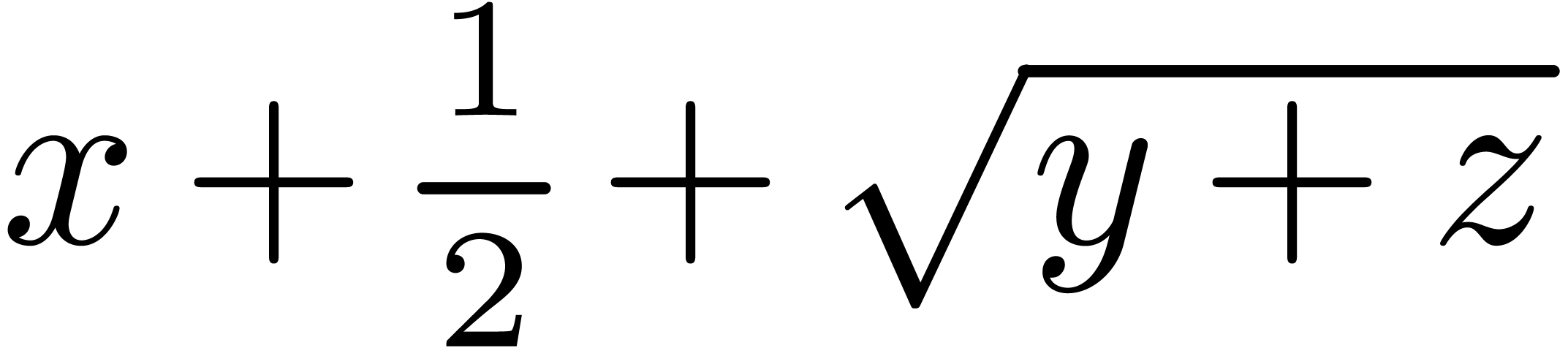| Conservative conversion between LaTeX and TeXmacs  |
|
| April 15, 2014 |
|
 . This work has
been supported by the Digiteo 2009-36HD grant and
Région Ile-de-France.
. This work has
been supported by the Digiteo 2009-36HD grant and
Région Ile-de-France.
Abstract
Back and forth converters between two document formats
are said to be conservative if the following holds: given a source
document 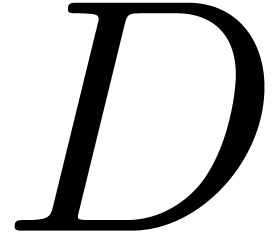 , its conversion
, its conversion
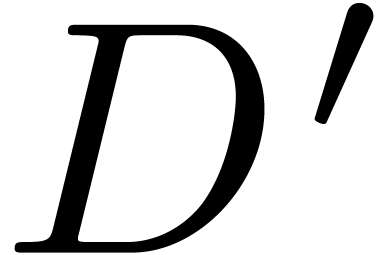 , a locally modified
version
, a locally modified
version 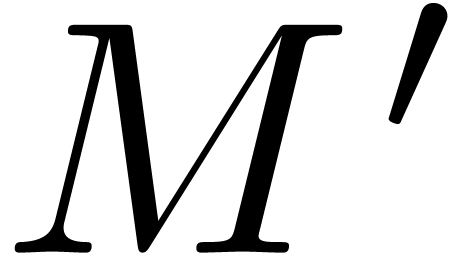 of and the
back conversion
of and the
back conversion 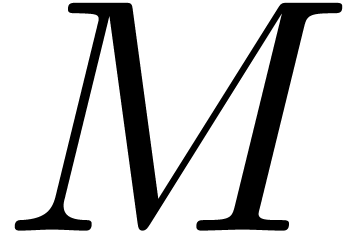 of , the document is a
locally modified version of .
We will describe mechanisms for the implementation of such converters,
with the LaTeX and TeXmacs formats as our guiding example.
of , the document is a
locally modified version of .
We will describe mechanisms for the implementation of such converters,
with the LaTeX and TeXmacs formats as our guiding example.
Keywords: Conservative document conversion, LaTeX conversion, TeXmacs, mathematical editing
The TeXmacs project [7, 10] aims at creating a
free scientific office suite with an integrated structured mathematical
text editor [8], tools for graphical drawings and
presentations, a spreadsheed, interfaces to various computer algebra
systems, and so on. Although TeXmacs aims at a typesetting quality which
is at least as good as TeX and LaTeX [14, 15],
the system is not based on these latter systems. In particular, a new
incremental typesetting engine was implemented from scratch, which
allows documents to be edited in a wysiwyg and thereby more user
friendly manner. This design choice made it also possible or at least
easier to use TeXmacs as an interface for external systems, or as an
editor for technical drawings. However, unlike existing graphical
front-ends for LaTeX such as
Since LaTeX is still the standard for scientific publications in areas such as mathematics, physics and computer science, good compatibility between TeXmacs and LaTeX is a major issue. Several use cases are possible in this respect. For the publication of papers, good converters from TeXmacs to LaTeX are a prerequisite. New TeXmacs users also would like to import their old LaTeX papers into TeXmacs. The most complex types of conversion arise when a TeXmacs user collaborates with a person who refuses to use anything else but LaTeX. In that case, there is a need for lossless converters between both formats.
Unfortunately, TeX and LaTeX do not really provide a data format, but rather a programming language. Furthermore, unlike most other existing programming languages, the TeX system does not provide a formal grammar for the set of parsable documents. Moreover, the TeX syntax can be self-modified at run-time and many basic TeX/LaTeX capabilities are build upon syntactic tricks. This makes it extremely hard (or even impossible in practice) to design lossless converters between LaTeX and essentially different formats. Current software for conversions from LaTeX [1, 2, 4–6, 11, 13, 16–21] therefore involves a lot of heuristics; we refer to section 3 for a quick survey of existing approaches.
Nevertheless, even if we accept that the conversion problem is hard in general, we would like our heuristic converters to address some important practical use cases. For instance, assume that Alice writes a LaTeX document and sends it to her colleague Bob. Now Bob makes a minor correction in the LaTeX document using TeXmacs and sends it back to Alice. Then Alice would like to recover her original LaTeX document except for the minor change made by Bob (which might possibly be exported in the wrong way). Converters between LaTeX and TeXmacs which admit this property will be called conservative.
There are several approaches to the implementation of conservative converters. First of all, we might re-implement our converters from scratch while taking into account the additional requirement. However, it took a lot of work and effort to develop the existing heuristic converters, so this option is not particularly nice from the implementers' perspective. Another idea would be to “hack” some parts of the existing code and turn it into something more conservative. Nevertheless, the existing converters are extremely complex; in particular, they cover numerous kinds of irregularities inside LaTeX. Adding an additional layer of complexification might easily break existing mechanisms.
Therefore, we want to regard the current converters between LaTeX and TeXmacs as black boxes. The aim of this paper is to describe conservative converters on top of these black boxes, which are currently under development. In particular, we guarantee that failure of the conservative converters only occurs in cases of failure of the original converters. Although our techniques were only tested for conversions between TeXmacs and LaTeX, it is likely that they can be used for other formats as well.
The first major ingredient for our converters (see section 4) is to generate, along with the main conversion, a correspondence between well chosen parts of the source document and their conversions in the target document. In particular, we want to track the image of each paragraph in the source document. Ideally speaking, assuming that we have a nice parse tree for the source document, we want to track the images of all subtrees. In order to construct such correspondences, we will add markers to the source document, convert the marked source document, and finally remove the markers from the obtained marked target document. Optionally, we may want to verify that the addition and removal of markers does not disrupt the conversion process and that we obtain the same final document as in the case of a plain conversion.
