 reduces in
polynomial time to an NP-complete problem
reduces in
polynomial time to an NP-complete problem  ,
then is NP-complete as well. This allows us to
use NP-completeness as a surrogate for “lower bound”.
,
then is NP-complete as well. This allows us to
use NP-completeness as a surrogate for “lower bound”.
Joris van der Hoeven
CNRS, École polytechnique, Institut
Polytechnique de Paris
Laboratoire d'informatique de l'École
polytechnique (LIX, UMR 7161)
Bâtiment Alan Turing, CS35003
1, rue Honoré d'Estienne d'Orves
91120 Palaiseau, France
vdhoeven@lix.polytechnique.fr
July 5, 2022
In this paper, we survey various basic and higher level tasks in computer algebra from the complexity perspective. Particular attention is paid to problems that are fundamental from this point of view and interconnections between other problems.
Which problems in symbolic computation can be solved reasonably fast? Given a problem, would it be possible to predict how much time is needed to solve it? The area of computational complexity was designed to provide answers to such questions. However, symbolic computation has a few particularities that call for extra or separate techniques.
One particularity is that the most prominent algorithms typically get implemented, so we can check theory against practice. A satisfactory complexity theory in our area should at least be able to explain or model running times that are observed in practice.
However, such a theory should be more than an ennobled tool for benchmarking. We also wish to gain insight into the intrinsic complexity of problems, understand how the complexities of different problems are related, and identify the most central computational tasks in a given area (these tasks typically require highly optimized implementations).
Traditionally, a distinction is made between the analysis of
algorithms (how to analyze the complexity of a given algorithm) and
complexity theory (fitting problems into complexity classes and
proving lower bounds). This paper partially falls in the second
category, since we will be interested in classes of algorithms
and problems. Such a broader perspective is particularly useful if you
want to implement a new computer algebra system, like
However, traditional complexity theory is not very adequate for computer algebra, due to the disproportionate focus on lower bounds and coarse complexity classes. Fortunately, as will be argued in Section 3, we already have many ingredients for developing a more meaningful complexity theory for our area. I found it non-trivial to organize these ingredients into a “grand theory”. In this survey, I will therefore focus on concrete examples that reflect the general spirit.
The first series of examples in Section 4 concerns basic operations like multiplication, division, gcds, etc. for various algebras. We will see how various basic complexities are related and how some of them can be derived using general techniques.
In Section 5, we will turn to the higher level problem of polynomial system solving. My interest in this problem is more recent and driven by complexity considerations. I will survey advantages and limitations of the main existing approaches and highlight a few recent results.
Standard theoretical computer science courses on computability and complexity theory [101] promise insight into two questions:
What can we compute?
What can we compute efficiently?
Whereas there is broad consensus about the definition of computability (Church' thesis), it is harder to give a precise definition of “efficiency”. For this, traditional complexity theory heavily relies on complexity classes (such as P, NP, etc.) in order to describe the difficulty of problems. In principle, this provides some flexibility, although many courses single out P as “the” class of problems that can be solved “efficiently”.
Now the question Q2 is actually too hard for virtually
all interesting problems, since it involves proving notoriously
difficult lower bounds. Our introductory course goes on with the
definition of reductions to relate the difficulties of
different problems: if problem reduces in
polynomial time to an NP-complete problem ,
then is NP-complete as well. This allows us to
use NP-completeness as a surrogate for “lower bound”.
A big part of complexity theory is then devoted to proving such hardness results: the emphasis is on what cannot be computed fast; understanding which problems can be solved efficiently (and why and how) is less of a concern (this is typically delegated to other areas, such as algorithms).
There are numerous reasons why this state of the art is unsatisfactory for symbolic computation. At best, negative hardness results may be useful in the sense that they may prevent us from losing our time on searching for efficient solutions. Although:
“You prove that problems are hard and I write computer
programs that solve them.”
(Richard Jenks [81])
For instance, deciding whether a system of polynomial equations over
 has a solution is a typical NP-complete
problem, since it is equivalent to SAT [24]. At the same
time, the computer algebra community has a long and successful history
of solving polynomial systems [16, 29], at
least for specific instances. From a theoretical point of view,
it was also proved recently that all solutions of a generic
dense system of polynomial equations over
has a solution is a typical NP-complete
problem, since it is equivalent to SAT [24]. At the same
time, the computer algebra community has a long and successful history
of solving polynomial systems [16, 29], at
least for specific instances. From a theoretical point of view,
it was also proved recently that all solutions of a generic
dense system of polynomial equations over  can be
computed in expected quasi-optimal time in terms of the expected output
size; see [75] and Section 5.5 below.
can be
computed in expected quasi-optimal time in terms of the expected output
size; see [75] and Section 5.5 below.
In the past decade, there has been a lot of work to understand such paradoxes and counter some of the underlying criticism. For instance, the specific nature of certain input instances is better taken into account via, e.g., parametric or instance complexity [108]. Complexity classes with more practical relevance than P have also received wider attention [117].
But even such upgraded complexity theories continue to miss important
points. First of all, lower bound proofs are rarely good for
applications: for the above polynomial time reduction of problem to the NP-complete problem , any polynomial time reduction will do. If
we are lucky to hit an easy instance of ,
such a reduction typically produces an intractable instance of . In other words: negative
reductions do not need to be efficient.
Secondly, the desire to capture practical complexity via asymptotic complexity classes [81, Cook's (amended) thesis] is unrealistic: even a constant time algorithm (like any algorithm on a finite computer which terminates) is not necessarily “practical” if the constant gets large; constants are essential in practice, but hidden through asymptotics.
A more subtle blind spot concerns the framework of complexity classes itself, which has modeled the way how several generations have been thinking about computational complexity. Is it really most appropriate to put problems into pigeonholes P, NP, EXP, L, etc.? Sorting and matrix multiplication are both in P; does this mean that these problems are related? In computer algebra we have efficient ways to reduce division and gcds to multiplication [35, 15]; the complexities of interpolation, multi-point evaluation, factorization, and root finding are also tightly related (see Section 5); a good complexity theory should reflect such interconnections.
Implementors tend to have a more pragmatic point of view on complexity:
“Do you want to know whether your algorithm is faster? Take
your stopwatch and run it.”
(Mark van Hoeij)
It is true that a complexity-oriented approach to the development of
algorithms (as advocated by the author of these lines) may be overkill.
For instance, there has been a tendency in computer algebra to redevelop
a lot of linear algebra algorithms to obtain complexities that are good
in terms of the exponent 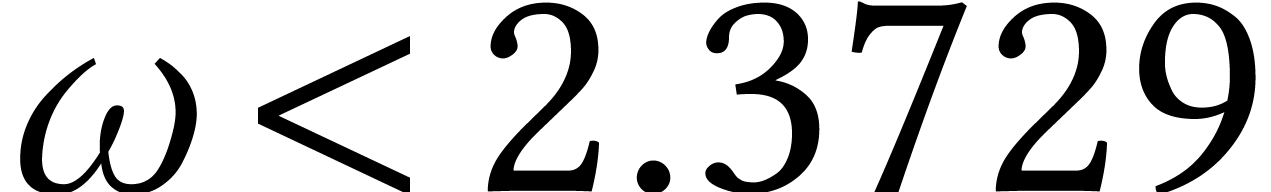 of matrix
multiplication [34]. But
of matrix
multiplication [34]. But  stays
desperately close to
stays
desperately close to  , in
practice.
, in
practice.
Yet, there are obvious pitfalls when throwing all complexity considerations overboard: your stopwatch will not predict whether you should take a cup of coffee while your algorithm runs, or whether you should rather go to bed.
What one often needs is a rough educated idea about expected running
times. Such a relaxed attitude towards complexity is omnipresent in
neighboring areas such as numerical analysis. The popular textbook [104] is full with assertions like “the LU-decomposition
[...] requires about 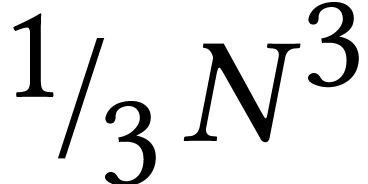 executions [...]”
(end of Section 2.3.1), “the total operation count for both
eigenvalues and eigenvectors is
executions [...]”
(end of Section 2.3.1), “the total operation count for both
eigenvalues and eigenvectors is 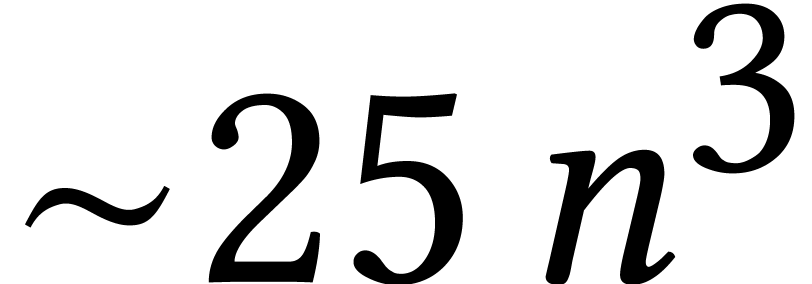 ”
(Section 11.7), etc.
”
(Section 11.7), etc.
Another obvious problem with benchmarks is that experiments on computers from fifty years ago may be hard to reproduce today; and they probably lost a lot of their significance with time.
But there are also less obvious and more serious problems when your
stopwatch is all you got. I hit one such problem during the development
of relaxed power series arithmetic [52, 54].
Polya showed [103] that the generating series of the number
of stereoisomers with molecular formula 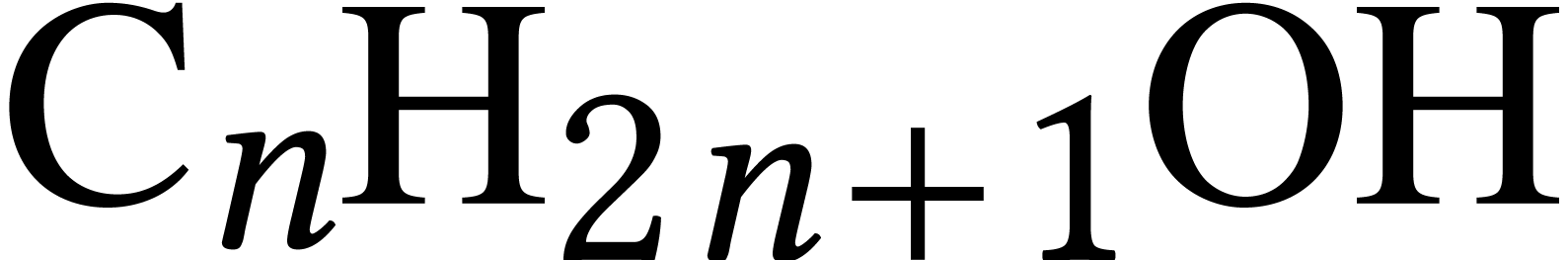 satisfies the equation
satisfies the equation
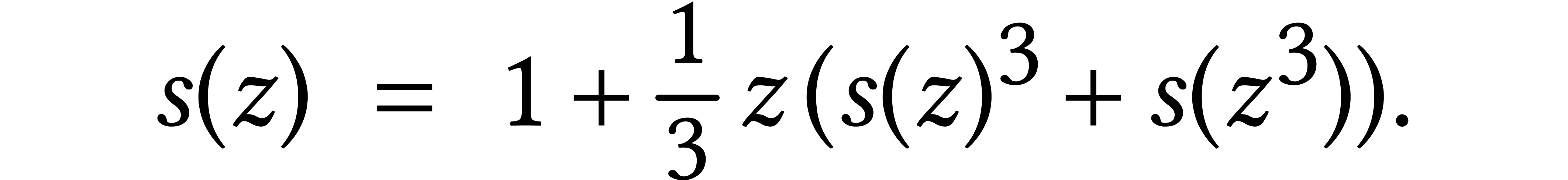
Many terms of this series can be computed using relaxed arithmetic. However, when doing so for rational coefficients, timings were much slower than expected. The reason was that GMP [39] used a naive algorithm for large gcd computations at that time. This came as a big surprise to me: if I had just tried the new algorithms with a stopwatch in my hand, then I probably would have concluded that they were no good!
This was really a serious problem. Around the same period, at every computer algebra meeting, there would be an afternoon on fast linear algebra without divisions (variants of Bareiss' algorithm). This research direction became pointless when GMP eventually integrated a better algorithm to compute gcds.
When implementing your own algorithm in a modern computer algebra system, you typically rely on a lot of other algorithms, some of which may even be secret in proprietary systems. You also rely on very complex hardware with multi-core SIMD processors and many levels of cache memory. One of the aims of complexity theory as opposed to the analysis and benchmarking of a single algorithm should be to get a grip on the broad picture.
A better global understanding might guide future developments. For instance, working in algebraic extensions has bad press in computer algebra for being slow; “rational” algorithms have been developed to counter this problem. But is this really warranted from a complexity point of view? Could it be that algebraic extensions simply are not implemented that well?
In symbolic computation, it is also natural to privilege symbolic and algebraic methods over numeric or analytic ones, both because many of us simply like them better and because we have more efficient support for them in existing systems. But maybe some algebraic problems could be solved more efficiently using numerical methods. What about relying more heavily on homotopy methods for polynomial system solving? What about numerical differential Galois theory [23]?
How does the ISSAC community deal with complexity issues? In Table 1 , I compiled some statistics for actual papers in the proceedings, while limiting myself to the years 1997, 2004, 2012, 2017, and 2021. I checked whether the papers contained benchmarks, a complexity analysis, both, or nothing at all.
It is clear from Table 1 that the ISSAC community cares about complexity issues. Many papers contain a detailed complexity analysis. For high-level algorithms with irregular complexities, authors often provide benchmarks instead. Besides providing interesting insights, one may also note that “objective” benchmarks and complexity results are frequently used to promote a new algorithm, especially when there are several existing methods to solve the same problem.
Only a few papers mention traditional complexity classes and lower bounds are rarely examined through the lens of computational hardness. Instead, it is typically more relevant to determine the cost and the size of the output for generic instances. For instance, instead of proving that “polynomial system solving is hard”, one would investigate the complexity of solving a generic system in terms of the Bézout bound (which is reached for such a system).
Most theoretical complexity results are stated in the form of upper bounds. Both algebraic and bit-complexity models are very popular; occasionally, bounds are stated differently, e.g. in terms of heights, condition numbers, probability of success, etc.
One interesting characteristic of algorithms in symbolic computation is
that their complexities can often be expressed in terms of the basic
complexities of multiplying 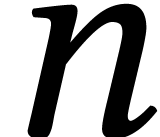 -bit
integers, degree
-bit
integers, degree  polynomials, and
polynomials, and  matrices. Several papers even use special notations
matrices. Several papers even use special notations 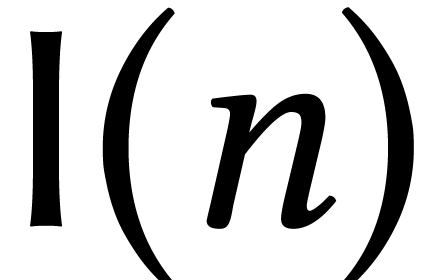 ,
, 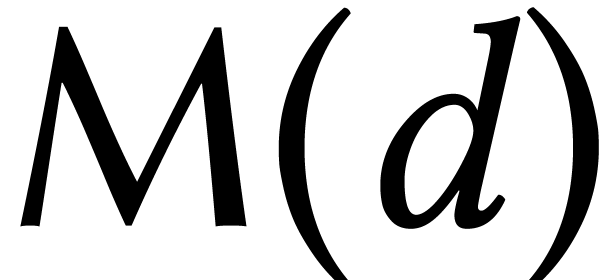 ,
and
,
and 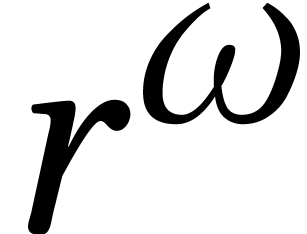 for these complexities. In a similar manner,
number theorists introduced
for these complexities. In a similar manner,
number theorists introduced
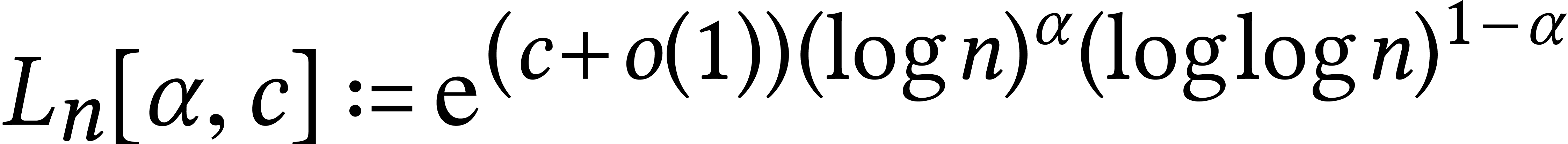
in order to express the complexities of fast algorithms for integer factorization and discrete logarithms. We will return to these observations in Section 3.2 below.
In the past decade, there have been many developments “beyond the worst-case” analysis of algorithms [108]. To which extent are these developments relevant to the ISSAC community? For instance, a hard problem may become easier for particular input distributions that are meaningful in practice. It is important to describe and understand such distributions more precisely. Surprisingly, very few papers in our area pursue this point of view. On the other hand, there are many lists of “interesting” problems for benchmarking. Conversely, only the last page 660 of [108] contains a table with experimental timings.
In my personal research, I also encountered various interesting
algorithms that scream for yet other non-traditional analyses: amortized
complexity (fast algorithms modulo precomputations [73]),
conjectured complexity (dependence on plausible but unproven conjectures
[49]), heuristic complexity [69], irregular
complexity (various operations over finite fields 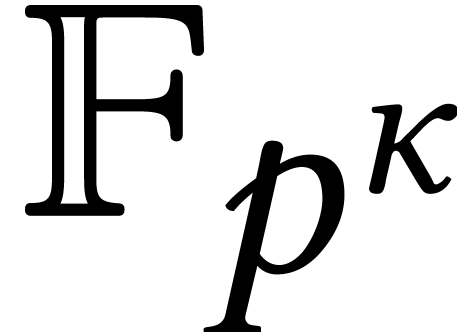 can be done faster if
can be done faster if  is composite or smooth [67, 76]).
is composite or smooth [67, 76]).
Hardy already noted that many natural orders of growth can be expressed
using exp-log functions [43]; this in particular holds for
the asymptotic complexities of many algorithms. Instead of searching for
“absolute” complexity bounds, it has become common to
express complexities in terms of other, more “fundamental”
complexities such as , , ,
and 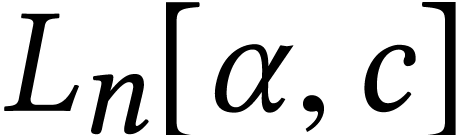 that were introduced above.
that were introduced above.
In a similar way as traditional complexity theory is organized through complexity classes P, NP, EXP, L, etc., I think that fundamental complexities can play a similar role for symbolic computation and beyond.
Whereas complexity classes give a rough idea about how fast certain problems can be solved, fundamental complexities provide more detailed information such as “the problem essentially reduces to linear algebra”.
In fact, the language of complexity bounds (especially when enriched
with notations such as ,
, and ) is more expressive and precise than the language
of complexity classes: whereas

vaguely states that primality can be checked “fast”,
states that computing gcds essentially reduces to multiplication, plausibly using a dichotomic algorithm.
Another advantage of (re-)organizing complexity theory in this direction is that fundamental complexities are hardware-oblivious: the bound (1) holds on Turing machines, for algebraic complexity models, on quantum computers, as well as on many parallel machines. Deciding whether integer factorization can be done in polynomial time may lead to different outcomes on Turing machines and quantum computers.
With the help of fundamental complexities, even constant factors can be made more precise. For instance, [35, Exercise 11.6] indicates how to prove that
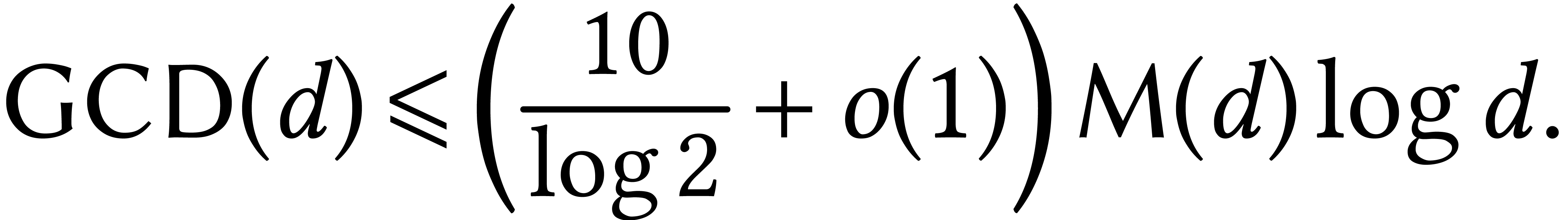
This often makes it possible to predict running times very accurately, provided we know the performance of a few basic algorithms. Implementors can then optimize these basic algorithms.
Fundamental algorithms may also be implemented in hardware. For
instance, Apple's new M1 processor contains a matrix coprocessor. With
suitable hardware, it might very well be possible to
“achieve” 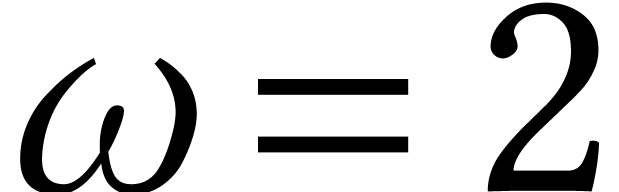 for many real world
applications.
for many real world
applications.
The question remains which complexities are worthy to be dubbed “fundamental”. This question is actually a productive common thread whenever you want to understand complexity issues in some area. It asks you to identify the most fundamental algorithmic building blocks. Sometimes, this requires the introduction of a new fundamental complexity (such as modular composition or multi-point evaluation for polynomial system solving; see Section 5 below). Sometimes, you may find out that your area reduces to another one from an algorithmic point of view. For instance, computations with the most common Ore operators essentially reduce to polynomial linear algebra.
Asymptotic complexity bounds can be treacherous from a practical point
of view. The most notorious example is matrix multiplication: it has
been proved that [34], but I am not
aware of any implementation that performs better than Strassen's
algorithm [115] for which 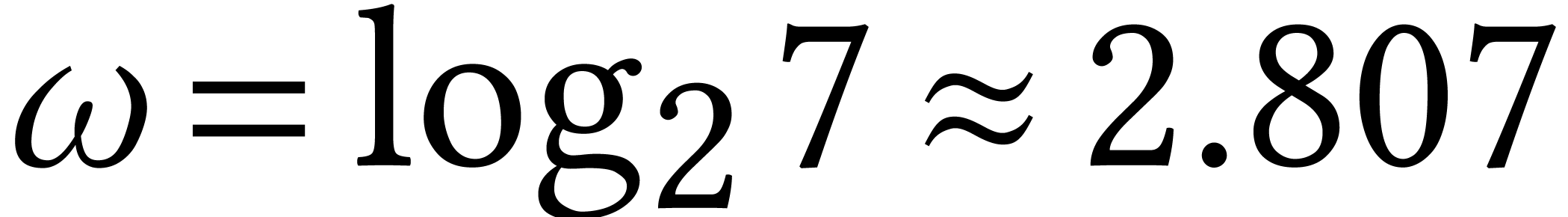 .
A more interesting example is Kedlaya–Umans' recent algorithm for
modular composition [84]. We were unable to make it work
fast in practice [70, Conclusion], but it is unclear
whether variants of the algorithm might allow for efficient
implementations.
.
A more interesting example is Kedlaya–Umans' recent algorithm for
modular composition [84]. We were unable to make it work
fast in practice [70, Conclusion], but it is unclear
whether variants of the algorithm might allow for efficient
implementations.
Whereas hardness results dissuade implementors from overly efficient solutions for certain problems, the main practical interest of the above complexity bounds is to dissuade complexity theorists from trying to prove overly pessimistic lower bounds.
One useful indicator for practical differences in performance is the
crossover point: if is asymptotically
faster than , for which size
 of the input does
actually become faster? Curiously, crossover points are often mentioned
en passant when discussing benchmarks, but they have not really
been the subject of systematic studies: does anyone know what is the
crossover point between naive matrix multiplication and any of the
asymptotically fast algorithms with
of the input does
actually become faster? Curiously, crossover points are often mentioned
en passant when discussing benchmarks, but they have not really
been the subject of systematic studies: does anyone know what is the
crossover point between naive matrix multiplication and any of the
asymptotically fast algorithms with 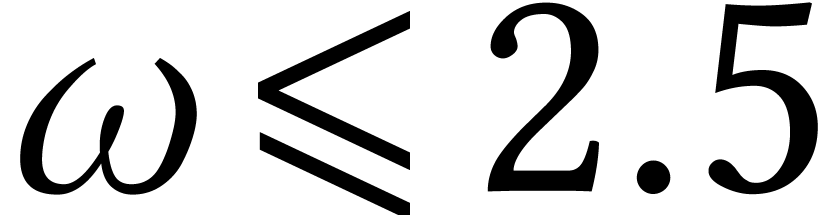 ?
?
It is illuminating to study the complexities of
and near the crossover point. For
instance, for Strassen's algorithm versus naive matrix multiplication,
assume that the crossover point is  .
Then this means that we need a matrix of size
.
Then this means that we need a matrix of size  in
order to gain a factor two with Strassen's method: for
in
order to gain a factor two with Strassen's method: for 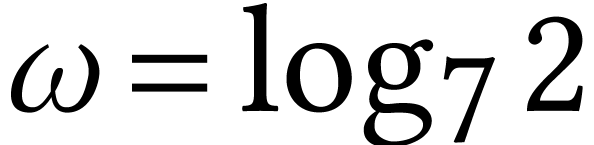 , we have
, we have 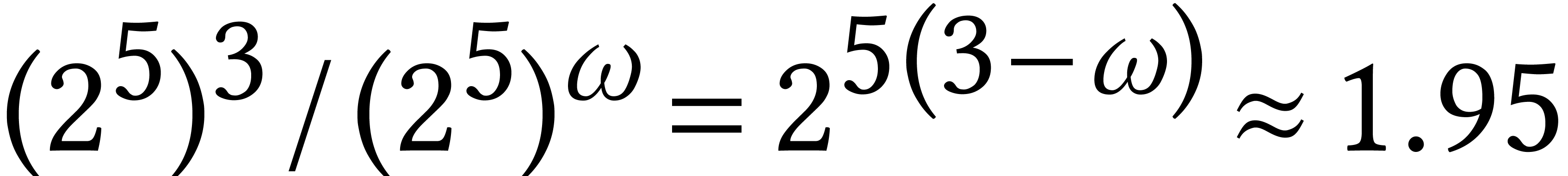 .
.
