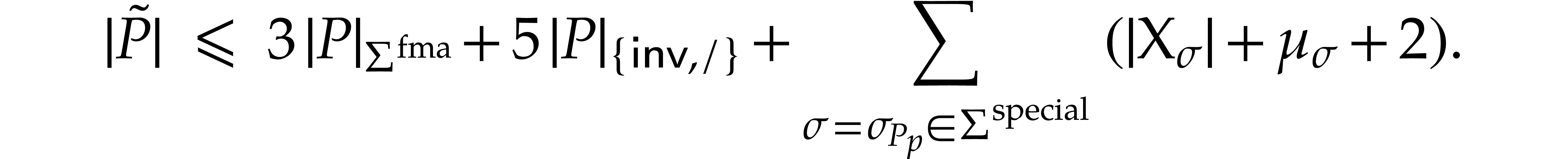| Polynomialization of ordinary
differential equations given by straight-line programs   |
|
| Preliminary version of February 6, 2026 |
|
 . Grégoire
Lecerf and Arnaud Minondo have been supported by the French ANR-22-CE48-0016 NODE project. Joris van der Hoeven
has been supported by an ERC-2023-ADG grant for the ODELIX
project (number 101142171).
. Grégoire
Lecerf and Arnaud Minondo have been supported by the French ANR-22-CE48-0016 NODE project. Joris van der Hoeven
has been supported by an ERC-2023-ADG grant for the ODELIX
project (number 101142171).
Funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency. Neither the European Union nor the granting authority can be held responsible for them. |
 |
Given a system of ordinary differential equations represented by a straight-line program, we show how to compute an equivalent ordinary differential system represented by a straight-line program which only uses ring operations. Under mild assumptions, our method essentially runs in linear time. |
In this paper,  will represent either
will represent either  or
or  . Let
. Let  be an open subset of
be an open subset of 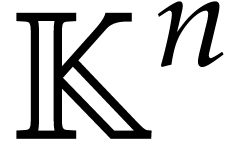 ,
let
,
let  be a map
be a map 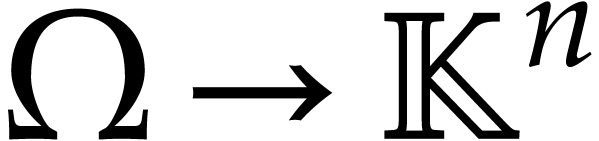 ,
we will consider the Ordinary Differential Equation (ODE)
,
we will consider the Ordinary Differential Equation (ODE)
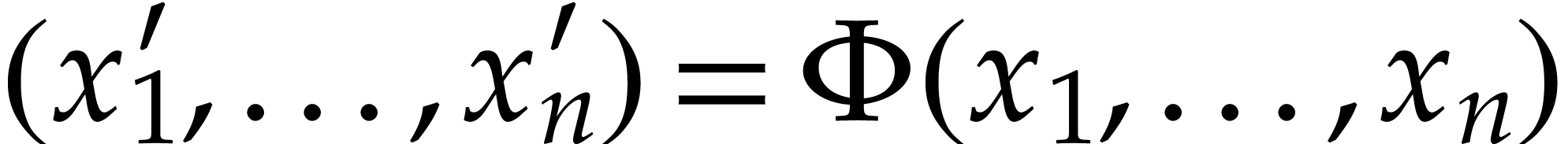 |
(1) |
where 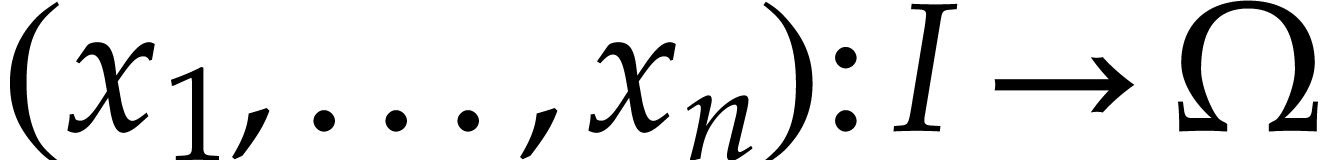 stands for an unknown function on an open
interval
stands for an unknown function on an open
interval  . A
polynomialization of is a polynomial
map
. A
polynomialization of is a polynomial
map 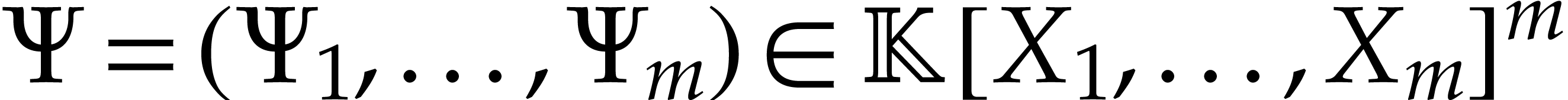 with
with  such that any
solution
such that any
solution  of
of 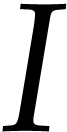 extends into a solution
extends into a solution  of
of
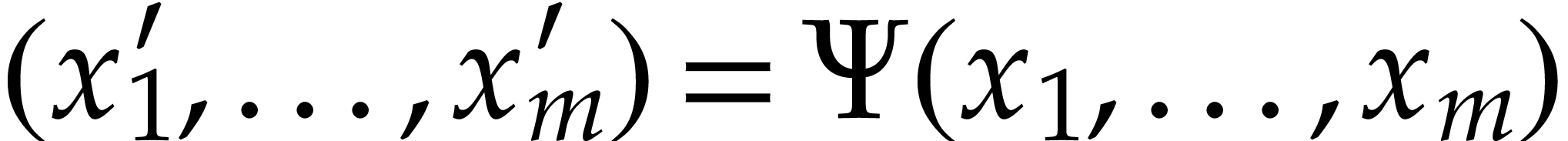 |
(2) |
which is also defined on . We
say that a solution of (1)
satisfies the initial condition
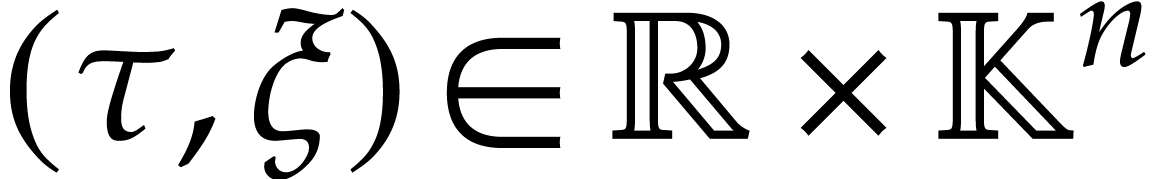
if  and
and 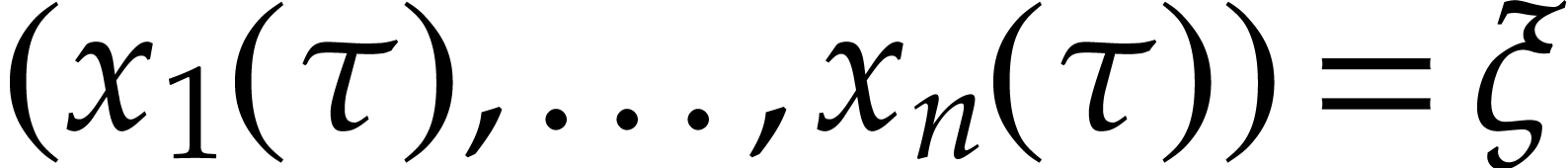 .
Finding such solutions is called an initial value problem.
.
Finding such solutions is called an initial value problem.
This paper is devoted to the fast computation of polynomializations of
, along with the
corresponding initial conditions.
ODEs arising in many areas of physics and chemistry are often non-linear
and include divisions, exponentiations, logarithms, square roots, etc.
Although methods for ODE polynomialization are well known, we are not
aware of complexity bounds for the case where is
given by a Straight-Line Program (SLP for short, defined in section 2). Although numerical integrators typically allow to be an arbitrary blackbox function, it is most common
that the implementation of is actually an SLP.
Our motivation is three-fold. From a theoretical point of view, we are interested in a sharp worst case complexity bound.
Polynomialization is of practical interest, because the quotients and
special functions occurring in are typically
more expensive to evaluate than the simpler ring operations occurring in
 . For example, when using a
recent Intel
. For example, when using a
recent Intel
Of course, in order to apply our work to speed up the numerical
integration of (1), one should use an ODE solver that is
able to exploit the lower evaluation cost of , while not suffering too much from the increased
dimension 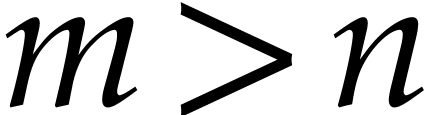 . This is typically
the case for Runge–Kutta integrators [4], for which
the complexity depends linearly on the evaluation cost of . Lazy Taylor series integrators [10]
implicitly use something close to polynomialization for the evaluation
of (e.g. exponentials
. This is typically
the case for Runge–Kutta integrators [4], for which
the complexity depends linearly on the evaluation cost of . Lazy Taylor series integrators [10]
implicitly use something close to polynomialization for the evaluation
of (e.g. exponentials 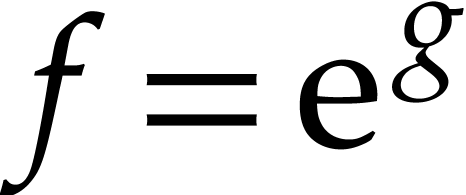 are evaluated by solving the equation
are evaluated by solving the equation 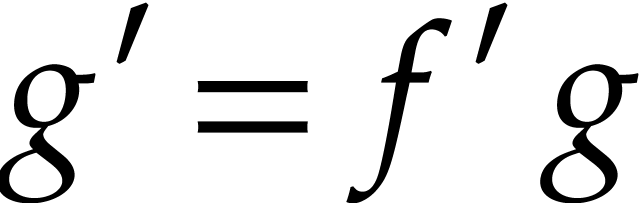 ). On the other hand, integrators that also
compute the first variation (e.g. in order to improve the
stability) may suffer from the increased dimension.
). On the other hand, integrators that also
compute the first variation (e.g. in order to improve the
stability) may suffer from the increased dimension.
Finally, we plan to use polynomialization to simplify bound computations
for certified Runge–Kutta ODE solvers as in [2]. Such
bound computations are easier and tighter for SLPs that only use ring
operations. Decreasing the degrees of the polynomials 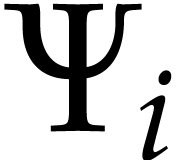 is also beneficial for this application.
is also beneficial for this application.
Polynomialization is certainly part of the folklore of differential
algebra. Recent studies focus on quadratization, i.e. a
polynomialization 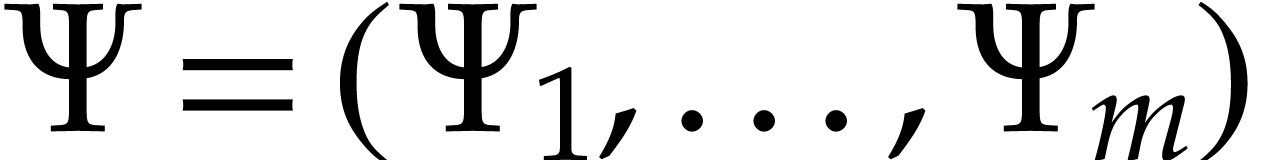 with
with 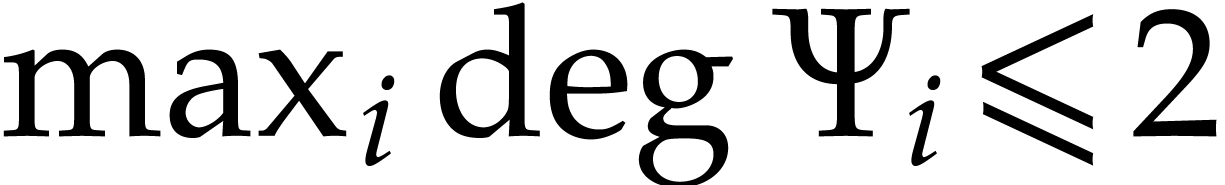 . Quadratization was established at least more than
a century ago: historical and recent references, along with various
applications, can be found in [5, 6, 8,
9, 15]. Polynomialization is achieved in
quadratic time in [8, 9] for a dense
representation of polynomials. In [8] the problem of
finding the minimal number of extra variables necessary for
quadratization is shown to be NP-hard. In [5] a
quadratization with minimal order (namely
. Quadratization was established at least more than
a century ago: historical and recent references, along with various
applications, can be found in [5, 6, 8,
9, 15]. Polynomialization is achieved in
quadratic time in [8, 9] for a dense
representation of polynomials. In [8] the problem of
finding the minimal number of extra variables necessary for
quadratization is shown to be NP-hard. In [5] a
quadratization with minimal order (namely 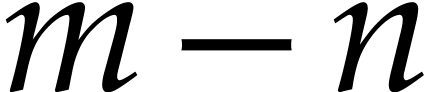 )
is achieved for the dense representation of . Polynomializations and quadratizations are not
unique, and preserving stability is sometimes more important than the
sole complexity issue; see various strategies in [6].
)
is achieved for the dense representation of . Polynomializations and quadratizations are not
unique, and preserving stability is sometimes more important than the
sole complexity issue; see various strategies in [6].
Our first contribution is a new method for polynomializing ODEs represented by SLPs at the price of increasing the number of instructions by a small constant factor. The precise overhead depends on the arithmetic instructions allowed by the SLP framework. Theorem 9 focuses on SLPs that only use additions, subtractions, and products, while Theorem 11 achieves a lower overhead if we also allow “Fused Multiply-Add” instructions.
Our second contribution concerns practical improvements over our worst
case complexity bound. On the one hand, we restrict the additional costs
to the subexpressions actually involved in the instructions of which are not polynomials. On the other hand, we try to
minimize the number of extra variables, namely . Our optimizations and heuristics take linear time
up to logarithmic factors. Even when polynomializing just a few
instructions of a small SLP, our method turns out to of significant
practical interest.
Our third contribution is an implementation of our polynomialization
algorithm within the
Given  , we write
, we write  . Given two tuples
. Given two tuples 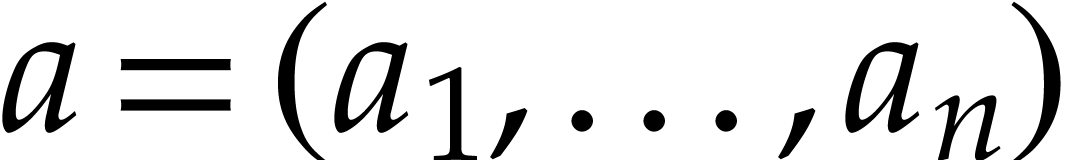 and
and
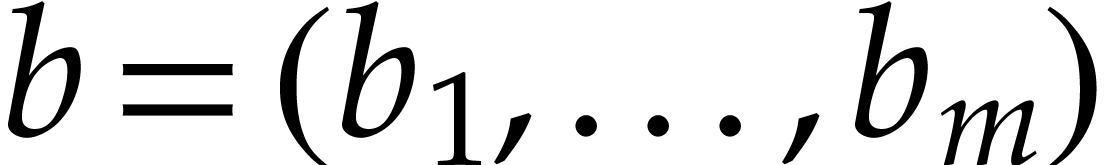 , their
concatenation
, their
concatenation 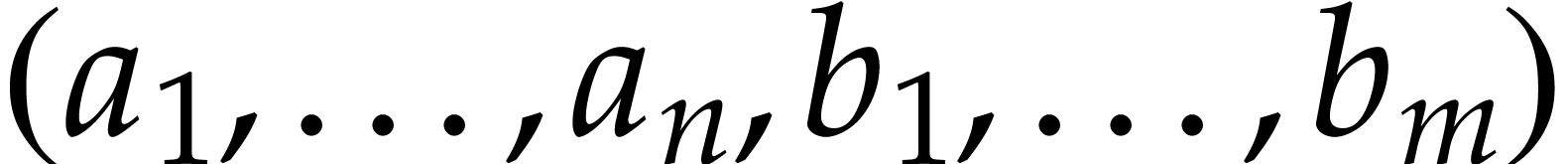 is written
is written  . We will encode names of variables by integers
(typically of
. We will encode names of variables by integers
(typically of 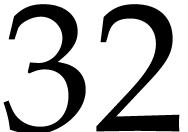 bit or
bit or  bit
machine size). For complexity analyses, we will assume that these
integers are of size
bit
machine size). For complexity analyses, we will assume that these
integers are of size 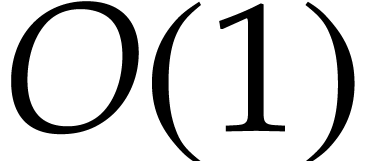 and count unit time for
operations on such integers. Similarly, we assume that elements of take unit size. (Here we note that our main
polynomialization algorithms from Theorems 9 and 11
require no arithmetic operations in .)
Below, we follow the SLP framework of [12].
and count unit time for
operations on such integers. Similarly, we assume that elements of take unit size. (Here we note that our main
polynomialization algorithms from Theorems 9 and 11
require no arithmetic operations in .)
Below, we follow the SLP framework of [12].
Let 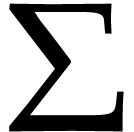 be a set of operation symbols together with
a function
be a set of operation symbols together with
a function 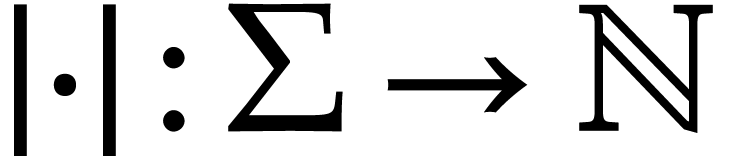 . We call a signature and
. We call a signature and  the
arity of
the
arity of  , for any
operation
, for any
operation 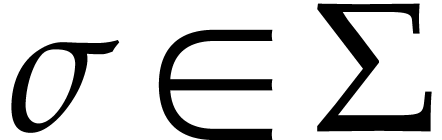 . A domain
with signature is a set
. A domain
with signature is a set  together with a function
together with a function 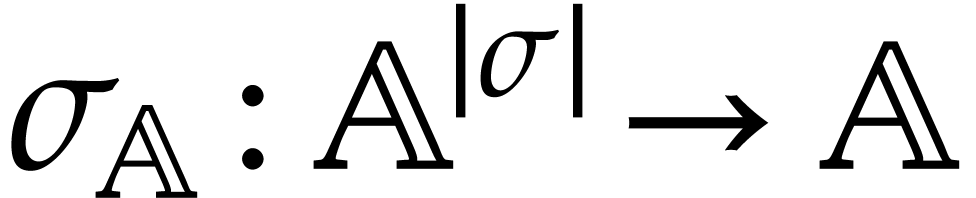 for every . We often write
instead of
for every . We often write
instead of  if no confusion can arise.
if no confusion can arise.
Let be a domain with signature . An instruction is a tuple
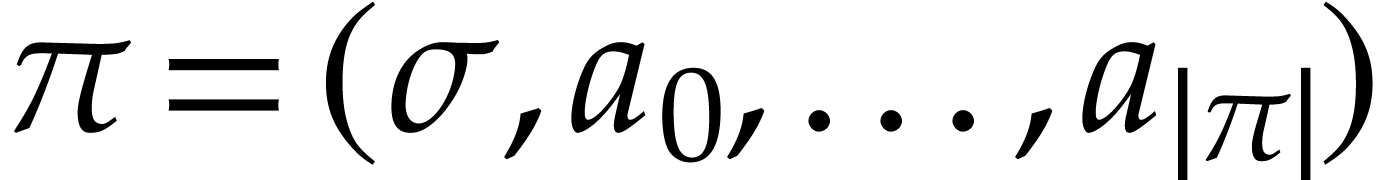
with operation 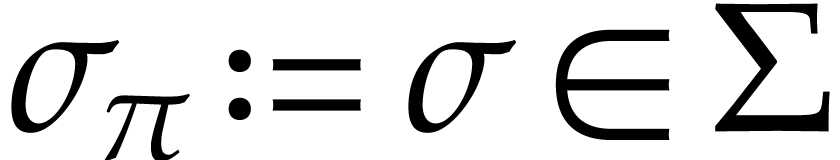 and arguments
and arguments
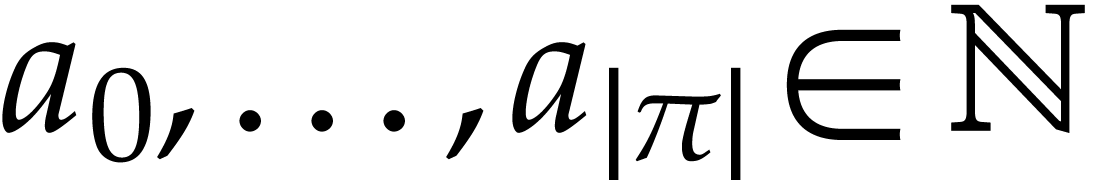 , where
, where 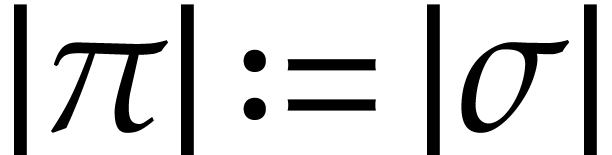 . We call
. We call 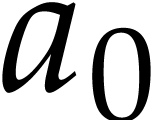 the
destination argument or operand and
the
destination argument or operand and  the source arguments or operands. We denote by
the source arguments or operands. We denote by 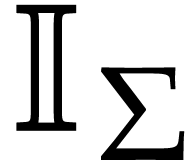 the set of such instructions. Given , we also let
the set of such instructions. Given , we also let
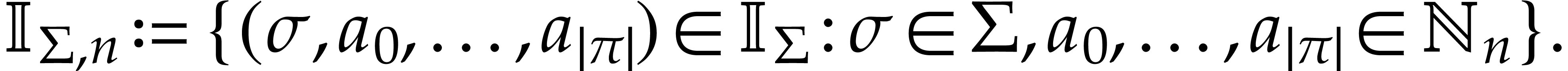
A straight-line program (SLP) over
is a quadruple 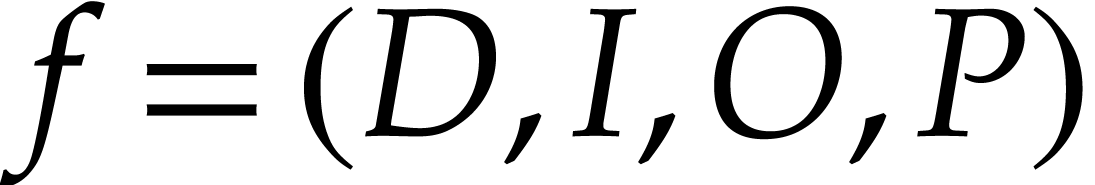 , where
, where
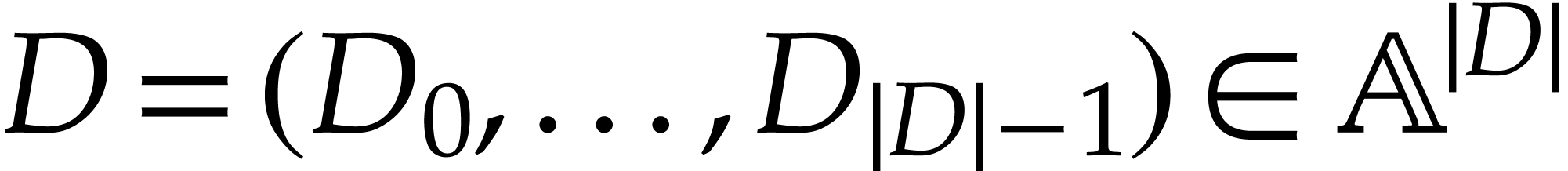 is a tuple of data fields,
is a tuple of data fields,
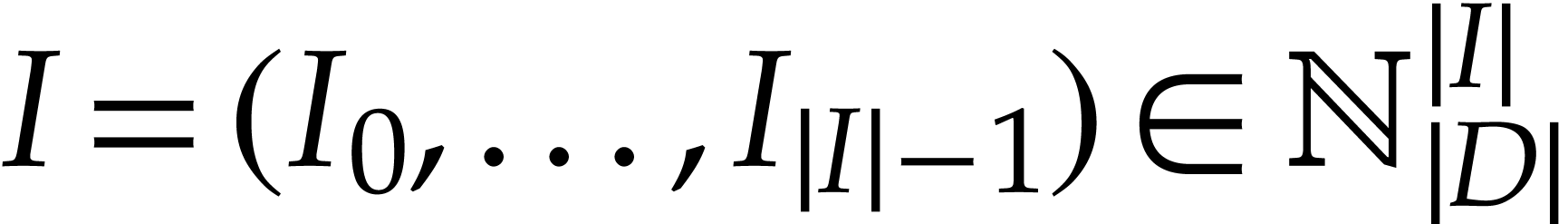 is a tuple of pairwise distinct input
locations,
is a tuple of pairwise distinct input
locations,
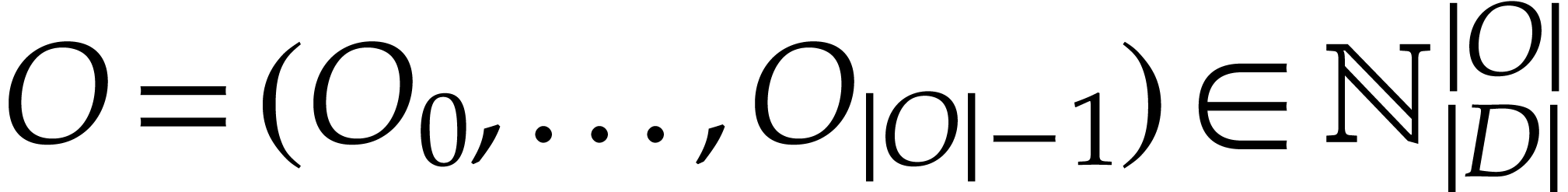 is a tuple of output locations,
is a tuple of output locations,
 is a tuple of instructions.
is a tuple of instructions.
We regard  as the working space for our
SLP. Each location in this working space can be represented using an
integer in
as the working space for our
SLP. Each location in this working space can be represented using an
integer in 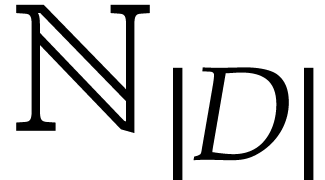 and instructions directly operate on
the working space as follows.
and instructions directly operate on
the working space as follows.
