Short SLPs for sparse polynomial
maps  |
|
| Preliminary version of June 18, 2026 |
|
 . Grégoire
Lecerf and Arnaud Minondo have been supported by the French ANR-22-CE48-0016 NODE project. Joris van der Hoeven
has been supported by an ERC-2023-ADG grant for the ODELIX
project (number 101142171).
. Grégoire
Lecerf and Arnaud Minondo have been supported by the French ANR-22-CE48-0016 NODE project. Joris van der Hoeven
has been supported by an ERC-2023-ADG grant for the ODELIX
project (number 101142171).
Funded by the European Union. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency. Neither the European Union nor the granting authority can be held responsible for them. |
 |
Given a finite number of sparse polynomials, we present a new algorithm, along with its C++ implementation, to compute an efficient straight-line program which is able to simultaneously evaluate these polynomials at a given point. |
Let  be an effective ring. In other words,
elements of can be represented on a computer and
we have algorithms for all ring operations. Let
be an effective ring. In other words,
elements of can be represented on a computer and
we have algorithms for all ring operations. Let 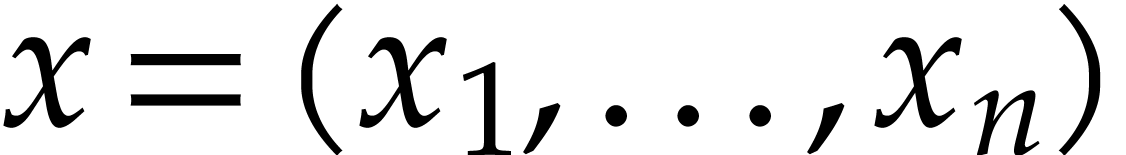 be a system of coordinates and let
be a system of coordinates and let 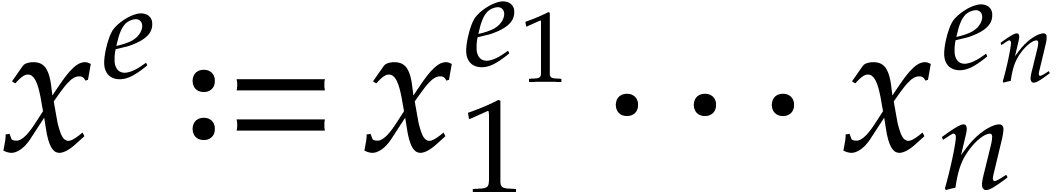 for any
for any  . A sparse polynomial in
. A sparse polynomial in
 over is an expression of
the form
over is an expression of
the form
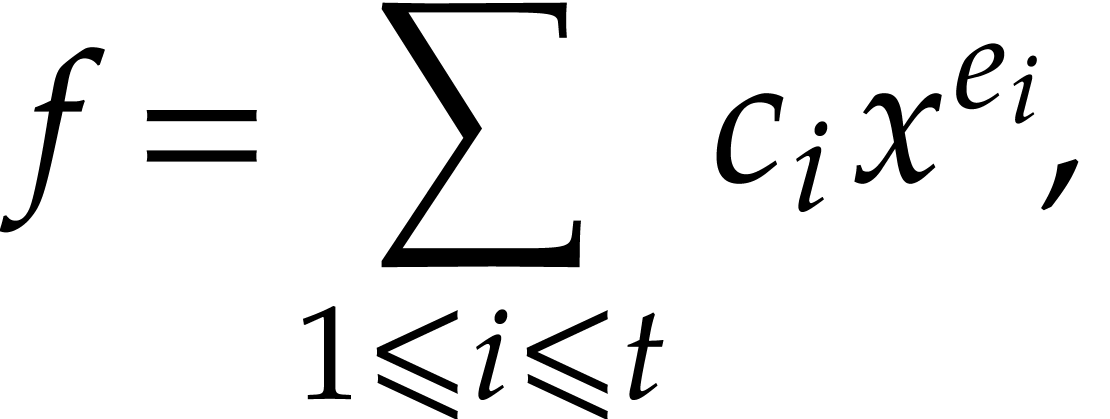 |
(1) |
with  and
and 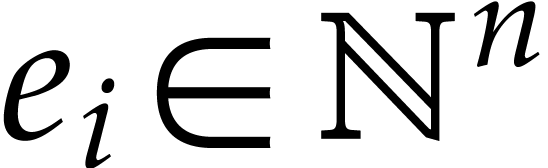 for
for 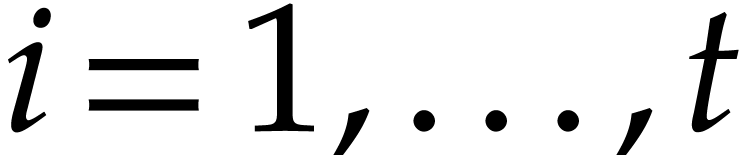 . We write
. We write 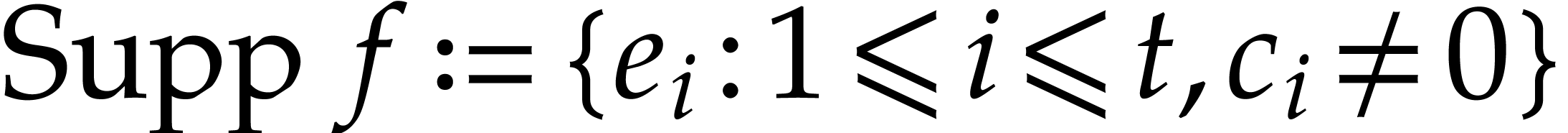 for the support of
for the support of  .
Given a vector
.
Given a vector 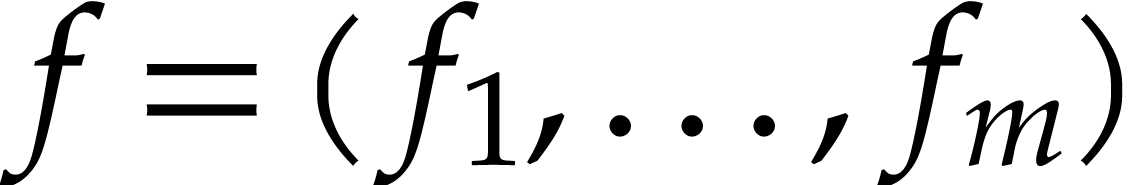 of sparse polynomials, we may
consider the polynomial map
of sparse polynomials, we may
consider the polynomial map
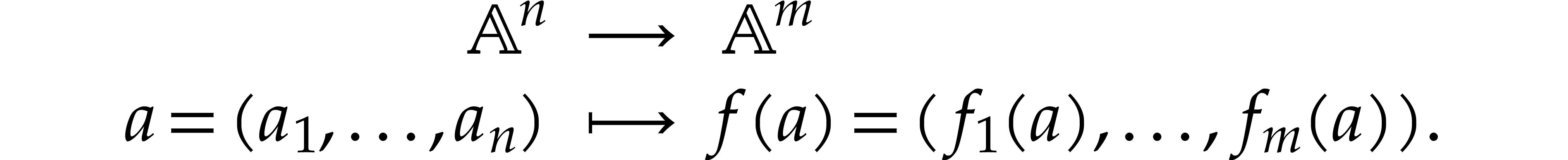
A natural question is how to evaluate this map as efficiently as possible. Since such sparse polynomial maps only involve additions, multiplications, and possibly subtractions, it is also natural to search for an evaluation algorithm in the form of a straight-line program (SLP). We recall that an SLP is a sequence of arithmetic instructions, without any branchings or loops; see the definition in [5] for instance, or the one from [15] for modern implementation aspects. The goal of this paper is to efficiently compute a short SLP for the evaluation of a sparse polynomial map.
Whereas the size of an SLP is easily measured by the number of
operations in , there are
several natural measures for the size of a sparse polynomial (1):
its number of terms  , its
expression size
, its
expression size
or its bit size
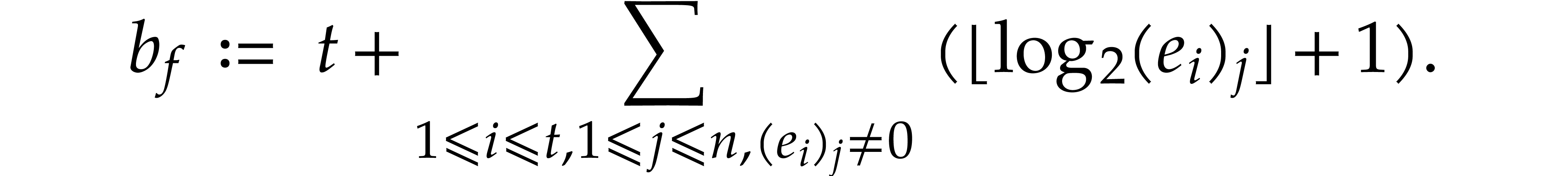
(For simplicity, we always regard coefficients in
as having unit size.) More generally, for a vector
of sparse polynomials, we define 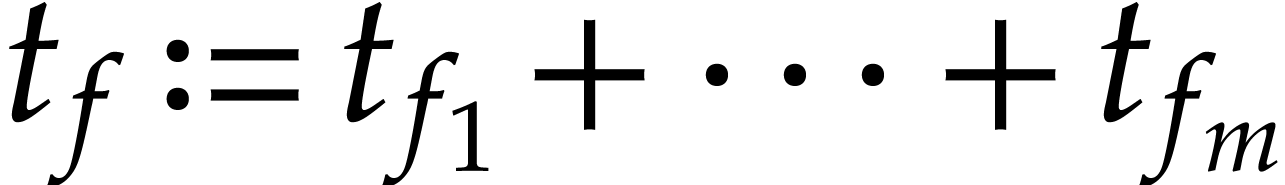 ,
,
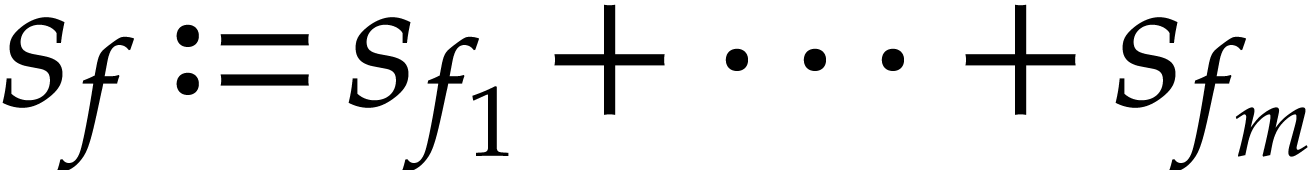 , and
, and 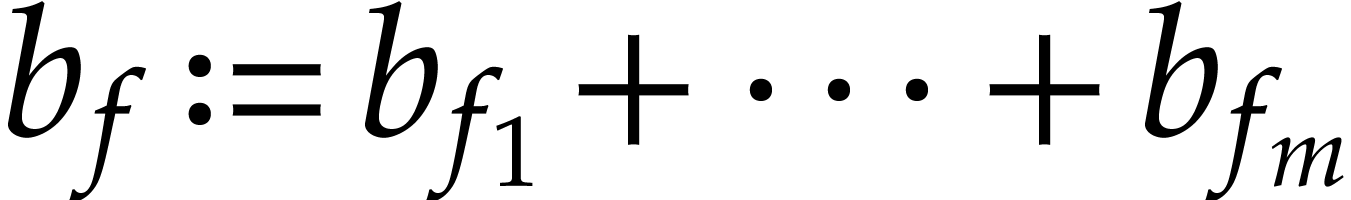 . In this case, one might also consider size
measures that take into account common monomials
. In this case, one might also consider size
measures that take into account common monomials 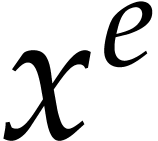 or terms
or terms 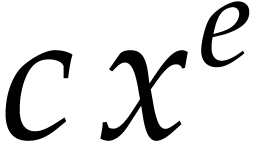 in distinct polynomials
in distinct polynomials 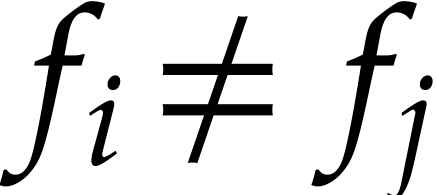 .
.
It is not hard to see that 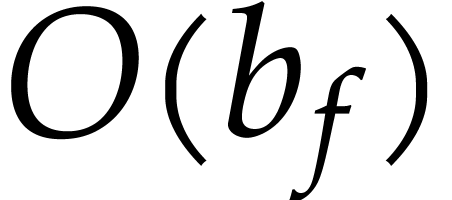 operations always
suffice for the evaluation of (using binary
powering), whereas
operations always
suffice for the evaluation of (using binary
powering), whereas 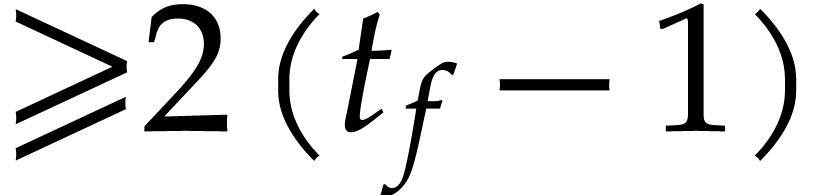 binary sums and products are
generally necessary for dense polynomials [19]. This lower
bound is reached when
binary sums and products are
generally necessary for dense polynomials [19]. This lower
bound is reached when 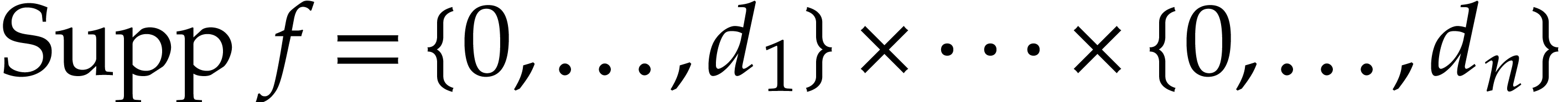 by using a multivariate
Horner scheme.
by using a multivariate
Horner scheme.
Finding an SLP of optimal size is a very difficult problem (see recent
advances in [17]), due to the fact that small SLPs like
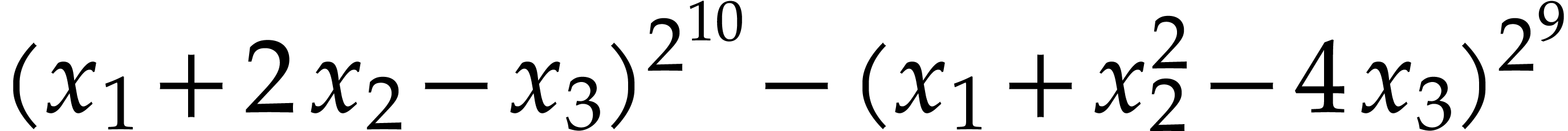 may become very large when expanding them as
sparse polynomials; see also Remark 2 below. Our goal in
this paper is not to design an algorithm with an optimal or
provingly good complexity in all cases. We will rather describe an easy
to implement algorithm that performs well in practice, as illustrated on
both random polynomials and a database with more than 600 examples. It
turns out that the computed SLP is often of size
may become very large when expanding them as
sparse polynomials; see also Remark 2 below. Our goal in
this paper is not to design an algorithm with an optimal or
provingly good complexity in all cases. We will rather describe an easy
to implement algorithm that performs well in practice, as illustrated on
both random polynomials and a database with more than 600 examples. It
turns out that the computed SLP is often of size 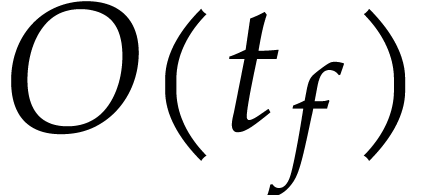 , whereas the computation of the SLP always takes at
most
, whereas the computation of the SLP always takes at
most 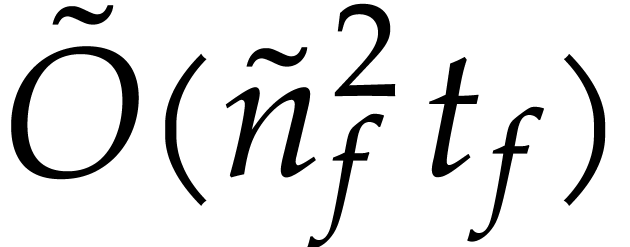 operations, where
operations, where 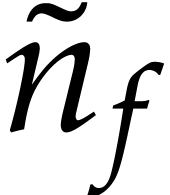 is the largest number of variables that occur in a single term of . We also note that the degrees of
most polynomials in our database are modest.
is the largest number of variables that occur in a single term of . We also note that the degrees of
most polynomials in our database are modest.
In section 2 we start with a review of existing approaches.
Already in the case when the input polynomials 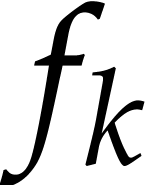 are simple powers or monomials, it is an interesting question how to
efficiently find a short SLP for their (joint) evaluation. Classical
algorithms for these cases are due to Brauer [4], Straus
[23], Yao [24], and Pippenger [20,
21, 22]; we refer to [2] for a
nice survey. For the general case, the most common implementation
strategy is based on multivariate Horner schemes [6, 7]; see also sections 2.4 and 3.3.
But more dedicated bilinear schemes [13, section 4.4.3] or
expensive partial factorization schemes [18] have also been
studied: see sections 2.5 and 2.6.
are simple powers or monomials, it is an interesting question how to
efficiently find a short SLP for their (joint) evaluation. Classical
algorithms for these cases are due to Brauer [4], Straus
[23], Yao [24], and Pippenger [20,
21, 22]; we refer to [2] for a
nice survey. For the general case, the most common implementation
strategy is based on multivariate Horner schemes [6, 7]; see also sections 2.4 and 3.3.
But more dedicated bilinear schemes [13, section 4.4.3] or
expensive partial factorization schemes [18] have also been
studied: see sections 2.5 and 2.6.
In section 3 we present our new algorithm. It takes
advantages of various ingredients. We first reduce to the case when all
terms occurring in the
are simple products (with 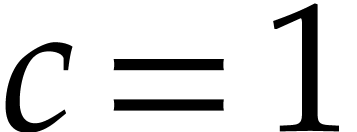 and
and  for
for 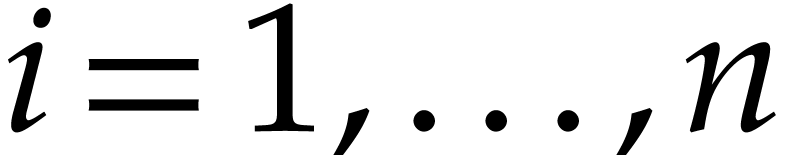 ). We next rely on a fast
greedy method for the efficient evaluation of multiple products. We
pursue with a simple greedy strategy to factor out some of the
variables. The resulting SLP may finally be further simplified using
common subexpression elimination and combining some of the additions and
multiplications into “fused multiply-add” (FMA)
instructions, which can be used to quickly evaluate the final SLP on
modern hardware.
). We next rely on a fast
greedy method for the efficient evaluation of multiple products. We
pursue with a simple greedy strategy to factor out some of the
variables. The resulting SLP may finally be further simplified using
common subexpression elimination and combining some of the additions and
multiplications into “fused multiply-add” (FMA)
instructions, which can be used to quickly evaluate the final SLP on
modern hardware.
In our last section 4 we report on our implementation of the algorithm of section 3 inside JIL [1, 15] and show that it is well suited for sparse polynomials that are typically encountered in computer algebra. We complete our implementation by combining efficient strategies to handle polynomials across the full spectrum from sparse to dense.
In this section, we start with a review of known methods for evaluating monomials and polynomials.
One important special case that has been studied extensively in the
literature concerns the computations of powers 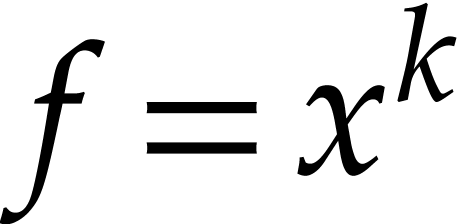 with
with 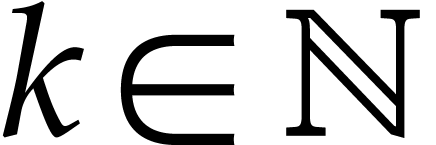 . Brauer gave the first
algorithm to compute
. Brauer gave the first
algorithm to compute 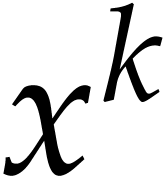 using
using 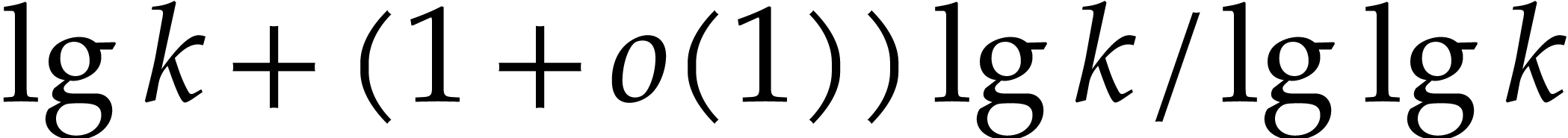 multiplications [4], where
multiplications [4], where 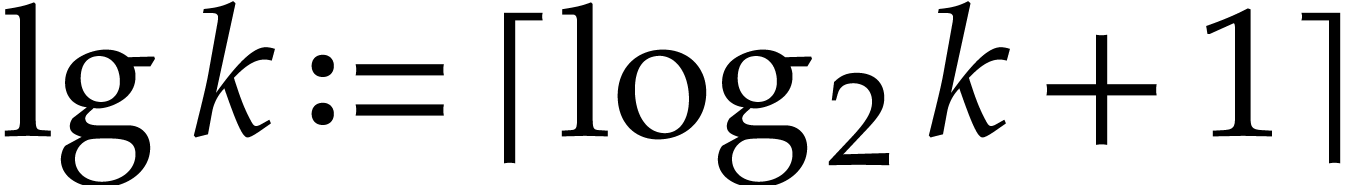 .
The idea is to compute the
.
The idea is to compute the 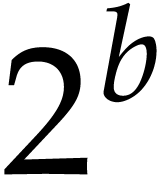 -adic
expansion
-adic
expansion
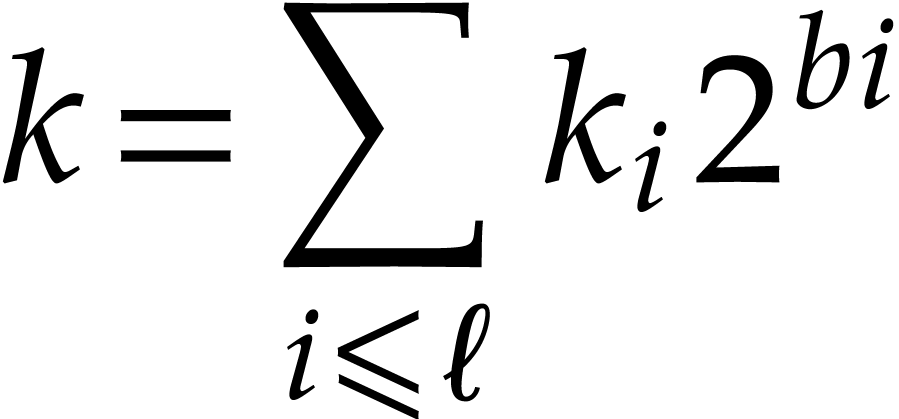
of 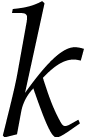 for
for 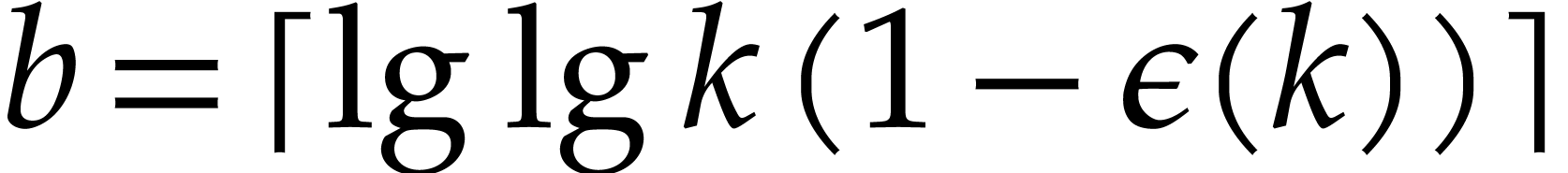 .
Here
.
Here 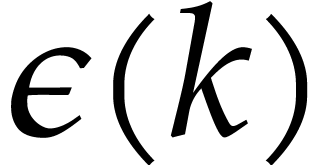 stands for a suitable function with
stands for a suitable function with 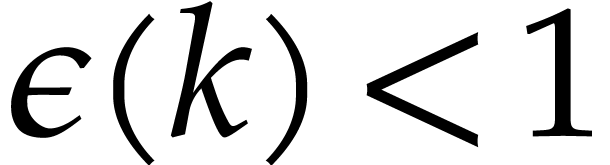 for all and which tends very
slowly to zero. One may for instance take
for all and which tends very
slowly to zero. One may for instance take 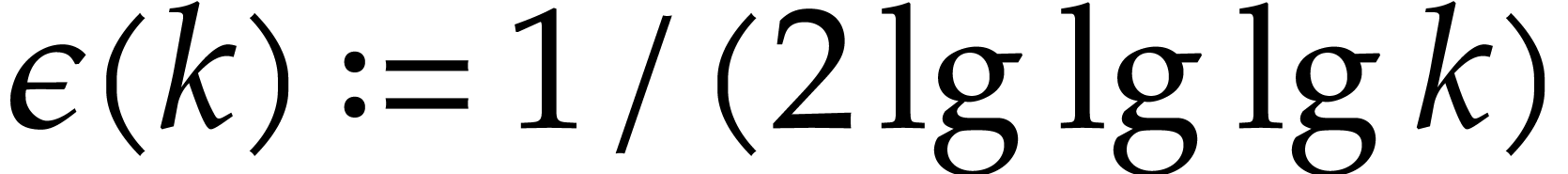 .
