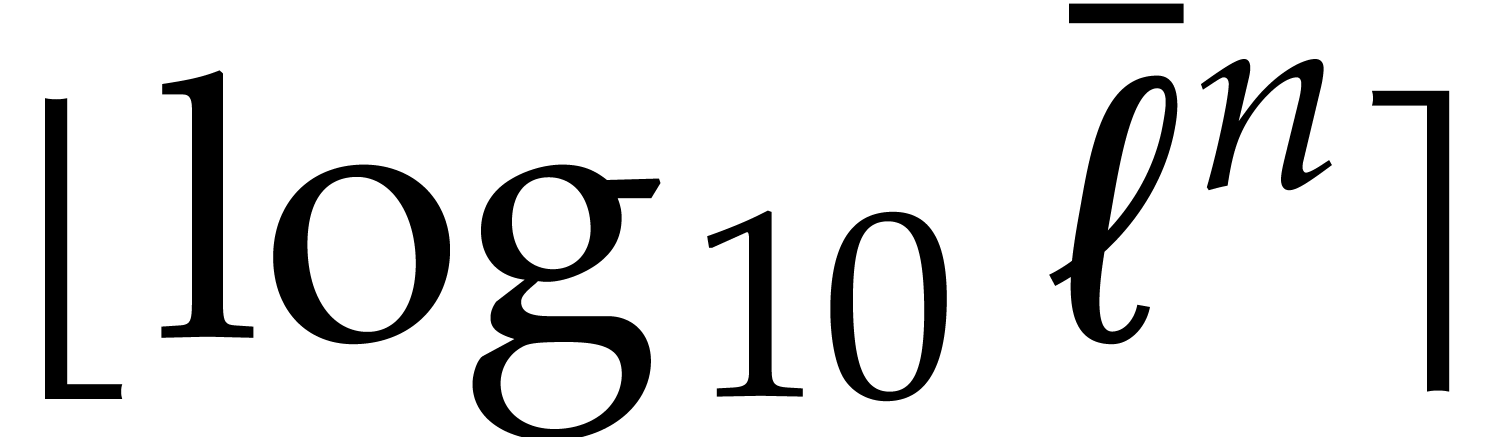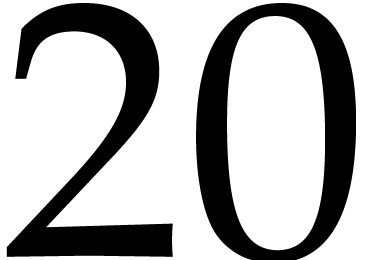| Fast multivariate multi-point evaluation
revisited |
|
Joris van der Hoevena,
Grégoire Lecerfb
|
|
CNRS (UMR 7161, LIX)
Laboratoire d'informatique de l'École
polytechnique
Campus de l'École polytechnique
1, rue Honoré d'Estienne d'Orves
Bâtiment Alan Turing, CS35003
91120 Palaiseau, France
|
|
a. Email:
vdhoeven@lix.polytechnique.fr
|
|
b. Email:
lecerf@lix.polytechnique.fr
|
|
| Final version of February 2020 |
|
In 2008, Kedlaya and Umans designed the first multivariate
multi-point evaluation algorithm over finite fields with an
asymptotic complexity that can be made arbitrarily close to
linear. However, it remains a major challenge to make their
algorithm efficient for practical input sizes. In this paper, we
revisit and improve their algorithm, while keeping this ultimate
goal in mind. In addition we sharpen the known complexity bounds
for modular composition of univariate polynomials over finite
fields.
|
1.Introduction
Let  be a commutative ring with unity, and let
be a commutative ring with unity, and let
 be a multivariate polynomial. The
multi-point evaluation problem consists in evaluating
be a multivariate polynomial. The
multi-point evaluation problem consists in evaluating 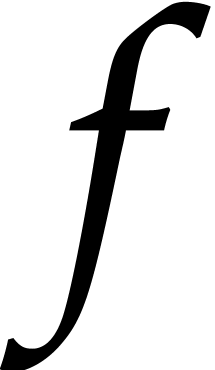 at several given points
at several given points  in
in  . Let
. Let  be
polynomials in
be
polynomials in  of degrees
of degrees  and let
and let  be a monic polynomial in of degree
be a monic polynomial in of degree  . The
modular composition problem consists in computing
. The
modular composition problem consists in computing 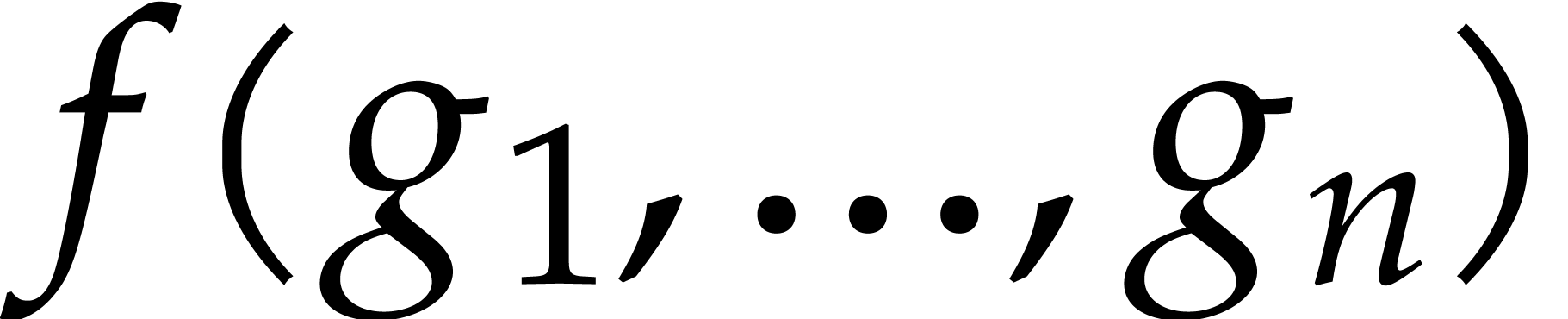 modulo . This
is equivalent to the computation of the remainder
modulo . This
is equivalent to the computation of the remainder 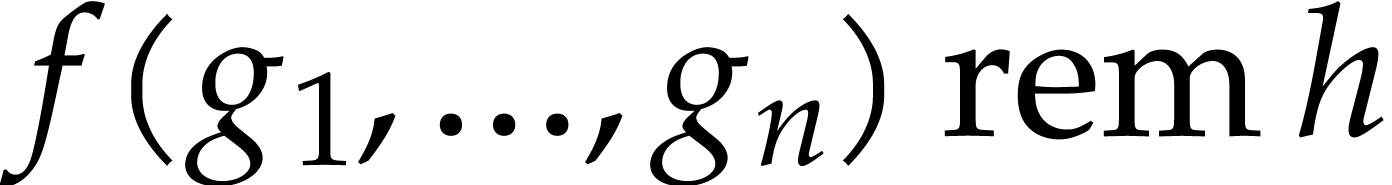 of the Euclidean division of by . It turns out that these two problems are
related and that they form important building blocks in computer
algebra. Theoretically speaking, Kedlaya and Umans have given efficient
solutions to both problems when is a finite ring
of the form
of the Euclidean division of by . It turns out that these two problems are
related and that they form important building blocks in computer
algebra. Theoretically speaking, Kedlaya and Umans have given efficient
solutions to both problems when is a finite ring
of the form 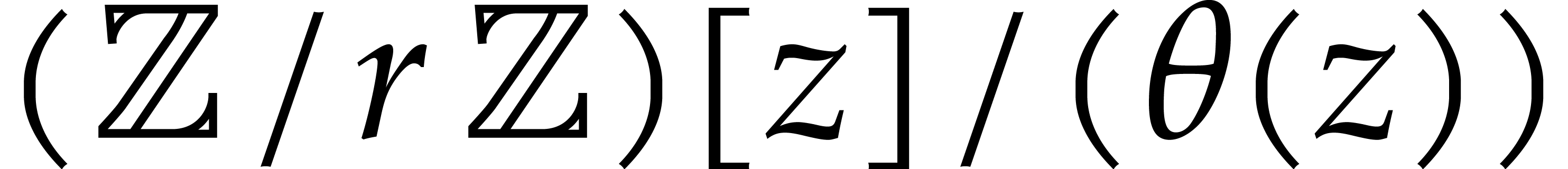 where
where  is a
monic polynomial [34]. The design of practically efficient
algorithms remains an important challenge. The purpose of this paper is
to revisit the algorithms by Kedlaya and Umans in detail, to sharpen
their theoretical complexity bounds, and get some insight into the
required data size for which this approach outperforms asymptotically
slower algorithms.
is a
monic polynomial [34]. The design of practically efficient
algorithms remains an important challenge. The purpose of this paper is
to revisit the algorithms by Kedlaya and Umans in detail, to sharpen
their theoretical complexity bounds, and get some insight into the
required data size for which this approach outperforms asymptotically
slower algorithms.
1.1.Related work
Let  denote a complexity function that bounds the
number of operations in required to multiply two
polynomials of degree
denote a complexity function that bounds the
number of operations in required to multiply two
polynomials of degree  in . We will often use the soft-Oh notation:
in . We will often use the soft-Oh notation:
 means that
means that  ;
see [13, chapter 25, section 7] for technical details. The
least integer larger or equal to
;
see [13, chapter 25, section 7] for technical details. The
least integer larger or equal to  is written
is written
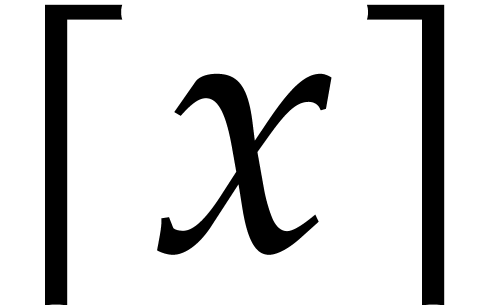 . The largest integer smaller
or equal to is written
. The largest integer smaller
or equal to is written  . The -module
of polynomials of degree is denoted by
. The -module
of polynomials of degree is denoted by  .
.
Multi-point evaluation
In the univariate case when 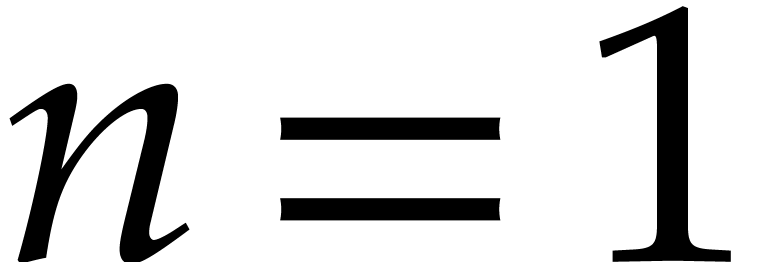 ,
the evaluation of
,
the evaluation of  at
points in can be achieved with
at
points in can be achieved with  operations in . We refer the
reader to [13, chapter 10] for the description of the well
known algorithm based on remainder trees. Algorithms with the smallest
constant hidden in the “
operations in . We refer the
reader to [13, chapter 10] for the description of the well
known algorithm based on remainder trees. Algorithms with the smallest
constant hidden in the “ ”
may be found in [6]. By allowing precomputations that only
depend on the set of points, this evaluation complexity even drops to
”
may be found in [6]. By allowing precomputations that only
depend on the set of points, this evaluation complexity even drops to
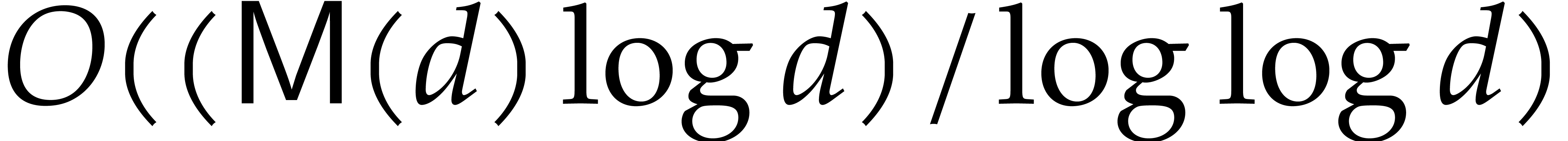 as shown in [23]. For specific sets
of points, such as geometric progressions or TFT points, multi-point
evaluation requires only
as shown in [23]. For specific sets
of points, such as geometric progressions or TFT points, multi-point
evaluation requires only 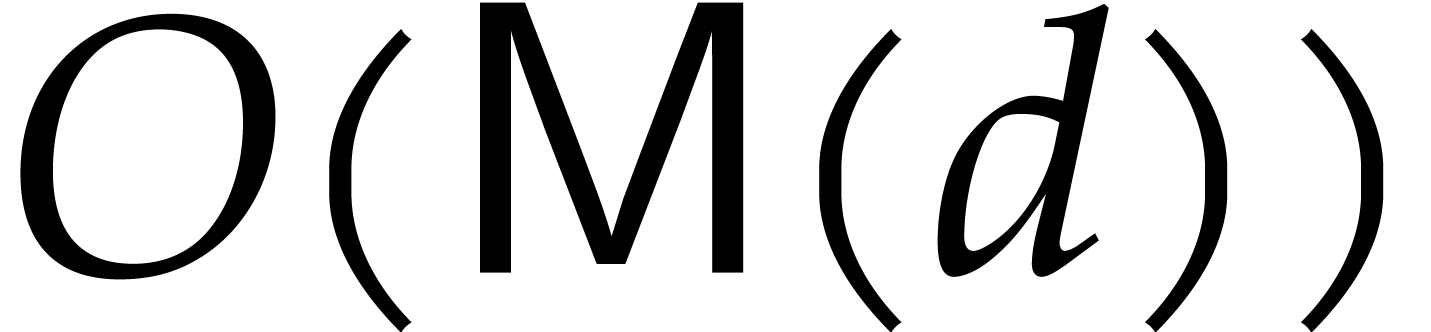 operations in ; see [4, 7,
21].
operations in ; see [4, 7,
21].
The univariate situation does not extend to several variables, unless
the set 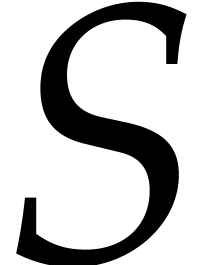 of evaluation points has good
properties. For instance if has the form
of evaluation points has good
properties. For instance if has the form  with
with 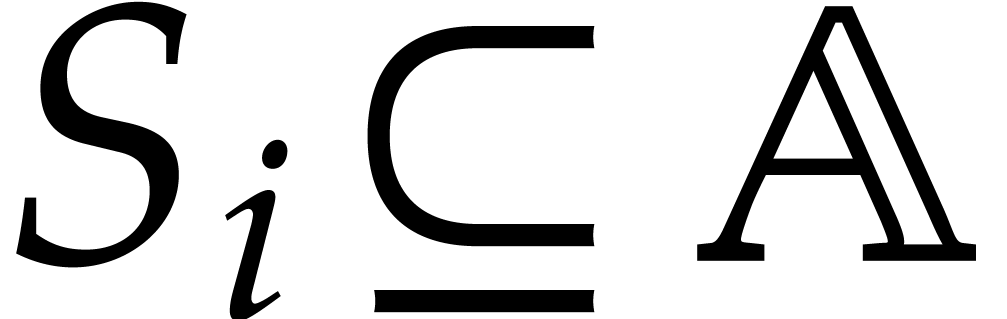 ,
then fast univariate evaluations may be applied coordinate by
coordinate. Fast algorithms also exist for suitable initial segments of
such Cartesian products [29]. Other specific families of
sets of points are used for fast evaluation and interpolation of
multivariate polynomials in sparse representation; see [1,
24] for some recent results.
,
then fast univariate evaluations may be applied coordinate by
coordinate. Fast algorithms also exist for suitable initial segments of
such Cartesian products [29]. Other specific families of
sets of points are used for fast evaluation and interpolation of
multivariate polynomials in sparse representation; see [1,
24] for some recent results.
In the bivariate case when 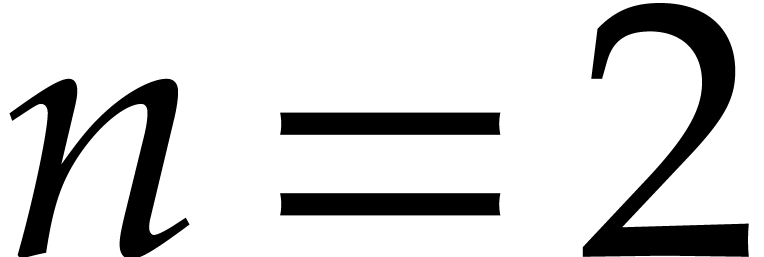 ,
a smart use of the univariate case leads to a cost
,
a smart use of the univariate case leads to a cost 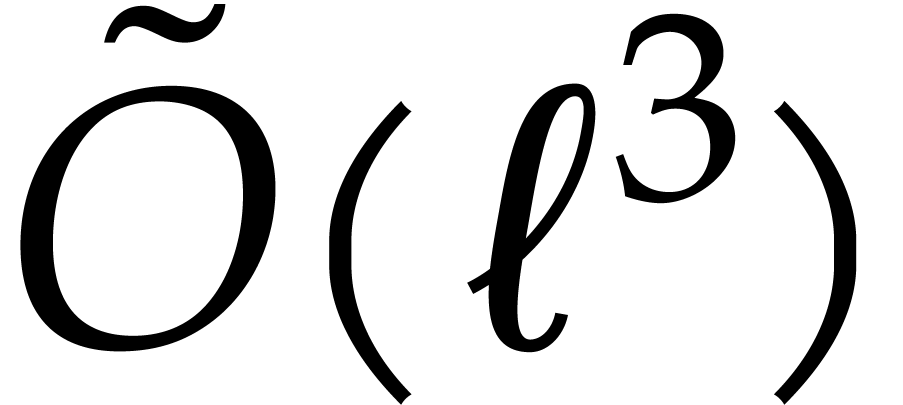 , where
, where  bounds the
partial degrees of [36, Theorem 3].
In 2004, Nüsken and Ziegler improved this bound to
bounds the
partial degrees of [36, Theorem 3].
In 2004, Nüsken and Ziegler improved this bound to 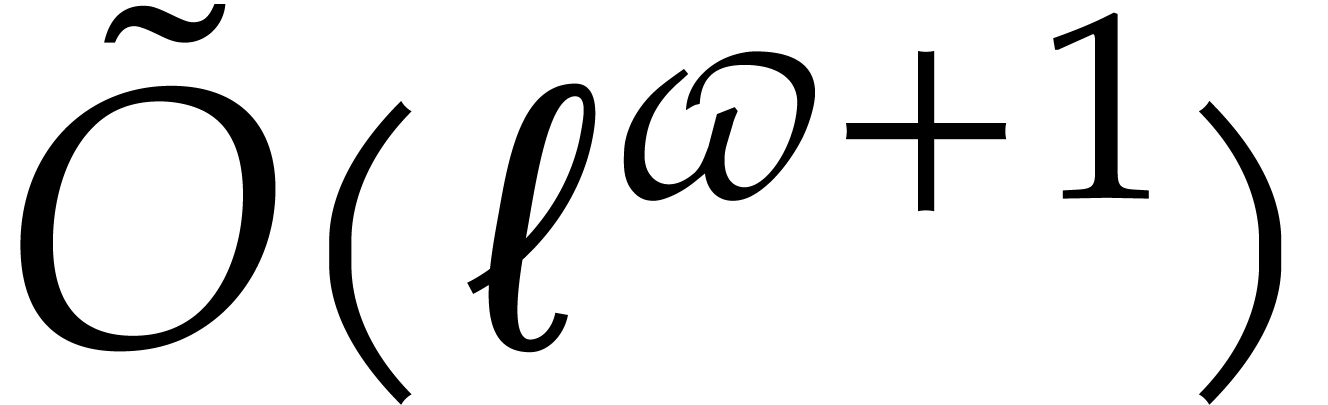 [36, Result 4]—here the constant
[36, Result 4]—here the constant 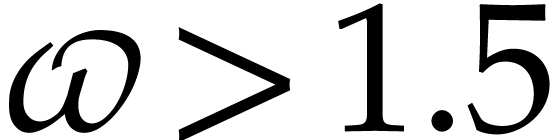 is such that a
is such that a  matrix over
may be multiplied with another
matrix over
may be multiplied with another 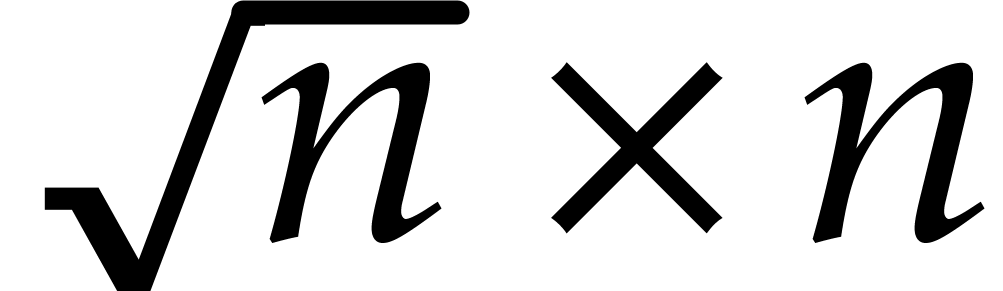 rectangular
matrix with
rectangular
matrix with 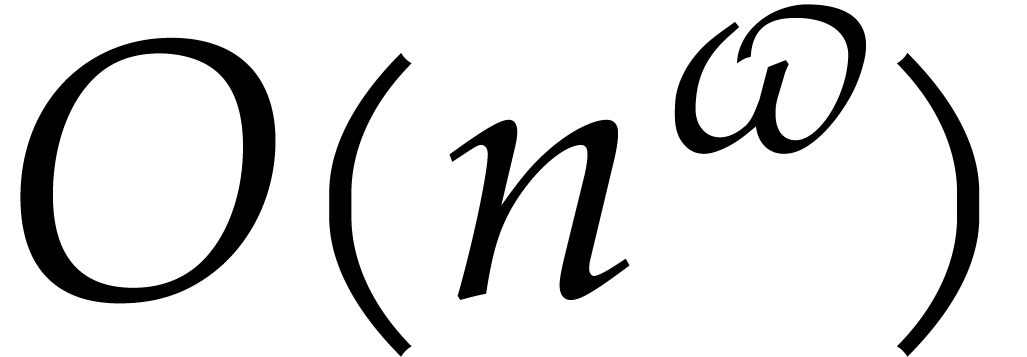 operations in . When is a field the best
currently known bound
operations in . When is a field the best
currently known bound  is due to Huang and Pan
[30, Theorem 10.1].
is due to Huang and Pan
[30, Theorem 10.1].
In 2008, Kedlaya and Umans achieved a major breakthrough for the general
case [33]. In [34, Corollary 4.3] they showed
the following statement (simplified here for conciseness): let  be a fixed rational value, given
be a fixed rational value, given  in
in 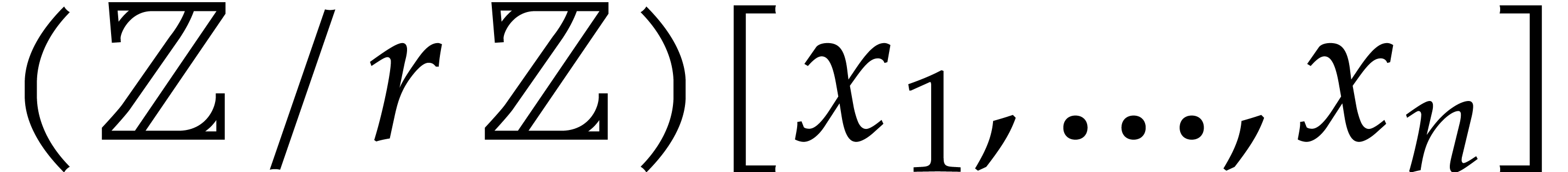 with partial degrees in any
with partial degrees in any 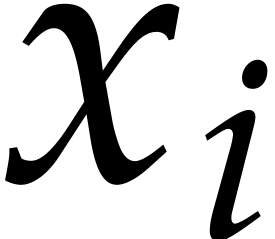 at most , and evaluation
points in
at most , and evaluation
points in 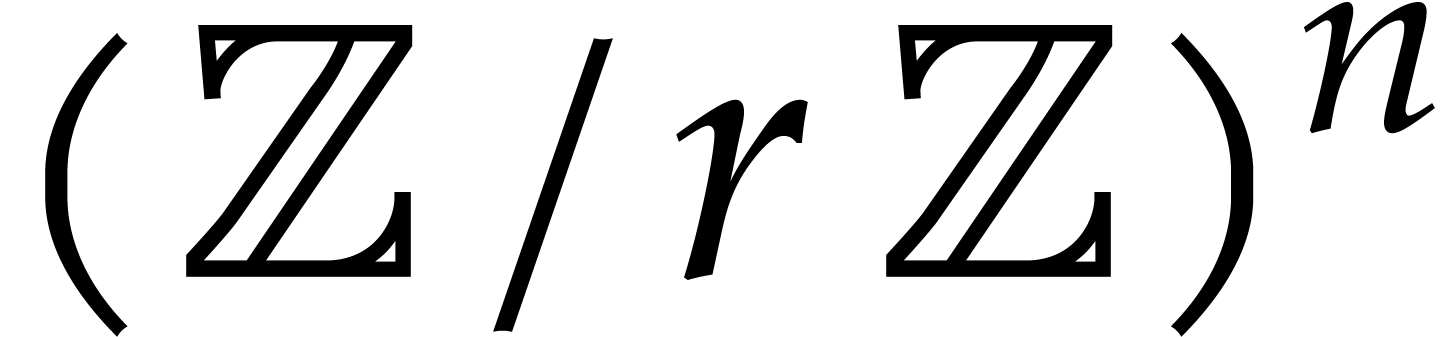 ,
then
,
then  can be computed with
can be computed with 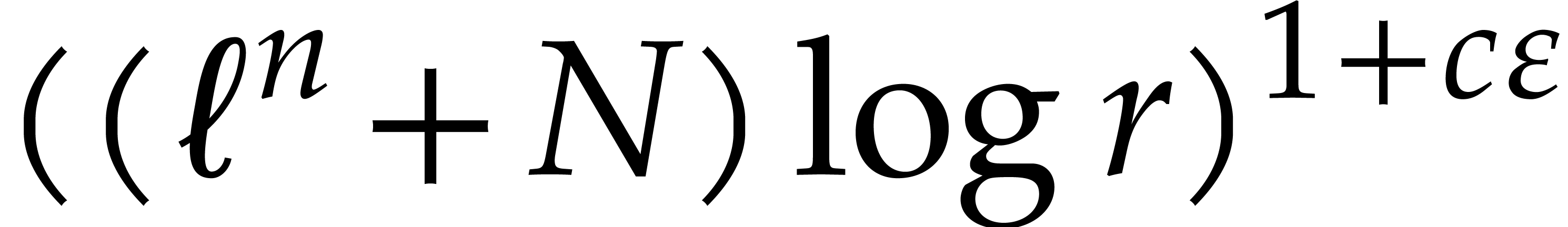 bit operations, provided that
bit operations, provided that 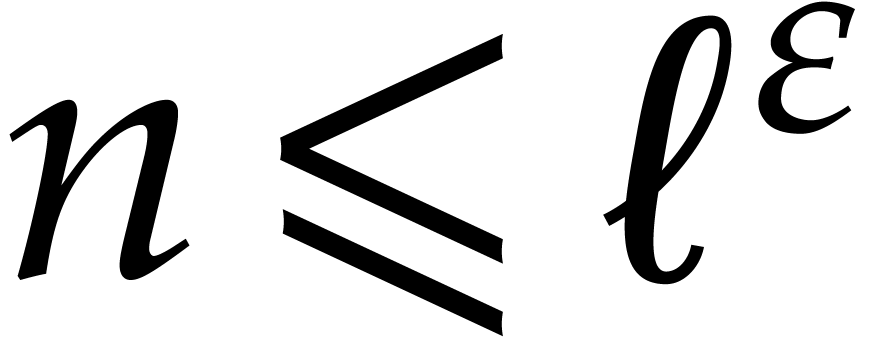 and where
and where  is a constant independent of
is a constant independent of  . This result was stated for random access memory
machines. In fact, some of the underlying arguments (such as the use of
lookup tables) need to be adapted to make them work properly on Turing
machines. This is one of our contributions in this paper. In a nutshell
the Kedlaya–Umans algorithm proceeds as follows (see section 3.1):
. This result was stated for random access memory
machines. In fact, some of the underlying arguments (such as the use of
lookup tables) need to be adapted to make them work properly on Turing
machines. This is one of our contributions in this paper. In a nutshell
the Kedlaya–Umans algorithm proceeds as follows (see section 3.1):
-
If 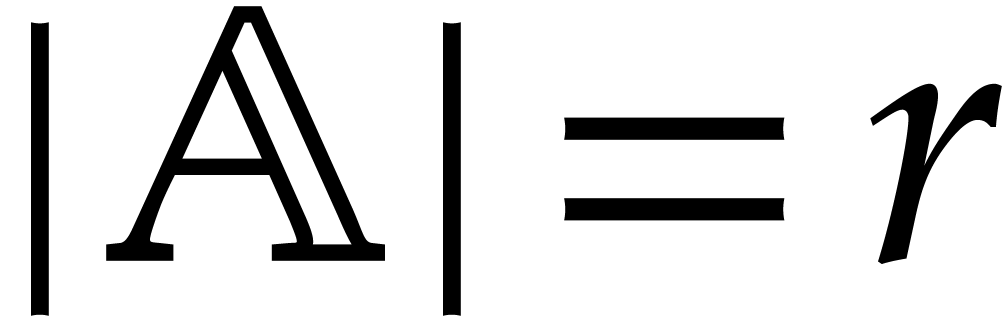 is “sufficiently small”, then
we exhaustively evaluate at all points in
, using fast univariate
multi-point evaluation with respect to each coordinate.
is “sufficiently small”, then
we exhaustively evaluate at all points in
, using fast univariate
multi-point evaluation with respect to each coordinate.
-
Otherwise, the evaluation of at is reduced to the evaluation of the preimage 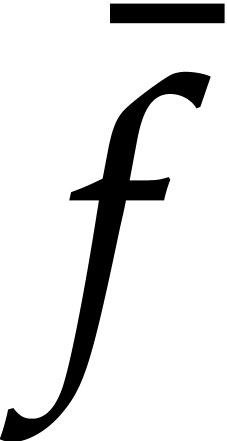 of in
of in 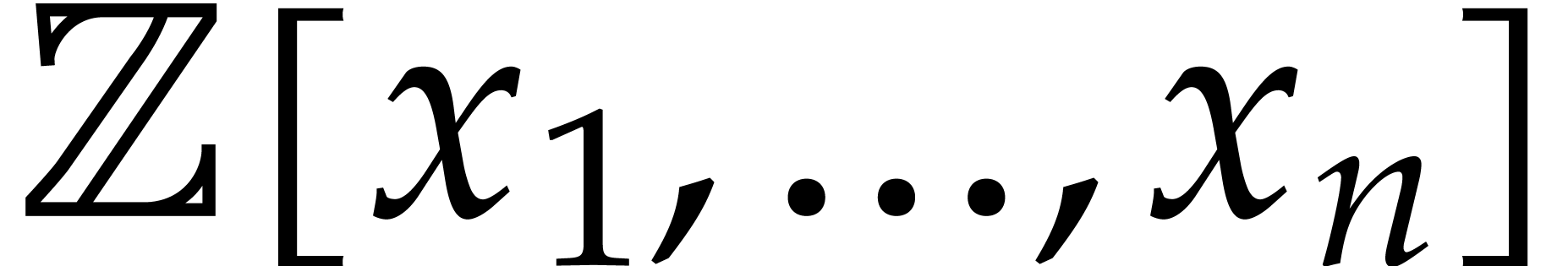 at the preimages
at the preimages  of
in
of
in 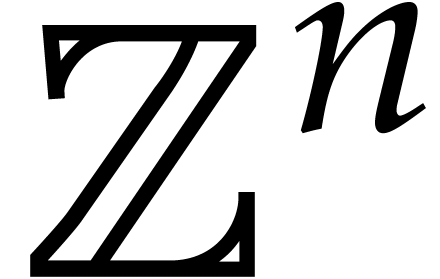 . Through the Chinese
remaindering theorem, the latter evaluation over
. Through the Chinese
remaindering theorem, the latter evaluation over  further reduces to several independent multi-point evaluation
problems modulo “many” prime numbers
further reduces to several independent multi-point evaluation
problems modulo “many” prime numbers  that are “much smaller” than
that are “much smaller” than 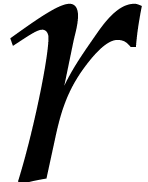 . These evaluations of
mod
. These evaluations of
mod 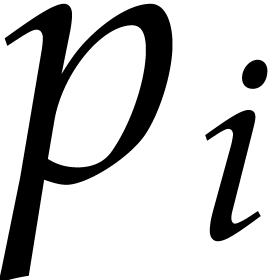 at
at  are handled
recursively, for
are handled
recursively, for 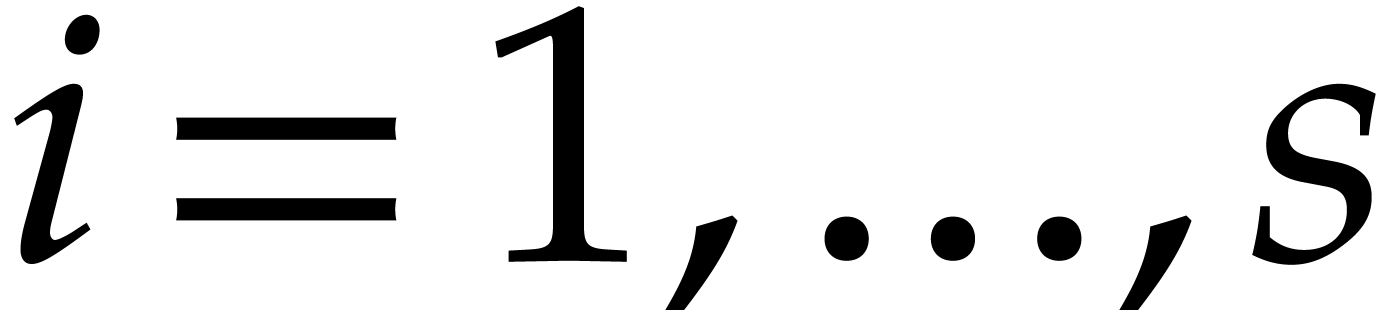 .
.
Modular composition
Let us first discuss the standard modular composition problem when . Let 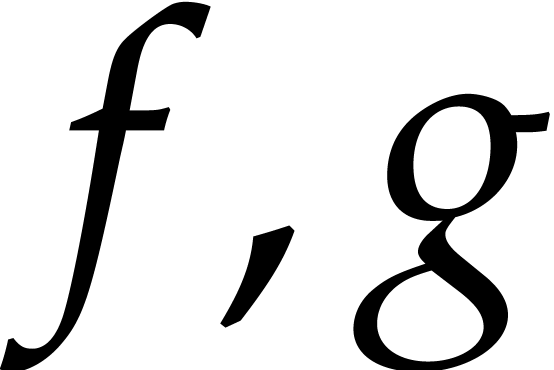 and
be polynomials in of
respective degrees , and , with
monic. The naive modular composition algorithm
takes
and
be polynomials in of
respective degrees , and , with
monic. The naive modular composition algorithm
takes  operations in . In 1978, Brent and Kung [9] gave an
algorithm with cost
operations in . In 1978, Brent and Kung [9] gave an
algorithm with cost 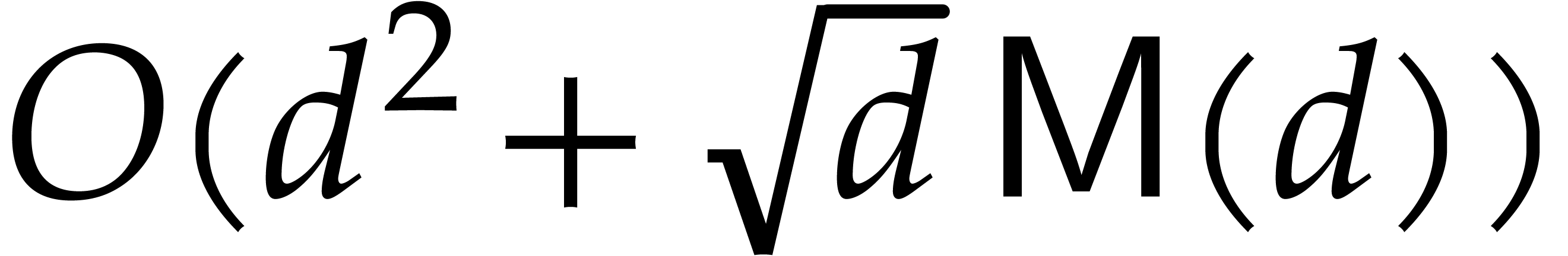 , which
uses the baby-step giant-step technique [39].
Their algorithm even yields a sub-quadratic cost
, which
uses the baby-step giant-step technique [39].
Their algorithm even yields a sub-quadratic cost 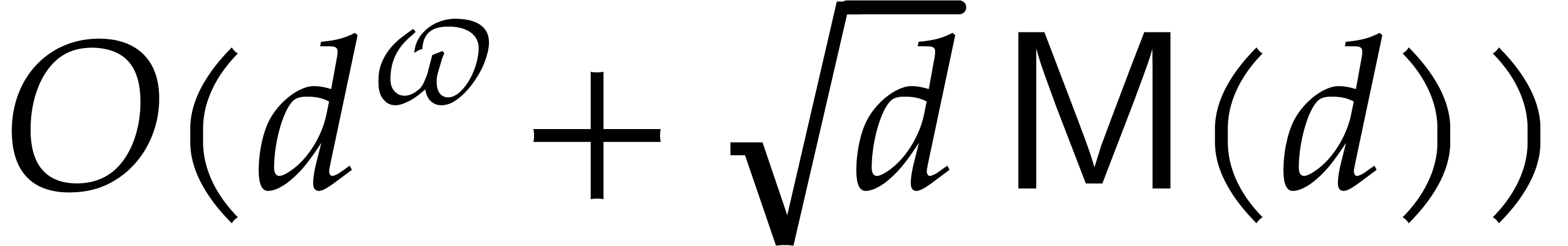 when using fast linear algebra; see [32, p. 185].
when using fast linear algebra; see [32, p. 185].
The major breakthrough for this problem is again due to Kedlaya and
Umans [33, 34] in the case when is a finite field  (and even more
generally a finite ring of the form for any
integer and monic). For
any fixed real value , they
have shown that the composition
(and even more
generally a finite ring of the form for any
integer and monic). For
any fixed real value , they
have shown that the composition  could be
computed modulo using
could be
computed modulo using 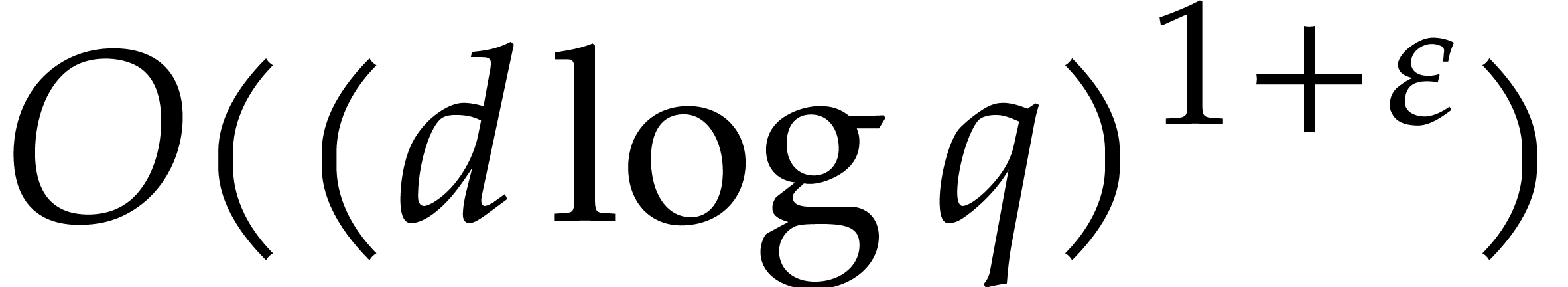 bit operations.
bit operations.
The special case of power series composition corresponds to 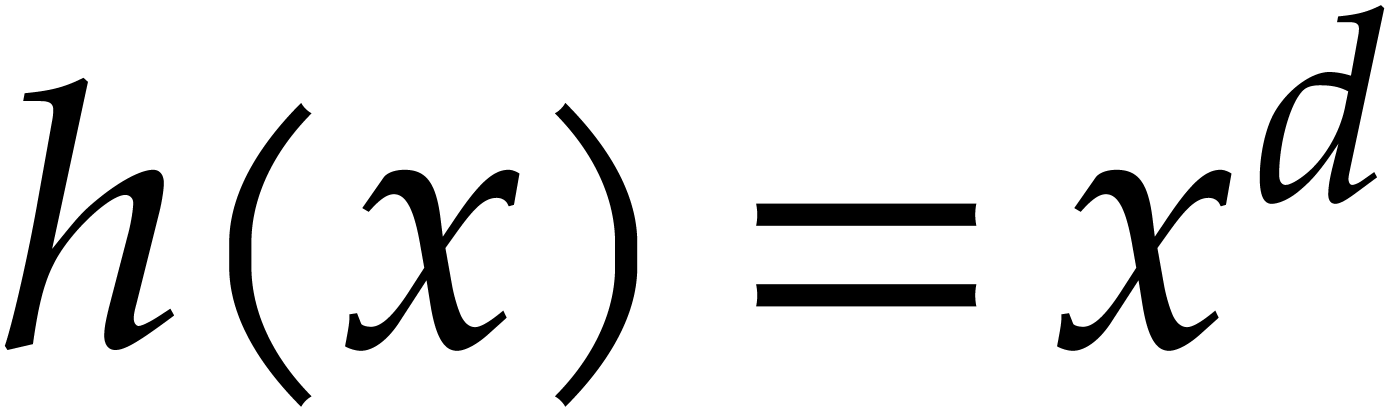 . The best known complexity bound in the
algebraic model when is a field, written
. The best known complexity bound in the
algebraic model when is a field, written  for convenience, is still due to Brent and Kung: in
[9], they achieved
for convenience, is still due to Brent and Kung: in
[9], they achieved 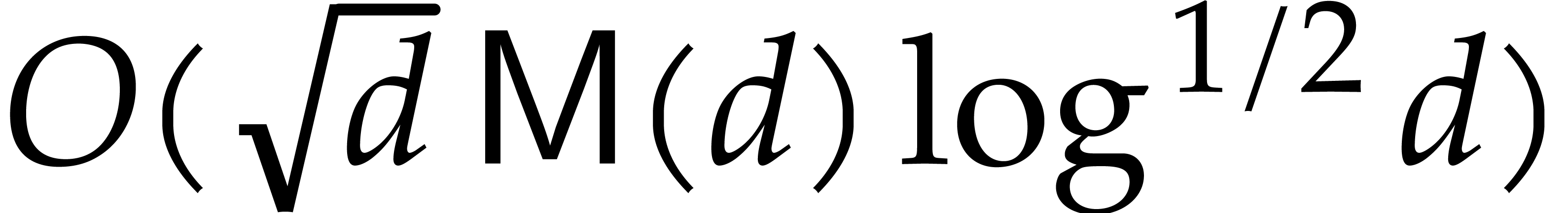 operations in
, under the condition that
operations in
, under the condition that
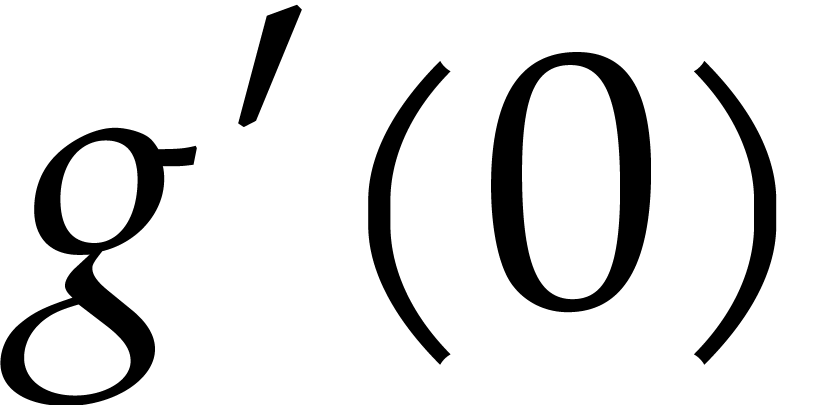 is invertible and that the characteristic of
is at least
is invertible and that the characteristic of
is at least 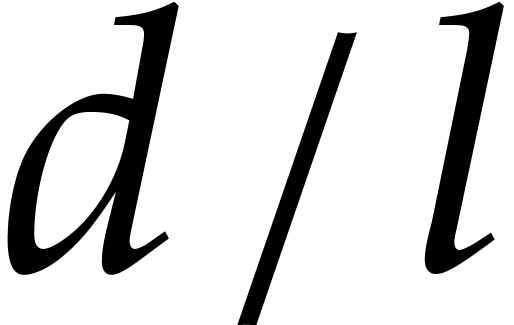 ,
where
,
where 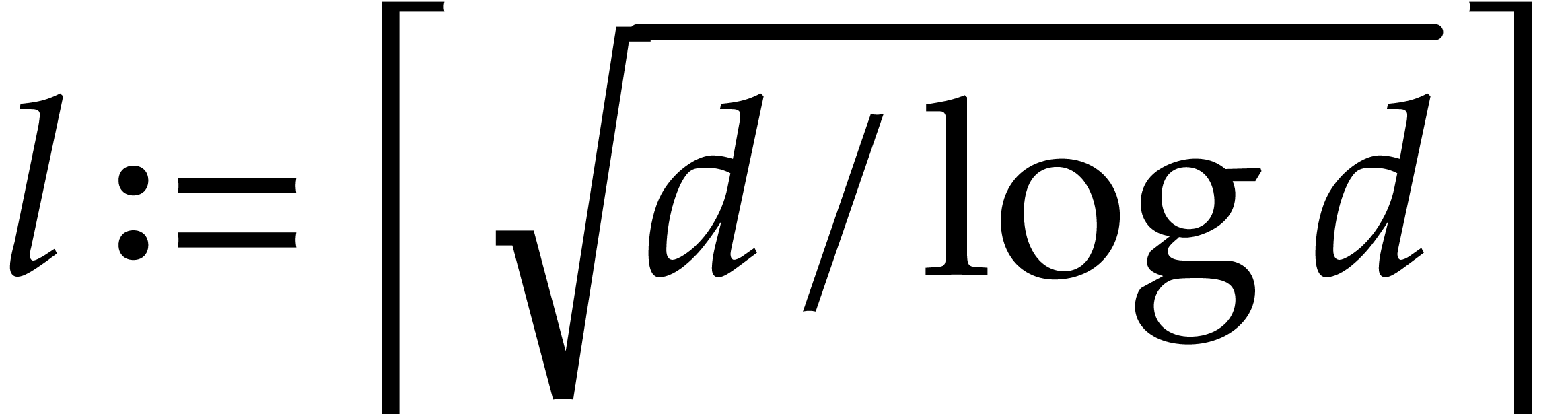 . The variant proposed
by van der Hoeven [20, section 3.4.3] raises the condition
on . For fields with small
characteristic
. The variant proposed
by van der Hoeven [20, section 3.4.3] raises the condition
on . For fields with small
characteristic 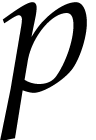 , Bernstein
[3] proposed an algorithm that is softly linear in but linear in .
These algorithms have been generalized to moduli
of the form
, Bernstein
[3] proposed an algorithm that is softly linear in but linear in .
These algorithms have been generalized to moduli
of the form 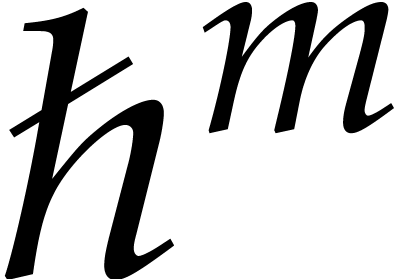 in [25]; it is shown
therein that such a composition reduces to one power series composition
at order
in [25]; it is shown
therein that such a composition reduces to one power series composition
at order 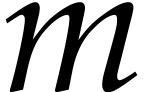 over
over 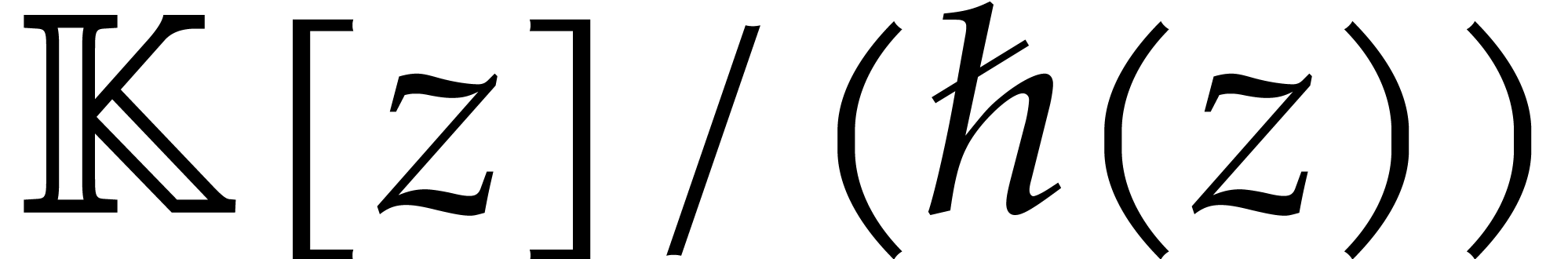 ,
plus compositions modulo
,
plus compositions modulo  , and one characteristic polynomial computation
modulo . Let us finally
mention that an optimized variant, in terms of the constant hidden in
the “”, of the
Brent–Kung algorithm has been proposed recently by Johansson in
[31], and that series with integer, rational or floating
point coefficients can often be composed in quasi-linear time in
suitable bit complexity models, as shown by Ritzmann [40];
see also [22].
, and one characteristic polynomial computation
modulo . Let us finally
mention that an optimized variant, in terms of the constant hidden in
the “”, of the
Brent–Kung algorithm has been proposed recently by Johansson in
[31], and that series with integer, rational or floating
point coefficients can often be composed in quasi-linear time in
suitable bit complexity models, as shown by Ritzmann [40];
see also [22].
Relationship between multi-point evaluation and modular
composition
Multi-point evaluation and modular composition are instances of
evaluation problems at points lying in different extensions of . The former case involves several
points with coordinates in .
The latter case implies one point in the extension 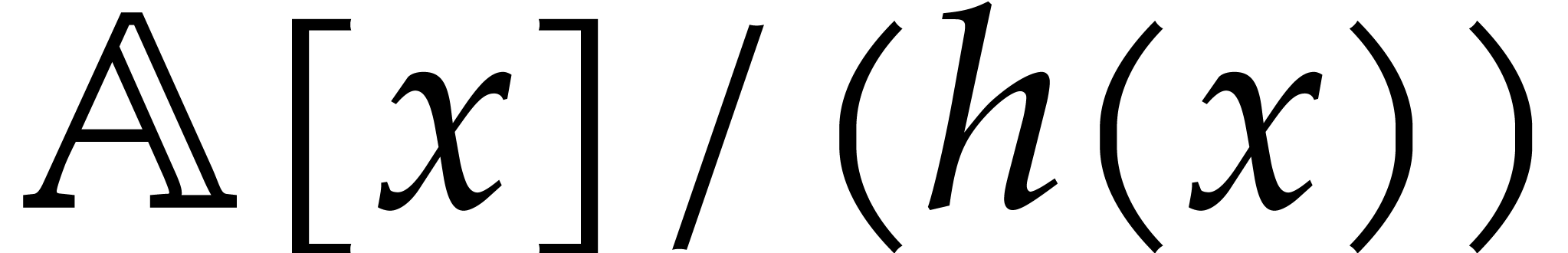 . In the next paragraphs we summarize known
conversions between evaluation problems.
. In the next paragraphs we summarize known
conversions between evaluation problems.
When , several algorithms are
known for converting evaluations at any set of points to specific sets
of points. For instance evaluating at roots of unity can be done fast
thanks to the seminal FFT algorithm, so we usually build fast algorithms
upon FFTs. Typically fast polynomial products are reduced to FFTs over
synthetic roots of unity lying in suitable extensions of by means of the Schönhage–Strassen algorithm.
And since fast multi-point evaluation reduces to polynomial products,
they thus reduce to FFTs. Such reductions to FFTs are omnipresent in
computer algebra.
Let us still assume that .
Let 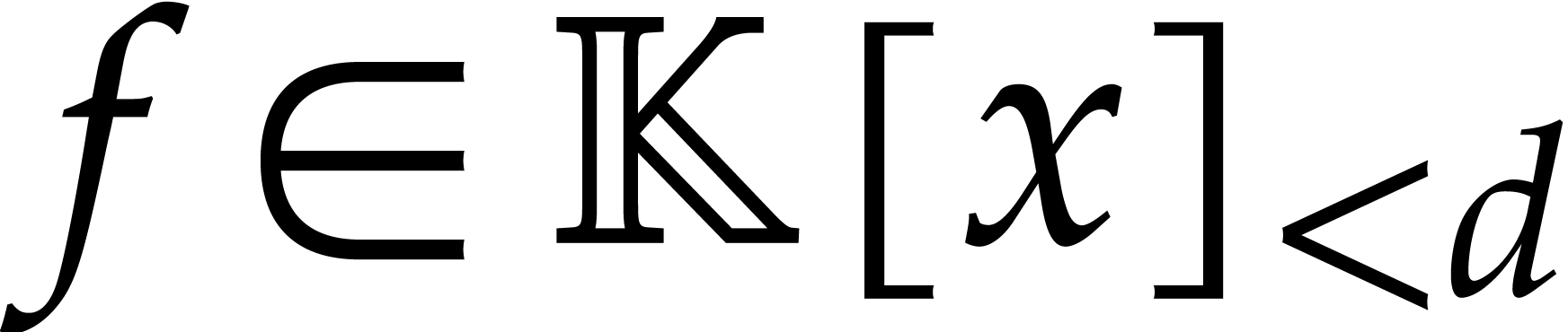 , let
, let  be given evaluation points in a field ,
and let
be given evaluation points in a field ,
and let  be pairwise distinct evaluation points
in . Let
be pairwise distinct evaluation points
in . Let 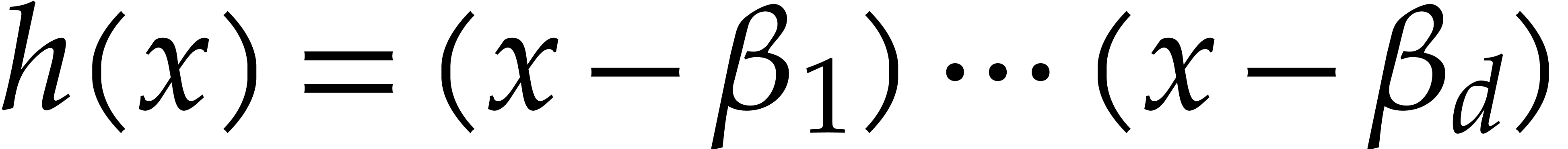 and let
and let 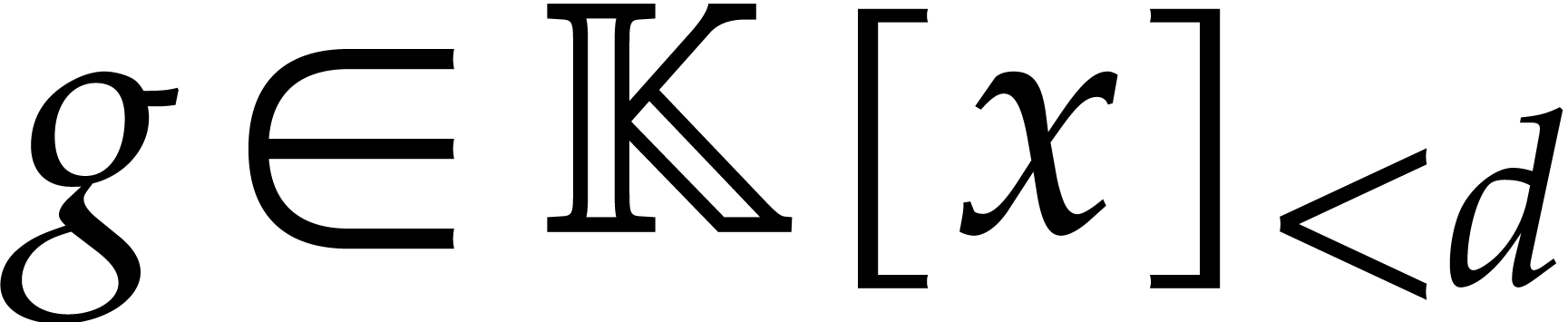 be such that
be such that 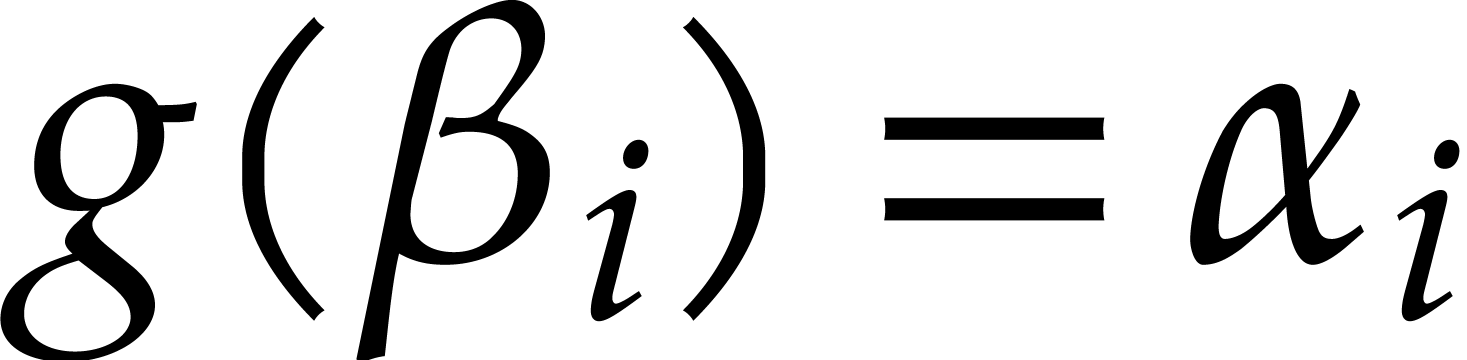 for
for
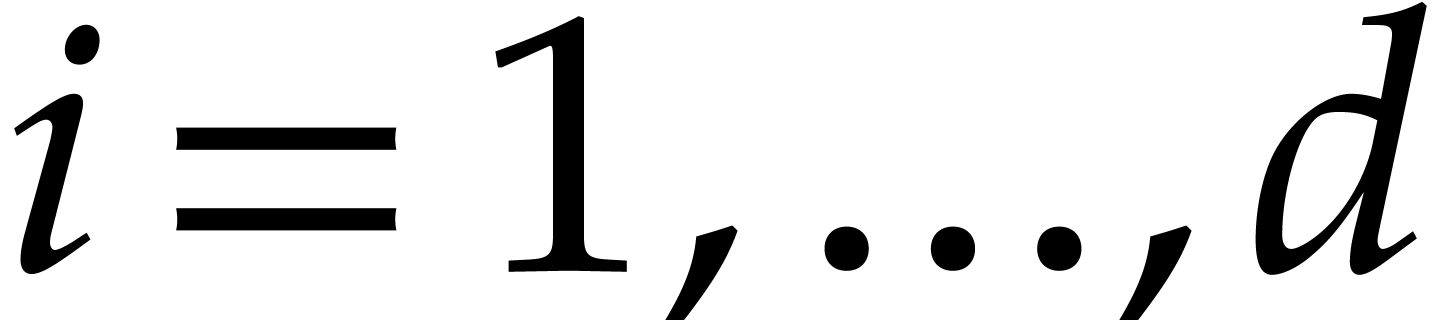 . Setting
. Setting 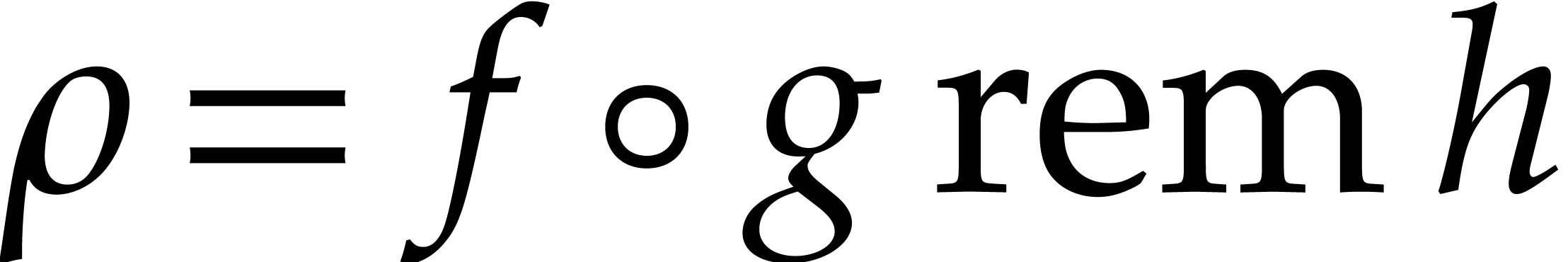 we have
we have 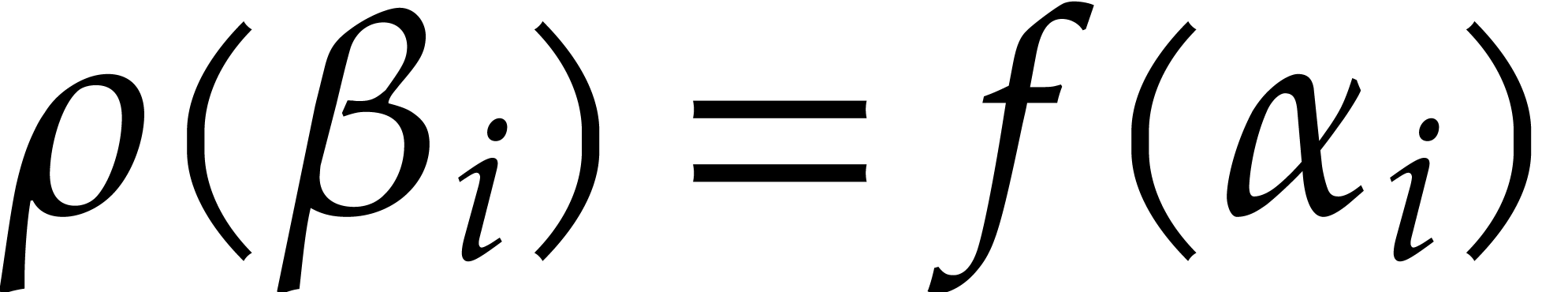 . So the evaluations
of at reduce to
evaluations and interpolations in degree
. So the evaluations
of at reduce to
evaluations and interpolations in degree  at the
chosen points plus one modular composition. Conversely given a modulus
, one may benefit from
factorizations of to compose modulo . We have studied this approach when has factors with large multiplicities in [25],
when it splits into linear factors over
at the
chosen points plus one modular composition. Conversely given a modulus
, one may benefit from
factorizations of to compose modulo . We have studied this approach when has factors with large multiplicities in [25],
when it splits into linear factors over  in [26], and also when it factors over an algebraic extension of
in [27].
in [26], and also when it factors over an algebraic extension of
in [27].
The key idea of Nüsken and Ziegler to speed up multi-point
evaluation is a reduction to modular composition; then their
aforementioned complexity bound follows from a variant of the
Brent–Kung algorithm. Assume .
In order to evaluate at
points they first compute 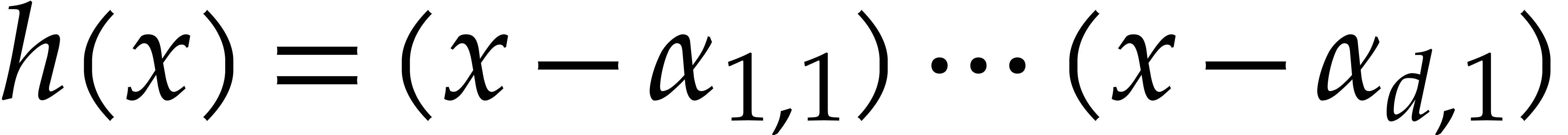 and interpolate
and interpolate  such that
such that 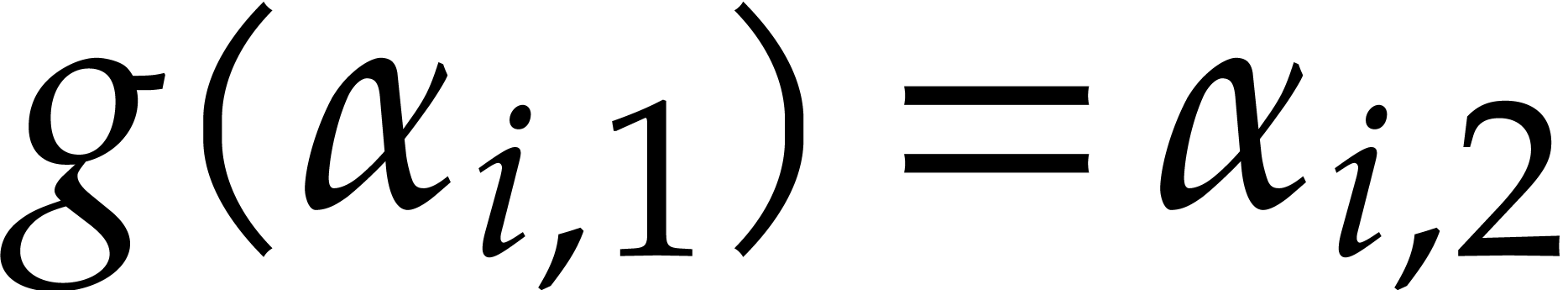 for (assuming the
for (assuming the 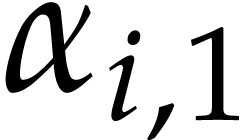 being
pairwise distinct, which is not restrictive). Then they compute
being
pairwise distinct, which is not restrictive). Then they compute 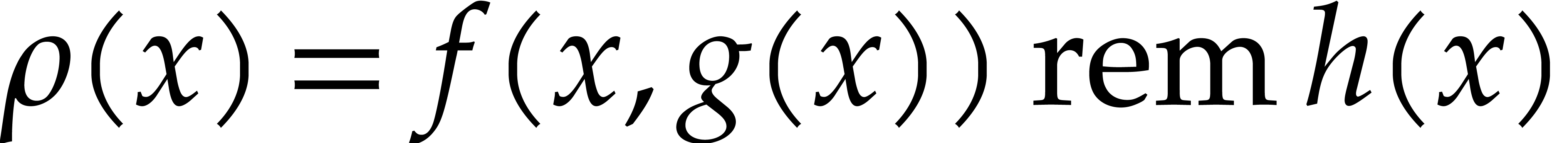 and deduce
and deduce 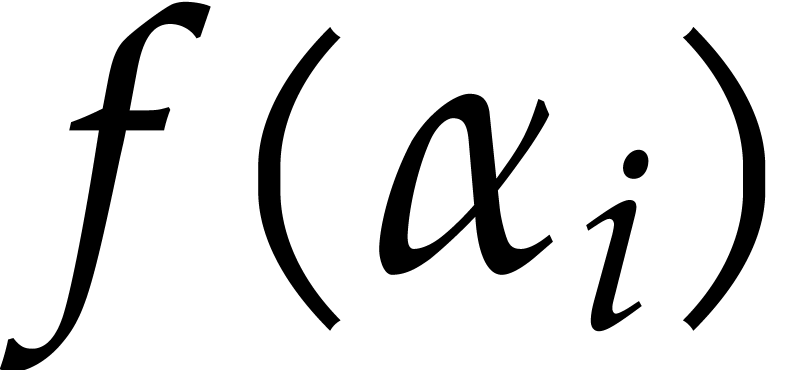 as
as 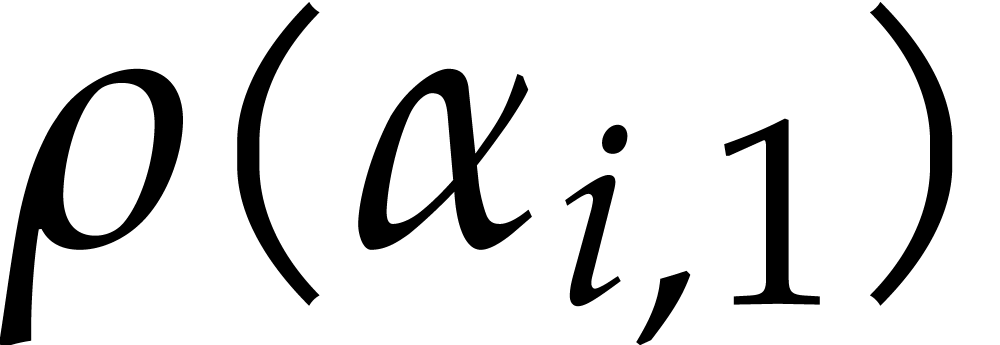 .
.
Over finite fields, Kedlaya and Umans showed an equivalence between
multi-point evaluation and modular composition. Using Kronecker
segmentation, Theorem 3.1 from [34] reduces such a
composition to multi-point evaluation for an increased number of
variables. Kedlaya and Umans' reduction in the opposite direction is
close to the one of Nüsken and Ziegler. Let  be pairwise distinct points in .
For each
be pairwise distinct points in .
For each  , they interpolate
, they interpolate
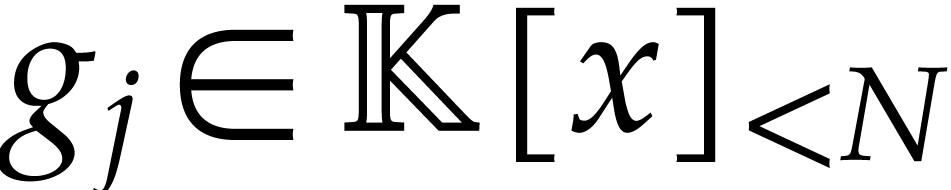 such that
such that 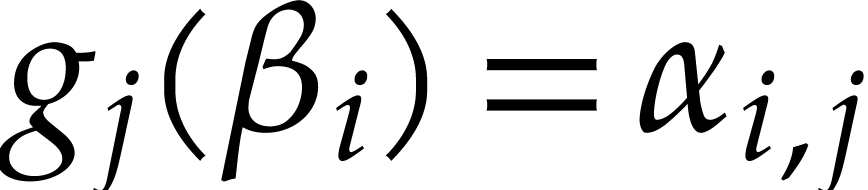 for
for  . Then they compute
. Then they compute  , so that
, so that 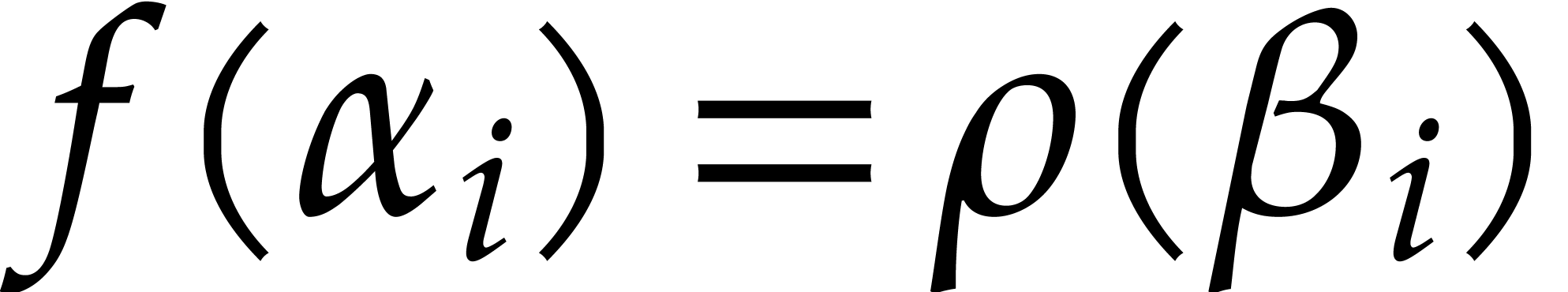 .
.
1.2.Contributions
On machines with random access memory, arbitrary memory accesses admit a
constant cost. This does not reflect the actual behavior of real
computers, on which memory is organized into different levels, with
efficient hardware support for copying contiguous blocks of memory from
one level to another. In this paper, we opted for the standard Turing
machine model with a finite number of tapes [38], which
charges a “maximal penalty” for non contiguous memory
accesses. This means in particular that complexity bounds established
for this model are likely to hold for any more or less realistic
alternative model. Our first contribution in the present paper is to
show that Kedlaya and Umans' complexity bounds hold in the Turing
machine model.
Our second contribution concerns sharper and more precise bit complexity
bounds. For multi-point evaluation over 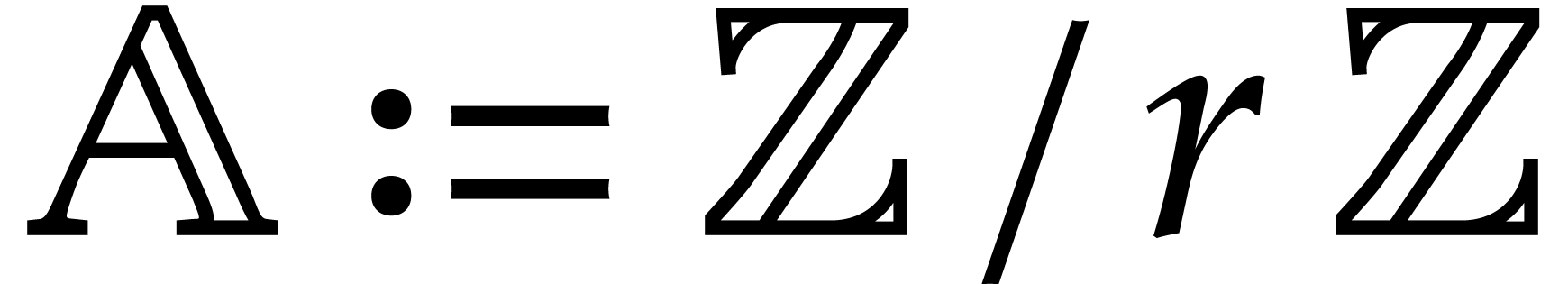 ,
we achieve softly linear time in the bit size of
and obtain more general explicit bounds in terms of
,
we achieve softly linear time in the bit size of
and obtain more general explicit bounds in terms of  ,
,  ,
the partial and total degrees of ,
without the assumption
,
the partial and total degrees of ,
without the assumption  as in [34,
Corollary 4.3]. We also put into evidence the advantage of taking much larger than the dense size of the support of
. In particular, we analyze
the threshold for which the average cost per evaluation point
stabilizes. Our algorithm closely follows the main ideas of Kedlaya and
Umans, but with two notable changes. On the one hand, using precise
estimates for the first Chebyshev function, we obtain sharper bounds for
the prime numbers to be used during the multi-modular stage of the
algorithm; see section 3.3. On the other hand, when
as in [34,
Corollary 4.3]. We also put into evidence the advantage of taking much larger than the dense size of the support of
. In particular, we analyze
the threshold for which the average cost per evaluation point
stabilizes. Our algorithm closely follows the main ideas of Kedlaya and
Umans, but with two notable changes. On the one hand, using precise
estimates for the first Chebyshev function, we obtain sharper bounds for
the prime numbers to be used during the multi-modular stage of the
algorithm; see section 3.3. On the other hand, when 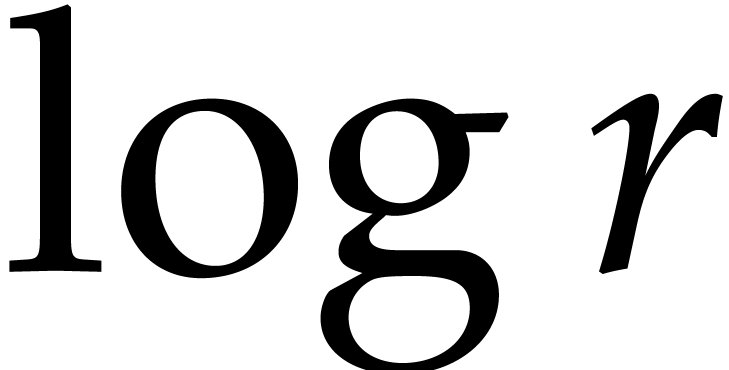 becomes very large, we fall back to the naive
evaluation algorithm, and thereby achieve a softly linear dependence in
.
becomes very large, we fall back to the naive
evaluation algorithm, and thereby achieve a softly linear dependence in
.
Let us now turn to multi-point evaluation over an extension ring of the
form 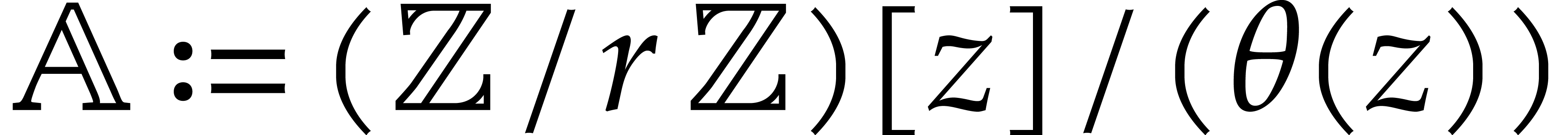 , where
is monic of degree
, where
is monic of degree 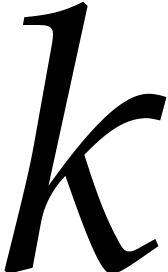 . Kedlaya
and Umans proposed a reduction to multi-point evaluation over
. Kedlaya
and Umans proposed a reduction to multi-point evaluation over 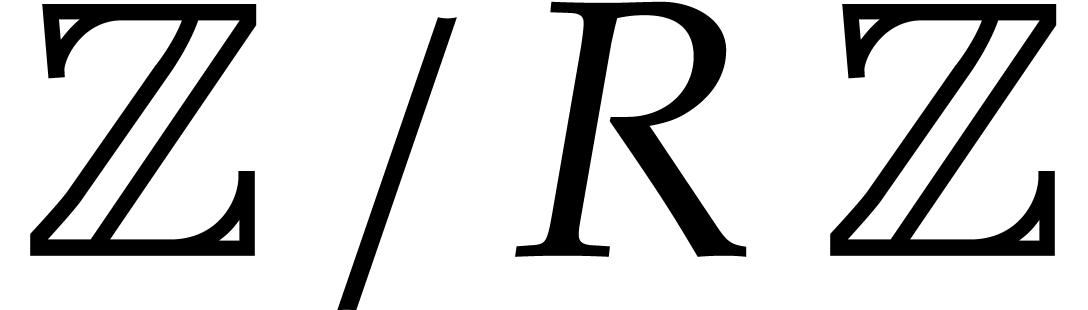 , with
, with  large, based on Kronecker substitution. In section 4, we
propose an alternative approach, based on univariate polynomial
evaluation, interpolation, and Chinese remaindering, to directly reduce
to several compositions over suitable finite prime fields.
large, based on Kronecker substitution. In section 4, we
propose an alternative approach, based on univariate polynomial
evaluation, interpolation, and Chinese remaindering, to directly reduce
to several compositions over suitable finite prime fields.
Our detailed analysis of multi-point evaluation is used in section 6 in order to obtain refined bounds for univariate modular
composition. In [34, Corollary 7.2] it is shown that
univariate modular composition in degree over a
finite field can be done in time 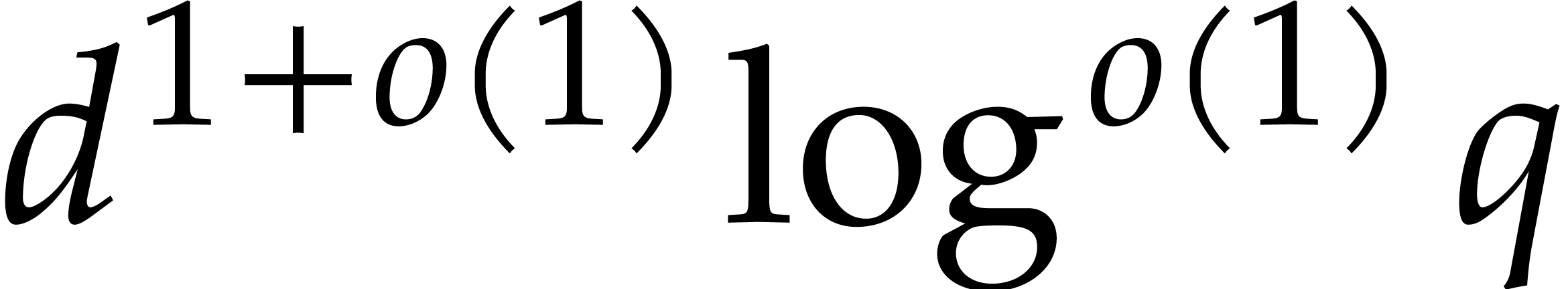 . Making use of the same reduction to
multi-point evaluation, the exponent in
. Making use of the same reduction to
multi-point evaluation, the exponent in 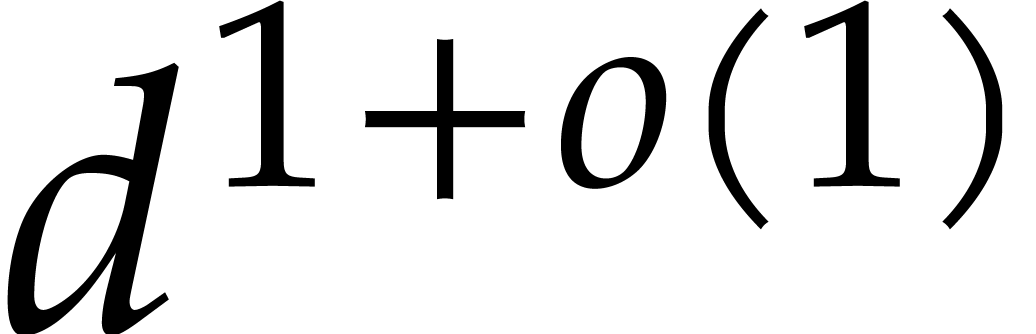 can be
made more explicit: in Theorem 6.2 we prove the bound
can be
made more explicit: in Theorem 6.2 we prove the bound
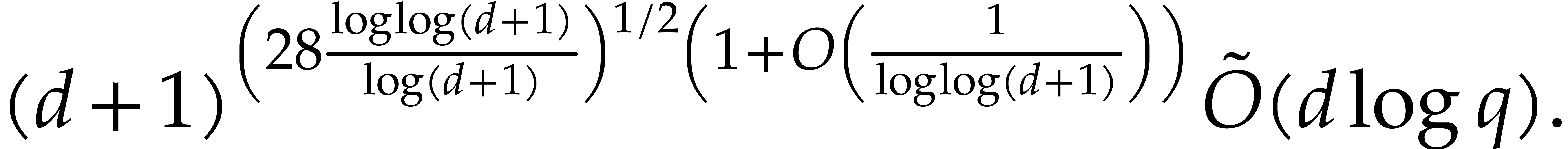
The new complexity bounds for multi-point evaluation are also crucial
for our new bit complexity bounds for multivariate modular composition
and the application to polynomial system solving in [28].
Section 7 addresses the special case when
is a field of small positive characteristic
. We closely revisit the
method proposed in [34, section 6], and again make the
complexity bound more explicit. Again we quantify the number of
evaluation points from which the average cost per point stabilizes, and
we deduce a sharpened complexity bound for modular composition.
2.Complexity model and basic
operations
We consider Turing machines with sufficiently many tapes. In fact seven
tapes are usually sufficient to implement all useful complexity bounds
for the elementary operations on polynomials, series and matrices
involved in the present paper (standard algorithms may be found in [42]). The number of symbols used by the machine is not of the
utmost importance, since it only impacts complexity bounds by constant
factors. In the sequel, Turing machines will always have two symbols
“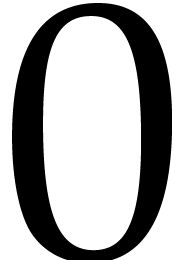 ” and
“
” and
“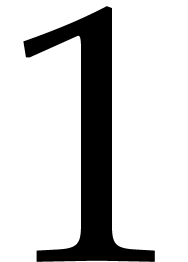 ”, as well as a
few specific additional ones dedicated to data representation.
”, as well as a
few specific additional ones dedicated to data representation.
Some algebraic structures involve a natural bit size for representing
their elements (e.g. modular integers, finite fields); others involve a
variable size (e.g. arbitrarily large integers, arrays, polynomials). In
both cases, elements are seen as sequences of symbols on tapes ended by
a specific symbol, written “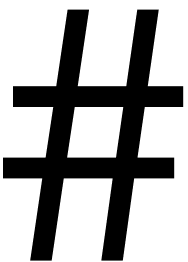 ”
in the sequel. Because heads of the machine can just move one cell left
or right at time, algorithms must take care of consuming data in the
most contiguous way as possible. In particular, we notice that loop
counters must be used with care: for instance, the naive implementation
of a loop “for
”
in the sequel. Because heads of the machine can just move one cell left
or right at time, algorithms must take care of consuming data in the
most contiguous way as possible. In particular, we notice that loop
counters must be used with care: for instance, the naive implementation
of a loop “for  from 1 to ” involves a non-constant number of
from 1 to ” involves a non-constant number of 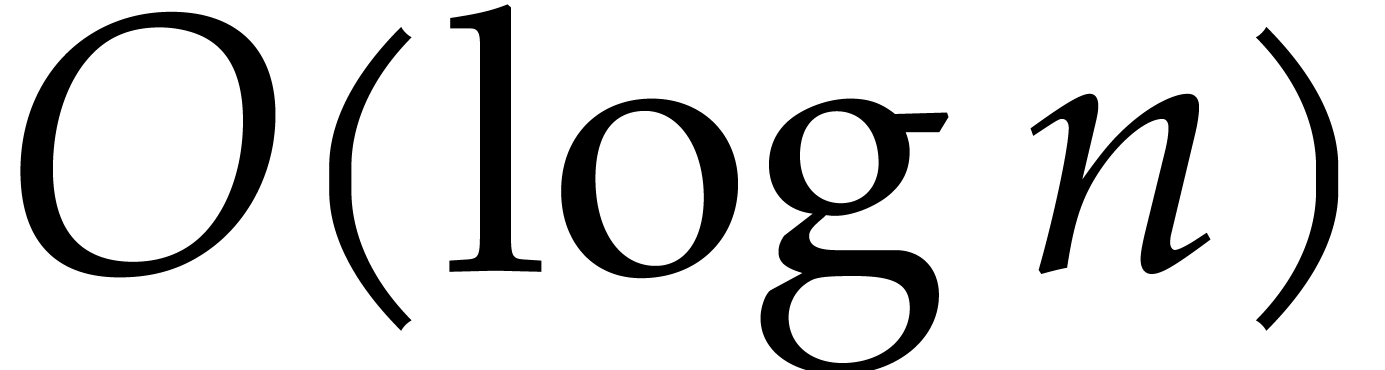 bit operations at each iteration: to increment by and to test whether is less than .
In this section we gather standard data types and elementary operations
needed in the next sections. We freely use well known complexity bounds
for polynomials and matrices from [13] and refer to [42] for more details on Turing machine implementations.
bit operations at each iteration: to increment by and to test whether is less than .
In this section we gather standard data types and elementary operations
needed in the next sections. We freely use well known complexity bounds
for polynomials and matrices from [13] and refer to [42] for more details on Turing machine implementations.
Integers
We use binary representation for integers, so that  has bit size
has bit size 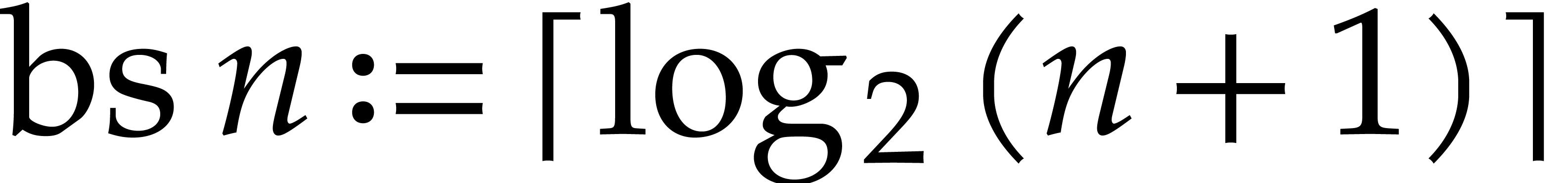 . A modular
integer in
. A modular
integer in 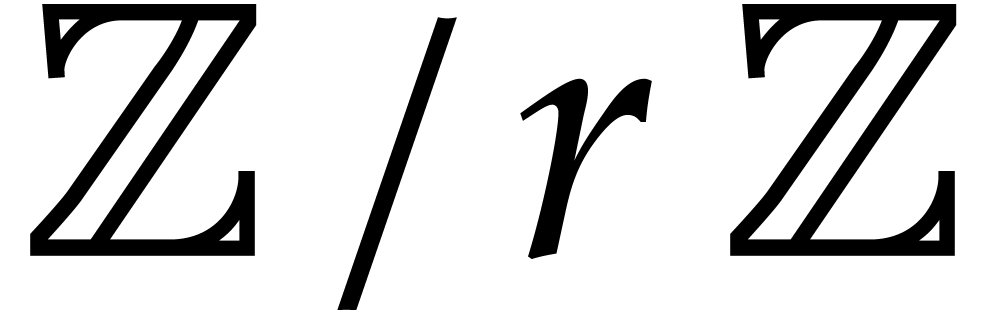 is represented by its natural
representative in
is represented by its natural
representative in 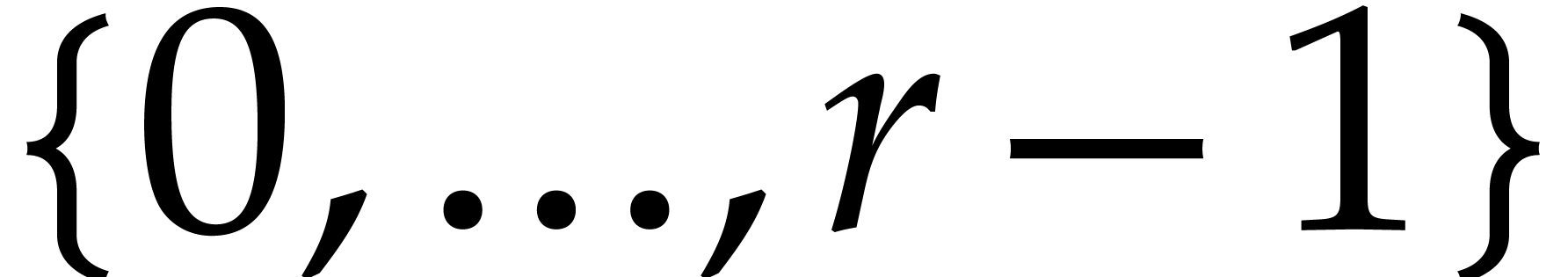 . Integers
may be added in linear time. The expression
. Integers
may be added in linear time. The expression 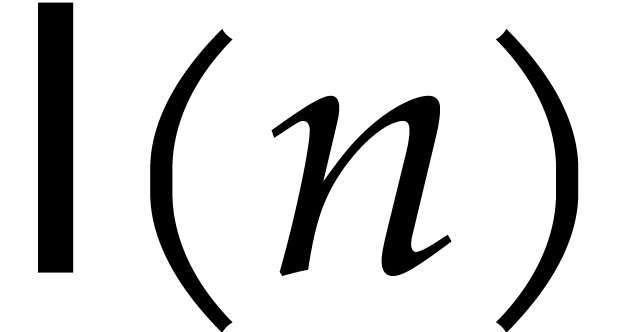 will
represent a nondecreasing cost function for multiplying two integers of
bit sizes
will
represent a nondecreasing cost function for multiplying two integers of
bit sizes 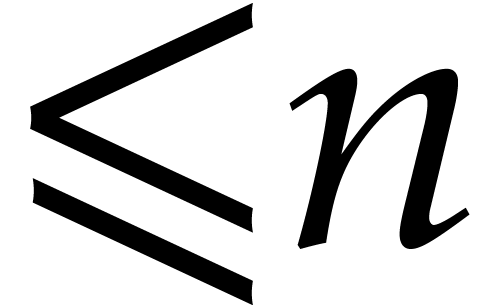 , which satisfies
, which satisfies
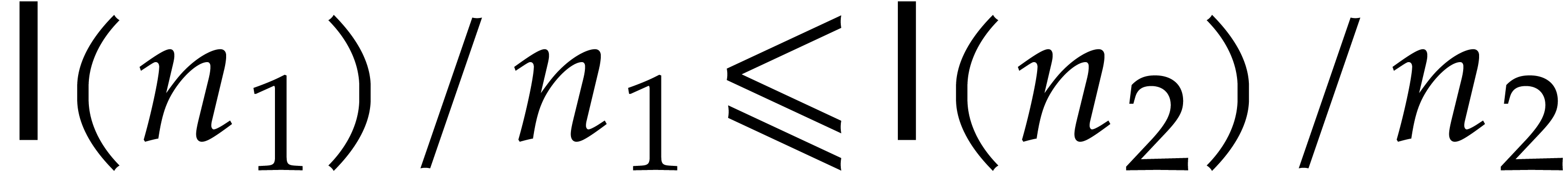 for all
for all 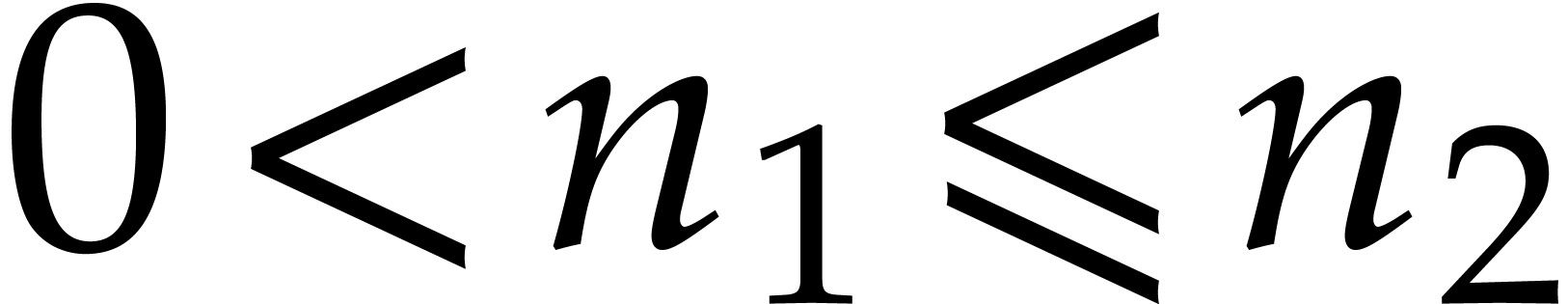 .
At present time the best known complexity bound is
.
At present time the best known complexity bound is 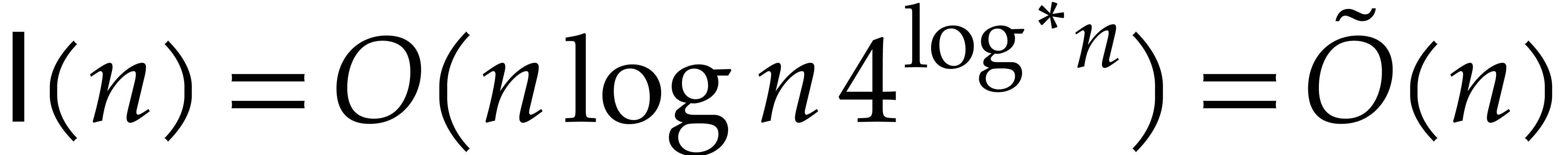 , where
, where  ;
see [16–18] and historical references
therein. The integer division in bit sizes takes
time
;
see [16–18] and historical references
therein. The integer division in bit sizes takes
time 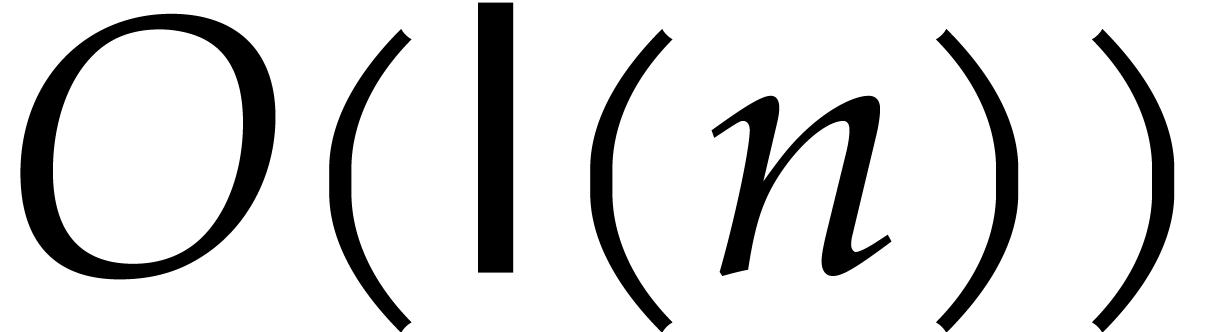 (see Lemma 2.15 below for
instance), and the extended gcd costs
(see Lemma 2.15 below for
instance), and the extended gcd costs 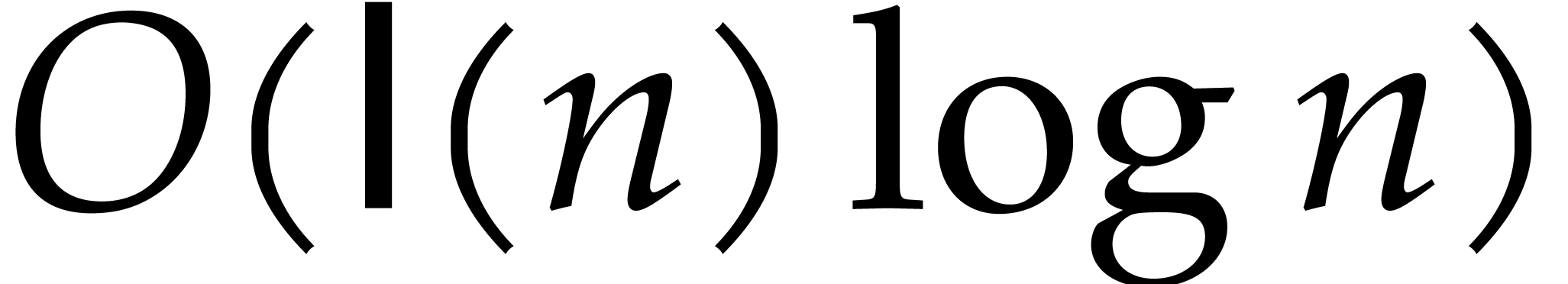 by [41]. Overall, all arithmetic operations in
take softly linear time.
by [41]. Overall, all arithmetic operations in
take softly linear time.
Arrays
One dimensional arrays are sequences of elements ended with the symbol
“”.
Example 2.1.
The vector 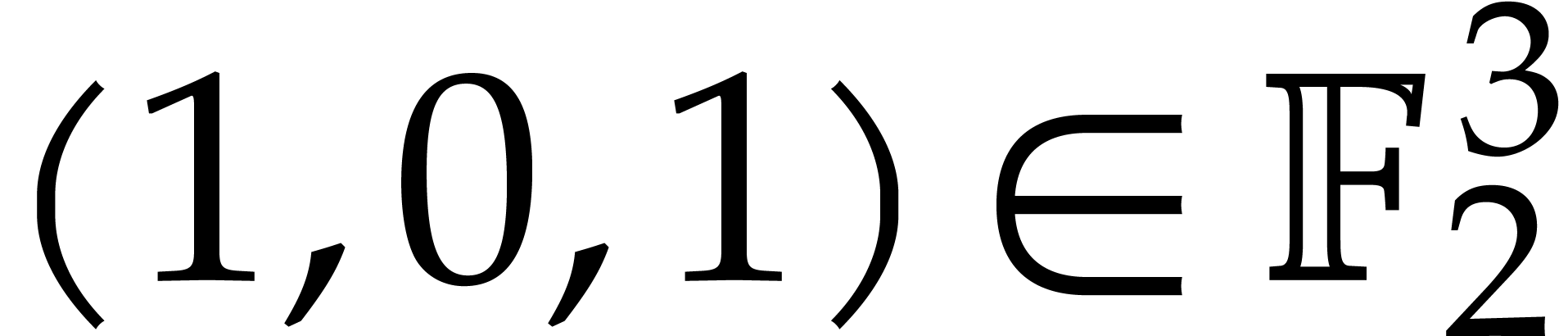 is stored as
is stored as 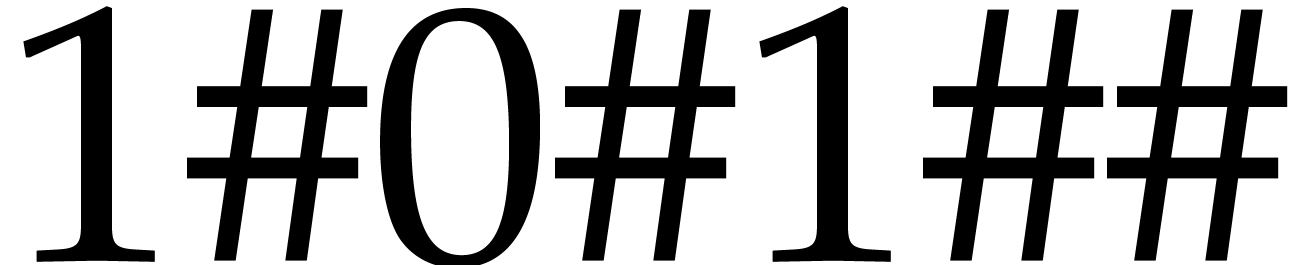 .
.
For bidimensional arrays we use column-major representation. Precisely
an array 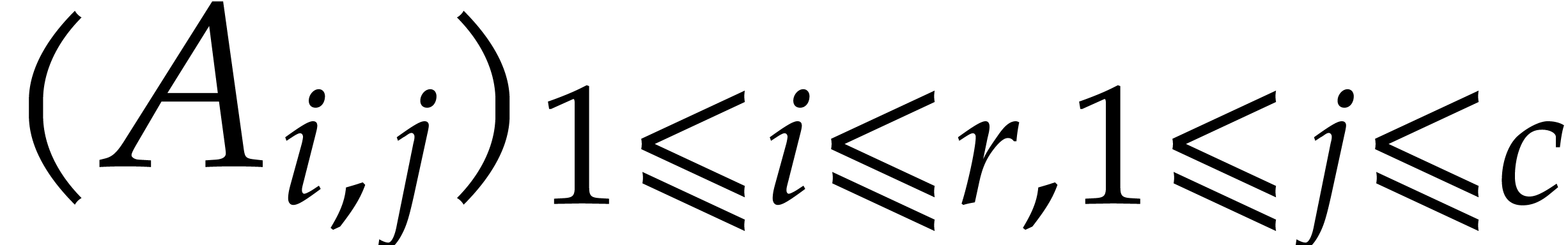 of size
of size  ( rows and columns), is stored
as the vector of its columns, that is
( rows and columns), is stored
as the vector of its columns, that is 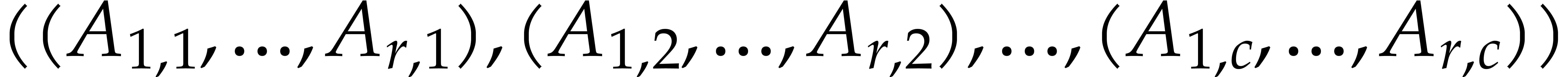 .
Such arrays are allowed to contain elements of different types and
sizes.
.
Such arrays are allowed to contain elements of different types and
sizes.
Example 2.2.
The matrix 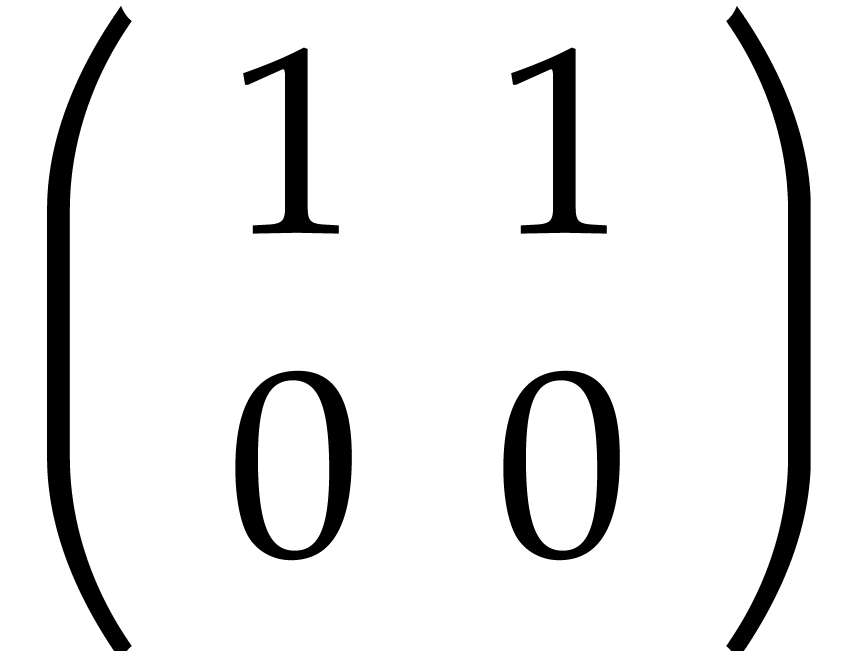 over
over  is stored as
is stored as 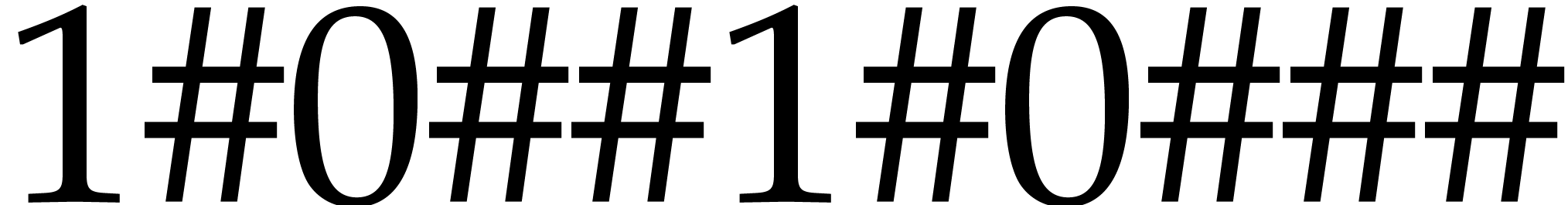 .
.
In the Turing machine model, it is not known how to perform
transpositions of bidimensional arrays in linear time. The following
lemma shows how to do transpositions with a logarithmic overhead. The
special case when all entries have the same bit size was treated before
in [5, appendix]. Notice that transpositions do not
preserve the total bit size for non square matrices, due to changes in
the number of “#” symbols.
Proof. We first handle the case 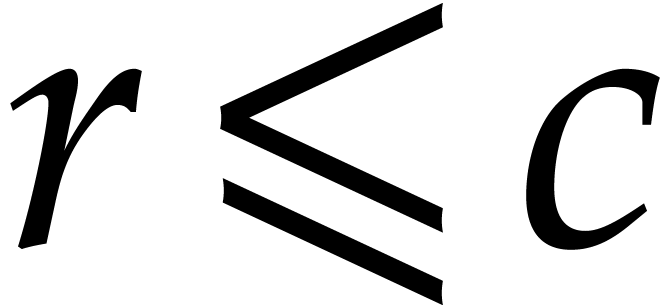 using the following “divide and conquer” algorithm. If
using the following “divide and conquer” algorithm. If  , then the array
, then the array  is encoded as
is encoded as 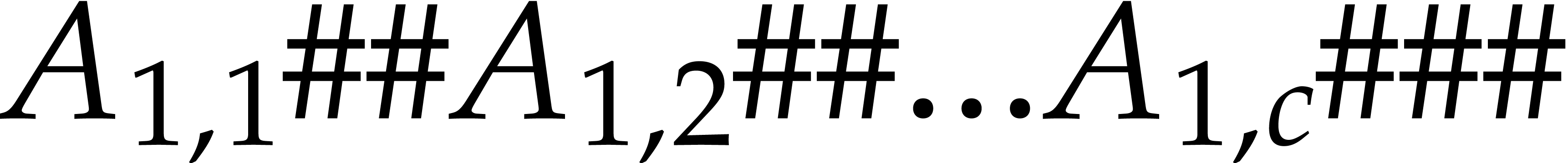 and we write its transpose
and we write its transpose 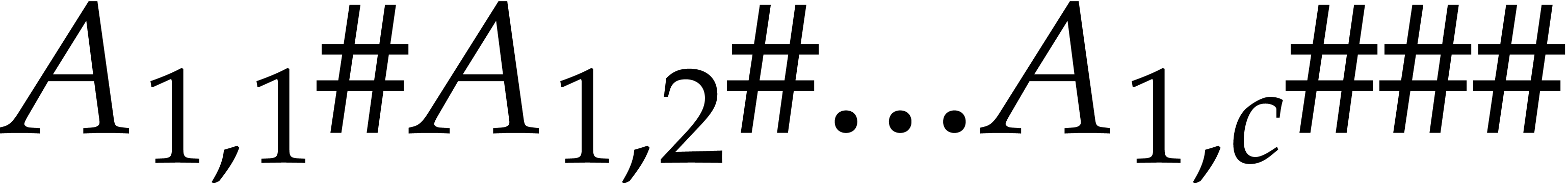 on the output tape using one linear traversal.
Otherwise, we split
on the output tape using one linear traversal.
Otherwise, we split  into two matrices
into two matrices  and
and  on separate tapes, where is made of the
on separate tapes, where is made of the 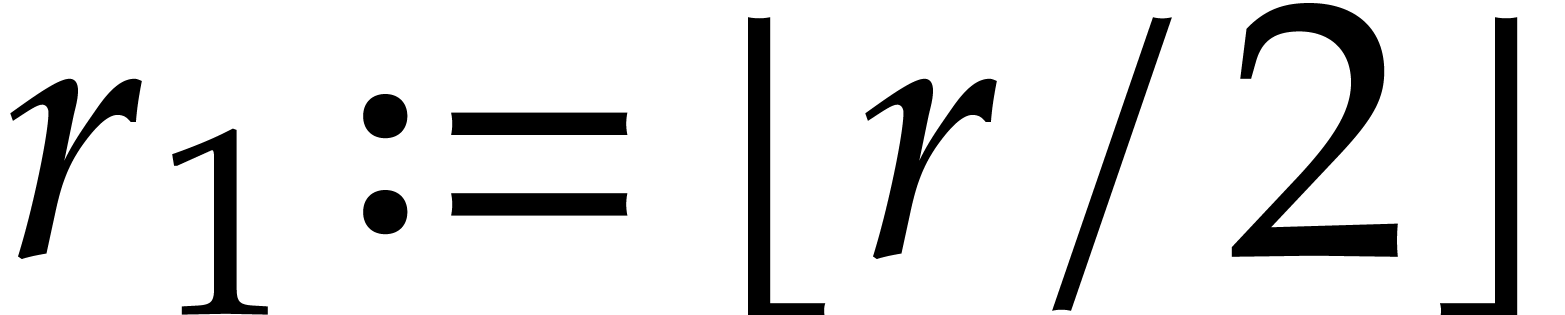 first rows of
, and
of the
first rows of
, and
of the 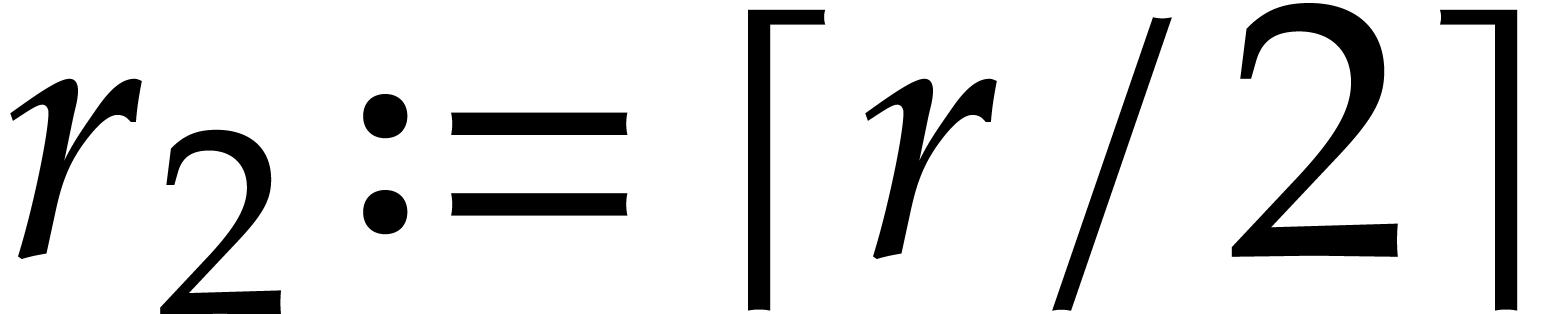 remaining ones. We recursively transpose
and and glue the results
together on the output tape.
remaining ones. We recursively transpose
and and glue the results
together on the output tape.
Clearly, the case when  can be handled in time
can be handled in time
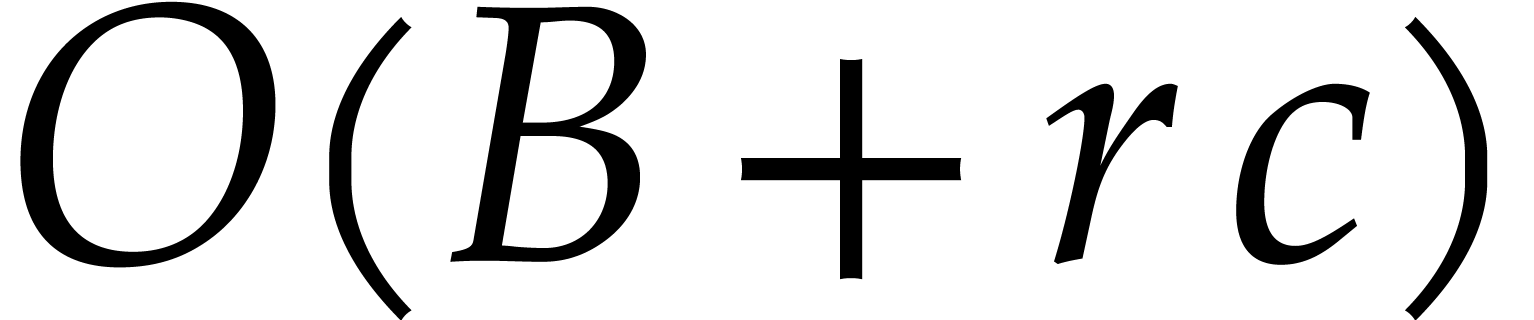 , as well as the algorithm
for splitting into and
, and the algorithm for
gluing the transposes of and
together into the transpose of .