Given a state  of our working space, the
execution of an instruction
of our working space, the
execution of an instruction 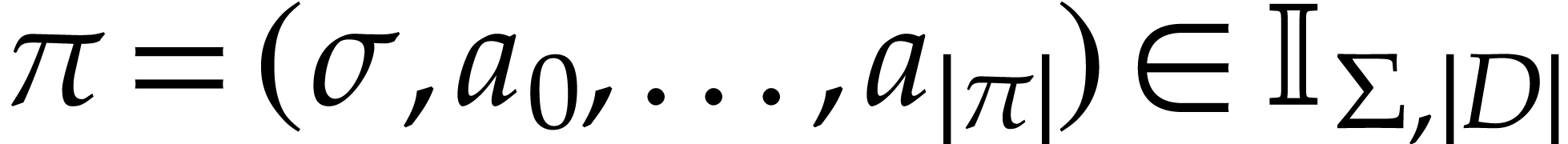 gives rise
to a new state
gives rise
to a new state 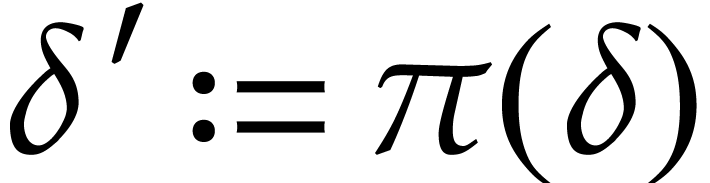 where
where 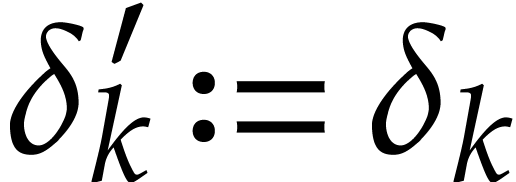 if
if
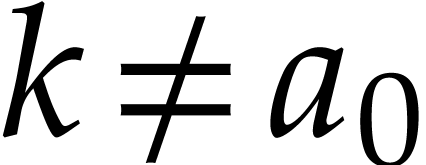 and
and 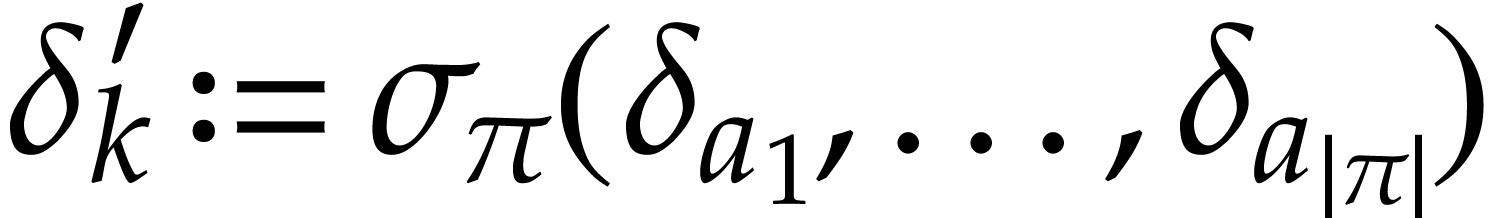 if
if 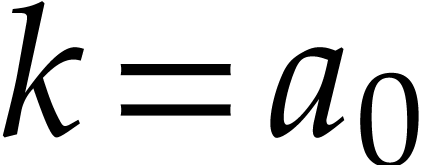 . Given input values
. Given input values 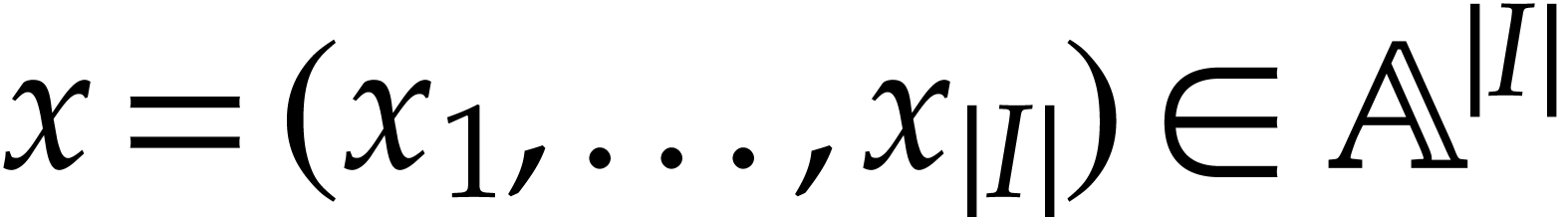 , the corresponding begin state
, the corresponding begin state  of our SLP is given by
of our SLP is given by 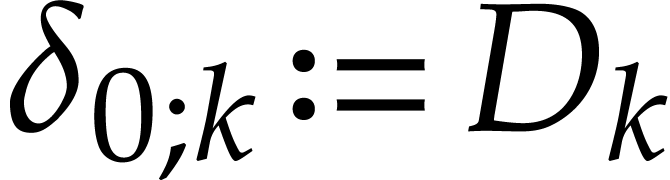 if
if  and
and 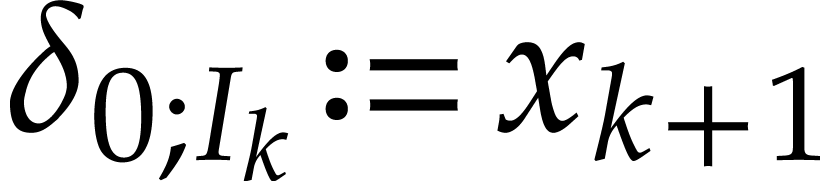 for
for 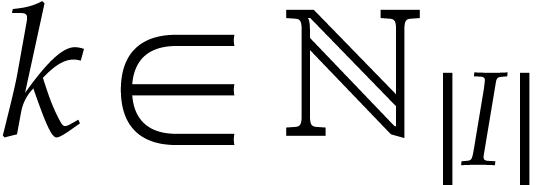 . Execution of the SLP next gives rise to a
sequence of states
. Execution of the SLP next gives rise to a
sequence of states 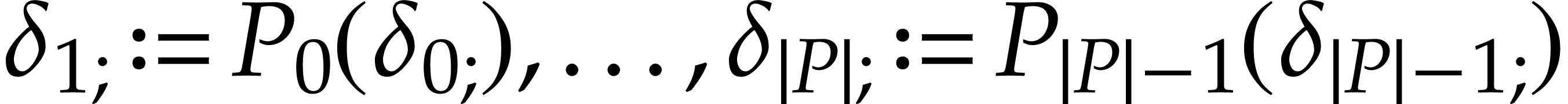 . The
output values
. The
output values 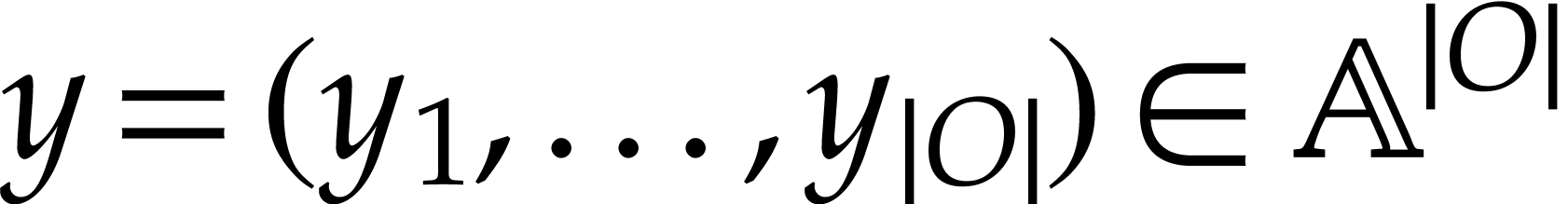 of our SLP are now given
by
of our SLP are now given
by 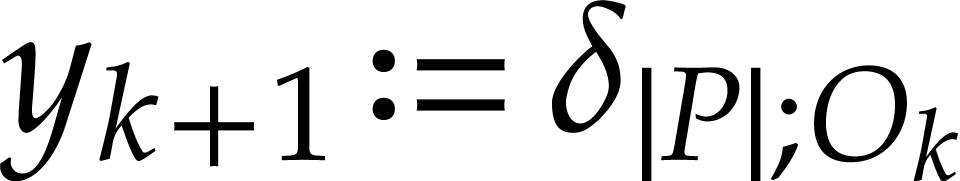 for
for 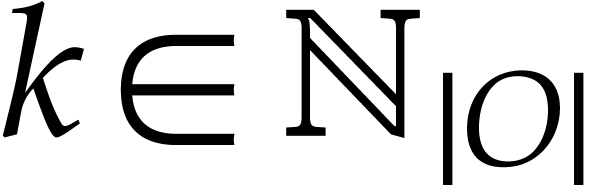 .
In this way our SLP
.
In this way our SLP 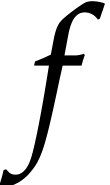 gives rise to a function
gives rise to a function
 that we will also denote by . Two SLPs are said to be equivalent
if they compute the same function.
that we will also denote by . Two SLPs are said to be equivalent
if they compute the same function.
It will be useful to call elements of
variables and denote them by more intelligible symbols like
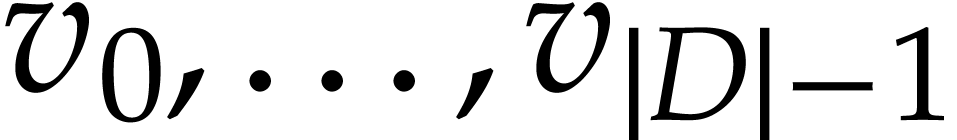 whenever convenient. The entries of and
whenever convenient. The entries of and  are called input and
output variables, respectively. Non-input variables that also
do not occur as destination operands of instructions in
are called input and
output variables, respectively. Non-input variables that also
do not occur as destination operands of instructions in 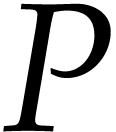 are called constants. An auxiliary variable is a
variable that is neither an input variable, nor an output variable, nor
a constant. Given a variable
are called constants. An auxiliary variable is a
variable that is neither an input variable, nor an output variable, nor
a constant. Given a variable 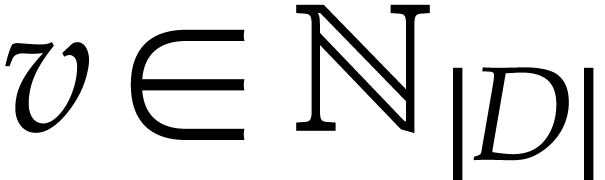 ,
the corresponding data field is
,
the corresponding data field is 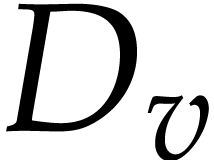 .
Input variables, output variables, and constants naturally correspond to
input fields, output fields, and constant
fields. For a subset
.
Input variables, output variables, and constants naturally correspond to
input fields, output fields, and constant
fields. For a subset  ,
we denote
,
we denote 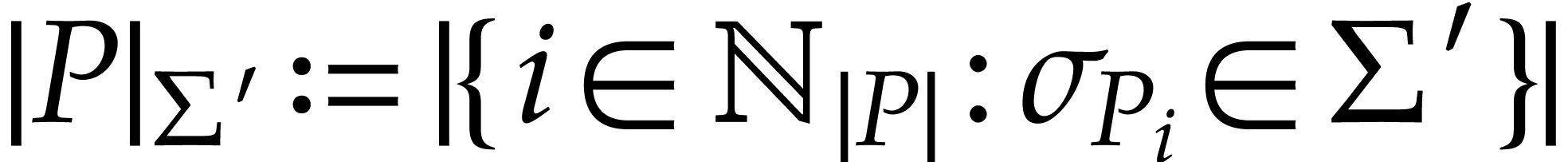 ; given , we also abbreviate
; given , we also abbreviate 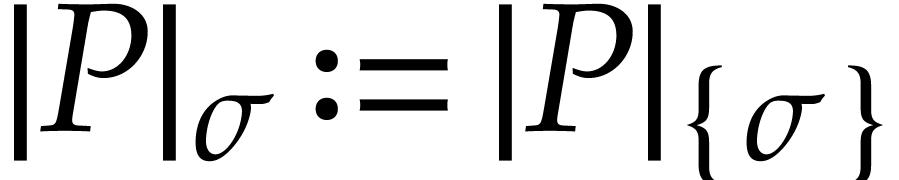 .
.
Example  and let
and let 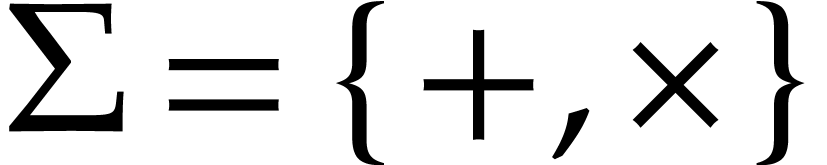 be the signatures of the
binary sum and product. Let
be the signatures of the
binary sum and product. Let  be the SLP defined
by
be the SLP defined
by 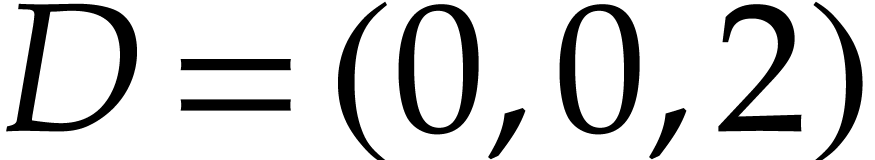 ,
, 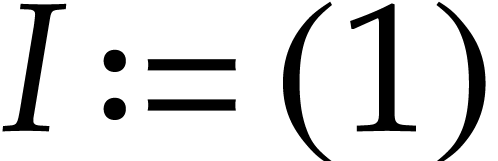 ,
, 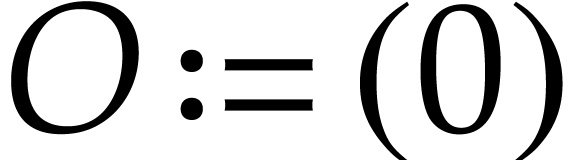 , and
, and
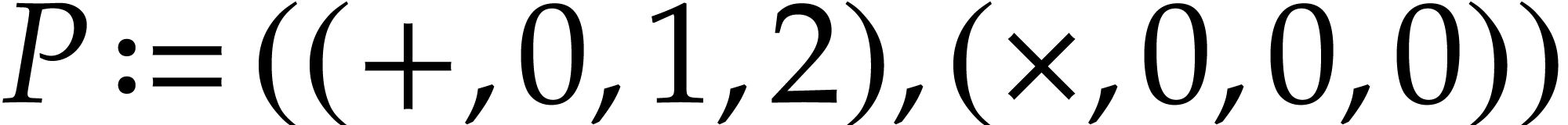 . With
. With 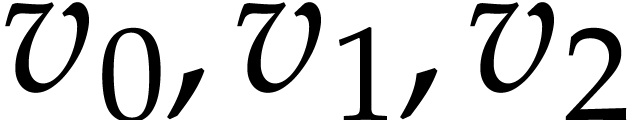 representing the values at positions
representing the values at positions 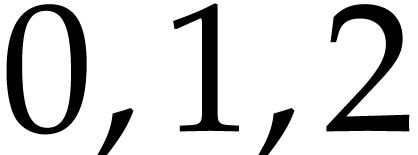 in the
working space, the instructions of
in the
working space, the instructions of 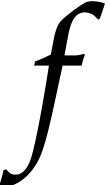 rewrite into
rewrite into
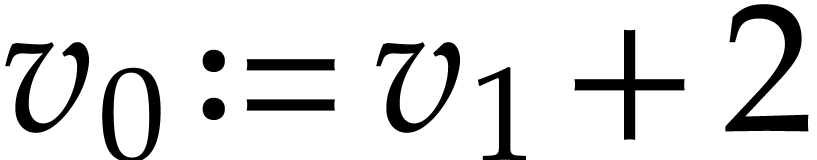 ,
, 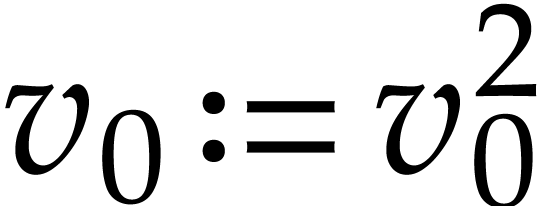 . Consequently, computes the
function
. Consequently, computes the
function 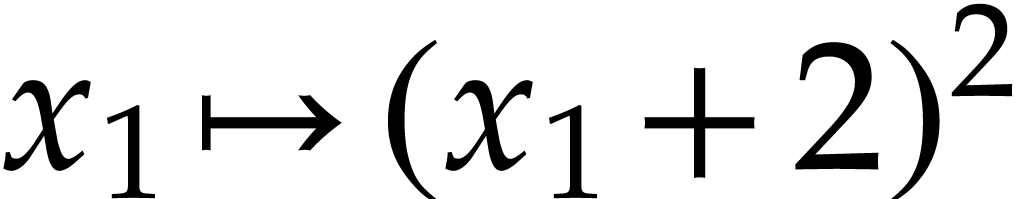 .
.
When dealing with operations that are only partially defined, such as the unary inverse over fields, we say that an SLP is executable at a given input when all its instructions have their arguments in their definition domain during the execution.
Remark  and
and  and in the instructions of
and in the instructions of  are at
most
are at
most 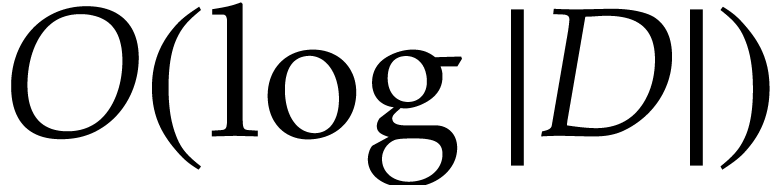 . For practical software
implementations it is fair to consider that we always have
. For practical software
implementations it is fair to consider that we always have 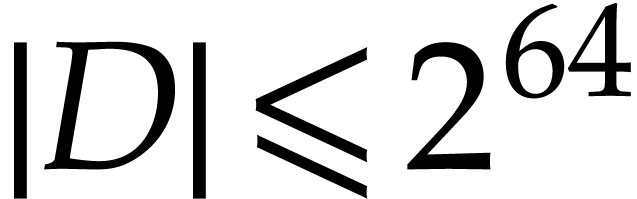 or even
or even 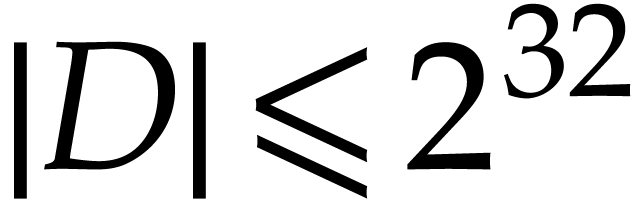 , so
that these integers can be represented by hardware integers. This also
“justifies” why we count a unit cost for integer operations
in our complexity analyses.
, so
that these integers can be represented by hardware integers. This also
“justifies” why we count a unit cost for integer operations
in our complexity analyses.
The standard signature of a ring ,
written 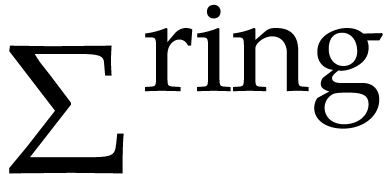 , will be the set of
the following operations:
, will be the set of
the following operations:
unary identity  , defined
by
, defined
by 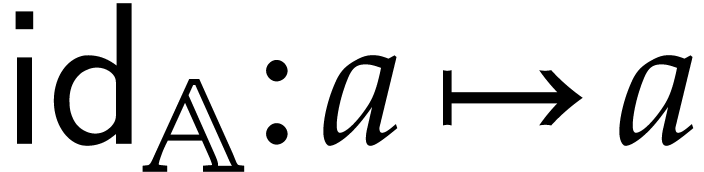 ,
,
unary negation 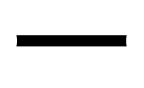 , defined
by
, defined
by 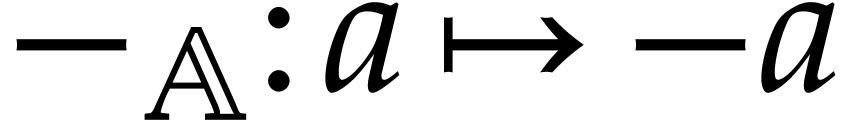 ,
,
binary subtraction, also written ,
defined by 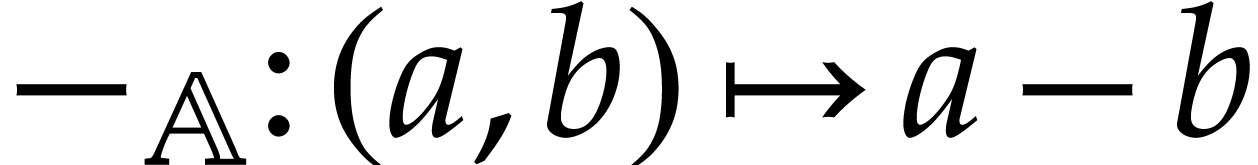 ,
,
binary addition  , defined
by
, defined
by 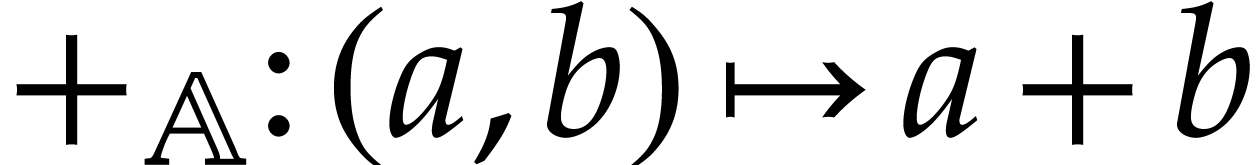 ,
,
binary multiplication  ,
defined by
,
defined by 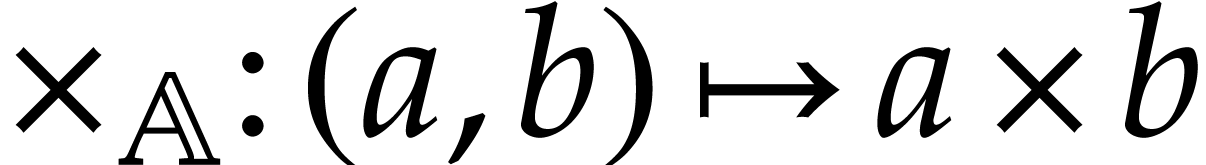 .
.
The standard signature of a field will
be the union  , where
, where 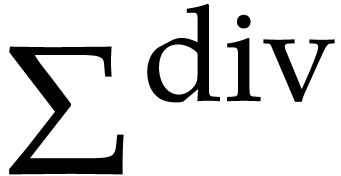 is the set of the following operations:
is the set of the following operations:
unary inversion  , defined
by
, defined
by 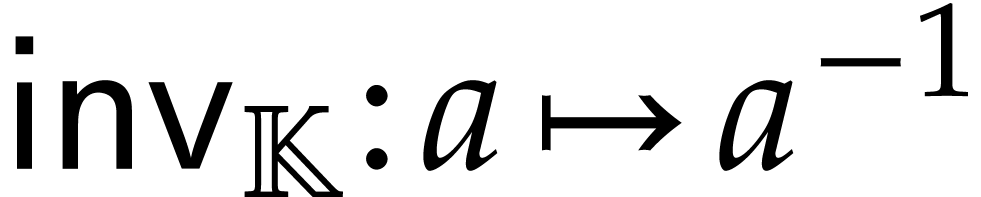 ,
,
binary division 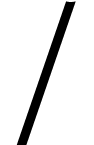 , defined
by
, defined
by 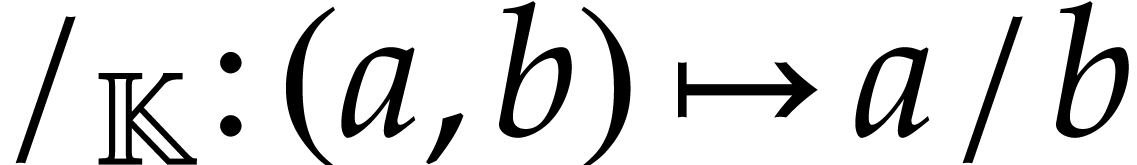 .
.
Let 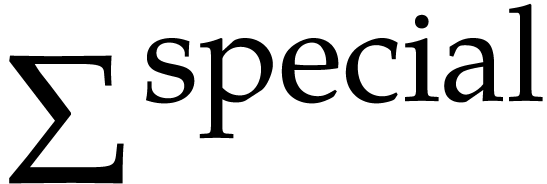 be a fixed finite set of operations of arity one such that each
be a fixed finite set of operations of arity one such that each 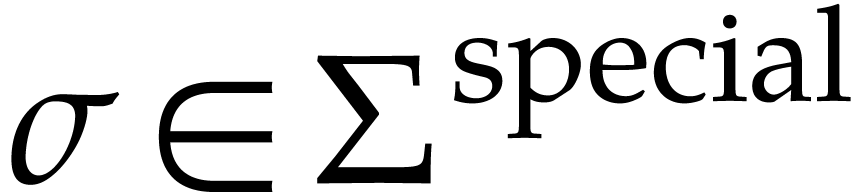 satisfies a differential equation
satisfies a differential equation
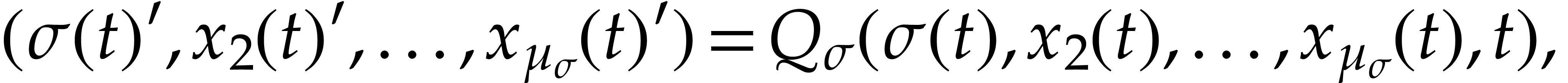
where 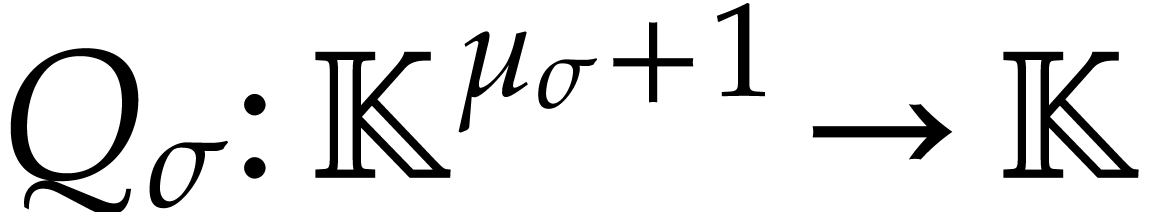 is given by an SLP with signature over . We
also assume that
is given by an SLP with signature over . We
also assume that 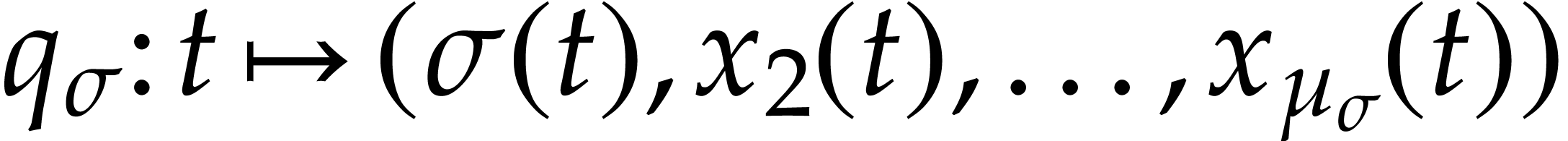 is given by an SLP with
signature
is given by an SLP with
signature  over .
In this case, we call a field with special
functions .
over .
In this case, we call a field with special
functions .
For convenience, 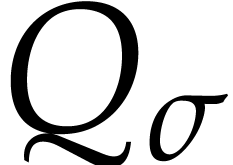 and
and 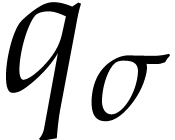 will be rewritten in terms of macro instructions (following the usual
programming language terminology). Precisely, we will assume given the
following data:
will be rewritten in terms of macro instructions (following the usual
programming language terminology). Precisely, we will assume given the
following data:
A segment of data 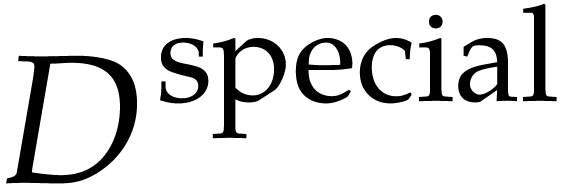 over
gathers all the constants and auxiliary variables involved in and for all .
over
gathers all the constants and auxiliary variables involved in and for all .
