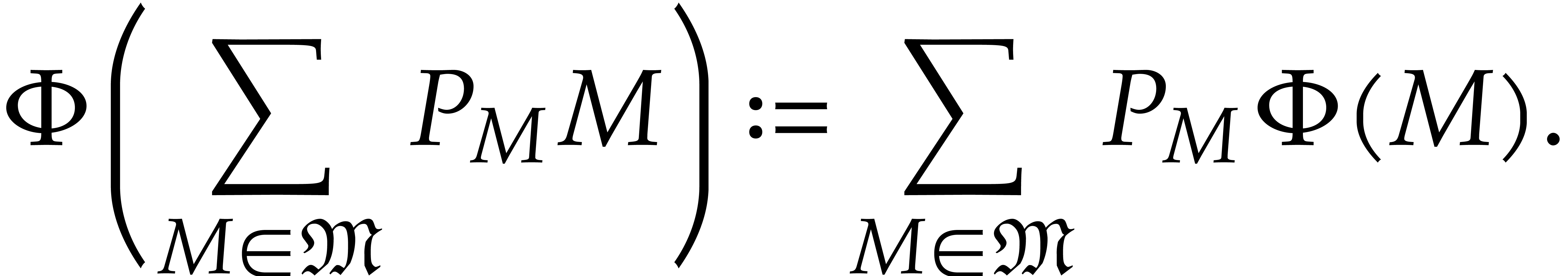
Let 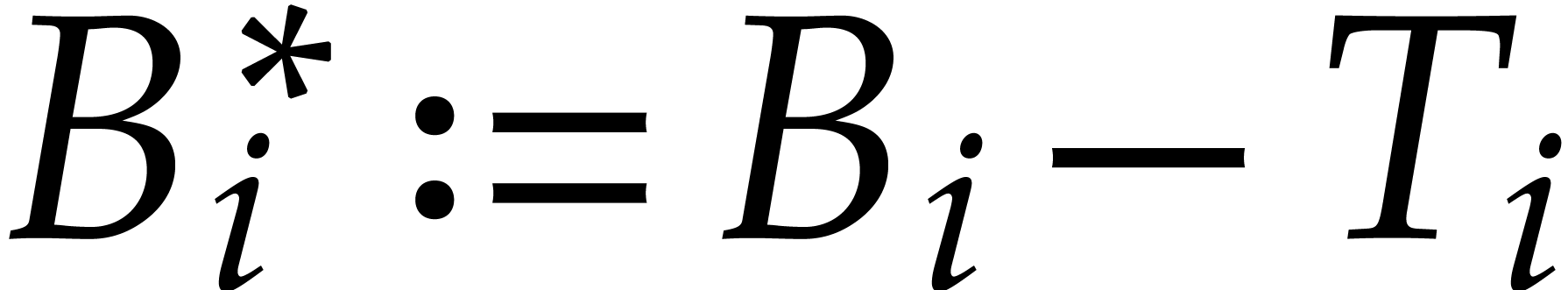 . By construction, we
have
. By construction, we
have
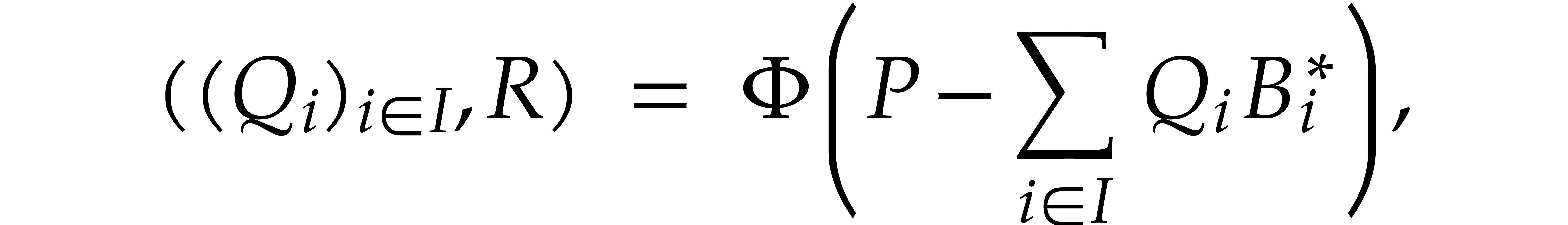
which allows us to regard as a fixed point of
the operator
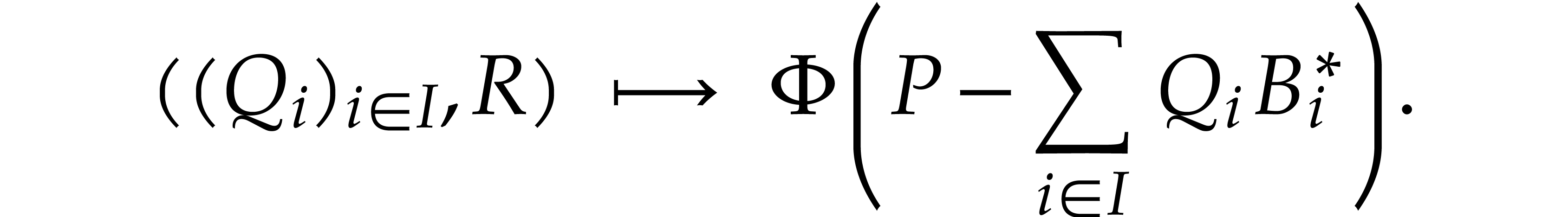
This operator is “recursive” in the sense of [9,
section 4.2] with respect to the ordering .
Consequently can be computed efficiently using
relaxed power series evaluation. The complexity of this relaxed
quasi-reduction is stated in Theorem 4.4 below for the
specific ordering used by our multi-point evaluation algorithm. This
definition and study of this ordering is the purpose of the next
section.
An admissible weight is an -tuple
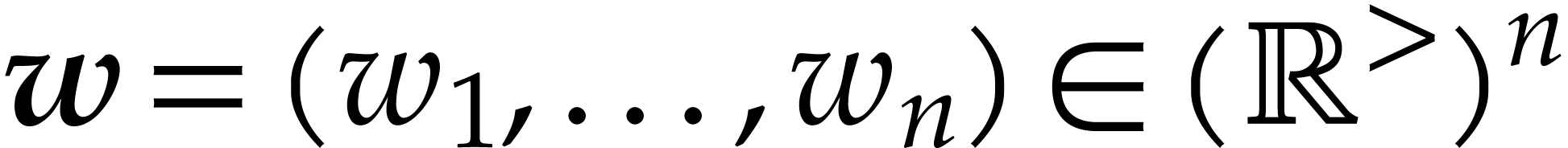 with
with 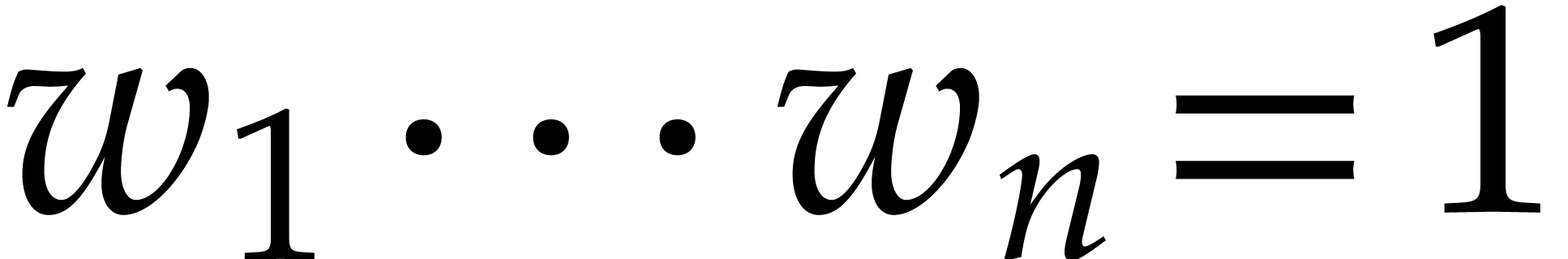 .
Given a monomial
.
Given a monomial  , we define
its
, we define
its  -degree by
-degree by
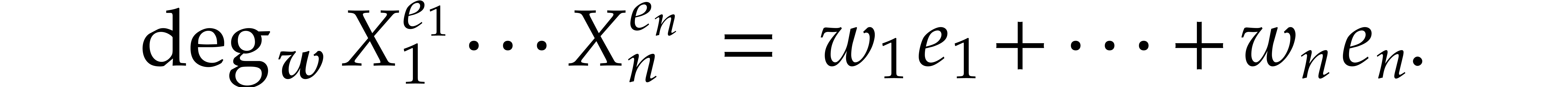
For a non-zero polynomial 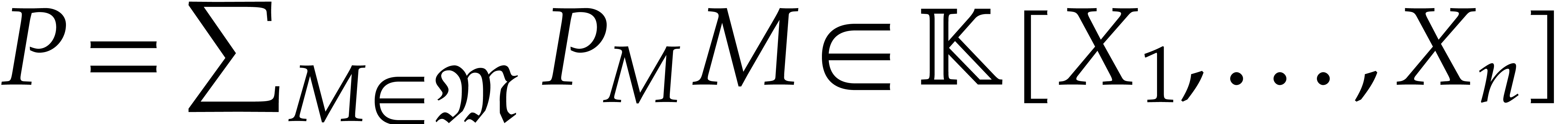 ,
we define its -degree
by
,
we define its -degree
by
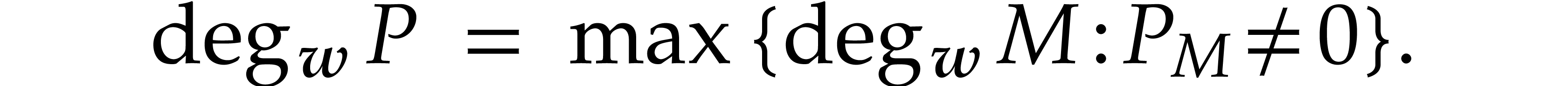
We also define the ordering 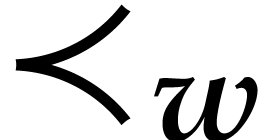 on
by
on
by
It is easy to check that is an admissible
ordering.
Consider a zero-dimensional ideal of and let
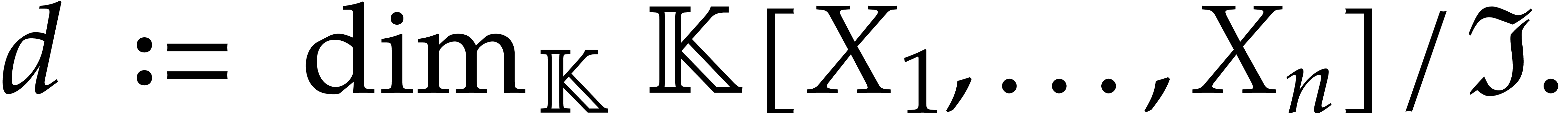
Given an admissible weight ,
there exists a unique non-zero polynomial 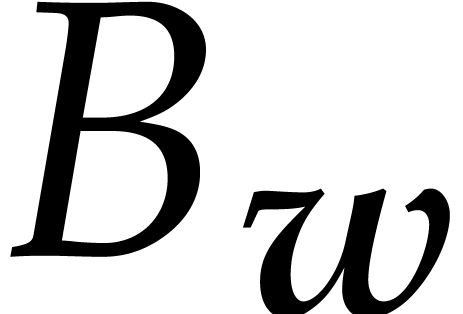 in the
reduced Gröbner basis of whose leading
monomial is minimal for and whose leading
coefficient is one. We call the -simplest element of . Note that there are at most
monomials below the leading monomial of for
.
in the
reduced Gröbner basis of whose leading
monomial is minimal for and whose leading
coefficient is one. We call the -simplest element of . Note that there are at most
monomials below the leading monomial of for
.
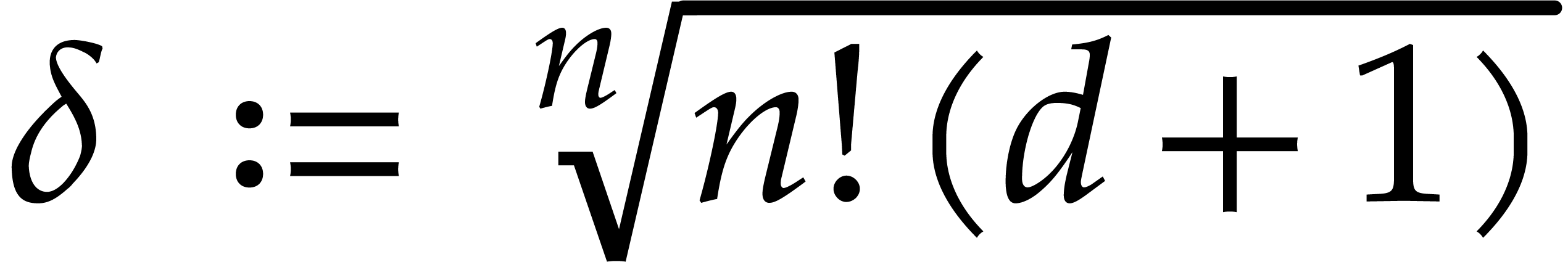
and consider the set 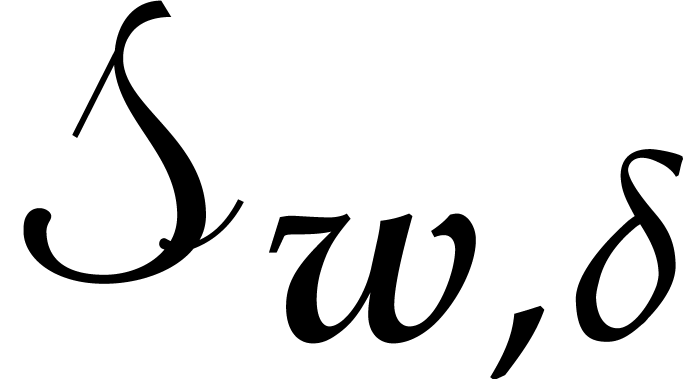 of monomials
of monomials  with
with 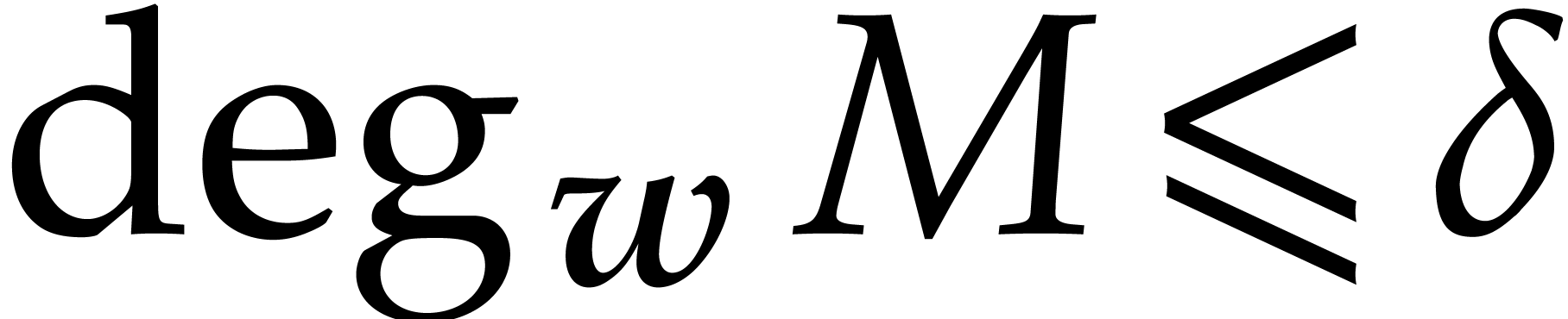 . Then
. Then
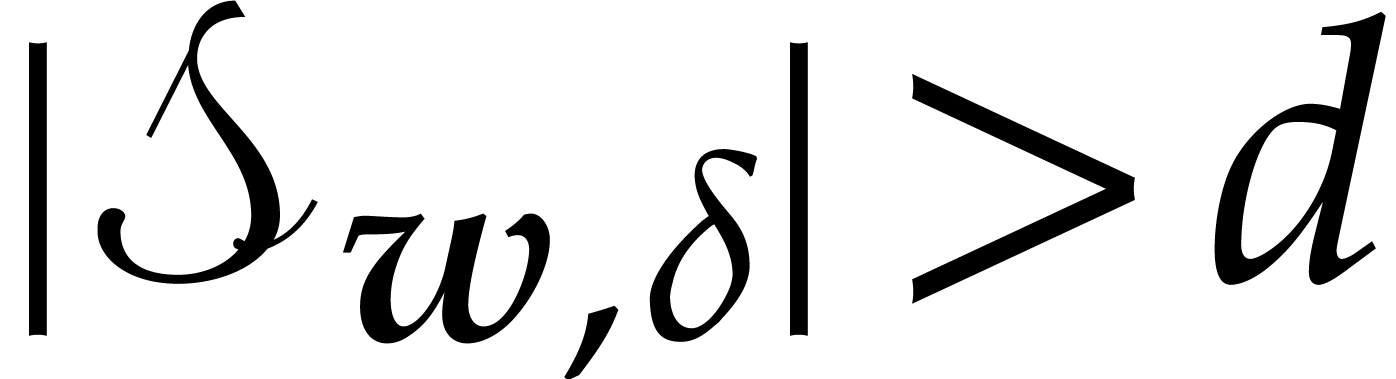 .
.
Proof. Let 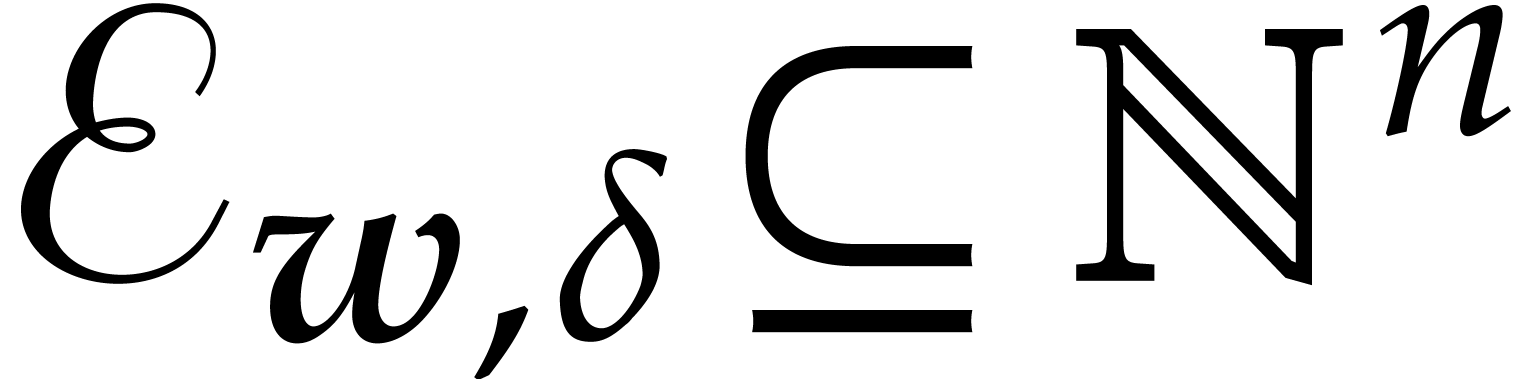 be the set of
exponents of , so we have
be the set of
exponents of , so we have
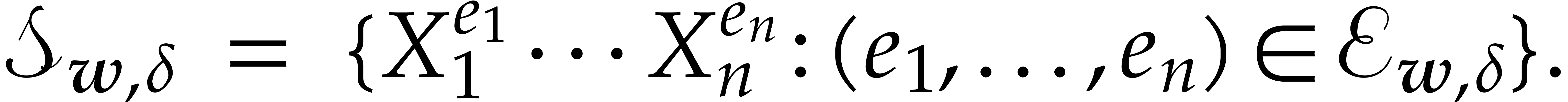
The set 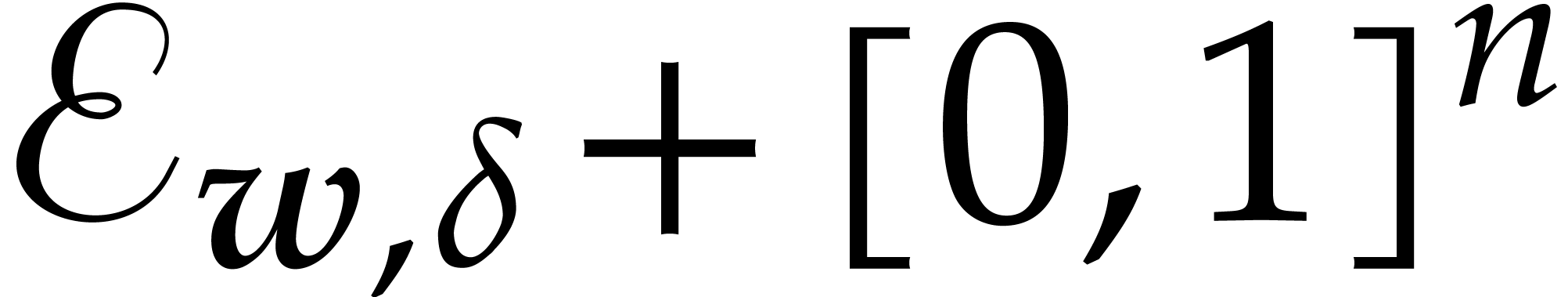 in particular contains the simplex
in particular contains the simplex
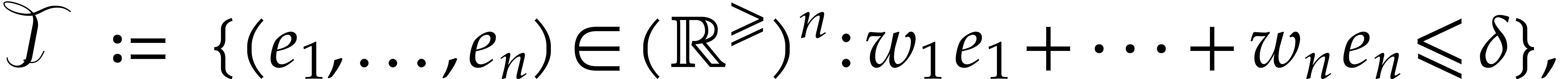
whose volume is given by
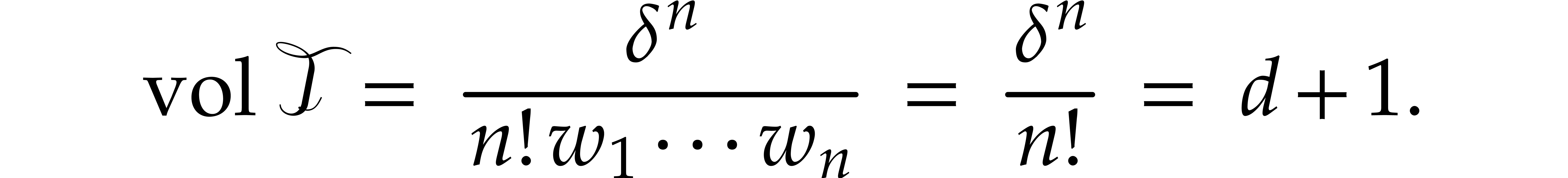
Consequently, 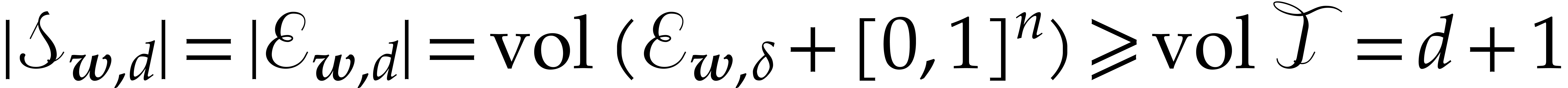 .
.
Proof. We say that  is an
initial segment
is an
initial segment  for
if
for
if 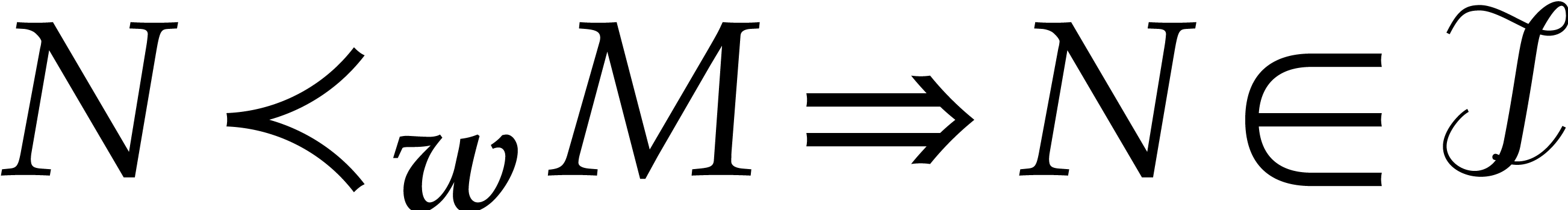 for all
for all  and
and 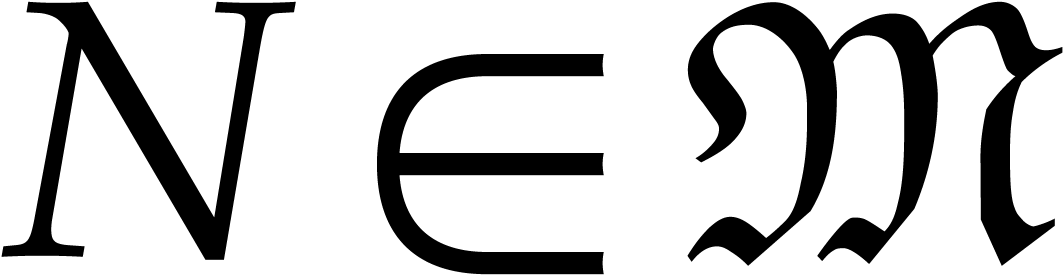 . By definition, the set is an initial segment for and it
contains at least
. By definition, the set is an initial segment for and it
contains at least  monomials. Consequently, the
set of linear combinations of monomials in
contains at least one non-zero element of
monomials. Consequently, the
set of linear combinations of monomials in
contains at least one non-zero element of  and
therefore . Now consider a
monomial in
and
therefore . Now consider a
monomial in  .
Then
.
Then 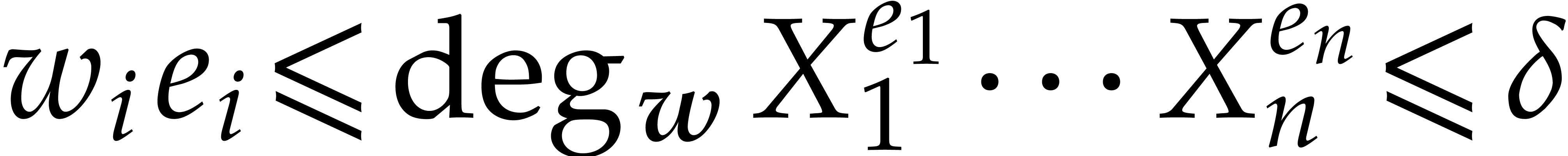 for
for  ,
whence
,
whence  .
.