Let
, as well as the algorithm
for splitting into and
, and the algorithm for
gluing the transposes of and
together into the transpose of .
Let  be a constant such that each of these
algorithms takes time at most
be a constant such that each of these
algorithms takes time at most 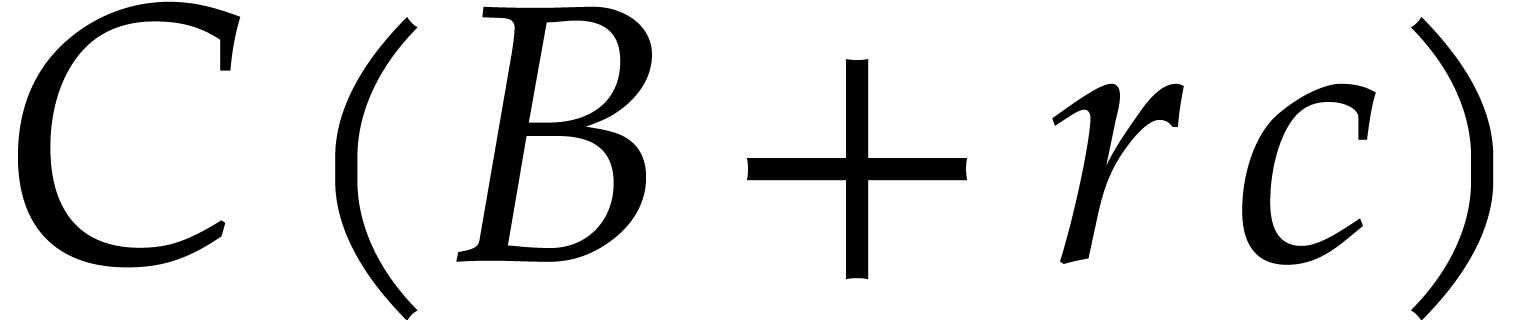 .
Let
.
Let 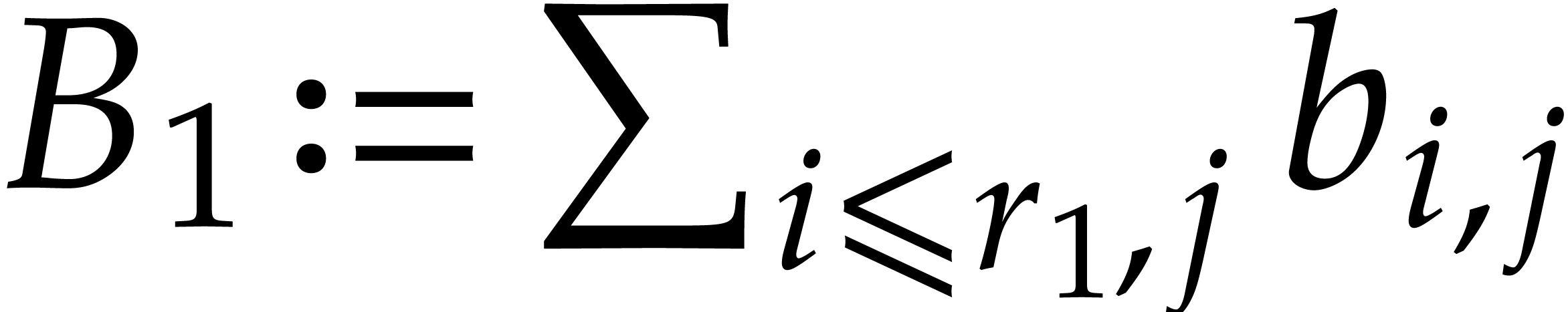 and
and 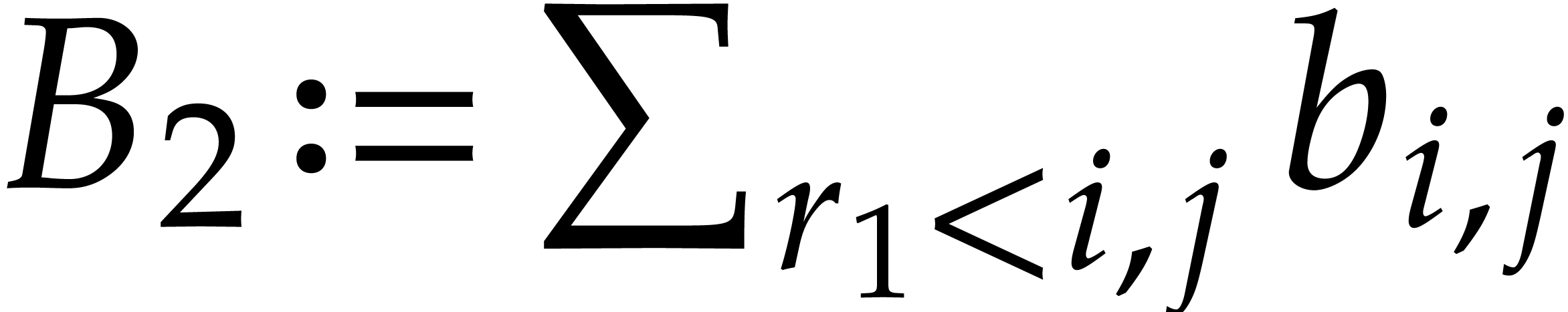 .
Let us show by induction over
.
Let us show by induction over 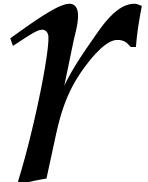 that the
transposition algorithm takes time
that the
transposition algorithm takes time  .
This is clear for . For
.
This is clear for . For  , the computation time is bounded
by
, the computation time is bounded
by
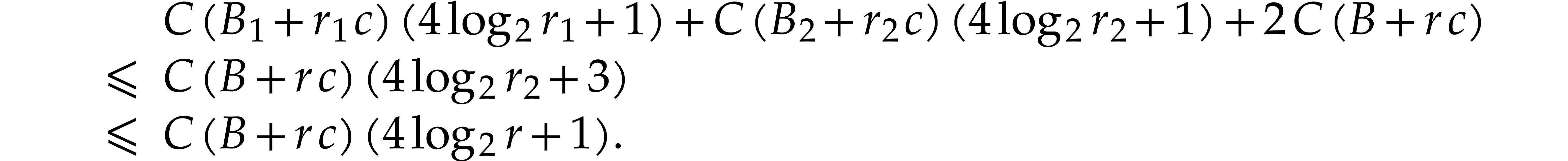
The case when 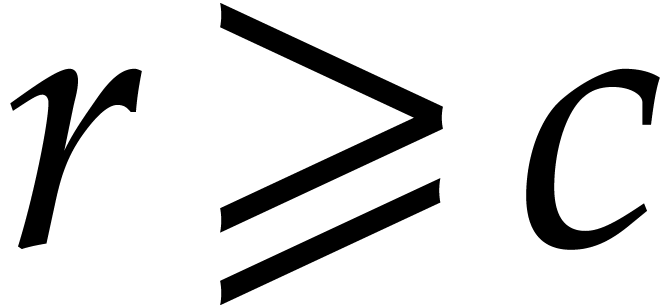 is handled in an essentially
similar way, by reverting the steps of the algorithm: if
is handled in an essentially
similar way, by reverting the steps of the algorithm: if 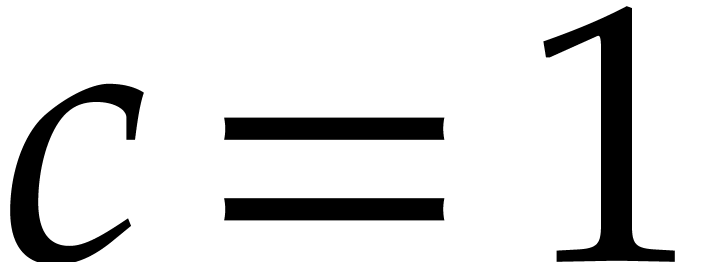 , then
, then 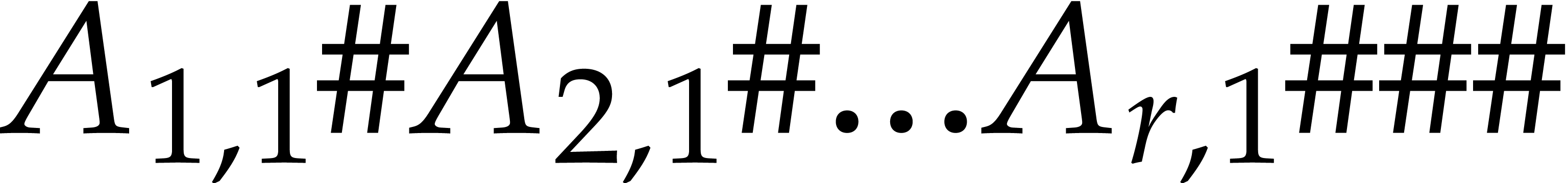 is rewritten
into
is rewritten
into 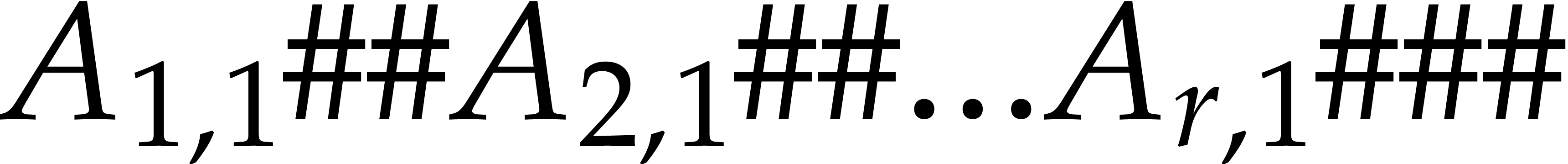 using one linear pass. If
using one linear pass. If  , then we recursively apply the algorithm on
the first
, then we recursively apply the algorithm on
the first 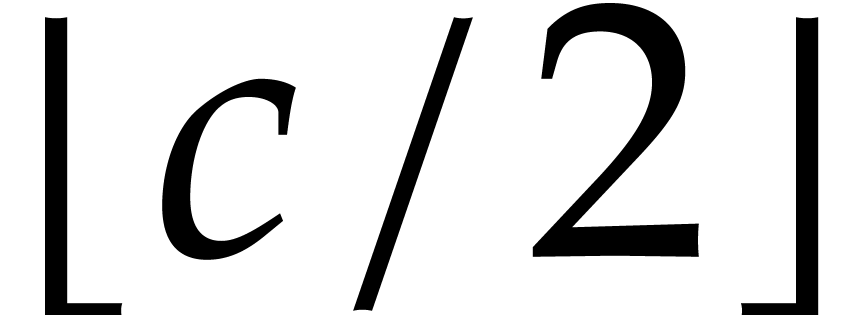 and the last
and the last 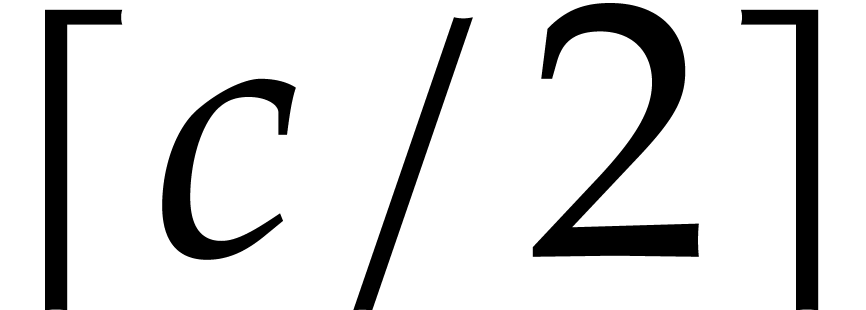 columns, and merge the results in a linear pass. The entire computation
can be done in time
columns, and merge the results in a linear pass. The entire computation
can be done in time 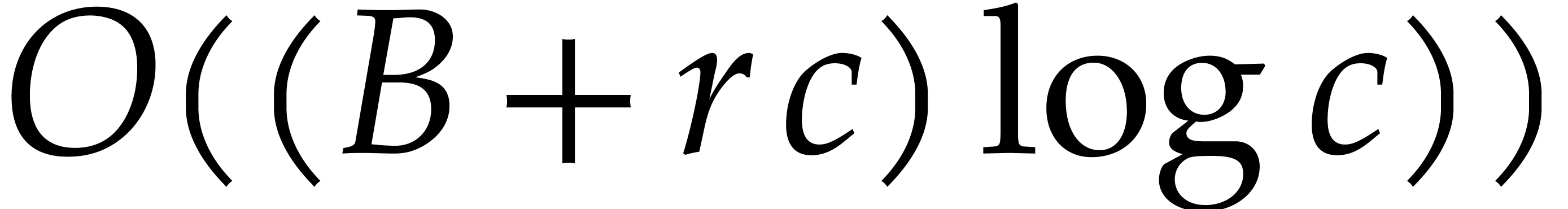 , by a
similar complexity analysis as above.
, by a
similar complexity analysis as above.
Univariate polynomials
For univariate polynomials we use dense representation, which means that
a polynomial of degree is stored as the vector
of its  coefficients from degrees to . Additions
and subtractions take linear time in .
Let
coefficients from degrees to . Additions
and subtractions take linear time in .
Let 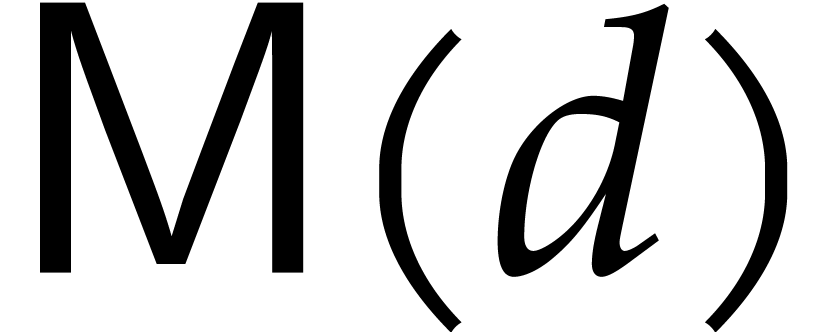 denote a cost function that yields an upper
bound for the number of operations in needed to
multiply two polynomials in
denote a cost function that yields an upper
bound for the number of operations in needed to
multiply two polynomials in 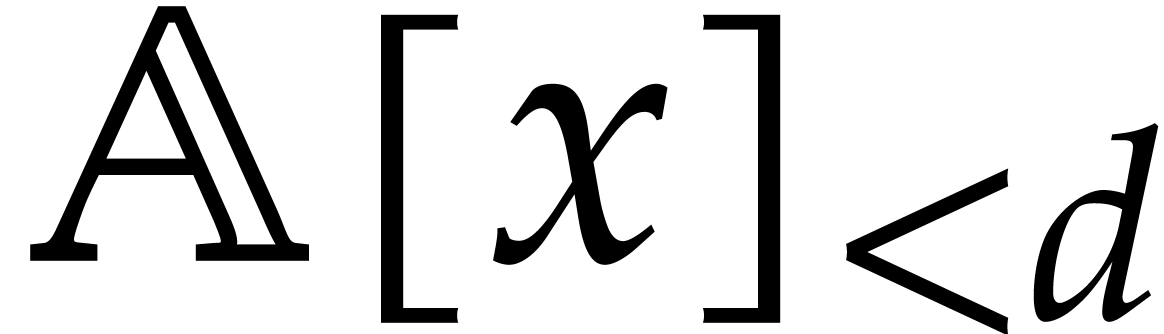 .
For a general ring one may take
.
For a general ring one may take 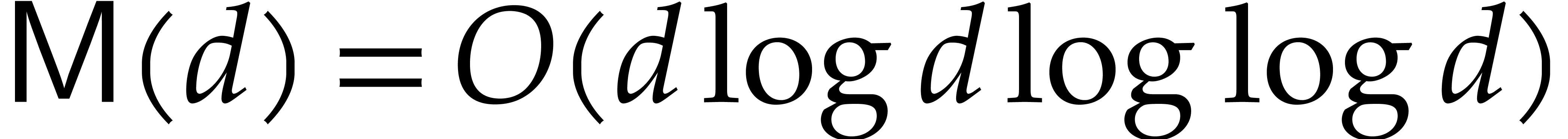 thanks to [10]. For finite fields better bounds exist, and
we write
thanks to [10]. For finite fields better bounds exist, and
we write 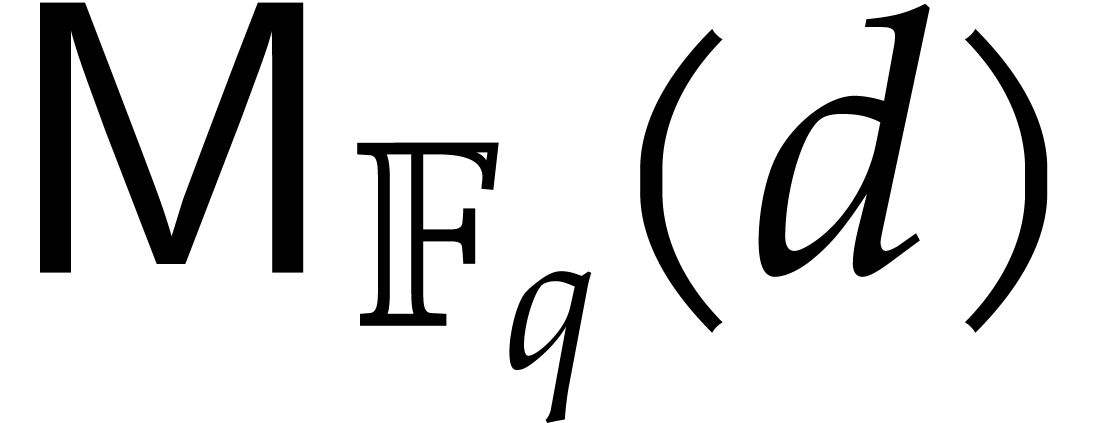 for the time taken by a Turing machine
to multiply two polynomials in
for the time taken by a Turing machine
to multiply two polynomials in 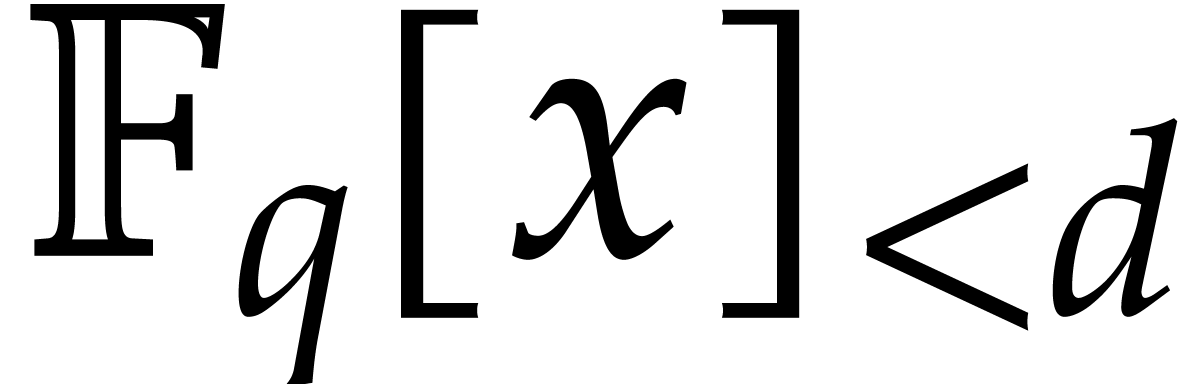 .
.
In what follows, any finite field with  and prime is always assumed to be
given as
and prime is always assumed to be
given as  with monic and
irreducible of degree .
Elements of are stored as their natural
representatives in
with monic and
irreducible of degree .
Elements of are stored as their natural
representatives in 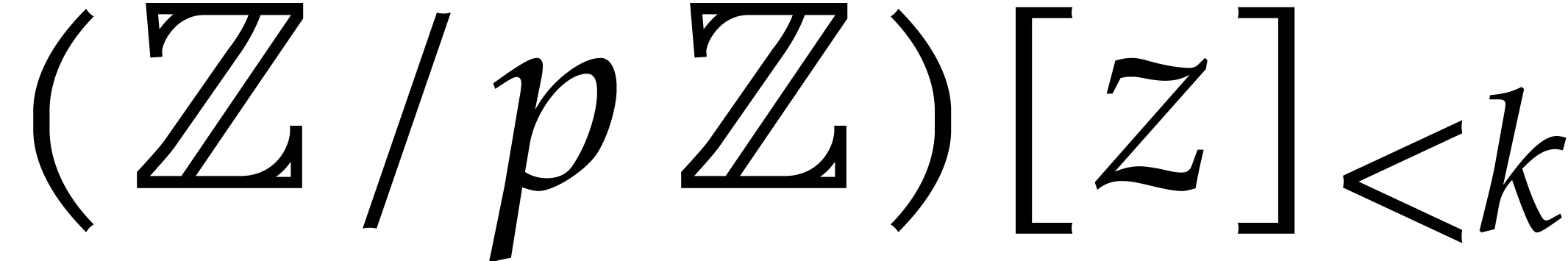 .
Additions and subtractions in take linear time,
one product takes time
.
Additions and subtractions in take linear time,
one product takes time 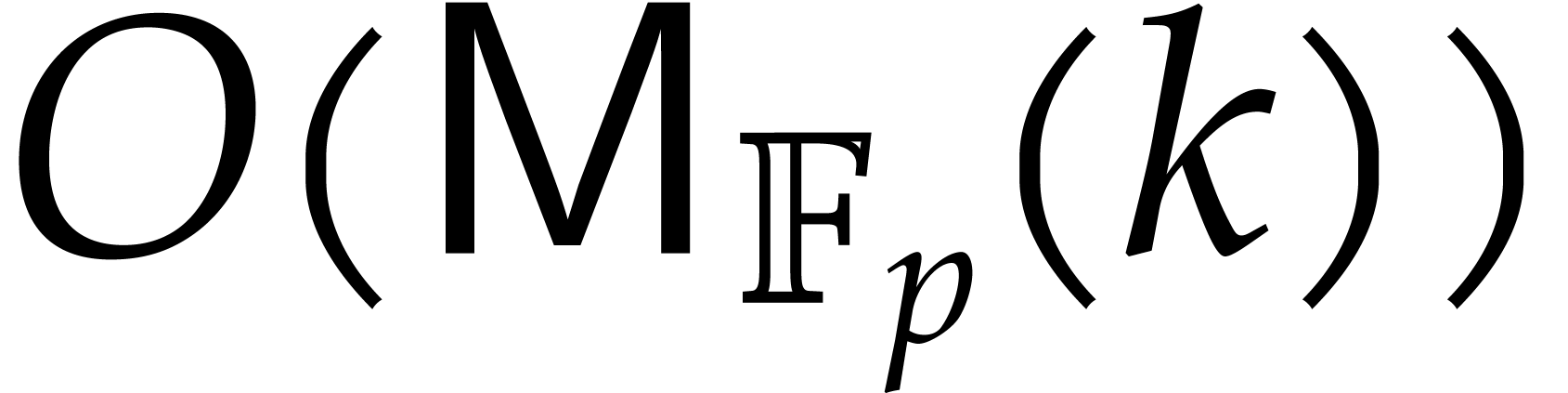 and one inversion
and one inversion 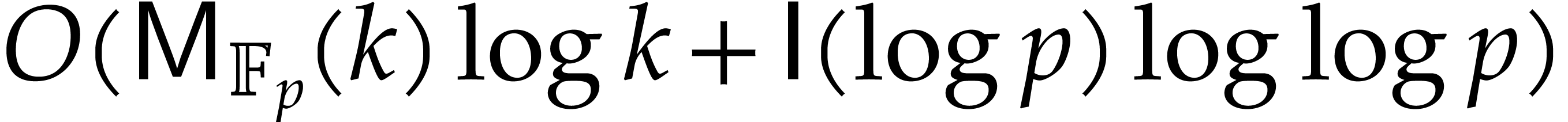 : see [13, part II],
for instance. In [15, 19], it was shown that
: see [13, part II],
for instance. In [15, 19], it was shown that
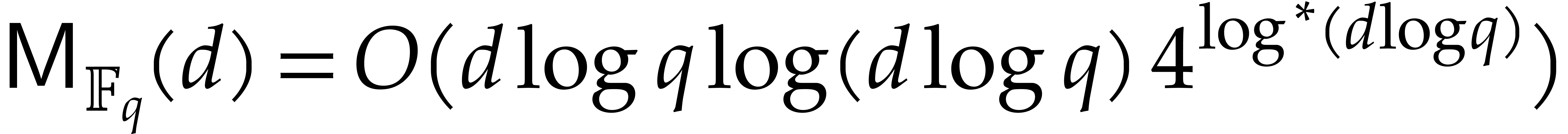 .
.
Multivariate polynomials
For a polynomial in a given number of variables
, we use the recursive
dense representation, by viewing as an
element of 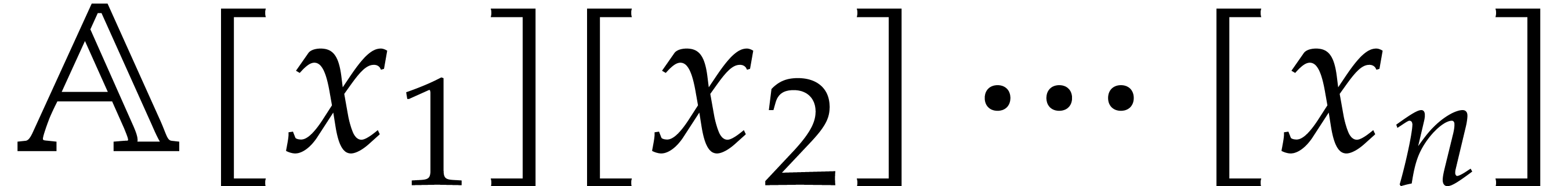 . In particular,
admits the same representation as its expansion
. In particular,
admits the same representation as its expansion
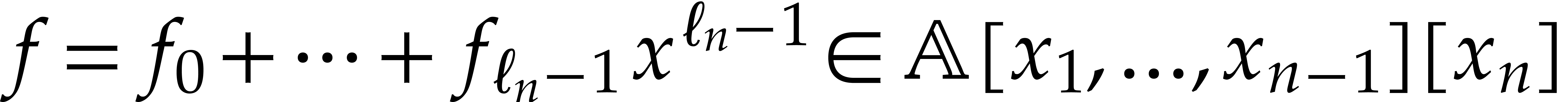 as a univariate polynomial in
as a univariate polynomial in 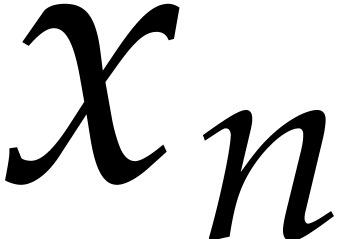 . In our algorithms, the number of variables
is not part of the representation of , so it must be supplied as a
separate parameter.
. In our algorithms, the number of variables
is not part of the representation of , so it must be supplied as a
separate parameter.
Example 2.4.
The univariate polynomial 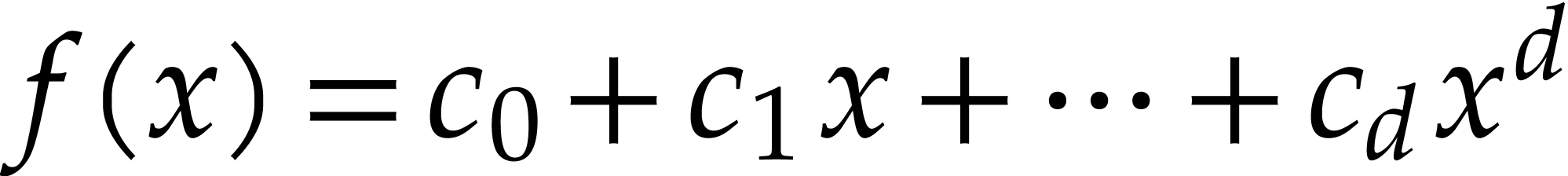 of degree
of degree  is represented by
is represented by 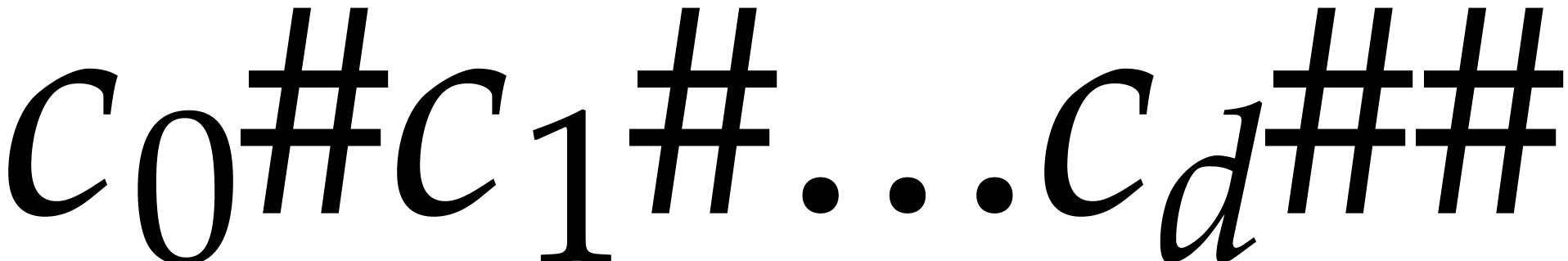 .
The bivariate polynomial
.
The bivariate polynomial 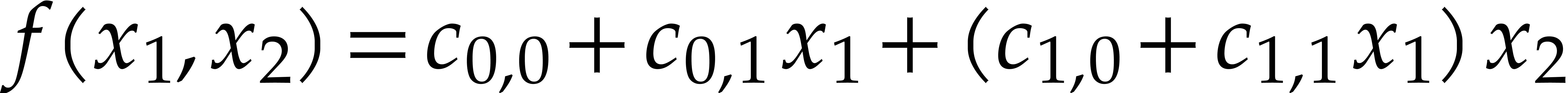 is represented by
is represented by 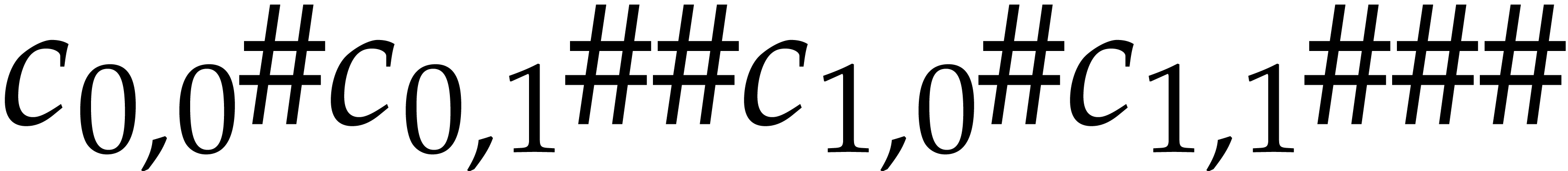 .
.
The support  of
is defined as the set of monomials with nonzero coefficients and we
write
of
is defined as the set of monomials with nonzero coefficients and we
write  for its cardinality. Assuming that, apart
from the mandatory trailing “#” symbol, the representations
of coefficients in do not involve the
“” symbol (this
can always be achieved through suitable renaming
for its cardinality. Assuming that, apart
from the mandatory trailing “#” symbol, the representations
of coefficients in do not involve the
“” symbol (this
can always be achieved through suitable renaming  ), we denote the number of “” symbols involved in the representation
of by
), we denote the number of “” symbols involved in the representation
of by 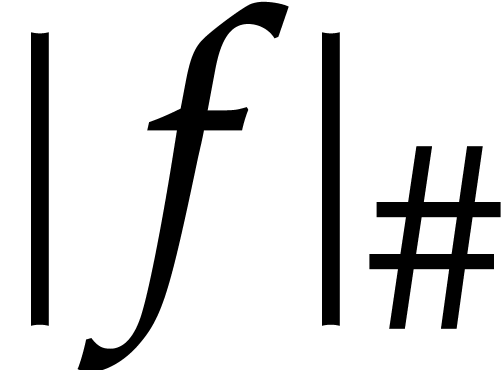 .
We notice that
.
We notice that 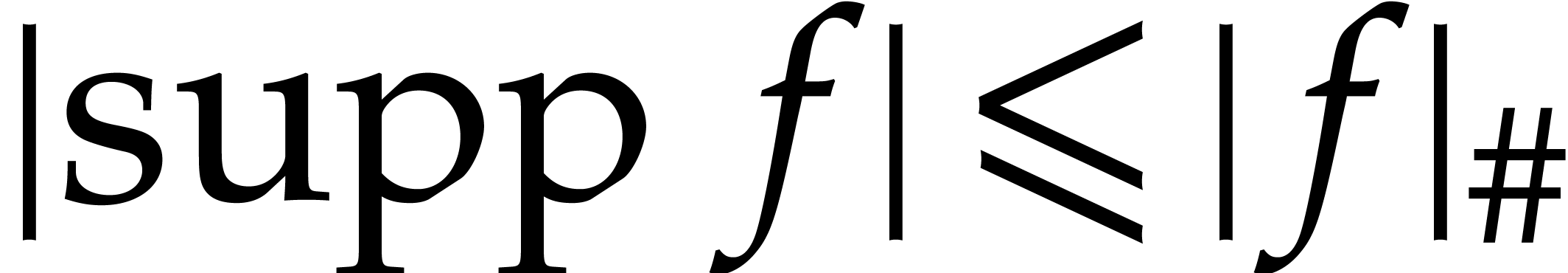 .
.
Proof. This follows by an easy induction over  : for
: for 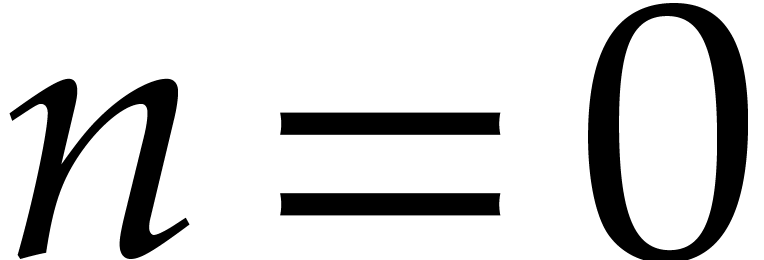 ,
we have nothing to do. If
,
we have nothing to do. If 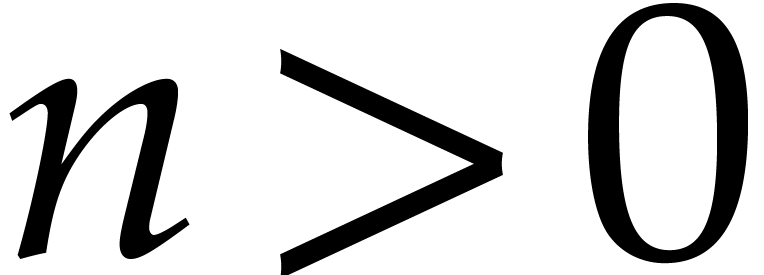 and
and 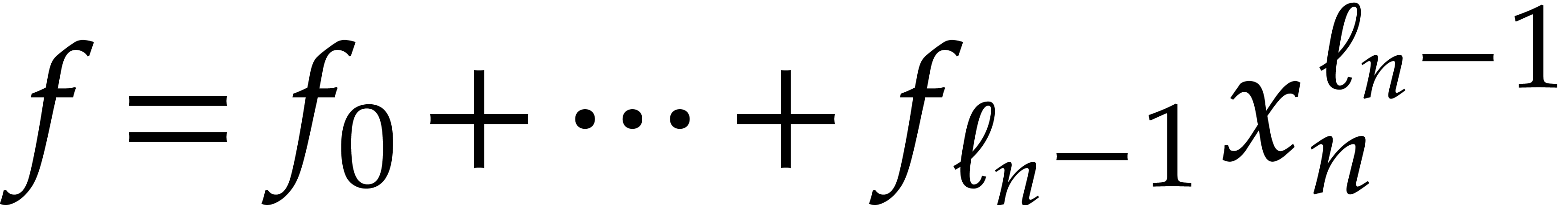 , then we get
, then we get
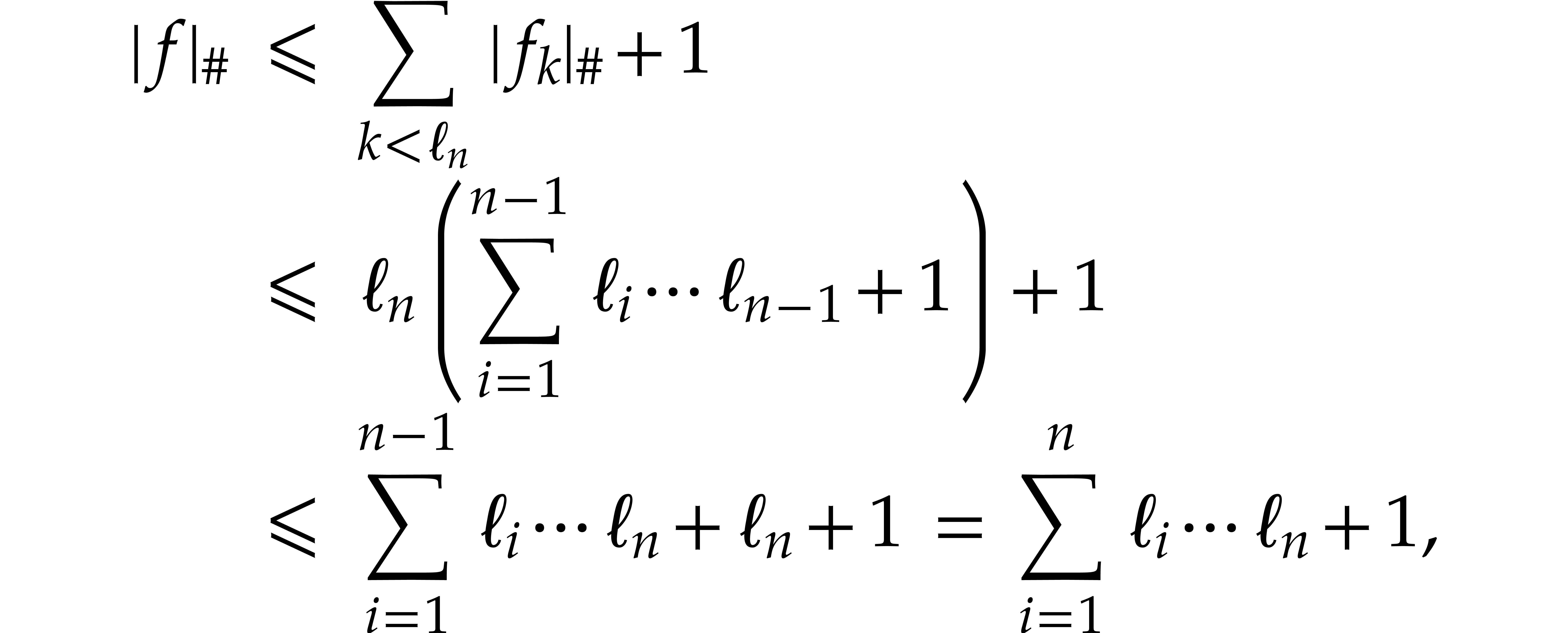
which concludes the proof.
If all the 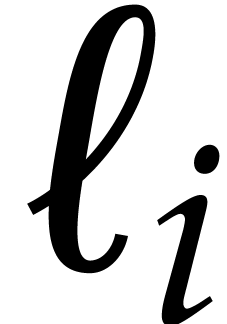 equal ,
then is the constant polynomial
equal ,
then is the constant polynomial  and its representation is
and its representation is  with
with  symbols “”. If
symbols “”. If
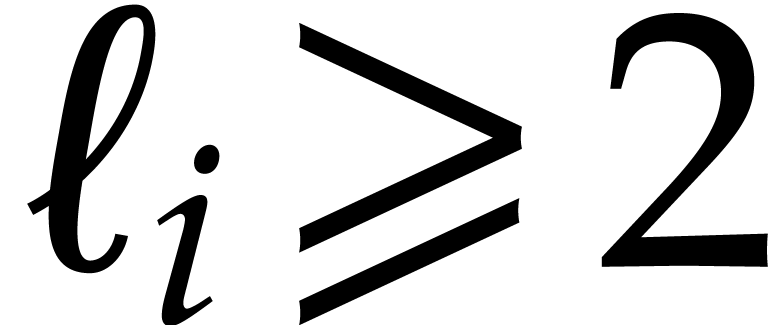 for all ,
then the number of becomes
for all ,
then the number of becomes 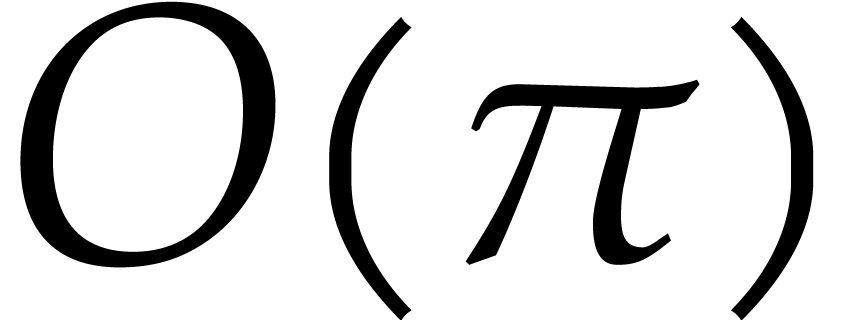 .
.
Proof. We use a similar induction as in the proof of
Lemma 2.5:
If 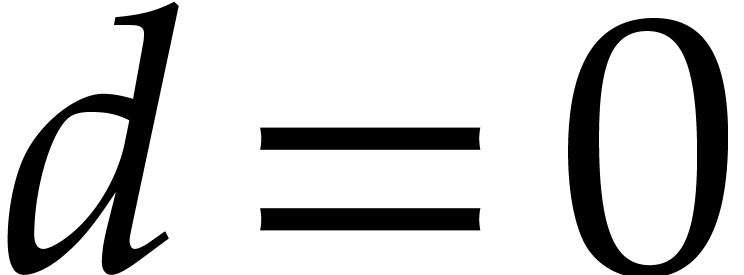 , then we already observed
that
, then we already observed
that 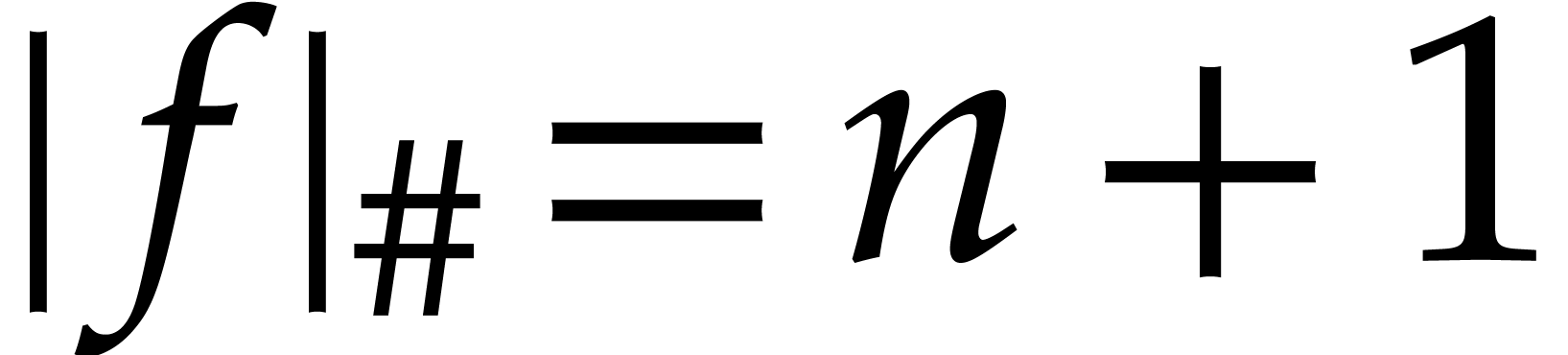 . If
. If 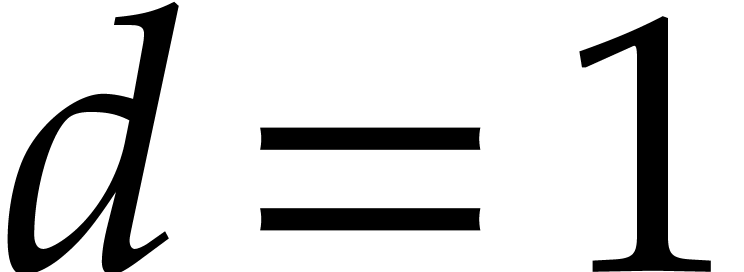 , then
, then 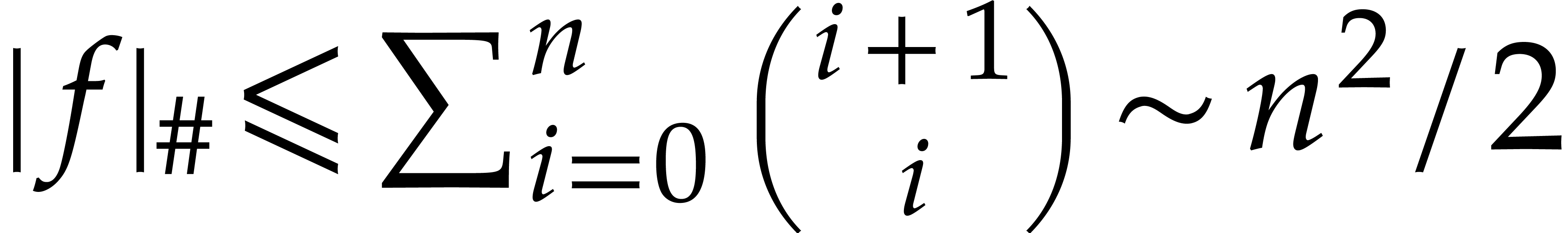 .
For the remainder of this subsection, we assume that the size of the
elements in is bounded by a constant
.
For the remainder of this subsection, we assume that the size of the
elements in is bounded by a constant  . In particular, the total size of
a multivariate polynomial is bounded by
. In particular, the total size of
a multivariate polynomial is bounded by 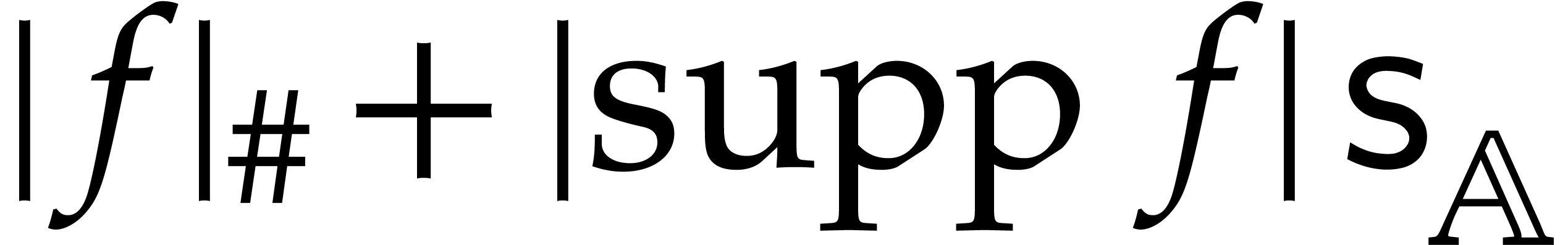 .
.
Proof. Recall that both  and
are considered to be the inputs. We use the
following recursive algorithm: if ,
then we have nothing to do. If ,
then we write and recursively compute partial
degree bounds
and
are considered to be the inputs. We use the
following recursive algorithm: if ,
then we have nothing to do. If ,
then we write and recursively compute partial
degree bounds 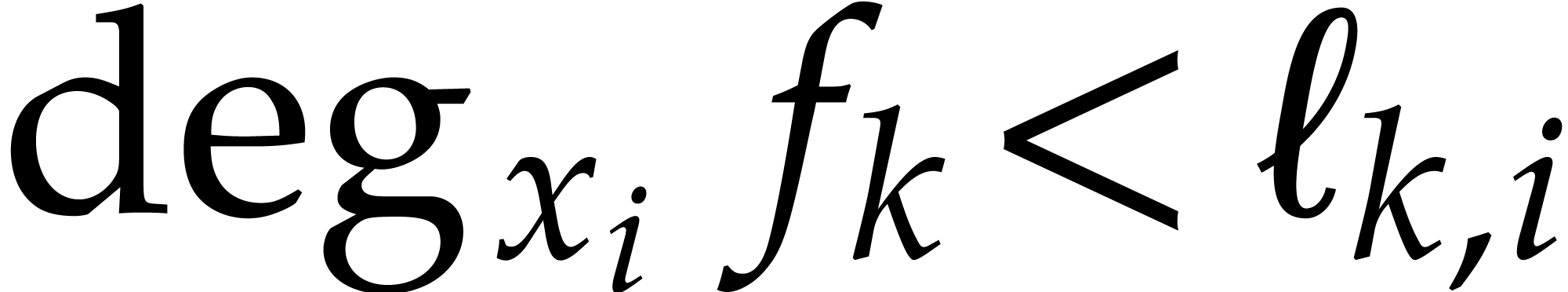 for the coefficients. We next
return
for the coefficients. We next
return 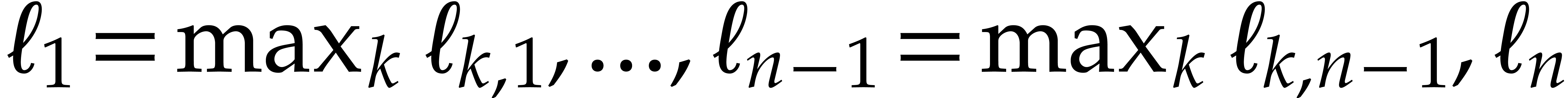 . The lemma clearly
holds for
. The lemma clearly
holds for 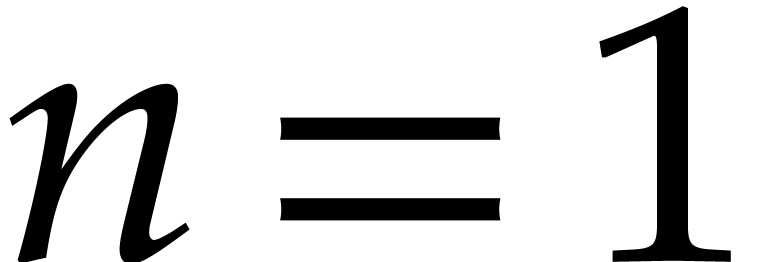 . By induction, the
recursive computations can be done in time
. By induction, the
recursive computations can be done in time
The computation of the maxima can be done using one linear pass in time
Determining  requires an additional time
requires an additional time 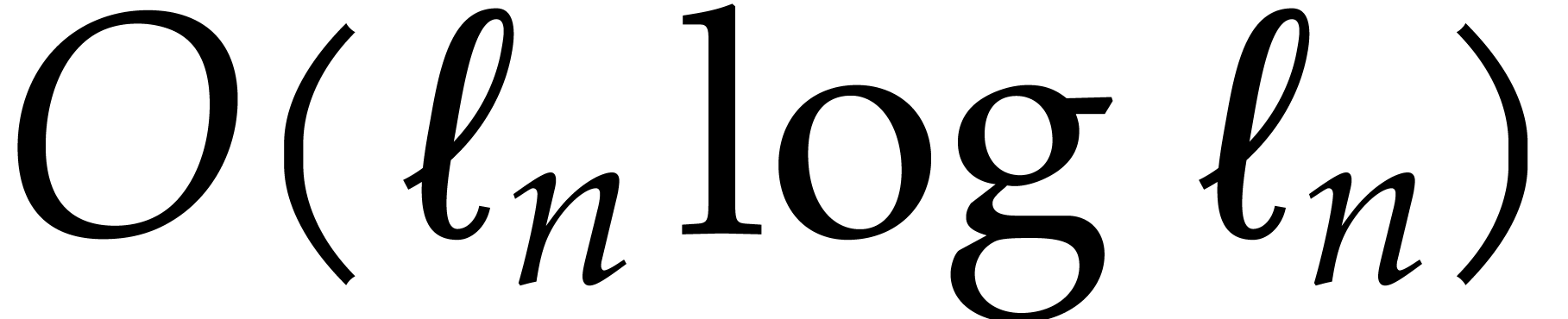 . Altogether, the computation takes
time
. Altogether, the computation takes
time  .
.
Proof. We use the following recursive algorithm: if
, then we have nothing to do.
If , then we write and recursively compute total degree bounds 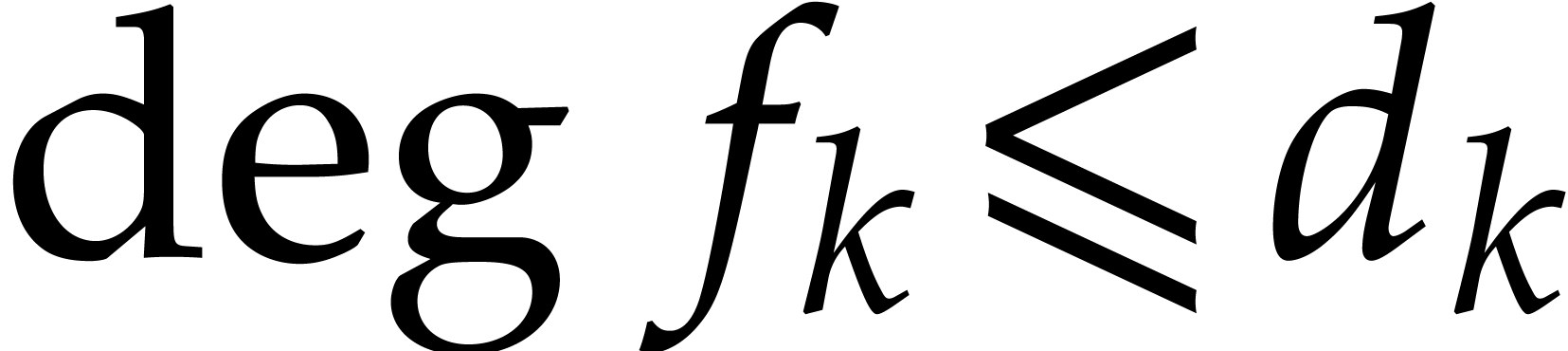 for the coefficients. We next return
for the coefficients. We next return 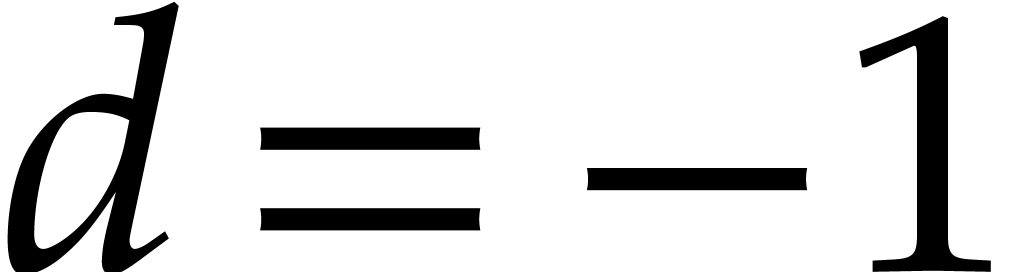 if
if 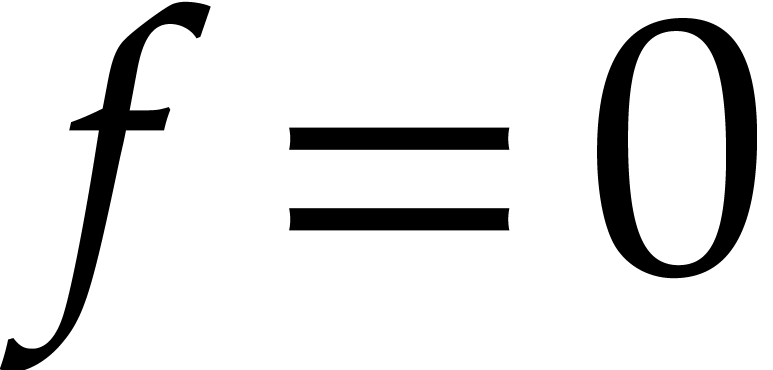 and
and 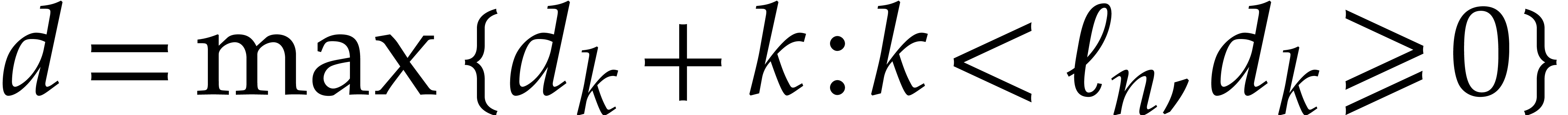 otherwise. The
complexity bound follows using a similar induction argument as in the
previous lemma.
otherwise. The
complexity bound follows using a similar induction argument as in the
previous lemma.
Evaluation and multi-remaindering
In the following paragraphs we recall the costs of integer
multi-remaindering and univariate multi-point evaluation together with
the inverse problems. The underlying techniques are well known. They are
recalled in the context of Turing machines for convenience.
Proof. We first compute the bidimensional array
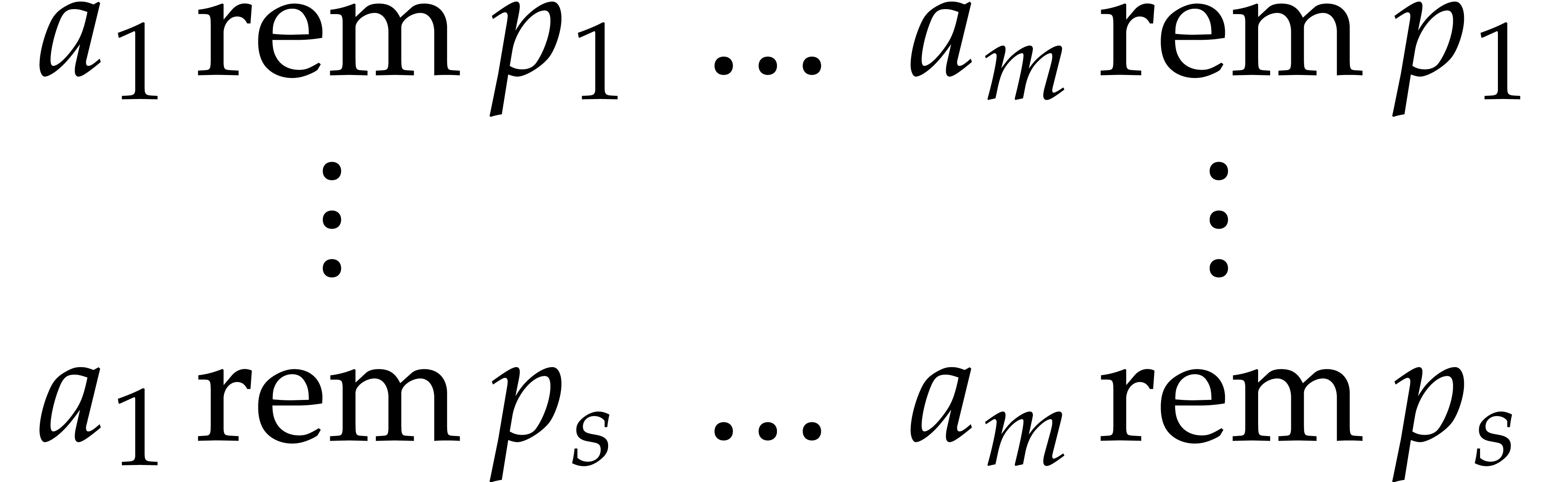
in time 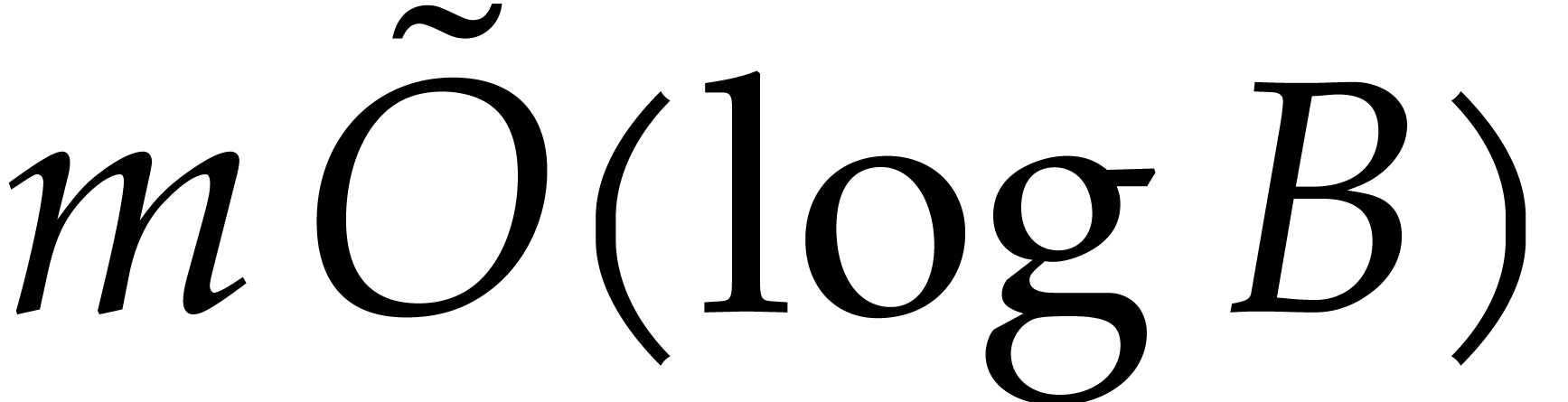 by using fast multi-remaindering [13, chapter 10]. Then we appeal to Lemma 2.3 to
obtain
by using fast multi-remaindering [13, chapter 10]. Then we appeal to Lemma 2.3 to
obtain  in time
in time  .
.
Proof. We first extract the vector  of all the nonzero coefficients of
of all the nonzero coefficients of  in time
in time 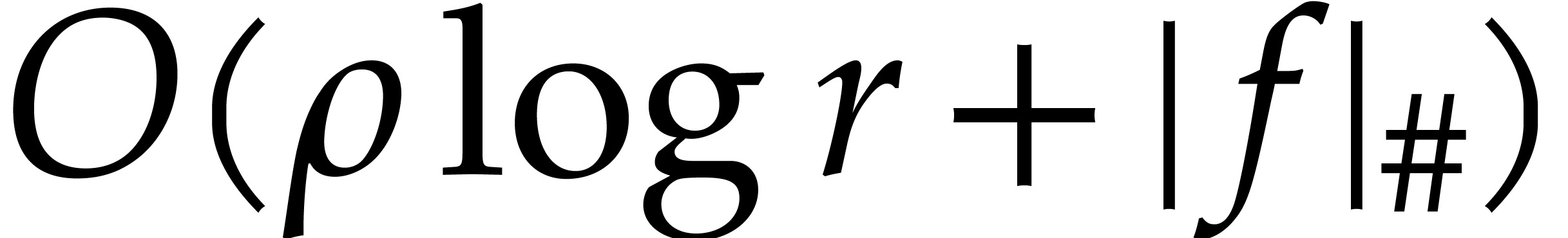 . We use the latter lemma on , which incurs time
. We use the latter lemma on , which incurs time  . Then we recover
. Then we recover  from
from
 and ,
for
and ,
for 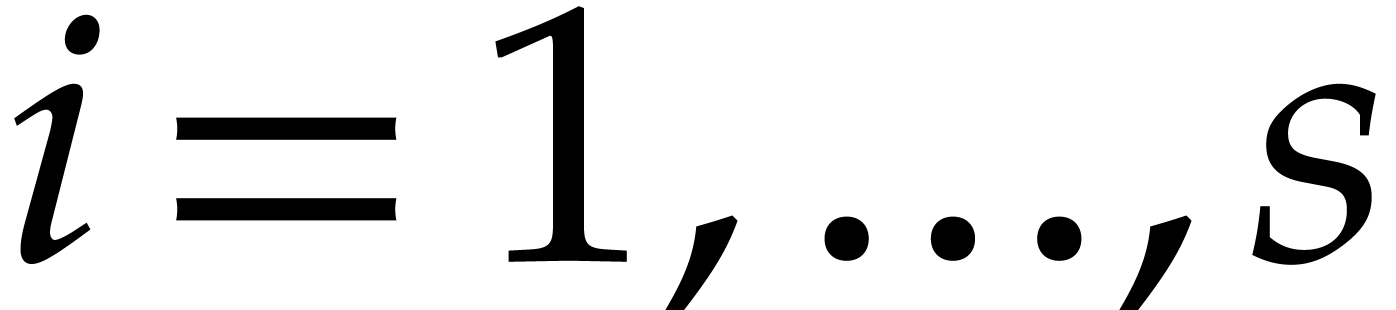 , in time
, in time 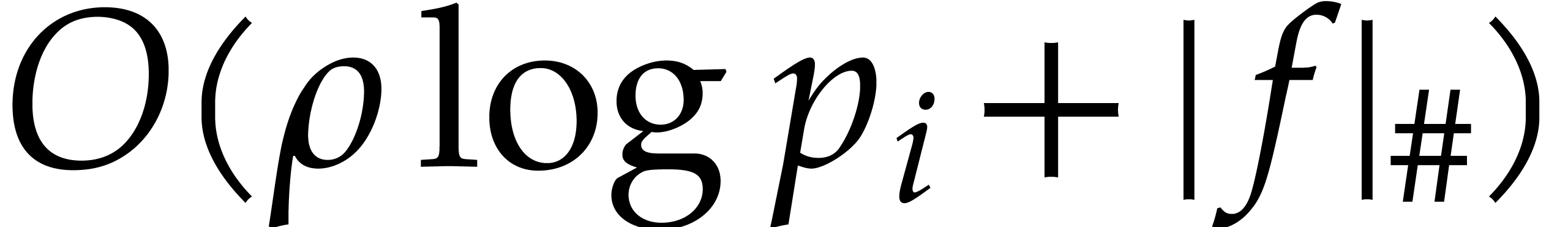 .
.
Proof. First we transpose the bidimensional array
 of size
of size  and then use
Chinese remaindering
and then use
Chinese remaindering 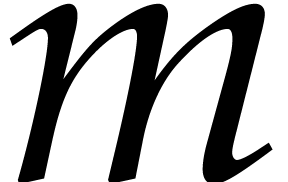 times. By Lemma 2.3
and [13, chapter 10], this can be done in time
times. By Lemma 2.3
and [13, chapter 10], this can be done in time 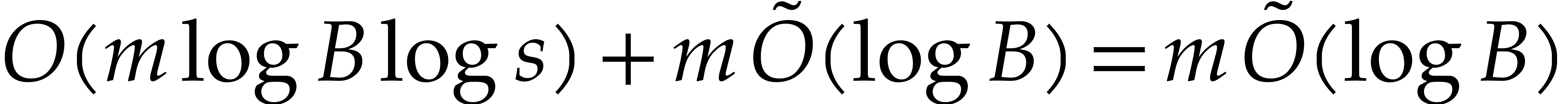 .
.
Proof. We first compute the bidimensional array
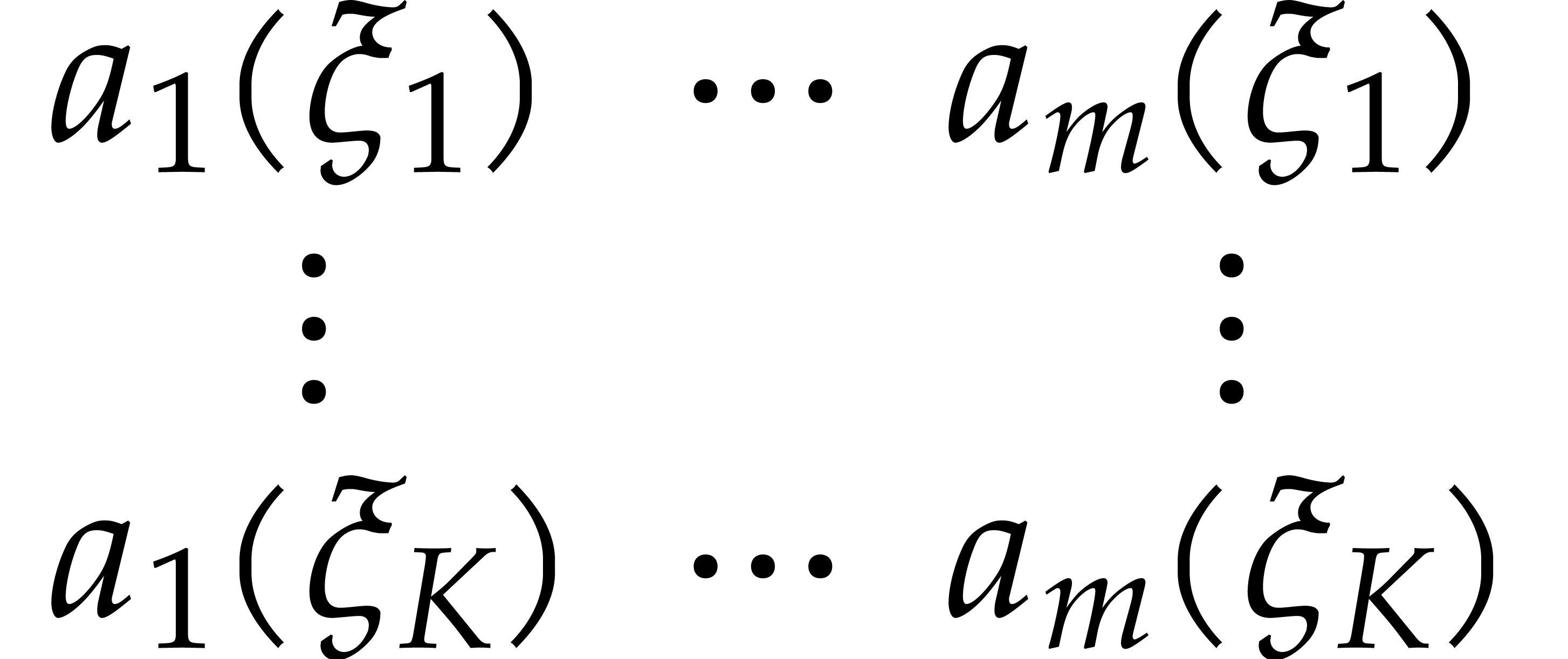
in time 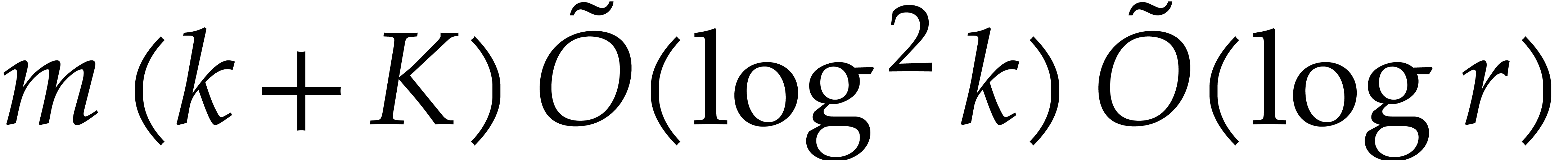 , using fast
univariate multi-point evaluation [13, chapter 12]. We next
transpose the array in time
, using fast
univariate multi-point evaluation [13, chapter 12]. We next
transpose the array in time 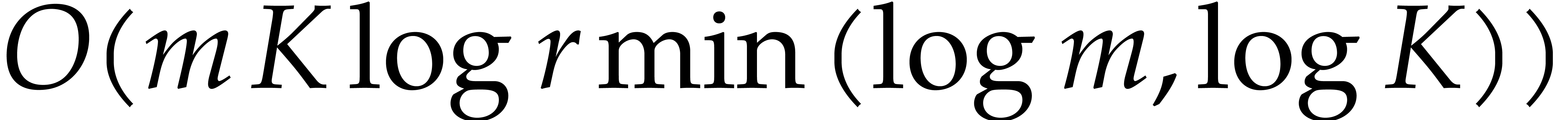 ,
using Lemma 2.3.
,
using Lemma 2.3.
Proof. We first extract the vector 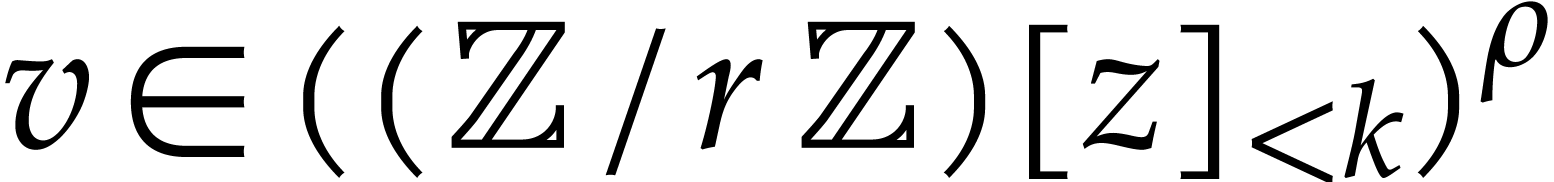 of all the nonzero coefficients of in time
of all the nonzero coefficients of in time 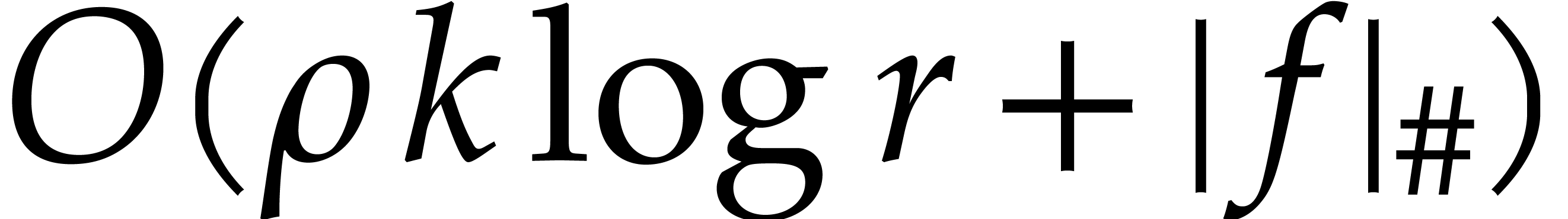 together with
together with 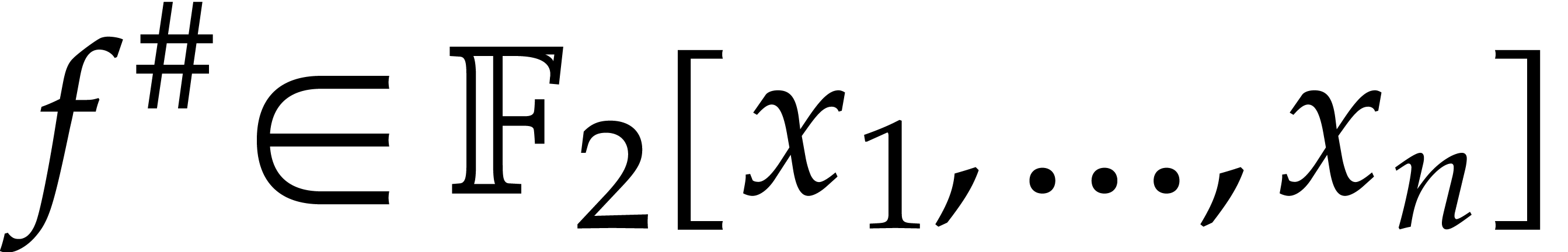 of the same
support as . We use the
latter lemma on , which
incurs time
of the same
support as . We use the
latter lemma on , which
incurs time

Then for  we recover the evaluation of at
we recover the evaluation of at  from
from 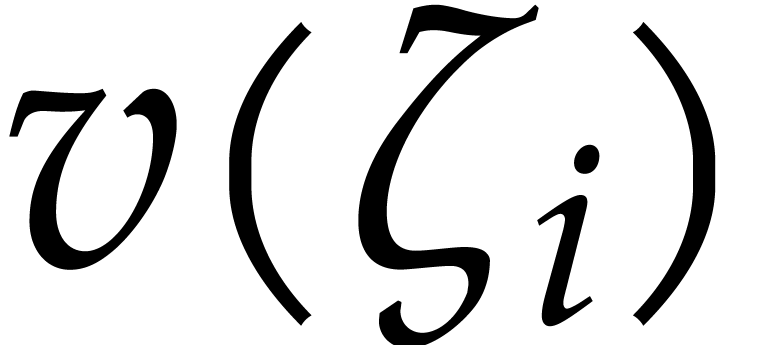 and
and  in time .
in time .
Proof. We first transpose the  array made of
array made of  to obtain
to obtain
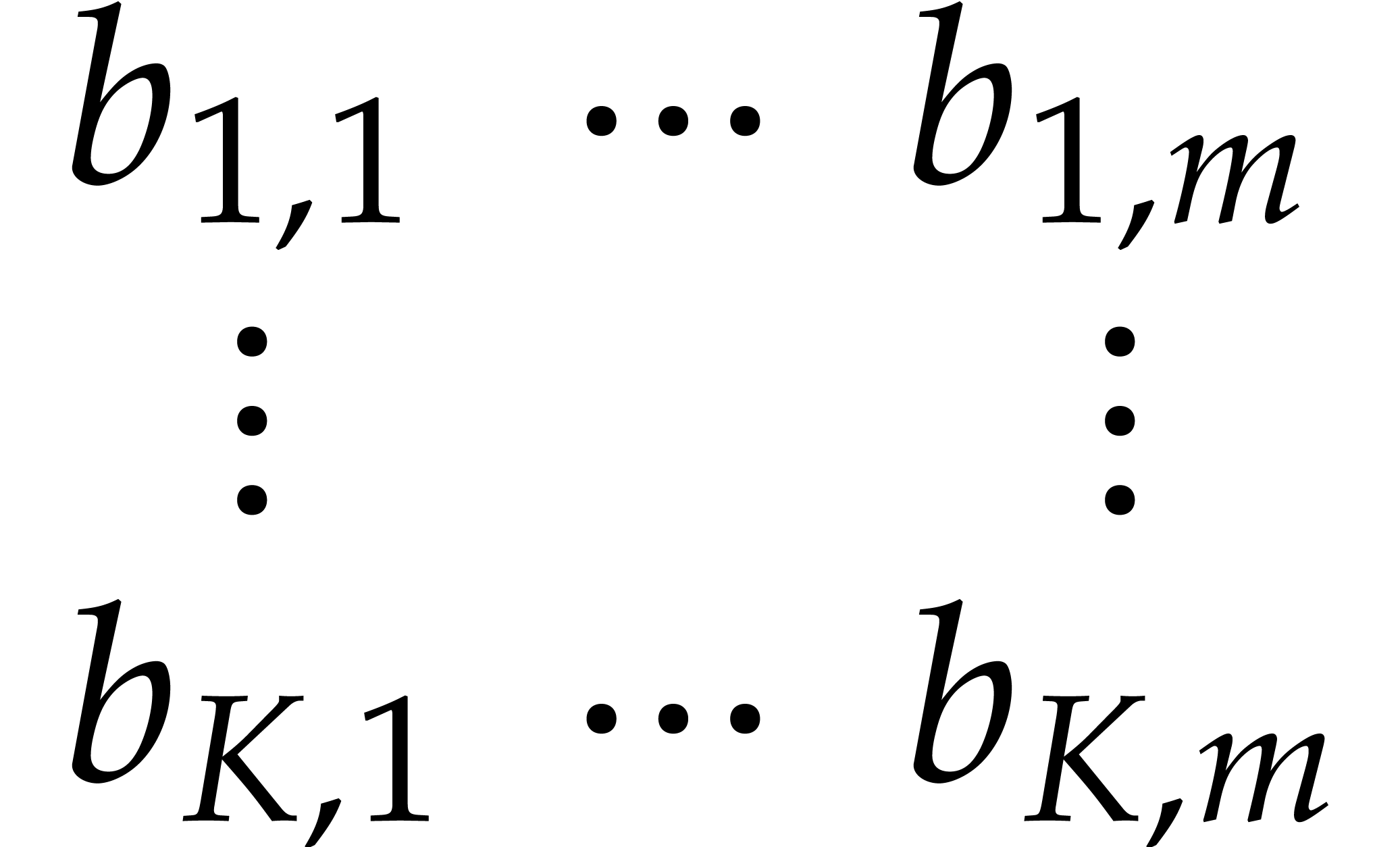
in time 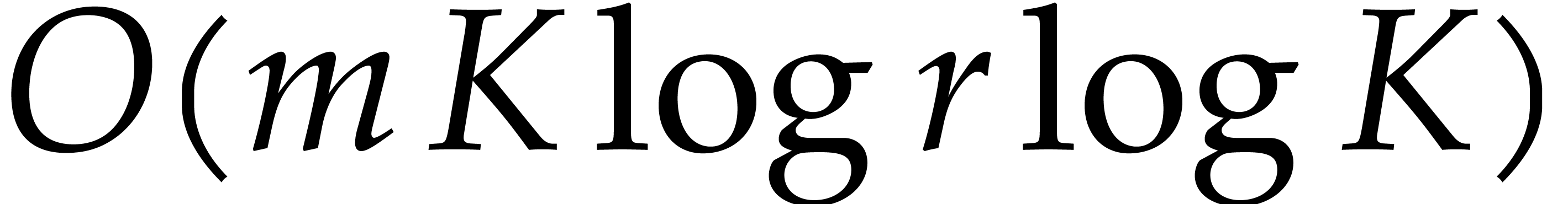 by Lemma 2.3. We next
obtain the result through interpolations, in
time
by Lemma 2.3. We next
obtain the result through interpolations, in
time 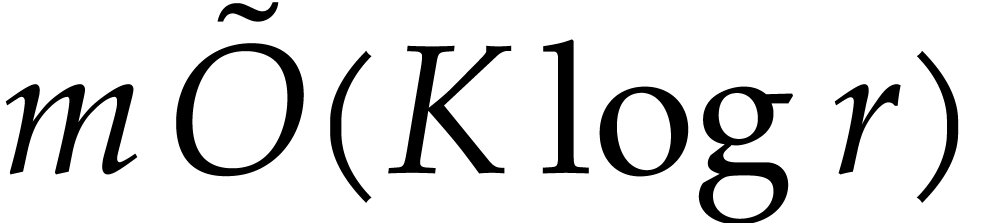 by [13, chapter 12].
by [13, chapter 12].
Lexicographic orders
We will have to use the lexicographic order on 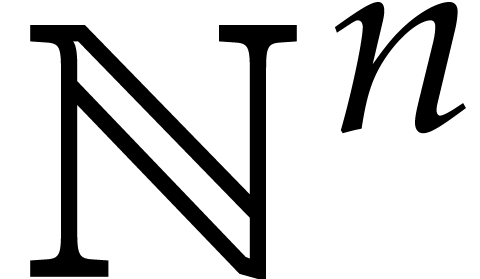 , written
, written 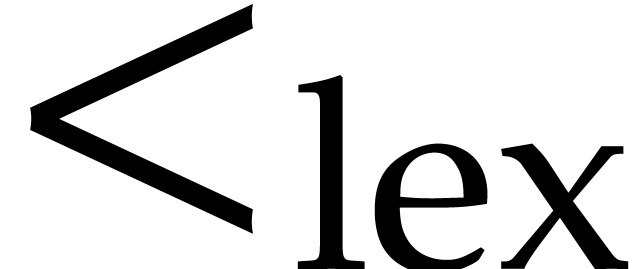 ,
defined by
,
defined by
Notice that in the dense polynomial representation used here,
coefficients are stored accordingly to the lexicographic order on the
exponent vectors; this corresponds to the usual lexicographic monomial
order induced by  .
.
Fixed point numbers
We use fixed point representation to approximate real numbers. The
number 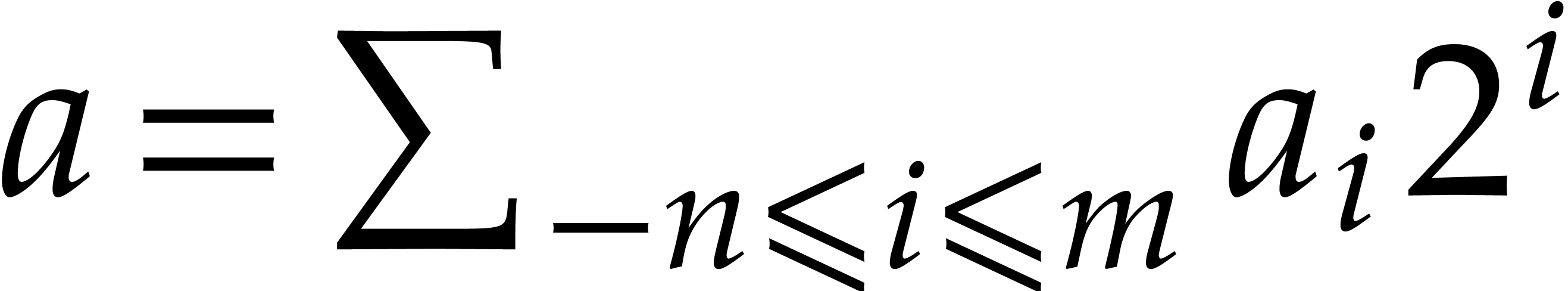 , with
, with  and
and 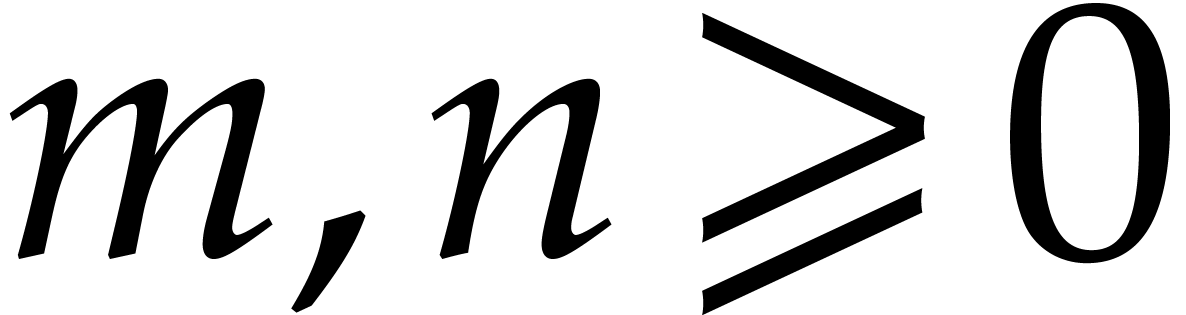 , is
represented by
, is
represented by 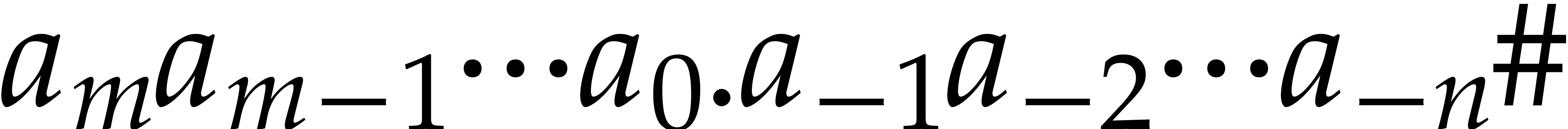 , where
“.” is a specific symbol of the machine. A negative number
starts with the symbol “-”. The bit size of
, where
“.” is a specific symbol of the machine. A negative number
starts with the symbol “-”. The bit size of  is
is 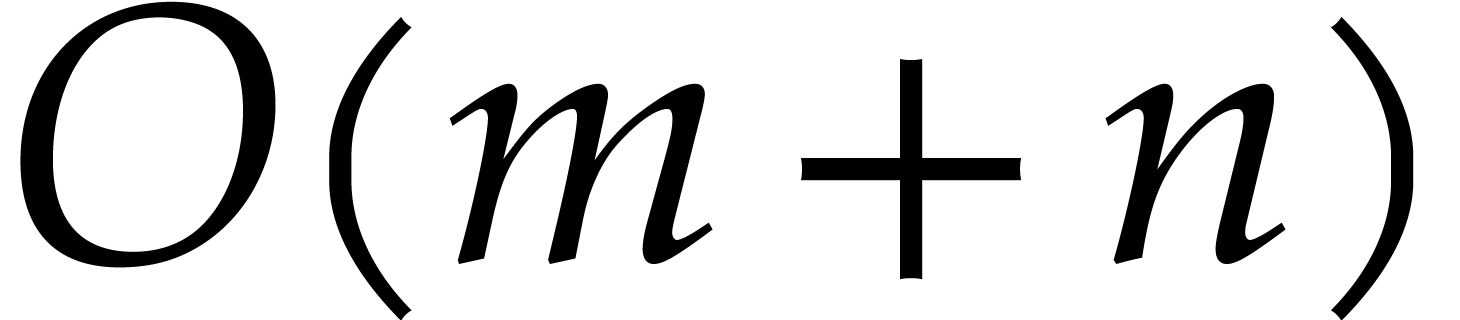 . The integer is called the (absolute) precision. Additions,
subtractions and reducing the precision take linear time. The product of
two fixed point numbers of bit size
. The integer is called the (absolute) precision. Additions,
subtractions and reducing the precision take linear time. The product of
two fixed point numbers of bit size  takes time
takes time
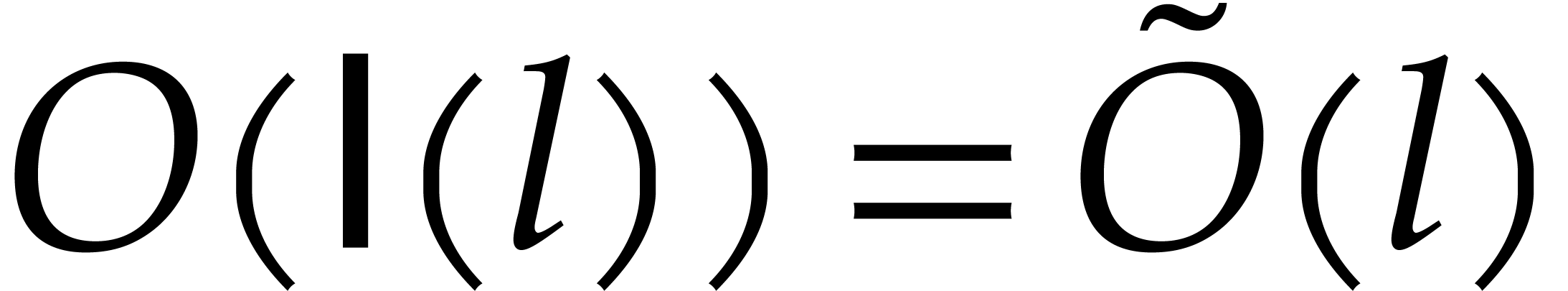 . We gather well known
results from [8].
. We gather well known
results from [8].
Proof. Without loss of generality we may assume
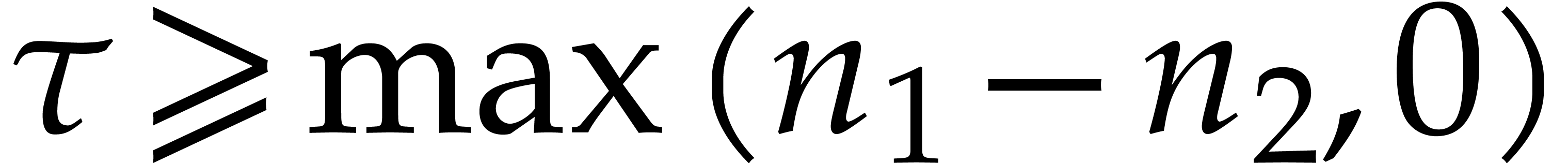 . We perform the following
long integer division in time
. We perform the following
long integer division in time 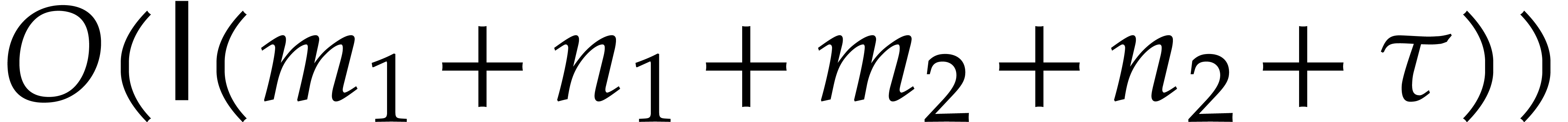 :
:
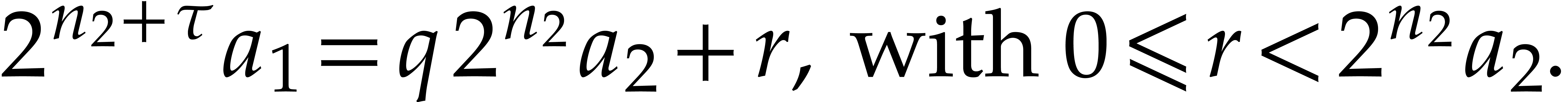
Then we have
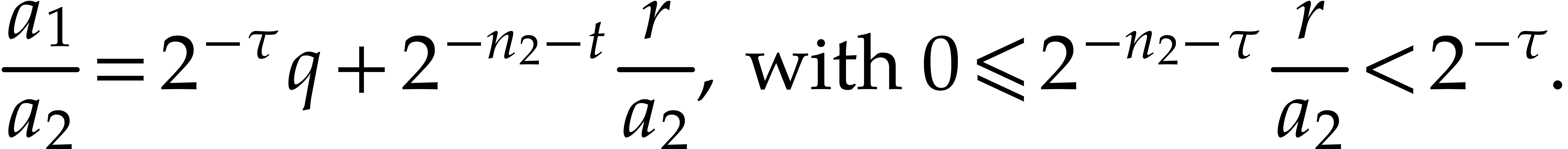
Consequently we may take 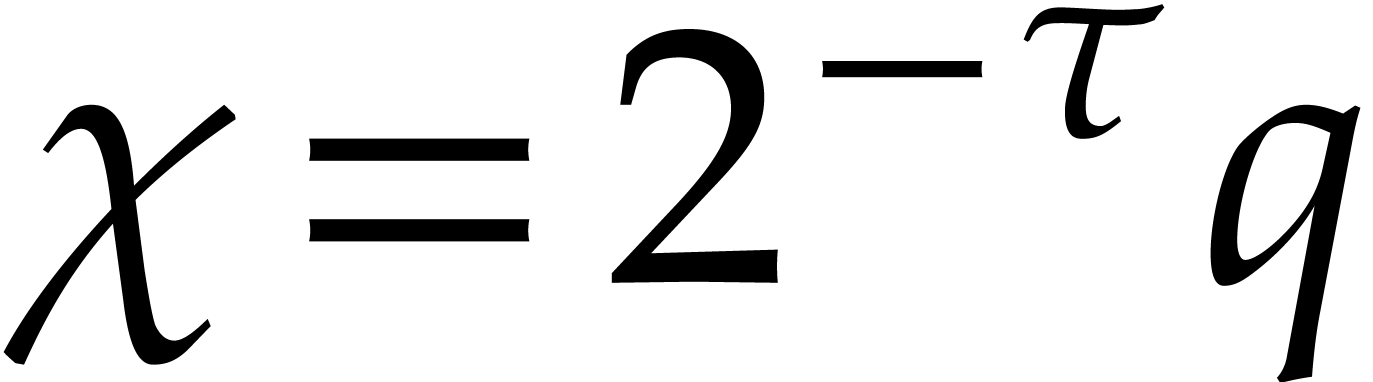 .
.
Proof. We write  with
with  and
and 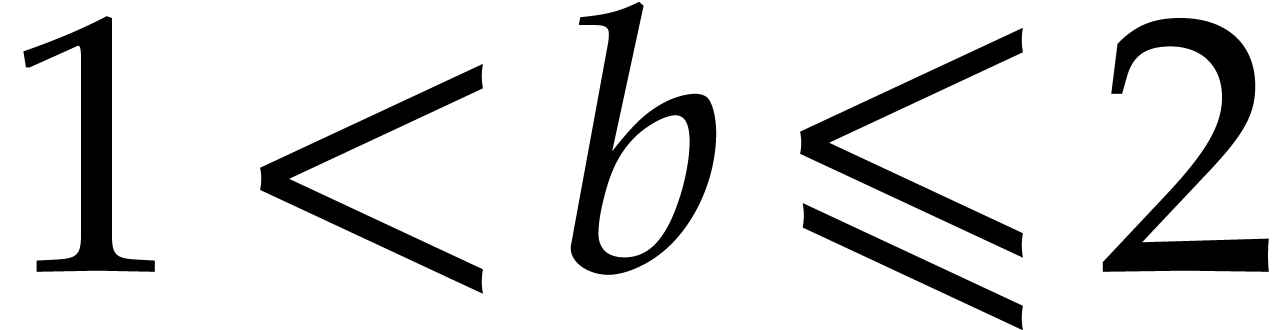 so
so 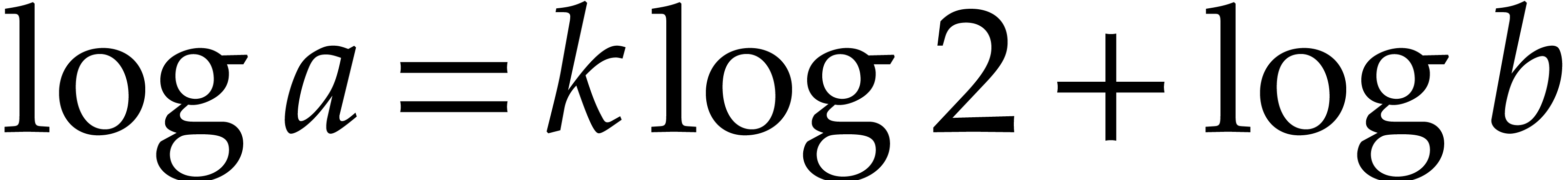 . By using [8, Theorem 6.1],
. By using [8, Theorem 6.1], 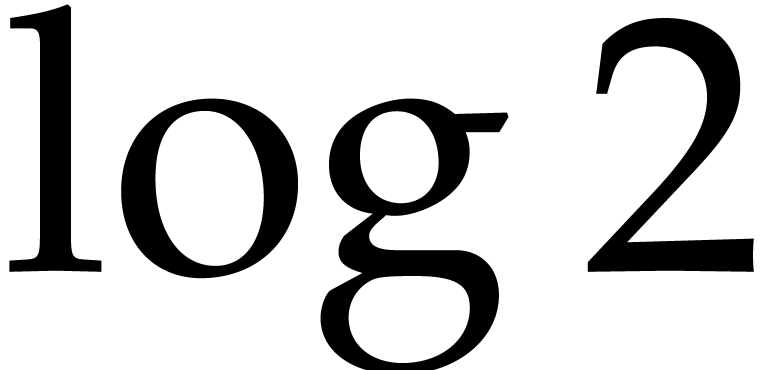 and
and 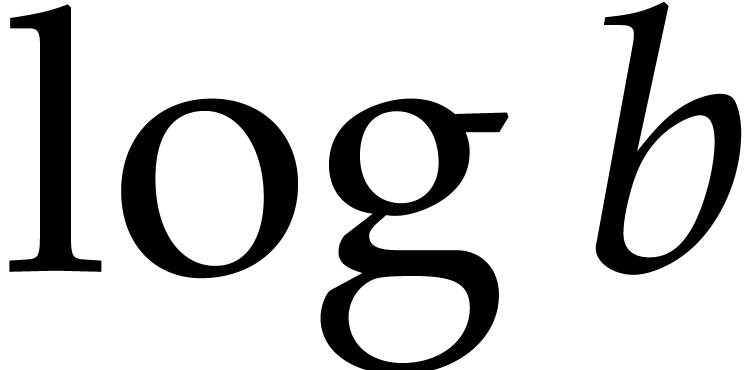 may be computed to precisions
may be computed to precisions
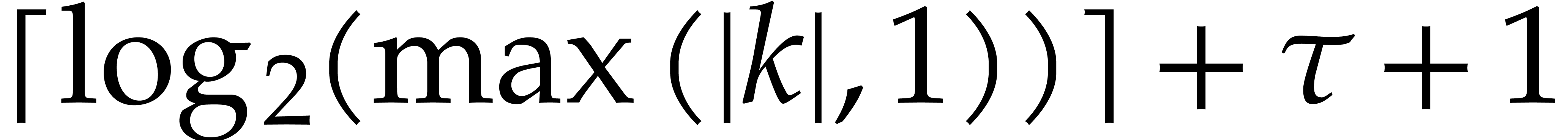 and
and  respectively in time
respectively in time
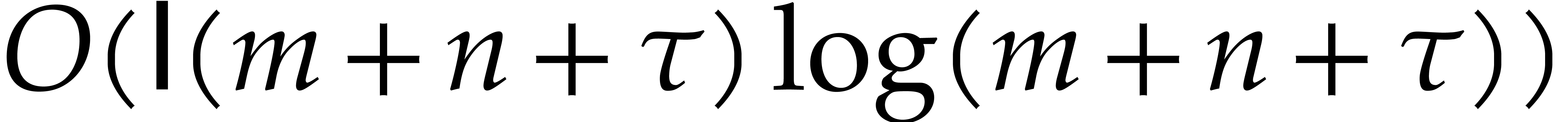 . Let us write
. Let us write 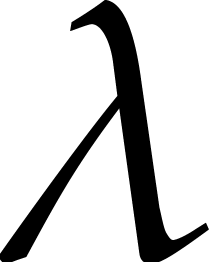 and
and 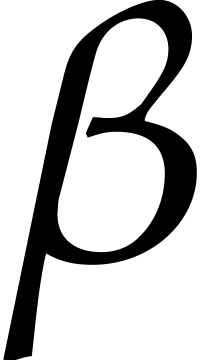 the respective approximations,
which satisfy
the respective approximations,
which satisfy
and  . Then
. Then 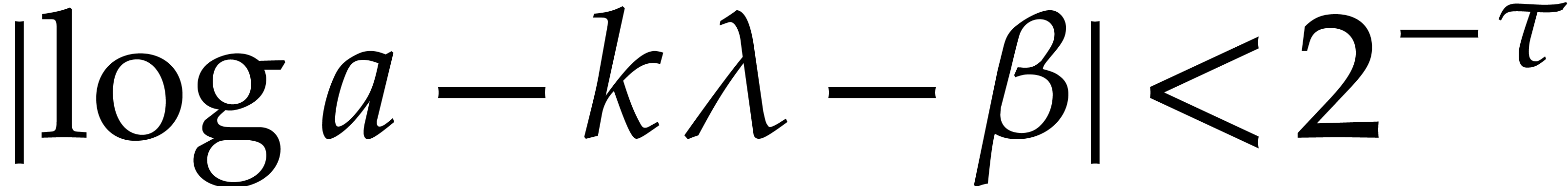 .
.
Proof. We write with 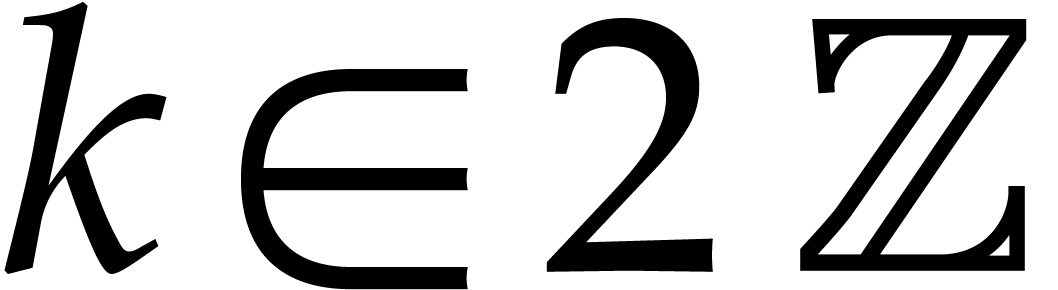 and
and  , so
we have
, so
we have 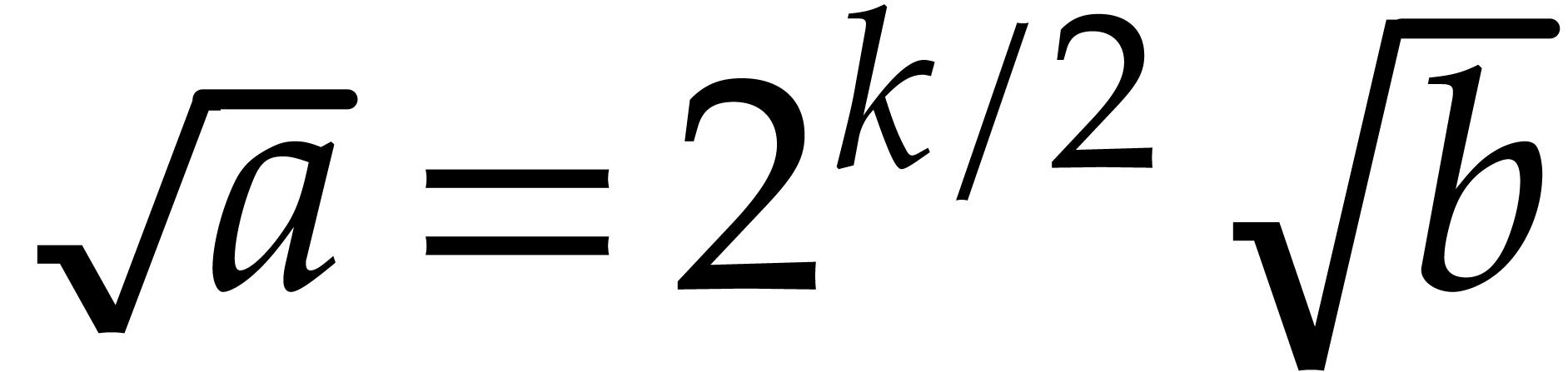 . By using [8,
Lemma 2.3],
. By using [8,
Lemma 2.3], 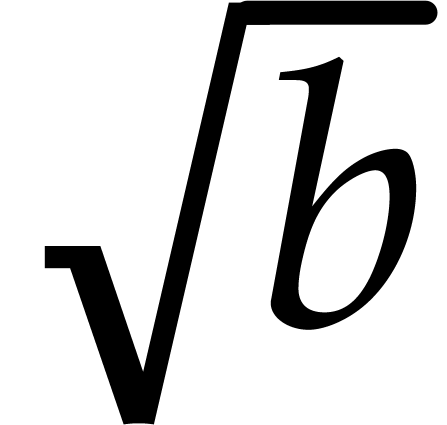 may be approximated to precision
may be approximated to precision
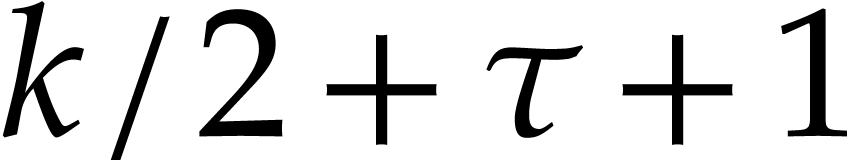 in time
in time 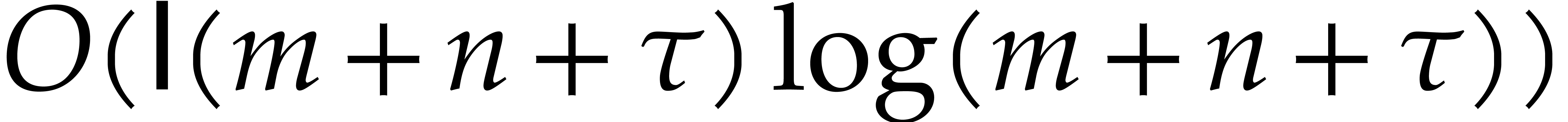 .
.
3.Fast multi-point evaluation
In this section is an integer with  and is a polynomial in with partial degree
and is a polynomial in with partial degree 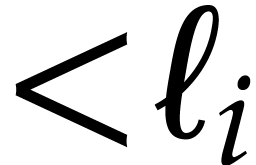 in for
in for 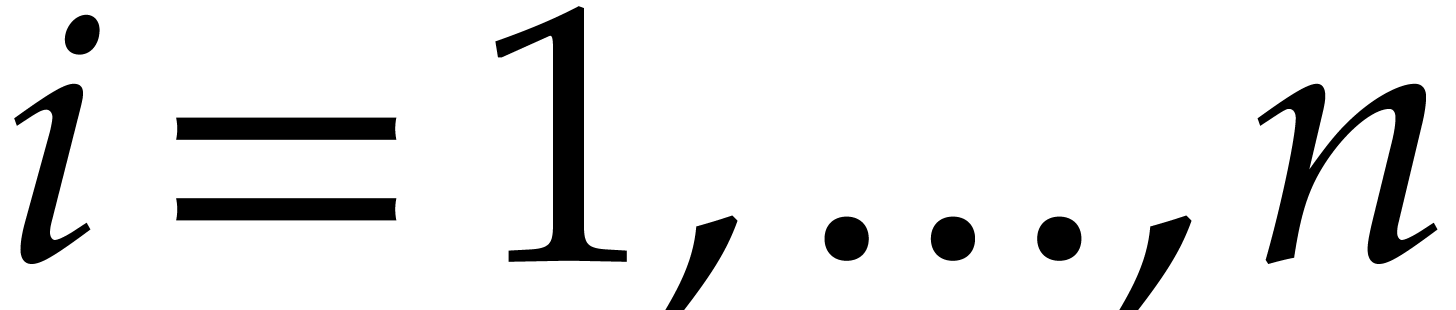 , and total
degree . We assume that is given in recursive dense representation for
, and total
degree . We assume that is given in recursive dense representation for 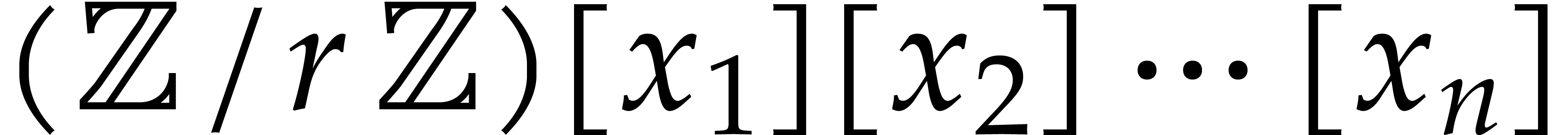 , as described in the previous
section, so the size of its representation is
, as described in the previous
section, so the size of its representation is 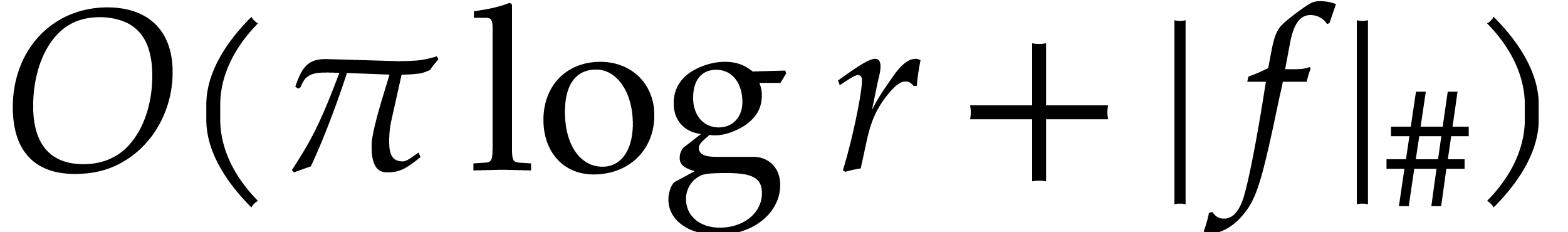 where
where 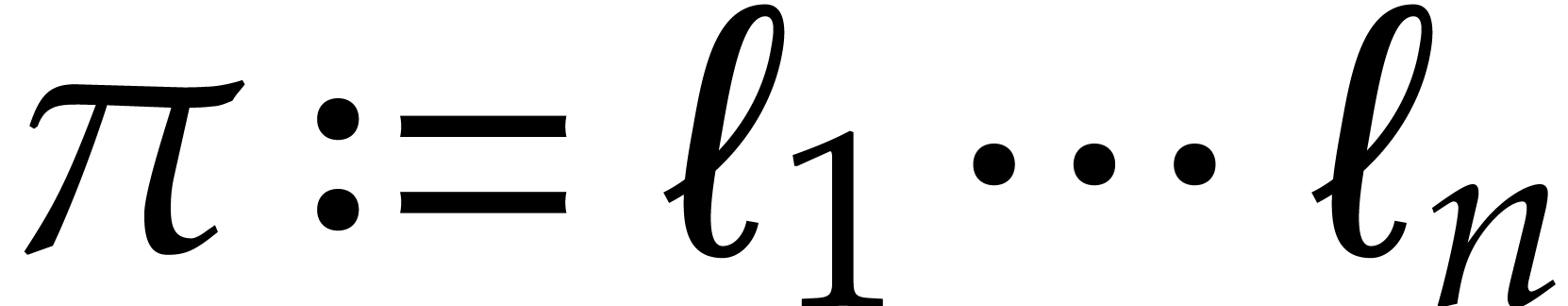 and represents the
number of in the representation of . The upper bounds and
for the partial and total degrees are not
necessarily sharp. Throughout this section, we assume that
and represents the
number of in the representation of . The upper bounds and
for the partial and total degrees are not
necessarily sharp. Throughout this section, we assume that 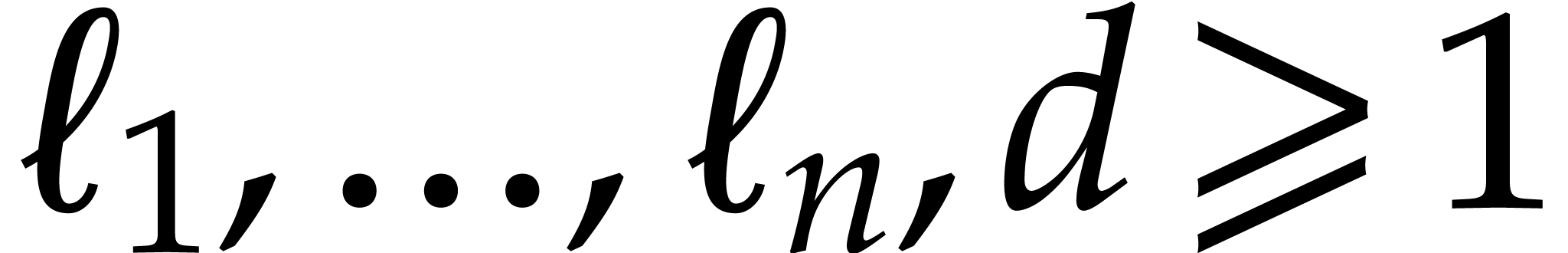 and that these bounds satisfy
and that these bounds satisfy
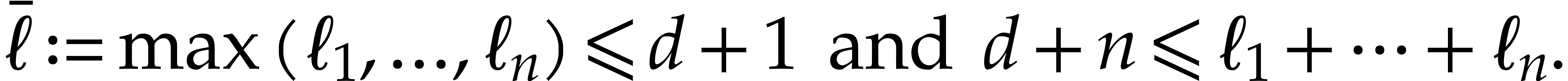 |
(3.1) |
We wish to evaluate at
points in , written .