For the conservative conversion itself, there are several approaches, which will be described in section 5. Our current implementations are mainly based on the “naive” approach from sections 5.1 and 5.2, which directly attempts to substitute unaltered document fragments by their original sources, when performing a backconversion of a modified converted document. We are also experimenting with more elaborate approaches for which modifications are regarded as patches and where the idea is to lift the conversion process to such patches.
As we mentioned in the introduction, TeX [14] is really a programming language rather than a data format. The main emphasis of TeX is on presentation and typesetting quality. TeX programs are strings with a highly customizable syntax; the set of TeX primitives can also easily be extended with user defined macros. We recall that LaTeX [15] is a set of macros, built upon TeX. It is intended to provide an additional layer of structural markup, thereby allowing for a limited degree of presentation/content separation. It inherits both advantages and disadvantages from the TeX system.
One of the major disadvantages of TeX and LaTeX is that it is hard or
even impossible to write reliable converters to other formats. For
instance, in a recent case study on existing LaTeX to
The TeXmacs document format is based on trees: all TeXmacs
documents or document fragments should be thought of as trees [9].
Of course, such trees can be serialized as strings in different ways: as
XML documents, as
|
|||||||||
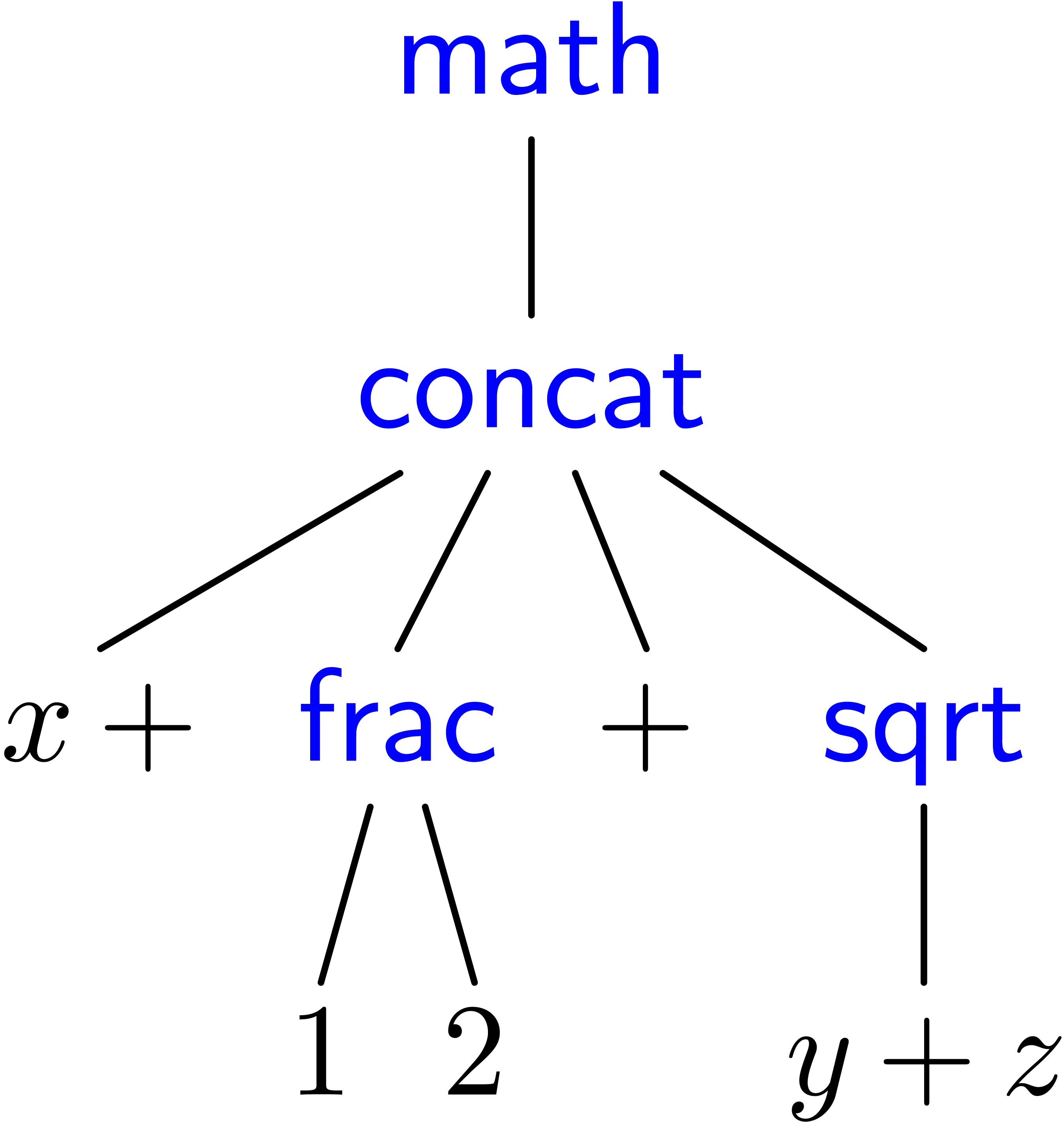
In the example, the concat tag stands for “horizontal concatenation” and its children expect “inline content”. Another important primitive which will be used in subsequent examples is document; this tag is used for “vertical concatenation” and it provides “block content”.
Not so surprisingly, the interoperability with LaTeX is an asymmetric problem. Conversion to LaTeX is considered the easier problem, since we are free to restrict ourselves to a subset of LaTeX. However, even this problem is quite non trivial, due to lack of orthogonality and arbitrary restrictions inside LaTeX (see section 2.1). Nevertheless, conversion from LaTeX to other formats is indeed the most difficult problem, usually. Although the techniques described in this paper work both ways, we will therefore use this harder direction for our examples.
The main obstacle when converting LaTeX documents to other formats is
that arbitrary LaTeX documents are hard to parse. One way to bypass this
problem is to let TeX do the parsing for you. Some existing converters
which use this approach are
It supposes that you installed a complete TeX distribution (usually large in size), whose version is compatible with the one required by the source.
It only works for complete documents, and not for code snippets.
User defined macros are expanded and thereby lose their semantics.
Concerning the last point, we agree with [12]: “macro expanding then translating is best suited to display and does not provide converted documents suitable for further use”, so this strategy does not fit our needs. Also, even if we could preprocess sources in order to protect user defined markup, the two first concerns are too restrictive for our project.
The remaining strategy is to parse ourselves the LaTeX source files.
This approach has been followed by software such as
The existing LaTeX to TeXmacs converter uses a custom TeX/LaTeX parser, with the ability to conserve the semantics of user defined macros. Many filters are applied to the parsed LaTeX document in order to get a suitable TeXmacs tree. Some example transformations which are applied are the following:
expansion of “dangerous” macros, such as \def\b{\begin};
cutting the source file into small pieces, thereby reducing the risk of serious parse errors due to (text/math) mode changes;
many local and global tree rewritings (whitespace handling, basic normalizations and simplifications, renaming nodes, reordering children, migrating label definitions, extracting metadata, etc.);
adding semantics to mathematical content (disambiguation of operators and whitespace, matching delimiters, etc.);
(optionally) compile the LaTeX document with the
Due to the combined complexity of these transformations, we cannot make certain useful assumptions on the behavior of our converter, especially:
The conversion of a concatenation of snippets might not be the concatenation of the conversion of the snippets.
Local changes inside snippets may result in global changes.
Two conversions of the same document at different times might result in different results. This is for instance due to time stamping by external tools involved in the conversion of pictures.
The converter from TeXmacs to LaTeX does not have to cope with the LaTeX parsing problem. Nevertheless, arbitrary restrictions inside LaTeX and the general lack of orthogonality make the production of high quality LaTeX documents (including preserved semantics of user defined macros) harder than it seems. The LaTeX export process is based on the following general ideas:
converting the document body tree into a LaTeX syntax tree;
building the preamble by tracking dependencies and taking into account all document style options;
writing the preamble and the body.