Now consider a finite non-empty set 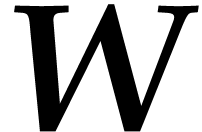 of
admissible weights. Given a monomial ,
we define its -degree
of
admissible weights. Given a monomial ,
we define its -degree
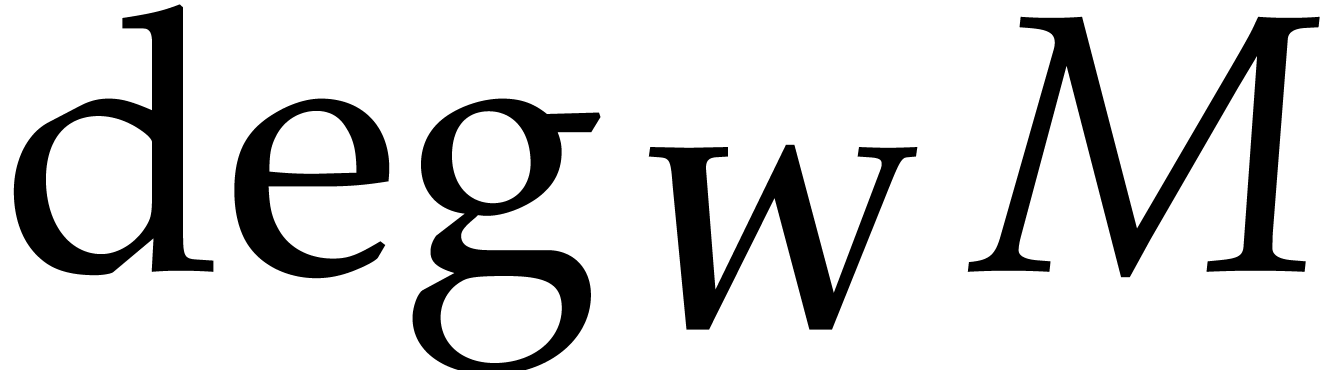 by
by
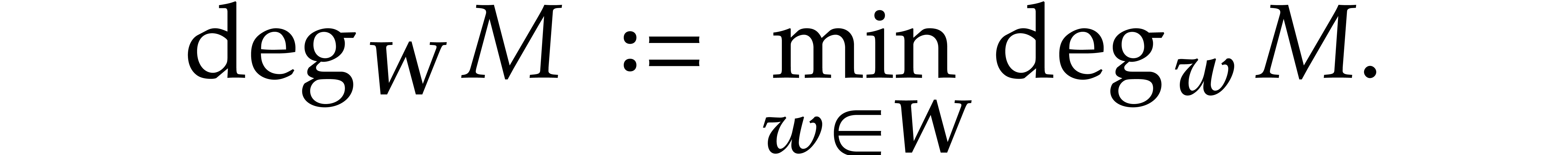
For a non-zero polynomial ,
we define its -degree
by
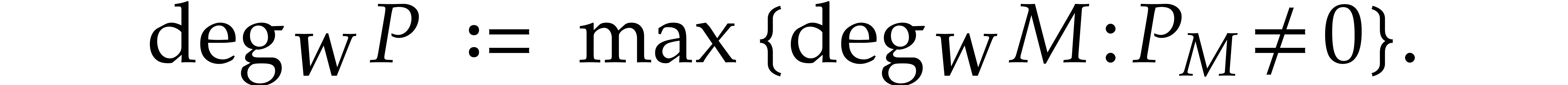
We define the heterogeneous ordering  by
by
Proof. For all  we have
we have
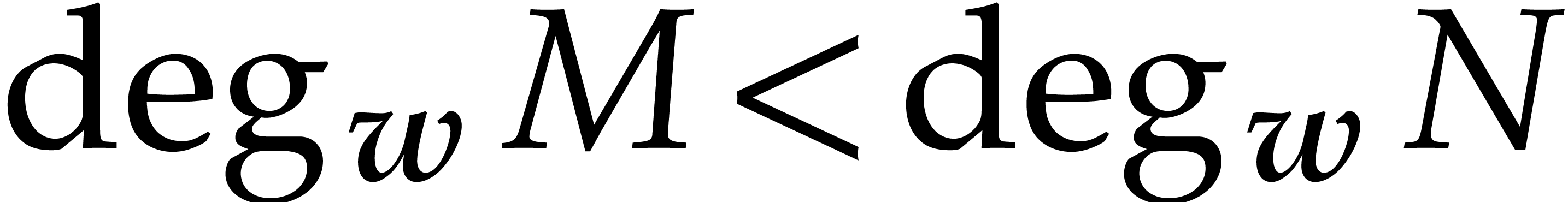 , whence
, whence 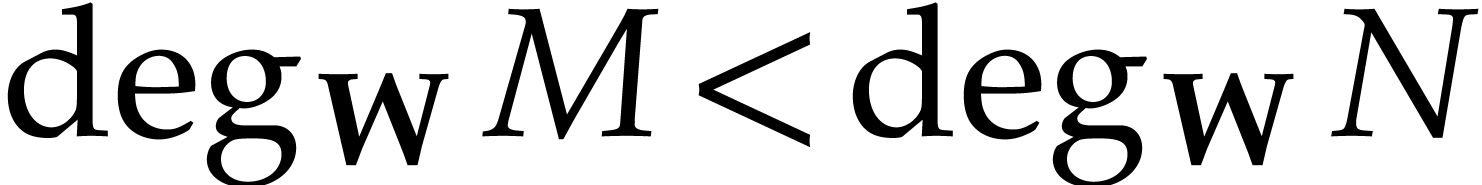 .
.
Example 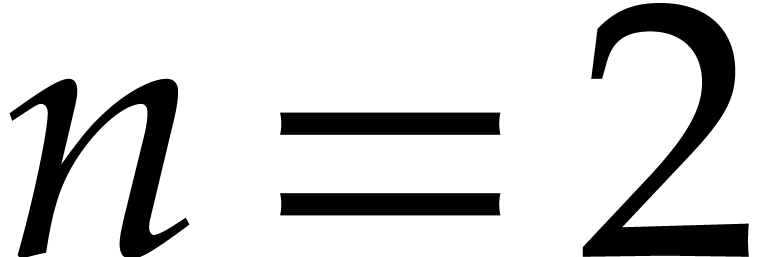 ,
, 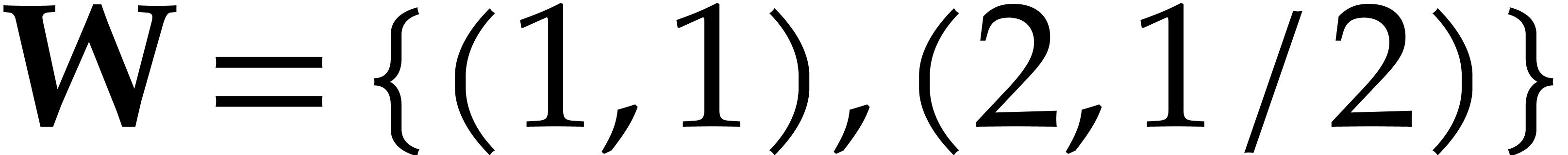 . With
. With 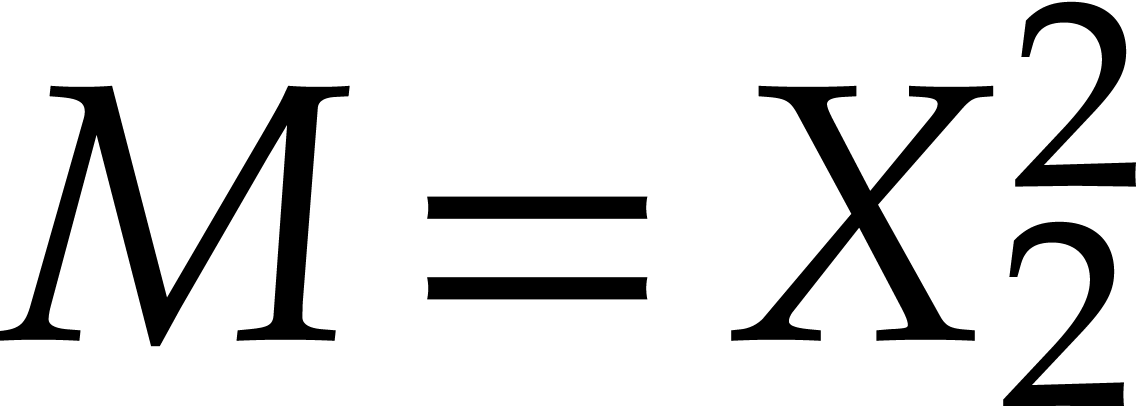 and
and 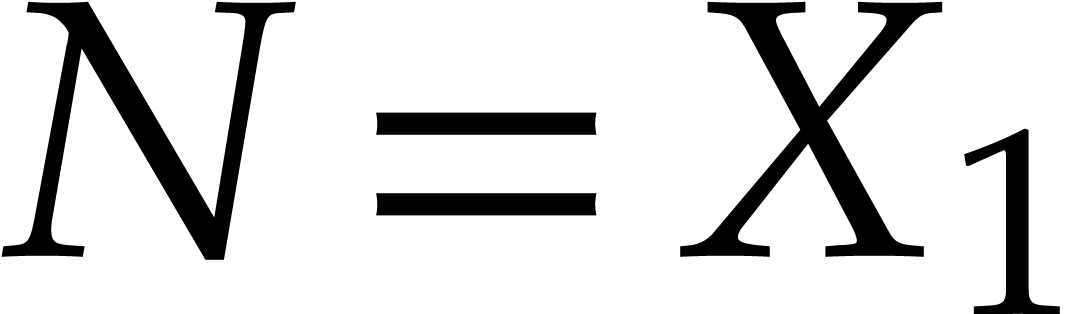 we have
we have
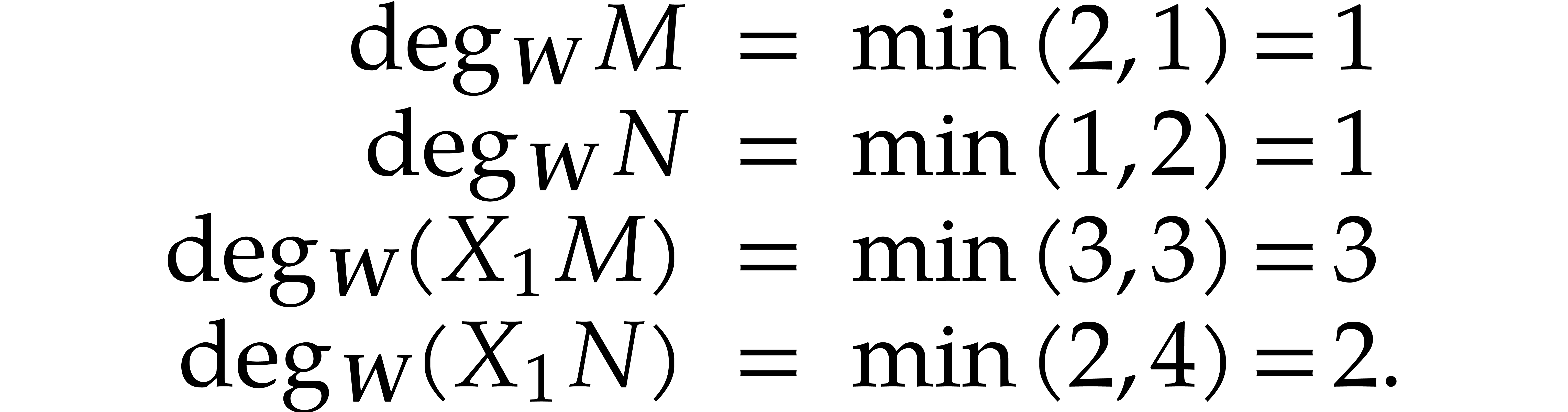
Therefore 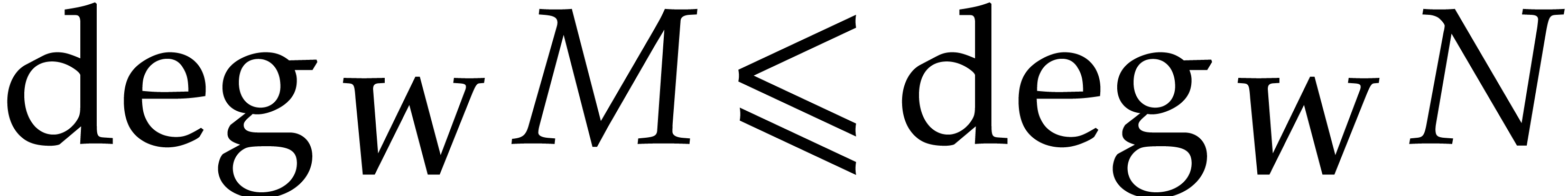 but
but 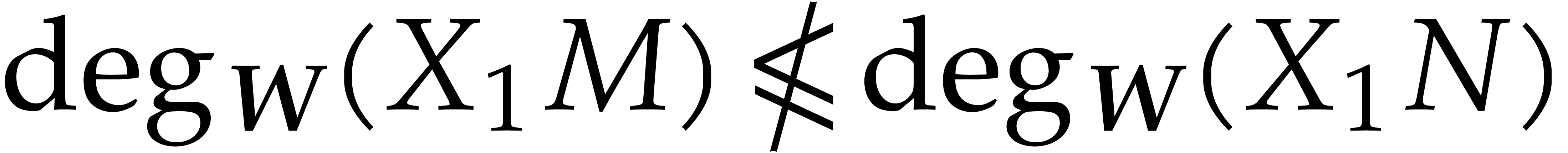 ,
which shows that the ordering is not admissible.
,
which shows that the ordering is not admissible.
Given  , its associated
cone
, its associated
cone  is defined by
is defined by
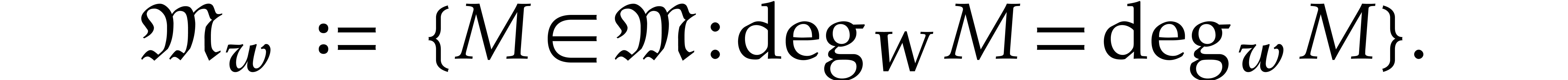
By construction, we have
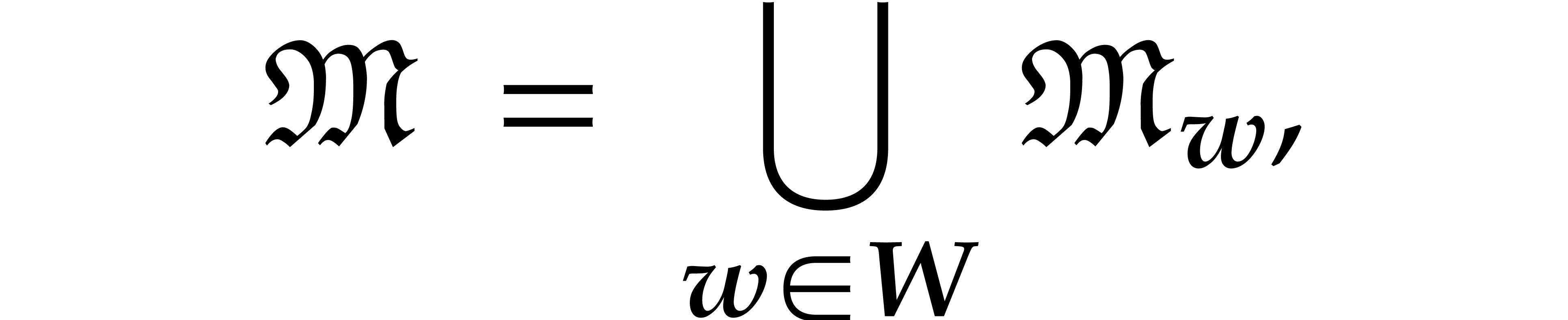
but this union is not necessarily disjoint. Given 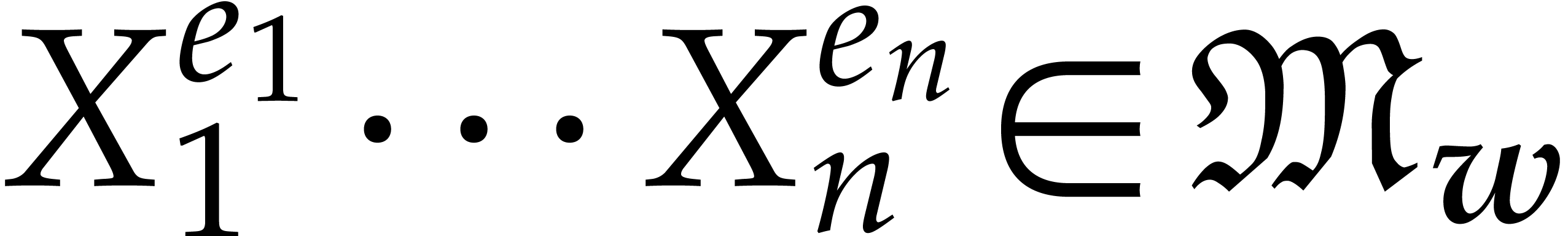 , we note that
, we note that 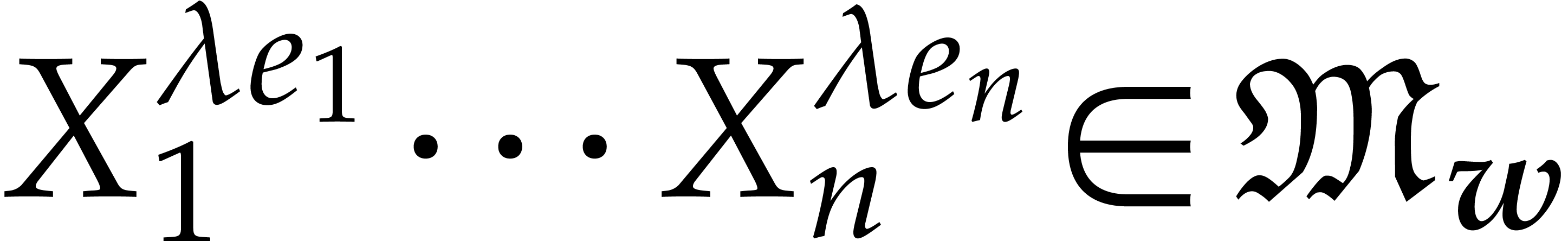 for any
for any  with
with  ;
this explains the terminology “cone”.
;
this explains the terminology “cone”.
Let again be a zero-dimensional ideal of and let 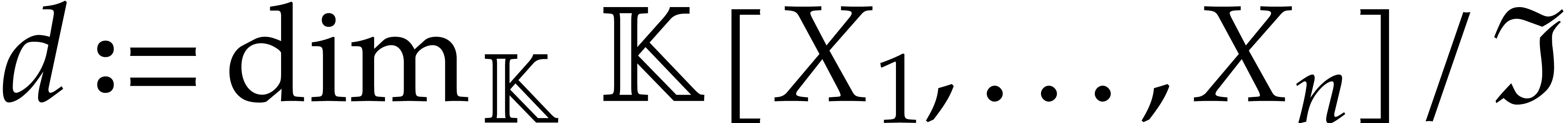 .
Let be a finite non-empty set of weights that
will play the role of the index set
.
Let be a finite non-empty set of weights that
will play the role of the index set 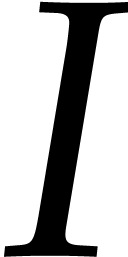 from section
2.4. For , let
be the -simplest
element of and let
from section
2.4. For , let
be the -simplest
element of and let
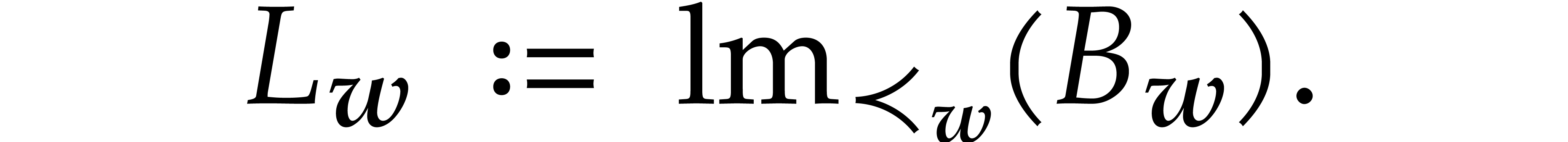
We also define
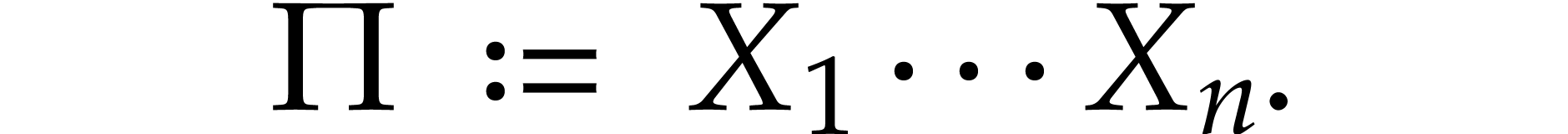
We endow with the lexicographical ordering 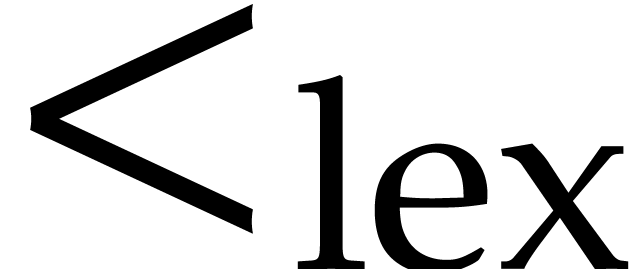 and fix the following selection strategy: for
increasing , we set
and fix the following selection strategy: for
increasing , we set
Now consider the total ordering  on that is defined by
on that is defined by
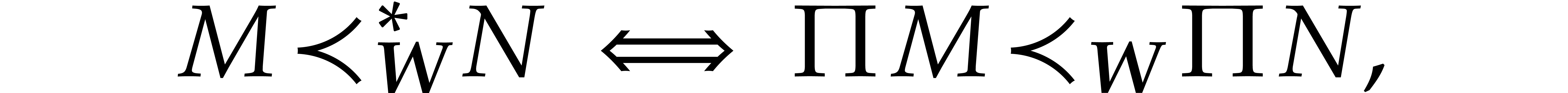
for all . We call a shifted heterogeneous ordering. The shift of
all exponents by one (through multiplication by  ) is motivated by the fact that the product of the
partial degrees of a monomial in
) is motivated by the fact that the product of the
partial degrees of a monomial in 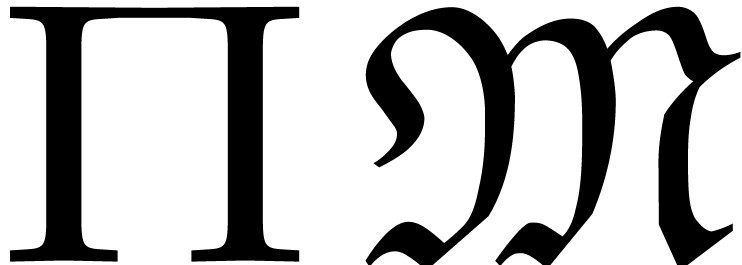 never vanishes.
This will be important in the next section in order to establish certain
degree bounds.
never vanishes.
This will be important in the next section in order to establish certain
degree bounds.
Proof. Consider 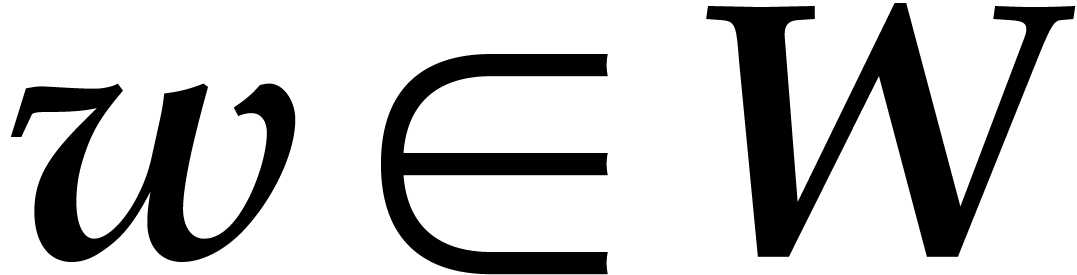 and
and
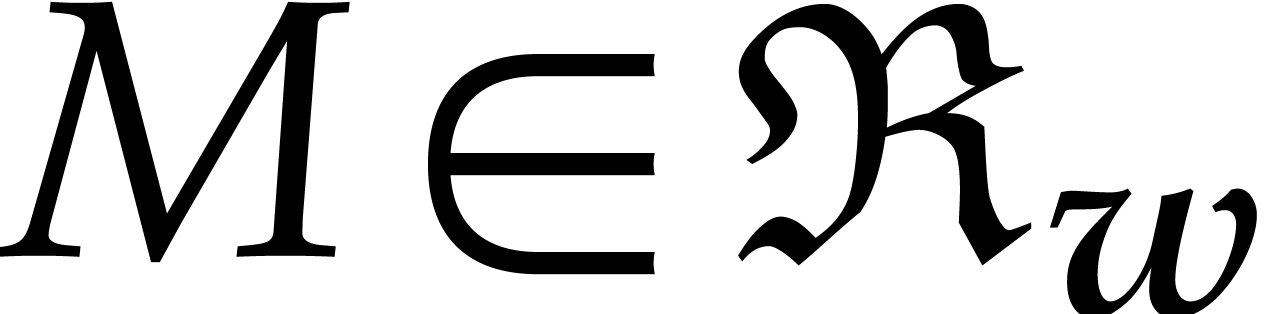 , so that
, so that
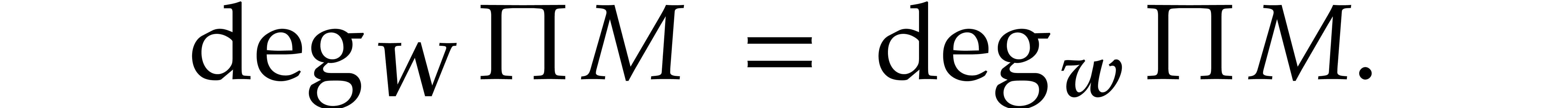
Given  , we need to prove that
, we need to prove that
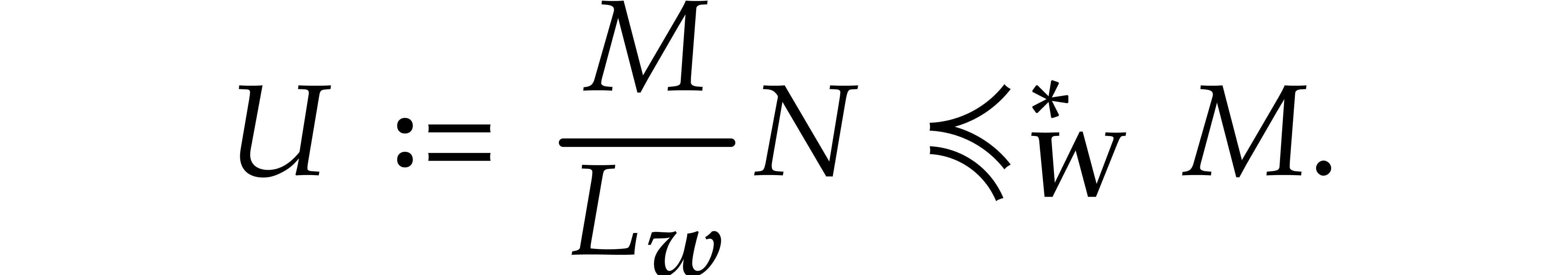
Now 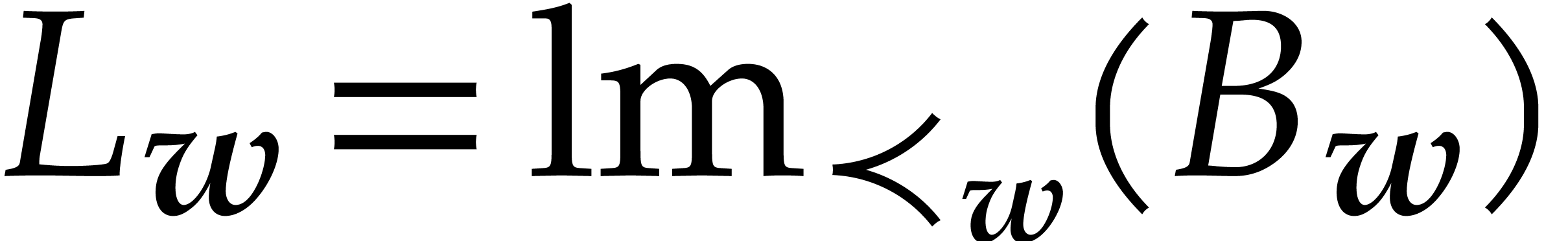 implies
implies 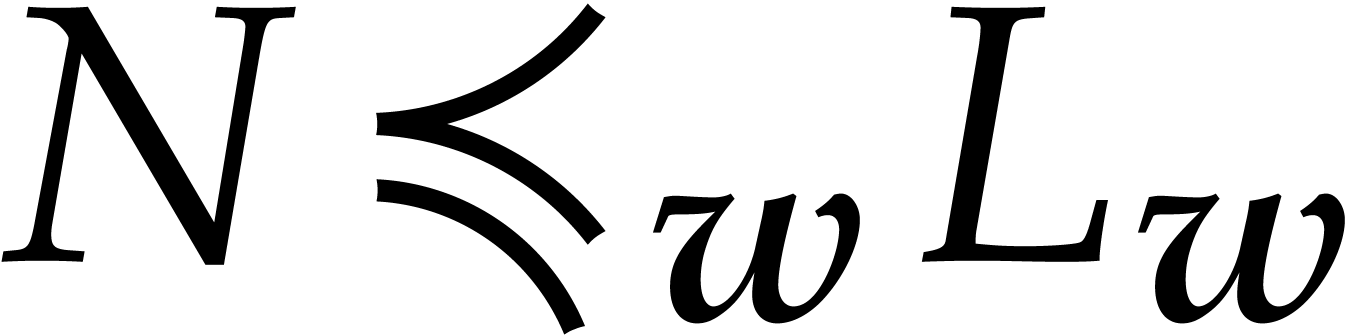 ,
whence
,
whence  . In particular,
. In particular,  and
and 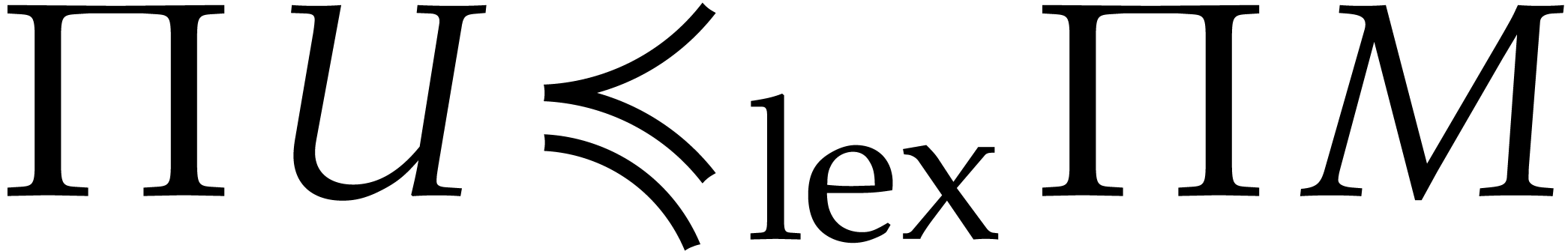 whenever
whenever 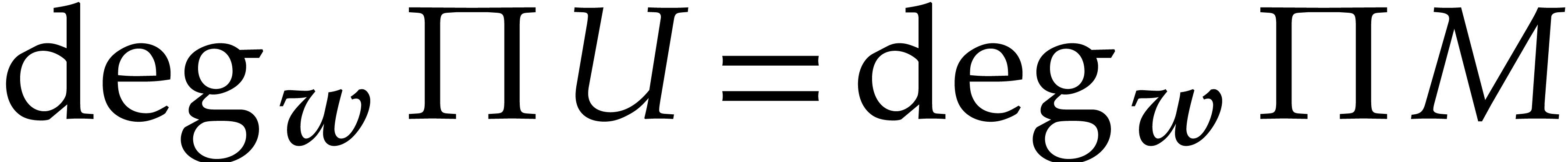 .