Now there are many recent bounds in the recent computer algebra
literature of the form 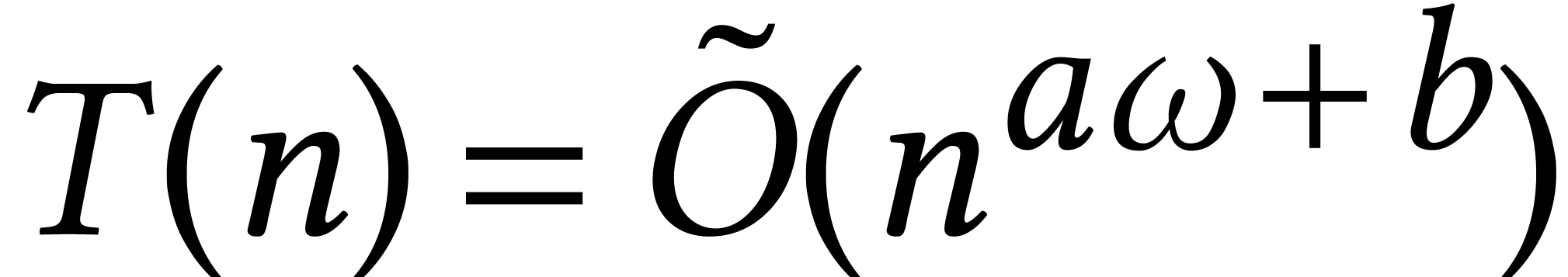 . Here
the soft-O notation
. Here
the soft-O notation 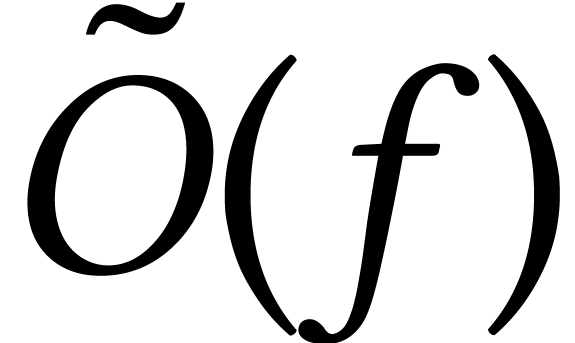 stands for
stands for 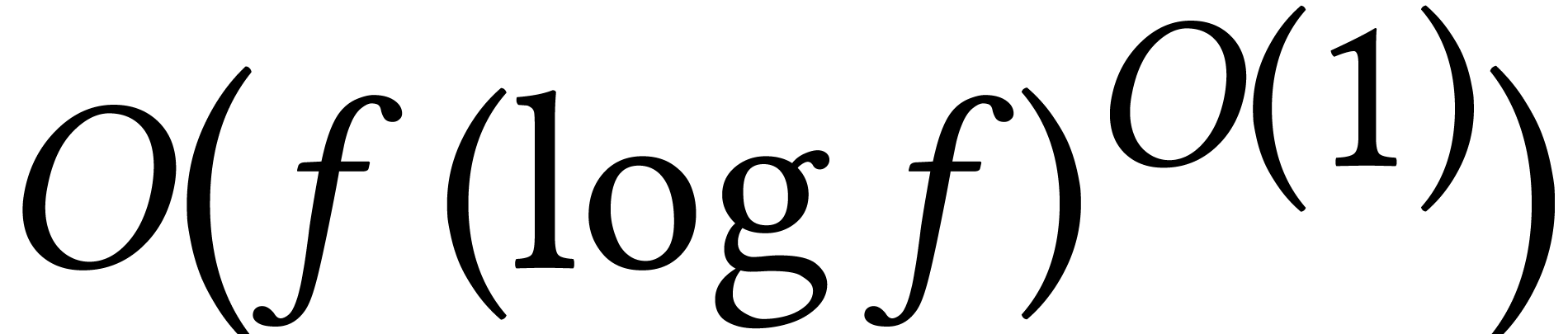 and serves to “discard” all logarithmic factors. Although I
think that it is a good practice to state complexity bounds in terms of
(for instance, might be
lower for sparse or structured matrices), I suspect that the discarded
logarithmic factors are often far more significant.
and serves to “discard” all logarithmic factors. Although I
think that it is a good practice to state complexity bounds in terms of
(for instance, might be
lower for sparse or structured matrices), I suspect that the discarded
logarithmic factors are often far more significant.
In this paper, I focus on sequential bit-complexity [101] and algebraic complexity [17]. Of course, modern computers come with complex cache hierarchies and they are highly parallel (distributed over networks, multi-core, and with wide SIMD instructions). A model for measuring the cost of cache misses was proposed in [33]. For a past ISSAC tutorial on parallel programming techniques in computer algebra, I refer to [94]. The Spiral project [106] is also noteworthy for using computer algebra to generate parallel code for low level transforms such as FFTs.
Computer algebra systems are usually developed in layers, as are mathematical theories. The bottom layer concerns numbers. The next layers contain basic data structures such as univariate polynomials, dense matrices, symbolic expressions, and so on. Gröbner bases, symbolic integration, etc. can be found in the top layers.
My mental picture of a complexity theory for computer algebra roughly follows the same structure. The aim is to understand the complexity issues layer by layer, starting with the lowest ones.
In order to figure out the cost of basic arithmetic operations,
multiplication is the central operation to analyze first. We have
already encountered the fundamental complexities
,
,
and
,
for which the best known bounds are summarized in Table
2
.
Multiplication is fundamental in two ways. On the one hand, many other operations can efficiently be reduced to multiplication. On the other hand, the techniques that allow for fast multiplication are typically important for other operations as well. In Table 3 , I summarized the complexity of multiplication for a few other important algebras.
Other noteworthy bounds in the same spirit concern truncated multiplication [96, 42, 46], middle products [41, 15], multivariate power series [88], symmetric polynomials [66], rectangular matrix multiplication [79, 86], and sparse differential operators [36].
Technically speaking, many algorithms for fast multiplication rely on evaluation-interpolation (or, more generally, they rewrite the problem into a simpler multiplication problem for another algebra). The complexity of such algorithms can be expressed in terms of the number of evaluation points and the cost of conversions.
For instance, given an evaluation-interpolation scheme for
degree polynomials, let 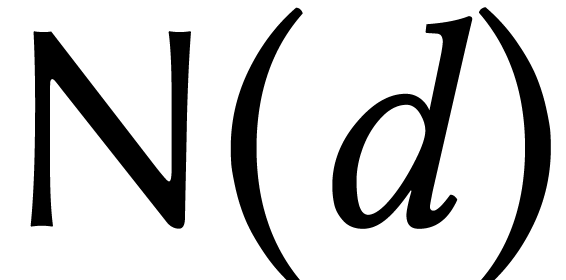 and
and 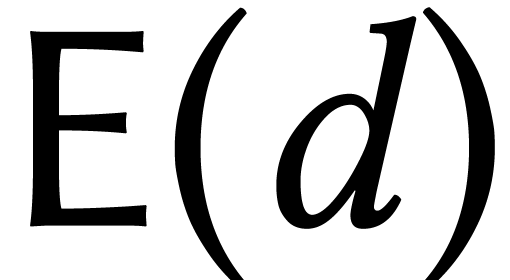 denote the number of evaluation points and
the cost of evaluation/interpolation. Then the complexity of multiplying
two matrices of degree in
denote the number of evaluation points and
the cost of evaluation/interpolation. Then the complexity of multiplying
two matrices of degree in 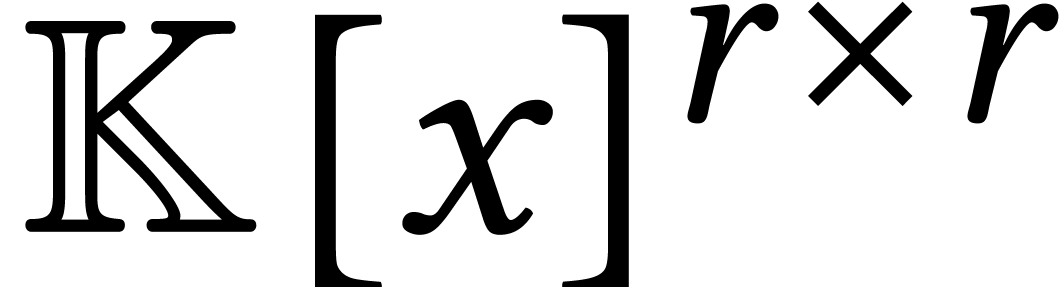 becomes
becomes
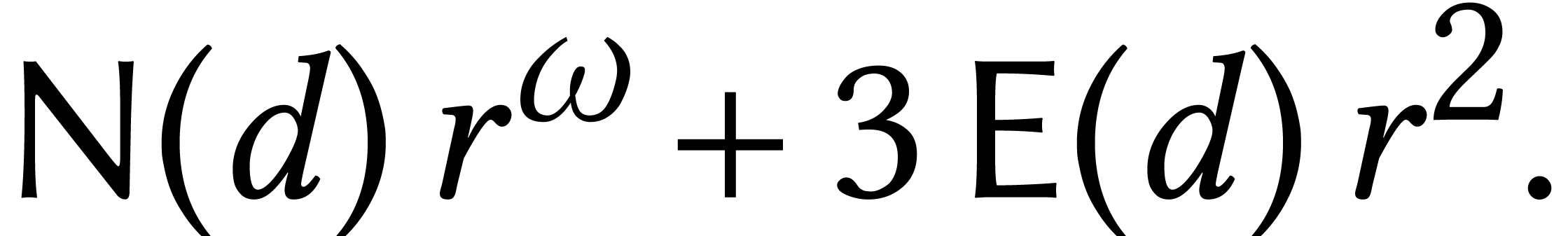
The evaluation-interpolation scheme should carefully be selected as a
function of and  ,
with a trade-off between the efficiency of the conversions and the
compactness of the evaluated polynomials.
,
with a trade-off between the efficiency of the conversions and the
compactness of the evaluated polynomials.
There exist numerous important schemes: fast Fourier transforms [25], Karatsuba and Toom-Cook transforms [83, 116], Chinese remaindering [26, 61], Nussbaumer (or Schönhage–Strassen) polynomial transforms [113, 99], truncated Fourier transforms [55], Chudnovsky2 evaluations and interpolations [21], and so on.
For other basic arithmetic operations like division, square roots, gcds, matrix decompositions, exp, log, etc., one may proceed in two stages: we first seek an efficient reduction to multiplication and then further optimize the method for particular multiplication schemes.
For instance, operations such as division and square root, but also exponentials of formal power series, can be reduced efficiently to multiplication using Newton's method [14]. When using such an algorithm in combination with FFT-multiplication, some of the FFTs are typically redundant. Constant factors can then be reduced by removing such redundancies [7, 8]. Note that Shoup's NTL library is an early example of a library that makes systematic use of specific optimizations for the FFT-model [114].
One may go one step further and modify the algorithms such that even more FFTs are saved, at the cost of making the computations in the FFT-model a bit more expensive. This technique of FFT trading leads to even better asymptotic constant factors or complexities [57, 45, 44, 61].
Table
4
contains a summary of the best known asymptotic complexity bounds for
various basic operations on integers and/or floating point numbers.
Similar bounds hold for polynomials and truncated power series. The
first three bounds were actually proved for polynomials and/or series,
while assuming the FFT-model: one degree
multiplication is equivalent to six DFTs of length
.
CRT stands for the Chinese remainder theorem; conversions in either
direction have the same softly linear complexity. This was originally
proved for polynomials, but also holds for integer moduli [15,
Section 2.7]. For amortized CRTs, the moduli are fixed, so
quantities that only depend on the moduli can be precomputed. A
holonomic function is a function that satisfies a linear
differential equation over 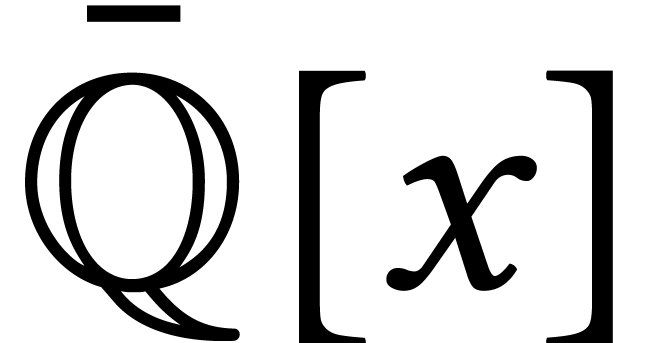 ,
where
,
where  is the field of algebraic numbers. Many
special functions are of this type.
is the field of algebraic numbers. Many
special functions are of this type.
Some bounds for transcendental operations are better for power series
than for numbers. For instance, exponentials can be computed in time
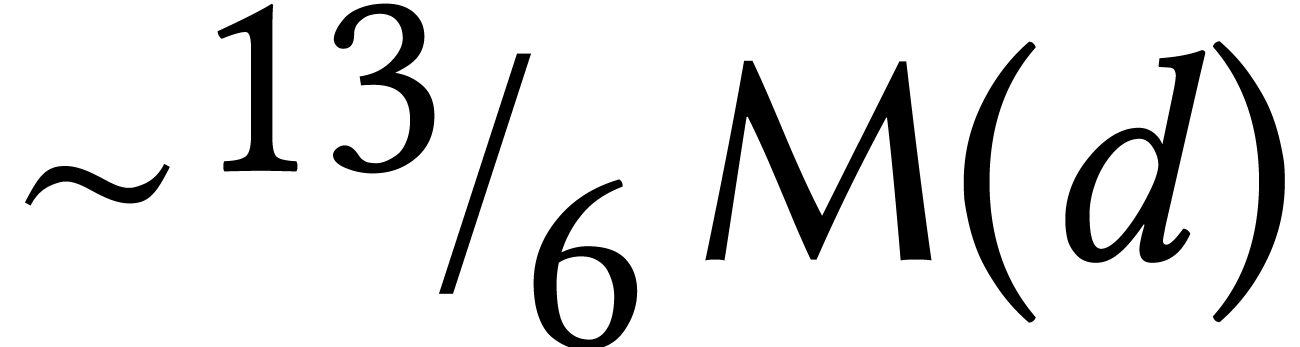 modulo
modulo 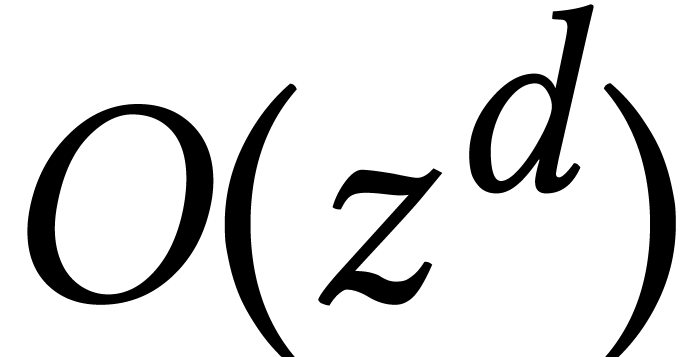 .
Using relaxed or online arithmetic, when coefficients
are fed one by one, solving power series equations is as efficient as
evaluating them [54, 63]. For instance, in the
Karatsuba model
.
Using relaxed or online arithmetic, when coefficients
are fed one by one, solving power series equations is as efficient as
evaluating them [54, 63]. For instance, in the
Karatsuba model 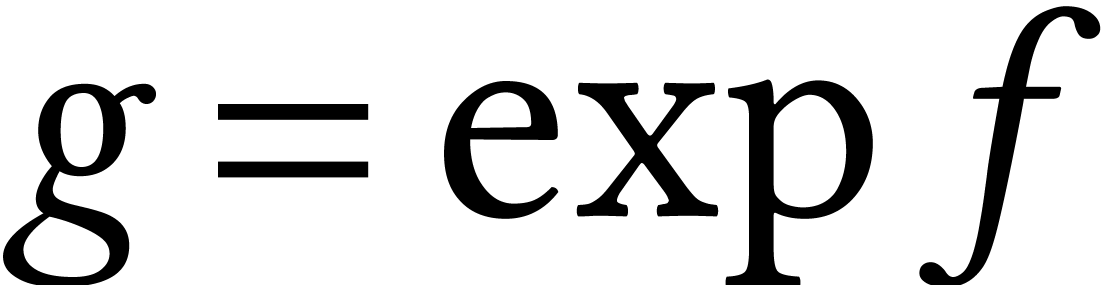 can be computed in time
can be computed in time 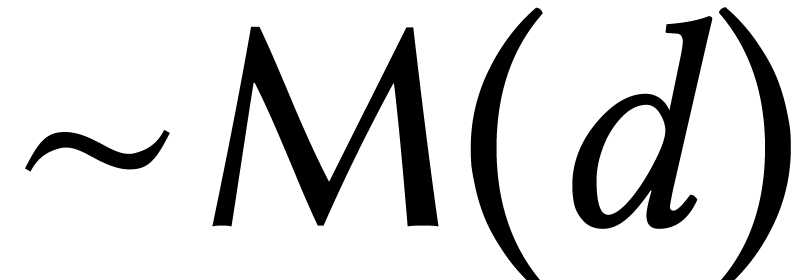 using
using 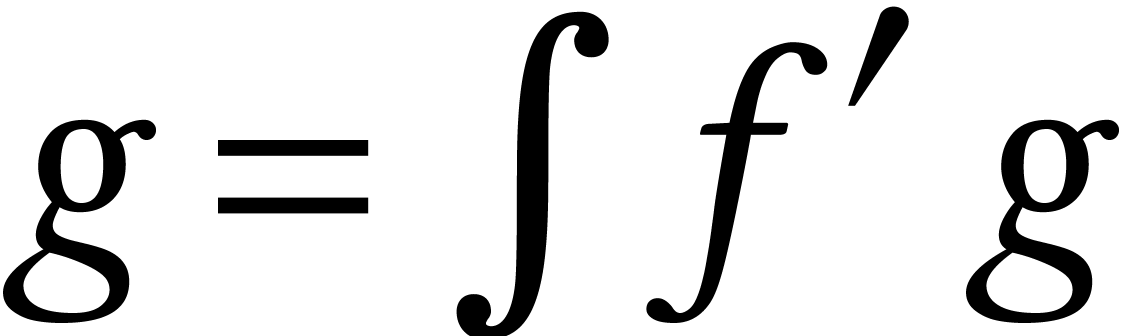 . In
the FFT-model, one has to pay a small, non-constant price for relaxed
multiplication (see Table 3).
. In
the FFT-model, one has to pay a small, non-constant price for relaxed
multiplication (see Table 3).
The numerical evaluation of analytic functions reduces into power series
computations and the computation of effective error bounds. This can be
used to solve many problems from numerical analysis with high precision.
For instance, the reliable integration of an algebraic dynamical system
between two fixed times and with a variable precision of bits takes 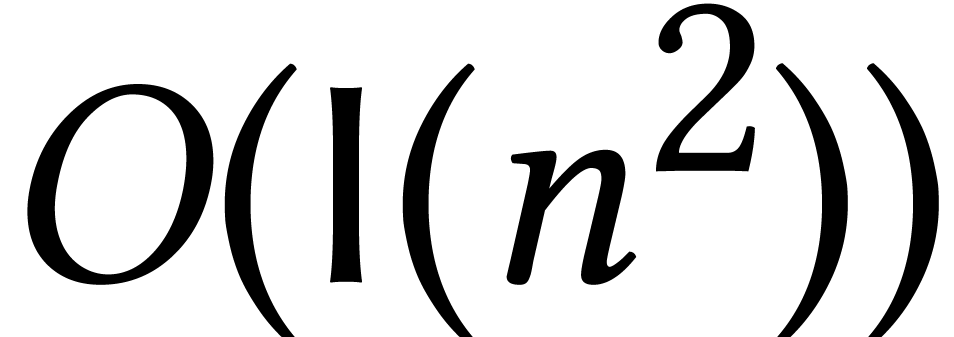 bit operations [58]. See [80, 90] for other software
packages for reliable numerical computations with high precision.
bit operations [58]. See [80, 90] for other software
packages for reliable numerical computations with high precision.
Similar tables as Table 4 can be compiled for other
algebras. For instance, the inverse of an matrix
with entries in a field  can be computed in time
can be computed in time
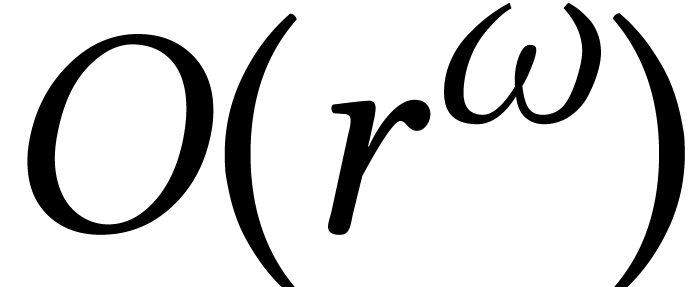 [115]. If
[115]. If 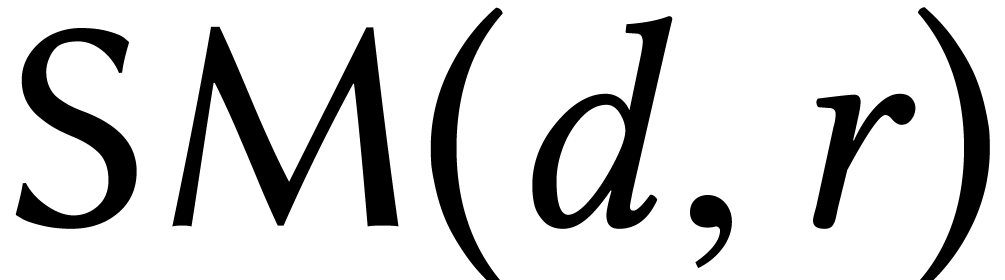 stands for the complexity of multiplying two operators in
stands for the complexity of multiplying two operators in 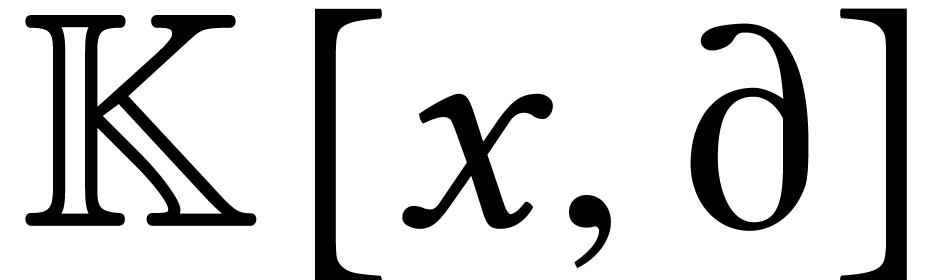 of degree
of degree 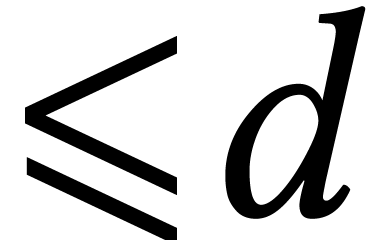 in
in  and order
and order 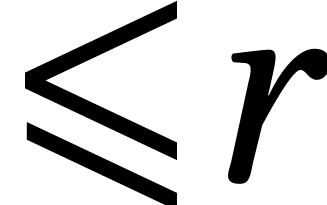 in
in  ,
then exact right division of two such operators can be done in time
,
then exact right division of two such operators can be done in time 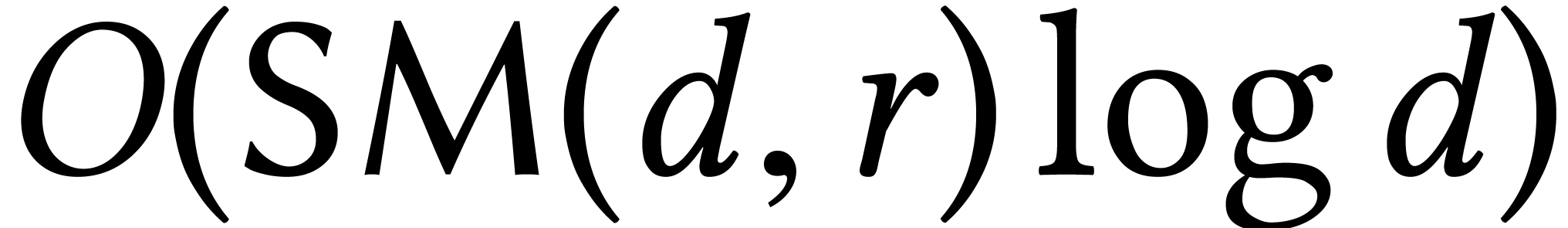 [62].
[62].
One big enemy of symbolic computation is intermediate expression
swell. This phenomenon ruins the complexity of many algorithms. For
instance, let 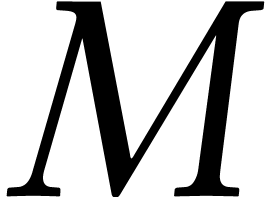 be an
matrix with formal entries
be an
matrix with formal entries 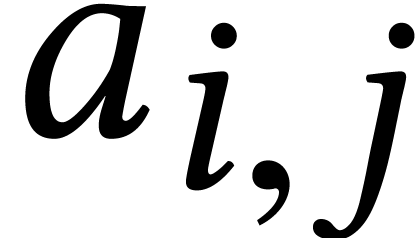 and consider the
computation of
and consider the
computation of 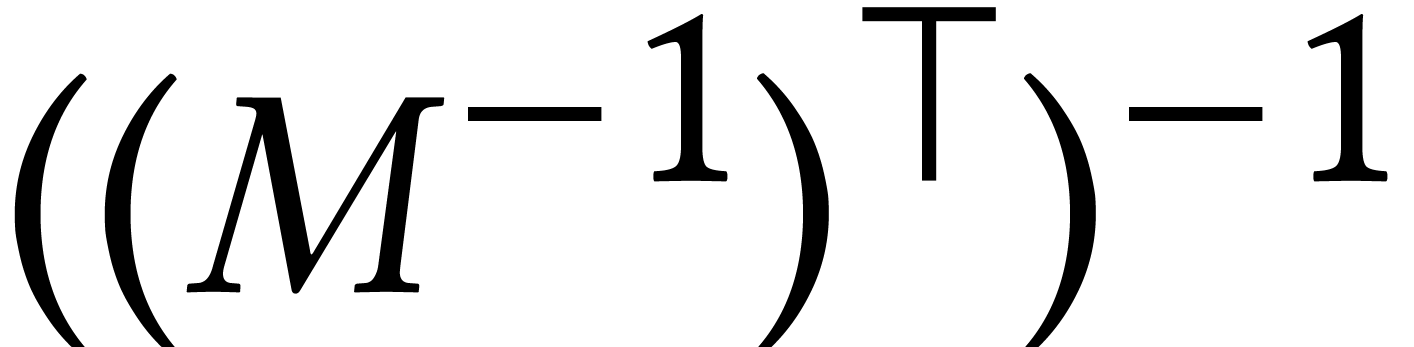 . For
. For 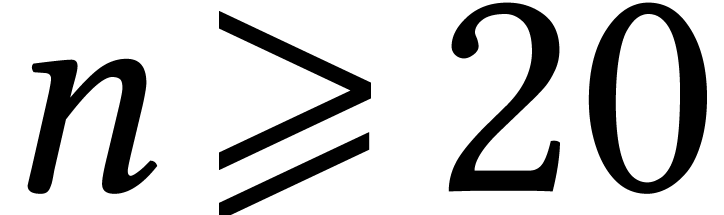 , the intermediate expression for
, the intermediate expression for
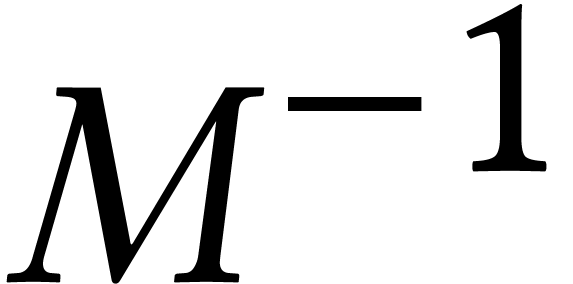 is prohibitively large, when fully expanded as a
rational function in the parameters .