Again, and for similar reasons as above, useful properties such as linearity, locality and time invariance cannot be guaranteed.
One important prerequisite for conservative converters is our ability to maintain the correspondence between parts of the source document and their images in the target document. When writing conservative converters from scratch, this correspondence can be ensured by design. In our setting, since traditional converters are already written, we consider them provided as if they were black boxes, independant from our conservative converters. Then, the key idea in order to maintain the correspondence between source and target is to add markers to the source document before doing the conversion. More precisely, we extend the source and target formats with one new special tag for marking text, say marker. Two design choices have now to be made.
First of all, the marker tag can either be punctual or scoped. In the first case, the tag takes a unique identifier as its single argument. In the second case, the tag takes the marked text as its additional second argument (for large multi-paragraph fragments of LaTeX, this requires marker to be an environment). For unparsed LaTeX source documents, substrings which correspond to logical subexpressions of the parse tree can be hard to determine. Consequently, punctual markers are most adequate for the initial conversions from LaTeX to TeXmacs. Nevertheless, using a post treatment, we will show in section 4.2 below that punctual markers may be grouped by pairs into scoped markers, while taking advantage of the tree structure of the generated TeXmacs document. For conversions from TeXmacs to LaTeX, we may directly work with scoped markers.
Secondly, we have to decide on the granularity of our conservative converters: the more markers we use, the more locality will be preserved for small changes. However, not all subtrees of the parse tree of the source document necessarily give rise to valid subexpressions of the target documents. Moreover, in the case of conversions from LaTeX to TeXmacs, we have no direct access to the parse tree of the source document, so appropriate places for markers have to be chosen with care. At least, we need to mark all paragraphs. More sophisticated implementations will also mark macro definitions in the preamble, cells of tables, and several well chosen commands or environments.
Example  ,
,  ,
, 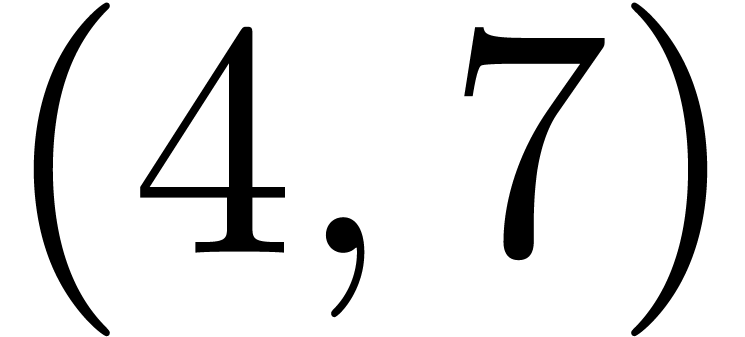 ,
,
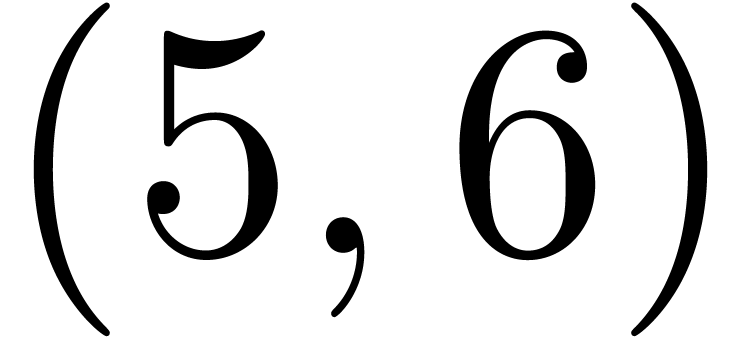 ,
, 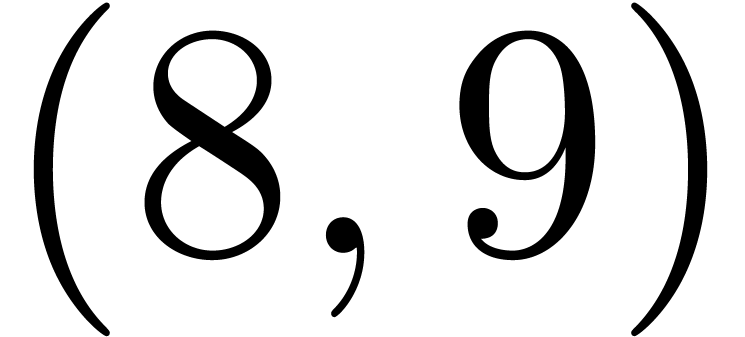 and
and
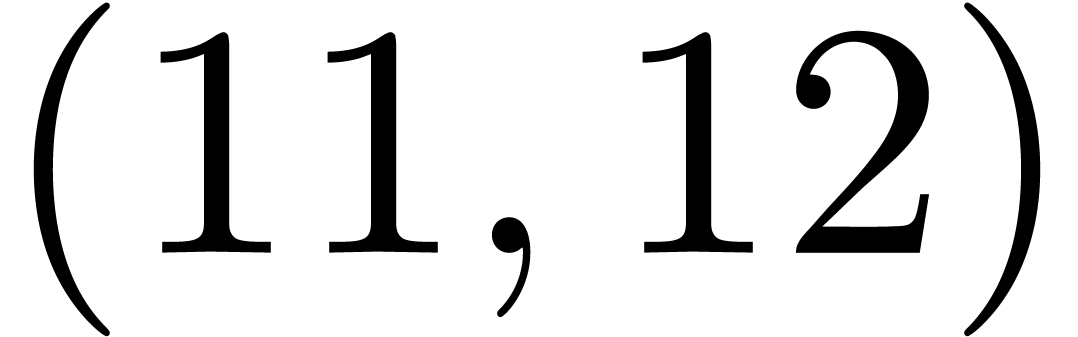 .
.
|
|||
In order to transform matching pairs of punctual markers inside LaTeX source documents into scoped markers, we will make use of the tree structure of the marked TeXmacs target document obtained after conversion.
Roughly speaking, for every subtree wich starts with marker 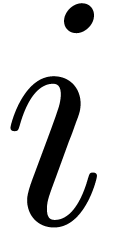 and ends with marker
and ends with marker 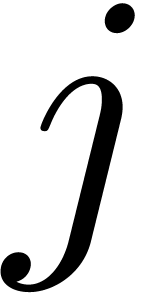 ,
we declare that
,
we declare that 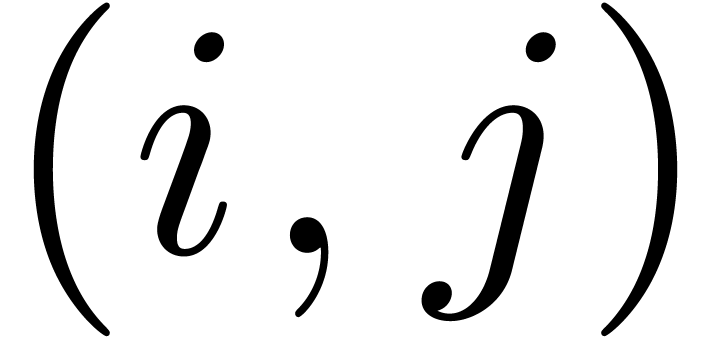 forms a matching pair. More
precise implementations should carefully take into account the special
nature of certain tags such as concat and document.
For instance, we may use the following algorithm:
forms a matching pair. More
precise implementations should carefully take into account the special
nature of certain tags such as concat and document.