.
If 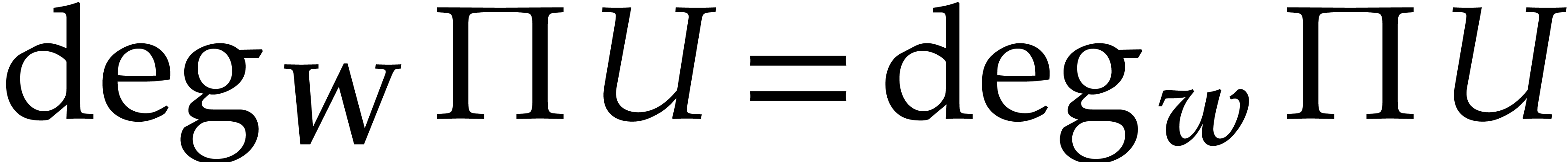 , then it follows that
, then it follows that
 or
or 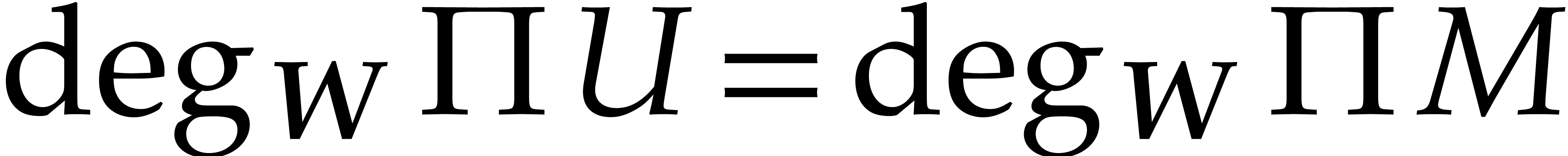 and , whence
and , whence 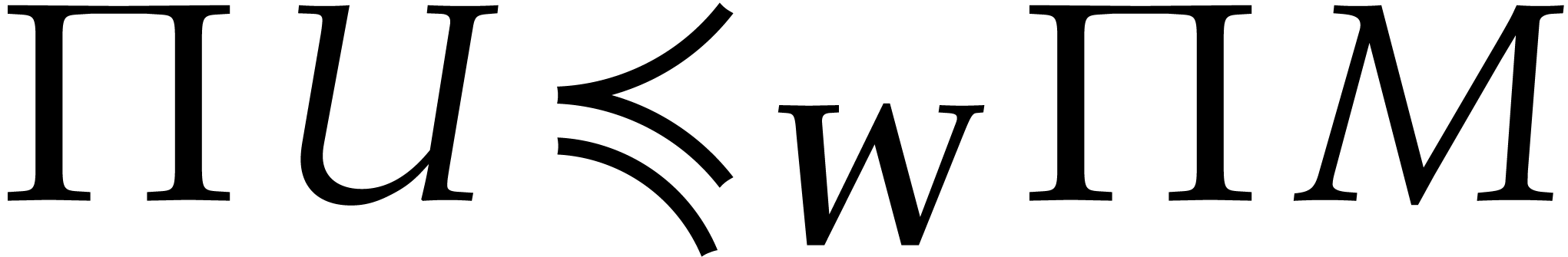 and
and  . Otherwise,
. Otherwise,
for some 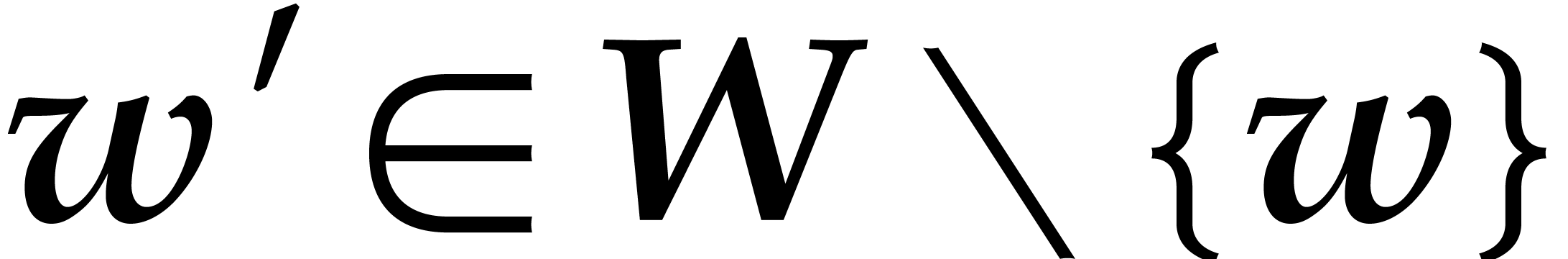 , whence
, whence  and
and  .
.
In this section we instantiate the weight family
considered in the previous section, and analyze the complexity of the
corresponding quasi-reduction.
Consider a zero-dimensional ideal of and let . In
order to devise an efficient algorithm to quasi-reduce polynomials with
respect to , our next task is
to specify a suitable set of weights .
We take 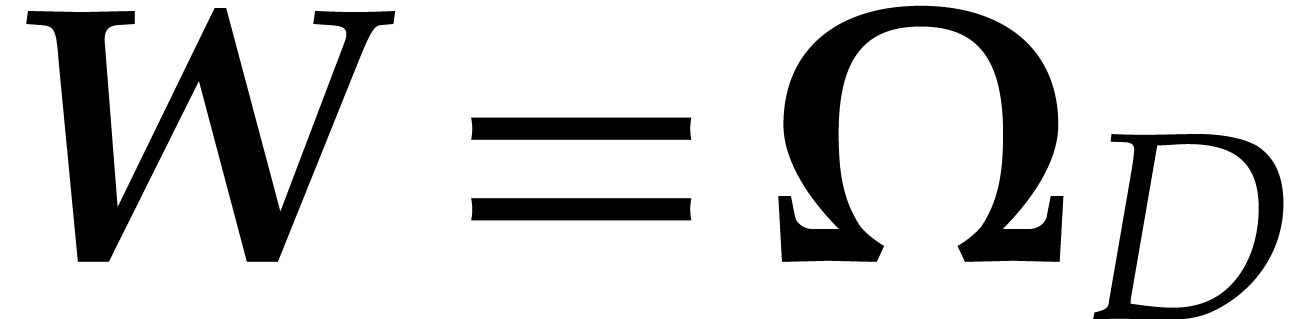 , with
, with
and where 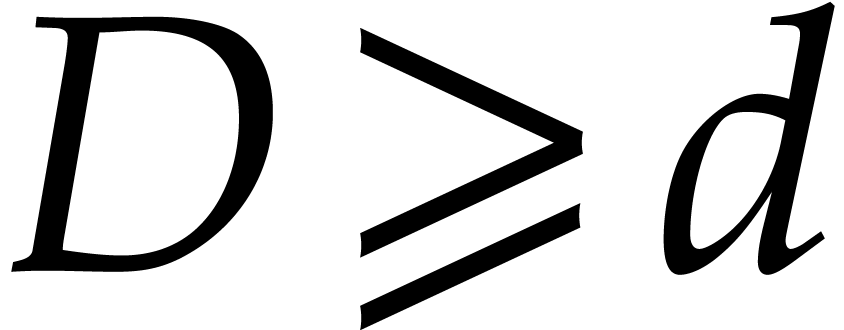 depends on the degree of the
polynomials that we wish to reduce.
depends on the degree of the
polynomials that we wish to reduce.
Proof. Consider 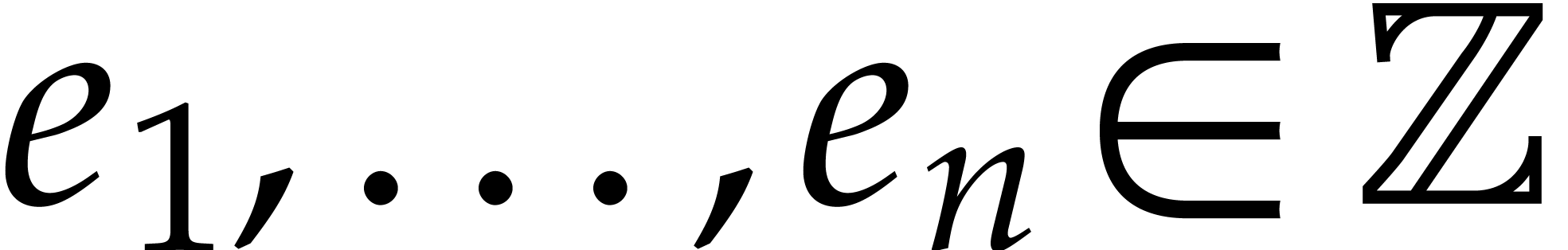 with
with
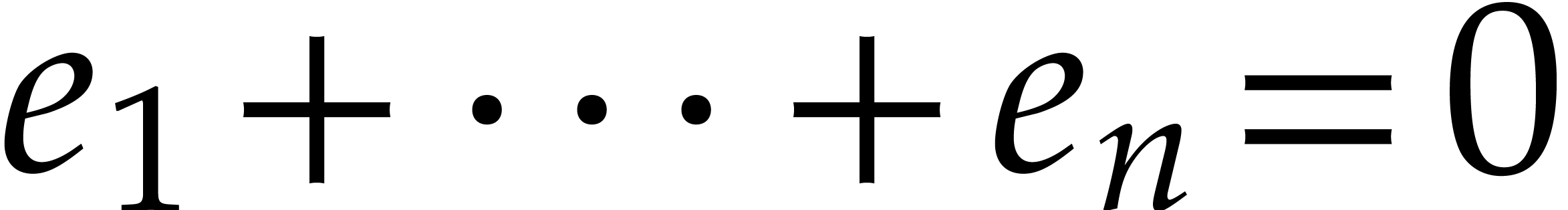 and
and  .
We have
.
We have 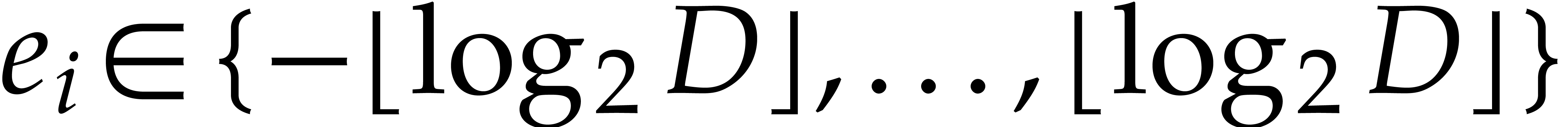 for
for  and
and 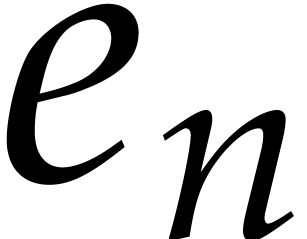 is determined uniquely in terms of
is determined uniquely in terms of  by
by 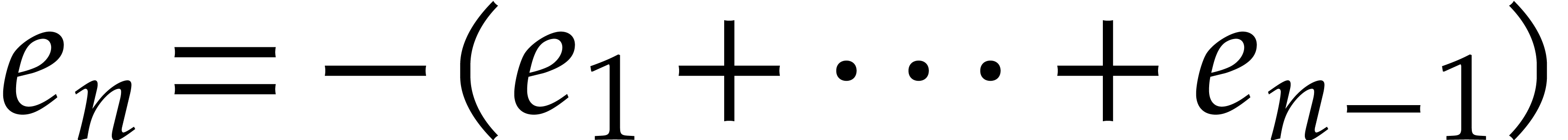 . There are at most
. There are at most 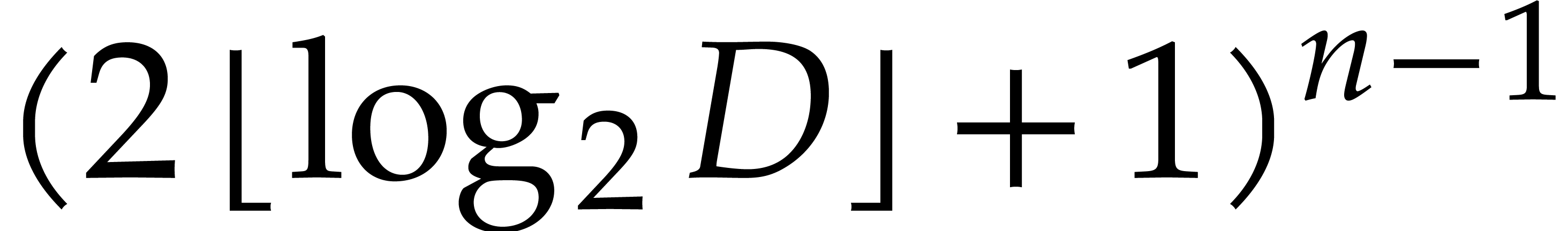 ways to pick
ways to pick  in this
manner.
in this
manner.
Assume that for some 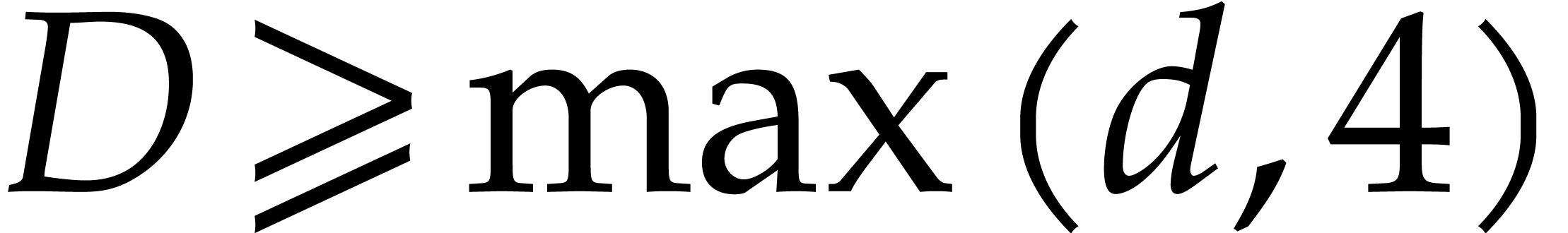 . We associate a selection procedure and a
quasi-admissible ordering to as in section 3.4.
. We associate a selection procedure and a
quasi-admissible ordering to as in section 3.4.
Proof. Assume the contrary and let  be the index for which
be the index for which 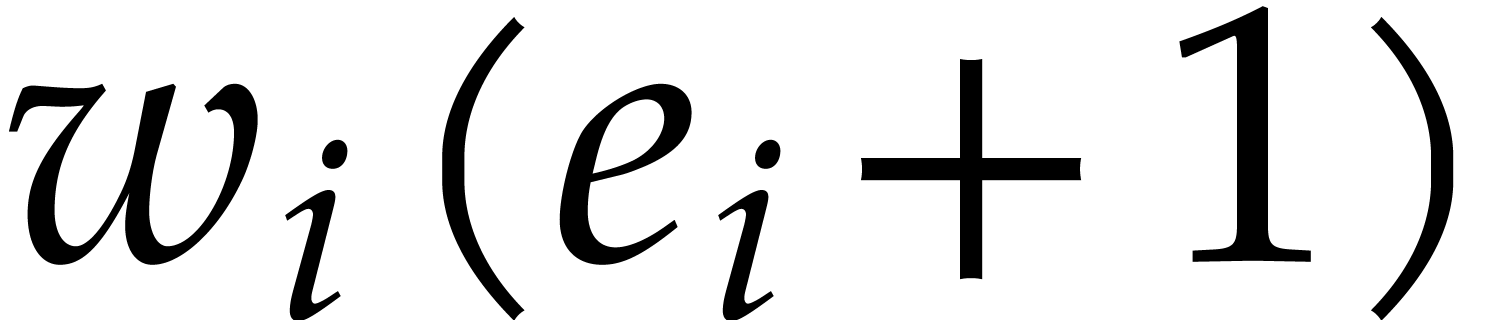 is maximal.
Similarly, let
is maximal.
Similarly, let 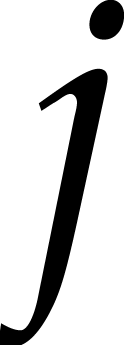 be the index for which
be the index for which 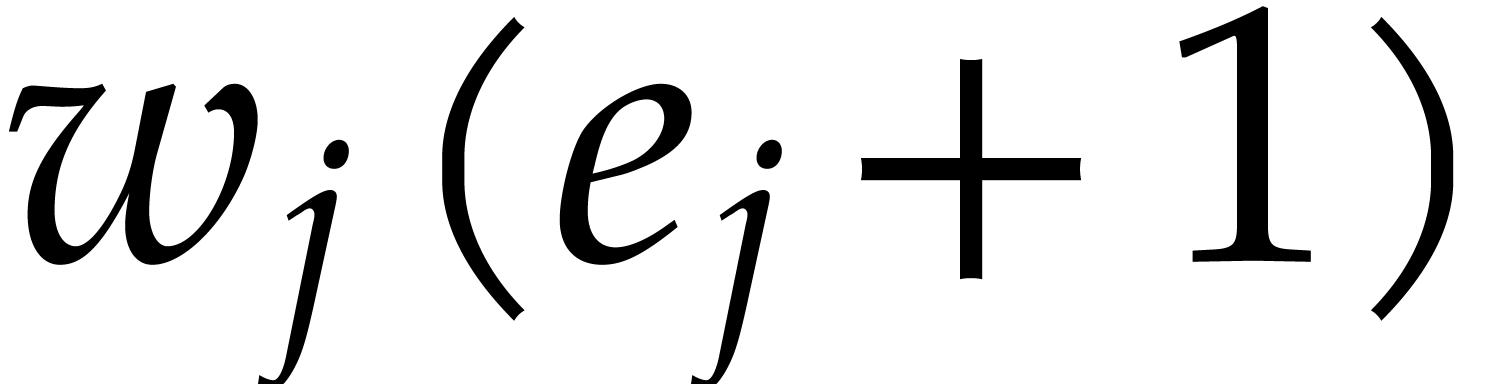 is minimal, so that
is minimal, so that 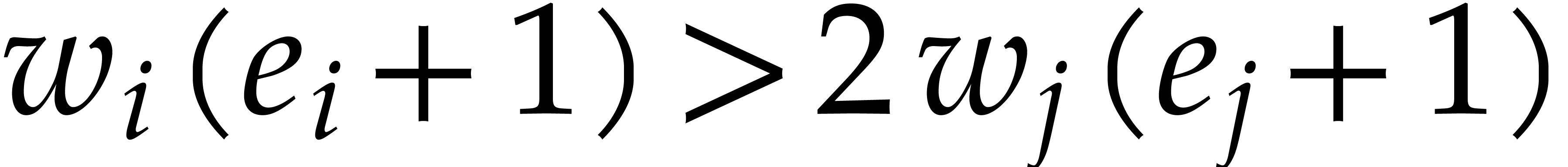 .
Since
.
Since
we have 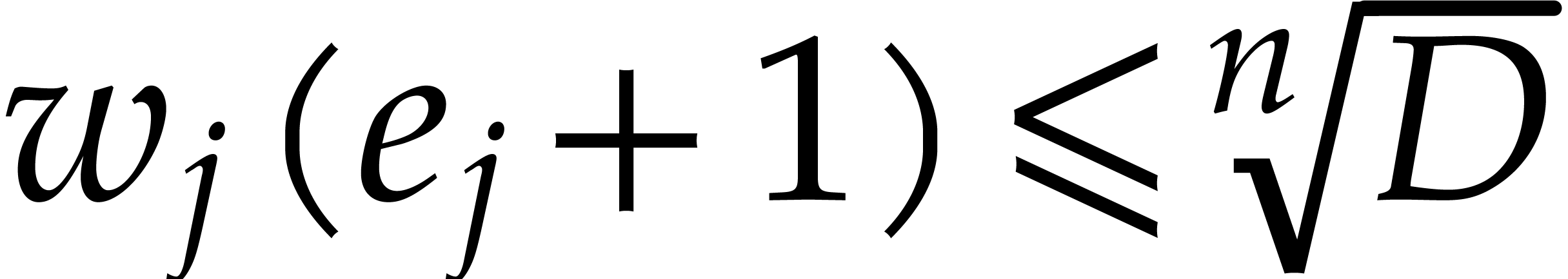 . In particular,
since
. In particular,
since 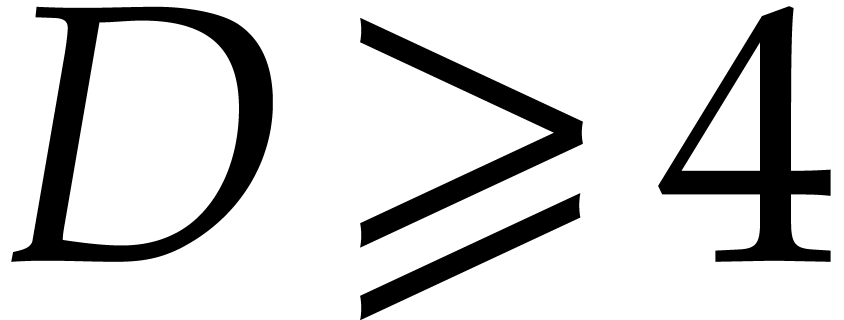 we have
we have 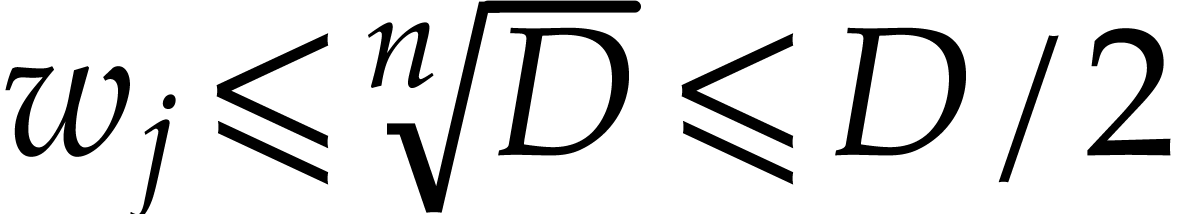 .
.