3.1.Overview of the multi-modular
approach
In order to evaluate at a point 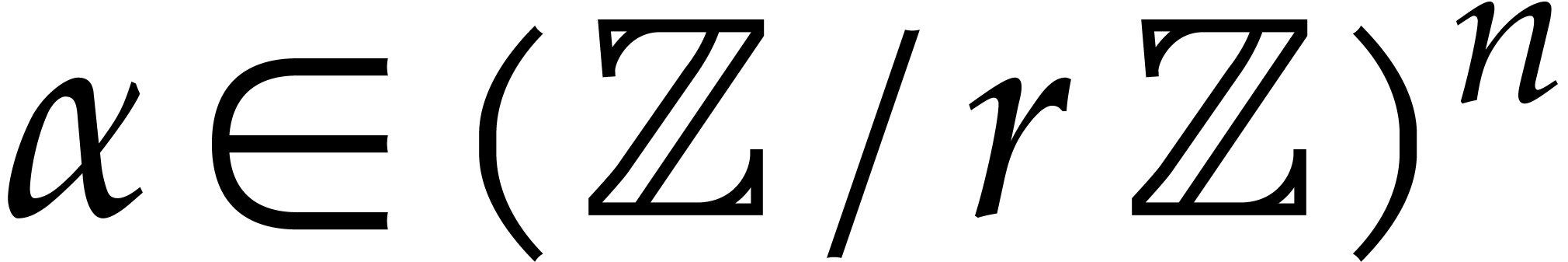 the initial idea consists in performing the
evaluation over , that is to
say by discarding the modulus .
We write
the initial idea consists in performing the
evaluation over , that is to
say by discarding the modulus .
We write 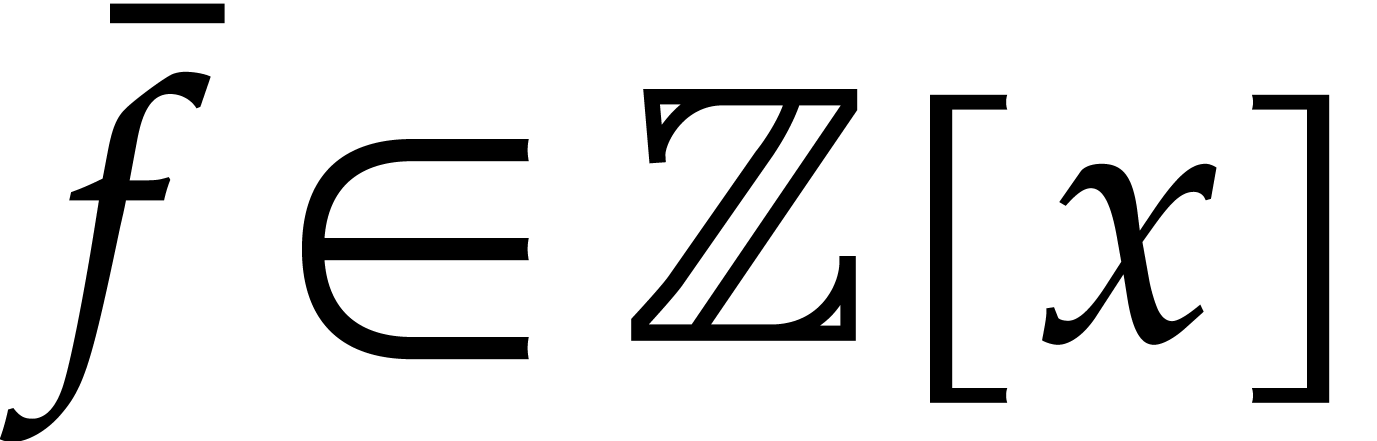 for the natural preimage of with coefficients in ,
and
for the natural preimage of with coefficients in ,
and 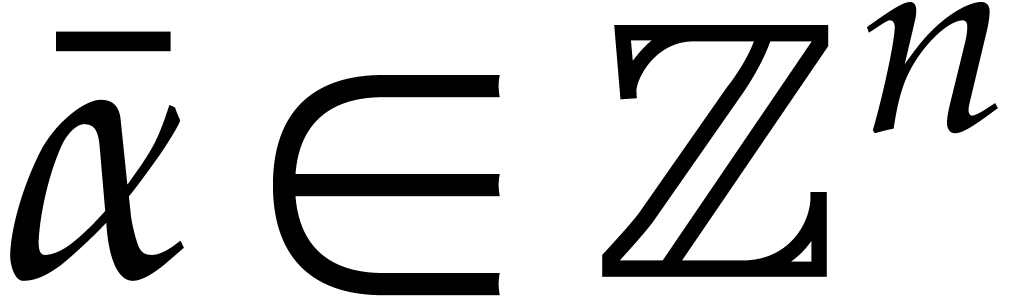 for the natural preimage of
for the natural preimage of  with entries in . In order to
compute
with entries in . In order to
compute 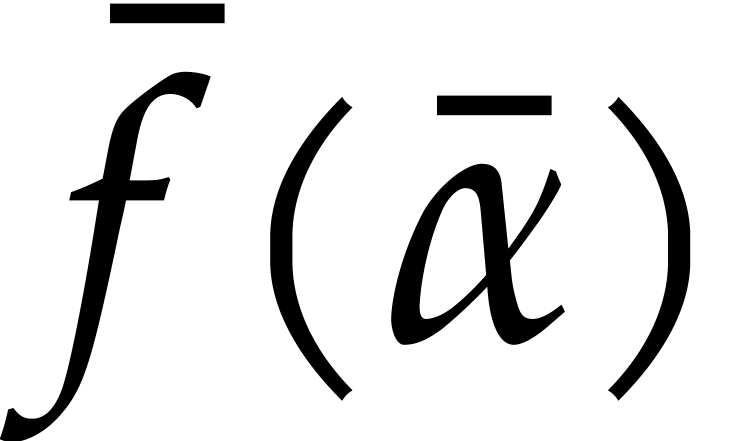 we construct an ad hoc sequence
of primes such that
we construct an ad hoc sequence
of primes such that 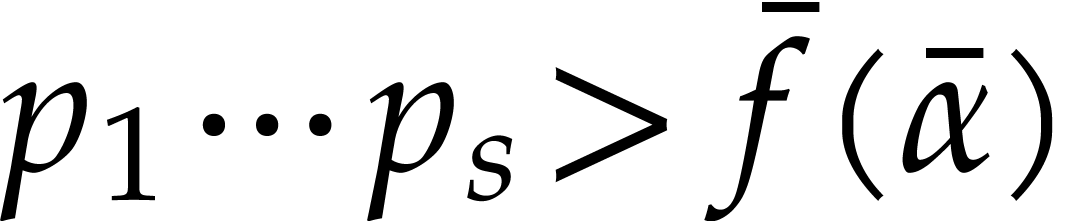 . In this way, may be
recovered by Chinese remaindering from
. In this way, may be
recovered by Chinese remaindering from  .
.
Minimizing the bit size of  is of the utmost
importance for efficiency. For this purpose we introduce the following
quantity
is of the utmost
importance for efficiency. For this purpose we introduce the following
quantity  which bounds the cardinality of the
support of both in terms of the partial and
total degrees:
which bounds the cardinality of the
support of both in terms of the partial and
total degrees:
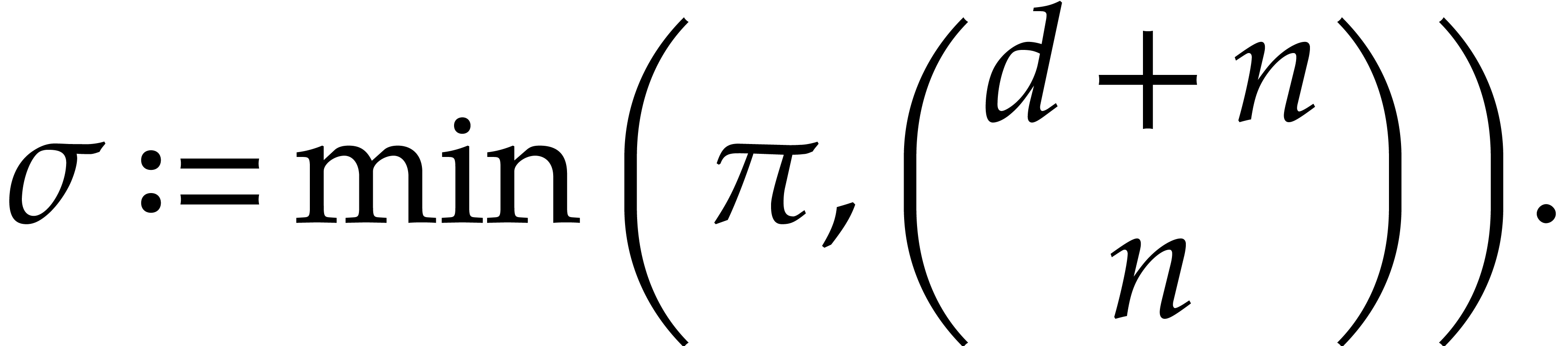
On the other hand the quantity
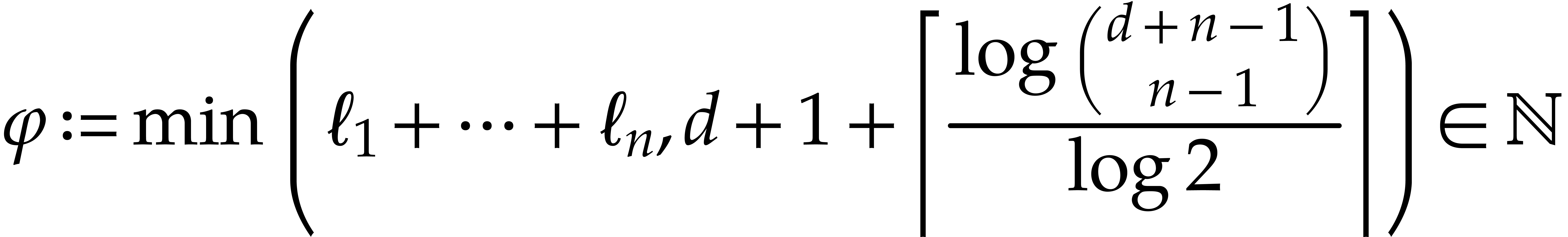 |
(3.2) |
is used as a bound for 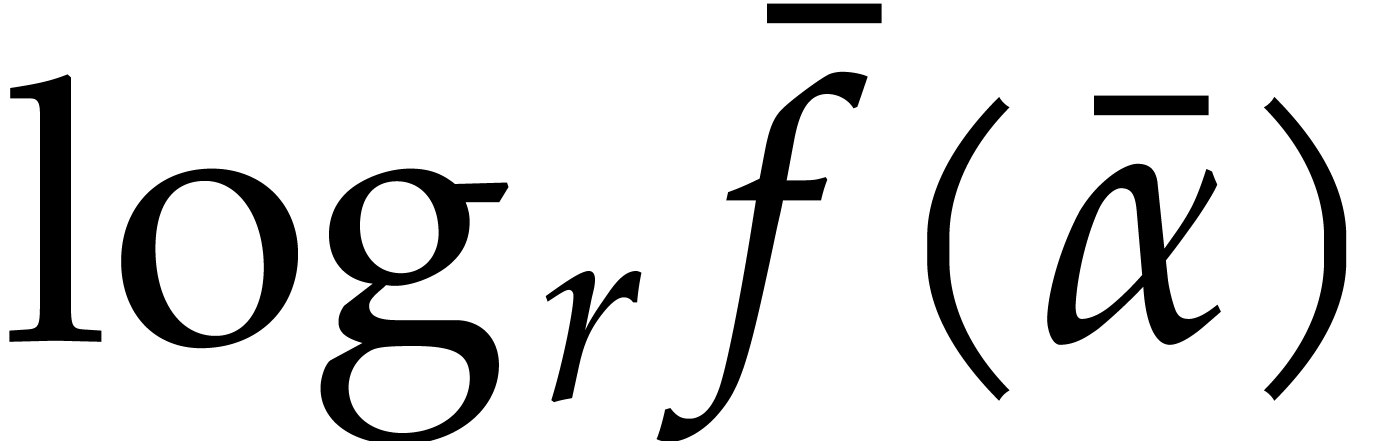 . It
satisfies the following inequality to be used several times in the
proofs when
. It
satisfies the following inequality to be used several times in the
proofs when  :
:
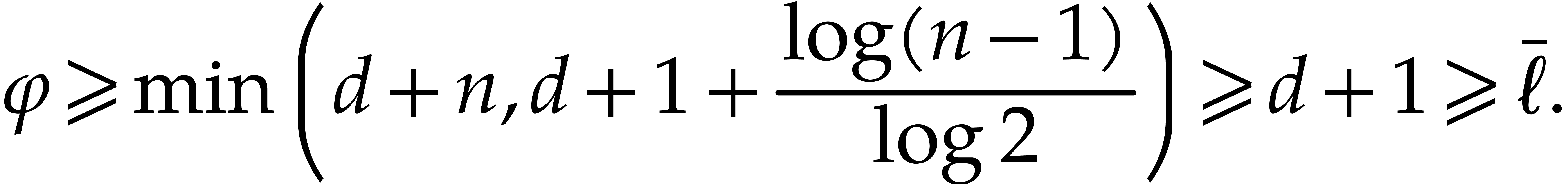 |
(3.3) |
Proof. We first prove that
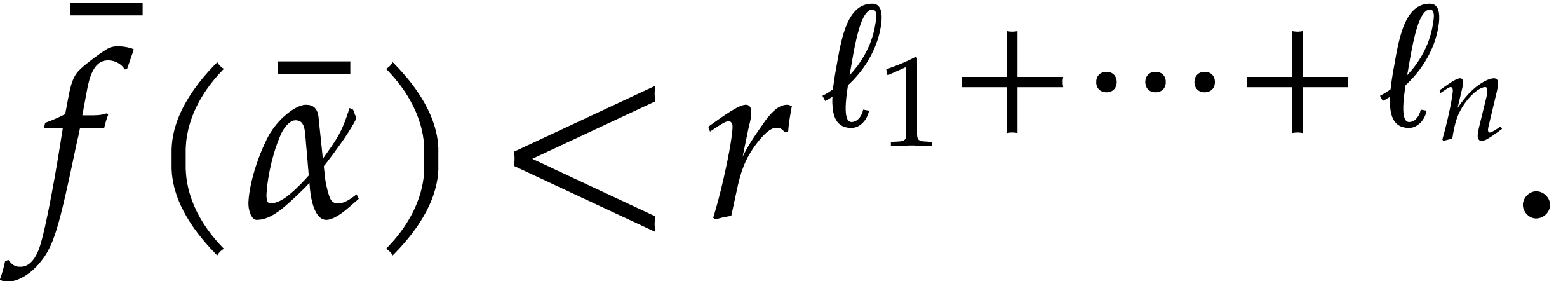 |
(3.4) |
This inequality trivially holds when .
Suppose by induction that it holds up to  variables. Then
variables. Then 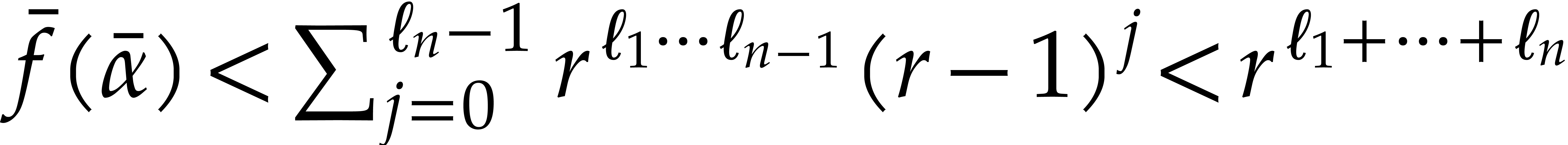 again holds for
variables.
again holds for
variables.
On the other hand we have
The conclusion simply follows from the assumption  .
.
Given 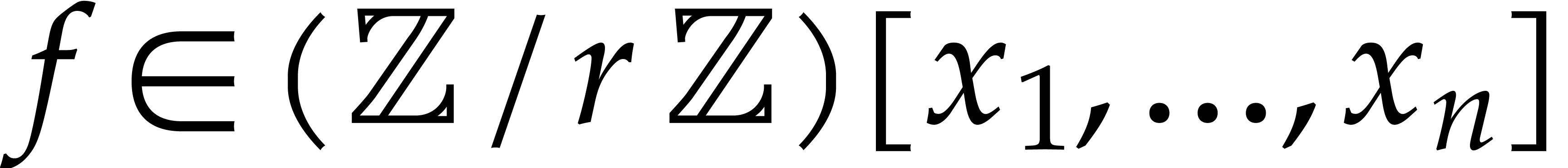 and evaluation
points in ,
the multi-point evaluation algorithm of this section works as follows:
and evaluation
points in ,
the multi-point evaluation algorithm of this section works as follows:
-
If is “sufficiently small”, then
we evaluate at all points in and read off the needed values. This task is detailed
in the next subsection.
-
Otherwise we compute prime numbers such that
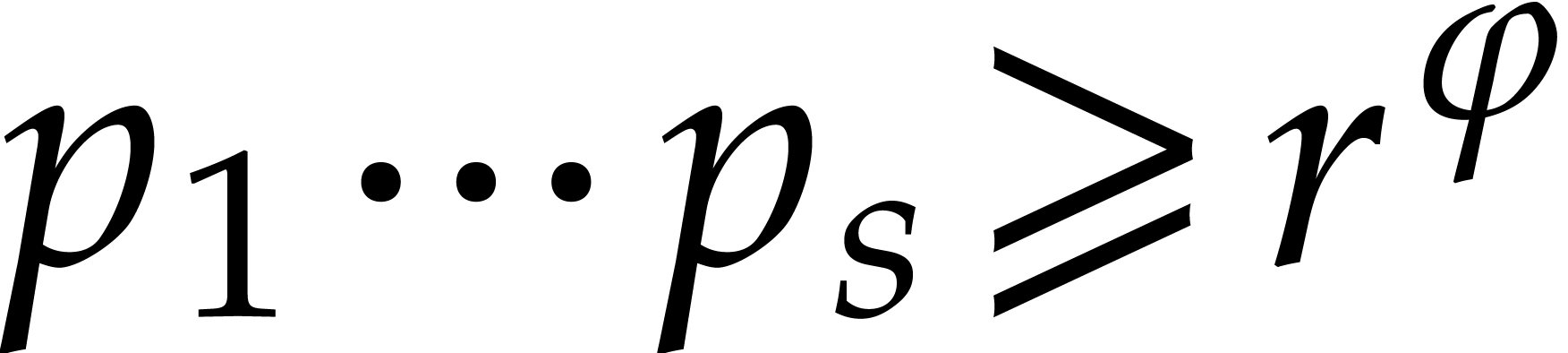 . This is addressed in
sections 3.3 and 3.4.
. This is addressed in
sections 3.3 and 3.4.
-
We evaluate at all
modulo for by
calling the algorithm recursively.
-
We reconstruct the values of at all by Chinese remaindering and perform the final
divisions by .
We will be able to take all the of the order of
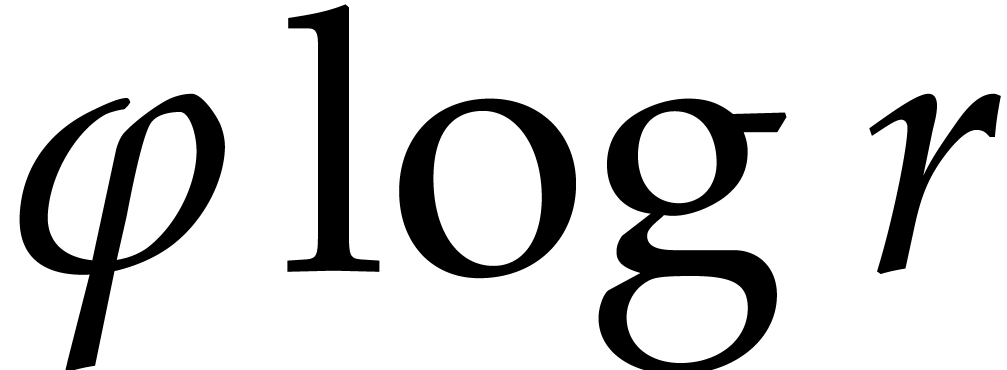 . Therefore, the bit size of
the modulus when entering the first recursive call is of the order , then
. Therefore, the bit size of
the modulus when entering the first recursive call is of the order , then 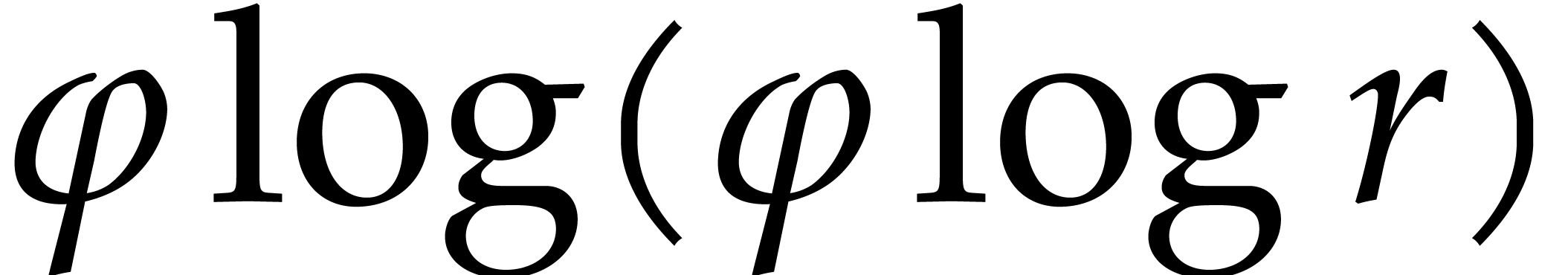 at
depth
at
depth 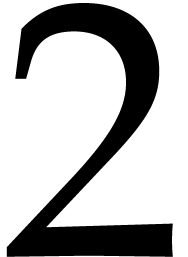 , then
, then 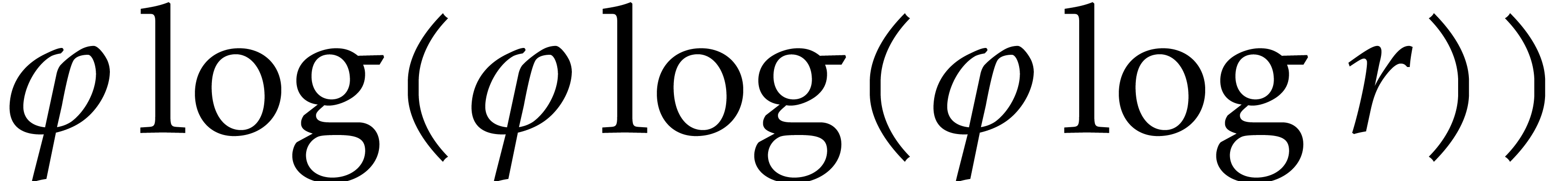 at depth
at depth 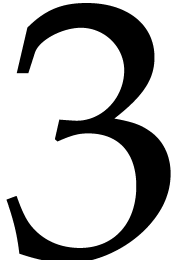 , etc. The total bit
size of all recursive problems to be solved at depth
, etc. The total bit
size of all recursive problems to be solved at depth  turns out to grow with
turns out to grow with 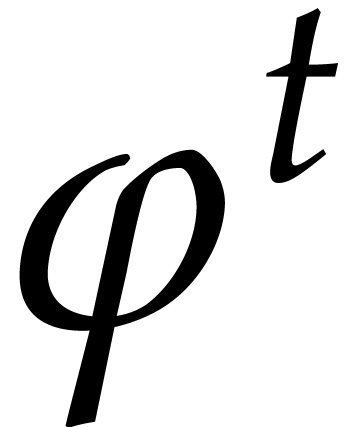 . In
section 3.5 we study the complexity of the algorithm in
terms of the depth . Section
3.6 is devoted to finding a suitable value for to end the recursive calls. Roughly speaking, the property
“sufficiently small” from step 1 becomes “ is of the order
. In
section 3.5 we study the complexity of the algorithm in
terms of the depth . Section
3.6 is devoted to finding a suitable value for to end the recursive calls. Roughly speaking, the property
“sufficiently small” from step 1 becomes “ is of the order 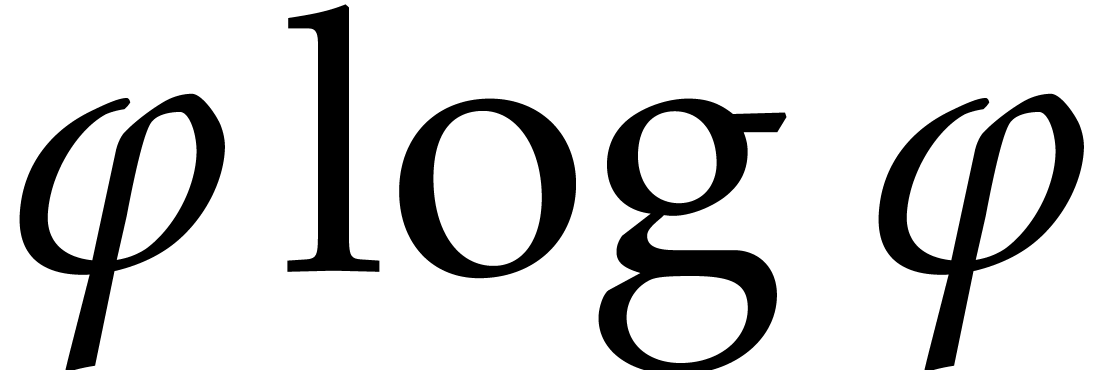 ”,
so the time spent in the exhaustive evaluation of step 1 is of the order
”,
so the time spent in the exhaustive evaluation of step 1 is of the order
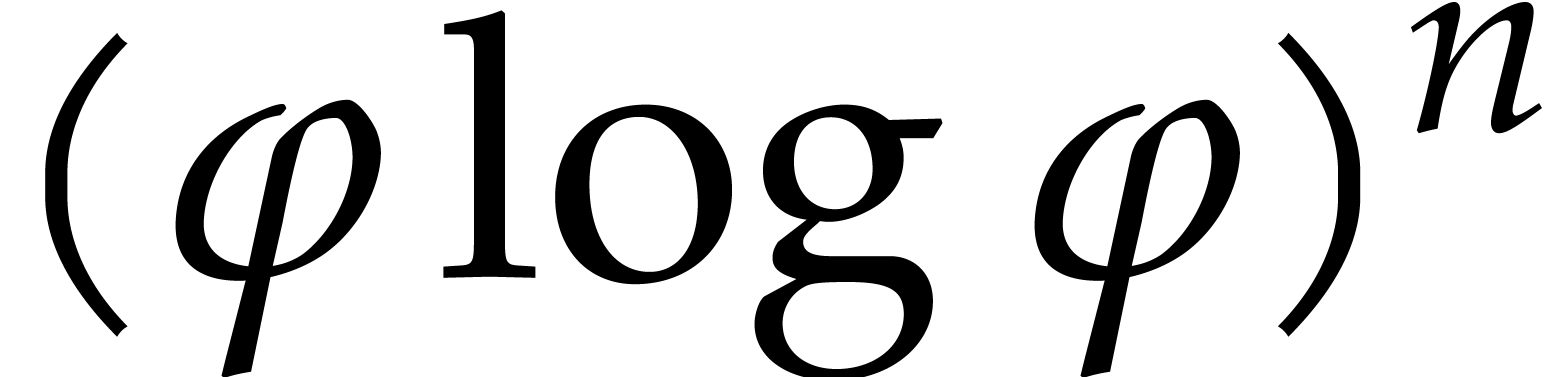 .
.
3.2.Exhaustive evaluation
We begin with studying the base case of the multi-modular algorithm,
i.e. the exhaustive evaluation at all points of . We recall that this algorithm is
used for sufficiently small values of .
We regard the evaluation of at all points in
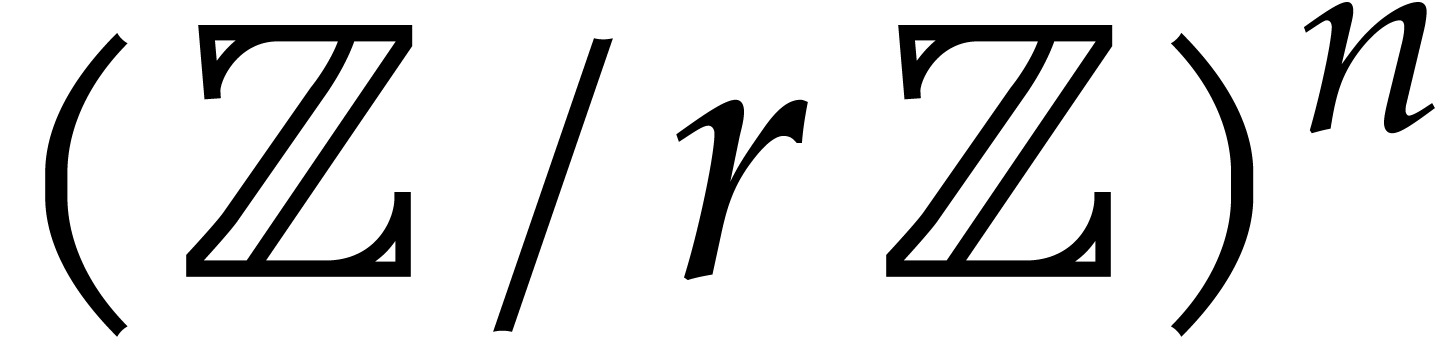 as a vector in
as a vector in  .
.
Proof. Detecting if is the
constant polynomial  takes time
takes time 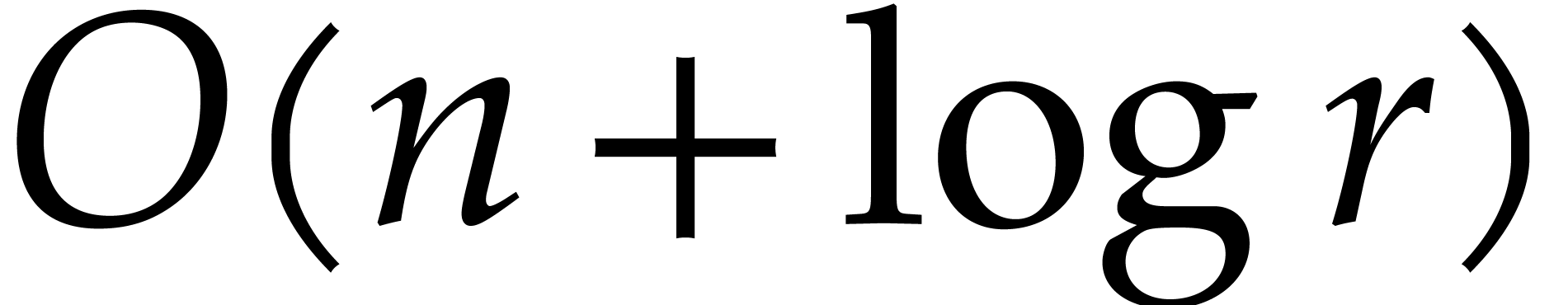 . If so, then it suffices to copy onto the destination tapes
. If so, then it suffices to copy onto the destination tapes 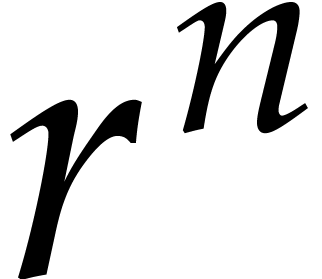 times.
This costs
times.
This costs 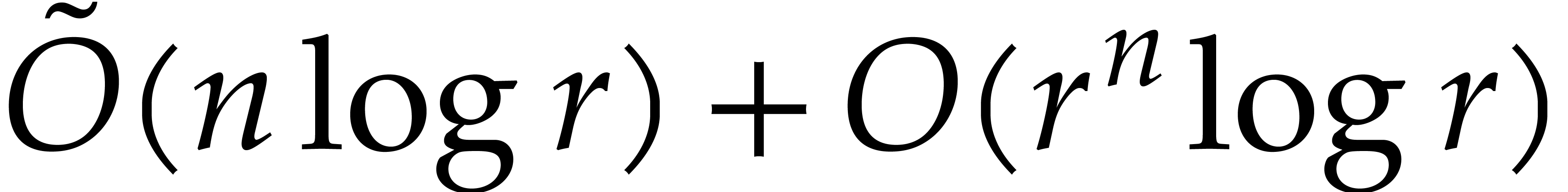 . From now we
assume that is not a constant, whence
. From now we
assume that is not a constant, whence  ,
, 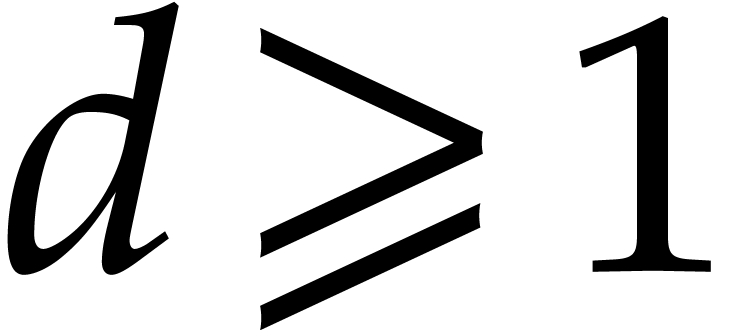 and
and 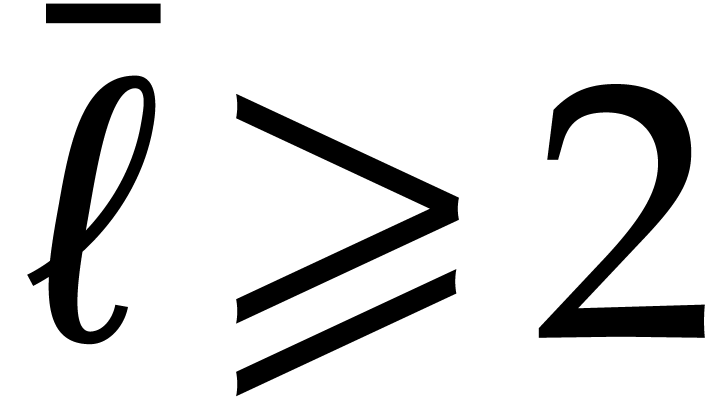 .
.
We interpret as a univariate polynomial and recursively evaluate the coefficients 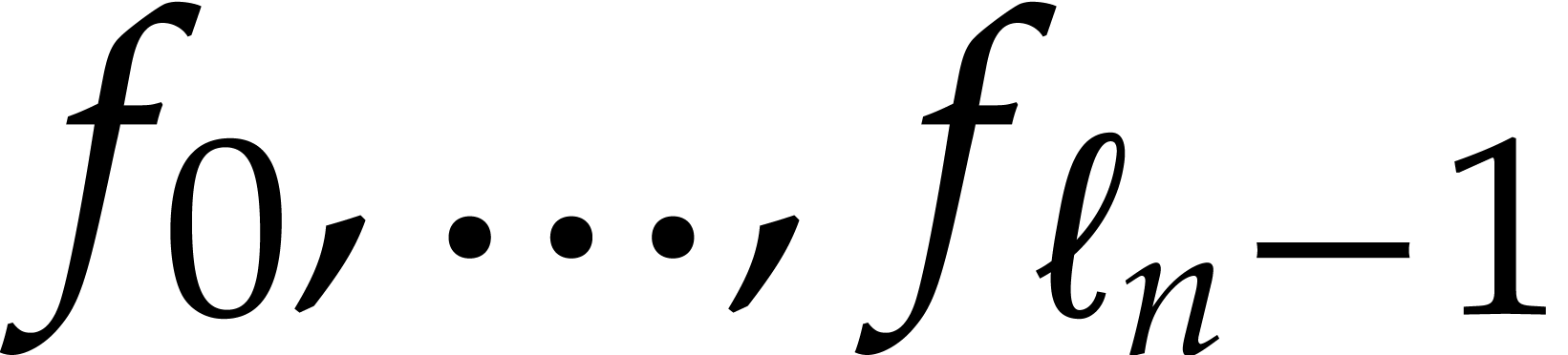 at all points in
at all points in 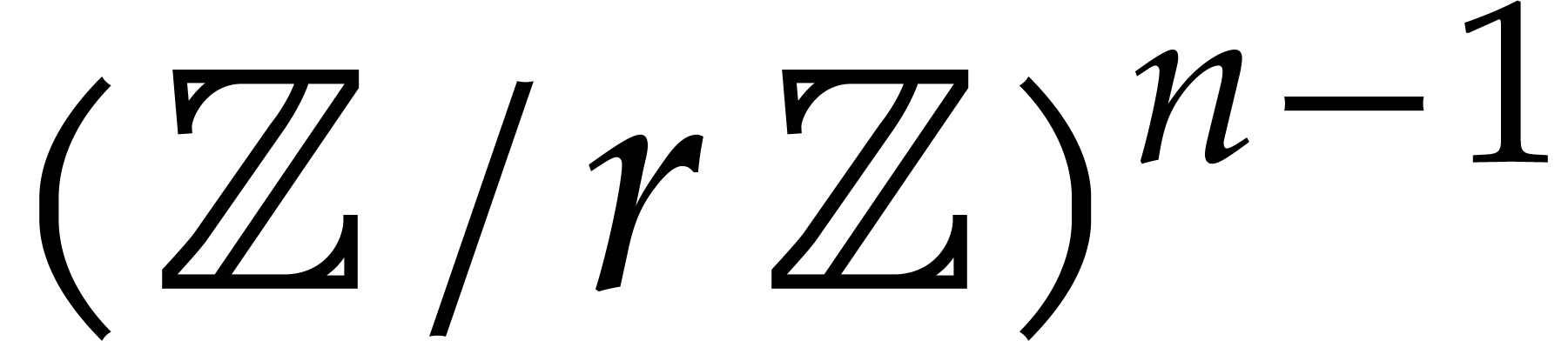 .
After one
.
After one 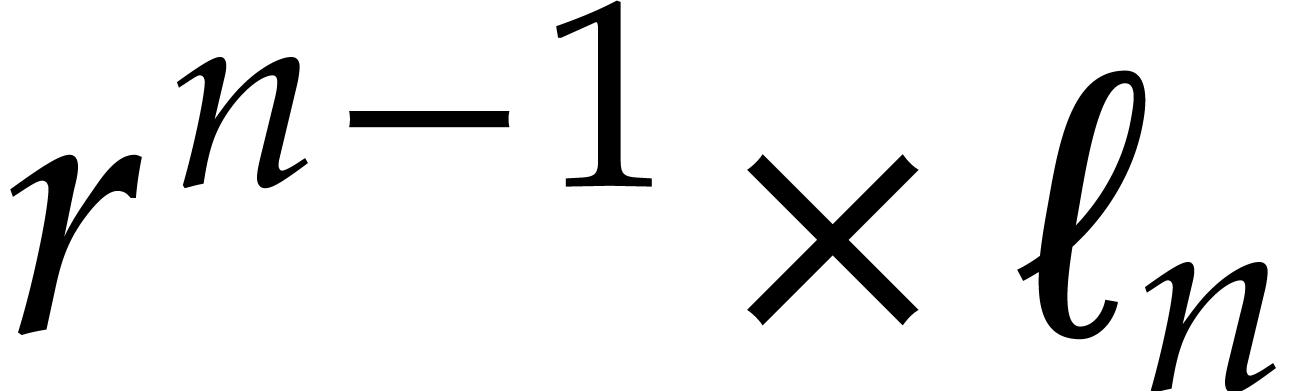 matrix transposition of cost
matrix transposition of cost 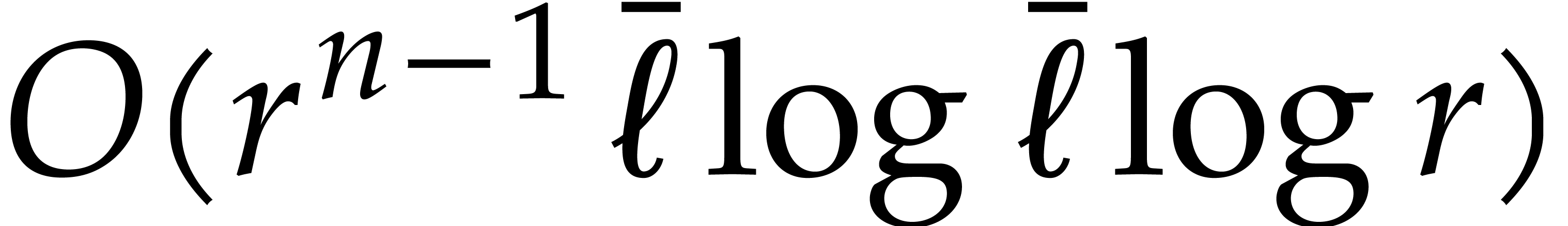 , this yields a vector of
, this yields a vector of 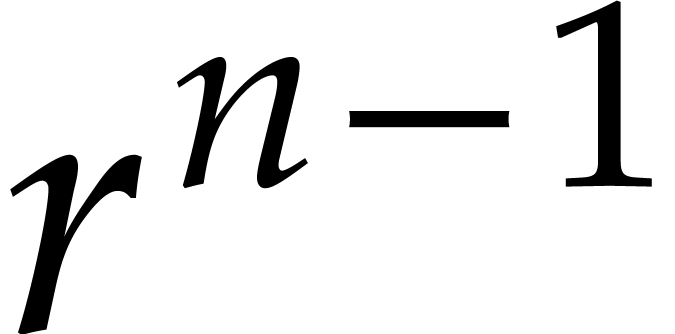 univariate polynomials
univariate polynomials
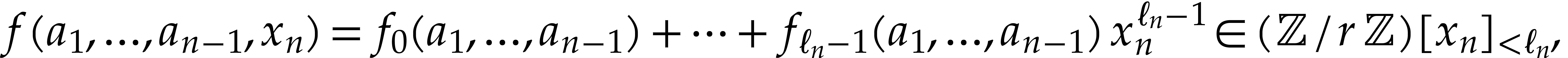
where  ranges over .
Using multi-point evaluations of these
polynomials at all
ranges over .
Using multi-point evaluations of these
polynomials at all  of cost
of cost  , we finally obtain the vector of all
, we finally obtain the vector of all  with
with  . Denoting
by
. Denoting
by 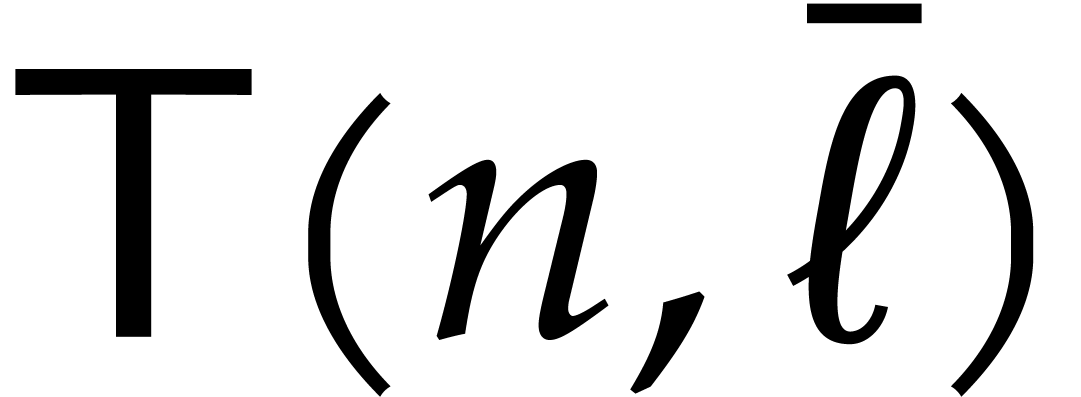 the cost of the algorithm, we thus obtain
the cost of the algorithm, we thus obtain
By induction over , it
follows that
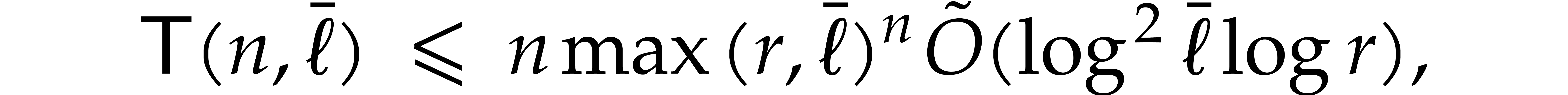
which implies the claimed bound.
In order to evaluate at a specific sequence of points in ,
we next wrap the latter lemma in the following algorithm that simply
reads off the requested values once the exhaustive evaluation is done.
This task is immediate in the RAM model, but induces a logarithmic
overhead on Turing machines.
-
Input
;
a sequence
of points in
.
-
Output
-
.
Proposition 3.3.
Algorithm 3.1 is correct and takes
time
Proof. The cost of step 1 is given in Lemma 3.2.
In the Turing machine model the loop counter  and
the bounds
and
the bounds  and
and  do not
need to be explicitly computed in step 2. Instead it suffices to
allocate an array of bits once on an auxiliary
tape and use it to split the sequence of evaluation points into
subsequences of elements—except the last
one which has cardinality
do not
need to be explicitly computed in step 2. Instead it suffices to
allocate an array of bits once on an auxiliary
tape and use it to split the sequence of evaluation points into
subsequences of elements—except the last
one which has cardinality  .
.
With this point of view in mind, each step 2.b and 2.d requires time
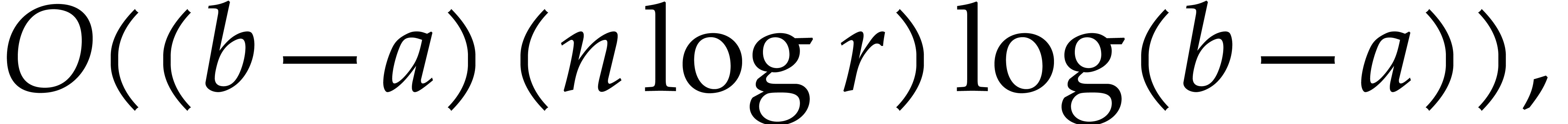
so the sum over all the values of is
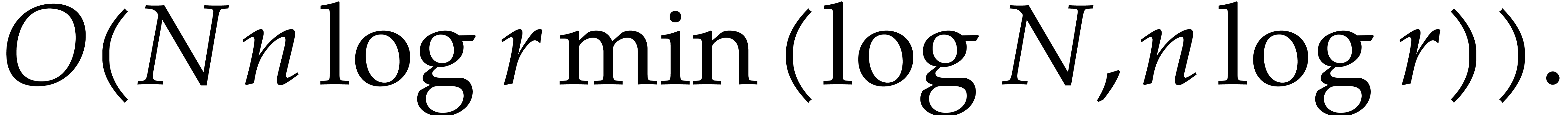
Each step 2.c takes time 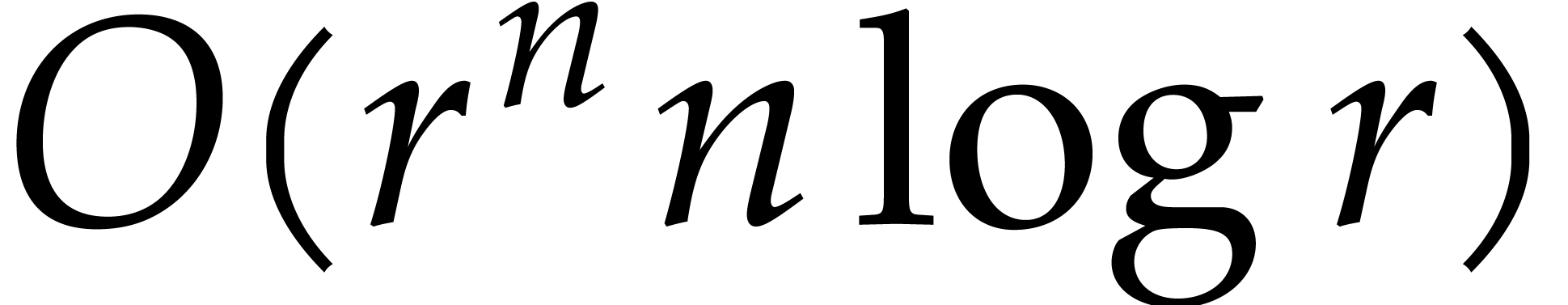 .
The total cost of all steps 2.c is therefore bounded by
.
The total cost of all steps 2.c is therefore bounded by 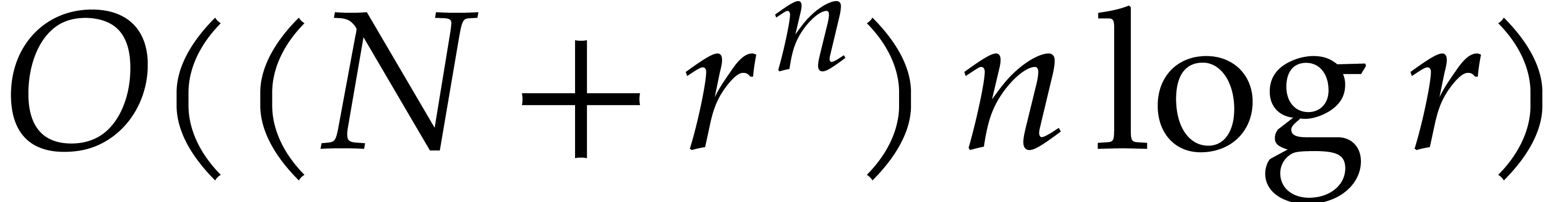 .
.
3.3.The first Chebyshev
function
Multi-modular techniques classically involve bounds on the first
Chebyshev function
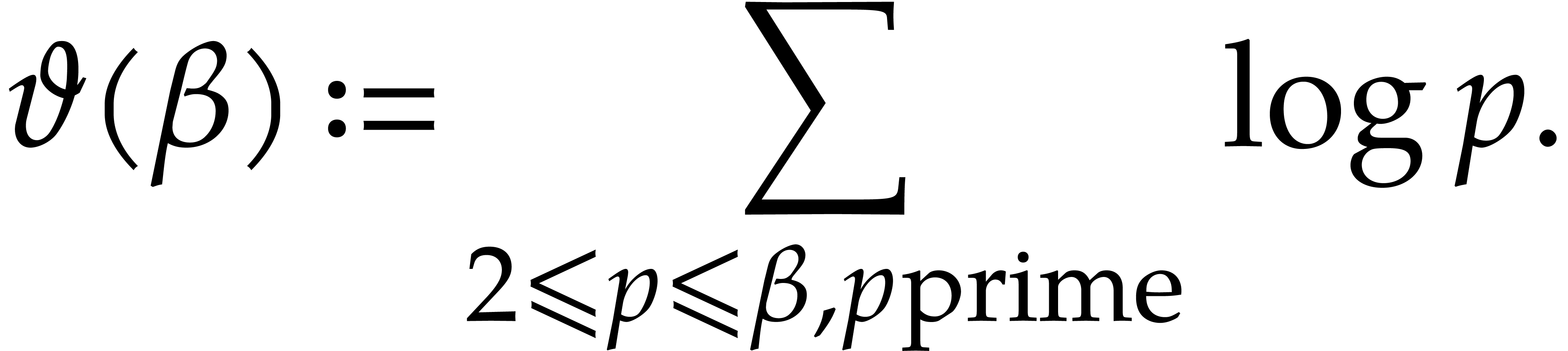
For many applications, crude estimates on  suffice. For our refined complexity analysis of the Kedlaya–Umans
algorithm, we rely on the somewhat better estimate
suffice. For our refined complexity analysis of the Kedlaya–Umans
algorithm, we rely on the somewhat better estimate
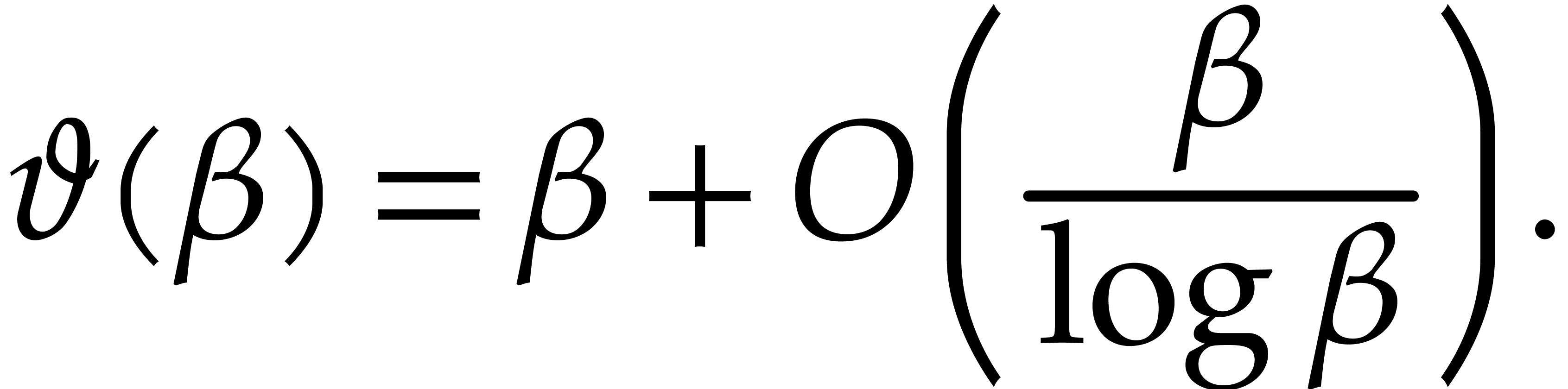 |
(3.6) |
More precisely, it was shown by Barkley Rosser and Schoenfeld [2,
Theorem 31] that, for all 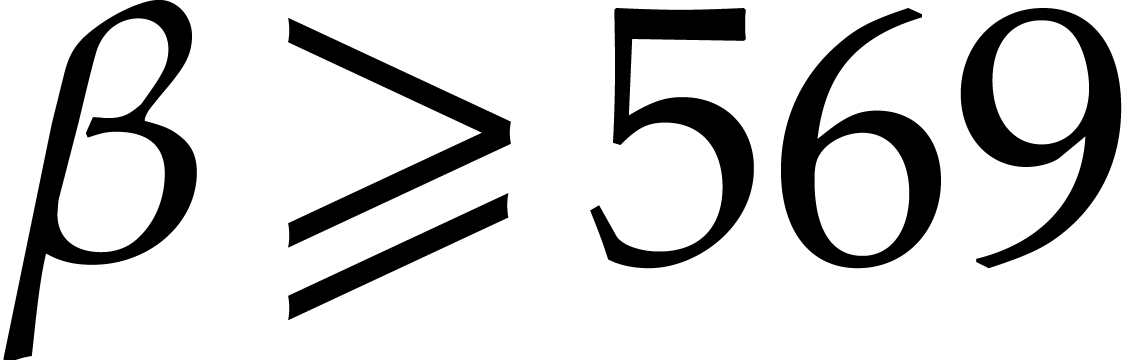 ,
,
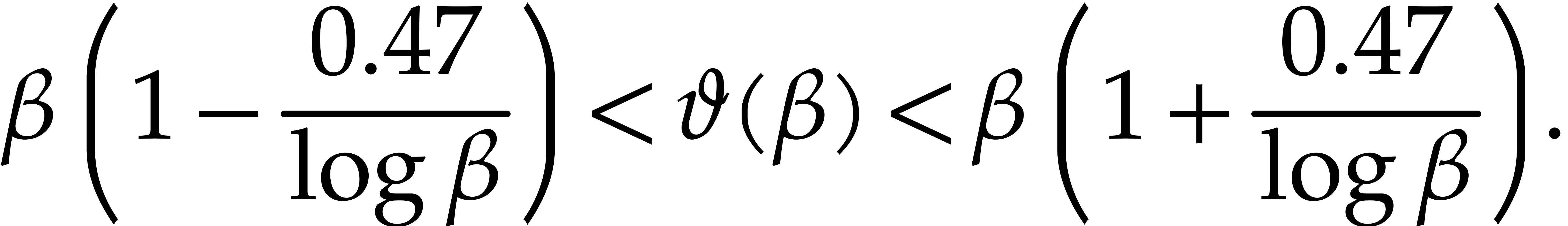
Even sharper bounds may be found in [12], but they will not
be necessary here. From now on  represents a
constant in
represents a
constant in  such that
such that
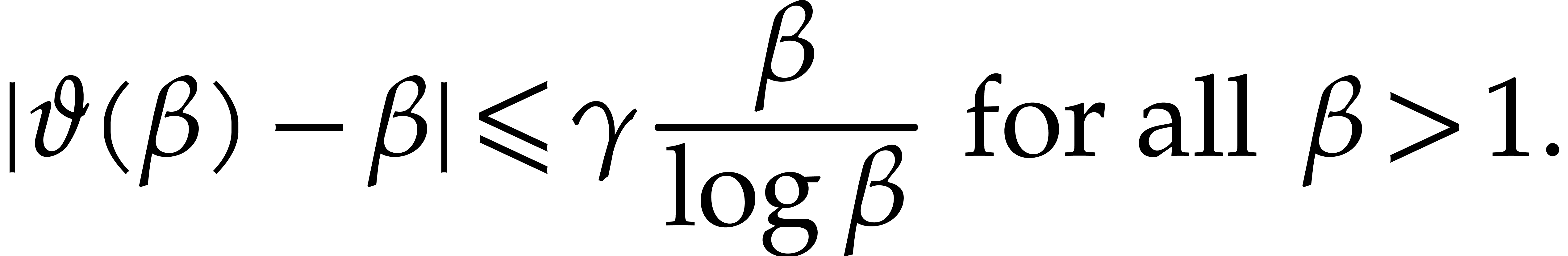 |
(3.7) |
Lemma 3.4. There exists 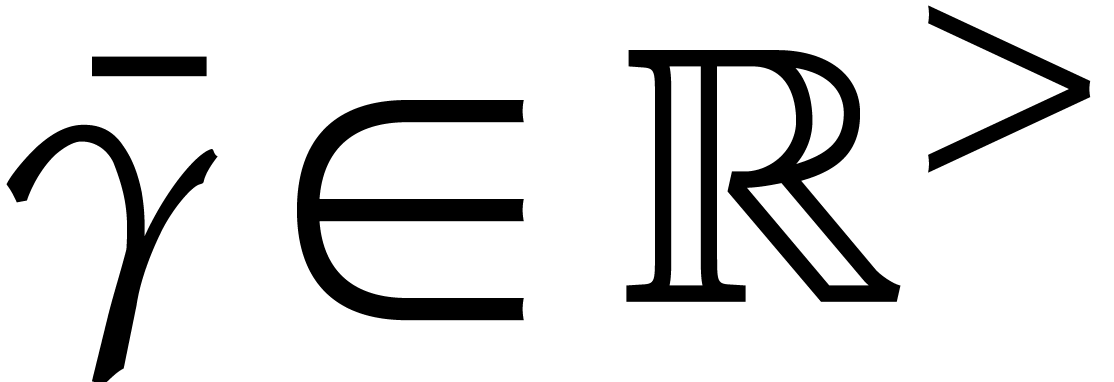 such that
such that
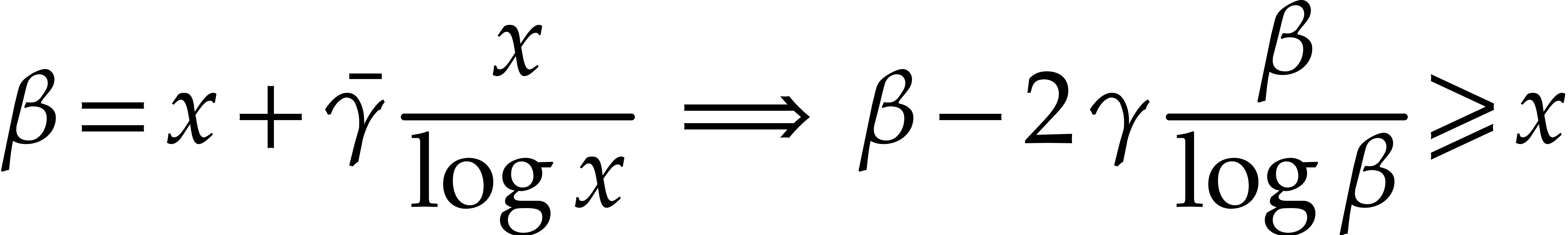
holds for all  .
.
Proof. For fixed 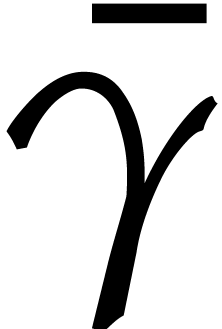 and large
and large
 , one has
, one has
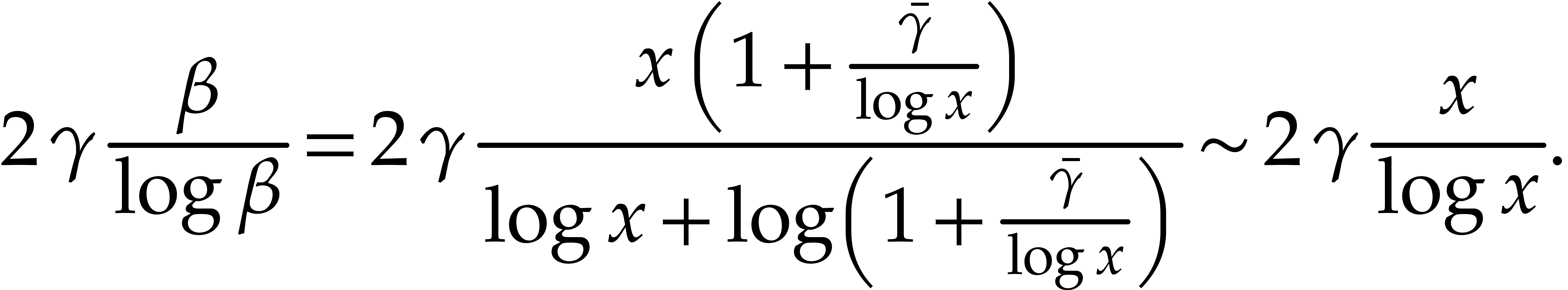
Taking 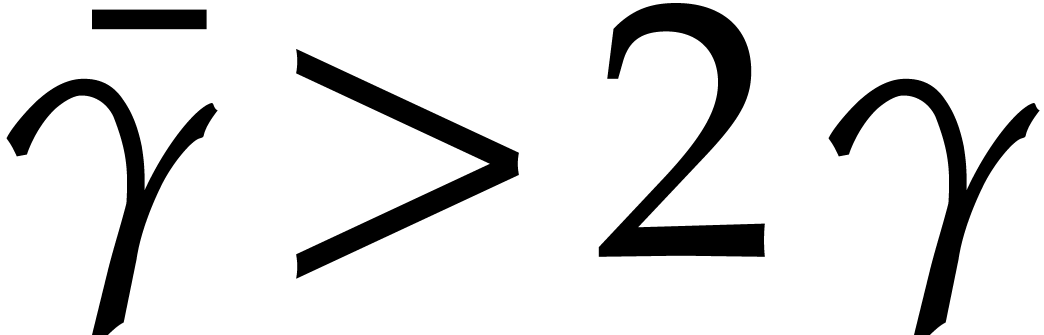 and sufficiently
large (say
and sufficiently
large (say  ), it follows that
), it follows that
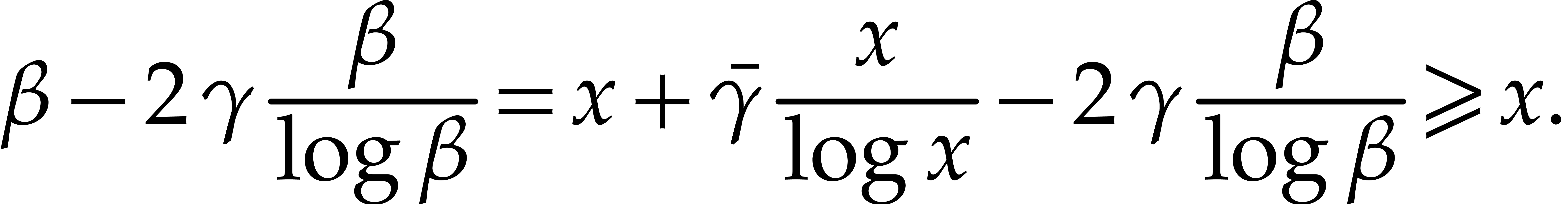
Then it suffices to further increase so that the
implication also holds on the interval 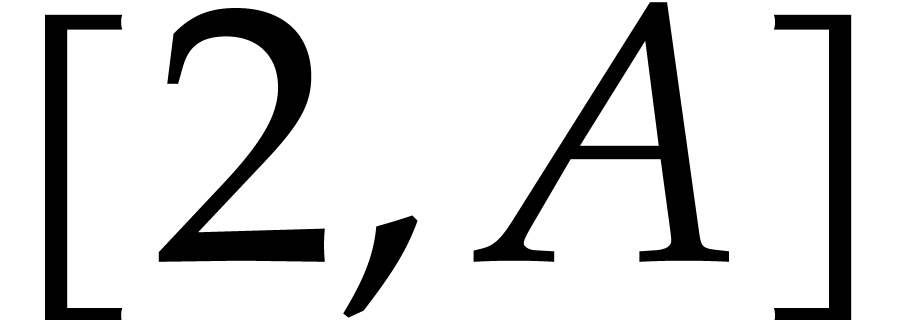 .
.
In the rest of this section the constant 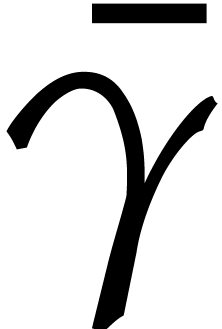 of the
lemma will be used via the following function:
of the
lemma will be used via the following function:
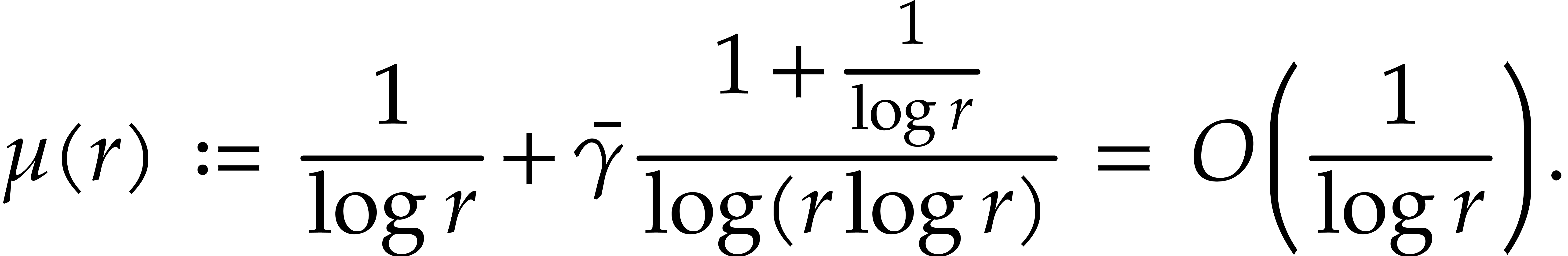 |
(3.8) |
It is also convenient to introduce the function
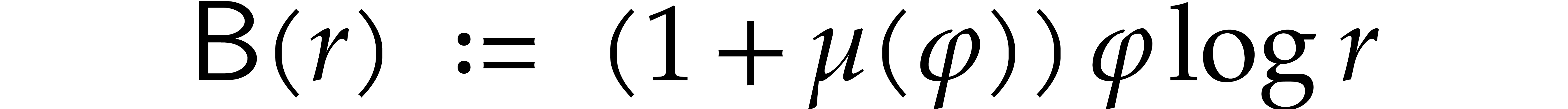 |
(3.9) |
that will bound the inflation of the modulus at successive recursive
calls of our main algorithm. We will write 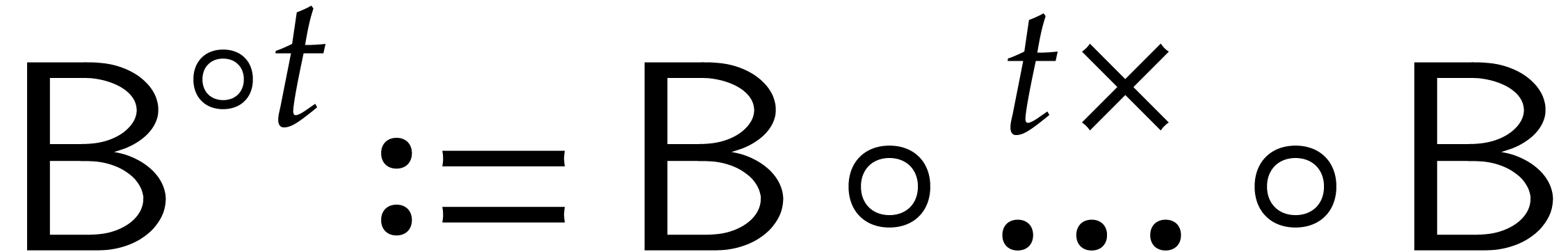 for
the -th iterate of this
function.
for
the -th iterate of this
function.
3.4.Computing prime numbers
Generating prime numbers is a standard task. In the next paragraphs we
include the needed results for completeness.
Proof. We use the well known Eratosthenes sieve. On
the same tape we generate all the integer multiples of 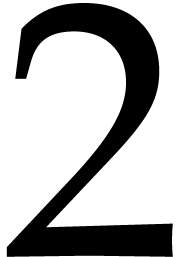 not larger than , followed by
all the multiples of 3 not larger than ,
then all the multiples of
not larger than , followed by
all the multiples of 3 not larger than ,
then all the multiples of  not larger than , etc. The total number of
multiples generated in this way is
not larger than , etc. The total number of
multiples generated in this way is 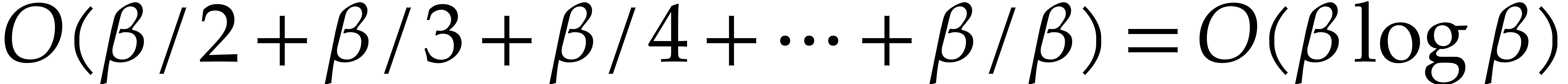 .
These multiples can all be generated in time
.
These multiples can all be generated in time 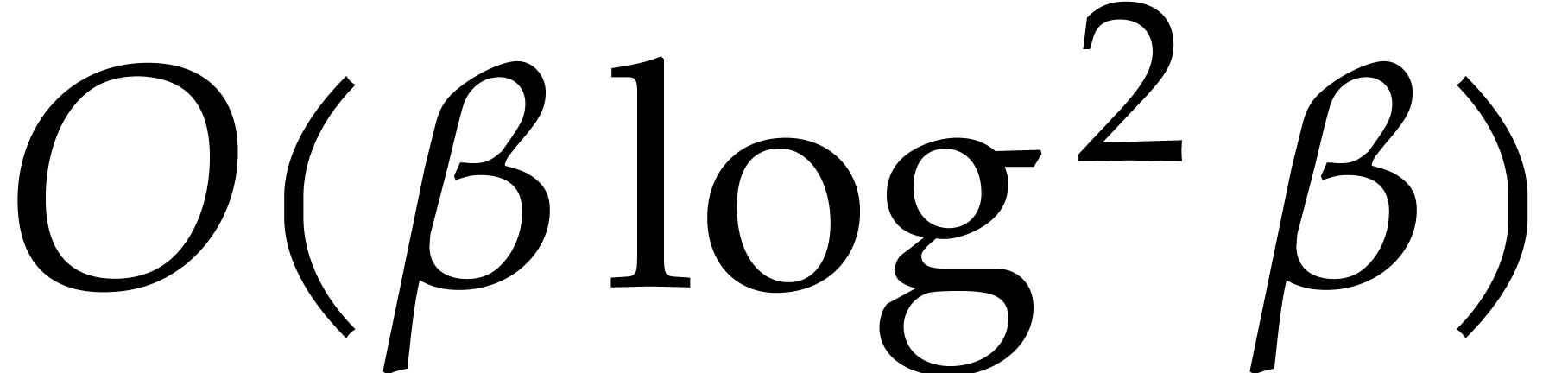 . Then we sort these integers in increasing order
and remove duplicates in time
. Then we sort these integers in increasing order
and remove duplicates in time 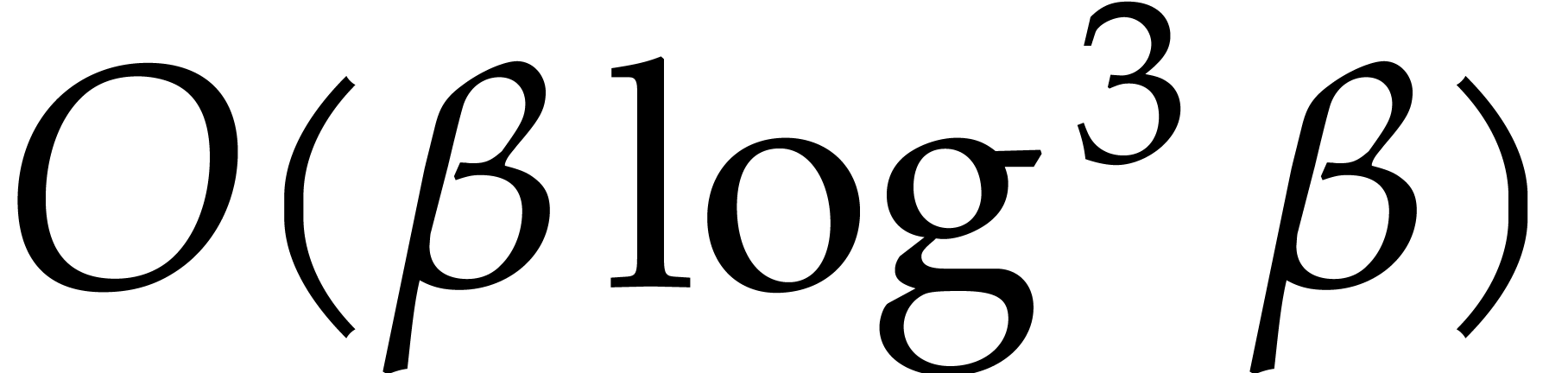 .
The integers
.
The integers 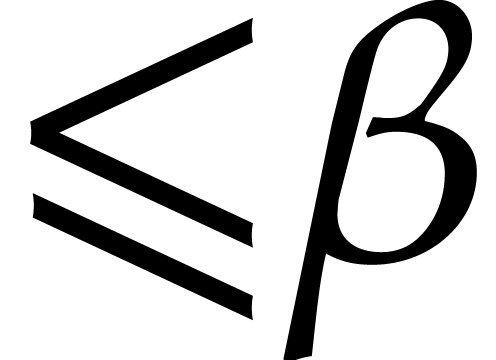 which are not listed in this way
are exactly the requested prime numbers, which can thus be deduced with
further
which are not listed in this way
are exactly the requested prime numbers, which can thus be deduced with
further 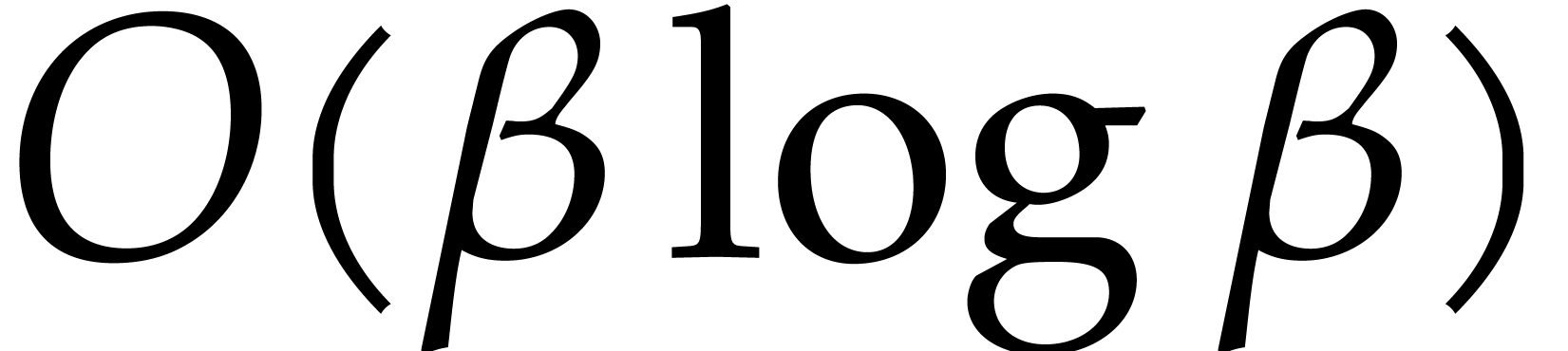 bit operations.
bit operations.
The following algorithm computes consecutive prime numbers larger than a
given integer 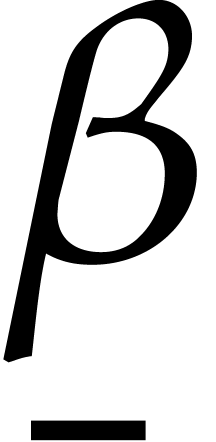 , such that
their product exceeds a given threshold
, such that
their product exceeds a given threshold  .
.
Proposition 3.6.
Algorithm 3.2 is correct and takes
time 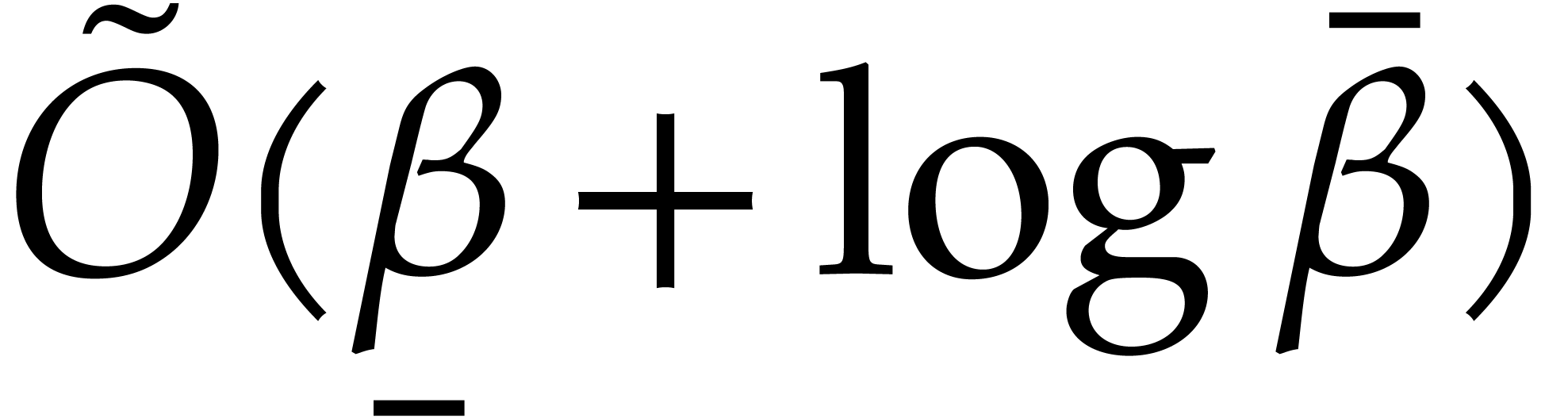 . In addition we have
. In addition we have
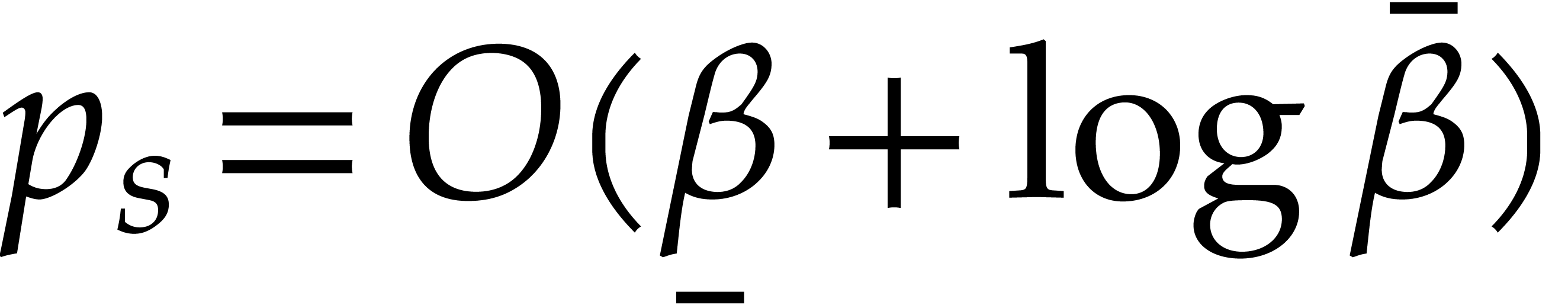 .
.
Proof. After step 3 we have 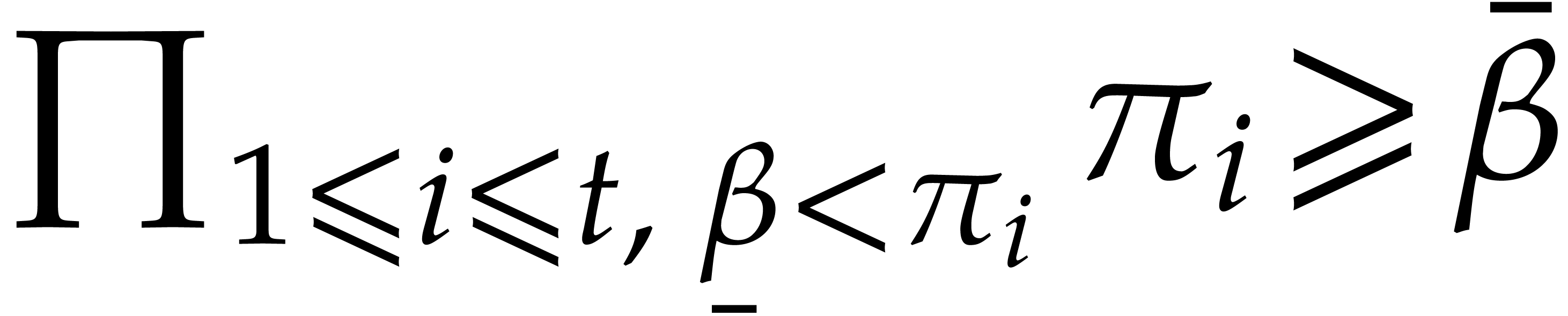 , so the rest of the algorithm corresponds to a
binary search to obtain the minimal index
, so the rest of the algorithm corresponds to a
binary search to obtain the minimal index  such
that
such
that 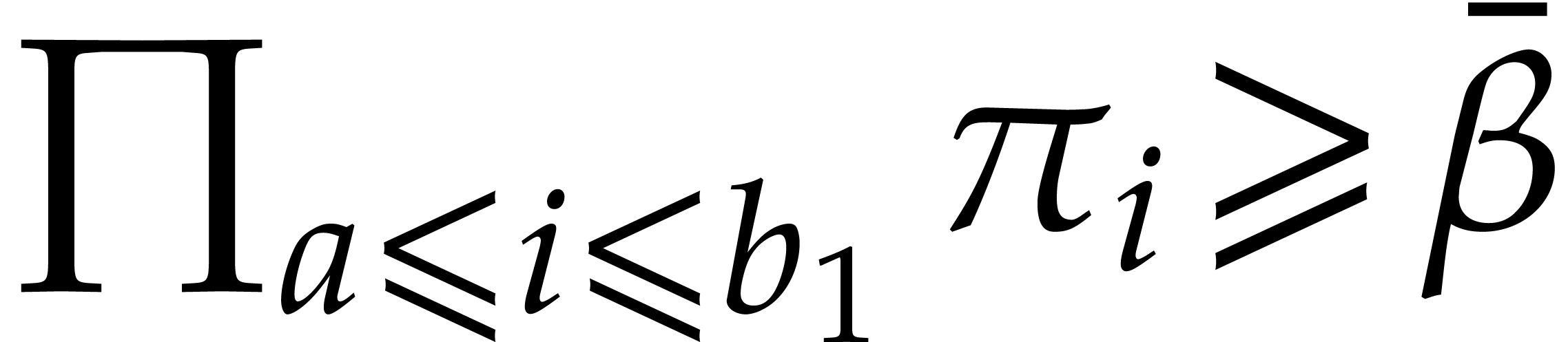 . During the
“while” loop of step 6 we have
. During the
“while” loop of step 6 we have 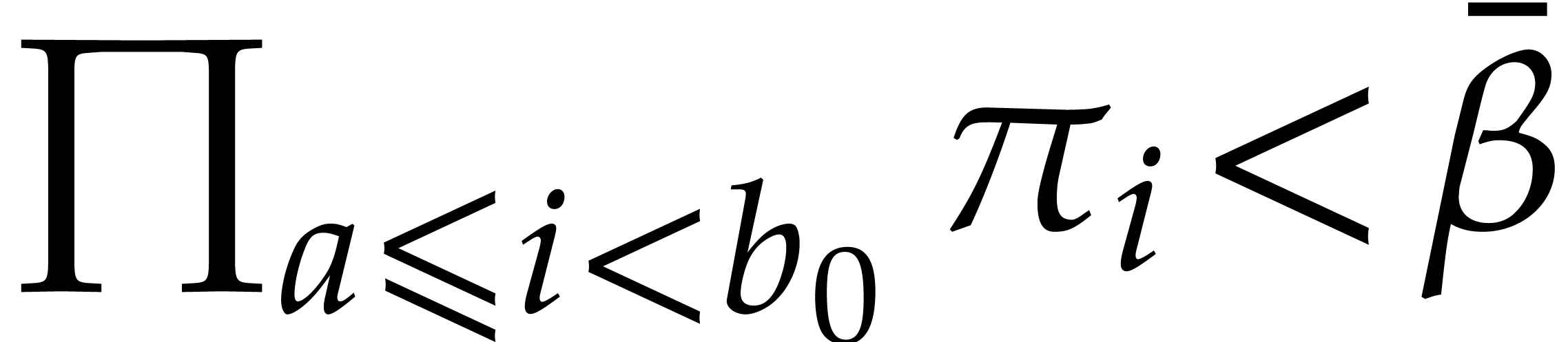 and
. So when
and
. So when  the minimal sequence is actually found. Since
the minimal sequence is actually found. Since  at
each step of the “while” loop, either
at
each step of the “while” loop, either 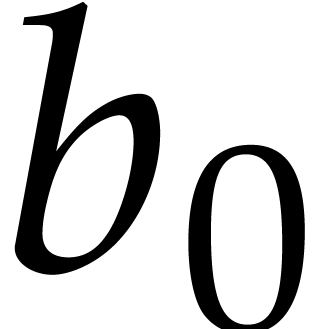 increases or decreases strictly. Consequently
the algorithm returns the correct result.
increases or decreases strictly. Consequently
the algorithm returns the correct result.
We exit step 3 once 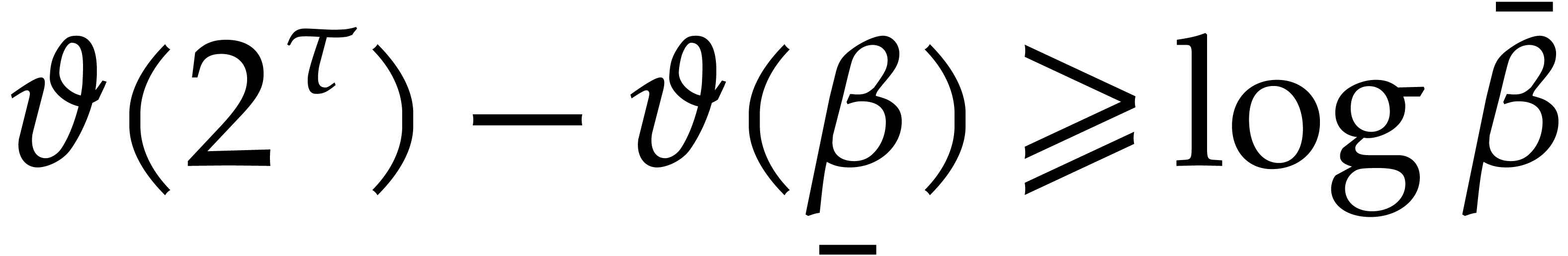 . Thanks
to (3.6), this condition is met for
. Thanks
to (3.6), this condition is met for
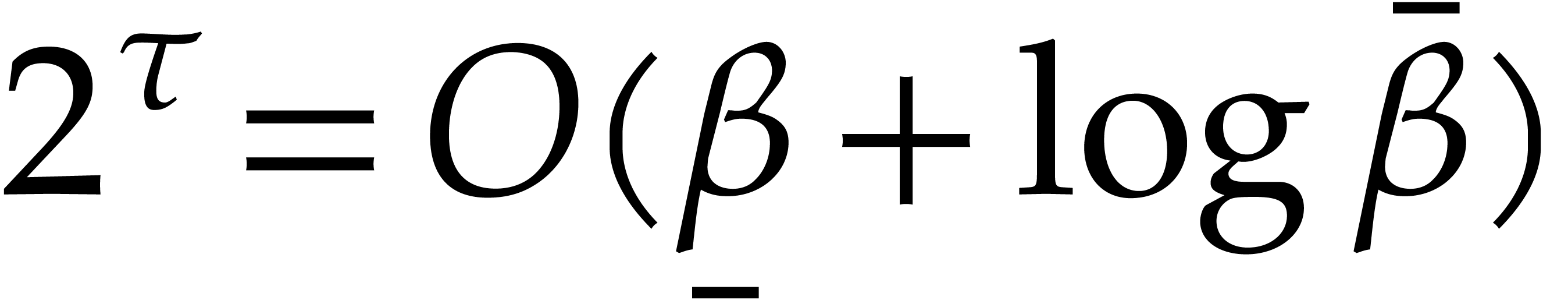 , after time , by Lemma 3.5. The binary search
also takes time .
, after time , by Lemma 3.5. The binary search
also takes time .
3.5.The main recursion
We are now ready to present the multi-modular evaluation algorithm. The
parameter indicates the allowed depth for the
recursive calls.
-
Input
;
a sequence
of points in
;
a nonnegative integer
;
 as defined in
(3.2)
.
as defined in
(3.2)
.
-
Output
-
.
-
Assumption
-
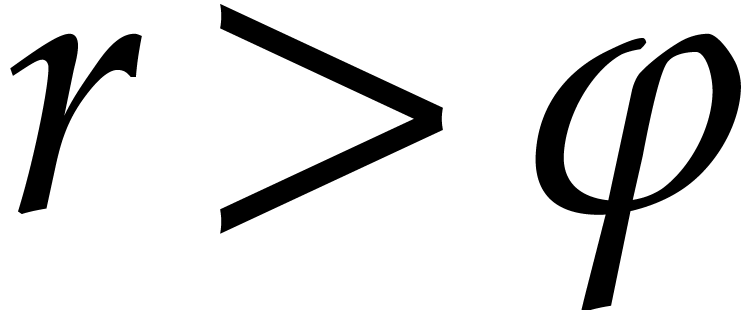 .
.
Proof. Lemma 3.1 ensures that the
multi-modular approach works well, whence the correctness of the
algorithm. From now assume  and . Inequality (3.1),
combined to the definition of
and . Inequality (3.1),
combined to the definition of  ,
implies
,
implies 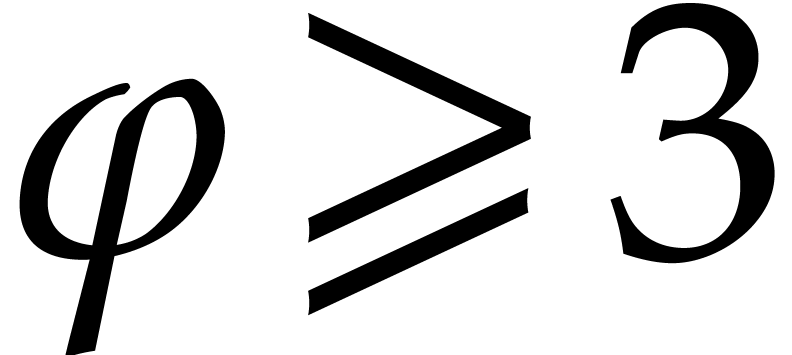 . If
is bounded, then so are ,
, and
. If
is bounded, then so are ,
, and  . Consequently we may freely assume that is sufficiently large in the cost analysis. From (3.7), for all
. Consequently we may freely assume that is sufficiently large in the cost analysis. From (3.7), for all  we
obtain
we
obtain
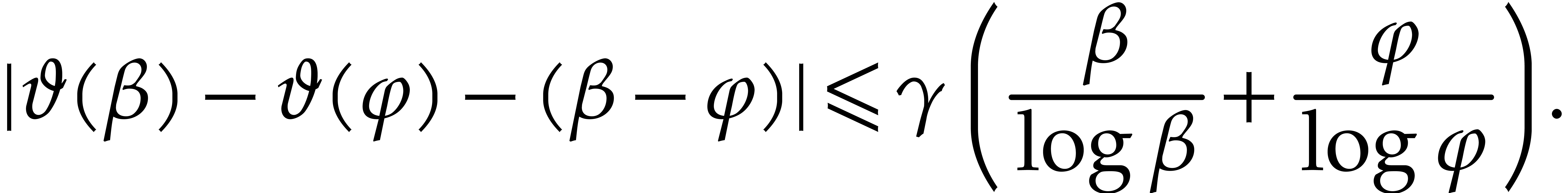
Since 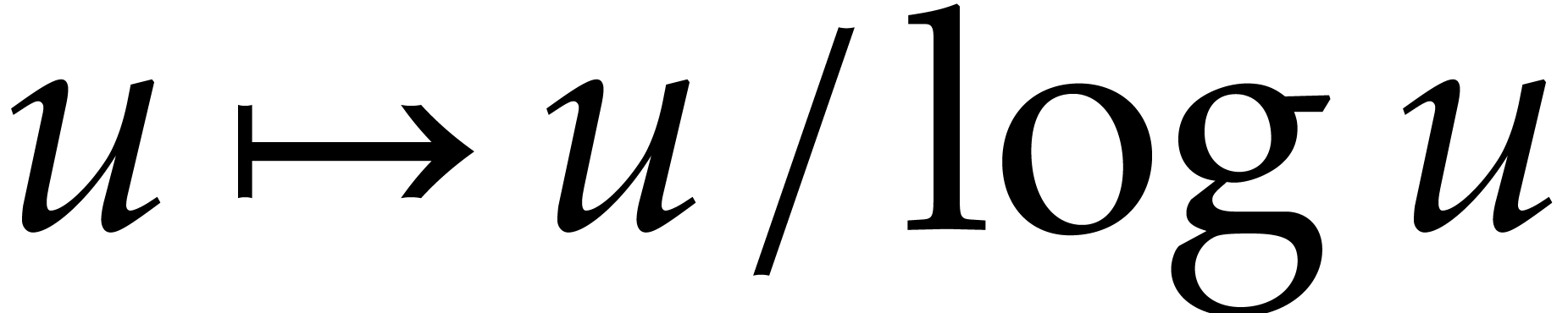 is increasing for all
is increasing for all 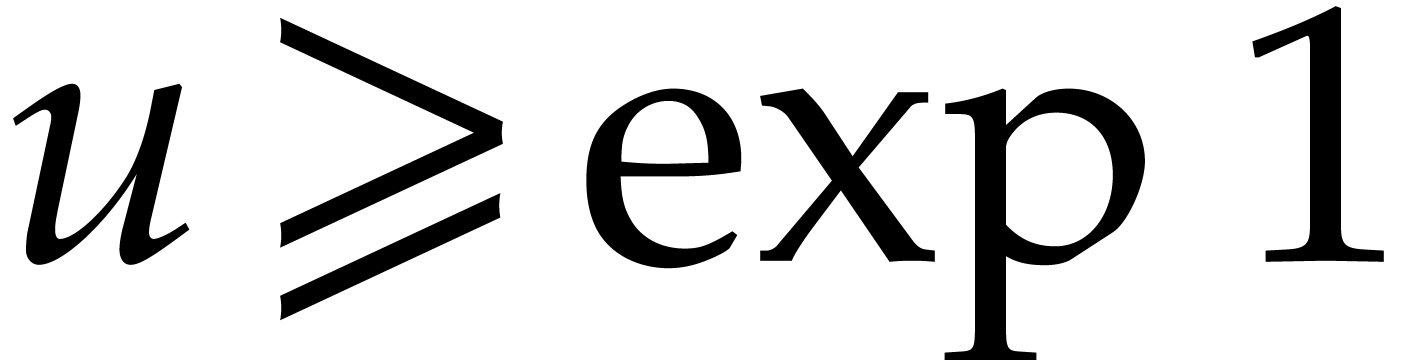 , we deduce
, we deduce
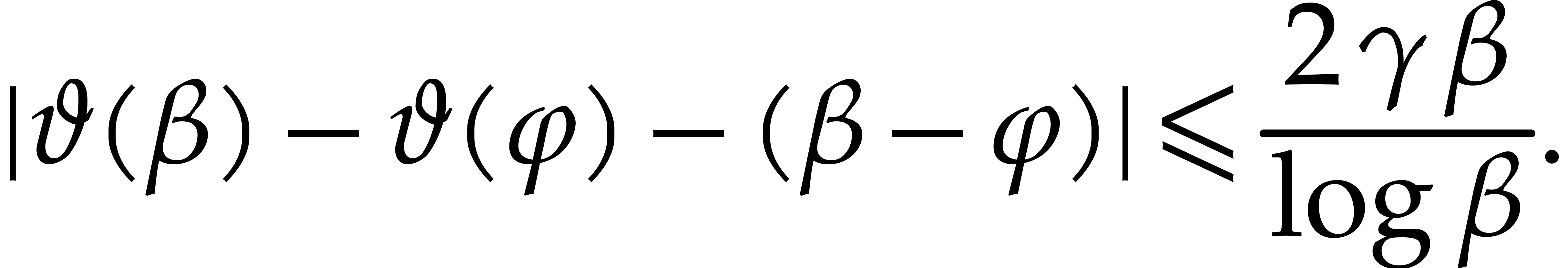
The condition 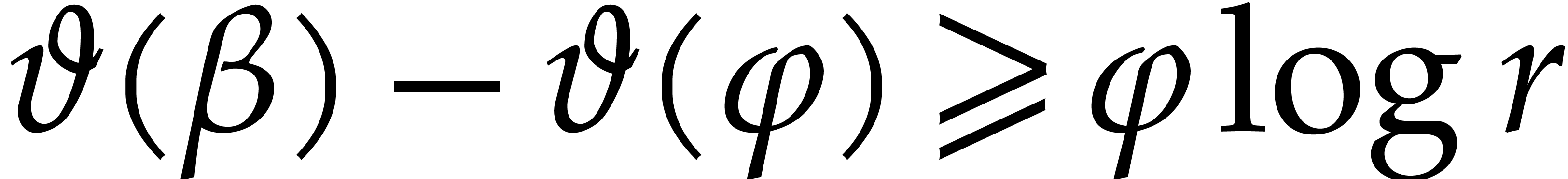 is therefore satisfied whenever
is therefore satisfied whenever
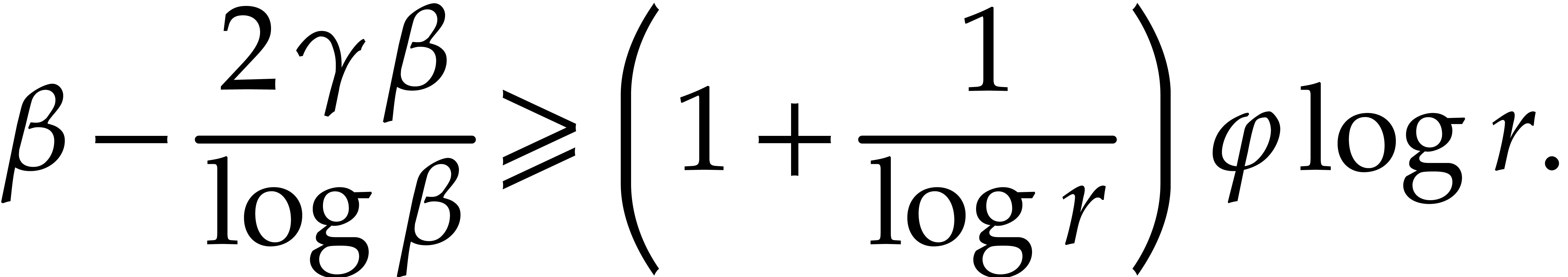 |
(3.10) |
By Lemma 3.4, there exists such
that (3.10) is satisfied when is larger than
It follows that
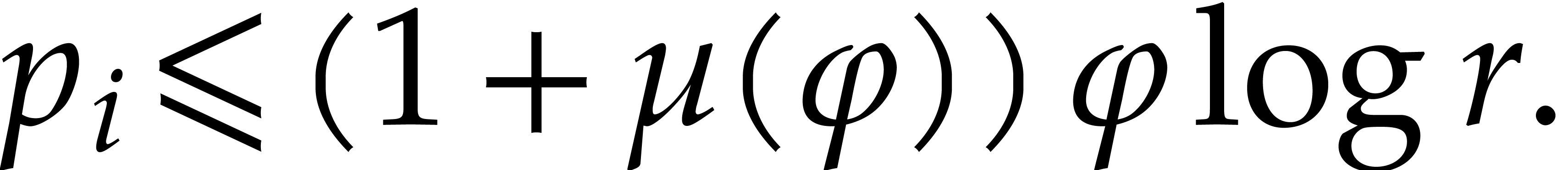 |
(3.11) |
From 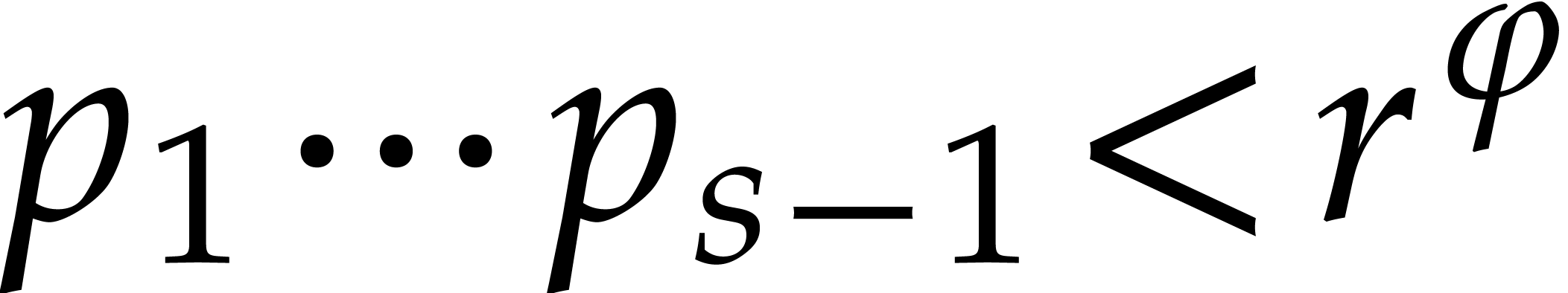 , we deduce that
, we deduce that
By Proposition 3.6, step 2 takes time 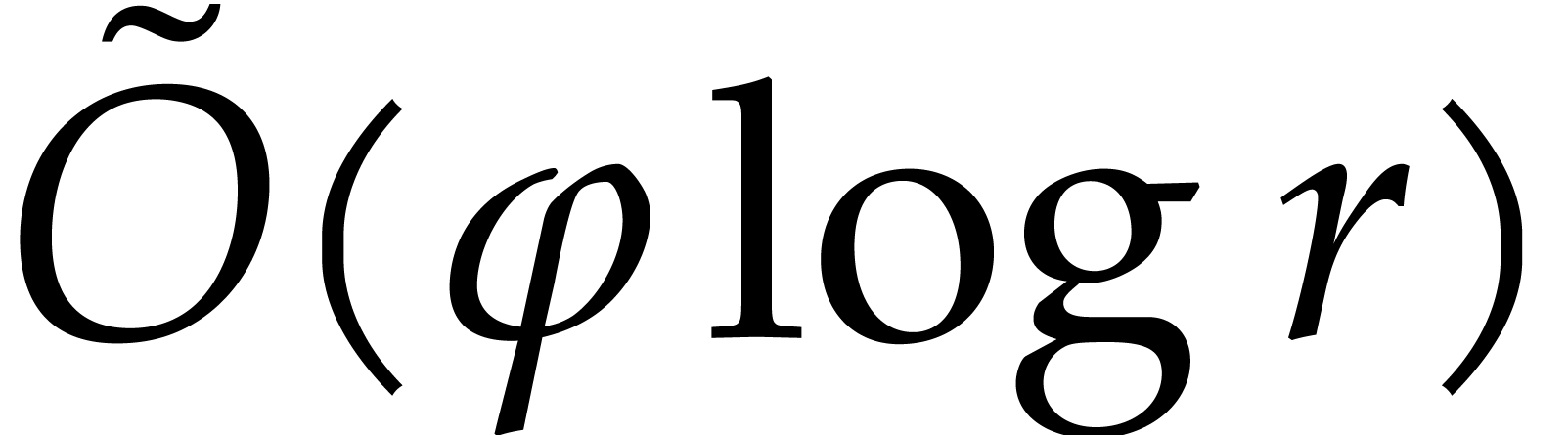 . The number of “#” in the
representation of is
. The number of “#” in the
representation of is 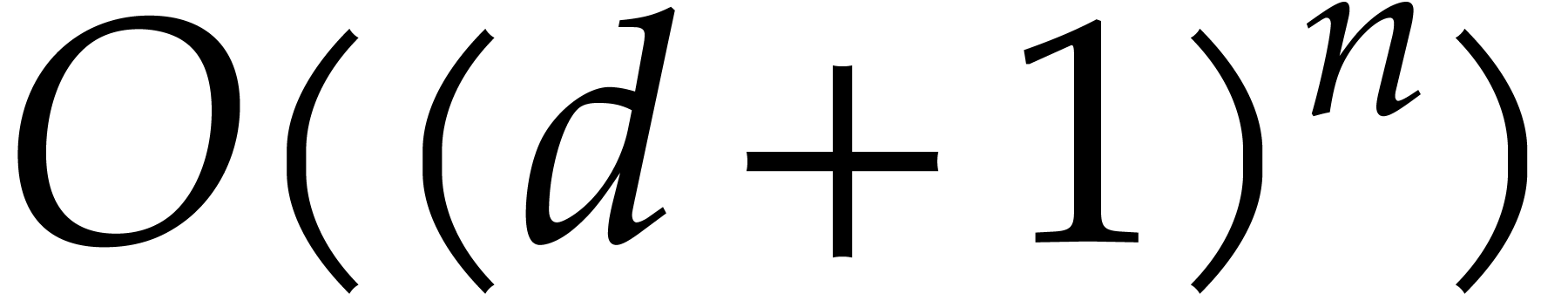 by
Lemma 2.5. Consequently the multi-remaindering of in step 3 takes time
by
Lemma 2.5. Consequently the multi-remaindering of in step 3 takes time 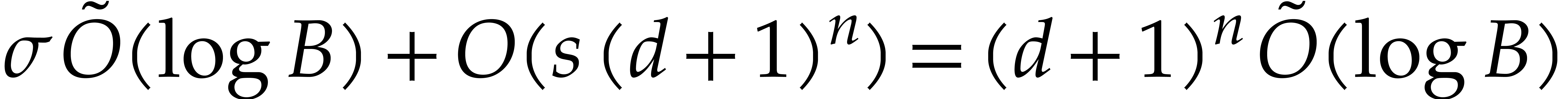 by Lemma 2.10. By Lemma 2.9 the multi-remaindering of takes time
by Lemma 2.10. By Lemma 2.9 the multi-remaindering of takes time 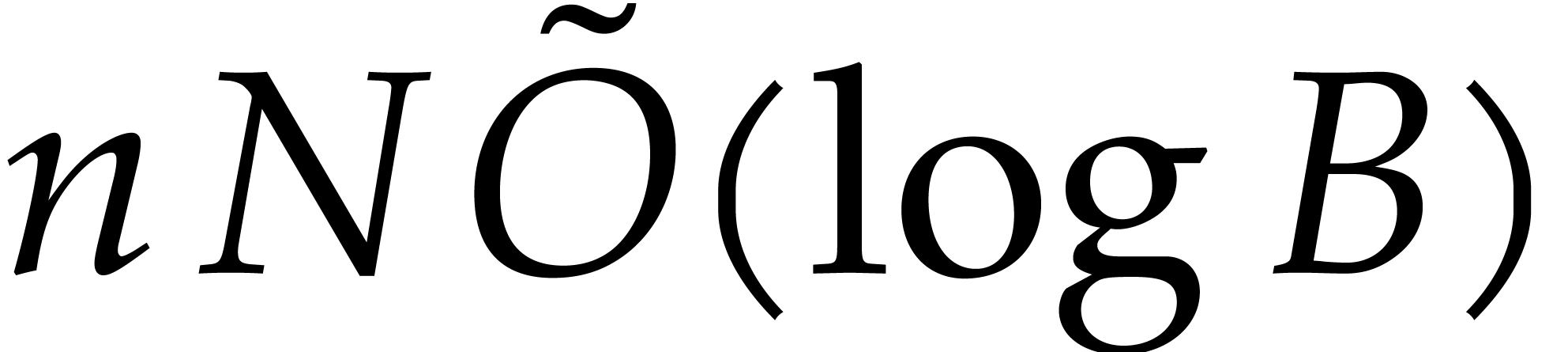 .
In total step 3 contributes to
.
In total step 3 contributes to
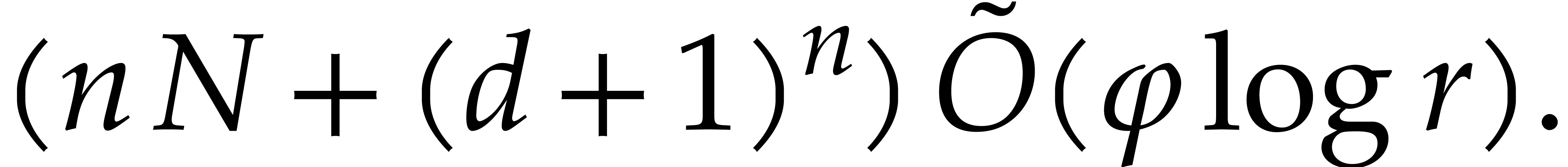
Step 5 costs 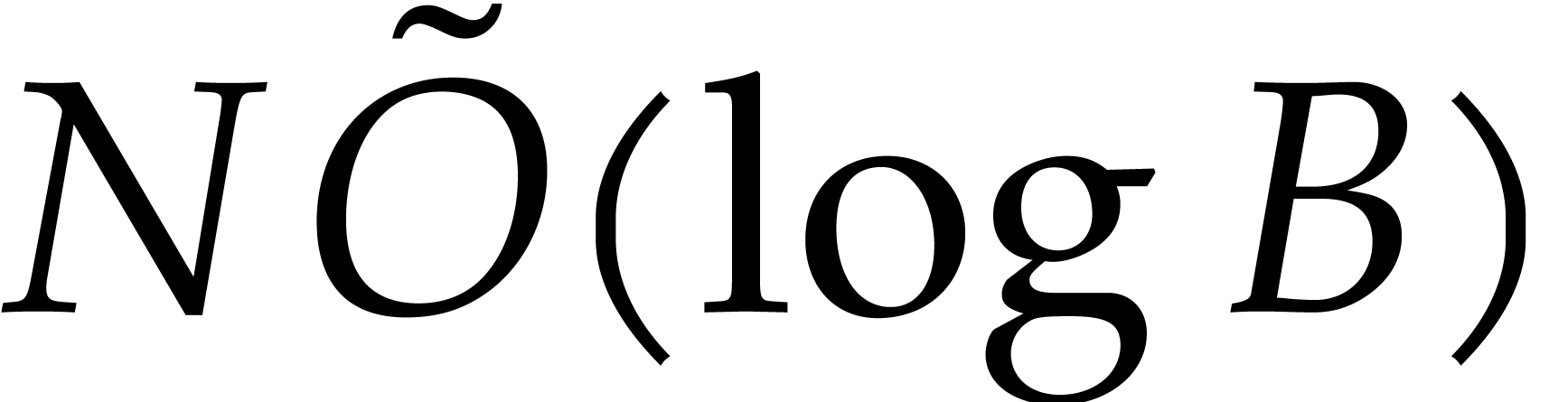 by Lemma 2.11. The
cost of step 6 is also dominated by .
by Lemma 2.11. The
cost of step 6 is also dominated by .