But the end-result
is prohibitively large, when fully expanded as a
rational function in the parameters .
But the end-result 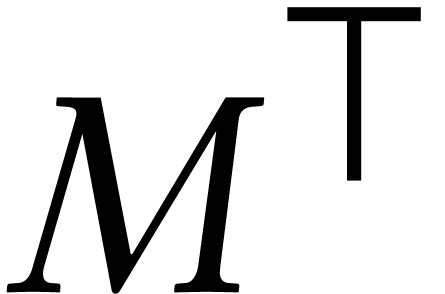 is fairly
small. The technique of sparse interpolation proposes a remedy
to this problem.
is fairly
small. The technique of sparse interpolation proposes a remedy
to this problem.
In general, we start with a blackbox function 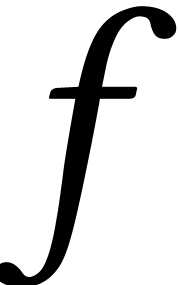 , such as the above function that associates to
, such as the above function that associates to 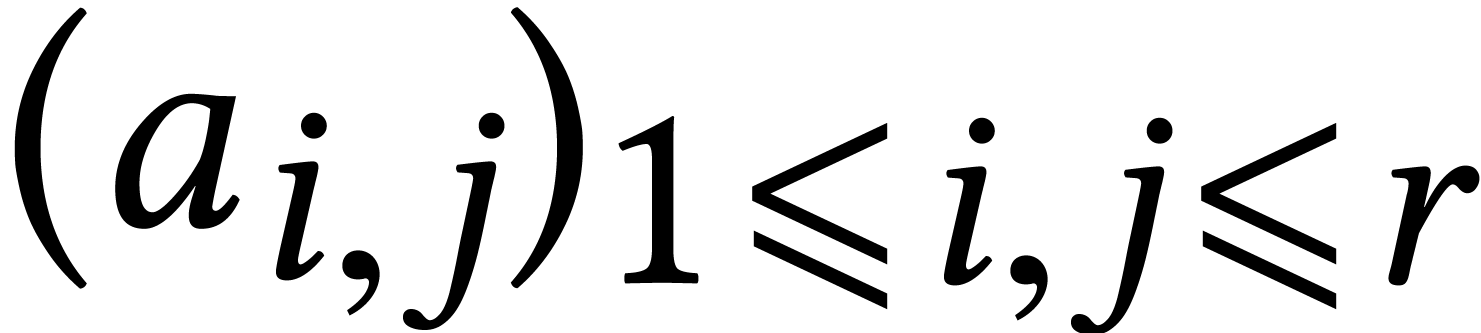 . The
function is usually given by a DAG that computes
one or more polynomials or rational functions that involve many
parameters. The DAG should be of reasonable size, so that it can be
evaluated fast. In our example, the DAG might use Gaussian elimination
to compute the inverses. Then sparse interpolation allows for the
efficient symbolic reconstruction of the actual polynomials or rational
functions computed by ,
whenever these are reasonably small. This is an old topic [105,
5, 18] with a lot of recent progress; see [107] for a nice survey.
. The
function is usually given by a DAG that computes
one or more polynomials or rational functions that involve many
parameters. The DAG should be of reasonable size, so that it can be
evaluated fast. In our example, the DAG might use Gaussian elimination
to compute the inverses. Then sparse interpolation allows for the
efficient symbolic reconstruction of the actual polynomials or rational
functions computed by ,
whenever these are reasonably small. This is an old topic [105,
5, 18] with a lot of recent progress; see [107] for a nice survey.
Let us focus on the case when computes a
polynomial with rational coefficients. From a complexity perspective,
the most important parameters are the size 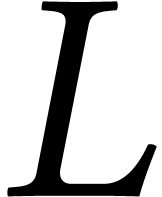 of
as a DAG, the size
of
as a DAG, the size  of
its support as a polynomial, and the bit size
of
its support as a polynomial, and the bit size 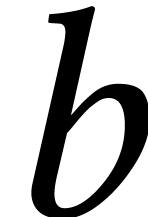 of
the coefficients (the degree and dimension are typically small with
respect to
of
the coefficients (the degree and dimension are typically small with
respect to  , so we will
ignore them for simplicity). Sparse interpolation goes in two stages: we
first determine the support of ,
typically using a probabilistic algorithm of Monte Carlo type. We next
determine the coefficients.
, so we will
ignore them for simplicity). Sparse interpolation goes in two stages: we
first determine the support of ,
typically using a probabilistic algorithm of Monte Carlo type. We next
determine the coefficients.
Now the first stage can be done modulo a sufficiently large prime 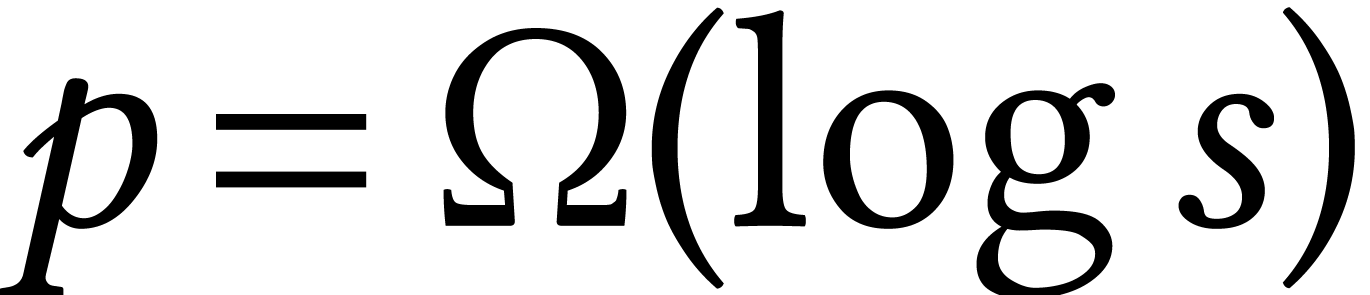 , so the complexity hardly depends
on . Using Prony's algorithm
[105], this stage first involves
, so the complexity hardly depends
on . Using Prony's algorithm
[105], this stage first involves  evaluations of of cost
evaluations of of cost 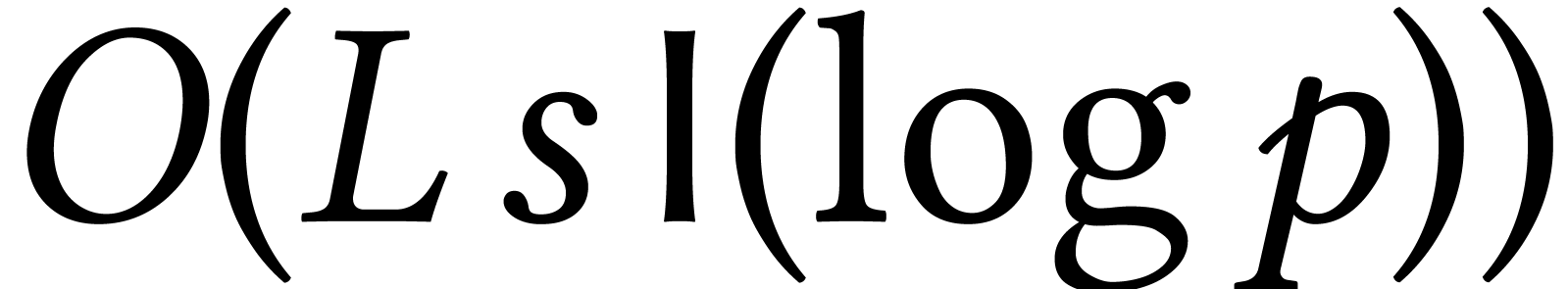 ; using Cantor–Zassenhaus for polynomial root
finding [20], we next need
; using Cantor–Zassenhaus for polynomial root
finding [20], we next need 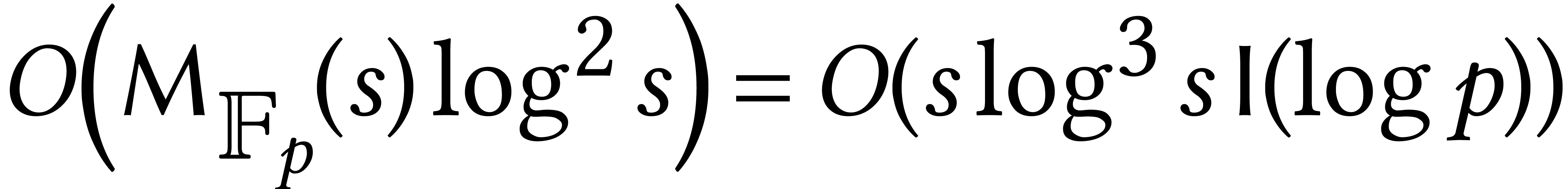 operations to recover the support. Finally, the coefficients can be
computed using transposed polynomial interpolation [18, 11], in time
operations to recover the support. Finally, the coefficients can be
computed using transposed polynomial interpolation [18, 11], in time 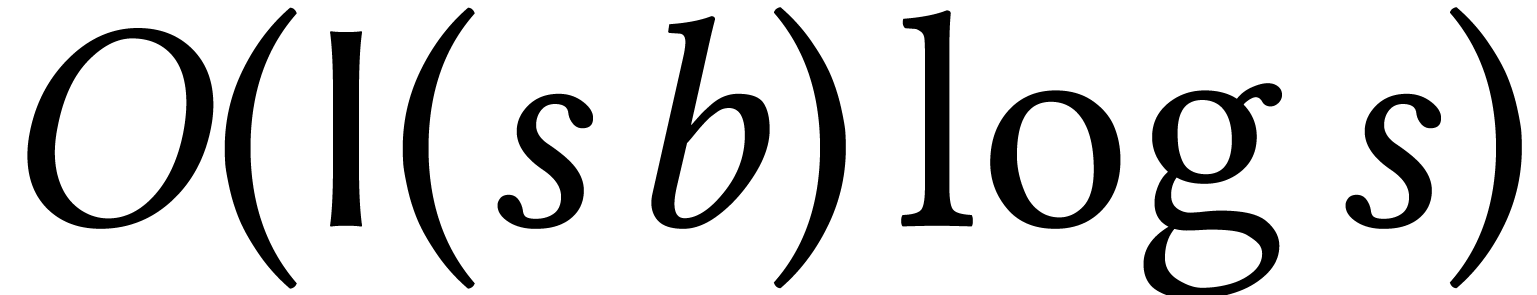 .
.
The dominant term in the resulting complexity 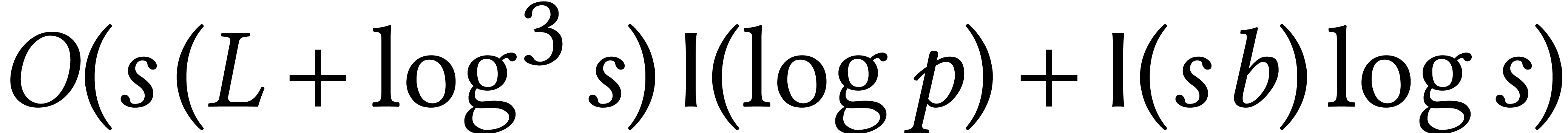 depends on the asymptotic region we are in. The logarithmic terms are
significant. For instance, if
depends on the asymptotic region we are in. The logarithmic terms are
significant. For instance, if  for the above
matrix , then
for the above
matrix , then 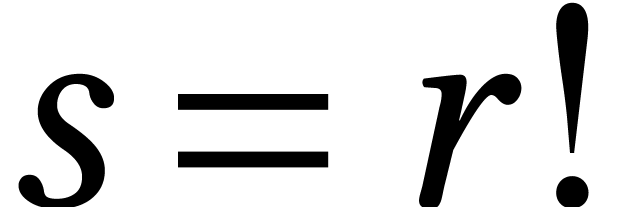 ,
,  ,
,
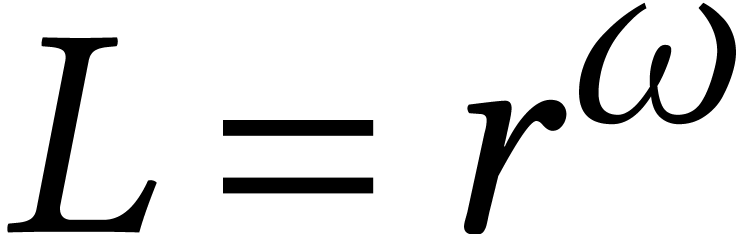 , and
, and 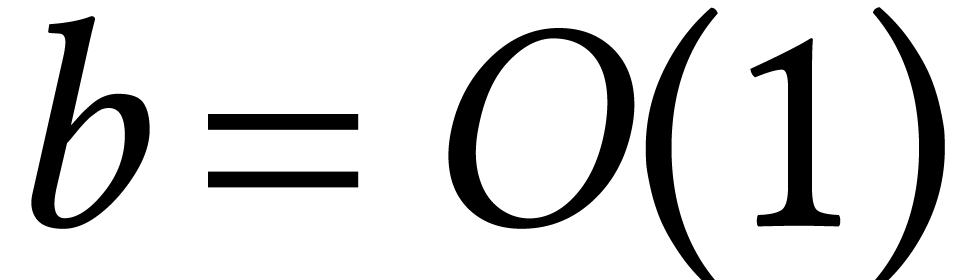 , whence the Cantor–Zassenhaus step dominates
the cost. In [40, 78], it was shown how to
save a factor
, whence the Cantor–Zassenhaus step dominates
the cost. In [40, 78], it was shown how to
save a factor 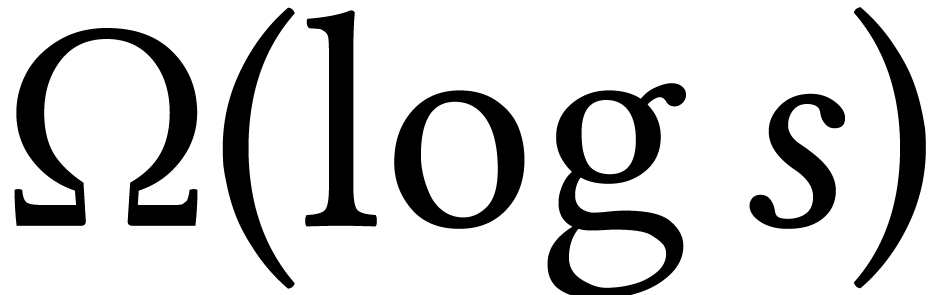 by using the tangent Graeffe
method; after that, the evaluation step dominates the cost.
by using the tangent Graeffe
method; after that, the evaluation step dominates the cost.
For basic arithmetic operations on sparse polynomials or low dimensional
linear algebra with sparse polynomial coefficients, the evaluation cost
can be amortized using multi-point evaluation;
this essentially achieves 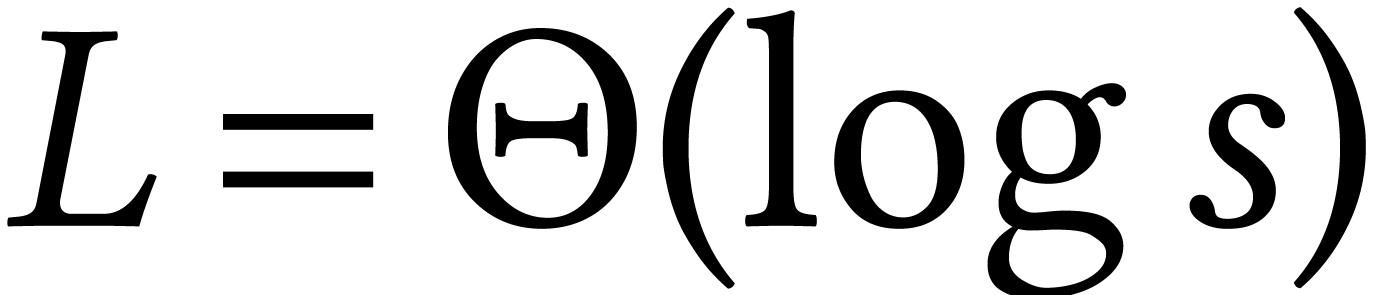 .
In such situations, both Prony's algorithm and the tangent Graeffe
algorithm become suboptimal. It then becomes better to evaluate directly
at suitable roots of unity using FFTs, which allows for another
.
In such situations, both Prony's algorithm and the tangent Graeffe
algorithm become suboptimal. It then becomes better to evaluate directly
at suitable roots of unity using FFTs, which allows for another 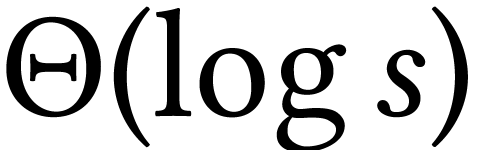 speed-up, also for the computation of the
coefficients. In particular, sparse polynomial multiplication becomes
almost as fast as dense multiplication. However, the technical details
are subtle and can be found in [69, 64].
speed-up, also for the computation of the
coefficients. In particular, sparse polynomial multiplication becomes
almost as fast as dense multiplication. However, the technical details
are subtle and can be found in [69, 64].
One central problem in symbolic computation is polynomial system solving. Now the mere decision problem whether there exists one solution is a notorious NP-hard problem. However, most algorithms in computer algebra concern the computation of all solutions, for various representations of solutions. The number of solutions may be huge, but the cost of finding them is often reasonable with respect to the size of the output.
In this section, we focus on the complete resolution of a generic affine
system of polynomial equations of degrees  . For definiteness, we assume that
the coefficients are in ,
. For definiteness, we assume that
the coefficients are in ,
 , or
, or 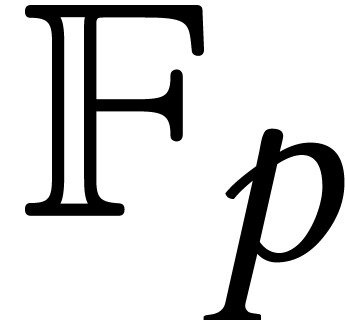 . For simplicity, we also assume that
. For simplicity, we also assume that 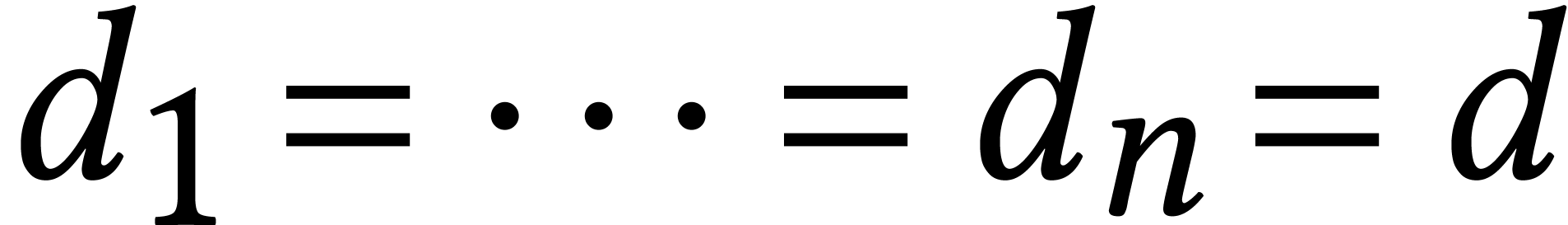 . For such a generic system, all solutions are
isolated and simple and the number of solutions reaches the
Bézout bound
. For such a generic system, all solutions are
isolated and simple and the number of solutions reaches the
Bézout bound  .
.
There exist several approaches for polynomial system solving:
Gröbner bases.
Numeric homotopies.
Geometric resolution.
Triangular systems.
We will restrict our exposition to the first three approaches. But we start with a survey of the related problem of multi-point evaluation, followed by an investigation of the univariate case, which calls for separate techniques.
Let be a field and  an
algebra over . The problem of
multi-point evaluation takes
an
algebra over . The problem of
multi-point evaluation takes  and
and 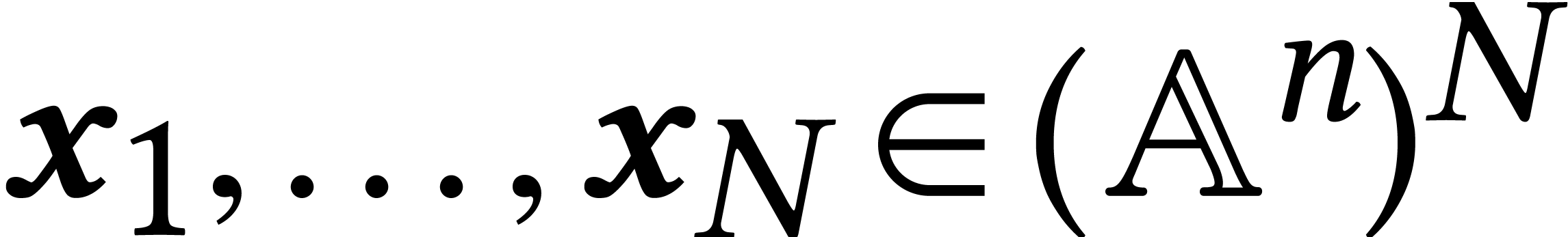 as input and should produce
as input and should produce  as
output. This problem is closely related to polynomial system solving:
given a tentative solution of such a system, we may check whether it is
an actual solution using multi-point evaluation. For complex or
as
output. This problem is closely related to polynomial system solving:
given a tentative solution of such a system, we may check whether it is
an actual solution using multi-point evaluation. For complex or  -adic solutions, we may also double
the precision of an approximate solution through a combination of
Newton's method and multi-point evaluation.
-adic solutions, we may also double
the precision of an approximate solution through a combination of
Newton's method and multi-point evaluation.
Using the technique of remainder trees [35, Chapter 10], it
is classical that the univariate case with 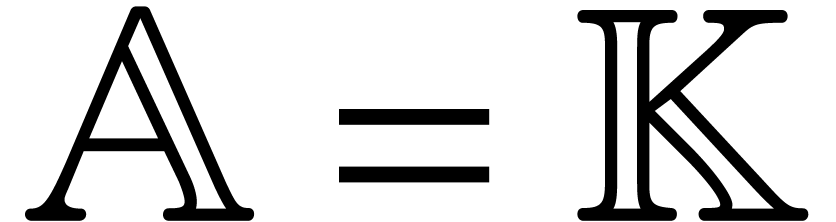 can
be solved in softly optimal time
can
be solved in softly optimal time 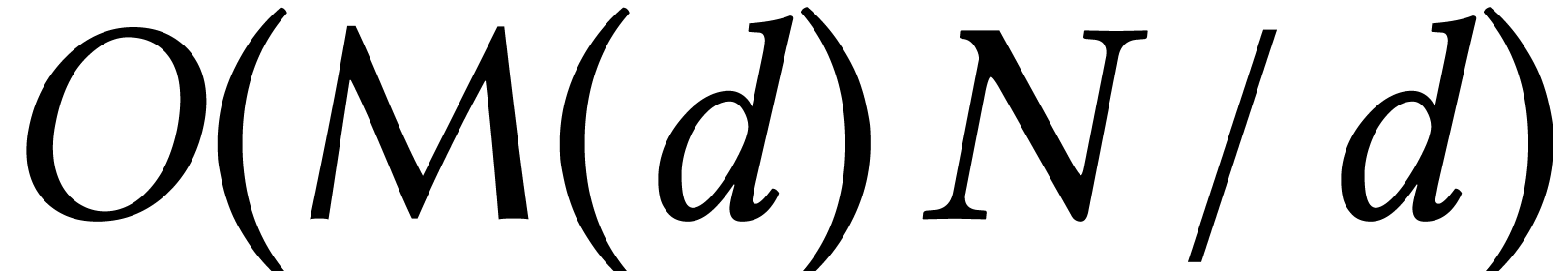 if
if 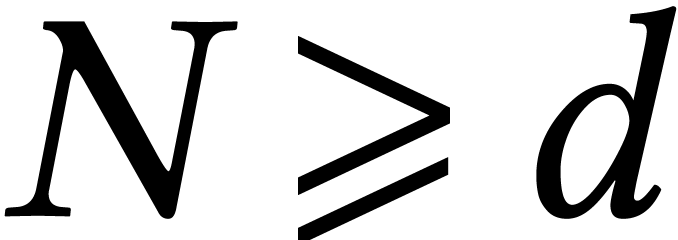 and
and 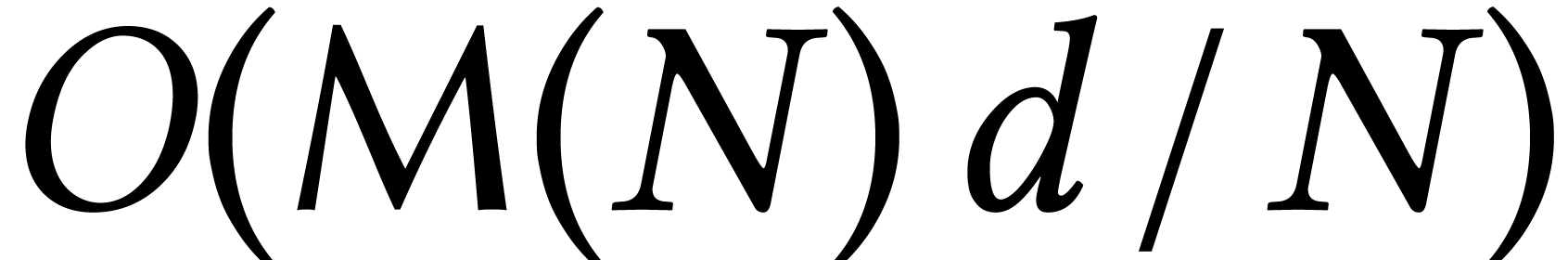 if
if 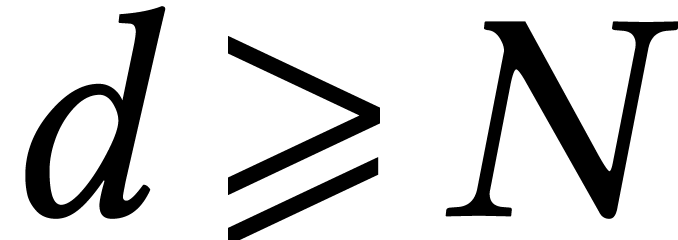 .
.