For all , a macro
instruction 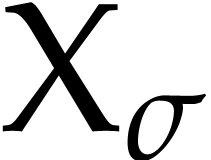 takes
takes 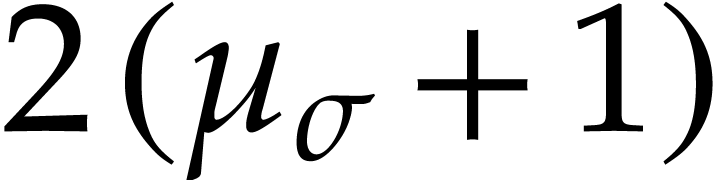 integer arguments and returns a sequence of instructions of length
written
integer arguments and returns a sequence of instructions of length
written 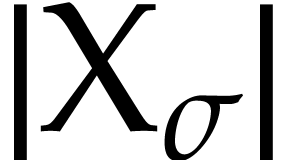 . The last
argument of stands for the position of in the working space. For any
. The last
argument of stands for the position of in the working space. For any 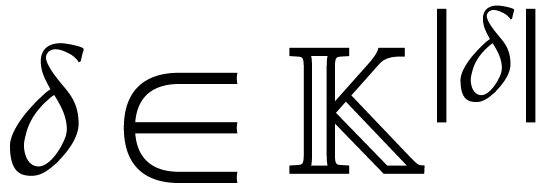 and for all
and for all 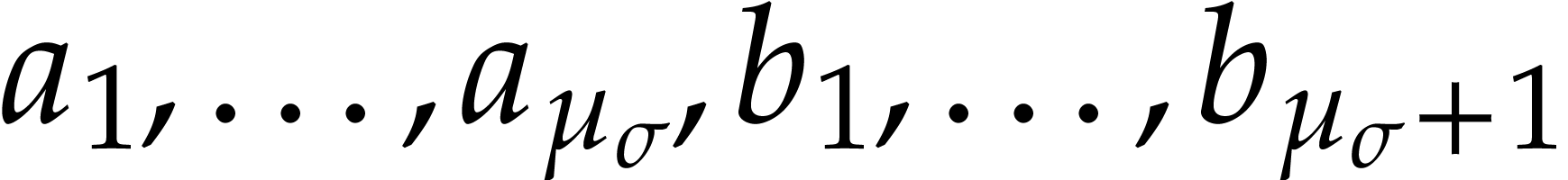 in
in 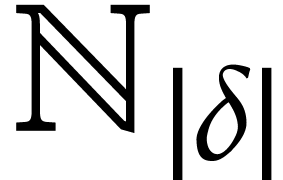 ,
the execution of
,
the execution of 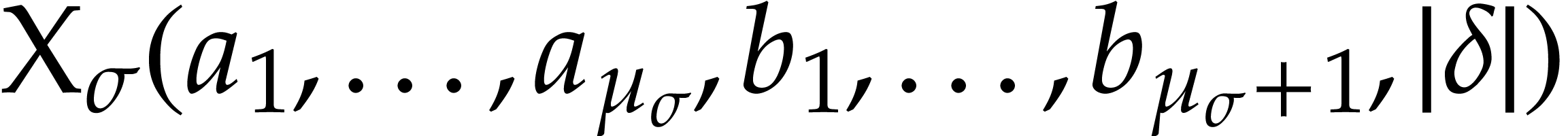 at the state
at the state 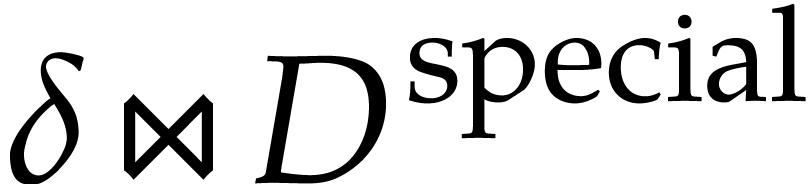 performs
performs 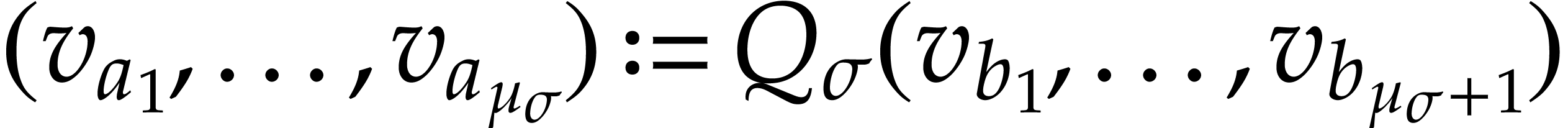 and only modifies the
values at positions
and only modifies the
values at positions  inside
inside  (the data fields in may be modified freely).
(the data fields in may be modified freely).
For all , a macro
instruction 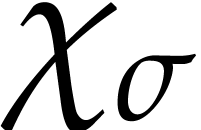 takes
takes 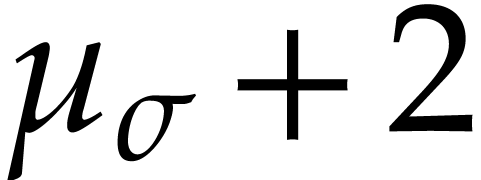 integer arguments and returns a sequence of instructions of length
written
integer arguments and returns a sequence of instructions of length
written 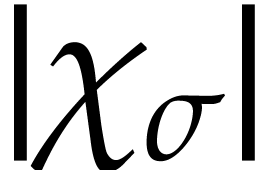 . Again, the last
argument of is the position of in the working space. For any
and all
. Again, the last
argument of is the position of in the working space. For any
and all 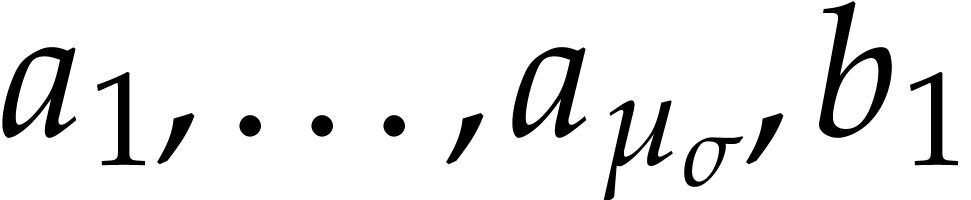 in ,
the execution of
in ,
the execution of 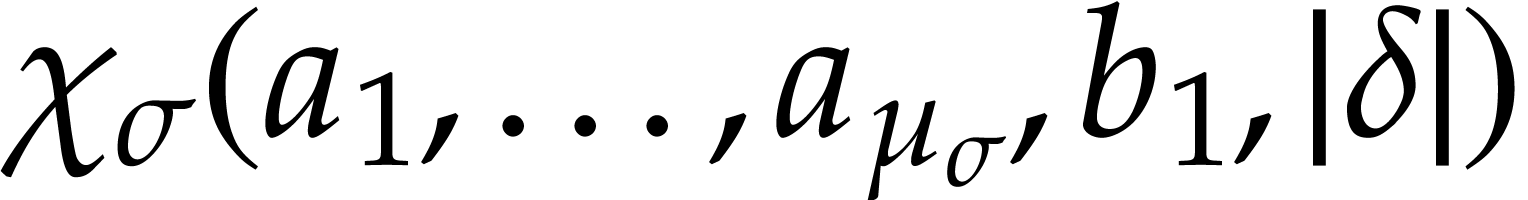 at the state performs
at the state performs 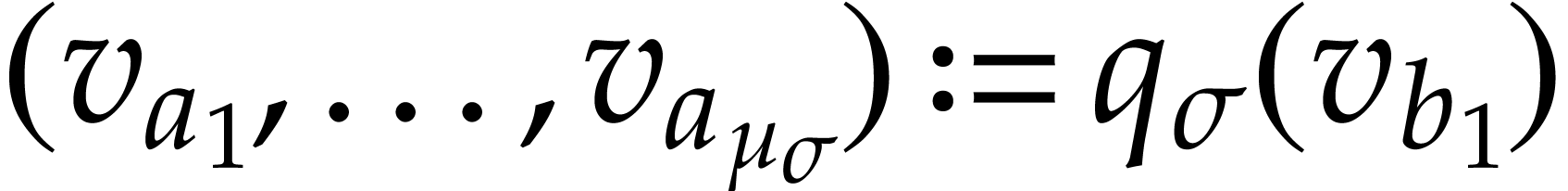 and only modifies the
values at positions inside
(the data fields in may be modified freely).
and only modifies the
values at positions inside
(the data fields in may be modified freely).
Example  function may be included in with
the defining functions
function may be included in with
the defining functions 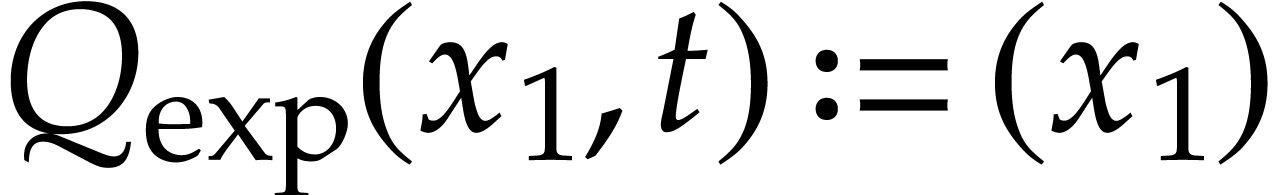 and
and 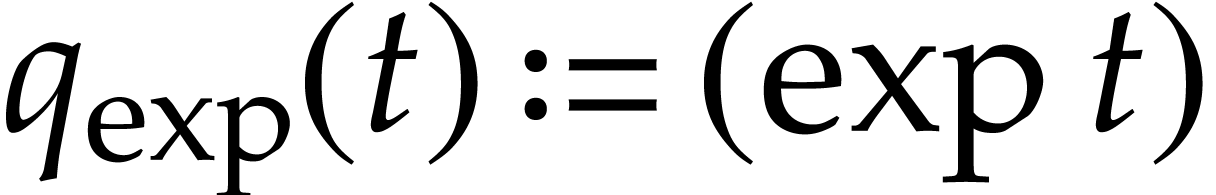 . We may take
. We may take 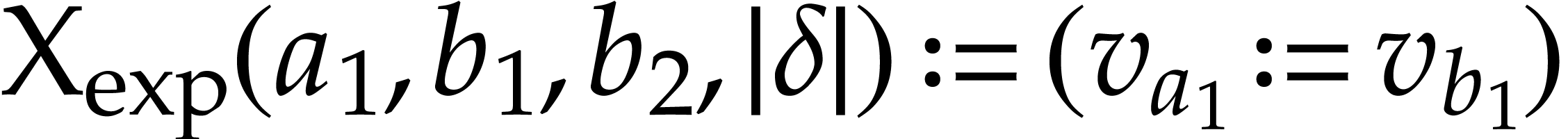 and
and 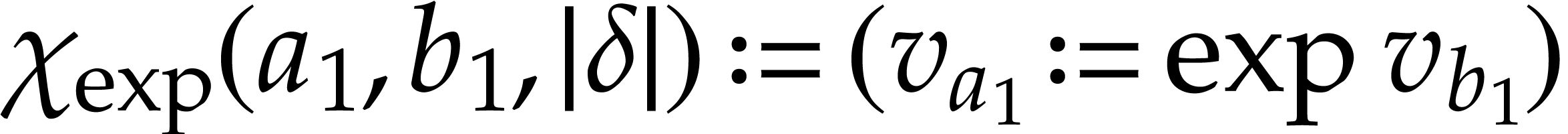 .
.
Example  function may be included in with
the defining functions
function may be included in with
the defining functions 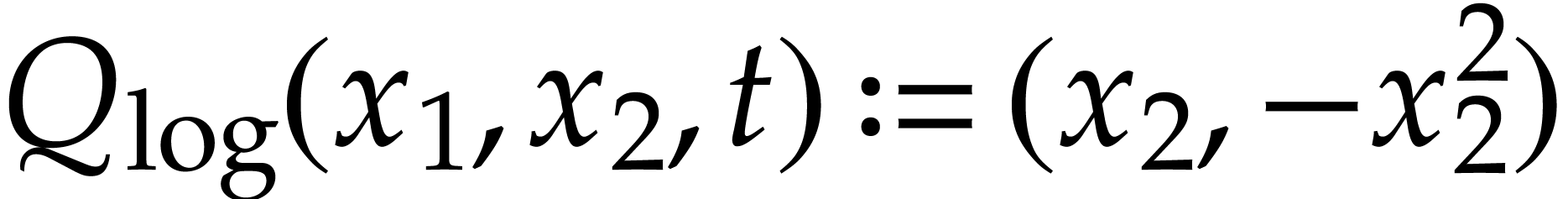 and
and 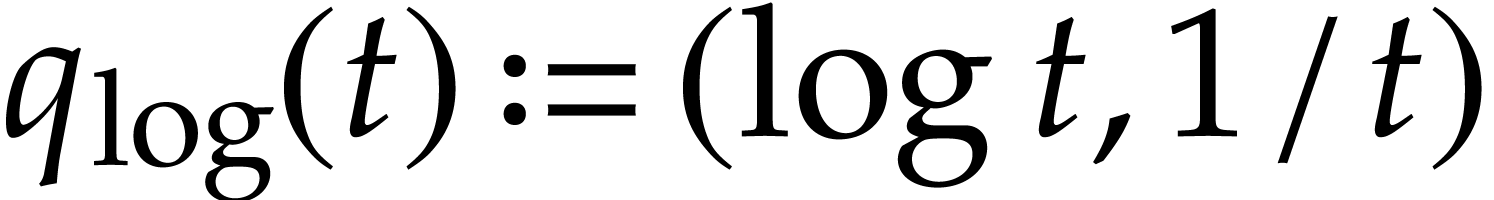 . We may take
. We may take 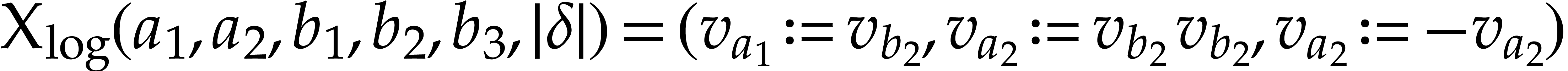 and
and 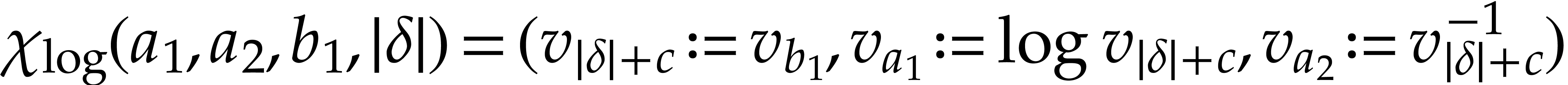 , where
, where  stands for the position of an auxiliary variable in .
stands for the position of an auxiliary variable in .
Example  , the fractional power
function
, the fractional power
function 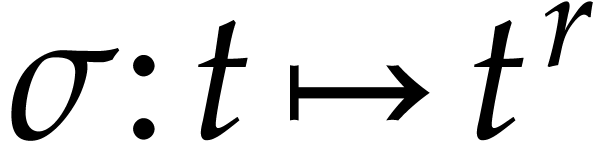 may be included in
with the defining functions
may be included in
with the defining functions 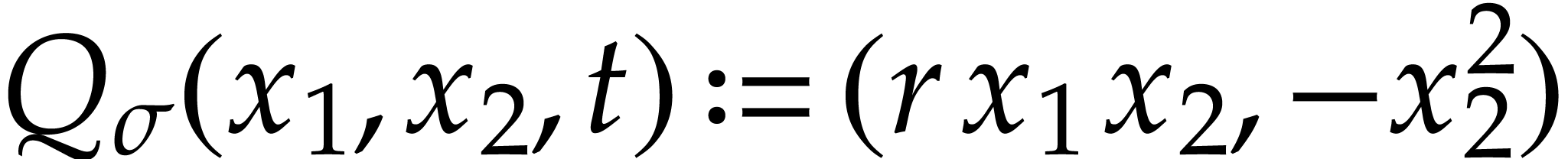 and
and 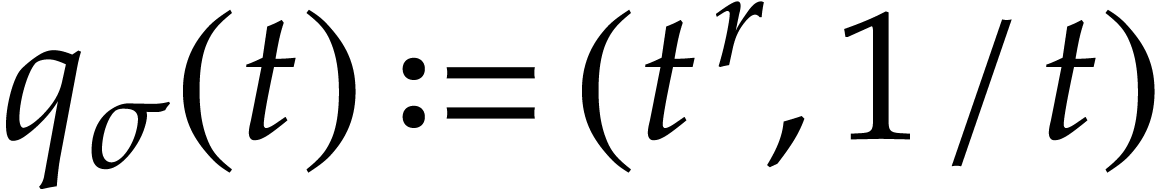 . If the constant
. If the constant 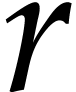 is
stored at position
is
stored at position 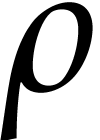 in
and if stands for the position of an auxiliary
variable in , then we may
take
in
and if stands for the position of an auxiliary
variable in , then we may
take 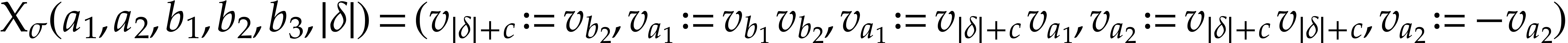 and
and 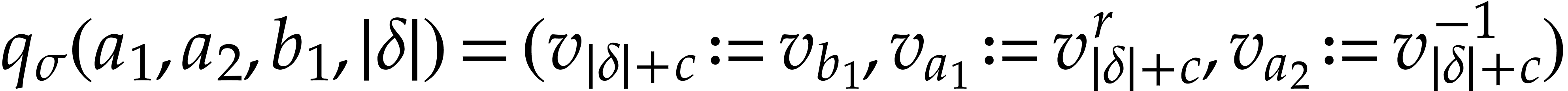 .
.
An SLP 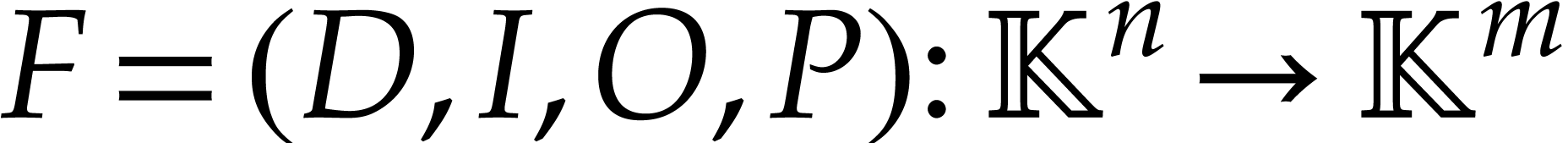 with signature
with signature  may be transformed into an equivalent SLP with at most
may be transformed into an equivalent SLP with at most  divisions: one for each output. (In fact, one may even reduce to the
case when we perform just one division, but this will not be needed in
what follows.)
divisions: one for each output. (In fact, one may even reduce to the
case when we perform just one division, but this will not be needed in
what follows.)
Let us show how to compute an SLP 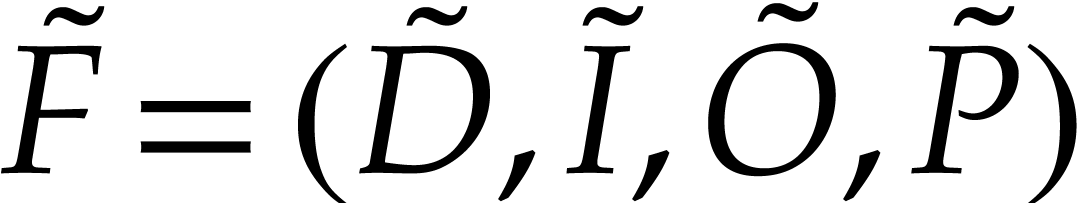 for evaluating
polynomials
for evaluating
polynomials  such that
such that 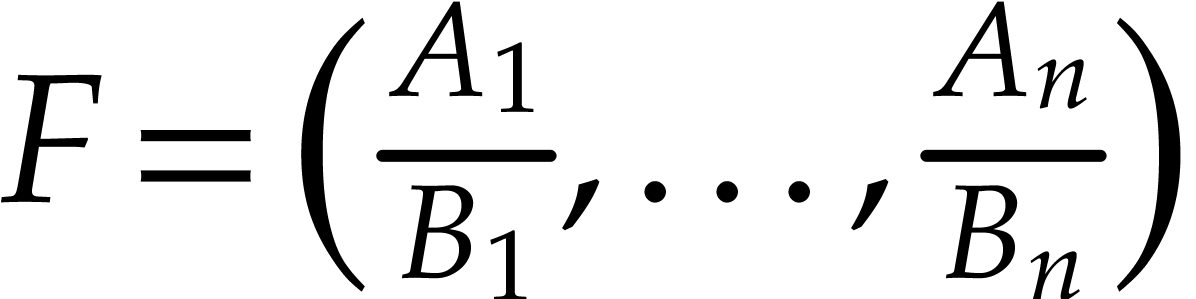 and none of the
and none of the 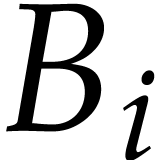 vanishes at the set
vanishes at the set  of points where
of points where 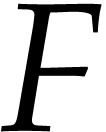 is executable.
Roughly speaking, we obtain the
is executable.
Roughly speaking, we obtain the  and by rewriting elements of as
fractions, which are encoded as pairs of (not necessarily coprime)
numerators and denominators. This rewriting process is well known and
takes linear time. It is a special instantiation of the lifting
algorithm from [12, section 5.5].
and by rewriting elements of as
fractions, which are encoded as pairs of (not necessarily coprime)
numerators and denominators. This rewriting process is well known and
takes linear time. It is a special instantiation of the lifting
algorithm from [12, section 5.5].
We now describe 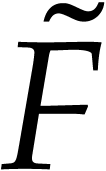 more precisely and bound its
size. We define the following tuples:
more precisely and bound its
size. We define the following tuples:
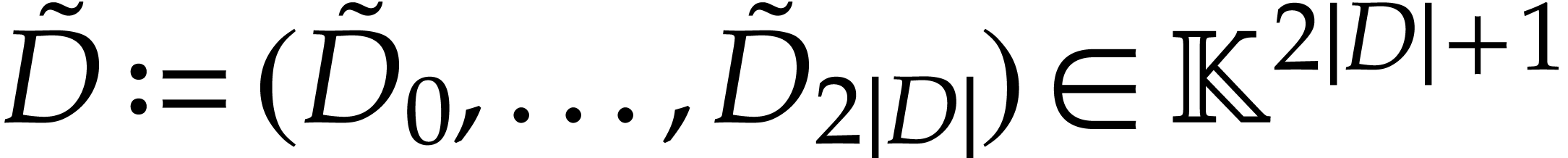 is defined by
is defined by 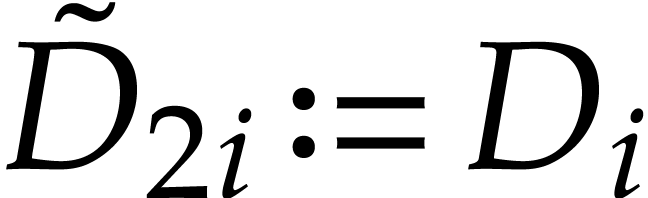 and
and
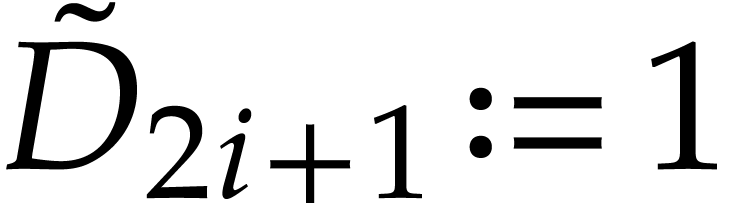 for
for 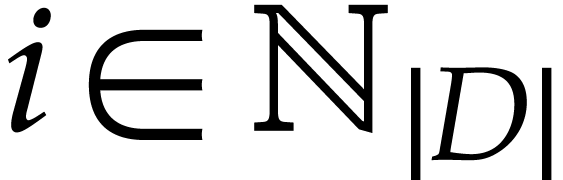 .
The last entry
.