Let 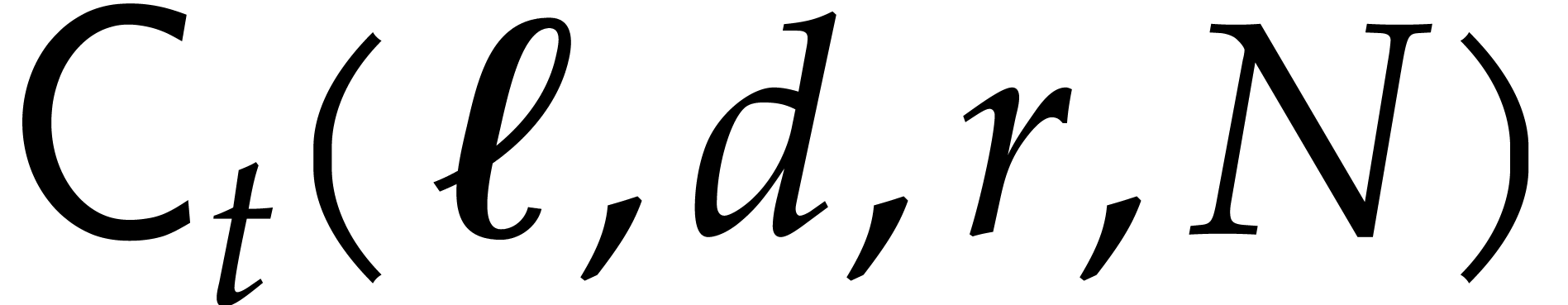 denote the cost function of Algorithm 3.3, for
denote the cost function of Algorithm 3.3, for  being fixed. In other words,
the constants hidden in the “
being fixed. In other words,
the constants hidden in the “ ”
of the rest of the proof do not depend on
”
of the rest of the proof do not depend on 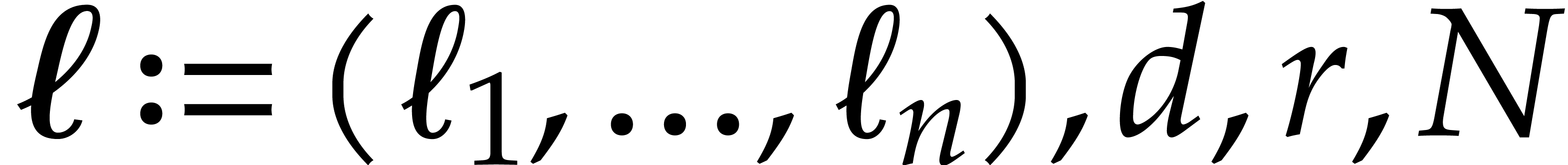 but on
. Since
but on
. Since 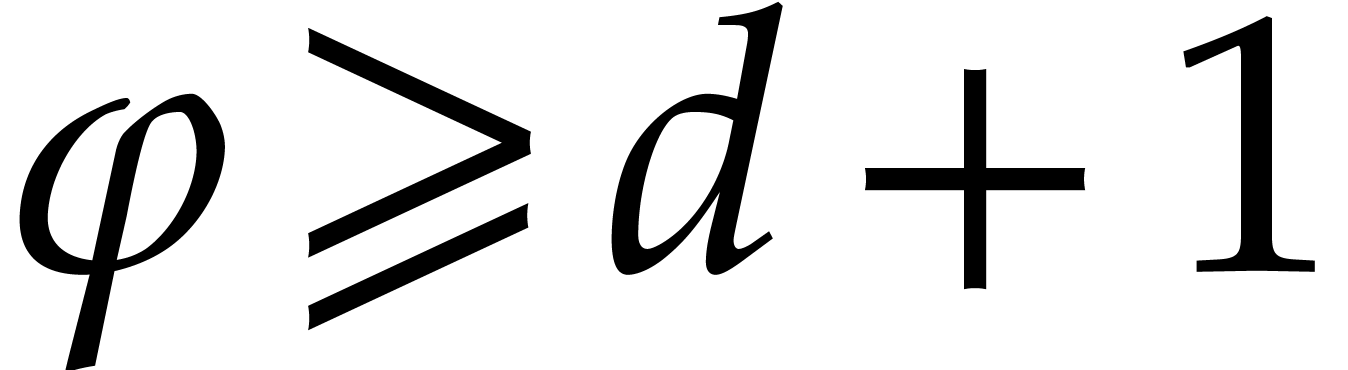 by (3.3), we have
by (3.3), we have 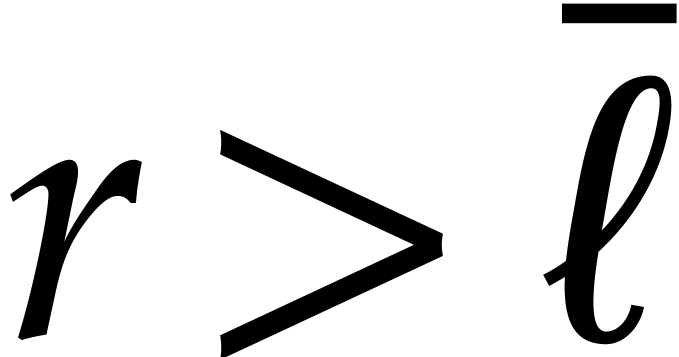 . Proposition 3.3 yields the cost
of step 1:
. Proposition 3.3 yields the cost
of step 1:
By summing the costs of steps 2 to 6, we deduce that
 |
(3.13) |
Consequently, if 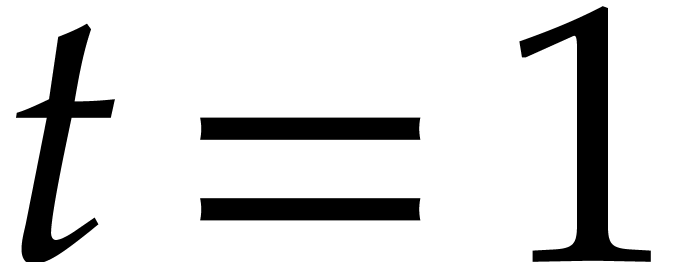 , using the
bounds (3.11), (3.12), and
, using the
bounds (3.11), (3.12), and
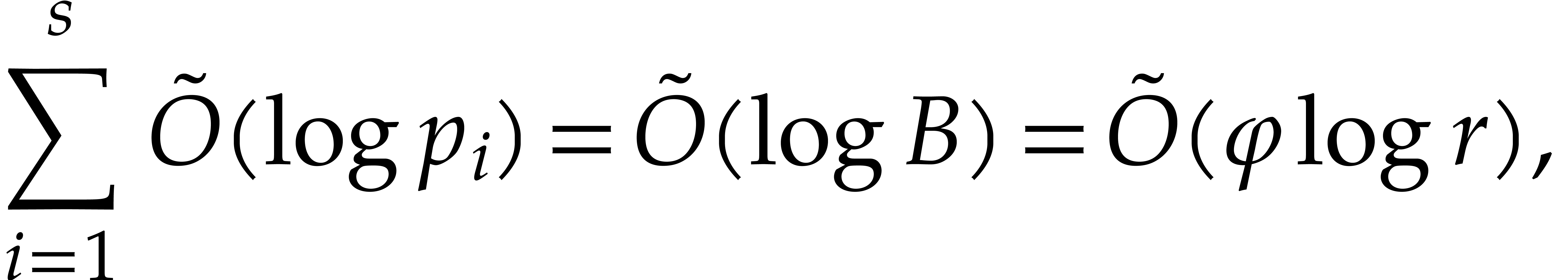
the cost of Algorithm 3.3 simplifies as follows:
Using (3.3) again gives 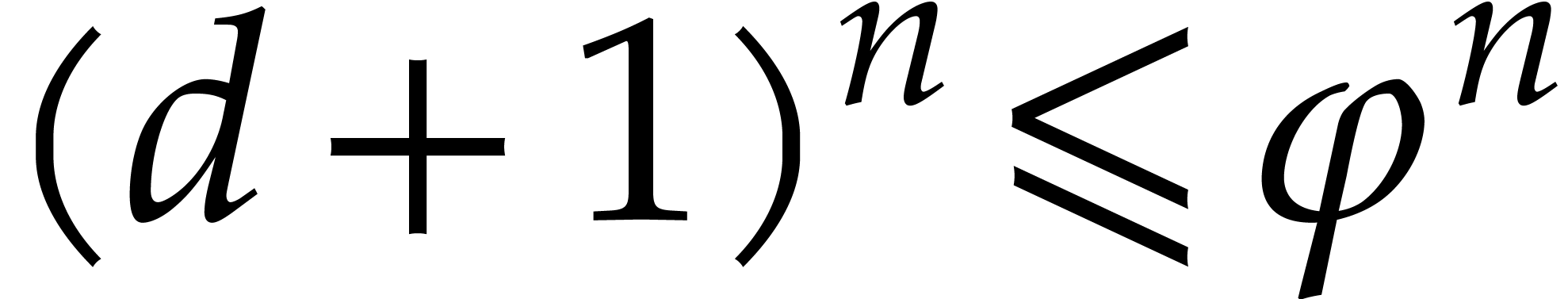 , whence
, whence
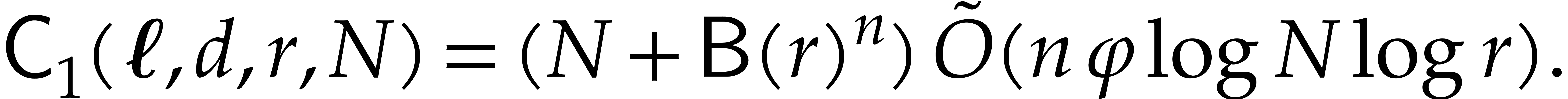
Now assume by induction that  holds for some
holds for some
 . Combining (3.11) and (3.13) we
deduce that:
. Combining (3.11) and (3.13) we
deduce that:
We claim that 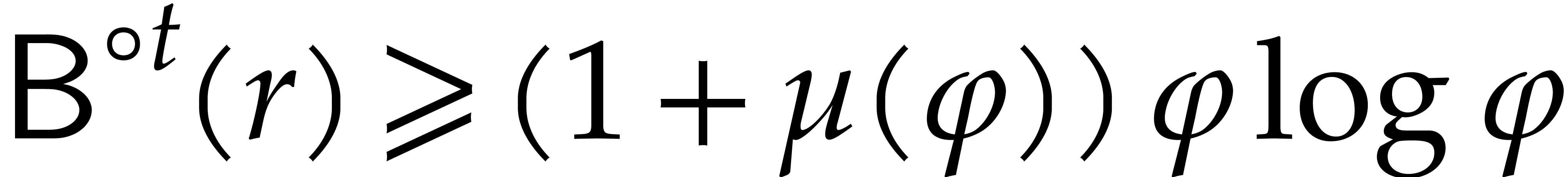 for all
for all  which implies
which implies  and concludes the proof. The
latter claim is proved by induction on .
It clearly holds for . Assume
it holds for
and concludes the proof. The
latter claim is proved by induction on .
It clearly holds for . Assume
it holds for  . Then, using
, we verify that
. Then, using
, we verify that
which concludes the proof of the claim.
3.6.The main complexity bound
In order to complete Algorithm 3.3, we still have to
specify how to set the parameter in terms of
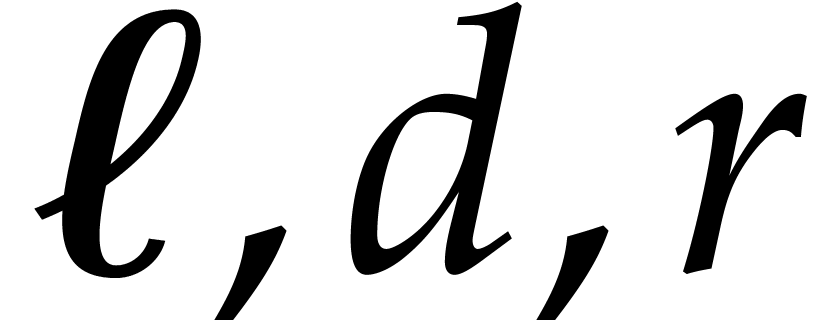 . It is natural to let increase as a function of . Yet we cannot take
arbitrarily large because the complexity in Proposition 3.7
involves a factor . The key
idea here is to observe that, if is very large,
namely when
. It is natural to let increase as a function of . Yet we cannot take
arbitrarily large because the complexity in Proposition 3.7
involves a factor . The key
idea here is to observe that, if is very large,
namely when 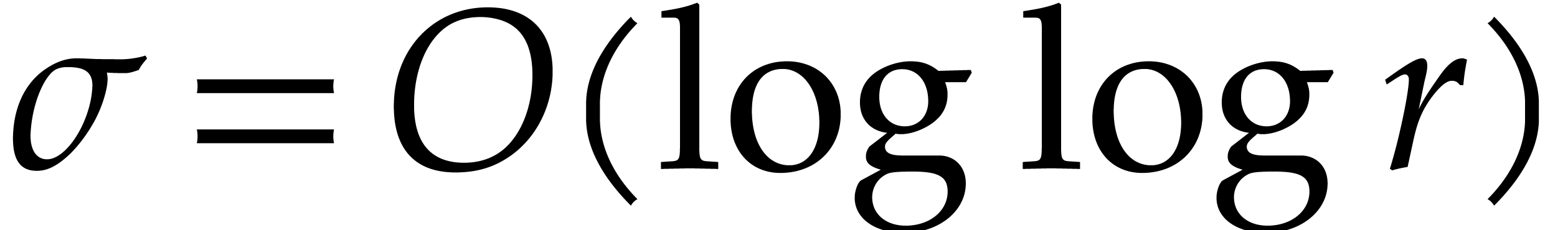 , then we may use
the naive algorithm to evaluate independently at
each
, then we may use
the naive algorithm to evaluate independently at
each 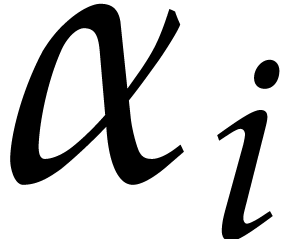 . This leads to the
following complexity bound.
. This leads to the
following complexity bound.
Proof. If ,
then is constant and we just copy the input. If
, then we expand as a univariate polynomial in and
recursively evaluate at the point . This yields a univariate polynomial  in that we evaluate at
in that we evaluate at 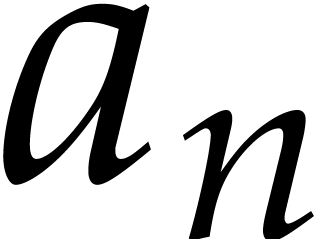 using Horner's method. Using induction over , it is not hard to show that the algorithm
essentially performs
using Horner's method. Using induction over , it is not hard to show that the algorithm
essentially performs 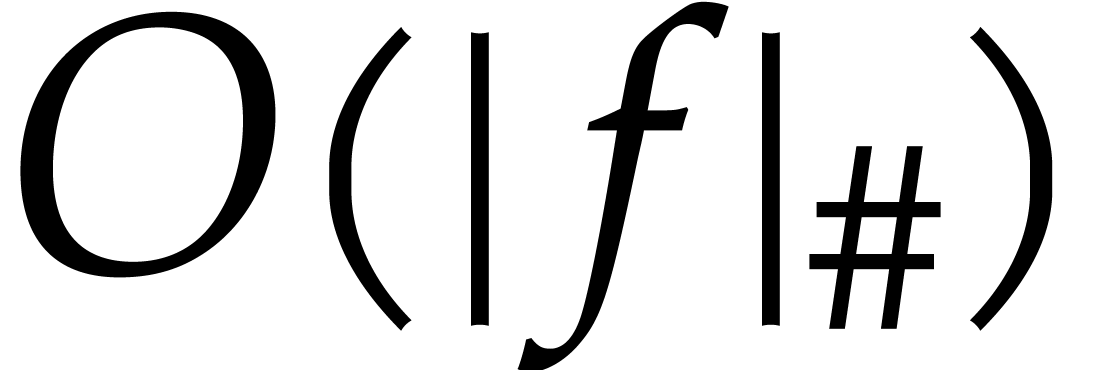 ring operations in
ring operations in  , which can be done in time
, which can be done in time 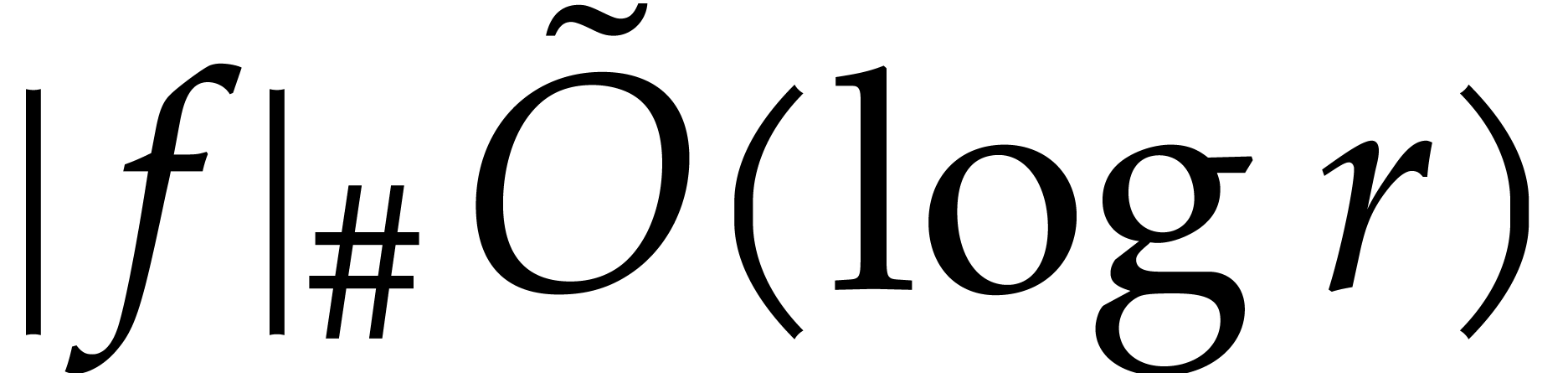 . We finally recall that
. We finally recall that 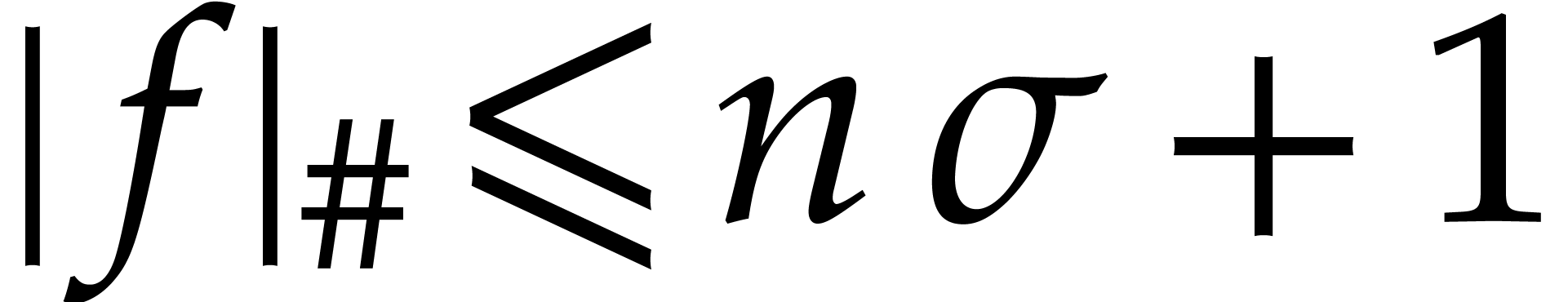 , by Lemmas 2.5 and 2.6.
, by Lemmas 2.5 and 2.6.
We are now ready to present the top level multi-point evaluation
procedure. Recall that the bit size of an integer
is given by 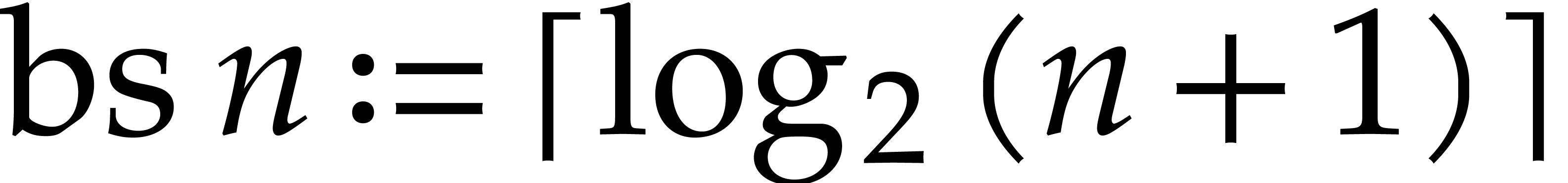 .
.
-
Input
;
a sequence
of points in
.
-
Output
-
.
Proposition 3.9.
Algorithm 3.4 is correct and takes
time
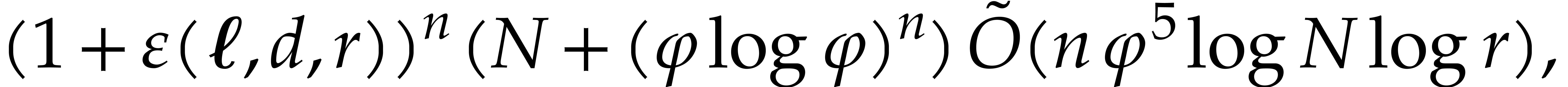
where 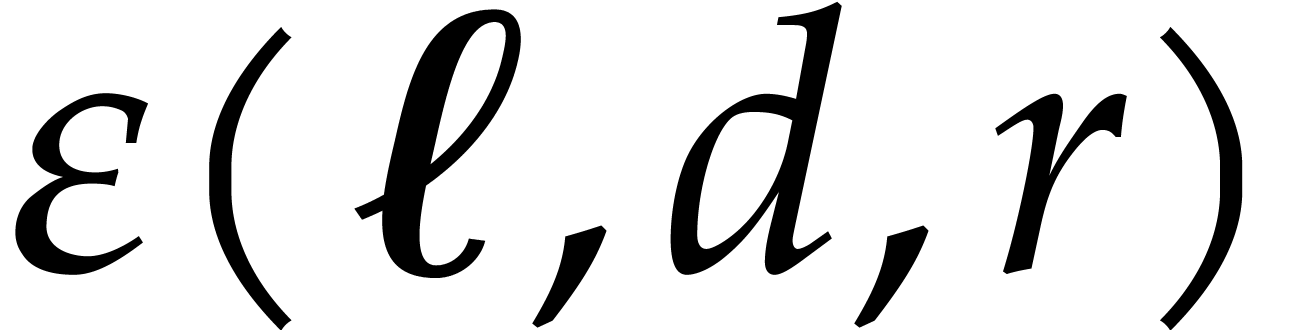 is a function which tends to
is a function which tends to 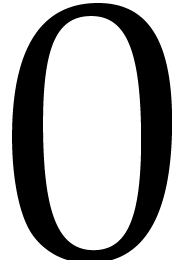 when
when 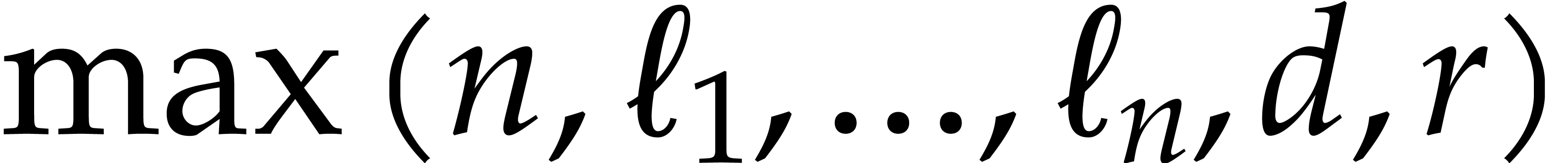 tends to infinity.
tends to infinity.
Proof. When we arrive at step 5 with 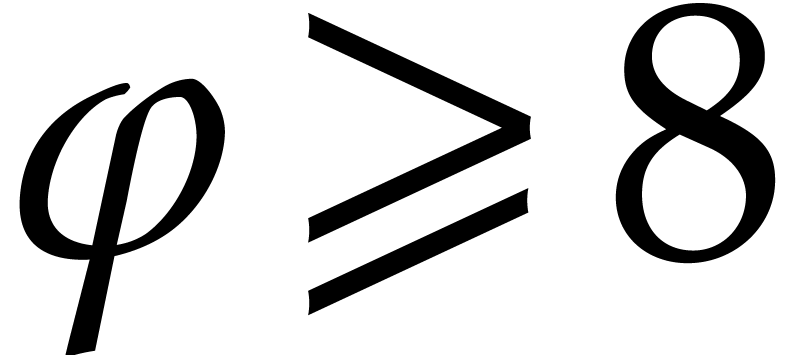 and
and  , the
inequality
, the
inequality 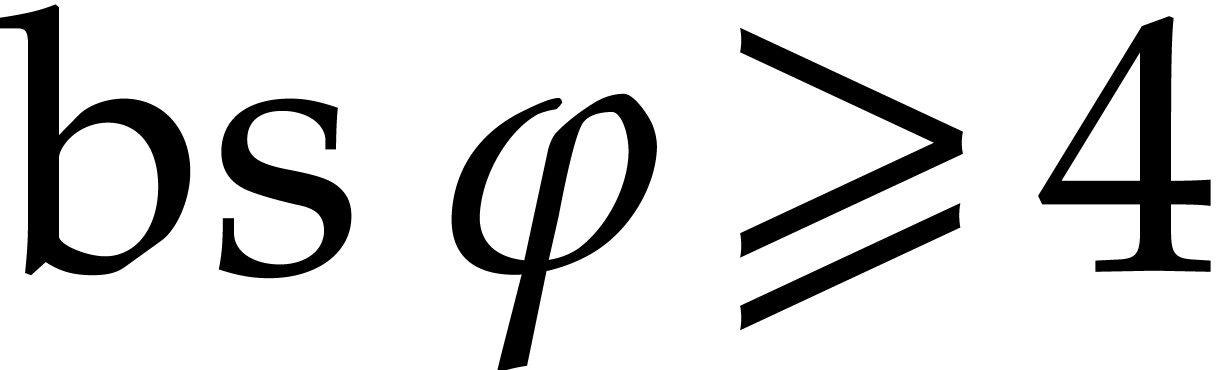 holds, whence
holds, whence 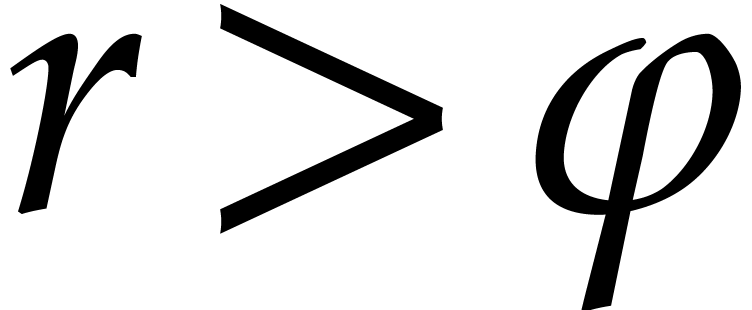 . Consequently the assumption of Algorithm 3.3
is satisfied. This proves the correctness of the algorithm thanks to
Propositions 3.3 and 3.7.
. Consequently the assumption of Algorithm 3.3
is satisfied. This proves the correctness of the algorithm thanks to
Propositions 3.3 and 3.7.
If , then multi-point
evaluation costs
which is below the bound of the proposition. From now on we assume that
. Recall that by (3.3).
The quantities  may be obtained in time
may be obtained in time
by combining Lemmas 2.5, 2.7 and 2.8.
By the subproduct tree technique, we may compute  in time
in time 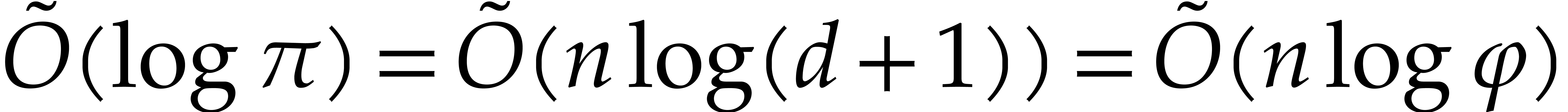 , and
, and  in time
in time 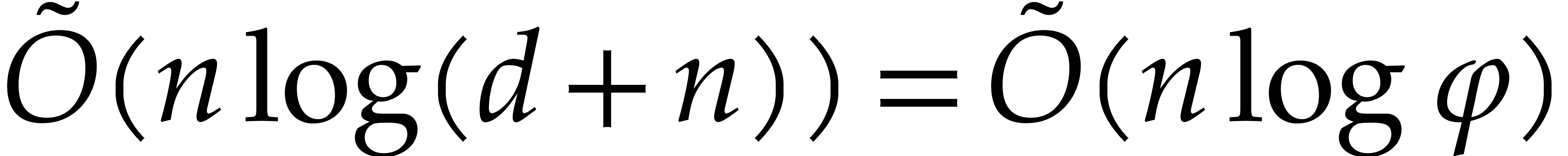 . The
cost for summing
. The
cost for summing  is . We may also compute
is . We may also compute 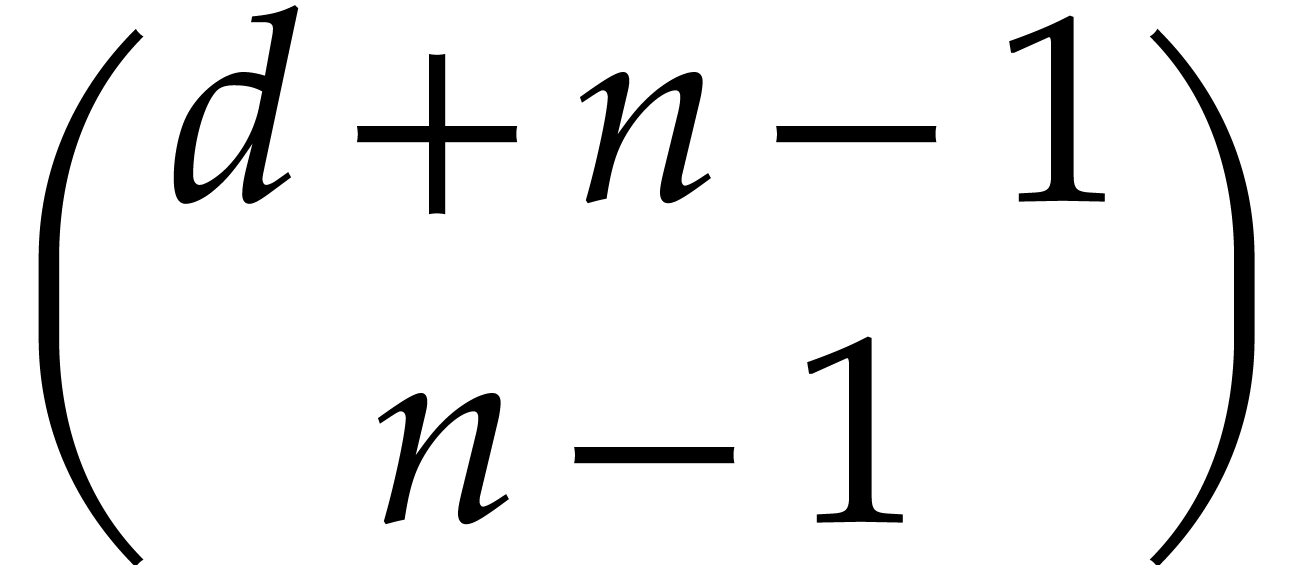 in
time and then easily deduce
in
time and then easily deduce 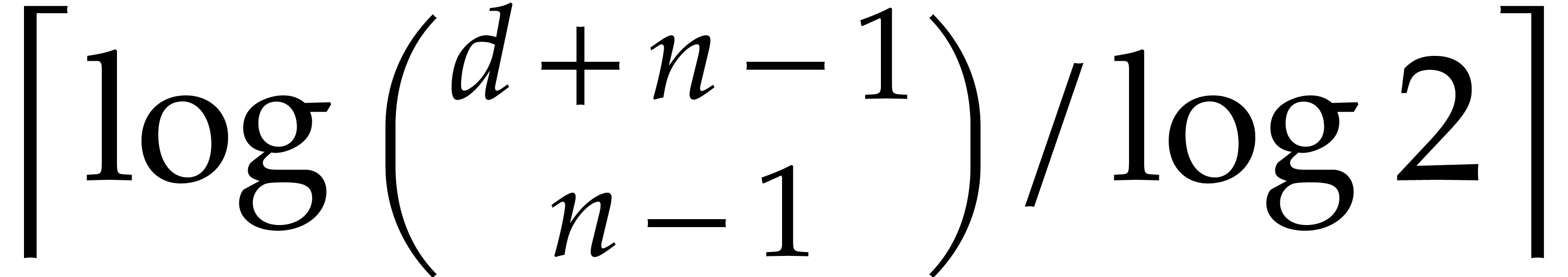 as the bit size of
as the bit size of 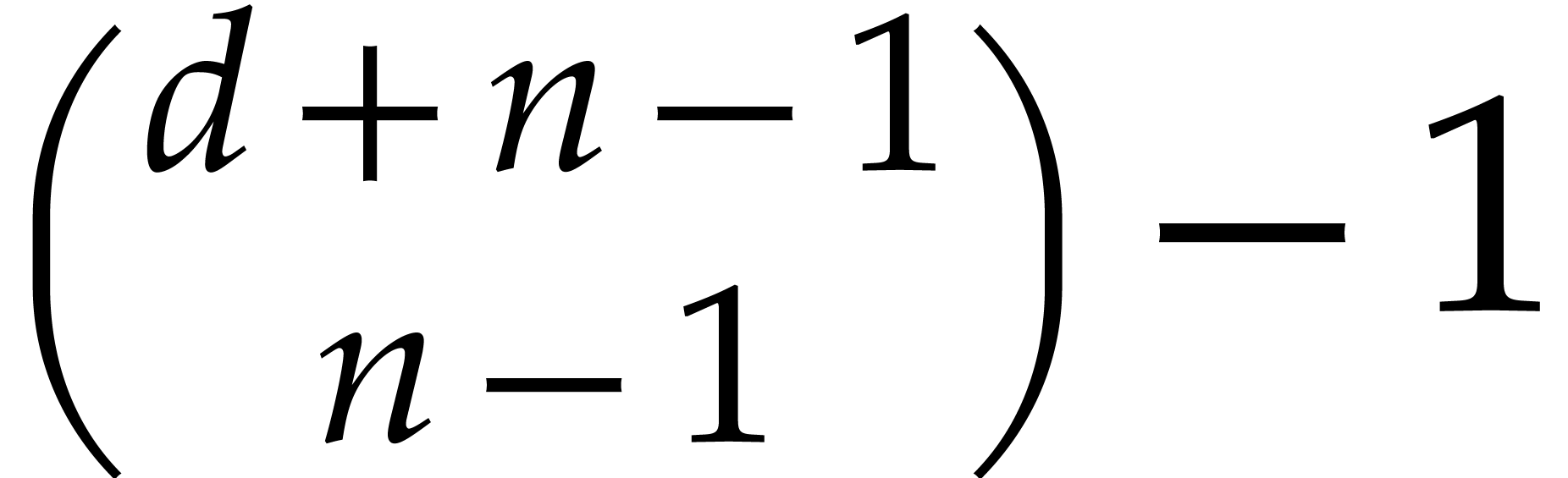 . Overall
the cost of step 2 is negligible.
. Overall
the cost of step 2 is negligible.
Let 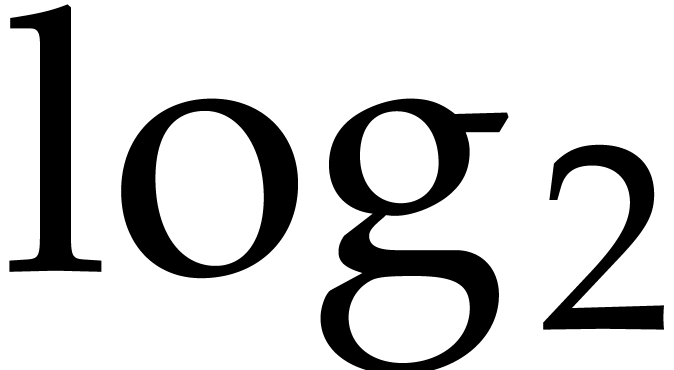 denote the logarithm function in base . The bit size
denote the logarithm function in base . The bit size 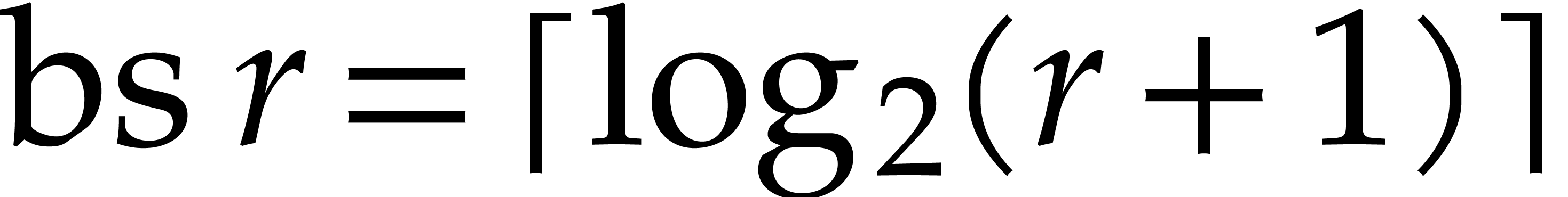 of and then
of and then  may be
obtained in time
may be
obtained in time  . We have
. We have
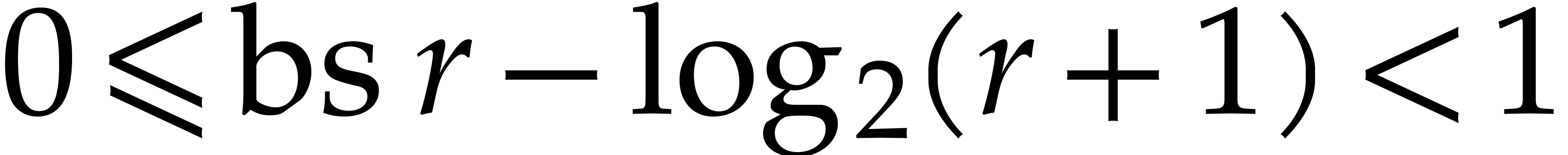 and
and 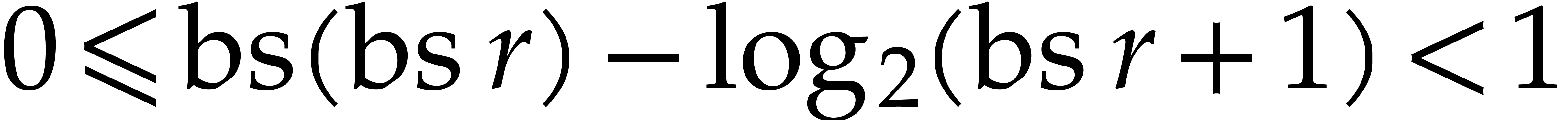 ,
whence
,
whence
The naive evaluation in step 3 costs 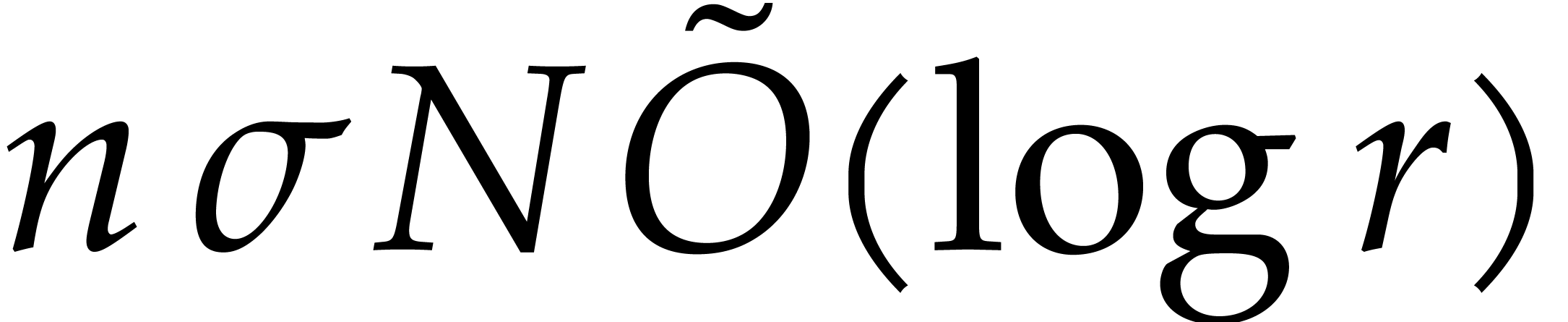 by Lemma 3.8. So when
by Lemma 3.8. So when 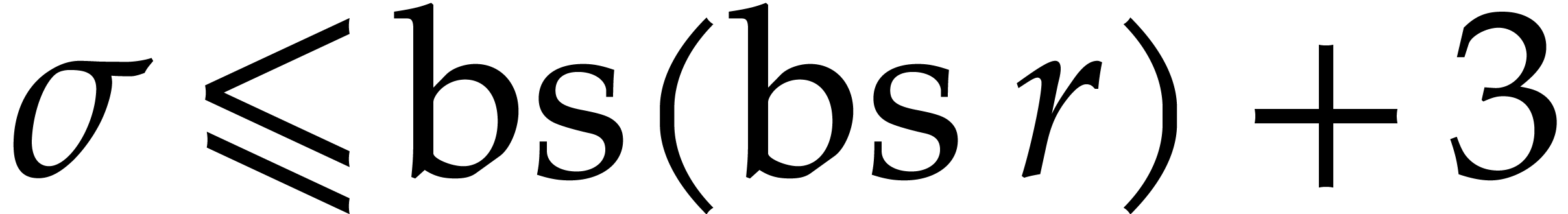 this cost drops to
this cost drops to 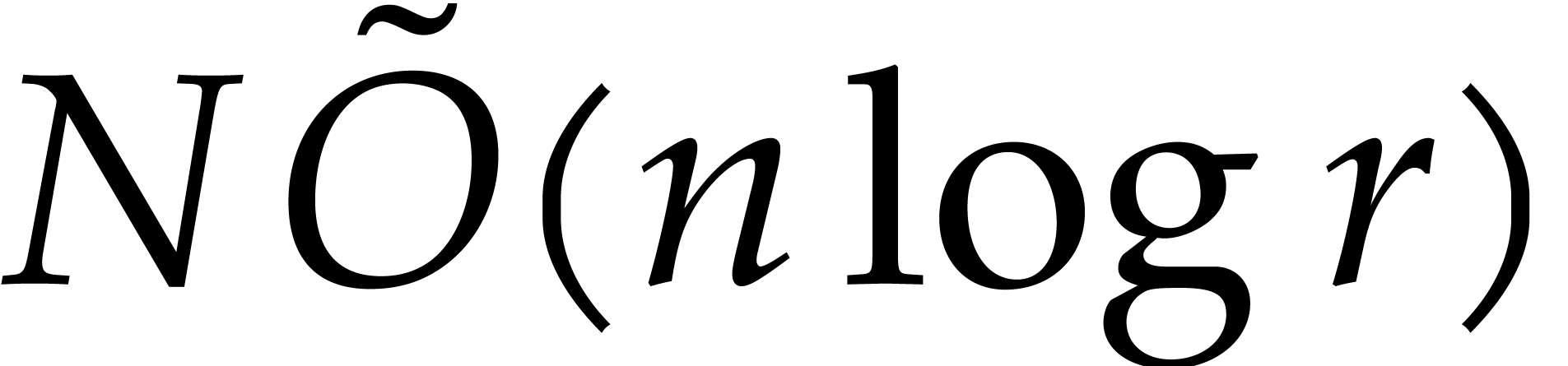 .
.
From now we may assume that 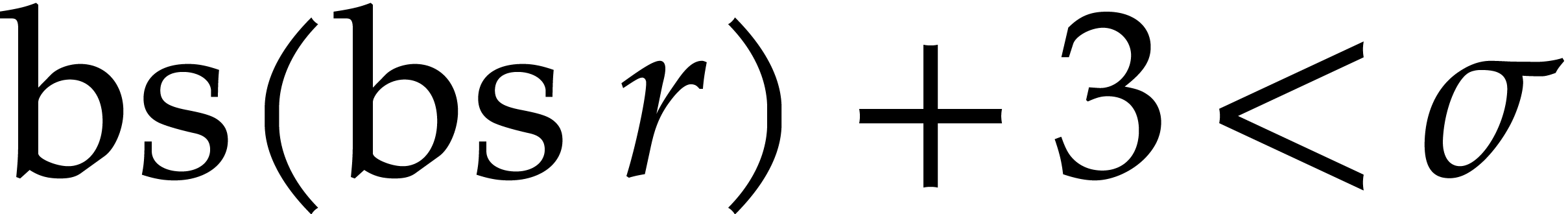 .
If is bounded, then so are all other parameters
.
If is bounded, then so are all other parameters
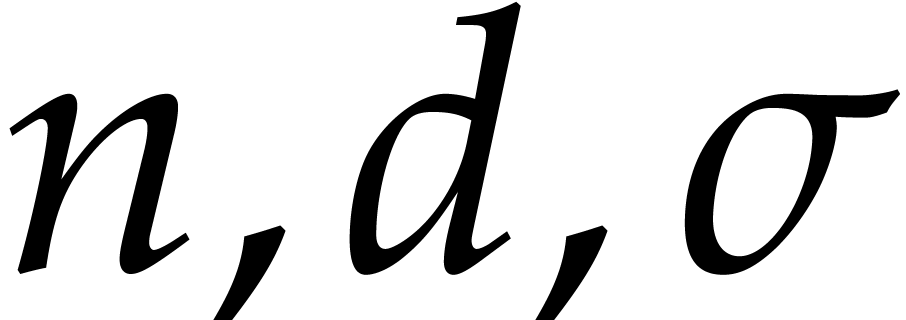 by (3.3) and
, whence the execution takes
time
by (3.3) and
, whence the execution takes
time 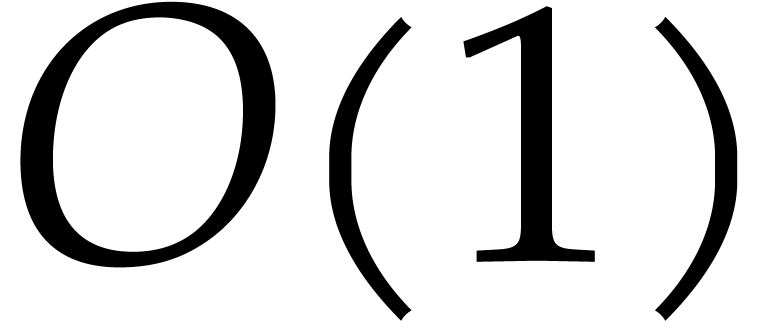 . If
and
. If
and 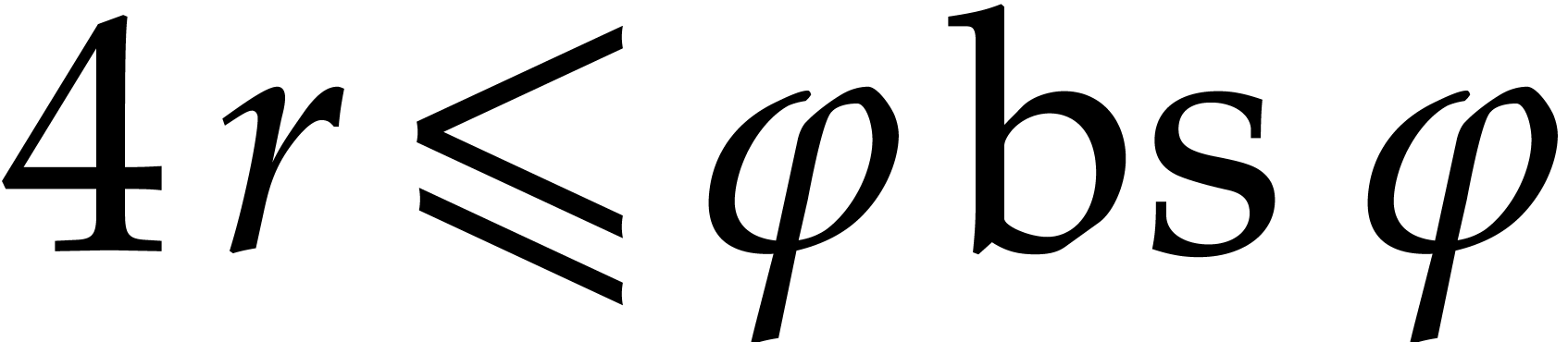 , then we have
, then we have
so we may use Proposition 3.3 to bound the time of step 4
by
Let us now consider step 5, where we have and
, whence , as previously mentioned. For our complexity
analysis, we may freely assume that is
sufficiently large. In particular, by using (3.14),
inequality implies
On the one hand 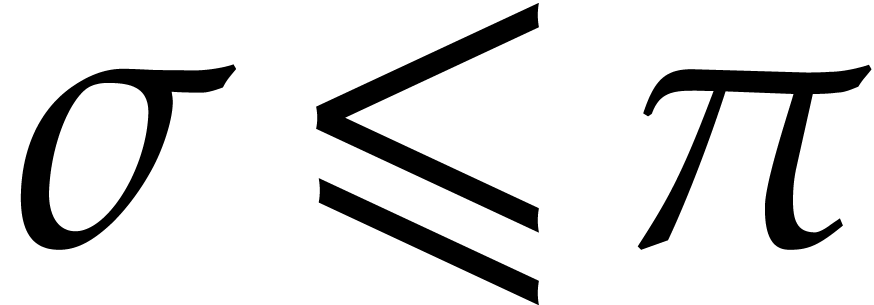 implies
implies 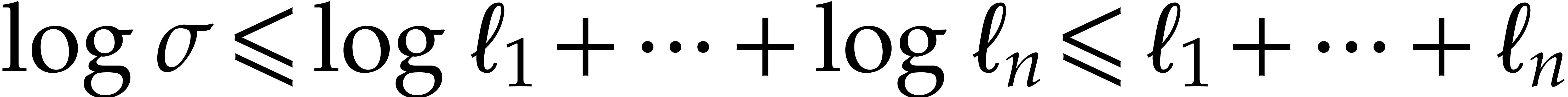 . On the other hand
. On the other hand 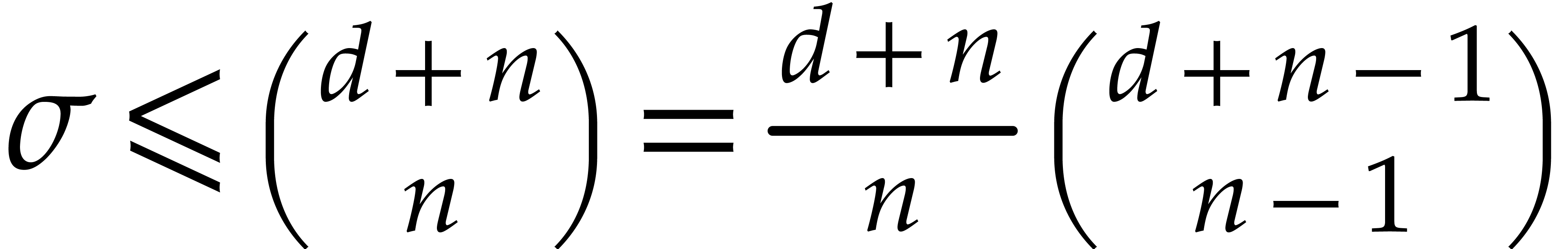 implies
implies
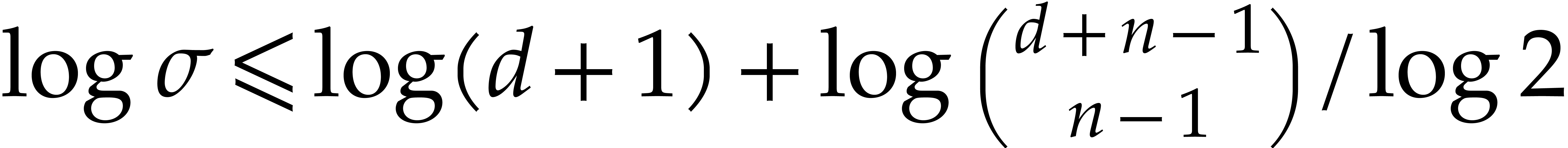 . Consequently we have
. Consequently we have 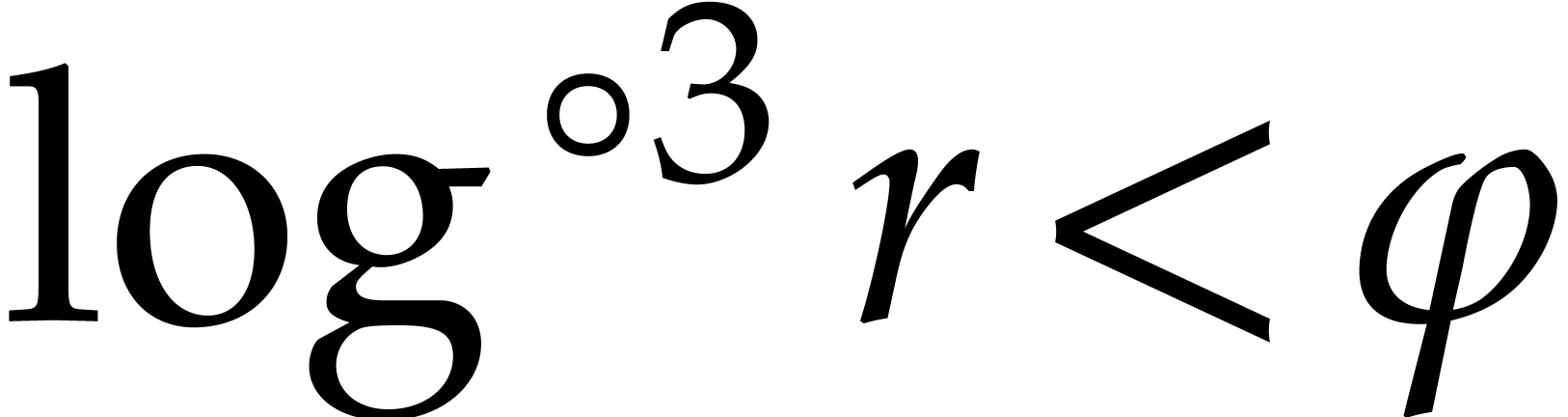 and deduce:
and deduce:
Therefore the cost of Algorithm 3.3 with parameter 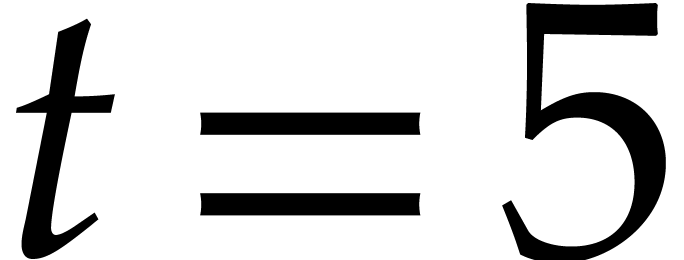 is
is
by Proposition 3.7 and equation (3.8).
By gathering costs of each step we thus obtain that Algorithm 3.4
takes time
for some universal constant  .
Finally we set
.
Finally we set
 |
(3.15) |
to conclude the proof.
Proof. We may compute 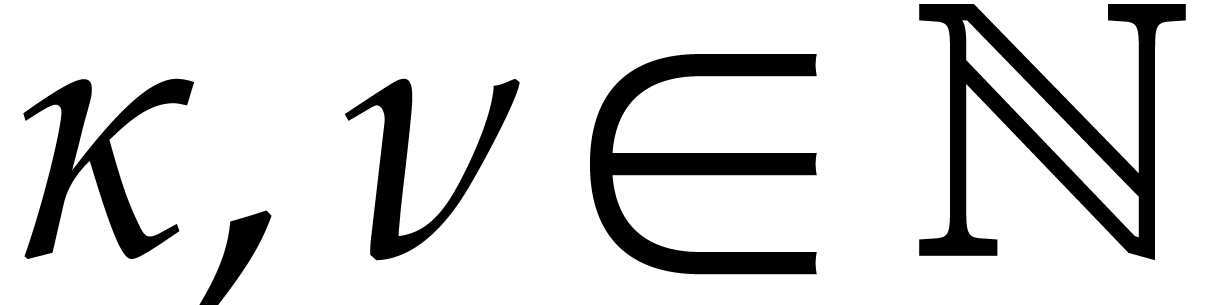 with
with
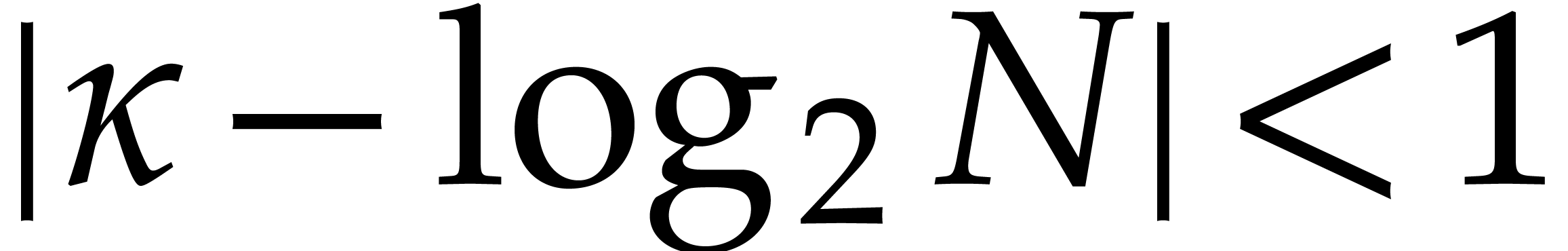 and
and 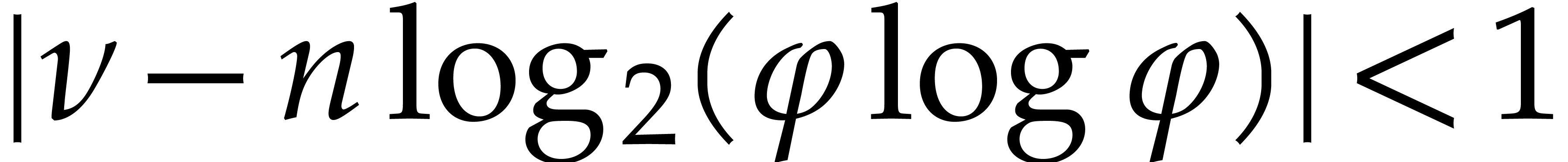 in time
in time 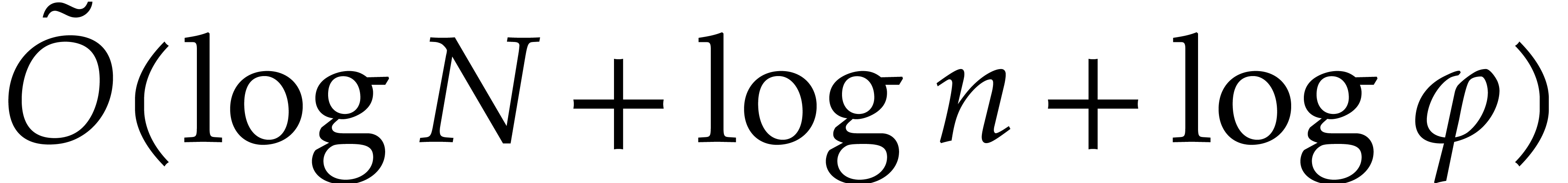 thanks to the lemmas from the end of section 2.
If
thanks to the lemmas from the end of section 2.
If  , then
, then 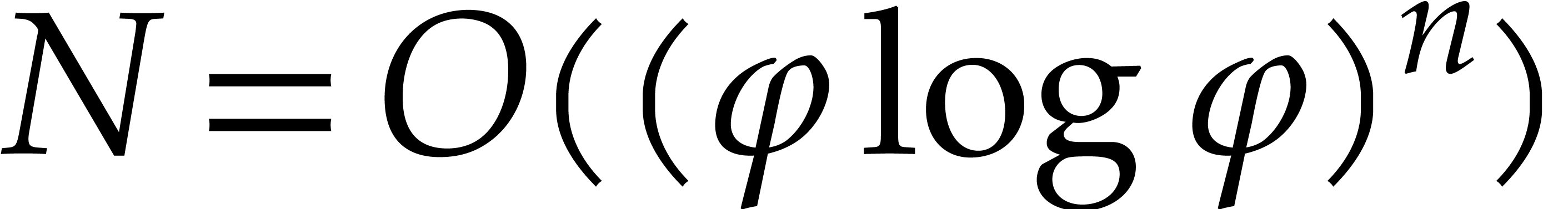 and the result directly follows from Proposition 3.9.
Otherwise we apply the evaluation algorithm several times with sets of
evaluation points of cardinality at most
and the result directly follows from Proposition 3.9.
Otherwise we apply the evaluation algorithm several times with sets of
evaluation points of cardinality at most 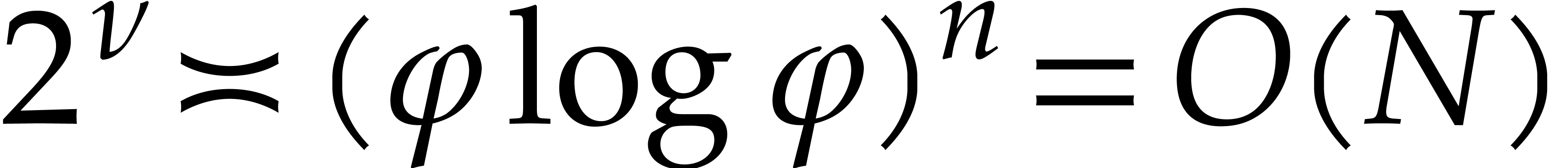 .
.
4.Extension rings
In this section and 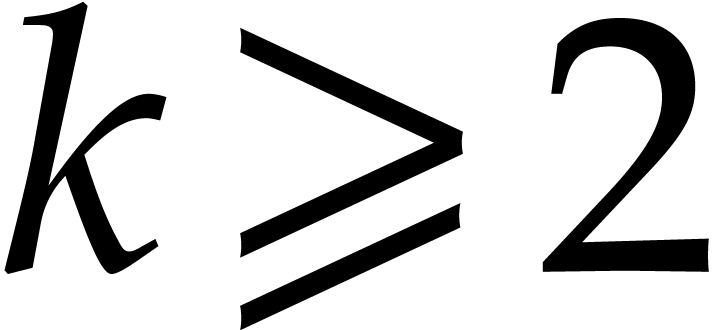 represent integers and we study multi-point multivariate evaluation over
represent integers and we study multi-point multivariate evaluation over
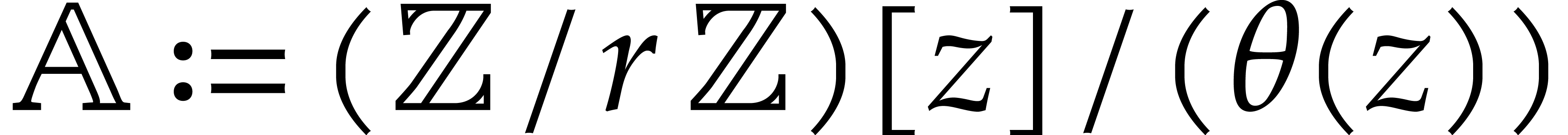 , where
is a monic polynomial in
, where
is a monic polynomial in 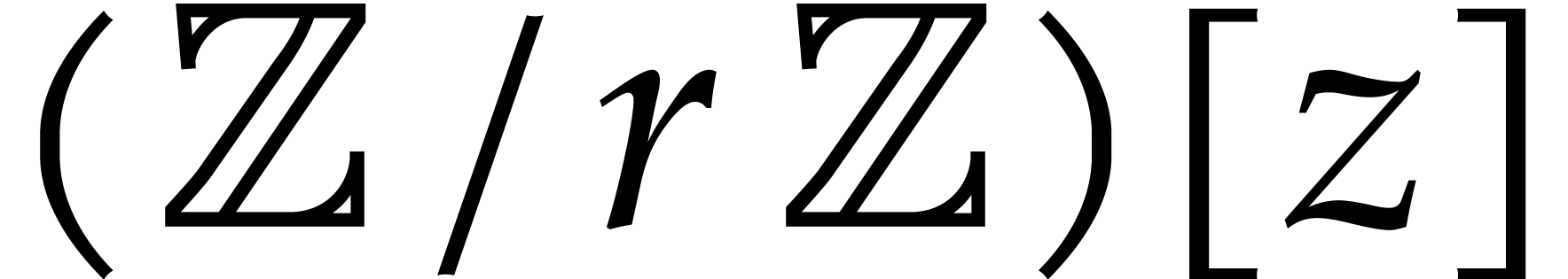 of degree . The approach developed in the next paragraphs
lifts this problem to an evaluation problem over , so that fast univariate evaluation/interpolation
in
of degree . The approach developed in the next paragraphs
lifts this problem to an evaluation problem over , so that fast univariate evaluation/interpolation
in  may be used.
may be used.
4.1.Reduction to prime fields
We endow  with the usual norm
with the usual norm  :
:
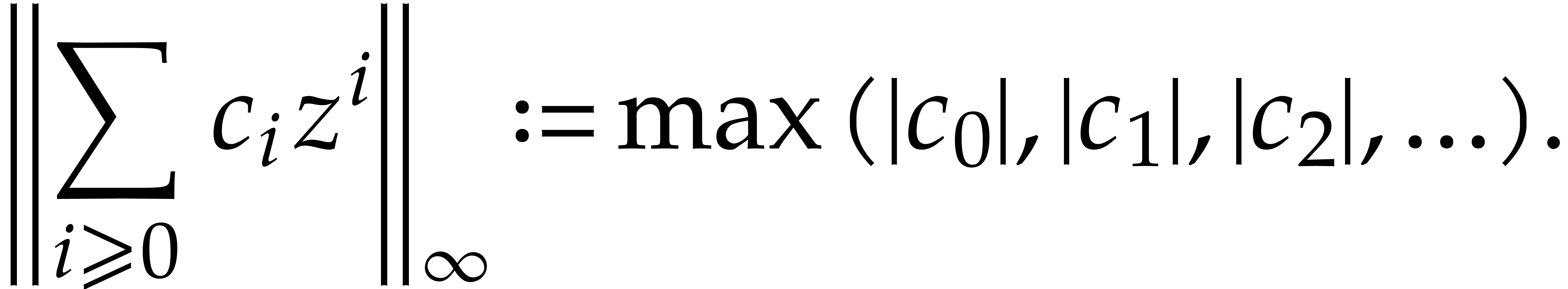
Lemma 4.1. For all  we have
we have 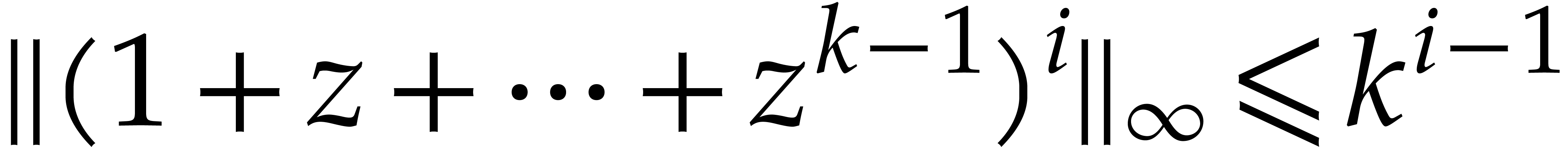 .
.
Proof. The proof is done by induction on  . The inequality is an equality for
. The inequality is an equality for
 . Then we verify that
. Then we verify that  holds for .
holds for .
Proof. The degree bound is clear. Now consider the
polynomials
From Lemma 4.1 we obtain
The conclusion follows by applying (3.4)
and (3.5) to the polynomial 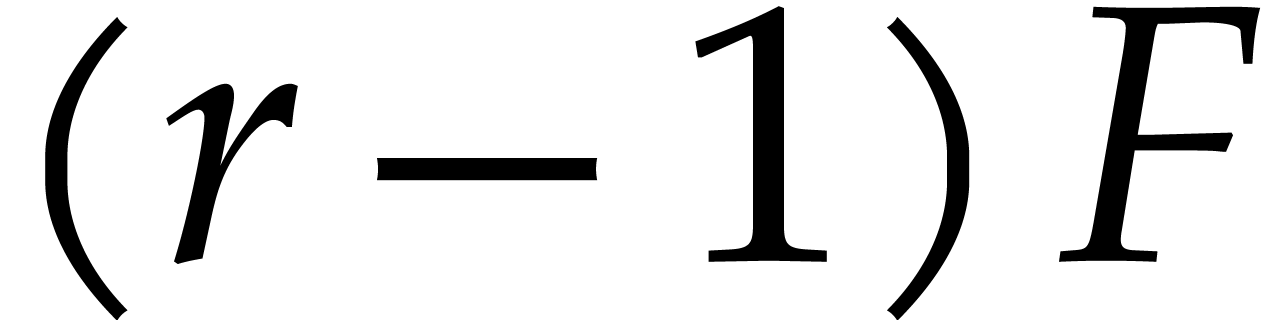 .
.
-
Input
;
;
a sequence
of points in
.
-
Output
-
.
-
Assumption
-
is monic of degree .
Proof. The correctness follows from Lemma 4.2.
The quantities may be obtained in time
by Lemmas 2.5, 2.7 and 2.8. As in
the beginning of the proof of Proposition 3.9, the cost for
deducing and is
negligible. The degree 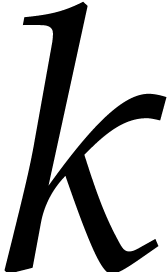 of
of  may be obtained in time
may be obtained in time 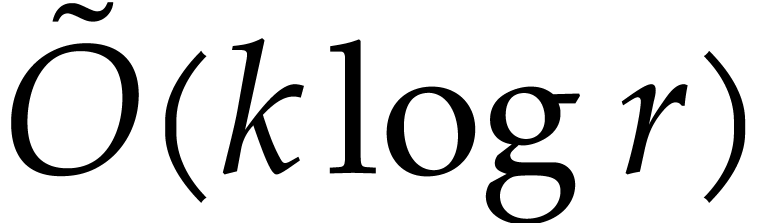 .
Then, computing
.
Then, computing  requires time
requires time 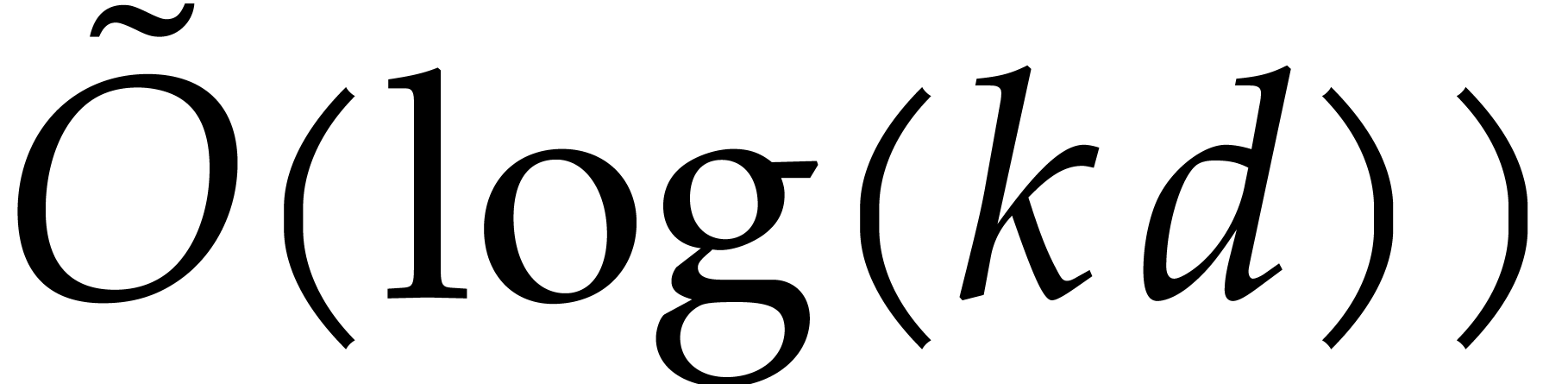 . To obtain
. To obtain  we first
evaluate
we first
evaluate 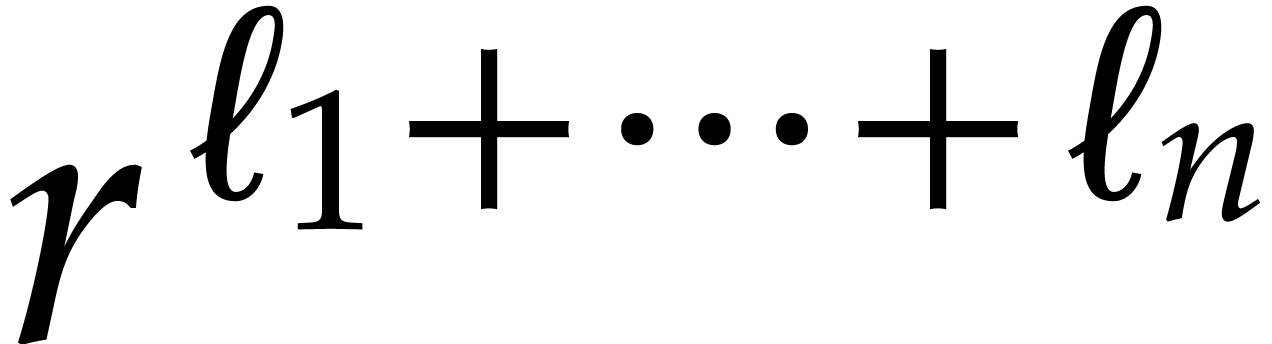 in time
in time 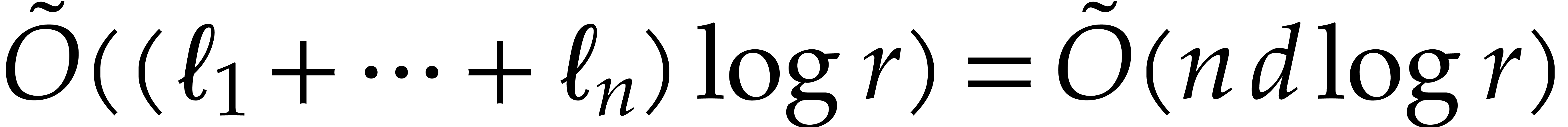 and
then
and
then  in time
in time  .
Overall step 1 takes negligible time
.
Overall step 1 takes negligible time
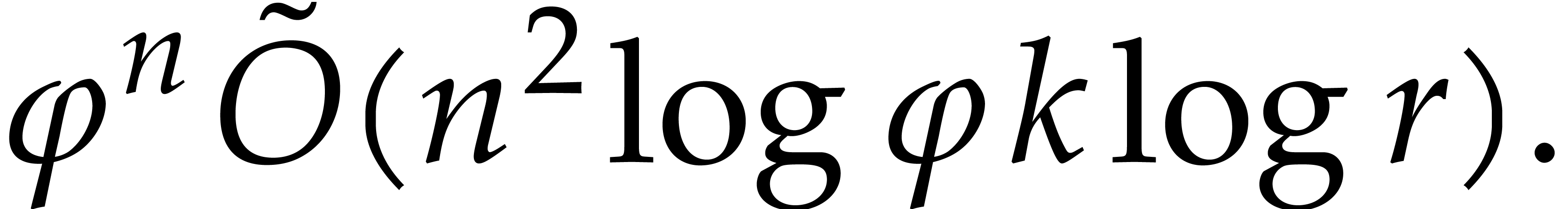 |
(4.1) |
If 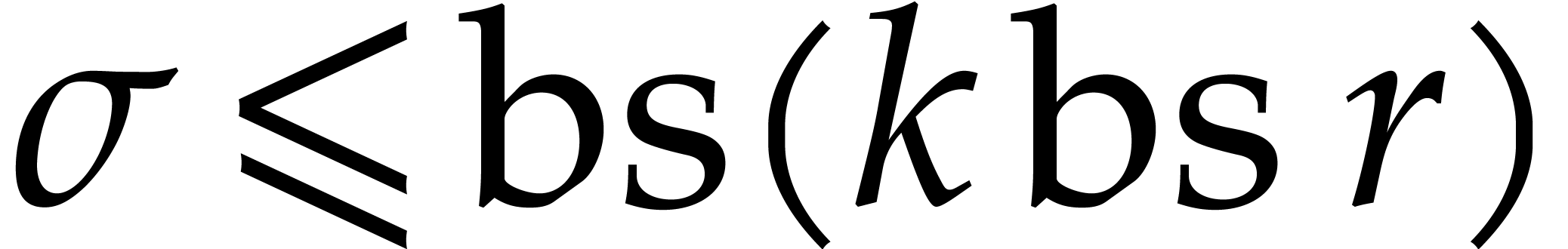 , then the naive algorithm
in step 2 runs in time
, then the naive algorithm
in step 2 runs in time
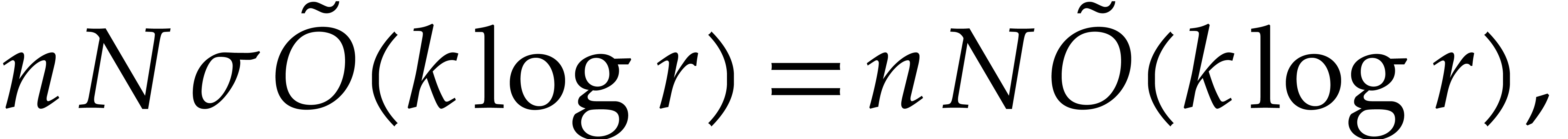 |
(4.2) |
by adapting Lemma 3.8. Proposition 3.6 implies
that step 3 takes time
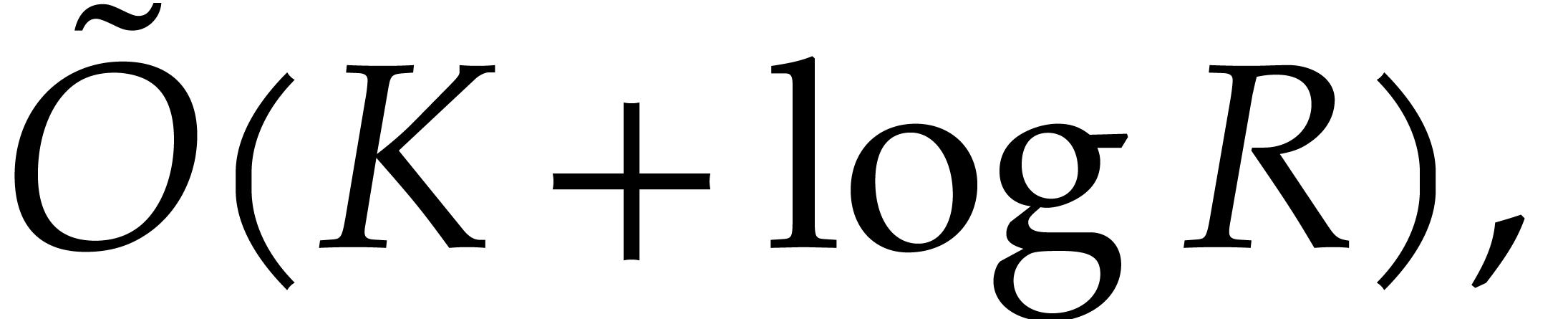 |
(4.3) |
and we have 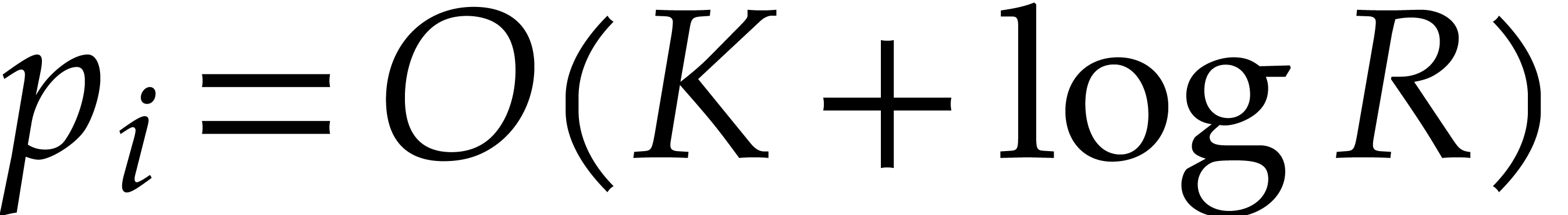 whence
whence 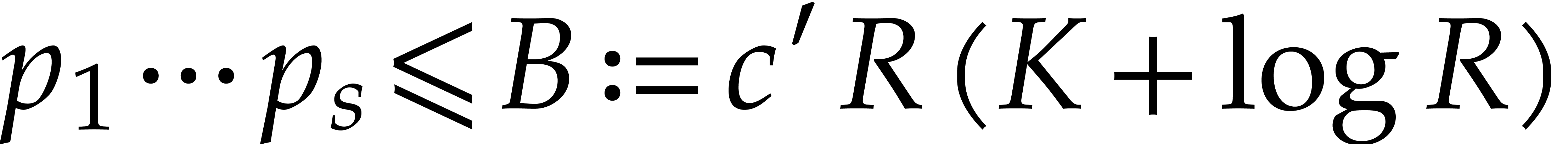 ,
for a universal constant
,
for a universal constant 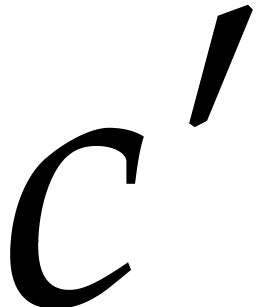 .
.
The cost of step 4 is obtained by adapting Lemmas 2.9 and
2.10 to  :
:
 |
(4.4) |
Let us now examine the cost of step 5. For fixed , the specializations of  and
the
and
the 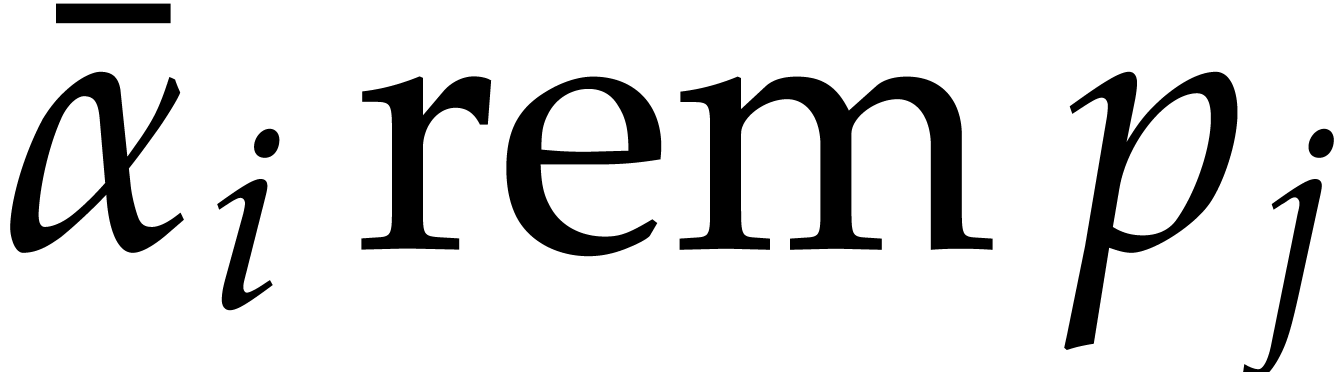 for
for 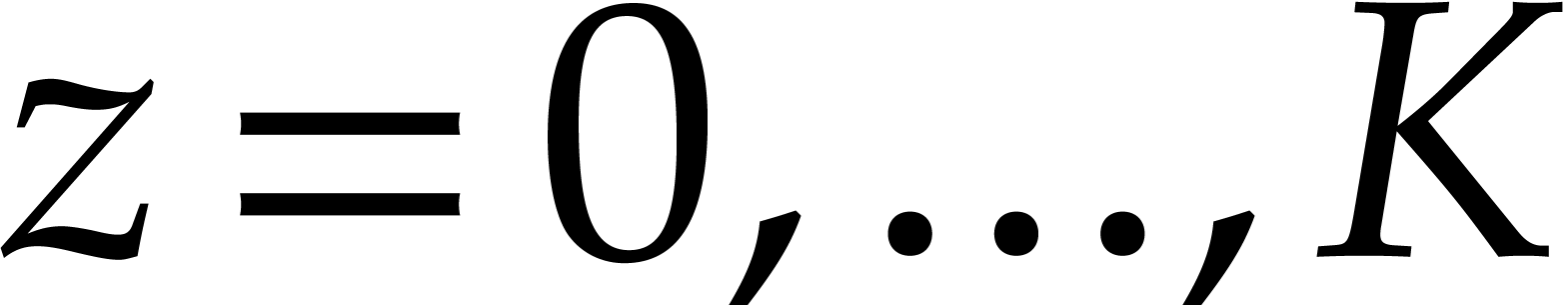 in steps 5.a and
5.b require time
in steps 5.a and
5.b require time
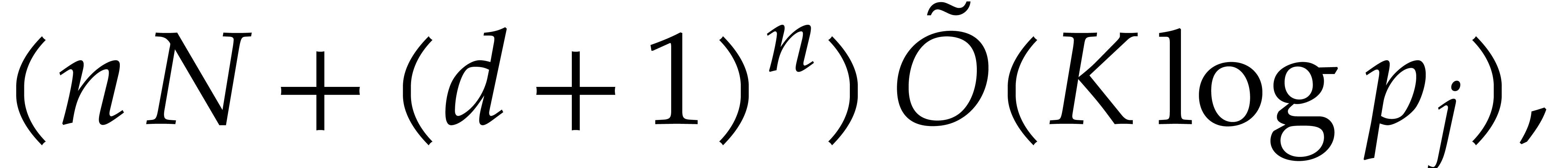
by Lemmas 2.12 and 2.13. By Theorem 3.10,
the evaluations in step 5.c take time
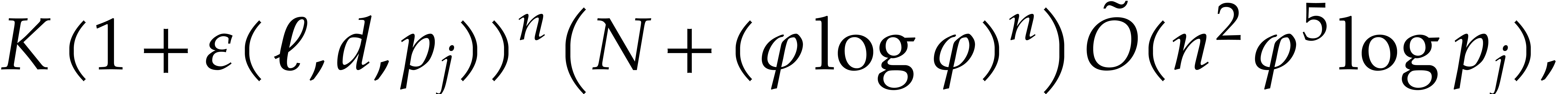
where (3.15) implies 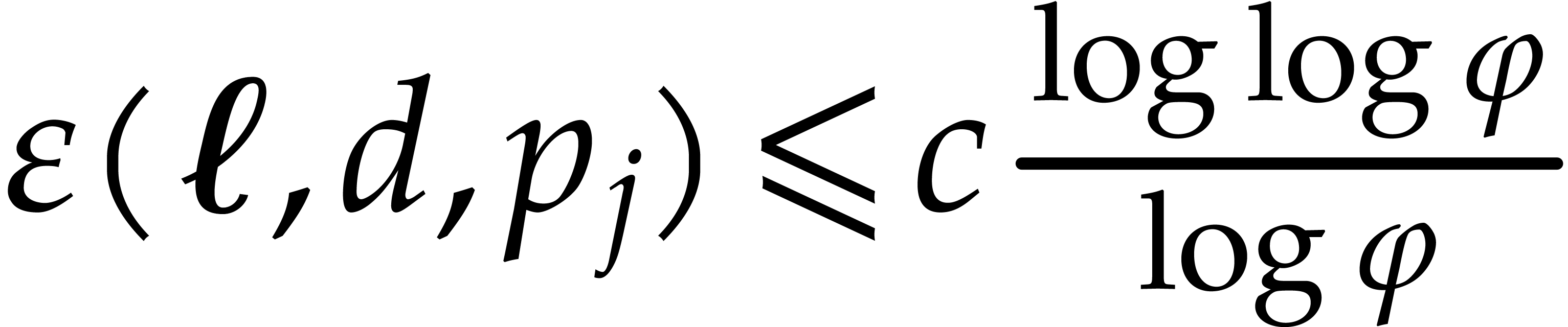 . The cost of step 5.d is
. The cost of step 5.d is 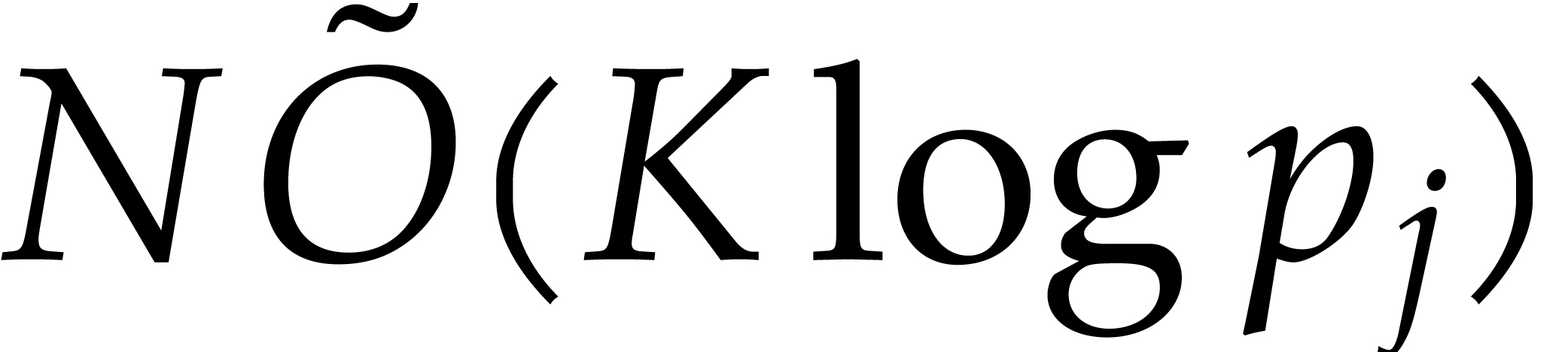 by Lemma 2.14. It follows that the total cost of step 5 is
by Lemma 2.14. It follows that the total cost of step 5 is
The cost of step 6 is provided by Lemma 2.11, that is
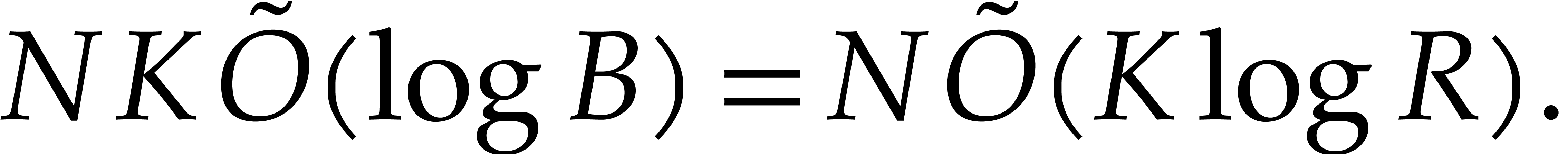 |
(4.6) |
Finally the cost of step 7 is
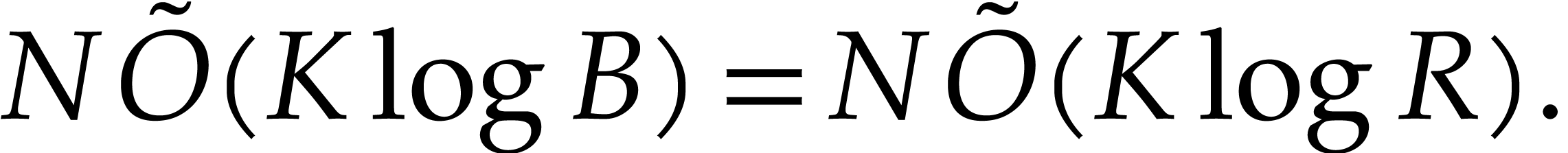 |
(4.7) |
Summing all costs from (4.1)–(4.7), we obtain the total cost of the
algorithm
We conclude that the function
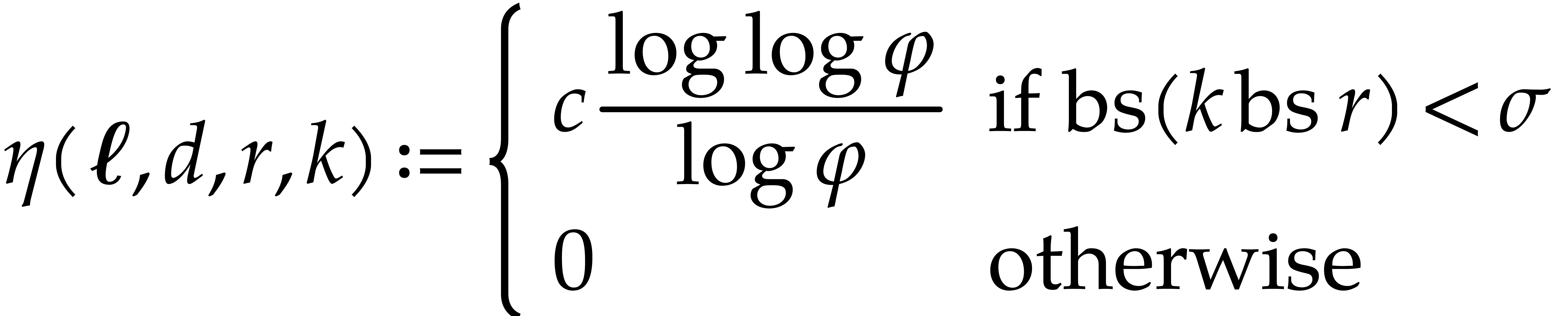
satisfies the requirement of the proposition.
Proof. If ,
then we use fast univariate multi-point evaluation. Otherwise we use
Proposition 4.3 in combination with 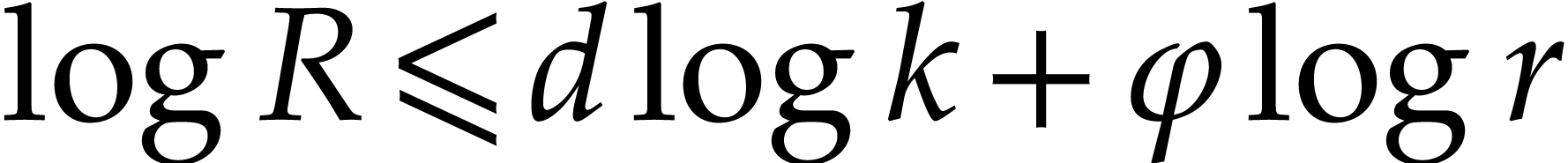 .
.
4.2.Corollaries in terms of partial and total
degrees
The first corollary is a complexity bound in terms of the partial
degrees, while the second one concerns the total degree.
Proof. We apply Theorem 4.4 with 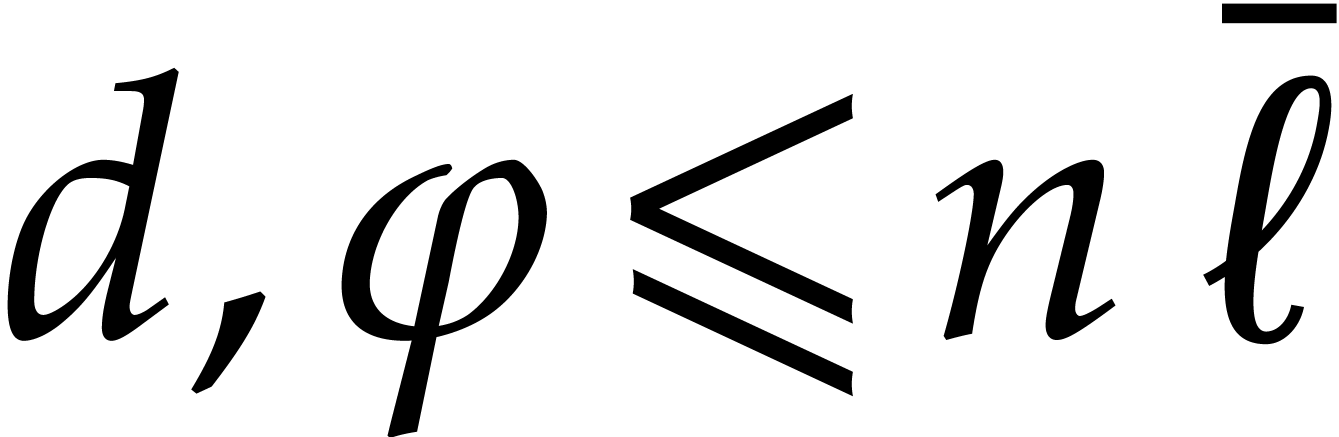 .
.
Proof. We apply Theorem 4.4 with 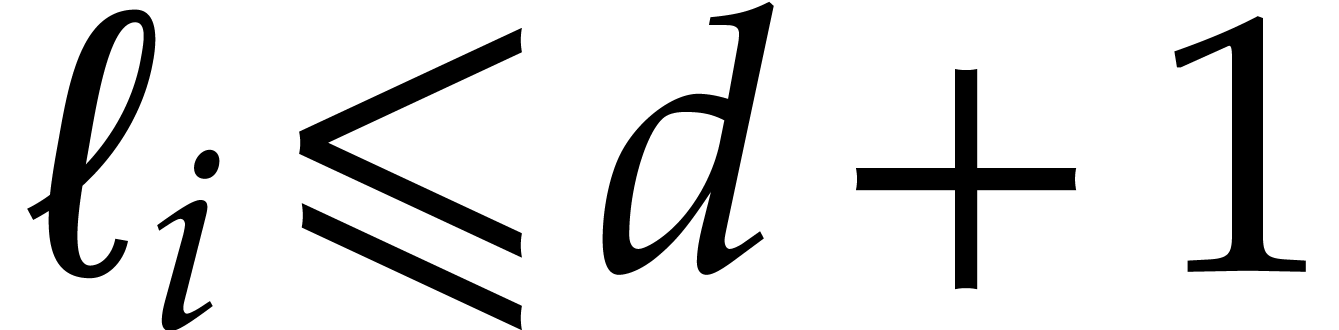 and make use of the well known inequality
and make use of the well known inequality 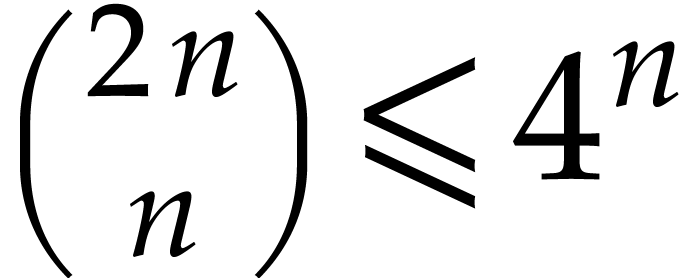 . If
. If  ,
then
,
then
Otherwise,
In both cases we thus have 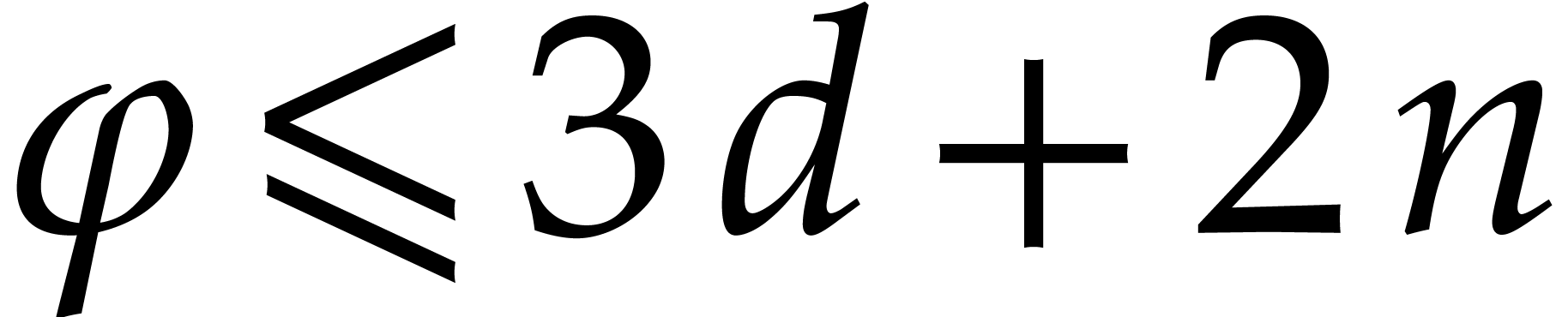 .
.
5.Kronecker segmentation
If the partial degrees are large with respect to the number of the
variables, then we may use Kronecker segmentation on
in order to decrease the dependency in in the
complexity bounds from the two previous sections. We first analyze the
cost of Kronecker segmentation on Turing machines and then show how to
reduce the complexity of multi-point evaluation. Throughout this
section, is an effective ring whose elements
occupy at most cells on tapes and whose
arithmetic operations take softly linear time.
5.1.Univariate case
Let  be integers
be integers  .
The Kronecker substitution map is the unique -algebra morphism determined by
.
The Kronecker substitution map is the unique -algebra morphism determined by
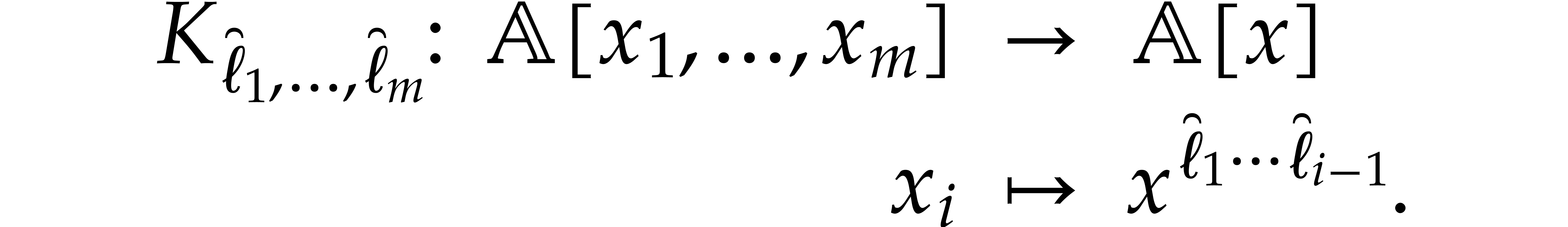
When restricted to the space of polynomials of partial degree 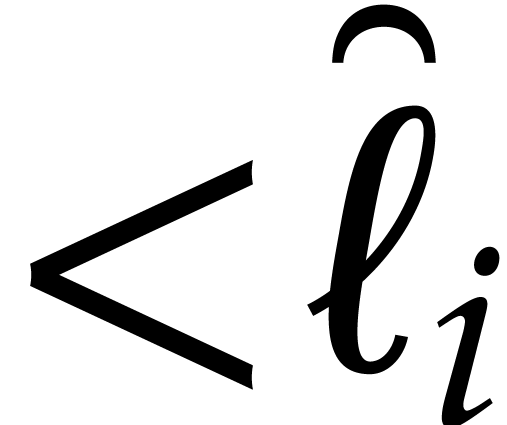 in , it becomes
an -linear isomorphism onto
the space of polynomials in of degree
in , it becomes
an -linear isomorphism onto
the space of polynomials in of degree 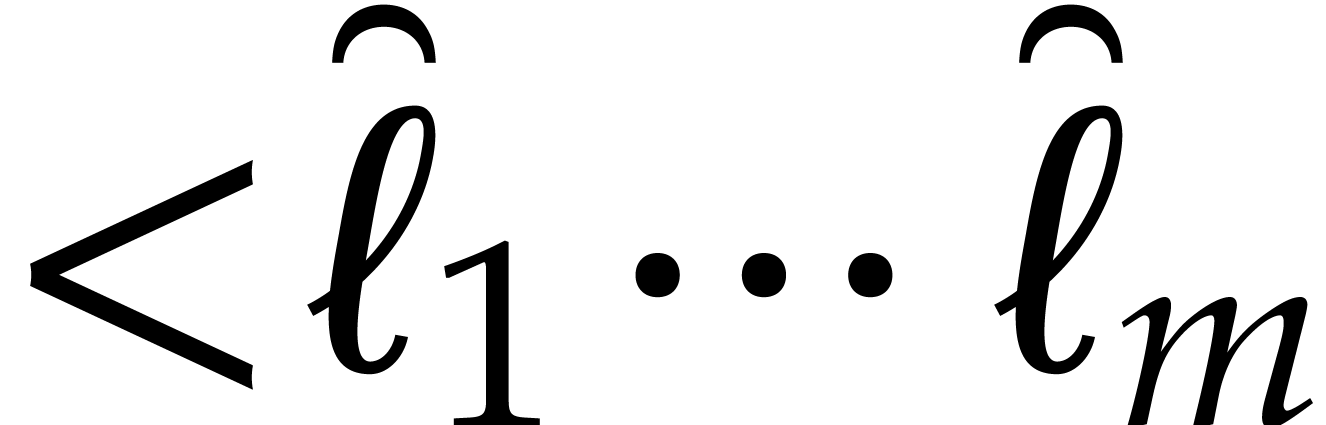 . The Kronecker segmentation
associated to transforms the univariate
polynomial
. The Kronecker segmentation
associated to transforms the univariate
polynomial  of degree
into the multivariate polynomial
of degree
into the multivariate polynomial 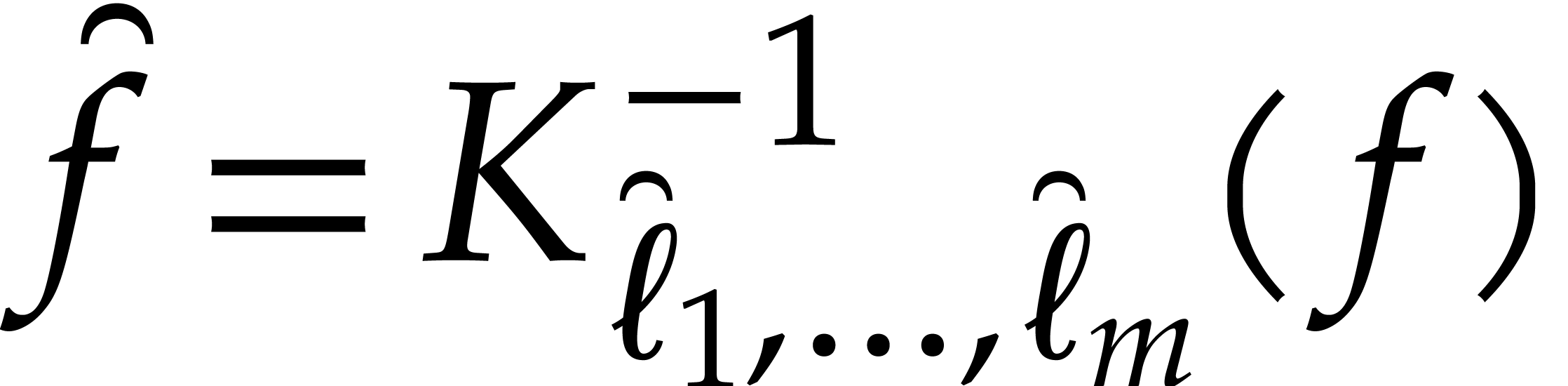 ,
so that
,
so that
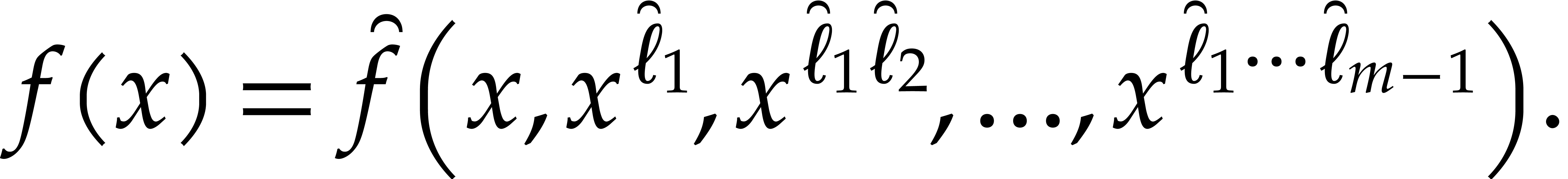
-
Input
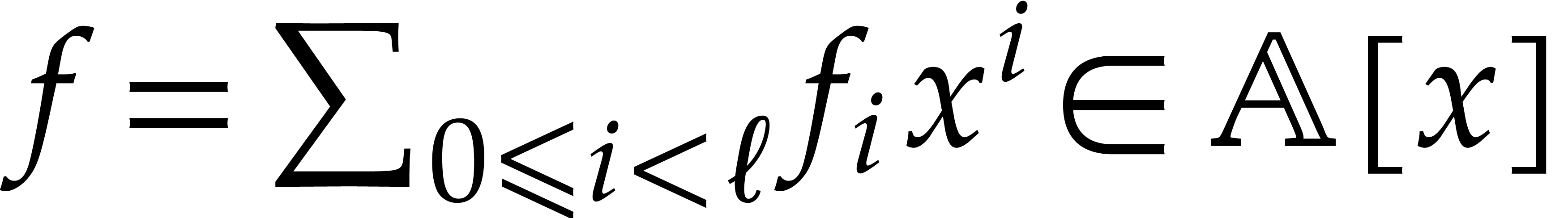 ;
a sequence
of integers
.
;
a sequence
of integers
.
-
Output
-
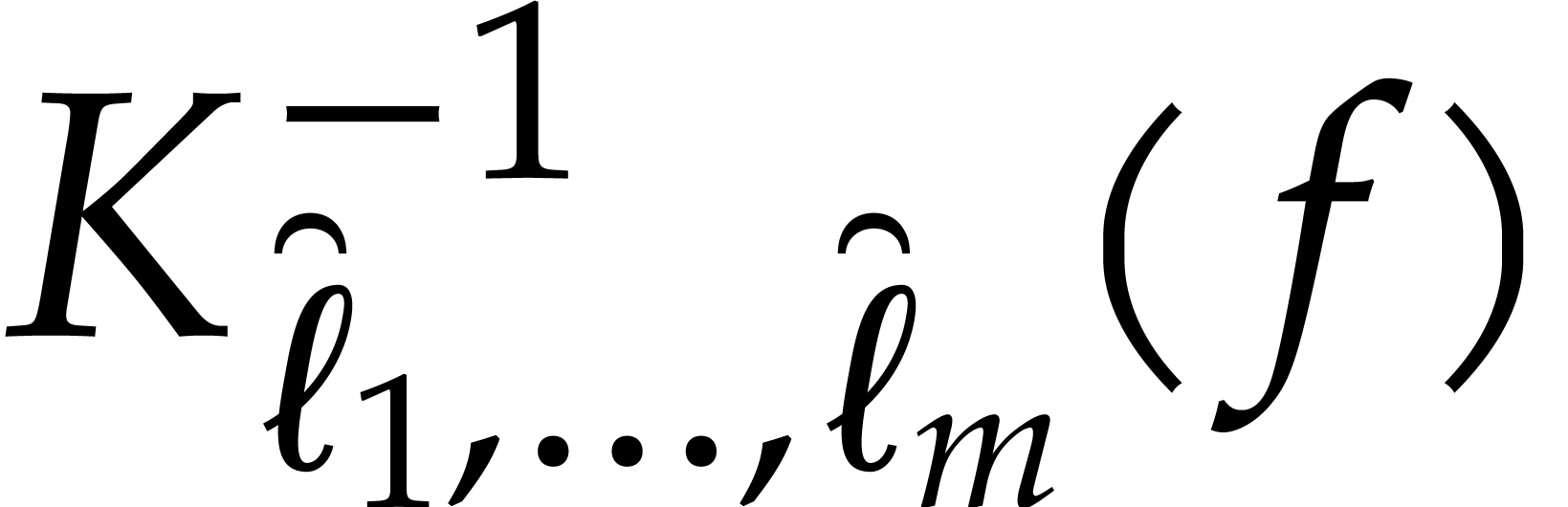 .
.
-
Assumption
-
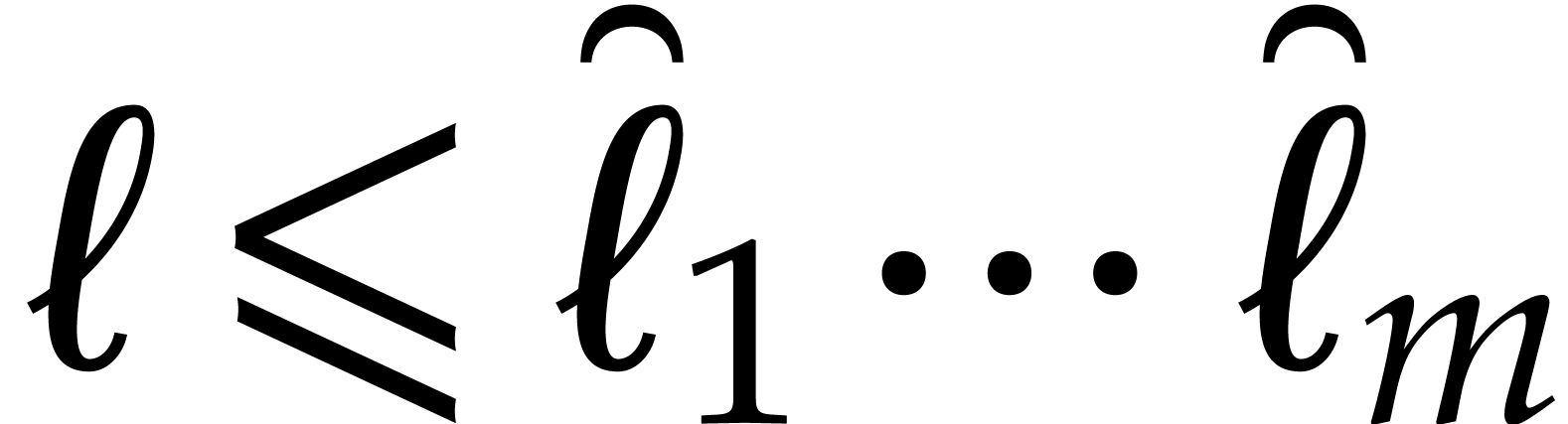 .
.
Proposition 5.1.
Algorithm 5.1 is correct and takes
time 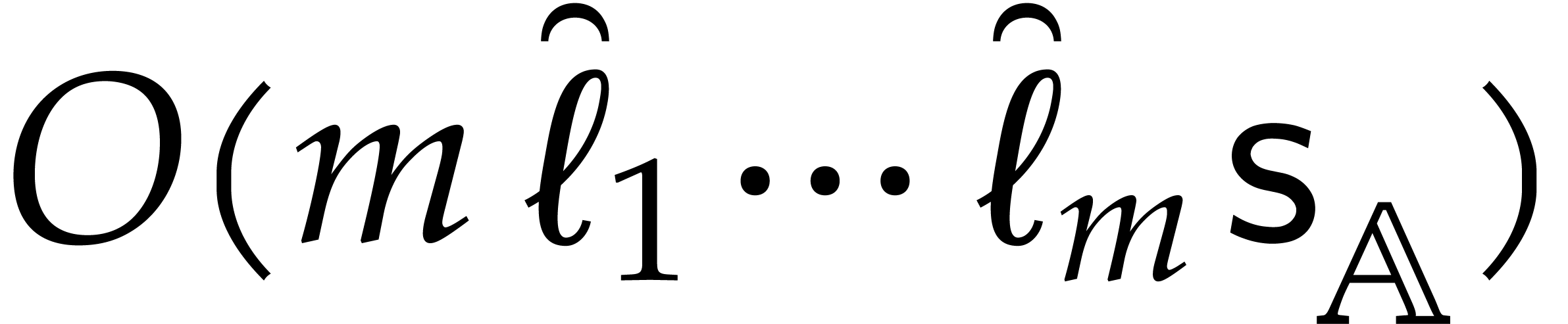 .
.