Then computing
.
Then computing 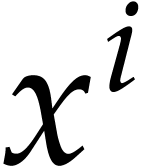 for
for  takes
time
takes
time 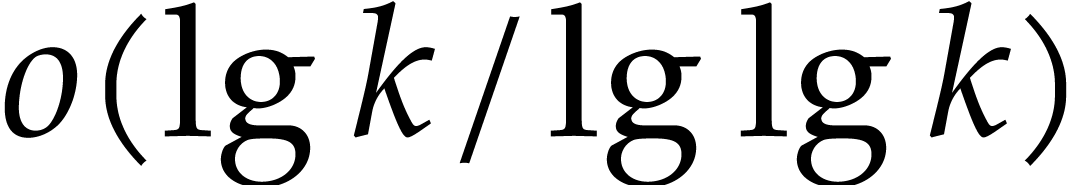 . After that, setting
. After that, setting
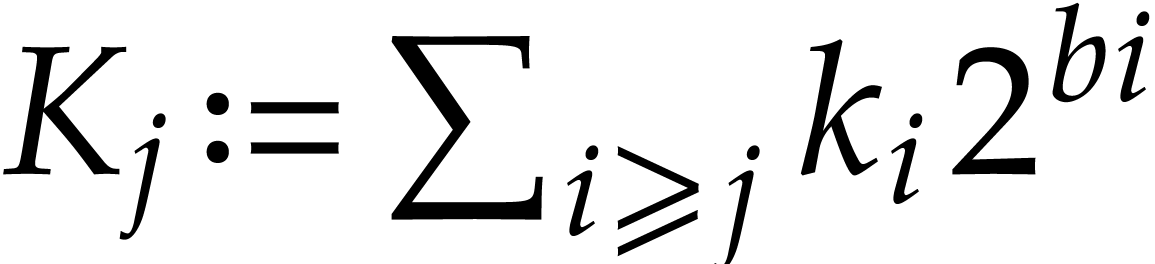 , computing
, computing 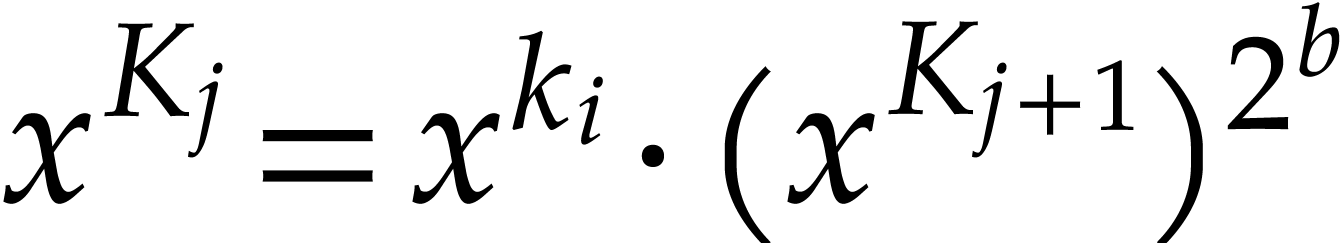 in terms of
in terms of 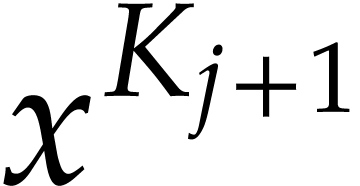 requires
requires 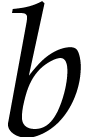 squarings and one multiplication. Since
squarings and one multiplication. Since  ,
the stated complexity bound follows. Erdős proved that this bound
is essentially optimal [11].
,
the stated complexity bound follows. Erdős proved that this bound
is essentially optimal [11].
In general, the computation of using only
multiplications can be modeled by an addition chain  for . This
means that
for . This
means that 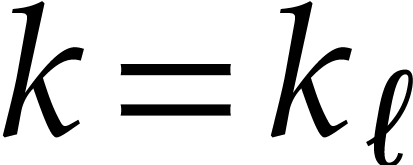 , where
, where  are positive integers such that
are positive integers such that 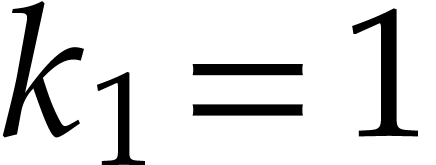 and for each
and for each 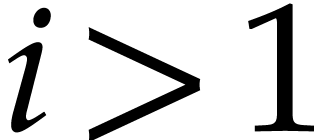 , there exist
, there exist
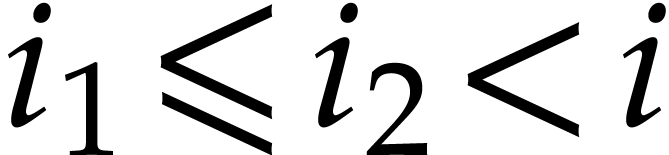 with
with  .
In practice, we may compute addition chains of small length for all
integers until as follows. We start with the
trivial addition chain for
.
In practice, we may compute addition chains of small length for all
integers until as follows. We start with the
trivial addition chain for 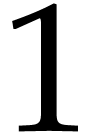 .
Assuming that we have computed addition chains for all integers below
, we determine the smallest
.
Assuming that we have computed addition chains for all integers below
, we determine the smallest
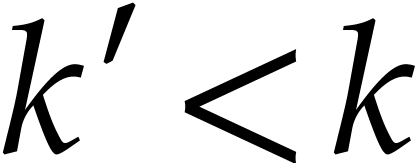 such that the addition chain
such that the addition chain  for
for 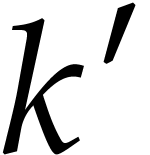 is of smallest length with
is of smallest length with 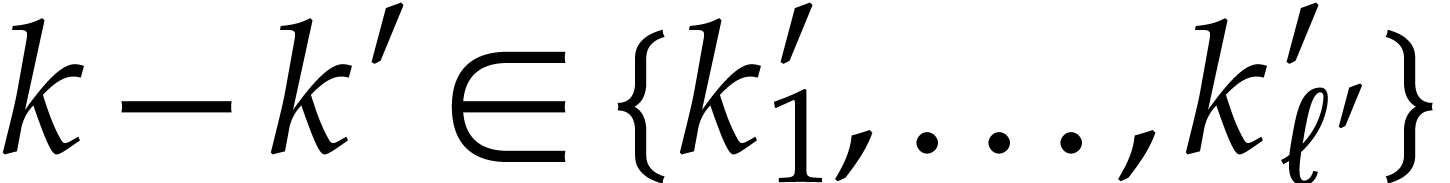 . Then sorting
. Then sorting 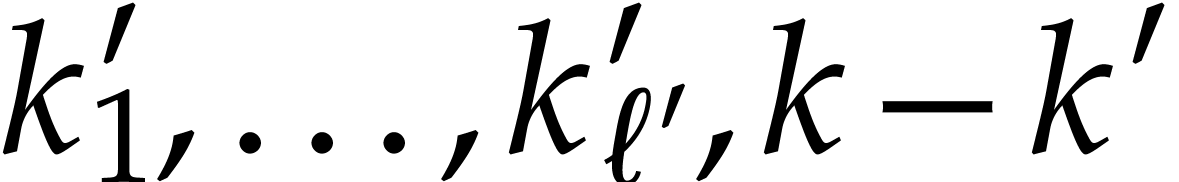 yields
an addition chain for .
yields
an addition chain for .
For each , we actually only
need to store the corresponding in a table in
order to efficiently recover the addition chain. The algorithm can also
be represented by a labeled tree [8, Section 4.6.3] in
which the node labeled by has the node labeled
by as its parent:
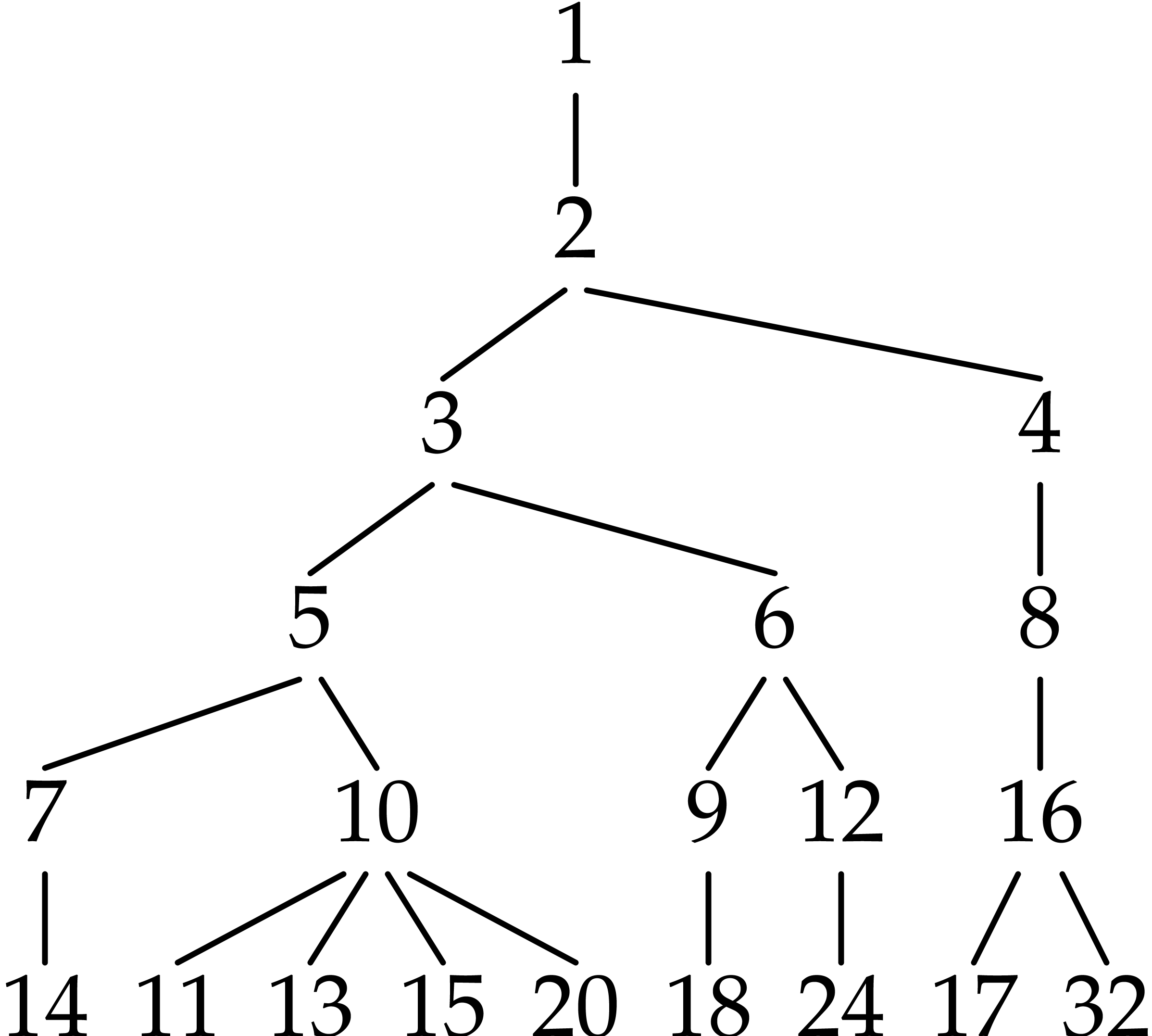
For instance, 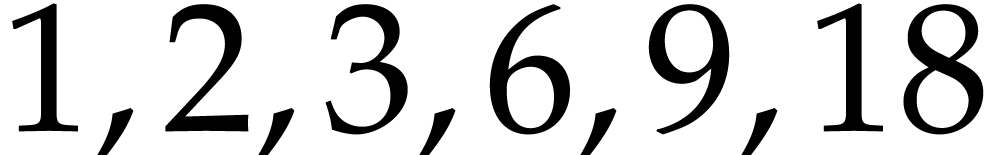 is an addition chain for
is an addition chain for 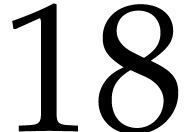 . In our implementation, we
precompute this table (or tree) up to a certain threshold. For above the threshold we resort to a -adic method as above for a suitable value of (see also below).
. In our implementation, we
precompute this table (or tree) up to a certain threshold. For above the threshold we resort to a -adic method as above for a suitable value of (see also below).
The -adic approach from the
previous subsection generalizes to the computation of multiple powers
instead of a single one. It was first shown by Yao [24]
that 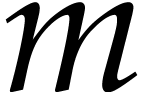 powers
powers 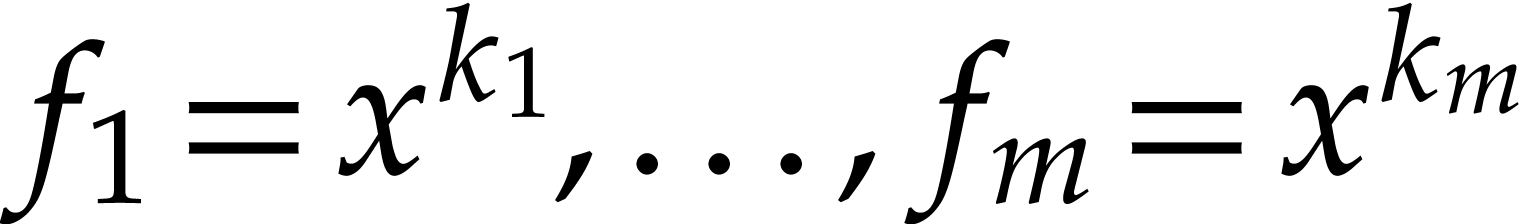 can be
computed in time
can be
computed in time
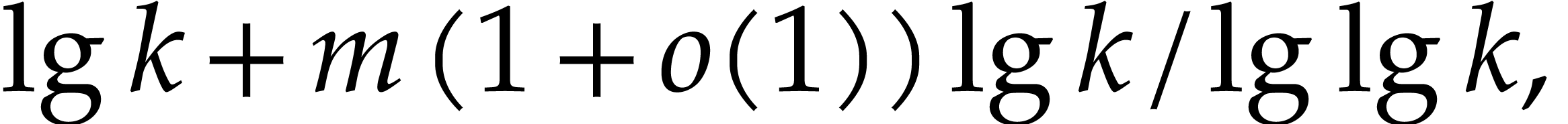
where 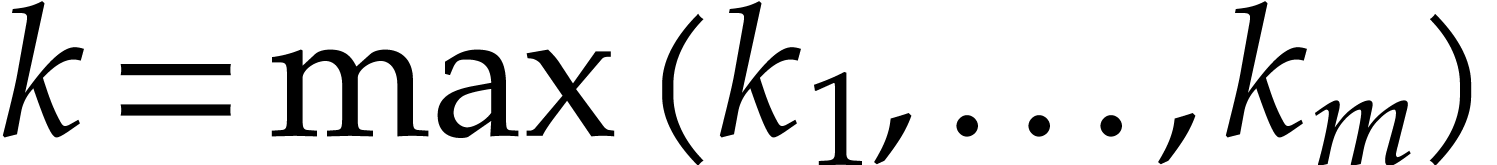 . Yao's method consists
of first computing
. Yao's method consists
of first computing 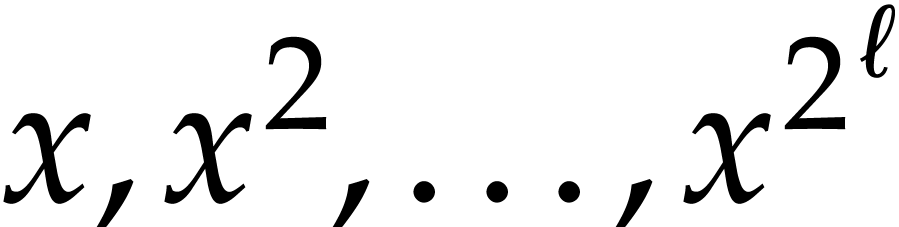 with
with 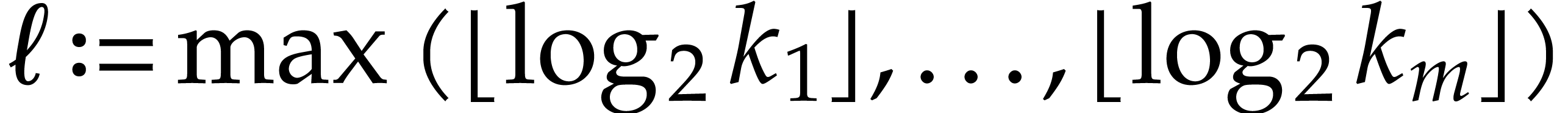 and then to call the following algorithm times
for the computation of
and then to call the following algorithm times
for the computation of 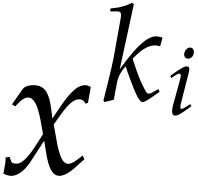 for
for 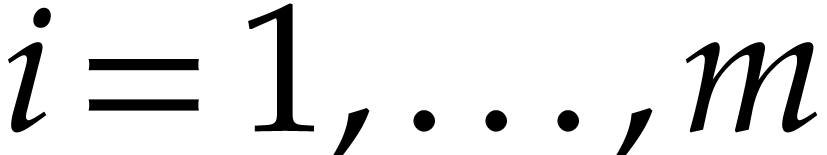 :
:
Algorithm
Output: .
Let 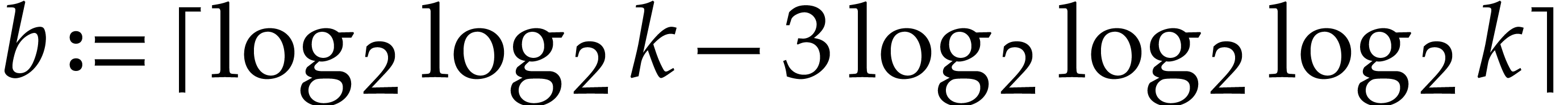 ,
, 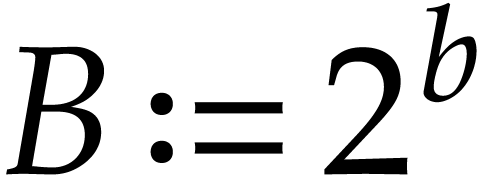 and let
and let 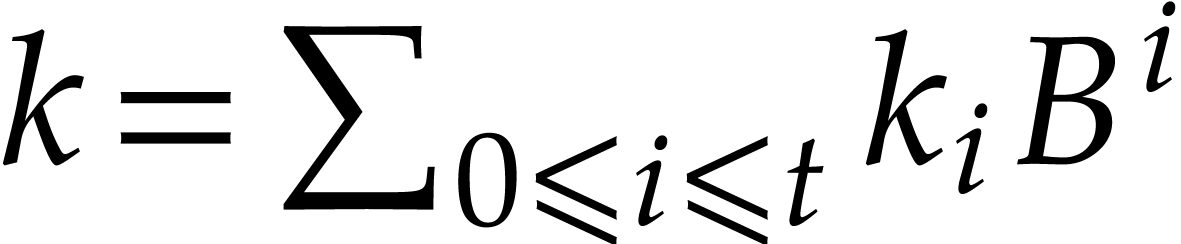 stand for the
stand for the
 -adic expansion of
, with
-adic expansion of
, with  .
.
For  compute
compute 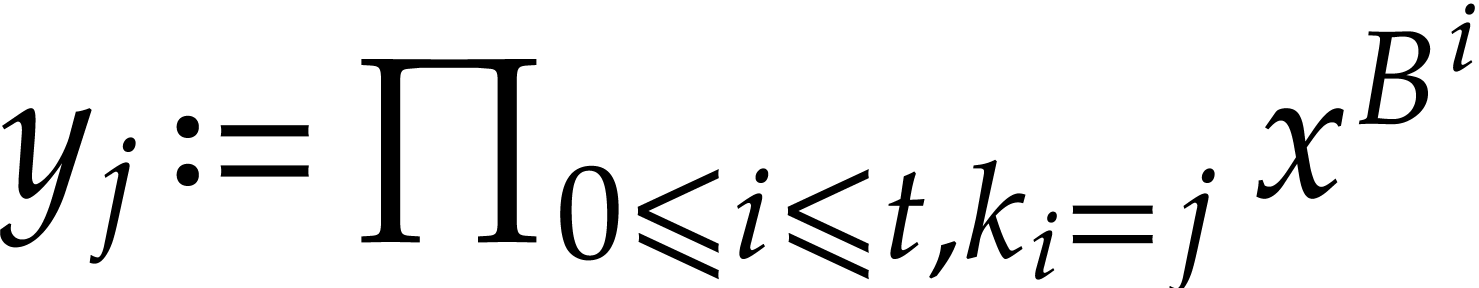 .
.
Return 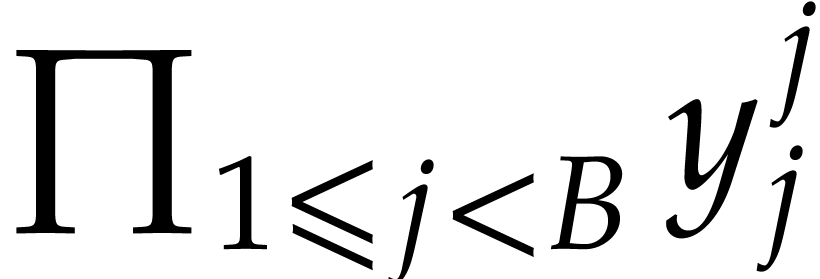 .
.
The condition  is used to ensure that
is used to ensure that  , but steps 2 and 3 can still be
applied to lower values of ,
by taking
, but steps 2 and 3 can still be
applied to lower values of ,
by taking 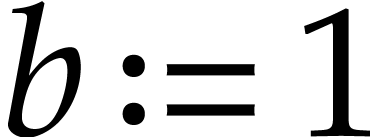 or
or 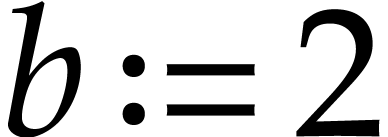 instead of
the value from step 1. If
instead of
the value from step 1. If 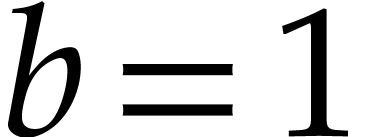 ,
then the average number of bits of is about
,
then the average number of bits of is about
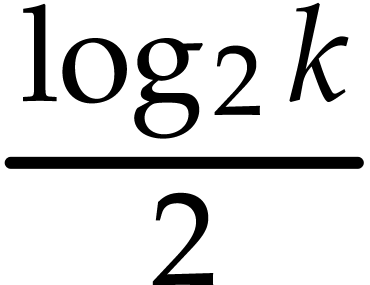 , so Algorithm 1
performs about
, so Algorithm 1
performs about 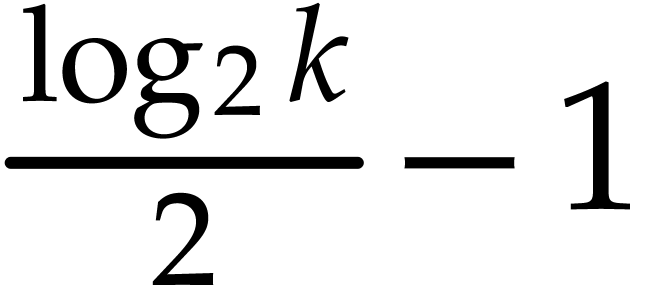 products. If
products. If 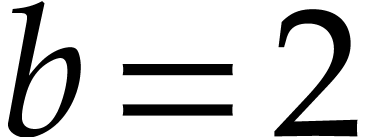 , then the average number of digits
, then the average number of digits 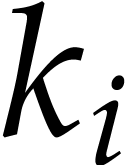 equal to a given
equal to a given 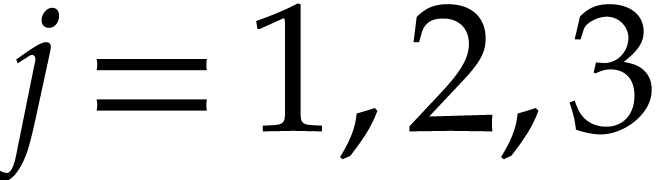 is roughly
is roughly 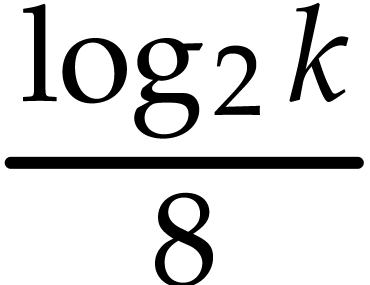 , so the number of products is
, so the number of products is 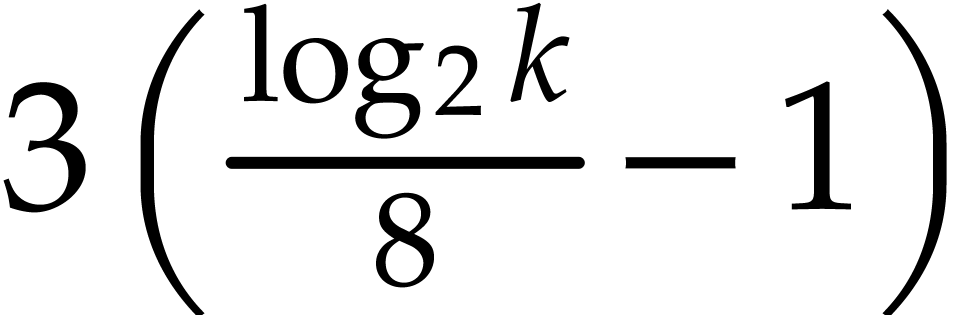 in step 2, and then
in step 2, and then 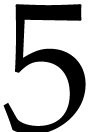 in step
3. Consequently, choosing is advantageous over
using only when
in step
3. Consequently, choosing is advantageous over
using only when
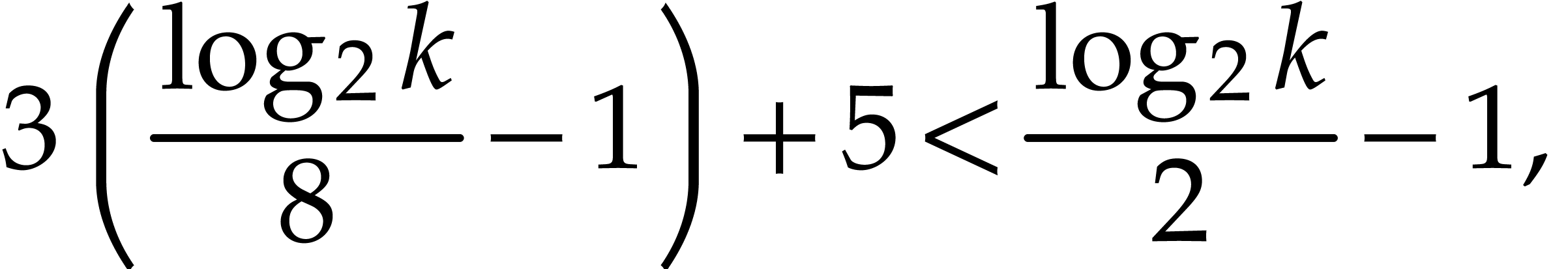
which means
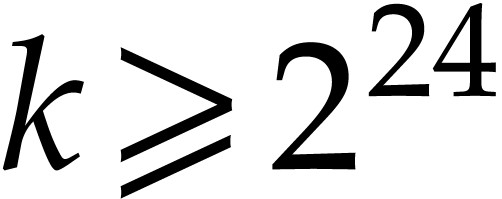 .