The special case when 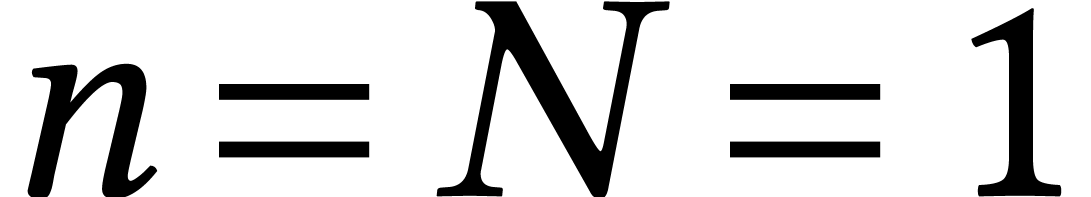 and
is an algebraic extension of (typically of
degree ) is called the
problem of modular composition. This problem can be solved in
time
and
is an algebraic extension of (typically of
degree ) is called the
problem of modular composition. This problem can be solved in
time 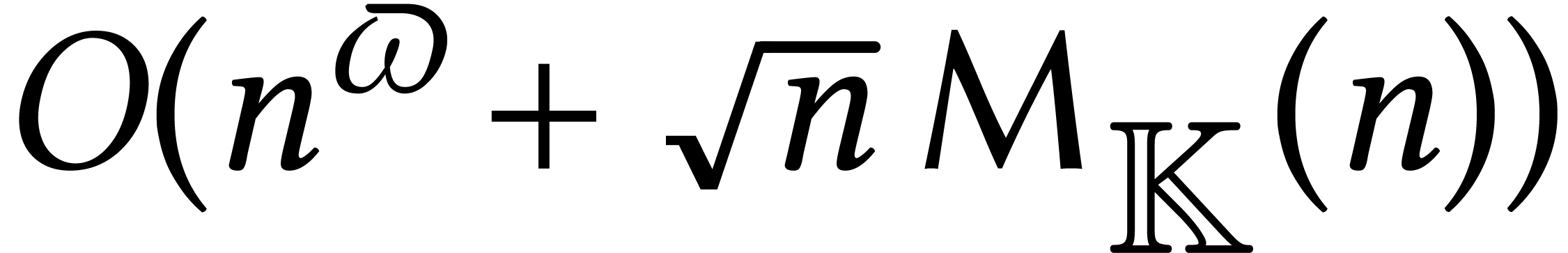 using Stockmeyer and Paterson's
baby-step-giant-step technique; see [102] and [82,
p. 185]. The constant
using Stockmeyer and Paterson's
baby-step-giant-step technique; see [102] and [82,
p. 185]. The constant 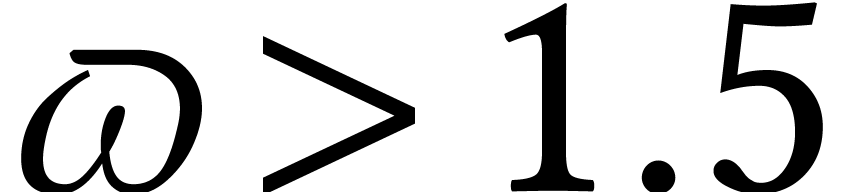 is such that a
is such that a  matrix over may be multiplied with
another
matrix over may be multiplied with
another 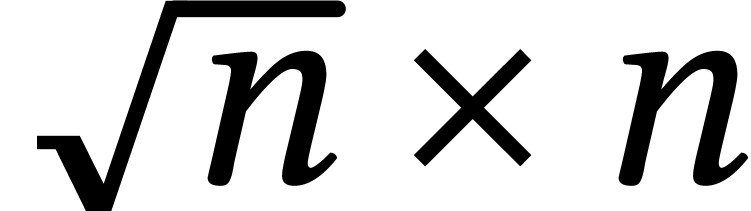 rectangular matrix in time
rectangular matrix in time 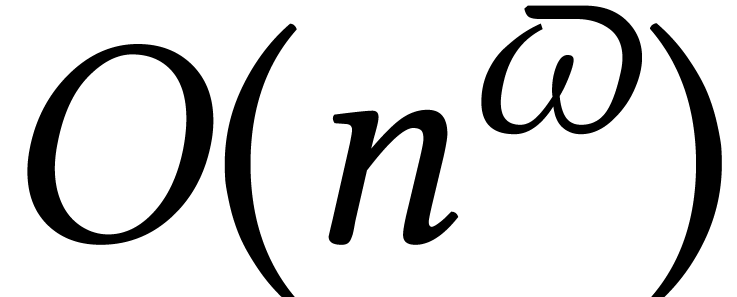 . One may take
. One may take 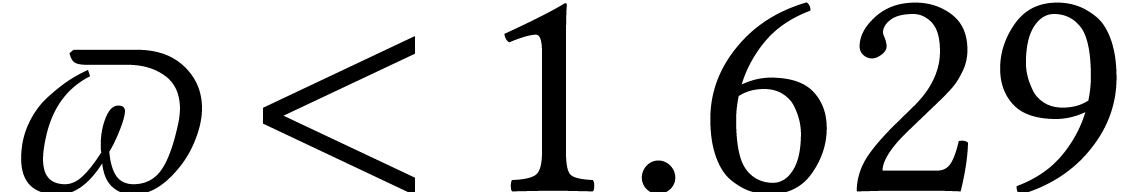 [86, 73]. The same technique can be applied for
other multi-point/modular evaluation problems [68, Section
3].
[86, 73]. The same technique can be applied for
other multi-point/modular evaluation problems [68, Section
3].
A breakthrough was made in 2008 by Kedlaya and Umans [84],
who showed that modular composition and multi-point evaluation with are related and that they can both be performed with
quasi-optimal complexity. For instance, the complexity of modular
composition is 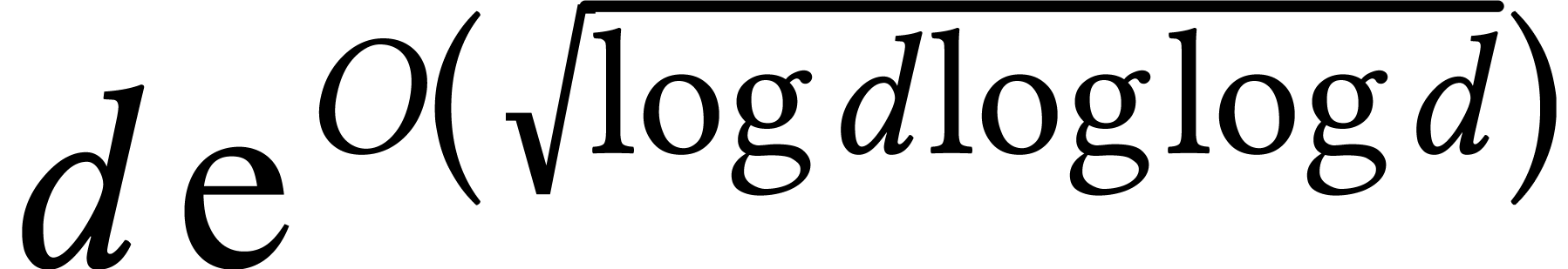 .
Unfortunately, their algorithms do not seem to be efficient in practice
[70, Conclusion]; being non-algebraic, their approach is
also not generally applicable in characteristic zero.
.
Unfortunately, their algorithms do not seem to be efficient in practice
[70, Conclusion]; being non-algebraic, their approach is
also not generally applicable in characteristic zero.
In the past decade, Grégoire Lecerf and I have investigated
several more practical alternatives for Kedlaya-Umans' algorithms. Over
the integers and rationals, modular composition can be done in softly
optimal time for large precisions [71]. Over finite fields
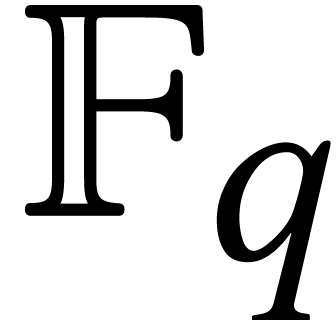 with
with 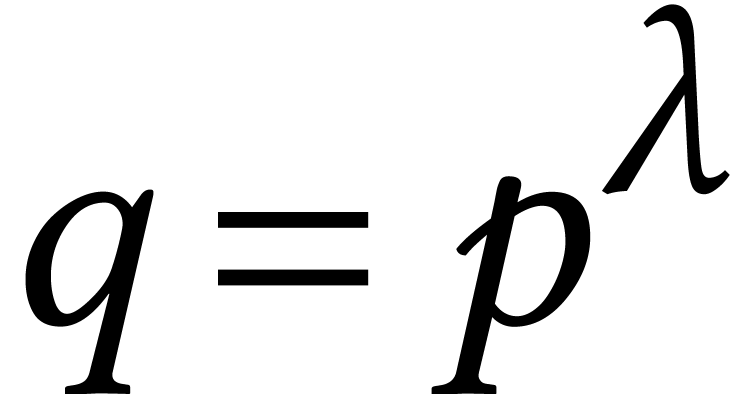 and prime, it helps when
and prime, it helps when 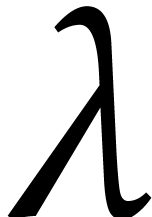 is composite
[67]; if is smooth, then
composition modulo a fixed irreducible polynomial of degree can even be done in softly optimal time.
is composite
[67]; if is smooth, then
composition modulo a fixed irreducible polynomial of degree can even be done in softly optimal time.
There has also been progress on the problem of amortized multi-point evaluation, when the evaluation points are fixed [74, 97, 72]. This has culminated in a softly optimal algorithm for any fixed dimension [73]. It would be interesting to know whether general multi-point evaluation can be reduced to the amortized case.
Consider the problem of computing the complex roots  of a square-free polynomial
of a square-free polynomial 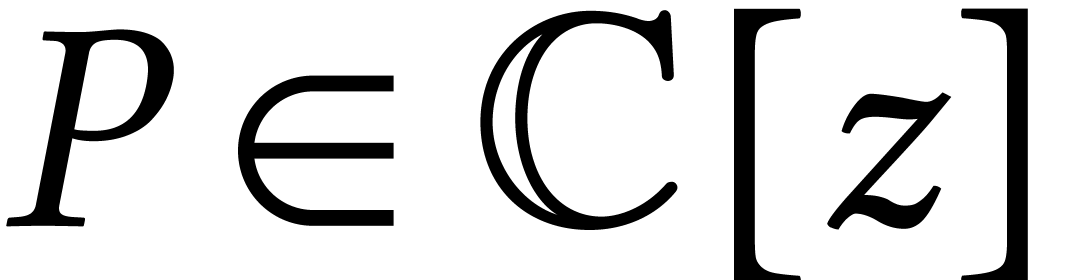 .
Obviously, this problem is equivalent to the problem to factor
.
Obviously, this problem is equivalent to the problem to factor 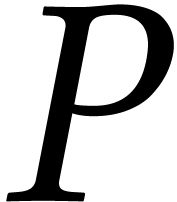 over .
over .
If we have good approximations of the roots, then we may use Newton's
method to double the precision of these approximations. Provided that
our bit-precision is sufficiently large, this
can be done for all roots together using multi-point evaluation, in
softly optimal time 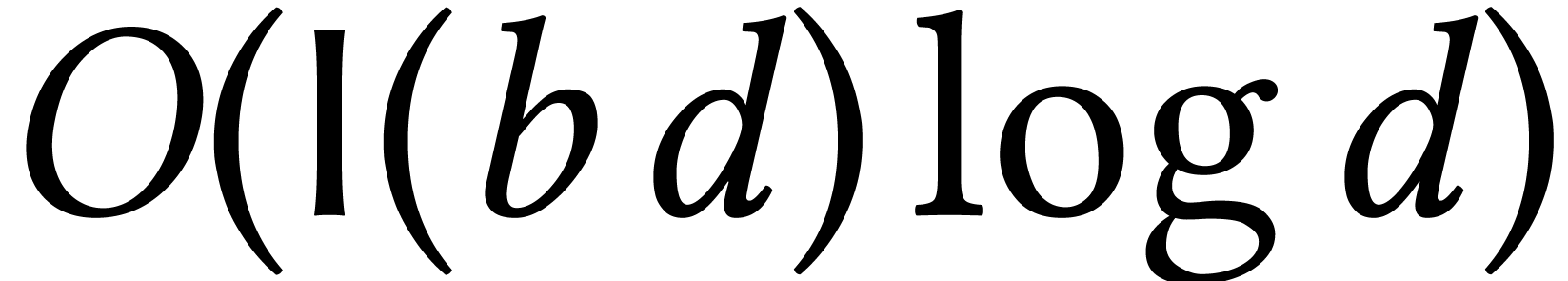 . Our
problem thus contains two main difficulties: how to find good initial
approximations and what to do for small bit-precisions?
. Our
problem thus contains two main difficulties: how to find good initial
approximations and what to do for small bit-precisions?
Based on earlier work by Schönhage [112], the root
finding problem for large precisions was solved in a softly optimal way
by Pan [100]. Assuming that 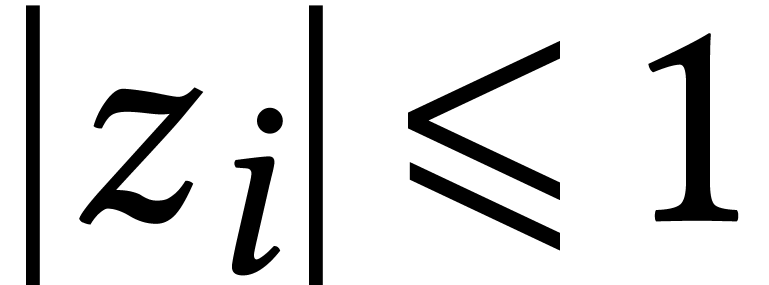 for all
for all
 , he essentially showed that
can be factored with
bits of precision in time
, he essentially showed that
can be factored with
bits of precision in time 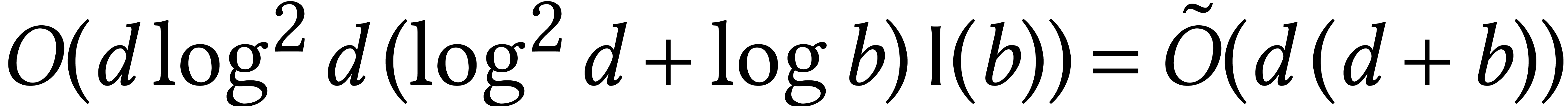 .
In particular, the soft optimality occurs as soon as
.
In particular, the soft optimality occurs as soon as 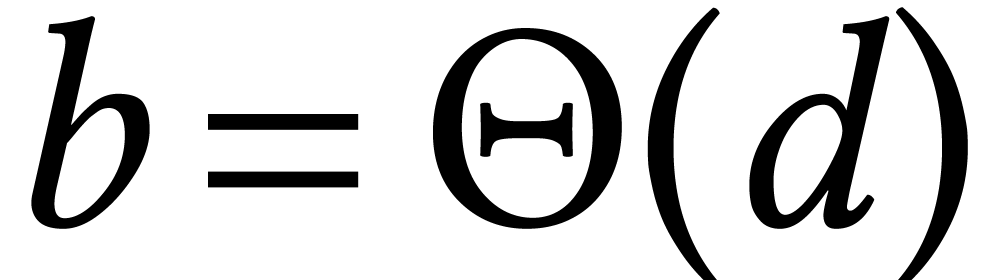 .
.
The remaining case when 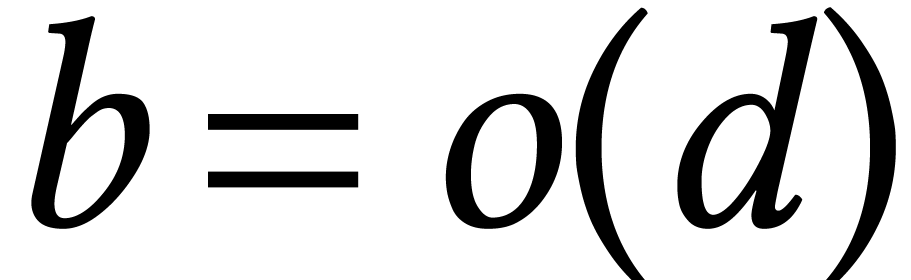 was solved recently by
Moroz [95]. He shows how to isolate the roots of in time
was solved recently by
Moroz [95]. He shows how to isolate the roots of in time 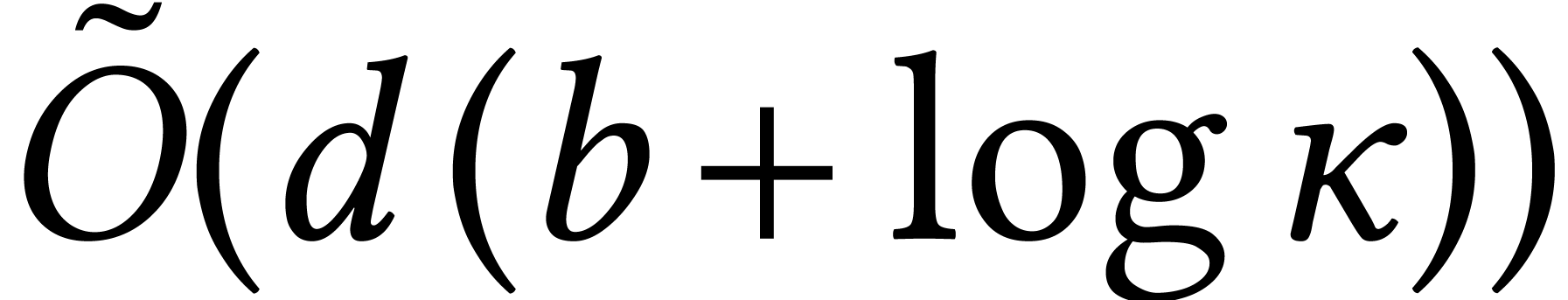 , where
is a suitable condition number. A crucial
ingredient of his algorithm is fast multi-point evaluation for small
. Moroz shows that this can
be done in time
, where
is a suitable condition number. A crucial
ingredient of his algorithm is fast multi-point evaluation for small
. Moroz shows that this can
be done in time 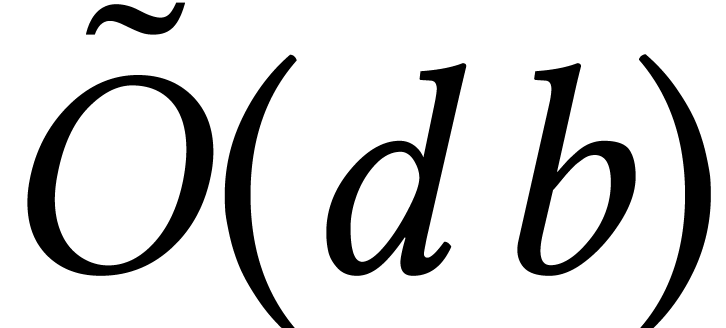 , by
improving drastically on ideas from [56, Section 3.2]. A
refined analysis shows that his algorithm can be made to run in time
, by
improving drastically on ideas from [56, Section 3.2]. A
refined analysis shows that his algorithm can be made to run in time
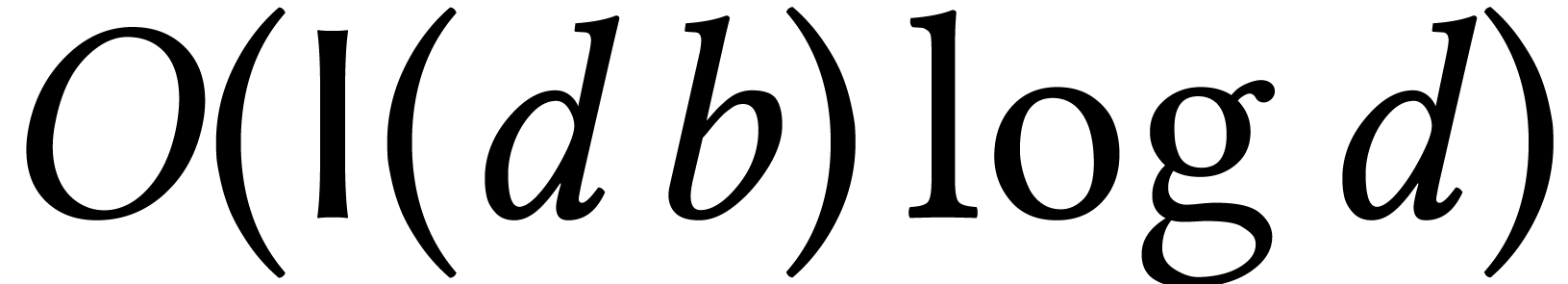 when
when 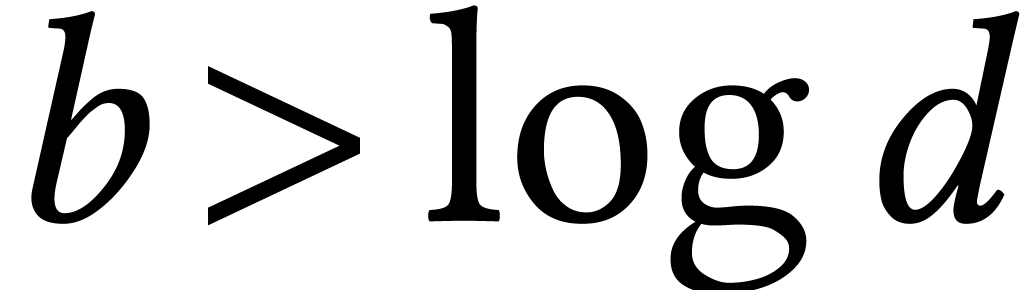 .
.
For polynomials  , one may
also ask for an algorithm to factor over
, one may
also ask for an algorithm to factor over  instead of approximating its roots in . The famous LLL-algorithm provided the first
polynomial-time algorithm for this task [89]. A practically
more efficient method was proposed in [50]. For subsequent
improvements on the complexity of lattice reduction and its application
to factoring, see [51, 98].
instead of approximating its roots in . The famous LLL-algorithm provided the first
polynomial-time algorithm for this task [89]. A practically
more efficient method was proposed in [50]. For subsequent
improvements on the complexity of lattice reduction and its application
to factoring, see [51, 98].
When has coefficients in the finite field with 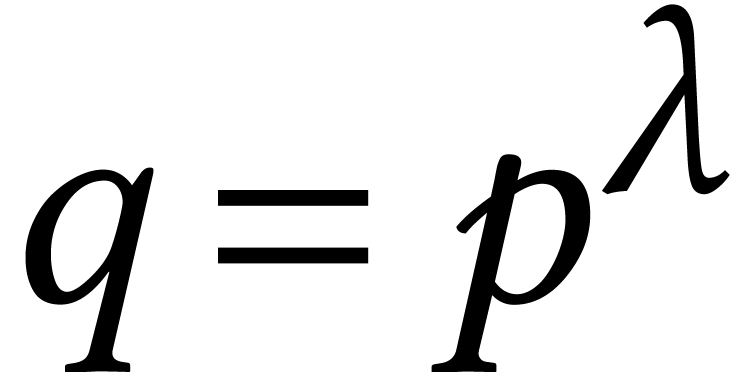 and
prime, the best current general purpose factorization algorithm is
(Las-Vegas) probabilistic and due to Cantor–Zassenhaus [20];
it has (expected) complexity
and
prime, the best current general purpose factorization algorithm is
(Las-Vegas) probabilistic and due to Cantor–Zassenhaus [20];
it has (expected) complexity 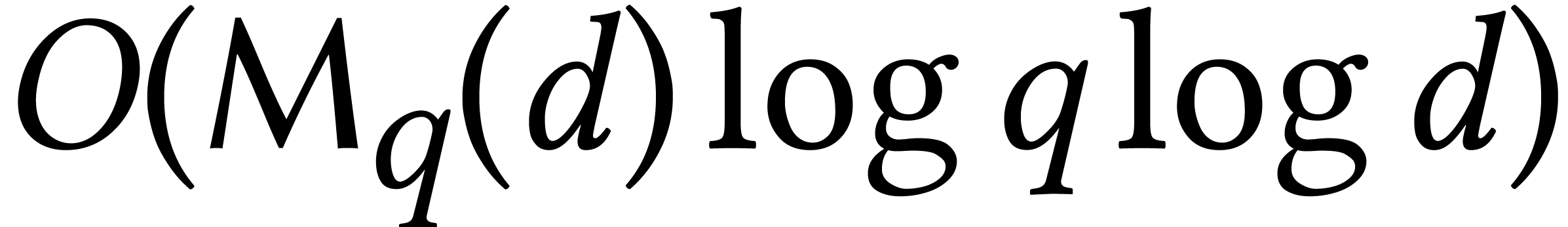 ,
where
,
where 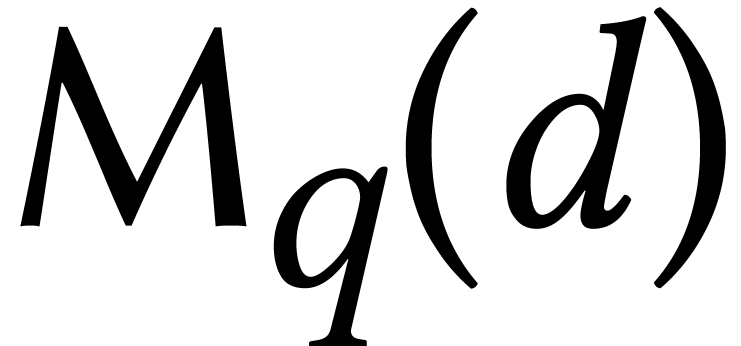 stands for the cost of multiplying two
polynomials of degree over
(assuming a plausible number-theoretic conjecture, we have
stands for the cost of multiplying two
polynomials of degree over
(assuming a plausible number-theoretic conjecture, we have 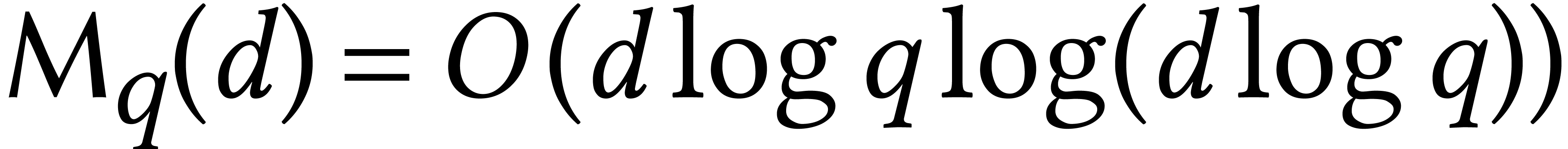 ). Note that the bit-complexity of the
Cantor–Zassenhaus algorithm is quadratic in
). Note that the bit-complexity of the
Cantor–Zassenhaus algorithm is quadratic in 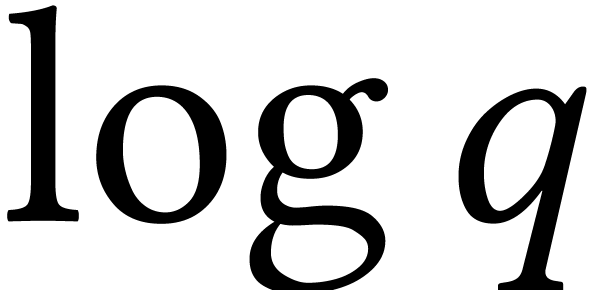 . If splits over , then the Tangent-Graeffe
algorithm is often more efficient [40, 78]. In
particular, if
. If splits over , then the Tangent-Graeffe
algorithm is often more efficient [40, 78]. In
particular, if 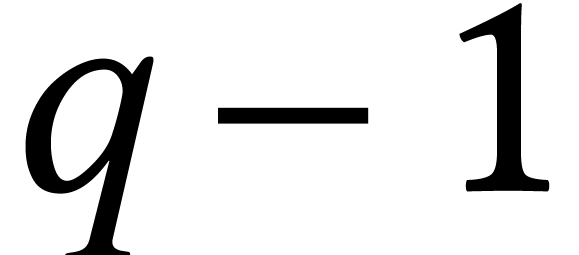 is smooth, then the complexity
drops to
is smooth, then the complexity
drops to 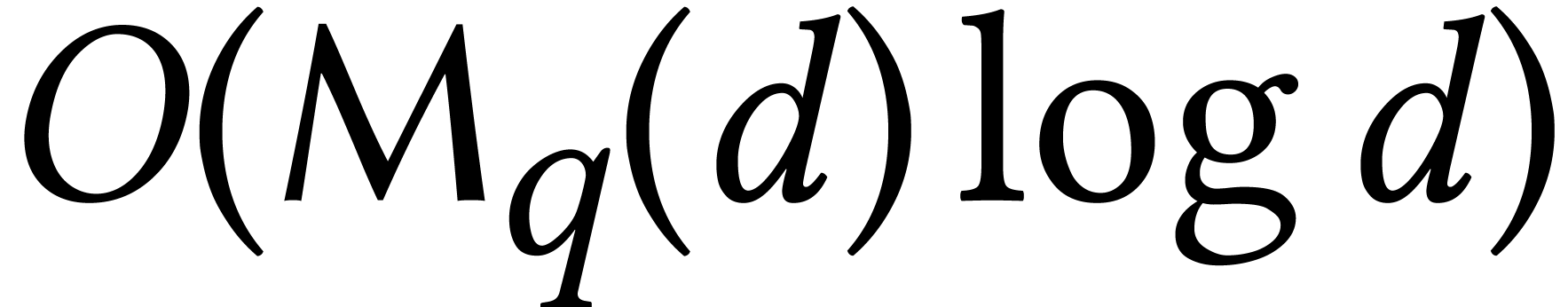 .