Proof. The correctness is clear. Let  represent the cost function of the algorithm. Step 1 takes
linear time in the size of ,
that is
represent the cost function of the algorithm. Step 1 takes
linear time in the size of ,
that is 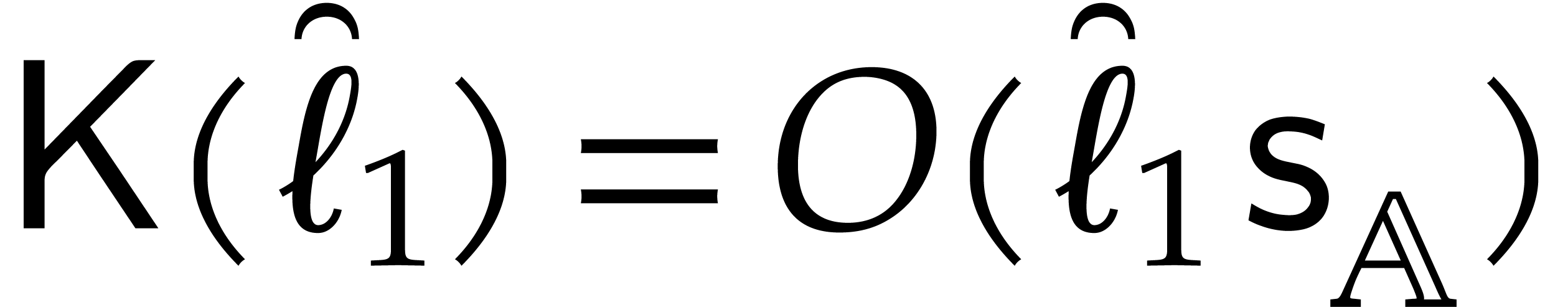 . Step 2 requires one
linear traversal and
. Step 2 requires one
linear traversal and 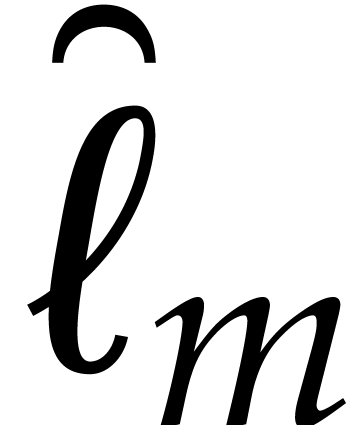 recursive calls, whence
recursive calls, whence
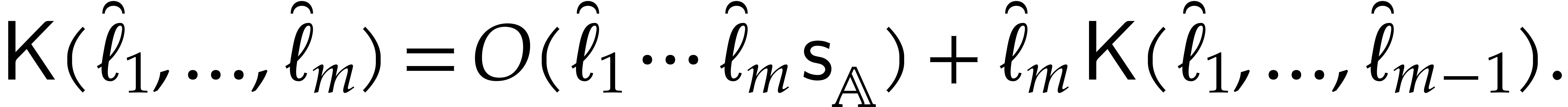
By induction over , it
follows that 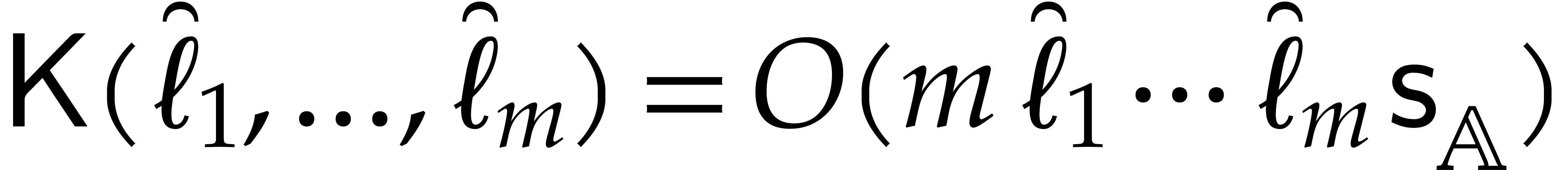 .
.
The cost of the Kronecker substitution, stated in the next proposition,
will be needed in section 7 only.
Proof. The proof is done by induction on . We will require in addition that
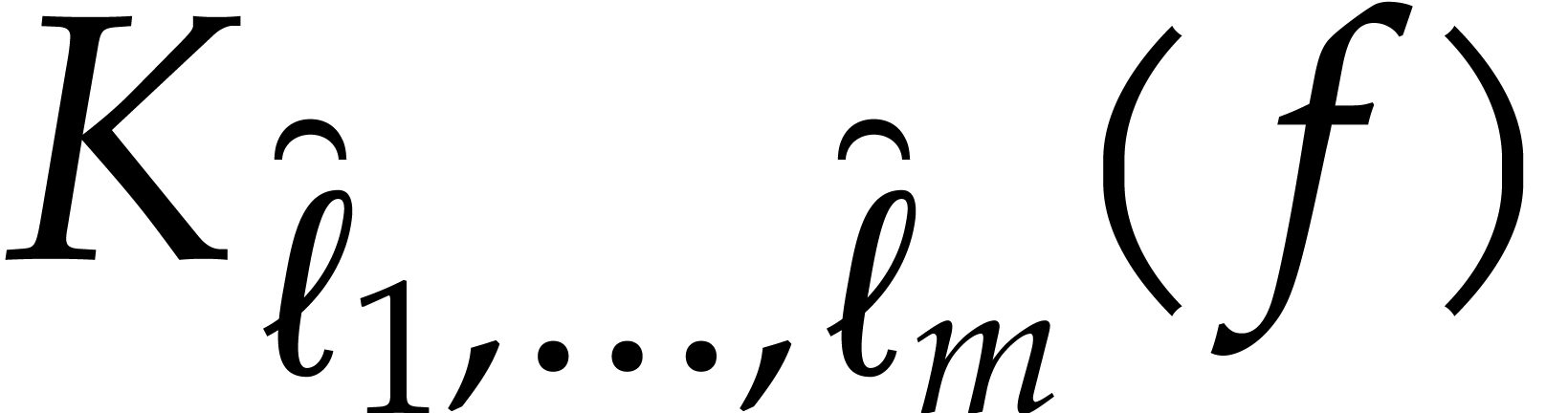 is zero padded up to degree
is zero padded up to degree 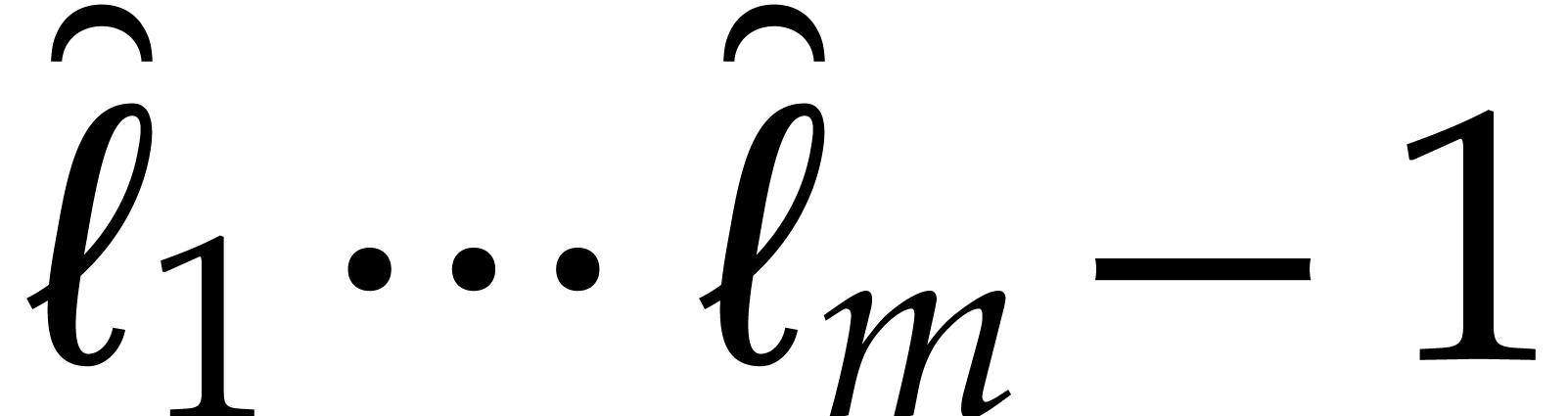 (at the end, we may clearly remove trailing zeros in linear time). The
case
(at the end, we may clearly remove trailing zeros in linear time). The
case 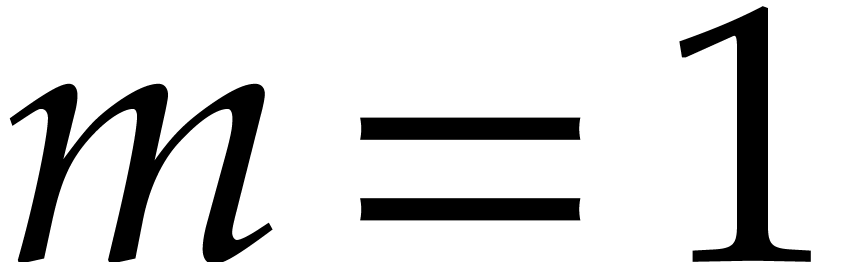 corresponds to a simple zero padding up to
degree
corresponds to a simple zero padding up to
degree 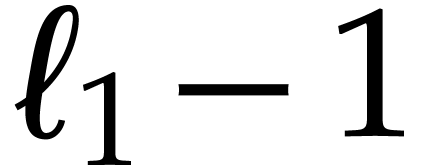 , which takes time
, which takes time
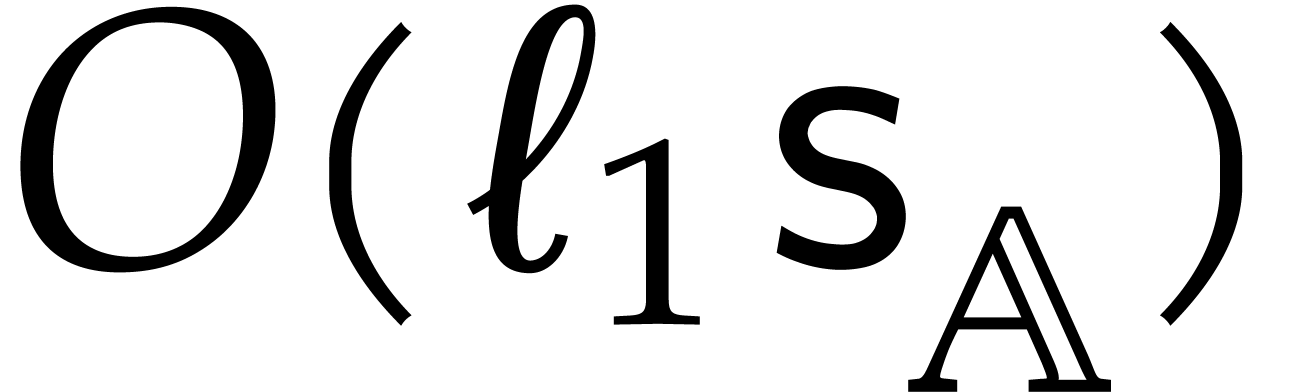 . If
. If  , then we write
, then we write 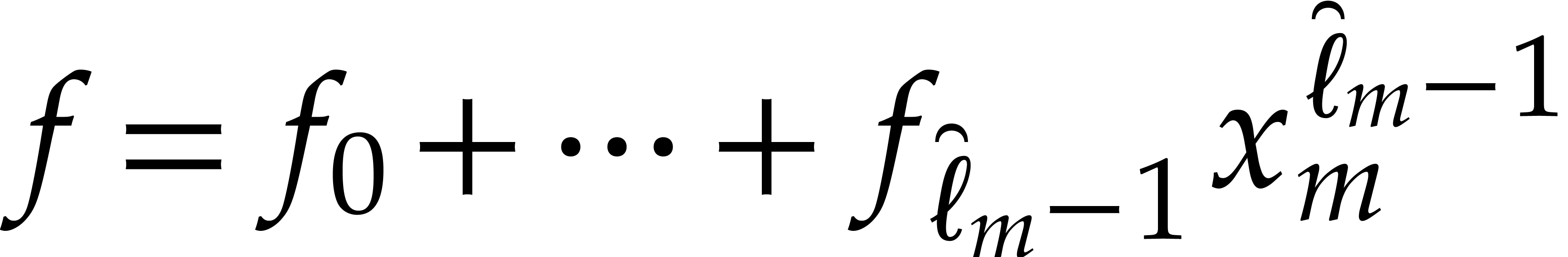 ,
we recursively compute
,
we recursively compute 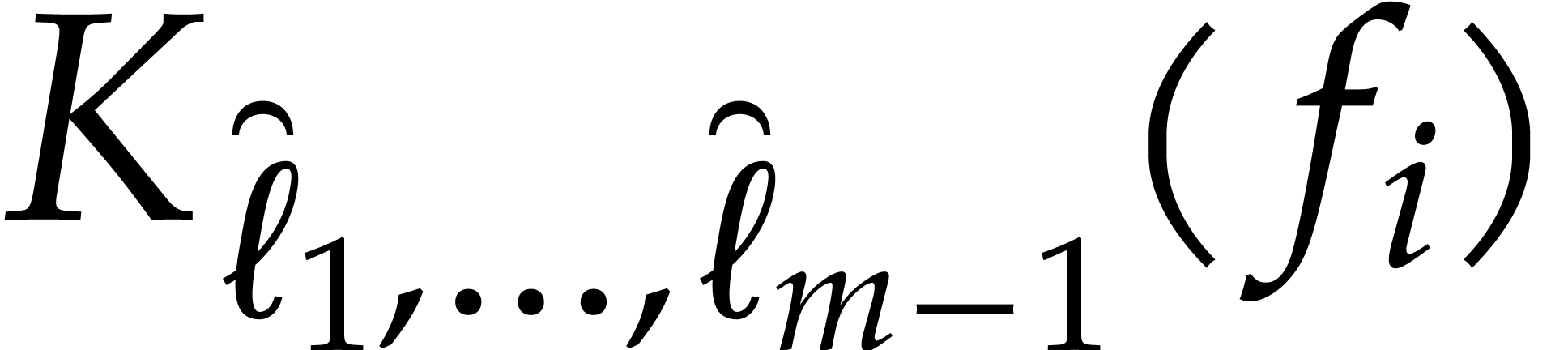 for
for 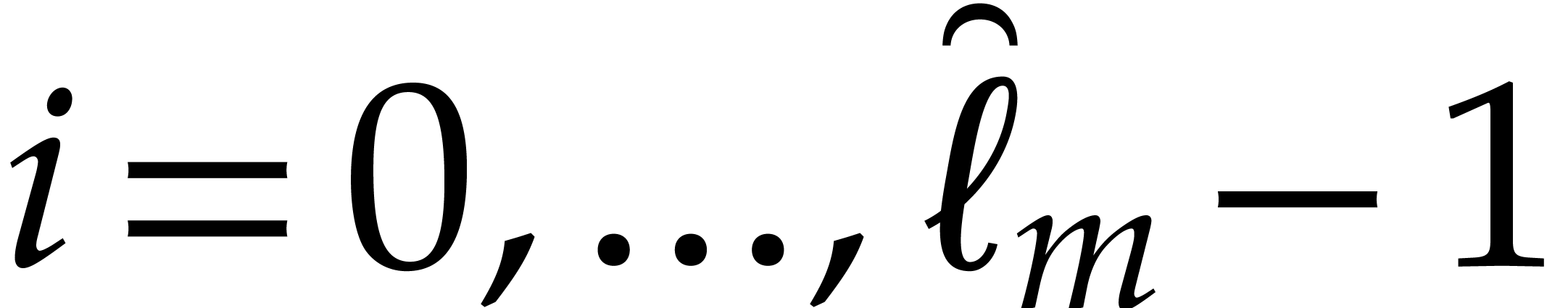 , and concatenate the results onto the output
tape. The complexity bound is straightforward.
, and concatenate the results onto the output
tape. The complexity bound is straightforward.
Only the univariate Kronecker segmentation is actually needed for the
modular composition algorithm of the next section. In the rest of this
section we introduce the multivariate segmentation and make use of it in
order to speed up multi-point evaluation.
5.2.Multivariate case
Now consider a multivariate polynomial of
partial degree in for
. For , let 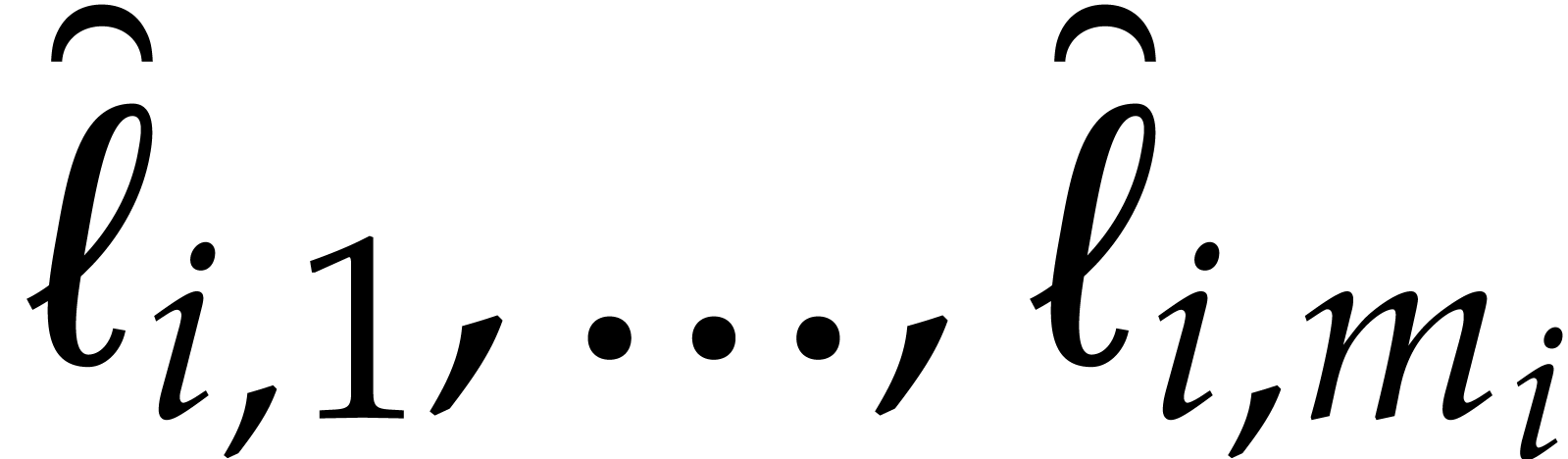 be integers such that
be integers such that
 |
(5.1) |
We introduce the multivariate Kronecker substitution map
This map restricts to an -linear
isomorphism between polynomials of partial degree 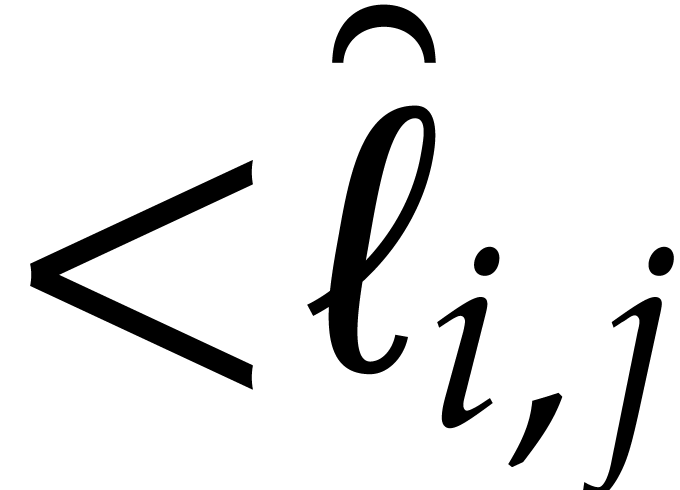 in
in  and polynomials in
and polynomials in  of
partial degree
of
partial degree 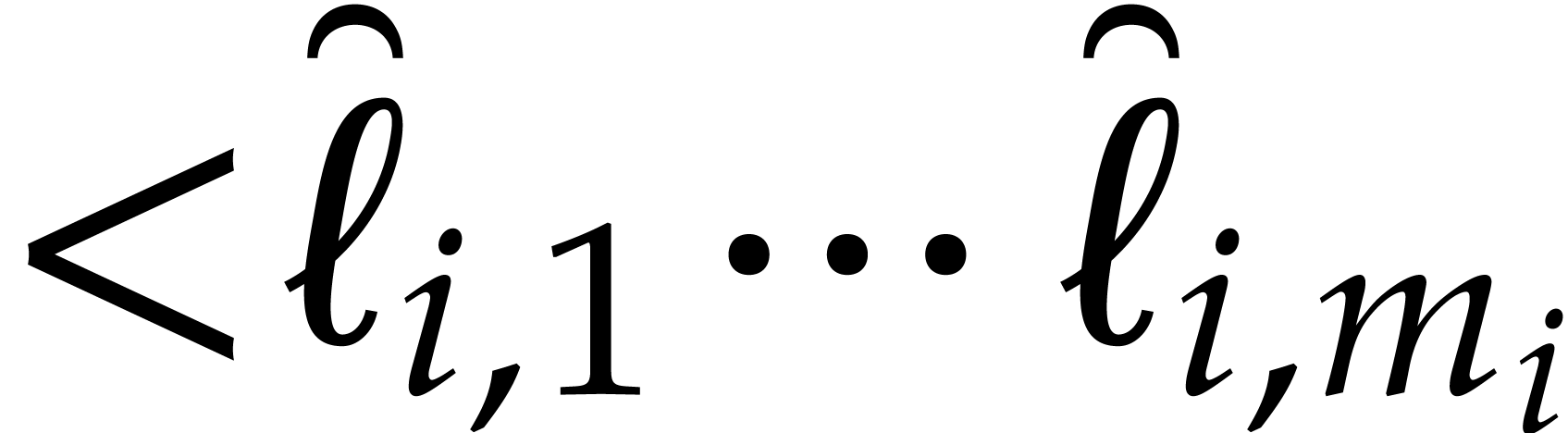 in .
In this context, the Kronecker segmentation of
is defined as
in .
In this context, the Kronecker segmentation of
is defined as 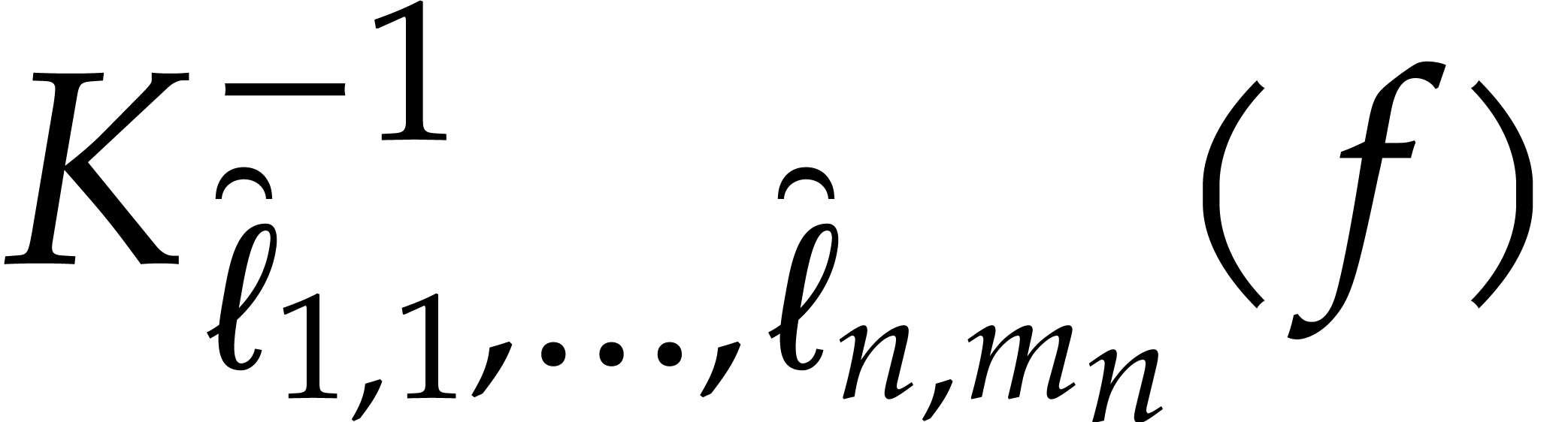 .
.
Proof. If ,
then we may use Proposition 5.1. Otherwise we consider in the form 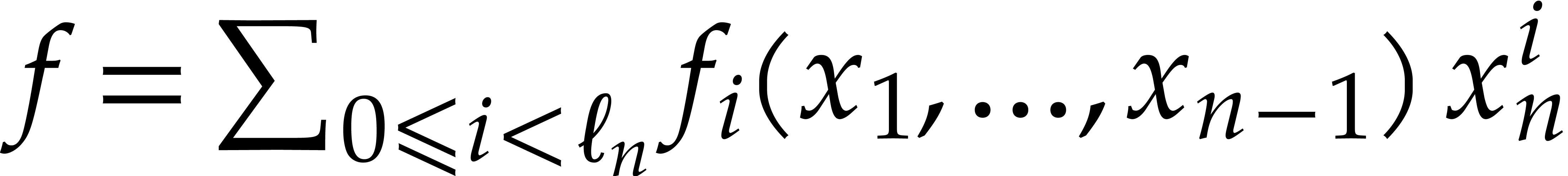 .
Let
.
Let 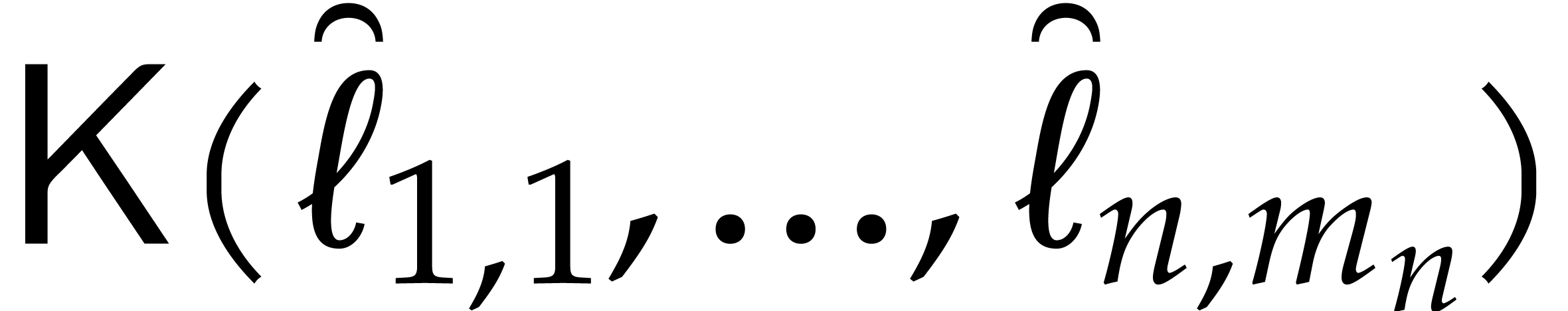 represent the cost of the segmentation of
. By Lemma 2.5
the representation size of each
represent the cost of the segmentation of
. By Lemma 2.5
the representation size of each  is
is 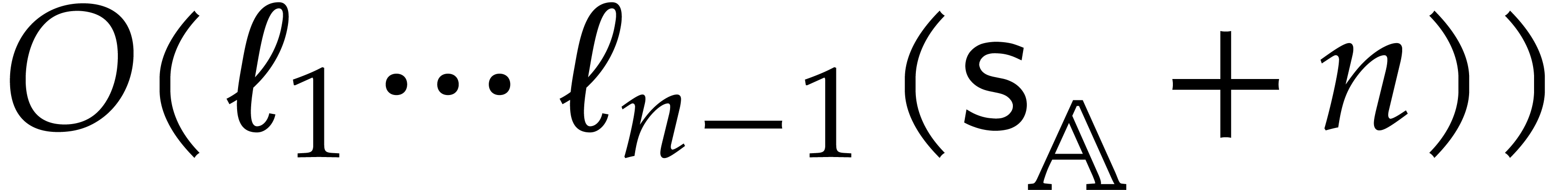 . If
. If 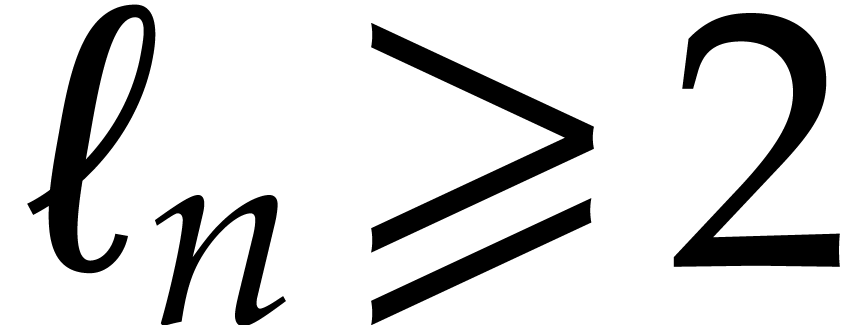 ,
then Proposition 5.1 gives
,
then Proposition 5.1 gives
Otherwise, we simply have 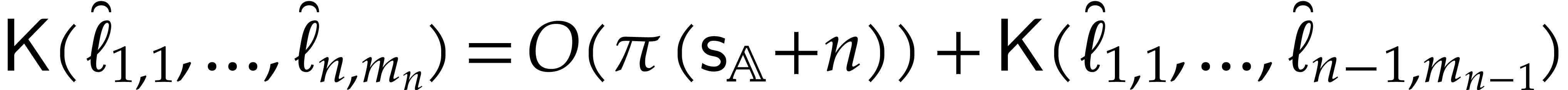 .
It follows that
.
It follows that  .
.
5.3.Application to multi-point evaluation
In the rest of this section we explain how to decrease the cost of
multi-point evaluation using Kronecker segmentation of .
Recall that 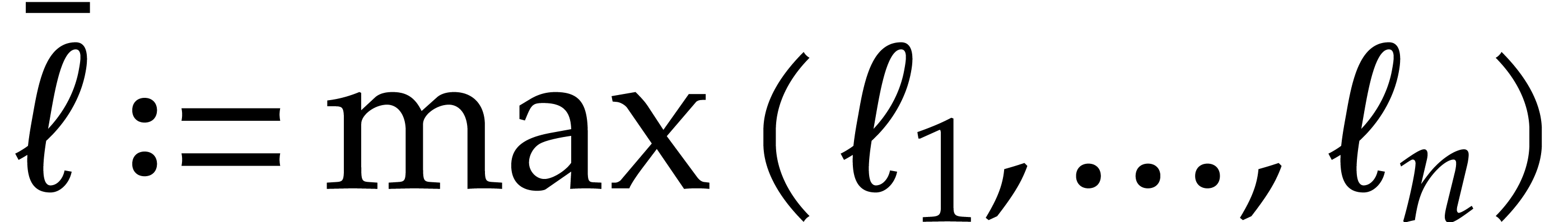 . Let
. Let 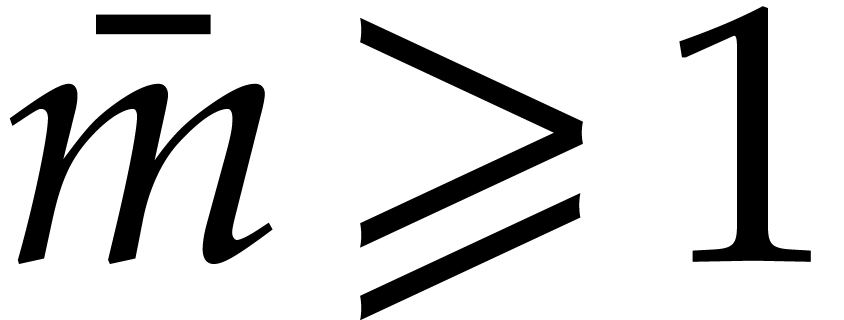 be an integer. For with
be an integer. For with  , let
, let
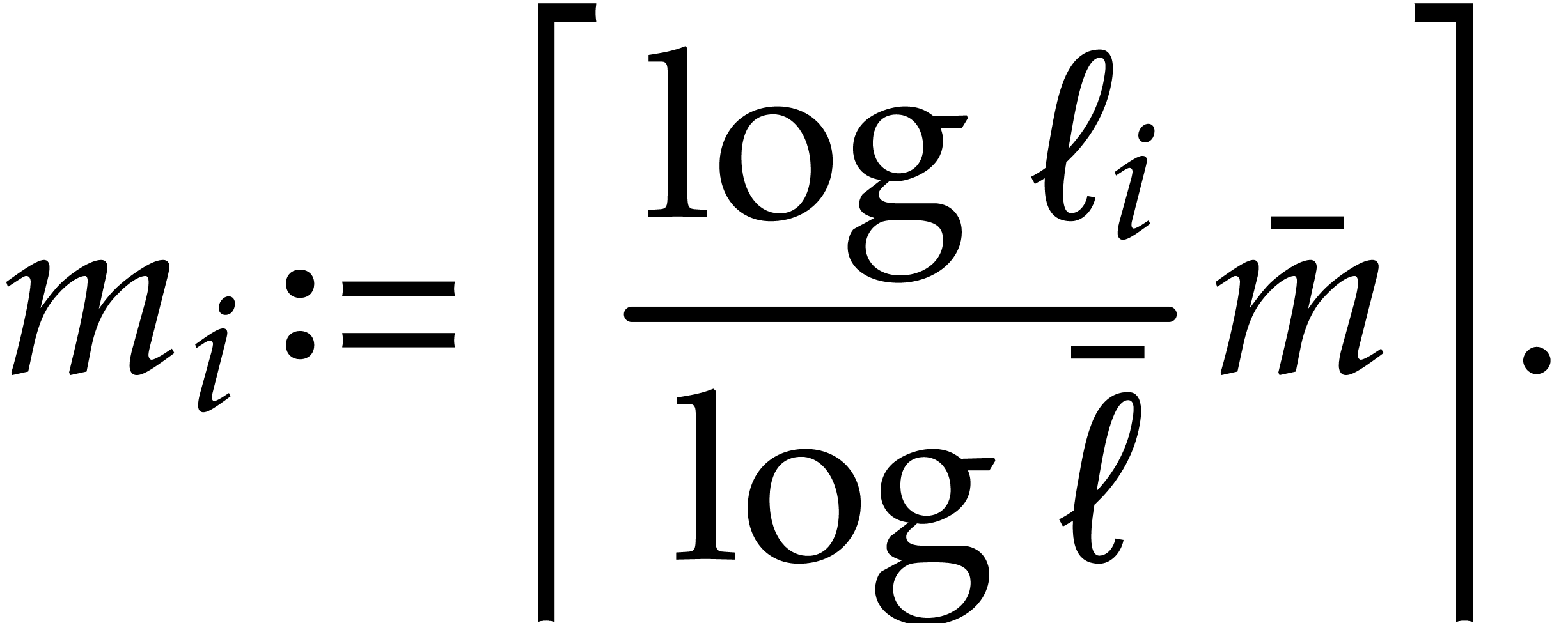
We thus have
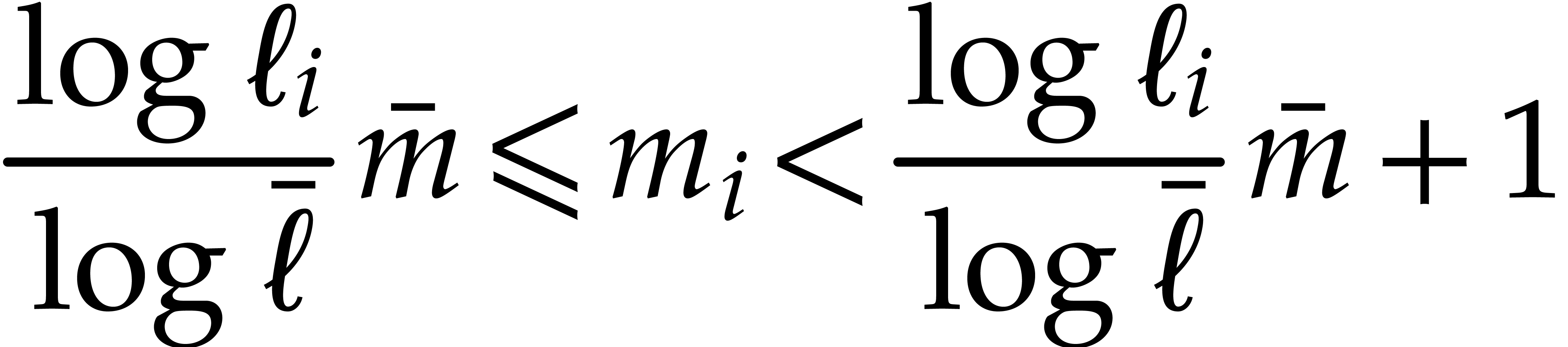
which implies
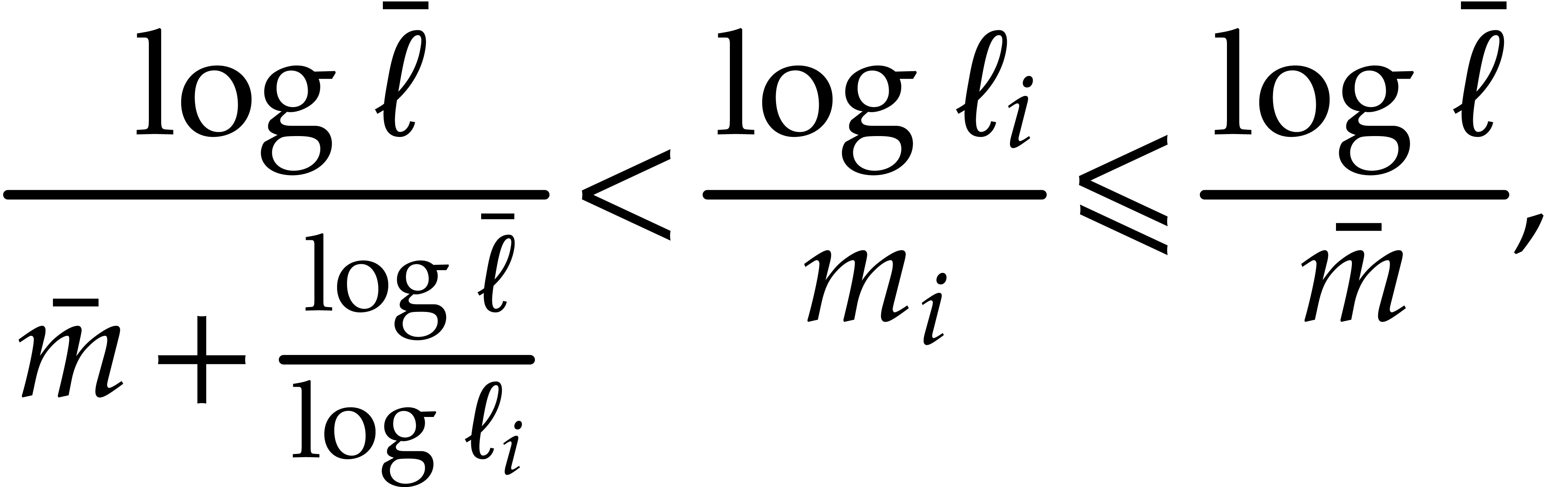
whence
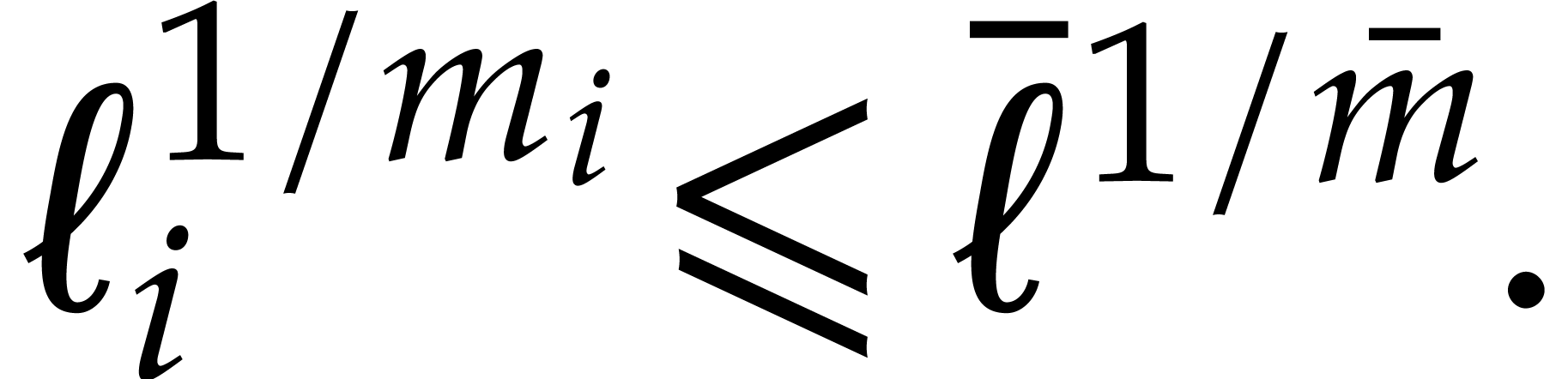 |
(5.3) |
If 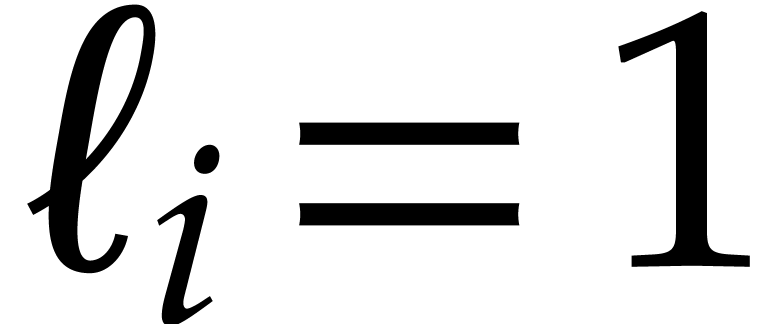 , then we set
, then we set 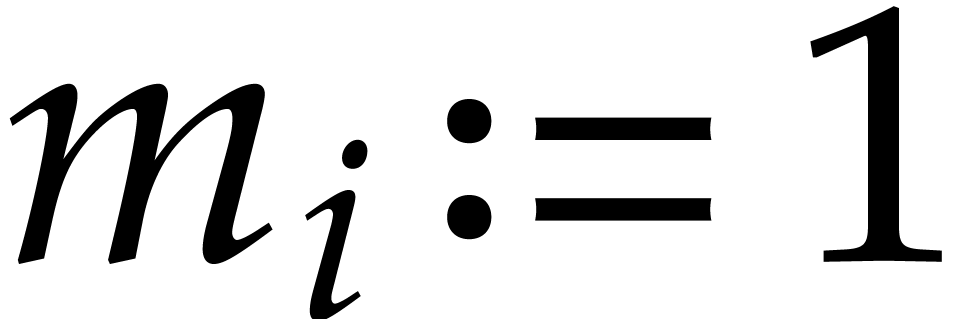 so that inequality (5.3)
still holds. In addition, if
so that inequality (5.3)
still holds. In addition, if 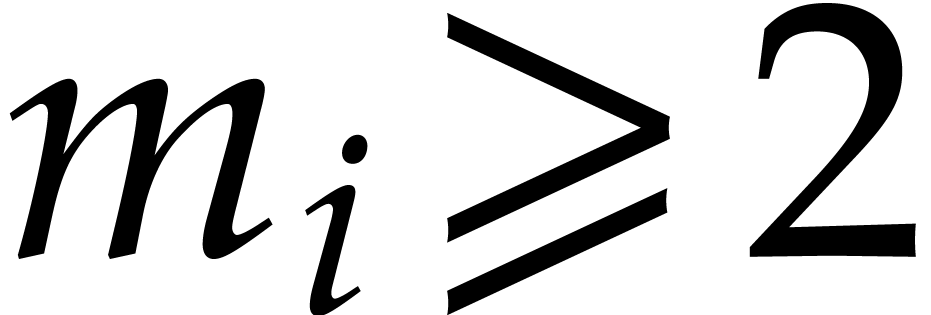 ,
then
,
then 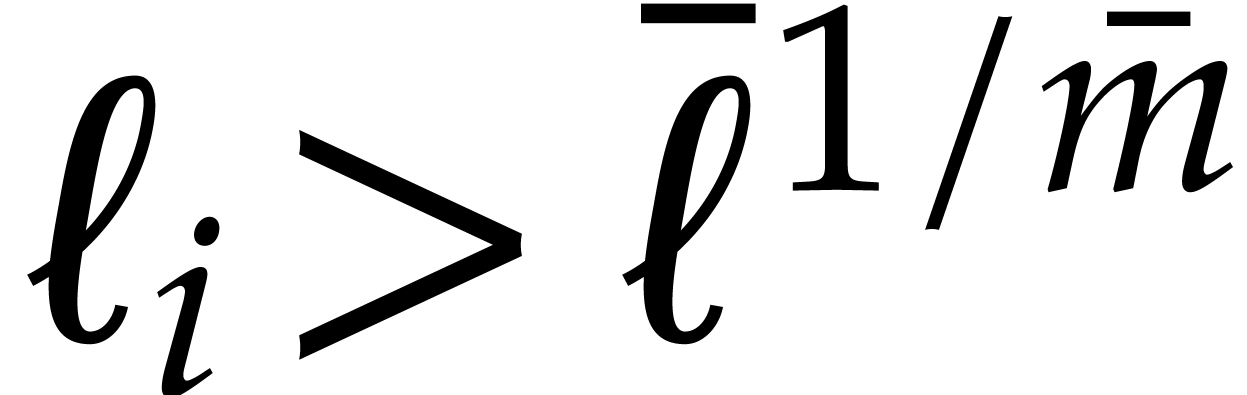 , whence
, whence 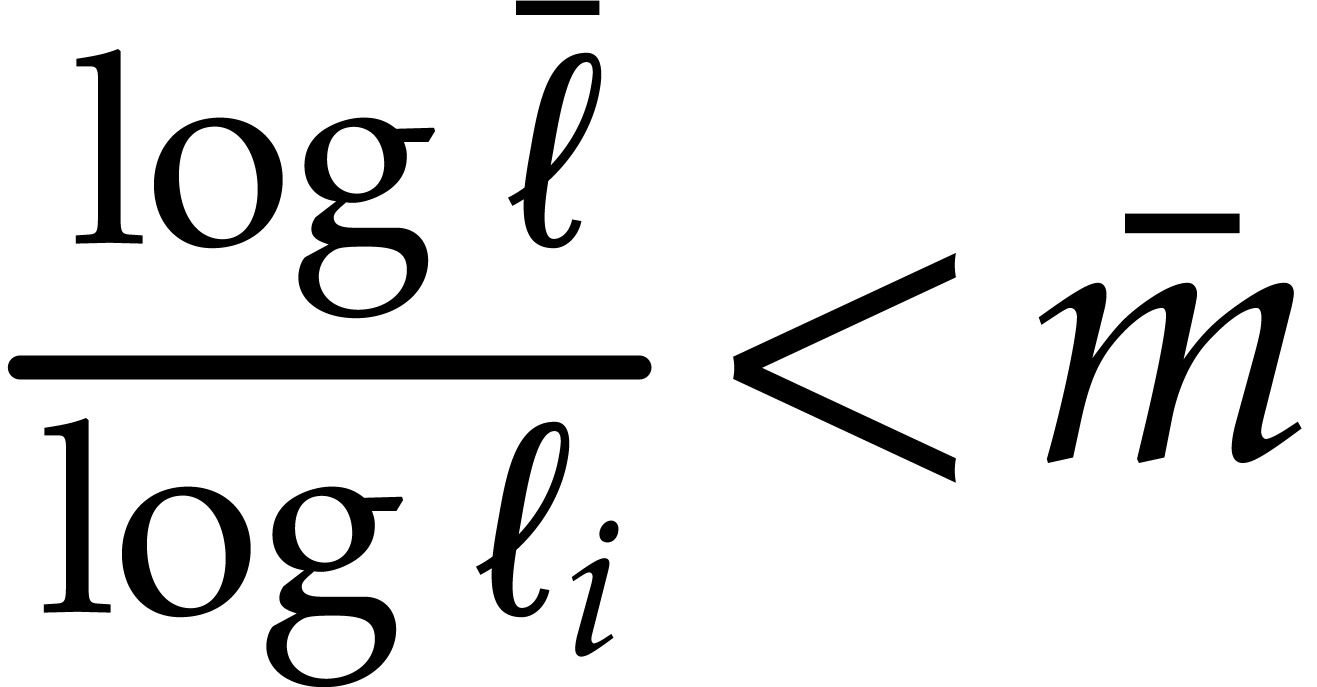 , and
, and
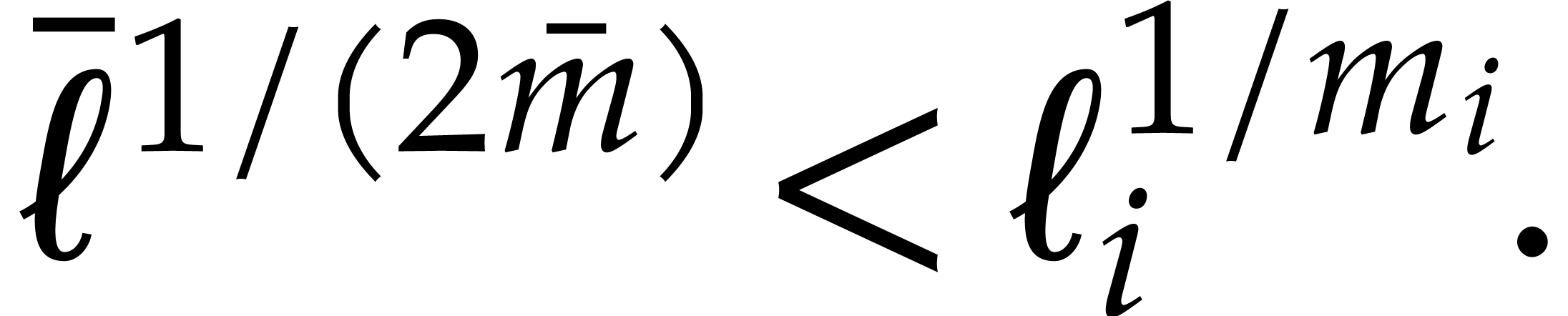 |
(5.4) |
Notice that we have 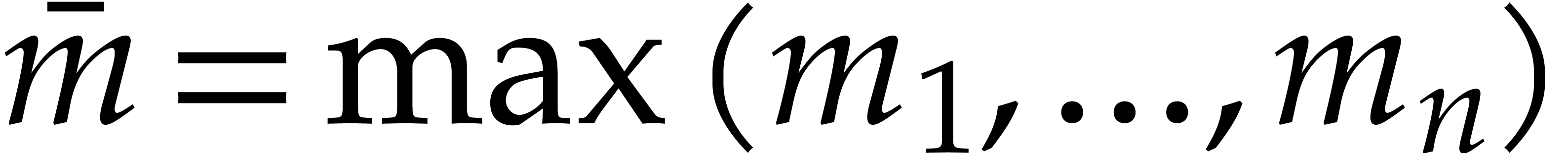 . For all
. For all
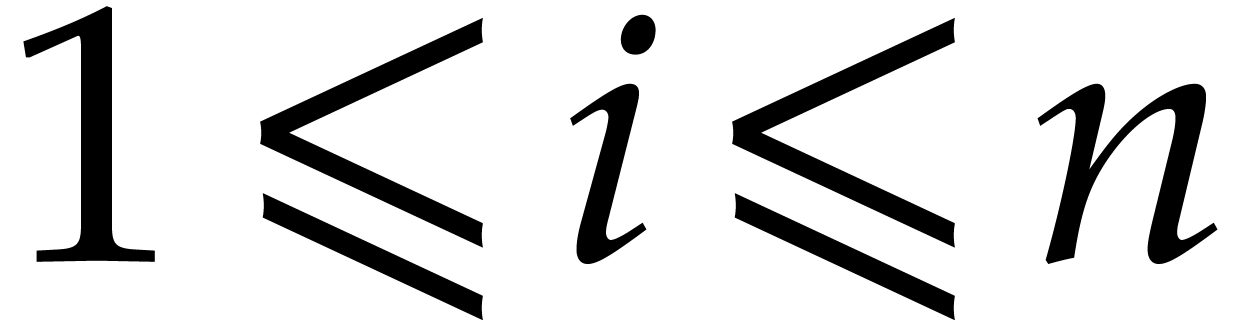 we introduce
we introduce
so 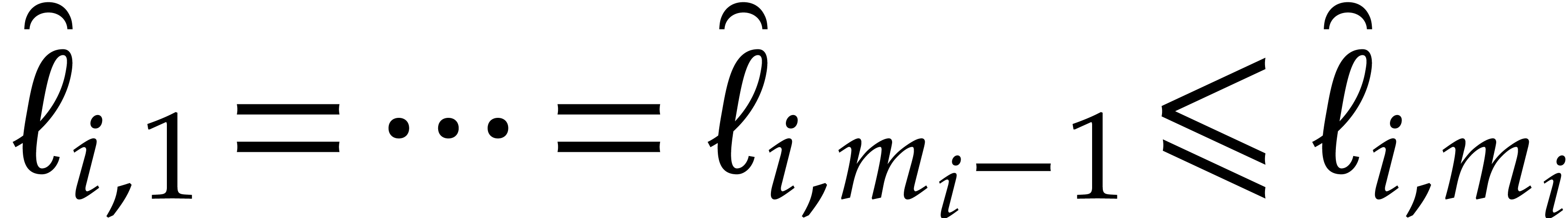 and
and 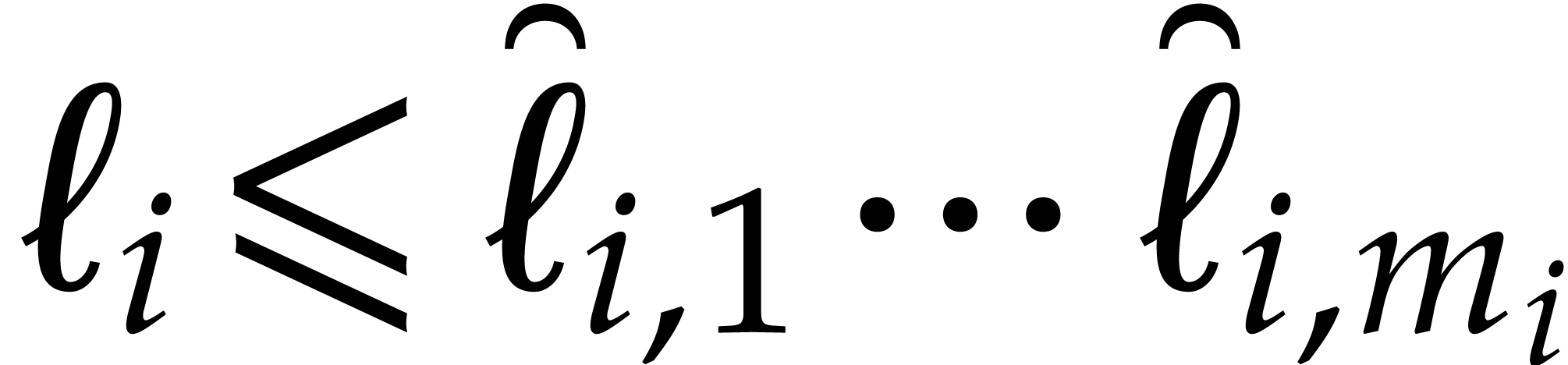 hold. From
hold. From
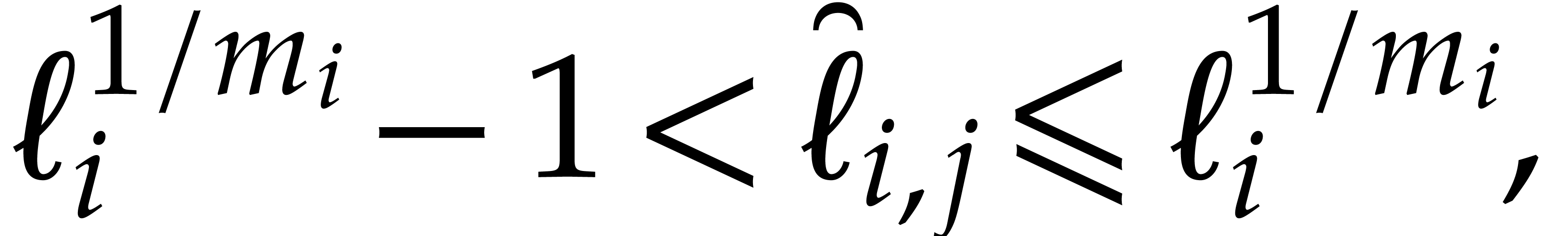 |
(5.5) |
for  , and
, and
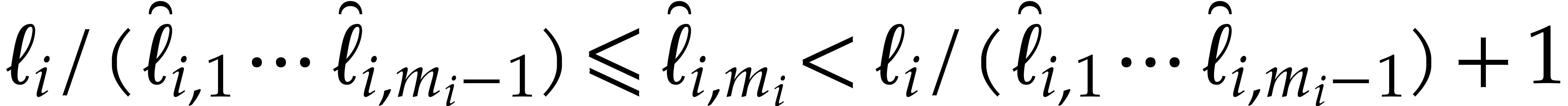 |
(5.6) |
we deduce that
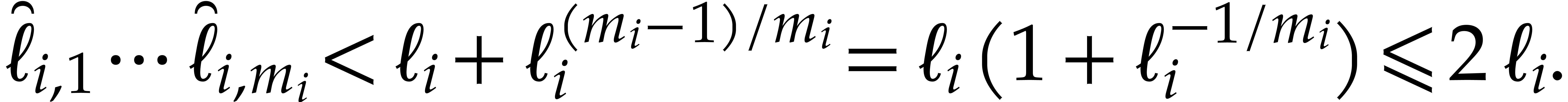 |
(5.7) |
In a dual manner to the Kronecker substitution map (5.2) associated to the 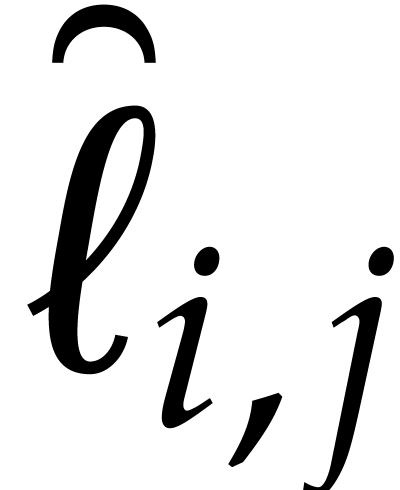 we
introduce the map
we
introduce the map
where  . Letting
. Letting 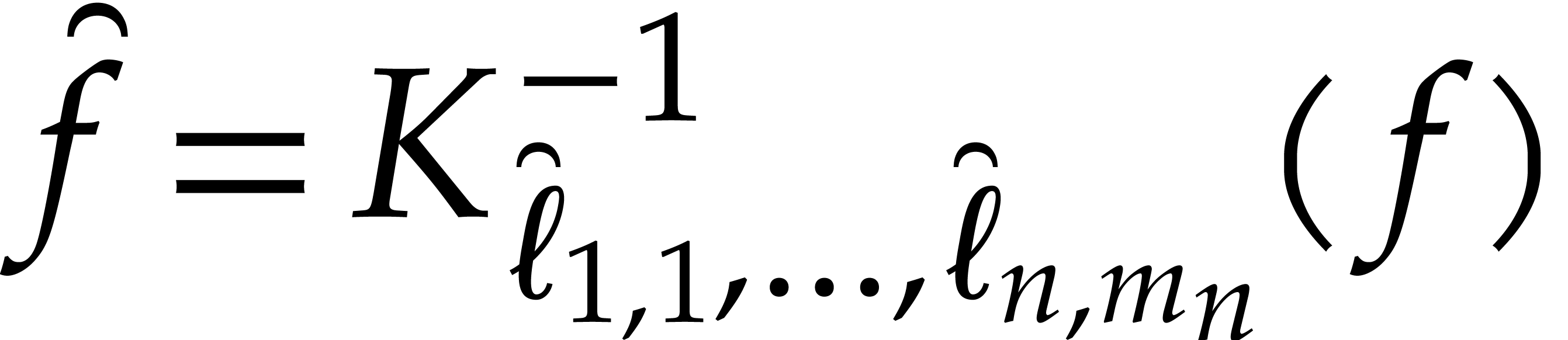 we thus have
we thus have
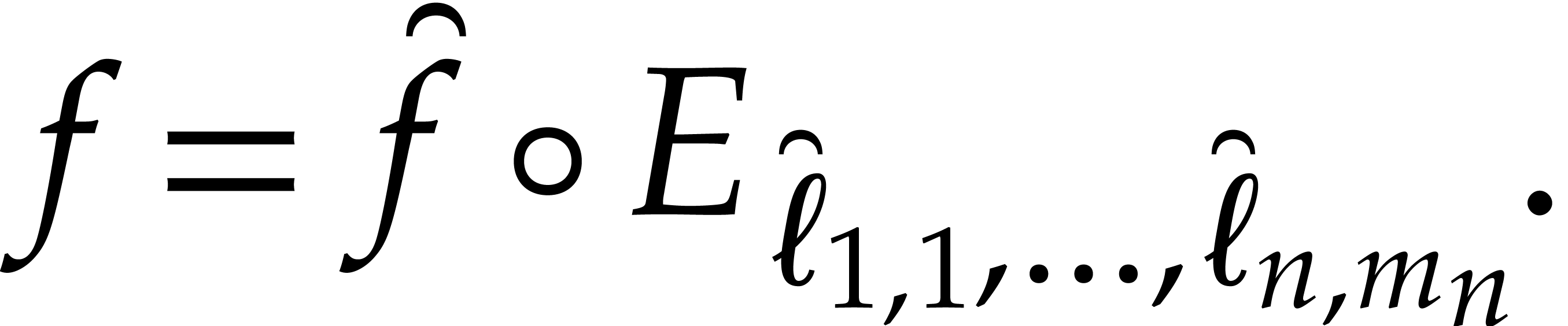
In this way we reduce the multi-point evaluation in
variables and partial degree bounds  to
evaluation in
to
evaluation in 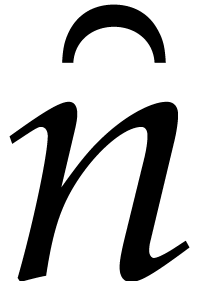 variables and partial degree
bounds
variables and partial degree
bounds  . Notice that this
segmentation generically builds a polynomial
. Notice that this
segmentation generically builds a polynomial 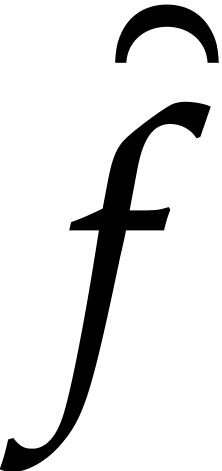 of
total degree close to the sum of its partial degrees. The cardinality of
the support of is the same as of the support of
, but its number of
“#” symbols in the representation is larger. From (5.7) we deduce that
of
total degree close to the sum of its partial degrees. The cardinality of
the support of is the same as of the support of
, but its number of
“#” symbols in the representation is larger. From (5.7) we deduce that
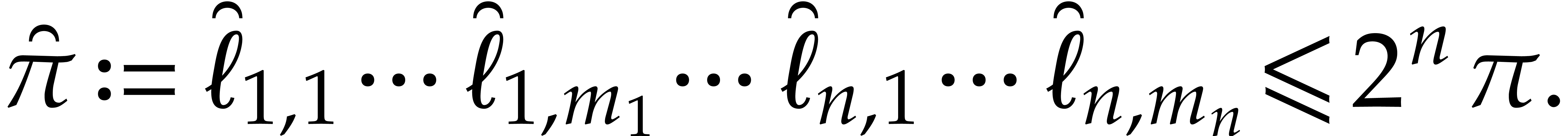 |
(5.8) |
The latter 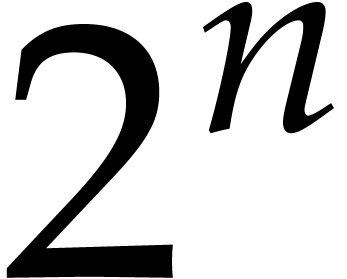 may be replaced by a smaller value
may be replaced by a smaller value
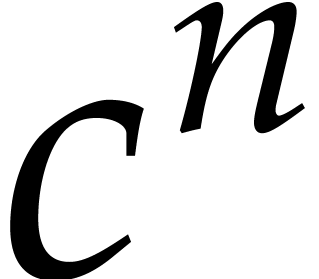 with
with  arbitrarily close
to whenever
arbitrarily close
to whenever  is
sufficiently large. The reduction process is summarized in the following
algorithm.
is
sufficiently large. The reduction process is summarized in the following
algorithm.
Proposition 5.4.
Algorithm 5.2 is correct and takes
time
Proof. The correctness is clear from the
definitions. The quantities  may be obtained in
time
may be obtained in
time 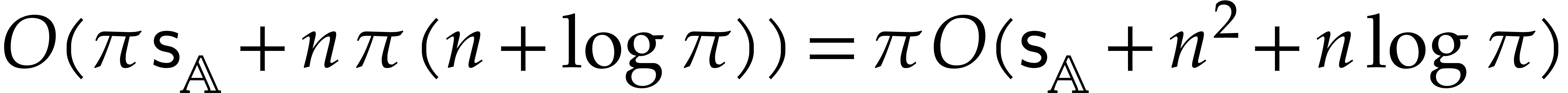 by Lemmas 2.5 and 2.7.
Then we use a binary search to determine
by Lemmas 2.5 and 2.7.
Then we use a binary search to determine 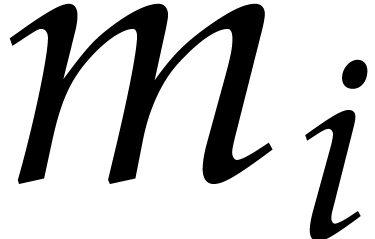 as the
first integer such that
as the
first integer such that  in time
in time 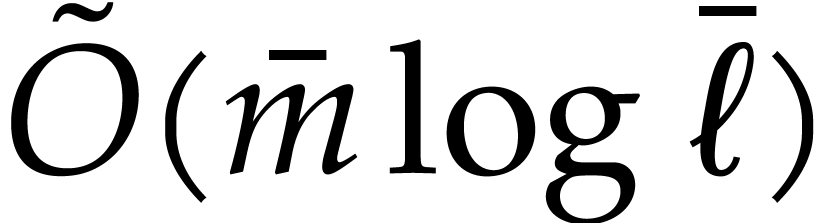 . By Proposition 5.3 the
segmentation in step 2 takes time
. By Proposition 5.3 the
segmentation in step 2 takes time 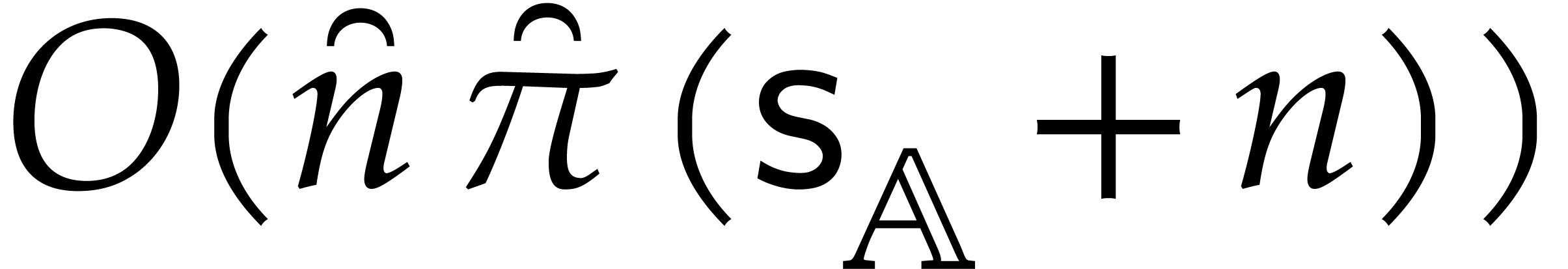 .
Using binary powering, step 3 involves
.
Using binary powering, step 3 involves 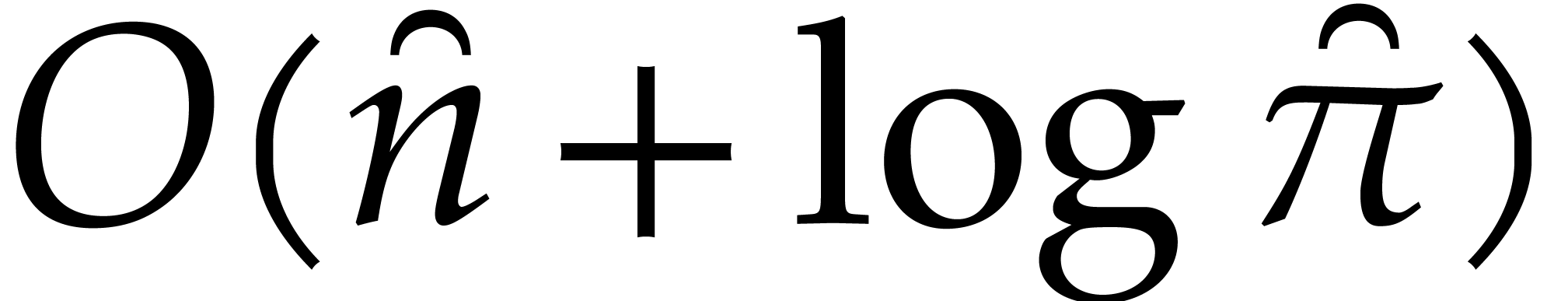 operations in for each point .
operations in for each point .
Proof. We may freely assume that 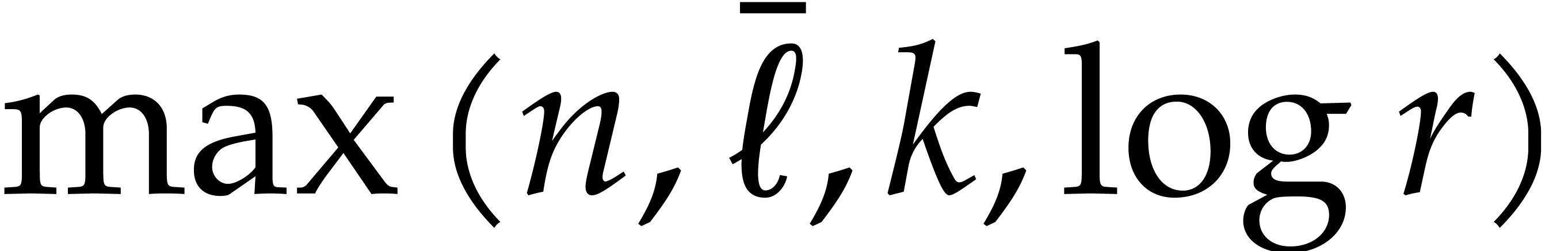 is sufficiently large, so that the cost of multi-modular evaluation is
is sufficiently large, so that the cost of multi-modular evaluation is
by Theorem 4.4. If 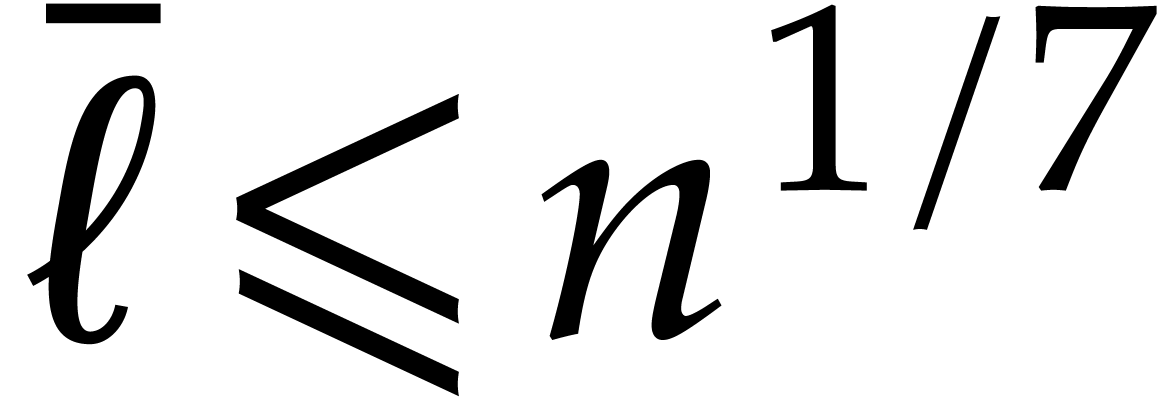 ,
then we deduce the complexity bound
,
then we deduce the complexity bound
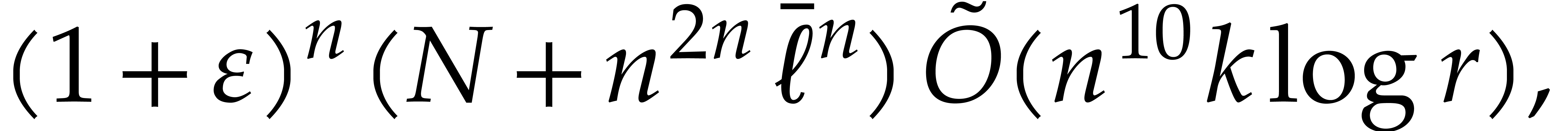
so we are done.
From now we assume that 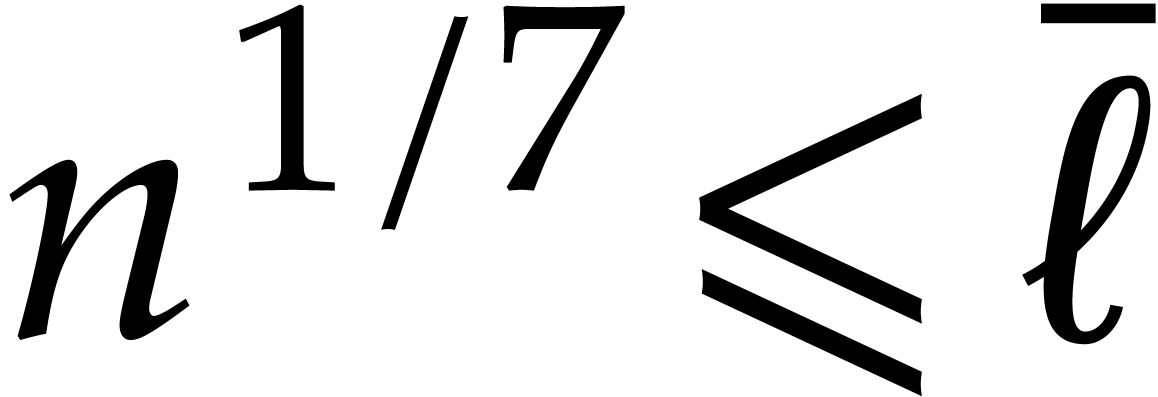 . If
. If
 is bounded, then so is , and we may appeal to the naive evaluation
algorithm; the conclusion follows by adapting Lemma 3.8 to
. We may thus further assume
that is sufficiently large to satisfy
is bounded, then so is , and we may appeal to the naive evaluation
algorithm; the conclusion follows by adapting Lemma 3.8 to
. We may thus further assume
that is sufficiently large to satisfy
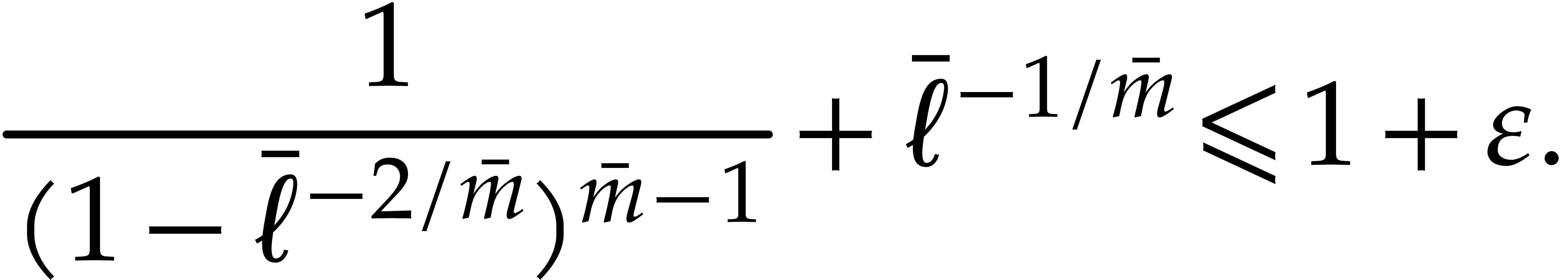
If 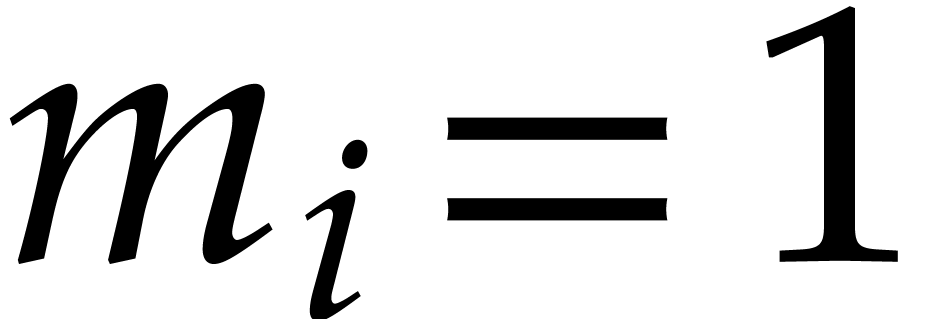 , then
, then 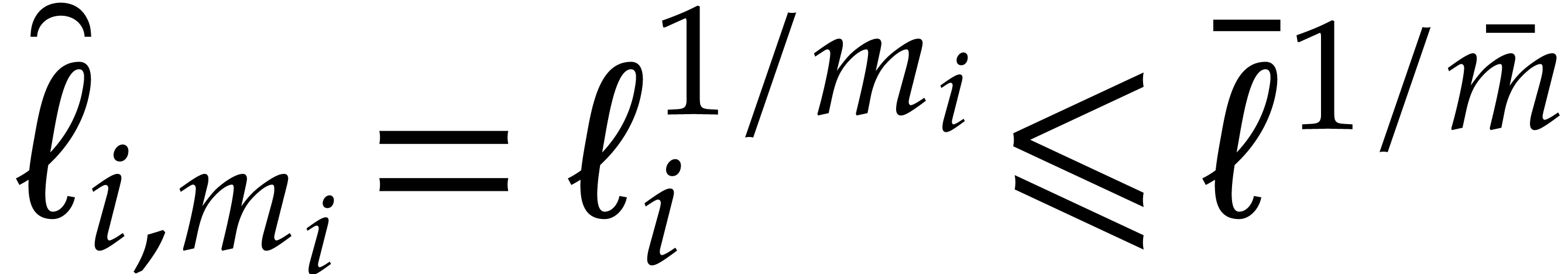 . Otherwise, (5.3),
(5.4), (5.5),
and (5.6) imply
. Otherwise, (5.3),
(5.4), (5.5),
and (5.6) imply
whence
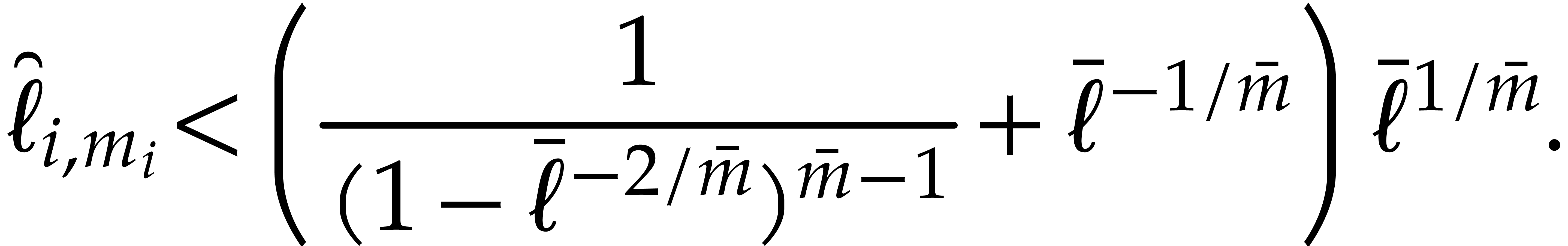
For all 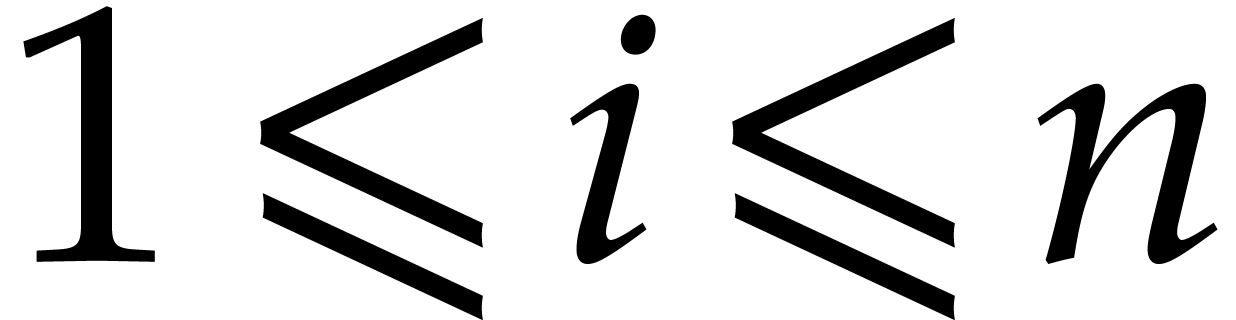 we thus have
we thus have 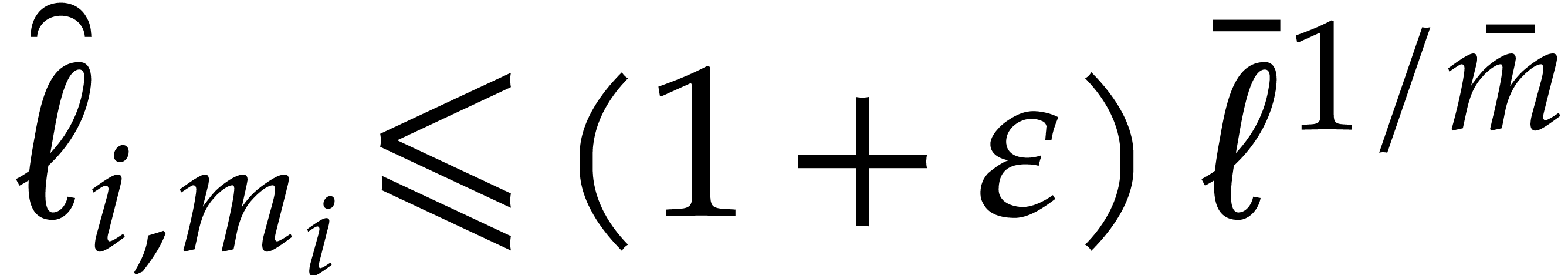 . It follows that
. It follows that
and
Using Proposition 5.4, we compute  and the
and the  by Algorithm 5.2 in time
by Algorithm 5.2 in time
Then Theorem 4.4 ensures that the evaluation of at all the takes time
 |
(5.9) |
where 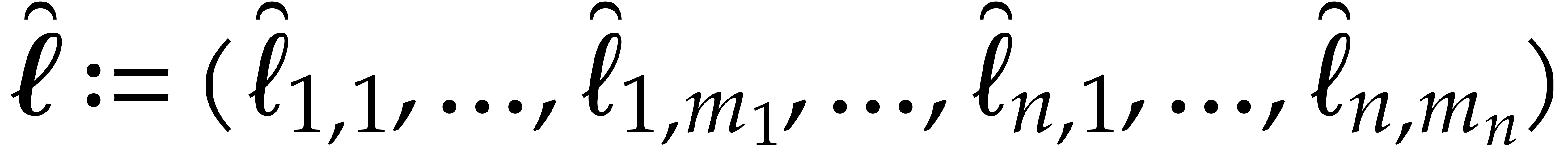 . Now we further assume
that
. Now we further assume
that 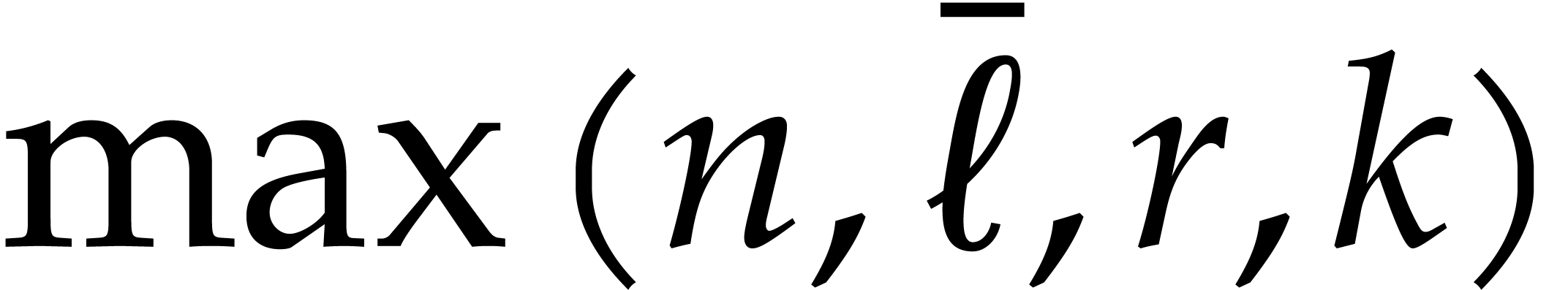 is sufficiently large such that
is sufficiently large such that
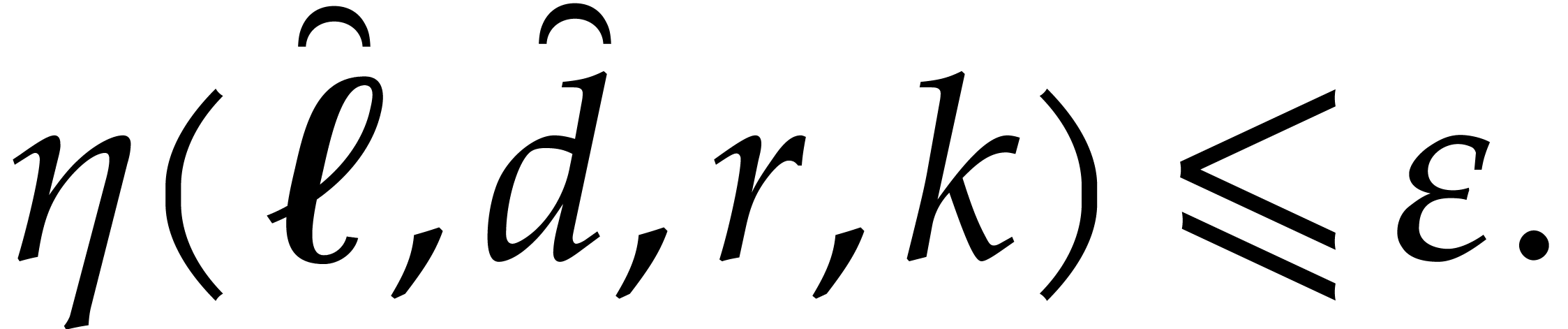
Then the cost (5.9) rewrites into
5.4.Consequence in terms of total degree
In the univariate case it is well known that a polynomial of degree may be evaluated at points in
softly linear time. In the multivariate setting we wish to reach softly
linear time for the evaluation in degree ,
with variables, at 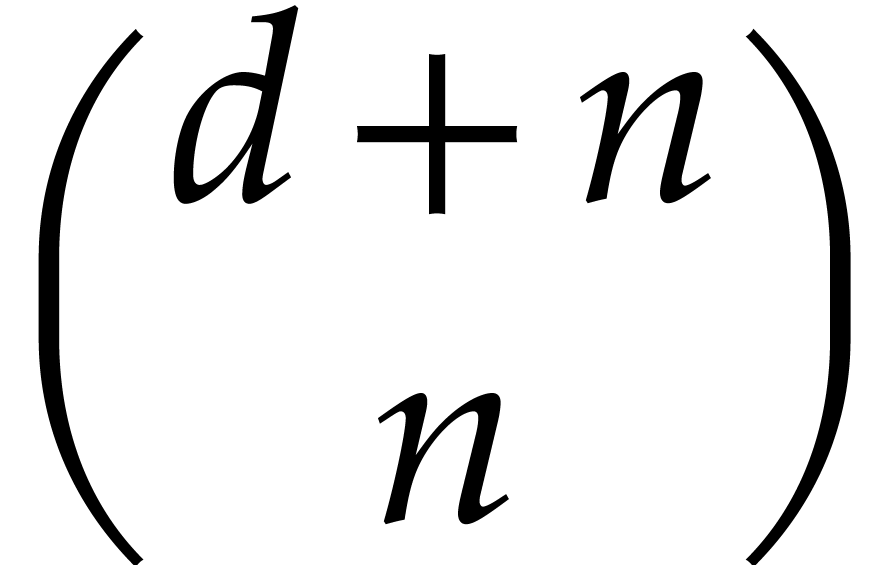 points. Although such a complexity bound seems out of reach for the
present techniques, the aim of this section is to prove a slightly
weaker bound. We start with a simple lemma.
points. Although such a complexity bound seems out of reach for the
present techniques, the aim of this section is to prove a slightly
weaker bound. We start with a simple lemma.
Lemma 5.6. For all positive integers and we have
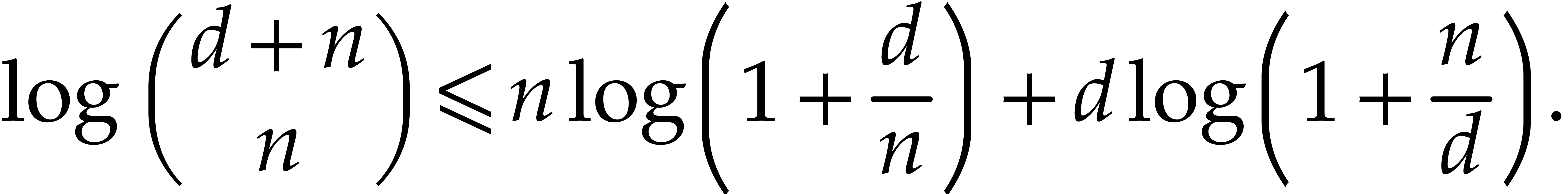
Proof. The bound is proved as follows:
Proof. If 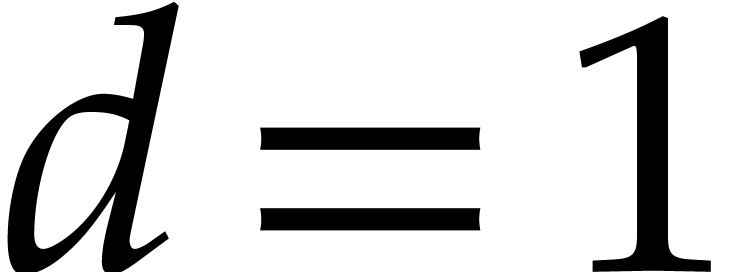 ,
then Lemma 3.8 ensures evaluation time
,
then Lemma 3.8 ensures evaluation time 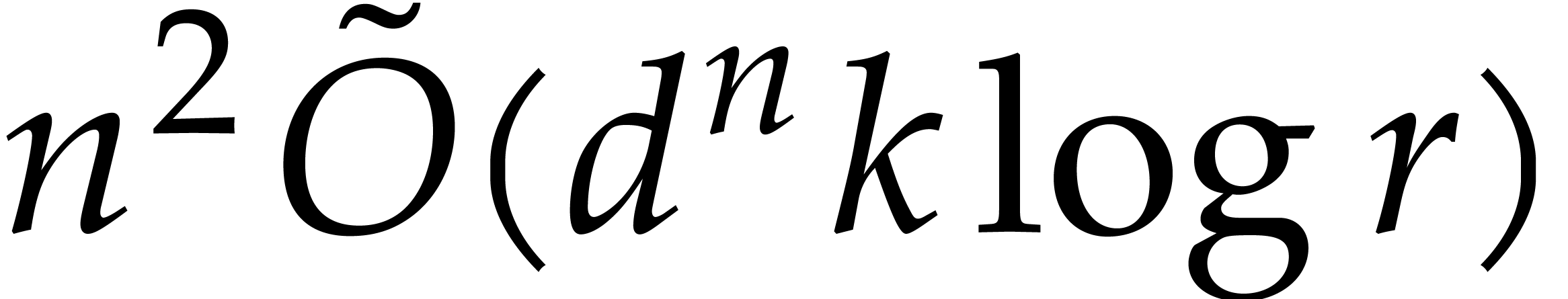 . From now on we may assume
. From now on we may assume 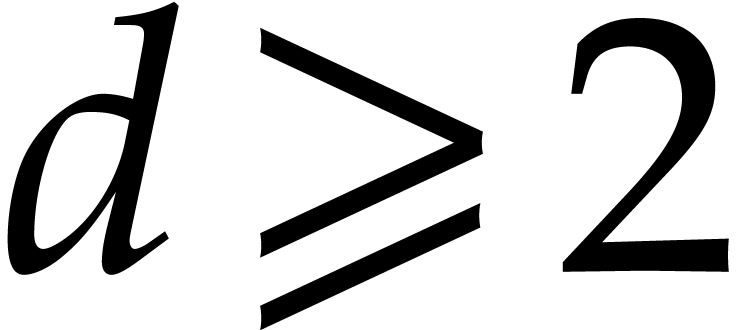 .
.
First we examine the case when 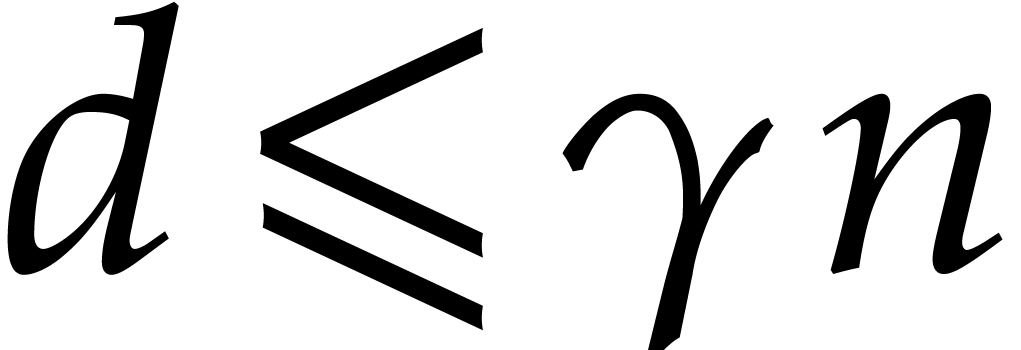 for a constant
for a constant
 to be fixed. Lemma 5.6 combined to
the fact that the function
to be fixed. Lemma 5.6 combined to
the fact that the function 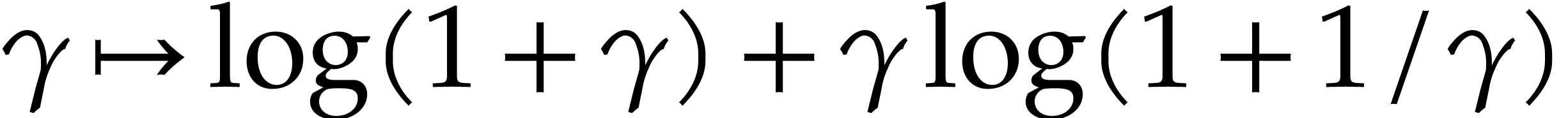 is nondecreasing
yields
is nondecreasing
yields
We fix the constant  sufficiently small such that
sufficiently small such that
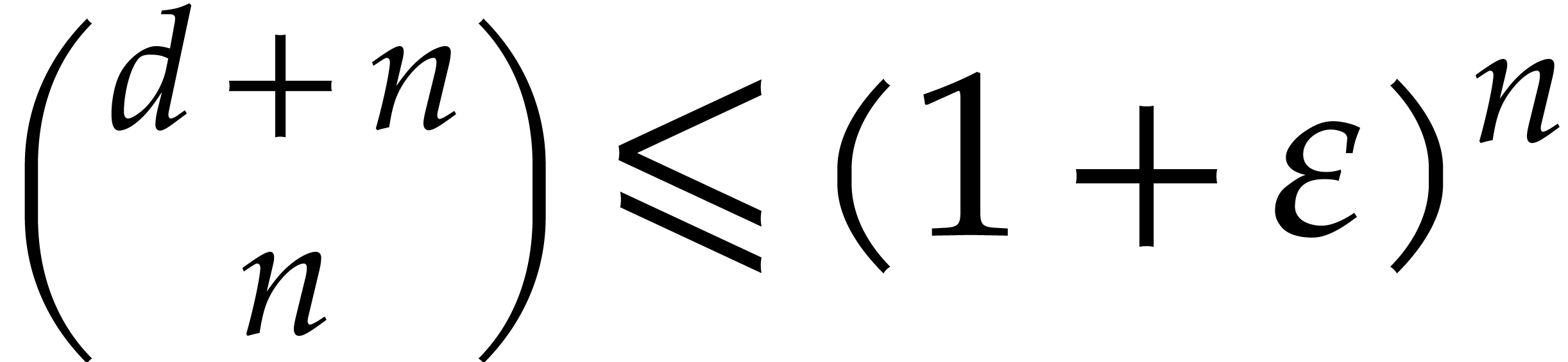 . By Lemma 3.8,
the evaluations can be achieved in time
. By Lemma 3.8,
the evaluations can be achieved in time 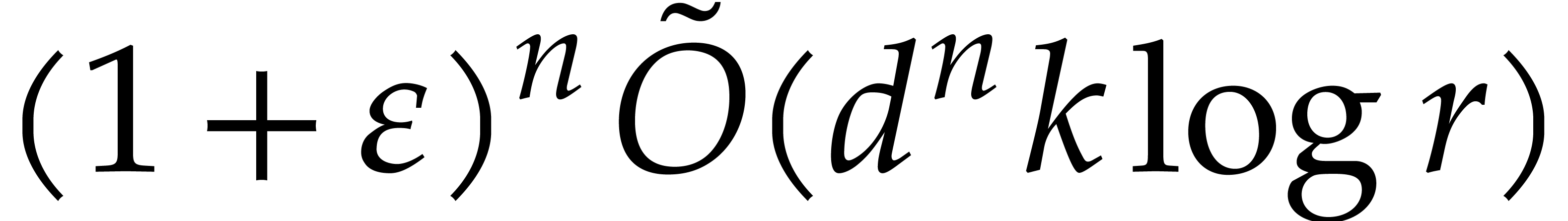 .
.
From now we may assume that 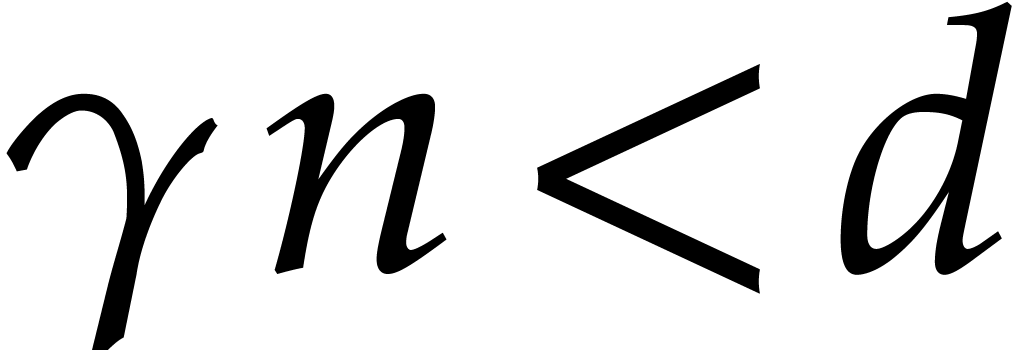 holds. If is bounded, then so is and Lemma
3.8 again leads to an evaluation time
holds. If is bounded, then so is and Lemma
3.8 again leads to an evaluation time 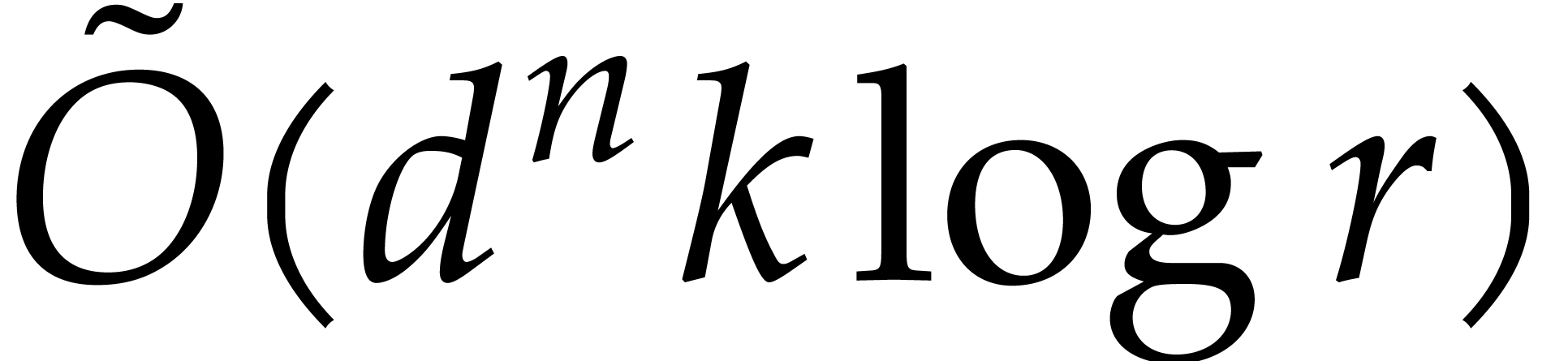 . Consequently we may further assume that is sufficiently large to satisfy
. Consequently we may further assume that is sufficiently large to satisfy
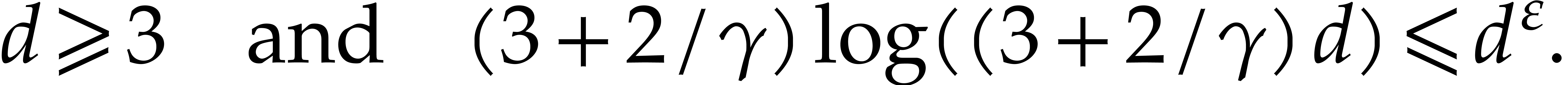 |
(5.10) |
Setting 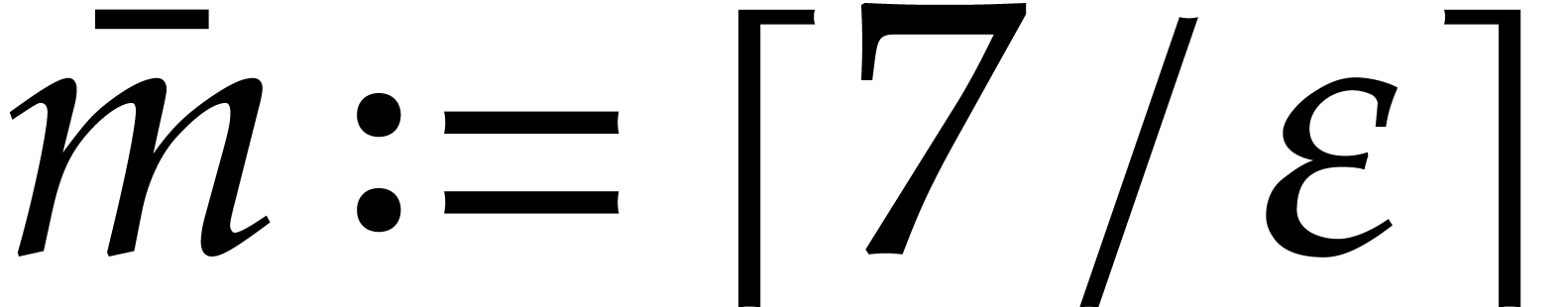 , Theorem 5.5
provides us with the time complexity bound
, Theorem 5.5
provides us with the time complexity bound
For a universal constant 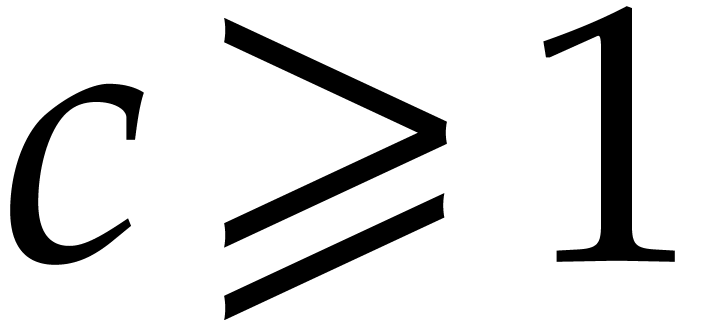 ,
this bound simplifies to
,
this bound simplifies to
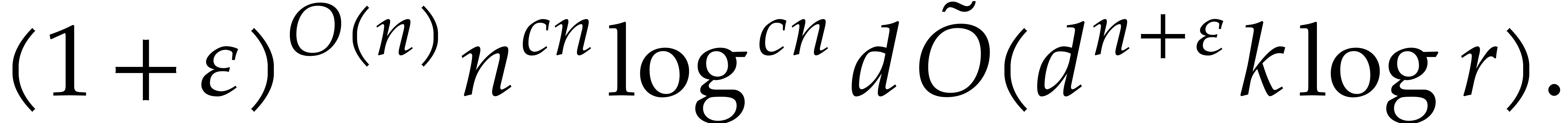
Whenever 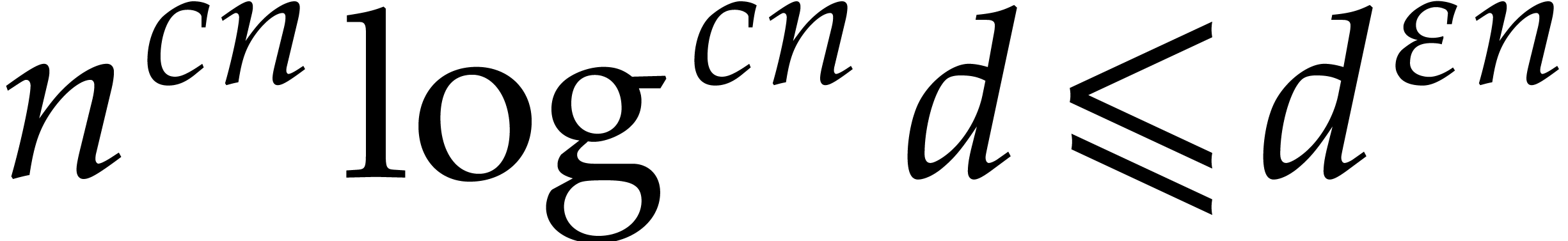 the latter cost further simplifies to
the latter cost further simplifies to
We now consider the other case when 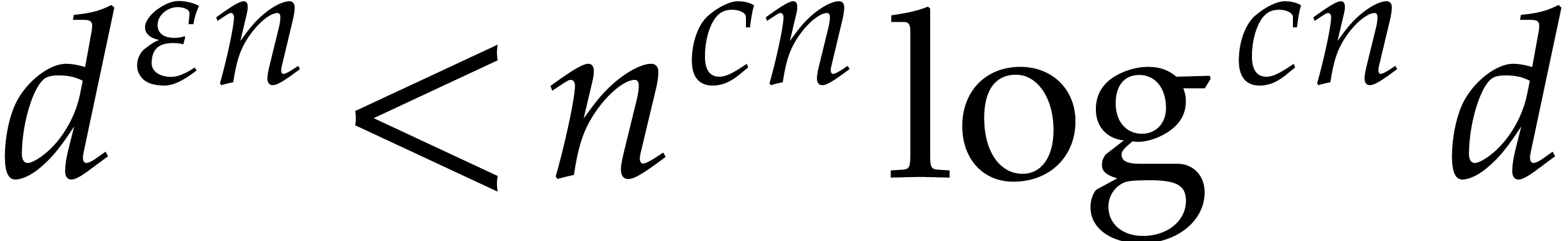 ,
so we have
,
so we have 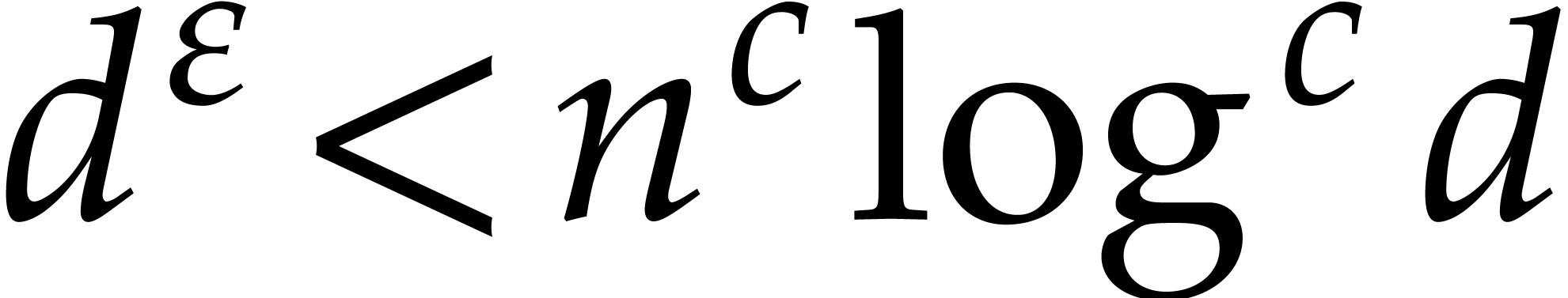 , hence
, hence 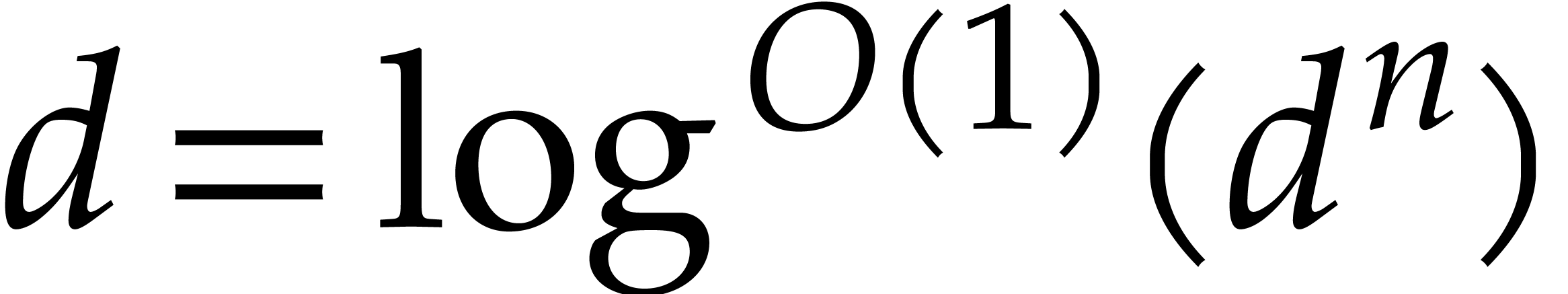 . In this case, Corollary 4.6
gives the cost
. In this case, Corollary 4.6
gives the cost
which is bounded from above by
In all cases with , we have
thus proved the complexity bound
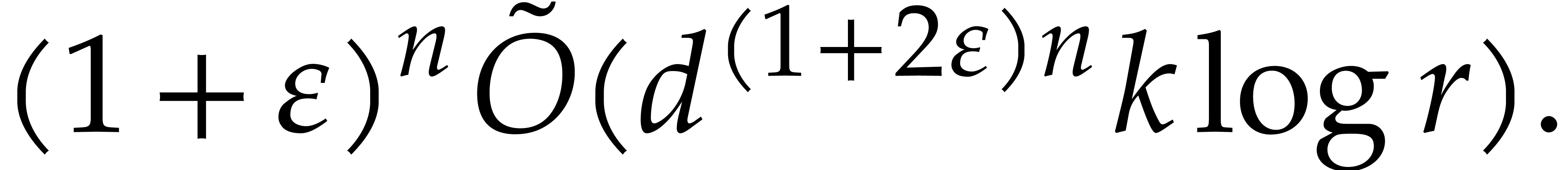
Since , we have 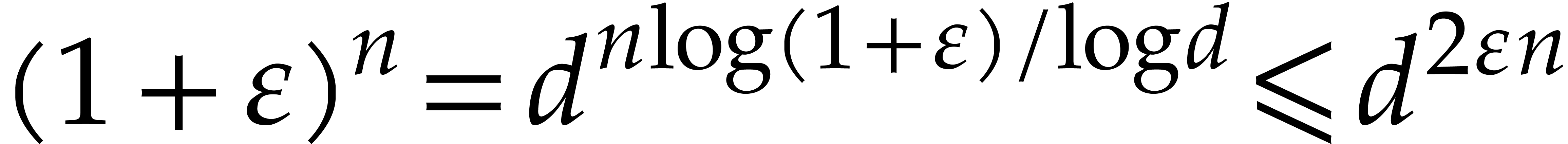 , so the total running time is bounded by
, so the total running time is bounded by 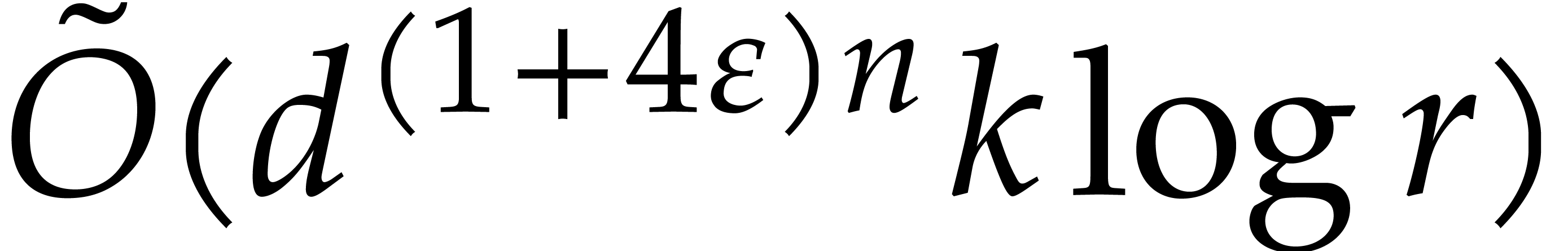 . We conclude by applying this for
. We conclude by applying this for
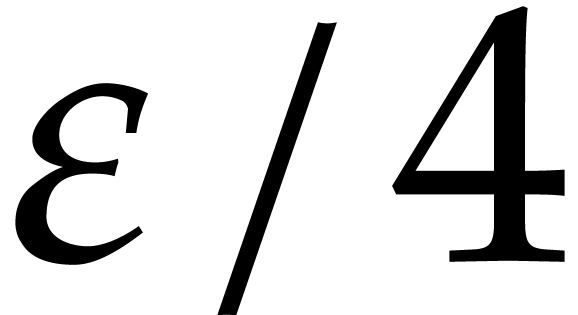 instead of
instead of  .