The number of products performed by Yao's method for
.
The number of products performed by Yao's method for
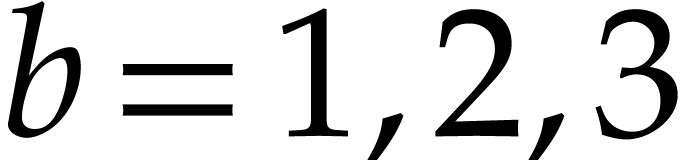 to compute
powers with random exponents in the range
to compute
powers with random exponents in the range
 for
for
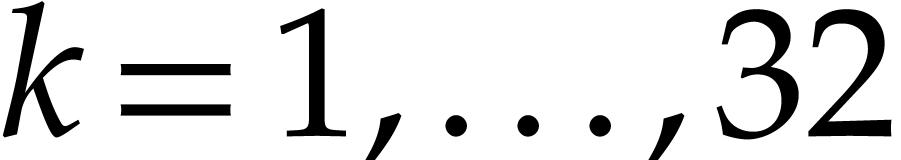 is shown in Figure
1
. The abscissa represents
,
and the ordinate displays the number of multiplications divided by
(averaged over 100 runs).
is shown in Figure
1
. The abscissa represents
,
and the ordinate displays the number of multiplications divided by
(averaged over 100 runs).
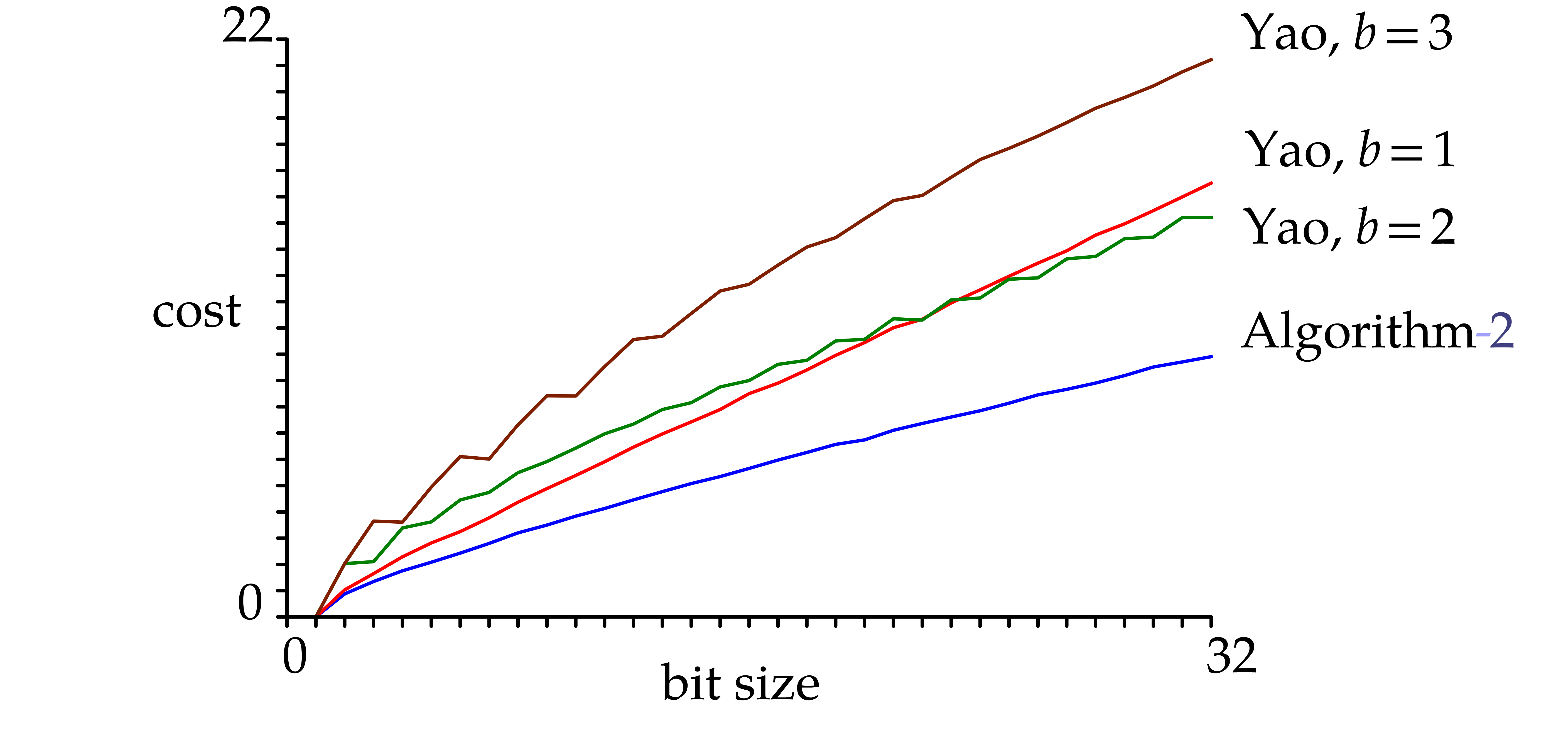 |
Figure 1. Computation of several powers using Yao's method and Algorithm 2. |
The original condition and the weakened
condition show that Yao's method is mostly of
theoretical interest. For practical purposes, we therefore designed
Algorithm 2 below, based on ‑adic
expansions. It incorporates opportunistic optimizations whenever
possible. As shown in Figure 1, this algorithm improves
upon Yao's method for the exponent sizes that we are interested in.
Algorithm
Output: 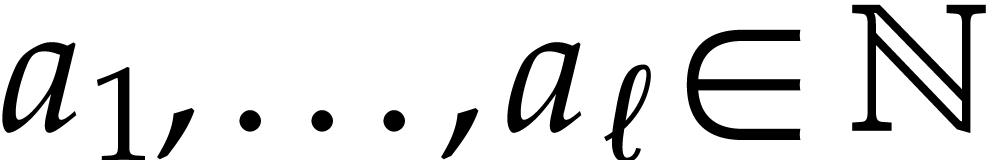 is an addition chain
with
is an addition chain
with  .
.
If 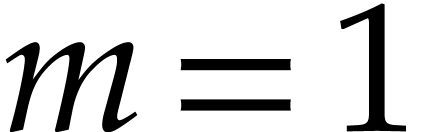 and
and 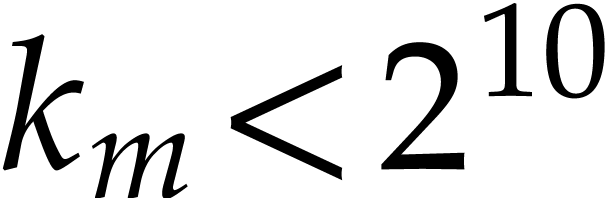 ,
then use the algorithm from section 2.1.
,
then use the algorithm from section 2.1.
Let 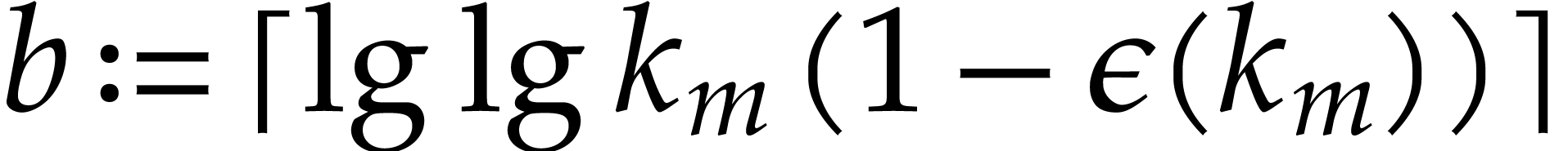 .
.
Apply the algorithm recursively to the sorted elements of

Let  be the result.
be the result.
Apply the algorithm recursively to the sorted elements of 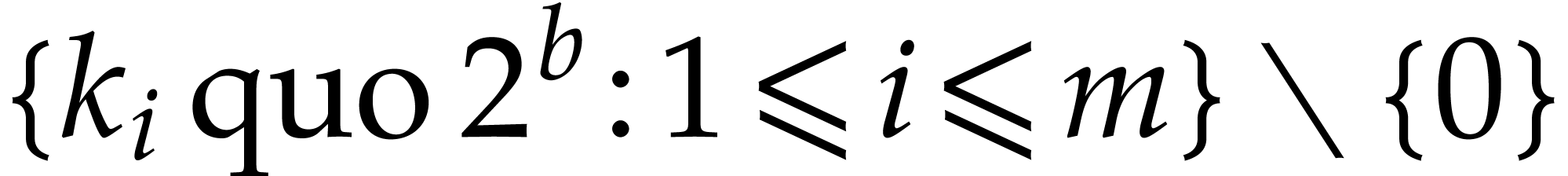 . Let
. Let  be the result.
be the result.
Sort the list 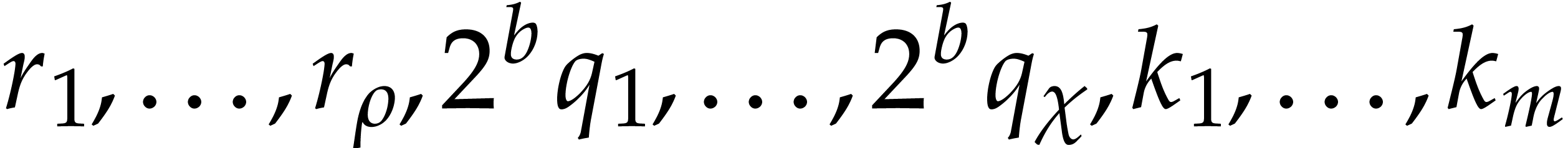 ,
remove multiple entries, and return the result.
,
remove multiple entries, and return the result.
Example 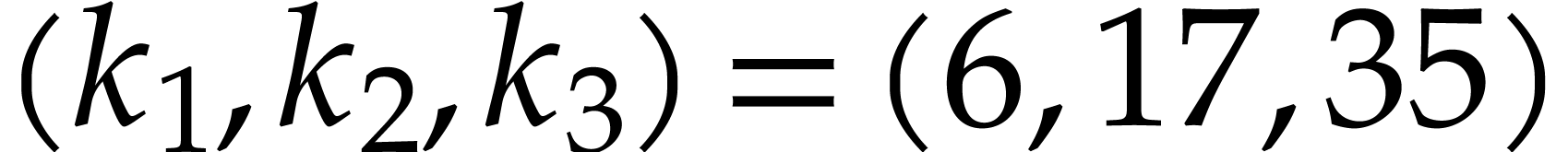 , Algorithm 2 returns
the addition chain
, Algorithm 2 returns
the addition chain 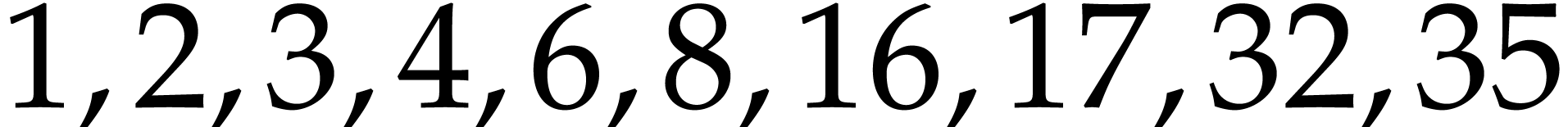 . An
optimal addition chain is
. An
optimal addition chain is 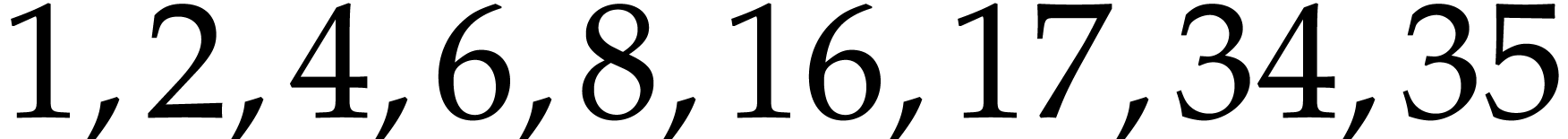 .
.
Remark  , the problem of finding the
absolute shortest addition chain
, the problem of finding the
absolute shortest addition chain  with is known to be NP-complete [10].
with is known to be NP-complete [10].
The -adic approach can also
be used for the computation of power products. This was already realized
by Straus [23], who showed that 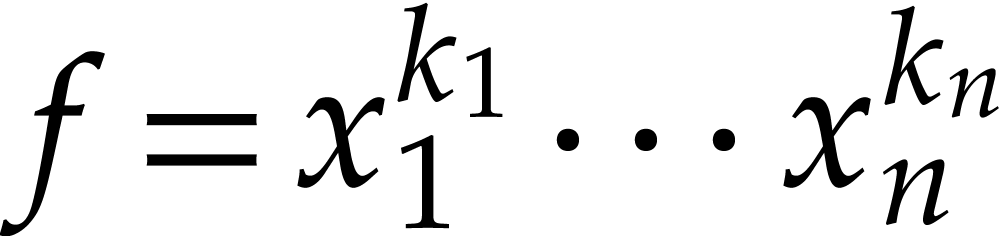 can
be computed using
can
be computed using 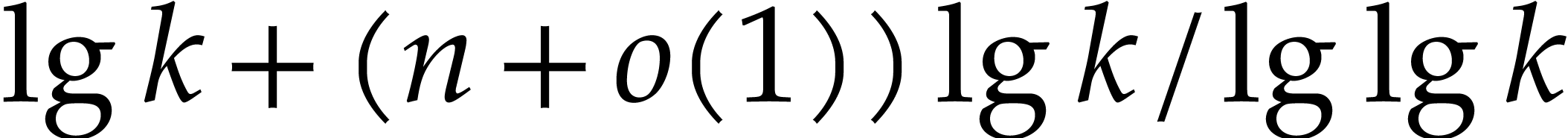 multiplications, where
multiplications, where 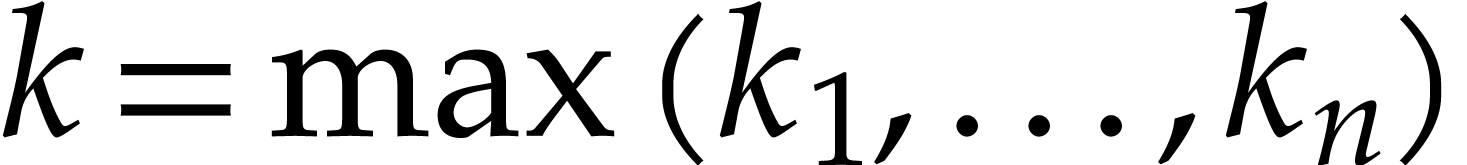 , and provided that
, and provided that  . The similarity between the complexities of
Straus' and Yao's algorithms is not accidental, since both problems are
equivalent due to a suitable application of the transposition principle.
For more details and historical references, we refer to Bernstein's
survey [2].
. The similarity between the complexities of
Straus' and Yao's algorithms is not accidental, since both problems are
equivalent due to a suitable application of the transposition principle.
For more details and historical references, we refer to Bernstein's
survey [2].
Another interesting observation due to Straus is that, for the
computation of a single power product  ,
the naive strategy to compute and multiply
,
the naive strategy to compute and multiply  is
typically not the fastest. In our implementation, for small exponents,
we found it simpler to simultaneously replace all powers
is
typically not the fastest. In our implementation, for small exponents,
we found it simpler to simultaneously replace all powers 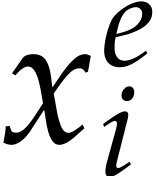 that occur in our vector of sparse
polynomials by new variables. For each variable
that occur in our vector of sparse
polynomials by new variables. For each variable 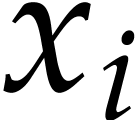 , this requires us to call Algorithm 2
for the list of all exponents
, this requires us to call Algorithm 2
for the list of all exponents 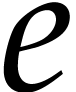 such that occurs in .
Consequently, we do not benefit from the additional improvements that
Straus provides for large exponents; however, we describe an alternate
practical strategy in section 3.2.
such that occurs in .
Consequently, we do not benefit from the additional improvements that
Straus provides for large exponents; however, we describe an alternate
practical strategy in section 3.2.
In fact, Pippenger also proposed an algorithm [20, 21,
22] for evaluating multiple power products 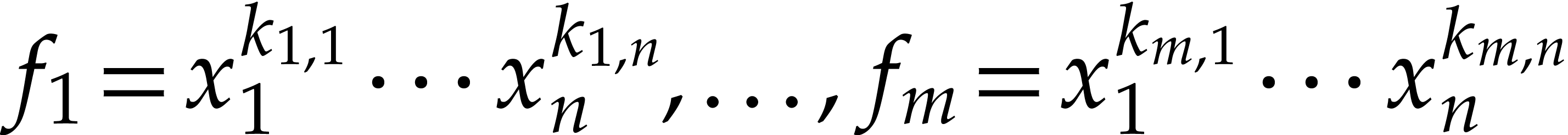 . This algorithm is more elaborate to implement
and we again refer to Bernstein's survey [2] for an
overview. In section 3.4, we will present an efficient and
easily implementable alternative for a key step in Pippenger's algorithm
for the case when
. This algorithm is more elaborate to implement
and we again refer to Bernstein's survey [2] for an
overview. In section 3.4, we will present an efficient and
easily implementable alternative for a key step in Pippenger's algorithm
for the case when 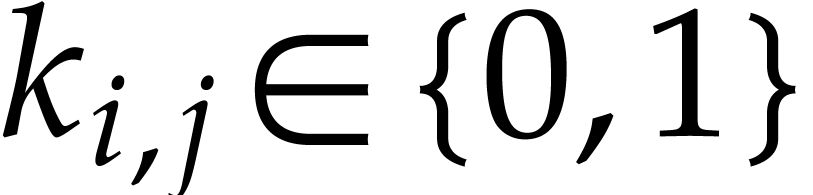 for all
for all 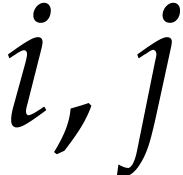 .
.
Let us now return to the problem of computing an SLP for evaluating a
single sparse polynomial (1). In computer algebra systems,
sparse polynomials are often represented recursively as polynomials in a
single variable , whose
coefficients are sparse polynomials in the remaining variables 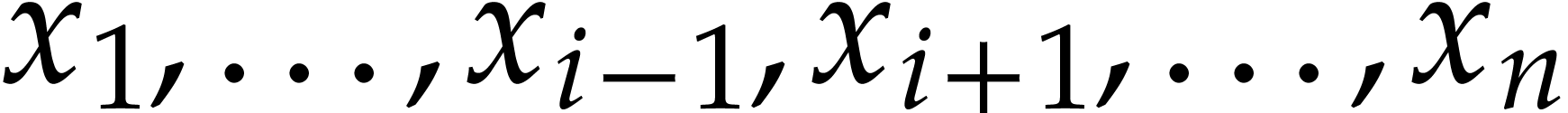 . This allows us to evaluate each
of the univariate polynomials in this representation using Horner's
method (or using a variant of Horner's method if the univariate
polynomials are themselves represented in a sparse manner).
. This allows us to evaluate each
of the univariate polynomials in this representation using Horner's
method (or using a variant of Horner's method if the univariate
polynomials are themselves represented in a sparse manner).
Another option is to decompose 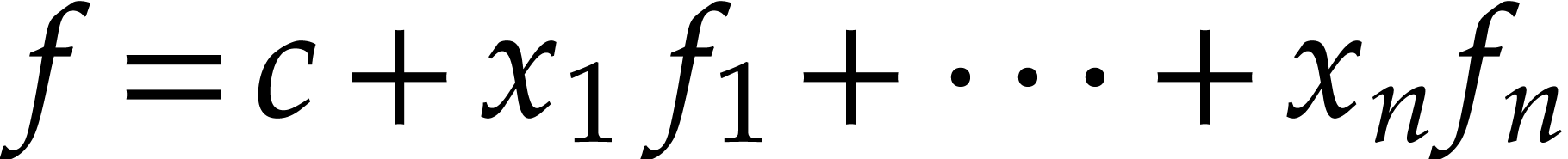 with
with  and where some of the terms may be zero and left out. We
may then recursively expand
and where some of the terms may be zero and left out. We
may then recursively expand  in a similar manner.
Of course, we may also impose additional constraints on . For instance, if is
our main expansion variable as above, then we may require
in a similar manner.
Of course, we may also impose additional constraints on . For instance, if is
our main expansion variable as above, then we may require 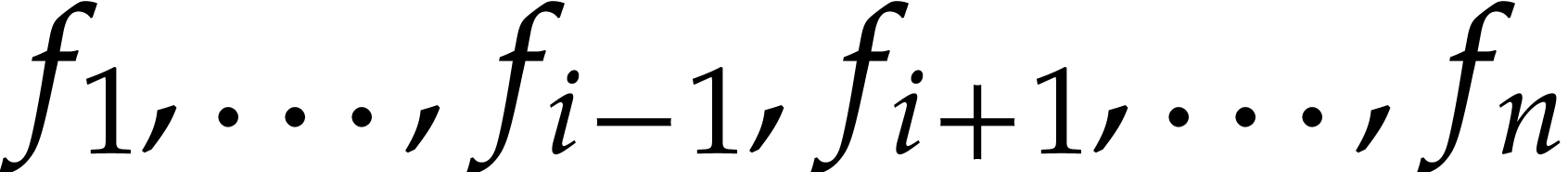 not to depend on .
not to depend on .
Such multivariate Horner schemes have been studied in several works [6, 7]. One major issue concerns the choice of the
main expansion variable and the subsequent
choices of the main expansion variables for all recursive coefficients.
In lucky cases, typically when the support of is
rather dense, multivariate Horner schemes may return an SLP of size
. However, on many examples
from our data base, the size of the computed SLP is closer to 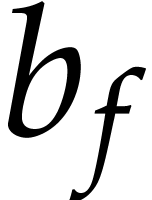 . Multivariate Horner schemes
nonetheless remain a good “naive way” to evaluate sparse
polynomials, since they are easy to implement and always outperform
brute force evaluation of the expression (1).
. Multivariate Horner schemes
nonetheless remain a good “naive way” to evaluate sparse
polynomials, since they are easy to implement and always outperform
brute force evaluation of the expression (1).
Consider a sparse polynomial 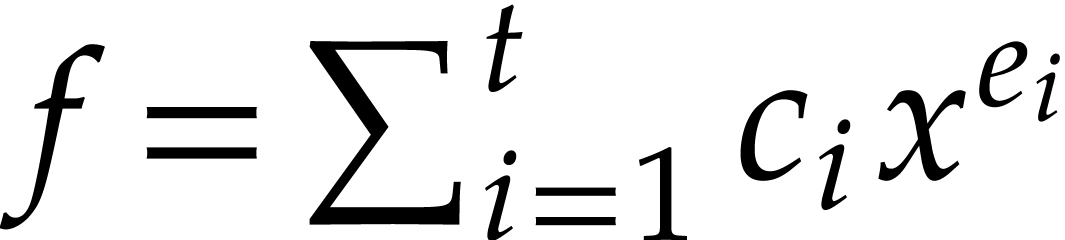 with support
with support 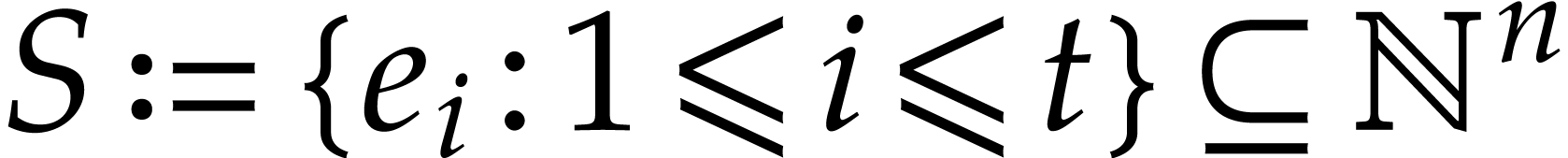 . If has a
“dense flavor”, then it is often possible to subdivide the
set of variables
. If has a
“dense flavor”, then it is often possible to subdivide the
set of variables  into two subsets, say
into two subsets, say 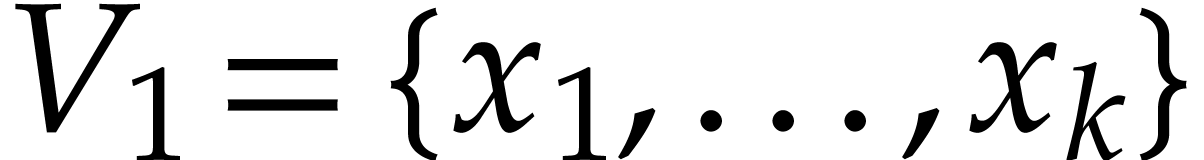 and
and 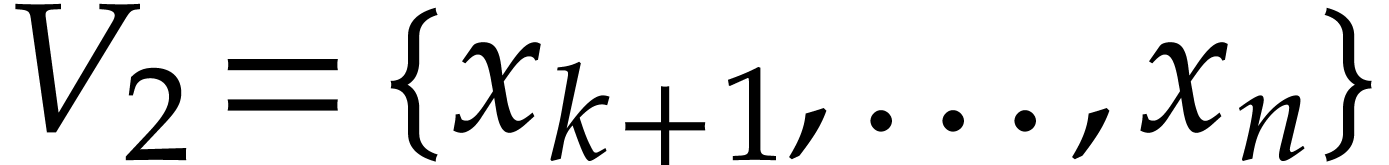 , in such a
way that the projected supports
, in such a
way that the projected supports
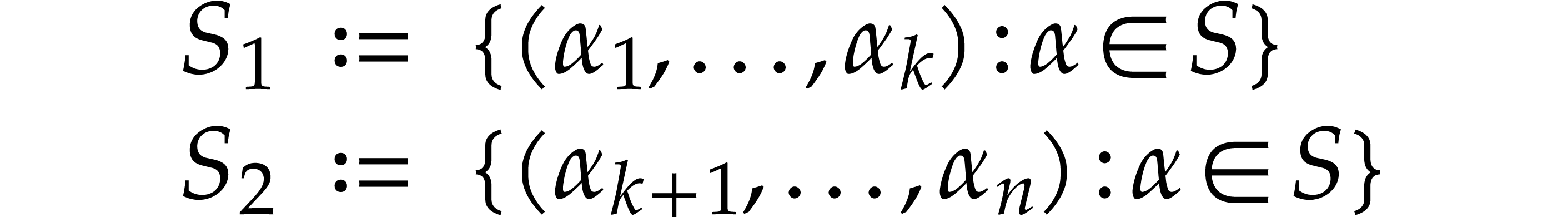
are significantly smaller than  .