.
If is large, then factorization over can be reduced efficiently to modular composition [82]. This yields the bound 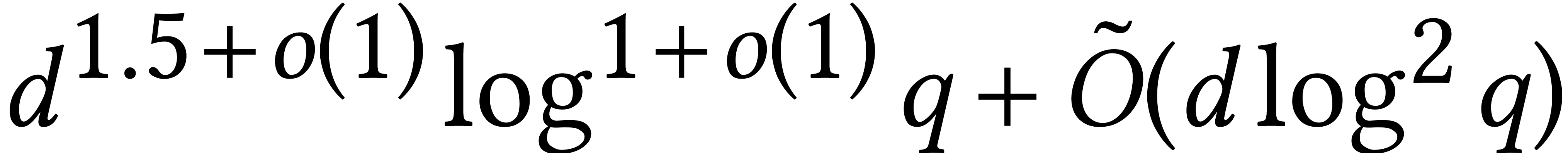 when using
Kedlaya–Umans' algorithm for modular composition. If is composite, then [67] describes faster
algorithms for modular composition. If is smooth
and is bounded, then factorization can even be
done in softly optimal time
when using
Kedlaya–Umans' algorithm for modular composition. If is composite, then [67] describes faster
algorithms for modular composition. If is smooth
and is bounded, then factorization can even be
done in softly optimal time 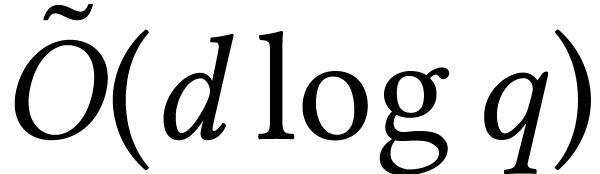 [76].
[76].
Macaulay matrices are a classical tool to reduce the resolution of
generic polynomial systems to linear algebra. For
affine equations of degree ,
the complexity of this method is 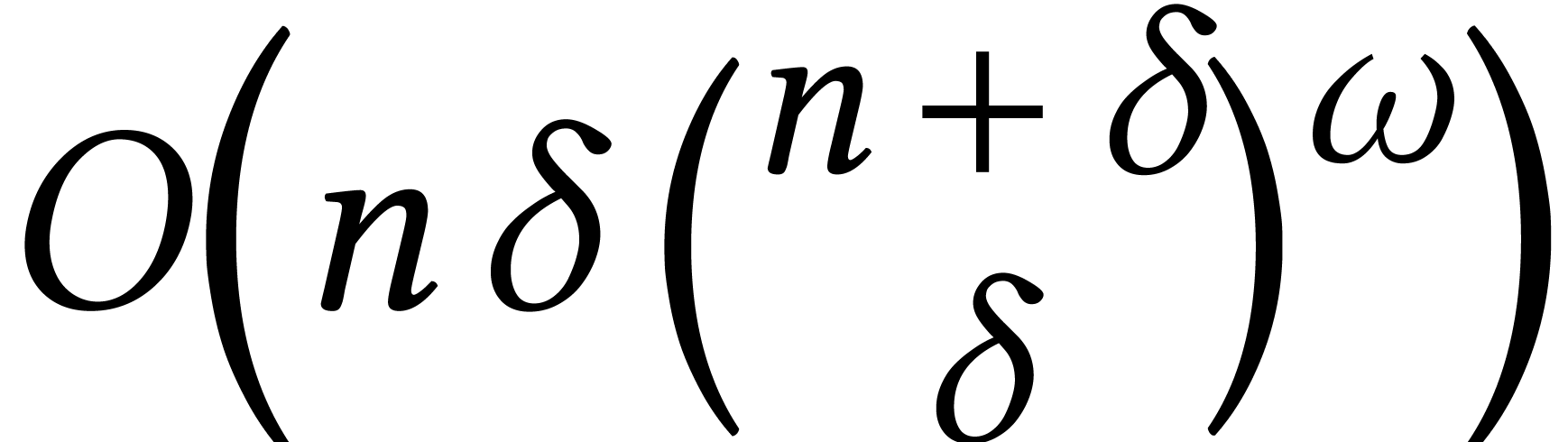 ,
where
,
where 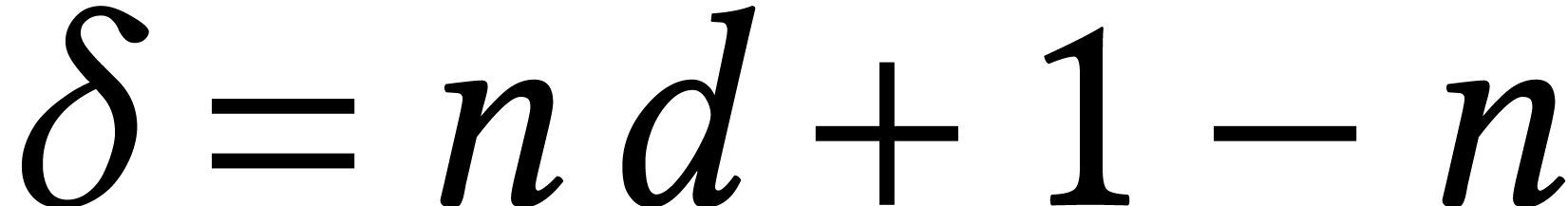 [10, Théorème
26.15]. For a fixed dimension ,
this bound becomes
[10, Théorème
26.15]. For a fixed dimension ,
this bound becomes 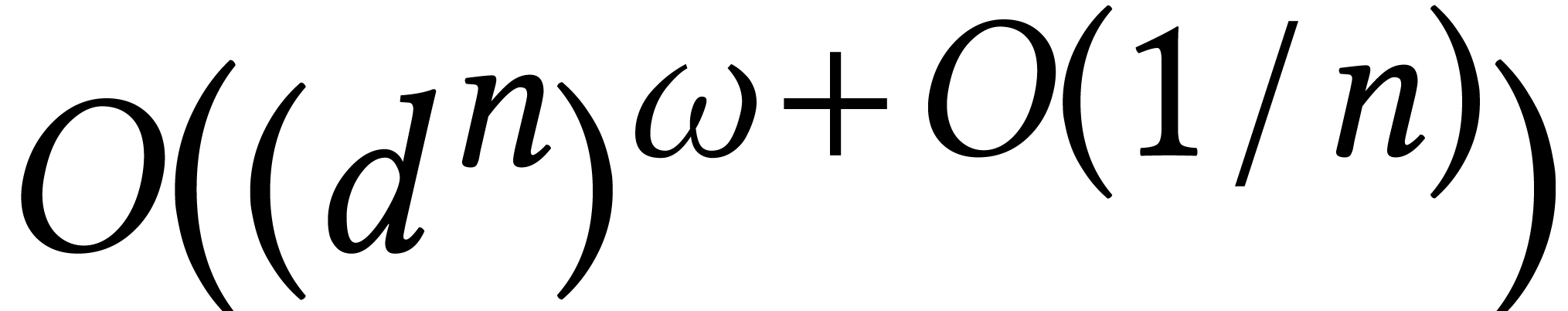 . Many
modern Gröbner basis implementations essentially use this method,
while avoiding the computation of rows (or columns) that can be
predicted to vanish. In particular, Faugère's F5 algorithm [30] can be formulated in this way [2] and runs in
time
. Many
modern Gröbner basis implementations essentially use this method,
while avoiding the computation of rows (or columns) that can be
predicted to vanish. In particular, Faugère's F5 algorithm [30] can be formulated in this way [2] and runs in
time 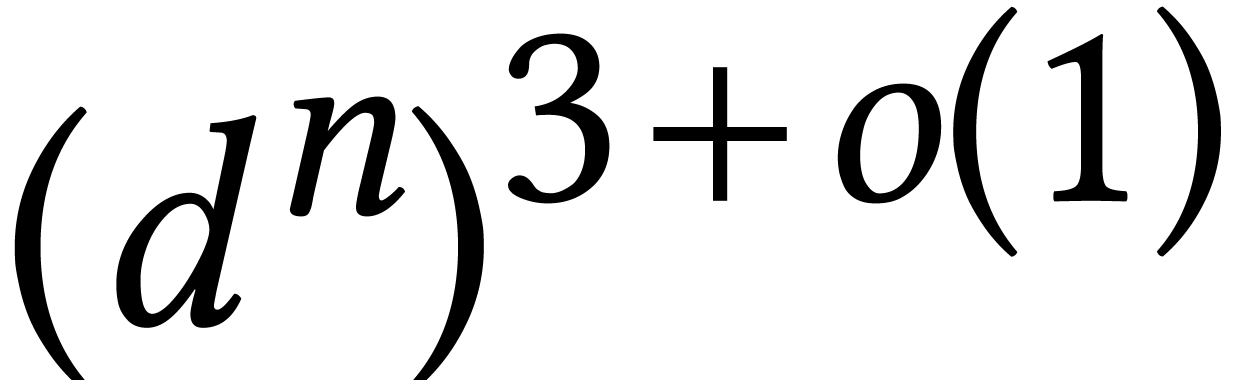 , uniformly in and . For a
generic system of equations of degree , it follows that we can compute a
Gröbner basis with quasi-cubic complexity in terms of the number
, uniformly in and . For a
generic system of equations of degree , it follows that we can compute a
Gröbner basis with quasi-cubic complexity in terms of the number
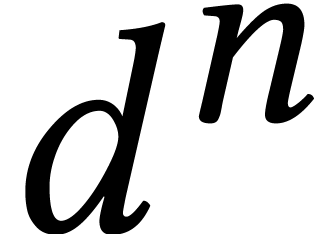 of solutions.
of solutions.
Practical Gröbner basis computations are most efficient with
respect to graded monomial orderings. But solutions of the system are
more convenient to read from Gröbner bases with respect to
lexicographical orderings. Changes of orderings for zero-dimensional
systems can be performed efficiently using the FGLM algorithm [28].
For a generic system, the complexity of a recent optimization of this
method is 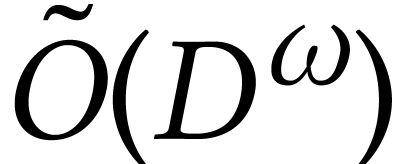 , where
, where 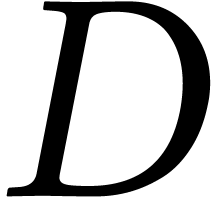 is the number of solutions [31].
is the number of solutions [31].
But is the computation of a Gröbner basis intrinsically a linear
algebra problem? After all, gcds of univariate polynomials can be
computed in softly optimal time. It turns out that better algorithms
also exist in the bivariate case. One subtlety is that the standard
representation of a Gröbner basis for a generic system with 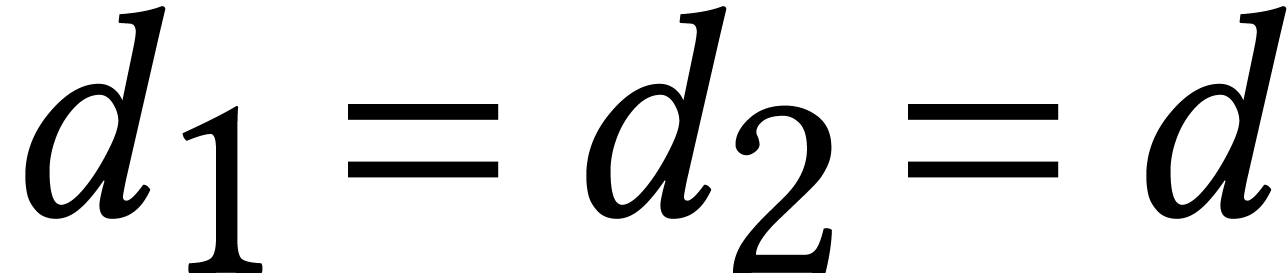 already requires
already requires 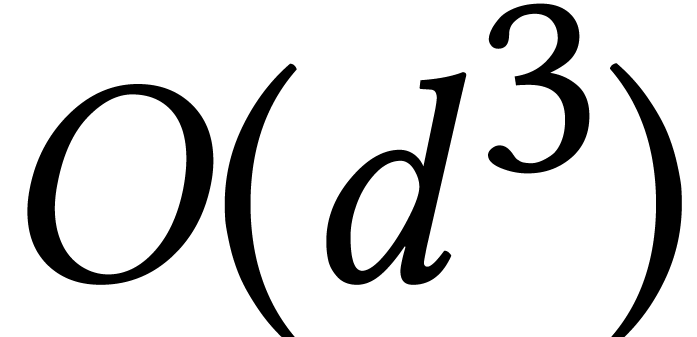 space with
respect to a graded monomial ordering. In [65], it was
shown that generic bivariate Gröbner bases can be computed in
softly optimal time
space with
respect to a graded monomial ordering. In [65], it was
shown that generic bivariate Gröbner bases can be computed in
softly optimal time 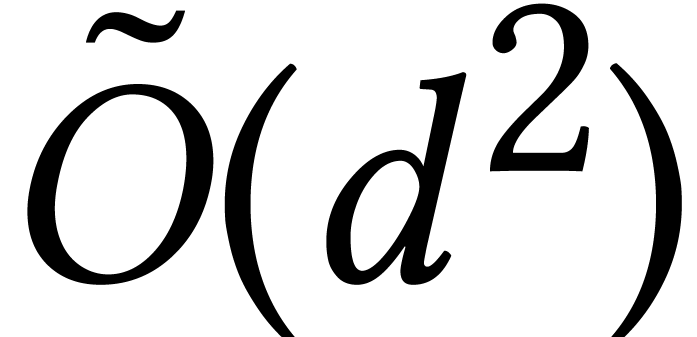 when using a suitable, more
compact representation.
when using a suitable, more
compact representation.
Some softly optimal techniques also exist also for higher dimensions, such as fast relaxed reduction [60] and heterogeneous Gröbner bases [73]. It is unclear whether these techniques can be used to break the linear algebra barrier.
Remark. Let 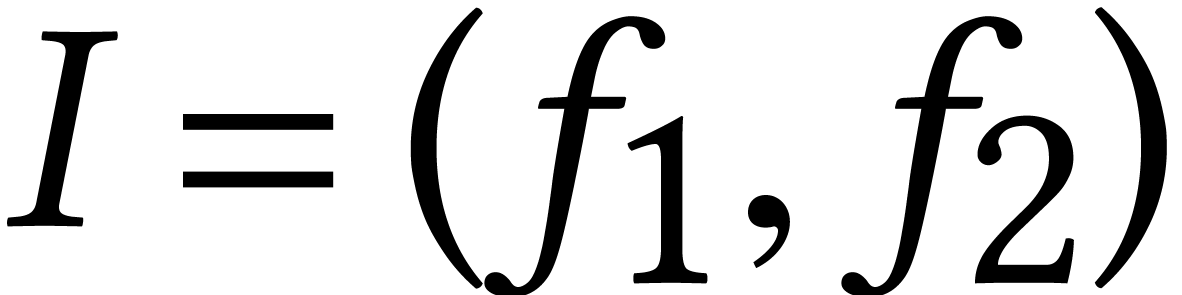 be the ideal generated by two
generic bivariate polynomials of degree
be the ideal generated by two
generic bivariate polynomials of degree 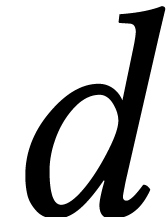 .
The fast algorithm from [65] for computing a Gröbner
basis of
.
The fast algorithm from [65] for computing a Gröbner
basis of 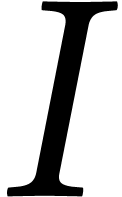 also allows the resultant of
also allows the resultant of 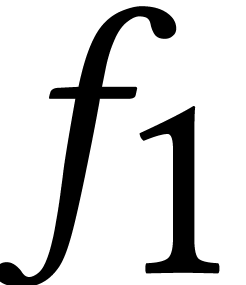 and
and 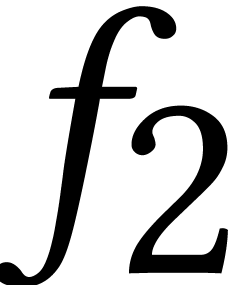 to be computed faster. Until
recently, complexity bounds for this task were softly cubic
to be computed faster. Until
recently, complexity bounds for this task were softly cubic 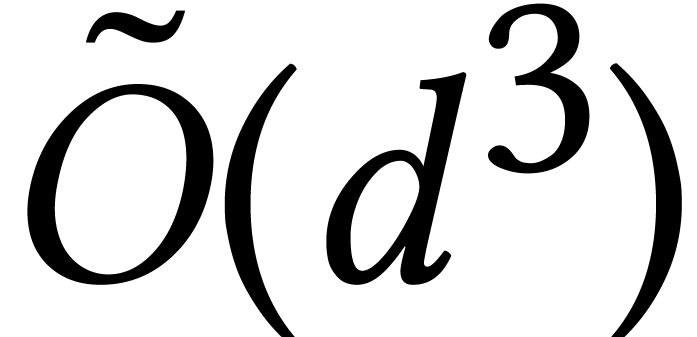 . Over fields with finite characteristic, the
complexity drops to
. Over fields with finite characteristic, the
complexity drops to 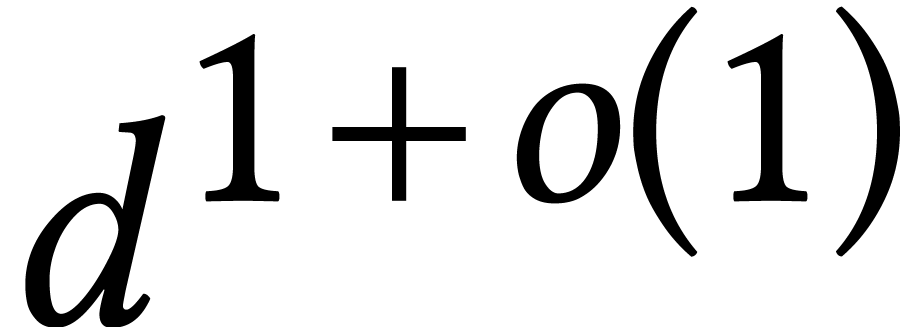 , using
fast bivariate multi-point evaluation [84]. For general
coefficient fields, Villard [118] recently gave an
algebraic algorithm for a slightly different problem that runs in time
, using
fast bivariate multi-point evaluation [84]. For general
coefficient fields, Villard [118] recently gave an
algebraic algorithm for a slightly different problem that runs in time
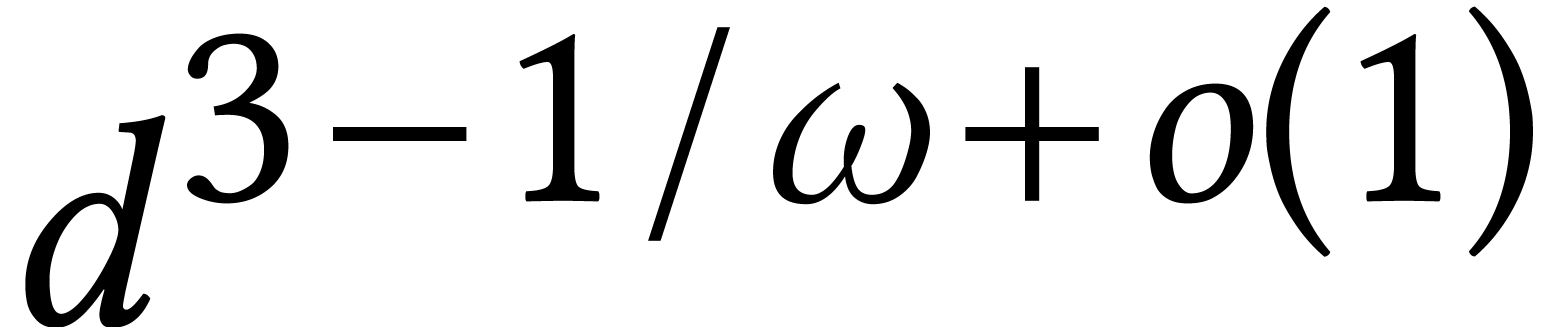 .
.
When  , another popular method
to solve polynomial systems is to use numeric homotopies [3].
Given generic equations
, another popular method
to solve polynomial systems is to use numeric homotopies [3].
Given generic equations  of degree , the idea is to
find equations
of degree , the idea is to
find equations  of the same degrees that can be
solved easily and then to continuously deform the easy equations in the
target equations while following the solutions. For instance, one may
take
of the same degrees that can be
solved easily and then to continuously deform the easy equations in the
target equations while following the solutions. For instance, one may
take 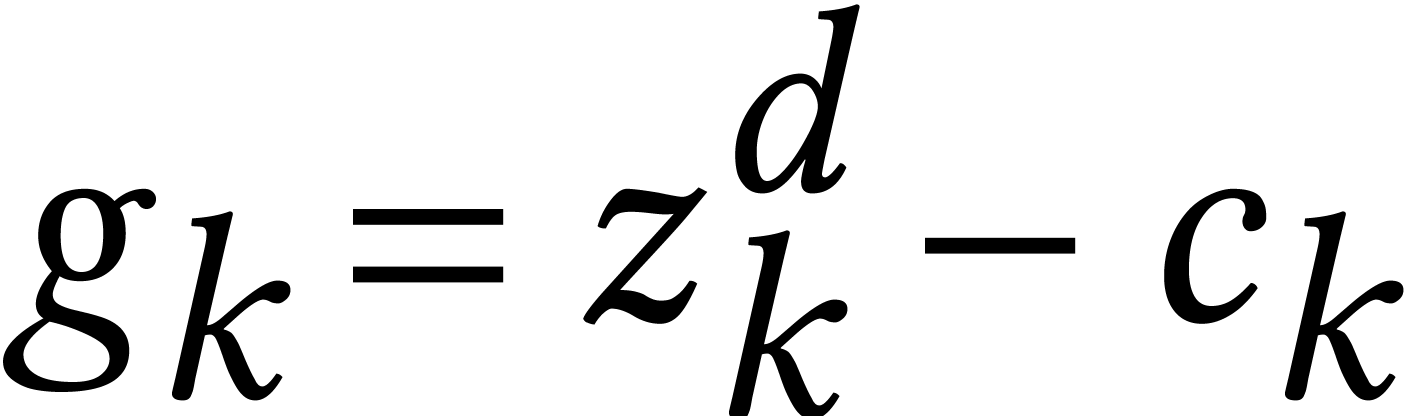 and
and 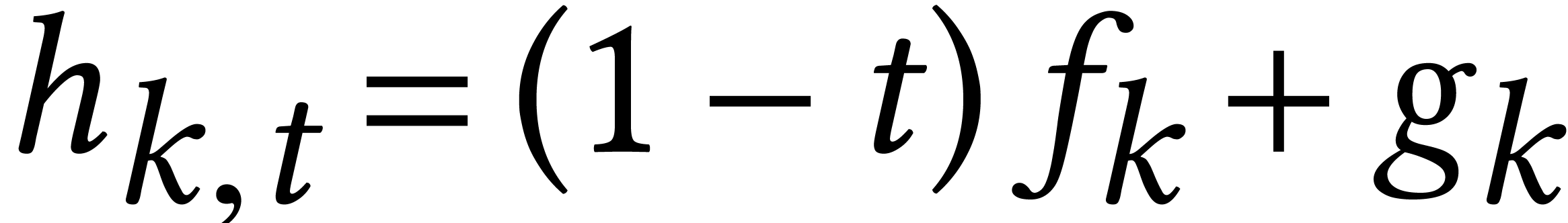 for random
constants
for random
constants  and follow the solutions of
and follow the solutions of  from
from 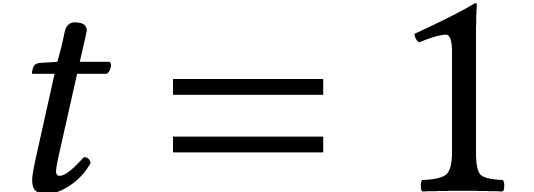 until
until 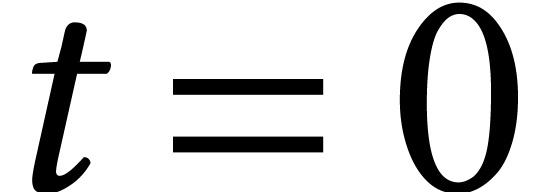 .
.
The theoretical complexity of such methods has extensively been studied
in the BSS model [9], in which arithmetic operations on
real numbers with arbitrary precision can be done with unit cost. This
model is suitable for well conditioned problems from classical numerical
analysis, when all computations can be done using machine precision.