The last entry 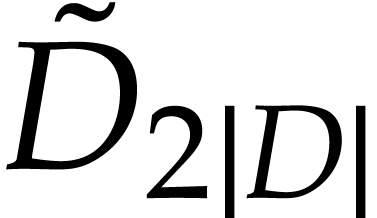 is an auxiliary variable
which may be filled arbitrarily. An entry at position
is an auxiliary variable
which may be filled arbitrarily. An entry at position 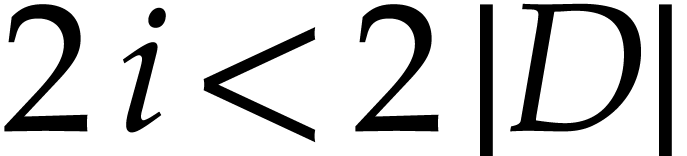 represents a numerator whose corresponding denominator
is at position
represents a numerator whose corresponding denominator
is at position 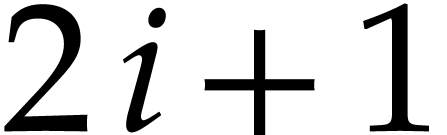 ;
;
 ;
;
 . The entries
. The entries  and
and 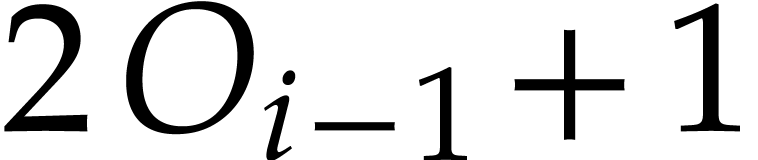 represent the values of
and for
represent the values of
and for 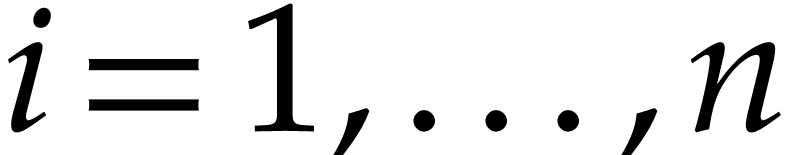 ;
;
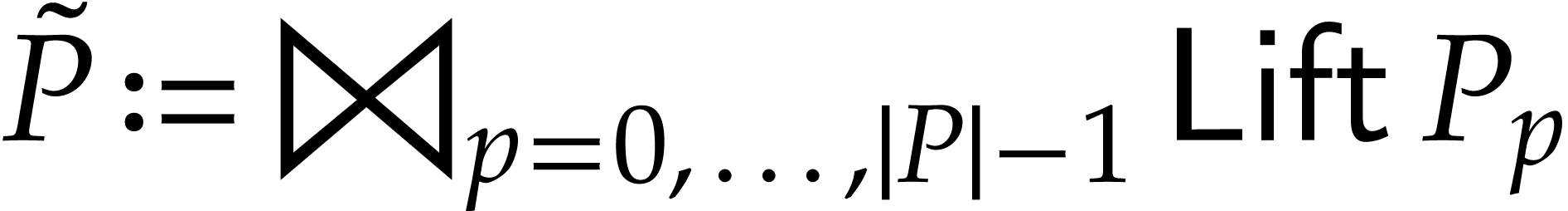 , where
, where 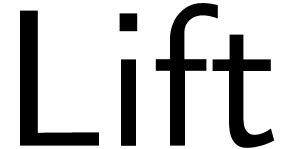 maps instructions of to sequences of
instructions, as follows, where we write
maps instructions of to sequences of
instructions, as follows, where we write 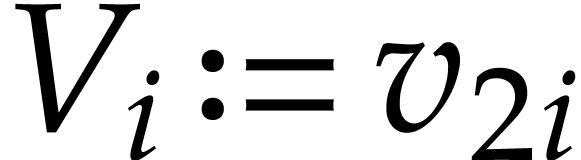 ,
,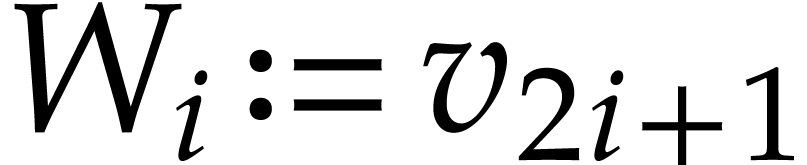 , and
, and 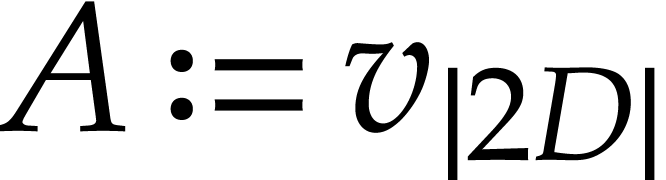 as shorthands:
as shorthands:
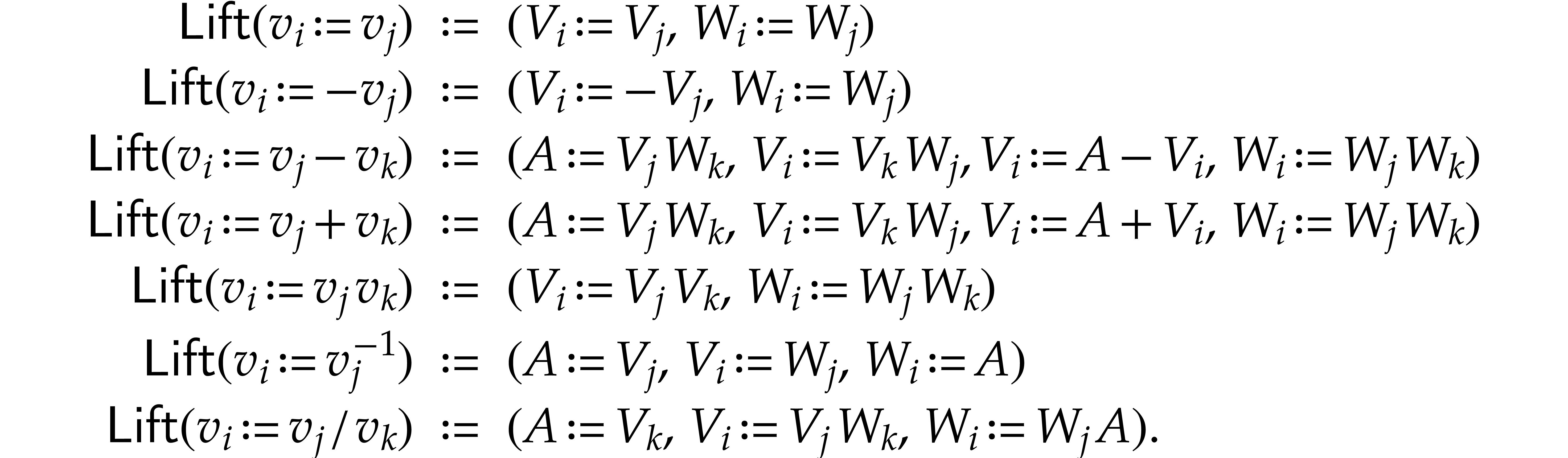
For example, with 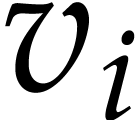 representing the value at
position
representing the value at
position  in the working space, the of a sum
in the working space, the of a sum 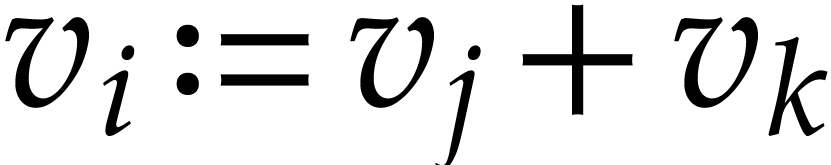 consists in computing
consists in computing
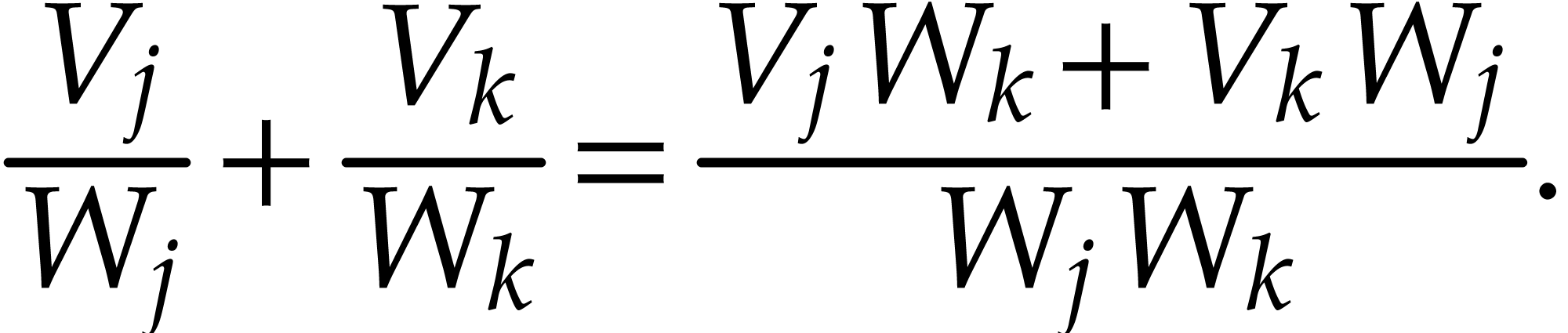
We observe that  is executable over , that none of the
vanishes at for ,
and that
is executable over , that none of the
vanishes at for ,
and that
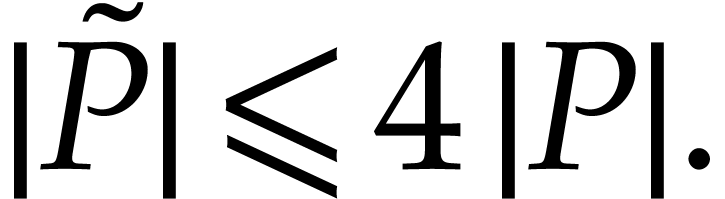 |
(3) |
Example 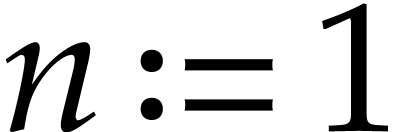 and let be the SLP defined by
and let be the SLP defined by
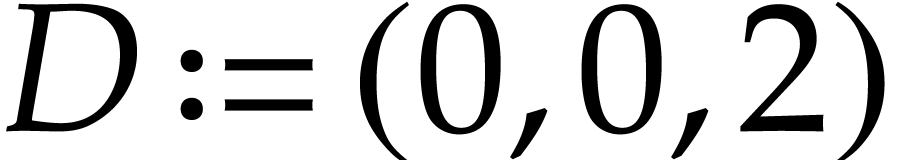 , , , and
, , , and
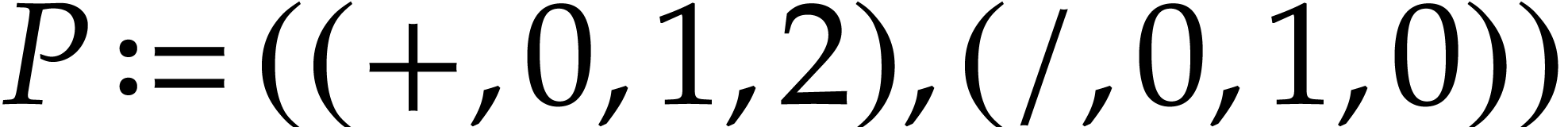 . With
representing the values at positions of the
working space, the instructions of rewrite into
,
. With
representing the values at positions of the
working space, the instructions of rewrite into
, 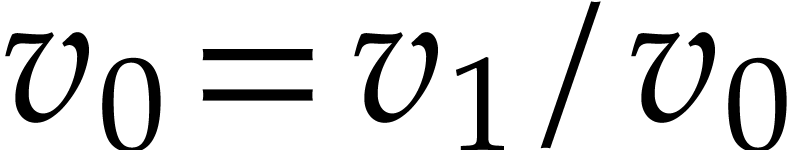 . Consequently, computes the
rational function
. Consequently, computes the
rational function 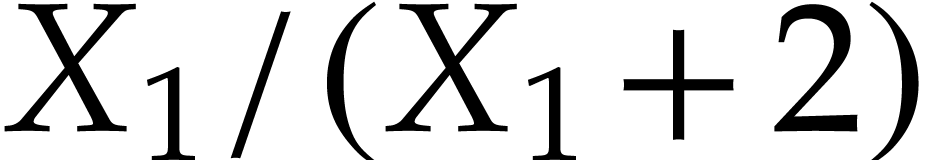 . Applying
the above construction gives us
. Applying
the above construction gives us 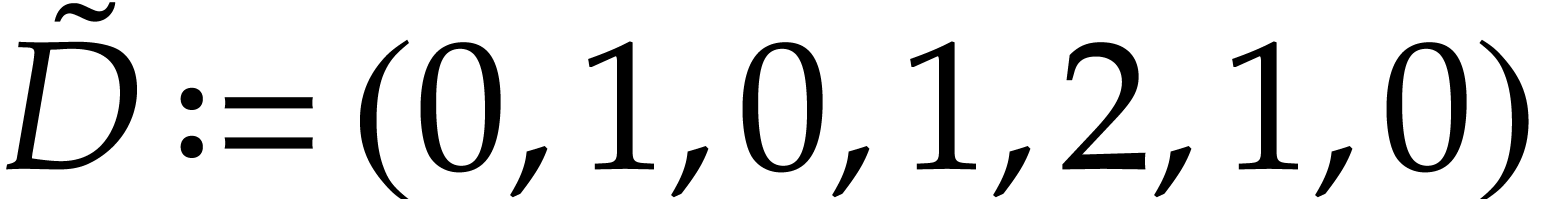 ,
,
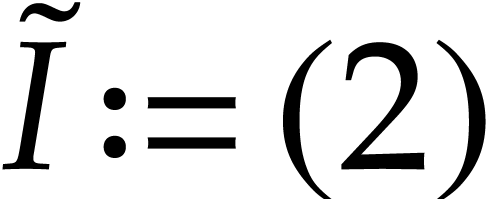 ,
, 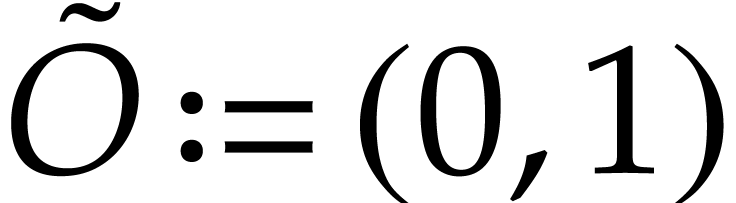 , and
, and 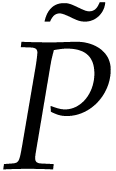 corresponds to the
following sequence of instructions:
corresponds to the
following sequence of instructions: 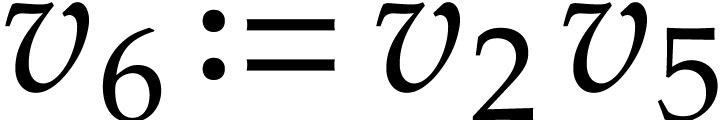 ,
,
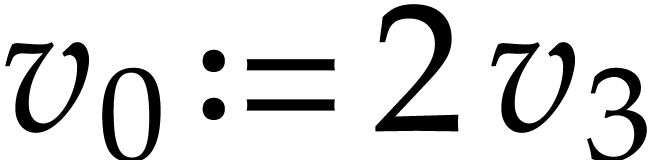 ,
, 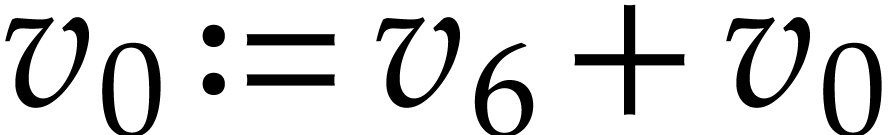 ,
, 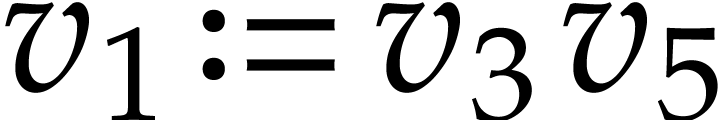 ,
, 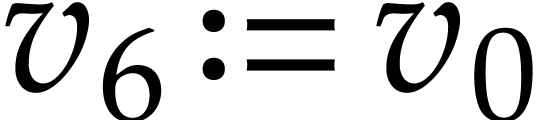 ,
, 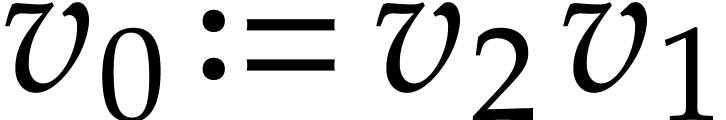 ,
,
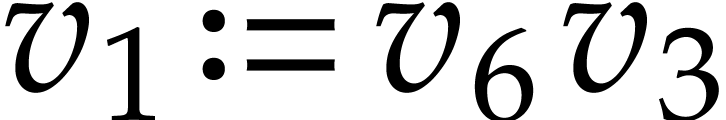 . The expressions of the
output values at positions
. The expressions of the
output values at positions 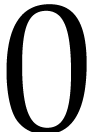 and
and 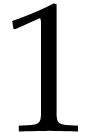 are
are 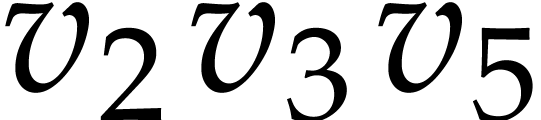 and
and 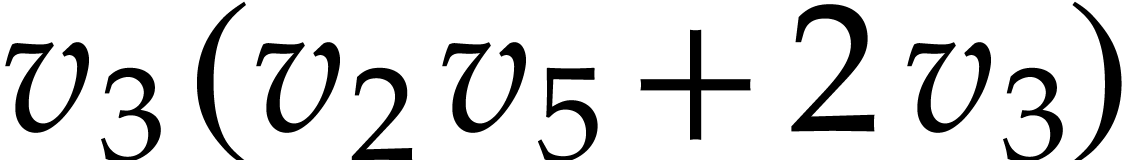 .
So we have
.
So we have 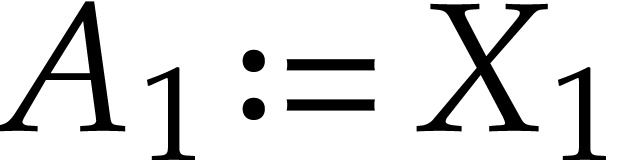 and
and 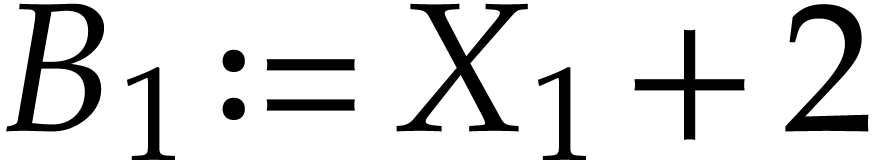 .
.
Example and let be the SLP defined by
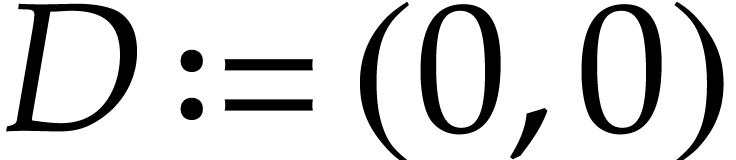 , , , and
, , , and
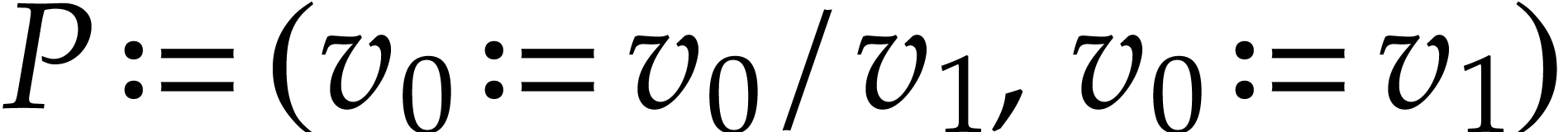 . Although the first
instruction is useless, is not executable at
. On the other hand, we have
. Although the first
instruction is useless, is not executable at
. On the other hand, we have
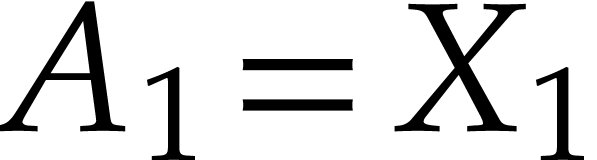 and
and 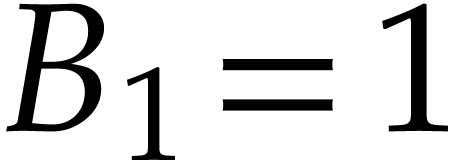 .
This shows that
.
This shows that  may be inverted over a domain
strictly larger than
may be inverted over a domain
strictly larger than  .
.
Remark 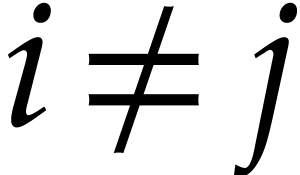 , then one
may take
, then one
may take 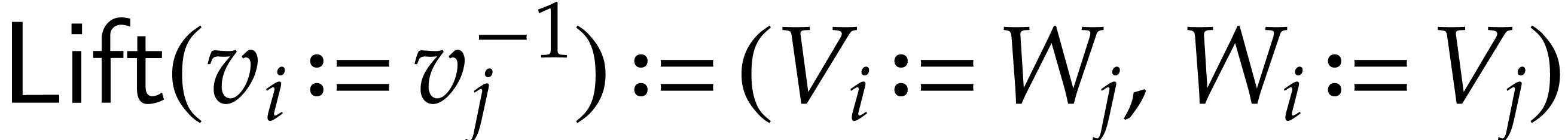 . Our implementation
in JIL systematically exploits such optimizations; see also [12,
section 5.5].
. Our implementation
in JIL systematically exploits such optimizations; see also [12,
section 5.5].
An SLP with signature
may be transformed into an SLP over with signature which evaluates
over 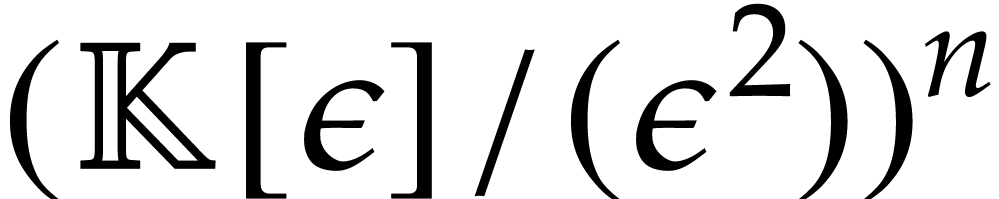 ,
where
,
where 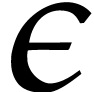 is a new variable. We define the following
tuples:
is a new variable. We define the following
tuples:
is defined by and
 for .
The last entry is an auxiliary variable
which may be filled arbitrarily. A variable
for .
The last entry is an auxiliary variable
which may be filled arbitrarily. A variable  for becomes
for becomes 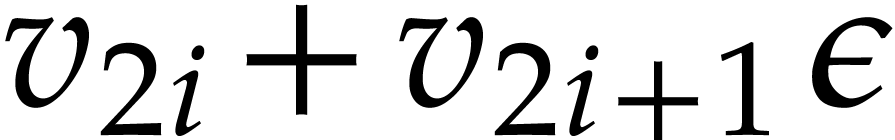 for
.
for
.
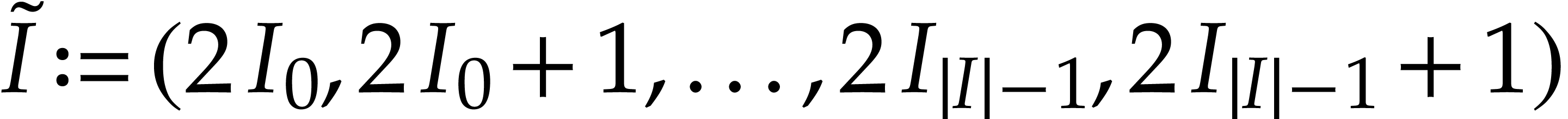 ;
;
;
, where
maps instructions of to sequences of
instructions, as follows, where we use 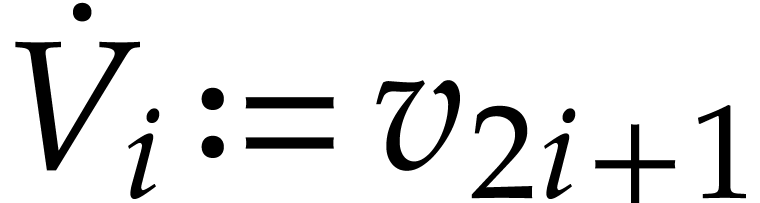 , and
as shorthands:
, and
as shorthands:
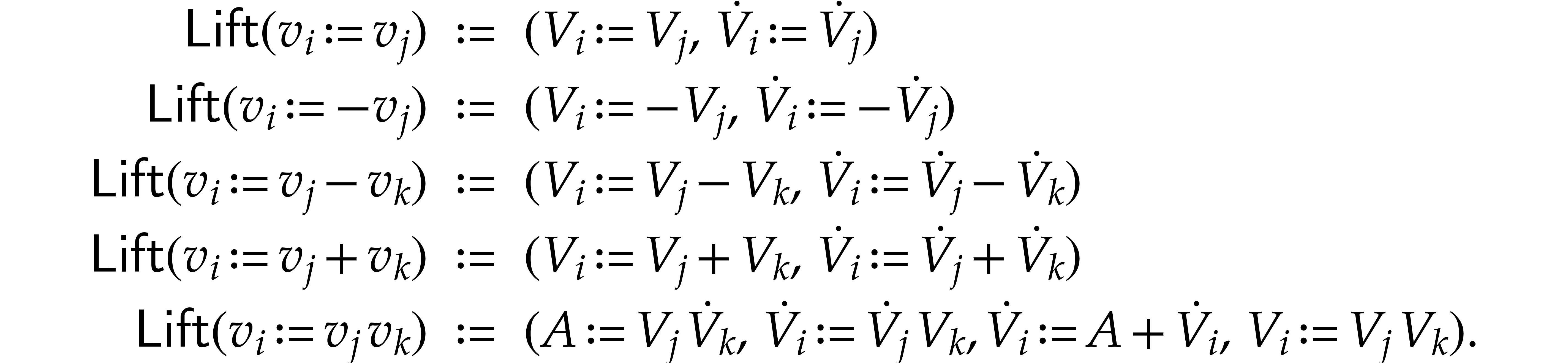
Consequently,
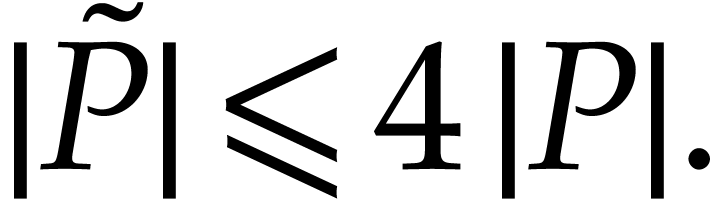 |
(4) |
We begin this section with a rather natural method for polynomializing
SLPs over with signature . Then, we present our new faster and general
approach.
Let 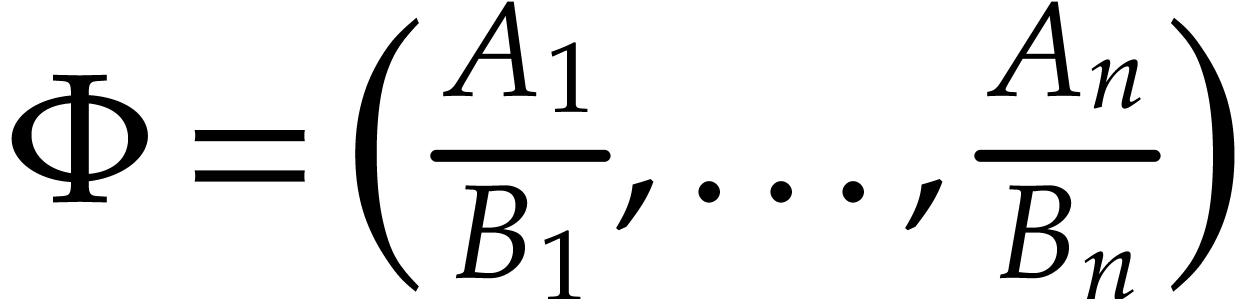 where
where 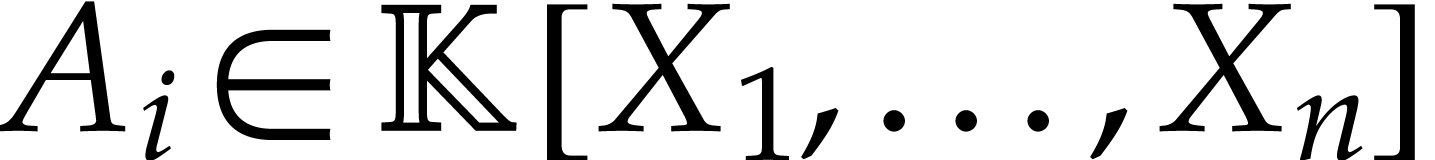 and
and 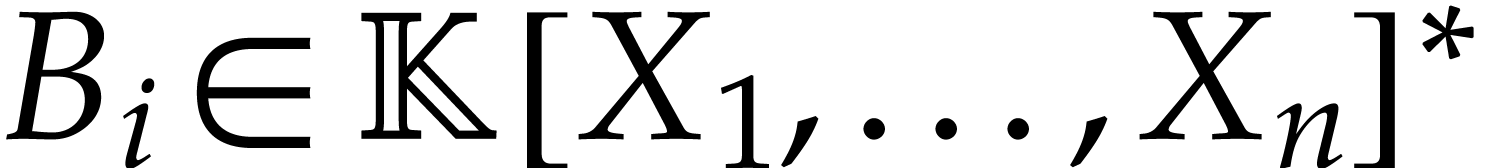 for , and let
be a solution of . We introduce
the functions
for , and let
be a solution of . We introduce
the functions
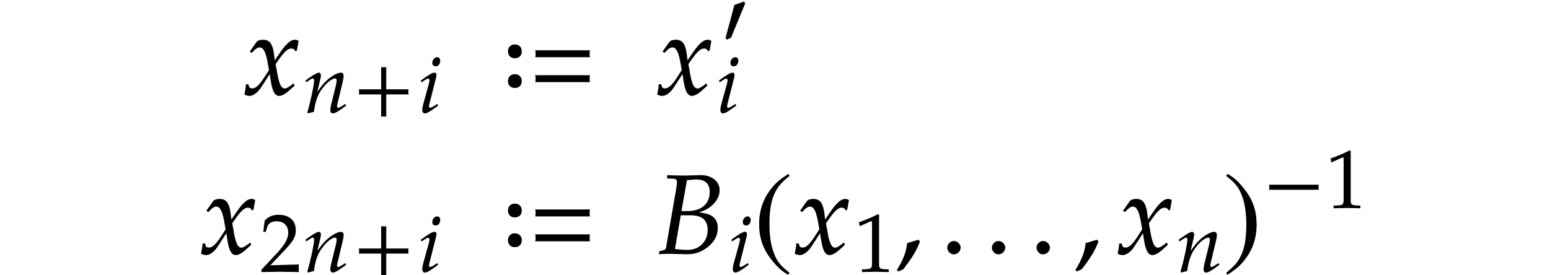
over , for , and obtain
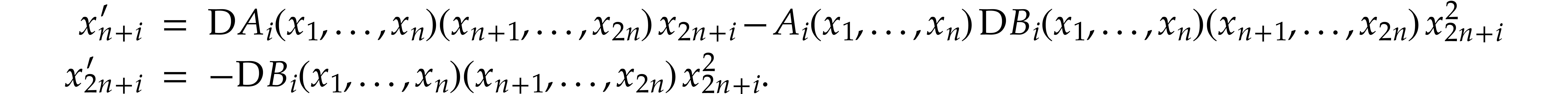
Letting
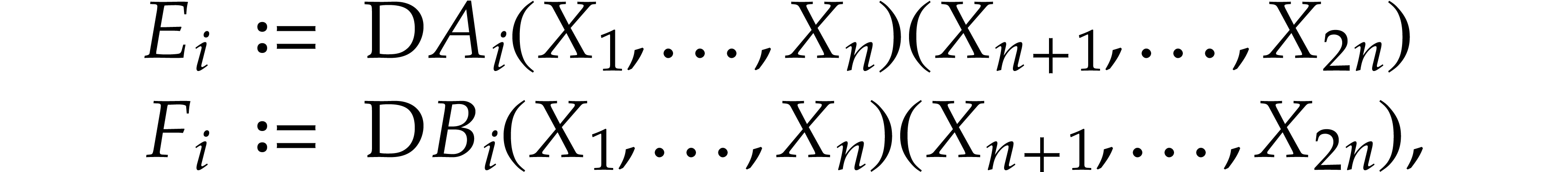
the polynomial map
is a polynomialization of ,
since
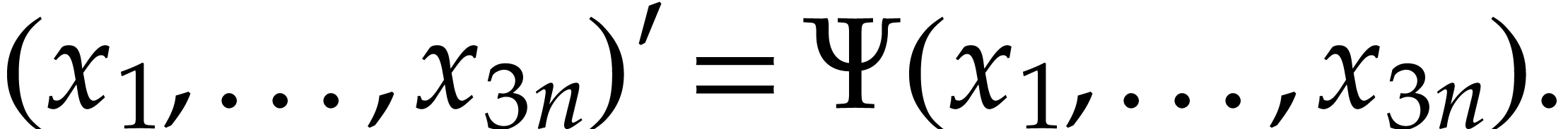
The computation of can be done efficiently as
follows.
From the SLP for with signature
we first determine an SLP with signature which computes  .
The number of instructions of is
.