If 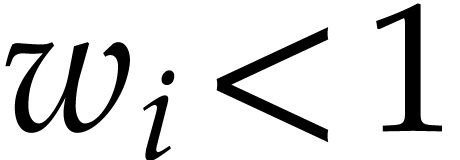 , then there must exist at
least one index
, then there must exist at
least one index 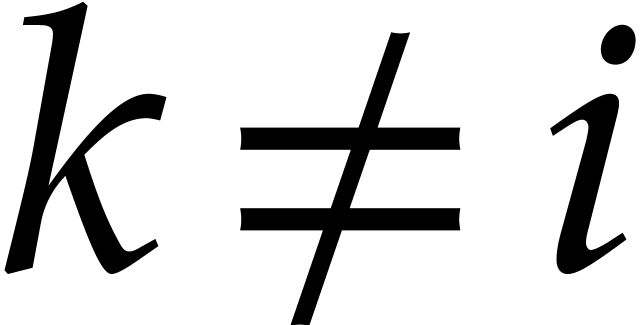 with
with 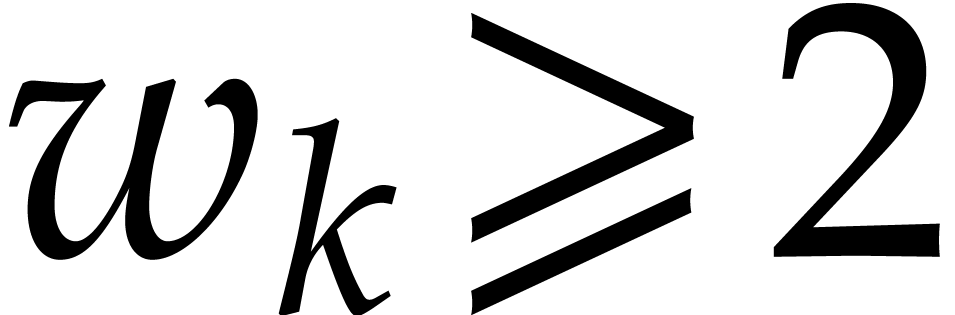 and
and
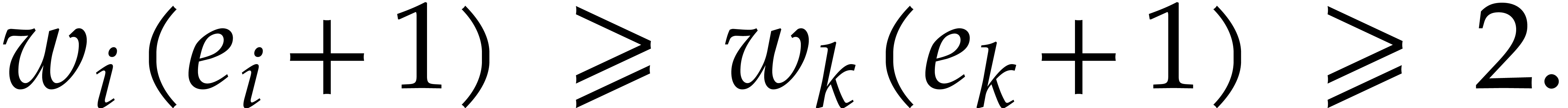
Since 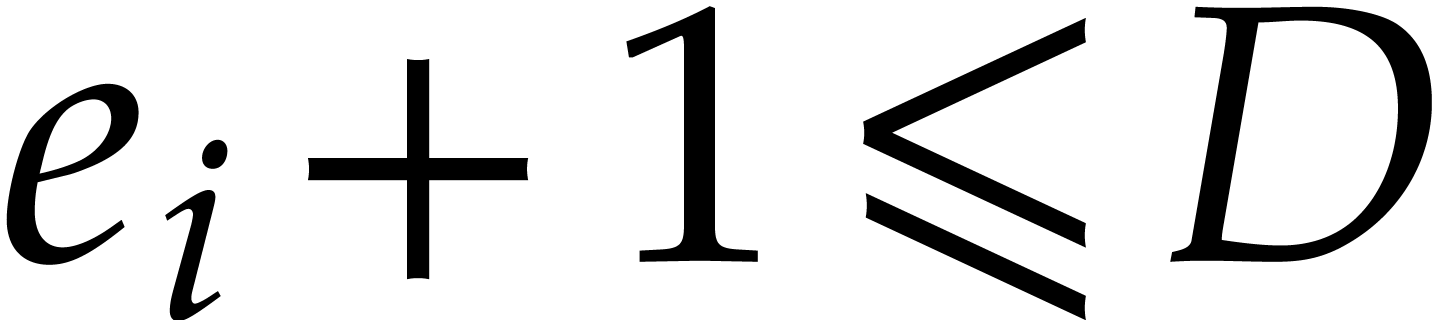 , this yields
, this yields 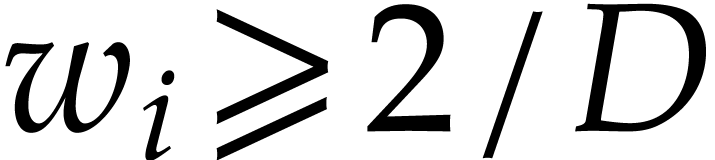 . If
. If 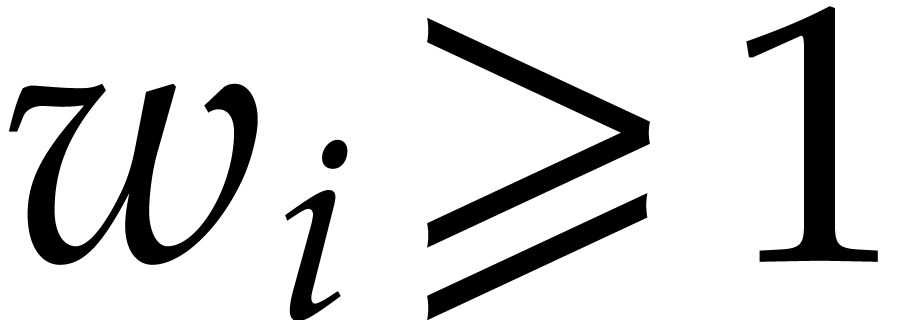 then
then
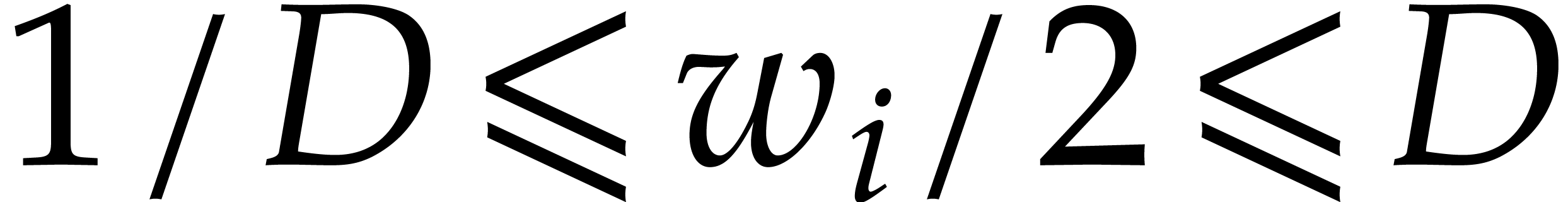 , since
, since 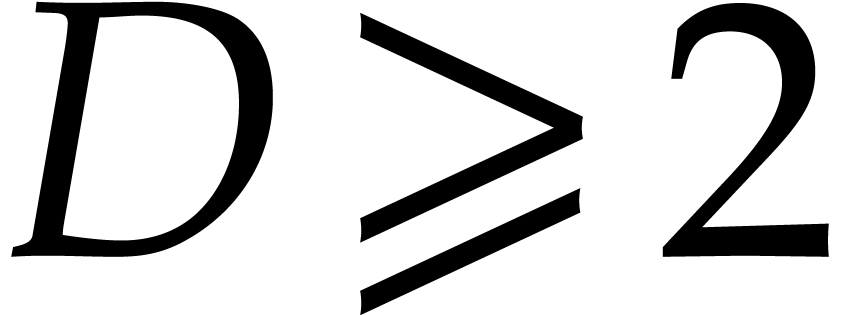 . In both cases we consider the weight
. In both cases we consider the weight  with
with  ,
,
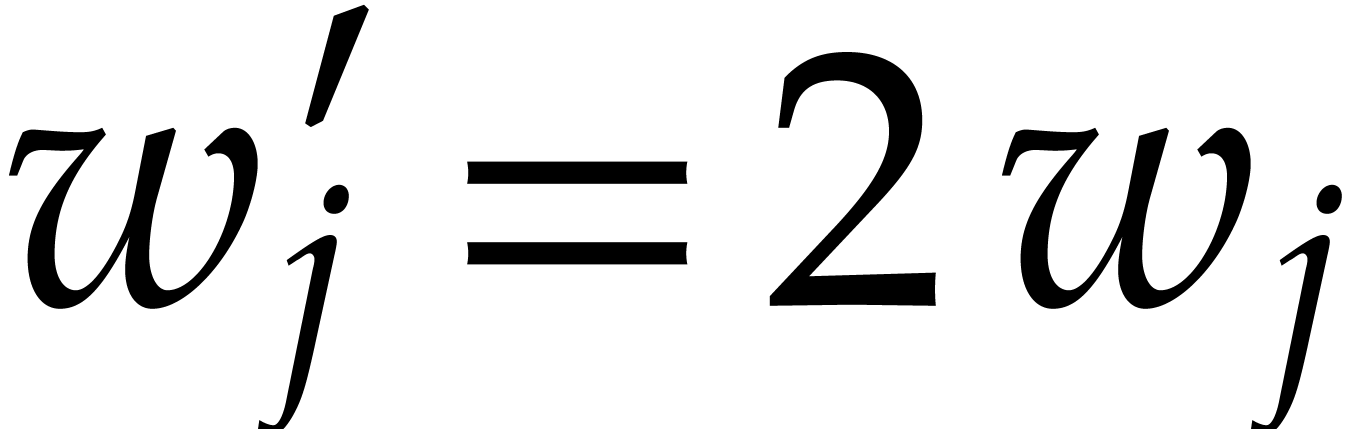 , and
, and 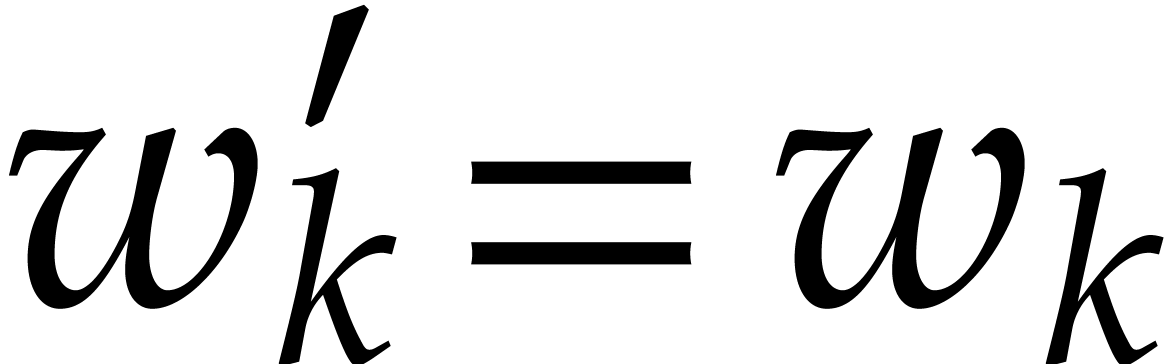 for all
for all 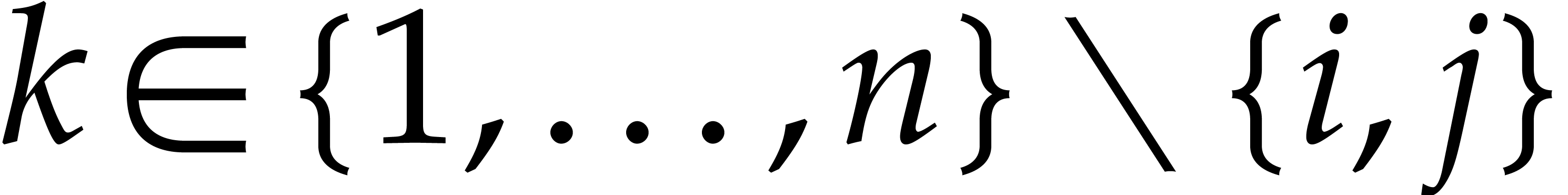 . By what precedes,
we have
. By what precedes,
we have  .
.
We now verify that
This contradicts our assumption that  ,
i.e.
,
i.e. 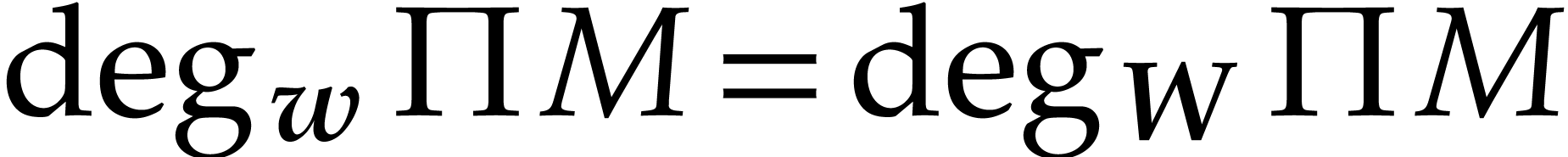 .
.
Proof. Lemma 4.2 implies
but also

The result follows by extracting 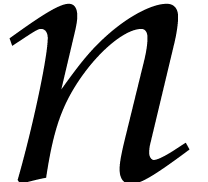 -th
roots.
-th
roots.
We define  to be the set of polynomials such that
to be the set of polynomials such that 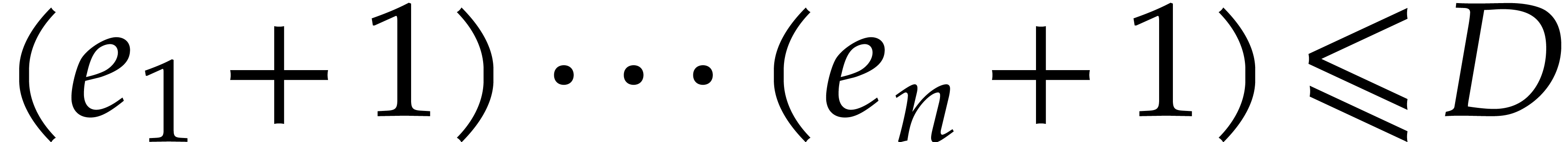 for all
for all 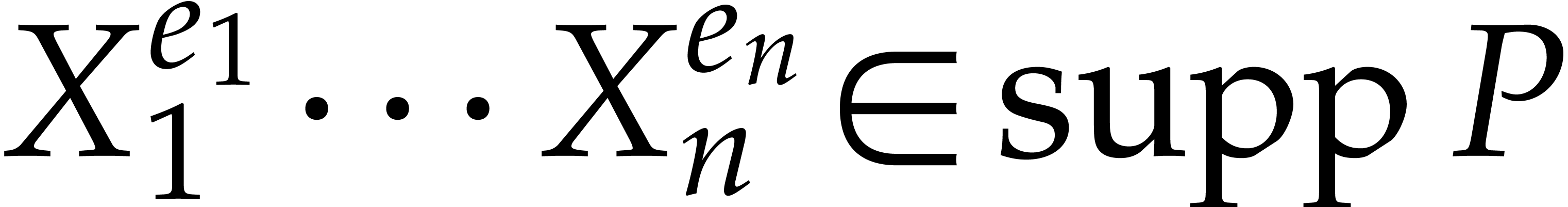 . Given
. Given 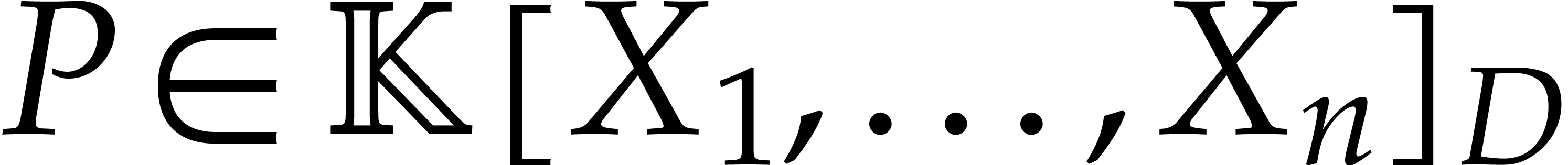 ,
let us now examine the complexity of extended quasi-reduction.
,
let us now examine the complexity of extended quasi-reduction.
with 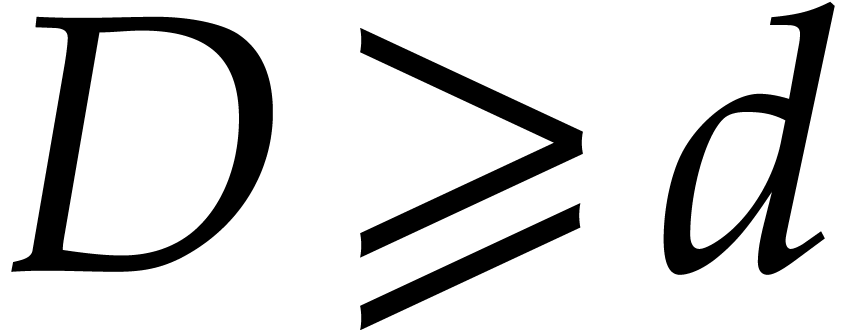 , we may compute its extended quasi-reduction
, we may compute its extended quasi-reduction
using
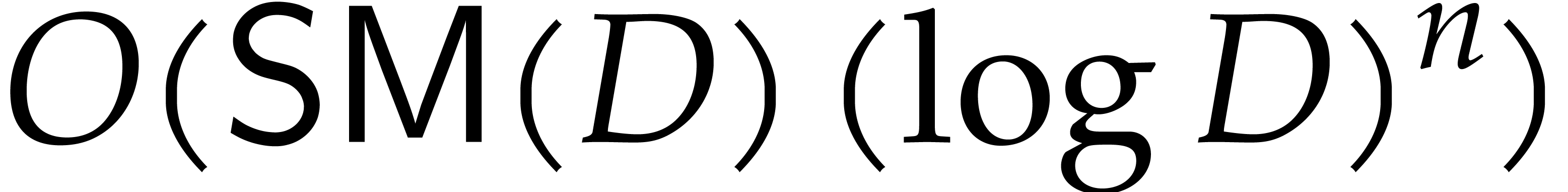
operations in (for any fixed value of ). In addition, for all , we have
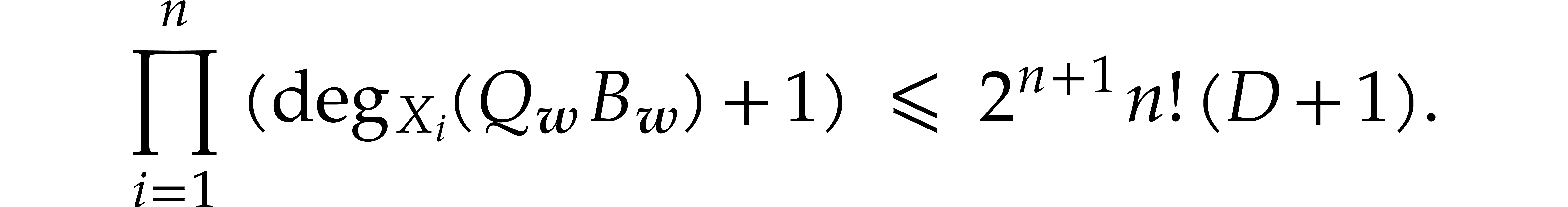
Proof. We solve 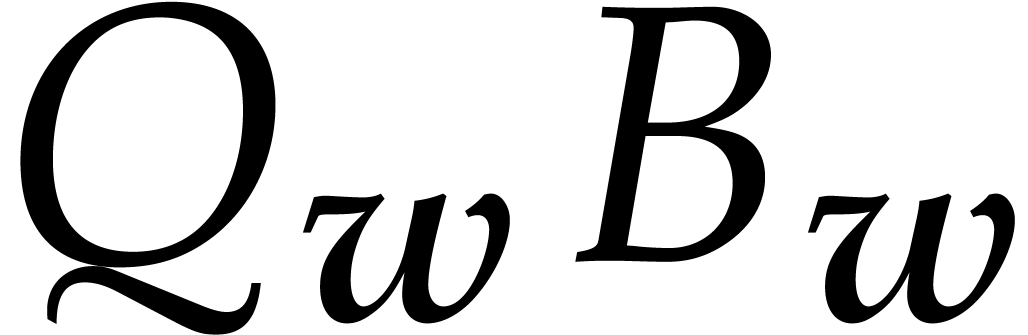 is computed in a relaxed
manner with respect to a different ordering (namely, ). More precisely, for each individual product
, we recall from
is computed in a relaxed
manner with respect to a different ordering (namely, ). More precisely, for each individual product
, we recall from
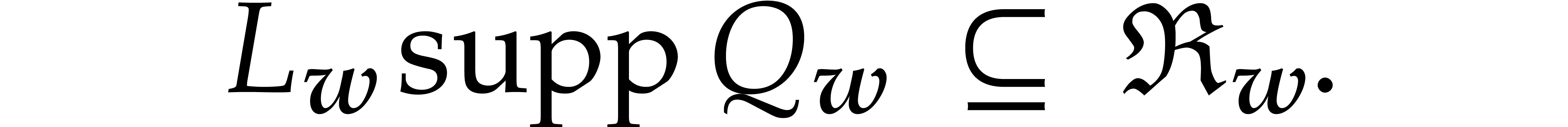
So we can actually compute using the relaxed
product algorithm from Theorem 2.4 with respect to the
ordering . Here we note that
the supports of  and are
contained in dense blocks of similar proportions: for
and are
contained in dense blocks of similar proportions: for  , Corollary 3.2 yields
, Corollary 3.2 yields

whereas Corollary 4.3 implies
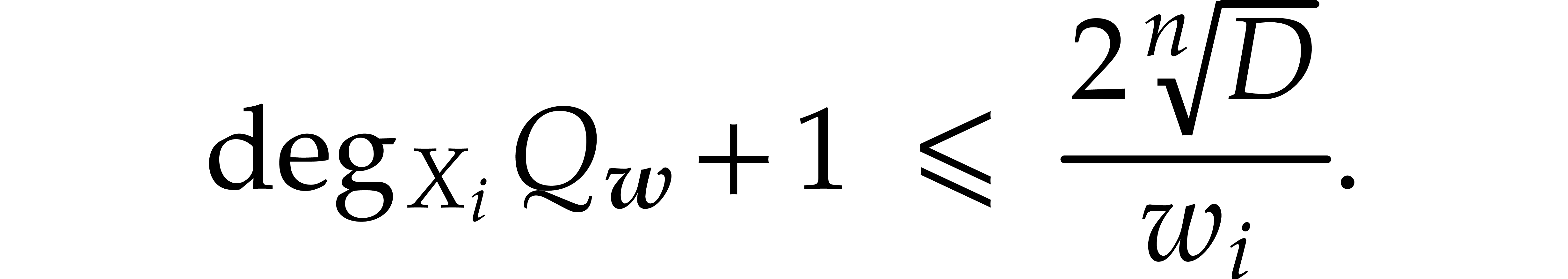
Indeed, for any 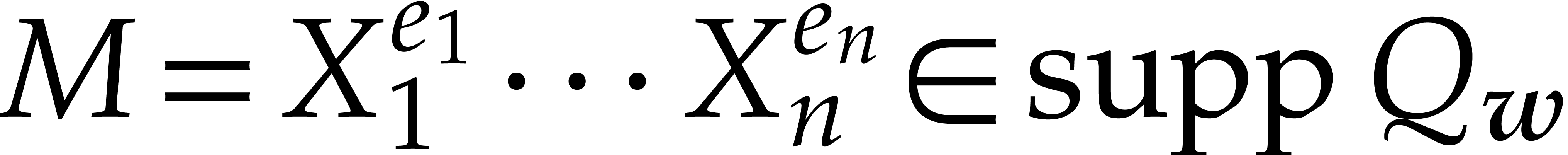 , we have
, we have
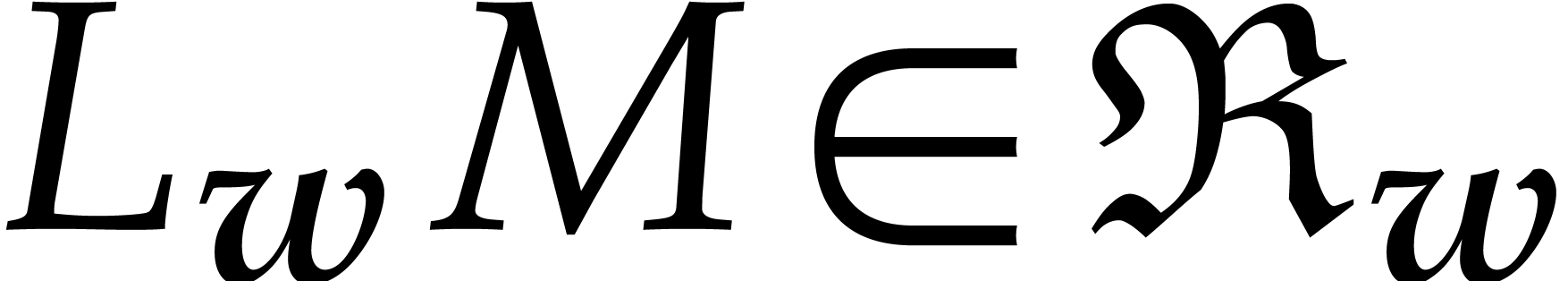 , whence
and
, whence
and 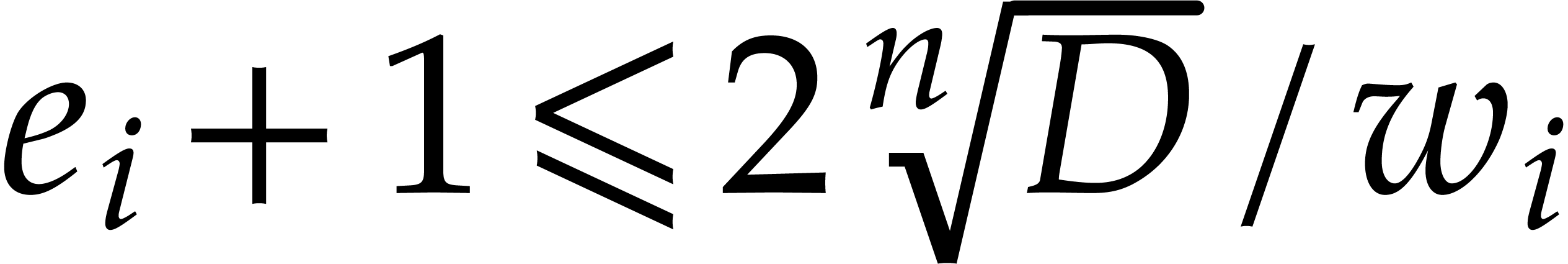 . Let
. Let 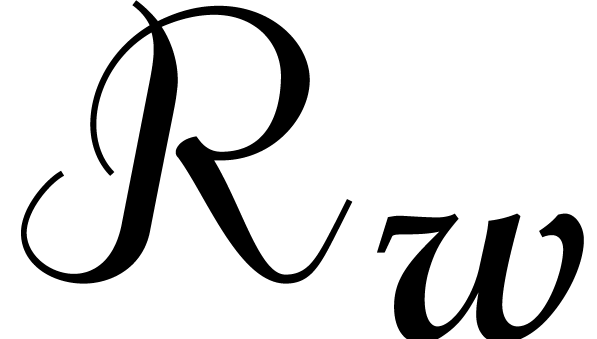 be the set of monomials
be the set of monomials  with
with 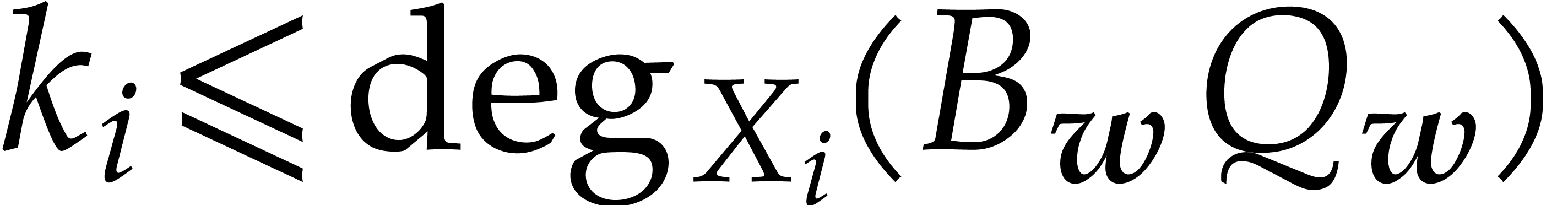 for , so that
for , so that 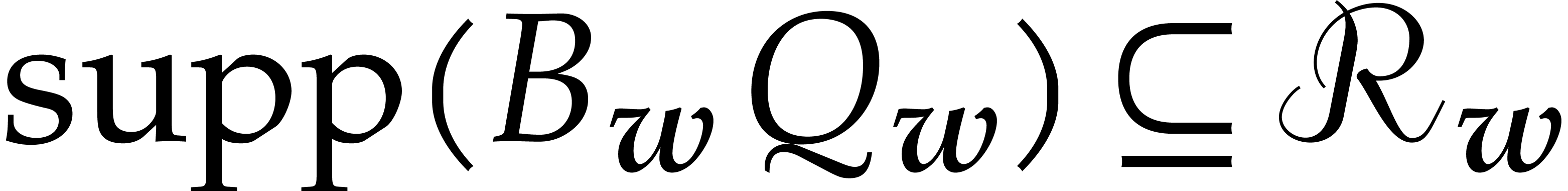 and
and
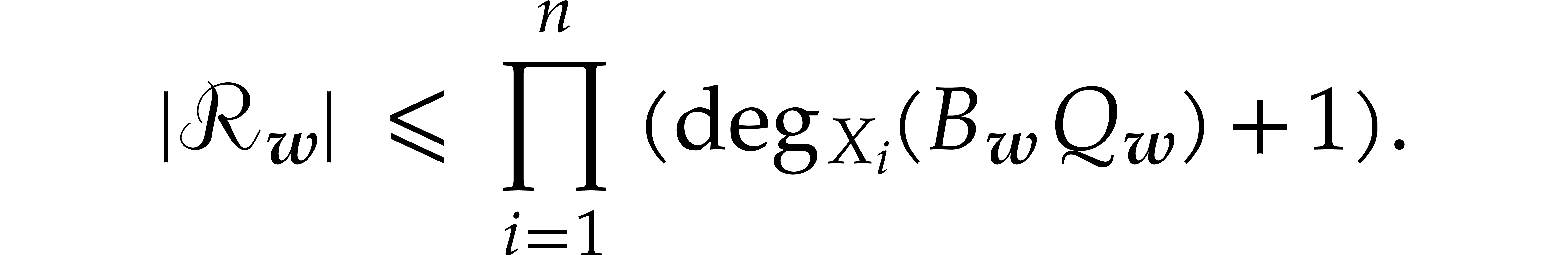
Using , we deduce that
It particular, as a side remark, we note that the dense multiplication
of and can be done using
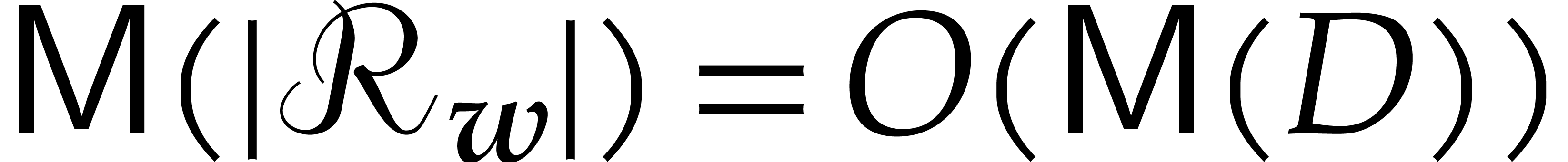 operations in .
operations in .