.
6.Modular composition
In this section, is an effective field, is a monic polynomial in 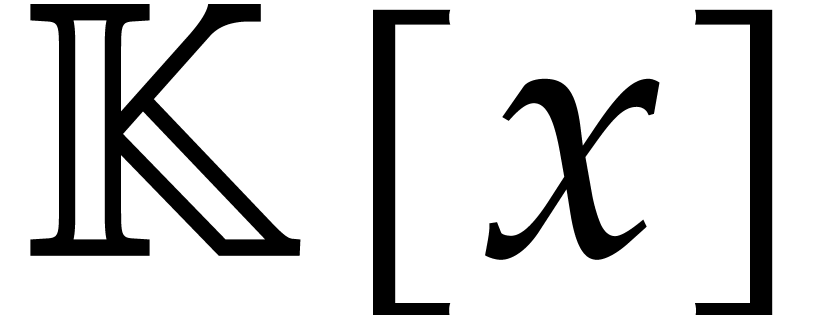 of
degree , and
are two polynomials in
of
degree , and
are two polynomials in 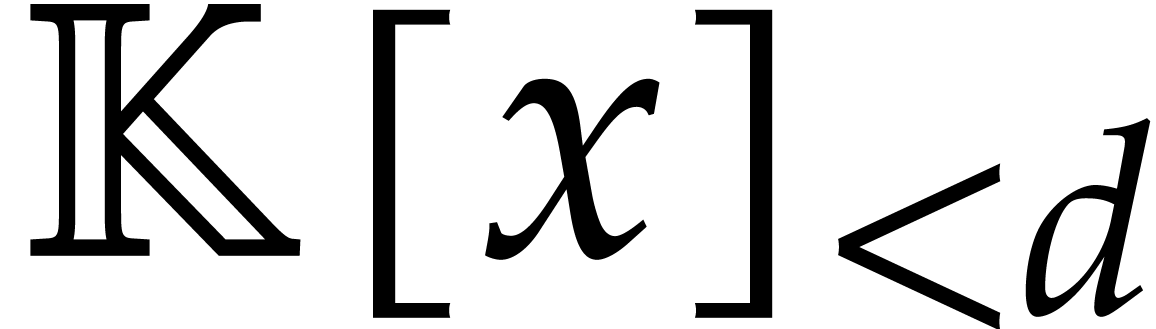 . We
want to compute
. We
want to compute  . We first
describe and analyze the algorithm in the algebraic complexity model and
then return to Turing machines in the case when
is a finite field.
. We first
describe and analyze the algorithm in the algebraic complexity model and
then return to Turing machines in the case when
is a finite field.
Let 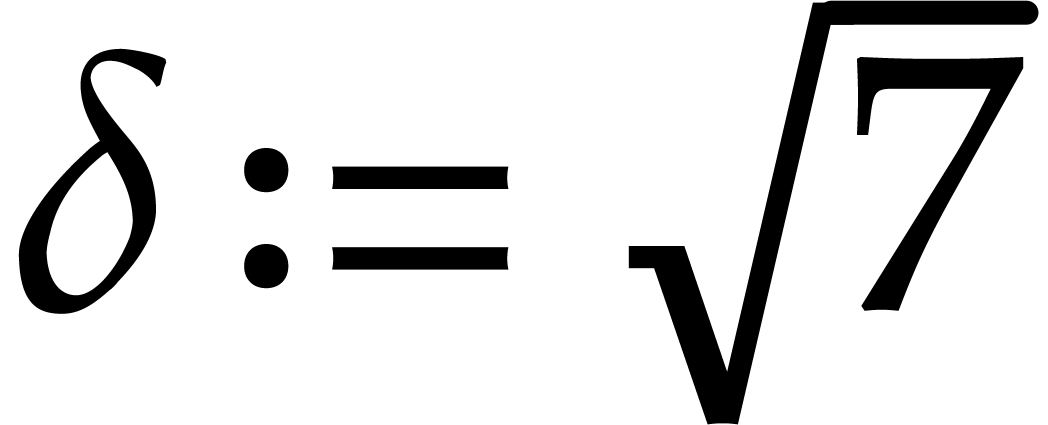 . This precise choice of
. This precise choice of
 will be motivated below. We let
be an integer such that
will be motivated below. We let
be an integer such that
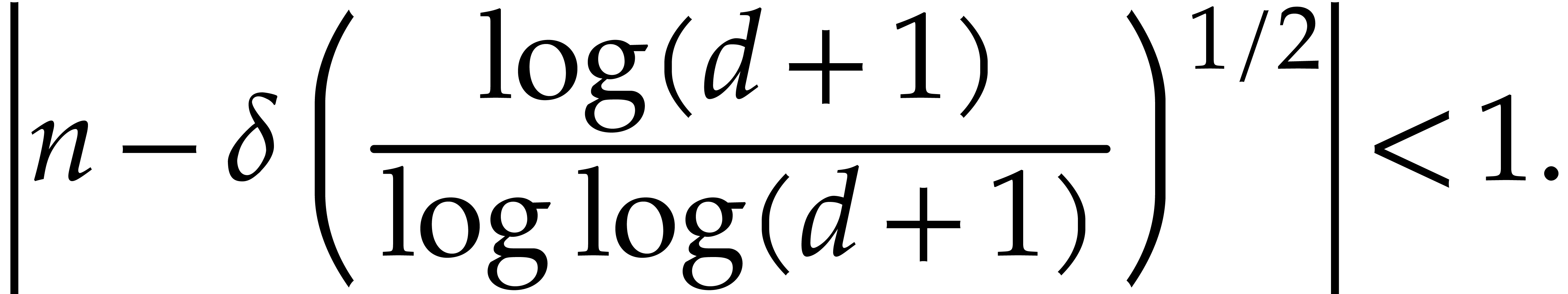 |
(6.1) |
In particular, we have
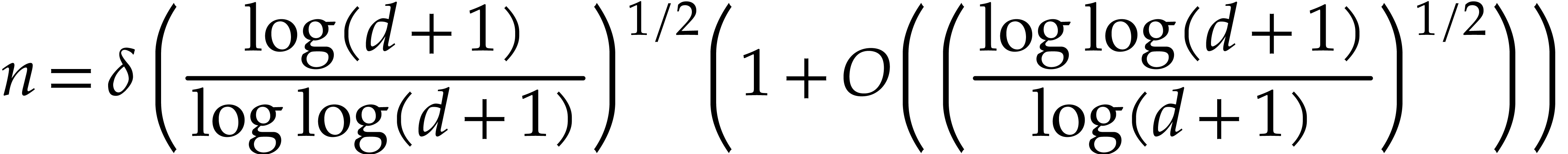
and
so that
tends to  for large values of . Now we define
for large values of . Now we define
so that 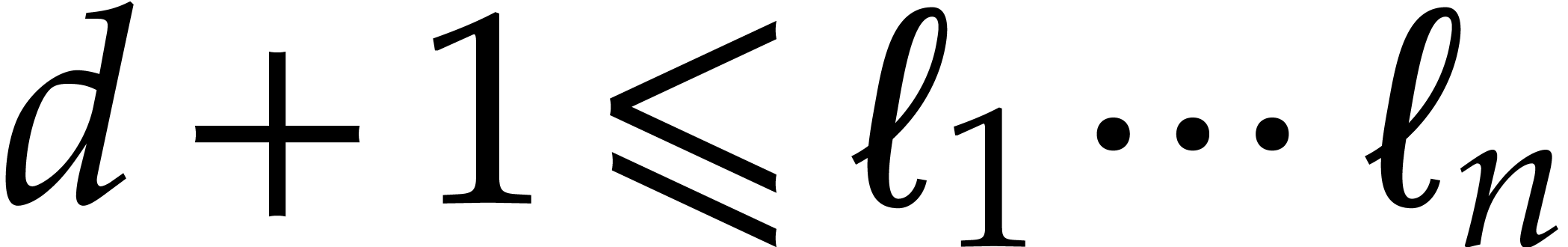 . If
is sufficiently large, then for all . In addition, from
. If
is sufficiently large, then for all . In addition, from
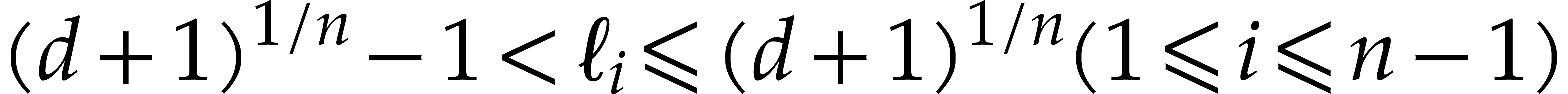
and

we deduce
 |
(6.3) |
We are now ready to state the modular composition algorithm.
The following proposition summarizes the cost in terms of arithmetic
operations in .
Proposition 6.1.
Algorithm 6.1 is correct and takes
 operations in
operations in  plus the
multi-point evaluation of step 5.
plus the
multi-point evaluation of step 5.
Proof. If is sufficiently
large, then for all . Step 3 performs
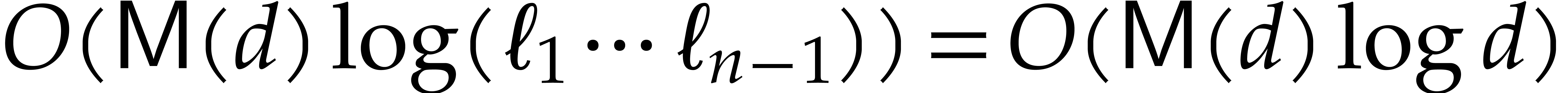
operations in in view of (6.3).
Steps 4 and 6 respectively take time 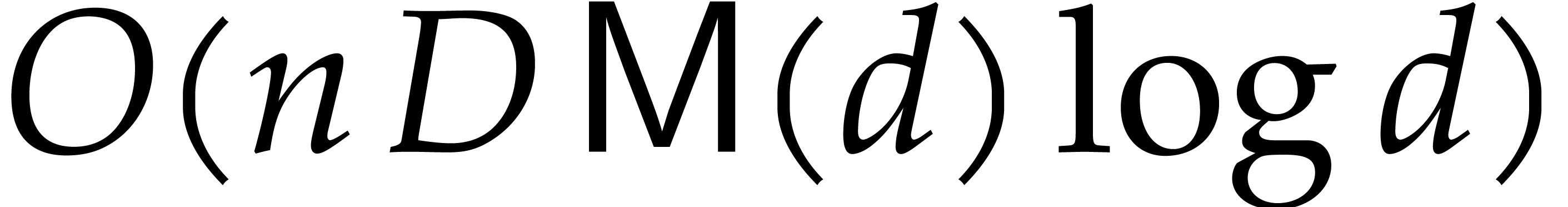 and
and 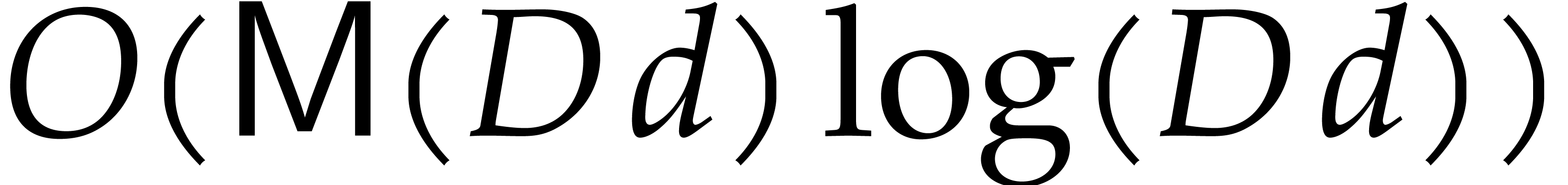 . Step 7 takes
. Step 7 takes 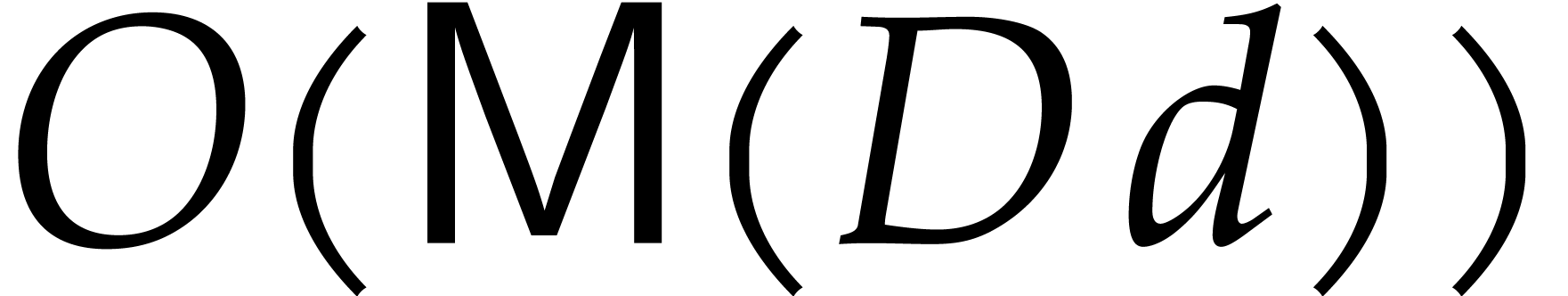 additional operations in .
additional operations in .
From now we return to the Turing machine model.
Proof. The integer can be
computed in time 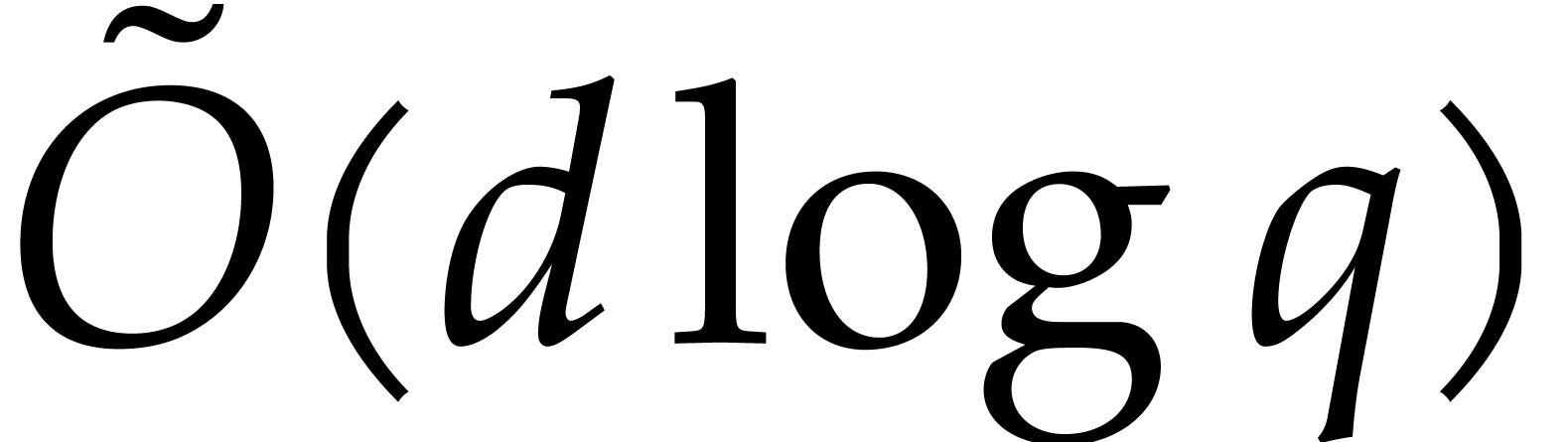 . Without
loss of generality we may suppose ,
so that
. Without
loss of generality we may suppose ,
so that 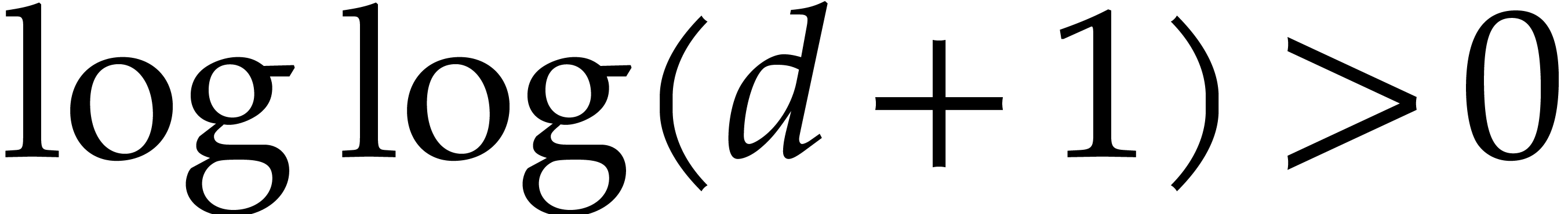 . Since
. Since 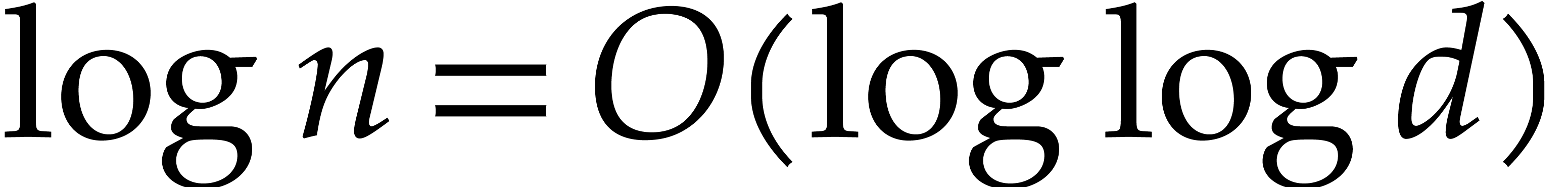 , Lemmas 2.15, 2.16
and 2.17 allow us to routinely compute
in time
, Lemmas 2.15, 2.16
and 2.17 allow us to routinely compute
in time 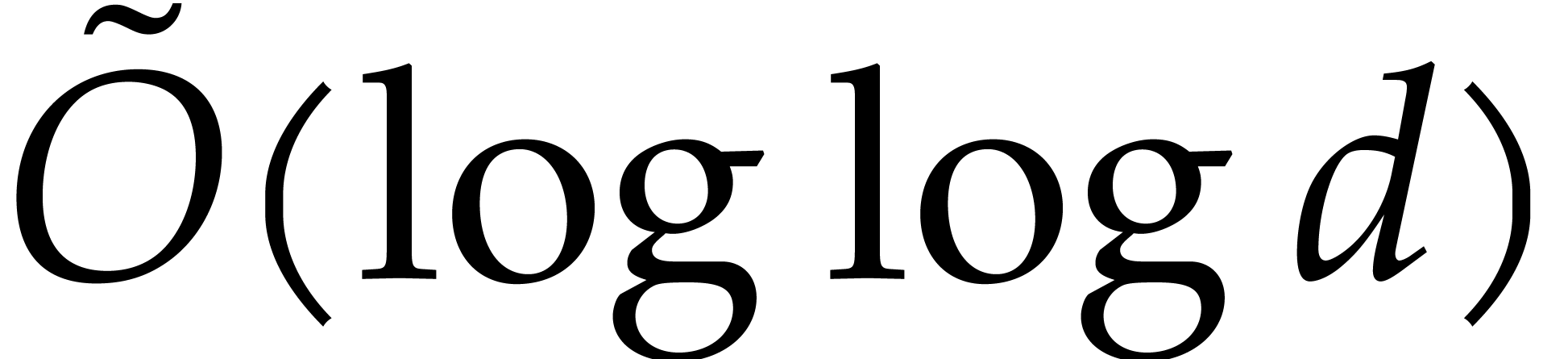 . We compute
. We compute  as the largest integer such that
as the largest integer such that 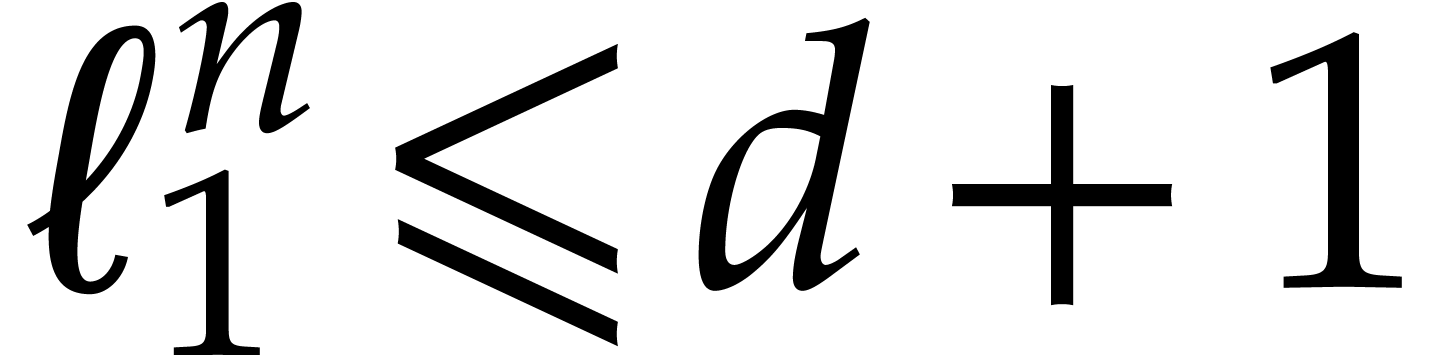 , in time
, in time 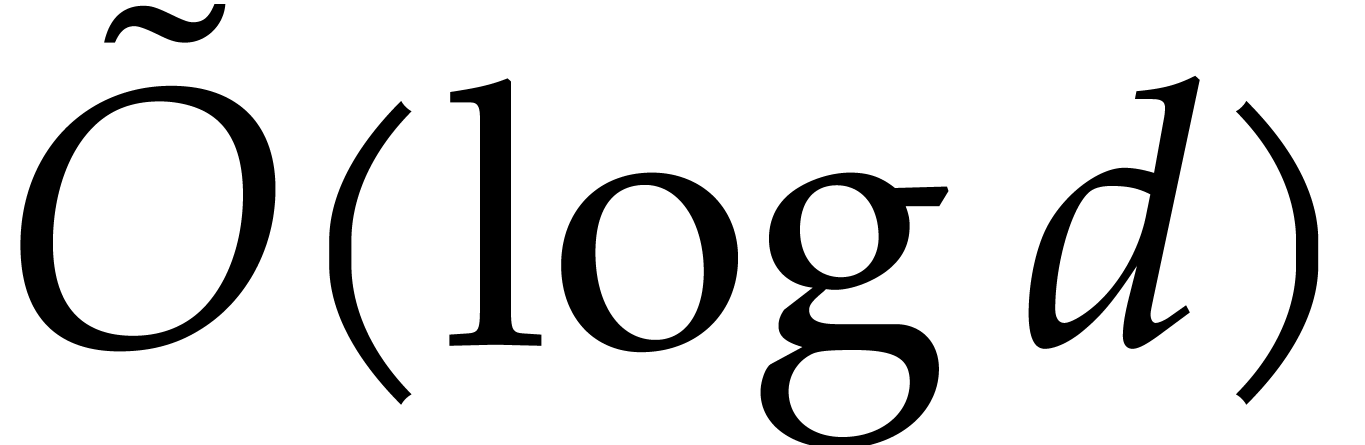 ,
and deduce with additional cost .
,
and deduce with additional cost .
The sum  may be bounded from above as follows:
may be bounded from above as follows:
From (6.2) we obtain
Since 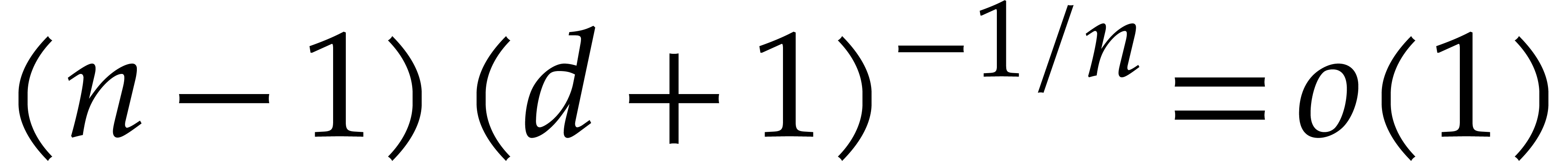 we deduce that
we deduce that
It follows that
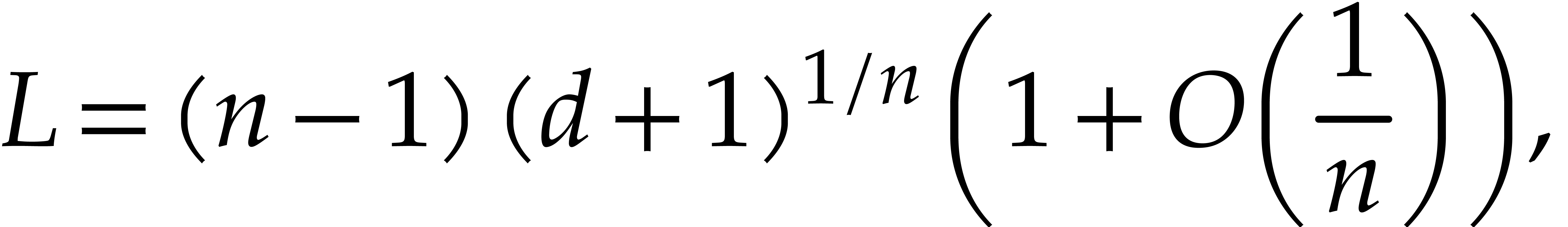 |
(6.4) |
whence
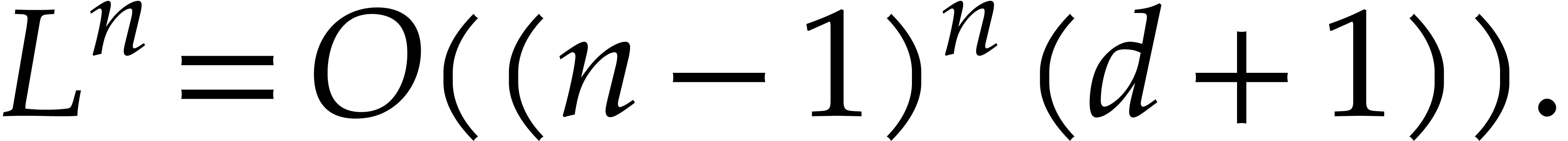 |
(6.5) |
We then obtain
and
which imply that 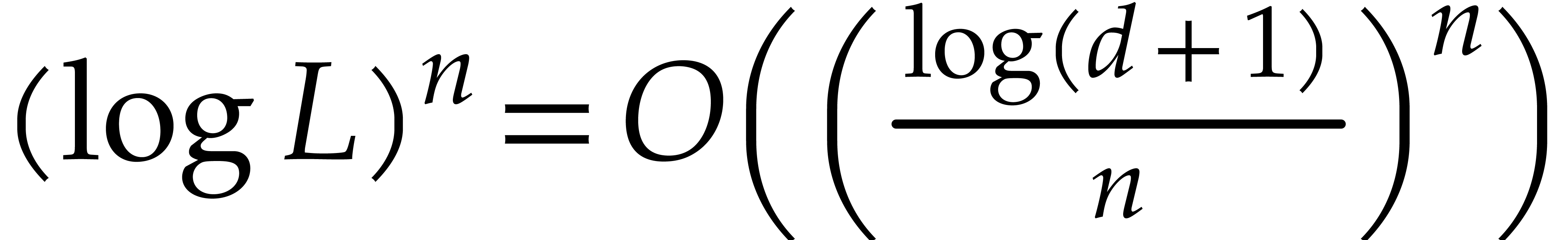 . Combined
with (6.5), this yields
. Combined
with (6.5), this yields
On the other hand, thanks to (6.4),
we have
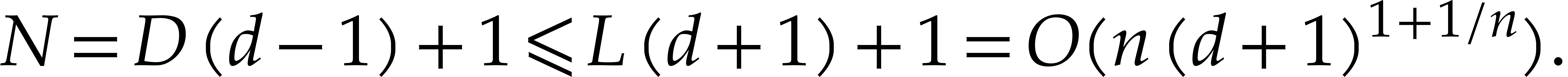 |
(6.6) |
First we handle the case when 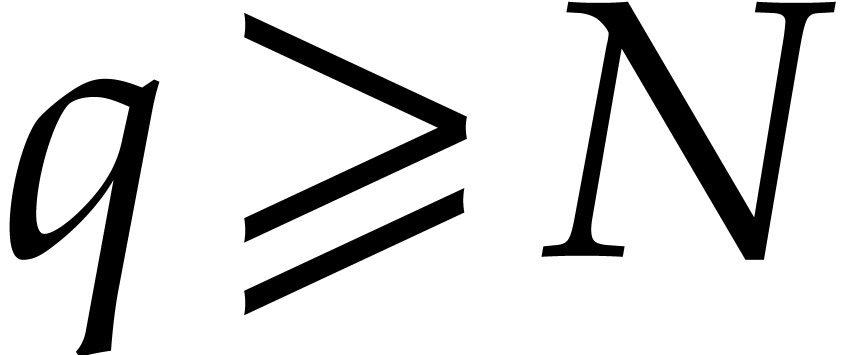 .
We may generate
.
We may generate  pairwise distinct
pairwise distinct 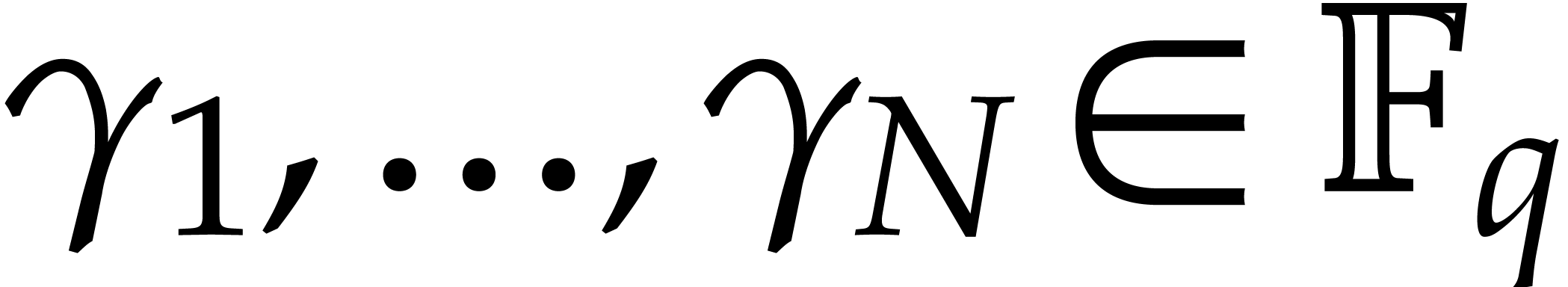 in time
in time 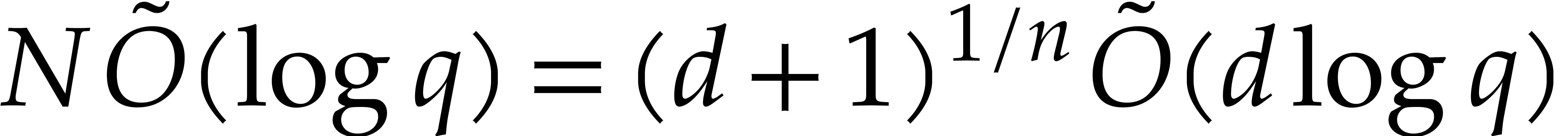 and use Algorithm 6.1.
Step 5 takes time
and use Algorithm 6.1.
Step 5 takes time
by Theorem 4.4. This bound simplifies into
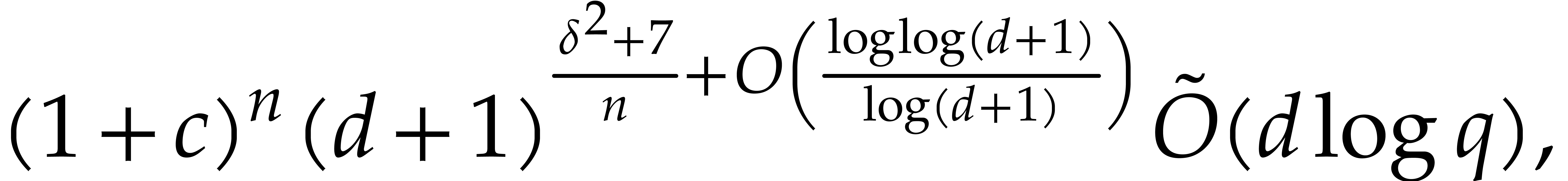
for some constant . Notice
that
so  minimizes
minimizes  .
Now
.
Now
so step 5 takes
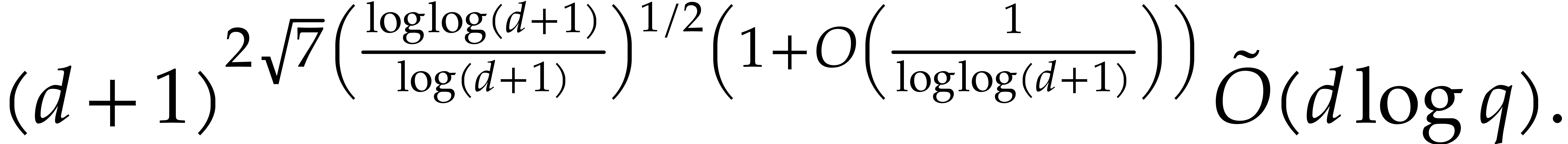
Step 2 of Algorithm 6.1 takes time 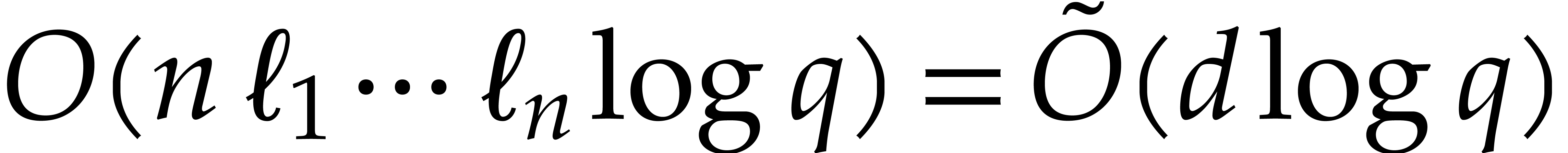 by Proposition 5.1 and (6.3).
The cost for other steps, as analyzed by Proposition 6.1,
amounts to
by Proposition 5.1 and (6.3).
The cost for other steps, as analyzed by Proposition 6.1,
amounts to
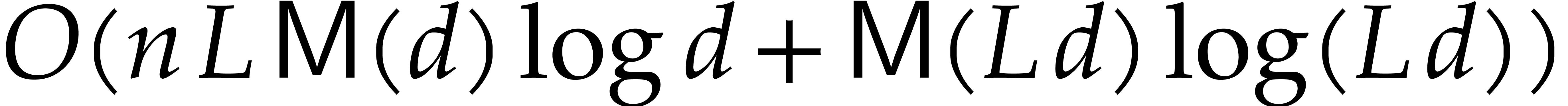
operations in , which
simplifies into 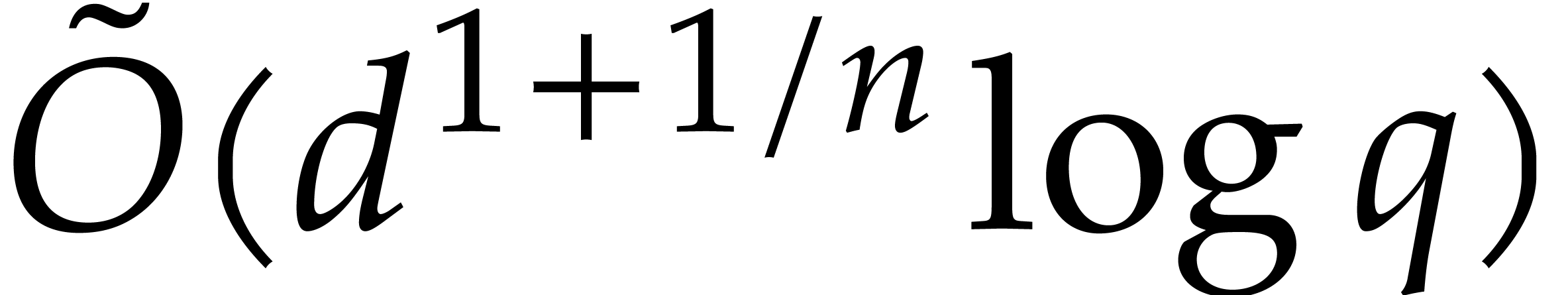 . We are done
with the case .
. We are done
with the case .
It remains to deal with the case 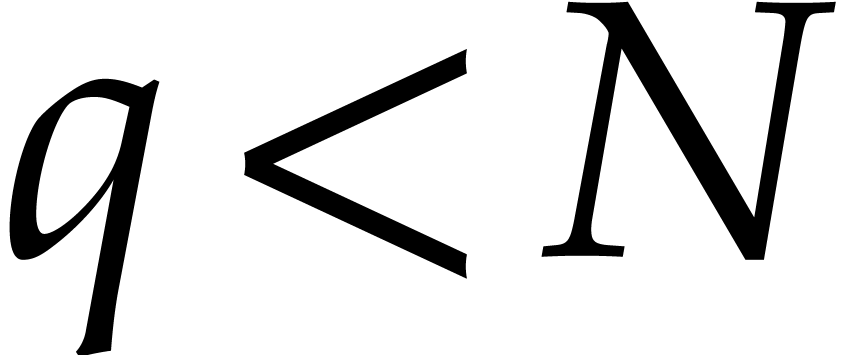 .
Basically we construct a suitable algebraic extension
.
Basically we construct a suitable algebraic extension 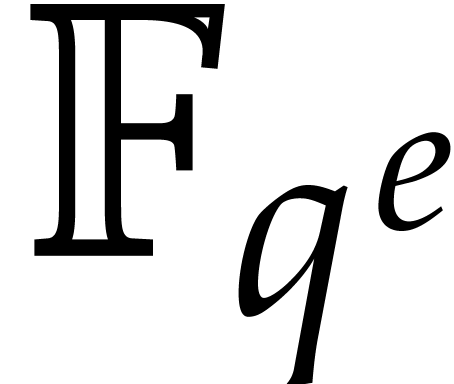 of and run Algorithm 6.1 over instead of .
In fact we need
of and run Algorithm 6.1 over instead of .
In fact we need 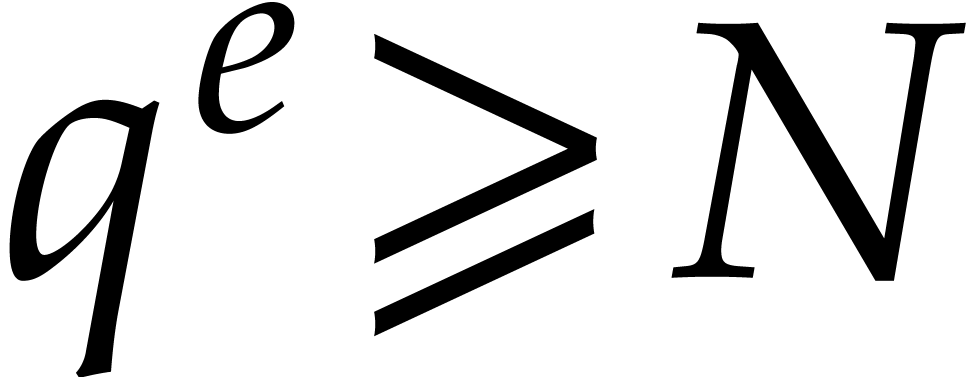 to hold. We compute the first
integer
to hold. We compute the first
integer  such that
such that 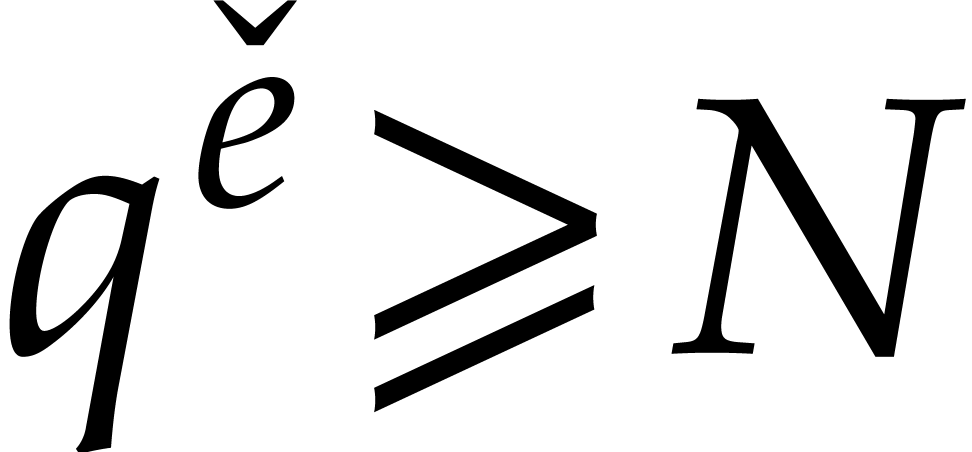 ,
in time
,
in time 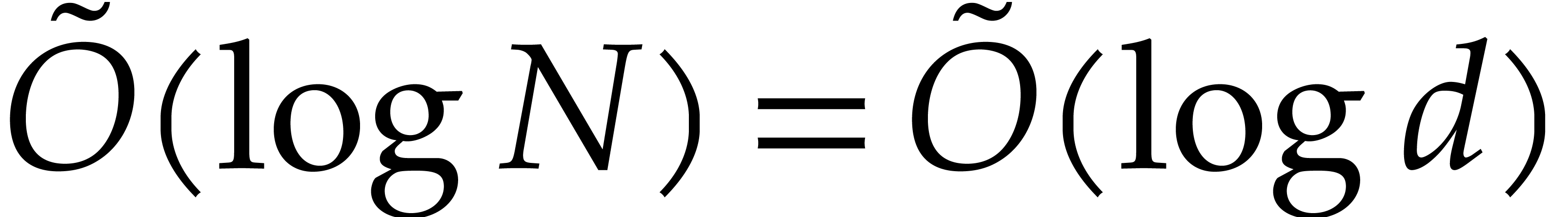 , so we have
, so we have 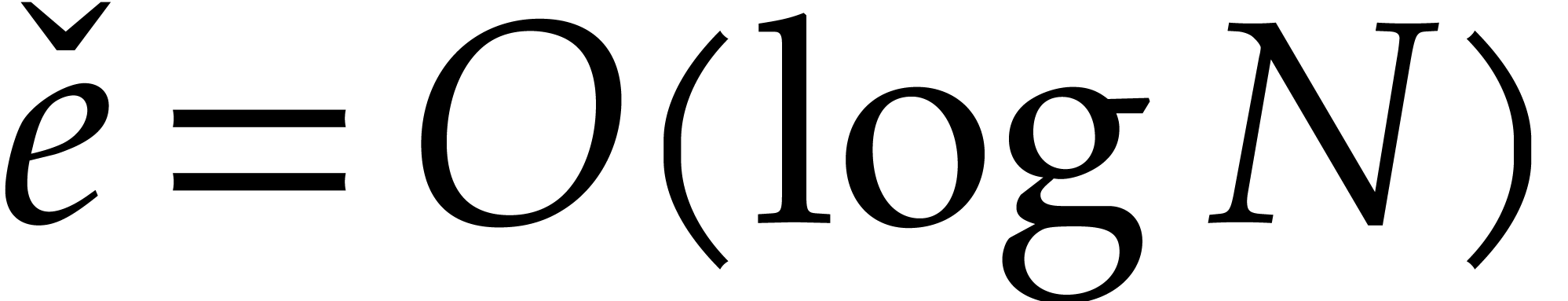 . We next compute the smallest
integer
. We next compute the smallest
integer  that its coprime with . Since
that its coprime with . Since 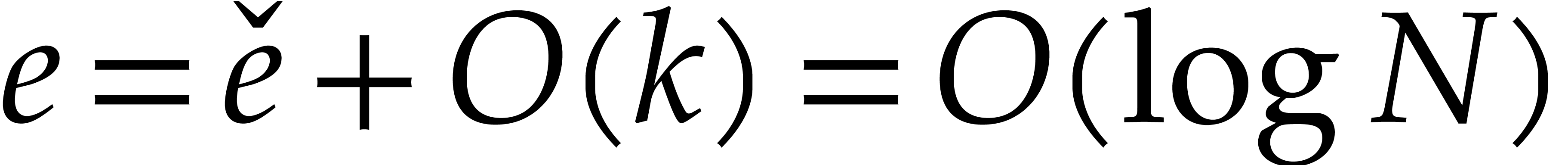 ,
this takes time
,
this takes time 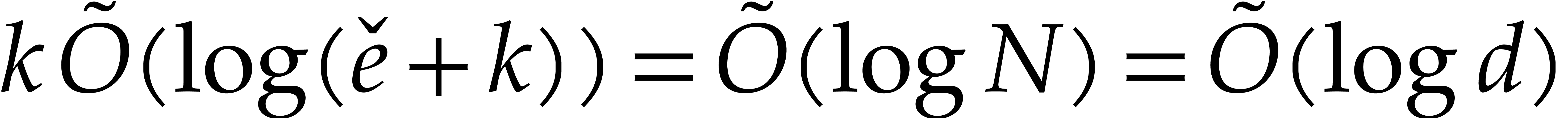 . We proceed
with the construction of an irreducible polynomial
. We proceed
with the construction of an irreducible polynomial 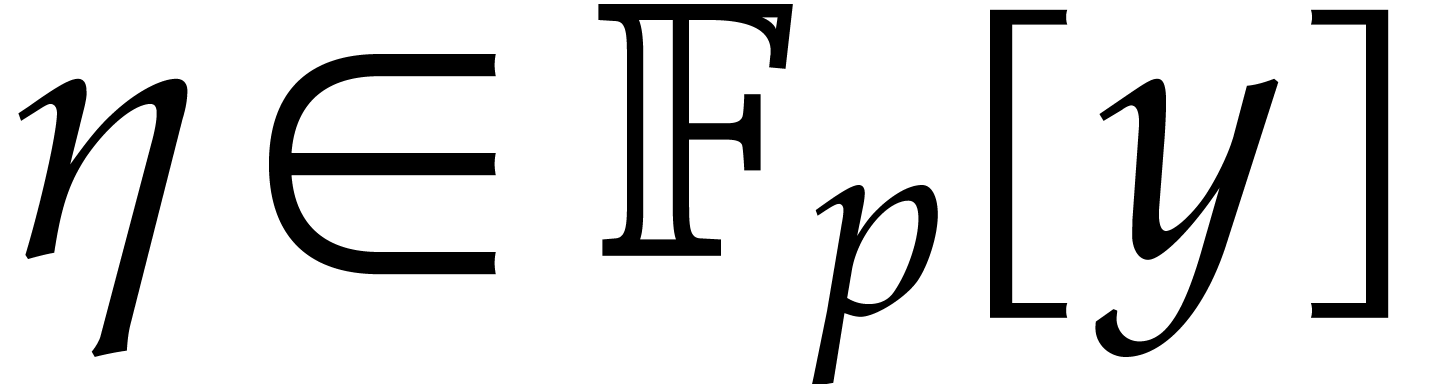 of degree
of degree  . Using [43,
Theorem 3.2], this can be done in time
. Using [43,
Theorem 3.2], this can be done in time
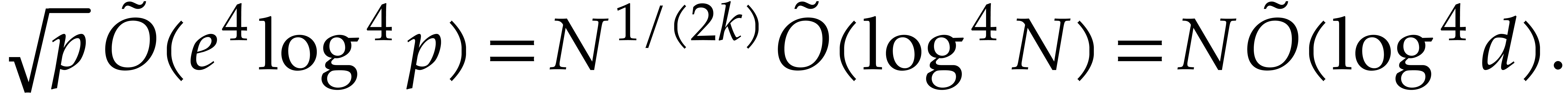
This includes the computation of the irreducible factorization of : the primes  can be computed in time
can be computed in time 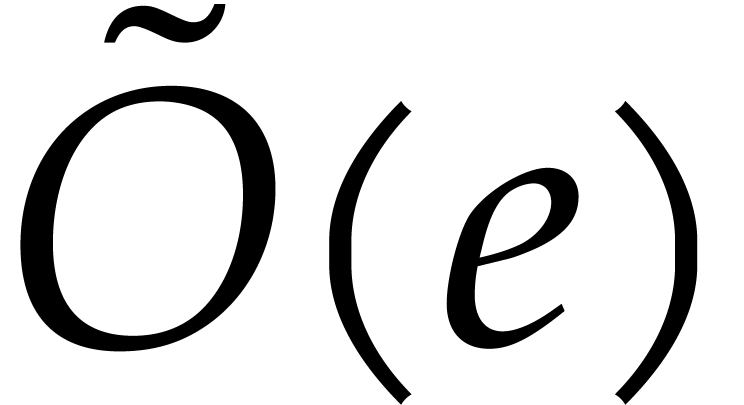 by Lemma 3.5,
so the prime factors of may be deduced in time
by Lemma 3.5,
so the prime factors of may be deduced in time
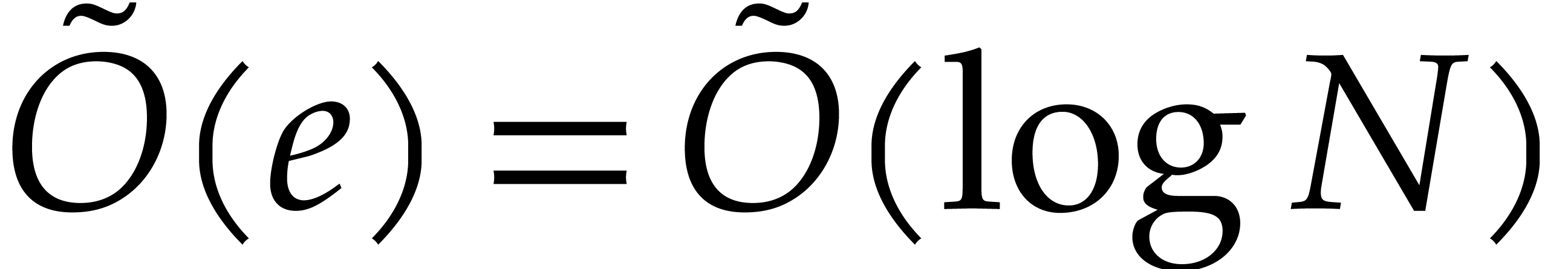 .
.
We let  represent the monic part of the resultant
represent the monic part of the resultant
 in
in  and we write
and we write 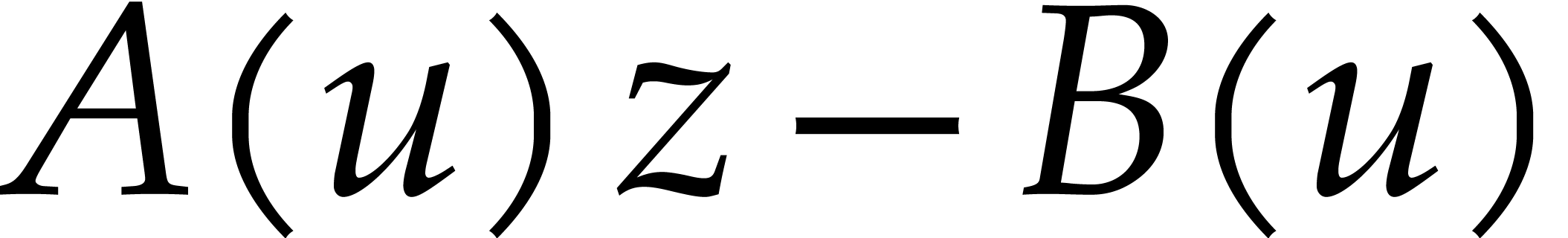 for the corresponding subresultant of degree
for the corresponding subresultant of degree  in . It is
well known that
in . It is
well known that  is irreducible and that is invertible modulo (see for
instance [43, Lemma 2.4]). Setting
is irreducible and that is invertible modulo (see for
instance [43, Lemma 2.4]). Setting 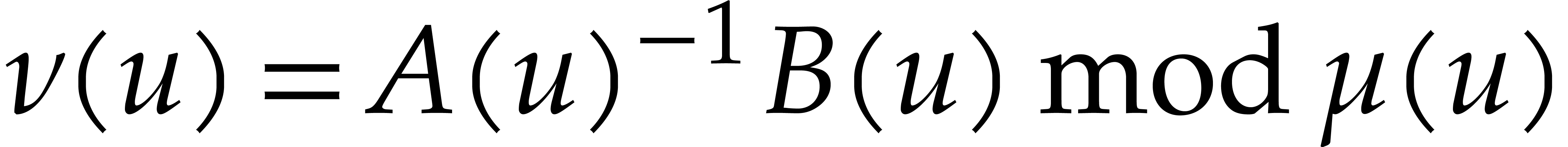 , we then have the following isomorphism:
, we then have the following isomorphism:
We identify 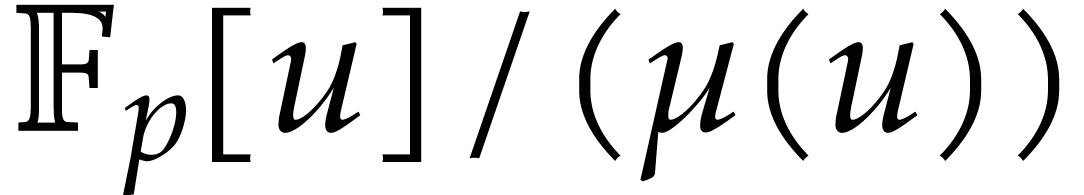 to
to  .
We may obtain and
.
We may obtain and  in
time
in
time 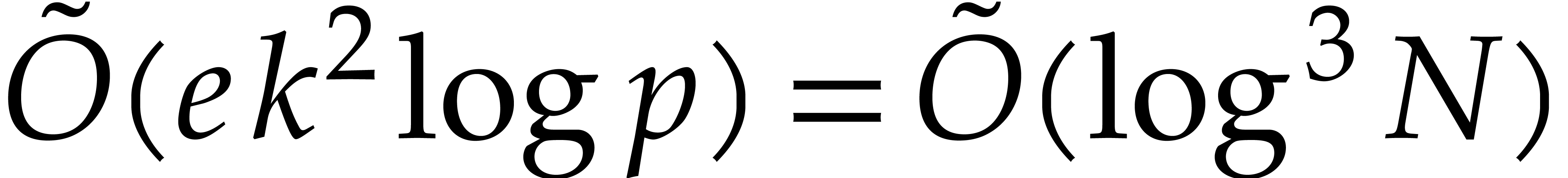 (see [35, Corollary 31] for
fast algorithms, but it would be sufficient here to appeal to naive
methods). An element of represented by
(see [35, Corollary 31] for
fast algorithms, but it would be sufficient here to appeal to naive
methods). An element of represented by  may be sent into in time
may be sent into in time 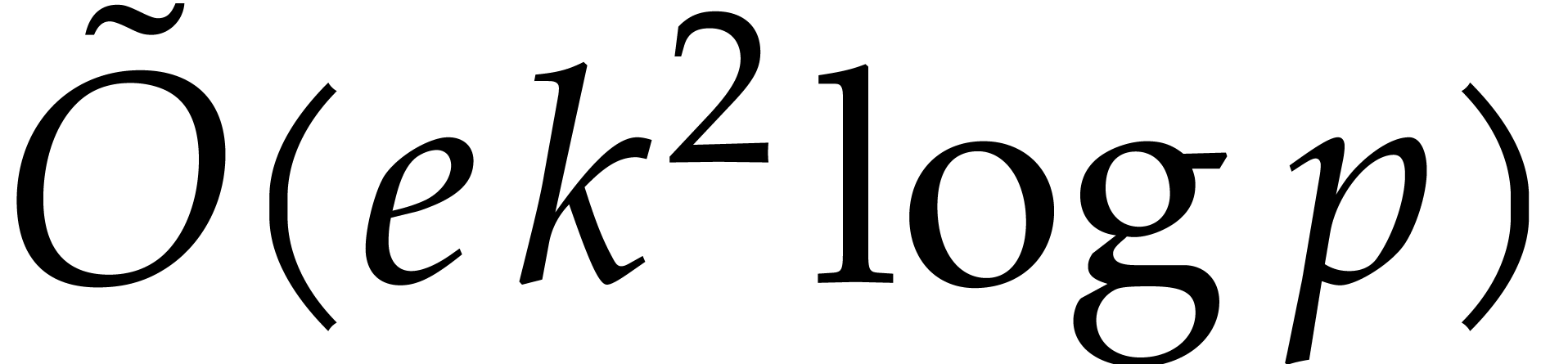 . For the backward conversion we
simply replace
. For the backward conversion we
simply replace  by
by  and
reduce modulo
and
reduce modulo  and
and  ,
which takes time
,
which takes time 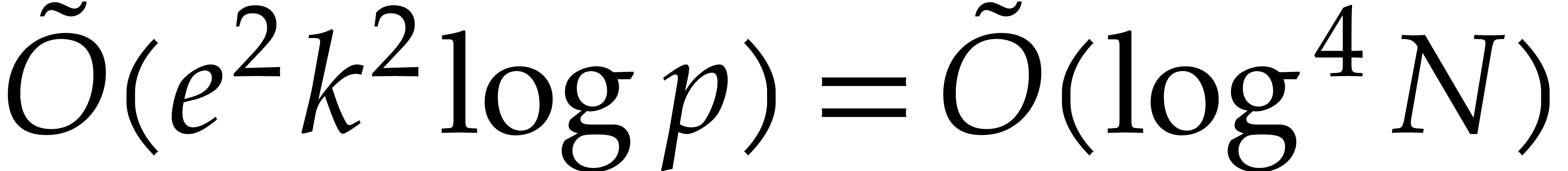 .
Consequently applying Algorithm 6.1 over
instead of only involves and additional overhead
of
.
Consequently applying Algorithm 6.1 over
instead of only involves and additional overhead
of 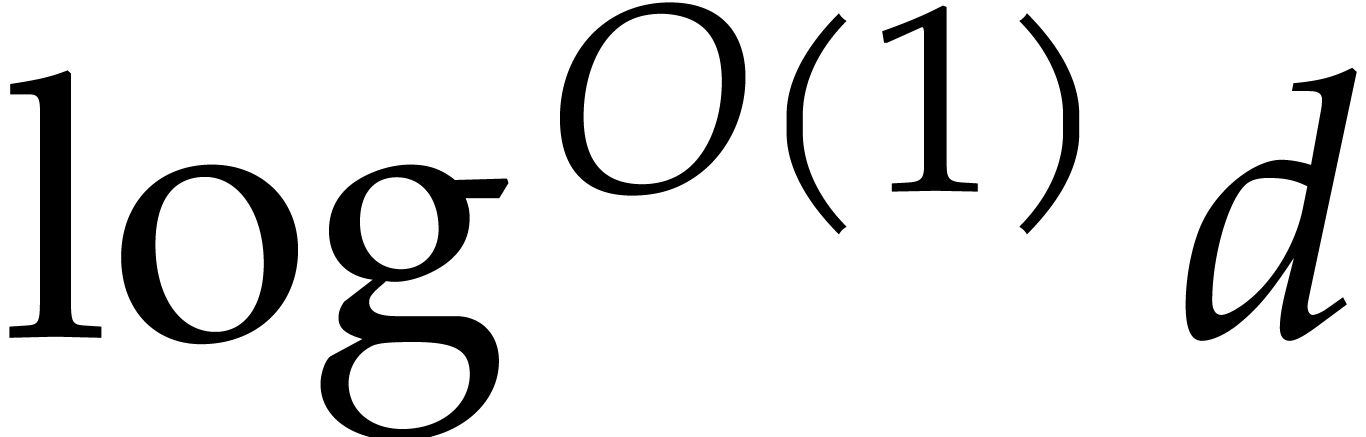 in the total complexity.
in the total complexity.
Remark 6.3.
Instead of relying on Theorem 4.4 in step 5, one
might wonder whether it is interesting to consider Theorem 5.5.
It turns out that the same complexity analysis applies with  , with a similar complexity result.
, with a similar complexity result.
Remark 6.4.
In practice, the case when at the end of
the proof can be handled more efficiently by constructing irreducible
polynomials by means of a faster, although probabilistic Las Vegas
algorithm; see [13, chapter 14] and [43] for
instance. It is also worth it to build an extension of
of smooth degree with 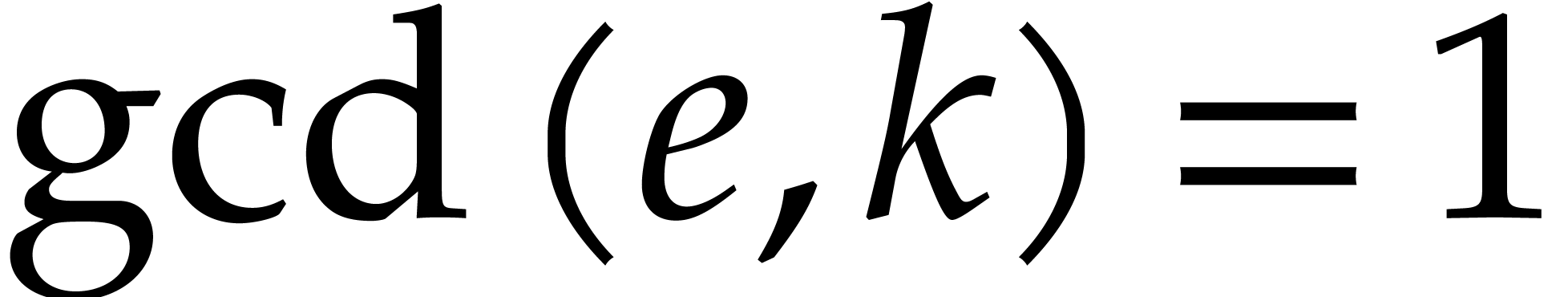 , which allows the isomorphism (6.7) to
be computed more efficiently [27].
, which allows the isomorphism (6.7) to
be computed more efficiently [27].
7.Fields of small positive
characteristic
For the case when is a field of small
characteristic , Kedlaya and
Umans also designed an algebraic algorithm for fast multi-point
evaluation [34, Theorem 6.3]. This algorithm turns out to
be somewhat more efficient than those from the previous sections. In the
present section, we adapt their techniques and prove a complexity bound
in terms of the total degree instead of the partial degrees. We also
refine their complexity estimates for multi-point evaluation and modular
composition.
The base field is written with
and prime; we assume it is explicitly given as
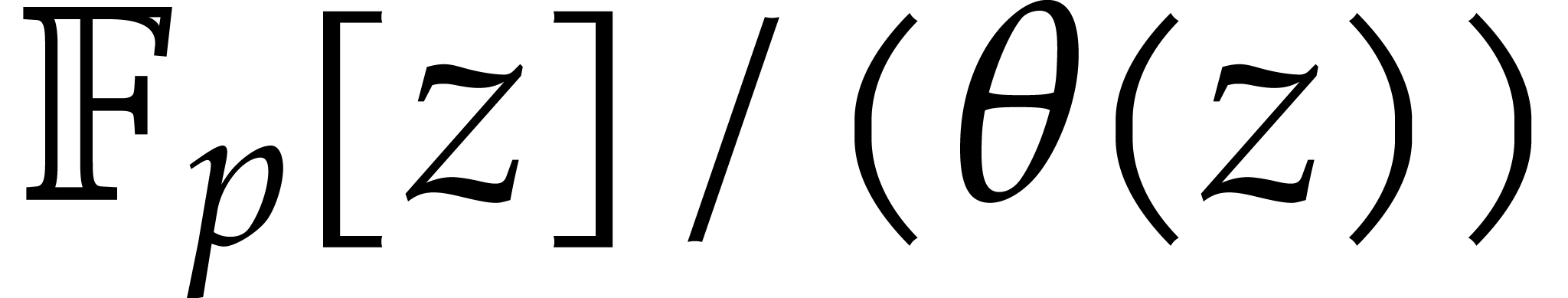 with monic and
irreducible of degree . We
let
with monic and
irreducible of degree . We
let  represent a constant such that two
represent a constant such that two  matrices can be multiplied with
matrices can be multiplied with 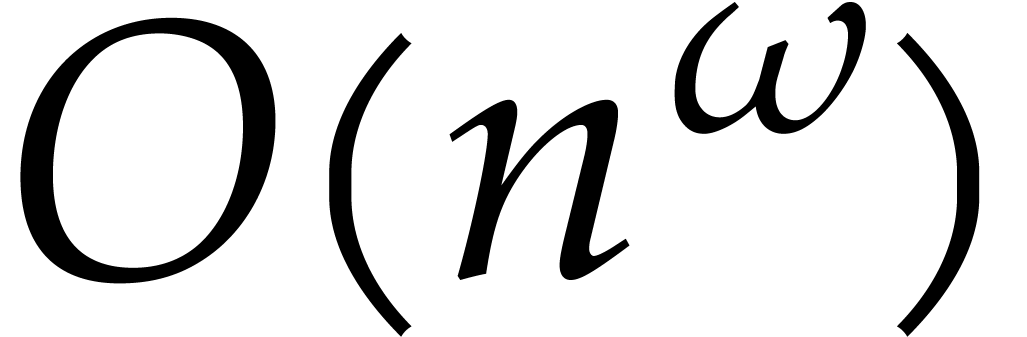 ring operations.
ring operations.
7.1.Multi-point evaluation
We begin with -th root
extractions in . It is well
known that such root extractions reduce to linear algebra via
the so-called Pietr-Berlekamp matrix of the isomorphism  of in the canonical basis
of in the canonical basis  . Once the inverse of this matrix is known, each
root extraction takes
. Once the inverse of this matrix is known, each
root extraction takes 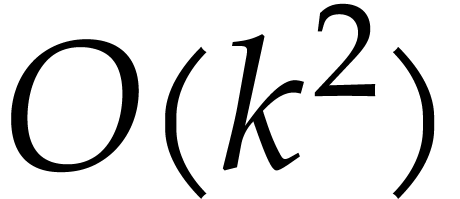 ring operations in
ring operations in  , and root
extractions take
, and root
extractions take 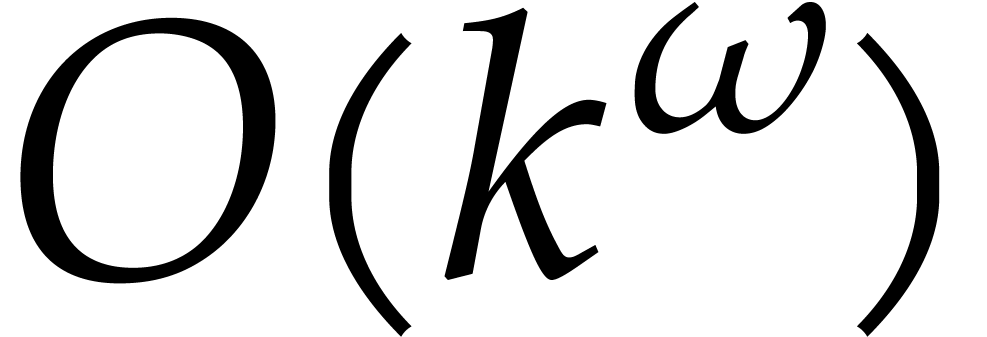 ring operations in . We could use this strategy in this section
but it would involve an extra factor
ring operations in . We could use this strategy in this section
but it would involve an extra factor 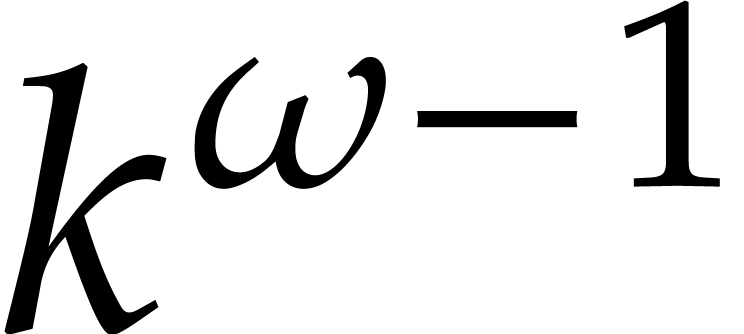 in our
complexity estimates. Instead, since we focus on the case when remains small, it is worth using the following algorithm,
borrowed from [34, Theorem 6.1] and originating from [37].
in our
complexity estimates. Instead, since we focus on the case when remains small, it is worth using the following algorithm,
borrowed from [34, Theorem 6.1] and originating from [37].
Proof. The identity 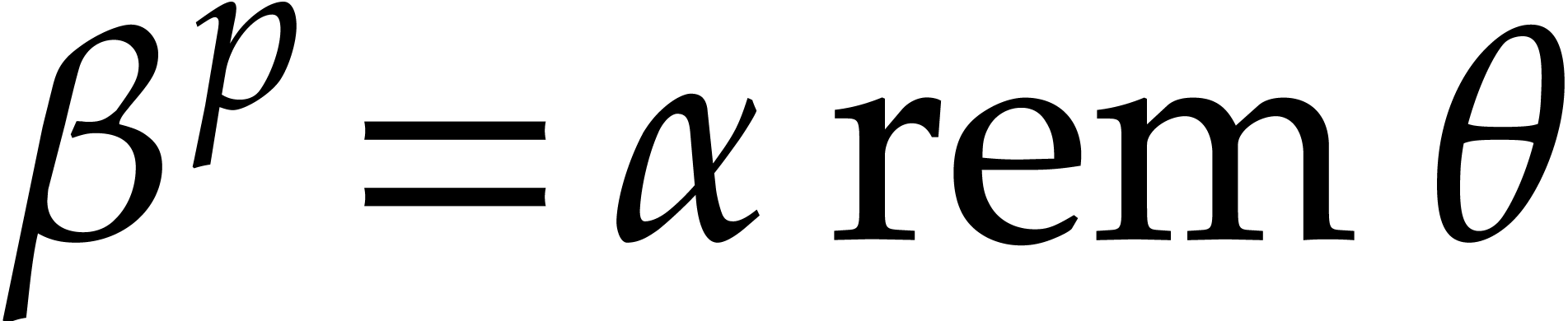 is
equivalent to
is
equivalent to 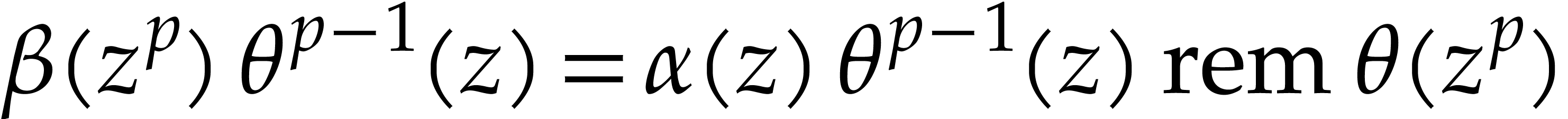 . For all
. For all  we have
we have 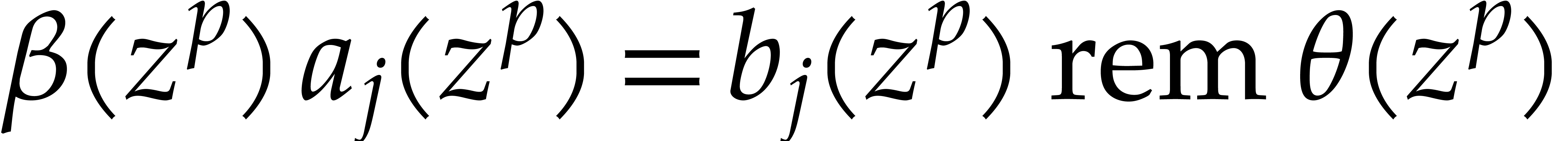 and thus
and thus 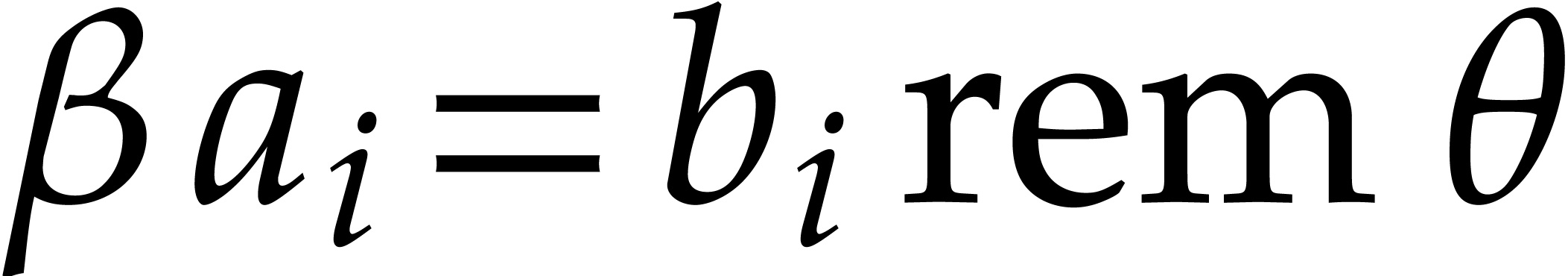 . Since is irreducible,
. Since is irreducible,
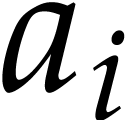 is invertible modulo . We are done with the correctness.
is invertible modulo . We are done with the correctness.
The computations in steps and 2 take 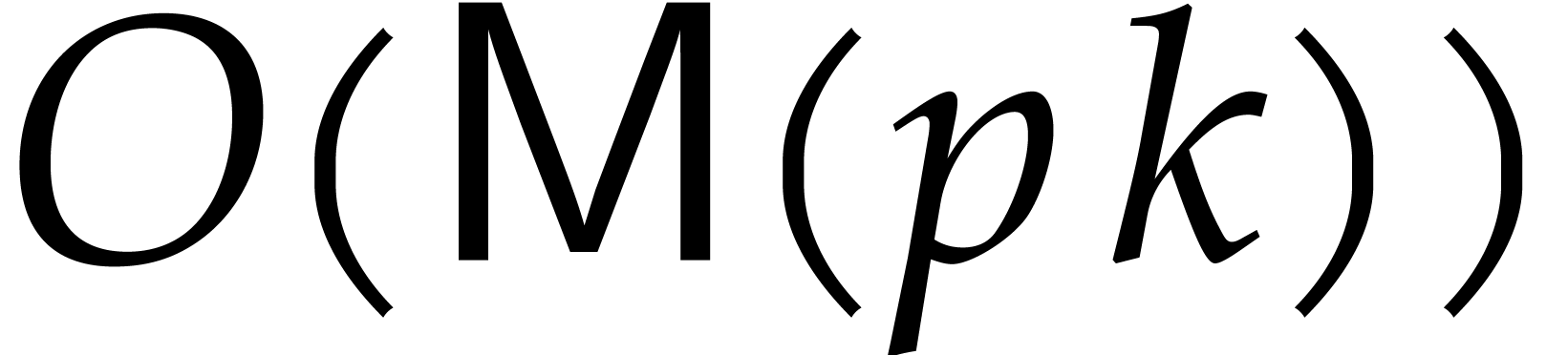 ring operations in .
Step 3 requires
ring operations in .
Step 3 requires 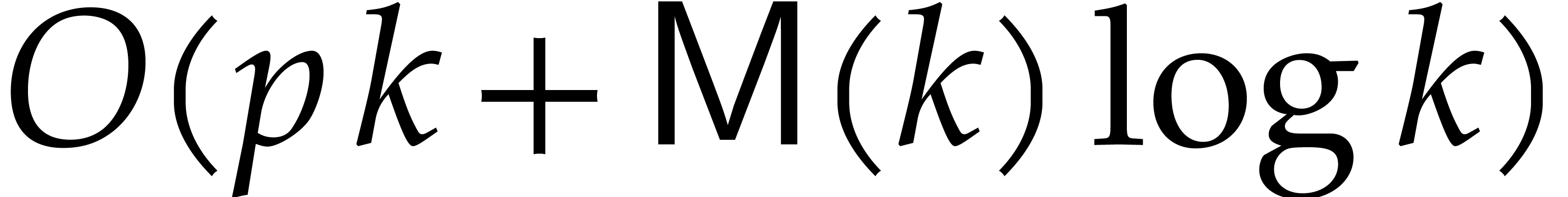 ring operations in plus
ring operations in plus 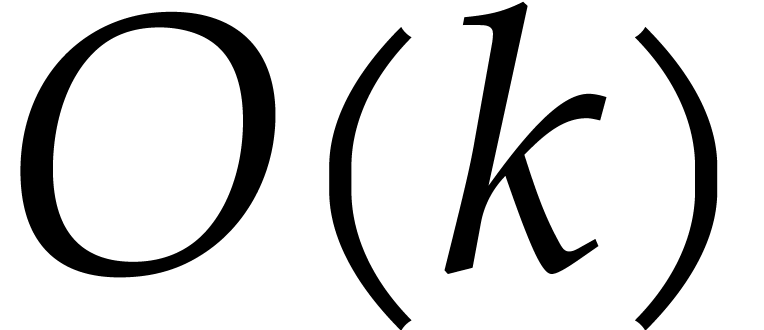 inversions in by using fast extended gcds.
inversions in by using fast extended gcds.
The next algorithm, borrowed from [34, section 6], performs
multivariate multi-point evaluations by reduction to the univariate
case.
Proposition 7.2.
Algorithm 7.2 is correct. If , then it takes time
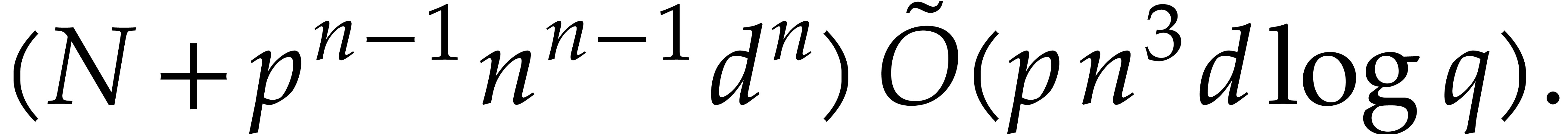
Proof. For  and
and  we write
we write 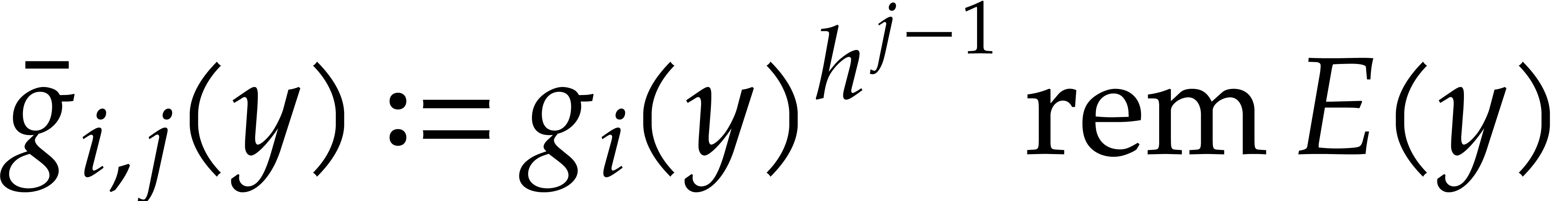 . Let
. Let
 represent the endomorphism of
represent the endomorphism of 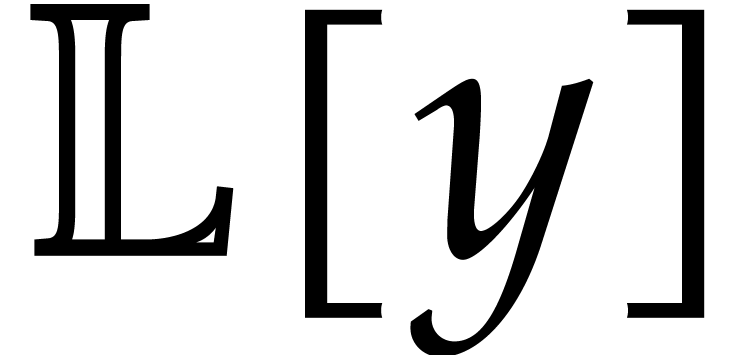 that rises coefficients to the
that rises coefficients to the  -th
power. Then
-th
power. Then
In particular 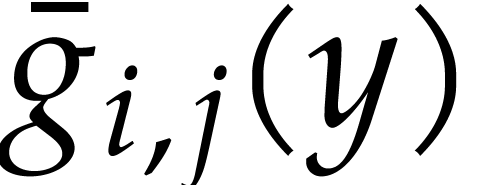 has degree
has degree 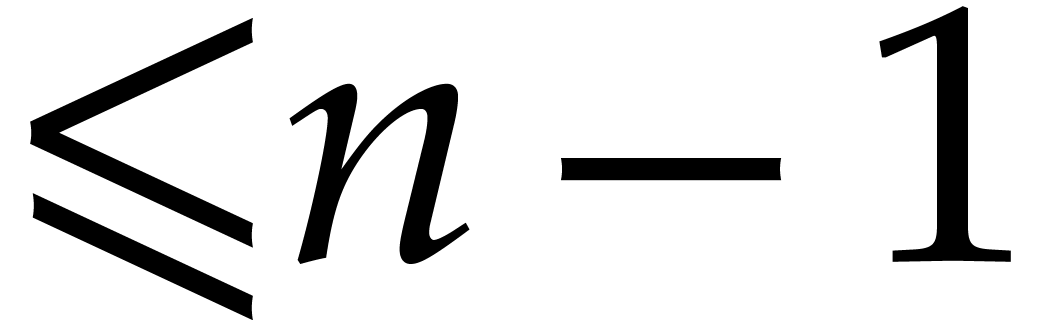 whence
whence 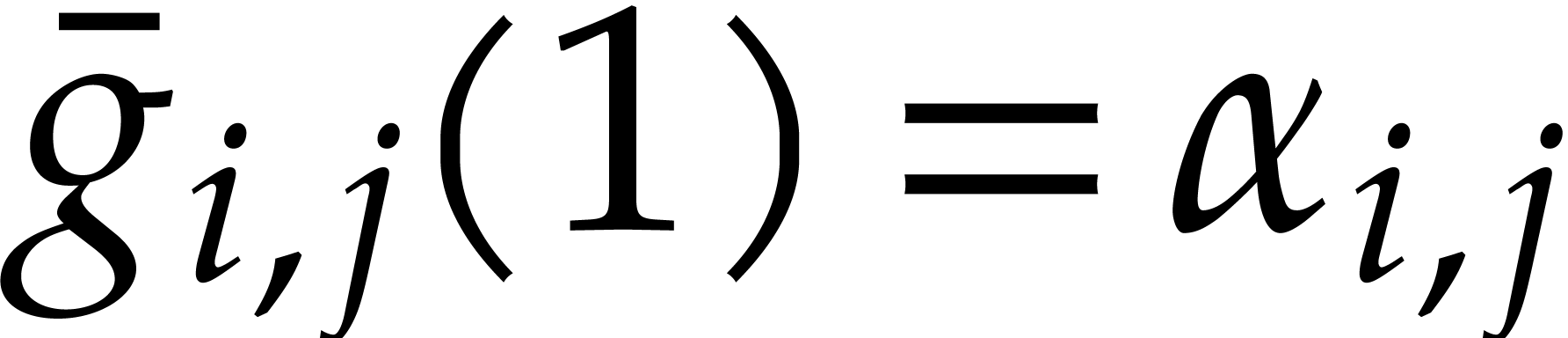 , by the assumption
, by the assumption
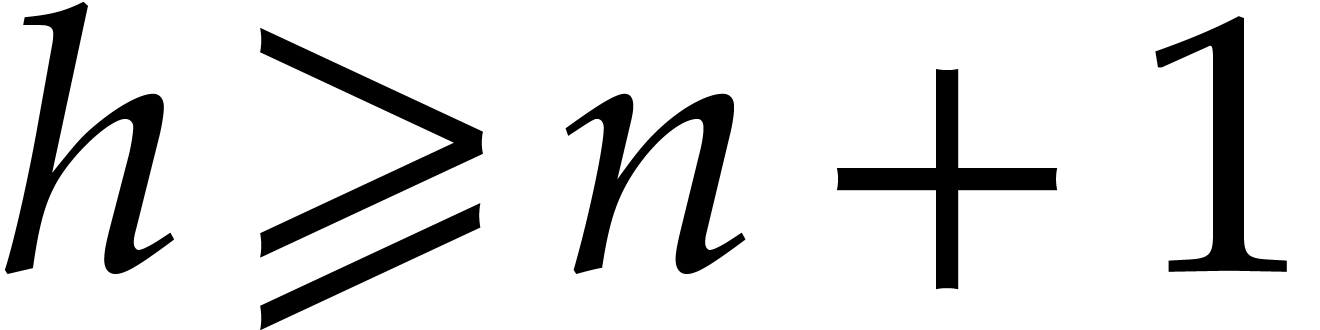 . Now
. Now
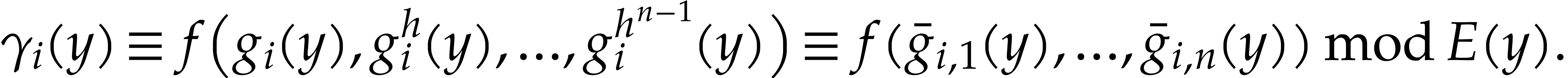
Since 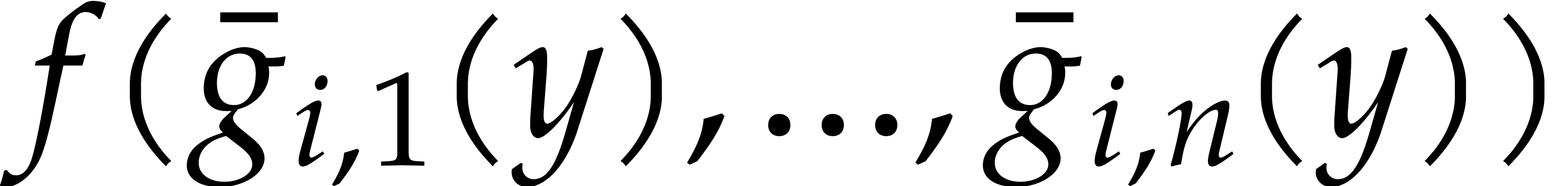 has degree
has degree 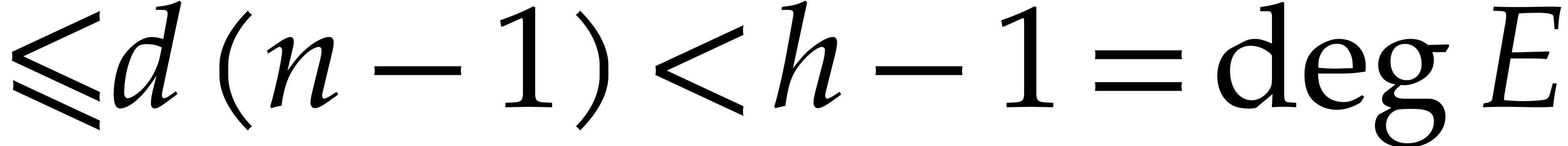 ,
we deduce that it coincides with
,
we deduce that it coincides with  ,
whence
,
whence 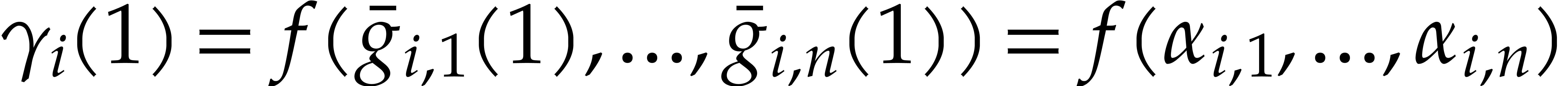 . We are done with the
correctness.
. We are done with the
correctness.
Step 1 takes time
By Lemmas 2.6 and 2.8. Steps 2 and 4 take
negligible time.
By construction, we have
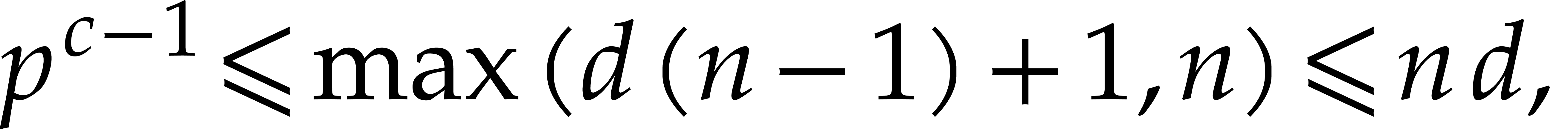
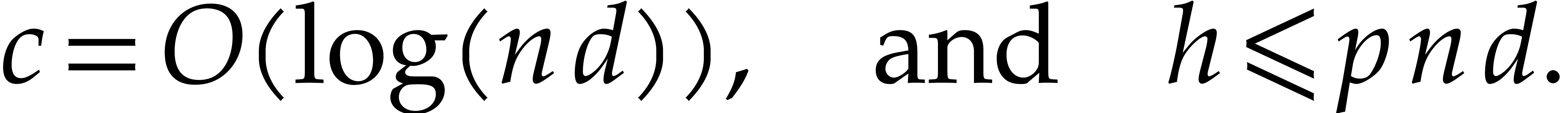 |
(7.1) |
In step 3, the construction of may be done
deterministically in time
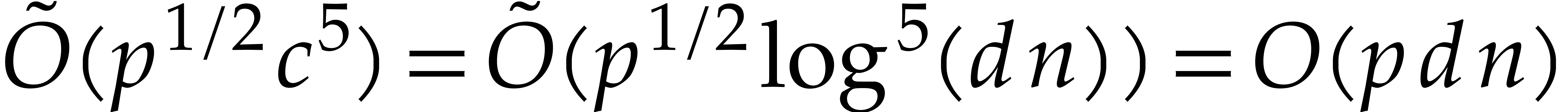
by means of [43, Theorem 3.2] (this includes the
computation of the irreducible factorization of ).
Now [44, Theorem 1.1] provides us with a universal constant
such that there exists a monic polynomial  of degree
of degree  with
with 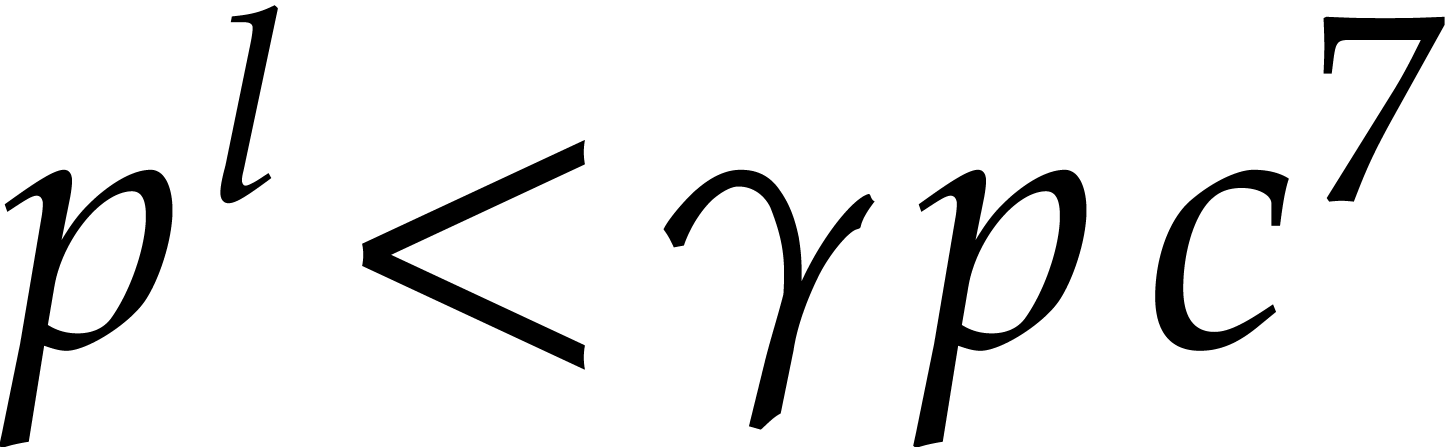 , for which
, for which 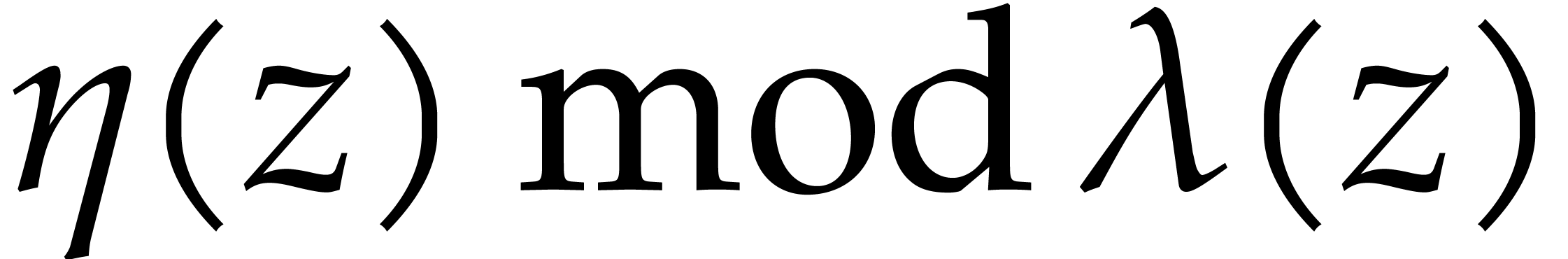 is a
primitive element. It thus suffices to enumerate all the monic
polynomials of increasing degrees
is a
primitive element. It thus suffices to enumerate all the monic
polynomials of increasing degrees  and to stop as
soon as one discovers a primitive one. The loop terminates after testing
and to stop as
soon as one discovers a primitive one. The loop terminates after testing
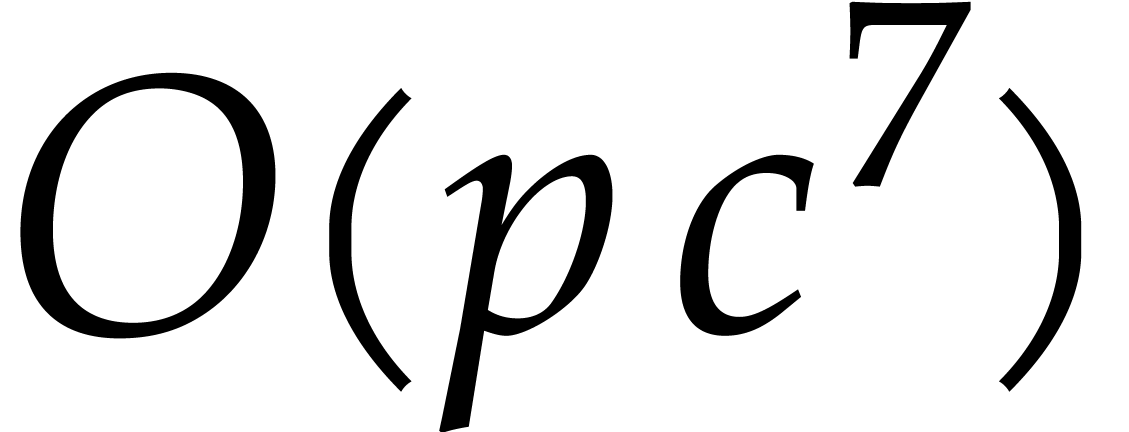 candidates.
candidates.
Verifying that a candidate polynomial  is a
primitive element for the multiplicative group of
is a
primitive element for the multiplicative group of 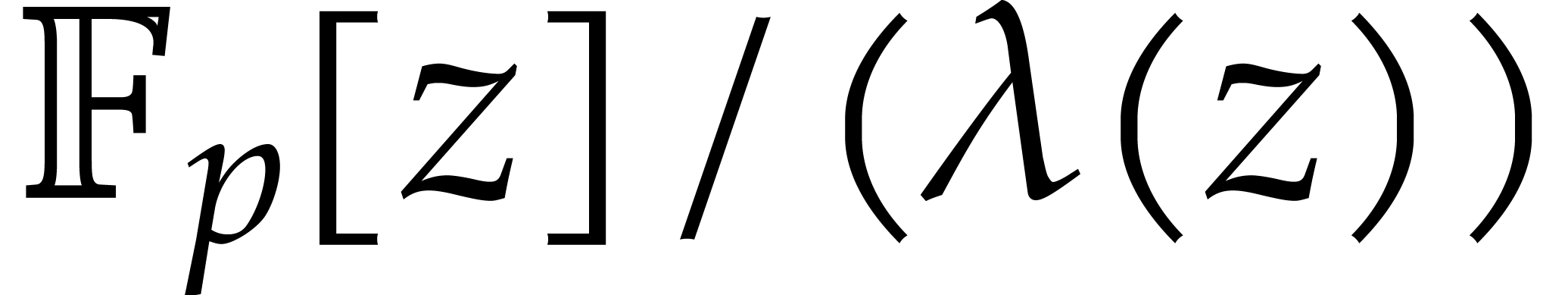 can be done as follows. We first compute the irreducible factorization
of
can be done as follows. We first compute the irreducible factorization
of 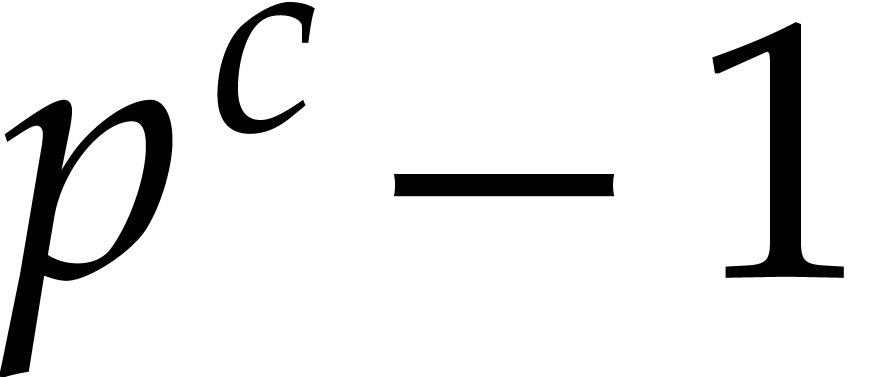 in time
in time 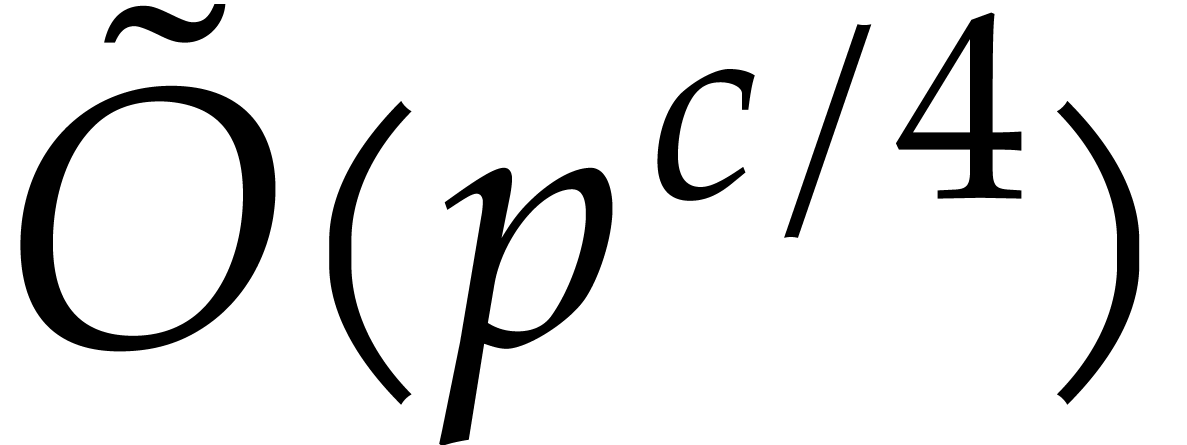 (see for
instance [11, Theorem 1.1]). We next verify that
(see for
instance [11, Theorem 1.1]). We next verify that
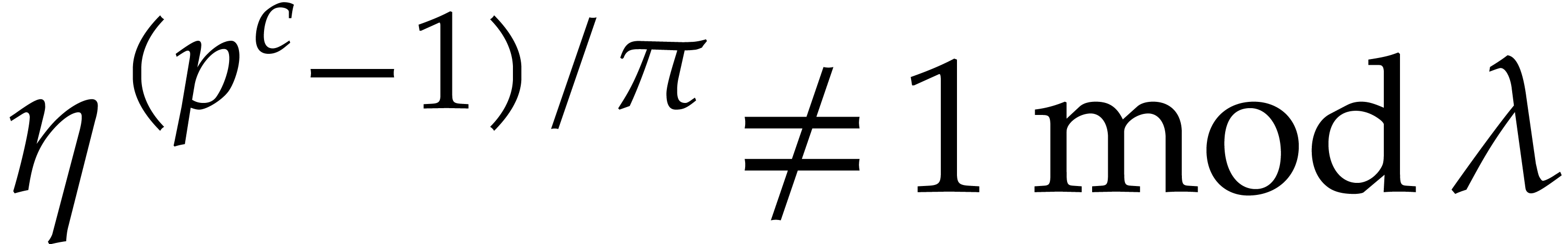
for each prime divisor of
in time 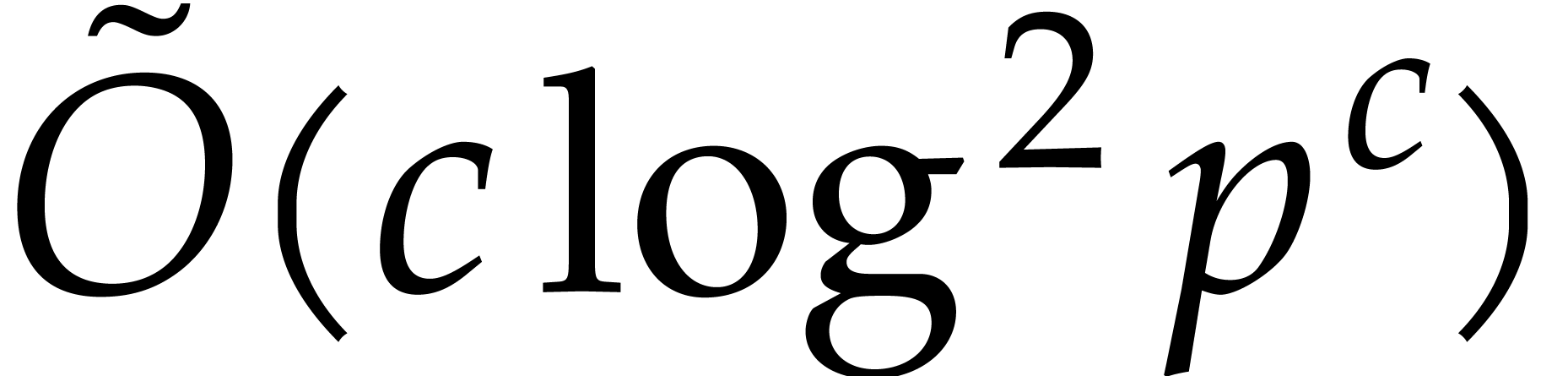 . Altogether, this
allows us to compute deterministically in time
. Altogether, this
allows us to compute deterministically in time
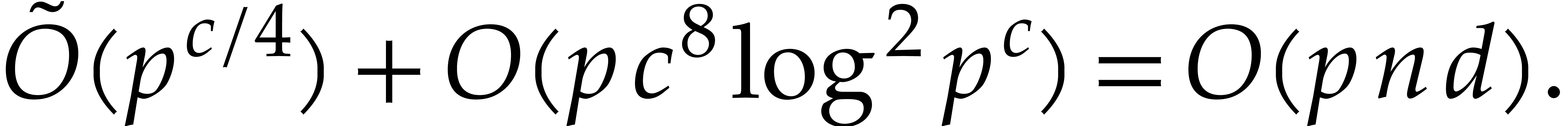
Now each step 5.a requires extractions of  -th roots in . In total, they take time
-th roots in . In total, they take time
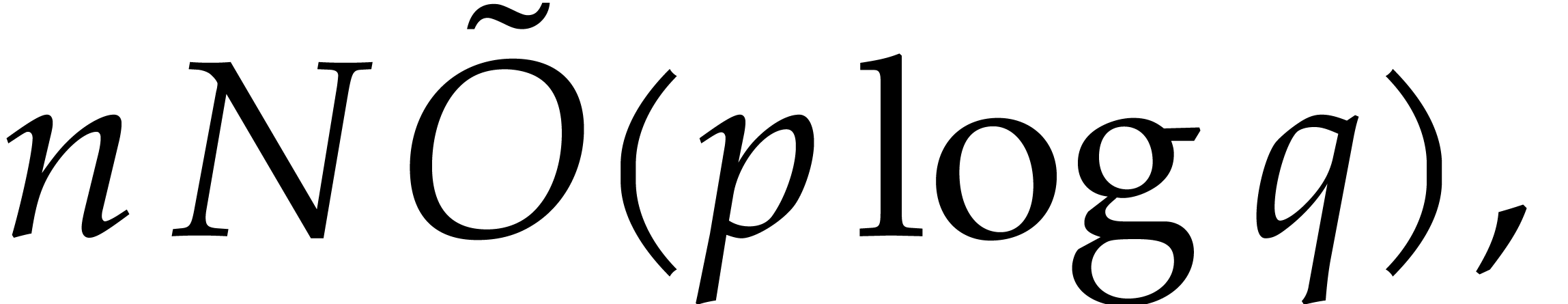
by Proposition 7.1. The total cost of step 5.b is 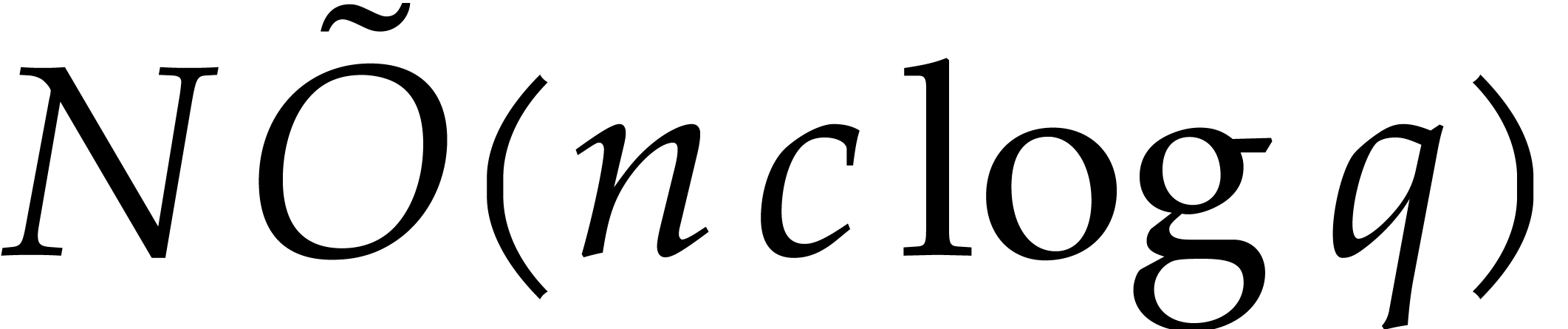 .
.
Since the partial degrees of are  and since
and since  , the
polynomial
, the
polynomial  is the Kronecker substitution
is the Kronecker substitution 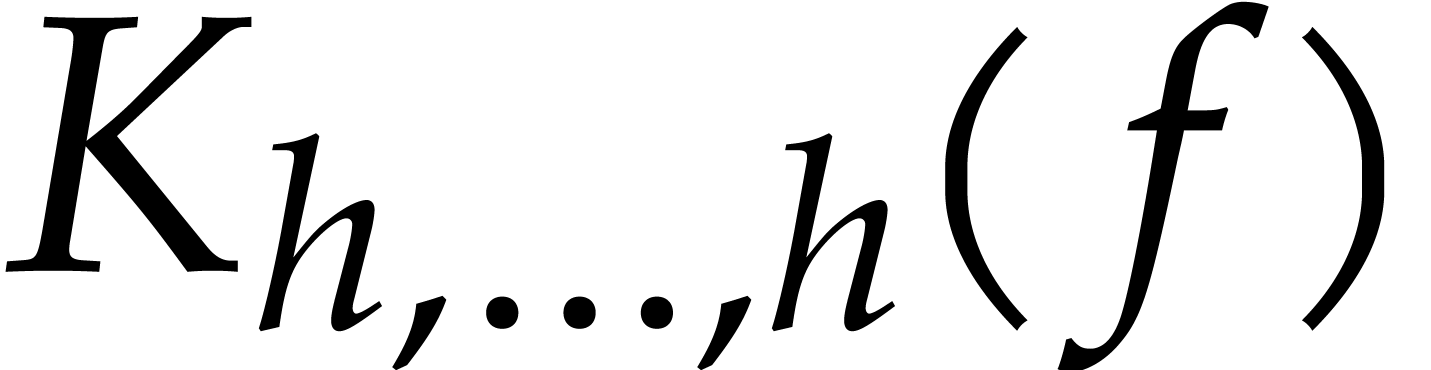 , following the notation of section
5.1. The univariate polynomial in
step 6 may be obtained in time
, following the notation of section
5.1. The univariate polynomial in
step 6 may be obtained in time
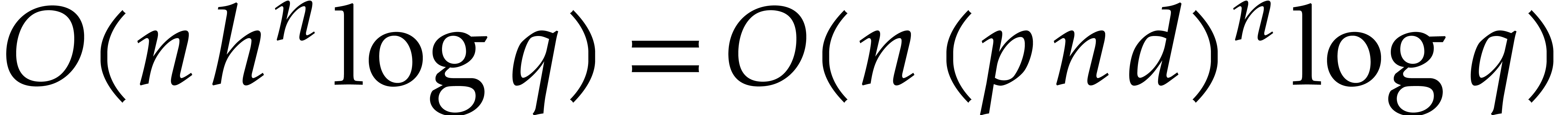
by Proposition 5.2, thanks to (7.1)
and the assumption that .
Then the simultaneous evaluation of at points in  takes
takes
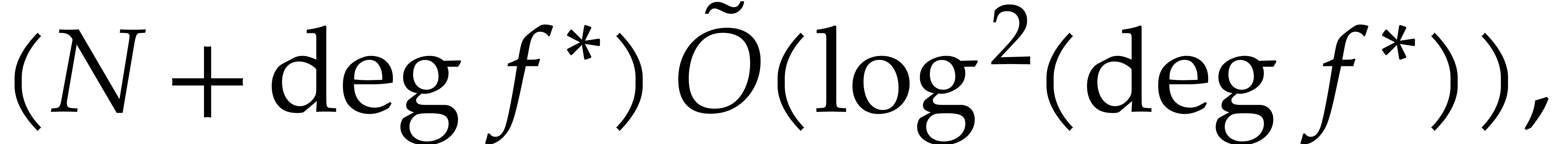
operations in  which corresponds to time
which corresponds to time
|
|
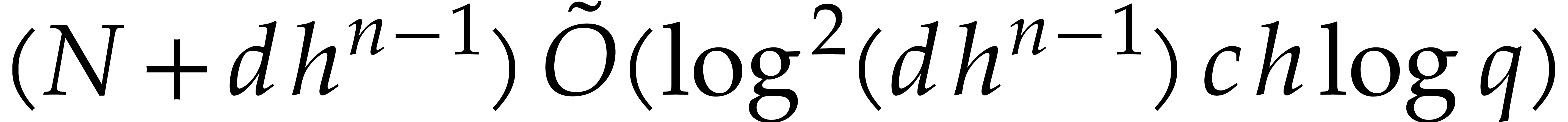 |
(since deg
f∗⩽d*hn-1) |
|
 |
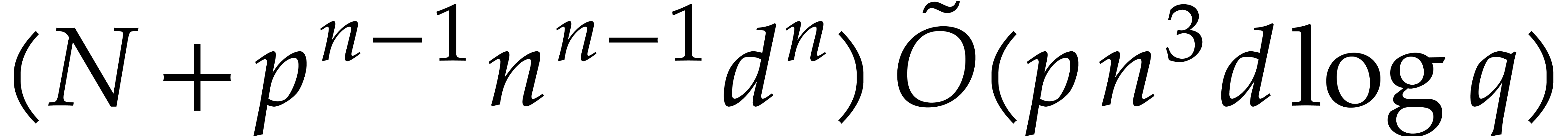 |
by (7.1). |
The final evaluations in step 7 take time  .
.
Remark 7.3.
Notice that  is not necessarily a field.
As an optimization, it is worth taking
is not necessarily a field.
As an optimization, it is worth taking 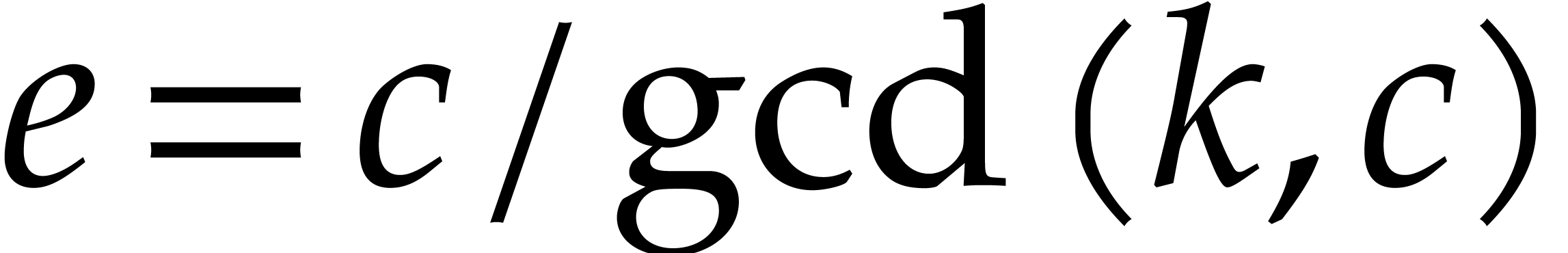 and build
the extension
and build
the extension 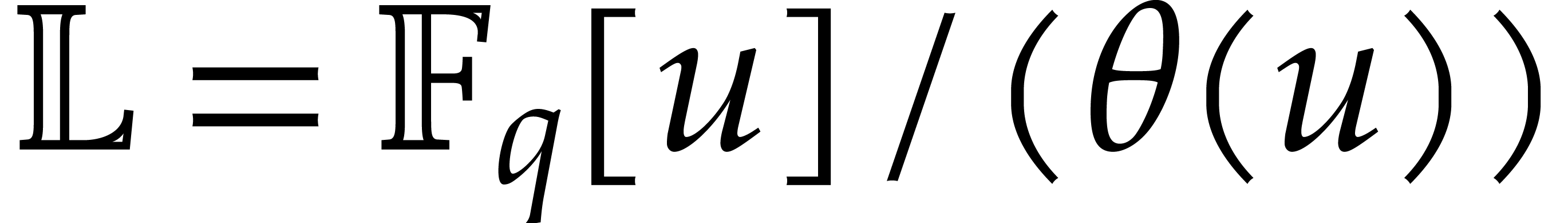 of degree
of . Then we compute a
primitive root in of
order
of degree
of . Then we compute a
primitive root in of
order  . In practice, it is
also worth using faster probabilistic algorithms in step 3.