The number of instructions of is  using
using
By computing 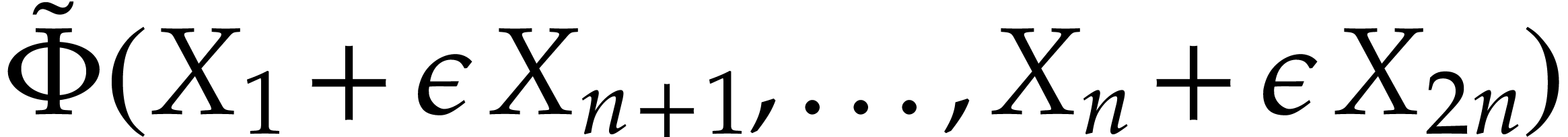 modulo
modulo 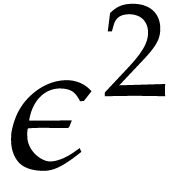 we
next build another SLP for evaluating ,
,
we
next build another SLP for evaluating ,
, 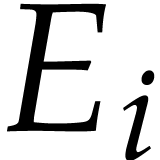 , and
, and 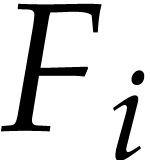 for
using at most
for
using at most 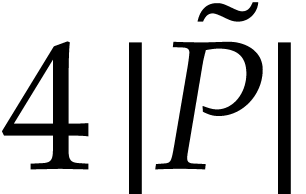 instructions, by
instructions, by
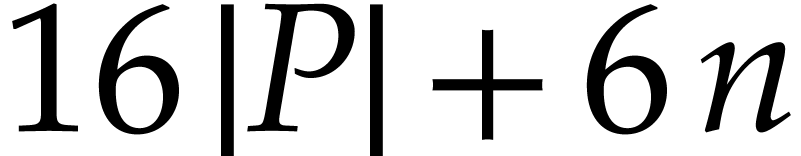 |
(5) |
for the polynomialization of .
As to the initial conditions, we take:
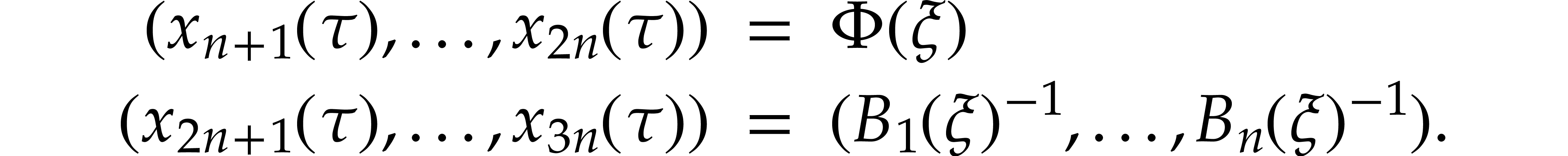
This requires 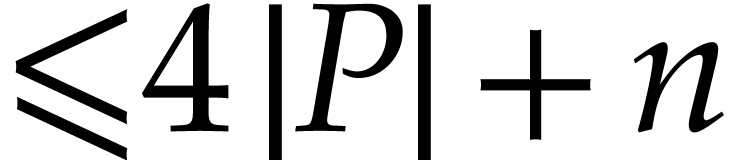 ring operations plus
ring operations plus 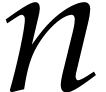 inversions.
inversions.
In the previous subsection, we reduced the polynomialization of to the case when it is explicitly given by rational
functions. In this subsection, we present a new faster and more general
method, which directly transforms all divisions and special functions of
the SLP of . Roughly
speaking, a special instruction 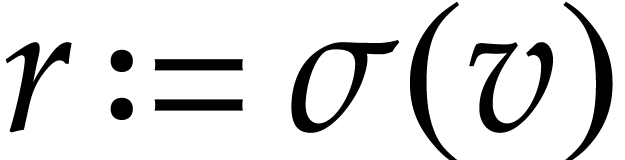 gives rise to
gives rise to
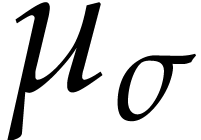 new unknown functions
new unknown functions  with
with 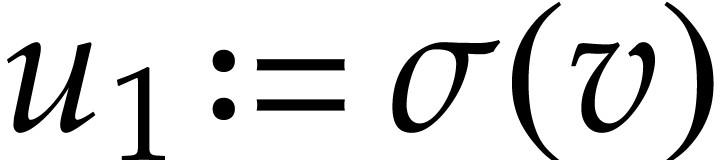 and which satisfy the differential equation
and which satisfy the differential equation
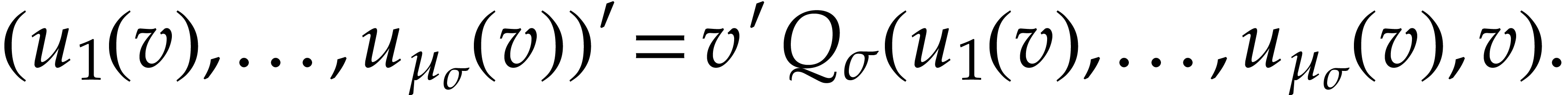
Our method is detailed in the proof of the following theorem, which
improves upon the above polynomialization with cost
 be given by an SLP
be given by an SLP 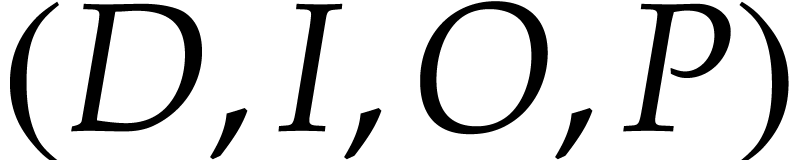 over
over  with signature and let
with signature and let  ,
,
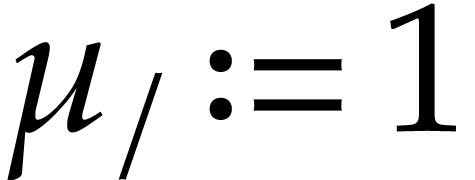 , and
, and
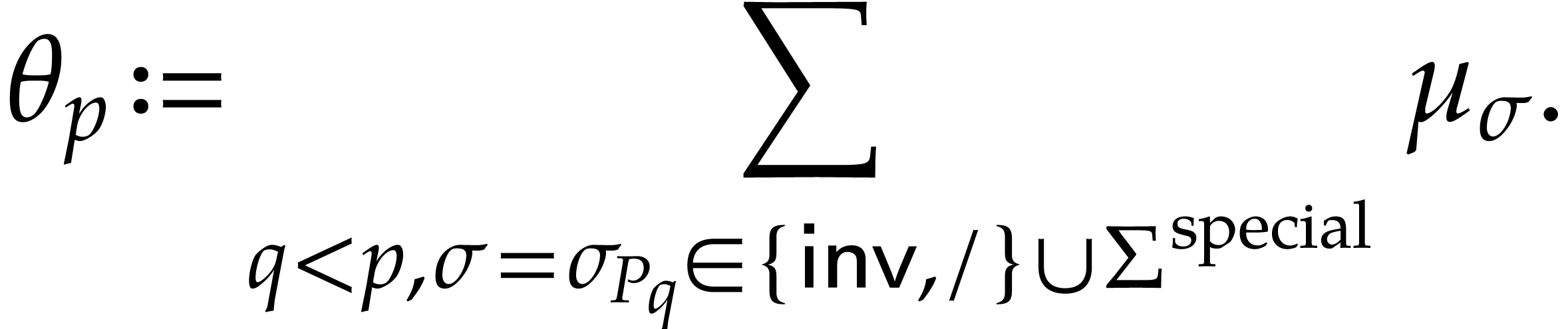
We can compute the following SLPs over in
time 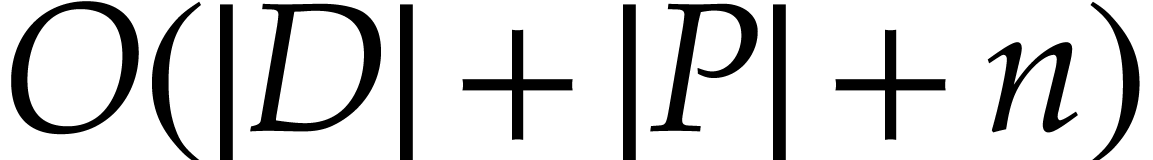 :
:
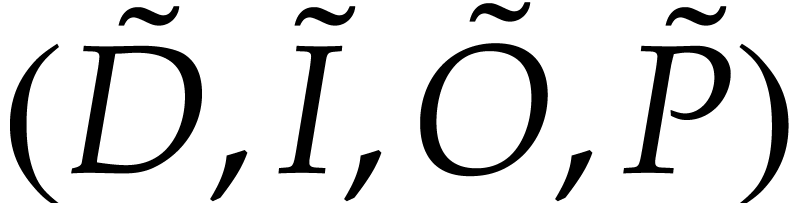 uses and
represents a polynomialization of such that
uses and
represents a polynomialization of such that 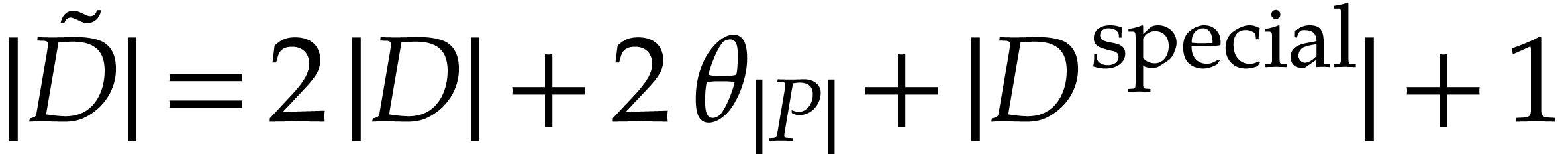 ,
,
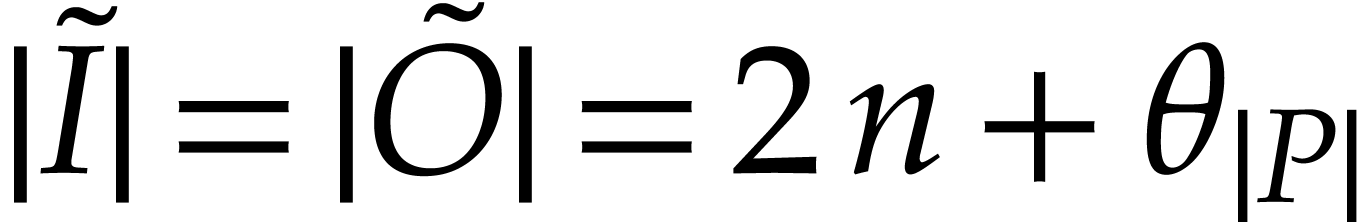 , and
, and
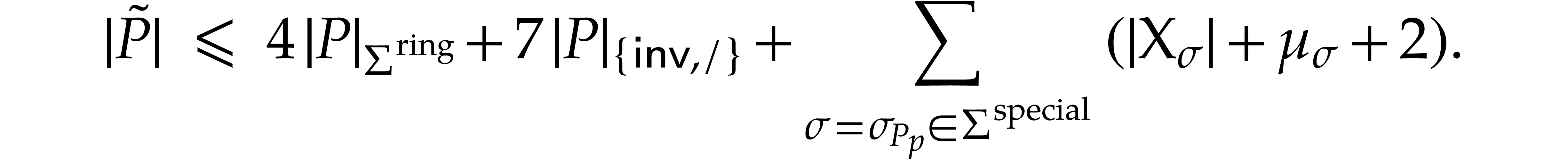
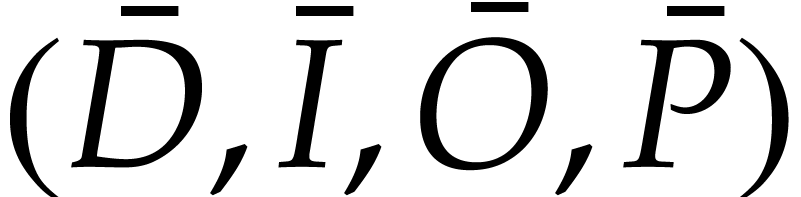 uses ,
computes the initial value
uses ,
computes the initial value  for from an initial value
for from an initial value  for
at
for
at  ,
and satisfies
,
and satisfies 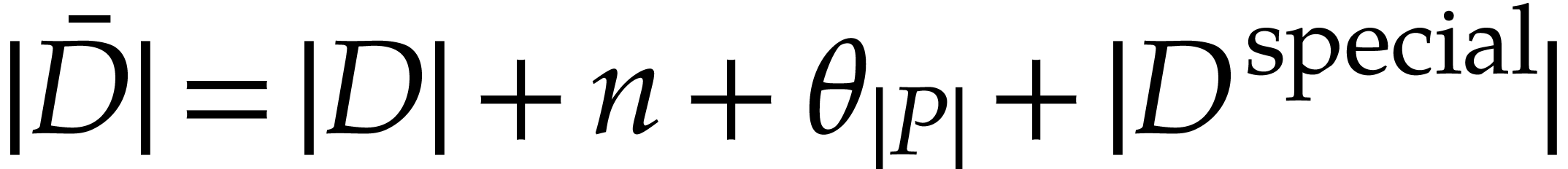 ,
, 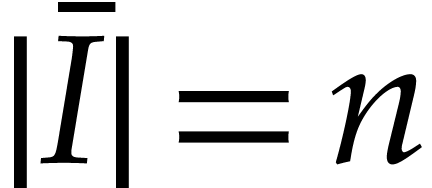 ,
, 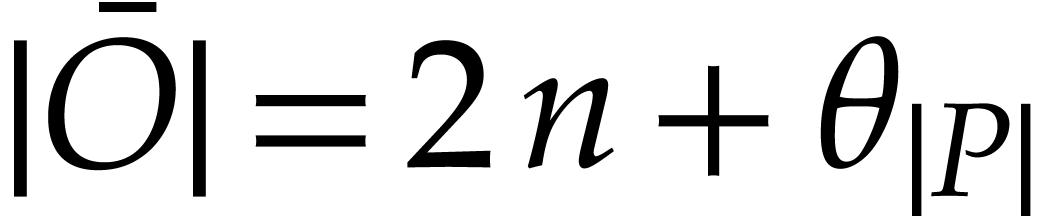 , and
, and 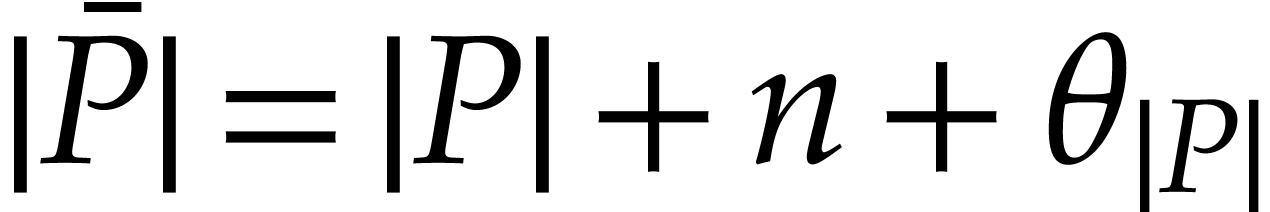 .
.
Proof. The tuples 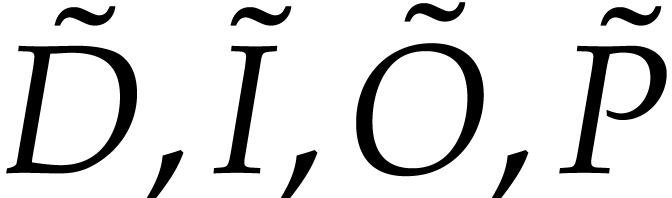 are
defined as follows:
are
defined as follows:
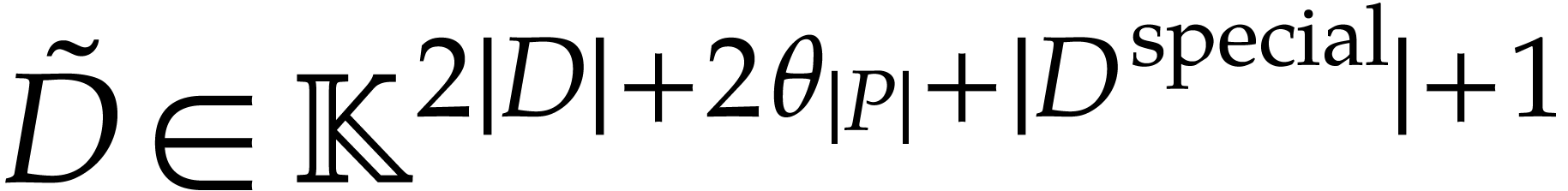 with ,
for ,
with ,
for ,
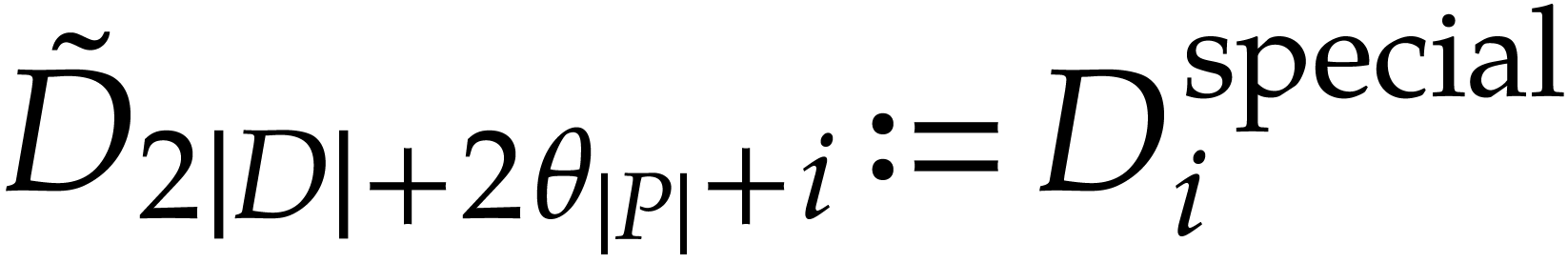 for
for 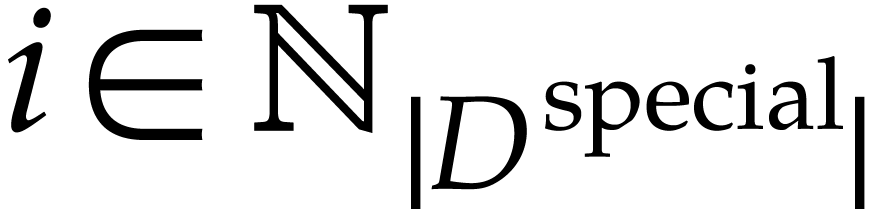 .
Other entries of
.
Other entries of 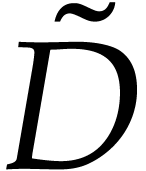 may be filled arbitrarily;
may be filled arbitrarily;
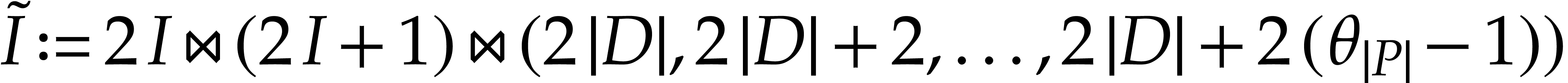 ;
;
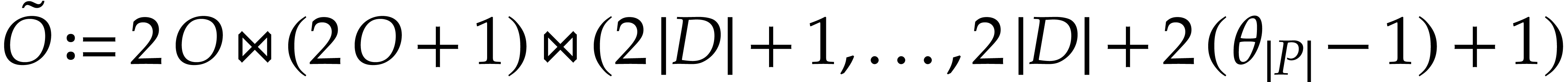 ;
;
, where
maps instructions of to tuples of
instructions with signature .
If 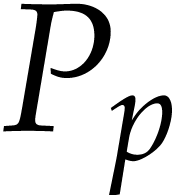 has type then we
abbreviate
has type then we
abbreviate 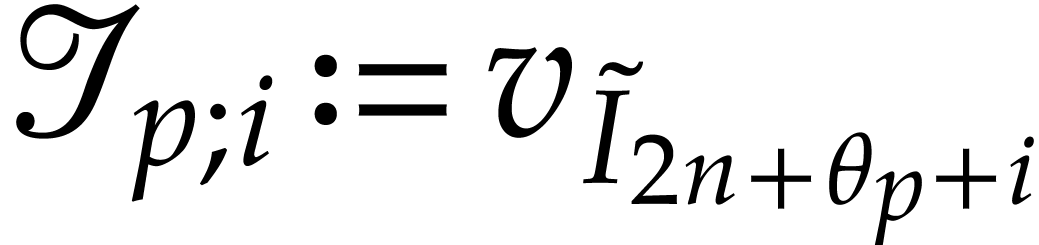 ,
, 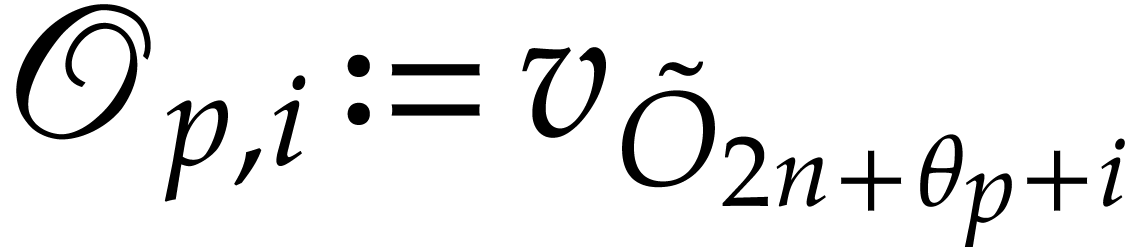 and let
and let 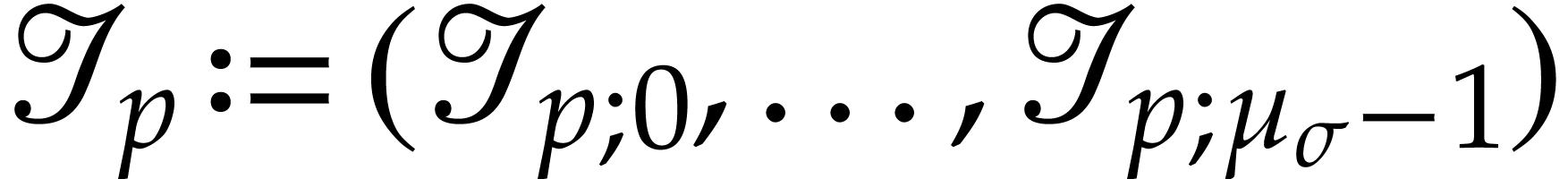 ,
,
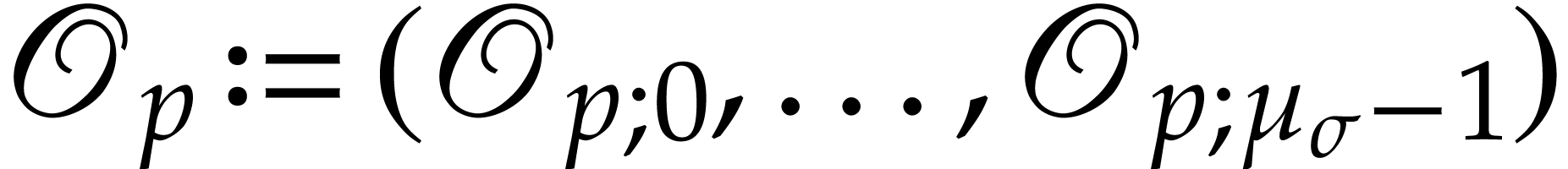 . We also abbreviate
, ,
. We also abbreviate
, , 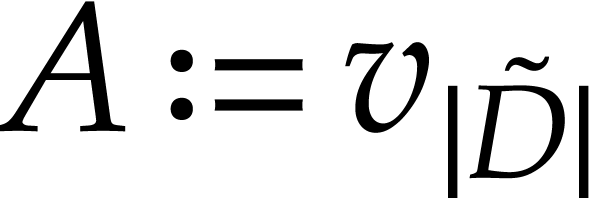 .
The value of
.
The value of 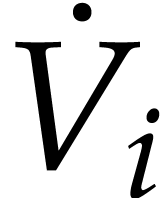 will actually be the derivative
of the value of
will actually be the derivative
of the value of 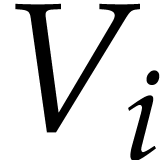 , and
, and
 will be an auxiliary variable. If
will be an auxiliary variable. If 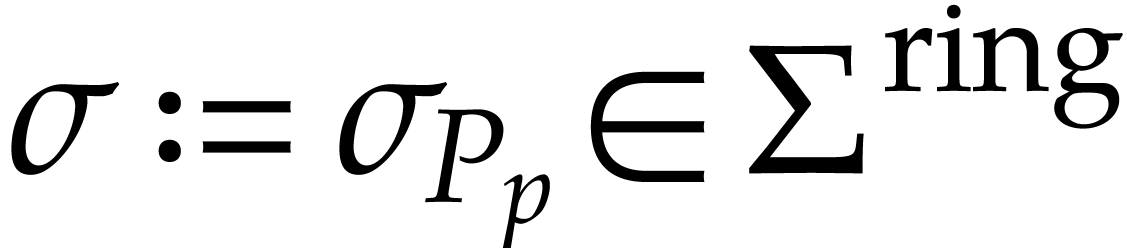 , then we take
, then we take
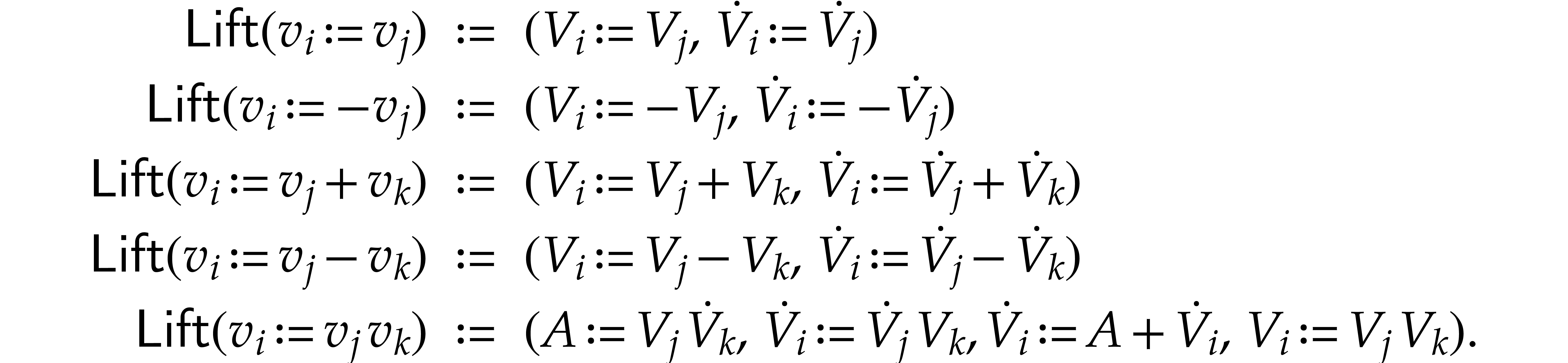
If 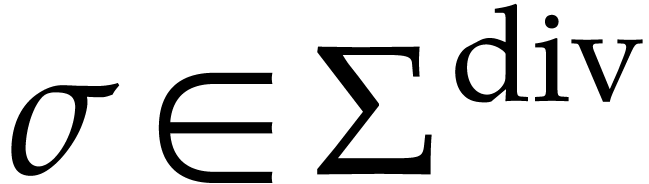 , then we define
, then we define
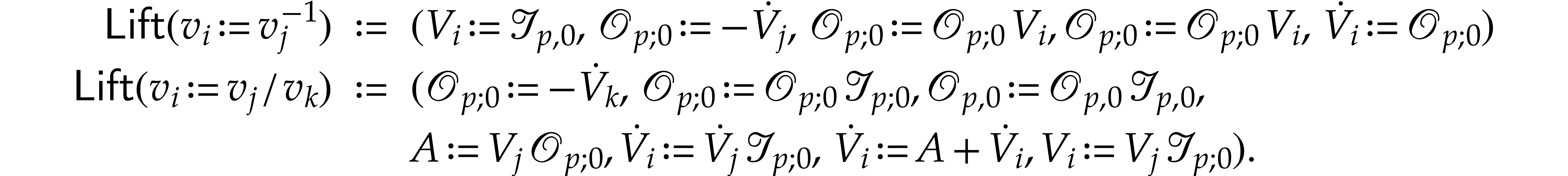
If , then we take
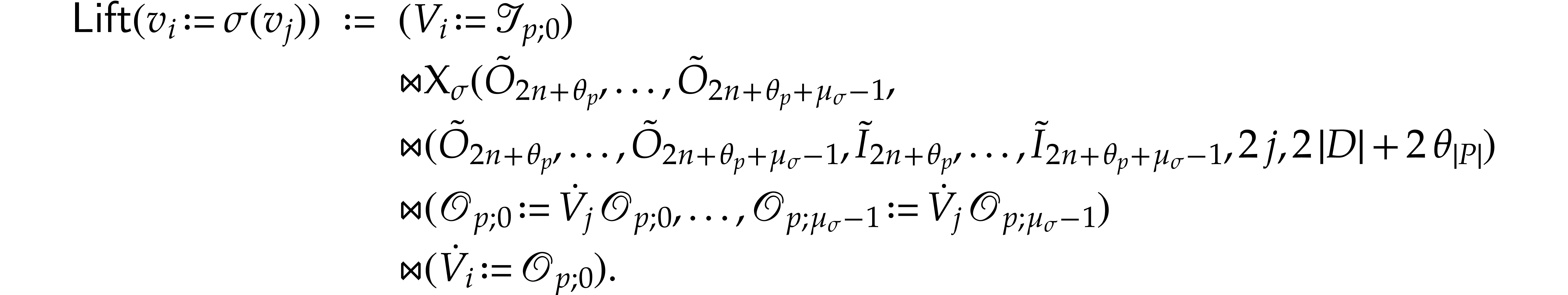
Let us now prove that 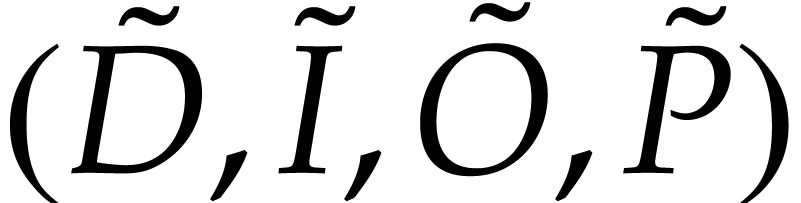 represents a
polynomialization of . We
first need to introduce appropriate notation. For this, let
represents a
polynomialization of . We
first need to introduce appropriate notation. For this, let 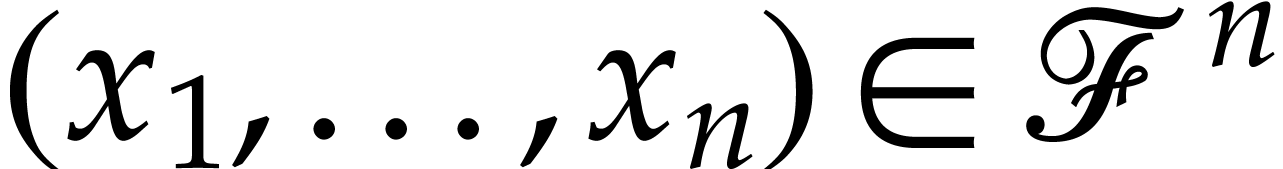 be a solution of (1), where
be a solution of (1), where  is the space of differentiable functions of the interval
is the space of differentiable functions of the interval  to . Now
consider the evaluation of at
to . Now
consider the evaluation of at  over , as described in
section 2.1, but with the modification that we introduce
new function variables
over , as described in
section 2.1, but with the modification that we introduce
new function variables 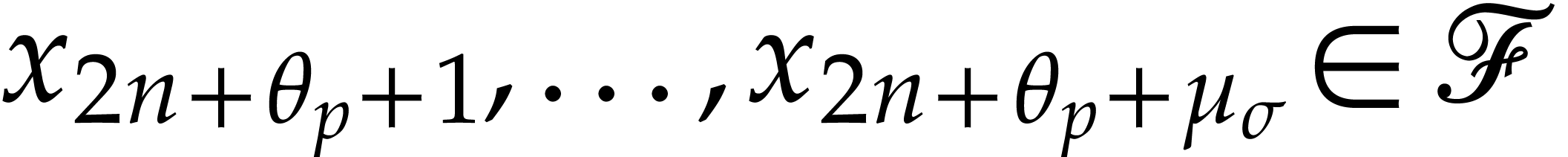 whenever we execute an
instruction with
whenever we execute an
instruction with 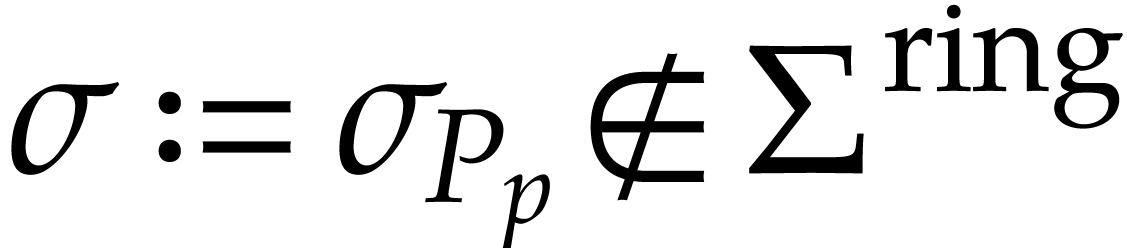 .