As to the relaxed product of and , we first note that 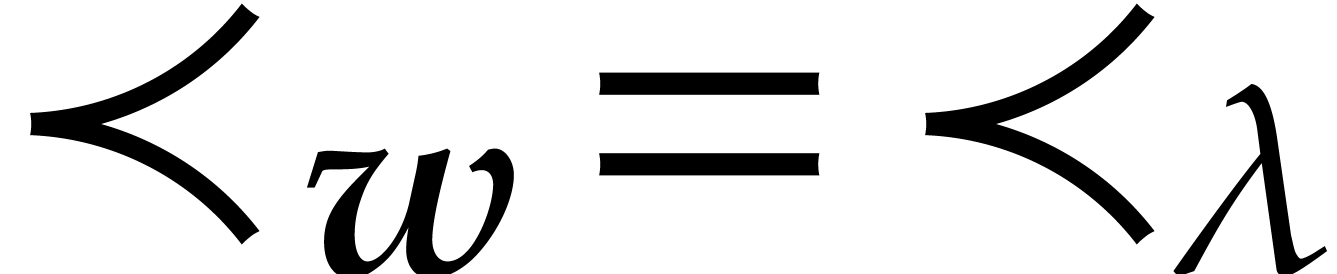 , with the notation from Example 2.3,
where
, with the notation from Example 2.3,
where 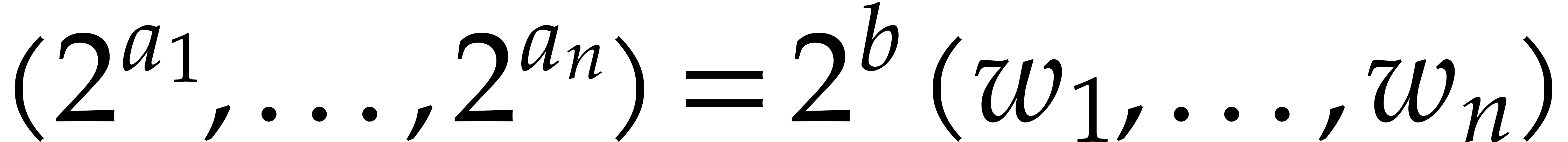 with and
with and 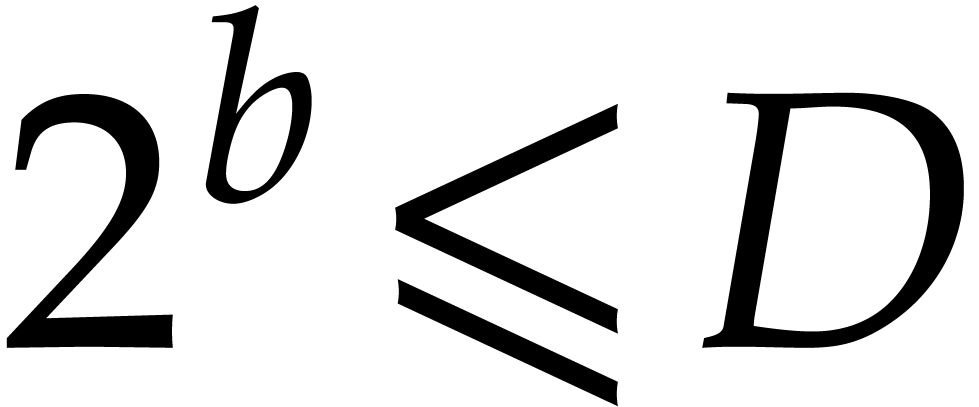 . Consequently,
. Consequently,
and
By Theorem 2.4, we may thus compute the relaxed product of
and in time
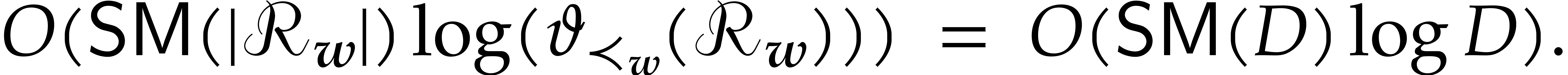
We need to do 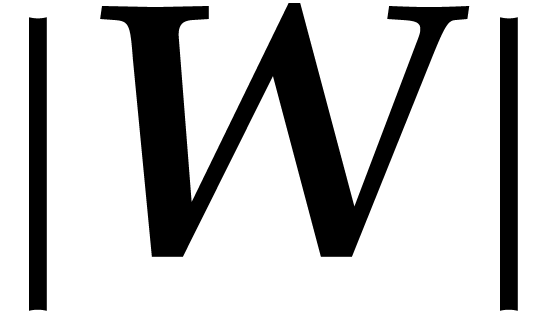 such relaxed multiplications. Now
such relaxed multiplications. Now
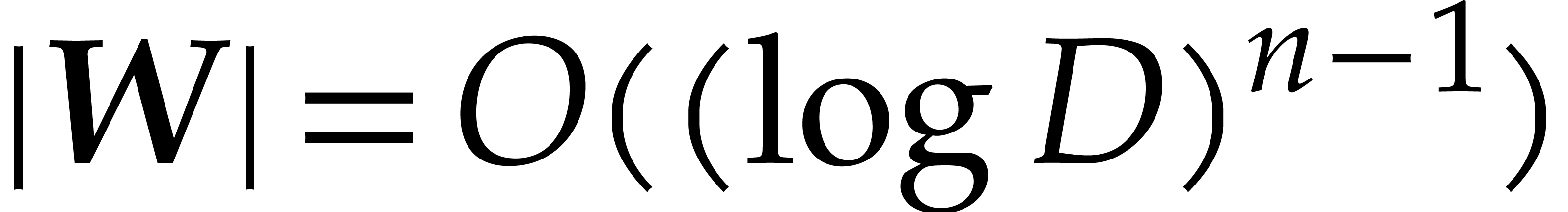 by Lemma 4.1, so the complete
computation takes
by Lemma 4.1, so the complete
computation takes 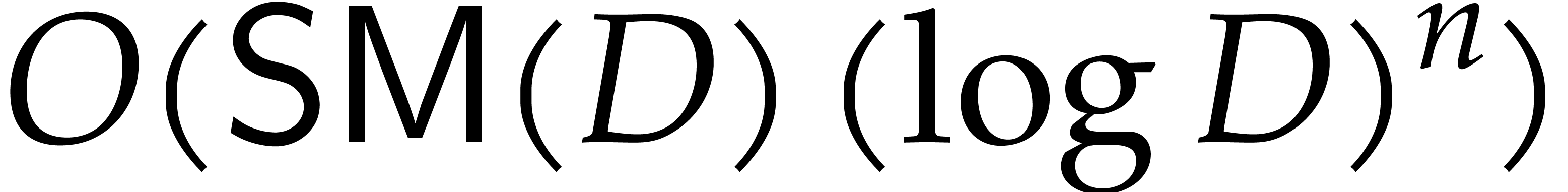 operations in .
operations in .
We finish this section with a bound for the size of reduced polynomials.
Proof. Assume for contradiction that there
exists an 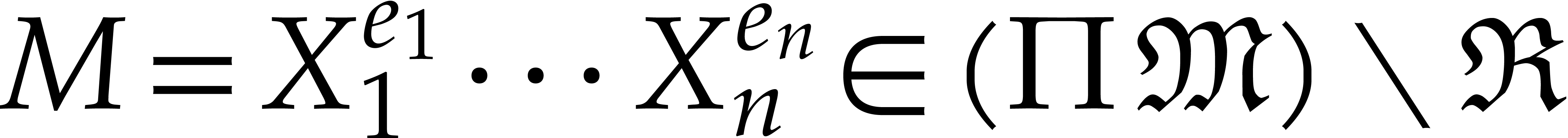 with
with
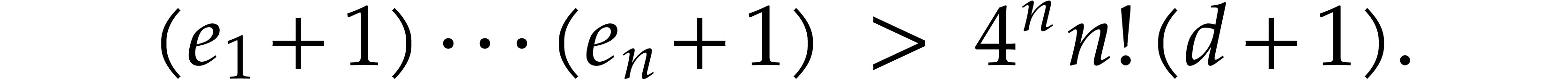
Setting

our assumption can be rewritten as
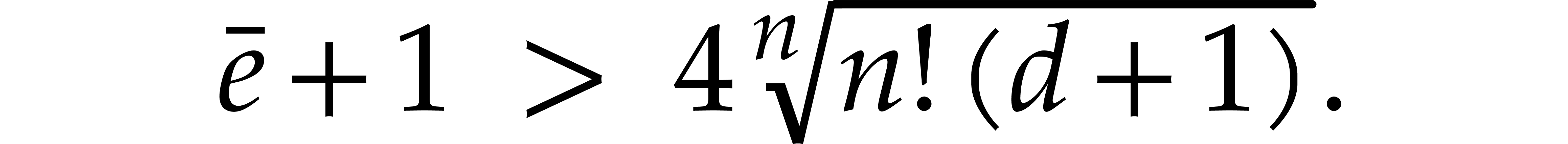
Let be such that
For , Corollary 4.3
implies
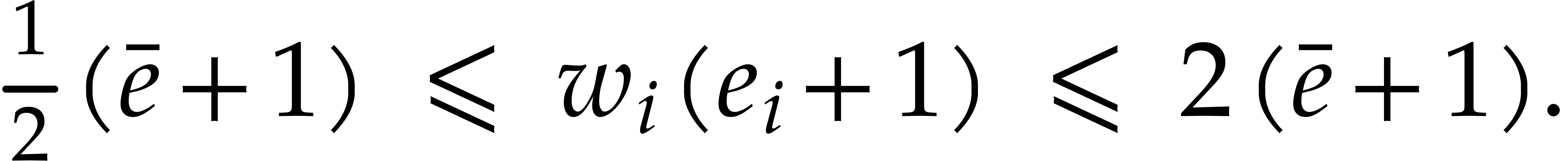
Using Corollary 3.2 and our assumption that 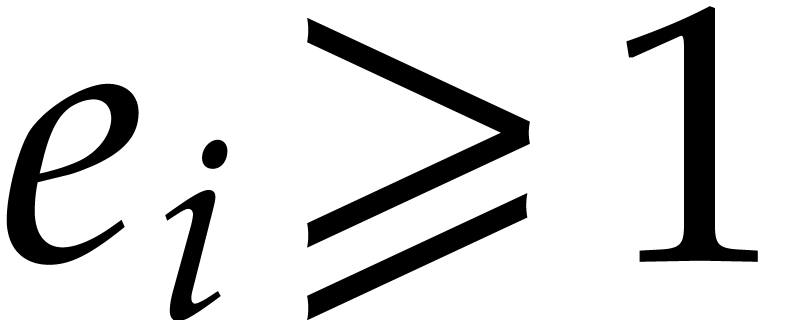 , this yields
, this yields
This shows that  divides
divides  . In combination with our assumption that
. In combination with our assumption that  , this means that , a contradiction.
, this means that , a contradiction.
One limitation of Proposition 4.5 is that it does not apply
to monomials such that  for some index . In this
section, we show how to treat such lower dimensional
“border” monomials by adapting our reduction process. For
any fixed subset
for some index . In this
section, we show how to treat such lower dimensional
“border” monomials by adapting our reduction process. For
any fixed subset 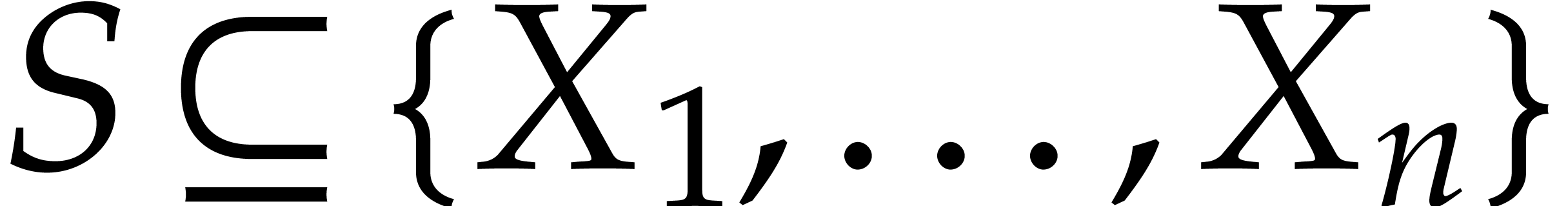 , we will
use the fact that the reduction process from the previous subsections
can be applied to polynomials in the variables from
, we will
use the fact that the reduction process from the previous subsections
can be applied to polynomials in the variables from  and the ideal
and the ideal  . We next
combine the reduction processes for all such subsets .
. We next
combine the reduction processes for all such subsets .
Given a finite subset 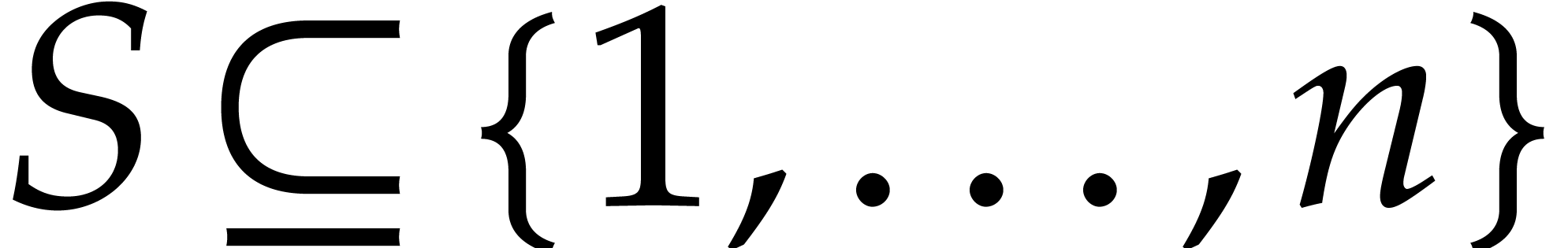 , we
write
, we
write
We note that  is an ideal of
is an ideal of  with
with  . Given , we define
. Given , we define

to be the set of active coordinates of . For any two subsets  ,
we define
,
we define
and note that this defines a total ordering on the set of subsets of
 .
.
A generalized weight is a tuple  and we
call
and we
call
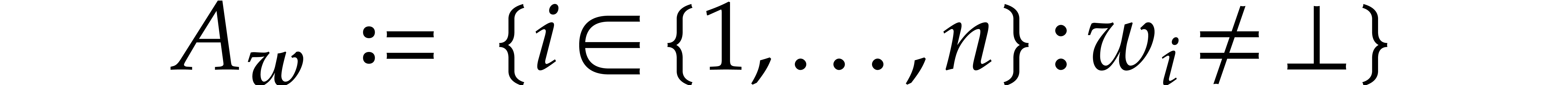
its set of active coordinates. We say that
is admissible if 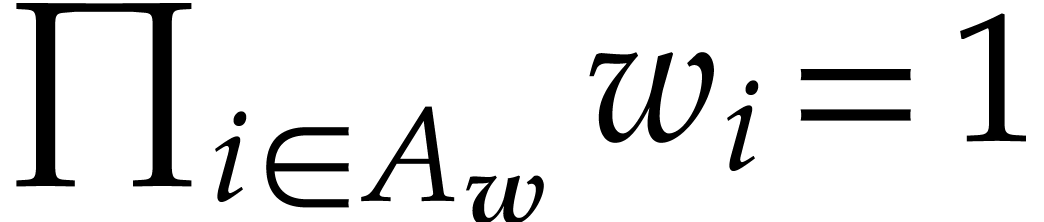 .
For any monomial
.
For any monomial  , we define
its -degree by
, we define
its -degree by
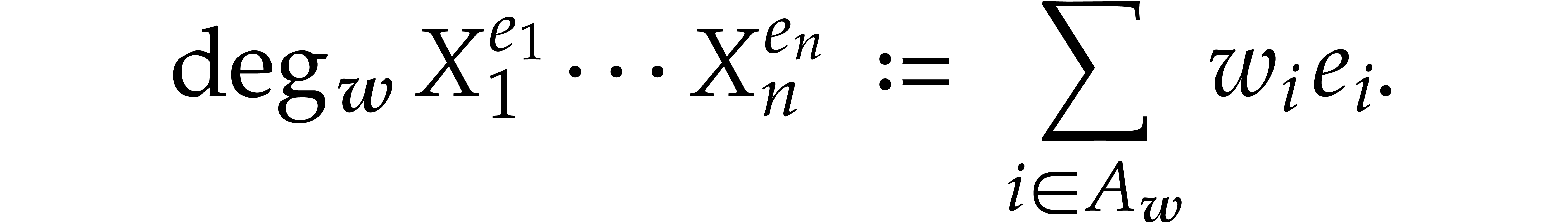
The -degree induces an
ordering on 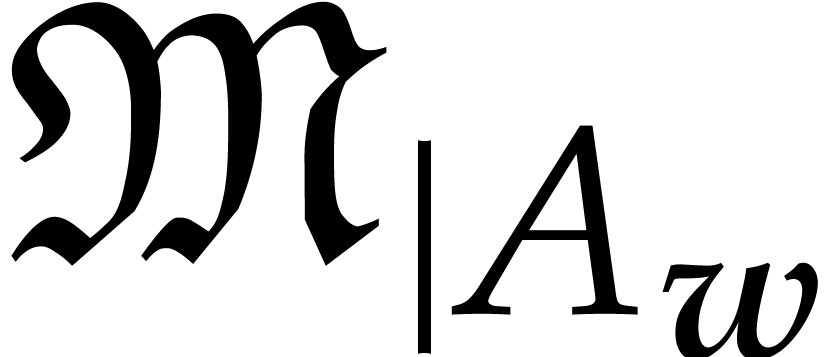 by setting
by setting
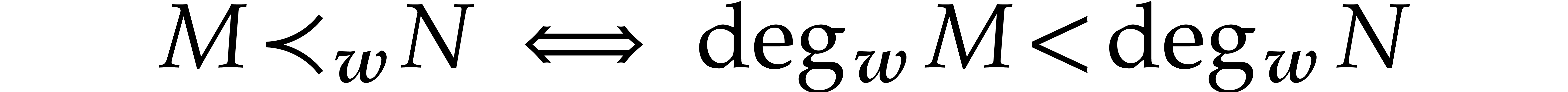
for all 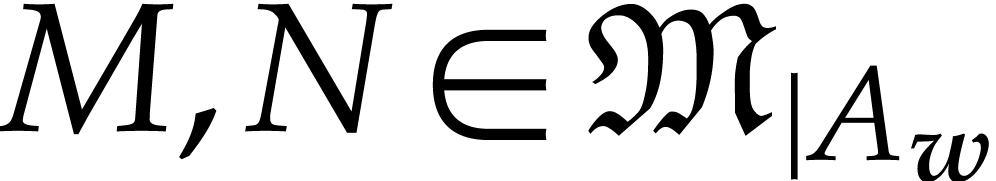 . We may naturally
extend the notions of -degree,
leading monomials, etc. to polynomials in
. We may naturally
extend the notions of -degree,
leading monomials, etc. to polynomials in  . We also define the -simplest element of
. We also define the -simplest element of  to be
the unique monic polynomial
to be
the unique monic polynomial 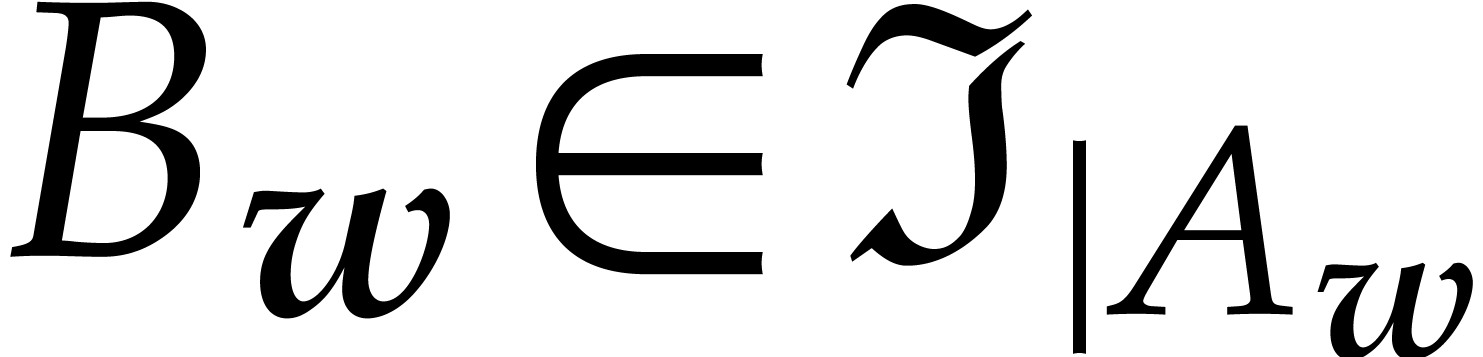 whose leading
monomial is minimal for .
whose leading
monomial is minimal for .
Given a set of generalized weights and , we define

If  is non-empty, then we define
is non-empty, then we define
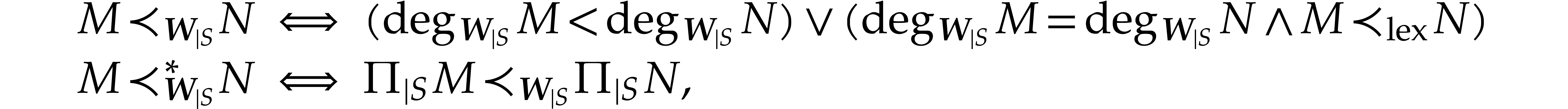
for all  .
.
We next extend the definitions from section 3.4 to the case
when is a set of generalized weights with 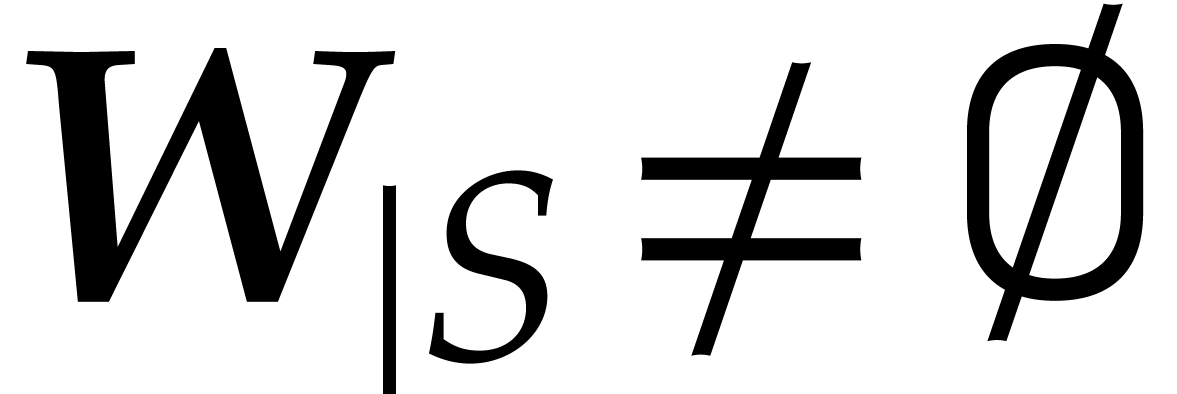 for every subset .
For each , we take to be the -simplest
element of and let
for every subset .
For each , we take to be the -simplest
element of and let
We will sometimes write 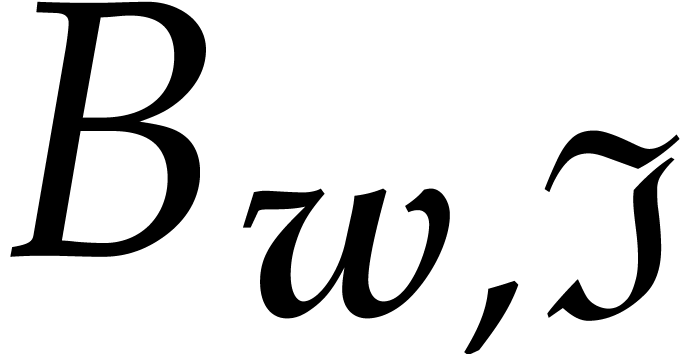 instead of when we need to emphasize the dependence on . After declaring that
instead of when we need to emphasize the dependence on . After declaring that 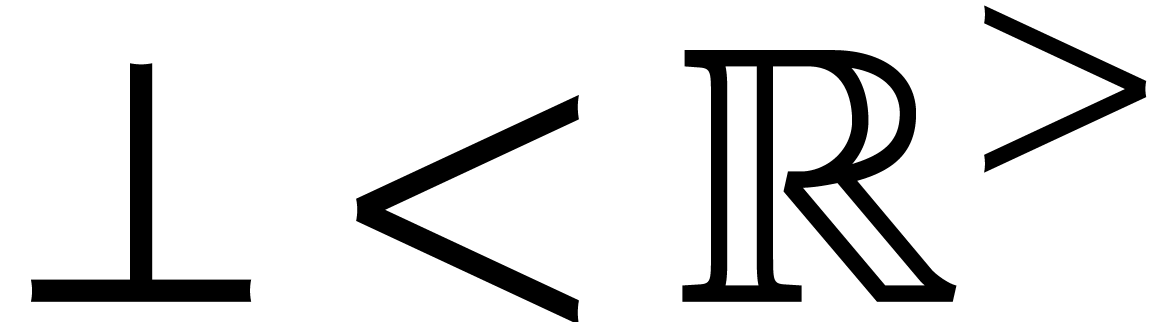 , the set can still be
endowed with the lexicographical ordering. For increasing , we now set
, the set can still be
endowed with the lexicographical ordering. For increasing , we now set
Sometimes, we will write 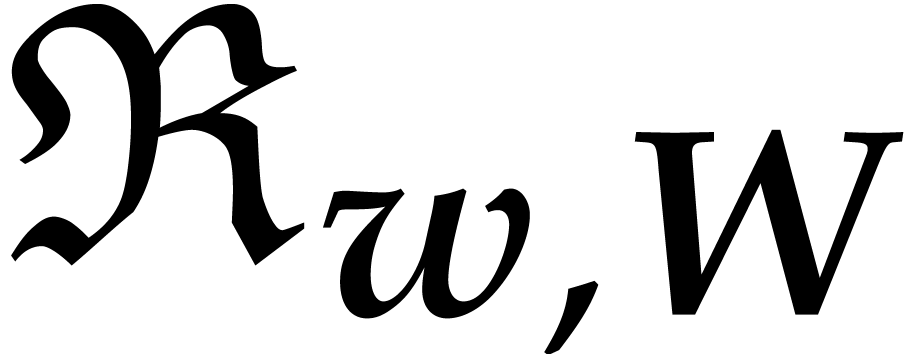 instead of
instead of  when we need to emphasize the dependence on . Finally, we define our total ordering on by
when we need to emphasize the dependence on . Finally, we define our total ordering on by
for all .
is
quasi-admissible.