For instance, if is a generic polynomial in
.
For instance, if is a generic polynomial in 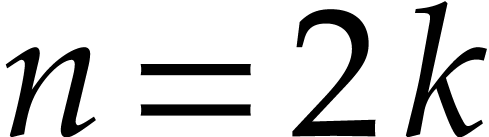 variables of total degree
variables of total degree 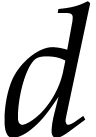 , so that
, so that  ,
then
,
then 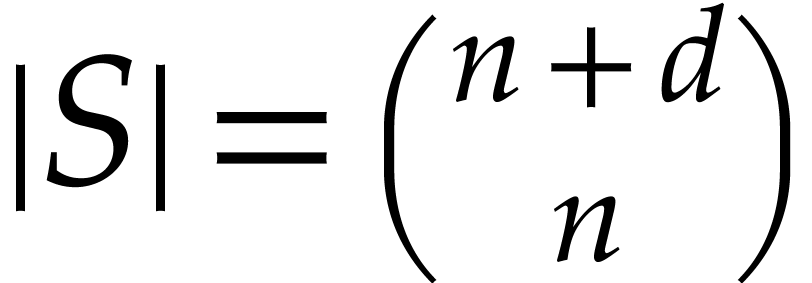 and
and 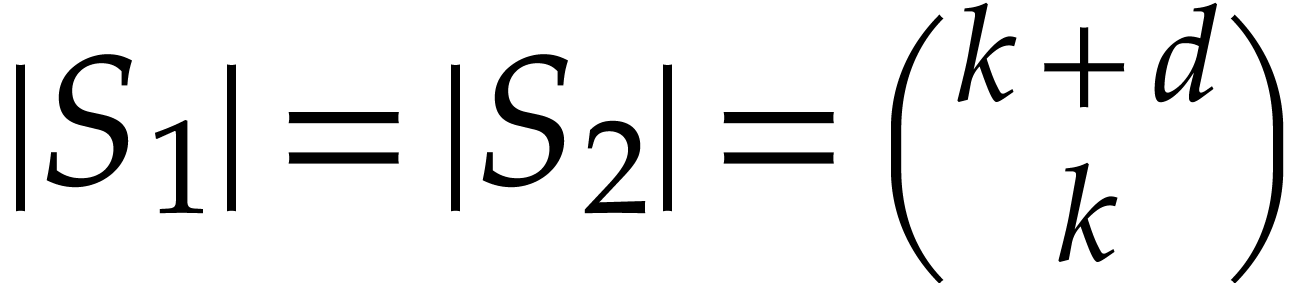 .
If
.
If 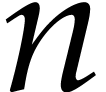 is fixed and
is fixed and 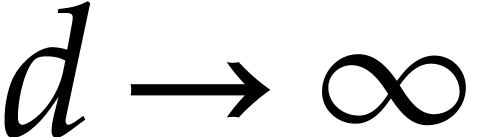 ,
then this yields
,
then this yields 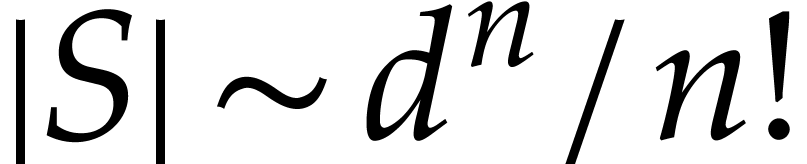 and
and
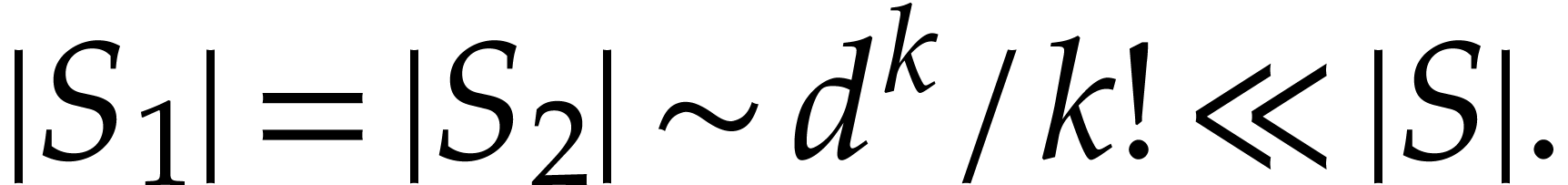
In this favorable situation, we may first compute the power products
 for all
for all 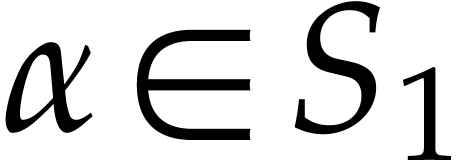 ,
as well as the power products
,
as well as the power products  for all
for all 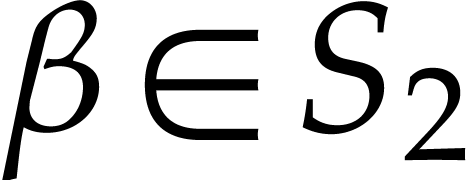 , and then deduce all power
products
, and then deduce all power
products 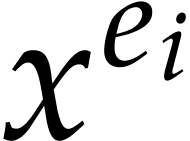 for using only
for using only
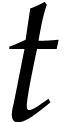 additional multiplications. Assuming that
additional multiplications. Assuming that  , the entire evaluation of can then be done using
, the entire evaluation of can then be done using  multiplications and FMA instructions; Here an
FMA instruction is of the form
multiplications and FMA instructions; Here an
FMA instruction is of the form 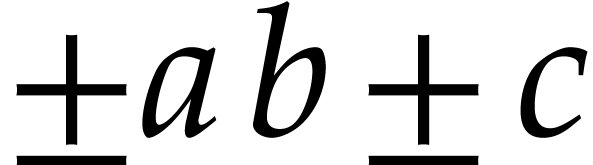 .
One may view this method as re-interpreting as a
bilinear polynomial in the variables and .
.
One may view this method as re-interpreting as a
bilinear polynomial in the variables and .
Remark  can be performed in a suitable FFT model or using modular arithmetic. In
that case, the transforms (FFT transforms or modular reductions) of the
coefficients
can be performed in a suitable FFT model or using modular arithmetic. In
that case, the transforms (FFT transforms or modular reductions) of the
coefficients 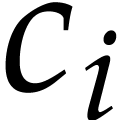 can be precomputed. For the
evaluation of
can be precomputed. For the
evaluation of 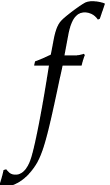 , we then
compute the power products and
as above, along with their transforms. We next do the multiplications
, we then
compute the power products and
as above, along with their transforms. We next do the multiplications
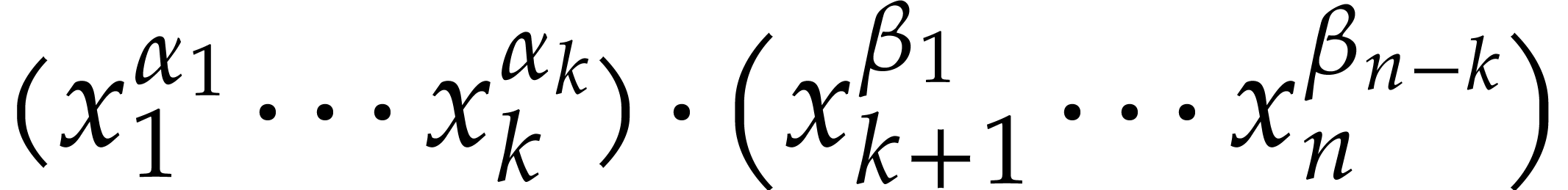 in the transformed model, as well as all the
FMAs. We finally transform the result back to the final value in . The bulk of the computation then
reduces to
in the transformed model, as well as all the
FMAs. We finally transform the result back to the final value in . The bulk of the computation then
reduces to 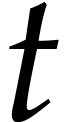 multiplications and
FMAs in the transformed model. This technique was proposed in [13,
section 4.4.3].
multiplications and
FMAs in the transformed model. This technique was proposed in [13,
section 4.4.3].
Example 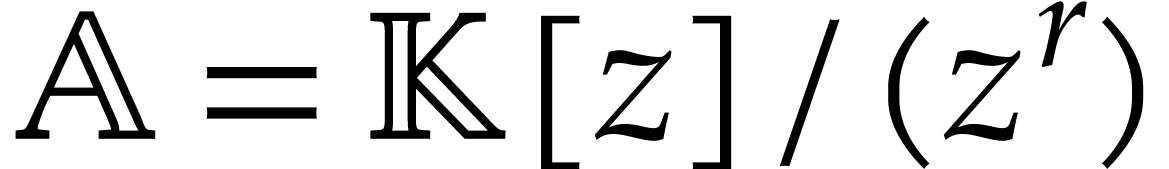 is a ring of power series over a field
is a ring of power series over a field  and assume that the are actually
in . Assuming that contains a primitive root of unity
and assume that the are actually
in . Assuming that contains a primitive root of unity 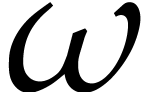 of smooth order
of smooth order 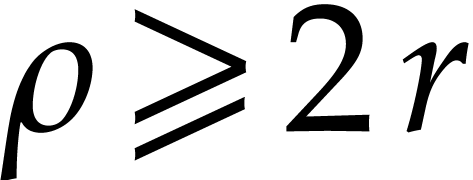 , then we may
use FFTs of length
, then we may
use FFTs of length 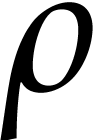 to transform elements of into vectors in
to transform elements of into vectors in 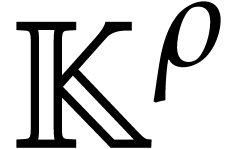 .
If the are in ,
then we rather need an of smooth order
.
If the are in ,
then we rather need an of smooth order 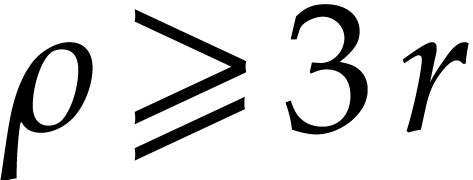 instead. If we subdivide our set of variables into
instead. If we subdivide our set of variables into 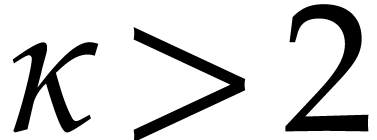 instead of two sets, then similar ideas still apply,
but we need an of smooth order
instead of two sets, then similar ideas still apply,
but we need an of smooth order 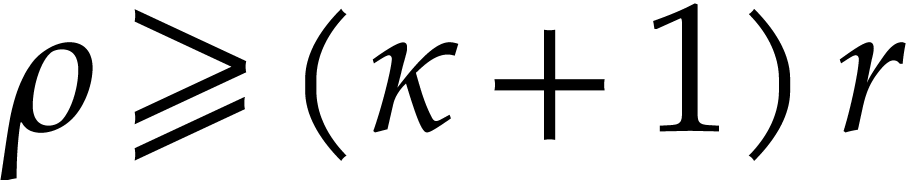 . Similar remarks apply for modular arithmetic.
. Similar remarks apply for modular arithmetic.
The smallest SLP that evaluates a given sparse polynomial may be much smaller than the input polynomial. One example is the polynomial
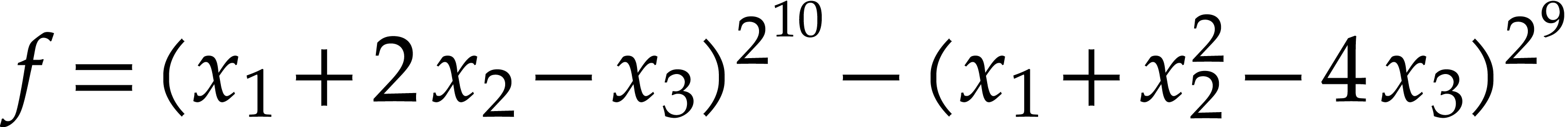 |
(2) |
from the introduction, where 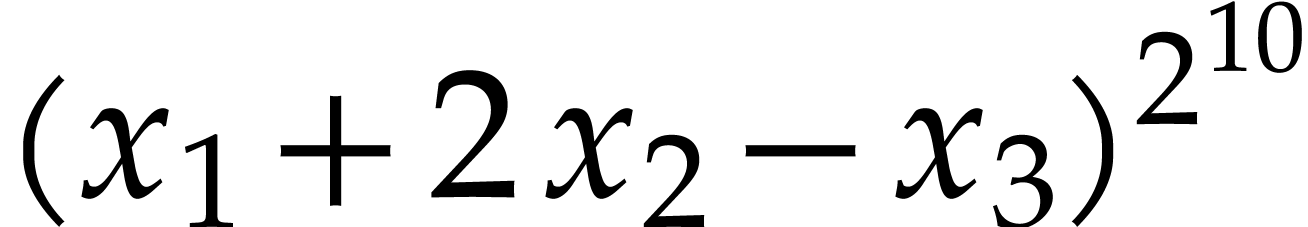 and
and 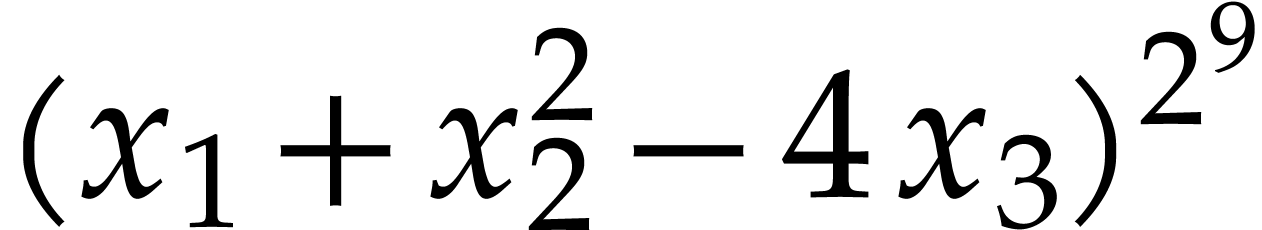 can be computed using repeated squarings. Unfortunately,
finding such SLPs from their expanded representations is very hard in
general. Nonetheless, it is often possible to find at least some partial
factorizations that may help to speed up the evaluation.
can be computed using repeated squarings. Unfortunately,
finding such SLPs from their expanded representations is very hard in
general. Nonetheless, it is often possible to find at least some partial
factorizations that may help to speed up the evaluation.
The problem of factoring sparse polynomials in the traditional mathematical sense has been studied extensively. We refer to [9] for some recent algorithms and historical references. However, the kind of “factorizations” as in (2) that we are really after are not exclusively multiplicative, but may involve both additions and multiplications. In fact, the multivariate Horner schemes that we discussed in section 2.4 can be regarded as easy-to-compute additive-multiplicative factorizations, by recursively factoring out single variables. We will also use this kind of factorizations in section 3.3 below.
In [18], a reasonably efficient algorithm has been
presented for finding “syntactic factorizations”, in which
none of the terms of the expanded products and sums overlap. For
instance, 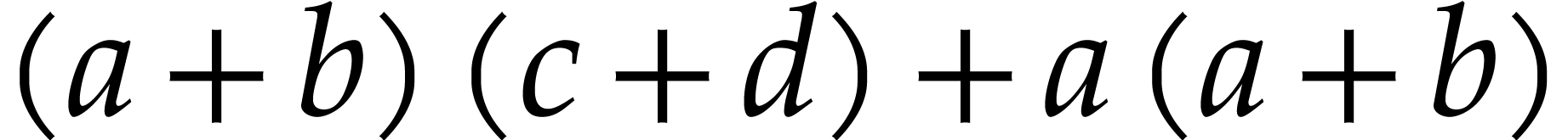 is a syntactical factorization of
is a syntactical factorization of
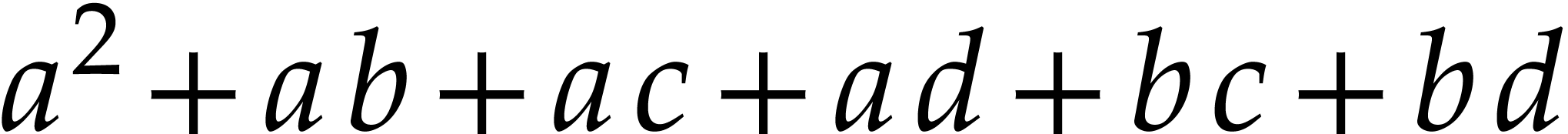 , but
, but  is not a syntactical factorization of
is not a syntactical factorization of  ,
because of the two “overlapping” terms
,
because of the two “overlapping” terms 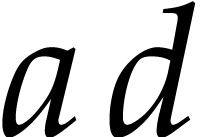 and
and 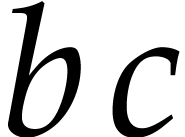 . The algorithm from [18] works well for applications in which syntactic
factorizations are likely to occur, such as input polynomials that are
themselves the expanded result of some algebraic computation (in [18] a generic resultant was used as the running example).
. The algorithm from [18] works well for applications in which syntactic
factorizations are likely to occur, such as input polynomials that are
themselves the expanded result of some algebraic computation (in [18] a generic resultant was used as the running example).
In this paper, we focus on SLP transforms which can be computed in quasi-linear time or almost, so we regard the computation of more clever additive-multiplicative factorizations as a more or less independent problem to which we plan to return in future work.
Let be the input variables. Consider a vector
of sparse polynomials with
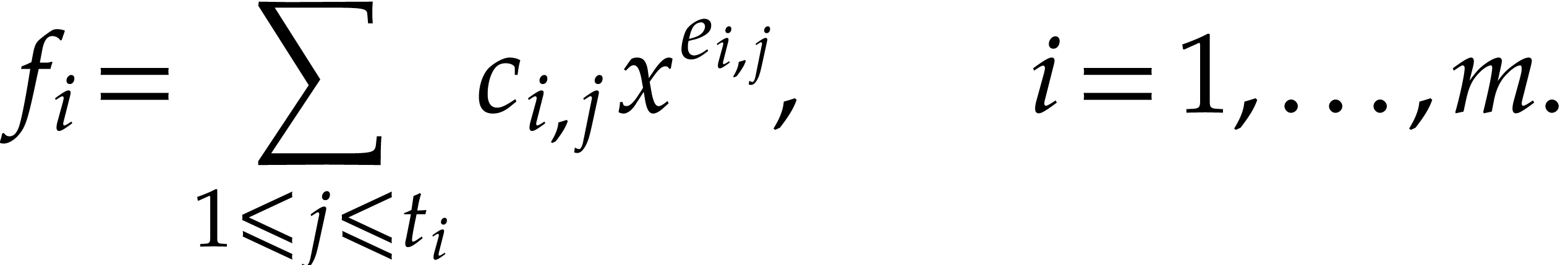
In this section, we present our main algorithm to compute an SLP for the
efficient evaluation of 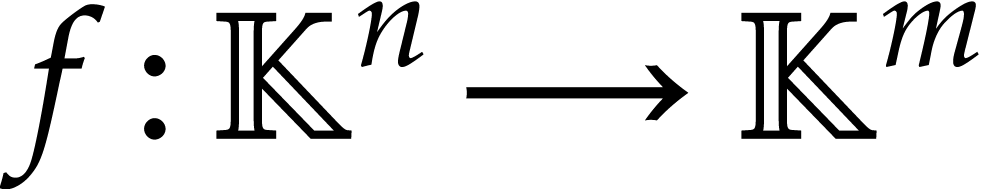 as a polynomial map. In
brief, our algorithm proceeds as follows:
as a polynomial map. In
brief, our algorithm proceeds as follows:
All powers of individual variables are evaluated and replaced with new variables; coefficients are also replaced by new variables. Consequently, each term of the polynomial is expressed as a product of distinct variables.
Horner‑type factorizations are applied to the polynomials obtained in step 1.
We collect all remaining products of distinct variables that need to be evaluated and use a greedy algorithm to evaluate them simultaneously.
The final straight‑line program is then simplified and optimized for the target hardware.
The first step of our algorithm is a reduction to the case where 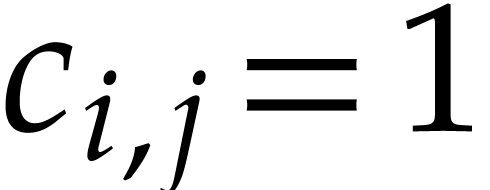 and
and 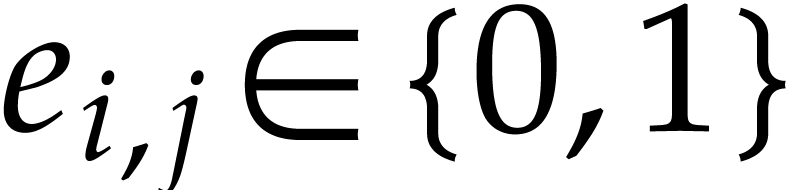 for all . We do this by first introducing new variables
for all . We do this by first introducing new variables
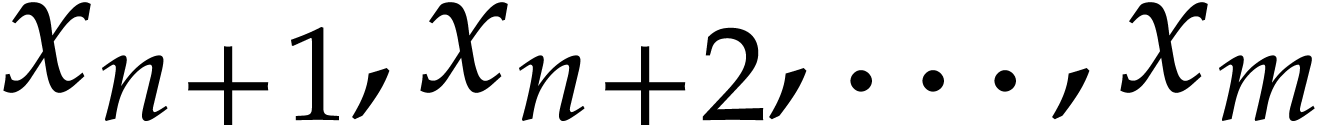 for all constants
for all constants 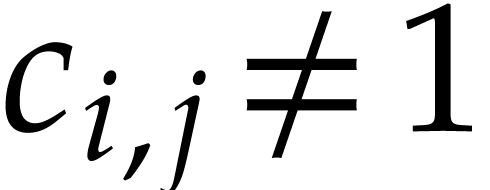 .
Whenever a constant occurs multiple times, we understand that we
introduce a single variable to represent all these identical constants.
.
Whenever a constant occurs multiple times, we understand that we
introduce a single variable to represent all these identical constants.
For each variable 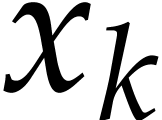 , we next
collect the set
, we next
collect the set 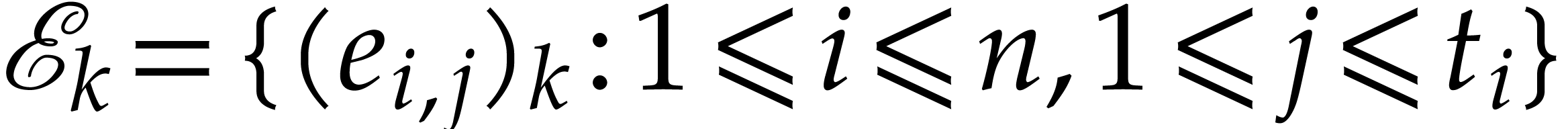 of all non-zero exponents
of all non-zero exponents  such that
such that 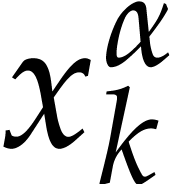 occurs in one of
the terms of one of the
occurs in one of
the terms of one of the 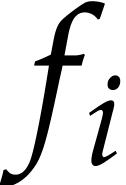 . All
sets
. All
sets 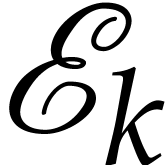 can be determined jointly using a hash
table and one linear pass. Whenever
can be determined jointly using a hash
table and one linear pass. Whenever 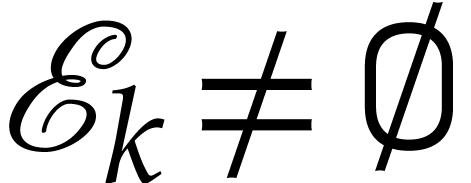 ,
we next use Algorithm 2 to compute an addition chain for
the sorted list of elements of .
This addition chain gives rise to an SLP of the same length minus one
for the computation of for all
,
we next use Algorithm 2 to compute an addition chain for
the sorted list of elements of .