Let
.
Let 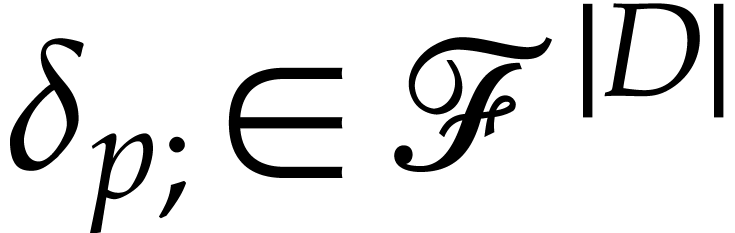 be the current state of the working space
just before the execution of .
If
be the current state of the working space
just before the execution of .
If 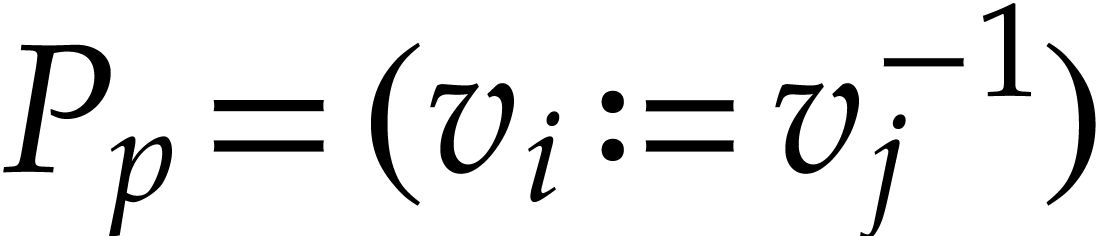 , then we define
, then we define 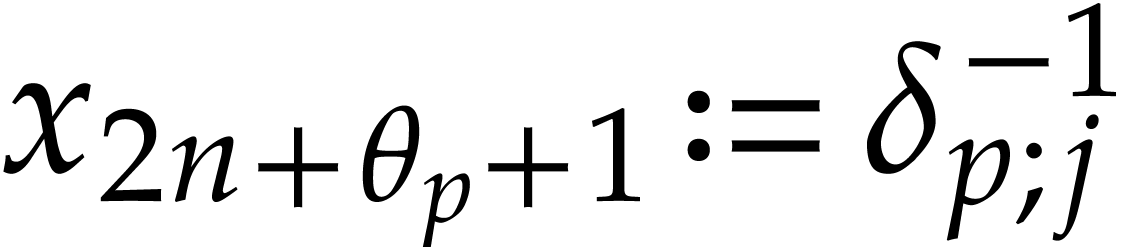 . If
. If 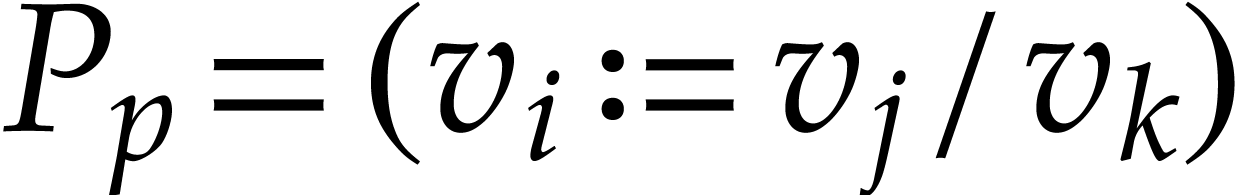 ,
then we take
,
then we take 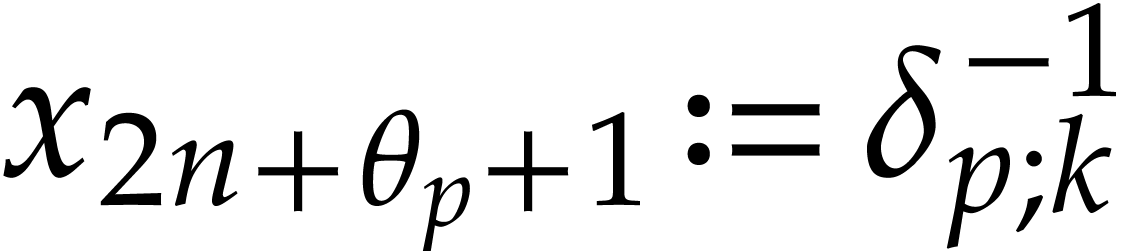 . If
. If 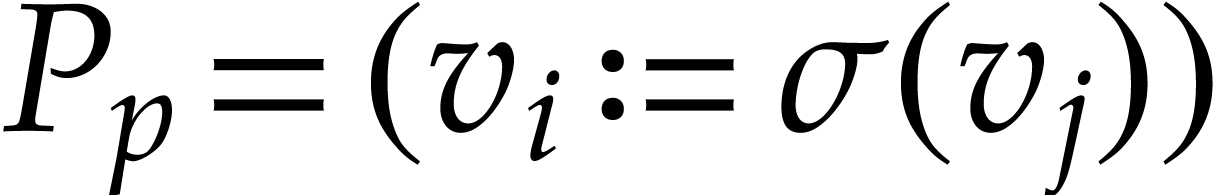 with , then we
define
with , then we
define
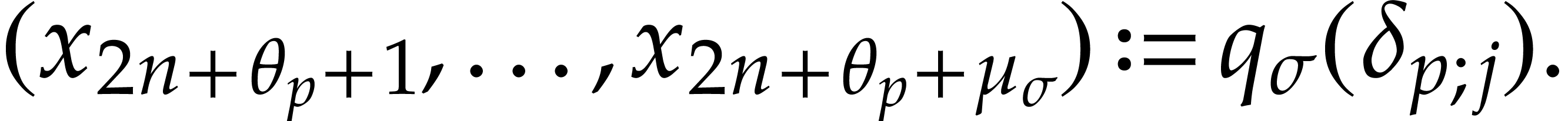
For 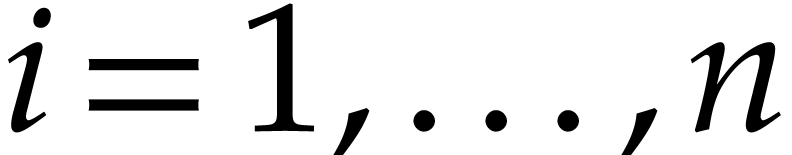 , we also define
, we also define 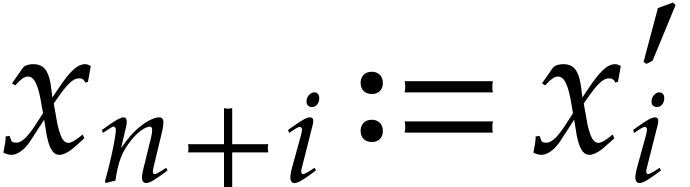 and we claim that
and we claim that
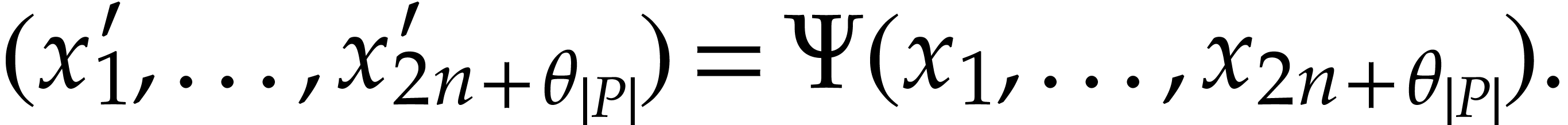
We now evaluate 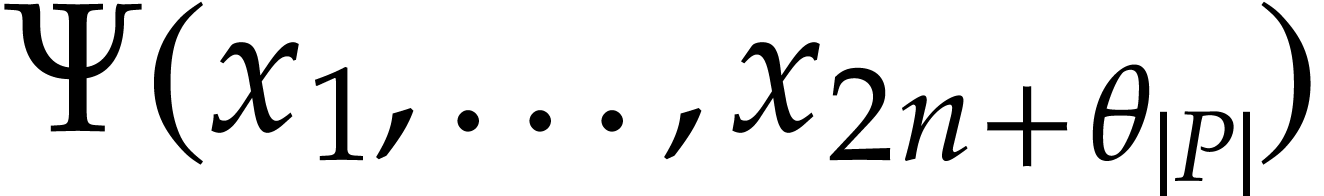 over . Let
over . Let 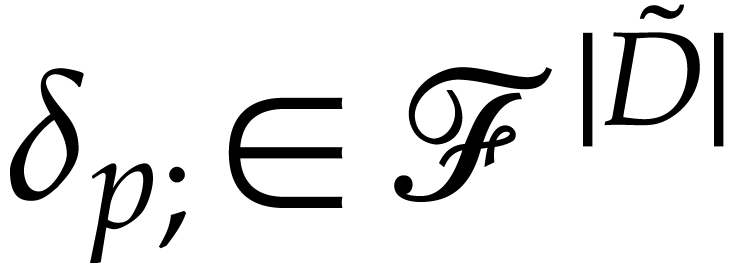 be the state just
before the execution of
be the state just
before the execution of 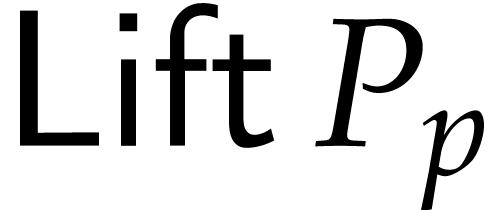 . It
will be convenient to abuse notation and use
. It
will be convenient to abuse notation and use  as
an abbreviation of the current state
as
an abbreviation of the current state 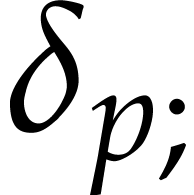 in addition
to the usual semantics as a tuple of variables. We claim that we always
have
in addition
to the usual semantics as a tuple of variables. We claim that we always
have 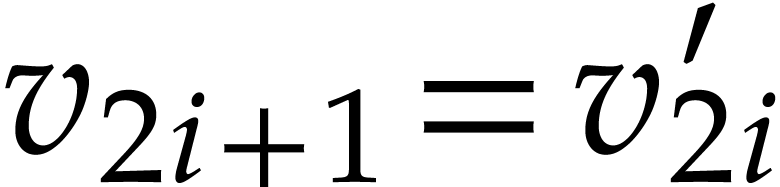 , i.e.
, i.e.
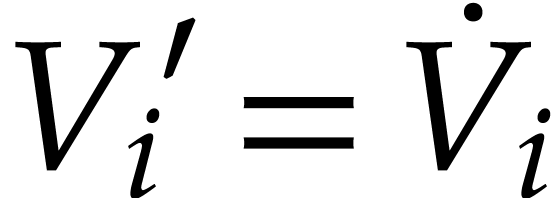 , for all . Just after copying the input values into the
working space (and assuming that all auxiliary variables are initialized
with zeros), the claim clearly holds. Assuming that the claim holds
before the execution of , we
need to show that it still holds afterwards.
, for all . Just after copying the input values into the
working space (and assuming that all auxiliary variables are initialized
with zeros), the claim clearly holds. Assuming that the claim holds
before the execution of , we
need to show that it still holds afterwards.
If or 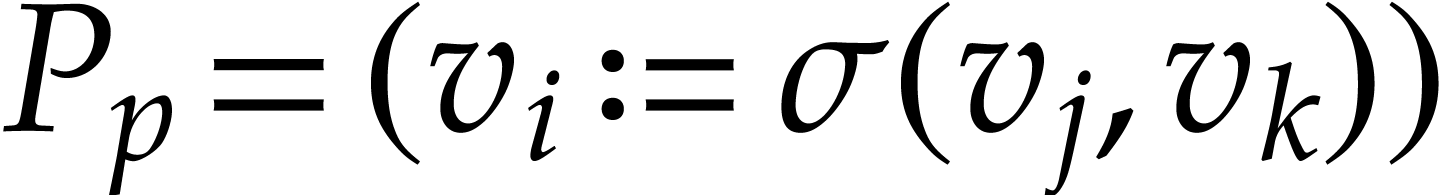 with
with 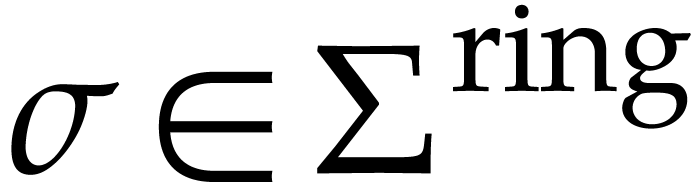 , then is the same
operation
, then is the same
operation  with arguments
with arguments 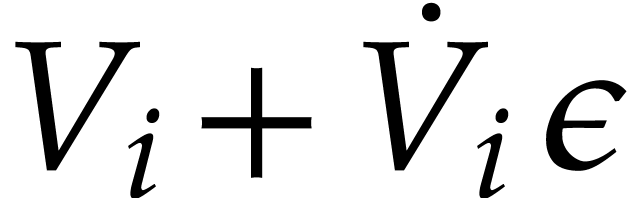 ,
, 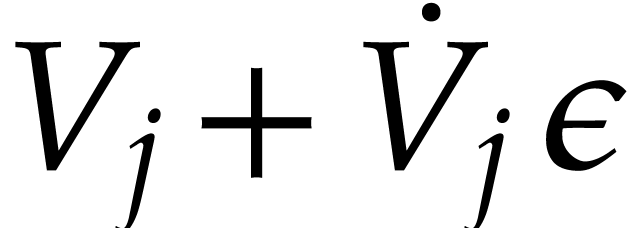 , and
possibly
, and
possibly 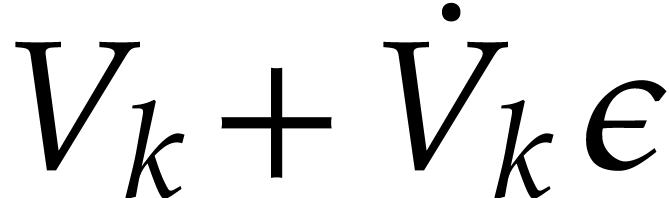 in
in 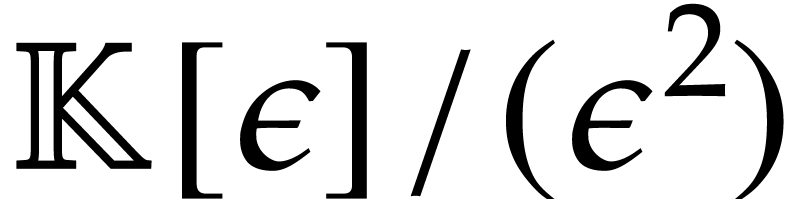 .
Since
.
Since 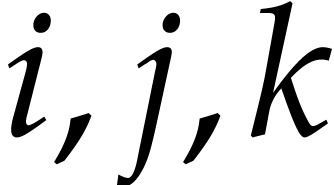 belong to ,
the claim holds after the execution of .
belong to ,
the claim holds after the execution of .
If , then
corresponds to computing
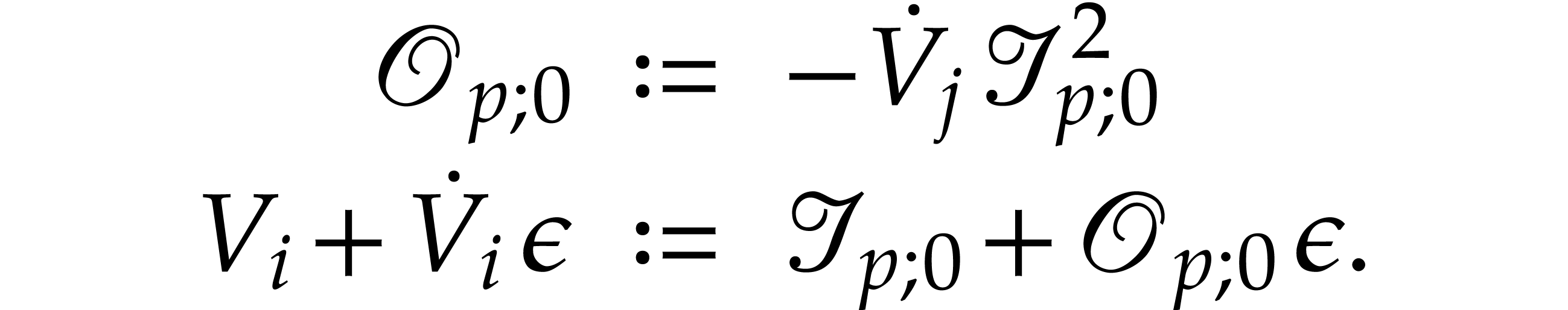
By definition, we have 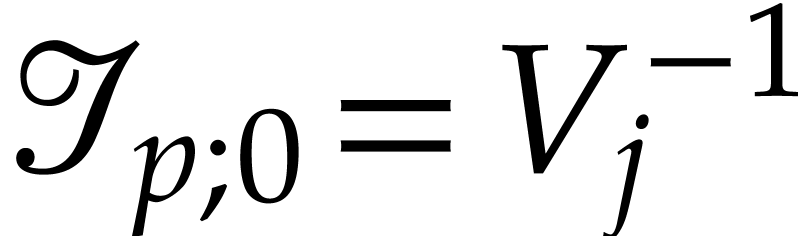 hence
hence 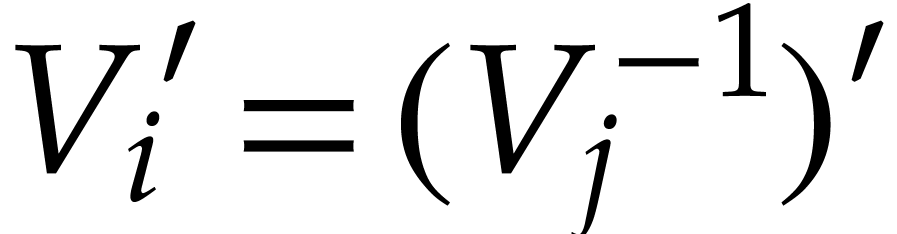 . Therefore
. Therefore 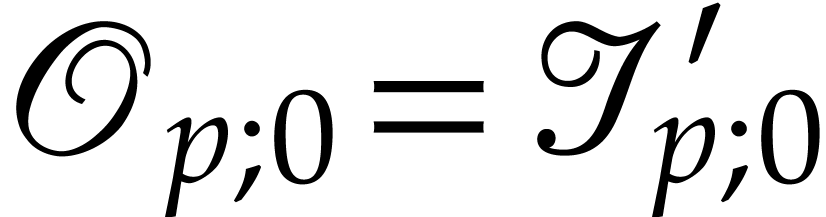 after the
execution, as claimed.
after the
execution, as claimed.
If , then
corresponds to computing
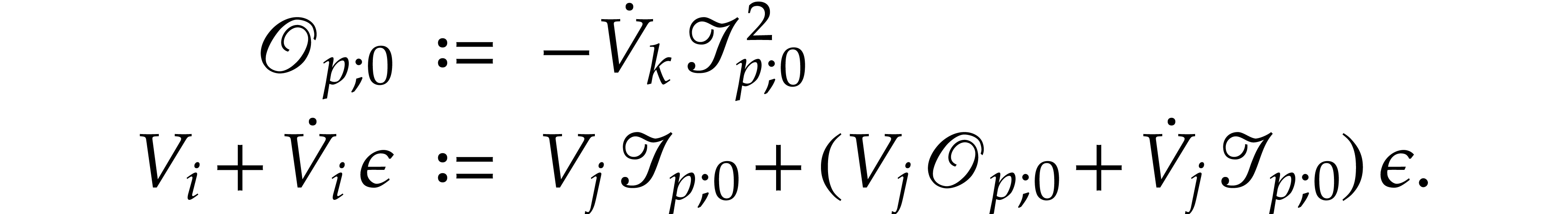
From 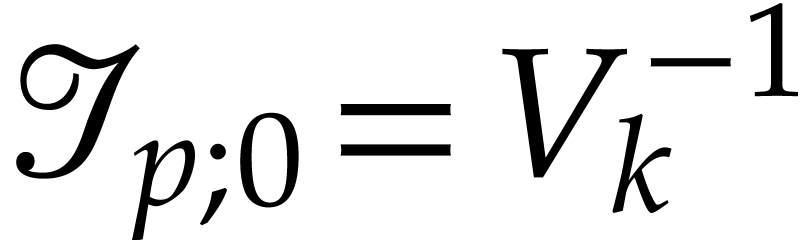 we obtain
we obtain 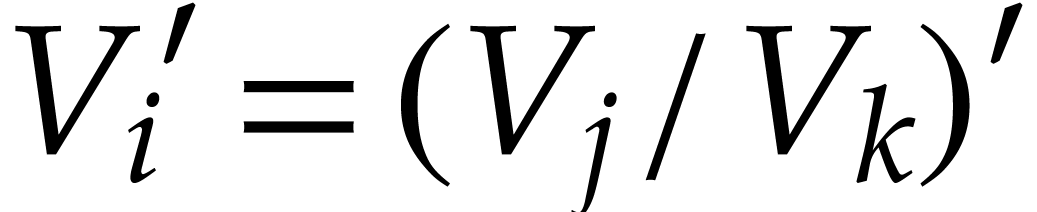 .
Hence and
.
Hence and 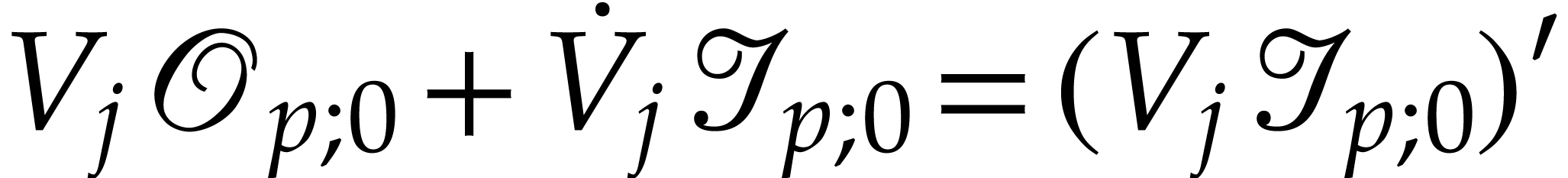 after the
execution, as claimed.
after the
execution, as claimed.
If with ,
then computes
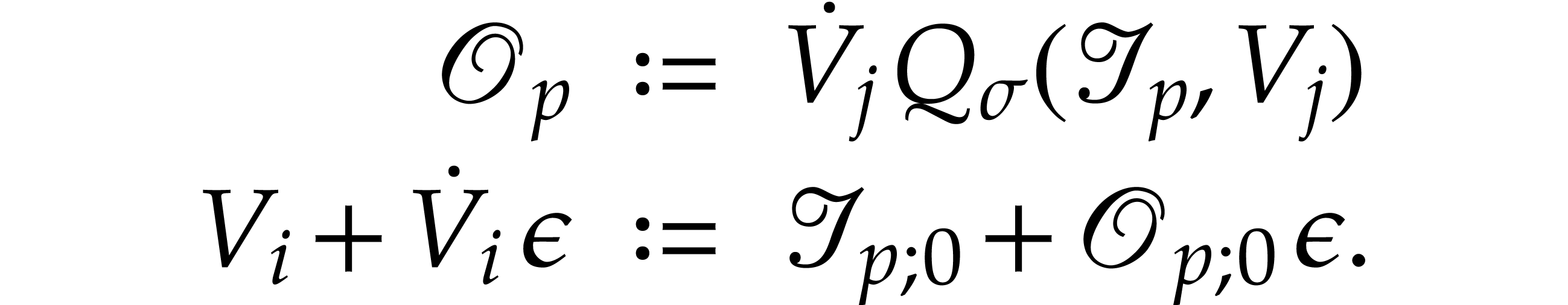
Consequently, and our claim again holds after
the execution of . This
completes the proof of the first assertion.