Proof. It is straightforward to check that is indeed a total ordering such that

for all 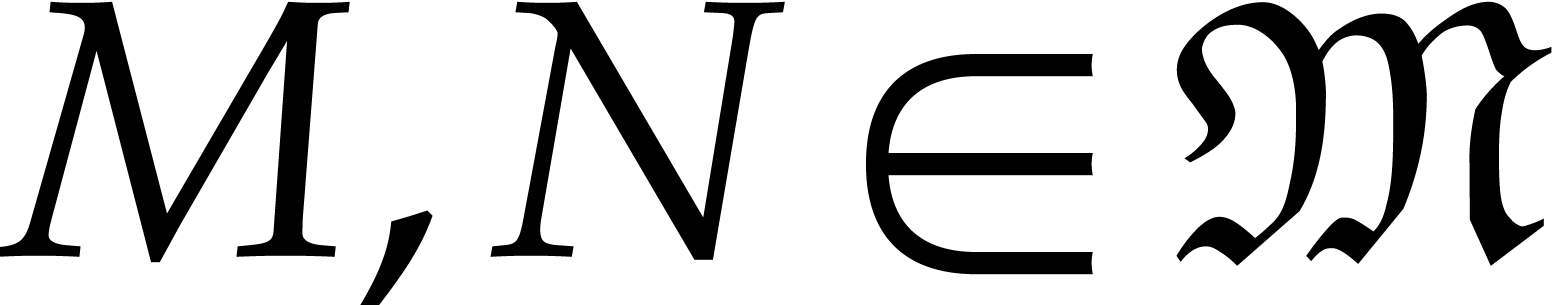 , by extending Lemma
3.3. Now consider and
, by extending Lemma
3.3. Now consider and
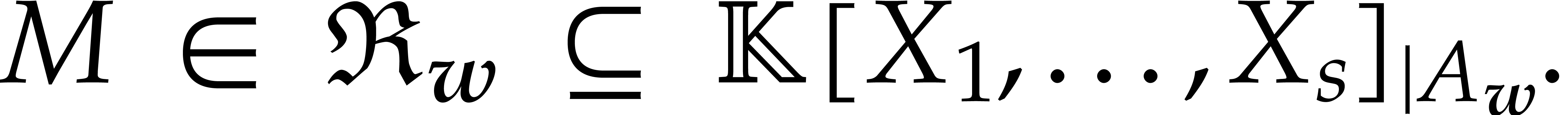
Given 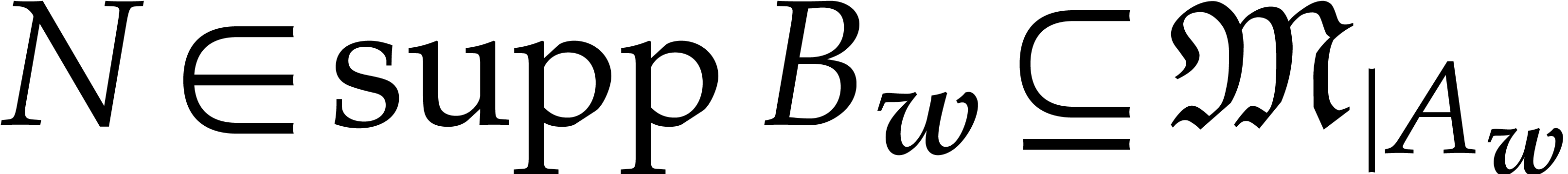 , Proposition 3.5
implies
, Proposition 3.5
implies
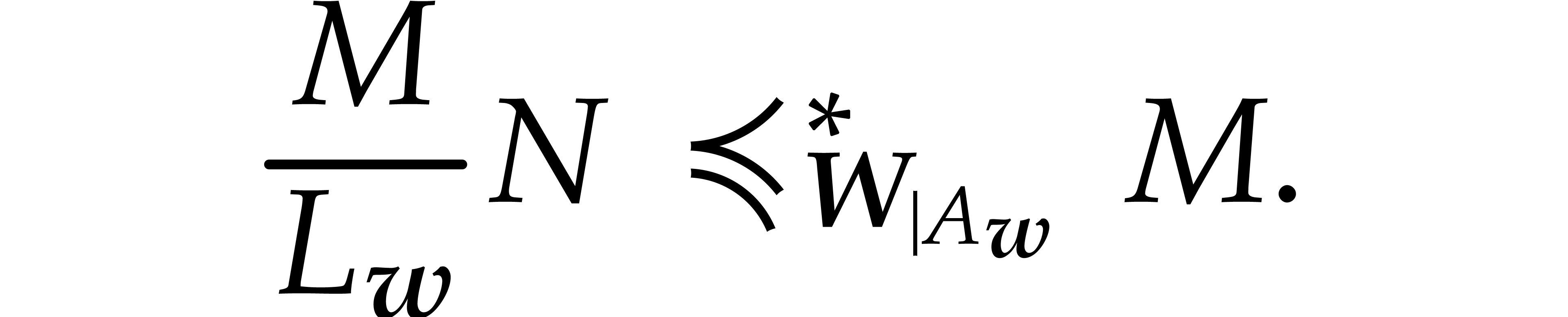
If 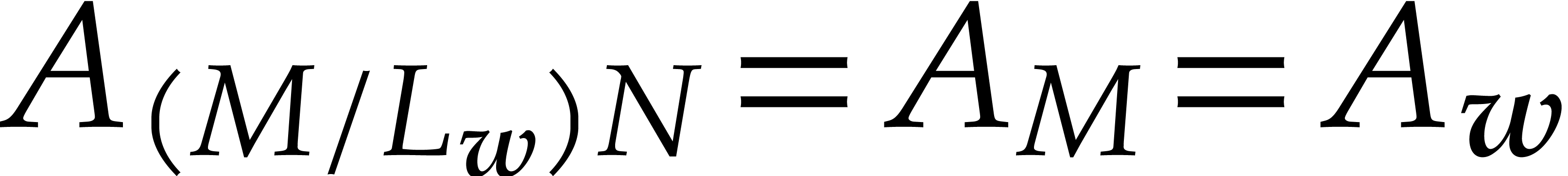 , then this yields
, then this yields
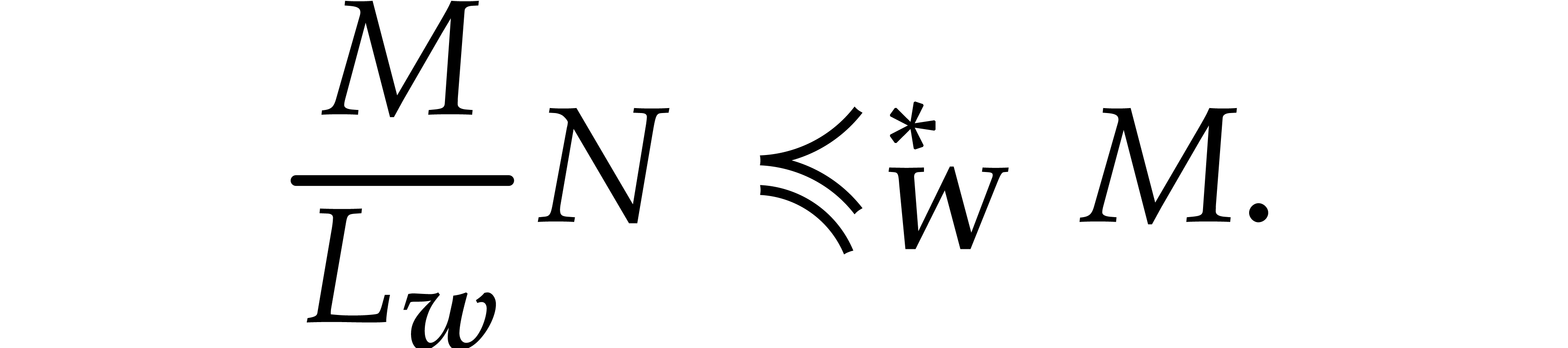
Otherwise, we have  , so
, so 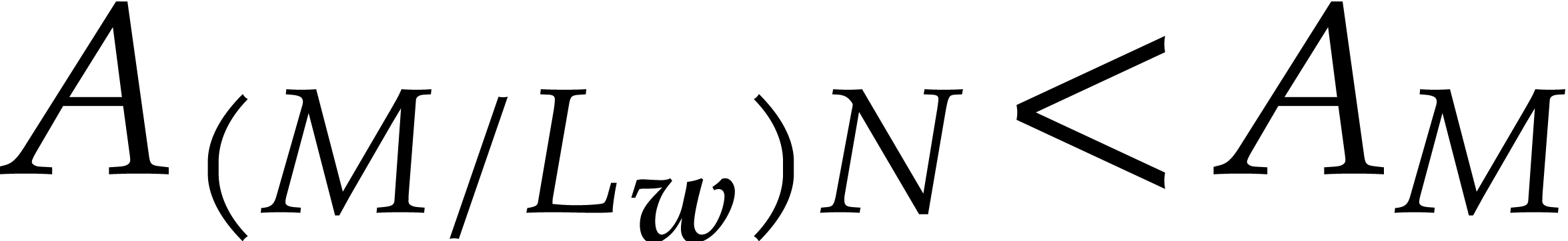 , with the same conclusion.
, with the same conclusion.
Given a general weight 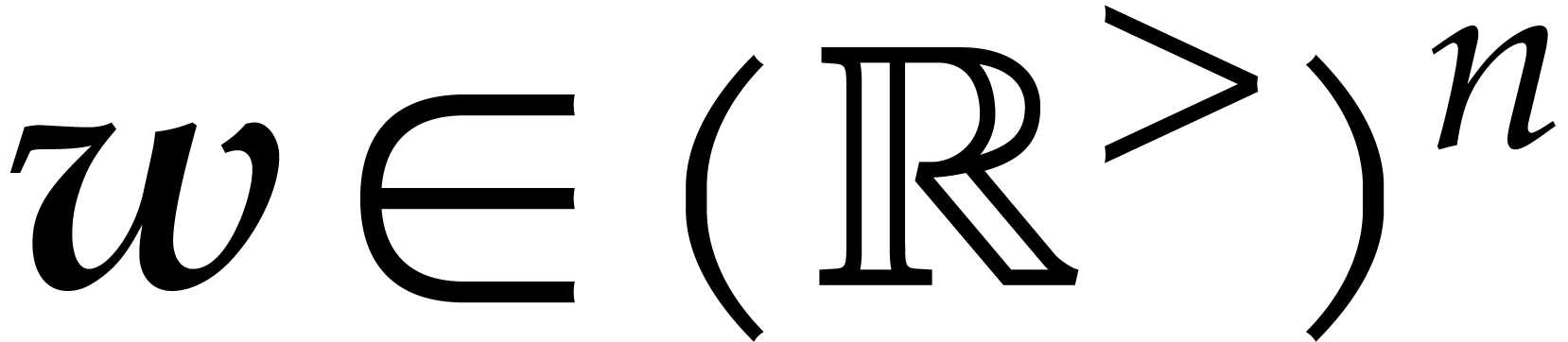 and a subset
and a subset 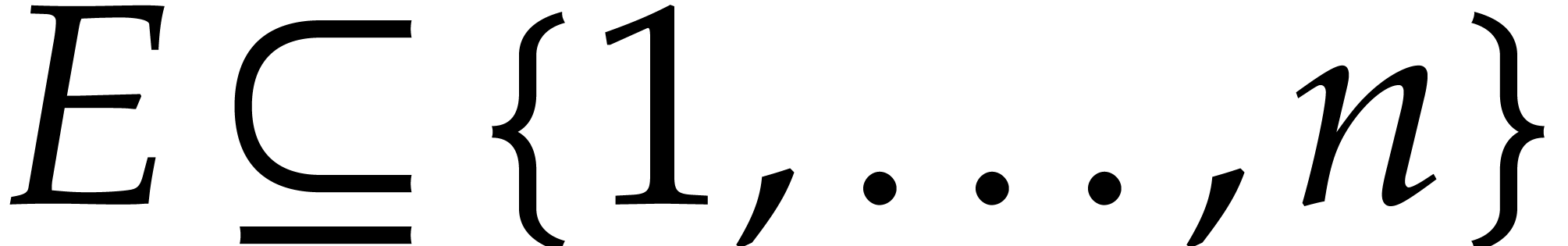 such that
such that 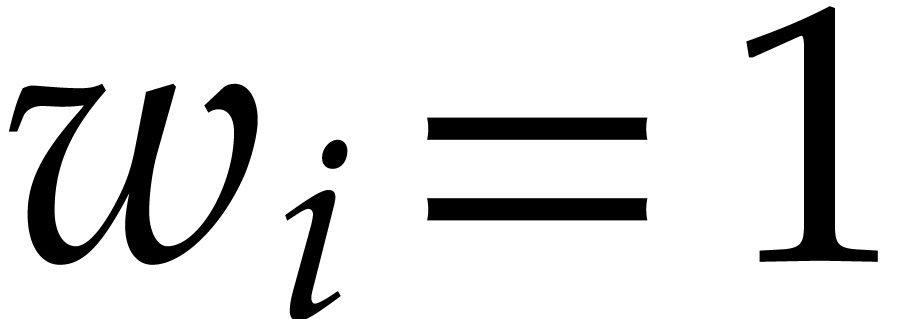 for all
for all 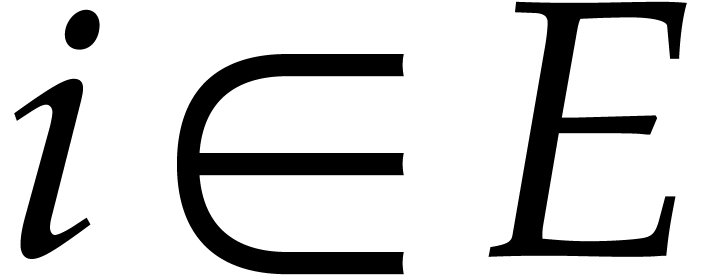 , we define
, we define 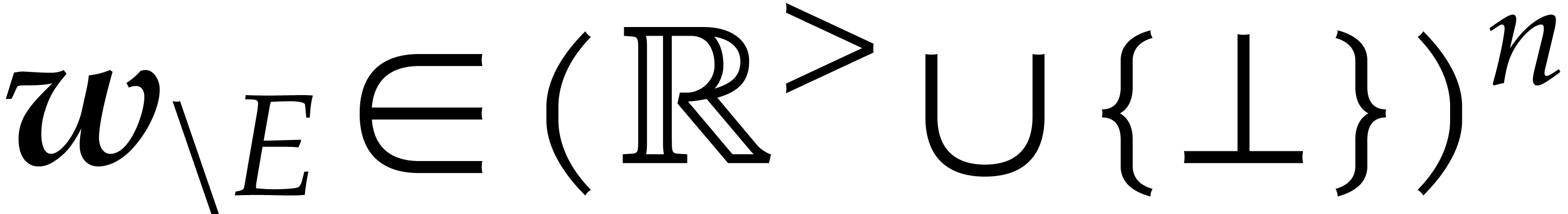 to be the
generalized weight
to be the
generalized weight 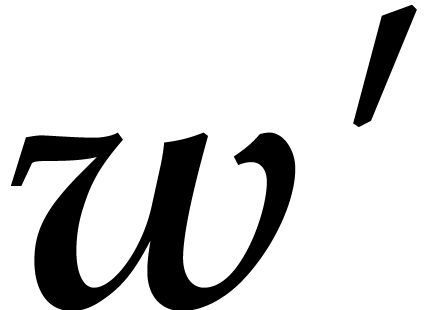 with
with  if
if  and
and  if . If is admissible,
then we note that
if . If is admissible,
then we note that 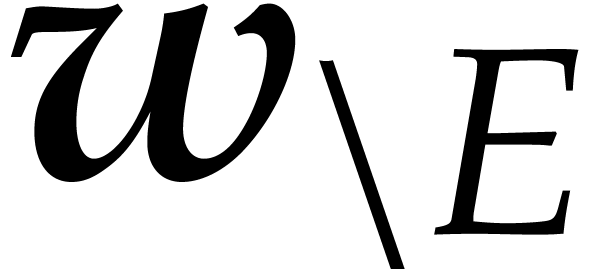 is again admissible. Given
, we define
is again admissible. Given
, we define
Note that Lemma 4.1 directly implies
The complexity bound from Theorem 4.4 also still holds in our new setting:
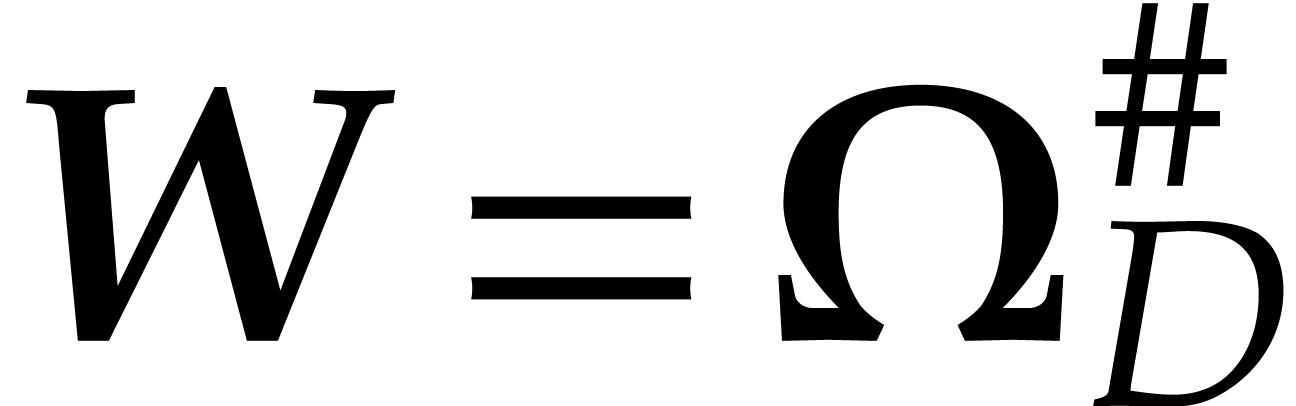 . Given , we may compute an extended
quasi-reduction
. Given , we may compute an extended
quasi-reduction
operations in . In
addition, for all , we
have
Proof. For each ,
we have

Using the same arguments as in the proof of Theorem 4.4, we
obtain that the relaxed product can be computed
in time 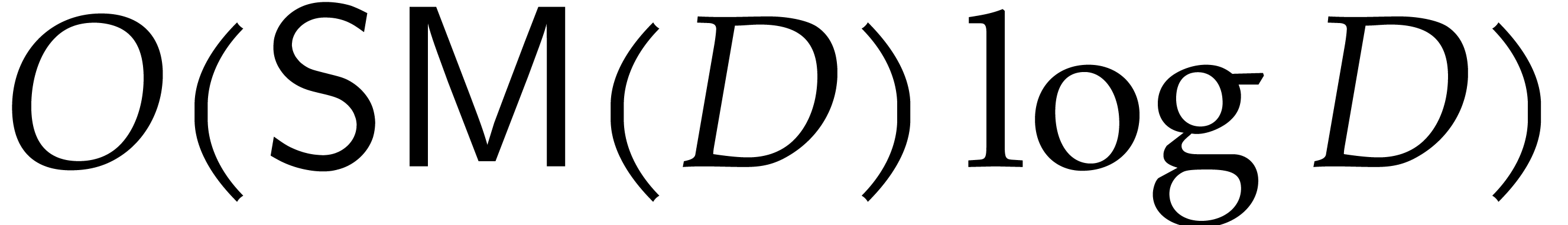 . Since there are
. Since there are
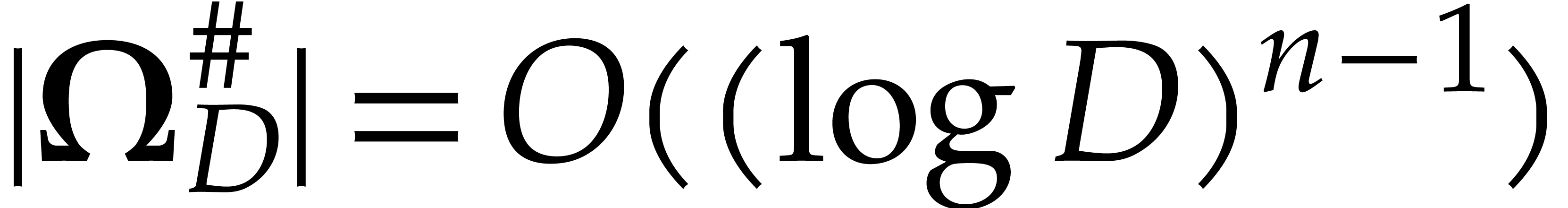 such products to be computed, the complexity
bound follows. The inequality
such products to be computed, the complexity
bound follows. The inequality
This time, we have the following unconditional version of Proposition 4.5.
Proof. The monomial is
reduced with respect to 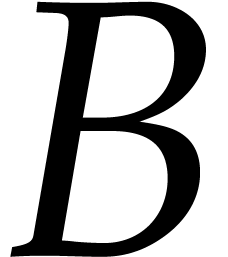 if and only if is reduced with respect to
if and only if is reduced with respect to 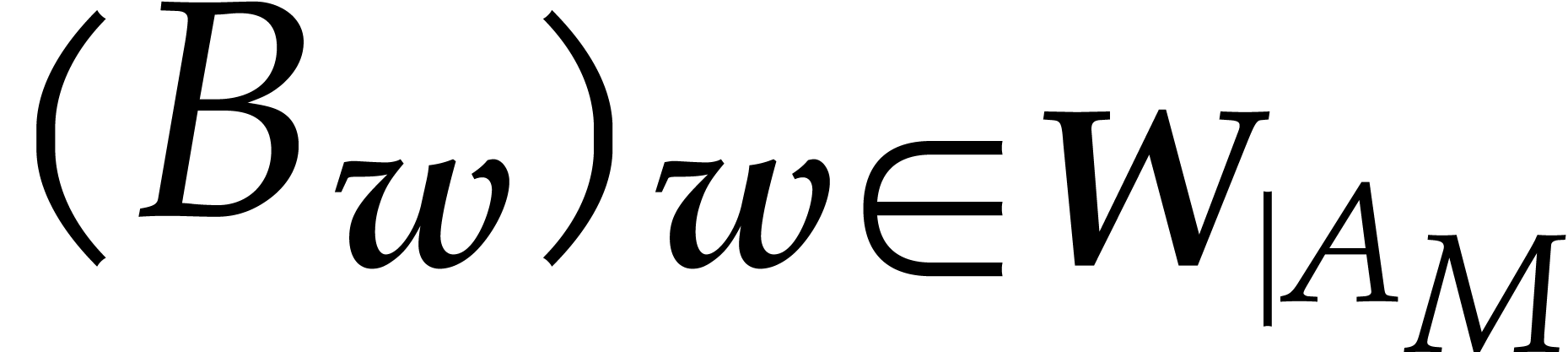 .
By Proposition 4.5, this implies
.
By Proposition 4.5, this implies
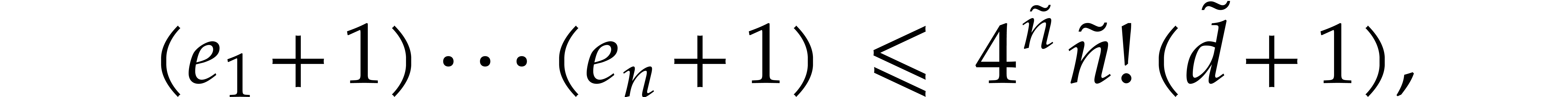
where 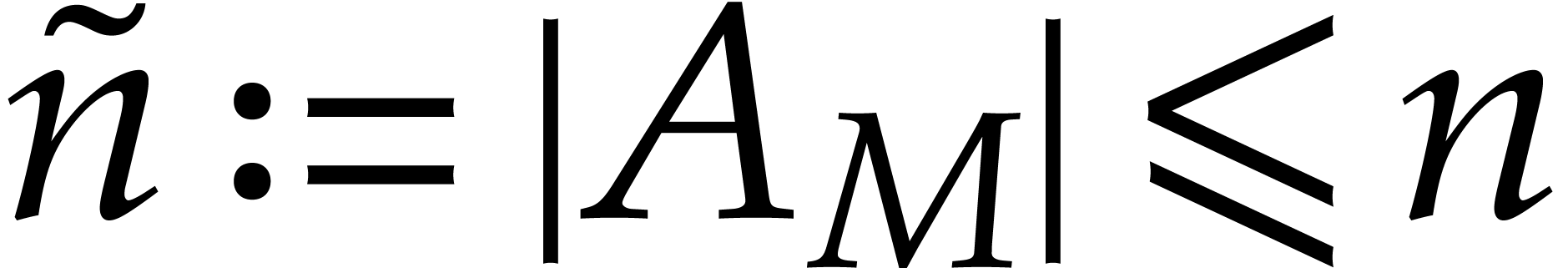 and
and  .
.
Let be a tuple of pairwise distinct points and
consider the problem of fast multi-point evaluation of a polynomial at . For
simplicity of the exposition, it is convenient to restrict ourselves to
the case when 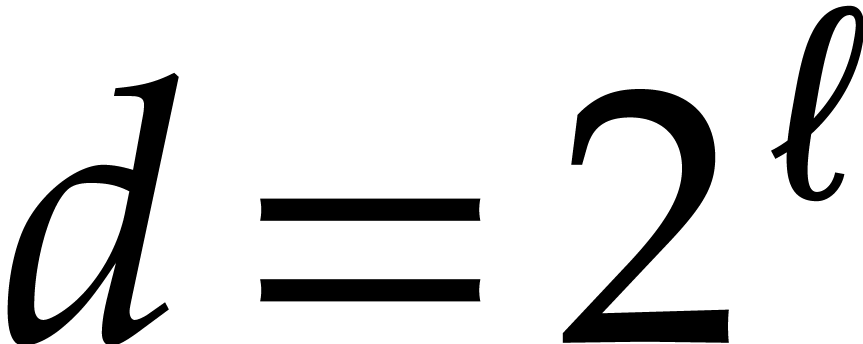 is a power of two (without loss of
generality, we may reduce to this case by adding extra points). We
define
is a power of two (without loss of
generality, we may reduce to this case by adding extra points). We
define
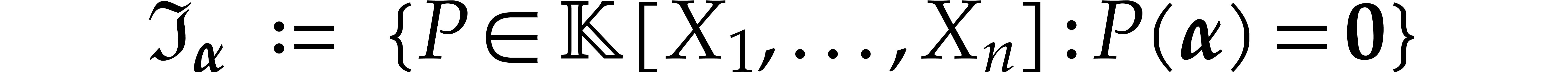
to be the vanishing ideal of .