. In practice, it is
also worth using faster probabilistic algorithms in step 3.
7.2.Modular composition
Let us now reanalyze the complexity of Algorithm 6.1 when
using Algorithm 7.2 for multi-point evaluations. For
simplicity we assume that is a fixed prime
number, so the constant hidden in the “” below actually depends on . This time, we let be
an integer such that
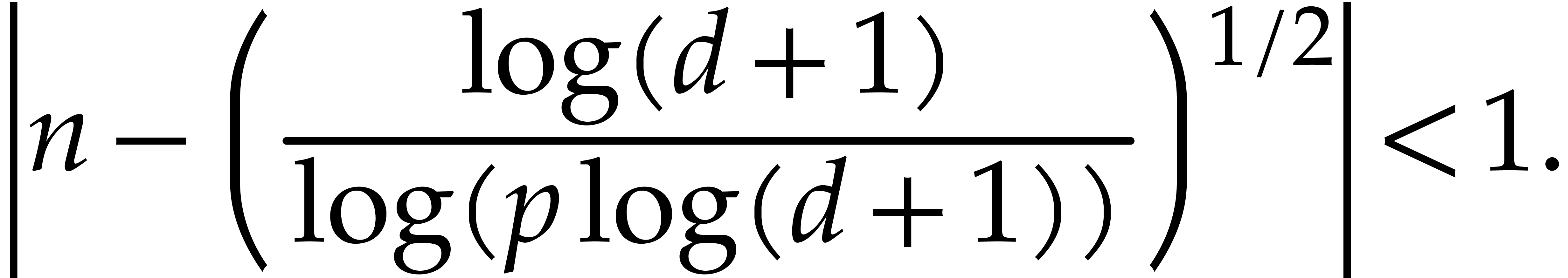 |
(7.2) |
Proof. We adapt the proof of Theorem 6.2
and use (7.2) for the value of instead of (6.1). Here, it is important
for to be fixed, in order to benefit from the
same kind of asymptotic expansions as in the case of Theorem 6.2:
and
In particular 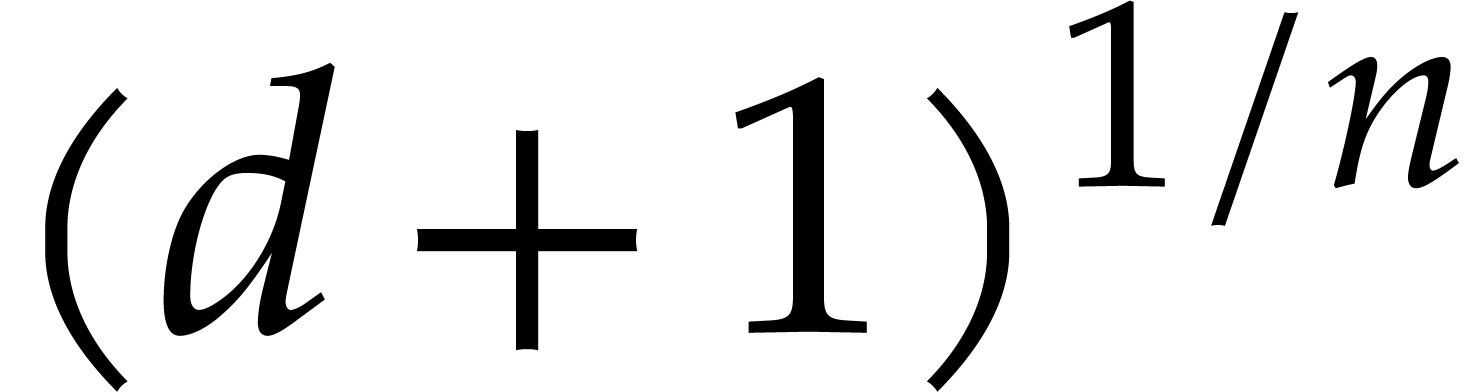 still tends to
still tends to  for large values of .
for large values of .
The main change is the use of Proposition 7.2 to obtain the
following cost for step 5 of Algorithm 6.1:
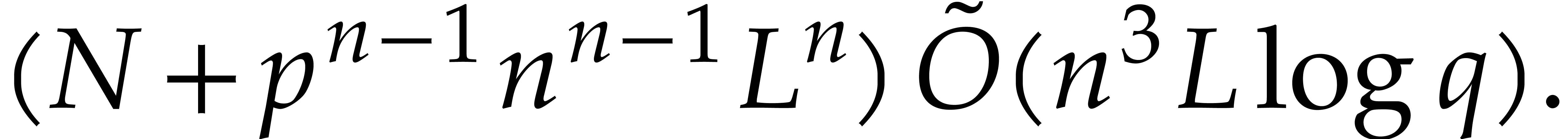
By using (6.4), (6.5), (6.6), and
the fact that 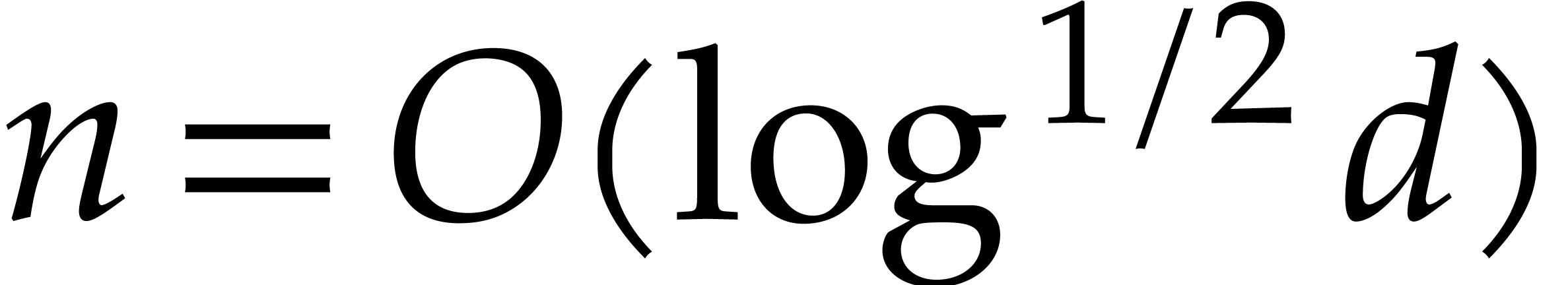 , the latter
cost is bounded by
, the latter
cost is bounded by
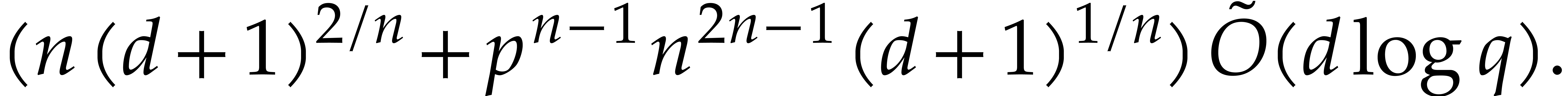
We then need to upper bound the term
Now for sufficiently large ,
we have
It follows that
On the other hand, we have
which concludes the proof.
For small fixed values of ,
Theorem 7.4 therefore improves upon Theorem 6.2.
This happens roughly whenever  ,
which rewrites into
,
which rewrites into 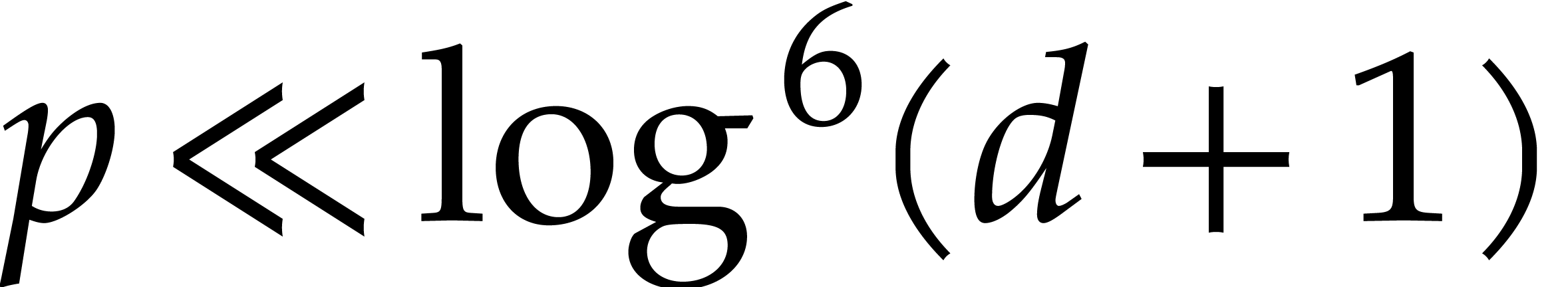 . A more
precise complexity analysis in terms of the parameter
could be developed under the latter condition.
. A more
precise complexity analysis in terms of the parameter
could be developed under the latter condition.
8.Conclusion
An important application of the present results concerns polynomial
system solving, for which we prove new complexity bounds in [28]:
the key algorithms are the Kronecker solver [14] and fast
multivariate modular composition. For the latter problem, we mostly
follow the strategy deployed in the proof of Proposition 5.7.
Besides technical adaptations to Turing machines and various refinements
within the asymptotic complexity bounds, our main improvements upon
Kedlaya and Umans' algorithms concern complexity analyses in terms of
the total degree, and the way we appeal to the naive evaluation
algorithm as a fallback in Theorem 3.10. In particular, our
complexity bounds are quasi-optimal with respect to the bit size of the
elements in the ground ring.
Another major motivation behind our work is to understand how relevant
the new complexity bounds are for practical implementations.
Unfortunately, the input sizes for which our optimized variants of
Kedlaya and Umans' algorithms become faster than previous approaches
still seem to be extremely large. It is instructive to discuss, even in
very informal terms, the orders of magnitude of the cross-over points.
In the univariate case over , fast algorithms for multi-point evaluation
allow for an average evaluation cost per point of 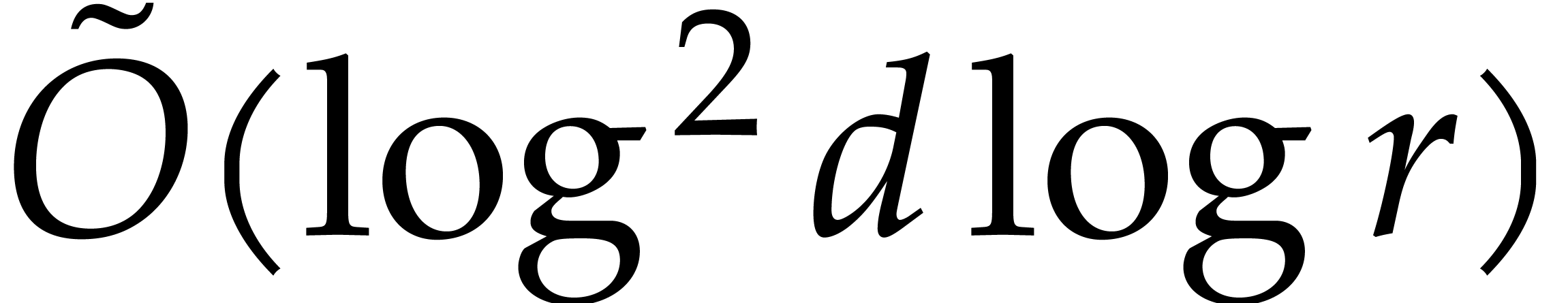 , by means of the classical subproduct tree
technique [13, chapter 10], and as soon as the number of
points is of the order of the degree. In the same spirit, in order to
minimize the average cost per evaluation point, Theorem 3.10
indicates that it is favorable to take of the
order of (that is larger than the cardinality of
the support of ).
, by means of the classical subproduct tree
technique [13, chapter 10], and as soon as the number of
points is of the order of the degree. In the same spirit, in order to
minimize the average cost per evaluation point, Theorem 3.10
indicates that it is favorable to take of the
order of (that is larger than the cardinality of
the support of ).
To simplify the discussion, we discard the factor
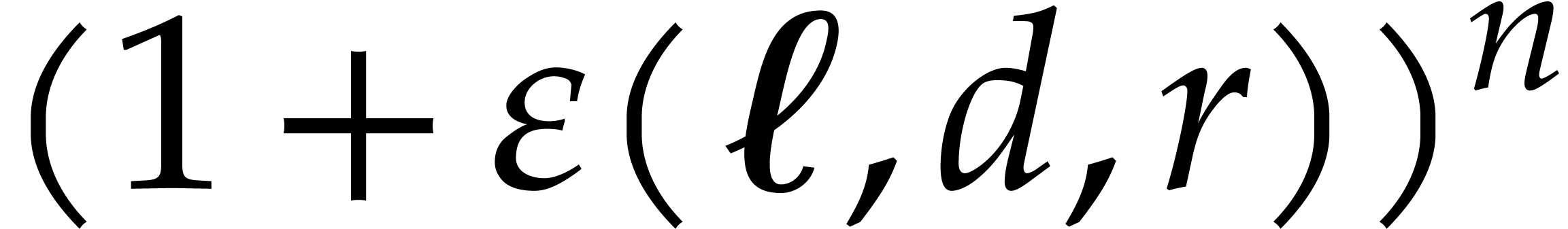 occurring in Theorem
3.10
, and we focus on the case when
occurring in Theorem
3.10
, and we focus on the case when
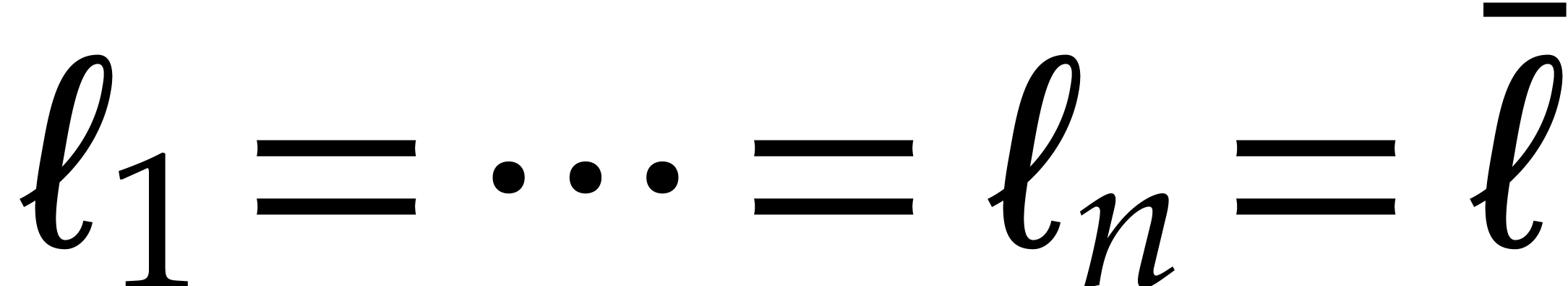 and
and
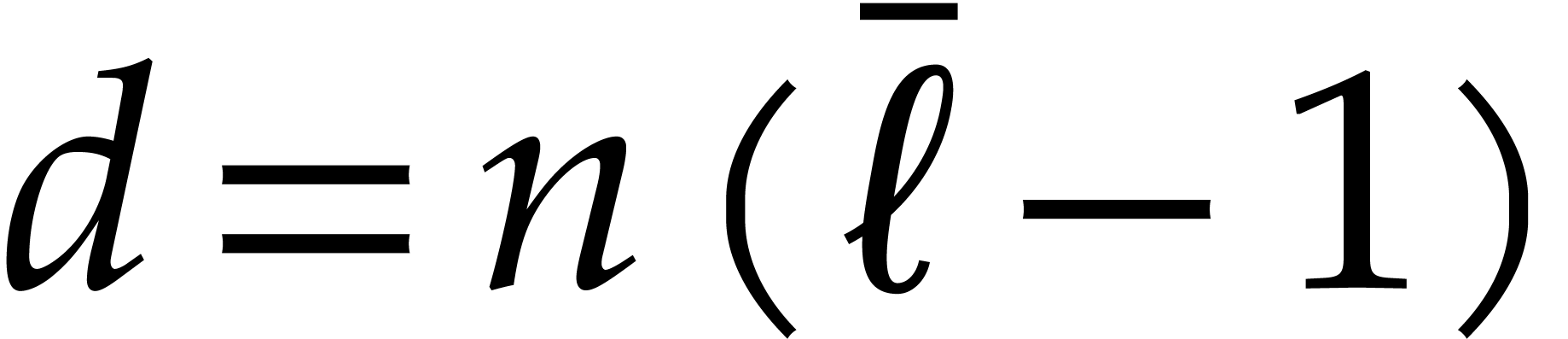 .
So when
.
So when
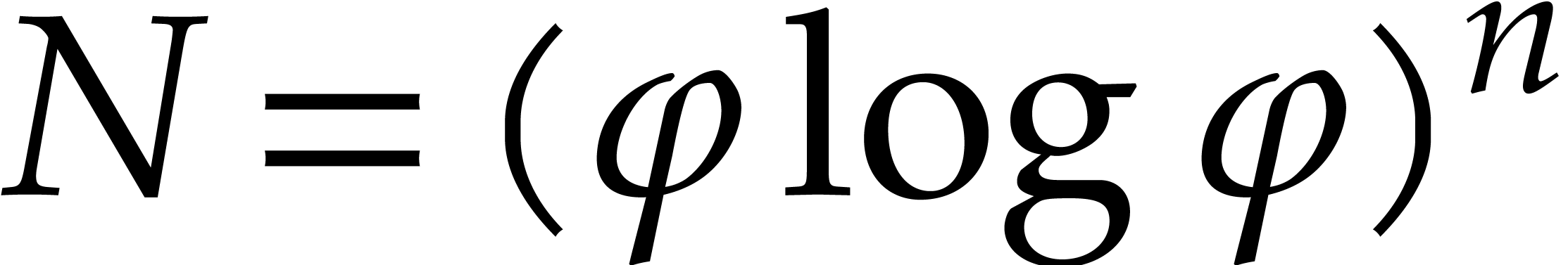 ,
the average cost per point roughly becomes
,
the average cost per point roughly becomes
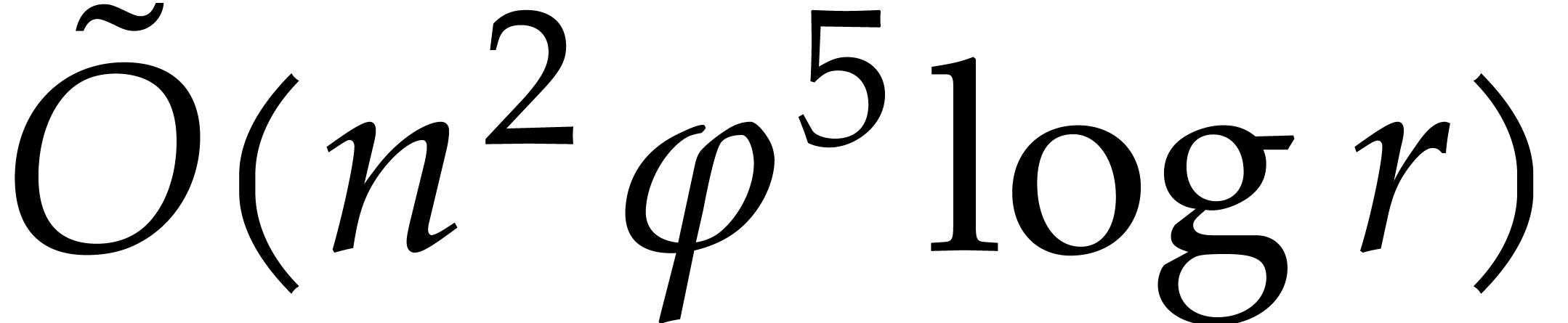 .
Recall that this average cost is
.
Recall that this average cost is
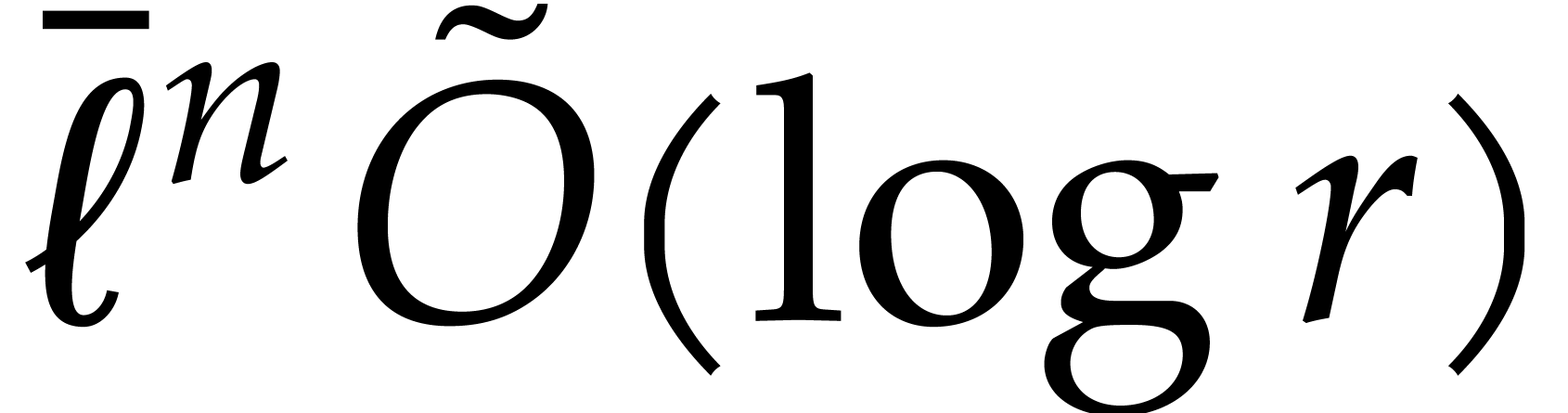 with the naive approach. The ratio between both bounds is therefore of
the order
with the naive approach. The ratio between both bounds is therefore of
the order
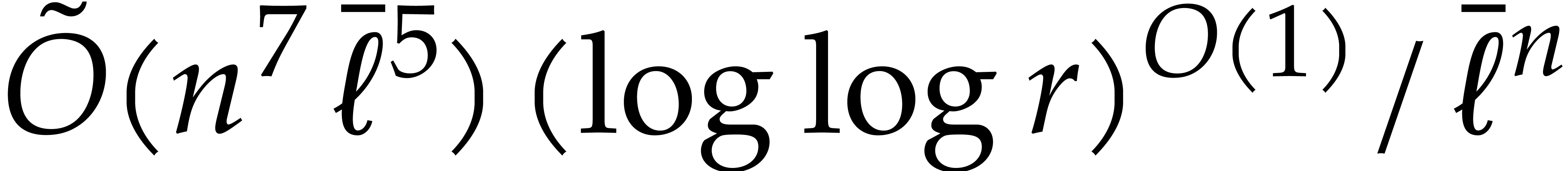 .
In Table
8.1
.
In Table
8.1
we report on the first values of
 such that
such that
 ,
namely
,
namely
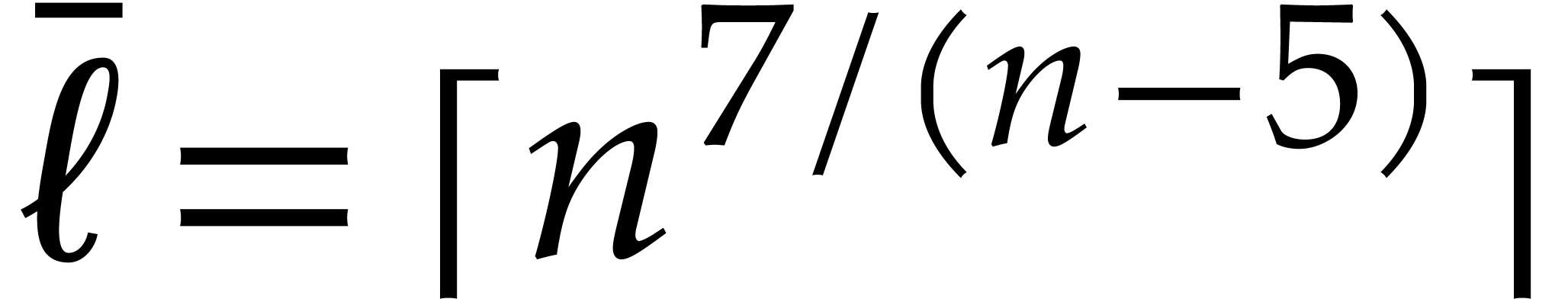 ,
along with the closest integer to
,
along with the closest integer to
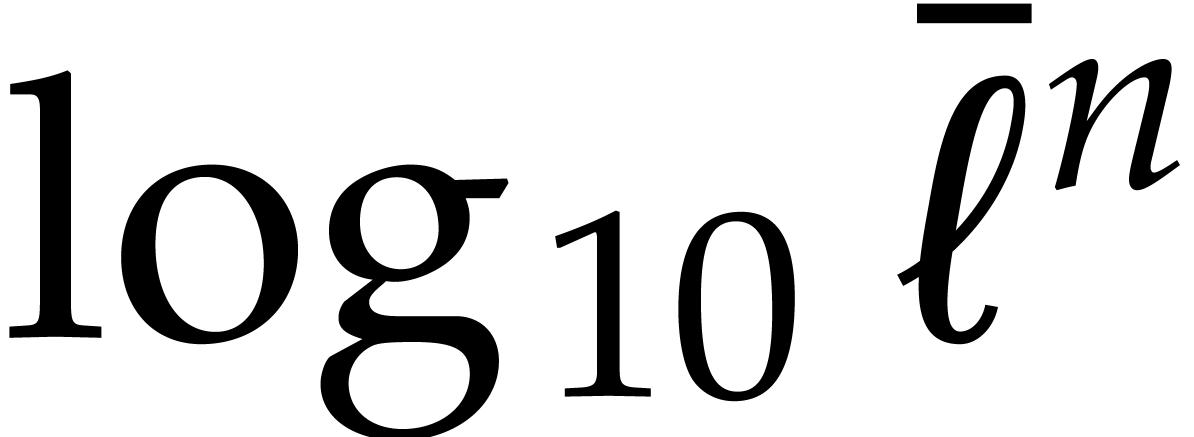 .
Whenever the same value of
is encountered for different values of
,
we only display the case with smallest
.
Whenever the same value of
is encountered for different values of
,
we only display the case with smallest
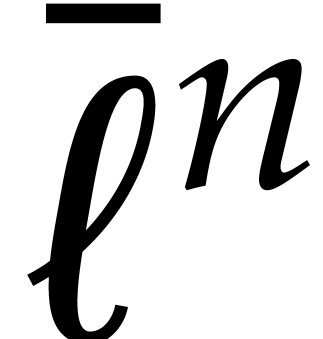 .
We observe that the sizes of the corresponding input polynomials are
not realistic for a common workstation.
.
We observe that the sizes of the corresponding input polynomials are
not realistic for a common workstation.
The above factor  corresponds to the value
corresponds to the value  in Algorithm 3.3. In practice it turns
out to be more interesting to use smaller values for . In fact, it is worth using Algorithm 3.3
with
in Algorithm 3.3. In practice it turns
out to be more interesting to use smaller values for . In fact, it is worth using Algorithm 3.3
with  whenever
whenever  ,
since
,
since
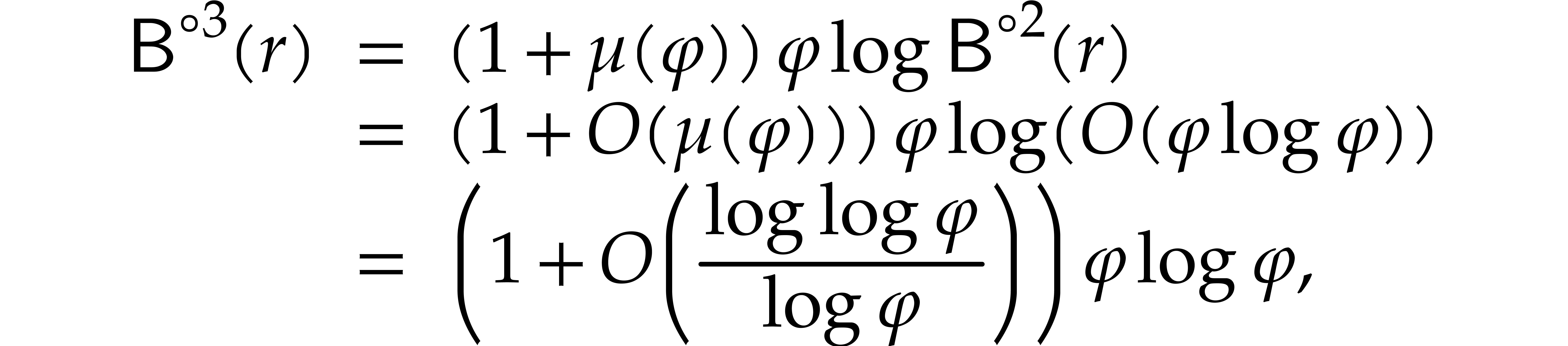
and the cost given in Proposition
3.7
drops to
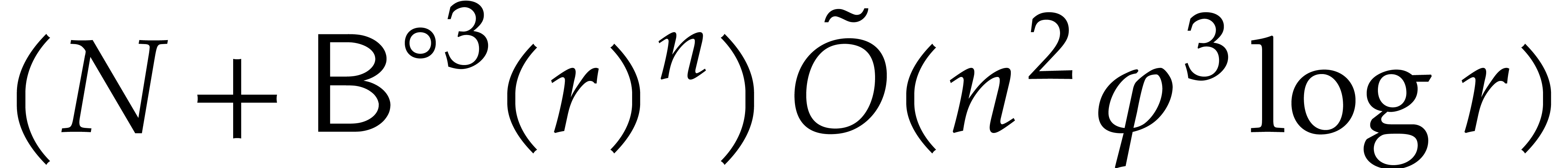 .
Table
8.2
.
Table
8.2
|
|
Table 8.2. Efficiency threshold
orders for the complexity bound of Proposition 3.7
with  . .
|
displays the first resulting values of
for which
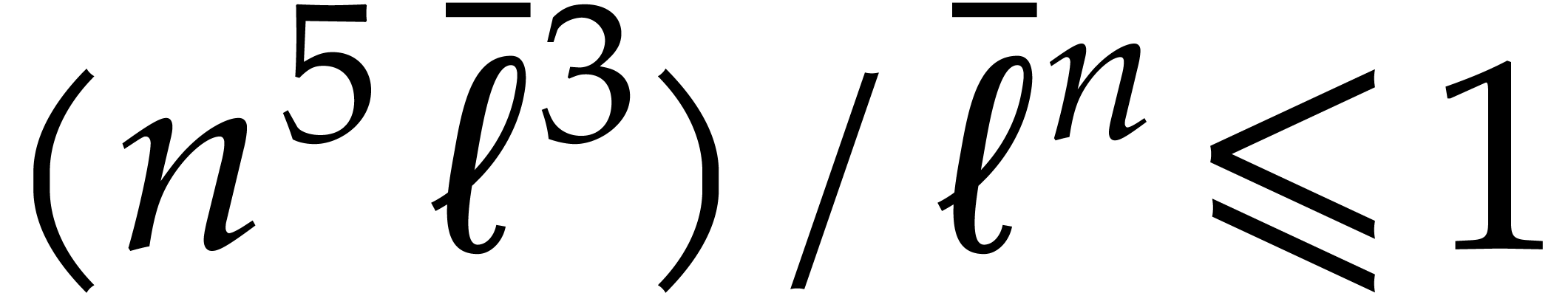 .
Considering for instance that
is a 64 bit integer, we may thus use Algorithm
3.3
with
whenever
.
Considering for instance that
is a 64 bit integer, we may thus use Algorithm
3.3
with
whenever
 .
Consequently, for input polynomial sizes of about 100 MB, the fast
algorithm might start to be of interest. Yet, the orders of magnitude
considered here are quite optimistic and we expect the actual thresholds
to be larger.
.
Consequently, for input polynomial sizes of about 100 MB, the fast
algorithm might start to be of interest. Yet, the orders of magnitude
considered here are quite optimistic and we expect the actual thresholds
to be larger.
In small positive characteristic  ,
Proposition 7.2 seems more promising for practical
purposes. For
,
Proposition 7.2 seems more promising for practical
purposes. For 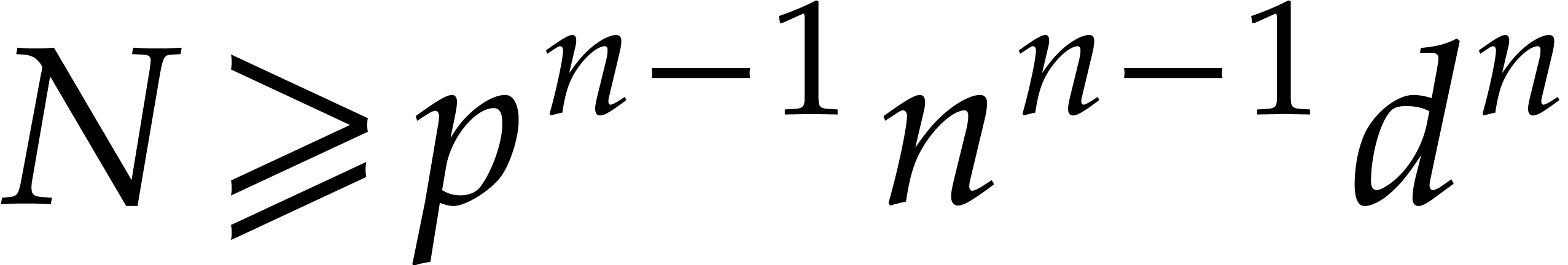 , the average
cost per evaluation point drops to
, the average
cost per evaluation point drops to 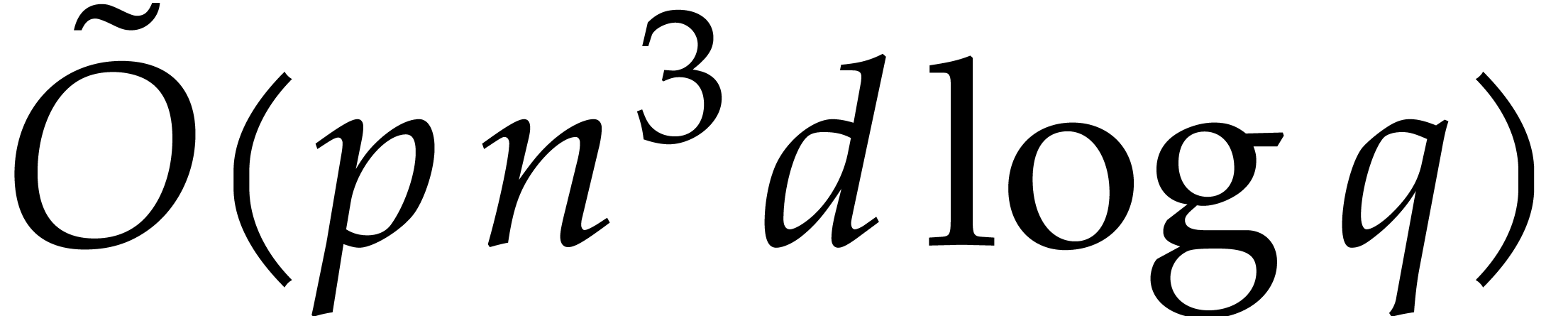 .
The efficiency ratio with respect to the naive algorithm is thus of the
order
.
The efficiency ratio with respect to the naive algorithm is thus of the
order 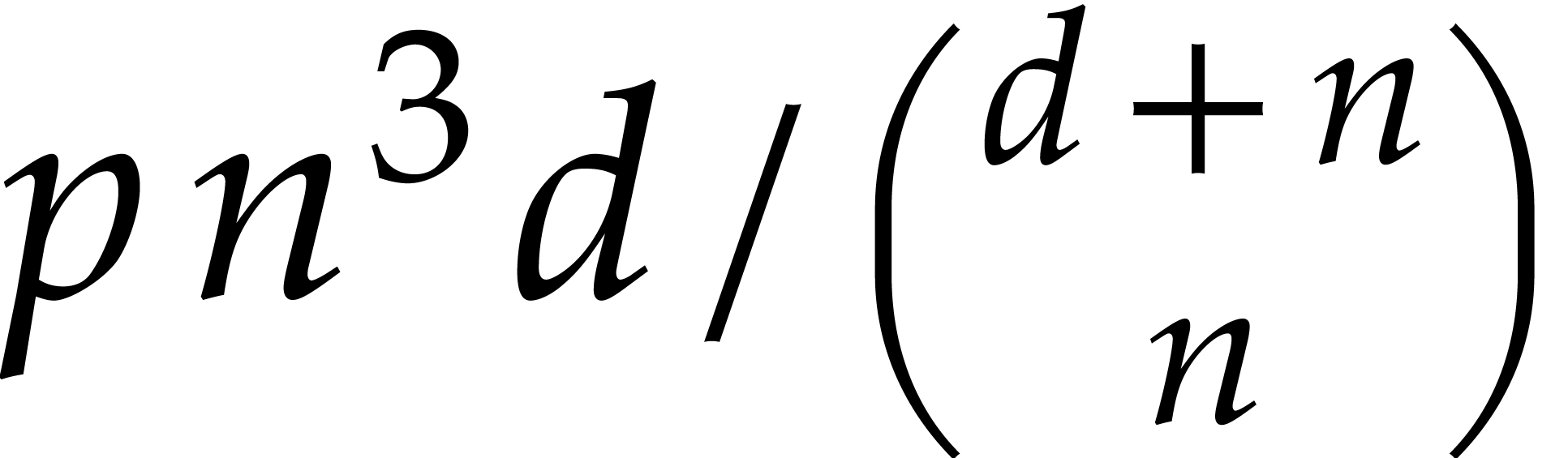 . For instance, with
. For instance, with
 and ,
this ratio rewrites into
and ,
this ratio rewrites into 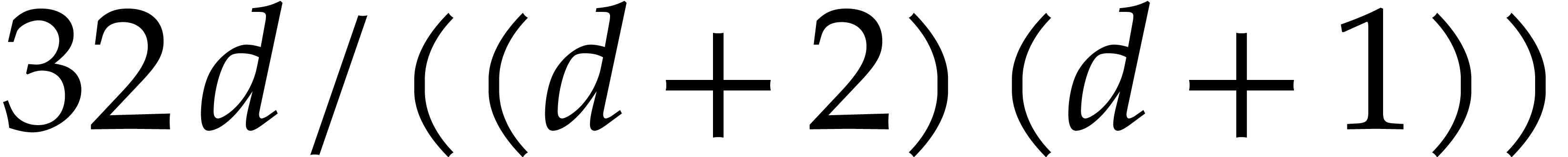 .
Consequently, Algorithm 7.2 might be relevant in practice
for input data of a few kilobytes. However we are not aware of such an
efficient implementation.
.
Consequently, Algorithm 7.2 might be relevant in practice
for input data of a few kilobytes. However we are not aware of such an
efficient implementation.
For the above reasons, faster software implementations of multivariate
multi-point evaluation and modular composition remain major challenges.
At least, we hope that our new detailed complexity bounds will stimulate
more theoretical and practical research in this area. For example, is it
possible to decrease the contribution of in
Theorem 3.10? Or, still in Theorem 3.10, could
one decrease the exponent  of ? Is it possible to improve upon the constant
of ? Is it possible to improve upon the constant
 in Theorem 6.2?
in Theorem 6.2?
Acknowledgments
. We thank the anonymous referees for their helpful comments.
Bibliography
-
[1]
-
A. Arnold, M. Giesbrecht, and D. S. Roche. Faster
sparse multivariate polynomial interpolation of straight-line
programs. J. Symbolic Comput., 75:4–24, 2016.
-
[2]
-
J. Barkley Rosser and L. Schoenfeld. Approximate
formulas for some functions of prime numbers. Ill. J.
Math, 6:64–94, 1962.
-
[3]
-
D. J. Bernstein. Composing power series over a finite
ring in essentially linear time. J. Symbolic Comput.,
26(3):339–341, 1998.
-
[4]
-
L. I. Bluestein. A linear filtering approach to the
computation of discrete Fourier transform. IEEE Transactions
on Audio and Electroacoustics, 18(4):451–455, 1970.
-
[5]
-
A. Bostan, P. Gaudry, and É. Schost. Linear
recurrences with polynomial coefficients and application to
integer factorization and Cartier–Manin operator. SIAM
J. Comput., 36:1777–1806, 2007.
-
[6]
-
A. Bostan, G. Lecerf, and É. Schost.
Tellegen's principle into practice. In Hoon Hong, editor,
Proceedings of the 2003 International Symposium on Symbolic
and Algebraic Computation, ISSAC '03, pages 37–44, New
York, NY, USA, 2003. ACM.
-
[7]
-
A. Bostan and É. Schost. Polynomial evaluation
and interpolation on special sets of points. J.
Complexity, 21(4):420–446, 2005.
-
[8]
-
R. P. Brent. Fast multiple-precision evaluation of
elementary functions. J. ACM, 23(2):242–251, 1976.
-
[9]
-
R. P. Brent and H. T. Kung. Fast algorithms for
manipulating formal power series. J. ACM,
25(4):581–595, 1978.
-
[10]
-
D. G. Cantor and E. Kaltofen. On fast multiplication
of polynomials over arbitrary algebras. Acta Infor.,
28:693–701, 1991.
-
[11]
-
E. Costa and D. Harvey. Faster deterministic integer
factorization. Math. Comp., 83(285):339–345, 2014.
-
[12]
-
P. Dusart. Estimates of some functions over primes
without R.H. Technical report, ArXiv, 2010. https://arxiv.org/abs/1002.0442.
-
[13]
-
J. von zur Gathen and J. Gerhard. Modern computer
algebra. Cambridge University Press, New York, 3rd edition,
2013.
-
[14]
-
M. Giusti, G. Lecerf, and B. Salvy. A Gröbner
free alternative for polynomial system solving. J.
complexity, 17(1):154–211, 2001.
-
[15]
-
D. Harvey and J. van der Hoeven. Faster integer and
polynomial multiplication using cyclotomic coefficient rings.
Technical report, ArXiv, 2017. http://arxiv.org/abs/1712.03693.
-
[16]
-
D. Harvey and J. van der Hoeven. Faster integer
multiplication using plain vanilla FFT primes. Math.
Comp., 88(315):501–514, 2019.
-
[17]
-
D. Harvey and J. van der Hoeven. Faster integer
multiplication using short lattice vectors. In ANTS XIII.
Proceedings of the Thirteenth Algorithmic Number Theory
Symposium, volume 2 of The Open Book Series, pages
293–310. Mathematical Sciences Publishers, 2019.
-
[18]
-
D. Harvey, J. van der Hoeven, and G. Lecerf. Even
faster integer multiplication. J. Complexity,
36:1–30, 2016.
-
[19]
-
D. Harvey, J. van der Hoeven, and G. Lecerf. Faster
polynomial multiplication over finite fields. J. ACM,
63(6), 2017. Article 52.
-
[20]
-
J. van der Hoeven. Relax, but don't be too lazy.
J. Symbolic Comput., 34(6):479–542, 2002.
-
[21]
-
J. van der Hoeven. The truncated Fourier transform
and applications. In J. Gutierrez, editor, Proceedings of the
2004 international symposium on Symbolic and algebraic
computation, ISSAC '04, pages 290–296, New York, NY,
USA, 2004. ACM.
-
[22]
-
J. van der Hoeven. Fast composition of numeric power
series. Technical Report 2008-09, Université Paris-Sud,
Orsay, France, 2008.
-
[23]
-
J. van der Hoeven. Faster Chinese remaindering.
Technical report, CNRS & École polytechnique, 2016.
http://hal.archives-ouvertes.fr/hal-01403810.
-
[24]
-
J. van der Hoeven and G. Lecerf. On the
bit-complexity of sparse polynomial and series multiplication.
J. Symbolic Comput., 50:227–254, 2013.
-
[25]
-
J. van der Hoeven and G. Lecerf. Composition modulo
powers of polynomials. In M. Blurr, editor, Proceedings of
the 2017 ACM on International Symposium on Symbolic and
Algebraic Computation, ISSAC '17, pages 445–452, New
York, NY, USA, 2017. ACM.
-
[26]
-
J. van der Hoeven and G. Lecerf. Modular composition
via complex roots. Technical report, CNRS & École
polytechnique, 2017. http://hal.archives-ouvertes.fr/hal-01455731.
-
[27]
-
J. van der Hoeven and G. Lecerf. Modular composition
via factorization. J. Complexity, 48:36–68, 2018.
-
[28]
-
J. van der Hoeven and G. Lecerf. On the complexity
exponent of polynomial system solving. https://hal.archives-ouvertes.fr/hal-01848572,
2018.
-
[29]
-
J. van der Hoeven and É. Schost. Multi-point
evaluation in higher dimensions. Appl. Alg. Eng. Comm.
Comp., 24(1):37–52, 2013.
-
[30]
-
Xiaohan Huang and V. Y. Pan. Fast rectangular matrix
multiplication and applications. J. Complexity,
14(2):257–299, 1998.
-
[31]
-
F. Johansson. A fast algorithm for reversion of power
series. Math. Comp., 84:475–484, 2015.
-
[32]
-
E. Kaltofen and V. Shoup. Fast polynomial
factorization over high algebraic extensions of finite fields.
In Proceedings of the 1997 International Symposium on
Symbolic and Algebraic Computation, ISSAC '97, pages
184–188, New York, NY, USA, 1997. ACM.
-
[33]
-
K. S. Kedlaya and C. Umans. Fast modular composition
in any characteristic. In FOCS'08: IEEE Conference on
Foundations of Computer Science, pages 146–155,
Washington, DC, USA, 2008. IEEE Computer Society.
-
[34]
-
K. S. Kedlaya and C. Umans. Fast polynomial
factorization and modular composition. SIAM J. Comput.,
40(6):1767–1802, 2011.
-
[35]
-
G. Lecerf. On the complexity of the
Lickteig–Roy subresultant algorithm. J. Symbolic
Comput., 92:243–268, 2019.
-
[36]
-
M. Nüsken and M. Ziegler. Fast multipoint
evaluation of bivariate polynomials. In S. Albers and T. Radzik,
editors, Algorithms – ESA 2004. 12th Annual European
Symposium, Bergen, Norway, September 14-17, 2004, volume
3221 of Lect. Notes Comput. Sci., pages 544–555.
Springer Berlin Heidelberg, 2004.
-
[37]
-
D. Panario and D. Thomson. Efficient th root computations in finite fields
of characteristic .
Des. Codes Cryptogr., 50(3):351–358, 2009.
-
[38]
-
C. H. Papadimitriou. Computational Complexity.
Addison-Wesley, 1994.
-
[39]
-
M. S. Paterson and L. J. Stockmeyer. On the number of
nonscalar multiplications necessary to evaluate polynomials.
SIAM J.Comput., 2(1):60–66, 1973.
-
[40]
-
P. Ritzmann. A fast numerical algorithm for the
composition of power series with complex coefficients.
Theoret. Comput. Sci., 44:1–16, 1986.
-
[41]
-
A. Schönhage. Schnelle Berechnung von
Kettenbruchentwicklungen. Acta Informatica,
1(2):139–144, 1971.
-
[42]
-
A. Schönhage, A. F. W. Grotefeld, and E. Vetter.
Fast algorithms: A multitape Turing machine
implementation. B. I. Wissenschaftsverlag, Mannheim, 1994.
-
[43]
-
V. Shoup. New algorithms for finding irreducible
polynomials over finite fields. Math. Comp.,
54(189):435–447, 1990.
-
[44]
-
V. Shoup. Searching for primitive roots in finite
fields. Math. Comp., 58:369–380, 1992.
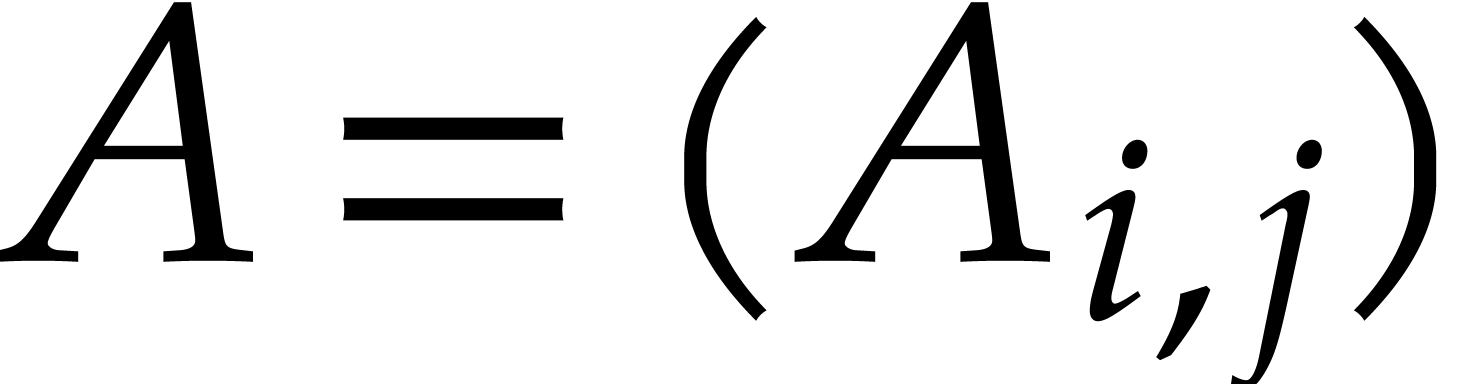 be an
be an  matrix. Let
matrix. Let 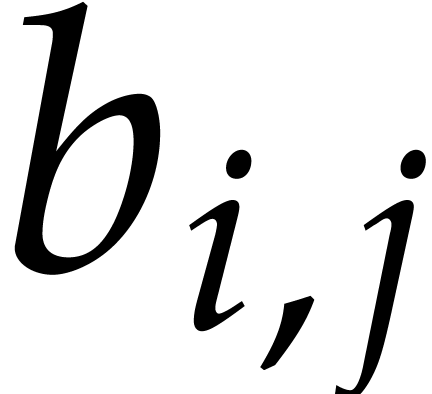 denote the size of
denote the size of 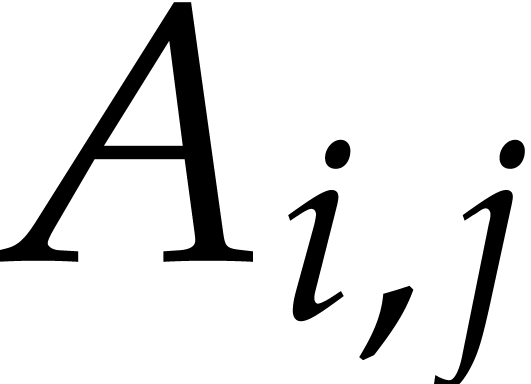 for all
for all 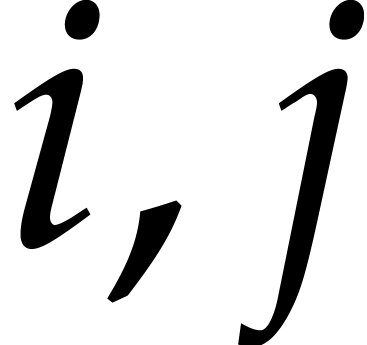 ,
,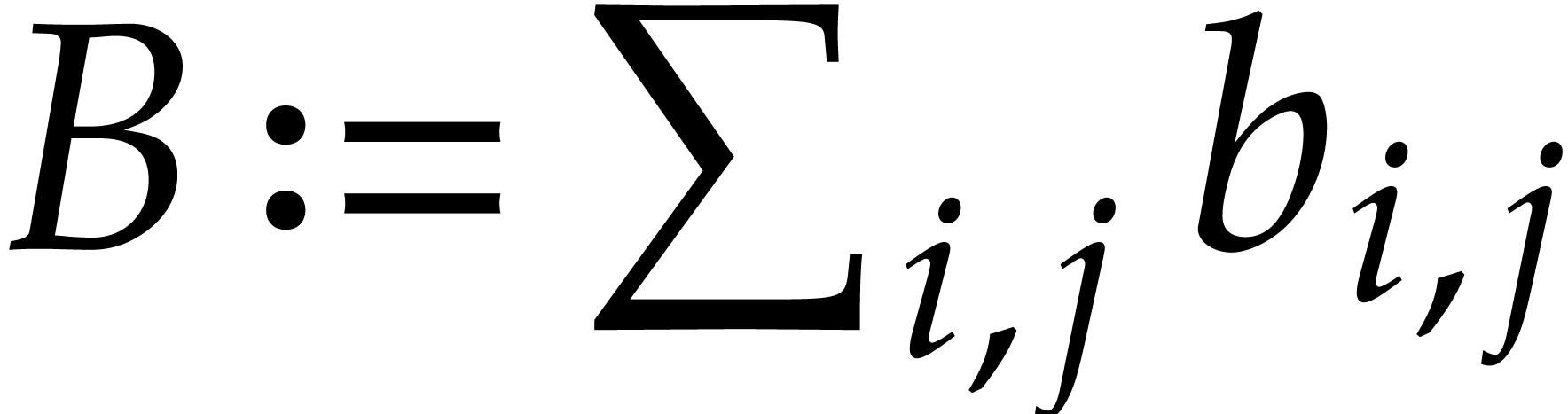 .
.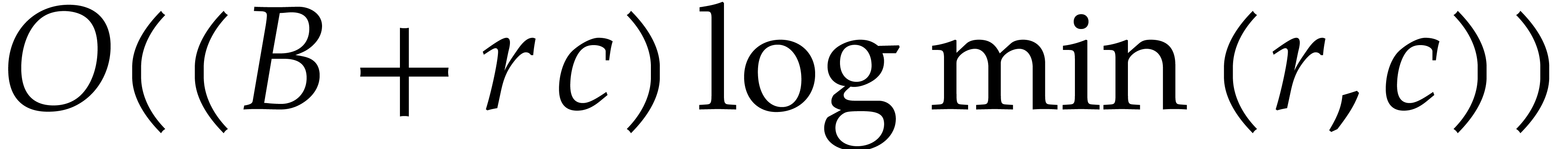 .
. .
.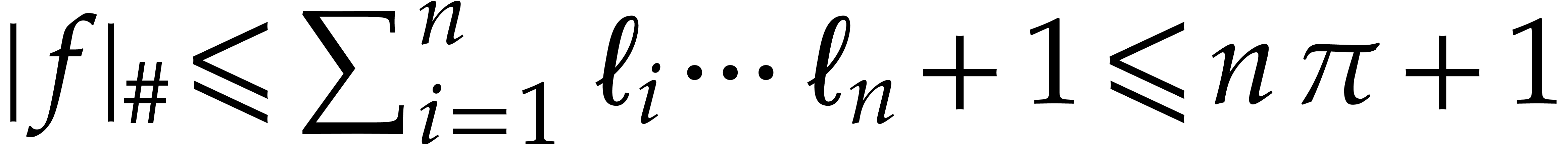 ,
,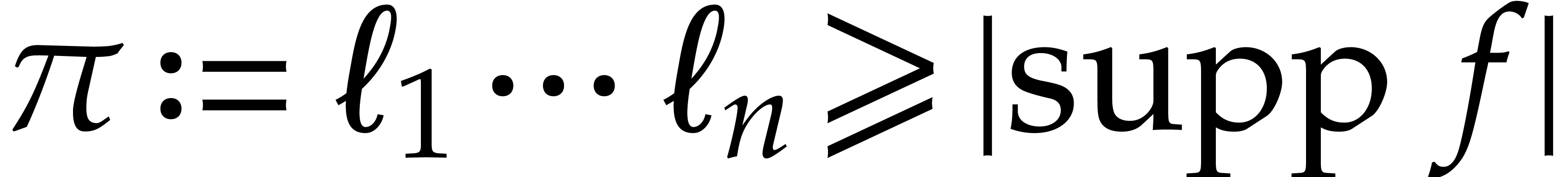 .
.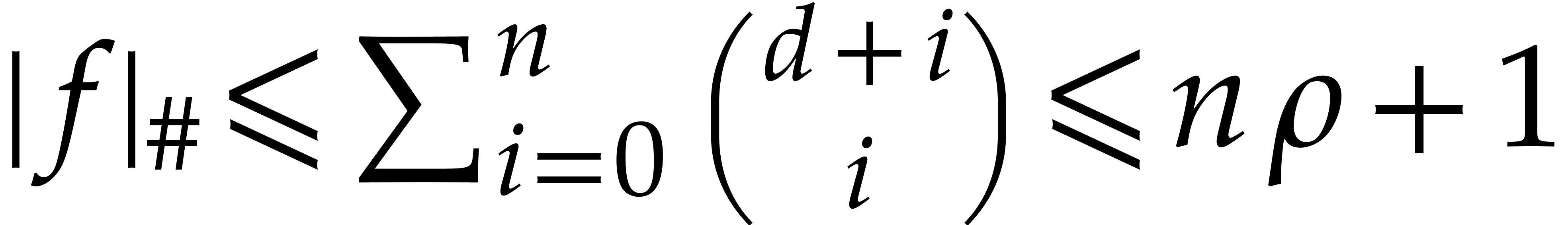 ,
,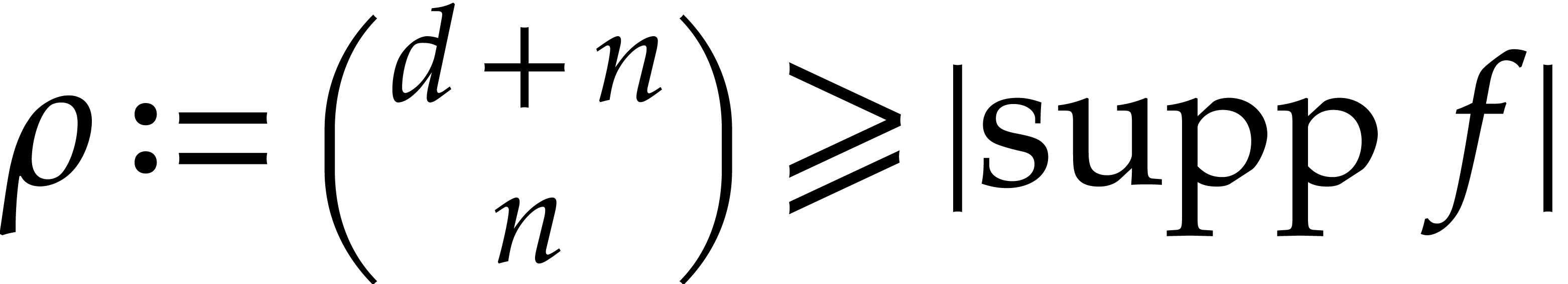 .
.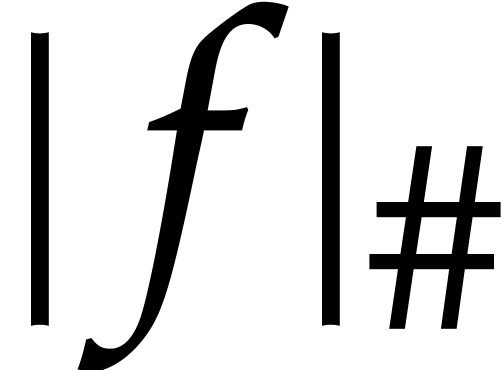
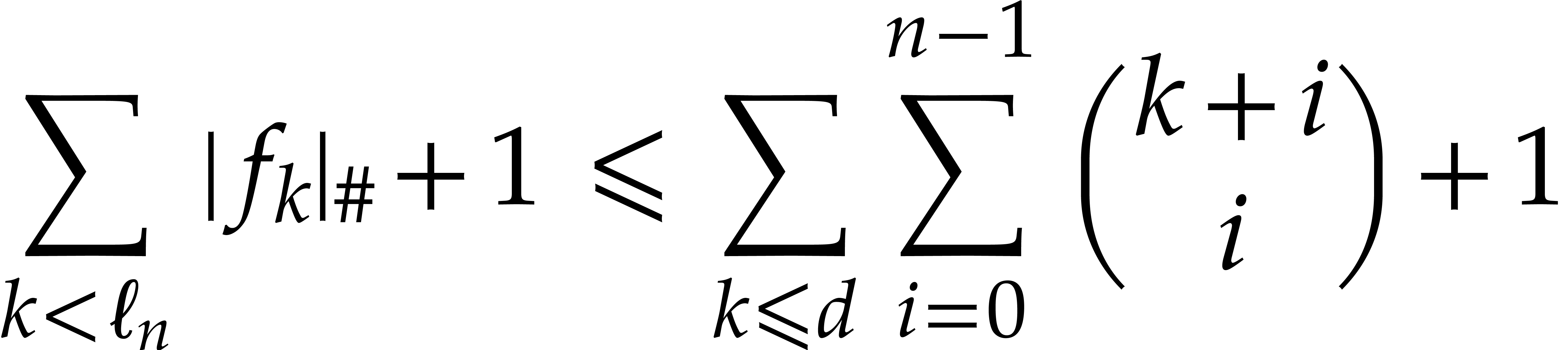
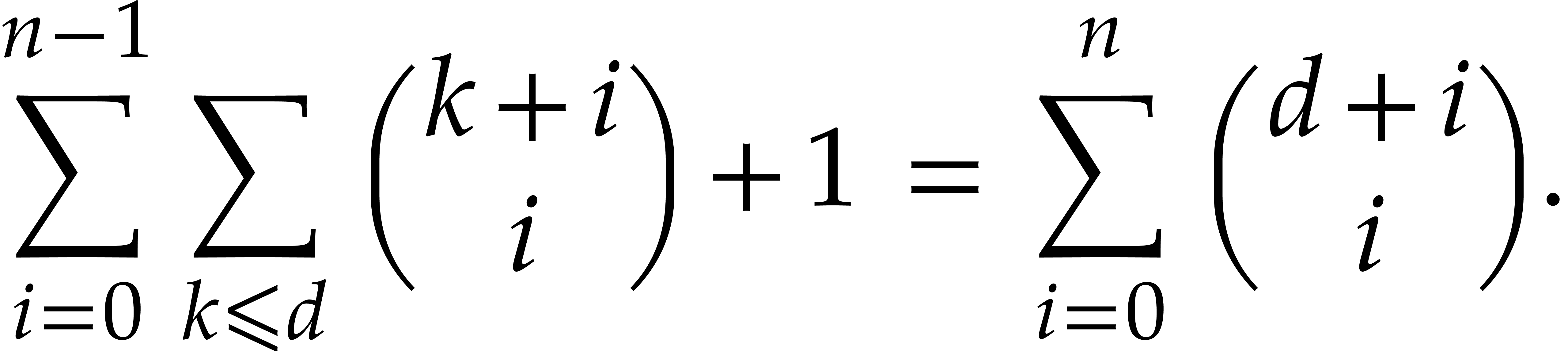
 of a nonzero
polynomial
of a nonzero
polynomial 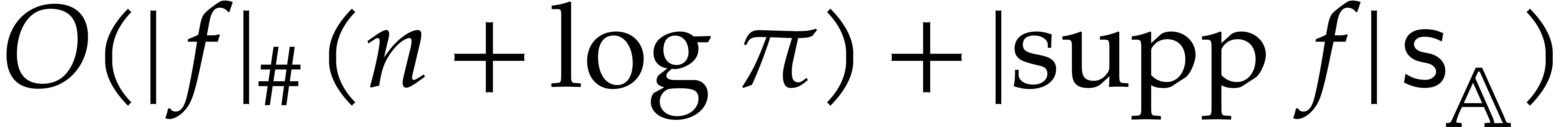 ,
, of a polynomial
of a polynomial 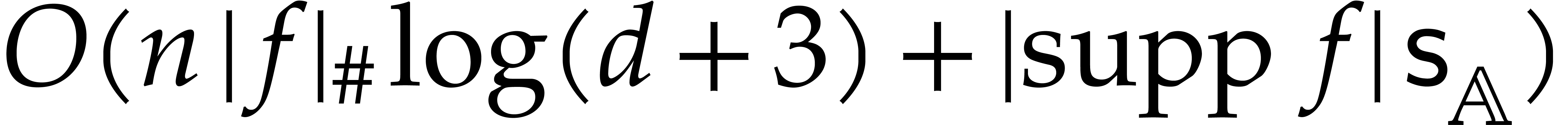 ,
, .
. be an array of integers in
be an array of integers in 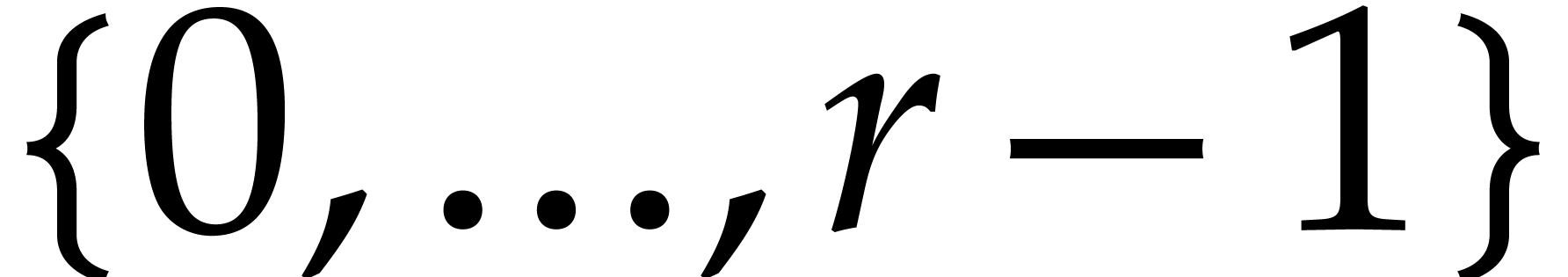 ,
,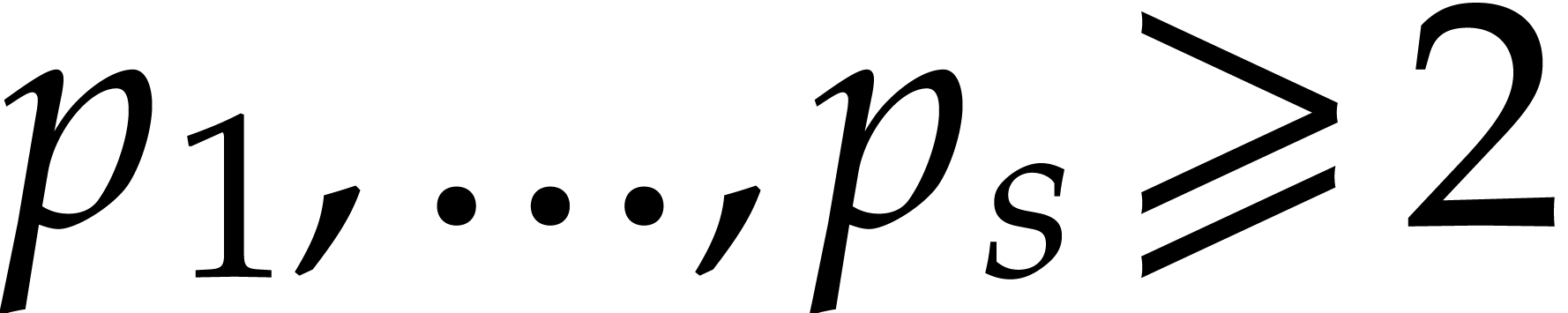 be integers such that
be integers such that  .
.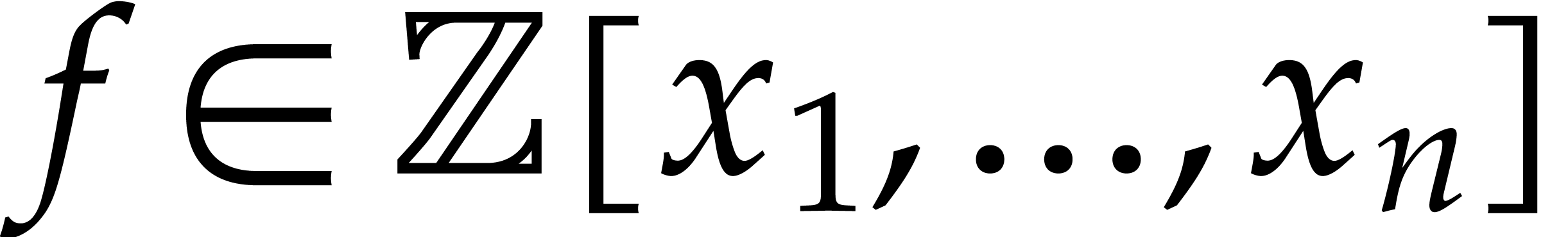 have its coefficients in
have its coefficients in  can be
computed in time
can be
computed in time 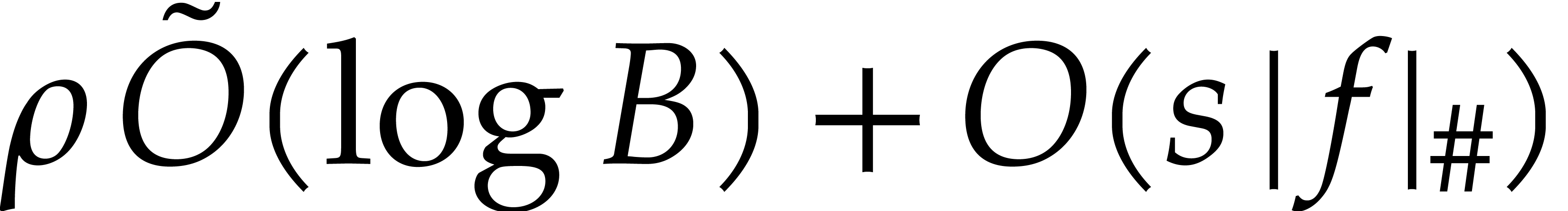 ,
, .
.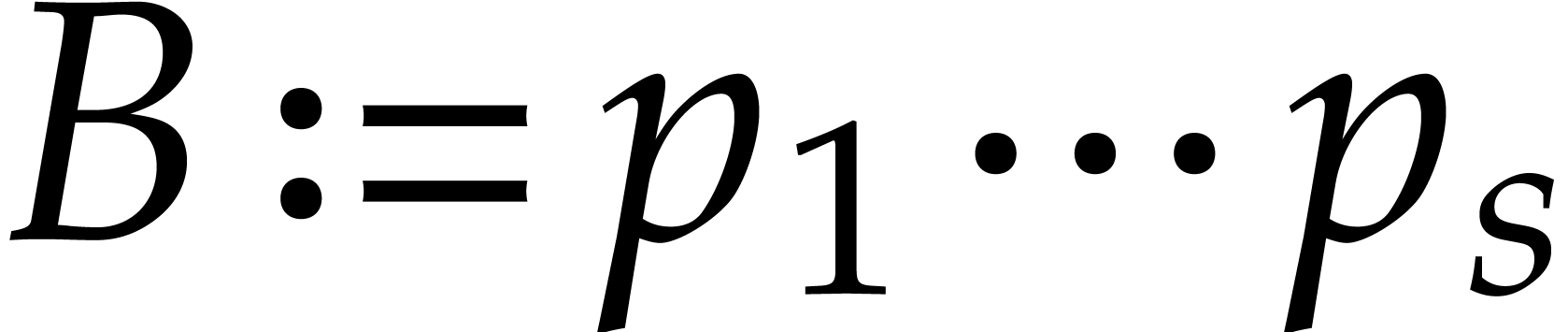 ,
, .
.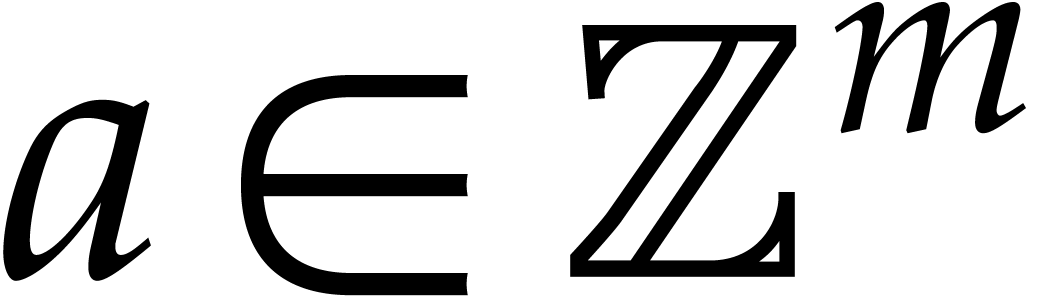 with entries in
with entries in  such that
such that 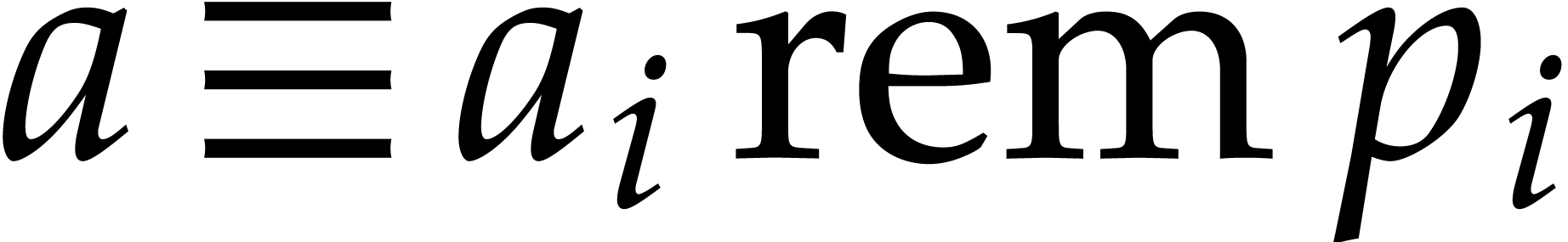 for
for 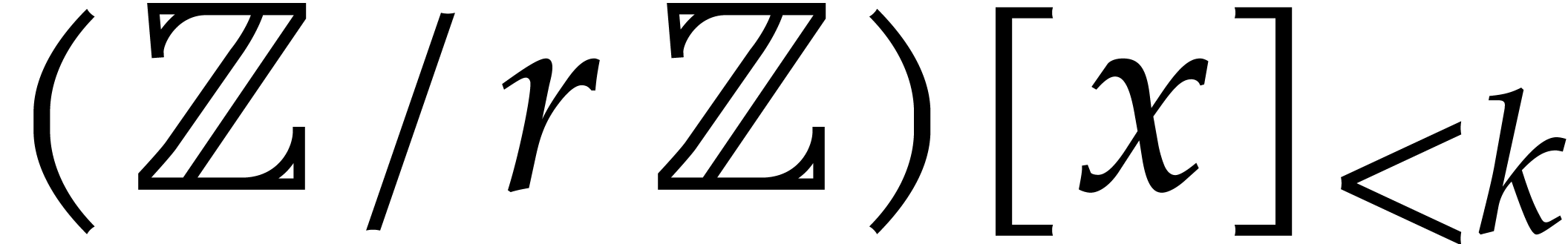 .
. we
may compute
we
may compute  in time
in time  .
. ,
, be elements
in
be elements
in 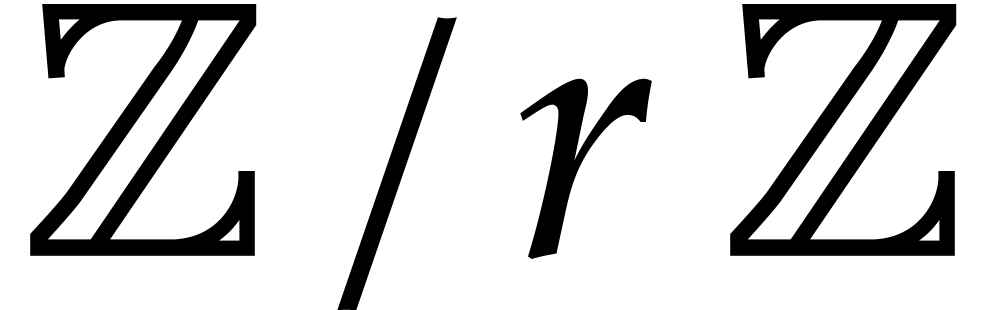 .
. can be computed in time
can be computed in time
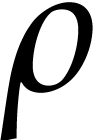 is the cardinality of the support of
is the cardinality of the support of
 .
. be vectors in
be vectors in 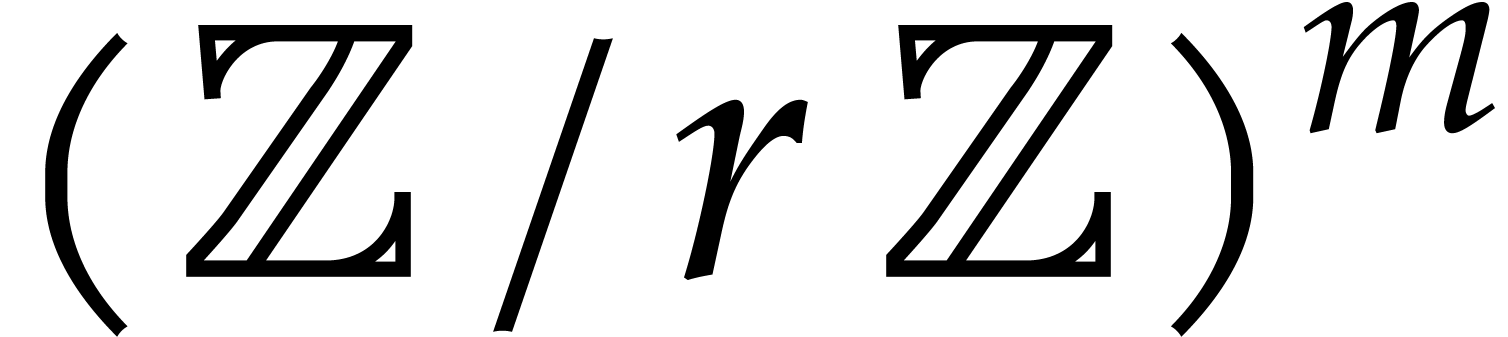 .
.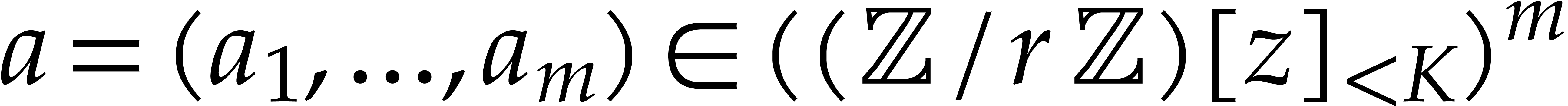 with
with
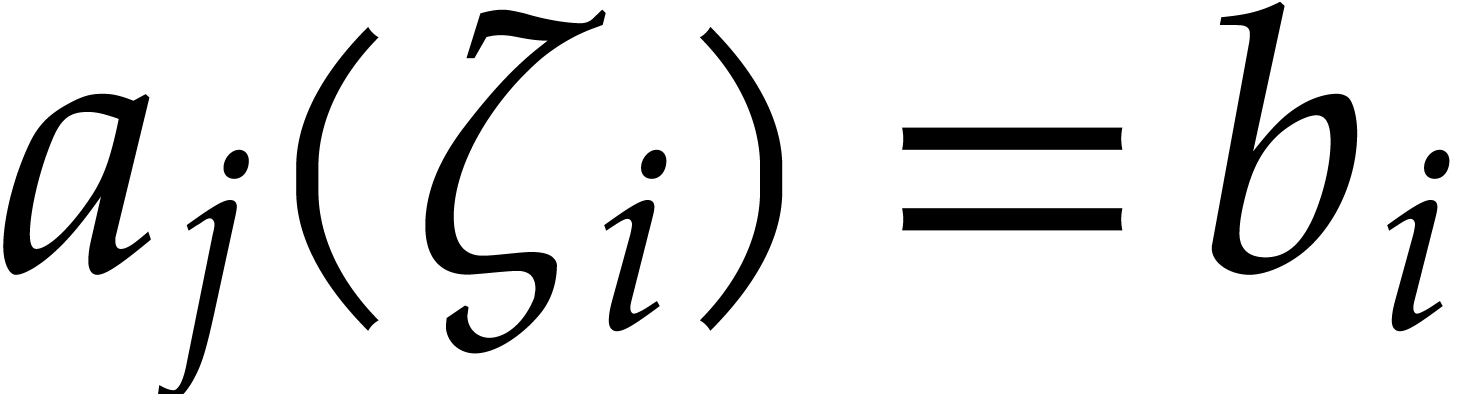 for
for 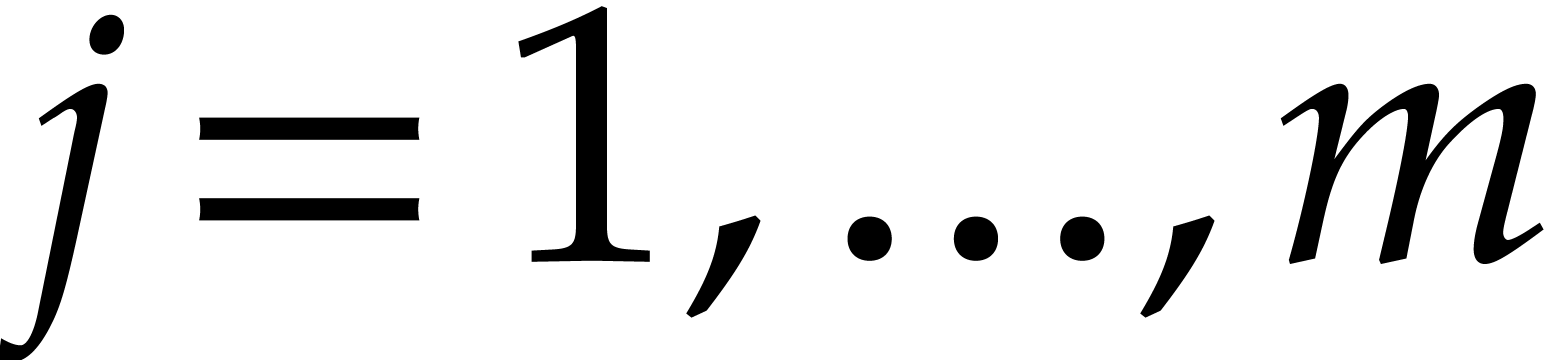 can be computed in time
can be computed in time 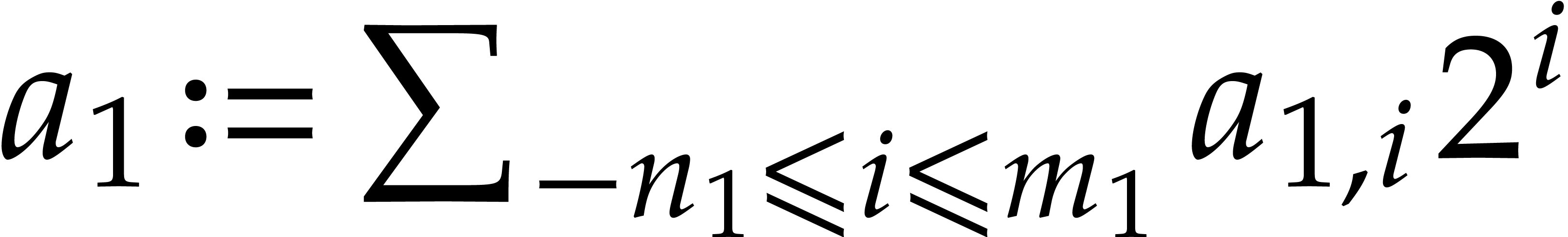 and
and 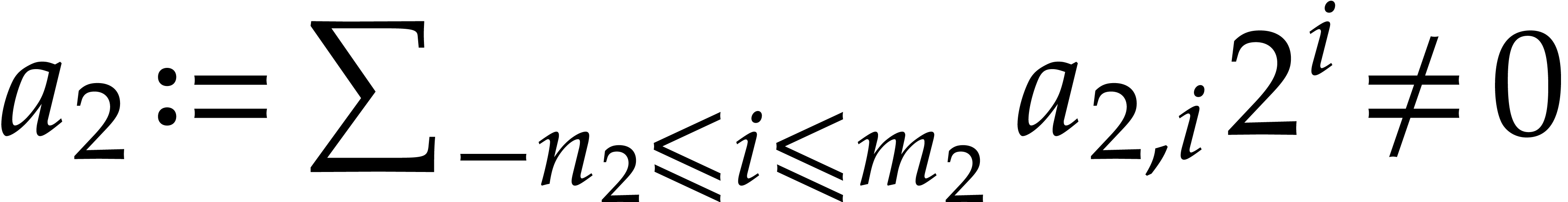 .
. of
of 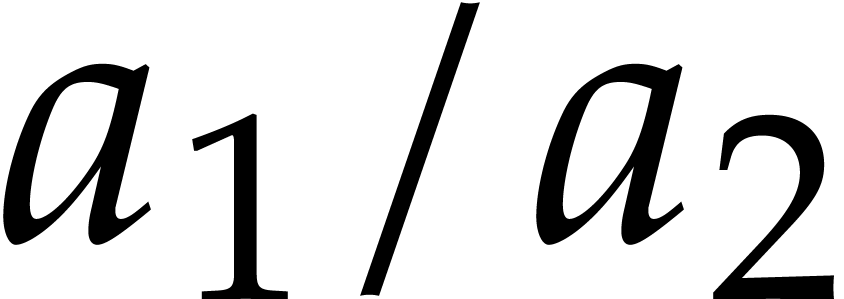 to
precision
to
precision  such that
such that 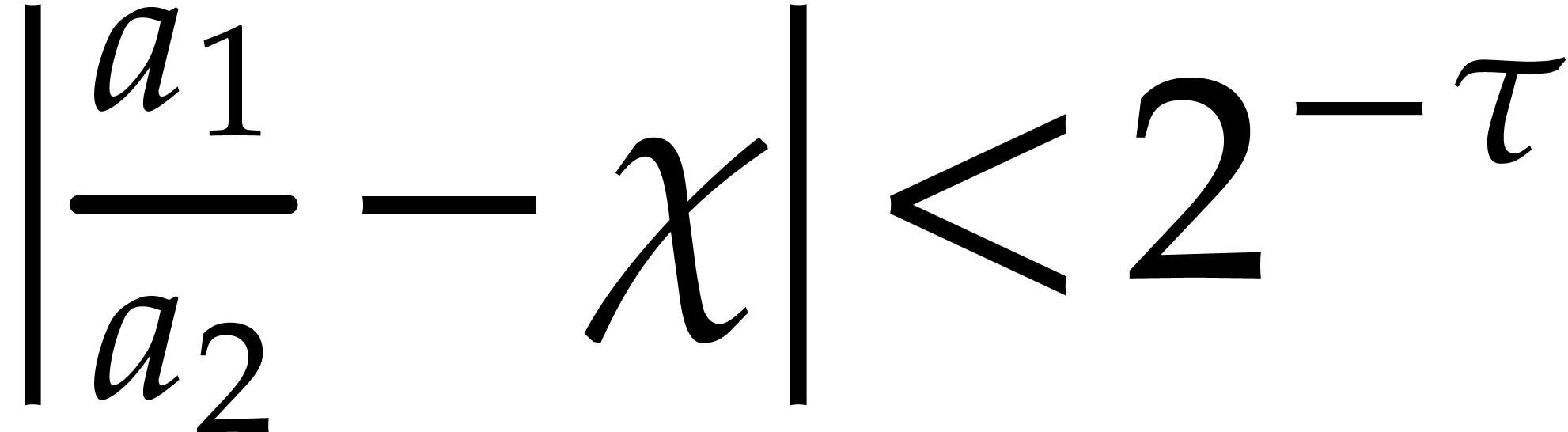 can be computed in time
can be computed in time 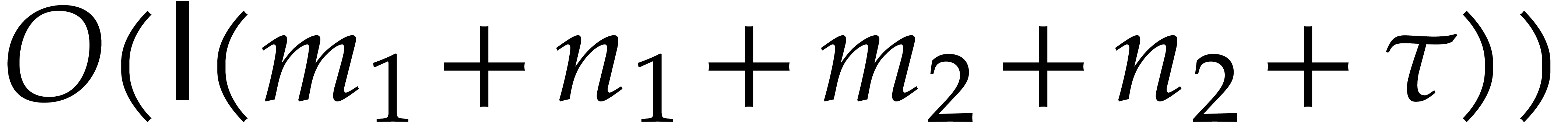 .
.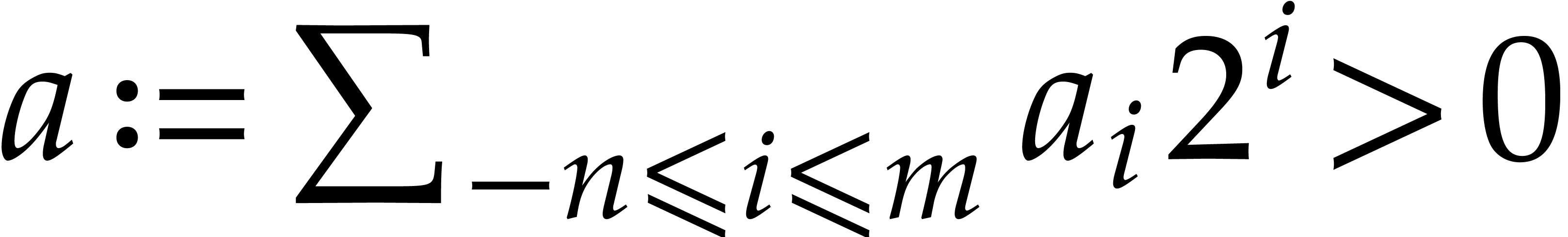 .
.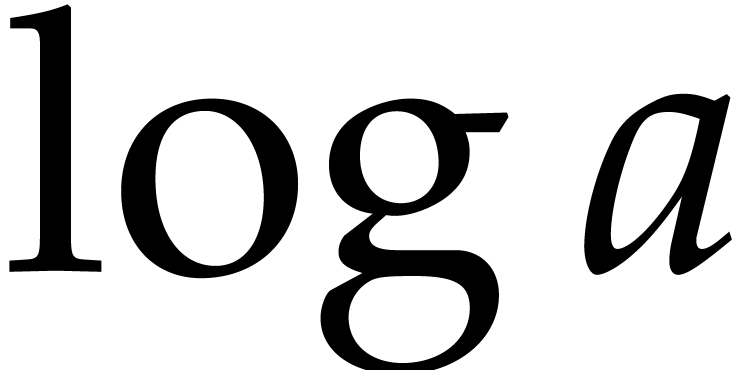 with
with 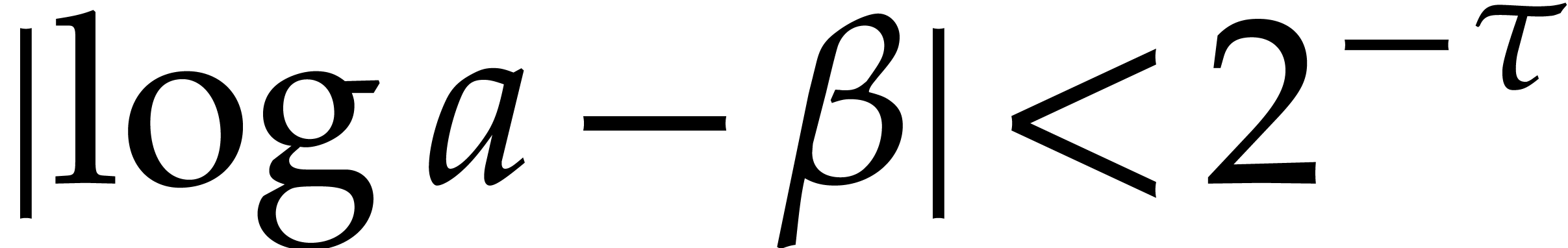 for
for 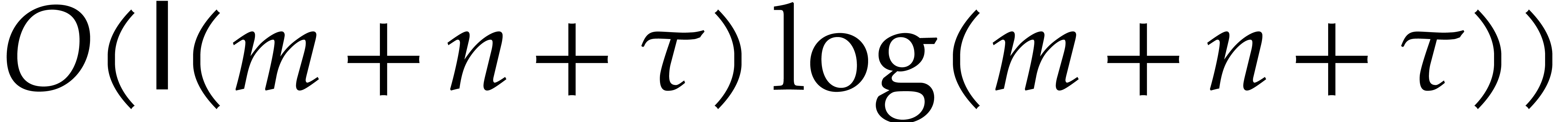 .
.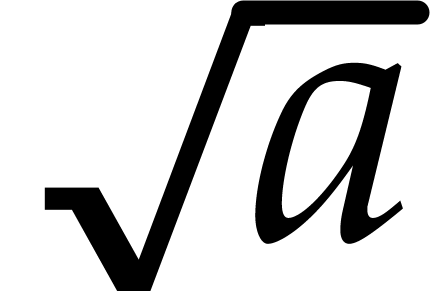 to
precision
to
precision  may be computed in time
may be computed in time 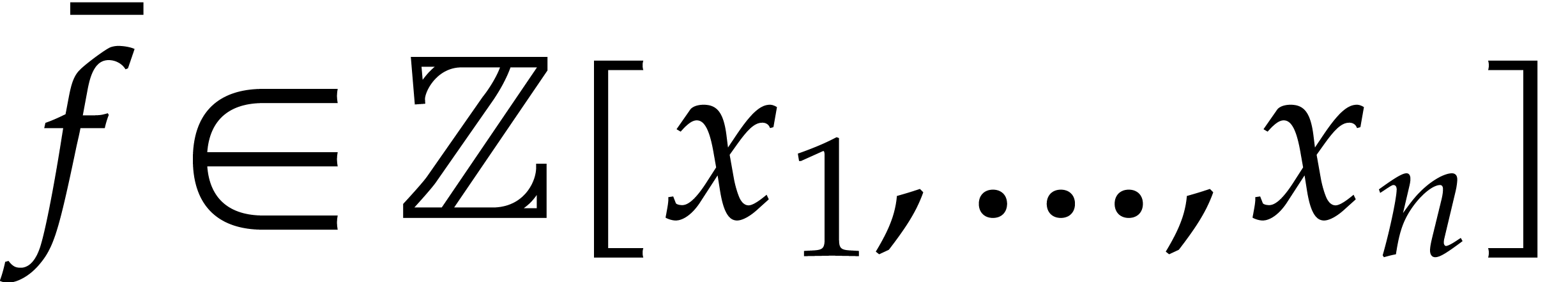 have coefficients in
have coefficients in  .
.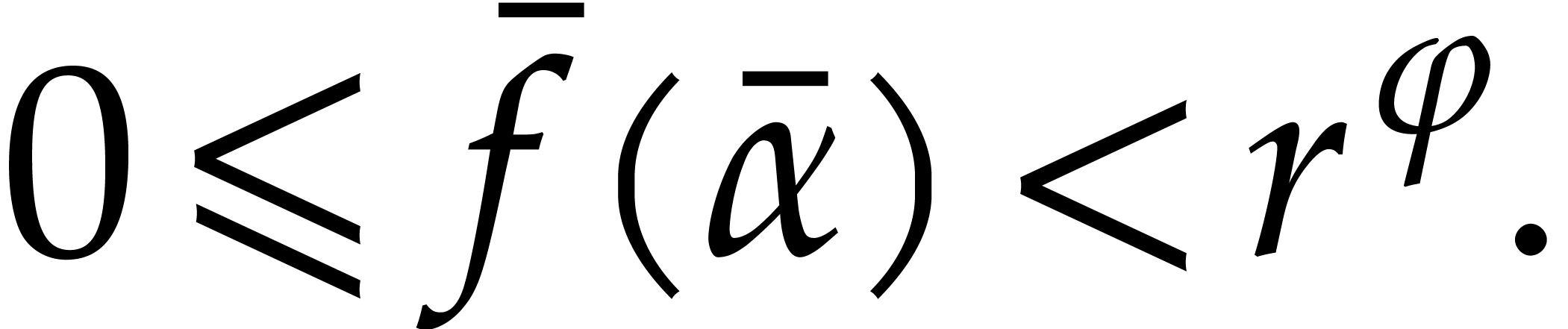
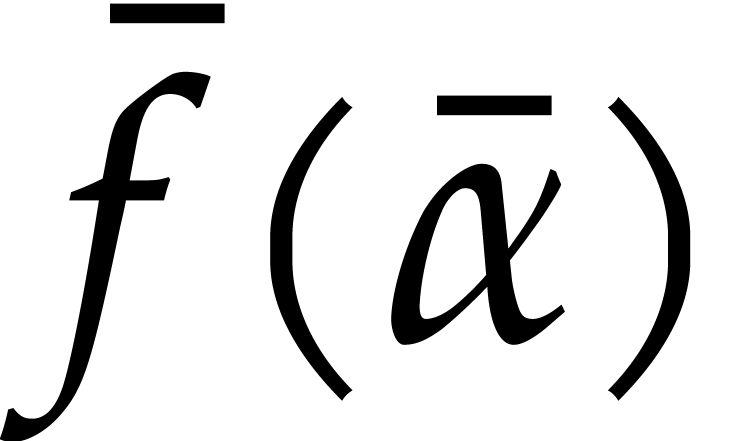
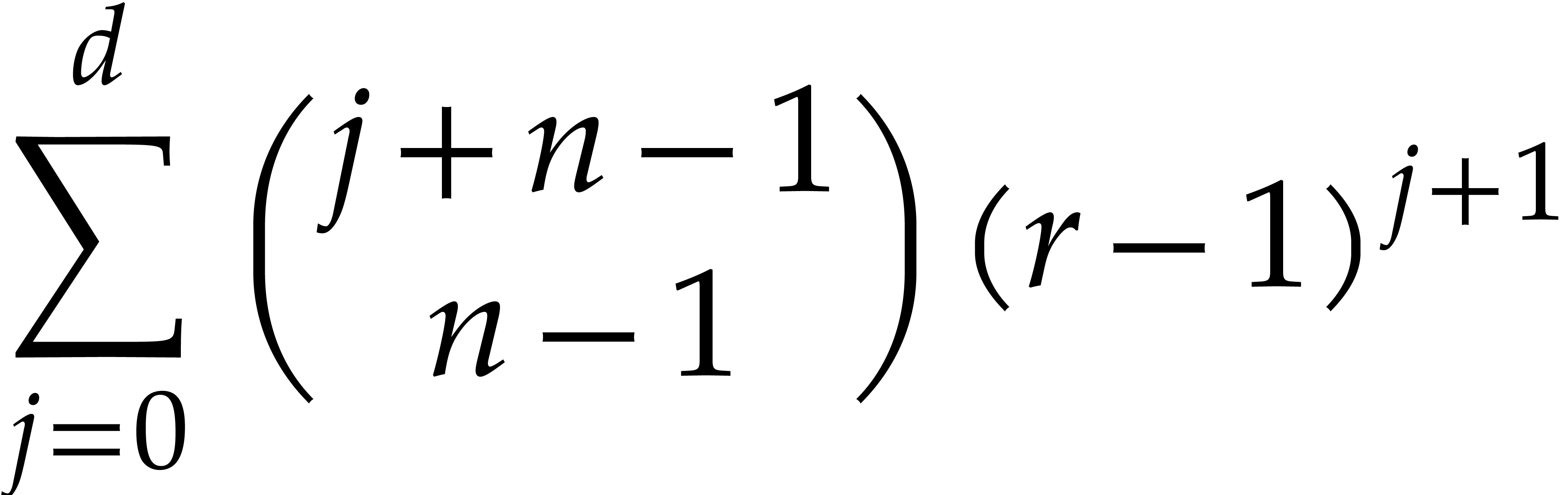
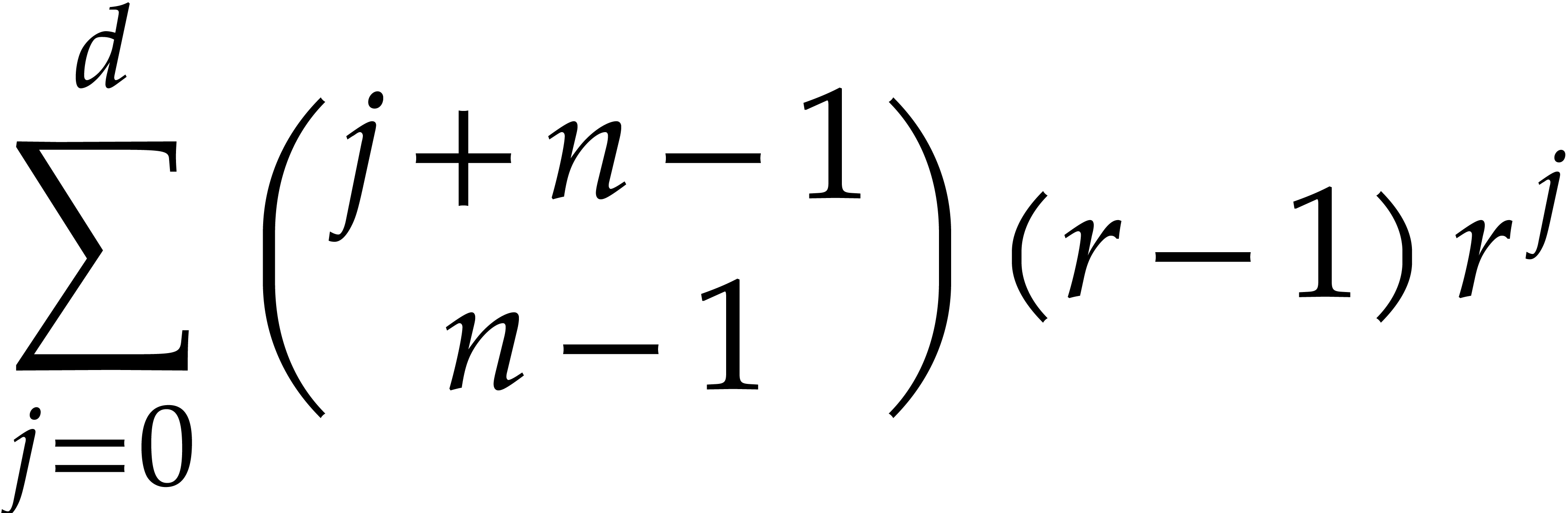
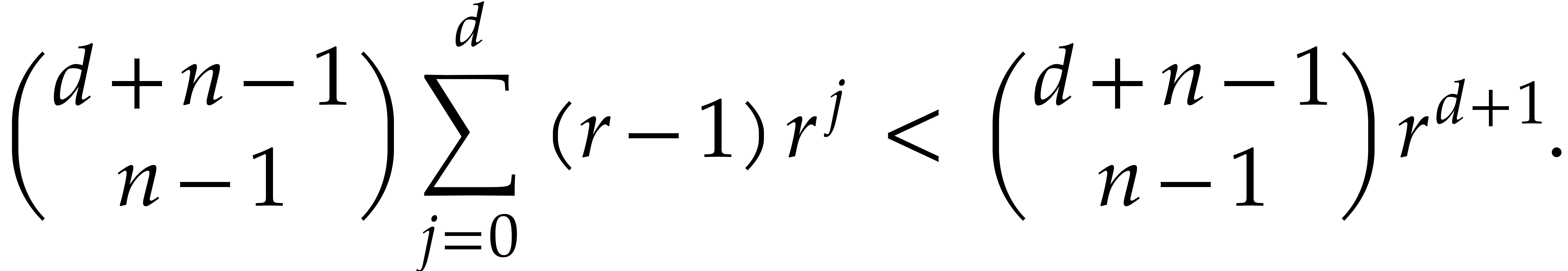
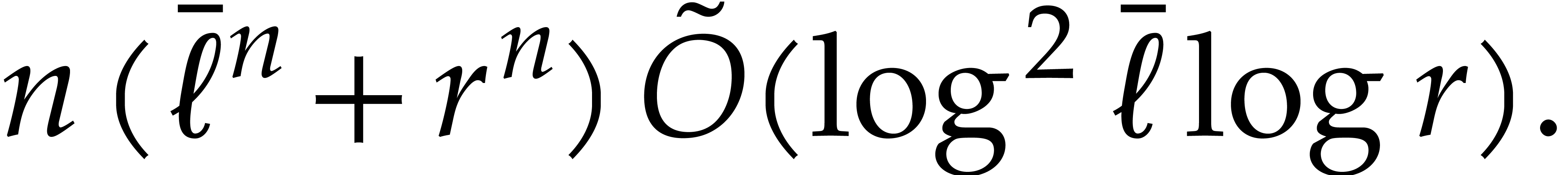
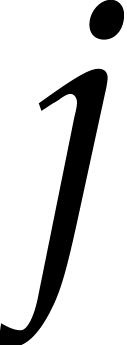 from
from 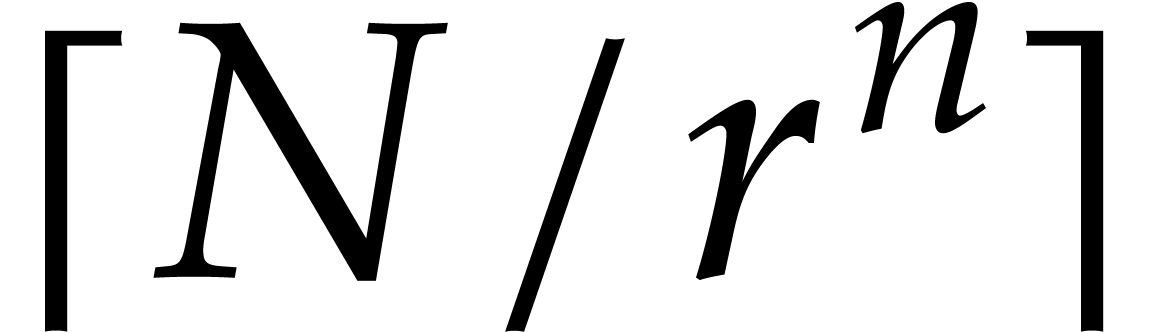 do
do
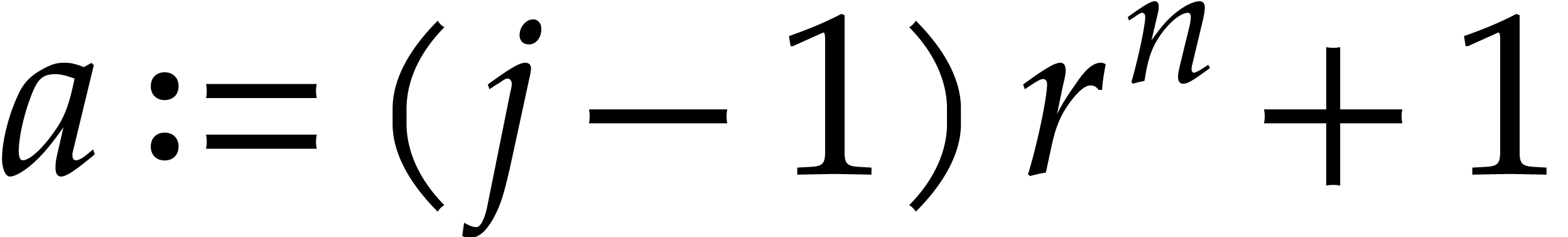 and
and 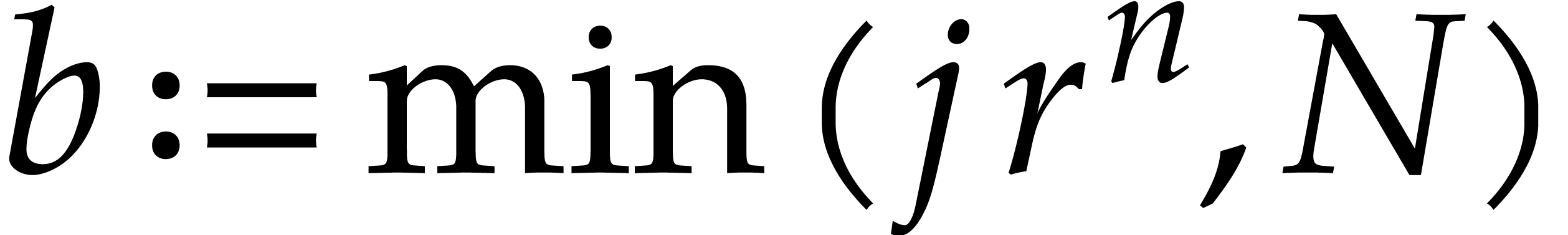 .
.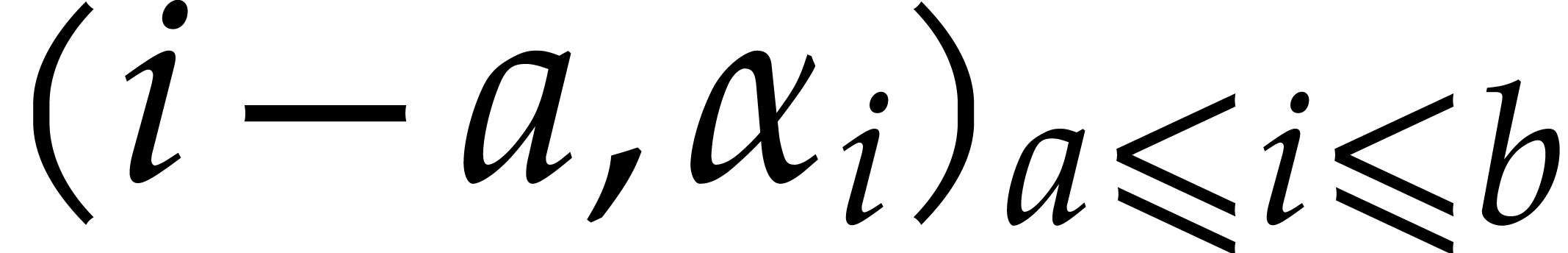 into
into 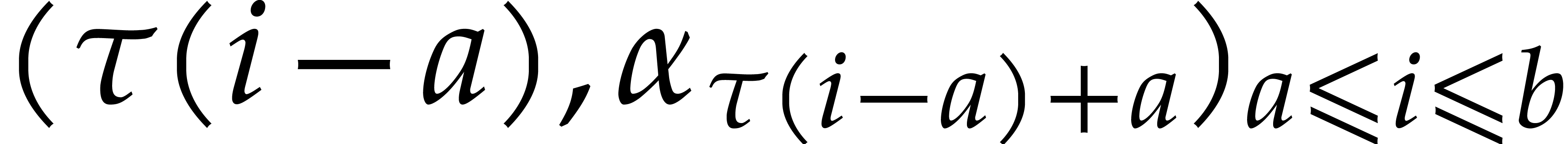 accordingly to the second coordinate
(where
accordingly to the second coordinate
(where  denotes a permutation of
denotes a permutation of
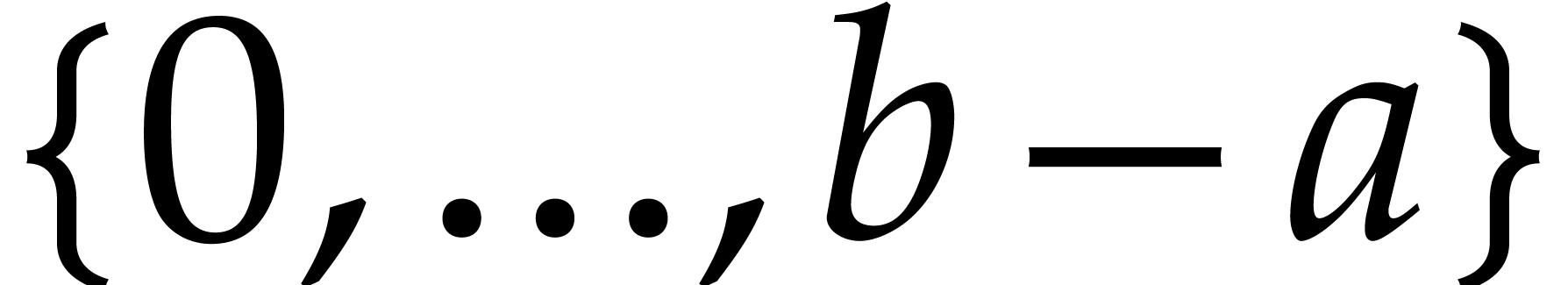 ).
).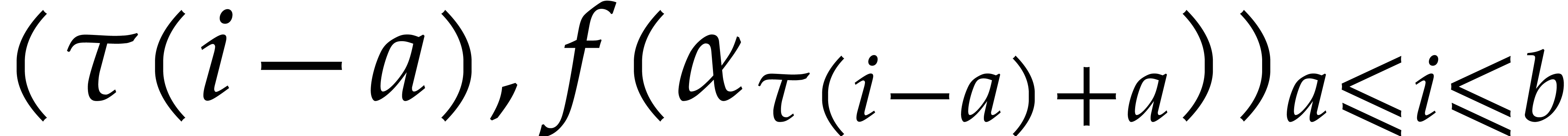 by using the
exhaustive evaluation of step 1.
by using the
exhaustive evaluation of step 1.
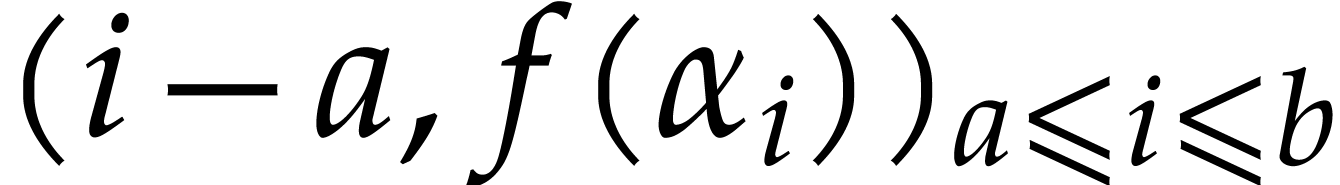 .
.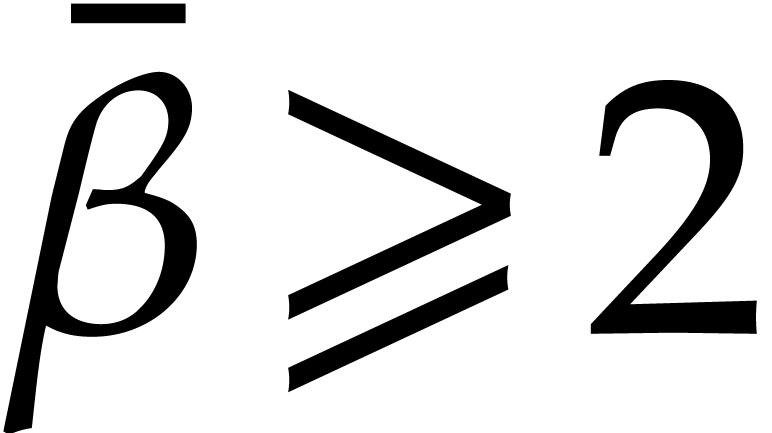 .