This addition chain gives rise to an SLP of the same length minus one
for the computation of for all 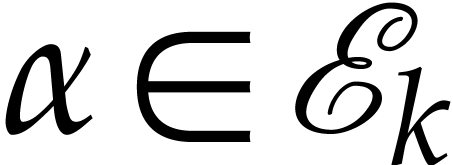 . For each with
. For each with 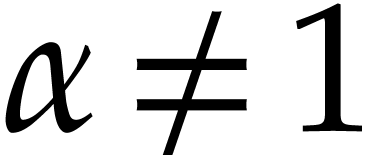 , we introduce a new variable
, we introduce a new variable 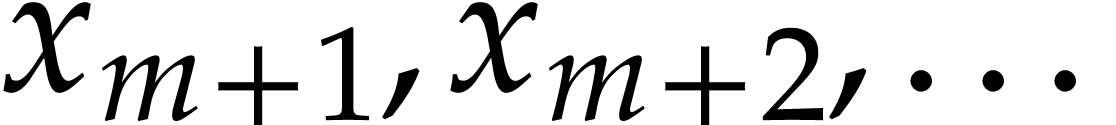 , and use the latter SLPs to
compute these new variables as a function of
, and use the latter SLPs to
compute these new variables as a function of  .
.
Example 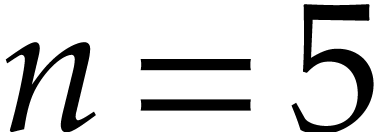 and
and
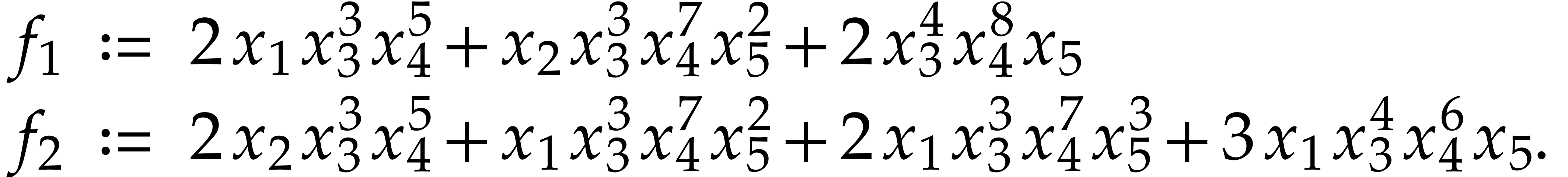 |
(3) |
We first introduce new variables 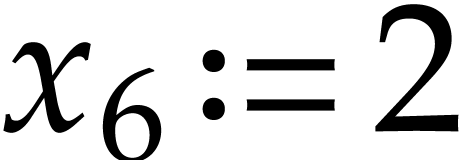 and
and 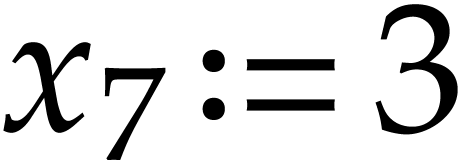 for the constants. We next need to introduce new variables
for all non-trivial powers. For the variable
for the constants. We next need to introduce new variables
for all non-trivial powers. For the variable 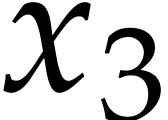 , we need to compute
, we need to compute 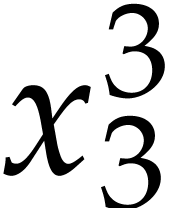 and
and
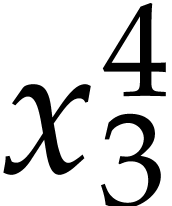 , which we do using Algorithm
2. This yields
, which we do using Algorithm
2. This yields 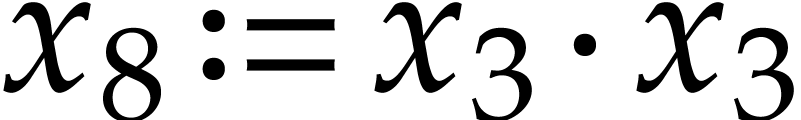 ,
,
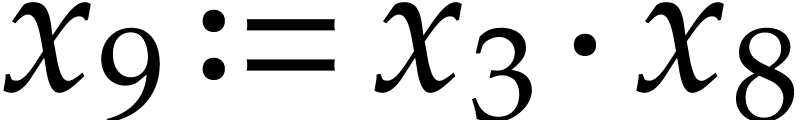 ,
, 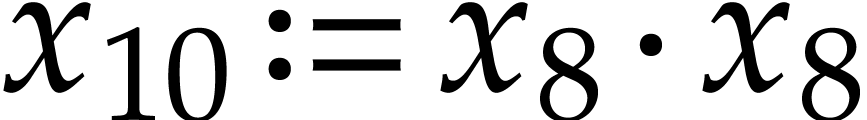 , so
, so 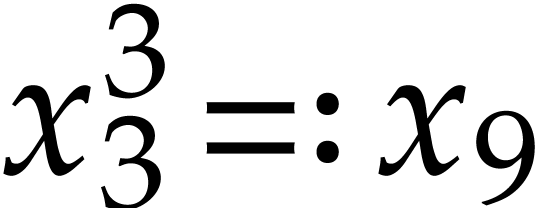 and
and 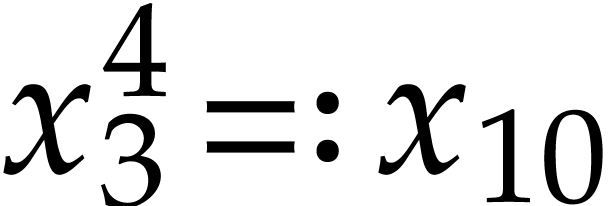 . We next need to compute
. We next need to compute 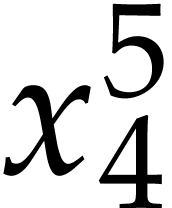 ,
, 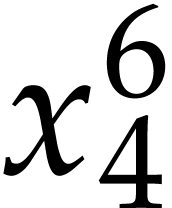 ,
,
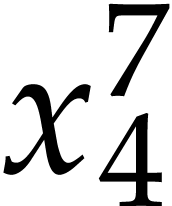 , and
, and 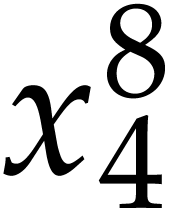 , which is done as follows:
, which is done as follows: 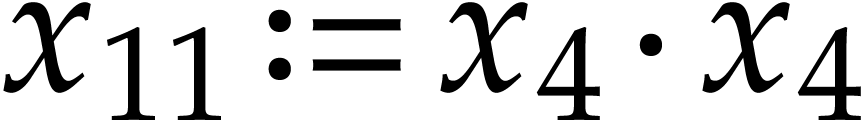 ,
, 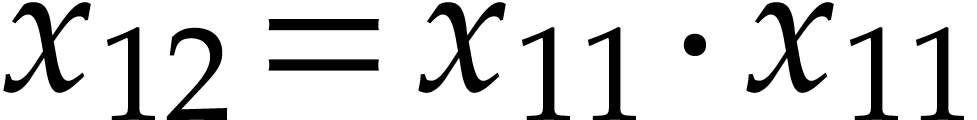 ,
, 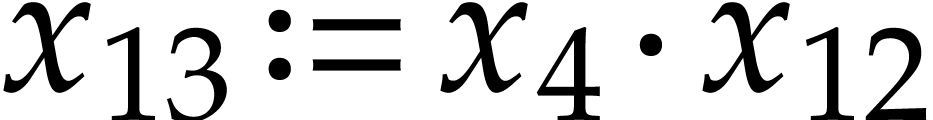 ,
, 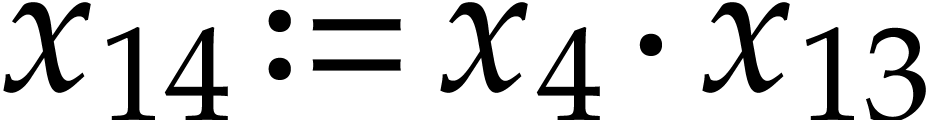 ,
,
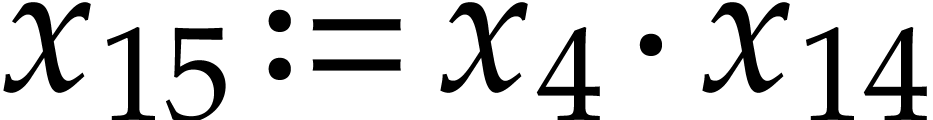 ,
, 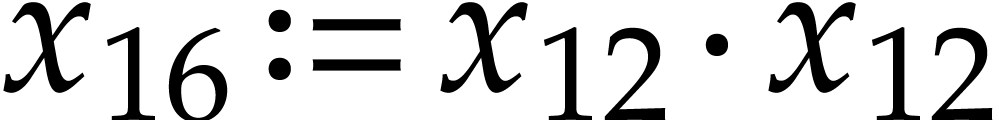 . We finally need to compute
. We finally need to compute 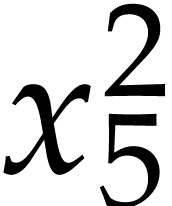 and
and 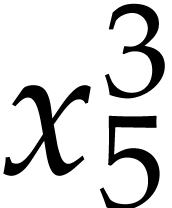 , which is done using
, which is done using
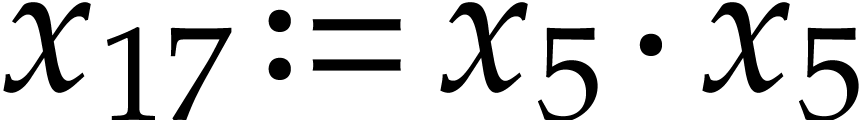 ,
, 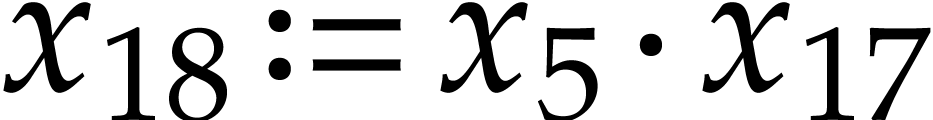 . After the introduction of these new variables, our
sparse polynomials are rewritten as
. After the introduction of these new variables, our
sparse polynomials are rewritten as
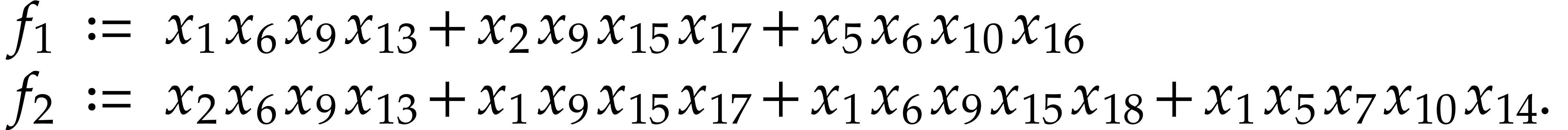 |
(4) |
We have just shown how to reduce our evaluation problem to the case where all input polynomials
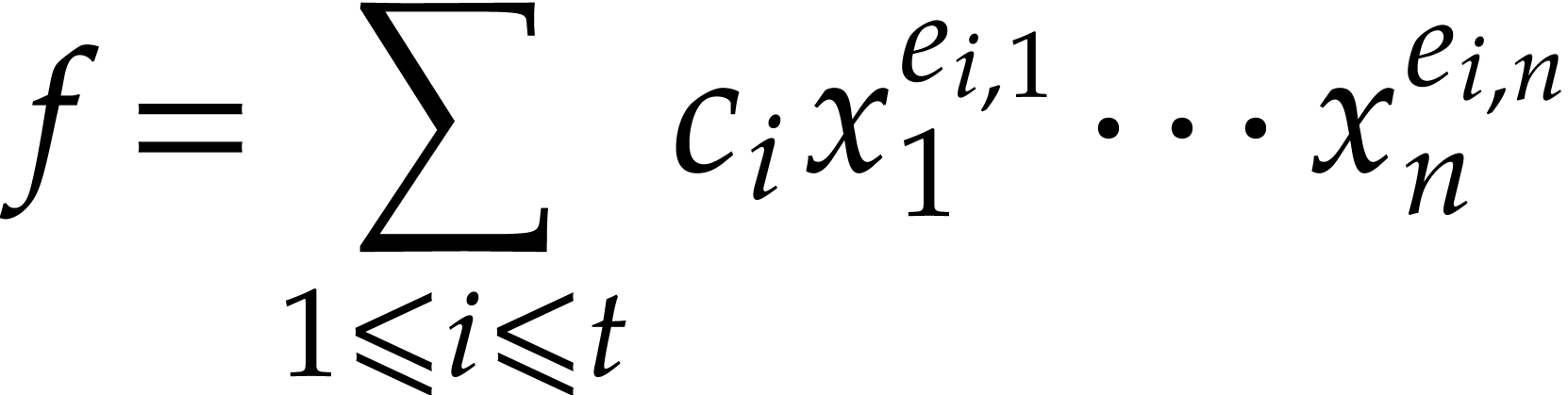
are sums of products of distinct variables. Instead of introducting a
distinct variable for each individual power 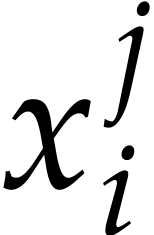 , it is also possible to further factor such powers
as products of powers of the form
, it is also possible to further factor such powers
as products of powers of the form 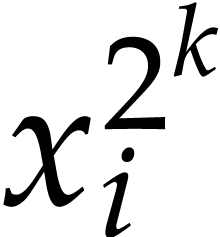 .
For this, we compute the
.
For this, we compute the 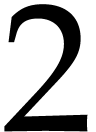 -adic
expansions of the exponents
-adic
expansions of the exponents
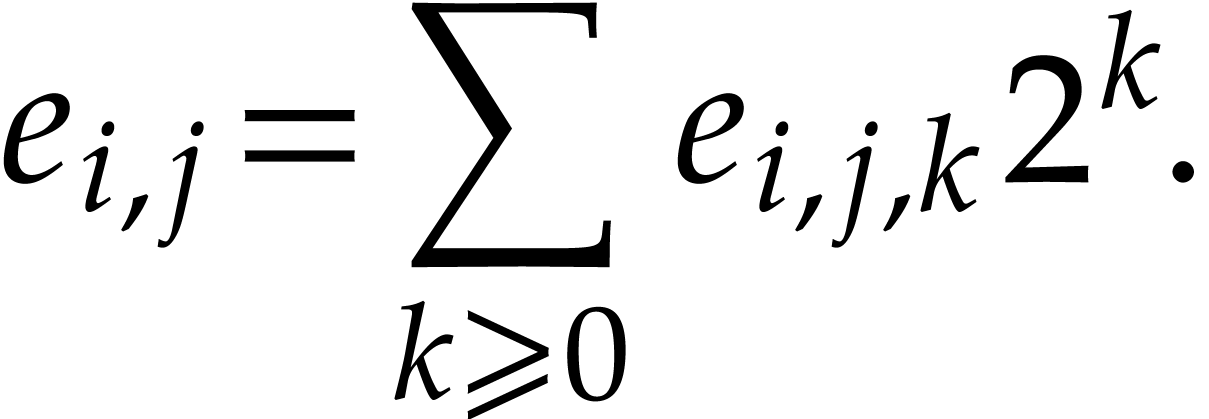
Setting 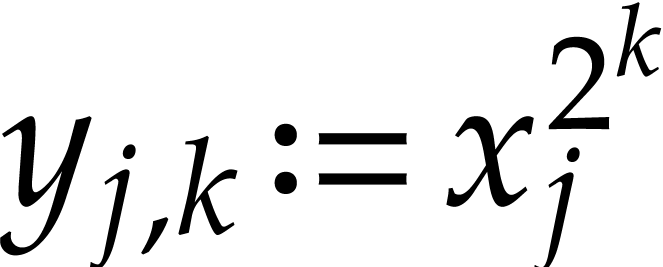 , we then have
, we then have
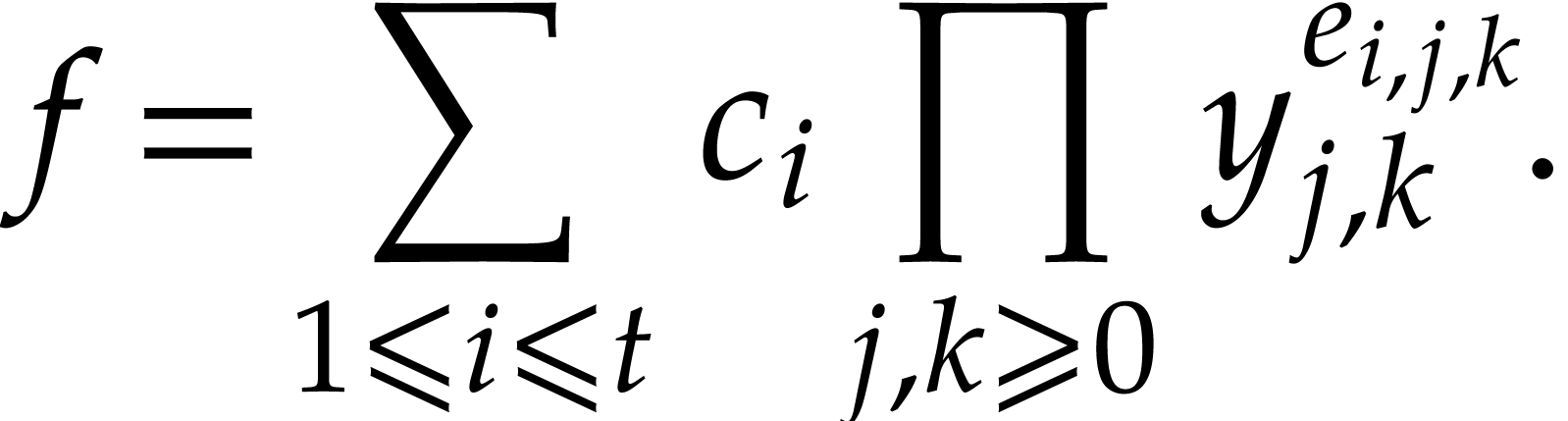 |
(5) |
As in the previous subsection, we introduce new variables for the
coefficients 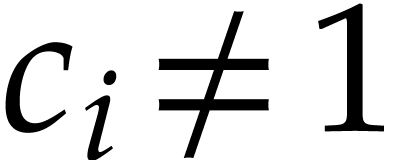 , whereas the
evaluation of the
, whereas the
evaluation of the 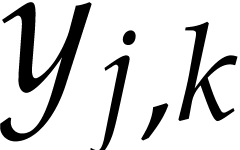 is done directly using binary
exponentiation instead of Algorithm 2.
is done directly using binary
exponentiation instead of Algorithm 2.
After applying one of the two rewriting algorithms described in the
previous subsections, the input polynomials  become sums of products of variables. Although finding the best possible
partial factorizations is a hard problem in general, we still can go for
“low hanging fruit”, by recursively factoring out single
variables from the polynomials
as long as possible.
become sums of products of variables. Although finding the best possible
partial factorizations is a hard problem in general, we still can go for
“low hanging fruit”, by recursively factoring out single
variables from the polynomials
as long as possible.
More precisely, for each polynomial ,
let be a variable such that the number of terms
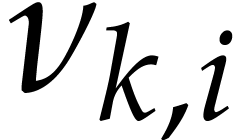 that depend on is
maximal. If
that depend on is
maximal. If 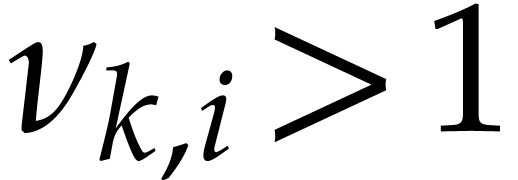 and
and  for some
small number
for some
small number 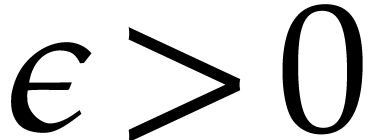 (say
(say 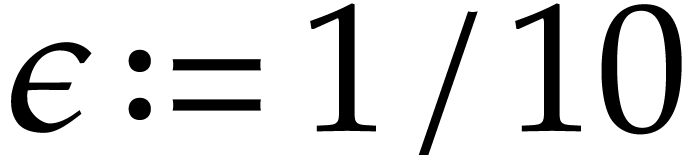 ),
then we decompose
),
then we decompose 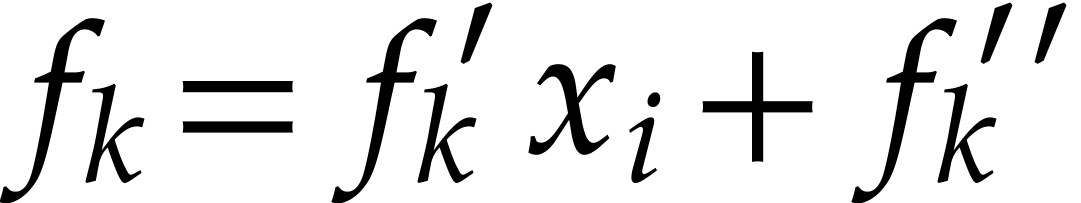 and replace
by the two polynomials
and replace
by the two polynomials 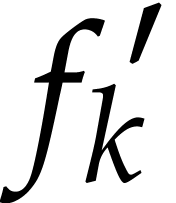 and
and 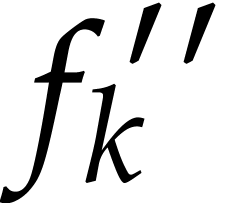 in the list (or just by
if
in the list (or just by
if 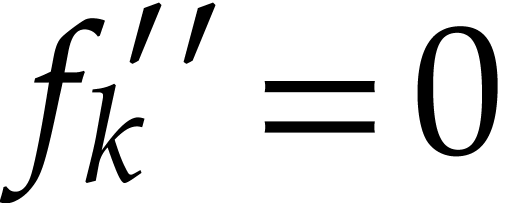 ). We keep doing this
until no such exists. Due to the threshold , this algorithm runs in
quasi-linear time.
). We keep doing this
until no such exists. Due to the threshold , this algorithm runs in
quasi-linear time.