For instance, we may use the following algorithm:
any concat tag or document tag starting and finishing by a marker is replaced by the corresponding pair;
any child of a concat tag or a document tag which is framed by two markers is replaced by the corresponding pair;
any concat tag or document tag with only one child which is a pair is replaced by the pair;
any remaining marker is removed.
Example
(document
(concat (marker "1") "First paragraph." (marker "2"))
(marker "3")
(remark
(document
(concat (marker "4") "Some mathematics")
(equation*
(document (concat (marker "5") "a+" (frac "b" "c") "." (marker "6"))))
(marker "7")
(concat (marker "8") "More text." (marker "9"))))
(marker "10")
(concat (marker "11") "Last paragraph." (marker "12")))
The pairs  ,
, 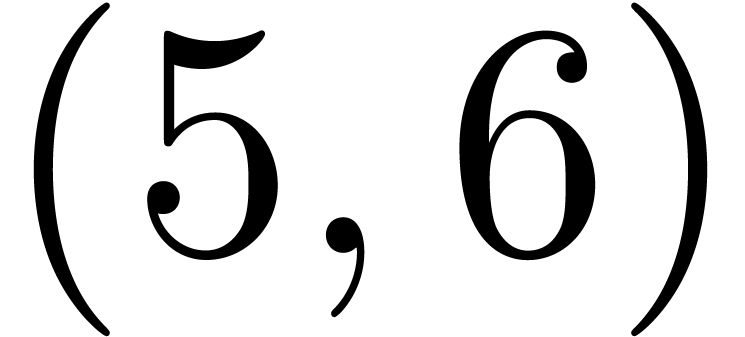 ,
, 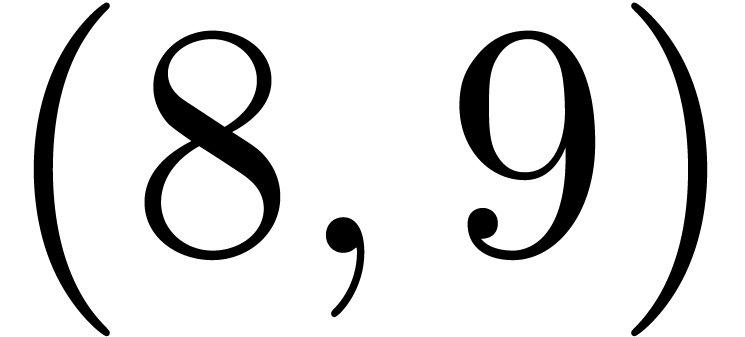 and
are detected as matching pairs of markers of inline content, whereas the
pair
and
are detected as matching pairs of markers of inline content, whereas the
pair 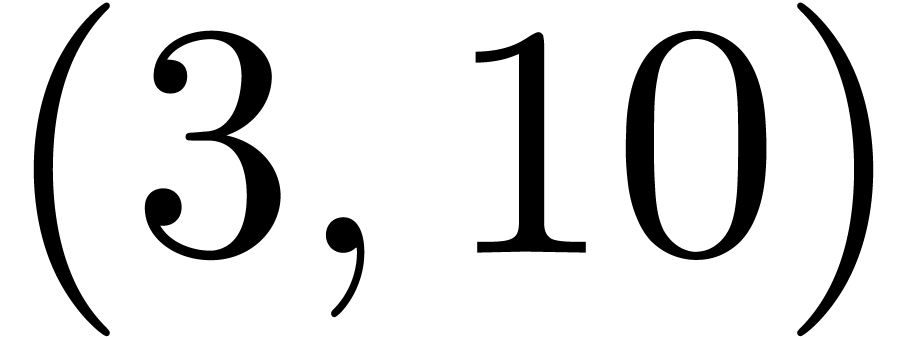 is detected as matching pair of block
content. The pair (4,7) does not match, but the matching algorithm can
be further tweaked to better handle this kind of situations.
is detected as matching pair of block
content. The pair (4,7) does not match, but the matching algorithm can
be further tweaked to better handle this kind of situations.
At a second stage, we may organize the matching pairs into a dag: a pair
will be a descendent of a pair 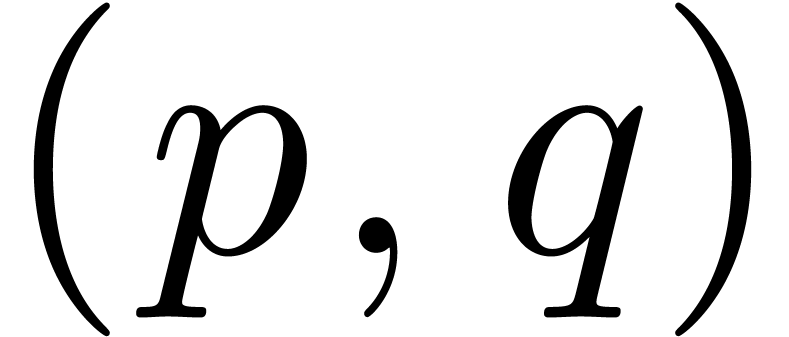 whenever the source string corresponding to is
included in the source string corresponding to . We will say that the dag is well formed
if it is actually a tree and whenever the source strings corresponding
to two different children of the same node never intersect.
whenever the source string corresponding to is
included in the source string corresponding to . We will say that the dag is well formed
if it is actually a tree and whenever the source strings corresponding
to two different children of the same node never intersect.
Example 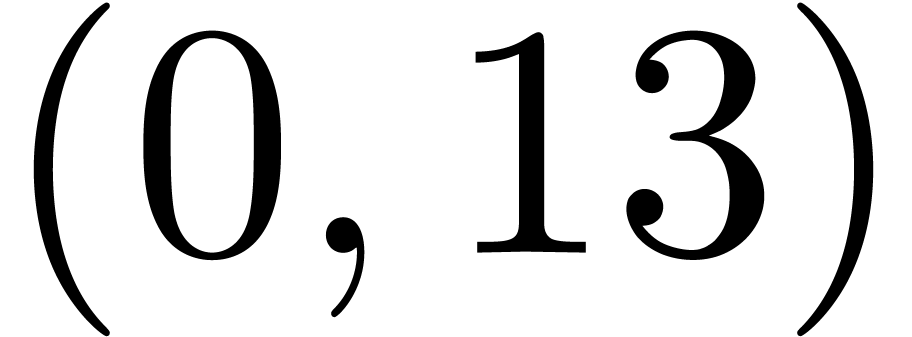 for the root, the dag of matching pairs is a well formed tree:
for the root, the dag of matching pairs is a well formed tree:

Example
\begin{figure}
\marker{2}\caption{\marker{3}Legend\marker{4}}
Some text.\marker{5}
\end{figure} |
 |
(big-figure
(concat
(marker "2")
"Some text."