.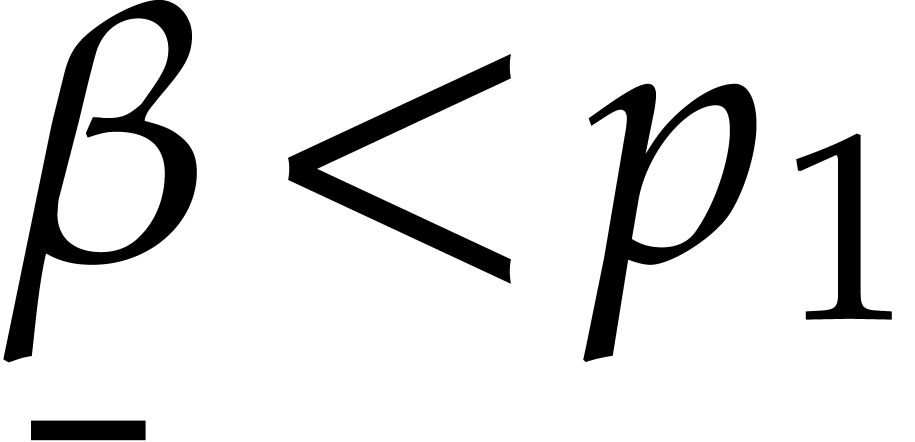 and
and 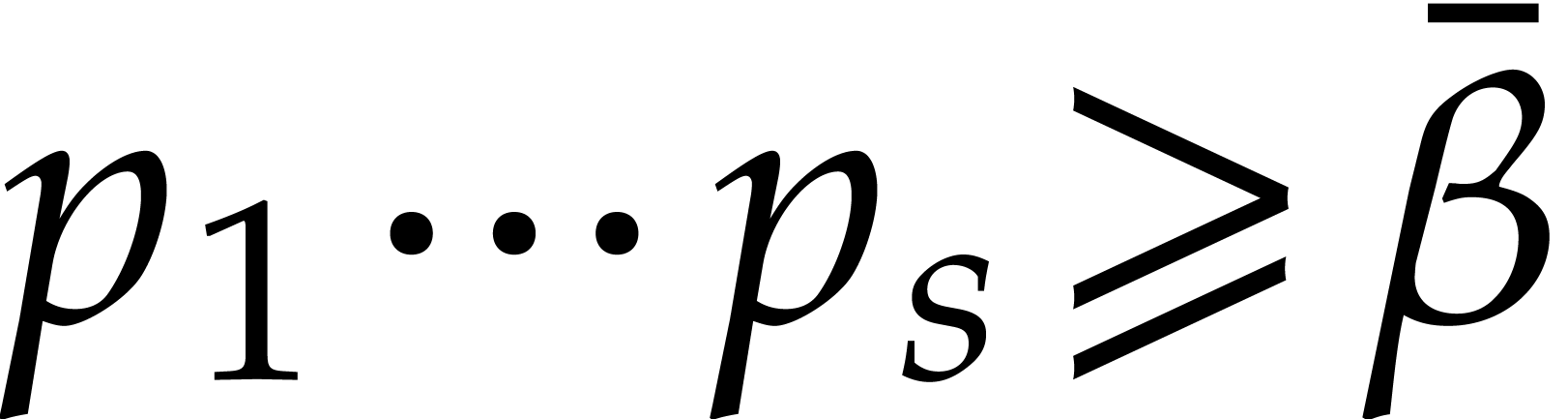 .
. .
. less or equal to
less or equal to  .
. ,
, ,
, and
and 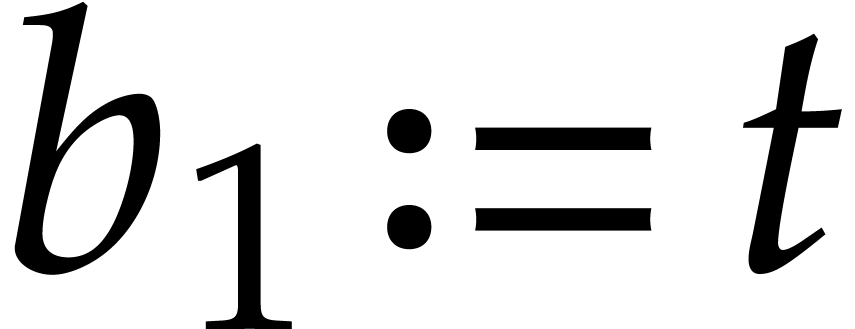 .
. ,
, .
. do
do
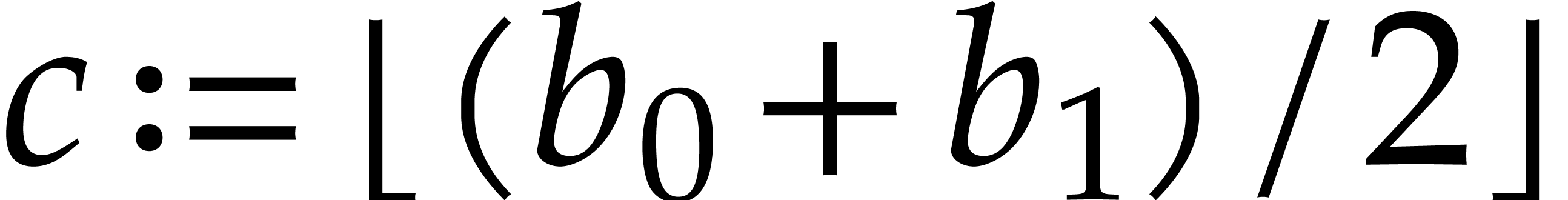 .
.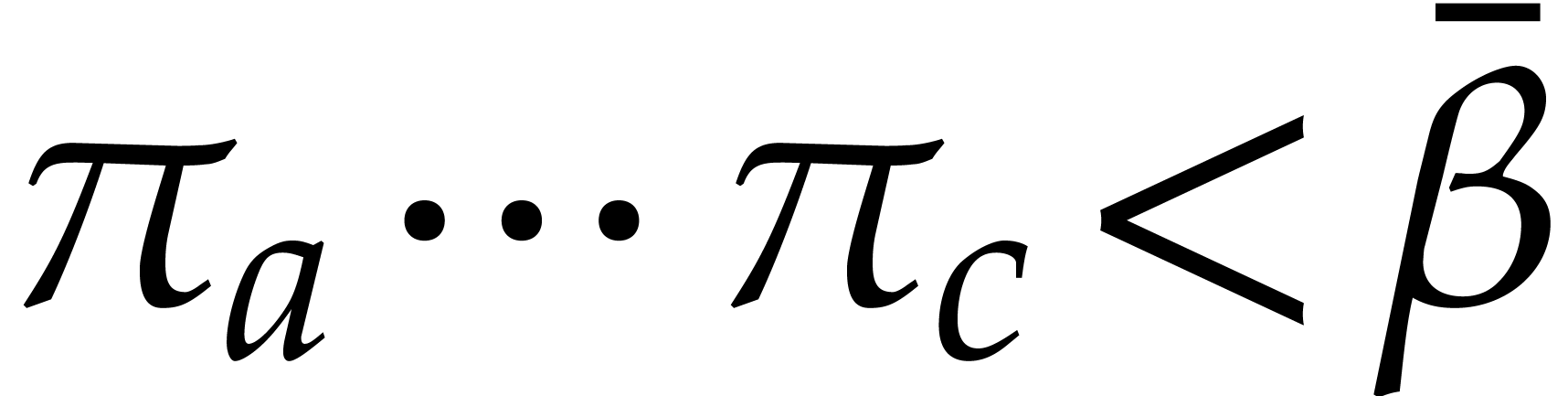 ,
, ,
, .
. .
. or if
or if  to compute the shortest sequence of
consecutive prime numbers
to compute the shortest sequence of
consecutive prime numbers  with
with  and
and  represent the canonical preimage of
represent the canonical preimage of
 ,
,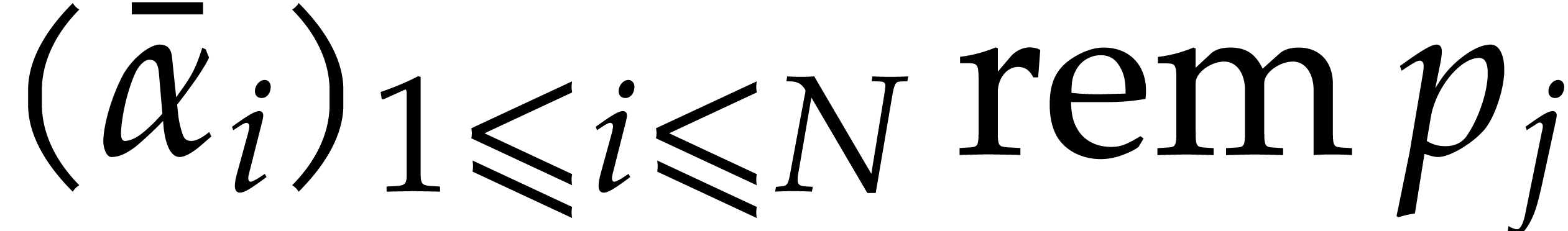 ,
, .
. ,
, modulo
modulo  by calling the
algorithm recursively with
by calling the
algorithm recursively with  .
.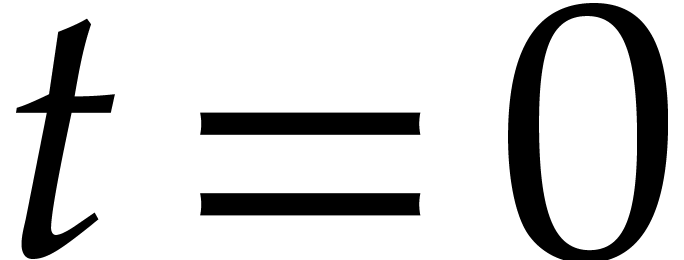 the algorithm takes time
the algorithm takes time
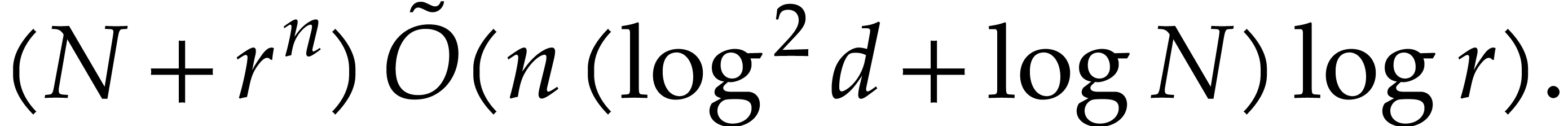
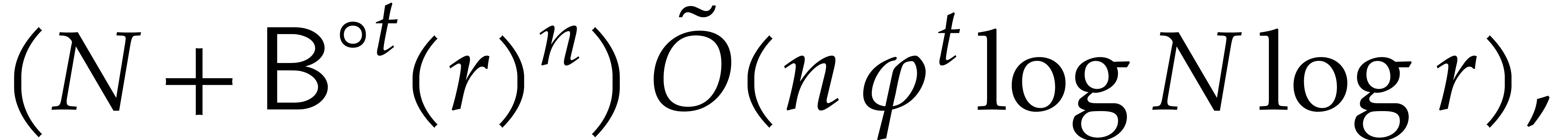
 is defined in
is defined in 
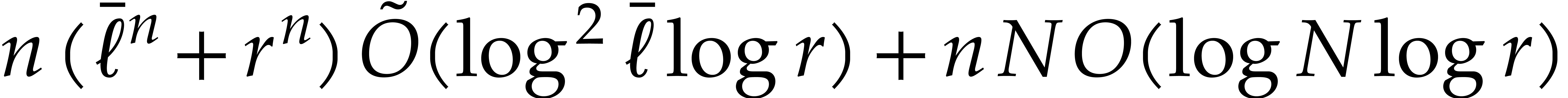
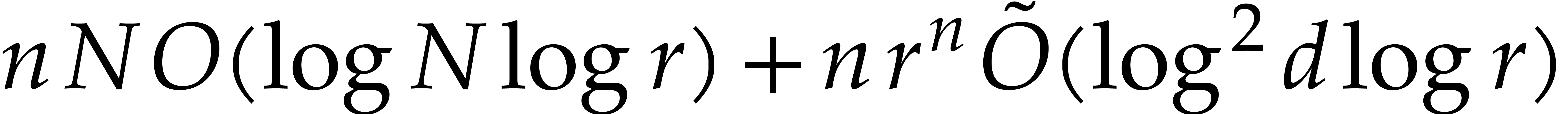
 in
in 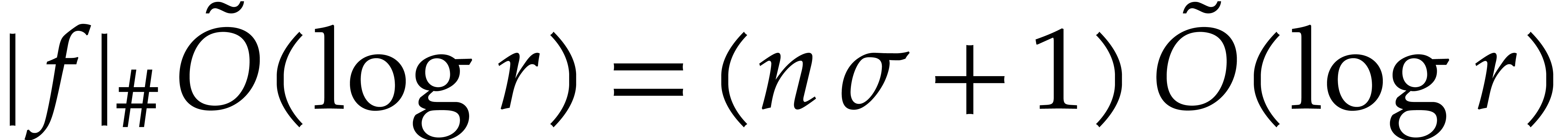 .
. .
. of
of  of
of  or
or  ,
, .
.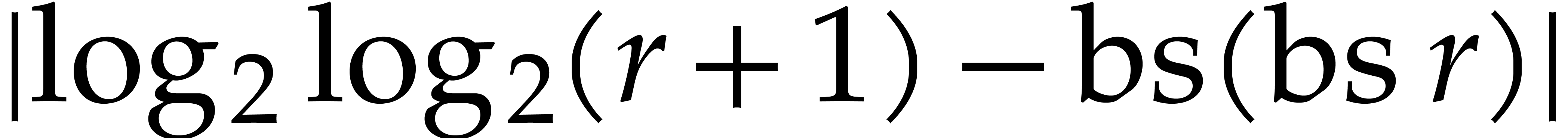
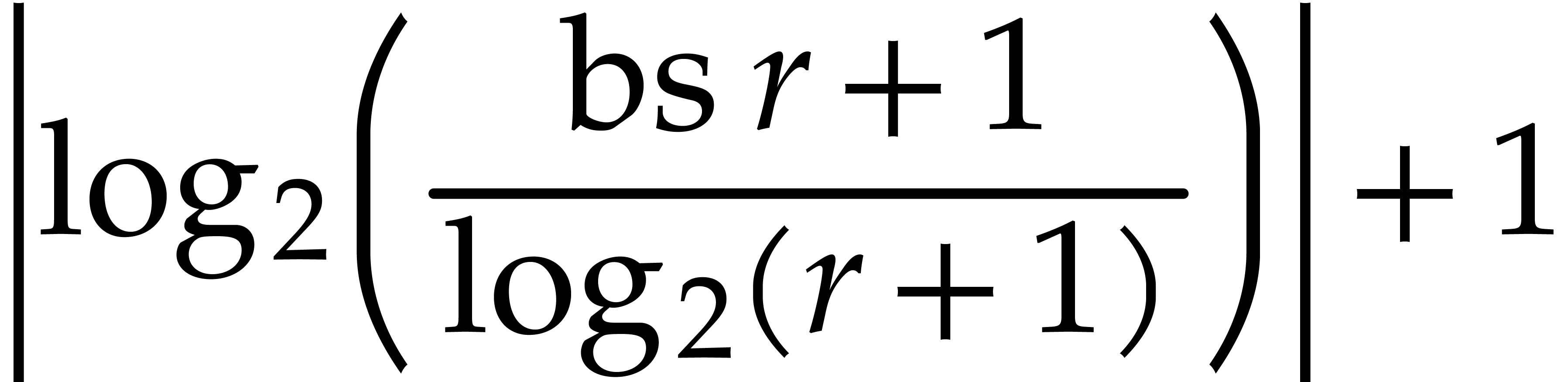
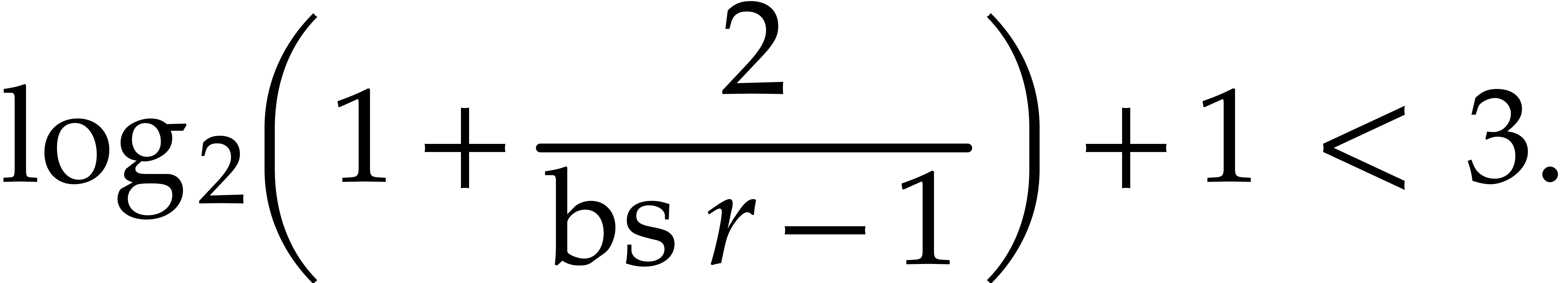
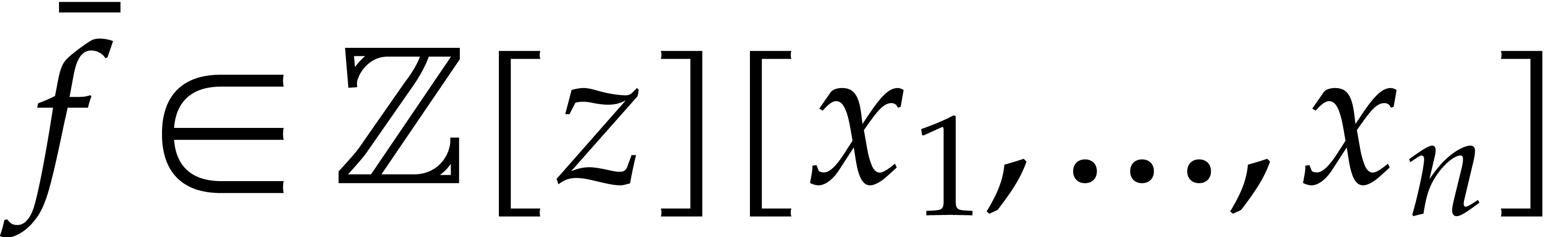 of partial degree
of partial degree 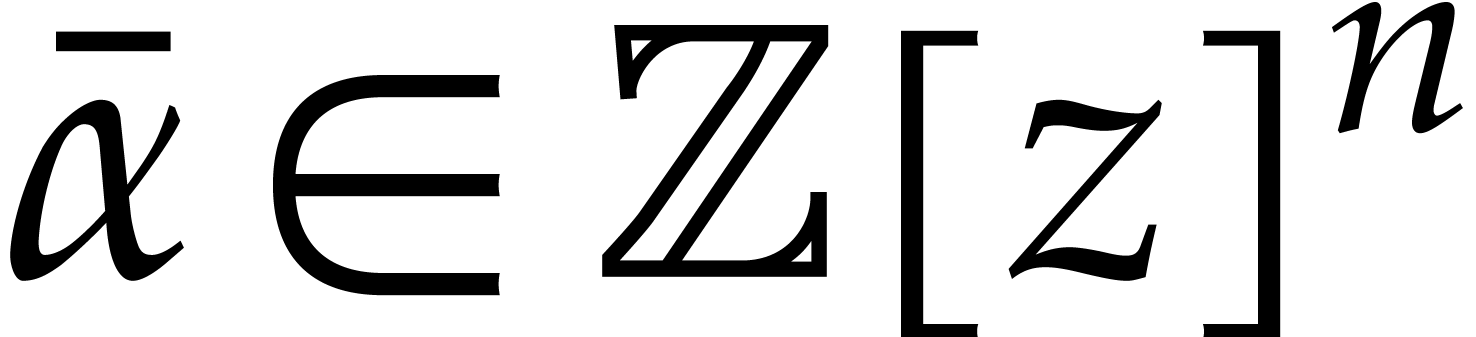 .
. and
and  have
their coefficients in
have
their coefficients in 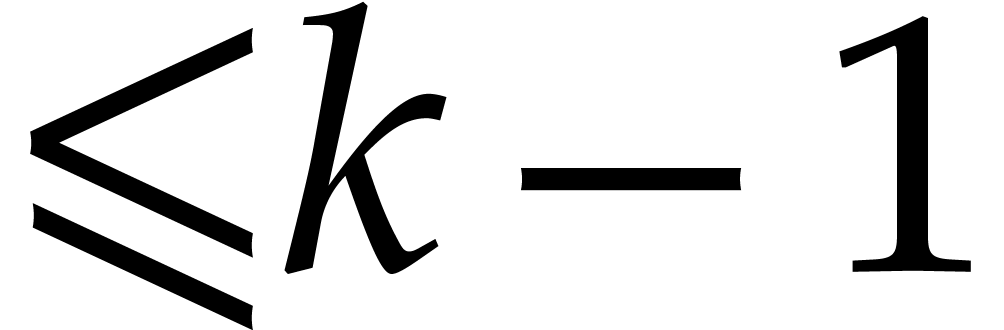 in
in 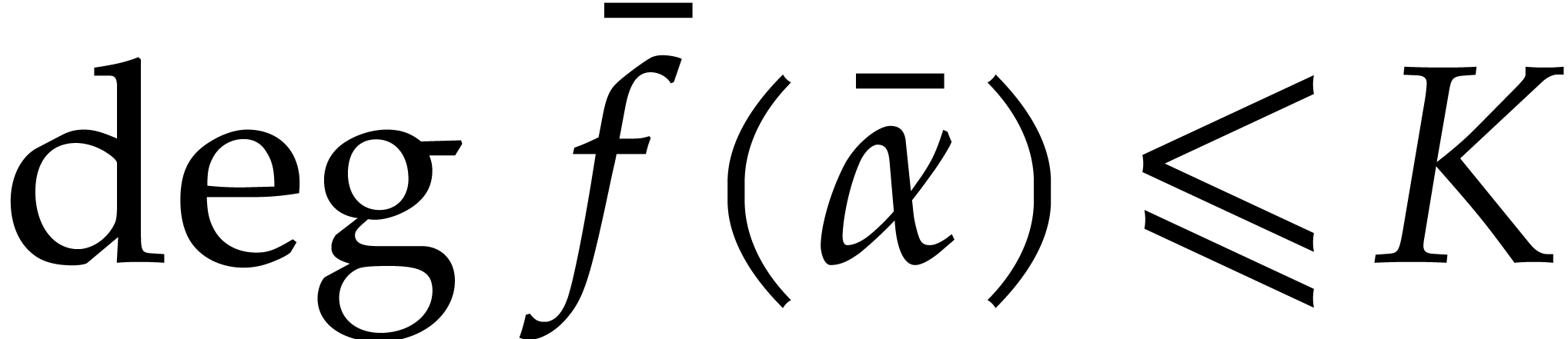 and
and 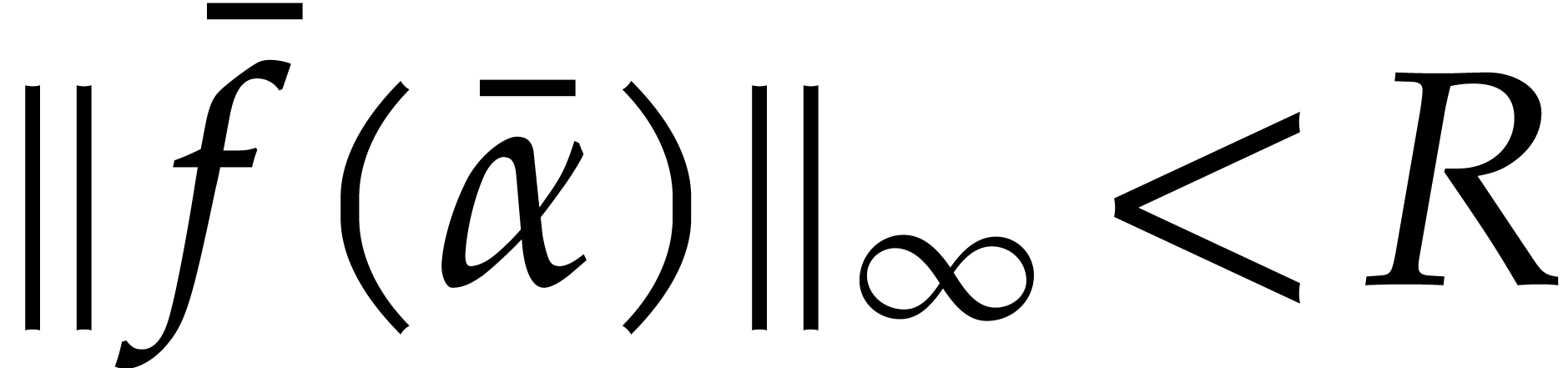 ,
,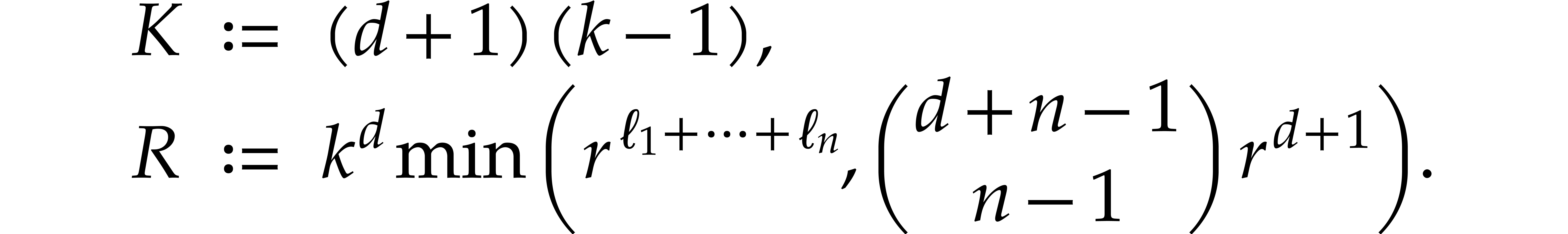
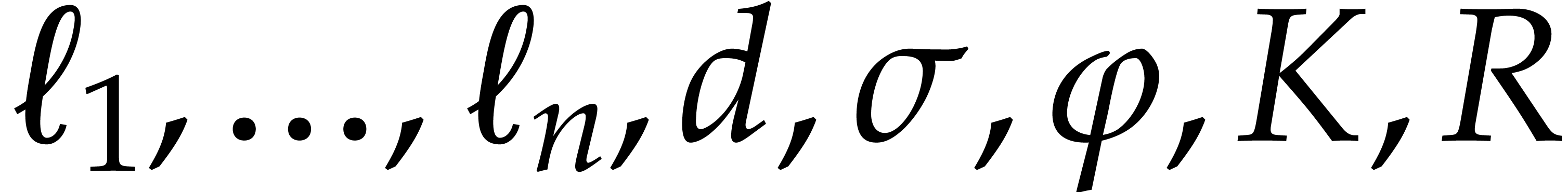 ,
, .
.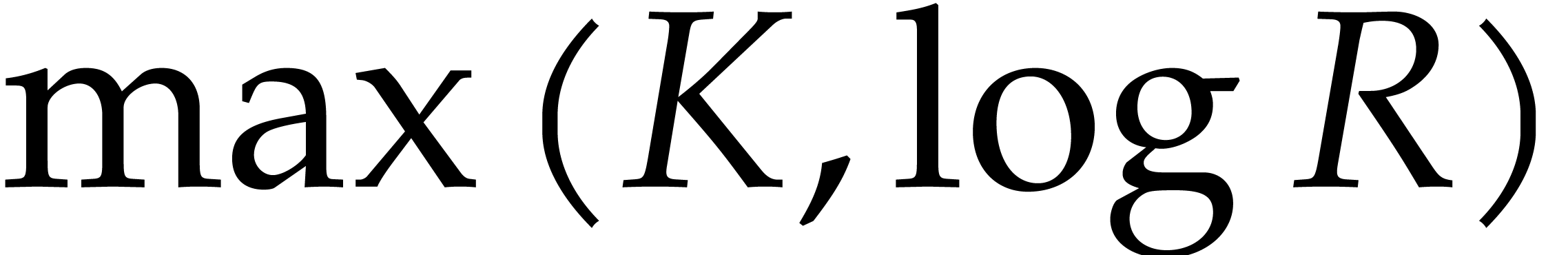 and
and
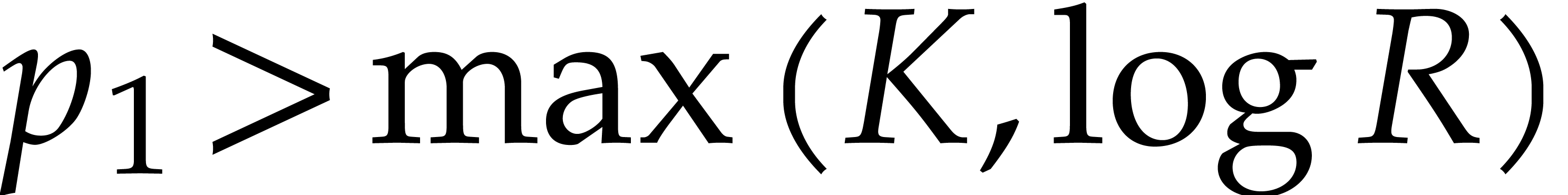 and
and 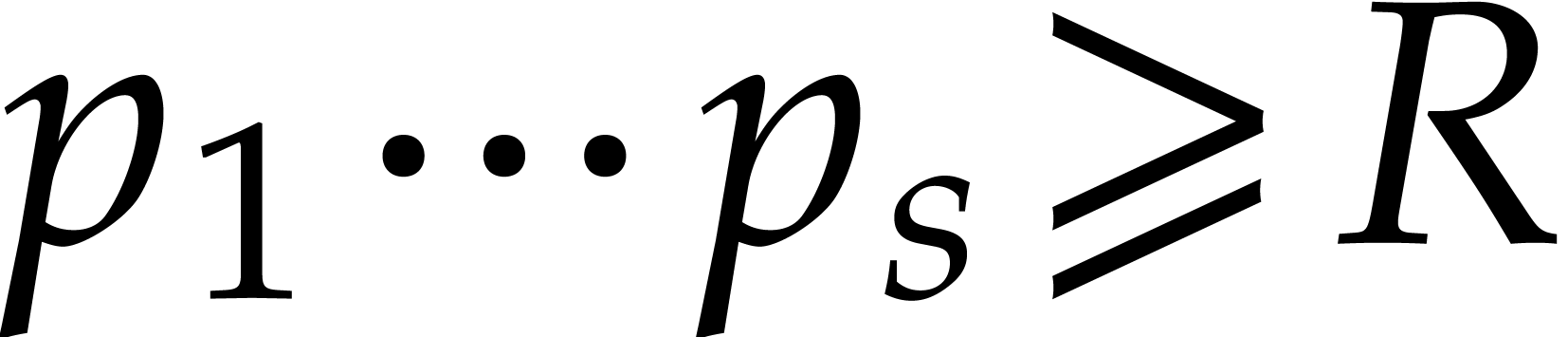 .
.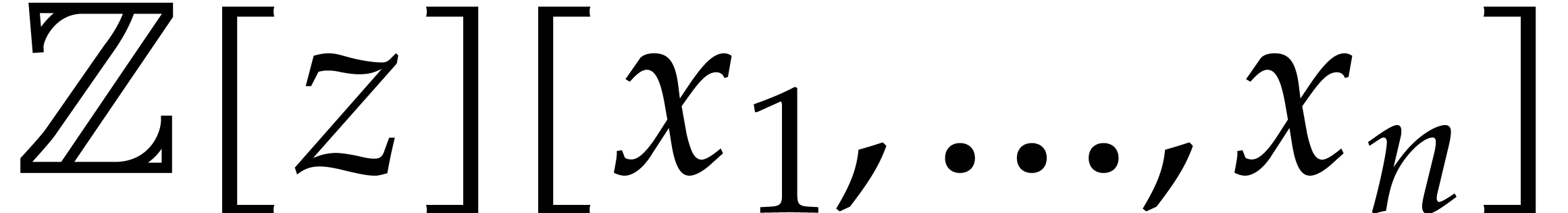 with degrees
with degrees 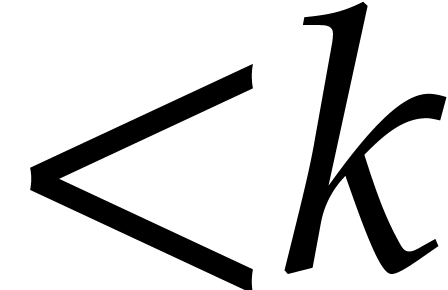 in
in 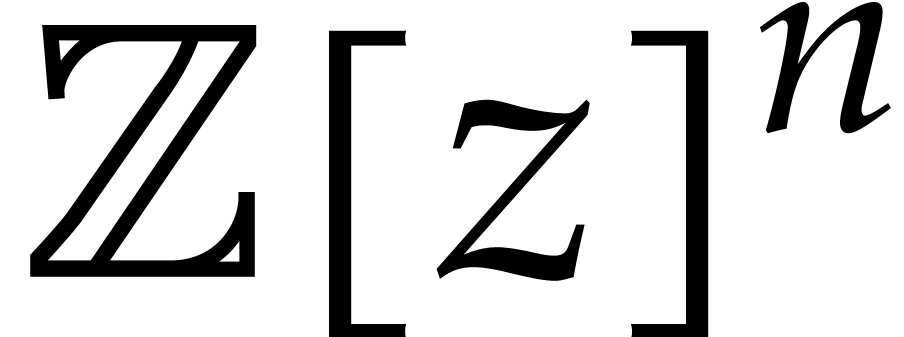 ,
,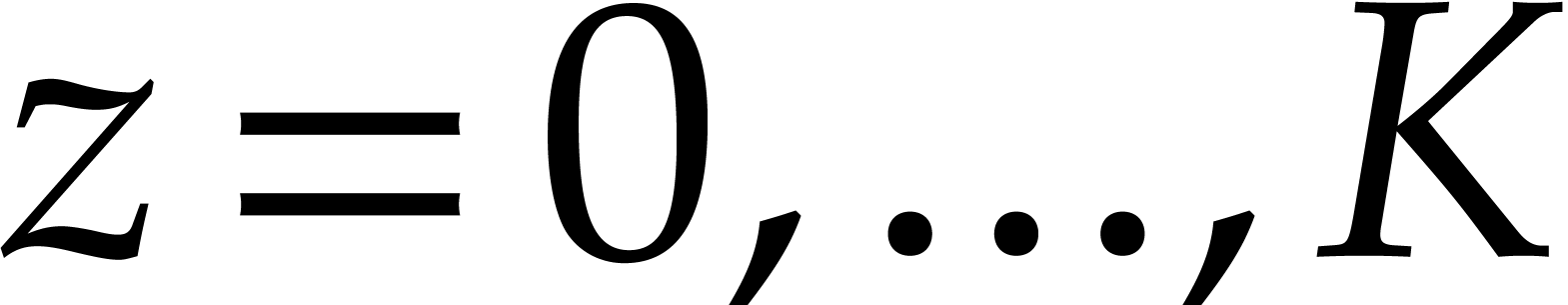 .
. for
for  .
.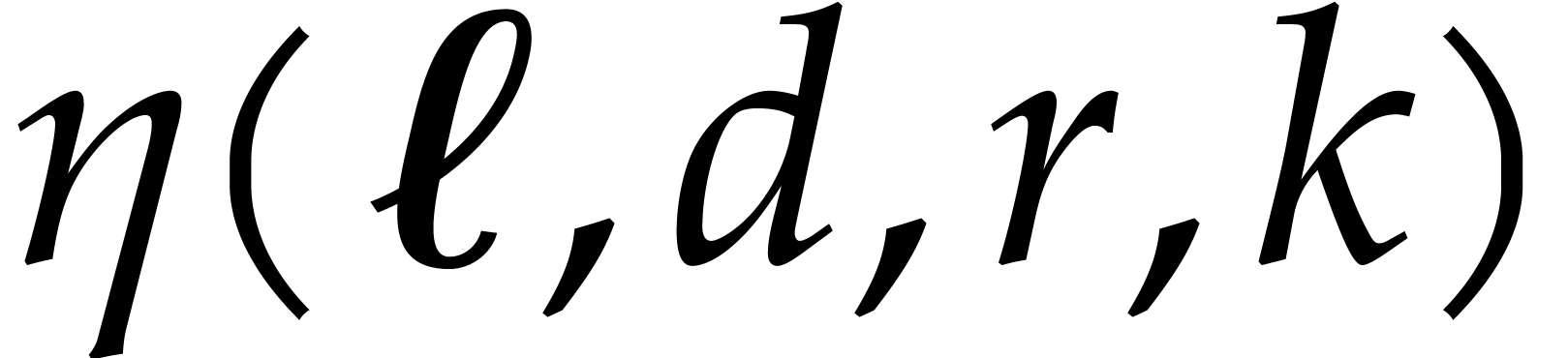 which tends to
which tends to
 tends to
infinity, such that the cost of Algorithm
tends to
infinity, such that the cost of Algorithm 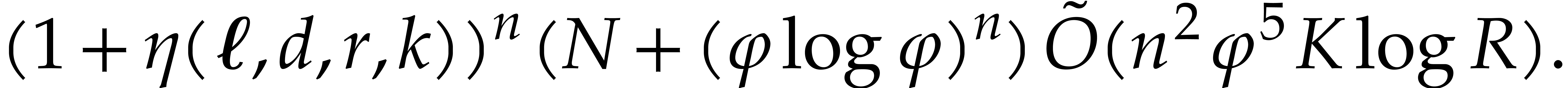
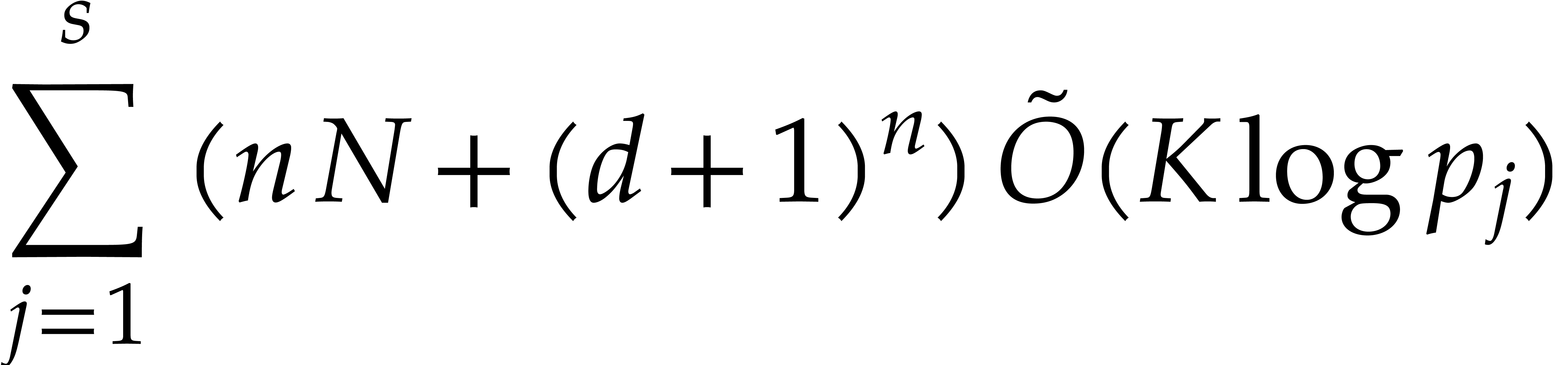
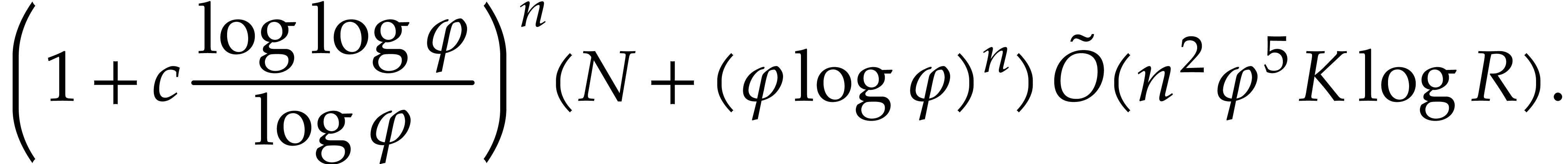
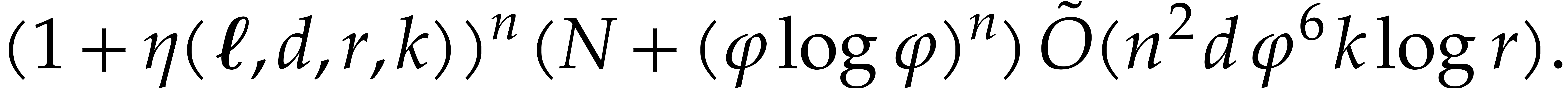
 be a fixed real
value. Let
be a fixed real
value. Let  in
in 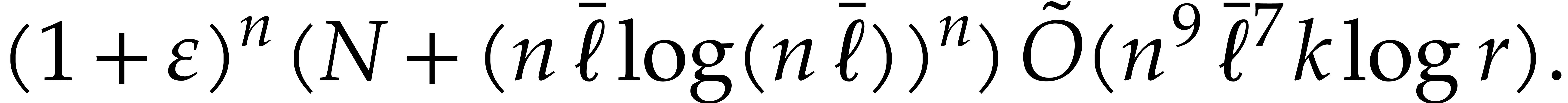
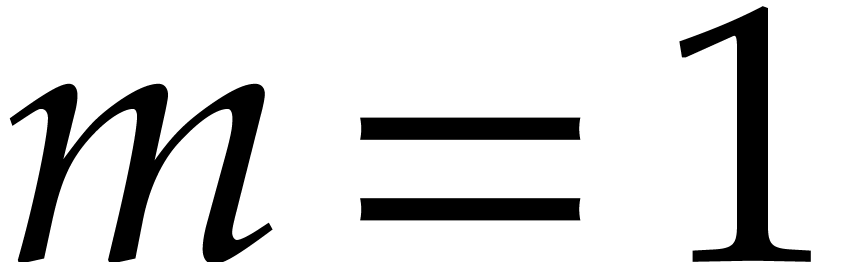 ,
,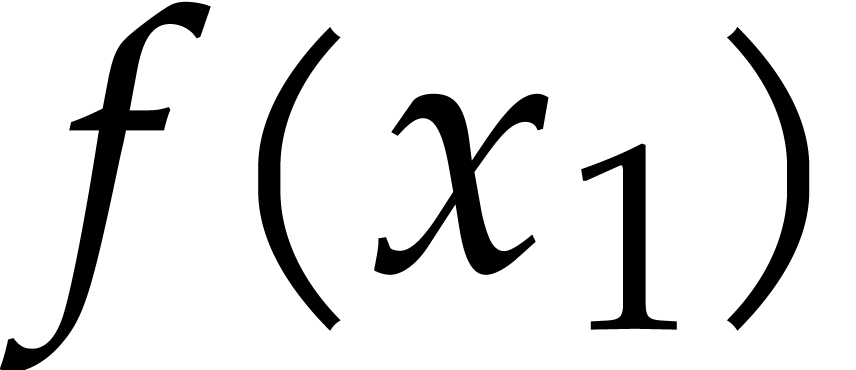 .
.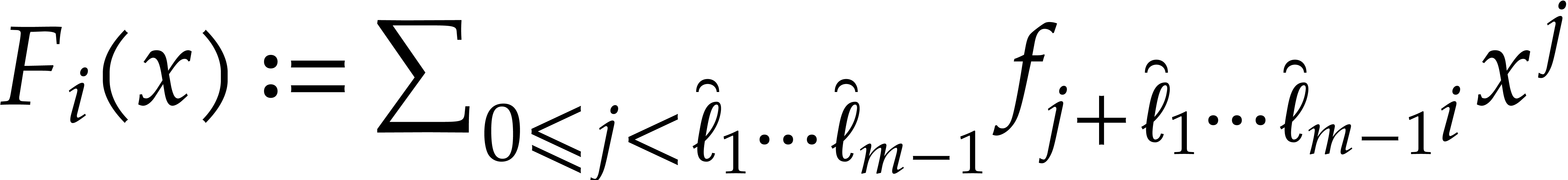 and integers
and integers
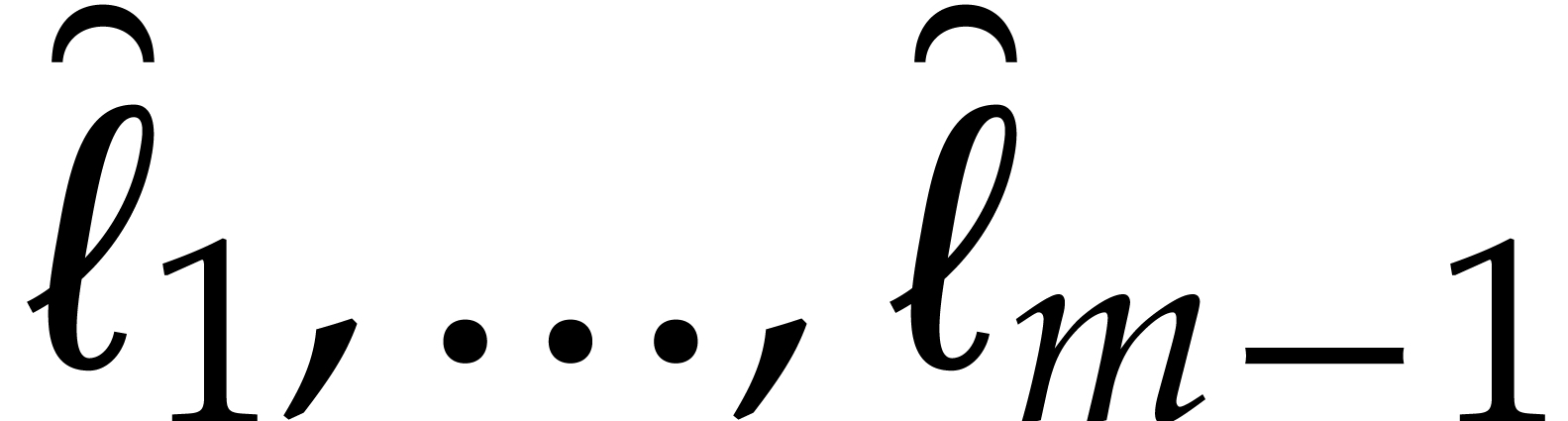 to obtain
to obtain 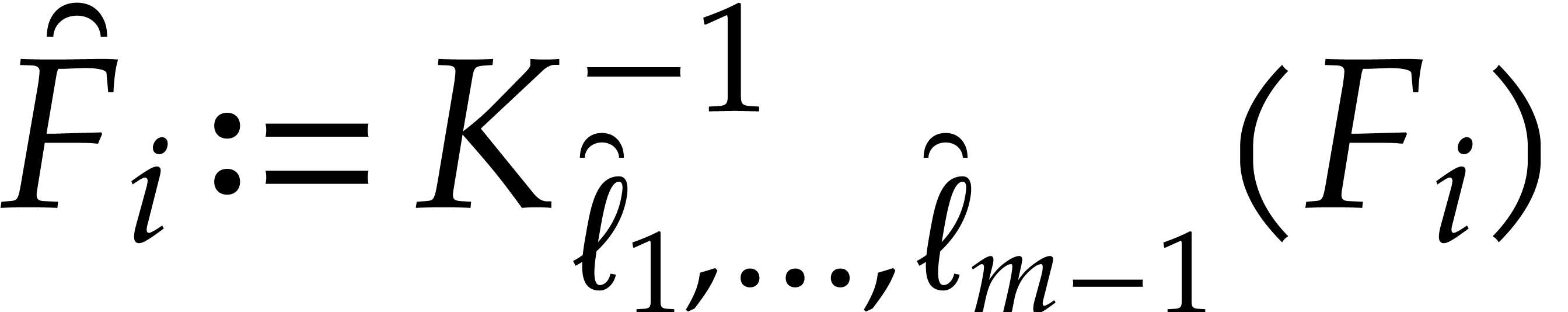 .
.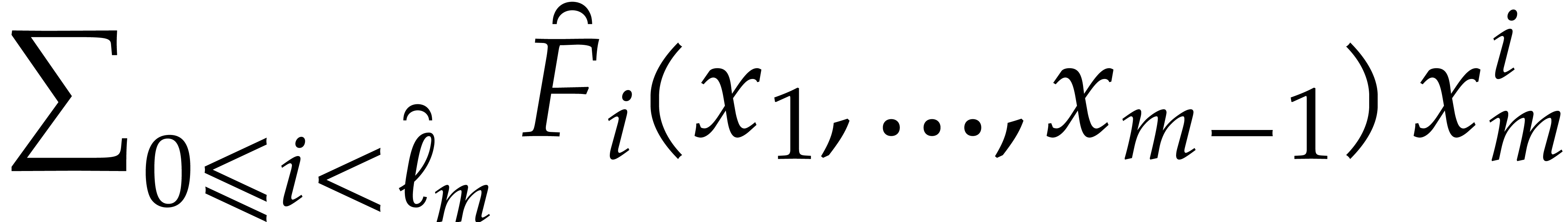 .
.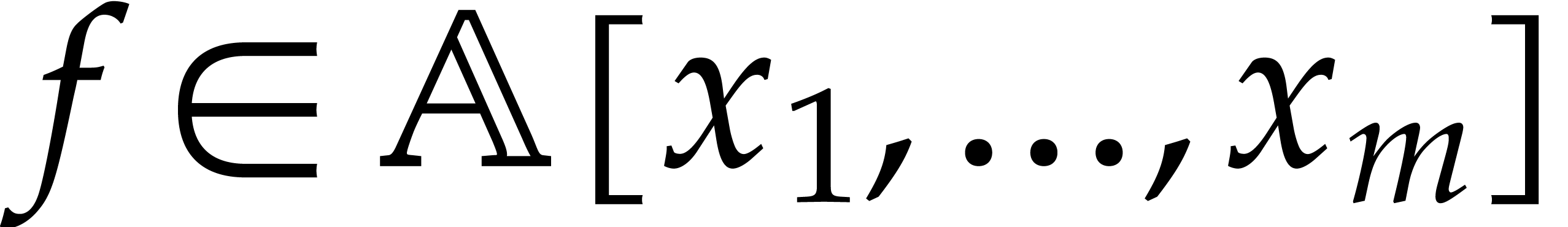 be of partial degree
be of partial degree
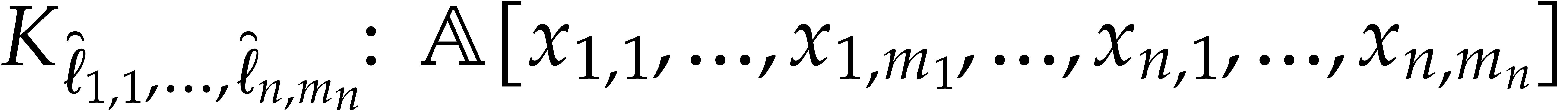
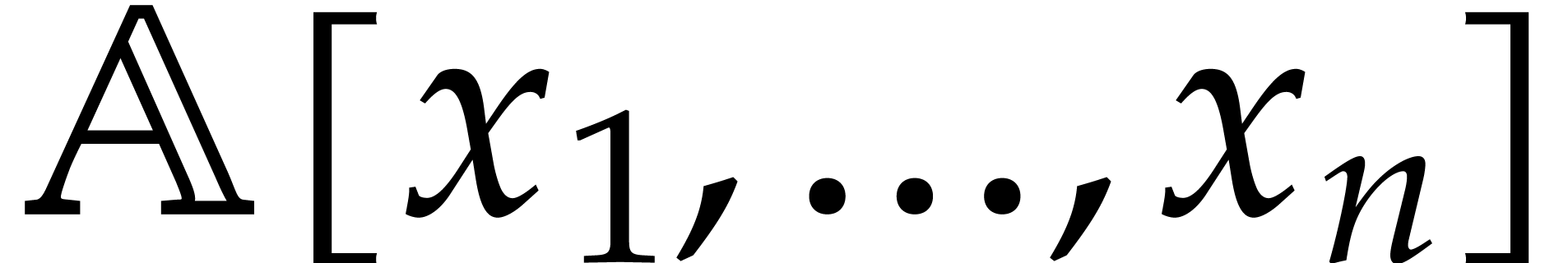
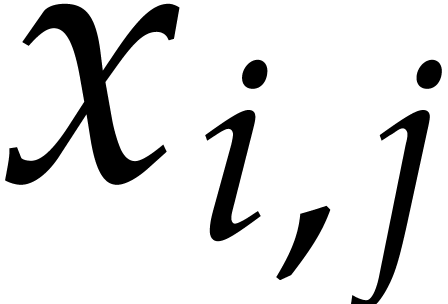
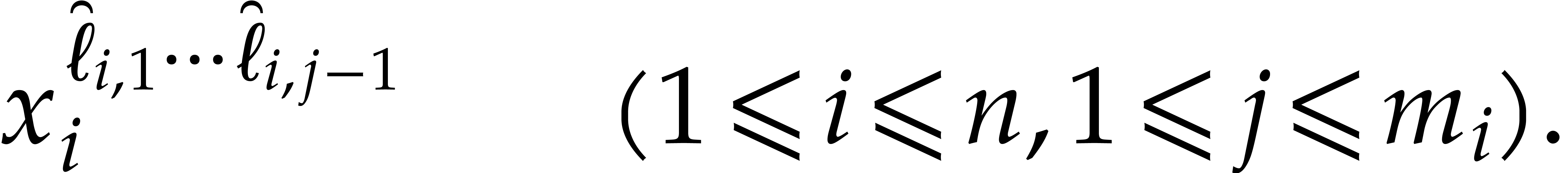

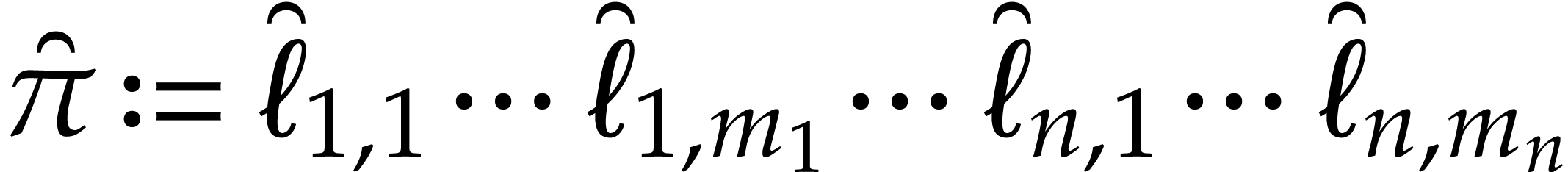 .
. .
. .
. .
.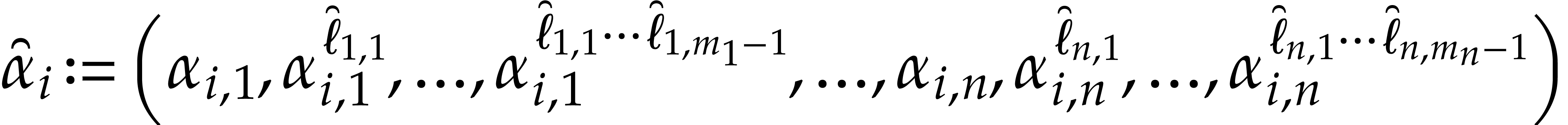 .
. .
.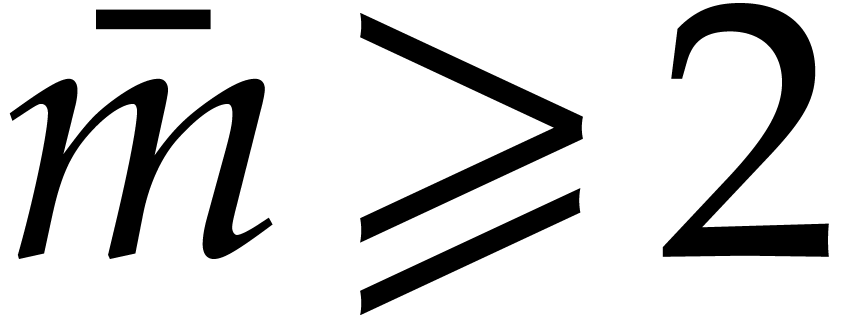 be a fixed integer. Let
be a fixed integer. Let 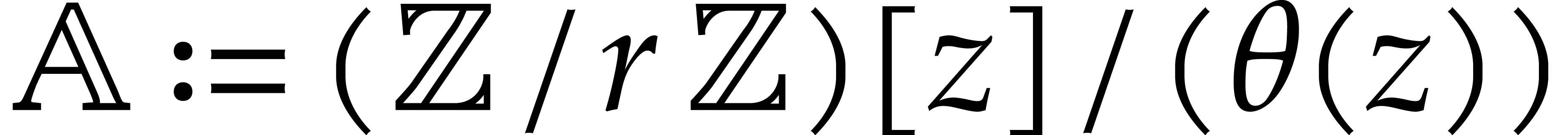 with
with  ,
,
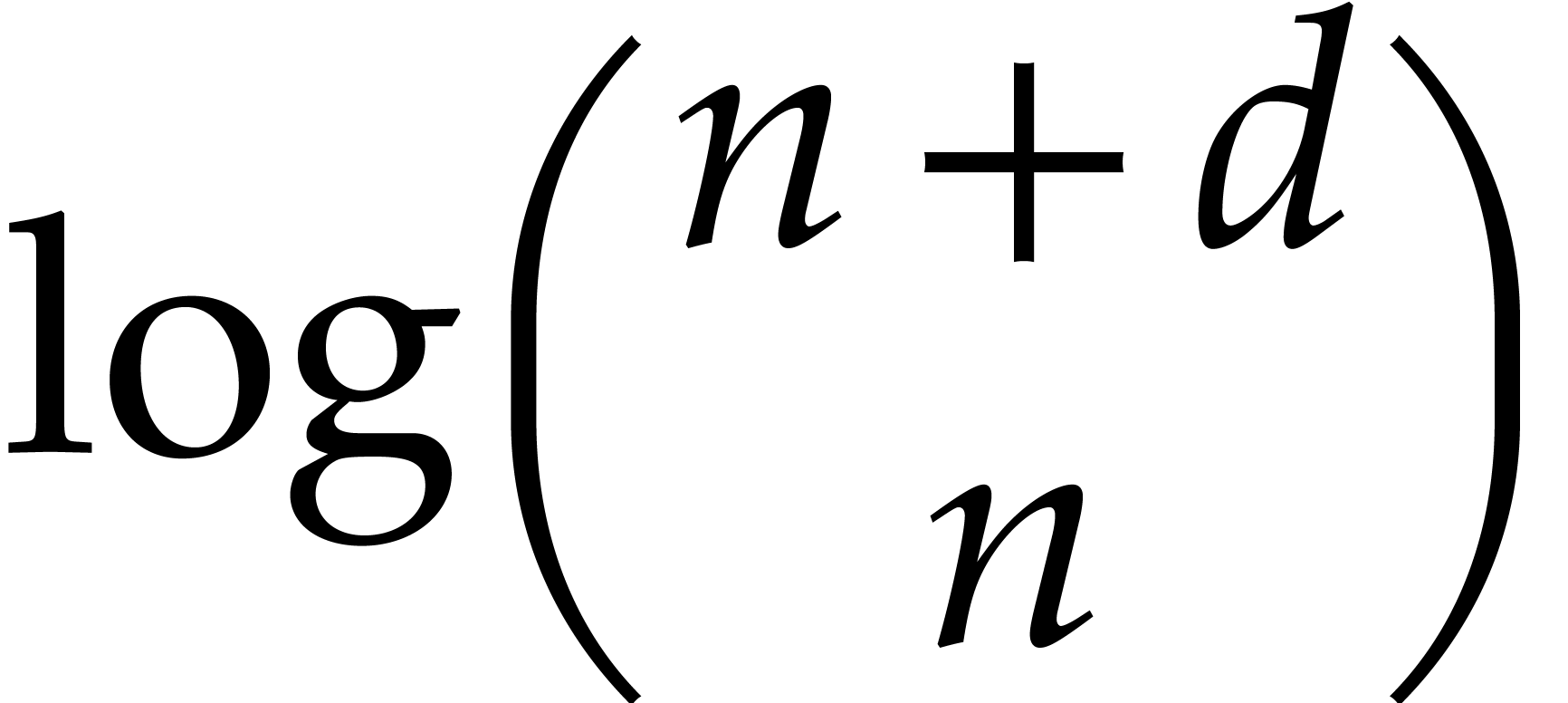
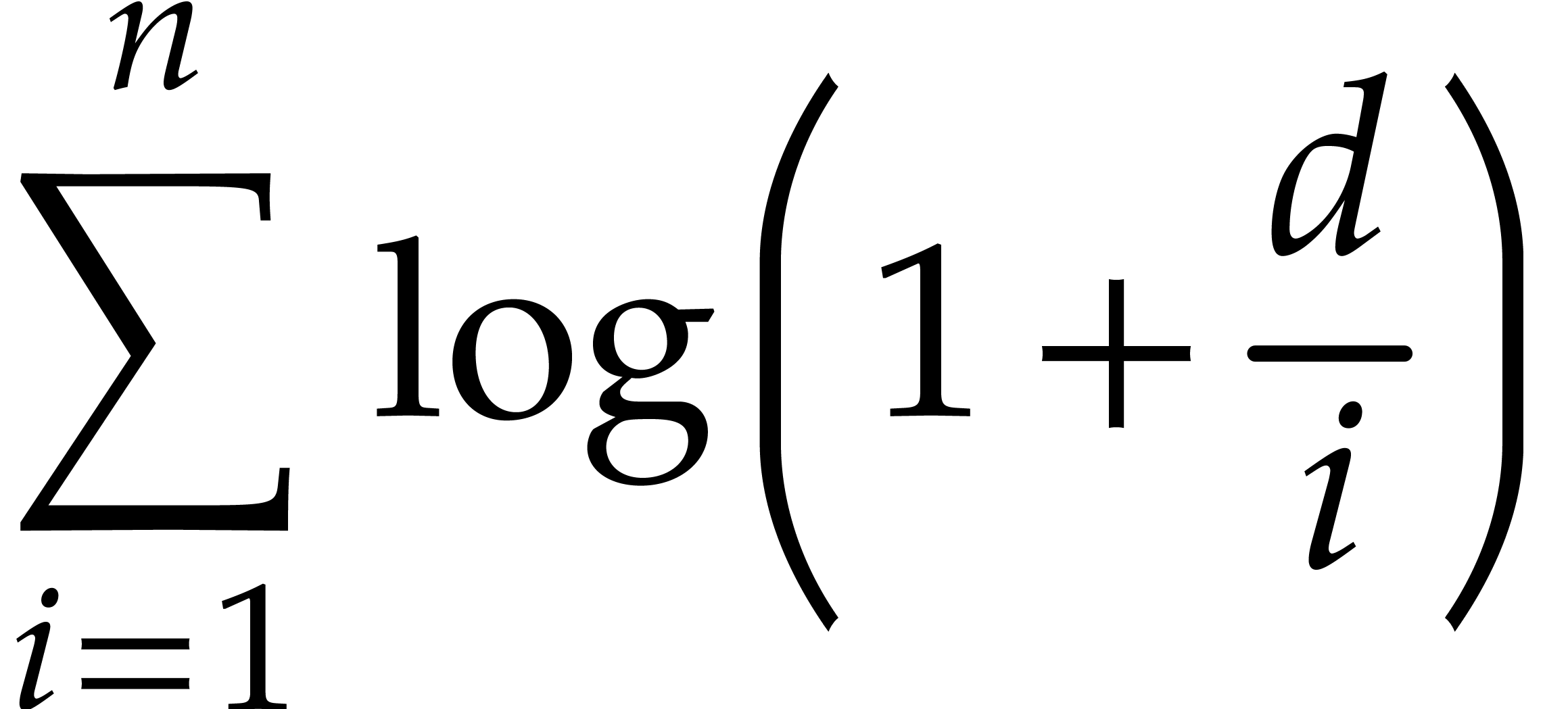
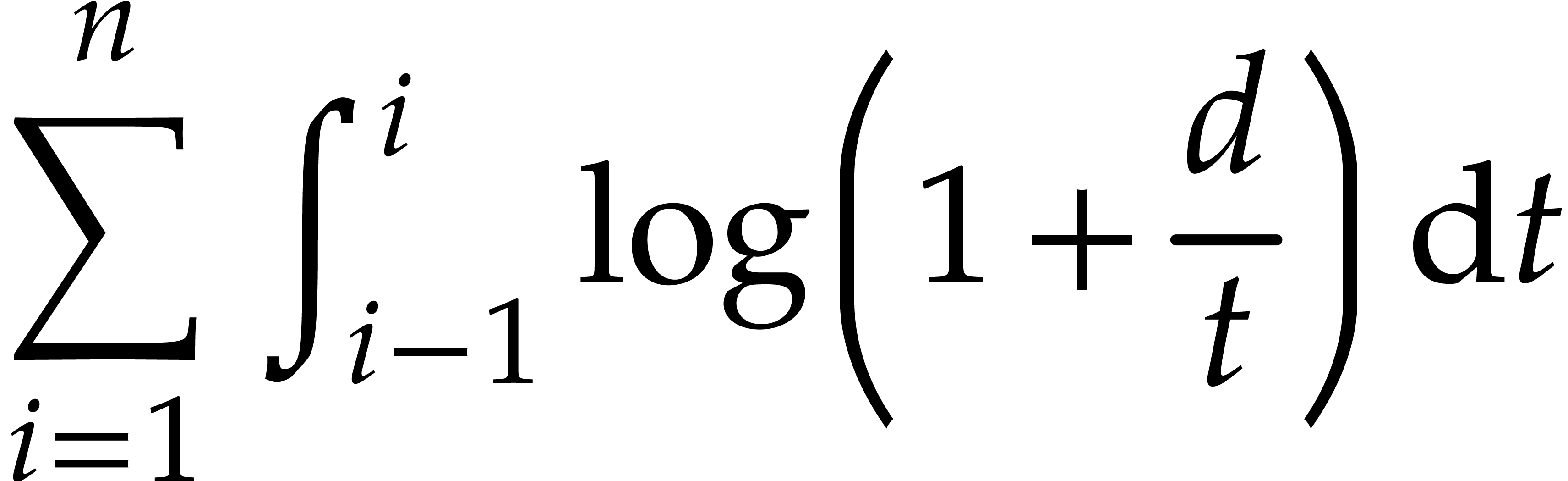
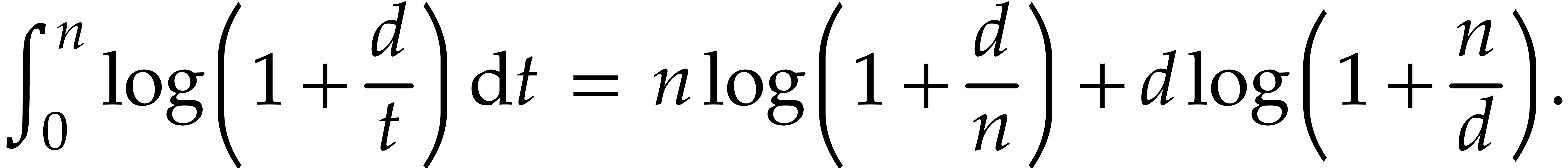
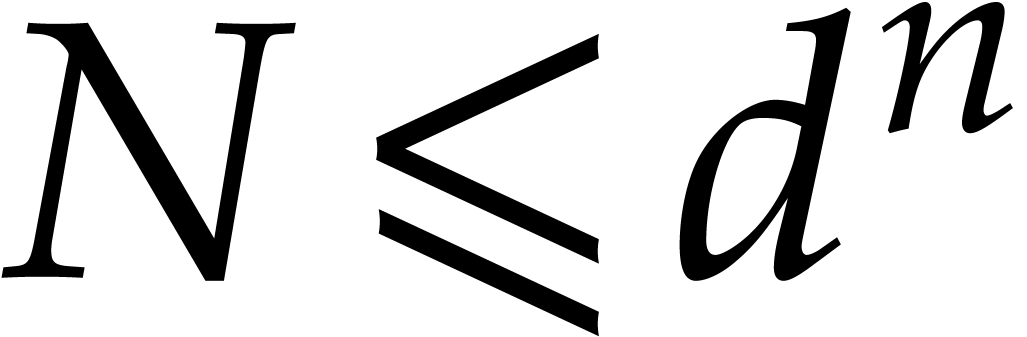 .
.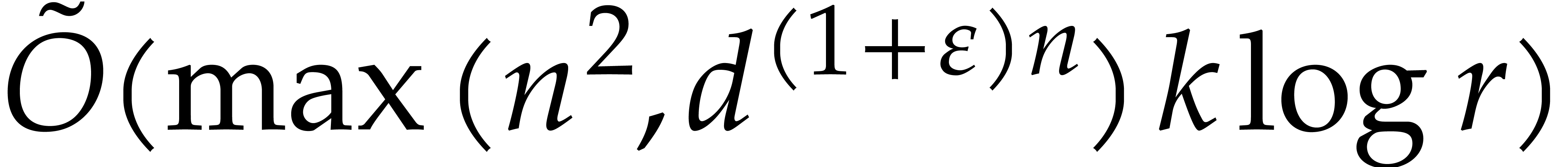 .
.
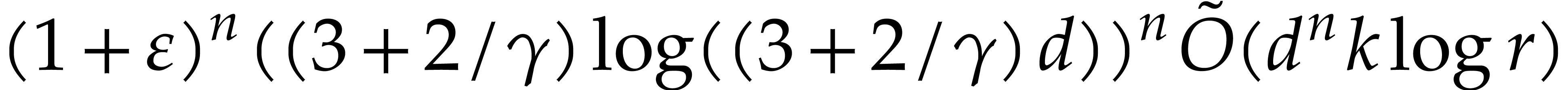
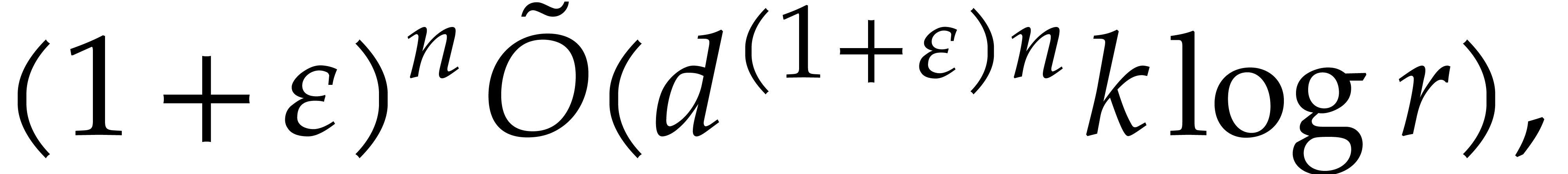

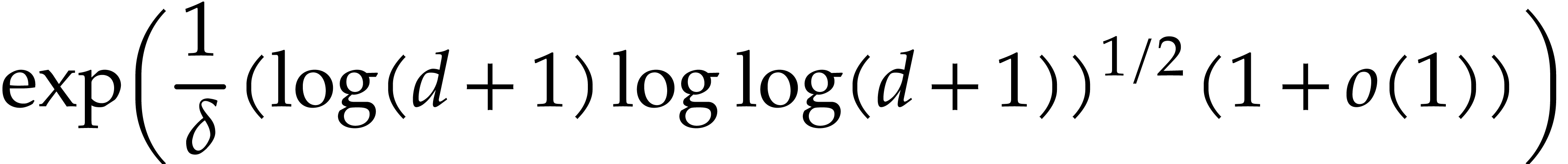
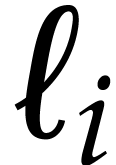
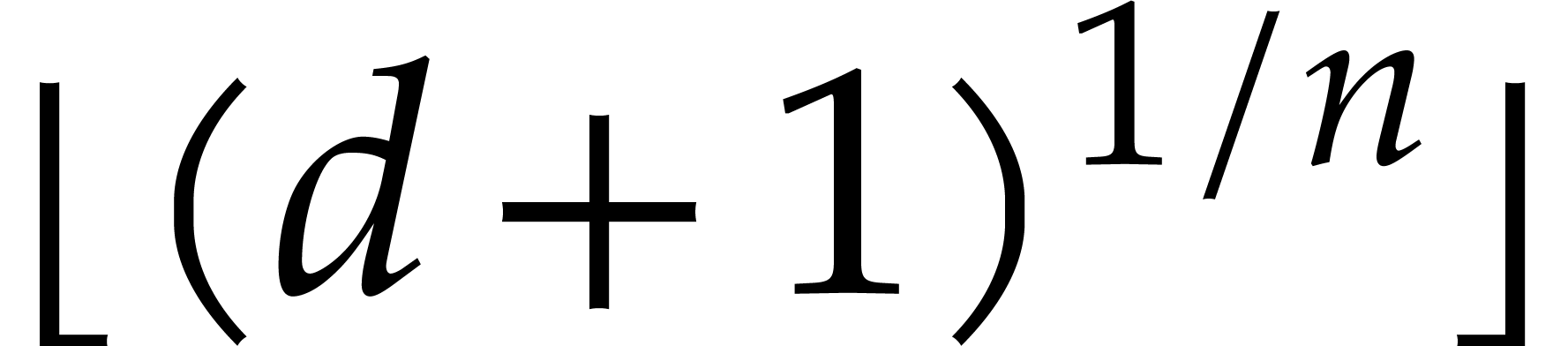
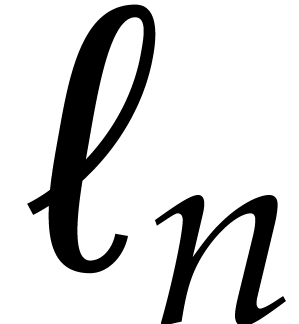
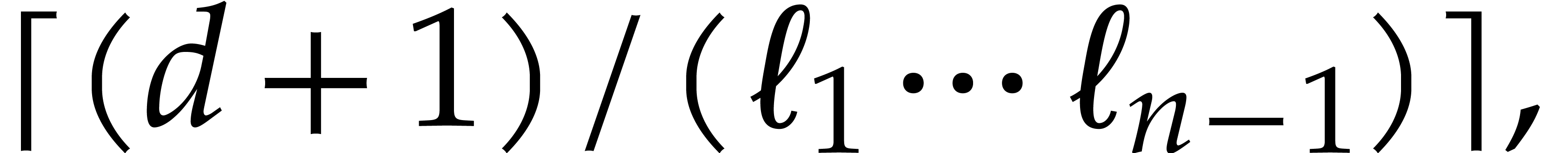
 ;
; in
in
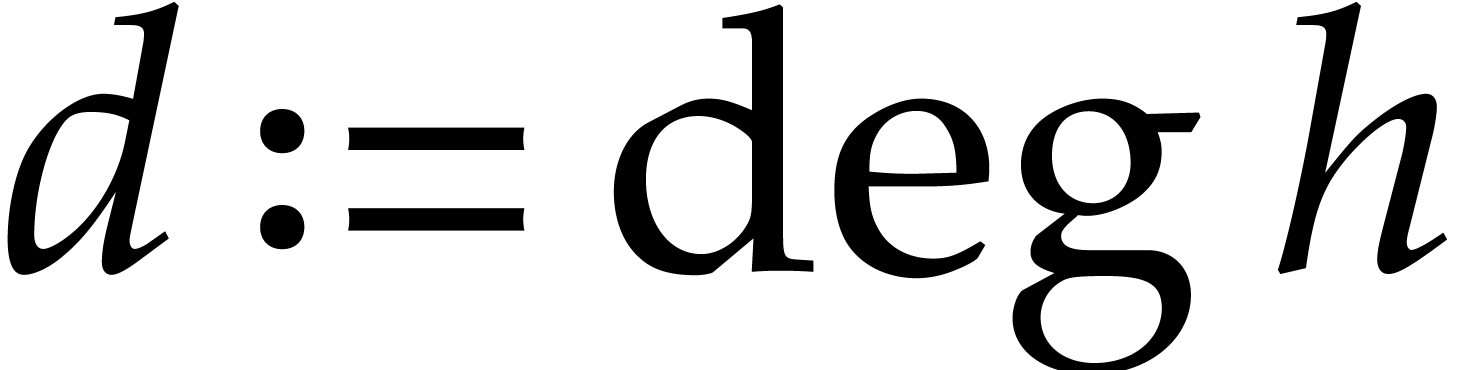 ,
, ,
, ,
, ,
,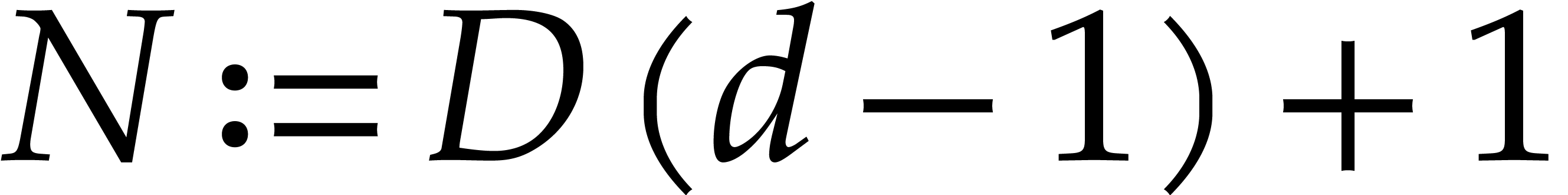 ,
,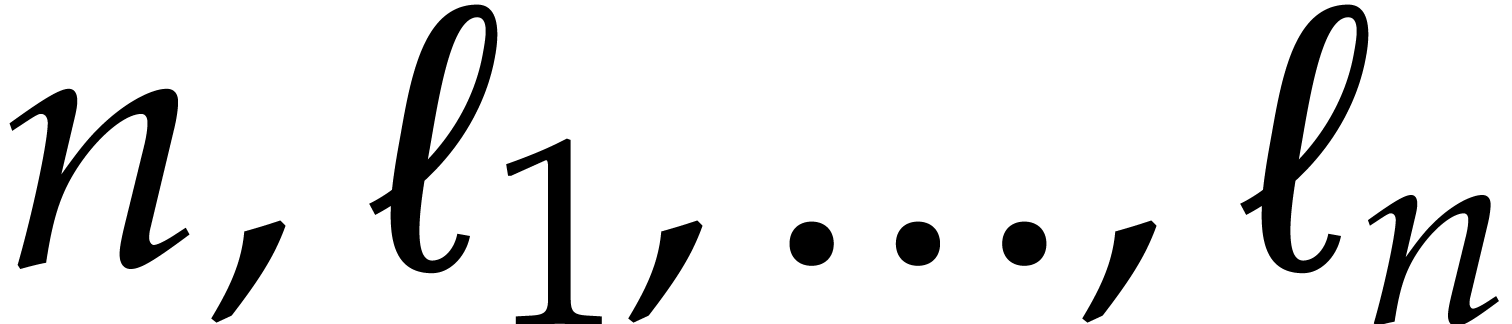 .
.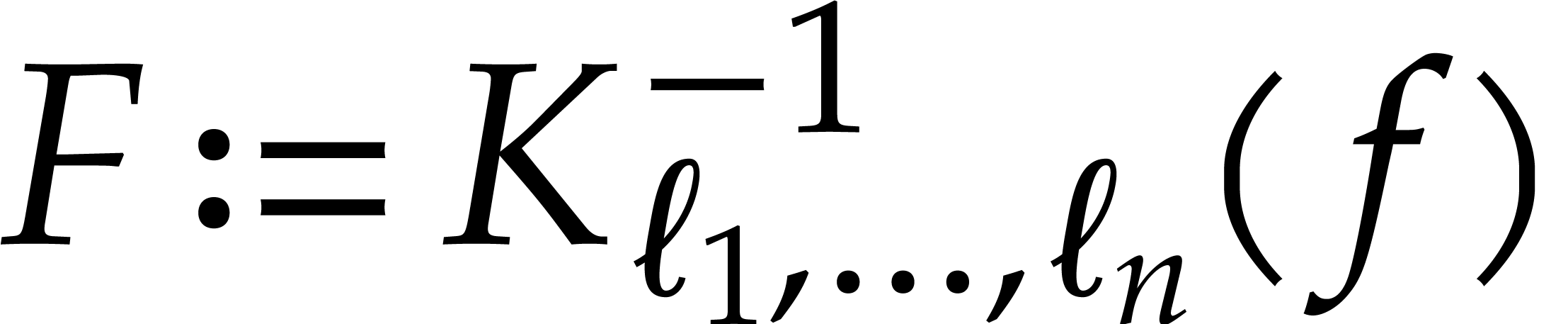 .
.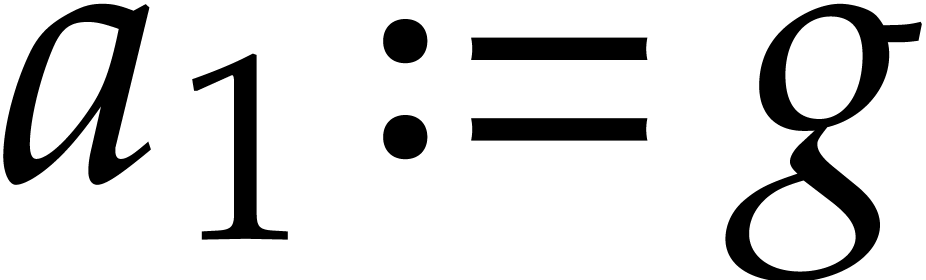 ,
,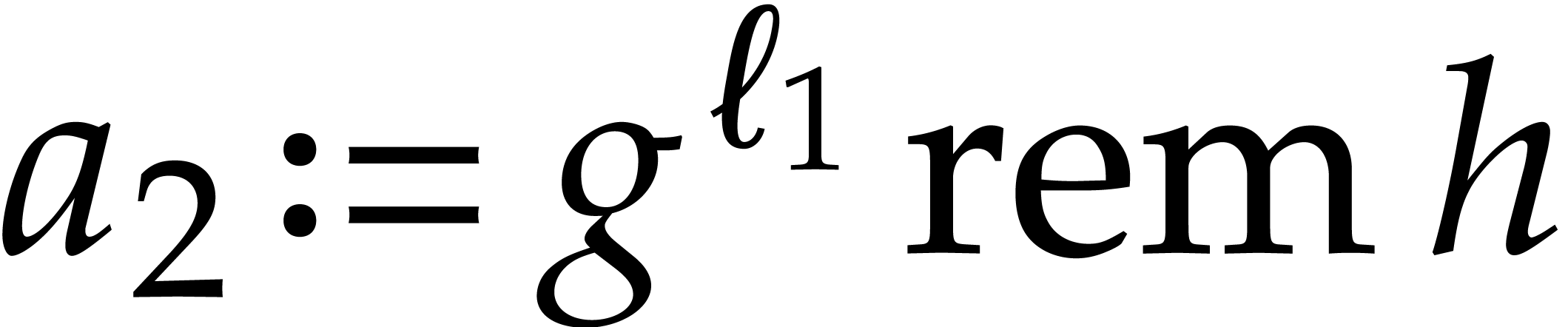 ,…,
,…,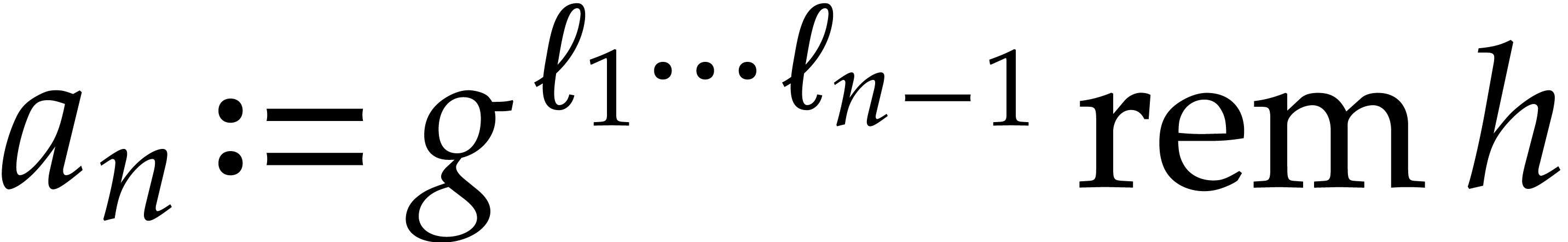 .
. for
for  at
at  such that
such that 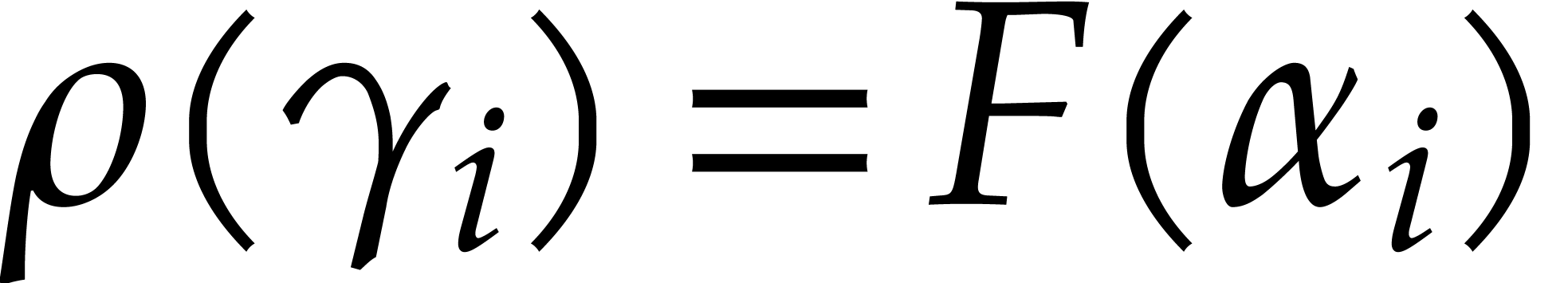 for
for  .
. be polynomials in
be polynomials in  such that
such that  is monic of degree
is monic of degree  have degrees
have degrees  .
. may be computed in time
may be computed in time
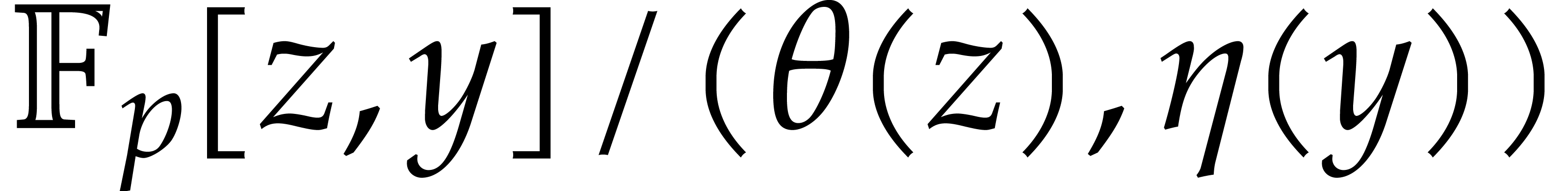
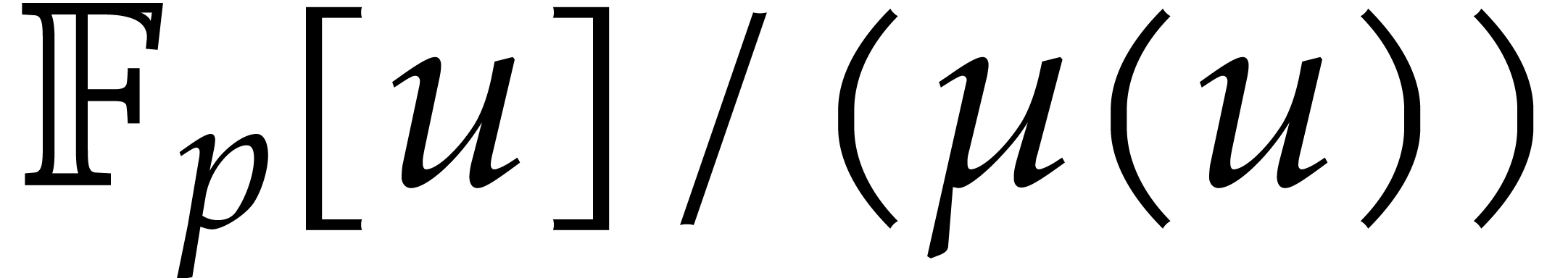

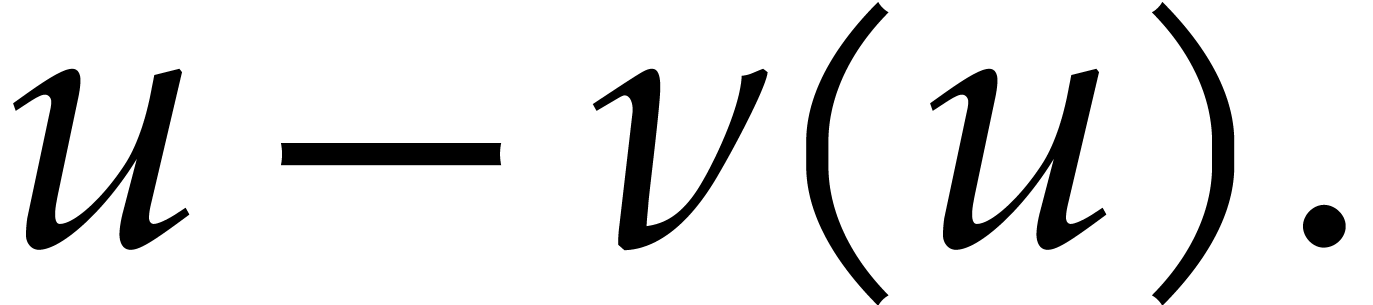
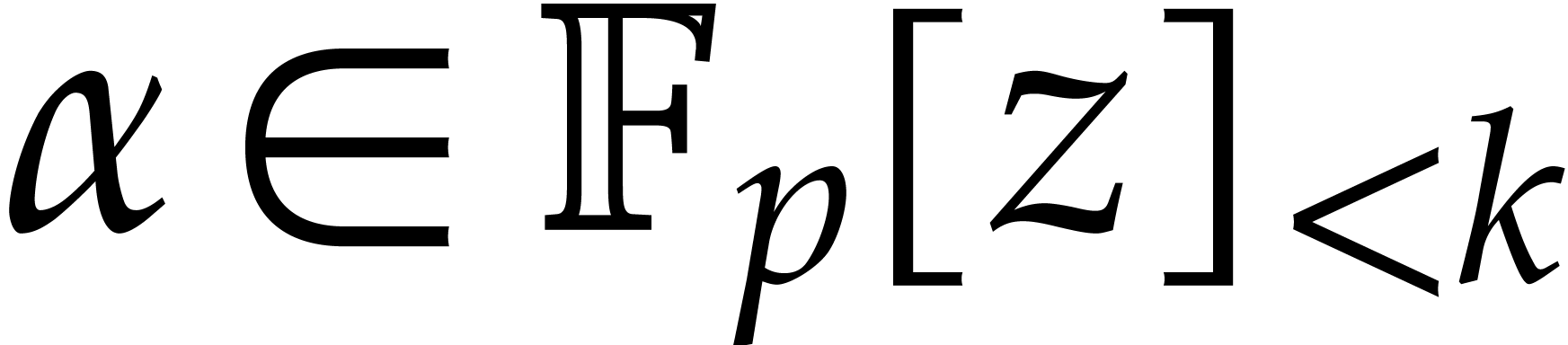 ,
,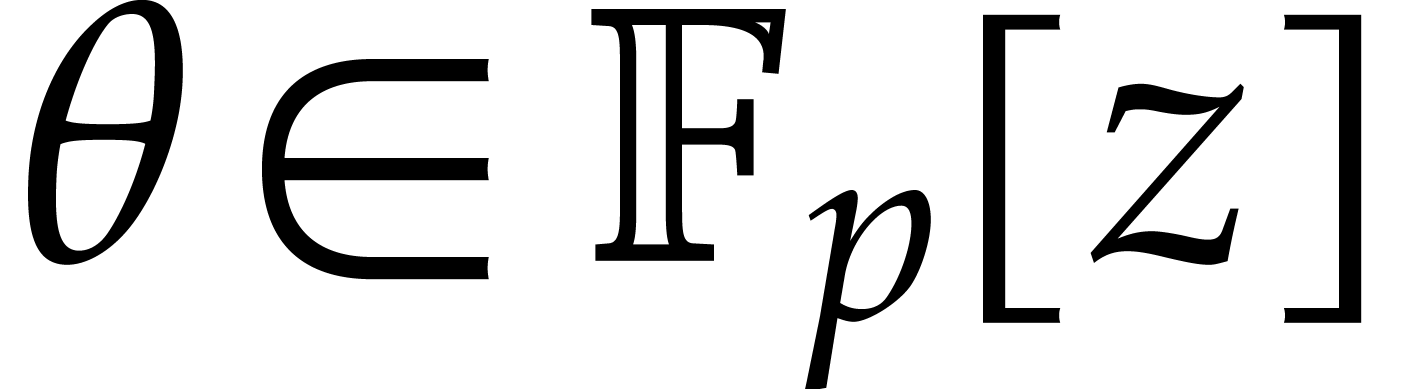 monic and irreducible of degree
monic and irreducible of degree
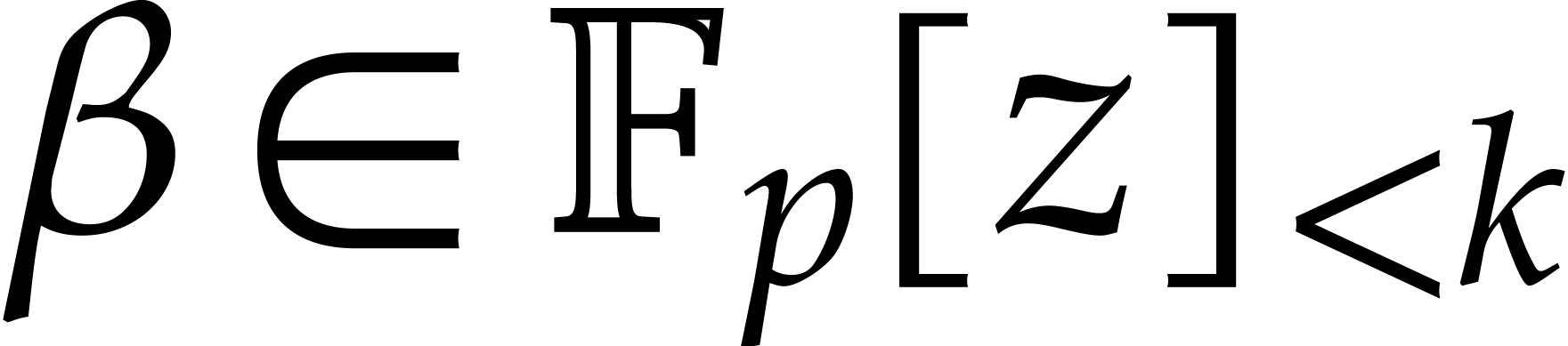 such that
such that 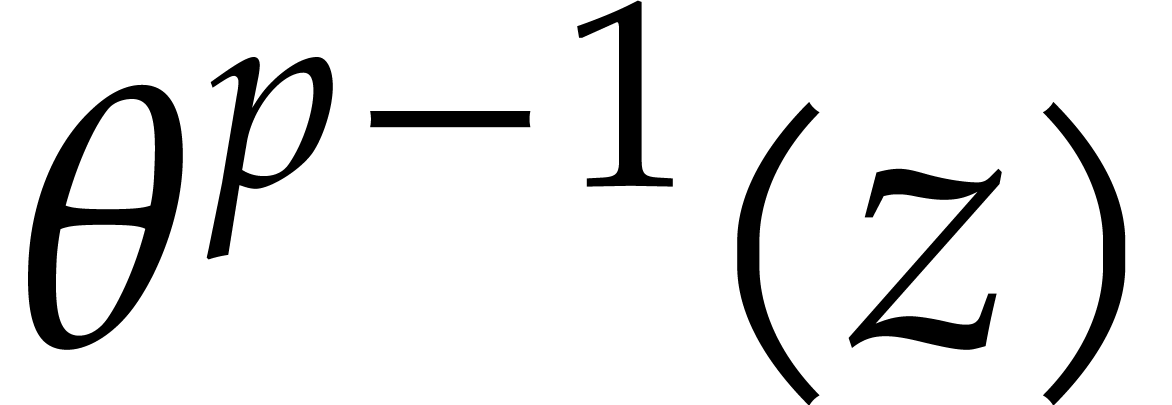 into
into 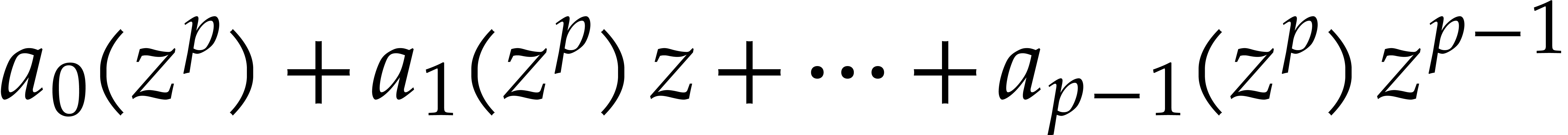 ,
,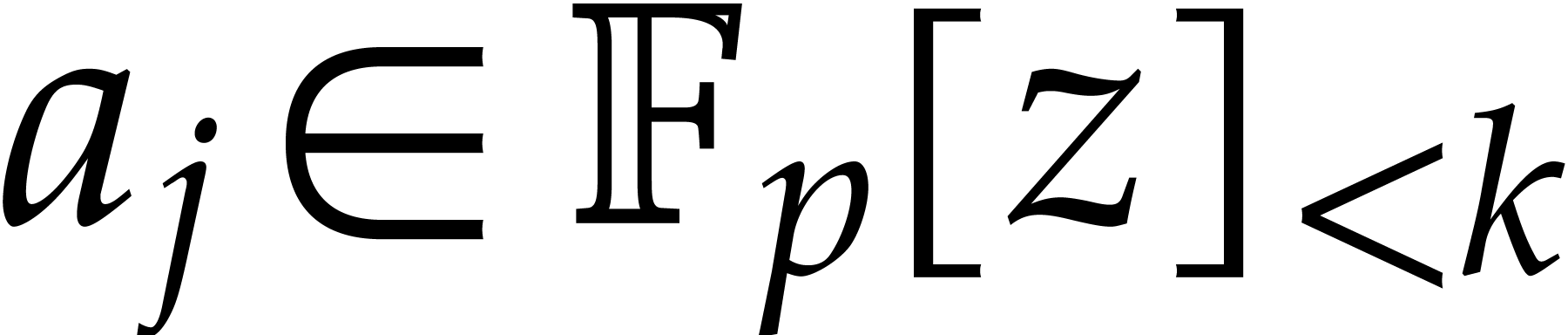 .
.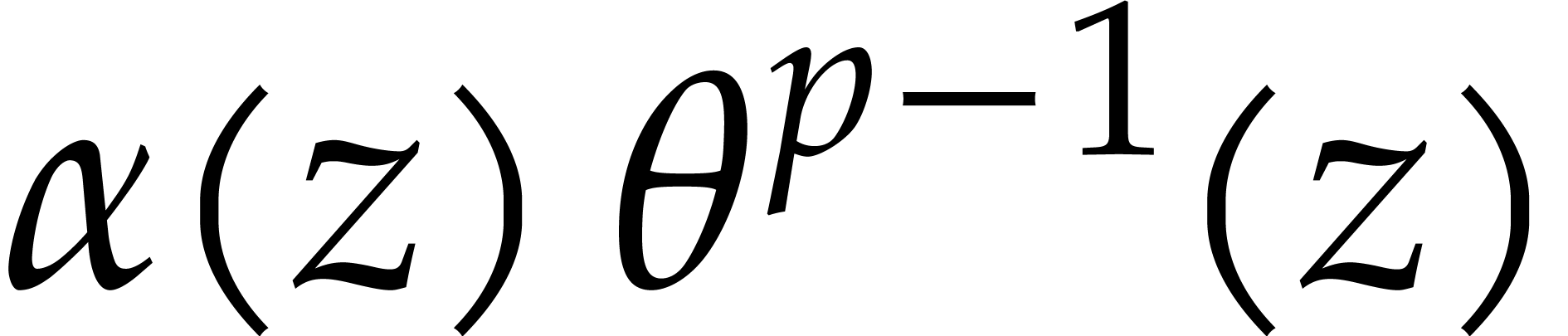 into
into 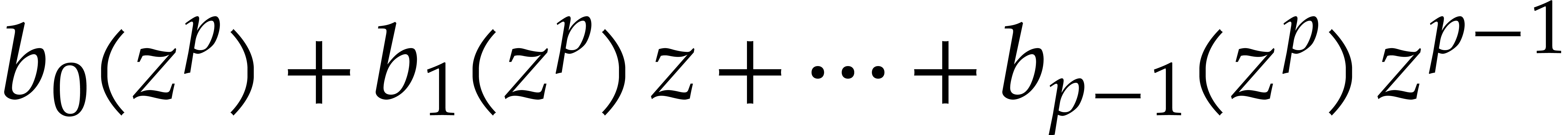 ,
,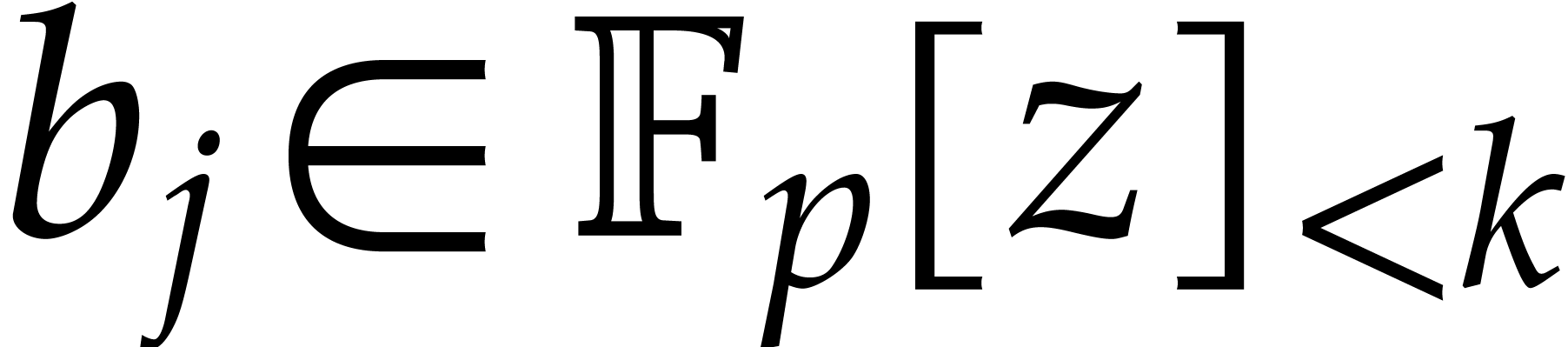 .
. ,
, ,
, .
.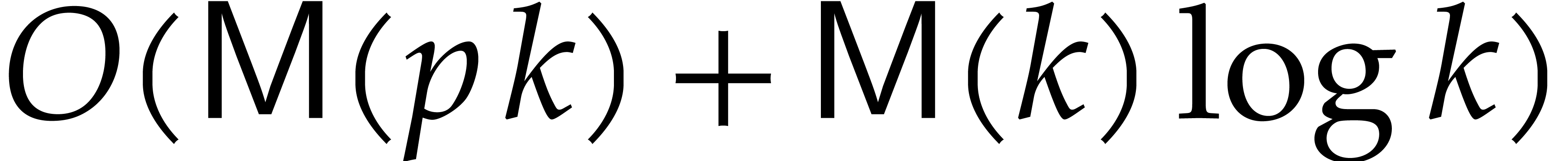 ring operations in
ring operations in 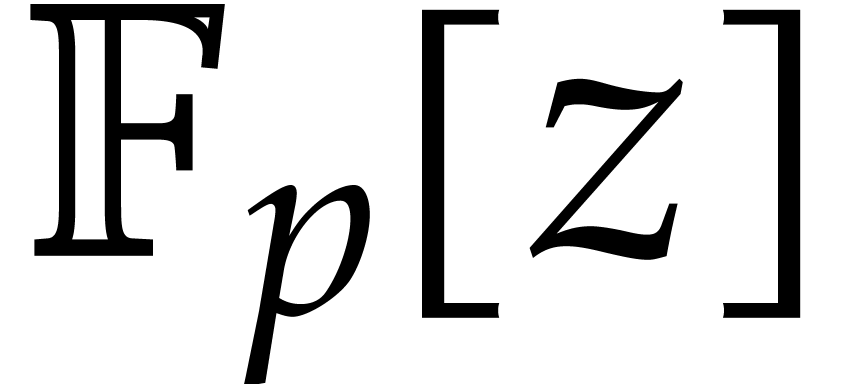 ;
;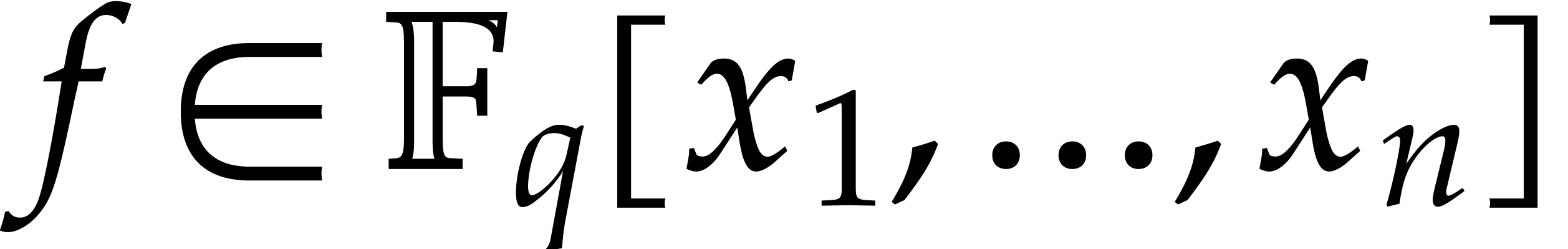 of total degree
of total degree
 .
. be minimal such that
be minimal such that  and
and  .
. of
degree
of
degree  of unity of maximal order
of unity of maximal order
 in
in  as an element of
as an element of  ,
,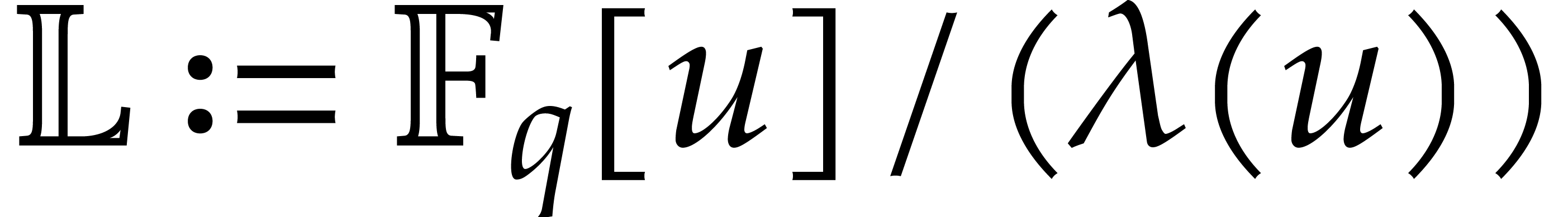 ,
, .
. .
.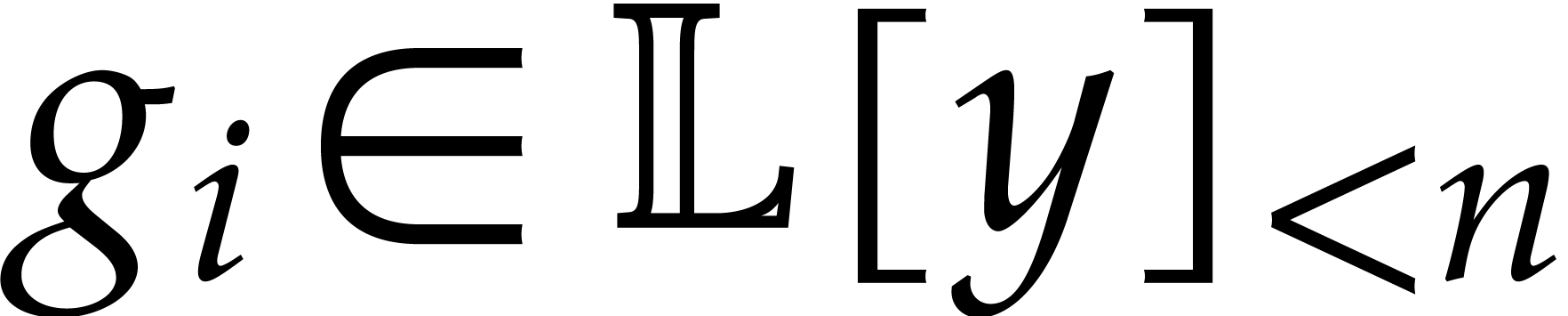 such that
such that 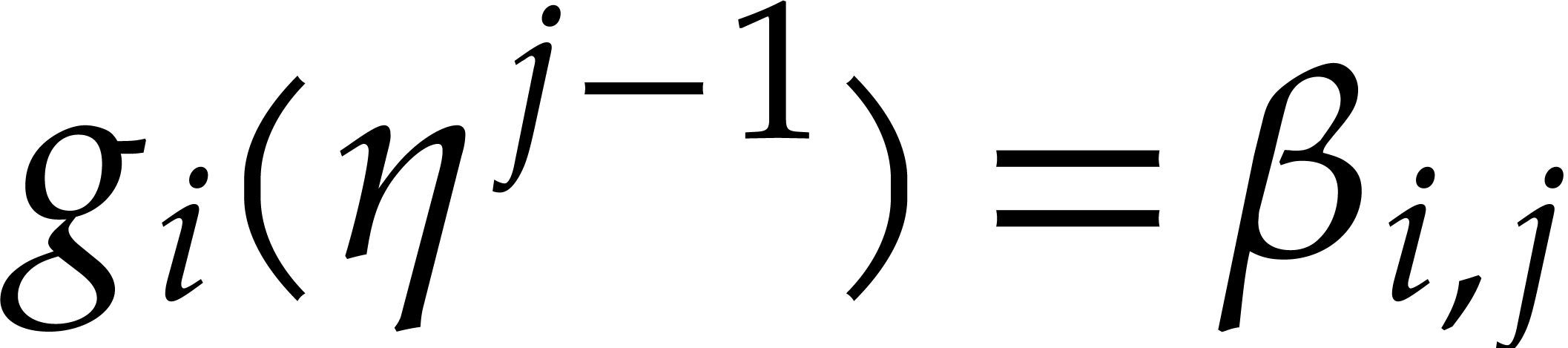 for
for 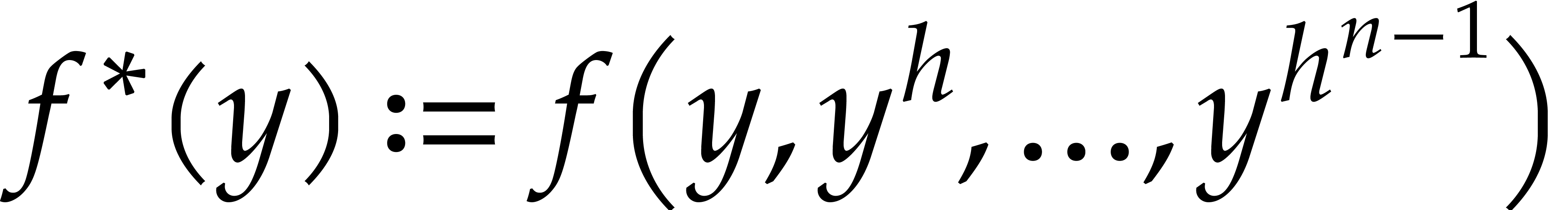 ,
,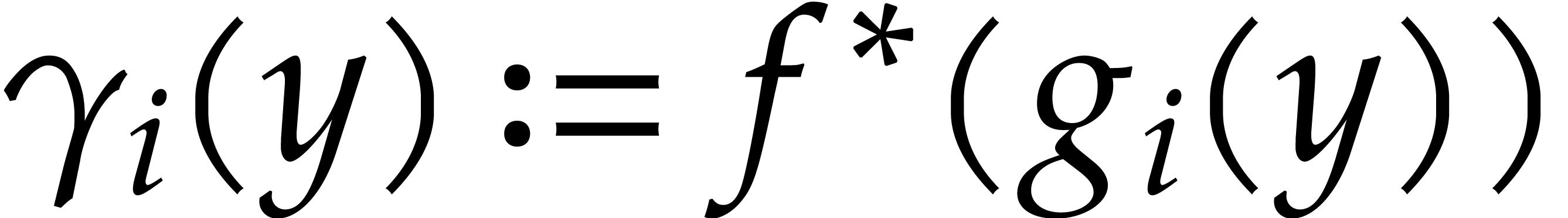 modulo
modulo 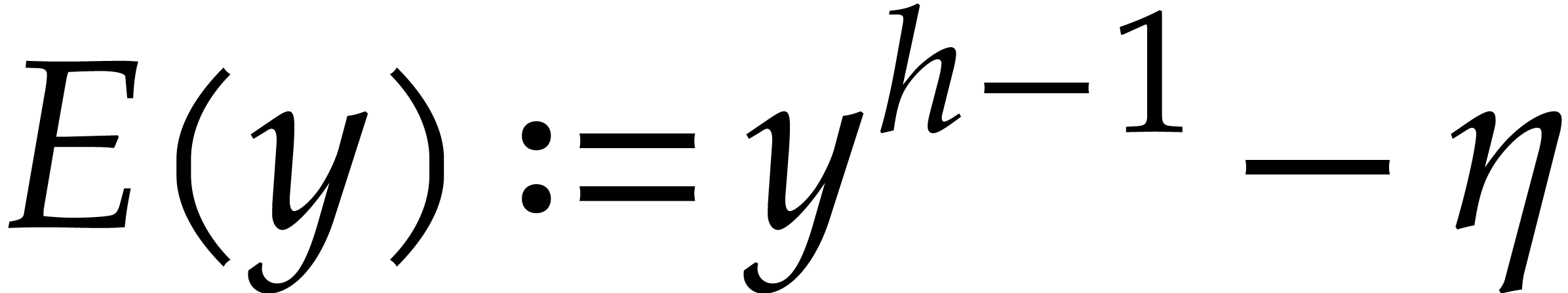 for
for  .
.