We assume that we precomputed 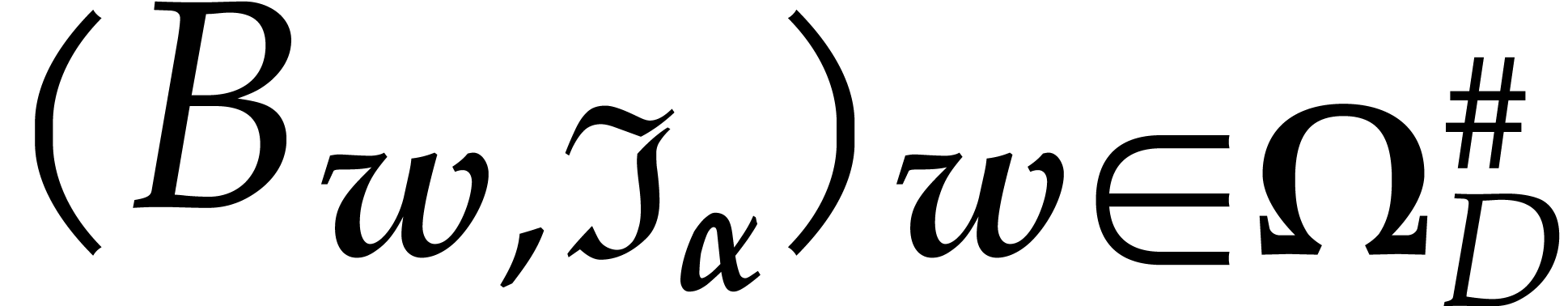 .
For any
.
For any 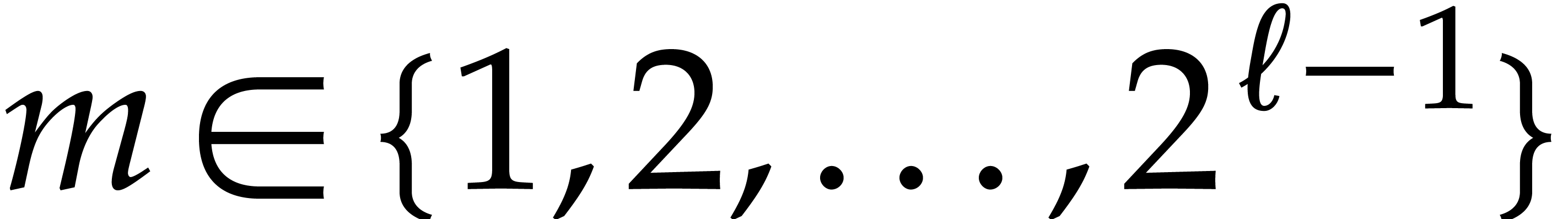 and
and 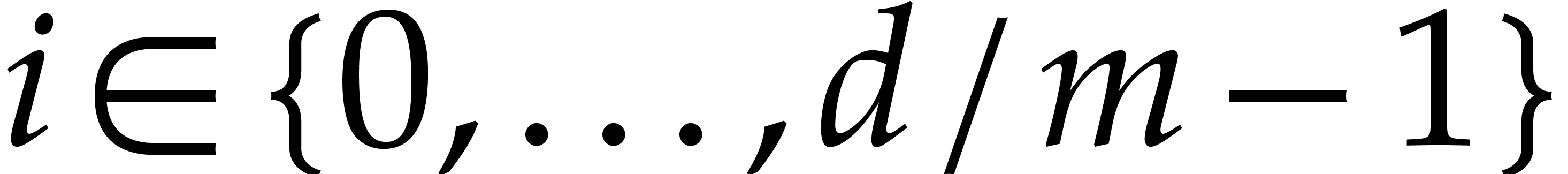 ,
we also assume that we precomputed
,
we also assume that we precomputed 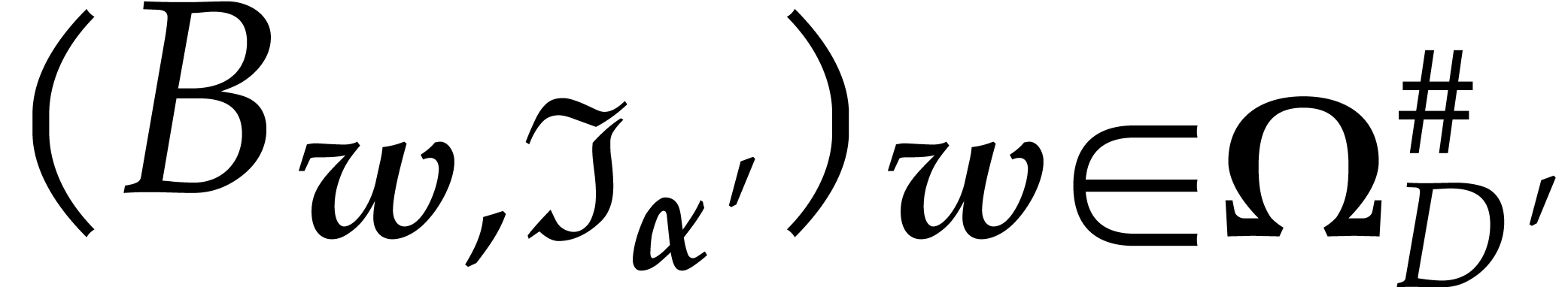 ,
where
,
where 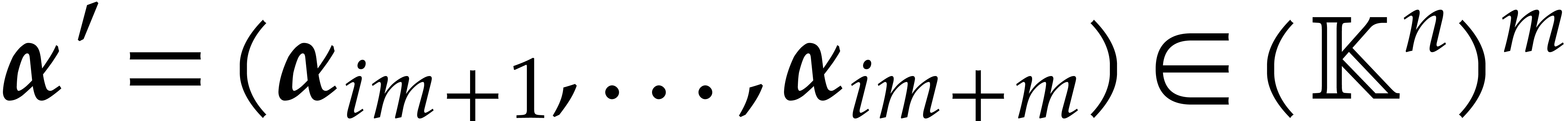 and
and 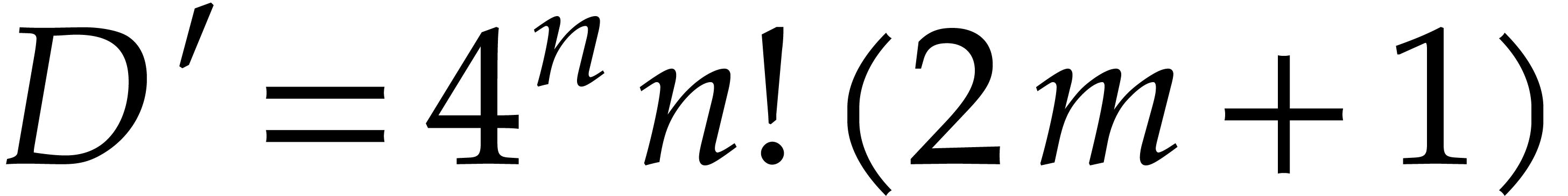 .
.
We are now ready to state our main algorithm.
Algorithm |
|
Proof. The algorithm is clearly correct if  . For any recursive call of the
algorithm with arguments
. For any recursive call of the
algorithm with arguments 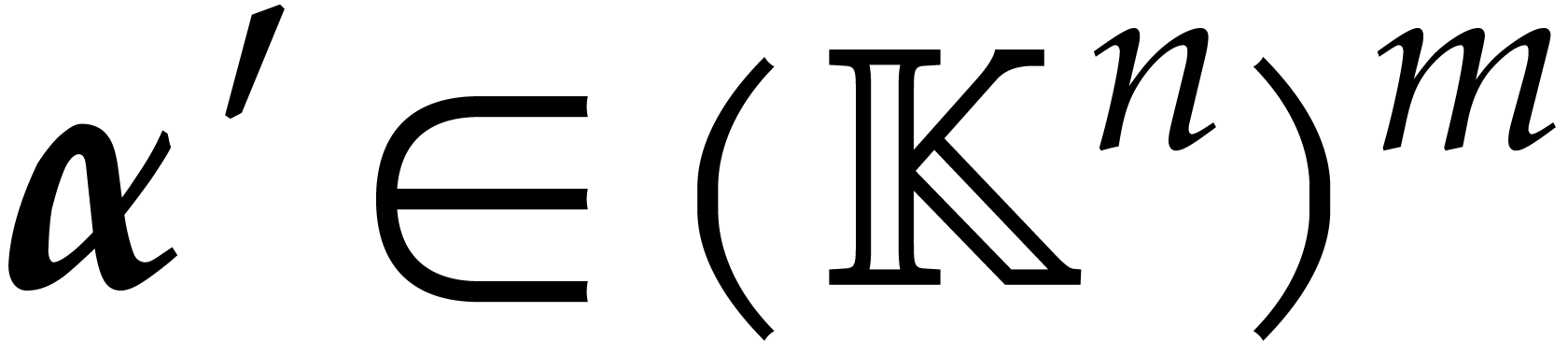 and
and 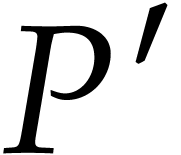 , Proposition 5.3 ensures that we
indeed have
, Proposition 5.3 ensures that we
indeed have 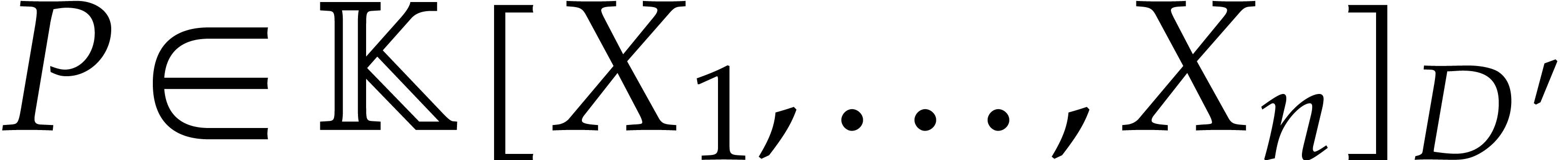 with .
The correctness of the general case easily follows from this.
with .
The correctness of the general case easily follows from this.
As to the complexity bound, let us first assume that 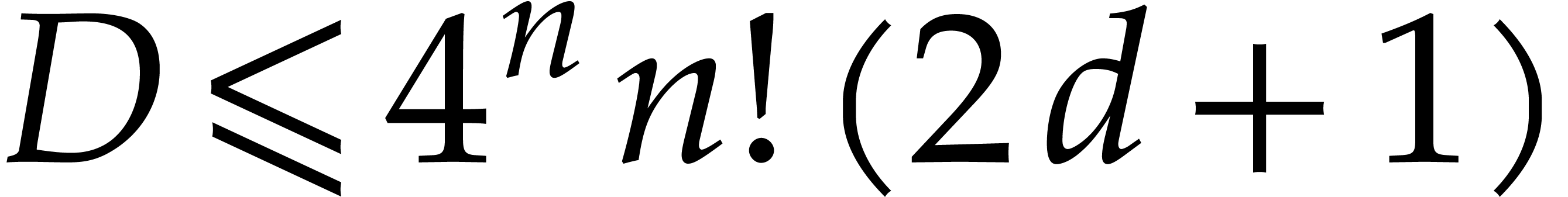 . Then the same condition is satisfied for all
recursive calls. Now the computation of
. Then the same condition is satisfied for all
recursive calls. Now the computation of  takes
takes
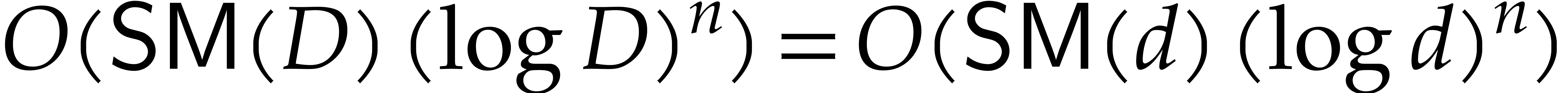
operations in , by Theorem 5.2. Hence, the total execution time 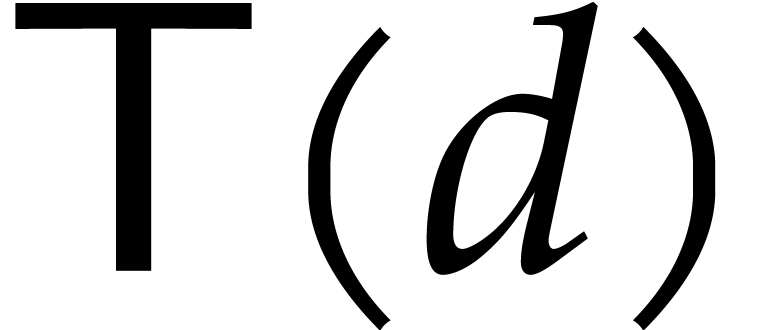 satisfies
satisfies
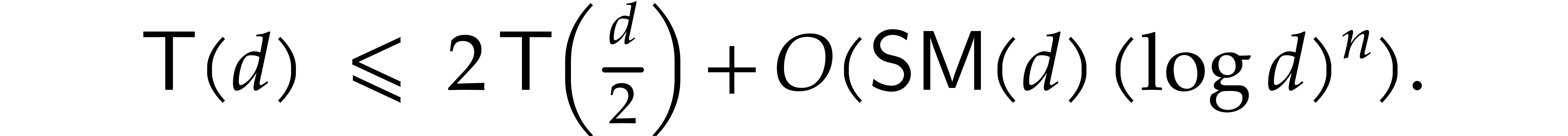
By unrolling this recurrence inequality, it follows that 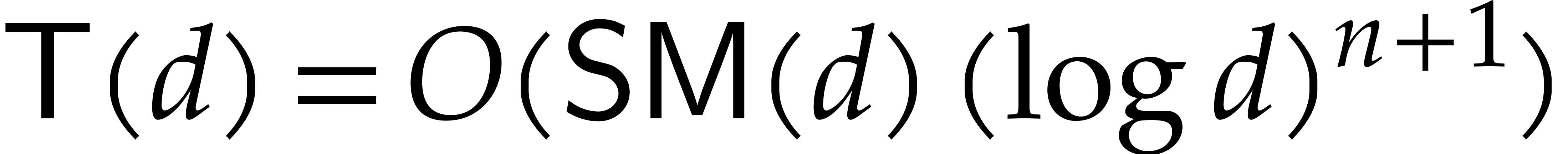 . If
. If 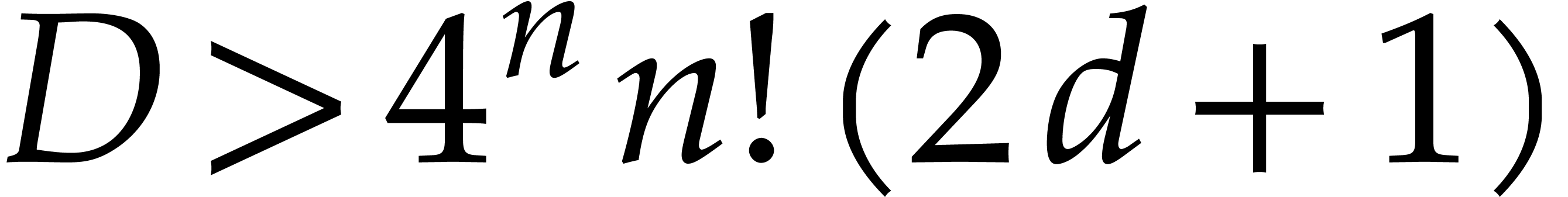 ,
then the computation of at the top-level
requires operations in
and we have just shown that the complexity of all recursive computations
is
,
then the computation of at the top-level
requires operations in
and we have just shown that the complexity of all recursive computations
is 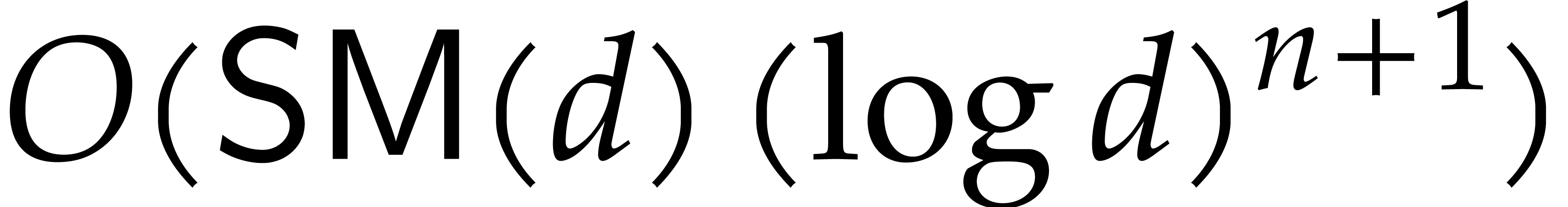 .
.
Proof of Theorem 1.1. The proof follows from Theorem 6.1 and Proposition 2.1, by analyzing the cardinalities of the supports involved in the quasi-reductions.
Let us revisit the quasi-reduction computed in step 2 of Algorithm 6.1. From (5.1) in Theorem 5.2 and
(5.2) in Proposition 5.3, it follows that we
may apply Proposition 2.1 for 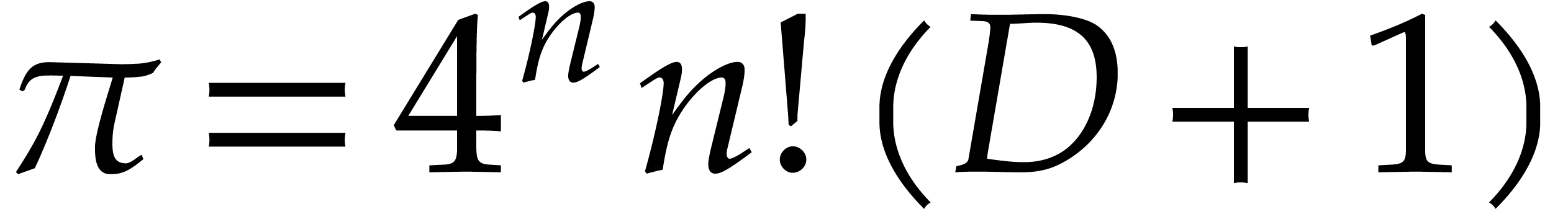 .
For the recursive quasi-reductions, we may use even smaller values for
.
For the recursive quasi-reductions, we may use even smaller values for
 . This justifies that we may
indeed take
. This justifies that we may
indeed take 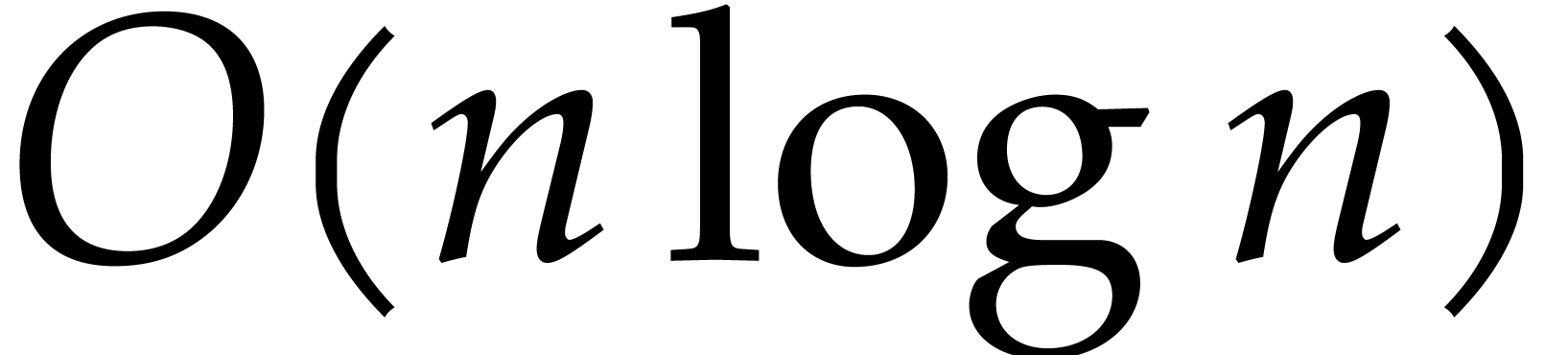 in Theorem 6.1.
in Theorem 6.1.
A. Borodin and R. T. Moenck. Fast modular transforms. J. Comput. System Sci., 8:366–386, 1974.
A. Bostan, G. Lecerf, and É. Schost. Tellegen's principle into practice. In Proceedings of the 2003 International Symposium on Symbolic and Algebraic Computation, ISSAC '03, pages 37–44. New York, NY, USA, 2003. ACM.
D. G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Inform., 28:693–701, 1991.
C. M. Fiduccia. Polynomial evaluation via the division algorithm: the fast Fourier transform revisited. In Proceedings of the Fourth Annual ACM Symposium on Theory of Computing, STOC '72, pages 88–93. New York, NY, USA, 1972. ACM.
D. Harvey and J. van der Hoeven. Faster polynomial multiplication over finite fields using cyclotomic coefficient rings. J. Complexity, 54:101404, 2019.
D. Harvey and J. van der Hoeven. Polynomial
multiplication over finite fields in time 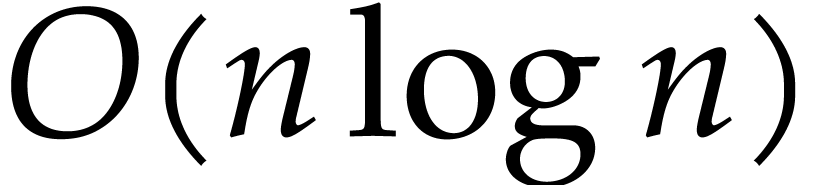 . Technical Report, HAL, 2019. https://hal.archives-ouvertes.fr/hal-02070816,
accepted for publication in J. ACM.
. Technical Report, HAL, 2019. https://hal.archives-ouvertes.fr/hal-02070816,
accepted for publication in J. ACM.
J. van der Hoeven. Relax, but don't be too lazy. J. Symbolic Comput., 34:479–542, 2002.
J. van der Hoeven. Faster Chinese remaindering. Technical Report, HAL, 2016. https://hal.archives-ouvertes.fr/hal-01403810.
J. van der Hoeven. On the complexity of multivariate polynomial division. In I. S. Kotsireas and E. Martínez-Moro, editors, Applications of Computer Algebra. Kalamata, Greece, July 20–23, 2015, volume 198 of Springer Proceedings in Mathematics & Statistics, pages 447–458. Cham, 2017. Springer International Publishing.
J. van der Hoeven. The Jolly Writer. Your Guide to GNU TeXmacs. Scypress, 2020.
J. van der Hoeven and G. Lecerf. On the bit-complexity of sparse polynomial multiplication. J. Symbolic Comput., 50:227–254, 2013.
J. van der Hoeven and G. Lecerf. Accelerated tower arithmetic. J. Complexity, 55:101402, 2019.
J. van der Hoeven and G. Lecerf. Fast multivariate multi-point evaluation revisited. J. Complexity, 56:101405, 2020.
J. van der Hoeven and G. Lecerf. Amortized bivariate multi-point evaluation. In M. Mezzarobba, editor, Proceedings of the 2021 International Symposium on Symbolic and Algebraic Computation, ISSAC '21, pages 179–185. New York, NY, USA, 2021. ACM.
J. van der Hoeven and G. Lecerf. Fast amortized multi-point evaluation. J. Complexity, 67:101574, 2021.
J. van der Hoeven and G. Lecerf. On the complexity exponent of polynomial system solving. Found. Comput. Math., 21:1–57, 2021.
J. Hopcroft and J. Musinski. Duality applied to the complexity of matrix multiplication and other bilinear forms. SIAM J. Comput., 2(3):159–173, 1973.
K. S. Kedlaya and C. Umans. Fast modular composition in any characteristic. In Proceedings of the 49th Annual IEEE Symposium on Foundations of Computer Science (FOCS 2008), pages 146–155. Los Alamitos, CA, USA, 2008. IEEE Computer Society.
K. S. Kedlaya and C. Umans. Fast polynomial factorization and modular composition. SIAM J. Comput., 40(6):1767–1802, 2011.
D. Le Brigand and J.-J. Risler. Algorithme de Brill–Noether et codes de Goppa. Bulletin de la société mathématique de France, 116(2):231–253, 1988.
F. Le Gall and F. Urrutia. Improved rectangular matrix multiplication using powers of the Coppersmith–Winograd tensor. In A. Czumaj, editor, Proceedings of the 2018 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 1029–1046. Philadelphia, PA, USA, 2018. SIAM.
R. T. Moenck and A. Borodin. Fast modular transforms via division. In 13th Annual Symposium on Switching and Automata Theory, pages 90–96. USA, 1972. IEEE.
V. Neiger, J. Rosenkilde, and G. Solomatov. Generic bivariate multi-point evaluation, interpolation and modular composition with precomputation. In A. Mantzaflaris, editor, Proceedings of the 45th International Symposium on Symbolic and Algebraic Computation, ISSAC '20, pages 388–395. New York, NY, USA, 2020. ACM.
M. Nüsken and M. Ziegler. Fast multipoint evaluation of bivariate polynomials. In S. Albers and T. Radzik, editors, Algorithms – ESA 2004. 12th Annual European Symposium, Bergen, Norway, September 14-17, 2004, volume 3221 of Lect. Notes Comput. Sci., pages 544–555. Springer Berlin Heidelberg, 2004.
L. Robbiano. Term orderings on the polynomial ring. In B. F. Caviness, editor, EUROCAL '85. European Conference on Computer Algebra. Linz, Austria, April 1-3, 1985. Proceedings. Volume 2: Research Contributions, volume 204 of Lect. Notes Comput. Sci., pages 513–517. Springer-Verlag Berlin Heidelberg, 1985.
D. S. Roche. What can (and can't) we do with sparse polynomials? In C. Arreche, editor, Proceedings of the 2018 ACM International Symposium on Symbolic and Algebraic Computation, ISSAC '18, pages 25–30. New York, NY, USA, 2018. ACM.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Inform., 7:395–398, 1977.
A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.