Example
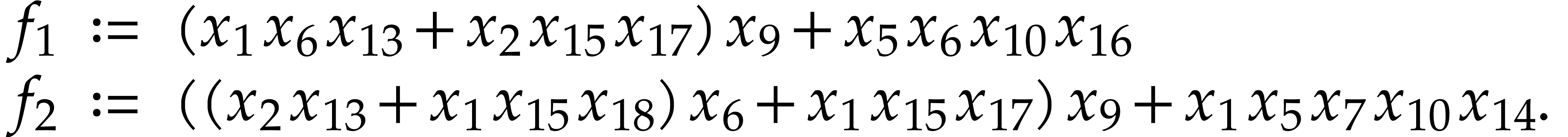
The algorithm of the next subsection will compute the values of  ,
, 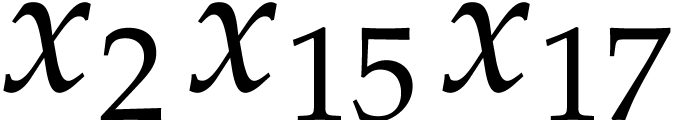 ,
,
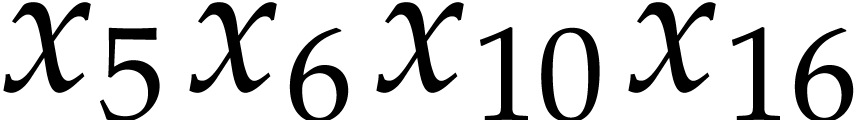 ,
, 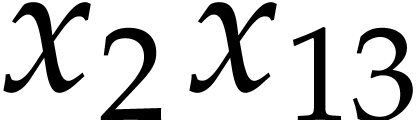 ,
, 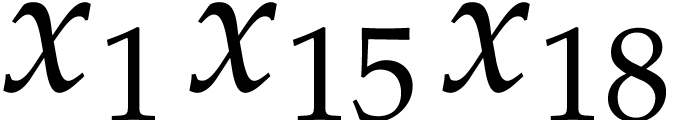 ,
, 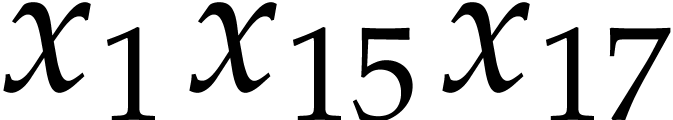 ,
, 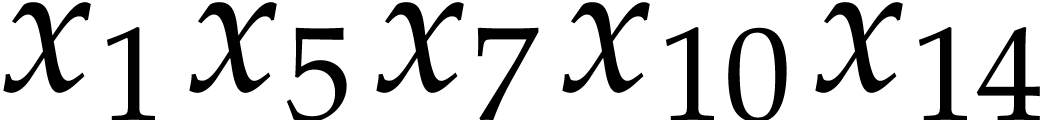 into the
variables
into the
variables 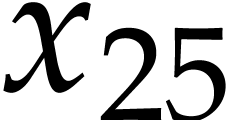 ,
, 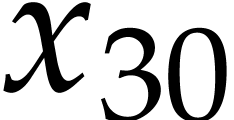 ,
, 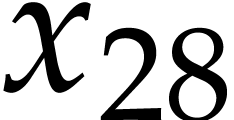 ,
,
 ,
, 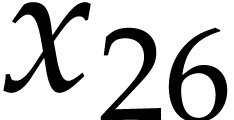 ,
, 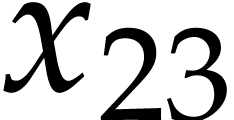 ,
,  ; see Example 9. In
order to compute
; see Example 9. In
order to compute 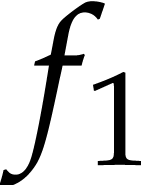 and
and 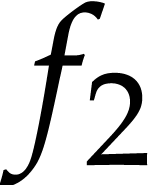 it
remains to perform the following instructions:
it
remains to perform the following instructions:
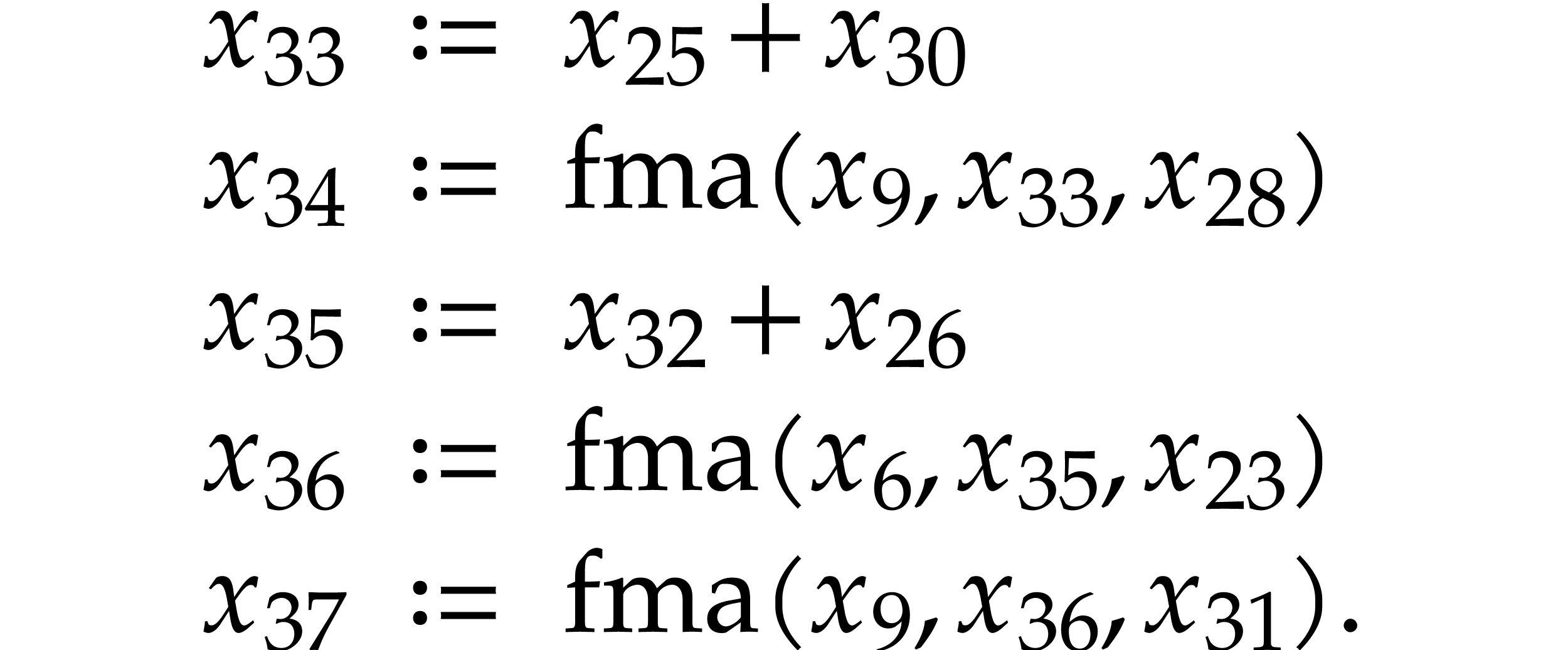
After this, we have 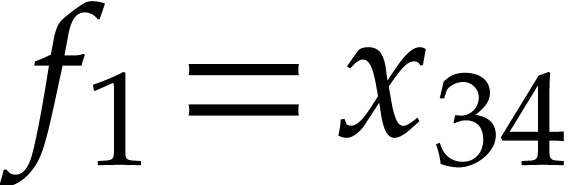 and
and 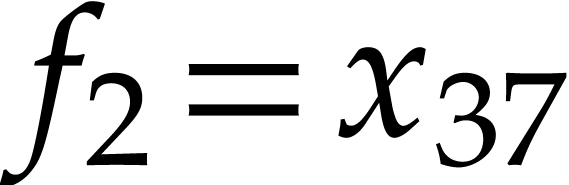 . Here
. Here 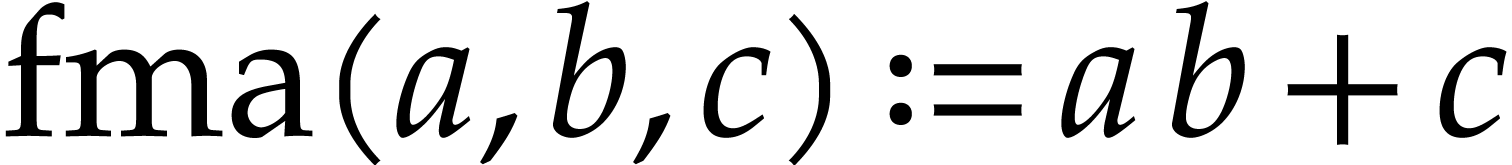 .
.
In this subsection, we turn to the core subalgorithm. As input, we have
a list  of pairwise distinct subsets of . As output, we produce an SLP that
takes as input and that computes
of pairwise distinct subsets of . As output, we produce an SLP that
takes as input and that computes 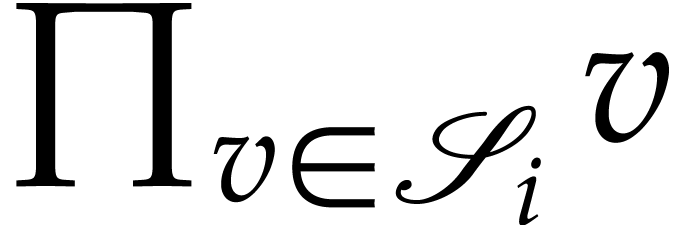 for
for 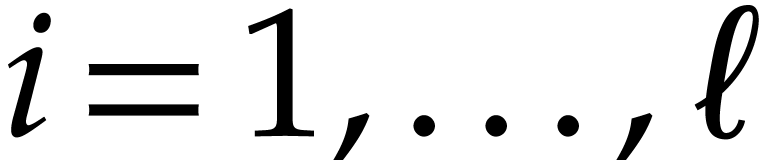 . Without
loss of generality we may assume that
. Without
loss of generality we may assume that 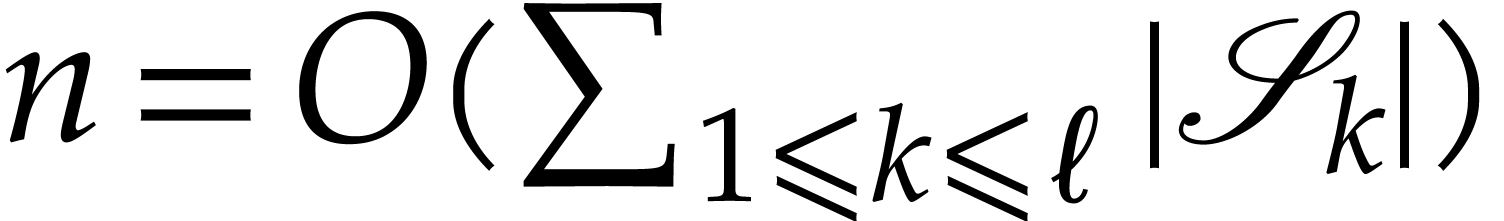 .
.
For the construction of our SLP we use a simple greedy approach: as long
as the list contains two entries  with
with 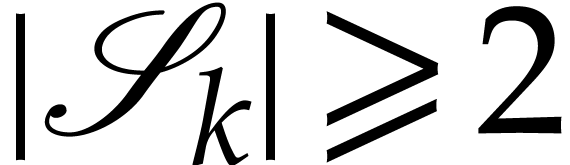 , we
determine variables ,
, we
determine variables , 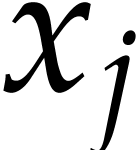 for which
for which 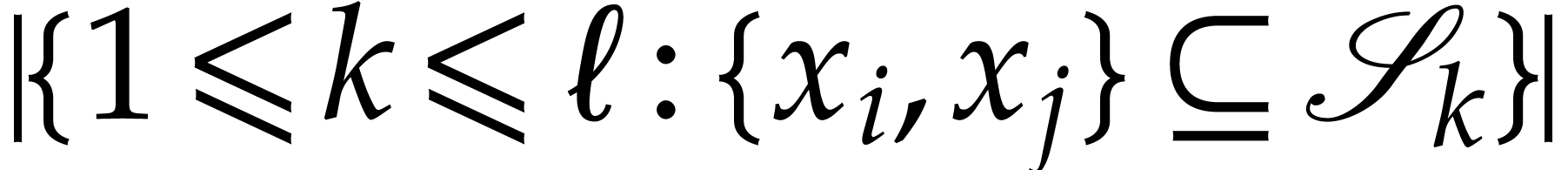 is maximal. We then
introduce a new variable
is maximal. We then
introduce a new variable 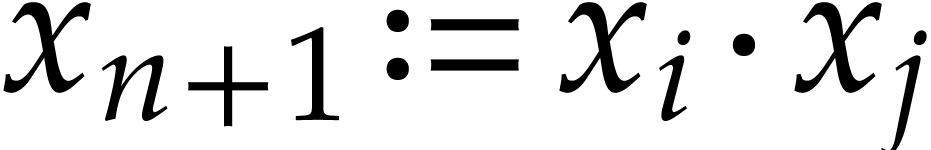 and replace
and replace 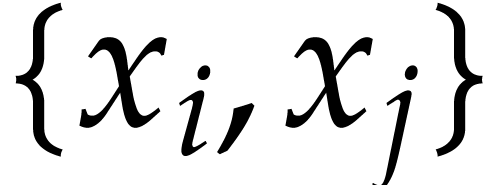 by
by 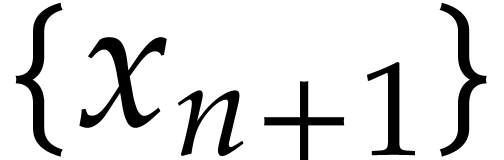 in the subsets
and increase by one. As soon as
in the subsets
and increase by one. As soon as 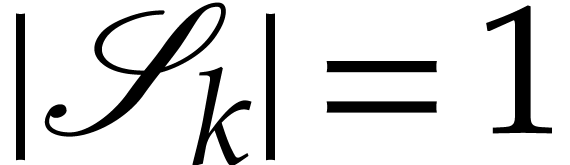 for all , the products
for all , the products 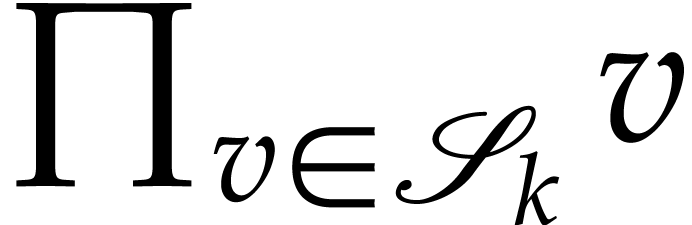 all become trivial. The algorithm runs as follows.
all become trivial. The algorithm runs as follows.
Algorithm
Output: an SLP for the computation of for 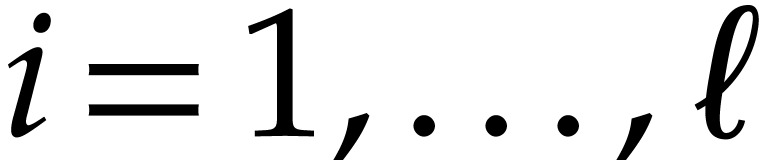 .
.
Start a new SLP 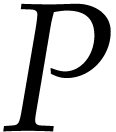 .
.
Create a binary search tree  that
associates to each pair
that
associates to each pair 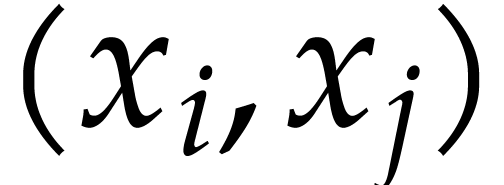 with
with 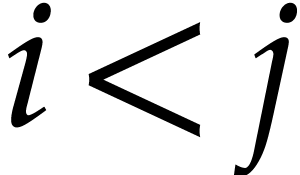 and
and 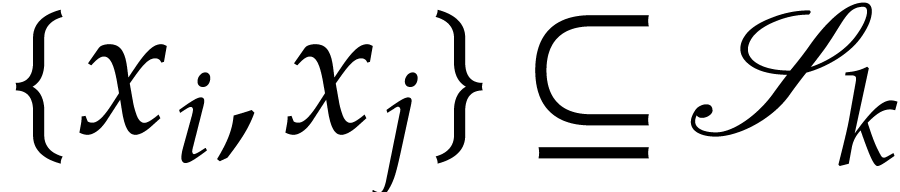 for some , the set
for some , the set 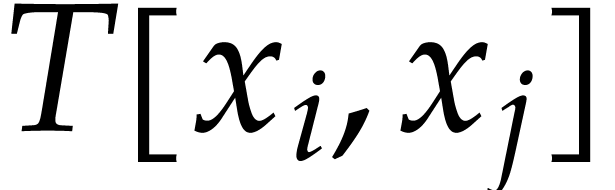 of
all with .
of
all with .
Create a heap  with triples
with triples 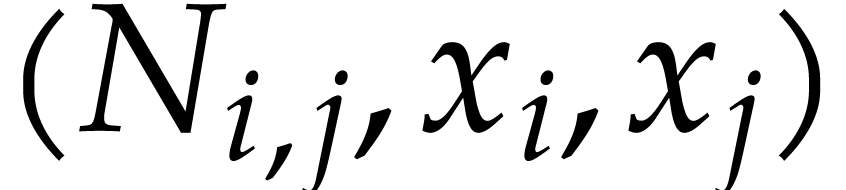 , where
, where 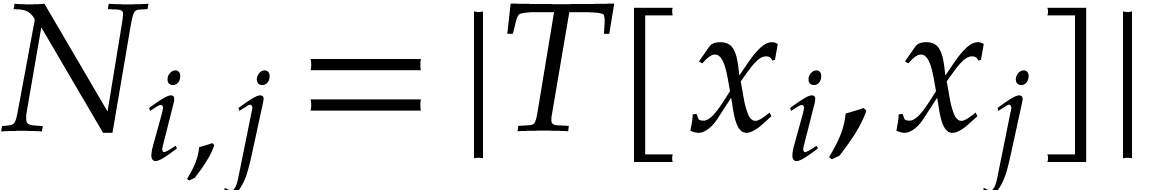 ,
ordered via
,
ordered via 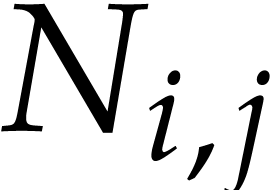 .
.
As long as the heap is non-empty, do the
following:
Extract and remove the highest triple
from .
If 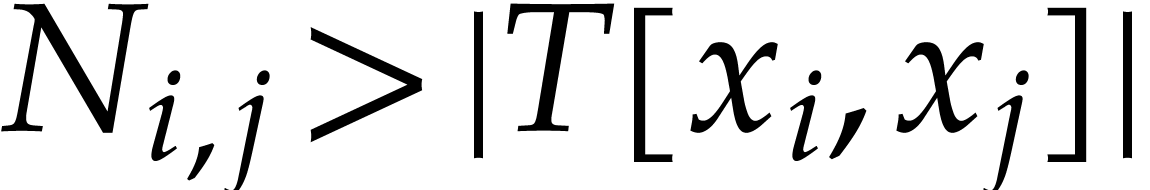 , then
continue the loop (with the next highest triple from ).
, then
continue the loop (with the next highest triple from ).
Create a new variable 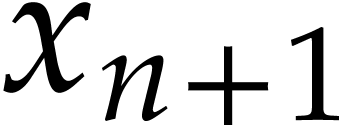 and append the
instruction to .
and append the
instruction to .
For all 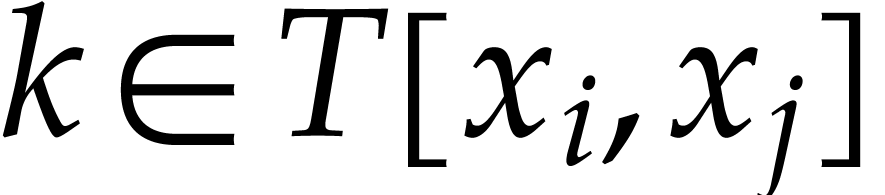 , update
, update
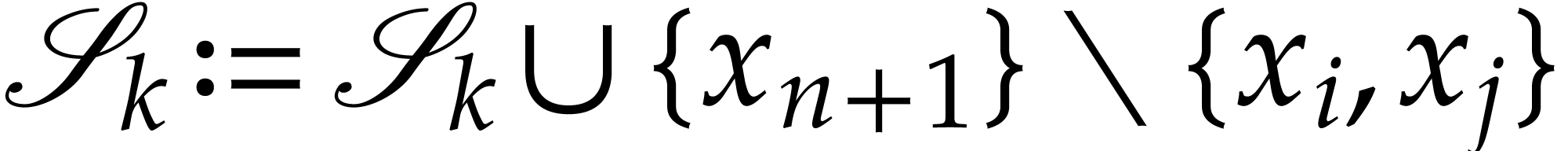 , update the
entries
, update the
entries 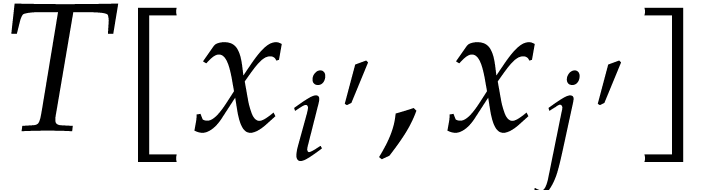 with
with 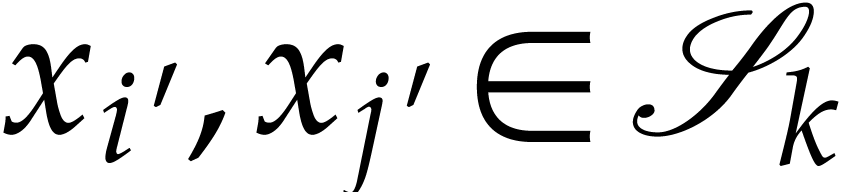 and such that at least one among
and such that at least one among 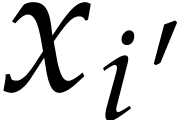 and
and
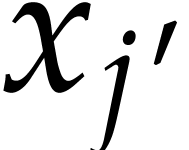 is in
is in 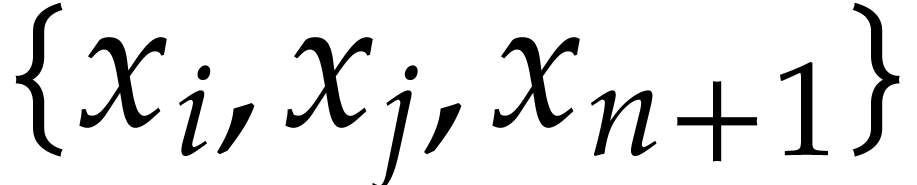 ,
and insert all new triples
,
and insert all new triples 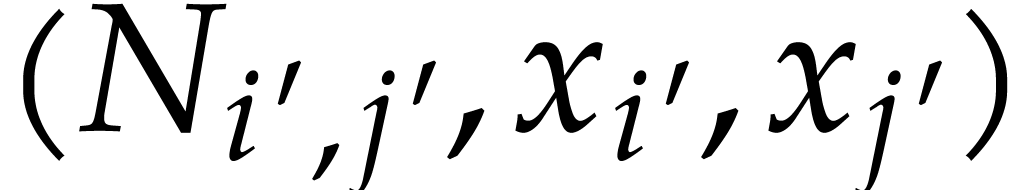 into
.
into
.
Update 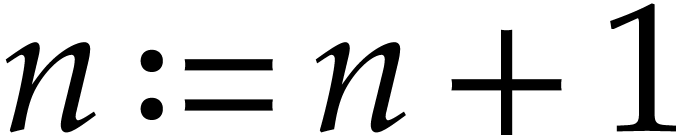 .
.
For 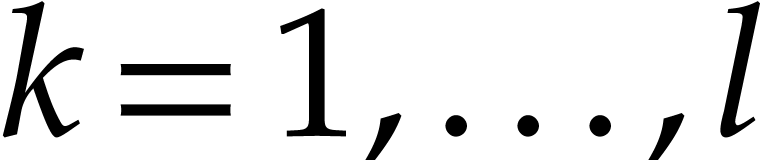 , append the
naive evaluation of to , and use this product as the -th output value of .
, append the
naive evaluation of to , and use this product as the -th output value of .
Return .
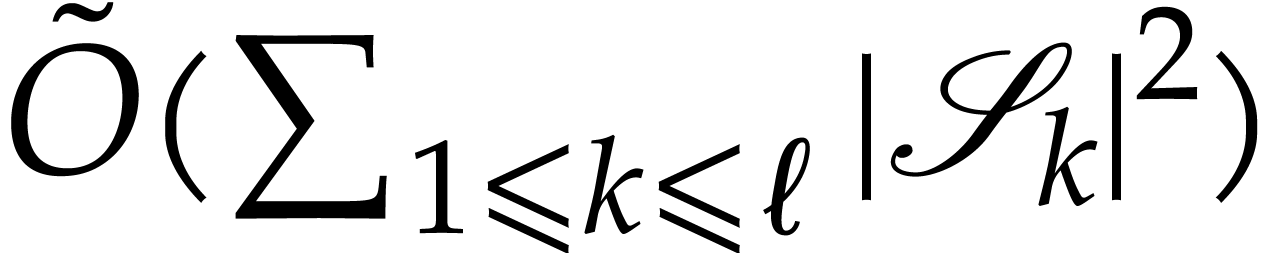 . The SLP in return performs at
most
. The SLP in return performs at
most 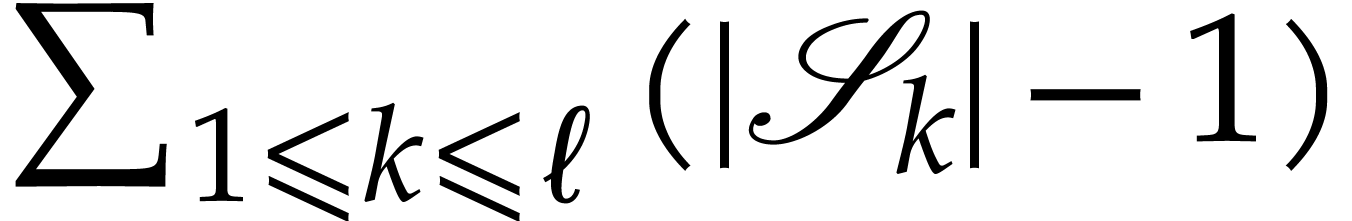 products.
products.
Proof. Let 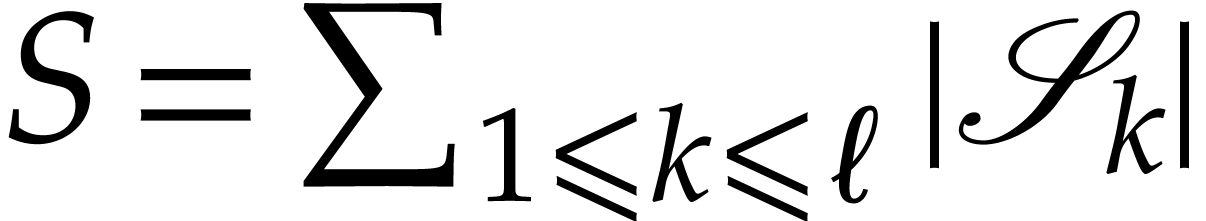 .
Steps 2 and 3 perform
.
Steps 2 and 3 perform 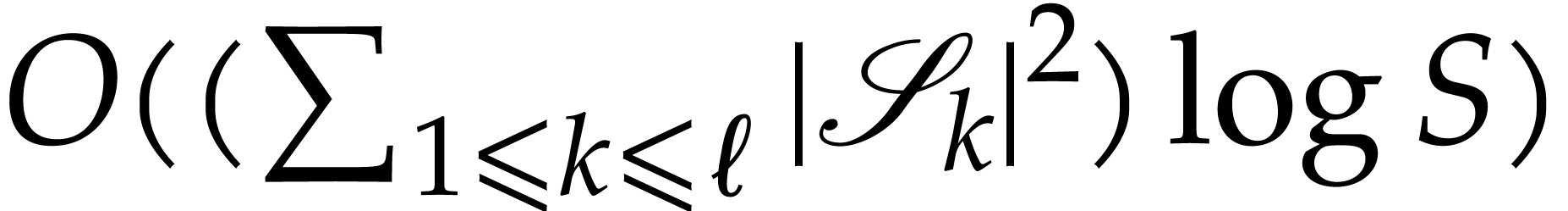 operations on integers of
bit size
operations on integers of
bit size 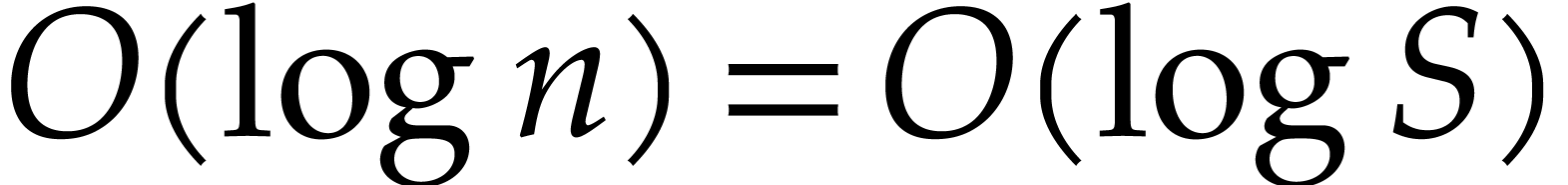 . If holds in step 4b, then the triple is no longer valid. Let
. If holds in step 4b, then the triple is no longer valid. Let
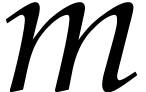 denote the value of
denote the value of 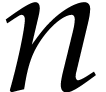 at
the end of the algorithm.
at
the end of the algorithm.