(marker "5"))
(concat
(marker "3")
"Legend"
(marker "4"))) |
|
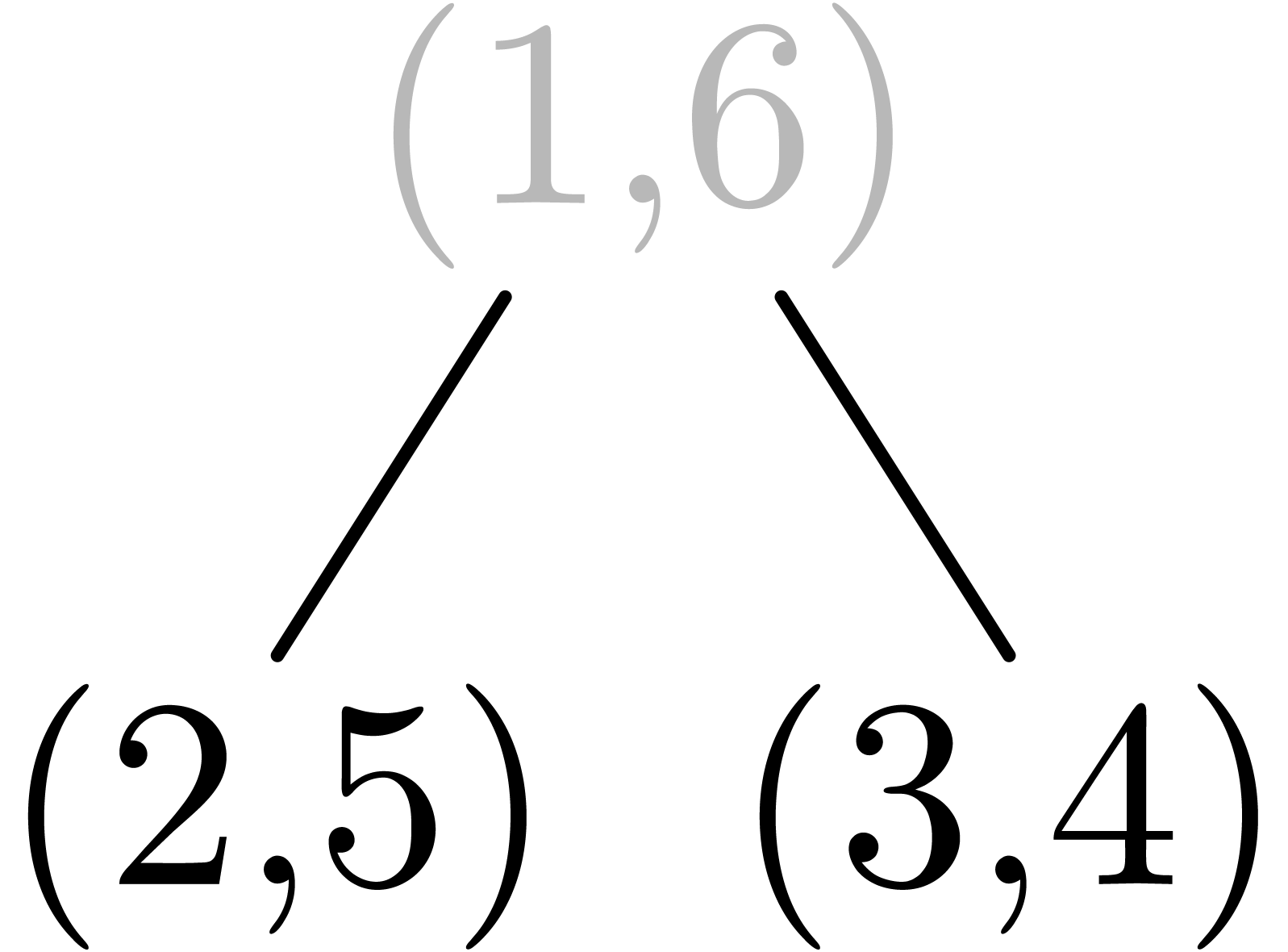 |
In unfavourable cases, such as Example 4, the dag of matching pairs does not yield a well formed tree. In such cases, we keep removing offending matching pairs until we do obtain a well formed tree. At the end of this process, we are ensured that marked subdocuments do not overlap in non structured ways, i.e. other than via inclusion. Consequently, it is possible to transform the document with punctual markers into a document with scoped markers.
Example
(document
(marker "1:2" "First paragraph.")
(marker "3:10"
(remark
(document
"Some mathematics"
(equation*
(document (marker "5:6" (concat "a+" (frac "b" "c") ".")))))
(marker "8:9" "More text.")))
(marker "11:12" "Last paragraph." ))
In most cases, removal of the markers from the conversion of a marked source document yields the same result as the direct conversion of the source document, modulo some normalization, such as merging and removing concat tags. However, this is not always the case. Let us give a few examples of how this basic principle may fail.
Example
\begin{verbatim}
Some text.
\end{verbatim} |
|
\begin{verbatim}
\marker{1}Some text.\marker{2}
\end{verbatim} |
 |
||
(verbatim
"\marker{1}Some text.\marker{2}") |
Example
In order to guarantee that our marking and unmarking mechanisms never deteriorate the quality of the converters, we may use the following simple procedure: convert the source document both with and without the marking/unmarking mechanism. If the results are the same, then return the result. Otherwise, keep locating those markers which are responsable for the differences and put them into a blacklist. Now keep repeating the same process, while no longer inserting the markers in the blacklist during the marking procedure. In the worst case, this process will put all markers on the blacklist, in which case conversion with and without the marking/unmarking mechanism coincide.
In order to allow for subsequent conservative back and forth
conversions, the result of a conservative conversion should contain
additional information on how the recover the original source file. More
precisely, when converting a source document 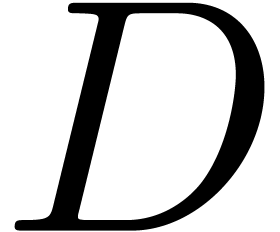 from format
from format  into format
into format  , the target document will consist of a quadruple
, the target document will consist of a quadruple
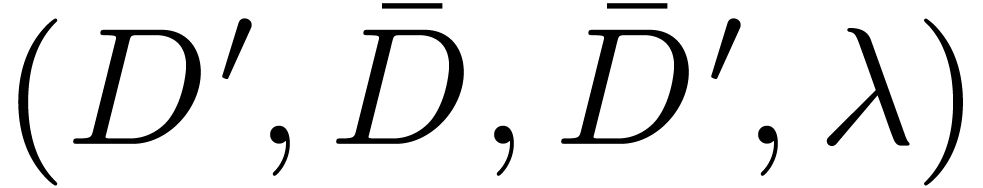 , where
, where
is the target document of format .
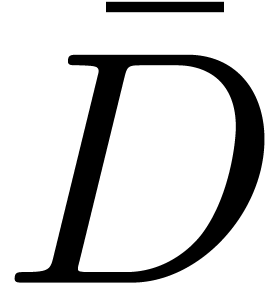 is the marked source document which gave
rise to the marked version
is the marked source document which gave
rise to the marked version 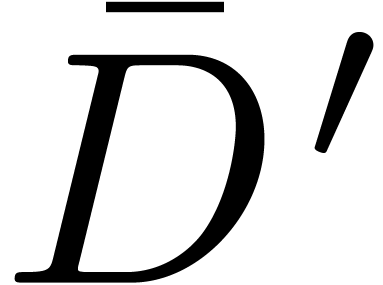 of the target
document.
of the target
document.
 is a mapping which associates one of the two
formats or to every
identifier for a marked subdocument.
is a mapping which associates one of the two
formats or to every
identifier for a marked subdocument.
If our target format is TeXmacs, then we simply store , and
as attachments to TeXmacs files. If LaTeX is our target format, then, by
default, we put , and inside a comment at the end of
the document. Alternatively, we may store ,
and in a separate file,
which will be consulted whenever we convert a modification of the target
document back to . The last
strategy has the advantage that we do not clobber the converted file.
However, one will only benefit from the conservative converters when the
LaTeX reimportation is done on the same computer and via the
same user account.
Remark  as a separate mapping, it also possible to
suffix identifiers for marked subdocuments by a letter for the original
format of the marked text.
as a separate mapping, it also possible to
suffix identifiers for marked subdocuments by a letter for the original
format of the marked text.
Example will associate
“LaTeX” to each of the identifiers 1:2, 3:10, 5:6, 8:9, 11:12.
If the LaTeX source file was a modified version of the result of
exporting a TeXmacs file to LaTeX, then the mapping
will associate TeXmacs to every node of the tree, except for those nodes
which correspond to substrings in which modifications took place.