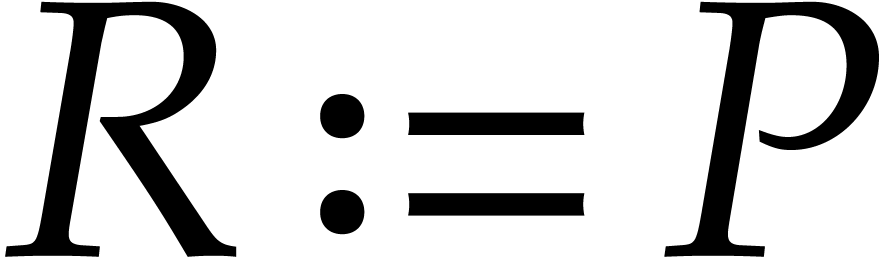 and
and 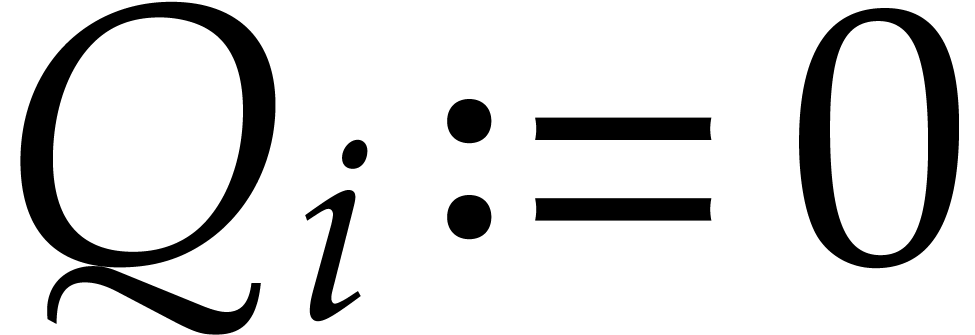 for all
for all 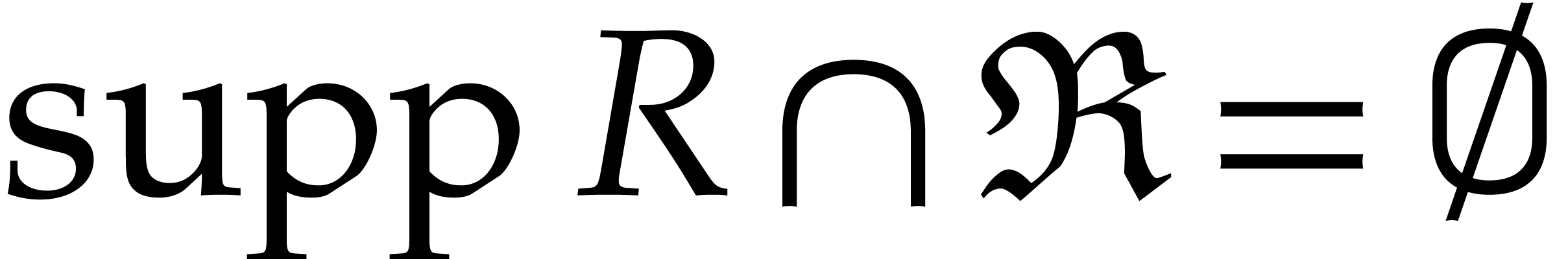 do:
do:
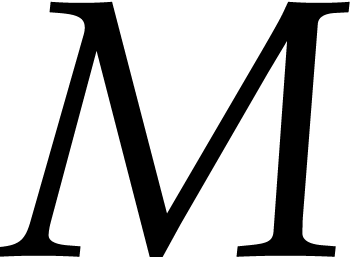 be the largest monomial of
be the largest monomial of
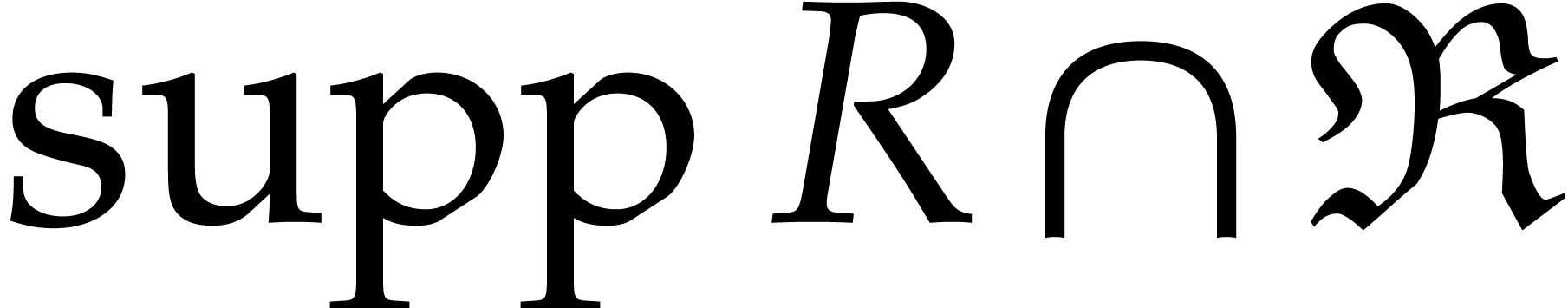 ;
;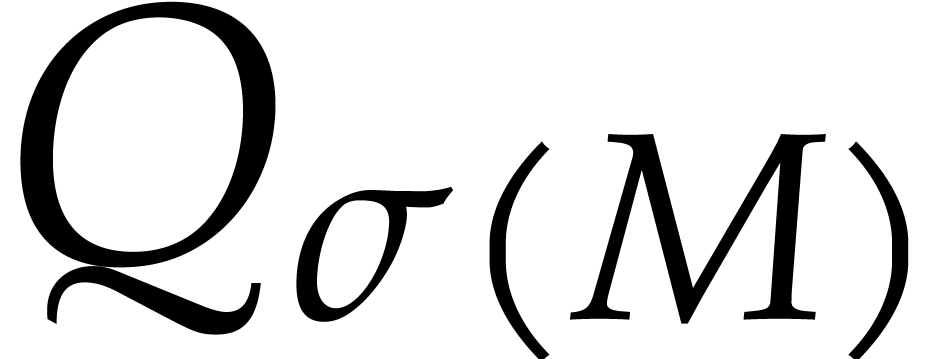 by
by 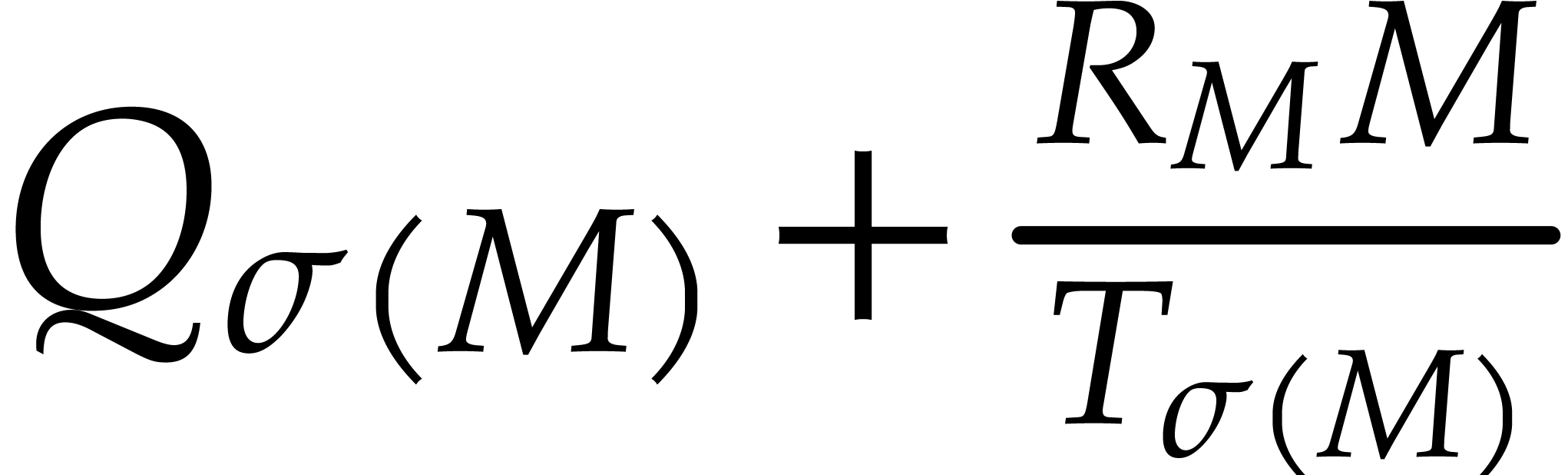 ;
;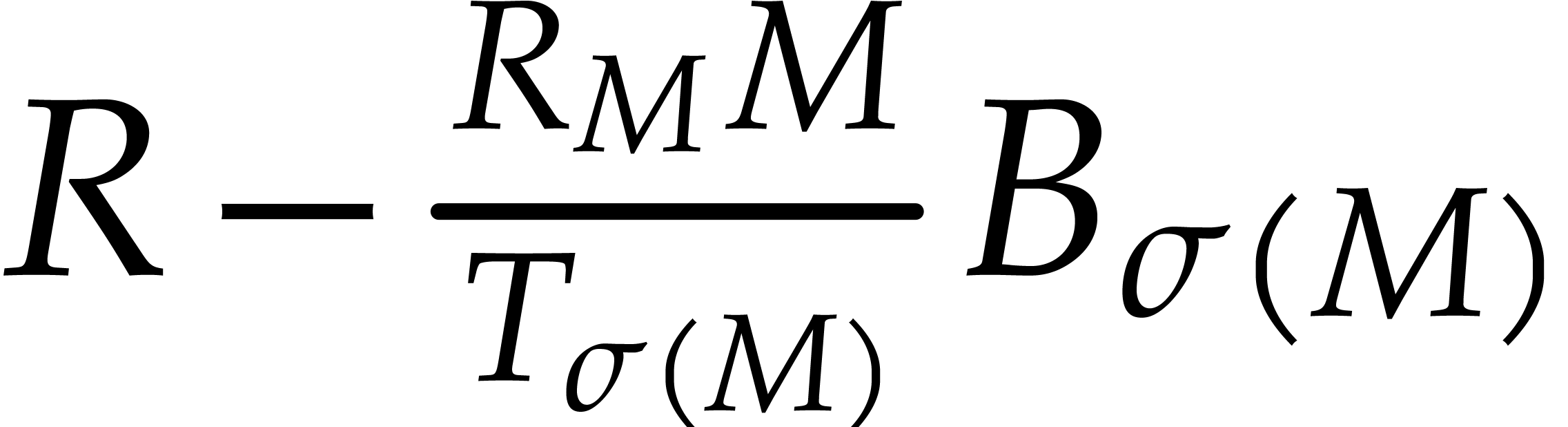 .
.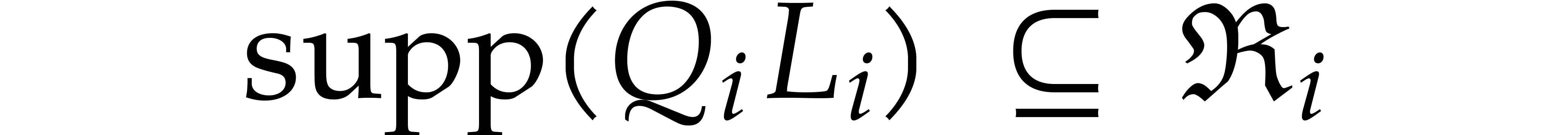
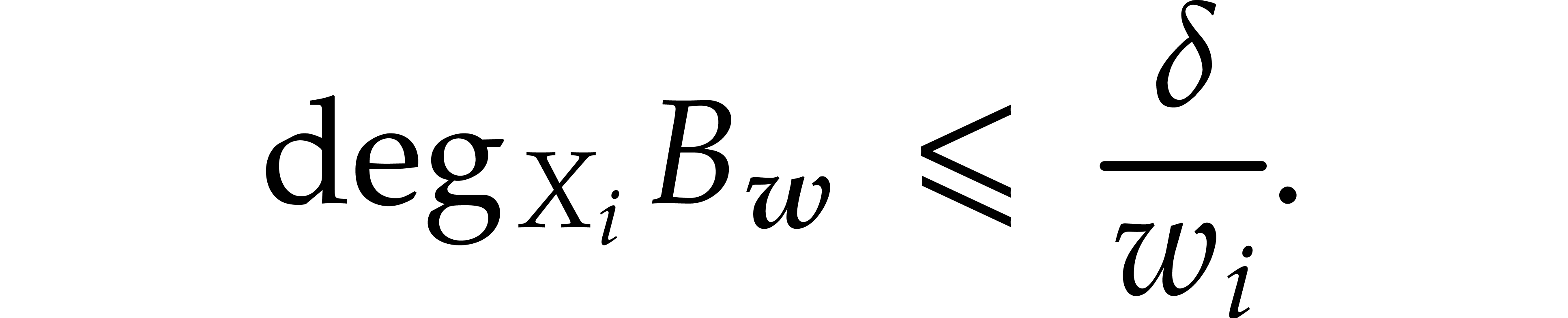
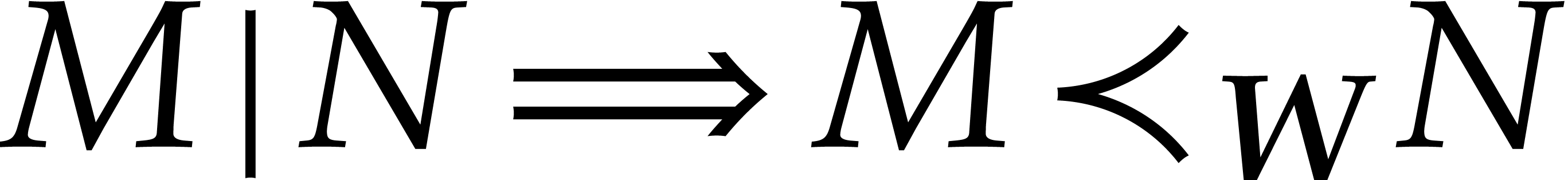 for all different
for all different 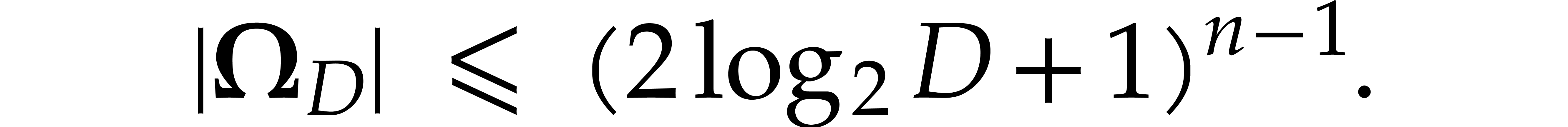
 and
and  with
with
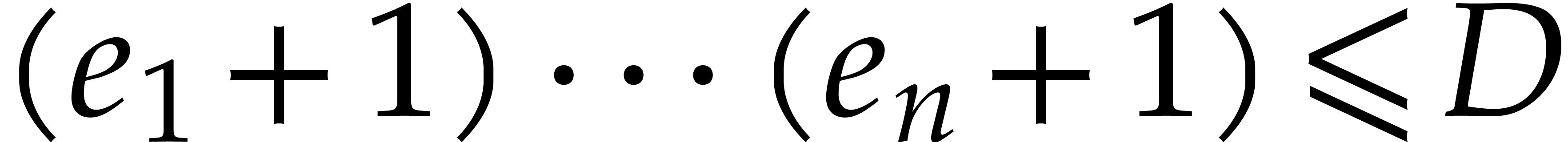 .
.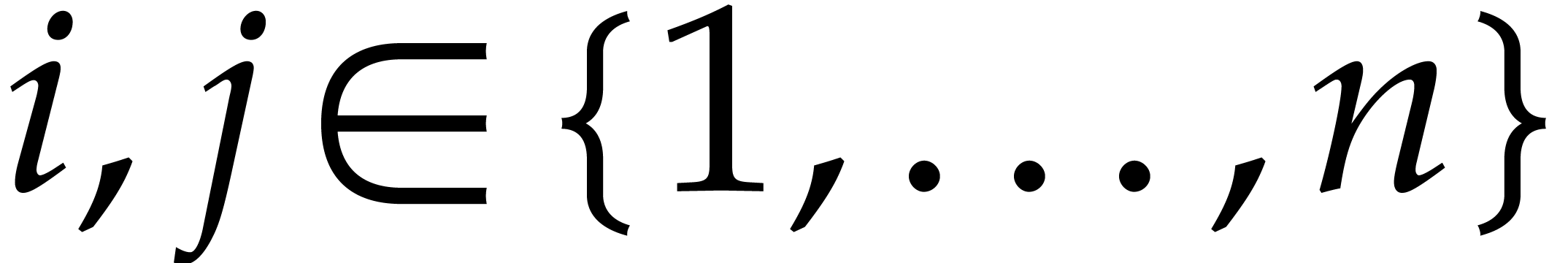 ,
,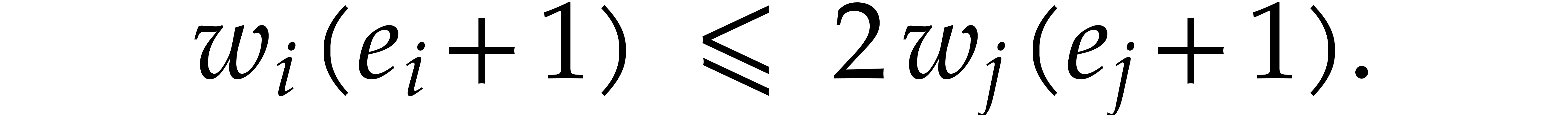
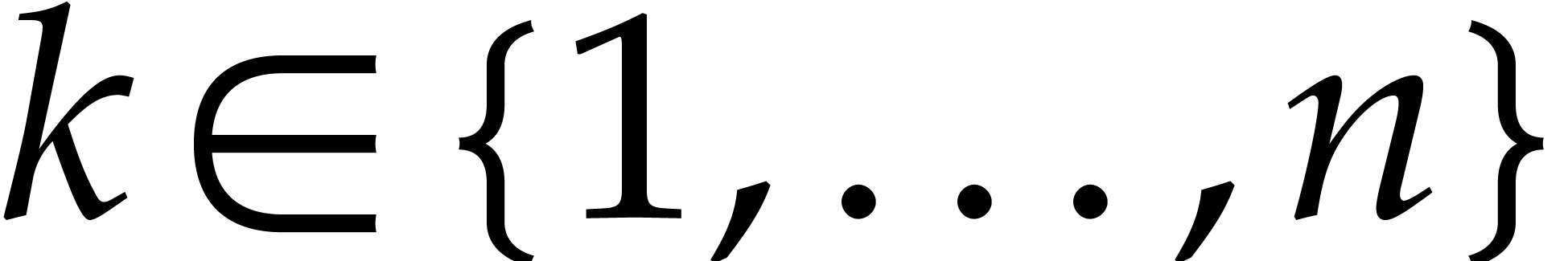 .
.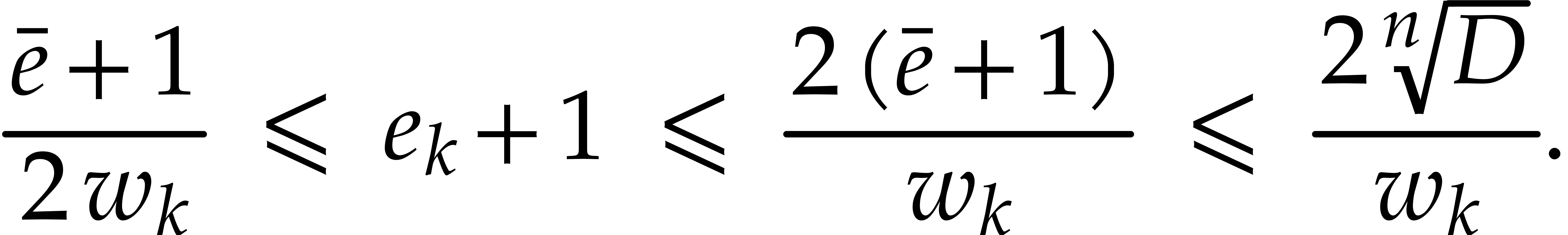
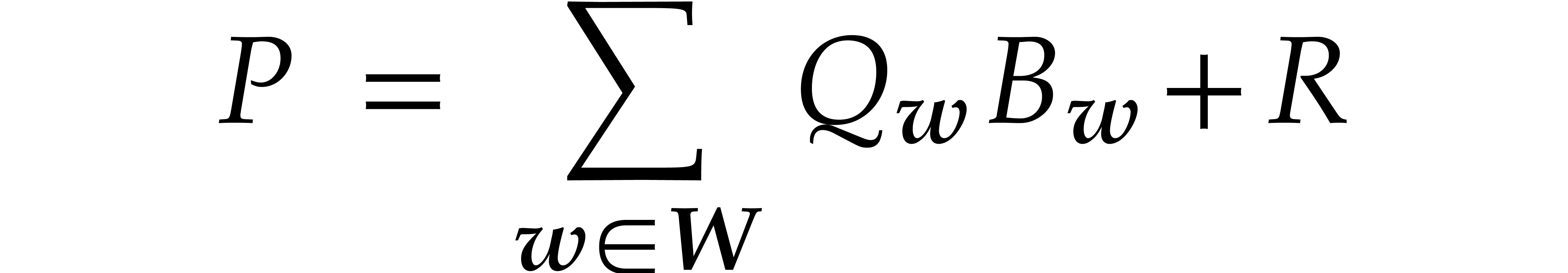
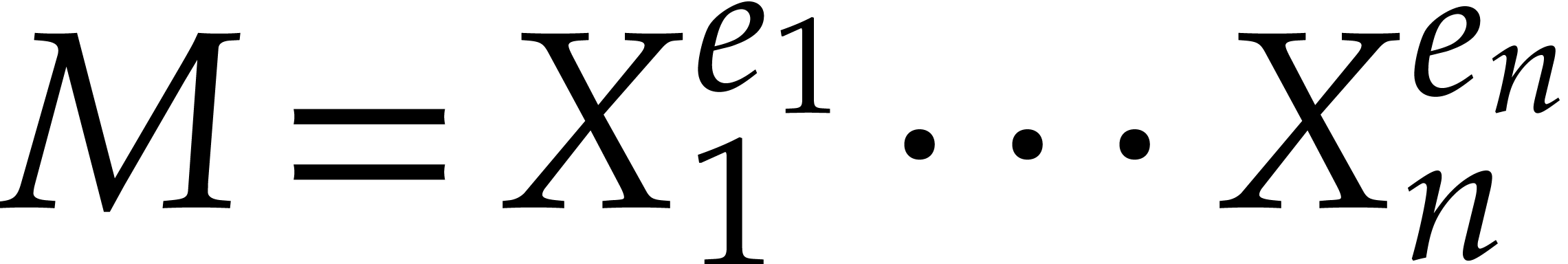 with
with
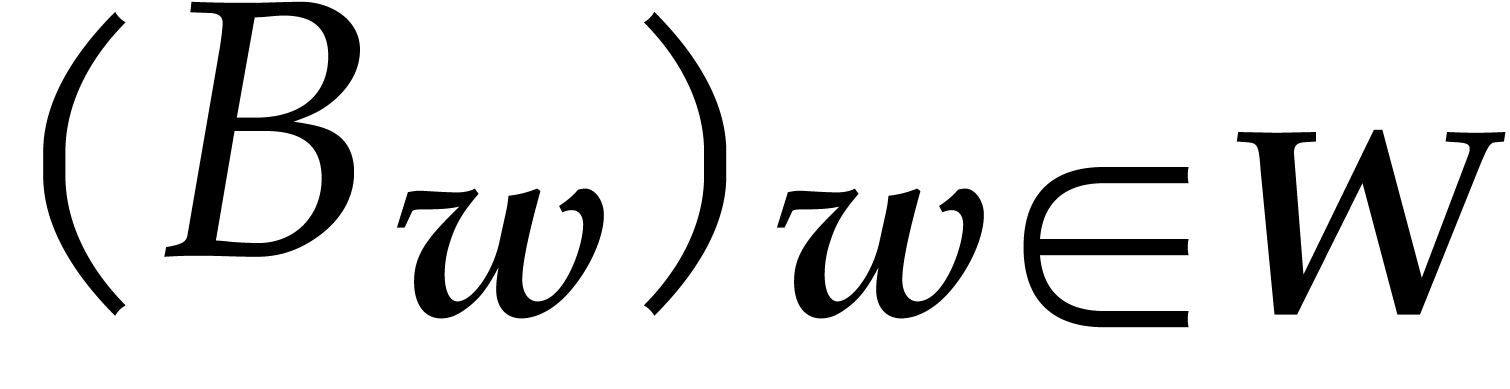 ,
,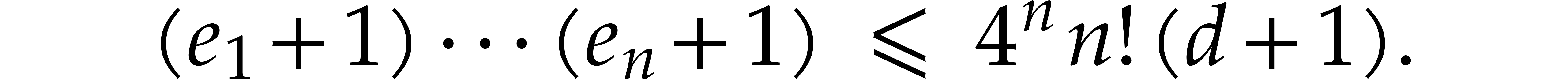
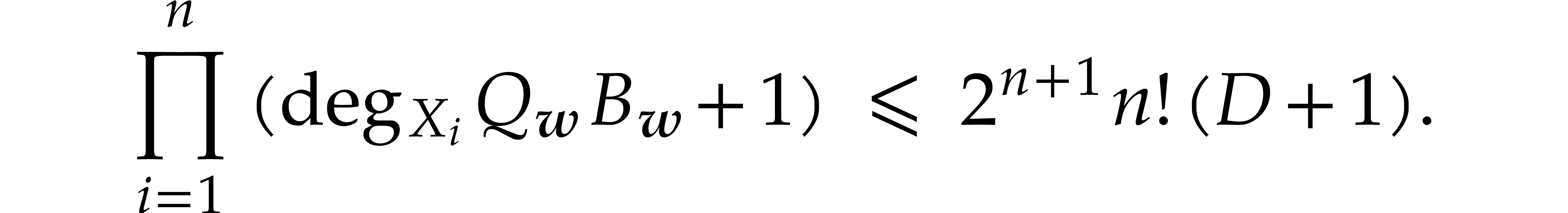
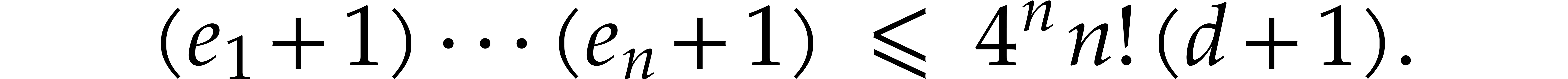
 .
. ,
,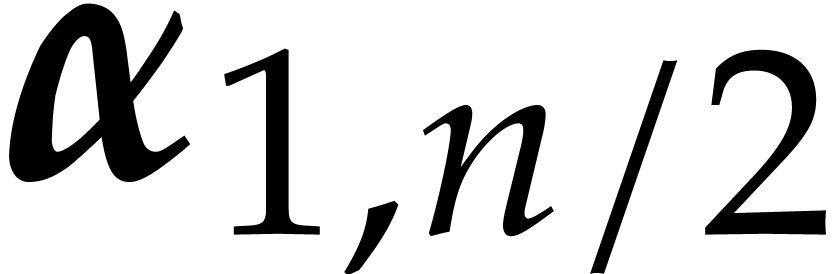 and
and
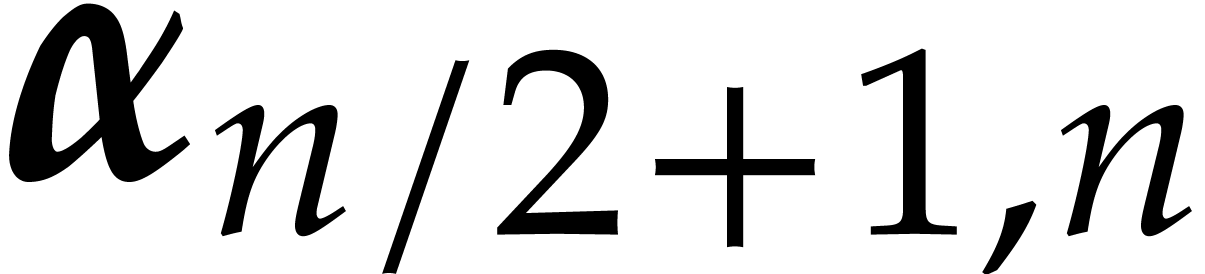 and
and