The bit cost of each update caused by  in step 4d
is
in step 4d
is 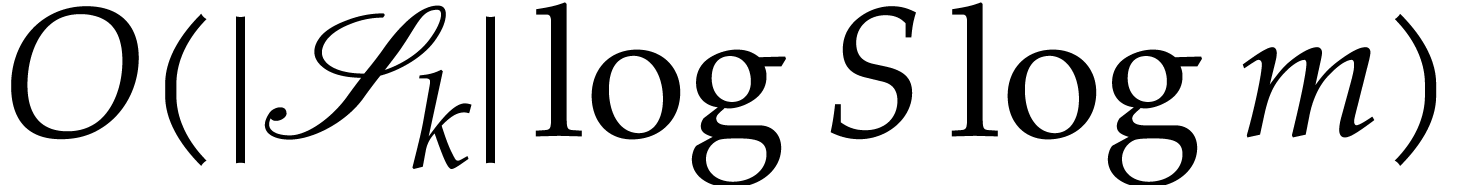 . Moreover, each can be updated at most
. Moreover, each can be updated at most  times.
Consequently,
times.
Consequently, 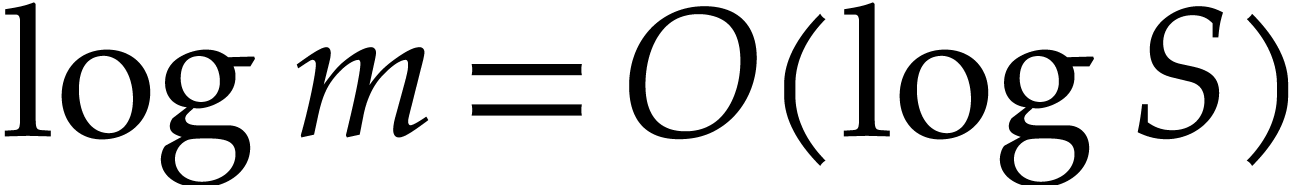 . Hence, the
total cost is .
. Hence, the
total cost is .
Remark  in Algorithm 3.
Assuming perfect hashing the asymptotic complexity is the same.
in Algorithm 3.
Assuming perfect hashing the asymptotic complexity is the same.
Example
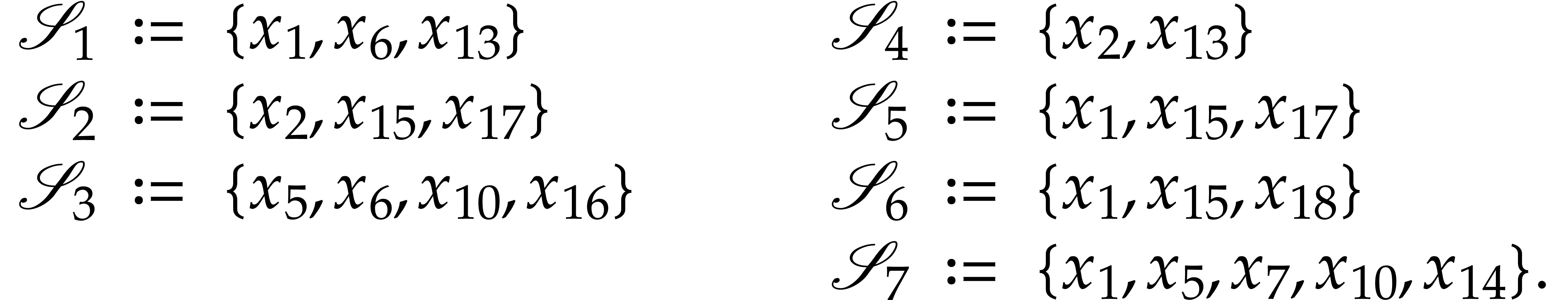 |
(6) |
The two variables 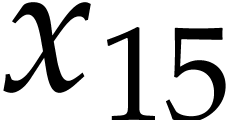 and
and 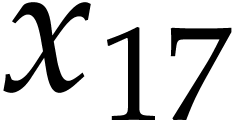 appear jointly in two of the .
The algorithm starts by picking
appear jointly in two of the .
The algorithm starts by picking 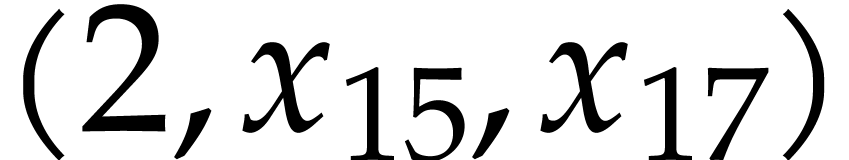 in step 4a, so
we append
in step 4a, so
we append 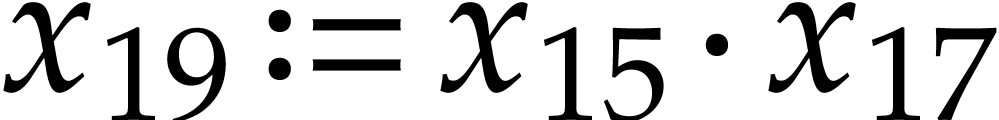 to the SLP, and also update
to the SLP, and also update 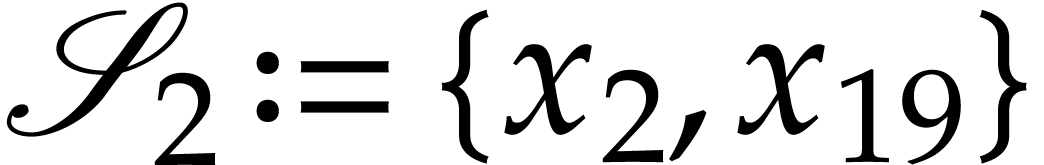 ,
, 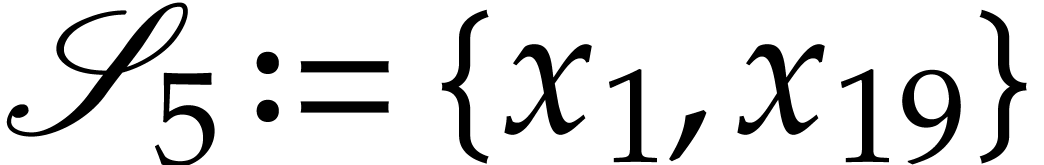 ,
and the table . We next pick
,
and the table . We next pick
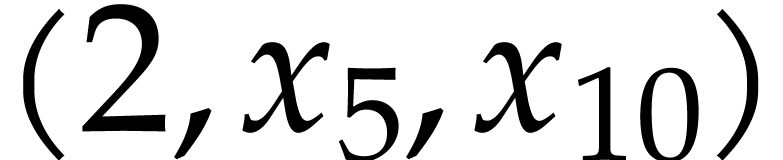 in step 4a, append
in step 4a, append 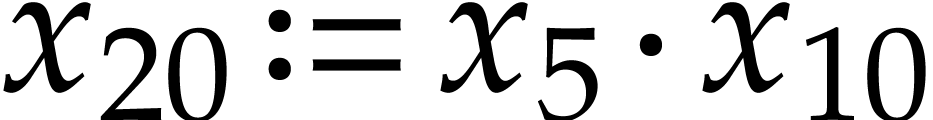 to
the SLP, and also update
to
the SLP, and also update 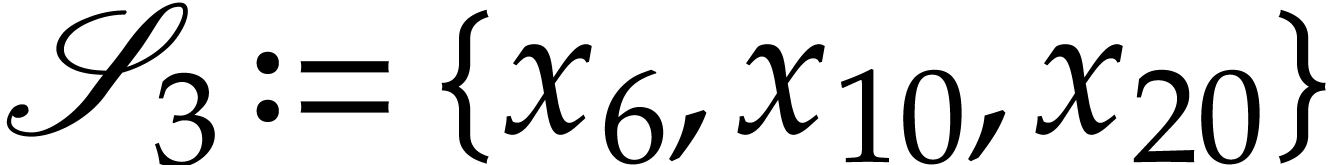 ,
,
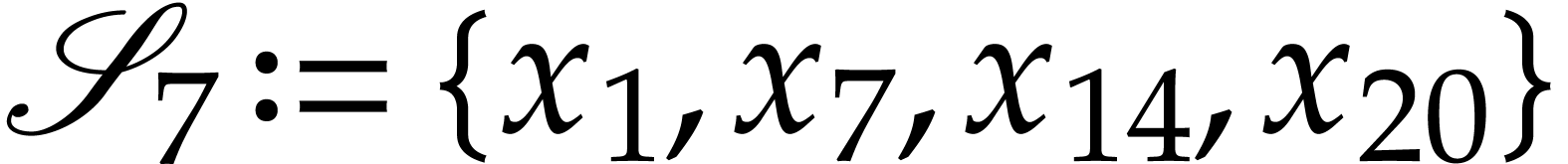 , and the table . We next pick
, and the table . We next pick 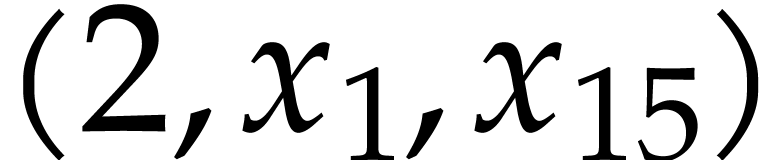 from the
heap, but since
from the
heap, but since 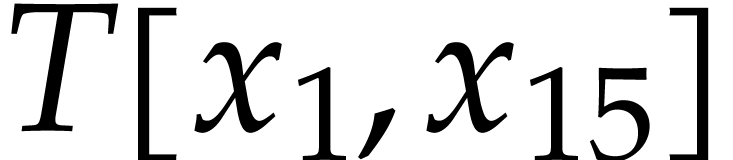 has been updated to
has been updated to 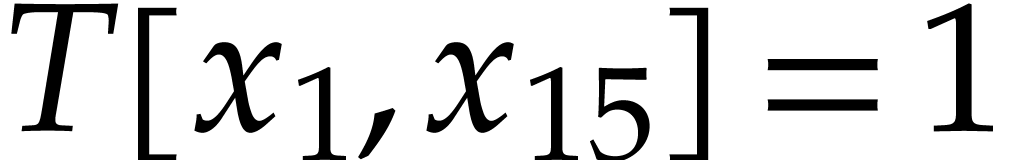 , we ignore this pick in step 4b and directly
continue with the next triple on the heap. From this point on, we only
retrieve triples
, we ignore this pick in step 4b and directly
continue with the next triple on the heap. From this point on, we only
retrieve triples 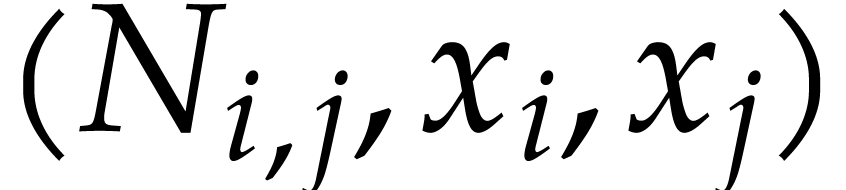 with
with 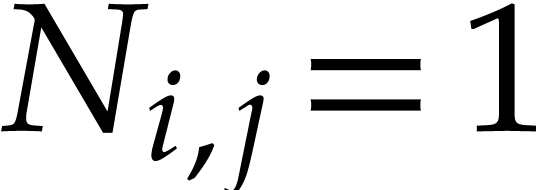 and further append the following instructions to the SLP (while
indicating their values in terms of
and further append the following instructions to the SLP (while
indicating their values in terms of  in grey):
in grey):

The output variables are ,
, , , , ,
.
As our final step, we try to combine as many additions with multiplications as possible into FMA instructions, and run common subexpression elimination on the result. Optionally, we may reschedule some of the instructions and try to reduce the number of variables that are being used.
Example 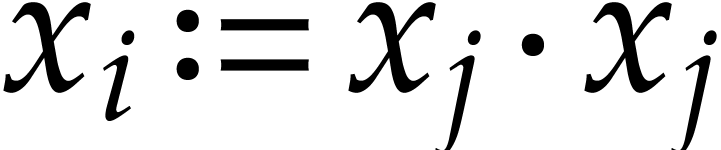 as squarings
as squarings 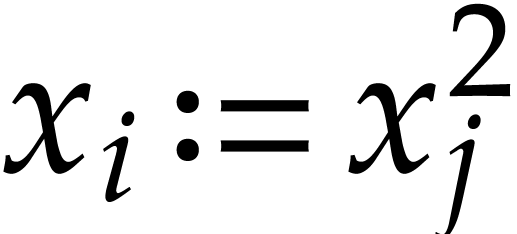 (which is more efficient for certain rings ).
On the other hand, common subexpression elimination leads to no further
simplifications. The final SLP is:
(which is more efficient for certain rings ).
On the other hand, common subexpression elimination leads to no further
simplifications. The final SLP is:
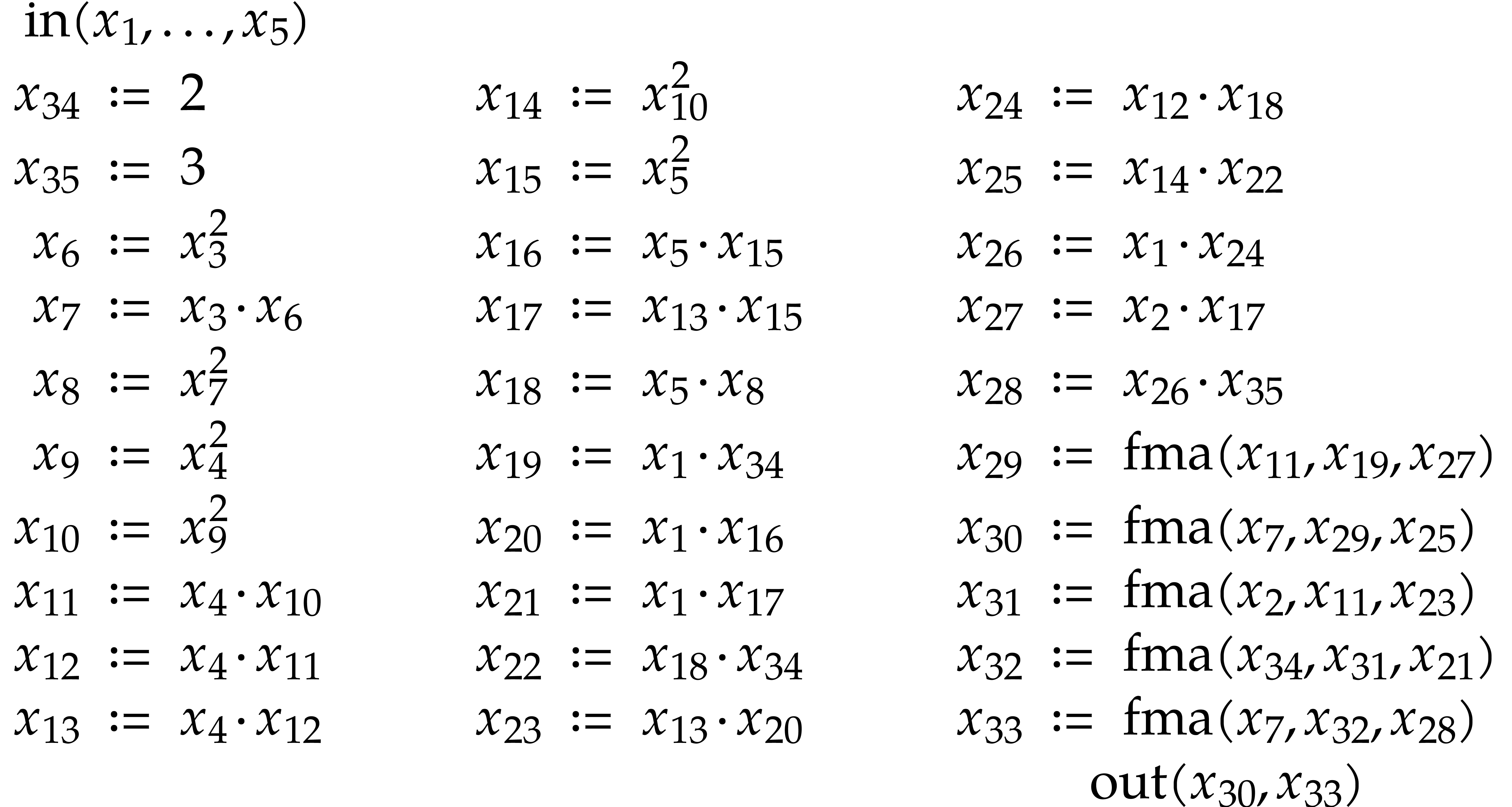
We implemented our new algorithm within the  multiple times efficiently. Typical applications
include numerical integration and polynomial system solving.
multiple times efficiently. Typical applications
include numerical integration and polynomial system solving.
The JIT compiler of  like
like  . In addition, if several competing SLPs are
available for the same task, then we can generate machine code for each
of them and empirically select the best SLP.
. In addition, if several competing SLPs are
available for the same task, then we can generate machine code for each
of them and empirically select the best SLP.
The source code of our evaluation can be found in the file src/slp/slp_spol.cpp
of
Currently, our implementation supports 32-bit integer exponents
represented by sparse vectors. The SLPs produced by our software include
the following operations: negation, binary addition, subtraction, and
possibly negated multiplication  ,
as well as ternary FMA instructions .
Our goal is to minimize the length
,
as well as ternary FMA instructions .
Our goal is to minimize the length 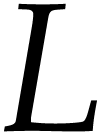 (i.e. the number of operations) of the generated SLP. Below
we analyze the obtained results for the following strategies.
(i.e. the number of operations) of the generated SLP. Below
we analyze the obtained results for the following strategies.
This strategy corresponds to our new polynomial evaluation algorithm from section 3, while using the algorithm from section 3.1 for the reduction to the case of sums of powers of distinct variables.
This is a variant of the “sparse” strategy in which we use the algorithm from section 3.2 instead of the one from section 3.1.
Here, the input polynomial is considered
in 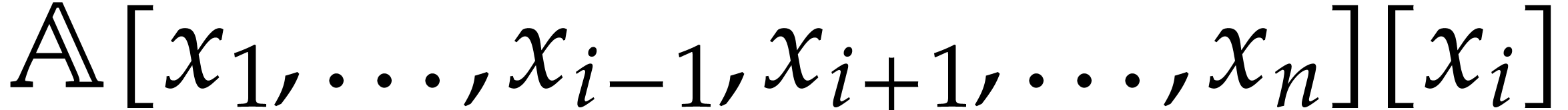 , where
, where  maximizes the number
maximizes the number 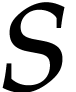 of
distinct exponents
of
distinct exponents  of
among the non-zero terms of :
of
among the non-zero terms of :
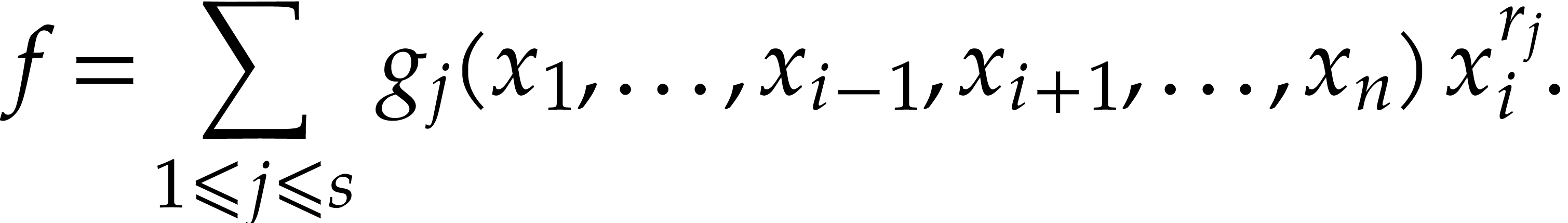 |
(7) |
We apply this Horner strategy recursively to evaluate all the
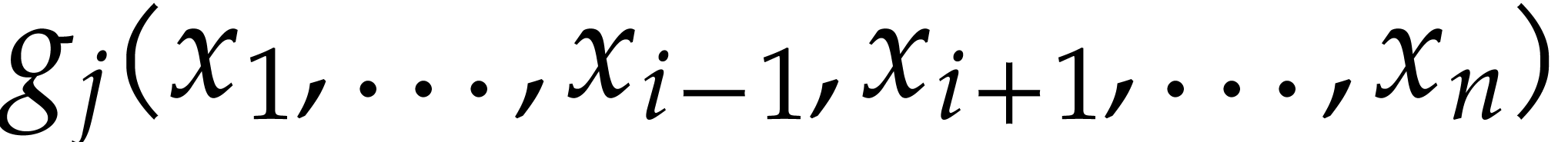 . Then the univariate
Horner scheme is applied to obtain the value of
using
. Then the univariate
Horner scheme is applied to obtain the value of
using
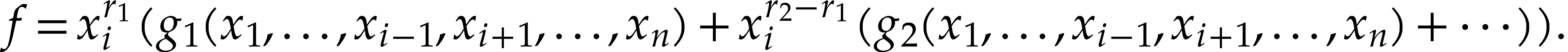
The powers 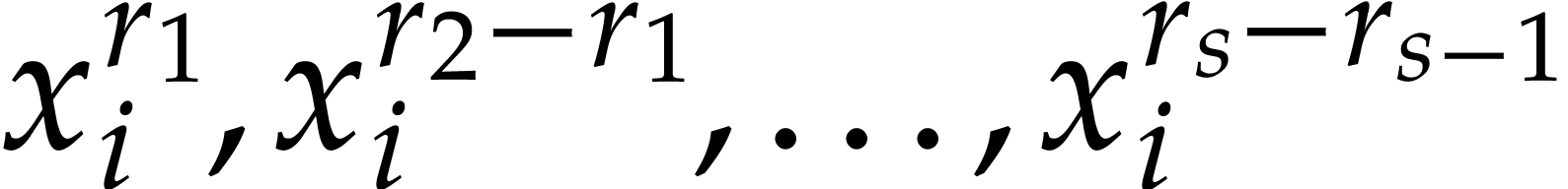 are computed using Algorithm 2.
are computed using Algorithm 2.
We have implemented an improved variant of the strategy presented
in [7, section 3]: selecting the variable as in the above “Horner” strategy, we
write

where 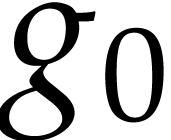 contains all the terms of that are not multiple of and
contains all the terms of that are not multiple of and
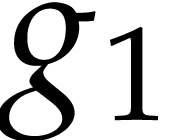 is not divisible by . The polynomials and
are evaluated recursively. We collect all
powers
is not divisible by . The polynomials and
are evaluated recursively. We collect all
powers 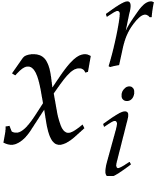 from all recursive evaluations
upfront and evaluate them using Algorithm 2.
from all recursive evaluations
upfront and evaluate them using Algorithm 2.
The strategies from section
3
were designed specifically for polynomials with few terms of small
degree. In particular, we considered the case of random polynomials with
terms in
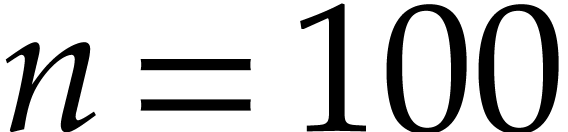 variables and exponents in
variables and exponents in
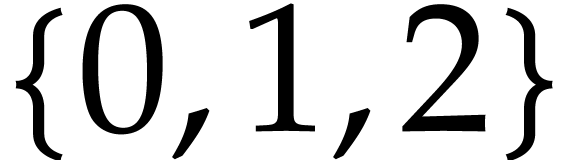 .
Figure
2
displays the length
of the generated SLP divided by
as a function of
.
The cost is averaged over 10 random samples. The costs of the
“sparse” and “exponent expansion” strategies are
actual identical in this special case. Those of “Horner” and
“greedy Horner” are almost the same.
.
Figure
2
displays the length
of the generated SLP divided by
as a function of
.
The cost is averaged over 10 random samples. The costs of the
“sparse” and “exponent expansion” strategies are
actual identical in this special case. Those of “Horner” and
“greedy Horner” are almost the same.