Let us return to the main problem of conservative conversion. Alice has
written a document in format , converts it to format
and gives the resulting document to Bob. Bob
makes some modifications and send a new version
back to Alice. How to convert the new version back to format while conserving as much as possible from the original
version for the unmodified parts?
Let us first describe a naive solution to this problem. We will assume
that the format is enriched with one new unary
tag invariant, with an expression of format as its unique argument. The conversion from to of such a tag will be precisely
this argument.
In the light of the section 4.4, Bob's new version
contains a marked copy of Alice's original
version as well as its marked conversion to
format . Now for every
subdocument  occurring in
which corresponds to a marked subdocument of
(and which is maximal with this property), we replace
by an invariant tag which admits the subdocument
occurring in
which corresponds to a marked subdocument of
(and which is maximal with this property), we replace
by an invariant tag which admits the subdocument  in corresponding to as its argument. We finally convert the obtained document
from to using our
slightly adapted black box converter.
in corresponding to as its argument. We finally convert the obtained document
from to using our
slightly adapted black box converter.
Example , and still occur in the new
document. Since corresponds to a subdocument of
, we only declare the
subdocuments corresponding to ,
and to remain invariant.
More precisely, we perform the conversion
(document
(invariant "First paragraph.")
(remark
(document
(invariant "Some mathematics
\[ a+\frac{b}{c}. \]")
"More text…"))
(invariant "Last paragraph.")) |
 |
First paragraph.
\begin{remark}
Some mathematics
\[ a+\frac{b}{c}. \]
More text…
\end{remark}
Last paragraph. |
Notice the change of indentation and the disappearance of the comment.
A few additional precautions are necessary in order to make the naive
approach fully work. First of all, during the replacement procedure of
subdocuments of by
invarianted subdocuments of , some subdocuments of
might correspond to several marked subdocuments
 of .
In that case, we first investigate some of the context in which occurred, such as the first
of .
In that case, we first investigate some of the context in which occurred, such as the first 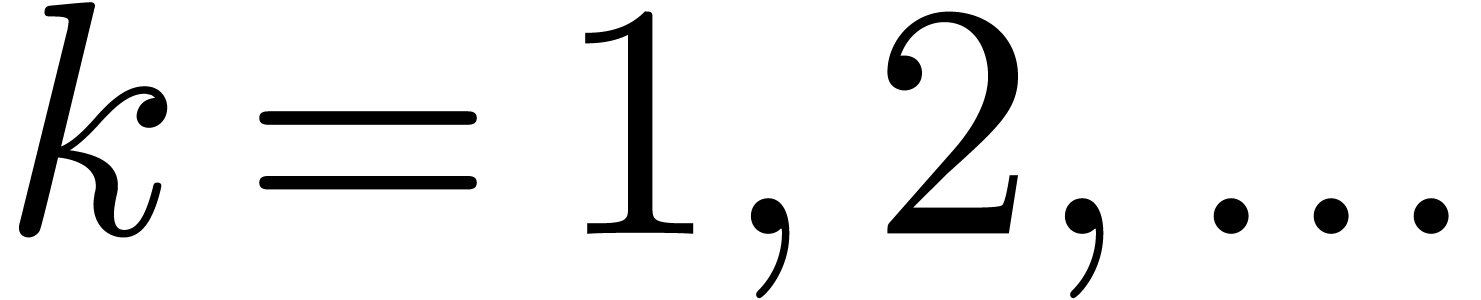 marked subdocuments before and after .
In many cases, there will be only one subdocument
marked subdocuments before and after .
In many cases, there will be only one subdocument 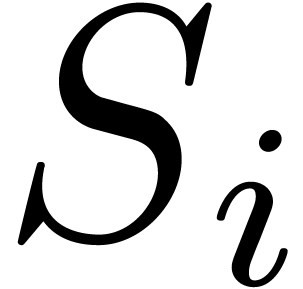 which will both correspond to and its context.
If such a preferred match cannot be found for
, then we renounce replacing
by an invariant tag.
which will both correspond to and its context.
If such a preferred match cannot be found for
, then we renounce replacing
by an invariant tag.
Secondly, the conversion algorithms are allowed to be context dependent.
For instance, ordinary text and mathematical formulas are usually not
converted in the same way. When replacing subdocuments
of by invarianted subdocuments
of , we thus have to verify
that the context of in
is similar to the context of in .
Some other improvements can be carried out in order to further improve the quality of naive conservative conversions. For instance, in Example 10, we observed that the comment before the remark is lost. This would not have been the case if Bob had only modified the last paragraph. It is a good practice to detect adjacent unchanged portions of text and keep the comments in the corresponding parts of the original source file, but it may be difficult to achieve.
Additional ad hoc techniques were used to solve others problems. For instance, certain editors automatically damage the line breaking of LaTeX source code. This issue has been addressed by normalizing whitespace before testing whether two subdocuments are identical.
Another strategy towards conservative editing is to determine the
changes between the conversion of Alice's
version and Bob's version in the form of a
“patch” 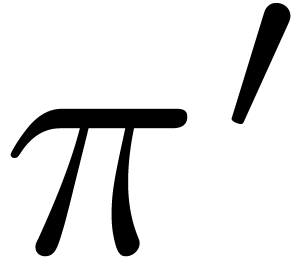 , and
then try to convert this patch into a patch
, and
then try to convert this patch into a patch  that can be applied to .
Before anything else, this requires us to fix formats
that can be applied to .
Before anything else, this requires us to fix formats  and
and 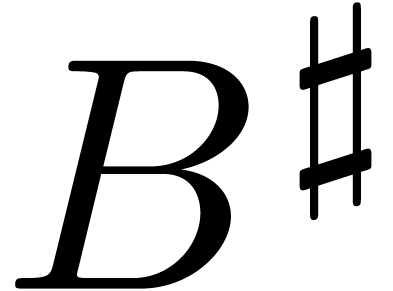 for the description of patches for the
formats and .
for the description of patches for the
formats and .