This holds in particular for random polynomial systems. It has been
shown in [4] that one solution path can then be followed in
expected average time 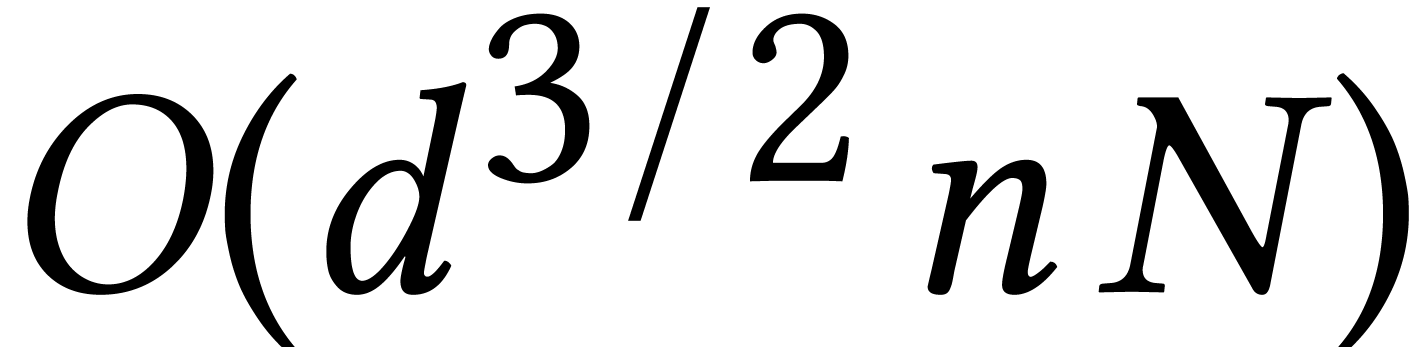 , where
, where
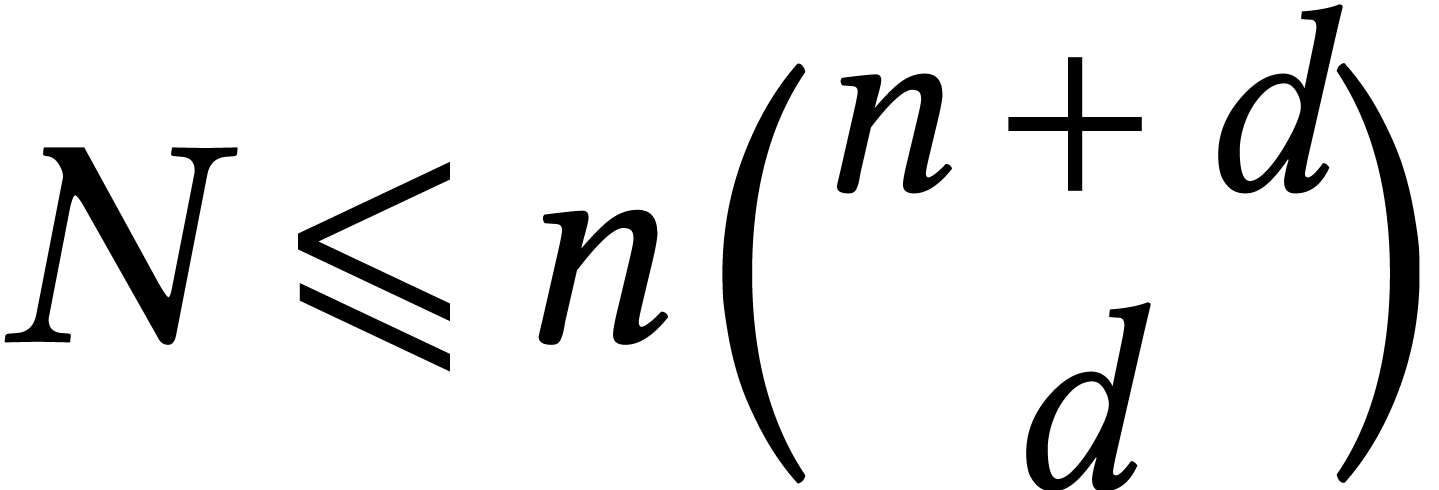 is the number of coefficients of for the dense encoding. This bound has been lowered to
is the number of coefficients of for the dense encoding. This bound has been lowered to
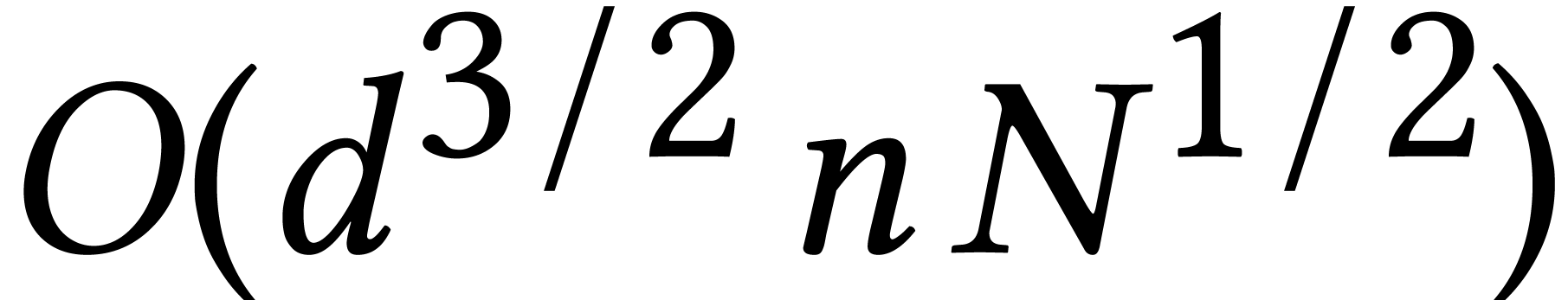 in [1]. A theoretical deterministic
algorithm that runs in average polynomial time was given in [85].
in [1]. A theoretical deterministic
algorithm that runs in average polynomial time was given in [85].
In practice, the observed number of homotopy steps seems to grow fairly
slowly with and for
random systems (a few hundred steps typically suffice), so the above
bounds are pessimistic. However, we are interested in the computation of
all solutions. When assuming that the average
number of steps remains bounded, this gives rise to a complexity 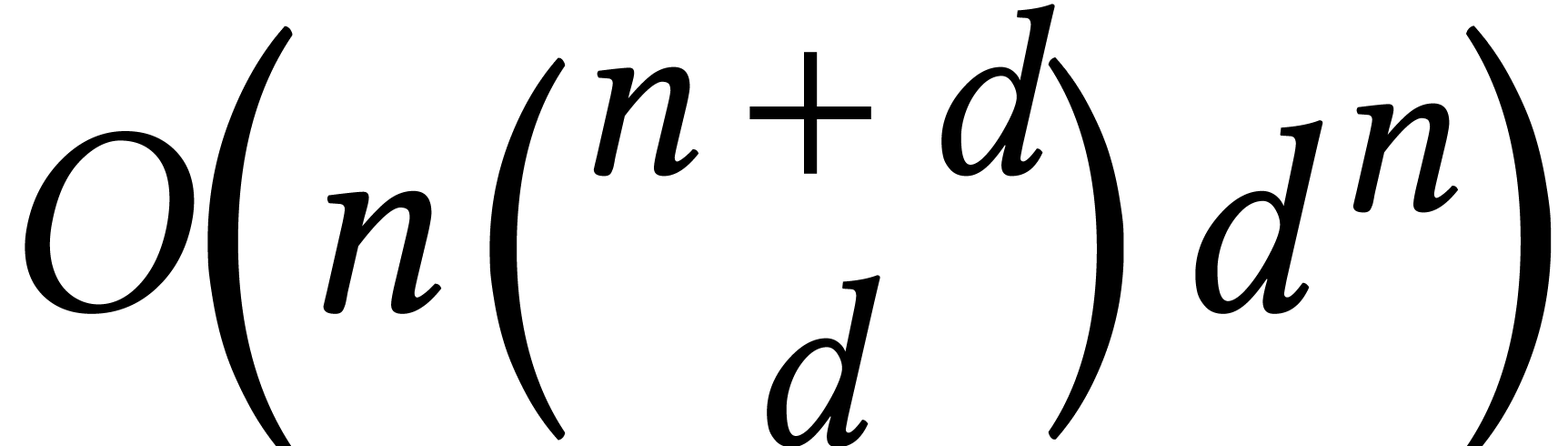 . If we also take into account the
required bit precision , then
the bit complexity becomes
. If we also take into account the
required bit precision , then
the bit complexity becomes 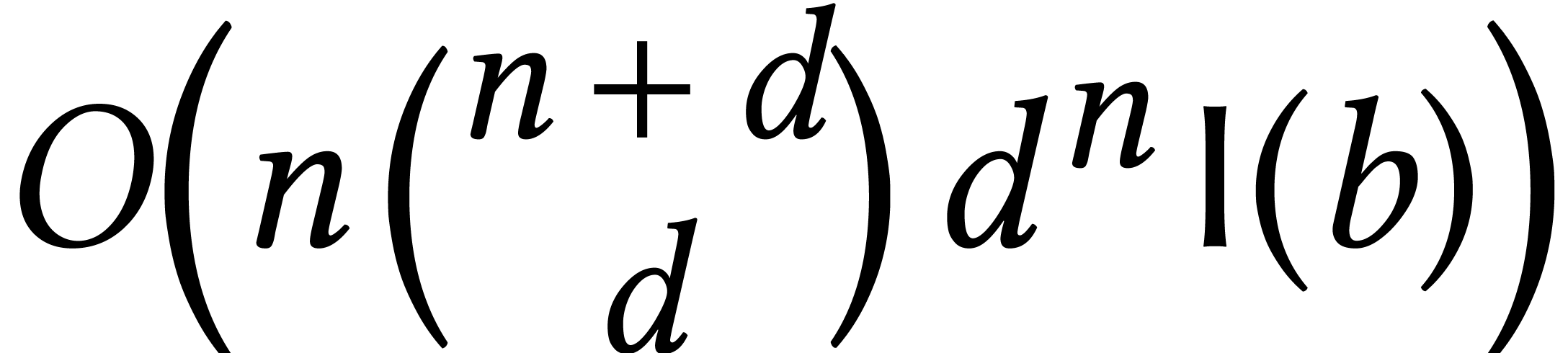 .
Fortunately, the bulk of the computation can usually be done with fixed
precision and we may directly use Newton's method to repeatedly double
the precision at the end . If
we were able to develop a softly optimal algorithm for numeric
multivariate multi-point evaluation, then the complexity would be
.
Fortunately, the bulk of the computation can usually be done with fixed
precision and we may directly use Newton's method to repeatedly double
the precision at the end . If
we were able to develop a softly optimal algorithm for numeric
multivariate multi-point evaluation, then the complexity would be 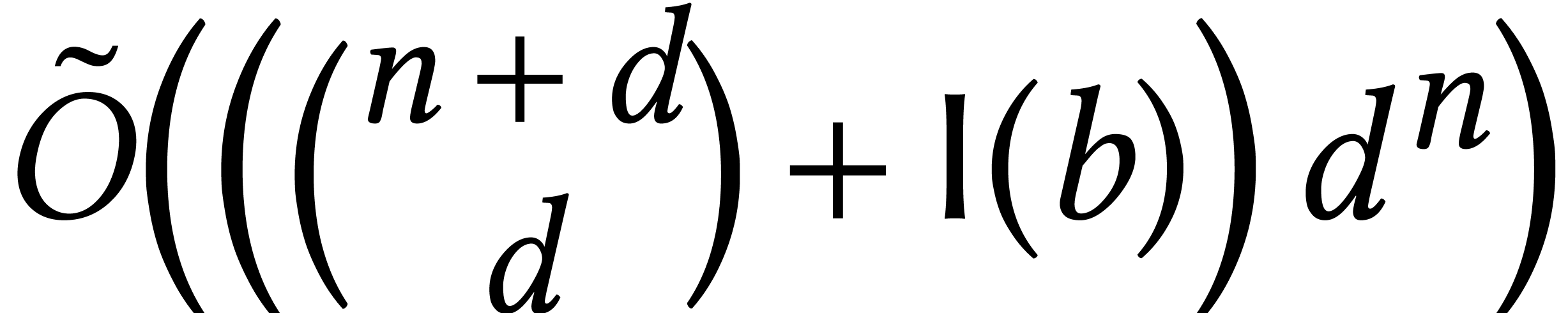 .
.
Numeric homotopies perform particularly well for random systems, which behave essentially like generic ones. However, the existing software is less robust than algebraic solvers for degenerate systems, especially in presence of solutions with high multiplicities. It remains a practical challenge to develop more robust homotopy solvers for general systems and a theoretical challenge to understand the complexity of this problem.
The technique of geometric resolution was developed in [38, 37] and further perfected in [87,
27]. It works over arbitrary fields
and polynomials that are given by a DAG of size . For simplicity, we assume that our system is
generic. After a random linear change of variables, the idea is to
successively solve the systems
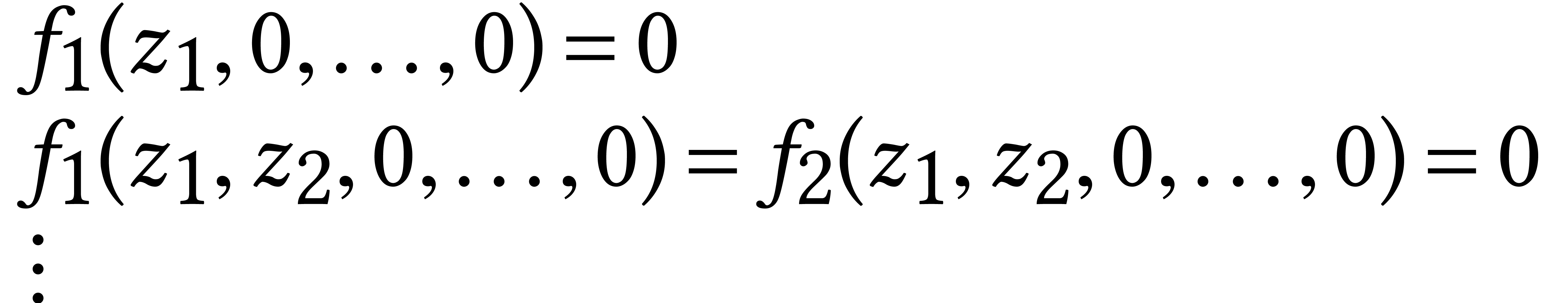
in the form 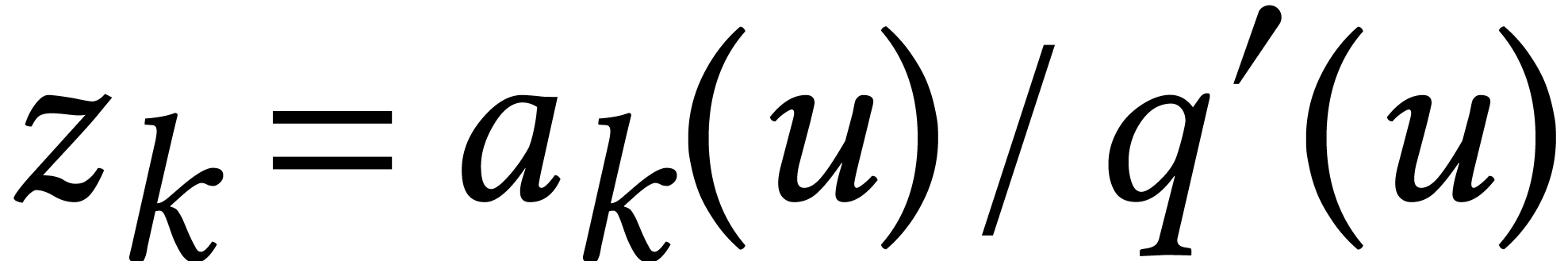 , where
, where  is a formal parameter that satisfies
is a formal parameter that satisfies 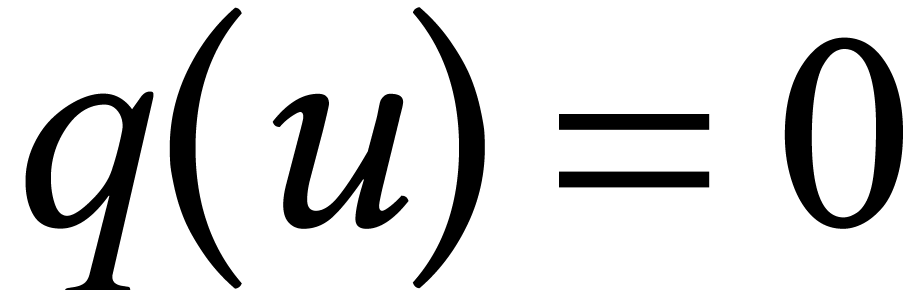 for
for  . This representation of
solutions is called the Kronecker representation. It is also a
rational univariate representation [109] with a
special type of denominator.
. This representation of
solutions is called the Kronecker representation. It is also a
rational univariate representation [109] with a
special type of denominator.
Let us focus on the last step which dominates the cost. The solutions
of the system
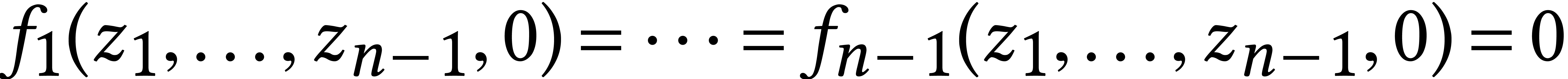
are first lifted into solutions 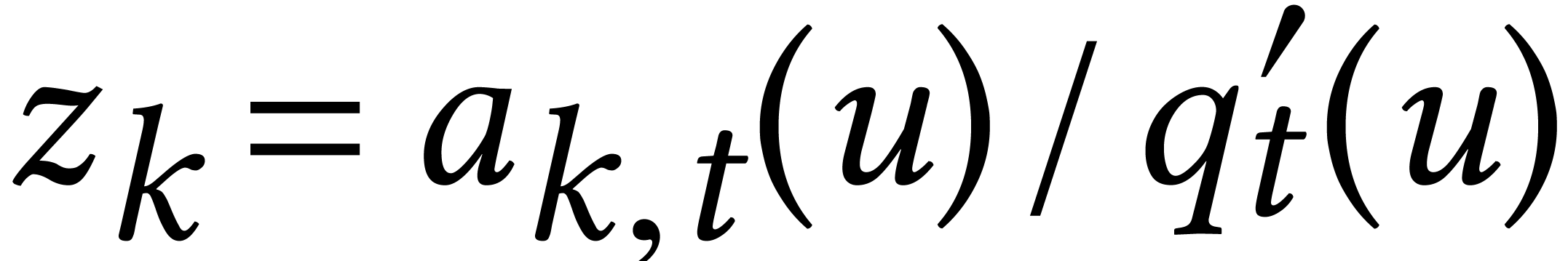 of the system
of the system
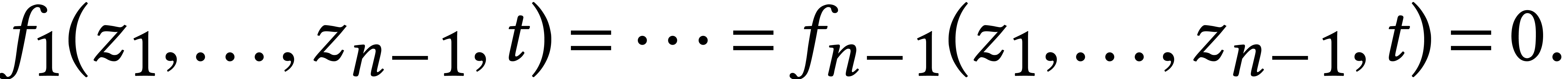
We next intersect with the hypersurface 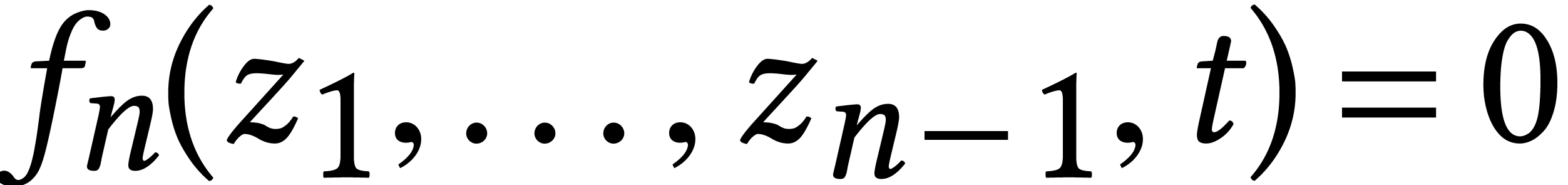 .
It turns out that it suffices to work with power series in
.
It turns out that it suffices to work with power series in 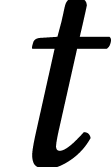 modulo
modulo 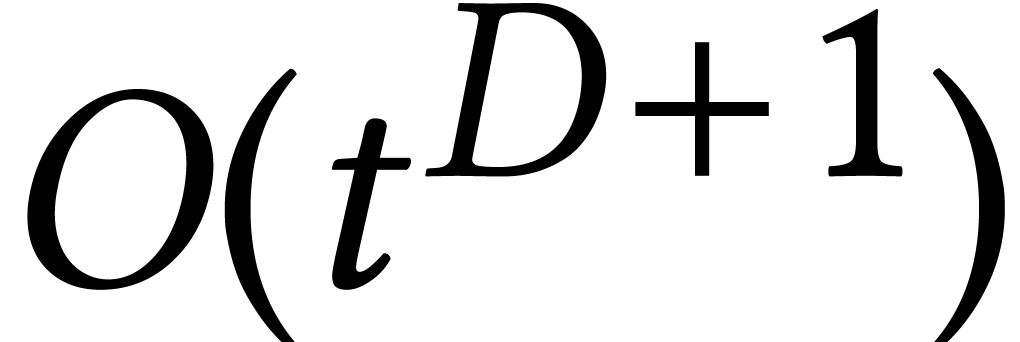 . Then
the intersection step gives rise to the computation of a large
resultant, which can be done in time
. Then
the intersection step gives rise to the computation of a large
resultant, which can be done in time 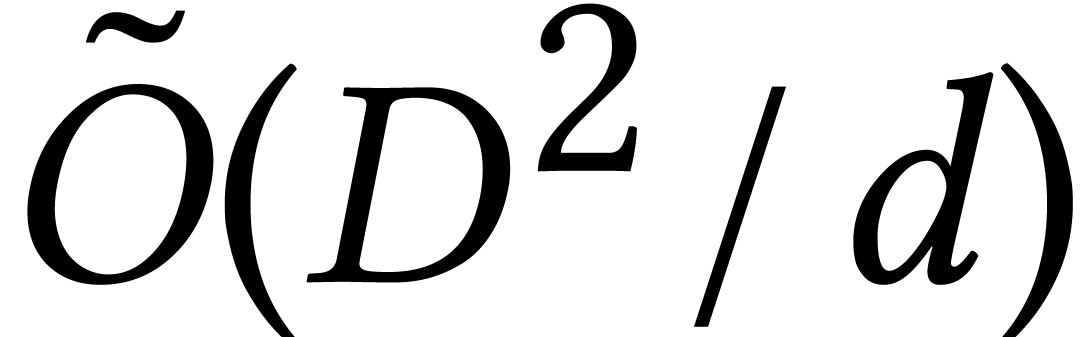 .
Altogether it is shown in [87] that the algorithm requires
.
Altogether it is shown in [87] that the algorithm requires
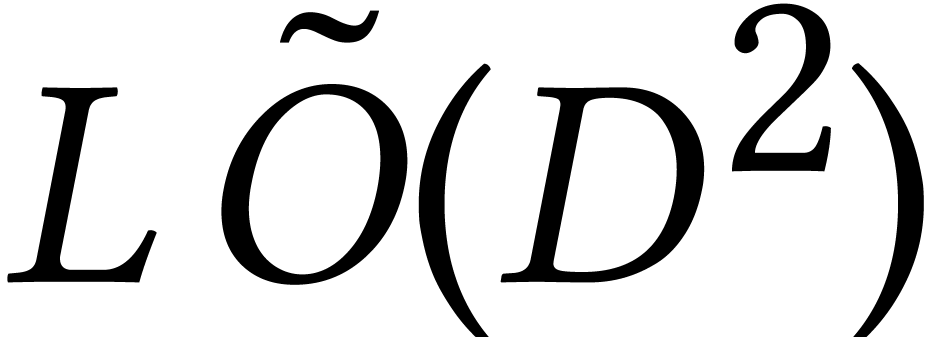 expected operations in .
expected operations in .
Now 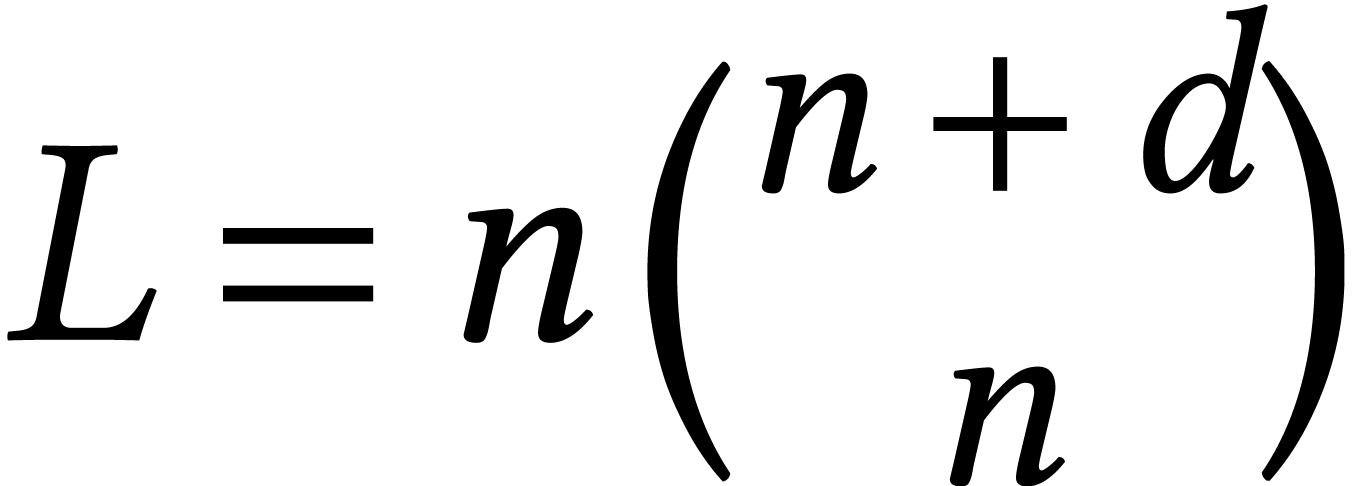 for a dense system of
equations of degree . For
large and fixed ,
we observe that
for a dense system of
equations of degree . For
large and fixed ,
we observe that 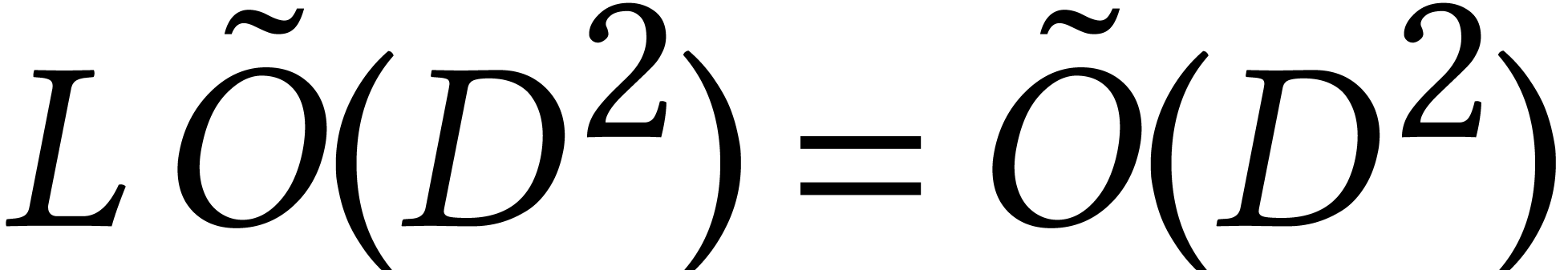 . However,
for fixed and large , the bound
. However,
for fixed and large , the bound 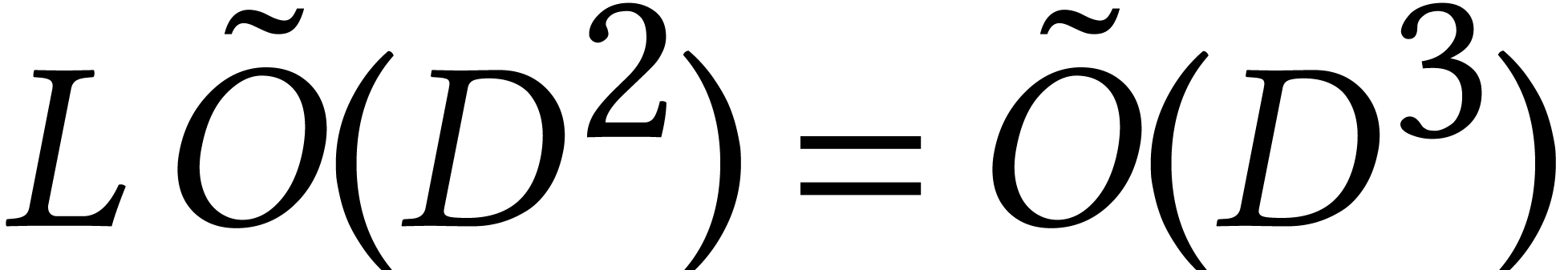 is only softly
cubic. Using variants of Kedlaya–Umans' algorithms for fast
multi-point evaluation, the cost of the polynomial evaluations can be
amortized, which leads to a quasi-quadratic bound
is only softly
cubic. Using variants of Kedlaya–Umans' algorithms for fast
multi-point evaluation, the cost of the polynomial evaluations can be
amortized, which leads to a quasi-quadratic bound 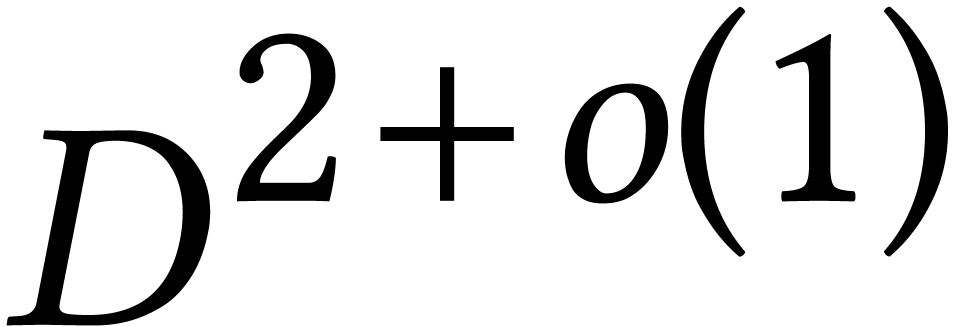 over finite fields [75]. When working over rational
numbers, the bit precision generically grows with
as well and the output is of size
over finite fields [75]. When working over rational
numbers, the bit precision generically grows with
as well and the output is of size 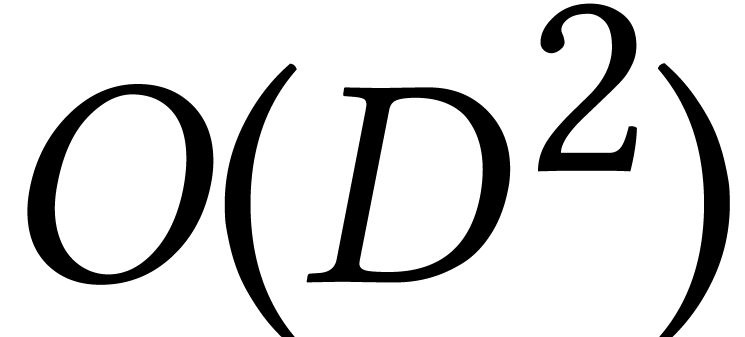 ;
in this case, the complexity bound actually becomes quasi-optimal [75, Theorem 6.11].