Let us now turn to the second assertion about the computation of the
initial value. The tuples 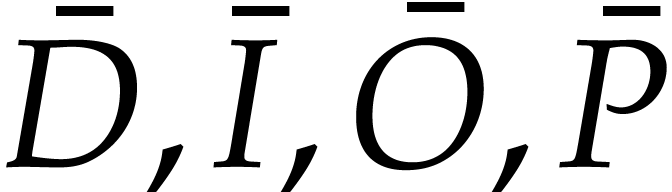 are defined as
follows:
are defined as
follows:
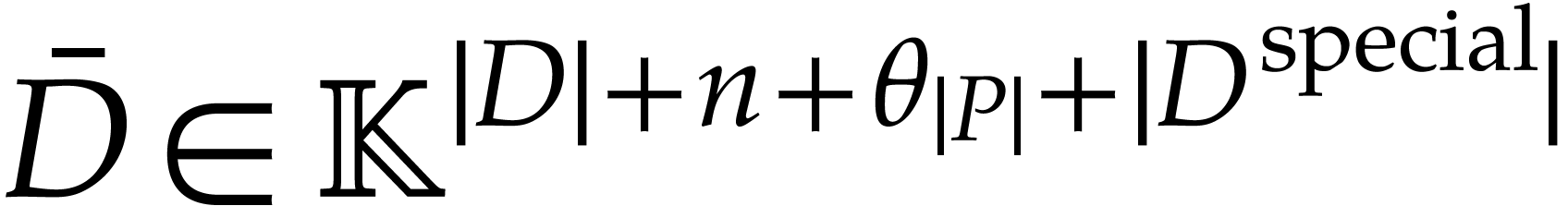 with
with 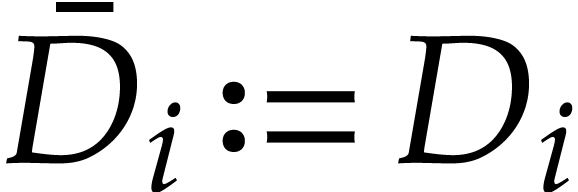 for and
for and 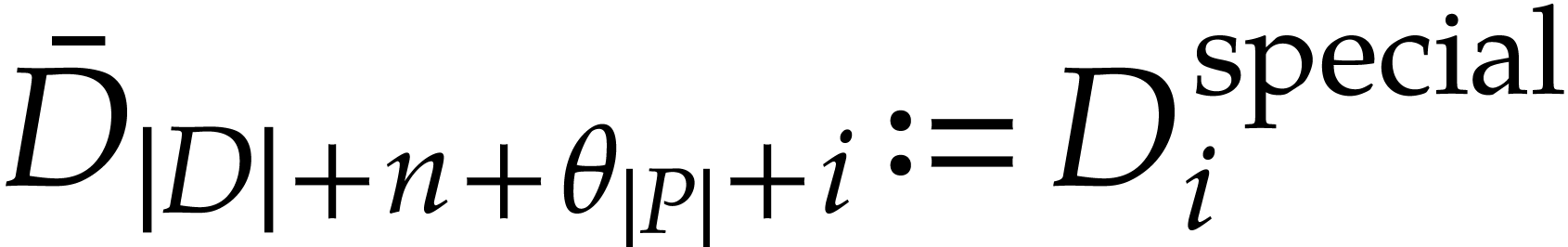 for . Other entries of
for . Other entries of 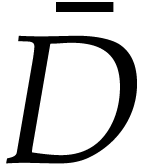 may
be filled arbitrarily;
may
be filled arbitrarily;
 ;
;
 ;
;
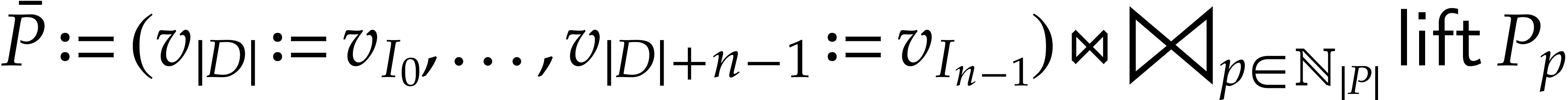 , where
, where  is a function which maps instructions of to
tuples of instructions as follows. If
is a function which maps instructions of to
tuples of instructions as follows. If 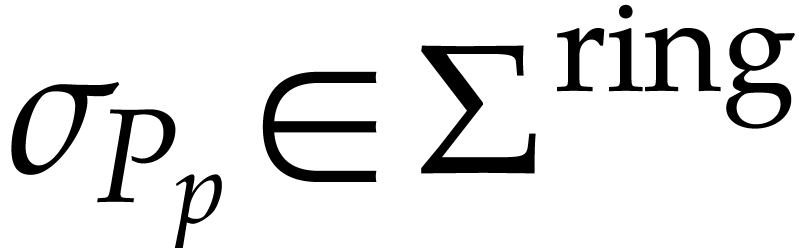 ,
then we take
,
then we take 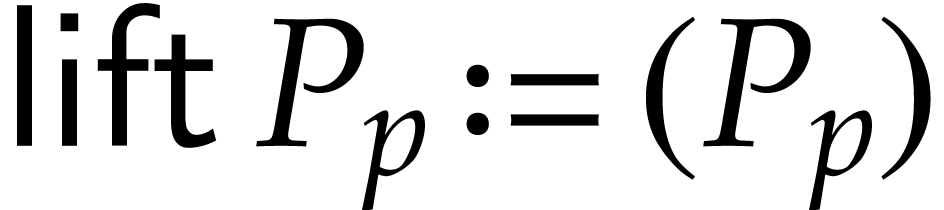 . If , then
. If , then
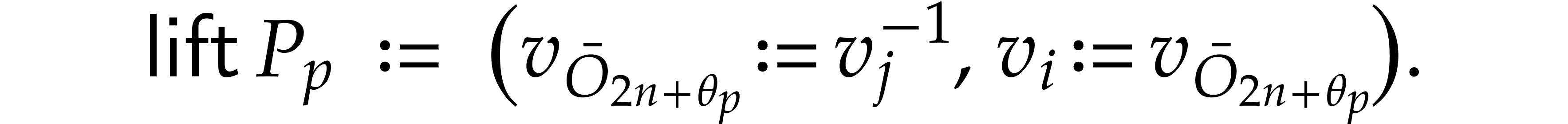
If , then
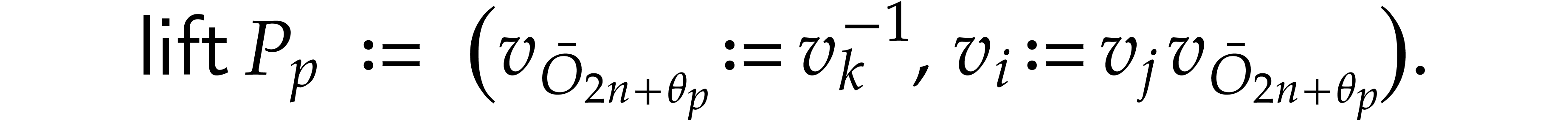
If with ,
then
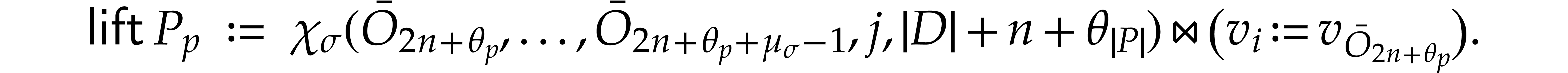
Let be a solution of 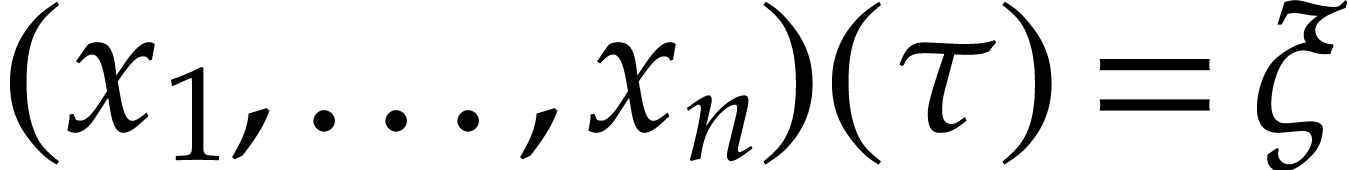 and let
and let  be defined as above. Let
be defined as above. Let 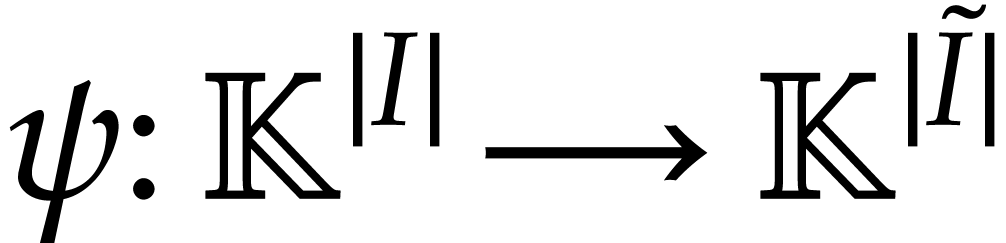 stand for
the map defined by the SLP
stand for
the map defined by the SLP 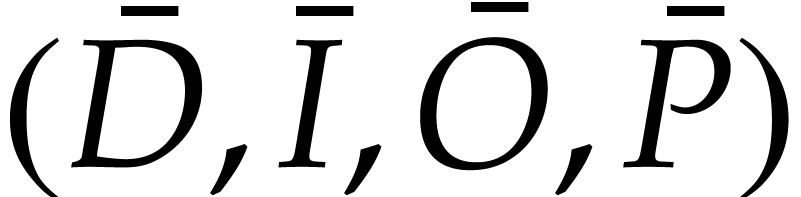 .
By construction,
.
By construction, 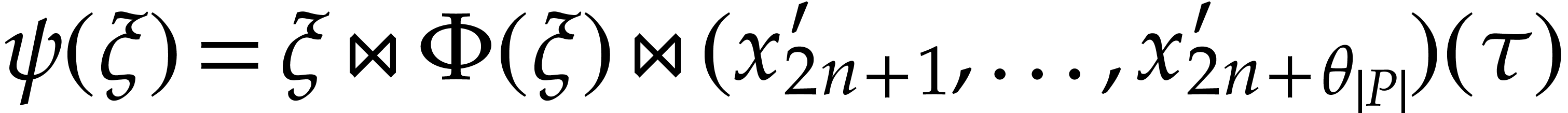 .
.
As for the complexity, we note that 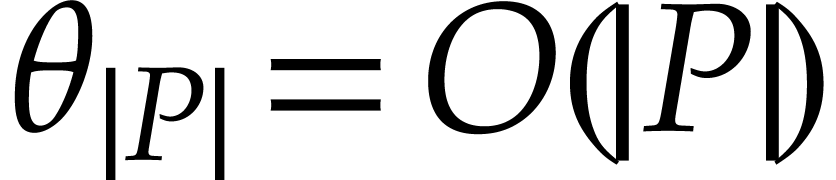 and that
and that
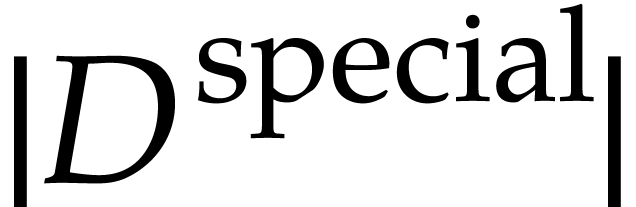 is a constant. The constructions of and take linear time.
is a constant. The constructions of and take linear time.
Remark 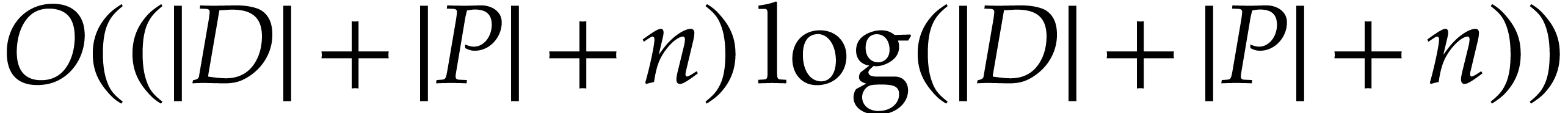 , due to the logarithmic space overhead for
storing the indices of variables. On the other hand, the algorithm
behind Theorem 9 uses no operations in , no hash tables, and no other complex
operations on integers.
, due to the logarithmic space overhead for
storing the indices of variables. On the other hand, the algorithm
behind Theorem 9 uses no operations in , no hash tables, and no other complex
operations on integers.
Modern computers often support an efficient so-called “Fused
Multiply-Add” (FMA) instruction set over floating point numbers in
single and double precisions. For Intel as fast as a
single product. This motivates us to define the FMA signature
as fast as a
single product. This motivates us to define the FMA signature
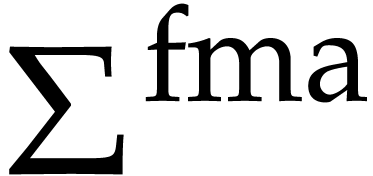 for a ring as , together with the following
operations:
for a ring as , together with the following
operations:
the fused multiply-add, defined by 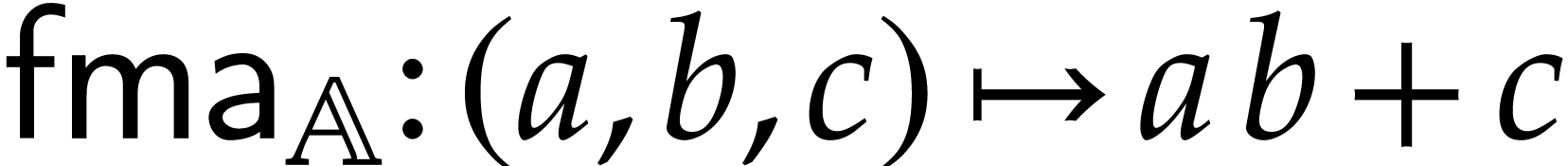 ,
,
the fused multiply-sub, defined by 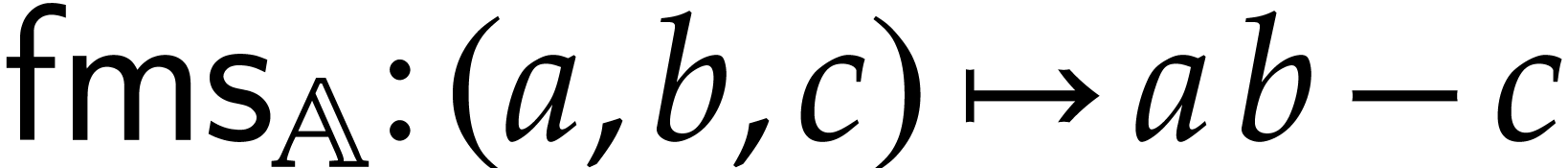 ,
,
the fused negative multiply-add, defined by 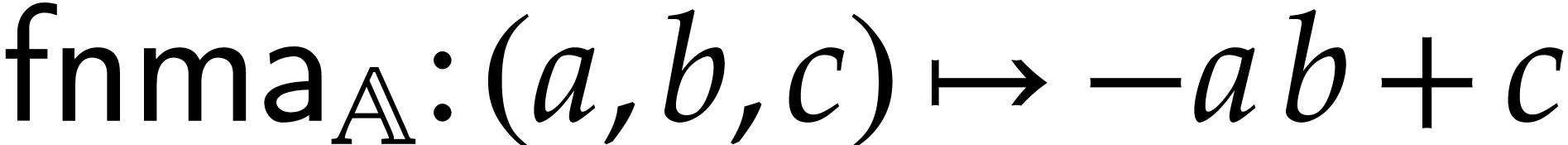 ,
,
the fused negative multiply-sub, defined by 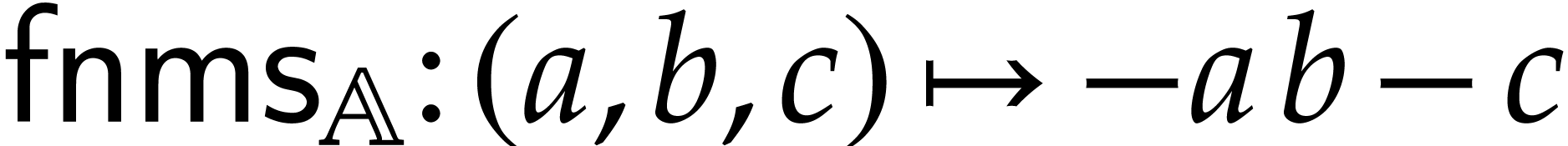 ,
,
the negative multiply, defined by 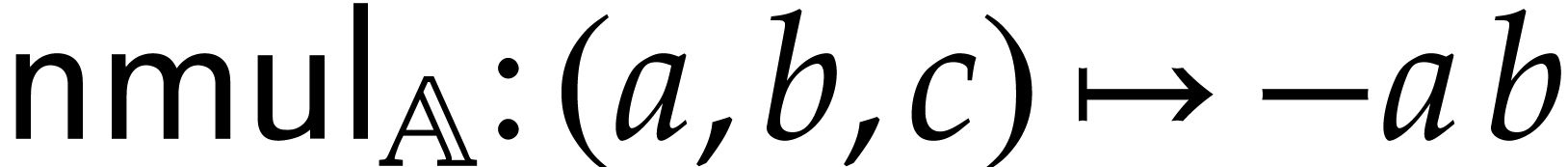 .
.
We revisit Theorem 9 with FMA signatures.
 to be of
signature , Theorem 9 holds with the sharper bound
to be of
signature , Theorem 9 holds with the sharper bound
Proof. The construction of the SLPs extends the one presented in the proof of Theorem 9, by taking FMA operations into account. On the one hand, we define
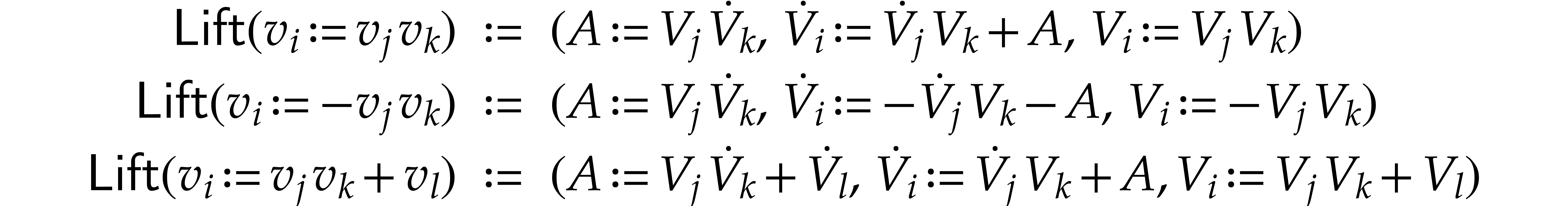
and similarly for  ,
,  , and
, and  ,
hence the contribution
,
hence the contribution 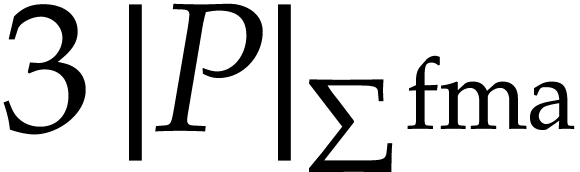 in the complexity bound.
One the other hand, we redefine
in the complexity bound.
One the other hand, we redefine
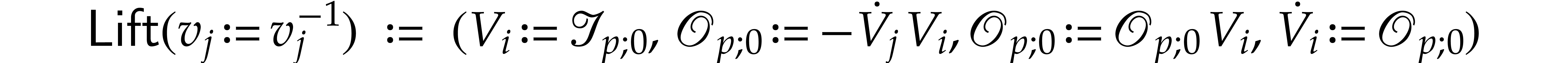
and
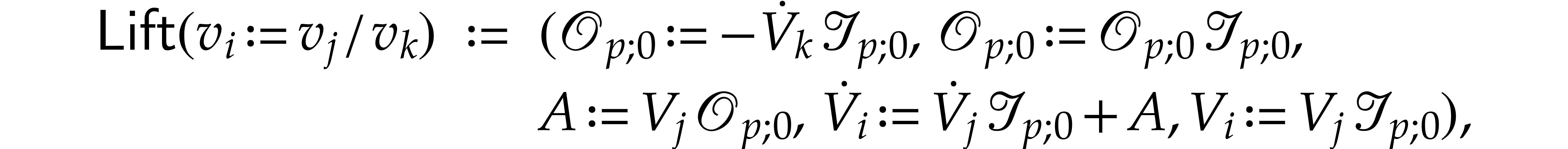
hence the contribution  in the complexity
bound.
in the complexity
bound.
Remark 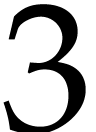 in can often be
further reduced. More precisely, let
in can often be
further reduced. More precisely, let  be the
number of ring nodes of whose ancestors are also
all ring nodes. Then it can be verified that (after simplification of
the SLP) the term can be replaced by
be the
number of ring nodes of whose ancestors are also
all ring nodes. Then it can be verified that (after simplification of
the SLP) the term can be replaced by 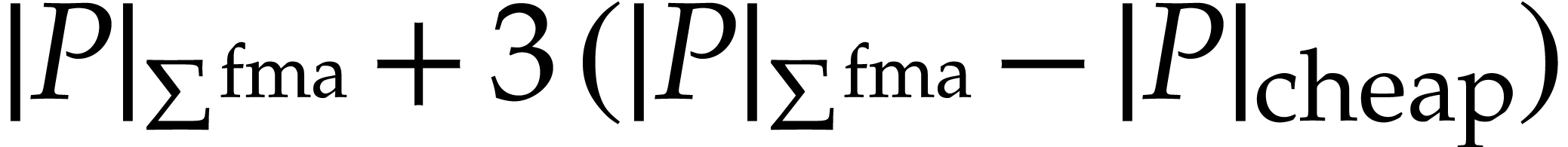 .
.
We implemented Theorem 11 within the
consists of all elementary functions 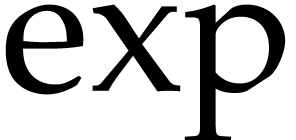 ,
,
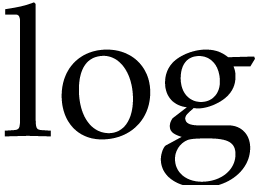 ,
,  ,
,  ,
,  ,
,  ,
,
 ,
,  ,
,  ,
, 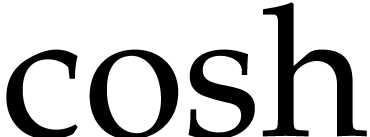 ,
,  ,
,
 ,
, 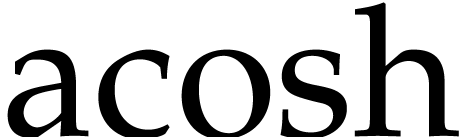 ,
,  ,
,  .
. 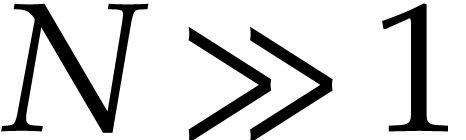 times in an
efficient manner.
times in an
efficient manner.
The JIT compiler of 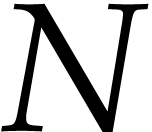 like
like 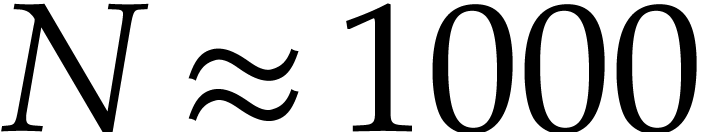 . In addition, if we have several competing
SLPs for the same task, then we may efficiently generate machine code
for each of them and empirically select the best SLP.
. In addition, if we have several competing
SLPs for the same task, then we may efficiently generate machine code
for each of them and empirically select the best SLP.
The source code of our polynomialization can be found in the file src/ode/slp_ode_polynomialize.cpp of are only performed during constant folding [12, section 4]. Therefore, the number of operations in never exceeds the number of instructions of the SLP
under simplification.
Roughly speaking, the overhead 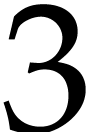 in the term of over .
In order to decrease this overhead, we first present an optimization
which aims at reducing the number of first order derivatives
in the term of over .
In order to decrease this overhead, we first present an optimization
which aims at reducing the number of first order derivatives 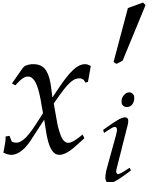 used by : we
will separate ring instructions needed by divisions and special
functions and other operations.
used by : we
will separate ring instructions needed by divisions and special
functions and other operations.
Example
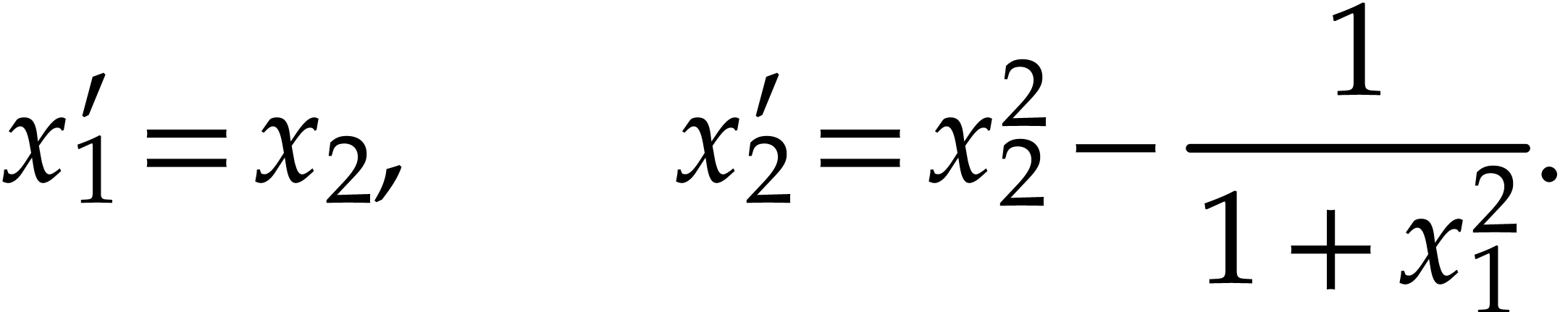
We represent it using the following SLP with signature :  with
with 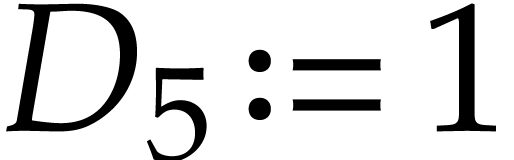 ,
, 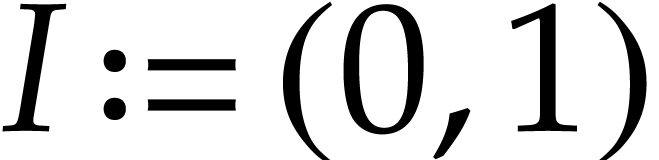 ,
,
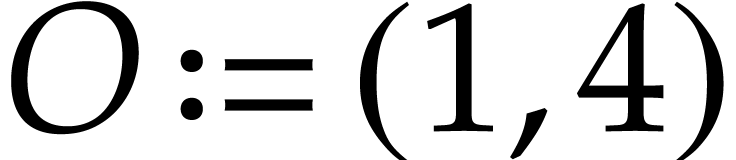 , and
, and 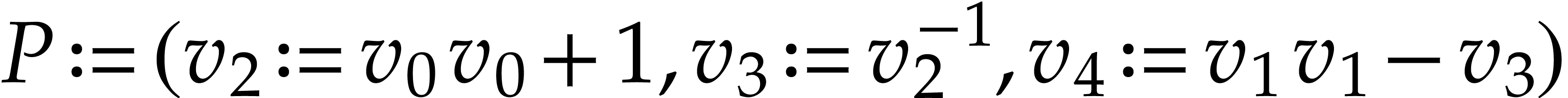 . The direct application of Theorem 11
leads to an SLP for a polynomialization
. The direct application of Theorem 11
leads to an SLP for a polynomialization  with
with
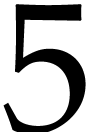 inputs and outputs and
inputs and outputs and 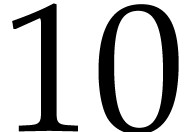 instructions, which drops to
instructions, which drops to  after
simplification. It turns out that this SLP is suboptimal since we may
simply define
after
simplification. It turns out that this SLP is suboptimal since we may
simply define 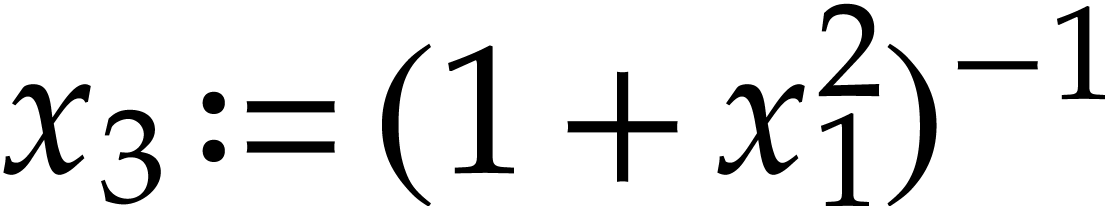 and obtain the following shorter
polynomialization:
and obtain the following shorter
polynomialization:
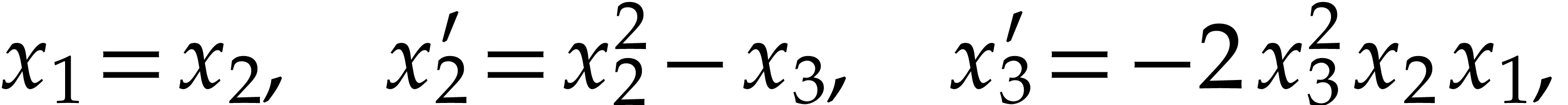 |
(7) |
which can be represented by an SLP with 5 instructions.