For instance, LaTeX documents are strings, so LaTeX patches could be
sets of triples 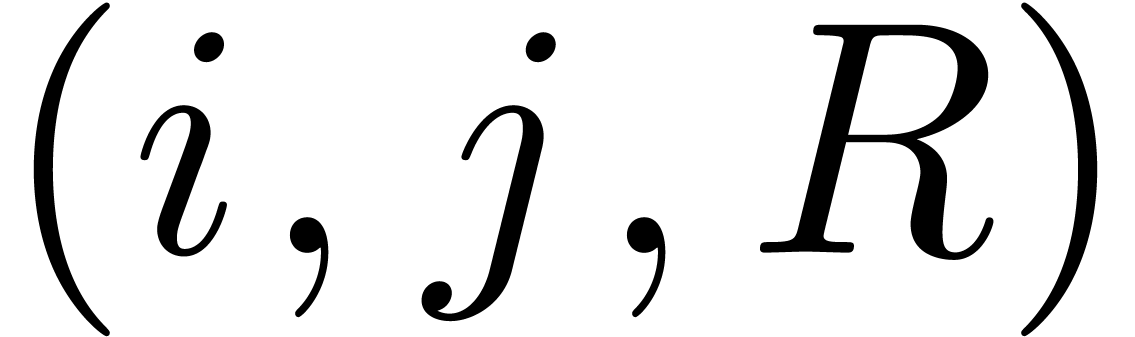 , where
, where 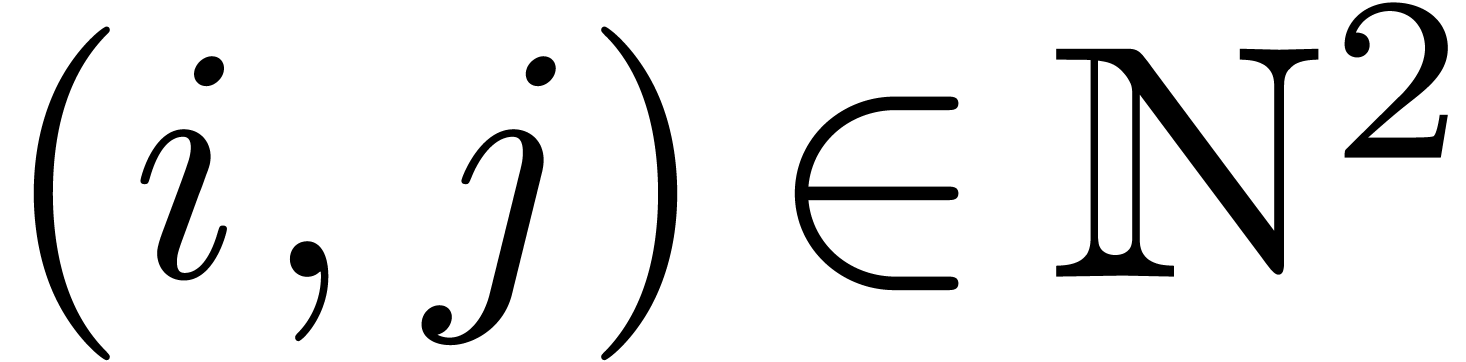 corresponds to a substring of the source string and
corresponds to a substring of the source string and
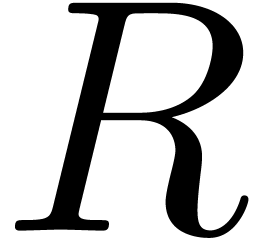 stands for a replacement string for this
substring. This language might be further extended with pairs
stands for a replacement string for this
substring. This language might be further extended with pairs 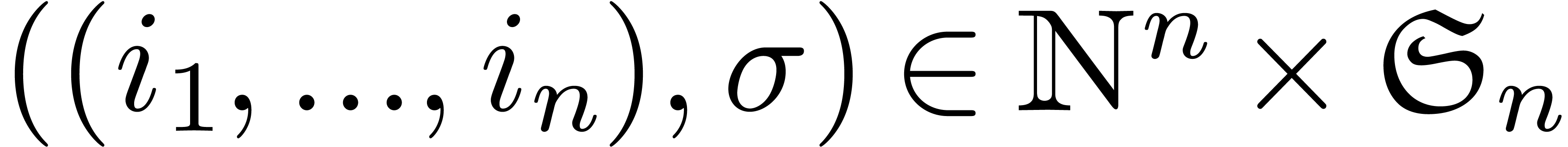 , where
, where  is
an
is
an 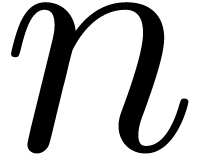 -tuple of positions
-tuple of positions  of the source string (of length
of the source string (of length 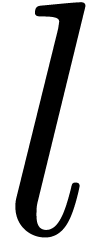 ) and
) and  a permutation.
The patch then applies the permutation to the
substrings
a permutation.
The patch then applies the permutation to the
substrings 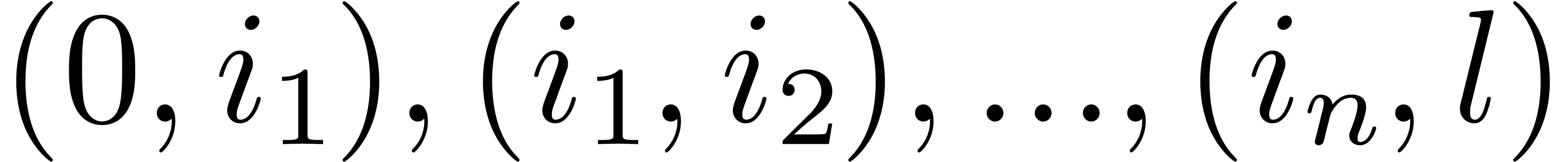 of the source string.
of the source string.
Similar patches can be used for TeXmacs trees, by operating on the children of a node instead of the characters in a string. In TeXmacs, we also implemented a few other types of elementary patches on trees for the insertion or removal of new nodes and splitting or joining nodes. However, we have not yet used these more complex kind of patches in our conservative converters. In general, we notice that richer patch formats lead to more conservative converters, but also make implementations more complex.
Let us study the most important kind of patches
which simply replaces a subdocument 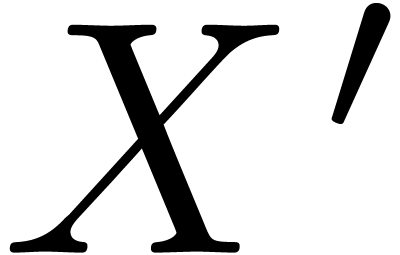 of by
of by 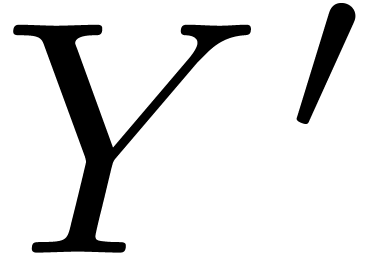 . If is marked inside ,
with
. If is marked inside ,
with 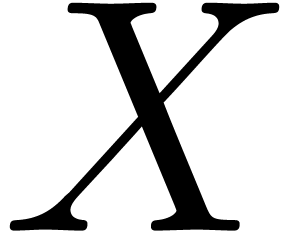 as the corresponding source in , then we take to be
the replacement of by contextual conversion
as the corresponding source in , then we take to be
the replacement of by contextual conversion 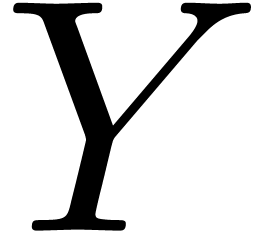 of into format . This contextual conversion of is obtained by performing a marked conversion of into format and then look for the
conversion of as a subdocument of .
of into format . This contextual conversion of is obtained by performing a marked conversion of into format and then look for the
conversion of as a subdocument of .
Example is
the patch which replaces subtree "More text."
by "More text…". This subtree "More text." corresponds to the pair of markers
and to the unique substring More
text. in the original source document. Consequently,  will be the patch which replaces this substring by More text…, which leads to the conservative
conversion
will be the patch which replaces this substring by More text…, which leads to the conservative
conversion
First paragraph.
%Some comments
\begin{remark}
Some mathematics
\[ a+\frac{b}{c}. \]
More text…
\end{remark}
Last paragraph.
Several things have to be fine tuned for the patch based approach.
Example 11 is particularly simple in the sense that the
patch which replaces "More
text." by "More text…"
replaces a subtree by another tree. More generally, we have to consider
the case when a succession of children of a subtree is replaced by a
sequence of trees. This occurs for instance when inserting or deleting a
certain number of paragraphs. For special types of nodes (such as the
TeXmacs document tag for successions of paragraphs), we
know how the node behaves under conversions, and we can devise an ad
hoc procedure for computing the patch .
In general however, we may have to replace by a
less fine grained patch which replaces the entire subtree by a new tree.
A similar situation arises when the patch
replaces as subdocument of
which is not marked inside ,
or when the subdocument of
does not lead to marked subdocument of the
marked conversion of into format . In these cases as well, a simple solution
again consists of replacing by a less fine
grained patch which replaces a larger subtree by another tree.
Example
which does not operate on a marked subtree of . Nevertheless, the patch which replaces the marked
subtree (concat "a+" (frac "b"
"c")) by (concat "a+" (frac
"x" "c")) does admit the required form.