;
in this case, the complexity bound actually becomes quasi-optimal [75, Theorem 6.11].
Can a complexity-driven approach help us to solve polynomial systems faster? In the above sections, we have seen that such an approach naturally leads to other questions:
What is the complexity of multivariate multi-point evaluation?
How can we take advantage of fast polynomial arithmetic?
How does bit complexity rhyme with numerical conditioning and clusters of solutions?
These questions are interesting for their own sake and they have indeed triggered at least some of the recent progress.
Acknowledgments. I wish to thank Amir Hashemi and Fatima Abu Salem for their careful reading and suggestions.
D. Armentano, C. Beltrán, P. Bürgisser, F. Cucker, and M. Shub. Condition length and complexity for the solution of polynomial systems. J. FOCM, 16:1401–1422, 2016.
M. Bardet, J.-C. Faugère, and B. Salvy. On the complexity of the F5 Gröbner basis algorithm. JSC, 70:49–70, 2015.
D. J. Bates, J. D. Hauenstein, A. J. Sommese, and C. W. Wampler. Numerically Solving Polynomial Systems with Bertini. SIAM, 2013.
C. Beltrán and L. M. Pardo. Fast linear homotopy to find approximate zeros of polynomial systems. Found. Comput. Math., 11:95–129, 2011.
M. Ben-Or and P. Tiwari. A deterministic algorithm for sparse multivariate polynomial interpolation. In Proc. ACM STOC '88, pages 301–309. New York, NY, USA, 1988.
A. Benoit, A. Bostan, and J. van der Hoeven. Quasi-optimal multiplication of linear differential operators. In Proc. FOCS '12, pages 524–530. New Brunswick, October 2012. IEEE.
D. J. Bernstein. Removing redundancy in high precision Newton iteration. Available from http://cr.yp.to/fastnewton.html, 2000.
D. J. Bernstein. Fast multiplication and its applications, pages 325–384. Mathematical Sciences Research Institute Publications. Cambridge University Press, United Kingdom, 2008.
L. Blum, F. Cucker, M. Shub, and S. Smale. Complexity and real computation. Springer-Verlag, 1998.
A. Bostan, F. Chyzak, M. Giusti, G. Lecerf, B. Salvy, and É. Schost. Algorithmes efficaces en calcul formel. Auto-édition, 2017.
A. Bostan, G. Lecerf, and É. Schost. Tellegen's principle into practice. In Proc. ISSAC '03, pages 37–44. Philadelphia, USA, August 2003.
A. Bostan and É. Schost. Polynomial evaluation and interpolation on special sets of points. J. of Complexity, 21(4):420–446, August 2005. Festschrift for the 70th Birthday of Arnold Schönhage.
R. P. Brent. Fast multiple-precision evaluation of elementary functions. Journal of the ACM, 23(2):242–251, 1976.
R. P. Brent and H. T. Kung. Fast algorithms for manipulating formal power series. Journal of the ACM, 25:581–595, 1978.
R. P. Brent and P. Zimmermann. Modern Computer Arithmetic. Cambridge University Press, 2010.
B. Buchberger. Ein Algorithmus zum auffinden der Basiselemente des Restklassenringes nach einem null-dimensionalen Polynomideal. PhD thesis, University of Innsbruck, 1965.
P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic complexity theory. Springer-Verlag, Berlin, 1997.
J. Canny, E. Kaltofen, and Y. Lakshman. Solving systems of non-linear polynomial equations faster. In Proc. ISSAC '89, pages 121–128. Portland, Oregon, July 1989.
D. G. Cantor and E. Kaltofen. On fast multiplication of polynomials over arbitrary algebras. Acta Informatica, 28:693–701, 1991.
D. G. Cantor and H. Zassenhaus. A new algorithm for factoring polynomials over finite fields. Math. Comp., 36(154):587–592, 1981.
D. V. Chudnovsky and G. V. Chudnovsky. Algebraic complexities and algebraic curves over finite fields. J. of Complexity, 4:285–316, 1988.
D. V. Chudnovsky and G. V. Chudnovsky. Computer algebra in the service of mathematical physics and number theory (Computers in mathematics, Stanford, CA, 1986). In Lect. Notes in Pure and Applied Math., volume 125, pages 109–232. New-York, 1990.
F. Chyzak, A. Goyer, and M. Mezzarobba. Symbolic-numeric factorization of differential operators. Technical Report https://hal.inria.fr/hal-03580658v1, HAL, 2022.
S. A. Cook. The complexity of theorem-proving procedures. In Proc. ACM STOC '71, pages 151–158. 1971.
J. W. Cooley and J. W. Tukey. An algorithm for the machine calculation of complex Fourier series. Math. Computat., 19:297–301, 1965.
J. Doliskani, P. Giorgi, R. Lebreton, and É. Schost. Simultaneous conversions with the Residue Number System using linear algebra. Transactions on Mathematical Software, 44(3), 2018. Article 27.
C. Durvye. Algorithmes pour la décomposition primaire des idéaux polynomiaux de dimension nulle donnés en évaluation. PhD thesis, Univ. de Versailles (France), 2008.
J. C. Faugère, P. Gianni, D. Lazard, and T. Mora. Efficient computation of zero-dimensional Gröbner bases by change of ordering. JSC, 16(4):329–344, 1993.
J.-C. Faugère. A new efficient algorithm for computing Gröbner bases (F4). Journal of Pure and Applied Algebra, 139(1–3):61–88, 1999.
J.-C. Faugère. A new efficient algorithm for computing Gröbner bases without reduction to zero (F5). In T. Mora, editor, Proc. ISSAC '02, pages 75–83. Lille, France, July 2002.
J.-C. Faugère, P. Gaudry, L. Huot, and G. Renault. Sub-cubic change of ordering for Gröbner basis: a probabilistic approach. In Proc. ISSAC '14, pages 170–177. Kobe, Japan, July 2014.
C. M. Fiduccia. Polynomial evaluation via the division algorithm: the fast Fourier transform revisited. In A. L. Rosenberg, editor, Proc. ACM STOC '72, pages 88–93. 1972.
M. Frigo, C. E. Leiserson, H. Prokop, and S. Ramachandran. Cache-oblivious algorithms. In Proc. FOCM '99, pages 285–297. 1999.
F. Le Gall. Powers of tensors and fast matrix multiplication. In Proc. ISSAC 2014, pages 296–303. Kobe, Japan, July 2014.
J. von zur Gathen and J. Gerhard. Modern Computer Algebra. Cambridge University Press, New York, NY, USA, 3rd edition, 2013.
M. Giesbrecht, Q.-L. Huang, and É Schost. Sparse multiplication of multivariate linear differential operators. In Proc. ISSAC '21, pages 155–162. New York, USA, 2021.
M. Giusti, K. Hägele, J. Heintz, J. E. Morais, J. L. Montaña, and L. M. Pardo. Lower bounds for diophantine approximation. Journal of Pure and Applied Algebra, 117–118:277–317, 1997.
M. Giusti, J. Heintz, J. E. Morais, and L. M. Pardo. When polynomial equation systems can be “solved” fast? In G. Cohen, M. Giusti, and T. Mora, editors, Proc. AAECC'11, volume 948 of Lecture Notes in Computer Science. Springer Verlag, 1995.
T. Granlund et al. GMP, the GNU multiple precision arithmetic library. http://www.swox.com/gmp, 1991.
B. Grenet, J. van der Hoeven, and G. Lecerf. Randomized root finding over finite fields using tangent Graeffe transforms. In Proc. ISSAC '15, pages 197–204. New York, NY, USA, 2015. ACM.
G. Hanrot, M. Quercia, and P. Zimmermann. The middle product algorithm I. speeding up the division and square root of power series. AAECC, 14:415–438, 2004.
G. Hanrot and P. Zimmermann. A long note on Mulders' short product. JSC, 37(3):391–401, 2004.
G. H. Hardy. Orders of infinity. Cambridge Univ. Press, 1910.
D. Harvey. Faster exponentials of power series. 2009. http://arxiv.org/abs/0911.3110.
D. Harvey. Faster algorithms for the square root and reciprocal of power series. Math. Comp., 80:387–394, 2011.
D. Harvey. Faster truncated integer multiplication. https://arxiv.org/abs/1703.00640, 2017.
D. Harvey and J. van der Hoeven. Faster polynomial multiplication over finite fields using cyclotomic coefficient rings. J. of Complexity, 54, 2019. Article ID 101404, 18 pages.
D. Harvey and J. van der Hoeven. Integer
multiplication in time  .
Annals of Mathematics, 193(2):563–617, 2021.
.
Annals of Mathematics, 193(2):563–617, 2021.
D. Harvey and J. van der Hoeven. Polynomial
multiplication over finite fields in time . JACM, 69(2), 2022. Article 12.
M. van Hoeij. Factoring polynomials and the knapsack problem. Journal of Number theory, 95(2):167–189, 2002.
M. van Hoeij and A. Novocin. Gradual sub-lattice reduction and a new complexity for factoring polynomials. In A. López-Ortiz, editor, LATIN 2010: Theoretical Informatics, pages 539–553. Berlin, Heidelberg, 2010. Springer Berlin Heidelberg.
J. van der Hoeven. Lazy multiplication of formal power series. In W. W. Küchlin, editor, Proc. ISSAC '97, pages 17–20. Maui, Hawaii, July 1997.
J. van der Hoeven. Fast evaluation of holonomic functions. TCS, 210:199–215, 1999.
J. van der Hoeven. Relax, but don't be too lazy. JSC, 34:479–542, 2002.
J. van der Hoeven. The truncated Fourier transform and applications. In Proc. ISSAC 2004, pages 290–296. Univ. of Cantabria, Santander, Spain, July 2004.
J. van der Hoeven. Fast composition of numeric power series. Technical Report 2008-09, Université Paris-Sud, Orsay, France, 2008.
J. van der Hoeven. Newton's method and FFT trading. JSC, 45(8):857–878, 2010.
J. van der Hoeven. Journées Nationales de Calcul Formel (2011), volume 2 of Les cours du CIRM, chapter Calcul analytique. CEDRAM, 2011. Exp. No. 4, 85 pages, http://ccirm.cedram.org/ccirm-bin/fitem?id=CCIRM_2011__2_1_A4_0.
J. van der Hoeven. Faster relaxed multiplication. In Proc. ISSAC '14, pages 405–412. Kobe, Japan, July 2014.
J. van der Hoeven. On the complexity of polynomial reduction. In Proc. Applications of Computer Algebra 2015, volume 198 of Springer Proceedings in Mathematics and Statistics, pages 447–458. Cham, 2015. Springer.
J. van der Hoeven. Faster Chinese remaindering. Technical Report, HAL, 2016. https://hal.archives-ouvertes.fr/hal-01403810.
J. van der Hoeven. On the complexity of skew arithmetic. AAECC, 27(2):105–122, 2016.
J. van der Hoeven. From implicit to recursive equations. AAECC, 30(3):243–262, 2018.
J. van der Hoeven. Probably faster multiplication of sparse polynomials. Technical Report, HAL, 2020. https://hal.archives-ouvertes.fr/hal-02473830.
J. van der Hoeven and R. Larrieu. Fast Gröbner basis computation and polynomial reduction for generic bivariate ideals. AAECC, 30(6):509–539, 2019.
J. van der Hoeven, R. Lebreton, and É. Schost. Structured FFT and TFT: symmetric and lattice polynomials. In Proc. ISSAC '13, pages 355–362. Boston, USA, June 2013.
J. van der Hoeven and G. Lecerf. Modular composition via factorization. J. of Complexity, 48:36–68, 2018.
J. van der Hoeven and G. Lecerf. Accelerated tower arithmetic. J. of Complexity, 55, 2019. Article ID 101402, 26 pages.
J. van der Hoeven and G. Lecerf. Sparse polynomial interpolation. Exploring fast heuristic algorithms over finite fields. Technical Report, HAL, 2019. https://hal.archives-ouvertes.fr/hal-02382117.
J. van der Hoeven and G. Lecerf. Fast multivariate multi-point evaluation revisited. J. of Complexity, 56, 2020. Article ID 101405, 38 pages.
J. van der Hoeven and G. Lecerf. Ultimate complexity for numerical algorithms. ACM Commun. Comput. Algebra, 54(1):1–13, 2020.
J. van der Hoeven and G. Lecerf. Amortized bivariate multi-point evaluation. In Proc. ISSAC '21, pages 179–185. New York, NY, USA, 2021. ACM.
J. van der Hoeven and G. Lecerf. Amortized multi-point evaluation of multivariate polynomials. Technical Report, HAL, 2021. https://hal.archives-ouvertes.fr/hal-03503021.
J. van der Hoeven and G. Lecerf. Fast amortized multi-point evaluation. J. of Complexity, 67, 2021. Article ID 101574, 15 pages.
J. van der Hoeven and G. Lecerf. On the complexity exponent of polynomial system solving. Found. of Comp. Math., 21:1–57, 2021.
J. van der Hoeven and G. Lecerf. Univariate polynomial factorization over large finite fields. AAECC, 2022. https://doi.org/10.1007/s00200-021-00536-1.
J. van der Hoeven, G. Lecerf, B. Mourrain et al. Mathemagix. 2002. http://www.mathemagix.org.
J. van der Hoeven and M. Monagan. Computing one billion roots using the tangent Graeffe method. ACM SIGSAM Commun. Comput. Algebra, 54(3):65–85, 2021.
X. Huang and V. Y. Pan. Fast rectangular matrix multiplication and applications. J. of Complexity, 14(2):257–299, 1998.
F. Johansson. Arb: a C library for ball arithmetic. ACM Commun. Comput. Algebra, 47(3/4):166–169, 2014.
E. Kaltofen. Symbolic computation and complexity theory. In Proc. ASCM '12, pages 3–7. Beijing, 2012.
E. Kaltofen and V. Shoup. Fast polynomial factorization over high algebraic extensions of finite fields. In Proc. ISSAC '97, pages 184–188. New York, NY, USA, 1997. ACM.
A. Karatsuba and J. Ofman. Multiplication of multidigit numbers on automata. Soviet Physics Doklady, 7:595–596, 1963.
K. S. Kedlaya and C. Umans. Fast polynomial factorization and modular composition. SIAM J. Comput., 40(6):1767–1802, 2011.
P. Lairez. A deterministic algorithm to compute approximate roots of polynomial systems in polynomial average time. Found. Comput. Math., 17:1265–1292, 2017.
F. Le Gall and F. Urrutia. Improved rectangular matrix multiplication using powers of the Coppersmith–Winograd tensor. In A. Czumaj, editor, Proc. ACM-SIAM SODA '18, pages 1029–1046. Philadelphia, PA, USA, 2018.
G. Lecerf. Une alternative aux méthodes de réécriture pour la résolution des systèmes algébriques. PhD thesis, École polytechnique, 2001.
G. Lecerf and É. Schost. Fast multivariate power series multiplication in characteristic zero. SADIO Electronic Journal on Informatics and Operations Research, 5(1):1–10, 2003.
A. K. Lenstra, H. W. Lenstra, and L. Lovász. Factoring polynomials with rational coefficients. Math. Ann., 261:515–534, 1982.
M. Mezzarobba. Rigorous multiple-precision evaluation of D-Finite functions in SageMath. Technical Report, HAL, 2016. https://hal.archives-ouvertes.fr/hal-01342769.
M. Mezzarobba. Autour de l'évaluation numérique des fonctions D-finies. PhD thesis, École polytechnique, Palaiseau, France.
R. T. Moenck and A. Borodin. Fast modular transforms via division. In Thirteenth annual IEEE symposium on switching and automata theory, pages 90–96. Univ. Maryland, College Park, Md., 1972.
N. Möller. On Schönhage's algorithm and subquadratic integer gcd computation. Math. Comp., 77(261):589–607, 2008.
M. Moreno Maza. Design and implementation of multi-threaded algorithms in polynomial algebra. In Proc. ISSAC '21, pages 15–20. New York, NY, USA, 2021. ACM.
G. Moroz. New data structure for univariate polynomial approximation and applications to root isolation, numerical multipoint evaluation, and other problems. In Proc. IEEE FOCS '21. Denver, United States, 2022.
T. Mulders. On short multiplication and division. AAECC, 11(1):69–88, 2000.
V. Neiger, J. Rosenkilde, and G. Solomatov. Generic bivariate multi-point evaluation, interpolation and modular composition with precomputation. In Proc. ISSAC '20, pages 388–395. New York, NY, USA, 2020. ACM.
A. Novocin, D. Stehlé, and G. Villard. An LLL-Reduction algorithm with quasi-linear time complexity: extended abstract. In Proc. ACM STOC '11, pages 403–412. New York, NY, USA, 2011.
H. J. Nussbaumer. Fast Fourier Transforms and Convolution Algorithms. Springer-Verlag, 1981.
V. Y. Pan. Univariate polynomials: nearly optimal algorithms for numerical factorization and root-finding. JSC, 33(5):701–733, 2002.
C. H. Papadimitriou. Computational Complexity. Addison-Wesley, 1994.
M. S. Paterson and L. J. Stockmeyer. On the number of nonscalar multiplications necessary to evaluate polynomials. SIAM J. Comput., 2(1):60–66, 1973.
G. Pólya. Kombinatorische Anzahlbestimmungen für Gruppen, Graphen und chemische Verbindungen. Acta Mathematica, 68:145–254, 1937.
W. H. Press, S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery. Numerical Recipes, The Art of Scientific Computing. Cambridge University Press, 3rd edition, 2007.
R. Prony. Essai expérimental et analytique sur les lois de la dilatabilité des fluides élastiques et sur celles de la force expansive de la vapeur de l'eau et de la vapeur de l'alkool, à différentes températures. J. de l'École Polytechnique Floréal et Plairial, an III, 1:24–76, 1795. Cahier 22.
M. Püschel, J. M. F. Moura, J. Johnson, D. Padua, M. Veloso, B. Singer, J. Xiong, F. Franchetti, A. Gacic, Y. Voronenko, K. Chen, R. W. Johnson, and N. Rizzolo. SPIRAL: code generation for DSP transforms. Proceedings of the IEEE, special issue on “Program Generation, Optimization, and Adaptation”, 93(2):232–275, 2005.
D. S. Roche. What can (and can't) we do with sparse polynomials? In Proc. ISSAC '18, pages 25–30. New York, NY, USA, 2018. ACM.
T. Roughgarden. Beyond the Worst-Case Analysis of Algorithms. Cambridge University Press, 2021.
F. Rouillier. Solving zero-dimensional systems through the rational univariate representation. AAECC, 9:433–461, 1999.
A. Schönhage. Schnelle Berechnung von Kettenbruchentwicklungen. Acta Informatica, 1(2):139–144, 1971.
A. Schönhage. Schnelle Multiplikation von Polynomen über Körpern der Charakteristik 2. Acta Informatica, 7:395–398, 1977.
A. Schönhage. The fundamental theorem of algebra in terms of computational complexity. Technical Report, Math. Inst. Univ. of Tübingen, 1982.
A. Schönhage and V. Strassen. Schnelle Multiplikation großer Zahlen. Computing, 7:281–292, 1971.
V. Shoup. NTL: a library for doing number theory. 1996. www.shoup.net/ntl.
V. Strassen. Gaussian elimination is not optimal. Numer. Math., 13:352–356, 1969.
A. L. Toom. The complexity of a scheme of functional elements realizing the multiplication of integers. Soviet Mathematics, 4(2):714–716, 1963.
V. Vassilevska Williams. On some fine-grained questions in algorithms and complexity. In Proc. Int. Cong. of Math. 2018, volume 4, pages 3465–3506. Rio de Janeiro, 2018.