In the above example, the second derivatives of 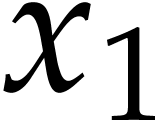 and
and 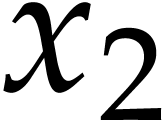 are not needed, because
are not needed, because 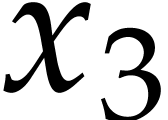 only depends on , whose first
derivative is available in the SLP of before
computing
only depends on , whose first
derivative is available in the SLP of before
computing 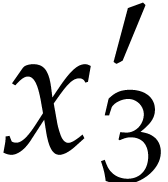 . We may compute
the shorter polynomialization in a more systematic manner using the
following optimization.
. We may compute
the shorter polynomialization in a more systematic manner using the
following optimization.
. If 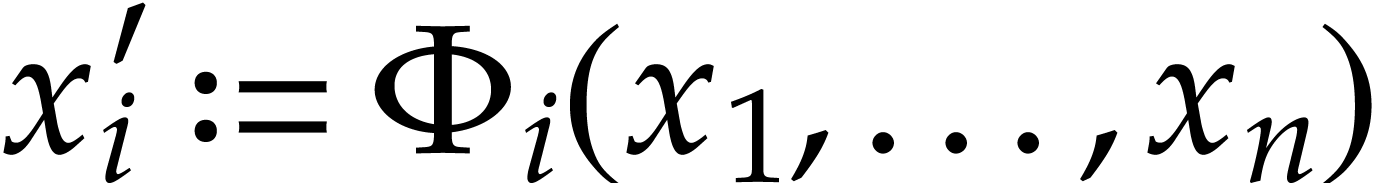 is computed before an
instruction
is computed before an
instruction 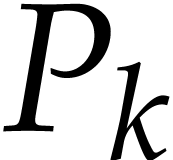 with
with 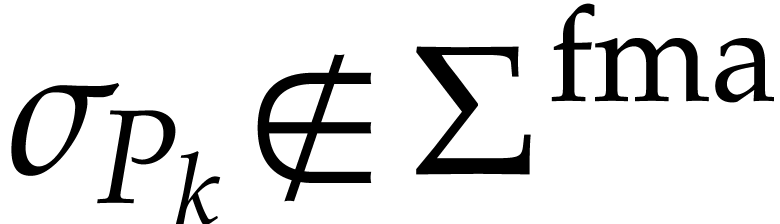 depends on
depends on 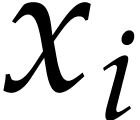 , then we may
modify the polynomialization constructed in
Theorems 9 and 11 as follows:
, then we may
modify the polynomialization constructed in
Theorems 9 and 11 as follows:
Just after 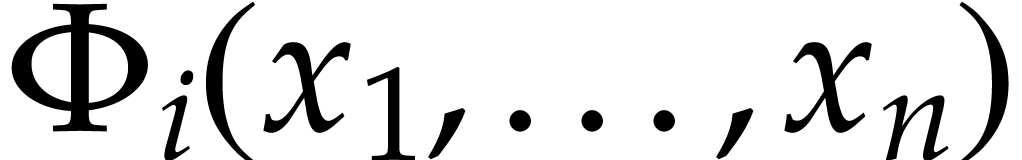 is computed, we copy its
value into the position of
is computed, we copy its
value into the position of 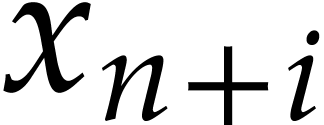 in the
working space;
in the
working space;
The output corresponding to 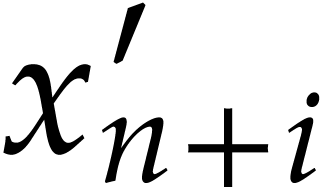 is discarded
in the SLP of .
is discarded
in the SLP of .
In order to implement Optimization 14 efficiently, we need
to solve the following problem: for a given subset  of instructions of the SLP of (namely the with
of instructions of the SLP of (namely the with 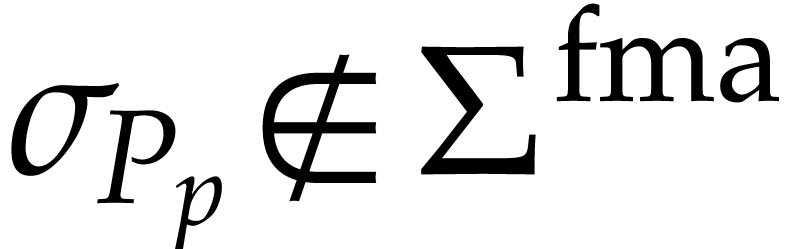 ) and
for each variable , we wish
to determine the first instruction in that
depends on . This is a common
task for compilers, which can be achieved in linear time using one
forward and one backward pass through the SLP.
) and
for each variable , we wish
to determine the first instruction in that
depends on . This is a common
task for compilers, which can be achieved in linear time using one
forward and one backward pass through the SLP.
More precisely, during the forward pass, one maintains an array that,
for each variable , indicates
the (index of the) last instruction that modifies . This information is used during the same pass to
build an array that, for each argument 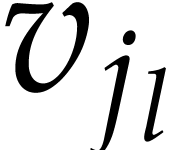 of an
instruction
of an
instruction 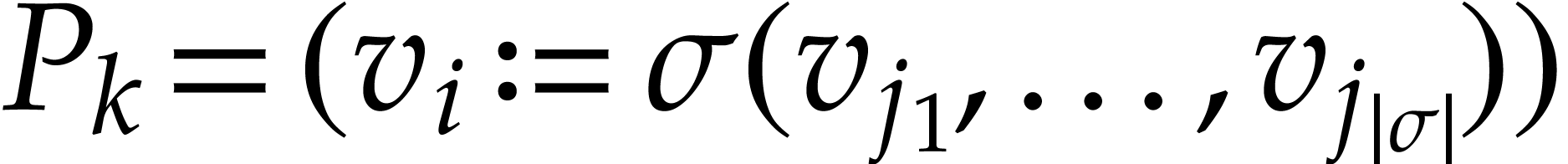 , indicates the
latest instruction that modified .
During the backward pass, for each instruction
, indicates the
latest instruction that modified .
During the backward pass, for each instruction 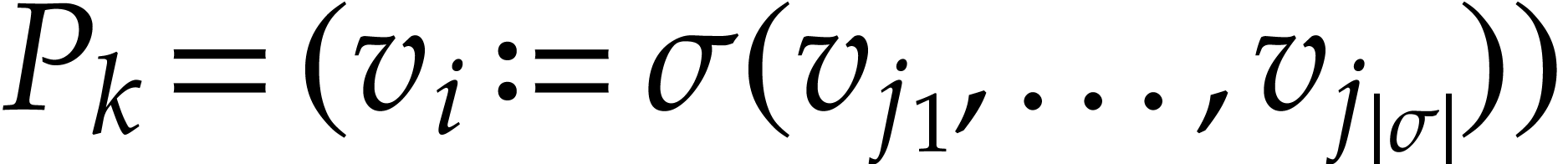 and each input variable , we
determine the first instruction in that depends
on .
and each input variable , we
determine the first instruction in that depends
on .
Remark
Example 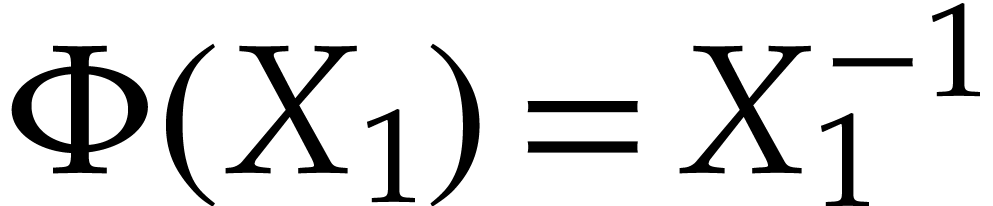 , then Optimization 14
yields the simplified polynomialization
, then Optimization 14
yields the simplified polynomialization 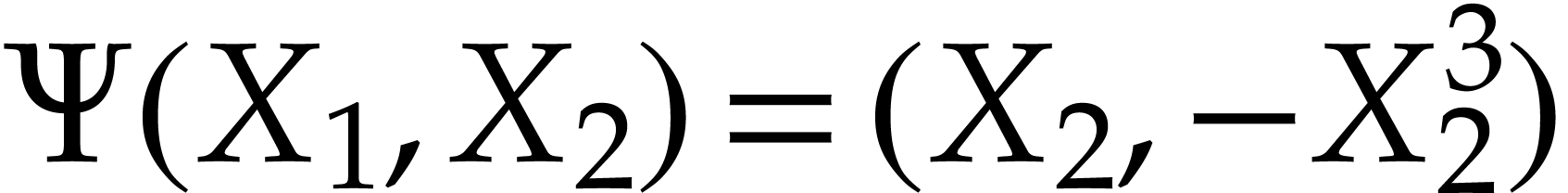 in terms
of the SLP defined by
in terms
of the SLP defined by  ,
, 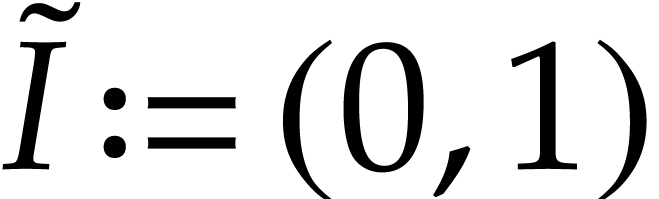 ,
, 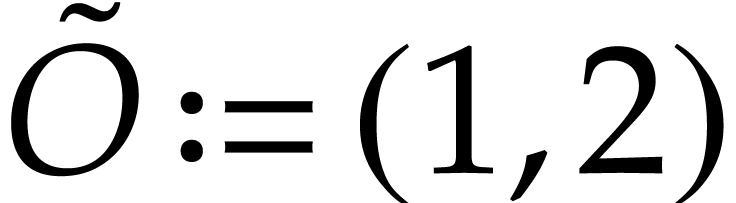 ,
and
,
and 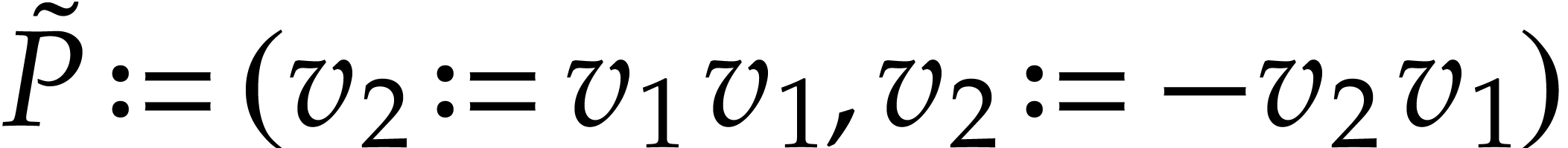 .
.
Example 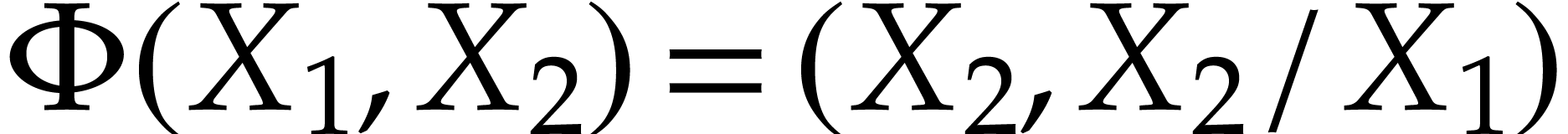 , then Optimization 14
yields the simplified polynomialization
, then Optimization 14
yields the simplified polynomialization 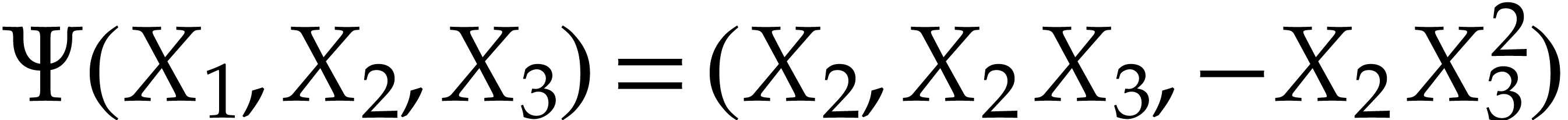 in terms
of a SLP with
in terms
of a SLP with 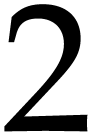 instructions.
instructions.
Example 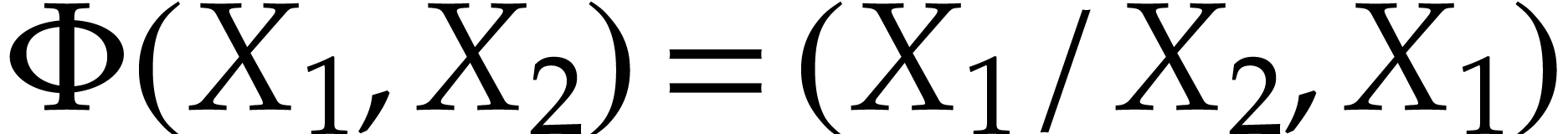 and Optimization 14 yields the
simplified polynomialization
and Optimization 14 yields the
simplified polynomialization 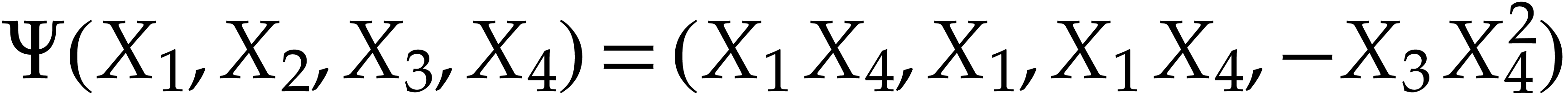 which takes instructions, but
which takes instructions, but 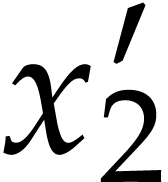 remains an
input of . This example
motivates our next optimization.
remains an
input of . This example
motivates our next optimization.
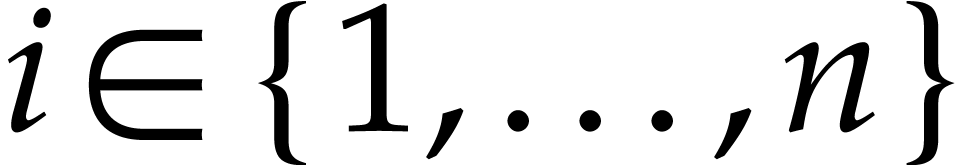 and
and  are such that
are such that
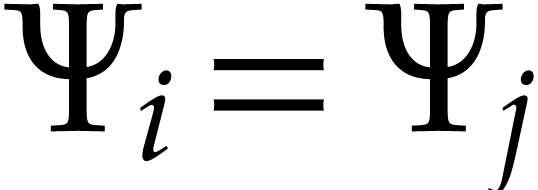 and
and 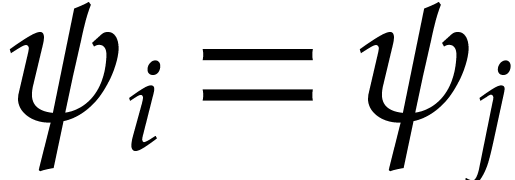 then we may
simplify the polynomialization into
then we may
simplify the polynomialization into 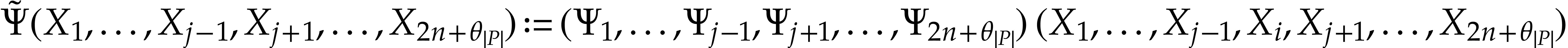 and
and 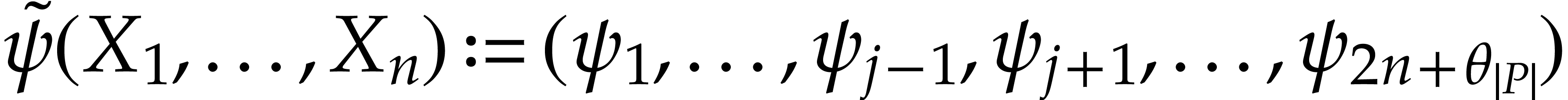 .
.
Example 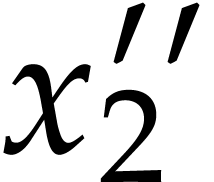 and
and 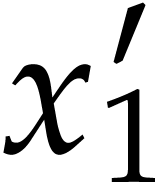 coincide. As for the initial conditions, we have
coincide. As for the initial conditions, we have 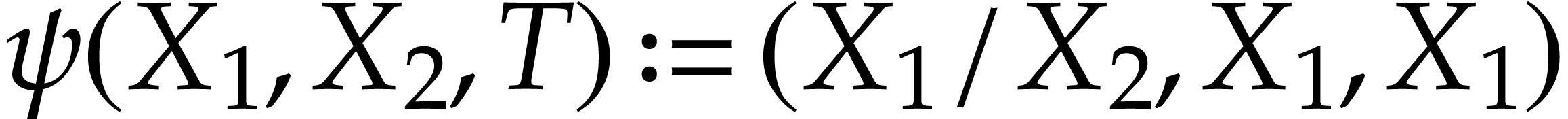 . Following Optimization 19, we may
simplify the polynomialization into
. Following Optimization 19, we may
simplify the polynomialization into 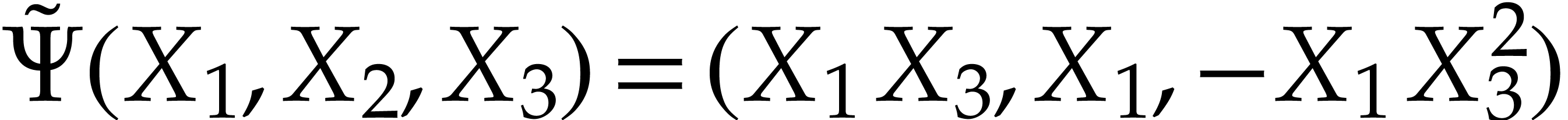 .
.
In order to minimize the number of extra variables in our
polynomializations, we may compute the values of  using and
using and 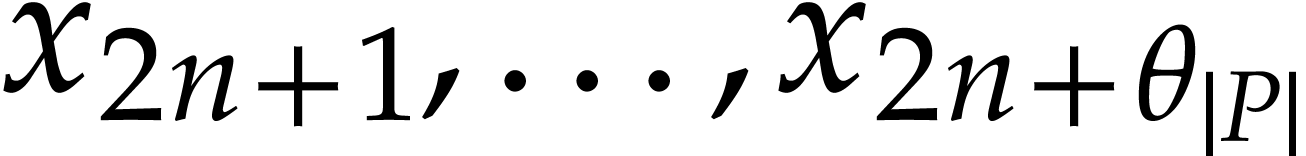 before
evaluating . For sure, we
obtain a polynomialization with only
before
evaluating . For sure, we
obtain a polynomialization with only 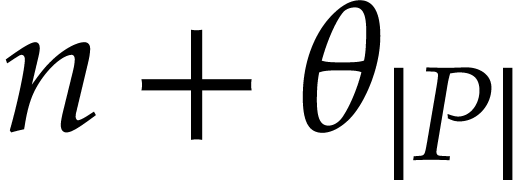 variables,
still in linear time, which is in general higher than the one obtained
in Theorems 9 and 11. Nevertheless, sometimes
and thanks to the simplification routine of
variables,
still in linear time, which is in general higher than the one obtained
in Theorems 9 and 11. Nevertheless, sometimes
and thanks to the simplification routine of
with
inputs can be obtained as follows:
Compute an SLP over
with signature in which takes 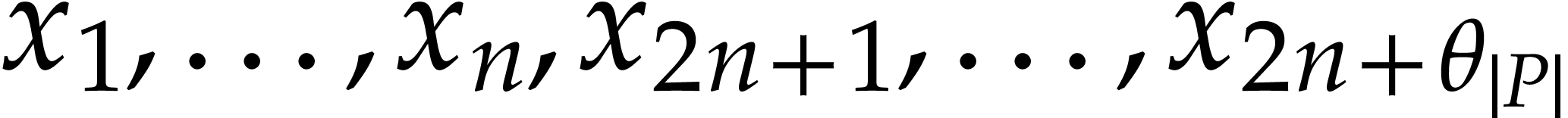 as input and returns
as input and returns  .
.
Construct the SLP of the polynomialization  which takes
which takes 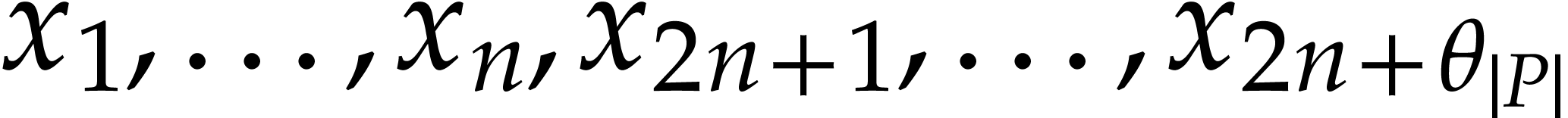 as input and returns
as input and returns  .
.
As for the initial conditions for ,
construct the SLP for 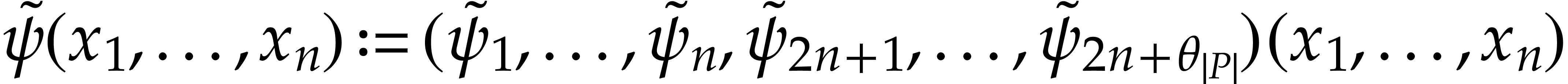 .
.
In our implementation, we compare the SLP resulting of Optimizations 14 and 19 with the one of Optimizations 21 and 19: we return the one which has the smallest number of instructions. In case of equality, we return the one with the smallest number of variables.
Example
Example 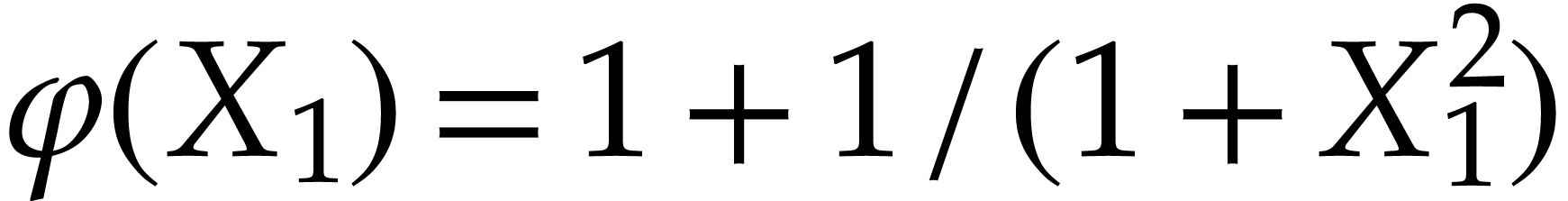 and
and 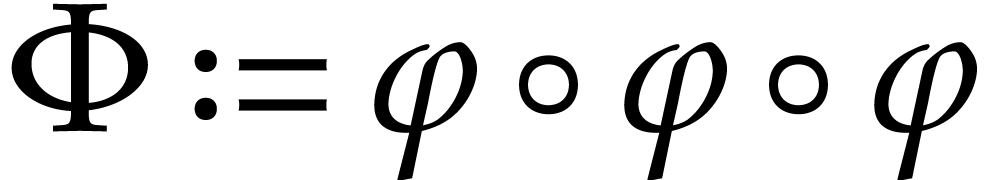 .
Evaluating takes 12 instructions. Optimizations
21 and 19 yield a polynomialization with 15
instructions, while Optimizations 14 and 19
yield 16 instructions.
.
Evaluating takes 12 instructions. Optimizations
21 and 19 yield a polynomialization with 15
instructions, while Optimizations 14 and 19
yield 16 instructions.
We have shown how the polynomialization of an ODE given by an SLP can be achieved in linear time. Combined with suitable optimizations, our implementation returns efficient ODEs, especially for numerical integration.
Quadratization seems to be a harder problem for SLPs. A first straightforward approach is to expand the SLP into a sparse polynomial and apply the algorithms from [5]. However, this approach destroys the SLP structure. In particular, occasional products of linear forms are all expanded. We expect that more natural quadratizations exist for SLPs. Finding such SLPs with a better complexity is an interesting problem for future investigation.
A. Ahlbäck, J. van der Hoeven, and G. Lecerf. JIL: a high performance library for straight-line programs. https://sourcesup.renater.fr/projects/jil, 2025.
J. Alexandre Dit Sandretto and A. Chapoutot. Validated explicit and implicit Runge–Kutta methods. Reliable Computing (electronic edition), 22:79–113, 2016.
P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic Complexity Theory, volume 315 of Grundlehren der Mathematischen Wissenschaften. Springer-Verlag, 1997.
J. C. Butcher. Numerical methods for ordinary differential equations. Wiley, Chichester, third edition, 2016.
A. Bychkov, O. Issan, G. Pogudin, and B. Kramer. Exact and optimal quadratization of nonlinear finite-dimensional nonautonomous dynamical systems. SIAM J. Appl. Dyn. Syst., 23(1):982–1016, 2024.
Y. Cai and G. Pogudin. Dissipative quadratizations of polynomial ODE systems. In B. Finkbeiner and L. Kovács, editors, Tools and Algorithms for the Construction and Analysis of Systems. TACAS 2024, volume 14571 of Lect. Notes Comput. Sci., pages 323–342. Springer, Cham, 2024.
J. von zur Gathen and J. Gerhard. Modern computer algebra. Cambridge University Press, New York, 3rd edition, 2013.
M. Hemery, F. Fages, and S. Soliman. On the complexity of quadratization for polynomial differential equations. In A. Abate, T. Petrov, and V. Wolf, editors, Computational Methods in Systems Biology. CMSB 2020, volume 12314 of Lect. Notes Comput. Sci., pages 120–140. Springer, Cham, 2020.
M. Hemery, F. Fages, and S. Soliman. Compiling elementary mathematical functions into finite chemical reaction networks via a polynomialization algorithm for ODEs. In E. Cinquemani and L. Paulevé, editors, Computational Methods in Systems Biology. CMBS 2021, volume 12881 of Lect. Notes Comput. Sci., pages 74–90. Springer, Cham, 2021.
J. van der Hoeven. Relax, but don't be too lazy. J. Symbolic Comput., 34:479–542, 2002.
J. van der Hoeven. The Jolly Writer. Your Guide to GNU TeXmacs. Scypress, 2020.
J. van der Hoeven and G. Lecerf. Towards a library for straight-line programs. Technical Report, HAL, 2025. https://hal.science/hal-05075591. Accepted for publication in Appl. Algebra Eng. Commun. Comput.
J. van der Hoeven, G. Lecerf, and A. Minondo. Static bounds for straight-line programs. Technical Report, HAL, 2025. https://hal.science/hal-05105518.
J. van der Hoeven et al. GNU TeXmacs. https://www.texmacs.org, 1998.
B. Kramer and G. Pogudin. Discovering Polynomial and Quadratic Structure in Nonlinear Ordinary Differential Equations. Technical Report 2502.10005, arXiv, 2025. https://arxiv.org/abs/2502.10005.
R. E. Moore, R. B. Kearfott, and M. J. Cloud. Introduction to Interval Analysis. SIAM Press, 2009.
C. H. Papadimitriou. Computational Complexity. Addison-Wesley, 1994.
 .
.