The quality of conservative converters can be further enhanced by
combining the naive and patch based approaches. Assume that is obtained from through the
application of a set  of independent patches
(i.e., acting on disjoint subdocuments of ). If
of independent patches
(i.e., acting on disjoint subdocuments of ). If 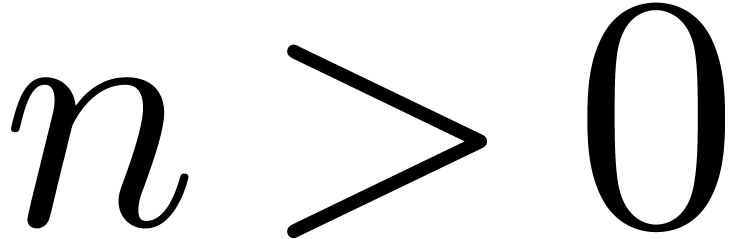 ,
then we will reduce the general “patch conversion” problem
to a problem of the same kind but with a strictly smaller number of
patches
,
then we will reduce the general “patch conversion” problem
to a problem of the same kind but with a strictly smaller number of
patches 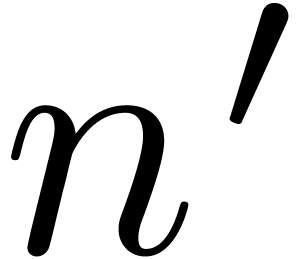 .
.
Consider a subdocument of
with the following properties:
The subdocument is marked inside and
corresponds to the subdocument of .
At least one of the patches  applies to a
part of .
applies to a
part of .
admits no strictly smaller subdocuments
satisfying the same properties.
Let 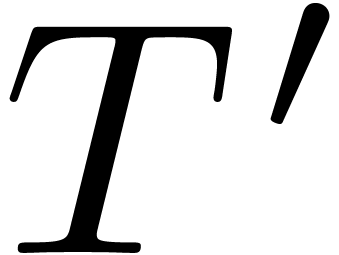 be the result of applying all relevant
patches to .
Now apply the marked version of the naive conversion techniques from
sections 5.1 and 5.2 to . This will yield a conservative contextual
conversion
be the result of applying all relevant
patches to .
Now apply the marked version of the naive conversion techniques from
sections 5.1 and 5.2 to . This will yield a conservative contextual
conversion  of into
format .
of into
format .
We now consider the new “source document” 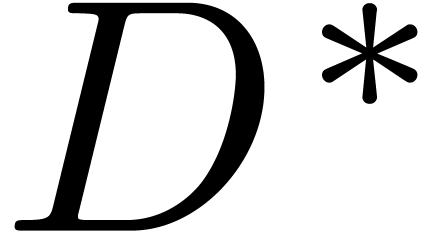 obtained from through the replacement of by .
Similarly, we consider the new “conversion”
obtained from through the replacement of by .
Similarly, we consider the new “conversion” 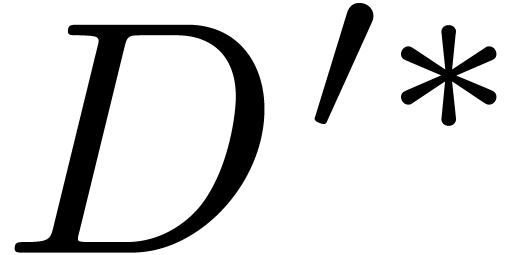 obtained from through the replacement of by . These
replacements admit marked versions which basically change nothing
outside and and remove
all markers strictly inside and . This completes our reduction of the general
“patch conversion” problem to one with strictly less patches
(namely, all remaining patches which did not apply to ). In practice, several non overlapping
subdocuments can be treated in a single
iteration, so as to increase the efficiency.
obtained from through the replacement of by . These
replacements admit marked versions which basically change nothing
outside and and remove
all markers strictly inside and . This completes our reduction of the general
“patch conversion” problem to one with strictly less patches
(namely, all remaining patches which did not apply to ). In practice, several non overlapping
subdocuments can be treated in a single
iteration, so as to increase the efficiency.
Conservative converters should make collaborations easier between people who are working with different authoring tools. Although we only considered conversions between TeXmacs and LaTeX here, our methods should also be useful for other formats. We also notice that the approach generalizes in a straightforward way to the documents which are written using three or more different tools or formats.
The implementations inside TeXmacs have only started quite recently and some time will still be needed for testing and maturing. Nevertheless, our first experiences are encouraging. Currently, we are still struggling with conservative conversions of user defined macros and metadata such as title information. Nevertheless, we are confident that a suitable solution can be worked out even for complex conversion challenges of this kind, by finetuning the grain of our marking algorithm, and through the progressive integration of the patch based approach.
Romeo Anghelache. Hermes. http://hermes.roua.org/, 2005.
M. Ettrich et al. The LyX document processor. http://www.lyx.org, 1995.
David Fuchs. The format of TeX's DVI files. TUGboat, 3(2):13–19, 1982.
José Grimm. Tralics. http://www-sop.inria.fr/marelle/tralics/, 2003.
E. Gurari. TeX4ht: LaTeX and TeX for hypertext. http://www.tug.org/applications/tex4ht/mn.html, 2010.
Sven Heinicke. LaTeX::Parser – Perl extension to parse LaTeX files. http://search.cpan.org/~svenh/LaTeX-Parser-0.01/Parser.pm, 2000.
J. van der Hoeven. GNU TeXmacs: A free, structured, wysiwyg and technical text editor. In Daniel Filipo, editor, Le document au XXI-ième siècle, volume 39–40, pages 39–50, Metz, 14–17 mai 2001. Actes du congrès GUTenberg.
J. van der Hoeven. Towards semantic mathematical editing. Technical report, HAL, 2011. http://hal.archives-ouvertes.fr/hal-00569351, submitted to JSC.
J. van der Hoeven. GNU TeXmacs User Manual, chapter 14: The TeXmacs format. HAL, 2013. http://hal.archives-ouvertes.fr/hal-00785535.
J. van der Hoeven et al. GNU TeXmacs. http://www.texmacs.org, 1998.
Ian Hutchinson. TtH, the TeX to html translator. http://hutchinson.belmont.ma.us/tth/, 1997.
Rodionov I. and S. Watt. A TeX to MathML converter. http://www.orcca.on.ca/MathML/texmml/textomml.html.
Jean-Paul Jorda and Xavier Trochu. LXir. http://www.lxir-latex.org/, 2007.
L. Lamport. LaTeX, a document preparation system. Addison Wesley, 1994.
J. MacFarlane. Pandoc: a universal document converter. http://johnmacfarlane.net/pandoc/index.html, 2012.
L. Maranget. HeVeA. http://para.inria.fr/~maranget/hevea/index.html, 2013.
B. Miller. LaTeXML: A LaTeX to XML converter. http://dlmf.nist.gov/LaTeXML/, 2013.
R. Moore. LaTeX2HTML. http://www.latex2html.org, 2001.
T. Sgouros. HyperLaTeX. http://hyperlatex.sourceforge.net, 2004.
Kevin Smith. plasTeX. http://plastex.sourceforge.net/, 2008.
M. Sofka. TeX to HTML translation via tagged DVI files. TUGboat, 19(2):214–222, 1998.
MacKichan Software. Scientific workplace. http://www.mackichan.com/index.html?products/swp.html~mainFrame, 1998.
H. Stamerjohanns, D. Ginev, C. David, D. Misev, V. Zamdzhiev, and M. Kohlhase. MathML-aware article conversion from LaTeX, a comparison study. In P. Sojka, editor, Towards Digital Mathematics Library, DML 2009 workshop, pages 109–120, Masaryk University, Brno, 2009. http://kwarc.info/kohlhase/papers/dml09-conversion.pdf.