G. Villard. On computing the resultant of generic bivariate polynomials. In Proc. ISSAC '18, pages 391–398. 2018.

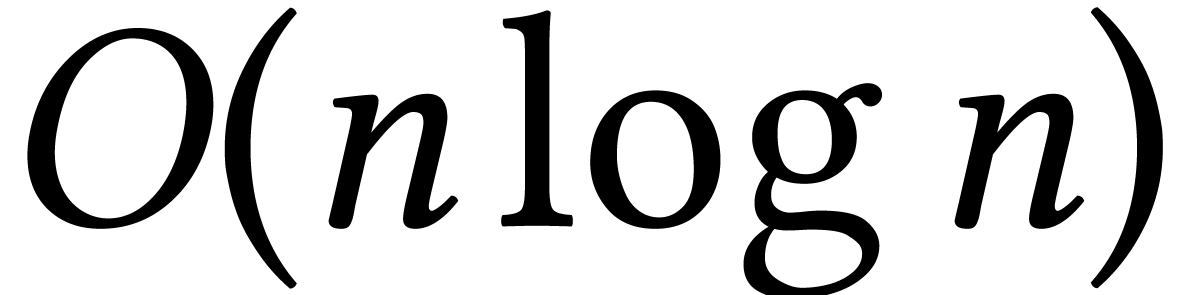
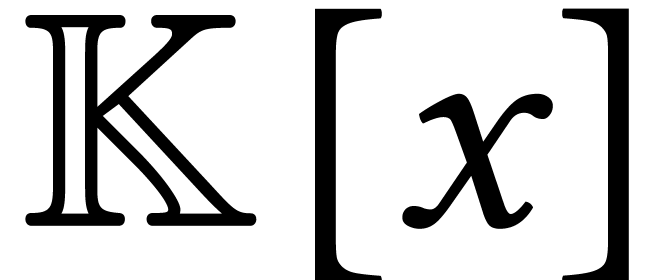
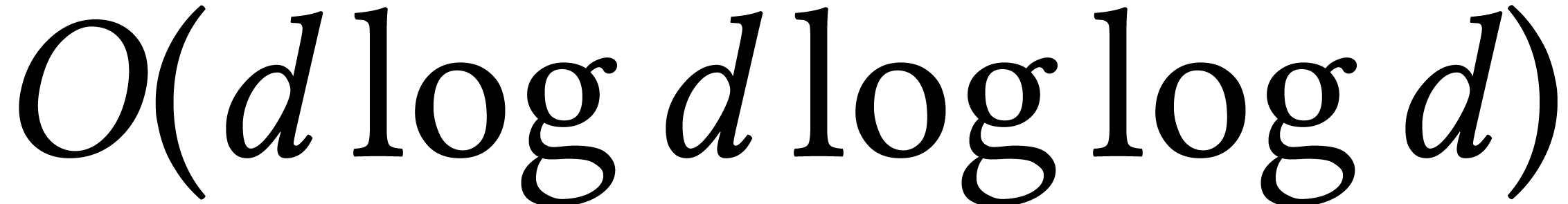
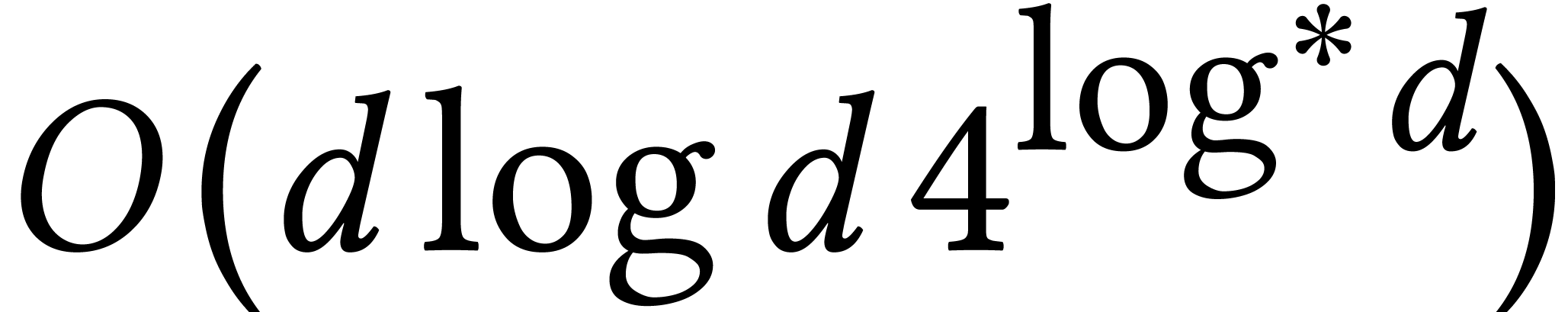
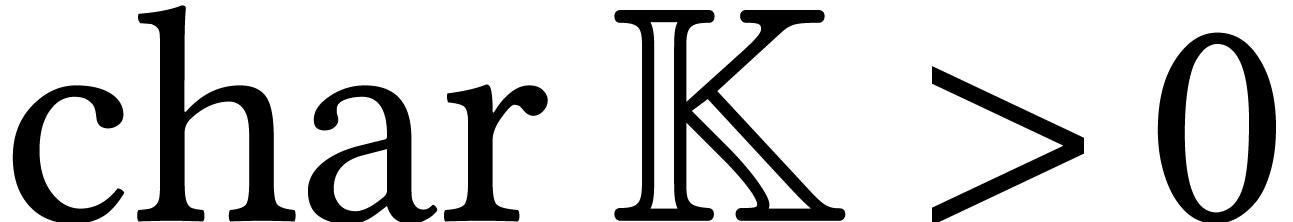
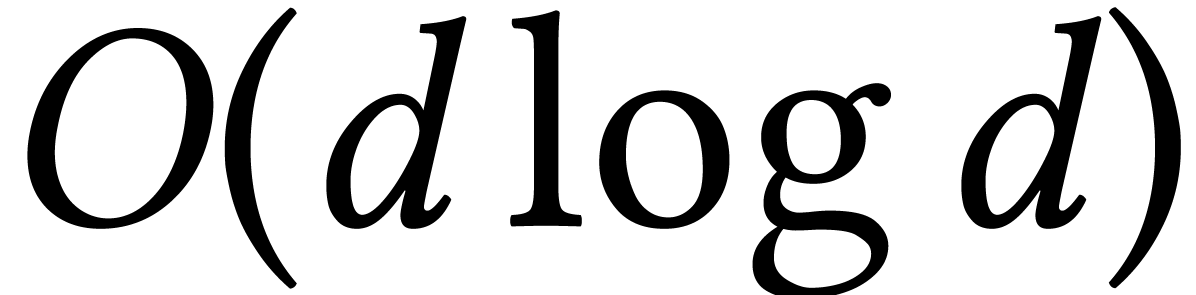
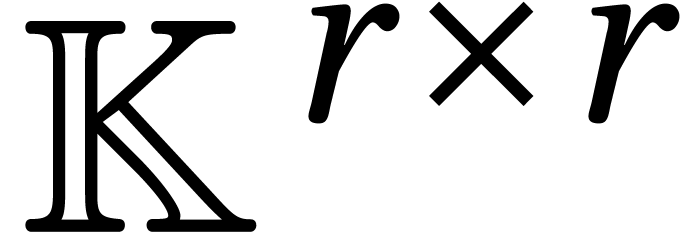
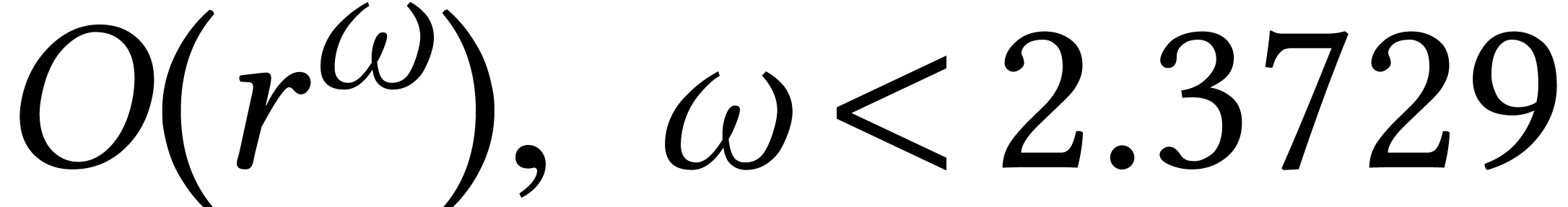
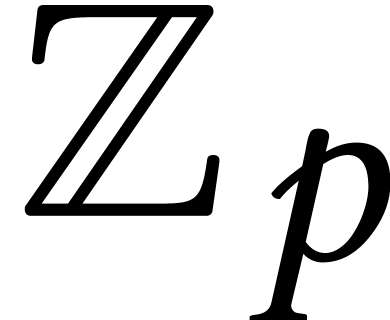
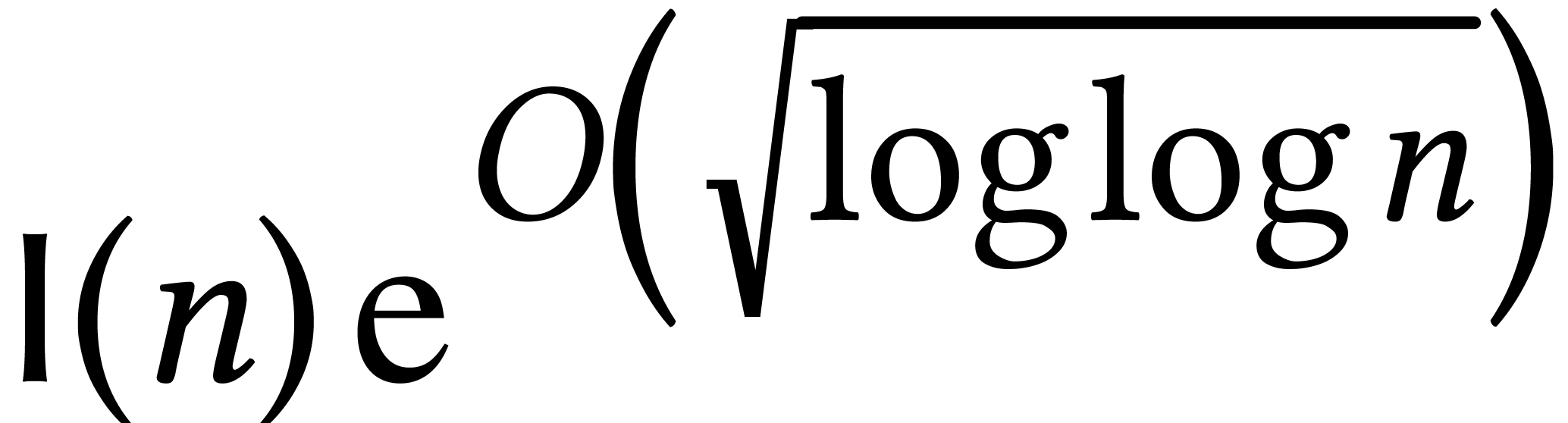

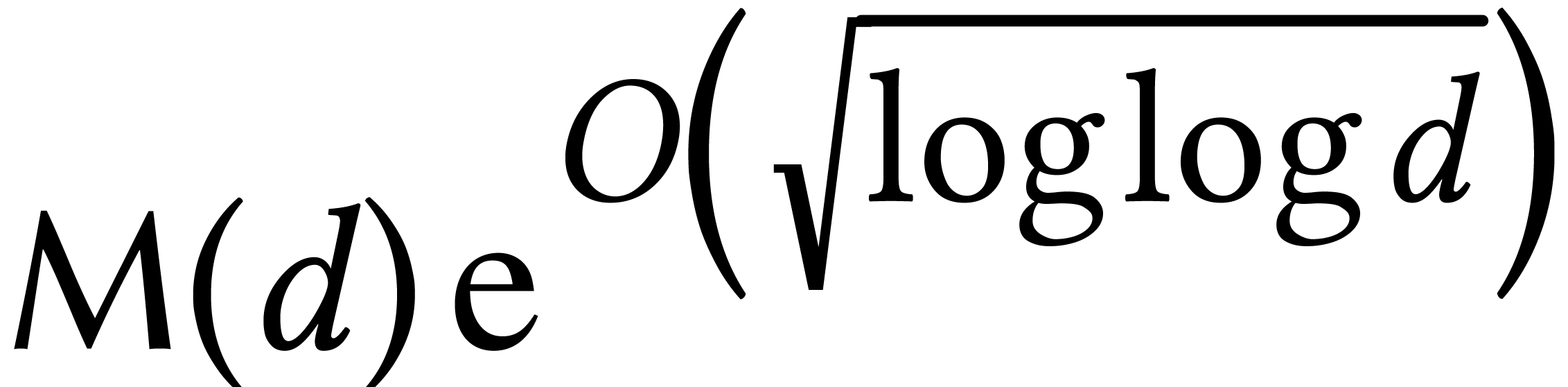
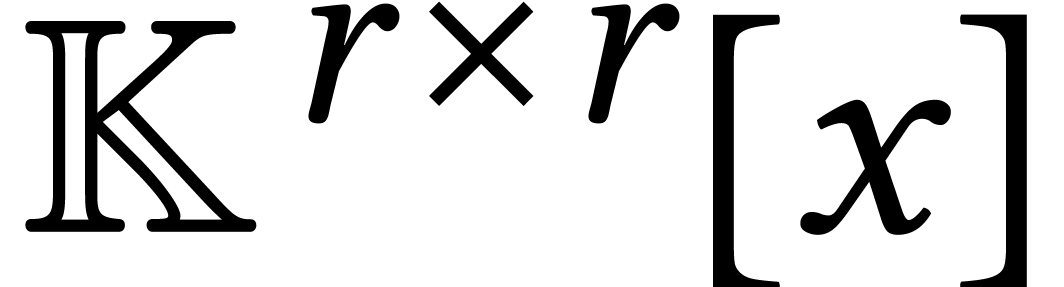
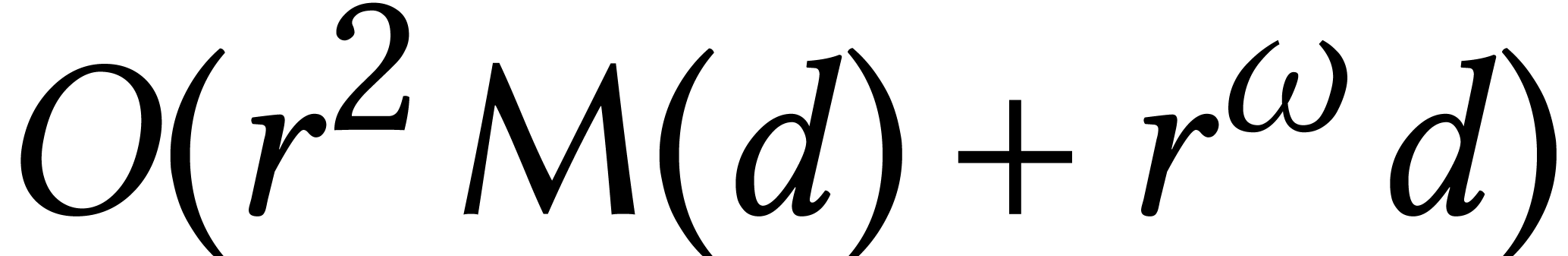
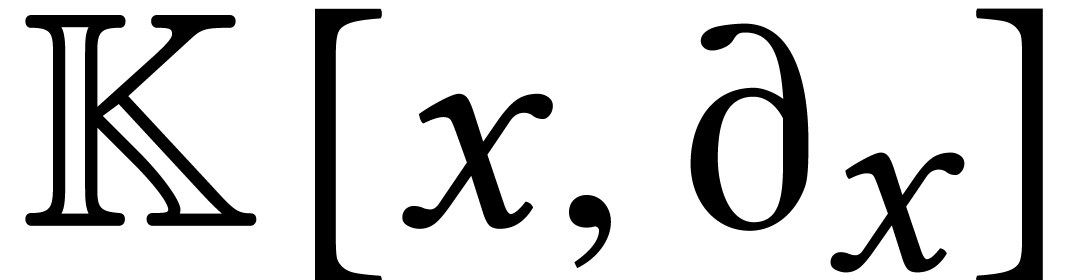
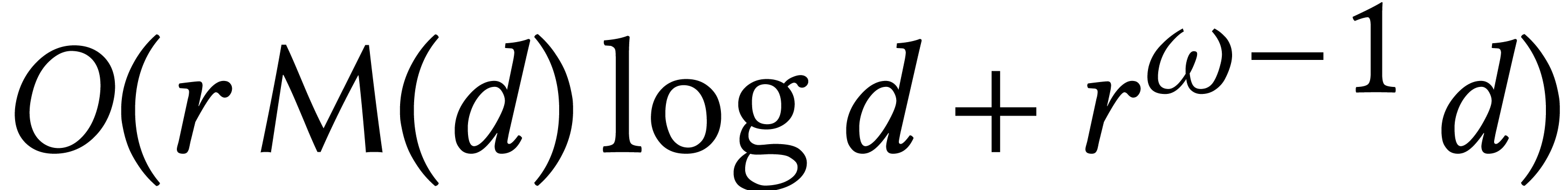
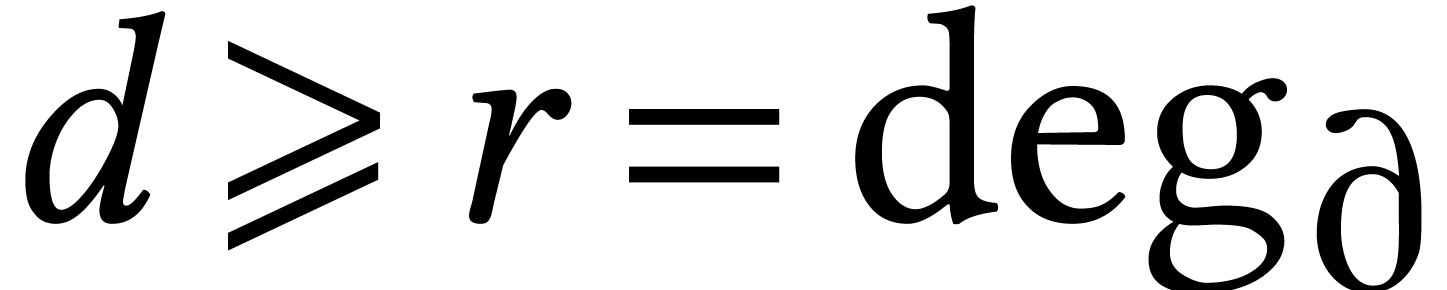
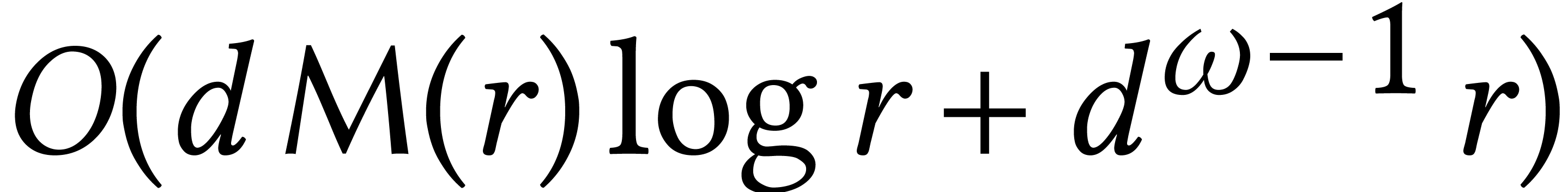
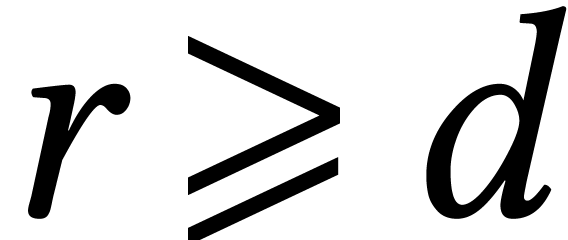
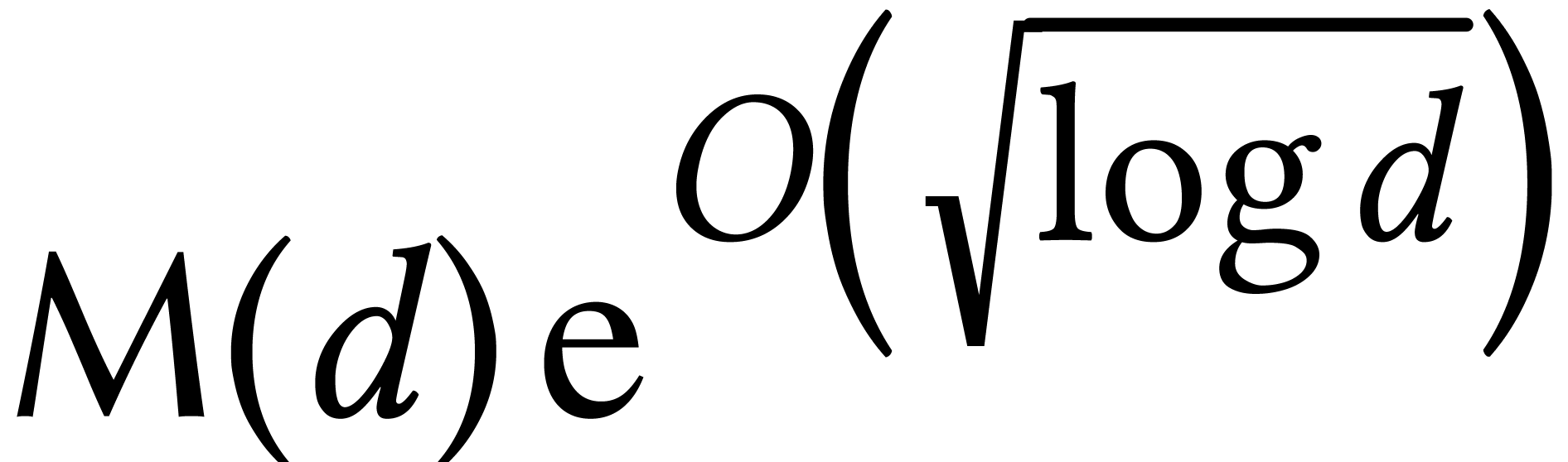
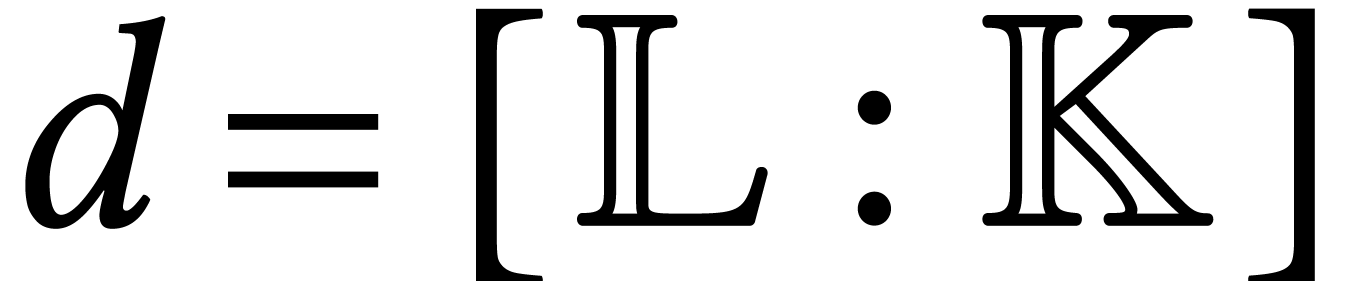
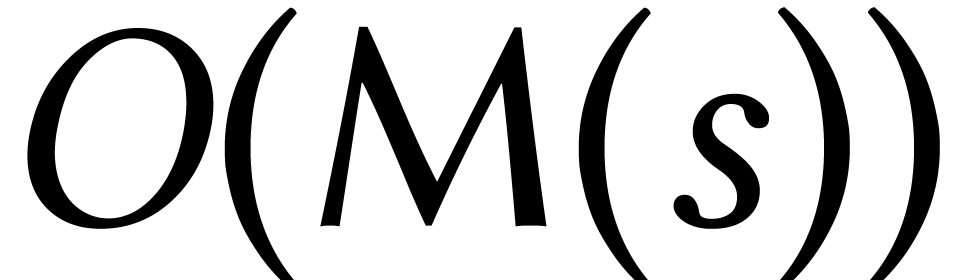
 stands for the total size of
the supports of the input and output.
stands for the total size of
the supports of the input and output.
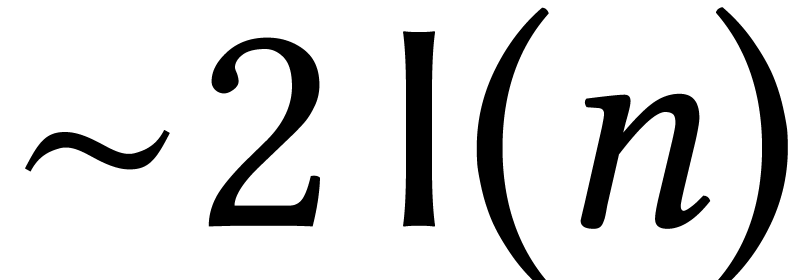
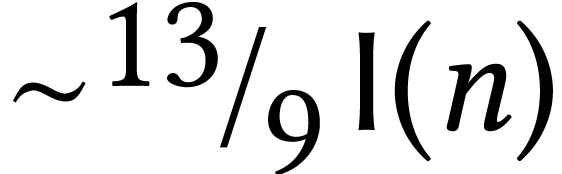
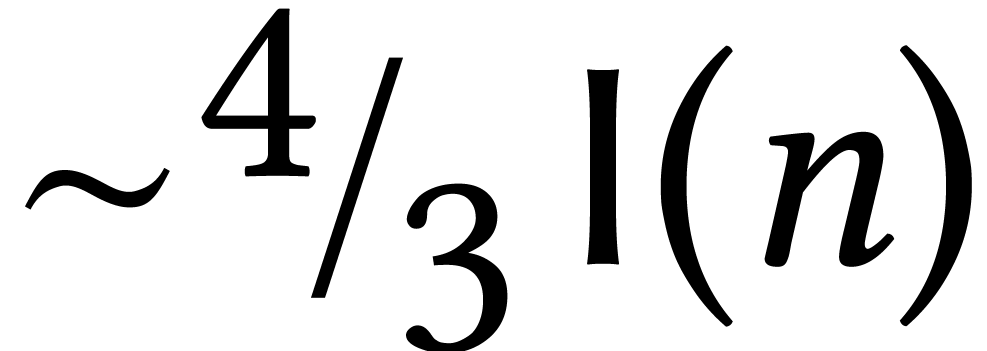
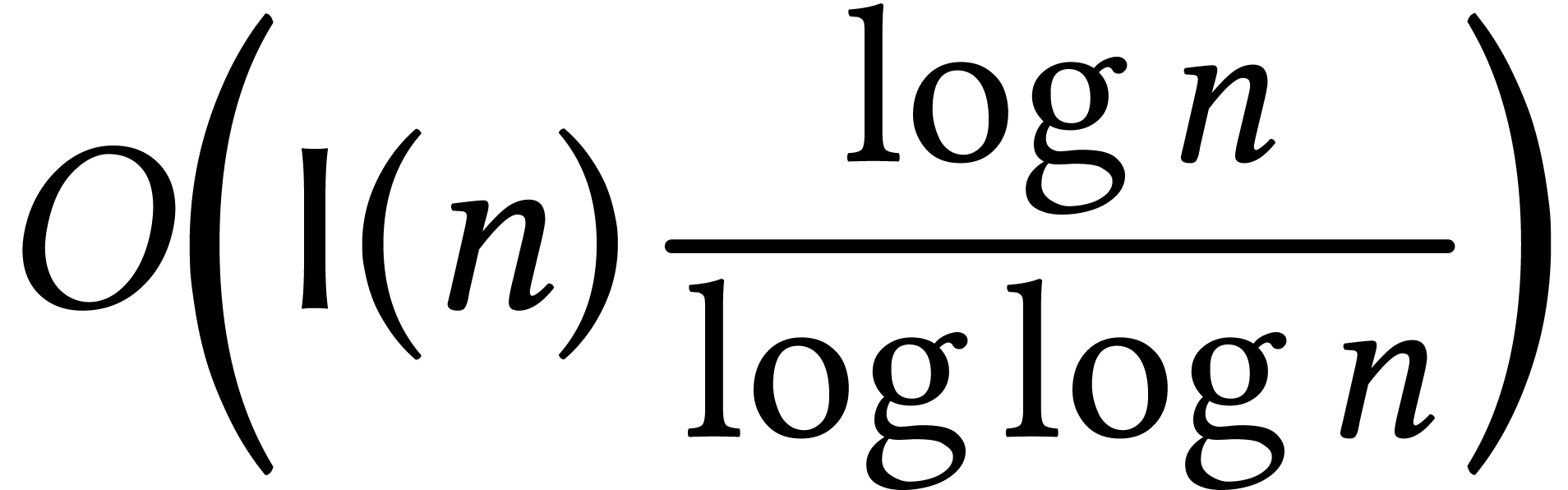
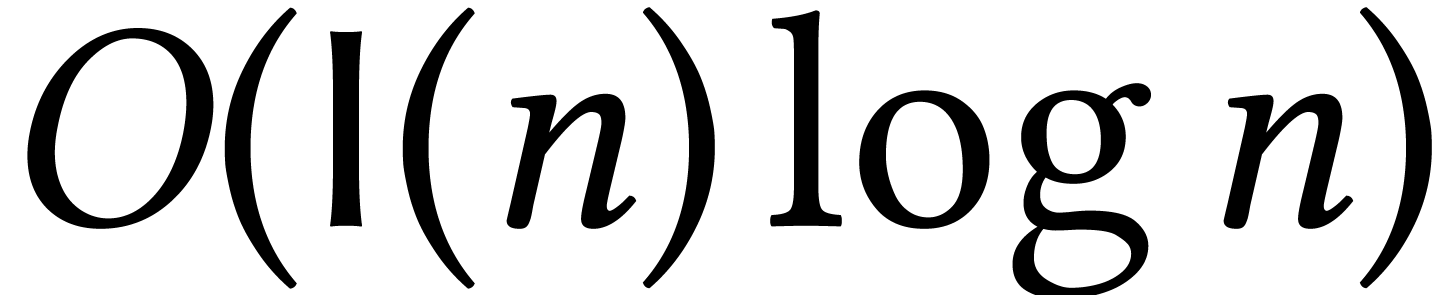
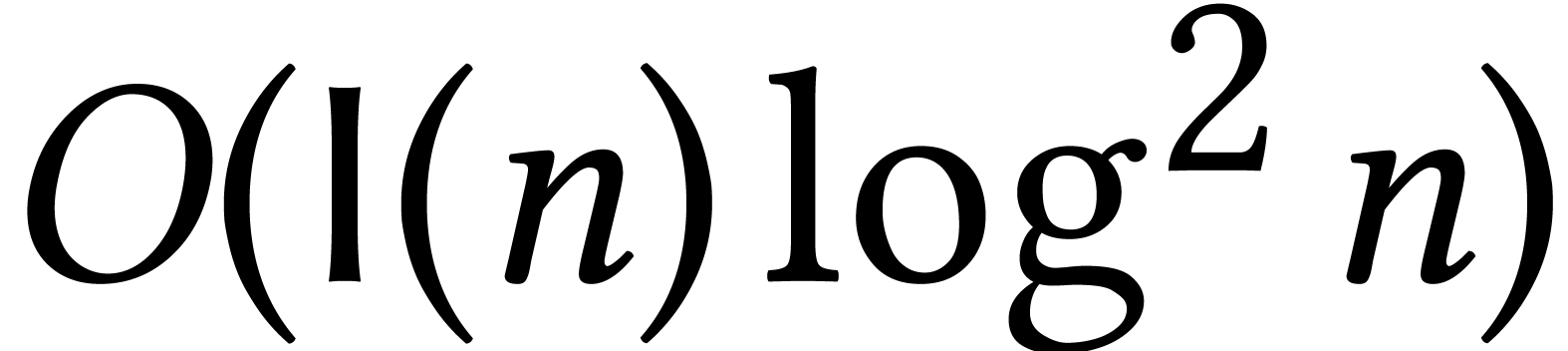
 -bit
-bit