Figure
3
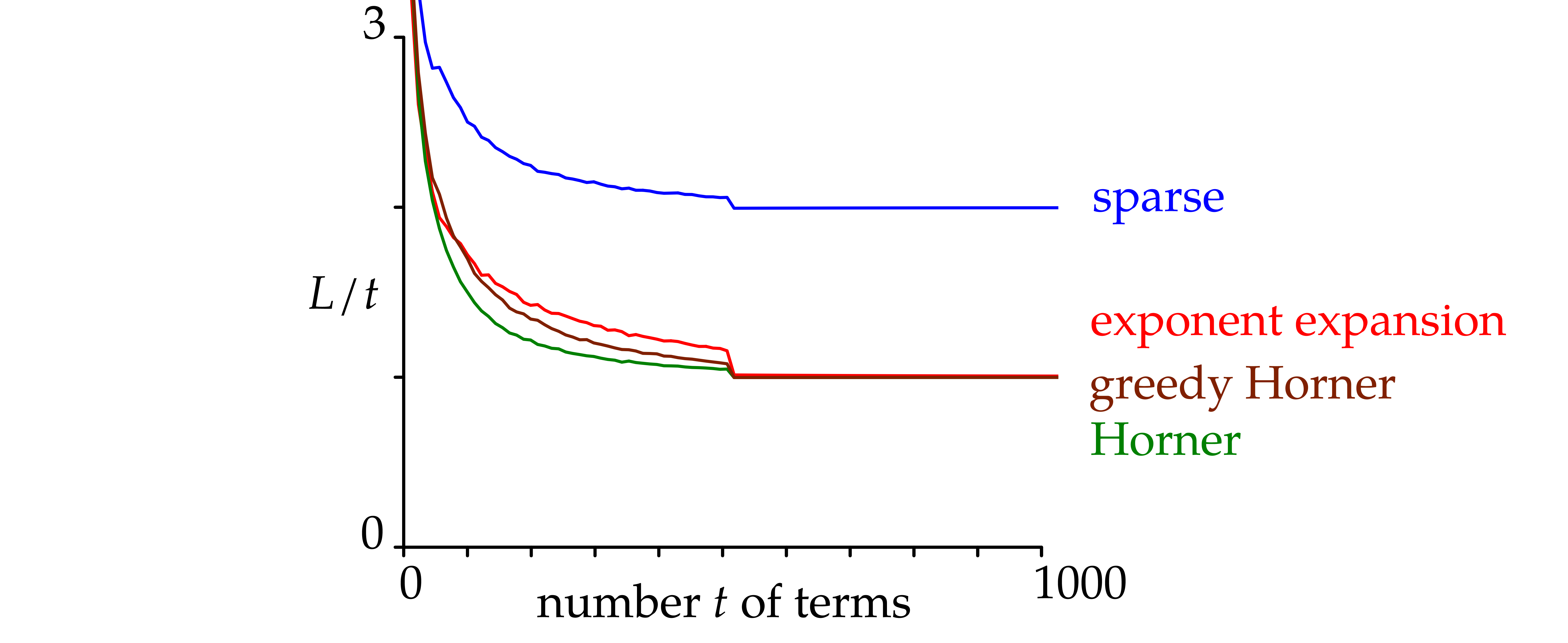
displays similar cost measures with
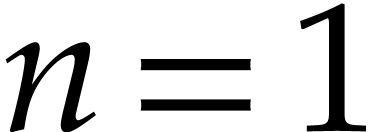 and exponents
and exponents
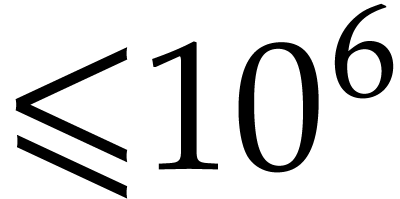 constructed randomly as follows: we first select a bit size
in
constructed randomly as follows: we first select a bit size
in
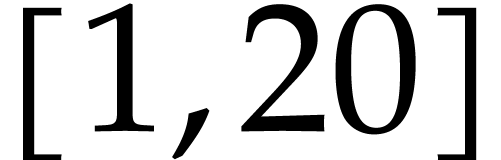 at random and then pick a random number uniformly in
at random and then pick a random number uniformly in
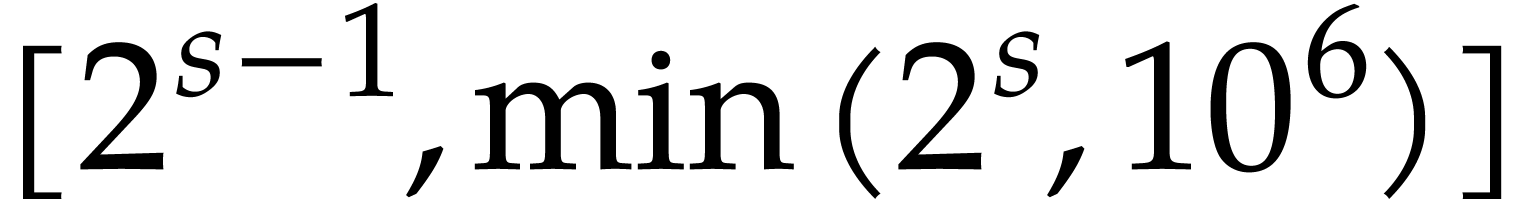 .
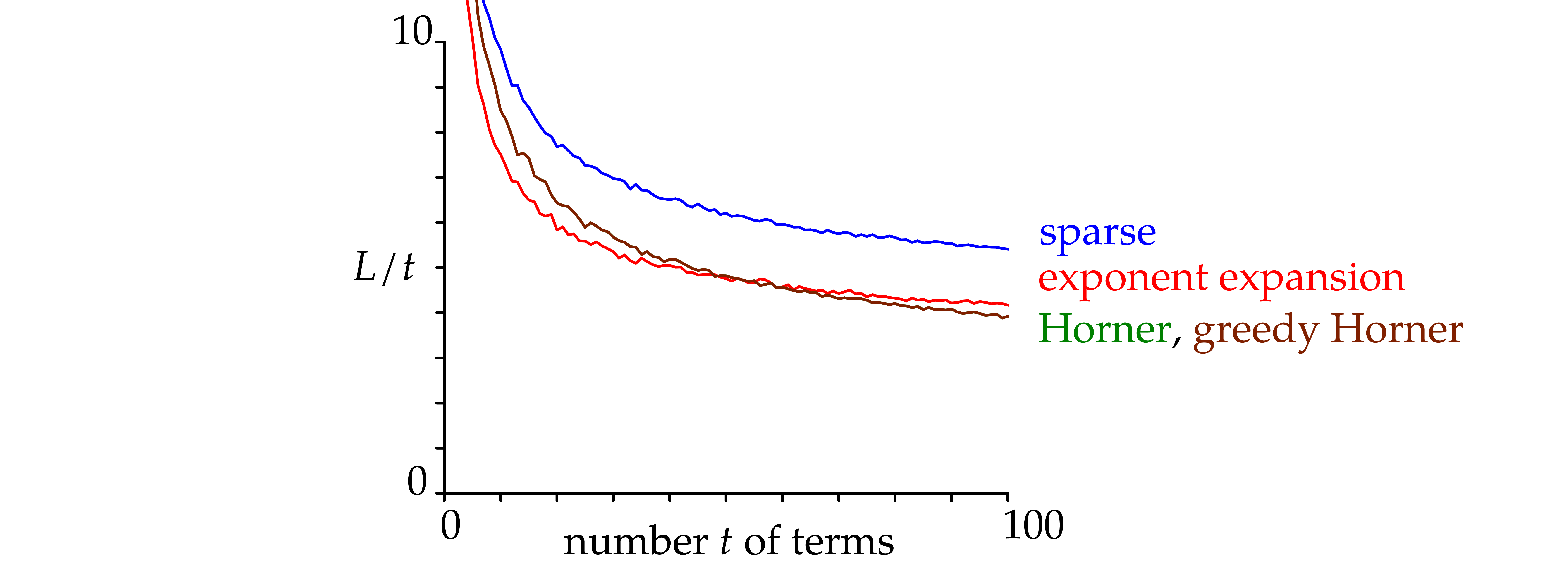
We observe that the “sparse” strategy is ineffective. With
fewer than about 50 terms, the “exponent expansion” strategy
performs best; thereafter, the “Horner” strategy (which
coincides with the “greedy Horner” strategy) becomes more
efficient. With a few variables (e.g., 2, 3, 4), the comparisons are
similar, with larger thresholds (
.
We observe that the “sparse” strategy is ineffective. With
fewer than about 50 terms, the “exponent expansion” strategy
performs best; thereafter, the “Horner” strategy (which
coincides with the “greedy Horner” strategy) becomes more
efficient. With a few variables (e.g., 2, 3, 4), the comparisons are
similar, with larger thresholds (
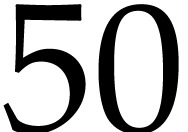 becomes approximately
becomes approximately
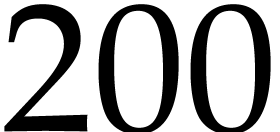 for
for
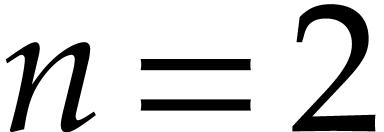 ).
).
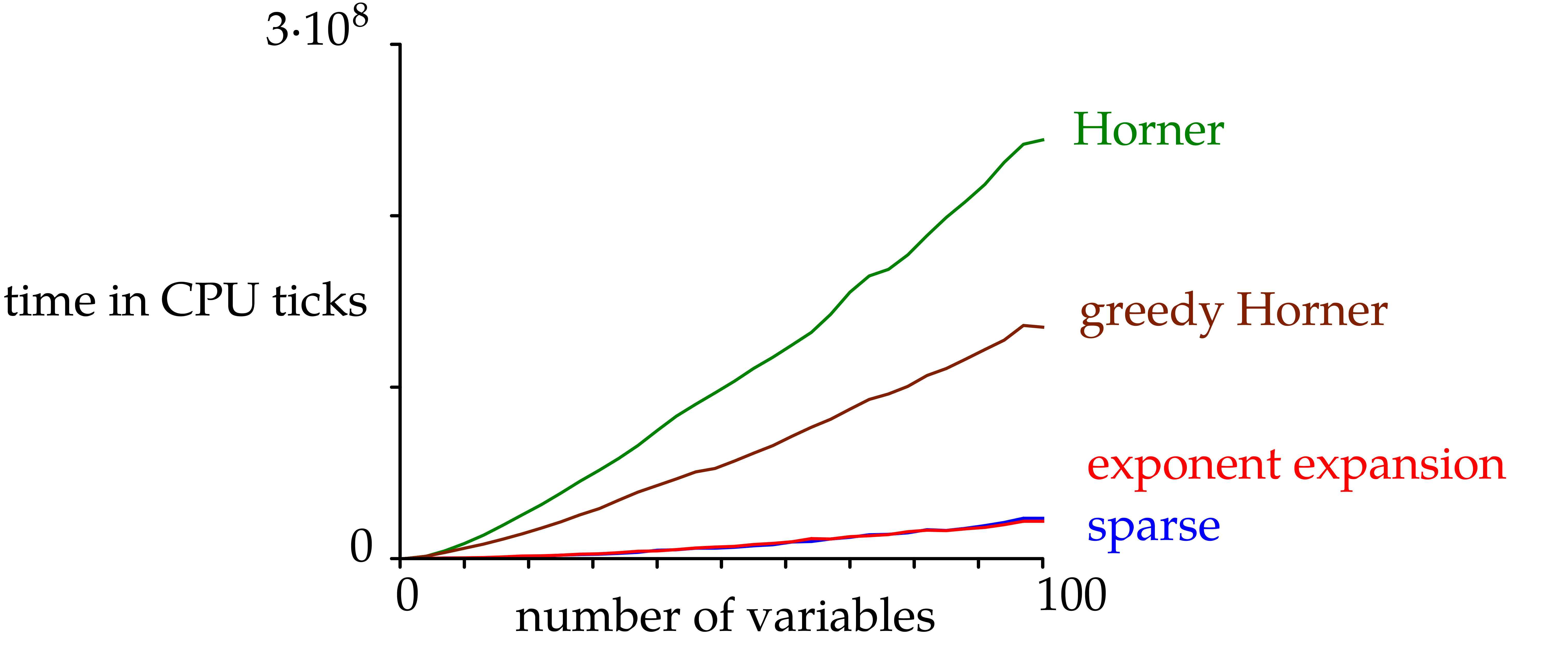
Figure
4
displays the time needed to build the SLPs using the four strategies:
we construct polynomials in
variables with at most 100 terms and random exponents in
.
Coefficients are random 64 bit integers. The cost is averaged over 10
random samples. We observe that the Horner strategies are considerably
less efficient than the sparse strategies when the number of variables
is large.
The “Horner” and “greedy Horner” strategies
coincide for univariate polynomials and are usually the most efficient.
The “exponent expansion” method is only slightly slower,
while the “sparse” strategy is suboptimal in this situation.
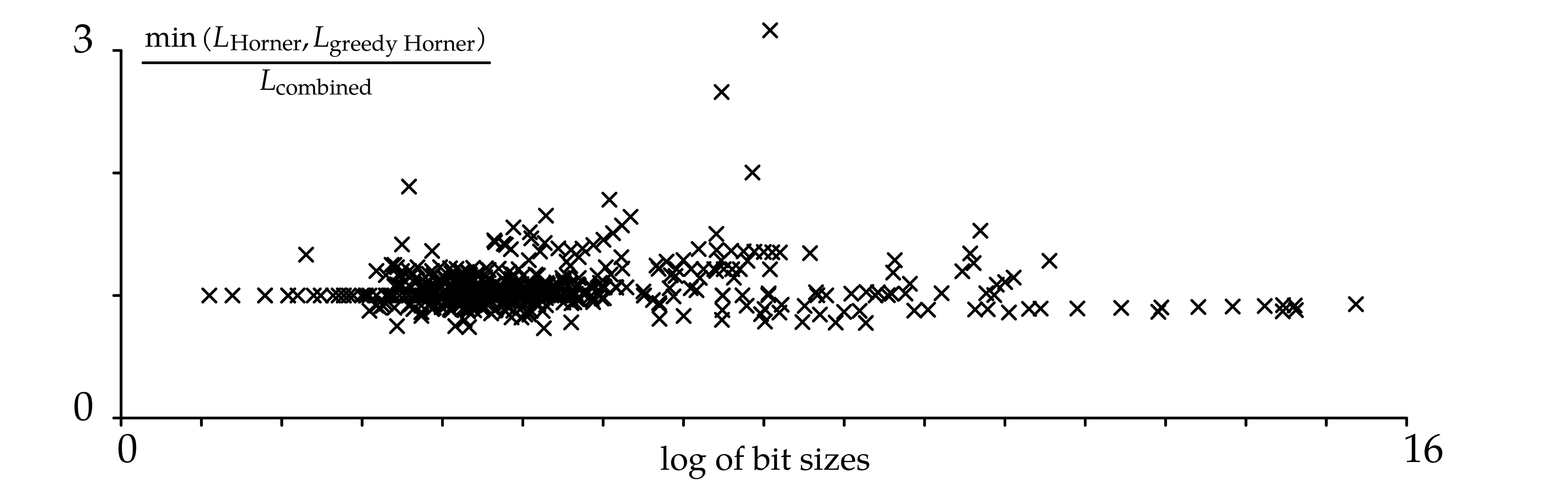
Figure 5 shows averaged ratios 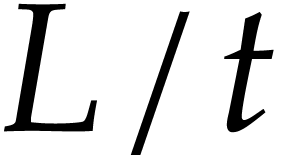 as a
function of (for
as a
function of (for 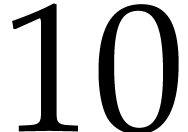 random
samples), this time for random bivariate dense polynomials of partial
degrees
random
samples), this time for random bivariate dense polynomials of partial
degrees  . The behavior is
roughly similar to what we observed in the univariate case. For
trivariate polynomials of partial degrees
. The behavior is
roughly similar to what we observed in the univariate case. For
trivariate polynomials of partial degrees 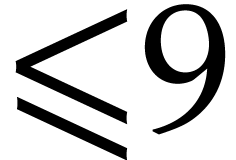 ,
the four strategies have closer efficiencies.
,
the four strategies have closer efficiencies.
 |
Considering the relative performance of the four strategies described above, and noting that the construction of an SLP via the Horner methods tends to become more expensive for sparse polynomials, we retained a “combined” default strategy for the evaluation of sparse polynomials in JIL. More precisely, our implementation selects the shortest SLP among the ones produced via the following strategies:
The first strategy is “exponent expansion”.
The second strategy performs a single step of the
“Horner” strategy (i.e. with respect to a single
variable), followed by the “exponent expansion” strategy
(where we evaluate all the 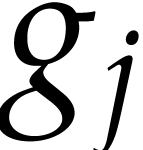 of equation
of equation
The third strategy performs two steps of the “Horner”
strategy, followed by the “exponent expansion” strategy:
after the first step of the “Horner” strategy and we
evaluate all the of
are considered as univariate polynomials in the same variable , where 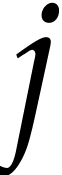 maximizes the number of distinct exponents of
among the union of the non-zero terms of
maximizes the number of distinct exponents of
among the union of the non-zero terms of  . Of course, we only apply this third strategy
when the second strategy produces a shorter SLP than the first one.
. Of course, we only apply this third strategy
when the second strategy produces a shorter SLP than the first one.
This “combined” strategy is almost always best for sparse multivariate polynomials. For denser polynomial, it still performs well, since the density is typically captured by one and sometimes two of the variables. The most expensive step of computing the SLP using the “combined” strategy is Algorithm 3. The other steps run in quasi‑linear time.
To benchmark the efficiency of our “combined” strategy, we
collected
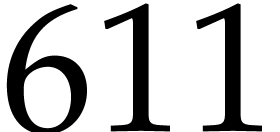 polynomial systems with integer coefficients primarily from the
polynomial systems with integer coefficients primarily from the
 ,
,
 ,
and
,
and
 of the SLPs produced by the “combined”,
“Horner”, and “greedy Horner” strategies. In
Figure
6
, each polynomial system is represented by a cross: the abscissa shows
the logarithm of the bit size of the system, and the ordinate shows
of the SLPs produced by the “combined”,
“Horner”, and “greedy Horner” strategies. In
Figure
6
, each polynomial system is represented by a cross: the abscissa shows
the logarithm of the bit size of the system, and the ordinate shows
 .
.
After a closer examination of the timings, we observed that relatively dense homogeneous bivariate polynomials are better suited for the “exponent expansion” method than for Horner's method. On the other hand, the points with low ordinates in Figure 6 often correspond to systems with a very specific structure, for example those labeled Singular_rcyclic in the database. These rare cases are where the “greedy Horner” method outperforms “combined”. Of course, in our software implementation, the user can select the strategy and even invoke an intensive search for optimal combinations. We are also investigating variants of our algorithms that use more aggressive factorizations in the same vein as [18]. We plan to detail this work in a future paper.
A. Ahlbäck, J. van der Hoeven, and G. Lecerf. JIL: a high performance library for straight-line programs. https://sourcesup.renater.fr/projects/jil, 2025.
D. J. Bernstein. Pippenger's exponentiation algorithm. Available at https://cr.yp.to/papers/pippenger.pdf, 2002.
J. Berthomieu, Ch. Eder, and M. Safey El Din. Msolve: a library for solving polynomial systems. In 2021 International Symposium on Symbolic and Algebraic Computation, ISSAC'21, pages 51–58. ACM.
A. Brauer. On addition chains. Bull. Amer. Math. Soc., 45(10):736–739, 1939.
P. Bürgisser, M. Clausen, and M. A. Shokrollahi. Algebraic Complexity Theory, volume 315 of Grundlehren der Mathematischen Wissenschaften. Springer-Verlag, 1997.
J. Carnicer and M. Gasca. Evaluation of multivariate polynomials and their derivatives. Math. Comp., 54(231–243), 1990.
M. Ceberio and V. Kreinovich. Greedy algorithms for optimizing multivariate Horner schemes. SIGSAM Bull., 38(1):8–15, 2004.
D.E. Knuth . The art of computing programming Vol.1, fundamental algorithms. Addison-Wesley, 3rd edition, 1997.
A. Demin and J. van der Hoeven. Factoring sparse polynomials fast. J. Complexity, 88:101934, 2025.
P. Downey, B. Leong, and R. Sethi. Computing sequences with addition chains. SIAM J. Comput., 10(3):638–646, 1981.
P. Erdős. Remarks on number theory III. On addition chains. Acta Arith., 6(1):77–81, 1960.
H.-G. Gräbe. The SymbolicData project. 2020. https://symbolicdata.github.io.
J. van der Hoeven. Calcul analytique. In Journées Nationales de Calcul Formel. 14 – 18 Novembre 2011, volume 1 of Les cours du CIRM, pages 1–85. CIRM, 2011. https://www.numdam.org/articles/10.5802/ccirm.16/.
J. van der Hoeven. The Jolly Writer. Your Guide to GNU TeXmacs. Scypress, 2020.
J. van der Hoeven and G. Lecerf. Towards a library for straight-line programs. Appl. Algebra Eng. Commun. Comput., 37:331–387, 2026.
J. van der Hoeven et al. GNU TeXmacs. https://www.texmacs.org, 1998.
R. Ilango. Constant depth formula and partial function versions of MCSP are hard. SIAM J. Comput., 53(6):FOCS20–317, 2022.
C. E. Leiserson, L. Li, M. Moreno Maza, and Y. Xie. Efficient evaluation of large polynomials. In K. Fukuda, J. van der Hoeven, M. Joswig, and N. Takayama, editors, Mathematical Software – ICMS 2010. Third International Congress on Mathematical Software, Kobe, Japan, September 13-17, 2010, Proceedings, volume 6327 of Lect. Notes Comput. Sci., pages 342–353. Springer, Berlin, Heidelberg, 2010.
V. Ya Pan. Methods of computing values of polynomials. Russ. Math. Surv., 21:105–136, 1966.
N. Pippenger. On the evaluation of powers and related problems. In 17th Annual Symposium on Foundations of Computer Science (SFCS 1976), pages 258–263. IEEE Computer Society, 1976.
N. Pippenger. The minimum number of edges in graphs with prescribed paths. Math. Syst. Theory, 12(1):325–330, 1978.
N. Pippenger. On the evaluation of powers and monomials. SIAM J. Comput., 9(2):230–250, 1980.
E. G. Straus. Addition chains of vectors (problem 5125). Am. Math. Mon., 71(7):806–808, 1964.
A. C.-C. Yao. On the evaluation of powers. SIAM J. Comput., 5(1):100–103, 1976.
 .
. in a
multiplicative monoid
in a
multiplicative monoid 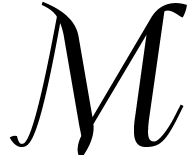 ,
,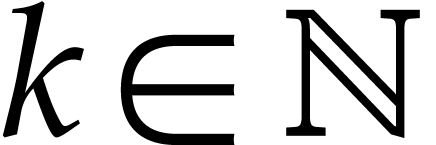 such that
such that 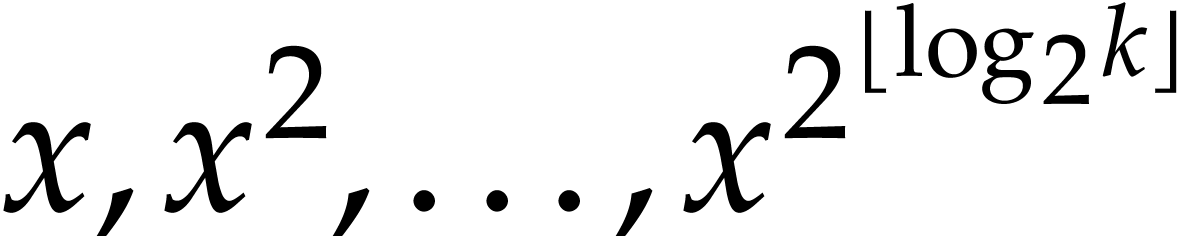 .
.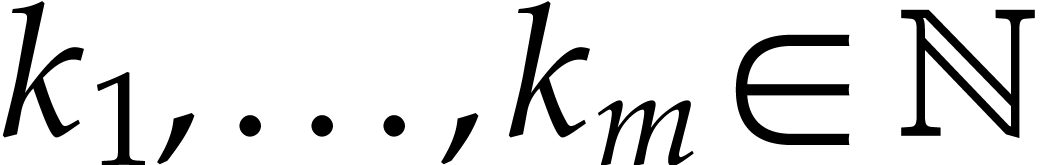 with
with  .
. of
of  .
.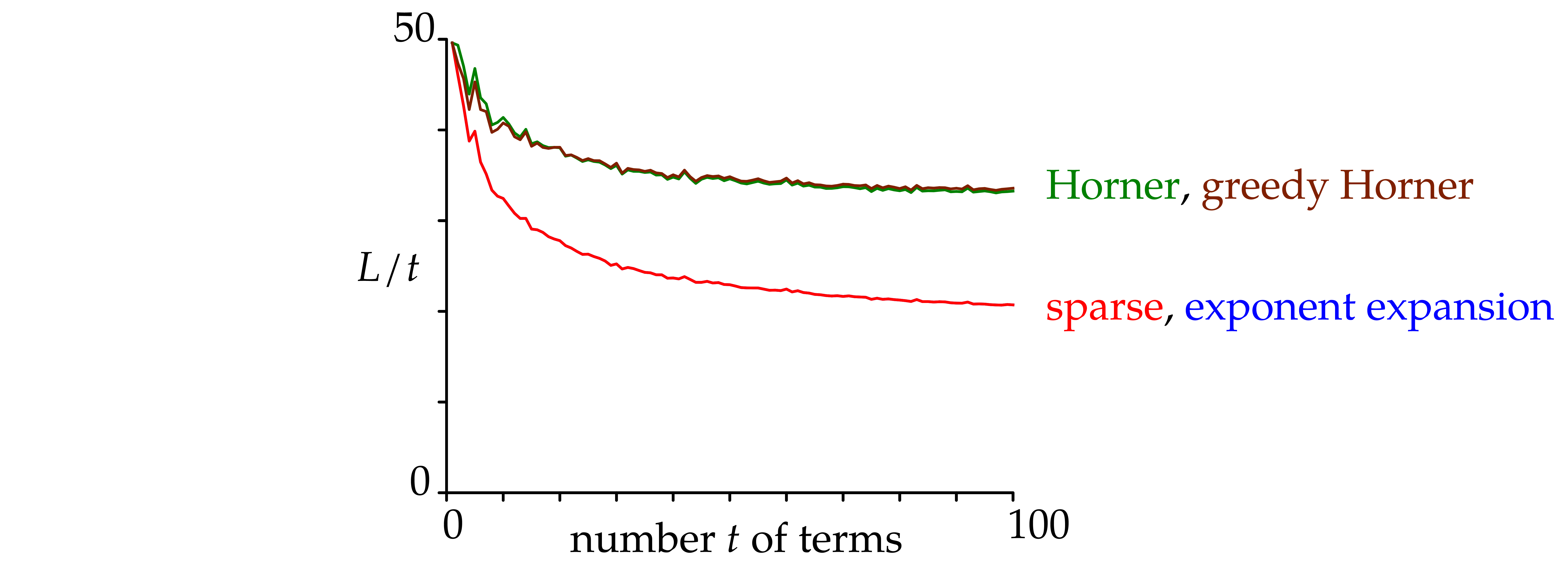
 as a function of
as a function of  is the length of the SLP
generated using different strategies, for random polynomials
with
is the length of the SLP
generated using different strategies, for random polynomials
with  variables and exponents in
variables and exponents in 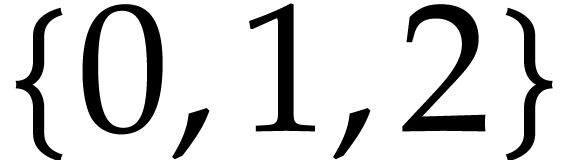 .
.
 .
.